

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,21 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Dataset Card for BEIR Benchmark
|
| 2 |
+
|
| 3 |
+
## Table of Contents
|
| 4 |
+
- [Dataset Description](#dataset-description)
|
| 5 |
+
- [Dataset Summary](#dataset-summary)
|
| 6 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 7 |
+
- [Languages](#languages)
|
| 8 |
+
|
| 9 |
+
## Dataset Description
|
| 10 |
+
|
| 11 |
+
- **Homepage:** https://buffetfs.github.io/
|
| 12 |
+
- **Repository:** https://github.com/AkariAsai/BUFFET
|
| 13 |
+
- **Paper:** https://buffetfs.github.io/static/files/buffet_paper.pdf
|
| 14 |
+
- **Point of Contact:** akari@cs.washigton.edu
|
| 15 |
+
|
| 16 |
+
### Dataset Summary
|
| 17 |
+
|
| 18 |
+
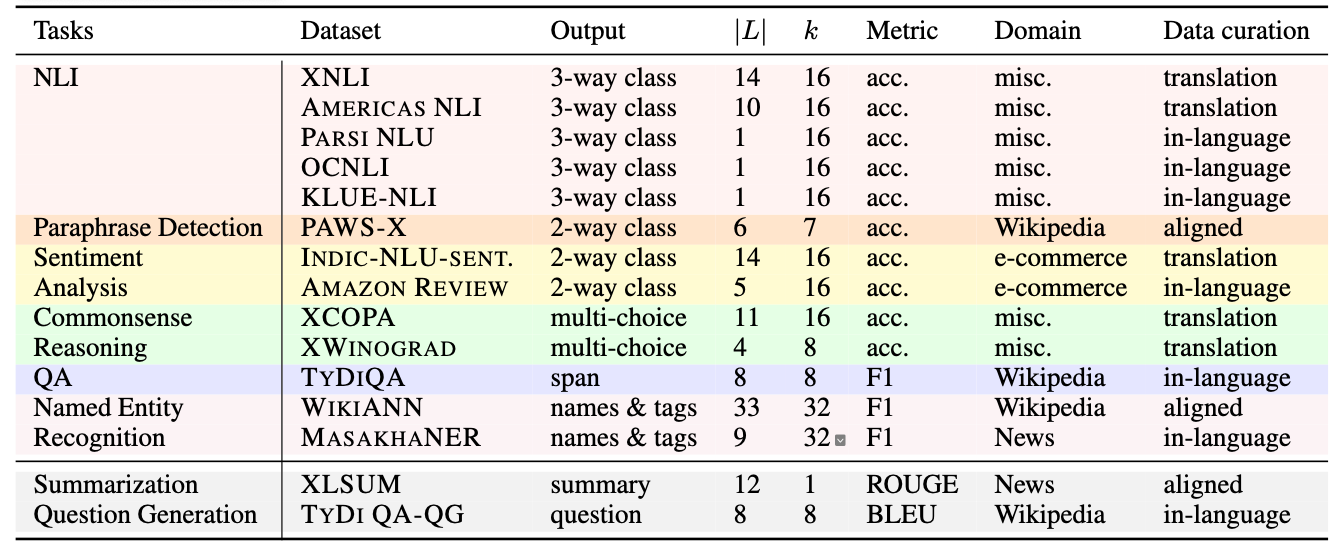
<b>BUFFET</b> unifies 15 diverse NLP datasets in typologically diverse 55 languages. The list of the datasets are available below.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
All these datasets have been preprocessed and can be used for your experiments.
|