

Merge branch 'main' of https://huggingface.co/KBLab/wav2vec2-large-voxrex-swedish into main
Browse files- README.md +16 -9
- chart_1.svg +0 -0
- comparison.png +0 -0
- tokenizer_config.json +9 -1
README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
language: sv
|
| 3 |
datasets:
|
| 4 |
- common_voice
|
| 5 |
- NST Swedish ASR Database
|
|
@@ -10,11 +10,11 @@ tags:
|
|
| 10 |
- audio
|
| 11 |
- automatic-speech-recognition
|
| 12 |
- speech
|
| 13 |
-
license: cc0
|
| 14 |
model-index:
|
| 15 |
- name: Wav2vec 2.0 large VoxRex Swedish
|
| 16 |
results:
|
| 17 |
-
- task:
|
| 18 |
name: Speech Recognition
|
| 19 |
type: automatic-speech-recognition
|
| 20 |
dataset:
|
|
@@ -22,18 +22,25 @@ model-index:
|
|
| 22 |
type: common_voice
|
| 23 |
args: sv-SE
|
| 24 |
metrics:
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
---
|
| 29 |
-
# Wav2vec 2.0 large VoxRex Swedish
|
|
|
|
|
|
|
| 30 |
|
| 31 |
Finetuned version of KBs [VoxRex large](https://huggingface.co/KBLab/wav2vec2-large-voxrex) model using Swedish radio broadcasts, NST and Common Voice data. Evalutation without a language model gives the following: WER for NST + Common Voice test set (2% of total sentences) is **3.617%**. WER for Common Voice test set is **9.914%** directly and **7.77%** with a 4-gram language model.
|
| 32 |
|
| 33 |
When using this model, make sure that your speech input is sampled at 16kHz.
|
| 34 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
## Training
|
| 36 |
-
This model has
|
| 37 |
|
| 38 |

|
| 39 |
|
|
@@ -46,7 +53,7 @@ from datasets import load_dataset
|
|
| 46 |
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
|
| 47 |
test_dataset = load_dataset("common_voice", "sv-SE", split="test[:2%]").
|
| 48 |
processor = Wav2Vec2Processor.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
|
| 49 |
-
model = Wav2Vec2ForCTC.from_pretrained("KBLab/wav2vec2-large-
|
| 50 |
resampler = torchaudio.transforms.Resample(48_000, 16_000)
|
| 51 |
# Preprocessing the datasets.
|
| 52 |
# We need to read the aduio files as arrays
|
|
|
|
| 1 |
---
|
| 2 |
+
language: sv
|
| 3 |
datasets:
|
| 4 |
- common_voice
|
| 5 |
- NST Swedish ASR Database
|
|
|
|
| 10 |
- audio
|
| 11 |
- automatic-speech-recognition
|
| 12 |
- speech
|
| 13 |
+
license: cc0-1.0
|
| 14 |
model-index:
|
| 15 |
- name: Wav2vec 2.0 large VoxRex Swedish
|
| 16 |
results:
|
| 17 |
+
- task:
|
| 18 |
name: Speech Recognition
|
| 19 |
type: automatic-speech-recognition
|
| 20 |
dataset:
|
|
|
|
| 22 |
type: common_voice
|
| 23 |
args: sv-SE
|
| 24 |
metrics:
|
| 25 |
+
- name: Test WER
|
| 26 |
+
type: wer
|
| 27 |
+
value: 9.914
|
| 28 |
---
|
| 29 |
+
# Wav2vec 2.0 large VoxRex Swedish (B)
|
| 30 |
+
|
| 31 |
+
**Disclaimer:** This is a work in progress. See [VoxRex](https://huggingface.co/KBLab/wav2vec2-large-voxrex) for more details.
|
| 32 |
|
| 33 |
Finetuned version of KBs [VoxRex large](https://huggingface.co/KBLab/wav2vec2-large-voxrex) model using Swedish radio broadcasts, NST and Common Voice data. Evalutation without a language model gives the following: WER for NST + Common Voice test set (2% of total sentences) is **3.617%**. WER for Common Voice test set is **9.914%** directly and **7.77%** with a 4-gram language model.
|
| 34 |
|
| 35 |
When using this model, make sure that your speech input is sampled at 16kHz.
|
| 36 |
|
| 37 |
+
# Performance\*
|
| 38 |
+
|
| 39 |
+

