 ## Capabilities
MERaLiON-AudioLLM is trained to mainly address 6 tasks, namely `Automatic Speech Recognition` (ASR),
`Speech Translation` (ST), `Spoken Question Answering` (SQA),
`Spoken Dialogue Summarization` (SDS), `Speech Instruction` (SI), `Paralinguistics` (PARA).
We benchmark MERaLiON-AudioLLM with a series of test sets from the [AudioBench benchmark](https://github.com/AudioLLMs/AudioBench)
against three well-known AudioLLMs: `Qwen2-Audio 7B`, `WavLLM`, and `SALMONN`. We also compared with a cascaded model,
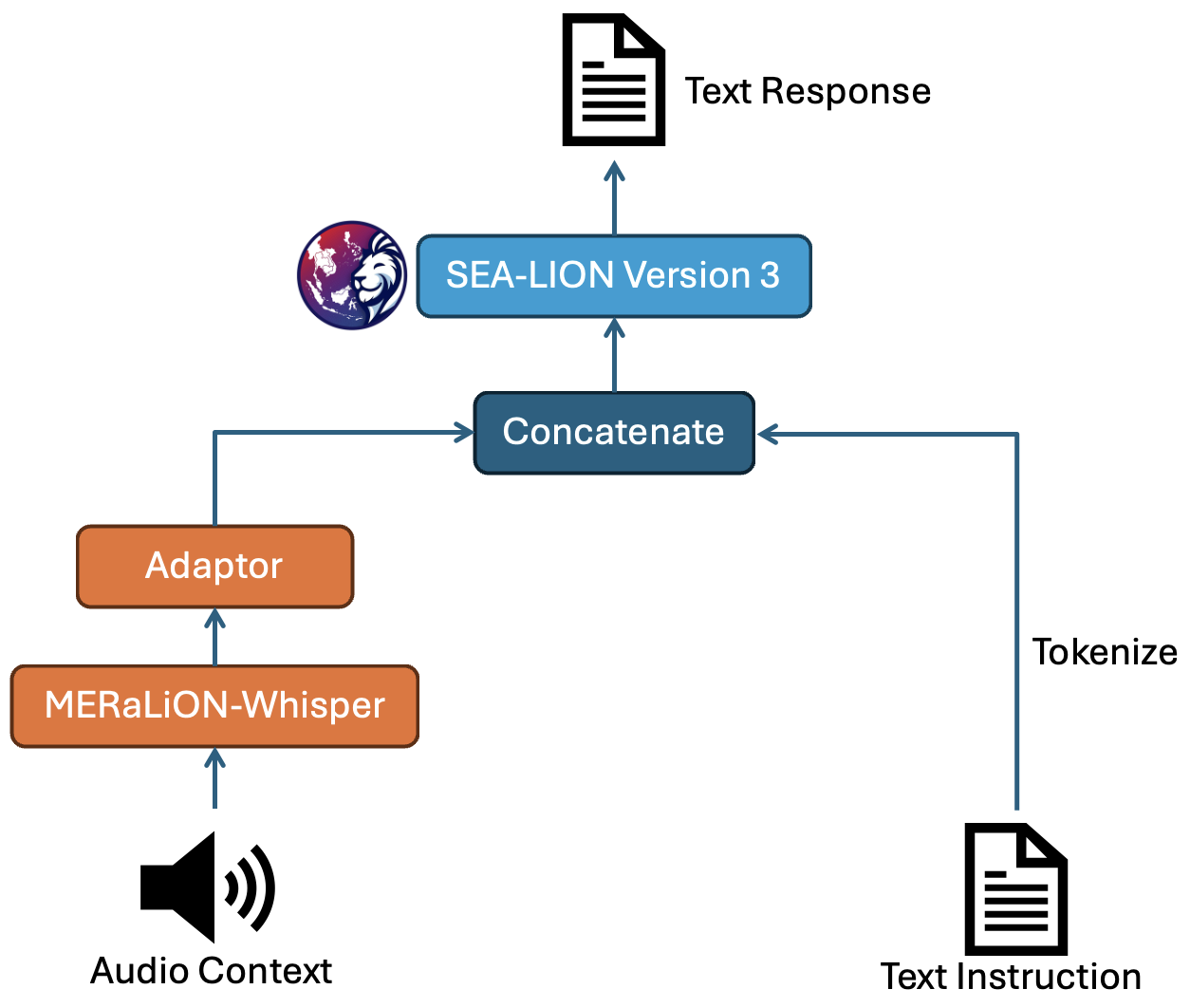
which feeds the transcriptions recognized by Whisper-large-v2 and the instruction prompts to a Gemma2 9B CPT SEA-LIONv3 Instruct model to
get the responses. We tuned its hyperparameters and prompt template to optimise performance across
various speech-to-text tasks. As is shown in the following table, MERaLiON-AudioLLM performs better in the Singapore local context,
as evidenced by evaluation results on Singapore's [Multitask National Speech Corpus](MERaLiON/MNSC) (MNSC) datasets.
