---
language:
- en
- ko
pipeline_tag: text-generation
tags:
- pytorch
- llama
- causal-lm
- 42dot_llm
license: cc-by-nc-4.0
---
# 42dot_LLM-SFT-1.3B
**42dot LLM-SFT** is a large language model (LLM) developed by [**42dot**](https://42dot.ai/) which is trained to follow natural language instructions.
42dot LLM-SFT is a part of **42dot LLM**, and derived from **42dot LLM-PLM** by supervised fine-tuning (SFT). This repository contains a 1.3B-parameter version.
## Model Description
### Hyperparameters
As same as 42dot LLM-PLM, the model is built upon a Transformer decoder architecture similar to the [LLaMA 2](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) and its hyperparameters are listed below.
| Params | Layers | Attention heads | Hidden size | FFN size | Max. length\* |
| -- | -- | -- | -- | -- | -- |
| 1.3B | 24 | 32 | 2,048 | 5,632 | 4,096 |
(\* unit: tokens)
### Supervised Fine-tuning
Fine-tuning took about 112 GPU hours (in NVIDIA A100). For the training dataset, we manually constructed (question or insturuction) and response pairs, which can either be single- or multi-turn.
### Evaluation
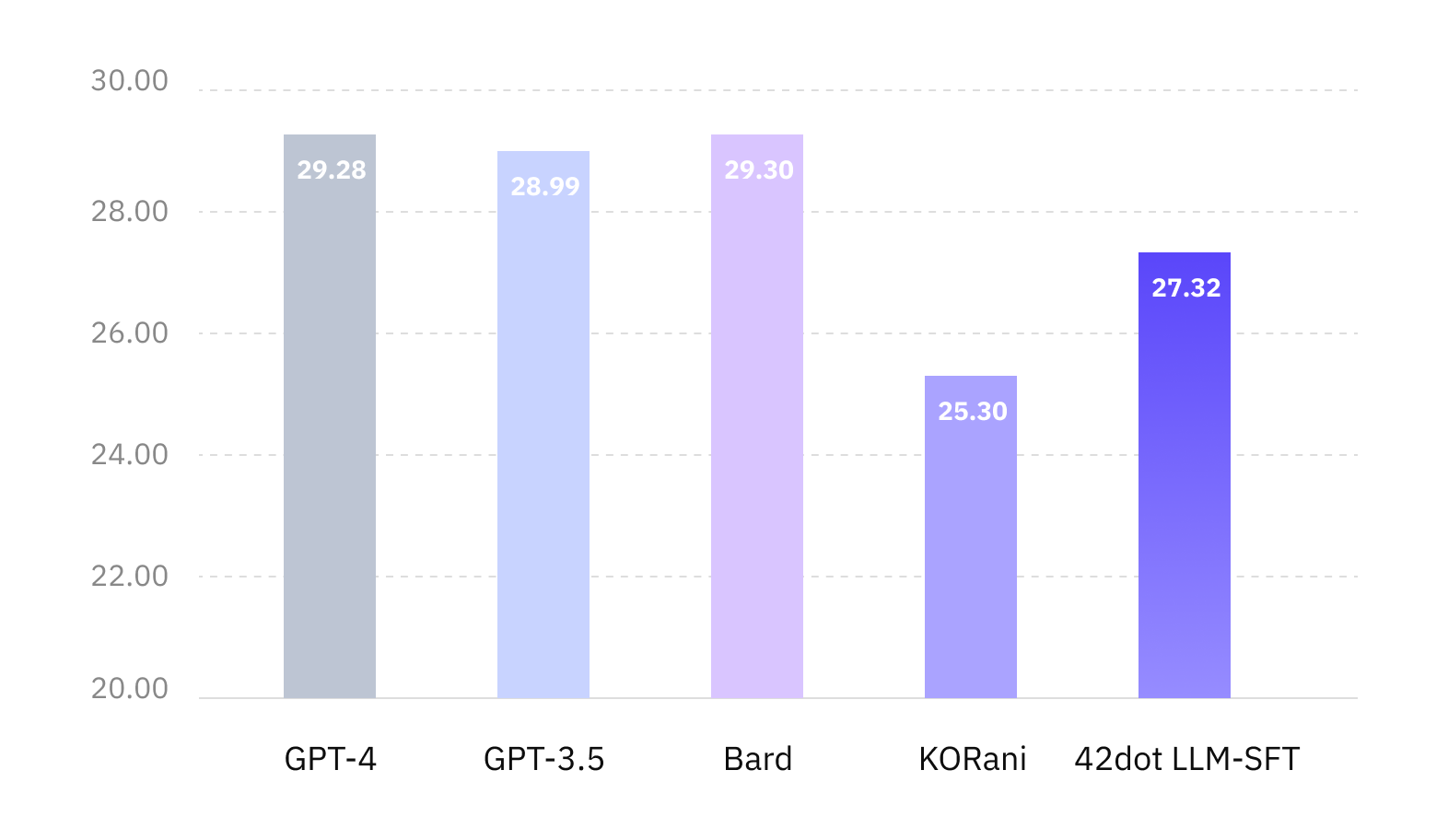
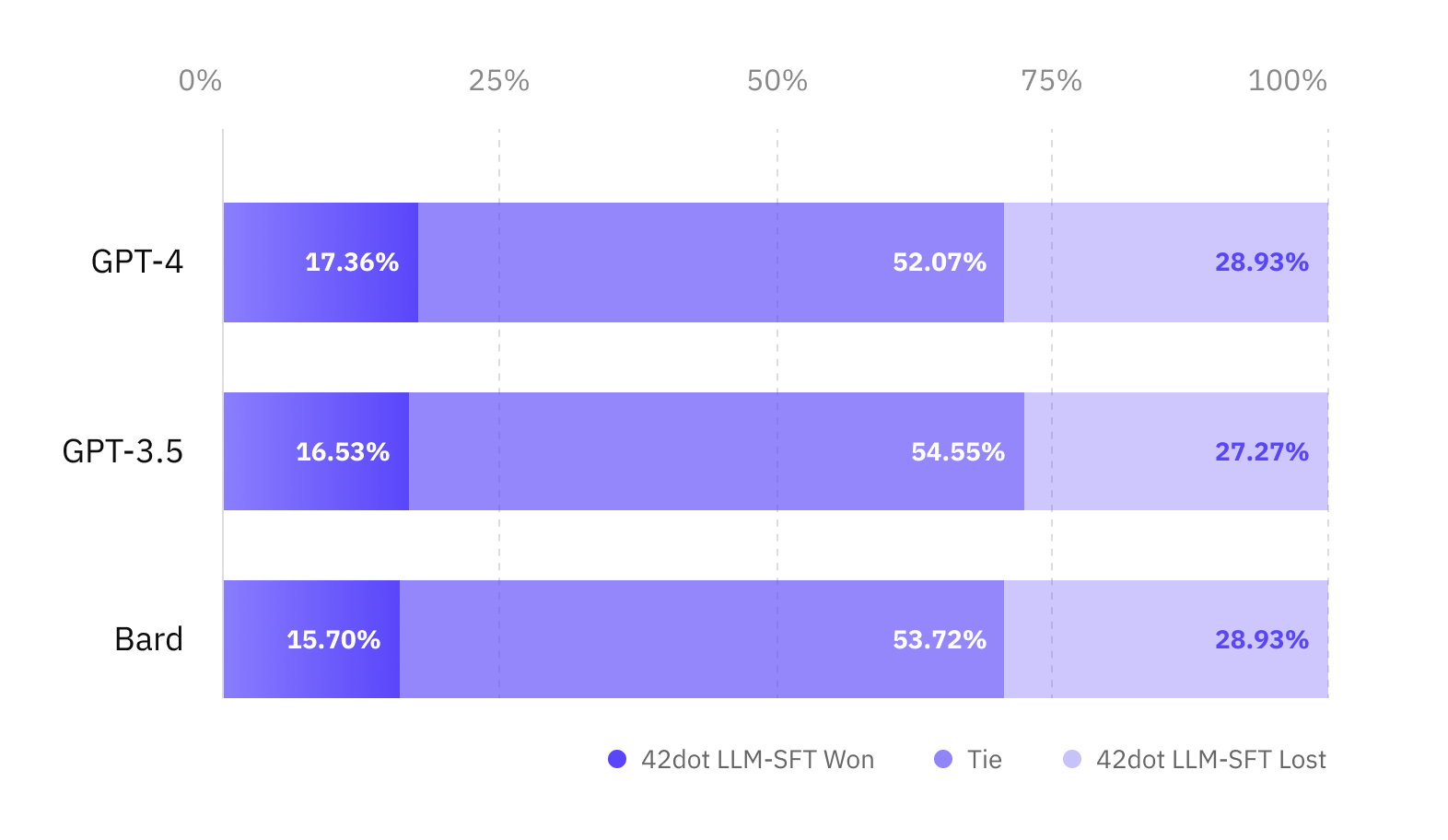
Inspired by recent attempts like [Vicuna](https://lmsys.org/blog/2023-03-30-vicuna/#how-good-is-vicuna), we evaluate 42dot LLM-SFT with other proprietary/open-sourced chatbots using GPT-4 for assessing various aspects of responses. The evaluation dataset consists of 121 prompts over 10 categories. The sample of the evaluation dataset and prompt template can be downloaded from our [GitHub repo](https://github.com/42dot/42dot_LLM).
- Baselines:
