
Commit
·
5ab77b0
1
Parent(s):
18f889e
model push
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- model/.msc +0 -0
- model/.mv +1 -0
- model/SenseVoiceSmall/README.md +219 -0
- model/SenseVoiceSmall/am.mvn +8 -0
- model/SenseVoiceSmall/chn_jpn_yue_eng_ko_spectok.bpe.model +3 -0
- model/SenseVoiceSmall/config.yaml +98 -0
- model/SenseVoiceSmall/configuration.json +14 -0
- model/SenseVoiceSmall/example/.DS_Store +0 -0
- model/SenseVoiceSmall/example/en.mp3 +0 -0
- model/SenseVoiceSmall/example/ja.mp3 +0 -0
- model/SenseVoiceSmall/example/ko.mp3 +0 -0
- model/SenseVoiceSmall/example/yue.mp3 +0 -0
- model/SenseVoiceSmall/example/zh.mp3 +0 -0
- model/SenseVoiceSmall/fig/aed_figure.png +0 -0
- model/SenseVoiceSmall/fig/asr_results.png +0 -0
- model/SenseVoiceSmall/fig/inference.png +0 -0
- model/SenseVoiceSmall/fig/sensevoice.png +0 -0
- model/SenseVoiceSmall/fig/ser_figure.png +0 -0
- model/SenseVoiceSmall/fig/ser_table.png +0 -0
- model/SenseVoiceSmall/model.pt +3 -0
- model/SenseVoiceSmall/model.py +895 -0
- model/SenseVoiceSmall/tokens.json +0 -0
- model/bert-base-chinese/.gitattributes +10 -0
- model/bert-base-chinese/README.md +75 -0
- model/bert-base-chinese/config.json +25 -0
- model/bert-base-chinese/flax_model.msgpack +3 -0
- model/bert-base-chinese/model.safetensors +3 -0
- model/bert-base-chinese/pytorch_model.bin +3 -0
- model/bert-base-chinese/tf_model.h5 +3 -0
- model/bert-base-chinese/tokenizer.json +0 -0
- model/bert-base-chinese/tokenizer_config.json +1 -0
- model/bert-base-chinese/vocab.txt +0 -0
- model/fsmn_vad/.msc +0 -0
- model/fsmn_vad/.mv +1 -0
- model/fsmn_vad/README.md +217 -0
- model/fsmn_vad/am.mvn +8 -0
- model/fsmn_vad/config.yaml +56 -0
- model/fsmn_vad/configuration.json +13 -0
- model/fsmn_vad/example/vad_example.wav +3 -0
- model/fsmn_vad/fig/struct.png +0 -0
- model/fsmn_vad/model.pt +3 -0
- model/gaudio/am.mvn +8 -0
- model/gaudio/audio_encoder.pt +3 -0
- model/gaudio/config.json +69 -0
- model/gaudio/preprocessor_config.json +82 -0
- model/gaudio/preprocessor_config.json.bak +25 -0
- model/gaudio/special_tokens_map.json +37 -0
- model/gaudio/text_encoder.pt +3 -0
- model/gaudio/tokenizer.json +0 -0
.gitattributes
CHANGED
|
@@ -38,3 +38,4 @@ results/check/speech_j.joblib filter=lfs diff=lfs merge=lfs -text
|
|
| 38 |
results/track_record/collator_print_first.joblib filter=lfs diff=lfs merge=lfs -text
|
| 39 |
results/track_record/outputs_loss.joblib filter=lfs diff=lfs merge=lfs -text
|
| 40 |
results/track_record/text_projection.joblib filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 38 |
results/track_record/collator_print_first.joblib filter=lfs diff=lfs merge=lfs -text
|
| 39 |
results/track_record/outputs_loss.joblib filter=lfs diff=lfs merge=lfs -text
|
| 40 |
results/track_record/text_projection.joblib filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
model/fsmn_vad/example/vad_example.wav filter=lfs diff=lfs merge=lfs -text
|
model/.msc
ADDED
|
Binary file (1.35 kB). View file
|
|
|
model/.mv
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Revision:master,CreatedAt:1727321787
|
model/SenseVoiceSmall/README.md
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
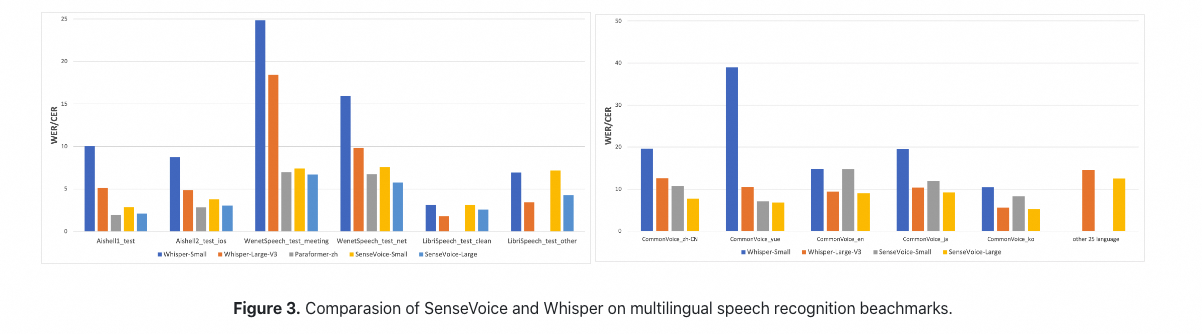
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
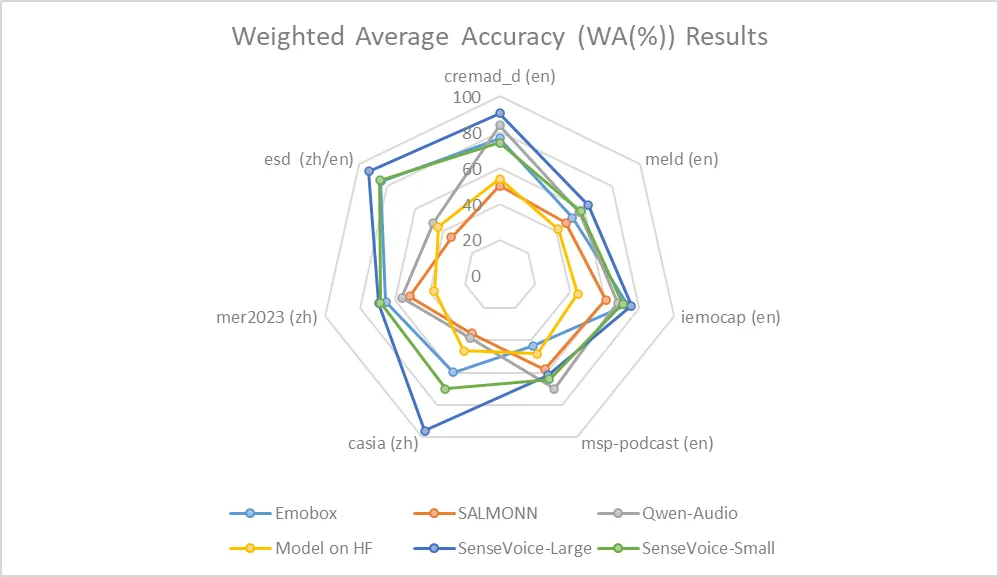
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
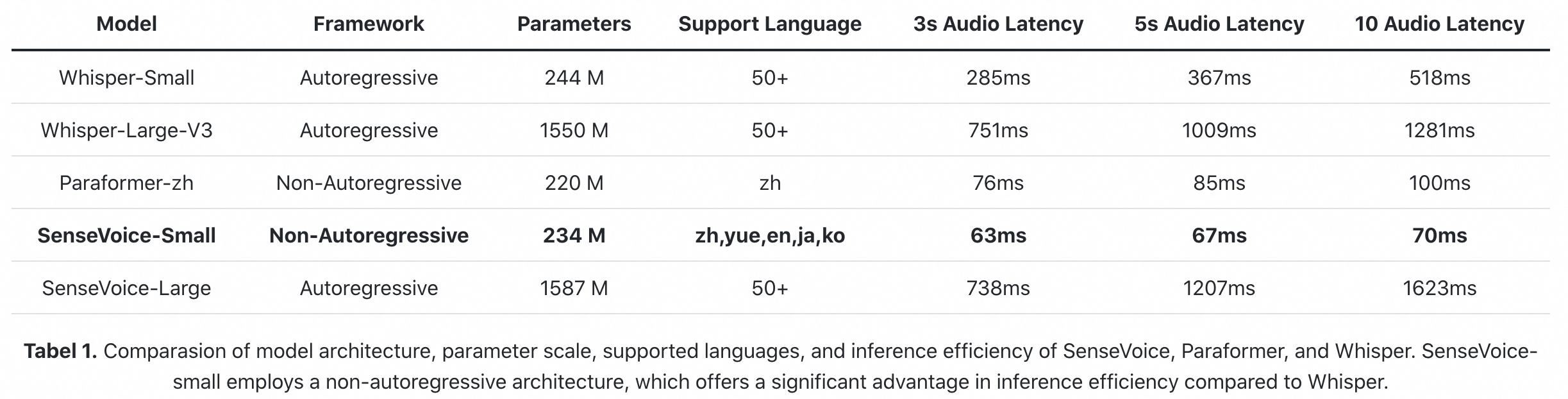
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
frameworks:
|
| 3 |
+
- Pytorch
|
| 4 |
+
license: Apache License 2.0
|
| 5 |
+
tasks:
|
| 6 |
+
- auto-speech-recognition
|
| 7 |
+
|
| 8 |
+
#model-type:
|
| 9 |
+
##如 gpt、phi、llama、chatglm、baichuan 等
|
| 10 |
+
#- gpt
|
| 11 |
+
|
| 12 |
+
#domain:
|
| 13 |
+
##如 nlp、cv、audio、multi-modal
|
| 14 |
+
#- nlp
|
| 15 |
+
|
| 16 |
+
#language:
|
| 17 |
+
##语言代码列表 https://help.aliyun.com/document_detail/215387.html?spm=a2c4g.11186623.0.0.9f8d7467kni6Aa
|
| 18 |
+
#- cn
|
| 19 |
+
|
| 20 |
+
#metrics:
|
| 21 |
+
##如 CIDEr、Blue、ROUGE 等
|
| 22 |
+
#- CIDEr
|
| 23 |
+
|
| 24 |
+
#tags:
|
| 25 |
+
##各种自定义,包括 pretrained、fine-tuned、instruction-tuned、RL-tuned 等训练方法和其他
|
| 26 |
+
#- pretrained
|
| 27 |
+
|
| 28 |
+
#tools:
|
| 29 |
+
##如 vllm、fastchat、llamacpp、AdaSeq 等
|
| 30 |
+
#- vllm
|
| 31 |
+
---
|
| 32 |
+
|
| 33 |
+
# Highlights
|
| 34 |
+
**SenseVoice**专注于高精度多语言语音识别、情感辨识和音频事件检测
|
| 35 |
+
- **多语言识别:** 采用超过40万小时数据训练,支持超过50种语言,识别效果上优于Whisper模型。
|
| 36 |
+
- **富文本识别:**
|
| 37 |
+
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
|
| 38 |
+
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
|
| 39 |
+
- **高效推理:** SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,10s音频推理仅耗时70ms,15倍优于Whisper-Large。
|
| 40 |
+
- **微调定制:** 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
|
| 41 |
+
- **服务部署:** 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java与c#等。
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
## <strong>[SenseVoice开源项目介绍](https://github.com/FunAudioLLM/SenseVoice)</strong>
|
| 45 |
+
<strong>[SenseVoice](https://github.com/FunAudioLLM/SenseVoice)</strong>开源模型是多语言音频理解模型,具有包括语音识别、语种识别、语音情感识别,声学事件检测能力。
|
| 46 |
+
|
| 47 |
+
[**github仓库**](https://github.com/FunAudioLLM/SenseVoice)
|
| 48 |
+
| [**最新动态**](https://github.com/FunAudioLLM/SenseVoice/blob/main/README_zh.md#%E6%9C%80%E6%96%B0%E5%8A%A8%E6%80%81)
|
| 49 |
+
| [**环境安装**](https://github.com/FunAudioLLM/SenseVoice/blob/main/README_zh.md#%E7%8E%AF%E5%A2%83%E5%AE%89%E8%A3%85)
|
| 50 |
+
|
| 51 |
+
# 模型结构图
|
| 52 |
+
SenseVoice多语言音频理解模型,支持语音识别、语种识别、语音情感识别、声学事件检测、逆文本正则化等能力,采用工业级数十万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于中文、粤语、英语、日语、韩语音频识别,并输出带有情感和事件的富文本转写结果。
|
| 53 |
+
|
| 54 |
+
<p align="center">
|
| 55 |
+
<img src="fig/sensevoice.png" alt="SenseVoice模型结构" width="1500" />
|
| 56 |
+
</p>
|
| 57 |
+
|
| 58 |
+
SenseVoice-Small是基于非自回归端到端框架模型,为了指定任务,我们在语音特征前添加四个嵌入作为输入传递给编码器:
|
| 59 |
+
- LID:用于预测音频语种标签。
|
| 60 |
+
- SER:用于预测音频情感标签。
|
| 61 |
+
- AED:用于预测音频包含的事件标签。
|
| 62 |
+
- ITN:用于指定识别输出文本是否进行逆文本正则化。
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# 依赖环境
|
| 66 |
+
|
| 67 |
+
推理之前,请务必更新funasr与modelscope版本
|
| 68 |
+
|
| 69 |
+
```shell
|
| 70 |
+
pip install -U funasr modelscope
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
# 用法
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
## 推理
|
| 77 |
+
|
| 78 |
+
### modelscope pipeline推理
|
| 79 |
+
```python
|
| 80 |
+
from modelscope.pipelines import pipeline
|
| 81 |
+
from modelscope.utils.constant import Tasks
|
| 82 |
+
|
| 83 |
+
inference_pipeline = pipeline(
|
| 84 |
+
task=Tasks.auto_speech_recognition,
|
| 85 |
+
model='iic/SenseVoiceSmall',
|
| 86 |
+
model_revision="master",
|
| 87 |
+
device="cuda:0",)
|
| 88 |
+
|
| 89 |
+
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav')
|
| 90 |
+
print(rec_result)
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
### 使用funasr推理
|
| 94 |
+
|
| 95 |
+
支持任意格式音频输入,支持任意时长输入
|
| 96 |
+
|
| 97 |
+
```python
|
| 98 |
+
from funasr import AutoModel
|
| 99 |
+
from funasr.utils.postprocess_utils import rich_transcription_postprocess
|
| 100 |
+
|
| 101 |
+
model_dir = "iic/SenseVoiceSmall"
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
model = AutoModel(
|
| 105 |
+
model=model_dir,
|
| 106 |
+
trust_remote_code=True,
|
| 107 |
+
remote_code="./model.py",
|
| 108 |
+
vad_model="fsmn-vad",
|
| 109 |
+
vad_kwargs={"max_single_segment_time": 30000},
|
| 110 |
+
device="cuda:0",
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
# en
|
| 114 |
+
res = model.generate(
|
| 115 |
+
input=f"{model.model_path}/example/en.mp3",
|
| 116 |
+
cache={},
|
| 117 |
+
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
|
| 118 |
+
use_itn=True,
|
| 119 |
+
batch_size_s=60,
|
| 120 |
+
merge_vad=True, #
|
| 121 |
+
merge_length_s=15,
|
| 122 |
+
)
|
| 123 |
+
text = rich_transcription_postprocess(res[0]["text"])
|
| 124 |
+
print(text)
|
| 125 |
+
```
|
| 126 |
+
参数说明:
|
| 127 |
+
- `model_dir`:模型名称,或本地磁盘中的模型路径。
|
| 128 |
+
- `trust_remote_code`:
|
| 129 |
+
- `True`表示model代码实现从`remote_code`处加载,`remote_code`指定`model`具体代码的位置(例如,当前目录下的`model.py`),支持绝对路径与相对路径,以及网络url。
|
| 130 |
+
- `False`表示,model代码实现为 [FunASR](https://github.com/modelscope/FunASR) 内部集成版本,此时修改当前目录下的`model.py`不会生效,因为加载的是funasr内部版本,模型代码[点击查看](https://github.com/modelscope/FunASR/tree/main/funasr/models/sense_voice)。
|
| 131 |
+
- `vad_model`:表示开启VAD,VAD的作用是将长音频切割成短音频,此时推理耗时包括了VAD与SenseVoice总耗时,为链路耗时,如果需要单独测试SenseVoice模型耗时,可以关闭VAD模型。
|
| 132 |
+
- `vad_kwargs`:表示VAD模型配置,`max_single_segment_time`: 表示`vad_model`最大切割音频时长, 单位是毫秒ms。
|
| 133 |
+
- `use_itn`:输出结果中是否包含标点与逆文本正则化。
|
| 134 |
+
