French to English Machine Translation
French to English language translation using sequence to sequence transformer.
View Demo
French to English language translation using sequence to sequence transformer.
View Demo
 This project aims to develop a machine translation system for translating French text into English. The system utilizes state-of-the-art neural network architectures and techniques in natural language processing (NLP) to accurately translate French sentences into their corresponding English equivalents.
### Built With
* [![Python][Python]][Python-url]
* [![TensorFlow][TensorFlow]][TensorFlow-url]
* [![Keras][Keras]][Keras-url]
* [![NumPy][NumPy]][NumPy-url]
* [![Pandas][Pandas]][Pandas-url]
## Getting Started
Please follow these simple steps to setup this project locally.
### Dependencies
Here are the list all libraries, packages and other dependencies that need to be installed to run this project.
For example, this is how you would list them:
* TensorFlow 2.16.1
```sh
conda install -c conda-forge tensorflow
```
* Keras 2.15.0
```sh
conda install -c conda-forge keras
```
* Gradio 4.24.0
```sh
conda install -c conda-forge gradio
```
* NumPy 1.26.4
```sh
conda install -c conda-forge numpy
```
### Alternative: Export Environment
Alternatively, clone the project repository, install it and have all dependencies needed.
```sh
conda env export > requirements.txt
```
Recreate it using:
```sh
conda env create -f requirements.txt
```
### Installation
```sh
# clone project
git clone https://huggingface.co/spaces/KameliaZaman/French-to-English-Translation/tree/main
# go inside the project directory
cd French-to-English-Translation
# install the required packages
pip install -r requirements.txt
# run the gradio app
python app.py
```
## Usage
#### Dataset
Dataset is from "https://www.kaggle.com/datasets/devicharith/language-translation-englishfrench" which contains 2 columns where one column has english words/sentences and the other one has french words/sentence
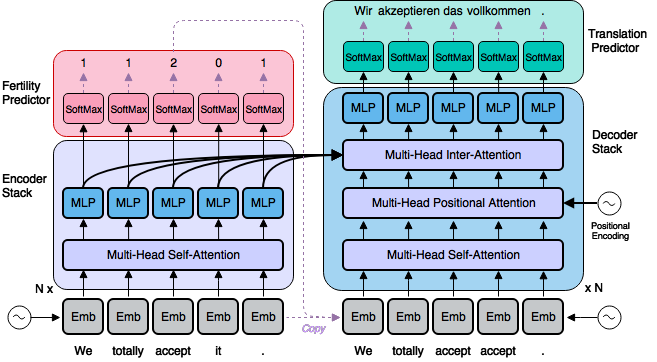
#### Model Architecture
The model architecture consists of an Encoder-Decoder Long Short-Term Memory network with an embedding layer. It was built on a Neural Machine Translation architecture where sequence-to-sequence framework with attention mechanisms was applied.
This project aims to develop a machine translation system for translating French text into English. The system utilizes state-of-the-art neural network architectures and techniques in natural language processing (NLP) to accurately translate French sentences into their corresponding English equivalents.
### Built With
* [![Python][Python]][Python-url]
* [![TensorFlow][TensorFlow]][TensorFlow-url]
* [![Keras][Keras]][Keras-url]
* [![NumPy][NumPy]][NumPy-url]
* [![Pandas][Pandas]][Pandas-url]
## Getting Started
Please follow these simple steps to setup this project locally.
### Dependencies
Here are the list all libraries, packages and other dependencies that need to be installed to run this project.
For example, this is how you would list them:
* TensorFlow 2.16.1
```sh
conda install -c conda-forge tensorflow
```
* Keras 2.15.0
```sh
conda install -c conda-forge keras
```
* Gradio 4.24.0
```sh
conda install -c conda-forge gradio
```
* NumPy 1.26.4
```sh
conda install -c conda-forge numpy
```
### Alternative: Export Environment
Alternatively, clone the project repository, install it and have all dependencies needed.
