
Commit
•
80817eb
1
Parent(s):
1e8bee5
Upload folder using huggingface_hub
Browse files- README.md +46 -0
- added_tokens.json +9 -0
- config.json +28 -0
- illustration.jpeg +0 -0
- pytorch_model.bin +3 -0
- sentencepiece.bpe.model +3 -0
- special_tokens_map.json +13 -0
- tokenizer.json +0 -0
- tokenizer_config.json +74 -0
README.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- fr
|
| 5 |
+
library_name: transformers
|
| 6 |
+
inference: false
|
| 7 |
+
---
|
| 8 |
+
# CamemBERT-L4
|
| 9 |
+
|
| 10 |
+
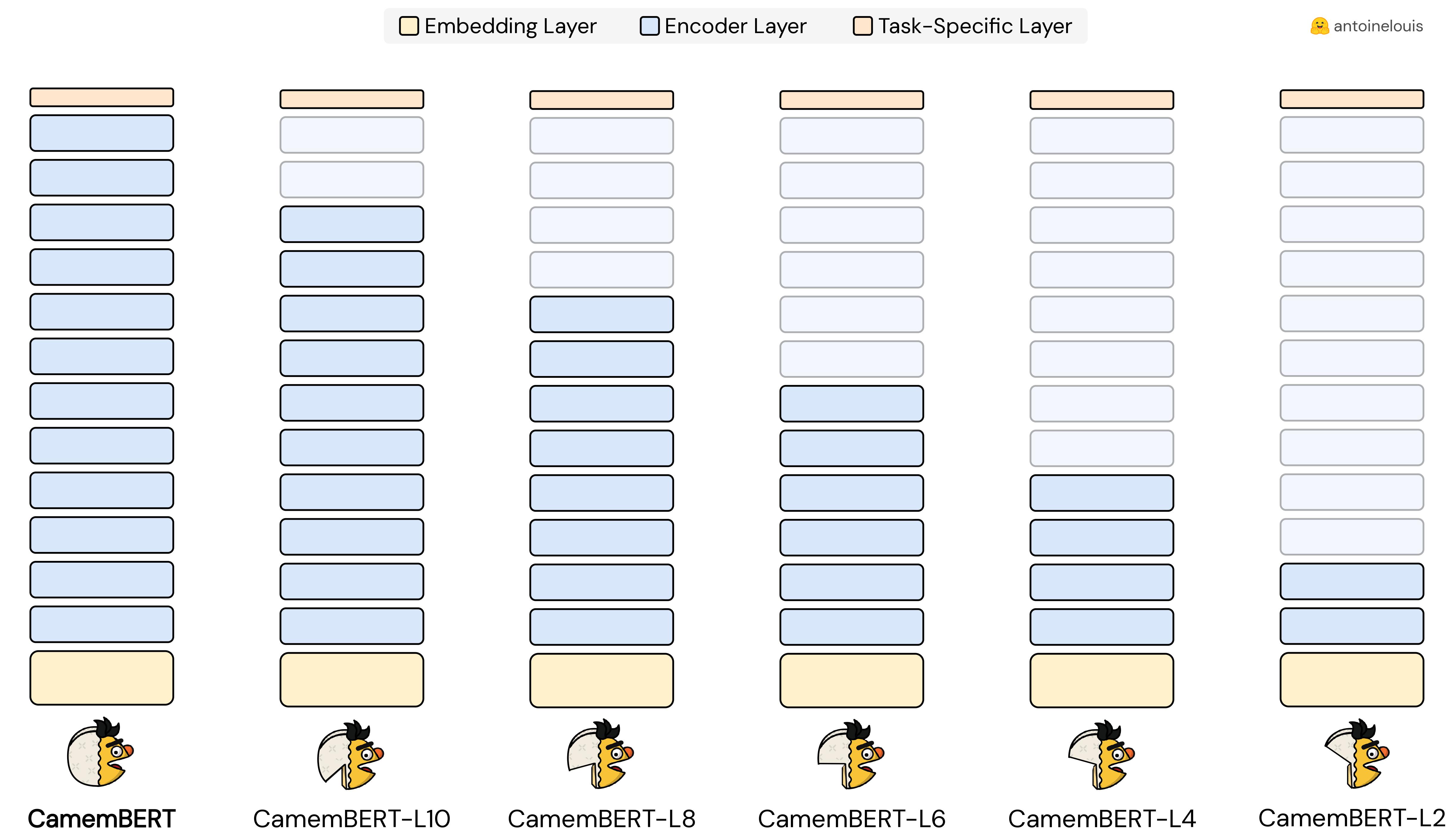
This model is a pruned version of the pre-trained [CamemBERT](https://huggingface.co/camembert-base) checkpoint, obtained by [dropping the top-layers](https://arxiv.org/abs/2004.03844) from the original model.
