---
license: apache-2.0
datasets:
- BAAI/OPI
language:
- en
pipeline_tag: text-generation
tags:
- biology
---

## Model Card of OPI_full_Galactica-6.7B
This repo is for the Open Protein Instructions (OPI) project, aiming to build and release a protein instruction dataset as well as propose to explore and benckmark LLMs for protein modeling in protein biology.
For more details of training and testing, please visit [https://github.com/baaihealth/opi](https://github.com/baaihealth/opi).
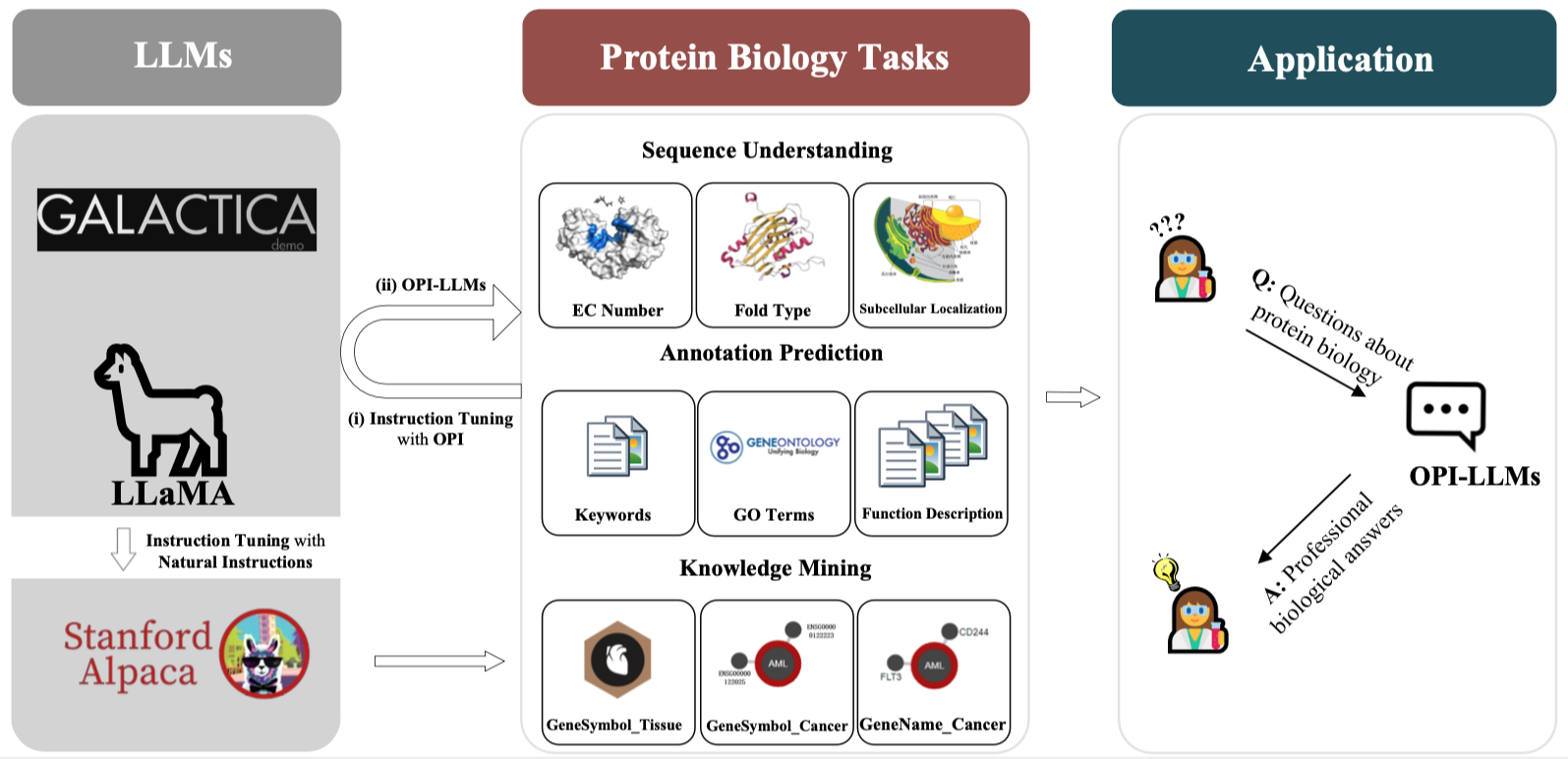
**Usage and License Notices:** [LLaMA](https://github.com/facebookresearch/llama) and [Galactica](https://github.com/paperswithcode/galai) are intended and licensed for research use only. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes. The weight diff for [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca) is also CC BY NC 4.0 (allowing only non-commercial use).
