
Commit
•
71ae6c3
1
Parent(s):
3dbe7e0
Upload 8 files
Browse files- .gitattributes +1 -0
- 2406.09308v1.pdf +3 -0
- gen_mat_lit_dataset.py +33 -0
- img.png +0 -0
- mat_lit_dataset.py +68 -0
- simple_dataset.py +62 -0
- transNAR.py +125 -0
- transNAR2.py +126 -0
- transNAR3.py +115 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
2406.09308v1.pdf filter=lfs diff=lfs merge=lfs -text
|
2406.09308v1.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a60258740c3fe0c93a38c81413b72bcb6ba0c943a7d2e890642b7c05349ee3fa
|
| 3 |
+
size 1228929
|
gen_mat_lit_dataset.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Criar o dataset de textos matemáticos
|
| 2 |
+
math_dataset = TransNARTextDataset('math', num_samples=1000, max_length=512, vocab_size=30522, device=device)
|
| 3 |
+
math_dataloader = DataLoader(math_dataset, batch_size=32, shuffle=True)
|
| 4 |
+
|
| 5 |
+
# Criar o dataset de textos literários
|
| 6 |
+
lit_dataset = TransNARTextDataset('literature', num_samples=1000, max_length=512, vocab_size=30522, device=device)
|
| 7 |
+
lit_dataloader = DataLoader(lit_dataset, batch_size=32, shuffle=True)
|
| 8 |
+
|
| 9 |
+
# Treinar o modelo TransNAR
|
| 10 |
+
for epoch in range(num_epochs):
|
| 11 |
+
model.train()
|
| 12 |
+
running_loss = 0.0
|
| 13 |
+
for (input_ids, attention_masks, labels) in math_dataloader:
|
| 14 |
+
optimizer.zero_grad()
|
| 15 |
+
outputs = model(input_ids, attention_masks)
|
| 16 |
+
loss = criterion(outputs, labels)
|
| 17 |
+
loss.backward()
|
| 18 |
+
optimizer.step()
|
| 19 |
+
running_loss += loss.item() * input_ids.size(0)
|
| 20 |
+
|
| 21 |
+
epoch_loss = running_loss / len(math_dataset)
|
| 22 |
+
print(f'Epoch {epoch+1}/{num_epochs}, Math Loss: {epoch_loss:.4f}')
|
| 23 |
+
|
| 24 |
+
# Avaliar o modelo no conjunto de dados literário
|
| 25 |
+
model.eval()
|
| 26 |
+
val_loss = 0.0
|
| 27 |
+
