---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- llm
- code
---
# CrystalChat
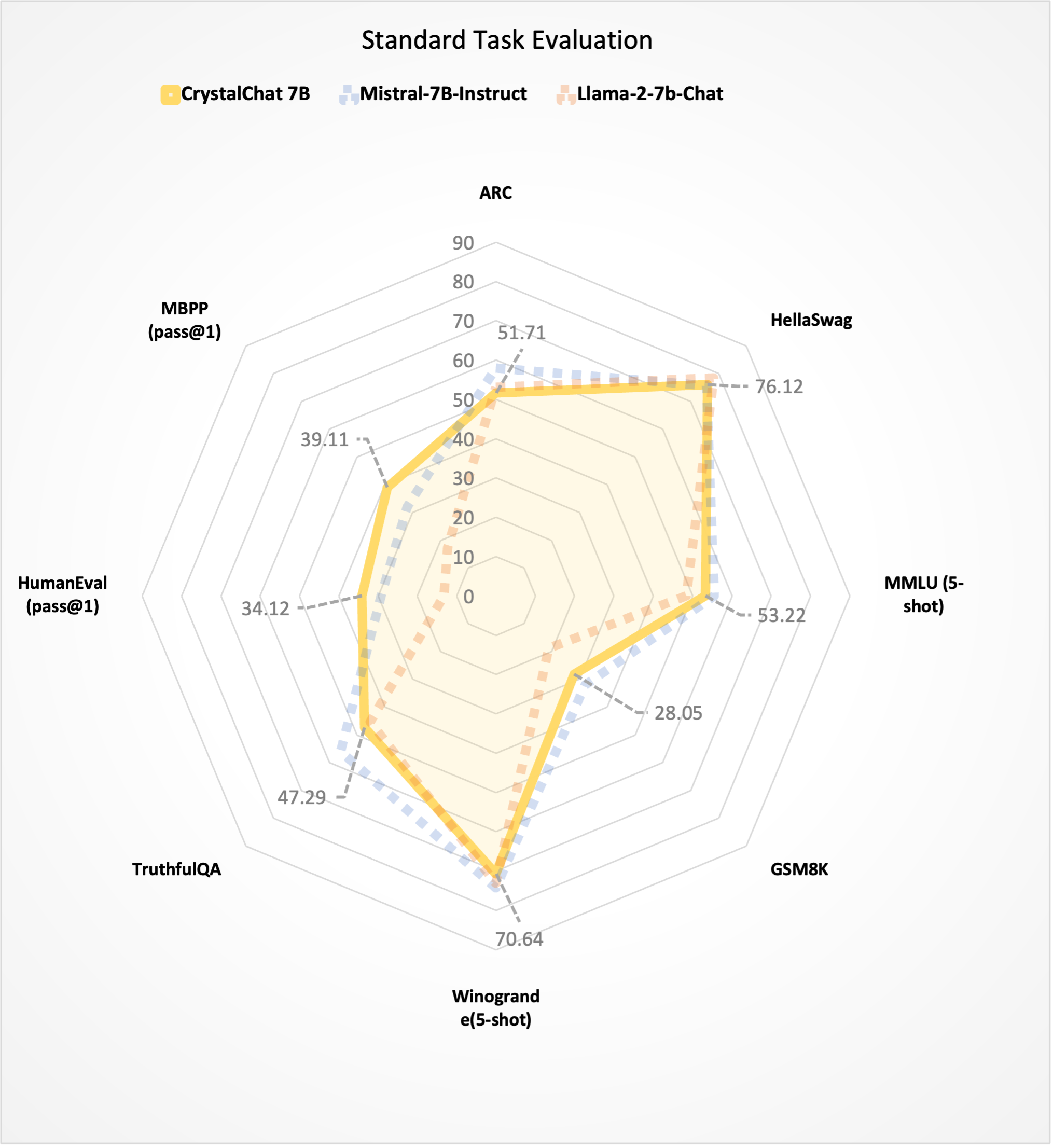
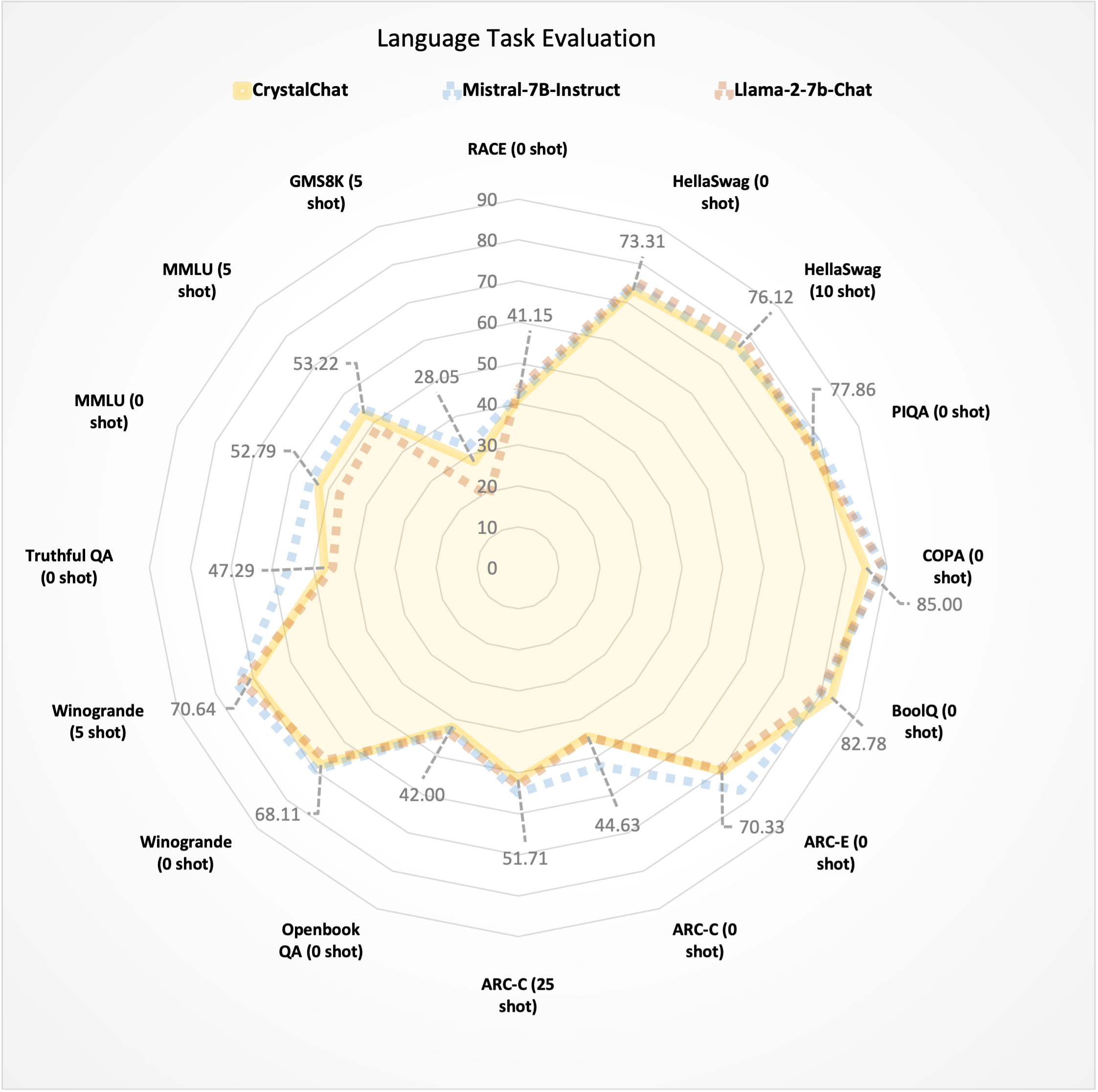
We present CrystalChat, an instruction following model finetuned from [LLM360/CrystalCoder](https://huggingface.co/LLM360/CrystalCoder). Here's a comparison table for some popular chat models.
