
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
In college I have weird 50 minute slots of time in between classes when it wouldn't make sense to walk all the way back to my dorm, but at the same time 50 minutes is a long wait. I would love to be able to meet up with friends who are also free during this time, but don't want to text every single friend asking if they are free.
## What it does
Users of Toggle can open up the website whenever they are free and click on the hour time slot they are in. Toggle then provides a list of suggestions for what to do. All the events entered for that time will show up on the right side of the screen.
Everyone is welcome to add to the events on Toggle and each school could have it's own version so that we all make the most of our free time on campus, by meeting new people and learning about new communities we might not have run into otherwise.
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
I learned and built in JavaScript in 36 hours!!
## What I learned
24 arrays was not the way to go - object arrays are a life-saver.
## What's next for Toggle | # Inspiration
We came to Stanford expecting a vibrant college atmosphere. Yet walk past a volleyball or basketball court at Stanford mid-Winter quarter, and you’ll probably find it empty. As college students, our lives revolve around two pillars: productivity and play. In an ideal world, we spend intentional parts of our day fully productive–activities dedicated to our fulfillment–and some parts of our day fully immersed in play–activities dedicated solely to our joy. In reality, though, students might party, but how often do they play? Large chunks of their day are spent in their dorm room, caught between these two choices, doing essentially nothing. This doesn’t improve their mental health.
Imagine, or rather, remember, when you were last in that spot. Even if you were struck by inspiration to get out and do something fun, who with? You could text your friends, but you don’t know enough people to play 4-on-4 soccer, or if anyone’s interested in joining you for some baking between classes.
# A Solution
When encountering this problem, frolic can help. Users can:
See existing events, sorted by events “containing” most of their friends at the top
Join an event, getting access to the names of all members of event (not just their friends)
Or, save/bookmark an event for later (no notification sent to others)
Access full info of events they’ve joined or saved in the “My Events” tab
Additional, nice-to-have features include:
Notification if their friend(s) have joined an event in case they’d like to join as well
# Challenges & An Important Lesson
Not only had none of us had iOS app development experience, but with less than 12 hours to go, we realized with the original environment and language we were working in (Swift and XCode), the learning curve to create the full app was far too steep. Thus, we essentially started anew. We realized the importance of reaching out for guidance from more experienced people early on, whether at a hackathon, academic, or career-setting.
/\* Deep down, we know how important times of play are–though, we often never seem to “have time” for it. In reality, this often is correlated with us being caught in a rift between the two poles we mentioned: not being totally productive, nor totally grasping the joy that we should ideally get from some everyday activities. \*/ | ## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows roommates to quickly schedule and assign chores, as well as provide a messageboard for common things.
## How we built it
Our solution is built on ruby-on-rails, meant to be a quick simple solution.
## Challenges we ran into
The time constraint made it hard to develop all the features we wanted, so we had to reduce scope on many sections and provide a limited feature-set.
## Accomplishments that we're proud of
We thought that we did a great job on the design, delivering a modern and clean look.
## What we learned
Prioritize features beforehand, and stick to features that would be useful to as many people as possible. So, instead of overloading features that may not be that useful, we should focus on delivering the core features and make them as easy as possible.
## What's next for LiveTogether
Finish the features we set out to accomplish, and finish theming the pages that we did not have time to concentrate on. We will be using LiveTogether with our roommates, and are hoping to get some real use out of it! | losing |
## Inspiration
A couple weeks ago, a friend was hospitalized for taking Advil–she accidentally took 27 pills, which is nearly 5 times the maximum daily amount. Apparently, when asked why, she responded that thats just what she always had done and how her parents have told her to take Advil. The maximum Advil you are supposed to take is 6 per day, before it becomes a hazard to your stomach.
#### PillAR is your personal augmented reality pill/medicine tracker.
It can be difficult to remember when to take your medications, especially when there are countless different restrictions for each different medicine. For people that depend on their medication to live normally, remembering and knowing when it is okay to take their medication is a difficult challenge. Many drugs have very specific restrictions (eg. no more than one pill every 8 hours, 3 max per day, take with food or water), which can be hard to keep track of. PillAR helps you keep track of when you take your medicine and how much you take to keep you safe by not over or under dosing.
We also saw a need for a medicine tracker due to the aging population and the number of people who have many different medications that they need to take. According to health studies in the U.S., 23.1% of people take three or more medications in a 30 day period and 11.9% take 5 or more. That is over 75 million U.S. citizens that could use PillAR to keep track of their numerous medicines.
## How we built it
We created an iOS app in Swift using ARKit. We collect data on the pill bottles from the iphone camera and passed it to the Google Vision API. From there we receive the name of drug, which our app then forwards to a Python web scraping backend that we built. This web scraper collects usage and administration information for the medications we examine, since this information is not available in any accessible api or queryable database. We then use this information in the app to keep track of pill usage and power the core functionality of the app.
## Accomplishments that we're proud of
This is our first time creating an app using Apple's ARKit. We also did a lot of research to find a suitable website to scrape medication dosage information from and then had to process that information to make it easier to understand.
## What's next for PillAR
In the future, we hope to be able to get more accurate medication information for each specific bottle (such as pill size). We would like to improve the bottle recognition capabilities, by maybe writing our own classifiers or training a data set. We would also like to add features like notifications to remind you of good times to take pills to keep you even healthier. | **check out the project demo during the closing ceremony!**
<https://youtu.be/TnKxk-GelXg>
## Inspiration
On average, half of patients with chronic illnesses like heart disease or asthma don’t take their medication. Reports estimates that poor medication adherence could be costing the country $300 billion in increased medical costs.
So why is taking medication so tough? People get confused and people forget.
When the pharmacy hands over your medication, it usually comes with a stack of papers, stickers on the pill bottles, and then in addition the pharmacist tells you a bunch of mumble jumble that you won’t remember.
<http://www.nbcnews.com/id/20039597/ns/health-health_care/t/millions-skip-meds-dont-take-pills-correctly/#.XE3r2M9KjOQ>
## What it does
The solution:
How are we going to solve this? With a small scrap of paper.
NekoTap helps patients access important drug instructions quickly and when they need it.
On the pharmacist’s end, he only needs to go through 4 simple steps to relay the most important information to the patients.
1. Scan the product label to get the drug information.
2. Tap the cap to register the NFC tag. Now the product and pill bottle are connected.
3. Speak into the app to make an audio recording of the important dosage and usage instructions, as well as any other important notes.
4. Set a refill reminder for the patients. This will automatically alert the patient once they need refills, a service that most pharmacies don’t currently provide as it’s usually the patient’s responsibility.
On the patient’s end, after they open the app, they will come across 3 simple screens.
1. First, they can listen to the audio recording containing important information from the pharmacist.
2. If they swipe, they can see a copy of the text transcription. Notice how there are easy to access zoom buttons to enlarge the text size.
3. Next, there’s a youtube instructional video on how to use the drug in case the patient need visuals.
Lastly, the menu options here allow the patient to call the pharmacy if he has any questions, and also set a reminder for himself to take medication.
## How I built it
* Android
* Microsoft Azure mobile services
* Lottie
## Challenges I ran into
* Getting the backend to communicate with the clinician and the patient mobile apps.
## Accomplishments that I'm proud of
Translations to make it accessible for everyone! Developing a great UI/UX.
## What I learned
* UI/UX design
* android development | ## Inspiration
While talking to Mitt from the CVS booth, he opened my eyes to a problem that I was previously unaware - counterfeits in the pharmaceutical industry. After a good amount of research, I learned that it was possible to make a solution during the hackathon. A friendly interface with a blockchain backend could track drugs immutably, and be able to track the item from factory to the consumer means safer prescription drugs for everyone.
## What it does
Using our app, users can scan the item, and use the provided passcode to make sure that item they have is legit. Using just the QR scanner on our app, it is very easy to verify the goods you bought, as well as the location the drugs were manufactured.
## How we built it
We started off wanting to ensure immutability for our users; after all, our whole platform is made for users to trust the items they scan. What came to our minds was using blockchain technology, which would allow us to ensure each and every item would remain immutable and publicly verifiable by any party. This way, users would know that the data we present is always true and legitimate. After building the blockchain technology with Node.js, we started working on the actual mobile platform. To create both iOS and Android versions simultaneously, we used AngularJS to create a shared codebase so we could easily adapt the app for both platforms. Although we didn't have any UI/UX experience, we tried to make the app as simple and user-friendly as possible. We incorporated Google Maps API to track and plot the location of where items are scanned to add that to our metadata and added native packages like QR code scanning and generation to make things easier for users to use. Although we weren't able to publish to the app stores, we tested our app using emulators to ensure all functionality worked as intended.
## Challenges we ran into
Our first challenge was learning how to build a blockchain ecosystem within a mobile app. Since the technology was somewhat foreign to us, we had to learn the in and outs of what "makes" a blockchain and how to ensure its immutability. After all, trust and security are our number one priorities and without them, our app was meaningless. In the end, we found a way to create this ecosystem and performed numerous unit tests to ensure it was up to industry standards. Another challenge we faced was getting the app to work in both iOS and Android environments. Since each platform had its set of "rules and standards", we had to make sure that our functions worked in both and that no errors were engendered from platform deviations.
## What's next for NativeChain
We hope to expand our target audience to secondhand commodities and the food industry. In today's society, markets such as eBay and Alibaba are flooded with counterfeit luxury goods such as clothing and apparel. When customers buy these goods from secondhand retailers on eBay, there's currently no way they can know for certain whether that item is legitimate as they claim; they solely rely on the seller's word. However, we hope to disrupt this and allow customers to immediately view where the item was manufactured and if it truly is from Gucci, rather than a counterfeit market in China. Another industry we hope to expand to is foods. People care about where the food they eat comes from, whether it's kosher and organic and non-GMO. Although the FDA regulates this to a certain extent, this data isn't easily accessible by customers. We want to provide a transparent and easy way to users to view the food they are eating by showing them data like where the honey was produced, where the cows were grown, and when their fruits were picked. Outbreaks such as the Chipotle Ecoli incident can be pinpointed as they can view where the incident started and to warn customers to not eat food coming from that area. | winning |
This project was developed with the RBC challenge in mind of developing the Help Desk of the future.
## What inspired us
We were inspired by our motivation to improve the world of work.
## Background
If we want technical support, we usually contact companies by phone, which is slow and painful for both users and technical support agents, especially when questions are obvious. Our solution is an online chat that responds to people immediately using our own bank of answers. This is a portable and a scalable solution.
## Try it!
<http://www.rbcH.tech>
## What we learned
Using NLP, dealing with devilish CORS, implementing docker successfully, struggling with Kubernetes.
## How we built
* Node.js for our servers (one server for our webapp, one for BotFront)
* React for our front-end
* Rasa-based Botfront, which is the REST API we are calling for each user interaction
* We wrote our own Botfront database during the last day and night
## Our philosophy for delivery
Hack, hack, hack until it works. Léonard was our webapp and backend expert, François built the DevOps side of things and Han solidified the front end and Antoine wrote + tested the data for NLP.
## Challenges we faced
Learning brand new technologies is sometimes difficult! Kubernetes (and CORS brought us some painful pain... and new skills and confidence.
## Our code
<https://github.com/ntnco/mchacks/>
## Our training data
<https://github.com/lool01/mchack-training-data> | # The Ultimate Water Heater
February 2018
## Authors
This is the TreeHacks 2018 project created by Amarinder Chahal and Matthew Chan.
## About
Drawing inspiration from a diverse set of real-world information, we designed a system with the goal of efficiently utilizing only electricity to heat and pre-heat water as a means to drastically save energy, eliminate the use of natural gases, enhance the standard of living, and preserve water as a vital natural resource.
Through the accruement of numerous API's and the help of countless wonderful people, we successfully created a functional prototype of a more optimal water heater, giving a low-cost, easy-to-install device that works in many different situations. We also empower the user to control their device and reap benefits from their otherwise annoying electricity bill. But most importantly, our water heater will prove essential to saving many regions of the world from unpredictable water and energy crises, pushing humanity to an inevitably greener future.
Some key features we have:
* 90% energy efficiency
* An average rate of roughly 10 kW/hr of energy consumption
* Analysis of real-time and predictive ISO data of California power grids for optimal energy expenditure
* Clean and easily understood UI for typical household users
* Incorporation of the Internet of Things for convenience of use and versatility of application
* Saving, on average, 5 gallons per shower, or over ****100 million gallons of water daily****, in CA alone. \*\*\*
* Cheap cost of installation and immediate returns on investment
## Inspiration
By observing the RhoAI data dump of 2015 Californian home appliance uses through the use of R scripts, it becomes clear that water-heating is not only inefficient but also performed in an outdated manner. Analyzing several prominent trends drew important conclusions: many water heaters become large consumers of gasses and yet are frequently neglected, most likely due to the trouble in attaining successful installations and repairs.
So we set our eyes on a safe, cheap, and easily accessed water heater with the goal of efficiency and environmental friendliness. In examining the inductive heating process replacing old stovetops with modern ones, we found the answer. It accounted for every flaw the data decried regarding water-heaters, and would eventually prove to be even better.
## How It Works
Our project essentially operates in several core parts running simulataneously:
* Arduino (101)
* Heating Mechanism
* Mobile Device Bluetooth User Interface
* Servers connecting to the IoT (and servicing via Alexa)
Repeat all processes simultaneously
The Arduino 101 is the controller of the system. It relays information to and from the heating system and the mobile device over Bluetooth. It responds to fluctuations in the system. It guides the power to the heating system. It receives inputs via the Internet of Things and Alexa to handle voice commands (through the "shower" application). It acts as the peripheral in the Bluetooth connection with the mobile device. Note that neither the Bluetooth connection nor the online servers and webhooks are necessary for the heating system to operate at full capacity.
The heating mechanism consists of a device capable of heating an internal metal through electromagnetic waves. It is controlled by the current (which, in turn, is manipulated by the Arduino) directed through the breadboard and a series of resistors and capacitors. Designing the heating device involed heavy use of applied mathematics and a deeper understanding of the physics behind inductor interference and eddy currents. The calculations were quite messy but mandatorily accurate for performance reasons--Wolfram Mathematica provided inhumane assistance here. ;)
The mobile device grants the average consumer a means of making the most out of our water heater and allows the user to make informed decisions at an abstract level, taking away from the complexity of energy analysis and power grid supply and demand. It acts as the central connection for Bluetooth to the Arduino 101. The device harbors a vast range of information condensed in an effective and aesthetically pleasing UI. It also analyzes the current and future projections of energy consumption via the data provided by California ISO to most optimally time the heating process at the swipe of a finger.
The Internet of Things provides even more versatility to the convenience of the application in Smart Homes and with other smart devices. The implementation of Alexa encourages the water heater as a front-leader in an evolutionary revolution for the modern age.
## Built With:
(In no particular order of importance...)
* RhoAI
* R
* Balsamiq
* C++ (Arduino 101)
* Node.js
* Tears
* HTML
* Alexa API
* Swift, Xcode
* BLE
* Buckets and Water
* Java
* RXTX (Serial Communication Library)
* Mathematica
* MatLab (assistance)
* Red Bull, Soylent
* Tetrix (for support)
* Home Depot
* Electronics Express
* Breadboard, resistors, capacitors, jumper cables
* Arduino Digital Temperature Sensor (DS18B20)
* Electric Tape, Duct Tape
* Funnel, for testing
* Excel
* Javascript
* jQuery
* Intense Sleep Deprivation
* The wonderful support of the people around us, and TreeHacks as a whole. Thank you all!
\*\*\* According to the Washington Post: <https://www.washingtonpost.com/news/energy-environment/wp/2015/03/04/your-shower-is-wasting-huge-amounts-of-energy-and-water-heres-what-to-do-about-it/?utm_term=.03b3f2a8b8a2>
Special thanks to our awesome friends Michelle and Darren for providing moral support in person! | ## Inspiration
When we were deciding what to build for our hack this time we had plenty of great ideas. We zeroed down on something that people like us would want to use. The hardest problem faced by people like us is managing the assignments, classes and the infamous LeetCode grind. Now it would have been most useful if we could design an app that would finish our homework for us without plagiarising things off of the internet but since we could not come up with that solution(believe me we tried) we did the next best thing. We tried our hands at making the LeetCode grind easier by using machine learning and data analytics. We are pretty sure every engineer has to go through this rite of passage. Since there is no way to circumvent this grind only our goal is to make it less painful and more focused.
## What it does
The goal of the project was clear from the onset, minimizing the effort and maximizing the learning thereby making the grind less tedious. We achieved this by using data analytics and machine learning to find the deficiencies in the user knowledge base and recommend questions with an aim to fill the gaps. We also allow the users to understand their data better by allowing the users to make simple queries over our chatbot which utilizes NLP to understand and answer the queries. The overall business logic is hosted on the cloud over the google app engine.
## How we built it
The project achieves its goals using 5 major components:
1. The web scrapper to scrap the user data from websites like LeetCode.
2. Data analytics and machine learning to find areas of weakness and processing the question bank to find the next best question in an attempt to maximize learning.
3. Google app engine to host the APIs created in java which connects our front end with the business logic in the backend.
4. Google dialogflow for the chatbot where users can make simple queries to understand their statistics better.
Android app client where the user interacts with all these components utilizing the synergy generated by the combination of the aforementioned amazing components.
## Challenges we ran into
There were a number of challenges that we ran into:-
1. Procuring the data: We had to build our own web scraper to extract the question bank and the data from the interview prep websites. The security measures employed by the websites didn't make our job any easier.
2. Learning new technology: We wanted to incorporate a chatbox into our app, this was something completely new to a few of us and learning it in a short amount of time to write production-quality code was an uphill battle.
3. Building the multiple components required to make our ambitious project work.
4. Lack of UI/UX expertise. It is a known fact that not many developers are good designers, even though we are proud of the UI that we were able to build but we feel we could have done better with mockups etc.
## Accomplishments that we are proud of
1. Completing the project in the stipulated time. Finishing the app for the demo seemed like an insurmountable task on Saturday night after little to no sleep the previous night.
2. Production quality code: We tried to keep our code as clean as possible by using best programming practices whenever we could so that the code is easier to manage, debug, and understand.
## What we learned
1. Building APIs in Spring Boot
2. Using MongoDB with Spring Boot
3. Configuring MongoDB in Google Cloud Compute
4. Deploying Spring Boot APIs in Google App Engine & basics of GAE
5. Chatbots & building chatbots in DialogFlow
6. Building APIs in NodeJS & linking them with DialogFlow via Fulfillment
7. Scrapping data using Selenium & the common challenges while scrapping large volumes of data
8. Parsing scrapped data & efficiently caching it
## What's next for CodeLearnDo
1. Incorporating leaderboards and a sense of community in the app to encourage learning. | winning |
## Inspiration
Greenhouses require increased disease control and need to closely monitor their plants to ensure they're healthy. In particular, the project aims to capitalize on the recent cannabis interest.
## What it Does
It's a sensor system composed of cameras, temperature and humidity sensors layered with smart analytics that allows the user to tell when plants in his/her greenhouse are diseased.
## How We built it
We used the Telus IoT Dev Kit to build the sensor platform along with Twillio to send emergency texts (pending installation of the IoT edge runtime as of 8 am today).
Then we used azure to do transfer learning on vggnet to identify diseased plants and identify them to the user. The model is deployed to be used with IoT edge. Moreover, there is a web app that can be used to show that the
## Challenges We Ran Into
The data-sets for greenhouse plants are in fairly short supply so we had to use an existing network to help with saliency detection. Moreover, the low light conditions in the dataset were in direct contrast (pun intended) to the PlantVillage dataset used to train for diseased plants. As a result, we had to implement a few image preprocessing methods, including something that's been used for plant health detection in the past: eulerian magnification.
## Accomplishments that We're Proud of
Training a pytorch model at a hackathon and sending sensor data from the STM Nucleo board to Azure IoT Hub and Twilio SMS.
## What We Learned
When your model doesn't do what you want it to, hyperparameter tuning shouldn't always be the go to option. There might be (in this case, was) some intrinsic aspect of the model that needed to be looked over.
## What's next for Intelligent Agriculture Analytics with IoT Edge | ## Inspiration
We wanted to create a proof-of-concept for a potentially useful device that could be used commercially and at a large scale. We ultimately designed to focus on the agricultural industry as we feel that there's a lot of innovation possible in this space.
## What it does
The PowerPlant uses sensors to detect whether a plant is receiving enough water. If it's not, then it sends a signal to water the plant. While our proof of concept doesn't actually receive the signal to pour water (we quite like having working laptops), it would be extremely easy to enable this feature.
All data detected by the sensor is sent to a webserver, where users can view the current and historical data from the sensors. The user is also told whether the plant is currently being automatically watered.
## How I built it
The hardware is built on an Arduino 101, with dampness detectors being used to detect the state of the soil. We run custom scripts on the Arduino to display basic info on an LCD screen. Data is sent to the websever via a program called Gobetwino, and our JavaScript frontend reads this data and displays it to the user.
## Challenges I ran into
After choosing our hardware, we discovered that MLH didn't have an adapter to connect it to a network. This meant we had to work around this issue by writing text files directly to the server using Gobetwino. This was an imperfect solution that caused some other problems, but it worked well enough to make a demoable product.
We also had quite a lot of problems with Chart.js. There's some undocumented quirks to it that we had to deal with - for example, data isn't plotted on the chart unless a label for it is set.
## Accomplishments that I'm proud of
For most of us, this was the first time we'd ever created a hardware hack (and competed in a hackathon in general), so managing to create something demoable is amazing. One of our team members even managed to learn the basics of web development from scratch.
## What I learned
As a team we learned a lot this weekend - everything from how to make hardware communicate with software, the basics of developing with Arduino and how to use the Charts.js library. Two of our team member's first language isn't English, so managing to achieve this is incredible.
## What's next for PowerPlant
We think that the technology used in this prototype could have great real world applications. It's almost certainly possible to build a more stable self-contained unit that could be used commercially. | # Easy-garden
Machine Learning model to take care of your plants easily.
## Inspiration
Most of the people like having plants in their home and office, because hey are beautiful and can connect us with nature just a little bit. But most of the time we really don´t take care of them, and they could get sick. Thinking of this, a system that can monitor the health of plants and tell you if one of them got a disease could be helpful. The system needs to be capturing images at real time and then classify it in diseased or healthy, in case of a disease it can notify you or even provide a treatment for the plant.
## What it does
It is a maching learning model that takes an input image and classify it into healthy or disease, displaying the result on the screen.
## How I build it
I use datasets of plants healthy and disease found in PlantVillage and developed a machine learning model in Tensorflow using keras API, getting either healthy or diseased.
The data set consisted in 1943 images are of category diseased and 1434 images are of category healthy. The size of each image is different so the image dimension. Most of the images are in jpeg but also contains some images in .png and gif.
To feed the maching learning model, it was needed to convert each pixel of the RGB color images to a pixel with value between 0 and 1, and resize all the images to a dimension of 170 x 170.
I use Tensorflow to feed the data to neural network, and created 3 datasets with different distributions of data, Training: 75%, Valid: 15% and Testing: 10%.
## Challenge I ran into
Testing a few differents models of convolution neural networks, there were so many different results and was a little difficult to adapt to another architecture at first, ending with the model Vgg16, that was pre-trained on imagenet but we still change the architecture a little bit it was posible to retrain the model just a bit before it ends.
App building continue to be a challenge but I have learned a lot about it, since I has no experience on that, and trying to combine it with AR was very difficult.
## What I learned
I learned a lot more neural networks models that haven't used before as well as some API's very useful to develop the idea, some shortcuts to display data and a lot about plant diseases. I learn some basic things about Azure and Kinvy platforms. | winning |
## Inspiration
* New ways of interacting with games (while VR is getting popular, there is not anything that you can play without a UI right now)
* Fully text-based game from the 80's
* Mental health application of choose your own adventure games
## What it does
* Natural language processing using Alexa
* Dynamic game-play based on choices that user makes
* Integrates data into
## How I built it
* Amazon Echo (Alexa)
* Node.js
* D3.js
## Challenges I ran into
* Visualizing the data from the game in a meaningful and interesting way as well as integrating that into the mental health theme
* Story-boarding (i.e. coming up with a short, sweet, and interesting plot that would get the message of our project across)
## Accomplishments that I'm proud of
* Being able to finish a demo-able project that we can further improve in the future; all within 36 hours
* Using new technologies like NLP and Alexa
* Working with a group of awesome developers and designers from all across the U.S. and the world
## What I learned
* I learned how to pick and choose the most appropriate APIs and libraries to accomplish the project at hand
* How to integrate the APIs into our project in a meaningful way to make UX interesting and innovative
* More experience with different JavaScript frameworks
## What's next for Sphinx
* Machine learning or AI integration in order to make a more versatile playing experience | ### Friday 7PM: Setting Things into Motion 🚶
>
> *Blast to the past - for everyone!*
>
>
>
ECHO enriches the lives of those with memory-related issues through reminiscence therapy. By recalling beloved memories from their past, those with dementia, Alzheimer’s and other cognitive conditions can restore their sense of continuity, rebuild neural pathways, and find fulfillment in the comfort of nostalgia. ECHO enables an AI-driven analytical approach to find insights into a patient’s emotions and recall, so that caregivers and family are better-equipped to provide.
### Friday 11PM: Making Strides 🏃♂️
>
> *The first step, our initial thoughts*
>
>
>
When it came to wrangling the frontend, we kept our users in mind and knew our highest priority was creating an application that was intuitive and easy to understand. We designed with the idea that ECHO could be seamlessly integrated into everyday life in mind.
### Saturday 9AM: Tripping 🤺
>
> *Whoops! Challenges and pitfalls*
>
>
>
As with any journey, we faced our fair share of obstacles and roadblocks on the way. While there were no issues finding the right APIs and tools to accomplish what we wanted, we had to scour different forums and tutorials to figure out how we could integrate those features. We built ECHO with Next.js and deployed on Vercel (and in the process, spent quite a few credits spamming a button while the app was frozen..!).
Backend was fairly painless, but frontend was a different story. Our vision came to life on Figma and was implemented with HTML/CSS on the ol’ reliable, VSC. We were perhaps a little too ambitious with the mockup and so removed a couple of the bells and whistles.
### Saturday 4PM: Finding Our Way 💪
>
> *One foot in front of the other - learning new things*
>
>
>
From here on out, we were in entirely uncharted territory and had to read up on documentation. Our AI, the Speech Prosody model from Hume, allowed us to take video input from a user and analyze a user’s tone and face in real-time. We learned how to use websockets for streaming APIs for those quick insights, as opposed to a REST API which (while more familiar to us) would have been more of a handful due to our real-time analysis goals.
### Saturday 10PM: What Brand Running Shoes 👟
>
> *Our tech stack*
>
>
>
Nikes.
Apart from the tools mentioned above, we have to give kudos to the platforms that we used for the safe-keeping of assets. To handle videos, we linked things up to Cloudinary so that users can play back old memories and reminisce, and used Postgres for data storage.
### Sunday 7AM: The Final Stretch 🏁
>
> *The power of friendship*
>
>
>
As a team composed of two UWaterloo CFM majors and a WesternU Engineering major, we had a lot of great ideas between us. When we put our heads together, we combined powers and developed ECHO.
Plus, Ethan very graciously allowed us to marathon this project at his house! Thank you for the dumplings.
### Sunday Onward: After Sunrise 🌅
>
> *Next horizons*
>
>
>
With this journey concluded, ECHO’s next great adventure will come in the form of adding cognitive therapy activities to stimulate the memory in a different way, as well as AI transcript composition (along with word choice analysis) for our recorded videos. | ## Inspiration
People struggle to work effectively in a home environment, so we were looking for ways to make it more engaging. Our team came up with the idea for InspireAR because we wanted to design a web app that could motivate remote workers be more organized in a fun and interesting way. Augmented reality seemed very fascinating to us, so we came up with the idea of InspireAR.
## What it does
InspireAR consists of the website, as well as a companion app. The website allows users to set daily goals at the start of the day. Upon completing all of their goals, the user is rewarded with a 3-D object that they can view immediately using their smartphone camera. The user can additionally combine their earned models within the companion app. The app allows the user to manipulate the objects they have earned within their home using AR technology. This means that as the user completes goals, they can build their dream office within their home using our app and AR functionality.
## How we built it
Our website is implemented using the Django web framework. The companion app is implemented using Unity and Xcode. The AR models come from echoAR. Languages used throughout the whole project consist of Python, HTML, CSS, C#, Swift and JavaScript.
## Challenges we ran into
Our team faced multiple challenges, as it is our first time ever building a website. Our team also lacked experience in the creation of back end relational databases and in Unity. In particular, we struggled with orienting the AR models within our app. Additionally, we spent a lot of time brainstorming different possibilities for user authentication.
## Accomplishments that we're proud of
We are proud with our finished product, however the website is the strongest component. We were able to create an aesthetically pleasing , bug free interface in a short period of time and without prior experience. We are also satisfied with our ability to integrate echoAR models into our project.
## What we learned
As a team, we learned a lot during this project. Not only did we learn the basics of Django, Unity, and databases, we also learned how to divide tasks efficiently and work together.
## What's next for InspireAR
The first step would be increasing the number and variety of models to give the user more freedom with the type of space they construct. We have also thought about expanding into the VR world using products such as Google Cardboard, and other accessories. This would give the user more freedom to explore more interesting locations other than just their living room. | losing |
## Inspiration:
We were inspired by the inconvenience faced by novice artists creating large murals, who struggle to use reference images for guiding their work. It can also help give confidence to young artists who need a confidence boost and are looking for a simple way to replicate references.
## What it does
An **AR** and **CV** based artist's aid that enables easy image tracing and color blocking guides (almost like "paint-by-numbers"!)
It achieves this by allowing the user to upload an image of their choosing, which is then processed into its traceable outlines and dominant colors. These images are then displayed in the real world on a surface of the artist's choosing, such as paper or a wall.
## How we built it
The base for the image processing functionality (edge-detection and color blocking) were **Python, OpenCV, numpy** and the **K-means** grouping algorithm. The image processing module was hosted on **Firebase**.
The end-user experience was driven using **Unity**. The user uploads an image to the app. The image is ported to Firebase, which then returns the generated images. We used the Unity engine along with **ARCore** to implement surface detection and virtually position the images in the real world. The UI was also designed through packages from Unity.
## Challenges we ran into
Our biggest challenge was the experience level of our team with the tech stack we chose to use. Since we were all new to Unity, we faced several bugs along the way and had to slowly learn our way through the project.
## Accomplishments that we're proud of
We are very excited to have demonstrated the accumulation of our image processing knowledge and to make contributions to Git.
## What we learned
We learned that our aptitude lies lower level, in robust languages like C++, as opposed to using pre-built systems to assist development, such as Unity. In the future, we may find easier success building projects to refine our current tech stacks as opposed to expanding them.
## What's next for [AR]t
After Hack the North, we intend to continue the project using C++ as the base for AR, which is more familiar to our team and robust. | ## 💡 Our Mission
Create an intuitive game but tough game that gets its players to challenge their speed & accuracy. We wanted to incorporate an active element to the game so that it can be played guilt free!
## 🧠 What it does
It shows a sequence of scenes before beginning the game, including the menu and instructions. After a player makes it past the initial screens, the game begins where a wall with a cutout starts moving towards the player. The player can see both the wall and themselves positioned on the environment, as the wall appears closer, the player must mimic the shape of the cutout to make it past the wall. The more walls you pass, the faster and tougher the walls get. The highest score with 3 lives wins!
## 🛠️ How we built it
We built the model to detect the person with their webcam using Movenet and built a custom model using Angle Heuristics to estimate similarity between users and expected pose. We built the game using React for the front end, designed the scenes and assets and built the backend using python flask.
## 🚧 Challenges we ran into
We were excited about trying out Unity, so we spent a around 10-12 trying to work with it. However, it was a lot more complex than we initially thought, and decided to pivot to building the UI using react towards the end of the first day. Although we became lot more familiar with working with Unity, and the structure of 2D games, it proved to be more difficult than we anticipated and had to change our gameplan to build a playable game.
## 🏆 Accomplishments that we're proud of
Considering that we completely changed our tech stack at around 1AM on the second day of hacking, we are proud that we built a working product in a extremely tight timeframe.
## 📚What we learned
This was the first time working with Unity for all of us. We got a surface level understanding of working with Unity and how game developers structure their games. We also explored graphic design to custom design the walls. Finally, working with an Angles Heuristics model was interesting too.
## ❓ What's next for Wall Guys
Next steps would be improve the UI and multiplayer! | ## Inspiration'
One of our team members saw two foxes playing outside a small forest. Eager he went closer to record them, but by the time he was there, the foxes were gone. Wishing he could have recorded them or at least gotten a recording from one of the locals, he imagined a digital system in nature. With the help of his team mates, this project grew into a real application and service which could change the landscape of the digital playground.
## What it does
It is a social media and educational application, which it stores the recorded data into a digital geographic tag, which is available for the users of the app to access and playback. Different from other social platforms this application works only if you are at the geographic location where the picture was taken and the footprint was imparted. In the educational part, the application offers overlays of monuments, buildings or historical landscapes, where users could scroll through historical pictures of the exact location they are standing. The images have captions which could be used as instructional and educational and offers the overlay function, for the user to get a realistic experience of the location on a different time.
## How we built it
Lots of hours of no sleep and thousands of git-hubs push and pulls. Seen more red lines this weekend than in years put together. Used API's and tons of trial and errors, experimentation's and absurd humour and jokes to keep us alert.
## Challenges we ran into
The app did not want to behave, the API's would give us false results or like in the case of google vision, which would be inaccurate. Fire-base merging with Android studio would rarely go down without a fight. The pictures we recorded would be horizontal and load horizontal, even if taken in vertical. The GPS location and AR would cause issues with the server, and many more we just don't want to recall...
## Accomplishments that we're proud of
The application is fully functional and has all the basic features we planned it to have since the beginning. We got over a lot of bumps on the road and never gave up. We are proud to see this app demoed at Penn Apps XX.
## What we learned
Fire-base from very little experience, working with GPS services, recording Longitude and Latitude from the pictures we taken to the server, placing digital tags on a spacial digital map, using map box. Working with the painful google vision to analyze our images before being available for service and located on the map.
## What's next for Timelens
Multiple features which we would love to have done at Penn Apps XX but it was unrealistic due to time constraint. New ideas of using the application in wider areas in daily life, not only in education and social networks. Creating an interaction mode between AR and the user to have functionality in augmentation. | losing |
## Inspiration
There are many scary things in the world ranging from poisonous spiders to horrifying ghosts, but none of these things scare people more than the act of public speaking. Over 75% of humans suffer from a fear of public speaking but what if there was a way to tackle this problem? That's why we created Strive.
## What it does
Strive is a mobile application that leverages voice recognition and AI technologies to provide instant actionable feedback in analyzing the voice delivery of a person's presentation. Once you have recorded your speech Strive will calculate various performance variables such as: voice clarity, filler word usage, voice speed, and voice volume. Once the performance variables have been calculated, Strive will then render your performance variables in an easy-to-read statistic dashboard, while also providing the user with a customized feedback page containing tips to improve their presentation skills. In the settings page, users will have the option to add custom filler words that they would like to avoid saying during their presentation. Users can also personalize their speech coach for a more motivational experience. On top of the in-app given analysis, Strive will also send their feedback results via text-message to the user, allowing them to share/forward an analysis easily.
## How we built it
Utilizing the collaboration tool Figma we designed wireframes of our mobile app. We uses services such as Photoshop and Gimp to help customize every page for an intuitive user experience. To create the front-end of our app we used the game engine Unity. Within Unity we sculpt each app page and connect components to backend C# functions and services. We leveraged IBM Watson's speech toolkit in order to perform calculations of the performance variables and used stdlib's cloud function features for text messaging.
## Challenges we ran into
Given our skillsets from technical backgrounds, one challenge we ran into was developing out a simplistic yet intuitive user interface that helps users navigate the various features within our app. By leveraging collaborative tools such as Figma and seeking inspiration from platforms such as Dribbble, we were able to collectively develop a design framework that best suited the needs of our target user.
## Accomplishments that we're proud of
Creating a fully functional mobile app while leveraging an unfamiliar technology stack to provide a simple application that people can use to start receiving actionable feedback on improving their public speaking skills. By building anyone can use our app to improve their public speaking skills and conquer their fear of public speaking.
## What we learned
Over the course of the weekend one of the main things we learned was how to create an intuitive UI, and how important it is to understand the target user and their needs.
## What's next for Strive - Your Personal AI Speech Trainer
* Model voices of famous public speakers for a more realistic experience in giving personal feedback (using the Lyrebird API).
* Ability to calculate more performance variables for a even better analysis and more detailed feedback | ## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front of a mirror could work, but it does not live up to the real environment of a public speaker. As a result, public speaking is dreaded not only for the act itself, but also because it's *difficult to feel ready*. If there was an efficient way of ensuring you aced a presentation, the negative connotation associated with them would no longer exist . That is why we have created Speech Simulator, a VR web application used for practice public speaking. With it, we hope to alleviate the stress that comes with speaking in front of others.
## What it does
Speech Simulator is an easy to use VR web application. Simply login with discord, import your script into the site from any device, then put on your VR headset to enter a 3D classroom, a common location for public speaking. From there, you are able to practice speaking. Behind the user is a board containing your script, split into slides, emulating a real powerpoint styled presentation. Once you have run through your script, you may exit VR, where you will find results based on the application's recording of your presentation. From your talking speed to how many filler words said, Speech Simulator will provide you with stats based on your performance as well as a summary on what you did well and how you can improve. Presentations can be attempted again and are saved onto our database. Additionally, any adjustments to the presentation templates can be made using our editing feature.
## How we built it
Our project was created primarily using the T3 stack. The stack uses **Next.js** as our full-stack React framework. The frontend uses **React** and **Tailwind CSS** for component state and styling. The backend utilizes **NextAuth.js** for login and user authentication and **Prisma** as our ORM. The whole application was type safe ensured using **tRPC**, **Zod**, and **TypeScript**. For the VR aspect of our project, we used **React Three Fiber** for rendering **Three.js** objects in, **React XR**, and **React Speech Recognition** for transcribing speech to text. The server is hosted on Vercel and the database on **CockroachDB**.
## Challenges we ran into
Despite completing, there were numerous challenges that we ran into during the hackathon. The largest problem was the connection between the web app on computer and the VR headset. As both were two separate web clients, it was very challenging to communicate our sites' workflow between the two devices. For example, if a user finished their presentation in VR and wanted to view the results on their computer, how would this be accomplished without the user manually refreshing the page? After discussion between using web-sockets or polling, we went with polling + a queuing system, which allowed each respective client to know what to display. We decided to use polling because it enables a severless deploy and concluded that we did not have enough time to setup websockets. Another challenge we had run into was the 3D configuration on the application. As none of us have had real experience with 3D web applications, it was a very daunting task to try and work with meshes and various geometry. However, after a lot of trial and error, we were able to manage a VR solution for our application.
## What we learned
This hackathon provided us with a great amount of experience and lessons. Although each of us learned a lot on the technological aspect of this hackathon, there were many other takeaways during this weekend. As this was most of our group's first 24 hour hackathon, we were able to learn to manage our time effectively in a day's span. With a small time limit and semi large project, this hackathon also improved our communication skills and overall coherence of our team. However, we did not just learn from our own experiences, but also from others. Viewing everyone's creations gave us insight on what makes a project meaningful, and we gained a lot from looking at other hacker's projects and their presentations. Overall, this event provided us with an invaluable set of new skills and perspective.
## What's next for VR Speech Simulator
There are a ton of ways that we believe can improve Speech Simulator. The first and potentially most important change is the appearance of our VR setting. As this was our first project involving 3D rendering, we had difficulty adding colour to our classroom. This reduced the immersion that we originally hoped for, so improving our 3D environment would allow the user to more accurately practice. Furthermore, as public speaking infers speaking in front of others, large improvements can be made by adding human models into VR. On the other hand, we also believe that we can improve Speech Simulator by adding more functionality to the feedback it provides to the user. From hand gestures to tone of voice, there are so many ways of differentiating the quality of a presentation that could be added to our application. In the future, we hope to add these new features and further elevate Speech Simulator. | ## Inspiration
Public speaking is a critical skill in our lives. The ability to communicate effectively and efficiently is a very crucial, yet difficult skill to hone. For a few of us on the team, having grown up competing in public speaking competitions, we understand too well the challenges that individuals looking to improve their public speaking and presentation skills face. Building off of our experience of effective techniques and best practices and through analyzing the speech patterns of very well-known public speakers, we have designed a web app that will target weaker points in your speech and identify your strengths to make us all better and more effective communicators.
## What it does
By analyzing speaking data from many successful public speakers from a variety industries and backgrounds, we have established relatively robust standards for optimal speed, energy levels and pausing frequency during a speech. Taking into consideration the overall tone of the speech, as selected by the user, we are able to tailor our analyses to the user's needs. This simple and easy to use web application will offer users insight into their overall accuracy, enunciation, WPM, pause frequency, energy levels throughout the speech, error frequency per interval and summarize some helpful tips to improve their performance the next time around.
## How we built it
For the backend, we built a centralized RESTful Flask API to fetch all backend data from one endpoint. We used Google Cloud Storage to store files greater than 30 seconds as we found that locally saved audio files could only retain about 20-30 seconds of audio. We also used Google Cloud App Engine to deploy our Flask API as well as Google Cloud Speech To Text to transcribe the audio. Various python libraries were used for the analysis of voice data, and the resulting response returns within 5-10 seconds. The web application user interface was built using React, HTML and CSS and focused on displaying analyses in a clear and concise manner. We had two members of the team in charge of designing and developing the front end and two working on the back end functionality.
## Challenges we ran into
This hackathon, our team wanted to focus on creating a really good user interface to accompany the functionality. In our planning stages, we started looking into way more features than the time frame could accommodate, so a big challenge we faced was firstly, dealing with the time pressure and secondly, having to revisit our ideas many times and changing or removing functionality.
## Accomplishments that we're proud of
Our team is really proud of how well we worked together this hackathon, both in terms of team-wide discussions as well as efficient delegation of tasks for individual work. We leveraged many new technologies and learned so much in the process! Finally, we were able to create a good user interface to use as a platform to deliver our intended functionality.
## What we learned
Following the challenge that we faced during this hackathon, we were able to learn the importance of iteration within the design process and how helpful it is to revisit ideas and questions to see if they are still realistic and/or relevant. We also learned a lot about the great functionality that Google Cloud provides and how to leverage that in order to make our application better.
## What's next for Talko
In the future, we plan on continuing to develop the UI as well as add more functionality such as support for different languages. We are also considering creating a mobile app to make it more accessible to users on their phones. | winning |
## Motivation
Our motivation was a grand piano that has sat in our project lab at SFU for the past 2 years. The piano was Richard Kwok's grandfathers friend and was being converted into a piano scroll playing piano. We had an excessive amount of piano scrolls that were acting as door stops and we wanted to hear these songs from the early 20th century. We decided to pursue a method to digitally convert the piano scrolls into a digital copy of the song.
The system scrolls through the entire piano scroll and uses openCV to convert the scroll markings to individual notes. The array of notes are converted in near real time to an MIDI file that can be played once complete.
## Technology
The scrolling through the piano scroll utilized a DC motor control by arduino via an H-Bridge that was wrapped around a Microsoft water bottle. While the notes were recorded using openCV via a Raspberry Pi 3, which was programmed in python. The result was a matrix representing each frame of notes from the Raspberry Pi camera. This array was exported to an MIDI file that could then be played.
## Challenges we ran into
The openCV required a calibration method to assure accurate image recognition.
The external environment lighting conditions added extra complexity in the image recognition process.
The lack of musical background in the members and the necessity to decrypt the piano scroll for the appropriate note keys was an additional challenge.
The image recognition of the notes had to be dynamic for different orientations due to variable camera positions.
## Accomplishments that we're proud of
The device works and plays back the digitized music.
The design process was very fluid with minimal set backs.
The back-end processes were very well-designed with minimal fluids.
Richard won best use of a sponsor technology in a technical pickup line.
## What we learned
We learned how piano scrolls where designed and how they were written based off desired tempo of the musician.
Beginner musical knowledge relating to notes, keys and pitches. We learned about using OpenCV for image processing, and honed our Python skills while scripting the controller for our hack.
As we chose to do a hardware hack, we also learned about the applied use of circuit design, h-bridges (L293D chip), power management, autoCAD tools and rapid prototyping, friction reduction through bearings, and the importance of sheave alignment in belt-drive-like systems. We also were exposed to a variety of sensors for encoding, including laser emitters, infrared pickups, and light sensors, as well as PWM and GPIO control via an embedded system.
The environment allowed us to network with and get lots of feedback from sponsors - many were interested to hear about our piano project and wanted to weigh in with advice.
## What's next for Piano Men
Live playback of the system | ## Inspiration
In the theme of sustainability, we noticed that a lot of people don't know what's recyclable. Some people recycle what shouldn't be and many people recycle much less than they could be. We wanted to find a way to improve recycling habits while also incentivizing people to recycle more. Cyke, pronounced psych,(psyched about recycling) was the result.
## What it does
Psych is a platform to get users in touch with local recycling facilities, to give recycling facilities more publicity, and to reward users for their good actions.
**For the user:** When a user creates an account for Cyke, their location is used to tell them what materials are able to be recycled and what materials aren't. Users are given a Cyke Card which has their rank. When a user recycles, the amount they recycled is measured and reported to Cyke, which stores that data in our CochroachDB database. Then, based on revenue share from recycling plants, users would be monetarily rewarded. The higher the person's rank, the more they receive for what they recycle. There are four ranks, ranging from "Learning" to "Superstar."
\**For Recycling Companies: \** For a recycling company to be listed on our website, they must agree to a revenue share corresponding to the amount of material recycled (can be discussed). This would be in return for guiding customers towards them and increasing traffic and recycling quality. Cyke provides companies with an overview of how well recycling is going: statistics over the past month or more, top individual contributors to their recycling plant, and an impact score relating to how much social good they've done by distributing money to users and charities. Individual staff members can also be invited to the Cyke page to view these statistics and other more detailed information.
## How we built it
Our site uses a **Node.JS** back-end, with **ejs** for the server-side rendering of pages. The backend connects to **CockroachDB** to store user and company information, recycling transactions, and a list of charities and how much has been donated to each.
## Challenges we ran into
We ran into challenges mostly with CockroachDB, one of us was able to successfully create a cluster and connect it via the MacOS terminal, however when it came to connecting it to our front-end there is existed a lot of issues with getting the right packages for the linux CLI as well as for connecting via our connection string. We spent quite a few hours on this as using CockroachDB serverless was an essential part of hosting info about our recyclers, recycling companies, transactions, and charities.
## Accomplishments that we're proud of
We’re proud of getting CockroachDB to function properly. For two of the three members on the team this was our first time using a Node.js back-end, so it was difficult and rewarding to complete. On top of being proud of getting our SQL database off the ground, we’re proud of our design. We worked a lot on the colors. We are also proud of using the serverless form of CockroachDB so our compute cluster is hosted google's cloud platform (GCP).
## What we've learned
Through some of our greatest challenges came some of our greatest learning advances. Through toiling through the CockroachDB and SQL table, of which none of us had previous experience with before, we learned a lot about environment variables and how to use express and pg driver to connect front-end and back-end elements.
## What's next for Cyke
To scale our solution, the next steps involve increasing personalization aspects of our application. For users that means, adding in capabilities that highlight local charities for users to donate to, and locale based recycling information. On the company side, there are optimizations that can be made around the information that we provide them, thus improving the impact score to consider more factors like how consistent their users are. | ## Inspiration
We were inspired by our shared love of dance. We knew we wanted to do a hardware hack in the healthcare and accessibility spaces, but we weren't sure of the specifics. While we were talking, we mentioned how we enjoyed dance, and the campus DDR machine was brought up. We decided to incorporate that into our hardware hack with this handheld DDR mat!
## What it does
The device is oriented so that there are LEDs and buttons that are in specified directions (i.e. left, right, top, bottom) and the user plays a song they enjoy next to the sound sensor that activates the game. The LEDs are activated randomly to the beat of the song and the user must click the button next to the lit LED.
## How we built it
The team prototyped the device for the Arduino UNO with the initial intention of using a sound sensor as the focal point and slowly building around it, adding features where need be. The team was only able to add three features to the device due to the limited time span of the event. The first feature the team attempted to add was LEDs that reacted to the sound sensor, so it would activate LEDs to the beat of a song. The second feature the team attempted to add was a joystick, however, the team soon realized that the joystick was very sensitive and it was difficult to calibrate. It was then replaced by buttons that operated much better and provided accessible feedback for the device. The last feature was an algorithm that added a factor of randomness to LEDs to maximize the "game" aspect.
## Challenges we ran into
There was definitely no shortage of errors while working on this project. Working with the hardware on hand was difficult, the team was nonplussed whether the issue on hand stemmed from the hardware or an error within the code.
## Accomplishments that we're proud of
The success of the aforementioned algorithm along with the sound sensor provided a very educational experience for the team. Calibrating the sound sensor and developing the functional prototype gave the team the opportunity to utilize prior knowledge and exercise skills.
## What we learned
The team learned how to work within a fast-paced environment and experienced working with Arduino IDE for the first time. A lot of research was dedicated to building the circuit and writing the code to make the device fully functional. Time was also wasted on the joystick due to the fact the values outputted by the joystick did not align with the one given by the datasheet. The team learned the importance of looking at recorded values instead of blindly following the datasheet.
## What's next for Happy Fingers
The next steps for the team are to develop the device further. With the extra time, the joystick method could be developed and used as a viable component. Working on delay on the LED is another aspect, doing client research to determine optimal timing for the game. To refine the game, the team is also thinking of adding a scoring system that allows the player to track their progress through the device recording how many times they clicked the LED at the correct time as well as a buzzer to notify the player they had clicked the incorrect button. Finally, in a true arcade fashion, a display that showed the high score and the player's current score could be added. | partial |
## Inspiration
As lane-keep assist and adaptive cruise control features are becoming more available in commercial vehicles, we wanted to explore the potential of a dedicated collision avoidance system
## What it does
We've created an adaptive, small-scale collision avoidance system that leverages Apple's AR technology to detect an oncoming vehicle in the system's field of view and respond appropriately, by braking, slowing down, and/or turning
## How we built it
Using Swift and ARKit, we built an image-detecting app which was uploaded to an iOS device. The app was used to recognize a principal other vehicle (POV), get its position and velocity, and send data (corresponding to a certain driving mode) to an HTTP endpoint on Autocode. This data was then parsed and sent to an Arduino control board for actuating the motors of the automated vehicle
## Challenges we ran into
One of the main challenges was transferring data from an iOS app/device to Arduino. We were able to solve this by hosting a web server on Autocode and transferring data via HTTP requests. Although this allowed us to fetch the data and transmit it via Bluetooth to the Arduino, latency was still an issue and led us to adjust the danger zones in the automated vehicle's field of view accordingly
## Accomplishments that we're proud of
Our team was all-around unfamiliar with Swift and iOS development. Learning the Swift syntax and how to use ARKit's image detection feature in a day was definitely a proud moment. We used a variety of technologies in the project and finding a way to interface with all of them and have real-time data transfer between the mobile app and the car was another highlight!
## What we learned
We learned about Swift and more generally about what goes into developing an iOS app. Working with ARKit has inspired us to build more AR apps in the future
## What's next for Anti-Bumper Car - A Collision Avoidance System
Specifically for this project, solving an issue related to file IO and reducing latency would be the next step in providing a more reliable collision avoiding system. Hopefully one day this project can be expanded to a real-life system and help drivers stay safe on the road | ## Inspiration
As OEMs(Original equipment manufacturers) and consumers keep putting on brighter and brighter lights, this can be blinding for oncoming traffic. Along with the fatigue and difficulty judging distance, it becomes increasingly harder to drive safely at night. Having an extra pair of night vision would be essential to protect your eyes and that's where the NCAR comes into play. The Nighttime Collision Avoidance Response system provides those extra sets of eyes via an infrared camera that uses machine learning to classify obstacles in the road that are detected and projects light to indicate obstacles in the road and allows safe driving regardless of the time of day.
## What it does
* NCAR provides users with an affordable wearable tech that ensures driver safety at night
* With its machine learning model, it can detect when humans are on the road when it is pitch black
* The NCAR alerts users of obstacles on the road by projecting a beam of light onto the windshield using the OLED Display
* If the user’s headlights fail, the infrared camera can act as a powerful backup light
## How we built it
* Machine Learning Model: Tensorflow API
* Python Libraries: OpenCV, PyGame
* Hardware: (Raspberry Pi 4B), 1 inch OLED display, Infrared Camera
## Challenges we ran into
* Training machine learning model with limited training data
* Infrared camera breaking down, we had to use old footage of the ml model
## Accomplishments that we're proud of
* Implementing a model that can detect human obstacles from 5-7 meters from the camera
* building a portable design that can be implemented on any car
## What we learned
* Learned how to code different hardware sensors together
* Building a Tensorflow model on a Raspberry PI
* Collaborating with people with different backgrounds, skills and experiences
## What's next for NCAR: Nighttime Collision Avoidance System
* Building a more custom training model that can detect and calculate the distances of the obstacles to the user
* A more sophisticated system of alerting users of obstacles on the path that is easy to maneuver
* Be able to adjust the OLED screen with a 3d printer to display light in a more noticeable way | ## Inspiration
We noticed one of the tracks involved creating a better environment for cities through the use of technology, also known as making our cities 'smarter.' We observed in places like Boston & Cambridge, there are many intersections with unsafe areas for pedestrians and drivers. **Furthermore, 50% of all accidents occur at Intersections, according to the Federal Highway Administration**. This can prove to be enhanced with careless drivers, lack of stop signs, confusing intersections, and more.
## What it does
This project uses a Raspberry Pi to predict potential dangerous driving situations. If we deduce that a potential collision can occur, our prototype will start creating a 'beeping' sound loud enough to gain the attention of those surrounding the scene. Ideally, our prototype will be attached onto traffic poles, similar to most traffic cameras.
## How we built it
We utilized a popular Computer Vision library known as OpenCV, in order to visualize our problem in Python. A demo of our prototype is shown in the GitHub repository, with a beeping sound occurring when the program finds a potential collision.
Our demonstration is built using Raspberry Pi & a Logitech Camera. Using Artificial Intelligence, we capture the current positions of cars, and calculate their direction and velocity. Using this information, we predicted potential close calls and accidents. In such a case, we make a beeping sound simulating a alarm to notify drivers and surrounding participants.
## Challenges we ran into
One challenge we ran into was detecting the car positions based on the frames in a reliable fashion.
A second challenge was calculating the speed and direction of vehicles based on the present frame & the previous frames.
A third challenge included being able to determine if two lines are crossing based on their respective starting and ending coordinates. Solving this proved vital in order to make sure we alerted those in the vicinity in a quick and proper manner.
## Accomplishments that we're proud of
We are proud that we were able to adapt this project to multiple levels. Even putting the camera up to a screen of a real collision video off Youtube resulted in the prototype alerting us of a potential crash **before the accident occurred**. We're also proud of the fact that we were able to abstract the hardware and make the layout of the final prototype aesthetically pleasing.
## What we learned
We learned about the potential of smart intersections, and the benefits it can provide in terms of safety to an ever advancing society. Surely, our implementation will be able to reduce the 50% of collisions that occur at intersections by making those around the area more aware of potential dangerous collisions. We also learned a lot about working with openCV and Camera Vision. This was definitely a unique experience, and we were even able to walk around the surrounding Harvard campus, trying to get good footage to test our model on.
## What's next for Traffic Eye
We think we could make a better prediction model, as well as creating a weather resilient model to account for varying types of weather throughout the year. We think a prototype like this can be scaled and placed on actual roads given enough R&D is done. This definitely can help our cities advance with rising capabilities in Artificial Intelligence & Computer Vision! | winning |
## Inspiration
Bill - "Blindness is a major problem today and we hope to have a solution that takes a step in solving this"
George - "I like engineering"
We hope our tool gives nonzero contribution to society.
## What it does
Generates a description of a scene and reads the description for visually impaired people. Leverages CLIP/recent research advancements and own contributions to solve previously unsolved problem (taking a stab at the unsolved **generalized object detection** problem i.e. object detection without training labels)
## How we built it
SenseSight consists of three modules: recorder, CLIP engine, and text2speech.
### Pipeline Overview
Once the user presses the button, the recorder beams it to the compute cluster server. The server runs a temporally representative video frame through the CLIP engine. The CLIP engine is our novel pipeline that emulates human sight to generate a scene description. Finally, the generated description is sent back to the user side, where the text is converted to audio to be read.
[Figures](https://docs.google.com/presentation/d/1bDhOHPD1013WLyUOAYK3WWlwhIR8Fm29_X44S9OTjrA/edit?usp=sharing)
### CLIP
CLIP is a model proposed by OpenAI that maps images to embeddings via an image encoder and text to embeddings via a text encoder. Similiar (image, text) pairs will have a higher dot product.
### Image captioning with CLIP
We can map the image embeddings to text embeddings via a simple MLP (since image -> text can be thought of as lossy compression). The mapped embedding is fed into a transformer decoder (GPT2) that is fine-tuned to produce text. This process is called CLIP text decoder.
### Recognition of Key Image Areas
The issue with Image captioning the fed input is that an image is composed of smaller images. The CLIP text decoder is trained on only images containing one single content (e.g. ImageNet/MS CoCo images). We need to extract the crops of the objects in the image and then apply CLIP text decoder. This process is called **generalized object detection**
**Generalized object detection** is unsolved. Most object detection involves training with labels. We propose a viable approach. We sample crops in the scene, just like how human eyes dart around their view. We evaluate the fidelity of these crops i.e. how much information/objects the crop contains by embedding the crop using clip and then searching a database of text embeddings. The database is composed of noun phrases that we extracted. The database can be huge, so we rely on SCANN (Google Research), a pipeline that uses machine learning based vector similarity search.
We then filter all subpar crops. The remaining crops are selected using an algorithm that tries to maximize the spatial coverage of k crop. To do so, we sample many sets of k crops and select the set with the highest all pairs distance.
## Challenges we ran into
The hackathon went smoothly, except for the minor inconvenience of getting the server + user side to run in sync.
## Accomplishments that we're proud of
Platform replicates the human visual process with decent results.
Subproblem is generalized object detection-- proposed approach involving CLIP embeddings and fast vector similarity search
Got hardware + local + server (machine learning models on MIT cluster) + remote apis to work in sync
## What's next for SenseSight
Better clip text decoder. Crops tend to generate redundant sentences, so additional pruning is needed. Use GPT3 to remove the redundancy and make the speech flower.
Realtime can be accomplished by using real networking protocols instead of scp + time.sleep hacks. To accelerate inference on crops, we can do multi GPU.
## Fun Fact
The logo is generated by DALL-E :p | ## Inspiration
The idea was to help people who are blind, to be able to discretely gather context during social interactions and general day-to-day activities
## What it does
The glasses take a picture and analyze them using Microsoft, Google, and IBM Watson's Vision Recognition APIs and try to understand what is happening. They then form a sentence and let the user know. There's also a neural network at play that discerns between the two dens and can tell who is in the frame
## How I built it
We took a RPi Camera and increased the length of the cable. We then made a hole in our lens of the glasses and fit it in there. We added a touch sensor to discretely control the camera as well.
## Challenges I ran into
The biggest challenge we ran into was Natural Language Processing, as in trying to parse together a human-sounding sentence that describes the scene.
## What I learned
I learnt a lot about the different vision APIs out there and creating/trainingyour own Neural Network.
## What's next for Let Me See
We want to further improve our analysis and reduce our analyzing time. | ## Inspiration
We wanted to solve a unique problem we felt was impacting many people but was not receiving enough attention. With emerging and developing technology, we implemented neural network models to recognize objects and images, and converting them to an auditory output.
## What it does
XTS takes an **X** and turns it **T**o **S**peech.
## How we built it
We used PyTorch, Torchvision, and OpenCV using Python. This allowed us to utilize pre-trained convolutional neural network models and region-based convolutional neural network models without investing too much time into training an accurate model, as we had limited time to build this program.
## Challenges we ran into
While attempting to run the Python code, the video rendering and text-to-speech were out of sync and the frame-by-frame object recognition was limited in speed by our system's graphics processing and machine-learning model implementing capabilities. We also faced an issue while trying to use our computer's GPU for faster video rendering, which led to long periods of frustration trying to solve this issue due to backwards incompatibilities between module versions.
## Accomplishments that we're proud of
We are so proud that we were able to implement neural networks as well as implement object detection using Python. We were also happy to be able to test our program with various images and video recordings, and get an accurate output. Lastly we were able to create a sleek user-interface that would be able to integrate our program.
## What we learned
We learned how neural networks function and how to augment the machine learning model including dataset creation. We also learned object detection using Python. | winning |
## Inspiration
Protogress has been developed to improve the urban planning process. As cities expand, urban planners and engineers need to have accurate data on the areas to be developed or redeveloped. To assist urban planners, Protogress is available to gather various information such as noise pollution, light intensity, and temperature to provide a better picture of the area. With its modular IoT design, it has the ability to provide low-cost preliminary surveys.
## What it does
Protogress utilizes two Arduino 101’s to realize an IoT network through various sensors to gather data on noise, light, human movement, and temperature throughout areas as small as individual homes to large areas like entire cities. The Arduinos form a network by communicating via Bluetooth Low Energy Technology. Through this network, Protogress is able to record and transmit data from our physical sensor network to the database to be displayed on a Google Maps interface.
## How It's Built
**Frontend**
The front end of the website was developed using MEAN stack to create intensity zones through a Google Maps API. It extracts the data from the Protogress Database gathered through one of our peripheral devices and uses the data on Google maps.
**Backend**
The Protogress Database uses MongoDB to store the data obtained the physical sensor network. The Central Arduino requests information from the peripheral devices, and documents the information in a Python script. In this script, the data is quantized into a value that is sensible to humans and than sent to be stored in the Protogress Database.
**Peripherals**
The Protogress IoT Network uses the Arduino 101 board to record data from its sensors and store onto our database. In our demo network, there are two Arduinos, the Sensor and Central. The Sensor will acquire constant analog signals from the sensors and is connected to the network through the built in Bluetooth Low Energy system on the Arduino. Central is connected to the internet through serial communication and a laptop. It can be set to gather information from the nearby Sensor as frequently as needed, however it is currently set request every ten seconds to minimize power consumption. Upon receiving data from the Sensor, it is recorded by a Python script to be uploaded to our database.
## Challenges
We faced several challenges when developing Protogress; Integration of google maps API with Angular, the quantiation of the sensors, and the Bluetooth communication of the Arduino.
## Accomplishments
Our greatest accomplishments were the successful quantization of sensor data, transmission of sensor data through Bluetooth Low Energy and our implementation of Google Maps API to display our data.
## What Was learned
We learned about Mean Stack development and how to incoporate it with the local host and the quantization issues with Arduino Groove kits.
## What's next for Protogress
Protogress can be modified for a variety of services, our next steps include adjustments of different sensors, creating a larger network with more devices, and developing a network that can be displayed real-time. Some applications include furthering the range of capabilities such as an pollution detector, and the possibility of permanent systems integrated with city infrastructures. This system demonstrates proof of concept and we envision Protogress to be realized with even lower cost microcontrollers and packaged in a sleek modular design.
With the addition of an air quality sensor Protogress can be used to monitor pollution emitted from heavy industrial zones. Protogress can also be used as a natural disaster sensor system with a vibration sensor or a rain sensor. With these sensors the Protogress can be placed on buildings or other structures to detect vibrations within buildings using vibration sensors or even sway of buildings. Ideally, Protogress will continue to be improved as a device made to assist in providing safety and allowing efficient development of entire communities. | ## Inspiration: Home security systems are very expensive and sometimes do not function as intended. Sometimes something simple may happen such as you forgetting the lights on at home or there may be something more drastic such as a large temperature change or even intruder. Our solution aims to be a cheap alert system that would detect three parameters and offer an alert to the user.
## What it does: Our project detects light, temperature and sounds and sends the necessary message to the user. Light sensors would be use to tell the user if they forgot their lights on and hence send an alert to the user. Temperature detection would be use to send drastic changes in temperature or sound to the user as alert messages which may include extreme cold in winter or extreme heat in summer. Sound detection would be used as a security system as it is configured to send alerts to the user once a certain decibel level is reached. Therefore very loud sounds such as breaking glass, shouting or even a gunshot may be detected and an alert sent to the user. These messages are all sent to the user's phone. If anything is wrong, there is a circuit with a red LED light that lights up whenever there is a situation. If the LED is off, the user gets no messages and everything is okay at home. Our project also associates user friendly colors with conditions for example heat is red and cold would be blue.
## How we built it: We used an Arduino as well as a Grove Kit in order to obtain sensors. These sensors were connected to the Arduino and we also attached a breadboard that would receive an input from the Arduino. We coded the entire project and uploaded it unto the chip. We then used an adapter to transfer the input from the Arduino to our phones and tested the output to ensure it worked.
## Challenges we ran into: Unfortunately there was a lack of hardware at our disposal. We wanted to implement bluetooth technology to send data to our phones without wires and even tweet weather alerts. However there was no bluetooth hardware components so we were unable to achieve this. Instead we just used an adapter to connect the arduino to our phone and show a test output. Testing was also an issue since we were not able to generate extreme cold and warm weathers so we had to change our code to test these parameters.
## Accomplishments that we're proud of: We had very little experience in using Grove Kits and were able to figure out a way to implement our project. Also we were able to change our original idea due to there being a limitation of bluetooth and WiFi shield components.
## What we learned: We learned how to use and code the sensors in a Grove Kit. We also improved our knowledge of Arduino and building circuits.
## What's next for Home Automation and Security: Future improvements and Modifications to improvements would be using bluetooth and WiFi to send twitter alerts to people on the user's contact list. In the future we may also include more components to the circuit for example installing a remote button that can contact the police in the case of there being an intruder. We may also install other types of sensors such as touch sensors that may be placed on a welcome mat or door handle during long periods away from home.
Code:
# include
# include "rgb\_lcd.h"
# include
rgb\_lcd lcd;
float temperature; //stores temperature
int lightValue; //stores light value
int soundValue; //stores sound value
bool errorTemp = false;
bool errorLight = false;
bool errorSound = false;
bool errorTempCold = false;
bool errorTempHot = false;
int lights = 0;
int cold = 0;
int hot = 0;
int intruder = 0;
const int B = 4275;
const int R0 = 100000;
const int pinTempSensor = A0;
const int pinLightSensor = A1;
const int pinSoundSensor = A2;
const int pinLEDRed = 9;
const int pinLEDGreen = 8;
void setup() {
lcd.begin(16, 2);
Serial.begin(9600);
}
void loop() {
temperature = 0;
temp(); //function that detects the temperature
light(); //function that detects light
sound(); //function that detects sounds
lightMessages(); //function that checks conditions
temperatureMessages(); //function that outputs everything to the user
ok(); //function that ensures all parameters are correctly calculated and tested
serialErrors(); //function that checks logic and sends data to output function
}
void light() {
lightValue = analogRead(pinLightSensor);
}
void sound() {
soundValue = analogRead(pinSoundSensor);
//Serial.println(soundValue);
if(soundValue > 500) {
errorSound = true;
} else {
errorSound = false;
}
}
void temp() {
int a = analogRead(pinTempSensor);
float R = 1023.0/((float)a)-1.0;
R = R0\*R;
temperature = 1.0/(log(R/R0)/B+1/298.15)-303.14; // convert to temperature via datasheet
delay(100);
}
void blinkLED() {
analogWrite(pinLEDRed, HIGH);
delay(500);
analogWrite(pinLEDRed, LOW);
delay(500);
}
void greenLED() {
analogWrite(pinLEDGreen, HIGH);
}
void screenRed() {
lcd.setRGB(255,0,0);
}
void screenBlue() {
lcd.setRGB(0,0,255);
}
void screenNormal() {
lcd.setRGB(0,50,50);
}
void serialErrors() {
if (errorSound == false) {
if (errorLight == true) {
cold = 0;
hot = 0;
intruder = 0;
if(lights == 0) {
Serial.println("Important: Lights are on at home!");
lights++;
} else {
Serial.print("");
}
} else if (errorTempCold == true) {
lights = 0;
hot = 0;
intruder = 0;
if(cold == 0) {
Serial.println("Important: The temperature at home is low!");
cold++;
} else {
Serial.print("");
}
} else if (errorTempHot == true) {
lights = 0;
cold = 0;
intruder = 0;
if(hot == 0){
Serial.println("Important: The temperature at home is high!");
hot++;
} else {
Serial.print("");
}
}
} else {
lights = 0;
cold = 0;
hot = 0;
if(intruder == 0) {
Serial.println("IMPORTANT: There was a very loud sound at home! Possible intruder.");
intruder++;
} else {
Serial.print("");
}
}
}
void ok() {
if(errorSound == false) {
if (errorTemp == false && errorLight == false) {
lcd.clear();
analogWrite(pinLEDGreen, HIGH);
lcd.setCursor(0, 0);
lcd.print("Everything is ok");
lcd.setCursor(1,1);
lcd.print("Temp = ");
lcd.print(temperature);
lcd.print("C");
screenNormal();
}
}
}
void lightMessages() {
if(lightValue > 500) {
lcd.clear();
lcd.setCursor(0, 0);
lcd.print("Lights are on!");
screenRed();
blinkLED();
errorLight = true;
} else {
errorLight = false;
}
}
void temperatureMessages() {
if (errorSound == false) {
if (temperature < 20) {
lcd.clear();
lcd.setCursor(0,1);
lcd.print("Extreme Cold!");
screenBlue();
blinkLED();
errorTemp = true;
errorTempCold = true;
errorTempHot = false;
} else if (temperature > 30) {
lcd.clear();
lcd.setCursor(0,1);
lcd.print("Extreme Heat!");
screenRed();
blinkLED();
errorTemp = true;
errorTempHot = true;
errorTempCold = false;
} else {
errorTemp = false;
errorTempHot = false;
errorTempCold = false;
}
} else {
lcd.clear();
lcd.setCursor(0,0);
lcd.print("LOUD SOUND");
lcd.setCursor(0,1);
lcd.print("DETECTED!");
screenRed();
blinkLED();
delay(5000);
if (soundValue < 500) {
errorSound = false;
} else {
errorSound = true;
}
}
} | ## Inspiration
As most of our team became students here at the University of Waterloo, many of us had our first experience living in a shared space with roommates. Without the constant nagging by parents to clean up after ourselves that we found at home and some slightly unorganized roommates, many shared spaces in our residences and apartments like kitchen counters became cluttered and unusable.
## What it does
CleanCue is a hardware product that tracks clutter in shared spaces using computer vision. By tracking unused items taking up valuable counter space and making speech and notification reminders, CleanCue encourages roommates to clean up after themselves. This product promotes individual accountability and respect, repairing relationships between roommates, and filling the need some of us have for nagging and reminders by parents.
## How we built it
The current iteration of CleanCue is powered by a Raspberry Pi with a Camera Module sending a video stream to an Nvidia CUDA enabled laptop/desktop. The laptop is responsible for running our OpenCV object detection algorithms, which enable us to log how long items are left unattended and send appropriate reminders to a speaker or notification services. We used Cohere to create unique messages with personality to make it more like a maternal figure. Additionally, we used some TTS APIs to emulate a voice of a mother.
## Challenges we ran into
Our original idea was to create a more granular product which would customize decluttering reminders based on the items detected. For example, this version of the product could detect perishable food items and make reminders to return items to the fridge to prevent food spoilage. However, the pre-trained OpenCV models that we used did not have enough variety in trained items and precision to support this goal, so we settled for this simpler version for this limited hackathon period.
## Accomplishments that we're proud of
We are proud of our planning throughout the event, which allowed us to both complete our project while also enjoying the event. Additionally, we are proud of how we broke down our tasks at the beginning, and identified what our MVP was, so that when there were problems, we knew what our core priorities were. Lastly, we are glad we submitted a working project to Hack the North!!!!
## What we learned
The core frameworks that our project is built out of were all new to the team. We had never used OpenCV or Taipy before, but had a lot of fun learning these tools. We also learned how to create improvised networking infrastructure to enable hardware prototyping in a public hackathon environment. Though not on the technical side, we also learned the importance of re-assessing if our solution actually was solving the problem we were intending to solve throughout the project and make necessary adjustments based on what we prioritized. Also, this was our first hardware hack!
## What's next for CleanCue
We definitely want to improve our prototype to be able to more accurately describe a wide array of kitchen objects, enabling us to tackle more important issues like food waste prevention. Further, we also realized that the technology in this project can also aid individuals with dementia. We would also love to explore more in the mobile app development space. We would also love to use this to notify any dangers within the kitchen, for example, a young child getting too close to the stove, or an open fire left on for a long time. Additionally, we had constraints based on hardware availability, and ideally, we would love to use an Nvidia Jetson based platform for hardware compactness and flexibility. | losing |
# nwfacts
[](https://github.com/adrianosela/nwfacts/blob/master/LICENSE)
[](https://nwfacts.tech)
The ultimate anti-bias tool for browsing the news.
## Contents
* [Aim and Motivations](#project-aim-and-motivations)
* [High Level Design](#design-specification)
* [Monetization](#means-to-monetization)
## Project Aim and Motivations
All humans are susceptible to a large number of well-understood [congnitive biases](https://en.wikipedia.org/wiki/List_of_cognitive_biases). These biases ultimately impact how we see and understand the world.
This is an [nwHacks](https://www.nwhacks.io/) 2020 project which aims to empower everyone to browse news articles consciously, scoring sources for measurable bias indicators such as sensational language and non-neutral sentiment.
Our final product is the result of the following secondary goals:
* Create something simple that makes the world a slightly better place by fighting misinformation, aligning with [Mozilla's campaign](https://foundation.mozilla.org/en/campaigns/eu-misinformation/)
* Explore the use of new technologies
+ [StdLib](https://stdlib.com/)'s AutoCode feature (in beta testing at the moment)
+ Google Cloud Platform's [Cloud Functions](https://cloud.google.com/functions/)
+ Google Cloud Platform's [Natural Language](https://cloud.google.com/natural-language/) processing
+ Delegating and managing DNS for multiple domains with [Domain.com](https://domain.com)
* Leverage team members' (very distinct) skills without having to settle for a single programming language by employing a microservice-like architecture, where different components are fully isolated and modular
* Take a shot at winning prizes! We have focused on featured challenges from Google Cloud, StdLib, and Domain.com
## Design Specification
### **System Architecture Diagram:**
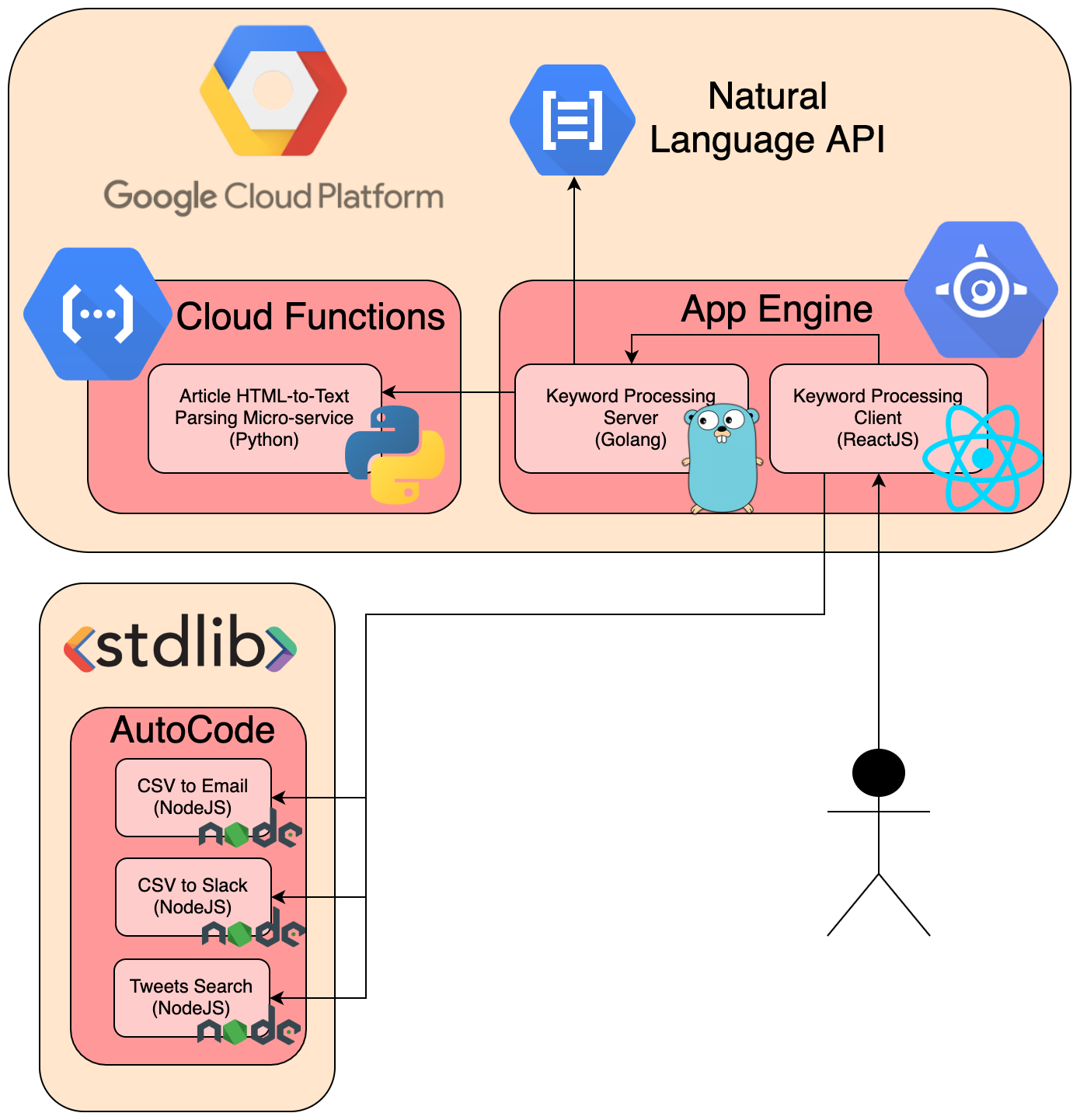
### **Components Specification:**
* **Keyword Processing Server (Golang)**
+ Receives keyword queries from HTTP clients
+ Fetches relevant news article URLs using the free [NewsAPI](https://newsapi.org/)
+ Parses articles' contents using our homegrown article-parsing Cloud Function
+ Runs several algorithmic and integrated third-party API bias-measuring functions (mostly [Natural Language Processing](https://en.wikipedia.org/wiki/Natural_language_processing) which gives us metrics that can help us understand the legitimacy, intent, and biases associated with a piece of text)
+ Returns article metadata along with relevant metric scores back to the client
+ \*Caches article results by URL due to the expensive nature of text and ML processing
* **Keyword Processing Client (ReactJS)**
+ Landing page style UI with a simple keyword search
+ Styled cards where each card contains releavant metadata and bias-metrics for a single article
+ Processing results export-to-CSV functionality
* **Google Cloud Function: Article HTML-to-Text Parsing (Python)**
+ Receives a list of URLs from HTTP clients
+ Uses the [Newspaper3k](https://newspaper.readthedocs.io/en/latest/) library to extract body text from an article given its URL
+ Returns a populated map of URL-to-body (text of article) back to the client
* **Serverless StdLib Function: Analytics-Export Flow (NodeJS)**
+ Receives raw result data from an HTTP client, which is our web application
+ Converts raw data onto a user-friendly CSV file
+ A) AutoCode built-in Slack integration that publishes the CSV to Slack
+ B) AutoCode custom integration for sending the CSV to a given email
* **Serverless StdLib Function: Relevant Tweets Search (NodeJS)**
+ Receives keywords to search for from an HTTP client
+ Returns relevant tweets back to the client
Note that our Golang server and React front-end are both hosted on Google App Engine.
## Means to Monetization
The website [nwfacts.tech](https://nwfacts.tech) is and will remain free whenever it is running. Eventually we could consider adding premium account functionality with access to more computationally expensive machine learning. | ## Inspiration
In a sense, social media has democratized news media itself -- through it, we have all become "news editors" to some degree, shaping what our friends read through our shares, likes, and comments. Is it any wonder, then, that "fake news" has become such a widespread problem? In such partisan times, it is easy to find ourselves ourselves siloed off within ideological echo chambers. After all, we are held in thrall not only by our cognitive biases to seek out confirmatory information, but also by the social media algorithms trained to feed such biases for the sake of greater ad revenue. Most worryingly, these ideological silos can serve as breeding grounds for fake news, as stories designed to mislead their audience are circulated within the target political community, building outrage and exacerbating ignorance with each new share.
We believe that the problem of fake news is intimately related to the problem of the ideological echo chambers we find ourselves inhabiting. As such, we designed "Open Mind" to attack these two problems at their root.
## What it does
"Open Mind" is a Google Chrome extension designed to (1) combat the proliferation of fake news, and (2) increase exposure to opposing viewpoints. It does so using a multifaceted approach -- first, it automatically "blocks" known fake news websites from being displayed on the user's browser, providing the user with a large warning screen and links to more reputable sources (the user can always click through to view the allegedly fake content, however; we're not censors!). Second, the user is given direct feedback on how partisan their reading patterns are, in the form of a dashboard which tracks their political browsing history. This dashboard then provides a list of recommended articles that users can read in order to "balance out" their reading history.
## How we built it
We used React for the front end, and a combination of Node.js and Python for the back-end. Our machine learning models for recommending articles were built using Python's Tensorflow library, and NLP was performed using the Alyien, Semantria, and Google Cloud Natural Language APIs.
## What we learned
We learned a great deal more about fake news, and NLP in particular.
## What's next for Open Mind
We aim to implement a "political thermometer" that appears next to political articles, showing the degree to which the particular article is conservative or liberal. In addition, we aim to verify a Facebook-specific "share verification" feature, where users are asked if they are sure they want to share an article that they have not already read (based on their browser history). | ## Inspiration 🤔
The brain, the body's command center, orchestrates every function, but damage to this vital organ in contact sports often goes unnoticed. Studies show that 99% of football players are diagnosed with CTE, 87% of boxers have experienced at least one concussion, and 15-30% of hockey injuries are brain-related. If only there were a way for players and coaches to monitor the brain health of players before any long-term damage can occur.
## Our Solution💡
Impactify addresses brain health challenges in contact sports by integrating advanced hardware into helmets used in sports like hockey, boxing, and football. This hardware records all impacts sustained during training or games, capturing essential data from each session. The collected data provides valuable insights into an athlete's brain health, enabling them to monitor and assess their cognitive well-being. By staying informed about potential head injuries or concussion risks, athletes can take proactive measures to protect their health. Whether you're a player who wants to track their own brain health or a coach who wants to track all their players' brain health, Impactify has a solution for both.
## How we built it 🛠️
Impactify leverages a mighty stack of technologies to optimize its development and performance. React was chosen for the front end due to its flexibility in building dynamic, interactive user interfaces, allowing for a seamless and responsive user experience. Django powers the backend, providing a robust and scalable framework for handling complex business logic, API development, and secure authentication. PostgreSQL was selected for data storage because of its reliability, advanced querying capabilities, and easy handling of large datasets. Last but not least, Docker was employed to manage dependencies across multiple devices. This helped maintain uniformity in the development and deployment processes, reducing the chances of environment-related issues.
On the hardware side, we used an ESP32 microprocessor connected to our team member's mobile hotspot, allowing the microprocessor to send data over the internet. The ESP32 was then connected to 4 pressure sensors and an accelerometer, where it reads the data at fixed intervals. The data is sent over the internet to our web server for further processing. The parts were then soldered together and neatly packed into our helmet, and we replaced all the padding to make the helmet wearable again. The hardware was powered with a 9V battery, and then LEDs and a power switch were added to the helmet so the user could turn it on and off. The LEDs served as a visual indicator of whether or not the ESP32 had an internet connection.
## Challenges we ran into 💥
The first challenge we had was getting all the sensors and components positioned in the correct locations within the helmet such that the data will be read accurately. On top of getting the correct positioning, the wiring and all the components must be put in place in such a way that it does not detract from the protective aspect of the helmet. Getting all the components hidden properly and securely was a great challenge and took hours of tinkering.
