diff --git a/Hotshot-XL/.gitignore b/Hotshot-XL/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..c9043211f5fd9137d916f2deba3dc8c95720ec14
--- /dev/null
+++ b/Hotshot-XL/.gitignore
@@ -0,0 +1,6 @@
+.DS_Store
+venv
+.idea
+__pycache__
+build
+*.egg-info
diff --git a/Hotshot-XL/1.gif b/Hotshot-XL/1.gif
new file mode 100644
index 0000000000000000000000000000000000000000..0109460ba2c4a5915a67b3b29c0016030981236f
--- /dev/null
+++ b/Hotshot-XL/1.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:eef68e44665177961530be278efcc1dca53208b3041319d502874c6592a66df9
+size 1322061
diff --git a/Hotshot-XL/2.gif b/Hotshot-XL/2.gif
new file mode 100644
index 0000000000000000000000000000000000000000..37ccaea979f1ef4d24d27552c0a5ff5cf907c842
--- /dev/null
+++ b/Hotshot-XL/2.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cd7cbe6d8657d604f9ea4495e51196ef91936c7bc4100752da629d79df78f26b
+size 1855296
diff --git a/Hotshot-XL/LICENSE b/Hotshot-XL/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/Hotshot-XL/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/Hotshot-XL/README.md b/Hotshot-XL/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..29c5ca4fe535cc0bb9ba76c5d7aefbde5daacdf3
--- /dev/null
+++ b/Hotshot-XL/README.md
@@ -0,0 +1,257 @@
+ Hotshot-XL
Hotshot-XL
+
+
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+
+
+Hotshot-XL is an AI text-to-GIF model trained to work alongside [Stable Diffusion XL](https://stability.ai/stable-diffusion).
+
+Hotshot-XL can generate GIFs with any fine-tuned SDXL model. This means two things:
+1. You’ll be able to make GIFs with any existing or newly fine-tuned SDXL model you may want to use.
+2. If you'd like to make GIFs of personalized subjects, you can load your own SDXL based LORAs, and not have to worry about fine-tuning Hotshot-XL. This is awesome because it’s usually much easier to find suitable images for training data than it is to find videos. It also hopefully fits into everyone's existing LORA usage/workflows :) See more [here](#text-to-gif-with-personalized-loras).
+
+Hotshot-XL is compatible with SDXL ControlNet to make GIFs in the composition/layout you’d like. See the [ControlNet](#text-to-gif-with-controlnet) section below.
+
+Hotshot-XL was trained to generate 1 second GIFs at 8 FPS.
+
+Hotshot-XL was trained on various aspect ratios. For best results with the base Hotshot-XL model, we recommend using it with an SDXL model that has been fine-tuned with 512x512 images. You can find an SDXL model we fine-tuned for 512x512 resolutions [here](https://huggingface.co/hotshotco/SDXL-512).
+
+# 🌐 Try It
+
+Try Hotshot-XL yourself here: https://www.hotshot.co
+
+Or, if you'd like to run Hotshot-XL yourself locally, continue on to the sections below.
+
+If you’re running Hotshot-XL yourself, you are going to be able to have a lot more flexibility/control with the model. As a very simple example, you’ll be able to change the sampler. We’ve seen best results with Euler-A so far, but you may find interesting results with some other ones.
+
+# 🔧 Setup
+
+### Environment Setup
+```
+pip install virtualenv --upgrade
+virtualenv -p $(which python3) venv
+source venv/bin/activate
+pip install -r requirements.txt
+```
+
+### Download the Hotshot-XL Weights
+
+```
+# Make sure you have git-lfs installed (https://git-lfs.com)
+git lfs install
+git clone https://huggingface.co/hotshotco/Hotshot-XL
+```
+
+or visit [https://huggingface.co/hotshotco/Hotshot-XL](https://huggingface.co/hotshotco/Hotshot-XL)
+
+### Download our fine-tuned SDXL model (or BYOSDXL)
+
+- *Note*: To maximize data and training efficiency, Hotshot-XL was trained at various aspect ratios around 512x512 resolution. For best results with the base Hotshot-XL model, we recommend using it with an SDXL model that has been fine-tuned with images around the 512x512 resolution. You can download an SDXL model we trained with images at 512x512 resolution below, or bring your own SDXL base model.
+
+```
+# Make sure you have git-lfs installed (https://git-lfs.com)
+git lfs install
+git clone https://huggingface.co/hotshotco/SDXL-512
+```
+
+or visit [https://huggingface.co/hotshotco/SDXL-512](https://huggingface.co/hotshotco/SDXL-512)
+
+# 🔮 Inference
+
+### Text-to-GIF
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif"
+```
+
+*What to Expect:*
+| **Prompt** | Sasquatch scuba diving | a camel smoking a cigarette | Ronald McDonald sitting at a vanity mirror putting on lipstick | drake licking his lips and staring through a window at a cupcake |
+|-----------|----------|----------|----------|----------|
+| **Output** |  |
|  |
| 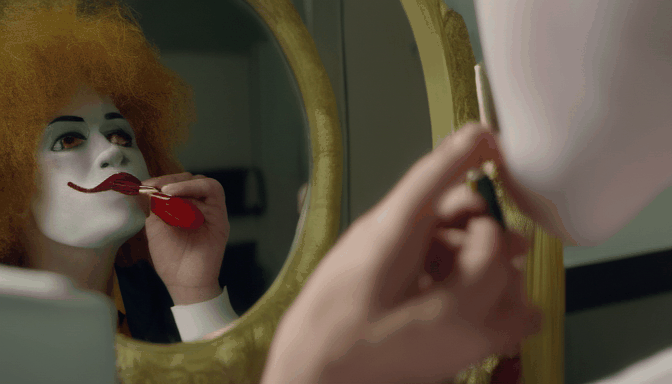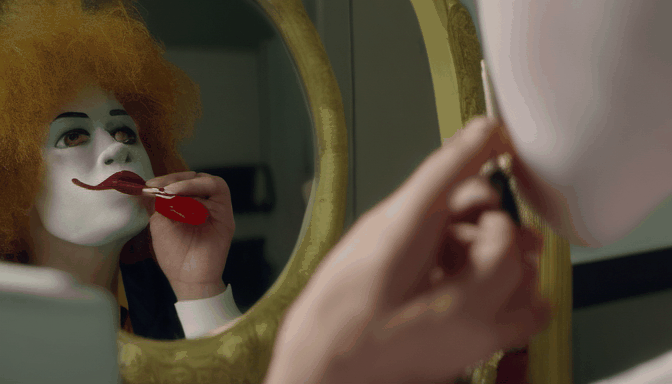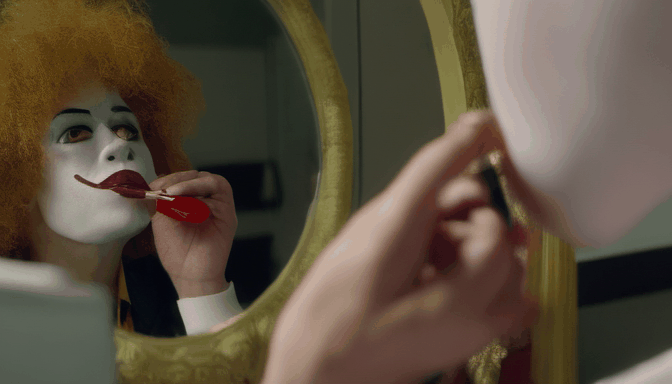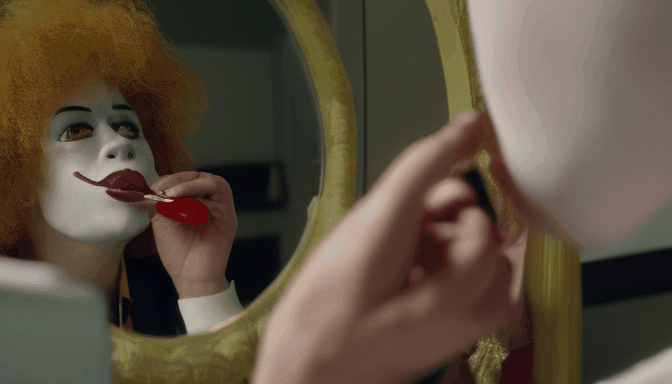 |
|  |
+
+### Text-to-GIF with personalized LORAs
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif" \
+ --spatial_unet_base="path/to/stabilityai/stable-diffusion-xl-base-1.0/unet" \
+ --lora="path/to/lora"
+```
+
+*What to Expect:*
+
+*Note*: The outputs below use the DDIMScheduler.
+
+| **Prompt** | sks person screaming at a capri sun | sks person kissing kermit the frog | sks person wearing a tuxedo holding up a glass of champagne, fireworks in background, hd, high quality, 4K |
+|-----------|----------|----------|----------|
+| **Output** |
|
+
+### Text-to-GIF with personalized LORAs
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif" \
+ --spatial_unet_base="path/to/stabilityai/stable-diffusion-xl-base-1.0/unet" \
+ --lora="path/to/lora"
+```
+
+*What to Expect:*
+
+*Note*: The outputs below use the DDIMScheduler.
+
+| **Prompt** | sks person screaming at a capri sun | sks person kissing kermit the frog | sks person wearing a tuxedo holding up a glass of champagne, fireworks in background, hd, high quality, 4K |
+|-----------|----------|----------|----------|
+| **Output** |  |
|  |
|  |
+
+### Text-to-GIF with ControlNet
+```
+python inference.py \
+ --prompt="a girl jumping up and down and pumping her fist, hd, high quality" \
+ --output="output.gif" \
+ --control_type="depth" \
+ --gif="https://media1.giphy.com/media/v1.Y2lkPTc5MGI3NjExbXNneXJicG1mOHJ2dzQ2Y2JteDY1ZWlrdjNjMjl3ZWxyeWFxY2EzdyZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/YOTAoXBgMCmFeQQzuZ/giphy.gif"
+```
+
+By default, Hotshot-XL will create key frames from your source gif using 8 equally spaced frames and crop the keyframes to the default aspect ratio. For finer grained control, learn how to [vary aspect ratios](#varying-aspect-ratios) and [vary frame rates/lengths](#varying-frame-rates--lengths-experimental).
+
+Hotshot-XL currently supports the use of one ControlNet model at a time; supporting Multi-ControlNet would be [exciting](#-further-work).
+
+*What to Expect:*
+| **Prompt** | pixar style girl putting two thumbs up, happy, high quality, 8k, 3d, animated disney render | keanu reaves holding a sign that says "HELP", hd, high quality | a woman laughing, hd, high quality | barack obama making a rainbow with their hands, the word "MAGIC" in front of them, wearing a blue and white striped hoodie, hd, high quality |
+|-----------|----------|----------|----------|----------|
+| **Output** |
|
+
+### Text-to-GIF with ControlNet
+```
+python inference.py \
+ --prompt="a girl jumping up and down and pumping her fist, hd, high quality" \
+ --output="output.gif" \
+ --control_type="depth" \
+ --gif="https://media1.giphy.com/media/v1.Y2lkPTc5MGI3NjExbXNneXJicG1mOHJ2dzQ2Y2JteDY1ZWlrdjNjMjl3ZWxyeWFxY2EzdyZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/YOTAoXBgMCmFeQQzuZ/giphy.gif"
+```
+
+By default, Hotshot-XL will create key frames from your source gif using 8 equally spaced frames and crop the keyframes to the default aspect ratio. For finer grained control, learn how to [vary aspect ratios](#varying-aspect-ratios) and [vary frame rates/lengths](#varying-frame-rates--lengths-experimental).
+
+Hotshot-XL currently supports the use of one ControlNet model at a time; supporting Multi-ControlNet would be [exciting](#-further-work).
+
+*What to Expect:*
+| **Prompt** | pixar style girl putting two thumbs up, happy, high quality, 8k, 3d, animated disney render | keanu reaves holding a sign that says "HELP", hd, high quality | a woman laughing, hd, high quality | barack obama making a rainbow with their hands, the word "MAGIC" in front of them, wearing a blue and white striped hoodie, hd, high quality |
+|-----------|----------|----------|----------|----------|
+| **Output** |  |
|  |
|  |
|  |
+| **Control** |
|
+| **Control** | |
|  |
|  |
|  |
+
+### Varying Aspect Ratios
+
+- *Note*: The base SDXL model is trained to best create images around 1024x1024 resolution. To maximize data and training efficiency, Hotshot-XL was trained at aspect ratios around 512x512 resolution. Please see [Additional Notes](#supported-aspect-ratios) for a list of aspect ratios the base Hotshot-XL model was trained with.
+
+Like SDXL, Hotshot-XL was trained at various aspect ratios with aspect ratio bucketing, and includes support for SDXL parameters like target-size and original-size. This means you can create GIFs at several different aspect ratios and resolutions, just with the base Hotshot-XL model.
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif" \
+ --width= \
+ --height=
+```
+
+*What to Expect:*
+| | 512x512 | 672x384 | 384x672 |
+|-----------|----------|----------|----------|
+| **a monkey playing guitar, nature footage, hd, high quality** |
|
+
+### Varying Aspect Ratios
+
+- *Note*: The base SDXL model is trained to best create images around 1024x1024 resolution. To maximize data and training efficiency, Hotshot-XL was trained at aspect ratios around 512x512 resolution. Please see [Additional Notes](#supported-aspect-ratios) for a list of aspect ratios the base Hotshot-XL model was trained with.
+
+Like SDXL, Hotshot-XL was trained at various aspect ratios with aspect ratio bucketing, and includes support for SDXL parameters like target-size and original-size. This means you can create GIFs at several different aspect ratios and resolutions, just with the base Hotshot-XL model.
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif" \
+ --width= \
+ --height=
+```
+
+*What to Expect:*
+| | 512x512 | 672x384 | 384x672 |
+|-----------|----------|----------|----------|
+| **a monkey playing guitar, nature footage, hd, high quality** |  |
|  |
|  |
+
+### Varying frame rates & lengths (*Experimental*)
+By default, Hotshot-XL is trained to generate GIFs that are 1 second long with 8FPS. If you'd like to play with generating GIFs with varying frame rates and time lengths, you can try out the parameters `video_length` and `video_duration`.
+
+`video_length` sets the number of frames. The default value is 8.
+
+`video_duration` sets the runtime of the output gif in milliseconds. The default value is 1000.
+
+Please note that you should expect unstable/"jittery" results when modifying these parameters as the model was only trained with 1s videos @ 8fps. You'll be able to improve the stability of results for different time lengths and frame rates by [fine-tuning Hotshot-XL](#-fine-tuning). Please let us know if you do!
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif" \
+ --video_length=16 \
+ --video_duration=2000
+```
+
+### Spatial Layers Only
+Hotshot-XL is trained to generate GIFs alongside SDXL. If you'd like to generate just an image, you can simply set `video_length=1` in your inference call and the Hotshot-XL temporal layers will be ignored, as you'd expect.
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.jpg" \
+ --video_length=1
+```
+
+### Additional Notes
+
+#### Supported Aspect Ratios
+Hotshot-XL was trained at the following aspect ratios; to reliably generate GIFs outside the range of these aspect ratios, you will want to fine-tune Hotshot-XL with videos at the resolution of your desired aspect ratio.
+
+| Aspect Ratio | Size |
+|--------------|------|
+| 0.42 |320 x 768|
+| 0.57 |384 x 672|
+| 0.68 |416 x 608|
+| 1.00 |512 x 512|
+| 1.46 |608 x 416|
+| 1.75 |672 x 384|
+| 2.40 |768 x 320|
+
+
+# 💪 Fine-Tuning
+The following section relates to fine-tuning the Hotshot-XL temporal model with additional text/video pairs. If you're trying to generate GIFs of personalized concepts/subjects, we'd recommend not fine-tuning Hotshot-XL, but instead training your own SDXL based LORAs and [just loading those](#text-to-gif-with-personalized-loras).
+
+### Fine-Tuning Hotshot-XL
+
+#### Dataset Preparation
+
+The `fine_tune.py` script expects your samples to be structured like this:
+
+```
+fine_tune_dataset
+├── sample_001
+│ ├── 0.jpg
+│ ├── 1.jpg
+│ ├── 2.jpg
+...
+...
+│ ├── n.jpg
+│ └── prompt.txt
+```
+
+Each sample directory should contain your **n key frames** and a `prompt.txt` file which contains the prompt.
+The final checkpoint will be saved to `output_dir`.
+We've found it useful to send validation GIFs to [Weights & Biases](www.wandb.ai) every so often. If you choose to use validation with Weights & Biases, you can set how often this runs with the `validate_every_steps` parameter.
+
+```
+accelerate launch fine_tune.py \
+ --output_dir="" \
+ --data_dir="fine_tune_dataset" \
+ --report_to="wandb" \
+ --run_validation_at_start \
+ --resolution=512 \
+ --mixed_precision=fp16 \
+ --train_batch_size=4 \
+ --learning_rate=1.25e-05 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=1000 \
+ --save_n_steps=20 \
+ --validate_every_steps=50 \
+ --vae_b16 \
+ --gradient_checkpointing \
+ --noise_offset=0.05 \
+ --snr_gamma \
+ --test_prompts="man sits at a table in a cafe, he greets another man with a smile and a handshakes"
+```
+
+# 📝 Further work
+There are lots of ways we are excited about improving Hotshot-XL. For example:
+
+- [ ] Fine-Tuning Hotshot-XL at larger frame rates to create longer/higher frame-rate GIFs
+- [ ] Fine-Tuning Hotshot-XL at larger resolutions to create higher resolution GIFs
+- [ ] Training temporal layers for a latent upscaler to produce higher resolution GIFs
+- [ ] Training an image conditioned "frame prediction" model for more coherent, longer GIFs
+- [ ] Training temporal layers for a VAE to mitigate flickering/dithering in outputs
+- [ ] Supporting Multi-ControlNet for greater control over GIF generation
+- [ ] Training & integrating different ControlNet models for further control over GIF generation (finer facial expression control would be very cool)
+- [ ] Moving Hotshot-XL into [AITemplate](https://github.com/facebookincubator/AITemplate) for faster inference times
+
+We 💗 contributions from the open-source community! Please let us know in the issues or PRs if you're interested in working on these improvements or anything else!
+
+# 🙏 Acknowledgements
+Text-to-Video models are improving quickly and the development of Hotshot-XL has been greatly inspired by the following amazing works and teams:
+
+- [SDXL](https://stability.ai/stable-diffusion)
+- [Align Your Latents](https://research.nvidia.com/labs/toronto-ai/VideoLDM/)
+- [Make-A-Video](https://makeavideo.studio/)
+- [AnimateDiff](https://animatediff.github.io/)
+- [Imagen Video](https://imagen.research.google/video/)
+
+We hope that releasing this model/codebase helps the community to continue pushing these creative tools forward in an open and responsible way.
diff --git a/Hotshot-XL/build/lib/hotshot_xl/__init__.py b/Hotshot-XL/build/lib/hotshot_xl/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..090de024570c67f7182c8e5b214c81f3aaadaf6e
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/__init__.py
@@ -0,0 +1,25 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Union
+
+import numpy as np
+import torch
+
+# don't remove these imports - they are needed to load from pretrain.
+from diffusers.models.modeling_utils import ModelMixin
+from .models.unet import UNet3DConditionModel
+
+from diffusers.utils import (
+ BaseOutput,
+)
+
+@dataclass
+class HotshotPipelineXLOutput(BaseOutput):
+ videos: Union[torch.Tensor, np.ndarray]
\ No newline at end of file
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/__init__.py b/Hotshot-XL/build/lib/hotshot_xl/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/resnet.py b/Hotshot-XL/build/lib/hotshot_xl/models/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b46c907610a9a4fb73288f280c79e923b86c89a
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/resnet.py
@@ -0,0 +1,134 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import torch.nn as nn
+from diffusers.models.resnet import Upsample2D, Downsample2D, LoRACompatibleConv
+from einops import rearrange
+
+
+class Upsample3D(Upsample2D):
+ def forward(self, hidden_states, output_size=None, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Upsample3D, self).forward(hidden_states, output_size, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Downsample3D(Downsample2D):
+
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Downsample3D, self).forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Conv3d(LoRACompatibleConv):
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super().forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class ResnetBlock3D(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="silu",
+ time_embedding_norm="default",
+ output_scale_factor=1.0,
+ use_in_shortcut=None,
+ conv_shortcut_bias: bool = True,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
+ self.conv1 = Conv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ if self.time_embedding_norm == "default":
+ time_emb_proj_out_channels = out_channels
+ elif self.time_embedding_norm == "scale_shift":
+ time_emb_proj_out_channels = out_channels * 2
+ else:
+ raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
+
+ self.time_emb_proj = torch.nn.Linear(temb_channels, time_emb_proj_out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = Conv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ assert non_linearity == "silu"
+
+ self.nonlinearity = nn.SiLU()
+
+ self.use_in_shortcut = self.in_channels != self.out_channels if use_in_shortcut is None else use_in_shortcut
+
+ self.conv_shortcut = None
+ if self.use_in_shortcut:
+ self.conv_shortcut = Conv3d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
+ )
+
+ def forward(self, input_tensor, temb):
+ hidden_states = input_tensor
+
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+
+ if temb is not None:
+ temb = self.nonlinearity(temb)
+ temb = self.time_emb_proj(temb)[:, :, None, None, None]
+
+ if temb is not None and self.time_embedding_norm == "default":
+ hidden_states = hidden_states + temb
+
+ hidden_states = self.norm2(hidden_states)
+
+ if temb is not None and self.time_embedding_norm == "scale_shift":
+ scale, shift = torch.chunk(temb, 2, dim=1)
+ hidden_states = hidden_states * (1 + scale) + shift
+
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ input_tensor = self.conv_shortcut(input_tensor)
+
+ output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
+
+ return output_tensor
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/transformer_3d.py b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_3d.py
new file mode 100644
index 0000000000000000000000000000000000000000..169f91ee6f2bcd568141a5776820429140370f6f
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_3d.py
@@ -0,0 +1,75 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Optional
+import torch
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.transformer_2d import Transformer2DModel
+from einops import rearrange, repeat
+from typing import Dict, Any
+
+
+@dataclass
+class Transformer3DModelOutput(BaseOutput):
+ """
+ The output of [`Transformer3DModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`:
+ The hidden states output conditioned on the `encoder_hidden_states` input.
+ """
+
+ sample: torch.FloatTensor
+
+
+class Transformer3DModel(Transformer2DModel):
+
+ def __init__(self, *args, **kwargs):
+ super(Transformer3DModel, self).__init__(*args, **kwargs)
+ nn.init.zeros_(self.proj_out.weight.data)
+ nn.init.zeros_(self.proj_out.bias.data)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ enable_temporal_layers: bool = True,
+ positional_embedding: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ):
+
+ is_video = len(hidden_states.shape) == 5
+
+ if is_video:
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ encoder_hidden_states = repeat(encoder_hidden_states, 'b n c -> (b f) n c', f=f)
+
+ hidden_states = super(Transformer3DModel, self).forward(hidden_states,
+ encoder_hidden_states,
+ timestep,
+ class_labels,
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ return_dict=False)[0]
+
+ if is_video:
+ hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+ if not return_dict:
+ return (hidden_states,)
+
+ return Transformer3DModelOutput(sample=hidden_states)
\ No newline at end of file
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/transformer_temporal.py b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_temporal.py
new file mode 100644
index 0000000000000000000000000000000000000000..772e51d55da5ebf3279235b482c1db7e46e2b603
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_temporal.py
@@ -0,0 +1,192 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import math
+from dataclasses import dataclass
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.attention import Attention, FeedForward
+from einops import rearrange, repeat
+from typing import Optional
+
+
+class PositionalEncoding(nn.Module):
+ """
+ Implements positional encoding as described in "Attention Is All You Need".
+ Adds sinusoidal based positional encodings to the input tensor.
+ """
+
+ _SCALE_FACTOR = 10000.0 # Scale factor used in the positional encoding computation.
+
+ def __init__(self, dim: int, dropout: float = 0.0, max_length: int = 24):
+ super(PositionalEncoding, self).__init__()
+
+ self.dropout = nn.Dropout(p=dropout)
+
+ # The size is (1, max_length, dim) to allow easy addition to input tensors.
+ positional_encoding = torch.zeros(1, max_length, dim)
+
+ # Position and dim are used in the sinusoidal computation.
+ position = torch.arange(max_length).unsqueeze(1)
+ div_term = torch.exp(torch.arange(0, dim, 2) * (-math.log(self._SCALE_FACTOR) / dim))
+
+ positional_encoding[0, :, 0::2] = torch.sin(position * div_term)
+ positional_encoding[0, :, 1::2] = torch.cos(position * div_term)
+
+ # Register the positional encoding matrix as a buffer,
+ # so it's part of the model's state but not the parameters.
+ self.register_buffer('positional_encoding', positional_encoding)
+
+ def forward(self, hidden_states: torch.Tensor, length: int) -> torch.Tensor:
+ hidden_states = hidden_states + self.positional_encoding[:, :length]
+ return self.dropout(hidden_states)
+
+
+class TemporalAttention(Attention):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.pos_encoder = PositionalEncoding(kwargs["query_dim"], dropout=0)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=8):
+ sequence_length = hidden_states.shape[1]
+ hidden_states = rearrange(hidden_states, "(b f) s c -> (b s) f c", f=number_of_frames)
+ hidden_states = self.pos_encoder(hidden_states, length=number_of_frames)
+
+ if encoder_hidden_states:
+ encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b s) n c", s=sequence_length)
+
+ hidden_states = super().forward(hidden_states, encoder_hidden_states, attention_mask=attention_mask)
+
+ return rearrange(hidden_states, "(b s) f c -> (b f) s c", s=sequence_length)
+
+
+@dataclass
+class TransformerTemporalOutput(BaseOutput):
+ sample: torch.FloatTensor
+
+
+class TransformerTemporal(nn.Module):
+ def __init__(
+ self,
+ num_attention_heads: int,
+ attention_head_dim: int,
+ in_channels: int,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ activation_fn: str = "geglu",
+ upcast_attention: bool = False,
+ ):
+ super().__init__()
+
+ inner_dim = num_attention_heads * attention_head_dim
+
+ self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ TransformerBlock(
+ dim=inner_dim,
+ num_attention_heads=num_attention_heads,
+ attention_head_dim=attention_head_dim,
+ dropout=dropout,
+ activation_fn=activation_fn,
+ attention_bias=attention_bias,
+ upcast_attention=upcast_attention,
+ cross_attention_dim=cross_attention_dim
+ )
+ for _ in range(num_layers)
+ ]
+ )
+ self.proj_out = nn.Linear(inner_dim, in_channels)
+
+ def forward(self, hidden_states, encoder_hidden_states=None):
+ _, num_channels, f, height, width = hidden_states.shape
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+
+ skip = hidden_states
+
+ hidden_states = self.norm(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf c h w -> bf (h w) c")
+ hidden_states = self.proj_in(hidden_states)
+
+ for block in self.transformer_blocks:
+ hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, number_of_frames=f)
+
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf (h w) c -> bf c h w", h=height, w=width).contiguous()
+
+ output = hidden_states + skip
+ output = rearrange(output, "(b f) c h w -> b c f h w", f=f)
+
+ return output
+
+
+class TransformerBlock(nn.Module):
+ def __init__(
+ self,
+ dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=0.0,
+ activation_fn="geglu",
+ attention_bias=False,
+ upcast_attention=False,
+ depth=2,
+ cross_attention_dim: Optional[int] = None
+ ):
+ super().__init__()
+
+ self.is_cross = cross_attention_dim is not None
+
+ attention_blocks = []
+ norms = []
+
+ for _ in range(depth):
+ attention_blocks.append(
+ TemporalAttention(
+ query_dim=dim,
+ cross_attention_dim=cross_attention_dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ upcast_attention=upcast_attention,
+ )
+ )
+ norms.append(nn.LayerNorm(dim))
+
+ self.attention_blocks = nn.ModuleList(attention_blocks)
+ self.norms = nn.ModuleList(norms)
+
+ self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
+ self.ff_norm = nn.LayerNorm(dim)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=None):
+
+ if not self.is_cross:
+ encoder_hidden_states = None
+
+ for block, norm in zip(self.attention_blocks, self.norms):
+ norm_hidden_states = norm(hidden_states)
+ hidden_states = block(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ number_of_frames=number_of_frames
+ ) + hidden_states
+
+ norm_hidden_states = self.ff_norm(hidden_states)
+ hidden_states = self.ff(norm_hidden_states) + hidden_states
+
+ output = hidden_states
+ return output
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/unet.py b/Hotshot-XL/build/lib/hotshot_xl/models/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..30b45fe9fcf7d2e0e898aa7ebd36494ee13998ef
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/unet.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Unet now supports SDXL
+
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.loaders import UNet2DConditionLoadersMixin
+from diffusers.utils import BaseOutput, logging
+from diffusers.models.activations import get_activation
+from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
+from diffusers.models.embeddings import (
+ GaussianFourierProjection,
+ ImageHintTimeEmbedding,
+ ImageProjection,
+ ImageTimeEmbedding,
+ TextImageProjection,
+ TextImageTimeEmbedding,
+ TextTimeEmbedding,
+ TimestepEmbedding,
+ Timesteps,
+)
+
+from diffusers.models.modeling_utils import ModelMixin
+from diffusers.models.embeddings import TimestepEmbedding, Timesteps
+from .unet_blocks import (
+ CrossAttnDownBlock3D,
+ CrossAttnUpBlock3D,
+ DownBlock3D,
+ UNetMidBlock3DCrossAttn,
+ UpBlock3D,
+ get_down_block,
+ get_up_block,
+)
+
+from .resnet import Conv3d
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet3DConditionOutput(BaseOutput):
+ """
+ The output of [`UNet2DConditionModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor = None
+
+
+class UNet3DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ "DownBlock3D",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlock3DCrossAttn",
+ up_block_types: Tuple[str] = (
+ "UpBlock3D",
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ ),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: Union[int, Tuple[int]] = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ transformer_layers_per_block: Union[int, Tuple[int]] = 1,
+ encoder_hid_dim: Optional[int] = None,
+ encoder_hid_dim_type: Optional[str] = None,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ addition_embed_type: Optional[str] = None,
+ addition_time_embed_dim: Optional[int] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ resnet_skip_time_act: bool = False,
+ resnet_out_scale_factor: int = 1.0,
+ time_embedding_type: str = "positional",
+ time_embedding_dim: Optional[int] = None,
+ time_embedding_act_fn: Optional[str] = None,
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ mid_block_only_cross_attention: Optional[bool] = None,
+ cross_attention_norm: Optional[str] = None,
+ addition_embed_type_num_heads=64,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ if num_attention_heads is not None:
+ raise ValueError(
+ "At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
+ )
+
+ # If `num_attention_heads` is not defined (which is the case for most models)
+ # it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
+ # The reason for this behavior is to correct for incorrectly named variables that were introduced
+ # when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
+ # Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
+ # which is why we correct for the naming here.
+ num_attention_heads = num_attention_heads or attention_head_dim
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+
+ self.conv_in = Conv3d(in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding)
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ if encoder_hid_dim_type is None and encoder_hid_dim is not None:
+ encoder_hid_dim_type = "text_proj"
+ self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
+ logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
+
+ if encoder_hid_dim is None and encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
+ )
+
+ if encoder_hid_dim_type == "text_proj":
+ self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
+ elif encoder_hid_dim_type == "text_image_proj":
+ # image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
+ self.encoder_hid_proj = TextImageProjection(
+ text_embed_dim=encoder_hid_dim,
+ image_embed_dim=cross_attention_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2
+ self.encoder_hid_proj = ImageProjection(
+ image_embed_dim=encoder_hid_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
+ )
+ else:
+ self.encoder_hid_proj = None
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ if addition_embed_type == "text":
+ if encoder_hid_dim is not None:
+ text_time_embedding_from_dim = encoder_hid_dim
+ else:
+ text_time_embedding_from_dim = cross_attention_dim
+
+ self.add_embedding = TextTimeEmbedding(
+ text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
+ )
+ elif addition_embed_type == "text_image":
+ # text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
+ self.add_embedding = TextImageTimeEmbedding(
+ text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
+ )
+ elif addition_embed_type == "text_time":
+ self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
+ self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif addition_embed_type == "image":
+ # Kandinsky 2.2
+ self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type == "image_hint":
+ # Kandinsky 2.2 ControlNet
+ self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type is not None:
+ raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
+
+ if time_embedding_act_fn is None:
+ self.time_embed_act = None
+ else:
+ self.time_embed_act = get_activation(time_embedding_act_fn)
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = only_cross_attention
+
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = False
+
+ if isinstance(num_attention_heads, int):
+ num_attention_heads = (num_attention_heads,) * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if isinstance(layers_per_block, int):
+ layers_per_block = [layers_per_block] * len(down_block_types)
+
+ if isinstance(transformer_layers_per_block, int):
+ transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ res = 2 ** i
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block[i],
+ transformer_layers_per_block=transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ num_attention_heads=num_attention_heads[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlock3DCrossAttn":
+ self.mid_block = UNetMidBlock3DCrossAttn(
+ transformer_layers_per_block=transformer_layers_per_block[-1],
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ num_attention_heads=num_attention_heads[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
+ raise ValueError("UNetMidBlock2DSimpleCrossAttn not supported")
+
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_num_attention_heads = list(reversed(num_attention_heads))
+ reversed_layers_per_block = list(reversed(layers_per_block))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ res = 2 ** (len(up_block_types) - 1 - i)
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=reversed_layers_per_block[i] + 1,
+ transformer_layers_per_block=reversed_transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ num_attention_heads=reversed_num_attention_heads[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+
+ self.conv_act = get_activation(act_fn)
+
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+
+ self.conv_out = Conv3d(block_out_channels[0], out_channels, kernel_size=conv_out_kernel,
+ padding=conv_out_padding)
+
+ def temporal_parameters(self) -> list:
+ output = []
+ all_blocks = self.down_blocks + self.up_blocks + [self.mid_block]
+ for block in all_blocks:
+ output.extend(block.temporal_parameters())
+ return output
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ return self.get_attn_processors(include_temporal_layers=False)
+
+ def get_attn_processors(self, include_temporal_layers=True) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+
+ if not include_temporal_layers:
+ if 'temporal' in name:
+ return processors
+
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]],
+ include_temporal_layers=False):
+ r"""
+ Sets the attention processor to use to compute attention.
+
+ Parameters:
+ processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ for **all** `Attention` layers.
+
+ If `processor` is a dict, the key needs to define the path to the corresponding cross attention
+ processor. This is strongly recommended when setting trainable attention processors.
