
url
stringlengths 61
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 75
75
| comments_url
stringlengths 70
70
| events_url
stringlengths 68
68
| html_url
stringlengths 51
51
| id
int64 1.92B
2.7B
| node_id
stringlengths 18
18
| number
int64 6.27k
7.3k
| title
stringlengths 2
150
| user
dict | labels
listlengths 0
2
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
1
| milestone
null | comments
sequencelengths 0
23
| created_at
timestamp[ns] | updated_at
int64 1.7k
1.73k
| closed_at
timestamp[ns] | author_association
stringclasses 4
values | active_lock_reason
null | body
stringlengths 3
47.9k
⌀ | closed_by
dict | reactions
dict | timeline_url
stringlengths 70
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
null | pull_request
null | is_pull_request
bool 1
class | time_to_close
float64 0
0
⌀ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/7100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7100/comments | https://api.github.com/repos/huggingface/datasets/issues/7100/events | https://github.com/huggingface/datasets/issues/7100 | 2,465,529,414 | I_kwDODunzps6S9P5G | 7,100 | IterableDataset: cannot resolve features from list of numpy arrays | {
"avatar_url": "https://avatars.githubusercontent.com/u/18899212?v=4",
"events_url": "https://api.github.com/users/VeryLazyBoy/events{/privacy}",
"followers_url": "https://api.github.com/users/VeryLazyBoy/followers",
"following_url": "https://api.github.com/users/VeryLazyBoy/following{/other_user}",
"gists_url": "https://api.github.com/users/VeryLazyBoy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/VeryLazyBoy",
"id": 18899212,
"login": "VeryLazyBoy",
"node_id": "MDQ6VXNlcjE4ODk5MjEy",
"organizations_url": "https://api.github.com/users/VeryLazyBoy/orgs",
"received_events_url": "https://api.github.com/users/VeryLazyBoy/received_events",
"repos_url": "https://api.github.com/users/VeryLazyBoy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/VeryLazyBoy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VeryLazyBoy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/VeryLazyBoy",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"Assign this issue to me under Hacktoberfest with hacktoberfest label inserted on the issue"
] | 1970-01-01T00:00:00.000001 | 1,727 | null | NONE | null | ### Describe the bug
when resolve features of `IterableDataset`, got `pyarrow.lib.ArrowInvalid: Can only convert 1-dimensional array values` error.
```
Traceback (most recent call last):
File "test.py", line 6
iter_ds = iter_ds._resolve_features()
File "lib/python3.10/site-packages/datasets/iterable_dataset.py", line 2876, in _resolve_features
features = _infer_features_from_batch(self.with_format(None)._head())
File "lib/python3.10/site-packages/datasets/iterable_dataset.py", line 63, in _infer_features_from_batch
pa_table = pa.Table.from_pydict(batch)
File "pyarrow/table.pxi", line 1813, in pyarrow.lib._Tabular.from_pydict
File "pyarrow/table.pxi", line 5339, in pyarrow.lib._from_pydict
File "pyarrow/array.pxi", line 374, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 344, in pyarrow.lib.array
File "pyarrow/array.pxi", line 42, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Can only convert 1-dimensional array values
```
### Steps to reproduce the bug
```python
from datasets import Dataset
import numpy as np
# create list of numpy
iter_ds = Dataset.from_dict({'a': [[[1, 2, 3], [1, 2, 3]]]}).to_iterable_dataset().map(lambda x: {'a': [np.array(x['a'])]})
iter_ds = iter_ds._resolve_features() # errors here
```
### Expected behavior
features can be successfully resolved
### Environment info
- `datasets` version: 2.21.0
- Platform: Linux-5.15.0-94-generic-x86_64-with-glibc2.35
- Python version: 3.10.13
- `huggingface_hub` version: 0.23.4
- PyArrow version: 15.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2023.10.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7100/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7100/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7097 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7097/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7097/comments | https://api.github.com/repos/huggingface/datasets/issues/7097/events | https://github.com/huggingface/datasets/issues/7097 | 2,458,455,489 | I_kwDODunzps6SiQ3B | 7,097 | Some of DownloadConfig's properties are always being overridden in load.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/29772899?v=4",
"events_url": "https://api.github.com/users/ductai199x/events{/privacy}",
"followers_url": "https://api.github.com/users/ductai199x/followers",
"following_url": "https://api.github.com/users/ductai199x/following{/other_user}",
"gists_url": "https://api.github.com/users/ductai199x/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ductai199x",
"id": 29772899,
"login": "ductai199x",
"node_id": "MDQ6VXNlcjI5NzcyODk5",
"organizations_url": "https://api.github.com/users/ductai199x/orgs",
"received_events_url": "https://api.github.com/users/ductai199x/received_events",
"repos_url": "https://api.github.com/users/ductai199x/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ductai199x/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ductai199x/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ductai199x",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,723 | null | NONE | null | ### Describe the bug
The `extract_compressed_file` and `force_extract` properties of DownloadConfig are always being set to True in the function `dataset_module_factory` in the `load.py` file. This behavior is very annoying because data extracted will just be ignored the next time the dataset is loaded.
See this image below:
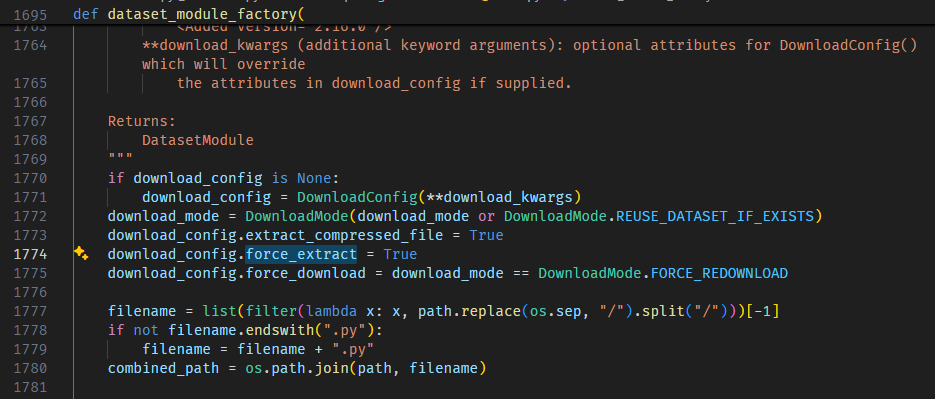
### Steps to reproduce the bug
1. Have a local dataset that contains archived files (zip, tar.gz, etc)
2. Build a dataset loading script to download and extract these files
3. Run the load_dataset function with a DownloadConfig that specifically set `force_extract` to False
4. The extraction process will start no matter if the archives was extracted previously
### Expected behavior
The extraction process should not run when the archives were previously extracted and `force_extract` is set to False.
### Environment info
datasets==2.20.0
python3.9 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7097/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7097/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7093 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7093/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7093/comments | https://api.github.com/repos/huggingface/datasets/issues/7093/events | https://github.com/huggingface/datasets/issues/7093 | 2,454,413,074 | I_kwDODunzps6SS18S | 7,093 | Add Arabic Docs to datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/53489256?v=4",
"events_url": "https://api.github.com/users/AhmedAlmaghz/events{/privacy}",
"followers_url": "https://api.github.com/users/AhmedAlmaghz/followers",
"following_url": "https://api.github.com/users/AhmedAlmaghz/following{/other_user}",
"gists_url": "https://api.github.com/users/AhmedAlmaghz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AhmedAlmaghz",
"id": 53489256,
"login": "AhmedAlmaghz",
"node_id": "MDQ6VXNlcjUzNDg5MjU2",
"organizations_url": "https://api.github.com/users/AhmedAlmaghz/orgs",
"received_events_url": "https://api.github.com/users/AhmedAlmaghz/received_events",
"repos_url": "https://api.github.com/users/AhmedAlmaghz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AhmedAlmaghz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AhmedAlmaghz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AhmedAlmaghz",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,723 | null | NONE | null | ### Feature request
Add Arabic Docs to datasets
[Datasets Arabic](https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx)
### Motivation
@AhmedAlmaghz
https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx
### Your contribution
@AhmedAlmaghz
https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7093/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7093/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7092 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7092/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7092/comments | https://api.github.com/repos/huggingface/datasets/issues/7092/events | https://github.com/huggingface/datasets/issues/7092 | 2,451,393,658 | I_kwDODunzps6SHUx6 | 7,092 | load_dataset with multiple jsonlines files interprets datastructure too early | {
"avatar_url": "https://avatars.githubusercontent.com/u/23384483?v=4",
"events_url": "https://api.github.com/users/Vipitis/events{/privacy}",
"followers_url": "https://api.github.com/users/Vipitis/followers",
"following_url": "https://api.github.com/users/Vipitis/following{/other_user}",
"gists_url": "https://api.github.com/users/Vipitis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Vipitis",
"id": 23384483,
"login": "Vipitis",
"node_id": "MDQ6VXNlcjIzMzg0NDgz",
"organizations_url": "https://api.github.com/users/Vipitis/orgs",
"received_events_url": "https://api.github.com/users/Vipitis/received_events",
"repos_url": "https://api.github.com/users/Vipitis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Vipitis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vipitis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Vipitis",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"I’ll take a look",
"Possible definitions of done for this issue:\r\n\r\n1. A fix so you can load your dataset specifically\r\n2. A general fix for datasets similar to this in the `datasets` library\r\n\r\nOption 1 is trivial. I think option 2 requires significant changes to the library.\r\n\r\nSince you outlined something akin to option 2 in `Expected behavior` I'm assuming that's what you'd like to see done. Is that right?\r\n\r\nIn the meantime, here's a solution for option 1:\r\n\r\n```python\r\nimport datasets\r\n\r\ndata_dir = './data/annotated/api'\r\n\r\nfeatures = datasets.Features({'id': datasets.Value(dtype='string'),\r\n 'name': datasets.Value(dtype='string'),\r\n 'author': datasets.Value(dtype='string'),\r\n 'description': datasets.Value(dtype='string'),\r\n 'tags': datasets.Sequence(feature=datasets.Value(dtype='string'), length=-1),\r\n 'likes': datasets.Value(dtype='int64'),\r\n 'viewed': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'date': datasets.Value(dtype='string'),\r\n 'time_retrieved': datasets.Value(dtype='string'),\r\n 'image_code': datasets.Value(dtype='string'),\r\n 'image_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'common_code': datasets.Value(dtype='string'),\r\n 'sound_code': datasets.Value(dtype='string'),\r\n 'sound_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'buffer_a_code': datasets.Value(dtype='string'),\r\n 'buffer_a_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'buffer_b_code': datasets.Value(dtype='string'),\r\n 'buffer_b_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'buffer_c_code': datasets.Value(dtype='string'),\r\n 'buffer_c_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'buffer_d_code': datasets.Value(dtype='string'),\r\n 'buffer_d_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'cube_a_code': datasets.Value(dtype='string'),\r\n 'cube_a_inputs': [{'channel': datasets.Value(dtype='int64'),\r\n 'ctype': datasets.Value(dtype='string'),\r\n 'id': datasets.Value(dtype='int64'),\r\n 'published': datasets.Value(dtype='int64'),\r\n 'sampler': {'filter': datasets.Value(dtype='string'),\r\n 'internal': datasets.Value(dtype='string'),\r\n 'srgb': datasets.Value(dtype='string'),\r\n 'vflip': datasets.Value(dtype='string'),\r\n 'wrap': datasets.Value(dtype='string')},\r\n 'src': datasets.Value(dtype='string')}],\r\n 'thumbnail': datasets.Value(dtype='string'),\r\n 'access': datasets.Value(dtype='string'),\r\n 'license': datasets.Value(dtype='string'),\r\n 'functions': datasets.Sequence(feature=datasets.Sequence(feature=datasets.Value(dtype='int64'), length=-1), length=-1),\r\n 'test': datasets.Value(dtype='string')})\r\n\r\ndatasets.load_dataset('json', data_dir=data_dir, features=features)\r\n```",
"As pointed out by @hvaara, you can define explicit features so that you avoid the `datasets` library having to infer them (from the first few samples).\r\n\r\nNote that the feature inference is done from the first few samples of JSON-Lines on purpose, so that the entire data does not need to be parsed twice (it would be inefficient for very large datasets).",
"I understand this. But can there be a solution that doesn't require the end user to write this shema by hand(in my case there is some fields that contain a nested structure)? \r\n\r\nMaybe offer an option to infer the shema automatically before loading the dataset. Or perhaps - trigger such a method when this error arises? \r\n\r\nIs this \"first few files\" heuristics accessible via kwargs perhaps. Maybe an error that says \r\n`Cloud not cast some structure into feature shema, consider increasing shema_files to a large number or all\".\r\n\r\nThere might be efficient implementations to solve this problem for larger datasets. ",
"@Vipitis raised a good point on the HF Discord regarding the use of a [dataset script](https://huggingface.co/docs/datasets/en/dataset_script) to provide the schema during initialization. Using this approach requires setting `trust_remote_code=True`, which is not allowed in certain evaluation frameworks.\r\n\r\nFor cases where using a dataset script is acceptable, would it be helpful to add functionality to the library (not necessarily in `load_dataset`) that can automatically discover the feature definitions and output them, so you don't have to manually define them?\r\n\r\nAlternatively, for situations where features need to be known at load-time without using a dataset script, another option could be loading the dataset schema from a file format that doesn't require `trust_remote_code=True`."
] | 1970-01-01T00:00:00.000001 | 1,723 | null | NONE | null | ### Describe the bug
likely related to #6460
using `datasets.load_dataset("json", data_dir= ... )` with multiple `.jsonl` files will error if one of the files (maybe the first file?) contains a full column of empty data.
### Steps to reproduce the bug
real world example:
data is available in this [PR-branch](https://github.com/Vipitis/shadertoys-dataset/pull/3/commits/cb1e7157814f74acb09d5dc2f1be3c0a868a9933). Because my files are chunked by months, some months contain all empty data for some columns, just by chance - these are `[]`. Otherwise it's all the same structure.
```python
from datasets import load_dataset
ds = load_dataset("json", data_dir="./data/annotated/api")
```
you get a long error trace, where in the middle it says something like
```cs
TypeError: Couldn't cast array of type struct<id: int64, src: string, ctype: string, channel: int64, sampler: struct<filter: string, wrap: string, vflip: string, srgb: string, internal: string>, published: int64> to null
```
toy example: (on request)
### Expected behavior
Some suggestions
1. give a better error message to the user
2. consider all files before deciding on a data structure for a given column.
3. if you encounter a new structure, and can't cast that to null, replace the null-hypothesis. (maybe something for pyarrow)
as a workaround I have lazily implemented the following (essentially step 2)
```python
import os
import jsonlines
import datasets
api_files = os.listdir("./data/annotated/api")
api_files = [f"./data/annotated/api/{f}" for f in api_files]
api_file_contents = []
for f in api_files:
with jsonlines.open(f) as reader:
for obj in reader:
api_file_contents.append(obj)
ds = datasets.Dataset.from_list(api_file_contents)
```
this works fine for my usecase, but is potentially slower and less memory efficient for really large datasets (where this is unlikely to happen in the first place).
### Environment info
- `datasets` version: 2.20.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.9.4
- `huggingface_hub` version: 0.23.4
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2023.10.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7092/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7092/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7090/comments | https://api.github.com/repos/huggingface/datasets/issues/7090/events | https://github.com/huggingface/datasets/issues/7090 | 2,449,699,490 | I_kwDODunzps6SA3Ki | 7,090 | The test test_move_script_doesnt_change_hash fails because it runs the 'python' command while the python executable has a different name | {
"avatar_url": "https://avatars.githubusercontent.com/u/271906?v=4",
"events_url": "https://api.github.com/users/yurivict/events{/privacy}",
"followers_url": "https://api.github.com/users/yurivict/followers",
"following_url": "https://api.github.com/users/yurivict/following{/other_user}",
"gists_url": "https://api.github.com/users/yurivict/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yurivict",
"id": 271906,
"login": "yurivict",
"node_id": "MDQ6VXNlcjI3MTkwNg==",
"organizations_url": "https://api.github.com/users/yurivict/orgs",
"received_events_url": "https://api.github.com/users/yurivict/received_events",
"repos_url": "https://api.github.com/users/yurivict/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yurivict/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yurivict/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yurivict",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,722 | null | NONE | null | ### Describe the bug
Tests should use the same pythin path as they are launched with, which in the case of FreeBSD is /usr/local/bin/python3.11
Failure:
```
if err_filename is not None:
> raise child_exception_type(errno_num, err_msg, err_filename)
E FileNotFoundError: [Errno 2] No such file or directory: 'python'
```
### Steps to reproduce the bug
regular test run using PyTest
### Expected behavior
n/a
### Environment info
FreeBSD 14.1 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7090/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7089/comments | https://api.github.com/repos/huggingface/datasets/issues/7089/events | https://github.com/huggingface/datasets/issues/7089 | 2,449,479,500 | I_kwDODunzps6SABdM | 7,089 | Missing pyspark dependency causes the testsuite to error out, instead of a few tests to be skipped | {
"avatar_url": "https://avatars.githubusercontent.com/u/271906?v=4",
"events_url": "https://api.github.com/users/yurivict/events{/privacy}",
"followers_url": "https://api.github.com/users/yurivict/followers",
"following_url": "https://api.github.com/users/yurivict/following{/other_user}",
"gists_url": "https://api.github.com/users/yurivict/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yurivict",
"id": 271906,
"login": "yurivict",
"node_id": "MDQ6VXNlcjI3MTkwNg==",
"organizations_url": "https://api.github.com/users/yurivict/orgs",
"received_events_url": "https://api.github.com/users/yurivict/received_events",
"repos_url": "https://api.github.com/users/yurivict/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yurivict/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yurivict/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yurivict",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,722 | null | NONE | null | ### Describe the bug
see the subject
### Steps to reproduce the bug
regular tests
### Expected behavior
n/a
### Environment info
version 2.20.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7089/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7088 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7088/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7088/comments | https://api.github.com/repos/huggingface/datasets/issues/7088/events | https://github.com/huggingface/datasets/issues/7088 | 2,447,383,940 | I_kwDODunzps6R4B2E | 7,088 | Disable warning when using with_format format on tensors | {
"avatar_url": "https://avatars.githubusercontent.com/u/42048782?v=4",
"events_url": "https://api.github.com/users/Haislich/events{/privacy}",
"followers_url": "https://api.github.com/users/Haislich/followers",
"following_url": "https://api.github.com/users/Haislich/following{/other_user}",
"gists_url": "https://api.github.com/users/Haislich/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Haislich",
"id": 42048782,
"login": "Haislich",
"node_id": "MDQ6VXNlcjQyMDQ4Nzgy",
"organizations_url": "https://api.github.com/users/Haislich/orgs",
"received_events_url": "https://api.github.com/users/Haislich/received_events",
"repos_url": "https://api.github.com/users/Haislich/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Haislich/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Haislich/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Haislich",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,722 | null | NONE | null | ### Feature request
If we write this code:
```python
"""Get data and define datasets."""
from enum import StrEnum
from datasets import load_dataset
from torch.utils.data import DataLoader
from torchvision import transforms
class Split(StrEnum):
"""Describes what type of split to use in the dataloader"""
TRAIN = "train"
TEST = "test"
VAL = "validation"
class ImageNetDataLoader(DataLoader):
"""Create an ImageNetDataloader"""
_preprocess_transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
]
)
def __init__(self, batch_size: int = 4, split: Split = Split.TRAIN):
dataset = (
load_dataset(
"imagenet-1k",
split=split,
trust_remote_code=True,
streaming=True,
)
.with_format("torch")
.map(self._preprocess)
)
super().__init__(dataset=dataset, batch_size=batch_size)
def _preprocess(self, data):
if data["image"].shape[0] < 3:
data["image"] = data["image"].repeat(3, 1, 1)
data["image"] = self._preprocess_transform(data["image"].float())
return data
if __name__ == "__main__":
dataloader = ImageNetDataLoader(batch_size=2)
for batch in dataloader:
print(batch["image"])
break
```
This will trigger an user warning :
```bash
datasets\formatting\torch_formatter.py:85: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})
```
### Motivation
This happens because the the way the formatted tensor is returned in `TorchFormatter._tensorize`.
This function handle values of different types, according to some tests it seems that possible value types are `int`, `numpy.ndarray` and `torch.Tensor`.
In particular this warning is triggered when the value type is `torch.Tensor`, because is not the suggested Pytorch way of doing it:
- https://stackoverflow.com/questions/55266154/pytorch-preferred-way-to-copy-a-tensor
- https://discuss.pytorch.org/t/it-is-recommended-to-use-source-tensor-clone-detach-or-sourcetensor-clone-detach-requires-grad-true/101218#:~:text=The%20warning%20points%20to%20wrapping%20a%20tensor%20in%20torch.tensor%2C%20which%20is%20not%20recommended.%0AInstead%20of%20torch.tensor(outputs)%20use%20outputs.clone().detach()%20or%20the%20same%20with%20.requires_grad_(True)%2C%20if%20necessary.
### Your contribution
A solution that I found to be working is to change the current way of doing it:
```python
return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})
```
To:
```python
if (isinstance(value, torch.Tensor)):
tensor = value.clone().detach()
if self.torch_tensor_kwargs.get('requires_grad', False):
tensor.requires_grad_()
return tensor
else:
return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})
``` | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7088/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7088/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7087/comments | https://api.github.com/repos/huggingface/datasets/issues/7087/events | https://github.com/huggingface/datasets/issues/7087 | 2,447,158,643 | I_kwDODunzps6R3K1z | 7,087 | Unable to create dataset card for Lushootseed language | {
"avatar_url": "https://avatars.githubusercontent.com/u/134876525?v=4",
"events_url": "https://api.github.com/users/vaishnavsudarshan/events{/privacy}",
"followers_url": "https://api.github.com/users/vaishnavsudarshan/followers",
"following_url": "https://api.github.com/users/vaishnavsudarshan/following{/other_user}",
"gists_url": "https://api.github.com/users/vaishnavsudarshan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vaishnavsudarshan",
"id": 134876525,
"login": "vaishnavsudarshan",
"node_id": "U_kgDOCAoNbQ",
"organizations_url": "https://api.github.com/users/vaishnavsudarshan/orgs",
"received_events_url": "https://api.github.com/users/vaishnavsudarshan/received_events",
"repos_url": "https://api.github.com/users/vaishnavsudarshan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vaishnavsudarshan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vaishnavsudarshan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vaishnavsudarshan",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Thanks for reporting.\r\n\r\nIt is weird, because the language entry is in the list. See: https://github.com/huggingface/huggingface.js/blob/98e32f0ed4ee057a596f66a1dec738e5db9643d5/packages/languages/src/languages_iso_639_3.ts#L15186-L15189\r\n\r\nI have reported the issue:\r\n- https://github.com/huggingface/huggingface.js/issues/834\r\n\r\n",
"As explained in the reported issue above, the problem only appears in the autocomplete field: you can still enter the `lut` language directly in the markdown editor window."
] | 1970-01-01T00:00:00.000001 | 1,722 | 1970-01-01T00:00:00.000001 | NONE | null | ### Feature request
While I was creating the dataset which contained all documents from the Lushootseed Wikipedia, the dataset card asked me to enter which language the dataset was in. Since Lushootseed is a critically endangered language, it was not available as one of the options. Is it possible to allow entering languages that aren't available in the options?
### Motivation
I'd like to add more information about my dataset in the dataset card, and the language is one of the most important pieces of information, since the entire dataset is primarily concerned collecting Lushootseed documents.
### Your contribution
I can submit a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7087/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7086/comments | https://api.github.com/repos/huggingface/datasets/issues/7086/events | https://github.com/huggingface/datasets/issues/7086 | 2,445,516,829 | I_kwDODunzps6Rw6Ad | 7,086 | load_dataset ignores cached datasets and tries to hit HF Hub, resulting in API rate limit errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/11379648?v=4",
"events_url": "https://api.github.com/users/tginart/events{/privacy}",
"followers_url": "https://api.github.com/users/tginart/followers",
"following_url": "https://api.github.com/users/tginart/following{/other_user}",
"gists_url": "https://api.github.com/users/tginart/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tginart",
"id": 11379648,
"login": "tginart",
"node_id": "MDQ6VXNlcjExMzc5NjQ4",
"organizations_url": "https://api.github.com/users/tginart/orgs",
"received_events_url": "https://api.github.com/users/tginart/received_events",
"repos_url": "https://api.github.com/users/tginart/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tginart/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tginart/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tginart",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,722 | null | NONE | null | ### Describe the bug
I have been running lm-eval-harness a lot which has results in an API rate limit. This seems strange, since all of the data should be cached locally. I have in fact verified this.
### Steps to reproduce the bug
1. Be Me
2. Run `load_dataset("TAUR-Lab/MuSR")`
3. Hit rate limit error
4. Dataset is in .cache/huggingface/datasets
5. ???
### Expected behavior
We should not run into API rate limits if we have cached the dataset
### Environment info
datasets 2.16.0
python 3.10.4 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7086/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7086/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7085 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7085/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7085/comments | https://api.github.com/repos/huggingface/datasets/issues/7085/events | https://github.com/huggingface/datasets/issues/7085 | 2,440,008,618 | I_kwDODunzps6Rb5Oq | 7,085 | [Regression] IterableDataset is broken on 2.20.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/5404177?v=4",
"events_url": "https://api.github.com/users/AjayP13/events{/privacy}",
"followers_url": "https://api.github.com/users/AjayP13/followers",
"following_url": "https://api.github.com/users/AjayP13/following{/other_user}",
"gists_url": "https://api.github.com/users/AjayP13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AjayP13",
"id": 5404177,
"login": "AjayP13",
"node_id": "MDQ6VXNlcjU0MDQxNzc=",
"organizations_url": "https://api.github.com/users/AjayP13/orgs",
"received_events_url": "https://api.github.com/users/AjayP13/received_events",
"repos_url": "https://api.github.com/users/AjayP13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AjayP13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AjayP13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AjayP13",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | [
"@lhoestq I detected this regression over on [DataDreamer](https://github.com/datadreamer-dev/DataDreamer)'s test suite. I put in these [monkey patches](https://github.com/datadreamer-dev/DataDreamer/blob/4cbaf9f39cf7bedde72bbaa68346e169788fbecb/src/_patches/datasets_reset_state_hack.py) in case that fixed it our tests failing in case it helps you figure out where this is coming from. I found it hard to reason through the resumable IterableDataset code though, so hopefully you have more intuition to implement a proper fix.",
"I believe these lines in `TypedExamplesIterable` are responsible for stopping the re-iteration of `IterableDataset`:\r\n\r\nhttps://github.com/huggingface/datasets/blob/ebec2691fb1e40145429f63375cef3f46d3011ab/src/datasets/iterable_dataset.py#L1616-L1619\r\n\r\nIn contrast to other `Iterable`s, there is no check on whether `self._state_dict` is None or not. This particular case stands out and seems less straightforward to comprehend why. @lhoestq could you please assist us with this? Your help is much appreciated.",
"Thanks for reporting for investigating - your assumption was correct @VeryLazyBoy !"
] | 1970-01-01T00:00:00.000001 | 1,724 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
In the latest version of datasets there is a major regression, after creating an `IterableDataset` from a generator and applying a few operations (`map`, `select`), you can no longer iterate through the dataset multiple times.
The issue seems to stem from the recent addition of "resumable IterableDatasets" (#6658) (@lhoestq). It seems like it's keeping state when it shouldn't.
### Steps to reproduce the bug
Minimal Reproducible Example (comparing `datasets==2.17.0` and `datasets==2.20.0`)
```
#!/bin/bash
# List of dataset versions to test
versions=("2.17.0" "2.20.0")
# Loop through each version
for version in "${versions[@]}"; do
# Install the specific version of the datasets library
pip3 install -q datasets=="$version" 2>/dev/null
# Run the Python script
python3 - <<EOF
from datasets import IterableDataset
from datasets.features.features import Features, Value
def test_gen():
yield from [{"foo": i} for i in range(10)]
features = Features([("foo", Value("int64"))])
d = IterableDataset.from_generator(test_gen, features=features)
mapped = d.map(lambda row: {"foo": row["foo"] * 2})
column = mapped.select_columns(["foo"])
print("Version $version - Iterate Once:", list(column))
print("Version $version - Iterate Twice:", list(column))
EOF
done
```
The output looks like this:
```
Version 2.17.0 - Iterate Once: [{'foo': 0}, {'foo': 2}, {'foo': 4}, {'foo': 6}, {'foo': 8}, {'foo': 10}, {'foo': 12}, {'foo': 14}, {'foo': 16}, {'foo': 18}]
Version 2.17.0 - Iterate Twice: [{'foo': 0}, {'foo': 2}, {'foo': 4}, {'foo': 6}, {'foo': 8}, {'foo': 10}, {'foo': 12}, {'foo': 14}, {'foo': 16}, {'foo': 18}]
Version 2.20.0 - Iterate Once: [{'foo': 0}, {'foo': 2}, {'foo': 4}, {'foo': 6}, {'foo': 8}, {'foo': 10}, {'foo': 12}, {'foo': 14}, {'foo': 16}, {'foo': 18}]
Version 2.20.0 - Iterate Twice: []
```
### Expected behavior
The expected behavior is it version 2.20.0 should behave the same as 2.17.0.
### Environment info
`datasets==2.20.0` on any platform. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7085/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7085/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7084 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7084/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7084/comments | https://api.github.com/repos/huggingface/datasets/issues/7084/events | https://github.com/huggingface/datasets/issues/7084 | 2,439,519,534 | I_kwDODunzps6RaB0u | 7,084 | More easily support streaming local files | {
"avatar_url": "https://avatars.githubusercontent.com/u/23191892?v=4",
"events_url": "https://api.github.com/users/fschlatt/events{/privacy}",
"followers_url": "https://api.github.com/users/fschlatt/followers",
"following_url": "https://api.github.com/users/fschlatt/following{/other_user}",
"gists_url": "https://api.github.com/users/fschlatt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fschlatt",
"id": 23191892,
"login": "fschlatt",
"node_id": "MDQ6VXNlcjIzMTkxODky",
"organizations_url": "https://api.github.com/users/fschlatt/orgs",
"received_events_url": "https://api.github.com/users/fschlatt/received_events",
"repos_url": "https://api.github.com/users/fschlatt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fschlatt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fschlatt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fschlatt",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,722 | null | CONTRIBUTOR | null | ### Feature request
Simplify downloading and streaming datasets locally. Specifically, perhaps add an option to `load_dataset(..., streaming="download_first")` or add better support for streaming symlinked or arrow files.
### Motivation
I have downloaded FineWeb-edu locally and currently trying to stream the dataset from the local files. I have both the raw parquet files using `hugginface-cli download --repo-type dataset HuggingFaceFW/fineweb-edu` and the processed arrow files using `load_dataset("HuggingFaceFW/fineweb-edu")`.
Streaming the files locally does not work well for both file types for two different reasons.
**Arrow files**
When running `load_dataset("arrow", data_files={"train": "~/.cache/huggingface/datasets/HuggingFaceFW___fineweb-edu/default/0.0.0/5b89d1ea9319fe101b3cbdacd89a903aca1d6052/fineweb-edu-train-*.arrow"})` resolving the data files is fast, but because `arrow` is not included in the known [extensions file list](https://github.com/huggingface/datasets/blob/ce4a0c573920607bc6c814605734091b06b860e7/src/datasets/utils/file_utils.py#L738) , all files are opened and scanned to determine the compression type. Adding `arrow` to the known extension types resolves this issue.
**Parquet files**
When running `load_dataset("arrow", data_files={"train": "~/.cache/huggingface/hub/dataset-HuggingFaceFW___fineweb-edu/snapshots/5b89d1ea9319fe101b3cbdacd89a903aca1d6052/data/CC-MAIN-*/train-*.parquet"})` the paths do not get resolved because the parquet files are symlinked from the blobs (which contain all files in case there are different versions). This occurs because the [pattern matching](https://github.com/huggingface/datasets/blob/ce4a0c573920607bc6c814605734091b06b860e7/src/datasets/data_files.py#L389) checks if the path is a file and does not check for symlinks. Symlinks (at least on my machine) are of type "other".
### Your contribution
I have created a PR for fixing arrow file streaming and symlinks. However, I have not checked locally if the tests work or new tests need to be added.
IMO, the easiest option would be to add a `streaming=download_first` option, but I'm afraid that exceeds my current knowledge of how the datasets library works. https://github.com/huggingface/datasets/pull/7083 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7084/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7084/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7080 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7080/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7080/comments | https://api.github.com/repos/huggingface/datasets/issues/7080/events | https://github.com/huggingface/datasets/issues/7080 | 2,434,275,664 | I_kwDODunzps6RGBlQ | 7,080 | Generating train split takes a long time | {
"avatar_url": "https://avatars.githubusercontent.com/u/35648800?v=4",
"events_url": "https://api.github.com/users/alexanderswerdlow/events{/privacy}",
"followers_url": "https://api.github.com/users/alexanderswerdlow/followers",
"following_url": "https://api.github.com/users/alexanderswerdlow/following{/other_user}",
"gists_url": "https://api.github.com/users/alexanderswerdlow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alexanderswerdlow",
"id": 35648800,
"login": "alexanderswerdlow",
"node_id": "MDQ6VXNlcjM1NjQ4ODAw",
"organizations_url": "https://api.github.com/users/alexanderswerdlow/orgs",
"received_events_url": "https://api.github.com/users/alexanderswerdlow/received_events",
"repos_url": "https://api.github.com/users/alexanderswerdlow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alexanderswerdlow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexanderswerdlow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alexanderswerdlow",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"@alexanderswerdlow \r\nWhen no specific split is mentioned, the load_dataset library will load all available splits of the dataset. For example, if a dataset has \"train\" and \"test\" splits, the load_dataset function will load both into the DatasetDict object.\r\n\r\n\r\n\r\n\r\nThe dataset PixArt-alpha/SAM-LLaVA-Captions10M may have been uploaded with different predefined splits (e.g., \"train\", \"test\", etc.), and by default, Hugging Face will load all splits unless you specifically request only one.\r\n\r\n### If you want to load only a specific split (e.g., only the \"train\" set), you can specify it in the split parameter like this:\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"PixArt-alpha/SAM-LLaVA-Captions10M\", split=\"train\")\r\n```\r\n\r\n### You can also load multiple splits if needed:\r\n```python\r\ndataset = load_dataset(\"PixArt-alpha/SAM-LLaVA-Captions10M\", split=[\"train\", \"test\"])\r\n```\r\n\r\n",
"@alexanderswerdlow, I will now work on this..\r\n\r\n## Idea:\r\nWhenever this code has ran:\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"PixArt-alpha/SAM-LLaVA-Captions10M\")\r\n```\r\n\r\nIt should show all the splits of the datasets, and user has to choose which one should be loaded before generating a split like this,,\r\n\r\n\r\n"
] | 1970-01-01T00:00:00.000001 | 1,727 | null | NONE | null | ### Describe the bug
Loading a simple webdataset takes ~45 minutes.
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("PixArt-alpha/SAM-LLaVA-Captions10M")
```
### Expected behavior
The dataset should load immediately as it does when loaded through a normal indexed WebDataset loader. Generating splits should be optional and there should be a message showing how to disable it.
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-4.18.0-372.32.1.el8_6.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.14
- `huggingface_hub` version: 0.24.1
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7080/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7080/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7079/comments | https://api.github.com/repos/huggingface/datasets/issues/7079/events | https://github.com/huggingface/datasets/issues/7079 | 2,433,363,298 | I_kwDODunzps6RCi1i | 7,079 | HfHubHTTPError: 500 Server Error: Internal Server Error for url: | {
"avatar_url": "https://avatars.githubusercontent.com/u/147971?v=4",
"events_url": "https://api.github.com/users/neoneye/events{/privacy}",
"followers_url": "https://api.github.com/users/neoneye/followers",
"following_url": "https://api.github.com/users/neoneye/following{/other_user}",
"gists_url": "https://api.github.com/users/neoneye/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/neoneye",
"id": 147971,
"login": "neoneye",
"node_id": "MDQ6VXNlcjE0Nzk3MQ==",
"organizations_url": "https://api.github.com/users/neoneye/orgs",
"received_events_url": "https://api.github.com/users/neoneye/received_events",
"repos_url": "https://api.github.com/users/neoneye/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/neoneye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neoneye/subscriptions",
"type": "User",
"url": "https://api.github.com/users/neoneye",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"same issue here. @albertvillanova @lhoestq ",
"Also impacted by this issue in many of my datasets (though not all) - in my case, this also seems to affect datasets that have been updated recently. Git cloning and the web interface still work:\r\n- https://huggingface.co/api/datasets/acmc/cheat_reduced\r\n- https://huggingface.co/api/datasets/acmc/ghostbuster_reuter_reduced\r\n- https://huggingface.co/api/datasets/acmc/ghostbuster_wp_reduced\r\n- https://huggingface.co/api/datasets/acmc/ghostbuster_essay_reduced\r\n\r\nOddly enough, the system status looks good: https://status.huggingface.co/",
"Hey how to download these datasets using git cloning?",
"Also reported here\r\nhttps://github.com/huggingface/huggingface_hub/issues/2425",
"I have been getting the same error for the past 8 hours as well",
"Same error since yesterday, fails on any new dataset created",
"Same here. I cannot download the HelpSteer2 dataset: https://huggingface.co/datasets/nvidia/HelpSteer2 which has been uploaded about a month ago",
"> Hey how to download these datasets using git cloning?\n\nYou'll find a guide [here](https://huggingface.co/docs/hub/en/datasets-downloading) 👍🏻",
"Same here for imdb dataset",
"It also happens with this dataset: https://huggingface.co/datasets/ylacombe/jenny-tts-6h-tagged",
"same here for all datsets in the sentence-tramsformers repo and related collections.\r\n\r\nsame issue with dataset that i recently uploaded on my repo.\r\nseems that the upload date of the datset is not relevat (getting this issue with both old datasets and newer ones)\r\n\r\nfor some reason, i was able to get the dataset by turning it private and accessing it with the id token (accessing it as public while providing the token doesn not work)..... but i can say if that is just a random coincidence.\r\n\r\nseems not much deterministic, for a specific dataset (sentence-transformer nq ) , that was \"down\" since some hours , worked for like 5-10 minutes, then stopped again\r\n\r\nnow even this dataset (that worked since some min ago, and that i'm in the middle of processing steps) stopped working: _https://huggingface.co/datasets/bobox/msmarco-bm25-EduScore/_\r\n\r\nas already pointed out, there are no updates on **_https://status.huggingface.co/_**\r\n\r\n\\n\r\n\\n\r\n\r\nan example of the whole error message:\r\n``` \r\nHfHubHTTPError \r\n\r\n[/usr/local/lib/python3.10/dist-packages/datasets/load.py](https://localhost:8080/#) in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, token, use_auth_token, task, streaming, num_proc, storage_options, trust_remote_code, **config_kwargs)\r\n 2592 \r\n 2593 # Create a dataset builder\r\n-> 2594 builder_instance = load_dataset_builder(\r\n 2595 path=path,\r\n 2596 name=name,\r\n\r\n[/usr/local/lib/python3.10/dist-packages/datasets/load.py](https://localhost:8080/#) in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, token, use_auth_token, storage_options, trust_remote_code, _require_default_config_name, **config_kwargs)\r\n 2264 download_config = download_config.copy() if download_config else DownloadConfig()\r\n 2265 download_config.storage_options.update(storage_options)\r\n-> 2266 dataset_module = dataset_module_factory(\r\n 2267 path,\r\n 2268 revision=revision,\r\n\r\n[/usr/local/lib/python3.10/dist-packages/datasets/load.py](https://localhost:8080/#) in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, cache_dir, trust_remote_code, _require_default_config_name, _require_custom_configs, **download_kwargs)\r\n 1912 f\"Couldn't find '{path}' on the Hugging Face Hub either: {type(e1).__name__}: {e1}\"\r\n 1913 ) from None\r\n-> 1914 raise e1 from None\r\n 1915 else:\r\n 1916 raise FileNotFoundError(\r\n\r\n[/usr/local/lib/python3.10/dist-packages/datasets/load.py](https://localhost:8080/#) in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, cache_dir, trust_remote_code, _require_default_config_name, _require_custom_configs, **download_kwargs)\r\n 1832 hf_api = HfApi(config.HF_ENDPOINT)\r\n 1833 try:\r\n-> 1834 dataset_info = hf_api.dataset_info(\r\n 1835 repo_id=path,\r\n 1836 revision=revision,\r\n\r\n[/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_validators.py](https://localhost:8080/#) in _inner_fn(*args, **kwargs)\r\n 112 kwargs = smoothly_deprecate_use_auth_token(fn_name=fn.__name__, has_token=has_token, kwargs=kwargs)\r\n 113 \r\n--> 114 return fn(*args, **kwargs)\r\n 115 \r\n 116 return _inner_fn # type: ignore\r\n\r\n[/usr/local/lib/python3.10/dist-packages/huggingface_hub/hf_api.py](https://localhost:8080/#) in dataset_info(self, repo_id, revision, timeout, files_metadata, token)\r\n 2362 \r\n 2363 r = get_session().get(path, headers=headers, timeout=timeout, params=params)\r\n-> 2364 hf_raise_for_status(r)\r\n 2365 data = r.json()\r\n 2366 return DatasetInfo(**data)\r\n\r\n[/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_errors.py](https://localhost:8080/#) in hf_raise_for_status(response, endpoint_name)\r\n 369 # Convert `HTTPError` into a `HfHubHTTPError` to display request information\r\n 370 # as well (request id and/or server error message)\r\n--> 371 raise HfHubHTTPError(str(e), response=response) from e\r\n 372 \r\n 373 \r\n\r\nHfHubHTTPError: 500 Server Error: Internal Server Error for url: https://huggingface.co/api/datasets/bobox/xSum-processed (Request ID: Root=1-66a527f0-756cfbc35cc466f075382289;7d5dc06a-37e9-4c22-874d-92b0b1023276)\r\n\r\nInternal Error - We're working hard to fix this as soon as possible!\r\n``` ",
"we're working on a fix !",
"We fixed the issue, you can load datasets again, sorry for the inconvenience !",
"I can confirm, it's working now. I can load the dataset, yay. Thank you @lhoestq ",
"@lhoestq thank you so much! ",
"Hi I'm getting the same error with this [dataset](https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset) \r\nWorking on the course of stable diffusion , trying to run this [notebook](https://colab.research.google.com/github/huggingface/diffusion-models-class/blob/main/unit1/01_introduction_to_diffusers.ipynb#scrollTo=-yX-MZhSsxwp) \r\nthis is the error: \r\n`HfHubHTTPError: 500 Server Error: Internal Server Error for url: https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset/resolve/3cdedf844922ab40393d46d4c7f81c596e1c6d45/data/train-00000-of-00001.parquet (Request ID: Root=1-66ed3481-3393f4ab268b711440d31e02;c3ca2a7d-ae7b-4ba3-9947-9426711946a8)\r\n\r\nInternal Error - We're working hard to fix this as soon as possible!`\r\n\r\n",
"Thanks for reporting, we are investigating !"
