
Upload folder using huggingface_hub
Browse files- .gitattributes +4 -0
- README.md +14 -0
- llama3-8B-DarkIdol-2.1-Uncensored-32K.f16.gguf +3 -0
- llama3-8B-DarkIdol-2.1-Uncensored-32K.q5_k.gguf +3 -0
- llama3-8B-DarkIdol-2.1-Uncensored-32K.q6_k.gguf +3 -0
- llama3-8B-DarkIdol-2.1-Uncensored-32K.q8_0.gguf +3 -0
- llama3-8B-DarkIdol-2.1-Uncensored-32K/README.md +292 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
llama3-8B-DarkIdol-2.1-Uncensored-32K.f16.gguf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
llama3-8B-DarkIdol-2.1-Uncensored-32K.q5_k.gguf filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
llama3-8B-DarkIdol-2.1-Uncensored-32K.q6_k.gguf filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
llama3-8B-DarkIdol-2.1-Uncensored-32K.q8_0.gguf filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
---
|
| 3 |
+
license: mit
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
My own (ZeroWw) quantizations.
|
| 9 |
+
output and embed tensors quantized to f16.
|
| 10 |
+
all other tensors quantized to q5_k or q6_k.
|
| 11 |
+
|
| 12 |
+
Result:
|
| 13 |
+
both f16.q6 and f16.q5 are smaller than q8_0 standard quantization
|
| 14 |
+
and they perform as well as the pure f16.
|
llama3-8B-DarkIdol-2.1-Uncensored-32K.f16.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:63a7efcd80141054da59c04a3c1ff6201553ad8ead4d751f089a318257a2159a
|
| 3 |
+
size 16068890528
|
llama3-8B-DarkIdol-2.1-Uncensored-32K.q5_k.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8770c306ecbdf9f2dfca338d9589582bc4c6606368d48e93a806009eb6303730
|
| 3 |
+
size 7042224032
|
llama3-8B-DarkIdol-2.1-Uncensored-32K.q6_k.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4a889efb0da49cb194cf1b4ebd20d903a088884a93a431c981fb753c2571eb08
|
| 3 |
+
size 7835471776
|
llama3-8B-DarkIdol-2.1-Uncensored-32K.q8_0.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0d9529a06d09571a64ddb59b53026c19b5843f74ab6e1e74a82961a95eaa5bbe
|
| 3 |
+
size 9525776288
|
llama3-8B-DarkIdol-2.1-Uncensored-32K/README.md
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama3
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- ja
|
| 6 |
+
- zh
|
| 7 |
+
tags:
|
| 8 |
+
- roleplay
|
| 9 |
+
- llama3
|
| 10 |
+
- sillytavern
|
| 11 |
+
- idol
|
| 12 |
+
---
|
| 13 |
+
# Special Thanks:
|
| 14 |
+
- Lewdiculous's superb gguf version, thank you for your conscientious and responsible dedication.
|
| 15 |
+
- https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF-IQ-Imatrix-Request
|
| 16 |
+
|
| 17 |
+
# Model Description:
|
| 18 |
+
The module combination has been readjusted to better fulfill various roles and has been adapted for mobile phones.
|
| 19 |
+
- Saving money(LLama 3)
|
| 20 |
+
- Uncensored
|
| 21 |
+
- Quick response
|
| 22 |
+
- The underlying model used is winglian/Llama-3-8b-64k-PoSE (The theoretical support is 64k, but I have only tested up to 32k. :)
|
| 23 |
+
- A scholarly response akin to a thesis.(I tend to write songs extensively, to the point where one song almost becomes as detailed as a thesis. :)
|
| 24 |
+
- DarkIdol:Roles that you can imagine and those that you cannot imagine.
