
bubbliiiing
commited on
Commit
·
c1ef6f4
1
Parent(s):
dcad9cf
Update Readme
Browse files- README.md +453 -130
- README_en.md +454 -125
README.md
CHANGED
|
@@ -14,7 +14,32 @@ EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI图片
|
|
| 14 |
[English](./README_en.md) | [简体中文](./README.md)
|
| 15 |
|
| 16 |
# 模型地址
|
| 17 |
-
EasyAnimateV5.1:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
|
| 19 |
7B:
|
| 20 |
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
|
@@ -32,6 +57,7 @@ EasyAnimateV5.1:
|
|
| 32 |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-Control-Camera)| 官方的视频相机控制权重,支持通过输入相机运动轨迹控制生成方向。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 33 |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh)| 官方的文生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 34 |
|
|
|
|
| 35 |
|
| 36 |
# 视频作品
|
| 37 |
|
|
@@ -213,116 +239,436 @@ EasyAnimateV5.1:
|
|
| 213 |
|
| 214 |
# 如何使用
|
| 215 |
|
| 216 |
-
#### a
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
|
| 260 |
-
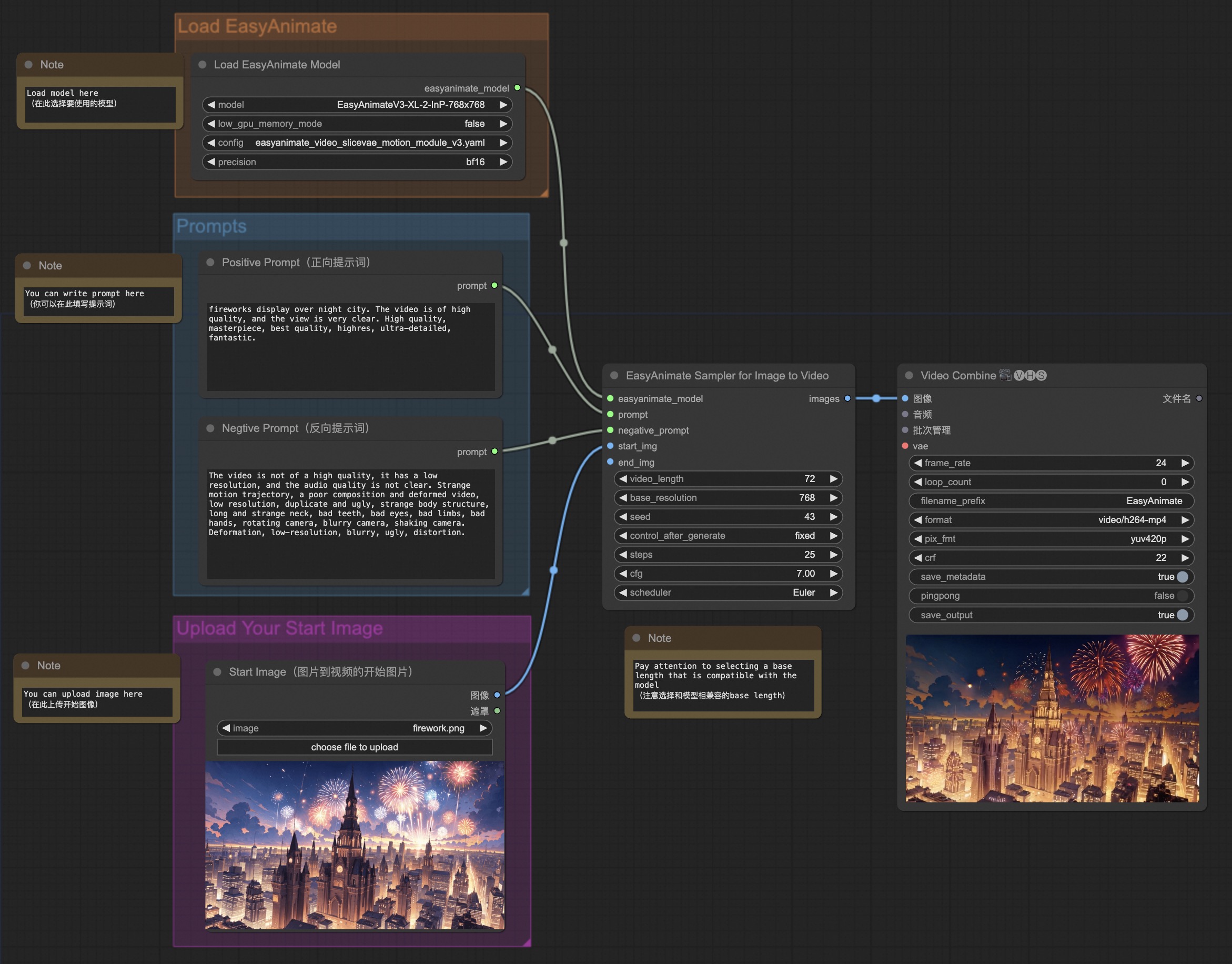
webui支持文生视频、图生视频、视频生视频和普通控制生视频(Canny、Pose、Depth等)
|
| 261 |
-
|
| 262 |
-
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
|
| 263 |
-
- 步骤2:运行app.py文件,进入gradio页面。
|
| 264 |
-
- 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。
|
| 265 |
-
|
| 266 |
-
# 快速启动
|
| 267 |
-
### 1. 云使用: AliyunDSW/Docker
|
| 268 |
-
#### a. 通过阿里云 DSW
|
| 269 |
-
DSW 有免费 GPU 时间,用户可申请一次,申请后3个月内有效。
|
| 270 |
-
|
| 271 |
-
阿里云在[Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1)提供免费GPU时间,获取并在阿里云PAI-DSW中使用,5分钟内即可启动EasyAnimate
|
| 272 |
-
|
| 273 |
-
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate_v5)
|
| 274 |
-
|
| 275 |
-
#### b. 通过ComfyUI
|
| 276 |
-
我们的ComfyUI界面如下,具体查看[ComfyUI README](https://github.com/aigc-apps/EasyAnimate/blob/main/comfyui/README.md)。
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
#### c. 通过docker
|
| 280 |
-
使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
|
| 281 |
```
|
| 282 |
-
# pull image
|
| 283 |
-
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 284 |
-
|
| 285 |
-
# enter image
|
| 286 |
-
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 287 |
-
|
| 288 |
-
# clone code
|
| 289 |
-
git clone https://github.com/aigc-apps/EasyAnimate.git
|
| 290 |
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
|
| 297 |
-
|
| 298 |
-
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 302 |
```
|
| 303 |
|
| 304 |
-
|
| 305 |
-
|
| 306 |
-
|
| 307 |
-
|
| 308 |
-
|
| 309 |
-
|
| 310 |
-
|
| 311 |
-
|
| 312 |
-
|
| 313 |
-
|
| 314 |
-
|
| 315 |
-
|
| 316 |
-
|
| 317 |
-
|
| 318 |
-
-
|
| 319 |
-
|
| 320 |
-
|
| 321 |
-
|
| 322 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 323 |
|
| 324 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 325 |
|
|
|
|
| 326 |
EasyAnimateV5.1-12B的视频大小可以由不同的GPU Memory生成,包括:
|
| 327 |
| GPU memory |384x672x25|384x672x49|576x1008x25|576x1008x49|768x1344x25|768x1344x49|
|
| 328 |
|----------|----------|----------|----------|----------|----------|----------|
|
|
@@ -339,9 +685,9 @@ EasyAnimateV5.1-7B的视频大小可以由不同的GPU Memory生成,包括:
|
|
| 339 |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 340 |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 341 |
|
| 342 |
-
✅ 表示它可以在"model_cpu_offload"的情况下运行,🧡代表它可以在"
|
| 343 |
|
| 344 |
-
有一些不支持torch.bfloat16的卡型,如2080ti、V100
|
| 345 |
|
| 346 |
EasyAnimateV5.1-12B使用不同GPU在25个steps中的生成时间如下:
|
| 347 |
| GPU |384x672x72|384x672x49|576x1008x25|576x1008x49|768x1344x25|768x1344x49|
|
|
@@ -349,29 +695,6 @@ EasyAnimateV5.1-12B使用不同GPU在25个steps中的生成时间如下:
|
|
| 349 |
| A10 24GB |约120秒 (4.8s/it)|约240秒 (9.6s/it)|约320秒 (12.7s/it)| 约750秒 (29.8s/it)| ❌ | ❌ |
|
| 350 |
| A100 80GB |约45秒 (1.75s/it)|约90秒 (3.7s/it)|约120秒 (4.7s/it)|约300秒 (11.4s/it)|约265秒 (10.6s/it)| 约710秒 (28.3s/it)|
|
| 351 |
|
| 352 |
-
|
| 353 |
-
#### b. 权重放置
|
| 354 |
-
我们最好将[权重](#model-zoo)按照指定路径进行放置:
|
| 355 |
-
|
| 356 |
-
EasyAnimateV5.1:
|
| 357 |
-
```
|
| 358 |
-
📦 models/
|
| 359 |
-
├── 📂 Diffusion_Transformer/
|
| 360 |
-
│ ├── 📂 EasyAnimateV5.1-12b-zh-InP/
|
| 361 |
-
│ ├── 📂 EasyAnimateV5.1-12b-zh-Control/
|
| 362 |
-
│ ├── 📂 EasyAnimateV5.1-12b-zh-Control-Camera/
|
| 363 |
-
│ └── 📂 EasyAnimateV5.1-12b-zh/
|
| 364 |
-
├── 📂 Personalized_Model/
|
| 365 |
-
│ └── your trained trainformer model / your trained lora model (for UI load)
|
| 366 |
-
```
|
| 367 |
-
|
| 368 |
-
# 联系我们
|
| 369 |
-
1. 扫描下方二维码或搜索群号:77450006752 来加入钉钉群。
|
| 370 |
-
2. 扫描下方二维码来加入微信群(如果二维码失效,可扫描最右边同学的微信,邀请您入群)
|
| 371 |
-
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/>
|
| 372 |
-
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/wechat.jpg" alt="Wechat group" width="30%"/>
|
| 373 |
-
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/person.jpg" alt="Person" width="30%"/>
|
| 374 |
-
|
| 375 |
# 参考文献
|
| 376 |
- CogVideo: https://github.com/THUDM/CogVideo/
|
| 377 |
- Flux: https://github.com/black-forest-labs/flux
|
|
|
|
| 14 |
[English](./README_en.md) | [简体中文](./README.md)
|
| 15 |
|
| 16 |
# 模型地址
|
| 17 |
+
EasyAnimateV5.1 for diffusers:
|
| 18 |
+
|
| 19 |
+
该权重文件主要用于 **[diffusers](https://github.com/huggingface/diffusers)** 仓库。
|
| 20 |
+
需要注意的是,**EasyAnimate** 仓库与 **diffusers** 仓库在权重格式和使用方式上存在些许差异,请务必仔细甄别。
|
| 21 |
+
|
| 22 |
+
7B:
|
| 23 |
+
| 名称 | 种类 | 存储空间 | Hugging Face | 描述 |
|
| 24 |
+
|--|--|--|--|--|
|
| 25 |
+
| EasyAnimateV5.1-7b-zh-InP | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers) | 官方的图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 26 |
+
| EasyAnimateV5.1-7b-zh-Control | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-Control-diffusers) | 官方的视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 27 |
+
| EasyAnimateV5.1-7b-zh-Control-Camera | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-Control-Camera-diffusers) | 官方的视频相机控制权重,支持通过输入相机运动轨迹控制生成方向。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 28 |
+
| EasyAnimateV5.1-7b-zh | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-diffusers) | 官方的文生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 29 |
+
|
| 30 |
+
12B:
|
| 31 |
+
| 名称 | 种类 | 存储空间 | Hugging Face | 描述 |
|
| 32 |
+
|--|--|--|--|--|
|
| 33 |
+
| EasyAnimateV5.1-12b-zh-InP | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers) | 官方的图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 34 |
+
| EasyAnimateV5.1-12b-zh-Control | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-diffusers) | 官方的视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 35 |
+
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera-diffusers) | 官方的视频相机控制权重,支持通过输入相机运动轨迹控制生成方向。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 36 |
+
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-diffusers) | 官方的文生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 37 |
+
|
| 38 |
+
<details>
|
| 39 |
+
<summary>EasyAnimateV5.1:</summary>
|
| 40 |
+
|
| 41 |
+
该权重文件主要用于 **[EasyAnimate](https://github.com/aigc-apps/EasyAnimate)** 仓库。
|
| 42 |
+
需要注意的是,**EasyAnimate** 仓库与 **diffusers** 仓库在权重格式和使用方式上存在些许差异,请务必仔细甄别。
|
| 43 |
|
| 44 |
7B:
|
| 45 |
| 名称 | 种类 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
|
|
|
| 57 |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-Control-Camera)| 官方的视频相机控制权重,支持通过输入相机运动轨迹控制生成方向。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 58 |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh)| 官方的文生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持多语言预测 |
|
| 59 |
|
| 60 |
+
</details>
|
| 61 |
|
| 62 |
# 视频作品
|
| 63 |
|
|
|
|
| 239 |
|
| 240 |
# 如何使用
|
| 241 |