+
+ """
+ count = len(self.get_attn_processors(include_temporal_layers=include_temporal_layers).keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+
+ if not include_temporal_layers:
+ if "temporal" in name:
+ return
+
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module splits the input tensor in slices to compute attention in
+ several steps. This is useful for saving some memory in exchange for a small decrease in speed.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
+ `"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ enable_temporal_attentions: bool = True
+ ) -> Union[UNet3DConditionOutput, Tuple]:
+ r"""
+ The [`UNet2DConditionModel`] forward method.
+
+ Args:
+ sample (`torch.FloatTensor`):
+ The noisy input tensor with the following shape `(batch, channel, height, width)`.
+ timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
+ encoder_hidden_states (`torch.FloatTensor`):
+ The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
+ encoder_attention_mask (`torch.Tensor`):
+ A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
+ `True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
+ which adds large negative values to the attention scores corresponding to "discard" tokens.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
+ tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
+ added_cond_kwargs: (`dict`, *optional*):
+ A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
+ are passed along to the UNet blocks.
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
+ a `tuple` is returned where the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2 ** self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # ensure attention_mask is a bias, and give it a singleton query_tokens dimension
+ # expects mask of shape:
+ # [batch, key_tokens]
+ # adds singleton query_tokens dimension:
+ # [batch, 1, key_tokens]
+ # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
+ # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
+ # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
+ if attention_mask is not None:
+ # assume that mask is expressed as:
+ # (1 = keep, 0 = discard)
+ # convert mask into a bias that can be added to attention scores:
+ # (keep = +0, discard = -10000.0)
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # convert encoder_attention_mask to a bias the same way we do for attention_mask
+ if encoder_attention_mask is not None:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=sample.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+ aug_emb = None
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # there might be better ways to encapsulate this.
+ class_labels = class_labels.to(dtype=sample.dtype)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ if self.config.addition_embed_type == "text":
+ aug_emb = self.add_embedding(encoder_hidden_states)
+ elif self.config.addition_embed_type == "text_image":
+ # Kandinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+
+ image_embs = added_cond_kwargs.get("image_embeds")
+ text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
+ aug_emb = self.add_embedding(text_embs, image_embs)
+ elif self.config.addition_embed_type == "text_time":
+ if "text_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
+ )
+ text_embeds = added_cond_kwargs.get("text_embeds")
+ if "time_ids" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
+ )
+ time_ids = added_cond_kwargs.get("time_ids")
+ time_embeds = self.add_time_proj(time_ids.flatten())
+ time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
+
+ add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
+ add_embeds = add_embeds.to(emb.dtype)
+ aug_emb = self.add_embedding(add_embeds)
+ elif self.config.addition_embed_type == "image":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ aug_emb = self.add_embedding(image_embs)
+ elif self.config.addition_embed_type == "image_hint":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ hint = added_cond_kwargs.get("hint")
+ aug_emb, hint = self.add_embedding(image_embs, hint)
+ sample = torch.cat([sample, hint], dim=1)
+
+ emb = emb + aug_emb if aug_emb is not None else emb
+
+ if self.time_embed_act is not None:
+ emb = self.time_embed_act(emb)
+
+ if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
+ # Kadinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(image_embeds)
+ # 2. pre-process
+
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ upsample_size=upsample_size,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet3DConditionOutput(sample=sample)
+
+ @classmethod
+ def from_pretrained_spatial(cls, pretrained_model_path, subfolder=None):
+
+ import os
+ import json
+
+ if subfolder is not None:
+ pretrained_model_path = os.path.join(pretrained_model_path, subfolder)
+
+ config_file = os.path.join(pretrained_model_path, 'config.json')
+
+ with open(config_file, "r") as f:
+ config = json.load(f)
+
+ config["_class_name"] = "UNet3DConditionModel"
+
+ config["down_block_types"] = [
+ "DownBlock3D",
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ ]
+ config["up_block_types"] = [
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ "UpBlock3D"
+ ]
+
+ config["mid_block_type"] = "UNetMidBlock3DCrossAttn"
+
+ model = cls.from_config(config)
+
+ model_files = [
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.bin'),
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.safetensors')
+ ]
+
+ model_file = None
+
+ for fp in model_files:
+ if os.path.exists(fp):
+ model_file = fp
+
+ if not model_file:
+ raise RuntimeError(f"{model_file} does not exist")
+
+ state_dict = torch.load(model_file, map_location="cpu")
+
+ model.load_state_dict(state_dict, strict=False)
+
+ return model
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/unet_blocks.py b/Hotshot-XL/build/lib/hotshot_xl/models/unet_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..e642d4f8b56600b58238fdb7a243fb1e360a621d
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/unet_blocks.py
@@ -0,0 +1,740 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Add temporal transformers to unet blocks
+
+import torch
+from torch import nn
+
+from .transformer_3d import Transformer3DModel
+from .resnet import Downsample3D, ResnetBlock3D, Upsample3D
+from .transformer_temporal import TransformerTemporal
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ downsample_type=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock3D":
+ return DownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D")
+ return CrossAttnDownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ upsample_type=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock3D":
+ return UpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D")
+ return CrossAttnUpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock3DCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ in_channels // num_attention_heads,
+ in_channels=in_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ return []
+
+
+class CrossAttnDownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if temporal_attention and enable_temporal_attentions:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class DownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states, encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class CrossAttnUpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ upsample_size=None,
+ cross_attention_kwargs=None,
+ attention_mask=None,
+ enable_temporal_attentions: bool = True
+ ):
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False,
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class UpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, encoder_hidden_states=None,
+ enable_temporal_attentions: bool = True):
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states) if enable_temporal_attentions and temporal_attention is not None else hidden_states
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
diff --git a/Hotshot-XL/build/lib/hotshot_xl/pipelines/__init__.py b/Hotshot-XL/build/lib/hotshot_xl/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..b084688662309ef71b429d20a5edfc9c8f494f9f
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
@@ -0,0 +1,1389 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Controlnet Pipeline to work temporally
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, ControlNetModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.utils.torch_utils import randn_tensor, is_compiled_module
+
+from ..models.unet import UNet3DConditionModel
+
+from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
+from einops import rearrange
+from tqdm import tqdm
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+ >>> from diffusers import ControlNetModel
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL",
+ ... controlnet=ControlNetModel.from_pretrained("diffusers/controlnet-canny-sdxl-1.0")
+ ... )
+
+ >>> def canny(image):
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> return Image.fromarray(image)
+
+ >>> # assuming you have 8 keyframes in current directory...
+
+ >>> keyframes = [f"image_{i}.jpg" for i in range(8)]
+ >>> control_images = [canny(Image.open(fp)) for fp in keyframes]
+
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor",
+ ... controlnet_conditioning_scale=0.7,
+ ... control_images=control_images
+ ).video
+ ```
+"""
+class HotshotXLControlNetPipeline(
+ DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
+ implemented for all pipelines (downloading, saving, running on a particular device, etc.).
+
+ The pipeline also inherits the following loading methods:
+ - [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
+ - [`loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
+ - [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
+ text_encoder ([`~transformers.CLIPTextModel`]):
+ Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
+ text_encoder_2 ([`~transformers.CLIPTextModelWithProjection`]):
+ Second frozen text-encoder
+ ([laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)).
+ tokenizer ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ tokenizer_2 ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ unet ([`UNet3DConditionModel`]):
+ A `UNet3DConditionModel` to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the `unet` during the denoising process. If you set multiple
+ ControlNets as a list, the outputs from each ControlNet are added together to create one combined
+ additional conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
+ Whether the negative prompt embeddings should always be set to 0. Also see the config of
+ `stabilityai/stable-diffusion-xl-base-1-0`.
+ add_watermarker (`bool`, *optional*):
+ Whether to use the [invisible_watermark](https://github.com/ShieldMnt/invisible-watermark/) library to
+ watermark output images. If not defined, it defaults to `True` if the package is installed; otherwise no
+ watermarker is used.
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
+ self.control_image_processor = VaeImageProcessor(
+ vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
+ )
+
+ self.watermark = None
+
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ control_guidance_start=0.0,
+ control_guidance_end=1.0,
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+
+ assert len(control_images) == video_length
+ # for image in control_images:
+ # self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ ...
+ # todo
+ #
+ # if not isinstance(image, list):
+ # raise TypeError("For multiple controlnets: `image` must be type `list`")
+ #
+ # # When `image` is a nested list:
+ # # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ # elif any(isinstance(i, list) for i in image):
+ # raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ # elif len(image) != len(self.controlnet.nets):
+ # raise ValueError(
+ # f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets."
+ # )
+ #
+ # for image_ in image:
+ # self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ if not isinstance(control_guidance_start, (tuple, list)):
+ control_guidance_start = [control_guidance_start]
+
+ if not isinstance(control_guidance_end, (tuple, list)):
+ control_guidance_end = [control_guidance_end]
+
+ if len(control_guidance_start) != len(control_guidance_end):
+ raise ValueError(
+ f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
+ )
+
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if len(control_guidance_start) != len(self.controlnet.nets):
+ raise ValueError(
+ f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
+ )
+
+ for start, end in zip(control_guidance_start, control_guidance_end):
+ if start >= end:
+ raise ValueError(
+ f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
+ )
+ if start < 0.0:
+ raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
+ if end > 1.0:
+ raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_np = isinstance(image, np.ndarray)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+ image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
+
+ if (
+ not image_is_pil
+ and not image_is_tensor
+ and not image_is_np
+ and not image_is_pil_list
+ and not image_is_tensor_list
+ and not image_is_np_list
+ ):
+ raise TypeError(
+ f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ else:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_images(
+ self,
+ images,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ images_pre_processed = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+
+ images_pre_processed = torch.cat(images_pre_processed, dim=0)
+
+ repeat_factor = [1] * len(images_pre_processed.shape)
+ repeat_factor[0] = batch_size * num_images_per_prompt
+ images_pre_processed = images_pre_processed.repeat(*repeat_factor)
+
+ images = images_pre_processed.unsqueeze(0)
+
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+
+ #image = image.repeat_interleave(repeat_by, dim=0)
+
+ images = images.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ repeat_factor = [1] * len(images.shape)
+ repeat_factor[0] = 2
+ images = images.repeat(*repeat_factor)
+
+ return images
+
+ # def prepare_images(self,
+ # images: list,
+ # width,
+ # height,
+ # batch_size,
+ # num_images_per_prompt,
+ # device,
+ # dtype,
+ # do_classifier_free_guidance=False,
+ # guess_mode=False):
+ #
+ # images = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+ #
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+ #
+ # image = image.repeat_interleave(repeat_by, dim=0)
+ #
+ # image = image.to(device=device, dtype=dtype)
+ #
+ # if do_classifier_free_guidance and not guess_mode:
+ # image = torch.cat([image] * 2)
+ #
+ # return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ #shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._get_add_time_ids
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ control_images: List[PIL.Image.Image] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ guess_mode: bool = False,
+ control_guidance_start: Union[float, List[float]] = 0.0,
+ control_guidance_end: Union[float, List[float]] = 1.0,
+ original_size: Tuple[int, int] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Tuple[int, int] = None,
+ negative_original_size: Optional[Tuple[int, int]] = None,
+ negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
+ negative_target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ The call function to the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
+ `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
+ specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
+ accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
+ and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
+ `init`, images must be passed as a list such that each element of the list can be correctly batched for
+ input to a single ControlNet.
+ height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ A higher guidance scale value encourages the model to generate images closely linked to the text
+ `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. If not defined, you need to
+ pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. This is sent to `tokenizer_2`
+ and `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
+ generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor is generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
+ provided, text embeddings are generated from the `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, pooled text embeddings are generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs (prompt
+ weighting). If not provided, pooled `negative_prompt_embeds` are generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between `PIL.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that calls every `callback_steps` steps during inference. The function is called with the
+ following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function is called. If not specified, the callback is called at
+ every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
+ [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
+ the corresponding scale as a list.
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ The ControlNet encoder tries to recognize the content of the input image even if you remove all
+ prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
+ control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
+ The percentage of total steps at which the ControlNet starts applying.
+ control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The percentage of total steps at which the ControlNet stops applying.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a specific image resolution. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a target image resolution. It should be as same
+ as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
+ otherwise a `tuple` is returned containing the output images.
+ """
+
+
+ if video_length > 1 and num_images_per_prompt > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ # align format for control guidance
+ if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
+ control_guidance_start = len(control_guidance_end) * [control_guidance_start]
+ elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
+ control_guidance_end = len(control_guidance_start) * [control_guidance_end]
+ elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
+ mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
+ control_guidance_start, control_guidance_end = mult * [control_guidance_start], mult * [
+ control_guidance_end
+ ]
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ controlnet_conditioning_scale,
+ control_guidance_start,
+ control_guidance_end,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt,
+ prompt_2,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+
+ assert len(control_images) == video_length * batch_size
+
+ images = self.prepare_images(
+ images=control_images,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ height, width = images.shape[-2:]
+ elif isinstance(controlnet, MultiControlNetModel):
+
+ raise Exception("not supported yet")
+
+ # images = []
+ #
+ # for image_ in control_images:
+ # image_ = self.prepare_image(
+ # image=image_,
+ # width=width,
+ # height=height,
+ # batch_size=batch_size * num_images_per_prompt,
+ # num_images_per_prompt=num_images_per_prompt,
+ # device=device,
+ # dtype=controlnet.dtype,
+ # do_classifier_free_guidance=do_classifier_free_guidance,
+ # guess_mode=guess_mode,
+ # )
+ #
+ # images.append(image_)
+ #
+ # image = images
+ # height, width = image[0].shape[-2:]
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7.1 Create tensor stating which controlnets to keep
+ controlnet_keep = []
+ for i in range(len(timesteps)):
+ keeps = [
+ 1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
+ for s, e in zip(control_guidance_start, control_guidance_end)
+ ]
+ controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
+
+ # 7.2 Prepare added time ids & embeddings
+ # if isinstance(image, list):
+ # original_size = original_size or image[0].shape[-2:]
+ # else:
+ original_size = original_size or images.shape[-2:]
+ target_size = target_size or (height, width)
+
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ if negative_original_size is not None and negative_target_size is not None:
+ negative_add_time_ids = self._get_add_time_ids(
+ negative_original_size,
+ negative_crops_coords_top_left,
+ negative_target_size,
+ dtype=prompt_embeds.dtype,
+ )
+ else:
+ negative_add_time_ids = add_time_ids
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+
+ images = rearrange(images, "b f c h w -> (b f) c h w")
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ control_model_input = latents
+ control_model_input = self.scheduler.scale_model_input(control_model_input, t)
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ controlnet_added_cond_kwargs = {
+ "text_embeds": add_text_embeds.chunk(2)[1],
+ "time_ids": add_time_ids.chunk(2)[1],
+ }
+ else:
+ control_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+ controlnet_added_cond_kwargs = added_cond_kwargs
+
+ if isinstance(controlnet_keep[i], list):
+ cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
+ else:
+ controlnet_cond_scale = controlnet_conditioning_scale
+ if isinstance(controlnet_cond_scale, list):
+ controlnet_cond_scale = controlnet_cond_scale[0]
+ cond_scale = controlnet_cond_scale * controlnet_keep[i]
+
+
+ # this will be non interlaced when arranged!
+ control_model_input = rearrange(control_model_input, "b c f h w -> (b f) c h w")
+ # if we chunked this by 2 - the top 8 frames will be positive for cfg
+ # the bottom half will be negative for cfg...
+
+ if video_length > 1:
+ # use repeat_interleave as we need to match the rearrangement above.
+
+ controlnet_prompt_embeds = controlnet_prompt_embeds.repeat_interleave(video_length, dim=0)
+ controlnet_added_cond_kwargs = {
+ "text_embeds": controlnet_added_cond_kwargs['text_embeds'].repeat_interleave(video_length, dim=0),
+ "time_ids": controlnet_added_cond_kwargs['time_ids'].repeat_interleave(video_length, dim=0)
+ }
+
+ # if type(image) is list:
+ # image = torch.cat(image, dim=0)
+
+ # todo - check if video_length > 1 this needs to produce num_frames * batch_size samples...
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ control_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=images,
+ conditioning_scale=cond_scale,
+ guess_mode=guess_mode,
+ added_cond_kwargs=controlnet_added_cond_kwargs,
+ return_dict=False,
+ )
+
+ for j, sample in enumerate(down_block_res_samples):
+ down_block_res_samples[j] = rearrange(sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ mid_block_res_sample = rearrange(mid_block_res_sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions=video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ # if not output_type == "latent":
+ # # make sure the VAE is in float32 mode, as it overflows in float16
+ # needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
+ #
+ # if needs_upcasting:
+ # self.upcast_vae()
+ # latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+ #
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ #
+ # # cast back to fp16 if needed
+ # if needs_upcasting:
+ # self.vae.to(dtype=torch.float16)
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.load_lora_weights
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.save_lora_weights
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = True,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._remove_text_encoder_monkey_patch
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_pipeline.py b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c3b41da67eacee21c8cb192de343e47d5fe30d0
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_pipeline.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Pipeline to work temporally
+
+
+import os
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL
+from hotshot_xl.models.unet import UNet3DConditionModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.utils.torch_utils import randn_tensor
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from tqdm import tqdm
+from einops import repeat, rearrange
+from diffusers.utils import deprecate, logging
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL"
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor"
+ ).video
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
+
+
+class HotshotXLPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *LoRA*: [`HotshotPipelineXL.load_lora_weights`]
+ - *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
+
+ as well as the following saving methods:
+ - *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion XL uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([` CLIPTextModelWithProjection`]):
+ Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
+ specifically the
+ [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
+ variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`CLIPTokenizer`):
+ Second Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet3DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ scheduler=scheduler,
+ )
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.default_sample_size = self.unet.config.sample_size
+ self.watermark = None
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ num_images_per_prompt: Optional[int] = 1,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ denoising_end (`float`, *optional*):
+ When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
+ completed before it is intentionally prematurely terminated. As a result, the returned sample will
+ still retain a substantial amount of noise as determined by the discrete timesteps selected by the
+ scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
+ "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
+ Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
+ of a plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.7):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+
+ Examples:
+
+ Returns:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] or `tuple`:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ if video_length > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ # 0. Default height and width to unet
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Prepare added time ids & embeddings
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ # todo - negative_original_size from latest diffusers for cfg
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ # 7.1 Apply denoising_end
+ if denoising_end is not None and type(denoising_end) == float and denoising_end > 0 and denoising_end < 1:
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (denoising_end * self.scheduler.config.num_train_timesteps)
+ )
+ )
+ num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
+ timesteps = timesteps[:num_inference_steps]
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions= video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # if not output_type == "latent":
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # apply watermark if available
+ # if self.watermark is not None:
+ # image = self.watermark.apply_watermark(image)
+
+ #image = self.image_processor.postprocess(image, output_type=output_type)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ #
+ # # Offload last model to CPU
+ # if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ # self.final_offload_hook.offload()
+ #
+ # if not return_dict:
+ # return (image,)
+ #
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/build/lib/hotshot_xl/utils.py b/Hotshot-XL/build/lib/hotshot_xl/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7660c2a756ecae141333a7081ea358549db6ba6
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/utils.py
@@ -0,0 +1,213 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Union
+from io import BytesIO
+import PIL
+from PIL import ImageSequence, Image
+import requests
+import os
+
+def get_image(img_path) -> PIL.Image.Image:
+ if img_path.startswith("http"):
+ return PIL.Image.open(requests.get(img_path, stream=True).raw)
+ if os.path.exists(img_path):
+ return Image.open(img_path)
+ raise Exception("File not found")
+
+def images_to_gif_bytes(images: List, duration: int = 1000) -> bytes:
+ with BytesIO() as output_buffer:
+ # Save the first image
+ images[0].save(output_buffer,
+ format='GIF',
+ save_all=True,
+ append_images=images[1:],
+ duration=duration,
+ loop=0) # 0 means the GIF will loop indefinitely
+
+ # Get the byte array from the buffer
+ gif_bytes = output_buffer.getvalue()
+
+ return gif_bytes
+
+
+def save_as_gif(images: List, file_path: str, duration: int = 1000):
+ with open(file_path, "wb") as f:
+ f.write(images_to_gif_bytes(images, duration))
+
+def scale_aspect_fill(img, new_width, new_height):
+ new_width = int(new_width)
+ new_height = int(new_height)
+
+ original_width, original_height = img.size
+ ratio_w = float(new_width) / original_width
+ ratio_h = float(new_height) / original_height
+
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(original_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(original_width * ratio_h)
+ resize_height = new_height
+
+ img_resized = img.resize((resize_width, resize_height), Image.LANCZOS)
+
+ # Calculate cropping boundaries and do crop
+ left = (resize_width - new_width) / 2
+ top = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ bottom = (resize_height + new_height) / 2
+
+ img_cropped = img_resized.crop((left, top, right, bottom))
+
+ return img_cropped
+
+def extract_gif_frames_from_midpoint(image: Union[str, PIL.Image.Image], fps: int=8, target_duration: int=1000) -> list:
+ # Load the GIF
+ image = get_image(image) if type(image) is str else image
+
+ frames = []
+
+ estimated_frame_time = None
+
+ # some gifs contain the duration - others don't
+ # so if there is a duration we will grab it otherwise we will fall back
+
+ for frame in ImageSequence.Iterator(image):
+
+ frames.append(frame.copy())
+ if 'duration' in frame.info:
+ frame_info_duration = frame.info['duration']
+ if frame_info_duration > 0:
+ estimated_frame_time = frame_info_duration
+
+ if estimated_frame_time is None:
+ if len(frames) <= 16:
+ # assume it's 8fps
+ estimated_frame_time = 1000 // 8
+ else:
+ # assume it's 15 fps
+ estimated_frame_time = 70
+
+ if len(frames) < fps:
+ raise ValueError(f"fps of {fps} is too small for this gif as it only has {len(frames)} frames.")
+
+ skip = len(frames) // fps
+ upper_bound_index = len(frames) - 1
+
+ best_indices = [x for x in range(0, len(frames), skip)][:fps]
+ offset = int(upper_bound_index - best_indices[-1]) // 2
+ best_indices = [x + offset for x in best_indices]
+ best_duration = (best_indices[-1] - best_indices[0]) * estimated_frame_time
+
+ while True:
+
+ skip -= 1
+
+ if skip == 0:
+ break
+
+ indices = [x for x in range(0, len(frames), skip)][:fps]
+
+ # center the indices, so we sample the middle of the gif...
+ offset = int(upper_bound_index - indices[-1]) // 2
+ if offset == 0:
+ # can't shift
+ break
+ indices = [x + offset for x in indices]
+
+ # is the new duration closer to the target than last guess?
+ duration = (indices[-1] - indices[0]) * estimated_frame_time
+ if abs(duration - target_duration) > abs(best_duration - target_duration):
+ break
+
+ best_indices = indices
+ best_duration = duration
+
+ return [frames[index] for index in best_indices]
+
+def get_crop_coordinates(old_size: tuple, new_size: tuple) -> tuple:
+ """
+ Calculate the crop coordinates after scaling an image to fit a new size.
+
+ :param old_size: tuple of the form (width, height) representing the original size of the image.
+ :param new_size: tuple of the form (width, height) representing the desired size after scaling.
+ :return: tuple of the form (left, upper, right, lower) representing the normalized crop coordinates.
+ """
+ # Check if the input tuples have the right form (width, height)
+ if not (isinstance(old_size, tuple) and isinstance(new_size, tuple) and
+ len(old_size) == 2 and len(new_size) == 2):
+ raise ValueError("old_size and new_size should be tuples of the form (width, height)")
+
+ # Extract the width and height from the old and new sizes
+ old_width, old_height = old_size
+ new_width, new_height = new_size
+
+ # Calculate the ratios for width and height
+ ratio_w = float(new_width) / old_width
+ ratio_h = float(new_height) / old_height
+
+ # Determine which dimension is fixed (width or height)
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(old_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(old_width * ratio_h)
+ resize_height = new_height
+
+ # Calculate cropping boundaries in the resized image space
+ left = (resize_width - new_width) / 2
+ upper = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ lower = (resize_height + new_height) / 2
+
+ # Normalize the cropping coordinates
+
+ # Return the normalized coordinates as a tuple
+ return (left, upper, right, lower)
+
+aspect_ratio_to_1024_map = {
+ "0.42": [640, 1536],
+ "0.57": [768, 1344],
+ "0.68": [832, 1216],
+ "1.00": [1024, 1024],
+ "1.46": [1216, 832],
+ "1.75": [1344, 768],
+ "2.40": [1536, 640]
+}
+
+res_to_aspect_map = {
+ 1024: aspect_ratio_to_1024_map,
+ 512: {key: [value[0] // 2, value[1] // 2] for key, value in aspect_ratio_to_1024_map.items()},
+}
+
+def best_aspect_ratio(aspect_ratio: float, resolution: int):
+
+ map = res_to_aspect_map[resolution]
+
+ d = 99999999
+ res = None
+ for key, value in map.items():
+ ar = value[0] / value[1]
+ diff = abs(aspect_ratio - ar)
+ if diff < d:
+ d = diff
+ res = value
+
+ ar = res[0] / res[1]
+ return f"{ar:.2f}", res
\ No newline at end of file
diff --git a/Hotshot-XL/dist/hotshot_xl-1.0-py3.8.egg b/Hotshot-XL/dist/hotshot_xl-1.0-py3.8.egg
new file mode 100644
index 0000000000000000000000000000000000000000..8b71a021b8a67dd6caeac9e37de7dda423d5b131
Binary files /dev/null and b/Hotshot-XL/dist/hotshot_xl-1.0-py3.8.egg differ
diff --git a/Hotshot-XL/docker/Dockerfile b/Hotshot-XL/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..3aa868315be12f0bcb825ac089d25ad2622dd485
--- /dev/null
+++ b/Hotshot-XL/docker/Dockerfile
@@ -0,0 +1,5 @@
+FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime
+
+COPY requirements.txt .
+
+RUN pip install --no-cache-dir -r requirements.txt
diff --git a/Hotshot-XL/docker/Readme.md b/Hotshot-XL/docker/Readme.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a3464fec291a451e39ad308428ae2277ca89fbf
--- /dev/null
+++ b/Hotshot-XL/docker/Readme.md
@@ -0,0 +1,41 @@
+# Setup
+
+This docker file is for the **environment only**. This is to keep the docker image as small as possible!
+
+## Quickstart
+
+Hotshot have their own docker image you can use directly:
+```
+docker pull hotshotapp/hotshot-xl-env:latest
+```
+
+Or you can build it yourself
+
+```
+cd docker
+docker build -t hotshotapp/hotshot-xl-env:latest .
+```
+
+## Running the docker image
+
+We recommend storing the weights locally on your machine. That way the weights persist if you kill the container!
+
+- Install the models to a folder locally (Optional)
+ ```
+ cd /path/to/models
+ git lfs install
+ git clone https://huggingface.co/hotshotco/Hotshot-XL
+ ```
+- Run the docker from the project root
+ - **Linux**
+ ```
+ docker run -it --gpus=all --rm -v $(pwd):/local -v /path/to/models:/models hotshotapp/hotshot-xl-env:latest
+ ```
+ - **Windows (Powershell)**
+ ```
+ docker run -it --gpus=all --rm -v ${PWD}:/local -v C:\path\to\models:/models hotshotapp/hotshot-xl-env:latest
+ ```
+
+If you want to download the models from within the container itself then you do not need to map the volumes and ` -v /path/to/models:/models` can be removed.
+
+**Note**: Ensure you have NVIDIA Docker runtime installed if you want to utilize GPU support with `--gpus=all`.
diff --git a/Hotshot-XL/docker/requirements.txt b/Hotshot-XL/docker/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0991a8c50d1fb50a49d71bf29a914fc8e98dea7e
--- /dev/null
+++ b/Hotshot-XL/docker/requirements.txt
@@ -0,0 +1,8 @@
+accelerate==0.23.0
+einops==0.7.0
+diffusers==0.21.4
+transformers==4.34.0
+wandb==0.15.11
+moviepy==1.0.3
+imageio==2.31.5
+xformers==0.0.22
diff --git a/Hotshot-XL/fine_tune.py b/Hotshot-XL/fine_tune.py
new file mode 100644
index 0000000000000000000000000000000000000000..38c4a345b990b5a1b49d180967c49a647c5c33fb
--- /dev/null
+++ b/Hotshot-XL/fine_tune.py
@@ -0,0 +1,987 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import math
+import os
+import traceback
+from pathlib import Path
+import time
+import torch
+import torch.utils.checkpoint
+import torch.multiprocessing as mp
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from diffusers import AutoencoderKL
+from diffusers.optimization import get_scheduler
+from diffusers import DDPMScheduler
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer, CLIPTextModelWithProjection
+import torch.nn.functional as F
+import gc
+from typing import Callable
+from PIL import Image
+import numpy as np
+from concurrent.futures import ThreadPoolExecutor
+from hotshot_xl.models.unet import UNet3DConditionModel
+from hotshot_xl.pipelines.hotshot_xl_pipeline import HotshotXLPipeline
+from hotshot_xl.utils import get_crop_coordinates, res_to_aspect_map, scale_aspect_fill
+from einops import rearrange
+from torch.utils.data import Dataset, DataLoader
+from datetime import timedelta
+from accelerate.utils.dataclasses import InitProcessGroupKwargs
+from diffusers.utils import is_wandb_available
+
+if is_wandb_available():
+ import wandb
+
+logger = get_logger(__file__)
+
+
+class HotshotXLDataset(Dataset):
+
+ def __init__(self, directory: str, make_sample_fn: Callable):
+ """
+
+ Training data folder needs to look like:
+ + training_samples
+ --- + sample_001
+ ------- + frame_0.jpg
+ ------- + frame_1.jpg
+ ------- + ...
+ ------- + frame_n.jpg
+ ------- + prompt.txt
+ --- + sample_002
+ ------- + frame_0.jpg
+ ------- + frame_1.jpg
+ ------- + ...
+ ------- + frame_n.jpg
+ ------- + prompt.txt
+
+ Args:
+ directory: base directory of the training samples
+ make_sample_fn: a delegate call to load the images and prep the sample for batching
+ """
+ samples_dir = [os.path.join(directory, p) for p in os.listdir(directory)]
+ samples_dir = [p for p in samples_dir if os.path.isdir(p)]
+ samples = []
+
+ for d in samples_dir:
+ file_paths = [os.path.join(d, p) for p in os.listdir(d)]
+ image_fps = [f for f in file_paths if os.path.splitext(f)[1] in {".png", ".jpg"}]
+ with open(os.path.join(d, "prompt.txt")) as f:
+ prompt = f.read().strip()
+
+ samples.append({
+ "image_fps": image_fps,
+ "prompt": prompt
+ })
+
+ self.samples = samples
+ self.length = len(samples)
+ self.make_sample_fn = make_sample_fn
+
+ def __len__(self):
+ return self.length
+
+ def __getitem__(self, index):
+ return self.make_sample_fn(
+ self.samples[index]
+ )
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default="hotshotco/Hotshot-XL",
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--unet_resume_path",
+ type=str,
+ default=None,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+
+ parser.add_argument(
+ "--data_dir",
+ type=str,
+ required=True,
+ help="Path to data to train.",
+ )
+
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="wandb",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+
+ parser.add_argument("--run_validation_at_start", action="store_true")
+ parser.add_argument("--max_vae_encode", type=int, default=None)
+ parser.add_argument("--vae_b16", action="store_true")
+ parser.add_argument("--disable_optimizer_restore", action="store_true")
+
+ parser.add_argument(
+ "--latent_nan_checking",
+ action="store_true",
+ help="Check if latents contain nans - important if vae is f16",
+ )
+ parser.add_argument(
+ "--test_prompts",
+ type=str,
+ default=None,
+ )
+ parser.add_argument(
+ "--project_name",
+ type=str,
+ default="fine-tune-hotshot-xl",
+ help="the name of the run",
+ )
+ parser.add_argument(
+ "--run_name",
+ type=str,
+ default="run-01",
+ help="the name of the run",
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="output",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--noise_offset", type=float, default=0.05, help="The scale of noise offset.")
+ parser.add_argument("--seed", type=int, default=111, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--aspect_ratio",
+ type=str,
+ default="1.75",
+ choices=list(res_to_aspect_map[512].keys()),
+ help="Aspect ratio to train at",
+ )
+
+ parser.add_argument("--xformers", action="store_true")
+
+ parser.add_argument(
+ "--train_batch_size", type=int, default=8, help="Batch size (per device) for the training dataloader."
+ )
+
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=9999999,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+
+ parser.add_argument(
+ "--validate_every_steps",
+ type=int,
+ default=100,
+ help="Run inference every",
+ )
+
+ parser.add_argument(
+ "--save_n_steps",
+ type=int,
+ default=100,
+ help="Save the model every n global_steps",
+ )
+
+ parser.add_argument(
+ "--save_starting_step",
+ type=int,
+ default=100,
+ help="The step from which it starts saving intermediary checkpoints",
+ )
+
+ parser.add_argument(
+ "--nccl_timeout",
+ type=int,
+ help="nccl_timeout",
+ default=3600
+ )
+
+ parser.add_argument("--snr_gamma", action="store_true")
+
+ args = parser.parse_args()
+
+ return args
+
+
+def add_time_ids(
+ unet_config,
+ unet_add_embedding,
+ text_encoder_2: CLIPTextModelWithProjection,
+ original_size: tuple,
+ crops_coords_top_left: tuple,
+ target_size: tuple,
+ dtype: torch.dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ unet_config.addition_time_embed_dim * len(add_time_ids) + text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = unet_add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+
+def main():
+ global_step = 0
+ min_steps_before_validation = 0
+
+ args = parse_args()
+
+ next_save_iter = args.save_starting_step
+
+ if args.save_starting_step < 1:
+ next_save_iter = None
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ kwargs_handlers=[InitProcessGroupKwargs(timeout=timedelta(args.nccl_timeout))]
+ )
+
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ nonlocal global_step
+
+ for model in models:
+ if isinstance(model, type(accelerator.unwrap_model(unet))):
+ model.save_pretrained(os.path.join(output_dir, 'unet'))
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_local_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Load the tokenizer
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+ tokenizer_2 = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer_2")
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ text_encoder_2 = CLIPTextModelWithProjection.from_pretrained(args.pretrained_model_name_or_path,
+ subfolder="text_encoder_2")
+
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
+
+ optimizer_resume_path = None
+
+ if args.unet_resume_path:
+ optimizer_fp = os.path.join(args.unet_resume_path, "optimizer.bin")
+
+ if os.path.exists(optimizer_fp):
+ optimizer_resume_path = optimizer_fp
+
+ unet = UNet3DConditionModel.from_pretrained(args.unet_resume_path,
+ subfolder="unet",
+ low_cpu_mem_usage=False,
+ device_map=None)
+
+ else:
+ unet = UNet3DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
+
+ if args.xformers:
+ vae.set_use_memory_efficient_attention_xformers(True, None)
+ unet.set_use_memory_efficient_attention_xformers(True, None)
+
+ unet_config = unet.config
+ unet_add_embedding = unet.add_embedding
+
+ unet.requires_grad_(False)
+
+ temporal_params = unet.temporal_parameters()
+
+ for p in temporal_params:
+ p.requires_grad_(True)
+
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+ text_encoder_2.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ learning_rate = args.learning_rate
+
+ params_to_optimize = [
+ {'params': temporal_params, "lr": learning_rate},
+ ]
+
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ if optimizer_resume_path and not args.disable_optimizer_restore:
+ logger.info("Restoring the optimizer.")
