
Commit
·
42472b3
0
Parent(s):
Duplicate from Weyaxi/commit-trash-huggingface-spaces-codes
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +63 -0
- README.md +202 -0
- errors.txt +24 -0
- names.txt +0 -0
- spaces.csv +0 -0
- spaces.zip +3 -0
- spaces/0019c/NewBing/Dockerfile +34 -0
- spaces/0019c/NewBing/README.md +12 -0
- spaces/01zhangclare/bingai/Dockerfile +34 -0
- spaces/01zhangclare/bingai/README.md +12 -0
- spaces/07jeancms/minima/README.md +13 -0
- spaces/07jeancms/minima/app.py +7 -0
- spaces/0x1337/vector-inference/README.md +12 -0
- spaces/0x1337/vector-inference/app.py +5 -0
- spaces/0x7194633/mbrat-ru-sum/README.md +12 -0
- spaces/0x7194633/mbrat-ru-sum/app.py +13 -0
- spaces/0x7194633/nllb-1.3B-demo/README.md +12 -0
- spaces/0x7194633/nllb-1.3B-demo/app.py +83 -0
- spaces/0x7194633/nllb-1.3B-demo/flores200_codes.py +211 -0
- spaces/0x876/Yotta_Mix/README.md +12 -0
- spaces/0x876/Yotta_Mix/app.py +3 -0
- spaces/0x90e/ESRGAN-MANGA/ESRGAN/architecture.py +37 -0
- spaces/0x90e/ESRGAN-MANGA/ESRGAN/block.py +261 -0
- spaces/0x90e/ESRGAN-MANGA/ESRGAN_plus/architecture.py +38 -0
- spaces/0x90e/ESRGAN-MANGA/ESRGAN_plus/block.py +287 -0
- spaces/0x90e/ESRGAN-MANGA/ESRGANer.py +156 -0
- spaces/0x90e/ESRGAN-MANGA/README.md +10 -0
- spaces/0x90e/ESRGAN-MANGA/app.py +86 -0
- spaces/0x90e/ESRGAN-MANGA/inference.py +59 -0
- spaces/0x90e/ESRGAN-MANGA/inference_manga_v2.py +46 -0
- spaces/0x90e/ESRGAN-MANGA/process_image.py +31 -0
- spaces/0x90e/ESRGAN-MANGA/run_cmd.py +9 -0
- spaces/0x90e/ESRGAN-MANGA/util.py +6 -0
- spaces/0xAnders/ama-bot/README.md +13 -0
- spaces/0xAnders/ama-bot/app.py +70 -0
- spaces/0xHacked/zkProver/Dockerfile +21 -0
- spaces/0xHacked/zkProver/README.md +11 -0
- spaces/0xHacked/zkProver/app.py +77 -0
- spaces/0xJustin/0xJustin-Dungeons-and-Diffusion/README.md +13 -0
- spaces/0xJustin/0xJustin-Dungeons-and-Diffusion/app.py +3 -0
- spaces/0xSpleef/openchat-openchat_8192/README.md +12 -0
- spaces/0xSpleef/openchat-openchat_8192/app.py +3 -0
- spaces/0xSynapse/Image_captioner/README.md +13 -0
- spaces/0xSynapse/Image_captioner/app.py +62 -0
- spaces/0xSynapse/LlamaGPT/README.md +13 -0
- spaces/0xSynapse/LlamaGPT/app.py +408 -0
- spaces/0xSynapse/PixelFusion/README.md +13 -0
- spaces/0xSynapse/PixelFusion/app.py +85 -0
- spaces/0xSynapse/Segmagine/README.md +13 -0
- spaces/0xSynapse/Segmagine/app.py +97 -0
.gitattributes
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.lz4 filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
# Audio files - uncompressed
|
| 38 |
+
*.pcm filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
*.sam filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
*.raw filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
# Audio files - compressed
|
| 42 |
+
*.aac filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
*.flac filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
*.mp3 filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
*.ogg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
*.wav filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
# Image files - uncompressed
|
| 48 |
+
*.bmp filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
*.gif filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
*.tiff filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
# Image files - compressed
|
| 53 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/guile/2.2/ccache/system/vm/assembler.go filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/guile/2.2/ccache/system/vm/dwarf.go filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
spaces/bigscience-data/bloom-tokenizer-multilinguality/index.html filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
spaces/bigscience-data/bloom-tokens/index.html filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
spaces/ghuron/artist/dataset/astro.sql filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
spaces/pdjewell/sommeli_ai/images/px.html filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
spaces/pdjewell/sommeli_ai/images/px_2d.html filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
spaces/pdjewell/sommeli_ai/images/px_3d.html filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
configs:
|
| 3 |
+
- config_name: default
|
| 4 |
+
data_files:
|
| 5 |
+
spaces.csv
|
| 6 |
+
|
| 7 |
+
license: other
|
| 8 |
+
language:
|
| 9 |
+
- code
|
| 10 |
+
size_categories:
|
| 11 |
+
- 100K<n<1M
|
| 12 |
+
---
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
# 📊 Dataset Description
|
| 16 |
+
|
| 17 |
+
This dataset comprises code files of Huggingface Spaces that have more than 0 likes as of November 10, 2023. This dataset contains various programming languages totaling in 672 MB of compressed and 2.05 GB of uncompressed data.
|
| 18 |
+
|
| 19 |
+
# 📝 Data Fields
|
| 20 |
+
|
| 21 |
+
| Field | Type | Description |
|
| 22 |
+
|------------|--------|------------------------------------------|
|
| 23 |
+
| repository | string | Huggingface Spaces repository names. |
|
| 24 |
+
| sdk | string | Software Development Kit of the space. |
|
| 25 |
+
| license | string | License type of the space. |
|
| 26 |
+
|
| 27 |
+
## 🧩 Data Structure
|
| 28 |
+
|
| 29 |
+
Data structure of the data.
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
spaces/
|
| 33 |
+
├─ author1/
|
| 34 |
+
│ ├─ space1
|
| 35 |
+
│ ├─ space2
|
| 36 |
+
├─ author2/
|
| 37 |
+
│ ├─ space1
|
| 38 |
+
│ ├─ space2
|
| 39 |
+
│ ├─ space3
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
# 🏛️ Licenses
|
| 43 |
+
|
| 44 |
+
Huggingface Spaces contains a variety of licenses. Here is the list of the licenses that this dataset contains:
|
| 45 |
+
|
| 46 |
+
```python
|
| 47 |
+
[
|
| 48 |
+
'None',
|
| 49 |
+
'mit',
|
| 50 |
+
'apache-2.0',
|
| 51 |
+
'openrail',
|
| 52 |
+
'gpl-3.0',
|
| 53 |
+
'other',
|
| 54 |
+
'afl-3.0',
|
| 55 |
+
'unknown',
|
| 56 |
+
'creativeml-openrail-m',
|
| 57 |
+
'cc-by-nc-4.0',
|
| 58 |
+
'cc-by-4.0',
|
| 59 |
+
'cc',
|
| 60 |
+
'cc-by-nc-sa-4.0',
|
| 61 |
+
'bigscience-openrail-m',
|
| 62 |
+
'bsd-3-clause',
|
| 63 |
+
'agpl-3.0',
|
| 64 |
+
'wtfpl',
|
| 65 |
+
'gpl',
|
| 66 |
+
'artistic-2.0',
|
| 67 |
+
'lgpl-3.0',
|
| 68 |
+
'cc-by-sa-4.0',
|
| 69 |
+
'Configuration error',
|
| 70 |
+
'bsd',
|
| 71 |
+
'cc-by-nc-nd-4.0',
|
| 72 |
+
'cc0-1.0',
|
| 73 |
+
'unlicense',
|
| 74 |
+
'llama2',
|
| 75 |
+
'bigscience-bloom-rail-1.0',
|
| 76 |
+
'gpl-2.0',
|
| 77 |
+
'bsd-2-clause',
|
| 78 |
+
'osl-3.0',
|
| 79 |
+
'cc-by-2.0',
|
| 80 |
+
'cc-by-3.0',
|
| 81 |
+
'cc-by-nc-3.0',
|
| 82 |
+
'cc-by-nc-2.0',
|
| 83 |
+
'cc-by-nd-4.0',
|
| 84 |
+
'openrail++',
|
| 85 |
+
'bigcode-openrail-m',
|
| 86 |
+
'bsd-3-clause-clear',
|
| 87 |
+
'eupl-1.1',
|
| 88 |
+
'cc-by-sa-3.0',
|
| 89 |
+
'mpl-2.0',
|
| 90 |
+
'c-uda',
|
| 91 |
+
'gfdl',
|
| 92 |
+
'cc-by-nc-sa-2.0',
|
| 93 |
+
'cc-by-2.5',
|
| 94 |
+
'bsl-1.0',
|
| 95 |
+
'odc-by',
|
| 96 |
+
'deepfloyd-if-license',
|
| 97 |
+
'ms-pl',
|
| 98 |
+
'ecl-2.0',
|
| 99 |
+
'pddl',
|
| 100 |
+
'ofl-1.1',
|
| 101 |
+
'lgpl-2.1',
|
| 102 |
+
'postgresql',
|
| 103 |
+
'lppl-1.3c',
|
| 104 |
+
'ncsa',
|
| 105 |
+
'cc-by-nc-sa-3.0'
|
| 106 |
+
]
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
# 📊 Dataset Statistics
|
| 110 |
+
|
| 111 |
+
| Language | File Extension | File Counts | File Size (MB) | Line Counts |
|
| 112 |
+
|------------|-----------------|-------------|----------------|-------------|
|
| 113 |
+
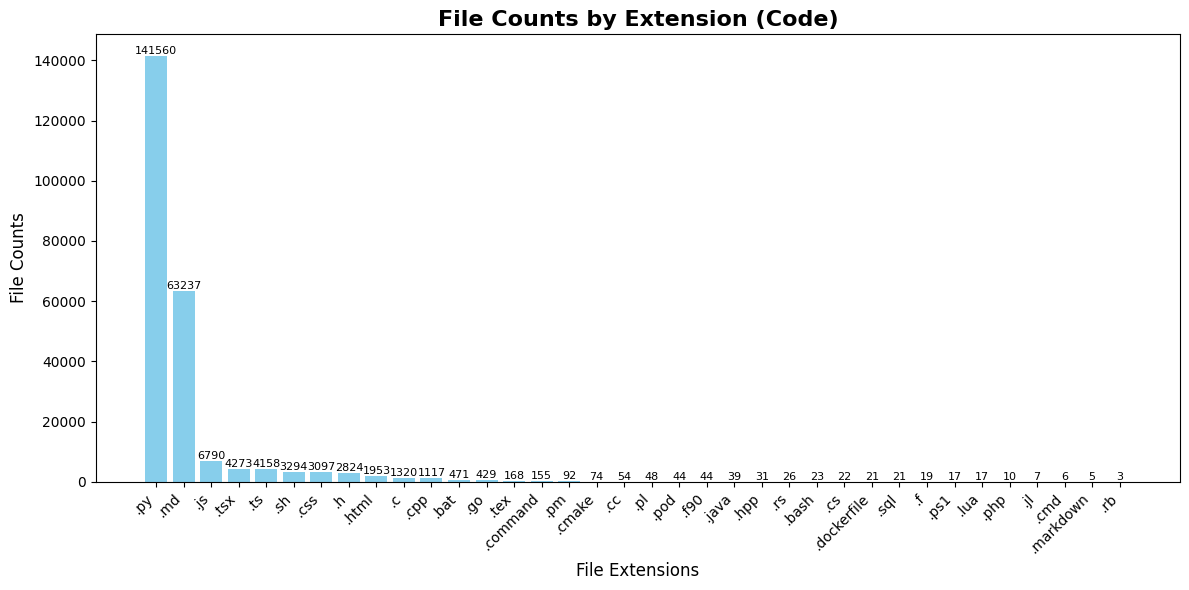
| Python | .py | 141,560 | 1079.0 | 28,653,744 |
|
| 114 |
+
| SQL | .sql | 21 | 523.6 | 645 |
|
| 115 |
+
| JavaScript | .js | 6,790 | 369.8 | 2,137,054 |
|
| 116 |
+
| Markdown | .md | 63,237 | 273.4 | 3,110,443 |
|
| 117 |
+
| HTML | .html | 1,953 | 265.8 | 516,020 |
|
| 118 |
+
| C | .c | 1,320 | 132.2 | 3,558,826 |
|
| 119 |
+
| Go | .go | 429 | 46.3 | 6,331 |
|
| 120 |
+
| CSS | .css | 3,097 | 25.6 | 386,334 |
|
| 121 |
+
| C Header | .h | 2,824 | 20.4 | 570,948 |
|
| 122 |
+
| C++ | .cpp | 1,117 | 15.3 | 494,939 |
|
| 123 |
+
| TypeScript | .ts | 4,158 | 14.8 | 439,551 |
|
| 124 |
+
| TSX | .tsx | 4,273 | 9.4 | 306,416 |
|
| 125 |
+
| Shell | .sh | 3,294 | 5.5 | 171,943 |
|
| 126 |
+
| Perl | .pm | 92 | 4.2 | 128,594 |
|
| 127 |
+
| C# | .cs | 22 | 3.9 | 41,265 |
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
## 🖥️ Language
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
## 📁 Size
|
| 135 |
+
|
| 136 |
+

|
| 137 |
+
|
| 138 |
+
## 📝 Line Count
|
| 139 |
+
|
| 140 |
+

|
| 141 |
+
|
| 142 |
+
# 🤗 Huggingface Spaces Statistics
|
| 143 |
+
|
| 144 |
+
## 🛠️ Software Development Kit (SDK)
|
| 145 |
+
|
| 146 |
+
Software Development Kit pie chart.
|
| 147 |
+
|
| 148 |
+

|
| 149 |
+
|
| 150 |
+
## 🏛️ License
|
| 151 |
+
|
| 152 |
+
License chart.
|
| 153 |
+
|
| 154 |
+

|
| 155 |
+
|
| 156 |
+
# 📅 Dataset Creation
|
| 157 |
+
|
| 158 |
+
This dataset was created in these steps:
|
| 159 |
+
|
| 160 |
+
1. Scraped all spaces using the Huggingface Hub API.
|
| 161 |
+
|
| 162 |
+
```python
|
| 163 |
+
from huggingface_hub import HfApi
|
| 164 |
+
api = HfApi()
|
| 165 |
+
|
| 166 |
+
spaces = api.list_spaces(sort="likes", full=1, direction=-1)
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
2. Filtered spaces with more than 0 likes.
|
| 170 |
+
|
| 171 |
+
```python
|
| 172 |
+
a = {}
|
| 173 |
+
|
| 174 |
+
for i in tqdm(spaces):
|
| 175 |
+
i = i.__dict__
|
| 176 |
+
if i['likes'] > 0:
|
| 177 |
+
try:
|
| 178 |
+
try:
|
| 179 |
+
a[i['id']] = {'sdk': i['sdk'], 'license': i['cardData']['license'], 'likes': i['likes']}
|
| 180 |
+
except KeyError:
|
| 181 |
+
a[i['id']] = {'sdk': i['sdk'], 'license': None, 'likes': i['likes']}
|
| 182 |
+
except:
|
| 183 |
+
a[i['id']] = {'sdk': "Configuration error", 'license': "Configuration error", 'likes': i['likes']}
|
| 184 |
+
|
| 185 |
+
data_list = [{'repository': key, 'sdk': value['sdk'], 'license': value['license'], 'likes': value['likes']} for key, value in a.items()]
|
| 186 |
+
|
| 187 |
+
df = pd.DataFrame(data_list)
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
3. Cloned spaces locally.
|
| 191 |
+
|
| 192 |
+
```python
|
| 193 |
+
from huggingface_hub import snapshot_download
|
| 194 |
+
|
| 195 |
+
programming = ['.asm', '.bat', '.cmd', '.c', '.h', '.cs', '.cpp', '.hpp', '.c++', '.h++', '.cc', '.hh', '.C', '.H', '.cmake', '.css', '.dockerfile', 'Dockerfile', '.f90', '.f', '.f03', '.f08', '.f77', '.f95', '.for', '.fpp', '.go', '.hs', '.html', '.java', '.js', '.jl', '.lua', 'Makefile', '.md', '.markdown', '.php', '.php3', '.php4', '.php5', '.phps', '.phpt', '.pl', '.pm', '.pod', '.perl', '.ps1', '.psd1', '.psm1', '.py', '.rb', '.rs', '.sql', '.scala', '.sh', '.bash', '.command', '.zsh', '.ts', '.tsx', '.tex', '.vb']
|
| 196 |
+
pattern = [f"*{i}" for i in programming]
|
| 197 |
+
|
| 198 |
+
for i in repos:
|
| 199 |
+
snapshot_download(i, repo_type="space", local_dir=f"spaces/{i}", allow_patterns=pattern)
