

Commit
•
c0c7665
1
Parent(s):
54323cf
Upload folder using huggingface_hub
Browse files
README.md
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
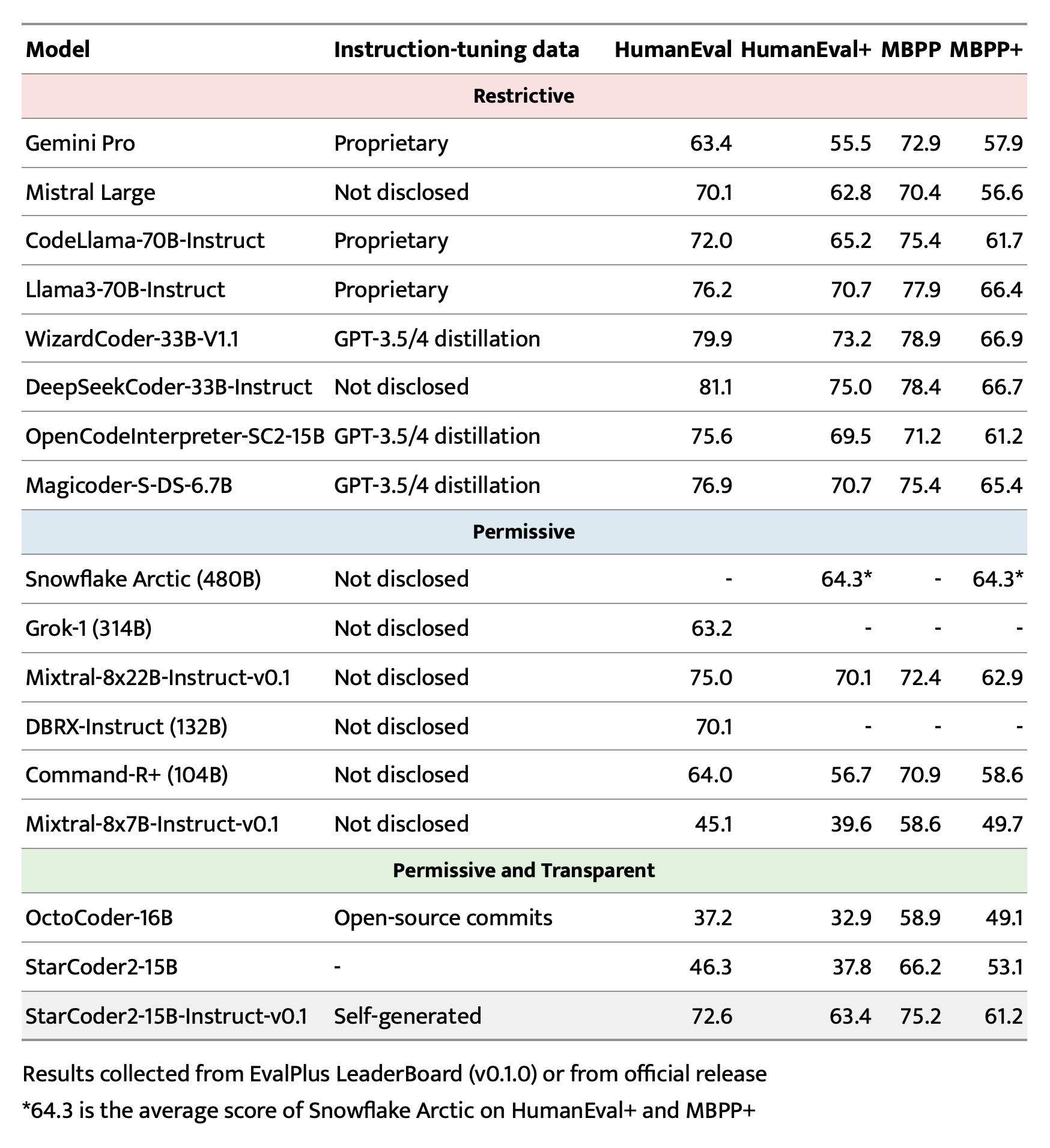
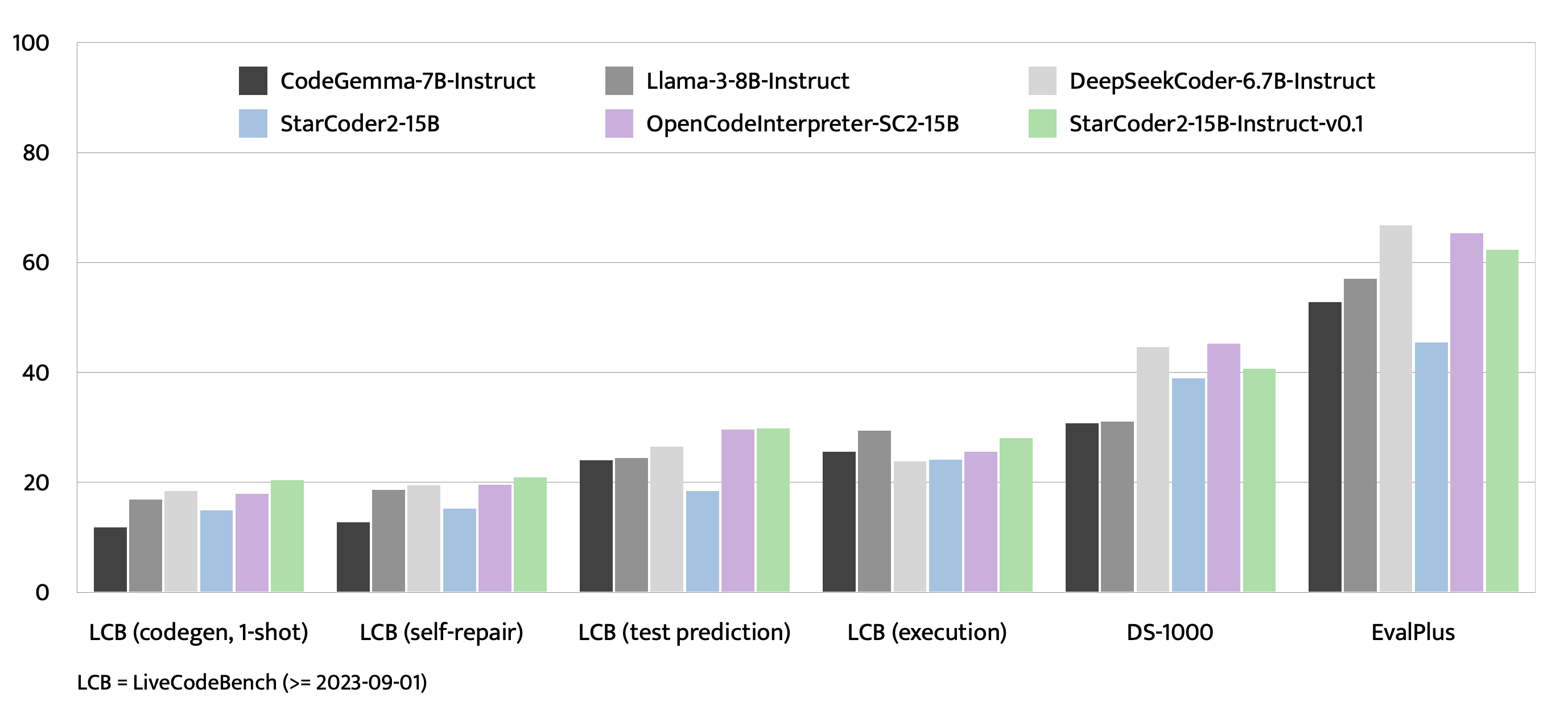
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
---
|
| 4 |
+
license: bigcode-openrail-m
|
| 5 |
+
library_name: transformers
|
| 6 |
+
tags:
|
| 7 |
+
- code
|
| 8 |
+
- GGUF
|
| 9 |
+
base_model: bigcode/starcoder2-15b
|
| 10 |
+
datasets:
|
| 11 |
+
- bigcode/self-oss-instruct-sc2-exec-filter-50k
|
| 12 |
+
pipeline_tag: text-generation
|
| 13 |
+
model-index:
|
| 14 |
+
- name: starcoder2-15b-instruct-v0.1
|
| 15 |
+
results:
|
| 16 |
+
- task:
|
| 17 |
+
type: text-generation
|
| 18 |
+
dataset:
|
| 19 |
+
name: LiveCodeBench (code generation)
|
| 20 |
+
type: livecodebench-codegeneration
|
| 21 |
+
metrics:
|
| 22 |
+
- type: pass@1
|
| 23 |
+
value: 20.4
|
| 24 |
+
verified: false
|
| 25 |
+
- task:
|
| 26 |
+
type: text-generation
|
| 27 |
+
dataset:
|
| 28 |
+
name: LiveCodeBench (self repair)
|
| 29 |
+
