
File size: 8,645 Bytes
7079747 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs.
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings.
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.
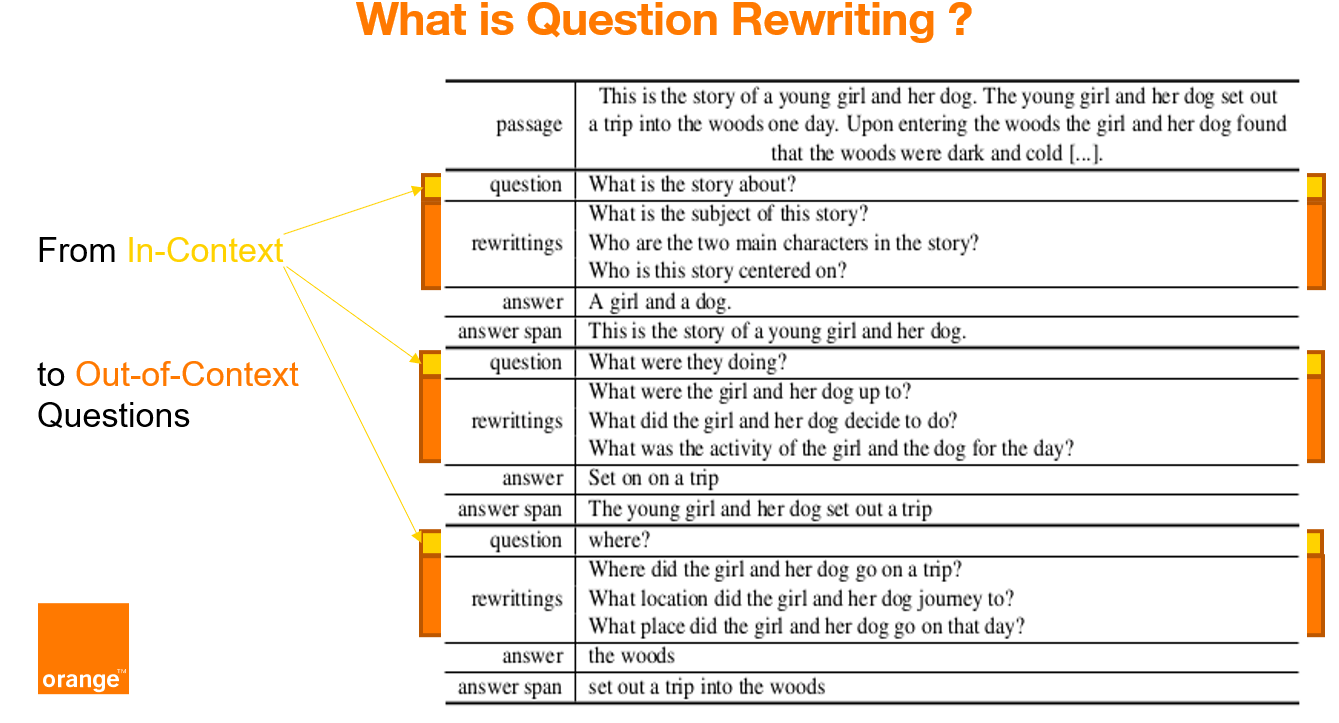
The annotations are published under the licence CC-BY-SA 4.0.
The original content of the dataset CoQA is under the distinct licences described below.
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license.
- Children's stories are collected from MCTest which comes with MSR-LA license.
- Middle/High school exam passages are collected from RACE which comes with its own license.
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see [K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015](http://arxiv.org/abs/1506.03340)).
"""
import csv
import json
import os
import datasets
_CITATION = """\
@inproceedings{brabant-etal-2022-coqar,
title = "{C}o{QAR}: Question Rewriting on {C}o{QA}",
author = "Brabant, Quentin and
Lecorv{\'e}, Gw{\'e}nol{\'e} and
Rojas Barahona, Lina M.",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.13",
pages = "119--126"
}
"""
_DESCRIPTION = """\
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs.
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings.
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.

The annotations are published under the licence CC-BY-SA 4.0.
The original content of the dataset CoQA is under the distinct licences described below.
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license.
- Children's stories are collected from MCTest which comes with MSR-LA license.
- Middle/High school exam passages are collected from RACE which comes with its own license.
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see [K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015](http://arxiv.org/abs/1506.03340)).
"""
_HOMEPAGE = "https://github.com/Orange-OpenSource/COQAR/"
_LICENSE = """
- Annotations, litterature and Wikipedia passages: licence CC-BY-SA 4.0.
- Children's stories are from MCTest (MSR-LA license).
- Exam passages come from RACE which has its own license.
- News passages are from the DeepMind CNN dataset (Apache license).
"""
_URLS = {
"train": "https://raw.githubusercontent.com/Orange-OpenSource/COQAR/master/data/CoQAR/train/coqar-train-v1.0.json",
"dev": "https://raw.githubusercontent.com/Orange-OpenSource/COQAR/master/data/CoQAR/dev/coqar-dev-v1.0.json"
}
class CoQAR(datasets.GeneratorBasedBuilder):
"""
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs.
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings.
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
"""
VERSION = datasets.Version("1.1.0")
def _info(self):
features = datasets.Features(
{
'conversation_id' : datasets.Value("string"),
'turn_id': datasets.Value("int16"),
'original_question' : datasets.Value("string"),
'question_paraphrases' : datasets.Sequence(feature=datasets.Value("string")),
'answer' : datasets.Value("string"),
'answer_span_start' : datasets.Value("int32"),
'answer_span_end' : datasets.Value("int32"),
'answer_span_text' : datasets.Value("string"),
'conversation_history' : datasets.Sequence(feature=datasets.Value("string")),
'file_name' : datasets.Value("string"),
'story': datasets.Value("string"),
'name': datasets.Value("string"),
}
)
return datasets.DatasetInfo(
# This is the description that will appear on the datasets page.
description=_DESCRIPTION,
# This defines the different columns of the dataset and their types
features=features,
homepage=_HOMEPAGE,
# License for the dataset if available
license=_LICENSE,
# Citation for the dataset
citation=_CITATION,
)
def _split_generators(self, dl_manager):
data_dir = dl_manager.download_and_extract(_URLS)
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
gen_kwargs={
"filepath": data_dir['train'],
"split": "train",
},
),
datasets.SplitGenerator(
name=datasets.Split.VALIDATION,
gen_kwargs={
"filepath": data_dir['dev'],
"split": "dev",
},
)
]
# method parameters are unpacked from `gen_kwargs` as given in `_split_generators`
def _generate_examples(self, filepath, split):
with open(filepath, 'r') as f:
dic = json.load(f)
i = 0
for datum in dic['data']:
history = []
for question, answer in zip(datum['questions'], datum['answers']):
yield i, {
'conversation_id' : datum['id'],
'turn_id': question['turn_id'],
'original_question' :question['input_text'],
'question_paraphrases' : question['paraphrase'],
'answer' : answer['input_text'],
'answer_span_start' : answer['span_start'],
'answer_span_end' : answer['span_end'],
'answer_span_text' : answer['span_text'],
'conversation_history' : list(history),
'file_name' : datum['filename'],
'story': datum['story'],
'name': datum['name']
}
history.append(question['input_text'])
history.append(answer['input_text'])
i+=1 |