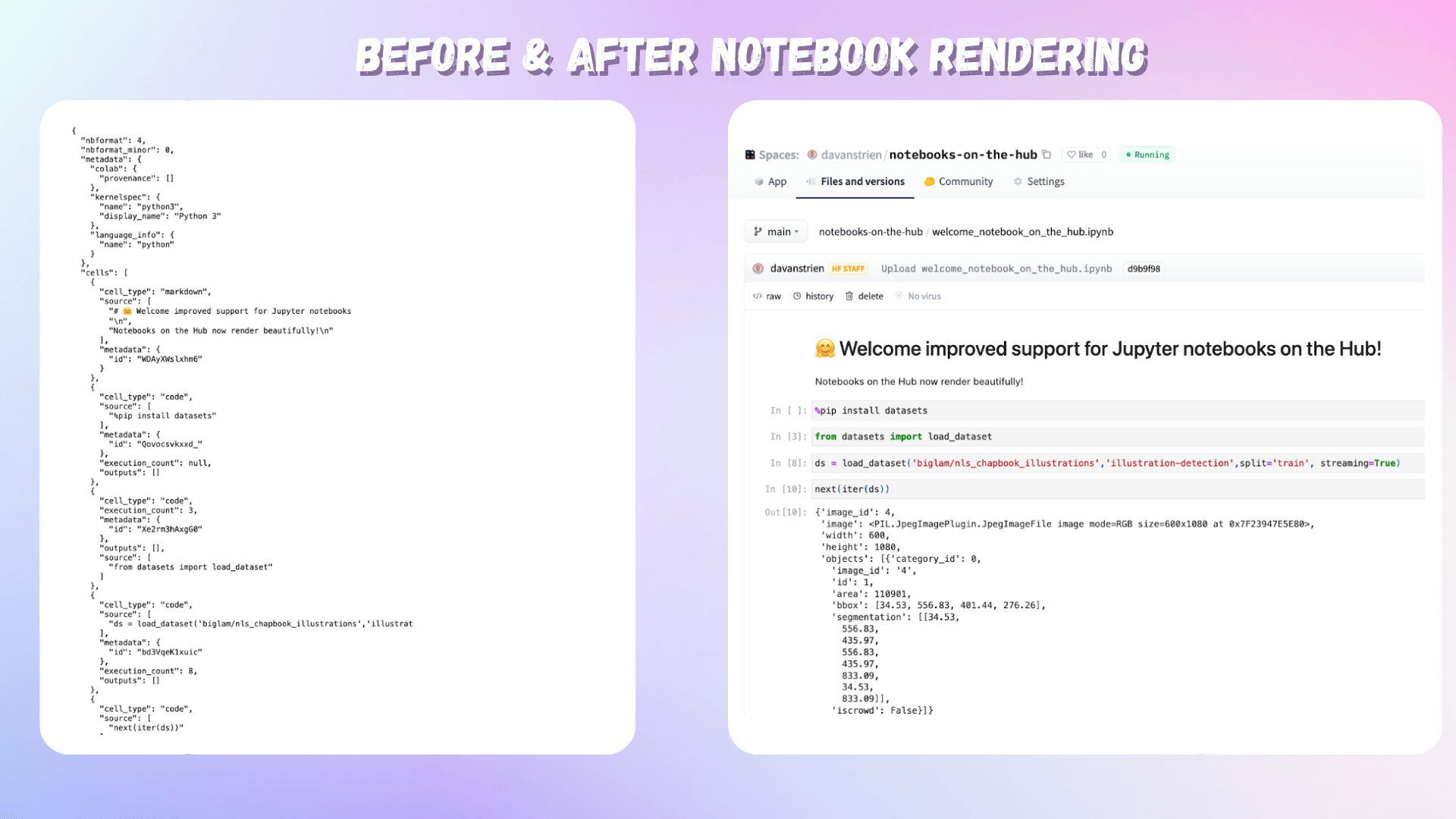
Synthetic Face Embeddings: Research Notes and Methodology By jadechip and 1 other • about 15 hours ago • 1
Mixture of Tunable Experts - Behavior Modification of DeepSeek-R1 at Inference Time By rbrt and 4 others • 1 day ago • 16
Fine-tuning SmolLM with Group Relative Policy Optimization (GRPO) by following the Methodologies By prithivMLmods • 3 days ago • 14
Agent Leaderboard: Evaluating AI Agents in Multi-Domain Scenarios By pratikbhavsar and 1 other • 8 days ago • 11
Synthetic Face Embeddings: Research Notes and Methodology By jadechip and 1 other • about 15 hours ago • 1
Mixture of Tunable Experts - Behavior Modification of DeepSeek-R1 at Inference Time By rbrt and 4 others • 1 day ago • 16
Fine-tuning SmolLM with Group Relative Policy Optimization (GRPO) by following the Methodologies By prithivMLmods • 3 days ago • 14
Agent Leaderboard: Evaluating AI Agents in Multi-Domain Scenarios By pratikbhavsar and 1 other • 8 days ago • 11