Another challenge that we faced was making sure that the data that was being read was accurate. We took a long time to callibrate the pressure sensors inside the helmet, because when the helmet is being worn, your head naturally excerts some pressure on the sides of the helmet. Making sure that our data input was reliable was a big challenge to overcome because we had to iterate multiple times on tinkering with the helmet, collecting data, and plotting it on a graph to visually inspect it, before we were satisfied with the result.
## Accomplishments that we're proud of 🥂
We are incredibly proud of how we turned our vision into a reality. Our team successfully implemented key features such as pressure and acceleration tracking within the helmet, and our software stack is robust and scalable with a React frontend and Django backend. We support individual user sessions and coach user management for sports teams, and have safety features such as sending an SMS to a coach if their player takes excessive damage. We developed React components that visualize the collected data, making the website easy to use, visually appealing and interactive. The hardware design was compact and elegant, seamlessly fitting into the helmet without compromising its structure.
## What we learned 🧠
Throughout this project, we learned a great deal about hardware integration, data visualization, and balancing safety with functionality. We also gained invaluable insights into optimizing the development process and managing complex technical challenges.
## What's next for Impactify 🔮
Moving forward, we aim to enhance the system by incorporating more sophisticated data analysis, providing even deeper insights into brain health aswell as fitting our hardware into a larger array of sports gear. We plan to expand the use of Impactify into more sports and further improve its ease of use for athletes and coaches alike. Additionally, we will explore ways to miniaturize the hardware even further to make the integration even more seamless. | partial |
# Team
Honeycrisp
# Inspiration
Every year there are dozens of heatstroke accidents that occur, a number of which are defined as vehicular heatstroke accidents. Our aim was to build a device for vehicles to best prevent these scenarios, whether there may be young children or pets left in said vehicles.
# What it does
Detector that detects temperature/environment conditions within a car and presence of any living being, so as to alert the owner when the environment reaches dangerous conditions for any living beings inside the vehicle (babies, pets, ...)
# How the Detector Works
The detector makes use of several sensors to determine whether the environmental conditions within a vehicle have reached dangerous levels, and whether there is presence of a living being within the vehicle. In the case where both are true it is to send a text message to the owner of the car warning them about the situation within the vehicle.
# How we built it
A team of 3 people made use of the Particle Electron board and several sensors (Gas sensors, Thermal sensors, Infrared Motion sensor as well as Audio Sensor) to create the project.
# Challenges we faced
There were challenges faced when dealing with the Particle Electron board, in that the sensors being used were made for an Arduino. This required specific libraries, which eventually caused the Particle Electron board to malfunction.
# Accomplishments
The team has no past experience working with a Particle Electron board, so for the work that was accomplished within the 24 hour span, we consider it a success.
# What we learned
We learned a lot about the Particle Electron board as well as the sensors that were utilized for this project
# Future
Future developments to improve our device further would include:
1. Considering sensors with more precision to ensure that the conditions and parameters being monitored are as
precise as required.
2. Implement multiple emergency measures, in the case where reaching the owner becomes difficult or the
conditions within the vehicle have reached alarming levels:
a. Turning on the A/C of the vehicle
b. Cracking the window slightly open for better circulation.
c. Have the vehicle make noise (either via the alarm system or car horn) to gain the attention of any
passerby or individuals within reasonable distances to call for aid.
d. Function that reports the incidence to 911, along with the location of the vehicle. | ## Inspiration
Coming from South-East Asia, we have seen the devastation that natural disasters can wreck havoc on urban populations
We wanted to create a probe that can assist on-site Search and Rescue team members to detect and respond to nearby survivors
## What it does
Each Dandelyon probe detects changes in its surroundings and pushes data regularly to the backend server.
Additionally, each probe has a buzzer that produces a noise if it detects changes in the environment to attract survivors.
Using various services, visualise data from all probes at the same time to investigate and determine areas of interest to rescue survivors.
## What it consists of
* Deployable IoT Probe
* Live data streams
* Data Visualisation on Microsoft Power BI
* Data Visualisation on WebApp with Pitney Bowes API(dandelyon.org)
## How we built it
**Hardware**
* Identified the sensors that we would be using
* Comprises of:
1. Cell battery
2. Breadboard
3. Jumper Wires
4. Particle Electron 2G (swapped over to our own Particle 3G as it has better connectivity) + Cellular antenna
5. GPS + external antenna
6. Sound detector sensor
7. Buzzer
8. Accelerometer
* Soldered pin headers onto sensors
* Tested the functionality of each sensor
1. Wired each sensor alone to the Electron
2. Downloaded the open source libraries for each sensor from GitHub
3. Wrote a code for main function for the sensor to communicate with the Electron
4. Read the output from each sensor and check if it's working
* Integrated every sensor with the Electron
* Tested the final functionality of the Electron
**Software**
* Infrastructure used
1. Azure IoT Hub
2. Azure Stream Analytics
3. Azure NoSQL
1. Microsoft Power BI
4. Google Cloud Compute
1. Particle Cloud with Microsoft Azure IoT Hub integration
* Backend Development
1. Flow of live data stream from Particle devices
2. Supplement live data with simulated data
3. Data is piped from Azure IoT Hub to PowerBI and Webapp Backend
4. PowerBI used to display live dashboards with live charts
5. WebApp displays map with live data
* WebApp Development
Deployed NodeJS server on Google Cloud Compute connected to Azure NoSQL database. Fetches live data for display on map.
## Challenges we ran into
Hardware Integration
Azure IoT Stream connecting to PowerBI as well as our custom back-end
Working with live data streams
## Accomplishments that we're proud of
Integrating the Full Hardware suite
Integrating Probe -> Particle Cloud -> Azure IoT -> Azure Stream Analytics -> PowerBI
and Azure Stream Analytics -> Azure NoSQL -> Node.Js -> PitneyBowes/Leaflet
## What we learned
## What's next for Dandelyon
Prototyping the delivery shell used to deploy Dandelyon probes from a high altitude
Developing on the backend interface used to manage and assign probe response | ## Inspiration
Inspired by carbon trading mechanism among nations proposed by Kyoto Protocol treaty in the response to the threat of climate change, and a bunch of cute gas sensors provided by MLH hardware lab, we want to build a similar mechanism among people to monetize our daily carbon emission rights, especially the vehicle carbon emission rights so as to raise people's awareness of green house gas(GHG) emission and climate change.
## What it does
We have designed a data platform for both regular users and the administrative party to manage carbon coins, a new financial concept we proposed, that refers to monetized personal carbon emission rights. To not exceed the annual limit of carbon emission, the administrative party will assign a certain amount of carbon coins to each user on a monthly/yearly basis, taking into consideration both the past carbon emission history and the future carbon emission amount predicted by machine learning algorithms. For regular users, they can monitor their real-time carbon coin consumption and trading carbon coins with each other once logging into our platform. Also, we designed a prototyped carbon emission measurement device for vehicles that includes a CO2 gas sensor, and an IoT system that can collect vehicle's carbon emission data and transmit these real-time data to our data cloud platform.
## How we built it
### Hardware
* Electronics
We built a real-time IoT system with Photon board that calculates the user carbon emission amount based on gas sensors’ input and update the right amount of account payable in their accounts. The Photon board processes the avarage concentration for the time of change from CO2 and CO sensors, and then use the Particle Cloud to publish the value to the web page.
* 3D Priniting
We designed the 3D structure for the eletronic parts. This strcture is meant to be attached to the end of the car gas pipe to measure the car carbon emission, whcih is one of the biggest emission for an average household. Similar structure design will be done for other carbon emission sources like heaters, air-conditioners as well in the future.
### Software
* Back end data analysis
We built a Long Short Term Memory(LSTM) model using Keras, a high-level neural networks API running on top of TensorFlow, to do time series prediction. Since we did not have enough carbon emission data in hand, we trained and evaluated our model on a energy consumption dataset, cause we found there is a strong correlation between the energy consumption data and the carbon emission data. Through this deep learning model, we can make a sound prediction of the carbon emission amount of the next month/year from the past emission history.
* Front end web interface
We built Web app where the user can access the real-time updates of their carbon consumption and balance, and the officials can suggest the currency value change based on the machine learning algorithm results shown in their own separate web interface.
## Challenges we ran into
* Machine learning algorithms
At first we have no clue about what kind of model should we use for time series prediction. After googling for a while, we found recurrent neural networks(RNN) that takes a history of past data points as input into the model is a common way for time series prediction, and its advanced variant, LSTM model has overcome some drawbacks of RNN. However, even for LSTM, we still have many ways to use this model: we have sequence-to-sequence prediction, sequence-to-one prediction and one-to-sequence prediction. After some failed experiments and carefully researching on the characteristics of our problem, finally we got a well-performed sequence-to-one LSTM model for energy consumption prediction.
* Hardware
We experience some technical difficulty when using the 3D printing with Ultimaker, but eventually use the more advanced FDM printer and get the part done. The gas sensor also takes us quite a while to calibrate and give out the right price based on consumption.
## Accomplishments that we're proud of
It feels so cool to propose this cool financial concept that can our planet a better place to live.
Though we only have 3 people, we finally turn tons of caffeine into what we want!
## What we learned
Sleep and Teamwork!!
## What's next for CarbonCoin
1) Expand sources of carbon emission measurements using our devices or convert other factors like electricity consumption into carbon emission as well. The module will be in the future incorprate into all the applicances.
2) Set up trading currency functionality to ensure the liquidity of CarbonCoin.
3) Explore the idea of blockchain usage on this idea | partial |
## Inspiration
Our inspiration stems from a fundamental realization about the critical role food plays in our daily lives. We've observed a disparity, especially in the United States, where the quality and origins of food are often overshadowed, leading to concerns about the overall health impact on consumers.
Several team members had the opportunity to travel to regions where food is not just sustenance but a deeply valued aspect of life. In these places, the connection between what we eat, our bodies, and the environment is highly emphasized. This experience ignited a passion within us to address the disconnect in food systems, prompting the creation of a solution that brings transparency, traceability, and healthier practices to the forefront of the food industry. Our goal is to empower individuals to make informed choices about their food, fostering a healthier society and a more sustainable relationship with the environment.
## What it does
There are two major issues that this app tries to address. The first is directed to those involved in the supply chain, like the producers, inspectors, processors, distributors, and retailers. The second is to the end user. For those who are involved in making the food, each step that moves on in the supply chain is tracked by the producer. For the consumer at the very end who will consume it, it will be a journey on where the food came from including its location, description, and quantity. Throughout its supply chain journey, each food shipment will contain a label that the producer will put on first. This is further stored on the blockchain for guaranteed immutability. As the shipment moves from place to place, each entity ("producer, processor, distributor, etc") will be allowed to make its own updated comment with its own verifiable signature and decentralized identifier (DiD). We did this through a unique identifier via a QR code. This then creates tracking information on that one shipment which will eventually reach the end consumer, who will be able to see the entire history by tracing a map of where the shipment has been.
## How we built it
In order to build this app, we used both blockchain and web2 in order to alleviate some of the load onto different servers. We wrote a solidity smart contract and used Hedera in order to guarantee the immutability of the record of the shipment, and then we have each identifier guaranteed its own verifiable certificate through its location placement. We then used a node express server that incorporated the blockchain with our SQLite database through Prisma ORM. We finally used Firebase to authenticate the whole app together in order to provide unique roles and identifiers. In the front end, we decided to build a react-native app in order to support both Android and iOS. We further used different libraries in order to help us integrate with QR codes and Google Maps. Wrapping all this together, we have a fully functional end-to-end user experience.
## Challenges we ran into
A major challenge that we ran into was that Hedera doesn't have any built-in support for constructing arrays of objects through our solidity contract. This was a major limitation as we had to find various other ways to ensure that our product guaranteed full transparency.
## Accomplishments that we're proud of
These are some of the accomplishments that we can achieve through our app
* Accurate and tamper-resistant food data
* Efficiently prevent, contain, or rectify contamination outbreaks while reducing the loss of revenue
* Creates more transparency and trust in the authenticity of Verifiable Credential data
* Verifiable Credentials help eliminate and prevent fraud
## What we learned
We learned a lot about the complexity of food chain supply. We understand that this issue may take a lot of helping hand to build out, but it's really possible to make the world a better place. To the producers, distributors, and those helping out with the food, it helps them prevent outbreaks by keeping track of certain information as the food shipments transfer from one place to another. They will be able to efficiently track and monitor their food supply chain system, ensuring trust between parties. The consumer wants to know where their food comes from, and this tool will be perfect for them to understand where they are getting their next meal to stay strong and fit.
## What's next for FoodChain
The next step is to continue to build out all the different moving parts of this app. There are a lot of different directions that one person can take app toward the complexity of the supply chain. We can continue to narrow down to a certain industry or we can make this inclusive using the help of web2 + web3. We look forward to utilizing this at some companies where they want to prove that their food ingredients and products are the best. | ## Inspiration
The counterfeiting industry is anticipated to grow to $2.8 trillion in 2022 costing 5.4 million jobs. These counterfeiting operations push real producers to bankruptcy as cheaper knockoffs with unknown origins flood the market. In order to solve this issue we developed a blockchain powered service with tags that uniquely identify products which cannot be faked or duplicated while also giving transparency. As consumers today not only value the product itself but also the story behind it.
## What it does
Certi-Chain uses a python based blockchain to authenticate any products with a Certi-Chain NFC tag. Each tag will contain a unique ID attached to the blockchain that cannot be faked. Users are able to tap their phones on any product containing a Certi-Chain tag to view the authenticity of a product through the Certi-Chain blockchain. Additionally if the product is authentic users are also able to see where the products materials were sourced and assembled.
## How we built it
Certi-Chain uses a simple python blockchain implementation to store the relevant product data. It uses a proof of work algorithm to add blocks to the blockchain and check if a blockchain is valid. Additionally, since this blockchain is decentralized, nodes (computers that host a blockchain) have to be synced using a consensus algorithm to decide which version of the blockchain from any node should be used.
In order to render web pages, we used Python Flask with our web server running the blockchain to fetch relative information from the blockchain and displayed it to the user in a style that is easy to understand. A web client to input information into the chain was also created using Flask to communicate with the server.
## Challenges we ran into
For all of our group members this project was one of the toughest we had. The first challenge we ran into was that once our idea was decided we quickly realized only one group member had the appropriate hardware to test our product in real life. Additionally, we deliberately chose an idea in which none of us had experience in. This meant we had to spent a portion of time to understand concepts such as blockchain and also using frameworks like flask. Beyond the starting choices we also hit several roadblocks as we were unable to get the blockchain running on the cloud for a significant portion of the project hindering the development. However, in the end we were able to effectively rack our minds on these issues and achieve a product that exceeded our expectations going in. In the end we were all extremely proud of our end result and we all believe that the struggle was definitely worth it in the end.
## Accomplishments that we're proud of
Our largest achievement was that we were able to accomplish all our wishes for this project in the short time span we were given. Not only did we learn flask, some more python, web hosting, NFC interactions, blockchain and more, we were also able to combine these ideas into one cohesive project. Being able to see the blockchain run for the first time after hours of troubleshooting was a magical moment for all of us. As for the smaller wins sprinkled through the day we were able to work with physical NFC tags and create labels that we stuck on just about any product we had. We also came out more confident in the skills we already knew and also developed new skills we gained on the way.
## What we learned
In the development of Certi-Check we learnt so much about blockchains, hashes, encryption, python web frameworks, product design, and also about the counterfeiting industry too. We came into the hackathon with only a rudimentary idea what blockchains even were and throughout the development process we came to understand the nuances of blockchain technology and security. As for web development and hosting using the flask framework to create pages that were populated with python objects was certainly a learning curve for us but it was a learning curve that we overcame. Lastly, we were all able to learn more about each other and also the difficulties and joys of pursuing a project that seemed almost impossible at the start.
## What's next for Certi-Chain
Our team really believes that what we made in the past 36 hours can make a real tangible difference in the world market. We would love to continue developing and pursuing this project so that it can be polished for real world use. This includes us tightening the security on our blockchain, looking into better hosting, and improving the user experience for anyone who would tap on a Certi-Chain tag. | ## Inspiration
In Canada, $31 billion worth of food ends up in the landfills every year. This comes from excess waste produced by unwanted ugly produce, restaurants overcooking etc. As a team we are concerned about the environment and the role we have to play in shaping a healthy future. While technology often has adverse effects on the environment, there is opportunity to reshape the world through utilizing the power of human connection that technology enables us to do across physical boundaries.
## What it does
SAVOURe is a web application with a proposed mobile design that strives to save excess edible food from the landfill by connecting stores, restaurants and events with hungry to people and those in need, who save the food from the landfill through purchasing it at a discounted rate. In particular our app would benefit students and people with lower income who struggle to eat enough each day.
It is built for the consumer and food provider perspectives. We created a database for the providers to quickly post to the community about excess food at their location. Providers specify the type of food, the discounted price, the time it’s available as well as any other specifications.
For the consumer side, we propose an mobile application that allows for quick browsing and purchasing of the food. They have the opportunity to discover nearby providers through an integrated map and once they purchase the food online, they can retrieve their food from the store locker (this alleviates any additional monitoring required by employees).
## How we built it
We started off with an ideation phase using colourful crayola markers and paper to hash out the essence of our idea. We then agreed upon what the minimum viable product was, the ability for browsing and restaurants to enter data to post food. From there we divided up the work into frontend, backend and ui/ux design.
## Challenges we ran into
One challenge we had was contraining the scope of our project. We brainstormed a lot of useful functionality that we believed would be useful for our user base, from creating “template” postings, to scanning QR code to access storage lockers that would contain the food items. Implementing all of this would have been impossible in the time frame, so we had to decide on a minimal set of functionality, and move many ideas to the “nice-to-have” column.
## Accomplishments that we're proud of
We are proud that we were trying to solve a problem that would make the world a better place. Not only are we creating a functional app, but we are also putting our skills to use for the improvement of humankind.
## What we learned
We learned that we can accomplish creating a solution when we are all heading in the same direction and combine our minds to think together utilizing each of our own strengths.
## What's next for SAVOURe
There was a lot of functionality we weren’t able to implement in the given time frame. So there is still plenty of ideas to add into the app. To make the app useful though, we would contact potential food providers, to get a set of discount postings to bring in a customer base. | partial |
## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before. | ## Inspiration
The need for faster and more reliable emergency communication in remote areas inspired the creation of FRED (Fire & Rescue Emergency Dispatch). Whether due to natural disasters, accidents in isolated locations, or a lack of cellular network coverage, emergencies in remote areas often result in delayed response times and first-responders rarely getting the full picture of the emergency at hand. We wanted to bridge this gap by leveraging cutting-edge satellite communication technology to create a reliable, individualized, and automated emergency dispatch system. Our goal was to create a tool that could enhance the quality of information transmitted between users and emergency responders, ensuring swift, better informed rescue operations on a case-by-case basis.
## What it does
FRED is an innovative emergency response system designed for remote areas with limited or no cellular coverage. Using satellite capabilities, an agentic system, and a basic chain of thought FRED allows users to call for help from virtually any location. What sets FRED apart is its ability to transmit critical data to emergency responders, including GPS coordinates, detailed captions of the images taken at the site of the emergency, and voice recordings of the situation. Once this information is collected, the system processes it to help responders assess the situation quickly. FRED streamlines emergency communication in situations where every second matters, offering precise, real-time data that can save lives.
## How we built it
FRED is composed of three main components: a mobile application, a transmitter, and a backend data processing system.
```
1. Mobile Application: The mobile app is designed to be lightweight and user-friendly. It collects critical data from the user, including their GPS location, images of the scene, and voice recordings.
2. Transmitter: The app sends this data to the transmitter, which consists of a Raspberry Pi integrated with Skylo’s Satellite/Cellular combo board. The Raspberry Pi performs some local data processing, such as image transcription, to optimize the data size before sending it to the backend. This minimizes the amount of data transmitted via satellite, allowing for faster communication.
3. Backend: The backend receives the data, performs further processing using a multi-agent system, and routes it to the appropriate emergency responders. The backend system is designed to handle multiple inputs and prioritize critical situations, ensuring responders get the information they need without delay.
4. Frontend: We built a simple front-end to display the dispatch notifications as well as the source of the SOS message on a live-map feed.
```
## Challenges we ran into
One major challenge was managing image data transmission via satellite. Initially, we underestimated the limitations on data size, which led to our satellite server rejecting the images. Since transmitting images was essential to our product, we needed a quick and efficient solution. To overcome this, we implemented a lightweight machine learning model on the Raspberry Pi that transcribes the images into text descriptions. This drastically reduced the data size while still conveying critical visual information to emergency responders. This solution enabled us to meet satellite data constraints and ensure the smooth transmission of essential data.
## Accomplishments that we’re proud of
We are proud of how our team successfully integrated several complex components—mobile application, hardware, and AI powered backend—into a functional product. Seeing the workflow from data collection to emergency dispatch in action was a gratifying moment for all of us. Each part of the project could stand alone, showcasing the rapid pace and scalability of our development process. Most importantly, we are proud to have built a tool that has the potential to save lives in real-world emergency scenarios, fulfilling our goal of using technology to make a positive impact.
## What we learned
Throughout the development of FRED, we gained valuable experience working with the Raspberry Pi and integrating hardware with the power of Large Language Models to build advanced IOT system. We also learned about the importance of optimizing data transmission in systems with hardware and bandwidth constraints, especially in critical applications like emergency services. Moreover, this project highlighted the power of building modular systems that function independently, akin to a microservice architecture. This approach allowed us to test each component separately and ensure that the system as a whole worked seamlessly.
## What’s next for FRED
Looking ahead, we plan to refine the image transmission process and improve the accuracy and efficiency of our data processing. Our immediate goal is to ensure that image data is captioned with more technical details and that transmission is seamless and reliable, overcoming the constraints we faced during development. In the long term, we aim to connect FRED directly to local emergency departments, allowing us to test the system in real-world scenarios. By establishing communication channels between FRED and official emergency dispatch systems, we can ensure that our product delivers its intended value—saving lives in critical situations. | *Inspiration*
One of the most important roles in our current society is the one taken by the varying first responders who ensure the safety of the public through many different means. Innovation which could help these first responders would always be favourable for society as it would follow from this innovation that more lives are saved through a more efficient approach by first responders to save lives.
*What it does*
The Watchdog app is a map which allows registered users to share locations of events which would be important to first responders. These events could have taken place at any time, as the purpose for them varies for the different first responders. For example, if many people report fires then from looking at the map, regardless of when these fires took place, firefighters can locate building complexes which might be prone to fire for some particular reason. It may be that firefighters can find where to pay more attention to as there would be a higher probability for these locations to have fires statistically. This app does not only help firefighters with these statistics, but also the police and paramedics. With reporting of petty crimes such as theft, police can find neighbourhoods where there is a statistical accumulation and focus resources there to improve efficiency. The same would go for paramedics for varying types of accidents which could occur from dangerous jobs such as construction, and paramedics would be more prepared for certain locations. Major cities have many delays due to accidents or other hindrances to travel and these delays are usually unavoidable and a nuisance to city travelers, so the app could also help typical citizens.
*How we built it*
The app was built using MongoDB, Express, and Node on the backend to manage the uploading of all reports added to the MongoDB database. React was used on the front end along with Google Cloud to generate the map using Google Maps API which the user can interact with, by adding their reports and viewing other reports.
*Challenges we ran into*
Our challenges mostly involved working with Google Maps API as doing so in React was new for all of us. Issues arose when trying to make the map interactable and using the map's features to add locations to the database, as we never worked with the map like this before. However, these challenges were overcome by learning the Google Maps documentation as well as we could, and ensuring that the features we wanted were added even if they were still simple.
*Accomplishments that we're proud of*
We're mostly proud of coming up with an idea that we believe could have a strong impact in the world when it comes to helping lives and being efficient with the limited time that first responders have. Technically, accomplishments with being able to make the map interactive despite limited experience with Google Maps API was something that we're proud of as well.
*What we learned*
We learned how to work with React and Google Maps API together, along with how to move data from interactive maps like that to an online database in MongoDB.
*What's next for Watchdog*
Watchdog can add features when it comes to creating reports. Features could vary, such as pictures of the incident or whether first responders were successful in preventing these incidents. The app is already published online so it can be used by people, and a main goal would be to make a mobile version so that more people could use it, even though it can be used by people right now. | winning |
## Inspiration
Save plate is an app that focuses on narrowing the equity differences in society.It is made with the passion to solve the SDG goals such as zero hunger, Improving life on land, sustainable cities and communities and responsible consumption and production.
## What it does
It helps give a platform to food facilities to distribute their untouched meals to the shelter via the plate saver app. It asks the restaurant to provide the number of meals that are available and could be picked up by the shelters. It also gives the flexibility to provide any kind of food restriction to respect cultural and health restrictions for food.
## How we built it
* Jav
## Challenges we ran into
There were many challenges that I and my teammates ran into were learning new skills, teamwork and brainstorming.
## Accomplishments that we're proud of
Creating maps, working with
## What we learned
We believe our app is needed not only in one region but entire world, we all are taking steps towards building a safe community for everyone Therefore we see our app's potential to run in collaboration with UN and together we fight world hunger. | ## Inspiration Behind Plate-O 🍽️
The inspiration for Plate-O comes from the intersection of convenience, financial responsibility, and the joy of discovering new meals. We all love ordering takeout, but there’s often that nagging question: “Can I really afford to order out again?” For many, budgeting around food choices can be stressful and time-consuming, yet essential for maintaining a healthy balance between indulgence and financial well-being. 🍔💡
Our goal with Plate-O was to create a seamless solution that alleviates this burden while still giving users the excitement of variety and novelty in their meals. We wanted to bridge the gap between smart personal finance and the spontaneity of food discovery, making it easier for people to enjoy new restaurants without worrying about breaking the bank. 🍕✨
What makes Plate-O truly special is its ability to learn from your habits and preferences, ensuring each recommendation is not only financially responsible but tailored to your unique tastes. By combining AI, personal finance insights, and your love for good food, we created a tool that makes managing your takeout spending effortless, leaving you more time to enjoy the experience. Bon Appétit! 📊🍽️
## How We Built Plate-O 🛠️
At the core of Plate-O is its AI-driven recommendation engine, designed to balance two crucial factors: your financial well-being and your culinary preferences. Here’s how we made it happen:
Backend: We used FastAPI to build a robust system for handling the user’s financial data, preferences, and restaurant options. By integrating the Capital One API, Plate-O can analyze your income, expenses, and savings to calculate an ideal takeout budget—maximizing enjoyment while minimizing financial strain. 💵📈
**Frontend**: Next.js powers our intuitive user interface. Users input their budget, and with just a few clicks, they get a surprise restaurant pick that fits their financial and taste profile. Our seamless UI makes ordering takeout a breeze. 📱✨
**Data Handling & Preferences**: MongoDB Atlas is our choice for managing user preferences—storing restaurant ratings, past orders, dietary restrictions, and other critical data. This backend allows us to constantly learn from user feedback and improve recommendations with every interaction. 📊🍴
**AI & Recommendation System**: Using Tune’s LLM-powered API, we process natural language inputs and preferences to predict what food users will love based on past orders and restaurant descriptions. The system evaluates each restaurant using criteria like sustainability scores, delivery speed, cost, and novelty. 🎯🍽️
**Surprise Meal Feature**: The magic happens when the system orders a surprise meal for users within their financial constraints. Plate-O delights users by taking care of the decision-making and getting better with each order. 🎉🛍️
## Challenges We Overcame at Plate-O 🚧
**-Budgeting Complexity**: One of our first hurdles was integrating the Capital One API in a meaningful way. We had to ensure that our budgeting model accounted for users’ income, expenses, and savings in real-time. This required significant computation beyond the API and iteration to create a seamless experience. 💰⚙️
**Recommendation Fine-Tuning:** Balancing taste preferences with financial responsibility wasn’t easy. Most consumer dining preference data is proprietary, forcing us to spend a lot of time refining the recommendation system to ensure it could accurately predict what users would enjoy with small amounts of data, leveraging open-source Large Language Models to improve results over time. 🤖🎯
**-Data Integration**: Gathering and analyzing user preference data in real-time presented technical challenges, particularly when optimizing the system to handle large restaurant datasets efficiently while providing quick recommendations. Combining two distinct datasets, the Yelp restaurant datalist and an Uber Eats csv also required a bit of Word2Vec ingenuity. 🗄️⚡
## Accomplishments at Plate-O 🏆
**-Smart Budgeting with AI**: Successfully implemented a model that combines personal finance data with restaurant preferences, offering tailored recommendations that help users stay financially savvy while enjoying variety in their takeout. 📊🍕
**- Novel User Experience**: Plate-O’s surprise meal feature takes the stress out of decision-making, delighting users with thoughtful recommendations that evolve with their taste profile. The platform bridges convenience and personalized dining experiences like never before. 🚀🥘
## Lessons Learned from Plate-O’s Journey 📚
**-Simplicity Wins**: At first, we aimed to include many complex features, but we quickly realized that simplicity and focus lead to a more streamlined and effective user experience. It’s better to do one thing exceptionally well—help users order takeout wisely. 🌟🍽️
**-The Power of Learning**: A key takeaway was understanding the importance of iterative learning in both our recommendation engine and product development process. Every user interaction provided valuable insights that made Plate-O better. 🔄💡
**-Balancing Functionality and Delight**: Creating a tool that is both functional and delightful requires finding a perfect balance between user needs and technical feasibility. With Plate-O, we learned to merge practicality with the joy of food discovery. 💼🎉
## The Future of Plate-O 🌟
**-Groceries and Beyond**: We envision expanding Plate-O beyond takeout, integrating grocery shopping and other spending categories into the platform to help users make smarter financial choices across their food habits. 🛒📊
**-Real-Time AI Assistance**: In the future, we plan to leverage AI agents that proactively guide users through their food budgeting journey, offering suggestions and optimizations for both takeout and groceries. 🤖🍱
**-Social Good**: While we already take environmental protection into account when recommending restaurants, we’re excited to explore adding complete restaurant ESG scores to help users make socially responsible dining choices, supporting local businesses and environmentally friendly options. 🌍🍽️
With Plate-O, we're not just changing how you order takeout; we're helping you become a more financially savvy foodie, one delicious meal at a time. | ## Inspiration
Reducing North American food waste.
## What it does
Food for All offers a platform granting the ability for food pantries and restaurants to connect. With a very intuitive interface, pantries and restaurants are able to register their organizations to request or offer food. Restaurants can estimate their leftover food, and instead of it going to waste, they are able to match with food pantries to make sure the food goes to a good cause.
Depending on the quantity of food requested and available to offer as well as location, the restaurants are given a list of the pantries that best match their availability.
## How we built it
Food for All is build using a full Node.js Stack. We used Express, BadCube, React, Shard and Axios to make the application possible.
## Challenges we ran into
The main challenges of developing Food for All were learning new frameworks and languages. Antonio and Vishnu had very little experience with JavaScript and nonrelational databases, as well as Express.
## Accomplishments that we're proud of
We are very proud of the implementation of the Google Maps API on the frontend and our ranking and matching algorithm for top shelters.
## What we learned
We learned how to make Rest APIs with Express. We also realized a decent way through our project that our nonrelational local database, Badcube, worked best when the project was beginning, but as the project scaled it has no ability to deal with nuanced objects or complex nested relationships, making it difficult to write and read data from.
## What's next for Food for All
In the future, we aim to work out the legal aspects to ensure the food is safely prepared and delivered to reduce the liability of the restaurants and shelters. We would also like to tweak certain aspects of the need determination algorithm used to find shelters that are at greatest need for food. Part of this involves more advanced statistical methods and a gradual transition from algorithmic to machine learning oriented methods. | partial |
## Inspiration
When I was 10, I played a text-adventure game related to simply traversing the world. It was small, there was no GUI, but even then, outside of Minecraft, it was one of the few games who captured my interest because of it's wide field and untapped ability for exploration. Recently I wanted to revisit that game, but I found that in the time a lot had changed. As such, we decided to re-explore that field ourselves using Generative AI to capture the non-linear storytelling, the exploration, and enjoy the books we read nowadays in a new refreshing light.
## What it does
Multivac stands for Multimedia Visual Adventure Console, because it uses both text and images to turn any piece of text into an interactive adventure. Basically, you can upload any book, and turn it into an interactive fiction game.
Multivac processes and chunks the uploaded story storing it in a vector database. From this, it creates a list of major states with chronological timestamps from the story that are pivotal points in the book that -- unless monumental work is done on your part -- will occur again. This allows Multivac to know what the main plot points of the story are, so that it has something to work off of. In addition, it helps the list of states helps to tie you back to the major plot points of your favorite books, allowing you to relive those memories from a new and fresh perspective. From this, Multivac uses relevant info from the story vector database, chat history vector database, state list and current timestamp to generate responses to the user that move the story along in a cohesive manner. Alongside these responses, Multivac generates images with Stable Diffusion that enhance the story being told -- allowing you to truly relive and feel immersed in the story **you're** writing.
## How we built it
For frontend, we used React and Typescript. For backend, we used Flask for server management. We used Langchain for querying Claude and Anthropic and we used Llamaindex to store story data and chat history in a Vector database and to do vector searches through Llamaindex's query engine. We also used Replicate AI's API to generate images with Stable Diffusion. For persistent database systems, we decided to create our own individual SQL-like system so we could avoid the additional overhead that came with SQL and it's cousins.
## Challenges we ran into
There were 2 major challenges we ran into.
The first one was related to building Multivac's response pipeline. It was our first time using vector databases and Llama-Index as a whole to search for relevant details within large bodies of text. As such, as you might imagine, there were quite a few bugs and unforeseen break points.
The second was related to the actual database system we were using. As one would imagine, there's a reason SQL is so popular. It wasn't until 3:00 A.M. at night, when we were creating and debugging our own operations for getting, writing, etc... from this database system did we truly understand SQL's beauty.
## Accomplishments that we're proud of
We are proud of creating a persistent database from scratch, as well as being able to build all the features we set out to create. We are also proud of completing the end to end pipeline using Llama-Index and LangChain (which was surprisingly difficult). We are especially proud of our UI as -- if we don't say so -- it looks pretty slick!
## What we learned
Couple of things.
Firstly, if your going to use a database system or your application requires persistent storage, use SQL or a founded database in the field. Don't make your own. Just because you can doesn't mean you should.
Secondly, we learned how to use Llama-Index to process, chunk and use text end-to-end in a vector DB for LLM calls.
Thirdly, we learned how tiring 1-day 2-night hackathons can be and how taxing they are on the human spirit.
Lastly, we learned how cool Harvard and MIT looks.
## What's next for Multivac
As of writing, we currently use a list of states to track where the user is in the story, but we want to expand Multivac to instead be a self-generative state machine with stochastic transitions. This would make the world feel more **alive** and grounded in reality (since the world doesn't always go your way) giving you further immersion to explore new paths in your favorite stories. This would also create more control over the story, allowing for more initial customization on the user's end regarding what journey they want to take. | ## Inspiration
As a video game lover and someone that's been working with Gen AI and LLMs for a while, I really wanted to see what combining both in complex and creative ways could lead to. I truly believe that not too far in the future we'll be able to explore worlds in RPGs where the non-playable-characters feel immersively alive, and part of their world. Also I was sleep-deprived and wanted to hack something silly :3
## What it does
I leveraged generative AI (Large Language Models), as well as Vector Stores and Prompt Chaining to 'train' an NPC without having to touch the model itself. Everything is done in context, and through external memory using the Vector Store. Furthermore, a seperate model is concurrently analyzing the conversation as it goes to calculate conversation metrics (familiarity, aggresivity, trust, ...) to trigger events and new prompts dynamically! Sadly there is no public demo for it, because I didn't want to force anyone to create their own api key to use my product, and the results just wouldn't be the same on small hostable free tier llms.
## How we built it
For the frontend, I wanted to challenge myself and not use any framework or library, so this was all done through good-old html and vanilla JS with some tailwind here and there. For the backend, I used the Python FastAPI framework to leverage async workflows and websockets for token streaming to the frontend. I use OpenAI models combined together using Langchain to create complex pipelines of prompts that work together to keep the conversation going and update its course dynamically depending on user input. Vector Stores serve as external memory for the LLM, which can query them through similarity search (or other algorithms) in real time to supplement its in-context conversation memory through two knowledge sources: 'global' knowledge, which can be made up of thousands of words or small text documents, sources that can be shared by NPCs inhabiting the same 'world'. These are things the NPC should know about the world around them, its history, its geography, etc. The other source is 'local' knowledge, which is mostly unique to the NPC: personal history, friends, daily life, hobbies, occupations, etc. The combination of both, accessible in real time, and easily enhanceable through other LLMs (more on this in 'what's next) leads us to a chatbot that's been essentially gaslit into a whole new virtual life! Furthermore, heuristically determined conversation 'metrics' are dynamically analyzed by a separate llm on the side, to trigger pre-determined events based on their evolution. Each NPC can have pre-set values for these metrics, along with their own metric-triggered events, which can lead to complex storylines and give way to cool applications (quest giving, ...)
## Challenges we ran into
I wanted to do this project solo, so I ran out of time on a few features. The token streaming for the frontend was somehow impossible to make work correctly. It was my first time coding a 'raw' API like this, so that was also quite a challenge, but got easier once I got the hang of it. I could say a similar thing for the frontend, but I had so much fun coding it that I wouldn't even count it as a challenge!
Working with LLM's is always quite a challenge, as trying to get correctly formatted outputs can be compared to asking a toddler
## Accomplishments that we're proud of
I'm proud of the idea and the general concept and design, as well as all the features and complexities I noted down that I couldn't implement! I'm also proud to have dedicated so much effort to such a useless, purely-for-fun scatter-brained 3-hours-of-sleep project in a way that I really haven't done before. I guess that's the point of hackathons! Despite a few things not working, I'm proud to have architectured quite a complex program in very little time, by myself, starting from nothing but sleep-deprivation-fueled jotted-down notes on my phone.
## What we learned
I learned a surprising amount of HTML, CSS and JS from this, elements of programming I always pushed away because I am a spoiled brat. I got to implement technologies I hadn't tried before as well, like Websockets and Vector Stores. As with every project, I learned about feature creep and properly organising my ideas in a way that something, anything can get done. I also learned that there is such a thing as too much caffeine, which I duely noted and will certainly regret tonight.
## What's next for GENPC
There's a lot of features I wanted to work on but didn't have time, and also a lot of potential for future additions. One I mentioned earlier is too automatically extend global or local knowledge through a separate LLM: given keywords or short phrases, a ton of text can be added to complement the existing data and further fine-tune the NPC.
There's also an 'improvement mode' I wanted to add, where you can directly write data into static memory through the chat mode. I also didn't have time to completely finish the vector store or conversation metric graph implementations, although at the time I'm writing this devpost I still have 2 more hours to grind >:)
There's a ton of stuff that can arise from this project in the future: this could become a scalable web-app, where NPCs can be saved and serialized to be used elsewhere. Conversations could be linked to voice-generation and facial animation AIs to further boost the immersiveness. A ton of heuristic optimizations can be added around the metric and trigger systems, like triggers influencing different metrics. The prompt chaining itself could become much more complex, with added layers of validation and analysis. The NPCs could be linked to other agentic models and perform complex actions in simulated worlds! | ## Inspiration
Virtually every classroom has a projector, whiteboard, and sticky notes. With OpenCV and Python being more accessible than ever, we wanted to create an augmented reality entertainment platform that any enthusiast could learn from and bring to their own place of learning. StickyAR is just that, with a super simple interface that can anyone can use to produce any tile-based Numpy game. Our first offering is *StickyJump* , a 2D platformer whose layout can be changed on the fly by placement of sticky notes. We want to demystify computer science in the classroom, and letting students come face to face with what's possible is a task we were happy to take on.
## What it does
StickyAR works by using OpenCV's Contour Recognition software to recognize the borders of a projector image and the position of human placed sticky notes. We then use a matrix transformation scheme to ensure that the positioning of the sticky notes align with the projector image so that our character can appear as if he is standing on top of the sticky notes. We then have code for a simple platformer that uses the sticky notes as the platforms our character runs, jumps, and interacts with!
## How we built it
We split our team of four into two sections, one half that works on developing the OpenCV/Data Transfer part of the project and the other half who work on the game side of the project. It was truly a team effort.
## Challenges we ran into
The biggest challenges we ran into were that a lot of our group members are not programmers by major. We also had a major disaster with Git that almost killed half of our project. Luckily we had some very gracious mentors come out and help us get things sorted out! We also first attempted to the game half of the project in unity which ended up being too much of a beast to handle.
## Accomplishments that we're proud of
That we got it done! It was pretty amazing to see the little square pop up on the screen for the first time on top of the spawning block. As we think more deeply about the project, we're also excited about how extensible the platform is for future games and types of computer vision features.
## What we learned
A whole ton about python, OpenCV, and how much we regret spending half our time working with Unity. Python's general inheritance structure came very much in handy, and its networking abilities were key for us when Unity was still on the table. Our decision to switch over completely to Python for both OpenCV and the game engine felt like a loss of a lot of our work at the time, but we're very happy with the end-product.
## What's next for StickyAR
StickyAR was designed to be as extensible as possible, so any future game that has colored tiles as elements can take advantage of the computer vision interface we produced. We've already thought through the next game we want to make - *StickyJam*. It will be a music creation app that sends a line across the screen and produces notes when it strikes the sticky notes, allowing the player to vary their rhythm by placement and color. | losing |
## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | ## Inspiration
Given that students are struggling to make friends online, we came up with an idea to make this easier. Our web application combines the experience of a video conferencing app with a social media platform.
## What it does
Our web app targets primarily students attending college lectures. We wanted to have an application that would allow users to enter their interests/hobbies/classes they are taking. Based on this information, other students would be able to search for people with similar interests and potentially reach out to them.
## How we built it
One of the main tools we were using was WebRTC that facilitates video and audio transmission among computers. We also used Google Cloud and Firebase for hosting the application and implementing user authentication. We used HTML/CSS/Javascript for building the front end.
## Challenges we ran into
Both of us were super new Google Cloud + Firebase and backend in general. The setup of both platforms took a significant amount of time. Also, we had some troubles with version control on Github.
## Accomplishments we are proud of
GETTING STARTED WITH BACKEND is a huge accomplishment!
## What we learned
Google Cloud, FIrebase, WebRTC - we got introduced to all of these tools during the hackathon.
## What’s next for Studypad
We will definitely continue working on this project and implement other features we were thinking about! | winning |
## What it does
From Here to There (FHTT) is an app that shows users their options for travel and allows them to make informed decisions about their form of transportation. The app shows statistics about different methods of transportation, including calories burned, CO2 emitted and estimated gas prices. See a route you like? Tap to open the route details in Google Maps.
## How we built it
Everything is written in Java using Android Studio. We are using the Google Maps Directions API to get most of our data. Other integrations include JSON simple and Firebase analytics.
## Challenges we ran into
We wanted to find ways to more positively influence users and have the app be more useful. The time pressure was both motivating and challenging.
## Accomplishments that we're proud of
Interaction with the Google Maps Directions API. The card based UI.
## What we learned
From this project, we have gained more experience working with JSON and AsyncTasks. We know more about the merits and limitations of various Google APIs and have a bit more practice implementing Material Design guidelines. We also used git with Android Studio for the first time.
## What's next for From Here to There
Integrating a API for fuel cost updates. Improving the accuracy of calorie/gas/CO2 estimates by setting up Firebase Authentication and Realtime Database to collect user data such as height, weight and car type. Using a user system to show "lifetime" impact of trips.
A compiled apk has been uploaded to the Github, try it out and let us know what you think! | ## Inspiration
Many of us tech enthusiasts have always been interested in owning an electric vehicle, however in my case like in India you can go 100s of miles without seeing a single charging point once you leave the big cities. In my case my dad was not ready to buy an electric car as its not even possible to travel from my home which is Bangalore to Manipal(Location of my University) as there aren't enough charging points on the way to make it. This gave me the idea for this project so that everyone in the future will be able to own an electric vehicle.
## What it does
Our application Elyryde allows owners of electric vehicles to find charging points on the way to their destination by using the map on the application. It also allows owners of electric vehicle charging points to list their charging point to generate revenue when the charging point is not being used.
This will also enable people to perform long distance road journeys as they would no longer have to worry about running out of charge on the way to their destination.
This app provides a push towards green and sustainable energy by making electric cars more accessible to people around the world.
## How we built it
Our application is built with Java for Android. We designed the application with authentication by email and password through firebase. We also set up a firebase realtime database to store longitude and latitude in order to plot them on the map. We also made use of Google maps api in order to plot the locations on the map and allow users to navigate to their nearest charging station.
## Challenges we ran into
The main challenge we faced was with the firebase integration since we were quite new to firebase.
We also fell short of time to build the profile page where the user could list his charging points.
## Accomplishments that we're proud of
We were able to contribute towards making a push for green sustainable environment where anyone can own an electric vehicle without any problems.
We hope that people in developing countries will soon be able to own electric vehicles without any problems.
## What we learned
Over the course of the hackathon we learnt about firebase integration with java. We also learnt about how much of a difference in carbon emissions can brought upon by making a switch away from fossil fuels and other polluting substances. Electric vehicles will help bring down pollution in many parts of the world.
## What's next for Elyryde
The app offers a beautiful solution towards the growing disparity in developing countries and electric vehicles. Machine Learning and Statical Analysis on the data collected has the potential in aiding corporate investors to Set-Up Charging Stations in strategic locations. It can allow high end investment as well as increase public utility. Something which our app also lacks is regulations, Creating a self-sustaining community of Electric Vehicle Users with some guidelines will further aid in democratizing the app. Finally, the app works towards sustainable development and hopefully more green-utility is can be added to it. | ## Inspiration
As college students learning to be socially responsible global citizens, we realized that it's important for all community members to feel a sense of ownership, responsibility, and equal access toward shared public spaces. Often, our interactions with public spaces inspire us to take action to help others in the community by initiating improvements and bringing up issues that need fixing. However, these issues don't always get addressed efficiently, in a way that empowers citizens to continue feeling that sense of ownership, or sometimes even at all! So, we devised a way to help FixIt for them!
## What it does
Our app provides a way for users to report Issues in their communities with the click of a button. They can also vote on existing Issues that they want Fixed! This crowdsourcing platform leverages the power of collective individuals to raise awareness and improve public spaces by demonstrating a collective effort for change to the individuals responsible for enacting it. For example, city officials who hear in passing that a broken faucet in a public park restroom needs fixing might not perceive a significant sense of urgency to initiate repairs, but they would get a different picture when 50+ individuals want them to FixIt now!
## How we built it
We started out by brainstorming use cases for our app and and discussing the populations we want to target with our app. Next, we discussed the main features of the app that we needed to ensure full functionality to serve these populations. We collectively decided to use Android Studio to build an Android app and use the Google Maps API to have an interactive map display.
## Challenges we ran into
Our team had little to no exposure to Android SDK before so we experienced a steep learning curve while developing a functional prototype in 36 hours. The Google Maps API took a lot of patience for us to get working and figuring out certain UI elements. We are very happy with our end result and all the skills we learned in 36 hours!
## Accomplishments that we're proud of
We are most proud of what we learned, how we grew as designers and programmers, and what we built with limited experience! As we were designing this app, we not only learned more about app design and technical expertise with the Google Maps API, but we also explored our roles as engineers that are also citizens. Empathizing with our user group showed us a clear way to lay out the key features of the app that we wanted to build and helped us create an efficient design and clear display.
## What we learned
As we mentioned above, this project helped us learn more about the design process, Android Studio, the Google Maps API, and also what it means to be a global citizen who wants to actively participate in the community! The technical skills we gained put us in an excellent position to continue growing!
## What's next for FixIt
An Issue’s Perspective
\* Progress bar, fancier rating system
\* Crowdfunding
A Finder’s Perspective
\* Filter Issues, badges/incentive system
A Fixer’s Perspective
\* Filter Issues off scores, Trending Issues | losing |
## Inspiration
Determined to create a project that was able to make impactful change, we sat and discussed together as a group our own lived experiences, thoughts, and opinions. We quickly realized the way that the lack of thorough sexual education in our adolescence greatly impacted each of us as we made the transition to university. Furthermore, we began to really see how this kind of information wasn't readily available to female-identifying individuals (and others who would benefit from this information) in an accessible and digestible manner. We chose to name our idea 'Illuminate' as we are bringing light to a very important topic that has been in the dark for so long.
## What it does
This application is a safe space for women (and others who would benefit from this information) to learn more about themselves and their health regarding their sexuality and relationships. It covers everything from menstruation to contraceptives to consent. The app also includes a space for women to ask questions, find which products are best for them and their lifestyles, and a way to find their local sexual health clinics. Not only does this application shed light on a taboo subject but empowers individuals to make smart decisions regarding their bodies.
## How we built it
Illuminate was built using Flutter as our mobile framework in order to be able to support iOS and Android.
We learned the fundamentals of the dart language to fully take advantage of Flutter's fast development and created a functioning prototype of our application.
## Challenges we ran into
As individuals who have never used either Flutter or Android Studio, the learning curve was quite steep. We were unable to even create anything for a long time as we struggled quite a bit with the basics. However, with lots of time, research, and learning, we quickly built up our skills and were able to carry out the rest of our project.
## Accomplishments that we're proud of
In all honesty, we are so proud of ourselves for being able to learn as much as we did about Flutter in the time that we had. We really came together as a team and created something we are all genuinely really proud of. This will definitely be the first of many stepping stones in what Illuminate will do!
## What we learned
Despite this being our first time, by the end of all of this we learned how to successfully use Android Studio, Flutter, and how to create a mobile application!
## What's next for Illuminate
In the future, we hope to add an interactive map component that will be able to show users where their local sexual health clinics are using a GPS system. | ## Inspiration
After looking at the Hack the 6ix prizes, we were all drawn to the BLAHAJ. On a more serious note, we realized that one thing we all have in common is accidentally killing our house plants. This inspired a sense of environmental awareness and we wanted to create a project that would encourage others to take better care of their plants.
## What it does
Poképlants employs a combination of cameras, moisture sensors, and a photoresistor to provide real-time insight into the health of our household plants. Using this information, the web app creates an interactive gaming experience where users can gain insight into their plants while levelling up and battling other players’ plants. Stronger plants have stronger abilities, so our game is meant to encourage environmental awareness while creating an incentive for players to take better care of their plants.
## How we built it + Back-end:
The back end was a LOT of python, we took a new challenge on us and decided to try out using socketIO, for a websocket so that we can have multiplayers, this messed us up for hours and hours, until we finally got it working. Aside from this, we have an arduino to read for the moistness of the soil, the brightness of the surroundings, as well as the picture of it, where we leveraged computer vision to realize what the plant is. Finally, using langchain, we developed an agent to handle all of the arduino info to the front end and managing the states, and for storage, we used mongodb to hold all of the data needed.
[backend explanation here]
### Front-end:
The front-end was developed with **React.js**, which we used to create a web-based game. We were inspired by the design of old pokémon games, which we thought might evoke nostalgia for many players.
## Challenges we ran into
We had a lot of difficulty setting up socketio and connecting the api with it to the front end or the database
## Accomplishments that we're proud of
We are incredibly proud of integrating our web sockets between frontend and backend and using arduino data from the sensors.
## What's next for Poképlants
* Since the game was designed with a multiplayer experience in mind, we want to have more social capabilities by creating a friends list and leaderboard
* Another area to explore would be a connection to the community; for plants that are seriously injured, we could suggest and contact local botanists for help
* Some users might prefer the feeling of a mobile app, so one next step would be to create a mobile solution for our project | ## Inspiration
Each living in a relatively suburban area, we are often quite confused when walking through larger cities. We can each associate with the frustration of not being able to find what seems to be even the simplest of things: a restroom nearby or a parking space we have been driving around endlessly to find. Unfortunately, we can also associate with the fear of danger present in many of these same cities. IntelliCity was designed to accommodate each one of these situations by providing users with a flexible, real-time app that reacts to the city around them.
## What it does
IntelliCity works by leveraging the power of crowdsourcing. Whenever users spot an object, event or place that fits into one of several categories, they can report it through a single button in our app. This is then relayed through our servers and other users on our app can view this report along with any associated images or descriptions, conveniently placed as a marker on a map.
## How we built it

IntelliCity was built using a variety of different frameworks and tools. Our front-end was designed using Flutter and the Google Maps API, which provided us with an efficient way to get geolocation data and place markers. Our backend was made using Flask and Google-Cloud.
## Challenges we ran into
Although we are quite happy with our final result, there were definitely a few hurdles we faced along the way. One of the most significant of these was properly optimizing our app for mobile devices, for which we were using Flutter, a relatively new framework for many of us. A significant challenge related to this was placing custom, location-dependent markers for individual reports. Another challenge we faced was transmitting the real-time data throughout our setup and having it finally appear on individual user accounts. Finally, a last challenge we faced was actually sending text messages to users when potential risks were identified in their area.
## Accomplishments that we're proud of
We are proud of getting a functional app for both mobile and web.
## What we learned
We learned a significant amount throughout this hackathon, about everything from using specific frameworks and APIS such as Flutter, Google-Maps, Flask and Twilio to communication and problem-solving skills.
## What's next for IntelliCity
In the future, we would like to add support for detailed analysis of specific cities. | winning |
## Inspiration
We are all a fan of Carrot, the app that rewards you for walking around. This gamification and point system of Carrot really contributed to its success. Carrot targeted the sedentary and unhealthy lives we were leading and tried to fix that. So why can't we fix our habit of polluting and creating greenhouse footprints using the same method? That's where Karbon comes in!
## What it does
Karbon gamifies how much you can reduce your CO₂ emissions by in a day. The more you reduce your carbon footprint, the more points you can earn. Users can then redeem these points at Eco-Friendly partners to either get discounts or buy items completely for free.
## How we built it
The app is created using Swift and Swift UI for the user interface. We also used HTML, CSS and Javascript to make a web app that shows the information as well.
## Challenges we ran into
Initially, when coming up with the idea and the economy of the app, we had difficulty modelling how points would be distributed by activity. Additionally, coming up with methods to track CO₂ emissions conveniently became an integral challenge to ensure a clean and effective user interface. As for technicalities, cleaning up the UI was a big issue as a lot of our time went into creating the app as we did not have much experience with the language.
## Accomplishments that we're proud of
Displaying the data using graphs
Implementing animated graphs
## What we learned
* Using animation in Swift
* Making Swift apps
* Making dynamic lists
* Debugging unexpected bugs
## What's next for Karbon
A fully functional Web app along with proper back and forth integration with the app. | ## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainability and environmental consciousness.
## What it does 🌎
Inspired by BeReal, the most popular app in 2022, BeGreen is your go-to platform for celebrating and sharing acts of sustainability. Everytime you make a sustainable choice, snap a photo, upload it, and you’ll be rewarded with Green points based on how impactful your act was! Compete with your friends to see who can rack up the most Green points by performing more acts of sustainability and even claim prizes once you have enough points 😍.
## How we built it 🧑💻
We used React with Javascript to create the app, coupled with firebase for the backend. We also used Microsoft Azure for computer vision and OpenAI for assessing the environmental impact of the sustainable act in a photo.
## Challenges we ran into 🥊
One of our biggest obstacles was settling on an idea as there were so many great challenges for us to be inspired from.
## Accomplishments that we're proud of 🏆
We are really happy to have worked so well as a team. Despite encountering various technological challenges, each team member embraced unfamiliar technologies with enthusiasm and determination. We were able to overcome obstacles by adapting and collaborating as a team and we’re all leaving uOttahack with new capabilities.
## What we learned 💚
Everyone was able to work with new technologies that they’ve never touched before while watching our idea come to life. For all of us, it was our first time developing a progressive web app. For some of us, it was our first time working with OpenAI, firebase, and working with routers in react.
## What's next for BeGreen ✨
It would be amazing to collaborate with brands to give more rewards as an incentive to make more sustainable choices. We’d also love to implement a streak feature, where you can get bonus points for posting multiple days in a row! | ## Inspiration
The majority of cleaning products in the United States contain harmful chemicals. Although many products pass EPA regulations, it is well known that many products still contain chemicals that can cause rashes, asthma, allergic reactions, and even cancer. It is important that the public has easy access to information of the chemicals that may be harmful to them as well as the environment.
## What it does
Our app allows users to scan a product's ingredient label and retrieves information on which ingredients to avoid for the better of the environment as well as their own health.
## How we built it
We used Xcode and Swift to design the iOS app. We then used Vision for iOS to detect text based off a still image. We used a Python scrapper to collect data from ewg.org, providing the product's ingredients as well as the side affects of certain harmful additives.
## Challenges we ran into
We had very limited experience for the idea that we have in developing an iOS app but, we wanted to challenge ourselves. The challenges the front end had were incorporating the camera feature and the text detector into a single app. As well as trying to navigate the changes between the newer version of Swift 11 from older versions. For our backend members, they had difficulties incorporating databases from Microsoft/Google, but ended up using JSON.
## Accomplishments that we're proud of
We are extremely proud of pushing ourselves to do something we haven't done before. Initially, we had some doubt in our project because of how difficult it was. But, as a team we were able to help each other along the way. We're very proud of creating a single app that can do both a camera feature and Optical Character Recognition because as we found out, it's very complicated and error prone. Additionally, for data scrapping, even though the HTML code was not consistent we managed to successfully scrap the necessary data by taking all corner cases into consideration with 100% success rate from more than three thousand HTML files and we are very proud of it.
## What we learned
Our teammates working in the front end learned how to use Xcode and Swift in under 24 hours. Our backend team members learned how to scrap the data from a website for the first time as well. Together, we learned how to alter our original expectations of our final product based on time constraint.
## What's next for Ingredient Label Scanner
Currently our project is specific to cleaning products, however in the future we would like to incorporate other products such as cosmetics, hair care, skin care, medicines, and food products. Additionally, we hope to alter the list of ingredients in a more visual way so that users can clearly understand which ingredients are more dangerous than others. | winning |
During the COVID-19 pandemic, time spent at home, time spent not exercising, and time spent alone has been at an all time high. This is why, we decided to introduce FITNER to the other fitness nerds like ourselves who struggle to find others to participate in exercise with. As we all know that it is easier to stay healthy, and happy with friends.
We created Fitner as a way to help you find friends to go hiking with, play tennis or even go bowling with! It can be difficult to practice the sport that you love when none of your existing friends are interested, and you do not have the time commitment to join a club. Fitner solves this issue by bridging the gap between fitness nerds who want to reach their potential but don't have the community to do so.
Fitner is a mobile application built with React Native for an iOS and Android front-end, and Google Cloud / Firebase as the backend. We were inspired by the opportunity to use Google Cloud platforms in our application, so we decided to do something we had never done before, which was real-time communication. Although it was our first time working with real-time communication, we found ourselves, in real-time, overtaking the challenges that came along with it. We are very proud of our work ethic, our resulting application and dedication to our first ever hackathon.
Future implementations of our application can include public chat rooms that users may join and plan public sporting events with, and a more sophisticated algorithm which would suggest members of the community that are at a similar skill and fitness goals as you. With FITNER, your fitness goals will be met easily and smoothly and you will meet lifelong friends on the way! | ## Inspiration
Fashion has always been a world that seemed far away from tech. We want to bridge this gap with "StyleList", which understands your fashion within a few swipes and makes personalized suggestions for your daily outfits. When you and I visit the Nordstorm website, we see the exact same product page. But we could have completely different styles and preferences. With Machine Intelligence, StyleList makes it convenient for people to figure out what they want to wear (you simply swipe!) and it also allows people to discover a trend that they favor!
## What it does
With StyleList, you don’t have to scroll through hundreds of images and filters and search on so many different websites to compare the clothes. Rather, you can enjoy a personalized shopping experience with a simple movement from your fingertip (a swipe!). StyleList shows you a few clothing items at a time. Like it? Swipe left. No? Swipe right! StyleList will learn your style and show you similar clothes to the ones you favored so you won't need to waste your time filtering clothes. If you find something you love and want to own, just click “Buy” and you’ll have access to the purchase page.
## How I built it
We use a web scrapper to get the clothing items information from Nordstrom.ca and then feed these data into our backend. Our backend is a Machine Learning model trained on the bank of keywords and it provides next items after a swipe based on the cosine similarities between the next items and the liked items. The interaction with the clothing items and the swipes is on our React frontend.
## Accomplishments that I'm proud of
Good teamwork! Connecting the backend, frontend and database took us more time than we expected but now we have a full stack project completed. (starting from scratch 36 hours ago!)
## What's next for StyleList
In the next steps, we want to help people who wonders "what should I wear today" in the morning with a simple one click page, where they fill in the weather and plan for the day then StyleList will provide a suggested outfit from head to toe! | ## Inspiration
The inspiration for FitBot came from the desire to help individuals improve their workout routines and achieve better fitness results. Many people struggle with maintaining proper form during exercises, which can lead to injuries and less effective workouts. FitBot aims to provide personalized feedback and expert advice, empowering users to enhance their performance, avoid injuries, and reach their fitness goals efficiently. By leveraging technology, FitBot makes professional-grade analysis accessible to everyone, ensuring that fitness enthusiasts of all levels can benefit from tailored motion improvement tips.
## What it does
The project is a **SwiftUI**-based fitness tracking app called "FitBot." It provides users with a visual representation of their performance through progress rings and offers personalized feedback based on their ratings. The app displays an overall rating along with detailed evaluations and suggestions for improvement, aiming to help users enhance their fitness routines and achieve their goals. The user interface is designed to be intuitive, with a sleek top bar and easy-to-read feedback messages, making it a valuable tool for anyone looking to track and improve their fitness performance.
## How we built it
The project is a SwiftUI-based fitness tracking app called "FitBot," designed to provide users with a visual representation of their performance through progress rings and personalized feedback based on their ratings. The app preprocesses input videos by converting them into GIF files, utilizes AWS Bedrock to call the Claude 3.5 model, and builds prompts to ask Claude for ratings, overall evaluations, and potential improvements. The user interface includes a sleek top bar and easy-to-read feedback messages, aiming to help users enhance their fitness routines and achieve their goals through clear, actionable insights.
## Challenges we ran into
During the development of FitBot, we faced several challenges that tested our skills and patience. We spent hours grappling with git workflow issues, such as resolving merge conflicts, managing diverged branches, and recovering lost files, which was crucial for smooth collaboration but quite time-consuming. Integrating video recording and storage using Swift and SwiftUI was another significant hurdle. Ensuring seamless interaction with the device's camera while maintaining optimal performance and a great user experience required meticulous attention to detail. Communicating with the backend also posed challenges, as we needed to reliably upload videos, receive detailed analysis, and handle any errors or interruptions gracefully. This involved extensive testing and debugging to create a robust and efficient system.
## Accomplishments that we're proud of
In this project, we used **AWS Bedrock Claude** to power our software and website designed to help people correct their fitness movements. This application not only effectively assists beginners in learning new exercises but also prevents injuries. We are very proud that this application can truly address users' pain points and protect their health. What is particularly impressive is that, by utilizing existing large models which only take in images, we can efficiently analyze videos to achieve this goal. With this application, users can engage in fitness training more safely and scientifically, thereby improving workout results and reducing the risk of injury.
## What we learned
We learned about using SwiftUI for creating the visual parts of apps on Apple devices. SwiftUI makes it easier to design how apps look with less code, and we can see our changes as we make them. We also learned how the part of the app you see and interact with (the front end) talks to the part that handles data and operations (the back end). This communication is important for making the app work smoothly and quickly. Plus, we picked up some basic design skills to make our apps look good and work well. These skills are important for building apps that people enjoy using.
## What's next for FitBot
We have exciting plans for the future of FitBot. Our next steps include deeply developing the app by integrating a regular chatbot system focused on fitness-related conversations. We aim to enhance the result page with improved visualization and interactivity, making the feedback more engaging and user-friendly.
**Furthermore, we want to expand the application to cover other sports and activities, including medical rehabilitation. We also plan to incorporate more tailored training programs and guidance for users of different skill levels, ensuring that everyone, from beginners to advanced athletes, can benefit from FitBot.** | winning |
## Inspiration
Inspired by personal experience of commonly getting separated in groups and knowing how inconvenient and sometimes dangerous it can be, we aimed to create an application that kept people together. We were inspired by how interlinked and connected we are today by our devices and sought to address social issues while using the advancements in decentralized compute and communication. We also wanted to build a user experience that is unique and can be built upon with further iterations and implementations.
## What it does
Huddle employs mesh networking capability to maintain a decentralized network among a small group of people, but can be scaled to many users. By having a mesh network of mobile devices, Huddle manages the proximity of its users. When a user is disconnected, Huddle notifies all of the devices on its network, thereby raising awareness, should someone lose their way.
The best use-case for Huddle is in remote areas where cell-phone signals are unreliable and managing a group can be cumbersome. In a hiking scenario, should a unlucky hiker choose the wrong path or be left behind, Huddle will reduce risks and keep the team together.
## How we built it
Huddle is an Android app built with the RightMesh API. With many cups of coffee, teamwork, brainstorming, help from mentors, team-building exercises, and hours in front of a screen, we produced our first Android app.
## Challenges we ran into
Like most hackathons, our first challenge was deciding on an idea to proceed with. We employed the use of various collaborative and brainstorming techniques, approached various mentors for their input, and eventually we decided on this scalable idea.
As mentioned, none of us developed an Android environment before, so we had a large learning curve to get our environment set-up, developing small applications, and eventually building the app you see today.
## Accomplishments that we're proud of
One of our goals was to be able to develop a completed product at the end. Nothing feels better than writing this paragraph after nearly 24 hours of non-stop hacking.
Once again, developing a rather complete Android app without any developer experience was a monumental achievement for us. Learning and stumbling as we go in a hackathon was a unique experience and we are really happy we attended this event, no matter how sleepy this post may seem.
## What we learned
One of the ideas that we gained through this process was organizing and running a rather tightly-knit developing cycle. We gained many skills in both user experience, learning how the Android environment works, and how we make ourselves and our product adaptable to change. Many design changes occured, and it was great to see that changes were still what we wanted and what we wanted to develop.
Aside from the desk experience, we also saw many ideas from other people, different ways of tackling similar problems, and we hope to build upon these ideas in the future.
## What's next for Huddle
We would like to build upon Huddle and explore different ways of using the mesh networking technology to bring people together in meaningful ways, such as social games, getting to know new people close by, and facilitating unique ways of tackling old problems without centralized internet and compute.
Also V2. | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | ## Inspiration
We wanted to try some new tech. Gain more experience. Learn as much as we could for our first hackathon.
Pebble seemed like the way to go.
We wanted to build an app for the Pebble smartwatch that takes advantage of its fitness capabilities. We also know that we are way more likely to commit (a follow through) to a workout if you have a friend with you, but sometimes it isn't always feasible to run with other people in the same location. We intended this app to let you virtually run with your friends (a race!).
## What it does
This app was designed to track your speed, and distance as you run. If you chose, you can "run with a friend". This app was supposed to collect real time data for both you and your friend. On your screen you would see your stats for the run as well as your friends; allowing for a race between the two of you without your friend being physically with you.
## How we built it
Built mainly in cloudpebble, tested with two pebble devices and android smartphones.
## Challenges we ran into
We had a lot of difficulty working with the gps and using that to find the distance traveled (we found it was not accurate enough). We also struggled with integrating the script written in the pebble java-script environment with the android side of the development (which was supposed to handle the data transfer between you and your friend).
## Accomplishments that I'm proud of
How fast we learned and our perseverance - sticking with a project and trying different strategies to accomplish a problem. A lot (understatement) of problem solving was involved.
## What I learned
Learned javascript, Android Studio, cloudpebble, pebble.js, and a whole lot of teamwork. We learned that pebble development has many facets, and although C is tougher, it makes integration easier and allows far more doors to be opened. We learned how complicated android app development can quickly become, and that simple solutions are a developers best friend.
## What's next for Running Together
The next step for Running Together is to create a catchy one word name like Facebook or Twitter. Also we need to add many core features and implement actual real time data. Finally, we need way more flashy features and microtransactions to keep the loyal user base hooked. | partial |
## Inspiration / What it does
Typical metrics designed to determine financial responsibility are antiquated. They rely on big credit companies and existing financial history. Voquality tries to level the playing field by allowing users to opt-in to use machine learning and language analysis to develop a profile measuring an individual's financial responsibility across a range of metrics.
## How we built it
Voquality is built as a mobile application that periodically records audio during an individuals awake hours. This data is housed on the user's phone and is password encrypted. At the end of the use period, the user is presented the data and has the choice whether to send the final metrics to the credit company/insurance company.
## Challenges we ran into
Linking the APIs together to do sentiment analysis and a method of scoring audio snippets.
## Accomplishments that we're proud of
Making strides to make financial opportunities more accessible to everyone.
## What we learned
How quickly prototype an application that has potential impact when respecting user privacy and data.
## What's next for Voquality
Improve the user's control of their data to ensure they choose who gets to use it and when. | ## Inspiration
As a group of passionate millennials, we look to support companies that align with our personal values. In addition, we have investment ideas that we get from interactions in our everyday lives. Building a portfolio of socially responsible companies that includes these ideas and testing those ideas, is a difficult process.
## How does it work?
We took a simplified approach by putting the power into your hands, literally. You can seamlessly start with an investment ideas with our Android app. From there our machine learning trained models map those ideas to companies around the idea. A portfolio is then built which you can adjust and view back tested performance on. There is also the moral compass rating which tells you how ethical the business is and other relevant portfolio metrics.
## What does it do?
* Uses an investment theme you have to curate a portfolio of companies relevant to it
* Provides a score which tells you how ethical a business is for investment considerations
* Allows you to backtest portfolios and see how they perform over time
* Additional portfolio metrics are provided using the BlackRock API to tell you risk and volatility
## Challenges
* Storing historical price data for all NYSE and NASDAQ listed equities and quickly accessing it from the database for charting
* Creating the algorithms to map ideas to relevant companies with accuracy
* Using general information from websites to do sentiment analysis and generate an ethical score
* Large amounts of keyword search data is hard from scraped website
* Working with Android UI components and getting it identical to our mockups
* Incorporating dates properly for use with the time series data | ## Inspiration
Frustrating and intimidating banking experience leads to loss of customers and we wanted to change that making banking fun and entertaining. Specifically, senior citizens find it harder to navigate online bank profiles and know their financial status. We decided to come up with an android app that lets you completely control your bank profile either using your voice or the chat feature. Easily integrate our app into your slack account and chat seamlessly.
## What it does
Vocalz allows you to control your online bank profile easily using either chat or voice features. Easily do all basic bank processes like sending money, ordering a credit card, knowing balances and so much more just using few voices or text commands. Unlike our competitors, we give personalized chat experience for our customers. In addition, Vocalz also recommends products from the bank they use according to their financial status as well as determine eligibility for loans. The future of banking is digital and we thrive to make the world better and convenient.
Slack integration makes it convenient for working professionals to easily access bank data within slack itself.
Join the workspace and use @ to call our Vocalzapp. Experience the next generation of banking directly from your slack account.
<https://join.slack.com/t/vocalzzz/shared_invite/enQtOTE0NTI3ODg2NjMxLTdmMWVjODc1YWMwNWQ0ZjI2MDJkODAyYzI2YTZiMmEzYjA3NmExYzZlNjM5Yzg0NGVjY2VlYjE5OGJhNGFmZTM>
Current Features
Know balance
Pay bills
Get customized product information from respective banks
Order credit cards/financial products
Open banking accounts
Transaction history
You can use either voice or chat features depending on your privacy needs.
## How we built it
We used Plaid API to get financial data from any bank in the world and we integrated it within our android app. After logging in securely using your bank credentials, Vocalz automatically customizes your voice-enabled and chat features according to the data provided by the bank. In our real product, We trained the IBM Watson chatbot with hundreds of bank terminology and used Dialogflow to create a seamless conversational experience for the customers. IBM Watson uses machine learning to understand the customer's needs and then responds accordingly regardless of spelling or grammar errors. For voice-enabled chat, we will use google's speech-to-text API which sends the information to IBM Watson and Google text-audio API will return the response as audio. The app will be deployed in the Google Cloud because of its high-security features.
For demo purposes and time constraints, we used Voiceflow to demonstrate how our voice-enabled features work.
## Challenges we ran into
Getting to know and learn the IBM Watson environment was very challenging for us as we don't have much experience in machine learning or dialogue flow. We also needed to find and research different API's required for our project. Training IBM Watson with specific and accurate words was very time consuming and we are proud of its present personalized features.
## Accomplishments that we're proud of
We ran into several challenges and we made sure we are on the right path. We wanted to make a difference in the world and we believe we did it.
## What we learned
We learned how to make custom chatbots and bring customized experience based on the app's needs. We learned different skills related to API's, android studio, machine learning within 36 hours of hacking.
## What's next for Vocalz RBC
Further training of our chatbot with more words making the app useful in different situations.
Notifications for banking-related deadlines, transactions
Create a personalized budget
Comparing different financial products and giving proper suggestions and recommendations.
Integrate VR/AR customer service experience | losing |
## Inspiration
We've always wanted to be able to point our phone at an object and know what that object is in another language. So we built that app.
## What it does
Point your phone's camera towards an object, and it will identify that object for you, using the Inception neural network. We translate the object from a source language (English) to a target language, usually a language that the user wants to learn using Google Translation API. Using AR Kit, we depict the image name, in both English and a foreign language, on top of the object. In order to help you find the word, we help you see some different ways of using that word in a sentence.
All in all, the app is a great resource for learning how to pronounce and learn about different objects in different languages.
## How we built it
We built the frontend mobile app in Swift, used AR Kit to place words on top of an object, and used Google Cloud functions to access APIs.
## Challenges we ran into
Dealing with Swift frontend frames, and getting authentication keys to work properly for APIs.
## Accomplishments that we're proud of
We built an app looks awesome with AR Kit, and has great functionality. We took an app idea and worked together to make it come to life.
## What we learned
We learned in greater depth how Swift 4 works, how to use AR Kit, and how easy it is to use Google Cloud functions to offload a server-like computation away from your app without having to set up a server.
## What's next for TranslateAR
IPO in December | ## Inspiration
It’s no secret that the COVID-19 pandemic ruined most of our social lives. ARoom presents an opportunity to boost your morale by supporting you to converse with your immediate neighbors and strangers in a COVID safe environment.
## What it does
Our app is designed to help you bring your video chat experience to the next level. By connecting to your webcam and microphone, ARoom allows you to chat with people living near you virtually. Coupled with an augmented reality system, our application also allows you to view 3D models and images for more interactivity and fun. Want to chat with new people? Open the map offered by ARoom to discover the other rooms available around you and join one to start chatting!
## How we built it
The front-end was created with Svelte, HTML, CSS, and JavaScript. We used Node.js and Express.js to design the backend, constructing our own voice chat API from scratch. We used VS Code’s Live Share plugin to collaborate, as many of us worked on the same files at the same time. We used the A-Frame web framework to implement Augmented Reality and the Leaflet JavaScript library to add a map to the project.
## Challenges we ran into
From the start, Svelte and A-Frame were brand new frameworks for every member of the team, so we had to devote a significant portion of time just to learn them. Implementing many of our desired features was a challenge, as our knowledge of the programs simply wasn’t comprehensive enough in the beginning. We encountered our first major problem when trying to implement the AR interactions with 3D models in A-Frame. We couldn’t track the objects on camera without using markers, and adding our most desired feature, interactions with users was simply out of the question. We tried to use MediaPipe to detect the hand’s movements to manipulate the positions of the objects, but after spending all of Friday night working on it we were unsuccessful and ended up changing the trajectory of our project.
Our next challenge materialized when we attempted to add a map to our function. We wanted the map to display nearby rooms, and allow users to join any open room within a certain radius. We had difficulties pulling the location of the rooms from other files, as we didn’t understand how Svelte deals with abstraction. We were unable to implement the search radius due to the time limit, but we managed to add our other desired features after an entire day and night of work.
We encountered various other difficulties as well, including updating the rooms when new users join, creating and populating icons on the map, and configuring the DNS for our domain.
## Accomplishments that we're proud of
Our team is extremely proud of our product, and the effort we’ve put into it. It was ¾ of our members’ first hackathon, and we worked extremely hard to build a complete web application. Although we ran into many challenges, we are extremely happy that we either overcame or found a way to work around every single one. Our product isn’t what we initially set out to create, but we are nonetheless delighted at its usefulness, and the benefit it could bring to society, especially to people whose mental health is suffering due to the pandemic. We are also very proud of our voice chat API, which we built from scratch.
## What we learned
Each member of our group has learned a fair bit over the last 36 hours. Using new frameworks, plugins, and other miscellaneous development tools allowed us to acquire heaps of technical knowledge, but we also learned plenty about more soft topics, like hackathons and collaboration. From having to change the direction of our project nearly 24 hours into the event, we learned that it’s important to clearly define objectives at the beginning of an event. We learned that communication and proper documentation is essential, as it can take hours to complete the simplest task when it involves integrating multiple files that several different people have worked on. Using Svelte, Leaflet, GitHub, and Node.js solidified many of our hard skills, but the most important lessons learned were of the other variety.
## What's next for ARoom
Now that we have a finished, complete, usable product, we would like to add several features that were forced to remain in the backlog this weekend. We plan on changing the map to show a much more general location for each room, for safety reasons. We will also prevent users from joining rooms more than an arbitrary distance away from their current location, to promote a more of a friendly neighborhood vibe on the platform. Adding a video and text chat, integrating Google’s Translation API, and creating a settings page are also on the horizon. | ## Inspiration
Languages are hard to learn and pronunciation is often especially difficult, which all of us had experienced first-hand. We decided to create a real-time augmented reality language learning game called Ceci ("this" in French, pronounced as say-see).
## What it does
Ceci quizzes the user on the vocabulary of the language they are studying based on what they see in the world. It highlights the word they are being quizzed on with a box around the corresponding object and recognizes it with machine learning. The user says the word, and Ceci uses voice recognition to detect whether or not they are correct. To incentivize the user, there is also a point system.
## How we built it
Using CoreML for machine learning, Ceci is able to detect and label possible objects to quiz the user on. Then, we used the built-in Xcode speech recognition tool to check the user's answers. In general, everything was written in Swift, including the point system that rewards correct answers.
## Challenges we ran into
We initially planned to use many ARKit features, but quickly discovered that the quality of the classification in its object detection is lacking. Object detection is central to Ceci, so we were forced to find something else. Instead, we used another machine learning library, and it was a bit of a challenge to go through the non-documented issues and limitations, due to the relative novelty of this technology.
## Accomplishments that we're proud of
We are proud that we were able to combine various exciting technologies into Ceci. For example, we used a scalable, mobile machine learning library that none of us have ever used before, and incorporated it along an Apple-developed speech-to-text transcription.
## What we learned
Most of the team wasn't familiar with Swift specifically and iOS development in general, and learned them to develop features like the points system. None of us had done iOS augmented reality before so we had to experiment with a lot of platforms and ideas to decide what was feasible. Also, most of the team didn't know most of the others when we started, so we learned how to work together most efficiently and to leverage our strengths.
## What's next for Ceci
We intend to and can pretty easily add more languages to Ceci such as German, Spanish, Russian, and Chinese (including Mandarin and Cantonese). We also want to make Ceci more social, adding support for sharing words learned and a leader board. In addition, building on the point system to make points redeemable for custom themes and improving the choice of quiz objects based on spaced repetition learning are major features we hope to implement. | partial |
## Inspiration
Have you ever crammed for an exam the night before?
Of course you have. So have we.
This application was inspired by the caffeine-filled all nighters we've pulled throughout our years in University. Katchup is an application to help you... well, catch up! Use Katchup to speed through lectures and only watch the content that you're interested in.
## What it does
Katchup allows you to search through #topics within a video.
For example, you're cramming for your COMP202 course and you can't seem to figure out what arrays do. Go through all your lectures and type '#arrays' in the search bar, and let Ketchup filter through the videos and give you only the segments of the video where arrays are mentioned.
## What's next for Katchup
Text summarization - let us summarize the entire lecture for you! Learn key topics at a glance.
Commenting feature - you can collaborate with other students
Video annotations | ## Inspiration
Lectures all around the world last on average 100.68 minutes. That number goes all the way up to 216.86 minutes for art students. As students in engineering, we spend roughly 480 hours a day listening to lectures. Add an additional 480 minutes for homework (we're told to study an hour for every hour in a lecture), 120 minutes for personal breaks, 45 minutes for hygeine, not to mention tutorials, office hours, and et. cetera. Thinking about this reminded us of the triangle of sleep, grades and a social life-- and how you can only pick two. We felt that this was unfair and that there had to be a way around this. Most people approach this by attending lectures at home. But often, they just put lectures at 2x speed, or skip sections altogether. This isn't an efficient approach to studying in the slightest.
## What it does
Our web-based application takes audio files- whether it be from lectures, interviews or your favourite podcast, and takes out all the silent bits-- the parts you don't care about. That is, the intermediate walking, writing, thinking, pausing or any waiting that happens. By analyzing the waveforms, we can algorithmically select and remove parts of the audio that are quieter than the rest. This is done over our python script running behind our UI.
## How I built it
We used PHP/HTML/CSS with Bootstrap to generate the frontend, hosted on a DigitalOcean LAMP droplet with a namecheap domain. On the droplet, we have hosted an Ubuntu web server, which hosts our python file which gets run on the shell.
## Challenges I ran into
For all members in the team, it was our first time approaching all of our tasks. Going head on into something we don't know about, in a timed and stressful situation such as a hackathon was really challenging, and something we were very glad that we persevered through.
## Accomplishments that I'm proud of
Creating a final product from scratch, without the use of templates or too much guidance from tutorials is pretty rewarding. Often in the web development process, templates and guides are used to help someone learn. However, we developed all of the scripting and the UI ourselves as a team. We even went so far as to design the icons and artwork ourselves.
## What I learned
We learnt a lot about the importance of working collaboratively to create a full-stack project. Each individual in the team was assigned a different compartment of the project-- from web deployment, to scripting, to graphic design and user interface. Each role was vastly different from the next and it took a whole team to pull this together. We all gained a greater understanding of the work that goes on in large tech companies.
## What's next for lectr.me
Ideally, we'd like to develop the idea to have much more features-- perhaps introducing video, and other options. This idea was really a starting point and there's so much potential for it.
## Examples
<https://drive.google.com/drive/folders/1eUm0j95Im7Uh5GG4HwLQXreF0Lzu1TNi?usp=sharing> | # Highlights
A product of [YHack '16](http://www.yhack.org/). Built by Aaron Vontell, Ali Benlalah & Cooper Pellaton.
## Table of Contents
* [Overview](#overview)
* [Machine Learning and More](#machine-learning-and-more)
* [Our Infrastructure](#our-infrastructure)
* [API](#api)
## Overview
The first thing you're probably thinking is what this ambiguiously named application is, and secondly, you're likely wondering why it has any significance. Firstly, Highlights is the missing component of your YouTube life, and secondly it's important because we leverage Machine Learning to find out what content is most important in a particular piece of media unlike it has ever been done before.
Imagine this scenario: you subscribe to 25+ YouTube channels but over the past 3 weeks you simply haven't had the time to watch videos because of work. Today, you decide that you want to watch one of your favorite vloggers, but realize you might lack the context to understand what has happened in her/his life since you last watched which lead her/him to this current place. Here enters Highlights. Simply download the Android application, log in with your Google credentials and you will be able to watch the so called *highlights* of your subscriptions for all of the videos which you haven't seen. Rather than investing hours in watching your favorite vlogger's past weeks worth of videos, you can get caught up in 30 seconds - 1 minute by simply being presented with all of the most important content in those videos in one place, seamlessly.
## Machine Learning and More
Now that you understand the place and signifiance of Highlights, a platform that can distill any media into bite sized chunks that can be consumed quickly in the order of their importance, it is important to explain the technical details of how we achieve such a gargantuant feat.
Let's break down the pipeline.
1. We start by accessing your Google account within the YouTube scope and get a list of your current subscriptions, 'activities' such as watched videos, comments, etc., your recommended videos and your home feed.
2. We take this data and extract the key features from it. Some of these include:
* The number of videos watched on a particular channel.
* The number of likes/dislikes you have and the categories on which they center.
* The number of views a particular video has/how often you watch videos after they have been posted.
* Number of days after publication. This is most important in determing the signficiance of a reccomended video to a particular user.
We go about this process for every video that the user has watched, or which exists in his or her feed to build a comprehensive feature set of the videos that are in their own unique setting.
