# 了解 Transformers 是如何“思考”的
- [参考论文](https://arxiv.org/pdf/2106.06981.pdf) 来自 Gail Weiss, Yoav Goldberg,Eran Yahav.
- 本博客文章由 [Sasha Rush](https://rush-nlp.com/) 和 [Gail Weiss](https://sgailw.cswp.cs.technion.ac.il/) 共同编写
- 库和交互 Notebook: [srush/raspy](https://github.com/srush/RASPy)
Transformer 模型是 AI 系统的基础。已经有了数不清的关于 "Transformer 如何工作" 的核心结构图表。
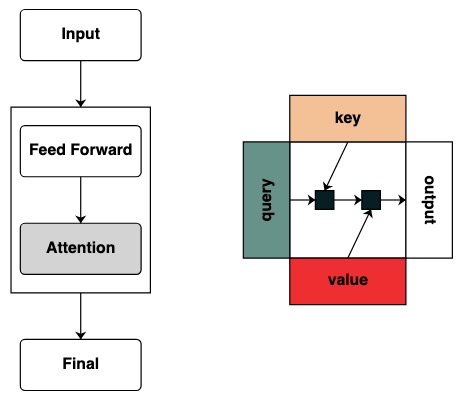
但是这些图表没有提供任何直观的计算该模型的框架表示。当研究者对于 Transformer 如何工作抱有兴趣时,直观的获取他运行的机制变得十分有用。
[Thinking Like Transformers](https://arxiv.org/pdf/2106.06981.pdf) 这篇论文中提出了 transformer 类的计算框架,这个框架直接计算和模仿 Transformer 计算。使用 [RASP](https://github.com/tech-srl/RASP) 编程语言,使每个程序编译成一个特殊的 Transformer 。
在这篇博客中,我用 python 复现了 RASP 的变体 (RASPy)。该语言大致与原始版本相当,但是多了一些我认为很有趣的变化。通过这些语言,作者 Gail Weiss 的工作,提供了一套具有挑战性的有趣且正确的方式可以帮助了解其工作原理。
```bash
!pip install git+https://github.com/srush/RASPy
```
在说起语言本身前,让我们先看一个例子,看看用 Transformers 编码是什么样的。这是一些计算翻转的代码,即反向输入序列。代码本身用两个 Transformer 层应用 attention 和数学计算到达这个结果。
```python
def flip():
length = (key(1) == query(1)).value(1)
flip = (key(length - indices - 1) == query(indices)).value(tokens)
return flip
flip()
```
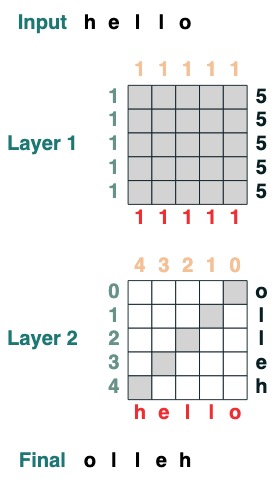
## 表格目录
- 部分一:Transformers 作为代码
- 部分二:用 Transformers 编写程序
## Transformers 作为代码
我们的目标是定义一套计算形式来最小化 Transformers 的表达。我们将通过类比,描述每个语言构造及其在 Transformers 中的对应。(正式语言规范请看 [全文](https://arxiv.org/pdf/2106.06981.pdf))
这个语言的核心单元是将一个序列转换成相同长度的另一个序列的序列操作。我后面将其称之为 transforms。
### 输入
在一个 Transformer 中,基本层是一个模型的前馈输入。这个输入通常包含原始的 token 和位置信息。
在代码中,tokens 的特征表示最简单的 transform,它返回经过模型的 tokens,默认输入序列是 "hello":
```python
tokens
```

如果我们想要改变 transform 里的输入,我们使用输入方法进行传值。
```python
tokens.input([5, 2, 4, 5, 2, 2])
```

作为 Transformers,我们不能直接接受这些序列的位置。但是为了模拟位置嵌入,我们可以获取位置的索引:
```python
indices
```

```python
sop = indices
sop.input("goodbye")
```

