

Update README.md
Browse files
README.md
CHANGED
|
@@ -11,71 +11,73 @@ pipeline_tag: visual-question-answering
|
|
| 11 |
---
|
| 12 |
|
| 13 |
|
| 14 |
-
[📃Paper] | [🌐Website](https://tiger-ai-lab.github.io/
|
| 15 |
|
| 16 |
|
| 17 |
-
,
|
| 22 |
-
a large video evaluation dataset with multi-aspect human scores
|
| 23 |
|
| 24 |
-
-
|
| 25 |
|
| 26 |
-
-
|
|
|
|
|
|
|
| 27 |
|
| 28 |
## Evaluation Results
|
| 29 |
|
| 30 |
-
We test our video evaluation model
|
| 31 |
For the first two benchmarks, we take Spearman corrleation between model's output and human ratings
|
| 32 |
averaged among all the evaluation aspects as indicator.
|
| 33 |
For GenAI-Bench and VBench, which include human preference data among two or more videos,
|
| 34 |
we employ the model's output to predict preferences and use pairwise accuracy as the performance indicator.
|
| 35 |
|
| 36 |
-
|
| 37 |
-
for VideoFeedback-test set, while for other three benchmarks
|
| 38 |
-
|
| 39 |
-
|
|
|
|
| 40 |
|
| 41 |
The evaluation results are shown below:
|
| 42 |
|
| 43 |
|
| 44 |
-
| metric | Final
|
| 45 |
-
|
| 46 |
-
|
|
| 47 |
-
|
|
| 48 |
-
| Gemini-1.5-Pro | <u>
|
| 49 |
-
| Gemini-1.5-Flash |
|
| 50 |
-
| GPT-4o |
|
| 51 |
-
| CLIP-sim |
|
| 52 |
-
| DINO-sim |
|
| 53 |
-
| SSIM-sim |
|
| 54 |
-
| CLIP-Score |
|
| 55 |
-
| LLaVA-1.5-7B |
|
| 56 |
-
| LLaVA-1.6-7B |
|
| 57 |
-
| X-CLIP-Score |
|
| 58 |
-
| PIQE |
|
| 59 |
-
| BRISQUE |
|
| 60 |
-
| Idefics2 |
|
| 61 |
-
|
|
| 62 |
-
|
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
| OpenFlamingo | - | - | - | - | - |
|
| 67 |
-
|
| 68 |
-
The best in MantisScore series is in bold and the best in baselines is underlined.
|
| 69 |
-
"-" means the answer of MLLM is meaningless or in wrong format.
|
| 70 |
|
| 71 |
## Usage
|
|
|
|
| 72 |
```
|
| 73 |
-
|
|
|
|
|
|
|
| 74 |
```
|
| 75 |
|
| 76 |
### Inference
|
| 77 |
```
|
| 78 |
-
cd
|
| 79 |
```
|
| 80 |
|
| 81 |
```python
|
|
@@ -85,7 +87,7 @@ from typing import List
|
|
| 85 |
from PIL import Image
|
| 86 |
import torch
|
| 87 |
from transformers import AutoProcessor
|
| 88 |
-
from models.idefics2 import Idefics2ForSequenceClassification
|
| 89 |
|
| 90 |
def _read_video_pyav(
|
| 91 |
frame_paths:List[str],
|
|
@@ -128,7 +130,7 @@ For this video, the text prompt is "{text_prompt}",
|
|
| 128 |
all the frames of video are as follows:
|
| 129 |
"""
|
| 130 |
|
| 131 |
-
model_name="TIGER-Lab/
|
| 132 |
video_path="video1.mp4"
|
| 133 |
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
|
| 134 |
|
|
@@ -170,25 +172,27 @@ num_aspects = logits.shape[-1]
|
|
| 170 |
aspect_scores = []
|
| 171 |
for i in range(num_aspects):
|
| 172 |
aspect_scores.append(round(logits[0, i].item(),ROUND_DIGIT))
