
Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
# **Abstract**
We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully designed the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-round multi-modal dialogue with users, generating and refining images according to the context.
Through our carefully designed holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models.
# **Hunyuan-DiT Key Features**
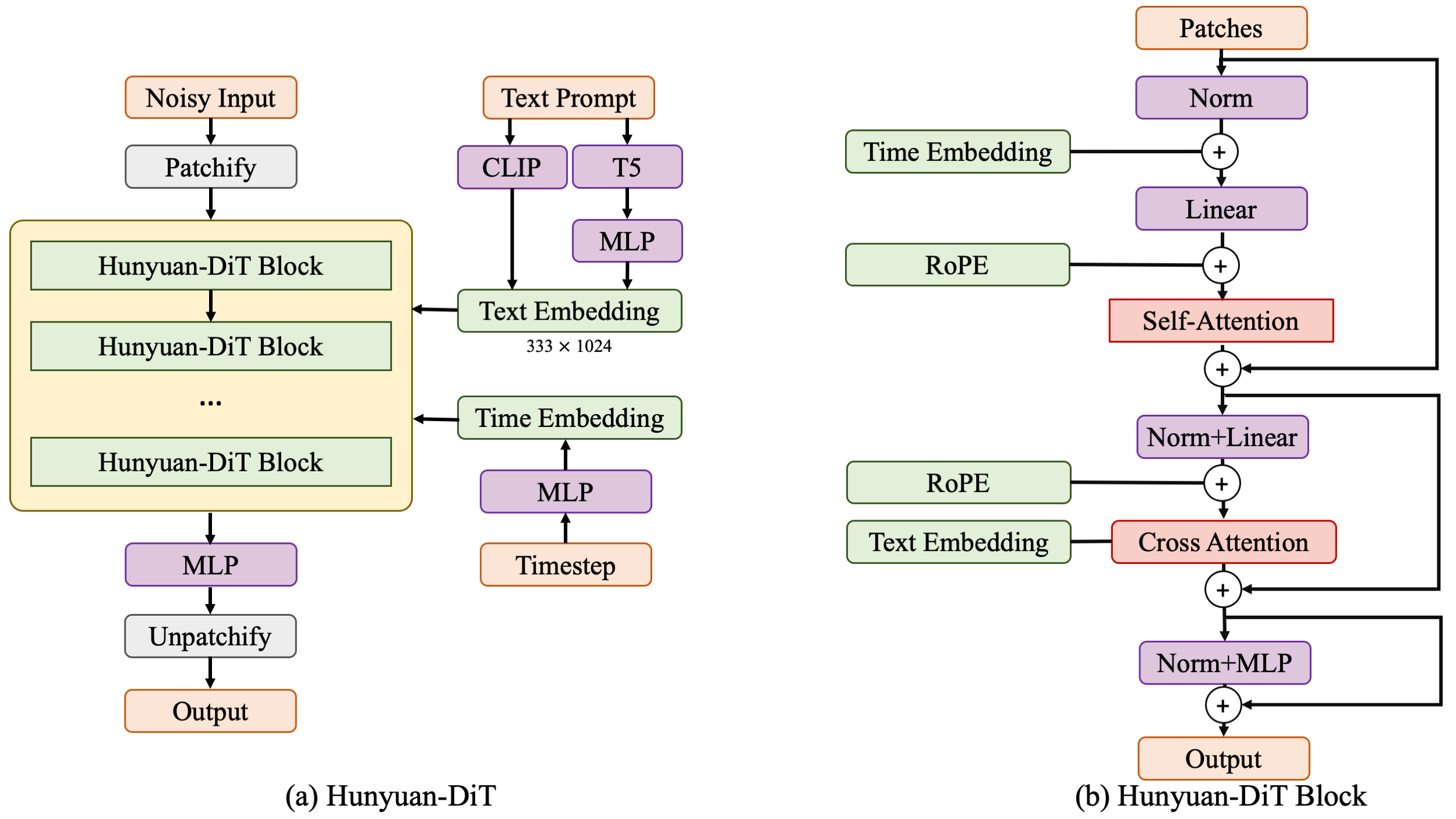
## **Chinese-English Bilingual DiT Architecture**
We propose HunyuanDiT, a text-to-image generation model based on Diffusion transformer with fine-grained understanding of Chinese and English. In order to build Hunyuan DiT, we carefully designed the Transformer structure, text encoder and positional encoding. We also built a complete data pipeline from scratch to update and evaluate data to help model optimization iterations. To achieve fine-grained text understanding, we train a multi-modal large language model to optimize text descriptions of images. Ultimately, Hunyuan DiT is able to conduct multiple rounds of dialogue with users, generating and improving images based on context.