+ try:
+
+ old_optimizer_state_dict = torch.load(optimizer_resume_path)
+
+ # Extract only the state
+ old_state = old_optimizer_state_dict['state']
+
+ # Set the state of the new optimizer
+ optimizer.load_state_dict({'state': old_state, 'param_groups': optimizer.param_groups})
+
+ del old_optimizer_state_dict
+ del old_state
+
+ torch.cuda.empty_cache()
+ torch.cuda.synchronize()
+ gc.collect()
+
+ logger.info(f"Restored the optimizer ok")
+
+ except:
+ logger.error("Failed to restore the optimizer...", exc_info=True)
+ traceback.print_exc()
+ raise
+
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ def compute_snr(timesteps):
+ """
+ Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
+ """
+ alphas_cumprod = noise_scheduler.alphas_cumprod
+ sqrt_alphas_cumprod = alphas_cumprod ** 0.5
+ sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
+
+ # Expand the tensors.
+ # Adapted from https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L1026
+ sqrt_alphas_cumprod = sqrt_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
+ while len(sqrt_alphas_cumprod.shape) < len(timesteps.shape):
+ sqrt_alphas_cumprod = sqrt_alphas_cumprod[..., None]
+ alpha = sqrt_alphas_cumprod.expand(timesteps.shape)
+
+ sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
+ while len(sqrt_one_minus_alphas_cumprod.shape) < len(timesteps.shape):
+ sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod[..., None]
+ sigma = sqrt_one_minus_alphas_cumprod.expand(timesteps.shape)
+
+ # Compute SNR.
+ snr = (alpha / sigma) ** 2
+ return snr
+
+ device = torch.device('cuda')
+
+ image_transforms = transforms.Compose(
+ [
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def image_to_tensor(img):
+ with torch.no_grad():
+
+ if img.mode != "RGB":
+ img = img.convert("RGB")
+
+ image = image_transforms(img).to(accelerator.device)
+
+ if image.shape[0] == 1:
+ image = image.repeat(3, 1, 1)
+
+ if image.shape[0] > 3:
+ image = image[:3, :, :]
+
+ return image
+
+ def make_sample(sample):
+
+ nonlocal unet_config
+ nonlocal unet_add_embedding
+
+ images = [Image.open(img) for img in sample['image_fps']]
+
+ og_size = images[0].size
+
+ for i, im in enumerate(images):
+ if im.mode != "RGB":
+ images[i] = im.convert("RGB")
+
+ aspect_ratio_map = res_to_aspect_map[args.resolution]
+
+ required_size = tuple(aspect_ratio_map[args.aspect_ratio])
+
+ if required_size != og_size:
+
+ def resize_image(x):
+ img_size = x.size
+ if img_size == required_size:
+ return x.resize(required_size, Image.LANCZOS)
+
+ return scale_aspect_fill(x, required_size[0], required_size[1])
+
+ with ThreadPoolExecutor(max_workers=len(images)) as executor:
+ images = list(executor.map(resize_image, images))
+
+ frames = torch.stack([image_to_tensor(x) for x in images])
+
+ l, u, *_ = get_crop_coordinates(og_size, images[0].size)
+ crop_coords = (l, u)
+
+ additional_time_ids = add_time_ids(
+ unet_config,
+ unet_add_embedding,
+ text_encoder_2,
+ og_size,
+ crop_coords,
+ (required_size[0], required_size[1]),
+ dtype=torch.float32
+ ).to(device)
+
+ input_ids_0 = tokenizer(
+ sample['prompt'],
+ padding="do_not_pad",
+ truncation=True,
+ max_length=tokenizer.model_max_length,
+ ).input_ids
+
+ input_ids_1 = tokenizer_2(
+ sample['prompt'],
+ padding="do_not_pad",
+ truncation=True,
+ max_length=tokenizer.model_max_length,
+ ).input_ids
+
+ return {
+ "frames": frames,
+ "input_ids_0": input_ids_0,
+ "input_ids_1": input_ids_1,
+ "additional_time_ids": additional_time_ids,
+ }
+
+ def collate_fn(examples: list) -> dict:
+
+ # Two Text encoders
+ # First Text Encoder -> Penultimate Layer
+ # Second Text Encoder -> Pooled Layer
+
+ input_ids_0 = [example['input_ids_0'] for example in examples]
+ input_ids_0 = tokenizer.pad({"input_ids": input_ids_0}, padding="max_length",
+ max_length=tokenizer.model_max_length, return_tensors="pt").input_ids
+
+ prompt_embeds_0 = text_encoder(
+ input_ids_0.to(device),
+ output_hidden_states=True,
+ )
+
+ # we take penultimate embeddings from the first text encoder
+ prompt_embeds_0 = prompt_embeds_0.hidden_states[-2]
+
+ input_ids_1 = [example['input_ids_1'] for example in examples]
+ input_ids_1 = tokenizer_2.pad({"input_ids": input_ids_1}, padding="max_length",
+ max_length=tokenizer.model_max_length, return_tensors="pt").input_ids
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ prompt_embeds = text_encoder_2(
+ input_ids_1.to(device),
+ output_hidden_states=True
+ )
+
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds_1 = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds = torch.concat([prompt_embeds_0, prompt_embeds_1], dim=-1)
+
+ *_, h, w = examples[0]['frames'].shape
+
+ return {
+ "frames": torch.stack([x['frames'] for x in examples]).to(memory_format=torch.contiguous_format).float(),
+ "prompt_embeds": prompt_embeds.to(memory_format=torch.contiguous_format).float(),
+ "pooled_prompt_embeds": pooled_prompt_embeds,
+ "additional_time_ids": torch.stack([x['additional_time_ids'] for x in examples]),
+ }
+
+ # Region - Dataloaders
+ dataset = HotshotXLDataset(args.data_dir, make_sample)
+ dataloader = DataLoader(dataset, args.train_batch_size, shuffle=True, collate_fn=collate_fn)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(dataloader) / args.gradient_accumulation_steps)
+
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ unet, optimizer, lr_scheduler, dataloader = accelerator.prepare(
+ unet, optimizer, lr_scheduler, dataloader
+ )
+
+ def to_images(video_frames: torch.Tensor):
+ import torchvision.transforms as transforms
+ to_pil = transforms.ToPILImage()
+ video_frames = rearrange(video_frames, "b c f w h -> b f c w h")
+ bsz = video_frames.shape[0]
+ images = []
+ for i in range(bsz):
+ video = video_frames[i]
+ for j in range(video.shape[0]):
+ image = to_pil(video[j])
+ images.append(image)
+ return images
+
+ def to_video_frames(images: list) -> np.ndarray:
+ x = np.stack([np.asarray(img) for img in images])
+ return np.transpose(x, (0, 3, 1, 2))
+
+ def run_validation(step=0, node_index=0):
+
+ nonlocal global_step
+ nonlocal accelerator
+
+ if args.test_prompts:
+ prompts = args.test_prompts.split("|")
+ else:
+ prompts = [
+ "a woman is lifting weights in a gym",
+ "a group of people are dancing at a party",
+ "a teddy bear doing the front crawl"
+ ]
+
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ logger.info(f"Running inference to test model at {step} steps")
+ with torch.no_grad():
+
+ pipe = HotshotXLPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ vae=vae,
+ )
+
+ videos = []
+
+ aspect_ratio_map = res_to_aspect_map[args.resolution]
+ w, h = aspect_ratio_map[args.aspect_ratio]
+
+ for prompt in prompts:
+ video = pipe(prompt,
+ width=w,
+ height=h,
+ original_size=(1920, 1080), # todo - pass in as args?
+ target_size=(args.resolution, args.resolution),
+ num_inference_steps=30,
+ video_length=8,
+ output_type="tensor",
+ generator=torch.Generator().manual_seed(111)).videos
+
+ videos.append(to_images(video))
+
+ for tracker in accelerator.trackers:
+
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [wandb.Video(to_video_frames(video), fps=8, format='mp4') for video in
+ videos],
+ }, step=global_step
+ )
+
+ del pipe
+
+ return
+
+ # Move text_encode and vae to gpu.
+ vae.to(accelerator.device, dtype=torch.bfloat16 if args.vae_b16 else torch.float32)
+ text_encoder.to(accelerator.device)
+ text_encoder_2.to(accelerator.device)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+
+ num_update_steps_per_epoch = math.ceil(len(dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterward we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initialize automatically on the main process.
+
+ if accelerator.is_main_process:
+ accelerator.init_trackers(args.project_name)
+
+ def bar(prg):
+ br = '|' + '█' * prg + ' ' * (25 - prg) + '|'
+ return br
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ if accelerator.is_main_process:
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+
+ latents_scaler = vae.config.scaling_factor
+
+ def save_checkpoint():
+ save_dir = Path(args.output_dir)
+ save_dir = str(save_dir)
+ save_dir = save_dir.replace(" ", "_")
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir, exist_ok=True)
+ accelerator.save_state(save_dir)
+
+ def save_checkpoint_and_wait():
+ if accelerator.is_main_process:
+ save_checkpoint()
+ accelerator.wait_for_everyone()
+
+ def save_model_and_wait():
+ if accelerator.is_main_process:
+ HotshotXLPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ vae=vae,
+ ).save_pretrained(args.output_dir, safe_serialization=True)
+ accelerator.wait_for_everyone()
+
+ def compute_loss_from_batch(batch: dict):
+ frames = batch["frames"]
+ bsz, number_of_frames, c, w, h = frames.shape
+
+ # Convert images to latent space
+ with torch.no_grad():
+
+ if args.max_vae_encode:
+ latents = []
+
+ x = rearrange(frames, "bs nf c h w -> (bs nf) c h w")
+
+ for latent_index in range(0, x.shape[0], args.max_vae_encode):
+ sample = x[latent_index: latent_index + args.max_vae_encode]
+
+ latent = vae.encode(sample.to(dtype=vae.dtype)).latent_dist.sample().float()
+ if len(latent.shape) == 3:
+ latent = latent.unsqueeze(0)
+
+ latents.append(latent)
+ torch.cuda.empty_cache()
+
+ latents = torch.cat(latents, dim=0)
+ else:
+
+ # convert the latents from 5d -> 4d, so we can run it though the vae encoder
+ x = rearrange(frames, "bs nf c h w -> (bs nf) c h w")
+
+ del frames
+
+ torch.cuda.empty_cache()
+
+ latents = vae.encode(x.to(dtype=vae.dtype)).latent_dist.sample().float()
+
+ if args.latent_nan_checking and torch.any(torch.isnan(latents)):
+ accelerator.print("NaN found in latents, replacing with zeros")
+ latents = torch.where(torch.isnan(latents), torch.zeros_like(latents), latents)
+
+ latents = rearrange(latents, "(b f) c h w -> b c f h w", b=bsz)
+
+ torch.cuda.empty_cache()
+
+ noise = torch.randn_like(latents, device=latents.device)
+
+ if args.noise_offset:
+ # https://www.crosslabs.org//blog/diffusion-with-offset-noise
+ noise += args.noise_offset * torch.randn(
+ (latents.shape[0], latents.shape[1], 1, 1, 1), device=latents.device
+ )
+
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long() # .repeat_interleave(number_of_frames)
+ latents = latents * latents_scaler
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+
+ prompt_embeds = batch['prompt_embeds']
+ add_text_embeds = batch['pooled_prompt_embeds']
+
+ additional_time_ids = batch['additional_time_ids'] # .repeat_interleave(number_of_frames, dim=0)
+
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": additional_time_ids}
+
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ noisy_latents.requires_grad = True
+
+ model_pred = unet(noisy_latents,
+ timesteps,
+ cross_attention_kwargs=None,
+ encoder_hidden_states=prompt_embeds,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ )[0]
+
+ if args.snr_gamma:
+ # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Since we predict the noise instead of x_0, the original formulation is slightly changed.
+ # This is discussed in Section 4.2 of the same paper.
+ snr = compute_snr(timesteps)
+ mse_loss_weights = (
+ torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snr
+ )
+ # We first calculate the original loss. Then we mean over the non-batch dimensions and
+ # rebalance the sample-wise losses with their respective loss weights.
+ # Finally, we take the mean of the rebalanced loss.
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
+
+ loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
+ return loss.mean()
+ else:
+ return F.mse_loss(model_pred.float(), target.float(), reduction='mean')
+
+ def process_batch(batch: dict):
+ nonlocal global_step
+ nonlocal next_save_iter
+
+ now = time.time()
+
+ with accelerator.accumulate(unet):
+
+ logging_data = {}
+ if global_step == 0:
+ # print(f"Running initial validation at step")
+ if accelerator.is_main_process and args.run_validation_at_start:
+ run_validation(step=global_step, node_index=accelerator.process_index // 8)
+ accelerator.wait_for_everyone()
+
+ loss = compute_loss_from_batch(batch)
+
+ accelerator.backward(loss)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(temporal_params, args.max_grad_norm)
+
+ optimizer.step()
+
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ fll = round((global_step * 100) / args.max_train_steps)
+ fll = round(fll / 4)
+ pr = bar(fll)
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "loss_time": (time.time() - now)}
+
+ if args.validate_every_steps is not None and global_step > min_steps_before_validation and global_step % args.validate_every_steps == 0:
+ if accelerator.is_main_process:
+ run_validation(step=global_step, node_index=accelerator.process_index // 8)
+
+ accelerator.wait_for_everyone()
+
+ for key, val in logging_data.items():
+ logs[key] = val
+
+ progress_bar.set_postfix(**logs)
+ progress_bar.set_description_str("Progress:" + pr)
+ accelerator.log(logs, step=global_step)
+
+ if accelerator.is_main_process \
+ and next_save_iter is not None \
+ and global_step < args.max_train_steps \
+ and global_step + 1 == next_save_iter:
+ save_checkpoint()
+
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ next_save_iter += args.save_n_steps
+
+ for epoch in range(args.num_train_epochs):
+ unet.train()
+
+ for step, batch in enumerate(dataloader):
+ process_batch(batch)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if global_step >= args.max_train_steps:
+ logger.info("Max train steps reached. Breaking while loop")
+ break
+
+ accelerator.wait_for_everyone()
+
+ save_model_and_wait()
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ mp.set_start_method('spawn')
+ main()
diff --git a/Hotshot-XL/hotshot_xl.egg-info/PKG-INFO b/Hotshot-XL/hotshot_xl.egg-info/PKG-INFO
new file mode 100644
index 0000000000000000000000000000000000000000..c5a69f0e876b5dc5487724466a0e4bbf785dae5f
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/PKG-INFO
@@ -0,0 +1,5 @@
+Metadata-Version: 2.1
+Name: hotshot-xl
+Version: 1.0
+Author: Natural Synthetics Inc
+License-File: LICENSE
diff --git a/Hotshot-XL/hotshot_xl.egg-info/SOURCES.txt b/Hotshot-XL/hotshot_xl.egg-info/SOURCES.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3ed4b371ebcd300dfc12e2ab0dc01179f8b1e105
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/SOURCES.txt
@@ -0,0 +1,19 @@
+LICENSE
+README.md
+setup.py
+hotshot_xl/__init__.py
+hotshot_xl/utils.py
+hotshot_xl.egg-info/PKG-INFO
+hotshot_xl.egg-info/SOURCES.txt
+hotshot_xl.egg-info/dependency_links.txt
+hotshot_xl.egg-info/requires.txt
+hotshot_xl.egg-info/top_level.txt
+hotshot_xl/models/__init__.py
+hotshot_xl/models/resnet.py
+hotshot_xl/models/transformer_3d.py
+hotshot_xl/models/transformer_temporal.py
+hotshot_xl/models/unet.py
+hotshot_xl/models/unet_blocks.py
+hotshot_xl/pipelines/__init__.py
+hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
+hotshot_xl/pipelines/hotshot_xl_pipeline.py
\ No newline at end of file
diff --git a/Hotshot-XL/hotshot_xl.egg-info/dependency_links.txt b/Hotshot-XL/hotshot_xl.egg-info/dependency_links.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/Hotshot-XL/hotshot_xl.egg-info/requires.txt b/Hotshot-XL/hotshot_xl.egg-info/requires.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2d1a81d2018e60ad898957360c90c60540ecd689
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/requires.txt
@@ -0,0 +1,5 @@
+torch>=2.0.1
+torchvision>=0.15.2
+diffusers>=0.21.4
+transformers>=4.33.3
+einops
diff --git a/Hotshot-XL/hotshot_xl.egg-info/top_level.txt b/Hotshot-XL/hotshot_xl.egg-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5d4814c5f5827393e60d27fbbc56f76343591f02
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/top_level.txt
@@ -0,0 +1 @@
+hotshot_xl
diff --git a/Hotshot-XL/hotshot_xl/__init__.py b/Hotshot-XL/hotshot_xl/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..090de024570c67f7182c8e5b214c81f3aaadaf6e
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/__init__.py
@@ -0,0 +1,25 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Union
+
+import numpy as np
+import torch
+
+# don't remove these imports - they are needed to load from pretrain.
+from diffusers.models.modeling_utils import ModelMixin
+from .models.unet import UNet3DConditionModel
+
+from diffusers.utils import (
+ BaseOutput,
+)
+
+@dataclass
+class HotshotPipelineXLOutput(BaseOutput):
+ videos: Union[torch.Tensor, np.ndarray]
\ No newline at end of file
diff --git a/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-38.pyc b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8314477c38f726534d49f13619dfb67ad53770e7
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-39.pyc b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b470ab2f7a9a638702e5840a2ad0fcc349883920
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/__pycache__/utils.cpython-39.pyc b/Hotshot-XL/hotshot_xl/__pycache__/utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2d4c0a2e2da291336b883d6807be026b5eddddab
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/__pycache__/utils.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__init__.py b/Hotshot-XL/hotshot_xl/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dbef36bf5a6f9e97ceec62f81b1e7c0e18e09795
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..df3b414c2761b4a650deca945fcdbdb5ed29c47a
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c4a6a79993ebb204d5474c552c74c4033da6449b
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0678bc932aec8d292fd98a4356598ec765d49666
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2469126f7a14d7de7f6aaa53f186ec6956b88e3e
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3edb0f7f7f8a8a6319c17916e61145a4751cc5cd
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..62a4da5e527e1f7aa34c19ae4b63a1db907f468e
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..09596b9533d22b0c8e58c6fe72ca84d01fa906f0
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f8ebddea6476de30f98291d7fb4402f75dd68dea
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d5e52f761f4b5d863d04ade537953181322ebbdb
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f9d3fe512196ae0e97609e0910cb29997dc011ad
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bfb4f31a082ce59bb9bcc48dd7f96835f83e4b90
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/resnet.py b/Hotshot-XL/hotshot_xl/models/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b46c907610a9a4fb73288f280c79e923b86c89a
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/resnet.py
@@ -0,0 +1,134 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import torch.nn as nn
+from diffusers.models.resnet import Upsample2D, Downsample2D, LoRACompatibleConv
+from einops import rearrange
+
+
+class Upsample3D(Upsample2D):
+ def forward(self, hidden_states, output_size=None, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Upsample3D, self).forward(hidden_states, output_size, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Downsample3D(Downsample2D):
+
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Downsample3D, self).forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Conv3d(LoRACompatibleConv):
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super().forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class ResnetBlock3D(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="silu",
+ time_embedding_norm="default",
+ output_scale_factor=1.0,
+ use_in_shortcut=None,
+ conv_shortcut_bias: bool = True,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
+ self.conv1 = Conv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ if self.time_embedding_norm == "default":
+ time_emb_proj_out_channels = out_channels
+ elif self.time_embedding_norm == "scale_shift":
+ time_emb_proj_out_channels = out_channels * 2
+ else:
+ raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
+
+ self.time_emb_proj = torch.nn.Linear(temb_channels, time_emb_proj_out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = Conv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ assert non_linearity == "silu"
+
+ self.nonlinearity = nn.SiLU()
+
+ self.use_in_shortcut = self.in_channels != self.out_channels if use_in_shortcut is None else use_in_shortcut
+
+ self.conv_shortcut = None
+ if self.use_in_shortcut:
+ self.conv_shortcut = Conv3d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
+ )
+
+ def forward(self, input_tensor, temb):
+ hidden_states = input_tensor
+
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+
+ if temb is not None:
+ temb = self.nonlinearity(temb)
+ temb = self.time_emb_proj(temb)[:, :, None, None, None]
+
+ if temb is not None and self.time_embedding_norm == "default":
+ hidden_states = hidden_states + temb
+
+ hidden_states = self.norm2(hidden_states)
+
+ if temb is not None and self.time_embedding_norm == "scale_shift":
+ scale, shift = torch.chunk(temb, 2, dim=1)
+ hidden_states = hidden_states * (1 + scale) + shift
+
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ input_tensor = self.conv_shortcut(input_tensor)
+
+ output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
+
+ return output_tensor
diff --git a/Hotshot-XL/hotshot_xl/models/transformer_3d.py b/Hotshot-XL/hotshot_xl/models/transformer_3d.py
new file mode 100644
index 0000000000000000000000000000000000000000..169f91ee6f2bcd568141a5776820429140370f6f
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/transformer_3d.py
@@ -0,0 +1,75 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Optional
+import torch
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.transformer_2d import Transformer2DModel
+from einops import rearrange, repeat
+from typing import Dict, Any
+
+
+@dataclass
+class Transformer3DModelOutput(BaseOutput):
+ """
+ The output of [`Transformer3DModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`:
+ The hidden states output conditioned on the `encoder_hidden_states` input.
+ """
+
+ sample: torch.FloatTensor
+
+
+class Transformer3DModel(Transformer2DModel):
+
+ def __init__(self, *args, **kwargs):
+ super(Transformer3DModel, self).__init__(*args, **kwargs)
+ nn.init.zeros_(self.proj_out.weight.data)
+ nn.init.zeros_(self.proj_out.bias.data)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ enable_temporal_layers: bool = True,
+ positional_embedding: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ):
+
+ is_video = len(hidden_states.shape) == 5
+
+ if is_video:
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ encoder_hidden_states = repeat(encoder_hidden_states, 'b n c -> (b f) n c', f=f)
+
+ hidden_states = super(Transformer3DModel, self).forward(hidden_states,
+ encoder_hidden_states,
+ timestep,
+ class_labels,
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ return_dict=False)[0]
+
+ if is_video:
+ hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+ if not return_dict:
+ return (hidden_states,)
+
+ return Transformer3DModelOutput(sample=hidden_states)
\ No newline at end of file
diff --git a/Hotshot-XL/hotshot_xl/models/transformer_temporal.py b/Hotshot-XL/hotshot_xl/models/transformer_temporal.py
new file mode 100644
index 0000000000000000000000000000000000000000..772e51d55da5ebf3279235b482c1db7e46e2b603
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/transformer_temporal.py
@@ -0,0 +1,192 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import math
+from dataclasses import dataclass
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.attention import Attention, FeedForward
+from einops import rearrange, repeat
+from typing import Optional
+
+
+class PositionalEncoding(nn.Module):
+ """
+ Implements positional encoding as described in "Attention Is All You Need".
+ Adds sinusoidal based positional encodings to the input tensor.
+ """
+
+ _SCALE_FACTOR = 10000.0 # Scale factor used in the positional encoding computation.
+
+ def __init__(self, dim: int, dropout: float = 0.0, max_length: int = 24):
+ super(PositionalEncoding, self).__init__()
+
+ self.dropout = nn.Dropout(p=dropout)
+
+ # The size is (1, max_length, dim) to allow easy addition to input tensors.
+ positional_encoding = torch.zeros(1, max_length, dim)
+
+ # Position and dim are used in the sinusoidal computation.
+ position = torch.arange(max_length).unsqueeze(1)
+ div_term = torch.exp(torch.arange(0, dim, 2) * (-math.log(self._SCALE_FACTOR) / dim))
+
+ positional_encoding[0, :, 0::2] = torch.sin(position * div_term)
+ positional_encoding[0, :, 1::2] = torch.cos(position * div_term)
+
+ # Register the positional encoding matrix as a buffer,
+ # so it's part of the model's state but not the parameters.
+ self.register_buffer('positional_encoding', positional_encoding)
+
+ def forward(self, hidden_states: torch.Tensor, length: int) -> torch.Tensor:
+ hidden_states = hidden_states + self.positional_encoding[:, :length]
+ return self.dropout(hidden_states)
+
+
+class TemporalAttention(Attention):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.pos_encoder = PositionalEncoding(kwargs["query_dim"], dropout=0)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=8):
+ sequence_length = hidden_states.shape[1]
+ hidden_states = rearrange(hidden_states, "(b f) s c -> (b s) f c", f=number_of_frames)
+ hidden_states = self.pos_encoder(hidden_states, length=number_of_frames)
+
+ if encoder_hidden_states:
+ encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b s) n c", s=sequence_length)
+
+ hidden_states = super().forward(hidden_states, encoder_hidden_states, attention_mask=attention_mask)
+
+ return rearrange(hidden_states, "(b s) f c -> (b f) s c", s=sequence_length)
+
+
+@dataclass
+class TransformerTemporalOutput(BaseOutput):
+ sample: torch.FloatTensor
+
+
+class TransformerTemporal(nn.Module):
+ def __init__(
+ self,
+ num_attention_heads: int,
+ attention_head_dim: int,
+ in_channels: int,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ activation_fn: str = "geglu",
+ upcast_attention: bool = False,
+ ):
+ super().__init__()
+
+ inner_dim = num_attention_heads * attention_head_dim
+
+ self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ TransformerBlock(
+ dim=inner_dim,
+ num_attention_heads=num_attention_heads,
+ attention_head_dim=attention_head_dim,
+ dropout=dropout,
+ activation_fn=activation_fn,
+ attention_bias=attention_bias,
+ upcast_attention=upcast_attention,
+ cross_attention_dim=cross_attention_dim
+ )
+ for _ in range(num_layers)
+ ]
+ )
+ self.proj_out = nn.Linear(inner_dim, in_channels)
+
+ def forward(self, hidden_states, encoder_hidden_states=None):
+ _, num_channels, f, height, width = hidden_states.shape
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+
+ skip = hidden_states
+
+ hidden_states = self.norm(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf c h w -> bf (h w) c")
+ hidden_states = self.proj_in(hidden_states)
+
+ for block in self.transformer_blocks:
+ hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, number_of_frames=f)
+
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf (h w) c -> bf c h w", h=height, w=width).contiguous()
+
+ output = hidden_states + skip
+ output = rearrange(output, "(b f) c h w -> b c f h w", f=f)
+
+ return output
+
+
+class TransformerBlock(nn.Module):
+ def __init__(
+ self,
+ dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=0.0,
+ activation_fn="geglu",
+ attention_bias=False,
+ upcast_attention=False,
+ depth=2,
+ cross_attention_dim: Optional[int] = None
+ ):
+ super().__init__()
+
+ self.is_cross = cross_attention_dim is not None
+
+ attention_blocks = []
+ norms = []
+
+ for _ in range(depth):
+ attention_blocks.append(
+ TemporalAttention(
+ query_dim=dim,
+ cross_attention_dim=cross_attention_dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ upcast_attention=upcast_attention,
+ )
+ )
+ norms.append(nn.LayerNorm(dim))
+
+ self.attention_blocks = nn.ModuleList(attention_blocks)
+ self.norms = nn.ModuleList(norms)
+
+ self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
+ self.ff_norm = nn.LayerNorm(dim)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=None):
+
+ if not self.is_cross:
+ encoder_hidden_states = None
+
+ for block, norm in zip(self.attention_blocks, self.norms):
+ norm_hidden_states = norm(hidden_states)
+ hidden_states = block(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ number_of_frames=number_of_frames
+ ) + hidden_states
+
+ norm_hidden_states = self.ff_norm(hidden_states)
+ hidden_states = self.ff(norm_hidden_states) + hidden_states
+
+ output = hidden_states
+ return output
diff --git a/Hotshot-XL/hotshot_xl/models/unet.py b/Hotshot-XL/hotshot_xl/models/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..30b45fe9fcf7d2e0e898aa7ebd36494ee13998ef
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/unet.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Unet now supports SDXL
+
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.loaders import UNet2DConditionLoadersMixin
+from diffusers.utils import BaseOutput, logging
+from diffusers.models.activations import get_activation
+from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
+from diffusers.models.embeddings import (
+ GaussianFourierProjection,
+ ImageHintTimeEmbedding,
+ ImageProjection,
+ ImageTimeEmbedding,
+ TextImageProjection,
+ TextImageTimeEmbedding,
+ TextTimeEmbedding,
+ TimestepEmbedding,
+ Timesteps,
+)
+
+from diffusers.models.modeling_utils import ModelMixin
+from diffusers.models.embeddings import TimestepEmbedding, Timesteps
+from .unet_blocks import (
+ CrossAttnDownBlock3D,
+ CrossAttnUpBlock3D,
+ DownBlock3D,
+ UNetMidBlock3DCrossAttn,
+ UpBlock3D,
+ get_down_block,
+ get_up_block,
+)
+
+from .resnet import Conv3d
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet3DConditionOutput(BaseOutput):
+ """
+ The output of [`UNet2DConditionModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor = None
+
+
+class UNet3DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ "DownBlock3D",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlock3DCrossAttn",
+ up_block_types: Tuple[str] = (
+ "UpBlock3D",
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ ),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: Union[int, Tuple[int]] = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ transformer_layers_per_block: Union[int, Tuple[int]] = 1,
+ encoder_hid_dim: Optional[int] = None,
+ encoder_hid_dim_type: Optional[str] = None,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ addition_embed_type: Optional[str] = None,
+ addition_time_embed_dim: Optional[int] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ resnet_skip_time_act: bool = False,
+ resnet_out_scale_factor: int = 1.0,
+ time_embedding_type: str = "positional",
+ time_embedding_dim: Optional[int] = None,
+ time_embedding_act_fn: Optional[str] = None,
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ mid_block_only_cross_attention: Optional[bool] = None,
+ cross_attention_norm: Optional[str] = None,
+ addition_embed_type_num_heads=64,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ if num_attention_heads is not None:
+ raise ValueError(
+ "At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
+ )
+
+ # If `num_attention_heads` is not defined (which is the case for most models)
+ # it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
+ # The reason for this behavior is to correct for incorrectly named variables that were introduced
+ # when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
+ # Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
+ # which is why we correct for the naming here.
+ num_attention_heads = num_attention_heads or attention_head_dim
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+
+ self.conv_in = Conv3d(in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding)
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ if encoder_hid_dim_type is None and encoder_hid_dim is not None:
+ encoder_hid_dim_type = "text_proj"
+ self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
+ logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
+
+ if encoder_hid_dim is None and encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
+ )
+
+ if encoder_hid_dim_type == "text_proj":
+ self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
+ elif encoder_hid_dim_type == "text_image_proj":
+ # image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
+ self.encoder_hid_proj = TextImageProjection(
+ text_embed_dim=encoder_hid_dim,
+ image_embed_dim=cross_attention_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2
+ self.encoder_hid_proj = ImageProjection(
+ image_embed_dim=encoder_hid_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
+ )
+ else:
+ self.encoder_hid_proj = None
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ if addition_embed_type == "text":
+ if encoder_hid_dim is not None:
+ text_time_embedding_from_dim = encoder_hid_dim
+ else:
+ text_time_embedding_from_dim = cross_attention_dim
+
+ self.add_embedding = TextTimeEmbedding(
+ text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
+ )
+ elif addition_embed_type == "text_image":
+ # text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
+ self.add_embedding = TextImageTimeEmbedding(
+ text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
+ )
+ elif addition_embed_type == "text_time":
+ self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
+ self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif addition_embed_type == "image":
+ # Kandinsky 2.2
+ self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type == "image_hint":
+ # Kandinsky 2.2 ControlNet
+ self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type is not None:
+ raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
+
+ if time_embedding_act_fn is None:
+ self.time_embed_act = None
+ else:
+ self.time_embed_act = get_activation(time_embedding_act_fn)
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = only_cross_attention
+
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = False
+
+ if isinstance(num_attention_heads, int):
+ num_attention_heads = (num_attention_heads,) * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if isinstance(layers_per_block, int):
+ layers_per_block = [layers_per_block] * len(down_block_types)
+
+ if isinstance(transformer_layers_per_block, int):
+ transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ res = 2 ** i
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block[i],
+ transformer_layers_per_block=transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ num_attention_heads=num_attention_heads[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlock3DCrossAttn":
+ self.mid_block = UNetMidBlock3DCrossAttn(
+ transformer_layers_per_block=transformer_layers_per_block[-1],
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ num_attention_heads=num_attention_heads[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
+ raise ValueError("UNetMidBlock2DSimpleCrossAttn not supported")
+
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_num_attention_heads = list(reversed(num_attention_heads))
+ reversed_layers_per_block = list(reversed(layers_per_block))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ res = 2 ** (len(up_block_types) - 1 - i)
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=reversed_layers_per_block[i] + 1,
+ transformer_layers_per_block=reversed_transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ num_attention_heads=reversed_num_attention_heads[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+
+ self.conv_act = get_activation(act_fn)
+
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+
+ self.conv_out = Conv3d(block_out_channels[0], out_channels, kernel_size=conv_out_kernel,
+ padding=conv_out_padding)
+
+ def temporal_parameters(self) -> list:
+ output = []
+ all_blocks = self.down_blocks + self.up_blocks + [self.mid_block]
+ for block in all_blocks:
+ output.extend(block.temporal_parameters())
+ return output
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ return self.get_attn_processors(include_temporal_layers=False)
+
+ def get_attn_processors(self, include_temporal_layers=True) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+
+ if not include_temporal_layers:
+ if 'temporal' in name:
+ return processors
+
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]],
+ include_temporal_layers=False):
+ r"""
+ Sets the attention processor to use to compute attention.
