---
license: cc-by-nc-4.0
base_model: Qwen/Qwen2-7B-Instruct
model-index:
- name: Dolphin
results: []
tags:
- RAG
- on-device language model
- Retrieval Augmented Generation
inference: false
space: false
spaces: false
language:
- en
---
# Dolphin: Long Context as a New Modality for on-device RAG
- Nexa Model Hub
- ArXiv

## Overview
Dolphin is a novel approach to accelerate language model inference by treating long context as a new modality, similar to image, audio, and video modalities in vision-language models. This innovative method incorporates a language encoder model to encode context information into embeddings, applying multimodal model concepts to enhance the efficiency of language model inference。 Below are model highlights:
- 🧠 Context as a distinct modality
- 🗜️ Language encoder for context compression
- 🔗 Multimodal techniques applied to language processing
- ⚡ Optimized for energy efficiency and on-device use
- 📜 Specialized for long context understanding
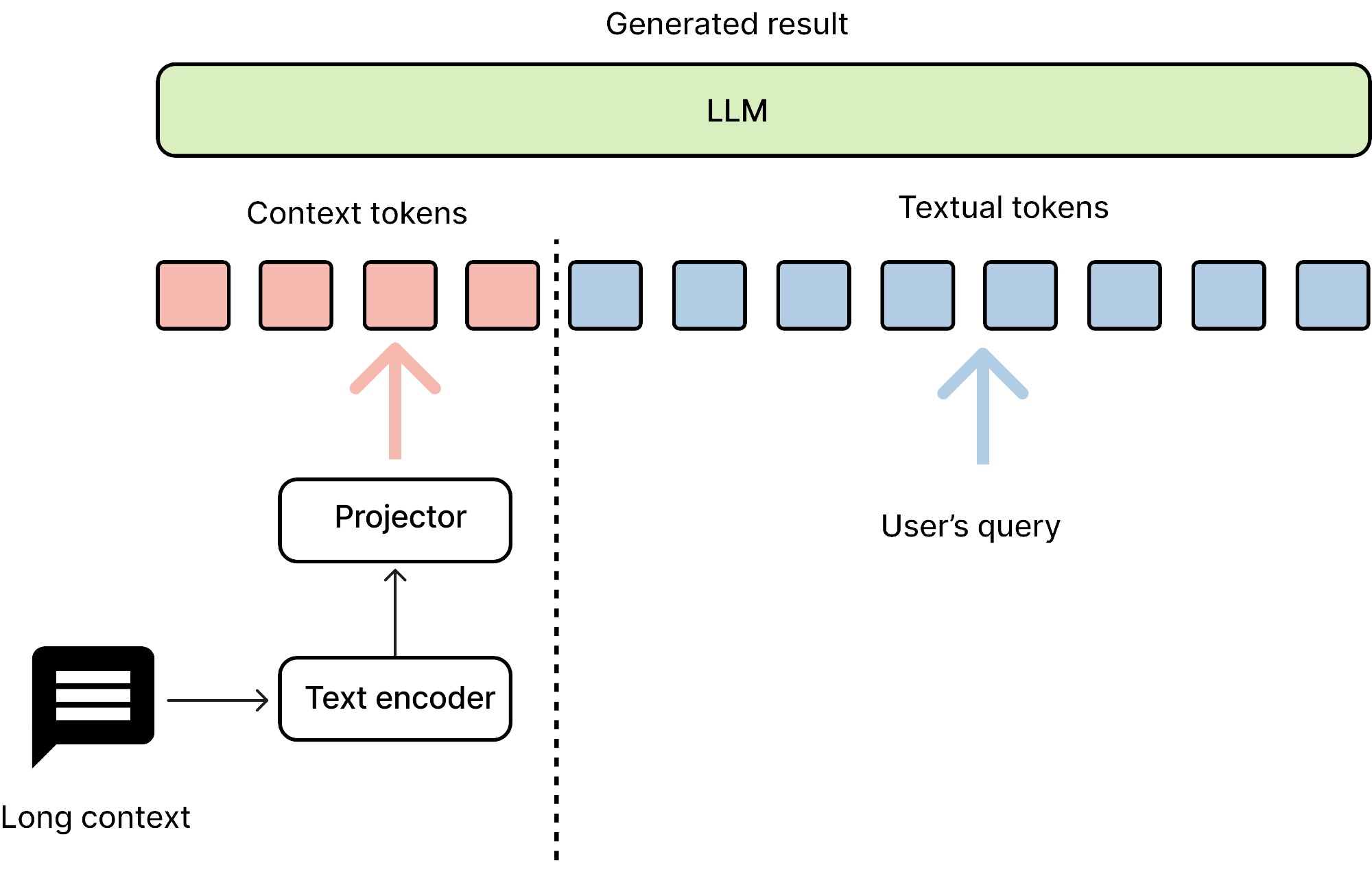
## Model Architecture
Dolphin employs a decoder-decoder framework with two main components:
