
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.11B
| node_id
stringlengths 18
32
| number
int64 1
3.59k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
int64 1,587B
1,642B
| updated_at
int64 1,587B
1,642B
| closed_at
int64 1,587B
1,642B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/648/comments | https://api.github.com/repos/huggingface/datasets/issues/648/events | https://github.com/huggingface/datasets/issues/648 | 704,753,123 | MDU6SXNzdWU3MDQ3NTMxMjM= | 648 | offset overflow when multiprocessing batched map on large datasets. | {
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"This should be fixed with #645 ",
"Feel free to re-open if it still occurs"
] | 1,600,481,711,000 | 1,600,534,027,000 | 1,600,533,991,000 | CONTRIBUTOR | null | It only happened when "multiprocessing" + "batched" + "large dataset" at the same time.
```
def bprocess(examples):
examples['len'] = []
for text in examples['text']:
examples['len'].append(len(text))
return examples
wiki.map(brpocess, batched=True, num_proc=8)
```
```
---------------------------------------------------------------------------
RemoteTraceback Traceback (most recent call last)
RemoteTraceback:
"""
Traceback (most recent call last):
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/multiprocessing/pool.py", line 121, in worker
result = (True, func(*args, **kwds))
File "/home/yisiang/datasets/src/datasets/arrow_dataset.py", line 153, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/yisiang/datasets/src/datasets/fingerprint.py", line 163, in wrapper
out = func(self, *args, **kwargs)
File "/home/yisiang/datasets/src/datasets/arrow_dataset.py", line 1486, in _map_single
batch = self[i : i + batch_size]
File "/home/yisiang/datasets/src/datasets/arrow_dataset.py", line 1071, in __getitem__
format_kwargs=self._format_kwargs,
File "/home/yisiang/datasets/src/datasets/arrow_dataset.py", line 972, in _getitem
data_subset = self._data.take(indices_array)
File "pyarrow/table.pxi", line 1145, in pyarrow.lib.Table.take
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/pyarrow/compute.py", line 268, in take
return call_function('take', [data, indices], options)
File "pyarrow/_compute.pyx", line 298, in pyarrow._compute.call_function
File "pyarrow/_compute.pyx", line 192, in pyarrow._compute.Function.call
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: offset overflow while concatenating arrays
"""
The above exception was the direct cause of the following exception:
ArrowInvalid Traceback (most recent call last)
in
30 owt = datasets.load_dataset('/home/yisiang/datasets/datasets/openwebtext/openwebtext.py', cache_dir='./datasets')['train']
31 print('load/create data from OpenWebText Corpus for ELECTRA')
---> 32 e_owt = ELECTRAProcessor(owt, apply_cleaning=False).map(cache_file_name=f"electra_owt_{c.max_length}.arrow")
33 dsets.append(e_owt)
34
~/Reexamine_Attention/electra_pytorch/_utils/utils.py in map(self, **kwargs)
126 writer_batch_size=10**4,
127 num_proc=num_proc,
--> 128 **kwargs
129 )
130
~/hugdatafast/hugdatafast/transform.py in my_map(self, *args, **kwargs)
21 if not cache_file_name.endswith('.arrow'): cache_file_name += '.arrow'
22 if '/' not in cache_file_name: cache_file_name = os.path.join(self.cache_directory(), cache_file_name)
---> 23 return self.map(*args, cache_file_name=cache_file_name, **kwargs)
24
25 @patch
~/datasets/src/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1285 logger.info("Spawning {} processes".format(num_proc))
1286 results = [pool.apply_async(self.__class__._map_single, kwds=kwds) for kwds in kwds_per_shard]
-> 1287 transformed_shards = [r.get() for r in results]
1288 logger.info("Concatenating {} shards from multiprocessing".format(num_proc))
1289 result = concatenate_datasets(transformed_shards)
~/datasets/src/datasets/arrow_dataset.py in (.0)
1285 logger.info("Spawning {} processes".format(num_proc))
1286 results = [pool.apply_async(self.__class__._map_single, kwds=kwds) for kwds in kwds_per_shard]
-> 1287 transformed_shards = [r.get() for r in results]
1288 logger.info("Concatenating {} shards from multiprocessing".format(num_proc))
1289 result = concatenate_datasets(transformed_shards)
~/miniconda3/envs/ml/lib/python3.7/multiprocessing/pool.py in get(self, timeout)
655 return self._value
656 else:
--> 657 raise self._value
658
659 def _set(self, i, obj):
ArrowInvalid: offset overflow while concatenating arrays
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/648/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/647/comments | https://api.github.com/repos/huggingface/datasets/issues/647/events | https://github.com/huggingface/datasets/issues/647 | 704,734,764 | MDU6SXNzdWU3MDQ3MzQ3NjQ= | 647 | Cannot download dataset_info.json | {
"login": "chiyuzhang94",
"id": 33407613,
"node_id": "MDQ6VXNlcjMzNDA3NjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/33407613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chiyuzhang94",
"html_url": "https://github.com/chiyuzhang94",
"followers_url": "https://api.github.com/users/chiyuzhang94/followers",
"following_url": "https://api.github.com/users/chiyuzhang94/following{/other_user}",
"gists_url": "https://api.github.com/users/chiyuzhang94/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chiyuzhang94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chiyuzhang94/subscriptions",
"organizations_url": "https://api.github.com/users/chiyuzhang94/orgs",
"repos_url": "https://api.github.com/users/chiyuzhang94/repos",
"events_url": "https://api.github.com/users/chiyuzhang94/events{/privacy}",
"received_events_url": "https://api.github.com/users/chiyuzhang94/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for reporting !\r\nWe should add support for servers without internet connection indeed\r\nI'll do that early next week",
"Thanks, @lhoestq !\r\nPlease let me know when it is available. ",
"Right now the recommended way is to create the dataset on a server with internet connection and then to save it and copy the serialized dataset to the server without internet connection.",
"#652 should allow you to load text/json/csv/pandas datasets without an internet connection **IF** you've the dataset script locally.\r\n\r\nExample: \r\nIf you have `datasets/text/text.py` locally, then you can do `load_dataset(\"./datasets/text\", data_files=...)`"
] | 1,600,479,315,000 | 1,600,676,922,000 | 1,600,676,922,000 | NONE | null | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text/default-53ee3045f07ba8ca/0.0.0/dataset_info.json
```
I tried to open this link manually, but I cannot access this file. How can I download this file and pass it through `dataset.load_dataset()` manually?
Versions:
Python version 3.7.3
PyTorch version 1.6.0
TensorFlow version 2.3.0
datasets version: 1.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/647/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/646/comments | https://api.github.com/repos/huggingface/datasets/issues/646/events | https://github.com/huggingface/datasets/pull/646 | 704,607,371 | MDExOlB1bGxSZXF1ZXN0NDg5NTAyMTM3 | 646 | Fix docs typos | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,457,547,000 | 1,600,705,854,000 | 1,600,704,852,000 | CONTRIBUTOR | null | This PR fixes few typos in the docs and the error in the code snippet in the set_format section in docs/source/torch_tensorflow.rst. `torch.utils.data.Dataloader` expects padded batches so it throws an error due to not being able to stack the unpadded tensors. If we follow the Quick tour from the docs where they add the `truncation=True, padding='max_length'` arguments to the tokenizer before passing data to Dataloader, we can easily fix the issue. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/646/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/646",
"html_url": "https://github.com/huggingface/datasets/pull/646",
"diff_url": "https://github.com/huggingface/datasets/pull/646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/646.patch",
"merged_at": 1600704852000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/645/comments | https://api.github.com/repos/huggingface/datasets/issues/645/events | https://github.com/huggingface/datasets/pull/645 | 704,542,234 | MDExOlB1bGxSZXF1ZXN0NDg5NDQ5MjAx | 645 | Don't use take on dataset table in pyarrow 1.0.x | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I tried lower batch sizes and it didn't accelerate filter (quite the opposite actually).\r\nThe slow-down also appears for pyarrow 0.17.1 for some reason, not sure it comes from these changes",
"I just checked the benchmarks of other PRs and some of them had 300s (!!) for filter. This needs some investigation..",
"Merging this one since it's not the cause of the the slow down"
] | 1,600,450,294,000 | 1,600,533,992,000 | 1,600,533,991,000 | MEMBER | null | Fix #615 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/645/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/645",
"html_url": "https://github.com/huggingface/datasets/pull/645",
"diff_url": "https://github.com/huggingface/datasets/pull/645.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/645.patch",
"merged_at": 1600533991000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/644/comments | https://api.github.com/repos/huggingface/datasets/issues/644/events | https://github.com/huggingface/datasets/pull/644 | 704,534,501 | MDExOlB1bGxSZXF1ZXN0NDg5NDQzMTk1 | 644 | Better windows support | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This PR is ready :)\r\nIt brings official support for windows.\r\n\r\nSome tests `AWSDatasetTest` are failing.\r\nThis is because I had to fix a few datasets that were not compatible with windows.\r\nThese test will pass once they got merged on master :)"
] | 1,600,449,456,000 | 1,601,042,550,000 | 1,601,042,548,000 | MEMBER | null | There are a few differences in the behavior of python and pyarrow on windows.
For example there are restrictions when accessing/deleting files that are open
Fix #590 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/644/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/644/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/644",
"html_url": "https://github.com/huggingface/datasets/pull/644",
"diff_url": "https://github.com/huggingface/datasets/pull/644.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/644.patch",
"merged_at": 1601042548000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/643/comments | https://api.github.com/repos/huggingface/datasets/issues/643/events | https://github.com/huggingface/datasets/issues/643 | 704,477,164 | MDU6SXNzdWU3MDQ0NzcxNjQ= | 643 | Caching processed dataset at wrong folder | {
"login": "mrm8488",
"id": 3653789,
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mrm8488",
"html_url": "https://github.com/mrm8488",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Thanks for reporting !\r\nIt uses a temporary file to write the data.\r\nHowever it looks like the temporary file is not placed in the right directory during the processing",
"Well actually I just tested and the temporary file is placed in the same directory, so it should work as expected.\r\nWhich version of `datasets` are you using ?",
"`datasets-1.0.1`\r\nHere you can reproduce it here:\r\nhttps://colab.research.google.com/drive/1O0KcepTFsmpkBbrbLLMq42iwTKmQh8d5?usp=sharing\r\n",
"It looks like a pyarrow issue with google colab.\r\nFor some reason this code increases the disk usage of google colab while it actually writes into google drive:\r\n\r\n```python\r\nimport pyarrow as pa\r\n\r\nstream = pa.OSFile(\"/content/drive/My Drive/path/to/file.arrow\", \"wb\")\r\nwriter = pa.RecordBatchStreamWriter(stream, schema=pa.schema({\"text\": pa.string()}))\r\nwriter.write_table(pa.Table.from_pydict({\"text\": [\"a\"*511 + \"\\n\"] * ((1 << 30) // 512)})) # 1GiB\r\nwriter.close()\r\nstream.close()\r\n```\r\n\r\nMoreover if I `rm` the file on google drive, it frees disk space on google colab.",
"It looks like replacing `pa.OSFile` by `open` fixes it, I'm going to open a PR",
"Ok. Thank you so much!",
"Actually I did more tests it doesn't >.<\r\nI'll let you know if I find a way to fix that",
"Actually I also have the issue when writing a regular text file\r\n\r\n```python\r\nf = open(\"/content/drive/My Drive/path/to/file\", \"w\")\r\nf.write((\"a\"*511 + \"\\n\") * ((1 << 30) // 512)) # 1GiB\r\nf.close()\r\n```\r\n\r\nIs that supposed to happen ?",
"The code you wrote should write a 1GB file in the Google Drive folder. Doesn't it? ",
"Yes it does, but the disk usage of google colab also increases by 1GB",
"I could check it and as you say as I write to te Drive disk the colab disk also increases...",
"To reproduce it: \r\n```bash\r\n!df -h | grep sda1\r\n```\r\n```python\r\nf = open(\"/content/drive/My Drive/test_to_remove.txt\", \"w\")\r\nf.write((\"a\"*511 + \"\\n\") * ((1 << 30) // 512)) # 1GiB\r\nf.write((\"a\"*511 + \"\\n\") * ((1 << 30) // 512)) # 1GiB\r\nf.close()\r\n```\r\n```bash\r\n!ls -lh /content/drive/My\\ Drive/test_to_remove.txt\r\n\r\n!df -h | grep sda1\r\n\r\n!rm -rf /content/drive/My\\ Drive/test_to_remove.txt\r\n\r\n```\r\n[Colab](https://colab.research.google.com/drive/1D0UiweCYQwwWZ65EEhuqqbaDDbhJYXfm?usp=sharing)\r\n\r\n\r\n"
] | 1,600,443,686,000 | 1,601,309,680,000 | null | NONE | null | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = dataset.map(encode, batched=True)
```
The file is about 4 GB, so I cannot process it on the Colab HD because there is no enough space. So I decided to mount my Google Drive fs and do it on it.
The dataset is cached in the right place but by processing it (applying `encode` function) seems to use a different folder because Colab HD starts to grow and it crashes when it should be done in the Drive fs.
What gets me crazy, it prints it is processing/encoding the dataset in the right folder:
```
Testing the mapped function outputs
Testing finished, running the mapping function on the dataset
Caching processed dataset at /content/drive/My Drive/text/default-ad3e69d6242ee916/0.0.0/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/cache-b16341780a59747d.arrow
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/643/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/642/comments | https://api.github.com/repos/huggingface/datasets/issues/642/events | https://github.com/huggingface/datasets/pull/642 | 704,397,499 | MDExOlB1bGxSZXF1ZXN0NDg5MzMwMDAx | 642 | Rename wnut fields | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,437,091,000 | 1,600,449,511,000 | 1,600,449,510,000 | MEMBER | null | As mentioned in #641 it would be cool to have it follow the naming of the other NER datasets | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/642/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/642",
"html_url": "https://github.com/huggingface/datasets/pull/642",
"diff_url": "https://github.com/huggingface/datasets/pull/642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/642.patch",
"merged_at": 1600449510000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/641/comments | https://api.github.com/repos/huggingface/datasets/issues/641/events | https://github.com/huggingface/datasets/pull/641 | 704,373,940 | MDExOlB1bGxSZXF1ZXN0NDg5MzExOTU3 | 641 | Add Polyglot-NER Dataset | {
"login": "joeddav",
"id": 9353833,
"node_id": "MDQ6VXNlcjkzNTM4MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9353833?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joeddav",
"html_url": "https://github.com/joeddav",
"followers_url": "https://api.github.com/users/joeddav/followers",
"following_url": "https://api.github.com/users/joeddav/following{/other_user}",
"gists_url": "https://api.github.com/users/joeddav/gists{/gist_id}",
"starred_url": "https://api.github.com/users/joeddav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joeddav/subscriptions",
"organizations_url": "https://api.github.com/users/joeddav/orgs",
"repos_url": "https://api.github.com/users/joeddav/repos",
"events_url": "https://api.github.com/users/joeddav/events{/privacy}",
"received_events_url": "https://api.github.com/users/joeddav/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @joeddav thanks for adding this! (I did a long webarchive.org session to actually find that dataset a while ago).\r\n\r\nOne question: should we manually correct the labeling scheme to (at least) IOB1?\r\n\r\nThat means \"LOC\" will be converted to \"I-LOC\". IOB1 is not explict. mentioned in the paper, but it is used in the documentation:\r\n\r\nhttps://polyglot.readthedocs.io/en/latest/NamedEntityRecognition.html",
"@stefan-it I went back and forth on this. My biggest problem with it is that once you are in IOB, there is the expectation that the beginning of new entities are marked with a `B-` (at least in the case of two back-to-back entities):\r\n```\r\nToday O\r\nAlice I-PER\r\nBob B-PER\r\nand O\r\nI O \r\nate O\r\nlasagna O\r\n```\r\nIf we just prepend `I-` to everything, `Bob` would be incorrectly tagged `I-PER`, meaning `Bob Alice` is a single entity. The current format is bad but is at least clear that it does not contain that information.\r\n\r\nBut I could go either way if someone has a strong opinion.",
"Indeed I'm not sure we can convert them to IOB because of this issue. I'm fine with keeping it like that",
"I'll do a release later today, hopefully we can include this dataset in the release :)\r\n\r\nLet me know if you need help with the dummy data",
"@lhoestq cool thanks, I think I've got it right now – just zipped them wrong. I'm running tests locally now and then will push.",
"@lhoestq set to merge?",
"@joeddav I'm fine with keeping the original labeling scheme :) "
] | 1,600,435,304,000 | 1,600,571,083,000 | 1,600,571,083,000 | CONTRIBUTOR | null | Adds the [Polyglot-NER dataset](https://sites.google.com/site/rmyeid/projects/polylgot-ner) with named entity tags for 40 languages. I include separate configs for each language as well as a `combined` config which lumps them all together. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/641/reactions",
"total_count": 6,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/641/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/641",
"html_url": "https://github.com/huggingface/datasets/pull/641",
"diff_url": "https://github.com/huggingface/datasets/pull/641.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/641.patch",
"merged_at": 1600571083000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/640/comments | https://api.github.com/repos/huggingface/datasets/issues/640/events | https://github.com/huggingface/datasets/pull/640 | 704,311,758 | MDExOlB1bGxSZXF1ZXN0NDg5MjYwNTc1 | 640 | Make shuffle compatible with temp_seed | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,429,138,000 | 1,600,429,671,000 | 1,600,429,670,000 | MEMBER | null | This code used to return different dataset at each run
```python
import dataset as ds
dataset = ...
with ds.temp_seed(42):
shuffled = dataset.shuffle()
```
Now it returns the same one since the seed is set | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/640/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/640",
"html_url": "https://github.com/huggingface/datasets/pull/640",
"diff_url": "https://github.com/huggingface/datasets/pull/640.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/640.patch",
"merged_at": 1600429670000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/639/comments | https://api.github.com/repos/huggingface/datasets/issues/639/events | https://github.com/huggingface/datasets/pull/639 | 704,217,963 | MDExOlB1bGxSZXF1ZXN0NDg5MTgxOTY3 | 639 | Update glue QQP checksum | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,420,095,000 | 1,600,429,028,000 | 1,600,429,027,000 | MEMBER | null | Fix #638 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/639/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/639",
"html_url": "https://github.com/huggingface/datasets/pull/639",
"diff_url": "https://github.com/huggingface/datasets/pull/639.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/639.patch",
"merged_at": 1600429027000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/638/comments | https://api.github.com/repos/huggingface/datasets/issues/638/events | https://github.com/huggingface/datasets/issues/638 | 704,146,956 | MDU6SXNzdWU3MDQxNDY5NTY= | 638 | GLUE/QQP dataset: NonMatchingChecksumError | {
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! Sure I'll take a look"
] | 1,600,412,950,000 | 1,600,429,027,000 | 1,600,429,027,000 | CONTRIBUTOR | null | Hi @lhoestq , I know you are busy and there are also other important issues. But if this is easy to be fixed, I am shamelessly wondering if you can give me some help , so I can evaluate my models and restart with my developing cycle asap. 😚
datasets version: editable install of master at 9/17
`datasets.load_dataset('glue','qqp', cache_dir='./datasets')`
```
Downloading and preparing dataset glue/qqp (download: 57.73 MiB, generated: 107.02 MiB, post-processed: Unknown size, total: 164.75 MiB) to ./datasets/glue/qqp/1.0.0/7c99657241149a24692c402a5c3f34d4c9f1df5ac2e4c3759fadea38f6cb29c4...
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
in
----> 1 datasets.load_dataset('glue','qqp', cache_dir='./datasets')
~/datasets/src/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, script_version, **config_kwargs)
609 download_config=download_config,
610 download_mode=download_mode,
--> 611 ignore_verifications=ignore_verifications,
612 )
613
~/datasets/src/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
467 if not downloaded_from_gcs:
468 self._download_and_prepare(
--> 469 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
470 )
471 # Sync info
~/datasets/src/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
527 if verify_infos:
528 verify_checksums(
--> 529 self.info.download_checksums, dl_manager.get_recorded_sizes_checksums(), "dataset source files"
530 )
531
~/datasets/src/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
37 if len(bad_urls) > 0:
38 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 39 raise NonMatchingChecksumError(error_msg + str(bad_urls))
40 logger.info("All the checksums matched successfully" + for_verification_name)
41
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://dl.fbaipublicfiles.com/glue/data/QQP-clean.zip']
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/638/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/638/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/637/comments | https://api.github.com/repos/huggingface/datasets/issues/637/events | https://github.com/huggingface/datasets/pull/637 | 703,539,909 | MDExOlB1bGxSZXF1ZXN0NDg4NjMwNzk4 | 637 | Add MATINF | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,345,493,000 | 1,600,348,998,000 | 1,600,348,997,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/637/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/637",
"html_url": "https://github.com/huggingface/datasets/pull/637",
"diff_url": "https://github.com/huggingface/datasets/pull/637.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/637.patch",
"merged_at": 1600348997000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/636/comments | https://api.github.com/repos/huggingface/datasets/issues/636/events | https://github.com/huggingface/datasets/pull/636 | 702,883,989 | MDExOlB1bGxSZXF1ZXN0NDg4MDg3OTA5 | 636 | Consistent ner features | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,271,785,000 | 1,600,336,379,000 | 1,600,336,378,000 | MEMBER | null | As discussed in #613 , this PR aims at making NER feature names consistent across datasets.
I changed the feature names of LinCE and XTREME/PAN-X | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/636/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/636",
"html_url": "https://github.com/huggingface/datasets/pull/636",
"diff_url": "https://github.com/huggingface/datasets/pull/636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/636.patch",
"merged_at": 1600336378000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/635/comments | https://api.github.com/repos/huggingface/datasets/issues/635/events | https://github.com/huggingface/datasets/pull/635 | 702,822,439 | MDExOlB1bGxSZXF1ZXN0NDg4MDM2OTE5 | 635 | Loglevel | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I think it's ready now @stas00, did you want to add something else ?\r\nThis PR includes your changes but with the level set to warning",
"LGTM, thank you, @lhoestq "
] | 1,600,267,073,000 | 1,600,336,339,000 | 1,600,336,338,000 | MEMBER | null | Continuation of #618 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/635/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/635/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/635",
"html_url": "https://github.com/huggingface/datasets/pull/635",
"diff_url": "https://github.com/huggingface/datasets/pull/635.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/635.patch",
"merged_at": 1600336338000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/634/comments | https://api.github.com/repos/huggingface/datasets/issues/634/events | https://github.com/huggingface/datasets/pull/634 | 702,676,041 | MDExOlB1bGxSZXF1ZXN0NDg3OTEzOTk4 | 634 | Add ConLL-2000 dataset | {
"login": "vblagoje",
"id": 458335,
"node_id": "MDQ6VXNlcjQ1ODMzNQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/458335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vblagoje",
"html_url": "https://github.com/vblagoje",
"followers_url": "https://api.github.com/users/vblagoje/followers",
"following_url": "https://api.github.com/users/vblagoje/following{/other_user}",
"gists_url": "https://api.github.com/users/vblagoje/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vblagoje/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vblagoje/subscriptions",
"organizations_url": "https://api.github.com/users/vblagoje/orgs",
"repos_url": "https://api.github.com/users/vblagoje/repos",
"events_url": "https://api.github.com/users/vblagoje/events{/privacy}",
"received_events_url": "https://api.github.com/users/vblagoje/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,254,851,000 | 1,600,339,090,000 | 1,600,339,090,000 | CONTRIBUTOR | null | Adds ConLL-2000 dataset used for text chunking. See https://www.clips.uantwerpen.be/conll2000/chunking/ for details and [motivation](https://github.com/huggingface/transformers/pull/7041#issuecomment-692710948) behind this PR | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/634/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/634",
"html_url": "https://github.com/huggingface/datasets/pull/634",
"diff_url": "https://github.com/huggingface/datasets/pull/634.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/634.patch",
"merged_at": 1600339090000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/633/comments | https://api.github.com/repos/huggingface/datasets/issues/633/events | https://github.com/huggingface/datasets/issues/633 | 702,440,484 | MDU6SXNzdWU3MDI0NDA0ODQ= | 633 | Load large text file for LM pre-training resulting in OOM | {
"login": "leethu2012",
"id": 29704017,
"node_id": "MDQ6VXNlcjI5NzA0MDE3",
"avatar_url": "https://avatars.githubusercontent.com/u/29704017?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leethu2012",
"html_url": "https://github.com/leethu2012",
"followers_url": "https://api.github.com/users/leethu2012/followers",
"following_url": "https://api.github.com/users/leethu2012/following{/other_user}",
"gists_url": "https://api.github.com/users/leethu2012/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leethu2012/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leethu2012/subscriptions",
"organizations_url": "https://api.github.com/users/leethu2012/orgs",
"repos_url": "https://api.github.com/users/leethu2012/repos",
"events_url": "https://api.github.com/users/leethu2012/events{/privacy}",
"received_events_url": "https://api.github.com/users/leethu2012/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Not sure what could cause that on the `datasets` side. Could this be a `Trainer` issue ? cc @julien-c @sgugger ?",
"There was a memory leak issue fixed recently in master. You should install from source and see if it fixes your problem.",
"@lhoestq @sgugger Thanks for your comments. I have install from source code as you told, but the problem is still there.\r\nTo reproduce the issue, just replace [these lines](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py#L241-L258) with: \r\n(load_dataset and DataCollatorForDatasetsLanguageModeling as [above mentioned](https://github.com/huggingface/datasets/issues/633#issue-702440484))\r\n```python\r\n dataset = load_dataset(\"bookcorpus\")\r\n dataset = dataset.train_test_split(test_size=0.1)\r\n train_dataset = dataset['train']\r\n eval_dataset = dataset['test'] if training_args.do_eval else None\r\n\r\n data_collator = DataCollatorForDatasetsLanguageModeling(\r\n tokenizer=tokenizer,\r\n mlm=data_args.mlm,\r\n mlm_probability=data_args.mlm_probability,\r\n block_size=data_args.block_size\r\n )\r\n```\r\nand run by:\r\n```bash\r\npython run_language_modeling.py\r\n--output_dir=output \\\r\n--model_type=bert \\\r\n--model_name_or_path=bert-base-uncased \\\r\n--do_train \\\r\n--do_eval \\\r\n--mlm \r\n```",
"Same here. Pre-training on wikitext-103 to do some test. At the end of the training it takes 32GB of RAM + ~30GB of SWAP. I installed dataset==1.1.0, not built from source. I will try uninstalling and building from source when it finish.",
"This seems to be on the `transformers` library side.\r\n\r\nIf you have more informations (pip env) or even better, a colab reproducing the error we can investigate.",
"It seems like it's solved with freshed versions of transformers. I have tried to replicate the error doing a fresh pip install transformers & datasets on colab and the error doesn't continue. On colab it keeps stable on 5GB! (Y)\r\n\r\nEdit: **Thanks for your great work**. Have a good day.",
"@gaceladri witch version transformers and datasets are you using now? I want to try again. Thanks.",
"transformers==3.3.1\r\ndatasets==1.1.0\r\ntokenizers==0.8.1rc2\r\n",
"doing some modifications to mobilebert\r\nhttps://colab.research.google.com/drive/1ba09ZOpyHGAOQLcsxiQAHRXl10qnMU5o?usp=sharing ",
"It does not happen to me anymore. Can we close? @leethu2012 ",
"It's happening to me again. After 4 hours of pre-training, my ram memory gets full and the kernel dies. I am using the last transformers version as today. 4.4.0 and the last version of datasets 1.2.1, both installed from master. The memory consumption keeps increasing.",
"It looks like it is something from pytorch/python itself :face_with_head_bandage: https://github.com/pytorch/pytorch/issues/13246 ",
"Thanks for the investigation @gaceladri \r\n\r\nApparently this happens when `num_workers>0` and has to do with objects being copied-on-write.\r\nDid you try setting num_workers to 0 @gaceladri ?\r\nIf the issue doesn't happen with `num_workers=0` then this would confirm that it's indeed related to this python/pytorch issue.\r\n\r\nSince a `Dataset` object is a wrapper of a pyarrow Table, we should investigate if the data being copied comes from the Table itself or from metadata in the `Dataset` object. If it comes from the metadata in the `Dataset` object, we should be able to implement a workaround. But if it comes from the Table, we'll need to see with the pyarrow team what we can do... ",
"@lhoestq I have tried and it keeps increasing also with `dataloader_num_workers=0`",
"Hmmm so this might come from another issue...\r\nSince it doesn't seem to be related to multiprocessing it should be easier to investigate though.\r\nDo you have some ideas @gaceladri ?",
"@lhoestq I looked quickly to a previously spoted bug in my env wandb /sdk/interface/interface.py, because sometimes when I load the dataset I got a multiprocessing error at line 510 in wandb...interface.py\r\n\r\nThis bug is reported here https://github.com/huggingface/datasets/issues/847\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nAssertionError Traceback (most recent call last)\r\n<timed eval> in <module>\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/transformers/trainer.py in train(self, model_path, trial)\r\n 877 print(len(epoch_iterator))\r\n 878 \r\n--> 879 for step, inputs in enumerate(epoch_iterator):\r\n 880 \r\n 881 start_step = time.time()\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/dataloader.py in __next__(self)\r\n 433 if self._sampler_iter is None:\r\n 434 self._reset()\r\n--> 435 data = self._next_data()\r\n 436 self._num_yielded += 1\r\n 437 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/dataloader.py in _next_data(self)\r\n 1083 else:\r\n 1084 del self._task_info[idx]\r\n-> 1085 return self._process_data(data)\r\n 1086 \r\n 1087 def _try_put_index(self):\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/dataloader.py in _process_data(self, data)\r\n 1109 self._try_put_index()\r\n 1110 if isinstance(data, ExceptionWrapper):\r\n-> 1111 data.reraise()\r\n 1112 return data\r\n 1113 \r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/_utils.py in reraise(self)\r\n 426 # have message field\r\n 427 raise self.exc_type(message=msg)\r\n--> 428 raise self.exc_type(msg)\r\n 429 \r\n 430 \r\n\r\nAssertionError: Caught AssertionError in DataLoader worker process 0.\r\nOriginal Traceback (most recent call last):\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py\", line 198, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py\", line 44, in fetch\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py\", line 44, in <listcomp>\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1083, in __getitem__\r\n format_kwargs=self._format_kwargs,\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1070, in _getitem\r\n format_kwargs=format_kwargs,\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 886, in _convert_outputs\r\n v = map_nested(command, v, **map_nested_kwargs)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/utils/py_utils.py\", line 216, in map_nested\r\n return function(data_struct)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 847, in command\r\n return torch.tensor(x, **format_kwargs)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/warnings.py\", line 101, in _showwarnmsg\r\n _showwarnmsg_impl(msg)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/warnings.py\", line 30, in _showwarnmsg_impl\r\n file.write(text)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/lib/redirect.py\", line 100, in new_write\r\n cb(name, data)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/wandb_run.py\", line 729, in _console_callback\r\n self._backend.interface.publish_output(name, data)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py\", line 186, in publish_output\r\n self._publish_output(o)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py\", line 191, in _publish_output\r\n self._publish(rec)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py\", line 510, in _publish\r\n if self._process and not self._process.is_alive():\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/multiprocessing/process.py\", line 134, in is_alive\r\n assert self._parent_pid == os.getpid(), 'can only test a child process'\r\nAssertionError: can only test a child process\r\n```\r\n\r\nMy workaround was to just comment those lines without looking to much into consecuences:\r\n\r\n```\r\ndef _publish(self, record: pb.Record, local: bool = None) -> None:\r\n #if self._process and not self._process.is_alive():\r\n # raise Exception(\"The wandb backend process has shutdown\")\r\n```\r\n\r\nIt worked so far... I need to try running without wandb and see if it could be causing something wrong with multiprocessing. I am going to try to launch the training setting wandb to false and I will let you know again.",
"@lhoestq But despite this, I got lost into the [class Dataset()](https://huggingface.co/docs/datasets/_modules/datasets/arrow_dataset.html#Dataset) reading the pyarrow files.\r\n\r\nEdit: but you should be rigth, that it does not have to be related to multiprocessing since it keeps happening when `num_workers=0` ",
"Or maybe wandb uses multiprocessing ? One process for wandb logging and one for actual training ? If this is the case then even setting `num_workers=0` would cause the process to be forked for wandb and therefore cause the memory issue.",
"@lhoestq could be, but if we set wandb to false this should not happen. I am going to try.",
"@lhoestq It keeps happening. I have uninstalled wandb from my env, setted `%env WANDB_DISABLED=true` on my notebook, and commented this func:\r\n\r\n```\r\ndef get_available_reporting_integrations():\r\n integrations = []\r\n if is_azureml_available():\r\n integrations.append(\"azure_ml\")\r\n if is_comet_available():\r\n integrations.append(\"comet_ml\")\r\n if is_mlflow_available():\r\n integrations.append(\"mlflow\")\r\n if is_tensorboard_available():\r\n integrations.append(\"tensorboard\")\r\n # if is_wandb_available():\r\n # integrations.append(\"wandb\")\r\n return integrations\r\n```\r\nAs a fast test and it keeps increasing the ram memory. Wandb could not be the blameworthy here.",
"Thanks for checking @gaceladri . Let's investigate the single process setting then.\r\nIf you have some sort of colab notebook with a minimal code example that shows this behavior feel free to share it @gaceladri so that we can play around with it to find what causes this. Otherwise I'll probably try to reproduce on my side at one point",
"@lhoestq sure. Here you have https://colab.research.google.com/drive/1ba09ZOpyHGAOQLcsxiQAHRXl10qnMU5o?usp=sharing let me know if the link works and it reproduces the issue. To me, it reproduces the issue, since if you start the training the ram memory keeps increasing.\r\n\r\nLet me know. Thanks!",
"Could the bug be comming from tokenizers?\r\n\r\nI got this warning at the terminal from my jupyter notebook: \r\n```\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\n```",
"I've never experienced memory issues with tokenizers so I don't know\r\nCc @n1t0 are you aware of any issue that would cause memory to keep increasing when the tokenizer is used in the Data Collator for language modeling ?",
"@lhoestq Thanks for pointing to n1t0, just to clarify. That warning was doing fine-tuning, without collator:\r\n```\r\n\r\nfrom datasets import load_dataset, load_metric\r\nimport numpy as np\r\n\r\nGLUE_TASKS = [\r\n \"cola\",\r\n \"mnli\",\r\n \"mnli-mm\",\r\n \"mrpc\",\r\n \"qnli\",\r\n \"qqp\",\r\n \"rte\",\r\n \"sst2\",\r\n \"stsb\",\r\n \"wnli\",\r\n]\r\ntask = \"mnli\"\r\nactual_task = \"mnli\" if task == \"mnli-mm\" else task\r\ndataset = load_dataset(\"glue\", actual_task)\r\nmetric = load_metric(\"glue\", actual_task)\r\nbatch_size = 16\r\nattention_type = \"linear\"\r\n\r\nfrom transformers.models.mobilebert_mod import (\r\n MobileBertForSequenceClassification,\r\n MobileBertTokenizerFast,\r\n)\r\nfrom transformers.models.mobilebert_mod.configuration_mobilebert import (\r\n MobileBertConfigMod,\r\n)\r\nfrom transformers import TrainingArguments, Trainer\r\n\r\nnum_labels = 3 if task.startswith(\"mnli\") else 1 if task == \"stsb\" else 2\r\ntokenizer = MobileBertTokenizerFast.from_pretrained(\r\n \"/media/ad/00b5422b-9d54-4449-8b5d-08eab5cdac8c/training_trfm/big_linear_layerdrop_shared/checkpoint-23000/\",\r\n max_len=512,\r\n)\r\nmodel = MobileBertForSequenceClassification.from_pretrained(\r\n \"/media/ad/00b5422b-9d54-4449-8b5d-08eab5cdac8c/training_trfm/big_linear_layerdrop_shared/checkpoint-23000/\",\r\n num_labels=num_labels,\r\n)\r\nprint(model.num_parameters())\r\n\r\ntask_to_keys = {\r\n \"cola\": (\"sentence\", None),\r\n \"mnli\": (\"premise\", \"hypothesis\"),\r\n \"mnli-mm\": (\"premise\", \"hypothesis\"),\r\n \"mrpc\": (\"sentence1\", \"sentence2\"),\r\n \"qnli\": (\"question\", \"sentence\"),\r\n \"qqp\": (\"question1\", \"question2\"),\r\n \"rte\": (\"sentence1\", \"sentence2\"),\r\n \"sst2\": (\"sentence\", None),\r\n \"stsb\": (\"sentence1\", \"sentence2\"),\r\n \"wnli\": (\"sentence1\", \"sentence2\"),\r\n}\r\n\r\nsentence1_key, sentence2_key = task_to_keys[task]\r\nif sentence2_key is None:\r\n print(f\"Sentence: {dataset['train'][0][sentence1_key]}\")\r\nelse:\r\n print(f\"Sentence 1: {dataset['train'][0][sentence1_key]}\")\r\n print(f\"Sentence 2: {dataset['train'][0][sentence2_key]}\")\r\n\r\n\r\ndef preprocess_function(examples):\r\n if sentence2_key is None:\r\n return tokenizer(examples[sentence1_key], truncation=True)\r\n return tokenizer(examples[sentence1_key], examples[sentence2_key], truncation=True)\r\n\r\n\r\nencoded_dataset = dataset.map(preprocess_function, batched=True)\r\nmetric_name = (\r\n \"pearson\"\r\n if task == \"stsb\"\r\n else \"matthews_correlation\"\r\n if task == \"cola\"\r\n else \"accuracy\"\r\n)\r\n\r\nargs = TrainingArguments(\r\n f\"test-glue/{task}_{attention_type}\",\r\n evaluation_strategy=\"steps\",\r\n learning_rate=1e-5,\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=batch_size,\r\n logging_steps=200,\r\n num_train_epochs=5,\r\n gradient_accumulation_steps=1,\r\n warmup_steps=10000,\r\n fp16=True,\r\n dataloader_num_workers=10,\r\n weight_decay=0.1,\r\n load_best_model_at_end=True,\r\n metric_for_best_model=metric_name,\r\n)\r\n\r\n\r\ndef compute_metrics(eval_pred):\r\n predictions, labels = eval_pred\r\n if task != \"stsb\":\r\n predictions = np.argmax(predictions, axis=1)\r\n else:\r\n predictions = predictions[:, 0]\r\n return metric.compute(predictions=predictions, references=labels)\r\n\r\n\r\nvalidation_key = (\r\n \"validation_mismatched\"\r\n if task == \"mnli-mm\"\r\n else \"validation_matched\"\r\n if task == \"mnli\"\r\n else \"validation\"\r\n)\r\n\r\ntrainer = Trainer(\r\n model,\r\n args,\r\n train_dataset=encoded_dataset[\"train\"],\r\n eval_dataset=encoded_dataset[validation_key],\r\n tokenizer=tokenizer,\r\n compute_metrics=compute_metrics,\r\n)\r\n\r\ntrainer.train()\r\n```\r\n\r\nNow, I have come back to pre-training. The changes that I think I have done are: not formatting the dataset to torch: ~~`big_dataset.set_format(type='torch', columns=[\"text\", \"input_ids\", \"attention_mask\", \"token_type_ids\"])`~~ so maybe some column is dropped and not freezed in memory and now I have not setted any validation dataset in the trainer. \r\n\r\nMy validation dataset before:\r\n```\r\nbook_corpus_eval = load_dataset(\r\n \"bookcorpus\",\r\n \"plain_text\",\r\n cache_dir=\"/home/ad/Desktop/bookcorpus\",\r\n split=\"train[98:99%]\",\r\n)\r\nbook_corpus_eval = book_corpus_eval.map(encode, batched=True)\r\nbook_corpus_eval.set_format(\r\n type=\"torch\", columns=[\"text\", \"input_ids\", \"attention_mask\", \"token_type_ids\"]\r\n)\r\n**book_corpus_eval = book_corpus_eval.select([i for i in range(1500)])**\r\n```\r\nMaybe _selecting_ or indexing the dataset before feeding it to the trainer, do something strange.\r\n\r\nMy trainer now:\r\n```\r\n\r\nbig_dataset = load_from_disk(\"/home/ad/Desktop/35percent_data.arrow/\")\r\n\r\nfrom transformers import DataCollatorForWholeWordMask\r\n\r\ndata_collator = DataCollatorForWholeWordMask(\r\n tokenizer=tokenizer, mlm=True, mlm_probability=0.15)\r\n\r\nfrom transformers import Trainer, TrainingArguments\r\n\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./big_linear_layerdrop_shared_silu_secondtry\",\r\n overwrite_output_dir=True,\r\n per_device_train_batch_size=60,\r\n per_device_eval_batch_size=60,\r\n save_steps=500,\r\n save_total_limit=10,\r\n logging_first_step=True,\r\n logging_steps=100,\r\n# evaluation_strategy='steps',\r\n# eval_steps=250,\r\n gradient_accumulation_steps=8,\r\n fp16=True,\r\n dataloader_num_workers=10,\r\n warmup_steps=15000,\r\n learning_rate=6e-4,\r\n adam_epsilon=1e-6,\r\n adam_beta2=0.98,\r\n weight_decay=0.01,\r\n max_grad_norm=1.0,\r\n max_steps=500000, \r\n)\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n data_collator=data_collator,\r\n train_dataset=big_dataset,\r\n# eval_dataset=book_corpus_eval,\r\n tokenizer=tokenizer)\r\n\r\nimport wandb\r\nwandb.login()\r\n\r\ntrainer.train()\r\n```\r\n\r\nAnd surprisingly, the ram now keeps going up and down. The training is up now for 12h without collapse the ram. I don't know what could cause the leakage. :mag: \r\n\r\nEdit: I didn't see the swap memory, that keeps increasing. So the problem persist. ",
"Thanks for sharing your results.\r\nSo you still had the issue for fine-tuning ?\r\nAnd the issue still appears with a bare-bone dataset from an arrow file...",
"Yes, on both cases. Fine-tuning a pre-trained model and pre-training from scratch with a local arrow file already pre-processed."