```sh
conda env export > requirements.txt
```
Recreate it using:
```sh
conda env create -f requirements.txt
```
### Installation
```sh
# clone project
git clone https://huggingface.co/spaces/KameliaZaman/French-to-English-Translation/tree/main
# go inside the project directory
cd French-to-English-Translation
# install the required packages
pip install -r requirements.txt
# run the gradio app
python app.py
```
## Usage
#### Dataset
Dataset is from "https://www.kaggle.com/datasets/devicharith/language-translation-englishfrench" which contains 2 columns where one column has english words/sentences and the other one has french words/sentence
#### Model Architecture
The model architecture consists of an Encoder-Decoder Long Short-Term Memory network with an embedding layer. It was built on a Neural Machine Translation architecture where sequence-to-sequence framework with attention mechanisms was applied.
 #### Data Preparation
- The parallel corpus containing French and English sentences is preprocessed.
- Text is tokenized and converted into numerical representations suitable for input to the neural network.
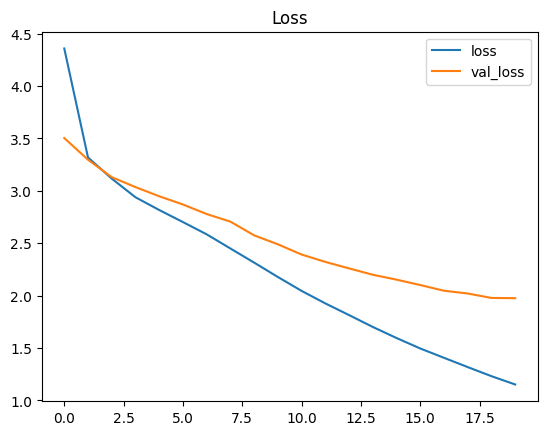
#### Model Training
- The sequence-to-sequence model is constructed, comprising an encoder and decoder.
- Training data is fed into the model, and parameters are optimized using backpropagation and gradient descent algorithms.
```sh
def create_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
# Create the model
model = Sequential()
model.add(Embedding(src_vocab_size, n_units, input_length=src_length, mask_zero=True))
model.add(LSTM(n_units))
model.add(RepeatVector(tar_timesteps))
model.add(LSTM(n_units, return_sequences=True))
model.add(TimeDistributed(Dense(tar_vocab, activation='softmax')))
return model
model = create_model(src_vocab_size, tar_vocab_size, src_length, tar_length, 256)
model.compile(optimizer='adam', loss='categorical_crossentropy')
history = model.fit(trainX,
trainY,
epochs=20,
batch_size=64,
validation_split=0.1,
verbose=1,
callbacks=[
EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
)
])
```
#### Data Preparation
- The parallel corpus containing French and English sentences is preprocessed.
- Text is tokenized and converted into numerical representations suitable for input to the neural network.
#### Model Training
- The sequence-to-sequence model is constructed, comprising an encoder and decoder.
- Training data is fed into the model, and parameters are optimized using backpropagation and gradient descent algorithms.
```sh
def create_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
# Create the model
model = Sequential()
model.add(Embedding(src_vocab_size, n_units, input_length=src_length, mask_zero=True))
model.add(LSTM(n_units))
model.add(RepeatVector(tar_timesteps))
model.add(LSTM(n_units, return_sequences=True))
model.add(TimeDistributed(Dense(tar_vocab, activation='softmax')))
return model
model = create_model(src_vocab_size, tar_vocab_size, src_length, tar_length, 256)
model.compile(optimizer='adam', loss='categorical_crossentropy')
history = model.fit(trainX,
trainY,
epochs=20,
batch_size=64,
validation_split=0.1,
verbose=1,
callbacks=[
EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
)
])
```
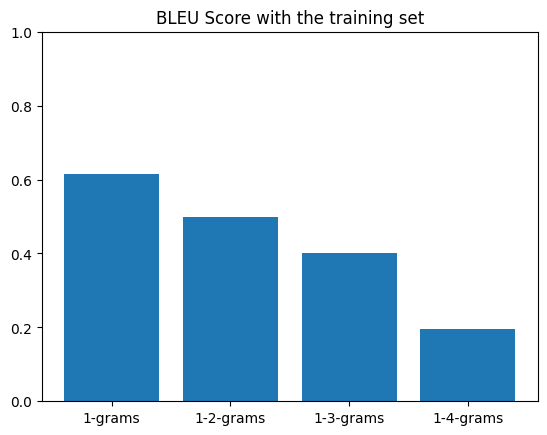
 #### Model Evaluation
- The trained model is evaluated on the test set to measure its accuracy.
