---
license: apache-2.0
datasets:
- TIGER-Lab/MMEB-train
language:
- en
metrics:
- accuracy
base_model:
- microsoft/Phi-3.5-vision-instruct
library_name: transformers
tags:
- Embedding
---
# VLM2Vec
This repo contains the code and data for [VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks](https://arxiv.org/abs/2410.05160). In this paper, we aimed at building a unified multimodal embedding model for any tasks. Our model is based on converting an existing well-trained VLM (Phi-3.5-V) into an embedding model.
 ## Release
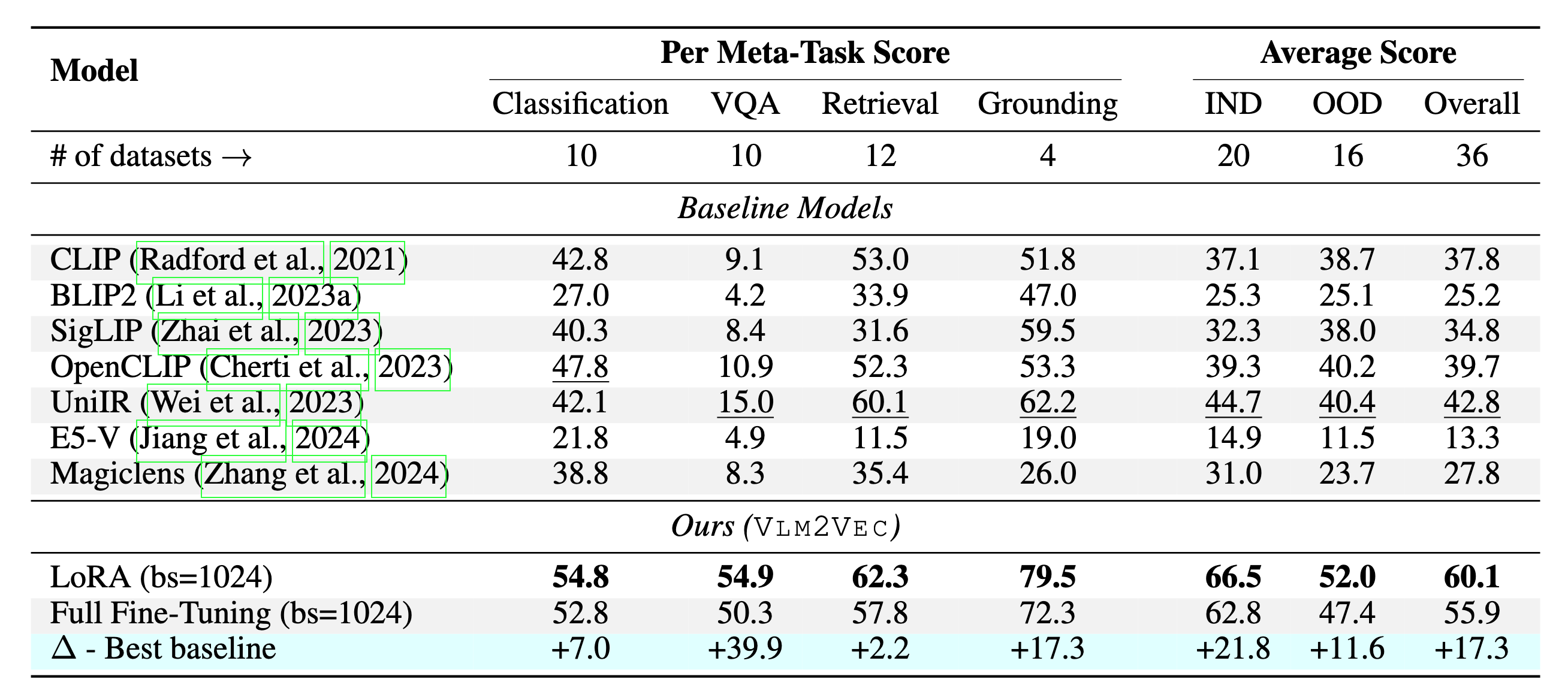
Our model is being trained on MMEB-train and evaluated on MMEB-eval with contrastive learning. We only use in-batch negatives for training. Our best results were based on Lora training with batch size of 1024. We also have checkpoint with full training with batch size of 2048. Our results on 36 evaluation datasets are:
### Train/Eval Data
- Train data: https://huggingface.co/datasets/TIGER-Lab/MMEB-train
- Eval data: https://huggingface.co/datasets/TIGER-Lab/MMEB-eval
### VLM2Vec Checkpoints
- [MMEB.lora8.bs1024](https://huggingface.co/TIGER-Lab/MMEB.lora8.bs1024/)
- [MMEB.fullmodel.bs2048](https://huggingface.co/TIGER-Lab/MMEB.fullmodel.bs2048/)
### Github
- [Github](https://github.com/TIGER-AI-Lab/VLM2Vec)
### Experimental Results
Our model can outperform the existing baselines by a huge margin.