- `batch_size_s` 表示采用动态batch,batch中总音频时长,单位为秒s。
|
| 135 |
+
- `merge_vad`:是否将 vad 模型切割的短音频碎片合成,合并后长度为`merge_length_s`,单位为秒s。
|
| 136 |
+
- `ban_emo_unk`:禁用emo_unk标签,禁用后所有的句子都会被赋与情感标签。默认`False`
|
| 137 |
+
|
| 138 |
+
```python
|
| 139 |
+
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
|
| 140 |
+
|
| 141 |
+
res = model.generate(
|
| 142 |
+
input=f"{model.model_path}/example/en.mp3",
|
| 143 |
+
cache={},
|
| 144 |
+
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
|
| 145 |
+
use_itn=True,
|
| 146 |
+
batch_size=64,
|
| 147 |
+
)
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
更多详细用法,请参考 [文档](https://github.com/modelscope/FunASR/blob/main/docs/tutorial/README.md)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
## 模型下载
|
| 155 |
+
上面代码会自动下载模型,如果您需要离线下载好模型,可以通过下面代码,手动下载,之后指定模型本地路径即可。
|
| 156 |
+
|
| 157 |
+
SDK下载
|
| 158 |
+
```bash
|
| 159 |
+
#安装ModelScope
|
| 160 |
+
pip install modelscope
|
| 161 |
+
```
|
| 162 |
+
```python
|
| 163 |
+
#SDK模型下载
|
| 164 |
+
from modelscope import snapshot_download
|
| 165 |
+
model_dir = snapshot_download('iic/SenseVoiceSmall')
|
| 166 |
+
```
|
| 167 |
+
Git下载
|
| 168 |
+
```
|
| 169 |
+
#Git模型下载
|
| 170 |
+
git clone https://www.modelscope.cn/iic/SenseVoiceSmall.git
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
## 服务部署
|
| 174 |
+
|
| 175 |
+
Undo
|
| 176 |
+
|
| 177 |
+
# Performance
|
| 178 |
+
|
| 179 |
+
## 语音识别效果
|
| 180 |
+
我们在开源基准数据集(包括 AISHELL-1、AISHELL-2、Wenetspeech、Librispeech和Common Voice)上比较了SenseVoice与Whisper的多语言语音识别性能和推理效率。在中文和粤语识别效果上,SenseVoice-Small模型具有明显的效果优势。
|
| 181 |
+
|
| 182 |
+
<p align="center">
|
| 183 |
+
<img src="fig/asr_results.png" alt="SenseVoice模型在开源测试集上的表现" width="2500" />
|
| 184 |
+
</p>
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
## 情感识别效果
|
| 189 |
+
由于目前缺乏被广泛使用的情感识别测试指标和方法,我们在多个测试集的多种指标进行测试,并与近年来Benchmark上的多个结果进行了全面的对比。所选取的测试集同时包含中文/英文两种语言以及表演、影视剧、自然对话等多种风格的数据,在不进行目标数据微调的前提下,SenseVoice能够在测试数据上达到和超过目前最佳情感识别模型的效果。
|
| 190 |
+
|
| 191 |
+
<p align="center">
|
| 192 |
+
<img src="fig/ser_table.png" alt="SenseVoice模型SER效果1" width="1500" />
|
| 193 |
+
</p>
|
| 194 |
+
|
| 195 |
+
同时,我们还在测试集上对多个开源情感识别模型进行对比,结果表明,SenseVoice-Large模型可以在几乎所有数据上都达到了最佳效果,而SenseVoice-Small模型同样可以在多数数据集上取得超越其他开源模型的效果。
|
| 196 |
+
|
| 197 |
+
<p align="center">
|
| 198 |
+
<img src="fig/ser_figure.png" alt="SenseVoice模型SER效果2" width="500" />
|
| 199 |
+
</p>
|
| 200 |
+
|
| 201 |
+
## 事件检测效果
|
| 202 |
+
|
| 203 |
+
尽管SenseVoice只在语音数据上进行训练,它仍然可以作为事件检测模型进行单独使用。我们在环境音分类ESC-50数据集上与目前业内广泛使用的BEATS与PANN模型的效果进行了对比。SenseVoice模型能够在这些任务上取得较好的效果,但受限于训练数据与训练方式,其事件分类效果专业的事件检测模型相比仍然有一定的差距。
|
| 204 |
+
|
| 205 |
+
<p align="center">
|
| 206 |
+
<img src="fig/aed_figure.png" alt="SenseVoice模型AED效果" width="500" />
|
| 207 |
+
</p>
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
## 推理效率
|
| 212 |
+
SenseVoice-Small模型采用非自回归端到端架构,推理延迟极低。在参数量与Whisper-Small模型相当的情况下,比Whisper-Small模型推理速度快7倍,比Whisper-Large模型快17倍。同时SenseVoice-small模型在音频时长增加的情况下,推理耗时也无明显增加。
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
<p align="center">
|
| 216 |
+
<img src="fig/inference.png" alt="SenseVoice模型的推理效率" width="1500" />
|
| 217 |
+
</p>
|
| 218 |
+
|
| 219 |
+
<p style="color: lightgrey;">如果您是本模型的贡献者,我们邀请您根据<a href="https://modelscope.cn/docs/ModelScope%E6%A8%A1%E5%9E%8B%E6%8E%A5%E5%85%A5%E6%B5%81%E7%A8%8B%E6%A6%82%E8%A7%88" style="color: lightgrey; text-decoration: underline;">模型贡献文档</a>,及时完善模型卡片内容。</p>
|
model/SenseVoiceSmall/am.mvn
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Nnet>
|
| 2 |
+
<Splice> 560 560
|
| 3 |
+
[ 0 ]
|
| 4 |
+
<AddShift> 560 560
|
| 5 |
+
<LearnRateCoef> 0 [ -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 ]
|
| 6 |
+
<Rescale> 560 560
|
| 7 |
+
<LearnRateCoef> 0 [ 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 ]
|
| 8 |
+
</Nnet>
|
model/SenseVoiceSmall/chn_jpn_yue_eng_ko_spectok.bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa87f86064c3730d799ddf7af3c04659151102cba548bce325cf06ba4da4e6a8
|
| 3 |
+
size 377341
|
model/SenseVoiceSmall/config.yaml
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
encoder: SenseVoiceEncoderSmall
|
| 2 |
+
encoder_conf:
|
| 3 |
+
output_size: 512
|
| 4 |
+
attention_heads: 4
|
| 5 |
+
linear_units: 2048
|
| 6 |
+
num_blocks: 50
|
| 7 |
+
tp_blocks: 20
|
| 8 |
+
dropout_rate: 0.1
|
| 9 |
+
positional_dropout_rate: 0.1
|
| 10 |
+
attention_dropout_rate: 0.1
|
| 11 |
+
input_layer: pe
|
| 12 |
+
pos_enc_class: SinusoidalPositionEncoder
|
| 13 |
+
normalize_before: true
|
| 14 |
+
kernel_size: 11
|
| 15 |
+
sanm_shfit: 0
|
| 16 |
+
selfattention_layer_type: sanm
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
model: SenseVoiceSmall
|
| 20 |
+
model_conf:
|
| 21 |
+
length_normalized_loss: true
|
| 22 |
+
sos: 1
|
| 23 |
+
eos: 2
|
| 24 |
+
ignore_id: -1
|
| 25 |
+
|
| 26 |
+
tokenizer: SentencepiecesTokenizer
|
| 27 |
+
tokenizer_conf:
|
| 28 |
+
bpemodel: null
|
| 29 |
+
unk_symbol: <unk>
|
| 30 |
+
split_with_space: true
|
| 31 |
+
|
| 32 |
+
frontend: WavFrontend
|
| 33 |
+
frontend_conf:
|
| 34 |
+
fs: 32000
|
| 35 |
+
window: hamming
|
| 36 |
+
n_mels: 80
|
| 37 |
+
frame_length: 25
|
| 38 |
+
frame_shift: 10
|
| 39 |
+
lfr_m: 7
|
| 40 |
+
lfr_n: 6
|
| 41 |
+
cmvn_file: null
|
| 42 |
+
dither: 0.0
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
dataset: SenseVoiceCTCDataset
|
| 46 |
+
dataset_conf:
|
| 47 |
+
index_ds: IndexDSJsonl
|
| 48 |
+
batch_sampler: EspnetStyleBatchSampler
|
| 49 |
+
data_split_num: 32
|
| 50 |
+
batch_type: token
|
| 51 |
+
batch_size: 14000
|
| 52 |
+
max_token_length: 2000
|
| 53 |
+
min_token_length: 60
|
| 54 |
+
max_source_length: 2000
|
| 55 |
+
min_source_length: 60
|
| 56 |
+
max_target_length: 200
|
| 57 |
+
min_target_length: 0
|
| 58 |
+
shuffle: true
|
| 59 |
+
num_workers: 4
|
| 60 |
+
sos: ${model_conf.sos}
|
| 61 |
+
eos: ${model_conf.eos}
|
| 62 |
+
IndexDSJsonl: IndexDSJsonl
|
| 63 |
+
retry: 20
|
| 64 |
+
|
| 65 |
+
train_conf:
|
| 66 |
+
accum_grad: 1
|
| 67 |
+
grad_clip: 5
|
| 68 |
+
max_epoch: 20
|
| 69 |
+
keep_nbest_models: 10
|
| 70 |
+
avg_nbest_model: 10
|
| 71 |
+
log_interval: 100
|
| 72 |
+
resume: true
|
| 73 |
+
validate_interval: 10000
|
| 74 |
+
save_checkpoint_interval: 10000
|
| 75 |
+
|
| 76 |
+
optim: adamw
|
| 77 |
+
optim_conf:
|
| 78 |
+
lr: 0.00002
|
| 79 |
+
scheduler: warmuplr
|
| 80 |
+
scheduler_conf:
|
| 81 |
+
warmup_steps: 25000
|
| 82 |
+
|
| 83 |
+
specaug: SpecAugLFR
|
| 84 |
+
specaug_conf:
|
| 85 |
+
apply_time_warp: false
|
| 86 |
+
time_warp_window: 5
|
| 87 |
+
time_warp_mode: bicubic
|
| 88 |
+
apply_freq_mask: true
|
| 89 |
+
freq_mask_width_range:
|
| 90 |
+
- 0
|
| 91 |
+
- 30
|
| 92 |
+
lfr_rate: 6
|
| 93 |
+
num_freq_mask: 1
|
| 94 |
+
apply_time_mask: true
|
| 95 |
+
time_mask_width_range:
|
| 96 |
+
- 0
|
| 97 |
+
- 12
|
| 98 |
+
num_time_mask: 1
|
model/SenseVoiceSmall/configuration.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "auto-speech-recognition",
|
| 4 |
+
"model": {"type" : "funasr"},
|
| 5 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 6 |
+
"model_name_in_hub": {
|
| 7 |
+
"ms":"",
|
| 8 |
+
"hf":""},
|
| 9 |
+
"file_path_metas": {
|
| 10 |
+
"init_param":"model.pt",
|
| 11 |
+
"config":"config.yaml",
|
| 12 |
+
"tokenizer_conf": {"bpemodel": "chn_jpn_yue_eng_ko_spectok.bpe.model"},
|
| 13 |
+
"frontend_conf":{"cmvn_file": "am.mvn"}}
|
| 14 |
+
}
|
model/SenseVoiceSmall/example/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
model/SenseVoiceSmall/example/en.mp3
ADDED
|
Binary file (57.4 kB). View file
|
|
|
model/SenseVoiceSmall/example/ja.mp3
ADDED
|
Binary file (57.8 kB). View file
|
|
|
model/SenseVoiceSmall/example/ko.mp3
ADDED
|
Binary file (27.9 kB). View file
|
|
|
model/SenseVoiceSmall/example/yue.mp3
ADDED
|
Binary file (31.2 kB). View file
|
|
|
model/SenseVoiceSmall/example/zh.mp3
ADDED
|
Binary file (45 kB). View file
|
|
|
model/SenseVoiceSmall/fig/aed_figure.png
ADDED

|
model/SenseVoiceSmall/fig/asr_results.png
ADDED
|
model/SenseVoiceSmall/fig/inference.png
ADDED
|
model/SenseVoiceSmall/fig/sensevoice.png
ADDED

|
model/SenseVoiceSmall/fig/ser_figure.png
ADDED
|
model/SenseVoiceSmall/fig/ser_table.png
ADDED

|
model/SenseVoiceSmall/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:833ca2dcfdf8ec91bd4f31cfac36d6124e0c459074d5e909aec9cabe6204a3ea
|
| 3 |
+
size 936291369
|
model/SenseVoiceSmall/model.py
ADDED
|
@@ -0,0 +1,895 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from typing import Iterable, Optional
|
| 6 |
+
|
| 7 |
+
from funasr.register import tables
|
| 8 |
+
from funasr.models.ctc.ctc import CTC
|
| 9 |
+
from funasr.utils.datadir_writer import DatadirWriter