1. A smaller decoder (0.5B parameters) for transforming information from extensive contexts
2. A larger decoder (7B parameters) for comprehending and generating responses to current queries
3. The architecture also includes a projector to align embeddings between the text encoder and the main decoder.
## Running the Model
Method 1 : download this repository and run the following commands:
```bash
git lfs install
git clone https://huggingface.co/NexaAIDev/Dolphin
python inference_example.py
```
Method 2 : install `nexaai-dolphin` package
```
pip install nexaai-dolphin
```
Then run the following commands:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
import torch
from dolphin.configuration_dolphin import DolphinConfig
from dolphin.modeling_dolphin import DolphinForCausalLM
def inference_instruct(mycontext, question, device="cuda:0"):
import time
MEMORY_SIZE = 32
start_time = time.time()
generated_token_ids = []
prompt = f" {question}"
text_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split("")]
input_ids = (
torch.tensor(
text_chunks[0] + [-1] * MEMORY_SIZE + text_chunks[1], dtype=torch.long
)
.unsqueeze(0)
.to(device)
)
# to process the context
context_tokenized = tokenizer(
mycontext + "".join([f"[memory_{i}]" for i in range(MEMORY_SIZE)]),
return_tensors="pt",
)
context_tokenized = {k: v.to(device) for k, v in context_tokenized.items()}
context_token_count = (context_tokenized["input_ids"]).shape[1] - MEMORY_SIZE
# We conduct a inference process
for i in range(context_token_count):
next_token = (
model(
input_ids,
context_input_ids=context_tokenized["input_ids"],
context_attention_mask=context_tokenized["attention_mask"],
)
.logits[:, -1]
.argmax(-1)
)
if next_token.item() == 151643:
break
generated_token_ids.append(next_token.item())
input_ids = torch.cat([input_ids, next_token.unsqueeze(1)], dim=-1)
result = tokenizer.decode(generated_token_ids)
print(f"Time taken: {time.time() - start_time}")
return result
if __name__ == "__main__":
device_name = "cuda:0" if torch.cuda.is_available() else "cpu"
AutoConfig.register("dolphin", DolphinConfig)
AutoModelForCausalLM.register(DolphinConfig, DolphinForCausalLM)
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('NexaAIDev/Dolphin')
model = AutoModelForCausalLM.from_pretrained('NexaAIDev/Dolphin', trust_remote_code=True, torch_dtype=torch.bfloat16, device_map=device_name)
# Run inference example
mycontext = "Nexa AI is a Cupertino-based company founded in May 2023 that researches and develops models and tools for on-device AI applications. The company is founded by Alex and Zack. The company is known for its Octopus-series models, which rival large-scale language models in capabilities such as function-calling, multimodality, and action-planning, while remaining efficient and compact for edge device deployment. Nexa AI's mission is to advance on-device AI in collaboration with the global developer community. To this end, the company has created an on-device model hub for users to find, share, and collaborate on open-source AI models optimized for edge devices, as well as an SDK for developers to run and deploy AI models locally"
question = "Who founded Nexa AI?"
# Pass the context and the correct device string
result = inference_instruct(mycontext, question, device=device_name)
print("Result:", result)
```
## Training Process
Dolphin's training involves three stages:
1. Restoration Training: Reconstructing original context from compressed embeddings
2. Continual Training: Generating context continuations from partial compressed contexts
3. Instruction Fine-tuning: Generating responses to queries given compressed contexts
This multi-stage approach progressively enhances the model's ability to handle long contexts and generate appropriate responses.
## Citation
If you use Dolphin in your research, please cite our paper:
```bibtex
@article{dolphin2024,
title={Dolphin: Long Context as a New Modality for Energy-Efficient On-Device Language Models},
author={[Author Names]},
journal={arXiv preprint arXiv:[paper_id]},
year={2024}
}
```
## Contact
For questions or feedback, please [contact us](octopus@nexa4ai.com)