## Release
Our model is being trained on MMEB-train and evaluated on MMEB-eval with contrastive learning. We only use in-batch negatives for training. Our best results were based on Lora training with batch size of 1024. We also have checkpoint with full training with batch size of 2048. Our results on 36 evaluation datasets are:
### Train/Eval Data
- Train data: https://huggingface.co/datasets/TIGER-Lab/MMEB-train
- Eval data: https://huggingface.co/datasets/TIGER-Lab/MMEB-eval
### VLM2Vec Checkpoints
- [MMEB.lora8.bs1024](https://huggingface.co/TIGER-Lab/MMEB.lora8.bs1024/)
- [MMEB.fullmodel.bs2048](https://huggingface.co/TIGER-Lab/MMEB.fullmodel.bs2048/)
### Github
- [Github](https://github.com/TIGER-AI-Lab/VLM2Vec)
### Experimental Results
Our model can outperform the existing baselines by a huge margin.
 ## How to use VLM2Vec
First you can clone our github
```bash
git clone https://github.com/TIGER-AI-Lab/VLM2Vec.git
pip -r requirements.txt
```
Then you can enter the directory to run the following command.
```python
from src.model import MMEBModel
from src.arguments import ModelArguments
import torch
from transformers import HfArgumentParser, AutoProcessor
from PIL import Image
import numpy as np
model_args = ModelArguments(
model_name='TIGER-Lab/VLM2Vec-Full',
pooling='last',
normalize=True)
model = MMEBModel.load(model_args)
model.eval()
model = model.to('cuda', dtype=torch.bfloat16)
processor = AutoProcessor.from_pretrained(
model_args.model_name,
trust_remote_code=True,
num_crops=4,
)
# Image + Text -> Text
inputs = processor('<|image_1|> Represent the given image with the following question: What is in the image', [Image.open('figures/example.jpg')])
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = 'A cat and a dog'
inputs = processor(string)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.2969]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
inputs = processor(string)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.2080]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor('Find me an everyday image that matches the given caption: A cat and a dog.',)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = '<|image_1|> Represent the given image.'
inputs = processor(string, [Image.open('figures/example.jpg')])
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## <|image_1|> Represent the given image. = tensor([[0.3105]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor('Find me an everyday image that matches the given caption: A cat and a tiger.',)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = '<|image_1|> Represent the given image.'
inputs = processor(string, [Image.open('figures/example.jpg')])
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## <|image_1|> Represent the given image. = tensor([[0.2158]], device='cuda:0', dtype=torch.bfloat16)
```
## Citation
```
@article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}
## How to use VLM2Vec
First you can clone our github
```bash
git clone https://github.com/TIGER-AI-Lab/VLM2Vec.git
pip -r requirements.txt
```
Then you can enter the directory to run the following command.
```python
from src.model import MMEBModel
from src.arguments import ModelArguments
import torch
from transformers import HfArgumentParser, AutoProcessor
from PIL import Image
import numpy as np
model_args = ModelArguments(
model_name='TIGER-Lab/VLM2Vec-Full',
pooling='last',
normalize=True)
model = MMEBModel.load(model_args)
model.eval()
model = model.to('cuda', dtype=torch.bfloat16)
processor = AutoProcessor.from_pretrained(
model_args.model_name,
trust_remote_code=True,
num_crops=4,
)
# Image + Text -> Text
inputs = processor('<|image_1|> Represent the given image with the following question: What is in the image', [Image.open('figures/example.jpg')])
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = 'A cat and a dog'
inputs = processor(string)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.2969]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
inputs = processor(string)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.2080]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor('Find me an everyday image that matches the given caption: A cat and a dog.',)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = '<|image_1|> Represent the given image.'
inputs = processor(string, [Image.open('figures/example.jpg')])
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## <|image_1|> Represent the given image. = tensor([[0.3105]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor('Find me an everyday image that matches the given caption: A cat and a tiger.',)
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = '<|image_1|> Represent the given image.'
inputs = processor(string, [Image.open('figures/example.jpg')])
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## <|image_1|> Represent the given image. = tensor([[0.2158]], device='cuda:0', dtype=torch.bfloat16)
```
## Citation
```
@article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}