

Update New_ViT_and_ALIGN_Models_From_Kakao_Brain_cn.md
Browse files
New_ViT_and_ALIGN_Models_From_Kakao_Brain_cn.md
CHANGED
|
@@ -27,11 +27,11 @@ Google 的 ViT 和 ALIGN 模型都使用了巨大的数据集(ViT 训练于 3
|
|
| 27 |
|
| 28 |
Kakao Brain 发布的 ViT 和 ALIGN 模型与 Google 的模型表现相当,某些方面甚至更好。Kakao Brain 的 ALIGN-B7-Base 模型虽然训练的数据对少得多( 7 亿VS 1.8 亿),但在图像 KNN 分类任务上表现与 Google 的 ALIGN-B7-Base 相当,在 MS-COCO 图像-文本检索、文本-图像检索任务上表现更好。Kakao Brain 的 ViT-L/16 在384×512的 ImageNet 和 ImageNet-ReaL 数据上的表现与 Google 的ViT-L/16 相当。这意味着同行可以使用Kakao Brain的 ViT 和 ALIGN 模型来复现 Google的 ViT 和 ALIGN ,尤其是当用户需要训练数据时。所以我们很高兴开源这些与现有技术相当的模型!
|
| 29 |
|
| 30 |
-
 数据集包含7亿图像-文本对,类似于 Google 的`ALIGN 1.8B`图像-文本数据集,是从网页上收集的“嘈杂”的html文本(alt-text)和图像对。`COYO-700M`和`ALIGN 1.8B`都是“嘈杂”的,只使用了适当的清洗处理。`COYO`类似于另一个开源的图像–文本数据集`LAION`,但有一些区别。尽管`LAION 2B`是一个更大的数据集,包含20亿个英语配对,但`COYO`的附带有更多元数据,为用户提供更多灵活性和更细粒度的使用。以下表格显示了它们之间的区别:`COYO`所有数据对都提供了美感评分,更健壮的水印评分和面部计数信息(face count data)。
|
| 37 |
|
|
@@ -53,11 +53,11 @@ Kakao Brain 发布的 ViT 和 ALIGN 模型与 Google 的模型表现相当,某
|
|
| 53 |
|
| 54 |
ViT—Vision Transformer 是谷歌于 2020 年提出的一种视觉模型,类似于文本Transformer架构。这是一种与卷积神经网络不同的视觉方法(AlexNet自2012年以来一直主导视觉任务)。同样表现下,它的计算效率比CNN高达四倍,且具有域不可知性(domain agnostic)。ViT将输入的图像分解成一系列图像块(patch),就像文本 Transformer 输入文本序列一样,然后为每个块提供位置嵌入以学习图像结构。ViT 的性能尤其在于具有出色的性能-计算权衡。谷歌的一些ViT模型是开源的,但其训练使用的JFT-300百万图像-标签对数据集尚未公开发布。Kakao Brain的训练模型是基于公开发布的COYO-Labeled-300M进行训练,对应的ViT模型在各种任务上具有相似表现,其代码、模型和训练数据(COYO-Labeled-300M)完全公开,以便能够进行复现和科学研究。
|
| 55 |
|
| 56 |
-
数据作为图像的描述,导致数据集不可避免地嘈杂,但更大的数据量(18亿对)使ALIGN能够在各种任务上表现出SoTA水平。Kakao Brain的模型是第一个ALIGN开源版本,它在 COYO 数据集上训练,表现比谷歌的结果更好。
|
| 59 |
|
| 60 |
-

|
|
| 138 |
|
| 139 |
[`https://huggingface.co/spaces/adirik/kakao-brain-vit`](https://huggingface.co/spaces/adirik/kakao-brain-vit)
|
| 140 |
|
| 141 |
-
。首先,下载预训练模型和其处理器(processor),处理器预处理图像和文本,使它们符合 ALIGN 的预期格式,以便将其输入到视觉和文本编码器中。这步导入了我们将要使用的模块并初始化预处理器和模型。
|
| 144 |
|
|
|
|
| 27 |
|
| 28 |
Kakao Brain 发布的 ViT 和 ALIGN 模型与 Google 的模型表现相当,某些方面甚至更好。Kakao Brain 的 ALIGN-B7-Base 模型虽然训练的数据对少得多( 7 亿VS 1.8 亿),但在图像 KNN 分类任务上表现与 Google 的 ALIGN-B7-Base 相当,在 MS-COCO 图像-文本检索、文本-图像检索任务上表现更好。Kakao Brain 的 ViT-L/16 在384×512的 ImageNet 和 ImageNet-ReaL 数据上的表现与 Google 的ViT-L/16 相当。这意味着同行可以使用Kakao Brain的 ViT 和 ALIGN 模型来复现 Google的 ViT 和 ALIGN ,尤其是当用户需要训练数据时。所以我们很高兴开源这些与现有技术相当的模型!