- Metrics such as BLEU score has been used to quantify the quality of translations.
#### Model Evaluation
- The trained model is evaluated on the test set to measure its accuracy.
- Metrics such as BLEU score has been used to quantify the quality of translations.
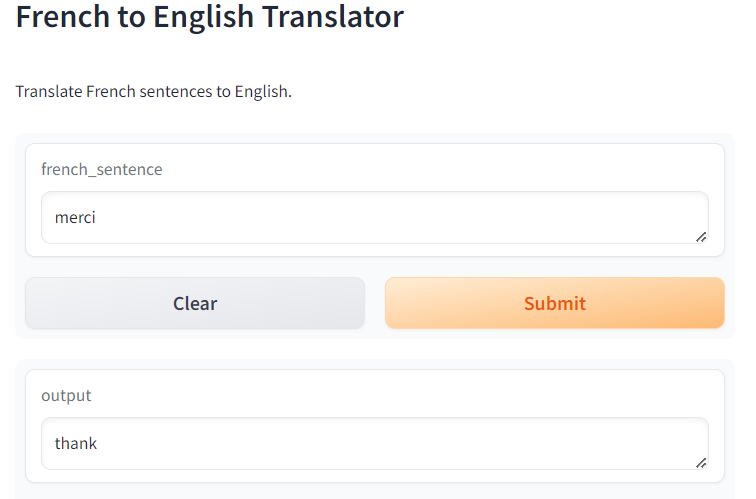
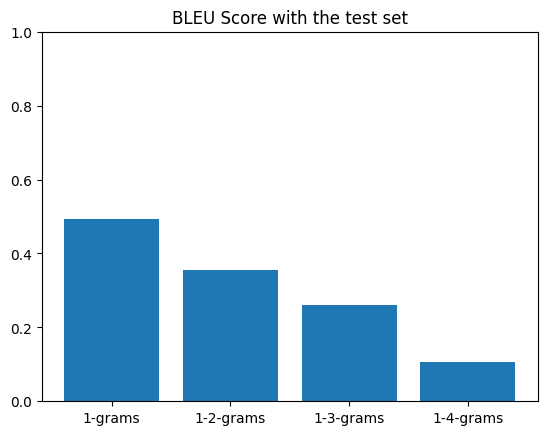 #### Deployment
- Gradio is utilized for deploying the trained model.
- Users can input a French text, and the model will translate it to English.
