🤗 HF Repo •🐱 Github Repo • 🐦 Twitter
📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
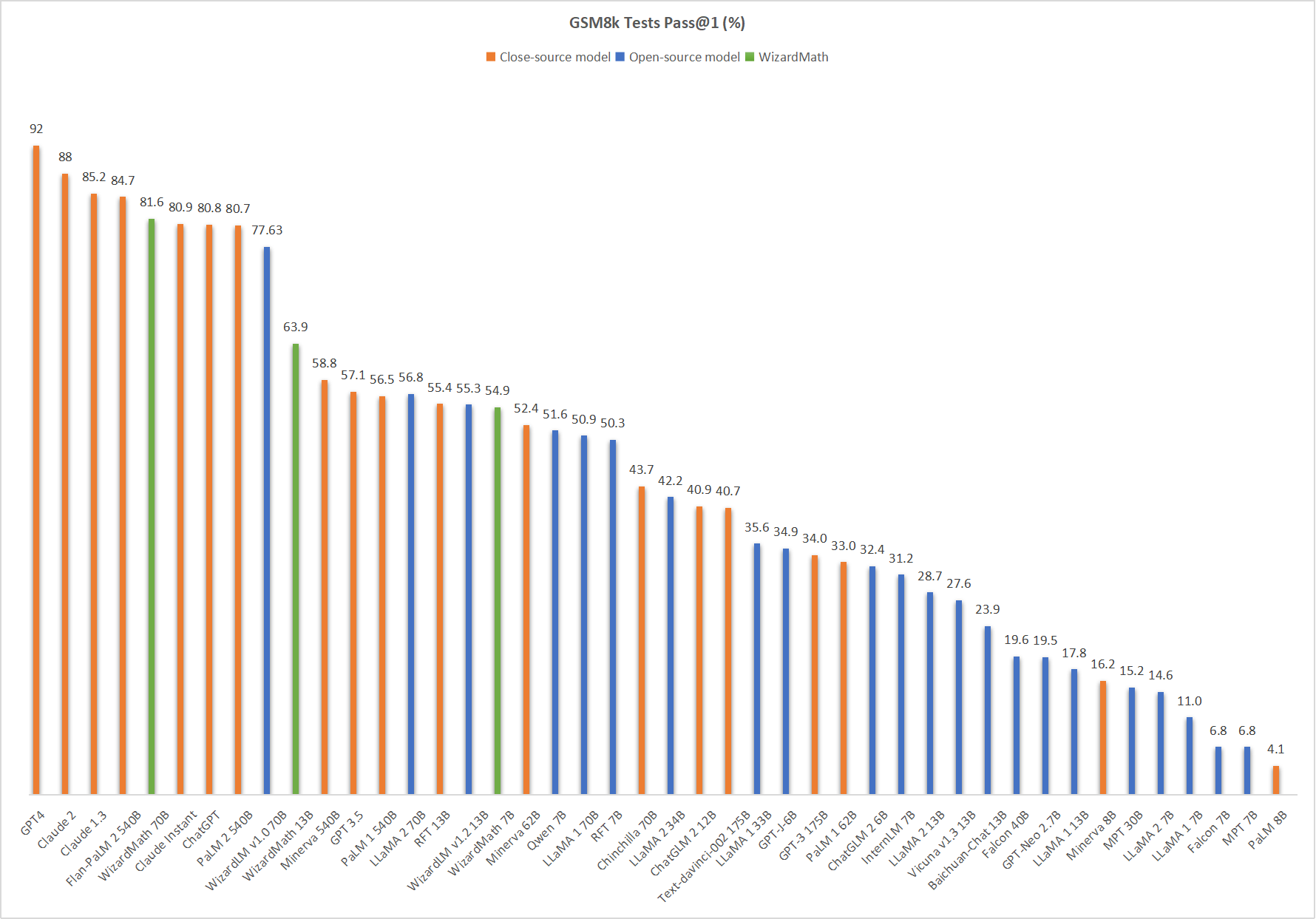
## News [12/19/2023] 🔥 We released **WizardMath-7B-V1.1** trained from Mistral-7B, the **SOTA 7B math LLM**, achieves **83.2 pass@1** on GSM8k, and **33.0 pass@1** on MATH. [12/19/2023] 🔥 **WizardMath-7B-V1.1** outperforms **ChatGPT 3.5**, **Gemini Pro**, **Mixtral MOE**, and **Claude Instant** on GSM8K pass@1. [12/19/2023] 🔥 **WizardMath-7B-V1.1** is comparable with **ChatGPT 3.5**, **Gemini Pro**, and surpasses **Mixtral MOE** on MATH pass@1. | Model | Checkpoint | Paper | GSM8k | MATH | | ----- |------| ---- |------|-------| | **WizardMath-7B-V1.1** | 🤗 HF Link | 📃 [WizardMath]| **83.2** | **33.0** | | WizardMath-70B-V1.0 | 🤗 HF Link | 📃 [WizardMath]| **81.6** | **22.7** | | WizardMath-13B-V1.0 | 🤗 HF Link | 📃 [WizardMath]| **63.9** | **14.0** | | WizardMath-7B-V1.0 | 🤗 HF Link | 📃 [WizardMath]| **54.9** | **10.7** | ## [12/19/2023] Comparing WizardMath-7B-V1.1 with other open source 7B size math LLMs. | Model | GSM8k Pass@1 | MATH Pass@1 | | ----- |------| ---- | | MPT-7B | 6.8 | 3.0 | |Llama 1-7B | 11.0 | 2.9 | |Llama 2-7B|12.3 |2.8 | |Yi-6b| 32.6 |5.8 | |Mistral-7B|37.8 |9.1 | |Qwen-7b|47.8 |9.3 | | RFT-7B | 50.3 | -- | | MAmmoTH-7B (COT) | 50.5 | 10.4 | | WizardMath-7B-V1.0 | 54.9 | 10.7 | |Abel-7B-001 |59.7 |13 | | MetaMath-7B | 66.5 | 19.8 | | Arithmo-Mistral-7B | 74.7 | 25.3 | |MetaMath-Mistral-7B|77.7 |28.2 | |Abel-7B-002 | 80.4 | 29.5 | | **WizardMath-7B-V1.1** | **83.2** | **33.0** | ## [12/19/2023] Comparing WizardMath-7B-V1.1 with large open source (30B~70B) LLMs. | Model | GSM8k Pass@1 | MATH Pass@1 | | ----- |------| ---- | | Llemma-34B | 51.5 | 25.0 | | Minerva-62B | 52.4 | 27.6 | | Llama 2-70B | 56.8 | 13.5 | | DeepSeek 67B | 63.4 | -- | | Gork 33B | 62.9 | 23.9 | | MAmmoTH-70B | 72.4 | 21.1 | | Yi-34B | 67.9 | 15.9 | | Mixtral 8x7B | 74.4 | 28.4 | | MetaMath-70B | 82.3 | 26.6 | | **WizardMath-7B-V1.1** | **83.2** | **33.0** | ## ❗ Data Contamination Check: Before model training, we carefully