|
| 200 |
+
````
|
| 201 |
+
|
| 202 |
+
4. Processed the data to derive statistics.
|
errors.txt
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ky2k/Toxicity_Classifier_POC
|
| 2 |
+
tialenAdioni/chat-gpt-api
|
| 3 |
+
Narsil/myspace
|
| 4 |
+
arxify/RVC-beta-v2-0618
|
| 5 |
+
WitchHuntTV/WinnieThePoohSVC_sovits4
|
| 6 |
+
yizhangliu/Grounded-Segment-Anything
|
| 7 |
+
Robert001/UniControl-Demo
|
| 8 |
+
internetsignal/audioLDM
|
| 9 |
+
inamXcontru/PoeticTTS
|
| 10 |
+
dcarpintero/nlp-summarizer-pegasus
|
| 11 |
+
SungBeom/chatwine-korean
|
| 12 |
+
x6/BingAi
|
| 13 |
+
1gistliPinn/ChatGPT4
|
| 14 |
+
colakin/video-generater
|
| 15 |
+
stomexserde/gpt4-ui
|
| 16 |
+
quidiaMuxgu/Expedit-SAM
|
| 17 |
+
NasirKhalid24/Dalle2-Diffusion-Prior
|
| 18 |
+
joaopereirajp/livvieChatBot
|
| 19 |
+
diacanFperku/AutoGPT
|
| 20 |
+
tioseFevbu/cartoon-converter
|
| 21 |
+
chuan-hd/law-assistant-chatbot
|
| 22 |
+
mshukor/UnIVAL
|
| 23 |
+
xuyingliKepler/openai_play_tts
|
| 24 |
+
TNR-5/lib111
|
names.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
spaces.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
spaces.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fbb4b253de8e51bfa330e5c7cf31f7841e64ef30c1718d4a05c75e21c8ccf729
|
| 3 |
+
size 671941275
|
spaces/0019c/NewBing/Dockerfile
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Build Stage
|
| 2 |
+
# 使用 golang:alpine 作为构建阶段的基础镜像
|
| 3 |
+
FROM golang:alpine AS builder
|
| 4 |
+
|
| 5 |
+
# 添加 git,以便之后能从GitHub克隆项目
|
| 6 |
+
RUN apk --no-cache add git
|
| 7 |
+
|
| 8 |
+
# 从 GitHub 克隆 go-proxy-bingai 项目到 /workspace/app 目录下
|
| 9 |
+
RUN git clone https://github.com/Harry-zklcdc/go-proxy-bingai.git /workspace/app
|
| 10 |
+
|
| 11 |
+
# 设置工作目录为之前克隆的项目目录
|
| 12 |
+
WORKDIR /workspace/app
|
| 13 |
+
|
| 14 |
+
# 编译 go 项目。-ldflags="-s -w" 是为了减少编译后的二进制大小
|
| 15 |
+
RUN go build -ldflags="-s -w" -tags netgo -trimpath -o go-proxy-bingai main.go
|
| 16 |
+
|
| 17 |
+
# Runtime Stage
|
| 18 |
+
# 使用轻量级的 alpine 镜像作为运行时的基础镜像
|
| 19 |
+
FROM alpine
|
| 20 |
+
|
| 21 |
+
# 设置工作目录
|
| 22 |
+
WORKDIR /workspace/app
|
| 23 |
+
|
| 24 |
+
# 从构建阶段复制编译后的二进制文件到运行时镜像中
|
| 25 |
+
COPY --from=builder /workspace/app/go-proxy-bingai .
|
| 26 |
+
|
| 27 |
+
# 设置环境变量,此处为随机字符
|
| 28 |
+
ENV Go_Proxy_BingAI_USER_TOKEN_1="1h_21qf8tNmRtDy5a4fZ05RFgkZeZ9akmnW9NtSo5s6aJilplld4X4Lj7BkJ3EQSNbu7tu-z_-OAHqeELJqlpF-bvOCMo5lWGjyCTcJcqIHnYiu_vlgrdDyo99wQHgsvNR5pKASGikeDgAVSN7CN6YM74n7glWgJ7hGpd33s9zcgdCea94XcsO5AmoPIoxA02O6zGkpTnIdc61W7D1WQUflqxgaSHCGWlrhw7aoPs-io"
|
| 29 |
+
|
| 30 |
+
# 暴露8080端口
|
| 31 |
+
EXPOSE 8080
|
| 32 |
+
|
| 33 |
+
# 容器启动时运行的命令
|
| 34 |
+
CMD ["/workspace/app/go-proxy-bingai"]
|
spaces/0019c/NewBing/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: NewBing
|
| 3 |
+
emoji: 🏢
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
license: mit
|
| 9 |
+
app_port: 8080
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/01zhangclare/bingai/Dockerfile
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Build Stage
|
| 2 |
+
# 使用 golang:alpine 作为构建阶段的基础镜像
|
| 3 |
+
FROM golang:alpine AS builder
|
| 4 |
+
|
| 5 |
+
# 添加 git,以便之后能从GitHub克隆项目
|
| 6 |
+
RUN apk --no-cache add git
|
| 7 |
+
|
| 8 |
+
# 从 GitHub 克隆 go-proxy-bingai 项目到 /workspace/app 目录下
|
| 9 |
+
RUN git clone https://github.com/Harry-zklcdc/go-proxy-bingai.git /workspace/app
|
| 10 |
+
|
| 11 |
+
# 设置工作目录为之前克隆的项目目录
|
| 12 |
+
WORKDIR /workspace/app
|
| 13 |
+
|
| 14 |
+
# 编译 go 项目。-ldflags="-s -w" 是为了减少编译后的二进制大小
|
| 15 |
+
RUN go build -ldflags="-s -w" -tags netgo -trimpath -o go-proxy-bingai main.go
|
| 16 |
+
|
| 17 |
+
# Runtime Stage
|
| 18 |
+
# 使用轻量级的 alpine 镜像作为运行时的基础镜像
|
| 19 |
+
FROM alpine
|
| 20 |
+
|
| 21 |
+
# 设置工作目录
|
| 22 |
+
WORKDIR /workspace/app
|
| 23 |
+
|
| 24 |
+
# 从构建阶段复制编译后的二进制文件到运行时镜像中
|
| 25 |
+
COPY --from=builder /workspace/app/go-proxy-bingai .
|
| 26 |
+
|
| 27 |
+
# 设置环境变量,此处为随机字符
|
| 28 |
+
ENV Go_Proxy_BingAI_USER_TOKEN_1="kJs8hD92ncMzLaoQWYtX5rG6bE3fZ4iO"
|
| 29 |
+
|
| 30 |
+
# 暴露8080端口
|
| 31 |
+
EXPOSE 8080
|
| 32 |
+
|
| 33 |
+
# 容器启动时运行的命令
|
| 34 |
+
CMD ["/workspace/app/go-proxy-bingai"]
|
spaces/01zhangclare/bingai/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Bingai
|
| 3 |
+
emoji: 🏃
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
license: mit
|
| 9 |
+
app_port: 8080
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/07jeancms/minima/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Minima
|
| 3 |
+
emoji: 🔥
|
| 4 |
+
colorFrom: yellow
|
| 5 |
+
colorTo: gray
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.35.2
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: apache-2.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/07jeancms/minima/app.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
def greet(name):
|
| 4 |
+
return "Hello " + name + "!!"
|
| 5 |
+
|
| 6 |
+
iface = gr.Interface(fn=greet, inputs="text", outputs="text")
|
| 7 |
+
iface.launch()
|
spaces/0x1337/vector-inference/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Vector Inference
|
| 3 |
+
emoji: 🏃
|
| 4 |
+
colorFrom: pink
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: gradio
|
| 7 |
+
app_file: app.py
|
| 8 |
+
pinned: false
|
| 9 |
+
license: wtfpl
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0x1337/vector-inference/app.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
gr.Interface.load("models/coder119/Vectorartz_Diffusion").launch()\
|
| 4 |
+
|
| 5 |
+
iface.launch()
|
spaces/0x7194633/mbrat-ru-sum/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Mbrat Ru Sum
|
| 3 |
+
emoji: 🦀
|
| 4 |
+
colorFrom: purple
|
| 5 |
+
colorTo: green
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.1.3
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0x7194633/mbrat-ru-sum/app.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from transformers import MBartTokenizer, MBartForConditionalGeneration
|
| 3 |
+
|
| 4 |
+
model_name = "IlyaGusev/mbart_ru_sum_gazeta"
|
| 5 |
+
tokenizer = MBartTokenizer.from_pretrained(model_name)
|
| 6 |
+
model = MBartForConditionalGeneration.from_pretrained(model_name)
|
| 7 |
+
|
| 8 |
+
def summarize(text):
|
| 9 |
+
input_ids = tokenizer.batch_encode_plus([text], return_tensors="pt", max_length=1024)["input_ids"].to(model.device)
|
| 10 |
+
summary_ids = model.generate(input_ids=input_ids, no_repeat_ngram_size=4)
|
| 11 |
+
return tokenizer.decode(summary_ids[0], skip_special_tokens=True)
|
| 12 |
+
|
| 13 |
+
gr.Interface(fn=summarize, inputs="text", outputs="text", description="Russian Summarizer").launch()
|
spaces/0x7194633/nllb-1.3B-demo/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Nllb Translation Demo
|
| 3 |
+
emoji: 👀
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: green
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.0.26
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0x7194633/nllb-1.3B-demo/app.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import time
|
| 5 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
|
| 6 |
+
from flores200_codes import flores_codes
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def load_models():
|
| 10 |
+
# build model and tokenizer
|
| 11 |
+
model_name_dict = {'nllb-distilled-1.3B': 'facebook/nllb-200-distilled-1.3B'}
|
| 12 |
+
|
| 13 |
+
model_dict = {}
|
| 14 |
+
|
| 15 |
+
for call_name, real_name in model_name_dict.items():
|
| 16 |
+
print('\tLoading model: %s' % call_name)
|
| 17 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(real_name)
|
| 18 |
+
tokenizer = AutoTokenizer.from_pretrained(real_name)
|
| 19 |
+
model_dict[call_name+'_model'] = model
|
| 20 |
+
model_dict[call_name+'_tokenizer'] = tokenizer
|
| 21 |
+
|
| 22 |
+
return model_dict
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def translation(source, target, text):
|
| 26 |
+
if len(model_dict) == 2:
|
| 27 |
+
model_name = 'nllb-distilled-1.3B'
|
| 28 |
+
|
| 29 |
+
start_time = time.time()
|
| 30 |
+
source = flores_codes[source]
|
| 31 |
+
target = flores_codes[target]
|
| 32 |
+
|
| 33 |
+
model = model_dict[model_name + '_model']
|
| 34 |
+
tokenizer = model_dict[model_name + '_tokenizer']
|
| 35 |
+
|
| 36 |
+
translator = pipeline('translation', model=model, tokenizer=tokenizer, src_lang=source, tgt_lang=target)
|
| 37 |
+
output = translator(text, max_length=400)
|
| 38 |
+
|
| 39 |
+
end_time = time.time()
|
| 40 |
+
|
| 41 |
+
output = output[0]['translation_text']
|
| 42 |
+
result = {'inference_time': end_time - start_time,
|
| 43 |
+
'source': source,
|
| 44 |
+
'target': target,
|
| 45 |
+
'result': output}
|
| 46 |
+
return result
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
if __name__ == '__main__':
|
| 50 |
+
print('\tinit models')
|
| 51 |
+
|
| 52 |
+
global model_dict
|
| 53 |
+
|
| 54 |
+
model_dict = load_models()
|
| 55 |
+
|
| 56 |
+
# define gradio demo
|
| 57 |
+
lang_codes = list(flores_codes.keys())
|
| 58 |
+
#inputs = [gr.inputs.Radio(['nllb-distilled-600M', 'nllb-1.3B', 'nllb-distilled-1.3B'], label='NLLB Model'),
|
| 59 |
+
inputs = [gr.inputs.Dropdown(lang_codes, default='English', label='Source'),
|
| 60 |
+
gr.inputs.Dropdown(lang_codes, default='Korean', label='Target'),
|
| 61 |
+
gr.inputs.Textbox(lines=5, label="Input text"),
|
| 62 |
+
]
|
| 63 |
+
|
| 64 |
+
outputs = gr.outputs.JSON()
|
| 65 |
+
|
| 66 |
+
title = "NLLB distilled 1.3B demo"
|
| 67 |
+
|
| 68 |
+
demo_status = "Demo is running on CPU"
|
| 69 |
+
description = f"Details: https://github.com/facebookresearch/fairseq/tree/nllb. {demo_status}"
|
| 70 |
+
examples = [
|
| 71 |
+
['English', 'Korean', 'Hi. nice to meet you']
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
gr.Interface(translation,
|
| 75 |
+
inputs,
|
| 76 |
+
outputs,
|
| 77 |
+
title=title,
|
| 78 |
+
description=description,
|
| 79 |
+
examples=examples,
|
| 80 |
+
examples_per_page=50,
|
| 81 |
+
).launch()
|
| 82 |
+
|
| 83 |
+
|
spaces/0x7194633/nllb-1.3B-demo/flores200_codes.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
codes_as_string = '''Acehnese (Arabic script) ace_Arab
|
| 2 |
+
Acehnese (Latin script) ace_Latn
|
| 3 |
+
Mesopotamian Arabic acm_Arab
|
| 4 |
+
Ta’izzi-Adeni Arabic acq_Arab
|
| 5 |
+
Tunisian Arabic aeb_Arab
|
| 6 |
+
Afrikaans afr_Latn
|
| 7 |
+
South Levantine Arabic ajp_Arab
|
| 8 |
+
Akan aka_Latn
|
| 9 |
+
Amharic amh_Ethi
|
| 10 |
+
North Levantine Arabic apc_Arab
|
| 11 |
+
Modern Standard Arabic arb_Arab
|
| 12 |
+
Modern Standard Arabic (Romanized) arb_Latn
|
| 13 |
+
Najdi Arabic ars_Arab
|
| 14 |
+
Moroccan Arabic ary_Arab
|
| 15 |
+
Egyptian Arabic arz_Arab
|
| 16 |
+
Assamese asm_Beng
|
| 17 |
+
Asturian ast_Latn
|
| 18 |
+
Awadhi awa_Deva
|
| 19 |
+
Central Aymara ayr_Latn
|
| 20 |
+
South Azerbaijani azb_Arab
|
| 21 |
+
North Azerbaijani azj_Latn
|
| 22 |
+
Bashkir bak_Cyrl
|
| 23 |
+
Bambara bam_Latn
|
| 24 |
+
Balinese ban_Latn
|
| 25 |
+
Belarusian bel_Cyrl
|
| 26 |
+
Bemba bem_Latn
|
| 27 |
+
Bengali ben_Beng
|
| 28 |
+
Bhojpuri bho_Deva
|
| 29 |
+
Banjar (Arabic script) bjn_Arab
|
| 30 |
+
Banjar (Latin script) bjn_Latn
|
| 31 |
+
Standard Tibetan bod_Tibt
|
| 32 |
+
Bosnian bos_Latn
|
| 33 |
+
Buginese bug_Latn
|
| 34 |
+
Bulgarian bul_Cyrl
|
| 35 |