|
| 25 |
+
- Roleplay
|
| 26 |
+
- Specialized in various role-playing scenarios
|
| 27 |
+
- more look at test role. (https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.2/resolve/main/test)
|
| 28 |
+
- more look at LM Studio presets (https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.2/resolve/main/config-presets)
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
# Chang Log
|
| 33 |
+
### 2024-06-26
|
| 34 |
+
- 32k
|
| 35 |
+
### 2024-06-26
|
| 36 |
+
- 之前版本的迭代太多了,已经开始出现过拟合现象.重新使用了新的工艺重新制作模型,虽然制作复杂了,结果很好,新的迭代工艺如图
|
| 37 |
+
- The previous version had undergone excessive iterations, resulting in overfitting. We have recreated the model using a new process, which, although more complex to produce, has yielded excellent results. The new iterative process is depicted in the figure.
|
| 38 |
+
|
| 39 |
+
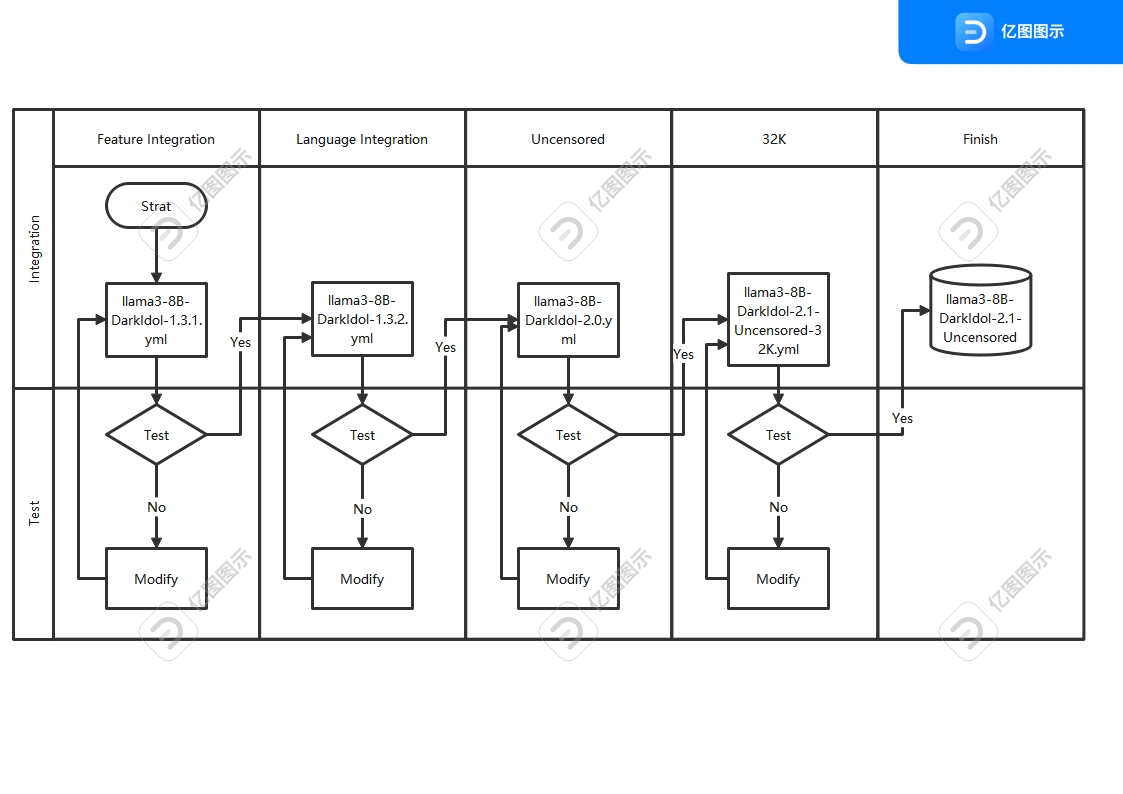
|
| 40 |
+
|
| 41 |
+
# Questions
|
| 42 |
+
- The model's response results are for reference only, please do not fully trust them.