## OPI-instruction tuning from original Galactica-6.7B model and LLaMA-7B model
For OPI-instruction tuning, we adopt the training script of [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca).
### 1. Galactica instruction-tuning with OPI
[Example: train_keywords.sh](https://github.com/baaihealth/opi/tree/main/train_galai/train_keywords.sh)
```
#!/bin/bash
OMP_NUM_THREADS=1 torchrun --nnodes=$1 --node_rank=$2 --nproc_per_node=3 train_galai/train.py \
--model_name_or_path path/to/galactica_base_model/galactica-$3 \
--data_path ./OPI_DATA/AP/Keywords/train/keywords_train.json \
--bf16 True \
--output_dir path/to/output/galai_ft_opi/galai_ft_keywords_$3_e$4 \
--num_train_epochs $4 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--deepspeed "./configs/default_offload_opt_param.json" \
--tf32 True
```
In the Shell above, you can setup your onw local LLM weights path or Huggingface model entry (e.g., *facebook/galactica-6.7b*) to ```model_name_or_path``` and you onw training results saving path to ```output_dir```.
To start training, please do like this:
```
bash train_galai/train_keywords.sh 1 0 6.7b 3
```
Explanation of such bash arguments:
```
1: nnodes \
0: node_rank \
6.7b: model size of Galactica \
3: total training epochs
```
### 2. LLaMA instruction-tuning with OPI
[Example: train_EC_number.sh](https://github.com/baaihealth/opi/tree/main/train_llama/train_EC_number.sh)
```
#!/bin/bash
OMP_NUM_THREADS=1 torchrun --nnodes=$1 --node_rank=$2 --nproc_per_node=3 train_llama/train.py \
--model_name_or_path path/to/llama_base_model/hf_version/llama-$3 \
--data_path ./OPI_DATA/SU/EC_number/train/CLEAN_EC_number_train.json \
--bf16 True \
--output_dir path/to/output/llama_ft_CLEAN_EC_number_$3_e$4 \
--num_train_epochs $4 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 16 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--deepspeed "./configs/default_offload_opt_param.json" \
--tf32 True
```
In the Shell above, you can setup your onw local LLM weights path or Huggingface model entry (e.g., *decapoda-research/llama-7b-hf*) to ```model_name_or_path``` and you onw training results saving path to ```output_dir```.
To start training, please do like this:
```
bash train_llama/train_EC_number.sh 1 0 7b 3
```
Explanation of such bash arguments:
```
1: nnodes \
0: node_rank \
7b: model size of LLaMA \
3: total training epochs
```
**Note**: As for the training, we take the suggestion to address out-of-memory issue from [tatsu-lab/stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca), using DeepSpeed ZeRO stage-3 with offload.