|
| 11 |
+
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
## Usage
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
from transformers import AutoTokenizer, AutoModel
|
| 18 |
+
|
| 19 |
+
tokenizer = AutoTokenizer.from_pretrained('antoinelouis/camembert-L4')
|
| 20 |
+
model = AutoModel.from_pretrained('antoinelouis/camembert-L4')
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Comparison
|
| 24 |
+
|
| 25 |
+
| Model | #Params | Size | Pruning |
|
| 26 |
+
|--------------------------------------------------------------------|:-------:|:-----:|:-------:|
|
| 27 |
+
| [CamemBERT](https://huggingface.co/camembert-base) | 110.6M | 445MB | - |
|
| 28 |
+
| | | | |
|
| 29 |
+
| [CamemBERT-L10](https://huggingface.co/antoinelouis/camembert-L10) | 96.4M | 368MB | -13% |
|
| 30 |
+
| [CamemBERT-L8](https://huggingface.co/antoinelouis/camembert-L8) | 82.3M | 314MB | -26% |
|
| 31 |
+
| [CamemBERT-L6](https://huggingface.co/antoinelouis/camembert-L6) | 68.1M | 260MB | -38% |
|
| 32 |
+
| **CamemBERT-L4** | 53.9M | 206MB | -51% |
|
| 33 |
+
| [CamemBERT-L4](https://huggingface.co/antoinelouis/camembert-L4) | 39.7M | 159MB | -64% |
|
| 34 |
+
|
| 35 |
+
## Citation
|
| 36 |
+
|
| 37 |
+
```bibtex
|
| 38 |
+
@online{louis2023,
|
| 39 |
+
author = 'Antoine Louis',
|
| 40 |
+
title = 'CamemBERT-L4: A Pruned Version of CamemBERT',
|
| 41 |
+
publisher = 'Hugging Face',
|
| 42 |
+
month = 'october',
|
| 43 |
+
year = '2023',
|
| 44 |
+
url = 'https://huggingface.co/antoinelouis/camembert-L4',
|
| 45 |
+
}
|
| 46 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s>": 6,
|
| 3 |
+
"</s>NOTUSED": 2,
|
| 4 |
+
"<mask>": 32004,
|
| 5 |
+
"<pad>": 1,
|
| 6 |
+
"<s>": 5,
|
| 7 |
+
"<s>NOTUSED": 0,
|
| 8 |
+
"<unk>": 4
|
| 9 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "camembert-base",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CamembertModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 5,
|
| 8 |
+
"classifier_dropout": null,
|
| 9 |
+
"eos_token_id": 6,
|
| 10 |
+
"hidden_act": "gelu",
|
| 11 |
+
"hidden_dropout_prob": 0.1,
|
| 12 |
+
"hidden_size": 768,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 3072,
|
| 15 |
+
"layer_norm_eps": 1e-05,
|
| 16 |
+
"max_position_embeddings": 514,
|
| 17 |
+
"model_type": "camembert",
|
| 18 |
+
"num_attention_heads": 12,
|
| 19 |
+
"num_hidden_layers": 4,
|
| 20 |
+
"output_past": true,
|
| 21 |
+
"pad_token_id": 1,
|
| 22 |
+
"position_embedding_type": "absolute",
|
| 23 |
+
"torch_dtype": "float32",
|
| 24 |
+
"transformers_version": "4.35.0.dev0",
|
| 25 |
+
"type_vocab_size": 1,
|
| 26 |
+
"use_cache": true,
|
| 27 |
+
"vocab_size": 32005
|
| 28 |
+
}
|
illustration.jpeg
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bbeaf4753390f081585fd998f7a140f06023d1daf67d0ce92a72731753f894f8
|
| 3 |
+
size 215698883
|
sentencepiece.bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:988bc5a00281c6d210a5d34bd143d0363741a432fefe741bf71e61b1869d4314
|
| 3 |
+
size 810912
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<s>NOTUSED",
|
| 4 |
+
"</s>NOTUSED"
|
| 5 |
+
],
|
| 6 |
+
"bos_token": "<s>",
|
| 7 |
+
"cls_token": "<s>",
|
| 8 |
+
"eos_token": "</s>",
|
| 9 |
+
"mask_token": "<mask>",
|
| 10 |
+
"pad_token": "<pad>",
|
| 11 |
+
"sep_token": "</s>",
|
| 12 |
+
"unk_token": "<unk>"
|
| 13 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<s>NOTUSED",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<pad>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>NOTUSED",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"4": {
|
| 28 |
+
"content": "<unk>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"5": {
|
| 36 |
+
"content": "<s>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"6": {
|
| 44 |
+
"content": "</s>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"32004": {
|
| 52 |
+
"content": "<mask>",
|
| 53 |
+
"lstrip": true,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
}
|
| 59 |
+
},
|
| 60 |
+
"additional_special_tokens": [
|
| 61 |
+
"<s>NOTUSED",
|
| 62 |
+
"</s>NOTUSED"
|
| 63 |
+
],
|
| 64 |
+
"bos_token": "<s>",
|
| 65 |
+
"clean_up_tokenization_spaces": true,
|
| 66 |
+
"cls_token": "<s>",
|
| 67 |
+
"eos_token": "</s>",
|
| 68 |
+
"mask_token": "<mask>",
|
| 69 |
+
"model_max_length": 512,
|
| 70 |
+
"pad_token": "<pad>",
|
| 71 |
+
"sep_token": "</s>",
|
| 72 |
+
"tokenizer_class": "CamembertTokenizer",
|
| 73 |
+
"unk_token": "<unk>"
|
| 74 |
+
}
|