type: livecodebench-selfrepair
|
| 30 |
+
metrics:
|
| 31 |
+
- type: pass@1
|
| 32 |
+
value: 20.9
|
| 33 |
+
verified: false
|
| 34 |
+
- task:
|
| 35 |
+
type: text-generation
|
| 36 |
+
dataset:
|
| 37 |
+
name: LiveCodeBench (test output prediction)
|
| 38 |
+
type: livecodebench-testoutputprediction
|
| 39 |
+
metrics:
|
| 40 |
+
- type: pass@1
|
| 41 |
+
value: 29.8
|
| 42 |
+
verified: false
|
| 43 |
+
- task:
|
| 44 |
+
type: text-generation
|
| 45 |
+
dataset:
|
| 46 |
+
name: LiveCodeBench (code execution)
|
| 47 |
+
type: livecodebench-codeexecution
|
| 48 |
+
metrics:
|
| 49 |
+
- type: pass@1
|
| 50 |
+
value: 28.1
|
| 51 |
+
verified: false
|
| 52 |
+
- task:
|
| 53 |
+
type: text-generation
|
| 54 |
+
dataset:
|
| 55 |
+
name: HumanEval
|
| 56 |
+
type: humaneval
|
| 57 |
+
metrics:
|
| 58 |
+
- type: pass@1
|
| 59 |
+
value: 72.6
|
| 60 |
+
verified: false
|
| 61 |
+
- task:
|
| 62 |
+
type: text-generation
|
| 63 |
+
dataset:
|
| 64 |
+
name: HumanEval+
|
| 65 |
+
type: humanevalplus
|
| 66 |
+
metrics:
|
| 67 |
+
- type: pass@1
|
| 68 |
+