### 前馈网络
经过输入层后,我们到达了前馈网络层。在 Transformer 中,这一步可以对于序列的每一个元素独立的应用数学运算。
在代码中,我们通过在 transforms 上计算表示这一步。在每一个序列的元素中都会进行独立的数学运算。
```python
tokens == "l"
```

结果是一个新的 transform,一旦重构新的输入就会按照重构方式计算:
```python
model = tokens * 2 - 1
model.input([1, 2, 3, 5, 2])
```

该运算可以组合多个 Transforms,举个例子,以上述的 token 和 indices 为例,这里可以类别 Transformer 可以跟踪多个片段信息:
```python
model = tokens - 5 + indices
model.input([1, 2, 3, 5, 2])
```

```python
(tokens == "l") | (indices == 1)
```

我们提供了一些辅助函数让写 transforms 变得更简单,举例来说,`where` 提供了一个类似 `if` 功能的结构。
```python
where((tokens == "h") | (tokens == "l"), tokens, "q")
```

`map` 使我们可以定义自己的操作,例如一个字符串以 `int` 转换。(用户应谨慎使用可以使用的简单神经网络计算的操作)
```python
atoi = tokens.map(lambda x: ord(x) - ord('0'))
atoi.input("31234")
```

函数 (functions) 可以容易的描述这些 transforms 的级联。举例来说,下面是应用了 where 和 atoi 和加 2 的操作
```python
def atoi(seq=tokens):
return seq.map(lambda x: ord(x) - ord('0'))
op = (atoi(where(tokens == "-", "0", tokens)) + 2)
op.input("02-13")
```

### 注意力筛选器
到开始应用注意力机制事情就变得开始有趣起来了。这将允许序列间的不同元素进行信息交换。
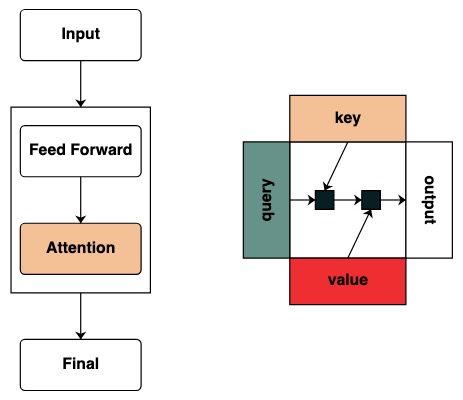
我们开始定义 key 和 query 的概念,Keys 和 Queries 可以直接从上面的 transforms 创建。举个例子,如果我们想要定义一个 key 我们称作 `key`。
```python
key(tokens)
```