] | 1,600,230,795,000 | 1,613,476,921,000 | null | NONE | null | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator used for language modeling based on DataCollatorForLazyLanguageModeling
- collates batches of tensors, honoring their tokenizer's pad_token
- preprocesses batches for masked language modeling
"""
block_size: int = 512
def __call__(self, examples: List[dict]) -> Dict[str, torch.Tensor]:
examples = [example['text'] for example in examples]
batch, attention_mask = self._tensorize_batch(examples)
if self.mlm:
inputs, labels = self.mask_tokens(batch)
return {"input_ids": inputs, "labels": labels}
else:
labels = batch.clone().detach()
if self.tokenizer.pad_token_id is not None:
labels[labels == self.tokenizer.pad_token_id] = -100
return {"input_ids": batch, "labels": labels}
def _tensorize_batch(self, examples: List[str]) -> Tuple[torch.Tensor, torch.Tensor]:
if self.tokenizer._pad_token is None:
raise ValueError(
"You are attempting to pad samples but the tokenizer you are using"
f" ({self.tokenizer.__class__.__name__}) does not have one."
)
tensor_examples = self.tokenizer.batch_encode_plus(
[ex for ex in examples if ex],
max_length=self.block_size,
return_tensors="pt",
pad_to_max_length=True,
return_attention_mask=True,
truncation=True,
)
input_ids, attention_mask = tensor_examples["input_ids"], tensor_examples["attention_mask"]
return input_ids, attention_mask
dataset = load_dataset('text', data_files='train.txt',cache_dir="./", , split='train')
data_collator = DataCollatorForDatasetsLanguageModeling(tokenizer=tokenizer, mlm=True,
mlm_probability=0.15, block_size=tokenizer.max_len)
trainer = Trainer(model=model, args=args, data_collator=data_collator,
train_dataset=train_dataset, prediction_loss_only=True, )
trainer.train(model_path=model_path)
```
This train.txt is about 1.1GB and has 90k lines where each line is a sequence of 4k words.
During training, the memory usage increased fast as the following graph and resulted in OOM before the finish of training.

Could you please give me any suggestions on why this happened and how to fix it?
Thanks. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/633/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/633/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/632/comments | https://api.github.com/repos/huggingface/datasets/issues/632/events | https://github.com/huggingface/datasets/pull/632 | 702,358,124 | MDExOlB1bGxSZXF1ZXN0NDg3NjQ5OTQ2 | 632 | Fix typos in the loading datasets docs | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"thanks!"
] | 1,600,216,061,000 | 1,600,705,871,000 | 1,600,239,164,000 | CONTRIBUTOR | null | This PR fixes two typos in the loading datasets docs, one of them being a broken link to the `load_dataset` function. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/632/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/632",
"html_url": "https://github.com/huggingface/datasets/pull/632",
"diff_url": "https://github.com/huggingface/datasets/pull/632.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/632.patch",
"merged_at": 1600239164000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/631/comments | https://api.github.com/repos/huggingface/datasets/issues/631/events | https://github.com/huggingface/datasets/pull/631 | 701,711,255 | MDExOlB1bGxSZXF1ZXN0NDg3MTE3OTA0 | 631 | Fix text delimiter | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Which OS are you using ?@abhi1nandy2",
"> Which OS are you using ?\r\n\r\nPRETTY_NAME=\"Debian GNU/Linux 9 (stretch)\"\r\nNAME=\"Debian GNU/Linux\"\r\nVERSION_ID=\"9\"\r\nVERSION=\"9 (stretch)\"\r\nVERSION_CODENAME=stretch\r\nID=debian\r\nHOME_URL=\"https://www.debian.org/\"\r\nSUPPORT_URL=\"https://www.debian.org/support\"\r\nBUG_REPORT_URL=\"https://bugs.debian.org/\"",
"Do you mind sharing the data you used (or part of it), so I can try to reproduce ?\r\nOr at least some info about the text file you're using ? (size, n of lines, encoding)",
"Lot of data, difficult to share. There are 46 shards, each having about 256000 lines. using `file` command gives this - `ASCII text, with very long lines`.",
"Ok I see, no problem :) \r\nI'll see what I can do\r\n\r\nCould you just test with one single dummy text file with a few lines to see if you're having the issue ?\r\nAlso which version of `datasets` do you have ?"
] | 1,600,157,322,000 | 1,600,786,986,000 | 1,600,158,385,000 | MEMBER | null | I changed the delimiter in the `text` dataset script.
It should fix the `pyarrow.lib.ArrowInvalid: CSV parse error` from #622
I changed the delimiter to an unused ascii character that is not present in text files : `\b` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/631/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/631",
"html_url": "https://github.com/huggingface/datasets/pull/631",
"diff_url": "https://github.com/huggingface/datasets/pull/631.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/631.patch",
"merged_at": 1600158385000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/630/comments | https://api.github.com/repos/huggingface/datasets/issues/630/events | https://github.com/huggingface/datasets/issues/630 | 701,636,350 | MDU6SXNzdWU3MDE2MzYzNTA= | 630 | Text dataset not working with large files | {
"login": "ksjae",
"id": 17930170,
"node_id": "MDQ6VXNlcjE3OTMwMTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/17930170?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ksjae",
"html_url": "https://github.com/ksjae",
"followers_url": "https://api.github.com/users/ksjae/followers",
"following_url": "https://api.github.com/users/ksjae/following{/other_user}",
"gists_url": "https://api.github.com/users/ksjae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ksjae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ksjae/subscriptions",
"organizations_url": "https://api.github.com/users/ksjae/orgs",
"repos_url": "https://api.github.com/users/ksjae/repos",
"events_url": "https://api.github.com/users/ksjae/events{/privacy}",
"received_events_url": "https://api.github.com/users/ksjae/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Seems like it works when setting ```block_size=2100000000``` or something arbitrarily large though.",
"Can you give us some stats on the data files you use as inputs?",
"Basically ~600MB txt files(UTF-8) * 59. \r\ncontents like ```안녕하세요, 이것은 예제로 한번 말해보는 텍스트입니다. 그냥 이렇다고요.<|endoftext|>\\n```\r\n\r\nAlso, it gets stuck for a loooong time at ```Testing the mapped function outputs```, for more than 12 hours(currently ongoing)",
"It gets stuck while doing `.map()` ? Are you using multiprocessing ?\r\nIf you could provide a code snippet it could be very useful",
"From transformers/examples/language-modeling/run-language-modeling.py :\r\n```\r\ndef get_dataset(\r\n args: DataTrainingArguments,\r\n tokenizer: PreTrainedTokenizer,\r\n evaluate: bool = False,\r\n cache_dir: Optional[str] = None,\r\n):\r\n file_path = args.eval_data_file if evaluate else args.train_data_file\r\n if True:\r\n dataset = load_dataset(\"text\", data_files=glob.glob(file_path), split='train', use_threads=True, \r\n ignore_verifications=True, save_infos=True, block_size=104857600)\r\n dataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n truncation=True, max_length=args.block_size), batched=True)\r\n dataset.set_format(type='torch', columns=['input_ids'])\r\n return dataset\r\n if args.line_by_line:\r\n return LineByLineTextDataset(tokenizer=tokenizer, file_path=file_path, block_size=args.block_size)\r\n else:\r\n return TextDataset(\r\n tokenizer=tokenizer,\r\n file_path=file_path,\r\n block_size=args.block_size,\r\n overwrite_cache=args.overwrite_cache,\r\n cache_dir=cache_dir,\r\n )\r\n```\r\n\r\nNo, I'm not using multiprocessing.",
"I am not able to reproduce on my side :/\r\n\r\nCould you send the version of `datasets` and `pyarrow` you're using ?\r\nCould you try to update the lib and try again ?\r\nOr do you think you could try to reproduce it on google colab ?",
"Huh, weird. It's fixed on my side too.\r\nBut now ```Caching processed dataset``` is taking forever - how can I disable it? Any flags?",
"Right after `Caching processed dataset`, your function is applied to the dataset and there's a progress bar that shows how much time is left. How much time does it take for you ?\r\n\r\nAlso caching isn't supposed to slow down your processing. But if you still want to disable it you can do `.map(..., load_from_cache_file=False)`",
"Ah, it’s much faster now(Takes around 15~20min). \r\nBTW, any way to set default tensor output as plain tensors with distributed training? The ragged tensors are incompatible with tpustrategy :(",
"> Ah, it’s much faster now(Takes around 15~20min).\r\n\r\nGlad to see that it's faster now. What did you change exactly ?\r\n\r\n> BTW, any way to set default tensor output as plain tensors with distributed training? The ragged tensors are incompatible with tpustrategy :(\r\n\r\nOh I didn't know about that. Feel free to open an issue to mention that.\r\nI guess what you can do for now is set the dataset format to numpy instead of tensorflow, and use a wrapper of the dataset that converts the numpy arrays to tf tensors.\r\n\r\n",
">>> Glad to see that it's faster now. What did you change exactly ?\r\nI don't know, it just worked...? Sorry I couldn't be more helpful.\r\n\r\nSetting with numpy array is a great idea! Thanks."
] | 1,600,149,756,000 | 1,601,072,503,000 | 1,601,072,503,000 | NONE | null | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
File "examples/language-modeling/run_language_modeling.py", line 144, in get_dataset
dataset = load_dataset("text", data_files=file_path, split='train+test')
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/load.py", line 611, in load_dataset
ignore_verifications=ignore_verifications,
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/builder.py", line 469, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/builder.py", line 546, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/builder.py", line 888, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/home/ksjae/.local/lib/python3.7/site-packages/tqdm/std.py", line 1129, in __iter__
for obj in iterable:
File "/home/ksjae/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.py", line 104, in _generate_tables
convert_options=self.config.convert_options,
File "pyarrow/_csv.pyx", line 714, in pyarrow._csv.read_csv
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
```
**pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries (try to increase block size?)**
It gives the same message for both 200MB, 10GB .tx files but not for 700MB file.
Can't upload due to size & copyright problem. sorry. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/630/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/629/comments | https://api.github.com/repos/huggingface/datasets/issues/629/events | https://github.com/huggingface/datasets/issues/629 | 701,517,550 | MDU6SXNzdWU3MDE1MTc1NTA= | 629 | straddling object straddles two block boundaries | {
"login": "bharaniabhishek123",
"id": 17970177,
"node_id": "MDQ6VXNlcjE3OTcwMTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/17970177?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bharaniabhishek123",
"html_url": "https://github.com/bharaniabhishek123",
"followers_url": "https://api.github.com/users/bharaniabhishek123/followers",
"following_url": "https://api.github.com/users/bharaniabhishek123/following{/other_user}",
"gists_url": "https://api.github.com/users/bharaniabhishek123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bharaniabhishek123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bharaniabhishek123/subscriptions",
"organizations_url": "https://api.github.com/users/bharaniabhishek123/orgs",
"repos_url": "https://api.github.com/users/bharaniabhishek123/repos",
"events_url": "https://api.github.com/users/bharaniabhishek123/events{/privacy}",
"received_events_url": "https://api.github.com/users/bharaniabhishek123/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"sorry it's an apache arrow issue."
] | 1,600,129,846,000 | 1,600,130,177,000 | 1,600,129,937,000 | NONE | null | I am trying to read json data (it's an array with lots of dictionaries) and getting block boundaries issue as below :
I tried calling read_json with readOptions but no luck .
```
table = json.read_json(fn)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "pyarrow/_json.pyx", line 246, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries (try to increase block size?)
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/629/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/629/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/628/comments | https://api.github.com/repos/huggingface/datasets/issues/628/events | https://github.com/huggingface/datasets/pull/628 | 701,496,053 | MDExOlB1bGxSZXF1ZXN0NDg2OTQyNzgx | 628 | Update docs links in the contribution guideline | {
"login": "M-Salti",
"id": 9285264,
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/M-Salti",
"html_url": "https://github.com/M-Salti",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks!"
] | 1,600,126,039,000 | 1,604,351,003,000 | 1,600,150,775,000 | CONTRIBUTOR | null | Fixed the `add a dataset` and `share a dataset` links in the contribution guideline to refer to the new docs website. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/628/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/628/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/628",
"html_url": "https://github.com/huggingface/datasets/pull/628",
"diff_url": "https://github.com/huggingface/datasets/pull/628.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/628.patch",
"merged_at": 1600150775000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/627/comments | https://api.github.com/repos/huggingface/datasets/issues/627/events | https://github.com/huggingface/datasets/pull/627 | 701,411,661 | MDExOlB1bGxSZXF1ZXN0NDg2ODcxMTg2 | 627 | fix (#619) MLQA features names | {
"login": "M-Salti",
"id": 9285264,
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/M-Salti",
"html_url": "https://github.com/M-Salti",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,116,119,000 | 1,604,351,072,000 | 1,600,239,251,000 | CONTRIBUTOR | null | Fixed the features names as suggested in (#619) in the `_generate_examples` and `_info` methods in the MLQA loading script and also changed the names in the `dataset_infos.json` file. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/627/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/627",
"html_url": "https://github.com/huggingface/datasets/pull/627",
"diff_url": "https://github.com/huggingface/datasets/pull/627.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/627.patch",
"merged_at": 1600239251000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/626/comments | https://api.github.com/repos/huggingface/datasets/issues/626/events | https://github.com/huggingface/datasets/pull/626 | 701,352,605 | MDExOlB1bGxSZXF1ZXN0NDg2ODIzMTY1 | 626 | Update GLUE URLs (now hosted on FB) | {
"login": "jeswan",
"id": 57466294,
"node_id": "MDQ6VXNlcjU3NDY2Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/57466294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeswan",
"html_url": "https://github.com/jeswan",
"followers_url": "https://api.github.com/users/jeswan/followers",
"following_url": "https://api.github.com/users/jeswan/following{/other_user}",
"gists_url": "https://api.github.com/users/jeswan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeswan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeswan/subscriptions",
"organizations_url": "https://api.github.com/users/jeswan/orgs",
"repos_url": "https://api.github.com/users/jeswan/repos",
"events_url": "https://api.github.com/users/jeswan/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeswan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,600,110,339,000 | 1,600,239,198,000 | 1,600,239,198,000 | CONTRIBUTOR | null | NYU is switching dataset hosting from Google to FB. This PR closes https://github.com/huggingface/datasets/issues/608 and is necessary for https://github.com/jiant-dev/jiant/issues/161. This PR updates the data URLs based on changes made in https://github.com/nyu-mll/jiant/pull/1112.
Note: rebased on huggingface/datasets | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/626/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/626",
"html_url": "https://github.com/huggingface/datasets/pull/626",
"diff_url": "https://github.com/huggingface/datasets/pull/626.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/626.patch",
"merged_at": 1600239198000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/625/comments | https://api.github.com/repos/huggingface/datasets/issues/625/events | https://github.com/huggingface/datasets/issues/625 | 701,057,799 | MDU6SXNzdWU3MDEwNTc3OTk= | 625 | dtype of tensors should be preserved | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Indeed we convert tensors to list to be able to write in arrow format. Because of this conversion we lose the dtype information. We should add the dtype detection when we do type inference. However it would require a bit of refactoring since currently the conversion happens before the type inference..\r\n\r\nAnd then for your information, when reading from arrow format we have to cast from arrow to numpy (which is fast since pyarrow has a numpy integration), and then to torch.\r\n\r\nHowever there's one thing that can help you: we make sure that the dtypes correspond to what is defined in `features`.\r\nTherefore what you can do is provide `features` in `.map(preprocess, feature=...)` to specify the output types.\r\n\r\nFor example in your case:\r\n```python\r\nfrom datasets import Features, Value, Sequence\r\n\r\nfeatures = Features({\r\n \"input_ids\": Sequence(Value(\"int32\")),\r\n \"sembedding\": Sequence(Value(\"float32\"))\r\n})\r\npreprocessed_dataset = dataset.map(preprocess, features=features)\r\n\r\npreprocessed_dataset.set_format(\"torch\", columns=[\"input_ids\", \"sembedding\"])\r\nprint(preprocessed_dataset[0][\"sembedding\"].dtype)\r\n# \"torch.float32\"\r\n```\r\n\r\nLet me know if it helps",
"If the arrow format is basically lists, why is the intermediate step to numpy necessary? I am a bit confused about that part.\r\n\r\nThanks for your suggestion. as I have currently implemented this, I cast to torch.Tensor in my collate_fn to save disk space (so I do not have to save padded tensors to max_len but can pad up to max batch len in collate_fn) at the cost of a bit slower processing. So for me this is not relevant anymore, but I am sure it is for others!",
"I'm glad you managed to figure something out :)\r\n\r\nCasting from arrow to numpy can be 100x faster than casting from arrow to list.\r\nThis is because arrow has an integration with numpy that allows it to instantiate numpy arrays with zero-copy from arrow.\r\nOn the other hand to create python lists it is slow since it has to recreate the list object by iterating through each element in python.",
"Ah that is interesting. I have no direct experience with arrow so I didn't know. ",
"I encountered a simliar issue: `datasets` converted my float numpy array to `torch.float64` tensors, while many pytorch operations require `torch.float32` inputs and it's very troublesome. \r\n\r\nI tried @lhoestq 's solution, but since it's mixed with the preprocess function, it's not very intuitive. \r\n\r\nI just want to share another possible simpler solution: directly cast the dtype of the processed dataset.\r\n\r\nNow I want to change the type of `labels` in `train_dataset` from float64 to float32, I can do this.\r\n\r\n```\r\nfrom datasets import Value, Sequence, Features\r\nfeats = train_dataset.features.copy()\r\nfeats['labels'].feature = Value(dtype='float32')\r\nfeats = Features(feats)\r\ntrain_dataset.cast_(feats)\r\n```\r\n",
"Reopening since @bhavitvyamalik started looking into it !\r\n\r\nAlso I'm posting here a function that could be helpful to support preserving the dtype of tensors.\r\n\r\nIt's used to build a pyarrow array out of a numpy array and:\r\n- it doesn't convert the numpy array to a python list\r\n- it keeps the precision of the numpy array for the pyarrow array\r\n- it works with multidimensional arrays (while `pa.array` can only take a 1D array as input)\r\n- it builds the pyarrow ListArray from offsets created on-the-fly and values that come from the flattened numpy array\r\n\r\n```python\r\nfrom functools import reduce\r\nfrom operator import mul\r\n\r\nimport numpy as np\r\nimport pyarrow as pa\r\n\r\ndef pa_ndarray(a):\r\n \"\"\"Build a PyArrow ListArray from a multidimensional NumPy array\"\"\"\r\n values = pa.array(a.flatten()) \r\n for i in range(a.ndim - 1): \r\n n_offsets = reduce(mul, a.shape[:a.ndim - i - 1], 1) \r\n step_offsets = a.shape[a.ndim - i - 1] \r\n offsets = pa.array(np.arange(n_offsets + 1) * step_offsets, type=pa.int32()) \r\n values = pa.ListArray.from_arrays(offsets, values) \r\n return values \r\n\r\nnarr = np.arange(42).reshape(7, 2, 3).astype(np.uint8)\r\nparr = pa_ndarray(narr)\r\nassert isinstance(parr, pa.Array)\r\nassert parr.type == pa.list_(pa.list_(pa.uint8()))\r\nassert narr.tolist() == parr.to_pylist()\r\n```\r\n\r\nThe only costly operation is the offsets computations. Since it doesn't iterate on the numpy array values this function is pretty fast.",
"@lhoestq Have you thought about this further?\r\n\r\nWe have a use case where we're attempting to load data containing numpy arrays using the `datasets` library.\r\n\r\nWhen using one of the \"standard\" methods (`[Value(...)]` or `Sequence()`) we see ~200 samples processed per second during the call to `_prepare_split`. This slowdown is caused by the vast number of calls to `encode_nested_example` (each sequence is converted to a list, and each element in the sequence...). \r\n\r\nUsing the `Feature` `ArrayND` improves this somewhat to ~500/s as it now uses numpy's `tolist()` rather than iterating over each value in the array and converting them individually.\r\n\r\nHowever, it's still pretty slow and in theory it should be possible to avoid the `numpy -> python -> arrow` dance altogether. To demonstrate this, if you keep the `Feature` set to an `ArrayND` but instead return a `pa_ndarray(...)` in `_generate_examples` it skips the conversion (`return obj, False`) and hits ~11_000/s. Two orders of magnitude speed up! The problem is this then fails later on when the `ArrowWriter` tries to write the examples to disk :-( \r\n\r\nIt would be nice to have first-class support for user-defined PyArrow objects. Is this a possibility? We have _large_ datasets where even an order of magnitude difference is important so settling on the middle ~500/s is less than ideal! \r\n\r\nIs there a workaround for this or another method that should be used instead that gets near-to or equal performance to returning PyArrow arrays?",
"Note that manually generating the table using `pyarrow` achieves ~30_000/s",
"Hi !\r\n\r\nIt would be awesome to achieve this speed for numpy arrays !\r\nFor now we have to use `encode_nested_example` to convert numpy arrays to python lists since pyarrow doesn't support multidimensional numpy arrays (only 1D).\r\n\r\nMaybe let's start a new PR from your PR @bhavitvyamalik (idk why we didn't answer your PR at that time, sorry about that).\r\nBasically the idea is to allow `TypedSequence` to support numpy arrays as you did, and remove the numpy->python casting in `_cast_to_python_objects`.\r\n\r\nThis is really important since we are starting to have a focus on other modalities than text as well (audio, images).\r\n\r\nThough until then @samgd, there is another feature that may interest you and that may give you the speed you want:\r\n\r\nIn a dataset script you can subclass either a GeneratorBasedBuilder (with the `_generate_examples ` method) or an ArrowBasedBuilder if you want. the ArrowBasedBuilder allows to yield arrow data by implementing the `_generate_tables` method (it's the same as `_generate_examples` except you must yield arrow tables). Since the data are already in arrow format, it doesn't call `encode_nested_example`. Let me know if that helps."
] | 1,600,087,085,000 | 1,629,189,004,000 | 1,629,189,004,000 | CONTRIBUTOR | null | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-have-the-same-dtype-float32/96221)).
As a user I did not expect this bug. I have a `map` function that I call on the Dataset that looks like this:
```python
def preprocess(sentences: List[str]):
token_ids = [[vocab.to_index(t) for t in s.split()] for s in sentences]
sembeddings = stransformer.encode(sentences)
print(sembeddings.dtype)
return {"input_ids": token_ids, "sembedding": sembeddings}
```
Given a list of `sentences` (`List[str]`), it converts those into token_ids on the one hand (list of lists of ints; `List[List[int]]`) and into sentence embeddings on the other (Tensor of dtype `torch.float32`). That means that I actually set the column "sembedding" to a tensor that I as a user expect to be a float32.
It appears though that behind the scenes, this tensor is converted into a **list**. I did not find this documented anywhere but I might have missed it. From a user's perspective this is incredibly important though, because it means you cannot do any data_type or tensor casting yourself in a mapping function! Furthermore, this can lead to issues, as was my case.
My model expected float32 precision, which I thought `sembedding` was because that is what `stransformer.encode` outputs. But behind the scenes this tensor is first cast to a list, and when we then set its format, as below, this column is cast not to float32 but to double precision float64.
```python
dataset.set_format(type="torch", columns=["input_ids", "sembedding"])
```
This happens because apparently there is an intermediate step of casting to a **numpy** array (?) **whose dtype creation/deduction is different from torch dtypes** (see the snippet below). As you can see, this means that the dtype is not preserved: if I got it right, the dataset goes from torch.float32 -> list -> float64 (numpy) -> torch.float64.
```python
import torch
import numpy as np
l = [-0.03010837361216545, -0.035979013890028, -0.016949838027358055]
torch_tensor = torch.tensor(l)
np_array = np.array(l)
np_to_torch = torch.from_numpy(np_array)
print(torch_tensor.dtype)
# torch.float32
print(np_array.dtype)
# float64
print(np_to_torch.dtype)
# torch.float64
```
This might lead to unwanted behaviour. I understand that the whole library is probably built around casting from numpy to other frameworks, so this might be difficult to solve. Perhaps `set_format` should include a `dtypes` option where for each input column the user can specify the wanted precision.
The alternative is that the user needs to cast manually after loading data from the dataset but that does not seem user-friendly, makes the dataset less portable, and might use more space in memory as well as on disk than is actually needed. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/625/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/624/comments | https://api.github.com/repos/huggingface/datasets/issues/624/events | https://github.com/huggingface/datasets/issues/624 | 700,541,628 | MDU6SXNzdWU3MDA1NDE2Mjg= | 624 | Add learningq dataset | {
"login": "krrishdholakia",
"id": 17561003,
"node_id": "MDQ6VXNlcjE3NTYxMDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/17561003?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/krrishdholakia",
"html_url": "https://github.com/krrishdholakia",
"followers_url": "https://api.github.com/users/krrishdholakia/followers",
"following_url": "https://api.github.com/users/krrishdholakia/following{/other_user}",
"gists_url": "https://api.github.com/users/krrishdholakia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/krrishdholakia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/krrishdholakia/subscriptions",
"organizations_url": "https://api.github.com/users/krrishdholakia/orgs",
"repos_url": "https://api.github.com/users/krrishdholakia/repos",
"events_url": "https://api.github.com/users/krrishdholakia/events{/privacy}",
"received_events_url": "https://api.github.com/users/krrishdholakia/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,599,992,427,000 | 1,600,077,002,000 | null | NONE | null | Hi,
Thank you again for this amazing repo.
Would it be possible for y'all to add the LearningQ dataset - https://github.com/AngusGLChen/LearningQ ?
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/624/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/623/comments | https://api.github.com/repos/huggingface/datasets/issues/623/events | https://github.com/huggingface/datasets/issues/623 | 700,235,308 | MDU6SXNzdWU3MDAyMzUzMDg= | 623 | Custom feature types in `load_dataset` from CSV | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Currently `csv` doesn't support the `features` attribute (unlike `json`).\r\nWhat you can do for now is cast the features using the in-place transform `cast_`\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset('csv', data_files=file_dict, delimiter=';', column_names=['text', 'label'])\r\ndataset.cast_(emotion_features)\r\n```\r\n",
"Thanks for the clarification!",
"Hi @lhoestq we've tried out your suggestion but are now running into the following error:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-163-81ffd5ac18c9> in <module>\r\n----> 1 dataset.cast_(emotion_features)\r\n\r\n/usr/local/lib/python3.6/dist-packages/datasets/dataset_dict.py in cast_(self, features)\r\n 125 self._check_values_type()\r\n 126 for dataset in self.values():\r\n--> 127 dataset.cast_(features=features)\r\n 128 \r\n 129 def remove_columns_(self, column_names: Union[str, List[str]]):\r\n\r\n/usr/local/lib/python3.6/dist-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)\r\n 161 # Call actual function\r\n 162 \r\n--> 163 out = func(self, *args, **kwargs)\r\n 164 \r\n 165 # Update fingerprint of in-place transforms + update in-place history of transforms\r\n\r\n/usr/local/lib/python3.6/dist-packages/datasets/arrow_dataset.py in cast_(self, features)\r\n 602 self._info.features = features\r\n 603 schema = pa.schema(features.type)\r\n--> 604 self._data = self._data.cast(schema)\r\n 605 \r\n 606 @fingerprint(inplace=True)\r\n\r\n/usr/local/lib/python3.6/dist-packages/pyarrow/table.pxi in pyarrow.lib.Table.cast()\r\n\r\nValueError: Target schema's field names are not matching the table's field names: ['text', 'label'], ['label', 'text']\r\n```\r\n\r\nLooking at the types in `emotion_features` we see that `label` and `text` appear to be swapped in the Arrow table:\r\n\r\n```\r\nemotion_features.type\r\nStructType(struct<label: int64, text: string>)\r\n```\r\n\r\nDid we define the `emotion_features` incorrectly? We just followed the instructions from the [docs](https://huggingface.co/docs/datasets/features.html?highlight=features#dataset-features), but perhaps we misunderstood something 😬 \r\n\r\n",
"In general, I don't think there is any hard reason we don't allow to use `features` in the csv script, right @lhoestq?\r\n\r\nShould I add it?",
"> In general, I don't think there is any hard reason we don't allow to use `features` in the csv script, right @lhoestq?\r\n> \r\n> Should I add it?\r\n\r\nSure let's add it. Setting the convert options should do the job\r\n\r\n> Hi @lhoestq we've tried out your suggestion but are now running into the following error:\r\n> \r\n> ```\r\n> ---------------------------------------------------------------------------\r\n> ValueError Traceback (most recent call last)\r\n> <ipython-input-163-81ffd5ac18c9> in <module>\r\n> ----> 1 dataset.cast_(emotion_features)\r\n>\r\n> /usr/local/lib/python3.6/dist-packages/pyarrow/table.pxi in pyarrow.lib.Table.cast()\r\n> \r\n> ValueError: Target schema's field names are not matching the table's field names: ['text', 'label'], ['label', 'text']\r\n> ```\r\n>\r\n> Did we define the `emotion_features` incorrectly? We just followed the instructions from the [docs](https://huggingface.co/docs/datasets/features.html?highlight=features#dataset-features), but perhaps we misunderstood something 😬\r\n\r\nThanks for reporting, that's a bug :) I'm fixing it right now",
"PR is open for the `ValueError: Target schema's field names are not matching the table's field names` error.\r\n\r\nI'm adding the features parameter to csv",
"Thanks a lot for the PR and quick fix @lhoestq!"