] | 1970-01-01T00:00:00.000001 | 1,726 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
newly uploaded datasets, since yesterday, yields an error.
old datasets, works fine.
Seems like the datasets api server returns a 500
I'm getting the same error, when I invoke `load_dataset` with my dataset.
Long discussion about it here, but I'm not sure anyone from huggingface have seen it.
https://discuss.huggingface.co/t/hfhubhttperror-500-server-error-internal-server-error-for-url/99580/1
### Steps to reproduce the bug
this api url:
https://huggingface.co/api/datasets/neoneye/simon-arc-shape-v4-rev3
respond with:
```
{"error":"Internal Error - We're working hard to fix this as soon as possible!"}
```
### Expected behavior
return no error with newer datasets.
With older datasets I can load the datasets fine.
### Environment info
# Browser
When I access the api in the browser:
https://huggingface.co/api/datasets/neoneye/simon-arc-shape-v4-rev3
```
{"error":"Internal Error - We're working hard to fix this as soon as possible!"}
```
### Request headers
```
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Encoding gzip, deflate, br, zstd
Accept-Language en-US,en;q=0.5
Connection keep-alive
Host huggingface.co
Priority u=1
Sec-Fetch-Dest document
Sec-Fetch-Mode navigate
Sec-Fetch-Site cross-site
Upgrade-Insecure-Requests 1
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:127.0) Gecko/20100101 Firefox/127.0
```
### Response headers
```
X-Firefox-Spdy h2
access-control-allow-origin https://huggingface.co
access-control-expose-headers X-Repo-Commit,X-Request-Id,X-Error-Code,X-Error-Message,X-Total-Count,ETag,Link,Accept-Ranges,Content-Range
content-length 80
content-type application/json; charset=utf-8
cross-origin-opener-policy same-origin
date Fri, 26 Jul 2024 19:09:45 GMT
etag W/"50-9qrwU+BNI4SD0Fe32p/nofkmv0c"
referrer-policy strict-origin-when-cross-origin
vary Origin
via 1.1 1624c79cd07e6098196697a6a7907e4a.cloudfront.net (CloudFront)
x-amz-cf-id SP8E7n5qRaP6i9c9G83dNAiOzJBU4GXSrDRAcVNTomY895K35H0nJQ==
x-amz-cf-pop CPH50-C1
x-cache Error from cloudfront
x-error-message Internal Error - We're working hard to fix this as soon as possible!
x-powered-by huggingface-moon
x-request-id Root=1-66a3f479-026417465ef42f49349fdca1
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/147971?v=4",
"events_url": "https://api.github.com/users/neoneye/events{/privacy}",
"followers_url": "https://api.github.com/users/neoneye/followers",
"following_url": "https://api.github.com/users/neoneye/following{/other_user}",
"gists_url": "https://api.github.com/users/neoneye/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/neoneye",
"id": 147971,
"login": "neoneye",
"node_id": "MDQ6VXNlcjE0Nzk3MQ==",
"organizations_url": "https://api.github.com/users/neoneye/orgs",
"received_events_url": "https://api.github.com/users/neoneye/received_events",
"repos_url": "https://api.github.com/users/neoneye/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/neoneye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neoneye/subscriptions",
"type": "User",
"url": "https://api.github.com/users/neoneye",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7079/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7079/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7077/comments | https://api.github.com/repos/huggingface/datasets/issues/7077/events | https://github.com/huggingface/datasets/issues/7077 | 2,432,345,489 | I_kwDODunzps6Q-qWR | 7,077 | column_names ignored by load_dataset() when loading CSV file | {
"avatar_url": "https://avatars.githubusercontent.com/u/9130265?v=4",
"events_url": "https://api.github.com/users/luismsgomes/events{/privacy}",
"followers_url": "https://api.github.com/users/luismsgomes/followers",
"following_url": "https://api.github.com/users/luismsgomes/following{/other_user}",
"gists_url": "https://api.github.com/users/luismsgomes/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/luismsgomes",
"id": 9130265,
"login": "luismsgomes",
"node_id": "MDQ6VXNlcjkxMzAyNjU=",
"organizations_url": "https://api.github.com/users/luismsgomes/orgs",
"received_events_url": "https://api.github.com/users/luismsgomes/received_events",
"repos_url": "https://api.github.com/users/luismsgomes/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/luismsgomes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/luismsgomes/subscriptions",
"type": "User",
"url": "https://api.github.com/users/luismsgomes",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"I confirm that `column_names` values are not copied to `names` variable because in this case `CsvConfig.__post_init__` is not called: `CsvConfig` is instantiated with default values and afterwards the `config_kwargs` are used to overwrite its attributes.\r\n\r\n@luismsgomes in the meantime, you can avoid the bug if you pass `names` instead of `column_names`."
] | 1970-01-01T00:00:00.000001 | 1,722 | null | NONE | null | ### Describe the bug
load_dataset() ignores the column_names kwarg when loading a CSV file. Instead, it uses whatever values are on the first line of the file.
### Steps to reproduce the bug
Call `load_dataset` to load data from a CSV file and specify `column_names` kwarg.
### Expected behavior
The resulting dataset should have the specified column names **and** the first line of the file should be considered as data values.
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-5.10.0-30-cloud-amd64-x86_64-with-glibc2.31
- Python version: 3.9.2
- `huggingface_hub` version: 0.24.2
- PyArrow version: 17.0.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7077/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7077/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7073 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7073/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7073/comments | https://api.github.com/repos/huggingface/datasets/issues/7073/events | https://github.com/huggingface/datasets/issues/7073 | 2,431,706,568 | I_kwDODunzps6Q8OXI | 7,073 | CI is broken for convert_to_parquet: Invalid rev id: refs/pr/1 404 error causes RevisionNotFoundError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Any recent change in the API backend rejecting parameter `revision=\"refs/pr/1\"` to `HfApi.preupload_lfs_files`?\r\n```\r\nf\"{endpoint}/api/{repo_type}s/{repo_id}/preupload/{revision}\"\r\n\r\nhttps://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/test-dataset-5188a8-17219154347516/preupload/refs%2Fpr%2F1.\r\nInvalid rev id: refs/pr/1\r\n```\r\n@Wauplin @huggingface/datasets @huggingface/moon-landing @huggingface/moon-landing-back ",
"I have temporarily fixed the CI with:\r\n- #7074\r\n\r\nHowever, the underlying issue must be fixed and #7074 must be reverted.",
"Hmm does it do the preupload call before creating the ref cc @Wauplin ?\r\n\r\n(in that case it should do a preupload call on the base branch with `?create_pr=1`)",
"@coyotte508, the CI test was implemented 2 months ago and it was working OK until yesterday. See the CI status of the commits in the main branch of `datasets`: https://github.com/huggingface/datasets/commits/main/",
"Yes i get that\r\n\r\nWe changed the preupload response to return the commit id in https://github.com/huggingface-internal/moon-landing/pull/10756\r\n\r\nThis line is probably causing the error: https://github.com/huggingface-internal/moon-landing/pull/10756/files#diff-558f6f9865e30bfa091b94d6a4a900138103ddb4eb0bec96b6deec5bf5626fa0R2322\r\n\r\nIt's weird the error is returned, it means that maybe a ref with 0 history (not even the first commit) was created\r\n\r\nDoes this change have any impact in production, or just the CI test? If it's just the CI test it should be fixed on your side, if it impacts production we can look at a solution",
"@coyotte508 it impacts production: `convert_to_parquet` raises the above error when the dataset has more that one configs/subsets:\r\n- First subset calls `push_to_hub` with `create_pr=True`\r\n- Second subset uses the `refs/pr/#` returned by the call above, and calls `push_to_hub` with `revision=\"refs/pr/#\"`",
"I tried removing the `mock_commit` call: https://github.com/huggingface/datasets/pull/7076\r\n\r\nAnd the tests seem to work.\r\n\r\nSo it's probably because the commit is not actually called, it doesn't actually create the pull request on the remote (and the associated `refs/pr/1`). But the `preupload` call is not mocked.\r\n\r\nAnyway it shouldn't impact production, since production isn't mocked",
"@coyotte508 thanks a lot for the investigation and sorry for the noise. \r\nI promise not trying to fix things when I have a slight fever: my head does not work well.\r\n\r\nWe need indeed to mock `preupload_lfs_files`: before it was not necessary, but now it is.",
"I fixed the test in:\r\n- #7078\r\n\r\nThanks again, @coyotte508."
] | 1970-01-01T00:00:00.000001 | 1,722 | 1970-01-01T00:00:00.000001 | MEMBER | null | See: https://github.com/huggingface/datasets/actions/runs/10095313567/job/27915185756
```
FAILED tests/test_hub.py::test_convert_to_parquet - huggingface_hub.utils._errors.RevisionNotFoundError: 404 Client Error. (Request ID: Root=1-66a25839-31ce7b475e70e7db1e4d44c2;b0c8870f-d5ef-4bf2-a6ff-0191f3df0f64)
Revision Not Found for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/test-dataset-5188a8-17219154347516/preupload/refs%2Fpr%2F1.
Invalid rev id: refs/pr/1
```
```
/opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/datasets/hub.py:86: in convert_to_parquet
dataset.push_to_hub(
/opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/datasets/dataset_dict.py:1722: in push_to_hub
split_additions, uploaded_size, dataset_nbytes = self[split]._push_parquet_shards_to_hub(
/opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/datasets/arrow_dataset.py:5511: in _push_parquet_shards_to_hub
api.preupload_lfs_files(
/opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/huggingface_hub/hf_api.py:4231: in preupload_lfs_files
_fetch_upload_modes(
/opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/huggingface_hub/utils/_validators.py:118: in _inner_fn
return fn(*args, **kwargs)
/opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/huggingface_hub/_commit_api.py:507: in _fetch_upload_modes
hf_raise_for_status(resp)
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7073/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7073/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7072 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7072/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7072/comments | https://api.github.com/repos/huggingface/datasets/issues/7072/events | https://github.com/huggingface/datasets/issues/7072 | 2,430,577,916 | I_kwDODunzps6Q36z8 | 7,072 | nm | {
"avatar_url": "https://avatars.githubusercontent.com/u/26392883?v=4",
"events_url": "https://api.github.com/users/brettdavies/events{/privacy}",
"followers_url": "https://api.github.com/users/brettdavies/followers",
"following_url": "https://api.github.com/users/brettdavies/following{/other_user}",
"gists_url": "https://api.github.com/users/brettdavies/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/brettdavies",
"id": 26392883,
"login": "brettdavies",
"node_id": "MDQ6VXNlcjI2MzkyODgz",
"organizations_url": "https://api.github.com/users/brettdavies/orgs",
"received_events_url": "https://api.github.com/users/brettdavies/received_events",
"repos_url": "https://api.github.com/users/brettdavies/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/brettdavies/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brettdavies/subscriptions",
"type": "User",
"url": "https://api.github.com/users/brettdavies",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | NONE | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/26392883?v=4",
"events_url": "https://api.github.com/users/brettdavies/events{/privacy}",
"followers_url": "https://api.github.com/users/brettdavies/followers",
"following_url": "https://api.github.com/users/brettdavies/following{/other_user}",
"gists_url": "https://api.github.com/users/brettdavies/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/brettdavies",
"id": 26392883,
"login": "brettdavies",
"node_id": "MDQ6VXNlcjI2MzkyODgz",
"organizations_url": "https://api.github.com/users/brettdavies/orgs",
"received_events_url": "https://api.github.com/users/brettdavies/received_events",
"repos_url": "https://api.github.com/users/brettdavies/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/brettdavies/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brettdavies/subscriptions",
"type": "User",
"url": "https://api.github.com/users/brettdavies",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7072/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7072/timeline | null | not_planned | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7071/comments | https://api.github.com/repos/huggingface/datasets/issues/7071/events | https://github.com/huggingface/datasets/issues/7071 | 2,430,313,011 | I_kwDODunzps6Q26Iz | 7,071 | Filter hangs | {
"avatar_url": "https://avatars.githubusercontent.com/u/61711045?v=4",
"events_url": "https://api.github.com/users/lucienwalewski/events{/privacy}",
"followers_url": "https://api.github.com/users/lucienwalewski/followers",
"following_url": "https://api.github.com/users/lucienwalewski/following{/other_user}",
"gists_url": "https://api.github.com/users/lucienwalewski/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lucienwalewski",
"id": 61711045,
"login": "lucienwalewski",
"node_id": "MDQ6VXNlcjYxNzExMDQ1",
"organizations_url": "https://api.github.com/users/lucienwalewski/orgs",
"received_events_url": "https://api.github.com/users/lucienwalewski/received_events",
"repos_url": "https://api.github.com/users/lucienwalewski/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lucienwalewski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucienwalewski/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lucienwalewski",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
When trying to filter my custom dataset, the process hangs, regardless of the lambda function used. It appears to be an issue with the way the Images are being handled. The dataset in question is a preprocessed version of https://huggingface.co/datasets/danaaubakirova/patfig where notably, I have converted the data to the Parquet format.
### Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset('lcolonn/patfig', split='test')
ds_filtered = ds.filter(lambda row: row['cpc_class'] != 'Y')
```
Eventually I ctrl+C and I obtain this stack trace:
```
>>> ds_filtered = ds.filter(lambda row: row['cpc_class'] != 'Y')
Filter: 0%| | 0/998 [00:00<?, ? examples/s]Filter: 0%| | 0/998 [00:35<?, ? examples/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 567, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/fingerprint.py", line 482, in wrapper
out = func(dataset, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 3714, in filter
indices = self.map(
^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 602, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 567, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 3161, in map
for rank, done, content in Dataset._map_single(**dataset_kwargs):
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 3552, in _map_single
batch = apply_function_on_filtered_inputs(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 3421, in apply_function_on_filtered_inputs
processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 6478, in get_indices_from_mask_function
num_examples = len(batch[next(iter(batch.keys()))])
~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/formatting/formatting.py", line 273, in __getitem__
value = self.format(key)
^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/formatting/formatting.py", line 376, in format
return self.formatter.format_column(self.pa_table.select([key]))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/formatting/formatting.py", line 443, in format_column
column = self.python_features_decoder.decode_column(column, pa_table.column_names[0])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/formatting/formatting.py", line 219, in decode_column
return self.features.decode_column(column, column_name) if self.features else column
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/features/features.py", line 2008, in decode_column
[decode_nested_example(self[column_name], value) if value is not None else None for value in column]
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/features/features.py", line 2008, in <listcomp>
[decode_nested_example(self[column_name], value) if value is not None else None for value in column]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/features/features.py", line 1351, in decode_nested_example
return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/datasets/features/image.py", line 188, in decode_example
image.load() # to avoid "Too many open files" errors
^^^^^^^^^^^^
File "/home/l-walewski/miniconda3/envs/patentqa/lib/python3.11/site-packages/PIL/ImageFile.py", line 293, in load
n, err_code = decoder.decode(b)
^^^^^^^^^^^^^^^^^
KeyboardInterrupt
```
Warning! This can even seem to cause some computers to crash.
### Expected behavior
Should return the filtered dataset
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-6.5.0-41-generic-x86_64-with-glibc2.35
- Python version: 3.11.9
- `huggingface_hub` version: 0.24.0
- PyArrow version: 17.0.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7071/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7071/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7070 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7070/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7070/comments | https://api.github.com/repos/huggingface/datasets/issues/7070/events | https://github.com/huggingface/datasets/issues/7070 | 2,430,285,235 | I_kwDODunzps6Q2zWz | 7,070 | how set_transform affects batch size? | {
"avatar_url": "https://avatars.githubusercontent.com/u/103993288?v=4",
"events_url": "https://api.github.com/users/VafaKnm/events{/privacy}",
"followers_url": "https://api.github.com/users/VafaKnm/followers",
"following_url": "https://api.github.com/users/VafaKnm/following{/other_user}",
"gists_url": "https://api.github.com/users/VafaKnm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/VafaKnm",
"id": 103993288,
"login": "VafaKnm",
"node_id": "U_kgDOBjLPyA",
"organizations_url": "https://api.github.com/users/VafaKnm/orgs",
"received_events_url": "https://api.github.com/users/VafaKnm/received_events",
"repos_url": "https://api.github.com/users/VafaKnm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/VafaKnm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VafaKnm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/VafaKnm",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
I am trying to fine-tune w2v-bert for ASR task. Since my dataset is so big, I preferred to use the on-the-fly method with set_transform. So i change the preprocessing function to this:
```
def prepare_dataset(batch):
input_features = processor(batch["audio"], sampling_rate=16000).input_features[0]
input_length = len(input_features)
labels = processor.tokenizer(batch["text"], padding=False).input_ids
batch = {
"input_features": [input_features],
"input_length": [input_length],
"labels": [labels]
}
return batch
train_ds.set_transform(prepare_dataset)
val_ds.set_transform(prepare_dataset)
```
After this, I also had to change the DataCollatorCTCWithPadding class like this:
```
@dataclass
class DataCollatorCTCWithPadding:
processor: Wav2Vec2BertProcessor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# Separate input_features and labels
input_features = [{"input_features": feature["input_features"][0]} for feature in features]
labels = [feature["labels"][0] for feature in features]
# Pad input features
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
# Pad and process labels
label_features = self.processor.tokenizer.pad(
{"input_ids": labels},
padding=self.padding,
return_tensors="pt",
)
labels = label_features["input_ids"]
attention_mask = label_features["attention_mask"]
# Replace padding with -100 to ignore these tokens during loss calculation
labels = labels.masked_fill(attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
```
But now a strange thing is happening, no matter how much I increase the batch size, the amount of V-RAM GPU usage does not change, while the number of total steps in the progress-bar (logging) changes. Is this normal or have I made a mistake?
### Steps to reproduce the bug
i can share my code if needed
### Expected behavior
Equal to the batch size value, the set_transform function is applied to the dataset and given to the model as a batch.
### Environment info
all updated versions | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7070/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7070/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7067 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7067/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7067/comments | https://api.github.com/repos/huggingface/datasets/issues/7067/events | https://github.com/huggingface/datasets/issues/7067 | 2,425,460,168 | I_kwDODunzps6QkZXI | 7,067 | Convert_to_parquet fails for datasets with multiple configs | {
"avatar_url": "https://avatars.githubusercontent.com/u/97585031?v=4",
"events_url": "https://api.github.com/users/HuangZhen02/events{/privacy}",
"followers_url": "https://api.github.com/users/HuangZhen02/followers",
"following_url": "https://api.github.com/users/HuangZhen02/following{/other_user}",
"gists_url": "https://api.github.com/users/HuangZhen02/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HuangZhen02",
"id": 97585031,
"login": "HuangZhen02",
"node_id": "U_kgDOBdEHhw",
"organizations_url": "https://api.github.com/users/HuangZhen02/orgs",
"received_events_url": "https://api.github.com/users/HuangZhen02/received_events",
"repos_url": "https://api.github.com/users/HuangZhen02/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HuangZhen02/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HuangZhen02/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HuangZhen02",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Many users have encountered the same issue, which has caused inconvenience.\r\n\r\nhttps://discuss.huggingface.co/t/convert-to-parquet-fails-for-datasets-with-multiple-configs/86733\r\n",
"Thanks for reporting.\r\n\r\nI will make the code more robust.",
"I have opened an issue in the huggingface-hub repo:\r\n- https://github.com/huggingface/huggingface_hub/issues/2419\r\n\r\nI am opening a PR to avoid calling `create_branch` if the branch already exists."
] | 1970-01-01T00:00:00.000001 | 1,722 | 1970-01-01T00:00:00.000001 | NONE | null | If the dataset has multiple configs, when using the `datasets-cli convert_to_parquet` command to avoid issues with the data viewer caused by loading scripts, the conversion process only successfully converts the data corresponding to the first config. When it starts converting the second config, it throws an error:
```
Traceback (most recent call last):
File "/opt/anaconda3/envs/dl/bin/datasets-cli", line 8, in <module>
sys.exit(main())
File "/opt/anaconda3/envs/dl/lib/python3.10/site-packages/datasets/commands/datasets_cli.py", line 41, in main
service.run()
File "/opt/anaconda3/envs/dl/lib/python3.10/site-packages/datasets/commands/convert_to_parquet.py", line 83, in run
dataset.push_to_hub(
File "/opt/anaconda3/envs/dl/lib/python3.10/site-packages/datasets/dataset_dict.py", line 1713, in push_to_hub
api.create_branch(repo_id, branch=revision, token=token, repo_type="dataset", exist_ok=True)
File "/opt/anaconda3/envs/dl/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
File "/opt/anaconda3/envs/dl/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 5503, in create_branch
hf_raise_for_status(response)
File "/opt/anaconda3/envs/dl/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 358, in hf_raise_for_status
raise BadRequestError(message, response=response) from e
huggingface_hub.utils._errors.BadRequestError: (Request ID: Root=1-669fc665-7c2e80d75f4337496ee95402;731fcdc7-0950-4eec-99cf-ce047b8d003f)
Bad request:
Invalid reference for a branch: refs/pr/1
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7067/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7067/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7066 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7066/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7066/comments | https://api.github.com/repos/huggingface/datasets/issues/7066/events | https://github.com/huggingface/datasets/issues/7066 | 2,425,125,160 | I_kwDODunzps6QjHko | 7,066 | One subset per file in repo ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | null | MEMBER | null | Right now we consider all the files of a dataset to be the same data, e.g.
```
single_subset_dataset/
├── train0.jsonl
├── train1.jsonl
└── train2.jsonl
```
but in cases like this, each file is actually a different subset of the dataset and should be loaded separately
```
many_subsets_dataset/
├── animals.jsonl
├── trees.jsonl
└── metadata.jsonl
```
It would be nice to detect those subsets automatically using a simple heuristic. For example we can group files together if their paths names are the same except some digits ? | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7066/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7066/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7065 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7065/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7065/comments | https://api.github.com/repos/huggingface/datasets/issues/7065/events | https://github.com/huggingface/datasets/issues/7065 | 2,424,734,953 | I_kwDODunzps6QhoTp | 7,065 | Cannot get item after loading from disk and then converting to iterable. | {
"avatar_url": "https://avatars.githubusercontent.com/u/21305646?v=4",
"events_url": "https://api.github.com/users/happyTonakai/events{/privacy}",
"followers_url": "https://api.github.com/users/happyTonakai/followers",
"following_url": "https://api.github.com/users/happyTonakai/following{/other_user}",
"gists_url": "https://api.github.com/users/happyTonakai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/happyTonakai",
"id": 21305646,
"login": "happyTonakai",
"node_id": "MDQ6VXNlcjIxMzA1NjQ2",
"organizations_url": "https://api.github.com/users/happyTonakai/orgs",
"received_events_url": "https://api.github.com/users/happyTonakai/received_events",
"repos_url": "https://api.github.com/users/happyTonakai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/happyTonakai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/happyTonakai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/happyTonakai",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
The dataset generated from local file works fine.
```py
root = "/home/data/train"
file_list1 = glob(os.path.join(root, "*part1.flac"))
file_list2 = glob(os.path.join(root, "*part2.flac"))
ds = (
Dataset.from_dict({"part1": file_list1, "part2": file_list2})
.cast_column("part1", Audio(sampling_rate=None, mono=False))
.cast_column("part2", Audio(sampling_rate=None, mono=False))
)
ids = ds.to_iterable_dataset(128)
ids = ids.shuffle(buffer_size=10000, seed=42)
dataloader = DataLoader(ids, num_workers=4, batch_size=8, persistent_workers=True)
for batch in dataloader:
break
```
But after saving it to disk and then loading it from disk, I cannot get data as expected.
```py
root = "/home/data/train"
file_list1 = glob(os.path.join(root, "*part1.flac"))
file_list2 = glob(os.path.join(root, "*part2.flac"))
ds = (
Dataset.from_dict({"part1": file_list1, "part2": file_list2})
.cast_column("part1", Audio(sampling_rate=None, mono=False))
.cast_column("part2", Audio(sampling_rate=None, mono=False))
)
ds.save_to_disk("./train")
ds = datasets.load_from_disk("./train")
ids = ds.to_iterable_dataset(128)
ids = ids.shuffle(buffer_size=10000, seed=42)
dataloader = DataLoader(ids, num_workers=4, batch_size=8, persistent_workers=True)
for batch in dataloader:
break
```
After a long time waiting, an error occurs:
```
Loading dataset from disk: 100%|█████████████████████████████████████████████████████████████████████████| 165/165 [00:00<00:00, 6422.18it/s]
Traceback (most recent call last):
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1133, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/multiprocessing/queues.py", line 113, in get
if not self._poll(timeout):
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/multiprocessing/connection.py", line 424, in _poll
r = wait([self], timeout)
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/multiprocessing/connection.py", line 931, in wait
ready = selector.select(timeout)
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/selectors.py", line 416, in select
fd_event_list = self._selector.poll(timeout)
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 3490529) is killed by signal: Killed.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/home/hanzerui/.vscode-server/extensions/ms-python.debugpy-2024.9.12011011/bundled/libs/debugpy/adapter/../../debugpy/launcher/../../debugpy/__main__.py", line 39, in <module>
cli.main()
File "/home/hanzerui/.vscode-server/extensions/ms-python.debugpy-2024.9.12011011/bundled/libs/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 430, in main
run()
File "/home/hanzerui/.vscode-server/extensions/ms-python.debugpy-2024.9.12011011/bundled/libs/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 284, in run_file
runpy.run_path(target, run_name="__main__")
File "/home/hanzerui/.vscode-server/extensions/ms-python.debugpy-2024.9.12011011/bundled/libs/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 321, in run_path
return _run_module_code(code, init_globals, run_name,
File "/home/hanzerui/.vscode-server/extensions/ms-python.debugpy-2024.9.12011011/bundled/libs/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 135, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "/home/hanzerui/.vscode-server/extensions/ms-python.debugpy-2024.9.12011011/bundled/libs/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 124, in _run_code
exec(code, run_globals)
File "/home/hanzerui/workspace/NetEase/test/test_datasets.py", line 60, in <module>
for batch in dataloader:
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 631, in __next__
data = self._next_data()
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1329, in _next_data
idx, data = self._get_data()
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1295, in _get_data
success, data = self._try_get_data()
File "/home/hanzerui/.conda/envs/mss/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1146, in _try_get_data
raise RuntimeError(f'DataLoader worker (pid(s) {pids_str}) exited unexpectedly') from e
RuntimeError: DataLoader worker (pid(s) 3490529) exited unexpectedly
```
It seems that streaming is not supported by `laod_from_disk`, so does that mean I cannot convert it to iterable?
### Steps to reproduce the bug
1. Create a `Dataset` from local files with `from_dict`
2. Save it to disk with `save_to_disk`
3. Load it from disk with `load_from_disk`
4. Convert to iterable with `to_iterable_dataset`
5. Loop the dataset
### Expected behavior
Get items faster than the original dataset generated from dict.
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-6.5.0-41-generic-x86_64-with-glibc2.35
- Python version: 3.10.14
- `huggingface_hub` version: 0.23.2
- PyArrow version: 17.0.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7065/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7065/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7063 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7063/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7063/comments | https://api.github.com/repos/huggingface/datasets/issues/7063/events | https://github.com/huggingface/datasets/issues/7063 | 2,424,488,648 | I_kwDODunzps6QgsLI | 7,063 | Add `batch` method to `Dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/61876623?v=4",
"events_url": "https://api.github.com/users/lappemic/events{/privacy}",
"followers_url": "https://api.github.com/users/lappemic/followers",
"following_url": "https://api.github.com/users/lappemic/following{/other_user}",
"gists_url": "https://api.github.com/users/lappemic/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lappemic",
"id": 61876623,
"login": "lappemic",
"node_id": "MDQ6VXNlcjYxODc2NjIz",
"organizations_url": "https://api.github.com/users/lappemic/orgs",
"received_events_url": "https://api.github.com/users/lappemic/received_events",
"repos_url": "https://api.github.com/users/lappemic/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lappemic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lappemic/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lappemic",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | CONTRIBUTOR | null | ### Feature request
Add a `batch` method to the Dataset class, similar to the one recently implemented for `IterableDataset` in PR #7054.
### Motivation
A batched iteration speeds up data loading significantly (see e.g. #6279)
### Your contribution
I plan to open a PR to implement this. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7063/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7063/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7061 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7061/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7061/comments | https://api.github.com/repos/huggingface/datasets/issues/7061/events | https://github.com/huggingface/datasets/issues/7061 | 2,423,786,881 | I_kwDODunzps6QeA2B | 7,061 | Custom Dataset | Still Raise Error while handling errors in _generate_examples | {
"avatar_url": "https://avatars.githubusercontent.com/u/68266028?v=4",
"events_url": "https://api.github.com/users/hahmad2008/events{/privacy}",
"followers_url": "https://api.github.com/users/hahmad2008/followers",
"following_url": "https://api.github.com/users/hahmad2008/following{/other_user}",
"gists_url": "https://api.github.com/users/hahmad2008/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hahmad2008",
"id": 68266028,
"login": "hahmad2008",
"node_id": "MDQ6VXNlcjY4MjY2MDI4",
"organizations_url": "https://api.github.com/users/hahmad2008/orgs",
"received_events_url": "https://api.github.com/users/hahmad2008/received_events",
"repos_url": "https://api.github.com/users/hahmad2008/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hahmad2008/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hahmad2008/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hahmad2008",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,725 | null | NONE | null | ### Describe the bug
I follow this [example](https://discuss.huggingface.co/t/error-handling-in-iterabledataset/72827/3) to handle errors in custom dataset. I am writing a dataset script which read jsonl files and i need to handle errors and continue reading files without raising exception and exit the execution.
```
def _generate_examples(self, filepaths):
errors=[]
id_ = 0
for filepath in filepaths:
try:
with open(filepath, 'r') as f:
for line in f:
json_obj = json.loads(line)
yield id_, json_obj
id_ += 1
except Exception as exc:
logger.error(f"error occur at filepath: {filepath}")
errors.append(error)
```
seems the logger.error is printed but still exception is raised the the run is exit.
```
Downloading and preparing dataset custom_dataset/default to /home/myuser/.cache/huggingface/datasets/custom_dataset/default-a14cdd566afee0a6/1.0.0/acfcc9fb9c57034b580c4252841
ERROR: datasets_modules.datasets.custom_dataset.acfcc9fb9c57034b580c4252841bb890a5617cbd28678dd4be5e52b81188ad02.custom_dataset: 2024-07-22 10:47:42,167: error occur at filepath: '/home/myuser/ds/corrupted-file.jsonl
Traceback (most recent call last):
File "/home/myuser/.cache/huggingface/modules/datasets_modules/datasets/custom_dataset/ac..2/custom_dataset.py", line 48, in _generate_examples
json_obj = json.loads(line)
File "myenv/lib/python3.8/json/__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "myenv/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "myenv/lib/python3.8/json/decoder.py", line 353, in raw_decode
obj, end = self.scan_once(s, idx)
json.decoder.JSONDecodeError: Invalid control character at: line 1 column 4 (char 3)
Generating train split: 0 examples [00:06, ? examples/s]>
RemoteTraceback:
"""
Traceback (most recent call last):
File "myenv/lib/python3.8/site-packages/datasets/builder.py", line 1637, in _prepare_split_single
num_examples, num_bytes = writer.finalize()
File "myenv/lib/python3.8/site-packages/datasets/arrow_writer.py", line 594, in finalize
raise SchemaInferenceError("Please pass `features` or at least one example when writing data")
datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "myenv/lib/python3.8/site-packages/multiprocess/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "myenv/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 1353, in
_write_generator_to_queue
for i, result in enumerate(func(**kwargs)):
File "myenv/lib/python3.8/site-packages/datasets/builder.py", line 1646, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
"""
The above exception was the direct cause of the following exception:
│ │
│ myenv/lib/python3.8/site-packages/datasets/utils/py_utils. │
│ py:1377 in <listcomp> │
│ │
│ 1374 │ │ │ │ if all(async_result.ready() for async_result in async_results) and queue │
│ 1375 │ │ │ │ │ break │
│ 1376 │ │ # we get the result in case there's an error to raise │
│ ❱ 1377 │ │ [async_result.get() for async_result in async_results] │
│ 1378 │
│ │
│ ╭──────────────────────────────── locals ─────────────────────────────────╮ │
│ │ .0 = <list_iterator object at 0x7f2cc1f0ce20> │ │
│ │ async_result = <multiprocess.pool.ApplyResult object at 0x7f2cc1f79c10> │ │
│ ╰─────────────────────────────────────────────────────────────────────────╯ │
│ │
│ myenv/lib/python3.8/site-packages/multiprocess/pool.py:771 │
│ in get │
│ │
│ 768 │ │ if self._success: │
│ 769 │ │ │ return self._value │
│ 770 │ │ else: │
│ ❱ 771 │ │ │ raise self._value │
│ 772 │ │
│ 773 │ def _set(self, i, obj): │
│ 774 │ │ self._success, self._value = obj │
│ │
│ ╭────────────────────────────── locals ──────────────────────────────╮ │
│ │ self = <multiprocess.pool.ApplyResult object at 0x7f2cc1f79c10> │ │
│ │ timeout = None │ │
│ ╰────────────────────────────────────────────────────────────────────╯ │
DatasetGenerationError: An error occurred while generating the dataset
```
### Steps to reproduce the bug
same as above
### Expected behavior
should handle error and continue reading remaining files
### Environment info
python 3.9 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7061/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7061/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7059 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7059/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7059/comments | https://api.github.com/repos/huggingface/datasets/issues/7059/events | https://github.com/huggingface/datasets/issues/7059 | 2,422,827,892 | I_kwDODunzps6QaWt0 | 7,059 | None values are skipped when reading jsonl in subobjects | {
"avatar_url": "https://avatars.githubusercontent.com/u/1929830?v=4",
"events_url": "https://api.github.com/users/PonteIneptique/events{/privacy}",
"followers_url": "https://api.github.com/users/PonteIneptique/followers",
"following_url": "https://api.github.com/users/PonteIneptique/following{/other_user}",
"gists_url": "https://api.github.com/users/PonteIneptique/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/PonteIneptique",
"id": 1929830,
"login": "PonteIneptique",
"node_id": "MDQ6VXNlcjE5Mjk4MzA=",
"organizations_url": "https://api.github.com/users/PonteIneptique/orgs",
"received_events_url": "https://api.github.com/users/PonteIneptique/received_events",
"repos_url": "https://api.github.com/users/PonteIneptique/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/PonteIneptique/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PonteIneptique/subscriptions",
"type": "User",
"url": "https://api.github.com/users/PonteIneptique",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
I have been fighting against my machine since this morning only to find out this is some kind of a bug.
When loading a dataset composed of `metadata.jsonl`, if you have nullable values (Optional[str]), they can be ignored by the parser, shifting things around.
E.g., let's take this example
Here are two version of a same dataset:
[not-buggy.tar.gz](https://github.com/user-attachments/files/16333532/not-buggy.tar.gz)
[buggy.tar.gz](https://github.com/user-attachments/files/16333553/buggy.tar.gz)
### Steps to reproduce the bug
1. Load the `buggy.tar.gz` dataset
2. Print baseline of `dts = load_dataset("./data")["train"][0]["baselines]`
3. Load the `not-buggy.tar.gz` dataset
4. Print baseline of `dts = load_dataset("./data")["train"][0]["baselines]`
### Expected behavior
Both should have 4 baseline entries:
1. Buggy should have None followed by three lists
2. Non-Buggy should have four lists, and the first one should be an empty list.
One does not work, 2 works. Despite accepting None in another position than the first one.
