---
license: apache-2.0
datasets:
- FreedomIntelligence/ApolloMoEDataset
language:
- ar
- en
- zh
- ko
- ja
- mn
- th
- vi
- lo
- mg
- de
- pt
- es
- fr
- ru
- it
- hr
- gl
- cs
- co
- la
- uk
- bs
- bg
- eo
- sq
- da
- sa
- gn
- sr
- sk
- gd
- lb
- hi
- ku
- mt
- he
- ln
- bm
- sw
- ig
- rw
- ha
metrics:
- accuracy
base_model:
- Qwen/Qwen2-7B
pipeline_tag: question-answering
tags:
- biology
- medical
---
# Democratizing Medical LLMs For Much More Languages
Covering 12 Major Languages including English, Chinese, French, Hindi, Spanish, Arabic, Russian, Japanese, Korean, German, Italian, Portuguese and 38 Minor Languages So far.
📃 Paper • 🌐 Demo • 🤗 ApolloMoEDataset • 🤗 ApolloMoEBench • 🤗 Models •🌐 Apollo • 🌐 ApolloMoE

## 🌈 Update
* **[2024.10.15]** ApolloMoE repo is published!🎉
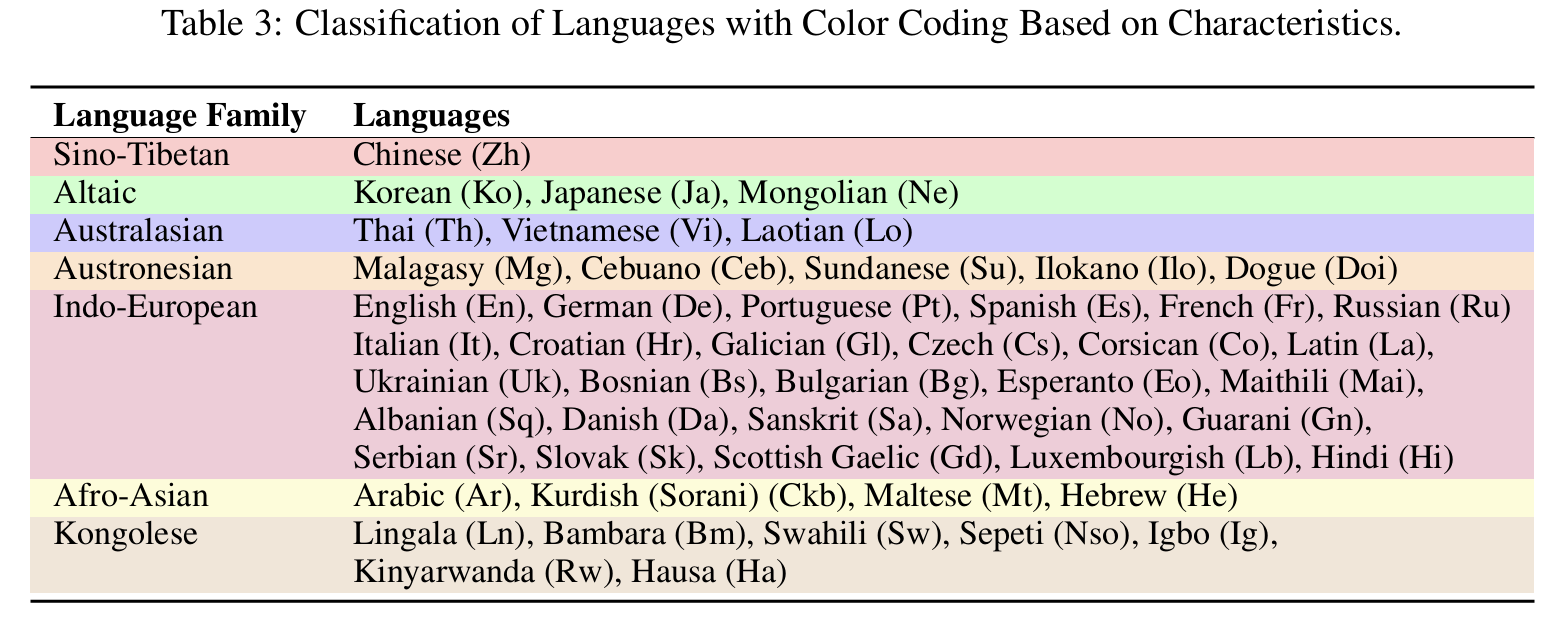
## Languages Coverage
12 Major Languages and 38 Minor Languages
Click to view the Languages Coverage
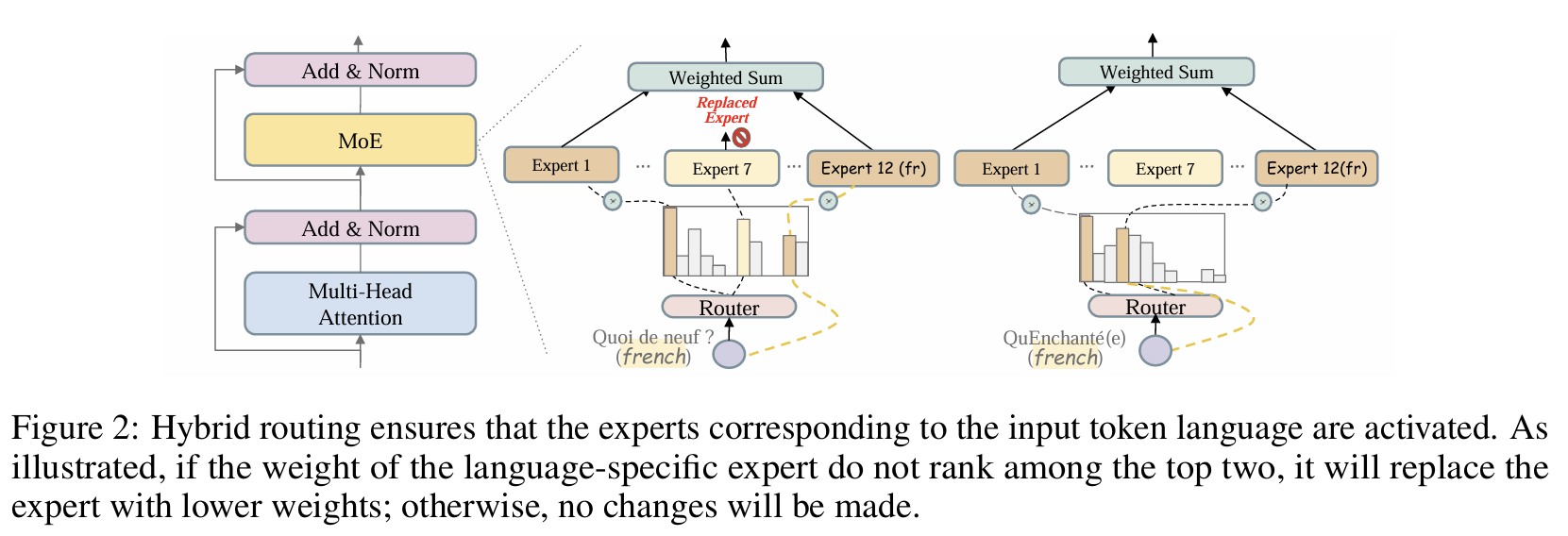
## Architecture
Click to view the MoE routing image
## Results
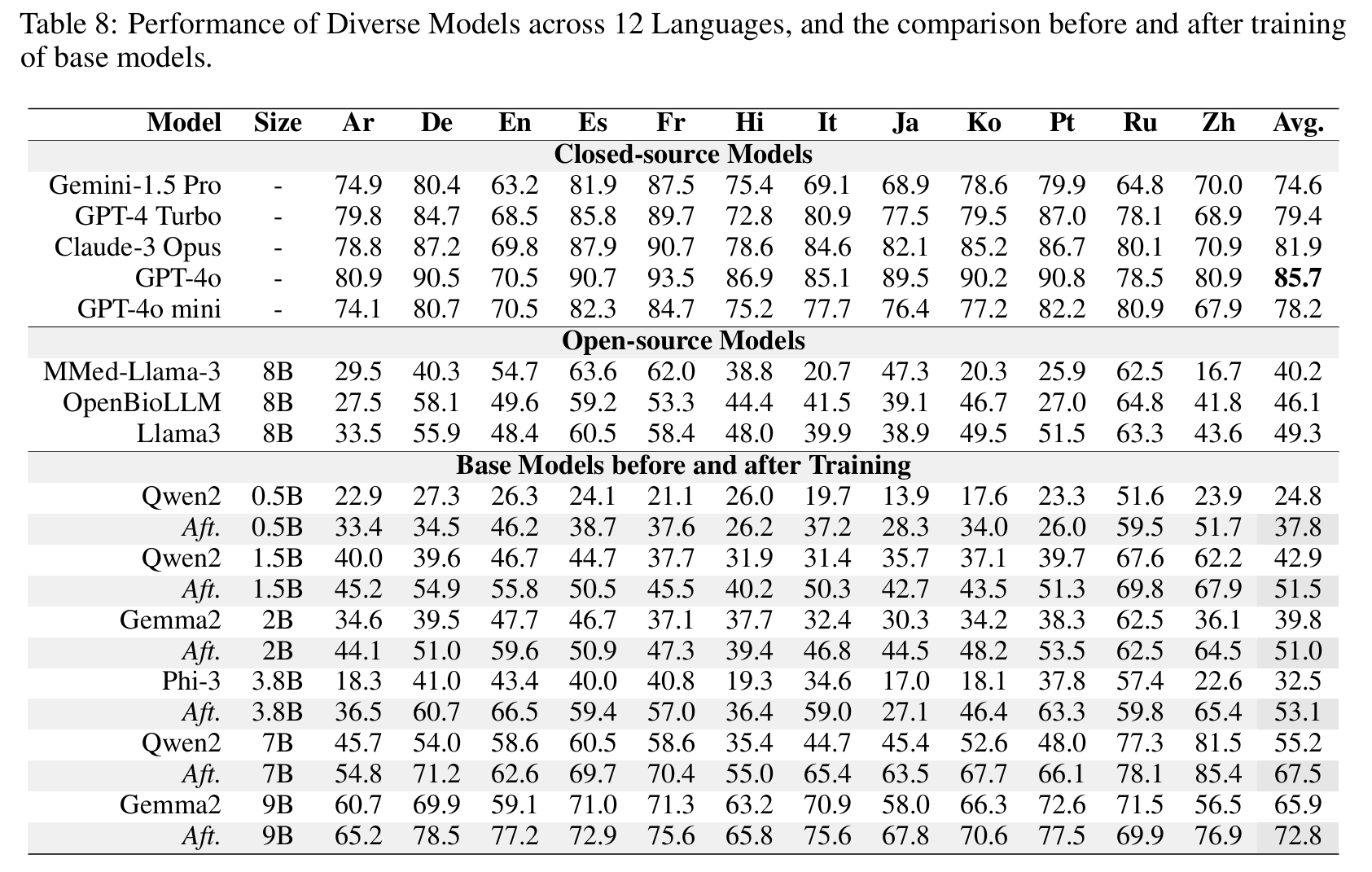
#### Dense
🤗 Apollo2-0.5B • 🤗 Apollo2-1.5B • 🤗 Apollo2-2B
🤗 Apollo2-3.8B • 🤗 Apollo2-7B • 🤗 Apollo2-9B
Click to view the Dense Models Results
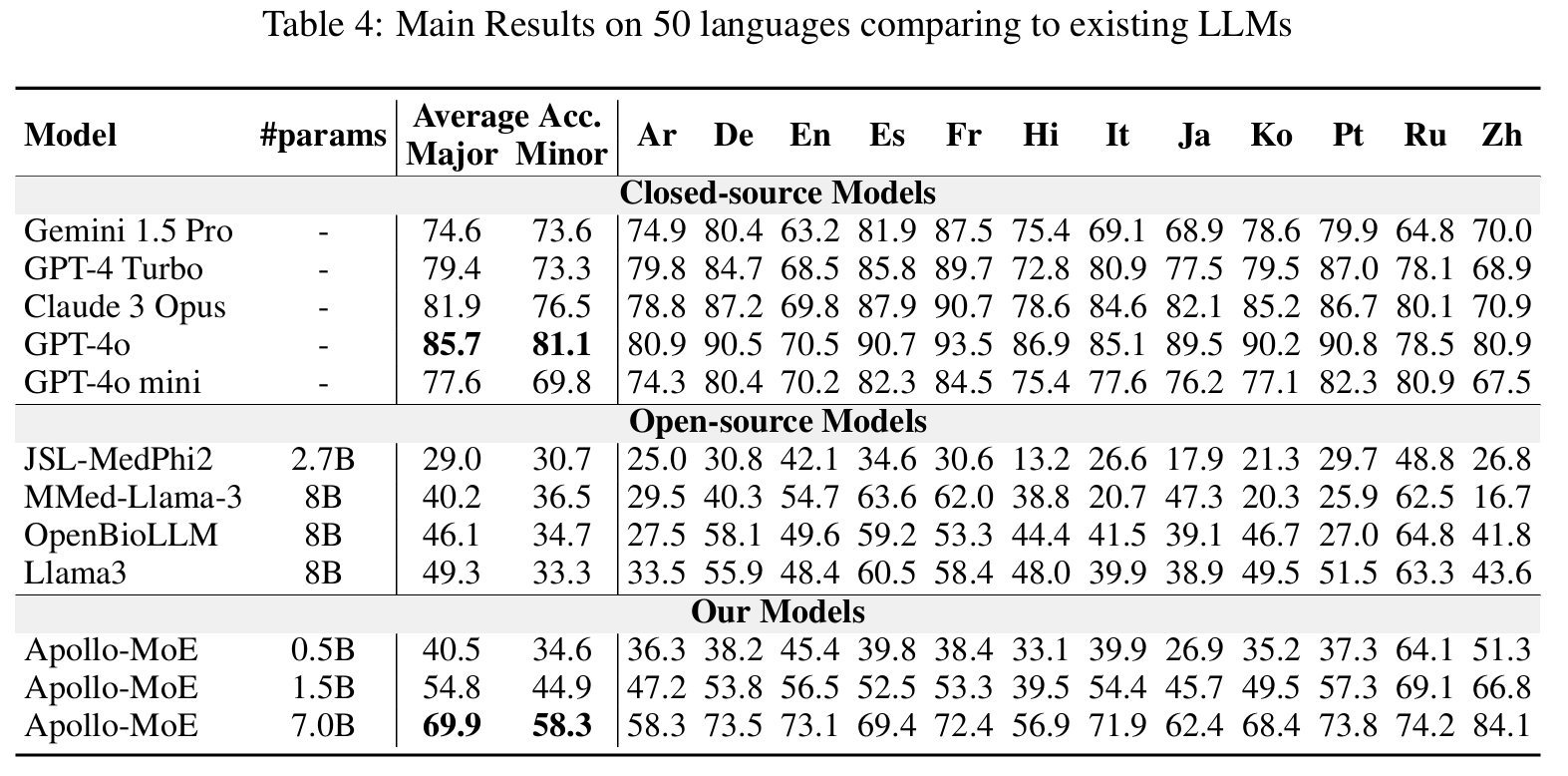
#### Post-MoE
🤗 Apollo-MoE-0.5B • 🤗 Apollo-MoE-1.5B • 🤗 Apollo-MoE-7B
Click to view the Post-MoE Models Results
## Usage Format
##### Apollo2
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
- 2B, 9B: User:{query}\nAssistant:{response}\