value: 63.4
|
| 69 |
+
verified: false
|
| 70 |
+
- task:
|
| 71 |
+
type: text-generation
|
| 72 |
+
dataset:
|
| 73 |
+
name: MBPP
|
| 74 |
+
type: mbpp
|
| 75 |
+
metrics:
|
| 76 |
+
- type: pass@1
|
| 77 |
+
value: 75.2
|
| 78 |
+
verified: false
|
| 79 |
+
- task:
|
| 80 |
+
type: text-generation
|
| 81 |
+
dataset:
|
| 82 |
+
name: MBPP+
|
| 83 |
+
type: mbppplus
|
| 84 |
+
metrics:
|
| 85 |
+
- type: pass@1
|
| 86 |
+
value: 61.2
|
| 87 |
+
verified: false
|
| 88 |
+
- task:
|
| 89 |
+
type: text-generation
|
| 90 |
+
dataset:
|
| 91 |
+
name: DS-1000
|
| 92 |
+
type: ds-1000
|
| 93 |
+
metrics:
|
| 94 |
+
- type: pass@1
|
| 95 |
+
value: 40.6
|
| 96 |
+
verified: false
|
| 97 |
+
quantized_by: andrijdavid
|
| 98 |
+
---
|
| 99 |
+
# starcoder2-15b-instruct-v0.1-GGUF
|
| 100 |
+
- Original model: [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1)
|
| 101 |
+
|
| 102 |
+
<!-- description start -->
|
| 103 |
+
## Description
|
| 104 |
+
|
| 105 |
+
This repo contains GGUF format model files for [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1).
