Open-source embeddings and LLMs outperform Gemini and OpenAI for Web Navigation while being faster and cheaper







TL;DR
- LaVague is a Large Action Model framework for building AI Web Agents.
- We use RAG on HTML to turn natural language instructions (e.g., “Click on ‘Login’”) into browser actions (e.g., generating and executing Selenium code).
- We have developed evaluation metrics, such as recall of the ground truth web elements for retrieval.
- We compare different open and proprietary LLMs in their ability to produce the right Selenium code given some instruction.
- We found that local embedding models such as bge-small are as performant as proprietary ones behind APIs like OpenAI or Gemini, while being cheaper and faster.
- We found that open-weight LLMs like Codestral are as performant as proprietary APIs like Gemini, but GPT-4o still dominates the podium.
Context
LLMs have unlocked the ability to build AI agents that can take action for our sake. Thanks to their ability to generate code that can pilot other systems, for instance, by producing Selenium code, it is now possible for AI to take action on the web.
LaVague is an open-source Large Action Model (LAM) framework to build AI Web Agents. LAMs are AI models specialized in generation action, which is usually either outputting a function to call and its arguments, or directly producing the code to perform the action and execute it.
We have provided several examples in our docs of different Agents that can be built:
- Data entry: Filling forms for job applications
- Information retrieval: Finding information in a Notion
- Web QA: Turning Gherkin specs into a Pytest on the fly
While extremely promising, LLMs have one issue: evaluating their performance. Contrary to regular ML systems that do classification or regression, such as recommender systems, LLMs produce arbitrary text, which can be hard to assess.
For instance, in web action generation, there can be many ways to generate selectors and code to target specific elements. One could use XPath, ID, etc.
Therefore, we need a reliable metric to assess whether a generated action performs as the user intended. Without good evaluation, it is impossible to optimize the action generation pipeline.
The Focus of This Article
As our mission at LaVague is to foster the building of Agents to the largest number, we have worked on sharing open-source datasets to evaluate and improve LAMs, as well as providing tools to make evaluation easy.
In this article, we will share our experiments on evaluating different LLMs to produce the right Selenium code, using datasets we have prepared to make evaluation easy, and evaluation tools for quick measurement of LLMs capabilities in action generation.
Workflow of LaVague
Before we examine the evaluation of models in Action generation, it’s relevant to review quickly how LaVague works to understand how the workflow is subdivided and better evaluate each module.
Big Picture of LaVague
LaVague is a Large Action Model framework for building AI Web Agents. Our goal is to make it easy for developers to design, deploy and share their Agents to automate tasks on the web.
Let's first define some of the key elements in our LaVague Agent architecture:
- Objective: The objective is the global goal that the user wants the Web Agent to achieve. For example: "Log into my account and change my username to The WaveHunter."
- Instruction: An instruction is a smaller step needed to move towards achieving the user's objective. For example: "Locate the username input field and enter the text 'user123'."
- World Model: The World Model analyzes the user's objective and the current state of a webpage to generate the next instruction needed in order to eventually achieve the objective.
- Action Engine: The Action Engine receives this instruction and generates the automation code required to perform this action.
- Driver: The webdriver is both leveraged for the execution of the action code generated by the Action Engine and provides the World Model with perception through screenshots and the HTML source code of the current state of the webpage.
Note: We call here Action Engine what people often refer to as Large Action Model. We prefer to call it Action Engine as Large Action Models are not necessarily models trained for action specifically. If properly prompt engineered, we can repurpose generalist LLMs like GPT4 to generate action code, which is what we do.
Hence we will use the name Action Engine to talk about the module in charge of action generation.
