

Update README.md
Browse files
README.md
CHANGED
|
@@ -87,7 +87,7 @@ with torch.inference_mode():
|
|
| 87 |
|
| 88 |
### Results
|
| 89 |
|
| 90 |
-
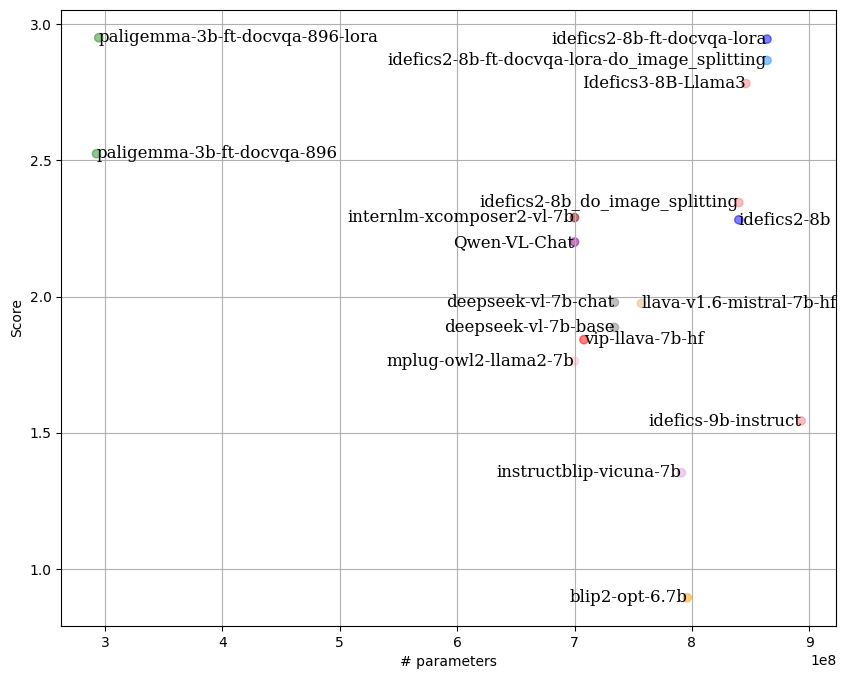
By following the **LLM-as-Juries** evaluation method, the following results were obtained using three judge models (GPT-4o, Gemini1.5 Pro and Claude 3.5-Sonnet). These models were evaluated based on the average of two criteria: response accuracy and completeness, similar to what the [SSA metric](https://arxiv.org/abs/2001.09977) aims to capture. This metric was adapted to the VQA context, with clear criteria for each score (0 to 5) to ensure the highest possible precision in meeting expectations.
|
| 91 |
|
| 92 |
|
| 93 |
|
|
|
|
| 87 |
|
| 88 |
### Results
|
| 89 |
|
| 90 |
+
By following the **[LLM-as-Juries](https://arxiv.org/abs/2404.18796)** evaluation method, the following results were obtained using three judge models (GPT-4o, Gemini1.5 Pro and Claude 3.5-Sonnet). These models were evaluated based on the average of two criteria: response accuracy and completeness, similar to what the [SSA metric](https://arxiv.org/abs/2001.09977) aims to capture. This metric was adapted to the VQA context, with clear criteria for each score (0 to 5) to ensure the highest possible precision in meeting expectations.
|
| 91 |
|
| 92 |

|
| 93 |
|