
Top 1 RP Performer on MT-bench 🤪
Next Gen Silicon-Based RP Maid
## WTF is This? Silicon-Maid-7B is another model targeted at being both strong at RP **and** being a smart cookie that can follow character cards very well. As of right now, Silicon-Maid-7B outscores both of my previous 7B RP models in my RP benchmark and I have been impressed by this model's creativity. It is suitable for RP/ERP and general use. It's built on [xDAN-AI/xDAN-L1-Chat-RL-v1](https://huggingface.co/xDAN-AI/xDAN-L1-Chat-RL-v1), a 7B model which scores unusually high on MT-Bench, and chargoddard/loyal-piano-m7, an Alpaca format 7B model with surprisingly creative outputs. I was excited to see this model for two main reasons: * MT-Bench normally correlates well with real world model quality * It was an Alpaca prompt model with high benches which meant I could try swapping out my Marcoroni frankenmerge used in my previous model. **MT-Bench Average Turn** | model | score | size |--------------------|-----------|-------- | gpt-4 | 8.99 | - | *xDAN-L1-Chat-RL-v1* | 8.35 | 7b | Starling-7B | 8.09 | 7b | Claude-2 | 8.06 | - | **Silicon-Maid** | **7.96** | **7b** | *Loyal-Macaroni-Maid*| 7.95 | 7b | gpt-3.5-turbo | 7.94 | 20b? | Claude-1 | 7.90 | - | OpenChat-3.5 | 7.81 | - | vicuna-33b-v1.3 | 7.12 | 33b | wizardlm-30b | 7.01 | 30b | Llama-2-70b-chat | 6.86 | 70b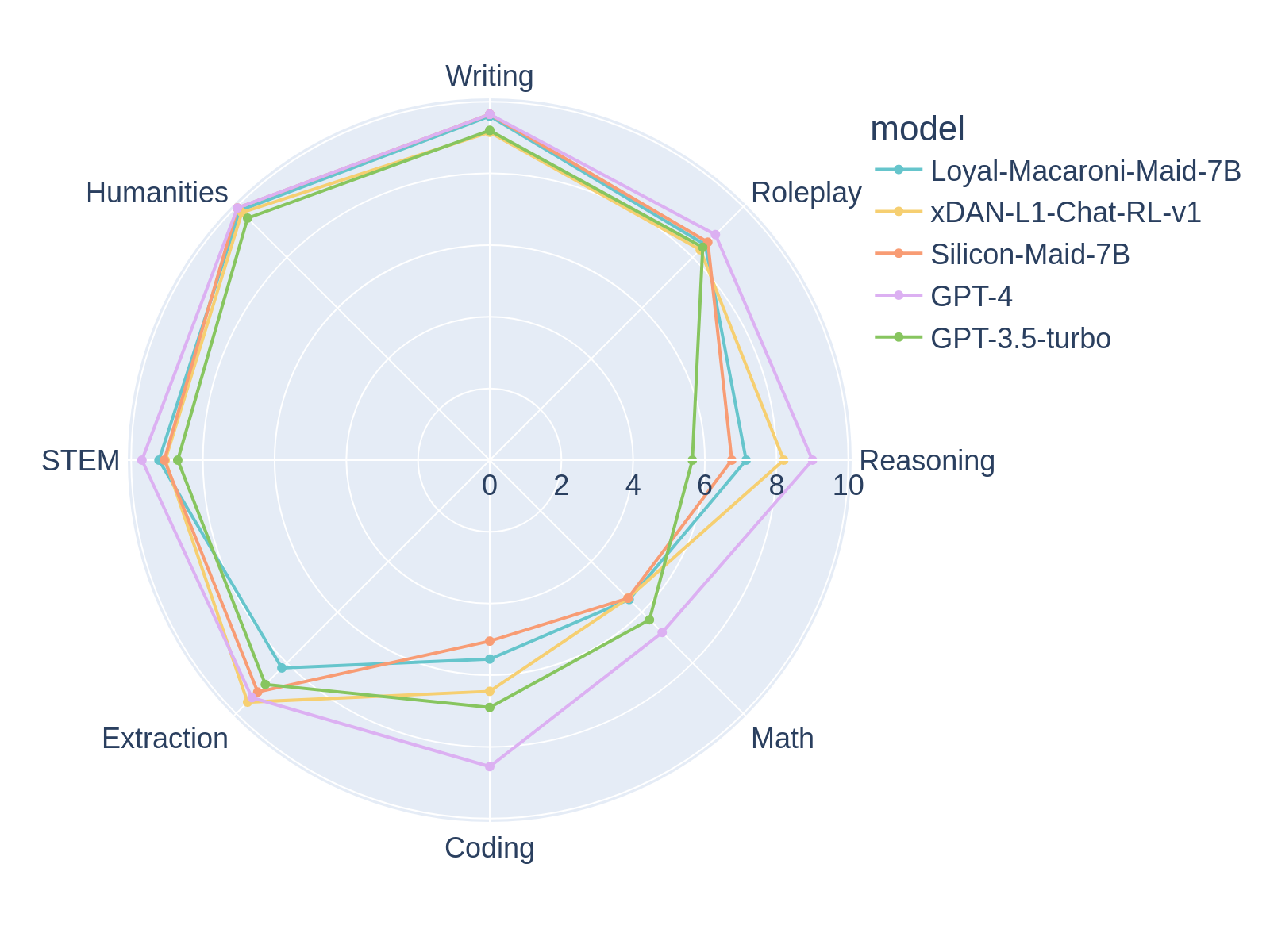 It's unclear to me if xDAN-L1-Chat-RL-v1 is overtly benchmaxxing but it seemed like a solid 7B from my limited testing (although nothing that screams 2nd best model behind GPT-4). Amusingly, the model lost almost all of its coding and math ability in the merge but somehow *improved* in "Extraction". This was a much greater MT-Bench dropoff than I expected, perhaps suggesting the Math/Coding ability in the original model was rather dense and susceptible to being lost to a DARE TIE merger?
