
File size: 19,745 Bytes
63fe63a 6d7ba01 63fe63a 6d7ba01 63fe63a 6d7ba01 63fe63a 6d7ba01 63fe63a 6d7ba01 63fe63a 6d7ba01 63fe63a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 |
---
license: other
license_name: qwen
license_link: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/blob/main/LICENSE
pipeline_tag: image-text-to-text
library_name: transformers
base_model: OpenGVLab/InternVL2_5-78B
base_model_relation: quantized
language:
- multilingual
tags:
- internvl
- custom_code
---
# InternVL2_5-78B-AWQ
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 Mini-InternVL\]](https://arxiv.org/abs/2410.16261) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We are excited to introduce **InternVL 2.5**, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality.

## InternVL 2.5 Family
In the following table, we provide an overview of the InternVL 2.5 series.
| Model Name | Vision Part | Language Part | HF Link |
| :-------------: | :-------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------: | :---------------------------------------------------------: |
| InternVL2_5-1B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-1B) |
| InternVL2_5-2B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [internlm2_5-1_8b-chat](https://huggingface.co/internlm/internlm2_5-1_8b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-2B) |
| InternVL2_5-4B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-4B) |
| InternVL2_5-8B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-8B) |
| InternVL2_5-26B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [internlm2_5-20b-chat](https://huggingface.co/internlm/internlm2_5-20b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-26B) |
| InternVL2_5-38B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-38B) |
| InternVL2_5-78B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2_5-78B) |
## Model Architecture
As shown in the following figure, InternVL 2.5 retains the same model architecture as its predecessors, InternVL 1.5 and 2.0, following the "ViT-MLP-LLM" paradigm. In this new version, we integrate a newly incrementally pre-trained InternViT with various pre-trained LLMs, including InternLM 2.5 and Qwen 2.5, using a randomly initialized MLP projector.

As in the previous version, we applied a pixel unshuffle operation, reducing the number of visual tokens to one-quarter of the original. Besides, we adopted a similar dynamic resolution strategy as InternVL 1.5, dividing images into tiles of 448×448 pixels. The key difference, starting from InternVL 2.0, is that we additionally introduced support for multi-image and video data.
## Training Strategy
### Dynamic High-Resolution for Multimodal Data
In InternVL 2.0 and 2.5, we extend the dynamic high-resolution training approach, enhancing its capabilities to handle multi-image and video datasets.

- For single-image datasets, the total number of tiles `n_max` are allocated to a single image for maximum resolution. Visual tokens are enclosed in `<img>` and `</img>` tags.
- For multi-image datasets, the total number of tiles `n_max` are distributed across all images in a sample. Each image is labeled with auxiliary tags like `Image-1` and enclosed in `<img>` and `</img>` tags.
- For videos, each frame is resized to 448×448. Frames are labeled with tags like `Frame-1` and enclosed in `<img>` and `</img>` tags, similar to images.
### Single Model Training Pipeline
The training pipeline for a single model in InternVL 2.5 is structured across three stages, designed to enhance the model's visual perception and multimodal capabilities.

- **Stage 1: MLP Warmup.** In this stage, only the MLP projector is trained while the vision encoder and language model are frozen. A dynamic high-resolution training strategy is applied for better performance, despite increased cost. This phase ensures robust cross-modal alignment and prepares the model for stable multimodal training.
- **Stage 1.5: ViT Incremental Learning (Optional).** This stage allows incremental training of the vision encoder and MLP projector using the same data as Stage 1. It enhances the encoder’s ability to handle rare domains like multilingual OCR and mathematical charts. Once trained, the encoder can be reused across LLMs without retraining, making this stage optional unless new domains are introduced.
- **Stage 2: Full Model Instruction Tuning.** The entire model is trained on high-quality multimodal instruction datasets. Strict data quality controls are enforced to prevent degradation of the LLM, as noisy data can cause issues like repetitive or incorrect outputs. After this stage, the training process is complete.
### Progressive Scaling Strategy
We introduce a progressive scaling strategy to align the vision encoder with LLMs efficiently. This approach trains with smaller LLMs first (e.g., 20B) to optimize foundational visual capabilities and cross-modal alignment before transferring the vision encoder to larger LLMs (e.g., 72B) without retraining. This reuse skips intermediate stages for larger models.