+
Catalan cat_Latn
|
| 36 |
+
Cebuano ceb_Latn
|
| 37 |
+
Czech ces_Latn
|
| 38 |
+
Chokwe cjk_Latn
|
| 39 |
+
Central Kurdish ckb_Arab
|
| 40 |
+
Crimean Tatar crh_Latn
|
| 41 |
+
Welsh cym_Latn
|
| 42 |
+
Danish dan_Latn
|
| 43 |
+
German deu_Latn
|
| 44 |
+
Southwestern Dinka dik_Latn
|
| 45 |
+
Dyula dyu_Latn
|
| 46 |
+
Dzongkha dzo_Tibt
|
| 47 |
+
Greek ell_Grek
|
| 48 |
+
English eng_Latn
|
| 49 |
+
Esperanto epo_Latn
|
| 50 |
+
Estonian est_Latn
|
| 51 |
+
Basque eus_Latn
|
| 52 |
+
Ewe ewe_Latn
|
| 53 |
+
Faroese fao_Latn
|
| 54 |
+
Fijian fij_Latn
|
| 55 |
+
Finnish fin_Latn
|
| 56 |
+
Fon fon_Latn
|
| 57 |
+
French fra_Latn
|
| 58 |
+
Friulian fur_Latn
|
| 59 |
+
Nigerian Fulfulde fuv_Latn
|
| 60 |
+
Scottish Gaelic gla_Latn
|
| 61 |
+
Irish gle_Latn
|
| 62 |
+
Galician glg_Latn
|
| 63 |
+
Guarani grn_Latn
|
| 64 |
+
Gujarati guj_Gujr
|
| 65 |
+
Haitian Creole hat_Latn
|
| 66 |
+
Hausa hau_Latn
|
| 67 |
+
Hebrew heb_Hebr
|
| 68 |
+
Hindi hin_Deva
|
| 69 |
+
Chhattisgarhi hne_Deva
|
| 70 |
+
Croatian hrv_Latn
|
| 71 |
+
Hungarian hun_Latn
|
| 72 |
+
Armenian hye_Armn
|
| 73 |
+
Igbo ibo_Latn
|
| 74 |
+
Ilocano ilo_Latn
|
| 75 |
+
Indonesian ind_Latn
|
| 76 |
+
Icelandic isl_Latn
|
| 77 |
+
Italian ita_Latn
|
| 78 |
+
Javanese jav_Latn
|
| 79 |
+
Japanese jpn_Jpan
|
| 80 |
+
Kabyle kab_Latn
|
| 81 |
+
Jingpho kac_Latn
|
| 82 |
+
Kamba kam_Latn
|
| 83 |
+
Kannada kan_Knda
|
| 84 |
+
Kashmiri (Arabic script) kas_Arab
|
| 85 |
+
Kashmiri (Devanagari script) kas_Deva
|
| 86 |
+
Georgian kat_Geor
|
| 87 |
+
Central Kanuri (Arabic script) knc_Arab
|
| 88 |
+
Central Kanuri (Latin script) knc_Latn
|
| 89 |
+
Kazakh kaz_Cyrl
|
| 90 |
+
Kabiyè kbp_Latn
|
| 91 |
+
Kabuverdianu kea_Latn
|
| 92 |
+
Khmer khm_Khmr
|
| 93 |
+
Kikuyu kik_Latn
|
| 94 |
+
Kinyarwanda kin_Latn
|
| 95 |
+
Kyrgyz kir_Cyrl
|
| 96 |
+
Kimbundu kmb_Latn
|
| 97 |
+
Northern Kurdish kmr_Latn
|
| 98 |
+
Kikongo kon_Latn
|
| 99 |
+
Korean kor_Hang
|
| 100 |
+
Lao lao_Laoo
|
| 101 |
+
Ligurian lij_Latn
|
| 102 |
+
Limburgish lim_Latn
|
| 103 |
+
Lingala lin_Latn
|
| 104 |
+
Lithuanian lit_Latn
|
| 105 |
+
Lombard lmo_Latn
|
| 106 |
+
Latgalian ltg_Latn
|
| 107 |
+
Luxembourgish ltz_Latn
|
| 108 |
+
Luba-Kasai lua_Latn
|
| 109 |
+
Ganda lug_Latn
|
| 110 |
+
Luo luo_Latn
|
| 111 |
+
Mizo lus_Latn
|
| 112 |
+
Standard Latvian lvs_Latn
|
| 113 |
+
Magahi mag_Deva
|
| 114 |
+
Maithili mai_Deva
|
| 115 |
+
Malayalam mal_Mlym
|
| 116 |
+
Marathi mar_Deva
|
| 117 |
+
Minangkabau (Arabic script) min_Arab
|
| 118 |
+
Minangkabau (Latin script) min_Latn
|
| 119 |
+
Macedonian mkd_Cyrl
|
| 120 |
+
Plateau Malagasy plt_Latn
|
| 121 |
+
Maltese mlt_Latn
|
| 122 |
+
Meitei (Bengali script) mni_Beng
|
| 123 |
+
Halh Mongolian khk_Cyrl
|
| 124 |
+
Mossi mos_Latn
|
| 125 |
+
Maori mri_Latn
|
| 126 |
+
Burmese mya_Mymr
|
| 127 |
+
Dutch nld_Latn
|
| 128 |
+
Norwegian Nynorsk nno_Latn
|
| 129 |
+
Norwegian Bokmål nob_Latn
|
| 130 |
+
Nepali npi_Deva
|
| 131 |
+
Northern Sotho nso_Latn
|
| 132 |
+
Nuer nus_Latn
|
| 133 |
+
Nyanja nya_Latn
|
| 134 |
+
Occitan oci_Latn
|
| 135 |
+
West Central Oromo gaz_Latn
|
| 136 |
+
Odia ory_Orya
|
| 137 |
+
Pangasinan pag_Latn
|
| 138 |
+
Eastern Panjabi pan_Guru
|
| 139 |
+
Papiamento pap_Latn
|
| 140 |
+
Western Persian pes_Arab
|
| 141 |
+
Polish pol_Latn
|
| 142 |
+
Portuguese por_Latn
|
| 143 |
+
Dari prs_Arab
|
| 144 |
+
Southern Pashto pbt_Arab
|
| 145 |
+
Ayacucho Quechua quy_Latn
|
| 146 |
+
Romanian ron_Latn
|
| 147 |
+
Rundi run_Latn
|
| 148 |
+
Russian rus_Cyrl
|
| 149 |
+
Sango sag_Latn
|
| 150 |
+
Sanskrit san_Deva
|
| 151 |
+
Santali sat_Olck
|
| 152 |
+
Sicilian scn_Latn
|
| 153 |
+
Shan shn_Mymr
|
| 154 |
+
Sinhala sin_Sinh
|
| 155 |
+
Slovak slk_Latn
|
| 156 |
+
Slovenian slv_Latn
|
| 157 |
+
Samoan smo_Latn
|
| 158 |
+
Shona sna_Latn
|
| 159 |
+
Sindhi snd_Arab
|
| 160 |
+
Somali som_Latn
|
| 161 |
+
Southern Sotho sot_Latn
|
| 162 |
+
Spanish spa_Latn
|
| 163 |
+
Tosk Albanian als_Latn
|
| 164 |
+
Sardinian srd_Latn
|
| 165 |
+
Serbian srp_Cyrl
|
| 166 |
+
Swati ssw_Latn
|
| 167 |
+
Sundanese sun_Latn
|
| 168 |
+
Swedish swe_Latn
|
| 169 |
+
Swahili swh_Latn
|
| 170 |
+
Silesian szl_Latn
|
| 171 |
+
Tamil tam_Taml
|
| 172 |
+
Tatar tat_Cyrl
|
| 173 |
+
Telugu tel_Telu
|
| 174 |
+
Tajik tgk_Cyrl
|
| 175 |
+
Tagalog tgl_Latn
|
| 176 |
+
Thai tha_Thai
|
| 177 |
+
Tigrinya tir_Ethi
|
| 178 |
+
Tamasheq (Latin script) taq_Latn
|
| 179 |
+
Tamasheq (Tifinagh script) taq_Tfng
|
| 180 |
+
Tok Pisin tpi_Latn
|
| 181 |
+
Tswana tsn_Latn
|
| 182 |
+
Tsonga tso_Latn
|
| 183 |
+
Turkmen tuk_Latn
|
| 184 |
+
Tumbuka tum_Latn
|
| 185 |
+
Turkish tur_Latn
|
| 186 |
+
Twi twi_Latn
|
| 187 |
+
Central Atlas Tamazight tzm_Tfng
|
| 188 |
+
Uyghur uig_Arab
|
| 189 |
+
Ukrainian ukr_Cyrl
|
| 190 |
+
Umbundu umb_Latn
|
| 191 |
+
Urdu urd_Arab
|
| 192 |
+
Northern Uzbek uzn_Latn
|
| 193 |
+
Venetian vec_Latn
|
| 194 |
+
Vietnamese vie_Latn
|
| 195 |
+
Waray war_Latn
|
| 196 |
+
Wolof wol_Latn
|
| 197 |
+
Xhosa xho_Latn
|
| 198 |
+
Eastern Yiddish ydd_Hebr
|
| 199 |
+
Yoruba yor_Latn
|
| 200 |
+
Yue Chinese yue_Hant
|
| 201 |
+
Chinese (Simplified) zho_Hans
|
| 202 |
+
Chinese (Traditional) zho_Hant
|
| 203 |
+
Standard Malay zsm_Latn
|
| 204 |
+
Zulu zul_Latn'''
|
| 205 |
+
|
| 206 |
+
codes_as_string = codes_as_string.split('\n')
|
| 207 |
+
|
| 208 |
+
flores_codes = {}
|
| 209 |
+
for code in codes_as_string:
|
| 210 |
+
lang, lang_code = code.split('\t')
|
| 211 |
+
flores_codes[lang] = lang_code
|
spaces/0x876/Yotta_Mix/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: CompVis Stable Diffusion V1 4
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: pink
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.39.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0x876/Yotta_Mix/app.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
gr.Interface.load("models/CompVis/stable-diffusion-v1-4").launch()
|
spaces/0x90e/ESRGAN-MANGA/ESRGAN/architecture.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import ESRGAN.block as B
|
| 5 |
+
|
| 6 |
+
class RRDB_Net(nn.Module):
|
| 7 |
+
def __init__(self, in_nc, out_nc, nf, nb, gc=32, upscale=4, norm_type=None, act_type='leakyrelu', \
|
| 8 |
+
mode='CNA', res_scale=1, upsample_mode='upconv'):
|
| 9 |
+
super(RRDB_Net, self).__init__()
|
| 10 |
+
n_upscale = int(math.log(upscale, 2))
|
| 11 |
+
if upscale == 3:
|
| 12 |
+
n_upscale = 1
|
| 13 |
+
|
| 14 |
+
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)
|
| 15 |
+
rb_blocks = [B.RRDB(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
|
| 16 |
+
norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
|
| 17 |
+
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
|
| 18 |
+
|
| 19 |
+
if upsample_mode == 'upconv':
|
| 20 |
+
upsample_block = B.upconv_blcok
|
| 21 |
+
elif upsample_mode == 'pixelshuffle':
|
| 22 |
+
upsample_block = B.pixelshuffle_block
|
| 23 |
+
else:
|
| 24 |
+
raise NotImplementedError('upsample mode [%s] is not found' % upsample_mode)
|
| 25 |
+
if upscale == 3:
|
| 26 |
+
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
|
| 27 |
+
else:
|
| 28 |
+
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
|
| 29 |
+
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
|
| 30 |
+
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
|
| 31 |
+
|
| 32 |
+
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*rb_blocks, LR_conv)),\
|
| 33 |
+
*upsampler, HR_conv0, HR_conv1)
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
x = self.model(x)
|
| 37 |
+
return x
|
spaces/0x90e/ESRGAN-MANGA/ESRGAN/block.py
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
####################
|
| 6 |
+
# Basic blocks
|
| 7 |
+
####################
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def act(act_type, inplace=True, neg_slope=0.2, n_prelu=1):
|
| 11 |
+
# helper selecting activation
|
| 12 |
+
# neg_slope: for leakyrelu and init of prelu
|
| 13 |
+
# n_prelu: for p_relu num_parameters
|
| 14 |
+
act_type = act_type.lower()
|
| 15 |
+
if act_type == 'relu':
|
| 16 |
+
layer = nn.ReLU(inplace)
|
| 17 |
+
elif act_type == 'leakyrelu':
|
| 18 |
+
layer = nn.LeakyReLU(neg_slope, inplace)
|
| 19 |
+
elif act_type == 'prelu':
|
| 20 |
+
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
|
| 21 |
+
else:
|
| 22 |
+
raise NotImplementedError('activation layer [%s] is not found' % act_type)
|
| 23 |
+
return layer
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def norm(norm_type, nc):
|
| 27 |
+
# helper selecting normalization layer
|
| 28 |
+
norm_type = norm_type.lower()
|
| 29 |
+
if norm_type == 'batch':
|
| 30 |
+
layer = nn.BatchNorm2d(nc, affine=True)
|
| 31 |
+
elif norm_type == 'instance':
|
| 32 |
+
layer = nn.InstanceNorm2d(nc, affine=False)
|
| 33 |
+
else:
|
| 34 |
+
raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
|
| 35 |
+
return layer
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def pad(pad_type, padding):
|
| 39 |
+
# helper selecting padding layer
|
| 40 |
+
# if padding is 'zero', do by conv layers
|
| 41 |
+
pad_type = pad_type.lower()
|
| 42 |
+
if padding == 0:
|
| 43 |
+
return None
|
| 44 |
+
if pad_type == 'reflect':
|
| 45 |
+
layer = nn.ReflectionPad2d(padding)
|
| 46 |
+
elif pad_type == 'replicate':
|
| 47 |
+
layer = nn.ReplicationPad2d(padding)
|
| 48 |
+
else:
|
| 49 |
+
raise NotImplementedError('padding layer [%s] is not implemented' % pad_type)
|
| 50 |
+
return layer
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def get_valid_padding(kernel_size, dilation):
|
| 54 |
+
kernel_size = kernel_size + (kernel_size - 1) * (dilation - 1)
|
| 55 |
+
padding = (kernel_size - 1) // 2
|
| 56 |
+
return padding
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class ConcatBlock(nn.Module):
|
| 60 |
+
# Concat the output of a submodule to its input
|
| 61 |
+
def __init__(self, submodule):
|
| 62 |
+
super(ConcatBlock, self).__init__()
|
| 63 |
+
self.sub = submodule
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
output = torch.cat((x, self.sub(x)), dim=1)
|
| 67 |
+
return output
|
| 68 |
+
|
| 69 |
+
def __repr__(self):
|
| 70 |
+
tmpstr = 'Identity .. \n|'
|
| 71 |
+
modstr = self.sub.__repr__().replace('\n', '\n|')
|
| 72 |
+
tmpstr = tmpstr + modstr
|
| 73 |
+
return tmpstr
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class ShortcutBlock(nn.Module):
|
| 77 |
+
#Elementwise sum the output of a submodule to its input
|
| 78 |
+
def __init__(self, submodule):
|
| 79 |
+
super(ShortcutBlock, self).__init__()
|
| 80 |
+
self.sub = submodule
|
| 81 |
+
|
| 82 |
+
def forward(self, x):
|
| 83 |
+
output = x + self.sub(x)
|
| 84 |
+
return output
|
| 85 |
+
|
| 86 |
+
def __repr__(self):
|
| 87 |
+
tmpstr = 'Identity + \n|'
|
| 88 |
+
modstr = self.sub.__repr__().replace('\n', '\n|')
|
| 89 |
+
tmpstr = tmpstr + modstr
|
| 90 |
+
return tmpstr
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def sequential(*args):
|
| 94 |
+
# Flatten Sequential. It unwraps nn.Sequential.
|
| 95 |
+
if len(args) == 1:
|
| 96 |
+
if isinstance(args[0], OrderedDict):
|
| 97 |
+
raise NotImplementedError('sequential does not support OrderedDict input.')
|
| 98 |
+
return args[0] # No sequential is needed.