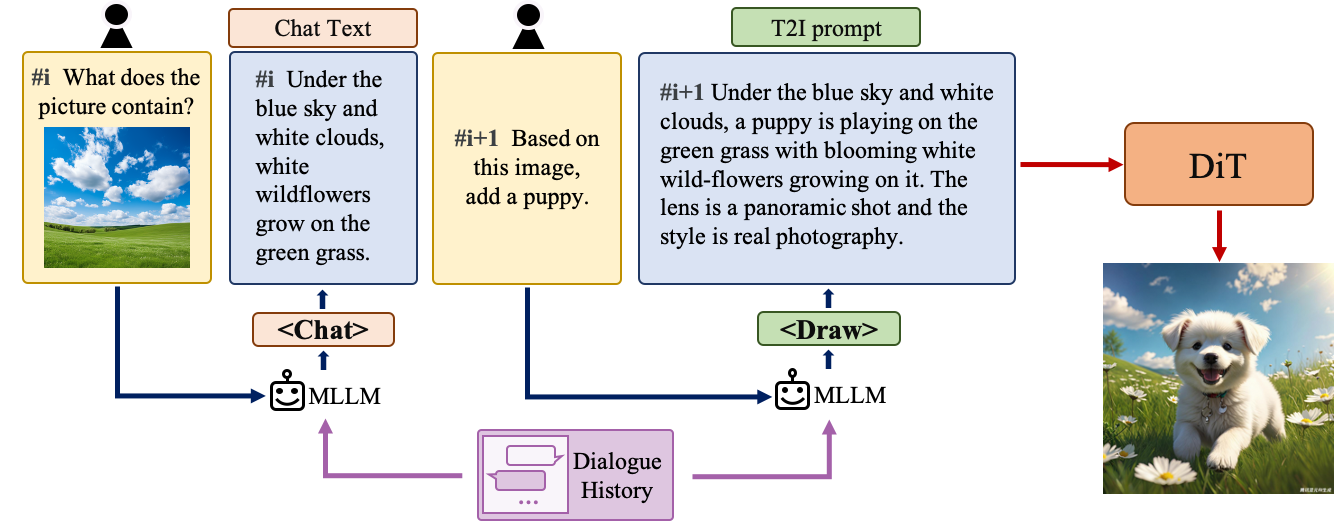
## **Multi-turn Text2Image Generation**
Understanding natural language instructions and performing multi-turn interaction with users are important for a
text-to-image system. It can help build a dynamic and iterative creation process that bring the user’s idea into reality
step by step. In this section, we will detail how we empower Hunyuan-DiT with the ability to perform multi-round
conversations and image generation. We train MLLM to understand the multi-round user dialogue
and output the new text prompt for image generation.
## **Comparisons**
In order to comprehensively compare the generation capabilities of HunyuanDiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
| Type | Model | Text-Image Consistency (%) | Excluding AI Artifacts (%) | Subject Clarity (%) | Aesthetics (%) | Overall (%) |
| Open Source |
SDXL | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 |
| Playground 2.5 | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 |
| Hunyuan-DiT | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 |
| Closed Source |
SD 3 | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 |
| MidJourney v6 | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 |
| DALL-E 3 | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 |
## **Visualization**
* **Chinese Elements**

* **Long Text Input**
 Comparison between Hunyuan-DiT and other text-to-image models. The image with the highest resolution on the far left is the result of Hunyuan-Dit. The others, from top left to bottom right, are as follows: Dalle3, Midjourney v6, SD3, Playground 2.5, PixArt, SDXL, Baidu Yige, WanXiang.
Comparison between Hunyuan-DiT and other text-to-image models. The image with the highest resolution on the far left is the result of Hunyuan-Dit. The others, from top left to bottom right, are as follows: Dalle3, Midjourney v6, SD3, Playground 2.5, PixArt, SDXL, Baidu Yige, WanXiang.
* **Multi-turn Text2Image Generation**
# **Dependencies and Installation**
Ensure your machine is equipped with a GPU having over 20GB of memory.
Begin by cloning the repository:
```bash
git clone https://github.com/tencent/HunyuanDiT
cd HunyuanDiT
```
We provide an `environment.yml` file for setting up a Conda environment.
Installation instructions for Conda are available [here](https://docs.anaconda.com/free/miniconda/index.html).
```shell
# Prepare conda environment
conda env create -f environment.yml
# Activate the environment
conda activate HunyuanDiT
# Install pip dependencies
python -m pip install -r requirements.txt
# Install flash attention v2 (for acceleration, requires CUDA 11.6 or above)
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.1.2.post3
```
# **Download Models**
To download the model, first install the huggingface-cli. Installation instructions are available [here](https://huggingface.co/docs/huggingface_hub/guides/cli):
```sh
# Create a directory named 'ckpts' where the model will be saved, fulfilling the prerequisites for running the demo.
mkdir ckpts
# Use the huggingface-cli tool to download the model.
# The download time may vary from 10 minutes to 1 hour depending on network conditions.
huggingface-cli download Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
```
All models will be automatically downloaded. For more information about the model, visit the Hugging Face repository [here](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT).
| Model | #Params | url|
|:-----------------|:--------|:--------------|
|mT5 | xxB | [mT5](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/mt5)|
| CLIP | xxB | [CLIP](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/clip_text_encoder)|
| DialogGen | 7B | [DialogGen](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/dialoggen)|
| sdxl-vae-fp16-fix | xxB | [sdxl-vae-fp16-fix](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/sdxl-vae-fp16-fix)|
| Hunyuan-DiT | xxB | [Hunyuan-DiT](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/model)|
# **Inference**
```bash
# prompt-enhancement + text2image, torch mode
python sample_t2i.py --prompt "渔舟唱晚"
# close prompt enhancement, torch mode
python sample_t2i.py --prompt "渔舟唱晚" --no-enhance
# close prompt enhancement, flash attention mode
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚"
```
more example prompts can be found in [example_prompts.txt](example_prompts.txt)
Note: 20G GPU memory is used for sampling in single GPU
# **BibTeX**
If you find Hunyuan-DiT useful for your research and applications, please cite using this BibTeX:
```BibTeX
@inproceedings{,
title={},
author={},
booktitle={},
year={2024}
}
```