Overall Workflow
All the elements previously described interact in the following workflow:
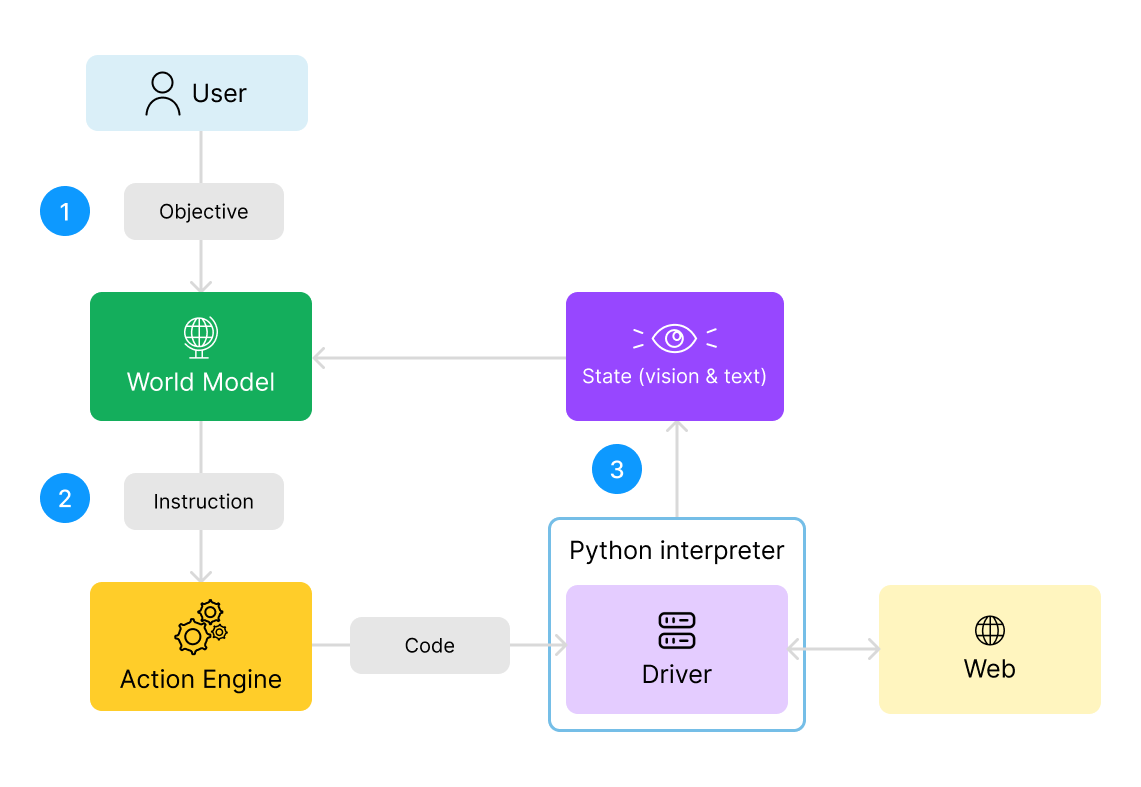
- The World Model handles the user's global objective. It considers this objective, along with the state of the webpage through screenshots and HTML code, and generates the next step, aka text instruction, needed to achieve this objective.
- This instruction is sent to the ActionEngine, which then generates the automation code needed to perform this step and executes it.
- The World Model then receives new text and image data, aka a new screenshot and the updated source code, to reflect the updated state of the web page. With this information, it can generate the next instruction needed to achieve the objective.
- This process repeats until the objective is achieved!
Zoom on Action Engine
As we saw, there are two main modules that do most of the work:
- The World Model does high-level reasoning and planning, using objectives and observation from the world, and outputs low-level instructions to the Action Engine.
- The Action Engine takes those low-level instructions and actually performs the desired actions.
We will focus here on the Action Engine, as without a good evaluation of action generation, we cannot measure the World Model's ability to provide the right instructions.