] | 1,599,916,894,000 | 1,601,495,503,000 | 1,601,455,194,000 | CONTRIBUTOR | null | I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotion dataset. To get the data you can use the following code:
```Python
from pathlib import Path
import wget
EMOTION_PATH = Path("./data/emotion")
DOWNLOAD_URLS = [
"https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1",
"https://www.dropbox.com/s/2mzialpsgf9k5l3/val.txt?dl=1",
"https://www.dropbox.com/s/ikkqxfdbdec3fuj/test.txt?dl=1",
]
if not Path.is_dir(EMOTION_PATH):
Path.mkdir(EMOTION_PATH)
for url in DOWNLOAD_URLS:
wget.download(url, str(EMOTION_PATH))
```
The first five lines of the train set are:
```
i didnt feel humiliated;sadness
i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake;sadness
im grabbing a minute to post i feel greedy wrong;anger
i am ever feeling nostalgic about the fireplace i will know that it is still on the property;love
i am feeling grouchy;anger
```
Here the code to reproduce the issue:
```Python
from datasets import Features, Value, ClassLabel, load_dataset
class_names = ["sadness", "joy", "love", "anger", "fear", "surprise"]
emotion_features = Features({'text': Value('string'), 'label': ClassLabel(names=class_names)})
file_dict = {'train': EMOTION_PATH/'train.txt'}
dataset = load_dataset('csv', data_files=file_dict, delimiter=';', column_names=['text', 'label'], features=emotion_features)
```
**Observed behaviour:**
```Python
dataset['train'].features
```
```Python
{'text': Value(dtype='string', id=None),
'label': Value(dtype='string', id=None)}
```
**Expected behaviour:**
```Python
dataset['train'].features
```
```Python
{'text': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], names_file=None, id=None)}
```
**Things I've tried:**
- deleting the cache
- trying other types such as `int64`
Am I missing anything? Thanks for any pointer in the right direction. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/623/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/622/comments | https://api.github.com/repos/huggingface/datasets/issues/622/events | https://github.com/huggingface/datasets/issues/622 | 700,225,826 | MDU6SXNzdWU3MDAyMjU4MjY= | 622 | load_dataset for text files not working | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Can you give us more information on your os and pip environments (pip list)?",
"@thomwolf Sure. I'll try downgrading to 3.7 now even though Arrow say they support >=3.5.\r\n\r\nLinux (Ubuntu 18.04) - Python 3.8\r\n======================\r\nPackage - Version\r\n---------------------\r\ncertifi 2020.6.20\r\nchardet 3.0.4\r\nclick 7.1.2\r\ndatasets 1.0.1\r\ndill 0.3.2\r\nfasttext 0.9.2\r\nfilelock 3.0.12\r\nfuture 0.18.2\r\nidna 2.10\r\njoblib 0.16.0\r\nnltk 3.5\r\nnumpy 1.19.1\r\npackaging 20.4\r\npandas 1.1.2\r\npip 20.0.2\r\nprotobuf 3.13.0\r\npyarrow 1.0.1\r\npybind11 2.5.0\r\npyparsing 2.4.7\r\npython-dateutil 2.8.1\r\npytz 2020.1\r\nregex 2020.7.14\r\nrequests 2.24.0\r\nsacremoses 0.0.43\r\nscikit-learn 0.23.2\r\nscipy 1.5.2\r\nsentence-transformers 0.3.6\r\nsentencepiece 0.1.91\r\nsetuptools 46.1.3\r\nsix 1.15.0\r\nstanza 1.1.1\r\nthreadpoolctl 2.1.0\r\ntokenizers 0.8.1rc2\r\ntorch 1.6.0+cu101\r\ntqdm 4.48.2\r\ntransformers 3.1.0\r\nurllib3 1.25.10\r\nwheel 0.34.2\r\nxxhash 2.0.0\r\n\r\nWindows 10 - Python 3.8\r\n================\r\nPackage - Version\r\n----------------------------\r\ncertifi 2020.6.20\r\nchardet 3.0.4\r\nclick 7.1.2\r\ndatasets 1.0.1\r\ndill 0.3.2\r\nfasttext 0.9.2\r\nfilelock 3.0.12\r\nfuture 0.18.2\r\nidna 2.10\r\njoblib 0.16.0\r\nnlp 0.4.0\r\nnltk 3.5\r\nnumpy 1.19.1\r\npackaging 20.4\r\npandas 1.1.1\r\npip 20.0.2\r\nprotobuf 3.13.0\r\npyarrow 1.0.1\r\npybind11 2.5.0\r\npyparsing 2.4.7\r\npython-dateutil 2.8.1\r\npytz 2020.1\r\nregex 2020.7.14\r\nrequests 2.24.0\r\nsacremoses 0.0.43\r\nscikit-learn 0.23.2\r\nscipy 1.5.2\r\nsentence-transformers 0.3.5.1\r\nsentencepiece 0.1.91\r\nsetuptools 46.1.3\r\nsix 1.15.0\r\nstanza 1.1.1\r\nthreadpoolctl 2.1.0\r\ntokenizers 0.8.1rc1\r\ntorch 1.6.0+cu101\r\ntqdm 4.48.2\r\ntransformers 3.0.2\r\nurllib3 1.25.10\r\nwheel 0.34.2\r\nxxhash 2.0.0",
"Downgrading to 3.7 does not help. Here is a dummy text file:\r\n\r\n```text\r\nVerzekering weigert vaker te betalen\r\nBedrijven van verzekeringen erkennen steeds minder arbeidsongevallen .\r\nIn 2012 weigerden de bedrijven te betalen voor 21.055 ongevallen op het werk .\r\nDat is 11,8 % van alle ongevallen op het werk .\r\nNog nooit weigerden verzekeraars zoveel zaken .\r\nIn 2012 hadden 135.118 mensen een ongeval op het werk .\r\nDat zijn elke werkdag 530 mensen .\r\nBij die ongevallen stierven 67 mensen .\r\nBijna 12.000 hebben een handicap na het ongeval .\r\nGeen echt arbeidsongeval Bedrijven moeten een verzekering hebben voor hun werknemers .\r\n```\r\n\r\nA temporary work around for the \"text\" type, is\r\n\r\n```python\r\ndataset = Dataset.from_dict({\"text\": Path(dataset_f).read_text().splitlines()})\r\n```",
"\r\n\r\neven i am facing the same issue.",
"@banunitte Please do not post screenshots in the future but copy-paste your code and the errors. That allows others to copy-and-paste your code and test it. You may also want to provide the Python version that you are using.",
"I have the exact same problem in Windows 10, Python 3.8.\r\n",
"I have the same problem on Linux of the script crashing with a CSV error. This may be caused by 'CRLF', when changed 'CRLF' to 'LF', the problem solved.",
"I pushed a fix for `pyarrow.lib.ArrowInvalid: CSV parse error`. Let me know if you still have this issue.\r\n\r\nNot sure about the windows one yet",
"To complete what @lhoestq is saying, I think that to use the new version of the `text` processing script (which is on master right now) you need to either specify the version of the script to be the `master` one or to install the lib from source (in which case it uses the `master` version of the script by default):\r\n```python\r\ndataset = load_dataset('text', script_version='master', data_files=XXX)\r\n```\r\nWe do versioning by default, i.e. your version of the dataset lib will use the script with the same version by default (i.e. only the `1.0.1` version of the script if you have the PyPI version `1.0.1` of the lib).",
"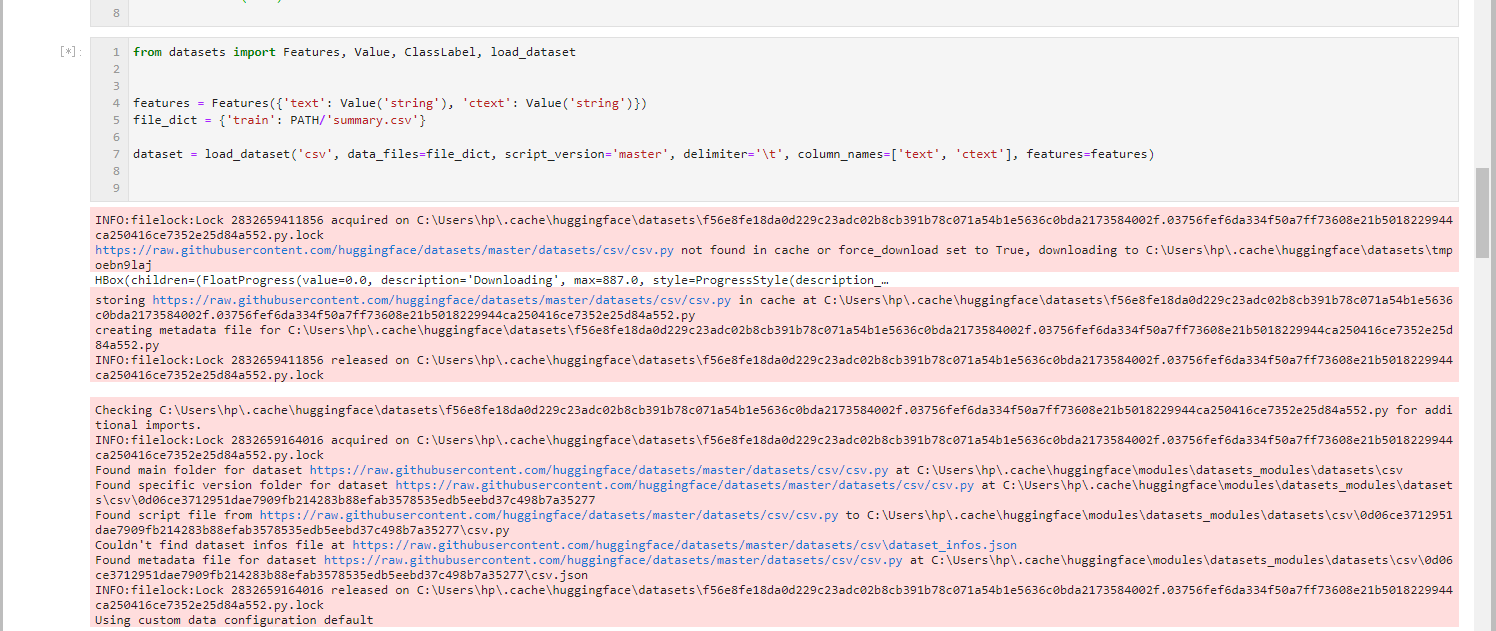\r\nwin10, py3.6\r\n\r\n\r\n```\r\nfrom datasets import Features, Value, ClassLabel, load_dataset\r\n\r\n\r\nfeatures = Features({'text': Value('string'), 'ctext': Value('string')})\r\nfile_dict = {'train': PATH/'summary.csv'}\r\n\r\ndataset = load_dataset('csv', data_files=file_dict, script_version='master', delimiter='\\t', column_names=['text', 'ctext'], features=features)\r\n```",
"```python\r\nTraceback` (most recent call last):\r\n File \"main.py\", line 281, in <module>\r\n main()\r\n File \"main.py\", line 190, in main\r\n train_data, test_data = data_factory(\r\n File \"main.py\", line 129, in data_factory\r\n train_data = load_dataset('text', \r\n File \"/home/me/Downloads/datasets/src/datasets/load.py\", line 608, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/me/Downloads/datasets/src/datasets/builder.py\", line 468, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/me/Downloads/datasets/src/datasets/builder.py\", line 546, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/me/Downloads/datasets/src/datasets/builder.py\", line 888, in _prepare_split\r\n for key, table in utils.tqdm(generator, unit=\" tables\", leave=False, disable=not_verbose):\r\n File \"/home/me/.local/lib/python3.8/site-packages/tqdm/std.py\", line 1130, in __iter__\r\n for obj in iterable:\r\n File \"/home/me/.cache/huggingface/modules/datasets_modules/datasets/text/512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7fcc649178b014/text.py\", line 103, in _generate_tables\r\n pa_table = pac.read_csv(\r\n File \"pyarrow/_csv.pyx\", line 617, in pyarrow._csv.read_csv\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 85, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: CSV parse error: Expected 1 columns, got 2\r\n```\r\n\r\nUnfortunately i am still getting this issue on Linux. I installed datasets from source and specified script_version to master.\r\n\r\n",
"> \r\n> win10, py3.6\r\n> \r\n> ```\r\n> from datasets import Features, Value, ClassLabel, load_dataset\r\n> \r\n> \r\n> features = Features({'text': Value('string'), 'ctext': Value('string')})\r\n> file_dict = {'train': PATH/'summary.csv'}\r\n> \r\n> dataset = load_dataset('csv', data_files=file_dict, script_version='master', delimiter='\\t', column_names=['text', 'ctext'], features=features)\r\n> ```\r\n\r\nSince #644 it should now work on windows @ScottishFold007 \r\n\r\n> Trying the following snippet, I get different problems on Linux and Windows.\r\n> \r\n> ```python\r\n> dataset = load_dataset(\"text\", data_files=\"data.txt\")\r\n> # or \r\n> dataset = load_dataset(\"text\", data_files=[\"data.txt\"])\r\n> ```\r\n>\r\n> Windows just seems to get stuck. Even with a tiny dataset of 10 lines, it has been stuck for 15 minutes already at this message:\r\n> \r\n> ```\r\n> Checking C:\\Users\\bramv\\.cache\\huggingface\\datasets\\b1d50a0e74da9a7b9822cea8ff4e4f217dd892e09eb14f6274a2169e5436e2ea.30c25842cda32b0540d88b7195147decf9671ee442f4bc2fb6ad74016852978e.py for additional imports.\r\n> Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\r\n> Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\r\n> Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py to C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\\text.py\r\n> Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text\\dataset_infos.json\r\n> Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\\text.json\r\n> Using custom data configuration default\r\n> ```\r\n\r\nSame for you @BramVanroy .\r\n\r\nNot sure about the one on linux though",
"> To complete what @lhoestq is saying, I think that to use the new version of the `text` processing script (which is on master right now) you need to either specify the version of the script to be the `master` one or to install the lib from source (in which case it uses the `master` version of the script by default):\r\n> \r\n> ```python\r\n> dataset = load_dataset('text', script_version='master', data_files=XXX)\r\n> ```\r\n> \r\n> We do versioning by default, i.e. your version of the dataset lib will use the script with the same version by default (i.e. only the `1.0.1` version of the script if you have the PyPI version `1.0.1` of the lib).\r\n\r\nLinux here:\r\n\r\nI was using the 0.4.0 nlp library load_dataset to load a text dataset of 9-10Gb without collapsing the RAM memory. However, today I got the csv error message mentioned in this issue. After installing the new (datasets) library from source and specifying the script_verson = 'master' I'm still having this same error message. Furthermore, I cannot use the dictionary \"trick\" to load the dataset since the system kills the process due to a RAM out of memory problem. Is there any other solution to this error? Thank you in advance. ",
"Hi @raruidol \r\nTo fix the RAM issue you'll need to shard your text files into smaller files (see https://github.com/huggingface/datasets/issues/610#issuecomment-691672919 for example)\r\n\r\nI'm not sure why you're having the csv error on linux.\r\nDo you think you could to to reproduce it on google colab for example ?\r\nOr send me a dummy .txt file that reproduces the issue ?",
"@lhoestq \r\n\r\nThe crash message shows up when loading the dataset:\r\n```\r\nprint('Loading corpus...') \r\nfiles = glob.glob('corpora/shards/*') \r\n-> dataset = load_dataset('text', script_version='master', data_files=files) \r\nprint('Corpus loaded.')\r\n```\r\nAnd this is the exact message:\r\n```\r\nTraceback (most recent call last):\r\n File \"run_language_modeling.py\", line 27, in <module>\r\n dataset = load_dataset('text', script_version='master', data_files=files)\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/load.py\", line 611, in load_dataset\r\n ignore_verifications=ignore_verifications,\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/builder.py\", line 471, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/builder.py\", line 548, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/builder.py\", line 892, in _prepare_split\r\n for key, table in utils.tqdm(generator, unit=\" tables\", leave=False, disable=not_verbose):\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/tqdm/std.py\", line 1130, in __iter__\r\n for obj in iterable:\r\n File \"/home/jupyter-raruidol/.cache/huggingface/modules/datasets_modules/datasets/text/512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7fcc649178b014/text.py\", line 107, in _generate_tables\r\n convert_options=self.config.convert_options,\r\n File \"pyarrow/_csv.pyx\", line 714, in pyarrow._csv.read_csv\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 84, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: CSV parse error: Expected 1 columns, got 2\r\n```\r\n\r\nAnd these are the pip packages I have atm and their versions:\r\n\r\n```\r\nPackage Version Location \r\n--------------- --------- -------------------------------------------------------------\r\ncertifi 2020.6.20 \r\nchardet 3.0.4 \r\nclick 7.1.2 \r\ndatasets 1.0.2 \r\ndill 0.3.2 \r\nfilelock 3.0.12 \r\nfuture 0.18.2 \r\nidna 2.10 \r\njoblib 0.16.0 \r\nnumpy 1.19.1 \r\npackaging 20.4 \r\npandas 1.1.1 \r\npip 19.0.3 \r\npyarrow 1.0.1 \r\npyparsing 2.4.7 \r\npython-dateutil 2.8.1 \r\npytz 2020.1 \r\nregex 2020.7.14 \r\nrequests 2.24.0 \r\nsacremoses 0.0.43 \r\nsentencepiece 0.1.91 \r\nsetuptools 40.8.0 \r\nsix 1.15.0 \r\ntokenizers 0.8.1rc2 \r\ntorch 1.6.0 \r\ntqdm 4.48.2 \r\ntransformers 3.0.2 /home/jupyter-raruidol/DebatAnalyser/env/src/transformers/src\r\n```\r\n\r\n\r\n",
"I tested on google colab which is also linux using this code:\r\n\r\n- first download an arbitrary text file\r\n```bash\r\nwget https://raw.githubusercontent.com/abisee/cnn-dailymail/master/url_lists/all_train.txt\r\n```\r\n- then run\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nd = load_dataset(\"text\", data_files=\"all_train.txt\", script_version='master')\r\n```\r\nAnd I don't get this issue.\r\n\r\n\\> Could you test on your side if these lines work @raruidol ?\r\n\r\nalso cc @Skyy93 as it seems you have the same issue\r\n\r\nIf it works:\r\nIt could mean that the issue could come from unexpected patterns in the files you want to use.\r\nIn that case we should find a way to handle them.\r\n\r\nAnd if it doesn't work:\r\nIt could mean that it comes from the way pyarrow reads text files on linux.\r\nIn that case we should report it to pyarrow and find a workaround in the meantime\r\n\r\nEither way it should help to find where this bug comes from and fix it :)\r\n\r\nThank you in advance !",
"Update: also tested the above code in a docker container from [jupyter/minimal-notebook](https://hub.docker.com/r/jupyter/minimal-notebook/) (based on ubuntu) and still not able to reproduce",
"It looks like with your text input file works without any problem. I have been doing some experiments this morning with my input files and I'm almost certain that the crash is caused by some unexpected pattern in the files. However, I've not been able to spot the main cause of it. What I find strange is that this same corpus was being loaded by the nlp 0.4.0 library without any problem... Where can I find the code where you structure the input text data in order to use it with pyarrow?",
"Under the hood it does\r\n```python\r\nimport pyarrow as pa\r\nimport pyarrow.csv\r\n\r\n# Use csv reader from Pyarrow with one column for text files\r\n\r\n# To force the one-column setting, we set an arbitrary character\r\n# that is not in text files as delimiter, such as \\b or \\v.\r\n# The bell character, \\b, was used to make beeps back in the days\r\nparse_options = pa.csv.ParseOptions( \r\n delimiter=\"\\b\", \r\n quote_char=False, \r\n double_quote=False, \r\n escape_char=False, \r\n newlines_in_values=False, \r\n ignore_empty_lines=False, \r\n)\r\n\r\nread_options= pa.csv.ReadOptions(use_threads=True, column_names=[\"text\"])\r\n\r\npa_table = pa.csv.read_csv(\"all_train.txt\", read_options=read_options, parse_options=parse_options)\r\n```\r\n\r\nNote that we changed the parse options with datasets 1.0\r\nIn particular the delimiter used to be `\\r` but this delimiter doesn't work on windows.",
"Could you try with `\\a` instead of `\\b` ? It looks like the bell character is \\a in python and not \\b",
"I was just exploring if the crash was happening in every shard or not, and which shards were generating the error message. With \\b I got the following list of shards crashing:\r\n\r\n```\r\nErrors on files: ['corpora/shards/shard_0069', 'corpora/shards/shard_0043', 'corpora/shards/shard_0014', 'corpora/shards/shard_0032', 'corpora/shards/shard_0088', 'corpora/shards/shard_0018', 'corpora/shards/shard_0073', 'corpora/shards/shard_0079', 'corpora/shards/shard_0038', 'corpora/shards/shard_0041', 'corpora/shards/shard_0007', 'corpora/shards/shard_0004', 'corpora/shards/shard_0102', 'corpora/shards/shard_0096', 'corpora/shards/shard_0030', 'corpora/shards/shard_0076', 'corpora/shards/shard_0067', 'corpora/shards/shard_0052', 'corpora/shards/shard_0026', 'corpora/shards/shard_0024', 'corpora/shards/shard_0064', 'corpora/shards/shard_0044', 'corpora/shards/shard_0013', 'corpora/shards/shard_0062', 'corpora/shards/shard_0057', 'corpora/shards/shard_0097', 'corpora/shards/shard_0094', 'corpora/shards/shard_0078', 'corpora/shards/shard_0075', 'corpora/shards/shard_0039', 'corpora/shards/shard_0077', 'corpora/shards/shard_0021', 'corpora/shards/shard_0040', 'corpora/shards/shard_0009', 'corpora/shards/shard_0023', 'corpora/shards/shard_0095', 'corpora/shards/shard_0107', 'corpora/shards/shard_0063', 'corpora/shards/shard_0086', 'corpora/shards/shard_0047', 'corpora/shards/shard_0089', 'corpora/shards/shard_0037', 'corpora/shards/shard_0101', 'corpora/shards/shard_0093', 'corpora/shards/shard_0082', 'corpora/shards/shard_0091', 'corpora/shards/shard_0065', 'corpora/shards/shard_0020', 'corpora/shards/shard_0070', 'corpora/shards/shard_0008', 'corpora/shards/shard_0058', 'corpora/shards/shard_0060', 'corpora/shards/shard_0022', 'corpora/shards/shard_0059', 'corpora/shards/shard_0100', 'corpora/shards/shard_0027', 'corpora/shards/shard_0072', 'corpora/shards/shard_0098', 'corpora/shards/shard_0019', 'corpora/shards/shard_0066', 'corpora/shards/shard_0042', 'corpora/shards/shard_0053']\r\n```\r\n\r\nI also tried with \\a and the list decreased but there were still several crashes:\r\n\r\n```\r\nErrors on files: ['corpora/shards/shard_0069', 'corpora/shards/shard_0055', 'corpora/shards/shard_0043', 'corpora/shards/shard_0014', 'corpora/shards/shard_0073', 'corpora/shards/shard_0025', 'corpora/shards/shard_0068', 'corpora/shards/shard_0102', 'corpora/shards/shard_0096', 'corpora/shards/shard_0076', 'corpora/shards/shard_0067', 'corpora/shards/shard_0026', 'corpora/shards/shard_0024', 'corpora/shards/shard_0044', 'corpora/shards/shard_0087', 'corpora/shards/shard_0092', 'corpora/shards/shard_0074', 'corpora/shards/shard_0094', 'corpora/shards/shard_0078', 'corpora/shards/shard_0039', 'corpora/shards/shard_0077', 'corpora/shards/shard_0040', 'corpora/shards/shard_0009', 'corpora/shards/shard_0107', 'corpora/shards/shard_0063', 'corpora/shards/shard_0103', 'corpora/shards/shard_0047', 'corpora/shards/shard_0033', 'corpora/shards/shard_0089', 'corpora/shards/shard_0037', 'corpora/shards/shard_0082', 'corpora/shards/shard_0071', 'corpora/shards/shard_0091', 'corpora/shards/shard_0065', 'corpora/shards/shard_0070', 'corpora/shards/shard_0058', 'corpora/shards/shard_0081', 'corpora/shards/shard_0060', 'corpora/shards/shard_0002', 'corpora/shards/shard_0059', 'corpora/shards/shard_0027', 'corpora/shards/shard_0072', 'corpora/shards/shard_0098', 'corpora/shards/shard_0019', 'corpora/shards/shard_0045', 'corpora/shards/shard_0036', 'corpora/shards/shard_0066', 'corpora/shards/shard_0053']\r\n```\r\n\r\nWhich means that it is quite possible that the assumption of that some unexpected pattern in the files is causing the crashes is true. If I am able to reach any conclusion I will post It here asap.",
"Hmmm I was expecting it to work with \\a, not sure why they appear in your text files though",
"Hi @lhoestq, is there any input length restriction which was not before the update of the nlp library?",
"No we never set any input length restriction on our side (maybe arrow but I don't think so)",
"@lhoestq Can you ever be certain that a delimiter character is not present in a plain text file? In other formats (e.g. CSV) , rules are set of what is allowed and what isn't so that it actually constitutes a CSV file. In a text file you basically have \"anything goes\", so I don't think you can ever be entirely sure that the chosen delimiter does not exist in the text file, or am I wrong? \r\n\r\nIf I understand correctly you choose a delimiter that we hope does not exist in the file, so that when the CSV parser starts splitting into columns, it will only ever create one column? Why can't we use a newline character though?",
"Okay, I have splitted the crashing shards into individual sentences and some examples of the inputs that are causing the crashes are the following ones:\r\n\r\n\r\n_4. DE L’ORGANITZACIÓ ESTAMENTAL A L’ORGANITZACIÓ EN CLASSES A mesura que es desenvolupava un sistema econòmic capitalista i naixia una classe burgesa cada vegada més preparada per a substituir els dirigents de les velles monarquies absolutistes, es qüestionava l’abundància de béns amortitzats, que com s’ha dit estaven fora del mercat i no pagaven tributs, pels perjudicis que ocasionaven a les finances públiques i a l’economia en general. Aquest estat d’opinió revolucionari va desembocar en un conjunt de mesures pràctiques de caràcter liberal. D’una banda, les que intentaven desposseir les mans mortes del domini de béns acumulats, procés que acostumem a denominar desamortització, i que no és més que la nacionalització i venda d’aquests béns eclesiàstics o civils en subhasta pública al millor postor. D’altra banda, les que redimien o reduïen els censos i delmes o aixecaven les prohibicions de venda, és a dir, les vinculacions. La desamortització, que va afectar béns dels ordes religiosos, dels pobles i d’algunes corporacions civils, no va ser un camí fàcil, perquè costava i costa trobar algú que sigui indiferent a la pèrdua de béns, drets i privilegis. I té una gran transcendència, va privar els antics estaments de les Espanyes, clero i pobles —la noblesa en queda al marge—, de la força econòmica que els donaven bona part de les seves terres i, en última instància, va preparar el terreny per a la substitució de la vella societat estamental per la nova societat classista. En aquesta societat, en teoria, les agrupacions socials són obertes, no tenen cap estatut jurídic privilegiat i estan definides per la possessió o no d’uns béns econòmics que són lliurement alienables. A les Espanyes la transformació va afectar poc l’aristocràcia latifundista, allà on n’hi havia. Aquesta situació va afavorir, en part, la persistència de la vella cultura de la societat estamental en determinats ambients, i això ha influït decisivament en la manca de democràcia que caracteritza la majoria de règims polítics que s’han anat succeint. Una manera de pensar que sempre sura en un moment o altre, i que de fet no acaba de desaparèixer del tot. 5. INICI DE LA DESAMORTITZACIÓ A LES ESPANYES Durant el segle xviii, dins d’aquesta visió lliberal, va agafar força en alguns cercles de les Espanyes el corrent d’opinió contrari a les mans mortes. Durant el regnat de Carles III, s’arbitraren les primeres mesures desamortitzadores proposades per alguns ministres il·lustrats. Aquestes disposicions foren modestes i poc eficaces, no van aturar l’acumulació de terres per part dels estaments que constituïen les mans mortes i varen afectar principalment béns dels pobles. L’Església no va ser tocada, excepte en el cas de 110_\r\n\r\n_la revolució liberal, perquè, encara que havia perdut els seus drets jurisdiccionals, havia conservat la majoria de terres i fins i tot les havia incrementat amb d’altres que procedien de la desamortització. En la nova situació, les mans mortes del bosc públic eren l’Estat, que no cerca mai l’autofinançament de les despeses de gestió; els diners que manquin ja els posarà l’Estat. 9. DEFENSA I INTENTS DE RECUPERACIÓ DELS BÉNS COMUNALS DESAMORTITZATS El procés de centralització no era senzill, perquè, d’una banda, la nova organització apartava de la gestió moltes corporacions locals i molts veïns que l’havien portada des de l’edat mitjana, i, de l’altra, era difícil de coordinar la nova silvicultura amb moltes pràctiques forestals i drets tradicionals, com la pastura, fer llenya o tallar un arbre aquí i un altre allà quan tenia el gruix suficient, les pràctiques que s’havien fet sempre. Les primeres passes de la nova organització centralitzada varen tenir moltes dificultats en aquells indrets en què els terrenys municipals i comunals tenien un paper important en l’economia local. La desobediència a determinades normes imposades varen prendre formes diferents. Algunes institucions, com, per exemple, la Diputació de Lleida, varen retardar la tramitació d’alguns expedients i varen evitar la venda de béns municipals. Molts pobles permeteren deixar que els veïns continuessin amb les seves pràctiques tradicionals, d’altres varen boicotejar les subhastes d’aprofitaments. L’Estat va reaccionar encomanant a la Guàrdia Civil el compliment de les noves directrius. Imposar el nou règim va costar a l’Administració un grapat d’anys, però de mica en mica, amb molta, molta guarderia i gens de negociació, ho va aconseguir. La nova gestió estatal dels béns municipals va deixar, com hem comentat, molta gent sense uns recursos necessaris per a la supervivència, sobre tot en àrees on predominaven les grans propietats, i on els pagesos sense terra treballaven de jornalers temporers. Això va afavorir que, a bona part de les Espanyes, les primeres lluites camperoles de la segona meitat del segle xix defensessin la recuperació dels comunals desamortitzats; per a molts aquella expropiació i venda dirigida pels governs monàrquics era la causa de molta misèria. D’altres, més radicalitzats, varen entendre que l’eliminació de la propietat col·lectiva i la gestió estatal dels boscos no desamortitzats suposava una usurpació pura i dura. En les zones més afectades per la desamortització això va donar lloc a un imaginari centrat en la defensa del comunal. La Segona República va arribar en una conjuntura econòmica de crisi, generada pel crac del 1929. Al camp, aquesta situació va produir una forta caiguda dels preus dels productes agraris i un increment important de l’atur. QUADERNS AGRARIS 42 (juny 2017), p. 105-126_\r\n\r\nI think that the main difference between the crashing samples and the rest is their length. Therefore, couldn't the length be causing the message errors? I hope with these samples you can identify what is causing the crashes considering that the 0.4.0 nlp library was loading them properly.",
"So we're using the csv reader to read text files because arrow doesn't have a text reader.\r\nTo workaround the fact that text files are just csv with one column, we want to set a delimiter that doesn't appear in text files.\r\nUntil now I thought that it would do the job but unfortunately it looks like even characters like \\a appear in text files.\r\n\r\nSo we have to option:\r\n- find another delimiter that does the job (maybe `\\x1b` esc or `\\x18` cancel)\r\n- don't use the csv reader from arrow but the text reader from pandas instead (or any other reader). The only important thing is that it must be fast (arrow's reader has a nice and fast multithreaded for csv that we're using now but hopefully we can find an alternative)\r\n\r\n\r\n\r\n> @lhoestq Can you ever be certain that a delimiter character is not present in a plain text file? In other formats (e.g. CSV) , rules are set of what is allowed and what isn't so that it actually constitutes a CSV file. In a text file you basically have \"anything goes\", so I don't think you can ever be entirely sure that the chosen delimiter does not exist in the text file, or am I wrong?\r\n\r\nAs long as the text file follows some encoding it wouldn't make sense to have characters such as the bell character. However I agree it can happen.\r\n\r\n> If I understand correctly you choose a delimiter that we hope does not exist in the file, so that when the CSV parser starts splitting into columns, it will only ever create one column? Why can't we use a newline character though?\r\n\r\nExactly. Arrow doesn't allow the newline character unfortunately.",
"> Okay, I have splitted the crashing shards into individual sentences and some examples of the inputs that are causing the crashes are the following ones\r\n\r\nThanks for digging into it !\r\n\r\nCharacters like \\a or \\b are not shown when printing the text, so as it is I can't tell if it contains unexpected characters.\r\nMaybe could could open the file in python and check if `\"\\b\" in open(\"path/to/file\", \"r\").read()` ?\r\n\r\n> I think that the main difference between the crashing samples and the rest is their length. Therefore, couldn't the length be causing the message errors? I hope with these samples you can identify what is causing the crashes considering that the 0.4.0 nlp library was loading them properly.\r\n\r\nTo check that you could try to run \r\n\r\n```python\r\nimport pyarrow as pa\r\nimport pyarrow.csv\r\n\r\nopen(\"dummy.txt\", \"w\").write(((\"a\" * 10_000) + \"\\n\") * 4) # 4 lines of 10 000 'a'\r\n\r\nparse_options = pa.csv.ParseOptions( \r\n delimiter=\"\\b\", \r\n quote_char=False, \r\n double_quote=False, \r\n escape_char=False, \r\n newlines_in_values=False, \r\n ignore_empty_lines=False, \r\n)\r\n\r\nread_options= pa.csv.ReadOptions(use_threads=True, column_names=[\"text\"])\r\n\r\npa_table = pa.csv.read_csv(\"dummy.txt\", read_options=read_options, parse_options=parse_options)\r\n```\r\n\r\non my side it runs without error though",
"That's true, It was my error printing the text that way. Maybe as a workaround, I can force all my input samples to have \"\\b\" at the end?",
"> That's true, It was my error printing the text that way. Maybe as a workaround, I can force all my input samples to have \"\\b\" at the end?\r\n\r\nI don't think it would work since we only want one column, and \"\\b\" is set to be the delimiter between two columns, so it will raise the same issue again. Pyarrow would think that there is more than one column if the delimiter is found somewhere.\r\n\r\nAnyway, I I'll work on a new text reader if we don't find the right workaround about this delimiter issue."
] | 1,599,914,968,000 | 1,603,883,251,000 | 1,603,883,250,000 | CONTRIBUTOR | null | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that you can use a string as input for data_files, but the signature is `Union[Dict, List]`.)
The problem on Linux is that the script crashes with a CSV error (even though it isn't a CSV file). On Windows the script just seems to freeze or get stuck after loading the config file.
Linux stack trace:
```
PyTorch version 1.6.0+cu101 available.
Checking /home/bram/.cache/huggingface/datasets/b1d50a0e74da9a7b9822cea8ff4e4f217dd892e09eb14f6274a2169e5436e2ea.30c25842cda32b0540d88b7195147decf9671ee442f4bc2fb6ad74016852978e.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7
Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py to /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.py
Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.json
Using custom data configuration default
Generating dataset text (/home/bram/.cache/huggingface/datasets/text/default-0907112cc6cd2a38/0.0.0/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7)
Downloading and preparing dataset text/default-0907112cc6cd2a38 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/bram/.cache/huggingface/datasets/text/default-0907112cc6cd2a38/0.0.0/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7...
Dataset not on Hf google storage. Downloading and preparing it from source
Downloading took 0.0 min
Checksum Computation took 0.0 min
Unable to verify checksums.
Generating split train
Traceback (most recent call last):
File "/home/bram/Python/projects/dutch-simplification/utils.py", line 45, in prepare_data
dataset = load_dataset("text", data_files=dataset_f)
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/load.py", line 608, in load_dataset
builder_instance.download_and_prepare(
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/builder.py", line 468, in download_and_prepare
self._download_and_prepare(
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/builder.py", line 546, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/builder.py", line 888, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/tqdm/std.py", line 1130, in __iter__
for obj in iterable:
File "/home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.py", line 100, in _generate_tables
pa_table = pac.read_csv(
File "pyarrow/_csv.pyx", line 714, in pyarrow._csv.read_csv
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: CSV parse error: Expected 1 columns, got 2
```
Windows just seems to get stuck. Even with a tiny dataset of 10 lines, it has been stuck for 15 minutes already at this message:
```
Checking C:\Users\bramv\.cache\huggingface\datasets\b1d50a0e74da9a7b9822cea8ff4e4f217dd892e09eb14f6274a2169e5436e2ea.30c25842cda32b0540d88b7195147decf9671ee442f4bc2fb6ad74016852978e.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7
Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py to C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\text.py
Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text\dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\text.json
Using custom data configuration default
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/622/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/622/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/621/comments | https://api.github.com/repos/huggingface/datasets/issues/621/events | https://github.com/huggingface/datasets/pull/621 | 700,171,097 | MDExOlB1bGxSZXF1ZXN0NDg1ODQ3ODYz | 621 | [docs] Index: The native emoji looks kinda ugly in large size | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,904,120,000 | 1,600,150,803,000 | 1,600,150,802,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/621/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/621",
"html_url": "https://github.com/huggingface/datasets/pull/621",
"diff_url": "https://github.com/huggingface/datasets/pull/621.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/621.patch",
"merged_at": 1600150802000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/620/comments | https://api.github.com/repos/huggingface/datasets/issues/620/events | https://github.com/huggingface/datasets/issues/620 | 699,815,135 | MDU6SXNzdWU2OTk4MTUxMzU= | 620 | map/filter multiprocessing raises errors and corrupts datasets | {
"login": "timothyjlaurent",
"id": 2000204,
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/timothyjlaurent",
"html_url": "https://github.com/timothyjlaurent",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"It seems that I ran into the same problem\r\n```\r\ndef tokenize(cols, example):\r\n for in_col, out_col in cols.items():\r\n example[out_col] = hf_tokenizer.convert_tokens_to_ids(hf_tokenizer.tokenize(example[in_col]))\r\n return example\r\ncola = datasets.load_dataset('glue', 'cola')\r\ntokenized_cola = cola.map(partial(tokenize, {'sentence': 'text_idxs'}),\r\n num_proc=2,)\r\n```\r\nand it outpus (exceprts)\r\n```\r\nConcatenating 2 shards from multiprocessing\r\nSet __getitem__(key) output type to python objects for ['idx', 'label', 'sentence', 'text_idxs'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nTesting the mapped function outputs\r\nTesting finished, running the mapping function on the dataset\r\nDone writing 532 indices in 4256 bytes .\r\nDone writing 531 indices in 4248 bytes .\r\nProcess #0 will write at /home/yisiang/.cache/huggingface/datasets/glue/cola/1.0.0/930e9d141872db65102cabb9fa8ac01c11ffc8a1b72c2e364d8cdda4610df542/tokenized_test_00000_of_00002.arrow\r\nProcess #1 will write at /home/yisiang/.cache/huggingface/datasets/glue/cola/1.0.0/930e9d141872db65102cabb9fa8ac01c11ffc8a1b72c2e364d8cdda4610df542/tokenized_test_00001_of_00002.arrow\r\nSpawning 2 processes\r\n```\r\nand then the program never stop.",
"same problem.\r\n`encoded_dataset = core_data.map(lambda examples: tokenizer(examples[\"query\"], examples[\"document\"], padding=True, truncation='longest_first', return_tensors=\"pt\", max_length=384), num_proc=16, keep_in_memory=True)`\r\nit outputs:\r\n```\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787500 indices in 25568400000 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nDone writing 1787499 indices in 25568385696 bytes .\r\nSet __getitem__(key) output type to python objects for ['document', 'is_random', 'query'] columns (when key is int or slice) and don't output other (un-formatted) columns.\r\nSpawning 16 processes\r\n```",
"Thanks for reporting.\r\n\r\n\r\nWhich tokenizers are you using ? What platform are you on ? Can you tell me which version of datasets and pyarrow you're using ? @timothyjlaurent @richarddwang @HuangLianzhe \r\n\r\nAlso if you're able to reproduce the issue on google colab that would be very helpful.\r\n\r\nI tried to run your code @richarddwang with the bert tokenizer and I wasn't able to reproduce",
"Hi, Sorry that I forgot to see what my version was.\r\nBut after updating datasets to master (editable install), and latest pyarrow. \r\nIt works now ~",
"Sorry, I just noticed this.\r\nI'm running this on MACOS the version of datasets I'm was 1.0.0 but I've also tried it on 1.0.2. `pyarrow==1.0.1`, Python 3.6\r\n\r\nConsider this code:\r\n```python\r\n\r\n loader_path = str(Path(__file__).parent / \"prodigy_dataset_builder.py\")\r\n ds = load_dataset(\r\n loader_path, name=\"prodigy-ds\", data_files=list(file_paths), cache_dir=cache_dir\r\n )[\"train\"]\r\n valid_relations = set(vocabulary.relation_types.keys())\r\n\r\n ds = ds.filter(filter_good_rows, fn_kwargs=dict(valid_rel_labels=valid_relations))\r\n\r\n ds = ds.map(map_bpe_encodings, batched=True, fn_kwargs=dict(tokenizer=vocabulary.tokenizer), num_proc=10)\r\n\r\n # add all feature data\r\n ner_ds: Dataset = ds.map(\r\n add_bio_tags,\r\n fn_kwargs=dict(ner_label_map=vocabulary.ner_labels, tokenizer=vocabulary.tokenizer),\r\n )\r\n rel_ds: Dataset = ner_ds.map(\r\n relation_ds_factory,\r\n batched=True,\r\n writer_batch_size=100,\r\n fn_kwargs=dict(tokenizer=vocabulary.tokenizer, vocabulary=vocabulary),\r\n )\r\n```\r\nThe loader is essentially a jsonloader with some extra error handling. The data is a jsonlines format with text field and a list of span objects and relation objects. \r\n\r\nIn the `ner_ds` a field, `ner_labels` is added, this is used in the downstream `relation_ds_factory`. It all runs fine in a single process but I get a KeyError error if run with num_proc set\r\n:\r\n\r\n```\r\n File \"/Users/timothy.laurent/src/inv-text2struct/text2struct/model/dataset.py\", line 348, in relation_ds_factory\r\n ner_labels = example[\"ner_labels\"]\r\nKeyError: 'ner_labels'\r\n``` \r\n\r\nThis is just one example of what goes wrong. I've started just saving the dataset as arrow at the end because it takes a long time to map/filter/shuffle and the caching isn't working (tracked it down to byte differences in the pickled functions). \r\n\r\n^^ Interestingly if I heed the warning from Tokenizers and set the environment variable, `TOKENIZERS_PARALLELISM=true` the map just hangs:\r\n\r\n```\r\n[I 200921 21:43:18 filelock:318] Lock 5694118768 released on /Users/timothy.laurent/.cache/huggingface/datasets/_Users_timothy.laurent_.cache_huggingface_datasets_prodigy_dataset_builder_prodigy-ds-5f34378723c4e83f_0.0.0_e67d9b43d5cd82c50b1eae8f2097daf95b601a04dc03ddd504f2b234a5fa247a.lock\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.34ba/s]\r\n#0: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#1: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#2: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#3: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#4: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#5: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#6: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#7: 0%| | 0/1 [00:00<?, ?ba/s]\r\n#8: 0%| | 0/1 [00:00<?, ?ba/s]\r\n```",
"Thank you, I was able to reproduce :)\r\nI'm on it",
"#659 should fix the `KeyError` issue. It was due to the formatting not getting updated the right way",
"Also maybe @n1t0 knows why setting `TOKENIZERS_PARALLELISM=true` creates deadlock issues when calling `map` with multiprocessing ?",
"@lhoestq \r\n\r\nThanks for taking a look. I pulled the master but I still see the key error.\r\n\r\n```\r\nTo disable this warning, you can either:\r\n - Avoid using `tokenizers` before the fork if possible\r\n - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\n#0: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 21.56ba/s]\r\n#1: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 17.71ba/s]\r\n#2: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 20.45ba/s]\r\n#3: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 26.05ba/s]\r\n#4: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 26.83ba/s]\r\n#5: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 27.00ba/s]\r\n#6: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 27.40ba/s]\r\n#7: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 25.91ba/s]\r\n#8: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 22.46ba/s]\r\n#9: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 20.15ba/s]\r\n#10: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 26.81ba/s]\r\n#11: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 27.45ba/s]\r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 322/322 [00:00<00:00, 1462.85ex/s]\r\nTraceback (most recent call last): | 0/1 [00:00<?, ?ba/s]\r\n File \"text2struct/run_model.py\", line 372, in <module>\r\n main()\r\n File \"text2struct/run_model.py\", line 368, in main | 0/1 [00:00<?, ?ba/s]\r\n run_model(auto_envvar_prefix=\"GFB_CIES\") # pragma: no cover\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs) | 0/1 [00:00<?, ?ba/s]\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/core.py\", line 1236, in invoke\r\n return Command.invoke(self, ctx)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/decorators.py\", line 21, in new_func\r\n return f(get_current_context(), *args, **kwargs)\r\n File \"text2struct/run_model.py\", line 136, in run_model\r\n ctx.invoke(ctx.command.commands[config_dict[\"mode\"]])\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/click/decorators.py\", line 21, in new_func\r\n return f(get_current_context(), *args, **kwargs)\r\n File \"text2struct/run_model.py\", line 187, in train\r\n run_train_model(_parse_subcommand(ctx))\r\n File \"text2struct/run_model.py\", line 241, in run_train_model\r\n checkpoint_steps=config.train.checkpoint_steps,\r\n File \"/Users/timothy.laurent/src/inv-text2struct/text2struct/model/train.py\", line 153, in alternate_training\r\n max_len=config.model.dim.max_len,\r\n File \"/Users/timothy.laurent/src/inv-text2struct/text2struct/model/dataset.py\", line 466, in load_prodigy_tf_datasets\r\n folder, file_patterns, vocabulary, cache_dir=cache_dir, test_pct=test_pct\r\n File \"/Users/timothy.laurent/src/inv-text2struct/text2struct/model/dataset.py\", line 447, in load_prodigy_arrow_datasets\r\n fn_kwargs=dict(tokenizer=vocabulary.tokenizer, vocabulary=vocabulary),\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1224, in map\r\n update_data = does_function_return_dict(test_inputs, test_indices)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1195, in does_function_return_dict\r\n function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)\r\n File \"/Users/timothy.laurent/src/inv-text2struct/text2struct/model/dataset.py\", line 348, in relation_ds_factory\r\n ner_labels = example[\"ner_labels\"]\r\nKeyError: 'ner_labels'\r\n\r\n```",
"The parallelism is automatically disabled on `tokenizers` when the process gets forked, while we already used the parallelism capabilities of a tokenizer. We have to do it in order to avoid having the process hang, because we cannot safely fork a multithreaded process (cf https://github.com/huggingface/tokenizers/issues/187).\r\nSo if possible, the tokenizers shouldn't be used before the fork, so that each process can then make use of the parallelism. Otherwise using `TOKENIZERS_PARALLELISM=false` is the way to go.",
"> Thanks for taking a look. I pulled the master but I still see the key error.\r\n\r\nI am no longer able to get the error since #659 was merged. Not sure why you still have it @timothyjlaurent \r\nMaybe it is a cache issue ? Could you try to use `load_from_cache_file=False` in your `.map()` calls ?",
"> The parallelism is automatically disabled on `tokenizers` when the process gets forked, while we already used the parallelism capabilities of a tokenizer. We have to do it in order to avoid having the process hang, because we cannot safely fork a multithreaded process (cf [huggingface/tokenizers#187](https://github.com/huggingface/tokenizers/issues/187)).\r\n> So if possible, the tokenizers shouldn't be used before the fork, so that each process can then make use of the parallelism. Otherwise using `TOKENIZERS_PARALLELISM=false` is the way to go.\r\n\r\nOk thanks :)\r\n\r\nIs there something we should do on the `datasets` side to avoid that that the program hangs ?\r\n\r\nAlso when doing `.map` with a tokenizer, the tokenizer is called once on the first examples of the dataset to check the function output before spawning the processes. Is that compatible with how tokenizers are supposed to be used with multiprocessing ?",
"#659 fixes the empty dict issue\r\n#688 fixes the hang issue",
"Hmmm I pulled the latest commit, `b93c5517f70a480533a44e0c42638392fd53d90`, and I'm still seeing both the hanging and the key error. ",
"Hi @timothyjlaurent \r\n\r\nThe hanging fix just got merged, that why you still had it.\r\n\r\nFor the key error it's possible that the code you ran reused cached datasets from where the KeyError bug was still there.\r\nCould you try to clear your cache or make sure that it doesn't reuse cached data with `.map(..., load_from_cache=False)` ?\r\nLet me know if it it helps",
"Hi @lhoestq , \r\n\r\nThanks for letting me know about the update.\r\n\r\nSo I don't think it's the caching - because hashing mechanism isn't stable for me -- but that's a different issue. In any case I `rm -rf ~/.cache/huggingface` to make a clean slate.\r\n\r\nI synced with master and I see the key error has gone away, I tried with and without the `TOKENIZERS_PARALLELISM` variable set and see the log line for setting the value false before the map.\r\n\r\nNow I'm seeing an issue with `.train_test_split()` on datasets that are the product of a multiprocess map.\r\n\r\nHere is the stack trace\r\n\r\n```\r\n File \"/Users/timothy.laurent/src/inv-text2struct/text2struct/model/dataset.py\", line 451, in load_prodigy_arrow_datasets\r\n ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/src/datasets/src/datasets/arrow_dataset.py\", line 168, in wrapper\r\n dataset.set_format(**new_format)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/src/datasets/src/datasets/fingerprint.py\", line 163, in wrapper\r\n out = func(self, *args, **kwargs)\r\n File \"/Users/timothy.laurent/.virtualenvs/inv-text2struct/src/datasets/src/datasets/arrow_dataset.py\", line 794, in set_format\r\n list(filter(lambda col: col not in self._data.column_names, columns)), self._data.column_names\r\nValueError: Columns ['train', 'test'] not in the dataset. Current columns in the dataset: ['_input_hash', '_task_hash', '_view_id', 'answer', 'encoding__ids', 'encoding__offsets', 'encoding__overflowing', 'encoding__tokens', 'encoding__words', 'ner_ids', 'ner_labels', 'relations', 'spans', 'text', 'tokens']\r\n```\r\n\r\n\r\n",
"Thanks for reporting.\r\nI'm going to fix that and add a test case so that it doesn't happen again :) \r\nI'll let you know when it's done\r\n\r\nIn the meantime if you could make a google colab that reproduces the issue it would be helpful ! @timothyjlaurent ",
"Sure thing, @lhoestq.\r\n\r\nhttps://colab.research.google.com/drive/1lg4fbyrUO6m8ssQ2dNdVFaUqMUfA2zZ3?usp=sharing",
"Thanks @timothyjlaurent ! I just merged a fix on master. I also checked your notebook and it looks like it's working now.\r\nI added some tests to make sure it works as expected now :)",
"Great, @lhoestq . I'm trying to verify in the colab:\r\nchanged\r\n```\r\n!pip install datasets\r\n```\r\nto \r\n\r\n```\r\n!pip install git+https://github.com/huggingface/datasets@master\r\n```\r\n\r\nBut I'm still seeing the error - I wonder why?",
"It works on my side @timothyjlaurent on google colab.\r\nDid you try to uninstall datasets first, before updating it to master's version ?",
"I didn't -- it was a new sessions --- buuut - look like it's working today -- woot! I'll close this issue. Thanks @lhoestq "
] | 1,599,863,406,000 | 1,602,174,707,000 | 1,602,174,706,000 | NONE | null | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
rel_ds_dict["validation"] = rel_ds_dict["test"]
return ner_ds_dict, rel_ds_dict
```
The first train_test_split, `ner_ds`/`ner_ds_dict`, returns a `train` and `test` split that are iterable.
