
2024-mcm-everitt-ryan/flan-t5-xl-job-bias-seq2seq-cls
Text2Text Generation
•
Updated
•
10
NLP, Large Language Models, Bias Detection, Diversity, Recruitment
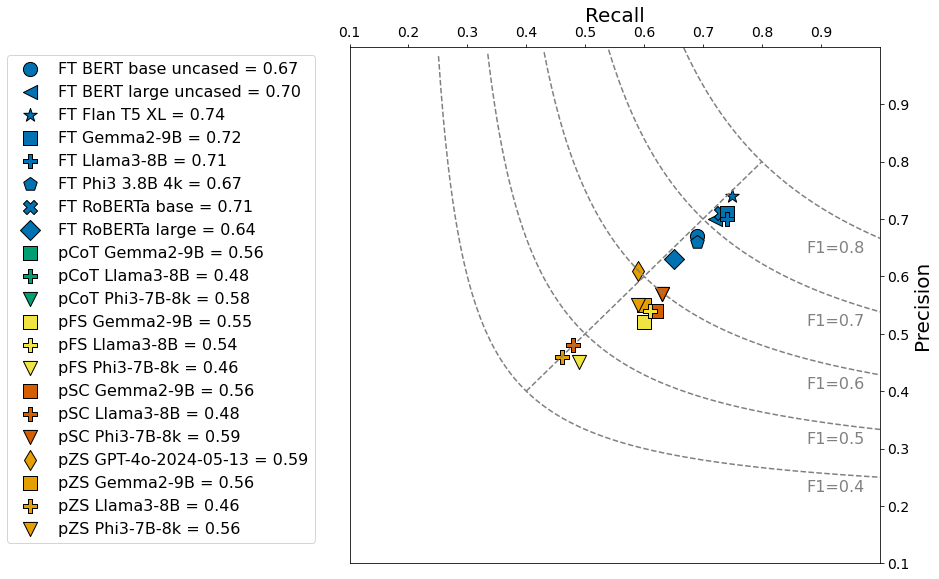
Abstract—This study explores the application of large language (LLM) models for detecting implicit bias in job descriptions, an important concern in human resources that shapes applicant pools and influences employer perception. We compare different LLM architectures—encoder, encoder-decoder, and decoder models—focusing on seven specific bias types. The research questions address the capability of foundation LLMs to detect implicit bias and the effectiveness of domain adaptation via fine-tuning versus prompt-tuning. Results indicate that fine-tuned models are more effective in detecting biases, with Flan-T5-XL emerging as the top performer, surpassing the zero-shot prompting of GPT-4o model. A labelled dataset consisting of verified gold-standard, silver-standard, and unverified bronze-standard data was created for this purpose and open-sourced to advance the field and serve as a valuable resource for future research.
In human resources, bias affects both employers and employees in explicit and implicit forms. Explicit bias is conscious and controllable, but can be illegal in employment contexts. Implicit bias is subtle, unconscious, and harder to address. Implicit bias in job descriptions is a major concern as it shapes the applicant pool and influences applicants’ decisions. Bias in the language of job descriptions can affect how attractive a role appears to different individuals and can impact employer perception. The challenge is to efficiently identify and mitigate these biases.
The application of large language models (LLMs) for detecting bias in job descriptions is promising but underexplored. This study examines the effectiveness of various LLM architectures (encoder, encoder-decoder, decoder) less than 10 billion parameters in detecting implicit bias.
We conceptualise the task of identifying implicit bias in job descriptions as a multi-label classification problem, where each job description is assigned a subset of labels from a set of eight categories—age, disability, feminine, masculine, general exclusionary, racial, sexuality, and neutral. This study investigates two primary research questions:
Can foundation LLMs accurately detect implicit bias in job descriptions without specific task training? We evaluate the performance of three topical decoder-only models under four distinct prompt settings, assessing their ability to extract relevant information from job descriptions and identify implicit bias.