### Environment info
- `datasets` version: 2.19.1
- Platform: Linux-6.5.0-44-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.23.0
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.3.1
| null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7059/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7059/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7058 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7058/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7058/comments | https://api.github.com/repos/huggingface/datasets/issues/7058/events | https://github.com/huggingface/datasets/issues/7058 | 2,422,560,355 | I_kwDODunzps6QZVZj | 7,058 | New feature type: Document | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | null | COLLABORATOR | null | It would be useful for PDF.
https://github.com/huggingface/dataset-viewer/issues/2991#issuecomment-2242656069 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7058/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7058/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7055 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7055/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7055/comments | https://api.github.com/repos/huggingface/datasets/issues/7055/events | https://github.com/huggingface/datasets/issues/7055 | 2,421,708,891 | I_kwDODunzps6QWFhb | 7,055 | WebDataset with different prefixes are unsupported | {
"avatar_url": "https://avatars.githubusercontent.com/u/106811348?v=4",
"events_url": "https://api.github.com/users/hlky/events{/privacy}",
"followers_url": "https://api.github.com/users/hlky/followers",
"following_url": "https://api.github.com/users/hlky/following{/other_user}",
"gists_url": "https://api.github.com/users/hlky/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hlky",
"id": 106811348,
"login": "hlky",
"node_id": "U_kgDOBl3P1A",
"organizations_url": "https://api.github.com/users/hlky/orgs",
"received_events_url": "https://api.github.com/users/hlky/received_events",
"repos_url": "https://api.github.com/users/hlky/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hlky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hlky/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hlky",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Since `datasets` uses is built on Arrow to store the data, it requires each sample to have the same columns.\r\n\r\nThis can be fixed by specifyign in advance the name of all the possible columns in the `dataset_info` in YAML, and missing values will be `None`",
"Thanks. This currently doesn't work for WebDataset because there's no `BuilderConfig` with `features` and in turn `_info` is missing `features=self.config.features`. I'll prepare a PR to fix this.\r\n\r\nNote it may be useful to add the [expected format of `features`](https://github.com/huggingface/datasets/blob/16fa4421f44b22bbbc607f379a93f45af468d1fc/src/datasets/features/features.py#L1757) to the documentation for [`Builder Parameters`](https://huggingface.co/docs/datasets/repository_structure#builder-parameters).\r\n",
"Oh good catch ! thanks\r\n\r\n> Note it may be useful to add the [expected format of features](https://github.com/huggingface/datasets/blob/16fa4421f44b22bbbc607f379a93f45af468d1fc/src/datasets/features/features.py#L1757) to the documentation for [Buil](https://huggingface.co/docs/datasets/repository_structure#builder-parameters)\r\n\r\nGood idea, let me open a PR",
"#7060 ",
"Actually I just tried with `datasets` on the `main` branch and having `features` defined in `dataset_info` worked for me\r\n\r\n```python\r\n>>> list(load_dataset(\"/Users/quentinlhoest/tmp\", streaming=True, split=\"train\"))\r\n[{'txt': 'hello there\\n', 'other': None}]\r\n```\r\nwhere `tmp` contains data.tar with \"hello there\\n\" in a text file and the README.md:\r\n```\r\n---\r\ndataset_info:\r\n features:\r\n - name: txt\r\n dtype: string\r\n - name: other\r\n dtype: string\r\n---\r\n\r\nThis is a dataset card\r\n```\r\n\r\nWhat error did you get when you tried to specify the columns in `dataset_info` ?",
"If you review the changes in #7060 you'll note that `features` are not passed to `DatasetInfo`.\r\n\r\nIn your case the features are being extracted by [this code](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/webdataset/webdataset.py#L72-L98).\r\n\r\nTry with the `Steps to reproduce the bug`. It's the same error mentioned in `Describe the bug` because `features` are not passed to `DatasetInfo`.\r\n\r\n`features` are [not used](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/builder.py#L365-L366) when the `BuilderConfig` has no `features` attribute. `WebDataset` uses the default [`BuilderConfig`](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/builder.py#L101-L124).\r\n\r\nThere is a [warning](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/load.py#L640-L648) that `features` are ignored.\r\n\r\nNote that as mentioned in `Describe the bug` this could also be resolved by removing the check [here](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/webdataset/webdataset.py#L76-L80) because Arrow actually handles this itself, Arrow sets any missing fields to `None`, at least in my case.",
"Note for anyone else who encounters this issue, every dataset type except folder-based types supported features in the [documented](https://huggingface.co/docs/datasets/repository_structure#builder-parameters) manner; [Arrow](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/arrow/arrow.py#L15-L21), [csv](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/csv/csv.py#L25-L68), [generator](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/generator/generator.py#L8-L19), [json](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/json/json.py#L42-L52), [pandas](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/pandas/pandas.py#L14-L20), [parquet](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/parquet/parquet.py#L16-L24), [spark](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/spark/spark.py#L31-L37), [sql](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/sql/sql.py#L24-L35) and [text](https://github.com/huggingface/datasets/blob/e83d6fa574710fcb44e341087239d2687183f62b/src/datasets/packaged_modules/text/text.py#L18-L27). `WebDataset` is different and requires [`dataset_info` which is vaguely documented](https://huggingface.co/docs/datasets/dataset_script#optional-generate-dataset-metadata) under dataset loading scripts.",
"Thanks for explaining. I see the Dataset Viewer is still failing - I'll update `datasets` in the Viewer to fix this"
] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
Consider a WebDataset with multiple images for each item where the number of images may vary: [example](https://huggingface.co/datasets/bigdata-pw/fashion-150k)
Due to this [code](https://github.com/huggingface/datasets/blob/87f4c2088854ff33e817e724e75179e9975c1b02/src/datasets/packaged_modules/webdataset/webdataset.py#L76-L80) an error is given.
```
The TAR archives of the dataset should be in WebDataset format, but the files in the archive don't share the same prefix or the same types.
```
The purpose of this check is unclear because PyArrow supports different keys.
Removing the check allows the dataset to be loaded and there's no issue when iterating through the dataset.
```
>>> from datasets import load_dataset
>>> path = "shards/*.tar"
>>> dataset = load_dataset("webdataset", data_files={"train": path}, split="train", streaming=True)
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 152/152 [00:00<00:00, 56458.93it/s]
>>> dataset
IterableDataset({
features: ['__key__', '__url__', '1.jpg', '2.jpg', '3.jpg', '4.jpg', 'json'],
n_shards: 152
})
```
### Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("bigdata-pw/fashion-150k")
```
### Expected behavior
Dataset loads without error
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-5.14.0-467.el9.x86_64-x86_64-with-glibc2.34
- Python version: 3.9.19
- `huggingface_hub` version: 0.23.4
- PyArrow version: 17.0.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/106811348?v=4",
"events_url": "https://api.github.com/users/hlky/events{/privacy}",
"followers_url": "https://api.github.com/users/hlky/followers",
"following_url": "https://api.github.com/users/hlky/following{/other_user}",
"gists_url": "https://api.github.com/users/hlky/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hlky",
"id": 106811348,
"login": "hlky",
"node_id": "U_kgDOBl3P1A",
"organizations_url": "https://api.github.com/users/hlky/orgs",
"received_events_url": "https://api.github.com/users/hlky/received_events",
"repos_url": "https://api.github.com/users/hlky/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hlky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hlky/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hlky",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7055/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7055/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7053 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7053/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7053/comments | https://api.github.com/repos/huggingface/datasets/issues/7053/events | https://github.com/huggingface/datasets/issues/7053 | 2,416,423,791 | I_kwDODunzps6QB7Nv | 7,053 | Datasets.datafiles resolve_pattern `TypeError: can only concatenate tuple (not "str") to tuple` | {
"avatar_url": "https://avatars.githubusercontent.com/u/48289218?v=4",
"events_url": "https://api.github.com/users/MatthewYZhang/events{/privacy}",
"followers_url": "https://api.github.com/users/MatthewYZhang/followers",
"following_url": "https://api.github.com/users/MatthewYZhang/following{/other_user}",
"gists_url": "https://api.github.com/users/MatthewYZhang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MatthewYZhang",
"id": 48289218,
"login": "MatthewYZhang",
"node_id": "MDQ6VXNlcjQ4Mjg5MjE4",
"organizations_url": "https://api.github.com/users/MatthewYZhang/orgs",
"received_events_url": "https://api.github.com/users/MatthewYZhang/received_events",
"repos_url": "https://api.github.com/users/MatthewYZhang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MatthewYZhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MatthewYZhang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MatthewYZhang",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Hi,\r\n\r\nThis issue was fixed in `datasets` 2.15.0:\r\n- #6105\r\n\r\nYou will need to update your `datasets`:\r\n```\r\npip install -U datasets\r\n```",
"Duplicate of:\r\n- #6100"
] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
in data_files.py, line 332,
`fs, _, _ = get_fs_token_paths(pattern, storage_options=storage_options)`
If we run the code on AWS, as fs.protocol will be a tuple like: `('file', 'local')`
So, `isinstance(fs.protocol, str) == False` and
`protocol_prefix = fs.protocol + "://" if fs.protocol != "file" else ""` will raise
`TypeError: can only concatenate tuple (not "str") to tuple`.
### Steps to reproduce the bug
Steps to reproduce:
1. Run on a cloud server like AWS,
2. `import datasets.data_files as datafile`
3. datafile.resolve_pattern('path/to/dataset', '.')
4. `TypeError: can only concatenate tuple (not "str") to tuple`
### Expected behavior
Should return path of the dataset, with fs.protocol at the beginning
### Environment info
- `datasets` version: 2.14.0
- Platform: Linux-3.10.0-1160.119.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.19
- Huggingface_hub version: 0.23.5
- PyArrow version: 16.1.0
- Pandas version: 1.1.5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7053/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7053/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7051/comments | https://api.github.com/repos/huggingface/datasets/issues/7051/events | https://github.com/huggingface/datasets/issues/7051 | 2,409,353,929 | I_kwDODunzps6Pm9LJ | 7,051 | How to set_epoch with interleave_datasets? | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanasdf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jonathanasdf",
"id": 511073,
"login": "jonathanasdf",
"node_id": "MDQ6VXNlcjUxMTA3Mw==",
"organizations_url": "https://api.github.com/users/jonathanasdf/orgs",
"received_events_url": "https://api.github.com/users/jonathanasdf/received_events",
"repos_url": "https://api.github.com/users/jonathanasdf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jonathanasdf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanasdf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jonathanasdf",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"This is not possible right now afaik :/\r\n\r\nMaybe we could have something like this ? wdyt ?\r\n\r\n```python\r\nds = interleave_datasets(\r\n [shuffled_dataset_a, dataset_b],\r\n probabilities=probabilities,\r\n stopping_strategy='all_exhausted',\r\n reshuffle_each_iteration=True,\r\n)",
"That would be helpful for this case! \r\n\r\nIf there was some way for from_generator to iterate over just a single shard of some dataset that would probably be more ideal. Maybe something like\r\n\r\n```\r\ndef from_dataset_generator(dataset, generator_fn, gen_kwargs):\r\n # calls generator_fn(dataset=dataset_shard, **gen_kwargs)\r\n```\r\n\r\nAnother transform I was trying to implement is an input bucketing transform. Essentially you need to iterate through a dataset and reorder the examples in them, which is not really possible with a `map()` call. But using `from_generator()` causes the final dataset to be a single shard and loses speed gains from multiple dataloader workers",
"I see, there are some internal functions to get a single shard already but the public `.shard()` method hasn't been implemented yet for `IterableDataset` :/\r\n\r\n(see the use of `ex_iterable.shard_data_sources` in `IterableDataset._prepare_ex_iterable_for_iteration` for example)",
"Would that be something planned on the roadmap for the near future, or do you suggest hacking through with internal APIs for now?",
"Ok this turned out to be not too difficult. Are there any obvious issues with my implementation?\r\n\r\n```\r\nclass ShuffleEveryEpochIterable(iterable_dataset._BaseExamplesIterable):\r\n \"\"\"ExamplesIterable that reshuffles the dataset every epoch.\"\"\"\r\n\r\n def __init__(\r\n self,\r\n ex_iterable: iterable_dataset._BaseExamplesIterable,\r\n generator: np.random.Generator,\r\n ):\r\n \"\"\"Constructor.\"\"\"\r\n super().__init__()\r\n self.ex_iterable = ex_iterable\r\n self.generator = generator\r\n\r\n def _init_state_dict(self) -> dict:\r\n self._state_dict = {\r\n 'ex_iterable': self.ex_iterable._init_state_dict(),\r\n 'epoch': 0,\r\n }\r\n return self._state_dict\r\n\r\n @typing.override\r\n def __iter__(self):\r\n epoch = self._state_dict['epoch'] if self._state_dict else 0\r\n for i in itertools.count(epoch):\r\n # Create effective seed using i (subtract in order to avoir overflow in long_scalars)\r\n effective_seed = copy.deepcopy(self.generator).integers(0, 1 << 63) - i\r\n effective_seed = (1 << 63) + effective_seed if effective_seed < 0 else effective_seed\r\n generator = np.random.default_rng(effective_seed)\r\n self.ex_iterable = self.ex_iterable.shuffle_data_sources(generator)\r\n if self._state_dict:\r\n self._state_dict['epoch'] = i\r\n self._state_dict['ex_iterable'] = self.ex_iterable._init_state_dict()\r\n it = iter(self.ex_iterable)\r\n yield from it\r\n\r\n @typing.override\r\n def shuffle_data_sources(self, generator):\r\n ex_iterable = self.ex_iterable.shuffle_data_sources(generator)\r\n return ShuffleEveryEpochIterable(ex_iterable, generator=generator)\r\n\r\n @typing.override\r\n def shard_data_sources(self, worker_id: int, num_workers: int):\r\n ex_iterable = self.ex_iterable.shard_data_sources(worker_id, num_workers)\r\n return ShuffleEveryEpochIterable(ex_iterable, generator=self.generator)\r\n\r\n @typing.override\r\n @property\r\n def n_shards(self) -> int:\r\n return self.ex_iterable.n_shards\r\n \r\ngenerator = np.random.default_rng(seed)\r\nshuffling = iterable_dataset.ShufflingConfig(generator=generator, _original_seed=seed)\r\nex_iterable = iterable_dataset.BufferShuffledExamplesIterable(\r\n dataset._ex_iterable, buffer_size=buffer_size, generator=generator\r\n)\r\nex_iterable = ShuffleEveryEpochIterable(ex_iterable, generator=generator)\r\ndataset = datasets.IterableDataset(\r\n ex_iterable=ex_iterable,\r\n info=dataset._info.copy(),\r\n split=dataset._split,\r\n formatting=dataset._formatting,\r\n shuffling=shuffling,\r\n distributed=copy.deepcopy(dataset._distributed),\r\n token_per_repo_id=dataset._token_per_repo_id,\r\n)\r\n```\r\n",
"Nice ! This iterable is infinite though no ? How would `interleave_dataset` know when to stop ?\r\n\r\nMaybe the re-shuffling can be implemented directly in `RandomlyCyclingMultiSourcesExamplesIterable` (which is the iterable used by `interleave_dataset`) ?",
"Infinite is fine for my usecases fortunately."
] | 1970-01-01T00:00:00.000001 | 1,722 | 1970-01-01T00:00:00.000001 | NONE | null | Let's say I have dataset A which has 100k examples, and dataset B which has 100m examples.
I want to train on an interleaved dataset of A+B, with stopping_strategy='all_exhausted' so dataset B doesn't repeat any examples. But every time A is exhausted I want it to be reshuffled (eg. calling set_epoch)
Of course I want to interleave as IterableDatasets / streaming mode so B doesn't have to get tokenized completely at the start.
How could I achieve this? I was thinking something like, if I wrap dataset A in some new IterableDataset with from_generator() and manually call set_epoch before interleaving it? But I'm not sure how to keep the number of shards in that dataset...
Something like
```
dataset_a = load_dataset(...)
dataset_b = load_dataset(...)
def epoch_shuffled_dataset(ds):
# How to make this maintain the number of shards in ds??
for epoch in itertools.count():
ds.set_epoch(epoch)
yield from iter(ds)
shuffled_dataset_a = IterableDataset.from_generator(epoch_shuffled_dataset, gen_kwargs={'ds': dataset_a})
interleaved = interleave_datasets([shuffled_dataset_a, dataset_b], probs, stopping_strategy='all_exhausted')
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanasdf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jonathanasdf",
"id": 511073,
"login": "jonathanasdf",
"node_id": "MDQ6VXNlcjUxMTA3Mw==",
"organizations_url": "https://api.github.com/users/jonathanasdf/orgs",
"received_events_url": "https://api.github.com/users/jonathanasdf/received_events",
"repos_url": "https://api.github.com/users/jonathanasdf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jonathanasdf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanasdf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jonathanasdf",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 2,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7051/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7049 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7049/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7049/comments | https://api.github.com/repos/huggingface/datasets/issues/7049/events | https://github.com/huggingface/datasets/issues/7049 | 2,408,514,366 | I_kwDODunzps6PjwM- | 7,049 | Save nparray as list | {
"avatar_url": "https://avatars.githubusercontent.com/u/48399040?v=4",
"events_url": "https://api.github.com/users/Sakurakdx/events{/privacy}",
"followers_url": "https://api.github.com/users/Sakurakdx/followers",
"following_url": "https://api.github.com/users/Sakurakdx/following{/other_user}",
"gists_url": "https://api.github.com/users/Sakurakdx/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Sakurakdx",
"id": 48399040,
"login": "Sakurakdx",
"node_id": "MDQ6VXNlcjQ4Mzk5MDQw",
"organizations_url": "https://api.github.com/users/Sakurakdx/orgs",
"received_events_url": "https://api.github.com/users/Sakurakdx/received_events",
"repos_url": "https://api.github.com/users/Sakurakdx/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Sakurakdx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sakurakdx/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Sakurakdx",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"In addition, when I use `set_format ` and index the ds, the following error occurs:\r\nthe code\r\n```python\r\nds.set_format(type=\"np\", colums=\"pixel_values\")\r\n```\r\nerror\r\n<img width=\"918\" alt=\"image\" src=\"https://github.com/user-attachments/assets/b28bbff2-20ea-4d28-ab62-b4ed2d944996\">\r\n",
"> Some people use the set_format function to convert the column back, but doesn't this lose precision?\r\n\r\nUnder the hood the data is saved in Arrow format using the same precision as your numpy arrays?\r\nBy default the Arrow data is read as python lists, but you can indeed read them back as numpy arrays with the same precision",
"(you can fix your second issue by fixing the typo `colums` -> `columns`)",
"> (you can fix your second issue by fixing the typo `colums` -> `columns`)\r\n\r\nYou are right, I was careless. Thank you.",
"> > Some people use the set_format function to convert the column back, but doesn't this lose precision?\r\n> \r\n> Under the hood the data is saved in Arrow format using the same precision as your numpy arrays? By default the Arrow data is read as python lists, but you can indeed read them back as numpy arrays with the same precision\r\n\r\nYes, after testing I found that there was no loss of precision. Thanks again for your answer."
] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
When I use the `map` function to convert images into features, datasets saves nparray as a list. Some people use the `set_format` function to convert the column back, but doesn't this lose precision?
### Steps to reproduce the bug
the map function
```python
def convert_image_to_features(inst, processor, image_dir):
image_file = inst["image_url"]
file = image_file.split("/")[-1]
image_path = os.path.join(image_dir, file)
image = Image.open(image_path)
image = image.convert("RGBA")
inst["pixel_values"] = processor(images=image, return_tensors="np")["pixel_values"]
return inst
```
main function
```python
map_fun = partial(
convert_image_to_features, processor=processor, image_dir=image_dir
)
ds = ds.map(map_fun, batched=False, num_proc=20)
print(type(ds[0]["pixel_values"])
```
### Expected behavior
(type < list>)
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-4.19.91-009.ali4000.alios7.x86_64-x86_64-with-glibc2.35
- Python version: 3.11.5
- `huggingface_hub` version: 0.23.4
- PyArrow version: 14.0.2
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/48399040?v=4",
"events_url": "https://api.github.com/users/Sakurakdx/events{/privacy}",
"followers_url": "https://api.github.com/users/Sakurakdx/followers",
"following_url": "https://api.github.com/users/Sakurakdx/following{/other_user}",
"gists_url": "https://api.github.com/users/Sakurakdx/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Sakurakdx",
"id": 48399040,
"login": "Sakurakdx",
"node_id": "MDQ6VXNlcjQ4Mzk5MDQw",
"organizations_url": "https://api.github.com/users/Sakurakdx/orgs",
"received_events_url": "https://api.github.com/users/Sakurakdx/received_events",
"repos_url": "https://api.github.com/users/Sakurakdx/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Sakurakdx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sakurakdx/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Sakurakdx",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7049/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7049/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7048 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7048/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7048/comments | https://api.github.com/repos/huggingface/datasets/issues/7048/events | https://github.com/huggingface/datasets/issues/7048 | 2,408,487,547 | I_kwDODunzps6Pjpp7 | 7,048 | ImportError: numpy.core.multiarray when using `filter` | {
"avatar_url": "https://avatars.githubusercontent.com/u/45195979?v=4",
"events_url": "https://api.github.com/users/kamilakesbi/events{/privacy}",
"followers_url": "https://api.github.com/users/kamilakesbi/followers",
"following_url": "https://api.github.com/users/kamilakesbi/following{/other_user}",
"gists_url": "https://api.github.com/users/kamilakesbi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kamilakesbi",
"id": 45195979,
"login": "kamilakesbi",
"node_id": "MDQ6VXNlcjQ1MTk1OTc5",
"organizations_url": "https://api.github.com/users/kamilakesbi/orgs",
"received_events_url": "https://api.github.com/users/kamilakesbi/received_events",
"repos_url": "https://api.github.com/users/kamilakesbi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kamilakesbi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamilakesbi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kamilakesbi",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Could you please check your `numpy` version?",
"I got this issue while using numpy version 2.0. \r\n\r\nI solved it by switching back to numpy 1.26.0 :) ",
"We recently added support for numpy 2.0, but it is not released yet.",
"Ok I see, thanks! I think we can close this issue for now as switching back to version 1.26.0 solves the problem :) "
] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
I can't apply the filter method on my dataset.
### Steps to reproduce the bug
The following snippet generates a bug:
```python
from datasets import load_dataset
ami = load_dataset('kamilakesbi/ami', 'ihm')
ami['train'].filter(
lambda example: example["file_name"] == 'EN2001a'
)
```
I get the following error:
`ImportError: numpy.core.multiarray failed to import (auto-generated because you didn't call 'numpy.import_array()' after cimporting numpy; use '<void>numpy._import_array' to disable if you are certain you don't need it).`
### Expected behavior
It should work properly!
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- `huggingface_hub` version: 0.23.4
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/45195979?v=4",
"events_url": "https://api.github.com/users/kamilakesbi/events{/privacy}",
"followers_url": "https://api.github.com/users/kamilakesbi/followers",
"following_url": "https://api.github.com/users/kamilakesbi/following{/other_user}",
"gists_url": "https://api.github.com/users/kamilakesbi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kamilakesbi",
"id": 45195979,
"login": "kamilakesbi",
"node_id": "MDQ6VXNlcjQ1MTk1OTc5",
"organizations_url": "https://api.github.com/users/kamilakesbi/orgs",
"received_events_url": "https://api.github.com/users/kamilakesbi/received_events",
"repos_url": "https://api.github.com/users/kamilakesbi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kamilakesbi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamilakesbi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kamilakesbi",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7048/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7048/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7047/comments | https://api.github.com/repos/huggingface/datasets/issues/7047/events | https://github.com/huggingface/datasets/issues/7047 | 2,406,495,084 | I_kwDODunzps6PcDNs | 7,047 | Save Dataset as Sharded Parquet | {
"avatar_url": "https://avatars.githubusercontent.com/u/43631024?v=4",
"events_url": "https://api.github.com/users/tom-p-reichel/events{/privacy}",
"followers_url": "https://api.github.com/users/tom-p-reichel/followers",
"following_url": "https://api.github.com/users/tom-p-reichel/following{/other_user}",
"gists_url": "https://api.github.com/users/tom-p-reichel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tom-p-reichel",
"id": 43631024,
"login": "tom-p-reichel",
"node_id": "MDQ6VXNlcjQzNjMxMDI0",
"organizations_url": "https://api.github.com/users/tom-p-reichel/orgs",
"received_events_url": "https://api.github.com/users/tom-p-reichel/received_events",
"repos_url": "https://api.github.com/users/tom-p-reichel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tom-p-reichel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tom-p-reichel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tom-p-reichel",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"To anyone else who finds themselves in this predicament, it's possible to read the parquet file in the same way that datasets writes it, and then manually break it into pieces. Although, you need a couple of magic options (`thrift_*`) to deal with the huge metadata, otherwise pyarrow immediately crashes.\r\n```python\r\nimport pyarrow.parquet as pq\r\nimport pyarrow as pa\r\n\r\nr = pq.ParquetReader()\r\n\r\nr.open(\"./outrageous-file.parquet\",thrift_string_size_limit=2**31-1, thrift_container_size_limit=2**31-1)\r\n\r\nfrom more_itertools import chunked\r\nimport tqdm\r\n\r\nfor i,chunk in tqdm.tqdm(enumerate(chunked(range(r.num_row_groups),10000))):\r\n w = pq.ParquetWriter(f\"./chunks.parquet/chunk{i}.parquet\",schema=r.schema_arrow)\r\n for idx in chunk:\r\n w.write_table(r.read_row_group(idx))\r\n w.close()\r\n```",
"You can also use `.shard()` and call `to_parquet()` on each shard in the meantime:\r\n\r\n```python\r\nnum_shards = 128\r\noutput_path_template = \"output_dir/{index:05d}.parquet\"\r\nfor index in range(num_shards):\r\n shard = ds.shard(index=index, num_shards=num_shards, contiguous=True)\r\n shard.to_parquet(output_path_template.format(index=index))\r\n```"
] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Feature request
`to_parquet` currently saves the dataset as one massive, monolithic parquet file, rather than as several small parquet files. It should shard large datasets automatically.
### Motivation
This default behavior makes me very sad because a program I ran for 6 hours saved its results using `to_parquet`, putting the entire billion+ row dataset into a 171 GB *single shard parquet file* which pyarrow, apache spark, etc. all cannot work with without completely exhausting the memory of my system. I was previously able to work with larger-than-memory parquet files, but not this one. I *assume* the reason why this is happening is because it is a single shard. Making sharding the default behavior puts datasets in parity with other frameworks, such as spark, which automatically shard when a large dataset is saved as parquet.
### Your contribution
I could change the logic here https://github.com/huggingface/datasets/blob/bf6f41e94d9b2f1c620cf937a2e85e5754a8b960/src/datasets/io/parquet.py#L109-L158
to use `pyarrow.dataset.write_dataset`, which seems to support sharding, or periodically open new files. We would only shard if the user passed in a path rather than file handle. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7047/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7041 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7041/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7041/comments | https://api.github.com/repos/huggingface/datasets/issues/7041/events | https://github.com/huggingface/datasets/issues/7041 | 2,404,576,038 | I_kwDODunzps6PUusm | 7,041 | `sort` after `filter` unreasonably slow | {
"avatar_url": "https://avatars.githubusercontent.com/u/56711045?v=4",
"events_url": "https://api.github.com/users/Tobin-rgb/events{/privacy}",
"followers_url": "https://api.github.com/users/Tobin-rgb/followers",
"following_url": "https://api.github.com/users/Tobin-rgb/following{/other_user}",
"gists_url": "https://api.github.com/users/Tobin-rgb/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tobin-rgb",
"id": 56711045,
"login": "Tobin-rgb",
"node_id": "MDQ6VXNlcjU2NzExMDQ1",
"organizations_url": "https://api.github.com/users/Tobin-rgb/orgs",
"received_events_url": "https://api.github.com/users/Tobin-rgb/received_events",
"repos_url": "https://api.github.com/users/Tobin-rgb/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tobin-rgb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tobin-rgb/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tobin-rgb",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"`filter` add an indices mapping on top of the dataset, so `sort` has to gather all the rows that are kept to form a new Arrow table and sort the table. Gathering all the rows can take some time, but is a necessary step. You can try calling `ds = ds.flatten_indices()` before sorting to remove the indices mapping."
] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
as the tittle says ...
### Steps to reproduce the bug
`sort` seems to be normal.
```python
from datasets import Dataset
import random
nums = [{"k":random.choice(range(0,1000))} for _ in range(100000)]
ds = Dataset.from_list(nums)
print("start sort")
ds = ds.sort("k")
print("finish sort")
```
but `sort` after `filter` is extremely slow.
```python
from datasets import Dataset
import random
nums = [{"k":random.choice(range(0,1000))} for _ in range(100000)]
ds = Dataset.from_list(nums)
ds = ds.filter(lambda x:x > 100, input_columns="k")
print("start sort")
ds = ds.sort("k")
print("finish sort")
```
### Expected behavior
Is this a bug, or is it a misuse of the `sort` function?
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-3.10.0-1127.19.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.13
- `huggingface_hub` version: 0.23.4
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2023.10.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7041/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7041/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7040 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7040/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7040/comments | https://api.github.com/repos/huggingface/datasets/issues/7040/events | https://github.com/huggingface/datasets/issues/7040 | 2,402,918,335 | I_kwDODunzps6POZ-_ | 7,040 | load `streaming=True` dataset with downloaded cache | {
"avatar_url": "https://avatars.githubusercontent.com/u/39429965?v=4",
"events_url": "https://api.github.com/users/wanghaoyucn/events{/privacy}",
"followers_url": "https://api.github.com/users/wanghaoyucn/followers",
"following_url": "https://api.github.com/users/wanghaoyucn/following{/other_user}",
"gists_url": "https://api.github.com/users/wanghaoyucn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wanghaoyucn",
"id": 39429965,
"login": "wanghaoyucn",
"node_id": "MDQ6VXNlcjM5NDI5OTY1",
"organizations_url": "https://api.github.com/users/wanghaoyucn/orgs",
"received_events_url": "https://api.github.com/users/wanghaoyucn/received_events",
"repos_url": "https://api.github.com/users/wanghaoyucn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wanghaoyucn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wanghaoyucn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wanghaoyucn",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"When you pass `streaming=True`, the cache is ignored. The remote data URL is used instead and the data is streamed from the remote server.",
"Thanks for your reply! So is there any solution to get my expected behavior besides clone the whole repo ? Or could I adjust my script to load the downloaded arrow files and generate the dataset streamingly?"
] | 1970-01-01T00:00:00.000001 | 1,720 | null | NONE | null | ### Describe the bug
We build a dataset which contains several hdf5 files and write a script using `h5py` to generate the dataset. The hdf5 files are large and the processed dataset cache takes more disk space. So we hope to try streaming iterable dataset. Unfortunately, `h5py` can't convert a remote URL into a hdf5 file descriptor. So we use `fsspec` as an interface like below:
```python
def _generate_examples(self, filepath, split):
for file in filepath:
with fsspec.open(file, "rb") as fs:
with h5py.File(fs, "r") as fp:
# for event_id in sorted(list(fp.keys())):
event_ids = list(fp.keys())
......
```
### Steps to reproduce the bug
The `fsspec` works, but it takes 10+ min to print the first 10 examples, which is even longer than the downloading time. I'm not sure if it just caches the whole hdf5 file and generates the examples.
### Expected behavior
So does the following make sense so far?
1. download the files
```python
dataset = datasets.load('path/to/myscripts', split="train", name="event", trust_remote_code=True)
```
2. load the iterable dataset faster (using the raw file cache at path `.cache/huggingface/datasets/downloads`)
```python
dataset = datasets.load('path/to/myscripts', split="train", name="event", trust_remote_code=True, streaming=true)
```
I made some tests, but the code above can't get the expected result. I'm not sure if this is supported. I also find the issue #6327 . It seemed similar to mine, but I couldn't find a solution.
### Environment info
- `datasets` = 2.18.0
- `h5py` = 3.10.0
- `fsspec` = 2023.10.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7040/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7040/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7037 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7037/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7037/comments | https://api.github.com/repos/huggingface/datasets/issues/7037/events | https://github.com/huggingface/datasets/issues/7037 | 2,400,192,419 | I_kwDODunzps6PEAej | 7,037 | A bug of Dataset.to_json() function | {
"avatar_url": "https://avatars.githubusercontent.com/u/26499566?v=4",
"events_url": "https://api.github.com/users/LinglingGreat/events{/privacy}",
"followers_url": "https://api.github.com/users/LinglingGreat/followers",
"following_url": "https://api.github.com/users/LinglingGreat/following{/other_user}",
"gists_url": "https://api.github.com/users/LinglingGreat/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LinglingGreat",
"id": 26499566,
"login": "LinglingGreat",
"node_id": "MDQ6VXNlcjI2NDk5NTY2",
"organizations_url": "https://api.github.com/users/LinglingGreat/orgs",
"received_events_url": "https://api.github.com/users/LinglingGreat/received_events",
"repos_url": "https://api.github.com/users/LinglingGreat/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LinglingGreat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LinglingGreat/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LinglingGreat",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Thanks for reporting, @LinglingGreat.\r\n\r\nI confirm this is a bug.",
"@albertvillanova I would like to take a shot at this if you aren't working on it currently. Let me know!"
] | 1970-01-01T00:00:00.000001 | 1,727 | null | NONE | null | ### Describe the bug
When using the Dataset.to_json() function, an unexpected error occurs if the parameter is set to lines=False. The stored data should be in the form of a list, but it actually turns into multiple lists, which causes an error when reading the data again.
The reason is that to_json() writes to the file in several segments based on the batch size. This is not a problem when lines=True, but it is incorrect when lines=False, because writing in several times will produce multiple lists(when len(dataset) > batch_size).
### Steps to reproduce the bug
try this code:
```python
from datasets import load_dataset
import json
train_dataset = load_dataset("Anthropic/hh-rlhf", data_dir="harmless-base")["train"]
output_path = "./harmless-base_hftojs.json"
print(len(train_dataset))
train_dataset.to_json(output_path, lines=False, force_ascii=False, indent=2)
with open(output_path, encoding="utf-8") as f:
data = json.loads(f.read())
```
it raise error: json.decoder.JSONDecodeError: Extra data: line 4003 column 1 (char 1373709)
Extra square brackets have appeared here:
<img width="265" alt="image" src="https://github.com/huggingface/datasets/assets/26499566/81492332-386d-42e8-88d1-b6d4ae3682cc">
### Expected behavior
The code runs normally.
### Environment info
datasets=2.20.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7037/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7037/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7035 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7035/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7035/comments | https://api.github.com/repos/huggingface/datasets/issues/7035/events | https://github.com/huggingface/datasets/issues/7035 | 2,400,021,225 | I_kwDODunzps6PDWrp | 7,035 | Docs are not generated when a parameter defaults to a NamedSplit value | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | MEMBER | null | While generating the docs, we get an error when some parameter defaults to a `NamedSplit` value, like:
```python
def call_function(split=Split.TRAIN):
...
```
The error is: ValueError: Equality not supported between split train and <class 'inspect._empty'>
See: https://github.com/huggingface/datasets/actions/runs/9869660902/job/27254359863?pr=7015
```
Building the MDX files: 97%|█████████▋| 58/60 [00:00<00:00, 91.94it/s]
Traceback (most recent call last):
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/build_doc.py", line 197, in build_mdx_files
content, new_anchors, source_files, errors = resolve_autodoc(
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/build_doc.py", line 123, in resolve_autodoc
doc = autodoc(
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/autodoc.py", line 499, in autodoc
method_doc, check = document_object(
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/autodoc.py", line 395, in document_object
signature = format_signature(obj)
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/autodoc.py", line 126, in format_signature
if param.default != inspect._empty:
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/datasets/splits.py", line 136, in __ne__
return not self.__eq__(other)
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/datasets/splits.py", line 379, in __eq__
raise ValueError(f"Equality not supported between split {self} and {other}")
ValueError: Equality not supported between split train and <class 'inspect._empty'>
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/runner/work/datasets/datasets/.venv/bin/doc-builder", line 8, in <module>
sys.exit(main())
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/commands/doc_builder_cli.py", line 47, in main
args.func(args)
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/commands/build.py", line 102, in build_command
build_doc(
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/build_doc.py", line 367, in build_doc
anchors_mapping, source_files_mapping = build_mdx_files(
File "/home/runner/work/datasets/datasets/.venv/lib/python3.10/site-packages/doc_builder/build_doc.py", line 230, in build_mdx_files
raise type(e)(f"There was an error when converting {file} to the MDX format.\n" + e.args[0]) from e
ValueError: There was an error when converting ../datasets/docs/source/package_reference/main_classes.mdx to the MDX format.
Equality not supported between split train and <class 'inspect._empty'>
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7035/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7035/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7033 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7033/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7033/comments | https://api.github.com/repos/huggingface/datasets/issues/7033/events | https://github.com/huggingface/datasets/issues/7033 | 2,397,419,768 | I_kwDODunzps6O5bj4 | 7,033 | `from_generator` does not allow to specify the split name | {
"avatar_url": "https://avatars.githubusercontent.com/u/227357?v=4",
"events_url": "https://api.github.com/users/pminervini/events{/privacy}",
"followers_url": "https://api.github.com/users/pminervini/followers",
"following_url": "https://api.github.com/users/pminervini/following{/other_user}",
"gists_url": "https://api.github.com/users/pminervini/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pminervini",
"id": 227357,
"login": "pminervini",
"node_id": "MDQ6VXNlcjIyNzM1Nw==",
"organizations_url": "https://api.github.com/users/pminervini/orgs",
"received_events_url": "https://api.github.com/users/pminervini/received_events",
"repos_url": "https://api.github.com/users/pminervini/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pminervini/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pminervini/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pminervini",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Thanks for reporting, @pminervini.\r\n\r\nI agree we should give the option to define the split name.\r\n\r\nIndeed, there is a PR that addresses precisely this issue:\r\n- #7015\r\n\r\nI am reviewing it.",
"Booom! thank you guys :)"
] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | CONTRIBUTOR | null | ### Describe the bug
I'm building train, dev, and test using `from_generator`; however, in all three cases, the logger prints `Generating train split:`
It's not possible to change the split name since it seems to be hardcoded: https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/generator/generator.py
### Steps to reproduce the bug
```
In [1]: from datasets import Dataset
In [2]: def gen():
...: yield {"pokemon": "bulbasaur", "type": "grass"}
...:
In [3]: ds = Dataset.from_generator(gen)
Generating train split: 1 examples [00:00, 133.89 examples/s]
```
### Expected behavior
It should be possible to specify any split name
### Environment info
- `datasets` version: 2.19.2
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.5
- `huggingface_hub` version: 0.23.3
- PyArrow version: 15.0.0
- Pandas version: 2.0.3
- `fsspec` version: 2023.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7033/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7033/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7031/comments | https://api.github.com/repos/huggingface/datasets/issues/7031/events | https://github.com/huggingface/datasets/issues/7031 | 2,395,401,692 | I_kwDODunzps6Oxu3c | 7,031 | CI quality is broken: use ruff check instead | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,720 | 1970-01-01T00:00:00.000001 | MEMBER | null | CI quality is broken: https://github.com/huggingface/datasets/actions/runs/9838873879/job/27159697027
```
error: `ruff <path>` has been removed. Use `ruff check <path>` instead.
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7031/timeline | null | not_planned | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7030 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7030/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7030/comments | https://api.github.com/repos/huggingface/datasets/issues/7030/events | https://github.com/huggingface/datasets/issues/7030 | 2,393,411,631 | I_kwDODunzps6OqJAv | 7,030 | Add option to disable progress bar when reading a dataset ("Loading dataset from disk") | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"You can disable progress bars for all of `datasets` with `disable_progress_bars`. [Link](https://huggingface.co/docs/datasets/en/package_reference/utilities#datasets.enable_progress_bars)\r\n\r\nSo you could do something like:\r\n\r\n```python\r\nfrom datasets import load_from_disk, enable_progress_bars, disable_progress_bars\r\n\r\ndisable_progress_bars()\r\n# Your code\r\nload_from_disk(....)\r\n\r\nenable_progress_bars()\r\n```\r\n",
"Thank you! Closing the issue."
] | 1970-01-01T00:00:00.000001 | 1,720 | 1970-01-01T00:00:00.000001 | NONE | null | ### Feature request
Add an option in load_from_disk to disable the progress bar even if the number of files is larger than 16.
### Motivation
I am reading a lot of datasets that it creates lots of logs.
<img width="1432" alt="image" src="https://github.com/huggingface/datasets/assets/57996478/8d4bbf03-6b89-44b6-937c-932f01b4eb2a">
### Your contribution
Seems like an easy fix to make. I can create a PR if necessary. | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7030/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7030/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7029 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7029/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7029/comments | https://api.github.com/repos/huggingface/datasets/issues/7029/events | https://github.com/huggingface/datasets/issues/7029 | 2,391,366,696 | I_kwDODunzps6OiVwo | 7,029 | load_dataset on AWS lambda throws OSError(30, 'Read-only file system') error | {
"avatar_url": "https://avatars.githubusercontent.com/u/171606538?v=4",
"events_url": "https://api.github.com/users/sugam-nexusflow/events{/privacy}",
"followers_url": "https://api.github.com/users/sugam-nexusflow/followers",
"following_url": "https://api.github.com/users/sugam-nexusflow/following{/other_user}",
"gists_url": "https://api.github.com/users/sugam-nexusflow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sugam-nexusflow",
"id": 171606538,
"login": "sugam-nexusflow",
"node_id": "U_kgDOCjqCCg",
"organizations_url": "https://api.github.com/users/sugam-nexusflow/orgs",
"received_events_url": "https://api.github.com/users/sugam-nexusflow/received_events",
"repos_url": "https://api.github.com/users/sugam-nexusflow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sugam-nexusflow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sugam-nexusflow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sugam-nexusflow",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"hi ! can you share the full stack trace ? this should help locate what files is not written in the cache_dir"
] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
I'm using AWS lambda to run a python application. I run the `load_dataset` function with cache_dir="/tmp" and is still throws the OSError(30, 'Read-only file system') error. Is even updated all the HF envs to point to /tmp dir but the issue still persists. I can confirm that the I can write to /tmp directory.