| Model | Trained Tokens | Avg. of Avg. | Language Avg. | Coding Avg. | ARC | HellaSwag | MMLU (5-shot) | GSM8K | Winogrande(5-shot) | TruthfulQA | HumanEval (pass@1) | MBPP (pass@1) |
|:------------------------:|:--------------:|:------------:|:-------------:|:-----------:|:-----:|:---------:|:-------------:|:-----:|:------------------:|:----------:|:------------------:|:-------------:|
| CrystalChat 7B | 1.275T | 44.96 | 53.29 | 36.62 | 51.71 | 76.12 | 53.22 | 28.05 | 70.64 | 47.29 | 34.12 | 39.11 |
| Mistral-7B-Instruct-v0.1 | - | 44.34 | 54.86 | 30.62 | 58.05 | 75.71 | 55.56 | 32.00 | 74.27 | 55.90 | 29.27 | 31.96 |
| CodeLlama-7b-Instruct | 2.5T | 40.91 | 45.29 | 36.52 | 43.35 | 66.14 | 42.75 | 15.92 | 64.33 | 39.23 | 34.12 | 38.91 |
| Llama-2-7b-Chat | 2T | 34.11 | 52.86 | 15.35 | 53.07 | 78.39 | 48.42 | 18.88 | 73.09 | 45.30 | 13.26 | 17.43 |
| AmberChat 7B | 1.25T | - | 44.76 | - | 42.83 | 74.03 | 38.88 | 5.31 | 66.77 | 40.72 | - | - |
|||
 |:--|:--|
|
|:--|:--|
| |
| ## Model Description
- **Model type:** Language model with the same architecture as LLaMA-7B
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Resources for more information:**
- [Training Code](https://github.com/LLM360/crystalcoder-train)
- [Data Preparation](https://github.com/LLM360/crystalcoder-data-prep)
- [Metrics](https://github.com/LLM360/Analysis360)
- [Fully processed CrystalCoder pretraining data](https://huggingface.co/datasets/LLM360/CrystalCoderDatasets)
# Loading CrystalChat
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("LLM360/CrystalChat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("LLM360/CrystalChat", trust_remote_code=True).to(device)
prompt = 'int add(int x, int y) {'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
gen_tokens = model.generate(input_ids, do_sample=True, max_length=400)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
```
# Citation
**BibTeX:**
```bibtex
@misc{liu2023llm360,
title={LLM360: Towards Fully Transparent Open-Source LLMs},
author={Zhengzhong Liu and Aurick Qiao and Willie Neiswanger and Hongyi Wang and Bowen Tan and Tianhua Tao and Junbo Li and Yuqi Wang and Suqi Sun and Omkar Pangarkar and Richard Fan and Yi Gu and Victor Miller and Yonghao Zhuang and Guowei He and Haonan Li and Fajri Koto and Liping Tang and Nikhil Ranjan and Zhiqiang Shen and Xuguang Ren and Roberto Iriondo and Cun Mu and Zhiting Hu and Mark Schulze and Preslav Nakov and Tim Baldwin and Eric P. Xing},
year={2023},
eprint={2312.06550},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Model Description
- **Model type:** Language model with the same architecture as LLaMA-7B
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Resources for more information:**
- [Training Code](https://github.com/LLM360/crystalcoder-train)
- [Data Preparation](https://github.com/LLM360/crystalcoder-data-prep)
- [Metrics](https://github.com/LLM360/Analysis360)
- [Fully processed CrystalCoder pretraining data](https://huggingface.co/datasets/LLM360/CrystalCoderDatasets)
# Loading CrystalChat
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("LLM360/CrystalChat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("LLM360/CrystalChat", trust_remote_code=True).to(device)
prompt = 'int add(int x, int y) {'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
gen_tokens = model.generate(input_ids, do_sample=True, max_length=400)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
```
# Citation
**BibTeX:**
```bibtex
@misc{liu2023llm360,
title={LLM360: Towards Fully Transparent Open-Source LLMs},
author={Zhengzhong Liu and Aurick Qiao and Willie Neiswanger and Hongyi Wang and Bowen Tan and Tianhua Tao and Junbo Li and Yuqi Wang and Suqi Sun and Omkar Pangarkar and Richard Fan and Yi Gu and Victor Miller and Yonghao Zhuang and Guowei He and Haonan Li and Fajri Koto and Liping Tang and Nikhil Ranjan and Zhiqiang Shen and Xuguang Ren and Roberto Iriondo and Cun Mu and Zhiting Hu and Mark Schulze and Preslav Nakov and Tim Baldwin and Eric P. Xing},
year={2023},
eprint={2312.06550},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```