for (input_ids, attention_masks, labels) in lit_dataloader:
|
| 28 |
+
with torch.no_grad():
|
| 29 |
+
outputs = model(input_ids, attention_masks)
|
| 30 |
+
loss = criterion(outputs, labels)
|
| 31 |
+
val_loss += loss.item() * input_ids.size(0)
|
| 32 |
+
val_loss /= len(lit_dataset)
|
| 33 |
+
print(f'Epoch {epoch+1}/{num_epochs}, Literature Validation Loss: {val_loss:.4f}')
|
img.png
ADDED
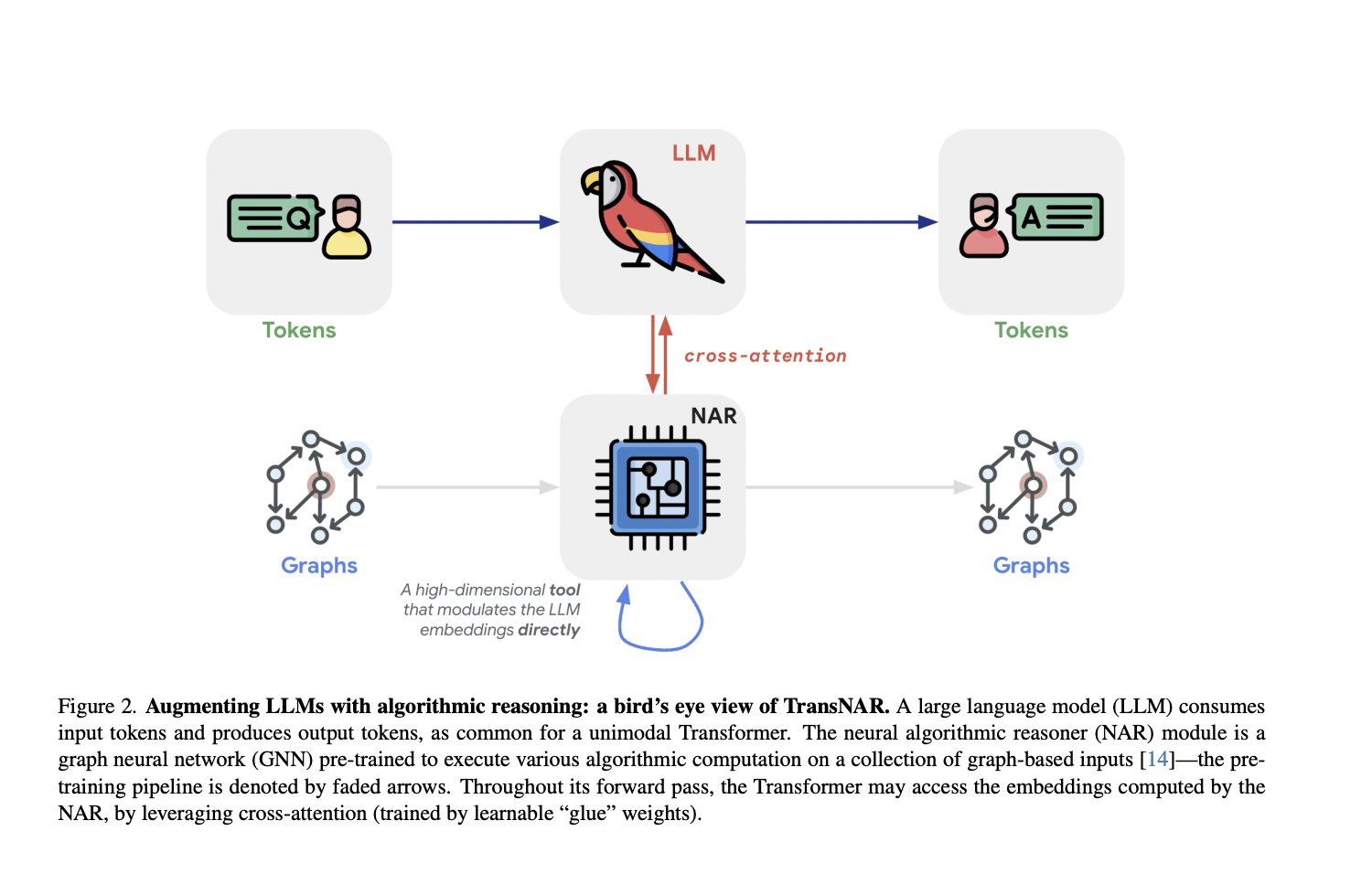
|
mat_lit_dataset.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils.data import Dataset
|
| 3 |
+
from transformers import AutoTokenizer
|
| 4 |
+
|
| 5 |
+
class TransNARTextDataset(Dataset):
|
| 6 |
+
def __init__(self, data_type, num_samples, max_length, vocab_size, device):
|
| 7 |
+
self.data_type = data_type
|
| 8 |
+
self.num_samples = num_samples
|
| 9 |
+
self.max_length = max_length
|
| 10 |
+
self.vocab_size = vocab_size
|
| 11 |
+
self.device = device
|
| 12 |
+
|
| 13 |
+
# Carregar o tokenizador pré-treinado
|
| 14 |
+
if data_type == 'math':
|
| 15 |
+
self.tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
|
| 16 |
+
elif data_type == 'literature':
|
| 17 |
+
self.tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
|
| 18 |
+
else:
|
| 19 |
+
raise ValueError("data_type must be 'math' or 'literature'")
|
| 20 |
+
|
| 21 |
+
# Gerar dados de entrada e labels
|
| 22 |
+
self.input_ids, self.attention_masks, self.labels = self.generate_data()
|
| 23 |
+
|
| 24 |
+
def __len__(self):
|
| 25 |
+
return self.num_samples
|
| 26 |
+
|
| 27 |
+
def __getitem__(self, idx):
|
| 28 |
+
return self.input_ids[idx], self.attention_masks[idx], self.labels[idx]
|
| 29 |
+
|
| 30 |
+
def generate_data(self):
|
| 31 |
+
input_ids = []
|
| 32 |
+
attention_masks = []
|
| 33 |
+
labels = []
|
| 34 |
+
|
| 35 |
+
for _ in range(self.num_samples):
|
| 36 |
+
if self.data_type == 'math':
|
| 37 |
+
text = self.generate_math_text()
|
| 38 |
+
