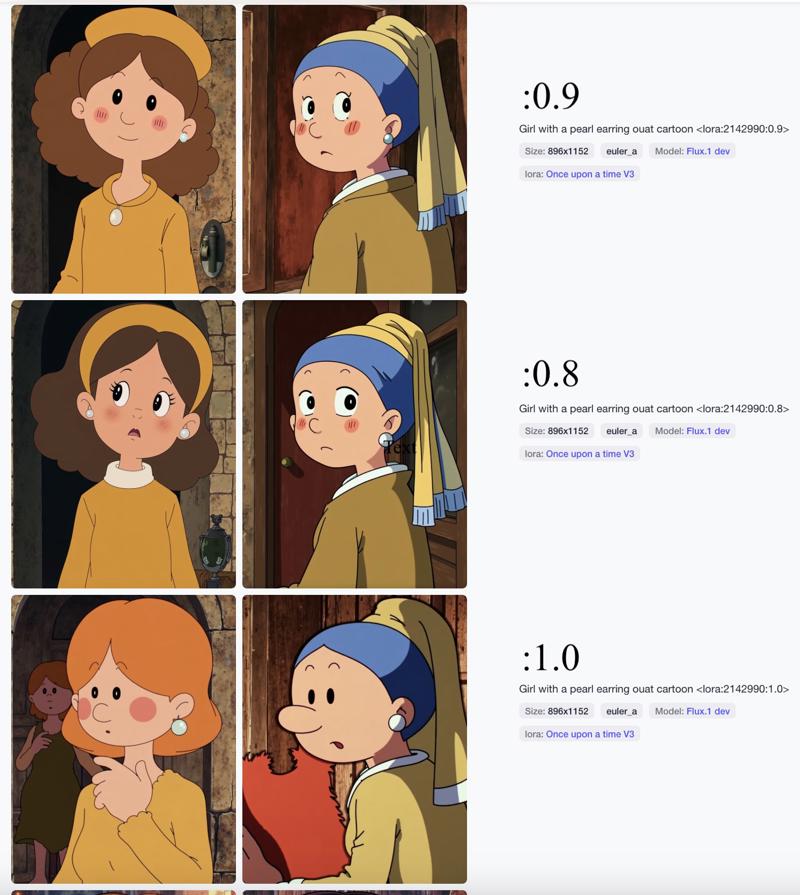
Once Upon a Time... ("Il était une fois...") is a French educational animation franchise.
Use ouat cartoon in your prompts
Fine tuned with Astria AI
A LoRA scale weight of 0.7-1.0 seems to be well
I've made the Florence-2 captioned Dataset availble on Huggingface
## Trigger words You should use `ouat cartoon` to trigger the image generation. ## Download model Weights for this model are available in Safetensors format. [Download](/Norod78/once-upon-a-time-cartoon-style-flux/tree/main) them in the Files & versions tab. ## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers) ```py from diffusers import AutoPipelineForText2Image import torch device = "cuda" if torch.cuda.is_available() else "cpu" pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.bfloat16).to(device) pipeline.load_lora_weights('Norod78/once-upon-a-time-cartoon-style-flux', weight_name='ouat_cartoon-OnceUponATimeV3-Flux-2142990.safetensors') image = pipeline('A socially awkward potato ouat cartoon ').images[0] ``` For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)