```sh
import string
import re
from unicodedata import normalize
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.models import Sequential,load_model
from keras.layers import LSTM,Dense,Embedding,RepeatVector,TimeDistributed
from keras.callbacks import EarlyStopping
from nltk.translate.bleu_score import corpus_bleu
import pandas as pd
from string import punctuation
import matplotlib.pyplot as plt
from IPython.display import Markdown, display
import gradio as gr
import tensorflow as tf
from tensorflow.keras.models import load_model
total_sentences = 10000
dataset = pd.read_csv("./eng_-french.csv", nrows = total_sentences)
def clean(string):
# Clean the string
string = string.replace("\u202f"," ") # Replace no-break space with space
string = string.lower()
# Delete the punctuation and the numbers
for p in punctuation + "«»" + "0123456789":
string = string.replace(p," ")
string = re.sub('\s+',' ', string)
string = string.strip()
return string
dataset = dataset.sample(frac=1, random_state=0)
dataset["English words/sentences"] = dataset["English words/sentences"].apply(lambda x: clean(x))
dataset["French words/sentences"] = dataset["French words/sentences"].apply(lambda x: clean(x))
dataset = dataset.values
dataset = dataset[:total_sentences]
source_str, target_str = "French", "English"
idx_src, idx_tar = 1, 0
def create_tokenizer(lines):
# fit a tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
def max_len(lines):
# max sentence length
return max(len(line.split()) for line in lines)
def encode_sequences(tokenizer, length, lines):
# encode and pad sequences
X = tokenizer.texts_to_sequences(lines) # integer encode sequences
X = pad_sequences(X, maxlen=length, padding='post') # pad sequences with 0 values
return X
def word_for_id(integer, tokenizer):
# map an integer to a word
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
def predict_seq(model, tokenizer, source):
# generate target from a source sequence
prediction = model.predict(source, verbose=0)[0]
integers = [np.argmax(vector) for vector in prediction]
target = list()
for i in integers:
word = word_for_id(i, tokenizer)
if word is None:
break
target.append(word)
return ' '.join(target)
src_tokenizer = create_tokenizer(dataset[:, idx_src])
src_vocab_size = len(src_tokenizer.word_index) + 1
src_length = max_len(dataset[:, idx_src])
tar_tokenizer = create_tokenizer(dataset[:, idx_tar])
model = load_model('./french_to_english_translator.h5')
def translate_french_english(french_sentence):
# Clean the input sentence
french_sentence = clean(french_sentence)
# Tokenize and pad the input sentence
input_sequence = encode_sequences(src_tokenizer, src_length, [french_sentence])
# Generate the translation
english_translation = predict_seq(model, tar_tokenizer, input_sequence)
return english_translation
gr.Interface(
fn=translate_french_english,
inputs="text",
outputs="text",
title="French to English Translator",
description="Translate French sentences to English."
).launch()
```
## Contributing
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
Don't forget to give the project a star! Thanks again!
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
## License
Distributed under the MIT License. See [MIT License](LICENSE) for more information.
## Contact
Kamelia Zaman Moon - kamelia.stu2017@juniv.edu
Project Link: [https://huggingface.co/spaces/KameliaZaman/French-to-English-Translation](https://huggingface.co/spaces/KameliaZaman/French-to-English-Translation/tree/main)
[Python]: https://img.shields.io/badge/python-3670A0?style=for-the-badge&logo=python&logoColor=ffdd54
[Python-url]: https://www.python.org/
[TensorFlow]: https://img.shields.io/badge/TensorFlow-%23FF6F00.svg?style=for-the-badge&logo=TensorFlow&logoColor=white
[TensorFlow-url]: https://tensorflow.org/
[Keras]: https://img.shields.io/badge/Keras-%23D00000.svg?style=for-the-badge&logo=Keras&logoColor=white
[Keras-url]: https://keras.io/
[NumPy]: https://img.shields.io/badge/numpy-%23013243.svg?style=for-the-badge&logo=numpy&logoColor=white
[NumPy-url]: https://numpy.org/
[Pandas]: https://img.shields.io/badge/pandas-%23150458.svg?style=for-the-badge&logo=pandas&logoColor=white
[Pandas-url]: https://pandas.pydata.org/
#### Deployment
- Gradio is utilized for deploying the trained model.
- Users can input a French text, and the model will translate it to English.