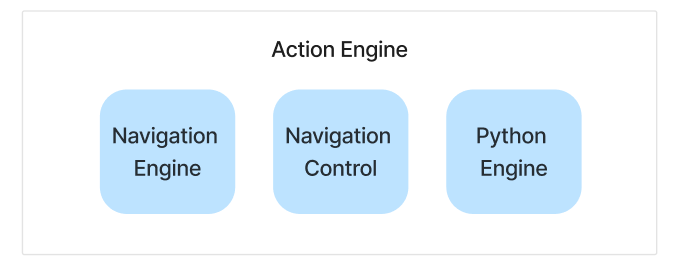
Our Action Engine has three main engines at its disposal:
- 🚄 Navigation Engine: Generates and executes Selenium code to perform an action on a web page
- 🐍 Python Engine: Generates and executes code for tasks that do not involve navigating or interacting with a web page, such as extracting information
- 🕹️ Navigation Control: Performs frequently required navigation tasks without needing to make any extra LLM calls. So far we have covered: scroll up, scroll down & wait
You can find more information about our Action Engine in our docs.
As of today, our Python Engine only has one function, and Navigation Controls are for things that do not require thinking, like waiting or scrolling, therefore we will omit those for our evaluation.
We will focus instead on the Navigation Engine, which is doing the bulk of the work: given an instruction like “Click on ‘Calendar’”, actually produces code to perform that action.
We want to evaluate the Navigation Engine's ability to produce code that correctly performs the desired action, which is a key component of our AI Web Agents.
Zoom on the Navigation Engine
To evaluate the Navigation Engine optimally, we will examine its workings to understand how it works. This will allow us to decompose evaluation into relevant submodules.
The Navigation Engine takes as inputs:
- The current HTML of the page being browsed
- The World Model’s instructions, like “Click on the PEFT section”
It works in two phases:
It works in two phases:
- Retrieval of relevant HTML chunks of the current page
- Generation of relevant action using retrieved chunks
For instance, given the request “Click on the PEFT section”, we get the following chunks:
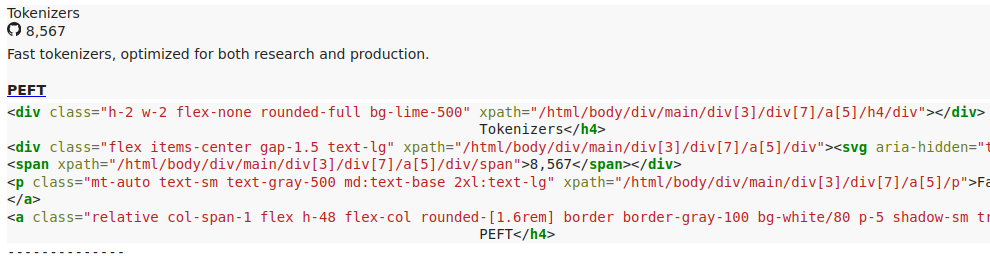
Examples of HTML chunks retrieved
By injecting this into the LLM along with the instructions, we get the following code:

Example of action code generated
You can find more about the Navigation Engine in our docs.
Now that we have defined more precisely how our framework works, and the module we want to evaluate, let’s now focus on the data and the metric.
Evaluation data
We will use for our evaluation two datasets:
- TheWave, an action dataset collected by BigAction, is an open-science initiative to promote the growth of Large Action Models by collecting datasets and training LAMs.
- WebLinx, a conversational web navigation dataset.
The format we use contains the following major fields:
- Raw HTML: HTML of the page to be interacted with
- Query: Instruction to be performed, like ‘Click on create account’
- Full XPath: XPath of the ground truth element to be interacted with
Evaluation metrics
Given our RAG workflow, it is important to evaluate the whole system in two steps:
- Is the retriever able to always find the right chunks of the HTML to answer a given request?
- Given these chunks, can the LLM generate the right action?
This is relatively classic when evaluating RAG pipelines, where recall and precision are used for evaluating the retriever, and some metric is provided for the generated code. Here we will use a similar metric for both retriever and LLM for action generation: backend node ID recall and precision of ground truth elements.
Here we assume we have access to the ground truth XPath of the element to be interacted with. This is the case of the datasets we use.
Retriever evaluation
Our objective here is to measure the ability of the retriever to find the ground truth elements.