|
| 242 |
+
#### a、Text to video
|
| 243 |
+
```python
|
| 244 |
+
import torch
|
| 245 |
+
import numpy as np
|
| 246 |
+
from diffusers import EasyAnimatePipeline
|
| 247 |
+
from diffusers.utils import export_to_video
|
| 248 |
+
|
| 249 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-7b-zh-diffusers" or "alibaba-pai/EasyAnimateV5.1-12b-zh-diffusers"
|
| 250 |
+
pipe = EasyAnimatePipeline.from_pretrained(
|
| 251 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-diffusers",
|
| 252 |
+
torch_dtype=torch.bfloat16
|
| 253 |
+
)
|
| 254 |
+
pipe.enable_model_cpu_offload()
|
| 255 |
+
pipe.vae.enable_tiling()
|
| 256 |
+
pipe.vae.enable_slicing()
|
| 257 |
+
|
| 258 |
+
prompt = (
|
| 259 |
+
"A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. "
|
| 260 |
+
"The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other "
|
| 261 |
+
"pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, "
|
| 262 |
+
"casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. "
|
| 263 |
+
"The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical "
|
| 264 |
+
"atmosphere of this unique musical performance."
|
| 265 |
+
)
|
| 266 |
+
negative_prompt = "bad detailed"
|
| 267 |
+
height = 512
|
| 268 |
+
width = 512
|
| 269 |
+
guidance_scale = 6
|
| 270 |
+
num_inference_steps = 50
|
| 271 |
+
num_frames = 49
|
| 272 |
+
seed = 43
|
| 273 |
+
generator = torch.Generator(device="cuda").manual_seed(seed)
|
| 274 |
+
|
| 275 |
+
video = pipe(
|
| 276 |
+
prompt=prompt,
|
| 277 |
+
negative_prompt=negative_prompt,
|
| 278 |
+
guidance_scale=guidance_scale,
|
| 279 |
+
num_inference_steps=num_inference_steps,
|
| 280 |
+
num_frames=num_frames,
|
| 281 |
+
height=height,
|
| 282 |
+
width=width,
|
| 283 |
+
generator=generator,
|
| 284 |
+
).frames[0]
|
| 285 |
+
export_to_video(video, "output.mp4", fps=8)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 286 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 287 |
|
| 288 |
+
#### b、Image to video
|
| 289 |
+
```python
|
| 290 |
+
import torch
|
| 291 |
+
from diffusers import EasyAnimateInpaintPipeline
|
| 292 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 293 |
+
get_image_to_video_latent
|
| 294 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 295 |
+
get_video_to_video_latent
|
| 296 |
+
from diffusers.utils import export_to_video, load_image, load_video
|
| 297 |
+
|
| 298 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers"
|
| 299 |
+
pipe = EasyAnimateInpaintPipeline.from_pretrained(
|
| 300 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers",
|
| 301 |
+
torch_dtype=torch.bfloat16
|
| 302 |
+
)
|
| 303 |
+
pipe.enable_model_cpu_offload()
|
| 304 |
+
pipe.vae.enable_tiling()
|
| 305 |
+
pipe.vae.enable_slicing()
|
| 306 |
+
|
| 307 |
+
prompt = "An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
|
| 308 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 309 |
+
|
| 310 |
+
validation_image_start = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg")
|
| 311 |
+
validation_image_end = None
|
| 312 |
+
sample_size = (448, 576)
|
| 313 |
+
num_frames = 49
|
| 314 |
+
|
| 315 |
+
input_video, input_video_mask = get_image_to_video_latent([validation_image_start], validation_image_end, num_frames, sample_size)
|
| 316 |
+
|
| 317 |
+
video = pipe(
|
| 318 |
+
prompt,
|
| 319 |
+
negative_prompt=negative_prompt,
|
| 320 |
+
num_frames=num_frames,
|
| 321 |
+
height=sample_size[0],
|
| 322 |
+
width=sample_size[1],
|
| 323 |
+
video=input_video,
|
| 324 |
+
mask_video=input_video_mask
|
| 325 |
+
)
|
| 326 |
+
export_to_video(video.frames[0], "output.mp4", fps=8)
|
| 327 |
+
```
|
| 328 |
+
#### c、Video to video
|
| 329 |
+
```python
|
| 330 |
+
import torch
|
| 331 |
+
from diffusers import EasyAnimateInpaintPipeline
|
| 332 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 333 |
+
get_image_to_video_latent
|
| 334 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 335 |
+
get_video_to_video_latent
|
| 336 |
+
from diffusers.utils import export_to_video, load_image, load_video
|
| 337 |
+
|
| 338 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers"
|
| 339 |
+
pipe = EasyAnimateInpaintPipeline.from_pretrained(
|
| 340 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers",
|
| 341 |
+
torch_dtype=torch.bfloat16
|
| 342 |
+
)
|
| 343 |
+
pipe.enable_model_cpu_offload()
|
| 344 |
+
pipe.vae.enable_tiling()
|
| 345 |
+
pipe.vae.enable_slicing()
|
| 346 |
+
|
| 347 |
+
prompt = "一只穿着小外套的猫咪正安静地坐在花园的秋千上弹吉他。它的小外套精致而合身,增添了几分俏皮与可爱。晚霞的余光洒在它柔软的毛皮上,给它的毛发镀上了一层温暖的金色光辉。和煦的微风轻轻拂过,带来阵阵花香和草木的气息,令人心旷神怡。周围斑驳的光影随着音乐的旋律轻轻摇曳,仿佛整个花园都在为这只小猫咪的演奏伴舞。阳光透过树叶间的缝隙,投下一片片光影交错的图案,与悠扬的吉他声交织在一起,营造出一种梦幻而宁静的氛围。猫咪专注而投入地弹奏着,每一个音符都似乎充满了魔力,让这个傍晚变得更加美好。"
|
| 348 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 349 |
+
sample_size = (384, 672)
|
| 350 |
+
num_frames = 49
|
| 351 |
+
input_video = load_video("https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP/resolve/main/asset/1.mp4")
|
| 352 |
+
input_video, input_video_mask, _ = get_video_to_video_latent(input_video, num_frames=num_frames, validation_video_mask=None, sample_size=sample_size)
|
| 353 |
+
video = pipe(
|
| 354 |
+
prompt,
|
| 355 |
+
num_frames=num_frames,
|
| 356 |
+
negative_prompt=negative_prompt,
|
| 357 |
+
height=sample_size[0],
|
| 358 |
+
width=sample_size[1],
|
| 359 |
+
video=input_video,
|
| 360 |
+
mask_video=input_video_mask,
|
| 361 |
+
strength=0.70
|
| 362 |
+
)
|
| 363 |
+
|
| 364 |
+
export_to_video(video.frames[0], "output.mp4", fps=8)
|
| 365 |
```
|
| 366 |
|
| 367 |
+
#### d、Control to video
|
| 368 |
+
```python
|
| 369 |
+
import numpy as np
|
| 370 |
+
import torch
|
| 371 |
+
from diffusers import EasyAnimateControlPipeline
|
| 372 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 373 |
+
get_video_to_video_latent
|
| 374 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 375 |
+
get_image_to_video_latent
|
| 376 |
+
from diffusers.utils import export_to_video, load_video
|
| 377 |
+
from PIL import Image
|
| 378 |
+
|
| 379 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-Control-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-Control-diffusers"
|
| 380 |
+
pipe = EasyAnimateControlPipeline.from_pretrained(
|
| 381 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-Control-diffusers",
|
| 382 |
+
torch_dtype=torch.bfloat16
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
pipe.enable_model_cpu_offload()
|
| 386 |
+
pipe.vae.enable_tiling()
|
| 387 |
+
pipe.vae.enable_slicing()
|
| 388 |
+
|
| 389 |
+
control_video = load_video(
|
| 390 |
+
"https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control/resolve/main/asset/pose.mp4"
|
| 391 |
+
)
|
| 392 |
+
prompt = (
|
| 393 |
+
"In this sunlit outdoor garden, a beautiful woman is dressed in a knee-length, sleeveless white dress. "
|
| 394 |
+
"The hem of her dress gently sways with her graceful dance, much like a butterfly fluttering in the breeze. "
|
| 395 |
+
"Sunlight filters through the leaves, casting dappled shadows that highlight her soft features and clear eyes, "
|
| 396 |
+
"making her appear exceptionally elegant. It seems as if every movement she makes speaks of youth and vitality. "
|
| 397 |
+
"As she twirls on the grass, her dress flutters, as if the entire garden is rejoicing in her dance. "
|
| 398 |
+
"The colorful flowers around her sway in the gentle breeze, with roses, chrysanthemums, and lilies each "
|
| 399 |
+
"releasing their fragrances, creating a relaxed and joyful atmosphere."