|
| 10 |
+
from funasr.models.paraformer.search import Hypothesis
|
| 11 |
+
from funasr.train_utils.device_funcs import force_gatherable
|
| 12 |
+
from funasr.losses.label_smoothing_loss import LabelSmoothingLoss
|
| 13 |
+
from funasr.metrics.compute_acc import compute_accuracy, th_accuracy
|
| 14 |
+
from funasr.utils.load_utils import load_audio_text_image_video, extract_fbank
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class SinusoidalPositionEncoder(torch.nn.Module):
|
| 18 |
+
""" """
|
| 19 |
+
|
| 20 |
+
def __int__(self, d_model=80, dropout_rate=0.1):
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
def encode(
|
| 24 |
+
self, positions: torch.Tensor = None, depth: int = None, dtype: torch.dtype = torch.float32
|
| 25 |
+
):
|
| 26 |
+
batch_size = positions.size(0)
|
| 27 |
+
positions = positions.type(dtype)
|
| 28 |
+
device = positions.device
|
| 29 |
+
log_timescale_increment = torch.log(torch.tensor([10000], dtype=dtype, device=device)) / (
|
| 30 |
+
depth / 2 - 1
|
| 31 |
+
)
|
| 32 |
+
inv_timescales = torch.exp(
|
| 33 |
+
torch.arange(depth / 2, device=device).type(dtype) * (-log_timescale_increment)
|
| 34 |
+
)
|
| 35 |
+
inv_timescales = torch.reshape(inv_timescales, [batch_size, -1])
|
| 36 |
+
scaled_time = torch.reshape(positions, [1, -1, 1]) * torch.reshape(
|
| 37 |
+
inv_timescales, [1, 1, -1]
|
| 38 |
+
)
|
| 39 |
+
encoding = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=2)
|
| 40 |
+
return encoding.type(dtype)
|
| 41 |
+
|
| 42 |
+
def forward(self, x):
|
| 43 |
+
batch_size, timesteps, input_dim = x.size()
|
| 44 |
+
positions = torch.arange(1, timesteps + 1, device=x.device)[None, :]
|
| 45 |
+
position_encoding = self.encode(positions, input_dim, x.dtype).to(x.device)
|
| 46 |
+
|
| 47 |
+
return x + position_encoding
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class PositionwiseFeedForward(torch.nn.Module):
|
| 51 |
+
"""Positionwise feed forward layer.
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
idim (int): Input dimenstion.
|
| 55 |
+
hidden_units (int): The number of hidden units.
|
| 56 |
+
dropout_rate (float): Dropout rate.
|
| 57 |
+
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
def __init__(self, idim, hidden_units, dropout_rate, activation=torch.nn.ReLU()):
|
| 61 |
+
"""Construct an PositionwiseFeedForward object."""
|
| 62 |
+
super(PositionwiseFeedForward, self).__init__()
|
| 63 |
+
self.w_1 = torch.nn.Linear(idim, hidden_units)
|
| 64 |
+
self.w_2 = torch.nn.Linear(hidden_units, idim)
|
| 65 |
+
self.dropout = torch.nn.Dropout(dropout_rate)
|
| 66 |
+
self.activation = activation
|
| 67 |
+
|
| 68 |
+
def forward(self, x):
|
| 69 |
+
"""Forward function."""
|
| 70 |
+
return self.w_2(self.dropout(self.activation(self.w_1(x))))
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class MultiHeadedAttentionSANM(nn.Module):
|
| 74 |
+
"""Multi-Head Attention layer.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
n_head (int): The number of heads.
|
| 78 |
+
n_feat (int): The number of features.
|
| 79 |
+
dropout_rate (float): Dropout rate.
|
| 80 |
+
|
| 81 |
+
"""
|
| 82 |
+
|
| 83 |
+
def __init__(
|
| 84 |
+
self,
|
| 85 |
+
n_head,
|
| 86 |
+
in_feat,
|
| 87 |
+
n_feat,
|
| 88 |
+
dropout_rate,
|
| 89 |
+
kernel_size,
|
| 90 |
+
sanm_shfit=0,
|
| 91 |
+
lora_list=None,
|
| 92 |
+
lora_rank=8,
|
| 93 |
+
lora_alpha=16,
|
| 94 |
+
lora_dropout=0.1,
|
| 95 |
+
):
|
| 96 |
+
"""Construct an MultiHeadedAttention object."""
|
| 97 |
+
super().__init__()
|
| 98 |
+
assert n_feat % n_head == 0
|
| 99 |
+
# We assume d_v always equals d_k
|
| 100 |
+
self.d_k = n_feat // n_head
|
| 101 |
+
self.h = n_head
|
| 102 |
+
# self.linear_q = nn.Linear(n_feat, n_feat)
|
| 103 |
+
# self.linear_k = nn.Linear(n_feat, n_feat)
|
| 104 |
+
# self.linear_v = nn.Linear(n_feat, n_feat)
|
| 105 |
+
|
| 106 |
+
self.linear_out = nn.Linear(n_feat, n_feat)
|
| 107 |
+
self.linear_q_k_v = nn.Linear(in_feat, n_feat * 3)
|
| 108 |
+
self.attn = None
|
| 109 |
+
self.dropout = nn.Dropout(p=dropout_rate)
|
| 110 |
+
|
| 111 |
+
self.fsmn_block = nn.Conv1d(
|
| 112 |
+
n_feat, n_feat, kernel_size, stride=1, padding=0, groups=n_feat, bias=False
|
| 113 |
+
)
|
| 114 |
+
# padding
|
| 115 |
+
left_padding = (kernel_size - 1) // 2
|
| 116 |
+
if sanm_shfit > 0:
|
| 117 |
+
left_padding = left_padding + sanm_shfit
|
| 118 |
+
right_padding = kernel_size - 1 - left_padding
|
| 119 |
+
self.pad_fn = nn.ConstantPad1d((left_padding, right_padding), 0.0)
|
| 120 |
+
|
| 121 |
+
def forward_fsmn(self, inputs, mask, mask_shfit_chunk=None):
|
| 122 |
+
b, t, d = inputs.size()
|
| 123 |
+
if mask is not None:
|
| 124 |
+
mask = torch.reshape(mask, (b, -1, 1))
|
| 125 |
+
if mask_shfit_chunk is not None:
|
| 126 |
+
mask = mask * mask_shfit_chunk
|
| 127 |
+
inputs = inputs * mask
|
| 128 |
+
|
| 129 |
+
x = inputs.transpose(1, 2)
|
| 130 |
+
x = self.pad_fn(x)
|
| 131 |
+
x = self.fsmn_block(x)
|
| 132 |
+
x = x.transpose(1, 2)
|
| 133 |
+
x += inputs
|
| 134 |
+
x = self.dropout(x)
|
| 135 |
+
if mask is not None:
|
| 136 |
+
x = x * mask
|
| 137 |
+
return x
|
| 138 |
+
|
| 139 |
+
def forward_qkv(self, x):
|
| 140 |
+
"""Transform query, key and value.
|
| 141 |
+
|
| 142 |
+
Args:
|
| 143 |
+
query (torch.Tensor): Query tensor (#batch, time1, size).
|
| 144 |
+
key (torch.Tensor): Key tensor (#batch, time2, size).
|
| 145 |
+
value (torch.Tensor): Value tensor (#batch, time2, size).
|
| 146 |
+
|
| 147 |
+
Returns:
|
| 148 |
+
torch.Tensor: Transformed query tensor (#batch, n_head, time1, d_k).
|
| 149 |
+
torch.Tensor: Transformed key tensor (#batch, n_head, time2, d_k).
|
| 150 |
+
torch.Tensor: Transformed value tensor (#batch, n_head, time2, d_k).
|
| 151 |
+
|
| 152 |
+
"""
|
| 153 |
+
b, t, d = x.size()
|
| 154 |
+
q_k_v = self.linear_q_k_v(x)
|
| 155 |
+
q, k, v = torch.split(q_k_v, int(self.h * self.d_k), dim=-1)
|
| 156 |
+
q_h = torch.reshape(q, (b, t, self.h, self.d_k)).transpose(
|
| 157 |
+
1, 2
|
| 158 |
+
) # (batch, head, time1, d_k)
|
| 159 |
+
k_h = torch.reshape(k, (b, t, self.h, self.d_k)).transpose(
|
| 160 |
+
1, 2
|
| 161 |
+
) # (batch, head, time2, d_k)
|
| 162 |
+
v_h = torch.reshape(v, (b, t, self.h, self.d_k)).transpose(
|
| 163 |
+
1, 2
|
| 164 |
+
) # (batch, head, time2, d_k)
|
| 165 |
+
|
| 166 |
+
return q_h, k_h, v_h, v
|
| 167 |
+
|
| 168 |
+
def forward_attention(self, value, scores, mask, mask_att_chunk_encoder=None):
|
| 169 |
+
"""Compute attention context vector.
|
| 170 |
+
|
| 171 |
+
Args:
|
| 172 |
+
value (torch.Tensor): Transformed value (#batch, n_head, time2, d_k).
|
| 173 |
+
scores (torch.Tensor): Attention score (#batch, n_head, time1, time2).
|
| 174 |
+
mask (torch.Tensor): Mask (#batch, 1, time2) or (#batch, time1, time2).
|
| 175 |
+
|
| 176 |
+
Returns:
|
| 177 |
+
torch.Tensor: Transformed value (#batch, time1, d_model)
|
| 178 |
+
weighted by the attention score (#batch, time1, time2).
|
| 179 |
+
|
| 180 |
+
"""
|
| 181 |
+
n_batch = value.size(0)
|
| 182 |
+
if mask is not None:
|
| 183 |
+
if mask_att_chunk_encoder is not None:
|
| 184 |
+
mask = mask * mask_att_chunk_encoder
|
| 185 |
+
|
| 186 |
+
mask = mask.unsqueeze(1).eq(0) # (batch, 1, *, time2)
|
| 187 |
+
|
| 188 |
+
min_value = -float(
|
| 189 |
+
"inf"
|
| 190 |
+
) # float(numpy.finfo(torch.tensor(0, dtype=scores.dtype).numpy().dtype).min)
|
| 191 |
+
scores = scores.masked_fill(mask, min_value)
|
| 192 |
+
attn = torch.softmax(scores, dim=-1).masked_fill(
|
| 193 |
+
mask, 0.0
|
| 194 |
+
) # (batch, head, time1, time2)
|
| 195 |
+
else:
|
| 196 |
+
attn = torch.softmax(scores, dim=-1) # (batch, head, time1, time2)
|
| 197 |
+
|
| 198 |
+
p_attn = self.dropout(attn)
|
| 199 |
+
x = torch.matmul(p_attn, value) # (batch, head, time1, d_k)
|
| 200 |
+
x = (
|
| 201 |
+
x.transpose(1, 2).contiguous().view(n_batch, -1, self.h * self.d_k)
|
| 202 |
+
) # (batch, time1, d_model)
|
| 203 |
+
|
| 204 |
+
return self.linear_out(x) # (batch, time1, d_model)
|
| 205 |
+
|
| 206 |
+
def forward(self, x, mask, mask_shfit_chunk=None, mask_att_chunk_encoder=None):
|
| 207 |
+
"""Compute scaled dot product attention.
|
| 208 |
+
|
| 209 |
+
Args:
|
| 210 |
+
query (torch.Tensor): Query tensor (#batch, time1, size).
|
| 211 |
+
key (torch.Tensor): Key tensor (#batch, time2, size).
|
| 212 |
+
value (torch.Tensor): Value tensor (#batch, time2, size).
|
| 213 |
+
mask (torch.Tensor): Mask tensor (#batch, 1, time2) or
|
| 214 |
+
(#batch, time1, time2).
|
| 215 |
+
|
| 216 |
+
Returns:
|
| 217 |
+
torch.Tensor: Output tensor (#batch, time1, d_model).