Here are the following steps before evaluating a given retrieval:
- First, we inject a unique ID, called backend node ID, to each element of the page
- Then using the ground truth XPath, we identify the ground truth element
- We then fetch its outerHTML, which contains the ground truth backend node IDs
Now to evaluate the chunks retrieved by our retriever:
- We extract the backend node IDs of the retrieved chunks
- We compute recall/precision of ground truth backend node IDs
###LLM evaluation
Our objective is to measure the ability of LLM to identify the right XPath and generate the right code given ground truth HTML chunks.
We will have a similar approach to the retriever:
- We generate the code to target a specific element
- We extract the backend node IDs contained in its outerHTML
- We compute recall/precision of ground truth backend node IDs
Note: we have chosen to use ground truth IDs recall / precision for the LLM while we could have used another metric, such as Intersection over Union. However, at the time of writing, our dataset is mostly static but some elements are not loaded systematically in the same manner, making it hard to leverage purely visual metrics.
Results
![]()
You can view and run the code for evaluating the models we will discuss here by clicking on the Colab link above.
We also provide documentation on how to use our evaluation tooling in our docs.
Given that the interface is relatively simple, we will focus more on the results of different setups on TheWave and WebLinx and their interpretation.
Retrieval
We have looked at the influence of different embedding models on the performance of the retriever (backend node ID recall) and the cost.
We have tried bge-small-en-v1.5, OpenAI text-embedding-3-large and Gemini text-embedding-004.