+
+ Parameters:
+ processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ for **all** `Attention` layers.
+
+ If `processor` is a dict, the key needs to define the path to the corresponding cross attention
+ processor. This is strongly recommended when setting trainable attention processors.
+
+ """
+ count = len(self.get_attn_processors(include_temporal_layers=include_temporal_layers).keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+
+ if not include_temporal_layers:
+ if "temporal" in name:
+ return
+
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module splits the input tensor in slices to compute attention in
+ several steps. This is useful for saving some memory in exchange for a small decrease in speed.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
+ `"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ enable_temporal_attentions: bool = True
+ ) -> Union[UNet3DConditionOutput, Tuple]:
+ r"""
+ The [`UNet2DConditionModel`] forward method.
+
+ Args:
+ sample (`torch.FloatTensor`):
+ The noisy input tensor with the following shape `(batch, channel, height, width)`.
+ timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
+ encoder_hidden_states (`torch.FloatTensor`):
+ The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
+ encoder_attention_mask (`torch.Tensor`):
+ A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
+ `True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
+ which adds large negative values to the attention scores corresponding to "discard" tokens.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
+ tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
+ added_cond_kwargs: (`dict`, *optional*):
+ A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
+ are passed along to the UNet blocks.
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
+ a `tuple` is returned where the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2 ** self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # ensure attention_mask is a bias, and give it a singleton query_tokens dimension
+ # expects mask of shape:
+ # [batch, key_tokens]
+ # adds singleton query_tokens dimension:
+ # [batch, 1, key_tokens]
+ # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
+ # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
+ # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
+ if attention_mask is not None:
+ # assume that mask is expressed as:
+ # (1 = keep, 0 = discard)
+ # convert mask into a bias that can be added to attention scores:
+ # (keep = +0, discard = -10000.0)
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # convert encoder_attention_mask to a bias the same way we do for attention_mask
+ if encoder_attention_mask is not None:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=sample.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+ aug_emb = None
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # there might be better ways to encapsulate this.
+ class_labels = class_labels.to(dtype=sample.dtype)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ if self.config.addition_embed_type == "text":
+ aug_emb = self.add_embedding(encoder_hidden_states)
+ elif self.config.addition_embed_type == "text_image":
+ # Kandinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+
+ image_embs = added_cond_kwargs.get("image_embeds")
+ text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
+ aug_emb = self.add_embedding(text_embs, image_embs)
+ elif self.config.addition_embed_type == "text_time":
+ if "text_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
+ )
+ text_embeds = added_cond_kwargs.get("text_embeds")
+ if "time_ids" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
+ )
+ time_ids = added_cond_kwargs.get("time_ids")
+ time_embeds = self.add_time_proj(time_ids.flatten())
+ time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
+
+ add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
+ add_embeds = add_embeds.to(emb.dtype)
+ aug_emb = self.add_embedding(add_embeds)
+ elif self.config.addition_embed_type == "image":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ aug_emb = self.add_embedding(image_embs)
+ elif self.config.addition_embed_type == "image_hint":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ hint = added_cond_kwargs.get("hint")
+ aug_emb, hint = self.add_embedding(image_embs, hint)
+ sample = torch.cat([sample, hint], dim=1)
+
+ emb = emb + aug_emb if aug_emb is not None else emb
+
+ if self.time_embed_act is not None:
+ emb = self.time_embed_act(emb)
+
+ if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
+ # Kadinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(image_embeds)
+ # 2. pre-process
+
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ upsample_size=upsample_size,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet3DConditionOutput(sample=sample)
+
+ @classmethod
+ def from_pretrained_spatial(cls, pretrained_model_path, subfolder=None):
+
+ import os
+ import json
+
+ if subfolder is not None:
+ pretrained_model_path = os.path.join(pretrained_model_path, subfolder)
+
+ config_file = os.path.join(pretrained_model_path, 'config.json')
+
+ with open(config_file, "r") as f:
+ config = json.load(f)
+
+ config["_class_name"] = "UNet3DConditionModel"
+
+ config["down_block_types"] = [
+ "DownBlock3D",
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ ]
+ config["up_block_types"] = [
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ "UpBlock3D"
+ ]
+
+ config["mid_block_type"] = "UNetMidBlock3DCrossAttn"
+
+ model = cls.from_config(config)
+
+ model_files = [
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.bin'),
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.safetensors')
+ ]
+
+ model_file = None
+
+ for fp in model_files:
+ if os.path.exists(fp):
+ model_file = fp
+
+ if not model_file:
+ raise RuntimeError(f"{model_file} does not exist")
+
+ state_dict = torch.load(model_file, map_location="cpu")
+
+ model.load_state_dict(state_dict, strict=False)
+
+ return model
diff --git a/Hotshot-XL/hotshot_xl/models/unet_blocks.py b/Hotshot-XL/hotshot_xl/models/unet_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..e642d4f8b56600b58238fdb7a243fb1e360a621d
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/unet_blocks.py
@@ -0,0 +1,740 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Add temporal transformers to unet blocks
+
+import torch
+from torch import nn
+
+from .transformer_3d import Transformer3DModel
+from .resnet import Downsample3D, ResnetBlock3D, Upsample3D
+from .transformer_temporal import TransformerTemporal
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ downsample_type=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock3D":
+ return DownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D")
+ return CrossAttnDownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ upsample_type=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock3D":
+ return UpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D")
+ return CrossAttnUpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock3DCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ in_channels // num_attention_heads,
+ in_channels=in_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ return []
+
+
+class CrossAttnDownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if temporal_attention and enable_temporal_attentions:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class DownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states, encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class CrossAttnUpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ upsample_size=None,
+ cross_attention_kwargs=None,
+ attention_mask=None,
+ enable_temporal_attentions: bool = True
+ ):
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False,
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class UpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, encoder_hidden_states=None,
+ enable_temporal_attentions: bool = True):
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states) if enable_temporal_attentions and temporal_attention is not None else hidden_states
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__init__.py b/Hotshot-XL/hotshot_xl/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-38.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..837f54d8354052949995f9225e3a0a32ee1f51a2
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-39.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..608c366d4065f2f3a3f9a30f6335dc2d2461dea8
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-38.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e486c8b99469f44e8ac918d8ca17a609ba526a80
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-39.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cc024d7d8ec3a1a56e5c4151dca7ba563b23730c
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-38.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84177377f32b1f5ecfca5aae0676e7429708f087
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-39.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..367a8a1151fa42951fbceff2ea6bfb17859716cd
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..b084688662309ef71b429d20a5edfc9c8f494f9f
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
@@ -0,0 +1,1389 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Controlnet Pipeline to work temporally
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, ControlNetModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.utils.torch_utils import randn_tensor, is_compiled_module
+
+from ..models.unet import UNet3DConditionModel
+
+from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
+from einops import rearrange
+from tqdm import tqdm
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+ >>> from diffusers import ControlNetModel
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL",
+ ... controlnet=ControlNetModel.from_pretrained("diffusers/controlnet-canny-sdxl-1.0")
+ ... )
+
+ >>> def canny(image):
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> return Image.fromarray(image)
+
+ >>> # assuming you have 8 keyframes in current directory...
+
+ >>> keyframes = [f"image_{i}.jpg" for i in range(8)]
+ >>> control_images = [canny(Image.open(fp)) for fp in keyframes]
+
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor",
+ ... controlnet_conditioning_scale=0.7,
+ ... control_images=control_images
+ ).video
+ ```
+"""
+class HotshotXLControlNetPipeline(
+ DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
+ implemented for all pipelines (downloading, saving, running on a particular device, etc.).
+
+ The pipeline also inherits the following loading methods:
+ - [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
+ - [`loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
+ - [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
+ text_encoder ([`~transformers.CLIPTextModel`]):
+ Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
+ text_encoder_2 ([`~transformers.CLIPTextModelWithProjection`]):
+ Second frozen text-encoder
+ ([laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)).
+ tokenizer ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ tokenizer_2 ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ unet ([`UNet3DConditionModel`]):
+ A `UNet3DConditionModel` to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the `unet` during the denoising process. If you set multiple
+ ControlNets as a list, the outputs from each ControlNet are added together to create one combined
+ additional conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
+ Whether the negative prompt embeddings should always be set to 0. Also see the config of
+ `stabilityai/stable-diffusion-xl-base-1-0`.
+ add_watermarker (`bool`, *optional*):
+ Whether to use the [invisible_watermark](https://github.com/ShieldMnt/invisible-watermark/) library to
+ watermark output images. If not defined, it defaults to `True` if the package is installed; otherwise no
+ watermarker is used.
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
+ self.control_image_processor = VaeImageProcessor(
+ vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
+ )
+
+ self.watermark = None
+
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ control_guidance_start=0.0,
+ control_guidance_end=1.0,
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+
+ assert len(control_images) == video_length
+ # for image in control_images:
+ # self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ ...
+ # todo
+ #
+ # if not isinstance(image, list):
+ # raise TypeError("For multiple controlnets: `image` must be type `list`")
+ #
+ # # When `image` is a nested list:
+ # # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ # elif any(isinstance(i, list) for i in image):
+ # raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ # elif len(image) != len(self.controlnet.nets):
+ # raise ValueError(
+ # f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets."
+ # )
+ #
+ # for image_ in image:
+ # self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ if not isinstance(control_guidance_start, (tuple, list)):
+ control_guidance_start = [control_guidance_start]
+
+ if not isinstance(control_guidance_end, (tuple, list)):
+ control_guidance_end = [control_guidance_end]
+
+ if len(control_guidance_start) != len(control_guidance_end):
+ raise ValueError(
+ f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
+ )
+
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if len(control_guidance_start) != len(self.controlnet.nets):
+ raise ValueError(
+ f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
+ )
+
+ for start, end in zip(control_guidance_start, control_guidance_end):
+ if start >= end:
+ raise ValueError(
+ f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
+ )
+ if start < 0.0:
+ raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
+ if end > 1.0:
+ raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_np = isinstance(image, np.ndarray)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+ image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
+
+ if (
+ not image_is_pil
+ and not image_is_tensor
+ and not image_is_np
+ and not image_is_pil_list
+ and not image_is_tensor_list
+ and not image_is_np_list
+ ):
+ raise TypeError(
+ f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ else:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_images(
+ self,
+ images,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ images_pre_processed = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+
+ images_pre_processed = torch.cat(images_pre_processed, dim=0)
+
+ repeat_factor = [1] * len(images_pre_processed.shape)
+ repeat_factor[0] = batch_size * num_images_per_prompt
+ images_pre_processed = images_pre_processed.repeat(*repeat_factor)
+
+ images = images_pre_processed.unsqueeze(0)
+
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+
+ #image = image.repeat_interleave(repeat_by, dim=0)
+
+ images = images.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ repeat_factor = [1] * len(images.shape)
+ repeat_factor[0] = 2
+ images = images.repeat(*repeat_factor)
+
+ return images
+
+ # def prepare_images(self,
+ # images: list,
+ # width,
+ # height,
+ # batch_size,
+ # num_images_per_prompt,
+ # device,
+ # dtype,
+ # do_classifier_free_guidance=False,
+ # guess_mode=False):
+ #
+ # images = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+ #
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+ #
+ # image = image.repeat_interleave(repeat_by, dim=0)
+ #
+ # image = image.to(device=device, dtype=dtype)
+ #
+ # if do_classifier_free_guidance and not guess_mode:
+ # image = torch.cat([image] * 2)
+ #
+ # return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ #shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._get_add_time_ids
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ control_images: List[PIL.Image.Image] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ guess_mode: bool = False,
+ control_guidance_start: Union[float, List[float]] = 0.0,
+ control_guidance_end: Union[float, List[float]] = 1.0,
+ original_size: Tuple[int, int] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Tuple[int, int] = None,
+ negative_original_size: Optional[Tuple[int, int]] = None,
+ negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
+ negative_target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ The call function to the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
+ `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
+ specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
+ accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
+ and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
+ `init`, images must be passed as a list such that each element of the list can be correctly batched for
+ input to a single ControlNet.
+ height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ A higher guidance scale value encourages the model to generate images closely linked to the text
+ `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. If not defined, you need to
+ pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. This is sent to `tokenizer_2`
+ and `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
+ generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor is generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
+ provided, text embeddings are generated from the `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, pooled text embeddings are generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs (prompt
+ weighting). If not provided, pooled `negative_prompt_embeds` are generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between `PIL.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that calls every `callback_steps` steps during inference. The function is called with the
+ following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function is called. If not specified, the callback is called at
+ every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
+ [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
+ the corresponding scale as a list.
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ The ControlNet encoder tries to recognize the content of the input image even if you remove all
+ prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
+ control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
+ The percentage of total steps at which the ControlNet starts applying.
+ control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The percentage of total steps at which the ControlNet stops applying.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a specific image resolution. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a target image resolution. It should be as same
+ as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
+ otherwise a `tuple` is returned containing the output images.
+ """
+
+
+ if video_length > 1 and num_images_per_prompt > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ # align format for control guidance
+ if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
+ control_guidance_start = len(control_guidance_end) * [control_guidance_start]
+ elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
+ control_guidance_end = len(control_guidance_start) * [control_guidance_end]
+ elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
+ mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
+ control_guidance_start, control_guidance_end = mult * [control_guidance_start], mult * [
+ control_guidance_end
+ ]
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ controlnet_conditioning_scale,
+ control_guidance_start,
+ control_guidance_end,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt,
+ prompt_2,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+
+ assert len(control_images) == video_length * batch_size
+
+ images = self.prepare_images(
+ images=control_images,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ height, width = images.shape[-2:]
+ elif isinstance(controlnet, MultiControlNetModel):
+
+ raise Exception("not supported yet")
+
+ # images = []
+ #
+ # for image_ in control_images:
+ # image_ = self.prepare_image(
+ # image=image_,
+ # width=width,
+ # height=height,
+ # batch_size=batch_size * num_images_per_prompt,
+ # num_images_per_prompt=num_images_per_prompt,
+ # device=device,
+ # dtype=controlnet.dtype,
+ # do_classifier_free_guidance=do_classifier_free_guidance,
+ # guess_mode=guess_mode,
+ # )
+ #
+ # images.append(image_)
+ #
+ # image = images
+ # height, width = image[0].shape[-2:]
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7.1 Create tensor stating which controlnets to keep
+ controlnet_keep = []
+ for i in range(len(timesteps)):
+ keeps = [
+ 1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
+ for s, e in zip(control_guidance_start, control_guidance_end)
+ ]
+ controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
+
+ # 7.2 Prepare added time ids & embeddings
+ # if isinstance(image, list):
+ # original_size = original_size or image[0].shape[-2:]
+ # else:
+ original_size = original_size or images.shape[-2:]
+ target_size = target_size or (height, width)
+
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ if negative_original_size is not None and negative_target_size is not None:
+ negative_add_time_ids = self._get_add_time_ids(
+ negative_original_size,
+ negative_crops_coords_top_left,
+ negative_target_size,
+ dtype=prompt_embeds.dtype,
+ )
+ else:
+ negative_add_time_ids = add_time_ids
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+
+ images = rearrange(images, "b f c h w -> (b f) c h w")
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ control_model_input = latents
+ control_model_input = self.scheduler.scale_model_input(control_model_input, t)
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ controlnet_added_cond_kwargs = {
+ "text_embeds": add_text_embeds.chunk(2)[1],
+ "time_ids": add_time_ids.chunk(2)[1],
+ }
+ else:
+ control_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+ controlnet_added_cond_kwargs = added_cond_kwargs
+
+ if isinstance(controlnet_keep[i], list):
+ cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
+ else:
+ controlnet_cond_scale = controlnet_conditioning_scale
+ if isinstance(controlnet_cond_scale, list):
+ controlnet_cond_scale = controlnet_cond_scale[0]
+ cond_scale = controlnet_cond_scale * controlnet_keep[i]
+
+
+ # this will be non interlaced when arranged!
+ control_model_input = rearrange(control_model_input, "b c f h w -> (b f) c h w")
+ # if we chunked this by 2 - the top 8 frames will be positive for cfg
+ # the bottom half will be negative for cfg...
+
+ if video_length > 1:
+ # use repeat_interleave as we need to match the rearrangement above.
+
+ controlnet_prompt_embeds = controlnet_prompt_embeds.repeat_interleave(video_length, dim=0)
+ controlnet_added_cond_kwargs = {
+ "text_embeds": controlnet_added_cond_kwargs['text_embeds'].repeat_interleave(video_length, dim=0),
+ "time_ids": controlnet_added_cond_kwargs['time_ids'].repeat_interleave(video_length, dim=0)
+ }
+
+ # if type(image) is list:
+ # image = torch.cat(image, dim=0)
+
+ # todo - check if video_length > 1 this needs to produce num_frames * batch_size samples...
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ control_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=images,
+ conditioning_scale=cond_scale,
+ guess_mode=guess_mode,
+ added_cond_kwargs=controlnet_added_cond_kwargs,
+ return_dict=False,
+ )
+
+ for j, sample in enumerate(down_block_res_samples):
+ down_block_res_samples[j] = rearrange(sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ mid_block_res_sample = rearrange(mid_block_res_sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions=video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ # if not output_type == "latent":
+ # # make sure the VAE is in float32 mode, as it overflows in float16
+ # needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
+ #
+ # if needs_upcasting:
+ # self.upcast_vae()
+ # latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+ #
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ #
+ # # cast back to fp16 if needed
+ # if needs_upcasting:
+ # self.vae.to(dtype=torch.float16)
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.load_lora_weights
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.save_lora_weights
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = True,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._remove_text_encoder_monkey_patch
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_pipeline.py b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c3b41da67eacee21c8cb192de343e47d5fe30d0
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_pipeline.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Pipeline to work temporally
+
+
+import os
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL
+from hotshot_xl.models.unet import UNet3DConditionModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.utils.torch_utils import randn_tensor
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from tqdm import tqdm
+from einops import repeat, rearrange
+from diffusers.utils import deprecate, logging
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL"
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor"
+ ).video
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
+
+
+class HotshotXLPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *LoRA*: [`HotshotPipelineXL.load_lora_weights`]
+ - *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
+
+ as well as the following saving methods:
+ - *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion XL uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([` CLIPTextModelWithProjection`]):
+ Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
+ specifically the
+ [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
+ variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`CLIPTokenizer`):
+ Second Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet3DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ scheduler=scheduler,
+ )
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.default_sample_size = self.unet.config.sample_size
+ self.watermark = None
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ num_images_per_prompt: Optional[int] = 1,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ denoising_end (`float`, *optional*):
+ When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
+ completed before it is intentionally prematurely terminated. As a result, the returned sample will
+ still retain a substantial amount of noise as determined by the discrete timesteps selected by the
+ scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
+ "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
+ Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
+ of a plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.7):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+
+ Examples:
+
+ Returns:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] or `tuple`:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ if video_length > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ # 0. Default height and width to unet
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Prepare added time ids & embeddings
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ # todo - negative_original_size from latest diffusers for cfg
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ # 7.1 Apply denoising_end
+ if denoising_end is not None and type(denoising_end) == float and denoising_end > 0 and denoising_end < 1:
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (denoising_end * self.scheduler.config.num_train_timesteps)
+ )
+ )
+ num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
+ timesteps = timesteps[:num_inference_steps]
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions= video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # if not output_type == "latent":
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # apply watermark if available
+ # if self.watermark is not None:
+ # image = self.watermark.apply_watermark(image)
+
+ #image = self.image_processor.postprocess(image, output_type=output_type)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ #
+ # # Offload last model to CPU
+ # if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ # self.final_offload_hook.offload()
+ #
+ # if not return_dict:
+ # return (image,)
+ #
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/hotshot_xl/utils.py b/Hotshot-XL/hotshot_xl/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7660c2a756ecae141333a7081ea358549db6ba6
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/utils.py
@@ -0,0 +1,213 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Union
+from io import BytesIO
+import PIL
+from PIL import ImageSequence, Image
+import requests
+import os
+
+def get_image(img_path) -> PIL.Image.Image:
+ if img_path.startswith("http"):
+ return PIL.Image.open(requests.get(img_path, stream=True).raw)
+ if os.path.exists(img_path):
+ return Image.open(img_path)
+ raise Exception("File not found")
+
+def images_to_gif_bytes(images: List, duration: int = 1000) -> bytes:
+ with BytesIO() as output_buffer:
+ # Save the first image
+ images[0].save(output_buffer,
+ format='GIF',
+ save_all=True,
+ append_images=images[1:],
+ duration=duration,
+ loop=0) # 0 means the GIF will loop indefinitely
+
+ # Get the byte array from the buffer
+ gif_bytes = output_buffer.getvalue()
+
+ return gif_bytes
+
+
+def save_as_gif(images: List, file_path: str, duration: int = 1000):
+ with open(file_path, "wb") as f:
+ f.write(images_to_gif_bytes(images, duration))
+
+def scale_aspect_fill(img, new_width, new_height):
+ new_width = int(new_width)
+ new_height = int(new_height)
+
+ original_width, original_height = img.size
+ ratio_w = float(new_width) / original_width
+ ratio_h = float(new_height) / original_height
+
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(original_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(original_width * ratio_h)
+ resize_height = new_height
+
+ img_resized = img.resize((resize_width, resize_height), Image.LANCZOS)
+
+ # Calculate cropping boundaries and do crop
+ left = (resize_width - new_width) / 2
+ top = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ bottom = (resize_height + new_height) / 2
+
+ img_cropped = img_resized.crop((left, top, right, bottom))
+
+ return img_cropped
+
+def extract_gif_frames_from_midpoint(image: Union[str, PIL.Image.Image], fps: int=8, target_duration: int=1000) -> list:
+ # Load the GIF
+ image = get_image(image) if type(image) is str else image
+
+ frames = []
+
+ estimated_frame_time = None
+
+ # some gifs contain the duration - others don't
+ # so if there is a duration we will grab it otherwise we will fall back
+
+ for frame in ImageSequence.Iterator(image):
+
+ frames.append(frame.copy())
+ if 'duration' in frame.info:
+ frame_info_duration = frame.info['duration']
+ if frame_info_duration > 0:
+ estimated_frame_time = frame_info_duration
+
+ if estimated_frame_time is None:
+ if len(frames) <= 16:
+ # assume it's 8fps
+ estimated_frame_time = 1000 // 8
+ else:
+ # assume it's 15 fps
+ estimated_frame_time = 70
+
+ if len(frames) < fps:
+ raise ValueError(f"fps of {fps} is too small for this gif as it only has {len(frames)} frames.")
+
+ skip = len(frames) // fps
+ upper_bound_index = len(frames) - 1
+
+ best_indices = [x for x in range(0, len(frames), skip)][:fps]
+ offset = int(upper_bound_index - best_indices[-1]) // 2
+ best_indices = [x + offset for x in best_indices]
+ best_duration = (best_indices[-1] - best_indices[0]) * estimated_frame_time
+
+ while True:
+
+ skip -= 1
+
+ if skip == 0:
+ break
+
+ indices = [x for x in range(0, len(frames), skip)][:fps]
+
+ # center the indices, so we sample the middle of the gif...
+ offset = int(upper_bound_index - indices[-1]) // 2
+ if offset == 0:
+ # can't shift
+ break
+ indices = [x + offset for x in indices]
+
+ # is the new duration closer to the target than last guess?
+ duration = (indices[-1] - indices[0]) * estimated_frame_time
+ if abs(duration - target_duration) > abs(best_duration - target_duration):
+ break
+
+ best_indices = indices
+ best_duration = duration
+
+ return [frames[index] for index in best_indices]
+
+def get_crop_coordinates(old_size: tuple, new_size: tuple) -> tuple:
+ """
+ Calculate the crop coordinates after scaling an image to fit a new size.
+
+ :param old_size: tuple of the form (width, height) representing the original size of the image.
+ :param new_size: tuple of the form (width, height) representing the desired size after scaling.
+ :return: tuple of the form (left, upper, right, lower) representing the normalized crop coordinates.
+ """
+ # Check if the input tuples have the right form (width, height)
+ if not (isinstance(old_size, tuple) and isinstance(new_size, tuple) and
+ len(old_size) == 2 and len(new_size) == 2):
+ raise ValueError("old_size and new_size should be tuples of the form (width, height)")
+
+ # Extract the width and height from the old and new sizes
+ old_width, old_height = old_size
+ new_width, new_height = new_size
+
+ # Calculate the ratios for width and height
+ ratio_w = float(new_width) / old_width
+ ratio_h = float(new_height) / old_height
+
+ # Determine which dimension is fixed (width or height)
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(old_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(old_width * ratio_h)
+ resize_height = new_height
+
+ # Calculate cropping boundaries in the resized image space
+ left = (resize_width - new_width) / 2
+ upper = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ lower = (resize_height + new_height) / 2
+
+ # Normalize the cropping coordinates
+
+ # Return the normalized coordinates as a tuple
+ return (left, upper, right, lower)
+
+aspect_ratio_to_1024_map = {
+ "0.42": [640, 1536],
+ "0.57": [768, 1344],
+ "0.68": [832, 1216],
+ "1.00": [1024, 1024],
+ "1.46": [1216, 832],
+ "1.75": [1344, 768],
+ "2.40": [1536, 640]
+}
+
+res_to_aspect_map = {
+ 1024: aspect_ratio_to_1024_map,
+ 512: {key: [value[0] // 2, value[1] // 2] for key, value in aspect_ratio_to_1024_map.items()},
+}
+
+def best_aspect_ratio(aspect_ratio: float, resolution: int):
+
+ map = res_to_aspect_map[resolution]
+
+ d = 99999999
+ res = None
+ for key, value in map.items():
+ ar = value[0] / value[1]
+ diff = abs(aspect_ratio - ar)
+ if diff < d:
+ d = diff
+ res = value
+
+ ar = res[0] / res[1]
+ return f"{ar:.2f}", res
\ No newline at end of file
diff --git a/Hotshot-XL/inference.py b/Hotshot-XL/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..5394321cd68466e8ef433d4afedb658c2dcccc85
--- /dev/null
+++ b/Hotshot-XL/inference.py
@@ -0,0 +1,223 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+
+sys.path.append("/")
+import os
+import argparse
+import torch
+from hotshot_xl.pipelines.hotshot_xl_pipeline import HotshotXLPipeline
+from hotshot_xl.pipelines.hotshot_xl_controlnet_pipeline import HotshotXLControlNetPipeline
+from hotshot_xl.models.unet import UNet3DConditionModel
+import torchvision.transforms as transforms
+from einops import rearrange
+from hotshot_xl.utils import save_as_gif, extract_gif_frames_from_midpoint, scale_aspect_fill
+from torch import autocast
+from diffusers import ControlNetModel
+from contextlib import contextmanager
+from diffusers.schedulers.scheduling_euler_ancestral_discrete import EulerAncestralDiscreteScheduler
+from diffusers.schedulers.scheduling_euler_discrete import EulerDiscreteScheduler
+
+SCHEDULERS = {
+ 'EulerAncestralDiscreteScheduler': EulerAncestralDiscreteScheduler,
+ 'EulerDiscreteScheduler': EulerDiscreteScheduler,
+ 'default': None,
+ # add more here
+}
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Hotshot-XL inference")
+ parser.add_argument("--pretrained_path", type=str, default="hotshotco/Hotshot-XL")
+ parser.add_argument("--xformers", action="store_true")
+ parser.add_argument("--spatial_unet_base", type=str)
+ parser.add_argument("--lora", type=str)
+ parser.add_argument("--output", type=str, required=True)
+ parser.add_argument("--steps", type=int, default=30)
+ parser.add_argument("--prompt", type=str,
+ default="a bulldog in the captains chair of a spaceship, hd, high quality")
+ parser.add_argument("--negative_prompt", type=str, default="blurry")
+ parser.add_argument("--seed", type=int, default=455)
+ parser.add_argument("--width", type=int, default=672)
+ parser.add_argument("--height", type=int, default=384)
+ parser.add_argument("--target_width", type=int, default=512)
+ parser.add_argument("--target_height", type=int, default=512)
+ parser.add_argument("--og_width", type=int, default=1920)
+ parser.add_argument("--og_height", type=int, default=1080)
+ parser.add_argument("--video_length", type=int, default=8)
+ parser.add_argument("--video_duration", type=int, default=1000)
+ parser.add_argument('--scheduler', type=str, default='EulerAncestralDiscreteScheduler',
+ help='Name of the scheduler to use')
+
+ parser.add_argument("--control_type", type=str, default=None, choices=["depth", "canny"])
+ parser.add_argument("--controlnet_conditioning_scale", type=float, default=0.7)
+ parser.add_argument("--control_guidance_start", type=float, default=0.0)
+ parser.add_argument("--control_guidance_end", type=float, default=1.0)
+ parser.add_argument("--gif", type=str, default=None)
+ parser.add_argument("--precision", type=str, default='f16', choices=[
+ 'f16', 'f32', 'bf16'
+ ])
+ parser.add_argument("--autocast", type=str, default=None, choices=[
+ 'f16', 'bf16'
+ ])
+
+ return parser.parse_args()
+
+
+to_pil = transforms.ToPILImage()
+
+
+def to_pil_images(video_frames: torch.Tensor, output_type='pil'):
+ video_frames = rearrange(video_frames, "b c f w h -> b f c w h")
+ bsz = video_frames.shape[0]
+ images = []
+ for i in range(bsz):
+ video = video_frames[i]
+ for j in range(video.shape[0]):
+ if output_type == "pil":
+ images.append(to_pil(video[j]))
+ else:
+ images.append(video[j])
+ return images
+
+@contextmanager
+def maybe_auto_cast(data_type):
+ if data_type:
+ with autocast("cuda", dtype=data_type):
+ yield
+ else:
+ yield
+
+
+def main():
+ args = parse_args()
+
+ if args.control_type and not args.gif:
+ raise ValueError("Controlnet specified but you didn't specify a gif!")
+
+ if args.gif and not args.control_type:
+ print("warning: gif was specified but no control type was specified. gif will be ignored.")
+
+ output_dir = os.path.dirname(args.output)
+ if output_dir:
+ os.makedirs(output_dir, exist_ok=True)
+
+ device = torch.device("cuda")
+
+ control_net_model_pretrained_path = None
+ if args.control_type:
+ control_type_to_model_map = {
+ "canny": "diffusers/controlnet-canny-sdxl-1.0",
+ "depth": "diffusers/controlnet-depth-sdxl-1.0",
+ }
+ control_net_model_pretrained_path = control_type_to_model_map[args.control_type]
+
+ data_type = torch.float32
+
+ if args.precision == 'f16':
+ data_type = torch.half
+ elif args.precision == 'f32':
+ data_type = torch.float32
+ elif args.precision == 'bf16':
+ data_type = torch.bfloat16
+
+ pipe_line_args = {
+ "torch_dtype": data_type,
+ "use_safetensors": True
+ }
+
+ PipelineClass = HotshotXLPipeline
+
+ if control_net_model_pretrained_path:
+ PipelineClass = HotshotXLControlNetPipeline
+ pipe_line_args['controlnet'] = \
+ ControlNetModel.from_pretrained(control_net_model_pretrained_path, torch_dtype=data_type)
+
+ if args.spatial_unet_base:
+
+ unet_3d = UNet3DConditionModel.from_pretrained(args.pretrained_path, subfolder="unet").to(device)
+
+ unet = UNet3DConditionModel.from_pretrained_spatial(args.spatial_unet_base).to(device)
+
+ temporal_layers = {}
+ unet_3d_sd = unet_3d.state_dict()
+
+ for k, v in unet_3d_sd.items():
+ if 'temporal' in k:
+ temporal_layers[k] = v
+
+ unet.load_state_dict(temporal_layers, strict=False)
+
+ pipe_line_args['unet'] = unet
+
+ del unet_3d_sd
+ del unet_3d
+ del temporal_layers
+
+ pipe = PipelineClass.from_pretrained(args.pretrained_path, **pipe_line_args).to(device)
+
+ if args.lora:
+ pipe.load_lora_weights(args.lora)
+
+ SchedulerClass = SCHEDULERS[args.scheduler]
+ if SchedulerClass is not None:
+ pipe.scheduler = SchedulerClass.from_config(pipe.scheduler.config)
+
+ if args.xformers:
+ pipe.enable_xformers_memory_efficient_attention()
+
+ generator = torch.Generator().manual_seed(args.seed) if args.seed else None
+
+ autocast_type = None
+ if args.autocast == 'f16':
+ autocast_type = torch.half
+ elif args.autocast == 'bf16':
+ autocast_type = torch.bfloat16
+
+ kwargs = {}
+
+ if args.gif and type(pipe) is HotshotXLControlNetPipeline:
+ kwargs['control_images'] = [
+ scale_aspect_fill(img, args.width, args.height).convert("RGB") \
+ for img in
+ extract_gif_frames_from_midpoint(args.gif, fps=args.video_length, target_duration=args.video_duration)
+ ]
+ kwargs['controlnet_conditioning_scale'] = args.controlnet_conditioning_scale
+ kwargs['control_guidance_start'] = args.control_guidance_start
+ kwargs['control_guidance_end'] = args.control_guidance_end
+
+ with maybe_auto_cast(autocast_type):
+
+ images = pipe(args.prompt,
+ negative_prompt=args.negative_prompt,
+ width=args.width,
+ height=args.height,
+ original_size=(args.og_width, args.og_height),
+ target_size=(args.target_width, args.target_height),
+ num_inference_steps=args.steps,
+ video_length=args.video_length,
+ generator=generator,
+ output_type="tensor", **kwargs).videos
+
+ images = to_pil_images(images, output_type="pil")
+
+ if args.video_length > 1:
+ save_as_gif(images, args.output, duration=args.video_duration // args.video_length)
+ else:
+ images[0].save(args.output, format='JPEG', quality=95)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Hotshot-XL/output.gif b/Hotshot-XL/output.gif
new file mode 100644
index 0000000000000000000000000000000000000000..4714db5a6ca255fa131def1461c9a90561863260
--- /dev/null
+++ b/Hotshot-XL/output.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cd22cd80f6cad88aa326846d6bf954f01044fce917229bdbc40e365493f3a161
+size 1606177
diff --git a/Hotshot-XL/requirements.txt b/Hotshot-XL/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..17c3d6faa34794c966483520aa46af2d0434150c
--- /dev/null
+++ b/Hotshot-XL/requirements.txt
@@ -0,0 +1,62 @@
+accelerate==0.23.0
+appdirs==1.4.4
+certifi==2023.7.22
+charset-normalizer==3.3.0
+click==8.1.7
+cmake==3.27.6
+decorator==4.4.2
+diffusers==0.21.4
+docker-pycreds==0.4.0
+einops==0.7.0
+filelock==3.12.4
+fsspec==2023.9.2
+gitdb==4.0.10
+GitPython==3.1.37
+huggingface-hub==0.16.4
+idna==3.4
+imageio==2.31.5
+imageio-ffmpeg==0.4.9
+importlib-metadata==6.8.0
+Jinja2==3.1.2
+lit==17.0.2
+MarkupSafe==2.1.3
+moviepy==1.0.3
+mpmath==1.3.0
+networkx==3.1
+numpy==1.26.0
+nvidia-cublas-cu11==11.10.3.66
+nvidia-cuda-cupti-cu11==11.7.101
+nvidia-cuda-nvrtc-cu11==11.7.99
+nvidia-cuda-runtime-cu11==11.7.99
+nvidia-cudnn-cu11==8.5.0.96
+nvidia-cufft-cu11==10.9.0.58
+nvidia-curand-cu11==10.2.10.91
+nvidia-cusolver-cu11==11.4.0.1
+nvidia-cusparse-cu11==11.7.4.91
+nvidia-nccl-cu11==2.14.3
+nvidia-nvtx-cu11==11.7.91
+packaging==23.2
+pathtools==0.1.2
+Pillow==10.0.1
+proglog==0.1.10
+protobuf==4.24.3
+psutil==5.9.5
+PyYAML==6.0.1
+regex==2023.10.3
+requests==2.31.0
+safetensors==0.3.3
+sentry-sdk==1.31.0
+setproctitle==1.3.3
+six==1.16.0
+smmap==5.0.1
+sympy==1.12
+tokenizers==0.14.0
+torch==2.0.1
+torchvision==0.15.2
+tqdm==4.66.1
+transformers==4.34.0
+triton==2.0.0
+typing_extensions==4.8.0
+urllib3==2.0.6
+wandb==0.15.11
+zipp==3.17.0
diff --git a/Hotshot-XL/run.sh b/Hotshot-XL/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ae415b2bb41371edf8d5f0d63e0a2be501208069
--- /dev/null
+++ b/Hotshot-XL/run.sh
@@ -0,0 +1,2 @@
+python inference.py --prompt="village men and women in a hut" --output="2.gif"
+
diff --git a/Hotshot-XL/setup.py b/Hotshot-XL/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1a7f0ca65d590e0ded9cd0d8747826b60e24add
--- /dev/null
+++ b/Hotshot-XL/setup.py
@@ -0,0 +1,15 @@
+from setuptools import setup, find_packages
+
+setup(
+ name='hotshot_xl',
+ version='1.0',
+ packages=find_packages(include=['hotshot_xl*',]),
+ author="Natural Synthetics Inc",
+ install_requires=[
+ "torch>=2.0.1",
+ "torchvision>=0.15.2",
+ "diffusers>=0.21.4",
+ "transformers>=4.33.3",
+ "einops"
+ ],
+)
\ No newline at end of file
|
+
+### Varying frame rates & lengths (*Experimental*)
+By default, Hotshot-XL is trained to generate GIFs that are 1 second long with 8FPS. If you'd like to play with generating GIFs with varying frame rates and time lengths, you can try out the parameters `video_length` and `video_duration`.