> [!NOTE]
> MNSC is a multitask speech understanding dataset derived and further annotated from [IMDA NSC Corpus](https://www.imda.gov.sg/how-we-can-help/national-speech-corpus).
> It focuses on the knowledge of Singapore's local accent, localised terms, and code-switching.
> [!NOTE]
> We assess ASR and ST tasks using Word Error Rate (WER) and BLEU scores, respectively.
> For other tasks, we employ the LLM-as-a-Judge framework,
> which uses a pre-trained large language model to evaluate task performance
> by generating and scoring responses based on criteria such as relevance, coherence, and accuracy.
> Refer to the [AudioBench paper](https://arxiv.org/abs/2406.16020) for more details.
## Capabilities
MERaLiON-AudioLLM is trained to mainly address 6 tasks, namely `Automatic Speech Recognition` (ASR),
`Speech Translation` (ST), `Spoken Question Answering` (SQA),
`Spoken Dialogue Summarization` (SDS), `Speech Instruction` (SI), `Paralinguistics` (PARA).
We benchmark MERaLiON-AudioLLM with a series of test sets from the [AudioBench benchmark](https://github.com/AudioLLMs/AudioBench)
against three well-known AudioLLMs: `Qwen2-Audio 7B`, `WavLLM`, and `SALMONN`. We also compared with a cascaded model,
which feeds the transcriptions recognized by Whisper-large-v2 and the instruction prompts to a Gemma2 9B CPT SEA-LIONv3 Instruct model to
get the responses. We tuned its hyperparameters and prompt template to optimise performance across
various speech-to-text tasks. As is shown in the following table, MERaLiON-AudioLLM performs better in the Singapore local context,
as evidenced by evaluation results on Singapore's [Multitask National Speech Corpus](MERaLiON/MNSC) (MNSC) datasets.
> [!NOTE]
> MNSC is a multitask speech understanding dataset derived and further annotated from [IMDA NSC Corpus](https://www.imda.gov.sg/how-we-can-help/national-speech-corpus).
> It focuses on the knowledge of Singapore's local accent, localised terms, and code-switching.
> [!NOTE]
> We assess ASR and ST tasks using Word Error Rate (WER) and BLEU scores, respectively.
> For other tasks, we employ the LLM-as-a-Judge framework,
> which uses a pre-trained large language model to evaluate task performance
> by generating and scoring responses based on criteria such as relevance, coherence, and accuracy.
