---
license: apache-2.0
tags:
- Turkish
- turkish
language:
- tr
base_model:
- answerdotai/ModernBERT-base
pipeline_tag: fill-mask
---
# Long Context Pretrained Text Encoder For Turkish Language
 This is a Turkish Base uncased ModernBERT model. Since this model is uncased: it does not make a difference between turkish and Turkish.
#### ⚠ Uncased use requires manual lowercase conversion
**Don't** use the `do_lower_case = True` flag with the tokenizer. Instead, convert your text to lower case as follows:
```python
text.replace("I", "ı").lower()
```
This is due to a [known issue](https://github.com/huggingface/transformers/issues/6680) with the tokenizer.
Be aware that this model may exhibit biased predictions as it was trained primarily on crawled data, which inherently can contain various biases.
## Example Usage
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained(
"99eren99/ModernBERT-base-Turkish-uncased-mlm", do_lower_case=False
)
#tokenizer.truncation_side = "right"
model = AutoModelForMaskedLM.from_pretrained(
"99eren99/ModernBERT-base-Turkish-uncased-mlm", torch_dtype="auto"
)
model.eval()
# model.to("cuda")
```
# Evaluations
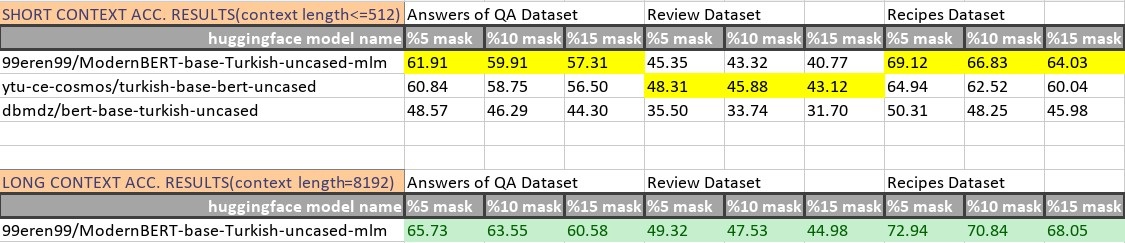
-Mask Prediction Top 1 Accuracies (you can find eval scripts in "./assets" folder):
This is a Turkish Base uncased ModernBERT model. Since this model is uncased: it does not make a difference between turkish and Turkish.
#### ⚠ Uncased use requires manual lowercase conversion
**Don't** use the `do_lower_case = True` flag with the tokenizer. Instead, convert your text to lower case as follows:
```python
text.replace("I", "ı").lower()
```
This is due to a [known issue](https://github.com/huggingface/transformers/issues/6680) with the tokenizer.
Be aware that this model may exhibit biased predictions as it was trained primarily on crawled data, which inherently can contain various biases.
## Example Usage
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained(
"99eren99/ModernBERT-base-Turkish-uncased-mlm", do_lower_case=False
)
#tokenizer.truncation_side = "right"
model = AutoModelForMaskedLM.from_pretrained(
"99eren99/ModernBERT-base-Turkish-uncased-mlm", torch_dtype="auto"
)
model.eval()
# model.to("cuda")
```
# Evaluations
-Mask Prediction Top 1 Accuracies (you can find eval scripts in "./assets" folder):