
End of training
Browse files- README.md +3 -2
- all_results.json +22 -0
- eval_results.json +17 -0
- train_results.json +8 -0
- trainer_state.json +0 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
- training_rewards_accuracies.png +0 -0
- training_sft_loss.png +0 -0
README.md
CHANGED
|
@@ -2,9 +2,10 @@
|
|
| 2 |
license: apache-2.0
|
| 3 |
library_name: peft
|
| 4 |
tags:
|
|
|
|
|
|
|
| 5 |
- trl
|
| 6 |
- dpo
|
| 7 |
-
- llama-factory
|
| 8 |
- generated_from_trainer
|
| 9 |
base_model: mistralai/Mistral-7B-Instruct-v0.3
|
| 10 |
model-index:
|
|
@@ -17,7 +18,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 17 |
|
| 18 |
# Mistral-7B-Instruct-v0.3-ORPO-SALT-HALF
|
| 19 |
|
| 20 |
-
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) on the
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
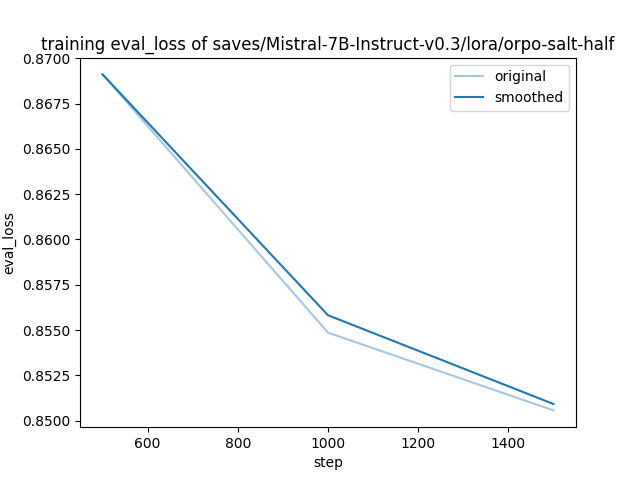
- Loss: 0.8506
|
| 23 |
- Rewards/chosen: -0.0787
|
|
|
|
| 2 |
license: apache-2.0
|
| 3 |
library_name: peft
|
| 4 |
tags:
|
| 5 |
+
- llama-factory
|
| 6 |
+
- lora
|
| 7 |
- trl
|
| 8 |
- dpo
|
|
|
|
| 9 |
- generated_from_trainer
|
| 10 |
base_model: mistralai/Mistral-7B-Instruct-v0.3
|
| 11 |
model-index:
|
|
|
|
| 18 |
|
| 19 |
# Mistral-7B-Instruct-v0.3-ORPO-SALT-HALF
|
| 20 |
|
| 21 |
+
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) on the dpo_mix_en and the bct_non_cot_dpo_500 datasets.
|
| 22 |
It achieves the following results on the evaluation set:
|
| 23 |
- Loss: 0.8506
|
| 24 |
- Rewards/chosen: -0.0787
|
all_results.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9974597798475866,
|
| 3 |
+
"eval_logits/chosen": -3.130527973175049,
|
| 4 |
+
"eval_logits/rejected": -3.1507296562194824,
|
| 5 |
+
"eval_logps/chosen": -0.7867480516433716,
|
| 6 |
+
"eval_logps/rejected": -0.9955620169639587,
|
| 7 |
+
"eval_loss": 0.8505691885948181,
|
| 8 |
+
"eval_odds_ratio_loss": 0.638211727142334,
|
| 9 |