|
| 218 |
+
|
| 219 |
+
"""
|
| 220 |
+
q_h, k_h, v_h, v = self.forward_qkv(x)
|
| 221 |
+
fsmn_memory = self.forward_fsmn(v, mask, mask_shfit_chunk)
|
| 222 |
+
q_h = q_h * self.d_k ** (-0.5)
|
| 223 |
+
scores = torch.matmul(q_h, k_h.transpose(-2, -1))
|
| 224 |
+
att_outs = self.forward_attention(v_h, scores, mask, mask_att_chunk_encoder)
|
| 225 |
+
return att_outs + fsmn_memory
|
| 226 |
+
|
| 227 |
+
def forward_chunk(self, x, cache=None, chunk_size=None, look_back=0):
|
| 228 |
+
"""Compute scaled dot product attention.
|
| 229 |
+
|
| 230 |
+
Args:
|
| 231 |
+
query (torch.Tensor): Query tensor (#batch, time1, size).
|
| 232 |
+
key (torch.Tensor): Key tensor (#batch, time2, size).
|
| 233 |
+
value (torch.Tensor): Value tensor (#batch, time2, size).
|
| 234 |
+
mask (torch.Tensor): Mask tensor (#batch, 1, time2) or
|
| 235 |
+
(#batch, time1, time2).
|
| 236 |
+
|
| 237 |
+
Returns:
|
| 238 |
+
torch.Tensor: Output tensor (#batch, time1, d_model).
|
| 239 |
+
|
| 240 |
+
"""
|
| 241 |
+
q_h, k_h, v_h, v = self.forward_qkv(x)
|
| 242 |
+
if chunk_size is not None and look_back > 0 or look_back == -1:
|
| 243 |
+
if cache is not None:
|
| 244 |
+
k_h_stride = k_h[:, :, : -(chunk_size[2]), :]
|
| 245 |
+
v_h_stride = v_h[:, :, : -(chunk_size[2]), :]
|
| 246 |
+
k_h = torch.cat((cache["k"], k_h), dim=2)
|
| 247 |
+
v_h = torch.cat((cache["v"], v_h), dim=2)
|
| 248 |
+
|
| 249 |
+
cache["k"] = torch.cat((cache["k"], k_h_stride), dim=2)
|
| 250 |
+
cache["v"] = torch.cat((cache["v"], v_h_stride), dim=2)
|
| 251 |
+
if look_back != -1:
|
| 252 |
+
cache["k"] = cache["k"][:, :, -(look_back * chunk_size[1]) :, :]
|
| 253 |
+
cache["v"] = cache["v"][:, :, -(look_back * chunk_size[1]) :, :]
|
| 254 |
+
else:
|
| 255 |
+
cache_tmp = {
|
| 256 |
+
"k": k_h[:, :, : -(chunk_size[2]), :],
|
| 257 |
+
"v": v_h[:, :, : -(chunk_size[2]), :],
|
| 258 |
+
}
|
| 259 |
+
cache = cache_tmp
|
| 260 |
+
fsmn_memory = self.forward_fsmn(v, None)
|
| 261 |
+
q_h = q_h * self.d_k ** (-0.5)
|
| 262 |
+
scores = torch.matmul(q_h, k_h.transpose(-2, -1))
|
| 263 |
+
att_outs = self.forward_attention(v_h, scores, None)
|
| 264 |
+
return att_outs + fsmn_memory, cache
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class LayerNorm(nn.LayerNorm):
|
| 268 |
+
def __init__(self, *args, **kwargs):
|
| 269 |
+
super().__init__(*args, **kwargs)
|
| 270 |
+
|
| 271 |
+
def forward(self, input):
|
| 272 |
+
output = F.layer_norm(
|
| 273 |
+
input.float(),
|
| 274 |
+
self.normalized_shape,
|
| 275 |
+
self.weight.float() if self.weight is not None else None,
|
| 276 |
+
self.bias.float() if self.bias is not None else None,
|
| 277 |
+
self.eps,
|
| 278 |
+
)
|
| 279 |
+
return output.type_as(input)
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
def sequence_mask(lengths, maxlen=None, dtype=torch.float32, device=None):
|
| 283 |
+
if maxlen is None:
|
| 284 |
+
maxlen = lengths.max()
|
| 285 |
+
row_vector = torch.arange(0, maxlen, 1).to(lengths.device)
|
| 286 |
+
matrix = torch.unsqueeze(lengths, dim=-1)
|
| 287 |
+
mask = row_vector < matrix
|
| 288 |
+
mask = mask.detach()
|
| 289 |
+
|
| 290 |
+
return mask.type(dtype).to(device) if device is not None else mask.type(dtype)
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
class EncoderLayerSANM(nn.Module):
|
| 294 |
+
def __init__(
|
| 295 |
+
self,
|
| 296 |
+
in_size,
|
| 297 |
+
size,
|
| 298 |
+
self_attn,
|
| 299 |
+
feed_forward,
|
| 300 |
+
dropout_rate,
|
| 301 |
+
normalize_before=True,
|
| 302 |
+
concat_after=False,
|
| 303 |
+
stochastic_depth_rate=0.0,
|
| 304 |
+
):
|
| 305 |
+
"""Construct an EncoderLayer object."""
|
| 306 |
+
super(EncoderLayerSANM, self).__init__()
|
| 307 |
+
self.self_attn = self_attn
|
| 308 |
+
self.feed_forward = feed_forward
|
| 309 |
+
self.norm1 = LayerNorm(in_size)
|
| 310 |
+
self.norm2 = LayerNorm(size)
|
| 311 |
+
self.dropout = nn.Dropout(dropout_rate)
|
| 312 |
+
self.in_size = in_size
|
| 313 |
+
self.size = size
|
| 314 |
+
self.normalize_before = normalize_before
|
| 315 |
+
self.concat_after = concat_after
|
| 316 |
+
if self.concat_after:
|
| 317 |
+
self.concat_linear = nn.Linear(size + size, size)
|
| 318 |
+
self.stochastic_depth_rate = stochastic_depth_rate
|
| 319 |
+
self.dropout_rate = dropout_rate
|
| 320 |
+
|
| 321 |
+
def forward(self, x, mask, cache=None, mask_shfit_chunk=None, mask_att_chunk_encoder=None):
|
| 322 |
+
"""Compute encoded features.
|
| 323 |
+
|
| 324 |
+
Args:
|
| 325 |
+
x_input (torch.Tensor): Input tensor (#batch, time, size).
|
| 326 |
+
mask (torch.Tensor): Mask tensor for the input (#batch, time).
|
| 327 |
+
cache (torch.Tensor): Cache tensor of the input (#batch, time - 1, size).
|
| 328 |
+
|
| 329 |
+
Returns:
|
| 330 |
+
torch.Tensor: Output tensor (#batch, time, size).
|
| 331 |
+
torch.Tensor: Mask tensor (#batch, time).
|
| 332 |
+
|
| 333 |
+
"""
|
| 334 |
+
skip_layer = False
|
| 335 |
+
# with stochastic depth, residual connection `x + f(x)` becomes
|
| 336 |
+
# `x <- x + 1 / (1 - p) * f(x)` at training time.
|
| 337 |
+
stoch_layer_coeff = 1.0
|
| 338 |
+
if self.training and self.stochastic_depth_rate > 0:
|
| 339 |
+
skip_layer = torch.rand(1).item() < self.stochastic_depth_rate
|
| 340 |
+
stoch_layer_coeff = 1.0 / (1 - self.stochastic_depth_rate)
|
| 341 |
+
|
| 342 |
+
if skip_layer:
|
| 343 |
+
if cache is not None:
|
| 344 |
+
x = torch.cat([cache, x], dim=1)
|
| 345 |
+
return x, mask
|
| 346 |
+
|
| 347 |
+
residual = x
|
| 348 |
+
if self.normalize_before:
|
| 349 |
+
x = self.norm1(x)
|
| 350 |
+
|
| 351 |
+
if self.concat_after:
|
| 352 |
+
x_concat = torch.cat(
|
| 353 |
+
(
|
| 354 |
+
x,
|
| 355 |
+
self.self_attn(
|
| 356 |
+
x,
|
| 357 |
+
mask,
|
| 358 |
+
mask_shfit_chunk=mask_shfit_chunk,
|
| 359 |
+
mask_att_chunk_encoder=mask_att_chunk_encoder,
|
| 360 |
+
),
|
| 361 |
+
),
|
| 362 |
+
dim=-1,
|
| 363 |
+
)
|
| 364 |
+
if self.in_size == self.size:
|
| 365 |
+
x = residual + stoch_layer_coeff * self.concat_linear(x_concat)
|
| 366 |
+
else:
|
| 367 |
+
x = stoch_layer_coeff * self.concat_linear(x_concat)
|
| 368 |
+
else:
|
| 369 |
+
if self.in_size == self.size:
|
| 370 |
+
x = residual + stoch_layer_coeff * self.dropout(
|
| 371 |
+
self.self_attn(
|
| 372 |
+
x,
|
| 373 |
+
mask,
|
| 374 |
+
mask_shfit_chunk=mask_shfit_chunk,
|
| 375 |
+
mask_att_chunk_encoder=mask_att_chunk_encoder,
|
| 376 |
+
)
|
| 377 |
+
)
|
| 378 |
+
else:
|
| 379 |
+
x = stoch_layer_coeff * self.dropout(
|
| 380 |
+
self.self_attn(
|
| 381 |
+
x,
|
| 382 |
+
mask,
|
| 383 |
+
mask_shfit_chunk=mask_shfit_chunk,
|
| 384 |
+
mask_att_chunk_encoder=mask_att_chunk_encoder,
|
| 385 |
+
)
|
| 386 |
+
)
|
| 387 |
+
if not self.normalize_before:
|
| 388 |
+
x = self.norm1(x)
|
| 389 |
+
|
| 390 |
+
residual = x
|
| 391 |
+
if self.normalize_before:
|
| 392 |
+
x = self.norm2(x)
|
| 393 |
+
x = residual + stoch_layer_coeff * self.dropout(self.feed_forward(x))
|
| 394 |
+
if not self.normalize_before:
|
| 395 |
+
x = self.norm2(x)
|
| 396 |
+
|
| 397 |
+
return x, mask, cache, mask_shfit_chunk, mask_att_chunk_encoder
|
| 398 |
+
|
| 399 |
+
def forward_chunk(self, x, cache=None, chunk_size=None, look_back=0):
|
| 400 |
+
"""Compute encoded features.
|
| 401 |
+
|
| 402 |
+
Args:
|
| 403 |
+
x_input (torch.Tensor): Input tensor (#batch, time, size).
|
| 404 |
+
mask (torch.Tensor): Mask tensor for the input (#batch, time).
|
| 405 |
+
cache (torch.Tensor): Cache tensor of the input (#batch, time - 1, size).
|
| 406 |
+
|
| 407 |
+
Returns:
|
| 408 |
+
torch.Tensor: Output tensor (#batch, time, size).
|
| 409 |
+
torch.Tensor: Mask tensor (#batch, time).