and rigorously checked all the training data, and used multiple deduplication methods to verify and prevent data leakage on GSM8k and MATH test set. | Model | Checkpoint | Paper |MT-Bench | AlpacaEval | GSM8k | HumanEval | License| | ----- |------| ---- |------|-------| ----- | ----- | ----- | | **WizardLM-70B-V1.0** | 🤗 HF Link |📃**Coming Soon**| **7.78** | **92.91%** |**77.6%** | **50.6 pass@1**| Llama 2 License | | WizardLM-13B-V1.2 | 🤗 HF Link | | 7.06 | 89.17% |55.3% | 36.6 pass@1| Llama 2 License | | WizardLM-13B-V1.1 | 🤗 HF Link | | 6.76 |86.32% | | 25.0 pass@1| Non-commercial| | WizardLM-30B-V1.0 | 🤗 HF Link | | 7.01 | | | 37.8 pass@1| Non-commercial | | WizardLM-13B-V1.0 | 🤗 HF Link | | 6.35 | 75.31% | | 24.0 pass@1 | Non-commercial| | WizardLM-7B-V1.0 | 🤗 HF Link | 📃 [WizardLM] | | | |19.1 pass@1 | Non-commercial| | Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License | | ----- |------| ---- |------|-------| ----- | ----- | | WizardCoder-Python-34B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 73.2 | 61.2 | [Demo](http://47.103.63.15:50085/) | Llama2 | | WizardCoder-15B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 59.8 |50.6 | -- | OpenRAIL-M | | WizardCoder-Python-13B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 64.0 | 55.6 | -- | Llama2 | | WizardCoder-Python-7B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 55.5 | 51.6 | [Demo](http://47.103.63.15:50088/) | Llama2 | | WizardCoder-3B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 34.8 |37.4 | -- | OpenRAIL-M | | WizardCoder-1B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 23.8 |28.6 | -- | OpenRAIL-M | **Github Repo**: https://github.com/nlpxucan/WizardLM/tree/main/WizardMath **Twitter**: https://twitter.com/WizardLM_AI/status/1689998428200112128 **Discord**: https://discord.gg/VZjjHtWrKs ## Comparing WizardMath-V1.0 with Other LLMs. 🔥 The following figure shows that our **WizardMath-70B-V1.0 attains the fifth position in this benchmark**, surpassing ChatGPT (81.6 vs. 80.8) , Claude Instant (81.6 vs. 80.9), PaLM 2 540B (81.6 vs. 80.7).