|
| 99 |
+
modules = []
|
| 100 |
+
for module in args:
|
| 101 |
+
if isinstance(module, nn.Sequential):
|
| 102 |
+
for submodule in module.children():
|
| 103 |
+
modules.append(submodule)
|
| 104 |
+
elif isinstance(module, nn.Module):
|
| 105 |
+
modules.append(module)
|
| 106 |
+
return nn.Sequential(*modules)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True,
|
| 110 |
+
pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
|
| 111 |
+
"""
|
| 112 |
+
Conv layer with padding, normalization, activation
|
| 113 |
+
mode: CNA --> Conv -> Norm -> Act
|
| 114 |
+
NAC --> Norm -> Act --> Conv (Identity Mappings in Deep Residual Networks, ECCV16)
|
| 115 |
+
"""
|
| 116 |
+
assert mode in ['CNA', 'NAC', 'CNAC'], 'Wong conv mode [%s]' % mode
|
| 117 |
+
padding = get_valid_padding(kernel_size, dilation)
|
| 118 |
+
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
|
| 119 |
+
padding = padding if pad_type == 'zero' else 0
|
| 120 |
+
|
| 121 |
+
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
|
| 122 |
+
dilation=dilation, bias=bias, groups=groups)
|
| 123 |
+
a = act(act_type) if act_type else None
|
| 124 |
+
if 'CNA' in mode:
|
| 125 |
+
n = norm(norm_type, out_nc) if norm_type else None
|
| 126 |
+
return sequential(p, c, n, a)
|
| 127 |
+
elif mode == 'NAC':
|
| 128 |
+
if norm_type is None and act_type is not None:
|
| 129 |
+
a = act(act_type, inplace=False)
|
| 130 |
+
# Important!
|
| 131 |
+
# input----ReLU(inplace)----Conv--+----output
|
| 132 |
+
# |________________________|
|
| 133 |
+
# inplace ReLU will modify the input, therefore wrong output
|
| 134 |
+
n = norm(norm_type, in_nc) if norm_type else None
|
| 135 |
+
return sequential(n, a, p, c)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
####################
|
| 139 |
+
# Useful blocks
|
| 140 |
+
####################
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class ResNetBlock(nn.Module):
|
| 144 |
+
"""
|
| 145 |
+
ResNet Block, 3-3 style
|
| 146 |
+
with extra residual scaling used in EDSR
|
| 147 |
+
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW 17)
|
| 148 |
+
"""
|
| 149 |
+
|
| 150 |
+
def __init__(self, in_nc, mid_nc, out_nc, kernel_size=3, stride=1, dilation=1, groups=1, \
|
| 151 |
+
bias=True, pad_type='zero', norm_type=None, act_type='relu', mode='CNA', res_scale=1):
|
| 152 |
+
super(ResNetBlock, self).__init__()
|
| 153 |
+
conv0 = conv_block(in_nc, mid_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
|
| 154 |
+
norm_type, act_type, mode)
|
| 155 |
+
if mode == 'CNA':
|
| 156 |
+
act_type = None
|
| 157 |
+
if mode == 'CNAC': # Residual path: |-CNAC-|
|
| 158 |
+
act_type = None
|
| 159 |
+
norm_type = None
|
| 160 |
+
conv1 = conv_block(mid_nc, out_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
|
| 161 |
+
norm_type, act_type, mode)
|
| 162 |
+
# if in_nc != out_nc:
|
| 163 |
+
# self.project = conv_block(in_nc, out_nc, 1, stride, dilation, 1, bias, pad_type, \
|
| 164 |
+
# None, None)
|
| 165 |
+
# print('Need a projecter in ResNetBlock.')
|
| 166 |
+
# else:
|
| 167 |
+
# self.project = lambda x:x
|
| 168 |
+
self.res = sequential(conv0, conv1)
|
| 169 |
+
self.res_scale = res_scale
|
| 170 |
+
|
| 171 |
+
def forward(self, x):
|
| 172 |
+
res = self.res(x).mul(self.res_scale)
|
| 173 |
+
return x + res
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
class ResidualDenseBlock_5C(nn.Module):
|
| 177 |
+
"""
|
| 178 |
+
Residual Dense Block
|
| 179 |
+
style: 5 convs
|
| 180 |
+
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
|
| 181 |
+
"""
|
| 182 |
+
|
| 183 |
+
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
|
| 184 |
+
norm_type=None, act_type='leakyrelu', mode='CNA'):
|
| 185 |
+
super(ResidualDenseBlock_5C, self).__init__()
|
| 186 |
+
# gc: growth channel, i.e. intermediate channels
|
| 187 |
+
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 188 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 189 |
+
self.conv2 = conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 190 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 191 |
+
self.conv3 = conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 192 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 193 |
+
self.conv4 = conv_block(nc+3*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 194 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 195 |
+
if mode == 'CNA':
|
| 196 |
+
last_act = None
|
| 197 |
+
else:
|
| 198 |
+
last_act = act_type
|
| 199 |
+
self.conv5 = conv_block(nc+4*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
|
| 200 |
+
norm_type=norm_type, act_type=last_act, mode=mode)
|
| 201 |
+
|
| 202 |
+
def forward(self, x):
|
| 203 |
+
x1 = self.conv1(x)
|
| 204 |
+
x2 = self.conv2(torch.cat((x, x1), 1))
|
| 205 |
+
x3 = self.conv3(torch.cat((x, x1, x2), 1))
|
| 206 |
+
x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
|
| 207 |
+
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
|
| 208 |
+
return x5.mul(0.2) + x
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class RRDB(nn.Module):
|
| 212 |
+
"""
|
| 213 |
+
Residual in Residual Dense Block
|
| 214 |
+
"""
|
| 215 |
+
|
| 216 |
+
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
|
| 217 |
+
norm_type=None, act_type='leakyrelu', mode='CNA'):
|
| 218 |
+
super(RRDB, self).__init__()
|
| 219 |
+
self.RDB1 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
|
| 220 |
+
norm_type, act_type, mode)
|
| 221 |
+
self.RDB2 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
|
| 222 |
+
norm_type, act_type, mode)
|
| 223 |
+
self.RDB3 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
|
| 224 |
+
norm_type, act_type, mode)
|
| 225 |
+
|
| 226 |
+
def forward(self, x):
|
| 227 |
+
out = self.RDB1(x)
|
| 228 |
+
out = self.RDB2(out)
|
| 229 |
+
out = self.RDB3(out)
|
| 230 |
+
return out.mul(0.2) + x
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
####################
|
| 234 |
+
# Upsampler
|
| 235 |
+
####################
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
def pixelshuffle_block(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True,
|
| 239 |
+
pad_type='zero', norm_type=None, act_type='relu'):
|
| 240 |
+
"""
|
| 241 |
+
Pixel shuffle layer
|
| 242 |
+
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional
|
| 243 |
+
Neural Network, CVPR17)
|
| 244 |
+
"""
|
| 245 |
+
conv = conv_block(in_nc, out_nc * (upscale_factor ** 2), kernel_size, stride, bias=bias,
|
| 246 |
+
pad_type=pad_type, norm_type=None, act_type=None)
|
| 247 |
+
pixel_shuffle = nn.PixelShuffle(upscale_factor)
|
| 248 |
+
|
| 249 |
+
n = norm(norm_type, out_nc) if norm_type else None
|
| 250 |
+
a = act(act_type) if act_type else None
|
| 251 |
+
return sequential(conv, pixel_shuffle, n, a)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
def upconv_blcok(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True,
|
| 255 |
+
pad_type='zero', norm_type=None, act_type='relu', mode='nearest'):
|
| 256 |
+
# Up conv
|
| 257 |
+
# described in https://distill.pub/2016/deconv-checkerboard/
|
| 258 |
+
upsample = nn.Upsample(scale_factor=upscale_factor, mode=mode)
|
| 259 |
+
conv = conv_block(in_nc, out_nc, kernel_size, stride, bias=bias,
|
| 260 |
+
pad_type=pad_type, norm_type=norm_type, act_type=act_type)
|
| 261 |
+
return sequential(upsample, conv)
|
spaces/0x90e/ESRGAN-MANGA/ESRGAN_plus/architecture.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import ESRGAN_plus.block as B
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class RRDB_Net(nn.Module):
|
| 8 |
+
def __init__(self, in_nc, out_nc, nf, nb, gc=32, upscale=4, norm_type=None, act_type='leakyrelu', \
|
| 9 |
+
mode='CNA', res_scale=1, upsample_mode='upconv'):
|
| 10 |
+
super(RRDB_Net, self).__init__()
|
| 11 |
+
n_upscale = int(math.log(upscale, 2))
|
| 12 |
+
if upscale == 3:
|
| 13 |
+
n_upscale = 1
|
| 14 |
+
|
| 15 |
+
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)
|
| 16 |
+
rb_blocks = [B.RRDB(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
|
| 17 |
+
norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
|
| 18 |
+
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
|
| 19 |
+
|
| 20 |
+
if upsample_mode == 'upconv':
|
| 21 |
+
upsample_block = B.upconv_blcok
|
| 22 |
+
elif upsample_mode == 'pixelshuffle':
|
| 23 |
+
upsample_block = B.pixelshuffle_block
|
| 24 |
+
else:
|
| 25 |
+
raise NotImplementedError('upsample mode [%s] is not found' % upsample_mode)
|
| 26 |
+
if upscale == 3:
|
| 27 |
+
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
|
| 28 |
+
else:
|
| 29 |
+
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
|
| 30 |
+
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
|
| 31 |
+
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
|
| 32 |
+
|
| 33 |
+
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*rb_blocks, LR_conv)),\
|
| 34 |
+
*upsampler, HR_conv0, HR_conv1)
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = self.model(x)
|
| 38 |
+
return x
|
spaces/0x90e/ESRGAN-MANGA/ESRGAN_plus/block.py
ADDED
|
@@ -0,0 +1,287 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
####################
|
| 6 |
+
# Basic blocks
|
| 7 |
+
####################
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def act(act_type, inplace=True, neg_slope=0.2, n_prelu=1):
|
| 11 |
+
# helper selecting activation
|
| 12 |
+
# neg_slope: for leakyrelu and init of prelu
|
| 13 |
+
# n_prelu: for p_relu num_parameters
|
| 14 |
+
act_type = act_type.lower()
|
| 15 |
+
if act_type == 'relu':
|
| 16 |
+
layer = nn.ReLU(inplace)
|
| 17 |
+
elif act_type == 'leakyrelu':
|
| 18 |
+
layer = nn.LeakyReLU(neg_slope, inplace)
|
| 19 |
+
elif act_type == 'prelu':
|
| 20 |
+
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
|
| 21 |
+
else:
|
| 22 |
+
raise NotImplementedError('activation layer [{:s}] is not found'.format(act_type))
|
| 23 |
+
return layer
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def norm(norm_type, nc):
|
| 27 |
+
# helper selecting normalization layer
|
| 28 |
+
norm_type = norm_type.lower()
|
| 29 |
+
if norm_type == 'batch':
|
| 30 |
+
layer = nn.BatchNorm2d(nc, affine=True)
|
| 31 |
+
elif norm_type == 'instance':
|
| 32 |
+
layer = nn.InstanceNorm2d(nc, affine=False)
|
| 33 |
+
else:
|
| 34 |
+
raise NotImplementedError('normalization layer [{:s}] is not found'.format(norm_type))
|
| 35 |
+
return layer
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def pad(pad_type, padding):
|
| 39 |
+
# helper selecting padding layer
|
| 40 |
+
# if padding is 'zero', do by conv layers
|
| 41 |
+
pad_type = pad_type.lower()
|
| 42 |
+
if padding == 0:
|
| 43 |
+
return None
|
| 44 |
+
if pad_type == 'reflect':
|
| 45 |
+
layer = nn.ReflectionPad2d(padding)
|
| 46 |
+
elif pad_type == 'replicate':
|
| 47 |
+
layer = nn.ReplicationPad2d(padding)
|
| 48 |
+
else:
|
| 49 |
+
raise NotImplementedError('padding layer [{:s}] is not implemented'.format(pad_type))
|
| 50 |
+
return layer
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def get_valid_padding(kernel_size, dilation):
|
| 54 |
+
kernel_size = kernel_size + (kernel_size - 1) * (dilation - 1)
|
| 55 |
+
padding = (kernel_size - 1) // 2
|
| 56 |
+
return padding
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class ConcatBlock(nn.Module):
|
| 60 |
+
# Concat the output of a submodule to its input
|
| 61 |
+
def __init__(self, submodule):
|
| 62 |
+
super(ConcatBlock, self).__init__()
|
| 63 |
+
self.sub = submodule
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
output = torch.cat((x, self.sub(x)), dim=1)
|
| 67 |
+
return output
|
| 68 |
+
|
| 69 |
+
def __repr__(self):
|
| 70 |
+
tmpstr = 'Identity .. \n|'
|
| 71 |
+
modstr = self.sub.__repr__().replace('\n', '\n|')
|
| 72 |
+
tmpstr = tmpstr + modstr
|
| 73 |
+
return tmpstr
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class ShortcutBlock(nn.Module):
|
| 77 |
+
#Elementwise sum the output of a submodule to its input
|
| 78 |
+
def __init__(self, submodule):
|
| 79 |
+
super(ShortcutBlock, self).__init__()
|
| 80 |
+
self.sub = submodule
|
| 81 |
+
|
| 82 |
+
def forward(self, x):
|
| 83 |
+
output = x + self.sub(x)
|
| 84 |
+
return output
|
| 85 |
+
|
| 86 |
+
def __repr__(self):
|
| 87 |
+
tmpstr = 'Identity + \n|'
|
| 88 |
+
modstr = self.sub.__repr__().replace('\n', '\n|')
|
| 89 |
+
tmpstr = tmpstr + modstr
|
| 90 |
+
return tmpstr
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def sequential(*args):
|
| 94 |
+
# Flatten Sequential. It unwraps nn.Sequential.
|
| 95 |
+
if len(args) == 1:
|
| 96 |
+
if isinstance(args[0], OrderedDict):
|
| 97 |
+
raise NotImplementedError('sequential does not support OrderedDict input.')
|
| 98 |
+
return args[0] # No sequential is needed.
|
| 99 |
+
modules = []
|
| 100 |
+
for module in args:
|
| 101 |
+
if isinstance(module, nn.Sequential):
|
| 102 |
+
for submodule in module.children():
|
| 103 |
+
modules.append(submodule)
|
| 104 |
+
elif isinstance(module, nn.Module):
|
| 105 |
+
modules.append(module)
|
| 106 |
+
return nn.Sequential(*modules)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True, \
|
| 110 |
+
pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
|
| 111 |
+
'''
|
| 112 |
+
Conv layer with padding, normalization, activation
|
| 113 |
+
mode: CNA --> Conv -> Norm -> Act
|
| 114 |
+
NAC --> Norm -> Act --> Conv (Identity Mappings in Deep Residual Networks, ECCV16)
|
| 115 |
+
'''
|
| 116 |
+
assert mode in ['CNA', 'NAC', 'CNAC'], 'Wong conv mode [{:s}]'.format(mode)
|
| 117 |
+
padding = get_valid_padding(kernel_size, dilation)
|
| 118 |
+
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
|
| 119 |
+
padding = padding if pad_type == 'zero' else 0
|
| 120 |
+
|
| 121 |
+
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
|
| 122 |
+
dilation=dilation, bias=bias, groups=groups)
|
| 123 |
+
a = act(act_type) if act_type else None
|
| 124 |
+
if 'CNA' in mode:
|
| 125 |
+
n = norm(norm_type, out_nc) if norm_type else None
|
| 126 |
+
return sequential(p, c, n, a)
|
| 127 |
+
elif mode == 'NAC':
|
| 128 |
+
if norm_type is None and act_type is not None:
|
| 129 |
+
a = act(act_type, inplace=False)
|
| 130 |
+
# Important!
|
| 131 |
+
# input----ReLU(inplace)----Conv--+----output
|
| 132 |
+
# |________________________|
|
| 133 |
+
# inplace ReLU will modify the input, therefore wrong output
|
| 134 |
+
n = norm(norm_type, in_nc) if norm_type else None
|
| 135 |
+
return sequential(n, a, p, c)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def conv1x1(in_planes, out_planes, stride=1):
|
| 139 |
+
"""1x1 convolution"""
|
| 140 |
+
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class GaussianNoise(nn.Module):
|
| 144 |
+
def __init__(self, sigma=0.1, is_relative_detach=False):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.sigma = sigma
|
| 147 |
+
self.is_relative_detach = is_relative_detach
|
| 148 |
+
self.noise = torch.tensor(0, dtype=torch.float).to(torch.device('cuda'))
|
| 149 |
+
|
| 150 |
+
def forward(self, x):
|
| 151 |
+
if self.training and self.sigma != 0:
|
| 152 |
+
scale = self.sigma * x.detach() if self.is_relative_detach else self.sigma * x
|
| 153 |
+
sampled_noise = self.noise.repeat(*x.size()).normal_() * scale
|
| 154 |
+
x = x + sampled_noise
|
| 155 |
+
return x
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
####################
|
| 159 |
+
# Useful blocks
|
| 160 |
+
####################
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
class ResNetBlock(nn.Module):
|
| 164 |
+
'''
|
| 165 |
+
ResNet Block, 3-3 style
|
| 166 |
+
with extra residual scaling used in EDSR
|
| 167 |
+
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW 17)
|
| 168 |
+
'''
|
| 169 |
+
|
| 170 |
+
def __init__(self, in_nc, mid_nc, out_nc, kernel_size=3, stride=1, dilation=1, groups=1, \
|
| 171 |
+
bias=True, pad_type='zero', norm_type=None, act_type='relu', mode='CNA', res_scale=1):
|
| 172 |
+
super(ResNetBlock, self).__init__()
|
| 173 |
+
conv0 = conv_block(in_nc, mid_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
|
| 174 |
+
norm_type, act_type, mode)
|
| 175 |
+
if mode == 'CNA':
|
| 176 |
+
act_type = None
|
| 177 |
+
if mode == 'CNAC': # Residual path: |-CNAC-|
|
| 178 |
+
act_type = None
|
| 179 |
+
norm_type = None
|
| 180 |
+
conv1 = conv_block(mid_nc, out_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
|
| 181 |
+
norm_type, act_type, mode)