对于 `query` 也一样
```python
query(tokens)
```

标量可以作为 `key` 或 `query` 使用,他们会广播到基础序列的长度。
```python
query(1)
```

我们创建了筛选器来应用 key 和 query 之间的操作。这对应于一个二进制矩阵,指示每个 query 要关注哪个 key。与 Transformers 不同,这个注意力矩阵未加入权重。
```python
eq = (key(tokens) == query(tokens))
eq
```
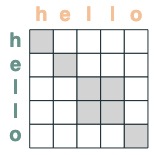
一些例子:
- 选择器的匹配位置偏移 1:
```python
offset = (key(indices) == query(indices - 1))
offset
```
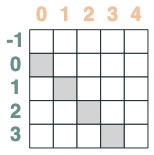
- key 早于 query 的选择器:
```python
before = key(indices) < query(indices)
before
```
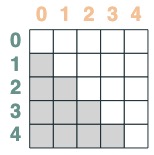
- key 晚于 query 的选择器:
```python
after = key(indices) > query(indices)
after
```
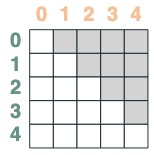
选择器可以通过布尔操作合并。比如,这个选择器将 before 和 eq 做合并,我们通过在矩阵中包含一对键和值来显示这一点。
```python
before & eq
```
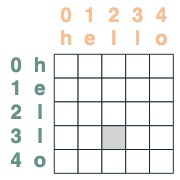
## 使用注意力机制
给一个注意力选择器,我们可以提供一个序列值做聚合操作。我们通过累加那些选择器选过的真值做聚合。
(请注意:在原始论文中,他们使用一个平均聚合操作并且展示了一个巧妙的结构,其中平均聚合能够代表总和计算。RASPy 默认情况下使用累加来使其简单化并避免碎片化。实际上,这意味着 raspy 可能低估了所需要的层数。基于平均值的模型可能需要这个层数的两倍)
注意聚合操作使我们能够计算直方图之类的功能。
```python
(key(tokens) == query(tokens)).value(1)
```
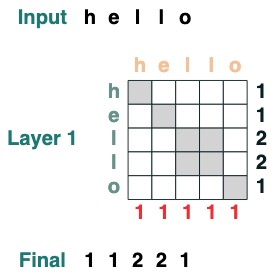
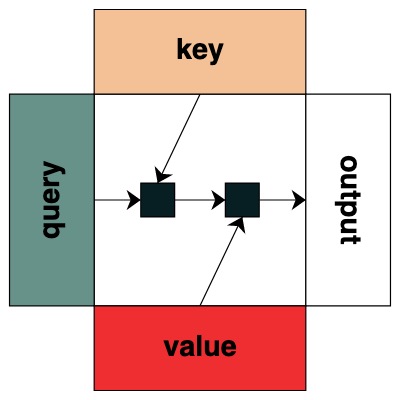
视觉上我们遵循图表结构,Query 在左边,Key 在上边,Value 在下面,输出在右边
一些注意力机制操作甚至不需要用到输入 token 。举例来说,去计算序列长度,我们创建一个 " select all " 的注意力筛选器并且给他赋值。
```python
length = (key(1) == query(1)).value(1)
length = length.name("length")
length
```
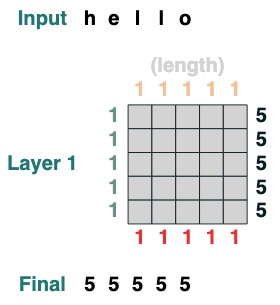