|
| 29 |
|
| 30 |
+

|
| 31 |
|
| 32 |
## COYO 数据集
|
| 33 |
|
| 34 |
+

|
| 35 |
|
| 36 |
本次发布的模型特别之处在于都是基于开源的 COYO 数据集训练的。[COYO](https://github.com/kakaobrain/coyo-dataset#dataset-preview) 数据集包含7亿图像-文本对,类似于 Google 的`ALIGN 1.8B`图像-文本数据集,是从网页上收集的“嘈杂”的html文本(alt-text)和图像对。`COYO-700M`和`ALIGN 1.8B`都是“嘈杂”的,只使用了适当的清洗处理。`COYO`类似于另一个开源的图像–文本数据集`LAION`,但有一些区别。尽管`LAION 2B`是一个更大的数据集,包含20亿个英语配对,但`COYO`的附带有更多元数据,为用户提供更多灵活性和更细粒度的使用。以下表格显示了它们之间的区别:`COYO`所有数据对都提供了美感评分,更健壮的水印评分和面部计数信息(face count data)。
|
| 37 |
|
|
|
|
| 53 |
|
| 54 |
ViT—Vision Transformer 是谷歌于 2020 年提出的一种视觉模型,类似于文本Transformer架构。这是一种与卷积神经网络不同的视觉方法(AlexNet自2012年以来一直主导视觉任务)。同样表现下,它的计算效率比CNN高达四倍,且具有域不可知性(domain agnostic)。ViT将输入的图像分解成一系列图像块(patch),就像文本 Transformer 输入文本序列一样,然后为每个块提供位置嵌入以学习图像结构。ViT 的性能尤其在于具有出色的性能-计算权衡。