+
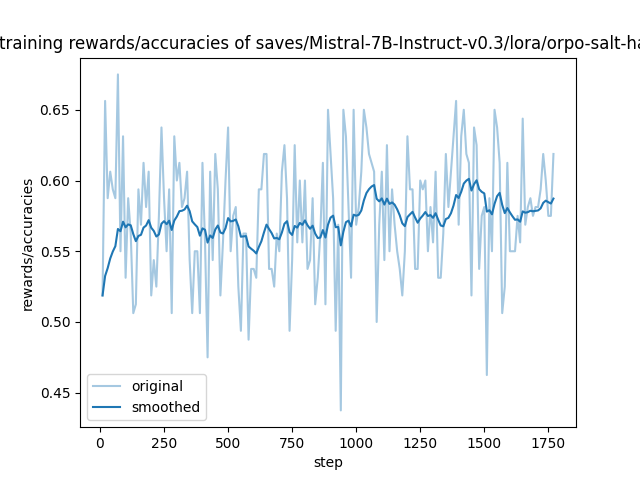
"eval_rewards/accuracies": 0.5723809599876404,
|
| 10 |
+
"eval_rewards/chosen": -0.0786748081445694,
|
| 11 |
+
"eval_rewards/margins": 0.020881392061710358,
|
| 12 |
+
"eval_rewards/rejected": -0.09955620020627975,
|
| 13 |
+
"eval_runtime": 194.0793,
|
| 14 |
+
"eval_samples_per_second": 5.41,
|
| 15 |
+
"eval_sft_loss": 0.7867480516433716,
|
| 16 |
+
"eval_steps_per_second": 2.705,
|
| 17 |
+
"total_flos": 2.0399855839629804e+18,
|
| 18 |
+
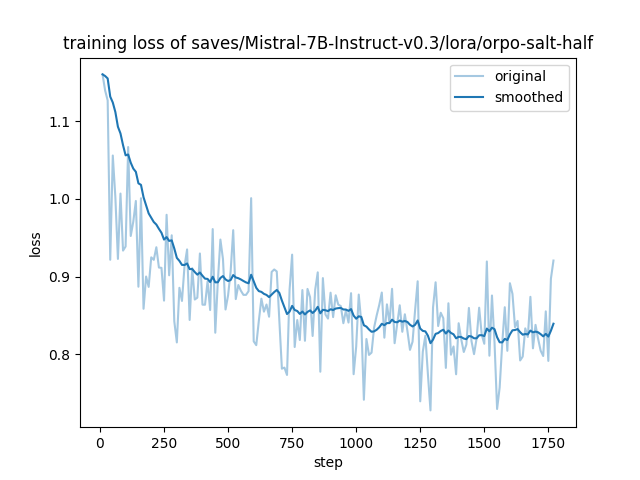
"train_loss": 0.8663494454938813,
|
| 19 |
+
"train_runtime": 17638.0542,
|
| 20 |
+
"train_samples_per_second": 1.607,
|
| 21 |
+
"train_steps_per_second": 0.1
|
| 22 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9974597798475866,
|
| 3 |
+
"eval_logits/chosen": -3.130527973175049,
|
| 4 |
+
"eval_logits/rejected": -3.1507296562194824,
|
| 5 |
+
"eval_logps/chosen": -0.7867480516433716,
|
| 6 |
+
"eval_logps/rejected": -0.9955620169639587,
|
| 7 |
+
"eval_loss": 0.8505691885948181,
|
| 8 |
+
"eval_odds_ratio_loss": 0.638211727142334,
|
| 9 |
+
"eval_rewards/accuracies": 0.5723809599876404,
|
| 10 |
+
"eval_rewards/chosen": -0.0786748081445694,
|
| 11 |
+
"eval_rewards/margins": 0.020881392061710358,
|
| 12 |
+
"eval_rewards/rejected": -0.09955620020627975,
|
| 13 |
+
"eval_runtime": 194.0793,
|
| 14 |
+
"eval_samples_per_second": 5.41,
|
| 15 |
+
"eval_sft_loss": 0.7867480516433716,
|
| 16 |
+
"eval_steps_per_second": 2.705
|
| 17 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9974597798475866,
|
| 3 |
+
"total_flos": 2.0399855839629804e+18,
|
| 4 |
+
"train_loss": 0.8663494454938813,
|
| 5 |
+
"train_runtime": 17638.0542,
|
| 6 |
+
"train_samples_per_second": 1.607,
|
| 7 |
+
"train_steps_per_second": 0.1
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|
training_rewards_accuracies.png
ADDED
|
training_sft_loss.png
ADDED

|