3. We proceed by feeding the data from the aforementioned investigation and probabilities by then generating a new machine learning model which we use to determine the likelihood of a user watching any particular reccomended video, etc.
4. For each video in the set we are about to iterate over, the video is either a recomended watch, or a video in the user's feed which she/he has not seen. They key to this process is a system we like to call 'video quanitization'. In this system we break each video down into it's components. We look at the differences between images and end up analyzing something near to every other 2, 3, or 4 frames in a video. This reduces the size of the video that we need to analyze while ensuring that we don't miss anything important. As you will not here, a lot of the processes we undertake have bases in very comprehensive and confusing mathematics. We've done our best to keep math out of this, but know that one of the most important tools in our toolset is the exponential moving average.
5. This is the most important part of our entire process, the scene detection. To distill this down to it's most basic principles we use features like lighting, edge/shape detection and more to determine how similar or different every frame is from the next. Using this methodology of trying to find the frames that are different we coin this change in setting a 'scene'. Now, 'scenes' by themselves are not exciting but coupled with our knowledge of the context of the video we are analyzing we can come up with very apt scenes. For instance, in a horror movie we know that we would be looking for something like 5-10 seconds in differences between the first frame of that series and the last frame; this is what is referred to as a 'jump' or 'scare' cut. So using our exponential moving average, and background subtraction we are able to figure out the changes in between, and validate scenes.
6. We pass this now deconstructed video into the next part of our pipeline where we will generate unique vectors for each of them that will be used in the next stage. What we are looking for here is the key features that define a frame. We are trying to understand, for example, what makes a 'jump' cut a 'jump' cut. Features that we are most commonly looking include
* Intensity of an analyzed area.
+ EX: The intensity of a background coloring vs edges, etc.
* The length of each scence.
* Background.
* Speed.
* Average Brightness
* Average background speed.
* Position
* etc.
Armed with this information we are able to derive a unqiue column vector for each scence which we will then feed into our neural net.
7. The meat and bones of our operation: the **neural net**! What we do here is not terribly complicated. At it's most basic principles, we take each of the above column vectors and feed it into this specialized machine learning model. What we are looking for is to derive a sort order for these features. Our initial training set, a group of 600 YouTube videos which @Ali spent a significant amount of time training, is used to help to advance this net. The gist of what we are trying to do is this: given a certain vector, we want to determine it's signifiance in the context of the YouTube univerise in which each of our users lives. To do this we abide by a semi-supervised learning model in which we are looking over the shoulder of the model to check the output. As time goes on, this model begins to tweak it's own parameters and produce the best possible output given any input vector.
8. Lastly, now having a sorted order of every scene in a user's YouTube universe, we go about reconstructing the top 'highlights' for each user. IE in part 7 of our pipeline we figured out which vectors carried the greatest weight. Now we want to turn these back into videos that the user can watch, quickly, and derive the greatest meaning from. Using a litany of Google's APIs we will turn the videoIds, categories, etc into parameterized links which the viewer is then shown within our application.
## Our Infrastructure
Our service is currently broken down into the following core components:
* Highlights Android Application
+ Built and tested on Android 7.0 Nougat, and uses the YouTube Android API Sample Project
+ Also uses various open source libraries (OkHTTP, Picasso, ParallaxEverywhere, etc...)
* Highlights Web Service (Backs the Pipeline)
* The 'Highlighter' or rather our ML component
## API
### POST
* `/api/get_subscriptions`
This requires the client to `POST` a body of the nature below. This will then trigger the endpoint to go and query the YouTube API for the user's subscriptions, and then build a list of the most recent videos which he/she has not seen yet.
```
{
"user":"Cooper Pellaton"
}
```
* `/api/get_videos`
*DEPRECATED*. This endpoint requires the client to `POST` a body similar to that below and then will fetch the user's most recent activity in list form from the YouTube API.
```
{
"user":"Cooper Pellaton"
}
```
### GET
* `/api/fetch_oauth`
So optimally, what should happen when you call this method is that the user should be prompted to enter her/his Google credentials to authorize the application to then be able to access her/his YouTube account.
- The way that this is currently architected, the user's entrance into our platform will immediately trigger learning to occur on their videos. We have since *DEPRECATED* our ML training endpoint in favor of one `GET` endpoint to retrieve this info.
* `/api/fetch_subscriptions`
To get the subscriptions for a current user in list form simply place a `GET` to this endpoint. Additionally, a call here will trigger the ML pipeline to begin based on the output of the subscriptions and user data.
* `/api/get_ml_data`
For each user there is a queue of their Highlights. When you query this endpoint the response will be the return of a dequeue operation on said queue. Hence, you are guaranteed to never have overlap or miss a video.
- To note: in testing we have a means to bypass the dequeue and instead append, constantly, directly to the queue so that you can ensure you are retrieving the appropriate response. | partial |
## Inspiration
One of the greatest challenges facing our society today is food waste. From an environmental perspective, Canadians waste about *183 kilograms of solid food* per person, per year. This amounts to more than six million tonnes of food a year, wasted. From an economic perspective, this amounts to *31 billion dollars worth of food wasted* annually.
For our hack, we wanted to tackle this problem and develop an app that would help people across the world do their part in the fight against food waste.
We wanted to work with voice recognition and computer vision - so we used these different tools to develop a user-friendly app to help track and manage food and expiration dates.
## What it does
greenEats is an all in one grocery and food waste management app. With greenEats, logging your groceries is as simple as taking a picture of your receipt or listing out purchases with your voice as you put them away. With this information, greenEats holds an inventory of your current groceries (called My Fridge) and notifies you when your items are about to expire.
Furthermore, greenEats can even make recipe recommendations based off of items you select from your inventory, inspiring creativity while promoting usage of items closer to expiration.
## How we built it
We built an Android app with Java, using Android studio for the front end, and Firebase for the backend. We worked with Microsoft Azure Speech Services to get our speech-to-text software working, and the Firebase MLKit Vision API for our optical character recognition of receipts. We also wrote a custom API with stdlib that takes ingredients as inputs and returns recipe recommendations.
## Challenges we ran into
With all of us being completely new to cloud computing it took us around 4 hours to just get our environments set up and start coding. Once we had our environments set up, we were able to take advantage of the help here and worked our way through.
When it came to reading the receipt, it was difficult to isolate only the desired items. For the custom API, the most painstaking task was managing the HTTP requests. Because we were new to Azure, it took us some time to get comfortable with using it.
To tackle these tasks, we decided to all split up and tackle them one-on-one. Alex worked with scanning the receipt, Sarvan built the custom API, Richard integrated the voice recognition, and Maxwell did most of the app development on Android studio.
## Accomplishments that we're proud of
We're super stoked that we offer 3 completely different grocery input methods: Camera, Speech, and Manual Input. We believe that the UI we created is very engaging and presents the data in a helpful way. Furthermore, we think that the app's ability to provide recipe recommendations really puts us over the edge and shows how we took on a wide variety of tasks in a small amount of time.
## What we learned
For most of us this is the first application that we built - we learned a lot about how to create a UI and how to consider mobile functionality. Furthermore, this was also our first experience with cloud computing and APIs. Creating our Android application introduced us to the impact these technologies can have, and how simple it really is for someone to build a fairly complex application.
## What's next for greenEats
We originally intended this to be an all-purpose grocery-management app, so we wanted to have a feature that could allow the user to easily order groceries online through the app, potentially based off of food that would expire soon.
We also wanted to implement a barcode scanner, using the Barcode Scanner API offered by Google Cloud, thus providing another option to allow for a more user-friendly experience. In addition, we wanted to transition to Firebase Realtime Database to refine the user experience.
These tasks were considered outside of our scope because of time constraints, so we decided to focus our efforts on the fundamental parts of our app. | ## Inspiration
In large lectures, students often have difficulty making friends and forming study groups due to the social anxieties attached to reaching out for help. Collaboration reinforces and heightens learning, so we sought to encourage students to work together and learn from each other.
## What it does
StudyDate is a personalized learning platform that assesses a user's current knowledge on a certain subject, and personalizes the lessons to cover their weaknesses. StudyDate also utilizes Facebook's Graph API to connect users with Facebook friends whose knowledge complement each other to promote mentorship and enhanced learning.
Moreover, StudyDate recommends and connects individuals together based on academic interests and past experience. Users can either study courses of interest online, share notes, chat with others online, or opt to meet in-person with others nearby.
## How we built it
We built our front-end in React.js and used node.js for RESTful requests to the database, Then, we integrated our web application with Facebook's API for authentication and Graph API.
## Challenges we ran into
We ran into challenges in persisting the state of Facebook authentication, and utilizing Facebook's Graph API to extract and recommend Facebook friends by matching with saved user data to discover friends with complementing knowledge. We also ran into challenges setting up the back-end infrastructure on Google Cloud.
## Accomplishments that we're proud of
We are proud of having built a functional, dynamic website that incorporates various aspects of profile and course information.
## What we learned
We learned a lot about implementing various functionalities of React.js such as page navigation and chat messages.
Completing this project also taught us about certain limitations, especially those dealing with using graphics. We also learned how to implement a login flow with Facebook API to store/pull user information from a database.
## What's next for StudyDate
We'd like to perform a Graph Representation of every user's knowledge base within a certain course subject and use a Machine Learning algorithm to better personalize lessons, as well as to better recommend Facebook friends or new friends in order to help users find friends/mentors who are experienced in same course. We also see StudyDate as a mobile application in the future with a dating app-like interface that allows users to select other students they are interested in working with. | ## Inspiration
It can be tough coming up with a unique recipe each and every week. Sometimes there are good deals for specific items (especially for university students) and determining what to cook with those ingredients may not be known. *Rad Kitchen says goodbye to last-minute trips to the grocery store and hello to delicious, home-cooked meals with the Ingredient Based Recipe Generator chrome extension.*
## What it does
Rad Kitchen is a Google Chrome extension, the ultimate tool for creating delicious recipes with the ingredients you already have on hand. This Chrome Extension is easy to install and is connected to Radish's ingredient website. By surfing and saving ingredients of interests from the Radish website, the user can store them in your personal ingredient library. The extension will then generate a recipe based on the ingredients you have saved and provide you with a list of recipes that you can make with the ingredients you already have. You can also search for recipes based on specific dietary restrictions or cuisine type. It gives a final image that shows what the dish may look like.
## How we built it
* Google Chrome extension using the React framework. The extension required a unique manifest.json file specific to Google Chrome extensions.
* Cohere NLP to take user input of different ingredients and generate a recipe.
* OpenAI's API to generate an image from text parameters. This creates a unique image to the prompt.
* Material UI and React to create an interactive website.
* Integrated Twilio to send the generated recipe and image via text message to the user. The user will input their number and Twilio API will be fetched. The goal is to create a more permanent place after the recipe is generated for people to refer to
## Challenges we ran into
* Parsing data - some issues with the parameters and confusion with objects, strings, and arrays
* Dealing with different APIs was a unique challenge (Dalle2 API was more limited)
* One of our group members could not make it to the event, so we were a smaller team
* Learning curve for creating a Chrome Extension
* Twilio API documentation
* Cohere API - Determining the best way to standardize message output while getting unique responses
## Accomplishments that we're proud of
* This was our first time building a Google Chrome extension. The file structure and specific-ness of the manifest.json file made it difficult. Manifest v3 quite different from Manifest v2.
* For this hackathon, it was really great to tie our project well with the different events we applied for
## What we learned
* How to create a Google Chrome extension. It cannot be overstated how new of an experience it was, and it is fascinating how useful a chrome extension can be as a technology
* How to do API calls and the importance of clear function calls
## What's next for Rad Kitchen
* Pitching and sharing the technology with Radish's team at this hackathon | winning |
## Inspiration
Imagine you're sitting in your favorite coffee shop and a unicorn startup idea pops into your head. You open your laptop and choose from a myriad selection of productivity tools to jot your idea down. It’s so fresh in your brain, you don’t want to waste any time so, fervently you type, thinking of your new idea and its tangential components. After a rush of pure ideation, you take a breath to admire your work, but disappointment. Unfortunately, now the hard work begins, you go back though your work, excavating key ideas and organizing them.
***Eddy is a brainstorming tool that brings autopilot to ideation. Sit down. Speak. And watch Eddy organize your ideas for you.***
## Learnings
Melding speech recognition and natural language processing tools required us to learn how to transcribe live audio, determine sentences from a corpus of text, and calculate the similarity of each sentence. Using complex and novel technology, each team-member took a holistic approach and learned news implementation skills on all sides of the stack.
## Features
1. **Live mindmap**—Automatically organize your stream of consciousness by simply talking. Using semantic search, Eddy organizes your ideas into coherent groups to help you find the signal through the noise.
2. **Summary Generation**—Helpful for live note taking, our summary feature converts the graph into a Markdown-like format.
3. **One-click UI**—Simply hit the record button and let your ideas do the talking.
4. **Team Meetings**—No more notetakers: facilitate team discussions through visualizations and generated notes in the background.

## Challenges
1. **Live Speech Chunking** - To extract coherent ideas from a user’s speech, while processing the audio live, we had to design a paradigm that parses overlapping intervals of speech, creates a disjoint union of the sentences, and then sends these two distinct groups to our NLP model for similarity.
2. **API Rate Limits**—OpenAI rate-limits required a more efficient processing mechanism for the audio and fewer round trip requests keyword extraction and embeddings.
3. **Filler Sentences**—Not every sentence contains a concrete and distinct idea. Some sentences go nowhere and these can clog up the graph visually.
4. **Visualization**—Force graph is a premium feature of React Flow. To mimic this intuitive design as much as possible, we added some randomness of placement; however, building a better node placement system could help declutter and prettify the graph.
## Future Directions
**AI Inspiration Enhancement**—Using generative AI, it would be straightforward to add enhancement capabilities such as generating images for coherent ideas, or business plans.
**Live Notes**—Eddy can be a helpful tool for transcribing and organizing meeting and lecture notes. With improvements to our summary feature, Eddy will be able to create detailed notes from a live recording of a meeting.
## Built with
**UI:** React, Chakra UI, React Flow, Figma
**AI:** HuggingFace, OpenAI Whisper, OpenAI GPT-3, OpenAI Embeddings, NLTK
**API:** FastAPI
# Supplementary Material
## Mindmap Algorithm
 | ## What it does
Paste in a text and it will identify the key scenes before turning it into a narrated movie. Favourite book, historical battle, or rant about work. Anything and everything, if you can read it, Lucid.ai can dream it.
## How we built it
Once you hit generate on the home UI, our frontend sends your text and video preferences to the backend, which uses our custom algorithm to cut up the text into key scenes. The backend then uses multithreading to make three simultaneous API calls. First, a call to GPT-3 to condense the chunks into image prompts to be fed into a Stable Diffusion/Deforum AI image generation model. Second, a sentiment keyword analysis using GPT-3, which is then fed to the Youtube API for a fitting background song. Finally, a call to TortoiseTTS generates a convincing narration of your text. Collected back at the front-end, you end up with a movie, all from a simple text.
## Challenges we ran into
Our main challenge was computing power. With no access to industry-grade GPU power, we were limited to running our models on personal laptop GPUs. External computing power also limited payload sizes, forcing us to find roundabout ways to communicate our data to the front-end.
## Accomplishments that we're proud of
* Extremely resilient commitment to the project, despite repeated technical setbacks
* Fast on-our-feet thinking when things don't go to plan
* A well-laid out front-end development plan
## What we learned
* AWS S3 Cloud Storage
* TortoiseTTS
* Learn how to dockerize large open source codebase
## What's next for Lucid.ai
* More complex camera motions beyond simple panning
* More frequent frame generation
* Real-time frame generation alongside video watching
* Parallel cloud computing to handle rendering at faster speeds | ## Inspiration
In the fast-paced world of networking and professional growth, connecting with students, peers, mentors, and like-minded individuals is essential. However, the need to manually jot down notes in Excel or the risk of missing out on valuable follow-up opportunities can be a real hindrance.
## What it does
Coffee Copilot transcribes, summarizes, and suggests talking points for your conversations, eliminating manual note-taking and maximizing networking efficiency. Also able to take forms with genesys.
## How we built it
**Backend**:
* Python + FastAPI was used to serve CRUD requests
* Cohere was used for both text summarization and text generation using their latest Coral model
* CockroachDB was used to store user and conversation data
* AssemblyAI was used for speech-to-text transcription and speaker diarization (i.e. identifying who is talking)
**Frontend**:
* We used Next.js for its frontend capabilities
## Challenges we ran into
We ran into a few of the classic problems - going in circles about what idea we wanted to implement, biting off more than we can chew with scope creep and some technical challenges that **seem** like they should be simple (such as sending an audio file as a blob to our backend 😒).
## Accomplishments that we're proud of
A huge last minute push to get us over the finish line.
## What we learned
We learned some new technologies like working with LLMs at the API level, navigating heavily asynchronous tasks and using event-driven patterns like webhooks. Aside of technologies, we learned how to disagree but move forwards, when to cut our losses and how to leverage each others strengths!
## What's next for Coffee Copilot
There's quite a few things on the horizon to look forwards to:
* Adding sentiment analysis
* Allow the user to augment the summary and the prompts that get generated
* Fleshing out the user structure and platform (adding authentication, onboarding more users)
* Using smart glasses to take pictures and recognize previous people you've met before | winning |
## **What is Cointree?**
Cointree is a platform where users get paid to go green.
Because living more sustainably shouldn't be more expensive. In fact, we should be rewarded for living sustainably – and that's exactly what Cointree does.
Cointree connects companies looking to offset carbon emissions with users looking to live a more sustainable life.
## **How does Cointree accomplish this?**
More and more companies want to become carbon neutral. Carbon offsets are a means for companies to become carbon neutral even if they still have to emit carbon dioxide in the air – by paying a third party to remove or not emit carbon dioxide by means such as reducing driving pollution, cutting down less trees, or building wind farms. But as these third parties have nearly quadrupled in size in just the past two years, debates have arised about the effectiveness and value which these carbon offsetting companies really provide.
Cointree takes a drastically different approach, instead connecting individual people to these companies who are willing to pay carbon offsets.
Cointree accomplishes this by having two different clients: an iOS app, and a web client.
The web client is for the companies paying carbon offsets, who can sign in, deposit currency, and view the progress on their carbon offset goals. In the process, we take a small cut out of the companie's deposit.
Meanwhile users install our Cointree iOS app. There they can announce that they, say, installed solar panels, or bought an electric vehicle, or even planted a tree. Then they demonstrate proof of completion (by scanning an invoice for instance), and they get paid. Simple as that.
You might be wondering, how exactly do we connect the two, and more importantly how do we store data in a safe, efficient, and accountable system? The answer, ***blockchain***.
## **What is unique about Cointree?**
At Cointree, all of our data is on the blockchain. And to us, that’s really important. We want the radical transparency that blockchain offers – it means that anyone can see what carbon offsets companies are paying, and keep them accountable. Indeed, the web client also acts as a log where anyone can see all the carbon offsets that a certain company bought. Real transparency.
We use Polygon's MATIC currency and Ethereum platform in order to develop a system where companies deposit MATIC into a smart contract that functions almost like a vault. When users demonstrate proof of completion of a certain task, we send money to their wallet (as a function of how much CO2 they removed / won't put into the atmosphere thanks to their task). Thanks to the speed and security of Polygon, we offer a really great experience here.
Check out our video for a deep-dive into how Cointree works on the blockchain. There's some pretty novel stuff in there (also check out our attached slides).
## Challenges we ran into
The biggest challenge was interfacing with the blockchain from a native iOS app. It's nearly impossible – blockchain is almost exclusively made for the web. But we didn't want to ditch using an iOS app though, since we wanted the smoothest possible experience for the end user. So instead we had to come up with clever work arounds to offload any interfacing done with the blockchain to our express.js backend.
## Accomplishments that we're proud of
We're really proud of the range of things we were able to make – from an iOS client to a web client, from smart contracts to REST APIs. All of our past experience as developers across our whole (short) lives came into use here.
## Want to view the source code?
[Cointree iOS App](https://github.com/nikitamounier/Cointree-iOS)
[Cointree Smart Contracts & REST API](https://github.com/sidereior/cointree-smartcontract)
[Cointree web client](https://github.com/jmurphy5613/cointree-web)
[Cointree backend](https://github.com/jmurphy5613/cointree-backend)
## What's next for Cointree
Expanding to new sustainable projects (planting of trees and growth of them, using public transport, etc.), third party company verification of invoices & receipts (these companies will check with their own databases to verify that invoices are not fraudulent), providing uses for sustainable companies or retailers to benefit (companies that sell products which we offer payment for--for example electric cars--can give a percent discount and can better reach their market segment), improvement of security with Vault Smart Contract and communication between Vault Smart Contract and IOS app, rework of NFT minting process and rather than minting NFT's which are expensive we can have a Parent Smart Contract and make children smart contracts for each company and use data in these to verify proofs of transactions without the cost. | ## Inspiration
As someone who has always wanted to speak in ASL (American Sign Language), I have always struggled with practicing my gestures, as I, unfortunately, don't know any ASL speakers to try and have a conversation with. Learning ASL is an amazing way to foster an inclusive community, for those who are hearing impaired or deaf. DuoASL is the solution for practicing ASL for those who want to verify their correctness!
## What it does
DuoASL is a learning app, where users can sign in to their respective accounts, and learn/practice their ASL gestures through a series of levels.
Each level has a *"Learn"* section, with a short video on how to do the gesture (ie 'hello', 'goodbye'), and a *"Practice"* section, where the user can use their camera to record themselves performing the gesture. This recording is sent to the backend server, where it is validated with our Action Recognition neural network to determine if you did the gesture correctly!
## How we built it
DuoASL is built up of two separate components;
**Frontend** - The Frontend was built using Next.js (React framework), Tailwind and Typescript. It handles the entire UI, as well as video collection during the *"Learn"* Section, which it uploads to the backend
**Backend** - The Backend was built using Flask, Python, Jupyter Notebook and TensorFlow. It is run as a Flask server that communicates with the front end and stores the uploaded video. Once a video has been uploaded, the server runs the Jupyter Notebook containing the Action Recognition neural network, which uses OpenCV and Tensorflow to apply the model to the video and determine the most prevalent ASL gesture. It saves this output to an array, which the Flask server reads and responds to the front end.
## Challenges we ran into
As this was our first time using a neural network and computer vision, it took a lot of trial and error to determine which actions should be detected using OpenCV, and how the landmarks from the MediaPipe Holistic (which was used to track the hands and face) should be converted into formatted data for the TensorFlow model. We, unfortunately, ran into a very specific and undocumented bug with using Python to run Jupyter Notebooks that import Tensorflow, specifically on M1 Macs. I spent a short amount of time (6 hours :) ) trying to fix it before giving up and switching the system to a different computer.
## Accomplishments that we're proud of
We are proud of how quickly we were able to get most components of the project working, especially the frontend Next.js web app and the backend Flask server. The neural network and computer vision setup was pretty quickly finished too (excluding the bugs), especially considering how for many of us this was our first time even using machine learning on a project!
## What we learned
We learned how to integrate a Next.js web app with a backend Flask server to upload video files through HTTP requests. We also learned how to use OpenCV and MediaPipe Holistic to track a person's face, hands, and pose through a camera feed. Finally, we learned how to collect videos and convert them into data to train and apply an Action Detection network built using TensorFlow
## What's next for DuoASL
We would like to:
* Integrate video feedback, that provides detailed steps on how to improve (using an LLM?)
* Add more words to our model!
* Create a practice section that lets you form sentences!
* Integrate full mobile support with a PWA! | ## Inspiration
We saw how messy bulletin boards looked with many event advertisements pasted all over. We thought they ruined building aesthetics. More seriously, because each event poster is usually printed many copies for display on multiple bulletin boards, and because the bulletin boards have to be updated often, these messy bulletin boards also contribute to a massive amount of wasted paper and ink.
We thought since almost everyone has a phone and since many people already get their event information from various social media/online sources, bulletin boards should be digitalized.
## What it does
Instead of bulletin boards having event advertisements, we thought they should be decorated with something prettier—perhaps artwork, along with a small QR code. Students can scan this QR code, which will bring them to each building's specific events site. These event sites will essentially become digital bulletin boards that host event ads, and students will be able to browse through them.
We believe that this way, building aesthetics can be significantly improved and the amount of wasted paper significantly reduced. Furthermore, posting to a singular digital bulletin board (as opposed to multiple physical bulletin boards) can help advertisers save time.
We also realize that a shortcoming of digital bulletin boards is that they will need to be intentionally pulled up. However, we think that if someone has no interest in keeping up with upcoming events, they will probably walk by physical bulletin boards without taking a second glance. If a person does want to know about upcoming events, they will be willing to look at physical bulletin boards and to pull up a digital bulletin board. In this case, a digital bulletin board is much more convenient because it can be browsed through wherever, whenever.
## How I built it
We built this app using HTML, CSS, Bootstrap, Javascript, and Python. We deployed this app using Google App Engine.
## Challenges I ran into
Originally, we wanted to make the updating process of this digital bulletin board more automated, but we couldn't find an effective way of doing so. In addition, although we both have some prior experience in front-end development, making this web app was much more difficult and time-consuming than we thought it would be.
## Accomplishments that I'm proud of
Learning how to use Google App Engine for deployment and improving our web-app development skills.
## What I learned
Google Cloud is very, very powerful and useful.
## What's next for UofTHacks
We would like to make the web-app more aesthetically pleasing. Furthermore, we would like to make the updating process of this digital bulletin board more automated. We also would like to add more functionality (e.g. curated events feed) through an API. | winning |
## Inspiration
The amount of data in the world today is mind-boggling. We are generating 2.5 quintillion bytes of data every day at our current pace, but the pace is only accelerating with the growth of IoT.
We felt that the world was missing a smart find-feature for videos. To unlock heaps of important data from videos, we decided on implementing an innovative and accessible solution to give everyone the ability to access important and relevant data from videos.
## What it does
CTRL-F is a web application implementing computer vision and natural-language-processing to determine the most relevant parts of a video based on keyword search and automatically produce accurate transcripts with punctuation.
## How we built it
We leveraged the MEVN stack (MongoDB, Express.js, Vue.js, and Node.js) as our development framework, integrated multiple machine learning/artificial intelligence techniques provided by industry leaders shaped by our own neural networks and algorithms to provide the most efficient and accurate solutions.
We perform key-word matching and search result ranking with results from both speech-to-text and computer vision analysis. To produce accurate and realistic transcripts, we used natural-language-processing to produce phrases with accurate punctuation.
We used Vue to create our front-end and MongoDB to host our database. We implemented both IBM Watson's speech-to-text API and Google's Computer Vision API along with our own algorithms to perform solid key-word matching.
## Challenges we ran into
Trying to implement both Watson's API and Google's Computer Vision API proved to have many challenges. We originally wanted to host our project on Google Cloud's platform, but with many barriers that we ran into, we decided to create a RESTful API instead.
Due to the number of new technologies that we were figuring out, it caused us to face sleep deprivation. However, staying up for way longer than you're supposed to be is the best way to increase your rate of errors and bugs.
## Accomplishments that we're proud of
* Implementation of natural-language-processing to automatically determine punctuation between words.
* Utilizing both computer vision and speech-to-text technologies along with our own rank-matching system to determine the most relevant parts of the video.
## What we learned
* Learning a new development framework a few hours before a submission deadline is not the best decision to make.
* Having a set scope and specification early-on in the project was beneficial to our team.
## What's next for CTRL-F
* Expansion of the product into many other uses (professional education, automate information extraction, cooking videos, and implementations are endless)
* The launch of a new mobile application
* Implementation of a Machine Learning model to let CTRL-F learn from its correct/incorrect predictions | 💡
## Inspiration
49 percent of women reported feeling unsafe walking alone after nightfall according to the Office for National Statistics (ONS). In light of recent sexual assault and harassment incidents in the London, Ontario and Western community, women now feel unsafe travelling alone more than ever.
Light My Way helps women navigate their travel through the safest and most well-lit path. Women should feel safe walking home from school, going out to exercise, or going to new locations, and taking routes with well-lit areas is an important precaution to ensure safe travel. It is essential to always be aware of your surroundings and take safety precautions no matter where and when you walk alone.
🔎
## What it does
Light My Way visualizes data of London, Ontario’s Street Lighting and recent nearby crimes in order to calculate the safest path for the user to take. Upon opening the app, the user can access “Maps” and search up their destination or drop a pin on a location. The app displays the safest route available and prompts the user to “Send Location” which sends the path that the user is taking to three contacts via messages. The user can then click on the google maps button in the lower corner that switches over to the google maps app to navigate the given path. In the “Alarm” tab, the user has access to emergency alert sounds that the user can use when in danger, and upon clicking the sounds play at a loud volume to alert nearby people for help needed.
🔨
## How we built it
React, Javascript, and Android studio were used to make the app. React native maps and directions were also used to allow user navigation through google cloud APIs. GeoJson files were imported of Street Lighting data from the open data website for the City of London to visualize street lights on the map. Figma was used for designing UX/UI.
🥇
## Challenges we ran into
We ran into a lot of trouble visualization such a large amount of data that we exported on the GeoJson street lights. We overcame that by learning about useful mapping functions in react that made marking the location easier.
⚠️
## Accomplishments that we're proud of
We are proud of making an app that can be of potential help to make women be safer walking alone. It is our first time using and learning React, as well as using google maps, so we are proud of our unique implementation of our app using real data from the City of London. It was also our first time doing UX/UI on Figma, and we are pleased with the results and visuals of our project.
🧠
## What we learned
We learned how to use React, how to implement google cloud APIs, and how to import GeoJson files into our data visualization. Through our research, we also became more aware of the issue that women face daily on feeling unsafe walking alone.
💭
## What's next for Light My Way
We hope to expand the app to include more data on crimes, as well as expand to cities surrounding London. We want to continue developing additional safety features in the app, as well as a chatting feature with the close contacts of the user. | ## Inspiration
Seeing the large homeless population in Los Angeles inspired us to find a better, easier, and more effective way to help our homeless neighbors.
## What it does
Direct deposit of money to homeless neighbor's Samaritan card, which can be used to purchase food, toiletries, etc.
## How I built it
## Challenges I ran into
Designing a card that supports displaying card balance. Similar to Coin.
## What's next for Samaritan
Testing and mplementation into areas with large homeless population | winning |
## Inspiration
The inspiration for this project was a group-wide understanding that trying to scroll through a feed while your hands are dirty or in use is near impossible. We wanted to create a computer program to allow us to scroll through windows without coming into contact with the computer, for eating, chores, or any other time when you do not want to touch your computer. This idea evolved into moving the cursor around the screen and interacting with a computer window hands-free, making boring tasks, such as chores, more interesting and fun.
## What it does
HandsFree allows users to control their computer without touching it. By tilting their head, moving their nose, or opening their mouth, the user can control scrolling, clicking, and cursor movement. This allows users to use their device while doing other things with their hands, such as doing chores around the house. Because HandsFree gives users complete **touchless** control, they’re able to scroll through social media, like posts, and do other tasks on their device, even when their hands are full.
## How we built it
We used a DLib face feature tracking model to compare some parts of the face with others when the face moves around.
To determine whether the user was staring at the screen, we compared the distance from the edge of the left eye and the left edge of the face to the edge of the right eye and the right edge of the face. We noticed that one of the distances was noticeably bigger than the other when the user has a tilted head. Once the distance of one side was larger by a certain amount, the scroll feature was disabled, and the user would get a message saying "not looking at camera."
To determine which way and when to scroll the page, we compared the left edge of the face with the face's right edge. When the right edge was significantly higher than the left edge, then the page would scroll up. When the left edge was significantly higher than the right edge, the page would scroll down. If both edges had around the same Y coordinate, the page wouldn't scroll at all.
To determine the cursor movement, we tracked the tip of the nose. We created an adjustable bounding box in the center of the users' face (based on the average values of the edges of the face). Whenever the nose left the box, the cursor would move at a constant speed in the nose's position relative to the center.
To determine a click, we compared the top lip Y coordinate to the bottom lip Y coordinate. Whenever they moved apart by a certain distance, a click was activated.
To reset the program, the user can look away from the camera, so the user can't track a face anymore. This will reset the cursor to the middle of the screen.
For the GUI, we used Tkinter module, an interface to the Tk GUI toolkit in python, to generate the application's front-end interface. The tutorial site was built using simple HTML & CSS.
## Challenges we ran into
We ran into several problems while working on this project. For example, we had trouble developing a system of judging whether a face has changed enough to move the cursor or scroll through the screen, calibrating the system and movements for different faces, and users not telling whether their faces were balanced. It took a lot of time looking into various mathematical relationships between the different points of someone's face. Next, to handle the calibration, we ran large numbers of tests, using different faces, distances from the screen, and the face's angle to a screen. To counter the last challenge, we added a box feature to the window displaying the user's face to visualize the distance they need to move to move the cursor. We used the calibrating tests to come up with default values for this box, but we made customizable constants so users can set their boxes according to their preferences. Users can also customize the scroll speed and mouse movement speed to their own liking.
## Accomplishments that we're proud of
We are proud that we could create a finished product and expand on our idea *more* than what we had originally planned. Additionally, this project worked much better than expected and using it felt like a super power.
## What we learned
We learned how to use facial recognition libraries in Python, how they work, and how they’re implemented. For some of us, this was our first experience with OpenCV, so it was interesting to create something new on the spot. Additionally, we learned how to use many new python libraries, and some of us learned about Python class structures.
## What's next for HandsFree
The next step is getting this software on mobile. Of course, most users use social media on their phones, so porting this over to Android and iOS is the natural next step. This would reach a much wider audience, and allow for users to use this service across many different devices. Additionally, implementing this technology as a Chrome extension would make HandsFree more widely accessible. | # 🍅 NutriSnap
### NutriSnap is an intuitive nutrition tracker that seamlessly integrates into your daily life.
## Inspiration
Every time you go to a restaurant, its highly likely that you see someone taking a picture of their food before they eat it. We wanted to create a seamless way for people to keep track of their nutritional intake, minimizing the obstacles required to be aware of the food you consume. Building on the idea that people already often take pictures of the food they eat, we decided to utilize something as simple as one's camera app to keep track of their daily nutritional intake.
## What it does
NutriSnap analyzes pictures of food to detect its nutritional value. After simply scanning a picture of food, it summarizes all its nutritional information and displays it to the user, while also adding it to a log of all consumed food so people have more insight on all the food they consume. NutriSnap has two fundamental features:
* scan UPC codes on purchased items and fetch its nutritional information
* detect food from an image using a public ML food-classification API and estimate its nutritional information
This information is summarized and displayed to the user in a clean and concise manner, taking their recommended daily intake values into account. Furthermore, it is added to a log of all consumed food items so the user can always access a history of their nutritional intake.
## How we built it
The app uses React Native for its frontend and a Python Django API for its backend. If the app detects a UPC code in the photo, it retrieves nutritional information from a [UPC food nutrition API](https://world.openfoodfacts.org) and summarizes its data in a clean and concise manner. If the app fails to detect a UPC code in the photo, it forwards the photo to its Django backend, which proceeds to classify all the food in the image using another [open API](https://www.logmeal.es). All collected nutritional data is forwarded to the [OpenAI API](https://platform.openai.com/docs/guides/text-generation/json-mode) to summarize nutritional information of the food item, and to provide the item with a nutrition rating betwween 1 and 10. This data is displayed to the user, and also added to their log of consumed food.
## What's next for NutriSnap
As a standalone app, NutriSnap is still pretty inconvenient to integrate into your daily life. One amazing update would be to make the API more independent of the frontend, allowing people to sync their Google Photos library so NutriSnap automatically detects and summarizes all consumed food without the need for any manual user input. | # 🎉 CoffeeStarter: Your Personal Networking Agent 🚀
Names: Sutharsika Kumar, Aarav Jindal, Tanush Changani & Pranjay Kumar
Welcome to **CoffeeStarter**, a cutting-edge tool designed to revolutionize personal networking by connecting you with alumni from your school's network effortlessly. Perfect for hackathons and beyond, CoffeeStarter blends advanced technology with user-friendly features to help you build meaningful professional relationships.
---
## 🌟 Inspiration
In a world where connections matter more than ever, we envisioned a tool that bridges the gap between ambition and opportunity. **CoffeeStarter** was born out of the desire to empower individuals to effortlessly connect with alumni within their school's network, fostering meaningful relationships that propel careers forward.
---
## 🛠️ What It Does
CoffeeStarter leverages the power of a fine-tuned **LLaMA** model to craft **personalized emails** tailored to each alumnus in your school's network. Here's how it transforms your networking experience:
* **📧 Personalized Outreach:** Generates authentic, customized emails using your resume to highlight relevant experiences and interests.
* **🔍 Smart Alumnus Matching:** Identifies and connects you with alumni that align with your professional preferences and career goals.
* **🔗 Seamless Integration:** Utilizes your existing data to ensure every interaction feels genuine and impactful.
---
## 🏗️ How We Built It
Our robust technology stack ensures reliability and scalability:
* **🗄️ Database:** Powered by **SQLite** for flexible and efficient data management.
* **🐍 Machine Learning:** Developed using **Python** to handle complex ML tasks with precision.
* **⚙️ Fine-Tuning:** Employed **Tune** for meticulous model fine-tuning, ensuring optimal performance and personalization.
---
## ⚔️ Challenges We Faced
Building CoffeeStarter wasn't without its hurdles:
* **🔒 SQLite Integration:** Navigating the complexities of SQLite required innovative solutions.
* **🚧 Firewall Obstacles:** Overcoming persistent firewall issues to maintain seamless connectivity.
* **📉 Model Overfitting:** Balancing the model to avoid overfitting while ensuring high personalization.
* **🌐 Diverse Dataset Creation:** Ensuring a rich and varied dataset to support effective networking outcomes.
* **API Integration:** Working with various API's to get as diverse a dataset and functionality as possible.
---
## 🏆 Accomplishments We're Proud Of
* **🌈 Diverse Dataset Development:** Successfully created a comprehensive and diverse dataset that enhances the accuracy and effectiveness of our networking tool.
* Authentic messages that reflect user writing styles which contributes to personalization.
---
## 📚 What We Learned
The journey taught us invaluable lessons:
* **🤝 The Complexity of Networking:** Understanding that building meaningful connections is inherently challenging.
* **🔍 Model Fine-Tuning Nuances:** Mastering the delicate balance between personalization and generalization in our models.
* **💬 Authenticity in Automation:** Ensuring our automated emails resonate as authentic and genuine, without echoing our training data.
---
## 🔮 What's Next for CoffeeStarter
We're just getting started! Future developments include:
* **🔗 Enhanced Integrations:** Expanding data integrations to provide even more personalized networking experiences and actionable recommendations for enhancing networking effectiveness.
* **🧠 Advanced Fine-Tuned Models:** Developing additional models tailored to specific networking needs and industries.
* **🤖 Smart Choosing Algorithms:** Implementing intelligent algorithms to optimize alumnus matching and connection strategies.
---
## 📂 Submission Details for PennApps XXV
### 📝 Prompt
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal.
### 📄 Version Including Resume
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. The student's resume is provided as an upload `{resume_upload}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Use the information from the given resume of the sender and their interests from `{website_survey}` and information of the receiver to make this message personalized to the intersection of both parties. Talk specifically about experiences that `{student, alumni, professional}` would find interesting about the receiver `{student, alumni, professional}`. Compare the resume and other input `{information}` to find commonalities and make a positive impression. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal. Once completed with the email, create a **1 - 10 score** with **1** being a very generic email and **10** being a very personalized email. Write this score at the bottom of the email.
## 🧑💻 Technologies Used
* **Frameworks & Libraries:**
+ **Python:** For backend development and machine learning tasks.
+ **SQLite:** As our primary database for managing user data.
+ **Tune:** Utilized for fine-tuning our LLaMA3 model.
* **External/Open Source Resources:**
+ **LLaMA Model:** Leveraged for generating personalized emails.
+ **Various Python Libraries:** Including Pandas for data processing and model training. | winning |
## Inspiration
All our team members enjoy reading as a hobby across numerous genres. Unfortunately, reading comprehension and literacy overall have been declining, which poses a massive problem for future generations. There are countless factors at play here, and we can't solve all of them, but we can definitely work to kindle a spark that might just blossom into a love for reading. Many of these adjacent tools are made for classroom settings. On the contrary, we're built for students, by students, and by readers, for readers.
## What it does
Storyscape is an application aimed at developing elementary and middle schoolers' grasp over the English language. Turn on your mic and get ready to read some words! To be specific, we have identified three core skills to be problematic: diction, sentence structure variety, and expressiveness. You will be given an unlimited amount of examples for each of these and the opportunity to practice and replicate these examples. With the help of our cat assistant, you can learn how to read passages expressively and eloquently!
## How we built it
Storyscape is built on five major technologies:
1. Google Gemini Flash -- speedy, cost-efficient, great at storytelling
2. Hume AI -- personable, easy to integrate TTS, and great for sentiment analysis
3. React/Next.js -- a popular JS framework that simplifies many best practices built for vercel
4. Vercel -- easy deployment to the web
5. Firebase -- a handy tool for auth, functions, storage and analytics
## Challenges we ran into
One major problem we faced during the competition was the cold weather at night. We struggled to get some quality sleep due to the lack of comfortable sleeping arrangements :(
## Accomplishments that we're proud of
* We would actually use this app ourselves after some minor improvements!
* Created a polished and aesthetically pleasing web app demonstrating AI technologies
* Stayed up 24 hours in a row
## What we learned
This hackathon was a great opportunity to learn about all the different AI technologies that are out there and how we can implement them into our lives. We learned about sentiment analysis, some handy prompt engineering, and some techniques to interface with AI in a smart way.
## What's next for Storyscape
We're still working on adding themes into the text adventures. With better prompt engineering and utilisation of the best models to foster a closer connection to the text, Storyscape can become a true companion for those who want to augment their English skills. | ## Inspiration
Between my friends and I, when there is a task everyone wants to avoid, we play a game to decide quickly. These tasks may include, ordering pizza or calling an uber for the group. The game goes like this, whoever thinks of this game first says "shotty not" and then touches their nose. Everyone else reacts to him and touches their nose as fast as they can. The person with the slowest reaction time is chosen to do the task. I often fall short when it comes to reaction time so I had to do something about it
## What it does
The module sits on top of your head, waiting to hear the phrase "shotty not." When it is recognized the finger will come down and touch your nose. You will never get caught off guard again.
## How I built it
The finger moves via a servo and is controlled by an arduino, it is connected to a python script that recognizes voice commands offline. The finger is mounted to the hat with some 3d printed parts.
## Challenges I ran into
The hardware lab did not have a voice recognition module or a bluetooth module for arduino. I had to figure out how to go about implementing voice recognition and connect it to the arduino.
## Accomplishments that I'm proud of
I was able to model and print all the parts to create a completely finished hack to the best of my abilities.
## What I learned
I learned to use a voice recognition library and use Pyserial to communicate to an arduino with a python program.
## What's next for NotMe
I will replace the python program with a bluetooth module to make the system more portable. This allows for real life use cases. | ## Inspiration
Currently the insurance claims process is quite labour intensive. A person has to investigate the car to approve or deny a claim, and so we aim to make the alleviate this cumbersome process smooth and easy for the policy holders.
## What it does
Quick Quote is a proof-of-concept tool for visually evaluating images of auto accidents and classifying the level of damage and estimated insurance payout.
## How we built it
The frontend is built with just static HTML, CSS and Javascript. We used Materialize css to achieve some of our UI mocks created in Figma. Conveniently we have also created our own "state machine" to make our web-app more responsive.
## Challenges we ran into
>
> I've never done any machine learning before, let alone trying to create a model for a hackthon project. I definitely took a quite a bit of time to understand some of the concepts in this field. *-Jerry*
>
>
>
## Accomplishments that we're proud of
>
> This is my 9th hackathon and I'm honestly quite proud that I'm still learning something new at every hackathon that I've attended thus far. *-Jerry*
>
>
>
## What we learned
>
> Attempting to do a challenge with very little description of what the challenge actually is asking for is like a toddler a man stranded on an island. *-Jerry*
>
>
>
## What's next for Quick Quote
Things that are on our roadmap to improve Quick Quote:
* Apply google analytics to track user's movement and collect feedbacks to enhance our UI.
* Enhance our neural network model to enrich our knowledge base.
* Train our data with more evalution to give more depth
* Includes ads (mostly auto companies ads). | partial |
## Inspiration
As we walk or drive around our neightborhood or countryside, we can see many signs and flyers that were put out by individual contractor or freelancer that specializes in one or more area of home improvement and repair, such as plumbing, fixing leaky ceiling, installing thermostat and etc. Since we are students who have just started living on our own near campus, many problems that come up in our apartment can be a pain in the back to deal with, especially if it's something urgent to be fixed, such as a clogged toilet. We came up with this idea to pair up home improvement contractor and home/aparment owners so that everybody can be beneficial from this SaaS.
## What it does
Warepair is a web app that bridges the gap between home improvement contractors/freelancers and homeowners. It is a platform that allows contractors and clients to easily find each other.
## How we built it
For frontend, we used React and other libraries to provide a minimalistic user interface for ease of use. For backend, we used Python and Flask to set up RESTful routes to value and respond to every single user input. It also acts as the middleware for us to perform CRUD on our Postgresql database. It is a relational database that allows us to have the same userid even when the user can both a contractor and homeowner. Using relationship database also helps us to perform data analytics in the future.
## Challenges we ran into
On the second day of the hackathon, we realized that the scope of this app was too big for us to complete within 36 hours. So we had to cut down the number of features to implement and really focus on the MVP. Another challenge has to do with the python backend we set up with Python. It was hard for us to connect fronend and backend because of the completely different set of modules for these two programming languages. However, we believe using Python can be beneficial to your data analysis because it provides powerful mathematical libraries.
## Accomplishments that we're proud of
We're proud of our use of the Google Map API which is something that none of the people on our team has implemented before. Setting tickers was also huge a milestone for us as we have incorporated our own feature onto the existing API. We also set up a thought-through schema in our database to support variability.
## What we learned
Teamwork is dreamwork! We had a great brainstorming session and decision-making process to go with Warepair. Warepair is a very marketable app that was challenging for us to develop, but also made us excited about the potential of this app. Lastly, we all have gained a better knowledge on fulllstack development for web application.
## What's next for Warepair
It's exciting to know many more features can be pushed out for Warepair to create a well-rounded user experience, such as verification and rating system of contractors, checkout process, and profile dashboard. We are looking forward to extending Warepair to mobile platforms because we believe Warepair provides the SaaS that everybody should easily have access to. | ## Inspiration
Our inspiration came from the annoying amount of times we have had to take out a calculator after a meal with friends and figure out how much to pay each other, make sure we have a common payment method (Venmo, Zelle), and remember if we paid each other back or not a week later. So to answer this question we came up with a Split that can easily divide our expenses for us, and organize the amount we owe a friend, and payments without having a common platform at all in one.
## What it does
This application allows someone to put in a value that someone owes them or they owe someone and organize it. During this implementation of a due to someone, you can also split an entire amount with multiple individuals which will be reflected in the amount owed to each person. Additionally, you are able to clear your debts and make payments through the built-in Checkbook service that allows you to pay just given their name, phone number, and value amount.
## How we built it
We built this project using html, css, python, and SQL implemented with Flask. Alongside using these different languages we utilized the Checkbook API to streamline the payment process.
## Challenges we ran into
Some challenges we ran into were, not knowing how to implement new parts of web development. We had difficulty implementing the API we used, “Checkbook” , using python into the backend of our website. We had no experience with APIs and so implementing this was a challenge that took some time to resolve.
Another challenge that we ran into was coming up with different ideas that were more complex than we could design. During the brainstorming phase we had many ideas of what would be impactful projects but were left with the issue of not knowing how to put that into code, so brainstorming, planning, and getting an attainable solution down was another challenge.
## Accomplishments that we're proud of
We were able to create a fully functioning, ready to use product with no prior experience with software engineering and very limited exposure to web dev.
## What we learned
Some things we learned from this project were first that communication was the most important thing in the starting phase of this project. While brainstorming, we had different ideas that we would agree on, start, and then consider other ideas which led to a loss of time.
After completing this project we found that communicating what we could do and committing to that idea would have been the most productive decision toward making a great project. To complement that, we also learned to play to our strengths in the building of this project.
In addition, we learned about how to best structure databases in SQL to achieve our intended goals and we learned how to implement APIs.
## What's next for Split
The next step for Split would be to move into a mobile application scene. Doing this would allow users to use this convenient application in the application instead of a browser.
Right now the app is fully supported for a mobile phone screen and thus users on iPhone could also use the “save to HomeScreen” feature to utilize this effectively as an app while we create a dedicated app.
Another feature that can be added to this application is bill scanning using a mobile camera to quickly split and organize payments. In addition, the app could be reframed as a social media with a messenger and friend system. | ## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to consistently improve his strength and balance. Through his story, we realized that so many people across North America require physiotherapy for far more severe conditions, be it from sports injuries, spinal chord injuries, or recovery from surgeries. Likewise, they will need to do at-home exercises individually, without supervision. For the patients, any repeated error can actually cause a deterioration in health. Therefore, we decided to leverage computer vision technology, to provide real-time feedback to patients to help them improve their rehab exercise form. At the same time, reports will be generated to the doctors, so that they may monitor the progress of patients and prioritize their urgency accordingly. We hope that phys.io will strengthen the feedback loop between patient and doctor, and accelerate the physical rehabilitation process for many North Americans.
## What it does
Through a mobile app, the patients will be able to film and upload a video of themselves completing a certain rehab exercise. The video then gets analyzed using a machine vision neural network, such that the movements of each body segment is measured. This raw data is then further processed to yield measurements and benchmarks for the relative success of the movement. In the app, the patients will receive a general score for their physical health as measured against their individual milestones, tips to improve the form, and a timeline of progress over the past weeks. At the same time, the same video analysis will be sent to the corresponding doctor's dashboard, in which the doctor will receive a more thorough medical analysis in how the patient's body is working together and a timeline of progress. The algorithm will also provide suggestions for the doctors' treatment of the patient, such as prioritizing a next appointment or increasing the difficulty of the exercise.
## How we built it
At the heart of the application is a Google Cloud Compute instance running together with a blobstore instance. The cloud compute cluster will ingest raw video posted to blobstore, and performs the machine vision analysis to yield the timescale body data.
We used Google App Engine and Firebase to create the rest of the web application and API's for the 2 types of clients we support: an iOS app, and a doctor's dashboard site. This manages day to day operations such as data lookup, and account management, but also provides the interface for the mobile application to send video data to the compute cluster. Furthermore, the app engine sinks processed results and feedback from blobstore and populates it into Firebase, which is used as the database and data-sync.
Finally, In order to generate reports for the doctors on the platform, we used stdlib's tasks and scale-able one-off functions to process results from Firebase over time and aggregate the data into complete chunks, which are then posted back into Firebase.
## Challenges we ran into
One of the major challenges we ran into was interfacing each technology with each other. Overall, the data pipeline involves many steps that, while each in itself is critical, also involve too many diverse platforms and technologies for the time we had to build it.
## What's next for phys.io
<https://docs.google.com/presentation/d/1Aq5esOgTQTXBWUPiorwaZxqXRFCekPFsfWqFSQvO3_c/edit?fbclid=IwAR0vqVDMYcX-e0-2MhiFKF400YdL8yelyKrLznvsMJVq_8HoEgjc-ePy8Hs#slide=id.g4838b09a0c_0_0> | losing |
## Inspiration
As a big data developer on my co-op term I use Terraform to create infrastructure as code (IaC) on Google Cloud Platform. While creating infrastructure, I wanted to have a simple way to see what infra I deployed and to what project.
## What it does
std-terraform is a Slack Bot & Github Infrastructure as code integration. When a developer pushed new code to Github to create new infra a Slack message is sent to a channel describing the infrastructure bing created.
## How I built it
I used the std library to create the slack integration and used Google Cloud Functions to do the backend data processing to find out the created infrastructure.
## Challenges I ran into
The std lib does not have an easy way to process data from Github so I had to work on Google Cloud Platform to do data processing and pass data back and forth.
## Accomplishments that I'm proud of
I was able to create modular and scalable code based on a serverless microservice structure. It successfully tracks Terraform infrastructure and passes back the modules in a user friendly manner. The code I created is all open source and free for anyone to use under the MIT license.
## What I learned
I learned how to use the std library and learned how to create an open source tool.
## What's next for std-terraform
I plan on integrating std-terraform at my co-op position to easily display all the infrastructure on our large infra. | ## Inspiration
When our team first came together in the days preceding HackHarvard, we agreed that if nothing else, our project would focus on helping society. Hannah told us about the nerve-wracking experience of watching from afar as her loved ones in Tampa prepared for and dealt with hurricanes Helene and Milton. It takes a significant amount of time, effort, and money to plan for the storm’s devastation. We were inspired to consolidate verified and reliable information about the steps needed before, during, and after an impending hurricane to minimize damage and cost, and be able to find resources, shelters and evacuation routes anytime.
## What it does
Once we decided on the issue to tackle, we spent a couple of hours planning the implementation to best serve our audience—people planning for and affected by hurricanes. We decided to design and build an app available on both Android and iOS devices to enhance accessibility.
The app features:
* A **homepage** with general hurricane preparation guides.
* A **map interface** using user latitude and longitude, displaying:
+ Flood, tropical storm, and hurricane affected areas nearby.
+ Toggles for nearby clinics, shelters, FEMA disaster relief centers, and supply drops.
## How we built it
We divided our team into roles:
* **Backend Development:** Led by Anmol and Hannah.
* **Frontend Development:** Led by Deep
* **Fullstack Support:** Naunidha
The frontend team developed in **ReactNative** for cross-platform compatibility (iOS and Android).
The backend team implemented services with **Python**, **Flask**, and **cloud hosting** using **Defang** and a backup **Linode** server for optimal performance. We containerized the backend using **Docker** to ensure a stable, continuous and high-quality experience that would scale without issue.
## Challenges we ran into
Some challenges we encountered include:
* **API access and costs:**
+ We initially wanted to include power outage data on a county level. However, the only service compiling this data, **poweroutages.us**, charges over $500 per month for API access, making it infeasible for us to include.
* **API integration:** Each API provided data in unique ways, requiring us to develop different methods to fetch and integrate endpoints.
* **ReactNative difficulties:** Working with ReactNative introduced challenges related to syntax and the nuances of deploying mobile apps.
* **Backend hosting:** With limited networking capabilities, we didn't want this to be a client-side app. So, we utilized **Defang** to host our backend with Docker containers.
## Accomplishments that we're proud of
We are incredibly proud of the project we built. Though our primary focus for now, was to provide immediate assistance in hurricanes, the name **"Crisis Companion"** stands for our goals to extend the product’s capabilities to support responses for other natural disasters. We aim to unify disparate datasets to serve under-duress people and communities more effectively.
## What we learned
Our team learned:
* The importance of early planning to align all project elements.
* How to navigate the complexities of **ReactNative** development.
* Strategies for **API management** and balancing accessibility with cost limitations.
* The value of **cloud-based solutions** to overcome device hosting restrictions.
## What's next for Crisis Companion
Moving forward, we aim to:
* Expand the app to assist with more types of natural disasters beyond hurricanes and floods.
* Integrate more **real-time data feeds** from live news sources.
* Explore partnerships with services like **poweroutages.us** or similar organizations to enhance the information available to users.
* Provide offline solutions (Bluetooth net like AirTags, Local caches, etc.). | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts and add the items into the database representing your fridge. Using the items you have in your fridge, our app will be able to recommend recipes for dishes for you to make.
## How We Built It
On the back-end, we have a Flask server that receives the image from the front-end through ngrok and then sends the image of the receipt to Google Cloud Vision to get the text extracted. We then post-process the data we receive to filter out any unwanted noise in the data.
On the front-end, our app is built using react-native, using axios to query from the recipe API, and then stores data into Firebase.
## Challenges We Ran Into
Some of the challenges we ran into included deploying our Flask to Google App Engine, and styling in react. We found that it was not possible to write into Google App Engine storage, instead we had to write into Firestore and have that interact with Google App Engine.
On the frontend, we had trouble designing the UI to be responsive across platforms, especially since we were relatively inexperienced with React Native development. We also had trouble finding a recipe API that suited our needs and had sufficient documentation. | losing |
## Inspiration
Social media platforms such as Facebook and Twitter have been extremely crucial in helping establish important political protests in nations such as Egypt during the Arab Spring, and mesh network based platforms hold importance in countries like China where national censorship prevents open communication. In addition to this, people in countries like India have easy access to smart phones because of how cheap android phones have become, but wifi/cellular access still remains expensive.
## What it does
Our project is called Wildfire. Wildfire is a peer to peer social media where users can follow other specific users to receive updates, posts, news articles, and other important information such as weather. The app works completely offline, by transmitting data through a network of other devices. In addition to this, we created a protocol for hubs, which centralizes the ad hoc network to specific locations, allowing mass storage of data on the hubs rather than users phones.
## How we built it
The peer to peer component of the hack uses Android Nearby, which is a protocol that uses hotspots, bluetooth, and sound to transmit messages to phones and hubs that are close to you. Using this SDK, we created a protocol to establish mesh networks between all the devices, and created an algorithm that efficiently transfers information across the network. Also, the hubs were created using android things devices, which can be built using cheap raspberry pis. This provides an advantage over other mesh networking/ad hoc network applications, because our hack uses a combination of persistent storage on the hubs, and ephemeral storage on the actual users' device, to ensure that you can use even devices that do not have a ton of storage capability to connect to a Wildfire network.
## Challenges we ran into
There were a couple of major problems we had to tackle. First of all, our social media is peer to peer, meaning all the data on the network is stored on the phones of users, which would be a problem if we stored ALL the data on EVERY single phone. To solve this problem, we came up with the idea for hubs, which provides centralized storage for data that do not move, lessening the load on each users phone for storage, which is a concern in regions where people might be purchasing phones that are cheaper and have less total storage. In addition to this, we have an intelligent algorithm that tries to predict a given users movement to allow them to act as a messenger between two separate users. This algorithm took a lot of thinking to actually transmit data efficiently, and is something we are extremely proud of.
## What we learned
We learned about a lot of the problems and solutions to the problems that come with working on a distributed system. We tried a bunch of different solutions, such as using distributed elections to decide a leader to establish ground truth, using a hub as a centralized location for data, creating an intelligent content delivery system using messengers, etc.
## What's next for Wildfire
We plan on making the wildfire app, the hub system, and our general p2p protocol open source, and our hope is that other developers can build p2p applications using our system. Also, potential applications for our hack include being able to create Wildfire networks across rural areas to allow quick communication, if end to end encryption is integrated, being able to use it to transmit sensitive information in social movements, and more. Wildfires are fires you cannot control, and so the probabilities for our system are endless. | ## Inspiration
While using ridesharing apps such as Uber and Lyft, passengers, particularly those of marginalized identities, have reported feeling unsafe or uncomfortable being alone in a car. From user interviews, every woman has mentioned personal safety as one of their top concerns within a rideshare. About 23% of American women have reported a driver for inappropriate behavior. Many apps have attempted to mitigate this issue by creating rideshare services that may hire only female drivers. However, these apps have quickly gotten shut down due to discrimination laws. Additionally, around 40% of Uber and Lyft drivers are white males, possibly due to the fact that many minorities may feel uncomfortable in certain situations as a driver. We aimed to create a rideshare app which would provide the same sense of safeness and comfort that the aforementioned apps aimed to provide while making sure that all backgrounds are represented and accounted for.
## What it does
Our app, Driversity (stylized DRiveristy), works similarly to other ridesharing apps, with features put in place to assure that both riders and drivers feel safe. The most important feature we'd like to highlight is a feature that allows the user to be alerted if a driver goes off the correct path to the destination designated by the rider. The app will then ask the user if they would like to call 911 to notify them of the driver's actions. Additionally, many of the user interviews we conducted stated that many women prefer to walk around, especially at night, while waiting for a rideshare driver to pick them up for safety concerns. The app provides an option for users to select in order to allow them to walk around while waiting for their rideshare, also notifying the driver of their dynamic location. After selecting a destination, the user will be able to select a driver from a selection of three drivers on the app. On this selection screen, the app details both identity and personality traits of the drivers, so that riders can select drivers they feel comfortable riding with. Users also have the option to provide feedback on their trip afterward, as well as rating the driver on various aspects such as cleanliness, safe driving, and comfort level. The app will also use these ratings to suggest drivers to users that users similar to them rated highly.
## How we built it
We built it using Android Studio in Java for full-stack development. We used the Google JavaScript Map API to display the map for the user when selecting destinations and tracking their own location on the map. We used Firebase to store information and for authentication of the user. We used DocuSign in order for drivers to sign preliminary papers. We used OpenXC to calculate if a driver was traveling safely and at the speed limit. In order to give drivers benefits, we are giving them the choice to take 5% of their income and invest it, and it will grow naturally as the market rises.
## Challenges we ran into
We weren't very familiar with Android Studio, so we first attempted to use React Native for our application, but we struggled a lot implementing many of the APIs we were using with React Native, so we decided to use Android Studio as we originally intended.
## What's next for Driversity
We would like to develop more features on the driver's side that would help the drivers feel more comfortable as well. We also would like to include the usage of the Amadeus travel APIs. | ## What it does
Danstrument lets you video call your friends and create music together using only your actions. You can start a call which generates a code that your friend can use to join.
## How we built it
We used Node.js to create our web app which employs WebRTC to allow video calling between devices. Movements are tracked with pose estimation from tensorflow and then vector calculations are done to trigger audio files.
## Challenges we ran into
Connecting different devices with WebRTC over an unsecured site proved to be very difficult. We also wanted to have continuous sound but found that libraries that could accomplish this caused too many problems so we chose to work with discrete sound bites instead.
## What's next for Danstrument
Annoying everyone around us. | partial |
## Inspiration
My friend and I needed to find an apartment in New York City during the Summer. We found it very difficult to look through multiple listing pages at once so we thought to make a bot to suggest apartments would be helpful. However, we did not stop there. We realized that we could also use Machine Learning so the bot would learn what we like and suggest better apartments. That is why we decided to do RealtyAI
## What it does
It is a facebook messenger bot that allows people to search through airbnb listings while learning what each user wants. By giving feedback to the bot, we learn your **general style** and thus we are able to recommend the apartments that you are going to like, under your budget, in any city of the world :) We can also book the apartment for you.
## How I built it
Our app used a flask app as a backend and facebook messenger to communicate with the user. The facebook bot was powered by api.ai and the ML was done on the backend with sklearn's Naive Bayes Classifier.
## Challenges I ran into
Our biggest challenge was using python's sql orm to store our data. In general, integrating the many libraries we used was quite challenging.
The next challenge we faced was time, our application was slow and timing out on multiple requests. So we implemented an in-memory cache of all the requests but most importantly we modified the design of the code to make it multi-threaded.
## Accomplishments that I'm proud of
Our workflow was very effective. Using Heroku, every commit to master immediately deployed on the server saving us a lot of time. In addition, we all managed the repo well and had few merge conflicts. We all used a shared database on AWS RDS which saved us a lot of database scheme migration nightmares.
## What I learned
We learned how to use python in depth with integration with MySQL and Sklearn. We also discovered how to spawn a database with AWS. We also learned how to save classifiers to the database and reload them.
## What's next for Virtual Real Estate Agent
If we win hopefully someone will invest! Can be used by companies for automatic accommodations for people having interviews. But only by individuals how just want to find the best apartment for their own style! | ## Inspiration
We were inspired by the story of the large and growing problem of stray, homeless, and missing pets, and the ways in which technology could be leveraged to solve it, by raising awareness, adding incentive, and exploiting data.
## What it does
Pet Detective is first and foremost a chat bot, integrated into a Facebook page via messenger. The chatbot serves two user groups: pet owners that have recently lost their pets, and good Samaritans that would like to help by reporting. Moreover, Pet Detective provides monetary incentive for such people by collecting donations from happily served users. Pet detective provides the most convenient and hassle free user experience to both user bases. A simple virtual button generated by the chatbot allows the reporter to allow the bot to collect location data. In addition, the bot asks for a photo of the pet, and runs computer vision algorithms in order to determine several attributes and match factors. The bot then places a track on the dog, and continues to alert the owner about potential matches by sending images. In the case of a match, the service sets up a rendezvous with a trusted animal care partner. Finally, Pet Detective collects data on these transactions and reports and provides a data analytics platform to pet care partners.
## How we built it
We used messenger developer integration to build the chatbot. We incorporated OpenCV to provide image segmentation in order to separate the dog from the background photo, and then used Google Cloud Vision service in order to extract features from the image. Our backends were built using Flask and Node.js, hosted on Google App Engine and Heroku, configured as microservices. For the data visualization, we used D3.js.
## Challenges we ran into
Finding the write DB for our uses was challenging, as well as setting up and employing the cloud platform. Getting the chatbot to be reliable was also challenging.
## Accomplishments that we're proud of
We are proud of a product that has real potential to do positive change, as well as the look and feel of the analytics platform (although we still need to add much more there). We are proud of balancing 4 services efficiently, and like our clever name/logo.
## What we learned
We learned a few new technologies and algorithms, including image segmentation, and some Google cloud platform instances. We also learned that NoSQL databases are the way to go for hackathons and speed prototyping.
## What's next for Pet Detective
We want to expand the capabilities of our analytics platform and partner with pet and animal businesses and providers in order to integrate the bot service into many different Facebook pages and websites. | ## Inspiration
The inspiration for the project was to design a model that could detect fake loan entries hidden amongst a set of real loan entries. Also, our group was eager to design a dashboard to help see these statistics - many similar services are good at identifying outliers in data but are unfriendly to the user. We wanted businesses to look at and understand fake data immediately because its important to recognize quickly.
## What it does
Our project handles back-end and front-end tasks. Specifically, on the back-end, the project uses libraries like Pandas in Python to parse input data from CSV files. Then, after creating histograms and linear regression models that detect outliers on given input, the data is passed to the front-end to display the histogram and present outliers on to the user for an easy experience.
## How we built it
We built this application using Python in the back-end. We utilized Pandas for efficiently storing data in DataFrames. Then, we used Numpy and Scikit-Learn for statistical analysis. On the server side, we built the website in HTML/CSS and used Flask and Django to handle events on the website and interaction with other parts of the code. This involved retrieving taking a CSV file from the user, parsing it into a String, running our back-end model, and displaying the results to the user.
## Challenges we ran into
There were many front-end and back-end issues, but they ultimately helped us learn. On the front-end, the biggest problem was using Django with the browser to bring this experience to the user. Also, on the back-end, we found using Keras to be an issue during the start of the process, so we had to switch our frameworks mid-way.
## Accomplishments that we're proud of
An accomplishment was being able to bring both sides of the development process together. Specifically, creating a UI with a back-end was a painful but rewarding experience. Also, implementing cool machine learning models that could actually find fake data was really exciting.
## What we learned
One of our biggest lessons was to use libraries more effectively to tackle the problem at hand. We started creating a machine learning model by using Keras in Python, which turned out to be ineffective to implement what we needed. After much help from the mentors, we played with other libraries that made it easier to implement linear regression, for example.
## What's next for Financial Outlier Detection System (FODS)
Eventually, we aim to use a sophisticated statistical tools to analyze the data. For example, a Random Forrest Tree could have been used to identify key characteristics of data, helping us decide our linear regression models before building them. Also, one cool idea is to search for linearly dependent columns in data. They would help find outliers and eliminate trivial or useless variables in new data quickly. | partial |
# SmartKart
A IoT shopping cart that follows you around combined with a cloud base Point of Sale and Store Management system. Provides a comprehensive solution to eliminate lineups in retail stores, engage with customers without being intrusive and a platform to implement detailed customer analytics.
Featured by nwHacks: <https://twitter.com/nwHacks/status/843275304332283905>
## Inspiration
We questioned the current self-checkout model. Why wait in line in order to do all the payment work yourself!? We are trying to make a system that alleviates much of the hardships of shopping; paying and carrying your items.
## Features
* A robot shopping cart that uses computer vision to follows you!
* Easy-to-use barcode scanning (with an awesome booping sound)
* Tactile scanning feedback
* Intuitive user-interface
* Live product management system, view how your customers shop in real time
* Scalable product database for large and small stores
* Live cart geo-location, with theft prevention | ## Inspiration
After looking at the Hack the 6ix prizes, we were all drawn to the BLAHAJ. On a more serious note, we realized that one thing we all have in common is accidentally killing our house plants. This inspired a sense of environmental awareness and we wanted to create a project that would encourage others to take better care of their plants.
## What it does
Poképlants employs a combination of cameras, moisture sensors, and a photoresistor to provide real-time insight into the health of our household plants. Using this information, the web app creates an interactive gaming experience where users can gain insight into their plants while levelling up and battling other players’ plants. Stronger plants have stronger abilities, so our game is meant to encourage environmental awareness while creating an incentive for players to take better care of their plants.
## How we built it + Back-end:
The back end was a LOT of python, we took a new challenge on us and decided to try out using socketIO, for a websocket so that we can have multiplayers, this messed us up for hours and hours, until we finally got it working. Aside from this, we have an arduino to read for the moistness of the soil, the brightness of the surroundings, as well as the picture of it, where we leveraged computer vision to realize what the plant is. Finally, using langchain, we developed an agent to handle all of the arduino info to the front end and managing the states, and for storage, we used mongodb to hold all of the data needed.
[backend explanation here]
### Front-end:
The front-end was developed with **React.js**, which we used to create a web-based game. We were inspired by the design of old pokémon games, which we thought might evoke nostalgia for many players.
## Challenges we ran into
We had a lot of difficulty setting up socketio and connecting the api with it to the front end or the database
## Accomplishments that we're proud of
We are incredibly proud of integrating our web sockets between frontend and backend and using arduino data from the sensors.
## What's next for Poképlants
* Since the game was designed with a multiplayer experience in mind, we want to have more social capabilities by creating a friends list and leaderboard
* Another area to explore would be a connection to the community; for plants that are seriously injured, we could suggest and contact local botanists for help
* Some users might prefer the feeling of a mobile app, so one next step would be to create a mobile solution for our project | ## Inspiration
Our inspiration came from a mix of previous experience with computer vision and recognizing how it can enhance the shopping experience and services. Understanding that sometimes customers may find it difficult to locate an employee, we decided to let customers notify employees by simply raising their hand.
## What it does
When a customer raises their hand, employees will be notified of the customer's location and be able to arrive at their location to provide assistance.
## How we built it
The cameras recognize customers raising their hands by machine learning via Tensorflow. A signal is then sent from each camera to a server, indicating whether there are people requesting help in an area. States of each area are then broadcasted to each employee to notify them of their requests.
## Challenges we ran into
Understanding Socket.io for the first time.
Setting up JavaScript and Python Clients with a JavaScript server.
## Accomplishments that we're proud of
For some of us, developing a project using tools we haven't used before such as Socket.io and Javascript.
How to set up a Server back-end.
For most of us, the first Hackathon we competed in and first productive all-nighter.
## What we learned
We learned how to collaborate effectively. We are used to coding solo, so it's not common for us to work with other programmers on a project. With the use of GitHub, we can keep track of each other's progress and improve our effectiveness in coding.
## What's next for Hey
The current prototype is still quite primitive. While it can be implemented with some success, there is still a lot of improvements to be made. One such example is to check the availability of an employee and deciding whether or not to send them a notification. Also, we can partition aisles by recognizing shelves and reducing the cameras needed, hence reducing operational costs. Multi-person tracking is also a goal for the betterment of this project. | winning |
## Inspiration
One of our team members was stunned by the number of colleagues who became self-described "shopaholics" during the pandemic. Understanding their wishes to return to normal spending habits, we thought of a helper extension to keep them on the right track.
## What it does
Stop impulse shopping at its core by incentivizing saving rather than spending with our Chrome extension, IDNI aka I Don't Need It! IDNI helps monitor your spending habits and gives recommendations on whether or not you should buy a product. It also suggests if there are local small business alternatives so you can help support your community!
## How we built it
React front-end, MongoDB, Express REST server
## Challenges we ran into
Most popular extensions have company deals that give them more access to product info; we researched and found the Rainforest API instead, which gives us the essential product info that we needed in our decision algorithm. However this proved, costly as each API call took upwards of 5 seconds to return a response. As such, we opted to process each product page manually to gather our metrics.
## Completion
In its current state IDNI is able to perform CRUD operations on our user information (allowing users to modify their spending limits and blacklisted items on the settings page) with our custom API, recognize Amazon product pages and pull the required information for our pop-up display, and dynamically provide recommendations based on these metrics.
## What we learned
Nobody on the team had any experience creating Chrome Extensions, so it was a lot of fun to learn how to do that. Along with creating our extensions UI using React.js this was a new experience for everyone. A few members of the team were also able to spend the weekend learning how to create an express.js API with a MongoDB database, all from scratch!
## What's next for IDNI - I Don't Need It!
We plan to look into banking integration, compatibility with a wider array of online stores, cleaner integration with small businesses, and a machine learning model to properly analyze each metric individually with one final pass of these various decision metrics to output our final verdict. Then finally, publish to the Chrome Web Store! | ## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future. | ## Inspiration
We wanted to find ways to make e-commerce more convenient, as well as helping e-commerce merchants gain customers. After a bit of research, we discovered that one of the most important factors that consumers value is sustainability. According to FlowBox, 65% of consumers said that they would purchase products from companies who promote sustainability. In addition, the fastest growing e-commerce platforms endorse sustainability. Therefore, we wanted to create a method that allows consumers access to information regarding the company's sustainability policies.
## What it does
Our project is a browser extension that allows users to browse e-commerce websites while being able to check the product manufactures'' sustainability via ratings out of 5 stars.
## How we built it
We started building the HTML as the skeleton of the browser extension. We then proceeded with JavaScript to connect the extension with ChatGPT. Then, we asked ChatGPT a question regarding the general consensus of a company's sustainability. We run this review through sentimental analysis, which returns a ratio of positive and negative sentiment with relevance towards sustainability. This information is then converted into a value out of 5 stars, which is displayed on the extension homepage. We finalized the project with CSS, making the extension look cleaner and more user friendly.
## Challenges we ran into
We had issues with running servers, as we struggled with the input and output of information.
We also ran into trouble with setting up the Natural Language Processing models from TensorFlow. There were multiple models trained using different datasets and methods, despite the fact they all use TensorFlow, they were developed at different times, which means different versions of TensorFlow were used. It made the debugging process a lot more extensive and made the implementation take a lot more time.
## Accomplishments that we're proud of
We are proud that we were able to create a browser extension that makes the lives of e-commerce developers and shoppers more convenient. We are also proud of making a visually appealing extension that is accessible to users. Furthermore, we are proud of implementing modern technology such as ChatGPT within our approach to solving the challenge.
## What we learned
We learned how to create a browser extension from scratch and implement the OpenAi API to connect our requests to ChatGPT. We also learned how to use Natural Language Processing to detect how positive or negative the response we received from ChatGPT was. Finally, we learned how to convert the polarity we received into a rating that is easy to read and accessible to users.
## What's next for E-commerce Sustainability Calculator
In the future, we would like to implement a feature that gives a rating to the reliability of our sustainability rating. Since there are many smaller and lesser known companies on e-commerce websites, they would not have that much information about their sustainability policies, so their sustainability rating would be a lot less accurate compared to a more relevant company. We would implement this by using the amount of google searches for a specific company as a metric to measure their relevance and then base a score using a scale that ranges the the number of google searches. | winning |
## Inspiration
It's easy to zone off in online meetings/lectures, and it's difficult to rewind without losing focus at the moment. It could also be disrespectful to others if you expose the fact that you weren't paying attention. Wouldn't it be nice if we can just quickly skim through a list of keywords to immediately see what happened?
## What it does
Rewind is an intelligent, collaborative and interactive web canvas with built in voice chat that maintains a list of live-updated keywords that summarize the voice chat history. You can see timestamps of the keywords and click on them to reveal the actual transcribed text.
## How we built it
Communications: WebRTC, WebSockets, HTTPS
We used WebRTC, a peer-to-peer protocol to connect the users though a voice channel, and we used websockets to update the web pages dynamically, so the users would get instant feedback for others actions. Additionally, a web server is used to maintain stateful information.
For summarization and live transcript generation, we used Google Cloud APIs, including natural language processing as well as voice recognition.
Audio transcription and summary: Google Cloud Speech (live transcription) and natural language APIs (for summarization)
## Challenges we ran into
There are many challenges that we ran into when we tried to bring this project to reality. For the backend development, one of the most challenging problems was getting WebRTC to work on both the backend and the frontend. We spent more than 18 hours on it to come to a working prototype. In addition, the frontend development was also full of challenges. The design and implementation of the canvas involved many trial and errors and the history rewinding page was also time-consuming. Overall, most components of the project took the combined effort of everyone on the team and we have learned a lot from this experience.
## Accomplishments that we're proud of
Despite all the challenges we ran into, we were able to have a working product with many different features. Although the final product is by no means perfect, we had fun working on it utilizing every bit of intelligence we had. We were proud to have learned many new tools and get through all the bugs!
## What we learned
For the backend, the main thing we learned was how to use WebRTC, which includes client negotiations and management. We also learned how to use Google Cloud Platform in a Python backend and integrate it with the websockets. As for the frontend, we learned to use various javascript elements to help develop interactive client webapp. We also learned event delegation in javascript to help with an essential component of the history page of the frontend.
## What's next for Rewind
We imagined a mini dashboard that also shows other live-updated information, such as the sentiment, summary of the entire meeting, as well as the ability to examine information on a particular user. | ## Inspiration
Blip emerged from a simple observation: in our fast-paced world, long-form content often goes unheard. Inspired by the success of short-form video platforms like Tiktok, we set out to revolutionize the audio space.
## What it does
Our vision is to create a platform where bite-sized audio clips could deliver maximum impact, allowing users to learn, stay informed, and be entertained in the snippets of time they have available throughout their day. Blip is precisely that. Blip offers a curated collection of short audio clips, personalized to each user's interests and schedule, ensuring they get the most relevant and engaging content whenever they have a few minutes to spare.
## How we built it
Building Blip was a journey that pushed our technical skills to new heights. We used a modern tech stack including TypeScript, NextJS, and TailwindCSS to create a responsive and intuitive user interface. The backend, powered by NextJS and enhanced with OpenAI and Cerebras APIs, presented unique challenges in processing and serving audio content efficiently. One of our proudest accomplishments was implementing an auto-play algorithm that allows users to listen to similar Blips, but also occasionally recommends more unique content.
## Challenges we ran into
The backend, powered by NextJS and enhanced with OpenAI and Cerebras APIs, presented unique challenges in processing and serving audio content efficiently. We had to make sure that no more audio clips than necessary were loaded at anytime to ensure browser speed optimality.
## Accomplishments that we're proud of
One of our proudest accomplishments was implementing an auto-play algorithm that allows users to listen to similar Blips, but also occasionally recommends more unique content. It allows users to listen to what they are comfortable with, yet also allows them to branch out.
## What we learned
Throughout the development process, we encountered and overcame numerous hurdles. Optimizing audio playback for seamless transitions between clips, ensuring UI-responsiveness, and efficiently utilizing sponsor APIs were just a few of the obstacles we faced. These challenges not only improved our problem-solving skills but also deepened our understanding of audio processing technologies and user experience design.
## What's next for Blip
The journey of creating Blip has been incredibly rewarding. We've learned the importance of user-centric design, found a new untapped market for entertainment, and harnessed the power of AI in enhancing content discovery and generation. Looking ahead, we're excited about the potential of Blip to transform how people consume audio content. Our roadmap includes expanding our content categories, scaling up our recommendation algorithm, and exploring partnerships with content creators and educators to bring even more diverse and engaging content to our platform.
Blip is more than just an app; it's a new way of thinking about audio content in the digital age. We're proud to have created a platform that makes learning and staying informed more accessible and enjoyable for everyone, regardless of their busy schedules. As we move forward, we're committed to continually improving and expanding Blip, always with our core mission in mind: to turn little moments into big ideas, one short-cast at a time. | ## Inspiration
The inspiration for the project was Covid-19. As we all know, because of the pandemic we remained seperate from our beloved sports and activities and even now, we are still having difficulties finding people around us to gather around for a sports event. This app has been designed to overcome that situation by bringing sports enthusiasts more closer to each and allowing people to meet in a simpler way with a goal.
## What it does
After signing up and logging in Connecthlete, you will be asked for the "sport you'd like to play". After choosing one sport, you will be redirected and will be shown under people that wants to play that sport just like you do. Afterwards, you can access the person's number and discuss it further about when to organize the meetup for the sports event.
## How we built it
We have built Connecthlete using android java and XML. After coding each activities in android studio, we've created a firebase database to store the usernames and their passwords with a randomly generated "key". Moreover, to test the app, we've used "android-studio" which allowed us to simulate the app on an emulator allowing us to keep track of the progress and minor bugs.
## Challenges we ran into
Extracting a random key from a database was a serious problem. In order to store multiple functionalities, we have decided to collect them all under a simple firebase key generated by firebase. However, after a long period of time, we have realized that it is not possible to access the key through android-studio terminal. Additionally, creating an app from scratch without any referance was another tough issue to be overcomed.
## Accomplishments that we're proud of
Thought of a mobile app that has not been made by someone before. The concept is different than the current available meeting applications.
## What we learned
Before doing this hackathlon, we were experienced with java. But using android studio java with XML is a way different experience than we thought. Working with databases were our first time too.
## What's next for Connecthlete
Although we've made quite a progress, Connecthlete must be more exact about one thing; connecting with other people. For instance, there can be a development of real-time user location service and people could show their availability to other people in the app with the real-time location when arranging a sports event. | winning |
## Inspiration
We recognized that many individuals are keen on embracing journaling as a habit, but hurdles like the "all or nothing" mindset often hinder their progress. The pressure to write extensively or perfectly every time can be overwhelming, deterring potential journalers. Consistency poses another challenge, with life's busy rhythm making it hard to maintain a daily writing routine. The common issue of forgetting to journal compounds the struggle, as people find it difficult to integrate this practice seamlessly into their day. Furthermore, the blank page can be intimidating, leaving many uncertain about what to write and causing them to abandon the idea altogether. In addressing these barriers, our aim with **Pawndr** is to make journaling an inviting, effortless, and supportive experience for everyone, encouraging a sustainable habit that fits naturally into daily life.
## What it does
**Pawndr** is a journaling app that connects with you through text and voice. You will receive conversational prompts delivered to their phone, sparking meaningful reflections wherever you are and making journaling more accessible and fun. Simply reply to our friendly messages with your thoughts or responses to our prompts, and watch your personal journey unfold. Your memories are safely stored, easy accessible through our web app, and beautifully organized. **Pawndr** is able to transform your daily moments into a rich tapestry of self-discovery.
## How we built it
The front-end was built using react.js. We built the backend using FastAPI, and used MongoDB as our database. We deployed our web application and API to a Google Cloud VM using nginx and uvicorn. We utilized Infobip to build our primary user interaction method. Finally, we made use of OpenAI's GPT 3 and Whisper APIs to power organic journaling conversations.
## Challenges we ran into
Our user stories required us to use 10 digit phone numbers for SMS messaging via Infobip. However, Canadian regulations blocked any live messages we sent using the Infobip API. Unfortunately, this was a niche problem that the sponsor reps could not help us with (we still really appreciate all of their help and support!! <3), so we pivoted to a WhatsApp interface instead.
## Accomplishments that we're proud of
We are proud of being able to quickly problem-solve and pivot to a WhatsApp interface upon the SMS difficulties. We are also proud of being able to integrate our project into an end-to-end working demo, allowing hackathon participants to experience our project vision.
## What we learned
We learned how to deploy a web app to a cloud VM using nginx. We also learned how to use Infobip to interface with WhatsApp business and SMS. We learned about the various benefits of journaling, the common barriers to journaling, and how to make journaling rewarding, effortless, and accessible to users.
## What's next for Pawndr
We want to implement more channels to allow our users to use any platform of their choice to journal with us (SMS, Messenger, WhatsApp, WeChat, etc.). We also hope to have more comprehensive sentiment analysis visualization, including plots of mood trends over time. | # BananaExpress
A self-writing journal of your life, with superpowers!
We make journaling easier and more engaging than ever before by leveraging **home-grown, cutting edge, CNN + LSTM** models to do **novel text generation** to prompt our users to practice active reflection by journaling!