+
+`video_length` sets the number of frames. The default value is 8.
+
+`video_duration` sets the runtime of the output gif in milliseconds. The default value is 1000.
+
+Please note that you should expect unstable/"jittery" results when modifying these parameters as the model was only trained with 1s videos @ 8fps. You'll be able to improve the stability of results for different time lengths and frame rates by [fine-tuning Hotshot-XL](#-fine-tuning). Please let us know if you do!
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.gif" \
+ --video_length=16 \
+ --video_duration=2000
+```
+
+### Spatial Layers Only
+Hotshot-XL is trained to generate GIFs alongside SDXL. If you'd like to generate just an image, you can simply set `video_length=1` in your inference call and the Hotshot-XL temporal layers will be ignored, as you'd expect.
+
+```
+python inference.py \
+ --prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
+ --output="output.jpg" \
+ --video_length=1
+```
+
+### Additional Notes
+
+#### Supported Aspect Ratios
+Hotshot-XL was trained at the following aspect ratios; to reliably generate GIFs outside the range of these aspect ratios, you will want to fine-tune Hotshot-XL with videos at the resolution of your desired aspect ratio.
+
+| Aspect Ratio | Size |
+|--------------|------|
+| 0.42 |320 x 768|
+| 0.57 |384 x 672|
+| 0.68 |416 x 608|
+| 1.00 |512 x 512|
+| 1.46 |608 x 416|
+| 1.75 |672 x 384|
+| 2.40 |768 x 320|
+
+
+# 💪 Fine-Tuning
+The following section relates to fine-tuning the Hotshot-XL temporal model with additional text/video pairs. If you're trying to generate GIFs of personalized concepts/subjects, we'd recommend not fine-tuning Hotshot-XL, but instead training your own SDXL based LORAs and [just loading those](#text-to-gif-with-personalized-loras).
+
+### Fine-Tuning Hotshot-XL
+
+#### Dataset Preparation
+
+The `fine_tune.py` script expects your samples to be structured like this:
+
+```
+fine_tune_dataset
+├── sample_001
+│ ├── 0.jpg
+│ ├── 1.jpg
+│ ├── 2.jpg
+...
+...
+│ ├── n.jpg
+│ └── prompt.txt
+```
+
+Each sample directory should contain your **n key frames** and a `prompt.txt` file which contains the prompt.
+The final checkpoint will be saved to `output_dir`.
+We've found it useful to send validation GIFs to [Weights & Biases](www.wandb.ai) every so often. If you choose to use validation with Weights & Biases, you can set how often this runs with the `validate_every_steps` parameter.
+
+```
+accelerate launch fine_tune.py \
+ --output_dir="" \
+ --data_dir="fine_tune_dataset" \
+ --report_to="wandb" \
+ --run_validation_at_start \
+ --resolution=512 \
+ --mixed_precision=fp16 \
+ --train_batch_size=4 \
+ --learning_rate=1.25e-05 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=1000 \
+ --save_n_steps=20 \
+ --validate_every_steps=50 \
+ --vae_b16 \
+ --gradient_checkpointing \
+ --noise_offset=0.05 \
+ --snr_gamma \
+ --test_prompts="man sits at a table in a cafe, he greets another man with a smile and a handshakes"
+```
+
+# 📝 Further work
+There are lots of ways we are excited about improving Hotshot-XL. For example:
+
+- [ ] Fine-Tuning Hotshot-XL at larger frame rates to create longer/higher frame-rate GIFs
+- [ ] Fine-Tuning Hotshot-XL at larger resolutions to create higher resolution GIFs
+- [ ] Training temporal layers for a latent upscaler to produce higher resolution GIFs
+- [ ] Training an image conditioned "frame prediction" model for more coherent, longer GIFs
+- [ ] Training temporal layers for a VAE to mitigate flickering/dithering in outputs
+- [ ] Supporting Multi-ControlNet for greater control over GIF generation
+- [ ] Training & integrating different ControlNet models for further control over GIF generation (finer facial expression control would be very cool)
+- [ ] Moving Hotshot-XL into [AITemplate](https://github.com/facebookincubator/AITemplate) for faster inference times
+
+We 💗 contributions from the open-source community! Please let us know in the issues or PRs if you're interested in working on these improvements or anything else!
+
+# 🙏 Acknowledgements
+Text-to-Video models are improving quickly and the development of Hotshot-XL has been greatly inspired by the following amazing works and teams:
+
+- [SDXL](https://stability.ai/stable-diffusion)
+- [Align Your Latents](https://research.nvidia.com/labs/toronto-ai/VideoLDM/)
+- [Make-A-Video](https://makeavideo.studio/)
+- [AnimateDiff](https://animatediff.github.io/)
+- [Imagen Video](https://imagen.research.google/video/)
+
+We hope that releasing this model/codebase helps the community to continue pushing these creative tools forward in an open and responsible way.
diff --git a/Hotshot-XL/build/lib/hotshot_xl/__init__.py b/Hotshot-XL/build/lib/hotshot_xl/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..090de024570c67f7182c8e5b214c81f3aaadaf6e
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/__init__.py
@@ -0,0 +1,25 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Union
+
+import numpy as np
+import torch
+
+# don't remove these imports - they are needed to load from pretrain.
+from diffusers.models.modeling_utils import ModelMixin
+from .models.unet import UNet3DConditionModel
+
+from diffusers.utils import (
+ BaseOutput,
+)
+
+@dataclass
+class HotshotPipelineXLOutput(BaseOutput):
+ videos: Union[torch.Tensor, np.ndarray]
\ No newline at end of file
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/__init__.py b/Hotshot-XL/build/lib/hotshot_xl/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/resnet.py b/Hotshot-XL/build/lib/hotshot_xl/models/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b46c907610a9a4fb73288f280c79e923b86c89a
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/resnet.py
@@ -0,0 +1,134 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import torch.nn as nn
+from diffusers.models.resnet import Upsample2D, Downsample2D, LoRACompatibleConv
+from einops import rearrange
+
+
+class Upsample3D(Upsample2D):
+ def forward(self, hidden_states, output_size=None, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Upsample3D, self).forward(hidden_states, output_size, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Downsample3D(Downsample2D):
+
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Downsample3D, self).forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Conv3d(LoRACompatibleConv):
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super().forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class ResnetBlock3D(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="silu",
+ time_embedding_norm="default",
+ output_scale_factor=1.0,
+ use_in_shortcut=None,
+ conv_shortcut_bias: bool = True,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
+ self.conv1 = Conv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ if self.time_embedding_norm == "default":
+ time_emb_proj_out_channels = out_channels
+ elif self.time_embedding_norm == "scale_shift":
+ time_emb_proj_out_channels = out_channels * 2
+ else:
+ raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
+
+ self.time_emb_proj = torch.nn.Linear(temb_channels, time_emb_proj_out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = Conv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ assert non_linearity == "silu"
+
+ self.nonlinearity = nn.SiLU()
+
+ self.use_in_shortcut = self.in_channels != self.out_channels if use_in_shortcut is None else use_in_shortcut
+
+ self.conv_shortcut = None
+ if self.use_in_shortcut:
+ self.conv_shortcut = Conv3d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
+ )
+
+ def forward(self, input_tensor, temb):
+ hidden_states = input_tensor
+
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+
+ if temb is not None:
+ temb = self.nonlinearity(temb)
+ temb = self.time_emb_proj(temb)[:, :, None, None, None]
+
+ if temb is not None and self.time_embedding_norm == "default":
+ hidden_states = hidden_states + temb
+
+ hidden_states = self.norm2(hidden_states)
+
+ if temb is not None and self.time_embedding_norm == "scale_shift":
+ scale, shift = torch.chunk(temb, 2, dim=1)
+ hidden_states = hidden_states * (1 + scale) + shift
+
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ input_tensor = self.conv_shortcut(input_tensor)
+
+ output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
+
+ return output_tensor
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/transformer_3d.py b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_3d.py
new file mode 100644
index 0000000000000000000000000000000000000000..169f91ee6f2bcd568141a5776820429140370f6f
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_3d.py
@@ -0,0 +1,75 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Optional
+import torch
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.transformer_2d import Transformer2DModel
+from einops import rearrange, repeat
+from typing import Dict, Any
+
+
+@dataclass
+class Transformer3DModelOutput(BaseOutput):
+ """
+ The output of [`Transformer3DModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`:
+ The hidden states output conditioned on the `encoder_hidden_states` input.
+ """
+
+ sample: torch.FloatTensor
+
+
+class Transformer3DModel(Transformer2DModel):
+
+ def __init__(self, *args, **kwargs):
+ super(Transformer3DModel, self).__init__(*args, **kwargs)
+ nn.init.zeros_(self.proj_out.weight.data)
+ nn.init.zeros_(self.proj_out.bias.data)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ enable_temporal_layers: bool = True,
+ positional_embedding: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ):
+
+ is_video = len(hidden_states.shape) == 5
+
+ if is_video:
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ encoder_hidden_states = repeat(encoder_hidden_states, 'b n c -> (b f) n c', f=f)
+
+ hidden_states = super(Transformer3DModel, self).forward(hidden_states,
+ encoder_hidden_states,
+ timestep,
+ class_labels,
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ return_dict=False)[0]
+
+ if is_video:
+ hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+ if not return_dict:
+ return (hidden_states,)
+
+ return Transformer3DModelOutput(sample=hidden_states)
\ No newline at end of file
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/transformer_temporal.py b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_temporal.py
new file mode 100644
index 0000000000000000000000000000000000000000..772e51d55da5ebf3279235b482c1db7e46e2b603
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/transformer_temporal.py
@@ -0,0 +1,192 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import math
+from dataclasses import dataclass
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.attention import Attention, FeedForward
+from einops import rearrange, repeat
+from typing import Optional
+
+
+class PositionalEncoding(nn.Module):
+ """
+ Implements positional encoding as described in "Attention Is All You Need".
+ Adds sinusoidal based positional encodings to the input tensor.
+ """
+
+ _SCALE_FACTOR = 10000.0 # Scale factor used in the positional encoding computation.
+
+ def __init__(self, dim: int, dropout: float = 0.0, max_length: int = 24):
+ super(PositionalEncoding, self).__init__()
+
+ self.dropout = nn.Dropout(p=dropout)
+
+ # The size is (1, max_length, dim) to allow easy addition to input tensors.
+ positional_encoding = torch.zeros(1, max_length, dim)
+
+ # Position and dim are used in the sinusoidal computation.
+ position = torch.arange(max_length).unsqueeze(1)
+ div_term = torch.exp(torch.arange(0, dim, 2) * (-math.log(self._SCALE_FACTOR) / dim))
+
+ positional_encoding[0, :, 0::2] = torch.sin(position * div_term)
+ positional_encoding[0, :, 1::2] = torch.cos(position * div_term)
+
+ # Register the positional encoding matrix as a buffer,
+ # so it's part of the model's state but not the parameters.
+ self.register_buffer('positional_encoding', positional_encoding)
+
+ def forward(self, hidden_states: torch.Tensor, length: int) -> torch.Tensor:
+ hidden_states = hidden_states + self.positional_encoding[:, :length]
+ return self.dropout(hidden_states)
+
+
+class TemporalAttention(Attention):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.pos_encoder = PositionalEncoding(kwargs["query_dim"], dropout=0)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=8):
+ sequence_length = hidden_states.shape[1]
+ hidden_states = rearrange(hidden_states, "(b f) s c -> (b s) f c", f=number_of_frames)
+ hidden_states = self.pos_encoder(hidden_states, length=number_of_frames)
+
+ if encoder_hidden_states:
+ encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b s) n c", s=sequence_length)
+
+ hidden_states = super().forward(hidden_states, encoder_hidden_states, attention_mask=attention_mask)
+
+ return rearrange(hidden_states, "(b s) f c -> (b f) s c", s=sequence_length)
+
+
+@dataclass
+class TransformerTemporalOutput(BaseOutput):
+ sample: torch.FloatTensor
+
+
+class TransformerTemporal(nn.Module):
+ def __init__(
+ self,
+ num_attention_heads: int,
+ attention_head_dim: int,
+ in_channels: int,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ activation_fn: str = "geglu",
+ upcast_attention: bool = False,
+ ):
+ super().__init__()
+
+ inner_dim = num_attention_heads * attention_head_dim
+
+ self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ TransformerBlock(
+ dim=inner_dim,
+ num_attention_heads=num_attention_heads,
+ attention_head_dim=attention_head_dim,
+ dropout=dropout,
+ activation_fn=activation_fn,
+ attention_bias=attention_bias,
+ upcast_attention=upcast_attention,
+ cross_attention_dim=cross_attention_dim
+ )
+ for _ in range(num_layers)
+ ]
+ )
+ self.proj_out = nn.Linear(inner_dim, in_channels)
+
+ def forward(self, hidden_states, encoder_hidden_states=None):
+ _, num_channels, f, height, width = hidden_states.shape
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+
+ skip = hidden_states
+
+ hidden_states = self.norm(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf c h w -> bf (h w) c")
+ hidden_states = self.proj_in(hidden_states)
+
+ for block in self.transformer_blocks:
+ hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, number_of_frames=f)
+
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf (h w) c -> bf c h w", h=height, w=width).contiguous()
+
+ output = hidden_states + skip
+ output = rearrange(output, "(b f) c h w -> b c f h w", f=f)
+
+ return output
+
+
+class TransformerBlock(nn.Module):
+ def __init__(
+ self,
+ dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=0.0,
+ activation_fn="geglu",
+ attention_bias=False,
+ upcast_attention=False,
+ depth=2,
+ cross_attention_dim: Optional[int] = None
+ ):
+ super().__init__()
+
+ self.is_cross = cross_attention_dim is not None
+
+ attention_blocks = []
+ norms = []
+
+ for _ in range(depth):
+ attention_blocks.append(
+ TemporalAttention(
+ query_dim=dim,
+ cross_attention_dim=cross_attention_dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ upcast_attention=upcast_attention,
+ )
+ )
+ norms.append(nn.LayerNorm(dim))
+
+ self.attention_blocks = nn.ModuleList(attention_blocks)
+ self.norms = nn.ModuleList(norms)
+
+ self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
+ self.ff_norm = nn.LayerNorm(dim)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=None):
+
+ if not self.is_cross:
+ encoder_hidden_states = None
+
+ for block, norm in zip(self.attention_blocks, self.norms):
+ norm_hidden_states = norm(hidden_states)
+ hidden_states = block(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ number_of_frames=number_of_frames
+ ) + hidden_states
+
+ norm_hidden_states = self.ff_norm(hidden_states)
+ hidden_states = self.ff(norm_hidden_states) + hidden_states
+
+ output = hidden_states
+ return output
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/unet.py b/Hotshot-XL/build/lib/hotshot_xl/models/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..30b45fe9fcf7d2e0e898aa7ebd36494ee13998ef
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/unet.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Unet now supports SDXL
+
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.loaders import UNet2DConditionLoadersMixin
+from diffusers.utils import BaseOutput, logging
+from diffusers.models.activations import get_activation
+from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
+from diffusers.models.embeddings import (
+ GaussianFourierProjection,
+ ImageHintTimeEmbedding,
+ ImageProjection,
+ ImageTimeEmbedding,
+ TextImageProjection,
+ TextImageTimeEmbedding,
+ TextTimeEmbedding,
+ TimestepEmbedding,
+ Timesteps,
+)
+
+from diffusers.models.modeling_utils import ModelMixin
+from diffusers.models.embeddings import TimestepEmbedding, Timesteps
+from .unet_blocks import (
+ CrossAttnDownBlock3D,
+ CrossAttnUpBlock3D,
+ DownBlock3D,
+ UNetMidBlock3DCrossAttn,
+ UpBlock3D,
+ get_down_block,
+ get_up_block,
+)
+
+from .resnet import Conv3d
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet3DConditionOutput(BaseOutput):
+ """
+ The output of [`UNet2DConditionModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor = None
+
+
+class UNet3DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ "DownBlock3D",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlock3DCrossAttn",
+ up_block_types: Tuple[str] = (
+ "UpBlock3D",
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ ),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: Union[int, Tuple[int]] = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ transformer_layers_per_block: Union[int, Tuple[int]] = 1,
+ encoder_hid_dim: Optional[int] = None,
+ encoder_hid_dim_type: Optional[str] = None,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ addition_embed_type: Optional[str] = None,
+ addition_time_embed_dim: Optional[int] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ resnet_skip_time_act: bool = False,
+ resnet_out_scale_factor: int = 1.0,
+ time_embedding_type: str = "positional",
+ time_embedding_dim: Optional[int] = None,
+ time_embedding_act_fn: Optional[str] = None,
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ mid_block_only_cross_attention: Optional[bool] = None,
+ cross_attention_norm: Optional[str] = None,
+ addition_embed_type_num_heads=64,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ if num_attention_heads is not None:
+ raise ValueError(
+ "At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
+ )
+
+ # If `num_attention_heads` is not defined (which is the case for most models)
+ # it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
+ # The reason for this behavior is to correct for incorrectly named variables that were introduced
+ # when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
+ # Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
+ # which is why we correct for the naming here.
+ num_attention_heads = num_attention_heads or attention_head_dim
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+
+ self.conv_in = Conv3d(in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding)
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ if encoder_hid_dim_type is None and encoder_hid_dim is not None:
+ encoder_hid_dim_type = "text_proj"
+ self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
+ logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
+
+ if encoder_hid_dim is None and encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
+ )
+
+ if encoder_hid_dim_type == "text_proj":
+ self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
+ elif encoder_hid_dim_type == "text_image_proj":
+ # image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
+ self.encoder_hid_proj = TextImageProjection(
+ text_embed_dim=encoder_hid_dim,
+ image_embed_dim=cross_attention_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2
+ self.encoder_hid_proj = ImageProjection(
+ image_embed_dim=encoder_hid_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
+ )
+ else:
+ self.encoder_hid_proj = None
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ if addition_embed_type == "text":
+ if encoder_hid_dim is not None:
+ text_time_embedding_from_dim = encoder_hid_dim
+ else:
+ text_time_embedding_from_dim = cross_attention_dim
+
+ self.add_embedding = TextTimeEmbedding(
+ text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
+ )
+ elif addition_embed_type == "text_image":
+ # text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
+ self.add_embedding = TextImageTimeEmbedding(
+ text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
+ )
+ elif addition_embed_type == "text_time":
+ self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
+ self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif addition_embed_type == "image":
+ # Kandinsky 2.2
+ self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type == "image_hint":
+ # Kandinsky 2.2 ControlNet
+ self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type is not None:
+ raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
+
+ if time_embedding_act_fn is None:
+ self.time_embed_act = None
+ else:
+ self.time_embed_act = get_activation(time_embedding_act_fn)
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = only_cross_attention
+
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = False
+
+ if isinstance(num_attention_heads, int):
+ num_attention_heads = (num_attention_heads,) * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if isinstance(layers_per_block, int):
+ layers_per_block = [layers_per_block] * len(down_block_types)
+
+ if isinstance(transformer_layers_per_block, int):
+ transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ res = 2 ** i
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block[i],
+ transformer_layers_per_block=transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ num_attention_heads=num_attention_heads[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlock3DCrossAttn":
+ self.mid_block = UNetMidBlock3DCrossAttn(
+ transformer_layers_per_block=transformer_layers_per_block[-1],
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ num_attention_heads=num_attention_heads[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
+ raise ValueError("UNetMidBlock2DSimpleCrossAttn not supported")
+
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_num_attention_heads = list(reversed(num_attention_heads))
+ reversed_layers_per_block = list(reversed(layers_per_block))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ res = 2 ** (len(up_block_types) - 1 - i)
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=reversed_layers_per_block[i] + 1,
+ transformer_layers_per_block=reversed_transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ num_attention_heads=reversed_num_attention_heads[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+
+ self.conv_act = get_activation(act_fn)
+
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+
+ self.conv_out = Conv3d(block_out_channels[0], out_channels, kernel_size=conv_out_kernel,
+ padding=conv_out_padding)
+
+ def temporal_parameters(self) -> list:
+ output = []
+ all_blocks = self.down_blocks + self.up_blocks + [self.mid_block]
+ for block in all_blocks:
+ output.extend(block.temporal_parameters())
+ return output
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ return self.get_attn_processors(include_temporal_layers=False)
+
+ def get_attn_processors(self, include_temporal_layers=True) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+
+ if not include_temporal_layers:
+ if 'temporal' in name:
+ return processors
+
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]],
+ include_temporal_layers=False):
+ r"""
+ Sets the attention processor to use to compute attention.
+
+ Parameters:
+ processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ for **all** `Attention` layers.
+
+ If `processor` is a dict, the key needs to define the path to the corresponding cross attention
+ processor. This is strongly recommended when setting trainable attention processors.
+
+ """
+ count = len(self.get_attn_processors(include_temporal_layers=include_temporal_layers).keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+
+ if not include_temporal_layers:
+ if "temporal" in name:
+ return
+
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module splits the input tensor in slices to compute attention in
+ several steps. This is useful for saving some memory in exchange for a small decrease in speed.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
+ `"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ enable_temporal_attentions: bool = True
+ ) -> Union[UNet3DConditionOutput, Tuple]:
+ r"""
+ The [`UNet2DConditionModel`] forward method.
+
+ Args:
+ sample (`torch.FloatTensor`):
+ The noisy input tensor with the following shape `(batch, channel, height, width)`.
+ timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
+ encoder_hidden_states (`torch.FloatTensor`):
+ The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
+ encoder_attention_mask (`torch.Tensor`):
+ A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
+ `True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
+ which adds large negative values to the attention scores corresponding to "discard" tokens.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
+ tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
+ added_cond_kwargs: (`dict`, *optional*):
+ A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
+ are passed along to the UNet blocks.
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
+ a `tuple` is returned where the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2 ** self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # ensure attention_mask is a bias, and give it a singleton query_tokens dimension
+ # expects mask of shape:
+ # [batch, key_tokens]
+ # adds singleton query_tokens dimension:
+ # [batch, 1, key_tokens]
+ # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
+ # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
+ # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
+ if attention_mask is not None:
+ # assume that mask is expressed as:
+ # (1 = keep, 0 = discard)
+ # convert mask into a bias that can be added to attention scores:
+ # (keep = +0, discard = -10000.0)
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # convert encoder_attention_mask to a bias the same way we do for attention_mask
+ if encoder_attention_mask is not None:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=sample.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+ aug_emb = None
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # there might be better ways to encapsulate this.
+ class_labels = class_labels.to(dtype=sample.dtype)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ if self.config.addition_embed_type == "text":
+ aug_emb = self.add_embedding(encoder_hidden_states)
+ elif self.config.addition_embed_type == "text_image":
+ # Kandinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+
+ image_embs = added_cond_kwargs.get("image_embeds")
+ text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
+ aug_emb = self.add_embedding(text_embs, image_embs)
+ elif self.config.addition_embed_type == "text_time":
+ if "text_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
+ )
+ text_embeds = added_cond_kwargs.get("text_embeds")
+ if "time_ids" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
+ )
+ time_ids = added_cond_kwargs.get("time_ids")
+ time_embeds = self.add_time_proj(time_ids.flatten())
+ time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
+
+ add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
+ add_embeds = add_embeds.to(emb.dtype)
+ aug_emb = self.add_embedding(add_embeds)
+ elif self.config.addition_embed_type == "image":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ aug_emb = self.add_embedding(image_embs)
+ elif self.config.addition_embed_type == "image_hint":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ hint = added_cond_kwargs.get("hint")
+ aug_emb, hint = self.add_embedding(image_embs, hint)
+ sample = torch.cat([sample, hint], dim=1)
+
+ emb = emb + aug_emb if aug_emb is not None else emb
+
+ if self.time_embed_act is not None:
+ emb = self.time_embed_act(emb)
+
+ if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
+ # Kadinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(image_embeds)
+ # 2. pre-process
+
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ upsample_size=upsample_size,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet3DConditionOutput(sample=sample)
+
+ @classmethod
+ def from_pretrained_spatial(cls, pretrained_model_path, subfolder=None):
+
+ import os
+ import json
+
+ if subfolder is not None:
+ pretrained_model_path = os.path.join(pretrained_model_path, subfolder)
+
+ config_file = os.path.join(pretrained_model_path, 'config.json')
+
+ with open(config_file, "r") as f:
+ config = json.load(f)
+
+ config["_class_name"] = "UNet3DConditionModel"
+
+ config["down_block_types"] = [
+ "DownBlock3D",
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ ]
+ config["up_block_types"] = [
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ "UpBlock3D"
+ ]
+
+ config["mid_block_type"] = "UNetMidBlock3DCrossAttn"
+
+ model = cls.from_config(config)
+
+ model_files = [
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.bin'),
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.safetensors')
+ ]
+
+ model_file = None
+
+ for fp in model_files:
+ if os.path.exists(fp):
+ model_file = fp
+
+ if not model_file:
+ raise RuntimeError(f"{model_file} does not exist")
+
+ state_dict = torch.load(model_file, map_location="cpu")
+
+ model.load_state_dict(state_dict, strict=False)
+
+ return model
diff --git a/Hotshot-XL/build/lib/hotshot_xl/models/unet_blocks.py b/Hotshot-XL/build/lib/hotshot_xl/models/unet_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..e642d4f8b56600b58238fdb7a243fb1e360a621d
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/models/unet_blocks.py
@@ -0,0 +1,740 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Add temporal transformers to unet blocks
+
+import torch
+from torch import nn
+
+from .transformer_3d import Transformer3DModel
+from .resnet import Downsample3D, ResnetBlock3D, Upsample3D
+from .transformer_temporal import TransformerTemporal
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ downsample_type=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock3D":
+ return DownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D")
+ return CrossAttnDownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ upsample_type=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock3D":
+ return UpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D")
+ return CrossAttnUpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock3DCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ in_channels // num_attention_heads,
+ in_channels=in_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ return []
+
+
+class CrossAttnDownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if temporal_attention and enable_temporal_attentions:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class DownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states, encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class CrossAttnUpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ upsample_size=None,
+ cross_attention_kwargs=None,
+ attention_mask=None,
+ enable_temporal_attentions: bool = True
+ ):
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False,
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class UpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, encoder_hidden_states=None,
+ enable_temporal_attentions: bool = True):
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states) if enable_temporal_attentions and temporal_attention is not None else hidden_states
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
diff --git a/Hotshot-XL/build/lib/hotshot_xl/pipelines/__init__.py b/Hotshot-XL/build/lib/hotshot_xl/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..b084688662309ef71b429d20a5edfc9c8f494f9f
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
@@ -0,0 +1,1389 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Controlnet Pipeline to work temporally
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, ControlNetModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.utils.torch_utils import randn_tensor, is_compiled_module
+
+from ..models.unet import UNet3DConditionModel
+
+from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
+from einops import rearrange
+from tqdm import tqdm
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+ >>> from diffusers import ControlNetModel
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL",
+ ... controlnet=ControlNetModel.from_pretrained("diffusers/controlnet-canny-sdxl-1.0")
+ ... )
+
+ >>> def canny(image):
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> return Image.fromarray(image)
+
+ >>> # assuming you have 8 keyframes in current directory...
+
+ >>> keyframes = [f"image_{i}.jpg" for i in range(8)]
+ >>> control_images = [canny(Image.open(fp)) for fp in keyframes]
+
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor",
+ ... controlnet_conditioning_scale=0.7,
+ ... control_images=control_images
+ ).video
+ ```
+"""
+class HotshotXLControlNetPipeline(
+ DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
+ implemented for all pipelines (downloading, saving, running on a particular device, etc.).
+
+ The pipeline also inherits the following loading methods:
+ - [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
+ - [`loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
+ - [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
+ text_encoder ([`~transformers.CLIPTextModel`]):
+ Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
+ text_encoder_2 ([`~transformers.CLIPTextModelWithProjection`]):
+ Second frozen text-encoder
+ ([laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)).
+ tokenizer ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ tokenizer_2 ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ unet ([`UNet3DConditionModel`]):
+ A `UNet3DConditionModel` to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the `unet` during the denoising process. If you set multiple
+ ControlNets as a list, the outputs from each ControlNet are added together to create one combined
+ additional conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
+ Whether the negative prompt embeddings should always be set to 0. Also see the config of
+ `stabilityai/stable-diffusion-xl-base-1-0`.
+ add_watermarker (`bool`, *optional*):
+ Whether to use the [invisible_watermark](https://github.com/ShieldMnt/invisible-watermark/) library to
+ watermark output images. If not defined, it defaults to `True` if the package is installed; otherwise no
+ watermarker is used.
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
+ self.control_image_processor = VaeImageProcessor(
+ vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
+ )
+
+ self.watermark = None
+
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ control_guidance_start=0.0,
+ control_guidance_end=1.0,
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+
+ assert len(control_images) == video_length
+ # for image in control_images:
+ # self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ ...
+ # todo
+ #
+ # if not isinstance(image, list):
+ # raise TypeError("For multiple controlnets: `image` must be type `list`")
+ #
+ # # When `image` is a nested list:
+ # # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ # elif any(isinstance(i, list) for i in image):
+ # raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ # elif len(image) != len(self.controlnet.nets):
+ # raise ValueError(
+ # f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets."
+ # )
+ #
+ # for image_ in image:
+ # self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ if not isinstance(control_guidance_start, (tuple, list)):
+ control_guidance_start = [control_guidance_start]
+
+ if not isinstance(control_guidance_end, (tuple, list)):
+ control_guidance_end = [control_guidance_end]
+
+ if len(control_guidance_start) != len(control_guidance_end):
+ raise ValueError(
+ f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
+ )
+
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if len(control_guidance_start) != len(self.controlnet.nets):
+ raise ValueError(
+ f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
+ )
+
+ for start, end in zip(control_guidance_start, control_guidance_end):
+ if start >= end:
+ raise ValueError(
+ f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
+ )
+ if start < 0.0:
+ raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
+ if end > 1.0:
+ raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_np = isinstance(image, np.ndarray)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+ image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
+
+ if (
+ not image_is_pil
+ and not image_is_tensor
+ and not image_is_np
+ and not image_is_pil_list
+ and not image_is_tensor_list
+ and not image_is_np_list
+ ):
+ raise TypeError(
+ f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ else:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_images(
+ self,
+ images,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ images_pre_processed = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+
+ images_pre_processed = torch.cat(images_pre_processed, dim=0)
+
+ repeat_factor = [1] * len(images_pre_processed.shape)
+ repeat_factor[0] = batch_size * num_images_per_prompt
+ images_pre_processed = images_pre_processed.repeat(*repeat_factor)
+
+ images = images_pre_processed.unsqueeze(0)
+
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+
+ #image = image.repeat_interleave(repeat_by, dim=0)
+
+ images = images.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ repeat_factor = [1] * len(images.shape)
+ repeat_factor[0] = 2
+ images = images.repeat(*repeat_factor)
+
+ return images
+
+ # def prepare_images(self,
+ # images: list,
+ # width,
+ # height,
+ # batch_size,
+ # num_images_per_prompt,
+ # device,
+ # dtype,
+ # do_classifier_free_guidance=False,
+ # guess_mode=False):
+ #
+ # images = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+ #
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+ #
+ # image = image.repeat_interleave(repeat_by, dim=0)
+ #
+ # image = image.to(device=device, dtype=dtype)
+ #
+ # if do_classifier_free_guidance and not guess_mode:
+ # image = torch.cat([image] * 2)
+ #
+ # return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ #shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._get_add_time_ids
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ control_images: List[PIL.Image.Image] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ guess_mode: bool = False,
+ control_guidance_start: Union[float, List[float]] = 0.0,
+ control_guidance_end: Union[float, List[float]] = 1.0,
+ original_size: Tuple[int, int] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Tuple[int, int] = None,
+ negative_original_size: Optional[Tuple[int, int]] = None,
+ negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
+ negative_target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ The call function to the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
+ `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
+ specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
+ accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
+ and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
+ `init`, images must be passed as a list such that each element of the list can be correctly batched for
+ input to a single ControlNet.