|
| 182 |
+
# if in_nc != out_nc:
|
| 183 |
+
# self.project = conv_block(in_nc, out_nc, 1, stride, dilation, 1, bias, pad_type, \
|
| 184 |
+
# None, None)
|
| 185 |
+
# print('Need a projecter in ResNetBlock.')
|
| 186 |
+
# else:
|
| 187 |
+
# self.project = lambda x:x
|
| 188 |
+
self.res = sequential(conv0, conv1)
|
| 189 |
+
self.res_scale = res_scale
|
| 190 |
+
|
| 191 |
+
def forward(self, x):
|
| 192 |
+
res = self.res(x).mul(self.res_scale)
|
| 193 |
+
return x + res
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
class ResidualDenseBlock_5C(nn.Module):
|
| 197 |
+
'''
|
| 198 |
+
Residual Dense Block
|
| 199 |
+
style: 5 convs
|
| 200 |
+
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
|
| 201 |
+
'''
|
| 202 |
+
|
| 203 |
+
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
|
| 204 |
+
norm_type=None, act_type='leakyrelu', mode='CNA', noise_input=True):
|
| 205 |
+
super(ResidualDenseBlock_5C, self).__init__()
|
| 206 |
+
# gc: growth channel, i.e. intermediate channels
|
| 207 |
+
self.noise = GaussianNoise() if noise_input else None
|
| 208 |
+
self.conv1x1 = conv1x1(nc, gc)
|
| 209 |
+
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 210 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 211 |
+
self.conv2 = conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 212 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 213 |
+
self.conv3 = conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 214 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 215 |
+
self.conv4 = conv_block(nc+3*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
|
| 216 |
+
norm_type=norm_type, act_type=act_type, mode=mode)
|
| 217 |
+
if mode == 'CNA':
|
| 218 |
+
last_act = None
|
| 219 |
+
else:
|
| 220 |
+
last_act = act_type
|
| 221 |
+
self.conv5 = conv_block(nc+4*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
|
| 222 |
+
norm_type=norm_type, act_type=last_act, mode=mode)
|
| 223 |
+
|
| 224 |
+
def forward(self, x):
|
| 225 |
+
x1 = self.conv1(x)
|
| 226 |
+
x2 = self.conv2(torch.cat((x, x1), 1))
|
| 227 |
+
x2 = x2 + self.conv1x1(x)
|
| 228 |
+
x3 = self.conv3(torch.cat((x, x1, x2), 1))
|
| 229 |
+
x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
|
| 230 |
+
x4 = x4 + x2
|
| 231 |
+
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
|
| 232 |
+
return self.noise(x5.mul(0.2) + x)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
class RRDB(nn.Module):
|
| 236 |
+
'''
|
| 237 |
+
Residual in Residual Dense Block
|
| 238 |
+
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)
|
| 239 |
+
'''
|
| 240 |
+
|
| 241 |
+
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
|
| 242 |
+
norm_type=None, act_type='leakyrelu', mode='CNA'):
|
| 243 |
+
super(RRDB, self).__init__()
|
| 244 |
+
self.RDB1 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
|
| 245 |
+
norm_type, act_type, mode)
|
| 246 |
+
self.RDB2 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
|
| 247 |
+
norm_type, act_type, mode)
|
| 248 |
+
self.RDB3 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
|
| 249 |
+
norm_type, act_type, mode)
|
| 250 |
+
self.noise = GaussianNoise()
|
| 251 |
+
|
| 252 |
+
def forward(self, x):
|
| 253 |
+
out = self.RDB1(x)
|
| 254 |
+
out = self.RDB2(out)
|
| 255 |
+
out = self.RDB3(out)
|
| 256 |
+
return self.noise(out.mul(0.2) + x)
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
####################
|
| 260 |
+
# Upsampler
|
| 261 |
+
####################
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def pixelshuffle_block(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True, \
|
| 265 |
+
pad_type='zero', norm_type=None, act_type='relu'):
|
| 266 |
+
'''
|
| 267 |
+
Pixel shuffle layer
|
| 268 |
+
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional
|
| 269 |
+
Neural Network, CVPR17)
|
| 270 |
+
'''
|
| 271 |
+
conv = conv_block(in_nc, out_nc * (upscale_factor ** 2), kernel_size, stride, bias=bias, \
|
| 272 |
+
pad_type=pad_type, norm_type=None, act_type=None)
|
| 273 |
+
pixel_shuffle = nn.PixelShuffle(upscale_factor)
|
| 274 |
+
|
| 275 |
+
n = norm(norm_type, out_nc) if norm_type else None
|
| 276 |
+
a = act(act_type) if act_type else None
|
| 277 |
+
return sequential(conv, pixel_shuffle, n, a)
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
def upconv_blcok(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True, \
|
| 281 |
+
pad_type='zero', norm_type=None, act_type='relu', mode='nearest'):
|
| 282 |
+
# Up conv
|
| 283 |
+
# described in https://distill.pub/2016/deconv-checkerboard/
|
| 284 |
+
upsample = nn.Upsample(scale_factor=upscale_factor, mode=mode)
|
| 285 |
+
conv = conv_block(in_nc, out_nc, kernel_size, stride, bias=bias, \
|
| 286 |
+
pad_type=pad_type, norm_type=norm_type, act_type=act_type)
|
| 287 |
+
return sequential(upsample, conv)
|
spaces/0x90e/ESRGAN-MANGA/ESRGANer.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image, ImageChops
|
| 2 |
+
import numpy as np
|
| 3 |
+
import cv2 as cv
|
| 4 |
+
import math
|
| 5 |
+
import torch
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
Borrowed and adapted from https://github.com/xinntao/Real-ESRGAN/blob/master/realesrgan/utils.py
|
| 10 |
+
Thank you xinntao!
|
| 11 |
+
"""
|
| 12 |
+
class ESRGANer():
|
| 13 |
+
"""A helper class for upsampling images with ESRGAN.
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
scale (int): Upsampling scale factor used in the networks. It is usually 2 or 4.
|
| 17 |
+
model (nn.Module): The defined network. Default: None.
|
| 18 |
+
tile (int): As too large images result in the out of GPU memory issue, so this tile option will first crop
|
| 19 |
+
input images into tiles, and then process each of them. Finally, they will be merged into one image.
|
| 20 |
+
0 denotes for do not use tile. Default: 500.
|
| 21 |
+
tile_pad (int): The pad size for each tile, to remove border artifacts. Default: 10.
|
| 22 |
+
pre_pad (int): Pad the input images to avoid border artifacts. Default: 10.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
def __init__(self,
|
| 26 |
+
scale=4,
|
| 27 |
+
model=None,
|
| 28 |
+
tile=300,
|
| 29 |
+
tile_pad=10,
|
| 30 |
+
pre_pad=10
|
| 31 |
+
):
|
| 32 |
+
self.scale = scale
|
| 33 |
+
self.tile_size = tile
|
| 34 |
+
self.tile_pad = tile_pad
|
| 35 |
+
self.pre_pad = pre_pad
|
| 36 |
+
self.mod_scale = None
|
| 37 |
+
|
| 38 |
+
self.model = model
|
| 39 |
+
|
| 40 |
+
def pre_process(self, img):
|
| 41 |
+
"""Pre-process, such as pre-pad and mod pad, so that the images can be divisible
|
| 42 |
+
"""
|
| 43 |
+
self.img = img
|
| 44 |
+
|
| 45 |
+
# pre_pad
|
| 46 |
+
if self.pre_pad != 0:
|
| 47 |
+
self.img = F.pad(self.img, (0, self.pre_pad, 0, self.pre_pad), 'reflect')
|
| 48 |
+
# mod pad for divisible borders
|
| 49 |
+
if self.scale == 2:
|
| 50 |
+
self.mod_scale = 2
|
| 51 |
+
elif self.scale == 1:
|
| 52 |
+
self.mod_scale = 4
|
| 53 |
+
if self.mod_scale is not None:
|
| 54 |
+
self.mod_pad_h, self.mod_pad_w = 0, 0
|
| 55 |
+
_, _, h, w = self.img.size()
|
| 56 |
+
if (h % self.mod_scale != 0):
|
| 57 |
+
self.mod_pad_h = (self.mod_scale - h % self.mod_scale)
|
| 58 |
+
if (w % self.mod_scale != 0):
|
| 59 |
+
self.mod_pad_w = (self.mod_scale - w % self.mod_scale)
|
| 60 |
+
self.img = F.pad(self.img, (0, self.mod_pad_w, 0, self.mod_pad_h), 'reflect')
|
| 61 |
+
|
| 62 |
+
def process(self):
|
| 63 |
+
# model inference
|
| 64 |
+
self.output = self.model(self.img)
|
| 65 |
+
|
| 66 |
+
def tile_process(self):
|
| 67 |
+
"""It will first crop input images to tiles, and then process each tile.
|
| 68 |
+
Finally, all the processed tiles are merged into one images.
|
| 69 |
+
|
| 70 |
+
Modified from: https://github.com/ata4/esrgan-launcher
|
| 71 |
+
"""
|
| 72 |
+
batch, channel, height, width = self.img.shape
|
| 73 |
+
output_height = height * self.scale
|
| 74 |
+
output_width = width * self.scale
|
| 75 |
+
output_shape = (batch, channel, output_height, output_width)
|
| 76 |
+
|
| 77 |
+
# start with black image
|
| 78 |
+
self.output = self.img.new_zeros(output_shape)
|
| 79 |
+
tiles_x = math.ceil(width / self.tile_size)
|
| 80 |
+
tiles_y = math.ceil(height / self.tile_size)
|
| 81 |
+
|
| 82 |
+
print("Image processing started...")
|
| 83 |
+
|
| 84 |
+
# loop over all tiles
|
| 85 |
+
for y in range(tiles_y):
|
| 86 |
+
for x in range(tiles_x):
|
| 87 |
+
# extract tile from input image
|
| 88 |
+
ofs_x = x * self.tile_size
|
| 89 |
+
ofs_y = y * self.tile_size
|
| 90 |
+
# input tile area on total image
|
| 91 |
+
input_start_x = ofs_x
|
| 92 |
+
input_end_x = min(ofs_x + self.tile_size, width)
|
| 93 |
+
input_start_y = ofs_y
|
| 94 |
+
input_end_y = min(ofs_y + self.tile_size, height)
|
| 95 |
+
|
| 96 |
+
# input tile area on total image with padding
|
| 97 |
+
input_start_x_pad = max(input_start_x - self.tile_pad, 0)
|
| 98 |
+
input_end_x_pad = min(input_end_x + self.tile_pad, width)
|
| 99 |
+
input_start_y_pad = max(input_start_y - self.tile_pad, 0)
|
| 100 |
+
input_end_y_pad = min(input_end_y + self.tile_pad, height)
|
| 101 |
+
|
| 102 |
+
# input tile dimensions
|
| 103 |
+
input_tile_width = input_end_x - input_start_x
|
| 104 |
+
input_tile_height = input_end_y - input_start_y
|
| 105 |
+
tile_idx = y * tiles_x + x + 1
|
| 106 |
+
input_tile = self.img[:, :, input_start_y_pad:input_end_y_pad, input_start_x_pad:input_end_x_pad]
|
| 107 |
+
|
| 108 |
+
# upscale tile
|
| 109 |
+
try:
|
| 110 |
+
with torch.no_grad():
|
| 111 |
+
output_tile = self.model(input_tile)
|
| 112 |
+
except RuntimeError as error:
|
| 113 |
+
print('Error', error)
|
| 114 |
+
print(f'Processing tile {tile_idx}/{tiles_x * tiles_y}')
|
| 115 |
+
|
| 116 |
+
# output tile area on total image
|
| 117 |
+
output_start_x = input_start_x * self.scale
|
| 118 |
+
output_end_x = input_end_x * self.scale
|
| 119 |
+
output_start_y = input_start_y * self.scale
|
| 120 |
+
output_end_y = input_end_y * self.scale
|
| 121 |
+
|
| 122 |
+
# output tile area without padding
|
| 123 |
+
output_start_x_tile = (input_start_x - input_start_x_pad) * self.scale
|
| 124 |
+
output_end_x_tile = output_start_x_tile + input_tile_width * self.scale
|
| 125 |
+
output_start_y_tile = (input_start_y - input_start_y_pad) * self.scale
|
| 126 |
+
output_end_y_tile = output_start_y_tile + input_tile_height * self.scale
|
| 127 |
+
|
| 128 |
+
# put tile into output image
|
| 129 |
+
self.output[:, :, output_start_y:output_end_y,
|
| 130 |
+
output_start_x:output_end_x] = output_tile[:, :, output_start_y_tile:output_end_y_tile,
|
| 131 |
+
output_start_x_tile:output_end_x_tile]
|
| 132 |
+
|
| 133 |
+
print('All tiles processed, saving output image!')
|
| 134 |
+
|
| 135 |
+
def post_process(self):
|
| 136 |
+
# remove extra pad
|
| 137 |
+
if self.mod_scale is not None:
|
| 138 |
+
_, _, h, w = self.output.size()
|
| 139 |
+
self.output = self.output[:, :, 0:h - self.mod_pad_h * self.scale, 0:w - self.mod_pad_w * self.scale]
|
| 140 |
+
# remove prepad
|
| 141 |
+
if self.pre_pad != 0:
|
| 142 |
+
_, _, h, w = self.output.size()
|
| 143 |
+
self.output = self.output[:, :, 0:h - self.pre_pad * self.scale, 0:w - self.pre_pad * self.scale]
|
| 144 |
+
return self.output
|
| 145 |
+
|
| 146 |
+
@torch.no_grad()
|
| 147 |
+
def enhance(self, img):
|
| 148 |
+
self.pre_process(img)
|
| 149 |
+
|
| 150 |
+
if self.tile_size > 0:
|
| 151 |
+
self.tile_process()
|
| 152 |
+
else:
|
| 153 |
+
self.process()
|
| 154 |
+
output_img = self.post_process()
|
| 155 |
+
|
| 156 |
+
return output_img
|
spaces/0x90e/ESRGAN-MANGA/README.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: ESRGAN MANGA
|
| 3 |
+
emoji: 🏃
|
| 4 |
+
colorFrom: red
|
| 5 |
+
colorTo: indigo
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.12.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
spaces/0x90e/ESRGAN-MANGA/app.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import util
|
| 3 |
+
import process_image
|
| 4 |
+
from run_cmd import run_cmd
|
| 5 |
+
|
| 6 |
+
is_colab = util.is_google_colab()
|
| 7 |
+
|
| 8 |
+
css = '''
|
| 9 |
+
.file-preview {
|
| 10 |
+
overflow: hidden !important;
|
| 11 |
+
margin: 5px 0 !important;
|
| 12 |
+
padding: 0 10px !important;
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
.file-preview div div:nth-child(2) {
|
| 16 |
+
flex-grow: 1 !important;
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
.file-preview div div:nth-child(3) {
|
| 20 |
+
text-align: right !important;
|
| 21 |
+
padding: 0.5rem 0;
|
| 22 |
+
width: auto;
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
#preview_file .h-full.min-h-\[15rem\].flex.justify-center.items-center {
|
| 26 |
+
min-height: initial !important;
|
| 27 |
+
padding: 10px 0;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
#preview_file a {
|
| 31 |
+
border-radius: 0.5rem;
|
| 32 |
+
padding-top: 0.5rem;
|
| 33 |
+
padding-bottom: 0.5rem;
|
| 34 |
+
padding-left: 1rem;
|
| 35 |
+
padding-right: 1rem;
|
| 36 |
+
font-size: 1rem;
|
| 37 |
+
line-height: 1.5rem;
|
| 38 |
+
font-weight: 600;
|
| 39 |
+
color: white;
|
| 40 |
+
background-color: gray;
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
.colab_img {
|
| 44 |
+
margin: 10px 0;
|
| 45 |
+
display: inline-block;
|
| 46 |
+
margin: 0 10px;
|
| 47 |
+
}
|
| 48 |
+
'''
|
| 49 |
+
|
| 50 |
+
title = "ESRGAN Upscaling With Custom Models"
|
| 51 |
+
|
| 52 |
+
with gr.Blocks(title=title, css=css) as demo:
|
| 53 |
+
gr.Markdown(
|
| 54 |
+
f"""
|
| 55 |
+
# {title}
|
| 56 |
+
This space uses old ESRGAN architecture to upscale images, using models made by the community.
|
| 57 |
+
|
| 58 |
+
Once the photo upscaled (*it can take a long time, this space only uses CPU*).