|
| 400 |
+
)
|
| 401 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 402 |
+
sample_size = (672, 384)
|
| 403 |
+
num_frames = 49
|
| 404 |
+
generator = torch.Generator(device="cuda").manual_seed(43)
|
| 405 |
+
input_video, _, _ = get_video_to_video_latent(np.array(control_video), num_frames, sample_size)
|
| 406 |
+
|
| 407 |
+
video = pipe(prompt, num_frames=num_frames, negative_prompt=negative_prompt, height=sample_size[0], width=sample_size[1], control_video=input_video, generator=generator).frames[0]
|
| 408 |
+
export_to_video(video, "output.mp4", fps=8)
|
| 409 |
+
```
|
| 410 |
|
| 411 |
+
#### e、Camera Control to video
|
| 412 |
+
由于镜头控制模型需要对镜头文件进行处理,请前往[asset](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera/blob/main/asset/)下载对应镜头移动的txt文件。
|
| 413 |
+
|
| 414 |
+
相关代码较为复杂,已经隐藏,请点击打开。
|
| 415 |
+
<details>
|
| 416 |
+
<summary>EasyAnimateV5.1:</summary>
|
| 417 |
+
|
| 418 |
+
```python
|
| 419 |
+
import numpy as np
|
| 420 |
+
import torch
|
| 421 |
+
from diffusers import EasyAnimateControlPipeline
|
| 422 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 423 |
+
get_video_to_video_latent
|
| 424 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 425 |
+
get_image_to_video_latent
|
| 426 |
+
from diffusers.utils import export_to_video, load_video, load_image
|
| 427 |
+
from einops import rearrange
|
| 428 |
+
from packaging import version as pver
|
| 429 |
+
from PIL import Image
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
class Camera(object):
|
| 433 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 434 |
+
"""
|
| 435 |
+
def __init__(self, entry):
|
| 436 |
+
fx, fy, cx, cy = entry[1:5]
|
| 437 |
+
self.fx = fx
|
| 438 |
+
self.fy = fy
|
| 439 |
+
self.cx = cx
|
| 440 |
+
self.cy = cy
|
| 441 |
+
w2c_mat = np.array(entry[7:]).reshape(3, 4)
|
| 442 |
+
w2c_mat_4x4 = np.eye(4)
|
| 443 |
+
w2c_mat_4x4[:3, :] = w2c_mat
|
| 444 |
+
self.w2c_mat = w2c_mat_4x4
|
| 445 |
+
self.c2w_mat = np.linalg.inv(w2c_mat_4x4)
|
| 446 |
+
|
| 447 |
+
def custom_meshgrid(*args):
|
| 448 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 449 |
+
"""
|
| 450 |
+
# ref: https://pytorch.org/docs/stable/generated/torch.meshgrid.html?highlight=meshgrid#torch.meshgrid
|
| 451 |
+
if pver.parse(torch.__version__) < pver.parse('1.10'):
|
| 452 |
+
return torch.meshgrid(*args)
|
| 453 |
+
else:
|
| 454 |
+
return torch.meshgrid(*args, indexing='ij')
|
| 455 |
+
|
| 456 |
+
def get_relative_pose(cam_params):
|
| 457 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 458 |
+
"""
|
| 459 |
+
abs_w2cs = [cam_param.w2c_mat for cam_param in cam_params]
|
| 460 |
+
abs_c2ws = [cam_param.c2w_mat for cam_param in cam_params]
|
| 461 |
+
cam_to_origin = 0
|
| 462 |
+
target_cam_c2w = np.array([
|
| 463 |
+
[1, 0, 0, 0],
|
| 464 |
+
[0, 1, 0, -cam_to_origin],
|
| 465 |
+
[0, 0, 1, 0],
|
| 466 |
+
[0, 0, 0, 1]
|
| 467 |
+
])
|
| 468 |
+
abs2rel = target_cam_c2w @ abs_w2cs[0]
|
| 469 |
+
ret_poses = [target_cam_c2w, ] + [abs2rel @ abs_c2w for abs_c2w in abs_c2ws[1:]]
|
| 470 |
+
ret_poses = np.array(ret_poses, dtype=np.float32)
|
| 471 |
+
return ret_poses
|
| 472 |
+
|
| 473 |
+
def ray_condition(K, c2w, H, W, device):
|
| 474 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 475 |
+
"""
|
| 476 |
+
# c2w: B, V, 4, 4
|
| 477 |
+
# K: B, V, 4
|
| 478 |
+
|
| 479 |
+
B = K.shape[0]
|
| 480 |
+
|
| 481 |
+
j, i = custom_meshgrid(
|
| 482 |
+
torch.linspace(0, H - 1, H, device=device, dtype=c2w.dtype),
|
| 483 |
+
torch.linspace(0, W - 1, W, device=device, dtype=c2w.dtype),
|
| 484 |
+
)
|
| 485 |
+
i = i.reshape([1, 1, H * W]).expand([B, 1, H * W]) + 0.5 # [B, HxW]
|
| 486 |
+
j = j.reshape([1, 1, H * W]).expand([B, 1, H * W]) + 0.5 # [B, HxW]
|
| 487 |
+
|
| 488 |
+
fx, fy, cx, cy = K.chunk(4, dim=-1) # B,V, 1
|
| 489 |
+
|
| 490 |
+
zs = torch.ones_like(i) # [B, HxW]
|
| 491 |
+
xs = (i - cx) / fx * zs
|
| 492 |
+
ys = (j - cy) / fy * zs
|
| 493 |
+
zs = zs.expand_as(ys)
|
| 494 |
+
|
| 495 |
+
directions = torch.stack((xs, ys, zs), dim=-1) # B, V, HW, 3
|
| 496 |
+
directions = directions / directions.norm(dim=-1, keepdim=True) # B, V, HW, 3
|
| 497 |
+
|
| 498 |
+
rays_d = directions @ c2w[..., :3, :3].transpose(-1, -2) # B, V, 3, HW
|
| 499 |
+
rays_o = c2w[..., :3, 3] # B, V, 3
|
| 500 |
+
rays_o = rays_o[:, :, None].expand_as(rays_d) # B, V, 3, HW
|
| 501 |
+
# c2w @ dirctions
|
| 502 |
+
rays_dxo = torch.cross(rays_o, rays_d)
|
| 503 |
+
plucker = torch.cat([rays_dxo, rays_d], dim=-1)
|
| 504 |
+
plucker = plucker.reshape(B, c2w.shape[1], H, W, 6) # B, V, H, W, 6
|
| 505 |
+
# plucker = plucker.permute(0, 1, 4, 2, 3)
|
| 506 |
+
return plucker
|
| 507 |
+
|
| 508 |
+
def process_pose_file(pose_file_path, width=672, height=384, original_pose_width=1280, original_pose_height=720, device='cpu', return_poses=False):
|
| 509 |
+
"""Modified from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 510 |
+
"""
|
| 511 |
+
with open(pose_file_path, 'r') as f:
|
| 512 |
+
poses = f.readlines()
|
| 513 |
+
|
| 514 |
+
poses = [pose.strip().split(' ') for pose in poses[1:]]
|
| 515 |
+
cam_params = [[float(x) for x in pose] for pose in poses]
|
| 516 |
+
if return_poses:
|
| 517 |
+
return cam_params
|
| 518 |
+
else:
|
| 519 |
+
cam_params = [Camera(cam_param) for cam_param in cam_params]
|
| 520 |
+
|
| 521 |
+
sample_wh_ratio = width / height
|
| 522 |
+
pose_wh_ratio = original_pose_width / original_pose_height # Assuming placeholder ratios, change as needed
|
| 523 |
+
|
| 524 |
+
if pose_wh_ratio > sample_wh_ratio:
|
| 525 |
+
resized_ori_w = height * pose_wh_ratio
|
| 526 |
+
for cam_param in cam_params:
|
| 527 |
+
cam_param.fx = resized_ori_w * cam_param.fx / width
|
| 528 |
+
else:
|
| 529 |
+
resized_ori_h = width / pose_wh_ratio
|
| 530 |
+
for cam_param in cam_params:
|
| 531 |
+
cam_param.fy = resized_ori_h * cam_param.fy / height
|
| 532 |
+
|
| 533 |
+
intrinsic = np.asarray([[cam_param.fx * width,
|
| 534 |
+
cam_param.fy * height,
|
| 535 |
+
cam_param.cx * width,
|
| 536 |
+
cam_param.cy * height]
|
| 537 |
+
for cam_param in cam_params], dtype=np.float32)
|
| 538 |
+
|
| 539 |
+
K = torch.as_tensor(intrinsic)[None] # [1, 1, 4]
|
| 540 |
+
c2ws = get_relative_pose(cam_params) # Assuming this function is defined elsewhere
|
| 541 |
+
c2ws = torch.as_tensor(c2ws)[None] # [1, n_frame, 4, 4]
|
| 542 |
+
plucker_embedding = ray_condition(K, c2ws, height, width, device=device)[0].permute(0, 3, 1, 2).contiguous() # V, 6, H, W
|
| 543 |
+
plucker_embedding = plucker_embedding[None]
|
| 544 |
+
plucker_embedding = rearrange(plucker_embedding, "b f c h w -> b f h w c")[0]