+ height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ A higher guidance scale value encourages the model to generate images closely linked to the text
+ `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. If not defined, you need to
+ pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. This is sent to `tokenizer_2`
+ and `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
+ generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor is generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
+ provided, text embeddings are generated from the `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, pooled text embeddings are generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs (prompt
+ weighting). If not provided, pooled `negative_prompt_embeds` are generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between `PIL.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that calls every `callback_steps` steps during inference. The function is called with the
+ following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function is called. If not specified, the callback is called at
+ every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
+ [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
+ the corresponding scale as a list.
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ The ControlNet encoder tries to recognize the content of the input image even if you remove all
+ prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
+ control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
+ The percentage of total steps at which the ControlNet starts applying.
+ control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The percentage of total steps at which the ControlNet stops applying.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a specific image resolution. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a target image resolution. It should be as same
+ as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
+ otherwise a `tuple` is returned containing the output images.
+ """
+
+
+ if video_length > 1 and num_images_per_prompt > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ # align format for control guidance
+ if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
+ control_guidance_start = len(control_guidance_end) * [control_guidance_start]
+ elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
+ control_guidance_end = len(control_guidance_start) * [control_guidance_end]
+ elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
+ mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
+ control_guidance_start, control_guidance_end = mult * [control_guidance_start], mult * [
+ control_guidance_end
+ ]
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ controlnet_conditioning_scale,
+ control_guidance_start,
+ control_guidance_end,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt,
+ prompt_2,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+
+ assert len(control_images) == video_length * batch_size
+
+ images = self.prepare_images(
+ images=control_images,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ height, width = images.shape[-2:]
+ elif isinstance(controlnet, MultiControlNetModel):
+
+ raise Exception("not supported yet")
+
+ # images = []
+ #
+ # for image_ in control_images:
+ # image_ = self.prepare_image(
+ # image=image_,
+ # width=width,
+ # height=height,
+ # batch_size=batch_size * num_images_per_prompt,
+ # num_images_per_prompt=num_images_per_prompt,
+ # device=device,
+ # dtype=controlnet.dtype,
+ # do_classifier_free_guidance=do_classifier_free_guidance,
+ # guess_mode=guess_mode,
+ # )
+ #
+ # images.append(image_)
+ #
+ # image = images
+ # height, width = image[0].shape[-2:]
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7.1 Create tensor stating which controlnets to keep
+ controlnet_keep = []
+ for i in range(len(timesteps)):
+ keeps = [
+ 1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
+ for s, e in zip(control_guidance_start, control_guidance_end)
+ ]
+ controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
+
+ # 7.2 Prepare added time ids & embeddings
+ # if isinstance(image, list):
+ # original_size = original_size or image[0].shape[-2:]
+ # else:
+ original_size = original_size or images.shape[-2:]
+ target_size = target_size or (height, width)
+
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ if negative_original_size is not None and negative_target_size is not None:
+ negative_add_time_ids = self._get_add_time_ids(
+ negative_original_size,
+ negative_crops_coords_top_left,
+ negative_target_size,
+ dtype=prompt_embeds.dtype,
+ )
+ else:
+ negative_add_time_ids = add_time_ids
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+
+ images = rearrange(images, "b f c h w -> (b f) c h w")
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ control_model_input = latents
+ control_model_input = self.scheduler.scale_model_input(control_model_input, t)
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ controlnet_added_cond_kwargs = {
+ "text_embeds": add_text_embeds.chunk(2)[1],
+ "time_ids": add_time_ids.chunk(2)[1],
+ }
+ else:
+ control_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+ controlnet_added_cond_kwargs = added_cond_kwargs
+
+ if isinstance(controlnet_keep[i], list):
+ cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
+ else:
+ controlnet_cond_scale = controlnet_conditioning_scale
+ if isinstance(controlnet_cond_scale, list):
+ controlnet_cond_scale = controlnet_cond_scale[0]
+ cond_scale = controlnet_cond_scale * controlnet_keep[i]
+
+
+ # this will be non interlaced when arranged!
+ control_model_input = rearrange(control_model_input, "b c f h w -> (b f) c h w")
+ # if we chunked this by 2 - the top 8 frames will be positive for cfg
+ # the bottom half will be negative for cfg...
+
+ if video_length > 1:
+ # use repeat_interleave as we need to match the rearrangement above.
+
+ controlnet_prompt_embeds = controlnet_prompt_embeds.repeat_interleave(video_length, dim=0)
+ controlnet_added_cond_kwargs = {
+ "text_embeds": controlnet_added_cond_kwargs['text_embeds'].repeat_interleave(video_length, dim=0),
+ "time_ids": controlnet_added_cond_kwargs['time_ids'].repeat_interleave(video_length, dim=0)
+ }
+
+ # if type(image) is list:
+ # image = torch.cat(image, dim=0)
+
+ # todo - check if video_length > 1 this needs to produce num_frames * batch_size samples...
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ control_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=images,
+ conditioning_scale=cond_scale,
+ guess_mode=guess_mode,
+ added_cond_kwargs=controlnet_added_cond_kwargs,
+ return_dict=False,
+ )
+
+ for j, sample in enumerate(down_block_res_samples):
+ down_block_res_samples[j] = rearrange(sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ mid_block_res_sample = rearrange(mid_block_res_sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions=video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ # if not output_type == "latent":
+ # # make sure the VAE is in float32 mode, as it overflows in float16
+ # needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
+ #
+ # if needs_upcasting:
+ # self.upcast_vae()
+ # latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+ #
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ #
+ # # cast back to fp16 if needed
+ # if needs_upcasting:
+ # self.vae.to(dtype=torch.float16)
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.load_lora_weights
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.save_lora_weights
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = True,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._remove_text_encoder_monkey_patch
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_pipeline.py b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c3b41da67eacee21c8cb192de343e47d5fe30d0
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/pipelines/hotshot_xl_pipeline.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Pipeline to work temporally
+
+
+import os
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL
+from hotshot_xl.models.unet import UNet3DConditionModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.utils.torch_utils import randn_tensor
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from tqdm import tqdm
+from einops import repeat, rearrange
+from diffusers.utils import deprecate, logging
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL"
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor"
+ ).video
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
+
+
+class HotshotXLPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *LoRA*: [`HotshotPipelineXL.load_lora_weights`]
+ - *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
+
+ as well as the following saving methods:
+ - *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion XL uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([` CLIPTextModelWithProjection`]):
+ Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
+ specifically the
+ [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
+ variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`CLIPTokenizer`):
+ Second Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet3DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ scheduler=scheduler,
+ )
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.default_sample_size = self.unet.config.sample_size
+ self.watermark = None
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ num_images_per_prompt: Optional[int] = 1,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ denoising_end (`float`, *optional*):
+ When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
+ completed before it is intentionally prematurely terminated. As a result, the returned sample will
+ still retain a substantial amount of noise as determined by the discrete timesteps selected by the
+ scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
+ "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
+ Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
+ of a plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.7):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+
+ Examples:
+
+ Returns:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] or `tuple`:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ if video_length > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ # 0. Default height and width to unet
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Prepare added time ids & embeddings
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ # todo - negative_original_size from latest diffusers for cfg
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ # 7.1 Apply denoising_end
+ if denoising_end is not None and type(denoising_end) == float and denoising_end > 0 and denoising_end < 1:
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (denoising_end * self.scheduler.config.num_train_timesteps)
+ )
+ )
+ num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
+ timesteps = timesteps[:num_inference_steps]
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions= video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # if not output_type == "latent":
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # apply watermark if available
+ # if self.watermark is not None:
+ # image = self.watermark.apply_watermark(image)
+
+ #image = self.image_processor.postprocess(image, output_type=output_type)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ #
+ # # Offload last model to CPU
+ # if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ # self.final_offload_hook.offload()
+ #
+ # if not return_dict:
+ # return (image,)
+ #
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/build/lib/hotshot_xl/utils.py b/Hotshot-XL/build/lib/hotshot_xl/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7660c2a756ecae141333a7081ea358549db6ba6
--- /dev/null
+++ b/Hotshot-XL/build/lib/hotshot_xl/utils.py
@@ -0,0 +1,213 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Union
+from io import BytesIO
+import PIL
+from PIL import ImageSequence, Image
+import requests
+import os
+
+def get_image(img_path) -> PIL.Image.Image:
+ if img_path.startswith("http"):
+ return PIL.Image.open(requests.get(img_path, stream=True).raw)
+ if os.path.exists(img_path):
+ return Image.open(img_path)
+ raise Exception("File not found")
+
+def images_to_gif_bytes(images: List, duration: int = 1000) -> bytes:
+ with BytesIO() as output_buffer:
+ # Save the first image
+ images[0].save(output_buffer,
+ format='GIF',
+ save_all=True,
+ append_images=images[1:],
+ duration=duration,
+ loop=0) # 0 means the GIF will loop indefinitely
+
+ # Get the byte array from the buffer
+ gif_bytes = output_buffer.getvalue()
+
+ return gif_bytes
+
+
+def save_as_gif(images: List, file_path: str, duration: int = 1000):
+ with open(file_path, "wb") as f:
+ f.write(images_to_gif_bytes(images, duration))
+
+def scale_aspect_fill(img, new_width, new_height):
+ new_width = int(new_width)
+ new_height = int(new_height)
+
+ original_width, original_height = img.size
+ ratio_w = float(new_width) / original_width
+ ratio_h = float(new_height) / original_height
+
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(original_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(original_width * ratio_h)
+ resize_height = new_height
+
+ img_resized = img.resize((resize_width, resize_height), Image.LANCZOS)
+
+ # Calculate cropping boundaries and do crop
+ left = (resize_width - new_width) / 2
+ top = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ bottom = (resize_height + new_height) / 2
+
+ img_cropped = img_resized.crop((left, top, right, bottom))
+
+ return img_cropped
+
+def extract_gif_frames_from_midpoint(image: Union[str, PIL.Image.Image], fps: int=8, target_duration: int=1000) -> list:
+ # Load the GIF
+ image = get_image(image) if type(image) is str else image
+
+ frames = []
+
+ estimated_frame_time = None
+
+ # some gifs contain the duration - others don't
+ # so if there is a duration we will grab it otherwise we will fall back
+
+ for frame in ImageSequence.Iterator(image):
+
+ frames.append(frame.copy())
+ if 'duration' in frame.info:
+ frame_info_duration = frame.info['duration']
+ if frame_info_duration > 0:
+ estimated_frame_time = frame_info_duration
+
+ if estimated_frame_time is None:
+ if len(frames) <= 16:
+ # assume it's 8fps
+ estimated_frame_time = 1000 // 8
+ else:
+ # assume it's 15 fps
+ estimated_frame_time = 70
+
+ if len(frames) < fps:
+ raise ValueError(f"fps of {fps} is too small for this gif as it only has {len(frames)} frames.")
+
+ skip = len(frames) // fps
+ upper_bound_index = len(frames) - 1
+
+ best_indices = [x for x in range(0, len(frames), skip)][:fps]
+ offset = int(upper_bound_index - best_indices[-1]) // 2
+ best_indices = [x + offset for x in best_indices]
+ best_duration = (best_indices[-1] - best_indices[0]) * estimated_frame_time
+
+ while True:
+
+ skip -= 1
+
+ if skip == 0:
+ break
+
+ indices = [x for x in range(0, len(frames), skip)][:fps]
+
+ # center the indices, so we sample the middle of the gif...
+ offset = int(upper_bound_index - indices[-1]) // 2
+ if offset == 0:
+ # can't shift
+ break
+ indices = [x + offset for x in indices]
+
+ # is the new duration closer to the target than last guess?
+ duration = (indices[-1] - indices[0]) * estimated_frame_time
+ if abs(duration - target_duration) > abs(best_duration - target_duration):
+ break
+
+ best_indices = indices
+ best_duration = duration
+
+ return [frames[index] for index in best_indices]
+
+def get_crop_coordinates(old_size: tuple, new_size: tuple) -> tuple:
+ """
+ Calculate the crop coordinates after scaling an image to fit a new size.
+
+ :param old_size: tuple of the form (width, height) representing the original size of the image.
+ :param new_size: tuple of the form (width, height) representing the desired size after scaling.
+ :return: tuple of the form (left, upper, right, lower) representing the normalized crop coordinates.
+ """
+ # Check if the input tuples have the right form (width, height)
+ if not (isinstance(old_size, tuple) and isinstance(new_size, tuple) and
+ len(old_size) == 2 and len(new_size) == 2):
+ raise ValueError("old_size and new_size should be tuples of the form (width, height)")
+
+ # Extract the width and height from the old and new sizes
+ old_width, old_height = old_size
+ new_width, new_height = new_size
+
+ # Calculate the ratios for width and height
+ ratio_w = float(new_width) / old_width
+ ratio_h = float(new_height) / old_height
+
+ # Determine which dimension is fixed (width or height)
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(old_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(old_width * ratio_h)
+ resize_height = new_height
+
+ # Calculate cropping boundaries in the resized image space
+ left = (resize_width - new_width) / 2
+ upper = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ lower = (resize_height + new_height) / 2
+
+ # Normalize the cropping coordinates
+
+ # Return the normalized coordinates as a tuple
+ return (left, upper, right, lower)
+
+aspect_ratio_to_1024_map = {
+ "0.42": [640, 1536],
+ "0.57": [768, 1344],
+ "0.68": [832, 1216],
+ "1.00": [1024, 1024],
+ "1.46": [1216, 832],
+ "1.75": [1344, 768],
+ "2.40": [1536, 640]
+}
+
+res_to_aspect_map = {
+ 1024: aspect_ratio_to_1024_map,
+ 512: {key: [value[0] // 2, value[1] // 2] for key, value in aspect_ratio_to_1024_map.items()},
+}
+
+def best_aspect_ratio(aspect_ratio: float, resolution: int):
+
+ map = res_to_aspect_map[resolution]
+
+ d = 99999999
+ res = None
+ for key, value in map.items():
+ ar = value[0] / value[1]
+ diff = abs(aspect_ratio - ar)
+ if diff < d:
+ d = diff
+ res = value
+
+ ar = res[0] / res[1]
+ return f"{ar:.2f}", res
\ No newline at end of file
diff --git a/Hotshot-XL/dist/hotshot_xl-1.0-py3.8.egg b/Hotshot-XL/dist/hotshot_xl-1.0-py3.8.egg
new file mode 100644
index 0000000000000000000000000000000000000000..8b71a021b8a67dd6caeac9e37de7dda423d5b131
Binary files /dev/null and b/Hotshot-XL/dist/hotshot_xl-1.0-py3.8.egg differ
diff --git a/Hotshot-XL/docker/Dockerfile b/Hotshot-XL/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..3aa868315be12f0bcb825ac089d25ad2622dd485
--- /dev/null
+++ b/Hotshot-XL/docker/Dockerfile
@@ -0,0 +1,5 @@
+FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime
+
+COPY requirements.txt .
+
+RUN pip install --no-cache-dir -r requirements.txt
diff --git a/Hotshot-XL/docker/Readme.md b/Hotshot-XL/docker/Readme.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a3464fec291a451e39ad308428ae2277ca89fbf
--- /dev/null
+++ b/Hotshot-XL/docker/Readme.md
@@ -0,0 +1,41 @@
+# Setup
+
+This docker file is for the **environment only**. This is to keep the docker image as small as possible!
+
+## Quickstart
+
+Hotshot have their own docker image you can use directly:
+```
+docker pull hotshotapp/hotshot-xl-env:latest
+```
+
+Or you can build it yourself
+
+```
+cd docker
+docker build -t hotshotapp/hotshot-xl-env:latest .
+```
+
+## Running the docker image
+
+We recommend storing the weights locally on your machine. That way the weights persist if you kill the container!
+
+- Install the models to a folder locally (Optional)
+ ```
+ cd /path/to/models
+ git lfs install
+ git clone https://huggingface.co/hotshotco/Hotshot-XL
+ ```
+- Run the docker from the project root
+ - **Linux**
+ ```
+ docker run -it --gpus=all --rm -v $(pwd):/local -v /path/to/models:/models hotshotapp/hotshot-xl-env:latest
+ ```
+ - **Windows (Powershell)**
+ ```
+ docker run -it --gpus=all --rm -v ${PWD}:/local -v C:\path\to\models:/models hotshotapp/hotshot-xl-env:latest
+ ```
+
+If you want to download the models from within the container itself then you do not need to map the volumes and ` -v /path/to/models:/models` can be removed.
+
+**Note**: Ensure you have NVIDIA Docker runtime installed if you want to utilize GPU support with `--gpus=all`.
diff --git a/Hotshot-XL/docker/requirements.txt b/Hotshot-XL/docker/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0991a8c50d1fb50a49d71bf29a914fc8e98dea7e
--- /dev/null
+++ b/Hotshot-XL/docker/requirements.txt
@@ -0,0 +1,8 @@
+accelerate==0.23.0
+einops==0.7.0
+diffusers==0.21.4
+transformers==4.34.0
+wandb==0.15.11
+moviepy==1.0.3
+imageio==2.31.5
+xformers==0.0.22
diff --git a/Hotshot-XL/fine_tune.py b/Hotshot-XL/fine_tune.py
new file mode 100644
index 0000000000000000000000000000000000000000..38c4a345b990b5a1b49d180967c49a647c5c33fb
--- /dev/null
+++ b/Hotshot-XL/fine_tune.py
@@ -0,0 +1,987 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import math
+import os
+import traceback
+from pathlib import Path
+import time
+import torch
+import torch.utils.checkpoint
+import torch.multiprocessing as mp
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from diffusers import AutoencoderKL
+from diffusers.optimization import get_scheduler
+from diffusers import DDPMScheduler
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer, CLIPTextModelWithProjection
+import torch.nn.functional as F
+import gc
+from typing import Callable
+from PIL import Image
+import numpy as np
+from concurrent.futures import ThreadPoolExecutor
+from hotshot_xl.models.unet import UNet3DConditionModel
+from hotshot_xl.pipelines.hotshot_xl_pipeline import HotshotXLPipeline
+from hotshot_xl.utils import get_crop_coordinates, res_to_aspect_map, scale_aspect_fill
+from einops import rearrange
+from torch.utils.data import Dataset, DataLoader
+from datetime import timedelta
+from accelerate.utils.dataclasses import InitProcessGroupKwargs
+from diffusers.utils import is_wandb_available
+
+if is_wandb_available():
+ import wandb
+
+logger = get_logger(__file__)
+
+
+class HotshotXLDataset(Dataset):
+
+ def __init__(self, directory: str, make_sample_fn: Callable):
+ """
+
+ Training data folder needs to look like:
+ + training_samples
+ --- + sample_001
+ ------- + frame_0.jpg
+ ------- + frame_1.jpg
+ ------- + ...
+ ------- + frame_n.jpg
+ ------- + prompt.txt
+ --- + sample_002
+ ------- + frame_0.jpg
+ ------- + frame_1.jpg
+ ------- + ...
+ ------- + frame_n.jpg
+ ------- + prompt.txt
+
+ Args:
+ directory: base directory of the training samples
+ make_sample_fn: a delegate call to load the images and prep the sample for batching
+ """
+ samples_dir = [os.path.join(directory, p) for p in os.listdir(directory)]
+ samples_dir = [p for p in samples_dir if os.path.isdir(p)]
+ samples = []
+
+ for d in samples_dir:
+ file_paths = [os.path.join(d, p) for p in os.listdir(d)]
+ image_fps = [f for f in file_paths if os.path.splitext(f)[1] in {".png", ".jpg"}]
+ with open(os.path.join(d, "prompt.txt")) as f:
+ prompt = f.read().strip()
+
+ samples.append({
+ "image_fps": image_fps,
+ "prompt": prompt
+ })
+
+ self.samples = samples
+ self.length = len(samples)
+ self.make_sample_fn = make_sample_fn
+
+ def __len__(self):
+ return self.length
+
+ def __getitem__(self, index):
+ return self.make_sample_fn(
+ self.samples[index]
+ )
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default="hotshotco/Hotshot-XL",
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--unet_resume_path",
+ type=str,
+ default=None,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+
+ parser.add_argument(
+ "--data_dir",
+ type=str,
+ required=True,
+ help="Path to data to train.",
+ )
+
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="wandb",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+
+ parser.add_argument("--run_validation_at_start", action="store_true")
+ parser.add_argument("--max_vae_encode", type=int, default=None)
+ parser.add_argument("--vae_b16", action="store_true")
+ parser.add_argument("--disable_optimizer_restore", action="store_true")
+
+ parser.add_argument(
+ "--latent_nan_checking",
+ action="store_true",
+ help="Check if latents contain nans - important if vae is f16",
+ )
+ parser.add_argument(
+ "--test_prompts",
+ type=str,
+ default=None,
+ )
+ parser.add_argument(
+ "--project_name",
+ type=str,
+ default="fine-tune-hotshot-xl",
+ help="the name of the run",
+ )
+ parser.add_argument(
+ "--run_name",
+ type=str,
+ default="run-01",
+ help="the name of the run",
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="output",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--noise_offset", type=float, default=0.05, help="The scale of noise offset.")
+ parser.add_argument("--seed", type=int, default=111, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--aspect_ratio",
+ type=str,
+ default="1.75",
+ choices=list(res_to_aspect_map[512].keys()),
+ help="Aspect ratio to train at",
+ )
+
+ parser.add_argument("--xformers", action="store_true")
+
+ parser.add_argument(
+ "--train_batch_size", type=int, default=8, help="Batch size (per device) for the training dataloader."
+ )
+
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=9999999,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+
+ parser.add_argument(
+ "--validate_every_steps",
+ type=int,
+ default=100,
+ help="Run inference every",
+ )
+
+ parser.add_argument(
+ "--save_n_steps",
+ type=int,
+ default=100,
+ help="Save the model every n global_steps",
+ )
+
+ parser.add_argument(
+ "--save_starting_step",
+ type=int,
+ default=100,
+ help="The step from which it starts saving intermediary checkpoints",
+ )
+
+ parser.add_argument(
+ "--nccl_timeout",
+ type=int,
+ help="nccl_timeout",
+ default=3600
+ )
+
+ parser.add_argument("--snr_gamma", action="store_true")
+
+ args = parser.parse_args()
+
+ return args
+
+
+def add_time_ids(
+ unet_config,
+ unet_add_embedding,
+ text_encoder_2: CLIPTextModelWithProjection,
+ original_size: tuple,
+ crops_coords_top_left: tuple,
+ target_size: tuple,
+ dtype: torch.dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ unet_config.addition_time_embed_dim * len(add_time_ids) + text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = unet_add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+
+def main():
+ global_step = 0
+ min_steps_before_validation = 0
+
+ args = parse_args()
+
+ next_save_iter = args.save_starting_step
+
+ if args.save_starting_step < 1:
+ next_save_iter = None
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ kwargs_handlers=[InitProcessGroupKwargs(timeout=timedelta(args.nccl_timeout))]
+ )
+
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ nonlocal global_step
+
+ for model in models:
+ if isinstance(model, type(accelerator.unwrap_model(unet))):
+ model.save_pretrained(os.path.join(output_dir, 'unet'))
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_local_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Load the tokenizer
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+ tokenizer_2 = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer_2")
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ text_encoder_2 = CLIPTextModelWithProjection.from_pretrained(args.pretrained_model_name_or_path,
+ subfolder="text_encoder_2")
+
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
+
+ optimizer_resume_path = None
+
+ if args.unet_resume_path:
+ optimizer_fp = os.path.join(args.unet_resume_path, "optimizer.bin")
+
+ if os.path.exists(optimizer_fp):
+ optimizer_resume_path = optimizer_fp
+
+ unet = UNet3DConditionModel.from_pretrained(args.unet_resume_path,
+ subfolder="unet",
+ low_cpu_mem_usage=False,
+ device_map=None)
+
+ else:
+ unet = UNet3DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
+
+ if args.xformers:
+ vae.set_use_memory_efficient_attention_xformers(True, None)
+ unet.set_use_memory_efficient_attention_xformers(True, None)
+
+ unet_config = unet.config
+ unet_add_embedding = unet.add_embedding
+
+ unet.requires_grad_(False)
+
+ temporal_params = unet.temporal_parameters()
+
+ for p in temporal_params:
+ p.requires_grad_(True)
+
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+ text_encoder_2.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ learning_rate = args.learning_rate
+
+ params_to_optimize = [
+ {'params': temporal_params, "lr": learning_rate},
+ ]
+
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ if optimizer_resume_path and not args.disable_optimizer_restore:
+ logger.info("Restoring the optimizer.")
+ try:
+
+ old_optimizer_state_dict = torch.load(optimizer_resume_path)
+
+ # Extract only the state
+ old_state = old_optimizer_state_dict['state']
+
+ # Set the state of the new optimizer
+ optimizer.load_state_dict({'state': old_state, 'param_groups': optimizer.param_groups})
+
+ del old_optimizer_state_dict
+ del old_state
+
+ torch.cuda.empty_cache()
+ torch.cuda.synchronize()
+ gc.collect()
+
+ logger.info(f"Restored the optimizer ok")
+
+ except:
+ logger.error("Failed to restore the optimizer...", exc_info=True)
+ traceback.print_exc()
+ raise
+
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ def compute_snr(timesteps):
+ """
+ Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
+ """
+ alphas_cumprod = noise_scheduler.alphas_cumprod
+ sqrt_alphas_cumprod = alphas_cumprod ** 0.5
+ sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
+
+ # Expand the tensors.
+ # Adapted from https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L1026
+ sqrt_alphas_cumprod = sqrt_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
+ while len(sqrt_alphas_cumprod.shape) < len(timesteps.shape):
+ sqrt_alphas_cumprod = sqrt_alphas_cumprod[..., None]
+ alpha = sqrt_alphas_cumprod.expand(timesteps.shape)
+
+ sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
+ while len(sqrt_one_minus_alphas_cumprod.shape) < len(timesteps.shape):
+ sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod[..., None]
+ sigma = sqrt_one_minus_alphas_cumprod.expand(timesteps.shape)
+
+ # Compute SNR.
+ snr = (alpha / sigma) ** 2
+ return snr
+
+ device = torch.device('cuda')
+
+ image_transforms = transforms.Compose(
+ [
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def image_to_tensor(img):
+ with torch.no_grad():
+
+ if img.mode != "RGB":
+ img = img.convert("RGB")
+
+ image = image_transforms(img).to(accelerator.device)
+
+ if image.shape[0] == 1:
+ image = image.repeat(3, 1, 1)
+
+ if image.shape[0] > 3:
+ image = image[:3, :, :]
+
+ return image
+
+ def make_sample(sample):
+
+ nonlocal unet_config
+ nonlocal unet_add_embedding
+
+ images = [Image.open(img) for img in sample['image_fps']]
+
+ og_size = images[0].size
+
+ for i, im in enumerate(images):
+ if im.mode != "RGB":
+ images[i] = im.convert("RGB")
+
+ aspect_ratio_map = res_to_aspect_map[args.resolution]
+
+ required_size = tuple(aspect_ratio_map[args.aspect_ratio])
+
+ if required_size != og_size:
+
+ def resize_image(x):
+ img_size = x.size
+ if img_size == required_size:
+ return x.resize(required_size, Image.LANCZOS)
+
+ return scale_aspect_fill(x, required_size[0], required_size[1])
+
+ with ThreadPoolExecutor(max_workers=len(images)) as executor:
+ images = list(executor.map(resize_image, images))
+
+ frames = torch.stack([image_to_tensor(x) for x in images])
+
+ l, u, *_ = get_crop_coordinates(og_size, images[0].size)
+ crop_coords = (l, u)
+
+ additional_time_ids = add_time_ids(
+ unet_config,
+ unet_add_embedding,
+ text_encoder_2,
+ og_size,
+ crop_coords,
+ (required_size[0], required_size[1]),
+ dtype=torch.float32
+ ).to(device)
+
+ input_ids_0 = tokenizer(
+ sample['prompt'],
+ padding="do_not_pad",
+ truncation=True,
+ max_length=tokenizer.model_max_length,
+ ).input_ids
+
+ input_ids_1 = tokenizer_2(
+ sample['prompt'],
+ padding="do_not_pad",
+ truncation=True,
+ max_length=tokenizer.model_max_length,
+ ).input_ids
+
+ return {
+ "frames": frames,
+ "input_ids_0": input_ids_0,
+ "input_ids_1": input_ids_1,
+ "additional_time_ids": additional_time_ids,
+ }
+
+ def collate_fn(examples: list) -> dict:
+
+ # Two Text encoders
+ # First Text Encoder -> Penultimate Layer
+ # Second Text Encoder -> Pooled Layer
+
+ input_ids_0 = [example['input_ids_0'] for example in examples]
+ input_ids_0 = tokenizer.pad({"input_ids": input_ids_0}, padding="max_length",
+ max_length=tokenizer.model_max_length, return_tensors="pt").input_ids
+
+ prompt_embeds_0 = text_encoder(
+ input_ids_0.to(device),
+ output_hidden_states=True,
+ )
+
+ # we take penultimate embeddings from the first text encoder
+ prompt_embeds_0 = prompt_embeds_0.hidden_states[-2]
+
+ input_ids_1 = [example['input_ids_1'] for example in examples]
+ input_ids_1 = tokenizer_2.pad({"input_ids": input_ids_1}, padding="max_length",
+ max_length=tokenizer.model_max_length, return_tensors="pt").input_ids
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ prompt_embeds = text_encoder_2(
+ input_ids_1.to(device),
+ output_hidden_states=True
+ )
+
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds_1 = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds = torch.concat([prompt_embeds_0, prompt_embeds_1], dim=-1)
+
+ *_, h, w = examples[0]['frames'].shape
+
+ return {
+ "frames": torch.stack([x['frames'] for x in examples]).to(memory_format=torch.contiguous_format).float(),
+ "prompt_embeds": prompt_embeds.to(memory_format=torch.contiguous_format).float(),
+ "pooled_prompt_embeds": pooled_prompt_embeds,
+ "additional_time_ids": torch.stack([x['additional_time_ids'] for x in examples]),
+ }
+
+ # Region - Dataloaders
+ dataset = HotshotXLDataset(args.data_dir, make_sample)
+ dataloader = DataLoader(dataset, args.train_batch_size, shuffle=True, collate_fn=collate_fn)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(dataloader) / args.gradient_accumulation_steps)
+
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ unet, optimizer, lr_scheduler, dataloader = accelerator.prepare(
+ unet, optimizer, lr_scheduler, dataloader
+ )
+
+ def to_images(video_frames: torch.Tensor):
+ import torchvision.transforms as transforms
+ to_pil = transforms.ToPILImage()
+ video_frames = rearrange(video_frames, "b c f w h -> b f c w h")
+ bsz = video_frames.shape[0]
+ images = []
+ for i in range(bsz):
+ video = video_frames[i]
+ for j in range(video.shape[0]):
+ image = to_pil(video[j])
+ images.append(image)
+ return images
+
+ def to_video_frames(images: list) -> np.ndarray:
+ x = np.stack([np.asarray(img) for img in images])
+ return np.transpose(x, (0, 3, 1, 2))
+
+ def run_validation(step=0, node_index=0):
+
+ nonlocal global_step
+ nonlocal accelerator
+
+ if args.test_prompts:
+ prompts = args.test_prompts.split("|")
+ else:
+ prompts = [
+ "a woman is lifting weights in a gym",
+ "a group of people are dancing at a party",
+ "a teddy bear doing the front crawl"
+ ]
+
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ logger.info(f"Running inference to test model at {step} steps")
+ with torch.no_grad():
+
+ pipe = HotshotXLPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ vae=vae,
+ )
+
+ videos = []
+
+ aspect_ratio_map = res_to_aspect_map[args.resolution]
+ w, h = aspect_ratio_map[args.aspect_ratio]
+
+ for prompt in prompts:
+ video = pipe(prompt,
+ width=w,
+ height=h,
+ original_size=(1920, 1080), # todo - pass in as args?
+ target_size=(args.resolution, args.resolution),
+ num_inference_steps=30,
+ video_length=8,
+ output_type="tensor",
+ generator=torch.Generator().manual_seed(111)).videos
+
+ videos.append(to_images(video))
+
+ for tracker in accelerator.trackers:
+
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [wandb.Video(to_video_frames(video), fps=8, format='mp4') for video in
+ videos],
+ }, step=global_step
+ )
+
+ del pipe
+
+ return
+
+ # Move text_encode and vae to gpu.
+ vae.to(accelerator.device, dtype=torch.bfloat16 if args.vae_b16 else torch.float32)
+ text_encoder.to(accelerator.device)
+ text_encoder_2.to(accelerator.device)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+
+ num_update_steps_per_epoch = math.ceil(len(dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterward we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initialize automatically on the main process.
