
File size: 1,757 Bytes
2c1575f e93a827 2c1575f 0ee90b1 2c1575f 0ee90b1 2c1575f 0ee90b1 2c1575f |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# RoBERTa-base Korean
## 모델 설명
이 RoBERTa 모델은 다양한 한국어 텍스트 데이터셋에서 **음절** 단위로 사전 학습되었습니다.
자체 구축한 한국어 음절 단위 vocab을 사용하였습니다.
## 아키텍처
- **모델 유형**: RoBERTa
- **아키텍처**: RobertaForMaskedLM
- **모델 크기**: 256 hidden size, 8 hidden layers, 8 attention heads
- **max_position_embeddings**: 514
- **intermediate_size**: 2048
- **vocab_size**: 1428
## 학습 데이터
사용된 데이터셋은 다음과 같습니다:
- **모두의말뭉치**: 채팅, 게시판, 일상대화, 뉴스, 방송대본, 책 등
- **AIHUB**: SNS, 유튜브 댓글, 도서 문장
- **기타**: 나무위키, 한국어 위키피디아
총 합산된 데이터는 약 11GB 입니다.
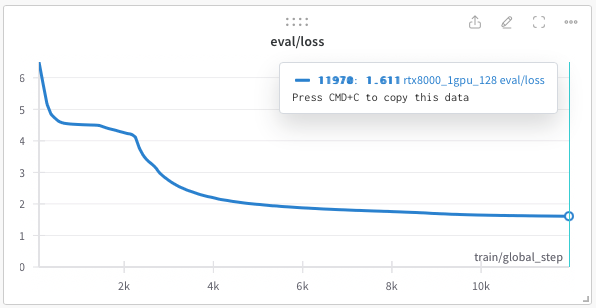
## 학습 상세
- **BATCH_SIZE**: 112 (GPU당)
- **ACCUMULATE**: 36
- **MAX_STEPS**: 12,500
- **Train Steps*Batch Szie**: **100M**
- **WARMUP_STEPS**: 2,400
- **최적화**: AdamW, LR 1e-3, BETA (0.9, 0.98), eps 1e-6
- **학습률 감쇠**: linear
- **사용된 하드웨어**: 2x RTX 8000 GPU

## 사용 방법
```python
from transformers import AutoModel, AutoTokenizer
# 모델과 토크나이저 불러오기
model = AutoModel.from_pretrained("your_model_name")
tokenizer = AutoTokenizer.from_pretrained("your_tokenizer_name")
# 텍스트를 토큰으로 변환하고 예측 수행
inputs = tokenizer("여기에 한국어 텍스트 입력", return_tensors="pt")
outputs = model(**inputs)
|