---
license: other
license_name: saipl
license_link: LICENSE
datasets:
- wikimedia/wikipedia
- rexarski/eli5_category
language:
- en
base_model:
- FacebookAI/roberta-large
pipeline_tag: text-classification
library_name: transformers
tags:
- genereted_text_detection
- llm_content_detection
- AI_detection
---

SuperAnnotate
AI Detector Low FPR
Fine-Tuned RoBERTa Large
## Description
The model designed to detect generated/synthetic text. \
At the moment, such functionality is critical for determining the author of the text. It's critical for your training data, detecting fraud and cheating in scientific and educational areas. \
Couple of articles about this problem: [*Problems with Synthetic Data*](https://www.aitude.com/problems-with-synthetic-data/) | [*Risk of LLMs in Education*](https://publish.illinois.edu/teaching-learninghub-byjen/risk-of-llms-in-education/)
## Model Details
### Model Description
- **Model type:** The custom architecture for binary sequence classification based on pre-trained RoBERTa, with a single output label.
- **Language(s):** Primarily English.
- **License:** [SAIPL](https://huggingface.co/SuperAnnotate/roberta-large-llm-content-detector-V2/blob/main/LICENSE)
- **Finetuned from model:** [RoBERTa Large](https://huggingface.co/FacebookAI/roberta-large)
### Model Sources
- **Repository:** [GitHub](https://github.com/superannotateai/generated_text_detector) for HTTP service
### Training Data
The training dataset for this version includes **44k pairs of text-label samples**, split equally between two parts:
1. **Custom Generation**: The first half of the dataset was generated using custom specially designed prompts and human version sourced from three domains:
- [**Wikipedia**](https://huggingface.co/datasets/wikimedia/wikipedia)
- [**Reddit ELI5 QA**](https://huggingface.co/datasets/rexarski/eli5_category)
- [**Scientific Papers**](https://www.tensorflow.org/datasets/catalog/scientific_papers) (extended to include the full text of sections).
Texts were generated by 14 different models across four major LLM families (GPT, LLaMA, Anthropic, and Mistral). Each sample consists of a single prompt paired with one human-written and one generated response, though prompts were excluded from training inputs.
2. **RAID Train Data Stratified Subset**: The second half is a carefully selected stratified subset from the RAID train dataset, ensuring equal representation across domains, model types, and attack methods. Each example pairs a human-authored text with a corresponding machine-generated response (produced by a single model with specific parameters and attacks applied).
This balanced dataset structure maintains approximately equal proportions of human and generated text samples, ensuring that each prompt aligns with one authentic and one generated answer.
> [!NOTE]
> Furthermore, key n-grams (n ranging from 2 to 5) that exhibited the highest correlation with target labels were identified and subsequently removed from the training data utilizing the chi-squared test.
### Peculiarity
In training, a primary objective was to maximize prediction accuracy while specifically minimizing the False Positive Rate (FPR), prioritizing the reduction of misclassifications in class 0 (i.e., reducing instances where human-written text is incorrectly classified as generated by an LLM).
## Usage
**Pre-requirements**: \
Install *generated_text_detector* \
Run following command: ```pip install git+https://github.com/superannotateai/generated_text_detector.git@v1.0.0```
```python
from generated_text_detector.utils.model.roberta_classifier import RobertaClassifier
from transformers import AutoTokenizer
import torch.nn.functional as F
model = RobertaClassifier.from_pretrained("SuperAnnotate/ai-detector-low-fpr")
tokenizer = AutoTokenizer.from_pretrained("SuperAnnotate/ai-detector-low-fpr")
text_example = "It's not uncommon for people to develop allergies or intolerances to certain foods as they get older. It's possible that you have always had a sensitivity to lactose (the sugar found in milk and other dairy products), but it only recently became a problem for you. This can happen because our bodies can change over time and become more or less able to tolerate certain things. It's also possible that you have developed an allergy or intolerance to something else that is causing your symptoms, such as a food additive or preservative. In any case, it's important to talk to a doctor if you are experiencing new allergy or intolerance symptoms, so they can help determine the cause and recommend treatment."
tokens = tokenizer.encode_plus(
text_example,
add_special_tokens=True,
max_length=512,
padding='longest',
truncation=True,
return_token_type_ids=True,
return_tensors="pt"
)
_, logits = model(**tokens)
proba = F.sigmoid(logits).squeeze(1).item()
print(proba)
```
## Training Detailes
A custom architecture was chosen for its ability to perform binary classification while providing a single model output, as well as for its customizable settings for smoothing integrated into the loss function.