|
| 106 |
+
|
| 107 |
+
<!-- description end -->
|
| 108 |
+
<!-- README_GGUF.md-about-gguf start -->
|
| 109 |
+
### About GGUF
|
| 110 |
+
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
|
| 111 |
+
Here is an incomplete list of clients and libraries that are known to support GGUF:
|
| 112 |
+
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
|
| 113 |
+
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
|
| 114 |
+
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
|
| 115 |
+
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
|
| 116 |
+
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
|
| 117 |
+
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
|
| 118 |
+
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
|
| 119 |
+
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
|
| 120 |
+
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
|
| 121 |
+
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
|
| 122 |
+
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
|
| 123 |
+
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
|
| 124 |
+
<!-- README_GGUF.md-about-gguf end -->
|
| 125 |
+
|
| 126 |
+
<!-- compatibility_gguf start -->
|
| 127 |
+
## Explanation of quantisation methods
|
| 128 |
+
<details>
|
| 129 |
+
<summary>Click to see details</summary>
|
| 130 |
+
The new methods available are:
|
| 131 |
+
|
| 132 |
+
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
|
| 133 |
+
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
|
| 134 |
+
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
|
| 135 |
+
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
|
| 136 |
+
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
|
| 137 |
+
</details>
|
| 138 |
+
<!-- compatibility_gguf end -->
|
| 139 |
+
|
| 140 |
+
<!-- README_GGUF.md-how-to-download start -->
|
| 141 |
+
## How to download GGUF files
|
| 142 |
+
|
| 143 |
+
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
|
| 144 |
+
|
| 145 |
+
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
|
| 146 |
+
|
| 147 |
+
* LM Studio
|
| 148 |
+
* LoLLMS Web UI
|
| 149 |
+
* Faraday.dev
|
| 150 |
+
|
| 151 |
+
### In `text-generation-webui`
|
| 152 |
+
|
| 153 |
+
Under Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00009.gguf.
|
| 154 |
+
|
| 155 |
+
Then click Download.
|
| 156 |
+
|
| 157 |
+
### On the command line, including multiple files at once
|
| 158 |
+
|
| 159 |
+
I recommend using the `huggingface-hub` Python library:
|
| 160 |
+
|
| 161 |
+
```shell
|
| 162 |
+
pip3 install huggingface-hub
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
Then you can download any individual model file to the current directory, at high speed, with a command like this:
|
| 166 |
+
|
| 167 |
+
```shell
|
| 168 |
+
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
<details>
|
| 172 |
+
<summary>More advanced huggingface-cli download usage (click to read)</summary>
|
| 173 |
+
|
| 174 |
+
You can also download multiple files at once with a pattern:
|
| 175 |
+
|
| 176 |
+
```shell
|
| 177 |
+
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
|
| 181 |
+
|
| 182 |
+
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
|
| 183 |
+
|
| 184 |
+
```shell
|
| 185 |
+
pip3 install huggingface_hub[hf_transfer]
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
|
| 189 |
+
|
| 190 |
+
```shell
|
| 191 |
+
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
|
| 195 |
+
</details>
|
| 196 |
+
<!-- README_GGUF.md-how-to-download end -->
|
| 197 |
+
<!-- README_GGUF.md-how-to-run start -->
|
| 198 |
+
## Example `llama.cpp` command
|
| 199 |
+
|
| 200 |
+
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
|
| 201 |
+
|
| 202 |
+
```shell
|
| 203 |
+
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00009.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
|
| 207 |
+
|
| 208 |
+
Change `-c 8192` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
|
| 209 |
+
|
| 210 |
+
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
|
| 211 |
+
|
| 212 |
+
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
|
| 213 |
+
|
| 214 |
+
## How to run in `text-generation-webui`
|
| 215 |
+
|
| 216 |
+