else:
|
| 39 |
+
text = self.generate_literature_text()
|
| 40 |
+
|
| 41 |
+
# Tokenizar o texto
|
| 42 |
+
encoded = self.tokenizer.encode_plus(
|
| 43 |
+
text,
|
| 44 |
+
max_length=self.max_length,
|
| 45 |
+
pad_to_max_length=True,
|
| 46 |
+
return_attention_mask=True,
|
| 47 |
+
return_tensors='pt',
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
input_ids.append(encoded['input_ids'])
|
| 51 |
+
attention_masks.append(encoded['attention_mask'])
|
| 52 |
+
labels.append(self.generate_label(text))
|
| 53 |
+
|
| 54 |
+
return torch.stack(input_ids).to(self.device), \
|
| 55 |
+
torch.stack(attention_masks).to(self.device), \
|
| 56 |
+
torch.stack(labels).to(self.device)
|
| 57 |
+
|
| 58 |
+
def generate_math_text(self):
|
| 59 |
+
# Gera texto matemático sintético
|
| 60 |
+
pass
|
| 61 |
+
|
| 62 |
+
def generate_literature_text(self):
|
| 63 |
+
# Gera texto de literatura sintético
|
| 64 |
+
pass
|
| 65 |
+
|
| 66 |
+
def generate_label(self, text):
|
| 67 |
+
# Gera label para o texto
|
| 68 |
+
pass
|
simple_dataset.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.optim as optim
|
| 4 |
+
from torch.utils.data import Dataset, DataLoader
|
| 5 |
+
|
| 6 |
+
# Definição do Dataset
|
| 7 |
+
class SimpleDataset(Dataset):
|
| 8 |
+
def __init__(self, num_samples, seq_length, input_dim):
|
| 9 |
+
self.num_samples = num_samples
|
| 10 |
+
self.seq_length = seq_length
|
| 11 |
+
self.input_dim = input_dim
|
| 12 |
+
self.data = torch.randn(num_samples, seq_length, input_dim)
|
| 13 |
+
self.labels = torch.randint(0, 2, (num_samples, seq_length, 50))
|
| 14 |
+
|
| 15 |
+
def __len__(self):
|
| 16 |
+
return self.num_samples
|
| 17 |
+
|
| 18 |
+
def __getitem__(self, idx):
|
| 19 |
+
return self.data[idx], self.labels[idx]
|
| 20 |
+
|
| 21 |
+
# Definição do modelo (usando TransNAR do exemplo anterior)
|
| 22 |
+
class TransNAR(nn.Module):