|
| 410 |
+
|
| 411 |
+
"""
|
| 412 |
+
|
| 413 |
+
residual = x
|
| 414 |
+
if self.normalize_before:
|
| 415 |
+
x = self.norm1(x)
|
| 416 |
+
|
| 417 |
+
if self.in_size == self.size:
|
| 418 |
+
attn, cache = self.self_attn.forward_chunk(x, cache, chunk_size, look_back)
|
| 419 |
+
x = residual + attn
|
| 420 |
+
else:
|
| 421 |
+
x, cache = self.self_attn.forward_chunk(x, cache, chunk_size, look_back)
|
| 422 |
+
|
| 423 |
+
if not self.normalize_before:
|
| 424 |
+
x = self.norm1(x)
|
| 425 |
+
|
| 426 |
+
residual = x
|
| 427 |
+
if self.normalize_before:
|
| 428 |
+
x = self.norm2(x)
|
| 429 |
+
x = residual + self.feed_forward(x)
|
| 430 |
+
if not self.normalize_before:
|
| 431 |
+
x = self.norm2(x)
|
| 432 |
+
|
| 433 |
+
return x, cache
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
@tables.register("encoder_classes", "SenseVoiceEncoderSmall")
|
| 437 |
+
class SenseVoiceEncoderSmall(nn.Module):
|
| 438 |
+
"""
|
| 439 |
+
Author: Speech Lab of DAMO Academy, Alibaba Group
|
| 440 |
+
SCAMA: Streaming chunk-aware multihead attention for online end-to-end speech recognition
|
| 441 |
+
https://arxiv.org/abs/2006.01713
|
| 442 |
+
"""
|
| 443 |
+
|
| 444 |
+
def __init__(
|
| 445 |
+
self,
|
| 446 |
+
input_size: int,
|
| 447 |
+
output_size: int = 256,
|
| 448 |
+
attention_heads: int = 4,
|
| 449 |
+
linear_units: int = 2048,
|
| 450 |
+
num_blocks: int = 6,
|
| 451 |
+
tp_blocks: int = 0,
|
| 452 |
+
dropout_rate: float = 0.1,
|
| 453 |
+
positional_dropout_rate: float = 0.1,
|
| 454 |
+
attention_dropout_rate: float = 0.0,
|
| 455 |
+
stochastic_depth_rate: float = 0.0,
|
| 456 |
+
input_layer: Optional[str] = "conv2d",
|
| 457 |
+
pos_enc_class=SinusoidalPositionEncoder,
|
| 458 |
+
normalize_before: bool = True,
|
| 459 |
+
concat_after: bool = False,
|
| 460 |
+
positionwise_layer_type: str = "linear",
|
| 461 |
+
positionwise_conv_kernel_size: int = 1,
|
| 462 |
+
padding_idx: int = -1,
|
| 463 |
+
kernel_size: int = 11,
|
| 464 |
+
sanm_shfit: int = 0,
|
| 465 |
+
selfattention_layer_type: str = "sanm",
|
| 466 |
+
**kwargs,
|
| 467 |
+
):
|
| 468 |
+
super().__init__()
|
| 469 |
+
self._output_size = output_size
|
| 470 |
+
|
| 471 |
+
self.embed = SinusoidalPositionEncoder()
|
| 472 |
+
|
| 473 |
+
self.normalize_before = normalize_before
|
| 474 |
+
|
| 475 |
+
positionwise_layer = PositionwiseFeedForward
|
| 476 |
+
positionwise_layer_args = (
|
| 477 |
+
output_size,
|
| 478 |
+
linear_units,
|
| 479 |
+
dropout_rate,
|
| 480 |
+
)
|
| 481 |
+
|
| 482 |
+
encoder_selfattn_layer = MultiHeadedAttentionSANM
|
| 483 |
+
encoder_selfattn_layer_args0 = (
|
| 484 |
+
attention_heads,
|
| 485 |
+
input_size,
|
| 486 |
+
output_size,
|
| 487 |
+
attention_dropout_rate,
|
| 488 |
+
kernel_size,
|
| 489 |
+
sanm_shfit,
|
| 490 |
+
)
|
| 491 |
+
encoder_selfattn_layer_args = (
|
| 492 |
+
attention_heads,
|
| 493 |
+
output_size,
|
| 494 |
+
output_size,
|
| 495 |
+
attention_dropout_rate,
|
| 496 |
+
kernel_size,
|
| 497 |
+
sanm_shfit,
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
self.encoders0 = nn.ModuleList(
|
| 501 |
+
[
|
| 502 |
+
EncoderLayerSANM(
|
| 503 |
+
input_size,
|
| 504 |
+
output_size,
|
| 505 |
+
encoder_selfattn_layer(*encoder_selfattn_layer_args0),
|
| 506 |
+
positionwise_layer(*positionwise_layer_args),
|
| 507 |
+
dropout_rate,
|
| 508 |
+
)
|
| 509 |
+
for i in range(1)
|
| 510 |
+
]
|
| 511 |
+
)
|
| 512 |
+
self.encoders = nn.ModuleList(
|
| 513 |
+
[
|
| 514 |
+
EncoderLayerSANM(
|
| 515 |
+
output_size,
|
| 516 |
+
output_size,
|
| 517 |
+
encoder_selfattn_layer(*encoder_selfattn_layer_args),
|
| 518 |
+
positionwise_layer(*positionwise_layer_args),
|
| 519 |
+
dropout_rate,
|
| 520 |
+
)
|
| 521 |
+
for i in range(num_blocks - 1)
|
| 522 |
+
]
|
| 523 |
+
)
|
| 524 |
+
|
| 525 |
+
self.tp_encoders = nn.ModuleList(
|
| 526 |
+
[
|
| 527 |
+
EncoderLayerSANM(
|
| 528 |
+
output_size,
|
| 529 |
+
output_size,
|
| 530 |
+
encoder_selfattn_layer(*encoder_selfattn_layer_args),
|
| 531 |
+
positionwise_layer(*positionwise_layer_args),
|
| 532 |
+
dropout_rate,
|
| 533 |
+
)
|
| 534 |
+
for i in range(tp_blocks)
|
| 535 |
+
]
|
| 536 |
+
)
|
| 537 |
+
|
| 538 |
+
self.after_norm = LayerNorm(output_size)
|
| 539 |
+
|
| 540 |
+
self.tp_norm = LayerNorm(output_size)
|
| 541 |
+
|
| 542 |
+
def output_size(self) -> int:
|
| 543 |
+
return self._output_size
|
| 544 |
+
|
| 545 |
+
def forward(
|
| 546 |
+
self,
|
| 547 |
+
xs_pad: torch.Tensor,
|
| 548 |
+
ilens: torch.Tensor,
|
| 549 |
+
):
|
| 550 |
+
"""Embed positions in tensor."""
|
| 551 |
+
masks = sequence_mask(ilens, device=ilens.device)[:, None, :]
|
| 552 |
+
|
| 553 |
+
xs_pad *= self.output_size() ** 0.5
|
| 554 |
+
|
| 555 |
+
xs_pad = self.embed(xs_pad)
|
| 556 |
+
|
| 557 |
+
# forward encoder1
|
| 558 |
+
for layer_idx, encoder_layer in enumerate(self.encoders0):
|
| 559 |
+
encoder_outs = encoder_layer(xs_pad, masks)
|
| 560 |
+
xs_pad, masks = encoder_outs[0], encoder_outs[1]
|
| 561 |
+
|
| 562 |
+
for layer_idx, encoder_layer in enumerate(self.encoders):
|
| 563 |
+
encoder_outs = encoder_layer(xs_pad, masks)
|
| 564 |
+
xs_pad, masks = encoder_outs[0], encoder_outs[1]
|
| 565 |
+
|
| 566 |
+
xs_pad = self.after_norm(xs_pad)
|
| 567 |
+
|
| 568 |
+
# forward encoder2
|
| 569 |
+
olens = masks.squeeze(1).sum(1).int()
|
| 570 |
+
|
| 571 |
+
for layer_idx, encoder_layer in enumerate(self.tp_encoders):
|
| 572 |
+
encoder_outs = encoder_layer(xs_pad, masks)
|
| 573 |
+
xs_pad, masks = encoder_outs[0], encoder_outs[1]
|
| 574 |
+
|
| 575 |
+
xs_pad = self.tp_norm(xs_pad)
|
| 576 |
+
return xs_pad, olens
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
@tables.register("model_classes", "SenseVoiceSmall")
|
| 580 |
+
class SenseVoiceSmall(nn.Module):
|
| 581 |
+
"""CTC-attention hybrid Encoder-Decoder model"""
|
| 582 |
+
|
| 583 |
+
def __init__(
|
| 584 |
+
self,
|
| 585 |
+
specaug: str = None,
|
| 586 |
+
specaug_conf: dict = None,
|
| 587 |
+
normalize: str = None,
|
| 588 |
+
normalize_conf: dict = None,
|
| 589 |
+
encoder: str = None,
|
| 590 |
+
encoder_conf: dict = None,
|
| 591 |
+
ctc_conf: dict = None,
|
| 592 |
+
input_size: int = 80,
|
| 593 |
+
vocab_size: int = -1,
|
| 594 |
+
ignore_id: int = -1,
|
| 595 |
+
blank_id: int = 0,
|
| 596 |
+
sos: int = 1,
|
| 597 |
+
eos: int = 2,
|
| 598 |
+
length_normalized_loss: bool = False,
|
| 599 |
+
**kwargs,
|
| 600 |
+
):
|
| 601 |
+
|
| 602 |
+
super().__init__()
|
| 603 |
+
|
| 604 |
+
if specaug is not None:
|
| 605 |
+
specaug_class = tables.specaug_classes.get(specaug)
|
| 606 |
+
specaug = specaug_class(**specaug_conf)
|
| 607 |
+
if normalize is not None:
|
| 608 |
+
normalize_class = tables.normalize_classes.get(normalize)
|
| 609 |
+
normalize = normalize_class(**normalize_conf)
|
| 610 |
+
encoder_class = tables.encoder_classes.get(encoder)
|
| 611 |
+
encoder = encoder_class(input_size=input_size, **encoder_conf)
|
| 612 |
+
encoder_output_size = encoder.output_size()
|
| 613 |
+
|
| 614 |
+
if ctc_conf is None:
|
| 615 |
+
ctc_conf = {}
|
| 616 |
+
ctc = CTC(odim=vocab_size, encoder_output_size=encoder_output_size, **ctc_conf)
|
| 617 |
+
|
| 618 |
+
self.blank_id = blank_id
|
| 619 |
+
self.sos = sos if sos is not None else vocab_size - 1
|
| 620 |
+
self.eos = eos if eos is not None else vocab_size - 1
|
| 621 |
+
self.vocab_size = vocab_size
|
| 622 |
+
self.ignore_id = ignore_id
|
| 623 |
+
self.specaug = specaug
|
| 624 |
+
self.normalize = normalize
|
| 625 |
+
self.encoder = encoder
|
| 626 |
+
self.error_calculator = None
|
| 627 |
+
|
| 628 |
+
self.ctc = ctc
|
| 629 |
+
|
| 630 |
+
self.length_normalized_loss = length_normalized_loss
|
| 631 |
+
self.encoder_output_size = encoder_output_size
|
| 632 |
+
|
| 633 |
+
self.lid_dict = {"auto": 0, "zh": 3, "en": 4, "yue": 7, "ja": 11, "ko": 12, "nospeech": 13}
|
| 634 |
+
self.lid_int_dict = {24884: 3, 24885: 4, 24888: 7, 24892: 11, 24896: 12, 24992: 13}
|
| 635 |
+
self.textnorm_dict = {"withitn": 14, "woitn": 15}
|
| 636 |
+
self.textnorm_int_dict = {25016: 14, 25017: 15}
|
| 637 |
+
self.embed = torch.nn.Embedding(7 + len(self.lid_dict) + len(self.textnorm_dict), input_size)
|
| 638 |
+
self.emo_dict = {"unk": 25009, "happy": 25001, "sad": 25002, "angry": 25003, "neutral": 25004}
|
| 639 |
+
|
| 640 |
+
self.criterion_att = LabelSmoothingLoss(
|
| 641 |
+
size=self.vocab_size,
|
| 642 |
+
padding_idx=self.ignore_id,
|
| 643 |
+
smoothing=kwargs.get("lsm_weight", 0.0),
|
| 644 |
+
normalize_length=self.length_normalized_loss,
|
| 645 |
+
)
|
| 646 |
+
|
| 647 |
+
@staticmethod
|
| 648 |
+
def from_pretrained(model:str=None, **kwargs):
|
| 649 |
+
from funasr import AutoModel
|
| 650 |
+
model, kwargs = AutoModel.build_model(model=model, trust_remote_code=True, **kwargs)
|
| 651 |
+
|
| 652 |
+
return model, kwargs
|
| 653 |
+
|
| 654 |
+
def forward(
|
| 655 |
+
self,
|
| 656 |
+
speech: torch.Tensor,
|
| 657 |
+
speech_lengths: torch.Tensor,
|
| 658 |
+
text: torch.Tensor,
|
| 659 |
+
text_lengths: torch.Tensor,
|
| 660 |
+
**kwargs,
|
| 661 |
+
):
|
| 662 |
+
"""Encoder + Decoder + Calc loss
|
| 663 |
+
Args:
|
| 664 |
+
speech: (Batch, Length, ...)
|
| 665 |
+
speech_lengths: (Batch, )
|
| 666 |
+
text: (Batch, Length)
|
| 667 |
+
text_lengths: (Batch,)
|
| 668 |
+
"""
|
| 669 |
+
# import pdb;
|
| 670 |
+
# pdb.set_trace()
|
| 671 |
+
if len(text_lengths.size()) > 1:
|
| 672 |
+
text_lengths = text_lengths[:, 0]
|
| 673 |
+
if len(speech_lengths.size()) > 1:
|
| 674 |
+
speech_lengths = speech_lengths[:, 0]
|
| 675 |
+
|
| 676 |
+
batch_size = speech.shape[0]
|
| 677 |
+
|
| 678 |
+
# 1. Encoder
|
| 679 |
+
encoder_out, encoder_out_lens = self.encode(speech, speech_lengths, text)
|
| 680 |
+
|
| 681 |
+
loss_ctc, cer_ctc = None, None
|
| 682 |
+
loss_rich, acc_rich = None, None
|
| 683 |
+
stats = dict()
|
| 684 |
+
|
| 685 |
+
loss_ctc, cer_ctc = self._calc_ctc_loss(
|
| 686 |
+
encoder_out[:, 4:, :], encoder_out_lens - 4, text[:, 4:], text_lengths - 4
|
| 687 |
+
)
|
| 688 |
+
|
| 689 |
+
loss_rich, acc_rich = self._calc_rich_ce_loss(
|
| 690 |
+
encoder_out[:, :4, :], text[:, :4]
|
| 691 |
+
)
|
| 692 |
+
|
| 693 |
+
loss = loss_ctc + loss_rich
|
| 694 |
+
# Collect total loss stats
|
| 695 |
+
stats["loss_ctc"] = torch.clone(loss_ctc.detach()) if loss_ctc is not None else None
|
| 696 |
+
stats["loss_rich"] = torch.clone(loss_rich.detach()) if loss_rich is not None else None
|
| 697 |
+
stats["loss"] = torch.clone(loss.detach()) if loss is not None else None
|
| 698 |
+
stats["acc_rich"] = acc_rich
|
| 699 |
+
|
| 700 |
+
# force_gatherable: to-device and to-tensor if scalar for DataParallel
|
| 701 |
+
if self.length_normalized_loss:
|
| 702 |
+
batch_size = int((text_lengths + 1).sum())
|
| 703 |
+
loss, stats, weight = force_gatherable((loss, stats, batch_size), loss.device)
|
| 704 |
+
return loss, stats, weight
|
| 705 |
+
|
| 706 |
+
def encode(
|
| 707 |
+
self,
|
| 708 |
+
speech: torch.Tensor,
|
| 709 |
+
speech_lengths: torch.Tensor,
|
| 710 |
+
text: torch.Tensor,
|
| 711 |
+
**kwargs,
|
| 712 |
+
):
|
| 713 |
+
"""Frontend + Encoder. Note that this method is used by asr_inference.py
|
| 714 |
+
Args:
|
| 715 |
+
speech: (Batch, Length, ...)
