## Stable Diffusion
*[Stable Diffusion](https://github.com/compvis/stable-diffusion) builds upon our previous work with the [CompVis group](https://ommer-lab.com/):*
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://ommer-lab.com/research/latent-diffusion-models/)
[Robin Rombach](https://github.com/rromb)\*,
[Andreas Blattmann](https://github.com/ablattmann)\*,
[Dominik Lorenz](https://github.com/qp-qp)\,
[Patrick Esser](https://github.com/pesser),
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)
_[CVPR '22 Oral](https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html) |
[GitHub](https://github.com/CompVis/latent-diffusion) | [arXiv](https://arxiv.org/abs/2112.10752) | [Project page](https://ommer-lab.com/research/latent-diffusion-models/)_

[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion
model.
Thanks to a generous compute donation from [Stability AI](https://stability.ai/) and support from [LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487),
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
See [this section](#stable-diffusion-v1) below and the [model card](https://huggingface.co/CompVis/stable-diffusion).
## News
- *2022-10-20* [v1.5 Text-to-Image Checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5)
- *2022-10-18* [Inpainting Model](#inpainting-with-stable-diffusion)

## Requirements
A suitable [conda](https://conda.io/) environment named `ldm` can be created
and activated with:
```
conda env create -f environment.yaml
conda activate ldm
```
You can also update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running
```
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
```
## Stable Diffusion v1
Stable Diffusion v1 refers to a specific configuration of the model
architecture that uses a downsampling-factor 8 autoencoder with an 860M UNet
and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and
then finetuned on 512x512 images.
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present
in its training data.
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](Stable_Diffusion_v1_Model_Card.md).*
The weights are available via [the CompVis](https://huggingface.co/CompVis) and [Runway organization at Hugging Face](https://huggingface.co/runwayml) under [a license which contains specific use-based restrictions to prevent misuse and harm as informed by the model card, but otherwise remains permissive](LICENSE). While commercial use is permitted under the terms of the license, **we do not recommend using the provided weights for services or products without additional safety mechanisms and considerations**, since there are [known limitations and biases](Stable_Diffusion_v1_Model_Card.md#limitations-and-bias) of the weights, and research on safe and ethical deployment of general text-to-image models is an ongoing effort. **The weights are research artifacts and should be treated as such.**
[The CreativeML OpenRAIL M license](LICENSE) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
### Weights
We currently provide the following checkpoints:
- [`sd-v1-1.ckpt`](https://huggingface.co/compvis): 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`sd-v1-2.ckpt`](https://huggingface.co/compvis): Resumed from `sd-v1-1.ckpt`.
515k steps at resolution `512x512` on [laion-aesthetics v2 5+](https://laion.ai/blog/laion-aesthetics/) (a subset of laion2B-en with estimated aesthetics score `> 5.0`, and additionally
filtered to images with an original size `>= 512x512`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the [LAION-5B](https://laion.ai/blog/laion-5b/) metadata, the aesthetics score is estimated using the [LAION-Aesthetics Predictor V2](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`sd-v1-3.ckpt`](https://huggingface.co/compvis): Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`sd-v1-4.ckpt`](https://huggingface.co/compvis): Resumed from `sd-v1-2.ckpt`. 225k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`sd-v1-5.ckpt`](https://huggingface.co/runwayml/stable-diffusion-v1-5): Resumed from `sd-v1-2.ckpt`. 595k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`sd-v1-5-inpainting.ckpt`](https://huggingface.co/runwayml/stable-diffusion-inpainting): Resumed from `sd-v1-5.ckpt`. 440k steps of inpainting training at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598). For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25\% mask everything.
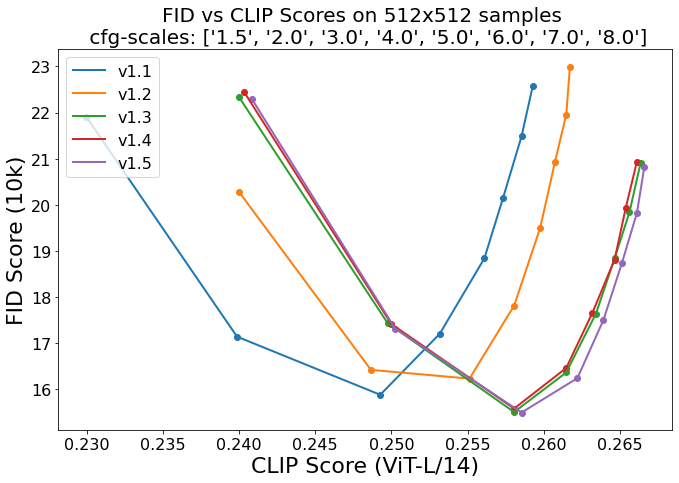
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:
### Text-to-Image with Stable Diffusion