Features:
* User photo --> unique question about that photo based on 3 creative techniques
+ Real time question generation based on (real-time) user journaling (and the rest of their writing)!
+ Ad-lib style questions - we extract location and analyze the user's activity to generate a fun question!
+ Question-corpus matching - we search for good questions about the user's current topics
* NLP on previous journal entries for sentiment analysis
I love our front end - we've re-imagined how easy and futuristic journaling can be :)
And, honestly, SO much more! Please come see!
♥️ from the Lotus team,
Theint, Henry, Jason, Kastan | ## Inspiration
We met at the event - on the spot. We are a diverse team, from different parts of the world and different ages, with up to 7 years of difference! We believe that there is an important evolution towards using data technology to make investment decisions & data applications to move to designing new financial products and services we have not even considered yet.
## What it does
Trendy analyzes over 300,000+ projects from Indiegogo, a crowd-funding website, for the last year. Trendy monitors and evaluates on average 20+ data points per company. Hence, we focus on 6 main variables and illustrate the use case based on statistical models. In order to keep the most user-friendly interface where we could still get as many info as possible, we have decided to create a chatbot on which the investor interacts with our platform.
The user may see graphs, trends analysis, and adjust his preferabilities accordingly.
## Challenges we ran into
We have had a lot of trouble setting up the cloud to host everything. We also have had a lot of struggles in order to build a bot, due to many restrictions Facebook has set. The challenges kept us apart from innovating more on our product.
## Accomplishments that we're proud of
We are very proud to have a very acute data analysis and a great interface. Our results are logical and we seem to have one of the best interfaces.
## What we learned
We learned a lot about cloud hosting, data management, and chatbot setup. More concretely, we have built ourselves a great platform to facilitate our financial wealth plan!
## What's next for Trendy
We foresee adding a couple of predictive analytics concepts to our trend hacking platform, like random forests, Kelly criterion, and a couple of others. Moreover, we envisage empowering our database and analysis' accuracy by implementing some Machine Learning models. | winning |
## Inspiration
We were inspired by the need to provide patients with a reliable tool that can simplify the process of online diagnosis. Too often, when we Google our symptoms, we're met with exaggerated results that make it seem like we’re facing life-threatening conditions. Our web app combines AI with real time data from Groq to create accurate and accessible solutions to the diagnosis without unnecessary panic.
## What it does
Our web app takes patient symptoms, synthesizes data using Fetch AI and Groq to provide real time diagnosis based on patient symptoms. Llama Guard ensures that the data is handled securely and protects sensitive information maintaining user privacy.
## How we built it
We used Fetch AI to have multi-agent communication to talk to each other, reflex for a user-friendly interface and Groq as a large language model to process and generate the potential diagnosis. Python served as the backbone of our app organizing the data flows between Fetch AI, Reflex and Groq while also handling backend logic for symptom processing and diagnosis generation. Llama Guard was integrated to ensure secure data management.
## Challenges we ran into
One of the challenges we faced was integrating Fetch.AI to process increasingly complex and case-specific data. We were able to overcome the challenge by using a bureau of local agents to simulate greedy linear search to efficiently narrow down a patient's ailment without an enormous space complexity. We also tapped into the vast resources of the Agentverse to enable user input, Groq interfacing, web scraping, summarization, diagnosis, and recommendation. It was also challenging to ensure Groq’s AI could deliver accurate diagnosis results. Balancing the need for user-friendly design with the complexity of medical data was another challenge.
## Accomplishments that we're proud of
We are proud of successfully integrating Fetch AI with verified websites like WebMD's data. Another accomplishment was the effective implementation of Groq's large language model, which provided reliable and precise diagnosis predictions. Ensuring that the AI could interpret and analyze symptom data without overwhelming or misinforming users was a critical milestone. We are proud of creating a secure environment through the integration of Llama Guard. This ensured not giving any misinformation or unnecessary panic to patients.
## What we learned
We learned a lot about using AI in healthcare applications, from securing data with Llama Guard to synthesizing real-time medical data. The project also fortified the importance of user-centered design in creating tools that patients trust and feel comfortable using.
## What's next for Pocketdoc
We are excited to hear back from our mentors and talk to actual health professionals to make sure Pocketdoc complies with health regulations. We also aim to introduce features like multilingual support, and deeper integration with wearable devices for real-time health monitoring. | ## Inspiration
We've all left a doctor's office feeling more confused than when we arrived. This common experience highlights a critical issue: over 80% of Americans say access to their complete health records is crucial, yet 63% lack their medical history and vaccination records since birth. Recognizing this gap, we developed our app to empower patients with real-time transcriptions of doctor visits, easy access to health records, and instant answers from our AI doctor avatar. Our goal is to ensure EVERYONE has the tools to manage their health confidently and effectively.
## What it does
Our app provides real-time transcription of doctor visits, easy access to personal health records, and an AI doctor for instant follow-up questions, empowering patients to manage their health effectively.
## How we built it
We used Node.js, Next.js, webRTC, React, Figma, Spline, Firebase, Gemini, Deepgram.
## Challenges we ran into
One of the primary challenges we faced was navigating the extensive documentation associated with new technologies. Learning to implement these tools effectively required us to read closely and understand how to integrate them in unique ways to ensure seamless functionality within our website. Balancing these complexities while maintaining a cohesive user experience tested our problem-solving skills and adaptability. Along the way, we struggled with Git and debugging.
## Accomplishments that we're proud of
Our proudest achievement is developing the AI avatar, as there was very little documentation available on how to build it. This project required us to navigate through various coding languages and integrate the demo effectively, which presented significant challenges. Overcoming these obstacles not only showcased our technical skills but also demonstrated our determination and creativity in bringing a unique feature to life within our application.
## What we learned
We learned the importance of breaking problems down into smaller, manageable pieces to construct something big and impactful. This approach not only made complex challenges more approachable but also fostered collaboration and innovation within our team. By focusing on individual components, we were able to create a cohesive and effective solution that truly enhances patient care. Also, learned a valuable lesson on the importance of sleep!
## What's next for MedicAI
With the AI medical industry projected to exceed $188 billion, we plan to scale our website to accommodate a growing number of users. Our next steps include partnering with hospitals to enhance patient access to our services, ensuring that individuals can seamlessly utilize our platform during their healthcare journey. By expanding our reach, we aim to empower more patients with the tools they need to manage their health effectively. | ## Inspiration
The intricate nature of diagnosing and treating diseases, combined with the burdensome process of managing patient data, drove us to develop a solution that harnesses the power of AI. Our goal was to simplify and expedite healthcare decision-making while maintaining the highest standards of patient privacy.
## What it does
Percival automates data entry by seamlessly accepting inputs from various sources, including text, speech-to-text transcripts, and PDFs. It anonymizes patient information, organizes it into medical forms, and compares it against a secure vector database of similar cases. This allows us to provide doctors with potential diagnoses and tailored treatment recommendations for various diseases.
## How we use K-means clustering?
To enhance the effectiveness of our recommendation system, we implemented a K-means clustering model using Databricks Open Source within our vector database. This model analyzes the symptoms and medical histories of patients to identify clusters of similar cases. By grouping patients with similar profiles, we can quickly retrieve relevant data that reflects shared symptoms and outcomes.
When a new patient record is entered, our system evaluates their symptoms and matches them against existing clusters in the database. This process allows us to provide doctors with recommendations that are not only data-driven but also highly relevant to the patient's unique situation. By leveraging the power of K-means clustering, we ensure that our recommendations are grounded in real-world patient data, improving the accuracy of diagnoses and treatment plans.
## How we built it
We employed a combination of technologies to bring Percival to life: Flask for server endpoint management, Cloudflare D1 for secure backend storage of user data and authentication, OpenAI Whisper for converting speech to text, the OpenAI API for populating PDF forms, Next.js for crafting a dynamic frontend experience, and finally Databricks Open-source for the K-means clustering to identify similar patients.
## Challenges we ran into
While integrating speech-to-text capabilities, we faced numerous hurdles, particularly in ensuring the accurate conversion of doctors' verbal notes into structured data for medical forms. The task required overcoming technical challenges in merging Next.js with speech input and effectively parsing the output from the Whisper model.
## Accomplishments that we're proud of
We successfully integrated diverse technologies to create a cohesive and user-friendly platform. We take pride in Percival's ability to transform doctors' verbal notes into structured medical forms while ensuring complete data anonymization. Our achievement in combining Whisper’s speech-to-text capabilities with OpenAI's language models to automate diagnosis recommendations represents a significant advancement. Additionally, establishing a secure vector database for comparing anonymized patient data to provide treatment suggestions marks a crucial milestone in enhancing the efficiency and accuracy of healthcare tools.
## What we learned
The development journey taught us invaluable lessons about securely and efficiently handling sensitive healthcare data. We gained insights into the challenges of working with speech-to-text models in a medical context, especially when managing diverse and large inputs. Furthermore, we recognized the importance of balancing automation with human oversight, particularly in making critical healthcare diagnoses and treatment decisions.
## What's next for Percival
Looking ahead, we plan to broaden Percival's capabilities to diagnose a wider range of diseases beyond AIDS. Our focus will be on enhancing AI models to address more complex cases, incorporating multiple languages into our speech-to-text feature for global accessibility, and introducing real-time data processing from wearable devices and medical equipment. We also aim to refine our vector database to improve the speed and accuracy of patient-to-case comparisons, empowering doctors to make more informed and timely decisions. | losing |
## Inspiration
Have you ever been frustrated looking for a grocery item, only realizing after that you passed by it multiple times? Ever wish you could receive store guidance without stepping out of your social bubble?
We are introducing **Aisle Atlas**! An interactive, computer vision companion residing right on top of your head. With its AI capabilities and convenience of use, our device allows anyone to become an "employee" of a supermarket. Through SMS messages, localization and effective mapping of grocery items, we aim to increase the efficiency and shopping experience for all.
## What it does
Imagine needing to buy an item/items but you're in a rush to be somewhere else. Maybe someone you know is already at the supermarket and only a text message away. Using a simple SMS text, Aisle Atlas allows you to send a grocery list that is automatically received. The items are then mapped immediately for the other shopper to find the shortest algorithm to grab all the components, with detailed instructions to arrive at each "station".
We then use localization to determine our current position within the store and the required path to each item. Once an item has been "completed", there is a basic fingerprint sensor attached to the side of our device. With one tap, that item is no longer at the top of the queue. You can track with live feed the positioning of the shopper and updates in real-time.
## How we built it
Our team wanted to implement a mix of both hardware and software. We 3D-printed a headband and support compartment, housing a Raspberry Pi, camera, batteries and a touch sensor. Our original idea was to attach the device to a hard hat, but we decided in the end to go with a sponsor bucket hat. This gave us more flexibility with materials and easier mounting conditions. We interfaced both firmware and software together to create a well-rounded project and demonstration.
We also used vision-based localization and object detection, as well as MappedIn with live location tracking.
## Challenges we ran into
In terms of challenges, our original plan was to use the Raspberry Pi Module 1.3 Cameras for our detection method. These were substantially smaller and convenient to place inside different types of headgear. We were to connect and see the camera availability but had increased difficulties taking a picture. In the end, we decided it would be simpler to implement a webcam for proof of concept, but its bulkier size was a new challenge on its own.
Another issue was our SSH authentication originally. We wanted to film a video feed at a nearby convenience store, but this required both the laptop and Raspberry Pi operating on the same Wifi network. We had issues connecting the pi to hotspots and it made it difficult to wander anywhere other than HackTheNorth Wifi locations.
Some other technical challenges were debating between stability vs latency tradeoffs. Tolerancing for 3-D prints was also difficult, as mechanical and electrical parts needed to integrate seamlessly for optimal performance.
## Accomplishments that we're proud of
Our team had a lot of fun working together on this project. We all had accomplishments we were proud of. In terms of mechanical products, our team gained experience with 3-D printing and other manufacturing tools such as soldering. Our team integrated a Raspberry Pi and camera as the fundamental hardware of our project. It was great to see the impacts of our software in real life. For software, we discussed lots of problems together and worked through many backend and front-end integration issues. We completed vision-only localization and mapping using the SIFT algorithm.
## What we learned
A huge step forward for us was learning about ngrok for rapid deployment. We gained well-rounded experiences in mechanical, electrical and software, and each worked on components that we enjoyed. There were lots of cool "aha" moments and we were excited to have fun together.
## What's next
In terms of hardware, we weren't able to implement the finger sensor effectively within the deadline. It would be great to add more ways for the user to interact. Another issue was the method by which our instructions were posted. Currently, they are simply posted to a webpage, but we would love to explore mobile apps and audio instructions for increased convenience.
Improving latency was one of the features we looked at from the software side.
Long-term, our project originally stemmed from some automating convenient tasks. This would include using a robot instead of a human with computer vision capabilities to complete all shopping tasks. There are so many additional features such as gamifying, better AI and detection capabilities, and a wider range of items to explore. | ## Inspiration
Our inspiration for this project was to help out our fellow friends who were often too scared/embarrassed to ask store employees for help regarding locating products within grocery stores. While online stores tended to thrive during COVID-19, many traditional retail stores struggled to make it through; many people expect no longer want to go somewhere to purchase products that could be found online. At the same time, we wanted an interesting idea to apply the knowledge we have passionately gained in the Computer Science field. While discussing and brainstorming with this idea, we also realized this could also easily be converted into an entrepreneurial venture with some post-hackathon efforts, which further motivated to pursue this idea. This also happened to become the first coding project that we worked together on as college roommates :)
## What it does
ReTale relieves everyone from the journey and quests taken to find products in the grocery store. For consumers, it serves as the convenience factor to purchase from nearby grocery stores as the amount of time it takes will be significantly cut down. This is thanks to our navigational system that maps out a path given the products in the shopping list feature that is available in our application. By following this computer generated path, you will be taking a much shorter route than aimlessly wandering the aisles looking for specific products on your shopping list. As you find your product on the shelf, you can use our barcode scanner to detect the object and strike it from your shopping list, as well as adding it to your cart to eventually conduct a quick no-contact checkout.
## How we built it
The app works by integrating multiple frameworks and languages. This app was made with a combination of Flutter, Android, and NodeJS, developed with Dart, Java, and JavaScript respectfully. In terms of our feature pipeline, we worked on developing each of the features with sample test cases first. From there, we went on to slowly integrate feature by feature into the main codebase. In terms of the technical details, the strength of the WIFI signals is parsed into a unique and custom formula that then generates a position with the process of triangulation. Using the in-app shopping list, a grid map (as created by the Admin of the store) will be pulled from the Firebase to generate the shortest path through the implementation of a custom pathfinding algorithm that is a variation on the tradition A\* Pathfinding with heuristics. The user can then move around in the store, and the path will be adapting to those actions. The UPC scanning was developed using a Flutter Package to maintain simplicity, from which UPC would be passed in as a query to a product finder API to find the product - in the future, we hope to allow stores to store these along with their maps, as that will allow for in-app, hassle-free checkout.
## Challenges we ran into
Our initial plan for the frontend of the mobile application was to use Flutter for its seamless and smooth visual aesthetic. However, after extensive research, we learned (to our disappointment) that Flutter didn't have a pre-existing package to parse the data we needed for location triangulation from nearby WIFI signals. With that newfound understanding, we continued to explore for viable solutions to our dire situation. We eventually came across a functional and well-documented package with all the data we would need; however, it would require us to program the android application in Java, something our team didn't have prior experience with. With some improvising, adapting, and overcoming, we learned a lot and was able to power through with our project to the finish line.
## Accomplishments that we're proud of
Despite some of the challenges we ran into, we are extremely proud of what we have been able to produce over the course of 36 hours. First and foremost, we were amazed that such a concept actually worked in practice. We were able to essentially develop a Minimum Viable Product for the ReTale project, going through enough experimentation to derive a custom equation that would serve as the formula for converting a WIFI signal with units of dbM to a distance in meters (m). We also were proud to achieve the seamless integration between platforms, something that was more of a non-functional requirement.
## What we learned
We learned a lot of unique application for the Math classes we had taken throughout high school. The things we had learned, especially the properties of figures and solving with specific variables in mind. The application of these skills made it easier to develop and enhance our unique WI-FI navigational system. Working with just the RAW wifi signals was also something that was very new to us, as most of the time we would just be using the WI-FI to transmit information or to access the internet. Once again, with some of the issues we ran into, we were forced to develop some aspects of our product in Java for Android, which was an interesting very valuable and experience.
## What's next for ReTale
As mentioned previously, this could possibly become an entrepreneurial venture that becomes the future for the retail industry. Due to the mutual benefit that it serves people and the stores, that there will be a possible demand for such a product. We also want to improve the feature set of the product even further. In the future roadmap, we would love to include crowd management, restocking alerts, weighted paths and so much more. We have a lot of faith in such an innovative product, with high goals and expectations for its future. | ## Inspiration
Food is a basic human need. As someone who often finds themselves wandering the aisles of Target, I know firsthand how easy it is to get lost among the countless products and displays. The experience can quickly become overwhelming, leading to forgotten items and a less-than-efficient shopping trip. This project was born from the desire to transform that chaos into a seamless shopping experience. We aim to create a tool that not only helps users stay organized with their grocery lists but also guides them through the store in a way that makes shopping enjoyable and stress-free.
## What it does
**TAShopping** is a smart grocery list app that records your grocery list in an intuitive user interface and generates a personalized route in **(almost)** any Target location across the United States. Users can easily add items to their lists, and the app will optimize their shopping journey by mapping out the most efficient path through the store.
## How we built it
* **Data Aggregation:** We utilized `Selenium` for web scraping, gathering product information and store layouts from Target's website.
* **Object Storage:** `Amazon S3` was used for storing images and other static files related to the products.
* **User Data Storage:** User preferences and grocery lists are securely stored using `Google Firebase`.
* **Backend Compute:** The backend is powered by `AWS Lambda`, allowing for serverless computing that scales with demand.
* **Data Categorization:** User items are classified with `Google Gemini`
* **API:** `AWS API Endpoint` provides a reliable way to interact with the backend services and handle requests from the front end.
* **Webapp:** The web application is developed using `Reflex`, providing a responsive and modern interface for users.
* **iPhone App:** The iPhone application is built with `Swift`, ensuring a seamless experience for iOS users.
## Challenges we ran into
* **Data Aggregation:** Encountered challenges with the rigidity of `Selenium` for scraping dynamic content and navigating web page structures.
* **Object Storage:** N/A (No significant issues reported)
* **User Data Storage:** N/A (No significant issues reported)
* **Backend Compute:** Faced long compute times; resolved this by breaking the Lambda function into smaller, more manageable pieces for quicker processing.
* **Backend Compute:** Dockerized various builds to ensure compatibility with the AWS Linux environment and streamline deployment.
* **API:** Managed the complexities of dealing with and securing credentials to ensure safe API access.
* **Webapp:** Struggled with a lack of documentation for `Reflex`, along with complicated Python dependencies that slowed development.
* **iPhone App:** N/A (No significant issues reported)
## Accomplishments that we're proud of
* Successfully delivered a finished product with a relatively good user experience that has received positive feedback.
* Achieved support for hundreds of Target stores across the United States, enabling a wide range of users to benefit from the app.
## What we learned
>
> We learned a lot about:
>
>
> * **Gemini:** Gained insights into effective data aggregation and user interface design.
> * **AWS:** Improved our understanding of cloud computing and serverless architecture with AWS Lambda.
> * **Docker:** Mastered the process of containerization for development and deployment, ensuring consistency across environments.
> * **Reflex:** Overcame challenges related to the framework, gaining hands-on experience with Python web development.
> * **Firebase:** Understood user authentication and real-time database capabilities through Google Firebase.
> * **User Experience (UX) Design:** Emphasized the importance of intuitive navigation and clear presentation of information in app design.
> * **Version Control:** Enhanced our collaboration skills and code management practices using Git.
>
>
>
## What's next for TAShopping
>
> There are many exciting features on the horizon, including:
>
>
> * **Google SSO for web app user data:** Implementing Single Sign-On functionality to simplify user authentication.
> * **Better UX for grocery list manipulation:** Improving the user interface for adding, removing, and organizing items on grocery lists.
> * **More stores:** Expanding support to additional retailers, including Walmart and Home Depot, to broaden our user base and shopping capabilities.
>
>
> | losing |
## Inspiration
• Saw a need for mental health service provision in Amazon Alexa
## What it does
• Created Amazon Alexa skill in Node.js to enable Alexa to empathize with and help a user who is feeling low
• Capabilities include: probing user for the cause of low mood, playing soothing music, reciting inspirational quote
## How we built it
• Created Amazon Alexa skill in Node.js using Amazon Web Services (AWS) and Lambda Function
## Challenges we ran into
• Accessing the web via Alexa, making sample utterances all-encompassing, how to work with Node.js
## Accomplishments that we're proud of
• Made a stable Alexa skill that is useful and extendable
## What we learned
• Node.js, How to use Amazon Web Services
## What's next for Alexa Baymax
• Add resources to Alexa Baymax (if the user has academic issues, can provide links to helpful websites), and emergency contact information, tailor playlist to user's taste and needs, may commercialize by adding an option for the user to book therapy/massage/counseling session | ## Inspiration
Therapy is all about creating a trusting relationship between the clients and their therapist. Building rapport, or trust, is the main job of a therapist, especially at the beginning. But in the current practices, therapists have to take notes throughout the session to keep track of their clients. This does 2 things:
* Deviate the therapists from getting fully involved in the sessions.
* Their clients feel disconnected from their therapists (due to minimal/no eye contact, more focus on note-taking than "connecting" with patients, etc.)
## What it does
Enter **MediScript**.
MediScript is an AI-powered android application that:
* documents the conversation in therapy sessions
* supports speaker diarization (multiple speaker labeling)
* determines the theme of the conversation (eg: negative news, drug usage, health issues, etc.)
* transparently share session transcriptions with clients or therapists as per their consent
With MediScript, we aim to automate the tedious note-taking procedures in therapy sessions and as a result, make therapy sessions engaging again!
## How we built it
We built an Android application, adhering to Material Design UI guidelines, and integrated it with the Chaquopy module to run python scripts directly via the android application. Moreover, the audio recording of each session is stored directly within the app which sends the recorded audio files over to an AWS S3 bucket. We made AssemblyAI API calls via the python scripts and accessed the session recording audio files over the same S3 bucket while calling the API.
Documenting conversations, multi-speaker labeling, and conversation theme detection - all of this was made possible by using the brilliant API by **AssemblyAI**.
## Challenges we ran into
Configuring python scripts with the android application proved to be a big challenge initially. We had to experiment with lots of modules before finding Chaquopy which was a perfect fit for our use-case. AsseblyAPI was quite easy to use but we had to figure out a way to host our .mp3 files over the internet so that the API could access them instantly.
## Accomplishments that we're proud of
None of us had developed an Android app before so this was certainly a rewarding experience for all 3 of us. We weren't sure we'd be able to build a functioning prototype in time but we're delighted with the results!
## What's next for MediScript
* Privacy inclusion: we wish to use more privacy-centric methods to share session transcripts with the therapists and their clients
* Make a more easy-to-use and clean UI
* Integrate emotion detection capabilities for better session logging. | # Moodify
Ever wanted to let your emotion dictate the songs you listen to? Well, Moodify's got you! Based on five common emotions, Moodify's brings up a list of recommended Spotify songs for you to listen away!
## Inspiration
As music lovers, we always choose songs based on how we feel. If we're happy, we might go for something upbeat, like hip-hop. If we're sad, something slower like ballads are the way to go. We wanted to make a web app that lets users explore songs they might not listen to usually, based on their mood.
We believed that music can change the world for the better, but first, we should start by connecting our human emotion with music.
## What it does
Moodify allows users to input their current emotion, and then is recommended different songs based on how they're feeling!
Each emotion that you select (Happy, Sad, Angry, Bored, Excited) corresponds to a different music genre, which pops out a list of songs based on that genre.
**Emotion to Genre:**
Happy -> Bubblegum Pop
Sad -> Soul
Angry -> Rock
Bored -> R & B
Excited -> Dancepop
## How we built it
For our front-end, we used React and Tailwind CSS for a smooth coding experience when creating the web application. We also used Figma for prototyping. For our back-end, we used the Spotify API and Axios to retrieve recommended songs, which can be stored in Firebase's NoSQL database Firestore.
## Challenges we ran into
We initially wanted to implement Computer Vision using GCP's Cloud Vision API. However, we were only able to used it for a Node.js application rather than for our React project, so we ultimately scrapped the idea.
## Accomplishments that we're proud of
Coming into this hackathon, most of our team were all beginners! None of us were fluent with JavaScript, so as while coding this project, we also had to learn JavaScript on top of learning React.
We're proud of being able to create a full-stack web application that is both fun and useful.
## What we learned
1. Learning to make sacrifices. With only 36 hours in the hackathon, we figured out that we couldn't simply implement every feature. We can't make as perfectly aligned to our original plan.
2. Learning to prioritize our well-being. We stayed up all night to work on the hackathon, but it simply wasn't worth it. For most of the hours into the night, we didn't make much progress. We learned that it's super important to also take breaks, and also get some rest - never work while feeling tired or sleepy!
## What's next for Moodify
Incorporate Computer Vision to sense the user's mood directly, which allows for recommendations on the spot. | partial |
**Made by Ella Smith (ella#4637) & Akram Hannoufa (ak\_hannou#7596) -- Team #15**
*Domain: <https://www.birtha.online/>*
## Inspiration
Conversations with friends and family about the difficulty of finding the right birth control pill on the first try.
## What it does
Determines the brand of hormonal contraceptive pill most likely to work for you using data gathered from drugs.com. Data includes: User Reviews, Drug Interactions, and Drug Effectiveness.
## How we built it
The front-end was built using HTML, CSS, JS, and Bootstrap. The data was scraped from drugs.com using Beautiful Soup web-scraper.
## Challenges we ran into
Having no experience in web-dev made this a particularly interesting learning experience. Determining how we would connect the scraped data to the front-end was challenging, as well as building a fully functional multi-page form proved to be difficult.
## Accomplishments that we're proud of
We are proud of the UI design, given it is our first attempt at web development. We are also proud of setting up a logic system that provides variability in the generated results. Additionally, figuring out how to web scrape was very rewarding.
## What we learned
We learned how to use version control software, specifically Git and GitHub. We also learned the basics of Bootstrap and developing a functional front-end using HTML, CSS, and JS.
## What's next for birtha
Giving more detailed and accurate results to the user by further parsing and analyzing the written user reviews. We would also like to add some more data sources to give even more complete results to the user. | ## Inspiration
Determined to create a project that was able to make impactful change, we sat and discussed together as a group our own lived experiences, thoughts, and opinions. We quickly realized the way that the lack of thorough sexual education in our adolescence greatly impacted each of us as we made the transition to university. Furthermore, we began to really see how this kind of information wasn't readily available to female-identifying individuals (and others who would benefit from this information) in an accessible and digestible manner. We chose to name our idea 'Illuminate' as we are bringing light to a very important topic that has been in the dark for so long.
## What it does
This application is a safe space for women (and others who would benefit from this information) to learn more about themselves and their health regarding their sexuality and relationships. It covers everything from menstruation to contraceptives to consent. The app also includes a space for women to ask questions, find which products are best for them and their lifestyles, and a way to find their local sexual health clinics. Not only does this application shed light on a taboo subject but empowers individuals to make smart decisions regarding their bodies.
## How we built it
Illuminate was built using Flutter as our mobile framework in order to be able to support iOS and Android.
We learned the fundamentals of the dart language to fully take advantage of Flutter's fast development and created a functioning prototype of our application.
## Challenges we ran into
As individuals who have never used either Flutter or Android Studio, the learning curve was quite steep. We were unable to even create anything for a long time as we struggled quite a bit with the basics. However, with lots of time, research, and learning, we quickly built up our skills and were able to carry out the rest of our project.
## Accomplishments that we're proud of
In all honesty, we are so proud of ourselves for being able to learn as much as we did about Flutter in the time that we had. We really came together as a team and created something we are all genuinely really proud of. This will definitely be the first of many stepping stones in what Illuminate will do!
## What we learned
Despite this being our first time, by the end of all of this we learned how to successfully use Android Studio, Flutter, and how to create a mobile application!
## What's next for Illuminate
In the future, we hope to add an interactive map component that will be able to show users where their local sexual health clinics are using a GPS system. | ## Inspiration
Our inspiration is based on hearing from industry colleagues that they often need to do research to keep up with the new research occurring in their domain. Research materials are often spread across multiple different sites and require users to actively search through information.
## What it does
We have created a web application that scrapes RSS feeds from the web and consolidates the information.
## How we built it
For our backend we are using google cloud Postgres storage, as well as pythonFastApi; and our front end uses react and a CSS framework called bulma.
## Challenges we ran into
We ran into some challenges with integrating with the database
## Accomplishments that we're proud of
We are proud of the various moving pieces coming together from the backend to the front end.
## What we learned
We learned about various different tools to help with development as well as the value of working in a team to debug/ troubleshoot issues.
## What's next for nuResearch
For the future, we also plan to use Twillio Sendgrid to send out email notifications to subscribers. | winning |
## Inspiration
The world is constantly chasing after smartphones with bigger screens and smaller bezels. But why wait for costly display technology, and why get rid of old phones that work just fine? We wanted to build an app to create the effect of the big screen using the power of multiple small screens.
## What it does
InfiniScreen quickly and seamlessly links multiple smartphones to play videos across all of their screens. Breathe life into old phones by turning them into a portable TV. Make an eye-popping art piece. Display a digital sign in a way that is impossible to ignore. Or gather some friends and strangers and laugh at memes together. Creative possibilities abound.
## How we built it
Forget Bluetooth, InfiniScreen seamlessly pairs nearby phones using ultrasonic communication! Once paired, devices communicate with a Heroku-powered server written in node.js, express.js, and socket.io for control and synchronization. After the device arrangement is specified and a YouTube video is chosen on the hosting phone, the server assigns each device a region of the video to play. Left/right sound channels are mapped based on each phone's location to provide true stereo sound support. Socket-emitted messages keep the devices in sync and provide play/pause functionality.
## Challenges we ran into
We spent a lot of time trying to implement all functionality using the Bluetooth-based Nearby Connections API for Android, but ended up finding that pairing was slow and unreliable. The ultrasonic+socket.io based architecture we ended up using created a much more seamless experience but required a large rewrite. We also encountered many implementation challenges while creating the custom grid arrangement feature, and trying to figure out certain nuances of Android (file permissions, UI threads) cost us precious hours of sleep.
## Accomplishments that we're proud of
It works! It felt great to take on a rather ambitious project and complete it without sacrificing any major functionality. The effect is pretty cool, too—we originally thought the phones might fall out of sync too easily, but this didn't turn out to be the case. The larger combined screen area also emphasizes our stereo sound feature, creating a surprisingly captivating experience.
## What we learned
Bluetooth is a traitor. Mad respect for UI designers.
## What's next for InfiniScreen
Support for different device orientations, and improved support for unusual aspect ratios. Larger selection of video sources (Dailymotion, Vimeo, random MP4 urls, etc.). Seeking/skip controls instead of just play/pause. | ## Check it out on GitHub!
The machine learning and web app segments are split into 2 different branches. Make sure to switch to these branches to see the source code! You can view the repository [here](https://github.com/SuddenlyBananas/be-right-back/).
## Inspiration
Inspired in part by the Black Mirror episode of the same title (though we had similar thoughts before we made the connection).
## What it does
The goal of the project is to be able to talk to a neural net simulation of your Facebook friends you've had conversations with. It uses a standard base model and customizes it based on message upload input. However, we ran into some struggles that prevented the full achievement of this goal.
The user downloads their message history data and uploads it to the site. Then, they can theoretically ask the bot to emulate one of their friends and the bot customizes the neural net model to fit the friend in question.
## How we built it
Tensor Flow for the machine learning aspect, Node JS and HTML5 for the data-managing website, Python for data scraping. Users can interact with the data through a Facebook Messenger Chat Bot.
## Challenges we ran into
AWS wouldn't let us rent a GPU-based E2 instance, and Azure didn't show anything for us either. Thus, training took much longer than expected.
In fact, we had to run back to an apartment at 5 AM to try to run it on a desktop with a GPU... which didn't end up working (as we found out when we got back half an hour after starting the training set).
The Facebook API proved to be more complex than expected, especially negotiating the 2 different user IDs assigned to Facebook and Messenger user accounts.
## Accomplishments that we're proud of
Getting a mostly functional machine learning model that can be interacted with live via a Facebook Messenger Chat Bot.
## What we learned
Communication between many different components of the app; specifically the machine learning server, data parsing script, web server, and Facebook app.
## What's next for Be Right Back
We would like to fully realize the goals of this project by training the model on a bigger data set and allowing more customization to specific users. | ## Inspiration
Our inspiration comes from many of our own experiences with dealing with mental health and self-care, as well as from those around us. We know what it's like to lose track of self-care, especially in our current environment, and wanted to create a digital companion that could help us in our journey of understanding our thoughts and feelings. We were inspired to create an easily accessible space where users could feel safe in confiding in their mood and check-in to see how they're feeling, but also receive encouraging messages throughout the day.
## What it does
Carepanion allows users an easily accessible space to check-in on their own wellbeing and gently brings awareness to self-care activities using encouraging push notifications. With Carepanion, users are able to check-in with their personal companion and log their wellbeing and self-care for the day, such as their mood, water and medication consumption, amount of exercise and amount of sleep. Users are also able to view their activity for each day and visualize the different states of their wellbeing during different periods of time. Because it is especially easy for people to neglect their own basic needs when going through a difficult time, Carepanion sends periodic notifications to the user with messages of encouragement and assurance as well as gentle reminders for the user to take care of themselves and to check-in.
## How we built it
We built our project through the collective use of Figma, React Native, Expo and Git. We first used Figma to prototype and wireframe our application. We then developed our project in Javascript using React Native and the Expo platform. For version control we used Git and Github.
## Challenges we ran into
Some challenges we ran into included transferring our React knowledge into React Native knowledge, as well as handling package managers with Node.js. With most of our team having working knowledge of React.js but being completely new to React Native, we found that while some of the features of React were easily interchangeable with React Native, some features were not, and we had a tricky time figuring out which ones did and didn't. One example of this is passing props; we spent a lot of time researching ways to pass props in React Native. We also had difficult time in resolving the package files in our application using Node.js, as our team members all used different versions of Node. This meant that some packages were not compatible with certain versions of Node, and some members had difficulty installing specific packages in the application. Luckily, we figured out that if we all upgraded our versions, we were able to successfully install everything. Ultimately, we were able to overcome our challenges and learn a lot from the experience.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to produce an application from ground up, from the design process to a working prototype. We are excited that we got to learn a new style of development, as most of us were new to mobile development. We are also proud that we were able to pick up a new framework, React Native & Expo, and create an application from it, despite not having previous experience.
## What we learned
Most of our team was new to React Native, mobile development, as well as UI/UX design. We wanted to challenge ourselves by creating a functioning mobile app from beginning to end, starting with the UI/UX design and finishing with a full-fledged application. During this process, we learned a lot about the design and development process, as well as our capabilities in creating an application within a short time frame.
We began by learning how to use Figma to develop design prototypes that would later help us in determining the overall look and feel of our app, as well as the different screens the user would experience and the components that they would have to interact with. We learned about UX, and how to design a flow that would give the user the smoothest experience. Then, we learned how basics of React Native, and integrated our knowledge of React into the learning process. We were able to pick it up quickly, and use the framework in conjunction with Expo (a platform for creating mobile apps) to create a working prototype of our idea.
## What's next for Carepanion
While we were nearing the end of work on this project during the allotted hackathon time, we thought of several ways we could expand and add to Carepanion that we did not have enough time to get to. In the future, we plan on continuing to develop the UI and functionality, ideas include customizable check-in and calendar options, expanding the bank of messages and notifications, personalizing the messages further, and allowing for customization of the colours of the app for a more visually pleasing and calming experience for users. | winning |
## Inspiration
Our idea was inspired by Duolingo. We noticed that the main component that the platform was missing was a tool for practicing your conversation skills. Upon learning about AssemblyAI's Speech-to-Text API, we decided that it might be possible to realize this idea ourselves.
## What it does
GrammarParrot allows users to practice their English speaking skills through simulated conversations. The website sends audio files recorded by the user to Assembly, which returns a transcript. The GrammarBot API uses this transcript and returns a list of grammatical errors for the user to review.
## How we built it
The front-end of this website was built using HTML, CSS and JavaScript, and is hosted on Netlify. The back-end was developed with Python's Flask and is hosted on the Google Cloud platform.
## Challenges we ran into
Hosting a Flask server on Google Cloud, making API calls.
## Accomplishments that we're proud of
We're proud of our fantastic front-end design and creating a fully-functioning back-end for the first time!
## What we learned
Hosting a Flask server on Google Cloud, making API calls, making animations with JavaScript and CSS, front-end design.
## What's next for GrammarParrot
Expanding to different languages, using a more powerful grammar API, using user-submitted questions, tracking user progress. | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlled machine. We wanted to take this a step further and make computers more accessible for people such as Robbie.
## What it does
We use a Google Cloud based API that helps us detect words and phrases captured from the microphone input. We then convert those phrases into commands for the computer to execute. Since the python script is run in the terminal it can be used across the computer and all its applications.
## How I built it
The first (and hardest) step was figuring out how to leverage Google's API to our advantage. We knew it was able to detect words from an audio file but there was more to this project than that. We started piecing libraries to get access to the microphone, file system, keyboard and mouse events, cursor x,y coordinates, and so much more. We build a large (~30) function library that could be used to control almost anything in the computer
## Challenges I ran into
Configuring the many libraries took a lot of time. Especially with compatibility issues with mac vs. windows, python2 vs. 3, etc. Many of our challenges were solved by either thinking of a better solution or asking people on forums like StackOverflow. For example, we wanted to change the volume of the computer using the fn+arrow key shortcut, but python is not allowed to access that key.
## Accomplishments that I'm proud of
We are proud of the fact that we had built an alpha version of an application we intend to keep developing, because we believe in its real-world applications. From a technical perspective, I was also proud of the fact that we were able to successfully use a Google Cloud API.
## What I learned
We learned a lot about how the machine interacts with different events in the computer and the time dependencies involved. We also learned about the ease of use of a Google API which encourages us to use more, and encourage others to do so, too. Also we learned about the different nuances of speech detection like how to tell the API to pick the word "one" over "won" in certain context, or how to change a "one" to a "1", or how to reduce ambient noise.
## What's next for Speech Computer Control
At the moment we are manually running this script through the command line but ideally we would want a more user friendly experience (GUI). Additionally, we had developed a chrome extension that numbers off each link on a page after a Google or Youtube search query, so that we would be able to say something like "jump to link 4". We were unable to get the web-to-python code just right, but we plan on implementing it in the near future. | ## Inspiration
Studying and working are completely different. But, one common thing between experiencing a study term and an internship that we noticed was that sometimes we wanted to have someone to talk to. But, evidently that's sometimes impossible, so given that we wanted to explore a little bit with AI and our drive to solve our problems for future terms (where school only gets harder), we brought λlbert to life.
## What it does
λlbert is your best friend! it simply requests you to talk (with your voice!) about something that you want to get off your chest. Then, based on that and what's been happening in the conversation previously, it will respond to you. This can be used in multiple ways -- therapy, entertainment, and so on. λlbert will never get bored of you, and frankly you also won't get bored of λlbert.
## How we built it
To run the backend, we use NodeJS and Express to manipulate given data to make calls to the Cohere API. This made the logic and error handling relatively simple, as our complementing frontend was built with HTML, CSS, and Typescript. The audio recordings that were taken in were converted to text using Assembly AI, and then the brains of λlbert were made using the Cohere API.
## Challenges we ran into
Sometimes, the Assembly AI API was returning values a little slower than expected. We ended up taking it as a positive though, as we were able to have a reason to implement promises to have a loading icon. :)
The audio format that was used to record the audio wasn't compatible with Assembly AI to process and transcript it, so there were some troubles with using conversion to binary to change the file formats internally. It took some time, but eventually worked smoothly.
Finally, we were aiming for a really clean interface that looked inviting for people to want to vent out to without looking too intimidating. So, there were lots of discussion and disagreement with the design of the page, and how much info we wanted to have on there. Eventually though, we landed on a design that we believe to be pretty clean.
## Accomplishments that we're proud of
After working and testing Assembly AI with multiple different tests of file formats, things started to make sense of how it was working under the hood. Once we were able to do this, it became much easier to program the transcription and process it.
As mentioned earlier, we believe we landed on a pretty simple but effective UI. For people with not the greatest artistic sense, that feeling always has a special place in our hearts. :)
## What we learned
A big realization was that even understanding the shallowest of levels of one's personality can go a long way. Seeing how λlbert's adversity was only being more effective as the conversation continued even though sometimes responses started off very well, it became very eye-opening to how much problems and thoughts in one's mind can be influenced simply with another opinion.
## What's next for λlbert
λlbert has lots of room for improvement, from simple areas like speed to more training to give even better responses. We would love to incorporate λlbert into different applications in the future, as we realize it is very light weight compared to a lot of software, but can come a very long way in helping someone in some way. | winning |
## Inspiration
The need for faster and more reliable emergency communication in remote areas inspired the creation of FRED (Fire & Rescue Emergency Dispatch). Whether due to natural disasters, accidents in isolated locations, or a lack of cellular network coverage, emergencies in remote areas often result in delayed response times and first-responders rarely getting the full picture of the emergency at hand. We wanted to bridge this gap by leveraging cutting-edge satellite communication technology to create a reliable, individualized, and automated emergency dispatch system. Our goal was to create a tool that could enhance the quality of information transmitted between users and emergency responders, ensuring swift, better informed rescue operations on a case-by-case basis.
## What it does
FRED is an innovative emergency response system designed for remote areas with limited or no cellular coverage. Using satellite capabilities, an agentic system, and a basic chain of thought FRED allows users to call for help from virtually any location. What sets FRED apart is its ability to transmit critical data to emergency responders, including GPS coordinates, detailed captions of the images taken at the site of the emergency, and voice recordings of the situation. Once this information is collected, the system processes it to help responders assess the situation quickly. FRED streamlines emergency communication in situations where every second matters, offering precise, real-time data that can save lives.
## How we built it
FRED is composed of three main components: a mobile application, a transmitter, and a backend data processing system.
```
1. Mobile Application: The mobile app is designed to be lightweight and user-friendly. It collects critical data from the user, including their GPS location, images of the scene, and voice recordings.
2. Transmitter: The app sends this data to the transmitter, which consists of a Raspberry Pi integrated with Skylo’s Satellite/Cellular combo board. The Raspberry Pi performs some local data processing, such as image transcription, to optimize the data size before sending it to the backend. This minimizes the amount of data transmitted via satellite, allowing for faster communication.
3. Backend: The backend receives the data, performs further processing using a multi-agent system, and routes it to the appropriate emergency responders. The backend system is designed to handle multiple inputs and prioritize critical situations, ensuring responders get the information they need without delay.
4. Frontend: We built a simple front-end to display the dispatch notifications as well as the source of the SOS message on a live-map feed.
```
## Challenges we ran into
One major challenge was managing image data transmission via satellite. Initially, we underestimated the limitations on data size, which led to our satellite server rejecting the images. Since transmitting images was essential to our product, we needed a quick and efficient solution. To overcome this, we implemented a lightweight machine learning model on the Raspberry Pi that transcribes the images into text descriptions. This drastically reduced the data size while still conveying critical visual information to emergency responders. This solution enabled us to meet satellite data constraints and ensure the smooth transmission of essential data.
## Accomplishments that we’re proud of
We are proud of how our team successfully integrated several complex components—mobile application, hardware, and AI powered backend—into a functional product. Seeing the workflow from data collection to emergency dispatch in action was a gratifying moment for all of us. Each part of the project could stand alone, showcasing the rapid pace and scalability of our development process. Most importantly, we are proud to have built a tool that has the potential to save lives in real-world emergency scenarios, fulfilling our goal of using technology to make a positive impact.
## What we learned
Throughout the development of FRED, we gained valuable experience working with the Raspberry Pi and integrating hardware with the power of Large Language Models to build advanced IOT system. We also learned about the importance of optimizing data transmission in systems with hardware and bandwidth constraints, especially in critical applications like emergency services. Moreover, this project highlighted the power of building modular systems that function independently, akin to a microservice architecture. This approach allowed us to test each component separately and ensure that the system as a whole worked seamlessly.
## What’s next for FRED
Looking ahead, we plan to refine the image transmission process and improve the accuracy and efficiency of our data processing. Our immediate goal is to ensure that image data is captioned with more technical details and that transmission is seamless and reliable, overcoming the constraints we faced during development. In the long term, we aim to connect FRED directly to local emergency departments, allowing us to test the system in real-world scenarios. By establishing communication channels between FRED and official emergency dispatch systems, we can ensure that our product delivers its intended value—saving lives in critical situations. | **In times of disaster, there is an outpouring of desire to help from the public. We built a platform which connects people who want to help with people in need.**
## Inspiration
Natural disasters are an increasingly pertinent global issue which our team is quite concerned with. So when we encountered the IBM challenge relating to this topic, we took interest and further contemplated how we could create a phone application that would directly help with disaster relief.
## What it does
**Stronger Together** connects people in need of disaster relief with local community members willing to volunteer their time and/or resources. Such resources include but are not limited to shelter, water, medicine, clothing, and hygiene products. People in need may input their information and what they need, and volunteers may then use the app to find people in need of what they can provide. For example, someone whose home is affected by flooding due to Hurricane Florence in North Carolina can input their name, email, and phone number in a request to find shelter so that this need is discoverable by any volunteers able to offer shelter. Such a volunteer may then contact the person in need through call, text, or email to work out the logistics of getting to the volunteer’s home to receive shelter.
## How we built it
We used Android Studio to build the Android app. We deployed an Azure server to handle our backend(Python). We used Google Maps API on our app. We are currently working on using Twilio for communication and IBM watson API to prioritize help requests in a community.
## Challenges we ran into
Integrating the Google Maps API into our app proved to be a great challenge for us. We also realized that our original idea of including a blood donation as one of the resources would require some correspondence with an organization such as the Red Cross in order to ensure the donation would be legal. Thus, we decided to add a blood donation to our future aspirations for this project due to the time constraint of the hackathon.
## Accomplishments that we're proud of
We are happy with our design and with the simplicity of our app. We learned a great deal about writing the server side of an app and designing an Android app using Java (and Google Map’s API” during the past 24 hours. We had huge aspirations and eventually we created an app that can potentially save people’s lives.
## What we learned
We learned how to integrate Google Maps API into our app. We learn how to deploy a server with Microsoft Azure. We also learned how to use Figma to prototype designs.
## What's next for Stronger Together
We have high hopes for the future of this app. The goal is to add an AI based notification system which alerts people who live in a predicted disaster area. We aim to decrease the impact of the disaster by alerting volunteers and locals in advance. We also may include some more resources such as blood donations. | ## Inspiration
We wanted to make an impact on the community through this Makeathon. Many disasters can lead to large and avoidable losses of lives and resources because of the delay in notifying the rescue teams. Some disasters even go unnoticed because of personal and political reasons. Thus, we decided to come up with a solution using Telus's LTE Developer Shield.
## What it does
We harnessed the power of Telus LTE Network to post emergency alerts on twitter in order to alert the owner as well as nearby police and fire station in cases of fire, flood, and other natural disasters. The tweet would contain all the necessary environmental conditions such as temperature, humidity, and GPS location making it easier for rescue teams to act accordingly.
## How we built it
We used a Raspberry Pi as the main controller and Telus IoT Dev Shield to seamlessly connect to the LTE network. We used python, tweepy, Solace to post an alert on Twitter using Twitter's API.
## Challenges we ran into
We ran into a lot of challenges and we learned a lot while solving each one of them. Our Raspberry Pi was not working as the SD card was broken. This caused further errors when trying to re-install Raspbian. Furthermore, our Telus Dev Shield was not connecting to the network due to an inconsistent signal. However, in the end, we were able to solve each one of them through thorough troubleshooting and we successfully completed the project.
## Accomplishments that we are proud of
We were able to implement all the features that we wanted to and we are proud to be able to finish the project in 24 hours.
## What we learnt
We learned how to install Raspbian and multiple dependencies on the Raspberry Pi and configure it by familiarizing ourselves with the terminal. We learned some technical aspects of the Telus Dev Shield and realized its potential to make a huge impact in the community. We also gained some important python skills. Using Twitter Developer Account, Azure IoT hub, tweepy were also great experiences.
## What's next for Telus-Telyou
Taking a step forward with the project, we would like to make it more efficient by adding more functions that it can perform. We could incorporate flood monitoring system and earthquake detection that would help our project to report more natural calamities and help try reduce their losses. We could also make the app to have access to various other social media platforms helping more people to easily access its information. Furthermore, we could incorporate ML/AI in order to create an accurate threshold for determining whether or not a natural disaster is occurring rather than a false positive. | winning |
## Inspiration
School buses are an integral part of education systems around the world. Parents expect that their children will be picked up or dropped off at the bus stop everyday without any harm or danger to their child. This unfortunately, is not always the case. Everyday many young school children are left behind, put on the wrong bus, or miss their bus stops leading to unimaginable scenarios for parents. It is therefore crucial that schools prioritize student safety and invest in technologies to keep our school children safe.
BusBuddy is a student safety system designed to be placed in school buses to provide clear communication to students, bus drivers, parents and school staff about the status of their students before they arrive at school and after they leave. The ultimate goal of this project is to prioritize the safety of students by leveraging AI to assist school staff in facilitating student transportation.
## What it does
There are many individuals concerned with student safety from school staff, to parents, to bus drivers, to the students themselves. We designed BusBuddy to provide a line of communication between everyone ultimately working together to provide a safer environment for students. Let’s explore what this looks like in every perspective.
Parents:
Once a parent decides they want their child to ride the school bus, the first step is to register their child into the BusBuddy system. From here, we collect the child’s name, picture, bus number, and bus stop. Parents are then notified when their children enter and exit the bus as well as where they boarded from and where they were dropped off by utilizing predetermined bus stop numbers.
Bus Driver:
Next, the bus driver will have full access to the names of the children that are supposed to be on their bus, their stops, and identifying information such as name and photo. This will assist the driver in making sure every student is exactly where they are supposed to be at all times throughout the process. BusBuddy will use its facial recognition software to track when a child has boarded the bus, as well as check that they are leaving at the right stop before they leave the bus.
Student
We designed BusBuddy to keep the process simple for students. Upon entering the bus, students are required to scan their face using a camera to verify they are getting onto the correct bus. If they are on the correct bus, BusBuddy will say “Welcome [Name]”, however, if they are on the wrong bus they as well as the bus driver will be notified along with their correct bus number or if they are not registered within the bus system. On the other hand, upon leaving the bus, they will once again scan their face to verify they get off at the correct stop.
## How we built it
The Magic School Bus is built using a backend composed of Python, integrated with a PostgresQL database hosted on the cloud using Railway. The facial recognition is designed using OpenCV, and the facial recognition library. All tied together with a React front-end.
## Challenges we ran into:
During this 24 hour period, we unfortunately ran into numerous issues. What was even worse was some of these issues were minor mistakes that we missed, like indentations, variable names, or accessing an array index that wasn’t initialized yet. However, we all managed to pull through and dig deep to attempt this challenging, but rewarding, project.
The 3 main issues we encountered were:
Choosing and Setting up a Database
Integrating the OpenCV window screen into our Front End React webpage
Overall code efficiency
Working with databases was a new challenge for most of us as we either had experiences just working with existing databases, or didn’t have enough knowledge about hosting services. We spent time as a team researching various databases for our specific use case. We wanted to have a cloud database, rather than hosting locally such as through Docker, and thus opted to use Railway with a PostgresQL database. Figuring out the most optimal database configuration was also a challenge in this aspect as we played around with ideas such as integrating Blob data types to ultimately deciding that since our images were of a small enough file size, directly converting the images to binary 64 and storing it as a string in our database would be most effective at our current stage of programming. Although this process may have been less efficient, it was our most ideal and simplest outcome for the hackathon purpose.
Working with OpenCV was not the main challenge, rather it was encapsulating the video capture into a flask endpoint that could then be integrated into a react component. This was a new challenge working with flask but through collaboration and research, our team was able to set up the localhost! However, the latency issues made the video mirroring nearly impossible to run smoothly. Thus, we opted to work in OpenCV for the demo while researching faster and more cost-friendly alternatives.
## Accomplishments that we are proud of
Our team’s quick thinking and ingenuity with Flask endpoints to embed the OpenCV window into a React based front end webpage
Our fast-learning of how to connect the Python backend code with the PostgresQL database, of which we utilized SQLAlchemy described below
Setting up a firebase authentication system for user authentication! This aided in our login aspect of the application, allowing parents to login and enroll their children
## What we learned
In terms of the backend and database configurations, there was a lot that we learned through this, from storing databases on cloud using Railway to using tools like SQLAlchemy to connect to this database. These were all new technologies to our team teaching us new tools to use when working with databases using Python.
This idea, and researching various technologies, their use cases, and how they can be utilized in our project, helped fuel our entrepreneurship mindset. Our team spent a good couple hours brainstorming how BusBuddy could be integrated into buses in the school system, researching what complications users could run into and building our project to address those issues. Overall, the process of creating a product from the ground up and seeing its demo was extremely fulfilling to our team. | ## Inspiration
Public transportation is a necessity to society. However, with the rapid spread of COVID-19 through crowded areas, especially in lines like city metros and busses, public transportation and travel have taken a massive hit. In fact, since the beginning of the pandemic, it is estimated that usage of public transportation has dropped between 70-80%. We set out to create a project that would not only make public transportation safer and more informed, but also directly reduce the threat of disease transmission through public transportation, thus restoring confidence in safe public transportation.
## What it does
SafeTravels improves safety in public transportation by enabling users to see the aggregated risk score associated with each transportation line and optimize their seating to minimize the risk of disease transfer. A unique RFID tag is tied to each user and is used to scan users into a seat and transportation line. By linking previous user history on other transportation rides, we can calculate the overall user risk and subsequently predict the transportation line risk. Based on this data, our software can recommend the safest times to travel. Furthermore, based on seating arrangements and user data, a euclidean based algorithm is utilized to calculate the safest seat to sit in within the transportation vehicle. Video analysis for mask detection and audio analysis for cough detection are also used to contribute to overall risk scores.
## How we built it
### Mobile App
A mobile app was created with Flutter using the Dart programming language. Users begin by signing up or logging in and linking their RFID tag to their account. Users are able to view public transportation schedules optimized for safety risk analysis. Seat recommendations are given within each ride based on the seat with the lowest disease transfer risk. All user and transportation data is encrypted with industry-level BCrypt protocol and transferred through a secure backend server.
### Administrator Website
The administrator website was created with React using HTML/CSS for the user interface and JavaScript for the functionality. Administrators can add transportation lines and times, as well as view existing lines. After inputting the desired parameters, the data is transferred through the server for secure storage and public access.
### Arduino Hardware
The Hardware was created with Arduino and programmed in C++. An MFRC522 RFID reader is used to scan user RFID tags. An ESP8266 WiFi module is utilized to cross reference the RFID tag with user IDs to fill seat charts and update risk scores for transportation lines and users. If a user does not scan an RFID tag, an ultrasonic sensor is used to update the attendance without linking the specific user information. Get requests are made with the server to securely communicate data and receive the success status to display as feedback to the user.
### Video Analysis (Mask Detection)
Video analysis is conducted at the end of every vehicle route by taking a picture of the inside and running it through a modified Mobile Net network. Our system uses OpenCV and Tensorflow to first use the Res10 net to detect faces and create a bounding box around the face that is then fed into our modified and trained Mobile Net network to output 2 classes, whether something is a mask or not a mask. The number of masks are counted and sent back to the server, which also triggers the recalculating of risks for all users
### Audio Analysis (Cough Detection)
We also conduct constant local audio analysis of the bus to detect coughs and count them as another data point into our risk calculation for that ride. Our audio analysis works by splitting each audio sample into windows, conducting STFT or Short Time Fourier Transform on that to create a 2D spectrogram of size 64 x 16. This is then fed into a custom convolutional neural network created with Tensorflow that calculates the probability of a cough (using the sigmoid activator). We pulled audio and trimmed it from Youtube according to the Google AudioSet, by getting audio labeled with cough and audio labeled as speech and background noise as non\_cough. We also implemented silence detection using the root mean square of the audio and a threshold to filter out silence and noise. This works in realtime and automatically increments the number on the server for each cough so the data is ready when the server recalculates risk.
### Backend Server
The backend was created with Node.js hosted on Amazon Web Services. The backend handles POST and GET requests from the app, hardware, and Raspberry Pi to enable full functionality and integrate each system component with one another for data transfer. All sensitive data is encrypted with BCrypt and stored on Google Firebase.
### Risk Calculation
A novel algorithm was developed to predict the risk associated with each transportation line and user. Transportation line risk aggregates each rider’s risk, mask percentage, and the duration multiplied by a standard figure for transmission. User risk uses the number of rides and risk of each ride within the last 14 days. Because transportation line risk and user risk are connection, they create a conditional probability tree (Markov chain) that continually updates with each ride
### Optimal Transportation Line and Seat
After the risk is calculated for each transportation line and user, algorithms were developed to pinpoint the optimal line/seat to minimize disease transmission risk. For optimal transportation lines, the lowest risk score for lines within user filters is highlighted. For optimal seat, the euclidean distance between other riders and their associated risk levels is summed for each empty seat, yielding the seat with the optimal score
## Challenges we ran into
One challenge that we ran into when doing the audio analysis was generating the correct size of spectrogram for input into the first layer of the neural network as well as experimenting with the correct window size and first layer size to determine the best accuracy. We also ran into problems when connecting our hardware to the server through http requests. Once the RFID tag could be read using the MFRC522 reader, we needed to transfer the tag id to the server to cross reference with the user id. Connecting to a WiFi network, connecting to the server, and sending the request was challenging, but we eventually figured out the libraries to use and timing sequence to successfully send a request and parse the response.
## Accomplishments that we're proud of
Within the 24 hour time period, we programmed over 3000 total lines of code and achieved full functionality in all components of the system. We are especially proud that we were able to complete the video/audio analysis for mask and cough detection. We implemented various machine learning models and analysis frameworks in python to analyze images and audio samples. We were also able to find and train the model on large data sets, yielding an accuracy of over 70%, a figure that can definitely increase with a larger data set. Lastly, we are also proud that we were able to integrate 5 distinct components of the system with one another through a central server despite working remotely with one another.
## What we learned
One skill we really learned was how to work well as a team despite being apart. We all have experience working together in person at hackathons, but working apart was challenging, especially when we are working on so many distinct components and tying them together. We also learned how to implement machine learning and neural network models for video and audio analysis. While we specifically looked for masks and coughs, we can edit the code and train with different data sets to accomplish other tasks.
## What's next for SafeTravels
We hope to touch up on our hardware design, improve our user experience, and strengthen our algorithms to the point where SafeTravels is commercially viable. While the core functionalities are fully functional, we still have work to do until it can be used by the public. However, we feel that SafeTravels can have massive implications in society today, especially during these challenging times. We hope to make an impact with our software and help people who truly need it. | ## Inspiration
After years of taking the STM (one of the many possible implementations that could make use of RailVision) and having one too many experiences of waiting in the freezing weather for a bus that would never come, the problem proposed by the RailVision challenge was one that was close to our hearts. Having a better organized public transit system and minimizing wait times are keys to a better and greener future in the transportation world.
## What it does
Long gone are the days where, after running — no, sprinting — from your bus stop to metro station, only to find out that you just missed it and that the next one is 30 minutes away. *Bummer.* With our project solution, this situation will (hopefully) be left in the past!
Given a database with times that passengers arrive at each station, using a local beam search heuristic, our code finds the optimal time to deploy the trains such that the average wait time for each passenger is minimized. Then the solution can be visualized through an animation which displays each train and station and concisely shows the time, number of passengers and other relevant information.
## How we built it
The first step we took to better understand the challenge domain was to think about additional constraints, namely the start times for the first and last train routes. Furthermore, there were better starting times than others (e.g. ending with 7 or 8) that allowed us to "time" the trains' arrival at a station with those of the passengers. These heuristics helped us form a good first "guess", which we would later use to find an optimal one. But before that, we coded a helper function that computed the wait time of the passengers. This function is crucial to solving the problem, as it is what we are trying to minimize. The optimization code was built using python and a variation on a genetic search algorithm. At each iteration, we generate k slightly differing train schedules using our input one, and keeping the n most optimal. After a number of iterations, we return the converged result.
We also added unit-testing and integration testing to assure ourselves with different code iterations that we were not breaking anything. This could be useful in the future if we wanted proper CI/CD.
For the visualization, we used Unity as it provided it us with stable and predictable frame updates, while also allowing a robust spawning system.
## Challenges we ran into
At first, it was difficult to figure out how to go about this problem since there are so many varying factors we needed to take into account. At first, we contemplated using other algorithms such as network flows or an instance of dynamic programming. We decided to go with an AI based search because with a good enough tentative schedule and enough iterations, then with an optimization algorithm, we would eventually converge to a point that minimizes the average wait times. Another challenge was coding the optimization, as libraries like numpy/scipy did not behave the way we wanted them to (e.g. not returning integer values).
Despite the logic behind the challenge itself that had to be tested via different algorithms, designing such systems can be tricky as well. It was important to spend the first few hours understanding what exactly we're trying to achieve as well as checking similar products and interfaces to design something "intuitive" and "straightforward" so we can represent to any kind of user.
On the visualization side, there were a good amount of issues. We initially decided to code the project in JS using React. However, after many hours of development, this turned to be problematic due to the complexity of the visualization and the multiple different instances of objects spawning at different times. In the end, we chose to use a more flexible and robust software to develop these almost game-like visualization: Unity. While needing to essentially restart, it was very worth-while.
*Finally, the consequences of sleep-deprivation might be apparent, as I forgot to save this draft the first time I wrote it, which makes me very sad.*
## Accomplishments that we're proud of
After all the efforts poured into this and great team work we had, it was nice to piece the code together to see it running and successfully finding solutions that were considerably better than what we had found by hand.
Learning how to work effectively as a team might be undoubtedly the most vital accomplishment for all of us. Joining as total strangers and ending up working through the same vision is something I'm truly proud of.
## What we learned
**Teamwork makes the dream work!**
Collaboration was crucial to allow the progress of this challenge. We all had different strengths that complemented each other. Everybody pulling their own weight ensured that no one broke their back having to carry all the load!
This was some of our team's first hackathon and it happened to be online. One of the most important things that we learned was the importance of networking. Trying to match with other students and finding a team based on a different skill set was one of the challenges. Breaking down the problem, brainstorming with team members, and defining our roles was the other challenge we faced throughout the hackathon.
**Test Early**
Test early to know about crucial possible problems early on so that you don't have any last minute surprises.
## What's next for RailVision
With our proposed solution, the next words you will hear from the STM lady will be:
*"Prochaine station, RailVision!"* | losing |
Inspiration
We decided to try the Best Civic Hack challenge with YHack & Yale Code4Good -- the collaboration with the New Haven/León Sister City Project. The purpose of this project is to both fundraise money, and raise awareness about the impact of greenhouse gases through technology.
What it does
The Carbon Fund Bot is a Facebook messenger chat agent based on the Yale Community Carbon Fund calculator. It ensues a friendly conversation with the user - estimating the amount of carbon emission from the last trip according to the source and destination of travel as well as the mode of transport used. It serves the purpose to raise money equivalent to the amount of carbon emission - thus donating the same to a worthy organization and raising awareness about the harm to the environment.
How we built it
We built the messenger chatbot with Node.js and Heroku. Firstly, we created a new messenger app from the facebook developers page. We used a facebook webhook for enabling communication between facebook users and the node.js application. To persist user information, we also used MongoDB (mLabs). According to the user's response, an appropriate response was generated. An API was used to calculate the distance between two endpoints (either areial or road distance) and their carbon emission units were computed using it.
Challenges we ran into
There was a steep curve for us learning Node.js and using callbacks in general. We spent a lot of time figuring out how to design the models, and how a user would interact with the system. Natural Language Processing was also a problem.
Accomplishments that we're proud of
We were able to integrate the easy to use and friendly Facebook Messenger through the API with the objective of working towards a social cause through this idea
What's next
Using Api.Ai for better NLP is on the cards. Using the logged journeys of users can be mined and can be used to gain valuable insights into carbon consumption. | ## Inspiration
University gets students really busy and really stressed, especially during midterms and exams. We would normally want to talk to someone about how we feel and how our mood is, but due to the pandemic, therapists have often been closed or fully online. Since people will be seeking therapy online anyway, swapping a real therapist with a chatbot trained in giving advice and guidance isn't a very big leap for the person receiving therapy, and it could even save them money. Further, since all the conversations could be recorded if the user chooses, they could track their thoughts and goals, and have the bot respond to them. This is the idea that drove us to build Companion!
## What it does
Companion is a full-stack web application that allows users to be able to record their mood and describe their day and how they feel to promote mindfulness and track their goals, like a diary. There is also a companion, an open-ended chatbot, which the user can talk to about their feelings, problems, goals, etc. With realtime text-to-speech functionality, the user can speak out loud to the bot if they feel it is more natural to do so. If the user finds a companion conversation helpful, enlightening or otherwise valuable, they can choose to attach it to their last diary entry.
## How we built it
We leveraged many technologies such as React.js, Python, Flask, Node.js, Express.js, Mongodb, OpenAI, and AssemblyAI. The chatbot was built using Python and Flask. The backend, which coordinates both the chatbot and a MongoDB database, was built using Node and Express. Speech-to-text functionality was added using the AssemblyAI live transcription API, and the chatbot machine learning models and trained data was built using OpenAI.
## Challenges we ran into
Some of the challenges we ran into were being able to connect between the front-end, back-end and database. We would accidentally mix up what data we were sending or supposed to send in each HTTP call, resulting in a few invalid database queries and confusing errors. Developing the backend API was a bit of a challenge, as we didn't have a lot of experience with user authentication. Developing the API while working on the frontend also slowed things down, as the frontend person would have to wait for the end-points to be devised. Also, since some APIs were relatively new, working with incomplete docs was sometimes difficult, but fortunately there was assistance on Discord if we needed it.
## Accomplishments that we're proud of
We're proud of the ideas we've brought to the table, as well the features we managed to add to our prototype. The chatbot AI, able to help people reflect mindfully, is really the novel idea of our app.
## What we learned
We learned how to work with different APIs and create various API end-points. We also learned how to work and communicate as a team. Another thing we learned is how important the planning stage is, as it can really help with speeding up our coding time when everything is nice and set up with everyone understanding everything.
## What's next for Companion
The next steps for Companion are:
* Ability to book appointments with a live therapists if the user needs it. Perhaps the chatbot can be swapped out for a real therapist for an upfront or pay-as-you-go fee.
* Machine learning model that adapts to what the user has written in their diary that day, that works better to give people sound advice, and that is trained on individual users rather than on one dataset for all users.
## Sample account
If you can't register your own account for some reason, here is a sample one to log into:
Email: [demo@example.com](mailto:demo@example.com)
Password: password | 
## Inspiration
It's September 8th 2017 and Hurricane Irma is twisting her way towards Florida. Like 95% of home-owning Floridians, you have a home insurance plan. But, like most others, you don't have full flood or natural disaster coverage - in fact, 70% of people don't, and even of those that do usually aren't fully covered. With the storm approaching Category 4/5 speeds and almost certain landfall, no traditional insurance company will take your business (a surefire loss for them). CNN is telling you it might be the most damaging storm of the century. You can get out of the state, for sure, but still you wonder how to protect your most valuable asset: your home.
With Insuricane, you can sign up for short-term home insurance using our webapp. Our servers immediately calculate the probability of damage to your home, our optimal hedging portfolio, and your initial payment.
## What it does
The basic idea of Insuricane that we can instantly hedge our risk of insuring your home (in a hurricane) by taking on a position in an negatively correlated portfolio. Most impoortantly, we can hedge the millisecond an order comes in, reducing basis risk by crafting the best hedge based on your home's precise location.

For example, we might short sell local utility and real estate holdings and go long on disaster suppliers like consumer packaged goods. For PennApps we've focused on utilities because there are several studies displaying a correlation following hurricanes. Here's the pipeline:
1. The user inputs their address and reqested insurance coverage (in USD).
2. We use NOAA hurricane data and our model to estimate the probability of the home being destroyed by the disaster. If it is too risky, we may chose not to offer the insurance product.
3. Converting their address to latitude and longitude, use EIA data to find nearby power stations and utilities. There are 117 spread around Florida.
4. We use a database we created to determine the owner of the power station. If the owner is not a publicly listed company, there is no way to use it to hedge and we delete the row.
5. We use EIA data on electrical plant construction costs to estimate the $ loss to the public company if the utility were to be destroyed, and sum over all their utilities (and subsidiaries) in the affected area. This is a function of the type of plant and the capacity (in megawatts). If the loss is immaterial to the company it will not effect their stock price, and thus cannot be used to hedge. In that case we throw the row out.
6. We determine the joint probability (i.e. home destroyed and asset destroyed) by a simple heuristic: inverse squared distance to the house.
7. Companies that have made it to this step are valid members of our heding portfolio. We weight them according to their correlation with the house (5) and how material the damage would be to the company (damage divided by market cap).
8. Having constructed a hedging portfolio and calculated the user's risk, we present the user with their premium. The premium is a lump-sum initial payment proportional to our estimation of our basis risk. The user can choose to buy the insurance or reject.
9. The user signs our agreement with DocuSign and receives a confirmation email.
10. Since this is a hackathon, the process stops here. If a real product, we'd automatically go short on our portfolio using a put spread in the options market (to hedge what is essentially binary payoff profile on our end).
## How we built it

The front end is built using React with Leaflet and DocuSign's API. The JS frontend interacts with a Python Flask microservice on GCP housing our data and GIS libraries. Our data on the precise location, power plant type, and owner was pieced together by several joins on [EIA](https://www.eia.gov/) datasets. Predicted hurricane wind speed, path data, and location are derived from two [NOAA](http://www.noaa.gov/) datasets.
Specifically, our datasets are as follows from NOAA:
* Source: [NOAA Irma](https://www.nhc.noaa.gov/gis/archive_forecast_results.php?id=al11&year=2017&name=Hurricane%20IRMA)
* Hurricane tracking folder: al112017\_5day\_037.zip (8:59 AM)
* Wind radius folder: al112017\_fcst\_037.zip (9:00 AM)
* We picked 9/8/17, 8-9AM as our "snapshot in time" for this case-study prototype, given that it is a couple days prior to landfall. At this point, there would be almost no supply of Floridian insurance, with a very strong probability of the hurricane causing destruction, but there would be time for people to act in emergency.
Our focus on Hurricane Irma allowed us to trim our database to Florida, though the EIA datasets are national and could be used for any US state. This was valuable in the time-sensitive goal of developing a working prototype. Ideally, a scaled implementation would include data and options across numerous different storms and regions of the nation.
We created a heuristics-based probabalistic model (lacking sufficiently detailed training data to build a linear/logistic model on) to forecast an estimation for the probability that a house/lat-long area is hit, including factors of:
* Distance to the center of the storm
* Which wind shield (nearest, middle, farthest) if any the house is in. This is correlated with the distance to the eye but provides us a proxy for wind speeds. Being closer to the center from these first two factors leads to a greater probability of the house being hit.
* Distances to various wind shields
This model gives us probabilities (as estimates) of damage in the area. This is a proxy for the amount that needs to be insured:
## Challenges we ran into and future improvements
* Our program takes in household location data and uses the storm tracking information to determine the likelihood of a house being hit by a storm. However, the sparsity of data we had made this challenging to do:
+ We did not have training or test data, which impeded us from using a trained regression model. Although there is data for general regions, our project focuses on specific properties and there is not data on a household level for destruction.
+ We also do not have wind speed or rainfall predictions at each level.
+ Although wind speed is a key factor for hurricane destructive power, the forecasts for it at specific points are not released in public data, meaning we cannot predict it in advance.
+ Moreover, rainfall estimates typically only are released closer to landfall, but the goal of this program would be to give people a system to purchase insurance on in advance of the storm approaching.
* The predictions we have are on daily forecasts from NOAA, which means we would not be able to interpolate data effectively between two days. Although that location ideally should not be incredibly important (it is unlikely to assume that people would only wait until the last half-day possible to purchase insurance), it makes our application less responsive than ideal.
* Moreover, we have downloaded data from a specific time frame (9/8/17, 8-9AM EST; 2 days prior to Floridian landfall of Irma). Having a way to stream in data as NOAA updates would be critical for usability of this product.
* It is also not possible for us to perform emergency insurance functions that take into account the chance of the house itself suffering a deal of damage (i.e. does a house look like it may be slightly damaged or completely flattened).
* Finally, we are generally underpredicting locations that are "farther along" the cone; namely; locations that are in the latter days of the cone and where the hurricane is estimated to turn towards. We can see this above in our Miami and Orlando graphs, and we can see below how, due to the days and uncertainty of storm movement, we see there is a greater error cone (the shaded blue below). This means we may actually underestimate the risk as it stands.
## What's next for Insuricane
We believe Insuricane should be made into a real product for the benefit of Americans at risk of hurricanes. Further back-testing of our models would validate the viability of this derivatives/insurance strategy, as we scale it beyond just a hurricane-based system towards numerous types of natural disasters.
Developing the business further, as with any insurance/risk management product we need to create an efficient way to manage claims and payouts to help consumers. There is valid argument that providing a derivatives product that consumers could directly buy from us, rather than an insurance policy, would be easier to manage than insurance; counterarguments to that include that (1) consumers may not feel as comfortable with financial trading and (2) people may not have credentials, etc. set up for themselves.
From a venture perspective, if we are to pursue it, we believe the best course is to see investment from a well heeled insurance company that could bear the counterparty risk. They would be an eager strategic investor because (1) people tend to buy more insurance after disaster strikes and (2) the investment would serve as a hedge against their existing business. Financial services institutions such as commercial banks may also be interested, as a means of both (1) providing additional value to their customers (especially if they have housing loan options) in times of need, and (2) breaking into the insurance field as a new disruptive player. | partial |
# QThrive
Web-based chatbot to facilitate journalling and self-care. Built for QHacks 2017 @ Queen's University. | ## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows roommates to quickly schedule and assign chores, as well as provide a messageboard for common things.
## How we built it
Our solution is built on ruby-on-rails, meant to be a quick simple solution.
## Challenges we ran into
The time constraint made it hard to develop all the features we wanted, so we had to reduce scope on many sections and provide a limited feature-set.
## Accomplishments that we're proud of
We thought that we did a great job on the design, delivering a modern and clean look.
## What we learned
Prioritize features beforehand, and stick to features that would be useful to as many people as possible. So, instead of overloading features that may not be that useful, we should focus on delivering the core features and make them as easy as possible.
## What's next for LiveTogether
Finish the features we set out to accomplish, and finish theming the pages that we did not have time to concentrate on. We will be using LiveTogether with our roommates, and are hoping to get some real use out of it! | ## Inspiration
Mental Health is a really common problem amongst humans and university students in general. I myself felt I was dealing with mental issues a couple years back and I found it quite difficult to reach out for help as it would make myself look weak to others. I recovered from my illness when I actually got the courage to ask someone for help. After talking with my peers, I found that this is a common problem amongst young adults. I wanted to create a product which provides you with the needed mental health resources without anyone finding out. Your data is never saved so you don't have to worry about anyone ever finding out.
## What it does
This product is called the MHR Finder Bot, but its MHR for short. This bot asks you 10 yes or no questions and then a question about your university, followed by your postal code. After you answer these question(if you feel comfortable), it provides you with some general resources, as well as personalized resources based on your postal code and university.
## How I built it
I built the chatbot using deep learning techniques. The bot is trained on a dataset and gives you resources based on your answers to the 12 questions that it asks you. I used special recurrent neural network to allow the bot to give resources based on the user's responses. I started by making the backend portion of the code. I finished that around the 24 hour mark and then I spent the next 12 hours working on the UI and making it simple and user friendly. I chose colors which aided with mental illnesses and have a easter egg in which the scroll wheel cursor is a heart. This is also very antonymous as mental illness is a very sensitive topic.
## Challenges I ran into
A challenge I ran into was making the UI side of things look appealing and welcoming. Additionally, close to the deadline of the project, I kept getting an error that one of the variables was used before defined and that as a challenging fix but I figured out the problem in the end.
## Accomplishments that we're proud of
I was proud that I was able to get a working Chat Bot done before the deadline considering I was working alone. Additionally, it was my first time using several technologies and libraries in python, so I was quite happy that I was able to use them to effectiveness. Finally, I find it an accomplishment that such a product can help others suffering from mental illnesses.
## What I learned
I improved my knowledge of TensorFlow and learned how to use new libraries such as nltk and pickle. Additionally, I was quite pleased that I was able to learn intents when making a chat bot.
## What's next for MHR Finder Bot
Currently, I made two chat bots over the 36 hours, one which is used finding mental health resources and the other can be used to simulate a normal conversion similar to ChatGPT. I would like to combine these two so that when trying to find mental health resources, you can | winning |
This code allows the user to take photos of animals, and the app determines whether the photos are pleasing enough for people to see the cuteness of the animals. | ## Inspiration
One of our own member's worry about his puppy inspired us to create this project, so he could keep an eye on him.
## What it does
Our app essentially monitors your dog(s) and determines their mood/emotional state based on their sound and body language, and optionally notifies the owner about any changes in it. Specifically, if the dog becomes agitated for any reasons, manages to escape wherever they are supposed to be, or if they fall asleep or wake up.
## How we built it
We built the behavioral detection using OpenCV and TensorFlow with a publicly available neural network. The notification system utilizes the Twilio API to notify owners via SMS. The app's user interface was created using JavaScript, CSS, and HTML.
## Challenges we ran into
We found it difficult to identify the emotional state of the dog using only a camera feed. Designing and writing a clean and efficient UI that worked with both desktop and mobile platforms was also challenging.
## Accomplishments that we're proud of
Our largest achievement was determining whether the dog was agitated, sleeping, or had just escaped using computer vision. We are also very proud of our UI design.
## What we learned
We learned some more about utilizing computer vision and neural networks.
## What's next for PupTrack
KittyTrack, possibly
Improving the detection, so it is more useful for our team member | # tokenizedHousing
**Building Housing Tokens to Create a Real Time Stock Market for Real Estate**
Real Estate is an industry stuck in the past. Despite the enormous demand for residential real estate investing, we still live under conditions where if you want to invest, you have to be very rich. Consequently, the working class does not have access to investing and cannot diversify their portfolio. Moreover, it is extremely easy for individuals to "short" residential properties, not allocating the market enough time to correct bubbles and deflationary periods. That is why The People's Estate is creating a system that is semi centralized to tokenize real estate and create the infrastructure for a real estate "stock market." Our protocols use the Stelllar Network, and its memo fields to have a publicly verifiable ledger for all transactions, while still maintaining AML and KYC compliant. The People's Estate is a team of individuals not much different than you working to decentralize real estate and give back power back to the people.
### API End Points:
**Create Account (Post)**
/api/addAccount
**Create Transcation (Post)**
/api/addTrans
**Create Tokenized Asset (Post)**
/api/addHouse
**Get A Certain Listing (Post)**
/api/houseId
**Get All Tokenized Listing (Get)**
/api/houses
### Other Requirements
You need to have node.js installed with an instance of mySQL server running on the computer
You also need to have a .env file with the following things:
MYSQL\_HOST=
MYSQL\_USER=
MYSQL\_ROOT\_PASSWORD=
MYSQL\_DATABASE=
MYSQL\_PORT=
SERVER\_PORT=
BASE\_ACCOUNT=
ISSUING\_SECRET=
### Notes
Only the index.html file in the public folder is functional when it comes to adding things to the databases and interacting with the databases, other files are for aesthetic and are not functional. They are more of mockups of what a future product may look like. Nevetheless, our future is bright and we are excited to work on bringing our vision to life. You do not want to miss out on The People's Estate. | winning |
## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | ## Inspiration
In recent times, we have witnessed undescribable tragedy occur during the war in Ukraine. The way of life of many citizens has been forever changed. In particular, the attacks on civilian structures have left cities covered in debris and people searching for their missing loved ones. As a team of engineers, we believe we could use our skills and expertise to facilitate the process of search and rescue of Ukrainian citizens.
## What it does
Our solution integrates hardware and software development in order to locate, register, and share the exact position of people who may be stuck or lost under rubble/debris. The team developed a rover prototype that navigates through debris and detects humans using computer vision. A picture and the geographical coordinates of the person found are sent to a database and displayed on a web application. The team plans to use a fleet of these rovers to make the process of mapping the area out faster and more efficient.
## How we built it
On the frontend, the team used React and the Google Maps API to map out the markers where missing humans were found by our rover. On the backend, we had a python script that used computer vision to detect humans and capture an image. Furthermore,
For the rover, we 3d printed the top and bottom chassis specifically for this design. After 3d printing, we integrated the arduino and attached the sensors and motors. We then calibrated the sensors for the accurate values.
To control the rover autonomously, we used an obstacle-avoider algorithm coded in embedded C.
While the rover is moving and avoiding obstacles, the phone attached to the top is continuously taking pictures. A computer vision model performs face detection on the video stream, and then stores the result in the local directory. If a face was detected, the image is stored on the IPFS using Estuary's API, and the GPS coordinates and CID are stored in a Firestore Database. On the user side of the app, the database is monitored for any new markers on the map. If a new marker has been added, the corresponding image is fetched from IPFS and shown on a map using Google Maps API.
## Challenges we ran into
As the team attempted to use the CID from the Estuary database to retrieve the file by using the IPFS gateway, the marker that the file was attached to kept re-rendering too often on the DOM. However, we fixed this by removing a function prop that kept getting called when the marker was clicked. Instead of passing in the function, we simply passed in the CID string into the component attributes. By doing this, we were able to retrieve the file.
Moreover, our rover was initally designed to work with three 9V batteries (one to power the arduino, and two for two different motor drivers). Those batteries would allow us to keep our robot as light as possible, so that it could travel at faster speeds. However, we soon realized that the motor drivers actually ran on 12V, which caused them to run slowly and burn through the batteries too quickly. Therefore, after testing different options and researching solutions, we decided to use a lithium-poly battery, which supplied 12V. Since we only had one of those available, we connected both the motor drivers in parallel.
## Accomplishments that we're proud of
We are very proud of the integration of hardware and software in our Hackathon project. We believe that our hardware and software components would be complete projects on their own, but the integration of both makes us believe that we went above and beyond our capabilities. Moreover, we were delighted to have finished this extensive project under a short period of time and met all the milestones we set for ourselves at the beginning.
## What we learned
The main technical learning we took from this experience was implementing the Estuary API, considering that none of our teammembers had used it before. This was our first experience using blockchain technology to develop an app that could benefit from use of public, descentralized data.
## What's next for Rescue Ranger
Our team is passionate about this idea and we want to take it further. The ultimate goal of the team is to actually deploy these rovers to save human lives.
The team identified areas for improvement and possible next steps. Listed below are objectives we would have loved to achieve but were not possible due to the time constraint and the limited access to specialized equipment.
* Satellite Mapping -> This would be more accurate than GPS.
* LIDAR Sensors -> Can create a 3D render of the area where the person was found.
* Heat Sensors -> We could detect people stuck under debris.
* Better Cameras -> Would enhance our usage of computer vision technology.
* Drones -> Would navigate debris more efficiently than rovers. | ## Inspiration
With the numerous natural disasters over the past few years, we feel it is extremely important to people to be informed and prepared to face such events. We provide people who lack the resources to stay safe and comfortable with the option to efficiently request such items from others. Danger is inevitable, and we must always prepare for the worst.
## What it does
Our app Relievaid strives to inform users of the importance of making preparations for natural disasters. By connecting users to detailed websites and providing a fun quiz, we encourage people to research ways to stay safe in emergency situations. We also provide an option for users in inconvenient situations to quickly request potentially valuable equipment by connecting the app to SMS messages.
## How we built it
We used Android Studio to develop our application. We coded the layout of the app using XML and user interface component with Java. We primarily used intents to navigate between different activities in the app, send SMS messages, and open web browsers from within the application. We researched credible sources to learn more about the value of emergency preparation for natural disasters and shared our knowledge through an interactive quiz.