### Steps to reproduce the bug
```python
d = load_dataset(
path=hugging_face_link,
split=split,
token=token,
cache_dir="/tmp/hugging_face_cache",
)
```
### Expected behavior
Everything written to the file system as part of the load_datasets function should be in the /tmp directory.
### Environment info
datasets version: 2.16.1
Platform: Linux-5.10.216-225.855.amzn2.x86_64-x86_64-with-glibc2.26
Python version: 3.11.9
huggingface_hub version: 0.19.4
PyArrow version: 16.1.0
Pandas version: 2.2.2
fsspec version: 2023.10.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7029/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7029/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7024 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7024/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7024/comments | https://api.github.com/repos/huggingface/datasets/issues/7024/events | https://github.com/huggingface/datasets/issues/7024 | 2,390,141,626 | I_kwDODunzps6Odqq6 | 7,024 | Streaming dataset not returning data | {
"avatar_url": "https://avatars.githubusercontent.com/u/91670254?v=4",
"events_url": "https://api.github.com/users/johnwee1/events{/privacy}",
"followers_url": "https://api.github.com/users/johnwee1/followers",
"following_url": "https://api.github.com/users/johnwee1/following{/other_user}",
"gists_url": "https://api.github.com/users/johnwee1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/johnwee1",
"id": 91670254,
"login": "johnwee1",
"node_id": "U_kgDOBXbG7g",
"organizations_url": "https://api.github.com/users/johnwee1/orgs",
"received_events_url": "https://api.github.com/users/johnwee1/received_events",
"repos_url": "https://api.github.com/users/johnwee1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/johnwee1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/johnwee1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/johnwee1",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,720 | null | NONE | null | ### Describe the bug
I'm deciding to post here because I'm still not sure what the issue is, or if I am using IterableDatasets wrongly.
I'm following the guide on here https://huggingface.co/learn/cookbook/en/fine_tuning_code_llm_on_single_gpu pretty much to a tee and have verified that it works when I'm fine-tuning on the provided dataset.
However, I'm doing some data preprocessing steps (filtering out entries), when I try to swap out the dataset for mine, it fails to train. However, I eventually fixed this by simply setting `stream=False` in `load_dataset`.
Coud this be some sort of network / firewall issue I'm facing?
### Steps to reproduce the bug
I made a post with greater description about how I reproduced this problem before I found my workaround: https://discuss.huggingface.co/t/problem-with-custom-iterator-of-streaming-dataset-not-returning-anything/94551
Here is the problematic dataset snippet, which works when streaming=False (and with buffer keyword removed from shuffle)
```
commitpackft = load_dataset(
"chargoddard/commitpack-ft-instruct", split="train", streaming=True
).filter(lambda example: example["language"] == "Python")
def form_template(example):
"""Forms a template for each example following the alpaca format for CommitPack"""
example["content"] = (
"### Human: " + example["instruction"] + " " + example["input"] + " ### Assistant: " + example["output"]
)
return example
dataset = commitpackft.map(
form_template,
remove_columns=["id", "language", "license", "instruction", "input", "output"],
).shuffle(
seed=42, buffer_size=10000
) # remove everything since its all inside "content" now
validation_data = dataset.take(4000)
train_data = dataset.skip(4000)
```
The annoying part about this is that it only fails during training and I don't know when it will fail, except that it always fails during evaluation.
### Expected behavior
The expected behavior is that I should be able to get something from the iterator when called instead of getting nothing / stuck in a loop somewhere.
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-5.4.0-121-generic-x86_64-with-glibc2.31
- Python version: 3.11.7
- `huggingface_hub` version: 0.23.4
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0
| null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7024/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7024/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7022 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7022/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7022/comments | https://api.github.com/repos/huggingface/datasets/issues/7022/events | https://github.com/huggingface/datasets/issues/7022 | 2,388,064,650 | I_kwDODunzps6OVvmK | 7,022 | There is dead code after we require pyarrow >= 15.0.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | There are code lines specific for pyarrow versions < 15.0.0.
However, we require pyarrow >= 15.0.0 since the merge of PR:
- #6892
Those code lines are now dead code and should be removed. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7022/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7022/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7020/comments | https://api.github.com/repos/huggingface/datasets/issues/7020/events | https://github.com/huggingface/datasets/issues/7020 | 2,387,940,990 | I_kwDODunzps6OVRZ- | 7,020 | Casting list array to fixed size list raises error | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | When trying to cast a list array to fixed size list, an AttributeError is raised:
> AttributeError: 'pyarrow.lib.FixedSizeListType' object has no attribute 'length'
Steps to reproduce the bug:
```python
import pyarrow as pa
from datasets.table import array_cast
arr = pa.array([[0, 1]])
array_cast(arr, pa.list_(pa.int64(), 2))
```
Stack trace:
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-12-6cb90a1d8216> in <module>
3
4 arr = pa.array([[0, 1]])
----> 5 array_cast(arr, pa.list_(pa.int64(), 2))
~/huggingface/datasets/src/datasets/table.py in wrapper(array, *args, **kwargs)
1802 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
1803 else:
-> 1804 return func(array, *args, **kwargs)
1805
1806 return wrapper
~/huggingface/datasets/src/datasets/table.py in array_cast(array, pa_type, allow_primitive_to_str, allow_decimal_to_str)
1920 else:
1921 array_values = array.values[
-> 1922 array.offset * pa_type.length : (array.offset + len(array)) * pa_type.length
1923 ]
1924 return pa.FixedSizeListArray.from_arrays(_c(array_values, pa_type.value_type), pa_type.list_size)
AttributeError: 'pyarrow.lib.FixedSizeListType' object has no attribute 'length'
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7020/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7018 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7018/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7018/comments | https://api.github.com/repos/huggingface/datasets/issues/7018/events | https://github.com/huggingface/datasets/issues/7018 | 2,383,700,286 | I_kwDODunzps6OFGE- | 7,018 | `load_dataset` fails to load dataset saved by `save_to_disk` | {
"avatar_url": "https://avatars.githubusercontent.com/u/2307997?v=4",
"events_url": "https://api.github.com/users/sliedes/events{/privacy}",
"followers_url": "https://api.github.com/users/sliedes/followers",
"following_url": "https://api.github.com/users/sliedes/following{/other_user}",
"gists_url": "https://api.github.com/users/sliedes/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sliedes",
"id": 2307997,
"login": "sliedes",
"node_id": "MDQ6VXNlcjIzMDc5OTc=",
"organizations_url": "https://api.github.com/users/sliedes/orgs",
"received_events_url": "https://api.github.com/users/sliedes/received_events",
"repos_url": "https://api.github.com/users/sliedes/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sliedes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sliedes/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sliedes",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"In my case the error was:\r\n```\r\nValueError: You are trying to load a dataset that was saved using `save_to_disk`. Please use `load_from_disk` instead.\r\n```\r\nDid you try `load_from_disk`?",
"More generally, any reason there is no API consistency between save_to_disk and push_to_hub ? \r\n\r\nWould be nice to be able to save_to_disk and then upload manually to the hub and load_dataset (which works in some situations but not all)..."
] | 1970-01-01T00:00:00.000001 | 1,722 | null | NONE | null | ### Describe the bug
This code fails to load the dataset it just saved:
```python
from datasets import load_dataset
from transformers import AutoTokenizer
MODEL = "google-bert/bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
dataset = load_dataset("yelp_review_full")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
tokenized_datasets.save_to_disk("dataset")
tokenized_datasets = load_dataset("dataset/") # raises
```
It raises `ValueError: Couldn't infer the same data file format for all splits. Got {NamedSplit('train'): ('arrow', {}), NamedSplit('test'): ('json', {})}`.
I believe this bug is caused by the [logic that tries to infer dataset format](https://github.com/huggingface/datasets/blob/9af8dd3de7626183a9a9ec8973cebc672d690400/src/datasets/load.py#L556). It counts the most common file extension. However, a small dataset can fit in a single `.arrow` file and have two JSON metadata files, causing the format to be inferred as JSON:
```shell
$ ls -l dataset/test
-rw-r--r-- 1 sliedes sliedes 191498784 Jul 1 13:55 data-00000-of-00001.arrow
-rw-r--r-- 1 sliedes sliedes 1730 Jul 1 13:55 dataset_info.json
-rw-r--r-- 1 sliedes sliedes 249 Jul 1 13:55 state.json
```
### Steps to reproduce the bug
Execute the code above.
### Expected behavior
The dataset is loaded successfully.
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-6.9.3-arch1-1-x86_64-with-glibc2.39
- Python version: 3.12.4
- `huggingface_hub` version: 0.23.4
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0
| null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7018/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7018/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7016 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7016/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7016/comments | https://api.github.com/repos/huggingface/datasets/issues/7016/events | https://github.com/huggingface/datasets/issues/7016 | 2,383,262,608 | I_kwDODunzps6ODbOQ | 7,016 | `drop_duplicates` method | {
"avatar_url": "https://avatars.githubusercontent.com/u/26205298?v=4",
"events_url": "https://api.github.com/users/MohamedAliRashad/events{/privacy}",
"followers_url": "https://api.github.com/users/MohamedAliRashad/followers",
"following_url": "https://api.github.com/users/MohamedAliRashad/following{/other_user}",
"gists_url": "https://api.github.com/users/MohamedAliRashad/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MohamedAliRashad",
"id": 26205298,
"login": "MohamedAliRashad",
"node_id": "MDQ6VXNlcjI2MjA1Mjk4",
"organizations_url": "https://api.github.com/users/MohamedAliRashad/orgs",
"received_events_url": "https://api.github.com/users/MohamedAliRashad/received_events",
"repos_url": "https://api.github.com/users/MohamedAliRashad/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MohamedAliRashad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MohamedAliRashad/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MohamedAliRashad",
"user_view_type": "public"
} | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"There is an open issue #2514 about this which also proposes solutions."
] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Feature request
`drop_duplicates` method for huggingface datasets (similiar in simplicity to the `pandas` one)
### Motivation
Ease of use
### Your contribution
I don't think i am good enough to help | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7016/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7016/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7013 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7013/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7013/comments | https://api.github.com/repos/huggingface/datasets/issues/7013/events | https://github.com/huggingface/datasets/issues/7013 | 2,382,976,738 | I_kwDODunzps6OCVbi | 7,013 | CI is broken for faiss tests on Windows: node down: Not properly terminated | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | Faiss tests on Windows make the CI run indefinitely until maximum execution time (360 minutes) is reached.
See: https://github.com/huggingface/datasets/actions/runs/9712659783
```
test (integration, windows-latest, deps-minimum)
The job running on runner GitHub Actions 60 has exceeded the maximum execution time of 360 minutes.
test (integration, windows-latest, deps-latest)
The job running on runner GitHub Actions 238 has exceeded the maximum execution time of 360 minutes.
```
```
____________________________ tests/test_search.py _____________________________
[gw1] win32 -- Python 3.8.10 C:\hostedtoolcache\windows\Python\3.8.10\x64\python.exe
worker 'gw1' crashed while running 'tests/test_search.py::IndexableDatasetTest::test_add_faiss_index'
____________________________ tests/test_search.py _____________________________
[gw2] win32 -- Python 3.8.10 C:\hostedtoolcache\windows\Python\3.8.10\x64\python.exe
worker 'gw2' crashed while running 'tests/test_search.py::IndexableDatasetTest::test_add_faiss_index'
```
```
tests/test_search.py::IndexableDatasetTest::test_add_faiss_index
[gw0] node down: Not properly terminated
[gw0] FAILED tests/test_search.py::IndexableDatasetTest::test_add_faiss_index
replacing crashed worker gw0
tests/test_search.py::IndexableDatasetTest::test_add_faiss_index
[gw1] node down: Not properly terminated
[gw1] FAILED tests/test_search.py::IndexableDatasetTest::test_add_faiss_index
replacing crashed worker gw1
tests/test_search.py::IndexableDatasetTest::test_add_faiss_index
[gw2] node down: Not properly terminated
[gw2] FAILED tests/test_search.py::IndexableDatasetTest::test_add_faiss_index
replacing crashed worker gw2
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7013/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7013/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7010 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7010/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7010/comments | https://api.github.com/repos/huggingface/datasets/issues/7010/events | https://github.com/huggingface/datasets/issues/7010 | 2,379,777,480 | I_kwDODunzps6N2IXI | 7,010 | Re-enable raising error from huggingface-hub FutureWarning in CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | Re-enable raising error from huggingface-hub FutureWarning in CI, which was disabled by PR:
- #6876
Note that this can only be done once transformers releases the fix:
- https://github.com/huggingface/transformers/pull/31007 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7010/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7010/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7008 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7008/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7008/comments | https://api.github.com/repos/huggingface/datasets/issues/7008/events | https://github.com/huggingface/datasets/issues/7008 | 2,379,591,141 | I_kwDODunzps6N1a3l | 7,008 | Support ruff 0.5.0 in CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | Support ruff 0.5.0 in CI.
Also revert:
- #7007 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7008/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7008/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7006 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7006/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7006/comments | https://api.github.com/repos/huggingface/datasets/issues/7006/events | https://github.com/huggingface/datasets/issues/7006 | 2,379,581,543 | I_kwDODunzps6N1Yhn | 7,006 | CI is broken after ruff-0.5.0: E721 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | After ruff-0.5.0 release (https://github.com/astral-sh/ruff/releases/tag/0.5.0), our CI is broken due to E721 rule.
See: https://github.com/huggingface/datasets/actions/runs/9707641618/job/26793170961?pr=6983
> src/datasets/features/features.py:844:12: E721 Use `is` and `is not` for type comparisons, or `isinstance()` for isinstance checks | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7006/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7006/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7005 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7005/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7005/comments | https://api.github.com/repos/huggingface/datasets/issues/7005/events | https://github.com/huggingface/datasets/issues/7005 | 2,378,424,349 | I_kwDODunzps6Nw-Ad | 7,005 | EmptyDatasetError: The directory at /metadata.jsonl doesn't contain any data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/117731544?v=4",
"events_url": "https://api.github.com/users/Aki1991/events{/privacy}",
"followers_url": "https://api.github.com/users/Aki1991/followers",
"following_url": "https://api.github.com/users/Aki1991/following{/other_user}",
"gists_url": "https://api.github.com/users/Aki1991/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Aki1991",
"id": 117731544,
"login": "Aki1991",
"node_id": "U_kgDOBwRw2A",
"organizations_url": "https://api.github.com/users/Aki1991/orgs",
"received_events_url": "https://api.github.com/users/Aki1991/received_events",
"repos_url": "https://api.github.com/users/Aki1991/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Aki1991/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aki1991/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Aki1991",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Hi ! `data_dir=` is for directories, can you try using `data_files=` instead ?",
"If you are trying to load your image dataset from a local folder, you should replace \"data_dir=path/to/jsonl/metadata.jsonl\" with the real folder path in your computer.\r\n\r\nhttps://huggingface.co/docs/datasets/en/image_load#imagefolder",
"Ah yes. My bad. I was giving file name. I should have given the folder directory as the path. That solved my issue. Thank you @albertvillanova and @lhoestq. "
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
while trying to load custom dataset from jsonl file, I get the error: "metadata.jsonl doesn't contain any data files"
### Steps to reproduce the bug
This is my [metadata_v2.jsonl](https://github.com/user-attachments/files/16016011/metadata_v2.json) file. I have this file in the folder with all images mentioned in that json(l) file.
Through below mentioned command I am trying to load_dataset so that I can upload it as mentioned here on the [official website](https://huggingface.co/docs/datasets/en/image_dataset#upload-dataset-to-the-hub).
````
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_dir="path/to/jsonl/metadata.jsonl")
````
error:
````
EmptyDatasetError Traceback (most recent call last)
Cell In[18], line 3
1 from datasets import load_dataset
----> 3 dataset = load_dataset("imagefolder",
4 data_dir="path/to/jsonl/file/metadata.jsonl")
5 dataset[0]["objects"]
File ~/anaconda3/envs/lvis/lib/python3.11/site-packages/datasets/load.py:2594, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, token, use_auth_token, task, streaming, num_proc, storage_options, trust_remote_code, **config_kwargs)
2589 verification_mode = VerificationMode(
2590 (verification_mode or VerificationMode.BASIC_CHECKS) if not save_infos else VerificationMode.ALL_CHECKS
2591 )
2593 # Create a dataset builder
-> 2594 builder_instance = load_dataset_builder(
2595 path=path,
2596 name=name,
2597 data_dir=data_dir,
2598 data_files=data_files,
2599 cache_dir=cache_dir,
2600 features=features,
2601 download_config=download_config,
2602 download_mode=download_mode,
2603 revision=revision,
2604 token=token,
2605 storage_options=storage_options,
2606 trust_remote_code=trust_remote_code,
2607 _require_default_config_name=name is None,
2608 **config_kwargs,
2609 )
2611 # Return iterable dataset in case of streaming
2612 if streaming:
File ~/anaconda3/envs/lvis/lib/python3.11/site-packages/datasets/load.py:2266, in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, token, use_auth_token, storage_options, trust_remote_code, _require_default_config_name, **config_kwargs)
2264 download_config = download_config.copy() if download_config else DownloadConfig()
2265 download_config.storage_options.update(storage_options)
-> 2266 dataset_module = dataset_module_factory(
2267 path,
2268 revision=revision,
2269 download_config=download_config,
2270 download_mode=download_mode,
2271 data_dir=data_dir,
2272 data_files=data_files,
2273 cache_dir=cache_dir,
2274 trust_remote_code=trust_remote_code,
2275 _require_default_config_name=_require_default_config_name,
2276 _require_custom_configs=bool(config_kwargs),
2277 )
2278 # Get dataset builder class from the processing script
2279 builder_kwargs = dataset_module.builder_kwargs
File ~/anaconda3/envs/lvis/lib/python3.11/site-packages/datasets/load.py:1805, in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, cache_dir, trust_remote_code, _require_default_config_name, _require_custom_configs, **download_kwargs)
1782 # We have several ways to get a dataset builder:
1783 #
1784 # - if path is the name of a packaged dataset module
(...)
1796
1797 # Try packaged
1798 if path in _PACKAGED_DATASETS_MODULES:
1799 return PackagedDatasetModuleFactory(
1800 path,
1801 data_dir=data_dir,
1802 data_files=data_files,
1803 download_config=download_config,
1804 download_mode=download_mode,
-> 1805 ).get_module()
1806 # Try locally
1807 elif path.endswith(filename):
File ~/anaconda3/envs/lvis/lib/python3.11/site-packages/datasets/load.py:1140, in PackagedDatasetModuleFactory.get_module(self)
1135 def get_module(self) -> DatasetModule:
1136 base_path = Path(self.data_dir or "").expanduser().resolve().as_posix()
1137 patterns = (
1138 sanitize_patterns(self.data_files)
1139 if self.data_files is not None
-> 1140 else get_data_patterns(base_path, download_config=self.download_config)
1141 )
1142 data_files = DataFilesDict.from_patterns(
1143 patterns,
1144 download_config=self.download_config,
1145 base_path=base_path,
1146 )
1147 supports_metadata = self.name in _MODULE_SUPPORTS_METADATA
File ~/anaconda3/envs/lvis/lib/python3.11/site-packages/datasets/data_files.py:503, in get_data_patterns(base_path, download_config)
501 return _get_data_files_patterns(resolver)
502 except FileNotFoundError:
--> 503 raise EmptyDatasetError(f"The directory at {base_path} doesn't contain any data files") from None
EmptyDatasetError: The directory at path/to/jsonl/file/metadata.jsonl doesn't contain any data files`
```
### Expected behavior
It should be able load the whole file in a format of "dataset" inside the dataset variable. But it gives error "The directory at "path/to/jsonl/metadata.jsonl" doesn't contain any data files."
### Environment info
I am using conda environment. | {
"avatar_url": "https://avatars.githubusercontent.com/u/117731544?v=4",
"events_url": "https://api.github.com/users/Aki1991/events{/privacy}",
"followers_url": "https://api.github.com/users/Aki1991/followers",
"following_url": "https://api.github.com/users/Aki1991/following{/other_user}",
"gists_url": "https://api.github.com/users/Aki1991/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Aki1991",
"id": 117731544,
"login": "Aki1991",
"node_id": "U_kgDOBwRw2A",
"organizations_url": "https://api.github.com/users/Aki1991/orgs",
"received_events_url": "https://api.github.com/users/Aki1991/received_events",
"repos_url": "https://api.github.com/users/Aki1991/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Aki1991/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aki1991/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Aki1991",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7005/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7005/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7001 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7001/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7001/comments | https://api.github.com/repos/huggingface/datasets/issues/7001/events | https://github.com/huggingface/datasets/issues/7001 | 2,372,930,879 | I_kwDODunzps6NcA0_ | 7,001 | Datasetbuilder Local Download FileNotFoundError | {
"avatar_url": "https://avatars.githubusercontent.com/u/12601271?v=4",
"events_url": "https://api.github.com/users/purefall/events{/privacy}",
"followers_url": "https://api.github.com/users/purefall/followers",
"following_url": "https://api.github.com/users/purefall/following{/other_user}",
"gists_url": "https://api.github.com/users/purefall/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/purefall",
"id": 12601271,
"login": "purefall",
"node_id": "MDQ6VXNlcjEyNjAxMjcx",
"organizations_url": "https://api.github.com/users/purefall/orgs",
"received_events_url": "https://api.github.com/users/purefall/received_events",
"repos_url": "https://api.github.com/users/purefall/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/purefall/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/purefall/subscriptions",
"type": "User",
"url": "https://api.github.com/users/purefall",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"Ok it seems the solution is to use the directory string without the trailing \"/\" which in my case as: \r\n\r\n`parquet_dir = \"~/data/Parquet\" `\r\n\r\nStill i think this is a weird behavior... "
] | 1970-01-01T00:00:00.000001 | 1,719 | null | NONE | null | ### Describe the bug
So I was trying to download a dataset and save it as parquet and I follow the [tutorial](https://huggingface.co/docs/datasets/filesystems#download-and-prepare-a-dataset-into-a-cloud-storage) of Huggingface. However, during the excution I face a FileNotFoundError.
I debug the code and it seems there is a bug there:
So first it creates a .incomplete folder and before moving its contents the following code deletes the directory
[Code](https://github.com/huggingface/datasets/blob/98fdc9e78e6d057ca66e58a37f49d6618aab8130/src/datasets/builder.py#L984)
hence as a result I face with:
``` FileNotFoundError: [Errno 2] No such file or directory: '~/data/Parquet/.incomplete '```
### Steps to reproduce the bug
```
from datasets import load_dataset_builder
from pathlib import Path
parquet_dir = "~/data/Parquet/"
Path(parquet_dir).mkdir(parents=True, exist_ok=True)
builder = load_dataset_builder(
"rotten_tomatoes",
)
builder.download_and_prepare(parquet_dir, file_format="parquet")
```
### Expected behavior
Downloads the files and saves as parquet
### Environment info
Ubuntu,
Python 3.10
```
datasets 2.19.1
``` | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7001/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7001/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/7000 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7000/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7000/comments | https://api.github.com/repos/huggingface/datasets/issues/7000/events | https://github.com/huggingface/datasets/issues/7000 | 2,372,887,585 | I_kwDODunzps6Nb2Qh | 7,000 | IterableDataset: Unsupported ScalarType BFloat16 | {
"avatar_url": "https://avatars.githubusercontent.com/u/170015089?v=4",
"events_url": "https://api.github.com/users/stoical07/events{/privacy}",
"followers_url": "https://api.github.com/users/stoical07/followers",
"following_url": "https://api.github.com/users/stoical07/following{/other_user}",
"gists_url": "https://api.github.com/users/stoical07/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stoical07",
"id": 170015089,
"login": "stoical07",
"node_id": "U_kgDOCiI5cQ",
"organizations_url": "https://api.github.com/users/stoical07/orgs",
"received_events_url": "https://api.github.com/users/stoical07/received_events",
"repos_url": "https://api.github.com/users/stoical07/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stoical07/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stoical07/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stoical07",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"@lhoestq Thank you for merging #6607, but unfortunately the issue persists for `IterableDataset` :pensive: ",
"Hi ! I opened https://github.com/huggingface/datasets/pull/7002 to fix this bug",
"Amazing, thank you so much @lhoestq! :pray:"
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
`IterableDataset.from_generator` crashes when using BFloat16:
```
File "/usr/local/lib/python3.11/site-packages/datasets/utils/_dill.py", line 169, in _save_torchTensor
args = (obj.detach().cpu().numpy(),)
^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: Got unsupported ScalarType BFloat16
```
### Steps to reproduce the bug
```python
import torch
from datasets import IterableDataset
def demo(x):
yield {"x": x}
x = torch.tensor([1.], dtype=torch.bfloat16)
dataset = IterableDataset.from_generator(
demo,
gen_kwargs=dict(x=x),
)
example = next(iter(dataset))
print(example)
```
### Expected behavior
Code sample should print:
```python
{'x': tensor([1.], dtype=torch.bfloat16)}
```
### Environment info
```
datasets==2.20.0
torch==2.2.2
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7000/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7000/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6997/comments | https://api.github.com/repos/huggingface/datasets/issues/6997/events | https://github.com/huggingface/datasets/issues/6997 | 2,371,966,127 | I_kwDODunzps6NYVSv | 6,997 | CI is broken for tests using hf-internal-testing/librispeech_asr_dummy | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | CI is broken: https://github.com/huggingface/datasets/actions/runs/9657882317/job/26637998686?pr=6996
```
FAILED tests/test_inspect.py::test_get_dataset_config_names[hf-internal-testing/librispeech_asr_dummy-expected4] - AssertionError: assert ['clean'] == ['clean', 'other']
Right contains one more item: 'other'
Full diff:
[
'clean',
- 'other',
]
FAILED tests/test_inspect.py::test_get_dataset_default_config_name[hf-internal-testing/librispeech_asr_dummy-None] - AssertionError: assert 'clean' is None
```
Note that repository was recently converted to Parquet: https://huggingface.co/datasets/hf-internal-testing/librispeech_asr_dummy/commit/5be91486e11a2d616f4ec5db8d3fd248585ac07a | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6997/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6995 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6995/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6995/comments | https://api.github.com/repos/huggingface/datasets/issues/6995/events | https://github.com/huggingface/datasets/issues/6995 | 2,370,713,475 | I_kwDODunzps6NTjeD | 6,995 | ImportError when importing datasets.load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/124846947?v=4",
"events_url": "https://api.github.com/users/Leo-Lsc/events{/privacy}",
"followers_url": "https://api.github.com/users/Leo-Lsc/followers",
"following_url": "https://api.github.com/users/Leo-Lsc/following{/other_user}",
"gists_url": "https://api.github.com/users/Leo-Lsc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Leo-Lsc",
"id": 124846947,
"login": "Leo-Lsc",
"node_id": "U_kgDOB3EDYw",
"organizations_url": "https://api.github.com/users/Leo-Lsc/orgs",
"received_events_url": "https://api.github.com/users/Leo-Lsc/received_events",
"repos_url": "https://api.github.com/users/Leo-Lsc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Leo-Lsc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Leo-Lsc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Leo-Lsc",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"What is the version of your installed `huggingface-hub`:\r\n```python\r\nimport huggingface_hub\r\nprint(huggingface_hub.__version__)\r\n```\r\n\r\nIt seems you have a very old version of `huggingface-hub`, where `CommitInfo` was not still implemented. You need to update it:\r\n```\r\npip install -U huggingface-hub\r\n```\r\n\r\nNote that `CommitInfo` was implemented in huggingface-hub 0.10.0 and datasets requires \"huggingface-hub>=0.21.2\"",
"The version of my huggingface-hub is 0.23.4.",
"The error message says there is no CommitInfo in your installed huggingface-hub library:\r\n```\r\nImportError: cannot import name 'CommitInfo' from 'huggingface_hub' (D:\\Anaconda3\\envs\\CS224S\\Lib\\site-packages\\huggingface_hub_init_.py)\r\n```\r\n\r\nAnd this is implemented since version 0.10.0:\r\n- https://github.com/huggingface/huggingface_hub/pull/1066",
"I am getting the exact same issue when I `import datasets`. The version of my huggingface-hub is also 0.23.4. I dont see a solution in the comments. Not sure why is this issue closed?",
"I closed the issue because the problem is not related to the `datasets` library.\r\n\r\nThe problem is with your local Python environment: it seems corrupted. You could try to remove it and regenerate it again.",
"I have recreated my conda environment but still run into the same issue. Here is my environment:\r\n```\r\nconda create --name esm python=3.10\r\n conda activate esm\r\n conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia\r\n pip3 install -r requirements.txt\r\n```\r\nRequirements.txt\r\n```\r\naccelerate\r\ndatasets==2.20.0\r\npyfastx\r\ntransformers\r\nboto3\r\nhuggingface_hub==0.23.4\r\n```\r\n\r\nAnd then I get:\r\n```\r\n>>> import datasets\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/fsx/ubuntu/miniconda3/envs/esm2/lib/python3.10/site-packages/datasets/__init__.py\", line 17, in <module>\r\n from .arrow_dataset import Dataset\r\n File \"/fsx/ubuntu/miniconda3/envs/esm2/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 63, in <module>\r\n from huggingface_hub import (\r\nImportError: cannot import name 'CommitInfo' from 'huggingface_hub' (/fsx/ubuntu/miniconda3/envs/esm2/lib/python3.10/site-packages/huggingface_hub/__init__.py)\r\n>>>\r\n```\r\n\r\n",
"You can check:\r\n```\r\n>>> import huggingface_hub\r\n>>> print(huggingface_hub.__version__)\r\n```",
"This is what I see:\r\n```\r\n>>> import huggingface_hub\r\n>>> print(huggingface_hub.__version__)\r\n0.23.4\r\n```",
"Installing `chardet` makes it work for some reason"
] | 1970-01-01T00:00:00.000001 | 1,731 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
I encountered an ImportError while trying to import `load_dataset` from the `datasets` module in Hugging Face. The error message indicates a problem with importing 'CommitInfo' from 'huggingface_hub'.
### Steps to reproduce the bug
1. pip install git+https://github.com/huggingface/datasets
2. from datasets import load_dataset
### Expected behavior
ImportError Traceback (most recent call last)
Cell In[7], [line 1](vscode-notebook-cell:?execution_count=7&line=1)
----> [1](vscode-notebook-cell:?execution_count=7&line=1) from datasets import load_dataset
[3](vscode-notebook-cell:?execution_count=7&line=3) train_set = load_dataset("mispeech/speechocean762", split="train")
[4](vscode-notebook-cell:?execution_count=7&line=4) test_set = load_dataset("mispeech/speechocean762", split="test")
File d:\Anaconda3\envs\CS224S\Lib\site-packages\datasets\__init__.py:[1](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:1)7
1 # Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
[2](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:2) #
[3](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:3) # Licensed under the Apache License, Version 2.0 (the "License");
(...)
[12](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:12) # See the License for the specific language governing permissions and
[13](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:13) # limitations under the License.
[15](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:15) __version__ = "2.20.1.dev0"
---> [17](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:17) from .arrow_dataset import Dataset
[18](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:18) from .arrow_reader import ReadInstruction
[19](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/__init__.py:19) from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
File d:\Anaconda3\envs\CS224S\Lib\site-packages\datasets\arrow_dataset.py:63
[61](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:61) import pyarrow.compute as pc
[62](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:62) from fsspec.core import url_to_fs
---> [63](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:63) from huggingface_hub import (
[64](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:64) CommitInfo,
[65](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:65) CommitOperationAdd,
...
[70](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:70) )
[71](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:71) from huggingface_hub.hf_api import RepoFile
[72](file:///D:/Anaconda3/envs/CS224S/Lib/site-packages/datasets/arrow_dataset.py:72) from multiprocess import Pool
ImportError: cannot import name 'CommitInfo' from 'huggingface_hub' (d:\Anaconda3\envs\CS224S\Lib\site-packages\huggingface_hub\__init__.py)
Output is truncated. View as a [scrollable element](command:cellOutput.enableScrolling?580889ab-0f61-4f37-9214-eaa2b3807f85) or open in a [text editor](command:workbench.action.openLargeOutput?580889ab-0f61-4f37-9214-eaa2b3807f85). Adjust cell output [settings](command:workbench.action.openSettings?%5B%22%40tag%3AnotebookOutputLayout%22%5D)...
### Environment info
Leo@DESKTOP-9NHUAMI MSYS /d/Anaconda3/envs/CS224S/Lib/site-packages/huggingface_hub
$ datasets-cli env
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "D:\Anaconda3\envs\CS224S\Scripts\datasets-cli.exe\__main__.py", line 4, in <module>
File "D:\Anaconda3\envs\CS224S\Lib\site-packages\datasets\__init__.py", line 17, in <module>
from .arrow_dataset import Dataset
File "D:\Anaconda3\envs\CS224S\Lib\site-packages\datasets\arrow_dataset.py", line 63, in <module>
from huggingface_hub import (
ImportError: cannot import name 'CommitInfo' from 'huggingface_hub' (D:\Anaconda3\envs\CS224S\Lib\site-packages\huggingface_hub\__init__.py)
(CS224S) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6995/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6995/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6992 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6992/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6992/comments | https://api.github.com/repos/huggingface/datasets/issues/6992/events | https://github.com/huggingface/datasets/issues/6992 | 2,367,890,622 | I_kwDODunzps6NIyS- | 6,992 | Dataset with streaming doesn't work with proxy | {
"avatar_url": "https://avatars.githubusercontent.com/u/57779173?v=4",
"events_url": "https://api.github.com/users/YHL04/events{/privacy}",
"followers_url": "https://api.github.com/users/YHL04/followers",
"following_url": "https://api.github.com/users/YHL04/following{/other_user}",
"gists_url": "https://api.github.com/users/YHL04/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/YHL04",
"id": 57779173,
"login": "YHL04",
"node_id": "MDQ6VXNlcjU3Nzc5MTcz",
"organizations_url": "https://api.github.com/users/YHL04/orgs",
"received_events_url": "https://api.github.com/users/YHL04/received_events",
"repos_url": "https://api.github.com/users/YHL04/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/YHL04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YHL04/subscriptions",
"type": "User",
"url": "https://api.github.com/users/YHL04",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"Hi ! can you try updating `datasets` and `huggingface_hub` ?\r\n\r\n```\r\npip install -U datasets huggingface_hub\r\n```"
] | 1970-01-01T00:00:00.000001 | 1,719 | null | NONE | null | ### Describe the bug
I'm currently trying to stream data using dataset since the dataset is too big but it hangs indefinitely without loading the first batch. I use AIMOS which is a supercomputer that uses proxy to connect to the internet. I assume it has to do with the network configurations. I've already set up both HTTP_PROXY and HTTPS_PROXY. streaming = False works fine.