### 3. Convert DeepSpeed-format weights
Once finished instruction tuning, the DeepSpeed-format weights should be converted to **pytorch_model.bin**, using the following script:
```
cd output_dir
python zero_to_fp32.py . pytorch_model.bin
```
### 4. Split pytorch_model.bin into chunks to speedup loading for inference
After step 3, you will get the **pytorch_model.bin** file. You can further split it to small chunks, e.g., pytorch_model-00001-of-00004.bin
pytorch_model-00002-of-00004.bin, pytorch_model-00003-of-00004.bin, pytorch_model-00004-of-00004.bin, in order to speedup loading it when inferenceing. However, it is not a must, if you don't want. If you would like to split it, please do like this:
```
cd model_split
python model_split.py --model_idx OPI-instruction-tuned-model-name
```
Then you will get a checkpoint folder suffixed with "**chunked**", which you can take as the **pretrained model path** for later evaluation job.
### 5. How to access OPI-instruction-tuned Galactica-6.7B model?
In this repo, we release the OPI_full_Galactica-6.7B model which is fine-funed on OPI full dataset, which can be accessed from [HuggingFace](https://huggingface.co/BAAI/OPI_full_Galactica-6.7B). Please feel free to contact us if there is any question.
## OPEval: Nine Evaluation tasks
For benchamarking, we design OPEval consisting of 3 types of evaluation tasks, each of which contains 3 specific ones, as shown in the following table.
| Task Type | Abbreviation | Task Name |
| :--------------------: | :----------: | :-----------------------------------------: |
| Sequence Understanding | SU | EC Number Prediction |
| Sequence Understanding | SU | Fold Type Prediction |
| Sequence Understanding | SU | Subcellular Localization Prediction |
| Annotation Prediction | AP | Function Keywords Prediction |
| Annotation Prediction | AP | Gene Ontology(GO) Terms Prediction |
| Annotation Prediction | AP | Function Description Prediction |
| Knowledge Mining | KM | Tissue Location Prediction from Gene Symbol |
| Knowledge Mining | KM | Cancer Prediction from Gene Symbol |
| Knowledge Mining | KM | Cancer Prediction from Gene Name |
## Evaluating various models with OPI data
### 1. Environment setup
```
pip install -r requirements.txt
```
As for the evaluation, we refer to the inference script from [Chinese-LLaMA-Alpaca](https://github.com/ymcui/Chinese-LLaMA-Alpaca).
### 2. Evaluation of Galactica
We evaluate OPI-instruction-tuned Galactica-6.7B model and origional Galactica-6.7B model.
**For OPI-instruction-tuned Galactica-6.7B model, please use the following script:**
```
cd eval_galai
python eval_galai.py --model_idx OPI-instruction-tuned-model-name --output_dir ./eval_galai_output --gpus=0
```
In the commands above, ```model_idx```is the model index you can allocate to your local LLM weights for you to easily access a LLM model when inferencing, which you can set it up in the [model_dict](eval_galai/eval_galai.py#L74) in [eval_galai.py](eval_galai/eval_galai.py#L74). ```output_dir```is where you save the evaluation results.
**For the original Galactica-6.7B model, please use the following script:**
```
cd eval_galai/infer_with_original_galai
bash galactica_infer.sh
```
### 3. Evaluation of Alpaca
For comparison, we evaluate Alpaca-7B model and [Galpaca-6.7B](https://huggingface.co/GeorgiaTechResearchInstitute/galpaca-6.7b) model. The Galpaca-6.7B model is contributed by Georgia Tech Research Institute on HuggingFace.
As for Alpaca-7B model, we first get [alpaca-7b-wdiff](https://huggingface.co/tatsu-lab/alpaca-7b-wdiff) from HuggingFace, which is the weight diff for [Stanford Alpaca-7B](https://github.com/tatsu-lab/stanford_alpaca/), then recover the original Alpaca-7B weights using the conversion script provided by [tatsu-lab/stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca).
The same script is used for evaluating Alpaca-7B and Galpaca-6.7B model, just by setting a different model_idx for a different model.