**Training Arguments**:
- **Base Model**: [FacebookAI/roberta-large](https://huggingface.co/FacebookAI/roberta-large)
- **Epochs**: 15
- **Learning Rate**: 5e-05
- **Weight Decay**: 0.0033
- **Label Smoothing**: 0
- **Pos Weight of Loss**: 0.5
- **Warmup Epochs**: 2
- **Optimizer**: SGD
- **Gradient Clipping**: 3.0
- **Scheduler**: Cosine with hard restarts
- **Number Scheduler Cycles**: 1
## Performance
This solution has been validated using the [RAID](https://raid-bench.xyz/) benchmark, which includes a diverse dataset covering:
- 11 LLM models
- 11 adversarial attacks
- 8 domains
The performance of detector is compared to other detectors on the [RAID leaderboard](https://raid-bench.xyz/leaderboard).
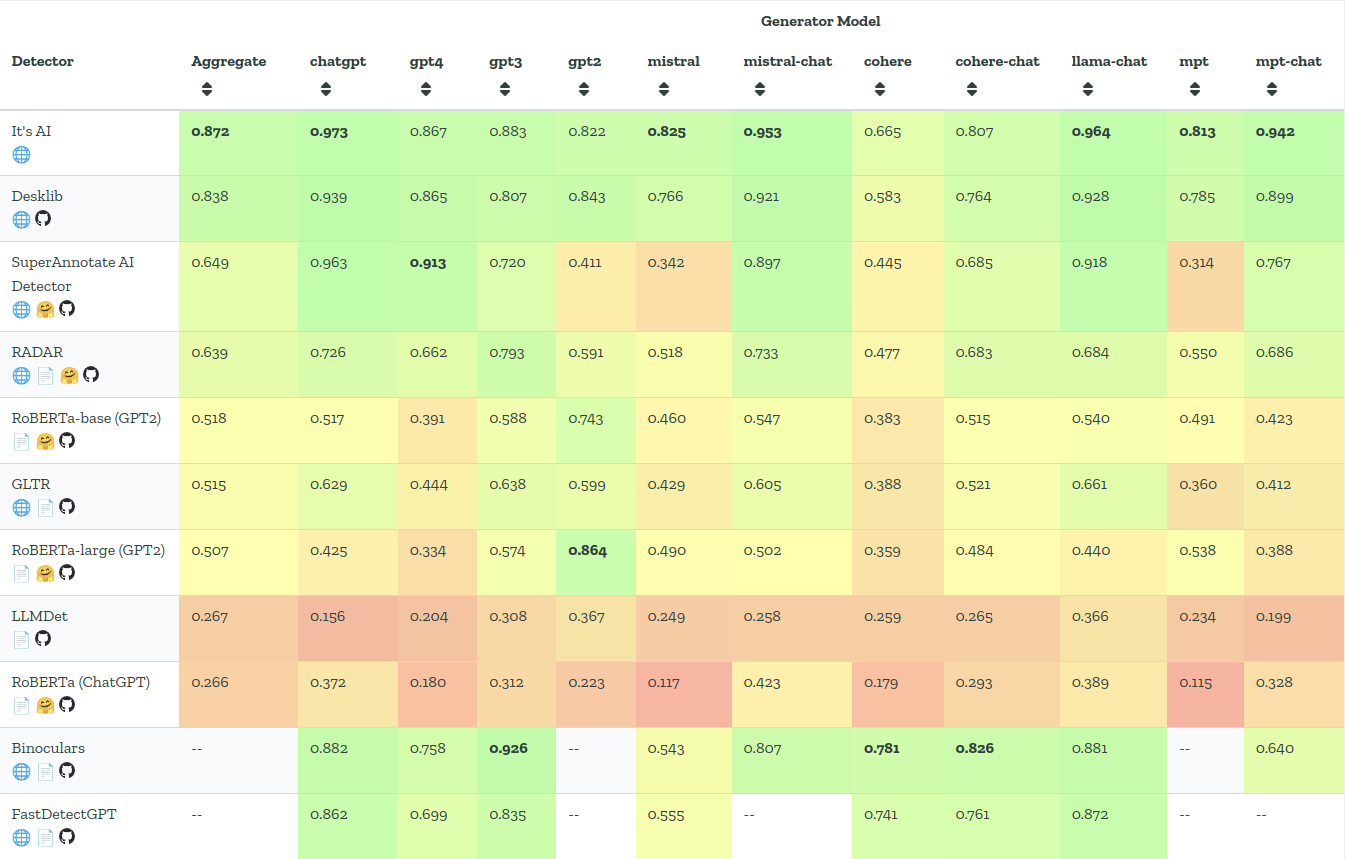
This is a snapshot of the leaderboard for October 2024