Compared to Qwen2-VL's 1.4 trillion tokens, InternVL2.5-78B uses only 120 billion tokens—less than one-tenth. This strategy minimizes redundancy, maximizes pre-trained component reuse, and enables efficient training for complex vision-language tasks.
### Training Enhancements
To improve real-world adaptability and performance, we introduce two key techniques:
- **Random JPEG Compression**: Random JPEG compression with quality levels between 75 and 100 is applied as a data augmentation technique. This simulates image degradation from internet sources, enhancing the model's robustness to noisy images.
- **Loss Reweighting**: To balance the NTP loss across responses of different lengths, we use a reweighting strategy called **square averaging**. This method balances contributions from responses of varying lengths, mitigating biases toward longer or shorter responses.
### Data Organization
#### Dataset Configuration
In InternVL 2.0 and 2.5, the organization of the training data is controlled by several key parameters to optimize the balance and distribution of datasets during training.

- **Data Augmentation:** JPEG compression is applied conditionally: enabled for image datasets to enhance robustness and disabled for video datasets to maintain consistent frame quality.
- **Maximum Tile Number:** The parameter `n_max` controls the maximum tiles per dataset. For example, higher values (24–36) are used for multi-image or high-resolution data, lower values (6–12) for standard images, and 1 for videos.
- **Repeat Factor:** The repeat factor `r` adjusts dataset sampling frequency. Values below 1 reduce a dataset's weight, while values above 1 increase it. This ensures balanced training across tasks and prevents overfitting or underfitting.
#### Data Filtering Pipeline
During development, we found that LLMs are highly sensitive to data noise, with even small anomalies—like outliers or repetitive data—causing abnormal behavior during inference. Repetitive generation, especially in long-form or CoT reasoning tasks, proved particularly harmful.

To address this challenge and support future research, we designed an efficient data filtering pipeline to remove low-quality samples.

The pipeline includes two modules, for **pure-text data**, three key strategies are used:
1. **LLM-Based Quality Scoring**: Each sample is scored (0–10) using a pre-trained LLM with domain-specific prompts. Samples scoring below a threshold (e.g., 7) are removed to ensure high-quality data.
2. **Repetition Detection**: Repetitive samples are flagged using LLM-based prompts and manually reviewed. Samples scoring below a stricter threshold (e.g., 3) are excluded to avoid repetitive patterns.
3. **Heuristic Rule-Based Filtering**: Anomalies like abnormal sentence lengths or duplicate lines are detected using rules. Flagged samples undergo manual verification to ensure accuracy before removal.
For **multimodal data**, two strategies are used:
1. **Repetition Detection**: Repetitive samples in non-academic datasets are flagged and manually reviewed to prevent pattern loops. High-quality datasets are exempt from this process.
2. **Heuristic Rule-Based Filtering**: Similar rules are applied to detect visual anomalies, with flagged data verified manually to maintain integrity.
#### Training Data
As shown in the following figure, from InternVL 1.5 to 2.0 and then to 2.5, the fine-tuning data mixture has undergone iterative improvements in scale, quality, and diversity. For more information about the training data, please refer to our technical report.

## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics


### OCR, Chart, and Document Understanding

### Multi-Image & Real-World Comprehension

### Comprehensive Multimodal & Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

## Evaluation on Language Capability
Training InternVL 2.0 models led to a decline in pure language capabilities. InternVL 2.5 addresses this by collecting more high-quality open-source data and filtering out low-quality data, achieving better preservation of pure language performance.
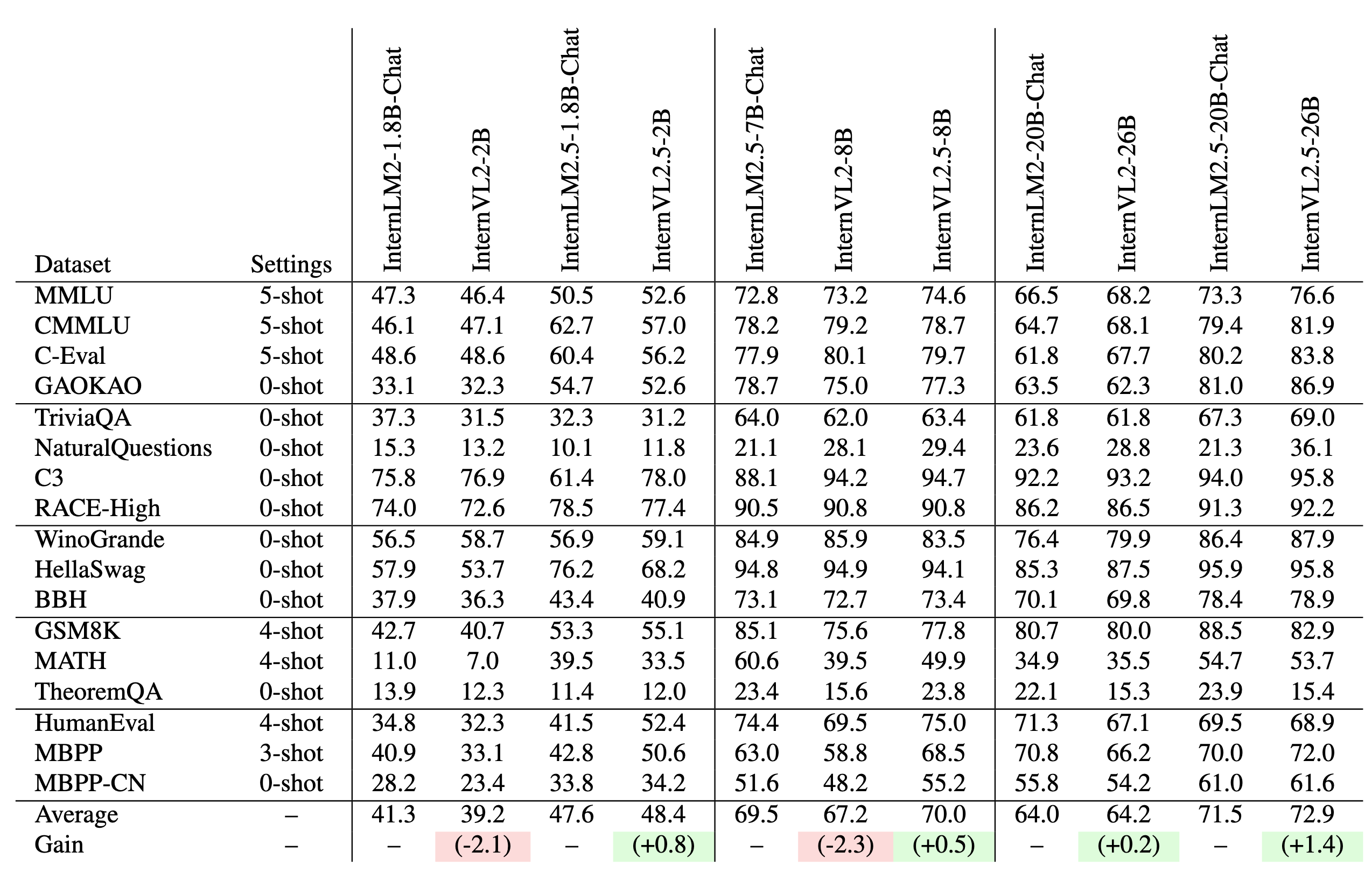
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.6.4
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2_5-78B-AWQ'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
response = pipe(('describe this image', image))
print(response.text)
```
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL2_5-78B-AWQ'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2_5-78B-AWQ'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2_5-78B-AWQ'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL2_5-78B-AWQ --server-port 23333 --tp 4
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the MIT License. This project uses the pre-trained Qwen2.5-72B-Instruct as a component, which is licensed under the Qwen License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
|