## Challenges we ran into
The biggest challenge was getting started with Android Studio for app development. While most members had some experience in Java, the Android Studio IDE had numerous unique features, including dependence on the XML markup language to develop layouts. The AsyncTask used for background processing in Android also had a steep learning curve, so we were unable to learn the mechanism sufficiently in our limited time. Troubleshooting bugs in Android Sutdio was particularly difficult due to our unfamiliarity.
## Accomplishments that we're proud of
We are proud of creating a useful product despite our limited experience in programming. Learning the basics of Android Studio, in particular, was a great accomplishment.
## What We learned
This weekend, we learned how to use Android Studio for app development as well as basics of the XML markup language for design. We also learned that while skill and experience are immensely important, creativity is needed to carry out meaningful ideas and develop useful products. We came to the hackathon with a bit of fear at our inexperience, but we now feel more confident in our abilities. We also learned the value of taking advantage of every member's strengths when working on a team project. Combining technical and artistic talents will create the most successful application.
## What's next for Relievaid
In the future, we plan to utilize APIs provided by services like Google Maps, which will enable us to obtain real-time data on climate and weather changes. We will also make use of open source data sets to acquire a more thorough understanding of the conditions, including time and location, natural disasters are most likely to occur. | winning |
## Inspiration
Using “nutrition” as a keyword in the Otsuka valuenex visualization tool, we found that there is a cluster of companies creating personalized nutrition and fitness plans. But when we used the “and” function to try to find intersections with mental wellness, we found that none of those companies that offer a personalized plan really focused on either stress or mental health. This inspired us to create a service where we use a data-driven, personalized, nutritional approach to reduce stress.
## What it does
We offer healthy recipe recommendations that are likely to reduce stress. We do this by looking at how the nutrients in the users’ past diets contributed to changes in stress. We combine this with their personal information to generate a model of which nutrients are likely to improve their mental wellness and recommend recipes that contain those nutrients. Most people do want to eat healthier, but they don’t because it is inconvenient and perceived to be less delicious. Our service makes it easy and convenient to eat delicious healthy food by making the recipe selection and ingredient collection processes simpler.
To personally tailor each user's recipe suggestions to their stress history, we have users save food items to their food log and fill out a daily questionnaire with common stress indicators. We then use the USDA food database to view the specific nutrients each food item has and use this data to calculate the relationship between the user's stress and the specific nutrients they consumed. Finally, we use this model to suggest future recipes that contain nutrients likely to reduce stress for that user.
In order to proactively reduce user's stress, we offer a simple interface to plan meals in advance for your entire week, an auto-generated ingredients list based on selected recipes for the week, and a seamless way to order and pay for the ingredients using the Checkbook API service. To make it easier for users, the food log will automatically populate each day with the ingredients from the recipes the user selected to eat for that day.
## How we built it
We used Bubble to build a no-code front end by dragging and dropping the design elements we needed. We used Bubble's USDA plugin to let users search for and enter foods that they consumed. The USDA food database is also used to determine the nutrients present in each of the foods the user reports consuming. We also used Bubble's Toolbox plugin to write Javascript code that allows us to run the Checkbook API. We use the Spoonacular API to get the recipe suggestions based on the user's personalized preference quiz answers where they give the types of cuisines they like and their dietary restrictions. We use a linear regression model to suggest future recipes for users based on the nutrients that are likely to reduce their stress.
## Challenges we ran into
One challenge for us was using Bubble. Only one team member had previous design experience, but everyone on the team wanted to contribute to building the front-end, so we faced a huge learning curve for all members of the team to learn about good design principles and how to space elements out on Bubble. Grouping elements together was sometimes weird on Bubble and caused issues with parts of our header not lining up the way we wanted it to. Elements would sometimes disappear under other elements and it would become hard to get them out. Formatting was weird because our laptops had different aspect ratios, so what looked good on one person's laptop looked bad on another person's laptop. We were debugging Bubble until the end of the hackathon.
## Accomplishments that we're proud of
Our team had little to no front-end design experience coming into this hackathon. We are proud of how much we all learned about front-end design through Bubble. We feel that moving forward, we can create better front-end designs for our future projects.
We are also proud of finding and figuring out how to use the Spoonacular API to get recipe recommendations. This API had very thorough documentation, so it was relatively easy to pick it up and figure out how to implement it.
## What we learned
The first thing we learned was how to use the Otsuka valuenex visualization tool for ideation. We found this tool to be extremely helpful with our brainstorming process and when coming up with our idea.
We learned how to use Bubble to create a front-end without needing to write code. Despite the struggles we initially faced, we grew to find Bubble more intuitive and fun to use with more practice and managed to create a pretty nice front-end for our service. We hosted our server on Bubble.
We also learned how to use the Checkbook API to seamlessly send and receive payments.
Finally, we learned how to use the Spoonacular API to generate recipe recommendations based on a set of parameters that includes preferred types of cuisines, dietary restrictions, and nutrients present in each dish.
## What's next for mood food
We feel very passionate about exploring this project in more depth by applying more complex machine learning models to determine better recipe recommendations for users. We would also like to have the opportunity to deploy this service to collect real data to analyze.
## Thanks
Thank you very much to Koji Yamada from Otsuka for meeting up with our team to discuss our idea and offer us feedback. We are very grateful to you for offering our team support in this form.
Thank you to the amazing TreeHacks organizers for putting together this awesome event. Everyone on our team learned a lot and had fun. | ## Inspiration
In the work from home era, many are missing the social aspect of in-person work. And what time of the workday most provided that social interaction? The lunch break. culina aims to bring back the social aspect to work from home lunches. Furthermore, it helps users reduce their food waste by encouraging the use of food that could otherwise be discarded and diversifying their palette by exposing them to international cuisine (that uses food they already have on hand)!
## What it does
First, users input the groceries they have on hand. When another user is found with a similar pantry, the two are matched up and displayed a list of healthy, quick recipes that make use of their mutual ingredients. Then, they can use our built-in chat feature to choose a recipe and coordinate the means by which they want to remotely enjoy their meal together.
## How we built it
The frontend was built using React.js, with all CSS styling, icons, and animation made entirely by us. The backend is a Flask server. Both a RESTful API (for user creation) and WebSockets (for matching and chatting) are used to communicate between the client and server. Users are stored in MongoDB. The full app is hosted on a Google App Engine flex instance and our database is hosted on MongoDB Atlas also through Google Cloud. We created our own recipe dataset by filtering and cleaning an existing one using Pandas, as well as scraping the image URLs that correspond to each recipe.
## Challenges we ran into
We found it challenging to implement the matching system, especially coordinating client state using WebSockets. It was also difficult to scrape a set of images for the dataset. Some of our team members also overcame technical roadblocks on their machines so they had to think outside the box for solutions.
## Accomplishments that we're proud of.
We are proud to have a working demo of such a complex application with many moving parts – and one that has impacts across many areas. We are also particularly proud of the design and branding of our project (the landing page is gorgeous 😍 props to David!) Furthermore, we are proud of the novel dataset that we created for our application.
## What we learned
Each member of the team was exposed to new things throughout the development of culina. Yu Lu was very unfamiliar with anything web-dev related, so this hack allowed her to learn some basics of frontend, as well as explore image crawling techniques. For Camilla and David, React was a new skill for them to learn and this hackathon improved their styling techniques using CSS. David also learned more about how to make beautiful animations. Josh had never implemented a chat feature before, and gained experience teaching web development and managing full-stack application development with multiple collaborators.
## What's next for culina
Future plans for the website include adding videochat component to so users don't need to leave our platform. To revolutionize the dating world, we would also like to allow users to decide if they are interested in using culina as a virtual dating app to find love while cooking. We would also be interested in implementing organization-level management to make it easier for companies to provide this as a service to their employees only. Lastly, the ability to decline a match would be a nice quality-of-life addition. | ## Inspiration
Among our group, we noticed we all know at least one person, who despite seeking medical and nutritional support, suffers from some unidentified food allergy. Seeing people struggle to maintain a healthy diet while "dancing" around foods that they are unsure if they should eat inspired us to do something about it; build **BYTEsense.**
## What it does
BYTEsense is an AI powered tool which personalizes itself to a users individual dietary needs. First, you tell the app what foods you ate, and rate your experience afterwards on a scale of 1-3 - The app then breaks down the food into its individual ingredients, remembers how your experience with them, and stores them to be referenced later. Then, after a sufficient amount of data has been collected, you can use the app to predict how **NEW** foods can affect you through our "How will I feel if I consume..." function!
## How we built it
The web app consists of two main functions, the training and the predicting functions. The training function was built beginning with the receiving of a food and an associated rating. This is then passed on through the OpenAI API to be broken apart to its individual ingredients through ChatGPT's chatting abilities. These ingredients, and their associated ratings, are then saved onto an SQL database which contains all known associations to date. **Furthermore**, there is always a possibility that two different dishes share an ingredient, but your experience is fully different! How do we adjust for that? Well naturally, that would imply that this ingredient is not the significant irritator, and we adjust the ratings according to both data points. Finally, the prediction function of the web app utilizes Cohere's AI endpoints to complete the predictions. Through use of Cohere's classify endpoint, we are able to train an algorithm which can classify a new dish into any of the three aforementioned categories, with relation to the previously acquired data!
The project was all built on Replit, allowing for us to collaborate and host it all in the same place!
## Challenges we ran into
We ran into many challenges over the course of the project. First, it began with our original plan of action being completely unusable after seeing updates to Cohere's API, effectively removing the custom embed models for classification and rerank. But that did not stop us! We readjusted, re-planned, and kept on it! Our next biggest problem was the coders nightmare, a tiny syntax error in our SQLite code which continuously that crashed our entire program. We spent over an hour locating the bug, and even more trying to figure out the issue (it was a wrong data type.). And our final immense issue came quite literally out of the blue, previously, we utilized Cohere's new Coral chatbot to identify ingredients in the various input, but, due to an apparent glitch in the responses - we got our responses sent over 15 times each prompt - we had made a last minute jump to OpenAI! Once we got past those, most other things seemed like a piece of cake - there were a lot of pieces - but we're happy to present the finished product!
## Accomplishments we are proud of:
There are many things that we as a team are proud of, from overcoming trials and tribulations, refusing sleep for nearly two days, and most importantly, producing a finished product. We are proud to see just how far we have come, from having no idea how to even approach LLM, to running a program utilizing **TWO** different ones. But most importantly, I think we are all proud of creating a product that really has potential to help people, using technology to better people's lives is something to be very proud of doing!
## What we learned:
What did we learn? Well, that depends who you ask! I feel like each member of the team learnt an unbelievable amount, whether it be from each other or individually. For instance, I learnt a lot about flask and front end development from working with a proficient teammate, and I hope I gave something to learn from too! Even more so, throughout the weekend we attended many workshops, ranging from ML, to LLM, Replit, and so many others, that even if we didn't use what we learnt there in this project, I have no doubt it will appear in a next!
## What’s next for BYTEsense:
All of us in the team honestly believe that BYTEsense has reached a level which is not only functional, but viable. As we keep on going all that is left is tidying up and cleaning some code and a potentially market ready app could be born! Who knows, maybe we'll be a sponsor one day!
But either way, I am definitely using a copy when I get back home! | winning |
## Inspiration
Our team wanted to build an application with social impact. We believe that change starts within a community, therefore, we brainstormed ways that people can make a change within the local community. We realized that homelessness and food insecurity is a large issue within the Hamilton community, and we thought of ways that people could help reduce this problem. One of our members recalled videos and documentaries online showing supermarkets and restaurants throwing out perfectly good food. Sometimes it would be food which they prepared by mistake, food close to its expiration date, or simply just food with damaged packaging.
1,098+ people in hamilton registered as ‘experiencing homelessness and accessing services’
3000+ people per day experiencing food insecurity per day in hamilton
77% of those experiencing homelessness have smartphones
## What it does
We came up with a creative solution, where local businesses (i.e. supermarkets, restaurants, etc) can post perfectly good food or beverages that are still good for consumption, and that would otherwise be thrown out. Those is the local community who need it can then find these places and pick up items. As a result, FoodCycle provides a green solution to reducing food waste while helping those within the local community.
## How I built it
* ReactJS
* Javascript
* HTML
* Node.js
* Google maps API
## Challenges I ran into
We ran into challenges with some of the Reactjs libraries and with styling of some components. However, we were able to overcome many these problems by finding creative alternatives and solutions.
## Accomplishments that I'm proud of
We are proud of our application and the idea. We are happy to create a hack that encourages social change and environmental sustainability.
## What I learned
Google maps API and ReactJS (many of our members are inexperienced in ReactJS).
In fact, this is one of our members' first time coding and hacking - needless to say, he was able to learn a lot!
## What's next for FoodCycle
We would like to improve this application by adding more advanced features, such as the ability to find providers in our network by searching a specific food. We would also like to implement a more friendly dashboard for users, and possibly create a native mobile application. Ideally, we would like those in the local community to participate in actively reducing food waste and helping those in need. | ## Inspiration
I was cooking at home one day and I kept noticing we had half a carrot, half an onion, and like a quarter of a pound of ground pork lying around all the time. More often than not it was from me cooking a fun dish that my mother have to somehow clean up over the week. So I wanted to create an app that would help me use those ingredients that I have neglected so that even if both my mother and I forget about it we would not contribute to food waste.
## What it does
Our app uses a database to store our user's fridge and keeps track of the food in their fridge. When the user wants a food recipe recommendation our app will help our user finish off their food waste. Using the power of chatGPT our app is super flexable and all the unknown food and food that you are too lazy to measure the weight of can be quickly put into a flexible and delicious recipe.
## How we built it
Using figma for design, react.JS bootstrap for frontend, flask backend, a mongoDB database, and openAI APIs we were able to create this stunning looking demo.
## Challenges we ran into
We messed up our database schema and poor design choices in our APIs resulting in a complete refactor. Our group also ran into problems with react being that we were relearning it. OpenAI API gave us inconsistency problems too. We pushed past these challenges together by dropping our immediate work and thinking of a solution together.
## Accomplishments that we're proud of
We finished our demo and it looks good. Our dev-ops practices were professional and efficient, our kan-ban board saved us a lot of time when planning and implementing tasks. We also wrote plenty of documentations where after our first bout of failure we planned out everything with our group.
## What we learned
We learned the importance of good API design and planning to save headaches when implementing out our API endpoints. We also learned much about the nuance and intricacies when using CORS technology. Another interesting thing we learned is how to write detailed prompts to retrieve formatted data from LLMs.
## What's next for Food ResQ : AI Recommended Recipes To Reduce Food Waste
We are planning to add a receipt scanning feature so that our users would not have to manually add in each ingredients into their fridge. We are also working on a feature where we would prioritize ingredients that are closer to expiry. Another feature we are looking at is notifications to remind our users that their ingredients should be used soon to drive up our engagement more. We are looking for payment processing vendors to allow our users to operate the most advanced LLMs at a slight premium for less than a coffee a month.
## Challenges, themes, prizes we are submitting for
Sponsor Challenges: None
Themes: Artificial Intelligence & Sustainability
Prizes: Best AI Hack, Best Sustainability Hack, Best Use of MongoDB Atlas, Most Creative Use of Github, Top 3 Prize | ## Inspiration
With billions of tons of food waste occurring in Canada every year. We knew that there needs to exist a cost-effective way to reduce food waste that can empower restaurant owners to make more eco-conscious decisions while also incentivizing consumers to choose more environmentally-friendly food options.
## What it does
Re-fresh is a two-pronged system that allows users to search for food from restaurants that would otherwise go to waste at a lower price than normal. On the restaurant side, we provide a platform to track and analyze inventory in a way that allows restaurants to better manage their requisitions for produce so that they do not generate any extra waste and they can ensure profits are not being thrown away.
## How we built it
For the backend portion of the app, we utilized cockroachDB in python and javascript as well as React Native for the user mobile app and the enterprise web application. To ensure maximum protection of our user data, we used SHA256 encryption to encrypt sensitive user information such as usernames and password.
## Challenges we ran into
Due to the lack of adequate documentation as well as a plethora of integration issues with react.js and node, cockroachDB was a difficult framework to work with. Other issues we ran into were some problems on the frontend with utilizing chart.js for displaying graphical representations of enterprise data.
## Accomplishments that we're proud of
We are proud of the end design of our mobile app and web application. Our team are not native web developers so it was a unique experience stepping out of our comfort zone and getting to try new frameworks and overall we are happy with what we learned as well as how we were able to utilize our brand understanding of programming principles to create this project.
## What we learned
We learned more about web development than what we knew before. We also learned that despite the design-oriented nature of frontend development there are many technical hurdles to go through when creating a full stack application and that there is a wide array of different frameworks and APIs that are useful in developing web applications.
## What's next for Re-Fresh
The next step for Re-Fresh is restructuring the backend architecture to allow ease of scalability for future development as well as hopefully being able to publish it and attract a customer-base. | losing |
## Inspiration
In a world where people are continually faced with complicated decisions, our team wanted to see if the latest AI models would be capable of navigating complex social and moral landscapes of the modern day. This inspired our central focus for this project: exploring the intersection of AI and ethical decision-making and creating an engaging way for people to reflect on their own senses of morality.
## What it does
GPTEthics offers an interactive web platform where:
* Users are presented with a variety of ethical dilemmas.
* Both the user and an AI agent respond to these scenarios.
* An AI-powered system evaluates and compares the responses, providing insights into human vs. AI approaches to moral reasoning.
## How we built it
Our solution integrates several key components:
* A Flask-based web application for scenario presentation
* An AI agent powered by GPT-4, AWS Bedrock, and Groq for generating responses
* An AI-driven scoring system to evaluate the ethical reasoning in responses
## Challenges we ran into
* Developing an objective and fair AI scoring system for subjective ethical issues
* Creating a diverse, representative set of ethical dilemmas
* Optimizing response times from AWS Bedrock through prompt engineering
## Accomplishments that we're proud of
* Successfully integrating AI into an ethics-focused, interactive experience
* Developing a tool that promotes thoughtful engagement with moral issues
* Implementing a cohesive web application that effectively utilizes multiple LLM APIs
## What we learned
* Valuable perspectives on how humans and AI approach ethical decision-making
* Understanding the complexities of designing impartial AI evaluation systems for subjective topics
* Recognizing the ongoing challenges LLMs face in providing robust ethical solutions
## What's next for GPTEthics
* Expanding our database of ethical scenarios
* Refining the AI agent and scoring system for improved performance
* Exploring the integration of user feedback to enhance the platform's effectiveness | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materials more seamless and convenient.
## What it does
Wise Up is a website that takes many different types of file format, as well as plain text, and separates the information into "pages". Using text embeddings, it can then quickly search through all the pages in a text and figure out which ones are most likely to contain the answer to a question that the user sends. It can also recursively summarize the file at different levels of compression.
## How we built it
With blood, sweat and tears! We used many tools offered to us throughout the challenge to simplify our life. We used Javascript, HTML and CSS for the website, and used it to communicate to a Flask backend that can run our python scripts involving API calls and such. We have API calls to openAI text embeddings, to cohere's xlarge model, to GPT-3's API, OpenAI's Whisper Speech-to-Text model, and several modules for getting an mp4 from a youtube link, a text from a pdf, and so on.
## Challenges we ran into
We had problems getting the backend on Flask to run on a Ubuntu server, and later had to instead run it on a Windows machine. Moreover, getting the backend to communicate effectively with the frontend in real time was a real challenge. Extracting text and page data from files and links ended up taking more time than expected, and finally, since the latency of sending information back and forth from the front end to the backend would lead to a worse user experience, we attempted to implement some features of our semantic search algorithm in the frontend, which led to a lot of difficulties in transferring code from Python to Javascript.
## Accomplishments that we're proud of
Since OpenAI's text embeddings are very good and very new, and we use GPT-3.5 based on extracted information to formulate the answer, we believe we likely equal the state of the art in the task of quickly analyzing text and answer complex questions on it, and the ease of use for many different file formats makes us proud that this project and website can be useful for so many people so often. To understand a textbook and answer questions about its content, or to find specific information without knowing any relevant keywords, this product is simply incredibly good, and costs pennies to run. Moreover, we have added an identification system (users signing up with a username and password) to ensure that a specific account is capped at a certain usage of the API, which is at our own costs (pennies, but we wish to avoid it becoming many dollars without our awareness of it.
## What we learned
As time goes on, not only do LLMs get better, but new methods are developed to use them more efficiently and for greater results. Web development is quite unintuitive for beginners, especially when different programming languages need to interact. One tool that has saved us a few different times is using json for data transfer, and aws services to store Mbs of data very cheaply. Another thing we learned is that, unfortunately, as time goes on, LLMs get bigger and so sometimes much, much slower; api calls to GPT3 and to Whisper are often slow, taking minutes for 1000+ page textbooks.
## What's next for Wise Up
What's next for Wise Up is to make our product faster and more user-friendly. A feature we could add is to summarize text with a fine-tuned model rather than zero-shot learning with GPT-3. Additionally, a next step is to explore partnerships with educational institutions and companies to bring Wise Up to a wider audience and help even more students and educators in their learning journey, or attempt for the website to go viral on social media by advertising its usefulness. Moreover, adding a financial component to the account system could let our users cover the low costs of the APIs, aws and CPU running Whisper. | ## Inspiration
Our inspiration stems from the prevalent issue of individuals enduring discrimination and mistreatment based on race, gender, sex, disability and are often unaware of their rights in such situations. They often struggle to find reliable sources of information or guidance on their rights and avenues for recourse. It contributes to inclusion and diversity in an organization by aiding in drafting inclusive policies, offering unbiased legal guidance, and supporting diverse hiring practices.
## What it does
It offers a specialized chatbot application designed specifically for legal documents encompassing human rights, equality laws, and issues relating to sexual orientation. It is designed to respond to specific user queries like "What are my rights on standard of living?" or "What can I do if I feel uncomfortable as an employee?" providing enhanced responses by analyzing relevant legal documents. It also gives user the link to the respective legal document where its easier for the user to further drill down.
## How we built it
The base architecture involves a Large Language model called "**flan-t5-xxl**". As we know, it is nearly impossible to fine tune the LLM as it has 11.3B parameters. Therefore, we employed an approach called as **Retrieval Augmented Generation** where the documents are created into a vectors using "*bge-large-en-v1.5*" embedding model from hugging face. Because of the large size of PDF documents, their vectors are stored in **ChromaDB** and are compared against user queries using semantic search for more efficient retrieval of relevant information using **Cosine similarity** measure. The retrieved relevant documents combined with query are then sent to the LLM for response. The solution was then deployed locally using **Flask** and model end points were exposed. The user front end was created in form of a Mobile application using **Flutter**.
## Challenges we ran into
1. Testing and deployment of other LLMs with parameters exceeding 20 Billion due to GPU resource constraints.
2. Creating the prompt for the Large Language Model (LLM) encountered a limitation when it reached the maximum token limit of 1024.
3. Programmatical authentication to hugging face due to token issues and getting 401 http code.
4. Finding the right legal documents that could be converted to vector embeddings.
5. We tried deploying the model to Azure cloud but we faced issues with Secondary Storage and GPU limitations.
## Accomplishments that we're proud of
We are proud of working on this cutting edge technology of LLMs, RAG and Semantic search. This is an effective solution that address a common challenge and will be helping a lot of people. We were also able to deploy the solution by exposing APIs and created an Mobile Application for streamline user interaction. Overall, we created an end to end impactful solution.
## What we learned
We have deepened our expertise in tailoring AI solutions to address specific use case, particularly in areas such as human rights and laws. We've utilized cutting-edge technology and gained insights into the end-to-end deployment process. We've also acquired knowledge on effectively delegating tasks, planning, teamwork, and time management skills.
## What's next for LegalGPT
1. Integration with a comprehensive legal research library, providing access to a vast repository of statutes, case laws, and legal literature for in-depth analysis and citation.
2. Improving the model performance by tuning the non trainable hyper-parameters.
3. Applying more NLP processing techniques on user queries and raw pdf documents.
4. Deploying the solution on public cloud such as Azure. | partial |
## Inspiration
Unhealthy diet is the leading cause of death in the U.S., contributing to approximately 678,000 deaths each year, due to nutrition and obesity-related diseases, such as heart disease, cancer, and type 2 diabetes. Let that sink in; the leading cause of death in the U.S. could be completely nullified if only more people cared to monitor their daily nutrition and made better decisions as a result. But **who** has the time to meticulously track every thing they eat down to the individual almond, figure out how much sugar, dietary fiber, and cholesterol is really in their meals, and of course, keep track of their macros! In addition, how would somebody with accessibility problems, say blindness for example, even go about using an existing app to track their intake? Wouldn't it be amazing to be able to get the full nutritional breakdown of a meal consisting of a cup of grapes, 12 almonds, 5 peanuts, 46 grams of white rice, 250 mL of milk, a glass of red wine, and a big mac, all in a matter of **seconds**, and furthermore, if that really is your lunch for the day, be able to log it and view rich visualizations of what you're eating compared to your custom nutrition goals?? We set out to find the answer by developing macroS.
## What it does
macroS integrates seamlessly with the Google Assistant on your smartphone and let's you query for a full nutritional breakdown of any combination of foods that you can think of. Making a query is **so easy**, you can literally do it while *closing your eyes*. Users can also make a macroS account to log the meals they're eating everyday conveniently and without hassle with the powerful built-in natural language processing model. They can view their account on a browser to set nutrition goals and view rich visualizations of their nutrition habits to help them outline the steps they need to take to improve.
## How we built it
DialogFlow and the Google Action Console were used to build a realistic voice assistant that responds to user queries for nutritional data and food logging. We trained a natural language processing model to identify the difference between a call to log a food eaten entry and simply a request for a nutritional breakdown. We deployed our functions written in node.js to the Firebase Cloud, from where they process user input to the Google Assistant when the test app is started. When a request for nutritional information is made, the cloud function makes an external API call to nutrionix that provides nlp for querying from a database of over 900k grocery and restaurant foods. A mongo database is to be used to store user accounts and pass data from the cloud function API calls to the frontend of the web application, developed using HTML/CSS/Javascript.
## Challenges we ran into
Learning how to use the different APIs and the Google Action Console to create intents, contexts, and fulfillment was challenging on it's own, but the challenges amplified when we introduced the ambitious goal of training the voice agent to differentiate between a request to log a meal and a simple request for nutritional information. In addition, actually finding the data we needed to make the queries to nutrionix were often nested deep within various JSON objects that were being thrown all over the place between the voice assistant and cloud functions. The team was finally able to find what they were looking for after spending a lot of time in the firebase logs.In addition, the entire team lacked any experience using Natural Language Processing and voice enabled technologies, and 3 out of the 4 members had never even used an API before, so there was certainly a steep learning curve in getting comfortable with it all.
## Accomplishments that we're proud of
We are proud to tackle such a prominent issue with a very practical and convenient solution that really nobody would have any excuse not to use; by making something so important, self-monitoring of your health and nutrition, much more convenient and even more accessible, we're confident that we can help large amounts of people finally start making sense of what they're consuming on a daily basis. We're literally able to get full nutritional breakdowns of combinations of foods in a matter of **seconds**, that would otherwise take upwards of 30 minutes of tedious google searching and calculating. In addition, we're confident that this has never been done before to this extent with voice enabled technology. Finally, we're incredibly proud of ourselves for learning so much and for actually delivering on a product in the short amount of time that we had with the levels of experience we came into this hackathon with.
## What we learned
We made and deployed the cloud functions that integrated with our Google Action Console and trained the nlp model to differentiate between a food log and nutritional data request. In addition, we learned how to use DialogFlow to develop really nice conversations and gained a much greater appreciation to the power of voice enabled technologies. Team members who were interested in honing their front end skills also got the opportunity to do that by working on the actual web application. This was also most team members first hackathon ever, and nobody had ever used any of the APIs or tools that we used in this project but we were able to figure out how everything works by staying focused and dedicated to our work, which makes us really proud. We're all coming out of this hackathon with a lot more confidence in our own abilities.
## What's next for macroS
We want to finish building out the user database and integrating the voice application with the actual frontend. The technology is really scalable and once a database is complete, it can be made so valuable to really anybody who would like to monitor their health and nutrition more closely. Being able to, as a user, identify my own age, gender, weight, height, and possible dietary diseases could help us as macroS give users suggestions on what their goals should be, and in addition, we could build custom queries for certain profiles of individuals; for example, if a diabetic person asks macroS if they can eat a chocolate bar for lunch, macroS would tell them no because they should be monitoring their sugar levels more closely. There's really no end to where we can go with this! | ## Inspiration
Vision—our most dominant sense—plays a critical role in every faucet and stage in our lives. Over 40 million people worldwide (and increasing) struggle with blindness and 20% of those over 85 experience permanent vision loss. In a world catered to the visually-abled, developing assistive technologies to help blind individuals regain autonomy over their living spaces is becoming increasingly important.
## What it does
ReVision is a pair of smart glasses that seamlessly intertwines the features of AI and computer vision to help blind people navigate their surroundings. One of our main features is the integration of an environmental scan system to describe a person’s surroundings in great detail—voiced through Google text-to-speech. Not only this, but the user is able to have a conversation with ALICE (Artificial Lenses Integrated Computer Eyes), ReVision’s own AI assistant. “Alice, what am I looking at?”, “Alice, how much cash am I holding?”, “Alice, how’s the weather?” are all examples of questions ReVision can successfully answer. Our glasses also detect nearby objects and signals buzzing when the user approaches an obstacle or wall.
Furthermore, ReVision is capable of scanning to find a specific object. For example—at an aisle of the grocery store—” Alice, where is the milk?” will have Alice scan the view for milk to let the user know of its position. With ReVision, we are helping blind people regain independence within society.
## How we built it
To build ReVision, we used a combination of hardware components and modules along with CV. For hardware, we integrated an Arduino uno to seamlessly communicate back and forth between some of the inputs and outputs like the ultrasonic sensor and vibrating buzzer for haptic feedback. Our features that helped the user navigate their world heavily relied on a dismantled webcam that is hooked up to a coco-ssd model and ChatGPT 4 to identify objects and describe the environment. We also used text-to-speech and speech-to-text to make interacting with ALICE friendly and natural.
As for the prototype of the actual product, we used stockpaper, and glue—held together with the framework of an old pair of glasses. We attached the hardware components to the inside of the frame, which pokes out to retain information. An additional feature of ReVision is the effortless attachment of the shade cover, covering the lens of our glasses. We did this using magnets, allowing for a sleek and cohesive design.
## Challenges we ran into
One of the most prominent challenges we conquered was soldering ourselves for the first time as well as DIYing our USB cord for this project. As well, our web camera somehow ended up getting ripped once we had finished our prototype and ended up not working. To fix this, we had to solder the wires and dissect our goggles to fix their composition within the frames.
## Accomplishments that we're proud of
Through human design thinking, we knew that we wanted to create technology that not only promotes accessibility and equity but also does not look too distinctive. We are incredibly proud of the fact that we created a wearable assistive device that is disguised as an everyday accessory.
## What we learned
With half our team being completely new to hackathons and working with AI, taking on this project was a large jump into STEM for us. We learned how to program AI, wearable technologies, and even how to solder since our wires were all so short for some reason. Combining and exchanging our skills and strengths, our team also learned design skills—making the most compact, fashionable glasses to act as a container for all the technologies they hold.
## What's next for ReVision
Our mission is to make the world a better place; step-by-step. For the future of ReVision, we want to expand our horizons to help those with other sensory disabilities such as deafness and even touch. | # Click through our slideshow for a neat overview!!
# Check out our demo [video](https://www.youtube.com/watch?v=hyWJAuR7EVY)
## The future of computing 🍎 👓 ⚙️ 🤖 🍳 👩🍳
How could Mixed Reality, Spatial Computing, and Generative AI transform our lives?
And what happens when you combine Vision Pro and AI? (spoiler: magic! 🔮)
Our goal was to create an interactive **VisionOS** app 🍎 powered by AI. While our app could be applied towards many things (like math tutoring, travel planning, etc.), we decided to make the demo use case fun.
We loved playing the game Cooking Mama 👩🍳 as kids so we made a **voice-activated conversational AI agent** that teaches you to cook healthy meals, invents recipes based on your preferences, and helps you find and order ingredients.
Overall, we want to demonstrate how the latest tech advances could transform our lives. Food is one of the most important, basic needs so we felt that it was an interesting topic. Additionally, many people struggle with nutrition so our project could help people eat healthier foods and live better, longer lives.
## What we created
* Conversational Vision Pro app that lets you talk to an AI nutritionist that speaks back to you in a realistic voice with low latency.
* Built-in AI agent that will create a custom recipe according to your preferences, identify the most efficient and cheapest way to purchase necessary ingredients in your area (least stores visited, least cost), and finally creates Instacart orders using their simulated API.
* Web version of agent at [recipes.reflex.run](https://recipes.reflex.run/) in a chat interface
* InterSystems IRIS vector database of 10k recipes with HyDE enabled semantic search
* Pretrained 40M LLM from scratch to create recipes
* Fine-tuned Mistral-7b using MonsterAPI to generate recipes
## How we built it
We divided tasks efficiently given the time frame to make sure we weren't bottlenecked by each other. For instance, Gao's first priority was to get a recipe LLM deployed so Molly and Park could use it in their tasks.
While we split up tasks, we also worked together to help each other debug and often pair programmed and swapped tasks if needed.
Various tools used: Xcode, Cursor, OpenAI API, MonsterAI API, IRIS Vector Database, Reflex.dev, SERP API,...
### Vision OS
* Talk to Vision Mama by running Whisper fully on device using CoreML and Metal
* Chat capability powered by GPT-3.5-turbo, our custom recipe-generating LLM (Mistral-7b backbone), and our agent endpoint.
* To ensure that you are able to see both Vision Mama's chats and her agentic skills, we have a split view that shows your conversation and your generated recipes
* Lastly, we use text-to-speech synthesis using ElevenLabs API for Vision Mama's voice
### AI Agent Pipeline for Recipe Generation, Food Search, and Instacart Ordering
We built an endpoint that we hit from our Vision Pro and our Reflex site.
Basically what happens is we submit a user's desired food such as "banana soup". We pass that to our fine-tuned Mistral-7b LLM to generate a recipe. Then, we quickly use GPT-4-turbo to parse the recipe and extract the ingredients. Then we use the SERP API on each ingredient to find where it can be purchased nearby. We prioritize cheaper ingredients and use an algorithm to try to visit the least number of stores to buy all ingredients. Finally, we populate an Instacart Order API call to purchase the ingredients (simulated for now since we do not have actual partner access to Instacart's API)
### Pre-training (using nanogpt architecture):
Created large dataset of recipes.
Tokenized our recipe dataset using BPE (GPT2 tokenizer)
Dataset details (9:1 split):
train: 46,826,468 tokens
val: 5,203,016 tokens
Trained for 1000 iterations with settings:
layers = 12
attention heads = 12
embedding dimension = 384
batch size = 32
In total, the LLM had 40.56 million parameters!
It took several hours to train on an M3 Mac with Metal Performance Shaders.
### Fine-tuning
While the pre-trained LLM worked ok and generated coherent (but silly) English recipes for the most part, we couldn't figure out how to deploy it in the time frame and it still wasn't good enough for our agent. So, we tried fine-tuning Mistral-7b, which is 175 times bigger and is much more capable. We curated fine-tuning datasets of several sizes (10k recipes, 50k recipes, 250k recipes). We prepared them into a specific prompt/completion format:
```
You are an expert chef. You know about a lot of diverse cuisines. You write helpful tasty recipes.\n\n###Instruction: please think step by step and generate a detailed recipe for {prompt}\n\n###Response:{completion}
```
We fine-tuned and deployed the 250k-fine-tuned model on the **MonsterAPI** platform, one of the sponsors of TreeHacks. We observed that using more fine-tuning data led to lower loss, but at diminishing returns.
### Reflex.dev Web Agent
Most people don't have Vision Pros so we wrapped our versatile agent endpoint into a Python-based Reflex app that you can chat with! [Try here](https://recipes.reflex.run/)
Note that heavy demand may overload our agent.
### IRIS Semantic Recipe Discovery
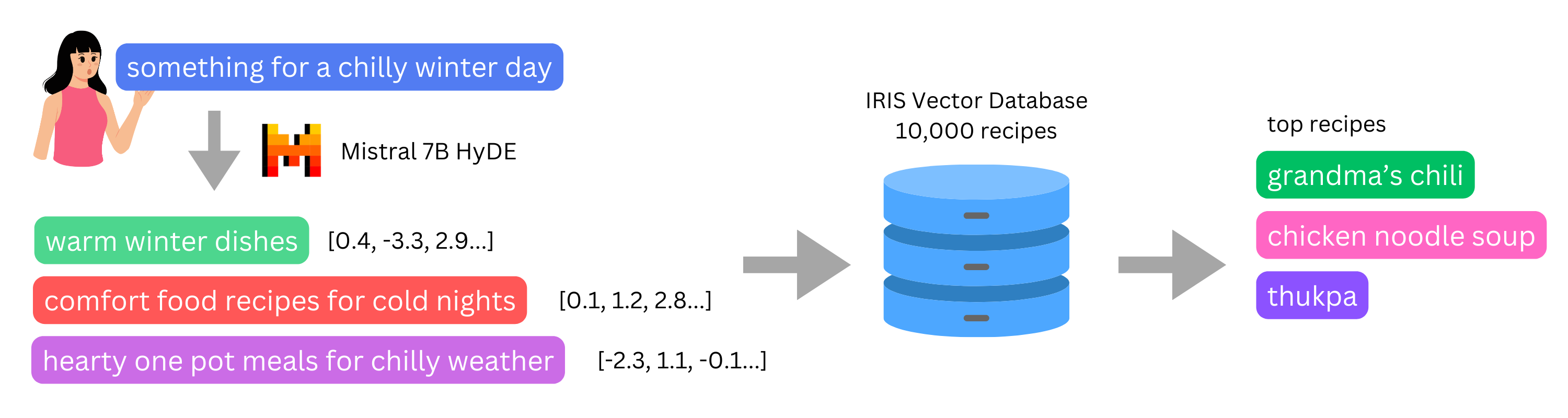
We used the IRIS Vector Database, running it on a Mac with Docker. We embedded 10,000 unique recipes from diverse cuisines using **OpenAI's text-ada-002 embedding**. We stored the embeddings and the recipes in an IRIS Vector Database. Then, we let the user input a "vibe", such as "cold rainy winter day". We use **Mistral-7b** to generate three **Hypothetical Document Embedding** (HyDE) prompts in a structured format. We then query the IRIS DB using the three Mistral-generated prompts. The key here is that regular semantic search does not let you search by vibe effectively. If you do semantic search on "cold rainy winter day", it is more likely to give you results that are related to cold or rain, rather than foods. Our prompting encourages Mistral to understand the vibe of your input and convert it to better HyDE prompts.
Real example:
User input: something for a chilly winter day
Generated Search Queries: {'queries': ['warming winter dishes recipes', 'comfort food recipes for cold days', 'hearty stews and soups for chilly weather']}
Result: recipes that match the intent of the user rather than the literal meaning of their query
## Challenges we ran into
Programming for the Vision Pro, a new way of coding without that much documentation available
Two of our team members wear glasses so they couldn't actually use the Vision Pro :(
Figuring out how to work with Docker
Package version conflicts :((
Cold starts on Replicate API
A lot of tutorials we looked at used the old version of the OpenAI API which is no longer supported
## Accomplishments that we're proud of
Learning how to hack on Vision Pro!
Making the Vision Mama 3D model blink
Pretraining a 40M parameter LLM
Doing fine-tuning experiments
Using a variant of HyDE to turn user intent into better semantic search queries
## What we learned
* How to pretrain LLMs and adjust the parameters
* How to use the IRIS Vector Database
* How to use Reflex
* How to use Monster API
* How to create APIs for an AI Agent
* How to develop for Vision Pro
* How to do Hypothetical Document Embeddings for semantic search
* How to work under pressure
## What's next for Vision Mama: LLM + Vision Pro + Agents = Fun & Learning
Improve the pre-trained LLM: MORE DATA, MORE COMPUTE, MORE PARAMS!!!
Host the InterSystems IRIS Vector Database online and let the Vision Mama agent query it
Implement the meal tracking photo analyzer into VisionOs app
Complete the payment processing for the Instacart API once we get developer access
## Impacts
Mixed reality and AI could enable more serious use cases like:
* Assisting doctors with remote robotic surgery
* Making high quality education and tutoring available to more students
* Amazing live concert and event experiences remotely
* Language learning practice partner
## Concerns
* Vision Pro is very expensive so most people can't afford it for the time being. Thus, edtech applications are limited.
* Data privacy
Thanks for checking out Vision Mama! | winning |
## Inspiration
We were inspired by our lack of decision making when it comes to choosing a place to eat.
## What it does
Our website random generates a restaurant based on the distance from the user and reviews.
## How we built it
We used react, css, html, and js.
## Challenges we ran into
We were unable to connect the backend and frontend.
## Accomplishments that we're proud of
We're proud of being able to learn google maps api in a short amount of time. Our frontend is also pretty dang seggsy.
## What we learned
We learned Google Maps API, react, javascript.
## What's next for nom button
Connecting frontend and backend, adding a map in the display of results, adding more filters | ## Inspiration
As humans, it is impossible to always be in perfect shape, health, and condition. This includes our mental health and wellbeing. To tackle this problem, we created a website that encourages users to complete simple tasks that have been proven to improve mood, drive, and wellbeing. These tasks include journaling, meditating and reflecting.
## What it does
It is a web-based platform with three main functions:
1. Generates reflective reminders and actionable suggestions
2. Provides a platform for journalling gratefulness and aspirations
3. Delivers sounds and visuals for peaceful meditation
## How we built it
We used HTML, CSS and vanilla Javascript to build the entire platform. We also used the following libraries:
* Wired-elements: <https://github.com/rough-stuff/wired-elements>
* Flaticons: <https://www.flaticon.com/>
* Button Hover: <https://codepen.io/davidicus/pen/emgQKJ>
## Challenges we ran into
Communication between the backend and frontend could've been better. Often times, the backend sent code to the frontend with very little details which caused some confusion. There were also some issues with the size of the MP4 file during the upload to GitHub.
## Accomplishments that we're proud of
We are proud to have finished the entire website way ahead of schedule with very minimal errors and problems. We are also proud of the user interface.
## What we learned
* Backend to frontend integration
* Github Pages
* VScode Live Share
* Software Architecture
## What's next for First Step
* Develop mobile version
* Deploy to web
* Improve responsive design | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allowing these health conscious people to feel at peace with their dieting plans. With NutroPNG, we enable these differences to be settled once in for all by allowing health freaks to keep up with their diet plans while still making restaurant eating possible.
## What it does
The user has the option to take a picture or upload their own picture using our the front end of our web application. With this input the backend detects the foods in the photo and labels them through AI image processing using Google Vision API. Finally with CalorieNinja API, these labels are sent to a remote database where we match up the labels to generate the nutritional contents of the food and we display these contents to our users in an interactive manner.
## How we built it
Frontend: Vue.js, tailwindCSS
Backend: Python Flask, Google Vision API, CalorieNinja API
## Challenges we ran into
As we are many first-year students, learning while developing a product within 24h is a big challenge.
## Accomplishments that we're proud of
We are proud to implement AI in a capacity to assist people in their daily lives. And to hopefully allow this idea to improve peoples relationships and social lives while still maintaining their goals.
## What we learned
As most of our team are first-year students with minimal experience, we've leveraged our strengths to collaborate together. As well, we learned to use the Google Vision API with cameras, and we are now able to do even more.
## What's next for McHacks
* Calculate sum of calories, etc.
* Use image processing to estimate serving sizes
* Implement technology into prevalent nutrition trackers, i.e Lifesum, MyPlate, etc.
* Collaborate with local restaurant businesses | losing |
## Inspiration & Instructions
We wanted to somehow guilt people into realizing the state of their bank accounts by showing them progressive picture reminders as their wallpaper. Hopefully, the people who use our app will want to save more and also maybe increase their earnings by investing in stocks, SPROUTING personal monetary growth.
To use our app, you can simply install it on your phone. The APK link is below, and it is fully functional. When you first open Sprout, we ask for your bank account information. We then take you to the next screen which will show your current balance and let you set your baseline and goal amounts for your balance. Below that is the current status of your representative plant’s health based on these amounts. Be sure to check the toggle to change the wallpaper of your phone to the plant so that you’re always aware! You can also navigate to a “How To Invest” page from the menu where you can get up-to-date analytical estimations of how you could earn more money through investing.
For a detailed demo, please see our video.
## What it does
Sprout is an Android app to help students and the general populace know how their bank account is doing. It basically sees your current balance, takes the minimum threshold you don’t want your balance to go under and what you’d love to see your balance to be above. Then, the app shows you a cute plant representing the state of your bank account, either living comfortably, living luxuriously, or dying miserably. It will update your phone background accordingly so that you would be able to know at all times. You can also get to a “How To Invest” page, which can briefly educate you on how you could earn more money through investing.
## How we built it
Two of us had experience with Android Development, so we decided we wanted to make an Android app. We used Android Studio as our IDE and Java as our language of choice. (For our plant designs, we used Adobe Illustrator.) To simulate information about a possible user’s account balance, we used the MINT API to fetch financial data. In order to incentivize our users to maybe invest their savings, we used the NASDAQ API to get stock information and used that to project earnings from the user’s balance had they invested some of it in the past. We offer some brief advice on how to start investing for beginners as well.
## Challenges we ran into
Random small bugs, but we squashed the majority of them. Our biggest problem was thinking of a good idea we would be able to implement well in the time that we had!
## Accomplishments that we're proud of
Our app has many features and a great design!
## What we learned
We can get a lot done in a short amount of time :^D
## What's next for Sprout?
Background app refresh to automatically check as transactions come in so that the most accurate plant can be shown.
## Built With
* Java
* Android Studio
* NASDAQ API
* Mint API
* Adobe Illustrator (for Designs)
## Try it out
Link to APK: <https://github.com/zoedt/yhack-2016/blob/master/app-debug.apk> | ## Inspiration
As university students, emergency funds may not be on the top of our priority list however, when the unexpected happens, we are often left wishing that we had saved for an emergency when we had the chance. When we thought about this as a team, we realized that the feeling of putting a set amount of money away every time income rolls through may create feelings of dread rather than positivity. We then brainstormed ways to make saving money in an emergency fund more fun and rewarding. This is how Spend2Save was born.
## What it does
Spend2Save allows the user to set up an emergency fund. The user inputs their employment status, baseline amount and goal for the emergency fund and the app will create a plan for them to achieve their goal! Users create custom in-game avatars that they can take care of. The user can unlock avatar skins, accessories, pets, etc. by "buying" them with funds they deposit into their emergency fund. The user will have milestones or achievements for reaching certain sub goals while also giving them extra motivation if their emergency fund falls below the baseline amount they set up. Users will also be able to change their employment status after creating an account in the case of a new job or career change and the app will adjust their deposit plan accordly.
## How we built it
We used Flutter to build the interactive prototype of our Android Application.
## Challenges we ran into
None of us had prior experience using Flutter, let alone mobile app development. Learning to use Flutter in a short period of time can easily be agreed upon to be the greatest challenge that we faced.
We originally had more features planned, with an implementation of data being stored using Firebase, so having to compromise our initial goals and focus our efforts on what is achievable in this time period proved to be challenging.
## Accomplishments that we're proud of
This was our first mobile app we developed (as well as our first hackathon).
## What we learned
This being our first Hackathon, almost everything we did provided a learning experience. The skills needed to quickly plan and execute a project were put into practice and given opportunities to grow. Ways to improve efficiency and team efficacy can only be learned through experience in a fast-paced environment such as this one.
As mentioned before, with all of us using Flutter for the first time, anything we did involving it was something new.
## What's next for Spend2Save
There is still a long way for us to grow as developers, so the full implementation of Spend2Save will rely on our progress.
We believe there is potential for such an application to appeal to its target audience and so we have planned projections for the future of Spend2Save. These projections include but are not limited to, plans such as integration with actual bank accounts at RBC. | ## Inspiration
As fans of films and being part of the generation that grew up with much of its video entertainment deriving from the internet, we were always drawn to video as a medium for personal expression. That being said, the industry has been hit with copious amounts of criticisms lately.
While the public is currently aware of the mistreatment of entertainment employees with the actors' and writers' strikes, they are still vastly aware of the undercompensation, mistreatment, and overworking of the people behind the scene.
Though critics have been harsh on current CGI and editing choices, the truth is the crew behind the scenes is overloaded with vast amounts and work and are not given the proper amount of time to complete their projects. They are rushed and forced to push uncompleted work to make unrealistic quotas.
This is where ClipCut comes in. Clip cut efficiently automates the preprocessing of the film leaving the user with digestible clips anywhere to sections of the movies to significant scenes of the film. ClipCut allows users to take each segment one by one describing it with transcribable text gathered from the scenes themselves. Moreover, Clip also uses generative AI to assign each segment a tone metric to aid users with basic scene analysis.
## What it does
ClipCut brings the power to the editors of films from animation to feature films. The software automates the preprocessing of the film, so film crews can allocate more of their time to use their artful skills to craft a more beautiful film.
Our product does all of the busy work of the film maker such as background noise suppression and stabilization. It is also able to transcribe scenes of the film and use that transcribable data along with sentiment analysis to sense the tone of the scene for the editor to swiftly work in.
The program gathers these scenes and cuts and creates segments which can be contextualized and identified by the transcripted dialogue. As the program compartmentalized the piece the artist is able to gain further insight without wasting the time of manually browsing through a possible feature length film.
Overall, our product does the following…
1. Automated background noise suppression and stabilization
2. Automated scene detection and cutting
3. Generates individual clip transcriptions
4. Generates sentiment analysis on each individual clip transcription for clip mood summary
## How we built it
ClipCut was built using a ReactJS frontend. We used Python and FastAPI to build an API to serve requests from ClipCut’s frontend. Our Python API used OpenCV scene detection in the backend. This allowed us to have maximum flexibility while also retaining the strong feature-set that ClipCut has to offer.
Our system was built upon high-level machine learning libraries and services. We used many technologies such as ChatGPT, OpenAI Whisper, and OpenCV to construct the multiple functionalities within the app, such as full video transcription, scene detection and cutting, sentiment analysis, and background noise suppression/stabilization.
## Challenges we ran into
As we went about the project we had to pivot more times than we would’ve hoped. We know this first hand as ClipCut wasn’t even our first idea. We tried several different ideas before ClipCut, but each had their own difficulties - from available APIs to technical feasibility given the time constraints. After an hour or two, we settled on ClipCut.
However, it wasn’t all sunshine and roses once we started on ClipCut. Every idea is never perfect the first time around, and we are first hand witnesses. We tried to use IBM Watson’s Video Analysis API, but soon realized the API has been recently deprecated. We switched to Google Cloud Video Intelligence API suite for analysing, editing, and storage, but the results were not up to our standard. Though the product worked, we were expecting better segments and clearer transcriptions.
The great search then continued again as we scoured the internet to find new services and APIs. We ended up writing these ourselves. Using various libraries, we build the majority of our processing algorithm to run on our own Fast API server.
## Accomplishments that we're proud of
We are extremely proud that we made the project completely end-to-end for our user base. The project has high ease of use for our users, and is scalable for any length of video/type.
Another accomplishment was not only the end product but also the work getting there. Finding and testing new technologies is always long and tedious. However, once we were able to find those hard-to-find services and APIs, we were able to make significant progress. Finally getting a product that would work in tandem with our application was always a major accomplishment.
A more sentimental accomplishment was our ability to grow and know each other. Though we were all strangers that met barely a day ago, we were able to grow closer and also have fun in and outside the competition. It never felt like work or a menial task when working with each other, and we are very happy to say we are proud of our teamwork and friendship we have gained through this competition.
## What we learned
Throughout our time building our project, we learned a great deal. As all great program ideas, we strayed off plan. Though we wanted to use Google Cloud Video Intelligence API as a tool to handle most of our video recognition and editing, we soon realized it was just not possible. We did a lot of research and found various other APIs and services that suited our project better. Although we thought it would be more convenient to use a tightly packaged suite, we realized we were wrong, and we had to branch out for a better, more reliable product.
Additionally, even though we ended with a successful product, we actually took a really long time to come up with the idea. At first, we were on the sustainability track trying to use AI to make green spaces. Problems soon arose with the API we were working with, and it was clear it would be an insurmountable problem. To be completely honest, we were stuck for a while. However, we were determined to make a great project for the competition, and we realized we had to move on and have another idea to do so.
## What's next for ClipCut
As ClipCut evolves we want to help create a greater user experience. We were limited in time, and we were still able to push a full end-to-end product. That being said, we know we still have much to improve on. If the user has more ease to examine and choose their segments, it would lead to a much better product. Additionally, we hope to eventually create a more involved environment for creators to use our product to do some of the editing.
Creating a full editing software in addition to our efficient automation preprocessing would be the most ideal situation. Though we don’t know how far we will get, we would like to see the project grow more than just a preprocessing software. It would be amazing if we could expand to editing and post production in the future.
Software wise, we have many different systems working behind the scenes, and although we want to expand the project we still also want to improve our existing structure. One example of this is the sentiment analysis of our segments using dialogue. We tried to convey the tone of the scenes as best as possible, but of course, movies aren’t so cut and dry. We hope to create more specific metrics with the sentiment analysis over time to better suit our users. | winning |
## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It was originally built using a web scraper that scraped from LinkedIn which was written in python. The web visualizer was built using javascript and the VisJS library to have a dynamic view and aesthetically pleasing physics. In order to have a clean display, web components were used.
## Challenges we ran into
Gathering and scraping the data was a big obstacle, had to pattern match using LinkedIn's data
## Accomplishments that we're proud of
It works!!!
## What we learned
Learning to use various libraries and how to setup a website
## What's next for Yeevaluation
Finetuning and reimplementing dynamic node graph, history. Revamping project, considering it was only made in 24 hours. | ## Inspiration
In the exciting world of hackathons, where innovation meets determination, **participants like ourselves often ask "Has my idea been done before?"** While originality is the cornerstone of innovation, there's a broader horizon to explore - the evolution of an existing concept. Through our AI-driven platform, hackers can gain insights into the uniqueness of their ideas. By identifying gaps or exploring similar projects' functionalities, participants can aim to refine, iterate, or even revolutionize existing concepts, ensuring that their projects truly stand out.
For **judges, the evaluation process is daunting.** With a multitude of projects to review in a short time frame, ensuring an impartial and comprehensive assessment can become extremely challenging. The introduction of an AI tool doesn't aim to replace the human element but rather to enhance it. By swiftly and objectively analyzing projects based on certain quantifiable metrics, judges can allocate more time to delve into the intricacies, stories, and the passion driving each team
## What it does
This project is a smart tool designed for hackathons. The tool measures the similarity and originality of new ideas against similar projects if any exist, we use web scraping and OpenAI to gather data and draw conclusions.
**For hackers:**
* **Idea Validation:** Before diving deep into development, participants can ascertain the uniqueness of their concept, ensuring they're genuinely breaking new ground.
* **Inspiration:** By observing similar projects, hackers can draw inspiration, identifying ways to enhance or diversify their own innovations.
**For judges:**
* **Objective Assessment:** By inputting a project's Devpost URL, judges can swiftly gauge its novelty, benefiting from AI-generated metrics that benchmark it against historical data.
* **Informed Decisions:** With insights on a project's originality at their fingertips, judges can make more balanced and data-backed evaluations, appreciating true innovation.
## How we built it
**Frontend:** Developed using React JS, our interface is user-friendly, allowing for easy input of ideas or Devpost URLs.
**Web Scraper:** Upon input, our web scraper dives into the content, extracting essential information that aids in generating objective metrics.
**Keyword Extraction with ChatGPT:** OpenAI's ChatGPT is used to detect keywords from the Devpost project descriptions, which are used to capture project's essence.
**Project Similarity Search:** Using the extracted keywords, we query Devpost for similar projects. It provides us with a curated list based on project relevance.
**Comparison & Analysis:** Each incoming project is meticulously compared with the list of similar ones. This analysis is multi-faceted, examining the number of similar projects and the depth of their similarities.
**Result Compilation:** Post-analysis, we present users with an 'originality score' alongside explanations for the determined metrics, keeping transparency.
**Output Display:** All insights and metrics are neatly organized and presented on our frontend website for easy consumption.
## Challenges we ran into
**Metric Prioritization:** Given the timeline restricted nature of a hackathon, one of the first challenges was deciding which metrics to prioritize. Striking the balance between finding meaningful data points that were both thorough and feasible to attain were crucial.
**Algorithmic Efficiency:** We struggled with concerns over time complexity, especially with potential recursive scenarios. Optimizing our algorithms, prompt engineering, and simplifying architecture was the solution.
*Finding a good spot to sleep.*
## Accomplishments that we're proud of
We took immense pride in developing a solution directly tailored for an environment we're deeply immersed in. By crafting a tool for hackathons, while participating in one, we felt showcases our commitment to enhancing such events. Furthermore, not only did we conceptualize and execute the project, but we also established a robust framework and thoughtfully designed architecture from scratch.
Another general Accomplishment was our team's synergy. We made efforts to ensure alignment, and dedicated time to collectively invest in and champion the idea, ensuring everyone was on the same page and were equally excited and comfortable with the idea. This unified vision and collaboration were instrumental in bringing HackAnalyzer to life.
## What we learned
We delved into the intricacies of full-stack development, gathering hands-on experience with databases, backend and frontend development, as well as the integration of AI. Navigating through API calls and using web scraping were also some key takeaways. Prompt Engineering taught us to meticulously balance the trade-offs when leveraging AI, especially when juggling cost, time, and efficiency considerations.
## What's next for HackAnalyzer
We aim to amplify the metrics derived from the Devpost data while enhancing the search function's efficiency. Our secondary and long-term objective is to transition the application to a mobile platform. By enabling students to generate a QR code, judges can swiftly access HackAnalyzer data, ensuring a more streamlined and effective evaluation process. | ## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As businesses and organizations grapple with increasingly massive datasets, the need for efficient, accurate, and rapid data analysis became evident. We even saw this within one of our sponsor's work, CapitalOne, in which they have volumes of financial transaction data, which is very difficult to manually, or even programmatically parse.
We recognized the frustration many professionals faced when dealing with cumbersome manual data analysis processes. By combining **advanced machine learning algorithms** with **user-friendly design**, we aimed to empower users from various domains to effortlessly extract valuable insights from their data.
## What it does
On our website, a user can upload their data, generally in the form of a .csv file, which will then be sent to our backend processes. These backend processes utilize Docker and MLBot to train a LLM which performs the proper data analyses.
## How we built it
Front-end was very simple. We created the platform using Next.js and React.js and hosted on Vercel.
The back-end was created using Python, in which we employed use of technologies such as Docker and MLBot to perform data analyses as well as return charts, which were then processed on the front-end using ApexCharts.js.
## Challenges we ran into
* It was some of our first times working in live time with multiple people on the same project. This advanced our understand of how Git's features worked.
* There was difficulty getting the Docker server to be publicly available to our front-end, since we had our server locally hosted on the back-end.
* Even once it was publicly available, it was difficult to figure out how to actually connect it to the front-end.
## Accomplishments that we're proud of
* We were able to create a full-fledged, functional product within the allotted time we were given.
* We utilized our knowledge of how APIs worked to incorporate multiple of them into our project.
* We worked positively as a team even though we had not met each other before.
## What we learned
* Learning how to incorporate multiple APIs into one product with Next.
* Learned a new tech-stack
* Learned how to work simultaneously on the same product with multiple people.
## What's next for DataDaddy
### Short Term
* Add a more diverse applicability to different types of datasets and statistical analyses.
* Add more compatibility with SQL/NoSQL commands from Natural Language.
* Attend more hackathons :)
### Long Term
* Minimize the amount of work workers need to do for their data analyses, almost creating a pipeline from data to results.
* Have the product be able to interpret what type of data it has (e.g. financial, physical, etc.) to perform the most appropriate analyses. | winning |
## Inspiration
Are you a student? Have you experienced the struggle of trawling through rooms on campus to find a nice, quiet space to study? Well, worry no more because Study Space aims to create an intelligent solution to this decade old problem!
## What it does
Study Space is an app that keeps track of the number of people in specific locations on campus in real time. It lets the user of the app figure out which rooms in campus are the least busy thus allowing for easier access to quiet study spots.
## How we built it
To build this app we used Android Studio to create client facing android apps for users phones as well as an app to be displayed on AndroidThings screens. We also used the 'Android Nearby' feature that is a part of AndroidThings to sniff the number of wireless devices in an area, and Firebase to store the number of devices, thus determining the occupancy, within an area.
## Challenges we ran into
We ran into many issues with AndroidThings not connecting to the internet (after 8 hours we realized it was a simple configuration issue where the internet connection in the AndroidManifest.xml was set to 'no'). We also had trouble figuring out the best way to sniff out devices with WiFi connectivity in a certain area since there are privacy concerns associated with getting this kind of data. In the end, we decided that ideally this app would be incorporated within existing University affiliated apps (e.g. PennMobile App) where the user would need to accept a condition stating that the app will anonymously log the phone's location strictly for this purpose.
## What we learned
We learned that sometimes working with hardware can be a pain in the butt. However, in the end, we found this hack to be very rewarding as it allowed us to create an end product that is only able to function due to the capabilities of the hardware included in AndroidThings. We also learned how to make native android apps (it was the first time that 2 members of our group ever created an android app with native code).
## What's next for Study Space
In the future, we would like to incorporate trends into our app in order to show users charts about when study areas are at their maximum/minimum occupancy. This would allow users to better plan future study session accordingly. We would also like to include push notifications with the app so that users are informed, at a time of their choosing, of the least busy places to study on campus. | ## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app. | ## Inspiration
Research has shown us that new hires, women and under-represented minorities in the workplace could feel intimidated or uncomfortable in team meetings. Since the start of remote work, new hires lack the in real life connections, are unable to take a pulse of the group and are fearful to speak what’s on their mind. Majority of the time this is also due to more experienced individuals interrupting them or talking over them without giving them a chance to speak up. This feeling of being left out often makes people not contribute to their highest potential. Links to the reference studies and articles are at the bottom.
As new hire interns every summer, we personally experienced the communication and participation problem in team meetings and stand ups. We were new and felt intimidated to share our thoughts in fear of them being dismissed or ignored. Even though we were new hires and had little background, we still had some sound ideas and opinions to share that were instead bottled up inside us.
We found out that the situation is the same for women in general and especially under-represented minorities. We built this tool for ourselves and to those around us to feel comfortable and inclusive in team meetings. Companies and organizations must do their part in ensuring that their workplace is an inclusive community for all and that everyone has the opportunity to participate equally in their highest potential. With the pandemic and widespread adoption of virtual meetings, this is an important problem globally that we must all address and we believe Vocal aims to help solve it.
## What it does
Vocal empowers new hires, women, and under-represented minorities to be more involved and engaged in virtual meetings for a more inclusive team.
Google Chrome is extremely prevalent and our solution is a proof-of-concept Chrome Extension and Web Dashboard that works with Google Meet meetings. Later we would support others platforms such as Zoom, Webex, Skype, and others.
When the user joins the Google Meet meeting, our Extension automatically detects it and collects statistics regarding the participation of each team member. A percentage is shown next to their name to indicate their contribution and also a ranking is shown that indicates how often you spoke compared to others. When the meeting ends, all of this data is sent to the web app dashboard using Google Cloud and Firebase database. On the web app, the users can see their participation in the current meeting and progress from the past meetings with different metrics. Plants are how we gamify participation. Your personal plant grows, the more you contribute in meetings. Meetings are organized through sprints and contribution throughout the sprint will be reflected in the growth of the plant.
**Dashboard**: You can see your personal participation statistics. It show your plant, monthly interaction level graph, percent interaction with other team members (how often and which teammates you piggy back on when responding). Lastly, it also has Overall Statistics such as percent increase in interactions compared to last week, meeting participation streak, average engagement time, and total time spoken. You can see your growth in participation reflected in the plant growth. **Vocal provides lots of priceless data for the management, HR, and for the team overall to improve productivity and inclusivity.**
**Team**: Many times our teammates are stressed or go through other feelings but simply bottle it up. In the Team page, we provide Team Sentiment Graph and Team Sentiments. The graphs shows how everyone in the team has been feeling for the current sprint. Team members would check in anonymously at the end of the every week on how they’re feeling (Stressed, Anxious, Neutral, Calm, Joyful) and the whole team can see it. If someone’s feeling low, other teammates can reach out anonymously in the chat and offer them support and they both can choose to reveal their identity if they want. **Feeling that your team cares about you and your mental health can foster an inclusive community.**
**Sprints Garden**: This includes all of the previous sprints that you completed. It also shows the whole team’s garden so you can compare across teammates on how much you have been contributing relatively.
**Profile**: This is your personal profile where you will see your personal details, the plants you have grown in the past over all the sprints you have worked on - your forest, your anonymous conversations with your team members. Your garden is here to motivate you and help you grow more plants and ultimately contribute more to meetings.
**Ethics/Privacy: We found very interesting ways to collect speaking data without being intrusive. When the user is talking only the mic pulses are recorded and analyzed as a person spoken. No voice data or transcription is done to ensure that everyone can feel safe while using the extension.**
**Sustainability/Social Good**: Companies that use Vocal can partner to plant the trees grown during sprints in real life by partnering with organizations that plant real trees under the corporate social responsibility (CSR) initiative.
## How we built it
The System is made up of three independent modules.
Chrome Extension: This module works with Google meet and calculates the statistics of the people who joined the meet and stores the information of the amount of time an individual contributes and pushes those values to the database.
Firebase: It stores the stats available for each user and their meeting attended. Percentage contribution, their role, etc.
Web Dashboard: Contains the features listed above. It fetches data from firebase and then renders it to display 3 sections on the portal. a. Personal Garden - where an individual can see their overall performance, their stats and maintain a personal plant streak. b. Group Garden - where you can see the overall performance of the team, team sentiment, anonymous chat function. After each sprint cycle, individual plants are added to the nursery. c. Profile with personal meeting logs, ideas and thoughts taken in real-time calls.
## Challenges we ran into
We had challenges while connecting the database with the chrome extension. The Google Meet statistics was also difficult to do since we needed to find clever ways to collect the speaking statistics without infringing on privacy. Also, 36 hours was a very short time span for us to implement so many features, we faced a lot of time pressure but we learned to work well under pressure!
## Accomplishments that we're proud of
This was an important problem that we all deeply cared about since we saw people around us face this on a daily basis. We come from different backgrounds, but for this project we worked as one team and used our expertise, and learned what we weren’t familiar with in this project. We are so proud to have created a tool to make under-represented minorities, women and new hires feel more inclusive and involved.
We see this product as a tool we’d love to use when we start our professional journeys. Something that brings out the benefits of remote work, at the same time being tech that is humane and delightful to use.
## What's next for Vocal
Vocal is a B2B product that companies and organizations can purchase. The chrome extension to show meeting participation would be free for everyone. The dashboard and the analytics will be priced depending on the company. The number of insights and data that can be extracted from one data point(user participation) will be beneficial to the company (HR & Management) to make their workplace more inclusive and productive. The data can also be analyzed to promote inclusion initiatives and other events to support new hires, women, and under-represented minorities.
We already have so many use cases that were hard to build in the duration of the hackathon. Our next step would be to create a Mobile app, more Video Calling platform integrations including Zoom, Microsoft Teams, Devpost video call, and implement chat features. We also see this also helping in other industries like ed-tech, where teachers and students could benefit form active participation.
## References
1. <https://www.nytimes.com/2020/04/14/us/zoom-meetings-gender.html>
2. <https://www.nature.com/articles/nature.2014.16270>
3. <https://www.fastcompany.com/3030861/why-women-fail-to-speak-up-at-high-level-meetings-and-what-everyone-can-do-about>
4. <https://hbr.org/2014/06/women-find-your-voice>
5. <https://www.cnbc.com/2020/09/03/45percent-of-women-business-leaders-say-its-difficult-for-women-to-speak-up-in-virtual-meetings.html> | partial |
## Inspiration
Bipolar is a mental health condition that affects %1 of the population in Canada which amount to 3.7 million people. One in eight adults will show symptoms of a mood disorder. My father was diagnosed with bipolar disorder and refused medication on the basis that he didn't feel himself. A standard medication for bipolar is lithium which is known to have this effect. Because this is a problem that affects a large number of Canadians, we wanted to develop a non-medicated solution. Additionally, Engineering is known for having a high rate of depression and we wanted to give people a tool to assist in finding activities that can improve their mental health.
## What it does
Our application is a one time set up device that uses AI to collect a rolling average of your mood everyday to create a mood chart. A mood chart is a tool used now for helping people with bipolar determine when they are in a manic or depressive swing. It's can also be used to identify triggers and predict potential swings. By prompting people to log about what happened to them during an extreme mood, we can better identify triggers for mania and depression, develop methods against them, and predict upcoming swings. Our application includes a function to log activities for a day which can be later examined by a user, psychiatrist, or AI. We wanted to include a notification system that could ask you how things were going (like a good friend would) when you swung out of your neutral state to do this.
## How we built it
We built a device using the DragonBoard 401c and developed a node application (to run on the dragonboard linux or a laptop windows machine) that can take pictures of a user and determine their emotional state using the Azure Face API. We collect data periodically over the month (a few shots a day) to get a better representation of your mood for that day without the hassle of having to log it. If you are very depressed or manic, it can be hard to maintain a routine so it was essential that this device not require consistent attention from the user. The mood chart is managed by a node server running on Huroku. We then have an andriod app that allows you to access the chart and see your moods and logs on a calendar.
## Challenges we ran into
It was our first time setting up a dragonboard device and we initially didn't have a way to interface with it due to a mistake by the MLH. We lost an hour or two running around to find a keyboard, mouse, and camera. This was the largest UI project Gary Bowen has ever been in charge of and we ran into some issues with formatting the data we were transmitting.
## Accomplishments that we're proud of
June Ha is proud of setting up a public server for the first time. Gary is proud of the implementing a smiley faced dropbox and all his debugging work. I'm proud of setting up the capture software on the Dragonboard and my laptop. And I'm proud that we managed to capture data with a cheap webcam on a dragonboard, use the mircosoft api to get the emotion, send that data back to our server for processing, and delivering all that in a handy mood chart on your phone.
## What we learned
I learned a bit about working my way around a linux machine and the Dragonboard 401c. Gary learned a lot of good debugging tools for android development, and June learned he should not be awake for 24 hours.
## What's next for palpable
We'd like to properly implement the notification function on our app. Develop a more cost effective wireless camera device for processing emotion. We'd also love to implement additional AI for smart suggestions and to possibly diagnose people that have a mood disorder and may not know it.
## Resources
<https://www.canada.ca/en/public-health/services/chronic-diseases/mental-illness/what-should-know-about-bipolar-disorder-manic-depression.html>
<https://en.wikipedia.org/wiki/Population_of_Canada>
<https://www.canada.ca/en/public-health/services/chronic-diseases/mental-illness/what-depression.html> | ## Care Me
**Overworked nurses are linked with a 40 percent of risk of death in patients**
Our solution automates menial tasks like serving food and water, so medical professionals can focus on the important human-necessary interactions. It uses a robotic delivery system which acts autonomously based on voice recognition demand. One robot is added to each hospital wing with a microphone available for patient use.
Our product is efficient, increasing valuable life-saving time for medical professionals and patients alike, reducing wait-time for everyone. It prioritizes safety, really addressing the issue of burnout and dangerous levels of stress and tiredness that medical professionals face head on. Hospitals and medical facilities will see a huge boost in productivity because of the decreased stress and additional freed time.
Our product integrates multiple hardware components seamlessly through different methods of connectivity. A Raspberry Pi drives the Google Natural Language Processing Libraries to analyze the user’s request at a simple button press as a user. Using radio communications, the robot is quickly notified of the request and begins retrieving the item, delivering it to the user. | ## Inspiration
For this hackathon, we wanted to build something that could have a positive impact on its users. We've all been to university ourselves, and we understood the toll, stress took on our minds. Demand for mental health services among youth across universities has increased dramatically in recent years. A Ryerson study of 15 universities across Canada show that all but one university increased their budget for mental health services. The average increase has been 35 per cent. A major survey of over 25,000 Ontario university students done by the American college health association found that there was a 50% increase in anxiety, a 47% increase in depression, and an 86 percent increase in substance abuse since 2009.
This can be attributed to the increasingly competitive job market that doesn’t guarantee you a job if you have a degree, increasing student debt and housing costs, and a weakening Canadian middle class and economy. It can also be contributed to social media, where youth are becoming increasingly digitally connected to environments like instagram. People on instagram only share the best, the funniest, and most charming aspects of their lives, while leaving the boring beige stuff like the daily grind out of it. This indirectly perpetuates the false narrative that everything you experience in life should be easy, when in fact, life has its ups and downs.
## What it does
One good way of dealing with overwhelming emotion is to express yourself. Journaling is an often overlooked but very helpful tool because it can help you manage your anxiety by helping you prioritize your problems, fears, and concerns. It can also help you recognize those triggers and learn better ways to control them. This brings us to our application, which firstly lets users privately journal online. We implemented the IBM watson API to automatically analyze the journal entries. Users can receive automated tonal and personality data which can depict if they’re feeling depressed or anxious. It is also key to note that medical practitioners only have access to the results, and not the journal entries themselves. This is powerful because it takes away a common anxiety felt by patients, who are reluctant to take the first step in healing themselves because they may not feel comfortable sharing personal and intimate details up front.
MyndJournal allows users to log on to our site and express themselves freely, exactly like they were writing a journal. The difference being, every entry in a persons journal is sent to IBM Watson's natural language processing tone analyzing API's, which generates a data driven image of the persons mindset. The results of the API are then rendered into a chart to be displayed to medical practitioners. This way, all the users personal details/secrets remain completely confidential and can provide enough data to counsellors to allow them to take action if needed.
## How we built it
On back end, all user information is stored in a PostgreSQL users table. Additionally all journal entry information is stored in a results table. This aggregate data can later be used to detect trends in university lifecycles.
An EJS viewing template engine is used to render the front end.
After user authentication, a journal entry prompt when submitted is sent to the back end to be fed asynchronously into all IBM water language processing API's. The results from which are then stored in the results table, with associated with a user\_id, (one to many relationship).
Data is pulled from the database to be serialized and displayed intuitively on the front end.
All data is persisted.
## Challenges we ran into
Rendering the data into a chart that was both visually appealing and provided clear insights.
Storing all API results in the database and creating join tables to pull data out.
## Accomplishments that we're proud of
Building a entire web application within 24 hours. Data is persisted in the database!
## What we learned
IBM Watson API's
ChartJS
Difference between the full tech stack and how everything works together
## What's next for MyndJournal
A key feature we wanted to add for the web app for it to automatically book appointments with appropriate medical practitioners (like nutritionists or therapists) if the tonal and personality results returned negative. This would streamline the appointment making process and make it easier for people to have access and gain referrals. Another feature we would have liked to add was for universities to be able to access information into what courses or programs are causing the most problems for the most students so that policymakers, counsellors, and people in authoritative positions could make proper decisions and allocate resources accordingly.
Funding please | partial |
## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | ## Inspiration
We wanted to watch videos together as a social activity during the pandemic but were unable as many platforms were hard to use or unstable. Therefore our team decided to create a platform that met our needs in terms of usability and functionality.
## What it does
Bubbles allow people to create viewing rooms and invite their rooms to watch synchronized videos. Viewers no longer have to conduct countdowns on their play buttons or have a separate chat while watching!
## How I built it
Our web app uses React for the frontend and interfaces with our Node.js REST API in the backend. The core of our app uses the Solace PubSub+ and the MQTT protocol to coordinate events such as video play/pause, a new member joining your bubble, and instant text messaging. Users broadcast events with the topic being their bubble room code, so only other people in the same room receive these events.
## Challenges I ran into
* Collaborating in a remote environment: we were in a discord call for the whole weekend, using Miro for whiteboarding, etc.
* Our teammates came from various technical backgrounds, and we all had a chance to learn a lot about the technologies we used and how to build a web app
* The project was so much fun we forgot to sleep and hacking was more difficult the next day
## Accomplishments that I'm proud of
The majority of our team was inexperienced in the technologies used. Our team is very proud that our product was challenging and was completed by the end of the hackathon.
## What I learned
We learned how to build a web app ground up, beginning with the design in Figma to the final deployment to GitHub and Heroku. We learned about React component lifecycle, asynchronous operation, React routers with a NodeJS backend, and how to interface all of this with a Solace PubSub+ Event Broker. But also, we learned how to collaborate and be productive together while still having a blast
## What's next for Bubbles
We will develop additional features regarding Bubbles. This includes seek syncing, user join messages and custom privilege for individuals. | ## Inspiration
It's my strong belief that education is a right to everyone, this software aims to make it easier, and more enjoyable for people to get involved and truly learn from school. That's what drove me to build this software as a web application, because the web can be accessed by any device (even a fridge), so there are no restrictions on who can use this software. The UI is minimal, simple and easy to navigate allowing non-technical users to easily understand and use the software.
## What it does
StudenTeacher is a web application built to give students the ability to be involved in their learning, **even during a pandemic**. Using WebRTC technology, students are able to join small meeting groups to teach each other concepts that they learned in class. The application was designed and developed to be easy to use and accessible to all users regardless of technical knowledge or technology available to them. As long as the user has an internet connection, they can use this application to get involved in their learning.
## How we built it
Built using Express as the major backend framework, MySQL as the DB, React as the front-end framework, Semantic UI for style and Peer JS + Socket.io for the WebRTC meetings.
## Challenges we ran into
I don't have much experience with WebRTC so one of the biggest challenges I ran into was setting up rooms using Peer JS and socket.io. In the end, I managed to do this by creating my own room manager and emitting all of the necessary information for peers associated to the room (side note: socket.io has room functionality, however, it can be inconsistent so I opted to use a more consistent and controllable method)
## Accomplishments that we're proud of
This was a very large project (admittedly I underestimated the size of), that was completed in a fairly short amount of time, so I'm proud the project was able to be completed. I'm also proud of the integration of React router with express routes, because on a lot of occasions the two can result in conflicts.
## What we learned
I got a lot better at creating software using WebRTC and at designing applications with multiple layers like this one. I also got better at managing the different components, from a front-end and back-end perspective.
## What's next for StudenTeacher
The software's source code has been released, so I'm hoping others will be inspired and help further develop this project just as I plan to. My plans for this software in the future include adding a better meeting system, cleaner UI for both the homepage and the classroom page as well as a profile system to give users more customizability. In the long run, I'm planning on keeping StudenTeacher open source so that schools can maintain the privacy of their students by hosting their own StudenTeacher applications. | winning |
# F.A.C.E. (FACE Analytics with Comp-vision Engineering)
## Idea
Using computer vision to provide business analytics on customers in brick and mortar stores
## Features
* number of customers over time period
* general customer demographics, such as age, and gender
* ability to see quantity of returning customers
* dashboard to view all of this information
* support for multiple cameras
## Technology
* Python script recording its camera, doing vision analysis, and then sending stats to node.js back-end
* express.js web-app providing communication between python scripts, mongodb, and dashboard.
* dashboard is built using bootstrap and jQuery | ## Inspiration
We were heavily focused on the machine learning aspect and realized that we lacked any datasets which could be used to train a model. So we tried to figure out what kind of activity which might impact insurance rates that we could also collect data for right from the equipment which we had.
## What it does
Insurity takes a video feed from a person driving and evaluates it for risky behavior.
## How we built it
We used Node.js, Express, and Amazon's Rekognition API to evaluate facial expressions and personal behaviors.
## Challenges we ran into
This was our third idea. We had to abandon two major other ideas because the data did not seem to exist for the purposes of machine learning. | ## Inspiration
We live in a society where data is extremely important. Technology all around us is constantly collecting it and it's generally being used to improve all our lives. Data allows us to make objectively better decisions guided by information. One relatively new way to gather data is through eye-tracking. Eye-tracking has many possible applications, including determining what a user is focusing on. Based on our experience with web development, we understand how tedious it is to get data on how your user is using your website. For example, are they focusing on what we want them to? Or are they spending time getting distracted by other content on the page? Up until now there hasn't been a great way to get this info, but now there is.
EYEs.py is an innovative solution to collect data through tracking eye movements. Compared to alternative methods of data collection, this approach allows developers to get data on user behaviour by tracking how they do things, rather than just what they do. This new analysis method is referred to by industry as behavioural analytics and is growing rapidly. Specifically, EYEs.py takes where the user is looking and creates a heat map from it to determine what the major areas of focus are on the webpage.
## What It Does
The AdHawk MiniLink's eye tracking sensors track the position of the eye and send it through the tethered USB connection to the computer to AdHawk Backend. From here the data travels through the AdHawk Python SDK and into our Python code where we populate a matrix with values from the eyesight tracking. These values are then used for the heat map with the darker areas having a higher amount of time spent looking at them relative to the light areas. To only capture eye movements on the screen, the forward facing camera on the glasses tracks the 4 markers on the corners of the page. Utilizing this allows the glasses to determine when the screens is being looked at.
## How We Built It
We built this project utilizing the AdHawk suite of products:
* AdHawk Microsystems MindLink glasses
* Utilized the AdHawkAPI to enable data collection
* AdHawk Python Software Development Kit (SDK)
* Object-oriented Python code
## Challenges We Ran Into
* Initially, we struggled to collect and store the data from the glasses through the API provided by AdHawk
* We had many issues with working with QT (the GUI system) that was already being used by Adhawk regarding formatting
* We had issues connecting to CockroachDB and sending data over
## Accomplishments That We're Proud Of
Most of us our team is first-time hackers, and we felt proud to complete a MVP (Minimum Viable Product) of an idea that we were all interested in building. It was also super cool to work with the AdHawk MindLink glasses as this technology was truly cutting edge and a rare opportunity. More importantly, we are proud of what we were able to accomplish with a completely foreign technology in roughly 48 hours.
## What We Learned
This project taught us many valuable lessons including:
* Organization (keeping track of everyone's tasks and their status)
* Collaboration (how to effectively utilize Git to work together efficiently)
* Dedication (persevering through a lack of sleep)
Additionally, it helped us improve our coding skills too especially with technologies such as:
* Python3
* CockroachDB (PostGreSQL)
* Github
## What's Next for EYEs.py
One of our favourite aspects of this projects is its potential. There are many features that we believe could be added to improve the usability, versatility, and efficacy, like:
* Create a recording tool to display the order in which each part of the website was viewed (i.e. the user first viewed the top left part of the page)
* Implementing a web-based front end with an API communication layer with Python backend
* Adapting our heat maps to adjust with scrolling and changing routes in a website
* Creating a dashboard for managing different user recordings and grouping the data
* Rescaling to prevent the tracking markers from covering content
* Combine insights with Microsoft Clarity and Google Analytics to get even more data on website performance for a wider variety of scenarios
* Train an AI/machine learning model to suggest changes by noticing pain points in the UI | winning |
## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conversion isn't always the best. I tend to use unnecessary filler words ("um, umm" etc.) and repeat the same adjectives over and over again. In order to improve my speech through practice against a program, I decided to create this application.
## What it does
InterPrep uses the IBM Watson "Speech-To-Text" API to convert spoken word into text. After doing this, it analyzes the words that are used by the user and highlights certain words that can be avoided, and maybe even improved to create a stronger presentation of ideas. By practicing speaking with InterPrep, one can keep track of their mistakes and improve themselves in time for "speaking events" such as interviews, speeches and/or presentations.
## How I built it
In order to build InterPrep, I used the Stdlib platform to host the site and create the backend service. The IBM Watson API was used to convert spoken word into text. The mediaRecorder API was used to receive and parse spoken text into an audio file which later gets transcribed by the Watson API.
The languages and tools used to build InterPrep are HTML5, CSS3, JavaScript and Node.JS.
## Challenges I ran into
"Speech-To-Text" API's, like the one offered by IBM tend to remove words of profanity, and words that don't exist in the English language. Therefore the word "um" wasn't sensed by the API at first. However, for my application, I needed to sense frequently used filler words such as "um", so that the user can be notified and can improve their overall speech delivery. Therefore, in order to implement this word, I had to create a custom language library within the Watson API platform and then connect it via Node.js on top of the Stdlib platform. This proved to be a very challenging task as I faced many errors and had to seek help from mentors before I could figure it out. However, once fixed, the project went by smoothly.
