
Commit
•
6762748
1
Parent(s):
a7b0070
ExLLaMA V2 quant of Yarn-Mistral-7b-128k-5.0bpw-h6-exl2
Browse files- README.md +59 -0
- added_tokens.json +5 -0
- config.json +36 -0
- generation_config.json +6 -0
- output.safetensors +3 -0
- pytorch_model.bin.index.json +298 -0
- special_tokens_map.json +10 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +44 -0
README.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
datasets:
|
| 3 |
+
- emozilla/yarn-train-tokenized-16k-mistral
|
| 4 |
+
metrics:
|
| 5 |
+
- perplexity
|
| 6 |
+
library_name: transformers
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Model Card: Nous-Yarn-Mistral-7b-128k
|
| 10 |
+
|
| 11 |
+
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
|
| 12 |
+
[GitHub](https://github.com/jquesnelle/yarn)
|
| 13 |
+
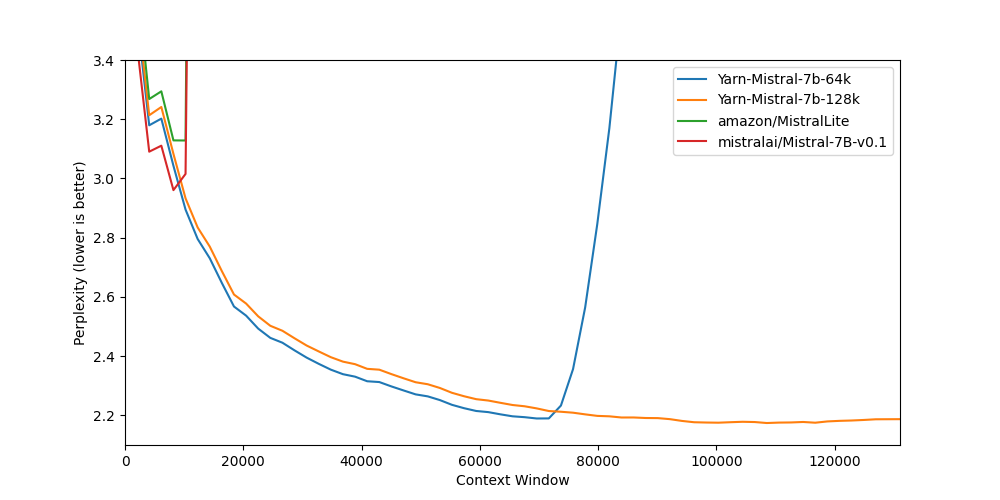
|
| 14 |
+
|
| 15 |
+
## Model Description
|
| 16 |
+
|
| 17 |
+
Nous-Yarn-Mistral-7b-128k is a state-of-the-art language model for long context, further pretrained on long context data for 1500 steps using the YaRN extension method.
|
| 18 |
+
It is an extension of [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) and supports a 128k token context window.
|
| 19 |
+
|
| 20 |
+
To use, pass `trust_remote_code=True` when loading the model, for example
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
model = AutoModelForCausalLM.from_pretrained("NousResearch/Yarn-Mistral-7b-128k",
|
| 24 |
+
use_flash_attention_2=True,
|
| 25 |
+
torch_dtype=torch.bfloat16,
|
| 26 |
+
device_map="auto",
|
| 27 |
+
trust_remote_code=True)
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
In addition you will need to use the latest version of `transformers` (until 4.35 comes out)
|
| 31 |
+
```sh
|
| 32 |
+
pip install git+https://github.com/huggingface/transformers
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
## Benchmarks
|
| 36 |
+
|
| 37 |
+
Long context benchmarks:
|
| 38 |
+
| Model | Context Window | 8k PPL | 16k PPL | 32k PPL | 64k PPL | 128k PPL |
|
| 39 |
+
|-------|---------------:|------:|----------:|-----:|-----:|------------:|
|
| 40 |
+
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 2.96 | - | - | - | - |
|
| 41 |
+
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 3.04 | 2.65 | 2.44 | 2.20 | - |
|
| 42 |
+
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 3.08 | 2.68 | 2.47 | 2.24 | 2.19 |
|
| 43 |
+
|
| 44 |
+
Short context benchmarks showing that quality degradation is minimal:
|
| 45 |
+
| Model | Context Window | ARC-c | Hellaswag | MMLU | Truthful QA |
|
| 46 |
+
|-------|---------------:|------:|----------:|-----:|------------:|
|
| 47 |
+
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 59.98 | 83.31 | 64.16 | 42.15 |
|
| 48 |
+
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 59.38 | 81.21 | 61.32 | 42.50 |
|
| 49 |
+
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 58.87 | 80.58 | 60.64 | 42.46 |
|
| 50 |
+
|
| 51 |
+
## Collaborators
|
| 52 |
+
|
| 53 |
+
- [bloc97](https://github.com/bloc97): Methods, paper and evals
|
| 54 |
+
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
|
| 55 |
+
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
|
| 56 |
+
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
| 57 |
+
|
| 58 |
+
The authors would like to thank LAION AI for their support of compute for this model.