Stable Diffusion is a latent diffusion model conditioned on the (non-pooled) text embeddings of a CLIP ViT-L/14 text encoder.
We provide a [reference script for sampling](#reference-sampling-script), but
there also exists a [diffusers integration](#diffusers-integration), which we
expect to see more active community development.
#### Reference Sampling Script
We provide a reference sampling script, which incorporates
- a [Safety Checker Module](https://github.com/CompVis/stable-diffusion/pull/36),
to reduce the probability of explicit outputs,
- an [invisible watermarking](https://github.com/ShieldMnt/invisible-watermark)
of the outputs, to help viewers [identify the images as machine-generated](scripts/tests/test_watermark.py).
After [obtaining the `stable-diffusion-v1-*-original` weights](#weights), link them
```
mkdir -p models/ldm/stable-diffusion-v1/
ln -s models/ldm/stable-diffusion-v1/model.ckpt
```
and sample with
```
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
```
By default, this uses a guidance scale of `--scale 7.5`, [Katherine Crowson's implementation](https://github.com/CompVis/latent-diffusion/pull/51) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler,
and renders images of size 512x512 (which it was trained on) in 50 steps. All supported arguments are listed below (type `python scripts/txt2img.py --help`).
```commandline
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
```
Note: The inference config for all v1 versions is designed to be used with EMA-only checkpoints.
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
non-EMA to EMA weights. If you want to examine the effect of EMA vs no EMA, we provide "full" checkpoints
which contain both types of weights. For these, `use_ema=False` will load and use the non-EMA weights.
#### Diffusers Integration
A simple way to download and sample Stable Diffusion is by using the [diffusers library](https://github.com/huggingface/diffusers/tree/main#new--stable-diffusion-is-now-fully-compatible-with-diffusers):
```py
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
### Image Modification with Stable Diffusion
By using a diffusion-denoising mechanism as first proposed by [SDEdit](https://arxiv.org/abs/2108.01073), the model can be used for different
tasks such as text-guided image-to-image translation and upscaling. Similar to the txt2img sampling script,
we provide a script to perform image modification with Stable Diffusion.
The following describes an example where a rough sketch made in [Pinta](https://www.pinta-project.com/) is converted into a detailed artwork.
```
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img --strength 0.8
```
Here, strength is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input. See the following example.
**Input**

**Outputs**


This procedure can, for example, also be used to upscale samples from the base model.
### Inpainting with Stable Diffusion

We provide a checkpoint finetuned for inpainting to perform text-based erase \&
replace functionality.
#### Quick Start
After [creating a suitable environment](#Requirements), download the [checkpoint finetuned for inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting) and run
```
streamlit run scripts/inpaint_st.py -- configs/stable-diffusion/v1-inpainting-inference.yaml
```
for a streamlit demo of the inpainting model.
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](Stable_Diffusion_v1_Model_Card.md).
#### Diffusers Integration
Another simple way to use the inpainting model is via the [diffusers library](https://github.com/huggingface/diffusers):
```py
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
revision="fp16",
torch_dtype=torch.float16,
)
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
#image and mask_image should be PIL images.
#The mask structure is white for inpainting and black for keeping as is
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
image.save("./yellow_cat_on_park_bench.png")
```
#### Evaluation
To assess the performance of the inpainting model, we used the same evaluation
protocol as in our [LDM paper](https://arxiv.org/abs/2112.10752). Since the
Stable Diffusion Inpainting Model acccepts a text input, we simply used a fixed
prompt of `photograph of a beautiful empty scene, highest quality settings`.
| Model | FID | LPIPS |
|-----------------------------|------|------------------|
| Stable Diffusion Inpainting | 1.00 | 0.141 (+- 0.082) |
| Latent Diffusion Inpainting | 1.50 | 0.137 (+- 0.080) |
| CoModGAN | 1.82 | 0.15 |
| LaMa | 2.21 | 0.134 (+- 0.080) |
#### Online Demo
If you want to try the model without setting things up locally, you can try the
[Erase \& Replace](https://app.runwayml.com/ai-tools/erase-and-replace) tool at [Runway](https://runwayml.com/):
https://user-images.githubusercontent.com/2175508/196499595-d8194abf-fec4-4927-bf14-af106fe4fa40.mp4
## Comments
- Our codebase for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
Thanks for open-sourcing!
- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
## BibTeX
```
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```