### Steps to reproduce the bug
use load_dataset with streaming = True in AIMOS
### Expected behavior
does not hang indefinitely and loads batches to start training run
### Environment info
_libgcc_mutex 0.1 conda_forge conda-forge
_openmp_mutex 4.5 2_gnu conda-forge
_pytorch_select 2.0 cuda_2 https://ftp.osuosl.org/pub/open-ce/1.10.0
abseil-cpp 20220623.0 h9888cd1_6 conda-forge
absl-py 1.0.0 py311h399429b_0 https://ftp.osuosl.org/pub/open-ce/1.10.0
aiofiles 23.2.1 pyhd8ed1ab_0 conda-forge
aiohttp 3.8.6 py311hf118e41_0
aiosignal 1.2.0 pyhd3eb1b0_0
archspec 0.2.3 pyhd8ed1ab_0 conda-forge
arrow-cpp 11.0.0 ha3edaa6_5_cpu conda-forge
async-timeout 4.0.2 py311h6ffa863_0
attrs 23.1.0 py311h6ffa863_0
av 10.0.0 py311he6153ed_2 https://ftp.osuosl.org/pub/open-ce/1.10.0
aws-c-auth 0.6.24 hb81f6d7_5 conda-forge
aws-c-cal 0.5.20 h3c2b4d9_6 conda-forge
aws-c-common 0.8.11 h4194056_0 conda-forge
aws-c-compression 0.2.16 ha19333d_3 conda-forge
aws-c-event-stream 0.2.18 h12a9399_6 conda-forge
aws-c-http 0.7.4 ha2cde00_2 conda-forge
aws-c-io 0.13.17 h9189062_2 conda-forge
aws-c-mqtt 0.8.6 h40d1a04_6 conda-forge
aws-c-s3 0.2.4 hbdbe4f0_3 conda-forge
aws-c-sdkutils 0.1.7 ha19333d_3 conda-forge
aws-checksums 0.1.14 ha19333d_3 conda-forge
aws-crt-cpp 0.19.7 hd018011_7 conda-forge
aws-sdk-cpp 1.10.57 hb9575ba_4 conda-forge
blas 1.0 openblas
blinker 1.8.2 pyhd8ed1ab_0 conda-forge
boltons 23.0.0 py311h6ffa863_0
boost-cpp 1.82.0 h25e6d66_2
bottleneck 1.3.5 py311h34f6284_0
brotli 1.0.9 hf118e41_7
brotli-bin 1.0.9 hf118e41_7
brotli-python 1.0.9 py311h4a02239_7
bzip2 1.0.8 h7b6447c_0
c-ares 1.19.1 hf118e41_0
ca-certificates 2024.6.2 h0f6029e_0 conda-forge
cachetools 5.3.3 pyhd8ed1ab_0 conda-forge
certifi 2024.6.2 pyhd8ed1ab_0 conda-forge
cffi 1.15.1 py311hf118e41_3
charset-normalizer 2.0.4 pyhd3eb1b0_0
click 8.1.7 unix_pyh707e725_0 conda-forge
conda 24.5.0 py311h1af927a_0 conda-forge
conda-content-trust 0.2.0 py311h6ffa863_0
conda-libmamba-solver 23.11.1 py311h6ffa863_0
conda-package-handling 2.2.0 py311h6ffa863_0
conda-package-streaming 0.9.0 py311h6ffa863_0
contourpy 1.0.5 py311h25e6d66_0
cryptography 41.0.3 py311hb0e80e7_0
cudatoolkit 11.8.0 hedcfb66_13 conda-forge
cudnn 8.9.2_11.8 h9ceb136_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
cycler 0.11.0 pyhd3eb1b0_0
datasets 2.12.0 py311h6ffa863_0
dill 0.3.6 py311h6ffa863_0
distro 1.9.0 pyhd8ed1ab_0 conda-forge
ffmpeg 4.2.2 opence_0 https://ftp.osuosl.org/pub/open-ce/1.10.0
filelock 3.9.0 py311h6ffa863_0
fmt 9.1.0 h25e6d66_0
fonttools 4.25.0 pyhd3eb1b0_0
freetype 2.12.1 hd23a775_0
frozendict 2.4.4 py311hb02d432_0 conda-forge
frozenlist 1.4.0 py311hf118e41_0
fsspec 2023.9.2 py311h6ffa863_0
gflags 2.2.2 he6710b0_0
giflib 5.2.1 hf118e41_3
glog 0.6.0 hbe088e0_0 conda-forge
gmp 6.3.0 h46f38da_0 conda-forge
gmpy2 2.1.5 py311h2758da7_1 conda-forge
google-auth 2.30.0 pyhff2d567_0 conda-forge
google-auth-oauthlib 0.5.3 pyhd8ed1ab_0 conda-forge
grpc-cpp 1.51.1 h8ba971d_1 conda-forge
grpcio 1.54.3 py311h414e0d3_0 https://ftp.osuosl.org/pub/open-ce/1.10.0
huggingface_hub 0.17.3 py311h6ffa863_0
icu 73.1 h4a02239_0
idna 3.4 py311h6ffa863_0
importlib-metadata 6.0.0 py311h6ffa863_0
jinja2 3.1.4 pyhd8ed1ab_0 conda-forge
jpeg 9e hf118e41_1
jsonpatch 1.32 pyhd3eb1b0_0
jsonpointer 2.1 pyhd3eb1b0_0
kiwisolver 1.4.4 py311h4a02239_0
krb5 1.20.1 hc019ccd_1
lame 3.100 hb283c62_1003 conda-forge
lcms2 2.12 h2045e0b_0
ld_impl_linux-ppc64le 2.38 hec883e6_1
lerc 3.0 h29c3540_0
leveldb 1.23 h24532b4_1 conda-forge
libabseil 20220623.0 cxx17_h9235812_6 conda-forge
libarchive 3.6.2 hd8ab008_2
libarrow 11.0.0 h837770b_5_cpu conda-forge
libboost 1.82.0 haf51a6a_2
libbrotlicommon 1.0.9 hf118e41_7
libbrotlidec 1.0.9 hf118e41_7
libbrotlienc 1.0.9 hf118e41_7
libcrc32c 1.1.2 h3b9df90_0 conda-forge
libcurl 8.4.0 h4d62439_0
libdeflate 1.17 hf118e41_1
libedit 3.1.20221030 hf118e41_0
libev 4.33 h140841e_1
libevent 2.1.10 h19c23f1_4 conda-forge
libexpat 2.6.2 h46f38da_0 conda-forge
libffi 3.4.4 h4a02239_0
libgcc-ng 13.2.0 h31e42bb_10 conda-forge
libgfortran-ng 11.2.0 hb3889a9_1
libgfortran5 11.2.0 h1234567_1
libgomp 13.2.0 h31e42bb_10 conda-forge
libgoogle-cloud 2.7.0 h11140b6_1 conda-forge
libgrpc 1.51.1 h4d29a31_1 conda-forge
libmamba 1.5.3 h7c6fafd_0
libmambapy 1.5.3 py311h828bf7b_0
libnghttp2 1.57.0 h44e5816_0
libnsl 2.0.1 ha17a0cc_0 conda-forge
libopenblas 0.3.23 hc5a31fb_2 https://ftp.osuosl.org/pub/open-ce/1.10.0
libopus 1.3.1 h4e0d66e_1 conda-forge
libpng 1.6.39 hf118e41_0
libprotobuf 3.21.12 h1776448_0 https://ftp.osuosl.org/pub/open-ce/1.10.0
libsolv 0.7.24 h0f529ac_0
libsqlite 3.45.3 hd4bbf49_0 conda-forge
libssh2 1.10.0 h50fa78f_2
libstdcxx-ng 13.2.0 h262982c_10 conda-forge
libthrift 0.18.0 h82f1162_0 conda-forge
libtiff 4.5.1 h4a02239_0
libutf8proc 2.8.0 hb283c62_0 conda-forge
libuuid 2.38.1 h4194056_0 conda-forge
libvpx 1.13.1 h46f38da_0 conda-forge
libwebp 1.3.2 h0f96ee2_0
libwebp-base 1.3.2 hf118e41_0
libxcrypt 4.4.36 ha17a0cc_1 conda-forge
libxml2 2.10.4 h18e3229_1
libzlib 1.2.13 h1f2b957_6 conda-forge
llvm-openmp 14.0.6 hc028133_0 https://ftp.osuosl.org/pub/open-ce/1.10.0
lmdb 0.9.31 ha17a0cc_1 conda-forge
lz4-c 1.9.4 h4a02239_0
markdown 3.4.4 pyhd8ed1ab_0 conda-forge
markupsafe 2.1.5 py311h32d8acf_0 conda-forge
matplotlib 3.8.0 py311h6ffa863_0
matplotlib-base 3.8.0 py311h52e1fcc_0
menuinst 2.1.1 py311h1af927a_0 conda-forge
mpc 1.3.1 heaf1863_0 conda-forge
mpfr 4.2.1 haad2271_1 conda-forge
mpmath 1.3.0 pyhd8ed1ab_0 conda-forge
multidict 6.0.2 py311hf118e41_0
multiprocess 0.70.14 py311h6ffa863_0
munkres 1.1.4 py_0
mypy_extensions 1.0.0 pyha770c72_0 conda-forge
nccl 2.18.3 cuda11.8_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
ncurses 6.4 h4a02239_0
nest-asyncio 1.6.0 pyhd8ed1ab_0 conda-forge
networkx 2.8.8 pyhd8ed1ab_0 conda-forge
nomkl 3.0 0 https://ftp.osuosl.org/pub/open-ce/1.10.0
numactl 2.0.16 hba61f60_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
numexpr 2.8.7 py311hc46fc55_0
numpy 1.24.3 py311h148a09e_0
numpy-base 1.24.3 py311h06b82f6_0
oauthlib 3.2.2 pyhd8ed1ab_0 conda-forge
openjpeg 2.4.0 hfe35807_0
openssl 3.3.1 h1f2b957_0 conda-forge
orc 1.8.2 h341c9a4_2 conda-forge
packaging 23.1 py311h6ffa863_0
pandas 2.1.1 py311h52e1fcc_0
pcre2 10.42 h280155c_0
pillow 10.0.1 py311he33076b_0
pip 23.3 py311h6ffa863_0
platformdirs 4.2.2 pyhd8ed1ab_0 conda-forge
pluggy 1.0.0 py311h6ffa863_1
pooch 1.8.2 pyhd8ed1ab_0 conda-forge
protobuf 4.21.12 py311ha7baec7_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
psutil 5.9.8 py311hd26027c_0 conda-forge
pyarrow 11.0.0 py311h04a18d5_1
pyasn1 0.6.0 pyhd8ed1ab_0 conda-forge
pyasn1-modules 0.4.0 pyhd8ed1ab_0 conda-forge
pybind11-abi 4 hd3eb1b0_1
pycosat 0.6.6 py311hf118e41_0
pycparser 2.21 pyhd3eb1b0_0
pyjwt 2.8.0 pyhd8ed1ab_1 conda-forge
pyopenssl 23.2.0 py311h6ffa863_0
pyparsing 3.0.9 py311h6ffa863_0
pyre-extensions 0.0.30 pyhd8ed1ab_0 conda-forge
pysocks 1.7.1 py311h6ffa863_0
python 3.11.8 h3332dee_0_cpython conda-forge
python-dateutil 2.8.2 pyhd3eb1b0_0
python-tzdata 2023.3 pyhd3eb1b0_0
python-xxhash 2.0.2 py311hf118e41_1
python_abi 3.11 4_cp311 conda-forge
pytorch 2.0.1 cuda11.8_py311_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
pytorch-base 2.0.1 cuda11.8_py311_pb4.21.12_4 https://ftp.osuosl.org/pub/open-ce/1.10.0
pytz 2023.3.post1 py311h6ffa863_0
pyu2f 0.1.5 pyhd8ed1ab_0 conda-forge
pyyaml 6.0.1 py311hf118e41_0
re2 2023.02.01 h883269e_0 conda-forge
readline 8.2 hf118e41_0
regex 2023.10.3 py311hf118e41_0
reproc 14.2.4 h29c3540_1
reproc-cpp 14.2.4 h29c3540_1
requests 2.31.0 py311h6ffa863_0
requests-oauthlib 2.0.0 pyhd8ed1ab_0 conda-forge
responses 0.13.3 pyhd3eb1b0_0
rsa 4.9 pyhd8ed1ab_0 conda-forge
ruamel.yaml 0.17.21 py311hf118e41_0
s2n 1.3.37 h5e47323_0 conda-forge
safetensors 0.4.0 py311hda16d9e_0
scipy 1.11.1 py311hd69e9bb_0 https://ftp.osuosl.org/pub/open-ce/1.10.0
sentencepiece 0.1.97 h1e74c73_py311_pb4.21.12_2 https://ftp.osuosl.org/pub/open-ce/1.10.0
setuptools 68.0.0 py311h6ffa863_0
six 1.16.0 pyhd3eb1b0_1
snappy 1.1.9 h29c3540_0
sqlite 3.41.2 hf118e41_0
sympy 1.12.1 pypyh2585a3b_103 conda-forge
tabulate 0.8.10 pyhd8ed1ab_0 conda-forge
tensorboard 2.13.0 pyhab0730d_pb4.21.12_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
tensorboard-data-server 0.7.0 pyh6f84499_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
tensorboard-plugin-wit 1.6.0 pyh9f0ad1d_0 conda-forge
tk 8.6.13 hd4bbf49_0 conda-forge
tokenizers 0.13.3 py311h3d4f45a_0
torchdata 0.6.0 py311_2 https://ftp.osuosl.org/pub/open-ce/1.10.0
torchsnapshot 0.1.0 pyhd8ed1ab_0 conda-forge
torchtext-base 0.15.2 cuda11.8_py311_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
torchtnt 0.2.4 pyhd8ed1ab_0 conda-forge
torchvision-base 0.15.2 cuda11.8_py311_1 https://ftp.osuosl.org/pub/open-ce/1.10.0
tornado 6.3.3 py311hf118e41_0
tqdm 4.65.0 py311h7837921_0
transformers 4.32.1 py311h6ffa863_0
truststore 0.8.0 py311h6ffa863_0
typing-extensions 4.7.1 py311h6ffa863_0
typing_extensions 4.7.1 py311h6ffa863_0
typing_inspect 0.9.0 pyhd8ed1ab_0 conda-forge
tzdata 2023c h04d1e81_0
urllib3 1.26.18 py311h6ffa863_0
utf8proc 2.6.1 h140841e_0
werkzeug 2.3.8 pyhd8ed1ab_0 conda-forge
wheel 0.41.2 py311h6ffa863_0
xxhash 0.8.0 h140841e_3
xz 5.4.2 hf118e41_0
yaml 0.2.5 h7b6447c_0
yaml-cpp 0.8.0 h4a02239_0
yarl 1.8.1 py311hf118e41_0
zipp 3.11.0 py311h6ffa863_0
zlib 1.2.13 h1f2b957_6 conda-forge
zstandard 0.19.0 py311hf118e41_0
zstd 1.5.5 h57e4825_0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6992/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6992/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6990/comments | https://api.github.com/repos/huggingface/datasets/issues/6990/events | https://github.com/huggingface/datasets/issues/6990 | 2,366,660,785 | I_kwDODunzps6NEGCx | 6,990 | Problematic rank after calling `split_dataset_by_node` twice | {
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "https://api.github.com/users/yzhangcs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yzhangcs",
"id": 18402347,
"login": "yzhangcs",
"node_id": "MDQ6VXNlcjE4NDAyMzQ3",
"organizations_url": "https://api.github.com/users/yzhangcs/orgs",
"received_events_url": "https://api.github.com/users/yzhangcs/received_events",
"repos_url": "https://api.github.com/users/yzhangcs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yzhangcs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yzhangcs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yzhangcs",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"ah yes good catch ! feel free to open a PR with your suggested fix"
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | CONTRIBUTOR | null | ### Describe the bug
I'm trying to split `IterableDataset` by `split_dataset_by_node`.
But when doing split on a already split dataset, the resulting `rank` is greater than `world_size`.
### Steps to reproduce the bug
Here is the minimal code for reproduction:
```py
>>> from datasets import load_dataset
>>> from datasets.distributed import split_dataset_by_node
>>> dataset = load_dataset('fla-hub/slimpajama-test', split='train', streaming=True)
>>> dataset = split_dataset_by_node(dataset, 1, 32)
>>> dataset._distributed
DistributedConfig(rank=1, world_size=32)
>>> dataset = split_dataset_by_node(dataset, 1, 15)
>>> dataset._distributed
DistributedConfig(rank=481, world_size=480)
```
As you can see, the second rank 481 > 480, which is problematic.
### Expected behavior
I think this error comes from this line @lhoestq
https://github.com/huggingface/datasets/blob/a6ccf944e42c1a84de81bf326accab9999b86c90/src/datasets/iterable_dataset.py#L2943-L2944
We may need to obtain the rank first. Then the above code gives
```py
>>> dataset._distributed
DistributedConfig(rank=16, world_size=480)
```
### Environment info
datasets==2.20.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6990/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6989 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6989/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6989/comments | https://api.github.com/repos/huggingface/datasets/issues/6989/events | https://github.com/huggingface/datasets/issues/6989 | 2,365,556,449 | I_kwDODunzps6M_4bh | 6,989 | cache in nfs error | {
"avatar_url": "https://avatars.githubusercontent.com/u/66729924?v=4",
"events_url": "https://api.github.com/users/simplew2011/events{/privacy}",
"followers_url": "https://api.github.com/users/simplew2011/followers",
"following_url": "https://api.github.com/users/simplew2011/following{/other_user}",
"gists_url": "https://api.github.com/users/simplew2011/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/simplew2011",
"id": 66729924,
"login": "simplew2011",
"node_id": "MDQ6VXNlcjY2NzI5OTI0",
"organizations_url": "https://api.github.com/users/simplew2011/orgs",
"received_events_url": "https://api.github.com/users/simplew2011/received_events",
"repos_url": "https://api.github.com/users/simplew2011/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/simplew2011/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simplew2011/subscriptions",
"type": "User",
"url": "https://api.github.com/users/simplew2011",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,718 | null | NONE | null | ### Describe the bug
- When reading dataset, a cache will be generated to the ~/. cache/huggingface/datasets directory
- When using .map and .filter operations, runtime cache will be generated to the /tmp/hf_datasets-* directory
- The default is to use the path of tempfile.tempdir
- If I modify this path to the NFS disk, an error will be reported, but the program will continue to run
- https://github.com/huggingface/datasets/blob/main/src/datasets/config.py#L257
```
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 315, in _bootstrap
self.run()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 616, in _run_server
server.serve_forever()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 182, in serve_forever
sys.exit(0)
SystemExit: 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 300, in _run_finalizers
finalizer()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 224, in __call__
res = self._callback(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 133, in _remove_temp_dir
rmtree(tempdir)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 718, in rmtree
_rmtree_safe_fd(fd, path, onerror)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 675, in _rmtree_safe_fd
onerror(os.unlink, fullname, sys.exc_info())
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 673, in _rmtree_safe_fd
os.unlink(entry.name, dir_fd=topfd)
OSError: [Errno 16] Device or resource busy: '.nfs000000038330a012000030b4'
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 315, in _bootstrap
self.run()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 616, in _run_server
server.serve_forever()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 182, in serve_forever
sys.exit(0)
SystemExit: 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 300, in _run_finalizers
finalizer()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 224, in __call__
res = self._callback(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 133, in _remove_temp_dir
rmtree(tempdir)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 718, in rmtree
_rmtree_safe_fd(fd, path, onerror)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 675, in _rmtree_safe_fd
onerror(os.unlink, fullname, sys.exc_info())
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 673, in _rmtree_safe_fd
os.unlink(entry.name, dir_fd=topfd)
OSError: [Errno 16] Device or resource busy: '.nfs0000000400064d4a000030e5'
```
### Steps to reproduce the bug
```
import os
import time
import tempfile
from datasets import load_dataset
def add_column(sample):
# print(type(sample))
# time.sleep(0.1)
sample['__ds__stats__'] = {'data': 123}
return sample
def filt_column(sample):
# print(type(sample))
if len(sample['content']) > 10:
return True
else:
return False
if __name__ == '__main__':
input_dir = '/mnt/temp/CN/small' # some json dataset
dataset = load_dataset('json', data_dir=input_dir)
temp_dir = '/media/release/release/temp/temp' # a nfs folder
os.makedirs(temp_dir, exist_ok=True)
# change huggingface-datasets runtime cache in nfs(default in /tmp)
tempfile.tempdir = temp_dir
aa = dataset.map(add_column, num_proc=64)
aa = aa.filter(filt_column, num_proc=64)
print(aa)
```
### Expected behavior
no error occur
### Environment info
datasets==2.18.0
ubuntu 20.04 | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6989/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6989/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6985 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6985/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6985/comments | https://api.github.com/repos/huggingface/datasets/issues/6985/events | https://github.com/huggingface/datasets/issues/6985 | 2,362,378,276 | I_kwDODunzps6Mzwgk | 6,985 | AttributeError: module 'pyarrow.lib' has no attribute 'ListViewType' | {
"avatar_url": "https://avatars.githubusercontent.com/u/26666267?v=4",
"events_url": "https://api.github.com/users/firmai/events{/privacy}",
"followers_url": "https://api.github.com/users/firmai/followers",
"following_url": "https://api.github.com/users/firmai/following{/other_user}",
"gists_url": "https://api.github.com/users/firmai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/firmai",
"id": 26666267,
"login": "firmai",
"node_id": "MDQ6VXNlcjI2NjY2MjY3",
"organizations_url": "https://api.github.com/users/firmai/orgs",
"received_events_url": "https://api.github.com/users/firmai/received_events",
"repos_url": "https://api.github.com/users/firmai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/firmai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/firmai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/firmai",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Please note that the error is raised just at import:\r\n```python\r\nimport pyarrow.parquet as pq\r\n```\r\n\r\nTherefore it must be caused by some problem with your pyarrow installation. I would recommend you uninstall and install pyarrow again.\r\n\r\nI also see that it seems you use conda to install pyarrow. Please note that pyarrow offers 3 different packages in conda-forge: https://arrow.apache.org/docs/python/install.html#using-conda\r\n```\r\nconda install -c conda-forge pyarrow\r\n```\r\n> While the pyarrow [conda-forge](https://conda-forge.org/) package is the right choice for most users, both a minimal and maximal variant of the package exist, either of which may be better for your use case. See [Differences between conda-forge packages](https://arrow.apache.org/docs/python/install.html#python-conda-differences).\r\n\r\nPlease, make sure you install the right one: I guess it is either `pyarrow` (or `pyarrow-all`).",
"I have same issue, please downgrade pyarrow==15.0.2, it seem datasets library need to be fix",
"It is not a problem with the `datasets` library: we support latest version of `pyarrow` and our Continuous Integration tests are using pyarrow 16.1.0 without any problem.\r\n\r\nThe error reported here is raised when importing pyarrow.parquet:\r\n```\r\n---> 29 import pyarrow.parquet as pq\r\n```\r\n```\r\nFile /opt/conda/lib/python3.10/site-packages/pyarrow/parquet/__init__.py:20\r\n 1 # Licensed to the Apache Software Foundation (ASF) under one\r\n 2 # or more contributor license agreements. See the NOTICE file\r\n 3 # distributed with this work for additional information\r\n (...)\r\n 17 \r\n 18 # flake8: noqa\r\n---> 20 from .core import *\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/pyarrow/parquet/core.py:33\r\n 30 import pyarrow as pa\r\n 32 try:\r\n---> 33 import pyarrow._parquet as _parquet\r\n 34 except ImportError as exc:\r\n 35 raise ImportError(\r\n 36 \"The pyarrow installation is not built with support \"\r\n 37 f\"for the Parquet file format ({str(exc)})\"\r\n 38 ) from None\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/pyarrow/_parquet.pyx:1, in init pyarrow._parquet()\r\n\r\nAttributeError: module 'pyarrow.lib' has no attribute 'ListViewType'\r\n```\r\n\r\nThis can only be explained if pyarrow was not properly installed. \r\n\r\nIf the user just installed `pyarrow-core` from conda-forge, then its parquet subpackage is not installed and cannot be imported. You can check pyarrow docs:\r\n- Differences between conda-forge packages: https://arrow.apache.org/docs/python/install.html#python-conda-differences\r\n> The `pyarrow-core` package includes the following functionality:\r\n> ...\r\n> The `pyarrow` package adds the following:\r\n> ...\r\n> Parquet (i.e., `pyarrow.parquet`)",
"I'm still seeing the same issue on datasets version 2.20.0. I installed pyarrow version 17.0.0 with `pip install`. Downgrading to pyarrow==15.0.2 also did not resolve the issue.",
"@RenaLu As of UTC time 07/27/2024 23:20:00, I hit the same issue and reinstalling `pyarrow==15.0.2` resolved the issue for me. You may want to check if your `pyarrow` is successfully downgraded.",
"I can confirm @albertvillanova's [analysis & suggestion](https://github.com/huggingface/datasets/issues/6985#issuecomment-2188022888) - `pip uninstall pyarrow` followed by `pip install pyarrow` solved it for me. \r\n\r\nI suspect this is because pyarrow was initially installed as a pandas extra `pandas[...,parquet,...]`, then pip-upgrading pyarrow resulted in the issue.\r\n\r\n@RenaLu did you uninstall pyarrow between changing versions?",
"After trying all the above combinations and failing, running the following in the notebook fixed the error!!\r\n`!conda install -c conda-forge -y datasets pyarrow libparquet`\r\nNote : Uninstall any existing dataset and pyarrow installations in the env before executing the above.",
"If on colab, remember to restart the runtime so the new pyarrow is imported. I also upgraded pip which is recommended in pyarrow's installation instructions.",
"fixed doing this: !pip install --upgrade datasets\r\n\r\n!pip show pyarrow\r\n!pip show datasets\r\n!pip uninstall -y pyarrow\r\n!pip install pyarrow --no-cache-dir\r\n!pip install pyarrow\r\n!pip install transformers\r\n!pip install --upgrade datasets\r\n!pip install datasets\r\n! pip install pyarrow\r\n! pip install pyarrow.parquet\r\n!pip install transformers\r\n\r\n# Import necessary libraries\r\nfrom datasets import load_dataset\r\nimport pyarrow.parquet as pq\r\nimport pyarrow.lib as lib\r\nimport pandas as pd\r\nfrom transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments\r\n",
"but now i cant run test, so i remove it, ERROR: Could not find a version that satisfies the requirement pyarrow.parquet (from versions: none)\r\nERROR: No matching distribution found for pyarrow.parquet will still running but will tell you this",
"I have the same question right now, python3.12 and transformers4.44.2, I have not fixed it"
] | 1970-01-01T00:00:00.000001 | 1,730 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
I have been struggling with this for two days, any help would be appreciated. Python 3.10
```
from setfit import SetFitModel
from huggingface_hub import login
access_token_read = "cccxxxccc"
# Authenticate with the Hugging Face Hub
login(token=access_token_read)
# Load the models from the Hugging Face Hub
trainer_relv = SetFitModel.from_pretrained("snowdere/trainer_relevance")
trainer_trust = SetFitModel.from_pretrained("snowdere/trainer_trust")
trainer_sent = SetFitModel.from_pretrained("snowdere/trainer_sent")
trainer_topic = SetFitModel.from_pretrained("snowdere/trainer_topic")
```
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 from setfit import SetFitModel
2 from huggingface_hub import login
4 access_token_read = "ccsddsds"
File /opt/conda/lib/python3.10/site-packages/setfit/__init__.py:7
4 import os
5 import warnings
----> 7 from .data import get_templated_dataset, sample_dataset
8 from .model_card import SetFitModelCardData
9 from .modeling import SetFitHead, SetFitModel
File /opt/conda/lib/python3.10/site-packages/setfit/data.py:5
3 import pandas as pd
4 import torch
----> 5 from datasets import Dataset, DatasetDict, load_dataset
6 from torch.utils.data import Dataset as TorchDataset
8 from . import logging
File /opt/conda/lib/python3.10/site-packages/datasets/__init__.py:18
1 # ruff: noqa
2 # Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
3 #
(...)
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
16 __version__ = "2.19.0"
---> 18 from .arrow_dataset import Dataset
19 from .arrow_reader import ReadInstruction
20 from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
File /opt/conda/lib/python3.10/site-packages/datasets/arrow_dataset.py:76
73 from tqdm.contrib.concurrent import thread_map
75 from . import config
---> 76 from .arrow_reader import ArrowReader
77 from .arrow_writer import ArrowWriter, OptimizedTypedSequence
78 from .data_files import sanitize_patterns
File /opt/conda/lib/python3.10/site-packages/datasets/arrow_reader.py:29
26 from typing import TYPE_CHECKING, List, Optional, Union
28 import pyarrow as pa
---> 29 import pyarrow.parquet as pq
30 from tqdm.contrib.concurrent import thread_map
32 from .download.download_config import DownloadConfig
File /opt/conda/lib/python3.10/site-packages/pyarrow/parquet/__init__.py:20
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
(...)
17
18 # flake8: noqa
---> 20 from .core import *
File /opt/conda/lib/python3.10/site-packages/pyarrow/parquet/core.py:33
30 import pyarrow as pa
32 try:
---> 33 import pyarrow._parquet as _parquet
34 except ImportError as exc:
35 raise ImportError(
36 "The pyarrow installation is not built with support "
37 f"for the Parquet file format ({str(exc)})"
38 ) from None
File /opt/conda/lib/python3.10/site-packages/pyarrow/_parquet.pyx:1, in init pyarrow._parquet()
AttributeError: module 'pyarrow.lib' has no attribute 'ListViewType'
```
setfit: 1.0.3
transformers: 4.41.2
lingua-language-detector: 2.0.2
polars: 0.20.31
lightning: None
google-cloud-bigquery: 3.24.0
shapely: 2.0.4
pyarrow: 16.0.0
### Steps to reproduce the bug
I have tried all version combinations for Dataset and Pyarrow, the all have the same error since a few days ago. This is accross multiple scripts I have.
### Expected behavior
Just ron normally.
### Environment info
3.10 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6985/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6985/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6984 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6984/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6984/comments | https://api.github.com/repos/huggingface/datasets/issues/6984/events | https://github.com/huggingface/datasets/issues/6984 | 2,362,143,554 | I_kwDODunzps6My3NC | 6,984 | Convert polars DataFrame back to datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/38550511?v=4",
"events_url": "https://api.github.com/users/ljw20180420/events{/privacy}",
"followers_url": "https://api.github.com/users/ljw20180420/followers",
"following_url": "https://api.github.com/users/ljw20180420/following{/other_user}",
"gists_url": "https://api.github.com/users/ljw20180420/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ljw20180420",
"id": 38550511,
"login": "ljw20180420",
"node_id": "MDQ6VXNlcjM4NTUwNTEx",
"organizations_url": "https://api.github.com/users/ljw20180420/orgs",
"received_events_url": "https://api.github.com/users/ljw20180420/received_events",
"repos_url": "https://api.github.com/users/ljw20180420/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ljw20180420/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ljw20180420/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ljw20180420",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Hi ! Thanks for reporting :)\r\n\r\nWe don't support `large_list` yet, though it should be added to `Sequence` IMO (maybe with a parameter `large=True` ?)"
] | 1970-01-01T00:00:00.000001 | 1,723 | 1970-01-01T00:00:00.000001 | NONE | null | ### Feature request
This returns error.
```python
from datasets import Dataset
dsdf = Dataset.from_dict({"x": [[1, 2], [3, 4, 5]], "y": ["a", "b"]})
Dataset.from_polars(dsdf.to_polars())
```
ValueError: Arrow type large_list<item: int64> does not have a datasets dtype equivalent.
### Motivation
When datasets contain Sequence data type, it will be converted to Arrow type large_list. However, the reverse (from large_list to Sequence) does not work.
### Your contribution
No | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6984/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6982 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6982/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6982/comments | https://api.github.com/repos/huggingface/datasets/issues/6982/events | https://github.com/huggingface/datasets/issues/6982 | 2,361,661,469 | I_kwDODunzps6MxBgd | 6,982 | cannot split dataset when using load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/17721894?v=4",
"events_url": "https://api.github.com/users/cybest0608/events{/privacy}",
"followers_url": "https://api.github.com/users/cybest0608/followers",
"following_url": "https://api.github.com/users/cybest0608/following{/other_user}",
"gists_url": "https://api.github.com/users/cybest0608/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cybest0608",
"id": 17721894,
"login": "cybest0608",
"node_id": "MDQ6VXNlcjE3NzIxODk0",
"organizations_url": "https://api.github.com/users/cybest0608/orgs",
"received_events_url": "https://api.github.com/users/cybest0608/received_events",
"repos_url": "https://api.github.com/users/cybest0608/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cybest0608/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cybest0608/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cybest0608",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"it seems the bug will happened in all windows system, I tried it in windows8.1, 10, 11 and all of them failed. But it won't happened in the Linux(Ubuntu and Centos7) and Mac (both my virtual and physical machine). I still don't know what the problem is. May be related to the path? I cannot run the split file in my windows server which created in Linux (even I replace the path in the arrow document)....work for it for a week but still cannot fix it .....upset",
"Have you properly logged in? Are you using the a valid token?\r\n\r\nNote that this dataset is gated and you must follow the right procedure to be able to access it. You can find more info in the docs: https://huggingface.co/docs/hub/datasets-gated#access-gated-datasets-as-a-user",
"> Have you properly logged in? Are you using the a valid token?\r\n> \r\n> Note that this dataset is gated and you must follow the right procedure to be able to access it. You can find more info in the docs: https://huggingface.co/docs/hub/datasets-gated#access-gated-datasets-as-a-user\r\n\r\nI finally found it what happened. It is not about the logging. When I copy the dataset from its original path (C:/Users/cybes/.cache/huggingface/datasets/downloads/extracted/XXX/cv-corpus-7.0-2021-07-21) to the desktop and load each tsv in it one by one , when I load the test spilt, the following warning occurs:\r\n\"ArrowInvalid: Failed to parse string: 'Benchmark' as a scalar of type double\"\r\n\r\nThen I manually deleted them in the \"segment\", the error won't happen anymore, even I replace the original path with these revised tsv and use the previous loading method (common_voice_train = load_dataset(\"mozilla-foundation/common_voice_7_0\", \"ja\", split=\"train\", trust_remote_code=True)). It can work properly."
] | 1970-01-01T00:00:00.000001 | 1,720 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
when I use load_dataset methods to load mozilla-foundation/common_voice_7_0, it can successfully download and extracted the dataset but It cannot generating the arrow document,
This bug happened in my server, my laptop, so as #6906 , but it won't happen in the google colab. I work for it for days, even I load the datasets from local path, it can Generating train split and validation split but bug happen again in test split.
### Steps to reproduce the bug
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("mozilla-foundation/common_voice_7_0", "ja", split="train", token=selftoken, trust_remote_code=True)
### Expected behavior
```
{
"name": "ValueError",
"message": "Instruction \"train\" corresponds to no data!",
"stack": "---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[2], line 3
1 from datasets import load_dataset, load_metric, Audio
----> 3 common_voice_train = load_dataset(\"mozilla-foundation/common_voice_7_0\", \"ja\", split=\"train\",token='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')#,trust_remote_code=True)#,streaming=True)
4 common_voice_test = load_dataset(\"mozilla-foundation/common_voice_7_0\", \"ja\", split=\"test\",token='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')#,trust_remote_code=True)#,streaming=True)
File c:\\Users\\cybes\\.conda\\envs\\ECoG\\lib\\site-packages\\datasets\\load.py:2626, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, token, use_auth_token, task, streaming, num_proc, storage_options, trust_remote_code, **config_kwargs)
2622 # Build dataset for splits
2623 keep_in_memory = (
2624 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
2625 )
-> 2626 ds = builder_instance.as_dataset(split=split, verification_mode=verification_mode, in_memory=keep_in_memory)
2627 # Rename and cast features to match task schema
2628 if task is not None:
2629 # To avoid issuing the same warning twice
File c:\\Users\\cybes\\.conda\\envs\\ECoG\\lib\\site-packages\\datasets\\builder.py:1266, in DatasetBuilder.as_dataset(self, split, run_post_process, verification_mode, ignore_verifications, in_memory)
1263 verification_mode = VerificationMode(verification_mode or VerificationMode.BASIC_CHECKS)
1265 # Create a dataset for each of the given splits
-> 1266 datasets = map_nested(
1267 partial(
1268 self._build_single_dataset,
1269 run_post_process=run_post_process,
1270 verification_mode=verification_mode,
1271 in_memory=in_memory,
1272 ),
1273 split,
1274 map_tuple=True,
1275 disable_tqdm=True,
1276 )
1277 if isinstance(datasets, dict):
1278 datasets = DatasetDict(datasets)
File c:\\Users\\cybes\\.conda\\envs\\ECoG\\lib\\site-packages\\datasets\\utils\\py_utils.py:484, in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, parallel_min_length, batched, batch_size, types, disable_tqdm, desc)
482 if batched:
483 data_struct = [data_struct]
--> 484 mapped = function(data_struct)
485 if batched:
486 mapped = mapped[0]
File c:\\Users\\cybes\\.conda\\envs\\ECoG\\lib\\site-packages\\datasets\\builder.py:1296, in DatasetBuilder._build_single_dataset(self, split, run_post_process, verification_mode, in_memory)
1293 split = Split(split)
1295 # Build base dataset
-> 1296 ds = self._as_dataset(
1297 split=split,
1298 in_memory=in_memory,
1299 )
1300 if run_post_process:
1301 for resource_file_name in self._post_processing_resources(split).values():
File c:\\Users\\cybes\\.conda\\envs\\ECoG\\lib\\site-packages\\datasets\\builder.py:1370, in DatasetBuilder._as_dataset(self, split, in_memory)
1368 if self._check_legacy_cache():
1369 dataset_name = self.name
-> 1370 dataset_kwargs = ArrowReader(cache_dir, self.info).read(
1371 name=dataset_name,
1372 instructions=split,
1373 split_infos=self.info.splits.values(),
1374 in_memory=in_memory,
1375 )
1376 fingerprint = self._get_dataset_fingerprint(split)
1377 return Dataset(fingerprint=fingerprint, **dataset_kwargs)
File c:\\Users\\cybes\\.conda\\envs\\ECoG\\lib\\site-packages\\datasets\\arrow_reader.py:256, in BaseReader.read(self, name, instructions, split_infos, in_memory)
254 msg = f'Instruction \"{instructions}\" corresponds to no data!'
255 #msg = f'Instruction \"{self._path}\",\"{name}\",\"{instructions}\",\"{split_infos}\" corresponds to no data!'
--> 256 raise ValueError(msg)
257 return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)
ValueError: Instruction \"train\" corresponds to no data!"
}
```
### Environment info
Environment:
python 3.9
windows 11 pro
VScode+jupyter | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6982/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6982/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6980 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6980/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6980/comments | https://api.github.com/repos/huggingface/datasets/issues/6980/events | https://github.com/huggingface/datasets/issues/6980 | 2,360,909,930 | I_kwDODunzps6MuKBq | 6,980 | Support NumPy 2.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/730137?v=4",
"events_url": "https://api.github.com/users/NeilGirdhar/events{/privacy}",
"followers_url": "https://api.github.com/users/NeilGirdhar/followers",
"following_url": "https://api.github.com/users/NeilGirdhar/following{/other_user}",
"gists_url": "https://api.github.com/users/NeilGirdhar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NeilGirdhar",
"id": 730137,
"login": "NeilGirdhar",
"node_id": "MDQ6VXNlcjczMDEzNw==",
"organizations_url": "https://api.github.com/users/NeilGirdhar/orgs",
"received_events_url": "https://api.github.com/users/NeilGirdhar/received_events",
"repos_url": "https://api.github.com/users/NeilGirdhar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NeilGirdhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NeilGirdhar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NeilGirdhar",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,720 | 1970-01-01T00:00:00.000001 | CONTRIBUTOR | null | ### Feature request
Support NumPy 2.0.
### Motivation
NumPy introduces the Array API, which bridges the gap between machine learning libraries. Many clients of HuggingFace are eager to start using the Array API.
Besides that, NumPy 2 provides a cleaner interface than NumPy 1.
### Tasks
NumPy 2.0 was released for testing so that libraries could ensure compatibility [since mid-March](https://github.com/numpy/numpy/issues/24300#issuecomment-1986815755). What needs to be done for HuggingFace to support Numpy 2?
- [x] Fix use of `array`: https://github.com/huggingface/datasets/pull/6976
- [ ] Remove [NumPy version limit](https://github.com/huggingface/datasets/pull/6975): https://github.com/huggingface/datasets/pull/6991 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6980/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6980/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6979 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6979/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6979/comments | https://api.github.com/repos/huggingface/datasets/issues/6979/events | https://github.com/huggingface/datasets/issues/6979 | 2,360,175,363 | I_kwDODunzps6MrWsD | 6,979 | How can I load partial parquet files only? | {
"avatar_url": "https://avatars.githubusercontent.com/u/21303438?v=4",
"events_url": "https://api.github.com/users/lucasjinreal/events{/privacy}",
"followers_url": "https://api.github.com/users/lucasjinreal/followers",
"following_url": "https://api.github.com/users/lucasjinreal/following{/other_user}",
"gists_url": "https://api.github.com/users/lucasjinreal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lucasjinreal",
"id": 21303438,
"login": "lucasjinreal",
"node_id": "MDQ6VXNlcjIxMzAzNDM4",
"organizations_url": "https://api.github.com/users/lucasjinreal/orgs",
"received_events_url": "https://api.github.com/users/lucasjinreal/received_events",
"repos_url": "https://api.github.com/users/lucasjinreal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lucasjinreal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucasjinreal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lucasjinreal",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Hello,\r\n\r\nHave you tried loading the dataset in streaming mode? [Documentation](https://huggingface.co/docs/datasets/v2.20.0/stream)\r\n\r\nThis way you wouldn't have to load it all. Also, let's be nice to Parquet, it's a really nice technology and we don't need to be mean :)",
"I have downloaded part of it, just want to know how to load part of it, stream mode is not work for me since my network (in china) not stable, I don't want do it all again and again.\r\n\r\nJust curious, doesn't there a way to load part of it?",
"Could you convert the IterableDataset to a Dataset after taking the first 100 rows with `.take`? This way, you would have a local copy of the first 100 rows on your system and thus won't need to download. Would that work?\r\n\r\nHere is a [SO question](https://stackoverflow.com/questions/76227219/can-i-convert-an-iterabledataset-to-dataset) detailing how to do the conversion.",
"I mean, the parquet is like:\r\n\r\n00000-0143554\r\n00001-0143554\r\n00002-0143554\r\n...\r\n00100-0143554\r\n...\r\n09100-0143554\r\n\r\nI just downloaded the first 9900 part of it. \r\n\r\nI can not load with load_dataset, it throw an error says my file is not same as parquet all amount.\r\n\r\nHow could I load the only I have? \r\n\r\n( I really don't want downlaod them all, cause, I don't need all, and pulus, its huge.... )\r\n\r\nAs I said, I have donwloaded about 9999... It's not about stream... I just wnat to konw how to load offline... part....",
"Hi, @lucasjinreal.\r\n\r\nI am not sure of understanding your issue. What is the error message and stack trace you get? What version of `datasets` are you using? Could you provide a reproducible example?\r\n\r\nWithout knowing all those details, I would naively say that you can load whatever number of Parquet files by using the \"parquet\" loader: https://huggingface.co/docs/datasets/loading#parquet\r\n```python\r\nds = load_dataset(\"parquet\", data_files=\"data/train-001*-of-00314.parquet\", split=\"train\")\r\n```",
"@albertvillanova Not sure you have tested with this or not, but I have tried,\r\n\r\nthe only error I got is it still laodding all parquet with a progress bar maxium to the whole number 014354, and it loads my 0 - 000999 part, then throws an error.\r\n\r\nSays Numinfo is not same.\r\n\r\nI am so confused,",
"Yes, my code snippet works.\n\nCould you copy-paste your code and the output? Otherwise we are not able to know what the issue is.",
"@albertvillanova Hi, thanks for the tracing of the issue.\r\n\r\nThis is the output:\r\n\r\n```\r\nython get_llava_recap_cc3m.py\r\nGenerating train split: 3%|███▋ | 101910/3199866 [00:16<08:30, 6065.67 examples/s]\r\nTraceback (most recent call last):\r\n File \"get_llava_recap_cc3m.py\", line 31, in <module>\r\n dataset = load_dataset(\"llava-recap-cc3m/\", data_files=\"data/train-0000*-of-00314.parquet\")\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/load.py\", line 2582, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1005, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1118, in _download_and_prepare\r\n verify_splits(self.info.splits, split_dict)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/info_utils.py\", line 101, in verify_splits\r\n raise NonMatchingSplitsSizesError(str(bad_splits))\r\ndatasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=156885281898.75, num_examples=3199866, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='train', num_bytes=4994080770, num_examples=101910, shard_lengths=[10191, 10291, 10291, 10291, 10291, 10191, 10191, 10291, 10291, 9591], dataset_name='llava-recap-cc3m')}]\r\n```\r\n\r\nthis is my code:\r\n\r\n```\r\ndataset = load_dataset(\"llava-recap-cc3m/\", data_files=\"data/train-0000*-of-00314.parquet\")\r\n```\r\n\r\nMy situation and requirements:\r\n\r\n00314 is all, but I downlaode about 150, half of it, as you can see, i used `0000*-of-00314.` which should be at most 99 file being loaded.\r\n\r\nBut it just fail.\r\n\r\nCan u understand my issue now?\r\n\r\nIf so, then **do not** suggest me with stream, Just want to know, is there a way to load part if it...... **and please don't say you can not replicate my issue when you have downloaded them all**, my english is not good, but I think all situations and all prerequists I have addressed already.\r\n\r\n",
"I see you did not use the \"parquet\" loader as I suggested in my code snippet above: https://github.com/huggingface/datasets/issues/6979#issuecomment-2182031415\r\nPlease try passing \"parquet\" instead of \"llava-recap-cc3m/\" to `load_dataset`, and the complete path to data files in `data_files`:\r\n```python\r\nload_dataset(\"parquet\", data_files=\"llava-recap-cc3m/data/train-001*-of-00314.parquet\")\r\n```",
"Let me explain that you get the error because of this content within the `dataset_info` YAML tag in the `llava-recap-cc3m/README.md`:\r\n```\r\n - name: train\r\n num_bytes: 156885281898.75\r\n num_examples: 3199866\r\n```\r\n\r\nBy default, if there is that content in the README file, `load_dataset` performs a basic check to verify it the generated number of examples matches the expected one and raises a `NonMatchingSplitsSizesError` if that is not the case. \r\n\r\nYou can avoid this basic check by passing `verification_mode=\"no_checks\"`:\r\n```python\r\nload_dataset(\"llava-recap-cc3m/\", data_files=\"data/train-0000*-of-00314.parquet\", verification_mode=\"no_checks\")\r\n```",
"And please, next time you have an issue, please fill the Bug template issue with all the necessary information: https://github.com/huggingface/datasets/issues/new?assignees=&labels=&projects=&template=bug-report.yml\r\n\r\nOtherwise it is very difficult for us to understand the underlying problem and to propose a pertinent solution.",
"thank u albert!\r\n\r\nIt solved my issue!"