|
| 43 |
+
- I am unable to test Japanese and Korean parts very well. Based on my testing, Korean performs excellently, but sometimes Japanese may have furigana (if anyone knows a good Japanese language module, - I need to replace the module for integration).
|
| 44 |
+
- With the new manufacturing process, overfitting and crashes have been reduced, but there may be new issues, so please leave a message if you encounter any.
|
| 45 |
+
- testing with other tools is not comprehensive.but there may be new issues, so please leave a message if you encounter any.
|
| 46 |
+
- The range between 32K and 64K was not tested, and the approach was somewhat casual. I didn't expect the results to be exceptionally good.
|
| 47 |
+
|
| 48 |
+
# 问题
|
| 49 |
+
- 模型回复结果仅供参考,请勿完全相信
|
| 50 |
+
- 日语,韩语部分我没办法进行很好的测试,根据我测试情况,韩语表现的很好,日语有时候会出现注音(谁知道好的日文语言模块,我需要换模块集成)
|
| 51 |
+
- 新工艺制作,过拟合现象和崩溃减少了,可能会有新的问题,碰到了请给我留言
|
| 52 |
+
- 32K-64k区间没有测试,做的有点随意,没想到结果特别的好
|
| 53 |
+
- 其他工具的测试不完善
|
| 54 |
+
|
| 55 |
+
# Stop Strings
|
| 56 |
+
```python
|
| 57 |
+
stop = [
|
| 58 |
+
"## Instruction:",
|
| 59 |
+
"### Instruction:",
|
| 60 |
+
"<|end_of_text|>",
|
| 61 |
+
" //:",
|
| 62 |
+
"</s>",
|
| 63 |
+
"<3```",
|
| 64 |
+
"### Note:",
|
| 65 |
+
"### Input:",
|
| 66 |
+
"### Response:",
|
| 67 |
+
"### Emoticons:"
|
| 68 |
+
],
|
| 69 |
+
```
|
| 70 |
+
# Model Use
|
| 71 |
+
- Koboldcpp https://github.com/LostRuins/koboldcpp
|
| 72 |
+
- Since KoboldCpp is taking a while to update with the latest llama.cpp commits, I'll recommend this [fork](https://github.com/Nexesenex/kobold.cpp) if anyone has issues.
|
| 73 |
+
- LM Studio https://lmstudio.ai/
|
| 74 |
+
- llama.cpp https://github.com/ggerganov/llama.cpp
|
| 75 |
+
- Backyard AI https://backyard.ai/
|
| 76 |
+
- Meet Layla,Layla is an AI chatbot that runs offline on your device.No internet connection required.No censorship.Complete privacy.Layla Lite https://www.layla-network.ai/
|
| 77 |
+
- Layla Lite llama3-8B-DarkIdol-1.1-Q4_K_S-imat.gguf https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K/blob/main/llama3-8B-DarkIdol-2.1-Uncensored-32K-Q4_K_S-imat.gguf?download=true
|
| 78 |
+
- more gguf at https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF-IQ-Imatrix-Request
|
| 79 |
+
# character
|
| 80 |
+
- https://character-tavern.com/
|
| 81 |
+
- https://characterhub.org/
|
| 82 |
+
- https://pygmalion.chat/
|
| 83 |
+
- https://aetherroom.club/
|
| 84 |
+
- https://backyard.ai/
|
| 85 |
+
- Layla AI chatbot
|
| 86 |
+
### If you want to use vision functionality:
|
| 87 |
+
* You must use the latest versions of [Koboldcpp](https://github.com/Nexesenex/kobold.cpp).
|
| 88 |
+
|
| 89 |
+
### To use the multimodal capabilities of this model and use **vision** you need to load the specified **mmproj** file, this can be found inside this model repo. [Llava MMProj](https://huggingface.co/Nitral-AI/Llama-3-Update-3.0-mmproj-model-f16)
|
| 90 |
+
|
| 91 |
+
* You can load the **mmproj** by using the corresponding section in the interface:
|
| 92 |
+

|
| 93 |
+
### Thank you:
|
| 94 |
+
To the authors for their hard work, which has given me more options to easily create what I want. Thank you for your efforts.