```
cd eval_alpaca
python eval_alpaca.py --model_idx alpaca-7b-recover --output_dir ./eval_alpaca_output --gpus=0 #original Alpaca-7B weights
```
In the commands above, ```model_idx```is the model index you can allocate to your local LLM weights for you to easily access a LLM model when inferencing, which you can set it up in the [model_dict](eval_galai/eval_galai.py#L74) in [eval_alpaca.py](eval_alpaca/eval_alpaca.py#L81). ```output_dir```is where you save the evaluation results.
### 4. Evaluation of LLaMA
For comparison, we evaluate OPI-instruction-tuned LLaMA-7B model and original LLaMA-7B model.
The same script is used for evaluating OPI-instruction-tuned LLaMA-7B model and original LLaMA-7B model, just by setting a different model_idx for a different model.
```
cd eval_llama
python eval_llama.py --model_idx llama_7b_hf --output_dir ./eval_llama_output --gpus=0 #original LLaMA-7B weights
```
In the commands above, ```model_idx```is the model index you can allocate to your local LLM weights for you to easily access a LLM model when inferencing, which you can set it up in the [model_dict](eval_galai/eval_galai.py#L74) in [eval_llama.py](eval_llama/eval_llama.py#L83). ```output_dir```is where you save the evaluation results.
### 5. The following table shows evaluation results of OPI_full_Galactica-6.7B model on 9 tasks.
| Task Type | Task Name | Testing file | Accuracy | Precision | Recall | F1 | Rouge-L |
| ---------------------- | ------------------------------------------- | ----------------------------- | :------: | :-------: | :----: | :---: | :-----: |
| Sequence Understanding | EC Number Prediction | CLEAN_EC_number_new_test | - | 0.181 | 0.174 | 0.176 | - |
| Sequence Understanding | EC Number Prediction | CLEAN_EC_number_price_test | - | 0.054 | 0.054 | 0.054 | - |
| Sequence Understanding | Fold Type Prediction | Remote_test_fold | 0.068 | - | - | - | - |
| Sequence Understanding | Fold Type Prediction | Remote_test_superfamily | 0.090 | - | - | - | - |
| Sequence Understanding | Fold Type Prediction | Remote_test_family | 0.416 | - | - | - | - |
| Sequence Understanding | Subcellular Localization Prediction | location_test | 0.678 | - | - | - | - |
| Annotation Prediction | Function Keywords Prediction | CASPSimilarSeq_keywords_test | - | 0.716 | 0.669 | 0.674 | - |
| Annotation Prediction | Function Keywords Prediction | IDFilterSeq_keywords_test | - | 0.822 | 0.771 | 0.778 | - |
| Annotation Prediction | Function Keywords Prediction | UniProtSeq_keywords_test | - | 0.871 | 0.802 | 0.820 | - |
| Annotation Prediction | Gene Ontology(GO) Terms Prediction | CASPSimilarSeq_go_test | - | 0.710 | 0.627 | 0.647 | - |
| Annotation Prediction | Gene Ontology(GO) Terms Prediction | IDFilterSeq_go_test | - | 0.724 | 0.637 | 0.656 | - |
| Annotation Prediction | Gene Ontology(GO) Terms Prediction | UniProtSeq_go_test | - | 0.759 | 0.683 | 0.698 | - |
| Annotation Prediction | Function Description Prediction | CASPSimilarSeq_function_test | - | - | - | - | 0.431 |
| Annotation Prediction | Function Description Prediction | IDFilterSeq_function_test | - | - | - | - | 0.624 |
| Annotation Prediction | Function Description Prediction | UniProtSeq_function_test | - | - | - | - | 0.696 |
| Knowledge Mining | Tissue Location Prediction from Gene Symbol | gene_symbol_to_tissue_test | - | 0.377 | 0.779 | 0.468 | - |
| Knowledge Mining | Cancer Prediction from Gene Symbol | gene_symbol_to_cancer_test | - | 0.554 | 0.433 | 0.465 | - |
| Knowledge Mining | Cancer Prediction from Gene Name | gene_name_to_cancer_test | - | 0.507 | 0.400 | 0.429 | - |
## Prediction (by OPI_full_Galactica-6.7B) v.s. Target
EC Number Prediction
```
Instruction:
What is the EC number of the input sequence?