] | 1970-01-01T00:00:00.000001 | 1,718 | 1970-01-01T00:00:00.000001 | NONE | null | I have a HUGE dataset about 14TB, I unable to download all parquet all. I just take about 100 from it.
dataset = load_dataset("xx/", data_files="data/train-001*-of-00314.parquet")
How can I just using 000 - 100 from a 00314 from all partially?
I search whole net didn't found a solution, **this is stupid if they didn't support it, and I swear I wont using stupid parquet any more**
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6979/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6979/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6977 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6977/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6977/comments | https://api.github.com/repos/huggingface/datasets/issues/6977/events | https://github.com/huggingface/datasets/issues/6977 | 2,359,295,045 | I_kwDODunzps6Mn_xF | 6,977 | load json file error with v2.20.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/15037766?v=4",
"events_url": "https://api.github.com/users/xiaoyaolangzhi/events{/privacy}",
"followers_url": "https://api.github.com/users/xiaoyaolangzhi/followers",
"following_url": "https://api.github.com/users/xiaoyaolangzhi/following{/other_user}",
"gists_url": "https://api.github.com/users/xiaoyaolangzhi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/xiaoyaolangzhi",
"id": 15037766,
"login": "xiaoyaolangzhi",
"node_id": "MDQ6VXNlcjE1MDM3NzY2",
"organizations_url": "https://api.github.com/users/xiaoyaolangzhi/orgs",
"received_events_url": "https://api.github.com/users/xiaoyaolangzhi/received_events",
"repos_url": "https://api.github.com/users/xiaoyaolangzhi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/xiaoyaolangzhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xiaoyaolangzhi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/xiaoyaolangzhi",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Thanks for reporting, @xiaoyaolangzhi.\r\n\r\nIndeed, we are currently requiring `pandas` >= 2.0.0.\r\n\r\nYou will need to update pandas in your local environment:\r\n```\r\npip install -U pandas\r\n``` ",
"Thank you very much."
] | 1970-01-01T00:00:00.000001 | 1,718 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
```
load_dataset(path="json", data_files="./test.json")
```
```
Generating train split: 0 examples [00:00, ? examples/s]
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/datasets/packaged_modules/json/json.py", line 132, in _generate_tables
pa_table = paj.read_json(
File "pyarrow/_json.pyx", line 308, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: JSON parse error: Column() changed from object to array in row 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1997, in _prepare_split_single
for _, table in generator:
File "/usr/local/lib/python3.10/dist-packages/datasets/packaged_modules/json/json.py", line 155, in _generate_tables
df = pd.read_json(f, dtype_backend="pyarrow")
File "/usr/local/lib/python3.10/dist-packages/pandas/util/_decorators.py", line 211, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/pandas/util/_decorators.py", line 331, in wrapper
return func(*args, **kwargs)
TypeError: read_json() got an unexpected keyword argument 'dtype_backend'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/t1.py", line 11, in <module>
load_dataset(path=data_path, data_files="./t2.json")
File "/usr/local/lib/python3.10/dist-packages/datasets/load.py", line 2616, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1029, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1124, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1884, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 2040, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.exceptions.DatasetGenerationError: An error occurred while generating the dataset
```
```
import pandas as pd
with open("./test.json", "r") as f:
df = pd.read_json(f, dtype_backend="pyarrow")
```
```
Traceback (most recent call last):
File "/app/t3.py", line 3, in <module>
df = pd.read_json(f, dtype_backend="pyarrow")
File "/usr/local/lib/python3.10/dist-packages/pandas/util/_decorators.py", line 211, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/pandas/util/_decorators.py", line 331, in wrapper
return func(*args, **kwargs)
TypeError: read_json() got an unexpected keyword argument 'dtype_backend'
```
### Steps to reproduce the bug
.
### Expected behavior
.
### Environment info
```
datasets 2.20.0
pandas 1.5.3
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/15037766?v=4",
"events_url": "https://api.github.com/users/xiaoyaolangzhi/events{/privacy}",
"followers_url": "https://api.github.com/users/xiaoyaolangzhi/followers",
"following_url": "https://api.github.com/users/xiaoyaolangzhi/following{/other_user}",
"gists_url": "https://api.github.com/users/xiaoyaolangzhi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/xiaoyaolangzhi",
"id": 15037766,
"login": "xiaoyaolangzhi",
"node_id": "MDQ6VXNlcjE1MDM3NzY2",
"organizations_url": "https://api.github.com/users/xiaoyaolangzhi/orgs",
"received_events_url": "https://api.github.com/users/xiaoyaolangzhi/received_events",
"repos_url": "https://api.github.com/users/xiaoyaolangzhi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/xiaoyaolangzhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xiaoyaolangzhi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/xiaoyaolangzhi",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6977/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6977/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6973 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6973/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6973/comments | https://api.github.com/repos/huggingface/datasets/issues/6973/events | https://github.com/huggingface/datasets/issues/6973 | 2,355,517,362 | I_kwDODunzps6MZley | 6,973 | IndexError during training with Squad dataset and T5-small model | {
"avatar_url": "https://avatars.githubusercontent.com/u/151521233?v=4",
"events_url": "https://api.github.com/users/ramtunguturi36/events{/privacy}",
"followers_url": "https://api.github.com/users/ramtunguturi36/followers",
"following_url": "https://api.github.com/users/ramtunguturi36/following{/other_user}",
"gists_url": "https://api.github.com/users/ramtunguturi36/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ramtunguturi36",
"id": 151521233,
"login": "ramtunguturi36",
"node_id": "U_kgDOCQgH0Q",
"organizations_url": "https://api.github.com/users/ramtunguturi36/orgs",
"received_events_url": "https://api.github.com/users/ramtunguturi36/received_events",
"repos_url": "https://api.github.com/users/ramtunguturi36/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ramtunguturi36/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ramtunguturi36/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ramtunguturi36",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"add remove_unused_columns=False to training_args\r\nhttps://github.com/huggingface/datasets/issues/6535#issuecomment-1874024704",
"Closing this issue because it was a reported and fixed in transformers."
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
I am encountering an IndexError while training a T5-small model on the Squad dataset using the transformers and datasets libraries. The error occurs even with a minimal reproducible example, suggesting a potential bug or incompatibility.
### Steps to reproduce the bug
1.Install the required libraries: !pip install transformers datasets
2.Run the following code:
!pip install transformers datasets
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, TrainingArguments, Trainer, DataCollatorWithPadding
# Load a small, publicly available dataset
from datasets import load_dataset
dataset = load_dataset("squad", split="train[:100]") # Use a small subset for testing
# Load a pre-trained model and tokenizer
model_name = "t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# Define a basic data collator
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# Define training arguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=2,
num_train_epochs=1,
)
# Create a trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
)
# Train the model
trainer.train()
### Expected behavior
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
[<ipython-input-23-f13a4b23c001>](https://localhost:8080/#) in <cell line: 34>()
32
33 # Train the model
---> 34 trainer.train()
10 frames
[/usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py](https://localhost:8080/#) in _check_valid_index_key(key, size)
427 if isinstance(key, int):
428 if (key < 0 and key + size < 0) or (key >= size):
--> 429 raise IndexError(f"Invalid key: {key} is out of bounds for size {size}")
430 return
431 elif isinstance(key, slice):
IndexError: Invalid key: 42 is out of bounds for size 0
### Environment info
transformers version:4.41.2
datasets version:1.18.4
Python version:3.10.12
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6973/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6973/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6967 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6967/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6967/comments | https://api.github.com/repos/huggingface/datasets/issues/6967/events | https://github.com/huggingface/datasets/issues/6967 | 2,349,146,398 | I_kwDODunzps6MBSEe | 6,967 | Method to load Laion400m | {
"avatar_url": "https://avatars.githubusercontent.com/u/6862868?v=4",
"events_url": "https://api.github.com/users/humanely/events{/privacy}",
"followers_url": "https://api.github.com/users/humanely/followers",
"following_url": "https://api.github.com/users/humanely/following{/other_user}",
"gists_url": "https://api.github.com/users/humanely/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/humanely",
"id": 6862868,
"login": "humanely",
"node_id": "MDQ6VXNlcjY4NjI4Njg=",
"organizations_url": "https://api.github.com/users/humanely/orgs",
"received_events_url": "https://api.github.com/users/humanely/received_events",
"repos_url": "https://api.github.com/users/humanely/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/humanely/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/humanely/subscriptions",
"type": "User",
"url": "https://api.github.com/users/humanely",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,718 | null | NONE | null | ### Feature request
Large datasets like Laion400m are provided as embeddings. The provided methods in load_dataset are not straightforward for loading embedding files, i.e. img_emb_XX.npy ; XX = 0 to 99
### Motivation
The trial and experimentation is the key pivot of HF. It would be great if HF can load embeddings files s,ealessly.
### Your contribution
I cam write the loader with some help. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6967/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6967/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6961 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6961/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6961/comments | https://api.github.com/repos/huggingface/datasets/issues/6961/events | https://github.com/huggingface/datasets/issues/6961 | 2,342,022,418 | I_kwDODunzps6LmG0S | 6,961 | Manual downloads should count as downloads | {
"avatar_url": "https://avatars.githubusercontent.com/u/8473183?v=4",
"events_url": "https://api.github.com/users/umarbutler/events{/privacy}",
"followers_url": "https://api.github.com/users/umarbutler/followers",
"following_url": "https://api.github.com/users/umarbutler/following{/other_user}",
"gists_url": "https://api.github.com/users/umarbutler/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/umarbutler",
"id": 8473183,
"login": "umarbutler",
"node_id": "MDQ6VXNlcjg0NzMxODM=",
"organizations_url": "https://api.github.com/users/umarbutler/orgs",
"received_events_url": "https://api.github.com/users/umarbutler/received_events",
"repos_url": "https://api.github.com/users/umarbutler/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/umarbutler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/umarbutler/subscriptions",
"type": "User",
"url": "https://api.github.com/users/umarbutler",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"We're unlikely to add more features/support for datasets with python loading scripts, which include datasets with manual download. Sorry for the inconvenience"
] | 1970-01-01T00:00:00.000001 | 1,718 | null | NONE | null | ### Feature request
I would like to request that manual downloads of data files from Hugging Face dataset repositories count as downloads of a dataset. According to the documentation for the Hugging Face Hub, that is currently not the case: https://huggingface.co/docs/hub/en/datasets-download-stats
### Motivation
This would ensure that downloads are accurately reported to end users.
### Your contribution
N/A | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6961/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6961/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6958/comments | https://api.github.com/repos/huggingface/datasets/issues/6958/events | https://github.com/huggingface/datasets/issues/6958 | 2,337,476,383 | I_kwDODunzps6LUw8f | 6,958 | My Private Dataset doesn't exist on the Hub or cannot be accessed | {
"avatar_url": "https://avatars.githubusercontent.com/u/39621324?v=4",
"events_url": "https://api.github.com/users/wangguan1995/events{/privacy}",
"followers_url": "https://api.github.com/users/wangguan1995/followers",
"following_url": "https://api.github.com/users/wangguan1995/following{/other_user}",
"gists_url": "https://api.github.com/users/wangguan1995/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wangguan1995",
"id": 39621324,
"login": "wangguan1995",
"node_id": "MDQ6VXNlcjM5NjIxMzI0",
"organizations_url": "https://api.github.com/users/wangguan1995/orgs",
"received_events_url": "https://api.github.com/users/wangguan1995/received_events",
"repos_url": "https://api.github.com/users/wangguan1995/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wangguan1995/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wangguan1995/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wangguan1995",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"I can load public dataset, but for my private dataset it fails",
"https://huggingface.co/docs/datasets/upload_dataset",
"I have checked the API HTTP link. Repository Not Found for url: https://huggingface.co/api/datasets/xxx/xxx.\r\n\r\n\r\n\r\nIt just works fine.",
"It seems that everything is in a mass huh....\r\n\r\n\r\n",
"https://huggingface.co/datasets/rajpurkar/squad/blob/main/squad.py fails again",
"https://github.com/huggingface/datasets/blob/main/templates/new_dataset_script.py#L81 can not use this, too complex. I just need a def to load my file to a dict",
"I am facing the same issue. Did you find a fix?",
"You should authenticate to be able to access private or gated repos: https://huggingface.co/docs/hub/datasets-gated#access-gated-datasets-as-a-user"
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
```
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 1852, in dataset_module_factory
raise DatasetNotFoundError(msg + f" at revision '{revision}'" if revision else msg)
datasets.exceptions.DatasetNotFoundError: Dataset 'xxx' doesn't exist on the Hub or cannot be accessed
>>> dataset = load_dataset("xxxx", token=True)
404 error 404 Client Error. (Request ID: Root=xxxx)
Repository Not Found for url: https://huggingface.co/api/datasets/xxx/xxx.
Please make sure you specified the correct `repo_id` and `repo_type`.
If you are trying to access a private or gated repo, make sure you are authenticated.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 2593, in load_dataset
builder_instance = load_dataset_builder(
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 2265, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 1910, in dataset_module_factory
raise e1 from None
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 1852, in dataset_module_factory
raise DatasetNotFoundError(msg + f" at revision '{revision}'" if revision else msg)
datasets.exceptions.DatasetNotFoundError: Dataset 'xxx' doesn't exist on the Hub or cannot be accessed
```
### Steps to reproduce the bug
123
### Expected behavior
123
### Environment info
123 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6958/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6953/comments | https://api.github.com/repos/huggingface/datasets/issues/6953/events | https://github.com/huggingface/datasets/issues/6953 | 2,333,366,120 | I_kwDODunzps6LFFdo | 6,953 | Remove canonical datasets from docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"Canonical datasets are no longer mentioned in the docs."
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | Remove canonical datasets from docs, now that we no longer have canonical datasets. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6953/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6951 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6951/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6951/comments | https://api.github.com/repos/huggingface/datasets/issues/6951/events | https://github.com/huggingface/datasets/issues/6951 | 2,333,231,042 | I_kwDODunzps6LEkfC | 6,951 | load_dataset() should load all subsets, if no specific subset is specified | {
"avatar_url": "https://avatars.githubusercontent.com/u/5577741?v=4",
"events_url": "https://api.github.com/users/windmaple/events{/privacy}",
"followers_url": "https://api.github.com/users/windmaple/followers",
"following_url": "https://api.github.com/users/windmaple/following{/other_user}",
"gists_url": "https://api.github.com/users/windmaple/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/windmaple",
"id": 5577741,
"login": "windmaple",
"node_id": "MDQ6VXNlcjU1Nzc3NDE=",
"organizations_url": "https://api.github.com/users/windmaple/orgs",
"received_events_url": "https://api.github.com/users/windmaple/received_events",
"repos_url": "https://api.github.com/users/windmaple/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/windmaple/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/windmaple/subscriptions",
"type": "User",
"url": "https://api.github.com/users/windmaple",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"@xianbaoqian ",
"Feel free to open a PR in `m-a-p/COIG-CQIA` to define a default subset. Currently there is no default.\r\n\r\nYou can find some documentation at https://huggingface.co/docs/hub/datasets-manual-configuration#multiple-configurations",
"@lhoestq \r\n\r\nWhilst having a default subset readily available (e.g. `all`) by the dataset author is an ideal solution, it is not always the reality.\r\n\r\nWithout the ability to fork the dataset, this can be problematic.\r\n\r\nAs far as I know, it is not possible at all to specify multiple subsets in a generalized programmatic way without hard coding subset names for a specific dataset.\r\n\r\nEven the ability to fetch subset names and loop over them would be sufficient.",
"Please note that each subset can have different feature columns, thus making it impossible to load them all into a unique Dataset instance.\r\n\r\nThat is why subsets were created: to support different but related datasets to coexist in a single dataset repository.\r\n\r\nIf you would like to programmatically get the list of subset names, you can use `datasets.get_dataset_config_names`: https://huggingface.co/docs/datasets/v2.20.0/en/load_hub#configurations",
"found a better method in another link that can not only obtain the subset but also get the corresponding split\r\nhttps://huggingface.co/docs/dataset-viewer/splits"
] | 1970-01-01T00:00:00.000001 | 1,732 | 1970-01-01T00:00:00.000001 | NONE | null | ### Feature request
Currently load_dataset() is forcing users to specify a subset. Example
`from datasets import load_dataset
dataset = load_dataset("m-a-p/COIG-CQIA")`
```---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-10-c0cb49385da6>](https://localhost:8080/#) in <cell line: 2>()
1 from datasets import load_dataset
----> 2 dataset = load_dataset("m-a-p/COIG-CQIA")
3 frames
[/usr/local/lib/python3.10/dist-packages/datasets/builder.py](https://localhost:8080/#) in _create_builder_config(self, config_name, custom_features, **config_kwargs)
582 if not config_kwargs:
583 example_of_usage = f"load_dataset('{self.dataset_name}', '{self.BUILDER_CONFIGS[0].name}')"
--> 584 raise ValueError(
585 "Config name is missing."
586 f"\nPlease pick one among the available configs: {list(self.builder_configs.keys())}"
ValueError: Config name is missing.
Please pick one among the available configs: ['chinese_traditional', 'coig_pc', 'exam', 'finance', 'douban', 'human_value', 'logi_qa', 'ruozhiba', 'segmentfault', 'wiki', 'wikihow', 'xhs', 'zhihu']
Example of usage:
`load_dataset('coig-cqia', 'chinese_traditional')`
```
This means a dataset cannot contain all the subsets at the same time. I guess one workaround is to manually specify the subset files like in [here](https://huggingface.co/datasets/m-a-p/COIG-CQIA/discussions/1#658698b44bb41498f75c5622), which is clumsy.
### Motivation
Ideally, if not subset is specified, the API should just try to load all subsets. This makes it much easier to handle datasets w/ subsets.
### Your contribution
Not sure since I'm not familiar w/ the lib src. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6951/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6951/timeline | null | not_planned | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6950 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6950/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6950/comments | https://api.github.com/repos/huggingface/datasets/issues/6950/events | https://github.com/huggingface/datasets/issues/6950 | 2,333,005,974 | I_kwDODunzps6LDtiW | 6,950 | `Dataset.with_format` behaves inconsistently with documentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/42494185?v=4",
"events_url": "https://api.github.com/users/iansheng/events{/privacy}",
"followers_url": "https://api.github.com/users/iansheng/followers",
"following_url": "https://api.github.com/users/iansheng/following{/other_user}",
"gists_url": "https://api.github.com/users/iansheng/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/iansheng",
"id": 42494185,
"login": "iansheng",
"node_id": "MDQ6VXNlcjQyNDk0MTg1",
"organizations_url": "https://api.github.com/users/iansheng/orgs",
"received_events_url": "https://api.github.com/users/iansheng/received_events",
"repos_url": "https://api.github.com/users/iansheng/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/iansheng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iansheng/subscriptions",
"type": "User",
"url": "https://api.github.com/users/iansheng",
"user_view_type": "public"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"Hi ! It seems the documentation was outdated in this paragraph\r\n\r\nI fixed it here: https://github.com/huggingface/datasets/pull/6956",
"Fixed."
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
The actual behavior of the interface `Dataset.with_format` is inconsistent with the documentation.
https://huggingface.co/docs/datasets/use_with_pytorch#n-dimensional-arrays
https://huggingface.co/docs/datasets/v2.19.0/en/use_with_tensorflow#n-dimensional-arrays
> If your dataset consists of N-dimensional arrays, you will see that by default they are considered as nested lists.
> In particular, a PyTorch formatted dataset outputs nested lists instead of a single tensor.
> A TensorFlow formatted dataset outputs a RaggedTensor instead of a single tensor.
But I get a single tensor by default, which is inconsistent with the description.
Actually the current behavior seems more reasonable to me. Therefore, the document needs to be modified.
### Steps to reproduce the bug
```python
>>> from datasets import Dataset
>>> data = [[[1, 2],[3, 4]],[[5, 6],[7, 8]]]
>>> ds = Dataset.from_dict({"data": data})
>>> ds = ds.with_format("torch")
>>> ds[0]
{'data': tensor([[1, 2],
[3, 4]])}
>>> ds = ds.with_format("tf")
>>> ds[0]
{'data': <tf.Tensor: shape=(2, 2), dtype=int64, numpy=
array([[1, 2],
[3, 4]])>}
```
### Expected behavior
```python
>>> from datasets import Dataset
>>> data = [[[1, 2],[3, 4]],[[5, 6],[7, 8]]]
>>> ds = Dataset.from_dict({"data": data})
>>> ds = ds.with_format("torch")
>>> ds[0]
{'data': [tensor([1, 2]), tensor([3, 4])]}
>>> ds = ds.with_format("tf")
>>> ds[0]
{'data': <tf.RaggedTensor [[1, 2], [3, 4]]>}
```
### Environment info
datasets==2.19.1
torch==2.1.0
tensorflow==2.13.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42494185?v=4",
"events_url": "https://api.github.com/users/iansheng/events{/privacy}",
"followers_url": "https://api.github.com/users/iansheng/followers",
"following_url": "https://api.github.com/users/iansheng/following{/other_user}",
"gists_url": "https://api.github.com/users/iansheng/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/iansheng",
"id": 42494185,
"login": "iansheng",
"node_id": "MDQ6VXNlcjQyNDk0MTg1",
"organizations_url": "https://api.github.com/users/iansheng/orgs",
"received_events_url": "https://api.github.com/users/iansheng/received_events",
"repos_url": "https://api.github.com/users/iansheng/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/iansheng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iansheng/subscriptions",
"type": "User",
"url": "https://api.github.com/users/iansheng",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6950/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6950/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6949/comments | https://api.github.com/repos/huggingface/datasets/issues/6949/events | https://github.com/huggingface/datasets/issues/6949 | 2,332,336,573 | I_kwDODunzps6LBKG9 | 6,949 | load_dataset error | {
"avatar_url": "https://avatars.githubusercontent.com/u/27952522?v=4",
"events_url": "https://api.github.com/users/frederichen01/events{/privacy}",
"followers_url": "https://api.github.com/users/frederichen01/followers",
"following_url": "https://api.github.com/users/frederichen01/following{/other_user}",
"gists_url": "https://api.github.com/users/frederichen01/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/frederichen01",
"id": 27952522,
"login": "frederichen01",
"node_id": "MDQ6VXNlcjI3OTUyNTIy",
"organizations_url": "https://api.github.com/users/frederichen01/orgs",
"received_events_url": "https://api.github.com/users/frederichen01/received_events",
"repos_url": "https://api.github.com/users/frederichen01/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/frederichen01/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/frederichen01/subscriptions",
"type": "User",
"url": "https://api.github.com/users/frederichen01",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Hi, @lion-ops.\r\n\r\nIn our Continuous Integration we have many tests on loading JSON files and all of them work properly.\r\n\r\nCould you please share your \"train.json\" file, so that we can try to reproduce the issue you have? ",
"> Hi, @lion-ops.\r\n> \r\n> In our Continuous Integration we have many tests on loading JSON files and all of them work properly.\r\n> \r\n> Could you please share your \"train.json\" file, so that we can try to reproduce the issue you have?\r\n\r\nThank you for your reply. I can load it normally in another server. Is it possible that the disk of my server is a network disk in the LAN, so it will be downloaded from the LAN and get stuck?"
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
Why does the program get stuck when I use load_dataset method, and it still gets stuck after loading for several hours? In fact, my json file is only 21m, and I can load it in one go using open('', 'r').
### Steps to reproduce the bug
1. pip install datasets==2.19.2
2. from datasets import Dataset, DatasetDict, NamedSplit, Split, load_dataset
3. data = load_dataset('json', data_files='train.json')
### Expected behavior
It is able to load my json correctly
### Environment info
datasets==2.19.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6949/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6949/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6948 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6948/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6948/comments | https://api.github.com/repos/huggingface/datasets/issues/6948/events | https://github.com/huggingface/datasets/issues/6948 | 2,331,758,300 | I_kwDODunzps6K-87c | 6,948 | to_tf_dataset: Visible devices cannot be modified after being initialized | {
"avatar_url": "https://avatars.githubusercontent.com/u/7151661?v=4",
"events_url": "https://api.github.com/users/logasja/events{/privacy}",
"followers_url": "https://api.github.com/users/logasja/followers",
"following_url": "https://api.github.com/users/logasja/following{/other_user}",
"gists_url": "https://api.github.com/users/logasja/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/logasja",
"id": 7151661,
"login": "logasja",
"node_id": "MDQ6VXNlcjcxNTE2NjE=",
"organizations_url": "https://api.github.com/users/logasja/orgs",
"received_events_url": "https://api.github.com/users/logasja/received_events",
"repos_url": "https://api.github.com/users/logasja/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/logasja/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/logasja/subscriptions",
"type": "User",
"url": "https://api.github.com/users/logasja",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,717 | null | NONE | null | ### Describe the bug
When trying to use to_tf_dataset with a custom data_loader collate_fn when I use parallelism I am met with the following error as many times as number of workers there were in ``num_workers``.
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/multiprocess/process.py", line 314, in _bootstrap
self.run()
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/datasets/utils/tf_utils.py", line 438, in worker_loop
tf.config.set_visible_devices([], "GPU") # Make sure workers don't try to allocate GPU memory
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/tensorflow/python/framework/config.py", line 566, in set_visible_devices
context.context().set_visible_devices(devices, device_type)
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/tensorflow/python/eager/context.py", line 1737, in set_visible_devices
raise RuntimeError(
RuntimeError: Visible devices cannot be modified after being initialized
### Steps to reproduce the bug
1. Download a dataset using HuggingFace load_dataset
2. Define a function that transforms the data in some way to be used in the collate_fn argument
3. Provide a ``batch_size`` and ``num_workers`` value in the ``to_tf_dataset`` function
4. Either retrieve directly or use tfds benchmark to test the dataset
``` python
from datasets import load_datasets
import tensorflow_datasets as tfds
from keras_cv.layers import Resizing
def data_loader(examples):
x = Resizing(examples[0]['image'], 256, 256, crop_to_aspect_ratio=True)
return {X[0]: x}
ds = load_datasets("logasja/FDF", split="test")
ds = ds.to_tf_dataset(collate_fn=data_loader, batch_size=16, num_workers=2)
tfds.benchmark(ds)
```
### Expected behavior
Use multiple processes to apply transformations from the collate_fn to the tf dataset on the CPU.
### Environment info
- `datasets` version: 2.19.1
- Platform: Linux-6.5.0-1023-oracle-x86_64-with-glibc2.35
- Python version: 3.11.8
- `huggingface_hub` version: 0.22.2
- PyArrow version: 15.0.2
- Pandas version: 2.2.1
- `fsspec` version: 2024.2.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6948/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6948/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6947 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6947/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6947/comments | https://api.github.com/repos/huggingface/datasets/issues/6947/events | https://github.com/huggingface/datasets/issues/6947 | 2,331,114,055 | I_kwDODunzps6K8fpH | 6,947 | FileNotFoundError:error when loading C4 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/62374585?v=4",
"events_url": "https://api.github.com/users/W-215/events{/privacy}",
"followers_url": "https://api.github.com/users/W-215/followers",
"following_url": "https://api.github.com/users/W-215/following{/other_user}",
"gists_url": "https://api.github.com/users/W-215/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/W-215",
"id": 62374585,
"login": "W-215",
"node_id": "MDQ6VXNlcjYyMzc0NTg1",
"organizations_url": "https://api.github.com/users/W-215/orgs",
"received_events_url": "https://api.github.com/users/W-215/received_events",
"repos_url": "https://api.github.com/users/W-215/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/W-215/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/W-215/subscriptions",
"type": "User",
"url": "https://api.github.com/users/W-215",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"same problem here",
"Hello,\r\n\r\nAre you sure you are really using datasets version 2.19.2? We just made the patch release yesterday specifically to fix this issue:\r\n- #6925\r\n\r\nI can't reproduce the error:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation')\r\nDownloading readme: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41.1k/41.1k [00:00<00:00, 596kB/s]\r\nDownloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40.7M/40.7M [00:04<00:00, 8.50MB/s]\r\nGenerating validation split: 45576 examples [00:01, 44956.75 examples/s]\r\n\r\nIn [3]: ds\r\nOut[3]: \r\nDataset({\r\n features: ['text', 'timestamp', 'url'],\r\n num_rows: 45576\r\n})\r\n```",
"> Hello,\r\n> \r\n> Are you sure you are really using datasets version 2.19.2? We just made the patch release yesterday specifically to fix this issue:\r\n> \r\n> * [Fix NonMatchingSplitsSizesError/ExpectedMoreSplits when passing data_dir/data_files in no-code Hub datasets #6925](https://github.com/huggingface/datasets/pull/6925)\r\n> \r\n> I can't reproduce the error:\r\n> \r\n> ```python\r\n> In [1]: from datasets import load_dataset\r\n> \r\n> In [2]: ds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation')\r\n> Downloading readme: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41.1k/41.1k [00:00<00:00, 596kB/s]\r\n> Downloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40.7M/40.7M [00:04<00:00, 8.50MB/s]\r\n> Generating validation split: 45576 examples [00:01, 44956.75 examples/s]\r\n> \r\n> In [3]: ds\r\n> Out[3]: \r\n> Dataset({\r\n> features: ['text', 'timestamp', 'url'],\r\n> num_rows: 45576\r\n> })\r\n> ```\r\nThank you for your reply,ExpectedMoreSplits was encountered in datasets version 2.12.2. After I updated the version, that is, datasets version 2.19.2, I encountered the FileNotFoundError problem mentioned above.",
"That might be due to a corrupted cache.\r\n\r\nPlease, retry loading the dataset passing: `download_mode=\"force_redownload\"`\r\n```python\r\nds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation', download_mode=\"force_redownload\")\r\n```\r\n\r\nIt the above command does not fix the issue, then you will need to fix the cache manually, by removing the corresponding directory inside `~/.cache/huggingface/`.\r\n",
"> That might be due to a corrupted cache.\r\n> \r\n> Please, retry loading the dataset passing: `download_mode=\"force_redownload\"`\r\n> \r\n> ```python\r\n> ds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation', download_mode=\"force_redownload\")\r\n> ```\r\n> \r\n> It the above command does not fix the issue, then you will need to fix the cache manually, by removing the corresponding directory inside `~/.cache/huggingface/`.\r\n\r\nThe two methods you mentioned above can not solve this problem, but the command line interface shows Downloading readme: 41.1kB [00:00, 281kB/s], and then FileNotFoundError appears. It is worth noting that I have no problem loading other datasets with the initial method, such as wikitext datasets",
"> The two methods you mentioned above can not solve this problem, but the command line interface shows Downloading readme: 41.1kB [00:00, 281kB/s], and then FileNotFoundError appears.\r\n\r\nSame issue encountered.\r\n",
"I really think the issue is caused by a corrupted cache, between versions 2.12.0 (there does not exist 2.12.2 version) and 2.19.2.\r\n\r\nAre you sure you removed all the corresponding corrupted directories within the cache?\r\n\r\nYou can easily check if the issue is caused by a corrupted cache by removing the entire cache:\r\n```shell\r\nmv ~/.cache/huggingface ~/.cache/huggingface.bak\r\n```\r\nand then reloading the dataset:\r\n```python\r\nds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation', download_mode=\"force_redownload\")\r\n```",
"@albertvillanova Thanks for the reply. I tried removing the entire cache and reloading the dataset as you suggest. However, the same issue still exists. \r\n\r\nAs a test, I switch to a new platform, which (is a Windows system and) hasn't downloaded huggingface dataset before, and the dataset is loaded successfully. So I think \"a corrupted cache\" explanation makes sense. I wonder, besides `~/.cache/huggingface`, is there any other directory that may save the cache thing?\r\n\r\nAs a side note, I am using `datasets==2.20.0` and proxy `export HF_ENDPOINT=https://hf-mirror.com`.",
"Ho @ZhangGe6,\r\n\r\nAs far as I know, that directory is the only one where the cache is saved, unless you configured another one. You can check it:\r\n```python\r\nimport datasets.config\r\n\r\nprint(datasets.config.HF_CACHE_HOME)\r\n# ~/.cache/huggingface\r\n\r\nprint(datasets.config.HF_DATASETS_CACHE)\r\n# ~/.cache/huggingface/datasets\r\n\r\nprint(datasets.config.HF_MODULES_CACHE)\r\n# ~/.cache/huggingface/modules\r\n\r\nprint(datasets.config.DOWNLOADED_DATASETS_PATH)\r\n# ~/.cache/huggingface/datasets/downloads\r\n\r\nprint(datasets.config.EXTRACTED_DATASETS_PATH)\r\n# ~/.cache/huggingface/datasets/downloads/extracted\r\n```\r\n\r\nAdditionally, `datasets` uses `huggingface_hub`, but its cache directory should also be inside `~/.cache/huggingface`, unless you configured another one. You can check it:\r\n```python\r\nimport huggingface_hub.constants\r\n\r\nprint(huggingface_hub.constants.HF_HOME)\r\n# ~/.cache/huggingface\r\n\r\nprint(huggingface_hub.constants.HF_HUB_CACHE)\r\n# ~/.cache/huggingface/hub\r\n```",
"@albertvillanova I checked the directories you listed, and find that they are the same as the ones you provided. I am going to find more clues and will update what I find here.",
"I've had a similar problem, and for some reason decreasing the number of workers in the dataloader solved it",
"Same issue.\r\n",
"Hi folks. Finally, I find it is a network issue that causes huggingface hub unreachable (in China).\r\n\r\nTo run the following script \r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation', download_mode=\"force_redownload\")\r\n```\r\nWithout setting `export HF_ENDPOINT=https://hf-mirror.com`, I get the following error log\r\n```bash\r\nTraceback (most recent call last):\r\n File \".\\demo.py\", line 8, in <module>\r\n ds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation', download_mode=\"force_redownload\")\r\n File \"D:\\SoftwareInstall\\Python\\lib\\site-packages\\datasets\\load.py\", line 2594, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"D:\\SoftwareInstall\\Python\\lib\\site-packages\\datasets\\load.py\", line 2266, in load_dataset_builder\r\n dataset_module = dataset_module_factory(\r\n File \"D:\\SoftwareInstall\\Python\\lib\\site-packages\\datasets\\load.py\", line 1914, in dataset_module_factory\r\n raise e1 from None\r\n File \"D:\\SoftwareInstall\\Python\\lib\\site-packages\\datasets\\load.py\", line 1845, in dataset_module_factory\r\n raise ConnectionError(f\"Couldn't reach '{path}' on the Hub ({e.__class__.__name__})\") from e\r\nConnectionError: Couldn't reach 'allenai/c4' on the Hub (ConnectionError)\r\n```\r\nAfter setting `export HF_ENDPOINT=https://hf-mirror.com`, I get the following error, which is exactly the same as what we are debugging in this issue\r\n```bash\r\nDownloading readme: 41.1kB [00:00, 41.1MB/s]\r\nTraceback (most recent call last):\r\n File \".\\demo.py\", line 8, in <module>\r\n ds = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation', download_mode=\"force_redownload\")\r\n File \"D:\\SoftwareInstall\\Python\\lib\\site-packages\\datasets\\load.py\", line 2594, in loa builder_instance = load_dataset_builder(\r\n File \"D:\\SoftwareInstall\\Python\\lib\\site-packages\\datasets\\load.py\", line 2266, in load_dataset_builder\r\n dataset_module = dataset_module_factory(\r\n raise FileNotFoundError(\r\nFileNotFoundError: Couldn't find a dataset script at C:\\Users\\ZhangGe\\Desktop\\allenai\\c4\\c4.py or any data file in the same directory. Couldn't find 'allenai/c4' on the Hugging Face Hub either: FileNotFoundError: Unable to find 'hf://datasets/allenai/c4@1588ec454eed extension ['.csv', '.tsv', '.json', '.jsonl', '.parquet', '.geoparquet', '.gpq', '.arrow', '.txt', '.tar', '.blp', '.bmp', '.dib', '.bufr', '.cur', '.pcx', '.dcx', '.dds', '.ps', '.eps', '.fit', '.fits', '.fli', '.flc', '.ftc', '.ftu', '.gbr', '.gif', '.grib', \r\n'.h5', '.hdf', '.png', '.apng', '.jp2', '.j2k', '.jpc', '.jpf', '.jpx', '.j2c', '.icns',pm', '.BLP', '.BMP', '.DIB', '.BUFR', '.CUR', '.PCX', '.DCX', '.DDS', '.PS', '.EPS', '.FIT', '.FITS', '.FLI', '.FLC', '.FTC', '.FTU', '.GBR', '.GIF', '.GRIB', '.H5', '.HDF', '.PNG', '.APNG', '.JP2', '.J2K', '.JPC', '.JPF', '.JPX', '.J2C', '.ICNS', '.ICO', '.IM', '.IIM', '.TIF', '.TIFF', '.JFIF', '.JPE', '.JPG', '.JPEG', '.MPG', '.MPEG', '.MSP', '.PCD', '.PXR', '.PBM', '.PGM', '.PPM', '.PNM', '.PSD', '.BW', '.RGB', '.RGBA', '.SGI', '.RAS', '.TGA', '.ICB', '.VDA', '.VST', '.WEBP', '.WMF', '.EMF', '.XBM', '.XPM', '.aiff', '.au', '.avr', '.caf', '.flac', '.htk', '.svx', '.mat4', '.mat5', '.mpc2k', '.ogg', '.paf', '.pvf', '.raw', '.rf64', '.sd2', '.sds', '.ircam', '.voc', '.w64', '.wav', '.nist', '.wavex', '.wve', '.xi', '.mp3', '.opus', '.AIFF', '.AU', '.AVR', '.CAF', '.FLAC', '.HTK', \r\n'.SVX', '.MAT4', '.MAT5', '.MPC2K', '.OGG', '.PAF', '.PVF', '.RAW', '.RF64', '.SD2', '.SDS', '.IRCAM', '.VOC', '.W64', '.WAV', '.NIST', '.WAVEX', '.WVE', '.XI', '.MP3', '.OPUS', '.zip']\r\n```\r\n\r\n**Using a proxy software that avoids the internet access restrictions imposed by China, I can download the dataset using the same script**\r\n```bash\r\nDownloading readme: 100%|███████████████████████████████████████████| 41.1k/41.1k [00:00<00:00, 312kB/s] \r\nDownloading data: 100%|████████████████████████████████████████████| 40.7M/40.7M [00:19<00:00, 2.07MB/s] \r\nGenerating validation split: 45576 examples [00:00, 54883.48 examples/s]\r\n```\r\nSo `allenai/c4` is still unreachable even after setting `export HF_ENDPOINT=https://hf-mirror.com`.",
"I have created an issue to inform the maintainers of `hf-mirror`:https://github.com/padeoe/hf-mirror-site/issues/30",
"Thanks for the investigation: so finally it is an issue with the specific endpoint you are using.\r\n\r\nYou properly opened an issue in their repo, so they can fix it.\r\n\r\nI am closing this issue here."
