

Update README.md
Browse files
README.md
CHANGED
|
@@ -3,15 +3,18 @@ library_name: transformers
|
|
| 3 |
tags: []
|
| 4 |
---
|
| 5 |
|
| 6 |
-
[📃Paper](https://arxiv.org/abs/2406.15252) | [🌐Website](https://tiger-ai-lab.github.io/VideoScore/) | [💻Github](https://github.com/TIGER-AI-Lab/VideoScore) | [🛢️Datasets](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback) | [🤗Model](https://huggingface.co/TIGER-Lab/VideoScore) | [🤗Demo](https://huggingface.co/spaces/TIGER-Lab/VideoScore)
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
## Introduction
|
| 12 |
-
- VideoScore is a
|
|
|
|
|
|
|
|
|
|
| 13 |
and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback),
|
| 14 |
-
a large video evaluation dataset with multi-aspect human scores.
|
| 15 |
|
| 16 |
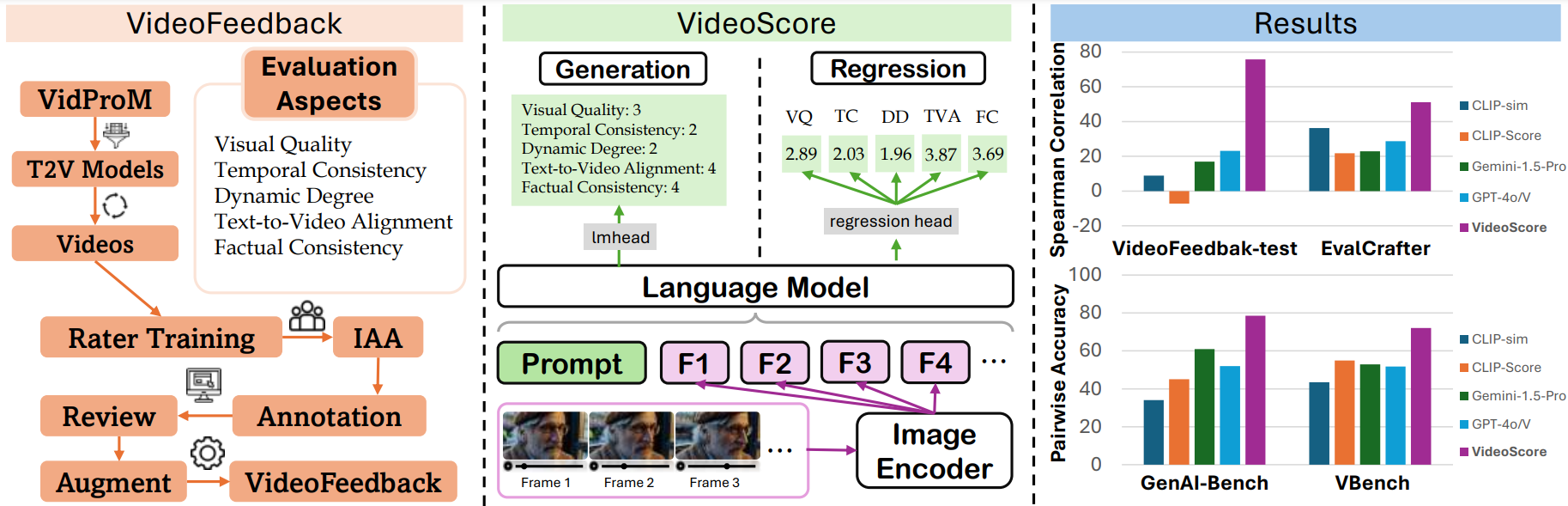
- VideoScore can reach 75+ Spearman correlation with humans on VideoEval-test, surpassing all the MLLM-prompting methods and feature-based metrics.
|
| 17 |
|
|
@@ -21,19 +24,31 @@ a large video evaluation dataset with multi-aspect human scores.
|
|
| 21 |
|
| 22 |
## Evaluation Results
|
| 23 |
|
| 24 |
-
We test
|
| 25 |
-
For the first two benchmarks, we take Spearman corrleation between model's output and human ratings
|
| 26 |
averaged among all the evaluation aspects as indicator.
|
| 27 |
-
For GenAI-Bench and VBench, which include human preference data among two or more videos,
|
| 28 |
-
we employ the model's output to predict preferences and use pairwise accuracy as the performance indicator.
|
| 29 |
-
|
| 30 |
-
- We use [VideoScore](https://huggingface.co/TIGER-Lab/VideoScore) trained on the entire VideoFeedback dataset
|
| 31 |
-
for VideoFeedback-test set, while for other three benchmarks.