|
| 95 |
+
- Hastagaras
|
| 96 |
+
- Gryphe
|
| 97 |
+
- cgato
|
| 98 |
+
- ChaoticNeutrals
|
| 99 |
+
- mergekit
|
| 100 |
+
- merge
|
| 101 |
+
- transformers
|
| 102 |
+
- llama
|
| 103 |
+
- Nitral-AI
|
| 104 |
+
- MLP-KTLim
|
| 105 |
+
- rinna
|
| 106 |
+
- hfl
|
| 107 |
+
- Rupesh2
|
| 108 |
+
- stephenlzc
|
| 109 |
+
- theprint
|
| 110 |
+
- Sao10K
|
| 111 |
+
- turboderp
|
| 112 |
+
- TheBossLevel123
|
| 113 |
+
- winglian
|
| 114 |
+
- .........
|
| 115 |
+
---
|
| 116 |
+
base_model:
|
| 117 |
+
- Nitral-AI/Hathor_Fractionate-L3-8B-v.05
|
| 118 |
+
- Hastagaras/Jamet-8B-L3-MK.V-Blackroot
|
| 119 |
+
- turboderp/llama3-turbcat-instruct-8b
|
| 120 |
+
- aifeifei798/Meta-Llama-3-8B-Instruct
|
| 121 |
+
- Sao10K/L3-8B-Stheno-v3.3-32K
|
| 122 |
+
- TheBossLevel123/Llama3-Toxic-8B-Float16
|
| 123 |
+
- cgato/L3-TheSpice-8b-v0.8.3
|
| 124 |
+
library_name: transformers
|
| 125 |
+
tags:
|
| 126 |
+
- mergekit
|
| 127 |
+
- merge
|
| 128 |
+
|
| 129 |
+
---
|
| 130 |
+
# llama3-8B-DarkIdol-1.3.1
|
| 131 |
+
|
| 132 |
+
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
|
| 133 |
+
|
| 134 |
+
## Merge Details
|
| 135 |
+
### Merge Method
|
| 136 |
+
|
| 137 |
+
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [aifeifei798/Meta-Llama-3-8B-Instruct](https://huggingface.co/aifeifei798/Meta-Llama-3-8B-Instruct) as a base.
|
| 138 |
+
|
| 139 |
+
### Models Merged
|
| 140 |
+
|
| 141 |
+
The following models were included in the merge:
|
| 142 |
+
* [Nitral-AI/Hathor_Fractionate-L3-8B-v.05](https://huggingface.co/Nitral-AI/Hathor_Fractionate-L3-8B-v.05)
|
| 143 |
+
* [Hastagaras/Jamet-8B-L3-MK.V-Blackroot](https://huggingface.co/Hastagaras/Jamet-8B-L3-MK.V-Blackroot)
|
| 144 |
+
* [turboderp/llama3-turbcat-instruct-8b](https://huggingface.co/turboderp/llama3-turbcat-instruct-8b)
|
| 145 |
+
* [Sao10K/L3-8B-Stheno-v3.3-32K](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.3-32K)
|
| 146 |
+
* [TheBossLevel123/Llama3-Toxic-8B-Float16](https://huggingface.co/TheBossLevel123/Llama3-Toxic-8B-Float16)
|
| 147 |
+
* [cgato/L3-TheSpice-8b-v0.8.3](https://huggingface.co/cgato/L3-TheSpice-8b-v0.8.3)
|
| 148 |
+
|
| 149 |
+
### Configuration
|
| 150 |
+
|
| 151 |
+
The following YAML configuration was used to produce this model:
|
| 152 |
+
|
| 153 |
+
```yaml
|
| 154 |
+
models:
|
| 155 |
+
- model: Sao10K/L3-8B-Stheno-v3.3-32K
|
| 156 |
+
- model: Hastagaras/Jamet-8B-L3-MK.V-Blackroot
|
| 157 |
+
- model: cgato/L3-TheSpice-8b-v0.8.3
|
| 158 |
+
- model: Nitral-AI/Hathor_Fractionate-L3-8B-v.05
|
| 159 |
+