|
| 716 |
+
speech_lengths: (Batch, )
|
| 717 |
+
ind: int
|
| 718 |
+
"""
|
| 719 |
+
|
| 720 |
+
# Data augmentation
|
| 721 |
+
if self.specaug is not None and self.training:
|
| 722 |
+
speech, speech_lengths = self.specaug(speech, speech_lengths)
|
| 723 |
+
|
| 724 |
+
# Normalization for feature: e.g. Global-CMVN, Utterance-CMVN
|
| 725 |
+
if self.normalize is not None:
|
| 726 |
+
speech, speech_lengths = self.normalize(speech, speech_lengths)
|
| 727 |
+
|
| 728 |
+
|
| 729 |
+
lids = torch.LongTensor([[self.lid_int_dict[int(lid)] if torch.rand(1) > 0.2 and int(lid) in self.lid_int_dict else 0 ] for lid in text[:, 0]]).to(speech.device)
|
| 730 |
+
language_query = self.embed(lids)
|
| 731 |
+
|
| 732 |
+
styles = torch.LongTensor([[self.textnorm_int_dict[int(style)]] for style in text[:, 3]]).to(speech.device)
|
| 733 |
+
style_query = self.embed(styles)
|
| 734 |
+
speech = torch.cat((style_query, speech), dim=1)
|
| 735 |
+
speech_lengths += 1
|
| 736 |
+
|
| 737 |
+
event_emo_query = self.embed(torch.LongTensor([[1, 2]]).to(speech.device)).repeat(speech.size(0), 1, 1)
|
| 738 |
+
input_query = torch.cat((language_query, event_emo_query), dim=1)
|
| 739 |
+
speech = torch.cat((input_query, speech), dim=1)
|
| 740 |
+
speech_lengths += 3
|
| 741 |
+
|
| 742 |
+
encoder_out, encoder_out_lens = self.encoder(speech, speech_lengths)
|
| 743 |
+
|
| 744 |
+
return encoder_out, encoder_out_lens
|
| 745 |
+
|
| 746 |
+
def _calc_ctc_loss(
|
| 747 |
+
self,
|
| 748 |
+
encoder_out: torch.Tensor,
|
| 749 |
+
encoder_out_lens: torch.Tensor,
|
| 750 |
+
ys_pad: torch.Tensor,
|
| 751 |
+
ys_pad_lens: torch.Tensor,
|
| 752 |
+
):
|
| 753 |
+
# Calc CTC loss
|
| 754 |
+
loss_ctc = self.ctc(encoder_out, encoder_out_lens, ys_pad, ys_pad_lens)
|
| 755 |
+
|
| 756 |
+
# Calc CER using CTC
|
| 757 |
+
cer_ctc = None
|
| 758 |
+
if not self.training and self.error_calculator is not None:
|
| 759 |
+
ys_hat = self.ctc.argmax(encoder_out).data
|
| 760 |
+
cer_ctc = self.error_calculator(ys_hat.cpu(), ys_pad.cpu(), is_ctc=True)
|
| 761 |
+
return loss_ctc, cer_ctc
|
| 762 |
+
|
| 763 |
+
def _calc_rich_ce_loss(
|
| 764 |
+
self,
|
| 765 |
+
encoder_out: torch.Tensor,
|
| 766 |
+
ys_pad: torch.Tensor,
|
| 767 |
+
):
|
| 768 |
+
decoder_out = self.ctc.ctc_lo(encoder_out)
|
| 769 |
+
# 2. Compute attention loss
|
| 770 |
+
loss_rich = self.criterion_att(decoder_out, ys_pad.contiguous())
|
| 771 |
+
acc_rich = th_accuracy(
|
| 772 |
+
decoder_out.view(-1, self.vocab_size),
|
| 773 |
+
ys_pad.contiguous(),
|
| 774 |
+
ignore_label=self.ignore_id,
|
| 775 |
+
)
|
| 776 |
+
|
| 777 |
+
return loss_rich, acc_rich
|
| 778 |
+
|
| 779 |
+
|
| 780 |
+
def inference(
|
| 781 |
+
self,
|
| 782 |
+
data_in,
|
| 783 |
+
data_lengths=None,
|
| 784 |
+
key: list = ["wav_file_tmp_name"],
|
| 785 |
+
tokenizer=None,
|
| 786 |
+
frontend=None,
|
| 787 |
+
**kwargs,
|
| 788 |
+
):
|
| 789 |
+
|
| 790 |
+
|
| 791 |
+
meta_data = {}
|
| 792 |
+
if (
|
| 793 |
+
isinstance(data_in, torch.Tensor) and kwargs.get("data_type", "sound") == "fbank"
|
| 794 |
+
): # fbank
|
| 795 |
+
speech, speech_lengths = data_in, data_lengths
|
| 796 |
+
if len(speech.shape) < 3:
|
| 797 |
+
speech = speech[None, :, :]
|
| 798 |
+
if speech_lengths is None:
|
| 799 |
+
speech_lengths = speech.shape[1]
|
| 800 |
+
else:
|
| 801 |
+
# extract fbank feats
|
| 802 |
+
time1 = time.perf_counter()
|
| 803 |
+
audio_sample_list = load_audio_text_image_video(
|
| 804 |
+
data_in,
|
| 805 |
+
fs=frontend.fs,
|
| 806 |
+
audio_fs=kwargs.get("fs", 16000),
|
| 807 |
+
data_type=kwargs.get("data_type", "sound"),
|
| 808 |
+
tokenizer=tokenizer,
|
| 809 |
+
)
|
| 810 |
+
time2 = time.perf_counter()
|
| 811 |
+
meta_data["load_data"] = f"{time2 - time1:0.3f}"
|
| 812 |
+
speech, speech_lengths = extract_fbank(
|
| 813 |
+
audio_sample_list, data_type=kwargs.get("data_type", "sound"), frontend=frontend
|
| 814 |
+
)
|
| 815 |
+
time3 = time.perf_counter()
|
| 816 |
+
meta_data["extract_feat"] = f"{time3 - time2:0.3f}"
|
| 817 |
+
meta_data["batch_data_time"] = (
|
| 818 |
+
speech_lengths.sum().item() * frontend.frame_shift * frontend.lfr_n / 1000
|
| 819 |
+
)
|
| 820 |
+
|
| 821 |
+
speech = speech.to(device=kwargs["device"])
|
| 822 |
+
speech_lengths = speech_lengths.to(device=kwargs["device"])
|
| 823 |
+
|
| 824 |
+
language = kwargs.get("language", "auto")
|
| 825 |
+
language_query = self.embed(
|
| 826 |
+
torch.LongTensor(
|
| 827 |
+
[[self.lid_dict[language] if language in self.lid_dict else 0]]
|
| 828 |
+
).to(speech.device)
|
| 829 |
+
).repeat(speech.size(0), 1, 1)
|
| 830 |
+
|
| 831 |
+
use_itn = kwargs.get("use_itn", False)
|
| 832 |
+
textnorm = kwargs.get("text_norm", None)
|
| 833 |
+
if textnorm is None:
|
| 834 |
+
textnorm = "withitn" if use_itn else "woitn"
|
| 835 |
+
textnorm_query = self.embed(
|
| 836 |
+
torch.LongTensor([[self.textnorm_dict[textnorm]]]).to(speech.device)
|
| 837 |
+
).repeat(speech.size(0), 1, 1)
|
| 838 |
+
speech = torch.cat((textnorm_query, speech), dim=1)
|
| 839 |
+
speech_lengths += 1
|
| 840 |
+
|
| 841 |
+
event_emo_query = self.embed(torch.LongTensor([[1, 2]]).to(speech.device)).repeat(
|
| 842 |
+
speech.size(0), 1, 1
|
| 843 |
+
)
|
| 844 |
+
input_query = torch.cat((language_query, event_emo_query), dim=1)
|
| 845 |
+
speech = torch.cat((input_query, speech), dim=1)
|
| 846 |
+
speech_lengths += 3
|
| 847 |
+
|
| 848 |
+
# Encoder
|
| 849 |
+
encoder_out, encoder_out_lens = self.encoder(speech, speech_lengths)
|
| 850 |
+
if isinstance(encoder_out, tuple):
|
| 851 |
+
encoder_out = encoder_out[0]
|
| 852 |
+
|
| 853 |
+
# c. Passed the encoder result and the beam search
|
| 854 |
+
ctc_logits = self.ctc.log_softmax(encoder_out)
|
| 855 |
+
if kwargs.get("ban_emo_unk", False):
|
| 856 |
+
ctc_logits[:, :, self.emo_dict["unk"]] = -float("inf")
|
| 857 |
+
|
| 858 |
+
results = []
|
| 859 |
+
b, n, d = encoder_out.size()
|
| 860 |
+
if isinstance(key[0], (list, tuple)):
|
| 861 |
+
key = key[0]
|
| 862 |
+
if len(key) < b:
|
| 863 |
+
key = key * b
|
| 864 |
+
for i in range(b):
|
| 865 |
+
x = ctc_logits[i, : encoder_out_lens[i].item(), :]
|
| 866 |
+
yseq = x.argmax(dim=-1)
|
| 867 |
+
yseq = torch.unique_consecutive(yseq, dim=-1)
|
| 868 |
+
|
| 869 |
+
ibest_writer = None
|
| 870 |
+
if kwargs.get("output_dir") is not None:
|
| 871 |
+
if not hasattr(self, "writer"):
|
| 872 |
+
self.writer = DatadirWriter(kwargs.get("output_dir"))
|
| 873 |
+
ibest_writer = self.writer[f"1best_recog"]
|
| 874 |
+
|
| 875 |
+
mask = yseq != self.blank_id
|
| 876 |
+
token_int = yseq[mask].tolist()
|
| 877 |
+
|
| 878 |
+
# Change integer-ids to tokens
|
| 879 |
+
text = tokenizer.decode(token_int)
|
| 880 |
+
|
| 881 |
+
result_i = {"key": key[i], "text": text}
|
| 882 |
+
results.append(result_i)
|
| 883 |
+
|
| 884 |
+
if ibest_writer is not None:
|
| 885 |
+
ibest_writer["text"][key[i]] = text
|
| 886 |
+
|
| 887 |
+
return results, meta_data
|
| 888 |
+
|
| 889 |
+
def export(self, **kwargs):
|
| 890 |
+
from export_meta import export_rebuild_model
|
| 891 |
+
|
| 892 |
+
if "max_seq_len" not in kwargs:
|
| 893 |
+
kwargs["max_seq_len"] = 512
|
| 894 |
+
models = export_rebuild_model(model=self, **kwargs)
|
| 895 |
+
return models
|
model/SenseVoiceSmall/tokens.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model/bert-base-chinese/.gitattributes
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.tar.gz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
model.safetensors filter=lfs diff=lfs merge=lfs -text
|
model/bert-base-chinese/README.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: zh
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
# Bert-base-chinese
|
| 6 |
+
|
| 7 |
+
## Table of Contents
|
| 8 |
+
- [Model Details](#model-details)
|
| 9 |
+
- [Uses](#uses)
|
| 10 |
+
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
|
| 11 |
+
- [Training](#training)
|
| 12 |
+
- [Evaluation](#evaluation)
|
| 13 |
+
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
## Model Details
|
| 17 |
+
|
| 18 |
+
### Model Description
|
| 19 |
+
|
| 20 |
+
This model has been pre-trained for Chinese, training and random input masking has been applied independently to word pieces (as in the original BERT paper).
|
| 21 |
+
|
| 22 |
+
- **Developed by:** HuggingFace team
|
| 23 |
+
- **Model Type:** Fill-Mask
|
| 24 |
+
- **Language(s):** Chinese
|
| 25 |
+
- **License:** [More Information needed]
|
| 26 |
+
- **Parent Model:** See the [BERT base uncased model](https://huggingface.co/bert-base-uncased) for more information about the BERT base model.