|
| 173 |
-
print(aspect_scores)
|
|
|
|
| 174 |
"""
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
|
|
|
| 178 |
"""
|
| 179 |
|
| 180 |
```
|
| 181 |
|
| 182 |
### Training
|
| 183 |
-
see [
|
| 184 |
|
| 185 |
### Evaluation
|
| 186 |
-
see [
|
| 187 |
|
| 188 |
## Citation
|
| 189 |
```bibtex
|
| 190 |
-
@article{
|
| 191 |
-
title = {
|
| 192 |
author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Yuchen and Chen, Wenhu},
|
| 193 |
journal = {ArXiv},
|
| 194 |
year = {2024},
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
|
| 14 |
+
[📃Paper](https://arxiv.org/abs/2406.15252) | [🌐Website](https://tiger-ai-lab.github.io/VideoScore/) | [💻Github](https://github.com/TIGER-AI-Lab/VideoScore) | [🛢️Datasets](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback) | [🤗Model](https://huggingface.co/TIGER-Lab/VideoScore) | [🤗Demo](https://huggingface.co/spaces/TIGER-Lab/VideoScore)
|
| 15 |
|
| 16 |
|
| 17 |
+
|
| 18 |
|
| 19 |
## Introduction
|
| 20 |
+
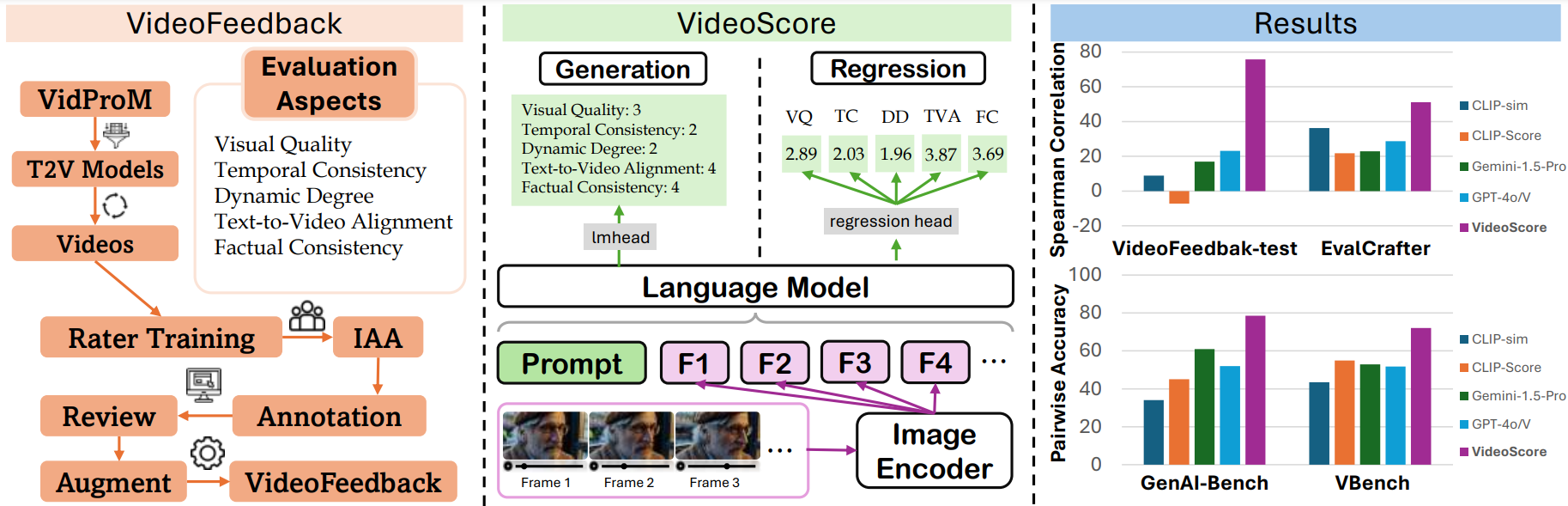
- VideoScore is a video quality evaluation model, taking [Mantis-8B-Idefics2](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) as base-model
|
| 21 |
and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback),
|
| 22 |
+
a large video evaluation dataset with multi-aspect human scores.
|
| 23 |
|
| 24 |
+
- VideoScore can reach 75+ Spearman correlation with humans on VideoEval-test, surpassing all the MLLM-prompting methods and feature-based metrics.
|
| 25 |
|
| 26 |
+
- VideoScore also beat the best baselines on other three benchmarks EvalCrafter, GenAI-Bench and VBench, showing high alignment with human evaluations.
|
| 27 |
+
|
| 28 |
+
- **This is the regression version of VideoScore**
|
| 29 |
|
| 30 |
## Evaluation Results
|
| 31 |
|
| 32 |
+
We test our video evaluation model VideoScore on VideoEval-test, EvalCrafter, GenAI-Bench and VBench.
|
| 33 |
For the first two benchmarks, we take Spearman corrleation between model's output and human ratings
|
| 34 |
averaged among all the evaluation aspects as indicator.
|
| 35 |
For GenAI-Bench and VBench, which include human preference data among two or more videos,
|
| 36 |
we employ the model's output to predict preferences and use pairwise accuracy as the performance indicator.
|
| 37 |
|
| 38 |
+
- We use [VideoScore](https://huggingface.co/TIGER-Lab/VideoScore) trained on the entire VideoFeedback dataset
|
| 39 |
+
for VideoFeedback-test set, while for other three benchmarks.
|
| 40 |
+
|
| 41 |
+
- We use [VideoScore-anno-only](https://huggingface.co/TIGER-Lab/VideoScore-anno-only) trained on VideoFeedback dataset
|
| 42 |
+
excluding the real videos.