|
| 23 |
+
# ... Definição do modelo como no exemplo anterior ...
|
| 24 |
+
|
| 25 |
+
# Inicializar o modelo, critério e otimizador
|
| 26 |
+
input_dim = 100
|
| 27 |
+
output_dim = 50
|
| 28 |
+
embed_dim = 256
|
| 29 |
+
num_heads = 8
|
| 30 |
+
num_layers = 6
|
| 31 |
+
ffn_dim = 1024
|
| 32 |
+
|
| 33 |
+
model = TransNAR(input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim)
|
| 34 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 35 |
+
model = model.to(device)
|
| 36 |
+
|
| 37 |
+
criterion = nn.BCEWithLogitsLoss()
|
| 38 |
+
optimizer = optim.Adam(model.parameters(), lr=1e-4)
|
| 39 |
+
|
| 40 |
+
# Criar o DataLoader
|
| 41 |
+
num_samples = 1000
|
| 42 |
+
seq_length = 100
|
| 43 |
+
batch_size = 32
|
| 44 |
+
dataset = SimpleDataset(num_samples, seq_length, input_dim)
|
| 45 |
+
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
|
| 46 |
+
|
| 47 |
+
# Loop de treinamento
|
| 48 |
+
num_epochs = 10
|
| 49 |
+
for epoch in range(num_epochs):
|
| 50 |
+
model.train()
|
| 51 |
+
running_loss = 0.0
|
| 52 |
+
for inputs, labels in dataloader:
|
| 53 |
+
inputs, labels = inputs.to(device), labels.to(device)
|
| 54 |
+
optimizer.zero_grad()
|
| 55 |
+
outputs = model(inputs)
|
| 56 |
+
loss = criterion(outputs, labels)
|
| 57 |
+
loss.backward()
|
| 58 |
+
optimizer.step()
|
| 59 |
+
running_loss += loss.item() * inputs.size(0)
|
| 60 |
+
|
| 61 |
+
epoch_loss = running_loss / len(dataset)
|
| 62 |
+
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}')
|
transNAR.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
class TransNAR(nn.Module):
|
| 7 |
+
def __init__(self, input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim, dropout=0.1):
|
| 8 |
+
super(TransNAR, self).__init__()
|
| 9 |
+
|
| 10 |
+
# Camada de Embedding
|
| 11 |
+
self.embedding = nn.Linear(input_dim, embed_dim)
|
| 12 |
+
self.pos_encoding = PositionalEncoding(embed_dim, dropout)
|
| 13 |
+
|
| 14 |
+
# Camadas Transformer
|
| 15 |
+
self.transformer_layers = nn.ModuleList([
|
| 16 |
+
TransformerLayer(embed_dim, num_heads, ffn_dim, dropout)
|
| 17 |
+
for _ in range(num_layers)
|
| 18 |
+
])
|
| 19 |
+
|
| 20 |
+
# Neural Algorithmic Reasoner (NAR)
|
| 21 |
+
self.nar = NAR(embed_dim)
|
| 22 |
+
|
| 23 |
+
# Decodificador
|
| 24 |
+
self.decoder = nn.Linear(embed_dim * 2, output_dim)
|
| 25 |
+
|
| 26 |
+
# Camada de normalização final
|
| 27 |
+
self.final_norm = nn.LayerNorm(output_dim)
|
| 28 |
+
|
| 29 |
+
def forward(self, x):
|
| 30 |
+
# Embedding e codificação posicional
|
| 31 |
+
x = self.embedding(x)
|
| 32 |
+
x = self.pos_encoding(x)
|
| 33 |
+
|
| 34 |
+
# Camadas Transformer
|
| 35 |
+
for layer in self.transformer_layers:
|
| 36 |
+
x = layer(x)
|
| 37 |
+
|
| 38 |
+
# Neural Algorithmic Reasoner
|
| 39 |
+
nar_output = self.nar(x)
|
| 40 |
+
|
| 41 |
+
# Concatenar saída do Transformer e do NAR
|
| 42 |
+
combined = torch.cat([x, nar_output], dim=-1)
|
| 43 |
+
|
| 44 |
+
# Decodificação
|
| 45 |
+
output = self.decoder(combined)
|
| 46 |
+
|
| 47 |
+
# Normalização final
|
| 48 |
+
output = self.final_norm(output)
|