这里有更多复杂的例子,下面将一步一步展示。(这有点像做采访一样)
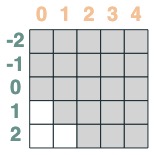
我们想要计算一个序列的相邻值的和,首先我们向前截断:
```python
WINDOW=3
s1 = (key(indices) >= query(indices - WINDOW + 1))
s1
```
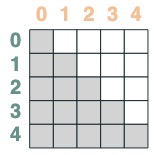
然后我们向后截断:
```python
s2 = (key(indices) <= query(indices))
s2
```
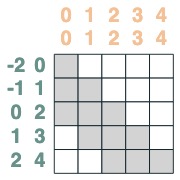
两者相交:
```python
sel = s1 & s2
sel
```
最终聚合:
```python
sum2 = sel.value(tokens)
sum2.input([1,3,2,2,2])
```
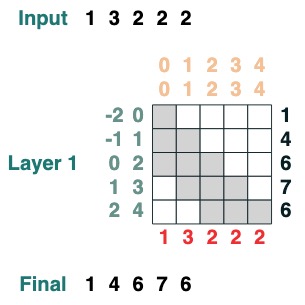
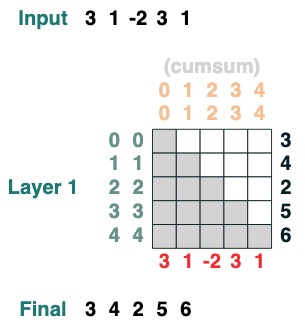
这里有个可以计算累计求和的例子,我们这里引入一个给 transform 命名的能力来帮助你调试。
```python
def cumsum(seq=tokens):
x = (before | (key(indices) == query(indices))).value(seq)
return x.name("cumsum")
cumsum().input([3, 1, -2, 3, 1])
```
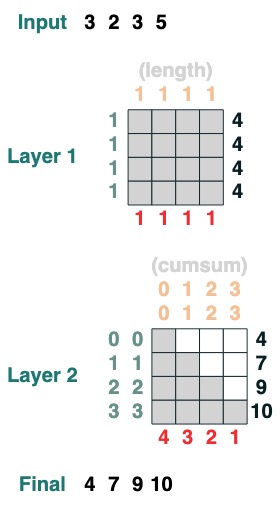
### 层
这个语言支持编译更加复杂的 transforms。他同时通过跟踪每一个运算操作计算层。
这里有个 2 层 transform 的例子,第一个对应于计算长度,第二个对应于累积总和。
```python
x = cumsum(length - indices)
x.input([3, 2, 3, 5])
```
## 用 transformers 进行编程
使用这个函数库,我们可以编写完成一个复杂任务
Gail Weiss,给过我一个极其挑战的问题来打破这个步骤
我们可以加载一个添加任意长度数字的 Transformer 吗?
例: 给一个字符串 "19492+23919", 我们可以加载正确的输出吗?
如果你想自己尝试,我们提供了一个[版本](https://colab.research.google.com/github/srush/raspy/blob/main/Blog.ipynb)你可以自己试试。
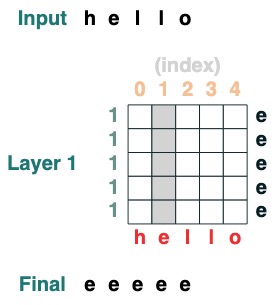
### 挑战一 : 选择一个给定的索引
加载一个在索引 i 处全元素都有值的序列
```python
def index(i, seq=tokens):
x = (key(indices) == query(i)).value(seq)
return x.name("index")
index(1)
```
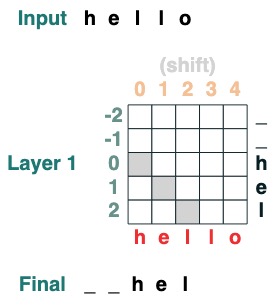
