|
--- |
|
license: apache-2.0 |
|
datasets: |
|
- datajuicer/redpajama-wiki-refined-by-data-juicer |
|
- datajuicer/redpajama-arxiv-refined-by-data-juicer |
|
- datajuicer/redpajama-c4-refined-by-data-juicer |
|
- datajuicer/redpajama-book-refined-by-data-juicer |
|
- datajuicer/redpajama-cc-2019-30-refined-by-data-juicer |
|
- datajuicer/redpajama-cc-2020-05-refined-by-data-juicer |
|
- datajuicer/redpajama-cc-2021-04-refined-by-data-juicer |
|
- datajuicer/redpajama-cc-2022-05-refined-by-data-juicer |
|
- datajuicer/redpajama-cc-2023-06-refined-by-data-juicer |
|
- datajuicer/redpajama-pile-stackexchange-refined-by-data-juicer |
|
- datajuicer/redpajama-stack-code-refined-by-data-juicer |
|
- datajuicer/the-pile-nih-refined-by-data-juicer |
|
- datajuicer/the-pile-europarl-refined-by-data-juicer |
|
- datajuicer/the-pile-philpaper-refined-by-data-juicer |
|
- datajuicer/the-pile-pubmed-abstracts-refined-by-data-juicer |
|
- datajuicer/the-pile-pubmed-central-refined-by-data-juicer |
|
- datajuicer/the-pile-freelaw-refined-by-data-juicer |
|
- datajuicer/the-pile-hackernews-refined-by-data-juicer |
|
--- |
|
|
|
This is a reference LLM from [Data-Juicer](https://github.com/alibaba/data-juicer). |
|
|
|
The model architecture is LLaMA-1.3B and we adopt the [OpenLLaMA](https://github.com/openlm-research/open_llama) implementation. |
|
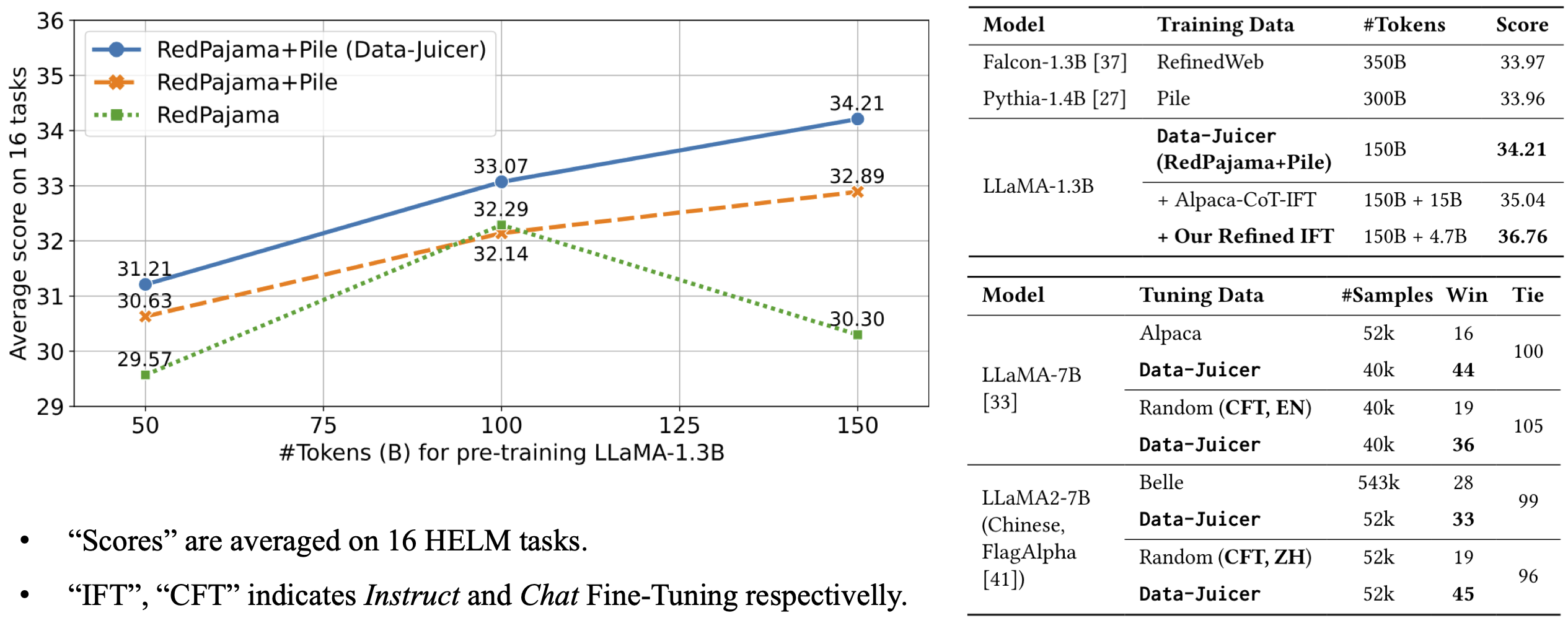
The model is pre-trained on 50B tokens of Data-Juicer's refined RedPajama and Pile. |
|
It achieves an average score of 31.21 over 16 HELM tasks, beating LLMs trained on original RedPajama and Pile datasets. |
|
|
|
For more details, please refer to our [paper](https://arxiv.org/abs/2309.02033). |
|
|
|
 |