|
| 59 |
+
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s>": 2,
|
| 3 |
+
"<s>": 1,
|
| 4 |
+
"<unk>": 0
|
| 5 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "NousResearch/Yarn-Mistral-7b-128k",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "configuration_mistral.MistralConfig",
|
| 8 |
+
"AutoModelForCausalLM": "modeling_mistral_yarn.MistralForCausalLM"
|
| 9 |
+
},
|
| 10 |
+
"bos_token_id": 1,
|
| 11 |
+
"eos_token_id": 2,
|
| 12 |
+
"hidden_act": "silu",
|
| 13 |
+
"hidden_size": 4096,
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"intermediate_size": 14336,
|
| 16 |
+
"max_position_embeddings": 32768,
|
| 17 |
+
"max_sequence_length": 131072,
|
| 18 |
+
"model_type": "mistral",
|
| 19 |
+
"num_attention_heads": 32,
|
| 20 |
+
"num_hidden_layers": 32,
|
| 21 |
+
"num_key_value_heads": 8,
|
| 22 |
+
"rms_norm_eps": 1e-05,
|
| 23 |
+
"rope_scaling": {
|
| 24 |
+
"factor": 16.0,
|
| 25 |
+
"finetuned": true,
|
| 26 |
+
"original_max_position_embeddings": 8192,
|
| 27 |
+
"type": "yarn"
|
| 28 |
+
},
|
| 29 |
+
"rope_theta": 10000.0,
|
| 30 |
+
"sliding_window": 131072,
|
| 31 |
+
"tie_word_embeddings": false,
|
| 32 |
+
"torch_dtype": "bfloat16",
|
| 33 |
+
"transformers_version": "4.35.0.dev0",
|
| 34 |
+
"use_cache": true,
|
| 35 |
+
"vocab_size": 32000
|
| 36 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.35.0.dev0"
|
| 6 |
+
}
|
output.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2d7fbe9a341149d687428310b03f0b9d6b8764f01e2e9020f600debaad98a6e
|
| 3 |
+
size 4735310528
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 14483464192
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00002-of-00002.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 242 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 243 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 244 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 245 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 246 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 247 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 248 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 249 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 250 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 251 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 252 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 253 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 254 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 255 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 256 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 257 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 258 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 259 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 260 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 261 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 262 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 263 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 264 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 265 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 266 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 267 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 268 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 269 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 270 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 271 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 272 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 273 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 274 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 275 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 276 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 277 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 278 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 279 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 280 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 281 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 282 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 283 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 284 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 285 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 286 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 287 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 288 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 289 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 290 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 291 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 292 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 293 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 294 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 295 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 296 |
+
"model.norm.weight": "pytorch_model-00002-of-00002.bin"
|
| 297 |
+
}
|
| 298 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<unk>",
|
| 4 |
+
"<s>",
|
| 5 |
+
"</s>"
|
| 6 |
+
],
|
| 7 |
+
"bos_token": "<s>",
|
| 8 |
+
"eos_token": "</s>",
|
| 9 |
+
"unk_token": "<unk>"
|
| 10 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
"additional_special_tokens": [
|
| 29 |
+
"<unk>",
|
| 30 |
+
"<s>",
|
| 31 |
+
"</s>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": "<s>",
|
| 34 |
+
"clean_up_tokenization_spaces": false,
|
| 35 |
+
"eos_token": "</s>",
|
| 36 |
+
"legacy": true,
|
| 37 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 38 |
+
"pad_token": null,
|
| 39 |
+
"sp_model_kwargs": {},
|
| 40 |
+
"spaces_between_special_tokens": false,
|
| 41 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 42 |
+
"unk_token": "<unk>",
|
| 43 |
+
"use_default_system_prompt": true
|
| 44 |
+
}
|