

Update README.md
Browse files
README.md
CHANGED
|
@@ -19,7 +19,7 @@ datasets:
|
|
| 19 |
<!-- markdownlint-disable no-duplicate-header -->
|
| 20 |
|
| 21 |
<div align="center">
|
| 22 |
-
<img src="https://github.com/IDEA-FinAI/Golden-Touchstone/blob/main/Touchstone-GPT-logo.png?raw=true" width="15%" alt="Golden-Touchstone" />
|
| 23 |
<h1 style="display: inline-block; vertical-align: middle; margin-left: 10px; font-size: 2em; font-weight: bold;">Golden-Touchstone Benchmark</h1>
|
| 24 |
</div>
|
| 25 |
|
|
@@ -48,15 +48,15 @@ Golden Touchstone is a simple, effective, and systematic benchmark for bilingual
|
|
| 48 |
|
| 49 |
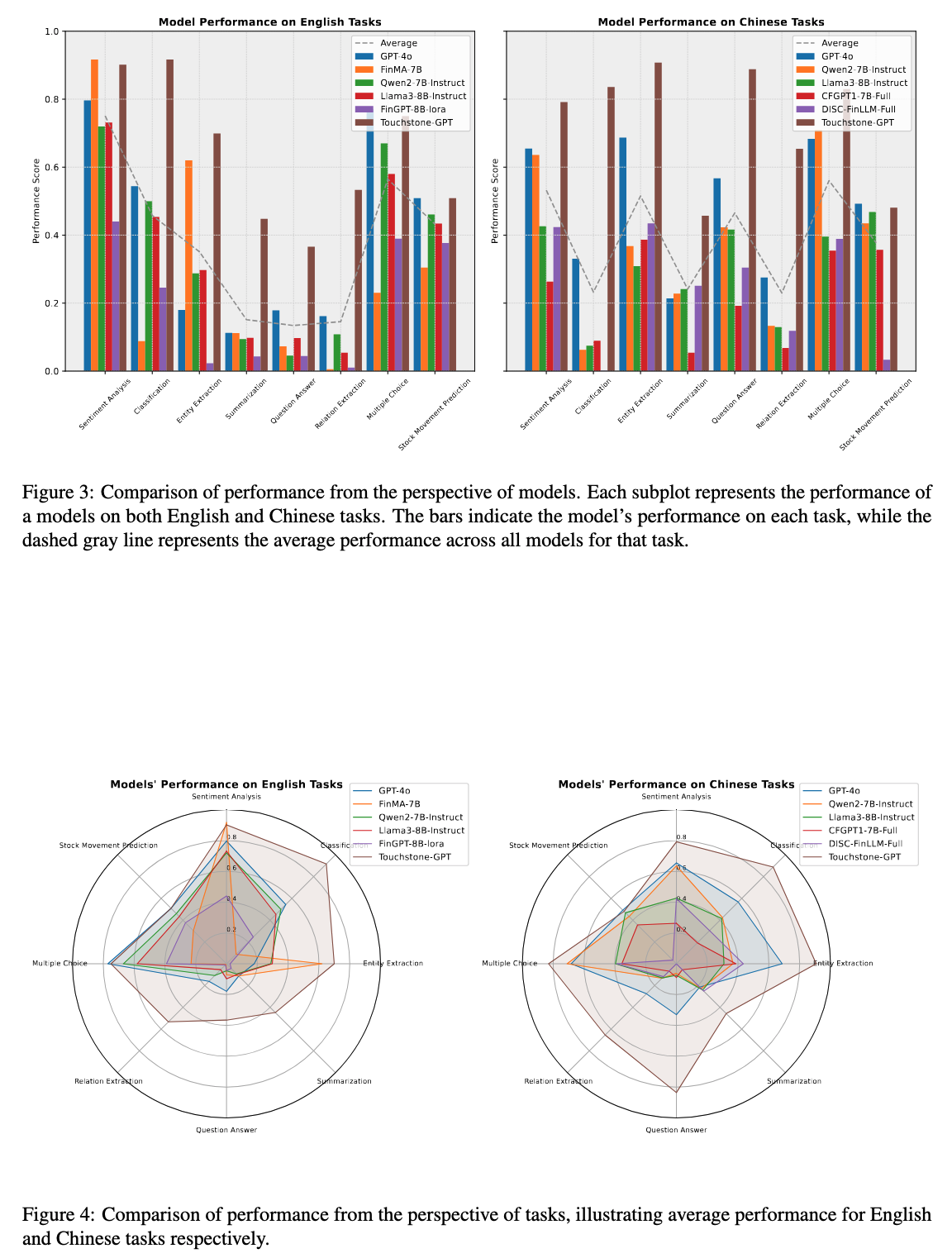
The paper shows the evaluation of the diversity, systematicness and LLM adaptability of each open source benchmark.
|
| 50 |
|
| 51 |
-

|
| 52 |
|
| 53 |
By collecting and selecting representative task datasets, we built our own Chinese-English bilingual Touchstone Benchmark, which includes 22 datasets
|
| 54 |
|
| 55 |
-

|
| 56 |
|
| 57 |
We extensively evaluated GPT-4o, llama3, qwen2, fingpt and our own trained Touchstone-GPT, analyzed the advantages and disadvantages of these models, and provided direction for subsequent research on financial large language models
|
| 58 |
|
| 59 |
-

|
| 60 |
|
| 61 |
## Evaluation of Touchstone Benchmark
|
| 62 |
|
|
|
|
| 19 |
<!-- markdownlint-disable no-duplicate-header -->
|
| 20 |
|
| 21 |
<div align="center">
|
| 22 |
+
<img src="https://github.com/IDEA-FinAI/Golden-Touchstone/blob/main/assets/Touchstone-GPT-logo.png?raw=true" width="15%" alt="Golden-Touchstone" />
|
| 23 |
<h1 style="display: inline-block; vertical-align: middle; margin-left: 10px; font-size: 2em; font-weight: bold;">Golden-Touchstone Benchmark</h1>
|
| 24 |
</div>
|
| 25 |
|
|
|
|
| 48 |
|
| 49 |
The paper shows the evaluation of the diversity, systematicness and LLM adaptability of each open source benchmark.
|
| 50 |
|
| 51 |
+

|
| 52 |
|
| 53 |
By collecting and selecting representative task datasets, we built our own Chinese-English bilingual Touchstone Benchmark, which includes 22 datasets
|
| 54 |
|
| 55 |
+

|
| 56 |
|
| 57 |
We extensively evaluated GPT-4o, llama3, qwen2, fingpt and our own trained Touchstone-GPT, analyzed the advantages and disadvantages of these models, and provided direction for subsequent research on financial large language models
|
| 58 |
|
| 59 |
+
|
| 60 |
|
| 61 |
## Evaluation of Touchstone Benchmark
|
| 62 |
|