|
| 59 |
+
""")
|
| 60 |
+
|
| 61 |
+
gr.HTML(value="For faster upscaling using GPU: <a href='https://colab.research.google.com/drive/1QfOA6BBdL4NrUmx-9d-pjacxNfu81HQo#scrollTo=H7qo-6AWFbLH' target='_blank'><img class='colab_img' src='https://colab.research.google.com/assets/colab-badge.svg' alt='Open In Colab'></a> buy me a coffee (beer) if this helped 🍺😁")
|
| 62 |
+
|
| 63 |
+
gr.HTML(value="<a href='https://ko-fi.com/Y8Y7GVAAF' target='_blank' style='display:block;margin-bottom:5px'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi1.png?v=3' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>")
|
| 64 |
+
|
| 65 |
+
with gr.Box():
|
| 66 |
+
with gr.Row():
|
| 67 |
+
with gr.Column():
|
| 68 |
+
input_image = gr.Image(type="pil", label="Input")
|
| 69 |
+
upscale_size = gr.Radio(["x4", "x2"], label="Upscale by:", value="x4")
|
| 70 |
+
upscale_type = gr.Radio(["Manga", "Anime", "Photo", "General"], label="Select the type of picture you want to upscale:", value="Manga")
|
| 71 |
+
|
| 72 |
+
with gr.Row():
|
| 73 |
+
upscale_btn = gr.Button(value="Upscale", variant="primary")
|
| 74 |
+
|
| 75 |
+
with gr.Column():
|
| 76 |
+
output_image = gr.Image(type="filepath", interactive=False, label="Upscaled image", elem_id="preview_img")
|
| 77 |
+
|
| 78 |
+
with gr.Row():
|
| 79 |
+
out_file = gr.File(interactive=False, show_label=False, elem_id="preview_file")
|
| 80 |
+
|
| 81 |
+
gr.HTML(value="<p><a href='https://upscale.wiki/wiki/Model_Database'>Model Database</a></p>")
|
| 82 |
+
|
| 83 |
+
upscale_btn.click(process_image.inference, inputs=[input_image, upscale_size, upscale_type], outputs=[output_image, out_file])
|
| 84 |
+
|
| 85 |
+
demo.queue()
|
| 86 |
+
demo.launch(debug=is_colab, share=is_colab, inline=is_colab)
|
spaces/0x90e/ESRGAN-MANGA/inference.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import ESRGAN.architecture as esrgan
|
| 6 |
+
import ESRGAN_plus.architecture as esrgan_plus
|
| 7 |
+
from run_cmd import run_cmd
|
| 8 |
+
from ESRGANer import ESRGANer
|
| 9 |
+
|
| 10 |
+
def is_cuda():
|
| 11 |
+
if torch.cuda.is_available():
|
| 12 |
+
return True
|
| 13 |
+
else:
|
| 14 |
+
return False
|
| 15 |
+
|
| 16 |
+
model_type = sys.argv[2]
|
| 17 |
+
|
| 18 |
+
if model_type == "Anime":
|
| 19 |
+
model_path = "models/4x-AnimeSharp.pth"
|
| 20 |
+
if model_type == "Photo":
|
| 21 |
+
model_path = "models/4x_Valar_v1.pth"
|
| 22 |
+
else:
|
| 23 |
+
model_path = "models/4x_NMKD-Siax_200k.pth"
|
| 24 |
+
|
| 25 |
+
OUTPUT_PATH = sys.argv[1]
|
| 26 |
+
device = torch.device('cuda' if is_cuda() else 'cpu')
|
| 27 |
+
|
| 28 |
+
if model_type != "Photo":
|
| 29 |
+
model = esrgan.RRDB_Net(3, 3, 64, 23, gc=32, upscale=4, norm_type=None, act_type='leakyrelu', mode='CNA', res_scale=1, upsample_mode='upconv')
|
| 30 |
+
else:
|
| 31 |
+
model = esrgan_plus.RRDB_Net(3, 3, 64, 23, gc=32, upscale=4, norm_type=None, act_type='leakyrelu', mode='CNA', res_scale=1, upsample_mode='upconv')
|
| 32 |
+
|
| 33 |
+
if is_cuda():
|
| 34 |
+
print("Using GPU 🥶")
|
| 35 |
+
model.load_state_dict(torch.load(model_path), strict=True)
|
| 36 |
+
else:
|
| 37 |
+
print("Using CPU 😒")
|
| 38 |
+
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')), strict=True)
|
| 39 |
+
|
| 40 |
+
model.eval()
|
| 41 |
+
|
| 42 |
+
for k, v in model.named_parameters():
|
| 43 |
+
v.requires_grad = False
|
| 44 |
+
model = model.to(device)
|
| 45 |
+
|
| 46 |
+
# Read image
|
| 47 |
+
img = cv2.imread(OUTPUT_PATH, cv2.IMREAD_COLOR)
|
| 48 |
+
img = img * 1.0 / 255
|
| 49 |
+
img = torch.from_numpy(np.transpose(img[:, :, [2, 1, 0]], (2, 0, 1))).float()
|
| 50 |
+
img_LR = img.unsqueeze(0)
|
| 51 |
+
img_LR = img_LR.to(device)
|
| 52 |
+
|
| 53 |
+
upsampler = ESRGANer(model=model)
|
| 54 |
+
output = upsampler.enhance(img_LR)
|
| 55 |
+
|
| 56 |
+
output = output.squeeze().float().cpu().clamp_(0, 1).numpy()
|
| 57 |
+
output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0))
|
| 58 |
+
output = (output * 255.0).round()
|
| 59 |
+
cv2.imwrite(OUTPUT_PATH, output, [int(cv2.IMWRITE_PNG_COMPRESSION), 5])
|
spaces/0x90e/ESRGAN-MANGA/inference_manga_v2.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import ESRGAN.architecture as arch
|
| 6 |
+
from ESRGANer import ESRGANer
|
| 7 |
+
|
| 8 |
+
def is_cuda():
|
| 9 |
+
if torch.cuda.is_available():
|
| 10 |
+
return True
|
| 11 |
+
else:
|
| 12 |
+
return False
|
| 13 |
+
|
| 14 |
+
model_path = 'models/4x_eula_digimanga_bw_v2_nc1_307k.pth'
|
| 15 |
+
OUTPUT_PATH = sys.argv[1]
|
| 16 |
+
device = torch.device('cuda' if is_cuda() else 'cpu')
|
| 17 |
+
|
| 18 |
+
model = arch.RRDB_Net(1, 1, 64, 23, gc=32, upscale=4, norm_type=None, act_type='leakyrelu', mode='CNA', res_scale=1, upsample_mode='upconv')
|
| 19 |
+
|
| 20 |
+
if is_cuda():
|
| 21 |
+
print("Using GPU 🥶")
|
| 22 |
+
model.load_state_dict(torch.load(model_path), strict=True)
|
| 23 |
+
else:
|
| 24 |
+
print("Using CPU 😒")
|
| 25 |
+
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')), strict=True)
|
| 26 |
+
|
| 27 |
+
model.eval()
|
| 28 |
+
|
| 29 |
+
for k, v in model.named_parameters():
|
| 30 |
+
v.requires_grad = False
|
| 31 |
+
model = model.to(device)
|
| 32 |
+
|
| 33 |
+
# Read image
|
| 34 |
+
img = cv2.imread(OUTPUT_PATH, cv2.IMREAD_GRAYSCALE)
|
| 35 |
+
img = img * 1.0 / 255
|
| 36 |
+
img = torch.from_numpy(img[np.newaxis, :, :]).float()
|
| 37 |
+
img_LR = img.unsqueeze(0)
|
| 38 |
+
img_LR = img_LR.to(device)
|
| 39 |
+
|
| 40 |
+
upsampler = ESRGANer(model=model)
|
| 41 |
+
output = upsampler.enhance(img_LR)
|
| 42 |
+
|
| 43 |
+
output = output.squeeze(dim=0).float().cpu().clamp_(0, 1).numpy()
|
| 44 |
+
output = np.transpose(output, (1, 2, 0))
|
| 45 |
+
output = (output * 255.0).round()
|
| 46 |
+
cv2.imwrite(OUTPUT_PATH, output, [int(cv2.IMWRITE_PNG_COMPRESSION), 5])
|
spaces/0x90e/ESRGAN-MANGA/process_image.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import gradio as gr
|
| 3 |
+
from run_cmd import run_cmd
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import tempfile
|
| 6 |
+
import uuid
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
temp_path = tempfile.gettempdir()
|
| 10 |
+
|
| 11 |
+
def inference(img, size, type):
|
| 12 |
+
if not img:
|
| 13 |
+
raise Exception("No image!")
|
| 14 |
+
|
| 15 |
+
OUTPUT_PATH = os.path.join(temp_path, f"{str(uuid.uuid4())[0:12]}_{size}.png")
|
| 16 |
+
|
| 17 |
+
img.save(OUTPUT_PATH)
|
| 18 |
+
|
| 19 |
+
if type == "Manga":
|
| 20 |
+
run_cmd(f"python inference_manga_v2.py {OUTPUT_PATH}")
|
| 21 |
+
else:
|
| 22 |
+
run_cmd(f"python inference.py {OUTPUT_PATH} {type}")
|
| 23 |
+
|
| 24 |
+
img_out = Image.open(OUTPUT_PATH)
|
| 25 |
+
|
| 26 |
+
if size == "x2":
|
| 27 |
+
img_out = img_out.resize((img_out.width // 2, img_out.height // 2), resample=Image.BICUBIC)
|
| 28 |
+
|
| 29 |
+
img_out = np.array(img_out)
|
| 30 |
+
|
| 31 |
+
return img_out, gr.File.update(value=OUTPUT_PATH)
|
spaces/0x90e/ESRGAN-MANGA/run_cmd.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from subprocess import call
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
def run_cmd(command):
|
| 5 |
+
try:
|
| 6 |
+
call(command, shell=True)
|
| 7 |
+
except KeyboardInterrupt:
|
| 8 |
+
print("Process interrupted")
|
| 9 |
+
sys.exit(1)
|
spaces/0x90e/ESRGAN-MANGA/util.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
def is_google_colab():
|
| 4 |
+
if os.getenv("COLAB_RELEASE_TAG"):
|
| 5 |
+
return True
|
| 6 |
+
return False
|
spaces/0xAnders/ama-bot/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Ama Bot
|
| 3 |
+
emoji: 🌍
|
| 4 |
+
colorFrom: gray
|
| 5 |
+
colorTo: yellow
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.32.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: apache-2.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xAnders/ama-bot/app.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
import git
|
| 4 |
+
|
| 5 |
+
git.Git().clone("https://github.com/Jesse-zj/bobo-test.git")
|
| 6 |
+
|
| 7 |
+
from llama_index import SimpleDirectoryReader, GPTListIndex, readers, GPTVectorStoreIndex, LLMPredictor, PromptHelper,ServiceContext
|
| 8 |
+
from llama_index import StorageContext, load_index_from_storage
|
| 9 |
+
from langchain import OpenAI
|
| 10 |
+
import sys
|
| 11 |
+
import os
|
| 12 |
+
from IPython.display import Markdown, display
|
| 13 |
+
|
| 14 |
+
openai_api_key = os.environ['OPENAI_API_KEY']
|
| 15 |
+
|
| 16 |
+
def construct_index(directory_path):
|
| 17 |
+
# set maximum input size
|
| 18 |
+
max_input_size = 4096
|
| 19 |
+
# set number of output tokens
|
| 20 |
+
num_outputs = 1000
|
| 21 |
+
# set maximum chunk overlap
|
| 22 |
+
max_chunk_overlap = 30
|
| 23 |
+
# set chunk size limit
|
| 24 |
+
chunk_size_limit = 600
|
| 25 |
+
|
| 26 |
+
# define LLM
|
| 27 |
+
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.5, model_name="text-davinci-003", max_tokens=num_outputs))
|
| 28 |
+
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
|
| 29 |
+
|
| 30 |
+
documents = SimpleDirectoryReader(directory_path).load_data()
|
| 31 |
+
|
| 32 |
+
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
|
| 33 |
+
|
| 34 |
+
index = GPTVectorStoreIndex.from_documents(
|
| 35 |
+
documents, service_context=service_context
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
index.storage_context.persist('index.json')
|
| 39 |
+
|
| 40 |
+
return index
|
| 41 |
+
|
| 42 |
+
def ask_ai(query):
|
| 43 |
+
# set maximum input size
|
| 44 |
+
max_input_size = 4096
|
| 45 |
+
# set number of output tokens
|
| 46 |
+
num_outputs = 1000
|
| 47 |
+
# set maximum chunk overlap
|
| 48 |
+
max_chunk_overlap = 30
|
| 49 |
+
# set chunk size limit
|
| 50 |
+
chunk_size_limit = 600
|
| 51 |
+
|
| 52 |
+
# define LLM
|
| 53 |
+
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.5, model_name="text-davinci-003", max_tokens=num_outputs))
|
| 54 |
+
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
|
| 55 |
+
|
| 56 |
+
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
|
| 57 |
+
# rebuild storage context
|
| 58 |
+
storage_context = StorageContext.from_defaults(persist_dir="index.json")
|
| 59 |
+
# load index
|
| 60 |
+
index = load_index_from_storage(storage_context, service_context=service_context)
|
| 61 |
+
|
| 62 |
+
query_engine = index.as_query_engine()
|
| 63 |
+
response = query_engine.query(query)
|
| 64 |
+
return str(response)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
construct_index('bobo-test')
|
| 68 |
+
|
| 69 |
+
iface = gr.Interface(fn=ask_ai, inputs="textbox", outputs="text")
|
| 70 |
+
iface.launch()
|
spaces/0xHacked/zkProver/Dockerfile
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.1.1-devel-ubuntu20.04
|
| 2 |
+
ARG DEBIAN_FRONTEND=noninteractive
|
| 3 |
+
ENV TZ=Asia/Hong_Kong
|
| 4 |
+
RUN apt-get update && apt-get install --no-install-recommends -y tzdata python3.9 python3.9-dev python3.9-venv build-essential && \
|
| 5 |
+
apt-get clean && rm -rf /var/lib/apt/lists/*
|
| 6 |
+
|
| 7 |
+
RUN useradd -m -u 1000 user
|
| 8 |
+
USER user
|
| 9 |
+
|
| 10 |
+
ENV HOME=/home/user \
|
| 11 |
+
PATH=/home/user/.local/bin:$PATH
|
| 12 |
+
|
| 13 |
+
WORKDIR $HOME/app
|
| 14 |
+
COPY --chown=user . $HOME/app
|
| 15 |
+
|
| 16 |
+
RUN python3.9 -m venv $HOME/app/venv && $HOME/app/venv/bin/pip install --no-cache-dir --upgrade pip
|
| 17 |
+
RUN $HOME/app/venv/bin/pip install --no-cache-dir --upgrade -r requirements.txt
|
| 18 |
+
|
| 19 |
+
RUN cd $HOME/app && chmod +x $HOME/app/bin/*
|
| 20 |
+
|
| 21 |
+
CMD ["/home/user/app/venv/bin/python", "app.py"]
|
spaces/0xHacked/zkProver/README.md
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: ZkProver
|
| 3 |
+
emoji: ⚡
|
| 4 |
+
colorFrom: red
|
| 5 |
+
colorTo: yellow
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
license: bsd
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xHacked/zkProver/app.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import tempfile
|
| 3 |
+
import uuid
|
| 4 |
+
import subprocess
|
| 5 |
+
import gradio as gr
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
BIN = os.path.join(os.path.dirname(__file__), "bin", "zkProver_linux_gpu")
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def run_zk_prover(network, block_number, contract, file):
|
| 12 |
+
if not contract:
|
| 13 |
+
raise gr.Error("contract is required")
|
| 14 |
+
if not file:
|
| 15 |
+
raise gr.Error('file is required')
|
| 16 |
+
args = [
|
| 17 |
+
BIN,
|
| 18 |
+
"evm", "-r", "https://rpc.flashbots.net/"
|
| 19 |
+
]
|
| 20 |
+
if block_number:
|
| 21 |
+
args.extend(["-b", str(block_number)])
|
| 22 |
+
proof_path = "/tmp/" + str(uuid.uuid4()) + ".bin"
|
| 23 |
+
args.extend(["-o", proof_path])
|
| 24 |
+
|
| 25 |
+
args.append(file.name + ":" + contract)
|
| 26 |
+
|
| 27 |
+
proc = subprocess.Popen(args,)
|
| 28 |
+
proc.wait()
|
| 29 |
+
|
| 30 |
+
if proc.returncode != 0:
|
| 31 |
+
raise gr.Error("generate proof failed")
|
| 32 |
+
return proof_path
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
with gr.Blocks() as demo:
|
| 36 |
+
gr.Markdown(
|
| 37 |
+
"""
|
| 38 |
+
# 0xHacked
|
| 39 |
+
This is the demo for [0xHacked](https://0xHacked.com), a trustless bug bounty platform. You can generate the proof of exploit here. However, due to the constraints of ZKP, the generation might be low on Huggingface.
|
| 40 |
+
<br/>
|
| 41 |
+
We recommend [compiling it from the source](https://github.com/0xHackedLabs/zkProver). The generation can be very quick on GPU. For more details, please refer to [0xHacked Documentation](https://docs.0xHacked.com).
|
| 42 |
+
<br/>
|
| 43 |
+
The sample PoC provided below takes ~800s to generate the proof. You can click "SushiRouterExploit.sol" below and hit "Run" to try it!
