

Commit
·
cc7bf2c
1
Parent(s):
b120b50
refactor: use hyperlinks for images
Browse files
README.md
CHANGED
|
@@ -86,19 +86,17 @@ model-index:
|
|
| 86 |
|
| 87 |
# StarCoder2-Instruct: Self-Aligned, Transparent, and Fully Permissive
|
| 88 |
|
| 89 |
-
|
| 90 |
-
<img src="https://huggingface.co/datasets/bigcode/admin_private/resolve/main/starcoder2_banner.png" alt="SC2" width="900" height="600">
|
| 91 |
-
</center> -->
|
| 92 |
|
| 93 |
## Model Summary
|
| 94 |
|
| 95 |
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
|
| 96 |
|
| 97 |
-
- **Model:** [bigcode/
|
| 98 |
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
| 99 |
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
| 100 |
|
| 101 |
-

|
|
|
|
|
|
|
| 90 |
|
| 91 |
## Model Summary
|
| 92 |
|
| 93 |
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
|
| 94 |
|
| 95 |
+
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
| 96 |
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
| 97 |
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
| 98 |
|
| 99 |
+

|
| 100 |
|
| 101 |
## Use
|
| 102 |
|
|
|
|
| 175 |
|
| 176 |
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
|
| 177 |
|
| 178 |
+
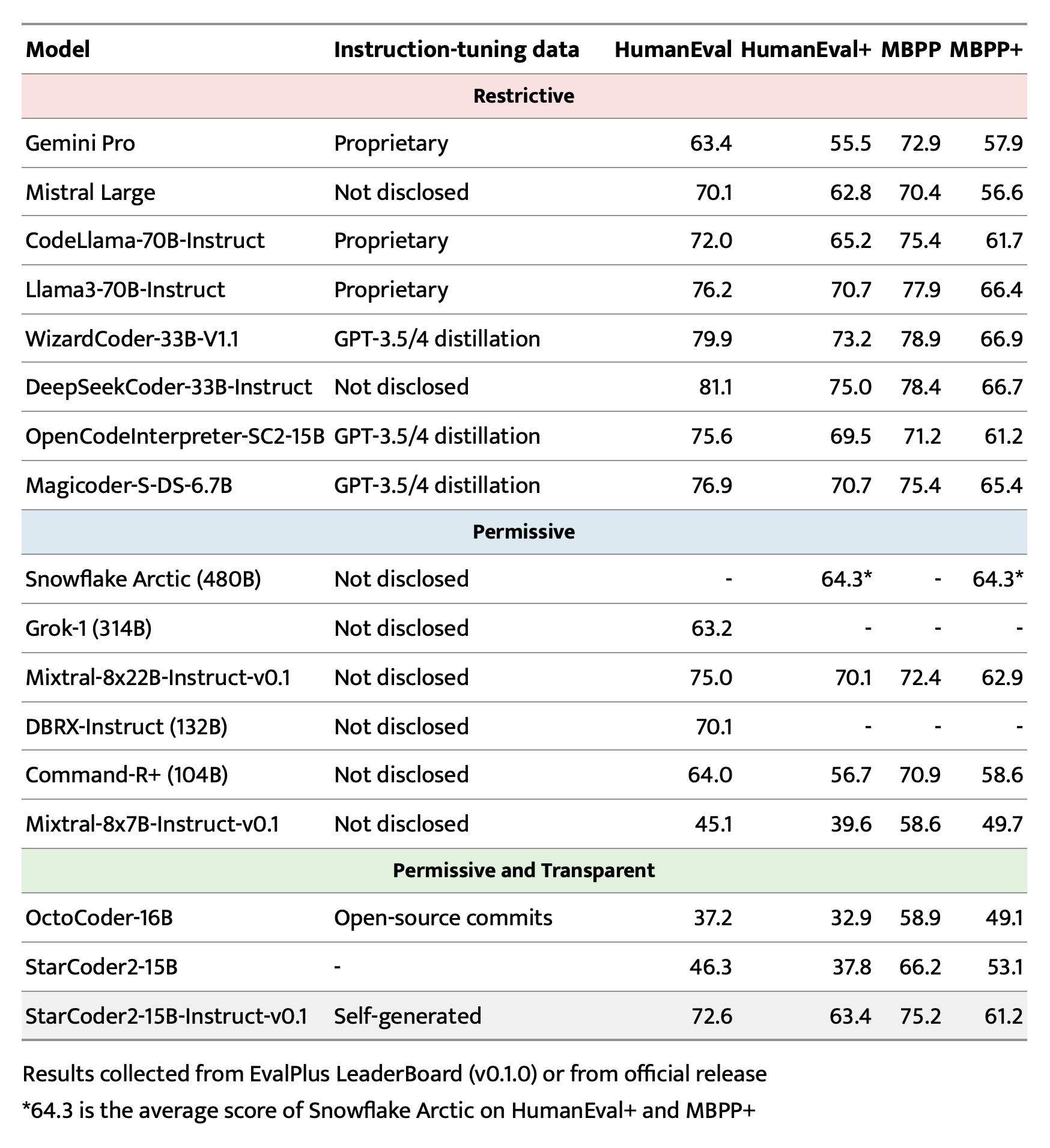
|
| 179 |
|
| 180 |
+
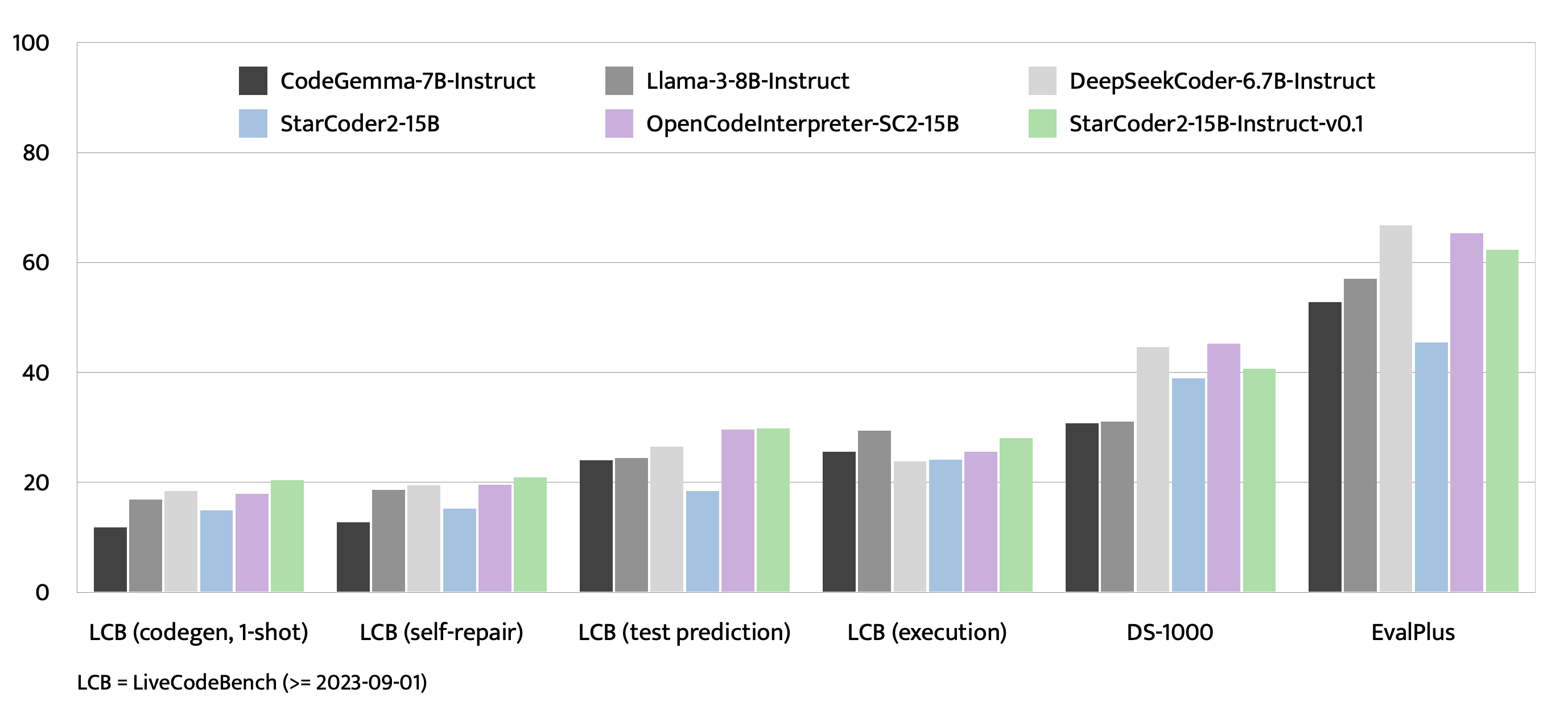
|
| 181 |
|
| 182 |
## Training Details
|
| 183 |
|
| 184 |
### Hyperparameters
|
| 185 |
|
| 186 |
+
- **Optimizer:** Adafactor
|
| 187 |
- **Learning rate:** 1e-5
|
| 188 |
- **Epoch:** 4
|
| 189 |
- **Batch size:** 64
|