谷歌的一些ViT模型是开源的,但其训练使用的JFT-300百万图像-标签对数据集尚未公开发布。Kakao Brain的训练模型是基于公开发布的COYO-Labeled-300M进行训练,对应的ViT模型在各种任务上具有相似表现,其代码、模型和训练数据(COYO-Labeled-300M)完全公开,以便能够进行复现和科学研究。
|
| 55 |
|
| 56 |
+
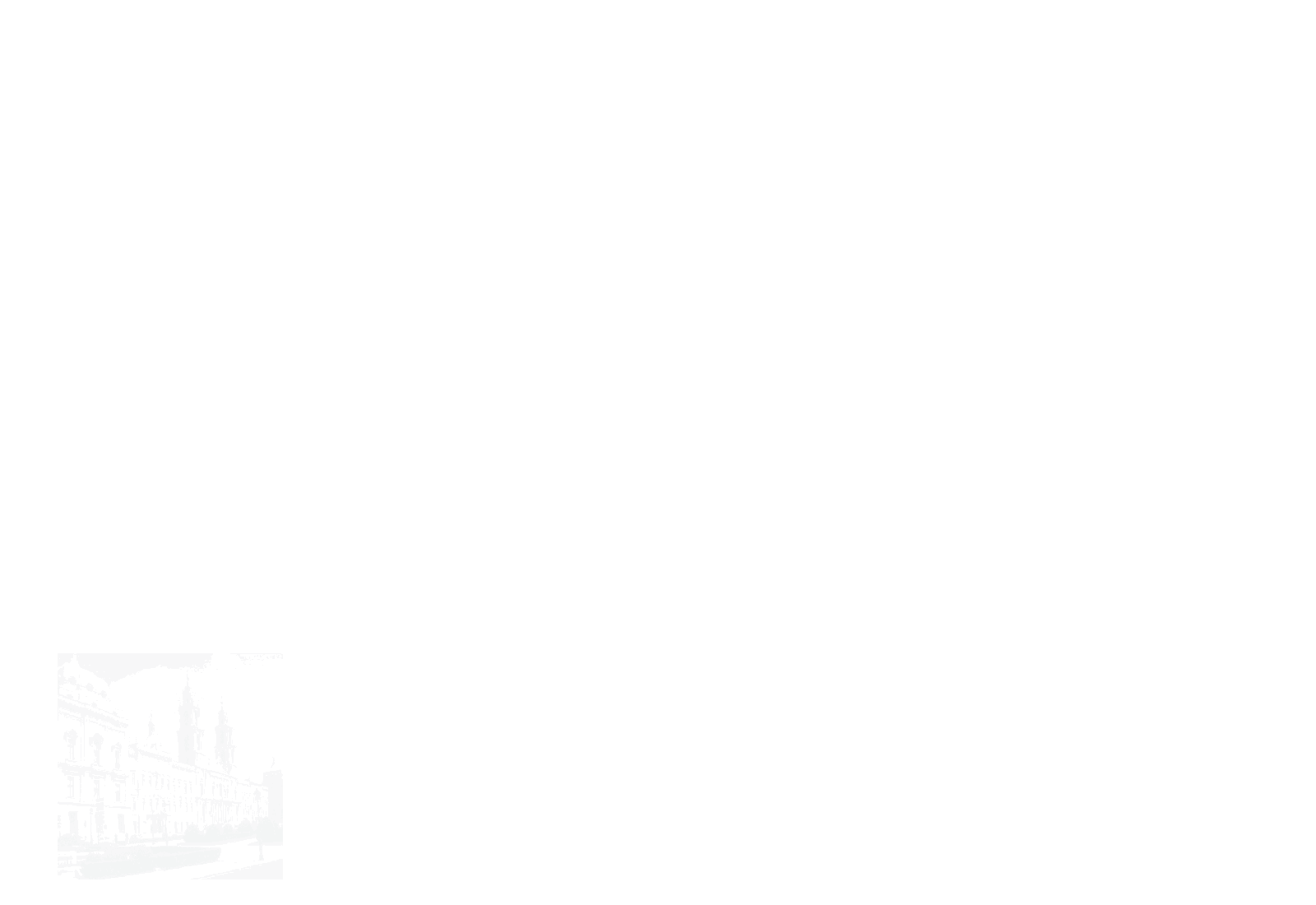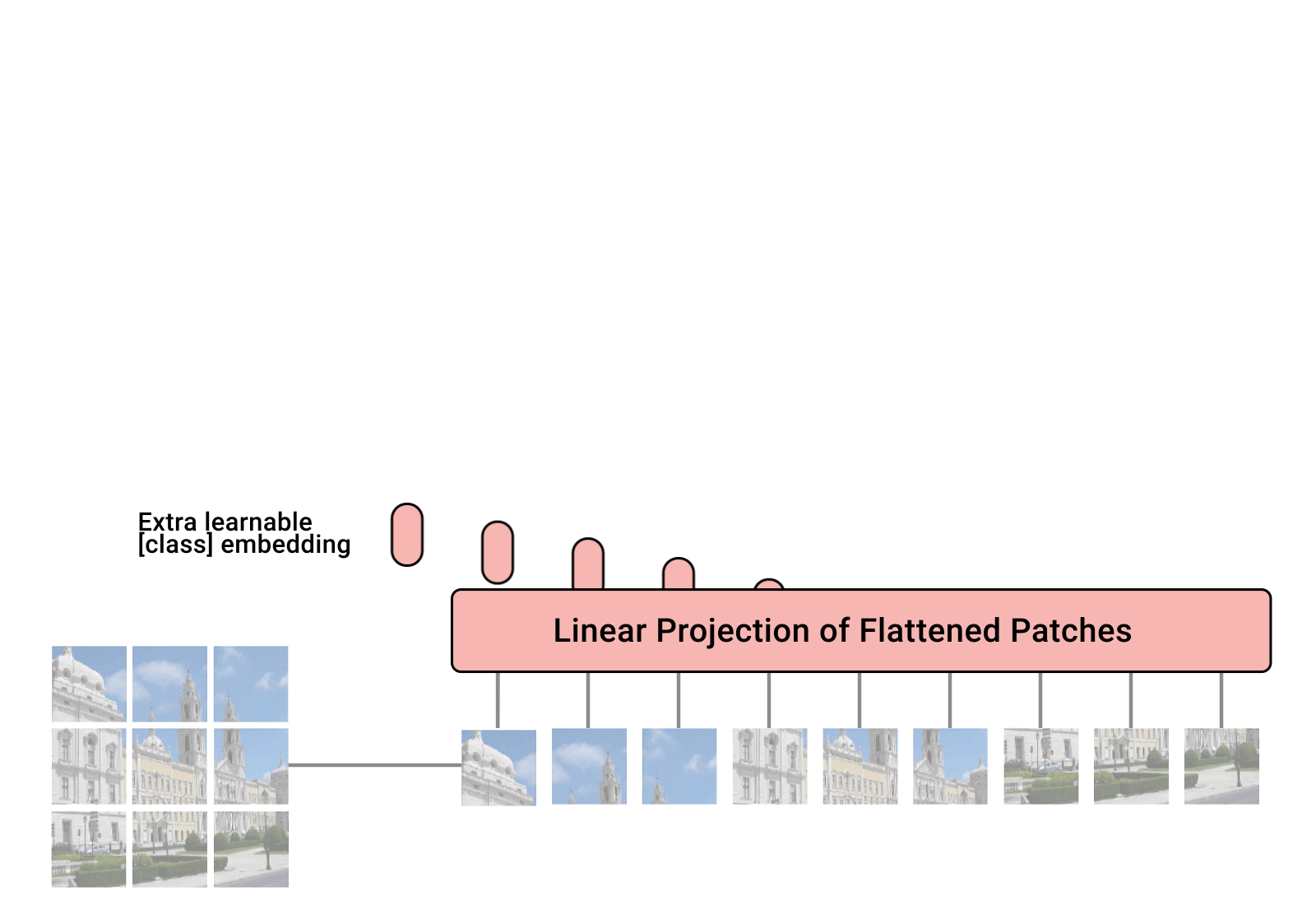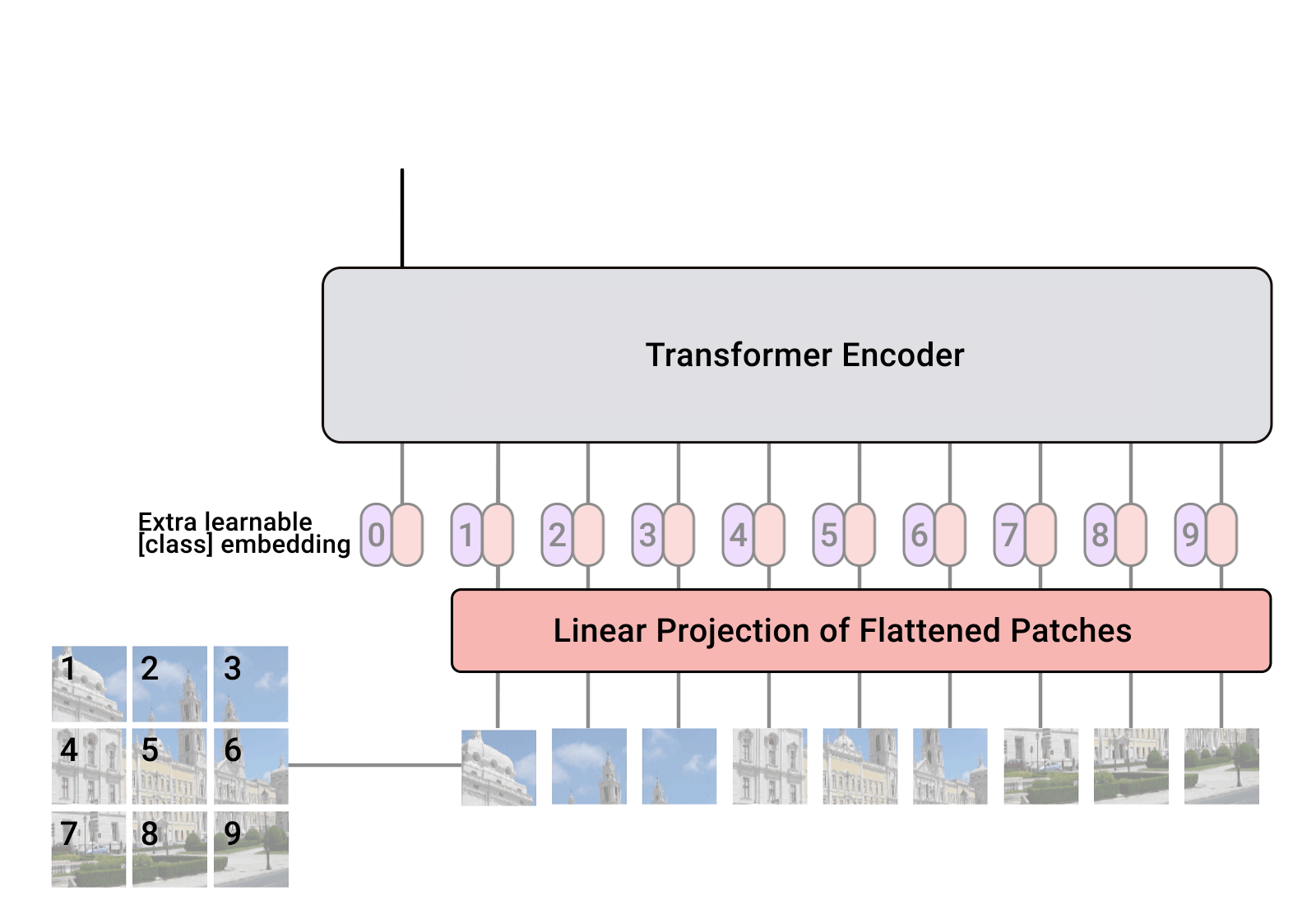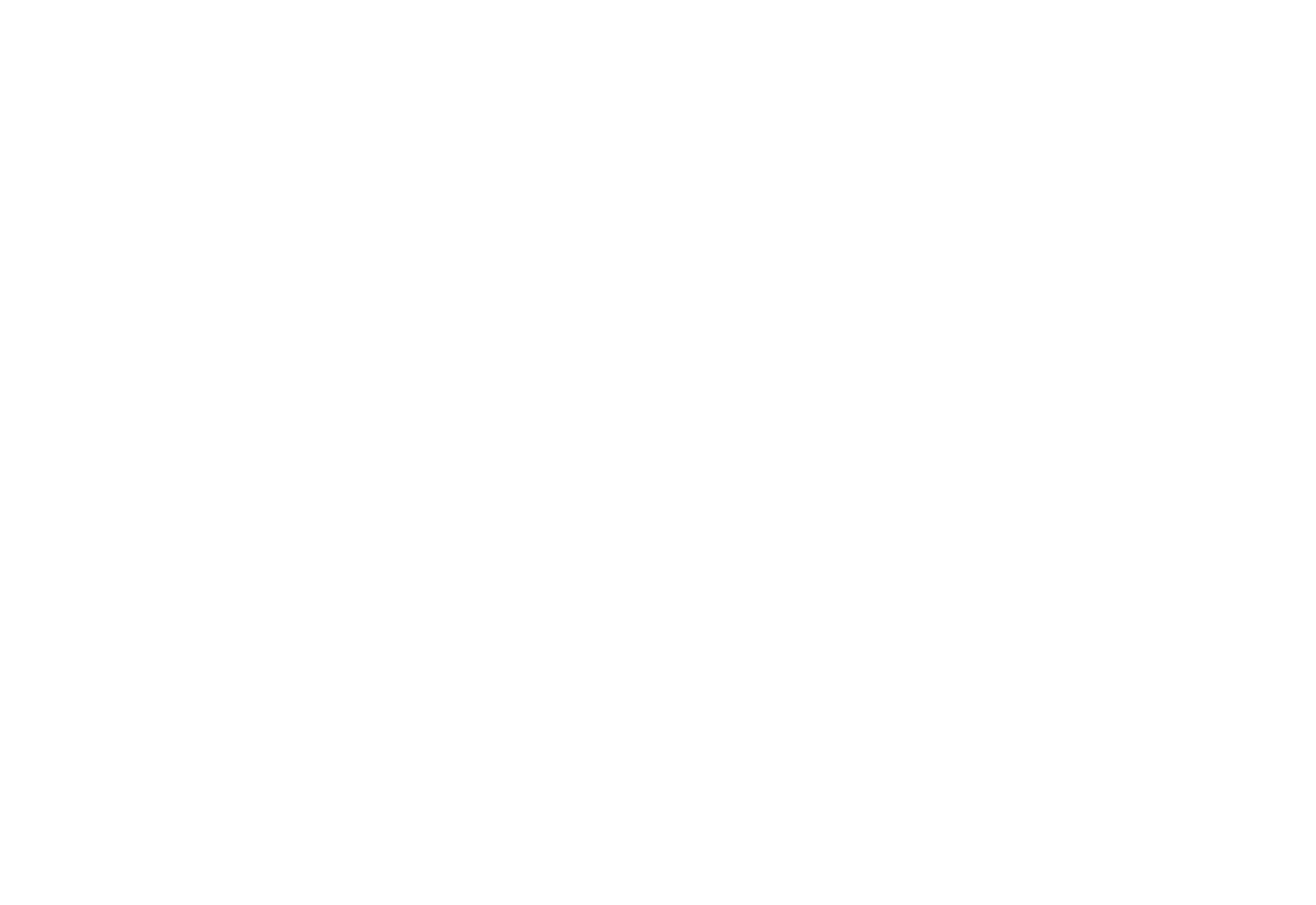
|
| 57 |
|
| 58 |