Input:
MSLLAYTNLLLQNGRIFRYYKKANIKKFIKKIIKLDLKSTPSEASVSRQTFLSTGLNSVKNAVQLQARKLLINNVLERVTPTLNSDLKKKAAKRLFYGDSAPFFALVGVSLASGSGLLTKDDELEGICWEIREAVSKGKWNDSESENVEQLQAANLDELDLGEPIAKGCNAVVYSAKLKNVQSNKLAHQLAVKMMFNYDVESNSTAILKAMYRETVPAMSYFFNQNLFNIENISDFKIRLPPHPNIVRMYSVFADRIPDLQCNKQLYPEALPPRINPEGSGRNMSLFLVMKRYDCTLKEYLRDKTPNMRSSILLLSQLLEAVAHMNIHNISHRDLKSDNILVDLSEGDAYPTIVITDFGCCLCDKQNGLVIPYRSEDQDKGGNRALMAPEIANAKPGTFSWLNYKKSDLWAVGAIAYEIFNIDNPFYDKTMKLLSKSYKEEDLPELPDTIPFIIRNLVSNMLSRSTNKRLDCDVAATVAQLYLWAPSSWLKENYTLPNSNEIIQWLLCLSSKVLCERDITARNKTNTMSESVSKAQYKGRRSLPEYELIASFLRRVRLHLVRKGLKWIQELHIYN
Prediction:
2.7.11.1
Target:
2.7.11.1
```
Fold Type Prediction
```
Instruction:
Please predict its folding type based on the protein sequence. Here, a number is assigned to each folding type, ranging from 0 to 1194.
Input:
GSGDSHPDFPEDADVDLKDVDKILLISEDLKNIGNTFFKSQNWEMAIKKYTKVLRYVEGSRAAAEDADGAKLQPVALSCVLNIGACKLKMSDWQGAVDSCLEALEIDPSNTKALYRRAQGWQGLKEYDQALADLKKAQEIAPEDKAIQAELLKVKQKIKAQKDKEKAAY
Prediction:
3
Target:
3
```
Subcellular Localization Prediction
```
Instruction:
By scrutinizing the protein's amino acid composition and sequence motifs, forecast its intracellular localization in eukaryotic cells.
Input:
MEDEAVLDRGASFLKHVCDEEEVEGHHTIYIGVHVPKSYRRRRRHKRKTGHREKKEKERISENYSDKSDVENADESSSSILKPLISPAAERIRFILGEEDDSPAPPQLFTELDELLAVDGQEMEWKETARWIKFEEKVEQGGERWSKPHVATLSLHSLFELRTCMEKGSIMLDREASSLPQLVEMIVDHQIETGLLKPDLKDKVTYTLLRKHRHQTKKSNLRSLADIGKTVSSASRMFTNPDNGSPAMTHRNLTSSSLNDISDKPEKDQLKNKFMKKLPRDAEASNVLVGEVDFLDSPFIAFVRLQQAVMLGALTEVPVPTRFLFILLGPKGKAKSYHEIGRAIATLMSDEVFHDIAYKAKDRQDLIAGIDEFLDEVIVLPPGEWDPAIRIEPPKSLPSSDKRKNMYSGGENVQMNGDTPPDGGHGGGGHADCEELQRTGRFCGGLIKDIKRKAPFFASDFYDALNIQALSAILFIYLATVTNAITFGGLLGDATDNMQGVLESFLGTAVSGAIFCLFAGQPLTILSSTGPVLVFERLLFNFSKDHNFDYLEFRLWIGLWSAFLCLILVATDASFLVQYFTRFTEEGFSSLISFIFIYDAFKKMIKLADYYPINSNFKVGYNTQFSCVCMPPDPVNISVSNDTTLAPEDLPTISSSNMYHNATFDWAFLTTKECLKYGGKLVGNNCGFVPDITLMSFILFLGTYTSSMALKKFKTSPYFPTTARKLISDFAIILPILIFCVIDALVGVDTPKLIVPSEFKPTSPNRGWFVAPFGGNPWWVYLAAAIPALLVTILIFMDQQITAVIVNRKEHKLKKGAGYHLDLFWVAILMVVCSFMALPWYVAATVISIAHIDSLKMETETSAPGEQPKFLGVREQRVTGTLVFILTGLSVFMAPILKFIPMPVLYGVFLYMGVASLNGVQFMDRLKLLLMPLKHQPDFIYLRHVPLRRVHLFTFLQVLCLALLWILKSTVAAIIFPVMILALVAVRKGMDYLFSQHDLSFLDDVIPEKDKKKKEDEKKKKKKKGSVDSDNDDSDCPYSEKVPSIKIPMDIMEQQPFLSDSKPSDRERSPTFLERHTSC