- model: TheBossLevel123/Llama3-Toxic-8B-Float16
|
| 160 |
+
- model: turboderp/llama3-turbcat-instruct-8b
|
| 161 |
+
- model: aifeifei798/Meta-Llama-3-8B-Instruct
|
| 162 |
+
merge_method: model_stock
|
| 163 |
+
base_model: aifeifei798/Meta-Llama-3-8B-Instruct
|
| 164 |
+
dtype: bfloat16
|
| 165 |
+
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
---
|
| 169 |
+
base_model:
|
| 170 |
+
- hfl/llama-3-chinese-8b-instruct-v3
|
| 171 |
+
- rinna/llama-3-youko-8b
|
| 172 |
+
- MLP-KTLim/llama-3-Korean-Bllossom-8B
|
| 173 |
+
library_name: transformers
|
| 174 |
+
tags:
|
| 175 |
+
- mergekit
|
| 176 |
+
- merge
|
| 177 |
+
|
| 178 |
+
---
|
| 179 |
+
# llama3-8B-DarkIdol-1.3.2
|
| 180 |
+
|
| 181 |
+
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
|
| 182 |
+
|
| 183 |
+
## Merge Details
|
| 184 |
+
### Merge Method
|
| 185 |
+
|
| 186 |
+
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using ./llama3-8B-DarkIdol-1.3.1 as a base.
|
| 187 |
+
|
| 188 |
+
### Models Merged
|
| 189 |
+
|
| 190 |
+
The following models were included in the merge:
|
| 191 |
+
* [hfl/llama-3-chinese-8b-instruct-v3](https://huggingface.co/hfl/llama-3-chinese-8b-instruct-v3)
|
| 192 |
+
* [rinna/llama-3-youko-8b](https://huggingface.co/rinna/llama-3-youko-8b)
|
| 193 |
+
* [MLP-KTLim/llama-3-Korean-Bllossom-8B](https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B)
|
| 194 |
+
|
| 195 |
+
### Configuration
|
| 196 |
+
|
| 197 |
+
The following YAML configuration was used to produce this model:
|
| 198 |
+
|
| 199 |
+
```yaml
|
| 200 |
+
models:
|
| 201 |
+
- model: hfl/llama-3-chinese-8b-instruct-v3
|
| 202 |
+
- model: rinna/llama-3-youko-8b
|
| 203 |
+
- model: MLP-KTLim/llama-3-Korean-Bllossom-8B
|
| 204 |
+
- model: ./llama3-8B-DarkIdol-1.3.1
|
| 205 |
+
merge_method: model_stock
|
| 206 |
+
base_model: ./llama3-8B-DarkIdol-1.3.1
|
| 207 |
+
dtype: bfloat16
|
| 208 |
+
|
| 209 |
+
```
|
| 210 |
+
---
|
| 211 |
+
base_model:
|
| 212 |
+
- theprint/Llama-3-8B-Lexi-Smaug-Uncensored
|
| 213 |
+
- Rupesh2/OrpoLlama-3-8B-instruct-uncensored
|
| 214 |
+
- stephenlzc/dolphin-llama3-zh-cn-uncensored
|
| 215 |
+
library_name: transformers
|
| 216 |
+
tags:
|
| 217 |
+
- mergekit
|
| 218 |
+
- merge
|
| 219 |
+
|
| 220 |
+
---
|
| 221 |
+
# llama3-8B-DarkIdol-2.0-Uncensored
|
| 222 |
+
|
| 223 |
+
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
|
| 224 |
+
|
| 225 |
+
## Merge Details
|
| 226 |
+
### Merge Method
|
| 227 |
+
|
| 228 |
+
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using ./llama3-8B-DarkIdol-1.3.2 as a base.