### 挑战二 :转换
通过 i 位置将所有 token 移动到右侧。
```python
def shift(i=1, default="_", seq=tokens):
x = (key(indices) == query(indices-i)).value(seq, default)
return x.name("shift")
shift(2)
```
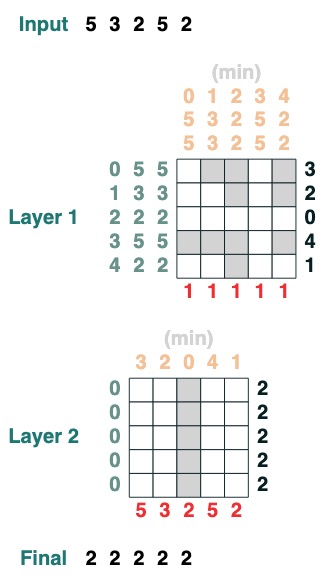
### 挑战三 :最小化
计算序列的最小值。(这一步开始变得困难,我们版本用了 2 层注意力机制)
```python
def minimum(seq=tokens):
sel1 = before & (key(seq) == query(seq))
sel2 = key(seq) < query(seq)
less = (sel1 | sel2).value(1)
x = (key(less) == query(0)).value(seq)
return x.name("min")
minimum()([5,3,2,5,2])
```
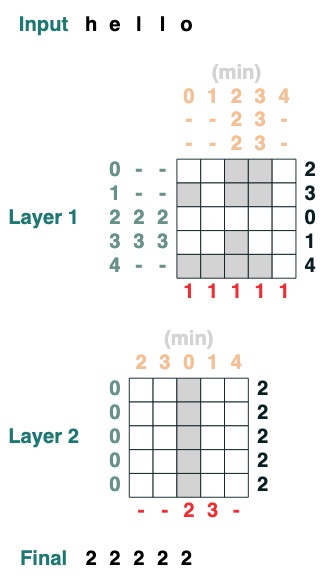
### 挑战四:第一索引
计算有 token q 的第一索引 (2 层)
```python
def first(q, seq=tokens):
return minimum(where(seq == q, indices, 99))
first("l")
```
### 挑战五 :右对齐
右对齐一个填充序列。例:"`ralign().inputs('xyz___') ='—xyz'`" (2 层)
```python
def ralign(default="-", sop=tokens):
c = (key(sop) == query("_")).value(1)
x = (key(indices + c) == query(indices)).value(sop, default)
return x.name("ralign")
ralign()("xyz__")
```
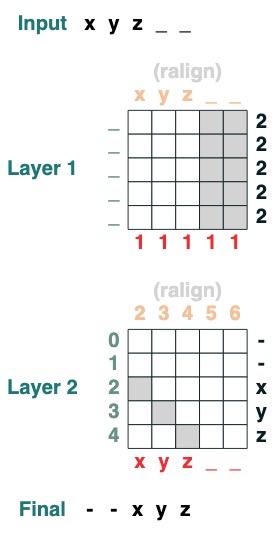
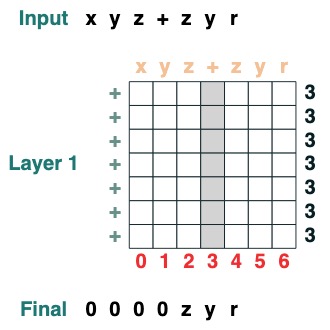
### 挑战六:分离
把一个序列在 token "v" 处分离成两部分然后右对齐 (2 层):
```python
def split(v, i, sop=tokens):
mid = (key(sop) == query(v)).value(indices)
if i == 0:
x = ralign("0", where(indices < mid, sop, "_"))
return x
else:
x = where(indices > mid, sop, "0")
return x
split("+", 1)("xyz+zyr")
```
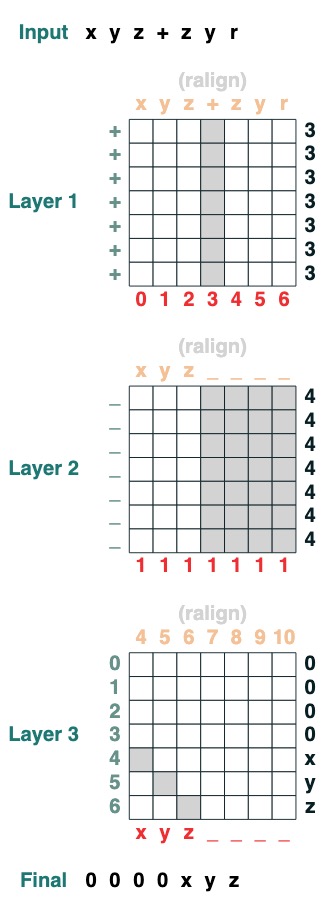
```python
split("+", 0)("xyz+zyr")
```