|
| 43 |
|
| 44 |
The evaluation results are shown below:
|
| 45 |
|
| 46 |
|
| 47 |
+
| metric | Final Avg Score | VideoFeedback-test | EvalCrafter | GenAI-Bench | VBench |
|
| 48 |
+
|:-----------------:|:--------------:|:--------------:|:-----------:|:-----------:|:----------:|
|
| 49 |
+
| VideoScore (reg) | **69.6** | 75.7 | **51.1** | **78.5** | **73.0** |
|
| 50 |
+
| VideoScore (gen) | 55.6 | **77.1** | 27.6 | 59.0 | 58.7 |
|
| 51 |
+
| Gemini-1.5-Pro | <u>39.7</u> | 22.1 | 22.9 | 60.9 | 52.9 |
|
| 52 |
+
| Gemini-1.5-Flash | 39.4 | 20.8 | 17.3 | <u>67.1</u> | 52.3 |
|
| 53 |
+
| GPT-4o | 38.9 | <u>23.1</u> | 28.7 | 52.0 | 51.7 |
|
| 54 |
+
| CLIP-sim | 31.7 | 8.9 | <u>36.2</u> | 34.2 | 47.4 |
|
| 55 |
+
| DINO-sim | 30.3 | 7.5 | 32.1 | 38.5 | 43.3 |
|
| 56 |
+
| SSIM-sim | 29.5 | 13.4 | 26.9 | 34.1 | 43.5 |
|
| 57 |
+
| CLIP-Score | 28.6 | -7.2 | 21.7 | 45.0 | 54.9 |
|
| 58 |
+
| LLaVA-1.5-7B | 27.1 | 8.5 | 10.5 | 49.9 | 39.4 |
|
| 59 |
+
| LLaVA-1.6-7B | 23.3 | -3.1 | 13.2 | 44.5 | 38.7 |
|
| 60 |
+
| X-CLIP-Score | 23.2 | -1.9 | 13.3 | 41.4 | 40.1 |
|
| 61 |
+
| PIQE | 19.6 | -10.1 | -1.2 | 34.5 |<u> 55.1</u>|
|
| 62 |
+
| BRISQUE | 19.0 | -20.3 | 3.9 | 38.5 | 53.7 |
|
| 63 |
+
| Idefics2 | 18.3 | 6.5 | 0.3 | 34.6 | 31.7 |
|
| 64 |
+
| MSE-dyn | 10.6 | -5.5 | -17.0 | 28.4 | 36.5 |
|
| 65 |
+
| SSIM-dyn | 9.2 | -12.9 | -26.4 | 31.4 | 44.5 |
|
| 66 |
+
|
| 67 |
+
The best in VideoScore series is in bold and the best in baselines is underlined.
|
| 68 |
+
<!-- "-" means the answer of MLLM is meaningless or in wrong format. -->
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
|
| 70 |
## Usage
|
| 71 |
+
### Installation
|
| 72 |
```
|
| 73 |
+
pip install git+https://github.com/TIGER-AI-Lab/VideoScore.git
|
| 74 |
+
# or
|
| 75 |
+
# pip install mantis-vl
|
| 76 |
```
|
| 77 |
|
| 78 |
### Inference
|
| 79 |
```
|
| 80 |
+
cd VideoScore/examples
|
| 81 |
```
|
| 82 |
|
| 83 |
```python
|
|
|
|
| 87 |
from PIL import Image
|
| 88 |
import torch
|
| 89 |
from transformers import AutoProcessor
|
| 90 |
+
from mantis.models.idefics2 import Idefics2ForSequenceClassification
|
| 91 |
|
| 92 |
def _read_video_pyav(
|
| 93 |
frame_paths:List[str],
|
|
|
|
| 130 |
all the frames of video are as follows:
|
| 131 |
"""
|
| 132 |
|
| 133 |
+
model_name="TIGER-Lab/VideoScore"
|
| 134 |
video_path="video1.mp4"
|
| 135 |
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
|
| 136 |
|
|
|
|
| 172 |
aspect_scores = []
|
| 173 |
for i in range(num_aspects):
|
| 174 |
aspect_scores.append(round(logits[0, i].item(),ROUND_DIGIT))
|
| 175 |
+
print(aspect_scores)
|
| 176 |
+
|
| 177 |
"""
|
| 178 |
+
model output on visual quality, temporal consistency, dynamic degree,
|
| 179 |
+
text-to-video alignment, factual consistency, respectively
|
| 180 |
+
|
| 181 |
+
[2.297, 2.469, 2.906, 2.766, 2.516]
|
| 182 |
"""
|
| 183 |
|
| 184 |
```
|
| 185 |
|
| 186 |
### Training
|
| 187 |
+
see [VideoScore/training](https://github.com/TIGER-AI-Lab/VideoScore/tree/main/training) for details
|
| 188 |
|
| 189 |
### Evaluation
|
| 190 |
+
see [VideoScore/benchmark](https://github.com/TIGER-AI-Lab/VideoScore/tree/main/benchmark) for details
|
| 191 |
|
| 192 |
## Citation
|
| 193 |
```bibtex
|
| 194 |
+
@article{he2024videoscore,
|
| 195 |
+
title = {VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation},
|
| 196 |
author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Yuchen and Chen, Wenhu},
|
| 197 |
journal = {ArXiv},
|
| 198 |
year = {2024},
|