```sh
import string
import re
from unicodedata import normalize
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.models import Sequential,load_model
from keras.layers import LSTM,Dense,Embedding,RepeatVector,TimeDistributed
from keras.callbacks import EarlyStopping
from nltk.translate.bleu_score import corpus_bleu
import pandas as pd
from string import punctuation
import matplotlib.pyplot as plt
from IPython.display import Markdown, display
import gradio as gr
import tensorflow as tf
from tensorflow.keras.models import load_model
total_sentences = 10000
dataset = pd.read_csv("./eng_-french.csv", nrows = total_sentences)
def clean(string):
# Clean the string
string = string.replace("\u202f"," ") # Replace no-break space with space
string = string.lower()
# Delete the punctuation and the numbers
for p in punctuation + "«»" + "0123456789":
string = string.replace(p," ")
string = re.sub('\s+',' ', string)
string = string.strip()
return string
dataset = dataset.sample(frac=1, random_state=0)
dataset["English words/sentences"] = dataset["English words/sentences"].apply(lambda x: clean(x))
dataset["French words/sentences"] = dataset["French words/sentences"].apply(lambda x: clean(x))
dataset = dataset.values
dataset = dataset[:total_sentences]
source_str, target_str = "French", "English"
idx_src, idx_tar = 1, 0
def create_tokenizer(lines):
# fit a tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
def max_len(lines):
# max sentence length
return max(len(line.split()) for line in lines)
def encode_sequences(tokenizer, length, lines):
# encode and pad sequences
X = tokenizer.texts_to_sequences(lines) # integer encode sequences
X = pad_sequences(X, maxlen=length, padding='post') # pad sequences with 0 values
return X
def word_for_id(integer, tokenizer):
# map an integer to a word
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
def predict_seq(model, tokenizer, source):
# generate target from a source sequence
prediction = model.predict(source, verbose=0)[0]
integers = [np.argmax(vector) for vector in prediction]
target = list()
for i in integers:
word = word_for_id(i, tokenizer)
if word is None:
break
target.append(word)
return ' '.join(target)
src_tokenizer = create_tokenizer(dataset[:, idx_src])
src_vocab_size = len(src_tokenizer.word_index) + 1
src_length = max_len(dataset[:, idx_src])
tar_tokenizer = create_tokenizer(dataset[:, idx_tar])
model = load_model('./french_to_english_translator.h5')
def translate_french_english(french_sentence):
# Clean the input sentence
french_sentence = clean(french_sentence)
# Tokenize and pad the input sentence
input_sequence = encode_sequences(src_tokenizer, src_length, [french_sentence])
# Generate the translation
english_translation = predict_seq(model, tar_tokenizer, input_sequence)
return english_translation
gr.Interface(
fn=translate_french_english,
inputs="text",
outputs="text",
title="French to English Translator",
description="Translate French sentences to English."
).launch()
```
## Contributing
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
Don't forget to give the project a star! Thanks again!
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
## License
Distributed under the MIT License. See [MIT License](LICENSE) for more information.
## Contact
Kamelia Zaman Moon - kamelia.stu2017@juniv.edu
Project Link: [https://huggingface.co/spaces/KameliaZaman/French-to-English-Translation](https://huggingface.co/spaces/KameliaZaman/French-to-English-Translation/tree/main)
[Python]: https://img.shields.io/badge/python-3670A0?style=for-the-badge&logo=python&logoColor=ffdd54
[Python-url]: https://www.python.org/
[TensorFlow]: https://img.shields.io/badge/TensorFlow-%23FF6F00.svg?style=for-the-badge&logo=TensorFlow&logoColor=white
[TensorFlow-url]: https://tensorflow.org/
[Keras]: https://img.shields.io/badge/Keras-%23D00000.svg?style=for-the-badge&logo=Keras&logoColor=white
[Keras-url]: https://keras.io/
[NumPy]: https://img.shields.io/badge/numpy-%23013243.svg?style=for-the-badge&logo=numpy&logoColor=white
[NumPy-url]: https://numpy.org/
[Pandas]: https://img.shields.io/badge/pandas-%23150458.svg?style=for-the-badge&logo=pandas&logoColor=white
[Pandas-url]: https://pandas.pydata.org/