## Accomplishments that I'm proud of
I am very proud of the entire application itself. Before coming to Qhacks, I only knew how to do Front-End Web Development. I didn't have any knowledge of back-end development or with using API's. Therefore, by creating an application that contains all of the things stated above, I am really proud of the project as a whole. In terms of smaller individual accomplishments, I am very proud of creating my own custom language library and also for using multiple API's in one application successfully.
## What I learned
I learned a lot of things during this hackathon. I learned back-end programming, how to use API's and also how to develop a coherent web application from scratch.
## What's next for InterPrep
I would like to add more features for InterPrep as well as improve the UI/UX in the coming weeks after returning back home. There is a lot that can be done with additional technologies such as Machine Learning and Artificial Intelligence that I wish to further incorporate into my project! | ## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | ## Inspiration
For many college students, finding time to socialize and make new friends is hard. Everyone's schedule seems perpetually busy, and arranging a dinner chat with someone you know can be a hard and unrewarding task. At the same time, however, having dinner alone is definitely not a rare thing. We've probably all had the experience of having social energy on a particular day, but it's too late to put anything on the calendar. Our SMS dinner matching project exactly aims to **address the missed socializing opportunities in impromptu same-day dinner arrangements**. Starting from a basic dining-hall dinner matching tool for Penn students only, we **envision an event-centered, multi-channel social platform** that would make organizing events among friend groups, hobby groups, and nearby strangers effortless and sustainable in the long term for its users.
## What it does
Our current MVP, built entirely within the timeframe of this hackathon, allows users to interact with our web server via **SMS text messages** and get **matched to other users for dinner** on the same day based on dining preferences and time availabilities.
### The user journey:
1. User texts anything to our SMS number
2. Server responds with a welcome message and lists out Penn's 5 dining halls for the user to choose from
3. The user texts a list of numbers corresponding to the dining halls the user wants to have dinner at
4. The server sends the user input parsing result to the user and then asks the user to choose between 7 time slots (every 30 minutes between 5:00 pm and 8:00 pm) to meet with their dinner buddy
5. The user texts a list of numbers corresponding to the available time slots
6. The server attempts to match the user with another user. If no match is currently found, the server sends a text to the user confirming that matching is ongoing. If a match is found, the server sends the matched dinner time and location, as well as the phone number of the matched user, to each of the two users matched
7. The user can either choose to confirm or decline the match
8. If the user confirms the match, the server sends the user a confirmation message; and if the other user hasn't confirmed, notifies the other user that their buddy has already confirmed the match
9. If both users in the match confirm, the server sends a final dinner arrangement confirmed message to both users
10. If a user decides to decline, a message will be sent to the other user that the server is working on making a different match
11. 30 minutes before the arranged time, the server sends each user a reminder
###Other notable backend features
12. The server conducts user input validation for each user text to the server; if the user input is invalid, it sends an error message to the user asking the user to enter again
13. The database maintains all requests and dinner matches made on that day; at 12:00 am each day, the server moves all requests and matches to a separate archive database
## How we built it
We used the Node.js framework and built an Express.js web server connected to a hosted MongoDB instance via Mongoose.
We used Twilio Node.js SDK to send and receive SMS text messages.
We used Cron for time-based tasks.
Our notable abstracted functionality modules include routes and the main web app to handle SMS webhook, a session manager that contains our main business logic, a send module that constructs text messages to send to users, time-based task modules, and MongoDB schema modules.
## Challenges we ran into
Writing and debugging async functions poses an additional challenge. Keeping track of potentially concurrent interaction with multiple users also required additional design work.
## Accomplishments that we're proud of
Our main design principle for this project is to keep the application **simple and accessible**. Compared with other common approaches that require users to download an app and register before they can start using the service, using our tool requires **minimal effort**. The user can easily start using our tool even on a busy day.
In terms of architecture, we built a **well-abstracted modern web application** that can be easily modified for new features and can become **highly scalable** without significant additional effort (by converting the current web server into the AWS Lambda framework).
## What we learned
1. How to use asynchronous functions to build a server - multi-client web application
2. How to use posts and webhooks to send and receive information
3. How to build a MongoDB-backed web application via Mongoose
4. How to use Cron to automate time-sensitive workflows
## What's next for SMS dinner matching
### Short-term feature expansion plan
1. Expand location options to all UCity restaurants by enabling users to search locations by name
2. Build a light-weight mobile app that operates in parallel with the SMS service as the basis to expand with more features
3. Implement friend group features to allow making dinner arrangements with friends
###Architecture optimization
4. Convert to AWS Lamdba serverless framework to ensure application scalability and reduce hosting cost
5. Use MongoDB indexes and additional data structures to optimize Cron workflow and reduce the number of times we need to run time-based queries
### Long-term vision
6. Expand to general event-making beyond just making dinner arrangements
7. Create explore (even list) functionality and event feed based on user profile
8. Expand to the general population beyond Penn students; event matching will be based on the users' preferences, location, and friend groups | winning |
## Inspiration 💡
The push behind EcoCart is the pressing call to weave sustainability into our everyday actions. I've envisioned a tool that makes it easy for people to opt for green choices when shopping.
## What it does 📑
EcoCart is your AI-guided Sustainable Shopping Assistant, designed to help shoppers minimize their carbon impact. It comes with a user-centric dashboard and a browser add-on for streamlined purchase monitoring.
By integrating EcoCart's browser add-on with favorite online shopping sites, users can easily oversee their carbon emissions. The AI functionality dives deep into the data, offering granular insights on the ecological implications of every transaction.
Our dashboard is crafted to help users see their sustainable journey and make educated choices. Engaging charts and a gamified approach nudge users towards greener options and aware buying behaviors.
EcoCart fosters an eco-friendly lifestyle, fusing AI, an accessible dashboard, and a purchase-monitoring add-on. Collectively, our choices can echo a positive note for the planet.
## How it's built 🏗️
EcoCart is carved out using avant-garde AI tools and a strong backend setup. While our AI digs into product specifics, the backend ensures smooth data workflow and user engagement. A pivotal feature is the inclusion of SGID to ward off bots and uphold genuine user interaction, delivering an uninterrupted user journey and trustworthy eco metrics.
## Challenges and hurdles along the way 🧱
* Regular hiccups with Chrome add-on's hot reloading during development
* Sparse online guides on meshing Supabase Google Auth with a Chrome add-on
* Encountered glitches when using Vite for bundling our Chrome extension
## Accomplishments that I'am proud of 🦚
* Striking user interface
* Working prototype
* Successful integration of Supabase in our Chrome add-on
* Advocacy for sustainability through #techforpublicgood
## What I've learned 🏫
* Integrating SGID into a NextJS CSR web platform
* Deploying Supabase in a Chrome add-on
* Crafting aesthetically appealing and practical charts via Chart.js
## What's next for EcoCart ⌛
* Expanding to more e-commerce giants like Carousell, Taobao, etc.
* Introducing a rewards mechanism linked with our gamified setup
* Launching a SaaS subscription model for our user base. | ## Inspiration
The inspiration for Green Cart is to support local farmers by connecting them directly to consumers for fresh and nutritious produce. The goal is to promote community support for farmers and encourage people to eat fresh and locally sourced food.
## What it does
GreenCart is a webapp that connects local farmers to consumers for fresh, nutritious produce, allowing consumers to buy directly from farmers in their community. The app provides a platform for consumers to browse and purchase produce from local farmers, and for farmers to promote and sell their products. Additionally, GreenCart aims to promote community support for farmers and encourage people to eat fresh and locally sourced food.
## How we built it
The GreenCart app was built using a combination of technologies including React, TypeScript, HTML, CSS, Redux and various APIs. React is a JavaScript library for building user interfaces, TypeScript is a typed superset of JavaScript that adds optional static types, HTML and CSS are used for creating the layout and styling of the app, Redux is a library that manages the state of the app, and the APIs allow the app to connect to different services and resources. The choice of these technologies allowed the team to create a robust and efficient app that can connect local farmers to consumers for fresh, nutritious produce while supporting the community.
## Challenges we ran into
The GreenCart webapp development team encountered a number of challenges during the design and development process. The initial setup of the project, which involved setting up the project structure using React, TypeScript, HTML, CSS, and Redux, and integrating various APIs, was a challenge. Additionally, utilizing Github effectively as a team to ensure proper collaboration and version control was difficult. Another significant challenge was designing the UI/UX of the app to make it visually appealing and user-friendly. The team also had trouble with the search function, making sure it could effectively filter and display results. Another major challenge was debugging and fixing issues with the checkout balance not working properly. Finally, time constraints were a challenge as the team had to balance the development of various features while meeting deadlines.
## Accomplishments that we're proud of
As this was the first time for most of the team members to use React, TypeScript, and other technologies, the development process presented some challenges. Despite this, the team was able to accomplish many things that they were proud of. Some examples of these accomplishments could include:
Successfully setting up the initial project structure and integrating the necessary technologies.
Implementing a user-friendly and visually appealing UI/UX design for the app.
Working collaboratively as a team and utilizing Github for version control and collaboration.
Successfully launching the web app and getting a positive feedback from users.
## What we learned
During this hackathon, the team learned a variety of things, including:
How to use React, TypeScript, HTML, CSS, and Redux to build a web application.
How to effectively collaborate as a team using Github for version control and issue tracking.
How to design and implement a user-friendly and visually appealing UI/UX.
How to troubleshoot and debug issues with the app, such as the blog page not working properly.
How to work under pressure and adapt to new technologies and challenges.
They also learn how to build a web app that can connect local farmers to consumers for fresh, nutritious produce while supporting the community.
Overall, the team gained valuable experience in web development, teamwork, and project management during this hackathon.
## What's next for Green Cart
Marketing and Promotion: Develop a comprehensive marketing and promotion strategy to attract customers and build brand awareness. This could include social media advertising, email campaigns, and influencer partnerships.
Improve User Experience: Continuously gather feedback from users and use it to improve the app's user experience. This could include adding new features, fixing bugs and optimizing the performance.
Expand the Product Offerings: Consider expanding the range of products offered on the app to attract a wider customer base. This could include organic and non-organic produce, meat, dairy and more.
Partnership with Local Organizations: Form partnerships with local organizations such as supermarkets, restaurants, and community groups to expand the reach of the app and increase the number of farmers and products available.
## Git Repo ;
<https://github.com/LaeekAhmed/Green-Cart/tree/master/Downloads/web_dev/Khana-master> | ## Inspiration
One of our team members was stunned by the number of colleagues who became self-described "shopaholics" during the pandemic. Understanding their wishes to return to normal spending habits, we thought of a helper extension to keep them on the right track.
## What it does
Stop impulse shopping at its core by incentivizing saving rather than spending with our Chrome extension, IDNI aka I Don't Need It! IDNI helps monitor your spending habits and gives recommendations on whether or not you should buy a product. It also suggests if there are local small business alternatives so you can help support your community!
## How we built it
React front-end, MongoDB, Express REST server
## Challenges we ran into
Most popular extensions have company deals that give them more access to product info; we researched and found the Rainforest API instead, which gives us the essential product info that we needed in our decision algorithm. However this proved, costly as each API call took upwards of 5 seconds to return a response. As such, we opted to process each product page manually to gather our metrics.
## Completion
In its current state IDNI is able to perform CRUD operations on our user information (allowing users to modify their spending limits and blacklisted items on the settings page) with our custom API, recognize Amazon product pages and pull the required information for our pop-up display, and dynamically provide recommendations based on these metrics.
## What we learned
Nobody on the team had any experience creating Chrome Extensions, so it was a lot of fun to learn how to do that. Along with creating our extensions UI using React.js this was a new experience for everyone. A few members of the team were also able to spend the weekend learning how to create an express.js API with a MongoDB database, all from scratch!
## What's next for IDNI - I Don't Need It!
We plan to look into banking integration, compatibility with a wider array of online stores, cleaner integration with small businesses, and a machine learning model to properly analyze each metric individually with one final pass of these various decision metrics to output our final verdict. Then finally, publish to the Chrome Web Store! | partial |
Check out our project at <http://gitcured.com/>
## Inspiration
* We chose the Treehacks Health challenge about creating a crowdsourced question platform for sparking conversations between patients and physicians in order to increase understanding of medical conditions.
* We really wanted to build a platform that did much more than just educate users with statistics and discussion boards. We also wanted to explore the idea that not many people understand how different medical conditions work conjunctively.
* Often, people don't realize that medical conditions don't happen one at a time. They can happen together, thus raising complications with prescribed medication that, when taken at the same time, can be dangerous together and may lead to unpredictable outcomes. These are issues that the medical community is well aware of but your average Joe might be oblivious to.
* Our platform encourages people to ask questions and discuss the effects of living with two or more common diseases, and take a closer look at the apex that form when these diseases begin to affect the effects of each other on one's body.
## What it does
* In essence, the platform wants patients to submit questions about their health, discuss these topics in a freestyle chat system while exploring statistics, cures and related diseases.
* By making each disease, symptom, and medication a tag rather than a category, the mixing of all topics is what fuels the full potential of this platform. Patients, and even physicians, who might explore the questions raised regarding the overlap between, for example Diabetes and HIV, contribute to the collective curiosity to find out what exactly happens when a patient is suffering both diseases at the same time, and the possible outcomes from the interactions between the drugs that treat both diseases.
* Each explored topic is searchable and the patient can delve quite deep into the many combinations of concepts. GitCured really is fueled by the questions that patients think of about their healthcare, and depend on their curiosity to learn and a strong community to discuss ideas in chat-style forums.
## How we built it
Languages used: Node.js, Sockets.IO, MongoDB, HTML/CSS, Javascript, ChartJS, Wolfram Alpha, Python, Bootstrap
## Challenges we ran into
* We had problems in implementing a multi-user real-time chat using sockets.io for every question that has been asked on our platform.
* Health data is incredibly hard to find. There are certain resources, such as data.gov and university research websites that are available, but there is no way to ensure quality data that can be easily parseable and usable for a health hack. Most data that we did find didn't help us much with the development of this app but it provided an insight to us to understand the magnitude of the health related problems.
* Another issue we faced was to differentiate ourselves from other services that meet part of the criteria of the prompt. Our focus was to critically think how each medical concept affects people, along with providing patients a platform to discuss their healthcare. The goal was to design a space that encourages creative and curious thinking, and ask questions that might never have been previously answered. We wanted to give patients a space to discuss and critically think about how each medical concept affects each other.
## Accomplishments that we're proud of
We were pretty surprised we got this far into the development of this app. While it isn't complete, as apps never are, we had a great experience of putting ideas together and building a health-focused web platform from scratch.
## What we learned
* There is a very big issue that there is no central and reliable source for health data. People may have clear statistics on finance or technology, but there is so much secrecy and inconsistencies that come with working with data in the medical field. This creates a big, and often invisible, problem where computer scientists find it harder and harder to analyze biomedical data compared to other types of data. If we hadn't committed to developing a patient platform, I think our team would have worked on designing a central bank of health data that can be easily implementable in new and important health software. Without good data, development of bio technology will always be slow when developers find themselves trapped or stuck. | ## Inspiration
Clicking cats are fun
## Controls
`right-click` to switch colors
`left-click` to shoot a cat
## Gameplay
You can only shoot down cats with the same color as your current color
## Future Improvements
* Add streaks, combos, multipliers
* Add loading screen, pause screen, game over screen
* Leaderboards
* Unlock new colors
* Background music
* Sound effects
* More polished UI
* Mobile support
* Build with Unity | ### 💡 Inspiration 💡
We call them heroes, **but the support we give them is equal to the one of a slave.**
Because of the COVID-19 pandemic, a lot of medics have to keep track of their patient's history, symptoms, and possible diseases. However, we've talked with a lot of medics, and almost all of them share the same problem when tracking the patients: **Their software is either clunky and bad for productivity, or too expensive to use on a bigger scale**. Most of the time, there is a lot of unnecessary management that needs to be done to get a patient on the record.
Moreover, the software can even get the clinician so tired they **have a risk of burnout, which makes their disease predictions even worse the more they work**, and with the average computer-assisted interview lasting more than 20 minutes and a medic having more than 30 patients on average a day, the risk is even worse. That's where we introduce **My MedicAid**. With our AI-assisted patient tracker, we reduce this time frame from 20 minutes to **only 5 minutes.** This platform is easy to use and focused on giving the medics the **ultimate productivity tool for patient tracking.**
### ❓ What it does ❓
My MedicAid gets rid of all of the unnecessary management that is unfortunately common in the medical software industry. With My MedicAid, medics can track their patients by different categories and even get help for their disease predictions **using an AI-assisted engine to guide them towards the urgency of the symptoms and the probable dangers that the patient is exposed to.** With all of the enhancements and our platform being easy to use, we give the user (medic) a 50-75% productivity enhancement compared to the older, expensive, and clunky patient tracking software.
### 🏗️ How we built it 🏗️
The patient's symptoms get tracked through an **AI-assisted symptom checker**, which uses [APIMedic](https://apimedic.com/i) to process all of the symptoms and quickly return the danger of them and any probable diseases to help the medic take a decision quickly without having to ask for the symptoms by themselves. This completely removes the process of having to ask the patient how they feel and speeds up the process for the medic to predict what disease their patient might have since they already have some possible diseases that were returned by the API. We used Tailwind CSS and Next JS for the Frontend, MongoDB for the patient tracking database, and Express JS for the Backend.
### 🚧 Challenges we ran into 🚧
We had never used APIMedic before, so going through their documentation and getting to implement it was one of the biggest challenges. However, we're happy that we now have experience with more 3rd party APIs, and this API is of great use, especially with this project. Integrating the backend and frontend was another one of the challenges.
### ✅ Accomplishments that we're proud of ✅
The accomplishment that we're the proudest of would probably be the fact that we got the management system and the 3rd party API working correctly. This opens the door to work further on this project in the future and get to fully deploy it to tackle its main objective, especially since this is of great importance in the pandemic, where a lot of patient management needs to be done.
### 🙋♂️ What we learned 🙋♂️
We learned a lot about CRUD APIs and the usage of 3rd party APIs in personal projects. We also learned a lot about the field of medical software by talking to medics in the field who have way more experience than us. However, we hope that this tool helps them in their productivity and to remove their burnout, which is something critical, especially in this pandemic.
### 💭 What's next for My MedicAid 💭
We plan on implementing an NLP-based service to make it easier for the medics to just type what the patient is feeling like a text prompt, and detect the possible diseases **just from that prompt.** We also plan on implementing a private 1-on-1 chat between the patient and the medic to resolve any complaints that the patient might have, and for the medic to use if they need more info from the patient. | partial |
## Inspiration
We wanted to create something like HackerTyper where you can fake being a hacker. Instead, we created *Harmony Hacker*, such that you can fake being a professional piano player with confidence.
## What it does
The piano keyboard in our project plays the notes of the MIDI song you select through its speaker, but the twist is that no matter which key you press; the pressed key will only trigger the **correct** note from the song. A touchscreen HDMI LCD that includes a switch function which changes from "hacker" mode to "normal piano" mode; a "song list" with a list of triggers that we input in; a reset function that replays the song; a "quit" function to stop the code; and a "slowness" bar to change to song speed. An ultrasonic sensor has been integrated with the song-playing system which changes the song volume depending on the distance of the player's body to the keyboard.
## How we built it
Our project consisted of:
* MIDI keyboard
* Raspberry Pi 4
* 7" touchscreen HDMI LCD by SunFounder
* Breadboard
* Jumper wires
* Resistors
* Ultrasonic sensor
* 5V 3A Power Supply
Initially, we block the local input from the keyboard by changing the local MIDI signal to off. Next, we detect the midi signals through the raspberry pi. By reading a MIDI song, we interject the user input and play the actual song (if hacker mode is turned on) by passing our output on the MIDI input of the piano. The ultrasonic sensor is used to change the volume of the piano: the closer you are, the louder it becomes.
## Challenges we ran into
Some major challenges we ran into were:
* deciding on a project idea
* gathering all the hardware components that we wanted
* handling stray notes and combined key presses using "chunking"
* make the ultrasonic sensor measurements accurate
## Accomplishments that we're proud of
* learned how to interface with a MIDI keyboard with Python over USB
* a minimum viable project built well under the deadline
* distance-based volume addon.
## What we learned
The technologies our team learned were tkinder and the mido Python library (for MIDI parsing). Furthermore, we learned to interface with the ultrasonic sensor through the raspberry pi and receive its input signals in the code.
## What's next for Harmony Hacker
We would like to add an addressable RGB LED light strip to show the user which note on the keyboard will be played next. It would also be great if we added a frequency sensor to change the colour of some RGB LED lights in a strip and their speed. | ## Inspiration
The best hacks are unexpected combinations of technology that are just plain fun, so we got our inspiration from that vibe. The original idea: A VR app. Then someone on the team suggested adding a piano keyboard and the rest followed from there.
## What it does
In the VR scene, a digital piano is mapped on top of the physical one (tracked via Quest controller). You can then play the instrument physically and see it animate in the digital world, with the world changing based on what's being played. Try different melodies and combinations of notes to see what happens!
## How we built it
Much love and pain. Mapping the digital piano on top of the physical one took a lot of careful measurement and alignment in order to create a piano based on the position of the Oculus Touch controller. Hands are tracked using the Quest's built-in hand tracking. A proprietary heuristic music analysis algorithm (if statements) decides how to change the scene based on what's played.
## Challenges we ran into
Hardware hacks are notorious for "integration hell," where getting everything to work together fluidly is very difficult and painful when it really doesn't seem like it should be. Getting the digital world to cooperate with the physical world isn't any different and honestly the fact that the digital piano even exists is incredibly impressive.
## Accomplishments that we're proud of
Created a beautiful app that combines the Metaverse with the... Realityverse? Lifeverse? Oh, it's just called the Universe? Anyways combining those was an impressive technical feat that we pulled off with 0 budget unlike those hacks at Valve with their fancy VR greenscreen cameras and controller finger tracking and...
## What we learned
The most recent Unity or C# experience any of us has was back in 2016. We now kinda know how to use Unity. Maybe.
## What's next for Mindful Melody VR
We were going to use ML to do sentiment analysis on the music but decided on a heuristic solution instead to simplify the scope. It would be cool to revisit the idea with more time. | ## Bringing your music to life, not just to your ears but to your eyes 🎶
## Inspiration 🍐
Composing music through scribbling notes or drag-and-dropping from MuseScore couldn't be more tedious. As pianists ourselves, we know the struggle of trying to bring our impromptu improvisation sessions to life without forgetting what we just played or having to record ourselves and write out the notes one by one.
## What it does 🎹
Introducing PearPiano, a cute little pear that helps you pair the notes to your thoughts. As a musician's best friend, Pear guides pianists through an augmented simulation of a piano where played notes are directly translated into a recording and stored for future use. Pear can read both single notes and chords played on the virtual piano, allowing playback of your music with cascading tiles for full immersion. Seek musical guidance from Pear by asking, "What is the key signature of C-major?" or "Tell me the notes of the E-major diminished 7th chord." To fine tune your compositions, use "Edit mode," where musicians can rewind the clip and drag-and-drop notes for instant changes.
## How we built it 🔧
Using Unity Game Engine and the Oculus Quest, musicians can airplay their music on an augmented piano for real-time music composition. We used OpenAI's Whisper for voice dictation and C# for all game-development scripts. The AR environment is entirely designed and generated using the Unity UI Toolkit, allowing our engineers to realize an immersive yet functional musical corner.
## Challenges we ran into 🏁
* Calibrating and configuring hand tracking on the Oculus Quest
* Reducing positional offset when making contact with the virtual piano keys
* Building the piano in Unity: setting the pitch of the notes and being able to play multiple at once
## Accomplishments that we're proud of 🌟
* Bringing a scaled **AR piano** to life with close-to-perfect functionalities
* Working with OpenAI to synthesize text from speech to provide guidance for users
* Designing an interactive and aesthetic UI/UX with cascading tiles upon recording playback
## What we learned 📖
* Designing and implementing our character/piano/interface in 3D
* Emily had 5 cups of coffee in half a day and is somehow alive
## What's next for PearPiano 📈
* VR overlay feature to attach the augmented piano to a real one, enriching each practice or composition session
* A rhythm checker to support an aspiring pianist to stay on-beat and in-tune
* A smart chord suggester to streamline harmonization and enhance the composition process
* Depth detection for each note-press to provide feedback on the pianist's musical dynamics
* With the up-coming release of Apple Vision Pro and Meta Quest 3, full colour AR pass-through will be more accessible than ever — Pear piano will "pair" great with all those headsets! | losing |
## Inspiration
Our project was inspired by the everyday challenges patients face, from remembering to take their medication to feeling isolated in their health journey. We saw the need for a solution that could do more than just manage symptoms—it needed to support patients emotionally, help prevent medication mistakes, and foster a sense of community. By using AI and creating a space where patients can connect with others in similar situations, we aim to improve not only their health outcomes but also their overall well-being.
## What it does
Our project helps patients stay on track with their medication by using Apollo, our assistant that reminds them and tracks how they're feeling. It keeps a journal of their mood, sentiment, and actions, which can be shared with healthcare providers for better diagnosis and treatment. Users can also connect with others going through similar challenges, forming a supportive community. Beyond that, the platform helps prevent errors with prescriptions and medication, answers questions about their meds, and encourages patients to take an active role in their care—leading to more accurate diagnoses and reducing their financial burden.
## How we built it
We built multiple components so that everyone could benefit from our voice assistant system. Our voice assistant, Apollo, reads the user's transcript using OCR and then stores it in a DB for future retrieval. The voice assistant then understands the user and talks to them so that it can obtain information while consoling them. We achieved this by building a sophisticated pipeline involving an STT, text processing, and TTS layer.
After the conversation is done, notes are made from the transcript and summarized using our LLM agents, which are then again stored in the database. Artemis helps the user connect with other individuals who have gone through similar problems by using a sophisticated RAG pipeline utilizing LangChain.
Our Emergency Pipeline understands the user's problem by using a voice channel powered by React Native, evaluates the issue, and answers it by using another RAG-centric approach. Finally, for each interaction, a sentiment analysis is done using the RoBERTa Large Model, maintaining records of the patient's behavior, activities, mood, etc., in an encrypted manner for future reference by both the user and their associated practitioners.
To make our system accessible to users, we developed both a React web application and a React Native mobile app . The web app provides a comprehensive interface for users to interact with our voice assistant system from their desktop browsers, offering full functionality and easy access to conversation history, summaries, and connections made through Artemis.
The React Native mobile app for Emergencies brings the power of our voice assistant to users' smartphones, allowing them to seek help easily in case of an emergency
## Challenges we ran into
One of the key challenges we faced was ensuring the usability of the system. We wanted to create an intuitive experience that would be easy for users to navigate, especially during moments of mental distress. Designing a UI that is both simple and effective was difficult, as we had to strike the right balance between offering powerful features and avoiding overwhelming the user with too much information or complexity.
## Accomplishments that we're proud of
One of the biggest accomplishments we’re proud of is how accessible and user-friendly our project is. We’ve built an AI-powered platform that makes managing health easier for everyone, including those who may not have easy access to healthcare. By integrating features like medication reminders, mood and sentiment tracking, and a supportive community, we’ve created a tool that’s inclusive and intuitive. Our platform bridges the gap for those who may struggle with traditional healthcare systems, offering real-time answers to medication questions and preventing errors, all while fostering patient engagement. This combination of accessibility and smart features empowers users to take control of their health in a meaningful way, ensuring patient safety.
## What we learned
Throughout this project, we gained valuable experience working with new APIs that we had never used before, which expanded our technical skills and allowed us to implement features more effectively. We also learned how to better manage project progress by setting clear goals, collaborating efficiently, and adapting to challenges as they arose. This taught us the importance of flexibility and communication within the team, helping us stay on track and deliver a functional product within the tight timeframe of the hackathon.
## What's next for SafeSpace
In the future, we plan to enhance the platform with a strong focus on patient safety by integrating a feature that checks drug interactions when a prescription is provided by a doctor, ensuring the well-being of patients and preventing harmful combinations. Additionally, we aim to implement anti-hallucination measures to prevent false diagnoses, and safeguarding the accuracy of the assistant’s recommendations and promoting patient safety. To further protect users, we will incorporate robust encryption techniques to securely manage and store sensitive data, ensuring the highest level of privacy and security for patient information. | ## Inspiration
About 4 months ago, I and Shubham came to know that one of our closest friends has been diagnosed with clinical depression. Having spent the majority of our time together, it never really struck us that the guy we loved hanging around with needed some emotional support throughout this time. That's when we set out to learn about self-care habits, mental wellbeing techniques, and the sheer importance of mental health in our lives.
4 months later, our friend is back to being the happy soul he was - but a lot of people can't recover that quickly (or recover at all).
Hence, our team aspired to develop a platform wherein anybody - irrespective of their socio-economic background, could use our platform and take their first steps for their pursuit towards a healthier mind!
## What it does
Aiden is an AI-based IVR trained to handle depressive episodes, help with anxiety or just simply talk to you using Solution-Focused Brief Therapy (SFBT) methods and other evidence-based techniques. The end-users just have to make a phone call and Aiden picks up the call to assist them. This type of infrastructure requires no internet connection or "smart" devices - just a simple device that can make calls. Thus, making mental health therapy accessible to more people!
Our team firmly believes in the idea, "You can't control something if you can't measure it."
Thus, Aiden comes packed with a powerful web dashboard that displays meaningful analytics and charts that can be used to track the progress of the end-users so they can strive for improvement.
The IVR system grants Aiden an advantage that existing products in the market do not possess - voice audio feedback of end-users. This audio feedback, coupled with the transcript of the user's conversation with Aiden is passed into a Speech Emotion Recognition (SER) model which then determines the emotion of the conversation. Audio-based data is of high importance as text-based emotion recognition can sometimes be misleading but the voice of the end-user can tell us a whole different story!
Furthermore, Aiden has an integration with the Facebook messenger that allows it to cater to the younger generations or anyone who prefers to text over calls.
## Key Benefits:
1. Highly scalable with no hardware dependencies and easy to deploy software. Our app can reach people who aren't well-versed with technology.
2. It can be immediately deployed and can handle multiple calls simultaneously.
3. Aiden can open doors for mental health and wellbeing in areas that do not have a proper mental healthcare infrastructure, especially in rural areas.
4. Act as a front-line tool at mental health helpline call centers so they can service more clients at a time.
5. The analyzed performance of the user can be seen on the web dashboard.
6. Accessible through the Facebook messenger app for user's convenience.
7. Uses audio and text transcripts to determine the behavioral and emotional state of the end-users.
8. Therapists can benefit from the analytics displayed in the web dashboard and can use that knowledge to direct their therapy practices. (therapists shall gain access to a user's dashboard only with their consent)
## ML Model Development Pipeline
### Speech Emotion Recognition (SER)
The SER model is used to detect the emotions based on the conversation of a user with Aiden.
##### Datasets:
1. [RAVDEES](https://zenodo.org/record/1188976): This dataset includes around 1500 audio file input
from 24 different actors. 12 male and 12 female where these actors record short audios in 8 different
emotions i.e 1 = neutral, 2 = calm, 3 = happy, 4 = sad, 5 = angry, 6 = fearful, 7 = disgust, 8 = surprised.
The RADVESS' file naming format is ‘modality-vocalChannel-emotionemotionalIntensity-statement-
repetition-actor.wav’.
2. [TESS](https://tspace.library.utoronto.ca/handle/1807/24487): 2800 files from TESS. A set of 200
target words were spoken in the carrier phrase "Say the word \_\_\_\_\_' by two actresses (aged 26 and
64 years) and recordings were made of the set portraying each of seven emotions (anger, disgust,
fear, happiness, pleasant surprise, sadness, and neutral).
##### Audio files:
Tested out the audio files by plotting out the waveform and a spectrogram to see the sample audio files.
##### Feature Extraction:
The next step involves extracting the features from the audio files which will help our model learn between these audio files. For feature extraction, we make use of the LibROSA library in python which is one of the libraries used for audio analysis.
##### Building the model:
Since the project is a classification problem, Convolution Neural Network seems the obvious choice. We also built Multilayer perceptrons and Long Short Term Memory models but they under-performed with very low accuracies which couldn't pass the test while predicting the right emotions.
Building and tuning a model is a very time-consuming process. The idea is to always start small without adding too many layers just for the sake of making it complex. After testing out with layers, the model which gave the max validation accuracy against test data was little more than 86%.
## Platform Architecture
1. IBM Watson Assistant to build the virtual assistant
2. Twilio for secure SIP Trunking
3. HTML/CSS, Bootstrap Studio, Javascript
4. WebHooks integration
5. Google Cloud Platform (GCP) for deploying the SER model
6. Google Firebase Realtime DB
7. Used Argon open-source template for dashboard (thanks @CreativeTim)
## Challenges we ran into
1. Both of us were relatively new to GCP so a huge chunk of our time was involved in learning how to deploy the SER model on GCP.
2. Pre-processing phase was difficult since we had to convert Stereo-type audio to Mono-type.
3. This was also my first time implementing an IVR using IBM Watson Assistant. The phone integration part proved to be a monumental task.
## Accomplishments That We're Proud Of
We managed to deliver what we had set out to do - to develop an easily accessible, and an effective platform to supplement the current mental healthcare infrastructure and allow more people to get involved in it. We also managed to build an SER model with an accuracy score of 86.61%.
## What We Learned
1. Through this project, we learned to deploy a complicated deep learning model on the GCP platform.
2. We also got a much better idea as to what it takes to develop a deep learning project - from finding datasets to training the model.
3. Learnt a lot about pre-processing, especially about handling audio files.
## What's next for Aiden
1. Our first priority is to work on the security aspects of this platform. We realise the sensitive data that this platform will hold. Thus, we're planning to look into Private AI by OpenMined as well as other security measures that we can take.
2. Support for multiple languages. | ## Inspiration
Given the increase in mental health awareness, we wanted to focus on therapy treatment tools in order to enhance the effectiveness of therapy. Therapists rely on hand-written notes and personal memory to progress emotionally with their clients, and there is no assistive digital tool for therapists to keep track of clients’ sentiment throughout a session. Therefore, we want to equip therapists with the ability to better analyze raw data, and track patient progress over time.
## Our Team
* Vanessa Seto, Systems Design Engineering at the University of Waterloo
* Daniel Wang, CS at the University of Toronto
* Quinnan Gill, Computer Engineering at the University of Pittsburgh
* Sanchit Batra, CS at the University of Buffalo
## What it does
Inkblot is a digital tool to give therapists a second opinion, by performing sentimental analysis on a patient throughout a therapy session. It keeps track of client progress as they attend more therapy sessions, and gives therapists useful data points that aren't usually captured in typical hand-written notes.
Some key features include the ability to scrub across the entire therapy session, allowing the therapist to read the transcript, and look at specific key words associated with certain emotions. Another key feature is the progress tab, that displays past therapy sessions with easy to interpret sentiment data visualizations, to allow therapists to see the overall ups and downs in a patient's visits.
## How we built it
We built the front end using Angular and hosted the web page locally. Given a complex data set, we wanted to present our application in a simple and user-friendly manner. We created a styling and branding template for the application and designed the UI from scratch.
For the back-end we hosted a REST API built using Flask on GCP in order to easily access API's offered by GCP.
Most notably, we took advantage of Google Vision API to perform sentiment analysis and used their speech to text API to transcribe a patient's therapy session.
## Challenges we ran into
* Integrated a chart library in Angular that met our project’s complex data needs
* Working with raw data
* Audio processing and conversions for session video clips
## Accomplishments that we're proud of
* Using GCP in its full effectiveness for our use case, including technologies like Google Cloud Storage, Google Compute VM, Google Cloud Firewall / LoadBalancer, as well as both Vision API and Speech-To-Text
* Implementing the entire front-end from scratch in Angular, with the integration of real-time data
* Great UI Design :)
## What's next for Inkblot
* Database integration: Keeping user data, keeping historical data, user profiles (login)
* Twilio Integration
* HIPAA Compliancy
* Investigate blockchain technology with the help of BlockStack
* Testing the product with professional therapists | losing |
## 💡 Inspiration
Echo was inspired by the traditional methods of storing contacts and memories: the rolodex and the photo album. The UI draws on some of these nostalgic details, like the polaroid-like image cards and the rotating contact card wheel.
## 🕸️ What it does
Take a stroll down memory lane with Echo, your digital Rolodex of nostalgia. Echo transforms your memories into a connected network, sorting "echoes" by the people in them. Share your cherished moments and watch your personal Rolodex of memories unfold in harmony with others.
## 🧰 How we built it
Front-end: The front-end was built with **React.js** and **Chakra UI**. The interactive 3D network of connections was developed and visualized with **Three.js**. The **IPFS** protocol was used to handle image uploads. **Auth0** handled user authentication and management.
Back-end: An **Express.js** server was used to stage API endpoints. Echo and user entities were created and stored in **AWS DynamoDB** tables, echo and user images were stored in **AWS S3** buckets as buffers and encoded/decoded with base64, and **AWS Rekognition** was used for facial comparison, indexing, and searching. **IPFS**, **Cairo**, and **Starknet** were used to generate, store, and share NFTs of echoes.
UX: Prototypes were designed and prototyped on **Figma** to create UI elements including buttons and pop-up overlays. **Spline** was used to prototype the 3D network, and then exported to Figma.
## 🧱 Challenges we ran into
* IMAGE FORMATS, TRANSFER, AND STORAGE
* DynamoDB is different from other NoSQL databases we've used in the past
* AWS Documentation is difficult to navigate and deeply nested
* AWS Rekognition has many limiting factors despite its powerful features
* Despite being very powerful, Three.js has a steep learning curve
## 🏆 Accomplishments that we're proud of
* Connecting a complex web of AWS services
* Publishing many composite API endpoints to enable full functionality of the app
* Designing and executing a unique visual way of exploring memories and connections with people
## 💭 What we learned
* **Jane:** I learned to use Spline to create a 3D rendering of the network UI.
* **Jason:** I learned Three.js using the React Three library to create interactive 3D visuals in the browser, involving 3D trigonometry and geometry. I also learned about graph theory, network theory, and Bezier curves.
* **Satyam:** I learned how to create smart contracts on Starknet using Cairo, learned about the different ERC types and their use cases, deployed my first ERC721 (NFT) smart contract, and learned how to use IPFS to upload images and get its link that we are passing for minting NFTs.
* **Victoria:** Using AWS Rekognition for facial comparison, integrating AWS S3 buckets and DynamoDB tables, how to deal with a mess of image formats, and implementing Auth0 for authentication in a React app.
## 〰️ What's next for Echo
* Connecting echoes by location and other metadata
* Adding more social features, like automatically sharing memories with friends
* Creating a more robust echo and user entity management system | ## Inspiration
As many of us grow older, we have more and more memories we all want to cherish and relive again. Sometimes, its that random photo from the past your phone brings up tha fills you up with nostalgia from the past. Why not find an immersive way to relive that experience all over again using today's tech.
This is what our project ReLive set out to do allowing you to relive the experience of those nostalgic past photos in the form of a digital photo album of 360° immersive experiences through VR and Google cardboard mimicking a View-master like experience.
## What it does
ReLive allows one to upload your precious nostalgic photos on to our web application. Our web application then takes those photos transforms those photos into a viewable 360 immersive VR viewer. Like a photo album, users can flip through pictures. However, unlike a photo album, users can their phone with the ReLive web app in Google Cardboard for an immersive nostalgic VR experience and ReLive those memories again today. In addition, like the classic View-Master, one can press the action button on the Cardboard viewer to flip through each photos and ReLive them one at a time.
Think photo album and viewmaster of the past meets the power of virtual reality and smartphones of today.
## How we built it
Used barebones HTML, CSS and Javascript to build the website. Used Firebase to store user inputted images and the songs we are to play for each image. We then fetched these images and used a JS library (panolense.js) to convert the images into a panorama in order to give the 3d visual effect. We then made this compatible with Google Cartboard so that the user can view and relive the memeory/ image in VR right infront of them.
## Challenges we ran into
The main challenge we faced was integrating everythig together. We were calling OpenAI's API for image captioning for sentiment analysis and passing that into Choere's API to give a song suggestion. We also had to get the image from the user and fetch it again. All this was being done in different envirnments and languages (API's in Jupyter Notebook) and the web app's backend in JS, so it was extremely challenging to put everything together (consideirng that we still are beginners!).
## Accomplishments that we're proud of
Getting the project up and running, especially the full VR immersive expereince, as this was our first time dealing with this type of stuff, especially doing it on a website.
## What we learned
We learned a lot of skills, like how to use Firebase, its access issues, backend development, VR, and API's.
## What's next for ReLive
Changing the environment from a panorama to an actual 3d rendered model of the image for VR using Unity so that the expereince is more immerisive. | ## Inspiration
2 days before flying to Hack the North, Darryl forgot his keys and spent the better part of an afternoon retracing his steps to find it- But what if there was a personal assistant that remembered everything for you? Memories should be made easier with the technologies we have today.
## What it does
A camera records you as you go about your day to day life, storing "comic book strip" panels containing images and context of what you're doing as you go about your life. When you want to remember something you can ask out loud, and it'll use Open AI's API to search through its "memories" to bring up the location, time, and your action when you lost it. This can help with knowing where you placed your keys, if you locked your door/garage, and other day to day life.
## How we built it
The React-based UI interface records using your webcam, screenshotting every second, and stopping at the 9 second mark before creating a 3x3 comic image. This was done because having static images would not give enough context for certain scenarios, and we wanted to reduce the rate of API requests per image. After generating this image, it sends this to OpenAI's turbo vision model, which then gives contextualized info about the image. This info is then posted sent to our Express.JS service hosted on Vercel, which in turn parses this data and sends it to Cloud Firestore (stored in a Firebase database). To re-access this data, the browser's built in speech recognition is utilized by us along with the SpeechSynthesis API in order to communicate back and forth with the user. The user speaks, the dialogue is converted into text and processed by Open AI, which then classifies it as either a search for an action, or an object find. It then searches through the database and speaks out loud, giving information with a naturalized response.
## Challenges we ran into
We originally planned on using a VR headset, webcam, NEST camera, or anything external with a camera, which we could attach to our bodies somehow. Unfortunately the hardware lottery didn't go our way; to combat this, we decided to make use of MacOS's continuity feature, using our iPhone camera connected to our macbook as our primary input.
## Accomplishments that we're proud of
As a two person team, we're proud of how well we were able to work together and silo our tasks so they didn't interfere with each other. Also, this was Michelle's first time working with Express.JS and Firebase, so we're proud of how fast we were able to learn!
## What we learned
We learned about OpenAI's turbo vision API capabilities, how to work together as a team, how to sleep effectively on a couch and with very little sleep.
## What's next for ReCall: Memories done for you!
We originally had a vision for people with amnesia and memory loss problems, where there would be a catalogue for the people that they've met in the past to help them as they recover. We didn't have too much context on these health problems however, and limited scope, so in the future we would like to implement a face recognition feature to help people remember their friends and family. | losing |
# Ascriber
Crawl your website for uncredited images and get warned about them.
Asciber will help you find unattributed images, their original attribution, and alternative, similar creative-commons licensed photos if necessary.
## APIs & Tech Used
* Google App Engine
* Google ML Cloud Vision API
* Google ML Cloud Natural Language API
* Wayback Machine Memento API | ## What's the problem?
Nowadays, it seems that fans expect to pay many multiples above face value to see their favourite artists perform. The average consumer simply cannot compete with sophisticated scalpers looking to make an easy profit. Popular concerts sell out in seconds, only to have the tickets immediately posted for resale at much higher prices.
Scalpers control the market - it's hurting venues, artists, and most importantly, fans.
## How does BloxOffice solve the problem?
Scalpers are in business for profit. If we can eliminate that incentive, there is no reason to scalp. Since every BloxOffice ticket transaction must occur on the blockchain, we are in control of the entire process.
\_ If a ticket is ever sold in the aftermarket for a profit, that profit is given back to the initial ticket issuer \_. Not only does this discourage scalping, it also allows an event organizer to capture the full value of their ticket sales.
## Tickets on the blockchain? What does that mean?
The BloxOffice system is built as a smart contract on the ethereum blockchain. The network controls the issuance of tickets and validates transfers. Each ticket holds the public address of its owner, so we know exactly who it belongs to.
It is impossible to create a fake ticket, as the origin of every ticket can be traced to its source. Additionally, since no transactions can be made off-chain, all transactions must follow our rules.
## Accomplishments that we're proud of
This is the first time our team has developed anything. Period. No experience with solidity, no experience with front-end dev, only basic coding knowledge. We are exceptionally proud of writing and deploying our smart contracts.
## Special Thanks!
\*\* Shoutout to the team from Scotiabank's Digital Factory! These heroes helped us all along the way \*\* | ## Inspiration
The amount of data in the world today is mind-boggling. We are generating 2.5 quintillion bytes of data every day at our current pace, but the pace is only accelerating with the growth of IoT.
We felt that the world was missing a smart find-feature for videos. To unlock heaps of important data from videos, we decided on implementing an innovative and accessible solution to give everyone the ability to access important and relevant data from videos.
## What it does
CTRL-F is a web application implementing computer vision and natural-language-processing to determine the most relevant parts of a video based on keyword search and automatically produce accurate transcripts with punctuation.
## How we built it
We leveraged the MEVN stack (MongoDB, Express.js, Vue.js, and Node.js) as our development framework, integrated multiple machine learning/artificial intelligence techniques provided by industry leaders shaped by our own neural networks and algorithms to provide the most efficient and accurate solutions.
We perform key-word matching and search result ranking with results from both speech-to-text and computer vision analysis. To produce accurate and realistic transcripts, we used natural-language-processing to produce phrases with accurate punctuation.
We used Vue to create our front-end and MongoDB to host our database. We implemented both IBM Watson's speech-to-text API and Google's Computer Vision API along with our own algorithms to perform solid key-word matching.
## Challenges we ran into
Trying to implement both Watson's API and Google's Computer Vision API proved to have many challenges. We originally wanted to host our project on Google Cloud's platform, but with many barriers that we ran into, we decided to create a RESTful API instead.
Due to the number of new technologies that we were figuring out, it caused us to face sleep deprivation. However, staying up for way longer than you're supposed to be is the best way to increase your rate of errors and bugs.
## Accomplishments that we're proud of
* Implementation of natural-language-processing to automatically determine punctuation between words.
* Utilizing both computer vision and speech-to-text technologies along with our own rank-matching system to determine the most relevant parts of the video.
## What we learned
* Learning a new development framework a few hours before a submission deadline is not the best decision to make.
* Having a set scope and specification early-on in the project was beneficial to our team.
## What's next for CTRL-F
* Expansion of the product into many other uses (professional education, automate information extraction, cooking videos, and implementations are endless)
* The launch of a new mobile application
* Implementation of a Machine Learning model to let CTRL-F learn from its correct/incorrect predictions | partial |
## Inspiration
We wanted to take it easier this hackathon and do a "fun" hack.
## What it does
The user can search for a song in the Spotify library, and Music in Motion will make a music video based off of the lyrics of the song.
## How we built it
Music in Motion first searches for the song in the Spotify library, then scrapes the internet for the lyrics to the song. It then takes main keywords from the lyrics and uses those to find relevant gifs for each line of the song. These gifs are put together in succession and synced with the lyrics of the song to create a music video.
## Challenges we ran into
Our initial plan to use .lrc files to sync lyrics with gifs was thrown out the window when we weren't able to secure a reliable source of .lrc files. However, we found other ways of getting lyric timings that were nearly the same quality.
## Accomplishments that we're proud of
Getting the lyrics/gifs to sync up with the music was very challenging. Although not always perfect, we're definitely proud of the quality of what we were able to accomplish.
It also looks nice. At least we think so.
## What we learned
APIs can be very unreliable. Documentation is important.
## What's next for Music In Motion
FInding a reliable way to get .lrc files or lyric timings for a given song. Also finding other, more reliable gif APIs, since Giphy didn't always have a gif for us. | ## Inspiration
As students who listen to music to help with our productivity, we wanted to not only create a music sharing application but also a website to allow others to discover new music, all through where they are located. We were inspired by Pokemon-Go but wanted to create a similar implementation with music for any user to listen to. Anywhere. Anytime.
## What it does
Meet Your Beat implements a live map where users are able to drop "beats" (a.k.a Spotify beacons). These beacons store a song on the map, allowing other users to click on the beacon and listen to the song. Using location data, users will be able to see other beacons posted around them that were created by others and have the ability to "tune into" the beacon by listening to the song stationed there. Multiple users can listen to the same beacon to simulate a "silent disco" as well.
## How I built it
We first customized the Google Map API to be hosted on our website, as well as fetch the Spotify data for a beacon when a user places their beat. We then designed the website and began implementing the SQL database to hold the user data.
## Challenges I ran into
* Having limited experience with Javascript and API usage
* Hosting our domain through Google Cloud, which we were unaccustomed to
## Accomplishments that I'm proud of
Our team is very proud of our ability to merge various elements for our website, such as the SQL database hosting the Spotify data for other users to access on the website. As well, we are proud of the fact that we learned so many new skills and languages to implement the API's and database
## What I learned
We learned a variety of new skills and languages to help us gather the data to implement the website. Despite numerous challenges, all of us took away something new, such as web development, database querying, and API implementation
## What's next for Meet Your Beat
* static beacons to have permanent stations at more notable landmarks. These static beacons could have songs with the highest ratings.
* share beacons with friends
* AR implementation
* mobile app implementation | ## Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
## What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
## How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions.
After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
## Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
## What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time.
On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
## What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward. | partial |
## Inspiration
The inspiration behind GenAI stems from a deep empathy for those struggling with emotional challenges. Witnessing the power of technology to foster connections, we envisioned an AI companion capable of providing genuine emotional support.
## What it does
GenAI is your compassionate emotional therapy AI friend. It provides a safe space for users to express their feelings, offering empathetic responses, coping strategies, and emotional support. It understands users' emotions, offering personalized guidance to improve mental well-being.
Additional functions:
**1)** Emotions recognition & control
**2)** Control of the level of lies and ethics
**3)** Speaking partner
**4)** Future optional video chat with the AI-generated person
**5)** Future meeting notetaker
## How we built it
GenAI was meticulously crafted using cutting-edge natural language processing and machine learning algorithms. Extensive research on emotional intelligence and human psychology informed our algorithms. Continuous user feedback played a pivotal role in refining GenAI’s responses, making them truly empathetic and supportive.
## Challenges we ran into
Integrating emotional analysis APIs seamlessly into GenAI was vital for its functionality. We faced difficulties in finding a reliable API that could accurately interpret and respond to users' emotions. After rigorous testing, we successfully integrated an API that met our high standards, ensuring GenAI's emotional intelligence. Training LLMs posed another challenge. We needed GenAI to understand context, tone, and emotion intricately. This required extensive training and fine-tuning of the language models. It demanded significant computational resources and time, but the result was an AI friend that could comprehend and respond to users with empathy and depth. Connecting the front end, developed using React, with the backend, powered by Jupyter Notebook, was a complex task. Ensuring real-time, seamless communication between the two was essential for GenAI's responsiveness. We implemented robust data pipelines and optimized API calls to guarantee swift and accurate exchanges, enabling GenAI to provide instant emotional support.
## Accomplishments that we're proud of
**1) Genuine Empathy:** GenAI delivers authentic emotional support, fostering a sense of connection.
**2) User Impact:** Witnessing positive changes in users’ lives reaffirms the significance of our mission.
**3) Continuous Improvement:** Regular updates and enhancements ensure GenAI remains effective and relevant.
## What we learned
Throughout the journey, we learned the profound impact of artificial intelligence on mental health. Understanding emotions, building a responsive interface, and ensuring user trust were pivotal lessons. The power of compassionate technology became evident as GenAI evolved.
## What's next for GenAI
Our journey doesn't end here. We aim to:
**1) Expand Features:** Introduce new therapeutic modules tailored to diverse user needs.
**2) Global Accessibility:** Translate GenAI into multiple languages, making it accessible worldwide.
**3) Collaborate with Experts:** Partner with psychologists to enhance GenAI's effectiveness.
**4) Research Advancements:** Stay abreast of the latest research to continually improve GenAI’s empathetic capabilities.
GenAI is not just a project; it's a commitment to mental well-being, blending technology and empathy to create a brighter, emotionally healthier future. | ## Inspiration
We were inspired by the growing need for accessible mental health resources and how AI can provide real-time, personalized support. As Stanford students immersed in a stressful college environment, we realized many people young and old face barriers to traditional therapy, such as time, cost, and availability, and we wanted to create a solution that addresses these issues. By combining AI-driven emotional analysis with schedule integration, we saw an opportunity to build a tool that offers meaningful, timely support in a flexible, tech-driven world.
## What it does
Aurora is an AI-powered therapist that listens to your voice and analyzes your facial expressions to understand your emotional state. It adjusts its responses based on your mood and volume, offering a personalized therapy experience. Aurora also integrates with your schedule through the Google Calendar API, providing therapy sessions that are more specific to your day-to-day activities. It ensures your mental well-being is always prioritized, even when you're short on time.
## How we built it
Aurora was built as a web app using TypeScript, React, and Tailwind CSS to create an adaptive and seamless user experience. Hume AI powers the emotional analysis, allowing us to capture nuanced emotional cues from users' voice and facial expressions. Deepgram handles speech transcription, while the Google Calendar API integrates scheduling information. We use Firebase to store user data and Gemini 1.5 Flash for generating thoughtful, personalized responses. Our Flask servers manage mic status, voice decibel tracking, and audio playback to make the interaction feel seamless and responsive.
## Challenges we ran into
One of the toughest challenges we faced was integrating the emotional and semantic analysis models from Hume with Deepgram’s speech-to-text model. Synchronizing these models in real-time was critical for ensuring that Aurora’s responses were both emotionally intelligent and contextually accurate. Since we relied heavily on multiple API-based models via web sockets, it was crucial to maintain seamless synchronization between them, especially when one model didn’t return optimal results. Robust error handling became a key focus to ensure that the user experience wasn’t compromised.
We also faced hurdles with the specific requirements of certain text-to-speech APIs. These APIs often had rigid input specifications that clashed with the outputs from our emotional and semantic models, leading to some tricky data flow issues. Finally, our desire to use streaming versions of the models for optimized performance posed additional difficulties. Streaming added complexity when transferring data between models, the backend, the database, and the UI, leading to bottlenecks that we had to troubleshoot to ensure smooth, real-time interactions.
## Accomplishments that we're proud of
We’re proud of successfully integrating a wide range of complex systems—from emotional analysis to real-time mic monitoring—and making them work together in a seamless user experience. We set out to tackle a highly ambitious task, knowing that the number of models, the amount of synchronization, and the level of communication required between various processes would be a significant technical challenge. On top of that, we aimed to optimize performance using streaming models for faster, real-time inference, which added even more complexity to the project.
Despite these challenges, we managed to bring all of these elements together into a coherent and fully functional product. We’re proud not only of the technical achievements but also of the impact our solution could have in making mental health support more accessible. The fact that we could take on such a difficult task and deliver a polished, responsive web app that feels intuitive and natural is something we’re excited to showcase.
## What we learned
Through Aurora’s development, we learned the incredible potential that arises when cutting-edge AI meets deep human empathy. Working with tools like Hume AI and Deepgram taught us how to harness real-time emotional data to craft experiences that resonate on a personal level. We also gained invaluable insights into designing systems that are not only technically robust but also user-centric, ensuring that every interaction feels fluid, meaningful, and intuitive. Most importantly, we learned the value of balancing technical innovation with emotional intelligence, a combination that can turn technology into a source of comfort and support.
## What's next for Aurora
In the near future, we plan to introduce new features that enhance both functionality and user experience. One of our top priorities is to add journaling capabilities, allowing users to log their thoughts and emotions after each session, creating a personal mental health record they can revisit. We're also looking into building in-session note-taking, where Aurora can automatically summarize key insights and actions from each therapy session, providing users with clear takeaways. Another exciting feature is push notifications for personalized check-ins—Aurora will remind users to take time for their mental well-being, especially during stressful periods, by analyzing their calendar. Additionally, we plan to implement a multi-language feature to make Aurora accessible to a wider, global audience. And, to make sessions even more engaging, we’ll explore the integration of guided meditations and breathing exercises directly within the app. | View the SlideDeck for this project at: [slides](https://docs.google.com/presentation/d/1G1M9v0Vk2-tAhulnirHIsoivKq3WK7E2tx3RZW12Zas/edit?usp=sharing)
## Inspiration / Why
It is no surprise that mental health has been a prevailing issue in modern society. 16.2 million adults in the US and 300 million people in the world have depression according to the World Health Organization. Nearly 50 percent of all people diagnosed with depression are also diagnosed with anxiety. Furthermore, anxiety and depression rates are a rising issue among the teenage and adolescent population. About 20 percent of all teens experience depression before they reach adulthood, and only 30 percent of depressed teens are being treated for it.
To help battle for mental well-being within this space, we created DearAI. Since many teenagers do not actively seek out support for potential mental health issues (either due to financial or personal reasons), we want to find a way to inform teens about their emotions using machine learning and NLP and recommend to them activities designed to improve their well-being.
## Our Product:
To help us achieve this goal, we wanted to create an app that integrated journaling, a great way for users to input and track their emotions over time. Journaling has been shown to reduce stress, improve immune function, boost mood, and strengthen emotional functions. Journaling apps already exist, however, our app performs sentiment analysis on the user entries to help users be aware of and keep track of their emotions over time.
Furthermore, every time a user inputs an entry, we want to recommend the user something that will lighten up their day if they are having a bad day, or something that will keep their day strong if they are having a good day. As a result, if the natural language processing results return a negative sentiment like fear or sadness, we will recommend a variety of prescriptions from meditation, which has shown to decrease anxiety and depression, to cat videos on Youtube. We currently also recommend dining options and can expand these recommendations to other activities such as outdoors activities (i.e. hiking, climbing) or movies.
**We want to improve the mental well-being and lifestyle of our users through machine learning and journaling.This is why we created DearAI.**
## Implementation / How
Research has found that ML/AI can detect the emotions of a user better than the user themself can. As a result, we leveraged the power of IBM Watson’s NLP algorithms to extract the sentiments within a user’s textual journal entries. With the user’s emotions now quantified, DearAI then makes recommendations to either improve or strengthen the user’s current state of mind. The program makes a series of requests to various API endpoints, and we explored many APIs including Yelp, Spotify, OMDb, and Youtube. Their databases have been integrated and this has allowed us to curate the content of the recommendation based on the user’s specific emotion, because not all forms of entertainment are relevant to all emotions.
For example, the detection of sadness could result in recommendations ranging from guided meditation to comedy. Each journal entry is also saved so that users can monitor the development of their emotions over time.
## Future
There are a considerable amount of features that we did not have the opportunity to implement that we believe would have improved the app experience. In the future, we would like to include video and audio recording so that the user can feel more natural speaking their thoughts and also so that we can use computer vision analysis on the video to help us more accurately determine users’ emotions. Also, we would like to integrate a recommendation system via reinforcement learning by having the user input whether our recommendations improved their mood or not, so that we can more accurately prescribe recommendations as well. Lastly, we can also expand the APIs we use to allow for more recommendations. | losing |
## Inspiration
An abundance of qualified applicants lose their chance to secure their dream job simply because they are unable to effectively present their knowledge and skills when it comes to the interview. The transformation of interviews into the virtual format due to the Covid-19 pandemic has created many challenges for the applicants, especially students as they have reduced access to in-person resources where they could develop their interview skills.
## What it does
Interviewy is an **Artificial Intelligence** based interface that allows users to practice their interview skills by providing them an analysis of their video recorded interview based on their selected interview question. Users can reflect on their confidence levels and covered topics by selecting a specific time-stamp in their report.
## How we built it
This Interface was built using the MERN stack
In the backend we used the AssemblyAI APIs for monitoring the confidence levels and covered topics. The frontend used react components.
## Challenges we ran into
* Learning to work with AssemblyAI
* Storing files and sending them over an API
* Managing large amounts of data given from an API
* Organizing the API code structure in a proper way
## Accomplishments that we're proud of
• Creating a streamlined Artificial Intelligence process
• Team perseverance
## What we learned
• Learning to work with AssemblyAI, Express.js
• The hardest solution is not always the best solution
## What's next for Interviewy
• Currently the confidence levels are measured through analyzing the words used during the interview. The next milestone of this project would be to analyze the alterations in tone of the interviewees in order to provide a more accurate feedback.
• Creating an API for analyzing the video and the gestures of the the interviewees | ## Inspiration
We were inspired to build Loki to illustrate the plausibility of social media platforms tracking user emotions to manipulate the content (and advertisements) that they view.
## What it does
Loki presents a news feed to the user much like other popular social networking apps. However, in the background, it uses iOS’ ARKit to gather the user’s facial data. This data is piped through a neural network model we trained to map facial data to emotions. We use the currently-detected emotion to modify the type of content that gets loaded into the news feed.
## How we built it
Our project consists of three parts:
1. Gather training data to infer emotions from facial expression
* We built a native iOS application view that displays the 51 facial attributes returned by ARKit.
* On the screen, a snapshot of the current face can be taken and manually annotated with one of four emotions [happiness, sadness, anger, and surprise]. That data is then posted to our backend server and stored in a Postgres database.
2. Train a neural network with the stored data to map the 51-dimensional facial data to one of four emotion classes. Therefore, we:
* Format the data from the database in a preprocessing step to fit into the purely numeric neural network
* Train the machine learning algorithm to discriminate different emotions
* Save the final network state and transform it into a mobile-enabled format using CoreMLTools
3. Use the machine learning approach to discreetly detect the emotion of iPhone users in a Facebook-like application.
* The iOS application utilizes the neural network to infer user emotions in real time and show post that fit the emotional state of the user
* With this proof of concept we showed how easy applications can use the camera feature to spy on users.
## Challenges we ran into
One of the challenges we ran into was the problem of converting the raw facial data into emotions. Since there are 51 distinct data points returned by the API, it would have been difficult to manually encode notions of different emotions. However, using our machine learning pipeline, we were able to solve this.
## Accomplishments that we're proud of
We’re proud of managing to build an entire machine learning pipeline that harnesses CoreML — a feature that is new in iOS 11 — to perform on-device prediction.
## What we learned
We learned that it is remarkably easy to detect a user’s emotion with a surprising level of accuracy using very few data points, which suggests that large platforms could be doing this right now.
## What's next for Loki
Loki is currently not saving any new data that it encounters. One possibility is for the application to record the expression of the user mapped to the social media post. Another possibility is to expand on our current list of emotions (happy, sad, anger, and surprise) as well as train on more data to provide more accurate recognition. Furthermore, we can utilize the model’s data points to create additional functionalities. | ## Inspiration
In the hectic moments before a job interview, users may experience a flurry of emotions, from nervousness to self-doubt, as they grapple with the pressure to perform well and make a positive impression on the interviewer. Our inspiration for Ai&U stemmed from our collective experiences with interviews and findings from the user research we conducted, in which users ranging from under 18 to 34 with diverse educational backgrounds and work experiences described their "nervousness," "lack of feedback," and "difficulty answering certain types of question." We noticed that traditional interview preparation methods, such as rehearsing responses or seeking advice from friends and mentors, often lack personalized feedback and fail to simulate the dynamic nature of real interview scenarios. According to the research survey, most users are comfortable interacting with an AI avatar for interview preparation.
Some users wished for a tool that would enact different company’s interview processes (like a boba shop vs tech corporate), analyze body language and take note of the times that they fidget or stutter, questions based on past interviews, and a way to know what interviewers think of their answers.
Recognizing the growing importance of AI technology in various fields, we saw an opportunity to leverage it to create a solution that addresses these shortcomings. By combining AI-driven simulation with personalized feedback and a friendly user experience, we aimed to provide users with a more effective and engaging way to enhance their confidence in interviews and increase their chances of success.
## What it does
Ai&U is a website that utilizes AI avatars to prepare users for interviews. Before the live interview with an AI avatar, users input the job description and resume. AI analyzes this information and prepares specific questions for the interview. During the interview, the AI interviewer reacts with expressions based on the user's responses. We used voice-to-text as well as AI avatars to implement these features. After the interview, Ai&U generates a feedback page along with an AI chat where users can receive personalized feedback and ask the AI interviewer questions directly.
## How we built it
We used Figma to design the entire website. Then, we used Next.js to build the frontend and Node.js for the backend,
## Challenges we ran into
It was difficult to connect the front and back end through API calls. We didn't have much experience with this, so it was quite challenging to make API endpoints.
## Accomplishments that we're proud of
We are really proud of the emphasis on the user throughout the design process. Creating the virtual interview avatar was also really cool, and we are proud that the feature was tested properly.
## What we learned
Through our user research and development process, we learned the importance of personalized feedback and real-time interaction in interview preparation. We discovered that users face various challenges, including nervousness, difficulty answering certain types of questions, and lack of feedback on their performance. We also learned a lot about team management and combining frontend and backend.
## What's next for Ai&U
Based on the survey results, we want to include the user's past interview results as a way to personalize future interview questions. For example, if the user has been weak in questions that account for "leadership and management" skills, future AI interviews may specifically tackle those types of questions. We also want to develop a feature in which users can choose their AI interviewer (Google software recruiter, BobaGuys manager, etc) for a more personalized and targeted mock interview. In addition, we want to record the user's interview with the AI and have it as part of the feedback page where specific phrases will have timestamps that the AI interviewer wants to comment on specifically. | partial |
## Inspiration
Our team firmly believes that one of the best ways to connect with others is through acts of service. Coming out of the pandemic, volunteers will be crucial to supporting those hit the hardest. Although many people often want to volunteer in their communities, their schedules are too variable to commit to a steady volunteer role. CheckIn solves this issue by “gig-ifying” volunteer work, connecting those looking to help with work whenever and wherever it is available.
## What it does
CheckIn is a web application that "gig-ifies" volunteering by connecting those looking to volunteer and help out in their local communities with local community groups. CheckIn has an intuitive and easy to use interface in order to make the user experience as seamless as possible. Our features include the ability to find volunteer opportunities using the integrated app or by using a time slider to select the time. As well our app provides the ability to find local community group to join for those looking for a more permanent role. We also use the Twilio API in order to send SMS messages which confirm participation and remind volunteers of upcoming commitments. Under the hood, users are able to create accounts and with these accounts see all their recorded volunteering history. Ultimately, CheckIn simplifies the volunteering experience to connect could-be volunteers with the organizations that need them.
## How we built it
We built the UI with React.js framework. For user authentication, we used Node.js and Express.js to link our frontend content with MongoDB. We built the Check-In feature with the Twilio SMS API, and used Google Maps API for the interactive map. Lastly, we also used a lot of React libraries/APIs, which were very fun to learn!
## Challenges we ran into
The first challenge we ran into was that one of our team members was unable to participate, leaving us short-handed for the duration of the hackathon. The biggest challenge we faced however was a lack of experience and prior knowledge. Coming into the hackathon, only one member of our team had worked with React and we had no backend knowledge and learning these skills as we went significantly slowed down our work rate.
## Accomplishments that we're proud of
Despite having a short-handed, inexperienced team, we were able to develop a fully fledged web application with both frontend and backend. Central to our goal was creating an intuitive and enjoyable user experience in order to make volunteering simple, and we are happy to say that we met this goal. Another goal was to fully implement all features of our app within the duration of the hackathon, a feat which we finally accomplished at 5:45am Sunday morning.
## What we learned
Coming into this project our team only had one member experienced with React and no backend experience. This meant that we had to learn React, as well as responsive web design in order to create an enjoyable user experience. Secondly, we had to learn how to use API's, specifically the google maps API and Twilio. Finally, we needed to learn how create a backend and integrate it into our application.
## What's next for CheckIn
In order to realize its vision of “gig-ified” volunteer work, CheckIn’s next steps include building iOS and Android applications to increase convenience for users. Additionally, CheckIn relies on a large network of users, both volunteers and volunteer opportunity organizers, in order to deliver its service. Its next steps will also include an advertising campaign and potential promotional period in order to boost its user base. | ## The beginning
We had always been fascinated by the incredibly varied talents that people could use for good. Serena had worked at a nonprofit, and witnessed firsthand how the volunteers that they found were eager to contribute their skills and knowledge for the cause. There was a glaring problem, though: not enough people knew which organizations fit their particular skillset. Nonprofits were needing skills - and there were people sitting at home, with those skills, wondering what to do.
Jackson was one of those people. During the pandemic, he developed an acute awareness of the needs of the community around him. He looked for places to volunteer - but it was difficult to determine which places were in need of which skills. He wanted to use his abilities to maximize his impact on the community - but he needed something to connect him to the right nonprofits.
## The idea
We decided to build a website - one with both a volunteer and organization portal. The idea was that volunteers would sign up, providing a ranked list of their skills, while organizations would create events, which looked for certain skills.
## The build
The frontend of the website was built in react, while the backend was built with django, and the server was deployed with Heroku. We took responses from organizations and volunteers, stored them in tables, and created connections. The process was hindered by hiccups in some utilities - Visual Studio Code’s Git extension, as well as npm, both gave us problems. However, through the unending wisdom of the internet, we were able to overcome those difficulties. With Serena working on the backend, and Jackson on the frontend, the result was a website that satisfied our vision - one that could take volunteer skill and match it to the needs of nonprofit events.
## The future
In the future, we hope to incorporate more information about volunteers, to help them better match with nonprofits - using an api to determine distance, for example. We also hope to introduce a friends feature to the site, which will allow volunteers to see events that other volunteers are interested in. There are dozens of other ways in which we could expand our site - but our ultimate goal was, and still is, to take human skill, and plug it into human need - and ultimately bring more hope to the community around us. | ## Inspiration
Covid-19 has turned every aspect of the world upside down. Unwanted things happen, situation been changed. Lack of communication and economic crisis cannot be prevented. Thus, we develop an application that can help people to survive during this pandemic situation by providing them **a shift-taker job platform which creates a win-win solution for both parties.**
## What it does
This application offers the ability to connect companies/manager that need employees to cover a shift for their absence employee in certain period of time without any contract. As a result, they will be able to cover their needs to survive in this pandemic. Despite its main goal, this app can generally be use to help people to **gain income anytime, anywhere, and with anyone.** They can adjust their time, their needs, and their ability to get a job with job-dash.
## How we built it
For the design, Figma is the application that we use to design all the layout and give a smooth transitions between frames. While working on the UI, developers started to code the function to make the application work.
The front end was made using react, we used react bootstrap and some custom styling to make the pages according to the UI. State management was done using Context API to keep it simple. We used node.js on the backend for easy context switching between Frontend and backend. Used express and SQLite database for development. Authentication was done using JWT allowing use to not store session cookies.
## Challenges we ran into
In the terms of UI/UX, dealing with the user information ethics have been a challenge for us and also providing complete details for both party. On the developer side, using bootstrap components ended up slowing us down more as our design was custom requiring us to override most of the styles. Would have been better to use tailwind as it would’ve given us more flexibility while also cutting down time vs using css from scratch.Due to the online nature of the hackathon, some tasks took longer.
## Accomplishments that we're proud of
Some of use picked up new technology logins while working on it and also creating a smooth UI/UX on Figma, including every features have satisfied ourselves.
Here's the link to the Figma prototype - User point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=68%3A3872&scaling=min-zoom)
Here's the link to the Figma prototype - Company/Business point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=107%3A10&scaling=min-zoom)
## What we learned
We learned that we should narrow down the scope more for future Hackathon so it would be easier and more focus to one unique feature of the app.
## What's next for Job-Dash
In terms of UI/UX, we would love to make some more improvement in the layout to better serve its purpose to help people find an additional income in job dash effectively. While on the developer side, we would like to continue developing the features. We spent a long time thinking about different features that will be helpful to people but due to the short nature of the hackathon implementation was only a small part as we underestimated the time that it will take. On the brightside we have the design ready, and exciting features to work on. | losing |
## What's next for [derma relief]: [Our Plan](https://youtu.be/DzFbTgcMm5g?t=62)
Check out our [GitHub](https://github.com/dynamicduho/reliefAR) [Figma](https://www.figma.com/proto/zxUyENXGh54EeSksJvDBzg/HTV-App-Prototype?node-id=154%3A2835&scaling=min-zoom&page-id=0%3A1&starting-point-node-id=154%3A2835)
## Inspiration
***You make 35000 decisions each day - [derma relief] uses AR to help you make better ones; for your skin, for your health, and for the world - one product at a time.***
Olivia, one of our teammates, had *serious allergic reactions to her sunscreen*, but had no idea what ingredients were causing them. Looking at the back for the list of ingredients only confused her more. When she searched on Google for one of the ingredients, she was shocked to find out that her sunscreen was also causing damage to coral reefs and killing aquatic habitats.
The fact is, most people don't read the ingredients list, and even if they do, they don't know what each ingredient does. Adding to that is the fact that many people have allergies, and most of them don't know why.
**The facts**: According to our user survey (n = 68 responses, blinded, anonymized, multiple platforms), 59% of users don't read the ingredients, and **86%** of respondents didn't know what was causing their allergies. Our small study is corroborated by others: [link](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5903167/)
*We wanted to fix that.*
Using an easy, visual way (AR), we wanted to help people like Olivia make quick, smart, sustainable purchase decisions that are tailored exactly to their personal environmental concerns and allergies, while making shopping more fun and interactive.
## Why the user survey influenced us to do exactly what we did
Our user survey genuinely surprised us. We found out that the most common influence in cosmetic purchase decisions was **friend recommendations (65%)**, while asking the pharmacist (experts) only accounted for 8%.
That's why we chose a mobile app. An app makes it easy to have features that
1. provide visual product information with AR
2. login / account system
3. track your personal set of allergies
4. purchase history
5. connect to social media/recommend items
6. add to shopping cart and checkout
7. see detailed product info and search for products instantly
8. news feed of expert and friend recommendations based on your allergies and skin type
9. get geofenced alerts and reminders
**AR**
* An ingredient list is long, hard to read, and confusing.
* Our AR provides a **visual** way to represent allergies and environmental impact, along with a **Matching Score** based on allergies and friends' recommendations, inspired by Netflix's matching system.
**User Profile/Login System**
* You are unique. Your allergies and skin type should be able to influence your decisions.
**News Feed**
* Consulting a pharmacist and dermatologist is the best way to understand your skin as they have expert knowledge of chemicals. We provide a platform for verified professionals to recommend products that match to your profile using AI.
* Friends play a large factor in the trustworthiness of a product. Their recos are shown in the feed.
* Distinguish between friends and verified experts in the newsfeed
## What it does
[derma relief] provides personalized matches to products using AR cards (see gallery), making it easy to scan a shelf of products for one that uniquely matches you.
Our features:
* personalized AR cards w/ match, allergy, and environmental info
* shopping cart & checkout
* news feed (friend, expert)
* purchase history + new allergy alert
* share to social media
* detailed product pages
* geofenced shopping notifications
* product ratings system
## How we built it
* 3D models: Blender and Cinema4D
* Wireframing: Figma
* AR: Flutter (Dart) w/ Sceneform, ARCore plugins, in VSCode w/ Android Studio SDKs
* UI: Flutter w/ material UI plug-ins in VSCode w/ Android Studio SDKs
* Authentication/User database: Firebase & Auth, Firestore
* Collaboration: VSCode liveshare, GitHub, Figma jamboard
* User Survey: Google Survey
* Pitch Deck: Figma prez plugin
## Challenges we ran into
* coordinating over 3 different time zones (ET, IST, MST) spanning 12 hours
* AR .obj files not rendering as .sfa due to deprecated sceneform plugins
* no to little flutter experience
* first time learning AR
* installing flutter, android studio on mac, windows for android
* 2 members of our team were coding blind (no androids)
* user research survey time constraints
* Sarthak's first hackathon
## Accomplishments that we're proud of
* Getting AR working!!!
* Getting a login system working
* User-first development w/ survey + market research :)))
* Learning a lot about people's product decisions
* Becoming friends :)
## What we learned
* Blender 3D & Cinema4D
* Flutter + Dart
* AR models and texturing
* Firebase/Auth
* Firestore | **Made by Ella Smith (ella#4637) & Akram Hannoufa (ak\_hannou#7596) -- Team #15**
*Domain: <https://www.birtha.online/>*
## Inspiration
Conversations with friends and family about the difficulty of finding the right birth control pill on the first try.
## What it does
Determines the brand of hormonal contraceptive pill most likely to work for you using data gathered from drugs.com. Data includes: User Reviews, Drug Interactions, and Drug Effectiveness.
## How we built it
The front-end was built using HTML, CSS, JS, and Bootstrap. The data was scraped from drugs.com using Beautiful Soup web-scraper.
## Challenges we ran into
Having no experience in web-dev made this a particularly interesting learning experience. Determining how we would connect the scraped data to the front-end was challenging, as well as building a fully functional multi-page form proved to be difficult.
## Accomplishments that we're proud of
We are proud of the UI design, given it is our first attempt at web development. We are also proud of setting up a logic system that provides variability in the generated results. Additionally, figuring out how to web scrape was very rewarding.
## What we learned
We learned how to use version control software, specifically Git and GitHub. We also learned the basics of Bootstrap and developing a functional front-end using HTML, CSS, and JS.
## What's next for birtha
Giving more detailed and accurate results to the user by further parsing and analyzing the written user reviews. We would also like to add some more data sources to give even more complete results to the user. | ## Inspiration
*TeeWorlds* (2007), *Super Meat Boy (2010)*, *Terraria* (2011), *BattleBlock Theater* (2013), *Starbound* (2016). At first glance, these 5 titles share very little with each other. They're all video games, they all feature platforming mechanics... Oh, and one more thing: They're all developed with Windows/MacOS users in mind.
With the exception of *Starbound*, all of these games are relatively old, having been around with me since I was still a middle schooler starting off with Computer Science and Web Development. These were both my forms of entertainment, as well as my introductions into what fantastic UI/UX looks like.
Times have changed significantly since that time. The HTML5 cache manifest for offline data storage was introduced & deprecated, the HTML5 canvas has become more powerful and more efficient, several services such as Heroku & GitHub Pages now allow for quick and easy hosting for personal projects. Just a few years ago, free hosting meant setting up with Google Cloud on Google App Engine or using a super shady 000WebHost.
Yet, despite all of these changes, the most we've seen with in-browser gaming has come from the dying Adobe Flash, or the Unity web plug ins. The only HTML5 web games out there are typically top-down, mechanically simple "\*.io" games, designed more for a quick fix than a construction of worlds.
With a little ingenuity & a lot of naivety, I want to challenge that. I want to build a proof of concept of what is possible in my time at PennApps, and grow that over time into a whole new game, and demonstrate the potential of world building through the web-based medium that has captured my attention for as long as video games have.
## What it does
A fast-paced & mechanically challenging boss fight between Oxymora, the Rainbow Arsonist, and Jeeeeney, the absolute emodiment of my irrational fear of a rogue genie from Aladdin.
**WASD** keys are used to conjure and throw potion-infused fireballs in any of the four cardinal directions, the **space bar** is used to jump/fly, the two brackets **[** and **]** are used to cycle between potions (of which there are only two). The **blueish-white** potion is an ice-based projectile; use this for higher damage and higher velocity. The **green** potion is a health-restoration projectile, or, as I like to call it, the **Healing Gun**.
There is a little randomness in the timing of the attacks and in the movements of the boss, but the game was continually playtested for balance. Learning the attack pattern is possible: watch for openings. When transparent, the boss can't receive or deal damage. Look for the holes in the bullet hell. The pattern is there.
## How I built it
The game is a technical demo of the capabilities of pure HTML5 and JavaScript. Both the graphics engine and the physics engine are in-house solutions, no frameworks were involved. The sprites & sound effects are free assets sourced from Itch.io for the sake of time, tweaked and modified by hand in Pixlr, an appropriately browser-based photo editor.
## Challenges I ran into
HTML5 presents several challenges in regards to performance. First and foremost, sprites cannot be flipped or rotated without significant performance drops, so flipped/rotated sprites were all created with Pixlr. By choice, I developed the physics & graphics engines from scratch for the project, which admittedly felt like biting off a lot more than I could chew.
## Accomplishments that I'm proud of
Developing Oxymora pushed me far out of my comfort zone as a developer. With zero reliance on frameworks or JavaScript libraries, I maintained a steady and grueling pace in creating the mechanics of the game and the engines that powers it. All in all, I'm just proud that I'm capable of creating games that I enjoy just as much as the ones I often indulge in.
## What I learned
* Working with sprites & animating them using HTML5 canvas
* Optimizing assets and operations for increased performance
* Developing fluid and intuitive in-game physics
## What's next for Oxymora
By the end of the 24 hours, most of the code was very, very wet (as in, opposite of Don't Repeat Yourself and keeping code dry), and large strands of spaghetti. In the future, I not only want to expand the world of Oxymora, but also refine the engine that it was built upon. Though it draws inspiration from Terraria, I'd very much like to avoid [building a massive world on top of a messy framework](https://github.com/raxod502/TerrariaClone/issues/2). The in-house physics engine will aid in creating the multiplayer game that I've dreamed of making, as understanding the physics will help me extrapolate player movement even in spite of higher latency, as well as mitigate cheating by detecting anomalies. | winning |
## Inspiration
We recognized that packages left on porch are unsafe and can be easily stolen by passerby and mailmen. Delivery that requires signatures is safer, but since homeowners are not always home, deliveries often fail, causing inconvenience for both homeowners and mailmen.
The act of picking up packages and carrying packages into home can also be physically straining for some.
Package storage systems are available in condos and urban locations, such as concierge or Amazon lockers, but unavailable in the suburbs or rural region, such as many areas of Brampton.
Because of these pain points, we believe there is market potential for homeowners in rural areas for a personal delivery storage solution. With smart home hacking and AI innovation in mind, we improve the lives of all homeowners by ensuring their packages are efficiently delivered and securely stored.
## What it does
OWO is a novel package storage system designed to prevent theft in residential homes. It uses facial recognition, user ID, and passcode to verify the identity of mailman before unlocking the device and placing the package on the device. The automated device is connected to the interior of the house and contains a uniquely designed joint to securely bring packages into home. Named "One Way Only", it effectively prevents any possible theft by passerby or even another mailman who have access to the device.
## How I built it
We built a fully animated CAD design with Fusion 360. Then, we proceeded with an operating and automated prototype and user interface using Arduino, C++, light fabrication, 3D printing. Finally, we set up an environment to integrate facial recognition and other Smart Home monitoring measures using Huawei Atlas 310 AI processor.
## What's next for One Way Only (OWO)
Build a 1:1 scaled high fidelity prototype for real-world testing. Design for manufacturing and installation. Reach out to potential partners to implement the system, such as Amazon. | ## Inspiration
This project was inspired by our curious naïveté in integrating interdisciplinary technologies… and the desperate need to wake up a certain friend incapable of waking up to any traditional alarm. Every Thursday at 5am, everyone but him within a 2 room radius would wake up to his alarm. We were drawn to the use of water as a potential alternative to a traditional alarm.
Thinking beyond an alarm, we found an opportunity to use robots to augment livestreams and strengthen the bond between content creators and consumers. As users donate to control the robot and interact with a creator, they receive NFTs of moments that can be cherished far into the future.
We came to see a use case in the realm of virtual human interactions. Particularly, we focused on how to foster a more meaningful connection between streamers and their audience, which platforms such as Twitch are constantly trying to find innovations in. By getting people more involved in the moments, we are able to create not only those interactions, but also create an in-person anchor point for the people, representing key components streaming sites have yet to utilize: the warmth and intimacy that real-world interactions and memories can provide.
## What it does
Users pay using Aptos for a water turret to spray water at somebody’s face. The user interacts with the [website](https://aquashot.tech/) we made, which has integration for Aptos' Petra wallet, as well as a livestream showing what a creator is doing. We mounted a separate webcam on a turret, which uses facial recognition to track people, and aims the water nozzle at their face. When someone donates through the site, the pump activates, and a recording of the moment is made into an NFT and sent back to the user's wallet. Overall, the interaction between our hardware and software (Web3 integration, CV, motor controls) is what drives the user experience.
## How we built it
We designed and fabricated the aqua shooter (our water-spraying turret-targeting robot) using 3D printing, laser cutting, soldering, and manual fabrication using various other tools. We used many libraries and programming languages to program the various parts of our project. We used Typescript, HTML, Python, and C++ programming languages, along with the most notable packages we used being React for the website, Aptos SDK for Aptos integration, OpenCV alongside the face\_recognition package for face tracking, and Pinata-python for uploading videos to IPFS.