The second, `rel_ds`/`rel_ds_dict` in this case, returns a Dataset dict that has rows but if selected from or sliced into into returns an empty dictionary. eg `rel_ds_dict['train'][0] == {}` and `rel_ds_dict['train'][0:100] == {}`.
Ok I think I know the problem -- the rel_ds was mapped though a mapper with `num_proc=12`. If I remove `num_proc`. The dataset loads.
I also see errors with other map and filter functions when `num_proc` is set.
```
Done writing 67 indices in 536 bytes .
Done writing 67 indices in 536 bytes .
Fatal Python error: PyCOND_WAIT(gil_cond) failed
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/620/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/619/comments | https://api.github.com/repos/huggingface/datasets/issues/619/events | https://github.com/huggingface/datasets/issues/619 | 699,733,612 | MDU6SXNzdWU2OTk3MzM2MTI= | 619 | Mistakes in MLQA features names | {
"login": "M-Salti",
"id": 9285264,
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/M-Salti",
"html_url": "https://github.com/M-Salti",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Indeed you're right ! Thanks for reporting that\r\n\r\nCould you open a PR to fix the features names ?"
] | 1,599,857,183,000 | 1,600,239,559,000 | 1,600,239,559,000 | CONTRIBUTOR | null | I think the following features in MLQA shouldn't be named the way they are:
1. `questions` (should be `question`)
2. `ids` (should be `id`)
3. `start` (should be `answer_start`)
The reasons I'm suggesting these features be renamed are:
* To make them consistent with other QA datasets like SQuAD, XQuAD, TyDiQA etc. and hence make it easier to concatenate multiple QA datasets.
* The features names are not the same as the ones provided in the original MLQA datasets (it uses the names I suggested).
I know these columns can be renamed using using `Dataset.rename_column_`, `questions` and `ids` can be easily renamed but `start` on the other hand is annoying to rename since it's nested inside the feature `answers`.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/619/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/618/comments | https://api.github.com/repos/huggingface/datasets/issues/618/events | https://github.com/huggingface/datasets/pull/618 | 699,684,831 | MDExOlB1bGxSZXF1ZXN0NDg1NDAxMzI5 | 618 | sync logging utils with transformers | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Also, some downloads and dataset processing can be quite long for large datasets like wikipedia/pg19/etc. We probably don't want to user to think that the library is hanging. Happy to reorganize logging between DEBUG/INFO/WARNING to make it less verbose by default though.",
"The problem is that `transformers` imports `datasets` and the latter starts logging on `import`: at least 3 info messages - apache beam/torch/tf available - so it injects noise whether one uses the library or not - i.e. no choice given to the user.\r\n\r\nWould you be open for me to changing this PR, to keep the initial level at INFO, but to keep the `DATASETS_VERBOSITY` env var it introduces, to let the user control the verbosity?\r\n\r\n",
"> Also, some downloads and dataset processing can be quite long for large datasets like wikipedia/pg19/etc. We probably don't want to user to think that the library is hanging.\r\n\r\nIf you're referring to tqdm progress reports, it's not affected by changing the logging levels. It's not using logging.",
"> The problem is that `transformers` imports `datasets` and the latter starts logging on `import`: at least 3 info messages - apache beam/torch/tf available - so it injects noise whether one uses the library or not - i.e. no choice given to the user.\r\n> \r\n> Would you be open for me to changing this PR, to keep the initial level at INFO, but to keep the `DATASETS_VERBOSITY` env var it introduces, to let the user control the verbosity?\r\n\r\nFor now we can do that, then I'll change some messages to warnings and set the default verbosity at warning as well at that point. Does it sound good to you ?\r\n\r\n> If you're referring to tqdm progress reports, it's not affected by changing the logging levels. It's not using logging.\r\n\r\nActually we configured some progress bars to be disabled depending on the logging level ^^'\r\n",
"> For now we can do that, then I'll change some messages to warnings and set the default verbosity at warning as well at that point. Does it sound good to you ?\r\n\r\nIf it is logical then by all means. \r\n\r\n> > If you're referring to tqdm progress reports, it's not affected by changing the logging levels. It's not using logging.\r\n> \r\n> Actually we configured some progress bars to be disabled depending on the logging level ^^'\r\n\r\nThis is very smart!\r\n\r\nI reverted s/WARNINGS/INFO/.\r\n\r\nThank you!",
"Note that it’s the same in `transformers` @stas00, tdqm are also controlled by the logging level there.",
"> Note that it’s the same in `transformers` @stas00, tdqm are also controlled by the logging level there.\r\n\r\nThat's good to know, @thomwolf - thank you!\r\n\r\nI see that it's controlled in `trainer.py`, but in `examples` it's not - since that's where I usually see the progressbars (and they are great!). But I suppose they aren't API, so `examples` can behave differently.",
"BTW, this is what I'm talking about:\r\n```\r\npython -c \"import transformers\"\r\n2020-09-14 21:00:58.032658: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1\r\nPyTorch version 1.7.0.dev20200910 available.\r\nTensorFlow version 2.3.0 available.\r\nApache Beam available.\r\n```\r\nwhy does the user need to see this? Especially, if they aren't even using `datasets` directly?",
"Yes you are right, we should re-think the logging level of various elements.\r\nI also think that the `set_format` messages are confusing when they are the results of our internal operations (as mentioned [here](https://discuss.huggingface.co/t/pipeline-with-custom-dataset-tokenizer-when-to-save-load-manually/1084/7?u=thomwolf))",
"Actually I continued this PR in #635 to set the level to warning and update the logging level of some messages.\r\n\r\nLet me know if it sounds good to you",
"Closing this one sice #635 got merged",
"Awesome! Thank you!\r\n\r\nAny ideas how to eliminate this remaining log line from tensorflow (I know it's not `datasets` related, but perhaps you know).\r\n```\r\npython -c \"import transformers\"\r\n2020-09-17 08:38:34.718410: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1\r\n```"
] | 1,599,853,573,000 | 1,600,357,259,000 | 1,600,336,427,000 | CONTRIBUTOR | null | sync the docs/code with the recent changes in transformers' `logging` utils:
1. change the default level to `WARNING`
2. add `DATASETS_VERBOSITY` env var
3. expand docs | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/618/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/618",
"html_url": "https://github.com/huggingface/datasets/pull/618",
"diff_url": "https://github.com/huggingface/datasets/pull/618.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/618.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/617/comments | https://api.github.com/repos/huggingface/datasets/issues/617/events | https://github.com/huggingface/datasets/issues/617 | 699,472,596 | MDU6SXNzdWU2OTk0NzI1OTY= | 617 | Compare different Rouge implementations | {
"login": "ibeltagy",
"id": 2287797,
"node_id": "MDQ6VXNlcjIyODc3OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2287797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibeltagy",
"html_url": "https://github.com/ibeltagy",
"followers_url": "https://api.github.com/users/ibeltagy/followers",
"following_url": "https://api.github.com/users/ibeltagy/following{/other_user}",
"gists_url": "https://api.github.com/users/ibeltagy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibeltagy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibeltagy/subscriptions",
"organizations_url": "https://api.github.com/users/ibeltagy/orgs",
"repos_url": "https://api.github.com/users/ibeltagy/repos",
"events_url": "https://api.github.com/users/ibeltagy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibeltagy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Updates - the differences between the following three\r\n(1) https://github.com/bheinzerling/pyrouge (previously popular. The one I trust the most)\r\n(2) https://github.com/google-research/google-research/tree/master/rouge\r\n(3) https://github.com/pltrdy/files2rouge (used in fairseq)\r\ncan be explained by two things, stemming and handling multiple sentences.\r\n\r\nStemming: \r\n(1), (2): default is no stemming. (3): default is with stemming ==> No stemming is the correct default as you did [here](https://github.com/huggingface/datasets/blob/master/metrics/rouge/rouge.py#L84)\r\n\r\nMultiple sentences:\r\n(1) `rougeL` splits text using `\\n`\r\n(2) `rougeL` ignores `\\n`. \r\n(2) `rougeLsum` splits text using `\\n`\r\n(3) `rougeL` splits text using `.`\r\n\r\nFor (2), `rougeL` and `rougeLsum` are identical if the sequence doesn't contain `\\n`. With `\\n`, it is `rougeLsum` that matches (1) not `rougeL`. \r\n\r\nOverall, and as far as I understand, for your implementation here https://github.com/huggingface/datasets/blob/master/metrics/rouge/rouge.py#L65 to match the default, you only need to change `rougeL` [here](https://github.com/huggingface/datasets/blob/master/metrics/rouge/rouge.py#L86) to `rougeLsum` to correctly compute metrics for text with newlines.\r\n\r\nTagging @sshleifer who might be interested.",
"Thanks for the clarification !\r\nWe're adding Rouge Lsum in #701 ",
"This is a real issue, sorry for missing the mention @ibeltagy\r\n\r\nWe implemented a more involved [solution](https://github.com/huggingface/transformers/blob/99cb924bfb6c4092bed9232bea3c242e27c6911f/examples/seq2seq/utils.py#L481) that enforces that sentences are split with `\\n` so that rougeLsum scores match papers even if models don't generate newlines. \r\n\r\nUnfortunately, the best/laziest way I found to do this introduced an `nltk` dependency (For sentence splitting, all sentences don't end in `.`!!!), but this might be avoidable with some effort.\r\n\r\n#### Sidebar: Wouldn't Deterministic Be Better?\r\n\r\n`rouge_scorer.scoring.BootstrapAggregator` is well named but is not deterministic which I would like to change for my mental health, unless there is some really good reason to sample 500 observations before computing f-scores.\r\n\r\nI have a fix on a branch, but I wanted to get some context before introducting a 4th way to compute rouge. Scores are generally within .03 Rouge2 of boostrap after multiplying by 100, e.g 22.05 vs 22.08 Rouge2.\r\n\r\n",
"> This is a real issue, sorry for missing the mention @ibeltagy\r\n> \r\n> We implemented a more involved [solution](https://github.com/huggingface/transformers/blob/99cb924bfb6c4092bed9232bea3c242e27c6911f/examples/seq2seq/utils.py#L481) that enforces that sentences are split with `\\n` so that rougeLsum scores match papers even if models don't generate newlines.\r\n> \r\n> Unfortunately, the best/laziest way I found to do this introduced an `nltk` dependency (For sentence splitting, all sentences don't end in `.`!!!), but this might be avoidable with some effort.\r\n\r\nThanks for the details, I didn't know about that. Maybe we should consider adding this processing step or at least mention it somewhere in the library or the documentation\r\n\r\n> #### Sidebar: Wouldn't Deterministic Be Better?\r\n> `rouge_scorer.scoring.BootstrapAggregator` is well named but is not deterministic which I would like to change for my mental health, unless there is some really good reason to sample 500 observations before computing f-scores.\r\n> \r\n> I have a fix on a branch, but I wanted to get some context before introducting a 4th way to compute rouge. Scores are generally within .03 Rouge2 of boostrap after multiplying by 100, e.g 22.05 vs 22.08 Rouge2.\r\n\r\nI think the default `n_samples` of the aggregator is 1000. We could increase it or at least allow users to change it if they want more precise results.",
"Hi, thanks for the solution. \r\n\r\nI am not sure if this is a bug, but on line [510](https://github.com/huggingface/transformers/blob/99cb924bfb6c4092bed9232bea3c242e27c6911f/examples/seq2seq/utils.py#L510), are pred, tgt supposed to be swapped?",
"This looks like a bug in an old version of the examples in `transformers`"
] | 1,599,839,372,000 | 1,617,211,713,000 | 1,601,632,338,000 | NONE | null | I used RougeL implementation provided in `datasets` [here](https://github.com/huggingface/datasets/blob/master/metrics/rouge/rouge.py) and it gives numbers that match those reported in the pegasus paper but very different from those reported in other papers, [this](https://arxiv.org/pdf/1909.03186.pdf) for example.
Can you make sure the google-research implementation you are using matches the official perl implementation?
There are a couple of python wrappers around the perl implementation, [this](https://pypi.org/project/pyrouge/) has been commonly used, and [this](https://github.com/pltrdy/files2rouge) is used in fairseq).
There's also a python reimplementation [here](https://github.com/pltrdy/rouge) but its RougeL numbers are way off.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/617/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/617/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/616/comments | https://api.github.com/repos/huggingface/datasets/issues/616/events | https://github.com/huggingface/datasets/issues/616 | 699,462,293 | MDU6SXNzdWU2OTk0NjIyOTM= | 616 | UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"I have the same issue",
"Same issue here when Trying to load a dataset from disk.",
"I am also experiencing this issue, and don't know if it's affecting my training.",
"Same here. I hope the dataset is not being modified in-place.",
"I think the only way to avoid this warning would be to do a copy of the numpy array before providing it.\r\n\r\nThis would slow down a bit the iteration over the dataset but maybe it would be safer. We could disable the copy with a flag on the `set_format` command.\r\n\r\nIn most typical cases of training a NLP model, PyTorch shouldn't modify the input so it's ok to have a non-writable array but I can understand the warning is a bit scary so maybe we could choose the side of non-warning/slower by default and have an option to speedup.\r\n\r\nWhat do you think @lhoestq ? ",
"@thomwolf Would it be possible to have the array look writeable, but raise an error if it is actually written to?\r\n\r\nI would like to keep my code free of warning, but I also wouldn't like to slow down the program because of unnecessary copy operations. ",
"@AndreasMadsen probably not I would guess (no free lunch hahah)",
"@thomwolf Why not? Writable is checked with `arr.flags.writeable`, and writing is done via magic methods.",
"Well because I don't know the internal of numpy as well as you I guess hahahah, do you want to try to open a PR proposing a solution?",
"@thomwolf @AndreasMadsen I think this is a terrible idea, n/o, and I am very much against it. Modifying internals of an array in such a hacky way is bound to run into other (user) issues down the line. To users it would not be clear at all what is going on e.g. when they check for write access (which will return True) but then they get a warning that the array is not writeable. That's extremely confusing. \r\n\r\nIf your only goal is to get rid of warnings in your code, then you can just use a [simplefilter](https://docs.python.org/3.8/library/warnings.html#temporarily-suppressing-warnings) for UserWarnings in your own code. Changing the code-base in such an intuitive way does not seem like a good way to go and sets a bad precedent, imo. \r\n\r\n(Feel free to disagree, of course.)\r\n\r\nIMO a warning can stay (as they can be filtered by users anyway), but it can be clarified why the warning takes place.",
"> To users it would not be clear at all what is going on e.g. when they check for write access (which will return True) but then they get a warning that the array is not writeable. That's extremely confusing.\r\n\r\nConfusion can be resolved with a helpful error message. In this case, that error message can be controlled by huggingface/datasets. The right argument here is that if code depends on `.flags.writable` being truthful (not just for warnings), then it will cause unavoidable errors. Although, I can't imagine such a use-case.\r\n\r\n> If your only goal is to get rid of warnings in your code, then you can just use a simplefilter for UserWarnings in your own code. Changing the code-base in such an intuitive way does not seem like a good way to go and sets a bad precedent, imo.\r\n\r\nI don't want to ignore all `UserWarnings`, nor all warnings regarding non-writable arrays. Ignoring warnings leads to hard to debug issues.\r\n\r\n> IMO a warning can stay (as they can be filtered by users anyway), but it can be clarified why the warning takes place.\r\n\r\nPlain use cases should really not generate warnings. It teaches developers to ignore warnings which is a terrible practice.\r\n\r\n---\r\n\r\nThe best solution would be to allow non-writable arrays in `DataLoader`, but that is a PyTorch issue.",
"> The right argument here is that if code depends on `.flags.writable` being truthful (not just for warnings), then it will cause unavoidable errors. Although, I can't imagine such a use-case.\r\n\r\nThat's exactly the argument in my first sentence. Too often someone \"cannot think of a use-case\", but you can not foresee the use-cases of a whole research community.\r\n \r\n> I don't want to ignore all `UserWarnings`, nor all warnings regarding non-writable arrays. Ignoring warnings leads to hard to debug issues.\r\n\r\nThat's fair.\r\n\r\n> Plain use cases should really not generate warnings. It teaches developers to ignore warnings which is a terrible practice.\r\n\r\nBut this is not a plain use-case (because Pytorch does not support these read-only tensors). Manually setting the flag to writable will solve the issue on the surface but is basically just a hack to compensate for something that is not allowed in another library. \r\n\r\nWhat about an \"ignore_warnings\" flag in `set_format` that when True wraps the offending code in a block to ignore userwarnings at that specific step in [_convert_outputs](https://github.com/huggingface/datasets/blob/880c2c76a8223a00c303eab2909371e857113063/src/datasets/arrow_dataset.py#L821)? Something like:\r\n\r\n```python\r\ndef _convert_outputs(..., ignore_warnings=True):\r\n ...\r\n with warnings.catch_warnings():\r\n if ignore_warnings:\r\n warnings.simplefilter(\"ignore\", UserWarning)\r\n return torch.tensor(...)\r\n# continues without warning filter after context manager...\r\n```",
"> But this is not a plain use-case (because Pytorch does not support these read-only tensors).\r\n\r\nBy \"plain\", I mean the recommended way to use `datasets` with PyTorch according to the `datasets` documentation.",
"This error is what I see when I run the first lines of the Pytorch Quickstart. It should also say that it should be ignored and/or how to fix it. BTW, this is a Pytorch error message -- not a Huggingface error message. My code runs anyway."
] | 1,599,838,756,000 | 1,626,988,341,000 | null | CONTRIBUTOR | null | I am trying out the library and want to load in pickled data with `from_dict`. In that dict, one column `text` should be tokenized and the other (an embedding vector) should be retained. All other columns should be removed. When I eventually try to set the format for the columns with `set_format` I am getting this strange Userwarning without a stack trace:
> Set __getitem__(key) output type to torch for ['input_ids', 'sembedding'] columns (when key is int or slice) and don't output other (un-formatted) columns.
> C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\datasets\arrow_dataset.py:835: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:141.)
> return torch.tensor(x, **format_kwargs)
The first one might not be related to the warning, but it is odd that it is shown, too. It is unclear whether that is something that I should do or something that that the program is doing at that moment.
Snippet:
```
dataset = Dataset.from_dict(torch.load("data/dummy.pt.pt"))
print(dataset)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
keys_to_retain = {"input_ids", "sembedding"}
dataset = dataset.map(lambda example: tokenizer(example["text"], padding='max_length'), batched=True)
dataset.remove_columns_(set(dataset.column_names) - keys_to_retain)
dataset.set_format(type="torch", columns=["input_ids", "sembedding"])
dataloader = torch.utils.data.DataLoader(dataset, batch_size=2)
print(next(iter(dataloader)))
```
PS: the input type for `remove_columns_` should probably be an Iterable rather than just a List. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/616/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 4
} | https://api.github.com/repos/huggingface/datasets/issues/616/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/615/comments | https://api.github.com/repos/huggingface/datasets/issues/615/events | https://github.com/huggingface/datasets/issues/615 | 699,410,773 | MDU6SXNzdWU2OTk0MTA3NzM= | 615 | Offset overflow when slicing a big dataset with an array of indices in Pyarrow >= 1.0.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Related: https://issues.apache.org/jira/browse/ARROW-9773\r\n\r\nIt's definitely a size thing. I took a smaller dataset with 87000 rows and did:\r\n```\r\nfor i in range(10,1000,20):\r\n table = pa.concat_tables([dset._data]*i)\r\n table.take([0])\r\n```\r\nand it broke at around i=300.\r\n\r\nAlso when `_indices` is not None, this breaks indexing by slice. E.g. `dset.shuffle()[:1]` breaks.\r\n\r\nLuckily so far I haven't seen `_indices.column(0).take` break, which means it doesn't break `select` or anything like that which is where the speed really matters, it's just `_getitem`. So I'm currently working around it by just doing the arrow v0 method in `_getitem`:\r\n```\r\n#if PYARROW_V0:\r\ndata_subset = pa.concat_tables(\r\n self._data.slice(indices_array[i].as_py(), 1) for i in range(len(indices_array))\r\n)\r\n#else:\r\n #data_subset = self._data.take(indices_array)\r\n```",
"Let me know if you meet other offset overflow issues @joeddav "
] | 1,599,835,838,000 | 1,600,534,060,000 | 1,600,533,991,000 | MEMBER | null | How to reproduce:
```python
from datasets import load_dataset
wiki = load_dataset("wikipedia", "20200501.en", split="train")
wiki[[0]]
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
<ipython-input-13-381aedc9811b> in <module>
----> 1 wikipedia[[0]]
~/Desktop/hf/nlp/src/datasets/arrow_dataset.py in __getitem__(self, key)
1069 format_columns=self._format_columns,
1070 output_all_columns=self._output_all_columns,
-> 1071 format_kwargs=self._format_kwargs,
1072 )
1073
~/Desktop/hf/nlp/src/datasets/arrow_dataset.py in _getitem(self, key, format_type, format_columns, output_all_columns, format_kwargs)
1037 )
1038 else:
-> 1039 data_subset = self._data.take(indices_array)
1040
1041 if format_type is not None:
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.take()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/compute.py in take(data, indices, boundscheck)
266 """
267 options = TakeOptions(boundscheck)
--> 268 return call_function('take', [data, indices], options)
269
270
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/_compute.pyx in pyarrow._compute.call_function()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/_compute.pyx in pyarrow._compute.Function.call()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: offset overflow while concatenating arrays
```
It seems to work fine with small datasets or with pyarrow 0.17.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/615/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/614/comments | https://api.github.com/repos/huggingface/datasets/issues/614/events | https://github.com/huggingface/datasets/pull/614 | 699,177,110 | MDExOlB1bGxSZXF1ZXN0NDg0OTQ2MzA1 | 614 | [doc] Update deploy.sh | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,822,373,000 | 1,600,073,359,000 | 1,600,073,357,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/614/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/614/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/614",
"html_url": "https://github.com/huggingface/datasets/pull/614",
"diff_url": "https://github.com/huggingface/datasets/pull/614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/614.patch",
"merged_at": 1600073357000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/613/comments | https://api.github.com/repos/huggingface/datasets/issues/613/events | https://github.com/huggingface/datasets/pull/613 | 699,117,070 | MDExOlB1bGxSZXF1ZXN0NDg0ODkyMTUx | 613 | Add CoNLL-2003 shared task dataset | {
"login": "vblagoje",
"id": 458335,
"node_id": "MDQ6VXNlcjQ1ODMzNQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/458335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vblagoje",
"html_url": "https://github.com/vblagoje",
"followers_url": "https://api.github.com/users/vblagoje/followers",
"following_url": "https://api.github.com/users/vblagoje/following{/other_user}",
"gists_url": "https://api.github.com/users/vblagoje/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vblagoje/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vblagoje/subscriptions",
"organizations_url": "https://api.github.com/users/vblagoje/orgs",
"repos_url": "https://api.github.com/users/vblagoje/repos",
"events_url": "https://api.github.com/users/vblagoje/events{/privacy}",
"received_events_url": "https://api.github.com/users/vblagoje/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I think we should somewhere mention, that is the dataset in IOB2 tagging scheme, whereas the original dataset uses IOB1 :)",
"Indeed this is something we want to mention.\r\n\r\nIf would want to add more details about the IOB1->2 change, feel free to ignore my suggestions and edit the description + update the dataset_info",
"@lhoestq do you want me to update it or you'll update it. I am ok either way",
"The best would be to mention this change in the description and then update the dataset_info.json file.\r\nCould you do that if you don't mind ?\r\n\r\nThen it should be ready to merge :)\r\n\r\nThanks again for adding this dataset !",
"No problem @lhoestq I'll do the update",
"@lhoestq please check if 847addf is exactly what we want",
"Is the German task also part of this? If not, can it be accessed via the Datasets library?"