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
can't load c4 datasets
When I replace the datasets package to 2.12.2 I get raise datasets.utils.info_utils.ExpectedMoreSplits: {'train'}
How can I fix this?
### Steps to reproduce the bug
1.from datasets import load_dataset
2.dataset = load_dataset('allenai/c4', data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation')
3. raise FileNotFoundError(
FileNotFoundError: Couldn't find a dataset script at local_path/c4_val/allenai/c4/c4.py or any data file in the same directory. Couldn't find 'allenai/c4' on the Hugging Face Hub either: FileNotFoundError: Unable to find 'hf://datasets/allenai/c4@1588ec454efa1a09f29cd18ddd04fe05fc8653a2/en/c4-validation.00003-of-00008.json.gz' with any supported extension ['.csv', '.tsv', '.json', '.jsonl', '.parquet', '.geoparquet', '.gpq', '.arrow', '.txt', '.tar', '.blp', '.bmp', '.dib', '.bufr', '.cur', '.pcx', '.dcx', '.dds', '.ps', '.eps', '.fit', '.fits', '.fli', '.flc', '.ftc', '.ftu', '.gbr', '.gif', '.grib', '.h5', '.hdf', '.png', '.apng', '.jp2', '.j2k', '.jpc', '.jpf', '.jpx', '.j2c', '.icns', '.ico', '.im', '.iim', '.tif', '.tiff', '.jfif', '.jpe', '.jpg', '.jpeg', '.mpg', '.mpeg', '.msp', '.pcd', '.pxr', '.pbm', '.pgm', '.ppm', '.pnm', '.psd', '.bw', '.rgb', '.rgba', '.sgi', '.ras', '.tga', '.icb', '.vda', '.vst', '.webp', '.wmf', '.emf', '.xbm', '.xpm', '.BLP', '.BMP', '.DIB', '.BUFR', '.CUR', '.PCX', '.DCX', '.DDS', '.PS', '.EPS', '.FIT', '.FITS', '.FLI', '.FLC', '.FTC', '.FTU', '.GBR', '.GIF', '.GRIB', '.H5', '.HDF', '.PNG', '.APNG', '.JP2', '.J2K', '.JPC', '.JPF', '.JPX', '.J2C', '.ICNS', '.ICO', '.IM', '.IIM', '.TIF', '.TIFF', '.JFIF', '.JPE', '.JPG', '.JPEG', '.MPG', '.MPEG', '.MSP', '.PCD', '.PXR', '.PBM', '.PGM', '.PPM', '.PNM', '.PSD', '.BW', '.RGB', '.RGBA', '.SGI', '.RAS', '.TGA', '.ICB', '.VDA', '.VST', '.WEBP', '.WMF', '.EMF', '.XBM', '.XPM', '.aiff', '.au', '.avr', '.caf', '.flac', '.htk', '.svx', '.mat4', '.mat5', '.mpc2k', '.ogg', '.paf', '.pvf', '.raw', '.rf64', '.sd2', '.sds', '.ircam', '.voc', '.w64', '.wav', '.nist', '.wavex', '.wve', '.xi', '.mp3', '.opus', '.AIFF', '.AU', '.AVR', '.CAF', '.FLAC', '.HTK', '.SVX', '.MAT4', '.MAT5', '.MPC2K', '.OGG', '.PAF', '.PVF', '.RAW', '.RF64', '.SD2', '.SDS', '.IRCAM', '.VOC', '.W64', '.WAV', '.NIST', '.WAVEX', '.WVE', '.XI', '.MP3', '.OPUS', '.zip']
### Expected behavior
The data was successfully imported
### Environment info
python version 3.9
datasets version 2.19.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6947/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6947/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6942 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6942/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6942/comments | https://api.github.com/repos/huggingface/datasets/issues/6942/events | https://github.com/huggingface/datasets/issues/6942 | 2,329,562,382 | I_kwDODunzps6K2k0O | 6,942 | Import sorting is disabled by flake8 noqa directive after switching to ruff linter | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,717 | 1970-01-01T00:00:00.000001 | MEMBER | null | When we switched to `ruff` linter in PR:
- #5519
import sorting was disabled in all files containing the `# flake8: noqa` directive
- https://github.com/astral-sh/ruff/issues/11679
We should re-enable import sorting on those files. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6942/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6942/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6941/comments | https://api.github.com/repos/huggingface/datasets/issues/6941/events | https://github.com/huggingface/datasets/issues/6941 | 2,328,930,165 | I_kwDODunzps6K0Kd1 | 6,941 | Supporting FFCV: Fast Forward Computer Vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/20135317?v=4",
"events_url": "https://api.github.com/users/Luciennnnnnn/events{/privacy}",
"followers_url": "https://api.github.com/users/Luciennnnnnn/followers",
"following_url": "https://api.github.com/users/Luciennnnnnn/following{/other_user}",
"gists_url": "https://api.github.com/users/Luciennnnnnn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Luciennnnnnn",
"id": 20135317,
"login": "Luciennnnnnn",
"node_id": "MDQ6VXNlcjIwMTM1MzE3",
"organizations_url": "https://api.github.com/users/Luciennnnnnn/orgs",
"received_events_url": "https://api.github.com/users/Luciennnnnnn/received_events",
"repos_url": "https://api.github.com/users/Luciennnnnnn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Luciennnnnnn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Luciennnnnnn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Luciennnnnnn",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,717 | null | NONE | null | ### Feature request
Supporting FFCV, https://github.com/libffcv/ffcv
### Motivation
According to the benchmark, FFCV seems to be fastest image loading method.
### Your contribution
no | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6941/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6940 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6940/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6940/comments | https://api.github.com/repos/huggingface/datasets/issues/6940/events | https://github.com/huggingface/datasets/issues/6940 | 2,328,637,831 | I_kwDODunzps6KzDGH | 6,940 | Enable Sharding to Equal Sized Shards | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,717 | null | NONE | null | ### Feature request
Add an option when sharding a dataset to have all shards the same size. Will be good to provide both an option of duplication, and by truncation.
### Motivation
Currently the behavior of sharding is "If n % i == l, then the first l shards will have length (n // i) + 1, and the remaining shards will have length (n // i).". However, when using FSDP we want the shards to have the same size. This requires the user to manually handle this situation, but it will be nice if we had an option to shard the dataset into equally sized shards.
### Your contribution
For now just a PR. I can also add code that does what is needed, but probably not efficient.
Shard to equal size by duplication:
```
remainder = len(dataset) % num_shards
num_missing_examples = num_shards - remainder
duplicated = dataset.select(list(range(num_missing_examples)))
dataset = concatenate_datasets([dataset, duplicated])
shard = dataset.shard(num_shards, shard_idx)
```
Or by truncation:
```
shard = dataset.shard(num_shards, shard_idx)
num_examples_per_shard = len(dataset) // num_shards
shard = shard.select(list(range(num_examples_per_shard)))
``` | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6940/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6940/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6939 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6939/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6939/comments | https://api.github.com/repos/huggingface/datasets/issues/6939/events | https://github.com/huggingface/datasets/issues/6939 | 2,328,059,386 | I_kwDODunzps6Kw136 | 6,939 | ExpectedMoreSplits error when using data_dir | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,717 | 1970-01-01T00:00:00.000001 | MEMBER | null | As reported by @regisss, an `ExpectedMoreSplits` error is raised when passing `data_dir`:
```python
from datasets import load_dataset
dataset = load_dataset(
"lvwerra/stack-exchange-paired",
split="train",
cache_dir=None,
data_dir="data/rl",
)
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/dist-packages/datasets/load.py", line 2609, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1027, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1140, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/usr/local/lib/python3.10/dist-packages/datasets/utils/info_utils.py", line 92, in verify_splits
raise ExpectedMoreSplits(str(set(expected_splits) - set(recorded_splits)))
datasets.utils.info_utils.ExpectedMoreSplits: {'test'}
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6939/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6939/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6937 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6937/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6937/comments | https://api.github.com/repos/huggingface/datasets/issues/6937/events | https://github.com/huggingface/datasets/issues/6937 | 2,327,212,611 | I_kwDODunzps6KtnJD | 6,937 | JSON loader implicitly coerces floats to integers | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,717 | null | MEMBER | null | The JSON loader implicitly coerces floats to integers.
The column values `[0.0, 1.0, 2.0]` are coerced to `[0, 1, 2]`.
See CI error in dataset-viewer: https://github.com/huggingface/dataset-viewer/actions/runs/9290164936/job/25576926446
```
=================================== FAILURES ===================================
___________________________ test_statistics_endpoint ___________________________
normal_user_public_json_dataset = 'DVUser/tmp-dataset-17170199043860'
def test_statistics_endpoint(normal_user_public_json_dataset: str) -> None:
dataset = normal_user_public_json_dataset
config, split = get_default_config_split()
statistics_response = poll_until_ready_and_assert(
relative_url=f"/statistics?dataset={dataset}&config={config}&split={split}",
check_x_revision=True,
dataset=dataset,
)
content = statistics_response.json()
assert len(content) == 3
assert sorted(content) == ["num_examples", "partial", "statistics"], statistics_response
statistics = content["statistics"]
num_examples = content["num_examples"]
partial = content["partial"]
assert isinstance(statistics, list), statistics
assert len(statistics) == 6
assert num_examples == 4
assert partial is False
string_label_column = statistics[0]
assert "column_name" in string_label_column
assert "column_statistics" in string_label_column
assert "column_type" in string_label_column
assert string_label_column["column_name"] == "col_1"
assert string_label_column["column_type"] == "string_label" # 4 unique values -> label
assert isinstance(string_label_column["column_statistics"], dict)
assert string_label_column["column_statistics"] == {
"nan_count": 0,
"nan_proportion": 0.0,
"no_label_count": 0,
"no_label_proportion": 0.0,
"n_unique": 4,
"frequencies": {
"There goes another one.": 1,
"Vader turns round and round in circles as his ship spins into space.": 1,
"We count thirty Rebel ships, Lord Vader.": 1,
"The wingman spots the pirateship coming at him and warns the Dark Lord": 1,
},
}
int_column = statistics[1]
assert "column_name" in int_column
assert "column_statistics" in int_column
assert "column_type" in int_column
assert int_column["column_name"] == "col_2"
assert int_column["column_type"] == "int"
assert isinstance(int_column["column_statistics"], dict)
assert int_column["column_statistics"] == {
"histogram": {"bin_edges": [0, 1, 2, 3, 3], "hist": [1, 1, 1, 1]},
"max": 3,
"mean": 1.5,
"median": 1.5,
"min": 0,
"nan_count": 0,
"nan_proportion": 0.0,
"std": 1.29099,
}
float_column = statistics[2]
assert "column_name" in float_column
assert "column_statistics" in float_column
assert "column_type" in float_column
assert float_column["column_name"] == "col_3"
> assert float_column["column_type"] == "float"
E AssertionError: assert 'int' == 'float'
E - float
E + int
tests/test_14_statistics.py:72: AssertionError
=========================== short test summary info ============================
FAILED tests/test_14_statistics.py::test_statistics_endpoint - AssertionError: assert 'int' == 'float'
- float
+ int
```
This bug was introduced after:
- #6914
We have reported the issue to pandas:
- https://github.com/pandas-dev/pandas/issues/58866 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6937/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6937/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6936 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6936/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6936/comments | https://api.github.com/repos/huggingface/datasets/issues/6936/events | https://github.com/huggingface/datasets/issues/6936 | 2,326,119,853 | I_kwDODunzps6KpcWt | 6,936 | save_to_disk() freezes when saving on s3 bucket with multiprocessing | {
"avatar_url": "https://avatars.githubusercontent.com/u/54974949?v=4",
"events_url": "https://api.github.com/users/ycattan/events{/privacy}",
"followers_url": "https://api.github.com/users/ycattan/followers",
"following_url": "https://api.github.com/users/ycattan/following{/other_user}",
"gists_url": "https://api.github.com/users/ycattan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ycattan",
"id": 54974949,
"login": "ycattan",
"node_id": "MDQ6VXNlcjU0OTc0OTQ5",
"organizations_url": "https://api.github.com/users/ycattan/orgs",
"received_events_url": "https://api.github.com/users/ycattan/received_events",
"repos_url": "https://api.github.com/users/ycattan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ycattan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ycattan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ycattan",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"I got the same issue. Any updates so far for this issue?"
] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
I'm trying to save a `Dataset` using the `save_to_disk()` function with:
- `num_proc > 1`
- `dataset_path` being a s3 bucket path e.g. "s3://{bucket_name}/{dataset_folder}/"
The hf progress bar shows up but the saving does not seem to start.
When using one processor only (`num_proc=1`), everything works fine.
When saving the dataset on local disk (as opposed to s3 bucket) with `num_proc > 1`, everything works fine.
Thank you for your help! :)
### Steps to reproduce the bug
I tried without any storage options:
```
from datasets import load_dataset
sandbox_ds = load_dataset("openai_humaneval")
sandbox_ds["test"].save_to_disk(
"s3://bucket-name/test_multiprocessing_saving/",
num_proc=4,
)
```
and with the specific s3fs storage options:
```
from datasets import load_dataset
from s3fs import S3FileSystem
def get_s3fs():
return S3FileSystem()
sandbox_ds = load_dataset("openai_humaneval")
sandbox_ds["test"].save_to_disk(
"s3://bucket-name/test_multiprocessing_saving/",
num_proc=4,
storage_options=get_s3fs().storage_options, # also tried: storage_options=S3FileSystem().storage_options
)
```
I'm guessing I might use `storage_options` parameter wrongly, but I didn't find anything online that made it work.
**NB**: Behavior is the same when trying to save the whole `DatasetDict`.
### Expected behavior
Progress bar fills in and saving is carried out.
### Environment info
`datasets==2.18.0` | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6936/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6936/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6935/comments | https://api.github.com/repos/huggingface/datasets/issues/6935/events | https://github.com/huggingface/datasets/issues/6935 | 2,325,612,022 | I_kwDODunzps6KngX2 | 6,935 | Support for pathlib.Path in datasets 2.19.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/12202811?v=4",
"events_url": "https://api.github.com/users/lamyiowce/events{/privacy}",
"followers_url": "https://api.github.com/users/lamyiowce/followers",
"following_url": "https://api.github.com/users/lamyiowce/following{/other_user}",
"gists_url": "https://api.github.com/users/lamyiowce/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lamyiowce",
"id": 12202811,
"login": "lamyiowce",
"node_id": "MDQ6VXNlcjEyMjAyODEx",
"organizations_url": "https://api.github.com/users/lamyiowce/orgs",
"received_events_url": "https://api.github.com/users/lamyiowce/received_events",
"repos_url": "https://api.github.com/users/lamyiowce/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lamyiowce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lamyiowce/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lamyiowce",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"+1 I just noticed this when I tried to update `datasets` today."
] | 1970-01-01T00:00:00.000001 | 1,724 | null | NONE | null | ### Describe the bug
After the recent update of `datasets`, Dataset.save_to_disk does not accept a pathlib.Path anymore. It was supported in 2.18.0 and previous versions. Is this intentional? Was it supported before only because of a Python dusk-typing miracle?
### Steps to reproduce the bug
```
from datasets import Dataset
import pathlib
path = pathlib.Path("./my_out_path")
Dataset.from_dict(
{"text": ["hello world"], "label": [777], "split": ["train"]}
.save_to_disk(path)
```
This results in an error when using datasets 2.19:
```
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
File "/Users/jb/scratch/venv/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 1515, in save_to_disk
fs, _ = url_to_fs(dataset_path, **(storage_options or {}))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/jb/scratch/venv/lib/python3.11/site-packages/fsspec/core.py", line 383, in url_to_fs
chain = _un_chain(url, kwargs)
^^^^^^^^^^^^^^^^^^^^^^
File "/Users/jb/scratch/venv/lib/python3.11/site-packages/fsspec/core.py", line 323, in _un_chain
if "::" in path
^^^^^^^^^^^^
TypeError: argument of type 'PosixPath' is not iterable
```
Converting to str works, however.
```
Dataset.from_dict(
{"text": ["hello world"], "label": [777], "split": ["train"]}
).save_to_disk(str(path))
```
### Expected behavior
My dataset gets saved to disk without an error.
### Environment info
aiohttp==3.9.5
aiosignal==1.3.1
attrs==23.2.0
certifi==2024.2.2
charset-normalizer==3.3.2
datasets==2.19.0
dill==0.3.8
filelock==3.14.0
frozenlist==1.4.1
fsspec==2024.3.1
huggingface-hub==0.23.2
idna==3.7
multidict==6.0.5
multiprocess==0.70.16
numpy==1.26.4
packaging==24.0
pandas==2.2.2
pyarrow==16.1.0
pyarrow-hotfix==0.6
python-dateutil==2.9.0.post0
pytz==2024.1
PyYAML==6.0.1
requests==2.32.3
six==1.16.0
tqdm==4.66.4
typing_extensions==4.12.0
tzdata==2024.1
urllib3==2.2.1
xxhash==3.4.1
yarl==1.9.4 | null | {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6935/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6935/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6930/comments | https://api.github.com/repos/huggingface/datasets/issues/6930/events | https://github.com/huggingface/datasets/issues/6930 | 2,323,225,922 | I_kwDODunzps6KeZ1C | 6,930 | ValueError: Couldn't infer the same data file format for all splits. Got {'train': ('json', {}), 'validation': (None, {})} | {
"avatar_url": "https://avatars.githubusercontent.com/u/41767521?v=4",
"events_url": "https://api.github.com/users/CLL112/events{/privacy}",
"followers_url": "https://api.github.com/users/CLL112/followers",
"following_url": "https://api.github.com/users/CLL112/following{/other_user}",
"gists_url": "https://api.github.com/users/CLL112/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/CLL112",
"id": 41767521,
"login": "CLL112",
"node_id": "MDQ6VXNlcjQxNzY3NTIx",
"organizations_url": "https://api.github.com/users/CLL112/orgs",
"received_events_url": "https://api.github.com/users/CLL112/received_events",
"repos_url": "https://api.github.com/users/CLL112/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/CLL112/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CLL112/subscriptions",
"type": "User",
"url": "https://api.github.com/users/CLL112",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [
"How do you solve it ?\r\n",
"> How do you solve it ?\r\n\r\nPlease check your Python environment and dataset version. I have just resolved the issue, which was caused by a Python environment switching error\r\n"
] | 1970-01-01T00:00:00.000001 | 1,721 | null | NONE | null | ### Describe the bug
When I run the code en = load_dataset("allenai/c4", "en", streaming=True), I encounter an error: raise ValueError(f"Couldn't infer the same data file format for all splits. Got {split_modules}") ValueError: Couldn't infer the same data file format for all splits. Got {'train': ('json', {}), 'validation': (None, {})}.
However, running dataset = load_dataset('allenai/c4', streaming=True, data_files={'validation': 'en/c4-validation.00003-of-00008.json.gz'}, split='validation') works fine. What is the issue here?
### Steps to reproduce the bug
run code:
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from datasets import load_dataset
en = load_dataset("allenai/c4", "en", streaming=True)
### Expected behavior
Successfully loaded the dataset.
### Environment info
- `datasets` version: 2.18.0
- Platform: Linux-6.5.0-28-generic-x86_64-with-glibc2.17
- Python version: 3.8.19
- `huggingface_hub` version: 0.22.2
- PyArrow version: 15.0.2
- Pandas version: 2.0.3
- `fsspec` version: 2024.2.0
| null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6930/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6929 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6929/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6929/comments | https://api.github.com/repos/huggingface/datasets/issues/6929/events | https://github.com/huggingface/datasets/issues/6929 | 2,322,980,077 | I_kwDODunzps6Kddzt | 6,929 | Avoid downloading the whole dataset when only README.me has been touched on hub. | {
"avatar_url": "https://avatars.githubusercontent.com/u/73740254?v=4",
"events_url": "https://api.github.com/users/zinc75/events{/privacy}",
"followers_url": "https://api.github.com/users/zinc75/followers",
"following_url": "https://api.github.com/users/zinc75/following{/other_user}",
"gists_url": "https://api.github.com/users/zinc75/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zinc75",
"id": 73740254,
"login": "zinc75",
"node_id": "MDQ6VXNlcjczNzQwMjU0",
"organizations_url": "https://api.github.com/users/zinc75/orgs",
"received_events_url": "https://api.github.com/users/zinc75/received_events",
"repos_url": "https://api.github.com/users/zinc75/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zinc75/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zinc75/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zinc75",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"you're right, we're tackling this here: https://github.com/huggingface/dataset-viewer/issues/2757",
"@severo : great !"
] | 1970-01-01T00:00:00.000001 | 1,717 | null | NONE | null | ### Feature request
`datasets.load_dataset()` triggers a new download of the **whole dataset** when the README.md file has been touched on huggingface hub, even if data files / parquet files are the exact same.
I think the current behaviour of the load_dataset function is triggered whenever a change of the hash of latest commit on huggingface hub, but is there a clever way to only download again the dataset **if and only if** data is modified ?
### Motivation
The current behaviour is a waste of network bandwidth / disk space / research time.
### Your contribution
I don't have time to submit a PR, but I hope a simple solution will emerge from this issue ! | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6929/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6929/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6924 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6924/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6924/comments | https://api.github.com/repos/huggingface/datasets/issues/6924/events | https://github.com/huggingface/datasets/issues/6924 | 2,320,531,015 | I_kwDODunzps6KUH5H | 6,924 | Caching map result of DatasetDict. | {
"avatar_url": "https://avatars.githubusercontent.com/u/56939432?v=4",
"events_url": "https://api.github.com/users/MostHumble/events{/privacy}",
"followers_url": "https://api.github.com/users/MostHumble/followers",
"following_url": "https://api.github.com/users/MostHumble/following{/other_user}",
"gists_url": "https://api.github.com/users/MostHumble/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MostHumble",
"id": 56939432,
"login": "MostHumble",
"node_id": "MDQ6VXNlcjU2OTM5NDMy",
"organizations_url": "https://api.github.com/users/MostHumble/orgs",
"received_events_url": "https://api.github.com/users/MostHumble/received_events",
"repos_url": "https://api.github.com/users/MostHumble/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MostHumble/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MostHumble/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MostHumble",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,716 | null | NONE | null | Hi!
I'm currenty using the map function to tokenize a somewhat large dataset, so I need to use the cache to save ~25 mins.
Changing num_proc incduces the recomputation of the map, I'm not sure why and if this is excepted behavior?
here it says, that cached files are loaded sequentially:
https://github.com/huggingface/datasets/blob/bb2664cf540d5ce4b066365e7c8b26e7f1ca4743/src/datasets/arrow_dataset.py#L3005-L3006
it seems like I can pass in a fingerprint, and load it directly:
https://github.com/huggingface/datasets/blob/bb2664cf540d5ce4b066365e7c8b26e7f1ca4743/src/datasets/arrow_dataset.py#L3108-L3125
**Environment Setup:**
- Python 3.11.9
- datasets 2.19.1 conda-forge
- Linux 6.1.83-1.el9.elrepo.x86_64
**MRE**
```python
fixed raw_datasets
fixed tokenize_function
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=9,
remove_columns=['text'],
load_from_cache_file= True,
desc="Running tokenizer on dataset line_by_line",
)
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=5,
remove_columns=['text'],
load_from_cache_file= True,
desc="Running tokenizer on dataset line_by_line",
)
``` | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6924/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6924/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6923/comments | https://api.github.com/repos/huggingface/datasets/issues/6923/events | https://github.com/huggingface/datasets/issues/6923 | 2,319,292,872 | I_kwDODunzps6KPZnI | 6,923 | Export Parquet Tablet Audio-Set is null bytes in Arrow | {
"avatar_url": "https://avatars.githubusercontent.com/u/140120605?v=4",
"events_url": "https://api.github.com/users/anioji/events{/privacy}",
"followers_url": "https://api.github.com/users/anioji/followers",
"following_url": "https://api.github.com/users/anioji/following{/other_user}",
"gists_url": "https://api.github.com/users/anioji/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anioji",
"id": 140120605,
"login": "anioji",
"node_id": "U_kgDOCFoSHQ",
"organizations_url": "https://api.github.com/users/anioji/orgs",
"received_events_url": "https://api.github.com/users/anioji/received_events",
"repos_url": "https://api.github.com/users/anioji/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anioji/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anioji/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anioji",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,716 | null | NONE | null | ### Describe the bug
Exporting the processed audio inside the table with the dataset.to_parquet function, the object pyarrow {bytes: null, path: "Some/Path"}
At the same time, the same dataset uploaded to the hub has bit arrays


### Steps to reproduce the bug
1.Get dataset from audio and cast it
2.Export and push dataset
3.It’s scary to be indignant at the difference in the uploaded dataset and the fact that it was saved locally
```py
from datasets import Dataset, Audio
df = Dataset.from_csv("./datasets.csv")
df = df.cast_column("audio", Audio(16000))
df.to_parquet("./datasets.parquet")
df.push_to_hub(repo_id="************", token="**********************")
```
You can use "try replicate case" for this
[replicate_packet.zip](https://github.com/huggingface/datasets/files/15457114/replicate_packet.zip)
### Expected behavior
Two parquet tables identical in content. It is obvious?
### Environment info
Python 3.11+ (I try did it in 3.12 and got same result ) | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6923/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6919 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6919/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6919/comments | https://api.github.com/repos/huggingface/datasets/issues/6919/events | https://github.com/huggingface/datasets/issues/6919 | 2,315,618,993 | I_kwDODunzps6KBYqx | 6,919 | Invalid YAML in README.md: unknown tag !<tag:yaml.org,2002:python/tuple> | {
"avatar_url": "https://avatars.githubusercontent.com/u/67964?v=4",
"events_url": "https://api.github.com/users/juanqui/events{/privacy}",
"followers_url": "https://api.github.com/users/juanqui/followers",
"following_url": "https://api.github.com/users/juanqui/following{/other_user}",
"gists_url": "https://api.github.com/users/juanqui/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/juanqui",
"id": 67964,
"login": "juanqui",
"node_id": "MDQ6VXNlcjY3OTY0",
"organizations_url": "https://api.github.com/users/juanqui/orgs",
"received_events_url": "https://api.github.com/users/juanqui/received_events",
"repos_url": "https://api.github.com/users/juanqui/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/juanqui/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/juanqui/subscriptions",
"type": "User",
"url": "https://api.github.com/users/juanqui",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,716 | null | NONE | null | ### Describe the bug
I wrote a notebook to load an existing dataset, process it, and upload as a private dataset using `dataset.push_to_hub(...)` at the end. The push to hub is failing with:
```
ValueError: Invalid metadata in README.md.
- Invalid YAML in README.md: unknown tag !<tag:yaml.org,2002:python[/tuple](http://192.168.1.128:8888/tuple)> (50:11)
47 | - 4
48 | - 4
49 | - 8
50 | - !!binary |
----------------^
51 | TwAAAA==
52 | '1': !!python[/object/apply](http://192.168.1.128:8888/object/apply):nump ...
```
My dataset has a `train` and `validation` dataset. These are the features:
```
{'c1': Value(dtype='string', id=None),
'c2': Value(dtype='string', id=None),
'c3': [{'value': Value(dtype='string', id=None),
'start': Value(dtype='int64', id=None),
'end': Value(dtype='int64', id=None),
'label': Value(dtype='string', id=None)}],
'c4': Value(dtype='string', id=None),
'c5': Value(dtype='string', id=None),
'c6': Value(dtype='string', id=None),
'c7': Value(dtype='string', id=None),
'c8': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None),
'c9': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'c10': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'labels': Sequence(feature=ClassLabel(names=['O', 'B-ABC', 'I-ABC', ...], id=None), length=-1, id=None),
'c12': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}
```
This used to work until I decided to cast the `labels` feature to a `Sequence(ClassLabel(...))` type with:
```
ds['train'] = ds['train'].cast_column("labels", Sequence(ClassLabel(names=list(labels))))
ds['validation'] = ds['validation'].cast_column("labels", Sequence(ClassLabel(names=list(labels))))
```
### Steps to reproduce the bug
1. Start with any token classification dataset.
2. Add a `labels` column with data such as `[0,0,0,12,13,13,13,0,0]`.
3. Cast the label column from `Sequence` to `Sequence(ClassLabel))` with:
```
labels = ['O', 'B-TEST', 'I-TEST']
ds = ds.cast_column("labels", Sequence(ClassLabel(names=labels)))
```
4. Push to hub with `ds.push_to_hub("me/awesome-stuff-dataset")`
### Expected behavior
I expected `push_to_hub` to successfully push my dataset to the hub without error.
### Environment info
Python 3.11.9
datasets==2.19.1
transformers==4.41.1
PyYAML==6.0.1 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6919/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6919/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6918/comments | https://api.github.com/repos/huggingface/datasets/issues/6918/events | https://github.com/huggingface/datasets/issues/6918 | 2,315,322,738 | I_kwDODunzps6KAQVy | 6,918 | NonMatchingSplitsSizesError when using data_dir | {
"avatar_url": "https://avatars.githubusercontent.com/u/86664538?v=4",
"events_url": "https://api.github.com/users/srehaag/events{/privacy}",
"followers_url": "https://api.github.com/users/srehaag/followers",
"following_url": "https://api.github.com/users/srehaag/following{/other_user}",
"gists_url": "https://api.github.com/users/srehaag/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srehaag",
"id": 86664538,
"login": "srehaag",
"node_id": "MDQ6VXNlcjg2NjY0NTM4",
"organizations_url": "https://api.github.com/users/srehaag/orgs",
"received_events_url": "https://api.github.com/users/srehaag/received_events",
"repos_url": "https://api.github.com/users/srehaag/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srehaag/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srehaag/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srehaag",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Thanks for reporting, @srehaag.\r\n\r\nWe are investigating this issue.",
"I confirm there is a bug for data-based Hub datasets when the user passes `data_dir`, which was introduced by PR:\r\n- #6714"
] | 1970-01-01T00:00:00.000001 | 1,717 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
Loading a dataset from with a data_dir argument generates a NonMatchingSplitsSizesError if there are multiple directories in the dataset.
This appears to happen because the expected split is calculated based on the data in all the directories whereas the recorded split is calculated based on the data in the directory specified using the data_dir argument.
This is recent behavior. Until the past few weeks loading using the data_dir argument worked without any issue.
### Steps to reproduce the bug
Simple test dataset available here: https://huggingface.co/datasets/srehaag/hf-bug-temp
The dataset contains two directories "data1" and "data2", each with a file called "train.parquet" with a 2 x 5 table.
from datasets import load_dataset
dataset = load_dataset("srehaag/hf-bug-temp", data_dir = "data1")
Generates:
---------------------------------------------------------------------------
NonMatchingSplitsSizesError Traceback (most recent call last)
Cell In[3], <a href='vscode-notebook-cell:?execution_count=3&line=2'>line 2</a>
<a href='vscode-notebook-cell:?execution_count=3&line=1'>1</a> from datasets import load_dataset
----> <a href='vscode-notebook-cell:?execution_count=3&line=2'>2</a> dataset = load_dataset("srehaag/hf-bug-temp", data_dir = "data1")
File ~/.python/current/lib/python3.10/site-packages/datasets/load.py:2609, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, token, use_auth_token, task, streaming, num_proc, storage_options, trust_remote_code, **config_kwargs)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2606'>2606</a> return builder_instance.as_streaming_dataset(split=split)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2608'>2608</a> # Download and prepare data
-> <a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2609'>2609</a> builder_instance.download_and_prepare(
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2610'>2610</a> download_config=download_config,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2611'>2611</a> download_mode=download_mode,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2612'>2612</a> verification_mode=verification_mode,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2613'>2613</a> num_proc=num_proc,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2614'>2614</a> storage_options=storage_options,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2615'>2615</a> )
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2617'>2617</a> # Build dataset for splits
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2618'>2618</a> keep_in_memory = (
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2619'>2619</a> keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/load.py:2620'>2620</a> )
File ~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1027, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, verification_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1025'>1025</a> if num_proc is not None:
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1026'>1026</a> prepare_split_kwargs["num_proc"] = num_proc
-> <a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1027'>1027</a> self._download_and_prepare(
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1028'>1028</a> dl_manager=dl_manager,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1029'>1029</a> verification_mode=verification_mode,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1030'>1030</a> **prepare_split_kwargs,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1031'>1031</a> **download_and_prepare_kwargs,
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1032'>1032</a> )
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1033'>1033</a> # Sync info
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1034'>1034</a> self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File ~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1140, in DatasetBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1137'>1137</a> dl_manager.manage_extracted_files()
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1139'>1139</a> if verification_mode == VerificationMode.BASIC_CHECKS or verification_mode == VerificationMode.ALL_CHECKS:
-> <a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1140'>1140</a> verify_splits(self.info.splits, split_dict)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1142'>1142</a> # Update the info object with the splits.
<a href='~/.python/current/lib/python3.10/site-packages/datasets/builder.py:1143'>1143</a> self.info.splits = split_dict
File ~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:101, in verify_splits(expected_splits, recorded_splits)
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:95'>95</a> bad_splits = [
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:96'>96</a> {"expected": expected_splits[name], "recorded": recorded_splits[name]}
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:97'>97</a> for name in expected_splits
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:98'>98</a> if expected_splits[name].num_examples != recorded_splits[name].num_examples
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:99'>99</a> ]
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:100'>100</a> if len(bad_splits) > 0:
--> <a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:101'>101</a> raise NonMatchingSplitsSizesError(str(bad_splits))
<a href='~/.python/current/lib/python3.10/site-packages/datasets/utils/info_utils.py:102'>102</a> logger.info("All the splits matched successfully.")
NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=212, num_examples=10, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='train', num_bytes=106, num_examples=5, shard_lengths=None, dataset_name='hf-bug-temp')}]
__________
By contrast, this loads the data from both data1/train.parquet and data2/train.parquet without any error message:
from datasets import load_dataset
dataset = load_dataset("srehaag/hf-bug-temp")
### Expected behavior
Should load the 5 x 2 table from data1/train.parquet without error message.
### Environment info
Used Codespaces to simplify environment (see details below), but bug is present across various configurations.
- `datasets` version: 2.19.1
- Platform: Linux-6.5.0-1021-azure-x86_64-with-glibc2.31
- Python version: 3.10.13
- `huggingface_hub` version: 0.23.1
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.3.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6918/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6918/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6917/comments | https://api.github.com/repos/huggingface/datasets/issues/6917/events | https://github.com/huggingface/datasets/issues/6917 | 2,314,683,663 | I_kwDODunzps6J90UP | 6,917 | WinError 32 The process cannot access the file during load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/56682168?v=4",
"events_url": "https://api.github.com/users/elwe-2808/events{/privacy}",
"followers_url": "https://api.github.com/users/elwe-2808/followers",
"following_url": "https://api.github.com/users/elwe-2808/following{/other_user}",
"gists_url": "https://api.github.com/users/elwe-2808/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/elwe-2808",
"id": 56682168,
"login": "elwe-2808",
"node_id": "MDQ6VXNlcjU2NjgyMTY4",
"organizations_url": "https://api.github.com/users/elwe-2808/orgs",
"received_events_url": "https://api.github.com/users/elwe-2808/received_events",
"repos_url": "https://api.github.com/users/elwe-2808/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/elwe-2808/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elwe-2808/subscriptions",
"type": "User",
"url": "https://api.github.com/users/elwe-2808",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,716 | null | NONE | null | ### Describe the bug
When I try to load the opus_book from hugging face (following the [guide on the website](https://huggingface.co/docs/transformers/main/en/tasks/translation))
```python
from datasets import load_dataset, Dataset
dataset = load_dataset("Helsinki-NLP/opus_books", "en-fr", features=["id", "translation"])
```
I get an error:
`PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:/Users/Me/.cache/huggingface/datasets/Helsinki-NLP___parquet/ca-de-a39f1ef185b9b73b/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec.incomplete\\parquet-train-00000-00000-of-NNNNN.arrow'
`
<details><summary>Full stacktrace</summary>
<p>
```python
AttributeError Traceback (most recent call last)
File c:\Users\Me\.conda\envs\ia\lib\site-packages\datasets\builder.py:1858, in ArrowBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
[1857](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/builder.py:1857) _time = time.time()
-> [1858](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/builder.py:1858) for _, table in generator:
[1859](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/builder.py:1859) if max_shard_size is not None and writer._num_bytes > max_shard_size:
File c:\Users\Me\.conda\envs\ia\lib\site-packages\datasets\packaged_modules\parquet\parquet.py:59, in Parquet._generate_tables(self, files)
[58](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/packaged_modules/parquet/parquet.py:58) def _generate_tables(self, files):
---> [59](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/packaged_modules/parquet/parquet.py:59) schema = self.config.features.arrow_schema if self.config.features is not None else None
[60](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/packaged_modules/parquet/parquet.py:60) if self.config.features is not None and self.config.columns is not None:
AttributeError: 'list' object has no attribute 'arrow_schema'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
File c:\Users\Me\.conda\envs\ia\lib\site-packages\datasets\builder.py:1882, in ArrowBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
[1881](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/builder.py:1881) num_shards = shard_id + 1
-> [1882](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/builder.py:1882) num_examples, num_bytes = writer.finalize()
[1883](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/builder.py:1883) writer.close()
File c:\Users\Me\.conda\envs\ia\lib\site-packages\datasets\arrow_writer.py:584, in ArrowWriter.finalize(self, close_stream)
[583](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/arrow_writer.py:583) # If schema is known, infer features even if no examples were written
--> [584](file:///C:/Users/Me/.conda/envs/ia/lib/site-packages/datasets/arrow_writer.py:584) if self.pa_writer is None and self.schema:
...
--> [627](file:///C:/Users/Me/.conda/envs/ia/lib/shutil.py:627) os.unlink(fullname)
[628](file:///C:/Users/Me/.conda/envs/ia/lib/shutil.py:628) except OSError:
[629](file:///C:/Users/Me/.conda/envs/ia/lib/shutil.py:629) onerror(os.unlink, fullname, sys.exc_info())
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:/Users/Me/.cache/huggingface/datasets/Helsinki-NLP___parquet/ca-de-a39f1ef185b9b73b/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec.incomplete\\parquet-train-00000-00000-of-NNNNN.arrow'
```
</p>
</details>
### Steps to reproduce the bug
Steps to reproduce:
Just execute these lines
```python
from datasets import load_dataset, Dataset
dataset = load_dataset("Helsinki-NLP/opus_books", "en-fr", features=["id", "translation"])
```
### Expected behavior
I expect the dataset to be loaded without any errors.
### Environment info
| Package| Version|
|--------|--------|
| transformers| 4.37.2|
| python| 3.9.19|
| pytorch| 2.3.0|
| datasets|2.12.0 |
| arrow | 1.2.3|
I am using Conda on Windows 11. | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6917/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6917/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6916/comments | https://api.github.com/repos/huggingface/datasets/issues/6916/events | https://github.com/huggingface/datasets/issues/6916 | 2,311,675,564 | I_kwDODunzps6JyV6s | 6,916 | ```push_to_hub()``` - Prevent Automatic Generation of Splits | {
"avatar_url": "https://avatars.githubusercontent.com/u/29337128?v=4",
"events_url": "https://api.github.com/users/jetlime/events{/privacy}",
"followers_url": "https://api.github.com/users/jetlime/followers",
"following_url": "https://api.github.com/users/jetlime/following{/other_user}",
"gists_url": "https://api.github.com/users/jetlime/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jetlime",
"id": 29337128,
"login": "jetlime",
"node_id": "MDQ6VXNlcjI5MzM3MTI4",
"organizations_url": "https://api.github.com/users/jetlime/orgs",
"received_events_url": "https://api.github.com/users/jetlime/received_events",
"repos_url": "https://api.github.com/users/jetlime/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jetlime/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jetlime/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jetlime",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,716 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
I currently have a dataset which has not been splited. When pushing the dataset to my hugging face dataset repository, it is split into a testing and training set. How can I prevent the split from happening?