## Challenges we ran into
The biggest challenge was integrating the software and hardware. With complex software and hardware components, we had to find ways to bring them all together at the last moment. Some of these included the installing of different software packages, the design of complex small parts, and finally the integration of everything after we had tested each individual component of the project and needed to tune it. Overall, the unpredictable results, or lack thereof, from these different components interacting was stress-test for communication, planning, and technical precision.
## Accomplishments that we're proud of
In a project with so many different parts, we are proud that we could integrate many different disciplines together and successfully come up with this unique system that brings both joy and utility to its users.
## What we learned
We learned many aspects in Aptos, OpenCV, and robotics through this compiled fun project! In addition, we learned how to integrate these very different disciplines into a complete project, ensuring precision on all fronts before piecing together the puzzle.
## What's next for AquaShot
Although we were only able to create one new avenue of physical interaction, we hope to continue expanding the ways that meaningful physical interactions can be included in virtual interactions. While this project’s goal was a mix of futuristic technologies for fun shenanigans, we look to bring these tools forward for the purpose of bridging the connectivity gap between the physical and virtual worlds. Indeed, the Aqua Shot should not be seen as a standalone, but rather an example feature of what the product could include.
In addition, there remains the possibility for an entirely new type of investment/trade market. On one hand, streamers will opt in on these technologies due to promises of higher donation revenue. On the other, viewers will be actively placing bets on moments and memories that will stand as valuable to the community, making them active entertainers as well. As a result, we envision an entirely new type of engagement in entertainment and human relationships. | ## Inspiration
More creators are coming online to create entertaining content for fans across the globe. On platforms like Twitch and YouTube, creators have amassed billions of dollars in revenue thanks to loyal fans who return to be part of the experiences they create.
Most of these experiences feel transactional, however: Twitch creators mostly generate revenue from donations, subscriptions, and currency like "bits," where Twitch often takes a hefty 50% of the revenue from the transaction.
Creators need something new in their toolkit. Fans want to feel like they're part of something.
## Purpose
Moments enables creators to instantly turn on livestreams that can be captured as NFTs for live fans at any moment, powered by livepeer's decentralized video infrastructure network.
>
> "That's a moment."
>
>
>
During a stream, there often comes a time when fans want to save a "clip" and share it on social media for others to see. When such a moment happens, the creator can press a button and all fans will receive a non-fungible token in their wallet as proof that they were there for it, stamped with their viewer number during the stream.
Fans can rewatch video clips of their saved moments in their Inventory page.
## Description
Moments is a decentralized streaming service that allows streamers to save and share their greatest moments with their fans as NFTs. Using Livepeer's decentralized streaming platform, anyone can become a creator. After fans connect their wallet to watch streams, creators can mass send their viewers tokens of appreciation in the form of NFTs (a short highlight clip from the stream, a unique badge etc.) Viewers can then build their collection of NFTs through their inventory. Many streamers and content creators have short viral moments that get shared amongst their fanbase. With Moments, a bond is formed with the issuance of exclusive NFTs to the viewers that supported creators at their milestones. An integrated chat offers many emotes for viewers to interact with as well. | partial |
## Inspiration
Virtually every classroom has a projector, whiteboard, and sticky notes. With OpenCV and Python being more accessible than ever, we wanted to create an augmented reality entertainment platform that any enthusiast could learn from and bring to their own place of learning. StickyAR is just that, with a super simple interface that can anyone can use to produce any tile-based Numpy game. Our first offering is *StickyJump* , a 2D platformer whose layout can be changed on the fly by placement of sticky notes. We want to demystify computer science in the classroom, and letting students come face to face with what's possible is a task we were happy to take on.
## What it does
StickyAR works by using OpenCV's Contour Recognition software to recognize the borders of a projector image and the position of human placed sticky notes. We then use a matrix transformation scheme to ensure that the positioning of the sticky notes align with the projector image so that our character can appear as if he is standing on top of the sticky notes. We then have code for a simple platformer that uses the sticky notes as the platforms our character runs, jumps, and interacts with!
## How we built it
We split our team of four into two sections, one half that works on developing the OpenCV/Data Transfer part of the project and the other half who work on the game side of the project. It was truly a team effort.
## Challenges we ran into
The biggest challenges we ran into were that a lot of our group members are not programmers by major. We also had a major disaster with Git that almost killed half of our project. Luckily we had some very gracious mentors come out and help us get things sorted out! We also first attempted to the game half of the project in unity which ended up being too much of a beast to handle.
## Accomplishments that we're proud of
That we got it done! It was pretty amazing to see the little square pop up on the screen for the first time on top of the spawning block. As we think more deeply about the project, we're also excited about how extensible the platform is for future games and types of computer vision features.
## What we learned
A whole ton about python, OpenCV, and how much we regret spending half our time working with Unity. Python's general inheritance structure came very much in handy, and its networking abilities were key for us when Unity was still on the table. Our decision to switch over completely to Python for both OpenCV and the game engine felt like a loss of a lot of our work at the time, but we're very happy with the end-product.
## What's next for StickyAR
StickyAR was designed to be as extensible as possible, so any future game that has colored tiles as elements can take advantage of the computer vision interface we produced. We've already thought through the next game we want to make - *StickyJam*. It will be a music creation app that sends a line across the screen and produces notes when it strikes the sticky notes, allowing the player to vary their rhythm by placement and color. | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | ## Inspiration:
We wanted to take an old classic and turn it into a fun game for all to enjoy. Immediately we thought of all the carnivals we missed out on due to the global pandemic. This pandemic caused us to be in our homes. We wanted to help people remember the fun they had playing these games. Our combined favorite game was the infamous balloon pop. We wanted to use computer vision and this game blended perfectly with that original idea.
## Purpose:
It is a summertime tradition to go out to the county fair where we live. We wanted to bring that fun to people around the world who could not go outside due to the global pandemic. Thus, we made a version of the infamous balloon pop, but with a twist. You use your finger as a blade to cut the balloons.
## Sources:
We hardcoded the GUI and the logic for the game using C++ and used OpenCV for the computer logic for tracking the finger for the game.
## Challenges:
Some challenges we faced during the creation of this game was learning OpenCV which we were unfamiliar with entering into the competition. On top of this another issue we had was combining this finger recognition software we created with Open CV and the front end game because both these codes were messy to integrate. Overall, to overcome these challenges we used our prior experience in coding and the internet to learn skills vital for this task.
## Strongest Aspects:
We are able to integrate both platforms the front end and back end also reliable detect finger.
## Learn:
The most important aspect of our project required us to learn the different functions of the OpenCV library. Specifically, we had to learn how to train our program to recognize the contours of different fingers, and how to create separate images from a webcam. Also, we learned how to integrate OpenCV tools in order to utilize the different objects. Next, we learned how to create the GUI using C++ to display the objects in our interface. All in all, we integrated what we learned from the OpenCV library and GUI to develop and design the main aspects of our game.
## Future Plans:
Some future plans of expansion we have for this game is to be able to create a more complex and appealing GUI using python or java, In addition, we would like to be able to add more features to our game in terms of what the user can slash or obstacles that fall down that if the user slashes they lose points. Overall, the major improvement we want to complete is the Graphical User Interface. | winning |
## Inspiration for Recyclable
We come across many instances when we don’t know if we can recycle an item and have to look it up on the web intensively to get to a conclusion. Whether it’s an used electrical appliance to a piece of broken furniture, there are ways to recycle these items; all it takes is a little research. However, not everyone has the access and enough time to research for recycling and they end up throwing away potentially recyclable materials creating a void in circular economy.
But, everyone now has a smartphone with a camera, so the answer to “is this recyclable” should be made easy with the minimal possible efforts from user end, with these contexts, we have developed **recyclable**, an user-friendly mobile application that tells you if the item is recyclable or not after a single camera click!
## How it works?
CAPTURE an item’s image, let recyclable, the app quickly identify your object and provide fast recommendations on whether the item is recyclable or not.
## How we built it
**Technologies used**: Figma (for design), Typescript, React Native, React Navigation, Tensorflow,
Tensorflowjs, OpenCV, Ascend AI, Mindspore, Mindspore XAI, Expo, Expo camera.
This is developed as a mobile application which is supported in 2 platforms - Android and ios.
We trained an image classification model to classify between different materials which can either be recyclable or non recyclable. We used latest MobileNetv2 architecture which is very lite and compatible in smaller devices, This model predicts with very good accuracy at the same time it is very fast. We trained our model on both Tensorflow as well as on Ascend AI platform using Mindspore.
## Challenges we ran into
Developing and deploying AscendAI model was new to us and understanding the vivid documentation needed time. However, we made sure to improve the performance in any possible way.
We achieved an accuracy of 93.75 on googlenet and 91.11 accuracy with MobileNetv2.
The above results depicts the power of MobileNetv2 which gave high accuracy with less parameters.
## Accomplishments that we're proud of
Developing a societal good solution has a potential market with evolving technologies simplifying the long-existing problems. We are proud about our first step towards ameliorating the environment, as we all play a crucial role in the future of our planet. We have developed a platform that offers greener and sustainable solutions to the users in a comprehensive manner.
## What we learned?
We learned new technologies like AscendAI, Expo, OpenCV while practicing our application development skills in React Native. We leveraged the GoogleNet network from Mindspore.
We have applied different optimizers like Adam, Adam weight decay, SGD etc. We had the best experience of Using Ascend AI Platform which is very simple to use and faster computation.
We also learned various business aspects to enhance the offered features.
## What's next for recyclable?
We can extend the features like:
*COMMUNITY* a platform to showcase your personalized uniquely recycled material and promote the sense of responsibility while celebrating the work.
*RESOURCES* allowing users to access research works on recycling.
*BONUS POINTs* for recyclers.
*EXPLORE* where your items can be recycled based on your location.
*FACILITIES* to see a map view of all recycling facilities close by.
etc. | ## Inspiration
McMaster's SRA presidential debate brought to light the issue of garbage sorting on campus. Many recycling bins were contaminated and were subsequently thrown into a landfill. During the project's development, we became aware of the many applications of this technology, including sorting raw materials, and manufacturing parts.
## What it does
The program takes a customizable trained deep learning model that can categorize over 1000 different classes of objects. When an object is placed in the foreground of the camera, its material is determined and its corresponding indicator light flashes. This is to replicate a small-scale automated sorting machine.
## How we built it
To begin, we studied relevant modules of the OpenCV library and explored ways to implement them for our specific project. We also determined specific categories/materials for different classes of objects to build our own library for sorting.
## Challenges we ran into
Due to time constraints, we were unable to train our own data set for the specific objects we wanted. Many pre-trained models are designed to run on much stronger hardware than a raspberry pi. Being limited to pre-trained databases added a level of difficulty for the software to detect our specific objects.
## Accomplishments that we're proud of
The project actually worked and was surprisingly better than we had anticipated. We are proud that we were able to find a compromise in the pre-trained model and still have a functioning application.
## What we learned
We learned how to use OpenCV for this application, and the many applications of this technology in the deep learning and IoT industry.
## What's next for Smart Materials Sort
We'd love to find a way to dynamically update the training model (supervised learning), and try the software with our own custom models. | ## Inspiration
As software engineers, we have all known what it's like to start from square one in our learning, especially when it comes to newer technologies constantly being developed around us like artificial intelligence. With concepts such as neural networks and machine learning becoming increasingly intimidating to tackle in modern day, we sought to take inspiration from simplistic user applications like Scratch that helped us learn to code with ordinary drag and drop mechanics! Optml provide a friendly, easy to use interface to build neural networks while getting introduced to the statistical concepts that make this technology possible.
## What it does
Optml allows the user to graphically design and tune their own machine learning model, learning what important terms mean, and more importantly, what they do in the process! The user can drag and drop to connect different types of nodes together to represent the different types of layers that can be utilized in a sequential model. Ranging from a simple perceptron, to AlexNet, to 3D convolutions, Optml already provides a wide range of network types to build. Once the user is satisfied with their model design, they can feed their training data and observe the results. Metrics will appear to document the accuracy and loss of the model as it undergoes training for a certain number of epochs. Furthermore, they can alter and perfect their layers and hyperparameters to get the best performing model they can.
For those trying to develop a use case, a download button is available to download the full h5 model with the trained weights. .h5 files can be easily used in keras based machine learning frameworks like tensorflow or huggingface, but can also be imported into other frameworks.
## Challenges we ran into
Another issue we ran into was the main thread in the backend was being clogged by the training process of large datasets. Our metrics logger was originally asynchronous, but we were training on CPU at the moment and it would use 100% CPU utilization. This would cause the server(a laptop)'s scheduler to shove the metrics updating thread in the back, not updating until the model was completely done training.
On a real server, or if we trained on a GPU this shouldn't have been an issue but in the meantime the metrics are logged synchronously.
## Accomplishments that we're proud of
Our graph that details the training data updates in real time as the model undergoes training. The UI's smoooth experience that works seamlessly with the processsing carried out in the backend is something we're incredibly proud of, as it gives us clear distinctions and differences on how changing the model can affect the end result of thet trained data.
## What we learned
Even though we were aware that different model architectures could have varying results, we were truly surprised at the variance in results we obtained in evaluating the training process of the model. Seemingly negligible changes to the data set size and neurons in a layer subjected us to wildly different ETAs from hours to milliseconds!
## What's next for optml
optiml is not yet capable of fully utilizing the powerful keras api, but we want to truly expand our reach to more capabilities. Visualization is a key tool in learning and we want to provide as much data to users as possible and allow them to experiment further! | partial |
## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app. | ## Inspiration
Our good friend's uncle was involved in a nearly-fatal injury. This led to him becoming deaf-blind at a very young age, without many ways to communicate with others. To help people like our friend's uncle, we decided to create HapticSpeak, a communication tool that transcends traditional barriers. As we have witnessed the challenges faced by deaf-blind individuals first hand, we were determined to bring help to these people.
## What it does
Our project HapticSpeak can take a users voice, and then converts the voice to text. The text is then converted to morse code. At this point, the morse code is sent to an arduino using the bluetooth module, where the arduino will decode the morse code into it's haptic feedback equivalents, allowing for the deafblind indivudals to understand what the user's said.
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for HapticSpeak | ## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandemic. The respondents also stated that some motivations included a loss of disposable time (due to an increase in workload from online learning), tight spending budgets, and fear of exposure to covid-19.
While developing our product strategy, we realized that a significant pain point in grocery shopping is the process of price-checking between different stores. This process would either require the user to visit each store (in-person and/or online) and check the inventory and manually price check. Consolidated platforms to help with grocery list generation and payment do not exist in the market today - as such, we decided to explore this idea.
**What does G.e.o.r.g.e stand for? : Grocery Examiner Organizer Registrator Generator (for) Everyone**
## What it does
The high-level workflow can be broken down into three major components:
1: Python (flask) and Firebase backend
2: React frontend
3: Stripe API integration
Our backend flask server is responsible for web scraping and generating semantic, usable JSON code for each product item, which is passed through to our React frontend.
Our React frontend acts as the hub for tangible user-product interactions. Users are given the option to search for grocery products, add them to a grocery list, generate the cheapest possible list, compare prices between stores, and make a direct payment for their groceries through the Stripe API.
## How we built it
We started our product development process with brainstorming various topics we would be interested in working on. Once we decided to proceed with our payment service application. We drew up designs as well as prototyped using Figma, then proceeded to implement the front end designs with React. Our backend uses Flask to handle Stripe API requests as well as web scraping. We also used Firebase to handle user authentication and storage of user data.
## Challenges we ran into
Once we had finished coming up with our problem scope, one of the first challenges we ran into was finding a reliable way to obtain grocery store information. There are no readily available APIs to access price data for grocery stores so we decided to do our own web scraping. This lead to complications with slower server response since some grocery stores have dynamically generated websites, causing some query results to be slower than desired. Due to the limited price availability of some grocery stores, we decided to pivot our focus towards e-commerce and online grocery vendors, which would allow us to flesh out our end-to-end workflow.
## Accomplishments that we're proud of
Some of the websites we had to scrape had lots of information to comb through and we are proud of how we could pick up new skills in Beautiful Soup and Selenium to automate that process! We are also proud of completing the ideation process with an application that included even more features than our original designs. Also, we were scrambling at the end to finish integrating the Stripe API, but it feels incredibly rewarding to be able to utilize real money with our app.
## What we learned
We picked up skills such as web scraping to automate the process of parsing through large data sets. Web scraping dynamically generated websites can also lead to slow server response times that are generally undesirable. It also became apparent to us that we should have set up virtual environments for flask applications so that team members do not have to reinstall every dependency. Last but not least, deciding to integrate a new API at 3am will make you want to pull out your hair, but at least we now know that it can be done :’)
## What's next for G.e.o.r.g.e.
Our next steps with G.e.o.r.g.e. would be to improve the overall user experience of the application by standardizing our UI components and UX workflows with Ecommerce industry standards. In the future, our goal is to work directly with more vendors to gain quicker access to price data, as well as creating more seamless payment solutions. | partial |
## Inspiration
Because of COVID-19, we're experiencing not only a global health crisis but also extreme psychological stress. The isolation and loneliness from social distancing, loss of personal and physical spaces, and not being able to enjoy the outdoors, for which there's growing evidence that nature helps relieve stress, are all taking its toll on people, To help relieve some of this stress using virtual reality, Moment of Bliss was created.
## What it does
Moment of Bliss is is a free VR therapy option for anyone who can use some respite from the stress of everyday life. While it's designed as a single player game, you can interact with other people virtually by leaving notes for the next person. It also offers a lot of open virtual space and ways to enjoy nature like birdwatching from the comfort of your room.
While the app was designed initially for veterans who may not have the means (e.g. transportation, nearby healthcare facility that offers it, money to pay for VR therapy) to take participate in virtual therapy for PTSD, the idea lends itself to a wider audience who fall under the umbrella of experiencing psychological stress. This app can also help people who cannot travel much or leave their space, have limited or no access to safe green spaces, are looking for free ways to destress, or want to feel connected with others while having a space they can call their own.
## How we built it
Unity, C#, EchoAR
## Challenges we ran into
I've learned that not all Unity projects translate nicely on webGL. I can build a standalone application and run it without issues, but when I built project in webGL and uploaded to simmer.io, the first scene works, but the main part of the project (lots of open natural space!) perhaps takes a long time to load because of its sheer size, so all I have is a still shot.
## Accomplishments that I'm proud of
Made a landscape from scratch in 3d using Unity!
## What I learned
A lot about Unity— start early. It took maybe 3x the amount of time to build the webGL product than it did to create a standalone app, and the standalone app took about 30 min to build. (Crazy, right?!)
## What's next for Moment of Bliss
Build out features (rainy area for those who enjoy listening to rain) and easter eggs | ## Inspiration
As university students, we are constantly pressured to prioritize recruiting while also balancing academics, extracurriculars, and well-being. We are expected to spend 10 hours or more on recruiting each week, and much of this time goes to mindlessly copying the same responses over and over again into job applications. We believe that with our application, we can significantly cut down these inefficiencies by storing and automatically filling repetitive portions of job applications.
## What it does
Our hack comes in two parts: a website application and a Chrome extension. The website application serves as a hub for all data entry and progress updates regarding job applications. Here, the user can identify commonly asked questions and prepare static responses. When filling out a job application, the user can open the Chrome extension, which will identify questions it has stored responses for and automatically fill out those fields.
## How we built it
The current demo of the application was made using Figma for the sketched and for the flow the app Overflow was used.
The frond end application would be done using HTML, CSS, Javascript and a framework such as React.
The extension was made using a manifest file, which includes the metadata for Chrome to be able to recognize it.
For the purposes of the Hackathon, the data was stored as a JSON file, but for future development it would be help in a secured database system.
## Challenges we ran into
From the beginning, we recognized that data security had to be a top priority, as our application could be storing possibly sensitive information regarding our users. We initially considered manually encrypting all of our stored data, but realized that we did not have the skills or resources to accomplish this task. In the end, we decided that it was in the best interest of our users and ourselves to outsource this to a professional data security company. This will not only ensure that our users' data is being kept secure, but also provide our users with peace of mind.
## Accomplishments that we're proud of
We are proud that we were able to have a demo displaying the user interface for where they would be entering their data. Being able to for the first time, create a Figma X Overflow product concept was an accomplishment. Further more, none of us had previously built a Google Chrome Extension before and learning how to do that and creating basic functionality is something we are extremely proud of.
## What we learned
We learned that there is a whole lot more that goes into making a pitch than initially expected. For instance, as a team we prioritized making our application functional, and it was only later that we realized our presentation needed to be more holistic approach, like including an action plan for development and deciding how we would finance the project.
## What's next for RE-Work
We hope to explore the idea of building an accompanying mobile app to increase accessibility and convenience for the user. This way, the user can access and edit their information easily on the go. Additionally, this would allow for push notifications to keep the user up to date on every related to job searching, and ease of mobile pay (ex. Apple Pay) when upgrading to our premium subscription.
## What it does | ## Inspiration
Having previously volunteered and worked with children with cerebral palsy, we were struck with the monotony and inaccessibility of traditional physiotherapy. We came up with a cheaper, more portable, and more engaging way to deliver treatment by creating virtual reality games geared towards 12-15 year olds. We targeted this age group because puberty is a crucial period for retention of plasticity in a child's limbs. We implemented interactive games in VR using Oculus' Rift and Leap motion's controllers.
## What it does
We designed games that targeted specific hand/elbow/shoulder gestures and used a leap motion controller to track the gestures. Our system improves motor skill, cognitive abilities, emotional growth and social skills of children affected by cerebral palsy.
## How we built it
Our games use of leap-motion's hand-tracking technology and the Oculus' immersive system to deliver engaging, exciting, physiotherapy sessions that patients will look forward to playing. These games were created using Unity and C#, and could be played using an Oculus Rift with a Leap Motion controller mounted on top. We also used an Alienware computer with a dedicated graphics card to run the Oculus.
## Challenges we ran into
The biggest challenge we ran into was getting the Oculus running. None of our computers had the ports and the capabilities needed to run the Oculus because it needed so much power. Thankfully we were able to acquire an appropriate laptop through MLH, but the Alienware computer we got was locked out of windows. We then spent the first 6 hours re-installing windows and repairing the laptop, which was a challenge. We also faced difficulties programming the interactions between the hands and the objects in the games because it was our first time creating a VR game using Unity, leap motion controls, and Oculus Rift.
## Accomplishments that we're proud of
We were proud of our end result because it was our first time creating a VR game with an Oculus Rift and we were amazed by the user experience we were able to provide. Our games were really fun to play! It was intensely gratifying to see our games working, and to know that it would be able to help others!
## What we learned
This project gave us the opportunity to educate ourselves on the realities of not being able-bodied. We developed an appreciation for the struggles people living with cerebral palsy face, and also learned a lot of Unity.
## What's next for Alternative Physical Treatment
We will develop more advanced games involving a greater combination of hand and elbow gestures, and hopefully get testing in local rehabilitation hospitals. We also hope to integrate data recording and playback functions for treatment analysis.
## Business Model Canvas
<https://mcgill-my.sharepoint.com/:b:/g/personal/ion_banaru_mail_mcgill_ca/EYvNcH-mRI1Eo9bQFMoVu5sB7iIn1o7RXM_SoTUFdsPEdw?e=SWf6PO> | losing |
## Inspiration
We got our inspiration from the countless calorie tracking apps. First of all, there isn't a single website we could find that tracked calories. There are a ton of apps, but not one website. Secondly, None of them offered recipes built in. In our website, the user can search for food items, and directly look at their recipes. Lastly, our nutrition analysis app analyses any food item you've ever heard of.
## What it does
Add food you eat in a day, track your calories, track fat%, and other nutrients, search recipes, and get DETAILED info about any food item/recipe.
## How we built it
Html, min.css, min.js, js, were planning on using deso/auth0 for login but couldnt due to time constraints.
## Challenges we ran into
We initially used react, but couldn't make the full app using react since we used static html to interact with the food apis. We also had another sole recipe finder app which we removed due to it being react only. Integrating the botdoc api was a MAJOR challenge, since we had no prior experience, and had no idea what we were doing basically. A suggestion to the BotDoc team would be to add demo apps to their documentation/tutorials, since currently theres literally nothing available except the documentation. The api is quite unheard of too as of now.
## Accomplishments that we're proud of
Making the website working, and getting it up and running using a github pages deployment
## What we learned
A LOT about botdoc, and refreshed our knowledge of html, css, js.
## What's next for Foodify
Improving the css firstly lol, right now its REALLY REALLY BAD. | ## Inspiration
We love cooking and watching food videos. From the Great British Baking Show to Instagram reels, we are foodies in every way. However, with the 119 billion pounds of food that is wasted annually in the United States, we wanted to create a simple way to reduce waste and try out new recipes.
## What it does
lettuce enables users to create a food inventory using a mobile receipt scanner. It then alerts users when a product approaches its expiration date and prompts them to notify their network if they possess excess food they won't consume in time. In such cases, lettuce notifies fellow users in their network that they can collect the surplus item. Moreover, lettuce offers recipe exploration and automatically checks your pantry and any other food shared by your network's users before suggesting new purchases.
## How we built it
lettuce uses React and Bootstrap for its frontend and uses Firebase for the database, which stores information on all the different foods users have stored in their pantry. We also use a pre-trained image-to-text neural network that enables users to inventory their food by scanning their grocery receipts. We also developed an algorithm to parse receipt text to extract just the food from the receipt.
## Challenges we ran into
One big challenge was finding a way to map the receipt food text to the actual food item. Receipts often use annoying abbreviations for food, and we had to find databases that allow us to map the receipt item to the food item.
## Accomplishments that we're proud of
lettuce has a lot of work ahead of it, but we are proud of our idea and teamwork to create an initial prototype of an app that may contribute to something meaningful to us and the world at large.
## What we learned
We learned that there are many things to account for when it comes to sustainability, as we must balance accessibility and convenience with efficiency and efficacy. Not having food waste would be great, but it's not easy to finish everything in your pantry, and we hope that our app can help find a balance between the two.
## What's next for lettuce
We hope to improve our recipe suggestion algorithm as well as the estimates for when food expires. For example, a green banana will have a different expiration date compared to a ripe banana, and our scanner has a universal deadline for all bananas. | ## Inspiration
Irresponsible substance use causes fatalities due to accidents and related incidents. Driving under the influence is one of the top 5 leading causes of death in young adults. 37 people die every day from a DUI-related accident--that's one person every 38 minutes. We aspire to build a convenient and accessible app that people can use to accurately determine whether they are in good condition to drive.
## What it does
BACScanner is a computer vision mobile app that compares iris–pupil ratio before and after substance intake for safer usage.
## How we built it
We built the mobile app with SwiftUI and the CV model using Pytorch and OpenCV. Our machine learning model was linked to the frontend by deploying a Flask API.
## Challenges we ran into
We were originally hoping to be able to figure out your sobriety based on one video of your eyes. However, found that it was fundamental to take a sober image as a control image to compare to and we had to amend our app to support taking a "before" image and an "after" image, comparing the two.
## Accomplishments that we're proud of
We implemented eye tracking and the segmentation neural network with 92% accuracy. We also made an elegant UI for the mobile app.
## What we learned
We learned about building full-stack apps that involve ML. Prior to this, we didn't know how to attach an ML model to a frontend app. We thus learned how to deploy our ML model to an API and link it to our front end using Flask.
## What's next for BACScanner
We hope to be able to add better recognition for narcotic usage, as right now our app can only accurately detect BAC. | winning |
## Summary
OrganSafe is a revolutionary web application that tackles the growing health & security problem of black marketing of donated organs. The verification of organ recipients leverages the Ethereum Blockchain to provide critical security and prevent improper allocation for such a pivotal resource.
## Inspiration
The [World Health Organization (WHO)](https://slate.com/business/2010/12/can-economists-make-the-system-for-organ-transplants-more-humane-and-efficient.html) estimates that one in every five kidneys transplanted per year comes from the black market. There is a significant demand for solving this problem which impacts thousands of people every year who are struggling to find a donor for a significantly need transplant. Modern [research](https://ieeexplore.ieee.org/document/8974526) has shown that blockchain validation of organ donation transactions can help reduce this problem and authenticate transactions to ensure that donated organs go to the right place!
## What it does
OrganSafe facilitates organ donations with authentication via the Ethereum Blockchain. Users can start by registering on OrganSafe with their health information and desired donation and then application's algorithms will automatically match the users based on qualifying priority for available donations. Hospitals can easily track donations of organs and easily record when recipients receive their donation.
## How we built it
This application was built using React.js for the frontend of the platform, Python Flask for the backend and API endpoints, and Solidity+Web3.js for Ethereum Blockchain.
## Challenges we ran into
Some of the biggest challenges we ran into were connecting the different components of our project. We had three major components: frontend, backend, and the blockchain that were developed on that needed to be integrated together. This turned to be the biggest hurdle in our project that we needed to figure out. Dealing with the API endpoints and Solidarity integration was one of the problems we had to leave for future developments. One solution to a challenge we solved was dealing with difficulty of the backend development and setting up API endpoints. Without a persistent data storage in the backend, we attempted to implement basic storage using localStorage in the browser to facilitate a user experience. This allowed us to implement a majority of our features as a temporary fix for our demonstration. Some other challenges we faced included figuring certain syntactical elements to the new technologies we dealt (such as using Hooks and States in React.js). It was a great learning opportunity for our group as immersing ourselves in the project allowed us to become more familiar with each technology!
## Accomplishments that we're proud of
One notable accomplishment is that every member of our group interface with new technology that we had little to no experience with! Whether it was learning how to use React.js (such as learning about React fragments) or working with Web3.0 technology such as the Ethereum Blockchain (using MetaMask and Solidity), each member worked on something completely new! Although there were many components we simply just did not have the time to complete due to the scope of TreeHacks, we were still proud with being able to put together a minimum viable product in the end!
## What we learned
* Fullstack Web Development (with React.js frontend development and Python Flask backend development)
* Web3.0 & Security (with Solidity & Ethereum Blockchain)
## What's next for OrganSafe
After TreeHacks, OrganSafe will first look to tackle some of the potential areas that we did not get to finish during the time of the Hackathon. Our first step would be to finish development of the full stack web application that we intended by fleshing out our backend and moving forward from there. Persistent user data in a data base would also allow users and donors to continue to use the site even after an individual session. Furthermore, scaling both the site and the blockchain for the application would allow greater usage by a larger audience, allowing more recipients to be matched with donors. | ## About the Project
### TLDR:
Caught a fish? Take a snap. Our AI-powered app identifies the catch, keeps track of stats, and puts that fish in your 3d, virtual, interactive aquarium! Simply click on any fish in your aquarium, and all its details — its rarity, location, and more — appear, bringing your fishing memories back to life. Also, depending on the fish you catch, reel in achievements, such as your first fish caught (ever!), or your first 20 incher. The cherry on top? All users’ catches are displayed on an interactive map (built with Leaflet), where you can discover new fishing spots, or plan to get your next big catch :)
### Inspiration
Our journey began with a simple observation: while fishing creates lasting memories, capturing those moments often falls short. We realized that a picture might be worth a thousand words, but a well-told fish tale is priceless. This spark ignited our mission to blend the age-old art of fishing with cutting-edge AI technology.
### What We Learned
Diving into this project was like casting into uncharted waters – exhilarating and full of surprises. We expanded our skills in:
* Integrating AI models (Google's Gemini LLM) for image recognition and creative text generation
* Crafting seamless user experiences in React
* Building robust backend systems with Node.js and Express
* Managing data with MongoDB Atlas
* Creating immersive 3D environments using Three.js
But beyond the technical skills, we learned the art of transforming a simple idea into a full-fledged application that brings joy and preserves memories.
### How We Built It
Our development process was as meticulously planned as a fishing expedition:
1. We started by mapping out the user journey, from snapping a photo to exploring their virtual aquarium.
2. The frontend was crafted in React, ensuring a responsive and intuitive interface.
3. We leveraged Three.js to create an engaging 3D aquarium, bringing caught fish to life in a virtual environment.
4. Our Node.js and Express backend became the sturdy boat, handling requests and managing data flow.
5. MongoDB Atlas served as our net, capturing and storing each precious catch securely.
6. The Gemini AI was our expert fishing guide, identifying species and spinning yarns about each catch.
### Challenges We Faced
Like any fishing trip, we encountered our fair share of challenges:
* **Integrating Gemini AI**: Ensuring accurate fish identification and generating coherent, engaging stories required fine-tuning and creative problem-solving.
* **3D Rendering**: Creating a performant and visually appealing aquarium in Three.js pushed our graphics programming skills to the limit.
* **Data Management**: Structuring our database to efficiently store and retrieve diverse catch data presented unique challenges.
* **User Experience**: Balancing feature-rich functionality with an intuitive, streamlined interface was a constant tug-of-war.
Despite these challenges, or perhaps because of them, our team grew stronger and more resourceful. Each obstacle overcome was like landing a prized catch, making the final product all the more rewarding.
As we cast our project out into the world, we're excited to see how it will evolve and grow, much like the tales of fishing adventures it's designed to capture. | # Ethoken
## Inspiration
We wanted to apply blockchain technologies towards the problems we identified in the banking industry.
## What it does
Ethoken is a mobile first banking platform that **decouples traditional banking services**. This allows users to fully customize their personal banking experience. Core to our platform is the belief that that we are moving to a future of open banking. Users will be able to pick and choose financial applications from different banks to design a unique banking platform personalized to their needs. We provide users a personal dashboard where they can pick and choose specific banking services to fit their lifestyles.
## How we built it
The DAPP (Decentralized Application) is built as a Node.js web app with the Express.js framework. By being a fully Decentralized Application, The back end is custom **Solidity Smart Contracts** that are hosted on the Ethereum blockchain. We use **web3.js** to relay with a remote Ethereum node. Authentication is done using **Uport Biometric Identity Management** which is highly secure and is required for app login and signing all transactions with a **biometrically verified hash ID**.
## Challenges we ran into
Building blockchain applications is challenging because it introduces new programming paradigms. Especially integrating uPort interact with Ethereum dApps right in your browser. Designing the UX/UI was also challenging requiring us to hide complex technologies under a simple, intuitive interface.
## Accomplishments that I'm proud of
Integrating smart contracts to work with the mobile and web interface.
## What I learned
Integrating Solidity, Web3, uPort, Node and Vue
## What's next for test
Developing new banking extensions that can be integrated into the Ethoken app.
## Getting Started
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes. See deployment for notes on how to deploy the project on a live system.
### Prerequisites
Uport installed from the app store on your phone.
### Installing
1. Simply clone the project and run: npm install
2. npm install
3. npm start
4. Visit <http://localhost:3000/>
5. That's it!
## Built With
* [Solidity](https://solidity.readthedocs.io/en/develop/) - Ethereum Smart contracts
* [Web3](https://github.com/ethereum/wiki/wiki/JavaScript-API) - Ethereum javascript interface
* [uPort](https://www.uport.me/) - Identity tracking
* [Node.js](https://nodejs.org/en/) - Server-side javascript framework
* [Vue.js](https://vuejs.org/) - Progressive javascript framework
## Authors
* [Daniel Anatolie](https://github.com/danielanatolie)
* [Behnam Ghassemi](https://github.com/behnamx)
* [Ryan Scovill](https://github.com/ryanscovill)
* [Matthew Siu](https://github.com/Siunami) | winning |
## Inspiration
The need for faster and more reliable emergency communication in remote areas inspired the creation of FRED (Fire & Rescue Emergency Dispatch). Whether due to natural disasters, accidents in isolated locations, or a lack of cellular network coverage, emergencies in remote areas often result in delayed response times and first-responders rarely getting the full picture of the emergency at hand. We wanted to bridge this gap by leveraging cutting-edge satellite communication technology to create a reliable, individualized, and automated emergency dispatch system. Our goal was to create a tool that could enhance the quality of information transmitted between users and emergency responders, ensuring swift, better informed rescue operations on a case-by-case basis.
## What it does
FRED is an innovative emergency response system designed for remote areas with limited or no cellular coverage. Using satellite capabilities, an agentic system, and a basic chain of thought FRED allows users to call for help from virtually any location. What sets FRED apart is its ability to transmit critical data to emergency responders, including GPS coordinates, detailed captions of the images taken at the site of the emergency, and voice recordings of the situation. Once this information is collected, the system processes it to help responders assess the situation quickly. FRED streamlines emergency communication in situations where every second matters, offering precise, real-time data that can save lives.
## How we built it
FRED is composed of three main components: a mobile application, a transmitter, and a backend data processing system.
```
1. Mobile Application: The mobile app is designed to be lightweight and user-friendly. It collects critical data from the user, including their GPS location, images of the scene, and voice recordings.
2. Transmitter: The app sends this data to the transmitter, which consists of a Raspberry Pi integrated with Skylo’s Satellite/Cellular combo board. The Raspberry Pi performs some local data processing, such as image transcription, to optimize the data size before sending it to the backend. This minimizes the amount of data transmitted via satellite, allowing for faster communication.
3. Backend: The backend receives the data, performs further processing using a multi-agent system, and routes it to the appropriate emergency responders. The backend system is designed to handle multiple inputs and prioritize critical situations, ensuring responders get the information they need without delay.
4. Frontend: We built a simple front-end to display the dispatch notifications as well as the source of the SOS message on a live-map feed.
```
## Challenges we ran into
One major challenge was managing image data transmission via satellite. Initially, we underestimated the limitations on data size, which led to our satellite server rejecting the images. Since transmitting images was essential to our product, we needed a quick and efficient solution. To overcome this, we implemented a lightweight machine learning model on the Raspberry Pi that transcribes the images into text descriptions. This drastically reduced the data size while still conveying critical visual information to emergency responders. This solution enabled us to meet satellite data constraints and ensure the smooth transmission of essential data.
## Accomplishments that we’re proud of
We are proud of how our team successfully integrated several complex components—mobile application, hardware, and AI powered backend—into a functional product. Seeing the workflow from data collection to emergency dispatch in action was a gratifying moment for all of us. Each part of the project could stand alone, showcasing the rapid pace and scalability of our development process. Most importantly, we are proud to have built a tool that has the potential to save lives in real-world emergency scenarios, fulfilling our goal of using technology to make a positive impact.
## What we learned
Throughout the development of FRED, we gained valuable experience working with the Raspberry Pi and integrating hardware with the power of Large Language Models to build advanced IOT system. We also learned about the importance of optimizing data transmission in systems with hardware and bandwidth constraints, especially in critical applications like emergency services. Moreover, this project highlighted the power of building modular systems that function independently, akin to a microservice architecture. This approach allowed us to test each component separately and ensure that the system as a whole worked seamlessly.
## What’s next for FRED
Looking ahead, we plan to refine the image transmission process and improve the accuracy and efficiency of our data processing. Our immediate goal is to ensure that image data is captioned with more technical details and that transmission is seamless and reliable, overcoming the constraints we faced during development. In the long term, we aim to connect FRED directly to local emergency departments, allowing us to test the system in real-world scenarios. By establishing communication channels between FRED and official emergency dispatch systems, we can ensure that our product delivers its intended value—saving lives in critical situations. | As a response to the ongoing wildfires devastating vast areas of Australia, our team developed a web tool which provides wildfire data visualization, prediction, and logistics handling. We had two target audiences in mind: the general public and firefighters. The homepage of Phoenix is publicly accessible and anyone can learn information about the wildfires occurring globally, along with statistics regarding weather conditions, smoke levels, and safety warnings. We have a paid membership tier for firefighting organizations, where they have access to more in-depth information, such as wildfire spread prediction.
We deployed our web app using Microsoft Azure, and used Standard Library to incorporate Airtable, which enabled us to centralize the data we pulled from various sources. We also used it to create a notification system, where we send users a text whenever the air quality warrants action such as staying indoors or wearing a P2 mask.
We have taken many approaches to improving our platform’s scalability, as we anticipate spikes of traffic during wildfire events. Our codes scalability features include reusing connections to external resources whenever possible, using asynchronous programming, and processing API calls in batch. We used Azure’s functions in order to achieve this.
Azure Notebook and Cognitive Services were used to build various machine learning models using the information we collected from the NASA, EarthData, and VIIRS APIs. The neural network had a reasonable accuracy of 0.74, but did not generalize well to niche climates such as Siberia.
Our web-app was designed using React, Python, and d3js. We kept accessibility in mind by using a high-contrast navy-blue and white colour scheme paired with clearly legible, sans-serif fonts. Future work includes incorporating a text-to-speech feature to increase accessibility, and a color-blind mode. As this was a 24-hour hackathon, we ran into a time challenge and were unable to include this feature, however, we would hope to implement this in further stages of Phoenix. | ## Inspiration
A couple weeks ago, a threat aimed at our university caused us to ponder current safety protocols and what would happen in the event of an emergency. Some students weren't even aware of the threat as they hadn't seen the e-mail. We felt that today's technology could empower us to react better to emergency situations, and we decided to prototype some of our ideas at YHack 2015.
## What it does
SafetyNet provides an infrastructure for "networks" (college campuses, hospitals, corporate offices) that allows both members and administrators to communicate rapidly and make informed decisions in emergency situations, preventing injury and even saving lives.
In an emergency situation, dispatchers can activate the emergency alert system, which gives a high-level overview of the situation and the location of all members of the network. The dispatcher can send out specific alerts that will reach members in just seconds, and the system will automatically calculate the fastest route to safety for each member, even when typical routes may be blocked or otherwise dangerous. Firefighters and other first responders can leverage our system to quickly locate those in dire need of help.
## How I built it
The SafetyNet application is built upon a PHP/MySQL back-end, which synchronizes data among all the components of the system. The dispatcher / administrative control panel is a highly-responsive web application powered by Javascript and AJAX requests. The mobile endpoints (the Android app and the ultra-thin web client) were written in Java and Javascript, respectively.
## Challenges I ran into
Mobile development took the most time and effort, despite the relative simplicity of the endpoint application. Features like push notifications, which provide speedy communication, and positioning, which provide the valuable location data to dispatchers, took a lot of time to set up and integrate cross-platform.
## Accomplishments that I'm proud of
The dispatcher / administrator control panel turned out very well with regards to design and functionality. We had a daunting task to keep the page in sync with the state of the frequently-updating database, but all of the pieces came together after a bit of hacking.
## What I learned
We learned about how ambitious it is to develop an application that spans multiple platforms. We had originally planned to create interfaces for numerous operating systems and wearables, but were limited to just a few under the 36 hour constraint. Similarly, we learned how flexible web development can be in a cross-platform environment.
## What's next for SafetyNet
We feel that this hack tackles a serious contemporary issue, and we think there is something to learn from what we've created at YHack. This application would likely require a lot of manpower to implement as-is, but it is an interesting concept that could be potentially integrated into future mobile operating systems in an effort to leverage newer technology to help us live better and keep us safe. | winning |
## Inspiration
University gets students really busy and really stressed, especially during midterms and exams. We would normally want to talk to someone about how we feel and how our mood is, but due to the pandemic, therapists have often been closed or fully online. Since people will be seeking therapy online anyway, swapping a real therapist with a chatbot trained in giving advice and guidance isn't a very big leap for the person receiving therapy, and it could even save them money. Further, since all the conversations could be recorded if the user chooses, they could track their thoughts and goals, and have the bot respond to them. This is the idea that drove us to build Companion!
## What it does
Companion is a full-stack web application that allows users to be able to record their mood and describe their day and how they feel to promote mindfulness and track their goals, like a diary. There is also a companion, an open-ended chatbot, which the user can talk to about their feelings, problems, goals, etc. With realtime text-to-speech functionality, the user can speak out loud to the bot if they feel it is more natural to do so. If the user finds a companion conversation helpful, enlightening or otherwise valuable, they can choose to attach it to their last diary entry.
## How we built it
We leveraged many technologies such as React.js, Python, Flask, Node.js, Express.js, Mongodb, OpenAI, and AssemblyAI. The chatbot was built using Python and Flask. The backend, which coordinates both the chatbot and a MongoDB database, was built using Node and Express. Speech-to-text functionality was added using the AssemblyAI live transcription API, and the chatbot machine learning models and trained data was built using OpenAI.
## Challenges we ran into
Some of the challenges we ran into were being able to connect between the front-end, back-end and database. We would accidentally mix up what data we were sending or supposed to send in each HTTP call, resulting in a few invalid database queries and confusing errors. Developing the backend API was a bit of a challenge, as we didn't have a lot of experience with user authentication. Developing the API while working on the frontend also slowed things down, as the frontend person would have to wait for the end-points to be devised. Also, since some APIs were relatively new, working with incomplete docs was sometimes difficult, but fortunately there was assistance on Discord if we needed it.
## Accomplishments that we're proud of
We're proud of the ideas we've brought to the table, as well the features we managed to add to our prototype. The chatbot AI, able to help people reflect mindfully, is really the novel idea of our app.
## What we learned
We learned how to work with different APIs and create various API end-points. We also learned how to work and communicate as a team. Another thing we learned is how important the planning stage is, as it can really help with speeding up our coding time when everything is nice and set up with everyone understanding everything.
## What's next for Companion
The next steps for Companion are:
* Ability to book appointments with a live therapists if the user needs it. Perhaps the chatbot can be swapped out for a real therapist for an upfront or pay-as-you-go fee.
* Machine learning model that adapts to what the user has written in their diary that day, that works better to give people sound advice, and that is trained on individual users rather than on one dataset for all users.
## Sample account
If you can't register your own account for some reason, here is a sample one to log into:
Email: [demo@example.com](mailto:demo@example.com)
Password: password | ## Inspiration
Senior suicides have tripled in the last decade due to the large baby boomer population retiring alone. Loneliness is the biggest problem seniors face that contributes to their mental health. According to an AARP survey, a third of adults over the age of 65 are lonely and highly prone to suicidal thoughts. With this in mind, we aspired to create a solution to this problem by allowing senior citizens to gain a friend!
## What It Does
GAiN a Friend is a speech-driven video chat service powered by Generative Adversarial Networks (GAN). This is done by selecting a human face and voice that resonates with the user most. After the persona is selected, the user can begin interacting with the GAN-generated person 24/7.
## How We Built It
GAiN a Friend is built using Generative AI, particularly Generative Adversarial Networks. In order to run these large models, we needed to use Deep Learning VMs from Google Cloud to run these models on high compute engines. For conversational AI and speech conversation, Houndify APIs were used.
## Ethical Considerations
Mass media has been increasingly focused on a future with AI, with movies such as Her and Ex Machina to TV shows such as Black Mirror. As our team was brainstorming this idea of a chatbot to improve communication and curb feelings of isolation, we kept considering the ethical implications of our work and focused on three main conditions.
1. Privacy and Data Ownership: As seen from the first ELIZA chatbot in the 1960s, humans are inclined to trust bots (and not believe that it's a program!) and tell it sensitive information. It is imperative that a user's valuable information stays with the user and does not fall into other hands. *With this in mind, our team decided to store the program and information locally and not share the data collected.* We are also not collecting any videos of the user to ensure that their autonomy is respected.
2. Transparency: In order to build trust between the user and company, we must be upfront about our chatbot. *To ensure there is no confusion between the bot and a human, we have added a disclaimer to our site letting the user know their conversation is with a bot.* Moreover, our code is open source so anyone that is curious to understand the "behind the scenes" of our chatbot is welcome to take a look!
3. User Safety and Protection: There have been many cases of hackers influencing digital personal assistants to go rogue or turn into wiretaps. *To ensure this doesn’t happen, our “friend” uses the Houndify small-talk API to make sure the user can have broad conversations.* Furthermore, with minorities and LGBTQ+ elders feeling significantly more lonely than others, our chatbot will not make any assumptions about the user and can be easily accessible by all populations.
## Challenges We Ran Into
* Learned how to use GANs for the first time
* Using Python 2.7 packages for Python 3.5 was... INSANELY CHALLENGING
* Dealing with deprecated packages
* Caching errors on Jupyter Notebook that have cryptic errors
* Using JavaScript in a Flask app for audio recording
* Learned how to use ethics into consideration in our design solution
* Working with team you've never worked with before
## Accomplishments That We Are Proud Of
We are proud of being an ALL WOMEN team :)
## What's Next for GAiN a Friend
In the future, this concept can easily be expanded to the service sector for service providers, such as psychologist, physicians, and family members. GAiN a Friend wants to incorporate additional API. Focus on a more accessible design for the App development to help elderly folks interact with the app better. | ## Inspiration
We got together a team passionate about social impact, and all the ideas we had kept going back to loneliness and isolation. We have all been in high pressure environments where mental health was not prioritized and we wanted to find a supportive and unobtrusive solution. After sharing some personal stories and observing our skillsets, the idea for Remy was born. **How can we create an AR buddy to be there for you?**
## What it does
**Remy** is an app that contains an AR buddy who serves as a mental health companion. Through information accessed from "Apple Health" and "Google Calendar," Remy is able to help you stay on top of your schedule. He gives you suggestions on when to eat, when to sleep, and personally recommends articles on mental health hygiene. All this data is aggregated into a report that can then be sent to medical professionals. Personally, our favorite feature is his suggestions on when to go on walks and your ability to meet other Remy owners.
## How we built it
We built an iOS application in Swift with ARKit and SceneKit with Apple Health data integration. Our 3D models were created from Mixima.
## Challenges we ran into
We did not want Remy to promote codependency in its users, so we specifically set time aside to think about how we could specifically create a feature that focused on socialization.
We've never worked with AR before, so this was an entirely new set of skills to learn. His biggest challenge was learning how to position AR models in a given scene.
## Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for.
## What we learned
Aside from this being many of the team's first times work on AR, the main learning point was about all the data that we gathered on the suicide epidemic for adolescents. Suicide rates have increased by 56% in the last 10 years, and this will only continue to get worse. We need change.
## What's next for Remy
While our team has set out for Remy to be used in a college setting, we envision many other relevant use cases where Remy will be able to better support one's mental health wellness.
Remy can be used as a tool by therapists to get better insights on sleep patterns and outdoor activity done by their clients, and this data can be used to further improve the client's recovery process. Clients who use Remy can send their activity logs to their therapists before sessions with a simple click of a button.
To top it off, we envisage the Remy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene tips and even lifestyle advice, Remy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery. | partial |
## Inspiration
The members are part of a working/studying community that tends to rely on caffeine to improve their performance and focus. Over the years, this community has been expanding, as the idea of drinking a coffee or energetic drink becomes a trending activity, fostering new types of beverages in the market and coffee shops. While caffeine benefits one's performance, people tend to overestimate the advantages and neglect caffeine's side effects. If you consumes in the wrong amount or at the wrong time, caffeine can take the entire productivity thing against you: you will feel more fatigue, headaches, excessive anxiety, or harm sleep quality. The team's members and many others have experienced the side effects, without exactly knowing the underlying cause and feeling even more frustrated because they assumed that caffeine would enhance their performance. Therefore, the team created the Caffeine Intake Advisor to prevent people from consuming caffeine in an ineffective and potentially unhealthy way.
Zepp's Smart watch also contributes to the ideation process. The advisor relies on a person's biological data to recommend accurate caffeine amounts, thus facilitating the user's life. Given that Zepp's Smart Watch is capable of collecting relevant and various data, such as sleep quality and stress level, the team is confident that the product will impact people's well-being.
## What it does
In terms of direct interaction with the user: when the user wants to consume caffeine and have a productive session soon, they will enter the Caffeine Intake Advisor app in the smartwatch. The app will ask about their caffeine beverage or food preference, their goal ( duration of the work session), and based on the datasets that reveal the user's past biological responses to specific amounts of caffeine, the user's on-time health metrics, and the time of the day, recommend a final amount of caffeine to the user.
In terms of what happens in the back end:
To recommend the amount of caffeine a user can drink per day, the app needs to know: the user’s regular caffeine intake and the user’s caffeine sensitivity. These variables will be measured through Step 2 below.
## How the user’s data will be collected and used:
### 1. (First, the app will give an initial questionnaire when the person creates the account) The questionnaire mainly aims to gather this information:
1. **Serving size:** Amount of caffeinated drinks that the person drinks per day ( as well as the amount of caffeinated food)
2. **Time**: The usual time period that the person is used to intake
3. **Variability**: Does the person consume the same serving size every day? Or they drink more at specific times of the day
4. **Duration of habit:** for how long does the person have this habit.
### 2.After, the app will begin to measure, for 5 days, the coffee sensitivity based on these real-time data:
1. Sleeping pattern: sleep time and wake-up time
2. Here is how the machine will track the sleeping pattern in these 5 days
1. I\***dentify the sleeping pattern baseline:**\* the usual sleep time and wake up time before the 5-days observation period. This can be extracted from the questionnaire above
2. **Identify the effects on sleeping pattern based on intake variation:** During the monitoring week, the person can consume different amounts of caffeine and vary the timing of caffeine intake on different days. For example, they might have a standard amount of caffeine (their usual) on some days and a reduced or increased amount on other days. They can also adjust the time of caffeine consumption, such as having caffeine earlier or later in the day. Record the sleep-related data at regular intervals throughout the monitoring week.
**After getting these data, the machine should :**
* Compare sleep patterns on days with standard caffeine intake to days with reduced or increased caffeine intake.
* Regular Timing and sleep pattern: Compare sleep patterns on days with standard caffeine intake to days with hours before the sleeping time ( this can be extracted from extracting the time of the day the person consume caffeine)
1. Stress level and Heart rate
2. Here is how the machine will track the stress and heart rate in these 5 days
1. Identify the person’s stress level and heart’s rate baseline\*\*\*: starts recording stress levels and heart rate from the moment the individual wakes up in the morning, before consuming any caffeine.
2. Measure the caffeine direct impact on the person :\*\*\* measure the stress and hear rate immediately after the person consumes their first dose of caffeine for the day.
### 3. After knowing the user’s Regular Caffeine Intake after 5 days. The watch can now recommend the caffeine intake every time the user wants to consume. To do that, the machine needs to calculate the `x amount of caffeine per y hours of focus` without yielding negative effects. To do that the machine will use this formula
**Caffeine Amount (mg) = Regular Caffeine Intake x Caffeine Sensitivity Factor x Study Duration x Time Gap Factor**
EXAMPLE:
```
**Hypothetical Values:**
- Regular Caffeine Intake: 200 mg (the individual's typical daily caffeine consumption)
- Caffeine Sensitivity Factor: 0.5 (a multiplier representing the individual's moderate caffeine sensitivity)
- Study Goal: Stay awake and enhance focus
- Study Duration: 4 hours (the intended duration of the study session)
- Time of Study: 7:00 PM to 11:00 PM (4 hours before the individual's typical bedtime at 11:00 PM)
- Desired Sleep Quality: The individual prefers to have high-quality sleep without disruptions.
**Simplified Calculation:**
Now, we'll consider the timing of caffeine consumption and its impact on sleep quality to estimate the amount of caffeine needed:
1. **Assessing Timing and Sleep Quality:**
- Calculate the time gap between the end of the study session (11:00 PM) and bedtime (11:00 PM). In this case, it's zero hours, indicating the study session ends at bedtime.
- Since the individual desires high-quality sleep, we aim to minimize caffeine's potential effects on sleep disruption.
2. **Caffeine Amount Calculation:**
- To achieve the study goal (staying awake and enhancing focus) without impacting sleep quality, we aim to use the caffeine primarily during the study session.
- We'll calculate the amount of caffeine needed during the study session to maintain focus, which is the 4-hour duration.
```
* T\*ime gap factor\* = hours before sleep time ( time when intaking caffeine - sleep time)
## How we built it
We use intel data to train an algorithm. Use minds dp to connect the machine learning algorithm with our software.
The process can be categorized into several components:
Researching Key Factors and Features to Include in the Smartwatch
We went through several scientific research about what factors affect people’s caffeine intake, and how different amounts of caffeine impact performance and trigger side effects based on people's caffeine sensitivity level and regular caffeine intake. We also organized a table that specifies types of caffeinated beverages and food according to the amount of caffeine based on their quantity in different units ( for example, in grams or ounces).
UI/UX Design/ Product Management
We first designed two types of wireframes of the smartwatch and tried which provided an easier and smoother process, so the user can get their caffeine intake recommendation as easily, convenient, and accurately as possible.
After deciding on the user flow, we looked into specific features and their placements on the interfaces, brainstorming the questions:
* Which feature is needed to accomplish task x
* Which feature is relevant ( but not necessary) to improve the user's experience during task x
* What is the hierarchy of the visual and textual elements that prevent cognitive load ( consider the smartwatch interface) and appeal to the user's intuitive navigation in the app
Training Algorithms
We make use of MindsDB pre-train models to predict the amount of caffeine each person can have according to the goal and body's condition. This algorithm is based on two types of datasets:
* existing datasets online backed up by scientific research: it includes the biological factors that contribute to user's caffeine sensitivity
* real-time data collected from the smartwatch of each user about their on-time body reactions ( through heartbeats, stress level, sleep quality) in the period of caffeine consumption.
After research and training , the algorithm derives in the formula:
Caffeine Amount (mg) = Regular Caffeine Intake x Caffeine Sensitivity Factor x Study Duration x Time Gap Factor.
Code
To implement back-end code to the hardware and display the codes in the smart watch's interface, the team used JavaScript in VS code. Additionally, we integrated our work with Zepp OS API and their AutoGUI, as well as Figma in into visualize the UI/UX aspect
## Challenges we ran into
One of the most significant challenges we met was discerning which features of the app to focus on, so we can maximize the social impact considering the time and resources constraints of the hackathon.
There is not enough real user datasets available to the public because of the confidentiality of human biological data and the lack of existing solutions that use these datasets ( the topic of caffeine intake has been limited to scholarly research, but not applied largely in today's enterprise solutions). This was time-consuming and frustrating at first since we didn't know which problem to work on as we didn't have previous user experiences to refer to. Therefore, we had to put extra effort and time into the research outlined in the section above, in which we had to calculate with MindDB the mathematical formulas, and from them, hypothesize the values and elaborate our own data sets.
## Accomplishments that we're proud of
One of our most notable achievements is integrating software with hardware given that no one in the team has any prior experience in this kind of development.
Another accomplishment is to work around our constraints and come up with a realistic and effective solution. Since there were no datasets regarding people’s reactions to varying amounts of caffeine, we had to draw on other types of data to estimate approximate statistics about a user’s caffeine sensitivity and regular intake. For example, we researched how factors like heart rate and sleep quality affect the caffeine effect on the user, and applied the insights on a mathematical formula to generate the data we needed
## What we learned
The team improved its ability to connect the application's front end with the back end. Additionally, we enhanced our skills in critical thinking, helping us decide which datasets to gather and how to use them effectively to benefit the user.
Moreover, we honed our problem-solving skills to explore methods that can have a substantial impact on the user.
Lastly, we enhanced our communication skills by presenting the key aspects of our solution concisely and providing clear responses to the judges' questions.
## What's next for Caffeine Intake Recommender
As we continue to develop our app, our aim is to make it more tailored to our users' needs. To provide even more personalized recommendations, we will also add questionnaire features for individual factors such as age, medications, pregnancy, menstrual cycles, and caffeine preferences. Our algorithms will monitor real-time data on users' responses to caffeine consumption and refine the predictions accordingly.
Moreover, we are working on integrating our app with other health and fitness apps and devices to create a more comprehensive view of users' health and fitness data. With this approach, users can get a more holistic understanding of their health and fitness. Specifically, we plan to add caffeine intake tracking to AI assistants such as Apple’s Siri and Amazon’s Alexa, with simple commands like "Alexa, log a cup of espresso."
These advancements will enable users to keep track of their caffeine intake more effectively and help them make better decisions for their overall health and wellness. | ## Inspiration:
The inspiration for this project was finding a way to incentivize healthy activity. While the watch shows people data like steps taken and calories burned, that alone doesn't encourage many people to exercise. By making the app, we hope to make exercise into a game that people look forward to doing rather than something they dread.
## What it does
Zepptchi is an app that allows the user to have their own virtual pet that they can take care of, similar to that of a Tamagotchi. The watch tracks the steps that the user takes and rewards them with points depending on how much they walk. With these points, the user can buy food to nourish their pet which incentivizes exercise. Beyond this, they can earn points to customize the appearance of their pet which further promotes healthy habits.
## How we built it
To build this project, we started by setting up the environment on the Huami OS simulator on a Macbook. This allowed us to test the code on a virtual watch before implementing it on a physical one. We used Visual Studio Code to write all of our code.
## Challenges we ran into
One of the main challenges we faced with this project was setting up the environment to test the watch's capabilities. Out of the 4 of us, only one could successfully install it. This was a huge setback for us since we could only write code on one device. This was worsened by the fact that the internet was unreliable so we couldn't collaborate through other means. One other challenge was
## Accomplishments that we're proud of
Our group was most proud of solving the issue where we couldn't get an image to display on the watch. We had been trying for a couple of hours to no avail but we finally found out that it was due to the size of the image. We are proud of this because fixing it showed that our work hadn't been for naught and we got to see our creation working right in front of us on a mobile device. On top of this, this is the first hackathon any of us ever attended so we are extremely proud of coming together and creating something potentially life-changing in such a short time.
## What we learned
One thing we learned is how to collaborate on projects with other people, especially when we couldn't all code simultaneously. We learned how to communicate with the one who *was* coding by asking questions and making observations to get to the right solution. This was much different than we were used to since school assignments typically only have one person writing code for the entire project. We also became fairly well-acquainted with JavaScript as none of us knew how to use it(at least not that well) coming into the hackathon.
## What's next for Zepptchi
The next step for Zepptchi is to include a variety of animals/creatures for the user to have as pets along with any customization that might go with it. This is crucial for the longevity of the game since people may no longer feel incentivized to exercise once they obtain the complete collection. Additionally, we can include challenges(such as burning x calories in 3 days) that give specific rewards to the user which can stave off the repetitive nature of walking steps, buying items, walking steps, buying items, and so on. With this app, we aim to gamify a person's well-being so that their future can be one of happiness and health. | # 💥 - How it all started
As students, we always try to optimize everything from our study habits to our sleep schedules. But above all, we agreed that the most important thing to optimize was also the most neglected: health. After a careful look into the current status of health-tracking apps, we noticed a few main problems.
A surplus of health apps: With an excessive number of health apps on the market, users can feel overwhelmed when choosing the right app for their needs while balancing trade-offs missed from other apps. This also leads to a variety of charges and memberships required for necessary health features.
Lacks a call to action: While the mass amount of health data from wearables is beneficial, health apps lack actionable steps you can take to improve in areas you are lacking.
Unclear impact: While metrics and health data are important, health apps fail to alert users of the severity of possible problems with their health. Users can’t differentiate a singularly bad day versus a heavy risk of depression with the current status of health apps.
# 📖 - What it does
We built OptiFi to create a novel, multifaceted approach to creating an all-inclusive health app based on users' health data. We created four main features to fully encapsulate the main use cases of a variety of health apps shown in the slideshow above: Diagnosis, Nutrition Scanner, Health Overview, and Automated Scheduler. Using advanced data analytics, generative AI, and cloud computing, we can take health data, create personalized daily habits, and import them straight into their Google calendar. Check out the other features:
##### Diagnostic:
Based on the data collected by your wearable health data tracking device, we diagnose the user with their three most prevalent health concerns with GPT-4o. Specifically, with OpenAI Assistants we added the user’s parsed health data to the LLM’s context window. The list of worries is supplemented by its estimated risk factor to communicate the severity of the situation if any health category is lacking.
##### Nutrition Scanner:
Our app also includes a scanner that uses Anthropic’s Claude 3.5 Sonnet via the Amazon Bedrock API to analyze the amount of calories in each picture. Using the camera app on any phone, snap a picture of any food you are about to consume and let our AI log the amount of calories in that meal. In addition, utilizing OpenVINO on Intel Tiber Developer Cloud, we provide healthy food recommendations similar to the foods you like so you can be happy and healthy!
##### Health Overview:
The health overview page displays all of your important health data in one easily consumable format. The interactive page allows you to easily view your daily habits from hours slept to steps walked, all condensed into one cohesive page. Furthermore, you can talk to our live AI Voicebot Doctor to answer any questions or health concerns. It will listen to your symptoms, confirm your diagnosis, and provide steps for a path to recovery all in a hyperrealistic-sounding voice provided by ElevenLabs.
##### Automated Scheduler:
Recommends healthy activities to plan in your schedule based on your diagnosis results with GPT-4o. Automatically adds accepted events into your calendar with Google Calendar API. The scheduled event includes what it is, the location, a description explaining why it recommended this event based on citations from your health data, a start time and date, and an end time and date.
# 🔧 - How we built it
##### Building the Calendar Scheduler:
Google Cloud (gcloud): for Google account authentication to access user calendars
Google Calendar API: for managing our health calendars and events
OpenAI API (GPT-4o): for generation of event timing and details
##### Building the Nutrition Scanner:
Anthropic’s Claude-Sonnet 3.5: for computer vision to determine calories in food screenshots
AWS Amazon Bedrock API: for accessing and interfacing the vision LLM
Pillow (PIL): to perform lossless compression of food PNG image inputs
Watchdog: file system listener to access recently uploaded food screenshots to the backend
##### Collecting user fitness and health data:
Apple HealthKit: for exporting Apple watch and iPhone fitness and health data
NumPy: for math and data processing
Pandas: for data processing, organization, and storage
##### Adding personalized recommendations:
Intel Tiber Developer Cloud: development environment and compute engine
Intel OpenVINO: for optimizing and deploying the neural network model
PyTorch: for building the recommendation model with neural networks and for additional optimization
##### AI Voicebot Doctor:
Assembly AI: for transcription of the conversation (both speech-to-text and text-to-speech)
OpenAI (GPT-4o): inputs text response from user to generate an appropriate response
ElevenLabs: for realistic AI audio generation (text to speech)
##### Building our web demos:
Gradio: an open-sourced Python package with customizable UI components to demo the many different features integrated into our application
# 📒 - The Efficacy of our Models
##### Collecting health and fitness data for our app:
By exporting data from the iPhone Health app, we can gain insights into sleep, exercise, and other activities. The Apple HealthKit data is stored in an XML file with each indicator paired with a value and datetime. So we chose to parse the data to a CSV, then aggregate the data with NumPy and Pandas to extract daily user data and data clean. Our result is tabular data that includes insights on sleep cycle durations, daily steps, heart rate variability when sleeping, basal energy burned, active energy burned, exercise minutes, and standing hours.
For aggregating sleep cycle data, we first identified “sessions”, which are periods in which an activity took place, like a sleep cycle. To do this we built an algorithm that analyzes the gaps between indicators, with large gaps (> 1hr) distinguishing between two different sessions. With these sessions, we could aggregate based on the datetimes of the sessions starts and ends to compute heart rate variability and sleep cycle data (REM, Core, Deep, Awake). The rest of our core data is combined using similar methodology and summations over datetimes to compile averages, durations, and sums (totals) statistics into an exported data frame for easy and comprehensive information access. This demonstrates our team’s commitment to scalability and building robust data pipelines, as our data processing techniques are suited for any data exported from the iPhone health app to organize as input for the LLMs context window. We chose GPT-4o as our LLM to diagnose the user’s top three most prevalent health concerns and the corresponding risk factor of each. We used an AI Assistant to parse the relevant information from the Health App data and limited the outputs to a large list of potential illnesses.
##### AI Voicebot Doctor
This script exemplifies an advanced, multi-service AI integration for real-time medical diagnostics using sophisticated natural language processing (NLP) and high-fidelity text-to-speech synthesis. The AI\_Assistant class initializes with secure environment configuration, instantiating AssemblyAI for real-time audio transcription, OpenAI for contextual NLP processing, and ElevenLabs for speech synthesis. It employs AssemblyAI’s RealtimeTranscriber to capture and process audio, dynamically handling transcription data through asynchronous callbacks. User inputs are appended to a persistent conversation history and processed by OpenAI’s gpt-4o model, generating diagnostic responses. These responses are then converted to speech using ElevenLabs' advanced synthesis, streamed back to the user. The script’s architecture demonstrates sophisticated concurrency and state management, ensuring robust, real-time interactive capabilities.
##### Our recommendation model:
We used the Small VM - Intel® Xeon 4th Gen ® Scalable processor compute instance in the Intel Tiber Developer Cloud as a development environment with compute resources to build our model. We collect user ratings and food data to store for further personalization. We then organize it into three tensor objects to prepare for model creation: Users, Food, and Ratings. Next, we build our recommendation model using PyTorch’s neural network library, stacking multiple embedding and linear layers and optimizing with mean squared error loss. After cross-checking with our raw user data, we tuned our hyperparameters and compiled the model with the Adam optimizer to achieve results that closely match our user’s preferences. Then, we exported our model into ONNX format for compatibility with OpenVINO. Converting our model into OpenVINO optimized our model inference, allowing for instant user rating predictions on food dishes and easy integration with our existing framework. To provide the user with the best recommendations while ensuring we keep some variability, we randomize a large sample from a pool of food dishes, taking the highest-rated dishes from that sample according to our model.
# 🚩 - Challenges we ran into
We did not have enough compute resources on our Intel Developer Cloud instance. The only instance available did not have enough memory to support fine tuning a large LLM, crashing our Jupyter notebooks upon run.
# 🏆 - Accomplishments that we're proud of
Connecting phone screenshots to the backend on our computers → implemented a file system listener to manipulate a Dropbox file path connecting to our smart devices
Automatically scheduling a Google Calendar event → used two intermediary LLMs between input and output with one formatted to give Event Name, Location, Description, Start Time and Date, and End Time and Date and the other to turn it into a JSON output. The JSON could then be reliably extracted as parameters into our Google Calendar API
Configuring cloud compute services and instances in both our local machine and virtual machine instance terminals
# 📝 - What we learned
Nicholas: "Creating animated high-fidelity mockups in Figma and leading a full software team as PM.”
Marcus: "Using cloud compute engines such as Intel Developer Cloud, AWS, and Google Cloud to bring advanced AI technology to my projects"
Steven: "Integrating file listeners to connect phone images uploaded to Dropbox with computer vision from LLMs on my local computer."
Sean: "How to data clean from XML files with Pandas for cohesive implementation with LLMs."
# ✈️ - What's next for OptiFi
We envision OptiFi’s future plans in phases. Each of these phases were inspired by leaders in the tech-startup space.
### PHASE 1: PRIORITIZE SPEED OF EXECUTION
Phase 1 involves the following goals:
* Completing a fully interactive frontend that connects with each other instead of disconnected parts
* Any investment will be spent towards recruiting a team of more engineers to speed up the production of our application
* Based on “the agility and speed of startups allow them to capitalize on new opportunities more effectively” (Sam Altman, CEO of OpenAI)
### PHASE 2: UNDERSTANDING USERS
* Mass user test our MVP through surveys, interviews, and focus groups
* Tools: Qualtrics, Nielsen, UserTesting, Hotjar, Optimizely, and the best of all – personal email/call reach out
* Based on “Hey, I’m the CEO. What do you need? That’s the most powerful thing.” (Jerry Tan, President and CEO of YCombinator)
### PHASE 3: SEEKING BRANDING MENTORSHIP
Phase 3 involves the following goals:
* Follow pioneers in becoming big in an existing market by establishing incredible branding like Dollar Shave Club and Patagonia
* Align with advocating for preventative care and early intervention
* Based on “Find mentors who will really support your company and cheerlead you on” (Caroline Winnett, SkyDeck Executive Director)
## 📋 - Evaluator's Guide to OptiFi
##### Intended for judges, however the viewing public is welcome to take a look.
Hey! We wanted to make this guide to help provide you with further information on our implementations of our AI and other programs and provide a more in-depth look to cater to both the viewing audience and evaluators like yourself.
#### Sponsor Services and Technologies We Have Used This Hackathon
##### AWS Bedrock
Diet is an important part of health! So we wanted a quick and easy way to introduce this without the user having to constantly input information.
In our project, we used AWS Bedrock for our Nutrition Scanner. We accessed Anthropic’s Claude 3.5 Sonnet, which has vision capabilities, with Amazon Bedrock’s API.
##### Gradio
* **Project Demos and Hosting:** We hosted our demo on a Gradio playground, utilizing their easy-to-use widgets for fast prototyping.
* **Frontend:** Gradio rendered all the components we needed, such as text input, buttons, images, and more.
* **Backend:** Gradio played an important role in our project in letting us connect all of our different modules. In this backend implementation, we seamlessly integrated our features, including the nutrition scanner, diagnostic, and calendar.
##### Intel Developer Cloud
Our project needed the computing power of Intel cloud computers to quickly train our custom AI model, our food recommendation system.
This leap in compute speed powered by Intel® cloud computing and OpenVINO enabled us to re-train our models with lightning speed as we worked to debug and integrate them into our backend. It also made fine-tuning our model much easier as we could tweak the hyperparameters and see their effects on model performance within seconds.
As more users join our app and scan their food with the Nutrition Scanner, the need for speed becomes increasingly important, so by running our model on Intel Developer Cloud, we are building a prototype that is scalable for a production-level app.
##### Open AI
To create calendar events and generate responses for our Voicebot, we used Open AI’s generative AI technology. We used GPT-3.5-turbo to create our Voicebot responses to the user, quickly getting information to the user. However, a more advanced model, GPT-4o, was necessary to not only follow the strict response guidelines for parsing responses but also to properly analyze user health data and metrics and determine the best solutions in the form of calendar events.
##### Assembly AI and ElevenLabs
We envision a future where it would be more convenient to find information by talking to an AI assistant versus a search function, enabling a hands-free experience.
With Assembly AI’s speech-to-text streaming technology, we could stream audio input from the user device’s microphone and send it to an LLM for prompting in real time! ElevenLabs on the other hand, we used for text-to-speech, speaking the output from the LLM prompt also in real time! Together, they craft an easy and seamless experience for the user.
##### GitHub
We used GitHub for our project by creating a GitHub repository to host our hackathon project's code. We leveraged GitHub not only for code hosting but also as a platform to collaborate, push code, and receive feedback. | partial |
## Inspiration
The other day, I heard my mom, a math tutor, tell her students "I wish you were here so I could give you some chocolate prizes!" We wanted to bring this incentive program back, even among COVID, so that students can have a more engaging learning experience.
## What it does
The student will complete a math worksheet and use the Raspberry Pi to take a picture of their completed work. The program then sends it to Google Cloud Vision API to extract equations. Our algorithms will then automatically mark the worksheet, annotate the jpg with Pure Image, and upload it to our website. The student then gains money based on the score that they received. For example, if they received a 80% on the worksheet, they will get 80 cents. Once the student has earned enough money, they can choose to buy a chocolate, where the program will check to ensure they have enough funds, and if so, will dispense it for them.
## How we built it
We used a Raspberry Pi to take pictures of worksheets, Google Cloud Vision API to extract text, and Pure Image to annotate the worksheet. The dispenser uses the Raspberry Pi and Lego to dispense the Mars Bars.
## Challenges we ran into
We ran into the problem that if the writing in the image was crooked, it would not detect the numbers on the same line. To fix this, we opted for line paper instead of blank paper which helped us to write straight.
## Accomplishments that we're proud of
We are proud of getting the Raspberry Pi and motor working as this was the first time using one. We are also proud of the gear ratio where we connected small gears to big gears ensuring high torque to enable us to move candy. We also had a lot of fun building the lego.
## What we learned
We learned how to use the Raspberry Pi, the Pi camera, and the stepper motor. We also learned how to integrate backend functions with Google Cloud Vision API
## What's next for Sugar Marker
We are hoping to build an app to allow students to take pictures, view their work, and purchase candy all from their phone. | ## What Inspired us
Due to COVID, many students like us have become accustomed to work on their schoolwork, projects and even hackathons remotely. This led students to use online resources at their disposal in order to facilitate their workload at home. One of the tools most used is “ctrl+f” which enables the user to quickly locate any text within a document. Thus, we came to a realisation that no such accurate method exists for images. This led to the birth of our project for this hackathon titled “PictoDocReader”.
## What you learned
We learned how to implement Dash in order to create a seamless user-interface for Python. We further learnt several 2D and 3D pattern matching algorithms such as, Knuth-Morris-Pratt, Bird Baker, Karp and Rabin and Aho-Corasick. However, only implemented the ones that led to the fastest and most accurate execution of the code.
Furthermore, we learnt how to convert PDFs to images (.png). This led to us learning about the colour profiles of images and how to manipulate the RGB values of any image using the numpy library along with matplotlib. We also learnt how to implement Threading in Python in order to run tasks simultaneously. We also learnt how to use Google Cloud services in order to use Google Cloud Storage to enable users to store their images and documents on the cloud.
## How you built your project
The only dependencies we required to create the project were PIL, matplotlib, numpy, dash and Google Cloud.
**PIL** - Used for converting a PDF file to a list of .png files and manipulating the colour profiles of an image.
**matplotlib** - To plot and convert an image to its corresponding matrix of RGB values.
**numpy** - Used for data manipulation on RGB matrices.
**dash** - Used to create an easy to use and seamless user-interface
**Google Cloud** - Used to enable users to store their images and documents on the cloud.
All the algorithms and techniques to parse and validate pixels were all programmed by the team members. Allowing us to cover any scenario due to complete independence from any libraries.
## Challenges we faced
The first challenge we faced was the inconsistency between the different RGB matrices for different documents. While some matrices contained RGB values, others were of the form RGBA. Therefore, this led to inconsistent results when we were traversing the matrices. The problem was solved using the slicing function from the numpy library in order to make every matrix uniform in size.
Trying to research best time complexity for 2d and 3d pattern matching algorithms. Most algorithms were designed for square images and square shaped documents. While we were working with any sized images and documents. Thus, we had to experiment and alter the algorithms to ensure they worked best for our application.
When we worked with large PDF files, the program tried to locate the image in each page one by one. Thus, we needed to shorten the time for PDFs to be fully scanned to make sure our application performs its tasks in a viable time period. Hence, we introduced threading into the project to reduce the scanning time when working with large PDF files as each page was scanned simultaneously. Although we have come to the realisation that threading is not ideal as the multi-processing greatly depends on the number of CPU cores of the user’s system. In an ideal world we would implement parallel processing instead of threading. | ## Inspiration
In modern day, **technology is everywhere**. Parents equip their children with devices at a young age, so why not take advantage of this and improve their learning! We want to help children in recognizing objects, and as well as pronouncing them (via text to speech).
## What it does
*NVision* teaches children the names of everyday objects in which they encounter (by taking a picture of it). The app then says the object name out loud.
## How we built it
We developed *NVision* in Android Studio. Java and XML was used to program the back-end, including various .json libraries. For our image recognition, we used Google Vision, communicating to our app with post requests. We also used domain.com to create a website to advertise our application on the web, which can be viewed here: [NVision](http://nvisionedu.com/)
## Challenges we ran into
At first, we encountered issues in implementing the camera feature into our app. Android studio is not exactly the most friendly programming interface! After a lot of debugging and some mentorship, we were able to get it working. Another challenge we faced was using the APIs within our app. We used Google Vision image recognition API to return a .json file corresponding to the image details. This required our app to communicate with the Google server, and none of us had experience with implementing network capabilities to our software.
Lastly, integrating our code together was a challenge, because we each worked separately, and we used used different libraries, code, and software. This app was relatively complex, so each of our parts were vastly different. We needed to first communicate with the camera, send the image to the server, retrieve the .json file, and parse it to a string array to be read outloud in a text to speech. Near the end of the 36 hours, we spent a lot of time simply putting together the pieces and making sure the app would run properly.
## Accomplishments that we are proud of
With most of the team being new to Android development, this was definitely a difficult and daunting task at first. We are proud that we finished with a functional app that has most of the features we wanted to include. In addition, no one on our team had experience with APIs, so we are happy with what we have created as a team.
## What we learned
Apart from the technical skills we gained, we learned that communication and teamwork is a crucial part of success when working on projects. By dividing the workload and having teammates to rely on really helped us be more efficient overall. Also, the level of programming we had to do was far beyond everything we did in school, so we had to both brush up on our comprehension as well as our coding skills. We also realized that our own knowledge could be severely lacking at times, and we should ask for help when needed.
## What's next for *NVision*
In the future, we would like to expand *NVision* to target other cultures. There are many children around the world that do not speak English as their first language, so we'd like to have our application relay the object detected in other languages. This will help kids that not only do not speak English, but also those that are trying to learn a new language. We already have a way to change the language of the text to speech, available in German as well as English, but we would have to use Google translate API to fully realize it's potential.
Furthermore, we realize that young children spending too much time in front of their screen would be detrimental to their health. We wish to implement parental controls as well as a timer to limit the use of our app. Parents will also be able to track the progress of their children's learning, perhaps by integrating a feedback system, such as a microphone, to tell if their children are advancing their vocabulary. | partial |
## Inspiration
As citizens who care deeply about the integrity of information that is being fed to the public, we were troubled by the rampant spread of misinformation and disinformation during (often political) live streams. Our goal is to create a tool that empowers viewers to discern truth from falsehood in **real-time**, ensuring a more informed and transparent viewing experience.
**Problem: Misinformation and disinformation through livestreams is incredibly rampant.**
## What it does
Transparify provides real-time contextual information and emotional analysis for livestream videos, enhancing transparency and helping viewers make informed decisions. It delivers live transcripts, detects emotional tone through voice and facial analysis, and fact-checks statements using you.com.
## How we built it
**The Tech-Stack**:
* Next.js / TailwindCSS / shadcn/ui: For building a responsive and intuitive web interface.
* Hume.ai: For emotion recognition through both facial detection and audio analysis.
* Groq: For advanced STT (speech-to-text) transcription.
* You.com: For real-time fact-checking.
**Pipeline Overview**: (see image for more details)
* Transcription: We use Groq’s whisper integration to transcribe the video’s speech into text.
* Emotion Analysis: Hume AI analyzes facial cues and vocal tones to determine the emotional impact and tone of the speaker’s presentation.
* Fact-Checking: The transcribed and analyzed content is checked for accuracy and context through you.com.
* Web App Integration: All data is seamlessly integrated into the web app built with Next.js for a smooth user experience.
We use Groq and its new whisper integration to get STT transcription from the video. We used Hume AI to provide context about the emotional impact of the presentation of the speaker through facial cues and emotion present in the voice of the speaker to inform the viewer of the likely tone of the address. which is then also checked for likely mistakes, and fed to you.com to verify the information presented by the speaker, providing additional context for whatever is being said. The web app was built using Next.js.
## Challenges we ran into
We originally used YouTube’s embed via iframe, but this didn’t work because many embeds don’t allow recording via HTML MediaRecorders
We devised a hack: use the audio from the computer, but this isn’t that helpful because it means users can’t talk + it’s not super accurate
Our solution: a temporary workaround had to be used in the form of sharing the user's tab with the video and sound playing.
LLM fact-checking being too slow: our solution was to use groq as the first-layer and then fetch you.com query and display it whenever it had loaded (even though this was often times slower than the real-time video)
Integrating both audio and video for Hume: Hume requires a web socket to connect to in order to process emotions (and requires separate tracks for audio and video). This was challenging to implement, but in the end we were able to get it done.
Logistic problems: how does this try to fix the problem we set out to solve? We had to brainstorm through the problem and see what would really be helpful to users and we ultimately decided on the final iteration of this.
## Accomplishments that we're proud of
We are proud of many things with this project:
Real-time analysis: from a technical standpoint, this is very difficult to do.
Seamless Integration: Successfully combining multiple advanced technologies into a cohesive and user-friendly application.
User Empowerment: Providing viewers with the tools to critically analyze livestream content in real-time, enhancing their understanding and decision-making.
## What we learned
We learned a lot, mainly in three areas:
Technical: we learned a lot about React, web sockets, working with many different APIs (Groq, You, Hume) and how these all come together in a working web application.
Domain-related: we learned a lot about how politicians are trained in acting/reacting to questions, as well as how powerful LLMs can be in this space, especially those that have access to the internet.
Teamwork: developed our ability to collaborate effectively, manage tight deadlines, and maintain focus during intensive work periods.
## What's next for Transparify
We think this idea is just a proof-of-concept. Although it may not be the best, there is **definitely** a future in which this service is extremely impactful. Imagine opening up your TV and there is real-time information like this on the side of news broadcasts, where there is important information that could change the trajectory of your life. It’s very important to keep the general public informed and stop the spread of misinformation/disinformation, and we think that Transparify is a proof-of-concept for how LLMs can curb this in the future.
Some future directions:
* We want to work on the speed.
* We want to work on making it more reliable.
* We want to increase support to other sources besides YouTube.