] | 1,599,818,550,000 | 1,601,894,585,000 | 1,600,338,998,000 | CONTRIBUTOR | null | Please consider adding CoNLL-2003 shared task dataset as it's beneficial for token classification tasks. The motivation behind this PR is the [PR](https://github.com/huggingface/transformers/pull/7041) in the transformers project. This dataset would be not only useful for the usual run-of-the-mill NER tasks but also for syntactic chunking and part-of-speech (POS) tagging. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/613/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/613/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/613",
"html_url": "https://github.com/huggingface/datasets/pull/613",
"diff_url": "https://github.com/huggingface/datasets/pull/613.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/613.patch",
"merged_at": 1600338998000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/612/comments | https://api.github.com/repos/huggingface/datasets/issues/612/events | https://github.com/huggingface/datasets/pull/612 | 699,008,644 | MDExOlB1bGxSZXF1ZXN0NDg0Nzk2Mjg5 | 612 | add multi-proc to dataset dict | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,812,293,000 | 1,599,819,613,000 | 1,599,819,611,000 | MEMBER | null | Add multi-proc to `DatasetDict` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/612/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/612",
"html_url": "https://github.com/huggingface/datasets/pull/612",
"diff_url": "https://github.com/huggingface/datasets/pull/612.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/612.patch",
"merged_at": 1599819611000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/611/comments | https://api.github.com/repos/huggingface/datasets/issues/611/events | https://github.com/huggingface/datasets/issues/611 | 698,863,988 | MDU6SXNzdWU2OTg4NjM5ODg= | 611 | ArrowCapacityError: List array cannot contain more than 2147483646 child elements, have 2147483648 | {
"login": "sangyx",
"id": 32364921,
"node_id": "MDQ6VXNlcjMyMzY0OTIx",
"avatar_url": "https://avatars.githubusercontent.com/u/32364921?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sangyx",
"html_url": "https://github.com/sangyx",
"followers_url": "https://api.github.com/users/sangyx/followers",
"following_url": "https://api.github.com/users/sangyx/following{/other_user}",
"gists_url": "https://api.github.com/users/sangyx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sangyx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sangyx/subscriptions",
"organizations_url": "https://api.github.com/users/sangyx/orgs",
"repos_url": "https://api.github.com/users/sangyx/repos",
"events_url": "https://api.github.com/users/sangyx/events{/privacy}",
"received_events_url": "https://api.github.com/users/sangyx/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Can you give us stats/information on your pandas DataFrame?",
"```\r\n<class 'pandas.core.frame.DataFrame'>\r\nInt64Index: 17136104 entries, 0 to 17136103\r\nData columns (total 6 columns):\r\n # Column Dtype \r\n--- ------ ----- \r\n 0 item_id int64 \r\n 1 item_titl object \r\n 2 start_price float64\r\n 3 shipping_fee float64\r\n 4 picture_url object \r\n 5 embeddings object \r\ndtypes: float64(2), int64(1), object(3)\r\nmemory usage: 915.2+ MB\r\n```",
"Thanks and some more on the `embeddings` and `picture_url` would be nice as well (type and max lengths of the elements)",
"`embedding` is `np.array` of shape `(128,)`. `picture_url` is url, such as 'https://i.ebayimg.com/00/s/MTE5OVgxNjAw/z/ZOsAAOSwAG9fHQq5/$_12.JPG?set_id=880000500F;https://i.ebayimg.com/00/s/MTE5OVgxNjAw/z/OSgAAOSwokBfHQq8/$_12.JPG?set_id=880000500F'",
"It looks like a Pyarrow limitation.\r\nI was able to reproduce the error with \r\n\r\n```python\r\nimport pandas as pd\r\nimport numpy as np\r\nimport pyarrow as pa\r\n\r\n n = 1713614\r\ndf = pd.DataFrame.from_dict({\"a\": list(np.zeros((n, 128))), \"b\": range(n)})\r\npa.Table.from_pandas(df)\r\n```\r\n\r\nI also tried with 50% of the dataframe and it actually works.\r\nI created an issue on Apache Arrow's JIRA [here](https://issues.apache.org/jira/browse/ARROW-9976)\r\n\r\nOne way to fix that would be to chunk the dataframe and concatenate arrow tables.",
"It looks like it's going to be fixed in pyarrow 2.0.0 :)\r\n\r\nIn the meantime I suggest to chunk big dataframes to create several small datasets, and then concatenate them using [concatenate_datasets](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=concatenate#datasets.concatenate_datasets)"
] | 1,599,802,152,000 | 1,601,046,895,000 | null | NONE | null | Hi, I'm trying to load a dataset from Dataframe, but I get the error:
```bash
---------------------------------------------------------------------------
ArrowCapacityError Traceback (most recent call last)
<ipython-input-7-146b6b495963> in <module>
----> 1 dataset = Dataset.from_pandas(emb)
~/miniconda3/envs/dev/lib/python3.7/site-packages/nlp/arrow_dataset.py in from_pandas(cls, df, features, info, split)
223 info.features = features
224 pa_table: pa.Table = pa.Table.from_pandas(
--> 225 df=df, schema=pa.schema(features.type) if features is not None else None
226 )
227 return cls(pa_table, info=info, split=split)
~/miniconda3/envs/dev/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_pandas()
~/miniconda3/envs/dev/lib/python3.7/site-packages/pyarrow/pandas_compat.py in dataframe_to_arrays(df, schema, preserve_index, nthreads, columns, safe)
591 for i, maybe_fut in enumerate(arrays):
592 if isinstance(maybe_fut, futures.Future):
--> 593 arrays[i] = maybe_fut.result()
594
595 types = [x.type for x in arrays]
~/miniconda3/envs/dev/lib/python3.7/concurrent/futures/_base.py in result(self, timeout)
426 raise CancelledError()
427 elif self._state == FINISHED:
--> 428 return self.__get_result()
429
430 self._condition.wait(timeout)
~/miniconda3/envs/dev/lib/python3.7/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
--> 384 raise self._exception
385 else:
386 return self._result
~/miniconda3/envs/dev/lib/python3.7/concurrent/futures/thread.py in run(self)
55
56 try:
---> 57 result = self.fn(*self.args, **self.kwargs)
58 except BaseException as exc:
59 self.future.set_exception(exc)
~/miniconda3/envs/dev/lib/python3.7/site-packages/pyarrow/pandas_compat.py in convert_column(col, field)
557
558 try:
--> 559 result = pa.array(col, type=type_, from_pandas=True, safe=safe)
560 except (pa.ArrowInvalid,
561 pa.ArrowNotImplementedError,
~/miniconda3/envs/dev/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/dev/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib._ndarray_to_array()
~/miniconda3/envs/dev/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowCapacityError: List array cannot contain more than 2147483646 child elements, have 2147483648
```
My code is :
```python
from nlp import Dataset
dataset = Dataset.from_pandas(emb)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/611/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/610/comments | https://api.github.com/repos/huggingface/datasets/issues/610/events | https://github.com/huggingface/datasets/issues/610 | 698,349,388 | MDU6SXNzdWU2OTgzNDkzODg= | 610 | Load text file for RoBERTa pre-training. | {
"login": "chiyuzhang94",
"id": 33407613,
"node_id": "MDQ6VXNlcjMzNDA3NjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/33407613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chiyuzhang94",
"html_url": "https://github.com/chiyuzhang94",
"followers_url": "https://api.github.com/users/chiyuzhang94/followers",
"following_url": "https://api.github.com/users/chiyuzhang94/following{/other_user}",
"gists_url": "https://api.github.com/users/chiyuzhang94/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chiyuzhang94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chiyuzhang94/subscriptions",
"organizations_url": "https://api.github.com/users/chiyuzhang94/orgs",
"repos_url": "https://api.github.com/users/chiyuzhang94/repos",
"events_url": "https://api.github.com/users/chiyuzhang94/events{/privacy}",
"received_events_url": "https://api.github.com/users/chiyuzhang94/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Could you try\r\n```python\r\nload_dataset('text', data_files='test.txt',cache_dir=\"./\", split=\"train\")\r\n```\r\n?\r\n\r\n`load_dataset` returns a dictionary by default, like {\"train\": your_dataset}",
"Hi @lhoestq\r\nThanks for your suggestion.\r\n\r\nI tried \r\n```\r\ndataset = load_dataset('text', data_files='test.txt',cache_dir=\"./\", split=\"train\")\r\nprint(dataset)\r\ndataset.set_format(type='torch',columns=[\"text\"])\r\ndataloader = torch.utils.data.DataLoader(dataset, batch_size=8)\r\nnext(iter(dataloader))\r\n```\r\n\r\nBut it still doesn't work and got error:\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-7-388aca337e2f> in <module>\r\n----> 1 next(iter(dataloader))\r\n\r\n/Library/Python/3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)\r\n 361 \r\n 362 def __next__(self):\r\n--> 363 data = self._next_data()\r\n 364 self._num_yielded += 1\r\n 365 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n\r\n/Library/Python/3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)\r\n 401 def _next_data(self):\r\n 402 index = self._next_index() # may raise StopIteration\r\n--> 403 data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n 404 if self._pin_memory:\r\n 405 data = _utils.pin_memory.pin_memory(data)\r\n\r\n/Library/Python/3.7/site-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)\r\n 42 def fetch(self, possibly_batched_index):\r\n 43 if self.auto_collation:\r\n---> 44 data = [self.dataset[idx] for idx in possibly_batched_index]\r\n 45 else:\r\n 46 data = self.dataset[possibly_batched_index]\r\n\r\n/Library/Python/3.7/site-packages/torch/utils/data/_utils/fetch.py in <listcomp>(.0)\r\n 42 def fetch(self, possibly_batched_index):\r\n 43 if self.auto_collation:\r\n---> 44 data = [self.dataset[idx] for idx in possibly_batched_index]\r\n 45 else:\r\n 46 data = self.dataset[possibly_batched_index]\r\n\r\n/Library/Python/3.7/site-packages/datasets-0.4.0-py3.7.egg/datasets/arrow_dataset.py in __getitem__(self, key)\r\n 1069 format_columns=self._format_columns,\r\n 1070 output_all_columns=self._output_all_columns,\r\n-> 1071 format_kwargs=self._format_kwargs,\r\n 1072 )\r\n 1073 \r\n\r\n/Library/Python/3.7/site-packages/datasets-0.4.0-py3.7.egg/datasets/arrow_dataset.py in _getitem(self, key, format_type, format_columns, output_all_columns, format_kwargs)\r\n 1056 format_columns=format_columns,\r\n 1057 output_all_columns=output_all_columns,\r\n-> 1058 format_kwargs=format_kwargs,\r\n 1059 )\r\n 1060 return outputs\r\n\r\n/Library/Python/3.7/site-packages/datasets-0.4.0-py3.7.egg/datasets/arrow_dataset.py in _convert_outputs(self, outputs, format_type, format_columns, output_all_columns, format_kwargs)\r\n 872 continue\r\n 873 if format_columns is None or k in format_columns:\r\n--> 874 v = map_nested(command, v, **map_nested_kwargs)\r\n 875 output_dict[k] = v\r\n 876 return output_dict\r\n\r\n/Library/Python/3.7/site-packages/datasets-0.4.0-py3.7.egg/datasets/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, types)\r\n 214 # Singleton\r\n 215 if not isinstance(data_struct, dict) and not isinstance(data_struct, types):\r\n--> 216 return function(data_struct)\r\n 217 \r\n 218 disable_tqdm = bool(logger.getEffectiveLevel() > INFO)\r\n\r\n/Library/Python/3.7/site-packages/datasets-0.4.0-py3.7.egg/datasets/arrow_dataset.py in command(x)\r\n 833 if x.dtype == np.object: # pytorch tensors cannot be instantied from an array of objects\r\n 834 return [map_nested(command, i, **map_nested_kwargs) for i in x]\r\n--> 835 return torch.tensor(x, **format_kwargs)\r\n 836 \r\n 837 elif format_type == \"tensorflow\":\r\n\r\nTypeError: new(): invalid data type 'str'\r\n```\r\n\r\nI found type can be ['numpy', 'torch', 'tensorflow', 'pandas'] only, how can I deal with the string type?",
"You need to tokenize the string inputs to convert them in integers before you can feed them to a pytorch dataloader.\r\n\r\nYou can read the quicktour of the datasets or the transformers libraries to know more about that:\r\n- transformers: https://huggingface.co/transformers/quicktour.html\r\n- dataset: https://huggingface.co/docs/datasets/quicktour.html",
"Hey @chiyuzhang94, I was also having trouble in loading a large text file (11GB).\r\nBut finally got it working. This is what I did after looking into the documentation.\r\n\r\n1. split the whole dataset file into smaller files\r\n```bash\r\nmkdir ./shards\r\nsplit -a 4 -l 256000 -d full_raw_corpus.txt ./shards/shard_\r\n````\r\n2. Pass paths of small data files to `load_dataset`\r\n```python\r\nfiles = glob.glob('shards/*')\r\nfrom datasets import load_dataset\r\ndataset = load_dataset('text', data_files=files, split='train')\r\n```\r\n(On passing the whole dataset file (11GB) directly to `load_dataset` was resulting into RAM issue)\r\n\r\n3. Tokenization\r\n```python\r\ndef encode(examples):\r\n return tokenizer(examples['text'], truncation=True, padding='max_length')\r\ndataset = dataset.map(encode, batched=True)\r\ndataset.set_format(type='torch', columns=['input_ids', 'attention_mask'])\r\n```\r\n Now you can pass `dataset` to `Trainer` or `pytorch DataLoader`\r\n```python\r\ndataloader = torch.utils.data.DataLoader(dataset, batch_size=4)\r\nnext(iter(dataloader))\r\n```\r\nHope this helps\r\n",
"Thanks, @thomwolf and @sipah00 ,\r\n\r\nI tried to implement your suggestions in my scripts. \r\nNow, I am facing some connection time-out error. I am using my local file, I have no idea why the module request s3 database.\r\n\r\nThe log is:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/.local/lib/python3.6/site-packages/requests/adapters.py\", line 449, in send\r\n raise err\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/util/connection.py\", line 74, in create_connection\r\n timeout=timeout\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 720, in urlopen\r\n sock.connect(sa)\r\nTimeoutError: [Errno 110] Connection timed out\r\n\r\nTraceback (most recent call last):\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 672, in urlopen\r\n method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/util/retry.py\", line 436, in increment\r\n chunked=chunked,\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 376, in _make_request\r\n raise MaxRetryError(_pool, url, error or ResponseError(cause))\r\nurllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/text/text.py (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection obj\r\nect at 0x7fff401e0e48>: Failed to establish a new connection: [Errno 110] Connection timed out',))\r\n\r\nTraceback (most recent call last):\r\n File \"/scratch/roberta_emohash/run_language_modeling.py\", line 1019, in <module>\r\n main()\r\n File \"/scratch/roberta_emohash/run_language_modeling.py\", line 962, in main\r\n train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)\r\n File \"/scratch/roberta_emohash/run_language_modeling.py\", line 177, in load_and_cache_examples\r\n return HG_Datasets(tokenizer, file_path, args)\r\n File \"/scratch/roberta_emohash/run_language_modeling.py\", line 117, in HG_Datasets\r\n dataset = load_dataset('text', data_files=files, cache_dir = args.data_cache_dir, split=\"train\")\r\n File \"/arc/project/evn_py36/datasets/datasets/src/datasets/load.py\", line 590, in load_dataset\r\n self._validate_conn(conn)\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 994, in _validate_conn\r\n conn.connect()\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/connection.py\", line 300, in connect\r\n conn = self._new_conn()\r\n File \"/home/.local/lib/python3.6/site-packages/urllib3/connection.py\", line 169, in _new_conn\r\n self, \"Failed to establish a new connection: %s\" % e\r\nurllib3.exceptions.NewConnectionError: <urllib3.connection.VerifiedHTTPSConnection object at 0x7fff401e0da0>: Failed to establish a new connection: [Errno 110] Connection timed out\r\n\r\n``` \r\n\r\nDo you have any experience on this issue?",
"No, I didn't encounter this problem, it seems to me a network problem",
"I noticed this is because I use a cloud server where does not provide for connections from our standard compute nodes to outside resources. \r\n\r\nFor the `datasets` package, it seems that if the loading script is not already cached in the library it will attempt to connect to an AWS resource to download the dataset loading script. \r\n\r\nI am wondering why the package works in this way. Do you have any suggestions to solve this issue? ",
"I solved the above issue by downloading text.py manually and passing the path to the `load_dataset` function. \r\n\r\nNow, I have a new issue with the Read-only file system.\r\n\r\nThe error is: \r\n```\r\nI0916 22:14:38.453380 140737353971520 filelock.py:274] Lock 140734268996072 acquired on /scratch/chiyuzh/roberta/text.py.lock\r\nFound main folder for dataset /scratch/chiyuzh/roberta/text.py at /home/chiyuzh/.cache/huggingface/modules/datasets_modules/datasets/text\r\nCreating specific version folder for dataset /scratch/chiyuzh/roberta/text.py at /home/chiyuzh/.cache/huggingface/modules/datasets_modules/datasets/text/512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7fcc649178b014\r\nI0916 22:14:38.530371 140737353971520 filelock.py:318] Lock 140734268996072 released on /scratch/chiyuzh/roberta/text.py.lock\r\nTraceback (most recent call last):\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling_hg.py\", line 1019, in <module>\r\n main()\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling_hg.py\", line 962, in main\r\n train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling_hg.py\", line 177, in load_and_cache_examples\r\n return HG_Datasets(tokenizer, file_path, args)\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling_hg.py\", line 117, in HG_Datasets\r\n dataset = load_dataset('/scratch/chiyuzh/roberta/text.py', data_files=files, cache_dir = args.data_cache_dir, split=\"train\")\r\n File \"/arc/project/chiyuzh/evn_py36/datasets/src/datasets/load.py\", line 590, in load_dataset\r\n path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True\r\n File \"/arc/project/chiyuzh/evn_py36/datasets/src/datasets/load.py\", line 385, in prepare_module\r\n os.makedirs(hash_folder_path)\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/os.py\", line 220, in makedirs\r\n mkdir(name, mode)\r\nOSError: [Errno 30] Read-only file system: '/home/chiyuzh/.cache/huggingface/modules/datasets_modules/datasets/text/512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7fcc649178b014'\r\n\r\n```\r\n\r\nI installed datasets at /project/chiyuzh/evn_py36/datasets/src where is a writable directory.\r\nI also tried change the environment variables to the writable directory:\r\n`export HF_MODULES_PATH=/project/chiyuzh/evn_py36/datasets/cache_dir/`\r\n`export HF_DATASETS_CACHE=/project/chiyuzh/evn_py36/datasets/cache_dir/`\r\n \r\nIn my scripts, I also changed to:\r\n`dataset = load_dataset('/scratch/chiyuzh/roberta/text.py', data_files=files, cache_dir = args.data_cache_dir, split=\"train\")`\r\n`data_cache_dir = $TMPDIR/data/` that also a writable directory.\r\n \r\nBut it still try to make directory at /home/chiyuzh/.cache/huggingface/modules/.\r\nDo you have any idea about this issue? @thomwolf \r\n",
"> Hey @chiyuzhang94, I was also having trouble in loading a large text file (11GB).\r\n> But finally got it working. This is what I did after looking into the documentation.\r\n> \r\n> 1. split the whole dataset file into smaller files\r\n> \r\n> ```shell\r\n> mkdir ./shards\r\n> split -a 4 -l 256000 -d full_raw_corpus.txt ./shards/shard_\r\n> ```\r\n> \r\n> 1. Pass paths of small data files to `load_dataset`\r\n> \r\n> ```python\r\n> files = glob.glob('shards/*')\r\n> from datasets import load_dataset\r\n> dataset = load_dataset('text', data_files=files, split='train')\r\n> ```\r\n> \r\n> (On passing the whole dataset file (11GB) directly to `load_dataset` was resulting into RAM issue)\r\n> \r\n> 1. Tokenization\r\n> \r\n> ```python\r\n> def encode(examples):\r\n> return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> dataset = dataset.map(encode, batched=True)\r\n> dataset.set_format(type='torch', columns=['input_ids', 'attention_mask'])\r\n> ```\r\n> \r\n> Now you can pass `dataset` to `Trainer` or `pytorch DataLoader`\r\n> \r\n> ```python\r\n> dataloader = torch.utils.data.DataLoader(dataset, batch_size=4)\r\n> next(iter(dataloader))\r\n> ```\r\n> \r\n> Hope this helps\r\n\r\nWhen I run 'dataset = dataset.map(encode, batched=True)',\r\nI encountered a problem like this:\r\n\r\n> Testing the mapped function outputs\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 300, in map\r\n for k, dataset in self.items()\r\n File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 300, in <dictcomp>\r\n for k, dataset in self.items()\r\n File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1224, in map\r\n update_data = does_function_return_dict(test_inputs, test_indices)\r\n File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1195, in does_function_return_dict\r\n function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)\r\n File \"<stdin>\", line 3, in encode\r\nTypeError: __init__() takes 1 positional argument but 2 were given",
"> > Hey @chiyuzhang94, I was also having trouble in loading a large text file (11GB).\r\n> > But finally got it working. This is what I did after looking into the documentation.\r\n> > \r\n> > 1. split the whole dataset file into smaller files\r\n> > \r\n> > ```shell\r\n> > mkdir ./shards\r\n> > split -a 4 -l 256000 -d full_raw_corpus.txt ./shards/shard_\r\n> > ```\r\n> > \r\n> > \r\n> > \r\n> > 1. Pass paths of small data files to `load_dataset`\r\n> > \r\n> > ```python\r\n> > files = glob.glob('shards/*')\r\n> > from datasets import load_dataset\r\n> > dataset = load_dataset('text', data_files=files, split='train')\r\n> > ```\r\n> > \r\n> > \r\n> > (On passing the whole dataset file (11GB) directly to `load_dataset` was resulting into RAM issue)\r\n> > \r\n> > 1. Tokenization\r\n> > \r\n> > ```python\r\n> > def encode(examples):\r\n> > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> > dataset = dataset.map(encode, batched=True)\r\n> > dataset.set_format(type='torch', columns=['input_ids', 'attention_mask'])\r\n> > ```\r\n> > \r\n> > \r\n> > Now you can pass `dataset` to `Trainer` or `pytorch DataLoader`\r\n> > ```python\r\n> > dataloader = torch.utils.data.DataLoader(dataset, batch_size=4)\r\n> > next(iter(dataloader))\r\n> > ```\r\n> > \r\n> > \r\n> > Hope this helps\r\n> \r\n> When I run 'dataset = dataset.map(encode, batched=True)',\r\n> I encountered a problem like this:\r\n> \r\n> > Testing the mapped function outputs\r\n> > Traceback (most recent call last):\r\n> > File \"\", line 1, in \r\n> > File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 300, in map\r\n> > for k, dataset in self.items()\r\n> > File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 300, in \r\n> > for k, dataset in self.items()\r\n> > File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1224, in map\r\n> > update_data = does_function_return_dict(test_inputs, test_indices)\r\n> > File \"/anaconda3/envs/torch-xla-1.6/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1195, in does_function_return_dict\r\n> > function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)\r\n> > File \"\", line 3, in encode\r\n> > TypeError: **init**() takes 1 positional argument but 2 were given\r\n\r\nWhat is your encoder function?",
"> ```python\r\n> def encode(examples):\r\n> return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> ```\r\n\r\nIt is the same as suggested:\r\n\r\n> def encode(examples):\r\n return tokenizer(examples['text'], truncation=True, padding='max_length')",
"> > ```python\r\n> > def encode(examples):\r\n> > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> > ```\r\n> \r\n> It is the same as suggested:\r\n> \r\n> > def encode(examples):\r\n> > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n\r\nDo you use this function in a `class` object? \r\n\r\ninit() takes 1 positional argument but 2 were given. I guess the additional argument is self?",
"> > > ```python\r\n> > > def encode(examples):\r\n> > > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> > > ```\r\n> > \r\n> > \r\n> > It is the same as suggested:\r\n> > > def encode(examples):\r\n> > > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> \r\n> Do you use this function in a `class` object?\r\n> \r\n> init() takes 1 positional argument but 2 were given. I guess the additional argument is self?\r\n\r\nThanks for your reply.\r\nCould you provide some simple example here?\r\nCurrently, I do not use this function in a class object. \r\nI think you are right and I was wondering how to construct this class.\r\nI try to modify it based on transformers' LineByLineTextDataset. Am I correct?\r\n\r\n> class LineByLineTextDataset(Dataset):\r\n \"\"\"\r\n This will be superseded by a framework-agnostic approach\r\n soon.\r\n \"\"\"\r\n\r\n def __init__(self, tokenizer: PreTrainedTokenizer, file_path: str, block_size: int):\r\n assert os.path.isfile(file_path), f\"Input file path {file_path} not found\"\r\n # Here, we do not cache the features, operating under the assumption\r\n # that we will soon use fast multithreaded tokenizers from the\r\n # `tokenizers` repo everywhere =)\r\n #logger.info(\"Creating features from dataset file at %s\", file_path)\r\n #with open(file_path, encoding=\"utf-8\") as f:\r\n # lines = [line for line in f.read().splitlines() if (len(line) > 0 and not line.isspace())]\r\n #batch_encoding = tokenizer(lines, add_special_tokens=True, truncation=True, max_length=block_size)\r\n\r\n\timport glob\r\n\tfiles = glob.glob('/home/mtzhang111/fairseq/cs_doc/shards/shard_003*')\r\n\tfrom datasets import load_dataset\r\n\tdataset = load_dataset('text', data_files=files)\r\n batch_encoding= dataset.map(encode, batched=True)\r\n self.examples = batch_encoding[\"input_ids\"]\r\n\t\r\n\r\n def encode(examples):\r\n return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n\r\n def __len__(self):\r\n return len(self.examples)\r\n\r\n def __getitem__(self, i) -> torch.Tensor:\r\n return torch.tensor(self.examples[i], dtype=torch.long)\r\n",
"> > > > ```python\r\n> > > > def encode(examples):\r\n> > > > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> > > > ```\r\n> > > \r\n> > > \r\n> > > It is the same as suggested:\r\n> > > > def encode(examples):\r\n> > > > return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> > \r\n> > \r\n> > Do you use this function in a `class` object?\r\n> > init() takes 1 positional argument but 2 were given. I guess the additional argument is self?\r\n> \r\n> Thanks for your reply.\r\n> Could you provide some simple example here?\r\n> Currently, I do not use this function in a class object.\r\n> I think you are right and I was wondering how to construct this class.\r\n> I try to modify it based on transformers' LineByLineTextDataset. Am I correct?\r\n> \r\n> > class LineByLineTextDataset(Dataset):\r\n> > \"\"\"\r\n> > This will be superseded by a framework-agnostic approach\r\n> > soon.\r\n> > \"\"\"\r\n> \r\n> ```\r\n> def __init__(self, tokenizer: PreTrainedTokenizer, file_path: str, block_size: int):\r\n> assert os.path.isfile(file_path), f\"Input file path {file_path} not found\"\r\n> # Here, we do not cache the features, operating under the assumption\r\n> # that we will soon use fast multithreaded tokenizers from the\r\n> # `tokenizers` repo everywhere =)\r\n> #logger.info(\"Creating features from dataset file at %s\", file_path)\r\n> #with open(file_path, encoding=\"utf-8\") as f:\r\n> # lines = [line for line in f.read().splitlines() if (len(line) > 0 and not line.isspace())]\r\n> #batch_encoding = tokenizer(lines, add_special_tokens=True, truncation=True, max_length=block_size)\r\n> \r\n> import glob\r\n> files = glob.glob('/home/mtzhang111/fairseq/cs_doc/shards/shard_003*')\r\n> from datasets import load_dataset\r\n> dataset = load_dataset('text', data_files=files)\r\n> batch_encoding= dataset.map(encode, batched=True)\r\n> self.examples = batch_encoding[\"input_ids\"]\r\n> \r\n> \r\n> def encode(examples):\r\n> return tokenizer(examples['text'], truncation=True, padding='max_length')\r\n> \r\n> def __len__(self):\r\n> return len(self.examples)\r\n> \r\n> def __getitem__(self, i) -> torch.Tensor:\r\n> return torch.tensor(self.examples[i], dtype=torch.long)\r\n> ```\r\n\r\nI am also struggling with this adaptation. \r\nI am not sure whether I am right.\r\n\r\nI think you don't need to construct `class LazyLineByLineTextDataset(Dataset)` at all. \r\ntorch.utils.data.Dataset is a generator. \r\n\r\nNow, we use `dataset = dataset.map(encode, batched=True)` as a generator. So we just pass dataset to torch.utils.data.DataLoader. ",
"@chiyuzhang94 Thanks for your reply. After some changes, currently, I managed to make the data loading process running.\r\nI published it in case you might want to take a look. Thanks for your help!\r\nhttps://github.com/shizhediao/Transformers_TPU",
"Hi @shizhediao ,\r\n\r\nThanks! It looks great!\r\n\r\nBut my problem still is the cache directory is a read-only file system. \r\n[As I mentioned](https://github.com/huggingface/datasets/issues/610#issuecomment-693912285), I tried to change the cache directory but it didn't work. \r\n\r\nDo you have any suggestions?\r\n\r\n",
"> I installed datasets at /project/chiyuzh/evn_py36/datasets/src where is a writable directory.\r\n> I also tried change the environment variables to the writable directory:\r\n> `export HF_MODULES_PATH=/project/chiyuzh/evn_py36/datasets/cache_dir/`\r\n\r\nI think it is `HF_MODULES_CACHE` and not `HF_MODULES_PATH` @chiyuzhang94 .\r\nCould you try again and let me know if it fixes your issue ?\r\n",
"We should probably add a section in the doc on the caching system with the env variables in particular.",
"Hi @thomwolf , @lhoestq ,\r\n\r\nThanks for your suggestions. With the latest version of this package, I can load text data without Internet. \r\n\r\nBut I found the speed of dataset loading is very slow. \r\n\r\nMy scrips like this: \r\n```\r\n def token_encode(examples):\r\n tokenizer_out = tokenizer(examples['text'], truncation=True, padding=\"max_length\", add_special_tokens=True, max_length=args.block_size)\r\n return tokenizer_out\r\n \r\n path = Path(file_path)\r\n files = sorted(path.glob('*'))\r\n dataset = load_dataset('./text.py', data_files=files, cache_dir = args.data_cache_dir, split=\"train\")\r\n dataset = dataset.map(token_encode, batched=True)\r\n\r\n dataset.set_format(type='torch', columns=['input_ids', 'attention_mask'])\r\n```\r\n\r\nI have 1,123,870,657 lines in my input directory. \r\nI can find the processing speed as following. It is very slow. \r\n```\r\n| 13/1123871 [00:02<62:37:39, 4.98ba/s]^M 0%| \r\n| 14/1123871 [00:03<61:27:31, 5.08ba/s]^M 0%| \r\n| 15/1123871 [00:03<66:34:19, 4.69ba/s]^M 0%| \r\n| 16/1123871 [00:03<68:25:01, 4.56ba/s]^M 0%| \r\n| 17/1123871 [00:03<72:00:03, 4.34ba/s]^M 0%| \r\n```\r\nDo you have any suggestions to accelerate this loading process?",
"You can use multiprocessing by specifying `num_proc=` in `.map()`\r\n\r\nAlso it looks like you have `1123871` batches of 1000 elements (default batch size), i.e. 1,123,871,000 lines in total.\r\nAm I right ?",
"> You can use multiprocessing by specifying `num_proc=` in `.map()`\r\n> \r\n> Also it looks like you have `1123871` batches of 1000 elements (default batch size), i.e. 1,123,871,000 lines in total.\r\n> Am I right ?\r\n\r\nHi @lhoestq ,\r\n\r\nThanks. I will try it.\r\n\r\nYou are right. I have 1,123,870,657 lines totally in the path. I split the large file into 440 small files. Each file has 2,560,000 lines.\r\n\r\nI have another question. Because I am using a cloud server where only allows running a job up to 7 days. Hence, I need to resume my model every week. If the script needs to load and process the dataset every time. It is very low efficient based on the current processing speed. Is it possible that I process the dataset once and use the process cache to in the future work? \r\n",
"Hi @lhoestq ,\r\n\r\nI tried to use multi-processor, but I got errors as follow: \r\nBecause I am using python distributed training, it seems some conflicts with the distributed job. \r\n\r\nDo you have any suggestions?\r\n```\r\nI0925 10:19:35.603023 140737353971520 filelock.py:318] Lock 140737229443368 released on /tmp/pbs.1120510.pbsha.ib.sockeye/cache/_tmp_pbs.1120510.pbsha.ib.sockeye_cache_text_default-7fb934ed6fac5d01_0.0.0_512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7\r\nfcc649178b014.lock\r\nTraceback (most recent call last):\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling.py\", line 1024, in <module>\r\n main()\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling.py\", line 967, in main\r\n train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling.py\", line 180, in load_and_cache_examples\r\n return HG_Datasets(tokenizer, file_path, args)\r\n File \"/scratch/chiyuzh/roberta/run_language_modeling.py\", line 119, in HG_Datasets\r\n dataset = dataset.map(token_encode, batched=True, batch_size = 10000, num_proc = 16)\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1287, in map\r\n transformed_shards = [r.get() for r in results]\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1287, in <listcomp>\r\n transformed_shards = [r.get() for r in results]\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/multiprocessing/pool.py\", line 644, in get\r\n raise self._value\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/multiprocessing/pool.py\", line 424, in _handle_tasks\r\n put(task)\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/multiprocessing/connection.py\", line 206, in send\r\n self._send_bytes(_ForkingPickler.dumps(obj))\r\n File \"/project/chiyuzh/evn_py36/lib/python3.6/multiprocessing/reduction.py\", line 51, in dumps\r\n cls(buf, protocol).dump(obj)\r\nAttributeError: Can't pickle local object 'HG_Datasets.<locals>.token_encode'\r\n```",
"For multiprocessing, the function given to `map` must be picklable.\r\nMaybe you could try to define `token_encode` outside `HG_Datasets` ?\r\n\r\nAlso maybe #656 could make functions defined locally picklable for multiprocessing, once it's merged.",
"> I have another question. Because I am using a cloud server where only allows running a job up to 7 days. Hence, I need to resume my model every week. If the script needs to load and process the dataset every time. It is very low efficient based on the current processing speed. Is it possible that I process the dataset once and use the process cache to in the future work?\r\n\r\nFeel free to save your processed dataset using `dataset.save_to_disk(\"path/to/save/directory\")`.\r\n\r\nThen you'll be able to reload it again using\r\n```python\r\nfrom datasets import load_from_disk\r\n\r\ndataset = load_from_disk(\"path/to/save/directory\")\r\n```",
"Hi @lhoestq ,\r\n\r\nThanks for your suggestion. \r\nI tried to process the dataset and save it to disk. \r\nI have 1.12B samples in the raw dataset. I used 16 processors.\r\nI run this process job for 7 days. But it didn't finish. I don't why the processing is such slow. \r\n\r\nThe log shows that some processors (\\#12, \\#14, \\#15) are very slow. The different processor has a different speed. These slow processors look like a bottleneck. \r\n\r\nCould you please give me any suggestion to improve the processing speed? \r\n\r\nThanks. \r\nChiyu\r\n\r\nHere is my code:\r\n```\r\ndef token_encode(examples):\r\n tokenizer_out = tokenizer(examples['text'], truncation=True, padding=\"max_length\", add_special_tokens=True, max_length=args.block_size)\r\n return tokenizer_out\r\n\r\npath = Path(file_path)\r\nfiles = sorted(path.glob('*'))\r\ndataset = load_dataset('./text.py', data_files=files, cache_dir = args.data_cache_dir, split=\"train\")\r\ndataset = dataset.map(token_encode, batched=True, batch_size = 16384, num_proc = 16)\r\ndataset.set_format(type='torch', columns=['input_ids', 'attention_mask'])\r\ndataset.save_to_disk(output_dir)\r\n```\r\nHere is the log. \r\n```\r\n^M#6: 1%|▏ | 59/4288 [55:10<66:11:58, 56.35s/ba]\r\n^M#1: 8%|▊ | 356/4288 [55:39<10:40:02, 9.77s/ba]\r\n^M#2: 5%|▍ | 210/4288 [55:33<17:47:19, 15.70s/ba]\r\n^M#0: 19%|█▉ | 836/4288 [55:53<4:08:56, 4.33s/ba]\r\n^M#0: 20%|█▉ | 837/4288 [55:57<4:01:52, 4.21s/ba]\r\n^M#1: 8%|▊ | 357/4288 [55:48<10:38:09, 9.74s/ba]\r\n^M#0: 20%|█▉ | 838/4288 [56:01<4:02:56, 4.23s/ba]\r\n^M#3: 4%|▎ | 155/4288 [55:43<24:41:20, 21.51s/ba]\r\n^M#0: 20%|█▉ | 839/4288 [56:05<4:04:48, 4.26s/ba]\r\n^M#12: 1%| | 29/4288 [54:50<133:20:53, 112.72s/ba]\r\n^M#2: 5%|▍ | 211/4288 [55:48<17:40:33, 15.61s/ba]\r\n^M#14: 0%| | 2/4288 [04:24<157:17:50, 132.12s/ba]\r\n^M#15: 0%| | 1/4288 [02:24<172:11:37, 144.60s/ba]\r\n```",
"Hi !\r\n\r\nAs far as I can tell, there could be several reasons for your processes to have different speeds:\r\n- some parts of your dataset have short passages while some have longer passages, that take more time to be processed\r\n- OR there are other processes running that prevent some of them to run at full speed\r\n- OR the value of `num_proc` is higher than the number of actual processes that you can run in parallel at full speed.\r\n\r\nSo I'd suggest you to check that you have nothing else running in parallel to your processing job, and also maybe take a look at the slow parts of the datasets.\r\nWhen doing multiprocessing, the dataset is sharded in `num_proc` contiguous parts that are processed individually in each process. If you want to take a look at the dataset processed in the 12th shard of 16 for example, you can do:\r\n\r\n```python\r\nmy_shard = dataset.shard(num_shards=16, index=12, contiguous=True)\r\n```\r\n\r\nHope this helps, let me know if you find what is causing this slow down.",
"Do you use a fast or a slow tokenizer from the `transformers` library @chiyuzhang94?",
"> Do you use a fast or a slow tokenizer from the `transformers` library @chiyuzhang94?\r\n\r\nHi @thomwolf ,\r\n I use this: \r\n```\r\nfrom transformers import\r\nAutoTokenizer.from_pretrained(args.model_name_or_path, cache_dir=args.cache_dir)\r\n```\r\n\r\nI guess this is a slow one, let me explore the fast tokenizer. ",
"> Hi !\r\n> \r\n> As far as I can tell, there could be several reasons for your processes to have different speeds:\r\n> \r\n> * some parts of your dataset have short passages while some have longer passages, that take more time to be processed\r\n> * OR there are other processes running that prevent some of them to run at full speed\r\n> * OR the value of `num_proc` is higher than the number of actual processes that you can run in parallel at full speed.\r\n> \r\n> So I'd suggest you to check that you have nothing else running in parallel to your processing job, and also maybe take a look at the slow parts of the datasets.\r\n> When doing multiprocessing, the dataset is sharded in `num_proc` contiguous parts that are processed individually in each process. If you want to take a look at the dataset processed in the 12th shard of 16 for example, you can do:\r\n> \r\n> ```python\r\n> my_shard = dataset.shard(num_shards=16, index=12, contiguous=True)\r\n> ```\r\n> \r\n> Hope this helps, let me know if you find what is causing this slow down.\r\n\r\nHi @lhoestq ,\r\n\r\nThanks for your suggestions. \r\nI don't think my problem is due to any one of these seasons. \r\n\r\n1. I have 1,123,870,657 lines totally in the path. I split the large file into 440 small files. Each file has 2,560,000 lines. The last file is smaller a little bit. But they are similar. I randomly shuffled all the 1,123,870,657 lines. Hence, the sequences should also be similar across all the files. \r\n\r\n2. I run this script on the entire node. I requested all the resources on the nodes (40 CPUs, 384GB memory). Hence, these were not any other processes. \r\n\r\n 3. As I say, the node has 40 CPUs, but I set num_proc = 16. This should not be a problem.",
"Hi @thomwolf \r\nI am using `RobertaTokenizerFast` now. \r\n\r\nBut the speed is still imbalanced, some processors are still slow. \r\nHere is the part of the log. #0 is always much fast than lower rank processors. \r\n\r\n```\r\n#15: 3%|▎ | 115/3513 [3:18:36<98:01:33, 103.85s/ba]\r\n#2: 24%|██▍ | 847/3513 [3:20:43<11:06:49, 15.01s/ba]\r\n#1: 37%|███▋ | 1287/3513 [3:20:52<6:19:02, 10.22s/ba]\r\n#0: 72%|███████▏ | 2546/3513 [3:20:52<1:51:03, 6.89s/ba]\r\n#3: 18%|█▊ | 617/3513 [3:20:36<15:50:30, 19.69s/ba]\r\n#0: 73%|███████▎ | 2547/3513 [3:20:59<1:50:25, 6.86s/ba]\r\n#1: 37%|███▋ | 1288/3513 [3:21:02<6:21:13, 10.28s/ba]\r\n#7: 7%|▋ | 252/3513 [3:20:09<44:09:03, 48.74s/ba]\r\n#12: 4%|▍ | 144/3513 [3:19:19<78:00:54, 83.36s/ba]\r\n#4: 14%|█▍ | 494/3513 [3:20:37<20:46:06, 24.77s/ba]\r\n#0: 73%|███████▎ | 2548/3513 [3:21:06<1:49:26, 6.80s/ba]\r\n#2: 24%|██▍ | 848/3513 [3:20:58<11:06:17, 15.00s/ba]\r\n```\r\nHere is my script related to the datasets processing, \r\n\r\n```\r\ntokenizer = RobertaTokenizerFast.from_pretrained(args.model_name_or_path, cache_dir=args.cache_dir)\r\n\r\ndef token_encode(examples):\r\n tokenizer_out = tokenizer(examples['text'], truncation=True, padding=\"max_length\", add_special_tokens=True, max_length=128)\r\n return tokenizer_out\r\n\r\ndef HG_Datasets(tokenizer, file_path, args):\r\n \r\n path = Path(file_path)\r\n files = sorted(path.glob('*'))\r\n dataset = load_dataset('./text.py', data_files=files, cache_dir = \"\"./, split=\"train\")\r\n dataset = dataset.map(token_encode, batched=True, batch_size = 20000, num_proc = 16)\r\n\r\n dataset.set_format(type='torch', columns=['input_ids', 'attention_mask'])\r\n return dataset\r\n\r\n```\r\nI have 1,123,870,657 lines totally in the path. I split the large file into 440 small files. Each file has 2,560,000 lines.\r\n\r\nCould you please give any suggestion? Thanks very much!!"
] | 1,599,763,298,000 | 1,618,044,244,000 | null | NONE | null | I migrate my question from https://github.com/huggingface/transformers/pull/4009#issuecomment-690039444
I tried to train a Roberta from scratch using transformers. But I got OOM issues with loading a large text file.
According to the suggestion from @thomwolf , I tried to implement `datasets` to load my text file. This test.txt is a simple sample where each line is a sentence.
```
from datasets import load_dataset
dataset = load_dataset('text', data_files='test.txt',cache_dir="./")
dataset.set_format(type='torch',columns=["text"])
dataloader = torch.utils.data.DataLoader(dataset, batch_size=8)
next(iter(dataloader))
```
But dataload cannot yield sample and error is:
```
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-12-388aca337e2f> in <module>
----> 1 next(iter(dataloader))
/Library/Python/3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)
361
362 def __next__(self):
--> 363 data = self._next_data()
364 self._num_yielded += 1
365 if self._dataset_kind == _DatasetKind.Iterable and \
/Library/Python/3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)
401 def _next_data(self):
402 index = self._next_index() # may raise StopIteration
--> 403 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
404 if self._pin_memory:
405 data = _utils.pin_memory.pin_memory(data)
/Library/Python/3.7/site-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
42 def fetch(self, possibly_batched_index):
43 if self.auto_collation:
---> 44 data = [self.dataset[idx] for idx in possibly_batched_index]
45 else:
46 data = self.dataset[possibly_batched_index]
/Library/Python/3.7/site-packages/torch/utils/data/_utils/fetch.py in <listcomp>(.0)
42 def fetch(self, possibly_batched_index):
43 if self.auto_collation:
---> 44 data = [self.dataset[idx] for idx in possibly_batched_index]
45 else:
46 data = self.dataset[possibly_batched_index]
KeyError: 0
```
`dataset.set_format(type='torch',columns=["text"])` returns a log says:
```
Set __getitem__(key) output type to torch for ['text'] columns (when key is int or slice) and don't output other (un-formatted) columns.
```
I noticed the dataset is `DatasetDict({'train': Dataset(features: {'text': Value(dtype='string', id=None)}, num_rows: 44)})`.
Each sample can be accessed by `dataset["train"]["text"]` instead of `dataset["text"]`.
Could you please give me any suggestions on how to modify this code to load the text file?
Versions:
Python version 3.7.3
PyTorch version 1.6.0
TensorFlow version 2.3.0
datasets version: 1.0.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/610/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/609/comments | https://api.github.com/repos/huggingface/datasets/issues/609/events | https://github.com/huggingface/datasets/pull/609 | 698,323,989 | MDExOlB1bGxSZXF1ZXN0NDg0MTc4Nzky | 609 | Update GLUE URLs (now hosted on FB) | {
"login": "jeswan",
"id": 57466294,
"node_id": "MDQ6VXNlcjU3NDY2Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/57466294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeswan",
"html_url": "https://github.com/jeswan",
"followers_url": "https://api.github.com/users/jeswan/followers",
"following_url": "https://api.github.com/users/jeswan/following{/other_user}",
"gists_url": "https://api.github.com/users/jeswan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeswan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeswan/subscriptions",
"organizations_url": "https://api.github.com/users/jeswan/orgs",
"repos_url": "https://api.github.com/users/jeswan/repos",
"events_url": "https://api.github.com/users/jeswan/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeswan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for opening this PR :) \r\n\r\nWe changed the name of the lib from nlp to datasets yesterday.\r\nCould you rebase from master and re-generate the dataset_info.json file to fix the name changes ?",
"Rebased changes here: https://github.com/huggingface/datasets/pull/626"
] | 1,599,761,792,000 | 1,600,110,362,000 | 1,600,110,361,000 | CONTRIBUTOR | null | NYU is switching dataset hosting from Google to FB. This PR closes https://github.com/huggingface/datasets/issues/608 and is necessary for https://github.com/jiant-dev/jiant/issues/161. This PR updates the data URLs based on changes made in https://github.com/nyu-mll/jiant/pull/1112. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/609/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/609",
"html_url": "https://github.com/huggingface/datasets/pull/609",
"diff_url": "https://github.com/huggingface/datasets/pull/609.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/609.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/608/comments | https://api.github.com/repos/huggingface/datasets/issues/608/events | https://github.com/huggingface/datasets/issues/608 | 698,291,156 | MDU6SXNzdWU2OTgyOTExNTY= | 608 | Don't use the old NYU GLUE dataset URLs | {
"login": "jeswan",
"id": 57466294,
"node_id": "MDQ6VXNlcjU3NDY2Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/57466294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeswan",
"html_url": "https://github.com/jeswan",
"followers_url": "https://api.github.com/users/jeswan/followers",
"following_url": "https://api.github.com/users/jeswan/following{/other_user}",
"gists_url": "https://api.github.com/users/jeswan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeswan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeswan/subscriptions",
"organizations_url": "https://api.github.com/users/jeswan/orgs",
"repos_url": "https://api.github.com/users/jeswan/repos",
"events_url": "https://api.github.com/users/jeswan/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeswan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Feel free to open the PR ;)\r\nThanks for updating the dataset_info.json file !"
] | 1,599,760,022,000 | 1,600,239,198,000 | 1,600,239,198,000 | CONTRIBUTOR | null | NYU is switching dataset hosting from Google to FB. Initial changes to `datasets` are in https://github.com/jeswan/nlp/commit/b7d4a071d432592ded971e30ef73330529de25ce. What tests do you suggest I run before opening a PR?
See: https://github.com/jiant-dev/jiant/issues/161 and https://github.com/nyu-mll/jiant/pull/1112 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/608/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/607/comments | https://api.github.com/repos/huggingface/datasets/issues/607/events | https://github.com/huggingface/datasets/pull/607 | 698,094,442 | MDExOlB1bGxSZXF1ZXN0NDgzOTcyMDg4 | 607 | Add transmit_format wrapper and tests | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,750,230,000 | 1,599,751,308,000 | 1,599,751,307,000 | MEMBER | null | Same as #605 but using a decorator on-top of dataset transforms that are not in place | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/607/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/607",
"html_url": "https://github.com/huggingface/datasets/pull/607",
"diff_url": "https://github.com/huggingface/datasets/pull/607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/607.patch",
"merged_at": 1599751307000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/606/comments | https://api.github.com/repos/huggingface/datasets/issues/606/events | https://github.com/huggingface/datasets/pull/606 | 698,050,442 | MDExOlB1bGxSZXF1ZXN0NDgzOTMzMDA1 | 606 | Quick fix :) | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
":heart:"
] | 1,599,748,326,000 | 1,599,754,712,000 | 1,599,754,710,000 | MEMBER | null | `nlp` => `datasets` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/606/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 1,
"hooray": 1,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/606/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/606",
"html_url": "https://github.com/huggingface/datasets/pull/606",
"diff_url": "https://github.com/huggingface/datasets/pull/606.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/606.patch",
"merged_at": 1599754710000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/605/comments | https://api.github.com/repos/huggingface/datasets/issues/605/events | https://github.com/huggingface/datasets/pull/605 | 697,887,401 | MDExOlB1bGxSZXF1ZXN0NDgzNzg1Mjc1 | 605 | [Datasets] Transmit format to children | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing as #607 was merged"
] | 1,599,741,018,000 | 1,599,754,521,000 | 1,599,754,521,000 | MEMBER | null | Transmit format to children obtained when processing a dataset.
Added a test.