| 49 |
+
|
| 50 |
+
return output
|
| 51 |
+
|
| 52 |
+
class TransformerLayer(nn.Module):
|
| 53 |
+
def __init__(self, embed_dim, num_heads, ffn_dim, dropout=0.1):
|
| 54 |
+
super(TransformerLayer, self).__init__()
|
| 55 |
+
self.self_attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
|
| 56 |
+
self.ffn = nn.Sequential(
|
| 57 |
+
nn.Linear(embed_dim, ffn_dim),
|
| 58 |
+
nn.ReLU(),
|
| 59 |
+
nn.Linear(ffn_dim, embed_dim)
|
| 60 |
+
)
|
| 61 |
+
self.norm1 = nn.LayerNorm(embed_dim)
|
| 62 |
+
self.norm2 = nn.LayerNorm(embed_dim)
|
| 63 |
+
self.dropout = nn.Dropout(dropout)
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
# Atenção
|
| 67 |
+
attn_output, _ = self.self_attn(x, x, x)
|
| 68 |
+
x = x + self.dropout(attn_output)
|
| 69 |
+
x = self.norm1(x)
|
| 70 |
+
|
| 71 |
+
# Feedforward
|
| 72 |
+
ffn_output = self.ffn(x)
|
| 73 |
+
x = x + self.dropout(ffn_output)
|
| 74 |
+
x = self.norm2(x)
|
| 75 |
+
|
| 76 |
+
return x
|
| 77 |
+
|
| 78 |
+
class NAR(nn.Module):
|
| 79 |
+
def __init__(self, embed_dim):
|
| 80 |
+
super(NAR, self).__init__()
|
| 81 |
+
self.reasoning_layers = nn.Sequential(
|
| 82 |
+
nn.Linear(embed_dim, embed_dim * 2),
|
| 83 |
+
nn.ReLU(),
|
| 84 |
+
nn.Linear(embed_dim * 2, embed_dim),
|
| 85 |
+
nn.Tanh()
|
| 86 |
+
)
|
| 87 |
+
self.gru = nn.GRU(embed_dim, embed_dim, batch_first=True)
|
| 88 |
+
self.output_layer = nn.Linear(embed_dim, embed_dim) # Nova camada para ajustar a saída
|
| 89 |
+
|
| 90 |
+
def forward(self, x):
|
| 91 |
+
reasoned = self.reasoning_layers(x)
|
| 92 |
+
output, _ = self.gru(reasoned)
|
| 93 |
+
output = self.output_layer(output) # Ajustar a dimensão
|
| 94 |
+
return output
|
| 95 |
+
|
| 96 |
+
class PositionalEncoding(nn.Module):
|
| 97 |
+
def __init__(self, embed_dim, dropout=0.1, max_len=5000):
|
| 98 |
+
super(PositionalEncoding, self).__init__()
|
| 99 |
+
self.dropout = nn.Dropout(p=dropout)
|
| 100 |
+
|
| 101 |
+
# Inicializa o tensor de codificação posicional
|
| 102 |
+
pe = torch.zeros(max_len, embed_dim)
|
| 103 |
+
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
|
| 104 |
+
div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-math.log(10000.0) / embed_dim))
|
| 105 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 106 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 107 |
+
pe = pe.unsqueeze(0).transpose(0, 1)
|
| 108 |
+
self.register_buffer('pe', pe)
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
x = x + self.pe[:x.size(0), :].to(x.device)
|
| 112 |
+
return self.dropout(x)
|
| 113 |
+
|
| 114 |
+
# Exemplo de uso
|
| 115 |
+
input_dim = 100
|
| 116 |
+
output_dim = 50
|
| 117 |
+
embed_dim = 256
|
| 118 |
+
num_heads = 8
|
| 119 |
+
num_layers = 6
|
| 120 |
+
ffn_dim = 1024
|
| 121 |
+
|
| 122 |
+
model = TransNAR(input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim)
|
| 123 |
+
input_data = torch.randn(32, 100, input_dim) # Corrigido para incluir a dimensão de embedding
|
| 124 |
+
output = model(input_data)
|
| 125 |
+
print(output.shape) # Deve imprimir torch.Size([32, 100, 50])
|