+
+ if accelerator.is_main_process:
+ accelerator.init_trackers(args.project_name)
+
+ def bar(prg):
+ br = '|' + '█' * prg + ' ' * (25 - prg) + '|'
+ return br
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ if accelerator.is_main_process:
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+
+ latents_scaler = vae.config.scaling_factor
+
+ def save_checkpoint():
+ save_dir = Path(args.output_dir)
+ save_dir = str(save_dir)
+ save_dir = save_dir.replace(" ", "_")
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir, exist_ok=True)
+ accelerator.save_state(save_dir)
+
+ def save_checkpoint_and_wait():
+ if accelerator.is_main_process:
+ save_checkpoint()
+ accelerator.wait_for_everyone()
+
+ def save_model_and_wait():
+ if accelerator.is_main_process:
+ HotshotXLPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ vae=vae,
+ ).save_pretrained(args.output_dir, safe_serialization=True)
+ accelerator.wait_for_everyone()
+
+ def compute_loss_from_batch(batch: dict):
+ frames = batch["frames"]
+ bsz, number_of_frames, c, w, h = frames.shape
+
+ # Convert images to latent space
+ with torch.no_grad():
+
+ if args.max_vae_encode:
+ latents = []
+
+ x = rearrange(frames, "bs nf c h w -> (bs nf) c h w")
+
+ for latent_index in range(0, x.shape[0], args.max_vae_encode):
+ sample = x[latent_index: latent_index + args.max_vae_encode]
+
+ latent = vae.encode(sample.to(dtype=vae.dtype)).latent_dist.sample().float()
+ if len(latent.shape) == 3:
+ latent = latent.unsqueeze(0)
+
+ latents.append(latent)
+ torch.cuda.empty_cache()
+
+ latents = torch.cat(latents, dim=0)
+ else:
+
+ # convert the latents from 5d -> 4d, so we can run it though the vae encoder
+ x = rearrange(frames, "bs nf c h w -> (bs nf) c h w")
+
+ del frames
+
+ torch.cuda.empty_cache()
+
+ latents = vae.encode(x.to(dtype=vae.dtype)).latent_dist.sample().float()
+
+ if args.latent_nan_checking and torch.any(torch.isnan(latents)):
+ accelerator.print("NaN found in latents, replacing with zeros")
+ latents = torch.where(torch.isnan(latents), torch.zeros_like(latents), latents)
+
+ latents = rearrange(latents, "(b f) c h w -> b c f h w", b=bsz)
+
+ torch.cuda.empty_cache()
+
+ noise = torch.randn_like(latents, device=latents.device)
+
+ if args.noise_offset:
+ # https://www.crosslabs.org//blog/diffusion-with-offset-noise
+ noise += args.noise_offset * torch.randn(
+ (latents.shape[0], latents.shape[1], 1, 1, 1), device=latents.device
+ )
+
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long() # .repeat_interleave(number_of_frames)
+ latents = latents * latents_scaler
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+
+ prompt_embeds = batch['prompt_embeds']
+ add_text_embeds = batch['pooled_prompt_embeds']
+
+ additional_time_ids = batch['additional_time_ids'] # .repeat_interleave(number_of_frames, dim=0)
+
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": additional_time_ids}
+
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ noisy_latents.requires_grad = True
+
+ model_pred = unet(noisy_latents,
+ timesteps,
+ cross_attention_kwargs=None,
+ encoder_hidden_states=prompt_embeds,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ )[0]
+
+ if args.snr_gamma:
+ # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Since we predict the noise instead of x_0, the original formulation is slightly changed.
+ # This is discussed in Section 4.2 of the same paper.
+ snr = compute_snr(timesteps)
+ mse_loss_weights = (
+ torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snr
+ )
+ # We first calculate the original loss. Then we mean over the non-batch dimensions and
+ # rebalance the sample-wise losses with their respective loss weights.
+ # Finally, we take the mean of the rebalanced loss.
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
+
+ loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
+ return loss.mean()
+ else:
+ return F.mse_loss(model_pred.float(), target.float(), reduction='mean')
+
+ def process_batch(batch: dict):
+ nonlocal global_step
+ nonlocal next_save_iter
+
+ now = time.time()
+
+ with accelerator.accumulate(unet):
+
+ logging_data = {}
+ if global_step == 0:
+ # print(f"Running initial validation at step")
+ if accelerator.is_main_process and args.run_validation_at_start:
+ run_validation(step=global_step, node_index=accelerator.process_index // 8)
+ accelerator.wait_for_everyone()
+
+ loss = compute_loss_from_batch(batch)
+
+ accelerator.backward(loss)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(temporal_params, args.max_grad_norm)
+
+ optimizer.step()
+
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ fll = round((global_step * 100) / args.max_train_steps)
+ fll = round(fll / 4)
+ pr = bar(fll)
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "loss_time": (time.time() - now)}
+
+ if args.validate_every_steps is not None and global_step > min_steps_before_validation and global_step % args.validate_every_steps == 0:
+ if accelerator.is_main_process:
+ run_validation(step=global_step, node_index=accelerator.process_index // 8)
+
+ accelerator.wait_for_everyone()
+
+ for key, val in logging_data.items():
+ logs[key] = val
+
+ progress_bar.set_postfix(**logs)
+ progress_bar.set_description_str("Progress:" + pr)
+ accelerator.log(logs, step=global_step)
+
+ if accelerator.is_main_process \
+ and next_save_iter is not None \
+ and global_step < args.max_train_steps \
+ and global_step + 1 == next_save_iter:
+ save_checkpoint()
+
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ next_save_iter += args.save_n_steps
+
+ for epoch in range(args.num_train_epochs):
+ unet.train()
+
+ for step, batch in enumerate(dataloader):
+ process_batch(batch)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if global_step >= args.max_train_steps:
+ logger.info("Max train steps reached. Breaking while loop")
+ break
+
+ accelerator.wait_for_everyone()
+
+ save_model_and_wait()
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ mp.set_start_method('spawn')
+ main()
diff --git a/Hotshot-XL/hotshot_xl.egg-info/PKG-INFO b/Hotshot-XL/hotshot_xl.egg-info/PKG-INFO
new file mode 100644
index 0000000000000000000000000000000000000000..c5a69f0e876b5dc5487724466a0e4bbf785dae5f
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/PKG-INFO
@@ -0,0 +1,5 @@
+Metadata-Version: 2.1
+Name: hotshot-xl
+Version: 1.0
+Author: Natural Synthetics Inc
+License-File: LICENSE
diff --git a/Hotshot-XL/hotshot_xl.egg-info/SOURCES.txt b/Hotshot-XL/hotshot_xl.egg-info/SOURCES.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3ed4b371ebcd300dfc12e2ab0dc01179f8b1e105
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/SOURCES.txt
@@ -0,0 +1,19 @@
+LICENSE
+README.md
+setup.py
+hotshot_xl/__init__.py
+hotshot_xl/utils.py
+hotshot_xl.egg-info/PKG-INFO
+hotshot_xl.egg-info/SOURCES.txt
+hotshot_xl.egg-info/dependency_links.txt
+hotshot_xl.egg-info/requires.txt
+hotshot_xl.egg-info/top_level.txt
+hotshot_xl/models/__init__.py
+hotshot_xl/models/resnet.py
+hotshot_xl/models/transformer_3d.py
+hotshot_xl/models/transformer_temporal.py
+hotshot_xl/models/unet.py
+hotshot_xl/models/unet_blocks.py
+hotshot_xl/pipelines/__init__.py
+hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
+hotshot_xl/pipelines/hotshot_xl_pipeline.py
\ No newline at end of file
diff --git a/Hotshot-XL/hotshot_xl.egg-info/dependency_links.txt b/Hotshot-XL/hotshot_xl.egg-info/dependency_links.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/Hotshot-XL/hotshot_xl.egg-info/requires.txt b/Hotshot-XL/hotshot_xl.egg-info/requires.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2d1a81d2018e60ad898957360c90c60540ecd689
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/requires.txt
@@ -0,0 +1,5 @@
+torch>=2.0.1
+torchvision>=0.15.2
+diffusers>=0.21.4
+transformers>=4.33.3
+einops
diff --git a/Hotshot-XL/hotshot_xl.egg-info/top_level.txt b/Hotshot-XL/hotshot_xl.egg-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5d4814c5f5827393e60d27fbbc56f76343591f02
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl.egg-info/top_level.txt
@@ -0,0 +1 @@
+hotshot_xl
diff --git a/Hotshot-XL/hotshot_xl/__init__.py b/Hotshot-XL/hotshot_xl/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..090de024570c67f7182c8e5b214c81f3aaadaf6e
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/__init__.py
@@ -0,0 +1,25 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Union
+
+import numpy as np
+import torch
+
+# don't remove these imports - they are needed to load from pretrain.
+from diffusers.models.modeling_utils import ModelMixin
+from .models.unet import UNet3DConditionModel
+
+from diffusers.utils import (
+ BaseOutput,
+)
+
+@dataclass
+class HotshotPipelineXLOutput(BaseOutput):
+ videos: Union[torch.Tensor, np.ndarray]
\ No newline at end of file
diff --git a/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-38.pyc b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8314477c38f726534d49f13619dfb67ad53770e7
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-39.pyc b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b470ab2f7a9a638702e5840a2ad0fcc349883920
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/__pycache__/__init__.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/__pycache__/utils.cpython-39.pyc b/Hotshot-XL/hotshot_xl/__pycache__/utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2d4c0a2e2da291336b883d6807be026b5eddddab
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/__pycache__/utils.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__init__.py b/Hotshot-XL/hotshot_xl/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dbef36bf5a6f9e97ceec62f81b1e7c0e18e09795
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..df3b414c2761b4a650deca945fcdbdb5ed29c47a
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/__init__.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c4a6a79993ebb204d5474c552c74c4033da6449b
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0678bc932aec8d292fd98a4356598ec765d49666
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/resnet.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2469126f7a14d7de7f6aaa53f186ec6956b88e3e
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3edb0f7f7f8a8a6319c17916e61145a4751cc5cd
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_3d.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..62a4da5e527e1f7aa34c19ae4b63a1db907f468e
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..09596b9533d22b0c8e58c6fe72ca84d01fa906f0
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/transformer_temporal.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f8ebddea6476de30f98291d7fb4402f75dd68dea
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d5e52f761f4b5d863d04ade537953181322ebbdb
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-38.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f9d3fe512196ae0e97609e0910cb29997dc011ad
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-39.pyc b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bfb4f31a082ce59bb9bcc48dd7f96835f83e4b90
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/models/__pycache__/unet_blocks.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/models/resnet.py b/Hotshot-XL/hotshot_xl/models/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b46c907610a9a4fb73288f280c79e923b86c89a
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/resnet.py
@@ -0,0 +1,134 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import torch.nn as nn
+from diffusers.models.resnet import Upsample2D, Downsample2D, LoRACompatibleConv
+from einops import rearrange
+
+
+class Upsample3D(Upsample2D):
+ def forward(self, hidden_states, output_size=None, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Upsample3D, self).forward(hidden_states, output_size, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Downsample3D(Downsample2D):
+
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super(Downsample3D, self).forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class Conv3d(LoRACompatibleConv):
+ def forward(self, hidden_states, scale: float = 1.0):
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ hidden_states = super().forward(hidden_states, scale)
+ return rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+
+class ResnetBlock3D(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="silu",
+ time_embedding_norm="default",
+ output_scale_factor=1.0,
+ use_in_shortcut=None,
+ conv_shortcut_bias: bool = True,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
+ self.conv1 = Conv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ if self.time_embedding_norm == "default":
+ time_emb_proj_out_channels = out_channels
+ elif self.time_embedding_norm == "scale_shift":
+ time_emb_proj_out_channels = out_channels * 2
+ else:
+ raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
+
+ self.time_emb_proj = torch.nn.Linear(temb_channels, time_emb_proj_out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = Conv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ assert non_linearity == "silu"
+
+ self.nonlinearity = nn.SiLU()
+
+ self.use_in_shortcut = self.in_channels != self.out_channels if use_in_shortcut is None else use_in_shortcut
+
+ self.conv_shortcut = None
+ if self.use_in_shortcut:
+ self.conv_shortcut = Conv3d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
+ )
+
+ def forward(self, input_tensor, temb):
+ hidden_states = input_tensor
+
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+
+ if temb is not None:
+ temb = self.nonlinearity(temb)
+ temb = self.time_emb_proj(temb)[:, :, None, None, None]
+
+ if temb is not None and self.time_embedding_norm == "default":
+ hidden_states = hidden_states + temb
+
+ hidden_states = self.norm2(hidden_states)
+
+ if temb is not None and self.time_embedding_norm == "scale_shift":
+ scale, shift = torch.chunk(temb, 2, dim=1)
+ hidden_states = hidden_states * (1 + scale) + shift
+
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ input_tensor = self.conv_shortcut(input_tensor)
+
+ output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
+
+ return output_tensor
diff --git a/Hotshot-XL/hotshot_xl/models/transformer_3d.py b/Hotshot-XL/hotshot_xl/models/transformer_3d.py
new file mode 100644
index 0000000000000000000000000000000000000000..169f91ee6f2bcd568141a5776820429140370f6f
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/transformer_3d.py
@@ -0,0 +1,75 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+from dataclasses import dataclass
+from typing import Optional
+import torch
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.transformer_2d import Transformer2DModel
+from einops import rearrange, repeat
+from typing import Dict, Any
+
+
+@dataclass
+class Transformer3DModelOutput(BaseOutput):
+ """
+ The output of [`Transformer3DModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`:
+ The hidden states output conditioned on the `encoder_hidden_states` input.
+ """
+
+ sample: torch.FloatTensor
+
+
+class Transformer3DModel(Transformer2DModel):
+
+ def __init__(self, *args, **kwargs):
+ super(Transformer3DModel, self).__init__(*args, **kwargs)
+ nn.init.zeros_(self.proj_out.weight.data)
+ nn.init.zeros_(self.proj_out.bias.data)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ enable_temporal_layers: bool = True,
+ positional_embedding: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ):
+
+ is_video = len(hidden_states.shape) == 5
+
+ if is_video:
+ f = hidden_states.shape[2]
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+ encoder_hidden_states = repeat(encoder_hidden_states, 'b n c -> (b f) n c', f=f)
+
+ hidden_states = super(Transformer3DModel, self).forward(hidden_states,
+ encoder_hidden_states,
+ timestep,
+ class_labels,
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ return_dict=False)[0]
+
+ if is_video:
+ hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f)
+
+ if not return_dict:
+ return (hidden_states,)
+
+ return Transformer3DModelOutput(sample=hidden_states)
\ No newline at end of file
diff --git a/Hotshot-XL/hotshot_xl/models/transformer_temporal.py b/Hotshot-XL/hotshot_xl/models/transformer_temporal.py
new file mode 100644
index 0000000000000000000000000000000000000000..772e51d55da5ebf3279235b482c1db7e46e2b603
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/transformer_temporal.py
@@ -0,0 +1,192 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+
+import torch
+import math
+from dataclasses import dataclass
+from torch import nn
+from diffusers.utils import BaseOutput
+from diffusers.models.attention import Attention, FeedForward
+from einops import rearrange, repeat
+from typing import Optional
+
+
+class PositionalEncoding(nn.Module):
+ """
+ Implements positional encoding as described in "Attention Is All You Need".
+ Adds sinusoidal based positional encodings to the input tensor.
+ """
+
+ _SCALE_FACTOR = 10000.0 # Scale factor used in the positional encoding computation.
+
+ def __init__(self, dim: int, dropout: float = 0.0, max_length: int = 24):
+ super(PositionalEncoding, self).__init__()
+
+ self.dropout = nn.Dropout(p=dropout)
+
+ # The size is (1, max_length, dim) to allow easy addition to input tensors.
+ positional_encoding = torch.zeros(1, max_length, dim)
+
+ # Position and dim are used in the sinusoidal computation.
+ position = torch.arange(max_length).unsqueeze(1)
+ div_term = torch.exp(torch.arange(0, dim, 2) * (-math.log(self._SCALE_FACTOR) / dim))
+
+ positional_encoding[0, :, 0::2] = torch.sin(position * div_term)
+ positional_encoding[0, :, 1::2] = torch.cos(position * div_term)
+
+ # Register the positional encoding matrix as a buffer,
+ # so it's part of the model's state but not the parameters.
+ self.register_buffer('positional_encoding', positional_encoding)
+
+ def forward(self, hidden_states: torch.Tensor, length: int) -> torch.Tensor:
+ hidden_states = hidden_states + self.positional_encoding[:, :length]
+ return self.dropout(hidden_states)
+
+
+class TemporalAttention(Attention):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.pos_encoder = PositionalEncoding(kwargs["query_dim"], dropout=0)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=8):
+ sequence_length = hidden_states.shape[1]
+ hidden_states = rearrange(hidden_states, "(b f) s c -> (b s) f c", f=number_of_frames)
+ hidden_states = self.pos_encoder(hidden_states, length=number_of_frames)
+
+ if encoder_hidden_states:
+ encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b s) n c", s=sequence_length)
+
+ hidden_states = super().forward(hidden_states, encoder_hidden_states, attention_mask=attention_mask)
+
+ return rearrange(hidden_states, "(b s) f c -> (b f) s c", s=sequence_length)
+
+
+@dataclass
+class TransformerTemporalOutput(BaseOutput):
+ sample: torch.FloatTensor
+
+
+class TransformerTemporal(nn.Module):
+ def __init__(
+ self,
+ num_attention_heads: int,
+ attention_head_dim: int,
+ in_channels: int,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ activation_fn: str = "geglu",
+ upcast_attention: bool = False,
+ ):
+ super().__init__()
+
+ inner_dim = num_attention_heads * attention_head_dim
+
+ self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ TransformerBlock(
+ dim=inner_dim,
+ num_attention_heads=num_attention_heads,
+ attention_head_dim=attention_head_dim,
+ dropout=dropout,
+ activation_fn=activation_fn,
+ attention_bias=attention_bias,
+ upcast_attention=upcast_attention,
+ cross_attention_dim=cross_attention_dim
+ )
+ for _ in range(num_layers)
+ ]
+ )
+ self.proj_out = nn.Linear(inner_dim, in_channels)
+
+ def forward(self, hidden_states, encoder_hidden_states=None):
+ _, num_channels, f, height, width = hidden_states.shape
+ hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
+
+ skip = hidden_states
+
+ hidden_states = self.norm(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf c h w -> bf (h w) c")
+ hidden_states = self.proj_in(hidden_states)
+
+ for block in self.transformer_blocks:
+ hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, number_of_frames=f)
+
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = rearrange(hidden_states, "bf (h w) c -> bf c h w", h=height, w=width).contiguous()
+
+ output = hidden_states + skip
+ output = rearrange(output, "(b f) c h w -> b c f h w", f=f)
+
+ return output
+
+
+class TransformerBlock(nn.Module):
+ def __init__(
+ self,
+ dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=0.0,
+ activation_fn="geglu",
+ attention_bias=False,
+ upcast_attention=False,
+ depth=2,
+ cross_attention_dim: Optional[int] = None
+ ):
+ super().__init__()
+
+ self.is_cross = cross_attention_dim is not None
+
+ attention_blocks = []
+ norms = []
+
+ for _ in range(depth):
+ attention_blocks.append(
+ TemporalAttention(
+ query_dim=dim,
+ cross_attention_dim=cross_attention_dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ upcast_attention=upcast_attention,
+ )
+ )
+ norms.append(nn.LayerNorm(dim))
+
+ self.attention_blocks = nn.ModuleList(attention_blocks)
+ self.norms = nn.ModuleList(norms)
+
+ self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
+ self.ff_norm = nn.LayerNorm(dim)
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, number_of_frames=None):
+
+ if not self.is_cross:
+ encoder_hidden_states = None
+
+ for block, norm in zip(self.attention_blocks, self.norms):
+ norm_hidden_states = norm(hidden_states)
+ hidden_states = block(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ number_of_frames=number_of_frames
+ ) + hidden_states
+
+ norm_hidden_states = self.ff_norm(hidden_states)
+ hidden_states = self.ff(norm_hidden_states) + hidden_states
+
+ output = hidden_states
+ return output
diff --git a/Hotshot-XL/hotshot_xl/models/unet.py b/Hotshot-XL/hotshot_xl/models/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..30b45fe9fcf7d2e0e898aa7ebd36494ee13998ef
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/unet.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Unet now supports SDXL
+
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.loaders import UNet2DConditionLoadersMixin
+from diffusers.utils import BaseOutput, logging
+from diffusers.models.activations import get_activation
+from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
+from diffusers.models.embeddings import (
+ GaussianFourierProjection,
+ ImageHintTimeEmbedding,
+ ImageProjection,
+ ImageTimeEmbedding,
+ TextImageProjection,
+ TextImageTimeEmbedding,
+ TextTimeEmbedding,
+ TimestepEmbedding,
+ Timesteps,
+)
+
+from diffusers.models.modeling_utils import ModelMixin
+from diffusers.models.embeddings import TimestepEmbedding, Timesteps
+from .unet_blocks import (
+ CrossAttnDownBlock3D,
+ CrossAttnUpBlock3D,
+ DownBlock3D,
+ UNetMidBlock3DCrossAttn,
+ UpBlock3D,
+ get_down_block,
+ get_up_block,
+)
+
+from .resnet import Conv3d
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet3DConditionOutput(BaseOutput):
+ """
+ The output of [`UNet2DConditionModel`].
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor = None
+
+
+class UNet3DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ "DownBlock3D",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlock3DCrossAttn",
+ up_block_types: Tuple[str] = (
+ "UpBlock3D",
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ ),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: Union[int, Tuple[int]] = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ transformer_layers_per_block: Union[int, Tuple[int]] = 1,
+ encoder_hid_dim: Optional[int] = None,
+ encoder_hid_dim_type: Optional[str] = None,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ addition_embed_type: Optional[str] = None,
+ addition_time_embed_dim: Optional[int] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ resnet_skip_time_act: bool = False,
+ resnet_out_scale_factor: int = 1.0,
+ time_embedding_type: str = "positional",
+ time_embedding_dim: Optional[int] = None,
+ time_embedding_act_fn: Optional[str] = None,
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ mid_block_only_cross_attention: Optional[bool] = None,
+ cross_attention_norm: Optional[str] = None,
+ addition_embed_type_num_heads=64,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ if num_attention_heads is not None:
+ raise ValueError(
+ "At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
+ )
+
+ # If `num_attention_heads` is not defined (which is the case for most models)
+ # it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
+ # The reason for this behavior is to correct for incorrectly named variables that were introduced
+ # when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
+ # Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
+ # which is why we correct for the naming here.
+ num_attention_heads = num_attention_heads or attention_head_dim
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+
+ self.conv_in = Conv3d(in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding)
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ if encoder_hid_dim_type is None and encoder_hid_dim is not None:
+ encoder_hid_dim_type = "text_proj"
+ self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
+ logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
+
+ if encoder_hid_dim is None and encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
+ )
+
+ if encoder_hid_dim_type == "text_proj":
+ self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
+ elif encoder_hid_dim_type == "text_image_proj":
+ # image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
+ self.encoder_hid_proj = TextImageProjection(
+ text_embed_dim=encoder_hid_dim,
+ image_embed_dim=cross_attention_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2
+ self.encoder_hid_proj = ImageProjection(
+ image_embed_dim=encoder_hid_dim,
+ cross_attention_dim=cross_attention_dim,
+ )
+ elif encoder_hid_dim_type is not None:
+ raise ValueError(
+ f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
+ )
+ else:
+ self.encoder_hid_proj = None
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ if addition_embed_type == "text":
+ if encoder_hid_dim is not None:
+ text_time_embedding_from_dim = encoder_hid_dim
+ else:
+ text_time_embedding_from_dim = cross_attention_dim
+
+ self.add_embedding = TextTimeEmbedding(
+ text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
+ )
+ elif addition_embed_type == "text_image":
+ # text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
+ # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
+ # case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
+ self.add_embedding = TextImageTimeEmbedding(
+ text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
+ )
+ elif addition_embed_type == "text_time":
+ self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
+ self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif addition_embed_type == "image":
+ # Kandinsky 2.2
+ self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type == "image_hint":
+ # Kandinsky 2.2 ControlNet
+ self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
+ elif addition_embed_type is not None:
+ raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
+
+ if time_embedding_act_fn is None:
+ self.time_embed_act = None
+ else:
+ self.time_embed_act = get_activation(time_embedding_act_fn)
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = only_cross_attention
+
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if mid_block_only_cross_attention is None:
+ mid_block_only_cross_attention = False
+
+ if isinstance(num_attention_heads, int):
+ num_attention_heads = (num_attention_heads,) * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if isinstance(layers_per_block, int):
+ layers_per_block = [layers_per_block] * len(down_block_types)
+
+ if isinstance(transformer_layers_per_block, int):
+ transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ res = 2 ** i
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block[i],
+ transformer_layers_per_block=transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ num_attention_heads=num_attention_heads[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlock3DCrossAttn":
+ self.mid_block = UNetMidBlock3DCrossAttn(
+ transformer_layers_per_block=transformer_layers_per_block[-1],
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ num_attention_heads=num_attention_heads[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
+ raise ValueError("UNetMidBlock2DSimpleCrossAttn not supported")
+
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_num_attention_heads = list(reversed(num_attention_heads))
+ reversed_layers_per_block = list(reversed(layers_per_block))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ res = 2 ** (len(up_block_types) - 1 - i)
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=reversed_layers_per_block[i] + 1,
+ transformer_layers_per_block=reversed_transformer_layers_per_block[i],
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ num_attention_heads=reversed_num_attention_heads[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ resnet_skip_time_act=resnet_skip_time_act,
+ resnet_out_scale_factor=resnet_out_scale_factor,
+ cross_attention_norm=cross_attention_norm,
+ attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+
+ self.conv_act = get_activation(act_fn)
+
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+
+ self.conv_out = Conv3d(block_out_channels[0], out_channels, kernel_size=conv_out_kernel,
+ padding=conv_out_padding)
+
+ def temporal_parameters(self) -> list:
+ output = []
+ all_blocks = self.down_blocks + self.up_blocks + [self.mid_block]
+ for block in all_blocks:
+ output.extend(block.temporal_parameters())
+ return output
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ return self.get_attn_processors(include_temporal_layers=False)
+
+ def get_attn_processors(self, include_temporal_layers=True) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+
+ if not include_temporal_layers:
+ if 'temporal' in name:
+ return processors
+
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]],
+ include_temporal_layers=False):
+ r"""
+ Sets the attention processor to use to compute attention.
+
+ Parameters:
+ processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ for **all** `Attention` layers.
+
+ If `processor` is a dict, the key needs to define the path to the corresponding cross attention
+ processor. This is strongly recommended when setting trainable attention processors.
+
+ """
+ count = len(self.get_attn_processors(include_temporal_layers=include_temporal_layers).keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+
+ if not include_temporal_layers:
+ if "temporal" in name:
+ return
+
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module splits the input tensor in slices to compute attention in
+ several steps. This is useful for saving some memory in exchange for a small decrease in speed.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
+ `"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ enable_temporal_attentions: bool = True
+ ) -> Union[UNet3DConditionOutput, Tuple]:
+ r"""
+ The [`UNet2DConditionModel`] forward method.
+
+ Args:
+ sample (`torch.FloatTensor`):
+ The noisy input tensor with the following shape `(batch, channel, height, width)`.
+ timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
+ encoder_hidden_states (`torch.FloatTensor`):
+ The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
+ encoder_attention_mask (`torch.Tensor`):
+ A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
+ `True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
+ which adds large negative values to the attention scores corresponding to "discard" tokens.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
+ tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
+ added_cond_kwargs: (`dict`, *optional*):
+ A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
+ are passed along to the UNet blocks.
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
+ a `tuple` is returned where the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2 ** self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # ensure attention_mask is a bias, and give it a singleton query_tokens dimension
+ # expects mask of shape:
+ # [batch, key_tokens]
+ # adds singleton query_tokens dimension:
+ # [batch, 1, key_tokens]
+ # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
+ # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
+ # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
+ if attention_mask is not None:
+ # assume that mask is expressed as:
+ # (1 = keep, 0 = discard)
+ # convert mask into a bias that can be added to attention scores:
+ # (keep = +0, discard = -10000.0)
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # convert encoder_attention_mask to a bias the same way we do for attention_mask
+ if encoder_attention_mask is not None:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=sample.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+ aug_emb = None
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ # `Timesteps` does not contain any weights and will always return f32 tensors
+ # there might be better ways to encapsulate this.
+ class_labels = class_labels.to(dtype=sample.dtype)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ if self.config.addition_embed_type == "text":
+ aug_emb = self.add_embedding(encoder_hidden_states)
+ elif self.config.addition_embed_type == "text_image":
+ # Kandinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+
+ image_embs = added_cond_kwargs.get("image_embeds")
+ text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
+ aug_emb = self.add_embedding(text_embs, image_embs)
+ elif self.config.addition_embed_type == "text_time":
+ if "text_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
+ )
+ text_embeds = added_cond_kwargs.get("text_embeds")
+ if "time_ids" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
+ )
+ time_ids = added_cond_kwargs.get("time_ids")
+ time_embeds = self.add_time_proj(time_ids.flatten())
+ time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
+
+ add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
+ add_embeds = add_embeds.to(emb.dtype)
+ aug_emb = self.add_embedding(add_embeds)
+ elif self.config.addition_embed_type == "image":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ aug_emb = self.add_embedding(image_embs)
+ elif self.config.addition_embed_type == "image_hint":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
+ )
+ image_embs = added_cond_kwargs.get("image_embeds")
+ hint = added_cond_kwargs.get("hint")
+ aug_emb, hint = self.add_embedding(image_embs, hint)
+ sample = torch.cat([sample, hint], dim=1)
+
+ emb = emb + aug_emb if aug_emb is not None else emb
+
+ if self.time_embed_act is not None:
+ emb = self.time_embed_act(emb)
+
+ if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
+ # Kadinsky 2.1 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
+ elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
+ # Kandinsky 2.2 - style
+ if "image_embeds" not in added_cond_kwargs:
+ raise ValueError(
+ f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
+ )
+ image_embeds = added_cond_kwargs.get("image_embeds")
+ encoder_hidden_states = self.encoder_hid_proj(image_embeds)
+ # 2. pre-process
+
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ upsample_size=upsample_size,
+ encoder_hidden_states=encoder_hidden_states,
+ enable_temporal_attentions=enable_temporal_attentions
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet3DConditionOutput(sample=sample)
+
+ @classmethod
+ def from_pretrained_spatial(cls, pretrained_model_path, subfolder=None):
+
+ import os
+ import json
+
+ if subfolder is not None:
+ pretrained_model_path = os.path.join(pretrained_model_path, subfolder)
+
+ config_file = os.path.join(pretrained_model_path, 'config.json')
+
+ with open(config_file, "r") as f:
+ config = json.load(f)
+
+ config["_class_name"] = "UNet3DConditionModel"
+
+ config["down_block_types"] = [
+ "DownBlock3D",
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ ]
+ config["up_block_types"] = [
+ "CrossAttnUpBlock3D",
+ "CrossAttnUpBlock3D",
+ "UpBlock3D"
+ ]
+
+ config["mid_block_type"] = "UNetMidBlock3DCrossAttn"
+
+ model = cls.from_config(config)
+
+ model_files = [
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.bin'),
+ os.path.join(pretrained_model_path, 'diffusion_pytorch_model.safetensors')
+ ]
+
+ model_file = None
+
+ for fp in model_files:
+ if os.path.exists(fp):
+ model_file = fp
+
+ if not model_file:
+ raise RuntimeError(f"{model_file} does not exist")
+
+ state_dict = torch.load(model_file, map_location="cpu")
+
+ model.load_state_dict(state_dict, strict=False)
+
+ return model
diff --git a/Hotshot-XL/hotshot_xl/models/unet_blocks.py b/Hotshot-XL/hotshot_xl/models/unet_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..e642d4f8b56600b58238fdb7a243fb1e360a621d
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/models/unet_blocks.py
@@ -0,0 +1,740 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Add temporal transformers to unet blocks
+
+import torch
+from torch import nn
+
+from .transformer_3d import Transformer3DModel
+from .resnet import Downsample3D, ResnetBlock3D, Upsample3D
+from .transformer_temporal import TransformerTemporal
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ downsample_type=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock3D":
+ return DownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D")
+ return CrossAttnDownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ transformer_layers_per_block=1,
+ num_attention_heads=None,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+ resnet_skip_time_act=False,
+ resnet_out_scale_factor=1.0,
+ cross_attention_norm=None,
+ attention_head_dim=None,
+ upsample_type=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock3D":
+ return UpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D")
+ return CrossAttnUpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ transformer_layers_per_block=transformer_layers_per_block,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ num_attention_heads=num_attention_heads,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock3DCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ in_channels // num_attention_heads,
+ in_channels=in_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ return []
+
+
+class CrossAttnDownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None,
+ cross_attention_kwargs=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if temporal_attention and enable_temporal_attentions:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class DownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample3D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None, enable_temporal_attentions: bool = True):
+ output_states = ()
+
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states, encoder_hidden_states=encoder_hidden_states)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class CrossAttnUpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ transformer_layers_per_block: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ num_attention_heads=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temporal_attentions = []
+
+ self.has_cross_attention = True
+ self.num_attention_heads = num_attention_heads
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if dual_cross_attention:
+ raise NotImplementedError
+ attentions.append(
+ Transformer3DModel(
+ num_attention_heads,
+ out_channels // num_attention_heads,
+ in_channels=out_channels,
+ num_layers=transformer_layers_per_block,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ upsample_size=None,
+ cross_attention_kwargs=None,
+ attention_mask=None,
+ enable_temporal_attentions: bool = True
+ ):
+ for resnet, attn, temporal_attention \
+ in zip(self.resnets, self.attentions, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ use_reentrant=False,
+ )[0]
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states).sample
+
+ if enable_temporal_attentions and temporal_attention:
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
+
+
+class UpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ temporal_attentions = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock3D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temporal_attentions.append(
+ TransformerTemporal(
+ num_attention_heads=8,
+ attention_head_dim=out_channels // 8,
+ in_channels=out_channels,
+ cross_attention_dim=None
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temporal_attentions = nn.ModuleList(temporal_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample3D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, encoder_hidden_states=None,
+ enable_temporal_attentions: bool = True):
+ for resnet, temporal_attention in zip(self.resnets, self.temporal_attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb,
+ use_reentrant=False)
+ if enable_temporal_attentions and temporal_attention is not None:
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(temporal_attention),
+ hidden_states, encoder_hidden_states,
+ use_reentrant=False)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temporal_attention(hidden_states,
+ encoder_hidden_states=encoder_hidden_states) if enable_temporal_attentions and temporal_attention is not None else hidden_states
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+ def temporal_parameters(self) -> list:
+ output = []
+ for block in self.temporal_attentions:
+ if block:
+ output.extend(block.parameters())
+ return output
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__init__.py b/Hotshot-XL/hotshot_xl/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-38.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..837f54d8354052949995f9225e3a0a32ee1f51a2
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-39.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..608c366d4065f2f3a3f9a30f6335dc2d2461dea8
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/__init__.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-38.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e486c8b99469f44e8ac918d8ca17a609ba526a80
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-39.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cc024d7d8ec3a1a56e5c4151dca7ba563b23730c
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_controlnet_pipeline.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-38.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84177377f32b1f5ecfca5aae0676e7429708f087
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-38.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-39.pyc b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..367a8a1151fa42951fbceff2ea6bfb17859716cd
Binary files /dev/null and b/Hotshot-XL/hotshot_xl/pipelines/__pycache__/hotshot_xl_pipeline.cpython-39.pyc differ
diff --git a/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..b084688662309ef71b429d20a5edfc9c8f494f9f
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_controlnet_pipeline.py
@@ -0,0 +1,1389 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Controlnet Pipeline to work temporally
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, ControlNetModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.utils.torch_utils import randn_tensor, is_compiled_module
+
+from ..models.unet import UNet3DConditionModel
+
+from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
+from einops import rearrange
+from tqdm import tqdm
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+ >>> from diffusers import ControlNetModel
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL",
+ ... controlnet=ControlNetModel.from_pretrained("diffusers/controlnet-canny-sdxl-1.0")
+ ... )
+
+ >>> def canny(image):
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> return Image.fromarray(image)
+
+ >>> # assuming you have 8 keyframes in current directory...