- 3.8B: <|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
##### Apollo-MoE
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
## Dataset & Evaluation
- Dataset
🤗 ApolloMoEDataset
Click to expand
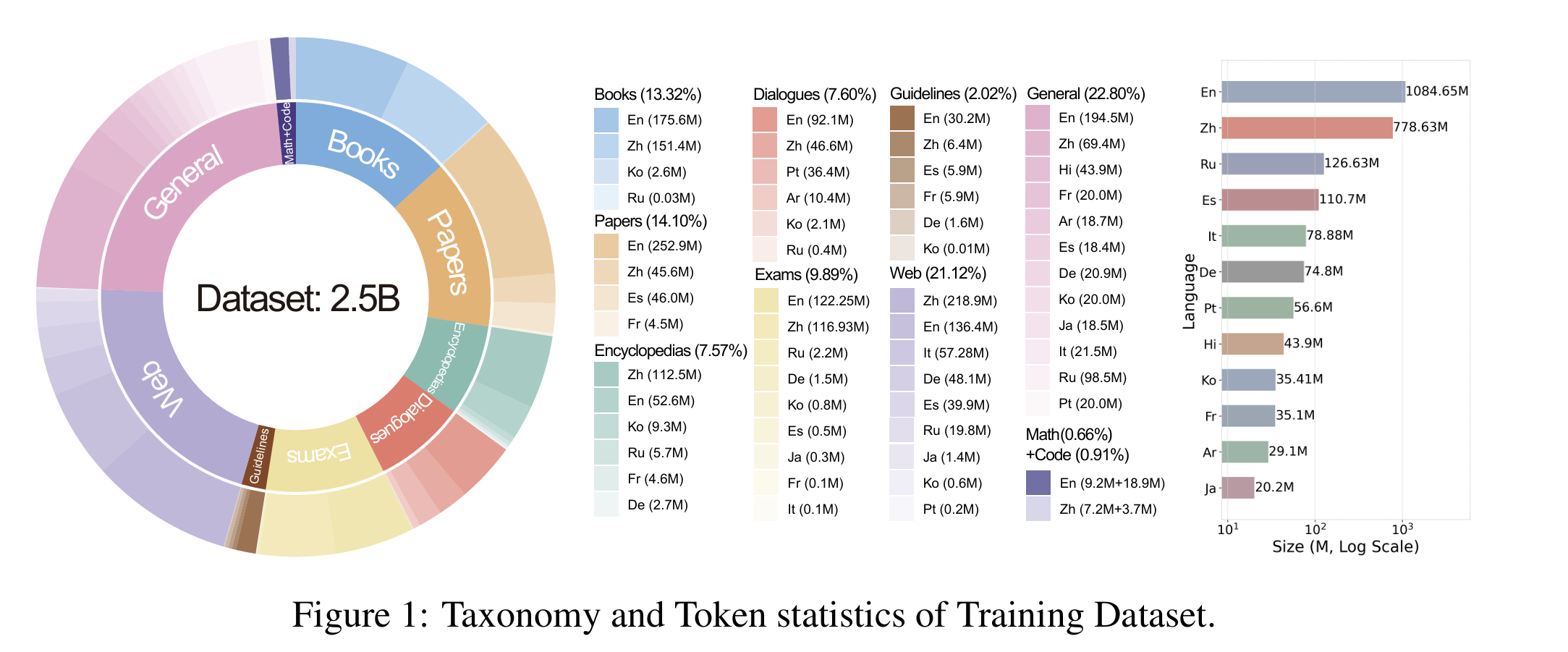
- [Data category](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/tree/main/train)
Click to expand
- EN:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa): Because the results fluctuated too much, they were not used in the paper.
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- ZH:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB): Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- [CExam](https://github.com/williamliujl/CMExam): Not used in the paper