transNAR2.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import math
|
| 5 |
+
from torch_geometric.nn import GCNConv
|
| 6 |
+
|
| 7 |
+
class TransNAR(nn.Module):
|
| 8 |
+
def __init__(self, input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim, dropout=0.1):
|
| 9 |
+
super(TransNAR, self).__init__()
|
| 10 |
+
|
| 11 |
+
# Camada de Embedding
|
| 12 |
+
self.embedding = nn.Linear(input_dim, embed_dim)
|
| 13 |
+
self.pos_encoding = PositionalEncoding(embed_dim, dropout)
|
| 14 |
+
|
| 15 |
+
# Camadas Transformer
|
| 16 |
+
self.transformer_layers = nn.ModuleList([
|
| 17 |
+
TransformerLayer(embed_dim, num_heads, ffn_dim, dropout)
|
| 18 |
+
for _ in range(num_layers)
|
| 19 |
+
])
|
| 20 |
+
|
| 21 |
+
# Neural Algorithmic Reasoner (NAR)
|
| 22 |
+
self.nar = NAR(embed_dim)
|
| 23 |
+
|
| 24 |
+
# Cross-Attention Layer
|
| 25 |
+
self.cross_attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
|
| 26 |
+
|
| 27 |
+
# Decodificador
|
| 28 |
+
self.decoder = nn.Linear(embed_dim, output_dim)
|
| 29 |
+
|
| 30 |
+
# Camada de normalização final
|
| 31 |
+
self.final_norm = nn.LayerNorm(output_dim)
|
| 32 |
+
|
| 33 |
+
def forward(self, x, edge_index, edge_attr):
|
| 34 |
+
# Embedding e codificação posicional
|
| 35 |
+
x = self.embedding(x)
|
| 36 |
+
x = self.pos_encoding(x)
|
| 37 |
+
|
| 38 |
+
# Camadas Transformer
|
| 39 |
+
for layer in self.transformer_layers:
|
| 40 |
+
x = layer(x)
|
| 41 |
+
|
| 42 |
+
# Neural Algorithmic Reasoner
|
| 43 |
+
nar_output = self.nar(x, edge_index, edge_attr)
|
| 44 |
+
|
| 45 |
+
# Cross-Attention between Transformer and NAR outputs
|
| 46 |
+
cross_attn_output, _ = self.cross_attention(x, nar_output, nar_output)
|
| 47 |
+
|
| 48 |
+
# Decodificação
|
| 49 |
+
output = self.decoder(cross_attn_output)
|
| 50 |
+
|
| 51 |
+
# Normalização final
|
| 52 |
+
output = self.final_norm(output)
|
| 53 |
+
|
| 54 |
+
return output
|
| 55 |
+
|
| 56 |
+
class TransformerLayer(nn.Module):
|
| 57 |
+
def __init__(self, embed_dim, num_heads, ffn_dim, dropout=0.1):
|
| 58 |
+
super(TransformerLayer, self).__init__()
|
| 59 |
+
self.self_attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
|
| 60 |
+
self.ffn = nn.Sequential(
|
| 61 |
+
nn.Linear(embed_dim, ffn_dim),
|
| 62 |
+
nn.ReLU(),
|
| 63 |
+
nn.Linear(ffn_dim, embed_dim)
|
| 64 |
+
)
|
| 65 |
+
self.norm1 = nn.LayerNorm(embed_dim)
|
| 66 |
+
self.norm2 = nn.LayerNorm(embed_dim)
|
| 67 |
+
self.dropout = nn.Dropout(dropout)
|
| 68 |
+
|
| 69 |
+
def forward(self, x):
|
| 70 |
+
# Atenção
|
| 71 |
+
attn_output, _ = self.self_attn(x, x, x)
|
| 72 |
+
x = x + self.dropout(attn_output)
|
| 73 |
+
x = self.norm1(x)
|
| 74 |
+
|
| 75 |
+
# Feedforward
|
| 76 |
+
ffn_output = self.ffn(x)
|
| 77 |
+
x = x + self.dropout(ffn_output)
|
| 78 |
+
x = self.norm2(x)
|
| 79 |
+
|
| 80 |
+
return x
|
| 81 |
+
|
| 82 |
+
class NAR(nn.Module):
|
| 83 |
+
def __init__(self, embed_dim):
|
| 84 |
+
super(NAR, self).__init__()
|
| 85 |
+
self.gcn1 = GCNConv(embed_dim, embed_dim * 2)
|
| 86 |
+
self.gcn2 = GCNConv(embed_dim * 2, embed_dim)
|
| 87 |
+
self.gru = nn.GRU(embed_dim, embed_dim, batch_first=True)