+
+ >>> keyframes = [f"image_{i}.jpg" for i in range(8)]
+ >>> control_images = [canny(Image.open(fp)) for fp in keyframes]
+
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor",
+ ... controlnet_conditioning_scale=0.7,
+ ... control_images=control_images
+ ).video
+ ```
+"""
+class HotshotXLControlNetPipeline(
+ DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
+ implemented for all pipelines (downloading, saving, running on a particular device, etc.).
+
+ The pipeline also inherits the following loading methods:
+ - [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
+ - [`loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
+ - [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
+ text_encoder ([`~transformers.CLIPTextModel`]):
+ Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
+ text_encoder_2 ([`~transformers.CLIPTextModelWithProjection`]):
+ Second frozen text-encoder
+ ([laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)).
+ tokenizer ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ tokenizer_2 ([`~transformers.CLIPTokenizer`]):
+ A `CLIPTokenizer` to tokenize text.
+ unet ([`UNet3DConditionModel`]):
+ A `UNet3DConditionModel` to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the `unet` during the denoising process. If you set multiple
+ ControlNets as a list, the outputs from each ControlNet are added together to create one combined
+ additional conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
+ Whether the negative prompt embeddings should always be set to 0. Also see the config of
+ `stabilityai/stable-diffusion-xl-base-1-0`.
+ add_watermarker (`bool`, *optional*):
+ Whether to use the [invisible_watermark](https://github.com/ShieldMnt/invisible-watermark/) library to
+ watermark output images. If not defined, it defaults to `True` if the package is installed; otherwise no
+ watermarker is used.
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
+ self.control_image_processor = VaeImageProcessor(
+ vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
+ )
+
+ self.watermark = None
+
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ control_guidance_start=0.0,
+ control_guidance_end=1.0,
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+
+ assert len(control_images) == video_length
+ # for image in control_images:
+ # self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ ...
+ # todo
+ #
+ # if not isinstance(image, list):
+ # raise TypeError("For multiple controlnets: `image` must be type `list`")
+ #
+ # # When `image` is a nested list:
+ # # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ # elif any(isinstance(i, list) for i in image):
+ # raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ # elif len(image) != len(self.controlnet.nets):
+ # raise ValueError(
+ # f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets."
+ # )
+ #
+ # for image_ in image:
+ # self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ if not isinstance(control_guidance_start, (tuple, list)):
+ control_guidance_start = [control_guidance_start]
+
+ if not isinstance(control_guidance_end, (tuple, list)):
+ control_guidance_end = [control_guidance_end]
+
+ if len(control_guidance_start) != len(control_guidance_end):
+ raise ValueError(
+ f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
+ )
+
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if len(control_guidance_start) != len(self.controlnet.nets):
+ raise ValueError(
+ f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
+ )
+
+ for start, end in zip(control_guidance_start, control_guidance_end):
+ if start >= end:
+ raise ValueError(
+ f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
+ )
+ if start < 0.0:
+ raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
+ if end > 1.0:
+ raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_np = isinstance(image, np.ndarray)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+ image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
+
+ if (
+ not image_is_pil
+ and not image_is_tensor
+ and not image_is_np
+ and not image_is_pil_list
+ and not image_is_tensor_list
+ and not image_is_np_list
+ ):
+ raise TypeError(
+ f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ else:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_images(
+ self,
+ images,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ images_pre_processed = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+
+ images_pre_processed = torch.cat(images_pre_processed, dim=0)
+
+ repeat_factor = [1] * len(images_pre_processed.shape)
+ repeat_factor[0] = batch_size * num_images_per_prompt
+ images_pre_processed = images_pre_processed.repeat(*repeat_factor)
+
+ images = images_pre_processed.unsqueeze(0)
+
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+
+ #image = image.repeat_interleave(repeat_by, dim=0)
+
+ images = images.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ repeat_factor = [1] * len(images.shape)
+ repeat_factor[0] = 2
+ images = images.repeat(*repeat_factor)
+
+ return images
+
+ # def prepare_images(self,
+ # images: list,
+ # width,
+ # height,
+ # batch_size,
+ # num_images_per_prompt,
+ # device,
+ # dtype,
+ # do_classifier_free_guidance=False,
+ # guess_mode=False):
+ #
+ # images = [self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) for image in images]
+ #
+ # image_batch_size = image.shape[0]
+ #
+ # if image_batch_size == 1:
+ # repeat_by = batch_size
+ # else:
+ # # image batch size is the same as prompt batch size
+ # repeat_by = num_images_per_prompt
+ #
+ # image = image.repeat_interleave(repeat_by, dim=0)
+ #
+ # image = image.to(device=device, dtype=dtype)
+ #
+ # if do_classifier_free_guidance and not guess_mode:
+ # image = torch.cat([image] * 2)
+ #
+ # return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ #shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._get_add_time_ids
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ control_images: List[PIL.Image.Image] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ guess_mode: bool = False,
+ control_guidance_start: Union[float, List[float]] = 0.0,
+ control_guidance_end: Union[float, List[float]] = 1.0,
+ original_size: Tuple[int, int] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Tuple[int, int] = None,
+ negative_original_size: Optional[Tuple[int, int]] = None,
+ negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
+ negative_target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ The call function to the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
+ `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
+ specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
+ accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
+ and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
+ `init`, images must be passed as a list such that each element of the list can be correctly batched for
+ input to a single ControlNet.
+ height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ A higher guidance scale value encourages the model to generate images closely linked to the text
+ `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. If not defined, you need to
+ pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. This is sent to `tokenizer_2`
+ and `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
+ generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor is generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
+ provided, text embeddings are generated from the `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, pooled text embeddings are generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs (prompt
+ weighting). If not provided, pooled `negative_prompt_embeds` are generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between `PIL.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that calls every `callback_steps` steps during inference. The function is called with the
+ following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function is called. If not specified, the callback is called at
+ every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
+ [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
+ the corresponding scale as a list.
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ The ControlNet encoder tries to recognize the content of the input image even if you remove all
+ prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
+ control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
+ The percentage of total steps at which the ControlNet starts applying.
+ control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The percentage of total steps at which the ControlNet stops applying.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a specific image resolution. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
+ micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+ negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ To negatively condition the generation process based on a target image resolution. It should be as same
+ as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
+ information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
+ otherwise a `tuple` is returned containing the output images.
+ """
+
+
+ if video_length > 1 and num_images_per_prompt > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ # align format for control guidance
+ if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
+ control_guidance_start = len(control_guidance_end) * [control_guidance_start]
+ elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
+ control_guidance_end = len(control_guidance_start) * [control_guidance_end]
+ elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
+ mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
+ control_guidance_start, control_guidance_end = mult * [control_guidance_start], mult * [
+ control_guidance_end
+ ]
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ control_images,
+ video_length,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ controlnet_conditioning_scale,
+ control_guidance_start,
+ control_guidance_end,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt,
+ prompt_2,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+
+ assert len(control_images) == video_length * batch_size
+
+ images = self.prepare_images(
+ images=control_images,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ height, width = images.shape[-2:]
+ elif isinstance(controlnet, MultiControlNetModel):
+
+ raise Exception("not supported yet")
+
+ # images = []
+ #
+ # for image_ in control_images:
+ # image_ = self.prepare_image(
+ # image=image_,
+ # width=width,
+ # height=height,
+ # batch_size=batch_size * num_images_per_prompt,
+ # num_images_per_prompt=num_images_per_prompt,
+ # device=device,
+ # dtype=controlnet.dtype,
+ # do_classifier_free_guidance=do_classifier_free_guidance,
+ # guess_mode=guess_mode,
+ # )
+ #
+ # images.append(image_)
+ #
+ # image = images
+ # height, width = image[0].shape[-2:]
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7.1 Create tensor stating which controlnets to keep
+ controlnet_keep = []
+ for i in range(len(timesteps)):
+ keeps = [
+ 1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
+ for s, e in zip(control_guidance_start, control_guidance_end)
+ ]
+ controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
+
+ # 7.2 Prepare added time ids & embeddings
+ # if isinstance(image, list):
+ # original_size = original_size or image[0].shape[-2:]
+ # else:
+ original_size = original_size or images.shape[-2:]
+ target_size = target_size or (height, width)
+
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ if negative_original_size is not None and negative_target_size is not None:
+ negative_add_time_ids = self._get_add_time_ids(
+ negative_original_size,
+ negative_crops_coords_top_left,
+ negative_target_size,
+ dtype=prompt_embeds.dtype,
+ )
+ else:
+ negative_add_time_ids = add_time_ids
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+
+ images = rearrange(images, "b f c h w -> (b f) c h w")
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ control_model_input = latents
+ control_model_input = self.scheduler.scale_model_input(control_model_input, t)
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ controlnet_added_cond_kwargs = {
+ "text_embeds": add_text_embeds.chunk(2)[1],
+ "time_ids": add_time_ids.chunk(2)[1],
+ }
+ else:
+ control_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+ controlnet_added_cond_kwargs = added_cond_kwargs
+
+ if isinstance(controlnet_keep[i], list):
+ cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
+ else:
+ controlnet_cond_scale = controlnet_conditioning_scale
+ if isinstance(controlnet_cond_scale, list):
+ controlnet_cond_scale = controlnet_cond_scale[0]
+ cond_scale = controlnet_cond_scale * controlnet_keep[i]
+
+
+ # this will be non interlaced when arranged!
+ control_model_input = rearrange(control_model_input, "b c f h w -> (b f) c h w")
+ # if we chunked this by 2 - the top 8 frames will be positive for cfg
+ # the bottom half will be negative for cfg...
+
+ if video_length > 1:
+ # use repeat_interleave as we need to match the rearrangement above.
+
+ controlnet_prompt_embeds = controlnet_prompt_embeds.repeat_interleave(video_length, dim=0)
+ controlnet_added_cond_kwargs = {
+ "text_embeds": controlnet_added_cond_kwargs['text_embeds'].repeat_interleave(video_length, dim=0),
+ "time_ids": controlnet_added_cond_kwargs['time_ids'].repeat_interleave(video_length, dim=0)
+ }
+
+ # if type(image) is list:
+ # image = torch.cat(image, dim=0)
+
+ # todo - check if video_length > 1 this needs to produce num_frames * batch_size samples...
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ control_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=images,
+ conditioning_scale=cond_scale,
+ guess_mode=guess_mode,
+ added_cond_kwargs=controlnet_added_cond_kwargs,
+ return_dict=False,
+ )
+
+ for j, sample in enumerate(down_block_res_samples):
+ down_block_res_samples[j] = rearrange(sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ mid_block_res_sample = rearrange(mid_block_res_sample, "(b f) c h w -> b c f h w", f=video_length)
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions=video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ # if not output_type == "latent":
+ # # make sure the VAE is in float32 mode, as it overflows in float16
+ # needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
+ #
+ # if needs_upcasting:
+ # self.upcast_vae()
+ # latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+ #
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ #
+ # # cast back to fp16 if needed
+ # if needs_upcasting:
+ # self.vae.to(dtype=torch.float16)
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.load_lora_weights
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.save_lora_weights
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = True,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._remove_text_encoder_monkey_patch
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_pipeline.py b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c3b41da67eacee21c8cb192de343e47d5fe30d0
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/pipelines/hotshot_xl_pipeline.py
@@ -0,0 +1,975 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Modifications:
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+# - Adapted the SDXL Pipeline to work temporally
+
+
+import os
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+from hotshot_xl import HotshotPipelineXLOutput
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL
+from hotshot_xl.models.unet import UNet3DConditionModel
+from diffusers.models.attention_processor import (
+ AttnProcessor2_0,
+ LoRAAttnProcessor2_0,
+ LoRAXFormersAttnProcessor,
+ XFormersAttnProcessor,
+)
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ replace_example_docstring,
+)
+from diffusers.utils.torch_utils import randn_tensor
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from tqdm import tqdm
+from einops import repeat, rearrange
+from diffusers.utils import deprecate, logging
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from hotshot_xl import HotshotPipelineXL
+
+ >>> pipe = HotshotXLPipeline.from_pretrained(
+ ... "hotshotco/Hotshot-XL"
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> video = pipe(prompt,
+ ... width=672, height=384,
+ ... original_size=(1920, 1080),
+ ... target_size=(512, 512),
+ ... output_type="tensor"
+ ).video
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
+
+
+class HotshotXLPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *LoRA*: [`HotshotPipelineXL.load_lora_weights`]
+ - *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
+
+ as well as the following saving methods:
+ - *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion XL uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([` CLIPTextModelWithProjection`]):
+ Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
+ specifically the
+ [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
+ variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`CLIPTokenizer`):
+ Second Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet3DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ scheduler=scheduler,
+ )
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.default_sample_size = self.unet.config.sample_size
+ self.watermark = None
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, LoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: procecss multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, video_length, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, video_length, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (
+ AttnProcessor2_0,
+ XFormersAttnProcessor,
+ LoRAXFormersAttnProcessor,
+ LoRAAttnProcessor2_0,
+ ),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ video_length: Optional[int] = 8,
+ num_images_per_prompt: Optional[int] = 1,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ negative_prompt_2: Optional[Union[str, List[str]]] = None,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ denoising_end (`float`, *optional*):
+ When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
+ completed before it is intentionally prematurely terminated. As a result, the returned sample will
+ still retain a substantial amount of noise as determined by the discrete timesteps selected by the
+ scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
+ "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
+ Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
+ of a plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.7):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+
+ Examples:
+
+ Returns:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] or `tuple`:
+ [`~hotshot_xl.HotshotPipelineXLOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ if video_length > 1:
+ print(f"Warning - setting num_images_per_prompt = 1 because video_length = {video_length}")
+ num_images_per_prompt = 1
+
+ # 0. Default height and width to unet
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ text_encoder_lora_scale = (
+ cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+ )
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = self.encode_prompt(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ lora_scale=text_encoder_lora_scale,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ video_length,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Prepare added time ids & embeddings
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ # todo - negative_original_size from latest diffusers for cfg
+
+ if do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ # 8. Denoising loop
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ # 7.1 Apply denoising_end
+ if denoising_end is not None and type(denoising_end) == float and denoising_end > 0 and denoising_end < 1:
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (denoising_end * self.scheduler.config.num_train_timesteps)
+ )
+ )
+ num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
+ timesteps = timesteps[:num_inference_steps]
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ enable_temporal_attentions= video_length > 1
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ # if not output_type == "latent":
+ # image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ # else:
+ # image = latents
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # apply watermark if available
+ # if self.watermark is not None:
+ # image = self.watermark.apply_watermark(image)
+
+ #image = self.image_processor.postprocess(image, output_type=output_type)
+
+ video = self.decode_latents(latents)
+
+ # Convert to tensor
+ if output_type == "tensor":
+ video = torch.from_numpy(video)
+
+ if not return_dict:
+ return video
+
+ return HotshotPipelineXLOutput(videos=video)
+
+ #
+ # # Offload last model to CPU
+ # if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ # self.final_offload_hook.offload()
+ #
+ # if not return_dict:
+ # return (image,)
+ #
+ # return StableDiffusionXLPipelineOutput(images=image)
+
+ # Overrride to properly handle the loading and unloading of the additional text encoder.
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ def save_lora_weights(
+ self,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ self.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ def decode_latents(self, latents):
+ video_length = latents.shape[2]
+ latents = 1 / self.vae.config.scaling_factor * latents
+ latents = rearrange(latents, "b c f h w -> (b f) c h w")
+ # video = self.vae.decode(latents).sample
+ video = []
+ for frame_idx in tqdm(range(latents.shape[0])):
+ video.append(self.vae.decode(
+ latents[frame_idx:frame_idx+1]).sample)
+ video = torch.cat(video)
+ video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
+ video = (video / 2.0 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
+ video = video.cpu().float().numpy()
+ return video
+
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
diff --git a/Hotshot-XL/hotshot_xl/utils.py b/Hotshot-XL/hotshot_xl/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7660c2a756ecae141333a7081ea358549db6ba6
--- /dev/null
+++ b/Hotshot-XL/hotshot_xl/utils.py
@@ -0,0 +1,213 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Union
+from io import BytesIO
+import PIL
+from PIL import ImageSequence, Image
+import requests
+import os
+
+def get_image(img_path) -> PIL.Image.Image:
+ if img_path.startswith("http"):
+ return PIL.Image.open(requests.get(img_path, stream=True).raw)
+ if os.path.exists(img_path):
+ return Image.open(img_path)
+ raise Exception("File not found")
+
+def images_to_gif_bytes(images: List, duration: int = 1000) -> bytes:
+ with BytesIO() as output_buffer:
+ # Save the first image
+ images[0].save(output_buffer,
+ format='GIF',
+ save_all=True,
+ append_images=images[1:],
+ duration=duration,
+ loop=0) # 0 means the GIF will loop indefinitely
+
+ # Get the byte array from the buffer
+ gif_bytes = output_buffer.getvalue()
+
+ return gif_bytes
+
+
+def save_as_gif(images: List, file_path: str, duration: int = 1000):
+ with open(file_path, "wb") as f:
+ f.write(images_to_gif_bytes(images, duration))
+
+def scale_aspect_fill(img, new_width, new_height):
+ new_width = int(new_width)
+ new_height = int(new_height)
+
+ original_width, original_height = img.size
+ ratio_w = float(new_width) / original_width
+ ratio_h = float(new_height) / original_height
+
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(original_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(original_width * ratio_h)
+ resize_height = new_height
+
+ img_resized = img.resize((resize_width, resize_height), Image.LANCZOS)
+
+ # Calculate cropping boundaries and do crop
+ left = (resize_width - new_width) / 2
+ top = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ bottom = (resize_height + new_height) / 2
+
+ img_cropped = img_resized.crop((left, top, right, bottom))
+
+ return img_cropped
+
+def extract_gif_frames_from_midpoint(image: Union[str, PIL.Image.Image], fps: int=8, target_duration: int=1000) -> list:
+ # Load the GIF
+ image = get_image(image) if type(image) is str else image
+
+ frames = []
+
+ estimated_frame_time = None
+
+ # some gifs contain the duration - others don't
+ # so if there is a duration we will grab it otherwise we will fall back
+
+ for frame in ImageSequence.Iterator(image):
+
+ frames.append(frame.copy())
+ if 'duration' in frame.info:
+ frame_info_duration = frame.info['duration']
+ if frame_info_duration > 0:
+ estimated_frame_time = frame_info_duration
+
+ if estimated_frame_time is None:
+ if len(frames) <= 16:
+ # assume it's 8fps
+ estimated_frame_time = 1000 // 8
+ else:
+ # assume it's 15 fps
+ estimated_frame_time = 70
+
+ if len(frames) < fps:
+ raise ValueError(f"fps of {fps} is too small for this gif as it only has {len(frames)} frames.")
+
+ skip = len(frames) // fps
+ upper_bound_index = len(frames) - 1
+
+ best_indices = [x for x in range(0, len(frames), skip)][:fps]
+ offset = int(upper_bound_index - best_indices[-1]) // 2
+ best_indices = [x + offset for x in best_indices]
+ best_duration = (best_indices[-1] - best_indices[0]) * estimated_frame_time
+
+ while True:
+
+ skip -= 1
+
+ if skip == 0:
+ break
+
+ indices = [x for x in range(0, len(frames), skip)][:fps]
+
+ # center the indices, so we sample the middle of the gif...
+ offset = int(upper_bound_index - indices[-1]) // 2
+ if offset == 0:
+ # can't shift
+ break
+ indices = [x + offset for x in indices]
+
+ # is the new duration closer to the target than last guess?
+ duration = (indices[-1] - indices[0]) * estimated_frame_time
+ if abs(duration - target_duration) > abs(best_duration - target_duration):
+ break
+
+ best_indices = indices
+ best_duration = duration
+
+ return [frames[index] for index in best_indices]
+
+def get_crop_coordinates(old_size: tuple, new_size: tuple) -> tuple:
+ """
+ Calculate the crop coordinates after scaling an image to fit a new size.
+
+ :param old_size: tuple of the form (width, height) representing the original size of the image.
+ :param new_size: tuple of the form (width, height) representing the desired size after scaling.
+ :return: tuple of the form (left, upper, right, lower) representing the normalized crop coordinates.
+ """
+ # Check if the input tuples have the right form (width, height)
+ if not (isinstance(old_size, tuple) and isinstance(new_size, tuple) and
+ len(old_size) == 2 and len(new_size) == 2):
+ raise ValueError("old_size and new_size should be tuples of the form (width, height)")
+
+ # Extract the width and height from the old and new sizes
+ old_width, old_height = old_size
+ new_width, new_height = new_size
+
+ # Calculate the ratios for width and height
+ ratio_w = float(new_width) / old_width
+ ratio_h = float(new_height) / old_height
+
+ # Determine which dimension is fixed (width or height)
+ if ratio_w > ratio_h:
+ # It must be fixed by width
+ resize_width = new_width
+ resize_height = round(old_height * ratio_w)
+ else:
+ # Fixed by height
+ resize_width = round(old_width * ratio_h)
+ resize_height = new_height
+
+ # Calculate cropping boundaries in the resized image space
+ left = (resize_width - new_width) / 2
+ upper = (resize_height - new_height) / 2
+ right = (resize_width + new_width) / 2
+ lower = (resize_height + new_height) / 2
+
+ # Normalize the cropping coordinates
+
+ # Return the normalized coordinates as a tuple
+ return (left, upper, right, lower)
+
+aspect_ratio_to_1024_map = {
+ "0.42": [640, 1536],
+ "0.57": [768, 1344],
+ "0.68": [832, 1216],
+ "1.00": [1024, 1024],
+ "1.46": [1216, 832],
+ "1.75": [1344, 768],
+ "2.40": [1536, 640]
+}
+
+res_to_aspect_map = {
+ 1024: aspect_ratio_to_1024_map,
+ 512: {key: [value[0] // 2, value[1] // 2] for key, value in aspect_ratio_to_1024_map.items()},
+}
+
+def best_aspect_ratio(aspect_ratio: float, resolution: int):
+
+ map = res_to_aspect_map[resolution]
+
+ d = 99999999
+ res = None
+ for key, value in map.items():
+ ar = value[0] / value[1]
+ diff = abs(aspect_ratio - ar)
+ if diff < d:
+ d = diff
+ res = value
+
+ ar = res[0] / res[1]
+ return f"{ar:.2f}", res
\ No newline at end of file
diff --git a/Hotshot-XL/inference.py b/Hotshot-XL/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..5394321cd68466e8ef433d4afedb658c2dcccc85
--- /dev/null
+++ b/Hotshot-XL/inference.py
@@ -0,0 +1,223 @@
+# Copyright 2023 Natural Synthetics Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+
+sys.path.append("/")
+import os
+import argparse
+import torch
+from hotshot_xl.pipelines.hotshot_xl_pipeline import HotshotXLPipeline
+from hotshot_xl.pipelines.hotshot_xl_controlnet_pipeline import HotshotXLControlNetPipeline
+from hotshot_xl.models.unet import UNet3DConditionModel
+import torchvision.transforms as transforms
+from einops import rearrange
+from hotshot_xl.utils import save_as_gif, extract_gif_frames_from_midpoint, scale_aspect_fill
+from torch import autocast
+from diffusers import ControlNetModel
+from contextlib import contextmanager
+from diffusers.schedulers.scheduling_euler_ancestral_discrete import EulerAncestralDiscreteScheduler
+from diffusers.schedulers.scheduling_euler_discrete import EulerDiscreteScheduler
+
+SCHEDULERS = {
+ 'EulerAncestralDiscreteScheduler': EulerAncestralDiscreteScheduler,
+ 'EulerDiscreteScheduler': EulerDiscreteScheduler,
+ 'default': None,
+ # add more here
+}
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Hotshot-XL inference")
+ parser.add_argument("--pretrained_path", type=str, default="hotshotco/Hotshot-XL")
+ parser.add_argument("--xformers", action="store_true")
+ parser.add_argument("--spatial_unet_base", type=str)
+ parser.add_argument("--lora", type=str)
+ parser.add_argument("--output", type=str, required=True)
+ parser.add_argument("--steps", type=int, default=30)
+ parser.add_argument("--prompt", type=str,
+ default="a bulldog in the captains chair of a spaceship, hd, high quality")
+ parser.add_argument("--negative_prompt", type=str, default="blurry")
+ parser.add_argument("--seed", type=int, default=455)
+ parser.add_argument("--width", type=int, default=672)
+ parser.add_argument("--height", type=int, default=384)
+ parser.add_argument("--target_width", type=int, default=512)
+ parser.add_argument("--target_height", type=int, default=512)
+ parser.add_argument("--og_width", type=int, default=1920)
+ parser.add_argument("--og_height", type=int, default=1080)
+ parser.add_argument("--video_length", type=int, default=8)
+ parser.add_argument("--video_duration", type=int, default=1000)
+ parser.add_argument('--scheduler', type=str, default='EulerAncestralDiscreteScheduler',
+ help='Name of the scheduler to use')
+
+ parser.add_argument("--control_type", type=str, default=None, choices=["depth", "canny"])
+ parser.add_argument("--controlnet_conditioning_scale", type=float, default=0.7)
+ parser.add_argument("--control_guidance_start", type=float, default=0.0)
+ parser.add_argument("--control_guidance_end", type=float, default=1.0)
+ parser.add_argument("--gif", type=str, default=None)
+ parser.add_argument("--precision", type=str, default='f16', choices=[
+ 'f16', 'f32', 'bf16'
+ ])
+ parser.add_argument("--autocast", type=str, default=None, choices=[
+ 'f16', 'bf16'
+ ])
+
+ return parser.parse_args()
+
+
+to_pil = transforms.ToPILImage()
+
+
+def to_pil_images(video_frames: torch.Tensor, output_type='pil'):
+ video_frames = rearrange(video_frames, "b c f w h -> b f c w h")
+ bsz = video_frames.shape[0]
+ images = []
+ for i in range(bsz):
+ video = video_frames[i]
+ for j in range(video.shape[0]):
+ if output_type == "pil":
+ images.append(to_pil(video[j]))
+ else:
+ images.append(video[j])
+ return images
+
+@contextmanager
+def maybe_auto_cast(data_type):
+ if data_type:
+ with autocast("cuda", dtype=data_type):
+ yield
+ else:
+ yield
+
+
+def main():
+ args = parse_args()
+
+ if args.control_type and not args.gif:
+ raise ValueError("Controlnet specified but you didn't specify a gif!")
+
+ if args.gif and not args.control_type:
+ print("warning: gif was specified but no control type was specified. gif will be ignored.")
+
+ output_dir = os.path.dirname(args.output)
+ if output_dir:
+ os.makedirs(output_dir, exist_ok=True)
+
+ device = torch.device("cuda")
+
+ control_net_model_pretrained_path = None
+ if args.control_type:
+ control_type_to_model_map = {
+ "canny": "diffusers/controlnet-canny-sdxl-1.0",
+ "depth": "diffusers/controlnet-depth-sdxl-1.0",
+ }
+ control_net_model_pretrained_path = control_type_to_model_map[args.control_type]
+
+ data_type = torch.float32
+
+ if args.precision == 'f16':
+ data_type = torch.half
+ elif args.precision == 'f32':
+ data_type = torch.float32
+ elif args.precision == 'bf16':
+ data_type = torch.bfloat16
+
+ pipe_line_args = {
+ "torch_dtype": data_type,
+ "use_safetensors": True
+ }
+
+ PipelineClass = HotshotXLPipeline
+
+ if control_net_model_pretrained_path:
+ PipelineClass = HotshotXLControlNetPipeline
+ pipe_line_args['controlnet'] = \
+ ControlNetModel.from_pretrained(control_net_model_pretrained_path, torch_dtype=data_type)
+
+ if args.spatial_unet_base:
+
+ unet_3d = UNet3DConditionModel.from_pretrained(args.pretrained_path, subfolder="unet").to(device)
+
+ unet = UNet3DConditionModel.from_pretrained_spatial(args.spatial_unet_base).to(device)
+
+ temporal_layers = {}
+ unet_3d_sd = unet_3d.state_dict()
+
+ for k, v in unet_3d_sd.items():
+ if 'temporal' in k:
+ temporal_layers[k] = v
+
+ unet.load_state_dict(temporal_layers, strict=False)
+
+ pipe_line_args['unet'] = unet
+
+ del unet_3d_sd
+ del unet_3d
+ del temporal_layers
+
+ pipe = PipelineClass.from_pretrained(args.pretrained_path, **pipe_line_args).to(device)
+
+ if args.lora:
+ pipe.load_lora_weights(args.lora)
+
+ SchedulerClass = SCHEDULERS[args.scheduler]
+ if SchedulerClass is not None:
+ pipe.scheduler = SchedulerClass.from_config(pipe.scheduler.config)
+
+ if args.xformers:
+ pipe.enable_xformers_memory_efficient_attention()
+
+ generator = torch.Generator().manual_seed(args.seed) if args.seed else None
+
+ autocast_type = None
+ if args.autocast == 'f16':
+ autocast_type = torch.half
+ elif args.autocast == 'bf16':
+ autocast_type = torch.bfloat16
+
+ kwargs = {}
+
+ if args.gif and type(pipe) is HotshotXLControlNetPipeline:
+ kwargs['control_images'] = [
+ scale_aspect_fill(img, args.width, args.height).convert("RGB") \
+ for img in
+ extract_gif_frames_from_midpoint(args.gif, fps=args.video_length, target_duration=args.video_duration)
+ ]
+ kwargs['controlnet_conditioning_scale'] = args.controlnet_conditioning_scale
+ kwargs['control_guidance_start'] = args.control_guidance_start
+ kwargs['control_guidance_end'] = args.control_guidance_end
+
+ with maybe_auto_cast(autocast_type):
+
+ images = pipe(args.prompt,
+ negative_prompt=args.negative_prompt,
+ width=args.width,
+ height=args.height,
+ original_size=(args.og_width, args.og_height),
+ target_size=(args.target_width, args.target_height),
+ num_inference_steps=args.steps,
+ video_length=args.video_length,
+ generator=generator,
+ output_type="tensor", **kwargs).videos
+
+ images = to_pil_images(images, output_type="pil")
+
+ if args.video_length > 1:
+ save_as_gif(images, args.output, duration=args.video_duration // args.video_length)
+ else:
+ images[0].save(args.output, format='JPEG', quality=95)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Hotshot-XL/output.gif b/Hotshot-XL/output.gif
new file mode 100644
index 0000000000000000000000000000000000000000..4714db5a6ca255fa131def1461c9a90561863260
--- /dev/null
+++ b/Hotshot-XL/output.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cd22cd80f6cad88aa326846d6bf954f01044fce917229bdbc40e365493f3a161
+size 1606177
diff --git a/Hotshot-XL/requirements.txt b/Hotshot-XL/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..17c3d6faa34794c966483520aa46af2d0434150c
--- /dev/null
+++ b/Hotshot-XL/requirements.txt
@@ -0,0 +1,62 @@
+accelerate==0.23.0
+appdirs==1.4.4
+certifi==2023.7.22
+charset-normalizer==3.3.0
+click==8.1.7
+cmake==3.27.6
+decorator==4.4.2
+diffusers==0.21.4
+docker-pycreds==0.4.0
+einops==0.7.0
+filelock==3.12.4
+fsspec==2023.9.2
+gitdb==4.0.10
+GitPython==3.1.37
+huggingface-hub==0.16.4
+idna==3.4
+imageio==2.31.5
+imageio-ffmpeg==0.4.9
+importlib-metadata==6.8.0
+Jinja2==3.1.2
+lit==17.0.2
+MarkupSafe==2.1.3
+moviepy==1.0.3
+mpmath==1.3.0
+networkx==3.1
+numpy==1.26.0
+nvidia-cublas-cu11==11.10.3.66
+nvidia-cuda-cupti-cu11==11.7.101
+nvidia-cuda-nvrtc-cu11==11.7.99
+nvidia-cuda-runtime-cu11==11.7.99
+nvidia-cudnn-cu11==8.5.0.96
+nvidia-cufft-cu11==10.9.0.58
+nvidia-curand-cu11==10.2.10.91
+nvidia-cusolver-cu11==11.4.0.1
+nvidia-cusparse-cu11==11.7.4.91
+nvidia-nccl-cu11==2.14.3
+nvidia-nvtx-cu11==11.7.91
+packaging==23.2
+pathtools==0.1.2
+Pillow==10.0.1
+proglog==0.1.10
+protobuf==4.24.3
+psutil==5.9.5
+PyYAML==6.0.1
+regex==2023.10.3
+requests==2.31.0
+safetensors==0.3.3
+sentry-sdk==1.31.0
+setproctitle==1.3.3
+six==1.16.0
+smmap==5.0.1
+sympy==1.12
+tokenizers==0.14.0
+torch==2.0.1
+torchvision==0.15.2
+tqdm==4.66.1
+transformers==4.34.0
+triton==2.0.0
+typing_extensions==4.8.0
+urllib3==2.0.6
+wandb==0.15.11
+zipp==3.17.0
diff --git a/Hotshot-XL/run.sh b/Hotshot-XL/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ae415b2bb41371edf8d5f0d63e0a2be501208069
--- /dev/null
+++ b/Hotshot-XL/run.sh
@@ -0,0 +1,2 @@
+python inference.py --prompt="village men and women in a hut" --output="2.gif"
+
diff --git a/Hotshot-XL/setup.py b/Hotshot-XL/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1a7f0ca65d590e0ded9cd0d8747826b60e24add
--- /dev/null
+++ b/Hotshot-XL/setup.py
@@ -0,0 +1,15 @@
+from setuptools import setup, find_packages
+
+setup(
+ name='hotshot_xl',
+ version='1.0',
+ packages=find_packages(include=['hotshot_xl*',]),
+ author="Natural Synthetics Inc",
+ install_requires=[
+ "torch>=2.0.1",
+ "torchvision>=0.15.2",
+ "diffusers>=0.21.4",
+ "transformers>=4.33.3",
+ "einops"
+ ],
+)
\ No newline at end of file