|
| 545 |
+
return plucker_embedding
|
| 546 |
+
|
| 547 |
+
def get_image_latent(ref_image=None, sample_size=None):
|
| 548 |
+
if ref_image is not None:
|
| 549 |
+
if isinstance(ref_image, str):
|
| 550 |
+
ref_image = Image.open(ref_image).convert("RGB")
|
| 551 |
+
ref_image = ref_image.resize((sample_size[1], sample_size[0]))
|
| 552 |
+
ref_image = torch.from_numpy(np.array(ref_image))
|
| 553 |
+
ref_image = ref_image.unsqueeze(0).permute([3, 0, 1, 2]).unsqueeze(0) / 255
|
| 554 |
+
else:
|
| 555 |
+
ref_image = torch.from_numpy(np.array(ref_image))
|
| 556 |
+
ref_image = ref_image.unsqueeze(0).permute([3, 0, 1, 2]).unsqueeze(0) / 255
|
| 557 |
+
|
| 558 |
+
return ref_image
|
| 559 |
+
|
| 560 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-7b-zh-Control-Camera-diffusers" or "alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera-diffusers"
|
| 561 |
+
pipe = EasyAnimateControlPipeline.from_pretrained(
|
| 562 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera-diffusers",
|
| 563 |
+
torch_dtype=torch.bfloat16
|
| 564 |
+
)
|
| 565 |
+
pipe.enable_model_cpu_offload()
|
| 566 |
+
pipe.vae.enable_tiling()
|
| 567 |
+
pipe.vae.enable_slicing()
|
| 568 |
+
|
| 569 |
+
input_video, input_video_mask = None, None
|
| 570 |
+
prompt = "Fireworks light up the evening sky over a sprawling cityscape with gothic-style buildings featuring pointed towers and clock faces. The city is lit by both artificial lights from the buildings and the colorful bursts of the fireworks. The scene is viewed from an elevated angle, showcasing a vibrant urban environment set against a backdrop of a dramatic, partially cloudy sky at dusk."
|
| 571 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 572 |
+
sample_size = (384, 672)
|
| 573 |
+
num_frames = 49
|
| 574 |
+
fps = 8
|
| 575 |
+
ref_image = load_image("https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera/resolve/main/asset/1.png")
|
| 576 |
+
|
| 577 |
+
control_camera_video = process_pose_file("/The_Path_To/Pan_Left.txt", sample_size[1], sample_size[0])
|
| 578 |
+
control_camera_video = control_camera_video[::int(24 // fps)][:num_frames].permute([3, 0, 1, 2]).unsqueeze(0)
|
| 579 |
+
ref_image = get_image_latent(sample_size=sample_size, ref_image=ref_image)
|
| 580 |
+
video = pipe(
|
| 581 |
+
prompt,
|
| 582 |
+
negative_prompt=negative_prompt,
|
| 583 |
+
num_frames=num_frames,
|
| 584 |
+
height=sample_size[0],
|
| 585 |
+
width=sample_size[1],
|
| 586 |
+
control_camera_video=control_camera_video,
|
| 587 |
+
ref_image=ref_image
|
| 588 |
+
).frames[0]
|
| 589 |
+
export_to_video(video, "output.mp4", fps=fps)
|
| 590 |
+
```
|
| 591 |
+
</details>
|
| 592 |
+
|
| 593 |
+
#### f、float8 model
|
| 594 |
+
由于EasyAnimateV5.1的参数非常大,我们需要考虑显存节省方案,以节省显存适应消费级显卡。我们可以将模型放入float8以节省显存。
|
| 595 |
+
|
| 596 |
+
以图生视频为例,我们将模型防止到float8上,然后在预测的时候转为bfloat16。
|
| 597 |
+
```python
|
| 598 |
+
"""Modified from https://github.com/kijai/ComfyUI-MochiWrapper
|
| 599 |
+
"""
|
| 600 |
+
import torch
|
| 601 |
+
import torch.nn as nn
|
| 602 |
+
from diffusers import EasyAnimateInpaintPipeline
|
| 603 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 604 |
+
get_video_to_video_latent
|
| 605 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 606 |
+
get_image_to_video_latent
|
| 607 |
+
from diffusers.utils import export_to_video, load_image, load_video
|
| 608 |
+
|
| 609 |
+
def autocast_model_forward(cls, origin_dtype, *inputs, **kwargs):
|
| 610 |
+
weight_dtype = cls.weight.dtype
|
| 611 |
+
cls.to(origin_dtype)
|
| 612 |
+
|
| 613 |
+
# Convert all inputs to the original dtype
|
| 614 |
+
inputs = [input.to(origin_dtype) for input in inputs]
|
| 615 |
+
out = cls.original_forward(*inputs, **kwargs)
|
| 616 |
+
|
| 617 |
+
cls.to(weight_dtype)
|
| 618 |
+
return out
|
| 619 |
+
|
| 620 |
+
def convert_weight_dtype_wrapper(module, origin_dtype):
|
| 621 |
+
for name, module in module.named_modules():
|
| 622 |
+
if name == "" or "embed_tokens" in name:
|
| 623 |
+
continue
|
| 624 |
+
original_forward = module.forward
|
| 625 |
+
if hasattr(module, "weight"):
|
| 626 |
+
setattr(module, "original_forward", original_forward)
|
| 627 |
+
setattr(
|
| 628 |
+
module,
|
| 629 |
+
"forward",
|
| 630 |
+
lambda *inputs, m=module, **kwargs: autocast_model_forward(m, origin_dtype, *inputs, **kwargs)
|
| 631 |
+
)
|
| 632 |
+
|
| 633 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers"
|
| 634 |
+
pipe = EasyAnimateInpaintPipeline.from_pretrained(
|
| 635 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers",
|
| 636 |
+
torch_dtype=torch.bfloat16
|
| 637 |
+
)
|
| 638 |
+
pipe.transformer = pipe.transformer.to(torch.float8_e4m3fn)
|
| 639 |
+
from fp8_optimization import convert_weight_dtype_wrapper
|
| 640 |
+
|
| 641 |
+
for _text_encoder in [pipe.text_encoder, pipe.text_encoder_2]:
|
| 642 |
+
if hasattr(_text_encoder, "visual"):
|
| 643 |
+
del _text_encoder.visual
|
| 644 |
+
convert_weight_dtype_wrapper(pipe.transformer, torch.bfloat16)
|
| 645 |
+
pipe.enable_model_cpu_offload()
|
| 646 |
+
pipe.vae.enable_tiling()
|
| 647 |
+
pipe.vae.enable_slicing()
|
| 648 |
+
|
| 649 |
+
prompt = "An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
|
| 650 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 651 |
+
validation_image_start = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg")
|
| 652 |
+
validation_image_end = None
|
| 653 |
+
sample_size = (448, 576)
|
| 654 |
+
num_frames = 49
|
| 655 |
+
input_video, input_video_mask = get_image_to_video_latent(
|
| 656 |
+
[validation_image_start], validation_image_end, num_frames, sample_size
|
| 657 |
+
)
|
| 658 |
+
|
| 659 |
+
video = pipe(
|
| 660 |
+
prompt,
|
| 661 |
+
negative_prompt=negative_prompt,
|
| 662 |
+
num_frames=num_frames,
|
| 663 |
+
height=sample_size[0],
|
| 664 |
+
width=sample_size[1],
|
| 665 |
+
video=input_video,
|
| 666 |
+
mask_video=input_video_mask
|
| 667 |
+
)
|
| 668 |
+
export_to_video(video.frames[0], "output.mp4", fps=8)
|
| 669 |
+
```
|
| 670 |
|
| 671 |
+
# 显存需求
|
| 672 |
EasyAnimateV5.1-12B的视频大小可以由不同的GPU Memory生成,包括:
|
| 673 |
| GPU memory |384x672x25|384x672x49|576x1008x25|576x1008x49|768x1344x25|768x1344x49|
|
| 674 |
|----------|----------|----------|----------|----------|----------|----------|
|
|
|
|
| 685 |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 686 |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 687 |
|
| 688 |
+
✅ 表示它可以在"model_cpu_offload"的情况下运行,🧡代表它可以在"model_cpu_offload" + float8的情况下运行,⭕️ 表示它可以在"sequential_cpu_offload"的情况下运行,当前由于qwen2vl不支持"sequential_cpu_offload",我们无法使用在diffusers中使用sequential_cpu_offload,具体修复时间未知,但可以在EasyAnimate官方仓库中使用,❌ 表示它无法运行。请注意,使用sequential_cpu_offload运行会更慢。