- Randomly sample 2,000 multiple-choice questions
- ES: [Head_qa](https://huggingface.co/datasets/head_qa)
- FR:
- [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- [MMLU_FR]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- HI: [MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- AR: [MMLU_AR](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- JA: [IgakuQA](https://github.com/jungokasai/IgakuQA)
- KO: [KorMedMCQA](https://huggingface.co/datasets/sean0042/KorMedMCQA)
- IT:
- [MedExpQA](https://huggingface.co/datasets/HiTZ/MedExpQA)
- [MMLU_IT]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- DE: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): German part
- PT: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): Portuguese part
- RU: [RuMedBench](https://github.com/sb-ai-lab/MedBench)
Click to expand
We take Apollo2-7B or Apollo-MoE-0.5B as example
1. Download Dataset for project:
```
bash 0.download_data.sh
```
2. Prepare test and dev data for specific model:
- Create test data for with special token
```
bash 1.data_process_test&dev.sh
```
3. Prepare train data for specific model (Create tokenized data in advance):
- You can adjust data Training order and Training Epoch in this step
```
bash 2.data_process_train.sh
```
4. Train the model
- If you want to train in Multi Nodes please refer to ./src/sft/training_config/zero_multi.yaml
```
bash 3.single_node_train.sh
```
5. Evaluate your model: Generate score for benchmark
```
bash 4.eval.sh
```