|
| 44 |
+
"""
|
| 45 |
+
)
|
| 46 |
+
with gr.Column():
|
| 47 |
+
with gr.Row():
|
| 48 |
+
with gr.Column():
|
| 49 |
+
network_input = gr.Dropdown(["Ethereum"], value="Ethereum", label='Network')
|
| 50 |
+
block_number_input = gr.Number(precision=0, label='Block Number')
|
| 51 |
+
contract_input = gr.Textbox(label='Poc Contract')
|
| 52 |
+
file_input = gr.File(file_types=[".sol"], label='Solidity File')
|
| 53 |
+
submit_btn = gr.Button(label="Submit")
|
| 54 |
+
with gr.Column():
|
| 55 |
+
fileout = gr.File(label='Proof File')
|
| 56 |
+
|
| 57 |
+
gr.Examples(
|
| 58 |
+
examples=[[
|
| 59 |
+
"Ethereum",
|
| 60 |
+
17007841,
|
| 61 |
+
"SushiExpProxy",
|
| 62 |
+
"./examples/SushiRouterExploit.sol"],
|
| 63 |
+
],
|
| 64 |
+
fn=run_zk_prover,
|
| 65 |
+
inputs=[network_input, block_number_input, contract_input, file_input],
|
| 66 |
+
outputs=fileout
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
submit_btn.click(
|
| 70 |
+
fn=run_zk_prover,
|
| 71 |
+
inputs=[network_input, block_number_input, contract_input, file_input],
|
| 72 |
+
outputs=fileout
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
demo.launch(server_name="0.0.0.0", server_port=7860)
|
| 77 |
+
|
spaces/0xJustin/0xJustin-Dungeons-and-Diffusion/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: 0xJustin Dungeons And Diffusion
|
| 3 |
+
emoji: 📊
|
| 4 |
+
colorFrom: pink
|
| 5 |
+
colorTo: blue
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.19.1
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: openrail
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xJustin/0xJustin-Dungeons-and-Diffusion/app.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
gr.Interface.load("models/0xJustin/Dungeons-and-Diffusion").launch()
|
spaces/0xSpleef/openchat-openchat_8192/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Openchat-openchat 8192
|
| 3 |
+
emoji: 🌍
|
| 4 |
+
colorFrom: red
|
| 5 |
+
colorTo: pink
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.35.2
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xSpleef/openchat-openchat_8192/app.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
gr.Interface.load("models/openchat/openchat_8192").launch()
|
spaces/0xSynapse/Image_captioner/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Image Captioner
|
| 3 |
+
emoji: ⚡
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: green
|
| 6 |
+
sdk: streamlit
|
| 7 |
+
sdk_version: 1.19.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: creativeml-openrail-m
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xSynapse/Image_captioner/app.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#imported all required libraries
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import torch
|
| 4 |
+
import requests
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from io import BytesIO
|
| 7 |
+
from transformers import ViTFeatureExtractor, AutoTokenizer, VisionEncoderDecoderModel
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
#used a pretrained model hosted on huggingface
|
| 11 |
+
loc = "ydshieh/vit-gpt2-coco-en"
|
| 12 |
+
|
| 13 |
+
feature_extractor = ViTFeatureExtractor.from_pretrained(loc)
|
| 14 |
+
tokenizer = AutoTokenizer.from_pretrained(loc)
|
| 15 |
+
model = VisionEncoderDecoderModel.from_pretrained(loc)
|
| 16 |
+
model.eval()
|
| 17 |
+
|
| 18 |
+
#defined a function for prediction
|
| 19 |
+
|
| 20 |
+
def predict(image):
|
| 21 |
+
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
|
| 22 |
+
|
| 23 |
+
with torch.no_grad():
|
| 24 |
+
output_ids = model.generate(pixel_values, max_length=16, num_beams=4, return_dict_in_generate=True).sequences
|
| 25 |
+
|
| 26 |
+
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
|
| 27 |
+
preds = [pred.strip() for pred in preds]
|
| 28 |
+
|
| 29 |
+
return preds
|
| 30 |
+
|
| 31 |
+
#defined a function for Streamlit App
|
| 32 |
+
def app():
|
| 33 |
+
st.title("ImaginateAI")
|
| 34 |
+
st.write("ViT and GPT2 are used to generate Image Caption for the uploaded image. COCO Dataset was used for training. This image captioning model might have some biases that I couldn’t figure during testing")
|
| 35 |
+
st.write("Upload an image or paste a URL to get predicted captions.")
|
| 36 |
+
|
| 37 |
+
upload_option = st.selectbox("Choose an option:", ("Upload Image", "Paste URL"))
|
| 38 |
+
|
| 39 |
+
if upload_option == "Upload Image":
|
| 40 |
+
uploaded_file = st.file_uploader("Upload an image", type=["jpg", "jpeg"])
|
| 41 |
+
|
| 42 |
+
if uploaded_file is not None:
|
| 43 |
+
image = Image.open(uploaded_file)
|
| 44 |
+
preds = predict(image)
|
| 45 |
+
st.image(image, caption="Uploaded Image", use_column_width=True)
|
| 46 |
+
st.write("Predicted Caption:", preds)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
elif upload_option == "Paste URL":
|
| 50 |
+
image_url = st.text_input("Enter Image URL")
|
| 51 |
+
if st.button("Submit") and image_url:
|
| 52 |
+
try:
|
| 53 |
+
response = requests.get(image_url, stream=True)
|
| 54 |
+
image = Image.open(BytesIO(response.content))
|
| 55 |
+
preds = predict(image)
|
| 56 |
+
st.image(image, caption="Image from URL", use_column_width=True)
|
| 57 |
+
st.write("Predicted Caption:", preds)
|
| 58 |
+
except:
|
| 59 |
+
st.write("Error: Invalid URL or unable to fetch image.")
|
| 60 |
+
|
| 61 |
+
if __name__ == "__main__":
|
| 62 |
+
app()
|
spaces/0xSynapse/LlamaGPT/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: LlamaGPT
|
| 3 |
+
emoji: 📚
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: blue
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.39.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: lgpl-3.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xSynapse/LlamaGPT/app.py
ADDED
|
@@ -0,0 +1,408 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Run codes."""
|
| 2 |
+
# pylint: disable=line-too-long, broad-exception-caught, invalid-name, missing-function-docstring, too-many-instance-attributes, missing-class-docstring
|
| 3 |
+
# ruff: noqa: E501
|
| 4 |
+
import gc
|
| 5 |
+
import os
|
| 6 |
+
import platform
|
| 7 |
+
import random
|
| 8 |
+
import time
|
| 9 |
+
from dataclasses import asdict, dataclass
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
|
| 12 |
+
# from types import SimpleNamespace
|
| 13 |
+
import gradio as gr
|
| 14 |
+
import psutil
|
| 15 |
+
from about_time import about_time
|
| 16 |
+
from ctransformers import AutoModelForCausalLM
|
| 17 |
+
from dl_hf_model import dl_hf_model
|
| 18 |
+
from loguru import logger
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# url = "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q2_K.bin"
|
| 24 |
+
#url = "https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/blob/main/llama-2-7b-chat.ggmlv3.q2_K.bin" # 2.87G
|
| 25 |
+
url = "https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/blob/main/llama-2-7b-chat.ggmlv3.q4_K_M.bin" # 2.87G
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
prompt_template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
|
| 29 |
+
|
| 30 |
+
### Instruction: {user_prompt}
|
| 31 |
+
|
| 32 |
+
### Response:
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
prompt_template = """System: You are a helpful,
|
| 36 |
+
respectful and honest assistant. Always answer as
|
| 37 |
+
helpfully as possible, while being safe. Your answers
|
| 38 |
+
should not include any harmful, unethical, racist,
|
| 39 |
+
sexist, toxic, dangerous, or illegal content. Please
|
| 40 |
+
ensure that your responses are socially unbiased and
|
| 41 |
+
positive in nature. If a question does not make any
|
| 42 |
+
sense, or is not factually coherent, explain why instead
|
| 43 |
+
of answering something not correct. If you don't know
|
| 44 |
+
the answer to a question, please don't share false
|
| 45 |
+
information.
|
| 46 |
+
User: {prompt}
|
| 47 |
+
Assistant: """
|
| 48 |
+
|
| 49 |
+
prompt_template = """System: You are a helpful assistant.
|
| 50 |
+
User: {prompt}
|
| 51 |
+
Assistant: """
|
| 52 |
+
|
| 53 |
+
prompt_template = """Question: {question}
|
| 54 |
+
Answer: Let's work this out in a step by step way to be sure we have the right answer."""
|
| 55 |
+
|
| 56 |
+
prompt_template = """[INST] <>
|
| 57 |
+
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible assistant. Think step by step.
|
| 58 |
+
<>
|
| 59 |
+
|
| 60 |
+
What NFL team won the Super Bowl in the year Justin Bieber was born?
|
| 61 |
+
[/INST]"""
|
| 62 |
+
|
| 63 |
+
prompt_template = """[INST] <<SYS>>
|
| 64 |
+
You are an unhelpful assistant. Always answer as helpfully as possible. Think step by step. <</SYS>>
|
| 65 |
+
|
| 66 |
+
{question} [/INST]
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
prompt_template = """[INST] <<SYS>>
|
| 70 |
+
You are a helpful assistant.
|
| 71 |
+
<</SYS>>
|
| 72 |
+
|
| 73 |
+
{question} [/INST]
|
| 74 |
+
"""
|
| 75 |
+
|
| 76 |
+
_ = [elm for elm in prompt_template.splitlines() if elm.strip()]
|
| 77 |
+
stop_string = [elm.split(":")[0] + ":" for elm in _][-2]
|
| 78 |
+
|
| 79 |
+
logger.debug(f"{stop_string=}")
|
| 80 |
+
|
| 81 |
+
_ = psutil.cpu_count(logical=False) - 1
|
| 82 |
+
cpu_count: int = int(_) if _ else 1
|
| 83 |
+
logger.debug(f"{cpu_count=}")
|
| 84 |
+
|
| 85 |
+
LLM = None
|
| 86 |
+
gc.collect()
|
| 87 |
+
|
| 88 |
+
try:
|
| 89 |
+
model_loc, file_size = dl_hf_model(url)
|
| 90 |
+
except Exception as exc_:
|
| 91 |
+
logger.error(exc_)
|
| 92 |
+
raise SystemExit(1) from exc_
|
| 93 |
+
|
| 94 |
+
LLM = AutoModelForCausalLM.from_pretrained(
|
| 95 |
+
model_loc,
|
| 96 |
+
model_type="llama",
|
| 97 |
+
# threads=cpu_count,
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
logger.info(f"done load llm {model_loc=} {file_size=}G")
|
| 101 |
+
|
| 102 |
+
os.environ["TZ"] = "Asia/Shanghai"
|
| 103 |
+
try:
|
| 104 |
+
time.tzset() # type: ignore # pylint: disable=no-member
|
| 105 |
+
except Exception:
|
| 106 |
+
# Windows
|
| 107 |
+
logger.warning("Windows, cant run time.tzset()")
|
| 108 |
+
|
| 109 |
+
_ = """
|
| 110 |
+
ns = SimpleNamespace(
|
| 111 |
+
response="",
|
| 112 |
+
generator=(_ for _ in []),
|
| 113 |
+
)
|
| 114 |
+
# """
|
| 115 |
+
|
| 116 |
+
@dataclass
|
| 117 |
+
class GenerationConfig:
|
| 118 |
+
temperature: float = 0.7
|
| 119 |
+
top_k: int = 50
|
| 120 |
+
top_p: float = 0.9
|
| 121 |
+
repetition_penalty: float = 1.0
|
| 122 |
+
max_new_tokens: int = 512
|
| 123 |
+
seed: int = 42
|
| 124 |
+
reset: bool = False
|
| 125 |
+
stream: bool = True
|
| 126 |
+
# threads: int = cpu_count
|
| 127 |
+
# stop: list[str] = field(default_factory=lambda: [stop_string])
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def generate(
|
| 131 |
+
question: str,
|
| 132 |
+
llm=LLM,
|
| 133 |
+
config: GenerationConfig = GenerationConfig(),
|
| 134 |
+
):
|
| 135 |
+
"""Run model inference, will return a Generator if streaming is true."""
|
| 136 |
+
# _ = prompt_template.format(question=question)
|
| 137 |
+
# print(_)
|
| 138 |
+
|
| 139 |
+
prompt = prompt_template.format(question=question)
|
| 140 |
+
|
| 141 |
+
return llm(
|
| 142 |
+
prompt,
|
| 143 |
+
**asdict(config),
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
logger.debug(f"{asdict(GenerationConfig())=}")
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def user(user_message, history):
|
| 151 |
+
# return user_message, history + [[user_message, None]]
|
| 152 |
+
history.append([user_message, None])
|
| 153 |
+
return user_message, history # keep user_message
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def user1(user_message, history):
|
| 157 |
+
# return user_message, history + [[user_message, None]]
|
| 158 |
+
history.append([user_message, None])
|
| 159 |
+
return "", history # clear user_message
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def bot_(history):
|
| 163 |
+
user_message = history[-1][0]
|
| 164 |
+
resp = random.choice(["How are you?", "I love you", "I'm very hungry"])
|
| 165 |
+
bot_message = user_message + ": " + resp
|
| 166 |
+
history[-1][1] = ""
|
| 167 |
+
for character in bot_message:
|
| 168 |
+
history[-1][1] += character
|
| 169 |
+
time.sleep(0.02)
|
| 170 |
+
yield history
|
| 171 |
+
|
| 172 |
+
history[-1][1] = resp
|
| 173 |
+
yield history
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def bot(history):
|
| 177 |
+
user_message = history[-1][0]
|
| 178 |
+
response = []
|
| 179 |
+
|
| 180 |
+
logger.debug(f"{user_message=}")
|
| 181 |
+
|
| 182 |
+
with about_time() as atime: # type: ignore
|
| 183 |
+
flag = 1
|
| 184 |
+
prefix = ""
|
| 185 |
+
then = time.time()
|
| 186 |
+
|
| 187 |
+
logger.debug("about to generate")
|
| 188 |
+
|
| 189 |
+
config = GenerationConfig(reset=True)
|
| 190 |
+
for elm in generate(user_message, config=config):
|
| 191 |
+
if flag == 1:
|
| 192 |
+
logger.debug("in the loop")
|
| 193 |
+
prefix = f"({time.time() - then:.2f}s) "
|
| 194 |
+
flag = 0
|
| 195 |
+
print(prefix, end="", flush=True)
|
| 196 |
+
logger.debug(f"{prefix=}")
|
| 197 |
+
print(elm, end="", flush=True)
|
| 198 |
+
# logger.debug(f"{elm}")
|
| 199 |
+
|
| 200 |
+
response.append(elm)
|
| 201 |
+
history[-1][1] = prefix + "".join(response)
|
| 202 |
+
yield history
|
| 203 |
+
|
| 204 |
+
_ = (
|
| 205 |
+
f"(time elapsed: {atime.duration_human}, " # type: ignore
|
| 206 |
+
f"{atime.duration/len(''.join(response)):.2f}s/char)" # type: ignore
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
history[-1][1] = "".join(response) + f"\n{_}"
|
| 210 |
+
yield history
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def predict_api(prompt):
|
| 214 |
+
logger.debug(f"{prompt=}")
|
| 215 |
+
try:
|
| 216 |
+
# user_prompt = prompt
|
| 217 |
+
config = GenerationConfig(
|
| 218 |
+
temperature=0.2,
|
| 219 |
+
top_k=10,
|
| 220 |
+
top_p=0.9,
|
| 221 |
+
repetition_penalty=1.0,
|
| 222 |
+
max_new_tokens=512, # adjust as needed
|
| 223 |
+
seed=42,
|
| 224 |
+
reset=True, # reset history (cache)
|
| 225 |
+
stream=False,
|
| 226 |
+
# threads=cpu_count,
|
| 227 |
+
# stop=prompt_prefix[1:2],
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
response = generate(
|
| 231 |
+
prompt,
|
| 232 |
+
config=config,
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
logger.debug(f"api: {response=}")
|
| 236 |
+
except Exception as exc:
|
| 237 |
+
logger.error(exc)
|
| 238 |
+
response = f"{exc=}"
|
| 239 |
+
# bot = {"inputs": [response]}
|
| 240 |
+
# bot = [(prompt, response)]
|
| 241 |
+
|
| 242 |
+
return response
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
css = """
|
| 246 |
+
.importantButton {
|
| 247 |
+
background: linear-gradient(45deg, #7e0570,#5d1c99, #6e00ff) !important;
|
| 248 |
+
border: none !important;
|
| 249 |
+
}
|
| 250 |
+
.importantButton:hover {
|
| 251 |
+
background: linear-gradient(45deg, #ff00e0,#8500ff, #6e00ff) !important;
|
| 252 |
+
border: none !important;
|
| 253 |
+
}
|
| 254 |
+
.disclaimer {font-variant-caps: all-small-caps; font-size: xx-small;}
|
| 255 |
+
.xsmall {font-size: x-small;}
|
| 256 |
+
"""
|
| 257 |
+
etext = """In America, where cars are an important part of the national psyche, a decade ago people had suddenly started to drive less, which had not happened since the oil shocks of the 1970s. """
|
| 258 |
+
examples_list = [
|
| 259 |
+
["What is the capital of India"],
|
| 260 |
+
["How to play Chess? Provide detailed steps."],
|
| 261 |
+
["If it takes 10 hours to dry 10 clothes, assuming all the clothes are hung together at the same time for drying , then how long will it take to dry a cloth?"],
|
| 262 |
+
["is infinity + 1 bigger than infinity?"],
|
| 263 |
+
["Explain the plot of Oppenheimer 2023 movie in a sentence."],
|
| 264 |
+
["How long does it take to become proficient in French, and what are the best methods for retaining information?"],
|
| 265 |
+
["What are some common mistakes to avoid when writing code?"],
|
| 266 |
+
["Build a prompt to generate a beautiful portrait of a horse"],
|
| 267 |
+
["Suggest four metaphors to describe the benefits of AI"],
|
| 268 |
+
["Write most important points of Bhagavad Gita"],
|
| 269 |
+
["Write a summary Why is it so hard to understand Quantum mechanics"],
|
| 270 |
+
|
| 271 |
+
]
|
| 272 |
+
|
| 273 |
+
logger.info("start block")
|
| 274 |
+
|
| 275 |
+
with gr.Blocks(
|
| 276 |
+
title="LlamaGPT🤖",
|
| 277 |
+
theme=gr.themes.Soft(text_size="sm", spacing_size="sm"),
|
| 278 |
+
css=css,
|
| 279 |
+
) as block:
|
| 280 |
+
# buff_var = gr.State("")
|
| 281 |
+
with gr.Accordion("LlamaGPT🧠", open=False, style={"text-align": "center", "font-weight": "bold"}):
|
| 282 |
+
|
| 283 |
+
gr.Markdown(
|
| 284 |
+
f"""<div style="text-align: center;">
|
| 285 |
+
<h5>Gradio Demo for Meta's Llama 2 7B-chat</h5><br>
|
| 286 |
+
Few examples are there as prompts to test the model. You probably should try on your own related prompts to test the bot.