|
| 689 |
|
| 690 |
+
有一些不支持torch.bfloat16的卡型,如2080ti、V100,需要使用torch.float16才可以运行。
|
| 691 |
|
| 692 |
EasyAnimateV5.1-12B使用不同GPU在25个steps中的生成时间如下:
|
| 693 |
| GPU |384x672x72|384x672x49|576x1008x25|576x1008x49|768x1344x25|768x1344x49|
|
|
|
|
| 695 |
| A10 24GB |约120秒 (4.8s/it)|约240秒 (9.6s/it)|约320秒 (12.7s/it)| 约750秒 (29.8s/it)| ❌ | ❌ |
|
| 696 |
| A100 80GB |约45秒 (1.75s/it)|约90秒 (3.7s/it)|约120秒 (4.7s/it)|约300秒 (11.4s/it)|约265秒 (10.6s/it)| 约710秒 (28.3s/it)|
|
| 697 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 698 |
# 参考文献
|
| 699 |
- CogVideo: https://github.com/THUDM/CogVideo/
|
| 700 |
- Flux: https://github.com/black-forest-labs/flux
|
README_en.md
CHANGED
|
@@ -13,7 +13,30 @@ EasyAnimate is a pipeline based on the transformer architecture, designed for ge
|
|
| 13 |
|
| 14 |
# Model zoo
|
| 15 |
|
| 16 |
-
EasyAnimateV5.1:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
7B:
|
| 19 |
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|
|
@@ -31,6 +54,8 @@ EasyAnimateV5.1:
|
|
| 31 |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-Control-Camera) | Official video camera control weights, supporting direction generation control by inputting camera motion trajectories. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 32 |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 33 |
|
|
|
|
|
|
|
| 34 |
# Video Result
|
| 35 |
|
| 36 |
### Image to Video with EasyAnimateV5.1-12b-zh-InP
|
|
@@ -212,118 +237,437 @@ Generic Control Video (Canny, Pose, Depth, etc.):
|
|
| 212 |
|
| 213 |
# How to use
|
| 214 |
|
| 215 |
-
#### a
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
WebUI supports text-to-video, image-to-video, video-to-video, and control-based video generation (such as Canny, Pose, Depth, etc.).
|
| 260 |
-
|
| 261 |
-
- Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder.
|
| 262 |
-
- Step 2: Run the app.py file to enter the Gradio page.
|
| 263 |
-
- Step 3: Choose the generation model from the page, fill in prompt, neg_prompt, guidance_scale, seed, etc., click generate, and wait for the results, which are stored in the sample folder.
|
| 264 |
-
|
| 265 |
-
# Quick Start
|
| 266 |
-
### 1. Cloud usage: AliyunDSW/Docker
|
| 267 |
-
#### a. From AliyunDSW
|
| 268 |
-
DSW has free GPU time, which can be applied once by a user and is valid for 3 months after applying.
|
| 269 |
-
|
| 270 |
-
Aliyun provide free GPU time in [Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1), get it and use in Aliyun PAI-DSW to start EasyAnimate within 5min!
|
| 271 |
-
|
| 272 |
-
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate_v5)
|
| 273 |
-
|
| 274 |
-
#### b. From ComfyUI
|
| 275 |
-
Our ComfyUI is as follows, please refer to [ComfyUI README](https://github.com/aigc-apps/EasyAnimate/blob/main/comfyui/README.md) for details.
|
| 276 |
-

|
| 277 |
-
|
| 278 |
-
#### c. From docker
|
| 279 |
-
If you are using docker, please make sure that the graphics card driver and CUDA environment have been installed correctly in your machine.
|
| 280 |
-
|
| 281 |
-
Then execute the following commands in this way:
|
| 282 |
```
|
| 283 |
-
# pull image
|
| 284 |
-
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 285 |
-
|
| 286 |
-
# enter image
|
| 287 |
-
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 288 |
-
|
| 289 |
-
# clone code
|
| 290 |
-
git clone https://github.com/aigc-apps/EasyAnimate.git
|
| 291 |
-
|
| 292 |
-
# enter EasyAnimate's dir
|
| 293 |
-
cd EasyAnimate
|
| 294 |
|
| 295 |
-
|
| 296 |
-
|
| 297 |
-
|
| 298 |
-
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
|
| 302 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 303 |
```
|
| 304 |
|
| 305 |
-
|
| 306 |
-
|
| 307 |
-
|
| 308 |
-
|
| 309 |
-
|
| 310 |
-
|
| 311 |
-
|
| 312 |
-
|
| 313 |
-
|
| 314 |
-
|
| 315 |
-
|
| 316 |
-
|
| 317 |
-
|
| 318 |
-
|
| 319 |
-
-
|
| 320 |
-
|
| 321 |
-
|
| 322 |
-
|
| 323 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 324 |
|
| 325 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 326 |
|
|
|
|
| 327 |
The video size for EasyAnimateV5.1-12B can be generated by different GPU Memory, including:
|
| 328 |
| GPU memory | 384x672x25 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|
| 329 |
|------------|------------|------------|------------|------------|------------|------------|
|
|
@@ -340,9 +684,9 @@ The video size for EasyAnimateV5.1-7B can be generated by different GPU Memory,
|
|
| 340 |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 341 |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 342 |
|
| 343 |
-
✅
|
| 344 |
|
| 345 |
-
Some GPUs that do not support torch.bfloat16, such as 2080ti and V100, require changing the
|
| 346 |
|
| 347 |
The generation time for EasyAnimateV5.1-12B using different GPUs over 25 steps is as follows:
|
| 348 |
|
|
@@ -351,23 +695,8 @@ The generation time for EasyAnimateV5.1-12B using different GPUs over 25 steps i
|
|
| 351 |
| A10 24GB | ~120s (4.8s/it) | ~240s (9.6s/it) | ~320s (12.7s/it) | ~750s (29.8s/it) | ❌ | ❌ |
|
| 352 |
| A100 80GB | ~45s (1.75s/it) | ~90s (3.7s/it) | ~120s (4.7s/it) | ~300s (11.4s/it) | ~265s (10.6s/it) | ~710s (28.3s/it) |
|
| 353 |
|
| 354 |
-
#### b. Weights
|
| 355 |
-
We'd better place the [weights](#model-zoo) along the specified path:
|
| 356 |
-
|
| 357 |
-
EasyAnimateV5.1:
|
| 358 |
-
```
|
| 359 |
-
📦 models/
|
| 360 |
-
├── 📂 Diffusion_Transformer/
|
| 361 |
-
│ ├── 📂 EasyAnimateV5.1-12b-zh-InP/
|
| 362 |
-
│ ├── 📂 EasyAnimateV5.1-12b-zh-Control/
|
| 363 |
-
│ ├── 📂 EasyAnimateV5.1-12b-zh-Control-Camera/
|
| 364 |
-
│ └── 📂 EasyAnimateV5.1-12b-zh/
|
| 365 |
-
├── 📂 Personalized_Model/
|
| 366 |
-
│ └── your trained trainformer model / your trained lora model (for UI load)
|
| 367 |
-
```
|
| 368 |
-
|
| 369 |
# Contact Us
|
| 370 |
-
1. Use Dingding to search group 77450006752 or Scan to join
|
| 371 |
2. You need to scan the image to join the WeChat group or if it is expired, add this student as a friend first to invite you.
|
| 372 |
|
| 373 |
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/>
|
|
|
|
| 13 |
|
| 14 |
# Model zoo
|
| 15 |
|
| 16 |
+
EasyAnimateV5.1 for diffusers:
|
| 17 |
+
|
| 18 |
+
This weight file is mainly used for the **[diffusers](https://github.com/huggingface/diffusers)** repository.
|
| 19 |
+
|
| 20 |
+
Please note that there are some differences in the weight format and usage between the EasyAnimate repository and the diffusers repository. Be sure to carefully distinguish between them.
