English | 简体中文
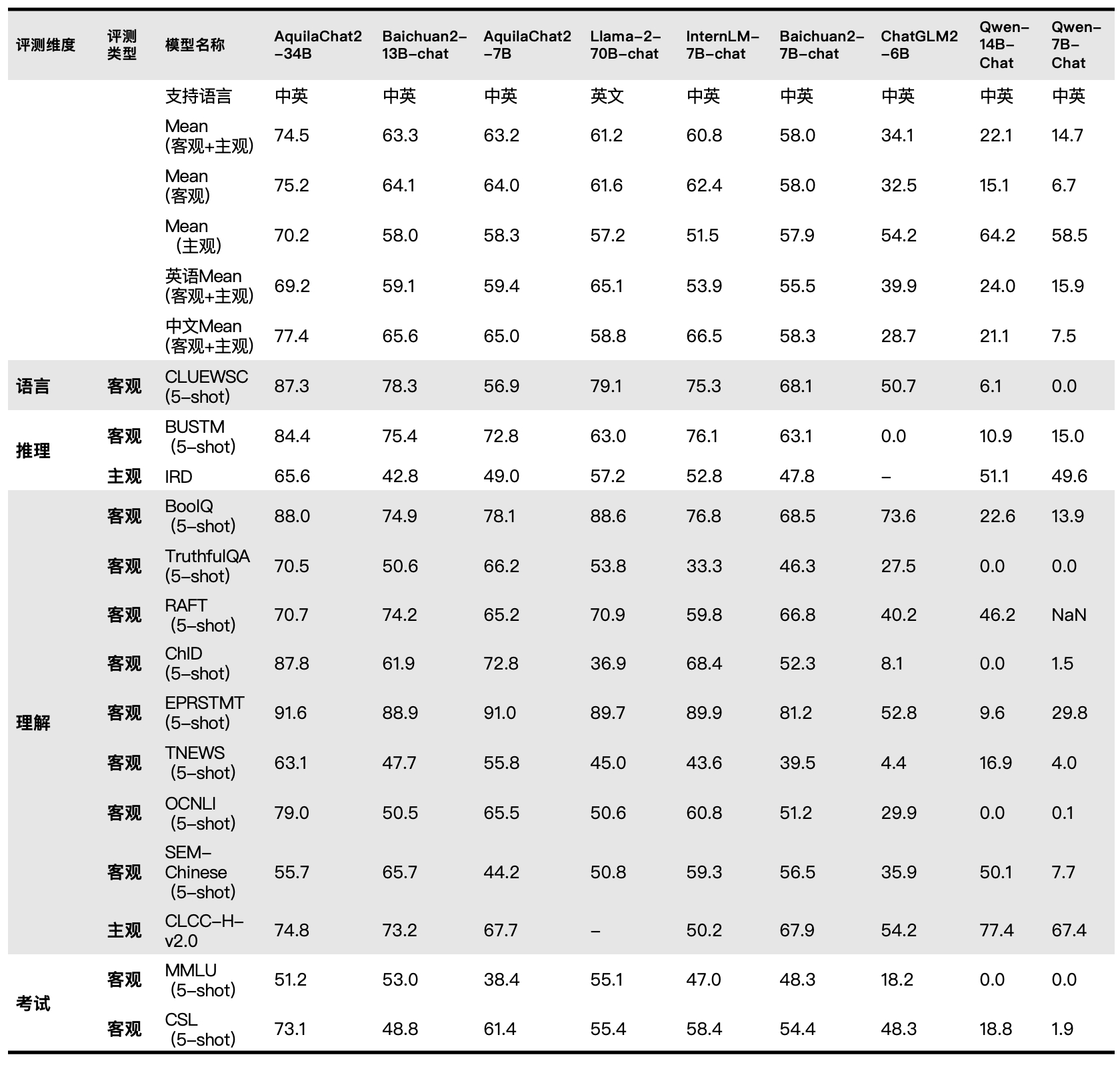
Aquila Language Model is the first open source language model that supports both Chinese and English knowledge, commercial license agreements, and compliance with domestic data regulations. - 🌟 **Supports open source commercial licenses**. The source code of the Aquila series models is based on the [Apache 2.0 agreement](https://www.apache.org/licenses/LICENSE-2.0), while the model weight is based on the [BAAI Aquila Model License Agreement](https://huggingface.co/BAAI/AquilaChat-7B/resolve/main/BAAI%20Aquila%20Model%20License%20Agreement.pdf). Users can use it for commercial purposes as long as they meet the licensing restrictions. - ✍️ **Possesses Chinese and English knowledge**. The Aquila series model is trained from scratch on a high-quality corpus of Chinese and English languages, with Chinese corpora accounting for about 40%, ensuring that the model accumulates native Chinese world knowledge during the pre-training phase, rather than translated knowledge. - 👮♀️ **Complies with domestic data regulations**. The Chinese corpora of the Aquila series models come from Intelligence Source's accumulated Chinese datasets over the years, including Chinese internet data from over 10,000 sources (more than 99% of which are domestic sources), as well as high-quality Chinese literature and book data supported by authoritative domestic organizations. We will continue to accumulate high-quality and diverse datasets and incorporate them into the subsequent training of the Aquila base models. - 🎯 **Continuous improvements and open sourcing**. We will continue to improve training data, optimize training methods, and enhance model performance, cultivate a flourishing "model tree" on a better base model foundation, and continuously update open-source versions. The additional details of the Aquila model will be presented in the official technical report. Please stay tuned for updates on official channels. ## Chat Model Performance
## Quick Start AquilaChat2-7B(Chat model)
### 1. Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = torch.device("cuda")
model_info = "BAAI/AquilaChat2-7B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True)
model.eval()
model.to(device)
text = "请给出10个要到北京旅游的理由。"
tokens = tokenizer.encode_plus(text)['input_ids'][:-1]
tokens = torch.tensor(tokens)[None,].to(device)
stop_tokens = ["###", "[UNK]", ""]
with torch.no_grad():
out = model.generate(tokens, do_sample=True, max_length=512, eos_token_id=100007, bad_words_ids=[[tokenizer.encode(token)[0] for token in stop_tokens]])[0]
out = tokenizer.decode(out.cpu().numpy().tolist())
print(out)
```
## License
AquilaChat2-7B open-source model is licensed under [ BAAI Aquila Model Licence Agreement](https://huggingface.co/BAAI/AquilaChat-7B/resolve/main/BAAI%20Aquila%20Model%20License%20Agreement.pdf)