Besides that, the merger is almost identical to the Loyal-Macaroni-Maid merger with a new base "smart cookie" model. If you liked any of my previous RP models, give this one a shot and let me know in the Community tab what you think!
### The Sauce
```
models: # Top-Loyal-Bruins-Maid-DARE-7B
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: xDAN-AI/xDAN-L1-Chat-RL-v1
parameters:
weight: 0.4
density: 0.8
- model: chargoddard/loyal-piano-m7
parameters:
weight: 0.3
density: 0.8
- model: Undi95/Toppy-M-7B
parameters:
weight: 0.2
density: 0.4
- model: NeverSleep/Noromaid-7b-v0.2
parameters:
weight: 0.2
density: 0.4
- model: athirdpath/NSFW_DPO_vmgb-7b
parameters:
weight: 0.2
density: 0.4
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: bfloat16
```
For more information about why I use this merger, see the [Loyal-Macaroni-Maid repo](https://huggingface.co/SanjiWatsuki/Loyal-Macaroni-Maid-7B#the-sauce-all-you-need-is-dare)
### Prompt Template (Alpaca)
I found the best SillyTavern results from using the Noromaid template but please try other templates! Let me know if you find anything good.
SillyTavern config files: [Context](https://files.catbox.moe/ifmhai.json), [Instruct](https://files.catbox.moe/ttw1l9.json).
Additionally, here is my highly recommended [Text Completion preset](https://huggingface.co/SanjiWatsuki/Loyal-Macaroni-Maid-7B/blob/main/Characters/MinP.json). You can tweak this by adjusting temperature up or dropping min p to boost creativity or raise min p to increase stability. You shouldn't need to touch anything else!
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
It's unclear to me if xDAN-L1-Chat-RL-v1 is overtly benchmaxxing but it seemed like a solid 7B from my limited testing (although nothing that screams 2nd best model behind GPT-4). Amusingly, the model lost almost all of its coding and math ability in the merge but somehow *improved* in "Extraction". This was a much greater MT-Bench dropoff than I expected, perhaps suggesting the Math/Coding ability in the original model was rather dense and susceptible to being lost to a DARE TIE merger?
Besides that, the merger is almost identical to the Loyal-Macaroni-Maid merger with a new base "smart cookie" model. If you liked any of my previous RP models, give this one a shot and let me know in the Community tab what you think!
### The Sauce
```
models: # Top-Loyal-Bruins-Maid-DARE-7B
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: xDAN-AI/xDAN-L1-Chat-RL-v1
parameters:
weight: 0.4
density: 0.8
- model: chargoddard/loyal-piano-m7
parameters:
weight: 0.3
density: 0.8
- model: Undi95/Toppy-M-7B
parameters:
weight: 0.2
density: 0.4
- model: NeverSleep/Noromaid-7b-v0.2
parameters:
weight: 0.2
density: 0.4
- model: athirdpath/NSFW_DPO_vmgb-7b
parameters:
weight: 0.2
density: 0.4
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: bfloat16
```
For more information about why I use this merger, see the [Loyal-Macaroni-Maid repo](https://huggingface.co/SanjiWatsuki/Loyal-Macaroni-Maid-7B#the-sauce-all-you-need-is-dare)
### Prompt Template (Alpaca)
I found the best SillyTavern results from using the Noromaid template but please try other templates! Let me know if you find anything good.
SillyTavern config files: [Context](https://files.catbox.moe/ifmhai.json), [Instruct](https://files.catbox.moe/ttw1l9.json).
Additionally, here is my highly recommended [Text Completion preset](https://huggingface.co/SanjiWatsuki/Loyal-Macaroni-Maid-7B/blob/main/Characters/MinP.json). You can tweak this by adjusting temperature up or dropping min p to boost creativity or raise min p to increase stability. You shouldn't need to touch anything else!
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```