|
| 27 |
+
|
| 28 |
+
### Model Sources
|
| 29 |
+
- **Paper:** [BERT](https://arxiv.org/abs/1810.04805)
|
| 30 |
+
|
| 31 |
+
## Uses
|
| 32 |
+
|
| 33 |
+
#### Direct Use
|
| 34 |
+
|
| 35 |
+
This model can be used for masked language modeling
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
## Risks, Limitations and Biases
|
| 40 |
+
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
|
| 41 |
+
|
| 42 |
+
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
## Training
|
| 46 |
+
|
| 47 |
+
#### Training Procedure
|
| 48 |
+
* **type_vocab_size:** 2
|
| 49 |
+
* **vocab_size:** 21128
|
| 50 |
+
* **num_hidden_layers:** 12
|
| 51 |
+
|
| 52 |
+
#### Training Data
|
| 53 |
+
[More Information Needed]
|
| 54 |
+
|
| 55 |
+
## Evaluation
|
| 56 |
+
|
| 57 |
+
#### Results
|
| 58 |
+
|
| 59 |
+
[More Information Needed]
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## How to Get Started With the Model
|
| 63 |
+
```python
|
| 64 |
+
from transformers import AutoTokenizer, AutoModelForMaskedLM
|
| 65 |
+
|
| 66 |
+
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
|
| 67 |
+
|
| 68 |
+
model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
|
| 69 |
+
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
model/bert-base-chinese/config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"BertForMaskedLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_probs_dropout_prob": 0.1,
|
| 6 |
+
"directionality": "bidi",
|
| 7 |
+
"hidden_act": "gelu",
|
| 8 |
+
"hidden_dropout_prob": 0.1,
|
| 9 |
+
"hidden_size": 768,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 3072,
|
| 12 |
+
"layer_norm_eps": 1e-12,
|
| 13 |
+
"max_position_embeddings": 512,
|
| 14 |
+
"model_type": "bert",
|
| 15 |
+
"num_attention_heads": 12,
|
| 16 |
+
"num_hidden_layers": 12,
|
| 17 |
+
"pad_token_id": 0,
|
| 18 |
+
"pooler_fc_size": 768,
|
| 19 |
+
"pooler_num_attention_heads": 12,
|
| 20 |
+
"pooler_num_fc_layers": 3,
|
| 21 |
+
"pooler_size_per_head": 128,
|
| 22 |
+
"pooler_type": "first_token_transform",
|
| 23 |
+
"type_vocab_size": 2,
|
| 24 |
+
"vocab_size": 21128
|
| 25 |
+
}
|
model/bert-base-chinese/flax_model.msgpack
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:76df8425215fb9ede22e0393e356f82a99d84e79f078cd141afbbf9277460c8e
|
| 3 |
+
size 409168515
|
model/bert-base-chinese/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3404a1ffd8da507042e8161013ba2a4fc49858b4e3f8fbf5ce5724f94883aec3
|
| 3 |
+
size 411553788
|
model/bert-base-chinese/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a693db616eaf647ed2bfe531e1fa446637358fc108a8bf04e8d4db17e837ee9
|
| 3 |
+
size 411577189
|
model/bert-base-chinese/tf_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:612acd33db45677c3d6ba70615336619dc65cddf1ecf9d39a22dd1934af4aff2
|
| 3 |
+
size 478309336
|
model/bert-base-chinese/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model/bert-base-chinese/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"do_lower_case": false, "model_max_length": 512}
|
model/bert-base-chinese/vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model/fsmn_vad/.msc
ADDED
|
Binary file (497 Bytes). View file
|
|
|
model/fsmn_vad/.mv
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Revision:v2.0.4,CreatedAt:1706001004
|
model/fsmn_vad/README.md
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tasks:
|
| 3 |
+
- voice-activity-detection
|
| 4 |
+
domain:
|
| 5 |
+
- audio
|
| 6 |
+
model-type:
|
| 7 |
+
- VAD model
|
| 8 |
+
frameworks:
|
| 9 |
+
- pytorch
|
| 10 |
+
backbone:
|
| 11 |
+
- fsmn
|
| 12 |
+
metrics:
|
| 13 |
+
- f1_score
|
| 14 |
+
license: Apache License 2.0
|
| 15 |
+
language:
|
| 16 |
+
- cn
|
| 17 |
+
tags:
|
| 18 |
+
- FunASR
|
| 19 |
+
- FSMN
|
| 20 |
+
- Alibaba
|
| 21 |
+
- Online
|
| 22 |
+
datasets:
|
| 23 |
+
train:
|
| 24 |
+
- 20,000 hour industrial Mandarin task
|
| 25 |
+
test:
|
| 26 |
+
- 20,000 hour industrial Mandarin task
|
| 27 |
+
widgets:
|
| 28 |
+
- task: voice-activity-detection
|
| 29 |
+
inputs:
|
| 30 |
+
- type: audio
|
| 31 |
+
name: input
|
| 32 |
+
title: 音频
|
| 33 |
+
examples:
|
| 34 |
+
- name: 1
|
| 35 |
+
title: 示例1
|
| 36 |
+
inputs:
|
| 37 |
+
- name: input
|
| 38 |
+
data: git://example/vad_example.wav
|
| 39 |
+
inferencespec:
|
| 40 |
+
cpu: 1 #CPU数量
|
| 41 |
+
memory: 4096
|
| 42 |
+
---
|
| 43 |
+
|
| 44 |
+
# FSMN-Monophone VAD 模型介绍
|
| 45 |
+
|
| 46 |
+
[//]: # (FSMN-Monophone VAD 模型)
|
| 47 |
+
|
| 48 |
+
## Highlight
|
| 49 |
+
- 16k中文通用VAD模型:可用于检测长语音片段中有效语音的起止时间点。
|
| 50 |
+
- 基于[Paraformer-large长音频模型](https://www.modelscope.cn/models/damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary)场景的使用
|
| 51 |
+
- 基于[FunASR框架](https://github.com/alibaba-damo-academy/FunASR),可进行ASR,VAD,[中文标点](https://www.modelscope.cn/models/damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/summary)的自由组合
|
| 52 |
+
- 基于音频数据的有效语音片段起止时间点检测
|
| 53 |
+
|
| 54 |
+
## <strong>[ModelScope-FunASR](https://github.com/alibaba-damo-academy/FunASR)</strong>
|
| 55 |
+
<strong>[FunASR](https://github.com/alibaba-damo-academy/FunASR)</strong>希望在语音识别方面建立学术研究和工业应用之间的桥梁。通过支持在ModelScope上发布的工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并促进语音识别生态系统的发展。
|
| 56 |
+
|
| 57 |
+
[**最新动态**](https://github.com/alibaba-damo-academy/FunASR#whats-new)
|
| 58 |
+
| [**环境安装**](https://github.com/alibaba-damo-academy/FunASR#installation)
|
| 59 |
+
| [**介绍文档**](https://alibaba-damo-academy.github.io/FunASR/en/index.html)
|
| 60 |
+
| [**中文教程**](https://github.com/alibaba-damo-academy/FunASR/wiki#funasr%E7%94%A8%E6%88%B7%E6%89%8B%E5%86%8C)
|
| 61 |
+
| [**服务部署**](https://github.com/alibaba-damo-academy/FunASR/tree/main/funasr/runtime)
|
| 62 |
+
| [**模型库**](https://github.com/alibaba-damo-academy/FunASR/blob/main/docs/model_zoo/modelscope_models.md)
|
| 63 |
+
| [**联系我们**](https://github.com/alibaba-damo-academy/FunASR#contact)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
## 项目介绍
|
| 67 |
+
|
| 68 |
+
FSMN-Monophone VAD是达摩院语音团队提出的高效语音端点检测模型,用于检测输入音频中有效语音的起止时间点信息,并将检测出来的有效音频片段输入识别引擎进行识别,减少无效语音带来的识别错误。
|
| 69 |
+
|
| 70 |
+
<p align="center">
|
| 71 |
+
<img src="fig/struct.png" alt="VAD模型结构" width="500" />
|
| 72 |
+
|
| 73 |
+
FSMN-Monophone VAD模型结构如上图所示:模型结构层面,FSMN模型结构建模时可考虑上下文信息,训练和推理速度快,且时延可控;同时根据VAD模型size以及低时延的要求,对FSMN的网络结构、右看帧数进行了适配。在建模单元层面,speech信息比较丰富,仅用单类来表征学习能力有限,我们将单一speech类升级为Monophone。建模单元细分,可以避免参数平均,抽象学习能力增强,区分性更好。
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
## 如何使用与训练自己的模型
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
本项目提供的预训练模型是基于大数据训练的通用领域VAD模型,开发者可以基于此模型进一步利用ModelScope的微调功能或者本项目对应的Github代码仓库[FunASR](https://github.com/alibaba-damo-academy/FunASR)进一步进行模型的效果优化。
|
| 80 |
+
|
| 81 |
+
### 在Notebook中开发
|
| 82 |
+
|
| 83 |
+
对于有开发需求的使用者,特别推荐您使用Notebook进行离线处理。先登录ModelScope账号,点击模型页面右上角的“在Notebook中打开”按钮出现对话框,首次使用会提示您关联阿里云账号,按提示操作即可。关联账号后可进入选择启动实例界面,选择计算资源,建立实例,待实例创建完成后进入开发环境,输入api调用实例。
|
| 84 |
+
|
| 85 |
+
#### 基于ModelScope进行推理
|
| 86 |
+
|
| 87 |
+
- 推理支持音频格式如下:
|
| 88 |
+
- wav文件路径,例如:data/test/audios/vad_example.wav
|
| 89 |
+
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav
|
| 90 |
+
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
|
| 91 |
+
- 已解析的audio音频,例如:audio, rate = soundfile.read("vad_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
|
| 92 |
+
- wav.scp文件,需符合如下要求:
|
| 93 |
+
|
| 94 |
+
```sh
|
| 95 |
+
cat wav.scp
|
| 96 |
+
vad_example1 data/test/audios/vad_example1.wav
|
| 97 |
+
vad_example2 data/test/audios/vad_example2.wav
|
| 98 |
+
...
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
- 若输入格式wav文件url,api调用方式可参考如下范例:
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
from modelscope.pipelines import pipeline
|
| 105 |
+
from modelscope.utils.constant import Tasks
|
| 106 |
+
|
| 107 |
+
inference_pipeline = pipeline(
|
| 108 |
+
task=Tasks.voice_activity_detection,
|
| 109 |
+
model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',
|
| 110 |
+
model_revision=None,
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
segments_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav')
|
| 114 |
+
print(segments_result)
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
- 输入音频为pcm格式,调用api时需要传入音频采样率参数audio_fs,例如:
|
| 118 |
+
|
| 119 |
+
```python
|
| 120 |
+
segments_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.pcm', audio_fs=16000)
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,参考示例如下:
|
| 124 |
+
|
| 125 |
+
```python
|
| 126 |
+
inference_pipeline = pipeline(
|
| 127 |
+
task=Tasks.voice_activity_detection,
|
| 128 |
+
model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',
|
| 129 |
+
model_revision=None,
|
| 130 |
+
output_dir='./output_dir',
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
inference_pipeline(audio_in="wav.scp")
|
| 134 |
+
```
|
| 135 |
+
识别结果输出路径结构如下:
|
| 136 |
+
|
| 137 |
+
```sh
|
| 138 |
+
tree output_dir/
|
| 139 |
+
output_dir/
|
| 140 |
+
└── 1best_recog
|
| 141 |
+
└── text
|
| 142 |
+
|
| 143 |
+
1 directory, 1 files
|
| 144 |
+
```
|
| 145 |
+
text:VAD检测语音起止时间点结果文件(单位:ms)
|
| 146 |
+
|
| 147 |
+
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
|
| 148 |
+
|
| 149 |
+
```python
|
| 150 |
+
import soundfile
|
| 151 |
+
|
| 152 |
+
waveform, sample_rate = soundfile.read("vad_example_zh.wav")
|
| 153 |
+
segments_result = inference_pipeline(audio_in=waveform)
|
| 154 |
+
print(segments_result)
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
- VAD常用参数调整说明(参考:vad.yaml文件):
|
| 158 |
+
- max_end_silence_time:尾部连续检测到多长时间静音进行尾点判停,参数范围500ms~6000ms,默认值800ms(该值过低容易出现语音提前截断的情况)。
|
| 159 |
+
- speech_noise_thres:speech的得分减去noise的得分大于此值则判断为speech,参数范围:(-1,1)
|
| 160 |
+
- 取值越趋于-1,噪音被误判定为语音的概率越大,FA越高
|
| 161 |
+
- 取值越趋于+1,语音被误判定为噪音的概率越大,Pmiss越高
|
| 162 |
+
- 通常情况下,该值会根据当前模型在长语音测试集上的效果取balance
|
| 163 |
+
|
| 164 |
+
#### 基于ModelScope进行微调
|
| 165 |
+
|
| 166 |
+
待开发
|
| 167 |
+
|
| 168 |
+
### 在本地机器中开发
|
| 169 |
+
|
| 170 |
+
#### 基于ModelScope进行微调和推理
|
| 171 |
+
|
| 172 |
+
支持基于ModelScope上数据集及私有数据集进行定制微调和推理,使用方式同Notebook中开发。
|
| 173 |
+
|
| 174 |
+
#### 基于FunASR进行微调和推理
|
| 175 |
+
|
| 176 |
+
FunASR框架支持魔搭社区开源的工业级的语音识别模型的training & finetuning,使得研究人员和开发者可以更加便捷的进行语音识别模型的研究和生产,目前已在Github开源:https://github.com/alibaba-damo-academy/FunASR
|
| 177 |
+
|
| 178 |
+
#### FunASR框架安装
|
| 179 |
+
|
| 180 |
+
- 安装FunASR和ModelScope,[详见](https://github.com/alibaba-damo-academy/FunASR/wiki)
|
| 181 |
+
|
| 182 |
+
```sh
|
| 183 |
+
pip3 install -U modelscope
|
| 184 |
+
git clone https://github.com/alibaba/FunASR.git && cd FunASR
|
| 185 |
+
pip3 install -e ./
|
| 186 |
+
```nstall --editable ./
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
#### 基于FunASR进行推理
|
| 190 |
+
|
| 191 |
+
接下来会以私有数据集为例,介绍如何在FunASR框架中使用VAD上进行推理。
|
| 192 |
+
|
| 193 |
+
```sh
|
| 194 |
+
cd egs_modelscope/vad/speech_fsmn_vad_zh-cn-16k-common/
|
| 195 |
+
python infer.py
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