|
| 287 |
+
</div>""",
|
| 288 |
+
elem_classes="xsmall",
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
# chatbot = gr.Chatbot().style(height=700) # 500
|
| 292 |
+
chatbot = gr.Chatbot(height=500)
|
| 293 |
+
|
| 294 |
+
# buff = gr.Textbox(show_label=False, visible=True)
|
| 295 |
+
|
| 296 |
+
with gr.Row():
|
| 297 |
+
with gr.Column(scale=5):
|
| 298 |
+
msg = gr.Textbox(
|
| 299 |
+
label="Chat Message Box",
|
| 300 |
+
placeholder="Ask me anything (press Shift+Enter or click Submit to send)",
|
| 301 |
+
show_label=False,
|
| 302 |
+
# container=False,
|
| 303 |
+
lines=6,
|
| 304 |
+
max_lines=30,
|
| 305 |
+
show_copy_button=True,
|
| 306 |
+
# ).style(container=False)
|
| 307 |
+
)
|
| 308 |
+
with gr.Column(scale=1, min_width=50):
|
| 309 |
+
with gr.Row():
|
| 310 |
+
submit = gr.Button("Submit", elem_classes="xsmall")
|
| 311 |
+
stop = gr.Button("Stop", visible=True)
|
| 312 |
+
clear = gr.Button("Clear History", visible=True)
|
| 313 |
+
with gr.Row(visible=False):
|
| 314 |
+
with gr.Accordion("Advanced Options:", open=False):
|
| 315 |
+
with gr.Row():
|
| 316 |
+
with gr.Column(scale=2):
|
| 317 |
+
system = gr.Textbox(
|
| 318 |
+
label="System Prompt",
|
| 319 |
+
value=prompt_template,
|
| 320 |
+
show_label=False,
|
| 321 |
+
container=False,
|
| 322 |
+
# ).style(container=False)
|
| 323 |
+
)
|
| 324 |
+
with gr.Column():
|
| 325 |
+
with gr.Row():
|
| 326 |
+
change = gr.Button("Change System Prompt")
|
| 327 |
+
reset = gr.Button("Reset System Prompt")
|
| 328 |
+
|
| 329 |
+
with gr.Accordion("Example Inputs", open=True):
|
| 330 |
+
examples = gr.Examples(
|
| 331 |
+
examples=examples_list,
|
| 332 |
+
inputs=[msg],
|
| 333 |
+
examples_per_page=40,
|
| 334 |
+
)
|
| 335 |
+
|
| 336 |
+
# with gr.Row():
|
| 337 |
+
with gr.Accordion("Disclaimer", open=False):
|
| 338 |
+
_ = Path(model_loc).name
|
| 339 |
+
gr.Markdown(
|
| 340 |
+
f"Disclaimer: {_} can produce factually incorrect output, and should not be relied on to produce "
|
| 341 |
+
"factually accurate information. {_} was trained on various public datasets; while great efforts "
|
| 342 |
+
"have been taken to clean the pretraining data, it is possible that this model could generate lewd, "
|
| 343 |
+
"biased, or otherwise offensive outputs.",
|
| 344 |
+
elem_classes=["disclaimer"],
|
| 345 |
+
)
|
| 346 |
+
|
| 347 |
+
msg_submit_event = msg.submit(
|
| 348 |
+
# fn=conversation.user_turn,
|
| 349 |
+
fn=user,
|
| 350 |
+
inputs=[msg, chatbot],
|
| 351 |
+
outputs=[msg, chatbot],
|
| 352 |
+
queue=True,
|
| 353 |
+
show_progress="full",
|
| 354 |
+
# api_name=None,
|
| 355 |
+
).then(bot, chatbot, chatbot, queue=True)
|
| 356 |
+
submit_click_event = submit.click(
|
| 357 |
+
# fn=lambda x, y: ("",) + user(x, y)[1:], # clear msg
|
| 358 |
+
fn=user1, # clear msg
|
| 359 |
+
inputs=[msg, chatbot],
|
| 360 |
+
outputs=[msg, chatbot],
|
| 361 |
+
queue=True,
|
| 362 |
+
# queue=False,
|
| 363 |
+
show_progress="full",
|
| 364 |
+
# api_name=None,
|
| 365 |
+
).then(bot, chatbot, chatbot, queue=True)
|
| 366 |
+
stop.click(
|
| 367 |
+
fn=None,
|
| 368 |
+
inputs=None,
|
| 369 |
+
outputs=None,
|
| 370 |
+
cancels=[msg_submit_event, submit_click_event],
|
| 371 |
+
queue=False,
|
| 372 |
+
)
|
| 373 |
+
clear.click(lambda: None, None, chatbot, queue=False)
|
| 374 |
+
|
| 375 |
+
with gr.Accordion("For Chat/Translation API", open=False, visible=False):
|
| 376 |
+
input_text = gr.Text()
|
| 377 |
+
api_btn = gr.Button("Go", variant="primary")
|
| 378 |
+
out_text = gr.Text()
|
| 379 |
+
|
| 380 |
+
api_btn.click(
|
| 381 |
+
predict_api,
|
| 382 |
+
input_text,
|
| 383 |
+
out_text,
|
| 384 |
+
api_name="api",
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
# block.load(update_buff, [], buff, every=1)
|
| 388 |
+
# block.load(update_buff, [buff_var], [buff_var, buff], every=1)
|
| 389 |
+
|
| 390 |
+
# concurrency_count=5, max_size=20
|
| 391 |
+
# max_size=36, concurrency_count=14
|
| 392 |
+
# CPU cpu_count=2 16G, model 7G
|
| 393 |
+
# CPU UPGRADE cpu_count=8 32G, model 7G
|
| 394 |
+
|
| 395 |
+
# does not work
|
| 396 |
+
_ = """
|
| 397 |
+
# _ = int(psutil.virtual_memory().total / 10**9 // file_size - 1)
|
| 398 |
+
# concurrency_count = max(_, 1)
|
| 399 |
+
if psutil.cpu_count(logical=False) >= 8:
|
| 400 |
+
# concurrency_count = max(int(32 / file_size) - 1, 1)
|
| 401 |
+
else:
|
| 402 |
+
# concurrency_count = max(int(16 / file_size) - 1, 1)
|
| 403 |
+
# """
|
| 404 |
+
|
| 405 |
+
concurrency_count = 1
|
| 406 |
+
logger.info(f"{concurrency_count=}")
|
| 407 |
+
|
| 408 |
+
block.queue(concurrency_count=concurrency_count, max_size=5).launch(debug=True)
|
spaces/0xSynapse/PixelFusion/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: PixelFusion
|
| 3 |
+
emoji: 🔥
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: yellow
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.39.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: gpl-3.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xSynapse/PixelFusion/app.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Neural Style Transfer using TensorFlow's Pretrained Style Transfer Model
|
| 3 |
+
https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2
|
| 4 |
+
|
| 5 |
+
'''
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
import tensorflow as tf
|
| 10 |
+
import tensorflow_hub as hub
|
| 11 |
+
from PIL import Image
|
| 12 |
+
import numpy as np
|
| 13 |
+
import cv2
|
| 14 |
+
import os
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
model = hub.load("https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2")
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# source: https://stackoverflow.com/questions/4993082/how-can-i-sharpen-an-image-in-opencv
|
| 22 |
+
def unsharp_mask(image, kernel_size=(5, 5), sigma=1.0, amount=1.0, threshold=0):
|
| 23 |
+
"""Return a sharpened version of the image, using an unsharp mask."""
|
| 24 |
+
blurred = cv2.GaussianBlur(image, kernel_size, sigma)
|
| 25 |
+
sharpened = float(amount + 1) * image - float(amount) * blurred
|
| 26 |
+
sharpened = np.maximum(sharpened, np.zeros(sharpened.shape))
|
| 27 |
+
sharpened = np.minimum(sharpened, 255 * np.ones(sharpened.shape))
|
| 28 |
+
sharpened = sharpened.round().astype(np.uint8)
|
| 29 |
+
if threshold > 0:
|
| 30 |
+
low_contrast_mask = np.absolute(image - blurred) < threshold
|
| 31 |
+
np.copyto(sharpened, image, where=low_contrast_mask)
|
| 32 |
+
return sharpened
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def style_transfer(content_img,style_image, style_weight = 1, content_weight = 1, style_blur=False):
|
| 36 |
+
content_img = unsharp_mask(content_img,amount=1)
|
| 37 |
+
content_img = tf.image.resize(tf.convert_to_tensor(content_img,tf.float32)[tf.newaxis,...] / 255.,(512,512),preserve_aspect_ratio=True)
|
| 38 |
+
style_img = tf.convert_to_tensor(style_image,tf.float32)[tf.newaxis,...] / 255.
|
| 39 |
+
if style_blur:
|
| 40 |
+
style_img= tf.nn.avg_pool(style_img, [3,3], [1,1], "VALID")
|
| 41 |
+
style_img = tf.image.adjust_contrast(style_img, style_weight)
|
| 42 |
+
content_img = tf.image.adjust_contrast(content_img,content_weight)
|
| 43 |
+
content_img = tf.image.adjust_saturation(content_img, 2)
|
| 44 |
+
content_img = tf.image.adjust_contrast(content_img,1.5)
|
| 45 |
+
stylized_img = model(content_img, style_img)[0]
|
| 46 |
+
|
| 47 |
+
return Image.fromarray(np.uint8(stylized_img[0]*255))
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
title = "PixelFusion🧬"
|
| 53 |
+
description = "Gradio Demo for Artistic Neural Style Transfer. To use it, simply upload a content image and a style image. [Learn More](https://www.tensorflow.org/tutorials/generative/style_transfer)."
|
| 54 |
+
article = "</br><p style='text-align: center'><a href='https://github.com/0xsynapse' target='_blank'>GitHub</a></p> "
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
content_input = gr.inputs.Image(label="Upload Your Image ",)
|
| 58 |
+
style_input = gr.inputs.Image( label="Upload Style Image ",shape= (256,256), )
|
| 59 |
+
style_slider = gr.inputs.Slider(0,2,label="Adjust Style Density" ,default=1,)
|
| 60 |
+
content_slider = gr.inputs.Slider(1,5,label="Content Sharpness" ,default=1,)
|
| 61 |
+
# style_checkbox = gr.Checkbox(value=False,label="Tune Style(experimental)")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
examples = [
|
| 65 |
+
["Content/content_1.jpg","Styles/style_1.jpg",1.20,1.70,"style_checkbox"],
|
| 66 |
+
["Content/content_2.jpg","Styles/style_2.jpg",0.91,2.54,"style_checkbox"],
|
| 67 |
+
["Content/content_3.png","Styles/style_3.jpg",1.02,2.47,"style_checkbox"]
|
| 68 |
+
]
|
| 69 |
+
interface = gr.Interface(fn=style_transfer,
|
| 70 |
+
inputs=[content_input,
|
| 71 |
+
style_input,
|
| 72 |
+
style_slider ,
|
| 73 |
+
content_slider,
|
| 74 |
+
# style_checkbox
|
| 75 |
+
],
|
| 76 |
+
outputs=gr.outputs.Image(type="pil"),
|
| 77 |
+
title=title,
|
| 78 |
+
description=description,
|
| 79 |
+
article=article,
|
| 80 |
+
examples=examples,
|
| 81 |
+
enable_queue=True
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
interface.launch()
|
spaces/0xSynapse/Segmagine/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Segmagine
|
| 3 |
+
emoji: 🚀
|
| 4 |
+
colorFrom: gray
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.39.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: lgpl-3.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
spaces/0xSynapse/Segmagine/app.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import matplotlib
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
from PIL import Image
|
| 11 |
+
|
| 12 |
+
from segment_anything import SamAutomaticMaskGenerator, SamPredictor, sam_model_registry
|
| 13 |
+
|
| 14 |
+
# suppress server-side GUI windows
|
| 15 |
+
matplotlib.pyplot.switch_backend('Agg')
|
| 16 |
+
|
| 17 |
+
# setup models
|
| 18 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 19 |
+
sam = sam_model_registry["vit_b"](checkpoint="./sam_vit_b_01ec64.pth")
|
| 20 |
+
sam.to(device=device)
|
| 21 |
+
mask_generator = SamAutomaticMaskGenerator(sam)
|
| 22 |
+
predictor = SamPredictor(sam)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# copied from: https://github.com/facebookresearch/segment-anything
|
| 26 |
+
def show_anns(anns):
|
| 27 |
+
if len(anns) == 0:
|
| 28 |
+
return
|
| 29 |
+
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
|
| 30 |
+
ax = plt.gca()
|
| 31 |
+
ax.set_autoscale_on(False)
|
| 32 |
+
polygons = []
|
| 33 |
+
color = []
|
| 34 |
+
for ann in sorted_anns:
|
| 35 |
+
m = ann['segmentation']
|
| 36 |
+
img = np.ones((m.shape[0], m.shape[1], 3))
|
| 37 |
+
color_mask = np.random.random((1, 3)).tolist()[0]
|
| 38 |
+
for i in range(3):
|
| 39 |
+
img[:,:,i] = color_mask[i]
|
| 40 |
+
ax.imshow(np.dstack((img, m*0.35)))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# demo function
|
| 44 |
+
def segment_image(input_image):
|
| 45 |
+
|
| 46 |
+
if input_image is not None:
|
| 47 |
+
|
| 48 |
+
# generate masks
|
| 49 |
+
masks = mask_generator.generate(input_image)
|
| 50 |
+
|
| 51 |
+
# add masks to image
|
| 52 |
+
plt.clf()
|
| 53 |
+
ppi = 100
|
| 54 |
+
height, width, _ = input_image.shape
|
| 55 |
+
plt.figure(figsize=(width / ppi, height / ppi)) # convert pixel to inches
|
| 56 |
+
plt.imshow(input_image)
|
| 57 |
+
show_anns(masks)
|
| 58 |
+
plt.axis('off')
|
| 59 |
+
|
| 60 |
+
# save and get figure
|
| 61 |
+
plt.savefig('output_figure.png', bbox_inches='tight')
|
| 62 |
+
output_image = cv2.imread('output_figure.png')
|
| 63 |
+
return Image.fromarray(output_image)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
with gr.Blocks() as demo:
|
| 67 |
+
|
| 68 |
+
with gr.Row():
|
| 69 |
+
gr.Markdown("## Segmagine 🎨")
|
| 70 |
+
with gr.Row():
|
| 71 |
+
gr.Markdown("Gradio demo for Segment Anything Model (SAM) by Meta AI Research, produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.[Learn More](https://segment-anything.com/)")
|
| 72 |
+
|
| 73 |
+
with gr.Row():
|
| 74 |
+
|
| 75 |
+
with gr.Column():
|
| 76 |
+
image_input = gr.Image()
|
| 77 |
+
segment_image_button = gr.Button('Generate Mask')
|
| 78 |
+
|
| 79 |
+
with gr.Column():
|
| 80 |
+
image_output = gr.Image()
|
| 81 |
+
|
| 82 |
+
segment_image_button.click(segment_image, inputs=[image_input], outputs=image_output)
|
| 83 |
+
|
| 84 |
+
gr.Examples(
|
| 85 |
+
examples=[
|
| 86 |
+
['./examples/dog.jpg'],
|
| 87 |
+
['./examples/groceries.jpg'],
|
| 88 |
+
['./examples/truck.jpg']
|
| 89 |
+
|
| 90 |
+
],
|
| 91 |
+
inputs=[image_input],
|
| 92 |
+
outputs=[image_output],
|
| 93 |
+
fn=segment_image,
|
| 94 |
+
#cache_examples=True
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
demo.launch()
|