Prediction:
membrane
Target:
membrane
```
Function Keywords Prediction
```
Instruction:
What are the UniProtKB keywords for this specific protein sequence?
Input:
MRGSFFSRLPPQLSLLLLLLLLLSWRRVWTQEHIGTDPSKSPVAPVCPEACSCSPGGKANCSALALPAVPAGLSWQVRSLLLDRNRVSTLPPGAFADAGALLYLVLRENRLRSVHARAFWGLGVLQRLDLSSNQLETLSPGTFTPLRALSFLSLAGNRLALLEPSILGPLPLLRVLSLQDNSLSALEAGLLNSLPALDVLRLHGNPWACSCALRPLCTWLRKHPRPTSETETLLCVSPKLQTLNLLTDFPDNAFKQCTQSLAARDLAVVYALGPASFLASLAICLALGSVLTACGARRRRRRTTVRHLIRRQPDPEGPASLEDVGSPTTTAIQA
Prediction:
Cell membrane ; Cytoplasm ; Cytoskeleton ; Disulfide bond ; Ion channel ; Ion transport ; Leucine-rich repeat ; Membrane ; Reference proteome ; Repeat ; Signal ; Transmembrane ; Transmembrane helix ; Transport
Target:
Cell membrane ; Cytoplasm ; Cytoskeleton ; Disulfide bond ; Ion channel ; Ion transport ; Leucine-rich repeat ; Membrane ; Reference proteome ; Repeat ; Signal ; Transmembrane ; Transmembrane helix ; Transport
```
Gene Ontology(GO) Terms Prediction
```
Instruction:
The Gene Ontology project (GO) provides a controlled vocabulary to describe gene and gene product attributes in any organism. There are 3 disjoint categories: cellular component, molecular function and biological process. Predict the GO term for a given protein sequence.
Input:
MEFVTNYTLEELKKRFTELGLEPYRAKQVFRWVYKKFVTDFEKMTDLGKKHRELLKEHFAFHPLEKLDRVEAPDAVKYLFKTKDGHILETVLIKERDHYTLCVSSQIGCAVGCTFCATALDGLKRNLSTAEIIDQYLQVQQDLGEEKIRNVVFMGMGEPLANYENVRKAVEIMVSPEGLDLSKRRITISTSGIVAQIKRMAQDPVMKEVNLAVSLNAVSQKKREELMPLTKTNTLEELMEVLKNYPLPKYRRITLEYVLIKGVNDSPNDAERLAKLIGRHKKKFKVNLIPFNPDPNLPYERPALTDIMKFQKVLWKYGISNFVRFSKGVEVFGACGQLRTQRLQLQRV
Prediction:
cytoplasm ; 4 iron, 4 sulfur cluster binding ; metal ion binding ; rRNA (adenine-C2-)-methyltransferase activity ; rRNA binding ; tRNA (adenine-C2-)-methyltransferase activity ; tRNA binding ; rRNA base methylation
Target:
cytoplasm ; 4 iron, 4 sulfur cluster binding ; metal ion binding ; rRNA (adenine-C2-)-methyltransferase activity ; rRNA binding ; tRNA (adenine-C2-)-methyltransferase activity ; tRNA binding ; rRNA base methylation ; tRNA methylation
```
Function Description Prediction
```
Instruction:
Generate the functional description in free-text form based on the protein sequence.