When concatenating datasets, if the formats are disparate, the concatenated dataset has a format reset to defaults. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/605/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/605",
"html_url": "https://github.com/huggingface/datasets/pull/605",
"diff_url": "https://github.com/huggingface/datasets/pull/605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/605.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/604/comments | https://api.github.com/repos/huggingface/datasets/issues/604/events | https://github.com/huggingface/datasets/pull/604 | 697,774,581 | MDExOlB1bGxSZXF1ZXN0NDgzNjgxNTc0 | 604 | Update bucket prefix | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,735,673,000 | 1,599,741,933,000 | 1,599,741,932,000 | MEMBER | null | cc @julien-c | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/604/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/604",
"html_url": "https://github.com/huggingface/datasets/pull/604",
"diff_url": "https://github.com/huggingface/datasets/pull/604.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/604.patch",
"merged_at": 1599741932000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/603/comments | https://api.github.com/repos/huggingface/datasets/issues/603/events | https://github.com/huggingface/datasets/pull/603 | 697,758,750 | MDExOlB1bGxSZXF1ZXN0NDgzNjY2ODk5 | 603 | Set scripts version to master | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,734,864,000 | 1,599,735,725,000 | 1,599,735,724,000 | MEMBER | null | By default the scripts version is master, so that if the library is installed with
```
pip install git+http://github.com/huggingface/nlp.git
```
or
```
git clone http://github.com/huggingface/nlp.git
pip install -e ./nlp
```
will use the latest scripts, and not the ones from the previous version. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/603/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/603/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/603",
"html_url": "https://github.com/huggingface/datasets/pull/603",
"diff_url": "https://github.com/huggingface/datasets/pull/603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/603.patch",
"merged_at": 1599735724000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/602/comments | https://api.github.com/repos/huggingface/datasets/issues/602/events | https://github.com/huggingface/datasets/pull/602 | 697,636,605 | MDExOlB1bGxSZXF1ZXN0NDgzNTU3NDM0 | 602 | apply offset to indices in multiprocessed map | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,728,070,000 | 1,599,735,819,000 | 1,599,735,817,000 | MEMBER | null | Fix #597
I fixed the indices by applying an offset.
I added the case to our tests to make sure it doesn't happen again.
I also added the message proposed by @thomwolf in #597
```python
>>> d.select(range(10)).map(fn, with_indices=True, batched=True, num_proc=2, load_from_cache_file=False)
Done writing 10 indices in 80 bytes .
Testing the mapped function outputs
[0, 1]
Testing finished, running the mapping function on the dataset
Done writing 5 indices in 41 bytes .
Done writing 5 indices in 41 bytes .
Spawning 2 processes
[0, 1, 2, 3, 4]
[5, 6, 7, 8, 9]
#0: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 377.90ba/s]
#1: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 378.92ba/s]
Concatenating 2 shards from multiprocessing
# Dataset(features: {'label': ClassLabel(num_classes=2, names=['neg', 'pos'], names_file=None, id=None), 'text': Value(dtype='string', id=None)}, num_rows: 10)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/602/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/602/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/602",
"html_url": "https://github.com/huggingface/datasets/pull/602",
"diff_url": "https://github.com/huggingface/datasets/pull/602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/602.patch",
"merged_at": 1599735817000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/601/comments | https://api.github.com/repos/huggingface/datasets/issues/601/events | https://github.com/huggingface/datasets/pull/601 | 697,574,848 | MDExOlB1bGxSZXF1ZXN0NDgzNTAzMjAw | 601 | check if trasnformers has PreTrainedTokenizerBase | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,724,496,000 | 1,599,735,697,000 | 1,599,735,696,000 | MEMBER | null | Fix #598 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/601/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/601",
"html_url": "https://github.com/huggingface/datasets/pull/601",
"diff_url": "https://github.com/huggingface/datasets/pull/601.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/601.patch",
"merged_at": 1599735696000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/600/comments | https://api.github.com/repos/huggingface/datasets/issues/600/events | https://github.com/huggingface/datasets/issues/600 | 697,496,913 | MDU6SXNzdWU2OTc0OTY5MTM= | 600 | Pickling error when loading dataset | {
"login": "kandorm",
"id": 17310286,
"node_id": "MDQ6VXNlcjE3MzEwMjg2",
"avatar_url": "https://avatars.githubusercontent.com/u/17310286?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kandorm",
"html_url": "https://github.com/kandorm",
"followers_url": "https://api.github.com/users/kandorm/followers",
"following_url": "https://api.github.com/users/kandorm/following{/other_user}",
"gists_url": "https://api.github.com/users/kandorm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kandorm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kandorm/subscriptions",
"organizations_url": "https://api.github.com/users/kandorm/orgs",
"repos_url": "https://api.github.com/users/kandorm/repos",
"events_url": "https://api.github.com/users/kandorm/events{/privacy}",
"received_events_url": "https://api.github.com/users/kandorm/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"When I change from python3.6 to python3.8, it works! ",
"Does it work when you install `nlp` from source on python 3.6?",
"No, still the pickling error.",
"I wasn't able to reproduce on google colab (python 3.6.9 as well) with \r\n\r\npickle==4.0\r\ndill=0.3.2\r\ntransformers==3.1.0\r\ndatasets=1.0.1 (also tried nlp 0.4.0)\r\n\r\nIf I try\r\n\r\n```python\r\nfrom datasets import load_dataset # or from nlp\r\nfrom transformers import BertTokenizer\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\ndataset = load_dataset(\"text\", data_files=file_path, split=\"train\")\r\ndataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n truncation=True, max_length=512), batched=True)\r\ndataset.set_format(type='torch', columns=['input_ids'])\r\n```\r\nIt runs without error",
"Closing since it looks like it's working on >= 3.6.9\r\nFeel free to re-open if you have other questions :)"
] | 1,599,719,288,000 | 1,601,044,314,000 | 1,601,044,314,000 | NONE | null | Hi,
I modified line 136 in the original [run_language_modeling.py](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py) as:
```
# line 136: return LineByLineTextDataset(tokenizer=tokenizer, file_path=file_path, block_size=args.block_size)
dataset = load_dataset("text", data_files=file_path, split="train")
dataset = dataset.map(lambda ex: tokenizer(ex["text"], add_special_tokens=True,
truncation=True, max_length=args.block_size), batched=True)
dataset.set_format(type='torch', columns=['input_ids'])
return dataset
```
When I run this with transformers (3.1.0) and nlp (0.4.0), I get the following error:
```
Traceback (most recent call last):
File "src/run_language_modeling.py", line 319, in <module>
main()
File "src/run_language_modeling.py", line 248, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
File "src/run_language_modeling.py", line 139, in get_dataset
dataset = dataset.map(lambda ex: tokenizer(ex["text"], add_special_tokens=True, truncation=True, max_length=args.block_size), batched=True)
File "/data/nlp/src/nlp/arrow_dataset.py", line 1136, in map
new_fingerprint=new_fingerprint,
File "/data/nlp/src/nlp/fingerprint.py", line 158, in wrapper
self._fingerprint, transform, kwargs_for_fingerprint
File "/data/nlp/src/nlp/fingerprint.py", line 105, in update_fingerprint
hasher.update(transform_args[key])
File "/data/nlp/src/nlp/fingerprint.py", line 57, in update
self.m.update(self.hash(value).encode("utf-8"))
File "/data/nlp/src/nlp/fingerprint.py", line 53, in hash
return cls.hash_default(value)
File "/data/nlp/src/nlp/fingerprint.py", line 46, in hash_default
return cls.hash_bytes(dumps(value))
File "/data/nlp/src/nlp/utils/py_utils.py", line 362, in dumps
dump(obj, file)
File "/data/nlp/src/nlp/utils/py_utils.py", line 339, in dump
Pickler(file, recurse=True).dump(obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/site-packages/dill/_dill.py", line 446, in dump
StockPickler.dump(self, obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 409, in dump
self.save(obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/site-packages/dill/_dill.py", line 1438, in save_function
obj.__dict__, fkwdefaults), obj=obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/site-packages/dill/_dill.py", line 1170, in save_cell
pickler.save_reduce(_create_cell, (f,), obj=obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 605, in save_reduce
save(cls)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/site-packages/dill/_dill.py", line 1365, in save_type
obj.__bases__, _dict), obj=obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/root/miniconda3/envs/py3.6/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 507, in save
self.save_global(obj, rv)
File "/root/miniconda3/envs/py3.6/lib/python3.6/pickle.py", line 927, in save_global
(obj, module_name, name))
_pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/600/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/599/comments | https://api.github.com/repos/huggingface/datasets/issues/599/events | https://github.com/huggingface/datasets/pull/599 | 697,377,786 | MDExOlB1bGxSZXF1ZXN0NDgzMzI3ODQ5 | 599 | Add MATINF dataset | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! sorry for the late response\r\n\r\nCould you try to rebase from master ? We changed the named of the library last week so you have to include this change in your code.\r\n\r\nCan you give me more details about the error you get when running the cli command ?\r\n\r\nNote that in case of a manual download you have to specify the directory where you downloaded the data with `--data_dir <path/to/the/directory>`",
"I fucked up the Git rebase lol. Closing it."
] | 1,599,708,669,000 | 1,600,345,045,000 | 1,600,345,045,000 | MEMBER | null | @lhoestq The command to create metadata failed. I guess it's because the zip is not downloaded from a remote address? How to solve that? Also the CI fails and I don't know how to fix that :( | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/599/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/599/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/599",
"html_url": "https://github.com/huggingface/datasets/pull/599",
"diff_url": "https://github.com/huggingface/datasets/pull/599.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/599.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/598/comments | https://api.github.com/repos/huggingface/datasets/issues/598/events | https://github.com/huggingface/datasets/issues/598 | 697,156,501 | MDU6SXNzdWU2OTcxNTY1MDE= | 598 | The current version of the package on github has an error when loading dataset | {
"login": "zeyuyun1",
"id": 43428393,
"node_id": "MDQ6VXNlcjQzNDI4Mzkz",
"avatar_url": "https://avatars.githubusercontent.com/u/43428393?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zeyuyun1",
"html_url": "https://github.com/zeyuyun1",
"followers_url": "https://api.github.com/users/zeyuyun1/followers",
"following_url": "https://api.github.com/users/zeyuyun1/following{/other_user}",
"gists_url": "https://api.github.com/users/zeyuyun1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zeyuyun1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zeyuyun1/subscriptions",
"organizations_url": "https://api.github.com/users/zeyuyun1/orgs",
"repos_url": "https://api.github.com/users/zeyuyun1/repos",
"events_url": "https://api.github.com/users/zeyuyun1/events{/privacy}",
"received_events_url": "https://api.github.com/users/zeyuyun1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for reporting !\r\nWhich version of transformers are you using ?\r\nIt looks like it doesn't have the PreTrainedTokenizerBase class",
"I was using transformer 2.9. And I switch to the latest transformer package. Everything works just fine!!\r\n\r\nThanks for helping! I should look more carefully next time. Didn't realize loading the data part requires using tokenizer.\r\n",
"Yes it shouldn’t fail with older version of transformers since this is only a special feature to make caching more efficient when using transformers for tokenization.\r\nWe’ll update this."
] | 1,599,685,403,000 | 1,599,719,121,000 | 1,599,692,248,000 | NONE | null | Instead of downloading the package from pip, downloading the version from source will result in an error when loading dataset (the pip version is completely fine):
To recreate the error:
First, installing nlp directly from source:
```
git clone https://github.com/huggingface/nlp.git
cd nlp
pip install -e .
```
Then run:
```
from nlp import load_dataset
dataset = load_dataset('wikitext', 'wikitext-2-v1',split = 'train')
```
will give error:
```
>>> dataset = load_dataset('wikitext', 'wikitext-2-v1',split = 'train')
Checking /home/zeyuy/.cache/huggingface/datasets/84a754b488511b109e2904672d809c041008416ae74e38f9ee0c80a8dffa1383.2e21f48d63b5572d19c97e441fbb802257cf6a4c03fbc5ed8fae3d2c2273f59e.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/nlp/0.4.0/datasets/wikitext/wikitext.py at /home/zeyuy/.cache/huggingface/modules/nlp_modules/datasets/wikitext
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/nlp/0.4.0/datasets/wikitext/wikitext.py at /home/zeyuy/.cache/huggingface/modules/nlp_modules/datasets/wikitext/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d
Found script file from https://raw.githubusercontent.com/huggingface/nlp/0.4.0/datasets/wikitext/wikitext.py to /home/zeyuy/.cache/huggingface/modules/nlp_modules/datasets/wikitext/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d/wikitext.py
Found dataset infos file from https://raw.githubusercontent.com/huggingface/nlp/0.4.0/datasets/wikitext/dataset_infos.json to /home/zeyuy/.cache/huggingface/modules/nlp_modules/datasets/wikitext/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d/dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/nlp/0.4.0/datasets/wikitext/wikitext.py at /home/zeyuy/.cache/huggingface/modules/nlp_modules/datasets/wikitext/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d/wikitext.json
Loading Dataset Infos from /home/zeyuy/.cache/huggingface/modules/nlp_modules/datasets/wikitext/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d
Overwrite dataset info from restored data version.
Loading Dataset info from /home/zeyuy/.cache/huggingface/datasets/wikitext/wikitext-2-v1/1.0.0/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d
Reusing dataset wikitext (/home/zeyuy/.cache/huggingface/datasets/wikitext/wikitext-2-v1/1.0.0/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d)
Constructing Dataset for split train, from /home/zeyuy/.cache/huggingface/datasets/wikitext/wikitext-2-v1/1.0.0/5de6e79516446f747fcccc09aa2614fa159053b75909594d28d262395f72d89d
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/load.py", line 600, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/builder.py", line 611, in as_dataset
datasets = utils.map_nested(
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/utils/py_utils.py", line 216, in map_nested
return function(data_struct)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/builder.py", line 631, in _build_single_dataset
ds = self._as_dataset(
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/builder.py", line 704, in _as_dataset
return Dataset(**dataset_kwargs)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/arrow_dataset.py", line 188, in __init__
self._fingerprint = generate_fingerprint(self)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/fingerprint.py", line 91, in generate_fingerprint
hasher.update(key)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/fingerprint.py", line 57, in update
self.m.update(self.hash(value).encode("utf-8"))
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/fingerprint.py", line 53, in hash
return cls.hash_default(value)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/fingerprint.py", line 46, in hash_default
return cls.hash_bytes(dumps(value))
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/utils/py_utils.py", line 361, in dumps
with _no_cache_fields(obj):
File "/home/zeyuy/miniconda3/lib/python3.8/contextlib.py", line 113, in __enter__
return next(self.gen)
File "/home/zeyuy/transformers/examples/language-modeling/nlp/src/nlp/utils/py_utils.py", line 348, in _no_cache_fields
if isinstance(obj, tr.PreTrainedTokenizerBase) and hasattr(obj, "cache") and isinstance(obj.cache, dict):
AttributeError: module 'transformers' has no attribute 'PreTrainedTokenizerBase'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/598/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/598/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/597/comments | https://api.github.com/repos/huggingface/datasets/issues/597/events | https://github.com/huggingface/datasets/issues/597 | 697,112,029 | MDU6SXNzdWU2OTcxMTIwMjk= | 597 | Indices incorrect with multiprocessing | {
"login": "joeddav",
"id": 9353833,
"node_id": "MDQ6VXNlcjkzNTM4MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9353833?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joeddav",
"html_url": "https://github.com/joeddav",
"followers_url": "https://api.github.com/users/joeddav/followers",
"following_url": "https://api.github.com/users/joeddav/following{/other_user}",
"gists_url": "https://api.github.com/users/joeddav/gists{/gist_id}",
"starred_url": "https://api.github.com/users/joeddav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joeddav/subscriptions",
"organizations_url": "https://api.github.com/users/joeddav/orgs",
"repos_url": "https://api.github.com/users/joeddav/repos",
"events_url": "https://api.github.com/users/joeddav/events{/privacy}",
"received_events_url": "https://api.github.com/users/joeddav/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"I fixed a bug that could cause this issue earlier today. Could you pull the latest version and try again ?",
"Still the case on master.\r\nI guess we should have an offset in the multi-procs indeed (hopefully it's enough).\r\n\r\nAlso, side note is that we should add some logging before the \"test\" to say we are testing the function otherwise its confusing for the user to see two outputs I think. Proposal (see the \"Testing the mapped function outputs:\" lines):\r\n```\r\n>>> d.select(range(10)).map(fn, with_indices=True, batched=True, num_proc=2)\r\nDone writing 10 indices in 80 bytes .\r\nDone writing 5 indices in 41 bytes .\r\nDone writing 5 indices in 41 bytes .\r\nSpawning 2 processes\r\nTesting the mapped function outputs:\r\ninds: [0, 1]\r\ninds: [0, 1]\r\nTesting finished, running the mapped function on the dataset:\r\n#0: 0%| | 0/1 [00:00<?, ?ba/s]\r\ninds: [0, 1, 2, 3, 4] inds: [0, 1, 2, 3, 4] | 0/1 [00:00<?, ?ba/s]\r\n#0: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1321.04ba/s]\r\n#1: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1841.22ba/s]\r\nConcatenating 2 shards from multiprocessing\r\nDataset(features: {'text': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=2, names=['neg', 'pos'], names_file=None, id=None)}, num_rows: 10)\r\n```"
] | 1,599,681,056,000 | 1,599,735,817,000 | 1,599,735,817,000 | CONTRIBUTOR | null | When `num_proc` > 1, the indices argument passed to the map function is incorrect:
```python
d = load_dataset('imdb', split='test[:1%]')
def fn(x, inds):
print(inds)
return x
d.select(range(10)).map(fn, with_indices=True, batched=True)
# [0, 1]
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
d.select(range(10)).map(fn, with_indices=True, batched=True, num_proc=2)
# [0, 1]
# [0, 1]
# [0, 1, 2, 3, 4]
# [0, 1, 2, 3, 4]
```
As you can see, the subset passed to each thread is indexed from 0 to N which doesn't reflect their positions in `d`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/597/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/596/comments | https://api.github.com/repos/huggingface/datasets/issues/596/events | https://github.com/huggingface/datasets/pull/596 | 696,928,139 | MDExOlB1bGxSZXF1ZXN0NDgyOTM5MTgw | 596 | [style/quality] Moving to isort 5.0.0 + style/quality on datasets and metrics | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Ready for review @lhoestq, just updated a few 156 files here"
] | 1,599,666,441,000 | 1,599,732,304,000 | 1,599,732,303,000 | MEMBER | null | Move the repo to isort 5.0.0.
Also start testing style/quality on datasets and metrics.
Specific rule: we allow F401 (unused imports) in metrics to be able to add imports to detect early on missing dependencies.
Maybe we could add this in datasets but while cleaning this I've seen many example of really unused imports in dataset so maybe it's better to have it as a line-by-line nova instead of a general rule like in metrics. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/596/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/596",
"html_url": "https://github.com/huggingface/datasets/pull/596",
"diff_url": "https://github.com/huggingface/datasets/pull/596.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/596.patch",
"merged_at": 1599732303000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/595/comments | https://api.github.com/repos/huggingface/datasets/issues/595/events | https://github.com/huggingface/datasets/issues/595 | 696,892,304 | MDU6SXNzdWU2OTY4OTIzMDQ= | 595 | `Dataset`/`DatasetDict` has no attribute 'save_to_disk' | {
"login": "sudarshan85",
"id": 488428,
"node_id": "MDQ6VXNlcjQ4ODQyOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/488428?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sudarshan85",
"html_url": "https://github.com/sudarshan85",
"followers_url": "https://api.github.com/users/sudarshan85/followers",
"following_url": "https://api.github.com/users/sudarshan85/following{/other_user}",
"gists_url": "https://api.github.com/users/sudarshan85/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sudarshan85/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sudarshan85/subscriptions",
"organizations_url": "https://api.github.com/users/sudarshan85/orgs",
"repos_url": "https://api.github.com/users/sudarshan85/repos",
"events_url": "https://api.github.com/users/sudarshan85/events{/privacy}",
"received_events_url": "https://api.github.com/users/sudarshan85/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"`pip install git+https://github.com/huggingface/nlp.git` should have done the job.\r\n\r\nDid you uninstall `nlp` before installing from github ?",
"> Did you uninstall `nlp` before installing from github ?\r\n\r\nI did not. I created a new environment and installed `nlp` directly from `github` and it worked!\r\n\r\nThanks.\r\n"
] | 1,599,663,712,000 | 1,599,668,419,000 | 1,599,668,418,000 | NONE | null | Hi,
As the title indicates, both `Dataset` and `DatasetDict` classes don't seem to have the `save_to_disk` method. While the file [`arrow_dataset.py`](https://github.com/huggingface/nlp/blob/34bf0b03bfe03e7f77b8fec1cd48f5452c4fc7c1/src/nlp/arrow_dataset.py) in the repo here has the method, the file `arrow_dataset.py` which is saved after `pip install nlp -U` in my `conda` environment DOES NOT contain the `save_to_disk` method. I even tried `pip install git+https://github.com/huggingface/nlp.git ` and still no luck. Do I need to install the library in another way? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/595/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/594/comments | https://api.github.com/repos/huggingface/datasets/issues/594/events | https://github.com/huggingface/datasets/pull/594 | 696,816,893 | MDExOlB1bGxSZXF1ZXN0NDgyODQ1OTc5 | 594 | Fix germeval url | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,658,175,000 | 1,599,658,475,000 | 1,599,658,474,000 | MEMBER | null | Continuation of #593 but without the dummy data hack | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/594/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/594",
"html_url": "https://github.com/huggingface/datasets/pull/594",
"diff_url": "https://github.com/huggingface/datasets/pull/594.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/594.patch",
"merged_at": 1599658474000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/593/comments | https://api.github.com/repos/huggingface/datasets/issues/593/events | https://github.com/huggingface/datasets/pull/593 | 696,679,182 | MDExOlB1bGxSZXF1ZXN0NDgyNzI5NTgw | 593 | GermEval 2014: new download urls | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"/cc: @vblagoje",
"Closing this one as #594 is merged (same changes except the dummy data hack)",
"Awesome @stefan-it ! @lhoestq how soon can I use the fixed GermEval dataset in HF token classification examples?",
"I've manually updated the script on S3, so you can actually use it right now with\r\n```python\r\nfrom nlp import load_dataset\r\n\r\ngermeval = load_dataset(\"germeval_14\")\r\n```\r\n\r\nnot sure if it's used in token classification examples already",
"Awesome. Not used yet but I am going to use it now. I've been working on an update for token classification examples and this was a missing piece. Thanks @stefan-it @lhoestq "
] | 1,599,646,049,000 | 1,599,661,014,000 | 1,599,658,515,000 | CONTRIBUTOR | null | Hi,
unfortunately, the download links for the GermEval 2014 dataset have changed: they're now located on a Google Drive.
I changed the URLs and bump version from 1.0.0 to 2.0.0. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/593/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/593/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/593",
"html_url": "https://github.com/huggingface/datasets/pull/593",
"diff_url": "https://github.com/huggingface/datasets/pull/593.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/593.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/592/comments | https://api.github.com/repos/huggingface/datasets/issues/592/events | https://github.com/huggingface/datasets/pull/592 | 696,619,986 | MDExOlB1bGxSZXF1ZXN0NDgyNjc4MDkw | 592 | Test in memory and on disk | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,641,970,000 | 1,599,659,404,000 | 1,599,659,403,000 | MEMBER | null | I added test parameters to do every test both in memory and on disk.
I also found a bug in concatenate_dataset thanks to the new tests and fixed it. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/592/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/592",
"html_url": "https://github.com/huggingface/datasets/pull/592",
"diff_url": "https://github.com/huggingface/datasets/pull/592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/592.patch",
"merged_at": 1599659403000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/591/comments | https://api.github.com/repos/huggingface/datasets/issues/591/events | https://github.com/huggingface/datasets/pull/591 | 696,530,413 | MDExOlB1bGxSZXF1ZXN0NDgyNjAxMzc1 | 591 | fix #589 (backward compat) | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,636,793,000 | 1,599,641,876,000 | 1,599,641,875,000 | MEMBER | null | Fix #589 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/591/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/591",
"html_url": "https://github.com/huggingface/datasets/pull/591",
"diff_url": "https://github.com/huggingface/datasets/pull/591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/591.patch",
"merged_at": 1599641874000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/590/comments | https://api.github.com/repos/huggingface/datasets/issues/590/events | https://github.com/huggingface/datasets/issues/590 | 696,501,827 | MDU6SXNzdWU2OTY1MDE4Mjc= | 590 | The process cannot access the file because it is being used by another process (windows) | {
"login": "saareliad",
"id": 22762845,
"node_id": "MDQ6VXNlcjIyNzYyODQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/22762845?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saareliad",
"html_url": "https://github.com/saareliad",
"followers_url": "https://api.github.com/users/saareliad/followers",
"following_url": "https://api.github.com/users/saareliad/following{/other_user}",
"gists_url": "https://api.github.com/users/saareliad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saareliad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saareliad/subscriptions",
"organizations_url": "https://api.github.com/users/saareliad/orgs",
"repos_url": "https://api.github.com/users/saareliad/repos",
"events_url": "https://api.github.com/users/saareliad/events{/privacy}",
"received_events_url": "https://api.github.com/users/saareliad/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi, which version of `nlp` are you using?\r\n\r\nBy the way we'll be releasing today a significant update fixing many issues (but also comprising a few breaking changes).\r\nYou can see more informations here #545 and try it by installing from source from the master branch.",
"I'm using version 0.4.0.\r\n\r\n",
"Ok, it's probably fixed on master. Otherwise if you can give me a fully self-contained exemple to reproduce the error, I can try to investigate.",
"I get the same behavior, on Windows, when `map`ping a function to a loaded dataset. \r\nThe error doesn't occur if I re-run the cell a second time though! \r\nI'm on version 1.0.1.",
"This is going to be fixed by #644 ",
"@saareliad I got the same issue that troubled me quite a while. Unfortunately, there are no good answers to this issue online, I tried it on Linux and that's absolutely fine. After hacking the source code, I solved this problem as follows.\r\n\r\nIn the source code file: arrow_dataset.py -> _map_single(...)\r\n\r\nchange\r\n```python\r\nif update_data and tmp_file is not None:\r\n shutil.move(tmp_file.name, cache_file_name)\r\n```\r\nto\r\n```python\r\ntmp_file.close()\r\nif update_data and tmp_file is not None:\r\n shutil.move(tmp_file.name, cache_file_name)\r\n```\r\n\r\nThen it works without needing multiple times runs to avoid the permission error.\r\nI know this solution is unusual since it changes the source code. Hopefully, the lib's contributors can have better solutions in the future.\r\n",
"@wangcongcong123 thanks for sharing.\n(BTW I also solved it locally on windows by putting the problematic line under try except and not using cache... On windows I just needed 1% of the dataset anyway)"
] | 1,599,634,896,000 | 1,601,042,548,000 | 1,601,042,548,000 | NONE | null | Hi, I consistently get the following error when developing in my PC (windows 10):
```
train_dataset = train_dataset.map(convert_to_features, batched=True)
File "C:\Users\saareliad\AppData\Local\Continuum\miniconda3\envs\py38\lib\site-packages\nlp\arrow_dataset.py", line 970, in map
shutil.move(tmp_file.name, cache_file_name)
File "C:\Users\saareliad\AppData\Local\Continuum\miniconda3\envs\py38\lib\shutil.py", line 803, in move
os.unlink(src)
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:\\Users\\saareliad\\.cache\\huggingface\\datasets\\squad\\plain_text\\1.0.0\\408a8fa46a1e2805445b793f1022e743428ca739a34809fce872f0c7f17b44ab\\tmpsau1bep1'
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/590/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/590/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/589/comments | https://api.github.com/repos/huggingface/datasets/issues/589/events | https://github.com/huggingface/datasets/issues/589 | 696,488,447 | MDU6SXNzdWU2OTY0ODg0NDc= | 589 | Cannot use nlp.load_dataset text, AttributeError: module 'nlp.utils' has no attribute 'logging' | {
"login": "ksjae",
"id": 17930170,
"node_id": "MDQ6VXNlcjE3OTMwMTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/17930170?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ksjae",
"html_url": "https://github.com/ksjae",
"followers_url": "https://api.github.com/users/ksjae/followers",
"following_url": "https://api.github.com/users/ksjae/following{/other_user}",
"gists_url": "https://api.github.com/users/ksjae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ksjae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ksjae/subscriptions",
"organizations_url": "https://api.github.com/users/ksjae/orgs",
"repos_url": "https://api.github.com/users/ksjae/repos",
"events_url": "https://api.github.com/users/ksjae/events{/privacy}",
"received_events_url": "https://api.github.com/users/ksjae/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,634,013,000 | 1,599,641,874,000 | 1,599,641,874,000 | NONE | null |
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/nlp/load.py", line 533, in load_dataset
builder_cls = import_main_class(module_path, dataset=True)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/nlp/load.py", line 61, in import_main_class
module = importlib.import_module(module_path)
File "/root/anaconda3/envs/pytorch/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/nlp/datasets/text/5dc629379536c4037d9c2063e1caa829a1676cf795f8e030cd90a537eba20c08/text.py", line 9, in <module>
logger = nlp.utils.logging.get_logger(__name__)
AttributeError: module 'nlp.utils' has no attribute 'logging'
```
Occurs on the following code, or any code including the load_dataset('text'):
```
dataset = load_dataset("text", data_files=file_path, split="train")
dataset = dataset.map(lambda ex: tokenizer(ex["text"], add_special_tokens=True,
truncation=True, max_length=args.block_size), batched=True)
dataset.set_format(type='torch', columns=['input_ids'])
return dataset
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/589/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/588/comments | https://api.github.com/repos/huggingface/datasets/issues/588/events | https://github.com/huggingface/datasets/pull/588 | 695,249,809 | MDExOlB1bGxSZXF1ZXN0NDgxNTE5NzQx | 588 | Support pathlike obj in load dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,495,201,000 | 1,599,551,119,000 | 1,599,551,118,000 | MEMBER | null | Fix #582
(I recreated the PR, I got an issue with git) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/588/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/588/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/588",
"html_url": "https://github.com/huggingface/datasets/pull/588",
"diff_url": "https://github.com/huggingface/datasets/pull/588.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/588.patch",
"merged_at": 1599551117000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/587/comments | https://api.github.com/repos/huggingface/datasets/issues/587/events | https://github.com/huggingface/datasets/pull/587 | 695,246,018 | MDExOlB1bGxSZXF1ZXN0NDgxNTE2Mzkx | 587 | Support pathlike obj in load dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,494,956,000 | 1,599,495,035,000 | 1,599,495,035,000 | MEMBER | null | Fix #582 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/587/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/587/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/587",
"html_url": "https://github.com/huggingface/datasets/pull/587",
"diff_url": "https://github.com/huggingface/datasets/pull/587.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/587.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/586/comments | https://api.github.com/repos/huggingface/datasets/issues/586/events | https://github.com/huggingface/datasets/pull/586 | 695,237,999 | MDExOlB1bGxSZXF1ZXN0NDgxNTA5MzU1 | 586 | Better message when data files is empty | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,494,397,000 | 1,599,642,009,000 | 1,599,642,008,000 | MEMBER | null | Fix #581 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/586/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/586/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/586",
"html_url": "https://github.com/huggingface/datasets/pull/586",
"diff_url": "https://github.com/huggingface/datasets/pull/586.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/586.patch",
"merged_at": 1599642007000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/585/comments | https://api.github.com/repos/huggingface/datasets/issues/585/events | https://github.com/huggingface/datasets/pull/585 | 695,191,209 | MDExOlB1bGxSZXF1ZXN0NDgxNDY4NTM4 | 585 | Fix select for pyarrow < 1.0.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,490,972,000 | 1,599,550,997,000 | 1,599,550,995,000 | MEMBER | null | Fix #583 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/585/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/585",
"html_url": "https://github.com/huggingface/datasets/pull/585",
"diff_url": "https://github.com/huggingface/datasets/pull/585.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/585.patch",
"merged_at": 1599550995000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/584/comments | https://api.github.com/repos/huggingface/datasets/issues/584/events | https://github.com/huggingface/datasets/pull/584 | 695,186,652 | MDExOlB1bGxSZXF1ZXN0NDgxNDY0NjEz | 584 | Use github versioning | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I noticed that datasets like `cnn_dailymail` need the `version` parameter to be passed to its `config_kwargs`.\r\nShall we rename the `version` paramater in `load_dataset` ? Maybe `repo_version` or `script_version` ?"
] | 1,599,490,695,000 | 1,599,658,655,000 | 1,599,658,654,000 | MEMBER | null | Right now dataset scripts and metrics are downloaded from S3 which is in sync with master. It means that it's not currently possible to pin the dataset/metric script version.
To fix that I changed the download url from S3 to github, and adding a `version` parameter in `load_dataset` and `load_metric` to pin a certain version of the lib, as in #562 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/584/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/584",
"html_url": "https://github.com/huggingface/datasets/pull/584",
"diff_url": "https://github.com/huggingface/datasets/pull/584.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/584.patch",
"merged_at": 1599658654000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/583/comments | https://api.github.com/repos/huggingface/datasets/issues/583/events | https://github.com/huggingface/datasets/issues/583 | 695,166,265 | MDU6SXNzdWU2OTUxNjYyNjU= | 583 | ArrowIndexError on Dataset.select | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,489,389,000 | 1,599,550,995,000 | 1,599,550,995,000 | MEMBER | null | If the indices table consists in several chunks, then `dataset.select` results in an `ArrowIndexError` error for pyarrow < 1.0.0
Example:
```python
from nlp import load_dataset
mnli = load_dataset("glue", "mnli", split="train")
shuffled = mnli.shuffle(seed=42)
mnli.select(list(range(len(mnli))))
```
raises:
```python
---------------------------------------------------------------------------
ArrowIndexError Traceback (most recent call last)
<ipython-input-64-006a5d38d418> in <module>
----> 1 mnli.shuffle(seed=42).select(list(range(len(mnli))))
~/Desktop/hf/nlp/src/nlp/fingerprint.py in wrapper(*args, **kwargs)
161 # Call actual function
162
--> 163 out = func(self, *args, **kwargs)
164
165 # Update fingerprint of in-place transforms + update in-place history of transforms
~/Desktop/hf/nlp/src/nlp/arrow_dataset.py in select(self, indices, keep_in_memory, indices_cache_file_name, writer_batch_size, new_fingerprint)
1653 if self._indices is not None:
1654 if PYARROW_V0:
-> 1655 indices_array = self._indices.column(0).chunk(0).take(indices_array)
1656 else:
1657 indices_array = self._indices.column(0).take(indices_array)
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib.Array.take()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowIndexError: take index out of bounds
```
This is because the `take` method is only done on the first chunk which only contains 1000 elements by default (mnli has ~400 000 elements).
Shall we change that to use
```python
pa.concat_tables(self._indices._indices.slice(i, 1) for i in indices_array)
```
instead of `take` ? @thomwolf | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/583/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/583/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/582/comments | https://api.github.com/repos/huggingface/datasets/issues/582/events | https://github.com/huggingface/datasets/issues/582 | 695,126,456 | MDU6SXNzdWU2OTUxMjY0NTY= | 582 | Allow for PathLike objects | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,486,891,000 | 1,599,551,117,000 | 1,599,551,117,000 | CONTRIBUTOR | null | Using PathLike objects as input for `load_dataset` does not seem to work. The following will throw an error.
```python
files = list(Path(r"D:\corpora\yourcorpus").glob("*.txt"))
dataset = load_dataset("text", data_files=files)
```
Traceback:
```
Traceback (most recent call last):
File "C:/dev/python/dutch-simplification/main.py", line 7, in <module>
dataset = load_dataset("text", data_files=files)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\load.py", line 548, in load_dataset
builder_instance.download_and_prepare(
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 470, in download_and_prepare
self._save_info()
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 564, in _save_info
self.info.write_to_directory(self._cache_dir)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\info.py", line 149, in write_to_directory
self._dump_info(f)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\info.py", line 156, in _dump_info
file.write(json.dumps(asdict(self)).encode("utf-8"))
File "c:\users\bramv\appdata\local\programs\python\python38\lib\json\__init__.py", line 231, in dumps
return _default_encoder.encode(obj)
File "c:\users\bramv\appdata\local\programs\python\python38\lib\json\encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "c:\users\bramv\appdata\local\programs\python\python38\lib\json\encoder.py", line 257, in iterencode
return _iterencode(o, 0)
TypeError: keys must be str, int, float, bool or None, not WindowsPath
```
We have to cast to a string explicitly to make this work. It would be nicer if we could actually use PathLike objects.
```python
files = [str(f) for f in Path(r"D:\corpora\wablieft").glob("*.txt")]
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/582/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/582/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/581/comments | https://api.github.com/repos/huggingface/datasets/issues/581/events | https://github.com/huggingface/datasets/issues/581 | 695,120,517 | MDU6SXNzdWU2OTUxMjA1MTc= | 581 | Better error message when input file does not exist | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,486,479,000 | 1,599,642,007,000 | 1,599,642,007,000 | CONTRIBUTOR | null | In the following scenario, when `data_files` is an empty list, the stack trace and error message could be improved. This can probably be solved by checking for each file whether it actually exists and/or whether the argument is not false-y.
```python
dataset = load_dataset("text", data_files=[])
```
Example error trace.
```
Using custom data configuration default
Downloading and preparing dataset text/default-d18f9b6611eb8e16 (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to C:\Users\bramv\.cache\huggingface\datasets\text\default-d18f9b6611eb8e16\0.0.0\3a79870d85f1982d6a2af884fde86a71c771747b4b161fd302d28ad22adf985b...
Traceback (most recent call last):
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 424, in incomplete_dir
yield tmp_dir
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 462, in download_and_prepare
self._download_and_prepare(
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 537, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 813, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\arrow_writer.py", line 217, in finalize
self.pa_writer.close()
AttributeError: 'NoneType' object has no attribute 'close'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/dev/python/dutch-simplification/main.py", line 7, in <module>
dataset = load_dataset("text", data_files=files)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\load.py", line 548, in load_dataset
builder_instance.download_and_prepare(
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 470, in download_and_prepare
self._save_info()
File "c:\users\bramv\appdata\local\programs\python\python38\lib\contextlib.py", line 131, in __exit__
self.gen.throw(type, value, traceback)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 430, in incomplete_dir
shutil.rmtree(tmp_dir)
File "c:\users\bramv\appdata\local\programs\python\python38\lib\shutil.py", line 737, in rmtree
return _rmtree_unsafe(path, onerror)
File "c:\users\bramv\appdata\local\programs\python\python38\lib\shutil.py", line 615, in _rmtree_unsafe
onerror(os.unlink, fullname, sys.exc_info())
File "c:\users\bramv\appdata\local\programs\python\python38\lib\shutil.py", line 613, in _rmtree_unsafe
os.unlink(fullname)
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:\\Users\\bramv\\.cache\\huggingface\\datasets\\text\\default-d18f9b6611eb8e16\\0.0.0\\3a79870d85f1982d6a2af884fde86a71c771747b4b161fd302d28ad22adf985b.incomplete\\text-train.arrow'
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/581/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/581/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/580/comments | https://api.github.com/repos/huggingface/datasets/issues/580/events | https://github.com/huggingface/datasets/issues/580 | 694,954,551 | MDU6SXNzdWU2OTQ5NTQ1NTE= | 580 | nlp re-creates already-there caches when using a script, but not within a shell | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Couln't reproduce on my side :/ \r\nlet me know if you manage to reproduce on another env (colab for example)",
"Fixed with a clean re-install!"
] | 1,599,474,230,000 | 1,599,491,949,000 | 1,599,488,801,000 | MEMBER | null | `nlp` keeps creating new caches for the same file when launching `filter` from a script, and behaves correctly from within the shell.
Example: try running
```
import nlp
hans_easy_data = nlp.load_dataset('hans', split="validation").filter(lambda x: x['label'] == 0)
hans_hard_data = nlp.load_dataset('hans', split="validation").filter(lambda x: x['label'] == 1)
```
twice. If launched from a `file.py` script, the cache will be re-created the second time. If launched as 3 shell/`ipython` commands, `nlp` will correctly re-use the cache.