|
| 88 |
+
|
| 89 |
+
def forward(self, x, edge_index, edge_attr):
|
| 90 |
+
x = F.relu(self.gcn1(x, edge_index))
|
| 91 |
+
x = self.gcn2(x, edge_index)
|
| 92 |
+
output, _ = self.gru(x.unsqueeze(1))
|
| 93 |
+
return output.squeeze(1)
|
| 94 |
+
|
| 95 |
+
class PositionalEncoding(nn.Module):
|
| 96 |
+
def __init__(self, embed_dim, dropout=0.1, max_len=5000):
|
| 97 |
+
super(PositionalEncoding, self).__init__()
|
| 98 |
+
self.dropout = nn.Dropout(p=dropout)
|
| 99 |
+
|
| 100 |
+
# Inicializa o tensor de codificação posicional
|
| 101 |
+
pe = torch.zeros(max_len, embed_dim)
|
| 102 |
+
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
|
| 103 |
+
div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-math.log(10000.0) / embed_dim))
|
| 104 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 105 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 106 |
+
pe = pe.unsqueeze(0).transpose(0, 1)
|
| 107 |
+
self.register_buffer('pe', pe)
|
| 108 |
+
|
| 109 |
+
def forward(self, x):
|
| 110 |
+
x = x + self.pe[:x.size(0), :].to(x.device)
|
| 111 |
+
return self.dropout(x)
|
| 112 |
+
|
| 113 |
+
# Exemplo de uso
|
| 114 |
+
input_dim = 100
|
| 115 |
+
output_dim = 50
|
| 116 |
+
embed_dim = 256
|
| 117 |
+
num_heads = 8
|
| 118 |
+
num_layers = 6
|
| 119 |
+
ffn_dim = 1024
|
| 120 |
+
|
| 121 |
+
model = TransNAR(input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim)
|
| 122 |
+
input_data = torch.randn(32, 100, input_dim)
|
| 123 |
+
edge_index = torch.tensor([[0, 1], [1, 0]]) # Example edge index
|
| 124 |
+
edge_attr = torch.randn(edge_index.size(1)) # Example edge attributes
|
| 125 |
+
output = model(input_data, edge_index, edge_attr)
|
| 126 |
+
print(output.shape) # Deve imprimir torch.Size([32, 100, 50])
|
transNAR3.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import math
|
| 5 |
+
from torch_geometric.nn import GCNConv
|
| 6 |
+
|
| 7 |
+
class TransNAR(nn.Module):
|
| 8 |
+
def __init__(self, input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim, dropout=0.1):
|
| 9 |
+
super(TransNAR, self).__init__()
|
| 10 |
+
|
| 11 |
+
# Camada de Embedding
|
| 12 |
+
self.embedding = nn.Linear(input_dim, embed_dim)
|
| 13 |
+
self.pos_encoding = PositionalEncoding(embed_dim, dropout)
|
| 14 |
+
|
| 15 |
+
# Inicialização dos pesos
|
| 16 |
+
self.initialize_weights()
|
| 17 |
+
|
| 18 |
+
# Camadas Transformer
|
| 19 |
+
self.transformer_layers = nn.ModuleList([
|
| 20 |
+
TransformerLayer(embed_dim, num_heads, ffn_dim, dropout)
|
| 21 |
+
for _ in range(num_layers)
|
| 22 |
+
])
|
| 23 |
+
|
| 24 |
+
# Neural Algorithmic Reasoner (NAR)
|
| 25 |
+
self.nar = NAR(embed_dim)
|
| 26 |
+
|
| 27 |
+
# Cross-Attention Layer
|
| 28 |
+
self.cross_attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
|
| 29 |
+
|
| 30 |
+
# Decodificador
|
| 31 |
+
self.decoder = nn.Linear(embed_dim, output_dim)
|
| 32 |
+
|
| 33 |
+
# Camada de normalização final
|
| 34 |
+
self.final_norm = nn.LayerNorm(output_dim)
|
| 35 |
+
|
| 36 |
+
# Otimizador
|
| 37 |
+
self.optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