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
|
| 217 |
+
|
| 218 |
+
## How to run from Python code
|
| 219 |
+
|
| 220 |
+
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
|
| 221 |
+
|
| 222 |
+
### How to load this model in Python code, using llama-cpp-python
|
| 223 |
+
|
| 224 |
+
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
|
| 225 |
+
|
| 226 |
+
#### First install the package
|
| 227 |
+
|
| 228 |
+
Run one of the following commands, according to your system:
|
| 229 |
+
|
| 230 |
+
```shell
|
| 231 |
+
# Base ctransformers with no GPU acceleration
|
| 232 |
+
pip install llama-cpp-python
|
| 233 |
+
# With NVidia CUDA acceleration
|
| 234 |
+
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
|
| 235 |
+
# Or with OpenBLAS acceleration
|
| 236 |
+
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
|
| 237 |
+
# Or with CLBLast acceleration
|
| 238 |
+
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
|
| 239 |
+
# Or with AMD ROCm GPU acceleration (Linux only)
|
| 240 |
+
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
|
| 241 |
+
# Or with Metal GPU acceleration for macOS systems only
|
| 242 |
+
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
|
| 243 |
+
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
|
| 244 |
+
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
|
| 245 |
+
pip install llama-cpp-python
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
#### Simple llama-cpp-python example code
|
| 249 |
+
|
| 250 |
+
```python
|
| 251 |
+
from llama_cpp import Llama
|
| 252 |
+
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
|
| 253 |
+
llm = Llama(
|
| 254 |
+
model_path="./Q4_0/Q4_0-00001-of-00009.gguf", # Download the model file first
|
| 255 |
+
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
|
| 256 |
+
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
|
| 257 |
+
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
|
| 258 |
+
)
|
| 259 |
+
# Simple inference example
|
| 260 |
+
output = llm(
|
| 261 |
+
"<PROMPT>", # Prompt
|
| 262 |
+
max_tokens=512, # Generate up to 512 tokens
|
| 263 |
+
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
|
| 264 |
+
echo=True # Whether to echo the prompt
|
| 265 |
+
)
|
| 266 |
+
# Chat Completion API
|
| 267 |
+
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00009.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
|
| 268 |
+
llm.create_chat_completion(
|
| 269 |
+
messages = [
|
| 270 |
+
{"role": "system", "content": "You are a story writing assistant."},
|
| 271 |
+
{
|
| 272 |
+
"role": "user",
|
| 273 |
+
"content": "Write a story about llamas."
|
| 274 |
+
}
|
| 275 |
+
]
|
| 276 |
+
)
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
## How to use with LangChain
|
| 280 |
+
|
| 281 |
+
Here are guides on using llama-cpp-python and ctransformers with LangChain:
|
| 282 |
+
|
| 283 |
+
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
|
| 284 |
+
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
|
| 285 |
+
|
| 286 |
+
<!-- README_GGUF.md-how-to-run end -->
|
| 287 |
+
|
| 288 |
+
<!-- footer end -->
|
| 289 |
+
|
| 290 |
+
<!-- original-model-card start -->
|
| 291 |
+
# Original model card: starcoder2-15b-instruct-v0.1
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
|
| 295 |
+
|
| 296 |
+

|
| 297 |
+
|
| 298 |
+
## Model Summary
|
| 299 |
+
|
| 300 |
+
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
|
| 301 |
+
|
| 302 |
+
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
| 303 |
+
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
| 304 |
+
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
| 305 |
+
- **Authors:**
|
| 306 |
+
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
|
| 307 |
+
[Federico Cassano](https://federico.codes/),
|
| 308 |
+
[Jiawei Liu](https://jw-liu.xyz),
|
| 309 |
+
[Yifeng Ding](https://yifeng-ding.com),
|
| 310 |
+
[Naman Jain](https://naman-ntc.github.io),
|
| 311 |
+
[Harm de Vries](https://www.harmdevries.com),
|
| 312 |
+
[Leandro von Werra](https://twitter.com/lvwerra),
|
| 313 |
+
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
|
| 314 |
+
[Lingming Zhang](https://lingming.cs.illinois.edu).
