

Upload folder using huggingface_hub (#2)
Browse files- 7e5067ca6d46c1de45e037b5e8968ef922ce701e8fb0796e0bb59aad07639037 (4bc65947f9c09afcd528e727193033109fb6695a)
- c638aa1443562c4ea9594336f48c8fe3f8f52becffc2a8dd32e5225d70e36244 (d25711e672617483b44bd0ee202ee16f7d9475fb)
- README.md +6 -3
- config.json +2 -2
- plots.png +0 -0
- smash_config.json +1 -1
README.md
CHANGED
|
@@ -1,5 +1,4 @@
|
|
| 1 |
---
|
| 2 |
-
library_name: pruna-engine
|
| 3 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 4 |
metrics:
|
| 5 |
- memory_disk
|
|
@@ -8,6 +7,8 @@ metrics:
|
|
| 8 |
- inference_throughput
|
| 9 |
- inference_CO2_emissions
|
| 10 |
- inference_energy_consumption
|
|
|
|
|
|
|
| 11 |
---
|
| 12 |
<!-- header start -->
|
| 13 |
<!-- 200823 -->
|
|
@@ -33,13 +34,14 @@ metrics:
|
|
| 33 |
|
| 34 |
## Results
|
| 35 |
|
| 36 |
-
|
| 37 |
|
| 38 |
**Frequently Asked Questions**
|
| 39 |
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 40 |
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 41 |
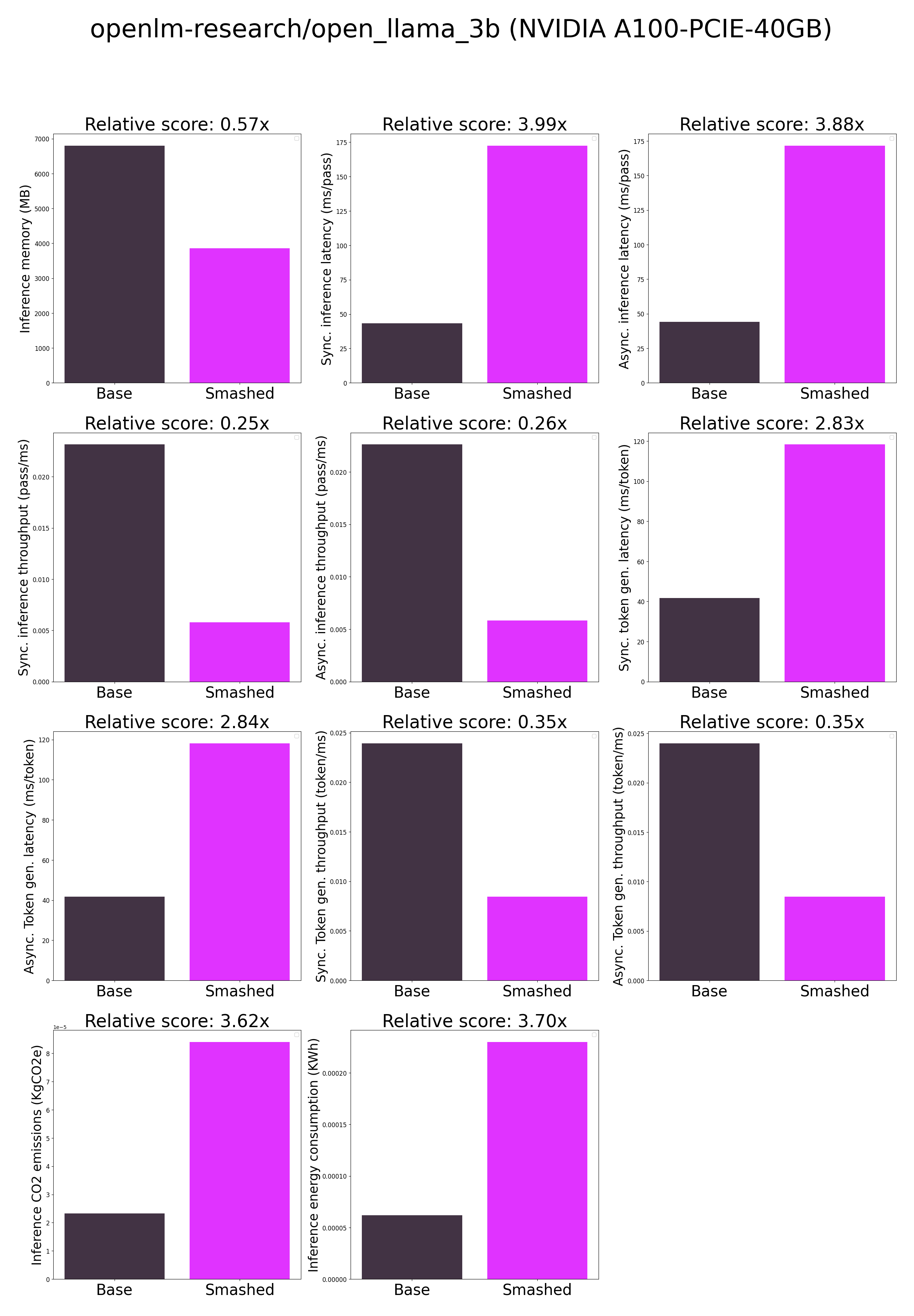
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
- ***What is the model format?*** We use safetensors.