As observed with @lhoestq. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/580/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/580/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/579 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/579/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/579/comments | https://api.github.com/repos/huggingface/datasets/issues/579/events | https://github.com/huggingface/datasets/pull/579 | 694,947,599 | MDExOlB1bGxSZXF1ZXN0NDgxMjU1OTI5 | 579 | Doc metrics | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,473,724,000 | 1,599,743,171,000 | 1,599,743,170,000 | MEMBER | null | Adding documentation on metrics loading/using/sharing | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/579/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/579/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/579",
"html_url": "https://github.com/huggingface/datasets/pull/579",
"diff_url": "https://github.com/huggingface/datasets/pull/579.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/579.patch",
"merged_at": 1599743170000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/578/comments | https://api.github.com/repos/huggingface/datasets/issues/578/events | https://github.com/huggingface/datasets/pull/578 | 694,849,940 | MDExOlB1bGxSZXF1ZXN0NDgxMTczNDE0 | 578 | Add CommonGen Dataset | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,466,637,000 | 1,599,479,429,000 | 1,599,479,347,000 | MEMBER | null | CC Authors:
@yuchenlin @MichaelZhouwang | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/578/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/578",
"html_url": "https://github.com/huggingface/datasets/pull/578",
"diff_url": "https://github.com/huggingface/datasets/pull/578.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/578.patch",
"merged_at": 1599479347000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/577/comments | https://api.github.com/repos/huggingface/datasets/issues/577/events | https://github.com/huggingface/datasets/issues/577 | 694,607,148 | MDU6SXNzdWU2OTQ2MDcxNDg= | 577 | Some languages in wikipedia dataset are not loading | {
"login": "gaguilar",
"id": 5833357,
"node_id": "MDQ6VXNlcjU4MzMzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5833357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gaguilar",
"html_url": "https://github.com/gaguilar",
"followers_url": "https://api.github.com/users/gaguilar/followers",
"following_url": "https://api.github.com/users/gaguilar/following{/other_user}",
"gists_url": "https://api.github.com/users/gaguilar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gaguilar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gaguilar/subscriptions",
"organizations_url": "https://api.github.com/users/gaguilar/orgs",
"repos_url": "https://api.github.com/users/gaguilar/repos",
"events_url": "https://api.github.com/users/gaguilar/events{/privacy}",
"received_events_url": "https://api.github.com/users/gaguilar/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Some wikipedia languages have already been processed by us and are hosted on our google storage. This is the case for \"fr\" and \"en\" for example.\r\n\r\nFor other smaller languages (in terms of bytes), they are directly downloaded and parsed from the wikipedia dump site.\r\nParsing can take some time for languages with hundreds of MB of xml.\r\n\r\nLet me know if you encounter an error or if you feel that is is taking too long for you.\r\nWe could process those that really take too much time",
"Ok, thanks for clarifying, that makes sense. I will time those examples later today and post back here.\r\n\r\nAlso, it seems that not all dumps should use the same date. For instance, I was checking the Spanish dump doing the following:\r\n```\r\ndata = nlp.load_dataset('wikipedia', '20200501.es', beam_runner='DirectRunner', split='train')\r\n```\r\n\r\nI got the error below because this URL does not exist: https://dumps.wikimedia.org/eswiki/20200501/dumpstatus.json. So I checked the actual available dates here https://dumps.wikimedia.org/eswiki/ and there is no 20200501. If one tries for a date available in the link, then the nlp library does not allow such a request because is not in the list of expected datasets.\r\n\r\n```\r\nDownloading and preparing dataset wikipedia/20200501.es (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/gaguilar/.cache/huggingface/datasets/wikipedia/20200501.es/1.0.0/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50...\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/load.py\", line 548, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/builder.py\", line 462, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/builder.py\", line 965, in _download_and_prepare\r\n super(BeamBasedBuilder, self)._download_and_prepare(\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/builder.py\", line 518, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/datasets/wikipedia/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50/wikipedia.py\", line 422, in _split_generators\r\n downloaded_files = dl_manager.download_and_extract({\"info\": info_url})\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/download_manager.py\", line 220, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/download_manager.py\", line 155, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/py_utils.py\", line 163, in map_nested\r\n return {\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/py_utils.py\", line 164, in <dictcomp>\r\n k: map_nested(\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/py_utils.py\", line 191, in map_nested\r\n return function(data_struct)\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/download_manager.py\", line 156, in <lambda>\r\n lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/file_utils.py\", line 191, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/gaguilar/.conda/envs/pytorch/lib/python3.8/site-packages/nlp/utils/file_utils.py\", line 356, in get_from_cache\r\n raise ConnectionError(\"Couldn't reach {}\".format(url))\r\nConnectionError: Couldn't reach https://dumps.wikimedia.org/eswiki/20200501/dumpstatus.json\r\n```",
"Thanks ! This will be very helpful.\r\n\r\nAbout the date issue, I think it's possible to use another date with\r\n\r\n```python\r\nload_dataset(\"wikipedia\", language=\"es\", date=\"...\", beam_runner=\"...\")\r\n```\r\n\r\nHowever we've not processed wikipedia dumps for other dates than 20200501 (yet ?)\r\n\r\nOne more thing that is specific to 20200501.es: it was available once but the `mwparserfromhell` was not able to parse it for some reason, so we didn't manage to get a processed version of 20200501.es (see #321 )",
"Cool! Thanks for the trick regarding different dates!\r\n\r\nI checked the download/processing time for retrieving the Arabic Wikipedia dump, and it took about 3.2 hours. I think that this may be a bit impractical when it comes to working with multiple languages (although I understand that storing those datasets in your Google storage may not be very appealing either). \r\n\r\nFor the record, here's what I did:\r\n```python\r\nimport nlp\r\nimport time\r\n\r\ndef timeit(filename):\r\n elapsed = time.time()\r\n data = nlp.load_dataset('wikipedia', filename, beam_runner='DirectRunner', split='train')\r\n elapsed = time.time() - elapsed\r\n print(f\"Loading the '{filename}' data took {elapsed:,.1f} seconds...\")\r\n return data\r\n\r\ndata = timeit('20200501.ar')\r\n```\r\n\r\nHere's the output:\r\n```\r\nDownloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13.0k/13.0k [00:00<00:00, 8.34MB/s]\r\nDownloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 28.7k/28.7k [00:00<00:00, 954kB/s]\r\nDownloading and preparing dataset wikipedia/20200501.ar (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/gaguil20/.cache/huggingface/datasets/wikipedia/20200501.ar/1.0.0/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50...\r\nDownloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 47.4k/47.4k [00:00<00:00, 1.40MB/s]\r\nDownloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 79.8M/79.8M [00:15<00:00, 5.13MB/s]\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 171M/171M [00:33<00:00, 5.13MB/s]\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 103M/103M [00:20<00:00, 5.14MB/s]\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 227M/227M [00:44<00:00, 5.06MB/s]\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 140M/140M [00:28<00:00, 4.96MB/s]\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 160M/160M [00:30<00:00, 5.20MB/s]\r\nDownloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 97.5M/97.5M [00:19<00:00, 5.06MB/s]\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 222M/222M [00:42<00:00, 5.21MB/s]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [03:16<00:00, 196.39s/sources]\r\nDataset wikipedia downloaded and prepared to /home/gaguil20/.cache/huggingface/datasets/wikipedia/20200501.ar/1.0.0/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50. Subsequent calls will reuse this data.\r\nLoading the '20200501.ar' data took 11,582.7 seconds...\r\n````",
"> About the date issue, I think it's possible to use another date with\r\n> ```python\r\n> load_dataset(\"wikipedia\", language=\"es\", date=\"...\", beam_runner=\"...\")\r\n> ```\r\n\r\nI tried your suggestion about the date and the function does not accept the language and date keywords. I tried both on `nlp` v0.4 and the new `datasets` library (v1.0.2):\r\n```\r\nload_dataset(\"wikipedia\", language=\"es\", date=\"20200601\", beam_runner='DirectRunner', split='train')\r\n```\r\nFor now, my quick workaround to keep things moving was to simply change the date inside the library at this line: [https://github.com/huggingface/datasets/blob/master/datasets/wikipedia/wikipedia.py#L403](https://github.com/huggingface/datasets/blob/master/datasets/wikipedia/wikipedia.py#L403)\r\n\r\nNote that the date and languages are valid: [https://dumps.wikimedia.org/eswiki/20200601/dumpstatus.json](https://dumps.wikimedia.org/eswiki/20200601/dumpstatus.json)\r\n\r\nAny suggestion is welcome :) @lhoestq \r\n\r\n\r\n## **[UPDATE]**\r\n\r\nThe workaround I mentioned fetched the data, but then I faced another issue (even the log says to report this as bug):\r\n```\r\nERROR:root:mwparserfromhell ParseError: This is a bug and should be reported. Info: C tokenizer exited with non-empty token stack.\r\n```\r\n\r\nHere's the full stack (which says that there is a key error caused by this key: `KeyError: '000nbsp'`):\r\n\r\n```Downloading and preparing dataset wikipedia/20200601.es (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/gustavoag/.cache/huggingface/datasets/wikipedia/20200601.es/1.0.0/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50...\r\nDownloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 74.7k/74.7k [00:00<00:00, 1.53MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 232M/232M [00:48<00:00, 4.75MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 442M/442M [01:39<00:00, 4.44MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 173M/173M [00:33<00:00, 5.12MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 344M/344M [01:14<00:00, 4.59MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 541M/541M [01:59<00:00, 4.52MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 476M/476M [01:31<00:00, 5.18MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 545M/545M [02:02<00:00, 4.46MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 299M/299M [01:01<00:00, 4.89MB/s]\r\nDownloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9.60M/9.60M [00:01<00:00, 4.84MB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 423M/423M [01:36<00:00, 4.38MB/s]\r\nWARNING:apache_beam.options.pipeline_options:Discarding unparseable args: ['--lang', 'es', '--date', '20200601', '--tokenizer', 'bert-base-multilingual-cased', '--cache', 'train', 'valid', '--max_dataset_length', '200000', '10000']\r\n\r\nERROR:root:mwparserfromhell ParseError: This is a bug and should be reported. Info: C tokenizer exited with non-empty token stack.\r\nERROR:root:mwparserfromhell ParseError: This is a bug and should be reported. Info: C tokenizer exited with non-empty token stack.\r\nERROR:root:mwparserfromhell ParseError: This is a bug and should be reported. Info: C tokenizer exited with non-empty token stack.\r\nERROR:root:mwparserfromhell ParseError: This is a bug and should be reported. Info: C tokenizer exited with non-empty token stack.\r\nTraceback (most recent call last):\r\n File \"apache_beam/runners/common.py\", line 961, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 553, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1095, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/datasets/wikipedia/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50/wikipedia.py\", line 500, in _clean_content\r\n text = _parse_and_clean_wikicode(raw_content, parser=mwparserfromhell)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/datasets/wikipedia/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50/wikipedia.py\", line 556, in _parse_and_clean_wikicode\r\n section_text.append(section.strip_code().strip())\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/mwparserfromhell/wikicode.py\", line 643, in strip_code\r\n stripped = node.__strip__(**kwargs)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/mwparserfromhell/nodes/html_entity.py\", line 63, in __strip__\r\n return self.normalize()\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/mwparserfromhell/nodes/html_entity.py\", line 178, in normalize\r\n return chrfunc(htmlentities.name2codepoint[self.value])\r\nKeyError: '000nbsp'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/runpy.py\", line 194, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/raid/data/gustavoag/projects/char2subword/research/preprocessing/split_wiki.py\", line 96, in <module>\r\n main()\r\n File \"/raid/data/gustavoag/projects/char2subword/research/preprocessing/split_wiki.py\", line 65, in main\r\n data = nlp.load_dataset('wikipedia', f'{args.date}.{args.lang}', beam_runner='DirectRunner', split='train')\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/load.py\", line 548, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/builder.py\", line 462, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/builder.py\", line 969, in _download_and_prepare\r\n pipeline_results = pipeline.run()\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/pipeline.py\", line 534, in run\r\n return self.runner.run_pipeline(self, self._options)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/direct/direct_runner.py\", line 119, in run_pipeline\r\n return runner.run_pipeline(pipeline, options)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 172, in run_pipeline\r\n self._latest_run_result = self.run_via_runner_api(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 183, in run_via_runner_api\r\n return self.run_stages(stage_context, stages)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 338, in run_stages\r\n stage_results = self._run_stage(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 512, in _run_stage\r\n last_result, deferred_inputs, fired_timers = self._run_bundle(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 556, in _run_bundle\r\n result, splits = bundle_manager.process_bundle(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 940, in process_bundle\r\n for result, split_result in executor.map(execute, zip(part_inputs, # pylint: disable=zip-builtin-not-iterating\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/concurrent/futures/_base.py\", line 611, in result_iterator\r\n yield fs.pop().result()\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/concurrent/futures/_base.py\", line 439, in result\r\n return self.__get_result()\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/concurrent/futures/_base.py\", line 388, in __get_result\r\n raise self._exception\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/utils/thread_pool_executor.py\", line 44, in run\r\n self._future.set_result(self._fn(*self._fn_args, **self._fn_kwargs))\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 932, in execute\r\n return bundle_manager.process_bundle(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 837, in process_bundle\r\n result_future = self._worker_handler.control_conn.push(process_bundle_req)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/worker_handlers.py\", line 352, in push\r\n response = self.worker.do_instruction(request)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/worker/sdk_worker.py\", line 479, in do_instruction\r\n return getattr(self, request_type)(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/worker/sdk_worker.py\", line 515, in process_bundle\r\n bundle_processor.process_bundle(instruction_id))\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/worker/bundle_processor.py\", line 977, in process_bundle\r\n input_op_by_transform_id[element.transform_id].process_encoded(\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/apache_beam/runners/worker/bundle_processor.py\", line 218, in process_encoded\r\n self.output(decoded_value)\r\n File \"apache_beam/runners/worker/operations.py\", line 330, in apache_beam.runners.worker.operations.Operation.output\r\n File \"apache_beam/runners/worker/operations.py\", line 332, in apache_beam.runners.worker.operations.Operation.output\r\n File \"apache_beam/runners/worker/operations.py\", line 195, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive\r\n File \"apache_beam/runners/worker/operations.py\", line 670, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/worker/operations.py\", line 671, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/common.py\", line 963, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 1030, in apache_beam.runners.common.DoFnRunner._reraise_augmented\r\n File \"apache_beam/runners/common.py\", line 961, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 553, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1122, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"apache_beam/runners/worker/operations.py\", line 195, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive\r\n File \"apache_beam/runners/worker/operations.py\", line 670, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/worker/operations.py\", line 671, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/common.py\", line 963, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 1030, in apache_beam.runners.common.DoFnRunner._reraise_augmented\r\n File \"apache_beam/runners/common.py\", line 961, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 553, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1122, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"apache_beam/runners/worker/operations.py\", line 195, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive\r\n File \"apache_beam/runners/worker/operations.py\", line 670, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/worker/operations.py\", line 671, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/common.py\", line 963, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 1045, in apache_beam.runners.common.DoFnRunner._reraise_augmented\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/future/utils/__init__.py\", line 446, in raise_with_traceback\r\n raise exc.with_traceback(traceback)\r\n File \"apache_beam/runners/common.py\", line 961, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 553, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1095, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/datasets/wikipedia/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50/wikipedia.py\", line 500, in _clean_content\r\n text = _parse_and_clean_wikicode(raw_content, parser=mwparserfromhell)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/nlp/datasets/wikipedia/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50/wikipedia.py\", line 556, in _parse_and_clean_wikicode\r\n section_text.append(section.strip_code().strip())\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/mwparserfromhell/wikicode.py\", line 643, in strip_code\r\n stripped = node.__strip__(**kwargs)\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/mwparserfromhell/nodes/html_entity.py\", line 63, in __strip__\r\n return self.normalize()\r\n File \"/home/gustavoag/anaconda3/envs/pytorch/lib/python3.8/site-packages/mwparserfromhell/nodes/html_entity.py\", line 178, in normalize\r\n return chrfunc(htmlentities.name2codepoint[self.value])\r\nKeyError: \"000nbsp [while running 'train/Clean content']\"```",
"@lhoestq Any updates on this? I have similar issues with the Romanian dump, tnx.",
"Hey @gaguilar ,\r\n\r\nI just found the [\"char2subword\" paper](https://arxiv.org/pdf/2010.12730.pdf) and I'm really interested in trying it out on own vocabs/datasets like for historical texts (I've already [trained some lms](https://github.com/stefan-it/europeana-bert) on newspaper articles with OCR errors).\r\n\r\nDo you plan to release the code for your paper or is it possible to get the implementation 🤔 Many thanks :hugs: ",
"Hi @stefan-it! Thanks for your interest in our work! We do plan to release the code, but we will make it available once the paper has been published at a conference. Sorry for the inconvenience!\r\n\r\nHi @lhoestq, do you have any insights for this issue by any chance? Thanks!",
"This is an issue on the `mwparserfromhell` side. You could try to update `mwparserfromhell` and see if it fixes the issue. If it doesn't we'll have to create an issue on their repo for them to fix it.\r\nBut first let's see if the latest version of `mwparserfromhell` does the job.",
"I think the work around as suggested in the issue [#886] is not working for several languages, such as `id`. For example, I tried all the dates to download dataset for `id` langauge from the following link: (https://github.com/huggingface/datasets/pull/886) [https://dumps.wikimedia.org/idwiki/](https://dumps.wikimedia.org/idwiki/ )\r\n\r\n> >>> dataset = load_dataset('wikipedia', language='id', date=\"20210501\", beam_runner='DirectRunner')\r\nWARNING:datasets.builder:Using custom data configuration 20210501.id-date=20210501,language=id\r\nDownloading and preparing dataset wikipedia/20210501.id (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /Users/.cache/huggingface/datasets/wikipedia/20210501.id-date=20210501,language=id/0.0.0/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1...\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/load.py\", line 745, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/builder.py\", line 574, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/builder.py\", line 1139, in _download_and_prepare\r\n super(BeamBasedBuilder, self)._download_and_prepare(\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/builder.py\", line 630, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/Users/.cache/huggingface/modules/datasets_modules/datasets/wikipedia/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1/wikipedia.py\", line 420, in _split_generators\r\n downloaded_files = dl_manager.download_and_extract({\"info\": info_url})\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 287, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 195, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 203, in map_nested\r\n mapped = [\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 204, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 142, in _single_map_nested\r\n return function(data_struct)\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 218, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 281, in cached_path\r\n output_path = get_from_cache(\r\n File \"/Users/opt/anaconda3/envs/proj/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 623, in get_from_cache\r\n raise ConnectionError(\"Couldn't reach {}\".format(url))\r\nConnectionError: Couldn't reach https://dumps.wikimedia.org/idwiki/20210501/dumpstatus.json\r\n\r\nMoreover the downloading speed for `non-en` language is very very slow. And interestingly the download stopped after approx a couple minutes due to the read time-out. I tried numerous times and the results is same. Is there any feasible way to download non-en language using huggingface?\r\n\r\n> File \"/Users/miislamg/opt/anaconda3/envs/proj-semlm/lib/python3.9/site-packages/requests/models.py\", line 760, in generate\r\n raise ConnectionError(e)\r\nrequests.exceptions.ConnectionError: HTTPSConnectionPool(host='dumps.wikimedia.org', port=443): Read timed out.\r\nDownloading: 7%|████████▎ | 10.2M/153M [03:35<50:07, 47.4kB/s]",
"Hi ! The link https://dumps.wikimedia.org/idwiki/20210501/dumpstatus.json seems to be working fine for me.\r\n\r\nRegarding the time outs, it must come either from an issue on the wikimedia host side, or from your internet connection.\r\nFeel free to try again several times.",
"I was trying to download dataset for `es` language, however I am getting the following error:\r\n```\r\ndataset = load_dataset('wikipedia', language='es', date=\"20210320\", beam_runner='DirectRunner') \r\n```\r\n\r\n```\r\nDownloading and preparing dataset wikipedia/20210320.es (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /scratch/user_name/datasets/wikipedia/20210320.es-date=20210320,language=es/0.0.0/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1...\r\nTraceback (most recent call last):\r\n File \"apache_beam/runners/common.py\", line 1233, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 581, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1368, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"/scratch/user_name/modules/datasets_modules/datasets/wikipedia/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1/wikipedia.py\", line 492, in _clean_content\r\n text = _parse_and_clean_wikicode(raw_content, parser=mwparserfromhell)\r\n File \"/scratch/user_name/modules/datasets_modules/datasets/wikipedia/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1/wikipedia.py\", line 548, in _parse_and_clean_wikicode\r\n section_text.append(section.strip_code().strip())\r\n File \"/opt/conda/lib/python3.7/site-packages/mwparserfromhell/wikicode.py\", line 639, in strip_code\r\n stripped = node.__strip__(**kwargs)\r\n File \"/opt/conda/lib/python3.7/site-packages/mwparserfromhell/nodes/html_entity.py\", line 60, in __strip__\r\n return self.normalize()\r\n File \"/opt/conda/lib/python3.7/site-packages/mwparserfromhell/nodes/html_entity.py\", line 150, in normalize\r\n return chr(htmlentities.name2codepoint[self.value])\r\nKeyError: '000nbsp'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"download_dataset_all.py\", line 8, in <module>\r\n dataset = load_dataset('wikipedia', language=language, date=\"20210320\", beam_runner='DirectRunner') \r\n File \"/opt/conda/lib/python3.7/site-packages/datasets/load.py\", line 748, in load_dataset\r\n use_auth_token=use_auth_token,\r\n File \"/opt/conda/lib/python3.7/site-packages/datasets/builder.py\", line 575, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/opt/conda/lib/python3.7/site-packages/datasets/builder.py\", line 1152, in _download_and_prepare\r\n pipeline_results = pipeline.run()\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/pipeline.py\", line 564, in run\r\n return self.runner.run_pipeline(self, self._options)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/direct/direct_runner.py\", line 131, in run_pipeline\r\n return runner.run_pipeline(pipeline, options)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 190, in run_pipeline\r\n pipeline.to_runner_api(default_environment=self._default_environment))\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 200, in run_via_runner_api\r\n return self.run_stages(stage_context, stages)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 366, in run_stages\r\n bundle_context_manager,\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 562, in _run_stage\r\n bundle_manager)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 602, in _run_bundle\r\n data_input, data_output, input_timers, expected_timer_output)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 903, in process_bundle\r\n result_future = self._worker_handler.control_conn.push(process_bundle_req)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/portability/fn_api_runner/worker_handlers.py\", line 378, in push\r\n response = self.worker.do_instruction(request)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/worker/sdk_worker.py\", line 610, in do_instruction\r\n getattr(request, request_type), request.instruction_id)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/worker/sdk_worker.py\", line 647, in process_bundle\r\n bundle_processor.process_bundle(instruction_id))\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/worker/bundle_processor.py\", line 1001, in process_bundle\r\n element.data)\r\n File \"/opt/conda/lib/python3.7/site-packages/apache_beam/runners/worker/bundle_processor.py\", line 229, in process_encoded\r\n self.output(decoded_value)\r\n File \"apache_beam/runners/worker/operations.py\", line 356, in apache_beam.runners.worker.operations.Operation.output\r\n File \"apache_beam/runners/worker/operations.py\", line 358, in apache_beam.runners.worker.operations.Operation.output\r\n File \"apache_beam/runners/worker/operations.py\", line 220, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive\r\n File \"apache_beam/runners/worker/operations.py\", line 717, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/worker/operations.py\", line 718, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/common.py\", line 1235, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 1300, in apache_beam.runners.common.DoFnRunner._reraise_augmented\r\n File \"apache_beam/runners/common.py\", line 1233, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 581, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1395, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"apache_beam/runners/worker/operations.py\", line 220, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive\r\n File \"apache_beam/runners/worker/operations.py\", line 717, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/worker/operations.py\", line 718, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/common.py\", line 1235, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 1300, in apache_beam.runners.common.DoFnRunner._reraise_augmented\r\n File \"apache_beam/runners/common.py\", line 1233, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 581, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1395, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"apache_beam/runners/worker/operations.py\", line 220, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive\r\n File \"apache_beam/runners/worker/operations.py\", line 717, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/worker/operations.py\", line 718, in apache_beam.runners.worker.operations.DoOperation.process\r\n File \"apache_beam/runners/common.py\", line 1235, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 1315, in apache_beam.runners.common.DoFnRunner._reraise_augmented\r\n File \"/opt/conda/lib/python3.7/site-packages/future/utils/__init__.py\", line 446, in raise_with_traceback\r\n raise exc.with_traceback(traceback)\r\n File \"apache_beam/runners/common.py\", line 1233, in apache_beam.runners.common.DoFnRunner.process\r\n File \"apache_beam/runners/common.py\", line 581, in apache_beam.runners.common.SimpleInvoker.invoke_process\r\n File \"apache_beam/runners/common.py\", line 1368, in apache_beam.runners.common._OutputProcessor.process_outputs\r\n File \"/scratch/user_name/modules/datasets_modules/datasets/wikipedia/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1/wikipedia.py\", line 492, in _clean_content\r\n text = _parse_and_clean_wikicode(raw_content, parser=mwparserfromhell)\r\n File \"/scratch/user_name/modules/datasets_modules/datasets/wikipedia/2fe8db1405aef67dff9fcc51e133e1f9c5b0106f9d9e9638188176d278fd5ff1/wikipedia.py\", line 548, in _parse_and_clean_wikicode\r\n section_text.append(section.strip_code().strip())\r\n File \"/opt/conda/lib/python3.7/site-packages/mwparserfromhell/wikicode.py\", line 639, in strip_code\r\n stripped = node.__strip__(**kwargs)\r\n File \"/opt/conda/lib/python3.7/site-packages/mwparserfromhell/nodes/html_entity.py\", line 60, in __strip__\r\n return self.normalize()\r\n File \"/opt/conda/lib/python3.7/site-packages/mwparserfromhell/nodes/html_entity.py\", line 150, in normalize\r\n return chr(htmlentities.name2codepoint[self.value])\r\nKeyError: \"000nbsp [while running 'train/Clean content']\"\r\n```",
"Hi ! This looks related to this issue: https://github.com/huggingface/datasets/issues/1994\r\nBasically the parser that is used (mwparserfromhell) has some issues for some pages in `es`.\r\nWe already reported some issues for `es` on their repo at https://github.com/earwig/mwparserfromhell/issues/247 but it looks like there are still a few issues. Might be a good idea to open a new issue on the mwparserfromhell repo"
] | 1,599,441,389,000 | 1,626,364,526,000 | null | CONTRIBUTOR | null | Hi,
I am working with the `wikipedia` dataset and I have a script that goes over 92 of the available languages in that dataset. So far I have detected that `ar`, `af`, `an` are not loading. Other languages like `fr` and `en` are working fine. Here's how I am loading them:
```
import nlp
langs = ['ar'. 'af', 'an']
for lang in langs:
data = nlp.load_dataset('wikipedia', f'20200501.{lang}', beam_runner='DirectRunner', split='train')
print(lang, len(data))
```
Here's what I see for 'ar' (it gets stuck there):
```
Downloading and preparing dataset wikipedia/20200501.ar (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/gaguilar/.cache/huggingface/datasets/wikipedia/20200501.ar/1.0.0/7be7f4324255faf70687be8692de57cf79197afdc33ff08d6a04ed602df32d50...
```
Note that those languages are indeed in the list of expected languages. Any suggestions on how to work around this? Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/577/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/577/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/576/comments | https://api.github.com/repos/huggingface/datasets/issues/576/events | https://github.com/huggingface/datasets/pull/576 | 694,348,645 | MDExOlB1bGxSZXF1ZXN0NDgwNzM3NDQ1 | 576 | Fix the code block in doc | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"thanks :)"
] | 1,599,392,455,000 | 1,599,464,252,000 | 1,599,464,238,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/576/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/576/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/576",
"html_url": "https://github.com/huggingface/datasets/pull/576",
"diff_url": "https://github.com/huggingface/datasets/pull/576.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/576.patch",
"merged_at": 1599464238000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/575/comments | https://api.github.com/repos/huggingface/datasets/issues/575/events | https://github.com/huggingface/datasets/issues/575 | 693,691,611 | MDU6SXNzdWU2OTM2OTE2MTE= | 575 | Couldn't reach certain URLs and for the ones that can be reached, code just blocks after downloading. | {
"login": "sudarshan85",
"id": 488428,
"node_id": "MDQ6VXNlcjQ4ODQyOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/488428?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sudarshan85",
"html_url": "https://github.com/sudarshan85",
"followers_url": "https://api.github.com/users/sudarshan85/followers",
"following_url": "https://api.github.com/users/sudarshan85/following{/other_user}",
"gists_url": "https://api.github.com/users/sudarshan85/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sudarshan85/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sudarshan85/subscriptions",
"organizations_url": "https://api.github.com/users/sudarshan85/orgs",
"repos_url": "https://api.github.com/users/sudarshan85/repos",
"events_url": "https://api.github.com/users/sudarshan85/events{/privacy}",
"received_events_url": "https://api.github.com/users/sudarshan85/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Update:\r\n\r\nThe imdb download completed after a long time (about 45 mins). Ofcourse once download loading was instantaneous. Also, the loaded object was of type `arrow_dataset`. \r\n\r\nThe urls for glue still doesn't work though.",
"Thanks for the report, I'll give a look!",
"I am also seeing a similar error when running the following:\r\n\r\n```\r\nimport nlp\r\ndataset = load_dataset('cola')\r\n```\r\nError:\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/js11133/.conda/envs/jiant/lib/python3.8/site-packages/nlp/load.py\", line 509, in load_dataset\r\n module_path = prepare_module(path, download_config=download_config, dataset=True)\r\n File \"/home/js11133/.conda/envs/jiant/lib/python3.8/site-packages/nlp/load.py\", line 248, in prepare_module\r\n local_path = cached_path(file_path, download_config=download_config)\r\n File \"/home/js11133/.conda/envs/jiant/lib/python3.8/site-packages/nlp/utils/file_utils.py\", line 191, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/js11133/.conda/envs/jiant/lib/python3.8/site-packages/nlp/utils/file_utils.py\", line 356, in get_from_cache\r\n raise ConnectionError(\"Couldn't reach {}\".format(url))\r\nConnectionError: Couldn't reach https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cola/cola.py\r\n```",
"@jeswan `\"cola\"` is not a valid dataset identifier (you can check the up-to-date list on https://huggingface.co/datasets) but you can find cola inside glue.",
"Ah right. Thanks!",
"Hi. Closing this one since #626 updated the glue urls.\r\n\r\n> 1. Why is it still blocking? Is it still downloading?\r\n\r\nAfter downloading it generates the arrow file by iterating through the examples.\r\nThe number of examples processed by second is shown during the processing (not sure why it was not the case for you)\r\n\r\n> 2. I specified split as train, so why is the test folder being populated?\r\n\r\nIt downloads every split\r\n\r\n\r\n\r\n"
] | 1,599,255,985,000 | 1,600,771,296,000 | 1,600,771,296,000 | NONE | null | Hi,
I'm following the [quick tour](https://huggingface.co/nlp/quicktour.html) and tried to load the glue dataset:
```
>>> from nlp import load_dataset
>>> dataset = load_dataset('glue', 'mrpc', split='train')
```
However, this ran into a `ConnectionError` saying it could not reach the URL (just pasting the last few lines):
```
/net/vaosl01/opt/NFS/su0/miniconda3/envs/hf/lib/python3.7/site-packages/nlp/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only)
354 " to False."
355 )
--> 356 raise ConnectionError("Couldn't reach {}".format(url))
357
358 # From now on, connected is True.
ConnectionError: Couldn't reach https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2Fmrpc_dev_ids.tsv?alt=media&token=ec5c0836-31d5-48f4-b431-7480817f1adc
```
I tried glue with cola and sst2. I got the same error, just instead of mrpc in the URL, it was replaced with cola and sst2.
Since this was not working, I thought I'll try another dataset. So I tried downloading the imdb dataset:
```
ds = load_dataset('imdb', split='train')
```
This downloads the data, but it just blocks after that:
```
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.56k/4.56k [00:00<00:00, 1.38MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.07k/2.07k [00:00<00:00, 1.15MB/s]
Downloading and preparing dataset imdb/plain_text (download: 80.23 MiB, generated: 127.06 MiB, post-processed: Unknown sizetotal: 207.28 MiB) to /net/vaosl01/opt/NFS/su0/huggingface/datasets/imdb/plain_text/1.0.0/76cdbd7249ea3548c928bbf304258dab44d09cd3638d9da8d42480d1d1be3743...
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 84.1M/84.1M [00:07<00:00, 11.1MB/s]
```
I checked the folder `$HF_HOME/datasets/downloads/extracted/<id>/aclImdb`. This folder is constantly growing in size. When I navigated to the train folder within, there was no file. However, the test folder seemed to be populating. The last time I checked it was 327M. I thought the Imdb dataset was smaller than that. My questions are:
1. Why is it still blocking? Is it still downloading?
2. I specified split as train, so why is the test folder being populated?
3. I read somewhere that after downloading, `nlp` converts the text files into some sort of `arrow` files, which will also take a while. Is this also happening here?
Thanks.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/575/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/575/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/574/comments | https://api.github.com/repos/huggingface/datasets/issues/574/events | https://github.com/huggingface/datasets/pull/574 | 693,364,853 | MDExOlB1bGxSZXF1ZXN0NDc5ODU5NzQy | 574 | Add modules cache | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"All the tests pass on my side. Not sure if it is a cache issue or a pytest issue or a circleci issue.\r\nEDIT: I have the same error on google colab. Trying to fix that",
"I think I fixed it (sorry didn't notice you were on it as well)"
] | 1,599,237,003,000 | 1,600,770,428,000 | 1,599,469,295,000 | MEMBER | null | As discusses in #554 , we should use a module cache directory outside of the python packages directory since we may not have write permissions.
I added a new HF_MODULES_PATH directory that is added to the python path when doing `import nlp`.
In this directory, a module `nlp_modules` is created so that datasets can be added to `nlp_modules.datasets` and metrics to `nlp_modules.metrics`. `nlp_modules` doesn't exist on Pypi.
If someone using cloudpickle still wants to have the downloaded dataset/metrics scripts to be inside the nlp directory, it is still possible to change the environment variable HF_MODULES_CACHE to be a path inside the nlp lib. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/574/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/574/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/574",
"html_url": "https://github.com/huggingface/datasets/pull/574",
"diff_url": "https://github.com/huggingface/datasets/pull/574.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/574.patch",
"merged_at": 1599469295000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/573/comments | https://api.github.com/repos/huggingface/datasets/issues/573/events | https://github.com/huggingface/datasets/pull/573 | 693,091,790 | MDExOlB1bGxSZXF1ZXN0NDc5NjE4Mzc2 | 573 | Faster caching for text dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,220,714,000 | 1,599,224,004,000 | 1,599,224,003,000 | MEMBER | null | As mentioned in #546 and #548 , hashing `data_files` contents to get the cache directory name for a text dataset can take a long time.
To make it faster I changed the hashing so that it takes into account the `path` and the `last modified timestamp` of each data file, instead of iterating through the content of each file to get a hash. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/573/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/573/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/573",
"html_url": "https://github.com/huggingface/datasets/pull/573",
"diff_url": "https://github.com/huggingface/datasets/pull/573.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/573.patch",
"merged_at": 1599224003000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/572/comments | https://api.github.com/repos/huggingface/datasets/issues/572/events | https://github.com/huggingface/datasets/pull/572 | 692,598,231 | MDExOlB1bGxSZXF1ZXN0NDc5MTgyNDU3 | 572 | Add CLUE Benchmark (11 datasets) | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks, @lhoestq! I've addressed the comments. \r\nAlso, I have tried to use `ClassLabel` [when possible](https://github.com/huggingface/nlp/pull/572/files#diff-1026ac7d7b78bf029cb0ebe63162c77dR297). Is there still somewhere else we can use `ClassLabel`? ",
"I believe CI failure is unrelated.",
"Great job! "
] | 1,599,184,660,000 | 1,599,472,751,000 | 1,599,472,750,000 | MEMBER | null | Add 11 tasks of [CLUE](https://github.com/CLUEbenchmark/CLUE). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/572/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/572/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/572",
"html_url": "https://github.com/huggingface/datasets/pull/572",
"diff_url": "https://github.com/huggingface/datasets/pull/572.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/572.patch",
"merged_at": 1599472750000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/571/comments | https://api.github.com/repos/huggingface/datasets/issues/571/events | https://github.com/huggingface/datasets/pull/571 | 692,109,287 | MDExOlB1bGxSZXF1ZXN0NDc4NzQ2MjMz | 571 | Serialization | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I've added save/load for dataset dicts.\r\n\r\nI agree that in the future we should also have a way to save indexes too, and also the in-place history of transforms.\r\n\r\nAlso I understand that it would be cool to have the load function directly at the root of the library, but I'm not sure this should be inside `load_dataset` that loads dataset scripts and data from the dataset repository. Maybe something like `load_from_disk` ?",
"Yes `load_from_disk` and `save_to_disk` could work as well.",
"I renamed save/load to save_to_dick/load_from_disk, and I added `nlp.load_from_disk`\r\n\r\n`nlp.load_from_disk` can load either a Dataset or a DatasetDict.",
"Awesome! Let's add them to the doc and we're good to go!"
] | 1,599,150,098,000 | 1,599,464,768,000 | 1,599,464,767,000 | MEMBER | null | I added `save` and `load` method to serialize/deserialize a dataset object in a folder.
It moves the arrow files there (or write them if the tables were in memory), and saves the pickle state in a json file `state.json`, except the info that are in a separate file `dataset_info.json`.