### 挑战七:滑动
将特殊 token "<" 替换为最接近的 "<" value (2 层):
```python
def slide(match, seq=tokens):
x = cumsum(match)
y = ((key(x) == query(x + 1)) & (key(match) == query(True))).value(seq)
seq = where(match, seq, y)
return seq.name("slide")
slide(tokens != "<").input("xxxh<<
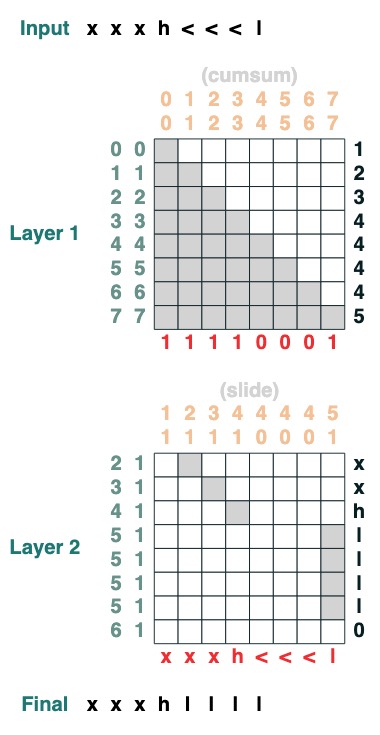
## 挑战八:增加
你要执行两个数字的添加。这是步骤。
```python
add().input("683+345")
```
0. 分成两部分。转制成整形。加入
>“683+345” => [0, 0, 0, 9, 12, 8]
1. 计算携带条款。三种可能性:1 个携带,0 不携带,< 也许有携带。
>[0, 0, 0, 9, 12, 8] => “00<100”
2. 滑动进位系数
> “00<100” => 001100"
3. 完成加法
这些都是 1 行代码。完整的系统是 6 个注意力机制。(尽管 Gail 说,如果你足够细心则可以在 5 个中完成!)。
```python
def add(sop=tokens):
# 0) Parse and add
x = atoi(split("+", 0, sop)) + atoi(split("+", 1, sop))
# 1) Check for carries
carry = shift(-1, "0", where(x > 9, "1", where(x == 9, "<", "0")))
# 2) In parallel, slide carries to their column
carries = atoi(slide(carry != "<", carry))
# 3) Add in carries.
return (x + carries) % 10
add()("683+345")
```
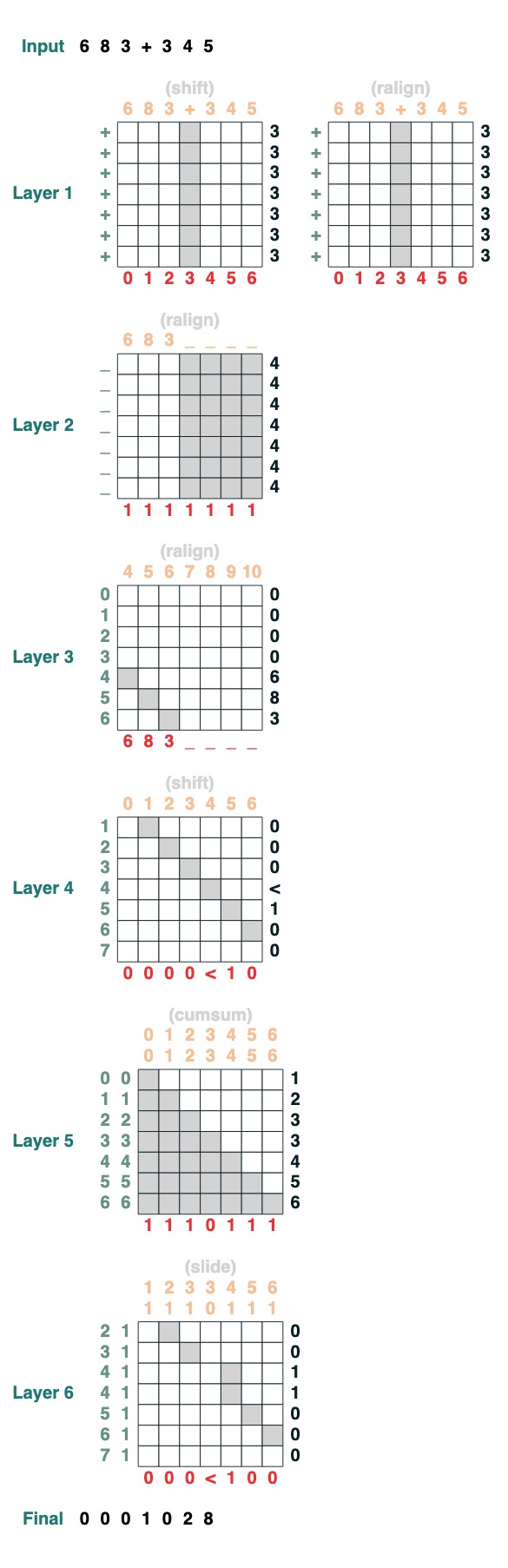
```python
683 + 345
```
```python
1028
```
完美搞定!
如果你对这个主题感兴趣想了解更多,请务必查看论文:
[Thinking Like Transformers](https://arxiv.org/pdf/2106.06981.pdf) 以及 [RASP 语言](https://github.com/tech-srl/RASP)。
如果你对「形式语言和神经网络」(FLaNN) 感兴趣或者有认识感兴趣的人,欢迎邀请他们加入我们的线上社区!
https://flann.super.site/
本篇博文,包含库、可视化和博文,可在 https://github.com/srush/raspy 查看和获取。
> 英文原文:[Thinking Like Transformers](https://srush.github.io/raspy/)
>
> 译者:innovation64 (李洋)