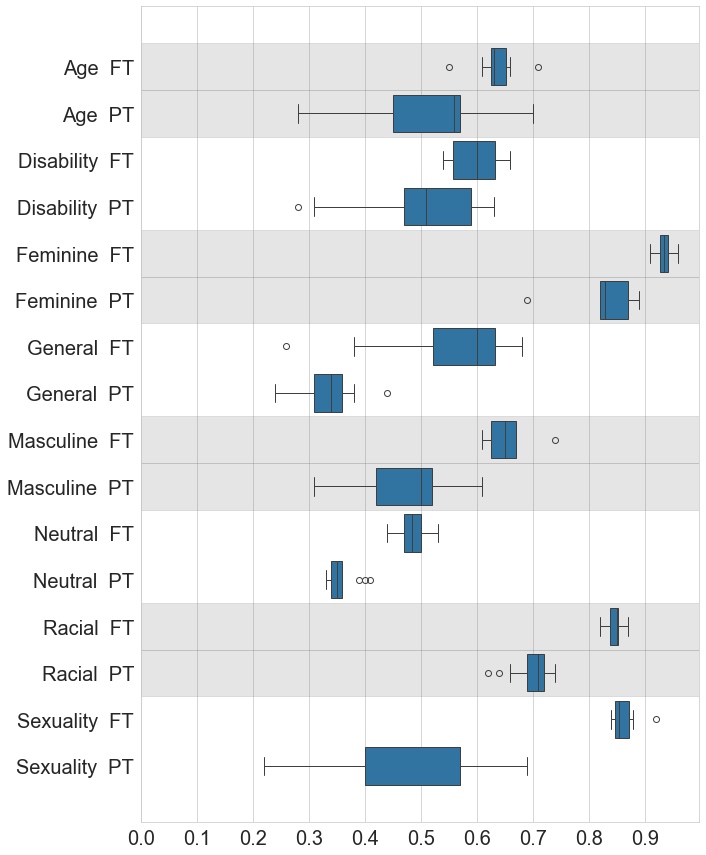
Does domain adaptation via fine-tuning foundational LLMs outperform prompt tuning for detecting implicit bias in job descriptions? We fine-tune models with varying architectures as text-classifiers on task-specific data and compare their performance to that of prompt-tuned models.
The models selected for our study are given.
Encoder Architecture:
Encoder-Decoder Architecture: We selected one prominent encoder-decoder model, Flan-T5. Developed by Google, Flan-T5 combines the strengths of an encoder to understand input data and a decoder to generate relevant outputs. Additionally, Flan-T5 incorporates instruction fine-tuning, which enables the model to improve its performance and generalisation to unseen tasks.
Decoder Architecture: We selected three prominent decoder-based models, all of which are autoregressive models that generate text by predicting the next word in a sequence.
Additionally, OpenAI’s GPT-4 autoregressive model was used for several purposes in this study: data preprocessing, data augmentation, and as a prompting baseline
We evaluated the instruction-tuned decoder models using four prompting approaches:
Zero-Shot (pZS): Models were prompted without providing examples and without task-specific training.