|
| 21 |
+
|
| 22 |
+
7B:
|
| 23 |
+
| Name | Type | Storage Space | Hugging Face | Description |
|
| 24 |
+
|--|--|--|--|--|
|
| 25 |
+
| EasyAnimateV5.1-7b-zh-InP | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-InP) | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 26 |
+
| EasyAnimateV5.1-7b-zh-Control | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-Control) | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, and trajectory control. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 27 |
+
| EasyAnimateV5.1-7b-zh-Control-Camera | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh-Control-Camera) | Official video camera control weights, supporting direction generation control by inputting camera motion trajectories. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 28 |
+
| EasyAnimateV5.1-7b-zh | EasyAnimateV5.1 | 30 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-7b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 29 |
+
|
| 30 |
+
12B:
|
| 31 |
+
| Name | Type | Storage Space | Hugging Face | Description |
|
| 32 |
+
|--|--|--|--|--|
|
| 33 |
+
| EasyAnimateV5.1-12b-zh-InP | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP) | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 34 |
+
| EasyAnimateV5.1-12b-zh-Control | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control) | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, and trajectory control. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 35 |
+
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera) | Official video camera control weights, supporting direction generation control by inputting camera motion trajectories. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 36 |
+
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 37 |
+
|
| 38 |
+
<details>
|
| 39 |
+
<summary>EasyAnimateV5.1:</summary>
|
| 40 |
|
| 41 |
7B:
|
| 42 |
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|
|
|
|
| 54 |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-Control-Camera) | Official video camera control weights, supporting direction generation control by inputting camera motion trajectories. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 55 |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
|
| 56 |
|
| 57 |
+
</details>
|
| 58 |
+
|
| 59 |
# Video Result
|
| 60 |
|
| 61 |
### Image to Video with EasyAnimateV5.1-12b-zh-InP
|
|
|
|
| 237 |
|
| 238 |
# How to use
|
| 239 |
|
| 240 |
+
#### a、Text to video
|
| 241 |
+
```python
|
| 242 |
+
import torch
|
| 243 |
+
import numpy as np
|
| 244 |
+
from diffusers import EasyAnimatePipeline
|
| 245 |
+
from diffusers.utils import export_to_video
|
| 246 |
+
|
| 247 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-7b-zh-diffusers" or "alibaba-pai/EasyAnimateV5.1-12b-zh-diffusers"
|
| 248 |
+
pipe = EasyAnimatePipeline.from_pretrained(
|
| 249 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-diffusers",
|
| 250 |
+
torch_dtype=torch.bfloat16
|
| 251 |
+
)
|
| 252 |
+
pipe.enable_model_cpu_offload()
|
| 253 |
+
pipe.vae.enable_tiling()
|
| 254 |
+
pipe.vae.enable_slicing()
|
| 255 |
+
|
| 256 |
+
prompt = (
|
| 257 |
+
"A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. "
|
| 258 |
+
"The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other "
|
| 259 |
+
"pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, "
|
| 260 |
+
"casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. "
|
| 261 |
+
"The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical "
|
| 262 |
+
"atmosphere of this unique musical performance."
|
| 263 |
+
)
|
| 264 |
+
negative_prompt = "bad detailed"
|
| 265 |
+
height = 512
|
| 266 |
+
width = 512
|
| 267 |
+
guidance_scale = 6
|
| 268 |
+
num_inference_steps = 50
|
| 269 |
+
num_frames = 49
|
| 270 |
+
seed = 43
|
| 271 |
+
generator = torch.Generator(device="cuda").manual_seed(seed)
|
| 272 |
+
|
| 273 |
+
video = pipe(
|
| 274 |
+
prompt=prompt,
|
| 275 |
+
negative_prompt=negative_prompt,
|
| 276 |
+
guidance_scale=guidance_scale,
|
| 277 |
+
num_inference_steps=num_inference_steps,
|
| 278 |
+
num_frames=num_frames,
|
| 279 |
+
height=height,
|
| 280 |
+
width=width,
|
| 281 |
+
generator=generator,
|
| 282 |
+
).frames[0]
|
| 283 |
+
export_to_video(video, "output.mp4", fps=8)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 284 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 285 |
|
| 286 |
+
#### b、Image to video
|
| 287 |
+
```python
|
| 288 |
+
import torch
|
| 289 |
+
from diffusers import EasyAnimateInpaintPipeline
|
| 290 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 291 |
+
get_image_to_video_latent
|
| 292 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 293 |
+
get_video_to_video_latent
|
| 294 |
+
from diffusers.utils import export_to_video, load_image, load_video
|
| 295 |
+
|
| 296 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers"
|
| 297 |
+
pipe = EasyAnimateInpaintPipeline.from_pretrained(
|
| 298 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers",
|
| 299 |
+
torch_dtype=torch.bfloat16
|
| 300 |
+
)
|
| 301 |
+
pipe.enable_model_cpu_offload()
|
| 302 |
+
pipe.vae.enable_tiling()
|
| 303 |
+
pipe.vae.enable_slicing()
|
| 304 |
+
|
| 305 |
+
prompt = "An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
|
| 306 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 307 |
+
|
| 308 |
+
validation_image_start = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg")
|
| 309 |
+
validation_image_end = None
|
| 310 |
+
sample_size = (448, 576)
|
| 311 |
+
num_frames = 49
|
| 312 |
+
|
| 313 |
+
input_video, input_video_mask = get_image_to_video_latent([validation_image_start], validation_image_end, num_frames, sample_size)
|
| 314 |
+
|
| 315 |
+
video = pipe(
|
| 316 |
+
prompt,
|
| 317 |
+
negative_prompt=negative_prompt,
|
| 318 |
+
num_frames=num_frames,
|
| 319 |
+
height=sample_size[0],
|
| 320 |
+
width=sample_size[1],
|
| 321 |
+
video=input_video,
|
| 322 |
+
mask_video=input_video_mask
|
| 323 |
+
)
|
| 324 |
+
export_to_video(video.frames[0], "output.mp4", fps=8)
|
| 325 |
+
```
|
| 326 |
+
#### c、Video to video
|
| 327 |
+
```python
|
| 328 |
+
import torch
|
| 329 |
+
from diffusers import EasyAnimateInpaintPipeline
|
| 330 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 331 |
+
get_image_to_video_latent
|
| 332 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 333 |
+
get_video_to_video_latent
|
| 334 |
+
from diffusers.utils import export_to_video, load_image, load_video
|
| 335 |
+
|
| 336 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers"
|
| 337 |
+
pipe = EasyAnimateInpaintPipeline.from_pretrained(
|
| 338 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers",
|
| 339 |
+
torch_dtype=torch.bfloat16
|
| 340 |
+
)
|
| 341 |
+
pipe.enable_model_cpu_offload()
|
| 342 |
+
pipe.vae.enable_tiling()
|
| 343 |
+
pipe.vae.enable_slicing()
|
| 344 |
+
|
| 345 |
+
prompt = "一只穿着小外套的猫咪正安静地坐在花园的秋千上弹吉他。它的小外套精致而合身,增添了几分俏皮与可爱。晚霞的余光洒在它柔软的毛皮上,给它的毛发镀上了一层温暖的金色光辉。和煦的微风轻轻拂过,带来阵阵花香和草木的气息,令人心旷神怡。周围斑驳的光影随着音乐的旋律轻轻摇曳,仿佛整个花园都在为这只小猫咪的演奏伴舞。阳光透过树叶间的缝隙,投下一片片光影交错的图案,与悠扬的吉他声交织在一起,营造出一种梦幻而宁静的氛围。猫咪专注而投入地弹奏着,每一个音符都似乎充满了魔力,让这个傍晚变得更加美好。"
|
| 346 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 347 |
+
sample_size = (384, 672)
|
| 348 |
+
num_frames = 49
|
| 349 |
+
input_video = load_video("https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP/resolve/main/asset/1.mp4")
|
| 350 |
+
input_video, input_video_mask, _ = get_video_to_video_latent(input_video, num_frames=num_frames, validation_video_mask=None, sample_size=sample_size)
|
| 351 |
+
video = pipe(
|
| 352 |
+
prompt,
|
| 353 |
+
num_frames=num_frames,
|
| 354 |
+
negative_prompt=negative_prompt,
|
| 355 |
+
height=sample_size[0],
|
| 356 |
+
width=sample_size[1],
|
| 357 |
+
video=input_video,
|
| 358 |
+
mask_video=input_video_mask,
|
| 359 |
+
strength=0.70
|
| 360 |
+
)
|
| 361 |
+
|
| 362 |
+
export_to_video(video.frames[0], "output.mp4", fps=8)
|
| 363 |
```
|
| 364 |
|
| 365 |
+
#### d、Control to video
|
| 366 |
+
```python
|
| 367 |
+
import numpy as np
|
| 368 |
+
import torch
|
| 369 |
+
from diffusers import EasyAnimateControlPipeline
|
| 370 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 371 |
+
get_video_to_video_latent
|
| 372 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 373 |
+
get_image_to_video_latent
|
| 374 |
+
from diffusers.utils import export_to_video, load_video
|
| 375 |
+
from PIL import Image
|
| 376 |
+
|
| 377 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-Control-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-Control-diffusers"
|
| 378 |
+
pipe = EasyAnimateControlPipeline.from_pretrained(
|
| 379 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-Control-diffusers",
|
| 380 |
+
torch_dtype=torch.bfloat16
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
pipe.enable_model_cpu_offload()
|
| 384 |
+
pipe.vae.enable_tiling()
|
| 385 |
+
pipe.vae.enable_slicing()
|
| 386 |
+
|
| 387 |
+
control_video = load_video(
|
| 388 |
+
"https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control/resolve/main/asset/pose.mp4"
|
| 389 |
+
)
|
| 390 |
+
prompt = (
|
| 391 |
+
"In this sunlit outdoor garden, a beautiful woman is dressed in a knee-length, sleeveless white dress. "
|
| 392 |
+
"The hem of her dress gently sways with her graceful dance, much like a butterfly fluttering in the breeze. "
|
| 393 |
+
"Sunlight filters through the leaves, casting dappled shadows that highlight her soft features and clear eyes, "
|
| 394 |
+
"making her appear exceptionally elegant. It seems as if every movement she makes speaks of youth and vitality. "
|
| 395 |
+
"As she twirls on the grass, her dress flutters, as if the entire garden is rejoicing in her dance. "
|
| 396 |
+
"The colorful flowers around her sway in the gentle breeze, with roses, chrysanthemums, and lilies each "
|
| 397 |
+
"releasing their fragrances, creating a relaxed and joyful atmosphere."