|
| 229 |
+
|
| 230 |
+
### Models Merged
|
| 231 |
+
|
| 232 |
+
The following models were included in the merge:
|
| 233 |
+
* [theprint/Llama-3-8B-Lexi-Smaug-Uncensored](https://huggingface.co/theprint/Llama-3-8B-Lexi-Smaug-Uncensored)
|
| 234 |
+
* [Rupesh2/OrpoLlama-3-8B-instruct-uncensored](https://huggingface.co/Rupesh2/OrpoLlama-3-8B-instruct-uncensored)
|
| 235 |
+
* [stephenlzc/dolphin-llama3-zh-cn-uncensored](https://huggingface.co/stephenlzc/dolphin-llama3-zh-cn-uncensored)
|
| 236 |
+
|
| 237 |
+
### Configuration
|
| 238 |
+
|
| 239 |
+
The following YAML configuration was used to produce this model:
|
| 240 |
+
|
| 241 |
+
```yaml
|
| 242 |
+
models:
|
| 243 |
+
- model: Rupesh2/OrpoLlama-3-8B-instruct-uncensored
|
| 244 |
+
- model: stephenlzc/dolphin-llama3-zh-cn-uncensored
|
| 245 |
+
- model: theprint/Llama-3-8B-Lexi-Smaug-Uncensored
|
| 246 |
+
- model: ./llama3-8B-DarkIdol-1.3.2
|
| 247 |
+
merge_method: model_stock
|
| 248 |
+
base_model: ./llama3-8B-DarkIdol-2.0-Uncensored
|
| 249 |
+
dtype: bfloat16
|
| 250 |
+
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
---
|
| 254 |
+
base_model:
|
| 255 |
+
- winglian/Llama-3-8b-64k-PoSE
|
| 256 |
+
library_name: transformers
|
| 257 |
+
tags:
|
| 258 |
+
- mergekit
|
| 259 |
+
- merge
|
| 260 |
+
|
| 261 |
+
---
|
| 262 |
+
# llama3-8B-DarkIdol-2.1-Uncensored-32K
|
| 263 |
+
|
| 264 |
+
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
|
| 265 |
+
|
| 266 |
+
## Merge Details
|
| 267 |
+
### Merge Method
|
| 268 |
+
|
| 269 |
+
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [winglian/Llama-3-8b-64k-PoSE](https://huggingface.co/winglian/Llama-3-8b-64k-PoSE) as a base.
|
| 270 |
+
|
| 271 |
+
### Models Merged
|
| 272 |
+
|
| 273 |
+
The following models were included in the merge:
|
| 274 |
+
* ./llama3-8B-DarkIdol-1.3.2
|
| 275 |
+
* ./llama3-8B-DarkIdol-2.0
|
| 276 |
+
* ./llama3-8B-DarkIdol-1.3.1
|
| 277 |
+
|
| 278 |
+
### Configuration
|
| 279 |
+
|
| 280 |
+
The following YAML configuration was used to produce this model:
|
| 281 |
+
|
| 282 |
+
```yaml
|
| 283 |
+
models:
|
| 284 |
+
- model: ./llama3-8B-DarkIdol-1.3.1
|
| 285 |
+
- model: ./llama3-8B-DarkIdol-1.3.2
|
| 286 |
+
- model: ./llama3-8B-DarkIdol-2.0
|
| 287 |
+
- model: winglian/Llama-3-8b-64k-PoSE
|
| 288 |
+
merge_method: model_stock
|
| 289 |
+
base_model: winglian/Llama-3-8b-64k-PoSE
|
| 290 |
+
dtype: bfloat16
|
| 291 |
+
|
| 292 |
+
```
|