|
| 40 |
+
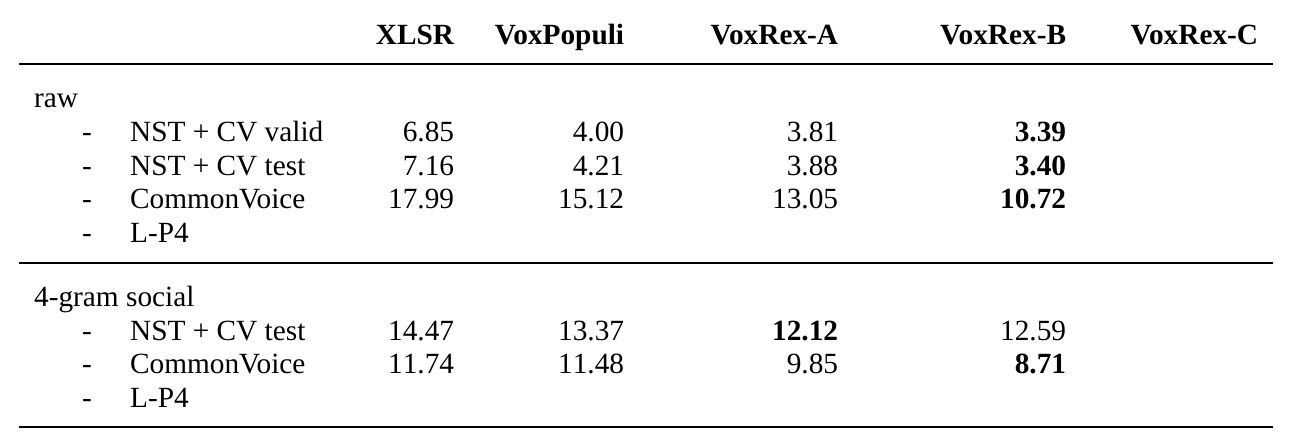
<center>*<i>Chart shows performance without the additional 20k steps of Common Voice fine-tuning</i></center>
|
| 41 |
+
|
| 42 |
## Training
|
| 43 |
+
This model has been fine-tuned for 120000 updates on NST + CommonVoice and then for an additional 20000 updates on CommonVoice only. The additional fine-tuning on CommonVoice hurts performance on the NST+CommonVoice test set somewhat and, unsurprisingly, improves it on the CommonVoice test set. It seems to perform generally better though [citation needed].
|
| 44 |
|
| 45 |

|
| 46 |
|
|
|
|
| 53 |
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
|
| 54 |
test_dataset = load_dataset("common_voice", "sv-SE", split="test[:2%]").
|
| 55 |
processor = Wav2Vec2Processor.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
|
| 56 |
+
model = Wav2Vec2ForCTC.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
|
| 57 |
resampler = torchaudio.transforms.Resample(48_000, 16_000)
|
| 58 |
# Preprocessing the datasets.
|
| 59 |
# We need to read the aduio files as arrays
|
chart_1.svg
CHANGED

|

|
comparison.png
ADDED
|
tokenizer_config.json
CHANGED
|
@@ -1 +1,9 @@
|
|
| 1 |
-
{
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token" : "<s>",
|
| 3 |
+
"do_lower_case" : true,
|
| 4 |
+
"eos_token" : "</s>",
|
| 5 |
+
"pad_token" : "<pad>",
|
| 6 |
+
"tokenizer_class" : "Wav2Vec2CTCTokenizer",
|
| 7 |
+
"unk_token" : "<unk>",
|
| 8 |
+
"word_delimiter_token" : "|"
|
| 9 |
+
}
|