|
| 32 |
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
## Usage
|
| 39 |
### Installation
|
|
@@ -57,7 +72,6 @@ from mantis.models.qwen2_vl import Qwen2VLForSequenceClassification
|
|
| 57 |
from transformers import Qwen2VLProcessor
|
| 58 |
from qwen_vl_utils import process_vision_info
|
| 59 |
|
| 60 |
-
MAX_NUM_FRAMES=16
|
| 61 |
ROUND_DIGIT=3
|
| 62 |
REGRESSION_QUERY_PROMPT = """
|
| 63 |
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
|
|
@@ -81,9 +95,9 @@ factual consistency: 1.8
|
|
| 81 |
|
| 82 |
For this video, the text prompt is "{text_prompt}",
|
| 83 |
all the frames of video are as follows:
|
| 84 |
-
"""
|
| 85 |
|
| 86 |
-
model_name="
|
| 87 |
video_path="video1.mp4"
|
| 88 |
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
|
| 89 |
|
|
@@ -96,6 +110,10 @@ model = Qwen2VLForSequenceClassification.from_pretrained(
|
|
| 96 |
processor = Qwen2VLProcessor.from_pretrained(model_name)
|
| 97 |
|
| 98 |
# Messages containing a images list as a video and a text query
|
|
|
|
|
|
|
|
|
|
|
|
|
| 99 |
messages = [
|
| 100 |
{
|
| 101 |
"role": "user",
|
|
@@ -107,12 +125,18 @@ messages = [
|
|
| 107 |
},
|
| 108 |
{"type": "text", "text": REGRESSION_QUERY_PROMPT.format(text_prompt=video_prompt)},
|
| 109 |
],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
}
|
| 111 |
]
|
| 112 |
|
| 113 |
# Preparation for inference
|
| 114 |
text = processor.apply_chat_template(
|
| 115 |
-
messages, tokenize=False, add_generation_prompt=
|
| 116 |
)
|
| 117 |
image_inputs, video_inputs = process_vision_info(messages)
|
| 118 |
inputs = processor(
|
|
@@ -123,7 +147,6 @@ inputs = processor(
|
|
| 123 |
return_tensors="pt",
|
| 124 |
)
|
| 125 |
inputs = inputs.to("cuda")
|
| 126 |
-
print(inputs['input_ids'].shape)
|
| 127 |
|
| 128 |
# Inference
|
| 129 |
with torch.no_grad():
|
|
@@ -140,8 +163,11 @@ print(aspect_scores)
|
|
| 140 |
"""
|
| 141 |
model output on visual quality, temporal consistency, dynamic degree,
|
| 142 |
text-to-video alignment, factual consistency, respectively
|
|
|
|
|
|
|
| 143 |
|
| 144 |
-
|
|
|
|
| 145 |
"""
|
| 146 |
```
|
| 147 |
|
|
|
|
| 3 |
tags: []
|
| 4 |
---
|
| 5 |
|
| 6 |
+
[📃Paper](https://arxiv.org/abs/2406.15252) | [🌐Website](https://tiger-ai-lab.github.io/VideoScore/) | [💻Github](https://github.com/TIGER-AI-Lab/VideoScore) | [🛢️Datasets](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback) | [🤗Model (VideoScore)](https://huggingface.co/TIGER-Lab/VideoScore) | [🤗Demo](https://huggingface.co/spaces/TIGER-Lab/VideoScore)
|
| 7 |
|
| 8 |
|
| 9 |

|
| 10 |
|
| 11 |
## Introduction
|
| 12 |
+
- 🧐🧐[VideoScore-Qwen2-VL](https://huggingface.co/TIGER-Lab/VideoScore-Qwen2-VL) is a variant from [VideoScore](https://huggingface.co/TIGER-Lab/VideoScore),
|
| 13 |
+
taking [Qwen2-VL](https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct) as base model, and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback) dataset.
|
| 14 |
+
|
| 15 |
+
- [VideoScore](https://huggingface.co/TIGER-Lab/VideoScore) series is a video quality evaluation model series, taking [Mantis-8B-Idefics2](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) or [Qwen/Qwen2-VL](https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct) as base-model
|
| 16 |
and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback),
|
| 17 |
+
a large video evaluation dataset with multi-aspect human scores.
|
| 18 |
|
| 19 |
- VideoScore can reach 75+ Spearman correlation with humans on VideoEval-test, surpassing all the MLLM-prompting methods and feature-based metrics.