|
|
|
|
| 43 |
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 44 |
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 45 |
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
|
@@ -59,12 +61,13 @@ You can run the smashed model with these steps:
|
|
| 59 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 60 |
|
| 61 |
model = AutoModelForCausalLM.from_pretrained("PrunaAI/openlm-research-open_llama_3b-bnb-8bit-smashed",
|
| 62 |
-
trust_remote_code=True)
|
| 63 |
tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_3b")
|
| 64 |
|
| 65 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 66 |
|
| 67 |
outputs = model.generate(input_ids, max_new_tokens=216)
|
|
|
|
| 68 |
```
|
| 69 |
|
| 70 |
## Configurations
|
|
|
|
| 1 |
---
|
|
|
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
metrics:
|
| 4 |
- memory_disk
|
|
|
|
| 7 |
- inference_throughput
|
| 8 |
- inference_CO2_emissions
|
| 9 |
- inference_energy_consumption
|
| 10 |
+
tags:
|
| 11 |
+
- pruna-ai
|
| 12 |
---
|
| 13 |
<!-- header start -->
|
| 14 |
<!-- 200823 -->
|
|
|
|
| 34 |
|
| 35 |
## Results
|
| 36 |
|
| 37 |
+

|
| 38 |
|
| 39 |
**Frequently Asked Questions**
|
| 40 |
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 41 |
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 42 |
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 43 |
- ***What is the model format?*** We use safetensors.
|
| 44 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 45 |
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 46 |
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 47 |
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
|
|
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
|
| 63 |
model = AutoModelForCausalLM.from_pretrained("PrunaAI/openlm-research-open_llama_3b-bnb-8bit-smashed",
|
| 64 |
+
trust_remote_code=True, device_map='auto')
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_3b")
|
| 66 |
|
| 67 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 68 |
|
| 69 |
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 70 |
+
tokenizer.decode(outputs[0])
|
| 71 |
```
|
| 72 |
|
| 73 |
## Configurations
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
@@ -21,7 +21,7 @@
|
|
| 21 |
"quantization_config": {
|
| 22 |
"bnb_4bit_compute_dtype": "bfloat16",
|
| 23 |
"bnb_4bit_quant_type": "fp4",
|
| 24 |
-
"bnb_4bit_use_double_quant":
|
| 25 |
"llm_int8_enable_fp32_cpu_offload": false,
|
| 26 |
"llm_int8_has_fp16_weight": false,
|
| 27 |
"llm_int8_skip_modules": [
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmp5hal5z1h",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 21 |
"quantization_config": {
|
| 22 |
"bnb_4bit_compute_dtype": "bfloat16",
|
| 23 |
"bnb_4bit_quant_type": "fp4",
|
| 24 |
+
"bnb_4bit_use_double_quant": false,
|
| 25 |
"llm_int8_enable_fp32_cpu_offload": false,
|
| 26 |
"llm_int8_has_fp16_weight": false,
|
| 27 |
"llm_int8_skip_modules": [
|
plots.png
ADDED
|
smash_config.json
CHANGED
|
@@ -8,7 +8,7 @@
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 12 |
"batch_size": 1,
|
| 13 |
"n_quantization_bits": 8,
|
| 14 |
"tokenizer": "LlamaTokenizerFast(name_or_path='openlm-research/open_llama_3b', vocab_size=32000, model_max_length=2048, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={\n\t0: AddedToken(\"<unk>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t1: AddedToken(\"<s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t2: AddedToken(\"</s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n}",
|
|
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/models1gzc3mge",
|
| 12 |
"batch_size": 1,
|
| 13 |
"n_quantization_bits": 8,
|
| 14 |
"tokenizer": "LlamaTokenizerFast(name_or_path='openlm-research/open_llama_3b', vocab_size=32000, model_max_length=2048, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={\n\t0: AddedToken(\"<unk>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t1: AddedToken(\"<s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t2: AddedToken(\"</s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n}",
|