Example:
```python
import nlp
squad = nlp.load_dataset("squad", split="train")
squad.save("tmp/squad")
squad = nlp.Dataset.load("tmp/squad")
```
`ls tmp/squad`
```
dataset_info.json squad-train.arrow state.json
```
`cat tmp/squad/state.json`
```json
{
"_data": null,
"_data_files": [
{
"filename": "squad-train.arrow",
"skip": 0,
"take": 87599
}
],
"_fingerprint": "61f452797a686bc1",
"_format_columns": null,
"_format_kwargs": {},
"_format_type": null,
"_indexes": {},
"_indices": null,
"_indices_data_files": [],
"_inplace_history": [
{
"transforms": []
}
],
"_output_all_columns": false,
"_split": "train"
}
```
`cat tmp/squad/dataset_info.json`
```json
{
"builder_name": "squad",
"citation": "@article{2016arXiv160605250R,\n author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},\n Konstantin and {Liang}, Percy},\n title = \"{SQuAD: 100,000+ Questions for Machine Comprehension of Text}\",\n journal = {arXiv e-prints},\n year = 2016,\n eid = {arXiv:1606.05250},\n pages = {arXiv:1606.05250},\narchivePrefix = {arXiv},\n eprint = {1606.05250},\n}\n",
"config_name": "plain_text",
"dataset_size": 89789763,
"description": "Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.\n",
"download_checksums": {
"https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json": {
"checksum": "95aa6a52d5d6a735563366753ca50492a658031da74f301ac5238b03966972c9",
"num_bytes": 4854279
},
"https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json": {
"checksum": "3527663986b8295af4f7fcdff1ba1ff3f72d07d61a20f487cb238a6ef92fd955",
"num_bytes": 30288272
}
},
"download_size": 35142551,
"features": {
"answers": {
"_type": "Sequence",
"feature": {
"answer_start": {
"_type": "Value",
"dtype": "int32",
"id": null
},
"text": {
"_type": "Value",
"dtype": "string",
"id": null
}
},
"id": null,
"length": -1
},
"context": {
"_type": "Value",
"dtype": "string",
"id": null
},
"id": {
"_type": "Value",
"dtype": "string",
"id": null
},
"question": {
"_type": "Value",
"dtype": "string",
"id": null
},
"title": {
"_type": "Value",
"dtype": "string",
"id": null
}
},
"homepage": "https://rajpurkar.github.io/SQuAD-explorer/",
"license": "",
"post_processed": {
"features": null,
"resources_checksums": {
"train": {},
"train[:10%]": {}
}
},
"post_processing_size": 0,
"size_in_bytes": 124932314,
"splits": {
"train": {
"dataset_name": "squad",
"name": "train",
"num_bytes": 79317110,
"num_examples": 87599
},
"validation": {
"dataset_name": "squad",
"name": "validation",
"num_bytes": 10472653,
"num_examples": 10570
}
},
"supervised_keys": null,
"version": {
"description": "New split API (https://tensorflow.org/datasets/splits)",
"major": 1,
"minor": 0,
"nlp_version_to_prepare": null,
"patch": 0,
"version_str": "1.0.0"
}
}
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/571/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/571/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/571",
"html_url": "https://github.com/huggingface/datasets/pull/571",
"diff_url": "https://github.com/huggingface/datasets/pull/571.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/571.patch",
"merged_at": 1599464767000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/570/comments | https://api.github.com/repos/huggingface/datasets/issues/570/events | https://github.com/huggingface/datasets/pull/570 | 691,846,397 | MDExOlB1bGxSZXF1ZXN0NDc4NTI3OTQz | 570 | add reuters21578 dataset | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"repos_url": "https://api.github.com/users/jplu/repos",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,128,747,000 | 1,599,130,012,000 | 1,599,130,011,000 | CONTRIBUTOR | null | Reopen a PR this the merge. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/570/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/570/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/570",
"html_url": "https://github.com/huggingface/datasets/pull/570",
"diff_url": "https://github.com/huggingface/datasets/pull/570.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/570.patch",
"merged_at": 1599130011000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/569/comments | https://api.github.com/repos/huggingface/datasets/issues/569/events | https://github.com/huggingface/datasets/pull/569 | 691,832,720 | MDExOlB1bGxSZXF1ZXN0NDc4NTE2Mzc2 | 569 | Revert "add reuters21578 dataset" | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"repos_url": "https://api.github.com/users/jplu/repos",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,127,576,000 | 1,599,127,633,000 | 1,599,127,632,000 | CONTRIBUTOR | null | Reverts huggingface/nlp#471 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/569/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/569/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/569",
"html_url": "https://github.com/huggingface/datasets/pull/569",
"diff_url": "https://github.com/huggingface/datasets/pull/569.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/569.patch",
"merged_at": 1599127632000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/568/comments | https://api.github.com/repos/huggingface/datasets/issues/568/events | https://github.com/huggingface/datasets/issues/568 | 691,638,656 | MDU6SXNzdWU2OTE2Mzg2NTY= | 568 | `metric.compute` throws `ArrowInvalid` error | {
"login": "ibeltagy",
"id": 2287797,
"node_id": "MDQ6VXNlcjIyODc3OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2287797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibeltagy",
"html_url": "https://github.com/ibeltagy",
"followers_url": "https://api.github.com/users/ibeltagy/followers",
"following_url": "https://api.github.com/users/ibeltagy/following{/other_user}",
"gists_url": "https://api.github.com/users/ibeltagy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibeltagy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibeltagy/subscriptions",
"organizations_url": "https://api.github.com/users/ibeltagy/orgs",
"repos_url": "https://api.github.com/users/ibeltagy/repos",
"events_url": "https://api.github.com/users/ibeltagy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibeltagy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hmm might be related to what we are solving in #564",
"Could you try to update to `datasets>=1.0.0` (we changed the name of the library) and try again ?\r\nIf is was related to the distributed setup settings it must be fixed.\r\nIf it was related to empty metric inputs it's going to be fixed in #654 ",
"Closing this one as it was fixed in #654 \r\nFeel free to re-open if you have other questions"
] | 1,599,109,017,000 | 1,601,915,633,000 | 1,601,915,633,000 | NONE | null | I get the following error with `rouge.compute`. It happens only with distributed training, and it occurs randomly I can't easily reproduce it. This is using `nlp==0.4.0`
```
File "/home/beltagy/trainer.py", line 92, in validation_step
rouge_scores = rouge.compute(predictions=generated_str, references=gold_str, rouge_types=['rouge2', 'rouge1', 'rougeL'])
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/metric.py", line 224, in compute
self.finalize(timeout=timeout)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/metric.py", line 213, in finalize
self.data = Dataset(**reader.read_files(node_files))
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/arrow_reader.py", line 217, in read_files
dataset_kwargs = self._read_files(files=files, info=self._info, original_instructions=original_instructions)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/arrow_reader.py", line 162, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/arrow_reader.py", line 276, in _get_dataset_from_filename
f = pa.ipc.open_stream(mmap)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/pyarrow/ipc.py", line 173, in open_stream
return RecordBatchStreamReader(source)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/pyarrow/ipc.py", line 64, in __init__
self._open(source)
File "pyarrow/ipc.pxi", line 469, in pyarrow.lib._RecordBatchStreamReader._open
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Tried reading schema message, was null or length 0
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/568/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/568/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/567 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/567/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/567/comments | https://api.github.com/repos/huggingface/datasets/issues/567/events | https://github.com/huggingface/datasets/pull/567 | 691,430,245 | MDExOlB1bGxSZXF1ZXN0NDc4MTc2Njgx | 567 | Fix BLEURT metrics for backward compatibility | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,081,755,000 | 1,599,118,192,000 | 1,599,118,190,000 | MEMBER | null | Fix #565 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/567/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/567/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/567",
"html_url": "https://github.com/huggingface/datasets/pull/567",
"diff_url": "https://github.com/huggingface/datasets/pull/567.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/567.patch",
"merged_at": 1599118190000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/566/comments | https://api.github.com/repos/huggingface/datasets/issues/566/events | https://github.com/huggingface/datasets/pull/566 | 691,160,208 | MDExOlB1bGxSZXF1ZXN0NDc3OTM2NTIz | 566 | Remove logger pickling to fix gg colab issues | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,063,381,000 | 1,599,150,713,000 | 1,599,150,712,000 | MEMBER | null | A `logger` objects are not picklable in google colab, contrary to `logger` objects in jupyter notebooks or in python shells.
It creates some issues in google colab right now.
Indeed by calling any `Dataset` method, the fingerprint update pickles the transform function, and as the logger comes with it, it results in an error (full stacktrace [here](http://pastebin.fr/64330)):
```python
/usr/local/lib/python3.6/dist-packages/zmq/backend/cython/socket.cpython-36m-x86_64-linux-gnu.so in zmq.backend.cython.socket.Socket.__reduce_cython__()
TypeError: no default __reduce__ due to non-trivial __cinit__
```
To fix that I no longer dump the transform (`_map_single`, `select`, etc.), but the full name only (`nlp.arrow_dataset.Dataset._map_single`, `nlp.arrow_dataset.Dataset.select`, etc.) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/566/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/566/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/566",
"html_url": "https://github.com/huggingface/datasets/pull/566",
"diff_url": "https://github.com/huggingface/datasets/pull/566.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/566.patch",
"merged_at": 1599150712000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/565/comments | https://api.github.com/repos/huggingface/datasets/issues/565/events | https://github.com/huggingface/datasets/issues/565 | 691,039,121 | MDU6SXNzdWU2OTEwMzkxMjE= | 565 | No module named 'nlp.logging' | {
"login": "melody-ju",
"id": 66633754,
"node_id": "MDQ6VXNlcjY2NjMzNzU0",
"avatar_url": "https://avatars.githubusercontent.com/u/66633754?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/melody-ju",
"html_url": "https://github.com/melody-ju",
"followers_url": "https://api.github.com/users/melody-ju/followers",
"following_url": "https://api.github.com/users/melody-ju/following{/other_user}",
"gists_url": "https://api.github.com/users/melody-ju/gists{/gist_id}",
"starred_url": "https://api.github.com/users/melody-ju/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/melody-ju/subscriptions",
"organizations_url": "https://api.github.com/users/melody-ju/orgs",
"repos_url": "https://api.github.com/users/melody-ju/repos",
"events_url": "https://api.github.com/users/melody-ju/events{/privacy}",
"received_events_url": "https://api.github.com/users/melody-ju/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for reporting.\r\n\r\nApparently this is a versioning issue: the lib downloaded the `bleurt` script from the master branch where we did this change recently. We'll fix that in a new release this week or early next week. Cc @thomwolf \r\n\r\nUntil that, I'd suggest you to download the right bleurt folder from github ([this one](https://github.com/huggingface/nlp/tree/0.4.0/metrics/bleurt)) and do\r\n\r\n```python\r\nfrom nlp import load_metric\r\n\r\nbleurt = load_metric(\"path/to/bleurt/folder\")\r\n```\r\n\r\nTo download it you can either clone the repo or download the `bleurt.py` file and place it in a folder named `bleurt` ",
"Actually we can fix this on our side, this script didn't had to be updated. I'll do it in a few minutes"
] | 1,599,054,590,000 | 1,599,118,190,000 | 1,599,118,190,000 | NONE | null | Hi, I am using nlp version 0.4.0. Trying to use bleurt as an eval metric, however, the bleurt script imports nlp.logging which creates the following error. What am I missing?
```
>>> import nlp
2020-09-02 13:47:09.210310: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
>>> bleurt = nlp.load_metric("bleurt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/melody/anaconda3/envs/transformers/lib/python3.6/site-packages/nlp/load.py", line 443, in load_metric
metric_cls = import_main_class(module_path, dataset=False)
File "/home/melody/anaconda3/envs/transformers/lib/python3.6/site-packages/nlp/load.py", line 61, in import_main_class
module = importlib.import_module(module_path)
File "/home/melody/anaconda3/envs/transformers/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 665, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 678, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/melody/anaconda3/envs/transformers/lib/python3.6/site-packages/nlp/metrics/bleurt/43448cf2959ea81d3ae0e71c5c8ee31dc15eed9932f197f5f50673cbcecff2b5/bleurt.py", line 20, in <module>
from nlp.logging import get_logger
ModuleNotFoundError: No module named 'nlp.logging'
```
Just to show once again that I can't import the logging module:
```
>>> import nlp
2020-09-02 13:48:38.190621: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
>>> nlp.__version__
'0.4.0'
>>> from nlp.logging import get_logger
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'nlp.logging'
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/565/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/565/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/564/comments | https://api.github.com/repos/huggingface/datasets/issues/564/events | https://github.com/huggingface/datasets/pull/564 | 691,000,020 | MDExOlB1bGxSZXF1ZXN0NDc3ODAyMTk2 | 564 | Wait for writing in distributed metrics | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I agree this fix the problem for the CI where the files are always created in a new and clean temporary directory.\r\n\r\nHowever, in a general setting of a succession of fast distributed operation, the files could already exist from previous metrics runs but one process may still finish before another has even started in which case it would mix results from separate operations.\r\n\r\nI feel like the most robust way to solve this is to setup a rendez-vous on the first time we write on files and where each process will test and only finish its operation when it cannot acquire a lock on all the other processes (meaning they all have started).\r\n\r\nWhat do you think?",
"What do you think of this @thomwolf ? I check all the locks before finalizing",
"Ok on my side @lhoestq (cannot add you as a reviewer)",
"The test doesn't pass if I add:\r\n```python\r\n import time\r\n if self.process_id == 1:\r\n time.sleep(0.5)\r\n```\r\nright before `self.add_batch` in `Metric.compute`.\r\n\r\nI'm investigating why it doesn't work in that case",
"It looks like the process 1 runs `_check_all_processes_locks` correctly and then finishes and releases its lock before process 0 even managed to to run `_check_all_processes_locks` correctly.",
"Strange!",
"I changed the way the rendez-vous is done @thomwolf , let me know what you think.\r\nThe idea is that the master process has an additional lock `rendez_vous_lock` to tell every other process to wait for everyone to be ready before starting to write"
] | 1,599,051,530,000 | 1,599,642,803,000 | 1,599,642,802,000 | MEMBER | null | There were CI bugs where a distributed metric would try to read all the files in process 0 while the other processes haven't started writing.
To fix that I added a custom locking mechanism that waits for the file to exist before trying to read it | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/564/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/564/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/564",
"html_url": "https://github.com/huggingface/datasets/pull/564",
"diff_url": "https://github.com/huggingface/datasets/pull/564.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/564.patch",
"merged_at": 1599642802000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/563/comments | https://api.github.com/repos/huggingface/datasets/issues/563/events | https://github.com/huggingface/datasets/pull/563 | 690,908,674 | MDExOlB1bGxSZXF1ZXN0NDc3NzI2MTEz | 563 | [Large datasets] Speed up download and processing | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Looks all good :)\r\nI rebased from master and added a test for parallel `map_nested`",
"you're da best"
] | 1,599,042,714,000 | 1,599,642,213,000 | 1,599,642,212,000 | MEMBER | null | Various improvements to speed-up creation and processing of large scale datasets.
Currently:
- distributed downloads
- remove etag from datafiles hashes to spare a request when restarting a failed download | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/563/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/563/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/563",
"html_url": "https://github.com/huggingface/datasets/pull/563",
"diff_url": "https://github.com/huggingface/datasets/pull/563.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/563.patch",
"merged_at": 1599642212000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/562/comments | https://api.github.com/repos/huggingface/datasets/issues/562/events | https://github.com/huggingface/datasets/pull/562 | 690,907,604 | MDExOlB1bGxSZXF1ZXN0NDc3NzI1MjMx | 562 | [Reproductibility] Allow to pin versions of datasets/metrics | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing this one in favor of #584 "
] | 1,599,042,613,000 | 1,599,656,694,000 | 1,599,656,694,000 | MEMBER | null | Repurpose the `version` attribute in datasets and metrics to let the user pin a specific version of datasets and metric scripts:
```
dataset = nlp.load_dataset('squad', version='1.0.0')
metric = nlp.load_metric('squad', version='1.0.0')
```
Notes:
- version number are the release version of the library
- currently only possible for canonical datasets/metrics, ie. integrated in the GitHub repo of the library | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/562/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/562/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/562",
"html_url": "https://github.com/huggingface/datasets/pull/562",
"diff_url": "https://github.com/huggingface/datasets/pull/562.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/562.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/561/comments | https://api.github.com/repos/huggingface/datasets/issues/561/events | https://github.com/huggingface/datasets/pull/561 | 690,871,415 | MDExOlB1bGxSZXF1ZXN0NDc3Njk1NDQy | 561 | Made `share_dataset` more readable | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,599,039,288,000 | 1,599,123,630,000 | 1,599,123,629,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/561/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/561/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/561",
"html_url": "https://github.com/huggingface/datasets/pull/561",
"diff_url": "https://github.com/huggingface/datasets/pull/561.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/561.patch",
"merged_at": 1599123629000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/560/comments | https://api.github.com/repos/huggingface/datasets/issues/560/events | https://github.com/huggingface/datasets/issues/560 | 690,488,764 | MDU6SXNzdWU2OTA0ODg3NjQ= | 560 | Using custom DownloadConfig results in an error | {
"login": "ynouri",
"id": 1789921,
"node_id": "MDQ6VXNlcjE3ODk5MjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1789921?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ynouri",
"html_url": "https://github.com/ynouri",
"followers_url": "https://api.github.com/users/ynouri/followers",
"following_url": "https://api.github.com/users/ynouri/following{/other_user}",
"gists_url": "https://api.github.com/users/ynouri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ynouri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ynouri/subscriptions",
"organizations_url": "https://api.github.com/users/ynouri/orgs",
"repos_url": "https://api.github.com/users/ynouri/repos",
"events_url": "https://api.github.com/users/ynouri/events{/privacy}",
"received_events_url": "https://api.github.com/users/ynouri/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"From my limited understanding, part of the issue seems related to the `prepare_module` and `download_and_prepare` functions each handling the case where no config is passed. For example, `prepare_module` does mutate the object passed and forces the flags `extract_compressed_file` and `force_extract` to `True`.\r\n\r\nSee:\r\n* https://github.com/huggingface/nlp/blob/5fb61e1012bda724a9b6b847307d90a1380abfa5/src/nlp/load.py#L227\r\n* https://github.com/huggingface/nlp/blob/5fb61e1012bda724a9b6b847307d90a1380abfa5/src/nlp/builder.py#L388\r\n\r\nMaybe a cleaner solution would be to always instantiate a default `DownloadConfig` object at the top-level, have it as non-optional for the lower-level functions and treat it as immutable. ",
"Thanks for the report, I'll take a look.\r\n\r\nWhat is your specific use-case for providing a DownloadConfig object?\r\n",
"Thanks. Our use case involves running a training job behind a corporate firewall with no access to any external resources (S3, GCP or other web resources).\r\n\r\nI was thinking about a 2-steps process:\r\n1) Download the resources / artifacts using some secure corporate channel, ie run `nlp.load_dataset()` without a specific `DownloadConfig`. After that, collect the files from the `$HF_HOME` folder\r\n2) Copy the `$HF_HOME` folder in the firewalled environment. Run `nlp.load_dataset()` with a custom config `DownloadConfig(local_files_only=True)`\r\n\r\nHowever this ends up a bit clunky in practice, even when solving the `DownloadConfig` issue above. For example, the `filename` hash computed in `get_from_cache()` differs in the `local_files_only=False` vs `local_files_only=True` case (local case defaults `etag` to `None`, which results in a different hash). So effectively step 2) above doesn't work because the hash computed differs from the hash in the cache folder. Some hacks / workaround are possible but this solution becomes very convoluted.\r\nhttps://github.com/huggingface/nlp/blob/c214aa5a4430c1df1bcd0619fd94d6abdf9d2da7/src/nlp/utils/file_utils.py#L417\r\n\r\nWould you recommend a different path?\r\n",
"I see.\r\n\r\nProbably the easiest way for you would be that we add simple serialization/deserialization methods to the Dataset and DatasetDict objects once the data files have been downloaded and all the dataset is processed.\r\n\r\nWhat do you think @lhoestq ?",
"This use-case will be solved with #571 ",
"Thank you very much @thomwolf and @lhoestq we will give it a try"
] | 1,598,998,982,000 | 1,599,508,257,000 | null | NONE | null | ## Version / Environment
Ubuntu 18.04
Python 3.6.8
nlp 0.4.0
## Description
Loading `imdb` dataset works fine when when I don't specify any `download_config` argument. When I create a custom `DownloadConfig` object and pass it to the `nlp.load_dataset` function, this results in an error.
## How to reproduce
### Example without DownloadConfig --> works
```python
import os
os.environ["HF_HOME"] = "/data/hf-test-without-dl-config-01/"
import logging
import nlp
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
imdb = nlp.load_dataset(path="imdb")
```
### Example with DownloadConfig --> doesn't work
```python
import os
os.environ["HF_HOME"] = "/data/hf-test-with-dl-config-01/"
import logging
import nlp
from nlp.utils import DownloadConfig
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
download_config = DownloadConfig()
imdb = nlp.load_dataset(path="imdb", download_config=download_config)
```
Error traceback:
```
Traceback (most recent call last):
File "/.../example_with_dl_config.py", line 13, in <module>
imdb = nlp.load_dataset(path="imdb", download_config=download_config)
File "/.../python3.6/python3.6/site-packages/nlp/load.py", line 549, in load_dataset
download_config=download_config, download_mode=download_mode, ignore_verifications=ignore_verifications,
File "/.../python3.6/python3.6/site-packages/nlp/builder.py", line 463, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/.../python3.6/python3.6/site-packages/nlp/builder.py", line 518, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/.../python3.6/python3.6/site-packages/nlp/datasets/imdb/76cdbd7249ea3548c928bbf304258dab44d09cd3638d9da8d42480d1d1be3743/imdb.py", line 86, in _split_generators
arch_path = dl_manager.download_and_extract(_DOWNLOAD_URL)
File "/.../python3.6/python3.6/site-packages/nlp/utils/download_manager.py", line 220, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/.../python3.6/python3.6/site-packages/nlp/utils/download_manager.py", line 158, in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
File "/.../python3.6/python3.6/site-packages/nlp/utils/download_manager.py", line 108, in _record_sizes_checksums
self._recorded_sizes_checksums[url] = get_size_checksum_dict(path)
File "/.../python3.6/python3.6/site-packages/nlp/utils/info_utils.py", line 79, in get_size_checksum_dict
with open(path, "rb") as f:
IsADirectoryError: [Errno 21] Is a directory: '/data/hf-test-with-dl-config-01/datasets/extracted/b6802c5b61824b2c1f7dbf7cda6696b5f2e22214e18d171ce1ed3be90c931ce5'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/560/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/560/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/559/comments | https://api.github.com/repos/huggingface/datasets/issues/559/events | https://github.com/huggingface/datasets/pull/559 | 690,411,263 | MDExOlB1bGxSZXF1ZXN0NDc3MzAzOTM2 | 559 | Adding the KILT knowledge source and tasks | {
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Feel free to merge when you are happy with it @yjernite :-)"
] | 1,598,990,713,000 | 1,599,242,747,000 | 1,599,242,747,000 | MEMBER | null | This adds Wikipedia pre-processed for KILT, as well as the task data. Only the question IDs are provided for TriviaQA, but they can easily be mapped back with:
```
import nlp
kilt_wikipedia = nlp.load_dataset('kilt_wikipedia')
kilt_tasks = nlp.load_dataset('kilt_tasks')
triviaqa = nlp.load_dataset('trivia_qa', 'unfiltered.nocontext')
triviaqa_map = {}
for k in ['train', 'validation', 'test']:
triviaqa_map = dict([(q_id, i) for i, q_id in enumerate(triviaqa[k]['question_id'])])
kilt_tasks[k + '_triviaqa'] = kilt_tasks[k + '_triviaqa'].filter(lambda x: x['id'] in triviaqa_map)
kilt_tasks[k + '_triviaqa'].map(lambda x: {'input': triviaqa[split][triviaqa_map[x['id']]]['question']})
```
It would be great to have the dataset by Monday, which is when the paper should land on Arxiv and @fabiopetroni is planning on tweeting about the paper and `facebookresearch` repository for the datasett | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/559/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/559/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/559",
"html_url": "https://github.com/huggingface/datasets/pull/559",
"diff_url": "https://github.com/huggingface/datasets/pull/559.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/559.patch",
"merged_at": 1599242747000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/558/comments | https://api.github.com/repos/huggingface/datasets/issues/558/events | https://github.com/huggingface/datasets/pull/558 | 690,318,105 | MDExOlB1bGxSZXF1ZXN0NDc3MjI2ODA0 | 558 | Rerun pip install -e | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,598,981,079,000 | 1,598,981,091,000 | 1,598,981,090,000 | MEMBER | null | Hopefully it fixes the github actions | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/558/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/558/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/558",
"html_url": "https://github.com/huggingface/datasets/pull/558",
"diff_url": "https://github.com/huggingface/datasets/pull/558.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/558.patch",
"merged_at": 1598981090000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/557/comments | https://api.github.com/repos/huggingface/datasets/issues/557/events | https://github.com/huggingface/datasets/pull/557 | 690,220,135 | MDExOlB1bGxSZXF1ZXN0NDc3MTQ1NjAx | 557 | Fix a few typos | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,598,972,604,000 | 1,599,032,348,000 | 1,599,032,347,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/557/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/557/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/557",
"html_url": "https://github.com/huggingface/datasets/pull/557",
"diff_url": "https://github.com/huggingface/datasets/pull/557.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/557.patch",
"merged_at": 1599032346000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/556/comments | https://api.github.com/repos/huggingface/datasets/issues/556/events | https://github.com/huggingface/datasets/pull/556 | 690,218,423 | MDExOlB1bGxSZXF1ZXN0NDc3MTQ0MTky | 556 | Add DailyDialog | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,598,972,475,000 | 1,599,147,723,000 | 1,599,147,519,000 | MEMBER | null | http://yanran.li/dailydialog.html
https://arxiv.org/pdf/1710.03957.pdf
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/556/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/556/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/556",
"html_url": "https://github.com/huggingface/datasets/pull/556",
"diff_url": "https://github.com/huggingface/datasets/pull/556.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/556.patch",
"merged_at": 1599147519000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/555/comments | https://api.github.com/repos/huggingface/datasets/issues/555/events | https://github.com/huggingface/datasets/pull/555 | 690,197,725 | MDExOlB1bGxSZXF1ZXN0NDc3MTI2OTIy | 555 | Upgrade pip in benchmark github action | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,598,971,046,000 | 1,598,973,976,000 | 1,598,973,975,000 | MEMBER | null | It looks like it fixes the `import nlp` issue we have | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/555/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/555/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/555",
"html_url": "https://github.com/huggingface/datasets/pull/555",
"diff_url": "https://github.com/huggingface/datasets/pull/555.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/555.patch",
"merged_at": 1598973975000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/554/comments | https://api.github.com/repos/huggingface/datasets/issues/554/events | https://github.com/huggingface/datasets/issues/554 | 690,173,214 | MDU6SXNzdWU2OTAxNzMyMTQ= | 554 | nlp downloads to its module path | {
"login": "danieldk",
"id": 49398,
"node_id": "MDQ6VXNlcjQ5Mzk4",
"avatar_url": "https://avatars.githubusercontent.com/u/49398?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danieldk",
"html_url": "https://github.com/danieldk",
"followers_url": "https://api.github.com/users/danieldk/followers",
"following_url": "https://api.github.com/users/danieldk/following{/other_user}",
"gists_url": "https://api.github.com/users/danieldk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danieldk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danieldk/subscriptions",
"organizations_url": "https://api.github.com/users/danieldk/orgs",
"repos_url": "https://api.github.com/users/danieldk/repos",
"events_url": "https://api.github.com/users/danieldk/events{/privacy}",
"received_events_url": "https://api.github.com/users/danieldk/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Indeed this is a known issue arising from the fact that we try to be compatible with cloupickle.\r\n\r\nDoes this also happen if you are installing in a virtual environment?",
"> Indeed this is a know issue with the fact that we try to be compatible with cloupickle.\r\n> \r\n> Does this also happen if you are installing in a virtual environment?\r\n\r\nThen it would work, because the package is in a writable path.",
"If it's fine for you then this is the recommended way to solve this issue.",
"> If it's fine for you then this is the recommended way to solve this issue.\r\n\r\nI don't want to use a virtual environment, because Nix is fully reproducible, and virtual environments are not. And I am the maintainer of the `transformers` in nixpkgs, so sooner or later I will have to package `nlp`, since it is becoming a dependency of `transformers` ;).",
"Ok interesting. We could have another check to see if it's possible to download and import the datasets script at another location than the module path. I think this would probably involve tweaking the python system path dynamically.\r\n\r\nI don't know anything about Nix so if you want to give this a try your self we can guide you or you can give us more information on your general project and how this works.\r\n\r\nRegarding `nlp` and `transformers`, we are not sure `nlp` will become a required dependency for `transformers`. It will probably be used a lot in the examples but I think it probably won't be a required dependency for the main package since we try to keep it as light as possible in terms of deps.\r\n\r\nHappy to help you make all these things work better for your use-case ",
"@danieldk modules are now installed in a different location (by default in the cache directory of the lib, in `~/.cache/huggingface/modules`). You can also change that using the environment variable `HF_MODULES_PATH`\r\n\r\nFeel free to play with this change from the master branch for now, and let us know if it sounds good for you :)\r\nWe plan to do a release in the next coming days",
"Awesome! I’ll hopefully have some time in the coming days to try this.",
"> Feel free to play with this change from the master branch for now, and let us know if it sounds good for you :)\r\n> We plan to do a release in the next coming days\r\n\r\nThanks for making this change! I just packaged the latest commit on master and it works like a charm now! :partying_face: "
] | 1,598,969,174,000 | 1,599,805,164,000 | 1,599,805,164,000 | NONE | null | I am trying to package `nlp` for Nix, because it is now an optional dependency for `transformers`. The problem that I encounter is that the `nlp` library downloads to the module path, which is typically not writable in most package management systems:
```>>> import nlp
>>> squad_dataset = nlp.load_dataset('squad')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/nix/store/2yhik0hhqayksmkkfb0ylqp8cf5wa5wp-python3-3.8.5-env/lib/python3.8/site-packages/nlp/load.py", line 530, in load_dataset
module_path, hash = prepare_module(path, download_config=download_config, dataset=True)
File "/nix/store/2yhik0hhqayksmkkfb0ylqp8cf5wa5wp-python3-3.8.5-env/lib/python3.8/site-packages/nlp/load.py", line 329, in prepare_module
os.makedirs(main_folder_path, exist_ok=True)
File "/nix/store/685kq8pyhrvajah1hdsfn4q7gm3j4yd4-python3-3.8.5/lib/python3.8/os.py", line 223, in makedirs
mkdir(name, mode)
OSError: [Errno 30] Read-only file system: '/nix/store/2yhik0hhqayksmkkfb0ylqp8cf5wa5wp-python3-3.8.5-env/lib/python3.8/site-packages/nlp/datasets/squad'
```
Do you have any suggested workaround for this issue?
Perhaps overriding the default value for `force_local_path` of `prepare_module`? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/554/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/554/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/553/comments | https://api.github.com/repos/huggingface/datasets/issues/553/events | https://github.com/huggingface/datasets/pull/553 | 690,143,182 | MDExOlB1bGxSZXF1ZXN0NDc3MDgxNTg2 | 553 | [Fix GitHub Actions] test adding tmate | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,598,966,883,000 | 1,620,239,078,000 | 1,599,123,673,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/553/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/553/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/553",
"html_url": "https://github.com/huggingface/datasets/pull/553",
"diff_url": "https://github.com/huggingface/datasets/pull/553.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/553.patch",
"merged_at": null
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/552/comments | https://api.github.com/repos/huggingface/datasets/issues/552/events | https://github.com/huggingface/datasets/pull/552 | 690,079,429 | MDExOlB1bGxSZXF1ZXN0NDc3MDI4MzMx | 552 | Add multiprocessing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Logging looks like\r\n\r\n```\r\nDone writing 21900 indices in 3854400 bytes .\r\nProcess #0 will write at playground/tmp_00000_of_00004.arrow\r\nDone writing 21900 indices in 3854400 bytes .\r\nProcess #1 will write at playground/tmp_00001_of_00004.arrow\r\nDone writing 21900 indices in 3854400 bytes .\r\nProcess #2 will write at playground/tmp_00002_of_00004.arrow\r\nDone writing 21899 indices in 3854224 bytes .\r\nProcess #3 will write at playground/tmp_00003_of_00004.arrow\r\nSpawning 4 processes\r\n#3: 100%|████████████████████████████████████████████████| 21899/21899 [00:02<00:00, 8027.41ex/s]\r\n#0: 100%|████████████████████████████████████████████████| 21900/21900 [00:02<00:00, 7982.87ex/s]\r\n#1: 100%|████████████████████████████████████████████████| 21900/21900 [00:02<00:00, 7923.89ex/s]\r\n#2: 100%|████████████████████████████████████████████████| 21900/21900 [00:02<00:00, 7920.04ex/s]\r\nConcatenating 4 shards from multiprocessing\r\n```",
"I added tests and improved logging.\r\nBoth `map` and `filter` support multiprocessing",
"A bit strange that the benchmarks on map/filter are worth than `master`.\r\n(maybe because they are not done on the same machine)",
"The benchmark also got worse in other PRs (see [here](https://github.com/huggingface/nlp/pull/550#commitcomment-41931609) for example, where we have 16sec for `map fast-tokenizer batched` and 18 sec for `map identity`)",
"Hi,\r\n\r\nwhen I use the multiprocessing in ```.map```:\r\n```\r\ndataset = load_dataset(\"text\", data_files=file_path, split=\"train\")\r\ndataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n truncation=True, max_length=args.block_size), batched=True, num_proc=16)\r\ndataset.set_format(type='torch', columns=['input_ids'])\r\n```\r\nI get the following error:\r\n```\r\nTraceback (most recent call last):\r\n File \"src/run.py\", line 373, in <module>\r\n main()\r\n File \"src/run.py\", line 295, in main\r\n get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None\r\n File \"src/run.py\", line 153, in get_dataset\r\n dataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1287, in map\r\n transformed_shards = [r.get() for r in results]\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1287, in <listcomp>\r\n transformed_shards = [r.get() for r in results]\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/multiprocessing/pool.py\", line 771, in get\r\n raise self._value\r\n put(task)\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/multiprocessing/connection.py\", line 206, in send\r\n self._send_bytes(_ForkingPickler.dumps(obj))\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/multiprocessing/reduction.py\", line 51, in dumps\r\n cls(buf, protocol).dump(obj)\r\nAttributeError: Can't pickle local object 'get_dataset.<locals>.<lambda>'\r\n```\r\nI think you should use [pathos](https://github.com/uqfoundation/pathos) to pickle the lambda function and some others!\r\nI change the 30 line of src/datasets/arrow_dataset.py as following:\r\n```\r\n# 30 line: from multiprocessing import Pool, RLock\r\nimport pathos\r\nfrom pathos.multiprocessing import Pool\r\nfrom multiprocessing import RLock\r\n```\r\nand it works!",
"That's very cool indeed !\r\nShall we condiser adding this dependency @thomwolf ?",
"We already use `dill` so that's definitely a very interesting option indeed!",
"it gets stuck on debian 9 when num_proc > 1\r\n",
"Are you using a tokenizer ?\r\nDid you try to set `TOKENIZERS_PARALLELISM=false` ?\r\n\r\nFeel free to discuss it in #620 , we're discussing this issue",
"I set `TOKENIZERS_PARALLELISM=false`. Just the warning went away. The program was still stuck\r\n"
] | 1,598,961,377,000 | 1,600,787,516,000 | 1,599,040,885,000 | MEMBER | null | Adding multiprocessing to `.map`
It works in 3 steps:
- shard the dataset in `num_proc` shards
- spawn one process per shard and call `map` on them
- concatenate the resulting datasets
Example of usage:
```python
from nlp import load_dataset
dataset = load_dataset("squad", split="train")
def function(x):
return {"lowered": x.lower()}
processed = d.map(
function,
input_columns=["context"],
num_proc=4,
cache_file_name="playground/tmp.arrow",
load_from_cache_file=False
)
```
Here it writes 4 files depending on the process rank:
- `playground/tmp_00000_of_00004.arrow`
- `playground/tmp_00001_of_00004.arrow`
- `playground/tmp_00002_of_00004.arrow`
- `playground/tmp_00003_of_00004.arrow`
The suffix format can be specified by the user.
If the `cache_file_name` is not specified, it writes into separated files depending on the fingerprint, as usual.
I still need to:
- write tests for this
- try to improve the logging (currently it shows 4 progress bars, but if one finishes before the others, then the following messages are written over the progress bars)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/552/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/552/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/552",
"html_url": "https://github.com/huggingface/datasets/pull/552",
"diff_url": "https://github.com/huggingface/datasets/pull/552.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/552.patch",
"merged_at": 1599040885000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/551/comments | https://api.github.com/repos/huggingface/datasets/issues/551/events | https://github.com/huggingface/datasets/pull/551 | 690,034,762 | MDExOlB1bGxSZXF1ZXN0NDc2OTkwNjAw | 551 | added HANS dataset | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,598,956,922,000 | 1,598,962,630,000 | 1,598,962,630,000 | MEMBER | null | Adds the [HANS](https://github.com/tommccoy1/hans) dataset to evaluate NLI systems. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/551/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/551/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/551",
"html_url": "https://github.com/huggingface/datasets/pull/551",
"diff_url": "https://github.com/huggingface/datasets/pull/551.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/551.patch",
"merged_at": 1598962630000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/550/comments | https://api.github.com/repos/huggingface/datasets/issues/550/events | https://github.com/huggingface/datasets/pull/550 | 689,775,914 | MDExOlB1bGxSZXF1ZXN0NDc2NzgyNDY1 | 550 | [BUGFIX] Solving mismatched checksum issue for the LinCE dataset (#539) | {
"login": "gaguilar",
"id": 5833357,
"node_id": "MDQ6VXNlcjU4MzMzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5833357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gaguilar",
"html_url": "https://github.com/gaguilar",
"followers_url": "https://api.github.com/users/gaguilar/followers",
"following_url": "https://api.github.com/users/gaguilar/following{/other_user}",
"gists_url": "https://api.github.com/users/gaguilar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gaguilar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gaguilar/subscriptions",
"organizations_url": "https://api.github.com/users/gaguilar/orgs",
"repos_url": "https://api.github.com/users/gaguilar/repos",
"events_url": "https://api.github.com/users/gaguilar/events{/privacy}",
"received_events_url": "https://api.github.com/users/gaguilar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks a lot for that!\r\nThe line you are mentioning is a bug indeed, do you mind fixing it at the same time?",
"No worries! \r\n\r\nI pushed right away the fix, but then I realized that the master branch already had it, so I ended up merging the master branch with lince locally and then overwriting the previous commit in origin/lince. Hopefully, this is not too messy :)\r\n"
] | 1,598,930,823,000 | 1,599,123,961,000 | 1,599,123,961,000 | CONTRIBUTOR | null | Hi,
I have added the updated `dataset_infos.json` file for the LinCE benchmark. This update is to fix the mismatched checksum bug #539 for one of the datasets in the LinCE benchmark. To update the file, I run this command from the nlp root directory:
```
python nlp-cli test ./datasets/lince --save_infos --all_configs
```
**NOTE**: I needed to change [this line](https://github.com/huggingface/nlp/blob/master/src/nlp/commands/dummy_data.py#L8) from: `from .utils.logging import get_logger` to `from nlp.utils.logging import get_logger`, otherwise the script was not able to import `get_logger`. However, I did not include that in this PR since that could have been just my environment (and another PR could be fixing this already if it is actually an issue). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/550/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/550/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/550",
"html_url": "https://github.com/huggingface/datasets/pull/550",
"diff_url": "https://github.com/huggingface/datasets/pull/550.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/550.patch",
"merged_at": 1599123961000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/549/comments | https://api.github.com/repos/huggingface/datasets/issues/549/events | https://github.com/huggingface/datasets/pull/549 | 689,766,465 | MDExOlB1bGxSZXF1ZXN0NDc2Nzc0OTI1 | 549 | Fix bleurt logging import | {
"login": "jbragg",
"id": 2238344,
"node_id": "MDQ6VXNlcjIyMzgzNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2238344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jbragg",
"html_url": "https://github.com/jbragg",
"followers_url": "https://api.github.com/users/jbragg/followers",
"following_url": "https://api.github.com/users/jbragg/following{/other_user}",
"gists_url": "https://api.github.com/users/jbragg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jbragg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jbragg/subscriptions",
"organizations_url": "https://api.github.com/users/jbragg/orgs",
"repos_url": "https://api.github.com/users/jbragg/repos",
"events_url": "https://api.github.com/users/jbragg/events{/privacy}",
"received_events_url": "https://api.github.com/users/jbragg/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"That’s a good point that we started to discuss internally as well. We should pin the dataset en metrics code by default indeed.\r\nLet’s update this in the coming release.",
"Ok closed this with #567 and we are working on a more general solution to pin dataset version in #562 (should be in the coming release)."
] | 1,598,929,285,000 | 1,599,156,286,000 | 1,599,123,860,000 | CONTRIBUTOR | null | Bleurt started throwing an error in some code we have.
This looks like the fix but...
It's also unnerving that even a prebuilt docker image with pinned versions can be working 1 day and then fail the next (especially for production systems).
Any way for us to pin your metrics code so that they are guaranteed not to to change and possibly fail on repository changes?
Thanks (and also for your continued work on the lib...) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/549/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/549/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/549",
"html_url": "https://github.com/huggingface/datasets/pull/549",
"diff_url": "https://github.com/huggingface/datasets/pull/549.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/549.patch",
"merged_at": null
} | true |