|
| 38 |
+
|
| 39 |
+
def initialize_weights(self):
|
| 40 |
+
# Inicialização de Xavier para camadas lineares
|
| 41 |
+
for m in self.modules():
|
| 42 |
+
if isinstance(m, nn.Linear):
|
| 43 |
+
nn.init.xavier_uniform_(m.weight)
|
| 44 |
+
nn.init.zeros_(m.bias)
|
| 45 |
+
|
| 46 |
+
# Inicialização normal para camadas de atenção
|
| 47 |
+
for m in self.modules():
|
| 48 |
+
if isinstance(m, nn.MultiheadAttention):
|
| 49 |
+
nn.init.normal_(m.in_proj_weight, std=0.02)
|
| 50 |
+
nn.init.normal_(m.out_proj.weight, std=0.02)
|
| 51 |
+
|
| 52 |
+
def forward(self, x, edge_index, edge_attr):
|
| 53 |
+
# Embedding e codificação posicional
|
| 54 |
+
x = self.embedding(x)
|
| 55 |
+
x = self.pos_encoding(x)
|
| 56 |
+
|
| 57 |
+
# Camadas Transformer
|
| 58 |
+
for layer in self.transformer_layers:
|
| 59 |
+
x = layer(x)
|
| 60 |
+
|
| 61 |
+
# Neural Algorithmic Reasoner
|
| 62 |
+
nar_output = self.nar(x, edge_index, edge_attr)
|
| 63 |
+
|
| 64 |
+
# Cross-Attention between Transformer and NAR outputs
|
| 65 |
+
cross_attn_output, _ = self.cross_attention(x, nar_output, nar_output)
|
| 66 |
+
|
| 67 |
+
# Decodificação
|
| 68 |
+
output = self.decoder(cross_attn_output)
|
| 69 |
+
|
| 70 |
+
# Normalização final
|
| 71 |
+
output = self.final_norm(output)
|
| 72 |
+
|
| 73 |
+
return output
|
| 74 |
+
|
| 75 |
+
def train_model(self, train_loader, val_loader, num_epochs):
|
| 76 |
+
for epoch in range(num_epochs):
|
| 77 |
+
self.train()
|
| 78 |
+
train_loss = 0
|
| 79 |
+
for batch in train_loader:
|
| 80 |
+
self.optimizer.zero_grad()
|
| 81 |
+
output = self(batch.x, batch.edge_index, batch.edge_attr)
|
| 82 |
+
loss = F.mse_loss(output, batch.y)
|
| 83 |
+
loss.backward()
|
| 84 |
+
self.optimizer.step()
|
| 85 |
+
train_loss += loss.item()
|
| 86 |
+
|
| 87 |
+
self.eval()
|
| 88 |
+
val_loss = 0
|
| 89 |
+
for batch in val_loader:
|
| 90 |
+
output = self(batch.x, batch.edge_index, batch.edge_attr)
|
| 91 |
+
loss = F.mse_loss(output, batch.y)
|
| 92 |
+
val_loss += loss.item()
|
| 93 |
+
|
| 94 |
+
print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss/len(train_loader)}, Val Loss: {val_loss/len(val_loader)}")
|
| 95 |
+
|
| 96 |
+
# Salvar checkpoint do modelo
|
| 97 |
+
torch.save(self.state_dict(), f'transnar_checkpoint_epoch_{epoch+1}.pth')
|
| 98 |
+
|
| 99 |
+
# Exemplo de uso
|
| 100 |
+
input_dim = 100
|
| 101 |
+
output_dim = 50
|
| 102 |
+
embed_dim = 256
|
| 103 |
+
num_heads = 8
|
| 104 |
+
num_layers = 6
|
| 105 |
+
ffn_dim = 1024
|
| 106 |
+
|
| 107 |
+
model = TransNAR(input_dim, output_dim, embed_dim, num_heads, num_layers, ffn_dim)
|
| 108 |
+
input_data = torch.randn(32, 100, input_dim)
|
| 109 |
+
edge_index = torch.tensor([[0, 1], [1, 0]]) # Example edge index
|
| 110 |
+
edge_attr = torch.randn(edge_index.size(1)) # Example edge attributes
|
| 111 |
+
|
| 112 |
+
# Treinamento do modelo
|
| 113 |
+
train_loader = ... # Carregador de dados de treinamento
|
| 114 |
+
val_loader = ... # Carregador de dados de validação
|
| 115 |
+
model.train_model(train_loader, val_loader, num_epochs=100)
|