|
| 315 |
+
|
| 316 |
+

|
| 317 |
+
|
| 318 |
+
## Use
|
| 319 |
+
|
| 320 |
+
### Intended use
|
| 321 |
+
|
| 322 |
+
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
|
| 323 |
+
|
| 324 |
+
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
|
| 325 |
+
|
| 326 |
+
```python
|
| 327 |
+
import transformers
|
| 328 |
+
import torch
|
| 329 |
+
|
| 330 |
+
pipeline = transformers.pipeline(
|
| 331 |
+
model="bigcode/starcoder2-15b-instruct-v0.1",
|
| 332 |
+
task="text-generation",
|
| 333 |
+
torch_dtype=torch.bfloat16,
|
| 334 |
+
device_map="auto",
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
def respond(instruction: str, response_prefix: str) -> str:
|
| 338 |
+
messages = [{"role": "user", "content": instruction}]
|
| 339 |
+
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
|
| 340 |
+
prompt += response_prefix
|
| 341 |
+
|
| 342 |
+
teminators = [
|
| 343 |
+
pipeline.tokenizer.eos_token_id,
|
| 344 |
+
pipeline.tokenizer.convert_tokens_to_ids("###"),
|
| 345 |
+
]
|
| 346 |
+
|
| 347 |
+
result = pipeline(
|
| 348 |
+
prompt,
|
| 349 |
+
max_length=256,
|
| 350 |
+
num_return_sequences=1,
|
| 351 |
+
do_sample=False,
|
| 352 |
+
eos_token_id=teminators,
|
| 353 |
+
pad_token_id=pipeline.tokenizer.eos_token_id,
|
| 354 |
+
truncation=True,
|
| 355 |
+
)
|
| 356 |
+
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
|
| 357 |
+
return response
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
|
| 361 |
+
response_prefix = ""
|
| 362 |
+
|
| 363 |
+
print(respond(instruction, response_prefix))
|
| 364 |
+
```
|
| 365 |
+
|
| 366 |
+
Here is the expected output:
|
| 367 |
+
|
| 368 |
+
``````
|
| 369 |
+
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
|
| 370 |
+
|
| 371 |
+
```python
|
| 372 |
+
from typing import TypeVar, Callable
|
| 373 |
+
|
| 374 |
+
T = TypeVar('T')
|
| 375 |
+
|
| 376 |
+
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
|
| 377 |
+
if len(items) <= 1:
|
| 378 |
+
return items
|
| 379 |
+
|
| 380 |
+
pivot = items[0]
|
| 381 |
+
less = [x for x in items[1:] if less_than(x, pivot)]
|
| 382 |
+
greater = [x for x in items[1:] if not less_than(x, pivot)]
|
| 383 |
+
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
|
| 384 |
+
```
|
| 385 |
+
``````
|
| 386 |
+
|
| 387 |
+
### Bias, Risks, and Limitations
|
| 388 |
+
|
| 389 |
+
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
|
| 390 |
+
|
| 391 |
+
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
|
| 392 |
+
|
| 393 |
+
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
## Training Details
|
| 400 |
+
|
| 401 |
+
### Hyperparameters
|
| 402 |
+
|
| 403 |
+
- **Optimizer:** Adafactor
|
| 404 |
+
- **Learning rate:** 1e-5
|
| 405 |
+
- **Epoch:** 4
|
| 406 |
+
- **Batch size:** 64
|
| 407 |
+
- **Warmup ratio:** 0.05
|
| 408 |
+
- **Scheduler:** Linear
|
| 409 |
+
- **Sequence length:** 1280
|
| 410 |
+
- **Dropout**: Not applied
|
| 411 |
+
|
| 412 |
+
### Hardware
|
| 413 |
+
|
| 414 |
+
1 x NVIDIA A100 80GB
|
| 415 |
+
|
| 416 |
+
## Resources
|
| 417 |
+
|
| 418 |
+
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
| 419 |
+
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
| 420 |
+
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
| 421 |
+
|
| 422 |
+
<!-- original-model-card end -->
|