谷歌在2021年推出了 ALIGN,它是一种基于“嘈杂”文本–图像数据训练的视觉语言模型,可用于各种视觉和跨模态任务,如文本-图像检索。ALIGN 采用简单的双编码器架构,通过对比损失函数学习图像和文本对,ALIGN 的“嘈杂”训练语料特点包括用语料规模弥补其噪音以及强大的鲁棒性。之前的视觉语言表示学习都是在手动标注的大规模数据集上进行训练,这就需要大量的预先处理和成本。ALIGN 的语料库使用HTML文本(alt-text)数据作为图像的描述,导致数据集不可避免地嘈杂,但更大的数据量(18亿对)使ALIGN能够在各种任务上表现出SoTA水平。Kakao Brain的模型是第一个ALIGN开源版本,它在 COYO 数据集上训练,表现比谷歌的结果更好。
|
| 59 |
|
| 60 |
+

|
| 61 |
|
| 62 |
## 如何使用COYO数据集
|
| 63 |
|
|
|
|
| 138 |
|
| 139 |
[`https://huggingface.co/spaces/adirik/kakao-brain-vit`](https://huggingface.co/spaces/adirik/kakao-brain-vit)
|
| 140 |
|
| 141 |
+

|
| 142 |
|
| 143 |
我们开始实验 ALIGN,它可用于检索文本或图像的多模态嵌入或执行零样本图像分类。ALIGN 的 Transformer 实现和用法类似于 [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip)。首先,下载预训练模型和其处理器(processor),处理器预处理图像和文本,使它们符合 ALIGN 的预期格式,以便将其输入到视觉和文本编码器中。这步导入了我们将要使用的模块并初始化预处理器和模型。
|
| 144 |
|