|
| 398 |
+
)
|
| 399 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 400 |
+
sample_size = (672, 384)
|
| 401 |
+
num_frames = 49
|
| 402 |
+
generator = torch.Generator(device="cuda").manual_seed(43)
|
| 403 |
+
input_video, _, _ = get_video_to_video_latent(np.array(control_video), num_frames, sample_size)
|
| 404 |
+
|
| 405 |
+
video = pipe(prompt, num_frames=num_frames, negative_prompt=negative_prompt, height=sample_size[0], width=sample_size[1], control_video=input_video, generator=generator).frames[0]
|
| 406 |
+
export_to_video(video, "output.mp4", fps=8)
|
| 407 |
+
```
|
| 408 |
|
| 409 |
+
#### e、Camera Control to video
|
| 410 |
+
Since the camera control model needs to process the camera files, please go to the [asset](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera/blob/main/asset/) page to download the corresponding TXT files for camera movements.
|
| 411 |
+
|
| 412 |
+
The relevant code is relatively complex and has been hidden. Please click to expand it.
|
| 413 |
+
|
| 414 |
+
<details>
|
| 415 |
+
<summary>EasyAnimateV5.1:</summary>
|
| 416 |
+
|
| 417 |
+
```python
|
| 418 |
+
import numpy as np
|
| 419 |
+
import torch
|
| 420 |
+
from diffusers import EasyAnimateControlPipeline
|
| 421 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 422 |
+
get_video_to_video_latent
|
| 423 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 424 |
+
get_image_to_video_latent
|
| 425 |
+
from diffusers.utils import export_to_video, load_video, load_image
|
| 426 |
+
from einops import rearrange
|
| 427 |
+
from packaging import version as pver
|
| 428 |
+
from PIL import Image
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
class Camera(object):
|
| 432 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 433 |
+
"""
|
| 434 |
+
def __init__(self, entry):
|
| 435 |
+
fx, fy, cx, cy = entry[1:5]
|
| 436 |
+
self.fx = fx
|
| 437 |
+
self.fy = fy
|
| 438 |
+
self.cx = cx
|
| 439 |
+
self.cy = cy
|
| 440 |
+
w2c_mat = np.array(entry[7:]).reshape(3, 4)
|
| 441 |
+
w2c_mat_4x4 = np.eye(4)
|
| 442 |
+
w2c_mat_4x4[:3, :] = w2c_mat
|
| 443 |
+
self.w2c_mat = w2c_mat_4x4
|
| 444 |
+
self.c2w_mat = np.linalg.inv(w2c_mat_4x4)
|
| 445 |
+
|
| 446 |
+
def custom_meshgrid(*args):
|
| 447 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 448 |
+
"""
|
| 449 |
+
# ref: https://pytorch.org/docs/stable/generated/torch.meshgrid.html?highlight=meshgrid#torch.meshgrid
|
| 450 |
+
if pver.parse(torch.__version__) < pver.parse('1.10'):
|
| 451 |
+
return torch.meshgrid(*args)
|
| 452 |
+
else:
|
| 453 |
+
return torch.meshgrid(*args, indexing='ij')
|
| 454 |
+
|
| 455 |
+
def get_relative_pose(cam_params):
|
| 456 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 457 |
+
"""
|
| 458 |
+
abs_w2cs = [cam_param.w2c_mat for cam_param in cam_params]
|
| 459 |
+
abs_c2ws = [cam_param.c2w_mat for cam_param in cam_params]
|
| 460 |
+
cam_to_origin = 0
|
| 461 |
+
target_cam_c2w = np.array([
|
| 462 |
+
[1, 0, 0, 0],
|
| 463 |
+
[0, 1, 0, -cam_to_origin],
|
| 464 |
+
[0, 0, 1, 0],
|
| 465 |
+
[0, 0, 0, 1]
|
| 466 |
+
])
|
| 467 |
+
abs2rel = target_cam_c2w @ abs_w2cs[0]
|
| 468 |
+
ret_poses = [target_cam_c2w, ] + [abs2rel @ abs_c2w for abs_c2w in abs_c2ws[1:]]
|
| 469 |
+
ret_poses = np.array(ret_poses, dtype=np.float32)
|
| 470 |
+
return ret_poses
|
| 471 |
+
|
| 472 |
+
def ray_condition(K, c2w, H, W, device):
|
| 473 |
+
"""Copied from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 474 |
+
"""
|
| 475 |
+
# c2w: B, V, 4, 4
|
| 476 |
+
# K: B, V, 4
|
| 477 |
+
|
| 478 |
+
B = K.shape[0]
|
| 479 |
+
|
| 480 |
+
j, i = custom_meshgrid(
|
| 481 |
+
torch.linspace(0, H - 1, H, device=device, dtype=c2w.dtype),
|
| 482 |
+
torch.linspace(0, W - 1, W, device=device, dtype=c2w.dtype),
|
| 483 |
+
)
|
| 484 |
+
i = i.reshape([1, 1, H * W]).expand([B, 1, H * W]) + 0.5 # [B, HxW]
|
| 485 |
+
j = j.reshape([1, 1, H * W]).expand([B, 1, H * W]) + 0.5 # [B, HxW]
|
| 486 |
+
|
| 487 |
+
fx, fy, cx, cy = K.chunk(4, dim=-1) # B,V, 1
|
| 488 |
+
|
| 489 |
+
zs = torch.ones_like(i) # [B, HxW]
|
| 490 |
+
xs = (i - cx) / fx * zs
|
| 491 |
+
ys = (j - cy) / fy * zs
|
| 492 |
+
zs = zs.expand_as(ys)
|
| 493 |
+
|
| 494 |
+
directions = torch.stack((xs, ys, zs), dim=-1) # B, V, HW, 3
|
| 495 |
+
directions = directions / directions.norm(dim=-1, keepdim=True) # B, V, HW, 3
|
| 496 |
+
|
| 497 |
+
rays_d = directions @ c2w[..., :3, :3].transpose(-1, -2) # B, V, 3, HW
|
| 498 |
+
rays_o = c2w[..., :3, 3] # B, V, 3
|
| 499 |
+
rays_o = rays_o[:, :, None].expand_as(rays_d) # B, V, 3, HW
|
| 500 |
+
# c2w @ dirctions
|
| 501 |
+
rays_dxo = torch.cross(rays_o, rays_d)
|
| 502 |
+
plucker = torch.cat([rays_dxo, rays_d], dim=-1)
|
| 503 |
+
plucker = plucker.reshape(B, c2w.shape[1], H, W, 6) # B, V, H, W, 6
|
| 504 |
+
# plucker = plucker.permute(0, 1, 4, 2, 3)
|
| 505 |
+
return plucker
|
| 506 |
+
|
| 507 |
+
def process_pose_file(pose_file_path, width=672, height=384, original_pose_width=1280, original_pose_height=720, device='cpu', return_poses=False):
|
| 508 |
+
"""Modified from https://github.com/hehao13/CameraCtrl/blob/main/inference.py
|
| 509 |
+
"""
|
| 510 |
+
with open(pose_file_path, 'r') as f:
|
| 511 |
+
poses = f.readlines()
|
| 512 |
+
|
| 513 |
+
poses = [pose.strip().split(' ') for pose in poses[1:]]
|
| 514 |
+
cam_params = [[float(x) for x in pose] for pose in poses]
|
| 515 |
+
if return_poses:
|
| 516 |
+
return cam_params
|
| 517 |
+
else:
|
| 518 |
+
cam_params = [Camera(cam_param) for cam_param in cam_params]
|
| 519 |
+
|
| 520 |
+
sample_wh_ratio = width / height
|
| 521 |
+
pose_wh_ratio = original_pose_width / original_pose_height # Assuming placeholder ratios, change as needed
|
| 522 |
+
|
| 523 |
+
if pose_wh_ratio > sample_wh_ratio:
|
| 524 |
+
resized_ori_w = height * pose_wh_ratio
|
| 525 |
+
for cam_param in cam_params:
|
| 526 |
+
cam_param.fx = resized_ori_w * cam_param.fx / width
|
| 527 |
+
else:
|
| 528 |
+
resized_ori_h = width / pose_wh_ratio
|
| 529 |
+
for cam_param in cam_params:
|
| 530 |
+
cam_param.fy = resized_ori_h * cam_param.fy / height
|
| 531 |
+
|
| 532 |
+
intrinsic = np.asarray([[cam_param.fx * width,
|
| 533 |
+
cam_param.fy * height,
|
| 534 |
+
cam_param.cx * width,
|
| 535 |
+
cam_param.cy * height]
|
| 536 |
+
for cam_param in cam_params], dtype=np.float32)
|
| 537 |
+
|
| 538 |
+
K = torch.as_tensor(intrinsic)[None] # [1, 1, 4]
|
| 539 |
+
c2ws = get_relative_pose(cam_params) # Assuming this function is defined elsewhere
|
| 540 |
+
c2ws = torch.as_tensor(c2ws)[None] # [1, n_frame, 4, 4]
|
| 541 |
+
plucker_embedding = ray_condition(K, c2ws, height, width, device=device)[0].permute(0, 3, 1, 2).contiguous() # V, 6, H, W
|
| 542 |
+
plucker_embedding = plucker_embedding[None]
|
| 543 |
+
plucker_embedding = rearrange(plucker_embedding, "b f c h w -> b f h w c")[0]
|
| 544 |
+
return plucker_embedding
|
| 545 |
+
|
| 546 |
+
def get_image_latent(ref_image=None, sample_size=None):
|
| 547 |
+
if ref_image is not None:
|
| 548 |
+
if isinstance(ref_image, str):
|
| 549 |
+
ref_image = Image.open(ref_image).convert("RGB")
|
| 550 |
+
ref_image = ref_image.resize((sample_size[1], sample_size[0]))
|
| 551 |
+
ref_image = torch.from_numpy(np.array(ref_image))
|
| 552 |
+
ref_image = ref_image.unsqueeze(0).permute([3, 0, 1, 2]).unsqueeze(0) / 255
|
| 553 |
+
else:
|
| 554 |
+
ref_image = torch.from_numpy(np.array(ref_image))
|
| 555 |
+
ref_image = ref_image.unsqueeze(0).permute([3, 0, 1, 2]).unsqueeze(0) / 255
|
| 556 |
+
|
| 557 |
+
return ref_image
|
| 558 |
+
|
| 559 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-7b-zh-Control-Camera-diffusers" or "alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera-diffusers"
|
| 560 |
+
pipe = EasyAnimateControlPipeline.from_pretrained(
|
| 561 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera-diffusers",
|
| 562 |
+
torch_dtype=torch.bfloat16
|
| 563 |
+
)
|
| 564 |
+
pipe.enable_model_cpu_offload()
|
| 565 |
+
pipe.vae.enable_tiling()
|
| 566 |
+
pipe.vae.enable_slicing()
|
| 567 |
+
|
| 568 |
+
input_video, input_video_mask = None, None
|
| 569 |
+
prompt = "Fireworks light up the evening sky over a sprawling cityscape with gothic-style buildings featuring pointed towers and clock faces. The city is lit by both artificial lights from the buildings and the colorful bursts of the fireworks. The scene is viewed from an elevated angle, showcasing a vibrant urban environment set against a backdrop of a dramatic, partially cloudy sky at dusk."