> Refer to the [AudioBench paper](https://arxiv.org/abs/2406.16020) for more details.
| Task | Dataset | MERaLiON | Qwen2-Audio 7B | WavLLM | SALMONN-7B | Cascaded Model |
|---|---|---|---|---|---|---|
| Automatic Speech Recognition WER (↓) |
LibriSpeech-Test-Clean | 0.03 | 0.03 | 0.02 | 0.10 | 0.03 |
| LibriSpeech-Test-Other | 0.05 | 0.06 | 0.05 | 0.10 | 0.05 | |
| Common-Voice-15-En-Test | 0.10 | 0.11 | 0.15 | 0.31 | 0.11 | |
| Earnings21-Test | 0.17 | 0.19 | 0.65 | 0.26 | 0.11 | |
| Earnings22-Test | 0.20 | 0.24 | 0.67 | 0.36 | 0.14 | |
| MNSC-ASR-Part 1 | 0.05 | 0.07 | - | 0.09 | 0.07 | |
| MNSC-ASR-Part 2 | 0.05 | 0.19 | - | 0.42 | 0.33 | |
| MNSC-ASR-Part 3 | 0.28 | 0.35 | - | 0.66 | 0.30 | |
| MNSC-ASR-Part 4 | 0.40 | 0.56 | - | 0.76 | 0.48 | |
| MNSC-ASR-Part 5 | 0.21 | 0.28 | - | 0.35 | 0.23 | |
| MNSC-ASR-Part 6 | 0.15 | 0.22 | - | 0.25 | 0.18 | |
| Speech Translation BLEU (↑) |
CoVoST 2 En → Id | 32.62 | 16.33 | 13.84 | 14.14 | 27.62 |
| CoVoST 2 En → Zh | 37.98 | 25.77 | 31.96 | 33.89 | 35.27 | |
| CoVoST 2 En → Ta | 8.50 | 0.03 | 0.00 | 0.00 | 8.46 | |
| CoVoST 2 Id → En | 37.07 | 6.33 | 5.93 | 26.89 | 46.80 | |
| CoVoST 2 Zh → En | 15.01 | 16.47 | 2.37 | 5.30 | 15.21 | |
| CoVoST 2 Ta → En | 3.97 | 0.04 | 0.17 | 0.36 | 2.83 | |
| Spoken Question Answering LLM-as-a-Judge (↑) |
SLUE-SQA-5 | 82.94 | 80.05 | 83.92 | 83.48 | 88.58 |
| Spoken-SQuAD | 70.33 | 64.86 | 77.65 | 66.40 | 88.62 | |
| CN-College-Listen-Test | 85.03 | 74.51 | 65.43 | 50.90 | 91.85 | |
| Singapore-Public-Speech-SQA | 60.32 | 58.31 | 58.55 | 59.24 | 73.11 | |
| MNSC-SQA-Part 3 | 51.4 | 42.0 | - | 40.60 | 53.20 | |
| MNSC-SQA-Part 4 | 49.0 | 39.6 | - | 36.60 | 60.20 | |
| MNSC-SQA-Part 5 | 58.2 | 51.6 | - | 44.60 | 67.20 | |
| MNSC-SQA-Part 6 | 65.2 | 53.6 | - | 46.80 | 71.60 | |
| Spoken Dialogue Summarization LLM-as-a-Judge (↑) |
MNSC-SDS-Part 3 | 46.80 | 33.80 | - | 9.0 | 45.40 |
| MNSC-SDS-Part 4 | 45.80 | 24.80 | - | 7.0 | 44.00 | |
| MNSC-SDS-Part 5 | 55.2 | 40.4 | - | 17.2 | 58.00 | |
| MNSC-SDS-Part 6 | 61.8 | 46.2 | - | 24.2 | 65.40 | |
| Speech Instruction LLM-as-a-Judge (↑) |
OpenHermes-Audio | 71.4 | 44.8 | 22.40 | 15.80 | 72.20 |
| Alpaca-GPT4-Audio | 73.4 | 52.6 | 21.60 | 17.20 | 73.80 | |
| Paralinguistics LLM-as-a-Judge (↑) |
VoxCeleb-Gender-Test | 99.53 | 99.12 | 69.68 | 88.81 | 35.25 |
| VoxCeleb-Accent-Test | 46.35 | 29.18 | - | 34.22 | 24.64 | |
| MELD-Sentiment-Test | 42.26 | 53.49 | 50.08 | 42.07 | 56.67 | |
| MELD-Emotion-Test | 30.15 | 40.54 | 41.07 | 30.73 | 47.39 |