|
| 20 |
|
|
|
|
| 24 |
|
| 25 |
## Evaluation Results
|
| 26 |
|
| 27 |
+
We test VideoScore-Qwen2-VL on VideoFeedback-test and take Spearman corrleation between model's output and human ratings
|
|
|
|
| 28 |
averaged among all the evaluation aspects as indicator.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
+
The evaluation results are shown below:
|
| 31 |
+
|
| 32 |
+
| metric | VideoFeedback-test |
|
| 33 |
+
|:-----------------:|:------------------:|
|
| 34 |
+
| VideoScore-Qwen2-VL | **74.9** |
|
| 35 |
+
| Gemini-1.5-Pro | 22.1 |
|
| 36 |
+
| Gemini-1.5-Flash | 20.8 |
|
| 37 |
+
| GPT-4o | <u>23.1</u> |
|
| 38 |
+
| CLIP-sim | 8.9 |
|
| 39 |
+
| DINO-sim | 7.5 |
|
| 40 |
+
| SSIM-sim | 13.4 |
|
| 41 |
+
| CLIP-Score | -7.2 |
|
| 42 |
+
| LLaVA-1.5-7B | 8.5 |
|
| 43 |
+
| LLaVA-1.6-7B | -3.1 |
|
| 44 |
+
| X-CLIP-Score | -1.9 |
|
| 45 |
+
| PIQE | -10.1 |
|
| 46 |
+
| BRISQUE | -20.3 |
|
| 47 |
+
| Idefics2 | 6.5 |
|
| 48 |
+
| MSE-dyn | -5.5 |
|
| 49 |
+
| SSIM-dyn | -12.9 |
|
| 50 |
+
|
| 51 |
+
The best in VideoScore series is in bold and the best in baselines is underlined.
|
| 52 |
|
| 53 |
## Usage
|
| 54 |
### Installation
|
|
|
|
| 72 |
from transformers import Qwen2VLProcessor
|
| 73 |
from qwen_vl_utils import process_vision_info
|
| 74 |
|
|
|
|
| 75 |
ROUND_DIGIT=3
|
| 76 |
REGRESSION_QUERY_PROMPT = """
|
| 77 |
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
|
|
|
|
| 95 |
|
| 96 |
For this video, the text prompt is "{text_prompt}",
|
| 97 |
all the frames of video are as follows:
|
| 98 |
+
"""
|
| 99 |
|
| 100 |
+
model_name="TIGER-Lab/VideoScore-Qwen2-VL"
|
| 101 |
video_path="video1.mp4"
|
| 102 |
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
|
| 103 |
|
|
|
|
| 110 |
processor = Qwen2VLProcessor.from_pretrained(model_name)
|
| 111 |
|
| 112 |
# Messages containing a images list as a video and a text query
|
| 113 |
+
response = ""
|
| 114 |
+
label_names = ["visual quality", "temporal consistency", "dynamic degree", "text-to-video alignment", "factual consistency"]
|
| 115 |
+
for i in range(len(label_names)):
|
| 116 |
+
response += f"The score for {label_names[i]} is {model.config.label_special_tokens[i]}. "
|
| 117 |
messages = [
|
| 118 |
{
|
| 119 |
"role": "user",
|
|
|
|
| 125 |
},
|
| 126 |
{"type": "text", "text": REGRESSION_QUERY_PROMPT.format(text_prompt=video_prompt)},
|
| 127 |
],
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"role": "assistant",
|
| 131 |
+
"content": [
|
| 132 |
+
{"type": "text", "text": response},
|
| 133 |
+
],
|
| 134 |
}
|
| 135 |
]
|
| 136 |
|
| 137 |
# Preparation for inference
|
| 138 |
text = processor.apply_chat_template(
|
| 139 |
+
messages, tokenize=False, add_generation_prompt=False
|
| 140 |
)
|
| 141 |
image_inputs, video_inputs = process_vision_info(messages)
|
| 142 |
inputs = processor(
|
|
|
|
| 147 |
return_tensors="pt",
|
| 148 |
)
|
| 149 |
inputs = inputs.to("cuda")
|
|
|
|
| 150 |
|
| 151 |
# Inference
|
| 152 |
with torch.no_grad():
|
|
|
|
| 163 |
"""
|
| 164 |
model output on visual quality, temporal consistency, dynamic degree,
|
| 165 |
text-to-video alignment, factual consistency, respectively
|
| 166 |
+
VideoScore:
|
| 167 |
+
[2.297, 2.469, 2.906, 2.766, 2.516]
|
| 168 |
|
| 169 |
+
VideoScore-Qwen2-VL:
|
| 170 |
+
[2.297, 2.531, 2.766, 2.312, 2.547]
|
| 171 |
"""
|
| 172 |
```
|
| 173 |
|