## 使用方式以及适用范围
|
| 199 |
+
|
| 200 |
+
运行范围
|
| 201 |
+
- 支持Linux-x86_64、Mac和Windows运行。
|
| 202 |
+
|
| 203 |
+
使用方式
|
| 204 |
+
- 直接推理:可以直接对长语音数据进行计算,有效语音片段的起止时间点信息(单位:ms)。
|
| 205 |
+
|
| 206 |
+
## 相关论文以及引用信息
|
| 207 |
+
|
| 208 |
+
```BibTeX
|
| 209 |
+
@inproceedings{zhang2018deep,
|
| 210 |
+
title={Deep-FSMN for large vocabulary continuous speech recognition},
|
| 211 |
+
author={Zhang, Shiliang and Lei, Ming and Yan, Zhijie and Dai, Lirong},
|
| 212 |
+
booktitle={2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 213 |
+
pages={5869--5873},
|
| 214 |
+
year={2018},
|
| 215 |
+
organization={IEEE}
|
| 216 |
+
}
|
| 217 |
+
```
|
model/fsmn_vad/am.mvn
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Nnet>
|
| 2 |
+
<Splice> 400 400
|
| 3 |
+
[ 0 ]
|
| 4 |
+
<AddShift> 400 400
|
| 5 |
+
<LearnRateCoef> 0 [ -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 ]
|
| 6 |
+
<Rescale> 400 400
|
| 7 |
+
<LearnRateCoef> 0 [ 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 ]
|
| 8 |
+
</Nnet>
|
model/fsmn_vad/config.yaml
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
frontend: WavFrontendOnline
|
| 2 |
+
frontend_conf:
|
| 3 |
+
fs: 16000
|
| 4 |
+
window: hamming
|
| 5 |
+
n_mels: 80
|
| 6 |
+
frame_length: 25
|
| 7 |
+
frame_shift: 10
|
| 8 |
+
dither: 0.0
|
| 9 |
+
lfr_m: 5
|
| 10 |
+
lfr_n: 1
|
| 11 |
+
|
| 12 |
+
model: FsmnVADStreaming
|
| 13 |
+
model_conf:
|
| 14 |
+
sample_rate: 16000
|
| 15 |
+
detect_mode: 1
|
| 16 |
+
snr_mode: 0
|
| 17 |
+
max_end_silence_time: 800
|
| 18 |
+
max_start_silence_time: 3000
|
| 19 |
+
do_start_point_detection: True
|
| 20 |
+
do_end_point_detection: True
|
| 21 |
+
window_size_ms: 200
|
| 22 |
+
sil_to_speech_time_thres: 150
|
| 23 |
+
speech_to_sil_time_thres: 150
|
| 24 |
+
speech_2_noise_ratio: 1.0
|
| 25 |
+
do_extend: 1
|
| 26 |
+
lookback_time_start_point: 200
|
| 27 |
+
lookahead_time_end_point: 100
|
| 28 |
+
max_single_segment_time: 60000
|
| 29 |
+
snr_thres: -100.0
|
| 30 |
+
noise_frame_num_used_for_snr: 100
|
| 31 |
+
decibel_thres: -100.0
|
| 32 |
+
speech_noise_thres: 0.6
|
| 33 |
+
fe_prior_thres: 0.0001
|
| 34 |
+
silence_pdf_num: 1
|
| 35 |
+
sil_pdf_ids: [0]
|
| 36 |
+
speech_noise_thresh_low: -0.1
|
| 37 |
+
speech_noise_thresh_high: 0.3
|
| 38 |
+
output_frame_probs: False
|
| 39 |
+
frame_in_ms: 10
|
| 40 |
+
frame_length_ms: 25
|
| 41 |
+
|
| 42 |
+
encoder: FSMN
|
| 43 |
+
encoder_conf:
|
| 44 |
+
input_dim: 400
|
| 45 |
+
input_affine_dim: 140
|
| 46 |
+
fsmn_layers: 4
|
| 47 |
+
linear_dim: 250
|
| 48 |
+
proj_dim: 128
|
| 49 |
+
lorder: 20
|
| 50 |
+
rorder: 0
|
| 51 |
+
lstride: 1
|
| 52 |
+
rstride: 0
|
| 53 |
+
output_affine_dim: 140
|
| 54 |
+
output_dim: 248
|
| 55 |
+
|
| 56 |
+
|
model/fsmn_vad/configuration.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "voice-activity-detection",
|
| 4 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 5 |
+
"model": {"type" : "funasr"},
|
| 6 |
+
"file_path_metas": {
|
| 7 |
+
"init_param":"model.pt",
|
| 8 |
+
"config":"config.yaml",
|
| 9 |
+
"frontend_conf":{"cmvn_file": "am.mvn"}},
|
| 10 |
+
"model_name_in_hub": {
|
| 11 |
+
"ms":"iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
|
| 12 |
+
"hf":""}
|
| 13 |
+
}
|
model/fsmn_vad/example/vad_example.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a7431f0169ef76ef630c945a1d2c3675d8c8c2df2ae4a6b16f8a88ba1bccfbbb
|
| 3 |
+
size 2261722
|
model/fsmn_vad/fig/struct.png
ADDED
|
model/fsmn_vad/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b3be75be477f0780277f3bae0fe489f48718f585f3a6e45d7dd1fbb1a4255fc5
|
| 3 |
+
size 1721366
|
model/gaudio/am.mvn
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Nnet>
|
| 2 |
+
<Splice> 560 560
|
| 3 |
+
[ 0 ]
|
| 4 |
+
<AddShift> 560 560
|
| 5 |
+
<LearnRateCoef> 0 [ -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 ]
|
| 6 |
+
<Rescale> 560 560
|
| 7 |
+
<LearnRateCoef> 0 [ 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 ]
|
| 8 |
+
</Nnet>
|
model/gaudio/audio_encoder.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:75759b2e87f6e8974f86d1d275c6a9d1c96f2a300b32e2c88ee5180331ff558a
|
| 3 |
+
size 884939345
|
model/gaudio/config.json
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"backbone_config": {
|
| 3 |
+
"encoder_conf": {
|
| 4 |
+
"attention_dropout_rate": 0.1,
|
| 5 |
+
"attention_heads": 4,
|
| 6 |
+
"dropout_rate": 0.1,
|
| 7 |
+
"kernel_size": 11,
|
| 8 |
+
"linear_units": 2048,
|
| 9 |
+
"normalize_before": true,
|
| 10 |
+
"num_blocks": 50,
|
| 11 |
+
"output_size": 512,
|
| 12 |
+
"sanm_shfit": 0,
|
| 13 |
+
"tp_blocks": 20,
|
| 14 |
+
"input_size": 560
|
| 15 |
+
},
|
| 16 |
+
"normalize": null,
|
| 17 |
+
"length_normalized_loss": true,
|
| 18 |
+
"input_size": 560,
|
| 19 |
+
"ignore_id": -1
|
| 20 |
+
},
|
| 21 |
+
"text_config": {
|
| 22 |
+
"model_type": "bert"
|
| 23 |
+
},
|
| 24 |
+
"backbone_layer": [10],
|
| 25 |
+
"backbone_load": "/root/autodl-tmp/gaudio/model/gaudio/audio_encoder.pt",
|
| 26 |
+
"text_backbone_load": "/root/autodl-tmp/gaudio/model/gaudio/text_encoder.pt",
|
| 27 |
+
|
| 28 |
+
"bbox_cost": 5.0,
|
| 29 |
+
"bbox_loss_coefficient": 5.0,
|
| 30 |
+
"class_cost": 1.0,
|
| 31 |
+
"giou_cost": 5.0,
|
| 32 |
+
"giou_loss_coefficient": 5.0,
|
| 33 |
+
"focal_alpha": 0.25,
|
| 34 |
+
"auxiliary_loss": false,
|
| 35 |
+
|
| 36 |
+
"activation_function": "leaky_relu",
|
| 37 |
+
"activation_dropout": 0.0,
|
| 38 |
+
"attention_dropout": 0.0,
|
| 39 |
+
"d_model": 256,
|
| 40 |
+
"dropout": 0.1,
|
| 41 |
+
|
| 42 |
+
"decoder_attention_heads": 8,
|
| 43 |
+
"decoder_bbox_embed_share": false,
|
| 44 |
+
"decoder_ffn_dim": 2048,
|
| 45 |
+
"decoder_layers": 6,
|
| 46 |
+
|
| 47 |
+
"encoder_attention_heads": 8,
|
| 48 |
+
"encoder_ffn_dim": 2048,
|
| 49 |
+
"encoder_layers": 6,
|
| 50 |
+
|
| 51 |
+
"fusion_dropout": 0.0,
|
| 52 |
+
"fusion_droppath": 0.1,
|
| 53 |
+
"init_std": 0.02,
|
| 54 |
+
"is_encoder_decoder": true,
|
| 55 |
+
"layer_norm_eps": 1e-05,
|
| 56 |
+
"max_text_len": 256,
|
| 57 |
+
|
| 58 |
+
"num_queries": 20,
|
| 59 |
+
"num_feature_levels": 1,
|
| 60 |
+
|
| 61 |
+
"position_embedding_type": "sine",
|
| 62 |
+
"positional_embedding_temperature": 20,
|
| 63 |
+
|
| 64 |
+
"text_enhancer_dropout": 0.0,
|
| 65 |
+
|
| 66 |
+
"model_type": "grounded-dino",
|
| 67 |
+
"torch_dtype": "float32",
|
| 68 |
+
"transformers_version": "4.40.0.dev0"
|
| 69 |
+
}
|
model/gaudio/preprocessor_config.json
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"data_type": "sound",
|
| 3 |
+
"feature_extractor_type": "GroundedAudioFeatureExtractor",
|
| 4 |
+
"feature_size": 80,
|
| 5 |
+
"frontend_config": {
|
| 6 |
+
"cmvn": null,
|
| 7 |
+
"cmvn_file": "/root/autodl-tmp/gaudio/model/gaudio_test/am.mvn",
|
| 8 |
+
"dither": 0.0,
|
| 9 |
+
"filter_length_max": -1,
|
| 10 |
+
"filter_length_min": -1,
|
| 11 |
+
"frame_length": 25,
|
| 12 |
+
"frame_shift": 10,
|
| 13 |
+
"fs": 32000,
|
| 14 |
+
"lfr_m": 7,
|
| 15 |
+
"lfr_n": 6,
|
| 16 |
+
"n_mels": 80,
|
| 17 |
+
"snip_edges": true,
|
| 18 |
+
"upsacle_samples": true,
|
| 19 |
+
"window": "hamming"
|
| 20 |
+
},
|
| 21 |
+
"vad_config": {
|
| 22 |
+
"vad_pretrain_path": "/root/autodl-tmp/gaudio/model/gaudio_test/vad.pt",
|
| 23 |
+
"frontend_config": {
|
| 24 |
+
"cmvn": null,
|
| 25 |
+
"cmvn_file": "/root/autodl-tmp/gaudio/model/gaudio_test/am.mvn",
|
| 26 |
+
"fs": 32000,
|
| 27 |
+
"window": "hamming",
|
| 28 |
+
"n_mels": 80,
|
| 29 |
+
"frame_length": 25,
|
| 30 |
+
"frame_shift": 10,
|
| 31 |
+
"dither": 0.0,
|
| 32 |
+
"lfr_m": 5,
|
| 33 |
+
"lfr_n": 1
|
| 34 |
+
},
|
| 35 |
+
"model_conf": {
|
| 36 |
+
"sample_rate": 32000,
|
| 37 |
+
"detect_mode": 1,
|
| 38 |
+
"snr_mode": 0,
|
| 39 |
+
"max_end_silence_time": 800,
|
| 40 |
+
"max_start_silence_time": 3000,
|
| 41 |
+
"do_start_point_detection": true,
|
| 42 |
+
"do_end_point_detection": true,
|
| 43 |
+
"window_size_ms": 200,
|
| 44 |
+
"sil_to_speech_time_thres": 150,
|
| 45 |
+
"speech_to_sil_time_thres": 150,
|
| 46 |
+
"speech_2_noise_ratio": 1.0,
|
| 47 |
+
"do_extend": 1,
|
| 48 |
+
"lookback_time_start_point": 200,
|
| 49 |
+
"lookahead_time_end_point": 100,
|
| 50 |
+
"max_single_segment_time": 60000,
|
| 51 |
+
"snr_thres": -100.0,
|
| 52 |
+
"noise_frame_num_used_for_snr": 100,
|
| 53 |
+
"decibel_thres": -100.0,
|
| 54 |
+
"speech_noise_thres": 0.6,
|
| 55 |
+
"fe_prior_thres": 0.0001,
|
| 56 |
+
"silence_pdf_num": 1,
|
| 57 |
+
"sil_pdf_ids": [0],
|
| 58 |
+
"speech_noise_thresh_low": -0.1,
|
| 59 |
+
"speech_noise_thresh_high": 0.3,
|
| 60 |
+
"output_frame_probs": false,
|
| 61 |
+
"frame_in_ms": 10,
|
| 62 |
+
"frame_length_ms": 25
|
| 63 |
+
},
|
| 64 |
+
"encoder_conf": {
|
| 65 |
+
"input_dim": 400,
|
| 66 |
+
"input_affine_dim": 140,
|
| 67 |
+
"fsmn_layers": 4,
|
| 68 |
+
"linear_dim": 250,
|
| 69 |
+
"proj_dim": 128,
|
| 70 |
+
"lorder": 20,
|
| 71 |
+
"rorder": 0,
|
| 72 |
+
"lstride": 1,
|
| 73 |
+
"rstride": 0,
|
| 74 |
+
"output_affine_dim": 140,
|
| 75 |
+
"output_dim": 248
|
| 76 |
+
}
|
| 77 |
+
},
|
| 78 |
+
"padding_side": "right",
|
| 79 |
+
"padding_value": 0.0,
|
| 80 |
+
"processor_class": "GroundedAudioProcessor",
|
| 81 |
+
"return_attention_mask": true
|
| 82 |
+
}
|
model/gaudio/preprocessor_config.json.bak
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"data_type": "sound",
|
| 3 |
+
"feature_extractor_type": "GroundedAudioFeatureExtractor",
|
| 4 |
+
"feature_size": 80,
|
| 5 |
+
"frontend_config": {
|
| 6 |
+
"cmvn": null,
|
| 7 |
+
"cmvn_file": "/root/autodl-tmp/gaudio/model/gaudio/am.mvn",
|
| 8 |
+
"dither": 0.0,
|
| 9 |
+
"filter_length_max": -1,
|
| 10 |
+
"filter_length_min": -1,
|
| 11 |
+
"frame_length": 25,
|
| 12 |
+
"frame_shift": 10,
|
| 13 |
+
"fs": 32000,
|
| 14 |
+
"lfr_m": 7,
|
| 15 |
+
"lfr_n": 6,
|
| 16 |
+
"n_mels": 80,
|
| 17 |
+
"snip_edges": true,
|
| 18 |
+
"upsacle_samples": true,
|
| 19 |
+
"window": "hamming"
|
| 20 |
+
},
|
| 21 |
+
"padding_side": "right",
|
| 22 |
+
"padding_value": 0.0,
|
| 23 |
+
"processor_class": "GroundedAudioProcessor",
|
| 24 |
+
"return_attention_mask": true
|
| 25 |
+
}
|
model/gaudio/special_tokens_map.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": {
|
| 3 |
+
"content": "[CLS]",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"mask_token": {
|
| 10 |
+
"content": "[MASK]",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "[PAD]",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"sep_token": {
|
| 24 |
+
"content": "[SEP]",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"unk_token": {
|
| 31 |
+
"content": "[UNK]",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
}
|
| 37 |
+
}
|
model/gaudio/text_encoder.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ea9e501c7b83c1fc4f2d2d9ac0c089c4a64029211183a4b3d64394af35f1e7a7
|
| 3 |
+
size 435643029
|
model/gaudio/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|