Few-Shot (pFS): Models were provided with a small number of example inputs and corresponding outputs, with the expectation that the model could generalise from these examples when given unseen inputs.
Chain-of-Thought (pCoT): Models were guided through a series of reasoning steps, with the expectation that breaking a complex problem into logical steps would enhance the reasoning performance. We utilised the Zero-Shot CoT method.
Self-Consistency (pSC): Multiple diverse outputs were generated for the same prompt, and the final answer was determined by selecting the most consistent response among these outputs. We applied three iterations of chain-of-thought reasoning with a majority vote for each label.
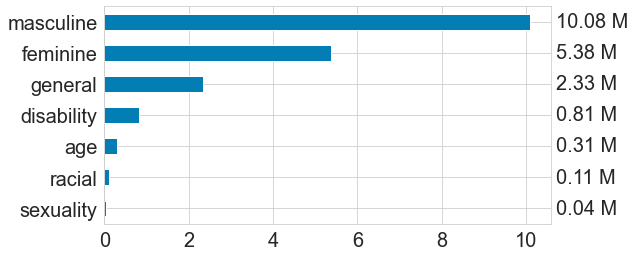 |
|---|
| Potential Bias Terms found in Real Job Description Dataset (in Millions) |
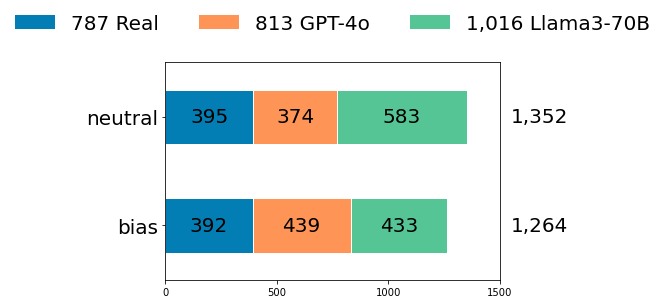 |
|---|
| Annotated Samples: Bias vs Neutral |
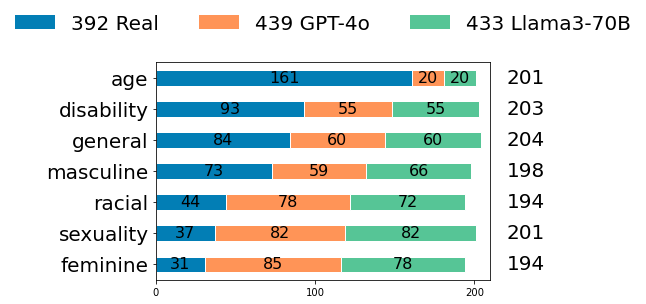 |
|---|
| Annotated Samples by Bias Category |
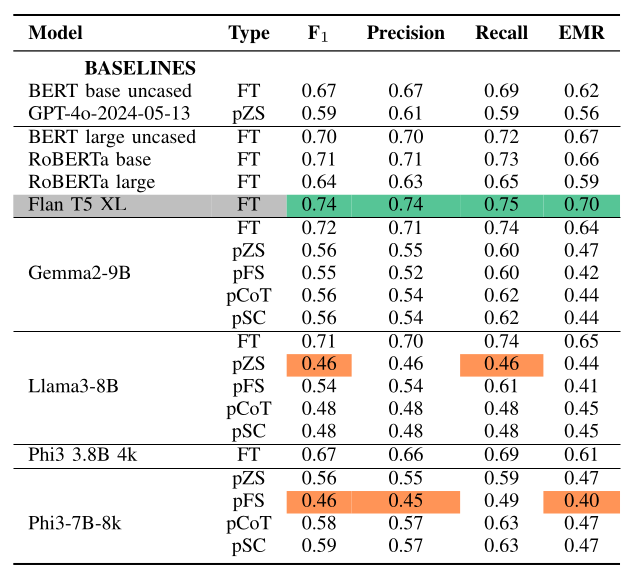 |
|---|
| Fine-Tuning vs Prompting Performance |
 |
|---|
| Model Performance: Precision vs Recall |
 |
|---|
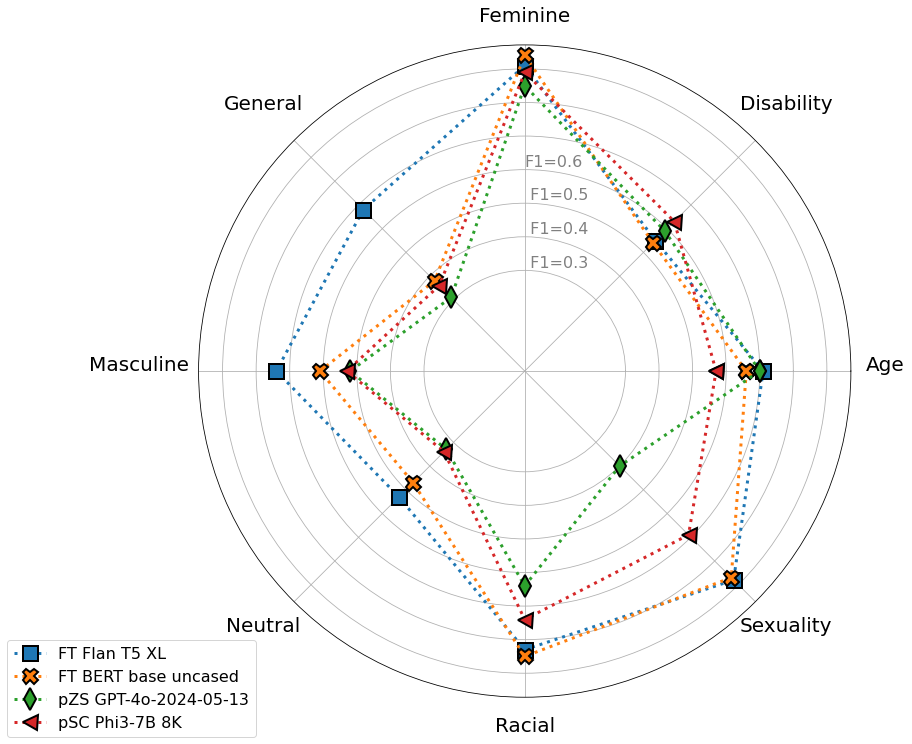
| Top Performers’ Comparison Against Baseline Models |
 |
|---|
| F1 Scores Across Various Categories and Experiments; Fine-Tuning (FT) and Prompting (PT) |