|
| 570 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 571 |
+
sample_size = (384, 672)
|
| 572 |
+
num_frames = 49
|
| 573 |
+
fps = 8
|
| 574 |
+
ref_image = load_image("https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera/resolve/main/asset/1.png")
|
| 575 |
+
|
| 576 |
+
control_camera_video = process_pose_file("/The_Path_To/Pan_Left.txt", sample_size[1], sample_size[0])
|
| 577 |
+
control_camera_video = control_camera_video[::int(24 // fps)][:num_frames].permute([3, 0, 1, 2]).unsqueeze(0)
|
| 578 |
+
ref_image = get_image_latent(sample_size=sample_size, ref_image=ref_image)
|
| 579 |
+
video = pipe(
|
| 580 |
+
prompt,
|
| 581 |
+
negative_prompt=negative_prompt,
|
| 582 |
+
num_frames=num_frames,
|
| 583 |
+
height=sample_size[0],
|
| 584 |
+
width=sample_size[1],
|
| 585 |
+
control_camera_video=control_camera_video,
|
| 586 |
+
ref_image=ref_image
|
| 587 |
+
).frames[0]
|
| 588 |
+
export_to_video(video, "output.mp4", fps=fps)
|
| 589 |
+
```
|
| 590 |
+
</details>
|
| 591 |
+
|
| 592 |
+
#### f、float8 model
|
| 593 |
+
Since the parameters of EasyAnimateV5.1 are very large, we need to consider memory-saving solutions to adapt to consumer-grade GPUs. We can convert the model to float8 to save GPU memory.
|
| 594 |
+
|
| 595 |
+
For example, in the case of text-to-video generation, we first load the model in float8 to save memory, and then convert it to bfloat16 during inference.
|
| 596 |
+
```python
|
| 597 |
+
"""Modified from https://github.com/kijai/ComfyUI-MochiWrapper
|
| 598 |
+
"""
|
| 599 |
+
import torch
|
| 600 |
+
import torch.nn as nn
|
| 601 |
+
from diffusers import EasyAnimateInpaintPipeline
|
| 602 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_control import \
|
| 603 |
+
get_video_to_video_latent
|
| 604 |
+
from diffusers.pipelines.easyanimate.pipeline_easyanimate_inpaint import \
|
| 605 |
+
get_image_to_video_latent
|
| 606 |
+
from diffusers.utils import export_to_video, load_image, load_video
|
| 607 |
+
|
| 608 |
+
def autocast_model_forward(cls, origin_dtype, *inputs, **kwargs):
|
| 609 |
+
weight_dtype = cls.weight.dtype
|
| 610 |
+
cls.to(origin_dtype)
|
| 611 |
+
|
| 612 |
+
# Convert all inputs to the original dtype
|
| 613 |
+
inputs = [input.to(origin_dtype) for input in inputs]
|
| 614 |
+
out = cls.original_forward(*inputs, **kwargs)
|
| 615 |
+
|
| 616 |
+
cls.to(weight_dtype)
|
| 617 |
+
return out
|
| 618 |
+
|
| 619 |
+
def convert_weight_dtype_wrapper(module, origin_dtype):
|
| 620 |
+
for name, module in module.named_modules():
|
| 621 |
+
if name == "" or "embed_tokens" in name:
|
| 622 |
+
continue
|
| 623 |
+
original_forward = module.forward
|
| 624 |
+
if hasattr(module, "weight"):
|
| 625 |
+
setattr(module, "original_forward", original_forward)
|
| 626 |
+
setattr(
|
| 627 |
+
module,
|
| 628 |
+
"forward",
|
| 629 |
+
lambda *inputs, m=module, **kwargs: autocast_model_forward(m, origin_dtype, *inputs, **kwargs)
|
| 630 |
+
)
|
| 631 |
+
|
| 632 |
+
# Models: "alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers" or "alibaba-pai/EasyAnimateV5.1-7b-zh-InP-diffusers"
|
| 633 |
+
pipe = EasyAnimateInpaintPipeline.from_pretrained(
|
| 634 |
+
"alibaba-pai/EasyAnimateV5.1-12b-zh-InP-diffusers",
|
| 635 |
+
torch_dtype=torch.bfloat16
|
| 636 |
+
)
|
| 637 |
+
pipe.transformer = pipe.transformer.to(torch.float8_e4m3fn)
|
| 638 |
+
from fp8_optimization import convert_weight_dtype_wrapper
|
| 639 |
+
|
| 640 |
+
for _text_encoder in [pipe.text_encoder, pipe.text_encoder_2]:
|
| 641 |
+
if hasattr(_text_encoder, "visual"):
|
| 642 |
+
del _text_encoder.visual
|
| 643 |
+
convert_weight_dtype_wrapper(pipe.transformer, torch.bfloat16)
|
| 644 |
+
pipe.enable_model_cpu_offload()
|
| 645 |
+
pipe.vae.enable_tiling()
|
| 646 |
+
pipe.vae.enable_slicing()
|
| 647 |
+
|
| 648 |
+
prompt = "An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
|
| 649 |
+
negative_prompt = "Twisted body, limb deformities, text subtitles, comics, stillness, ugliness, errors, garbled text."
|
| 650 |
+
validation_image_start = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg")
|
| 651 |
+
validation_image_end = None
|
| 652 |
+
sample_size = (448, 576)
|
| 653 |
+
num_frames = 49
|
| 654 |
+
input_video, input_video_mask = get_image_to_video_latent(
|
| 655 |
+
[validation_image_start], validation_image_end, num_frames, sample_size
|
| 656 |
+
)
|
| 657 |
+
|
| 658 |
+
video = pipe(
|
| 659 |
+
prompt,
|
| 660 |
+
negative_prompt=negative_prompt,
|
| 661 |
+
num_frames=num_frames,
|
| 662 |
+
height=sample_size[0],
|
| 663 |
+
width=sample_size[1],
|
| 664 |
+
video=input_video,
|
| 665 |
+
mask_video=input_video_mask
|
| 666 |
+
)
|
| 667 |
+
export_to_video(video.frames[0], "output.mp4", fps=8)
|
| 668 |
+
```
|
| 669 |
|
| 670 |
+
# GPU Memory
|
| 671 |
The video size for EasyAnimateV5.1-12B can be generated by different GPU Memory, including:
|
| 672 |
| GPU memory | 384x672x25 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|
| 673 |
|------------|------------|------------|------------|------------|------------|------------|
|
|
|
|
| 684 |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 685 |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 686 |
|
| 687 |
+
✅ Indicates that it can run under "model_cpu_offload", 🧡 indicates that it can run under "model_cpu_offload" + float8, and ⭕️ indicates that it can run under "sequential_cpu_offload". Currently, due to the fact that qwen2vl does not support "sequential_cpu_offload", we are unable to use "sequential_cpu_offload" in diffusers. The specific fix time is unknown, but it can be used in the official EasyAnimate repository. ❌ Indicates that it cannot run. Please note that running with "sequential_cpu_offload" will be slower.
|
| 688 |
|
| 689 |
+
Some GPUs that do not support torch.bfloat16, such as 2080ti and V100, require changing the torch.bfloat16 to torch.float16 in order to run.
|
| 690 |
|
| 691 |
The generation time for EasyAnimateV5.1-12B using different GPUs over 25 steps is as follows:
|
| 692 |
|
|
|
|
| 695 |
| A10 24GB | ~120s (4.8s/it) | ~240s (9.6s/it) | ~320s (12.7s/it) | ~750s (29.8s/it) | ❌ | ❌ |
|
| 696 |
| A100 80GB | ~45s (1.75s/it) | ~90s (3.7s/it) | ~120s (4.7s/it) | ~300s (11.4s/it) | ~265s (10.6s/it) | ~710s (28.3s/it) |
|
| 697 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 698 |
# Contact Us
|
| 699 |
+
1. Use Dingding to search group 77450006752 or Scan to join.
|
| 700 |
2. You need to scan the image to join the WeChat group or if it is expired, add this student as a friend first to invite you.
|
| 701 |
|
| 702 |
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/>
|