Input:
MAAPSGVHLLVRRGSHRIFSSPLNHIYLHKQSSSQQRRNFFFRRQRDISHSIVLPAAVSSAHPVPKHIKKPDYVTTGIVPDWGDSIEVKNEDQIQGLHQACQLARHVLLLAGKSLKVDMTTEEIDALVHREIISHNAYPSPLGYGGFPKSVCTSVNNVLCHGIPDSRPLQDGDIINIDVTVYYNGYHGDTSETFLVGNVDECGKKLVEVARRCRDEAIAACRAGAPFSVIGNTISHITHQNGFQVCPHFVGHGIGSYFHGHPEIWHHANDSDLPMEEGMAFTIEPIITEGSPEFKVLEDAWTVVSLDNQRSAQFEHTVLITSRGAQILTKLPHEA
Prediction:
Removes the N-terminal methionine from nascent proteins. The N-terminal methionine is often cleaved when the second residue in the primary sequence is small and uncharged (Met-Ala-, Cys, Gly, Pro, Ser, Thr, or Val). Requires deformylation of the N(alpha)-formylated initiator methionine before it can be hydrolyzed.
Target:
Removes the N-terminal methionine from nascent proteins. The N-terminal methionine is often cleaved when the second residue in the primary sequence is small and uncharged (Met-Ala-, Cys, Gly, Pro, Ser, Thr, or Val). Requires deformylation of the N(alpha)-formylated initiator methionine before it can be hydrolyzed (By similarity). May play a role in colon tumorigenesis.
```
Tissue Location Prediction from Gene Symbol
```
Instruction:
According to the relevant data reported in the scientific literature, the Gene symbol of a given protein can be used to predict which tissues the protein is expressed in.
Input:
TMEM198
Prediction:
adrenal gland, appendix, bone marrow, breast, bronchus, caudate, cerebellum, cerebral cortex, cervix, colon, duodenum, endometrium, epididymis, esophagus, fallopian tube, gallbladder, heart muscle, hippocampus, kidney, liver, lung, lymph node, nasopharynx, oral mucosa, ovary, pancreas, parathyroid gland, placenta, prostate, rectum, salivary gland, seminal vesicle, skeletal muscle, skin, small intestine, smooth muscle, soft tissue, spleen, stomach, testis, thyroid gland, tonsil, urinary bladder
Target:
adrenal gland, appendix, breast, bronchus, cerebral cortex, colon, fallopian tube, gallbladder, kidney, nasopharynx, prostate, rectum, salivary gland, seminal vesicle, skeletal muscle, small intestine, stomach, urinary bladder
```
Cancer Prediction from Gene Symbol
```
Instruction:
Return the name of the cancer corresponding to the given gene symbol.
Input:
FOXL2
Prediction:
granulosa-cell tumour of the ovary
Target:
granulosa-cell tumour of the ovary
```
Cancer Prediction from Gene Name
```
Instruction:
Give back the cancer name that is associated with the provided gene name.
Input:
immunoglobulin lambda locus
Prediction:
Burkitt lymphoma
Target:
Burkitt lymphoma
```
## Demo
We use the [FastChat](https://github.com/lm-sys/FastChat) platform to visually demonstrate the ability of OPI_full_Galactica-6.7B model on various evaluation tasks.