* We want to build a better UI. | ## Inspiration
In the current media landscape, control over distribution has become almost as important as the actual creation of content, and that has given Facebook a huge amount of power. The impact that Facebook newsfeed has in the formation of opinions in the real world is so huge that it potentially affected the 2016 election decisions, however these newsfeed were not completely accurate. Our solution? FiB because With 1.5 Billion Users, Every Single Tweak in an Algorithm Can Make a Change, and we dont stop at just one.
## What it does
Our algorithm is two fold, as follows:
**Content-consumption**: Our chrome-extension goes through your facebook feed in real time as you browse it and verifies the authenticity of posts. These posts can be status updates, images or links. Our backend AI checks the facts within these posts and verifies them using image recognition, keyword extraction, and source verification and a twitter search to verify if a screenshot of a twitter update posted is authentic. The posts then are visually tagged on the top right corner in accordance with their trust score. If a post is found to be false, the AI tries to find the truth and shows it to you.
**Content-creation**: Each time a user posts/shares content, our chat bot uses a webhook to get a call. This chat bot then uses the same backend AI as content consumption to determine if the new post by the user contains any unverified information. If so, the user is notified and can choose to either take it down or let it exist.
## How we built it
Our chrome-extension is built using javascript that uses advanced web scraping techniques to extract links, posts, and images. This is then sent to an AI. The AI is a collection of API calls that we collectively process to produce a single "trust" factor. The APIs include Microsoft's cognitive services such as image analysis, text analysis, bing web search, Twitter's search API and Google's Safe Browsing API. The backend is written in Python and hosted on Heroku. The chatbot was built using Facebook's wit.ai
## Challenges we ran into
Web scraping Facebook was one of the earliest challenges we faced. Most DOM elements in Facebook have div ids that constantly change, making them difficult to keep track of. Another challenge was building an AI that knows the difference between a fact and an opinion so that we do not flag opinions as false, since only facts can be false. Lastly, integrating all these different services, in different languages together using a single web server was a huge challenge.
## Accomplishments that we're proud of
All of us were new to Javascript so we all picked up a new language this weekend. We are proud that we could successfully web scrape Facebook which uses a lot of techniques to prevent people from doing so. Finally, the flawless integration we were able to create between these different services really made us feel accomplished.
## What we learned
All concepts used here were new to us. Two people on our time are first-time hackathon-ers and learned completely new technologies in the span of 36hrs. We learned Javascript, Python, flask servers and AI services.
## What's next for FiB
Hopefully this can be better integrated with Facebook and then be adopted by other social media platforms to make sure we stop believing in lies. | ## Inspiration
Our team wanted to make a smart power bar device to tackle the challenge of phantom power consumption. Phantom power is the power consumed by devices when they are plugged in and idle, accounting for approximately 10% of a home’s power consumption. [1] The best solution for this so far has been for users to unplug their devices after use. However, this method is extremely inconvenient for the consumer as there can be innumerable household devices that require being unplugged, such as charging devices for phones, laptops, vacuums, as well as TV’s, monitors, and kitchen appliances. [2] We wanted to make a device that optimized convenience for the user while increasing electrical savings and reducing energy consumption.
## What It Does
The device monitors power consumption and based on continual readings automatically shuts off power to idle devices. In addition to reducing phantom power consumption, the smart power bar monitors real-time energy consumption and provides graphical analytics to the user through MongoDB. The user is sent weekly power consumption update-emails, and notifications whenever the power is shut off to the smart power bar. It also has built-in safety features, to automatically cut power when devices draw a dangerous amount of current, or a manual emergency shut off button should the user determine their power consumption is too high.
## How We Built It
We developed a device using an alternating current sensor wired in series with the hot terminal of a power cable. The sensor converts AC current readings into 5V logic that can be read by an Arduino to measure both effective current and voltage. In addition, a relay is also wired in series with the hot terminal, which can be controlled by the Arduino’s 5V logic. This allows for both the automatic and manual control of the circuit, to automatically control power consumption based on predefined thresholds, or to turn on or off the circuit if the user believes the power consumption to be too high. In addition to the product’s controls, the Arduino microcontroller is connected to the Qualcomm 410C DragonBoard, where we used Python to push data sensor data to MongoDB, which updates trends in real-time for the user to see. In addition, we also send the user email updates through Python with the time-stamps based on when the power bar is shut off. This adds an extended layer of user engagement and notification to ensure they are aware of the system’s status at critical events.
## Challenges We Ran Into
One of our major struggles was with operating and connecting the DragonBoard, such as setting up connection and recognition of the monitor to be able to program and install packages on the DragonBoard. In addition, connecting to the shell was difficult, as well as any interfacing in general with peripherals was difficult and not necessarily straightforward, though we did find solutions to all of our problems.
We struggled with establishing a two-way connection between the Arduino and the DragonBoard, due to the Arduino microntrontroller shield that was supplied with the kit. Due to unknown hardware or communication problems between the Arduino shield and DragonBoard, the DragonBoard would continually shut off, making troubleshooting and integration between the hardware and software impossible.
Another challenge was tuning and compensating for error in the AC sensor module, as due to lack of access to a multimeter or an oscilloscope for most of our build, it was difficult to pinpoint exactly what the characteristic of the AC current sinusoids we were measuring. For context, we measured the current draw of 2-prong devices such as our phone and laptop chargers. Therefore, a further complication to accurately measure the AC current draws of our devices would have been to cut open our charging cables, which was out of the question considering they are our important personal devices.
## Accomplishments That We Are Proud Of
We are particularly proud of our ability to have found and successfully used sensors to quantify power consumption in our electrical devices. Coming into the competition as a team of mostly strangers, we cycled through different ideas ahead of the Makeathon that we would like to pursue, and 1 of them happened to be how to reduce wasteful power consumption in consumer homes. Finally meeting on the day of, we realized we wanted to pursue the idea, but unfortunately had none of the necessary equipment, such as AC current sensors, available. With some resourcefulness and quick-calling to stores in Toronto, we were luckily able to find components at the local electronics stores, such as Creatron and the Home Hardware, to find the components we needed to make the project we wanted.
In a short period of time, we were able to leverage the use of MongoDB to create an HMI for the user, and also read values from the microcontroller into the database and trend the values.
In addition, we were proud of our research into understanding the operation of the AC current sensor modules and then applying the theory behind AC to DC current and voltage conversion to approximate sensor readings to calculate apparent power generation. In theory the physics are very straightforward, however in practice, troubleshooting and accounting for noise and error in the sensor readings can be confusing!
## What's Next for SmartBar
We would build a more precise and accurate analytics system with an extended and extensible user interface for practical everyday use. This could include real-time cost projections for user billing cycles and power use on top of raw consumption data. As well, this also includes developing our system with more accurate and higher resolution sensors to ensure our readings are as accurate as possible. This would include extended research and development using more sophisticated testing equipment such as power supplies and oscilloscopes to accurately measure and record AC current draw. Not to mention, developing a standardized suite of sensors to offer consumers, to account for different types of appliances that require different size sensors, ranging from washing machines and dryers, to ovens and kettles and other smaller electronic or kitchen devices. Furthermore, we would use additional testing to characterize maximum and minimum thresholds for different types of devices, or more simply stated recording when the devices were actually being useful as opposed to idle, to prompt the user with recommendations for when their devices could be automatically shut off to save power. That would make the device truly customizable for different consumer needs, for different devices.
## Sources
[1] <https://www.hydroone.com/saving-money-and-energy/residential/tips-and-tools/phantom-power>
[2] <http://www.hydroquebec.com/residential/energy-wise/electronics/phantom-power.html> | partial |
This is a simulation of astronomical bodies interacting gravitationally, forming orbits.
Prize Submission:
Best Design,
Locals Only,
Lost Your Marbles,
Useless Stuff that Nobody Needs,
Best Domain Name Registered With Domain.com
Domain.com:
[Now online!](http://www.spacesim2k18.org)
[Video demo of website](https://youtu.be/1rnRuP8i8Vo)
We wanted to make the simulation interactive, shooting planets, manipulating gravity, to make a fun game! This simulation also allows testing to see what initial conditions allowed the formation of our solar system, and potentially in the future, macroscopic astronomical entities like galaxies! | We created this app in light of the recent wildfires that have raged across the west coast. As California Natives ourselves, we have witnessed the devastating effects of these fires first-hand. Not only do these wildfires pose a danger to those living around the evacuation area, but even for those residing tens to hundreds of miles away, the after-effects are lingering.
For many with sensitive respiratory systems, the wildfire smoke has created difficulty breathing and dizziness as well. One of the reasons we like technology is its ability to impact our lives in novel and meaningful ways. This is extremely helpful for people highly sensitive to airborne pollutants, such as some of our family members that suffer from asthma, and those who also own pets to find healthy outdoor spaces. Our app greatly simplifies the process of finding a location with healthier air quality amidst the wildfires and ensures that those who need essential exercise are able to do so.
We wanted to develop a web app that could help these who are particularly sensitive to smoke and ash to find a temporary respite from the harmful air quality in their area. With our app air.ly, users can navigate across North America to identify areas where the air quality is substantially better. Each dot color indicates a different air quality level ranging from healthy to hazardous. By clicking on a dot, users will be shown a list of outdoor recreation areas, parks, and landmarks they can visit to take a breather at.
We utilized a few different APIs in order to build our web app. The first step was to implement the Google Maps API using JavaScript. Next, we scraped location and air quality index data for each city within North America. After we were able to source real-time data from the World Air Quality Index API, we used the location information to connect to our Google Maps API implementation. Our code took in longitude and latitude data to place a dot on the location of each city within our map. This dot was color-coded based on its city AQI value.
At the same time, the longitude and latitude data was passed into our Yelp Fusion API implementation to find parks, hiking areas, and outdoor recreation local to the city. We processed the Yelp city and location data using Python and Flask integrations. The city-specific AQI value, as well as our local Yelp recommendations, were coded in HTML and CSS to display an info box upon clicking on a dot to help a user act on the real-time data. As a final touch, we also included a legend that indicated the AQI values with their corresponding dot colors to allow ease with user experience.
We really embraced the hacker resilience mindset to create a user-focused product that values itself on providing safe and healthy exploration during the current wildfire season. Thank you :) | ## Inspiration
We were inspired by seeing videos of AI powered simulations doing cool things, such as parking in a full parking lot: <https://www.youtube.com/watch?v=VMp6pq6_QjI>
## What it does
Crashes into walls and drives off the edge of the world
## How I built it
Trial and error
## Challenges I ran into
We had a difficult time getting the reward function correct and tuning the hyperparameters to allow the AI to learn. Although some of has have experience with supervised learning and machine learning for computer vision, we have never tried reinforcement learning before so all of the hyperparameters and details of the training were quite foreign
## Accomplishments that I'm proud of
Getting the car to move in the general direction of the goal (sometimes).
It's also really cool to see the AI sometimes take advantage of glitches in the environment and phase through multiple obstacles.
## What I learned
Reinforcement learning is difficult and not just a black box.
## What's next for GetDatParking.space | winning |
## Inspiration
(<http://televisedrevolution.com/wp-content/uploads/2015/08/mr_robot.jpg>)
If you watch Mr. Robot, then you know that the main character, Elliot, deals with some pretty serious mental health issues. One of his therapeutic techniques is to write his thoughts on a private journal. They're great... they get your feelings out, and acts as a point of reference to look back to in the future.
We took the best parts of what makes a diary/journal great, and made it just a little bit better - with Indico. In short, we help track your mental health similar to how FitBit tracks your physical health. By writing journal entries on our app, we automagically parse through the journal entries, record your emotional state at that point in time, and keep an archive of the post to aggregate a clear mental profile.
## What it does
This is a FitBit for your brain. As you record entries about your live in the private journal, the app anonymously sends the data to Indico and parses for personality, emotional state, keywords, and overall sentiment. It requires 0 effort on the user's part, and over time, we can generate an accurate picture of your overall mental state.
The posts automatically embeds the strongest emotional state from each post so you can easily find / read posts that evoke a certain feeling (joy, sadness, anger, fear, surprise). We also have a analytics dashboard that further analyzes the person's longterm emotional state.
We believe being cognizant of one self's own mental health is much harder, and just as important as their physical health. A long term view of their emotional state can help the user detect sudden changes in the baseline, or seek out help & support long before the situation becomes dire.
## How we built it
The backend is built on a simple Express server on top of Node.js. We chose React and Redux for the client, due to its strong unidirectional data flow capabilities, as well as the component based architecture (we're big fans of css-modules). Additionally, the strong suite of redux middlewares such as sagas (for side-effects), ImmutableJS, and reselect, helped us scaffold out a solid, stable application in just one day.
## Challenges we ran into
Functional programming is hard. It doesn't have any of the magic that two-way data-binding frameworks come with, such as MeteorJS or AngularJS. Of course, we made the decision to use React/Redux being aware of this. When you're hacking away - code can become messy. Functional programming can at least prevent some common mistakes that often make a hackathon project completely unusable post-hackathon.
Another challenge was the persistance layer for our application. Originally, we wanted to use MongoDB - due to our familiarity with the process of setup. However, to speed things up, we decided to use Firebase. In hindsight, it may have cause us more trouble - since none of us ever used Firebase before. However, learning is always part of the process and we're very glad to have learned even the prototyping basics of Firebase.
## Accomplishments that we're proud of
* Fully Persistant Data with Firebase
* A REAL, WORKING app (not a mockup, or just the UI build), we were able to have CRUD fully working, as well as the logic for processing the various data charts in analytics.
* A sweet UI with some snazzy animations
* Being able to do all this while having a TON of fun.
## What we learned
* Indico is actually really cool and easy to use (not just trying to win points here). Albeit it's not always 100% accurate, but building something like this without Indico would be extremely difficult, and similar apis I've tried is not close to being as easy to integrate.
* React, Redux, Node. A few members of the team learned the expansive stack in just a few days. They're not experts by any means, but they definitely were able to grasp concepts very fast due to the fact that we didn't stop pushing code to Github.
## What's next for Reflect: Journal + Indico to track your Mental Health
Our goal is to make the backend algorithms a bit more rigorous, add a simple authentication algorithm, and to launch this app, consumer facing. We think there's a lot of potential in this app, and there's very little (actually, no one that we could find) competition in this space. | ## Inspiration
Our inspiration for TRACY came from the desire to enhance tennis training through advanced technology. One of our members was a former tennis enthusiast who has always strived to refine their skills. They soon realized that the post-game analysis process took too much time in their busy schedule. We aimed to create a system that not only analyzes gameplay but also provides personalized insights for players to improve their skills.
## What it does and how we built it
TRACY utilizes computer vision algorithms and pre-trained neural networks to analyze tennis footage, tracking player movements, and ball trajectories. The system then employs ChatGPT for AI-driven insights, generating personalized natural language summaries highlighting players' strengths and weaknesses. The output includes dynamic visuals and statistical data using React.js, offering a comprehensive overview and further insights into the player's performance.
## Challenges we ran into
Developing a seamless integration between computer vision, ChatGPT, and real-time video analysis posed several challenges. Ensuring accuracy in 2D ball tracking from a singular camera angle, optimizing processing speed, and fine-tuning the algorithm for accurate tracking were a key hurdle we overcame during the development process. The depth of the ball became a challenge as we were limited to one camera angle but we were able to tackle it by using machine learning techniques.
## Accomplishments that we're proud of
We are proud to have successfully created TRACY, a system that brings together state-of-the-art technologies to provide valuable insights to tennis players. Achieving a balance between accuracy, speed, and interpretability was a significant accomplishment for our team.
## What we learned
Through the development of TRACY, we gained valuable insights into the complexities of integrating computer vision with natural language processing. We also enhanced our understanding of the challenges involved in real-time analysis of sports footage and the importance of providing actionable insights to users.
## What's next for TRACY
Looking ahead, we plan to further refine TRACY by incorporating user feedback and expanding the range of insights it can offer. Additionally, we aim to explore potential collaborations with tennis coaches and players to tailor the system to meet the diverse needs of the tennis community. | ## Inspiration
At the heart of our creation lies a profound belief in the power of genuine connections. Our project was born from the desire to create a safe space for authentic conversations, fostering empathy, understanding, and support. In a fast-paced, rapidly changing world, it is important for individuals to identify their mental health needs, and receive the proper support.
## What it does
Our project is an innovative chatbot leveraging facial recognition technology to detect and respond to users' moods, with a primary focus on enhancing mental health. By providing a platform for open expression, it aims to foster emotional well-being and create a supportive space for users to freely articulate their feelings.
## How we built it
We use opencv2 to actively analyze video and used its built-in facial recognition to build a cascade around individuals' faces when identified. Then, using the deepface library with a pre-trained model for identifying emotions, we assigned each cascaded face with an emotion in live time. Then, using this information, we used cohere's language learning model to then generate a message corresponding to the emotion the individual is feeling. The LLM is also used to chat back and forth between the user and the bot. Then all this information is displayed on the website which is designed using flask for the backend and html, css, react, nodejs for the frontend.
## Challenges we ran into
The largest adversity encountered was dealing with the front-end portion of it. Our group lacked experience with developing websites, and found many issues connecting the back-end to the front-end.
## Accomplishments that we're proud of
Creating the cascades around the faces, incorporating a machine learning model to the image processing, and attemping to work on front-end for the first time with no experience.
## What we learned
We learned how to create a project with a team and divide up tasks and combine them together to create one cohesive project. We also learned new technical skills (i.e how to use API's, machine learning, and front-end development)
## What's next for My Therapy Bot
Try and design a more visually appealing and interactive webpage to display our chat-bot. Ideally it would include live video feed of themselves with cascades and emotions while chatting. It would be nice to train our own machine learning model to determine expressions as well. | winning |
## Inspiration
Food is a passion, yet there is no easy way to share this passion. For others, food is a necessity, yet finding good recipes you want to cook has never been harder. Munchify is the social media for promoting the passion of food and cooking, empowering people to grab their forks and knives and dig in!
## What it does
In the app, we call recipes “munchies”, and the users are “munchers”. Once a user logs in, they have access to all munchies that have been uploaded by other users and the ability to upload their own munchies. A munchie contains the ingredients and directions, and also contains the nutritional data and a common category that the recipe relates to.
### Primary function
Munchify allows munchers to get the best possible recipe, plain and simple. Munchers can input ingredients they have on hand, relative costs, recipe names and tags. Making it extremely simple for anyone to find what they want to cook and eat. Easy as butter on toast!
### Social Media System
Munchers can visit other users by clicking on their icon. They view their munchies, amount of followers (munchers) and how many users they are following (munching). By creating a platform to serve good food from good people, Munchify strengthens the interactions between stuck-at-home-er’s and food enthusiasts alike.
## How we built it
### Initial Design
For the design of the project, Figma was our best friend. Within the span of an hour, we had a user authentication flow wireframe connected to a multi-panel and multi-modal home screen.
### Front end
Munchify’s core is built using the web. The majority of this team has previous web development experiences, but practically zero native app development experience. We leveraged this to our advantage by using Ionic React. Harnessing the flexibility of React, with the elegance of mobile app design. Ionic’s documentation was straight-foward and provided a lot of customization w/r/t their provided components.
### Backend and Database
Munchify’s entire backend database, authentication, and hosting is powered by Firebase. With their client side SDK for JS/TS, we were able to get up and running very quickly. A tremendous amount of time that is usually allocated to a backend server setup and signup authentication was now used towards building more features, as we set up Google Authentication with only a few mouse clicks! Cloud Firestore allowed us to have multiple collections and documents with near-instant queries. We also set up a custom Github Action to trigger an automated build and deployment to Firebase Hosting on push to the main branch, avoiding to deal with over-complicated build scripts.
## Challenges we ran into
As the number of recipes and users increase, the performance for searching for a recipe based on ingredient names drops drastically. This is because if the user inputs a slightly different version of an ingredient (egg vs eggs), the search won’t show up. To solve this issue, we gathered ingredients from large open datasets such as the ones from USDA or OpenFoodFacts, and parsed them into Munchify. These datasets also contain the nutritional facts of each ingredient. By formatting each recipe in a consistent manner, our general query performance increases drastically.
## Accomplishments that we're proud of
We are very proud of the minimum viable product for Munchify. The sleek and modern user interface exceeded our initial expectations when prototyping on Figma. We’re really proud of the way we worked together as a team, from start to finish. We pushed ourselves outside of our comfort zone, reading completely new documentation and frameworks. We are extremely grateful to be able to share this project and express our ideas on the theme of connectedness in front of the hacking community.
## What we learned
For all of us, we learned how to work with Ionic React to make a mobile app, and also learned how to interact with Firebase. We loved how simple it was to implement Firebase and we’re really proud of how well we made it work with our design.
We learned how to investigate and debug memory leaks the hard way. As a result of our inexperience with React’s useEffect hook, we actually reached the insanely high daily quota for Cloud Firestore. If we were to take one lesson away from this entire hackathon, it would be to be careful with your dependencies, kids!
## What's next for Munchify
We would like to add as much data regarding nutrients, ingredients, and cost to improve the user experience in making a recipe. This would allow our users to better express their recipe, contributing to the goal in encouraging people to cook.
A big feature of this app is the social media aspect. We would want to expand on the infrastructure of the social network so we can better recommend users and recipes.
Imagine a world with Munchify:
Interact with other users to share a passion for cooking
Recommendations for the best possible recipes tailored made for you
Get Munching! <https://munchify.space> | ## Inspiration
During our brainstorming, we were thinking about what we have in common as students and what we do often.
We are all students and want to cook at home to save money, but we often find ourselves in a situation where we have tons of ingredients that we cannot properly combine. With that in mind, we came up with an idea to build an app that helps you find the recipes that you can cook at home.
We are all excited about the project as it is something that a lot of people can utilize on a daily basis.
## What it does
Imagine you find yourself in a situation where you have some leftover chicken, pasta, milk, and spices. You can **open Mealify, input your ingredients, and get a list of recipes that you can cook with that inventory**.
## How we built it
For that idea, we decided to build a mobile app to ease the use of daily users - although you can also use it in the browser. Since our project is a full stack application, we enhanced our knowledge of all the stages of development. We started from finding the appropriate data, parsing it to the format we need and creating an appropriate SQL database. We then created our own backend API that is responsible for all the requests that our application uses - autocomplete of an ingredient for a user and actual finding of the ‘closest’ recipe. By using the custom created endpoints, we made the client part communicate with it by making appropriate requests and fetching responses. We then created the frontend part that lets a user naturally communicate with Mealify - using dynamic lists, different input types, and scrolling. The application is easy to use and does not rely on the user's proper inputs - we implemented the autocomplete option, and gave the option for units to not worry about proper spelling from a user.
## Challenges we ran into
We also recognized that it is possible that someone’s favorite meal is not in our database. In that case, we made a way to add a recipe to the database from a url. We used an ingredient parser to scan for all the ingredients needed for that recipe from the url. We then used Cohere to parse through the text on the url and find the exact quantity and units of the ingredient.
One challenge we faced was finding an API that could return recipes based on our ingredients and input parameters. So we decided to build our own API to solve that issue. Moreover, working on finding the ‘closest’ recipe algorithm was not trivial either. For that, we built a linear regression to find what would be the recipe that has the lowest cost for a user to buy additional ingredients. After the algorithm is performed, a user is presented with a number of recipes sorted in the order of ‘price’ - whether a user can already cook it or there's a small number of ingredients that needs to be purchased.
## Accomplishments that we're proud of
We're proud of how we were able to build a full-stack app and NLP model in such a short time.
## What we learned
We learned how to use Flutter, CockRoachDB, co:here, and building our API to deploy a full-stack mobile app and NLP model.
## What's next for Mealify
We can add additional functionality to let users add their own recipes! Eventually, we wouldn't rely as much our database and the users themselves can serve as the database by adding recipes. | ## Inspiration
Over the course of the past year, one of the most heavily impacted industries due to the COVID-19 pandemic is the service sector. Specifically, COVID-19 has transformed the financial viability of restaurant models. Moving forward, it is projected that 36,000 small restaurants will not survive the winter as successful restaurants have thus far relied on online dining services such as Grubhub or Doordash. However, these methods come at the cost of flat premiums on every sale, driving up the food price and cutting at least 20% from a given restaurant’s revenue. Within these platforms, the most popular, established restaurants are prioritized due to built-in search algorithms. As such, not all small restaurants can join these otherwise expensive options, and there is no meaningful way for small restaurants to survive during COVID.
## What it does
Potluck provides a platform for chefs to conveniently advertise their services to customers who will likewise be able to easily find nearby places to get their favorite foods. Chefs are able to upload information about their restaurant, such as their menus and locations, which is stored in Potluck’s encrypted database. Customers are presented with a personalized dashboard containing a list of ten nearby restaurants which are generated using an algorithm that factors in the customer’s preferences and sentiment analysis of previous customers. There is also a search function which will allow customers to find additional restaurants that they may enjoy.
## How I built it
We built a web app with Flask where users can feed in data for a specific location, cuisine of food, and restaurant-related tags. Based on this input, restaurants in our database are filtered and ranked based on the distance to the given user location calculated using Google Maps API and the Natural Language Toolkit (NLTK), and a sentiment score based on any comments on the restaurant calculated using Google Cloud NLP. Within the page, consumers can provide comments on their dining experience with a certain restaurant and chefs can add information for their restaurant, including cuisine, menu items, location, and contact information. Data is stored in a PostgreSQL-based database on Google Cloud.
## Challenges I ran into
One of the challenges that we faced was coming up a solution that matched the timeframe and bandwidth of our team. We did not want to be too ambitious with our ideas and technology yet provide a product that we felt was novel and meaningful.
We also found it difficult to integrate the backend with the frontend. For example, we needed the results from the Natural Language Toolkit (NLTK) in the backend to be used by the Google Maps JavaScript API in the frontend. By utilizing Jinja templates, we were able to serve the webpage and modify its script code based on the backend results from NLTK.
## Accomplishments that I'm proud of
We were able to identify a problem that was not only very meaningful to us and our community, but also one that we had a reasonable chance of approaching with our experience and tools. Not only did we get our functions and app to work very smoothly, we ended up with time to create a very pleasant user-experience and UI. We believe that how comfortable the user is when using the app is equally as important as how sophisticated the technology is.
Additionally, we were happy that we were able to tie in our product into many meaningful ideas on community and small businesses, which we believe are very important in the current times.
## What I learned
Tools we tried for the first time: Flask (with the additional challenge of running HTTPS), Jinja templates for dynamic HTML code, Google Cloud products (including Google Maps JS API), and PostgreSQL.
For many of us, this was our first experience with a group technical project, and it was very instructive to find ways to best communicate and collaborate, especially in this virtual setting. We benefited from each other’s experiences and were able to learn when to use certain ML algorithms or how to make a dynamic frontend.
## What's next for Potluck
For example, we want to incorporate an account system to make user-specific recommendations (Firebase). Additionally, regarding our Google Maps interface, we would like to have dynamic location identification. Furthermore, the capacity of our platform could help us expand program to pair people with any type of service, not just food. We believe that the flexibility of our app could be used for other ideas as well. | losing |
## Inspiration
The inspiration for this project was both personal experience and the presentation from Ample Labs during the opening ceremony. Last summer, Ryan was preparing to run a summer computer camp and taking registrations and payment on a website. A mother reached out to ask if we had any discounts available for low-income families. We have offered some in the past, but don't advertise for fear of misuse of the discounts by average or high-income families. We also wanted a way to verify this person's income. If we had WeProsper, verification would have been easy. In addition to the issues associated with income verification, it is likely that there are many programs out there (like the computer camps discounts) that low-income families aren't aware of. Ample Labs' presentation inspired us with the power of connecting people with services they should be able to access but aren't aware of. WeProsper would help low-income families be aware of the services available to them at a discount (transit passes, for another example) and verify their income easily in one place so they can access the services that they need without bundles of income verification paperwork. As such, WeProsper gives low-income families a chance to prosper and improve financial stability. By doing this, WeProsper would increase social mobility in our communities long-term.
## What it does
WeProsper provides a login system which allows users to verify their income by uploading a PDF of their notice of assessment or income proof documents from the CRA and visit service providers posted on the service with a unique code the service provider can verify with us to purchase the service. Unfortunately, not all of this functionality is implemented just yet. The login system works with Auth0, but the app mainly runs with dummy data otherwise.
## How We built it
We used Auth0, react, and UiPath to read the PDF doing our on-site demo. UiPath would need to be replaced in the future with a file upload on the site. The site is made with standard web technologies HTML, CSS and Javascript.
## Challenges We ran into
The team was working with technologies that are new to us, so a lot of the hackathon was spent learning these technologies. These technologies include UiPath and React.
## Accomplishments that we're proud of
We believe WeProsper has a great value proposition for both organizations and low-income families and isn't easy replicated with other solutions. We excited about the ability to share a proof-of-concept that could have massive social impact. Personally, we are also excited that every team member improved skills (technical and non-technical) that will be useful to them in the future.
## What we learned
The team learned a lot about React, and even just HTML/CSS. The team also learned a lot about how to share knowledge between team members with different backgrounds and experiences in order to develop the project.
## What's next for WeProsper
WeProsper would like to use AI to detect anomalies in the future when verifying income. | ## Inspiration
Getting your salary today is mundane - there are very limited options, and there's no way to make money from the money you're getting. We're introducing crypto into the world of salary making, allowing each receiver to make money from staking their salary, or donating to charities of their interest with full transparency!
## How we built it
Our prototype uses the Uniswap SDK and vercel.
## What's next for Cryptoroll
We're here to implement our idea - we have a timeline in place, and have created a prototype. The next step is beta testing, debugging, and then launching! | ## Inspiration
With our inability to acquire an oculus rift at YHack, we were looking forward to using one in any implementation. As we are entering the job market soon, in search of summer internships, we thought about how many people, students in particular, do not have sufficient interviewing experience. Thus, our idea was to use VR to provide these people with the ability to train and succeed with interviews.
## What it does
This hack simulates an interview scenario to aid in the practice of interviewing skills and the removal of improper speech patterns using Unity, Oculus and IBM Watson.
## How I built it
Using Unity, starting and interview scenes were created and animations were implemented. The backend of the speech processing system was built with IBM Watson Unity tools. These tools allowed for the integration for IBM speech to text api's and allow the user's speech to be converted into text and later processed for the output.
## Challenges I ran into
While implementing IBM Watson speech to text, Oculus Rift compatibility, and Unity Scenes, we came across a few errors. Firstly, we had been working in different versions of unity, so when the time came to compile our projects together there were compatibility issues.
## Accomplishments that I'm proud of
One things we are proud of how we overcame the many challenges that arose during this project. We were also proud of the overall implementation of the different facets of the hack and how we were able to mesh them all together.
## What I learned
All of us had to learn how to use and implement virtual reality as none of us had the opportunity to work with it before. We also learned a lot about Unity and implementing items such as VR and IBM Watson speech to text.
## What's next for InterVR
Implementing more thorough testing on the speech to text file would be the first large improvement that could be made for InterVR. Another improvement that could be made for InterVR is a more diverse cast of interviewers, additional scenes for the interviews, and more questions to allow the user to have a more specialized experience. | partial |
## Realm Inspiration
Our inspiration stemmed from our fascination in the growing fields of AR and virtual worlds, from full-body tracking to 3D-visualization. We were interested in realizing ideas in this space, specifically with sensor detecting movements and seamlessly integrating 3D gestures. We felt that the prime way we could display our interest in this technology and the potential was to communicate using it. This is what led us to create Realm, a technology that allows users to create dynamic, collaborative, presentations with voice commands, image searches and complete body-tracking for the most customizable and interactive presentations. We envision an increased ease in dynamic presentations and limitless collaborative work spaces with improvements to technology like Realm.
## Realm Tech Stack
Web View (AWS SageMaker, S3, Lex, DynamoDB and ReactJS): Realm's stack relies heavily on its reliance on AWS. We begin by receiving images from the frontend and passing it into SageMaker where the images are tagged corresponding to their content. These tags, and the images themselves, are put into an S3 bucket. Amazon Lex is used for dialog flow, where text is parsed and tools, animations or simple images are chosen. The Amazon Lex commands are completed by parsing through the S3 Bucket, selecting the desired image, and storing the image URL with all other on-screen images on to DynamoDB. The list of URLs are posted on an endpoint that Swift calls to render.
AR View ( AR-kit, Swift ): The Realm app renders text, images, slides and SCN animations in pixel perfect AR models that are interactive and are interactive with a physics engine. Some of the models we have included in our demo, are presentation functionality and rain interacting with an umbrella. Swift 3 allows full body tracking and we configure the tools to provide optimal tracking and placement gestures. Users can move objects in their hands, place objects and interact with 3D items to enhance the presentation.
## Applications of Realm:
In the future we hope to see our idea implemented in real workplaces in the future. We see classrooms using Realm to provide students interactive spaces to learn, professional employees a way to create interactive presentations, teams to come together and collaborate as easy as possible and so much more. Extensions include creating more animated/interactive AR features and real-time collaboration methods. We hope to further polish our features for usage in industries such as AR/VR gaming & marketing. | Demo: <https://youtu.be/cTh3Q6a2OIM?t=2401>
## Inspiration
Fun Mobile AR Experiences such as Pokemon Go
## What it does
First, a single player hides a virtual penguin somewhere in the room. Then, the app creates hundreds of obstacles for the other players in AR. The player that finds the penguin first wins!
## How we built it
We used AWS and Node JS to create a server to handle realtime communication between all players. We also used Socket IO so that we could easily broadcast information to all players.
## Challenges we ran into
For the majority of the hackathon, we were aiming to use Apple's Multipeer Connectivity framework for realtime peer-to-peer communication. Although we wrote significant code using this framework, we had to switch to Socket IO due to connectivity issues.
Furthermore, shared AR experiences is a very new field with a lot of technical challenges, and it was very exciting to work through bugs in ensuring that all users have see similar obstacles throughout the room.
## Accomplishments that we're proud of
For two of us, it was our very first iOS application. We had never used Swift before, and we had a lot of fun learning to use xCode. For the entire team, we had never worked with AR or Apple's AR-Kit before.
We are proud we were able to make a fun and easy to use AR experience. We also were happy we were able to use Retro styling in our application
## What we learned
-Creating shared AR experiences is challenging but fun
-How to work with iOS's Multipeer framework
-How to use AR Kit
## What's next for ScavengAR
* Look out for an app store release soon! | ## Inspiration
Too often, social media keeps us apart. What if there was a way to share photos online in a way that brings people together? Introducing ourboARd, an AR-based photo sharing app that gets users to gather around a digital board.
## What it does
ourboARd is a digital board that nourishes human connection. It does this by utilizing a physical tracker somewhere in the real world for people to scan with their phones in an AR environment to view and add images to the board as they please. Anyone can walk up to the AR tag, go to our website, and view the current board, as well as add photos and text notes.
## How we built it
Augmented reality enabled front-end with AR.js and Three.js.
Backend Flask API connected to a MongoDB Atlas database for image processing and storage.
Deployed the front-end on Netlify and used ngrok to allow proxy-enabled requests to the back-end.
## Challenges we ran into
Using AR.js and understanding the library for the first time.
Switching from our comfort zones with React that does a lot of the heavy lifting to pure HTML/JS/CSS.
CORS and HTTPS configurations for a secure deployment.
## Accomplishments that we're proud of
Got MongoDB Atlas database working so multiple people can contribute to the board.
Successful deployment to allow everyone to be able to access our web app through their phones.
## What we learned
When stuck on a user story, take a step back and reconsider if the user story is worth it and whether
a different user story could have a similar effect.
Balancing high-focus solo work with collaboration with teammates - balancing "flow" with staying in sync with the team.
## What's next for ourboARd
Ability to change image location on board.
Functionality to download the board.
View each individual image by tapping on it on the screen.
Utilize AI to censor vulgar language and images.
Improve image quality on the board. | winning |
# My Housing Search Journey: From Frustration to Innovation
As a former student, I personally experienced the frustration and challenges of finding suitable housing near the campus. The scattered information, countless websites, and tedious manual searches made the process daunting. This personal experience inspired me to create "Cal Housing", a revolutionary platform to transform the way people find their housing.
## **Inspiration**
The idea behind "Cal Housing" was born from my own struggles. I understood the pain points of students and professionals looking for housing near dynamic regions like Berkeley. I wanted to eliminate the compromise between price and distance, making the entire process more efficient, personalized, and stress-free.
## **What I Learned**
My journey involved diving deep into the real estate market, understanding the nuances of different neighborhoods, and learning about the preferences and pain points of prospective renters (especially students). I also delved into the potential of advanced AI technologies to solve these problems.
## **Building the Project**
* **Market Research**: I conducted extensive market research to identify gaps in the existing housing search platforms and the unique needs of our target audience.
* **AI Integration**: Leveraging LLM and AI models, we integrated algorithms that could process user preferences and property data efficiently, providing tailored recommendations.
* **User-Centric Design**: We designed the platform with the user in mind, making it intuitive, easy to navigate, and highly customizable. Users can specify their budget, proximity to Berkeley, and other preferences with just a few clicks.
## **Challenges**
* **Data Integration**: Gathering and integrating property data from sources was a significant challenge. Ensuring the data was up-to-date and accurate required a dedicated effort. Processing the back-end and managing the data baed on user preference was also one of the challenges.
* **Algorithm Refinement**: Developing AI algorithms that could accurately predict the ideal housing options for users while considering their individual preferences and budgets was complex and required continuous refinement.
* **Competitive Market**: The real estate and housing market is highly competitive. We faced challenges in differentiating ourselves and gaining trust among users.
## **Conclusion**
My personal experience as a student struggling to find suitable housing near the campus was the driving force behind the creation of "Cal Housing". Through dedication, innovation, and a commitment to solving the challenges of housing searches, we've built a platform that offers a streamlined, efficient, and personalized solution. Our mission is to ensure that no one has to compromise when finding their ideal home, and we're excited to continue improving and expanding our services in the future. | ## Inspiration
As students at UC Berkeley, we always look for ways to enhance our studying environment experience. In this pursuit, we find ourselves looking towards libraries as our answers. However, one issue that impedes this pursuit is the lack of open seats in a specific library. UC Berkeley is home to 24 libraries and knowing where to go during various times during the day is always a constant challenge.
## How you built your project
Aimed at solving this issue plaguing Berkeley students, our team developed a solution that allows individuals to visualize the availability of each library at Cal. Using Python, CockroachDB, React, Heroku, Figma, and the Google API, we developed our website that enables people to find the closest library with the greatest availability to spend less time roaming around and find the least crowded and maximize the time they spend working in the library.
## Challenges we ran into
While developing our project, a few of the issues that we faced were working with Postgres, interfacing the Google API and, finding a way to cache all the data using CockroachDB to limit the number of requests to the Google API. Overall, operating under the tight schedule restraints of the competition was an underlying challenge that helped refine our implementation.
## Accomplishments that we're proud of
After creating LiBearium, we are the proudest of finding a way to impact all Berkeley students, making Cal a better place for all.
## What we learned
Throughout this experience, we learned to work with many APIS, using data to run a nice-looking UI and learning how to use Chrome's geolocator.
## What's next for LiBearium
After LiBearium, we hope to expand this project to aid individuals looking for locations all around UC Berkeley. | ## Inspiration
We were inspired by a [recent article](https://www.cbc.ca/news/canada/manitoba/manitoba-man-heart-stops-toronto-airport-1.5430605) that we saw on the news, where there was a man who suffered a cardiac arrest while waiting for his plane. With the help of a bystander who was able to administer the AED and the CPR, he was able to make a full recovery.
We wanted to build a solution that is able to connect victims of cardiac arrests with bystanders who are willing to help, thereby [increasing their survival rates](https://www.ahajournals.org/doi/10.1161/CIRCOUTCOMES.109.889576) . We truly believe in the goodness and willingness of people to help.
## Problem Space
We wanted to be laser-focused in the problem that we are solving - helping victims of cardiac arrests. We did tons of research to validate that this was a problem to begin with, before diving deeper into the solution-ing space.
We also found that there are laws protecting those who try to offer help - indemnifying them of liabilities while performing CPR or AED: [Good Samaritan and the Chase Mceachern Act](https://www.toronto.ca/community-people/public-safety-alerts/training-first-aid-courses/). So why not ask everyone to help?
## What it does
Hero is a web and app based platform that empowers community members to assist in time sensitive medical emergencies especially cardiac arrests, by providing them a ML optimised route that maximizes the CA victim's chances of survival.
We have 2 components - Hero Command and Hero Deploy.
1) **Hero Command** is the interface that the EMS uses. It allows the location of cardiac arrests to be shown on a single map, as well as the nearby first-responders and AED Equipment. We scrapped the Ontario Goverment's AED listing to provide an accurate geo-location of an AED for each area.
Hero Command has a **ML Model** working in the background to find out the optimal route that the first-responder should take: should they go straight to the victim and perform CPR, or should they detour and collect the AED before proceeding to the victim (of which will take some time). This is done by training our model on a sample dataset and calculating an estimated survival percentage for each of the two routes.
2) **Hero Deploy** is the mobile application that our community of first-responders use. It will allow them to accept/reject the request, and provide the location and navigation instructions. It will also provide hands-free CPR audio guidance so that the community members can focus on CPR. \* Cue the Staying Alive music by the BeeGees \*
## How we built it
With so much passion, hard work and an awesome team. And honestly, youtube tutorials.
## Challenges I ran into
We **did not know how** to create an app - all of us were either web devs or data analysts. This meant that we had to watch alot of tutorials and articles to get up to speed. We initially considered abandoning this idea because of the inability to create an app, but we are so happy that we managed to do it together.
## Accomplishments that I'm proud of
Our team learnt so much things in the past few days, especially tech stacks and concepts that were super unfamiliar to us. We are glad to have created something that is viable, working, and has the potential to change how the world works and lives.
We built 3 things - ML Model, Web Interface and a Mobile Application
## What I learned
Hard work takes you far. We also learnt React Native, and how to train and use supervised machine learning models (which we did not have any experience in). We also worked on the business market validation such that the project that we are building is actually solving a real problem.
## What's next for Hero
Possibly introducing the idea to Government Services and getting their buy in. We may also explore other use cases that we can use Hero with | losing |
## Inspiration
For many college students, finding time to socialize and make new friends is hard. Everyone's schedule seems perpetually busy, and arranging a dinner chat with someone you know can be a hard and unrewarding task. At the same time, however, having dinner alone is definitely not a rare thing. We've probably all had the experience of having social energy on a particular day, but it's too late to put anything on the calendar. Our SMS dinner matching project exactly aims to **address the missed socializing opportunities in impromptu same-day dinner arrangements**. Starting from a basic dining-hall dinner matching tool for Penn students only, we **envision an event-centered, multi-channel social platform** that would make organizing events among friend groups, hobby groups, and nearby strangers effortless and sustainable in the long term for its users.
## What it does
Our current MVP, built entirely within the timeframe of this hackathon, allows users to interact with our web server via **SMS text messages** and get **matched to other users for dinner** on the same day based on dining preferences and time availabilities.
### The user journey:
1. User texts anything to our SMS number
2. Server responds with a welcome message and lists out Penn's 5 dining halls for the user to choose from
3. The user texts a list of numbers corresponding to the dining halls the user wants to have dinner at
4. The server sends the user input parsing result to the user and then asks the user to choose between 7 time slots (every 30 minutes between 5:00 pm and 8:00 pm) to meet with their dinner buddy
5. The user texts a list of numbers corresponding to the available time slots
6. The server attempts to match the user with another user. If no match is currently found, the server sends a text to the user confirming that matching is ongoing. If a match is found, the server sends the matched dinner time and location, as well as the phone number of the matched user, to each of the two users matched
7. The user can either choose to confirm or decline the match
8. If the user confirms the match, the server sends the user a confirmation message; and if the other user hasn't confirmed, notifies the other user that their buddy has already confirmed the match
9. If both users in the match confirm, the server sends a final dinner arrangement confirmed message to both users
10. If a user decides to decline, a message will be sent to the other user that the server is working on making a different match
11. 30 minutes before the arranged time, the server sends each user a reminder
###Other notable backend features
12. The server conducts user input validation for each user text to the server; if the user input is invalid, it sends an error message to the user asking the user to enter again
13. The database maintains all requests and dinner matches made on that day; at 12:00 am each day, the server moves all requests and matches to a separate archive database
## How we built it
We used the Node.js framework and built an Express.js web server connected to a hosted MongoDB instance via Mongoose.
We used Twilio Node.js SDK to send and receive SMS text messages.
We used Cron for time-based tasks.
Our notable abstracted functionality modules include routes and the main web app to handle SMS webhook, a session manager that contains our main business logic, a send module that constructs text messages to send to users, time-based task modules, and MongoDB schema modules.
## Challenges we ran into
Writing and debugging async functions poses an additional challenge. Keeping track of potentially concurrent interaction with multiple users also required additional design work.
## Accomplishments that we're proud of
Our main design principle for this project is to keep the application **simple and accessible**. Compared with other common approaches that require users to download an app and register before they can start using the service, using our tool requires **minimal effort**. The user can easily start using our tool even on a busy day.
In terms of architecture, we built a **well-abstracted modern web application** that can be easily modified for new features and can become **highly scalable** without significant additional effort (by converting the current web server into the AWS Lambda framework).
## What we learned
1. How to use asynchronous functions to build a server - multi-client web application
2. How to use posts and webhooks to send and receive information
3. How to build a MongoDB-backed web application via Mongoose
4. How to use Cron to automate time-sensitive workflows
## What's next for SMS dinner matching
### Short-term feature expansion plan
1. Expand location options to all UCity restaurants by enabling users to search locations by name
2. Build a light-weight mobile app that operates in parallel with the SMS service as the basis to expand with more features
3. Implement friend group features to allow making dinner arrangements with friends
###Architecture optimization
4. Convert to AWS Lamdba serverless framework to ensure application scalability and reduce hosting cost
5. Use MongoDB indexes and additional data structures to optimize Cron workflow and reduce the number of times we need to run time-based queries
### Long-term vision
6. Expand to general event-making beyond just making dinner arrangements
7. Create explore (even list) functionality and event feed based on user profile
8. Expand to the general population beyond Penn students; event matching will be based on the users' preferences, location, and friend groups | ## Inspiration
Have you ever wished you had…another you?
This thought has crossed all of our heads countless times as we find ourselves swamped in too many tasks, unable to keep up in meetings as information flies over our head, or wishing we had the feedback of a third perspective.
Our goal was to build an **autonomous agent** that could be that person for you — an AI that learns from your interactions and proactively takes **actions**, provides **answers**, offers advice, and more, to give back your time to you.
## What it does
Ephemeral is an **autonomous AI agent** that interacts with the world primarily through the modality of **voice**. It can sit in on meetings, calls, anywhere you have your computer out.
It’s power is the ability to take what it hears and proactively carry out repetitive actions for you such as be a real-time AI assistant in meetings, draft emails directly in your Google inbox, schedule calendar events and invite attendees, search knowledge corpuses or the web for answers to questions, image generation, and more.
Multiple users (in multiple languages!) can use the technology simultaneously through the server/client architecture that efficiently handles multiprocessing.
## How we built it

**Languages**: Python ∙ JavaScript ∙ HTML ∙ CSS
**Frameworks and Tools**: React.js ∙ PyTorch ∙ Flask ∙ LangChain ∙ OpenAI ∙ TogetherAI ∙ Many More
### 1. Audio to Text
We utilized OpenAI’s Whisper model and the python speech\_recognition library to convert audio in real-time to text that can be used by downstream functions.
### 2. Client → Server via Socket Connection
We use socket connections between the client and server to pass over the textual query to the server for it to determine a particular action and action parameters. The socket connections enable us to support multiprocessing as multiple clients can connect to the server simultaneously while performing concurrent logic (such as real-time, personalized agentic actions during a meeting).
### 3. Neural Network Action Classifier
We trained a neural network from scratch to handle the multi-class classification problem that is going from text to action (or none at all). Because the agent is constantly listening, we need a way to efficiently and accurately determine if each transcribed chunk necessitates a particular action (if so, which?) or none at all (most commonly).
We generated data for this task utilizing data augmentation sources such as ChatGPT (web).
### 4. LLM Logic: Query → Function Parameters
We use in-context learning via few-shot prompting and RAG to query the LLM for various agentic tasks. We built a RAG pipeline over the conversation history and past related, relevant meetings for context. The agentic tasks take in function parameters, which are generated by the LLM.
### 5. Server → Client Parameters via Socket Connection
We pass back the function parameters as a JSON object from the server socket to the client.
### 6. Client Side Handler: API Call
A client side handler receives a JSON object that includes which action (if any) was chosen by the Action Planner in step 3, then passes control to the appropriate handler function which handles authorizations and makes API calls to various services such as Google’s Gmail Client, Calendar API, text-to-speech, and more.
### 7. Client Action Notifications → File (monitored by Flask REST API)
After the completion of each action, the client server writes the results of the action down to a file which is then read by the React Web App to display ephemeral updates on a UI, in addition to suggestions/answers/discussion questions/advice on a polling basis.
### 8. React Web App and Ephemeral UI
To communicate updates to the user (specifically notifications and suggestions from Ephemeral), we poll the Flask API for any updates and serve it to the user via a React web app. Our app is called Ephemeral because we show information minimally yet expressively to the user, in order to promote focus in meetings.
## Challenges we ran into
We spent a significant amount of our time optimizing for lower latency, which is important for a real-time consumer-facing application. In order to do this, we created sockets to enable 2-way communication between the client(s) and the server. Then, in order to support concurrent and parallel execution, we added support for multithreading on the server-side.
Choosing action spaces that can be precisely articulated enough in text such that a language model can carry out actions was a troublesome task. We went through a lot of experimentation on different tasks to figure out which would have the highest value to humans and also the highest correctness guarantee.
## Accomplishments that we're proud of
Successful integration of numerous OSS and closed source models into a working product, including Llama-70B-Chat, Mistral-7B, Stable Diffusion 2.1, OpenAI TTS, OpenAI Whisper, and more.
Integration of real actions that we can see ourselves directly using was very cool to see go from a hypothetical to a reality. The potential for impact of this general workflow in various domains is not lost on us, as while the general productivity purpose stands, there are many more specific gains to be seen in fields such as digital education, telemedicine, and more!
## What we learned
The possibility of powerful autonomous agents to supplement human workflows signals the shift of a new paradigm where more and more our imprecise language can be taken by these programs and turned into real actions on behalf of us.
## What's next for Ephemeral
An agent is only constrained by the size of the action space you give it. We think that Ephemeral has the potential to grow boundlessly as more powerful actions are integrated into its planning capabilities and it returns more of a user’s time to them. | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | partial |
## Inspiration
We saw that lots of people were looking for a team to work with for this hackathon, so we wanted to find a solution
## What it does
I helps developers find projects to work, and helps project leaders find group members.
By using the data from Github commits, it can determine what kind of projects a person is suitable for.
## How we built it
We decided on building an app for the web, then chose a graphql, react, redux tech stack.
## Challenges we ran into
The limitations on the Github api gave us alot of troubles. The limit on API calls made it so we couldnt get all the data we needed. The authentication was hard to implement since we had to try a number of ways to get it to work. The last challenge was determining how to make a relationship between the users and the projects they could be paired up with.
## Accomplishments that we're proud of
We have all the parts for the foundation of a functional web app. The UI, the algorithms, the database and the authentication are all ready to show.
## What we learned
We learned that using APIs can be challenging in that they give unique challenges.
## What's next for Hackr\_matchr
Scaling up is next. Having it used for more kind of projects, with more robust matching algorithms and higher user capacity. | ## Inspiration
Our project, "**Jarvis**," was born out of a deep-seated desire to empower individuals with visual impairments by providing them with a groundbreaking tool for comprehending and navigating their surroundings. Our aspiration was to bridge the accessibility gap and ensure that blind individuals can fully grasp their environment. By providing the visually impaired community access to **auditory descriptions** of their surroundings, a **personal assistant**, and an understanding of **non-verbal cues**, we have built the world's most advanced tool for the visually impaired community.
## What it does
"**Jarvis**" is a revolutionary technology that boasts a multifaceted array of functionalities. It not only perceives and identifies elements in the blind person's surroundings but also offers **auditory descriptions**, effectively narrating the environmental aspects they encounter. We utilize a **speech-to-text** and **text-to-speech model** similar to **Siri** / **Alexa**, enabling ease of access. Moreover, our model possesses the remarkable capability to recognize and interpret the **facial expressions** of individuals who stand in close proximity to the blind person, providing them with invaluable social cues. Furthermore, users can ask questions that may require critical reasoning, such as what to order from a menu or navigating complex public-transport-maps. Our system is extended to the **Amazfit**, enabling users to get a description of their surroundings or identify the people around them with a single press.
## How we built it
The development of "**Jarvis**" was a meticulous and collaborative endeavor that involved a comprehensive array of cutting-edge technologies and methodologies. Our team harnessed state-of-the-art **machine learning frameworks** and sophisticated **computer vision techniques** to get analysis about the environment, like , **Hume**, **LlaVa**, **OpenCV**, a sophisticated computer vision techniques to get analysis about the environment, and used **next.js** to create our frontend which was established with the **ZeppOS** using **Amazfit smartwatch**.
## Challenges we ran into
Throughout the development process, we encountered a host of formidable challenges. These obstacles included the intricacies of training a model to recognize and interpret a diverse range of environmental elements and human expressions. We also had to grapple with the intricacies of optimizing the model for real-time usage on the **Zepp smartwatch** and get through the **vibrations** get enabled according to the **Hume** emotional analysis model, we faced issues while integrating **OCR (Optical Character Recognition)** capabilities with the **text-to speech** model. However, our team's relentless commitment and problem-solving skills enabled us to surmount these challenges.
## Accomplishments that we're proud of
Our proudest achievements in the course of this project encompass several remarkable milestones. These include the successful development of "**Jarvis**" a model that can audibly describe complex environments to blind individuals, thus enhancing their **situational awareness**. Furthermore, our model's ability to discern and interpret **human facial expressions** stands as a noteworthy accomplishment.
## What we learned
# Hume
**Hume** is instrumental for our project's **emotion-analysis**. This information is then translated into **audio descriptions** and the **vibrations** onto **Amazfit smartwatch**, providing users with valuable insights about their surroundings. By capturing facial expressions and analyzing them, our system can provide feedback on the **emotions** displayed by individuals in the user's vicinity. This feature is particularly beneficial in social interactions, as it aids users in understanding **non-verbal cues**.
# Zepp
Our project involved a deep dive into the capabilities of **ZeppOS**, and we successfully integrated the **Amazfit smartwatch** into our web application. This integration is not just a technical achievement; it has far-reaching implications for the visually impaired. With this technology, we've created a user-friendly application that provides an in-depth understanding of the user's surroundings, significantly enhancing their daily experiences. By using the **vibrations**, the visually impaired are notified of their actions. Furthermore, the intensity of the vibration is proportional to the intensity of the emotion measured through **Hume**.
# Ziiliz
We used **Zilliz** to host **Milvus** online, and stored a dataset of images and their vector embeddings. Each image was classified as a person; hence, we were able to build an **identity-classification** tool using **Zilliz's** reverse-image-search tool. We further set a minimum threshold below which people's identities were not recognized, i.e. their data was not in **Zilliz**. We estimate the accuracy of this model to be around **95%**.
# Github
We acquired a comprehensive understanding of the capabilities of version control using **Git** and established an organization. Within this organization, we allocated specific tasks labeled as "**TODO**" to each team member. **Git** was effectively employed to facilitate team discussions, workflows, and identify issues within each other's contributions.
The overall development of "**Jarvis**" has been a rich learning experience for our team. We have acquired a deep understanding of cutting-edge **machine learning**, **computer vision**, and **speech synthesis** techniques. Moreover, we have gained invaluable insights into the complexities of real-world application, particularly when adapting technology for wearable devices. This project has not only broadened our technical knowledge but has also instilled in us a profound sense of empathy and a commitment to enhancing the lives of visually impaired individuals.
## What's next for Jarvis
The future holds exciting prospects for "**Jarvis.**" We envision continuous development and refinement of our model, with a focus on expanding its capabilities to provide even more comprehensive **environmental descriptions**. In the pipeline are plans to extend its compatibility to a wider range of **wearable devices**, ensuring its accessibility to a broader audience. Additionally, we are exploring opportunities for collaboration with organizations dedicated to the betterment of **accessibility technology**. The journey ahead involves further advancements in **assistive technology** and greater empowerment for individuals with visual impairments. | ## Inspiration
Too often, social media keeps us apart. What if there was a way to share photos online in a way that brings people together? Introducing ourboARd, an AR-based photo sharing app that gets users to gather around a digital board.
## What it does
ourboARd is a digital board that nourishes human connection. It does this by utilizing a physical tracker somewhere in the real world for people to scan with their phones in an AR environment to view and add images to the board as they please. Anyone can walk up to the AR tag, go to our website, and view the current board, as well as add photos and text notes.
## How we built it
Augmented reality enabled front-end with AR.js and Three.js.
Backend Flask API connected to a MongoDB Atlas database for image processing and storage.
Deployed the front-end on Netlify and used ngrok to allow proxy-enabled requests to the back-end.
## Challenges we ran into
Using AR.js and understanding the library for the first time.
Switching from our comfort zones with React that does a lot of the heavy lifting to pure HTML/JS/CSS.
CORS and HTTPS configurations for a secure deployment.
## Accomplishments that we're proud of
Got MongoDB Atlas database working so multiple people can contribute to the board.
Successful deployment to allow everyone to be able to access our web app through their phones.
## What we learned
When stuck on a user story, take a step back and reconsider if the user story is worth it and whether
a different user story could have a similar effect.
Balancing high-focus solo work with collaboration with teammates - balancing "flow" with staying in sync with the team.
## What's next for ourboARd
Ability to change image location on board.
Functionality to download the board.
View each individual image by tapping on it on the screen.
Utilize AI to censor vulgar language and images.
Improve image quality on the board. | winning |
## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future. | ## About Us
Discord Team Channel: #team-64
omridan#1377,
dylan28#7389,
jordanbelinsky#5302,
Turja Chowdhury#6672
Domain.com domain: positivenews.space
## Inspiration
Over the last year headlines across the globe have been overflowing with negative content which clouded over any positive information. In addition everyone has been so focused on what has been going on in other corners of the world and have not been focusing on their local community. We wanted to bring some pride and positivity back into everyone's individual community by spreading positive headlines at the users users location. Our hope is that our contribution shines a light in these darkest of times and spreads a message of positivity to everyone who needs it!
## What it does
Our platform utilizes the general geolocation of the user along with a filtered API to produce positive articles about the users' local community. The page displays all the articles by showing the headlines and a brief summary and the user has the option to go directly to the source of the article or view the article on our platform.
## How we built it
The core of our project uses the Aylien news API to gather news articles from a specified country and city while reading only positive sentiments from those articles. We then used the IPStack API to gather the users location via their IP Address. To reduce latency and to maximize efficiency we used JavaScript in tandem with React opposed to a backend solution to code a filtration of the data received from the API's to display the information and imbed the links. Finally using a combination of React, HTML, CSS and Bootstrap a clean, modern and positive design for the front end was created to display the information gathered by the API's.
## Challenges we ran into
The most significant challenge we ran into while developing the website was determining the best way to filter through news articles and classify them as "positive". Due to time constraints the route we went with was to create a library of common keywords associated with negative news, filtering articles with the respective keywords out of the dictionary pulled from the API.
## Accomplishments that we're proud of
We managed to support a standard Bootstrap layout comprised of a grid consisting of rows and columns to enable both responsive design for compatibility purposes, and display more content on every device. Also utilized React functionality to enable randomized background gradients from a selection of pre-defined options to add variety to the site's appearance.
## What we learned
We learned a lot of valuable skills surrounding the aspect of remote group work. While designing this project, we were working across multiple frameworks and environments, which meant we couldn't rely on utilizing just one location for shared work. We made combined use of Repl.it for core HTML, CSS and Bootstrap and GitHub in conjunction with Visual Studio Code for the JavaScript and React workloads. While using these environments, we made use of Discord, IM Group Chats, and Zoom to allow for constant communication and breaking out into sub groups based on how work was being split up.
## What's next for The Good News
In the future, the next major feature to be incorporated is one which we titled "Travel the World". This feature will utilize Google's Places API to incorporate an embedded Google Maps window in a pop-up modal, which will allow the user to search or navigate and drop a pin anywhere around the world. The location information from the Places API will replace those provided by the IPStack API to provide positive news from the desired location. This feature aims to allow users to experience positive news from all around the world, rather than just their local community. We also want to continue iterating over our design to maximize the user experience. | ## Inspiration
The Rasberry Pi 4 is a great cheap device for hacking. It's discrete yet powerful enough to run most hacking tools found on Kali Linux. For this hack, I wanted to test out how Aircrack-ng tools would work on the RPI4.
## What it does
The hack captures a 4-Way Handshake and uses it to initiate a brute force its way into a wifi network using WPA/WPA2 authentication using a password list.
## What we learned
A big takeaway from this was the realization that nothing is as secure as we think it is, there'll always be an exploit that lets you in. It was also great using an RPI4 to test out hacking tools and not having to use a VM which can lead to some unexpected behavior.
## What's next for Wifi Hacking with a RPI4
I would like to buy the accessories that can make this hack 100% portable, so attaching an LCD screen and a power supply, that way this hack could be moved around and wouldn't be limited by big monitor I was using. | winning |
## Inspiration 💡
We love playing games, and one of our childhood memories was going to Arcades. As technology advances, our favourite pastimes have evolved alongside it. This inspired us to create Two-Pac, a retro-gamified photo album and a classic arcade game inspired by Pac-Man that takes its player on an interactive journey through their photo gallery and crafts narratives from the images of their favourite memories.
## What it does 🎯
* Our application gets 3 images from user's photo gallery, and evenly split them into 4 pieces (image shards) and place them into the Pac-Man maze. The goal of the player is to successfully collect the shards from the maze without being caught by the ghosts, allowing the player to relive the memories and experiences captured in the photo.
* Upon collecting a shard (of which there are 4 in each level), a part of the narrative associated with the image the shard belongs to is revealed to the player. Once the player collects all the shards on the current level or is caught by a ghost, the player's victory/loss is noted and the player progresses to the next level. The progression of the player is dynamic and depends on whether they win or lose on different levels.
* Upon completion of the levels, Two-Pac assembles the complete picture from the shards the player has collected through their victories and losses and reveals the formed narrative.
## How we built it 🦾
We built Two-Pac using Python, PyGame, Vision Transformers, and the Cohere API.
Our project heavily relies on a base Pac-Man game, which we implemented in PyGame. To put a spin on classic Pac-Man and turn it into a gamified photo album, we had to introduce the concept of an "image shard" to the game, for which we added additional code and novel sprites.
A fundamental aspect of our project is its ability to automatically generate descriptions and narratives from the players images. First, Two-Pac uses SOTA Vision Transformers to automatically generate captions for the images and then, using the captions, utilizes Cohere's Generation API to craft a dynamic and immersive narrative that links the memories of the images together.
Since the player's progression through the game impacts the narrative they face, we utilize the Game Tree data structure to capture the various possible game states. The nodes of the Game Tree represent states, while the edges represent the player winning/losing a level. Using the Cohere Generation API, we populate the different paths of the Game Tree, ensuring consistency between generated narratives by conditioning on the generated narrative of images in the ancestor states in the data structure.
Upon initialization of the game, the player's images are decomposed into 4 sub-images and stored as image shards. Upon completion of the game, Two-Pac uses stored information to recreate the (in?)complete image and narrative using the shards the player collects.
## Challenges we ran into 🚦
There were a few challenges that were particularly difficult.
One of our biggest challenges was with trying to incorporate the Cohere API with our Game Tree generation. We had a lot of difficulty trying to ensure that the LLM's output was consistent with the desired format. None of us had any prior experience with Prompt Engineering so we had to read guides and talk to the Cohere mentors for help. Ultimately, a Reddit post resolved our issues (apparently, if you want the LLM output to be parse-able you just need to mention it in the the input).
Another big challenge was with linking different parts of the program together. Different team members worked on different parts in isolation, and trying to make everyone's code adaptable with everyone else's was surprisingly difficult.
## Accomplishments that we're proud of 🌟
We did not know each other before the hackathon, and we take pride in the fact that we were able to get together, make a plan, and stick to it while supporting each other. Additionally, we find it really cool that we **bridged the disconnect between classical AI and modern AI** by using Game Trees, LLMs, and Vision Transformers to bring new life to a classic game.
## What we learned 🔍
Cindy: During the process of making Two-Pac, I learned to make use of all the available resources. And I also realize that being a good programmer is more than just coding, there are still a lot ahead of me for me to learn, such as operating systems.
Duc: I learned the skill of combining individual features together to form a bigger product. As a result, I also learned the importance of writing clean + concise code since ~~trash~~ poorly written code causes a lot of issues when debugging.
Rohan: I learned to take in a lot of new code and find ways to add on new features. This means that writing clean, decoupled code is really important.
Rudraksh: This was my first time having to work with Prompt Engineering. I learned that its advantageous to forgo conversational instructions and give concise and specific details about the format of the input and desired output.
## What's next for Two-Pac ❔
There are many features that we want to implement in the future. One feature we wanted to include but didn't have the time to implement was "song of the year" - using AI, we sought to estimate the year the photo was taken to play some music from that year when one of that image's shards was collected. | ## Inspiration
Pac-Man and Flappy Bird are two of the most famous retro games of the past 100 years. We decided to recreate these games, but with a twist. These games were integral parts of our childhood, and it was great to put our technical skills to use in a project that was both challenging and fun.
## What it does
Our games are a recreation of Pac-Man and Flappy Bird but without the use of a keyboard. The player uses his/her hand to direct the Pac-Man either top, down, left, or right. The player then opens and closes his/her hands into a fist to represent the jumping of the bird. The user scores are displayed on the screen and a frontend application displays the score leaderboards for the respective games.
## How we built it
Our project connects various facets of programming and math. We used primarily **Python** as our programming language. We utilized **Django** as a backend that includes **CRUD** functionality for user data. **Taipy** was used for the frontend, which provided incredibly easy to use and beautiful designs. PyGame was used for the general game logic using **OOP** and computer vision libraries like **OpenCV/Tensorflow/Mediapipe** were used together to handle hand gesture recognition.
## Challenges we ran into 😈
We faced many challenges both large and small.
One large and expected challenge was training a **Convolutional Neural Network** that would accurately detect hand signs. We initially implemented a ML solution that trained on thousands of images of our own hand using Google Teachable Machines but we were disappointed by the speed and accuracy of the model when using it to run our games. Fortunately, we were able to implement a completely new technique using hand landmark detection and linear algebra techniques to optimize our network solution. This let us find the direction of the finger for player direction and the distance of landmark points from the mean point on the hand to detect whether the hand was open or closed.
To handle the issue where we could not get consistent results depending on how far the hand was from the camera, we divided our distance between the total distance between the top of our finger and our wrist to ensure consistent accuracy in our inference.
The other major challenge was about optimizing for efficiency, mainly for the Pac-Man game. In order to move the Pac-Man, we had to translate the predicted hand signal from the Neural Network to PyGame. We tried many approaches to do so. One was using Django **REST** Framework to make a POST request for every hand sign recognized by the ML model. Another was for the ML model to write the predicted hand signal to another file, which would be read by **PyGame**. However, these approaches were slow and resulted in high latency and thus slow results on the GUI. To solve these issues, we utilized concurrent programming by implementing **multithreading**. Thanks to this, we were able to simultaneously run the game and ML model with great efficiency.
## Accomplishments that we're proud of
We were all able to learn from each other and expand upon our interests. For example, we often learn complex math in school, but we were able to find real life use cases for linear algebra to determine the direction of our finger which we are quite happy about.
## What we learned
We each learned varying things, whether it is learning about the intuition behind a neural network, the way to make API requests, and learning the intricacies of version control using Git.
## What's next for Telekinesis
Perhaps expanding upon the complexity of the game. | ## Inspiration
We all deal with nostalgia. Sometimes we miss our loved ones or places we visited and look back at our pictures. But what if we could revolutionize the way memories are shown? What if we said you can relive your memories and mean it literally?
## What it does
retro.act takes in a user prompt such as "I want uplifting 80s music" and will then use sentiment analysis and Cohere's chat feature to find potential songs out of which the user picks one. Then the user chooses from famous dance videos (such as by Michael Jackson). Finally, we will either let the user choose an image from their past or let our model match images based on the mood of the music and implant the dance moves and music into the image/s.
## How we built it
We used Cohere classify for sentiment analysis and to filter out songs whose mood doesn't match the user's current state. Then we use Cohere's chat and RAG based on the database of filtered songs to identify songs based on the user prompt. We match images to music by first generating a caption of the images using the Azure computer vision API doing a semantic search using KNN and Cohere embeddings and then use Cohere rerank to smooth out the final choices. Finally we make the image come to life by generating a skeleton of the dance moves using OpenCV and Mediapipe and then using a pretrained model to transfer the skeleton to the image.
## Challenges we ran into
This was the most technical project any of us have ever done and we had to overcome huge learning curves. A lot of us were not familiar with some of Cohere's features such as re rank, RAG and embeddings. In addition, generating the skeleton turned out to be very difficult. Apart from simply generating a skeleton using the standard Mediapipe landmarks, we realized we had to customize which landmarks we are connecting to make it a suitable input for the pertained model. Lastly, understanding and being able to use the model was a huge challenge. We had to deal with issues such as dependency errors, lacking a GPU, fixing import statements, deprecated packages.
## Accomplishments that we're proud of
We are incredibly proud of being able to get a very ambitious project done. While it was already difficult to get a skeleton of the dance moves, manipulating the coordinates to fit our pre trained model's specifications was very challenging. Lastly, the amount of experimentation and determination to find a working model that could successfully take in a skeleton and output an "alive" image.
## What we learned
We learned about using media pipe and manipulating a graph of coordinates depending on the output we need, We also learned how to use pre trained weights and run models from open source code. Lastly, we learned about various new Cohere features such as RAG and re rank.
## What's next for retro.act
Expand our database of songs and dance videos to allow for more user options, and get a more accurate algorithm for indexing to classify iterate over/classify the data from the db. We also hope to make the skeleton's motions more smooth for more realistic images. Lastly, this is very ambitious, but we hope to make our own model to transfer skeletons to images instead of using a pretrained one. | losing |
## Inspiration
Students have difficulty to find a public course group chat on social media. Though we have facebook course group, it more seems like a discussion board other than a chat group. And sometimes students lose track of announcements made on MyCourses if they do not log in.
## What it does
A useful website may help students find peers who take the same course with them in Cisco Spark Chat Group. When they enter their Cisco Spark email account and courses they are currently taking, they will join the matched course Cisco Spark groups immediately. Moreover, professors are our mainly users. They can create personal accounts and manage the course info with their account. Moreover, the essential function of our McGill Martlet bot is it can update any announcements the professor make on our website instantly in the group. Therefore, students do not need to suffer any delayed info or miss a
## How we built it
We built the website using javascript, html, and css. To create the McGill Martlet bot, we used java and Cisco Spark API.
## Challenges we ran into
It was challenging to figure out how Cisco Spark API worked, and how to use javascript and http server.
## Accomplishments that we're proud of
Smoothly integrating our website into the Cisco Spark App
Creating a professor assistant bot
Learning new APIs in a short time
Learning more about HTTP requests and Javascript servers
## What we learned
How to use Cisco Spark API
How to create a website
## What's next for Martlet@McGill
Allow professors to use our preset template to create their own course teaching web page.
And make the website come online. | ## Inspiration
We wanted something like amazon where you could get personalized suggestions for classes. Think the "items you may be interested in bar."
## What it does
You can sign up for the messenger bot on facebook. Once it's live, it will ask you about your classes and how you rate them. Then you can ask for a recommendation and get some classes our machine learning thought you'd be interested in.
## How I built it
We used the python flask framwork to build the front end facebook messenger bot. We connected a database to the program to store the classes and features of classes and to store user's ratings of the class. We used heroku to host both the database and the webserver. On the back end, we used a regression technique to make our class predictions.
## Challenges I ran into
Figuring out how to link a database to our program and how to host that database on heroku was extremely challenging. We also struggled to have the chatbot hold a longer conversation, as the framework means the chatbot by default forgets everything but the current message. Once we designed the framework to work around that, we found our chatbot was sending repetitive messages, though we never figured out why. On the machine learning side, we struggled to determine how accurate our model was from our small dataset of classes.
## Accomplishments that I'm proud of
Our chatbot can actually reply and sometimes is pretty consistent. Also the databases are updated consistently.
## What I learned
We learned a ton about sql and web hosting. The details of web hosting and how we could deploy our code was surprisingly challenging, so it was gratifying to see it work.
## What's next for ClassRate
The machine learning side still needs to be linked to the front end. In addition, we need more data about other classes for more accurate predictions. After that, we'd like to find a way to have users be able to add classes to our system and be able to track enjoyment over the course of a semester for better ratings. | ## Inspiration
How long does class attendance take? 3 minutes? With 60 classes, 4 periods a day, and 180 school days in a year, this program will save a cumulative 72 days every year! Our team recognized that the advent of neural networks yields momentous potential, and one such opportunity is face recognition. We utilized this cutting-edge technology to save time in regards to attendance.
## What it does
The program uses facial recognition to determine who enters and exits the room. With this knowledge, we can keep track of everyone who is inside, everyone who is outside, and the unrecognized people that are inside the room. Furthermore, we can display all of this on a front end html application.
## How I built it
A camera that is mounted by the door sends a live image feed to Raspberry pi, which then transfers that information to Flask. Flask utilizes neural networks and machine learning to study previous images of faces, and when someone enters the room, the program matches the face to a person in the database. Then, the program stores the attendees in the room, the people that are absent, and the unrecognized people. Finally, the front end program uses html, css, and javascript to display the live video feed, the people that are attending or absent, the faces of all unrecognized people.
## Challenges I ran into
When we were using the AWS, we uploaded to the bucket, and that triggered a Lamda. In short, we had too many problematic middle-men, and this was fixed by removing them and communicating directly. Another issue was trying to read from cameras that are not designed for Raspberry pi. Finally, we accidentally pushed the wrong html2 file, causing a huge merge conflict problem.
## Accomplishments that I'm proud of
We were successfully able to integrate neural networks with Flask to recognize faces. We were also able to make everything much more efficient than before.
## What I learned
We learned that it is often better to directly communicate with the needed software. There is no point in having middlemen unless they have a specific use. Furthermore, we also improved our server creating skills and gained many valuable insights. We also taught a team member how to use GIT and how to program in html.
## What's next for Big Brother
We would like to match inputs from external social media sites so that unrecognized attendees could be checked into an event. We also would like to export CSV files that display the attendees, their status, and unrecognized people. | losing |
## Inspiration
Our inspiration came from the famous subreddit r/place.
## What it does
Git-place is an interactive pixel art page on a GitHub repository. Anyone with a GitHub account can create pixel art on our projects README file.
## How we built it
The application was built using JavaScript, node, GitHub actions, GitHub issues, and GitHub itself.
## Challenges we ran into
Since we were utilizing GitHub actions as our main source of change within the repo itself, a challenge we faced was to test our code after pushing to our main branch. That made it difficult for us to predict the errors that would come with the changes, and made it so thorough testing was required.
We also faced some issues with learning about the differences between server-side java script and client-side JavaScript, which made it so some packages had to be utilized in different ways to be used properly.
## Accomplishments that we're proud of
We are very proud to have correctly utilized GitHub actions, as well as integrate automated repository changes as a main part of the flow of our system. Making a project that anybody on GitHub can use also made us feel good about our work at Hack Western, since it pushed us to learn more about sides of tech we did not know much about.
## What we learned
Working on this project taught we learned all kinds of things that we didn't know GitHub was capable of. Before starting this project neither of us had ever even created a GitHub issue. To make the project update and commit by itself we had to learn to create GitHub actions. We needed to learn how to control a Github action using yml.
## What's next for Git-place
Some future steps for Git-place are adding more colours that can be added to the canvas as well as making the program faster and able to handle more requests simultaneously. | +1 902 903 6416 (send 'cmd' to get started)
## Inspiration
We believe in the right of every individual to have access to information, regardless of price or censorship
## What it does
NoNet gives unfettered access to internets most popular service without an internet or data connection. It accomplishes this through sending SMS queries to a server which then processes the query and returns results that were previously only accessible to those with an uncensored internet connection. It works with Yelp, Google Search (headlines), Google Search (Articles/Websites), Wikipedia, and Google Translate.
some commands include:
* 'web: border wall' // returns top results from google
* 'url: [www.somesite.somearticle.com](http://www.somesite.somearticle.com)' // returns article content
* 'tr ru: Hello my russian friend!' // returns russian translation
* 'wiki: Berlin' // returns Wikipedia for Berlin
* 'cmd' // returns all commands available
The use cases are many:
* in many countries, everyone has a phone with sms, but data is prohibitively expensive so they have no internet access
* Countries like China have a censored internet, and this would give citizens the freedom to bybass that
* Authoritarian Countries turn of internet in times of mass unrest to keep disinformation
## How we built it
We integrated Twilio for SMS with a NodeJS server, hosted on Google App Engine, and using multiple API's
## Challenges we ran into
We faced challenges at every step of the way, from establishing two way messaging, to hosting the server, to parsing the correct information to fit sms format. We tackled the problems as a team and overcome them to produce a finished product
## Accomplishments that we're proud of:
"Weathering a Tsunami" - getting through all the challenges we faced and building a product that can truly help millions of people across the world
## What we learned
We learned how to face problems as well as new technologies
## What's next for NoNet
Potential Monetization Strategies would be to put ads in the start of queries (like translink bus stop messaging), or give premium call limits to registered numbers | ## Inspiration
As programming beginners and first time hackathon participants, we wanted to challenge ourselves by building an app and creating a software that recognizes text from an image. Our secondary goal was to create a practical product that solves a common problem. Hence, grocer.io was created.
## What it does
Grocer.io is a virtual fridge. It tracks the shelf life of the user’s ingredients: allowing them to eat it while it’s fresh. With the existing ingredients in the fridge, it also suggest recipes most appropriate for the age of the ingredients.
## How I built it
Using Android Studio, we created an app that reads text from an image and uploads the detected text to firebase’s real time database. We designed and organized the UI and UX with adobe photoshop, Adobe XD, and Photoshop
## Challenges I ran into
Knowing where to start:
This was everyone’s first time creating an app! We struggled a lot with knowing what platform to use as well as what we needed in order to put together each component of the app.
Firebase and Gradle:
We knew we wanted to use a database in our app, so we attempted to set up firebase (which we found out required some changes to our build.gradle files) At this point we didn’t actually know what gradle did, nor did we know that Android Studio automatically set up these files for us.
Phone-laptop compatibility:
When testing our app, we tried to use a variety of phones, source PCs and USB connection cables to get the connection recognized. One persistent issue was that the computer would not recognize our phone as an android device, preventing us from running tests.
Collaboration/file sharing:
It wasn’t until near the end of the Hackathon that we started using GitHub to track our project changes and file share. (one of our neighbouring teams had to teach us how to use it). Prior to using GitHub, we had a lot of issues keeping track of the most updated versions merging changes from different team members.
## Accomplishments that I'm proud of
We built our first app, learned how to use databases and upload real time data to it, and ideated a solution to a real life problem we identified.
## What I learned
We learned how to use android studio, implement databases using firebase, and github. We are very proud of how far we’ve come and now know what areas/ecosystems we need more practice with.
## What's next for grocer.io
Improving our Text Vision AI, Tracking item lifespan, Recipe recommendations, and Integrating front-end code. | partial |
## Inspiration
We were sitting together as a team after dinner when our team member pulled out her phone and mentioned she needed to log her food – mentioning how she found the app she used (MyFitnessPal) to be quite tedious. This was a sentiment shared by many users we've encountered and we decided there must be a way that we could make this process simple and smooth!
## What it does
Artemis is an Amazon Alexa experience that changes the way you engage in fitness and meal tracking. Log your food, caloric intake, and know what the breakdown of your daily diet is with a simple command. All you have to do is tell Artemis that you ate something, and she'll automatically record it for you, retrieve all pertinent nutrition information, and see how it stacks up with your daily goals. Check how you're doing at anytime by asking Artemis, "How am I doing?" or looking up your stats presented in a clear and digestible way at [www.artemisalexa.com](http://www.artemisalexa.com)
## How we built it
We took the foods processed from the language request, made a call to the Nutritionix API to get the caloric breakdown, and update the backend server which live-updates the dashboard. The smart-sensor waterbottle tracks water level by using ultrasonar waves that bounce back with distance data.
## Challenges we ran into
It's definitely difficult for us to model data beyond the two days we've been working on this project and we wanted to model a lot richer of a data set in our dashboard.
## Accomplishments that we're proud of
We're really proud of the product we've built!
* Polished and pleasant user experience
* Thorough coverage of conversation, can sustain a pertinent conversation with Artemis about healthy eating.
* Wide breadth of data visualization
* Categorical breakdown
* Variances for Caloric intake over the course of the day
* Items consumed as percentages of daily nutritional breakdown
* Light sensor for fluid color detection (aside from water – no cheating with soda!)
* Ultrasonar sensor that measures water level
## What's next for Artemis
* We're hoping to build Fitbit integration so that Alexa can directly log your food into one app. | ## Inspiration
One day Saaz was sitting at home thinking about his fitness goals and his diet. Looking in his fridge, he realized that, on days when his fridge was only filled with leftovers and leftover ingredients, it was very difficult for him to figure out what he could make that followed his nutrition goals. This dilemma is something Saaz and others like him often encounter, and so we created SmartPalate to solve it.
## What it does
SmartPalate uses AI to scan your fridge and pantry for all the ingredients you have at your disposal. It then comes up with multiple recipes that you can make with those ingredients. Not only can the user view step-by-step instructions on how to make these recipes, but also, by adjusting the nutrition information of the recipe using sliders, SmartPalate caters the recipe to the user's fitness goals without compromising the overall taste of the food.
## How we built it
The scanning and categorization of different food items in the fridge and pantry is done using YOLOv5, a single-shot detection convolutional neural network. These food items are sent as a list of ingredients into the Spoonacular API, which matches the ingredients to recipes that contain them. We then used a modified natural language processing model to split the recipe into 4 distinct parts: the meats, the carbs, the flavoring, and the vegetables. Once the recipe is split, we use the same NLP model to categorize our ingredients into whichever part they are used in, as well as to give us a rough estimate on the amount of ingredients used in 1 serving. Then, using the Spoonacular API and the estimated amount of ingredients used in 1 serving, we calculate the nutrition information for 1 serving of each part. Because the amount of each part can be increased or decreased without compromising the taste of the overall recipe, we are then able to use a Bayesian optimization algorithm to quickly adjust the number of servings of each part (and the overall nutrition of the meal) to meet the user's nutritional demands. User interaction with the backend is done with a cleanly built front end made with a React TypeScript stack through Flask.
## Challenges we ran into
One of the biggest challenges was identifying the subgroups in every meal(the meats, the vegetables, the carbs, and the seasonings/sauces). After trying multiple methods such as clustering, we settled on an approach that uses a state-of-the-art natural language model to identify the groups.
## Accomplishments that we're proud of
We are proud of the fact that you can scan your fridge with your phone instead of typing in individual items, allowing for a much easier user experience. Additionally, we are proud of the algorithm that we created to help users adjust the nutrition levels of their meals without compromising the overall taste of the meals.
## What we learned
Using our NLP model taught us just how unstable NLP is, and it showed us the importance of good prompt engineering. We also learned a great deal from our struggle to integrate the different parts of our project together, which required a lot of communication and careful code design.
## What's next for SmartPalate
We plan to allow users to rate and review the different recipes that they create. Additionally, we plan to add a social component to SmartPalate that allows people to share the nutritionally customized recipes that they created. | ## Inspiration
As a gym freak, it was always a major inconvenience to us that we have to manually enter the nutrition facts for every single meal.
We set out to make the process super simple using machine learning and azure.
## What it does
I automatically detect what food you ate just by looking at it! (using Azure)
## Challenges we ran into
The first challenge for us was that our team members were good at different languages. So we decided to work with something completely different that we both were not familiar with. We started with flutter, and then we also tried to learn Azure, and this is how we reached here
## Accomplishments that we're proud of
we were proud that we could learn JSON and flutter
## What we learned
JSON and Flutter
## What's next for NuTri
Subscription-based monetization
Personalized intake compute based on the statistical database from Azure
Implementing and fixing the number of features that are broken in a current state
Partnerships with fitness trainers and Exercise Centres
The target audience is the average gym-going folk | partial |
Subsets and Splits