Comparison of local bge-small, OpenAI and Gemini embeddings
First, we found that all these models provided a similar recall/precision.
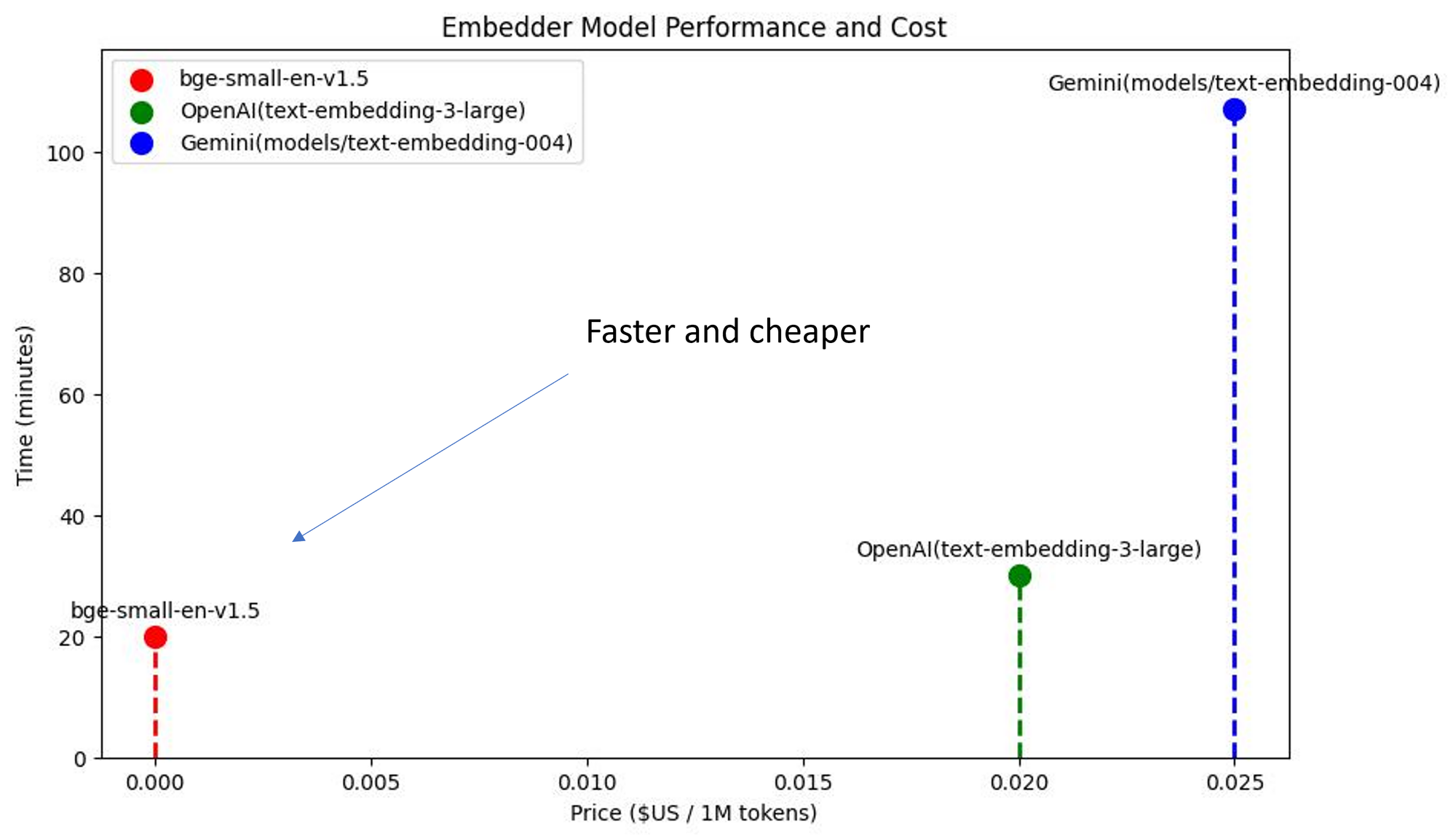
Comparison of different embedding models on inference time for benchmarking and price
Second, we looked at the time it took to evaluate our retriever on our whole benchmark. We also looked at the price per token associated with each solution.
We found that for the same performance (precision/recall), bge-small was faster and cheaper than the proprietary ones!
LLM
We also examined the ability of different models to generate the right action when fed the appropriate HTML chunks that contain the information about the element to interact with.
We evaluated several models, from open-source models like Llama3 8b to proprietary APIs like GPT-4o through Mistral’s Codestral.
Because we don’t know the number of parameters of proprietary APIs like Gemini and OpenAI, we could not do a real one-to-one comparison regarding the ratio of performance/parameters.
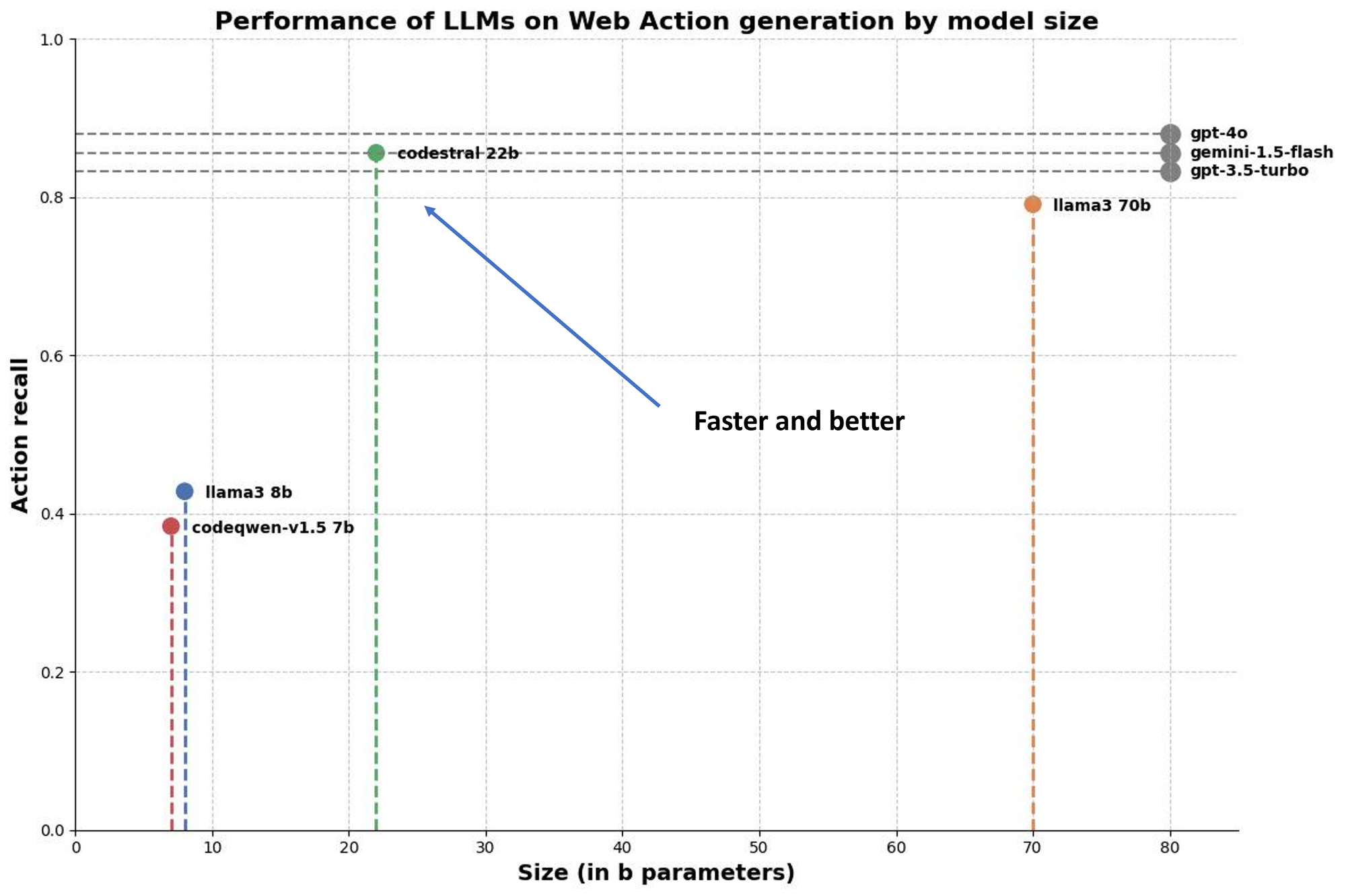
Comparison of LLM performance on code generation with respect to size
Our findings:
🥇GPT-4o still dominates the podium
🥈Codestral is on par with Gemini-1.5 Flash!
🥉Codestral outperforms GPT-3.5 and Llama 3 70b, which are roughly the same
The more a model is on the top left corner, the better it is in performance/cost.
💡Interesting phenomenon: there seems to be a class of models with a certain ratio of size to performance (we could plot a line between Llama 3 8b and Llama 3 70b).
However, Codestral seems to be in a class of its own: it’s outperforming Llama 3 70b with fewer parameters!
Conclusion
This article has shown how LaVague leverages LLMs to build large action models that automatically pilot a browser using natural language instructions only.