### Steps to reproduce the bug
1. Have a unsplit dataset
```python
Dataset({ features: ['input', 'output', 'Attack', '__index_level_0__'], num_rows: 944685 })
```
2. Push it to huggingface
```python
dataset.push_to_hub(dataset_name)
```
3. On the hugging face dataset repo, the dataset then appears to be splited:

4. Indeed, when loading the dataset from this repo, the dataset is split in two testing and training set.
```python
from datasets import load_dataset, Dataset
dataset = load_dataset("Jetlime/NF-CSE-CIC-IDS2018-v2", streaming=True)
dataset
```
output:
```
IterableDatasetDict({
train: IterableDataset({
features: ['input', 'output', 'Attack', '__index_level_0__'],
n_shards: 2
})
test: IterableDataset({
features: ['input', 'output', 'Attack', '__index_level_0__'],
n_shards: 1
})
```
### Expected behavior
The dataset shall not be splited, as not requested.
### Environment info
- `datasets` version: 2.19.1
- Platform: Linux-6.2.0-35-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.23.0
- PyArrow version: 15.0.2
- Pandas version: 2.2.2
- `fsspec` version: 2024.3.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/29337128?v=4",
"events_url": "https://api.github.com/users/jetlime/events{/privacy}",
"followers_url": "https://api.github.com/users/jetlime/followers",
"following_url": "https://api.github.com/users/jetlime/following{/other_user}",
"gists_url": "https://api.github.com/users/jetlime/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jetlime",
"id": 29337128,
"login": "jetlime",
"node_id": "MDQ6VXNlcjI5MzM3MTI4",
"organizations_url": "https://api.github.com/users/jetlime/orgs",
"received_events_url": "https://api.github.com/users/jetlime/received_events",
"repos_url": "https://api.github.com/users/jetlime/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jetlime/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jetlime/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jetlime",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6916/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6913 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6913/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6913/comments | https://api.github.com/repos/huggingface/datasets/issues/6913/events | https://github.com/huggingface/datasets/issues/6913 | 2,309,605,889 | I_kwDODunzps6JqcoB | 6,913 | Column order is nondeterministic when loading from JSON | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,716 | 1970-01-01T00:00:00.000001 | MEMBER | null | As reported by @meg-huggingface, the order of the JSON object keys is not preserved while loading a dataset from a JSON file with a list of objects.
For example, when loading a JSON files with a list of objects, each with the following ordered keys:
- [ID, Language, Topic],
the resulting dataset may have columns:
- [ID, Topic, Language], or
- [Topic, Language, ID], or
- [Topic, ID, Language],...
This issue is caused by the use of a Python set (which does not preserve the order):
https://github.com/huggingface/datasets/blob/60d21efbc01e15d0b596ac1072750cbecd91548a/src/datasets/packaged_modules/json/json.py#L168
introduced in
- #5772 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6913/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6913/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6912 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6912/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6912/comments | https://api.github.com/repos/huggingface/datasets/issues/6912/events | https://github.com/huggingface/datasets/issues/6912 | 2,309,365,961 | I_kwDODunzps6JpiDJ | 6,912 | Add MedImg for streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/72926928?v=4",
"events_url": "https://api.github.com/users/lhallee/events{/privacy}",
"followers_url": "https://api.github.com/users/lhallee/followers",
"following_url": "https://api.github.com/users/lhallee/following{/other_user}",
"gists_url": "https://api.github.com/users/lhallee/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhallee",
"id": 72926928,
"login": "lhallee",
"node_id": "MDQ6VXNlcjcyOTI2OTI4",
"organizations_url": "https://api.github.com/users/lhallee/orgs",
"received_events_url": "https://api.github.com/users/lhallee/received_events",
"repos_url": "https://api.github.com/users/lhallee/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhallee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhallee/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhallee",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [
"@mariosasko, @lhoestq, @albertvillanova\r\nHello! Can anyone help? or can you guys suggest who can help with this?",
"Hi ! Feel free to download the dataset and create a `Dataset` object with it.\r\n\r\nThen your'll be able to use `push_to_hub()` to upload the dataset to HF in Parquet format and make it streamable :)",
"> Hi ! Feel free to download the dataset and create a `Dataset` object with it.\r\n> \r\n> Then your'll be able to use `push_to_hub()` to upload the dataset to HF in Parquet format and make it streamable :)\r\n\r\nThe dataset is several TB in total, which I do not have the resources to handle.",
"Hi @lhoestq and @albertvillanova , just following up about this.",
"for big datasets you can push_to_hub one part at a time (e.g. as different splits) and merge the parts (just a simple modification in the YAML part of the README)",
"Sure, that makes sense. However, isn't there a size limit to what typical users can push?",
"Yes there is a limit, simply let us know by email at datasets [at] huggingface.co - this way we can give you a storage grant also help making sure the dataset is all good for people to use it easily",
"> Yes there is a limit, simply let us know by email at datasets [at] huggingface.co - this way we can give you a storage grant also help making sure the dataset is all good for people to use it easily\r\n\r\nGot it, that would be great."
] | 1970-01-01T00:00:00.000001 | 1,725 | null | NONE | null | ### Feature request
Host the MedImg dataset (similar to Imagenet but for biomedical images).
### Motivation
There is a clear need for biomedical image foundation models and large scale biomedical datasets that are easily streamable. This would be an excellent tool for the biomedical community.
### Your contribution
MedImg can be found [here](https://www.cuilab.cn/medimg/#). | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6912/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6912/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6908 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6908/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6908/comments | https://api.github.com/repos/huggingface/datasets/issues/6908/events | https://github.com/huggingface/datasets/issues/6908 | 2,304,958,116 | I_kwDODunzps6JYt6k | 6,908 | Fail to load "stas/c4-en-10k" dataset since 2.16 version | {
"avatar_url": "https://avatars.githubusercontent.com/u/38173059?v=4",
"events_url": "https://api.github.com/users/guch8017/events{/privacy}",
"followers_url": "https://api.github.com/users/guch8017/followers",
"following_url": "https://api.github.com/users/guch8017/following{/other_user}",
"gists_url": "https://api.github.com/users/guch8017/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/guch8017",
"id": 38173059,
"login": "guch8017",
"node_id": "MDQ6VXNlcjM4MTczMDU5",
"organizations_url": "https://api.github.com/users/guch8017/orgs",
"received_events_url": "https://api.github.com/users/guch8017/received_events",
"repos_url": "https://api.github.com/users/guch8017/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/guch8017/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guch8017/subscriptions",
"type": "User",
"url": "https://api.github.com/users/guch8017",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"I am not able to reproduce the error with datasets 2.19.1:\r\n```python\r\nIn [1]: from datasets import load_dataset; ds = load_dataset(\"stas/c4-en-10k\", streaming=True); item = next(iter(ds[\"train\"])); item\r\nOut[1]: {'text': 'Beginners BBQ Class Taking Place in Missoula!\\nDo you want to get better at making delicious BBQ? You will have the opportunity, put this on your calendar now. Thursday, September 22nd join World Class BBQ Champion, Tony Balay from Lonestar Smoke Rangers. He will be teaching a beginner level class for everyone who wants to get better with their culinary skills.\\nHe will teach you everything you need to know to compete in a KCBS BBQ competition, including techniques, recipes, timelines, meat selection and trimming, plus smoker and fire information.\\nThe cost to be in the class is $35 per person, and for spectators it is free. Included in the cost will be either a t-shirt or apron and you will be tasting samples of each meat that is prepared.'}\r\n\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"stas/c4-en-10k\", download_mode=\"force_redownload\"); ds\r\nDownloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13.3M/13.3M [00:00<00:00, 18.7MB/s]\r\nGenerating train split: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [00:00<00:00, 78548.55 examples/s]\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['text'],\r\n num_rows: 10000\r\n })\r\n})\r\n```\r\n\r\nLooking at your error traceback, I notice that the code line numbers do not correspond to the ones of datasets 2.19.1.\r\n\r\nAdditionally, I can't reproduce the issue with `HfFileSystem`:\r\n```python\r\nIn [1]: from huggingface_hub import HfFileSystem\r\n\r\nIn [2]: fs = HfFileSystem()\r\n\r\nIn [3]: with fs.open(\"datasets/stas/c4-en-10k/c4-en-10k.py\", \"rb\") as f:\r\n ...: data = f.read()\r\n ...: \r\n\r\nIn [4]: data[:20]\r\nOut[4]: b'# coding=utf-8\\n# Cop'\r\n```\r\n\r\nCould you please verify the `datasets` and `huggingface_hub` versions you are indeed using?\r\n```python\r\nimport datasets; print(datasets.__version__)\r\n\r\nimport huggingface_hub; print(huggingface_hub.__version__)\r\n```",
"Thanks for your reply! After I update the datasets version from 2.15.0 back to 2.19.1 again, it seems everything work well. Sorry for bordering you!"
] | 1970-01-01T00:00:00.000001 | 1,716 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
When update datasets library to version 2.16+ ( I test it on 2.16, 2.19.0 and 2.19.1), using the following code to load stas/c4-en-10k dataset
```python
from datasets import load_dataset, Dataset
dataset = load_dataset('stas/c4-en-10k')
```
and then it raise UnicodeDecodeError like
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/*/conda3/envs/watermark/lib/python3.10/site-packages/datasets/load.py", line 2523, in load_dataset
builder_instance = load_dataset_builder(
File "/home/*/conda3/envs/watermark/lib/python3.10/site-packages/datasets/load.py", line 2195, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/home/*/conda3/envs/watermark/lib/python3.10/site-packages/datasets/load.py", line 1846, in dataset_module_factory
raise e1 from None
File "/home/*/conda3/envs/watermark/lib/python3.10/site-packages/datasets/load.py", line 1798, in dataset_module_factory
can_load_config_from_parquet_export = "DEFAULT_CONFIG_NAME" not in f.read()
File "/home/*/conda3/envs/watermark/lib/python3.10/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
```
I found that fs.open loads a gzip file and parses it like plain text using utf-8 encoder.
```python
fs = HfFileSystem('https://huggingface.co')
fs.open("datasets/stas/c4-en-10k/c4-en-10k.py", "rb")
data = fs.read() # data is gzip bytes begin with b'\x1f\x8b\x08\x00\x00\tn\x88\x00...'
data2 = unzip_gzip_bytes(data) # data2 is what we want: '# coding=utf-8\n# Copyright 2020 The HuggingFace Datasets...'
```
### Steps to reproduce the bug
1. Install datasets between version 2.16 and 2.19
2. Use `datasets.load_dataset` method to load `stas/c4-en-10k` dataset.
### Expected behavior
Load dataset normally.
### Environment info
Platform = Linux-5.4.0-159-generic-x86_64-with-glibc2.35
Python = 3.10.14
Datasets = 2.19 | {
"avatar_url": "https://avatars.githubusercontent.com/u/38173059?v=4",
"events_url": "https://api.github.com/users/guch8017/events{/privacy}",
"followers_url": "https://api.github.com/users/guch8017/followers",
"following_url": "https://api.github.com/users/guch8017/following{/other_user}",
"gists_url": "https://api.github.com/users/guch8017/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/guch8017",
"id": 38173059,
"login": "guch8017",
"node_id": "MDQ6VXNlcjM4MTczMDU5",
"organizations_url": "https://api.github.com/users/guch8017/orgs",
"received_events_url": "https://api.github.com/users/guch8017/received_events",
"repos_url": "https://api.github.com/users/guch8017/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/guch8017/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guch8017/subscriptions",
"type": "User",
"url": "https://api.github.com/users/guch8017",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6908/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6908/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6907 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6907/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6907/comments | https://api.github.com/repos/huggingface/datasets/issues/6907/events | https://github.com/huggingface/datasets/issues/6907 | 2,303,855,833 | I_kwDODunzps6JUgzZ | 6,907 | Support the deserialization of json lines files comprised of lists | {
"avatar_url": "https://avatars.githubusercontent.com/u/8473183?v=4",
"events_url": "https://api.github.com/users/umarbutler/events{/privacy}",
"followers_url": "https://api.github.com/users/umarbutler/followers",
"following_url": "https://api.github.com/users/umarbutler/following{/other_user}",
"gists_url": "https://api.github.com/users/umarbutler/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/umarbutler",
"id": 8473183,
"login": "umarbutler",
"node_id": "MDQ6VXNlcjg0NzMxODM=",
"organizations_url": "https://api.github.com/users/umarbutler/orgs",
"received_events_url": "https://api.github.com/users/umarbutler/received_events",
"repos_url": "https://api.github.com/users/umarbutler/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/umarbutler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/umarbutler/subscriptions",
"type": "User",
"url": "https://api.github.com/users/umarbutler",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Update: I ended up deciding to go back to use lines of dictionaries instead of arrays, not because of this issue as my users would be capable of downloading my corpus without `datasets`, but the speed and storage savings are not currently worth breaking my API and harming the backwards compatibility of each new revision.\r\n\r\nWith that said, for a static dataset that is not regularly updated like mine, and particularly for extremely large datasets with millions or billions of rows, using arrays could have a meaningful impact, and so there is probably still value in supporting this structure, provided the effort is not too much."
] | 1970-01-01T00:00:00.000001 | 1,716 | null | NONE | null | ### Feature request
I manage a somewhat large and popular Hugging Face dataset known as the [Open Australian Legal Corpus](https://huggingface.co/datasets/umarbutler/open-australian-legal-corpus). I recently updated my corpus to be stored in a json lines file where each line is an array and each element represents a value at a particular column. Previously, my corpus was stored as a json lines file where each line was a dictionary and the keys were the fields.
Essentially, a line in my json lines file used to look like this:
```json
{"version_id":"","type":"","jurisdiction":"","source":"","citation":"","url":"","when_scraped":"","text":""}
```
And now it looks like this:
```json
["","","","","","","",""]
```
This saves 65 bytes per document and allows me very quickly serialise and deserialise documents via `msgspec`.
After making this change, I found that `datasets` was incapable of deserialising my Corpus without a custom loading script, even if I ensured that the `dataset_info` field in my dataset card contained the desired names of my features.
I would like to request that functionality be added to support this format which is more memory-efficent and faster than using dictionaries.
### Motivation
The [documentation](https://huggingface.co/docs/datasets/en/dataset_script) for creating dataset loading scripts asserts that:
> In the next major release, the new safety features of 🤗 Datasets will disable running dataset loading scripts by default, and you will have to pass trust_remote_code=True to load datasets that require running a dataset script.
I would rather not require my users to pass `trust_remote_code=True` which means that I will need built-in support for this format.
### Your contribution
I would be happy to submit a PR for this if this is something you would incorporate into `datasets` and if I can be pointed to where the code would need to go. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6907/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6907/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6906 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6906/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6906/comments | https://api.github.com/repos/huggingface/datasets/issues/6906/events | https://github.com/huggingface/datasets/issues/6906 | 2,303,679,119 | I_kwDODunzps6JT1qP | 6,906 | irc_disentangle - Issue with splitting data | {
"avatar_url": "https://avatars.githubusercontent.com/u/114260604?v=4",
"events_url": "https://api.github.com/users/eor51355/events{/privacy}",
"followers_url": "https://api.github.com/users/eor51355/followers",
"following_url": "https://api.github.com/users/eor51355/following{/other_user}",
"gists_url": "https://api.github.com/users/eor51355/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eor51355",
"id": 114260604,
"login": "eor51355",
"node_id": "U_kgDOBs96fA",
"organizations_url": "https://api.github.com/users/eor51355/orgs",
"received_events_url": "https://api.github.com/users/eor51355/received_events",
"repos_url": "https://api.github.com/users/eor51355/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eor51355/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eor51355/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eor51355",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Thank you I will try this out!\r\n\r\nOn Tue, Jun 11, 2024 at 3:55 AM Vincent Lau ***@***.***>\r\nwrote:\r\n\r\n> I add a \"streaming=True\" after the name of the dataset, and it\r\n> works.....hope it can help you\r\n>\r\n> And if you install the version datasets==2.15.0, this bug will not happen.\r\n> I don't know why, but all of them works\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/6906#issuecomment-2160041812>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/A3HXU7AMBT2MNO34SC3Z5G3ZG2UOXAVCNFSM6AAAAABH45CNPWVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDCNRQGA2DCOBRGI>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"I still find out that there are some strange bug in v2.15.0 of datasets. it seems like that the *.arrow file cannot be established. it may be an index of the subsets. well I still try to debug it. but, one of the most efficient way may be using the google colab to build this index in the ~/huggingface/datasets, and than download them to replace the local file.....lol......it works!",
"Yeah I did try what you suggested and it didn’t work. I was able to get it\r\non a local from someone who access the dataset in the past. Let me know\r\nwhen you end up fixing this bug.\r\n\r\nOn Tue, Jun 11, 2024 at 10:33 PM Vincent Lau ***@***.***>\r\nwrote:\r\n\r\n> I still find out that there are some strange bug in v2.15.0 of datasets.\r\n> it seems like that the *.arrow file cannot be established. it may be an\r\n> index of the subsets. well I still try to debug it. but, one of the most\r\n> efficient way may be using the google colab to build this index in the\r\n> ~/huggingface/datasets, and than download them to replace the local\r\n> file.....lol......it works!\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/6906#issuecomment-2161988798>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/A3HXU7BCJE2LOCWRVWPMNODZG6XPJAVCNFSM6AAAAABH45CNPWVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDCNRRHE4DQNZZHA>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"Could you please provide more information, as required by the Bug template: https://github.com/huggingface/datasets/issues/new?assignees=&labels=&projects=&template=bug-report.yml\r\n\r\nWithout all that information, it is very difficult for us to understand the underlying issue and to give a pertinent answer.\r\n\r\nWhat are the versions of the libraries you are using? Datasets, pyarrow, fsspec,...\r\n> Environment info\r\n> Please share your environemnt info with us. You can run the command datasets-cli env and copy-paste its output below.\r\n\r\nWhat is the output you get after executing these code lines?\r\n```python\r\nimport datasets\r\nds = datasets.load_dataset('irc_disentangle')\r\nds\r\n```\r\n\r\n",
"We have made the following fixes:\r\n- [Fix source data URL](https://huggingface.co/datasets/jkkummerfeld/irc_disentangle/discussions/4)\r\n- [Convert dataset to Parquet](https://huggingface.co/datasets/jkkummerfeld/irc_disentangle/discussions/5)",
"Thank you for the fixes. Sorry I lost this conversation in my inbox.\r\n\r\nOn Mon, Jul 8, 2024 at 2:18 AM Albert Villanova del Moral <\r\n***@***.***> wrote:\r\n\r\n> Closed #6906 <https://github.com/huggingface/datasets/issues/6906> as\r\n> completed.\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/6906#event-13418330895>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/A3HXU7HREJDE5BZSOEJFJI3ZLIVLNAVCNFSM6AAAAABH45CNPWVHI2DSMVQWIX3LMV45UABCJFZXG5LFIV3GK3TUJZXXI2LGNFRWC5DJN5XDWMJTGQYTQMZTGA4DSNI>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n"
] | 1970-01-01T00:00:00.000001 | 1,721 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
I am trying to access your database through python using "datasets.load_dataset("irc_disentangle")" and I am getting this error message:
ValueError: Instruction "train" corresponds to no data!
### Steps to reproduce the bug
import datasets
ds = datasets.load_dataset('irc_disentangle')
ds
### Expected behavior
The data is supposed to load into ds and be accessable as such:
ds['train'][1050], ds['train'][1055]
### Environment info
I tired Python 3.12 and 3.10 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6906/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6906/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6905 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6905/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6905/comments | https://api.github.com/repos/huggingface/datasets/issues/6905/events | https://github.com/huggingface/datasets/issues/6905 | 2,303,098,587 | I_kwDODunzps6JRn7b | 6,905 | Extraction protocol for arrow files is not defined | {
"avatar_url": "https://avatars.githubusercontent.com/u/26553095?v=4",
"events_url": "https://api.github.com/users/radulescupetru/events{/privacy}",
"followers_url": "https://api.github.com/users/radulescupetru/followers",
"following_url": "https://api.github.com/users/radulescupetru/following{/other_user}",
"gists_url": "https://api.github.com/users/radulescupetru/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/radulescupetru",
"id": 26553095,
"login": "radulescupetru",
"node_id": "MDQ6VXNlcjI2NTUzMDk1",
"organizations_url": "https://api.github.com/users/radulescupetru/orgs",
"received_events_url": "https://api.github.com/users/radulescupetru/received_events",
"repos_url": "https://api.github.com/users/radulescupetru/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/radulescupetru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/radulescupetru/subscriptions",
"type": "User",
"url": "https://api.github.com/users/radulescupetru",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,715 | null | NONE | null | ### Describe the bug
Passing files with `.arrow` extension into data_files argument, at least when `streaming=True` is very slow.
### Steps to reproduce the bug
Basically it goes through the `_get_extraction_protocol` method located [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_utils.py#L820)
The method then looks at some base known extensions where `arrow` is not defined so it proceeds to determine the compression with the magic number method which is slow when dealing with a lot of files which are stored in s3 and by looking at this predefined list, I don't see `arrow` in there either so in the end it return None:
```
MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL = {
bytes.fromhex("504B0304"): "zip",
bytes.fromhex("504B0506"): "zip", # empty archive
bytes.fromhex("504B0708"): "zip", # spanned archive
bytes.fromhex("425A68"): "bz2",
bytes.fromhex("1F8B"): "gzip",
bytes.fromhex("FD377A585A00"): "xz",
bytes.fromhex("04224D18"): "lz4",
bytes.fromhex("28B52FFD"): "zstd",
}
```
### Expected behavior
My expectation is that `arrow` would be in the known lists so it would return None without going through the magic number method.
### Environment info
datasets 2.19.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6905/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6905/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6903 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6903/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6903/comments | https://api.github.com/repos/huggingface/datasets/issues/6903/events | https://github.com/huggingface/datasets/issues/6903 | 2,300,436,053 | I_kwDODunzps6JHd5V | 6,903 | Add the option of saving in parquet instead of arrow | {
"avatar_url": "https://avatars.githubusercontent.com/u/18707623?v=4",
"events_url": "https://api.github.com/users/arita37/events{/privacy}",
"followers_url": "https://api.github.com/users/arita37/followers",
"following_url": "https://api.github.com/users/arita37/following{/other_user}",
"gists_url": "https://api.github.com/users/arita37/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/arita37",
"id": 18707623,
"login": "arita37",
"node_id": "MDQ6VXNlcjE4NzA3NjIz",
"organizations_url": "https://api.github.com/users/arita37/orgs",
"received_events_url": "https://api.github.com/users/arita37/received_events",
"repos_url": "https://api.github.com/users/arita37/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/arita37/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arita37/subscriptions",
"type": "User",
"url": "https://api.github.com/users/arita37",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"I think [`Dataset.to_parquet`](https://huggingface.co/docs/datasets/v1.10.2/package_reference/main_classes.html#datasets.Dataset.to_parquet) is what you're looking for.\r\n\r\nLet me know if I'm wrong ",
"No, it does not save the metadata json.\r\n\r\nWe have to recode all meta json load/save\r\nwith another custome functions.\r\n\r\nsave_to_disk\r\nand load should have option with\r\n“Parquet” instead of “arrow”\r\n\r\nsince “arrow” is never user for production \r\n(only parquet).\r\n\r\nThanks !\r\n\r\n> On May 17, 2024, at 5:38, Frédéric Branchaud-Charron ***@***.***> wrote:\r\n> \r\n> \r\n> I think Dataset.to_parquet is what you're looking for.\r\n> \r\n> Let me know if I'm wrong\r\n> \r\n> —\r\n> Reply to this email directly, view it on GitHub, or unsubscribe.\r\n> You are receiving this because you authored the thread.\r\n",
"You can use `to_parquet` and `ds.info.write_to_directory()` to save the dataset info",
"Ok,\r\n\r\nWhat about loading ?\r\n\r\nShould we do in 2 steps ?\r\n\r\n\r\n\r\n> On Jun 14, 2024, at 1:09, Quentin Lhoest ***@***.***> wrote:\r\n> \r\n> \r\n> You can use to_parquet and ds.info.write_to_directory() to save the dataset info\r\n> \r\n> —\r\n> Reply to this email directly, view it on GitHub, or unsubscribe.\r\n> You are receiving this because you authored the thread.\r\n",
"Yes, and there is DatasetInfo.from_directory(). to reload the info",
"Isn’t easier to combine both\r\ninto load_dataset and save_dataset\r\nwith parquet options.\r\n\r\n2) another question,\r\nHow can we download large dataset into disk directly without loading all in memory (!)\r\n\r\n\r\n\r\n\r\n> On Jun 14, 2024, at 19:54, Quentin Lhoest ***@***.***> wrote:\r\n> \r\n> \r\n> Yes, and there is DatasetInfo.from_directory(). to reload the info\r\n> \r\n> —\r\n> Reply to this email directly, view it on GitHub, or unsubscribe.\r\n> You are receiving this because you authored the thread.\r\n",
"`load_dataset` doesn't load the dataset in memory, it progressively writes to disk in Arrow format and then memory maps the Arrow files. This allows to load datasets bigger than memory and without filling your RAM",
"Sure.\r\nHow memory map is managed ?\r\nManaged by the OS ?\r\n\r\nWhy the need of save_dataset() ?\r\n\r\n\r\n\r\n> On Jun 15, 2024, at 0:06, Quentin Lhoest ***@***.***> wrote:\r\n> \r\n> \r\n> load_dataset doesn't load the dataset in memory, it progressively writes to disk in Arrow format and then memory maps the Arrow files. This allows to load datasets bigger than memory and without filling your RAM\r\n> \r\n> —\r\n> Reply to this email directly, view it on GitHub, or unsubscribe.\r\n> You are receiving this because you authored the thread.\r\n"
] | 1970-01-01T00:00:00.000001 | 1,718 | null | NONE | null | ### Feature request
In dataset.save_to_disk('/path/to/save/dataset'),
add the option to save in parquet format
dataset.save_to_disk('/path/to/save/dataset', format="parquet"),
because arrow is not used for Production Big data.... (only parquet)
### Motivation
because arrow is not used for Production Big data.... (only parquet)
### Your contribution
I can do the testing ! | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6903/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6903/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6901 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6901/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6901/comments | https://api.github.com/repos/huggingface/datasets/issues/6901/events | https://github.com/huggingface/datasets/issues/6901 | 2,300,167,465 | I_kwDODunzps6JGcUp | 6,901 | HTTPError 403 raised by CLI convert_to_parquet when creating script branch on 3rd party repos | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,715 | 1970-01-01T00:00:00.000001 | MEMBER | null | CLI convert_to_parquet cannot create "script" branch on 3rd party repos.
It can only create it on repos where the user executing the script has write access.
Otherwise, a 403 Forbidden HTTPError is raised:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_errors.py", line 304, in hf_raise_for_status
response.raise_for_status()
File "/usr/local/lib/python3.10/dist-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://huggingface.co/api/datasets/ORG/DATASET/branch/script
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/bin/datasets-cli", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.10/dist-packages/datasets/commands/datasets_cli.py", line 41, in main
service.run()
File "/usr/local/lib/python3.10/dist-packages/datasets/commands/convert_to_parquet.py", line 92, in run
create_branch(dataset_id, branch="script", repo_type="dataset", token=token, exist_ok=True)
File "/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/huggingface_hub/hf_api.py", line 5503, in create_branch
hf_raise_for_status(response)
File "/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_errors.py", line 367, in hf_raise_for_status
raise HfHubHTTPError(message, response=response) from e
huggingface_hub.utils._errors.HfHubHTTPError: (Request ID: Root=1-6645ee0d-4db1ed8a1fbe04956be15897;139a6e23-df7d-4f62-b5ba-adb6d8e6e696)
403 Forbidden: Forbidden: cannot write to script.
Cannot access content at: https://huggingface.co/api/datasets/ORG/DATASET/branch/script.
If you are trying to create or update content,make sure you have a token with the `write` role.
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6901/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6901/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6900 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6900/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6900/comments | https://api.github.com/repos/huggingface/datasets/issues/6900/events | https://github.com/huggingface/datasets/issues/6900 | 2,298,489,733 | I_kwDODunzps6JACuF | 6,900 | [WebDataset] KeyError with user-defined `Features` when a field is missing in an example | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"@lhoestq How difficult of fix is this?",
"It shouldn't be difficult, I think it's just a matter of adding the missing fields from `self.config.features` in `example` here: before it iterates on image_field_names and audio_field_names. A missing field should have a value set to None\r\n\r\nhttps://github.com/huggingface/datasets/blob/768cb35ede5a6c35fa7545aa3671f3e321c96440/src/datasets/packaged_modules/webdataset/webdataset.py#L113-L116",
"@lhoestq So like this then?\r\n\r\n``` \r\ndef _generate_examples(self, tar_paths, tar_iterators):\r\n image_field_names = [\r\n field_name for field_name, feature in self.info.features.items() if isinstance(feature, datasets.Image)\r\n ]\r\n audio_field_names = [\r\n field_name for field_name, feature in self.info.features.items() if isinstance(feature, datasets.Audio)\r\n ]\r\n\t\r\n all_field_names = list(self.config.features.keys())\r\n \r\n for tar_idx, (tar_path, tar_iterator) in enumerate(zip(tar_paths, tar_iterators)):\r\n for example_idx, example in enumerate(self._get_pipeline_from_tar(tar_path, tar_iterator)):\r\n for field_name in all_field_names:\r\n if field_name not in example:\r\n if field_name in self.config.features:\r\n example[field_name] = self.config.features[field_name]\r\n else:\r\n example[field_name] = None\r\n \r\n # Process image and audio fields\r\n for field_name in image_field_names + audio_field_names:\r\n if example[field_name] is not None:\r\n example[field_name] = {\"path\": example[\"__key__\"] + \".\" + field_name, \"bytes\": example[field_name]}\r\n \r\n yield f\"{tar_idx}_{example_idx}\", example\r\n```\r\n\r\nOr should we avoid trying add the missing values and just set them to None?\r\n\r\n```\r\n for field_name in all_field_names:\r\n if field_name not in example:\r\n example[field_name] = None\r\n```",
"Yup this is the solution !\r\n\r\n```python\r\n for field_name in all_field_names:\r\n if field_name not in example:\r\n example[field_name] = None\r\n```",
"@lhoestq Awesome, thanks! I made a PR with the fixes"
] | 1970-01-01T00:00:00.000001 | 1,719 | 1970-01-01T00:00:00.000001 | MEMBER | null | reported at https://huggingface.co/datasets/ProGamerGov/synthetic-dataset-1m-dalle3-high-quality-captions/discussions/1
```
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/webdataset/webdataset.py", line 109, in _generate_examples
example[field_name] = {"path": example["__key__"] + "." + field_name, "bytes": example[field_name]}
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 2,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6900/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6900/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6899/comments | https://api.github.com/repos/huggingface/datasets/issues/6899/events | https://github.com/huggingface/datasets/issues/6899 | 2,298,059,597 | I_kwDODunzps6I-ZtN | 6,899 | List of dictionary features get standardized | {
"avatar_url": "https://avatars.githubusercontent.com/u/11831521?v=4",
"events_url": "https://api.github.com/users/sohamparikh/events{/privacy}",
"followers_url": "https://api.github.com/users/sohamparikh/followers",
"following_url": "https://api.github.com/users/sohamparikh/following{/other_user}",
"gists_url": "https://api.github.com/users/sohamparikh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sohamparikh",
"id": 11831521,
"login": "sohamparikh",
"node_id": "MDQ6VXNlcjExODMxNTIx",
"organizations_url": "https://api.github.com/users/sohamparikh/orgs",
"received_events_url": "https://api.github.com/users/sohamparikh/received_events",
"repos_url": "https://api.github.com/users/sohamparikh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sohamparikh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sohamparikh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sohamparikh",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,715 | null | NONE | null | ### Describe the bug
Hi, i’m trying to create a HF dataset from a list using Dataset.from_list.
Each sample in the list is a dict with the same keys (which will be my features). The values for each feature are a list of dictionaries, and each such dictionary has a different set of keys. However, the datasets library standardizes all dictionaries under a feature and adds all possible keys (with None value) from all the dictionaries under that feature.
How can I keep the same set of keys as in the original list for each dictionary under a feature?
### Steps to reproduce the bug
```
from datasets import Dataset
# Define a function to generate a sample with "tools" feature
def generate_sample():
# Generate random sample data
sample_data = {
"text": "Sample text",
"feature_1": []
}
# Add feature_1 with random keys for this sample
feature_1 = [{"key1": "value1"}, {"key2": "value2"}] # Example feature_1 with random keys
sample_data["feature_1"].extend(feature_1)
return sample_data
# Generate multiple samples
num_samples = 10
samples = [generate_sample() for _ in range(num_samples)]
# Create a Hugging Face Dataset
dataset = Dataset.from_list(samples)
dataset[0]
```
```{'text': 'Sample text', 'feature_1': [{'key1': 'value1', 'key2': None}, {'key1': None, 'key2': 'value2'}]}```
### Expected behavior
```{'text': 'Sample text', 'feature_1': [{'key1': 'value1'}, {'key2': 'value2'}]}```
### Environment info
- `datasets` version: 2.19.1
- Platform: Linux-5.15.0-1040-nvidia-x86_64-with-glibc2.35
- Python version: 3.10.13
- `huggingface_hub` version: 0.23.0
- PyArrow version: 15.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2023.10.0 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6899/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6897 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6897/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6897/comments | https://api.github.com/repos/huggingface/datasets/issues/6897/events | https://github.com/huggingface/datasets/issues/6897 | 2,293,428,243 | I_kwDODunzps6IsvAT | 6,897 | datasets template guide :: issue in documentation YAML | {
"avatar_url": "https://avatars.githubusercontent.com/u/59658056?v=4",
"events_url": "https://api.github.com/users/bghira/events{/privacy}",
"followers_url": "https://api.github.com/users/bghira/followers",
"following_url": "https://api.github.com/users/bghira/following{/other_user}",
"gists_url": "https://api.github.com/users/bghira/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bghira",
"id": 59658056,
"login": "bghira",
"node_id": "MDQ6VXNlcjU5NjU4MDU2",
"organizations_url": "https://api.github.com/users/bghira/orgs",
"received_events_url": "https://api.github.com/users/bghira/received_events",
"repos_url": "https://api.github.com/users/bghira/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bghira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bghira/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bghira",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [
"Hello, @bghira.\r\n\r\nThanks for reporting. Please note that the text originating the error is not supposed to be valid YAML: it contains the instructions to generate the actual YAML content, that should replace the instructions comment.\r\n\r\nOn the other hand, I agree that it is not nice to have that YAML error message at the top of the page: \r\n\r\n\r\nI am proposing a change to make the YAML error disappear.",
"thanks albert! i looked at it for a while to figure it out. i think the `raw` view option is the correct way to look at it?"
] | 1970-01-01T00:00:00.000001 | 1,715 | 1970-01-01T00:00:00.000001 | NONE | null | ### Describe the bug
There is a YAML error at the top of the page, and I don't think it's supposed to be there
### Steps to reproduce the bug
1. Browse to [this tutorial document](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md)
2. Observe a big red error at the top
3. The rest of the document remains functional
### Expected behavior
I think the YAML block should be displayed or ignored.
### Environment info
N/A | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6897/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6897/timeline | null | completed | null | null | false | 0 |
https://api.github.com/repos/huggingface/datasets/issues/6896 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6896/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6896/comments | https://api.github.com/repos/huggingface/datasets/issues/6896/events | https://github.com/huggingface/datasets/issues/6896 | 2,293,176,061 | I_kwDODunzps6Irxb9 | 6,896 | Regression bug: `NonMatchingSplitsSizesError` for (possibly) overwritten dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/167943?v=4",
"events_url": "https://api.github.com/users/finiteautomata/events{/privacy}",
"followers_url": "https://api.github.com/users/finiteautomata/followers",
"following_url": "https://api.github.com/users/finiteautomata/following{/other_user}",
"gists_url": "https://api.github.com/users/finiteautomata/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/finiteautomata",
"id": 167943,
"login": "finiteautomata",
"node_id": "MDQ6VXNlcjE2Nzk0Mw==",
"organizations_url": "https://api.github.com/users/finiteautomata/orgs",
"received_events_url": "https://api.github.com/users/finiteautomata/received_events",
"repos_url": "https://api.github.com/users/finiteautomata/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/finiteautomata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/finiteautomata/subscriptions",
"type": "User",
"url": "https://api.github.com/users/finiteautomata",
"user_view_type": "public"
} | [] | open | false | null | [] | null | [] | 1970-01-01T00:00:00.000001 | 1,715 | null | NONE | null | ### Describe the bug
While trying to load the dataset `https://huggingface.co/datasets/pysentimiento/spanish-tweets-small`, I get this error:
```python
---------------------------------------------------------------------------
NonMatchingSplitsSizesError Traceback (most recent call last)
[<ipython-input-1-d6a3c721d3b8>](https://localhost:8080/#) in <cell line: 3>()
1 from datasets import load_dataset
2
----> 3 ds = load_dataset("pysentimiento/spanish-tweets-small")
3 frames
[/usr/local/lib/python3.10/dist-packages/datasets/load.py](https://localhost:8080/#) in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, token, use_auth_token, task, streaming, num_proc, storage_options, **config_kwargs)
2150
2151 # Download and prepare data
-> 2152 builder_instance.download_and_prepare(
2153 download_config=download_config,
2154 download_mode=download_mode,
[/usr/local/lib/python3.10/dist-packages/datasets/builder.py](https://localhost:8080/#) in download_and_prepare(self, output_dir, download_config, download_mode, verification_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
946 if num_proc is not None:
947 prepare_split_kwargs["num_proc"] = num_proc
--> 948 self._download_and_prepare(
949 dl_manager=dl_manager,
950 verification_mode=verification_mode,
[/usr/local/lib/python3.10/dist-packages/datasets/builder.py](https://localhost:8080/#) in _download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)
1059
1060 if verification_mode == VerificationMode.BASIC_CHECKS or verification_mode == VerificationMode.ALL_CHECKS:
-> 1061 verify_splits(self.info.splits, split_dict)
1062
1063 # Update the info object with the splits.
[/usr/local/lib/python3.10/dist-packages/datasets/utils/info_utils.py](https://localhost:8080/#) in verify_splits(expected_splits, recorded_splits)
98 ]
99 if len(bad_splits) > 0:
--> 100 raise NonMatchingSplitsSizesError(str(bad_splits))
101 logger.info("All the splits matched successfully.")
102
NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=82649695458, num_examples=597433111, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='train', num_bytes=3358310095, num_examples=24898932, shard_lengths=[3626991, 3716991, 4036990, 3506990, 3676990, 3716990, 2616990], dataset_name='spanish-tweets-small')}]
```
I think I had this dataset updated, might be related to #6271
It is working fine as late in `2.10.0` , but not in `2.13.0` onwards.
### Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("pysentimiento/spanish-tweets-small")
```
You can run it in [this notebook](https://colab.research.google.com/drive/1FdhqLiVimHIlkn7B54DbhizeQ4U3vGVl#scrollTo=YgA50cBSibUg)
### Expected behavior
Load the dataset without any error
### Environment info
- `datasets` version: 2.13.0
- Platform: Linux-6.1.58+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.20.3
- PyArrow version: 14.0.2
- Pandas version: 2.0.3 | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6896/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6896/timeline | null | null | null | null | false | null |
https://api.github.com/repos/huggingface/datasets/issues/6894 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6894/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6894/comments | https://api.github.com/repos/huggingface/datasets/issues/6894/events | https://github.com/huggingface/datasets/issues/6894 | 2,292,840,226 | I_kwDODunzps6Iqfci | 6,894 | Better document defaults of to_json | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null | [] | 1970-01-01T00:00:00.000001 | 1,715 | 1970-01-01T00:00:00.000001 | MEMBER | null | Better document defaults of `to_json`: the default format is [JSON-Lines](https://jsonlines.org/).
Related to:
- #6891 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6894/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6894/timeline | null | completed | null | null | false | 0 |