- [ChatGPT](https://chat.openai.com/) using GPT-3.5-turbo and GPT-4
- [Bard](https://bard.google.com/)
- [KORani-v2-13B](https://huggingface.co/KRAFTON/KORani-v1-13B)
| Model | GPT-3.5 | GPT-4 | Bard | KORani | 42dot LLM-SFT |
| :-- |:-------:|:--------:|:--------:|:------:|:---------:|
| Params | Unknown | Unknown | Unknown | 13B | 1.3B |
Response quality evaluation resultComparison between proprietary chatbots and 42dot LLM-SFT
## Limitations and Ethical Considerations
42dot LLM-SFT shares a number of well-known limitations of other LLMs. For example, it may generate false and misinformative content since 42dot LLM-SFT is also subject to [hallucination](https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)). In addition, 42dot LLM-SFT may generate toxic, harmful, and biased content due to the use of web-available training data in the pre-training phase. We strongly suggest that 42dot LLM-SFT users should be aware of those limitations and take necessary steps to mitigate those issues.
## Disclaimer
The contents generated by 42dot LLM series ("42dot LLM") do not necessarily reflect the views or opinions of 42dot Inc. ("42dot"). 42dot disclaims any and all liability to any part for any direct, indirect, implied, punitive, special, incidental, or other consequential damages arising from any use of the 42dot LLM and its generated contents.
## License
The 42dot LLM-SFT is licensed under the Creative Commons Attribution-NonCommercial 4.0 (CC BY-NC 4.0).
## Citation
```
@misc{42dot2023llm,
title={42dot LLM: A Series of Large Language Model by 42dot},
author={42dot Inc.},
year={2023},
url = {https://github.com/42dot/42dot_LLM},
version = {1.0.0},
}
```