This was done by performing RAG on the current HTML to interact with: we first extract the relevant HTML chunks to answer a given instruction and then inject that into an LLM to generate the desired action.
We have also defined relevant evaluation metrics and tried those with different models on datasets specifically designed for web action generation.
We have seen that local models are quite competitive in web navigation:
- Embeddings: a bge-small can be as performant but also faster and cheaper than Gemini or OpenAI
- LLMs: Codestral can be as good as Gemini 1.5 Flash, and even better than GPT-3.5.
Those are very promising data points that show how one could imagine running in the future local, private and customizable AI Web Agents to interact with the internet for us.
There is still a lot of work to be done. We have only looked at the Navigation Engine here, but the World Model is a key part of our architecture. Unfortunately, in our experiments, we found that no open-source model is as good as GPT-4o, and none is usable in practice.
This seems to stem from the fact that open-source Multimodal LLMs are still challenging to train, and the open-source community has not yet found systematic and reliable ways to leverage both vision and text inputs for LLMs.
However, we are confident a viable open-source Multimodal LLM will emerge, and we will integrate it as soon as possible into our default config for the World Model.
We hope you liked this article. We would be happy to have you join our community! If you are interested in large action models, Automation, and Agents, you can join our Discord to chat with us, ask questions, or contribute to our open-source project.
