
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## MoodBox
### Smart DJ'ing using Facial Recognition
You're hosting a party with your friends. You want to play the hippest music and you’re scared of your friends judging you for your taste in music.
You ask your friends what songs they want to listen to… And only one person replies with that one Bruno Mars song that you’re all sick of listening to.
Well fear not, with MoodBox you can now set a mood and our app will intelligently select the best songs from your friends’ public playlists!
### What it looks like
You set up your laptop on the side of the room so that it has a good view of the room. Create an empty playlist for your party. This playlist will contain all the songs for the night. Run our script with that playlist, sit back and relax.
Feel free to adjust the level of hypeness as your party progresses. Increase the hype as the party hits the drop and then make your songs more chill as the night winds down into the morning. It’s as simple as adjusting a slider in our dank UI.
### Behind the scenes
We used python’s `facial_recognition` package based on `opencv` library to implement facial recognition on ourselves. We have a map from our facial features from spotify user ids, which we use to find the saved songs.
We use the `spotipy` package to manipulate the playlist in real-time. Once we find a new face in the frame, we first read in the current mood from the slider, and find songs in that user’s public library of songs that match the mood set by the host the best.
Once someone is out of the frame for long enough, they get removed from our buffer, and their songs get removed from the playlist. This also ensures that the playlist is empty at the end of the party, and everyone goes home happy. | ## Inspiration
We aren't musicians. We can't dance. With AirTunes, we can try to do both! Superheroes are also pretty cool.
## What it does
AirTunes recognizes 10 different popular dance moves (at any given moment) and generates a corresponding sound. The sounds can be looped and added at various times to create an original song with simple gestures.
The user can choose to be one of four different superheroes (Hulk, Superman, Batman, Mr. Incredible) and record their piece with their own personal touch.
## How we built it
In our first attempt, we used OpenCV to maps the arms and face of the user and measure the angles between the body parts to map to a dance move. Although successful with a few gestures, more complex gestures like the "shoot" were not ideal for this method. We ended up training a convolutional neural network in Tensorflow with 1000 samples of each gesture, which worked better. The model works with 98% accuracy on the test data set.
We designed the UI using the kivy library in python. There, we added record functionality, the ability to choose the music and the superhero overlay, which was done with the use of rlib and opencv to detect facial features and map a static image over these features.
## Challenges we ran into
We came in with a completely different idea for the Hack for Resistance Route, and we spent the first day basically working on that until we realized that it was not interesting enough for us to sacrifice our cherished sleep. We abandoned the idea and started experimenting with LeapMotion, which was also unsuccessful because of its limited range. And so, the biggest challenge we faced was time.
It was also tricky to figure out the contour settings and get them 'just right'. To maintain a consistent environment, we even went down to CVS and bought a shower curtain for a plain white background. Afterward, we realized we could have just added a few sliders to adjust the settings based on whatever environment we were in.
## Accomplishments that we're proud of
It was one of our first experiences training an ML model for image recognition and it's a lot more accurate than we had even expected.
## What we learned
All four of us worked with unfamiliar technologies for the majority of the hack, so we each got to learn something new!
## What's next for AirTunes
The biggest feature we see in the future for AirTunes is the ability to add your own gestures. We would also like to create a web app as opposed to a local application and add more customization. | # Picify
**Picify** is a [Flask](http://flask.pocoo.org) application that converts your photos into Spotify playlists that can be saved for later listening, providing a uniquely personal way to explore new music. The experience is facilitated by interacting and integrating a wide range of services. Try it [here](http://picify.net/).
## Workflow
The main workflow for the app is as follows:
1. The user uploads a photo to the Picify Flask server.
2. The image is passed onto the [Google Cloud Vision](https://cloud.google.com/vision/) API, where labels and entities are predicted/extracted. This information then gets passed back to the Flask server.
3. The labels and entities are filtered by a dynamic confidence threshold which is iteratively lowered until a large enough set of descriptors for the image can be formed.
4. Each of the descriptors in the above set are then expanded into associated "moods" using the [Datamuse API](https://www.datamuse.com/api/).
5. All of the descriptors and associated moods are filtered against a whitelist of "musically-relevant" terms compiled from sources such as [AllMusic](https://www.allmusic.com/moods) and [Every Noise at Once](http://everynoise.com/genrewords.html), excepting descriptors with extremely high confidence (for example, for a picture of Skrillex this might be "Skrillex").
6. Finally, the processed words are matched against existing Spotify playlists, which are sampled to form the final playlist.
## Contributors
* [Macguire Rintoul](https://github.com/mrintoul)
* [Matt Wiens](https://github.com/mwiens91)
* [Sophia Chan](https://github.com/schan27) | winning |
## Inspiration
Hospital pain rating charts show the severity of pain, but when we spoke to medical professionals they wanted a greater level of detail. A single pain level datapoint doesn't let doctors follow trends when they change their treatment plan.
## What it does
Pulse allows a patient in hospital care or checking in to easily tell doctors where they're experiencing pain and how bad it is. This can help doctors triage incoming patients and monitor response to new treatment plans for patients with chronic pain.
## How we built it
We used Adobe Comet to rapidly iterate on a streamlined design, then moved to React Native to accelerate our mobile development process. We shared our progress and interface with medical mentors and doctors at every stage.
## Challenges we ran into
Debugging and working with Android devices was tricky at times, but we learned how to debug in an emulator and over USB. We also had to learn React Native as we wrote our app.
## Accomplishments that we're proud of
We integrated all feedback from mentors and doctors, so we know that they would actually use our software. We also learned React Native and made a clear UI flow.
## What we learned
Feedback from doctors in a range of medical fields taught us that the bridge between qualitative descriptions of pain and quantitative data needs to be smooth and consistent for each patient. Our team also learned React Native for this hack.
## What's next for Pulse
We hope to add more long-term data analysis to help doctors figure out how their treatment plans are affecting patients. | ## Inspiration
We were walking outside the colliseum when the idea hit us, a community driven Lost and Found that could help people come together when it came to losing items regardless of where they lost it.
## What it does
After you log into our system, you either be looking for an item or posting one to the community. Where you will put in such data as what it was, where, and a description to help retrieve said item.
## How I built it
For this we started with what we knew, which we thought was web development. Using Bootstrap for initial design and CSS for formatting changes. For the Back End it began with SQL and later evolved to include PHP. This includes the reading of plenty of documentation.
## Challenges I ran into
.Long story short, we did not know how to use API's in the first place. Our biggest challenge was finding the correct documentation and tutorials to assist us in developing our application.
Another challenge included the usage of Jquery for the first time in our projects.
## Accomplishments that I'm proud of
Most of the accomplishments in our project came from long hours of reading, learning, crying, and self pity. Although the obstacles were painful to overcome, both big and small, our team found our greatest accomplishments in our capability to work as a team.
## What I learned
This hackathon was a learning experience for all of us; from new languages to new implementations of a previously known language.
## What's next for FndIt!
We plan on building on top of our current foundation and optimize it into a mobile app. | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | losing |
## Inspiration
Every year, millions of people around the world choose not to recycle because they don't know how! We wanted to simplify recycling for the public.
## What it does
Robot Recycler uses a Kinect to search for recyclables, then either puts things in the trash, or the recycling! It's that easy!
## How I built it
We used the Kinect, Robot Operating System, and Arduino to build Robot Recycler.
## What's next for Robot Recycler
In the future, we'd like to add more models to our Kinect's library so that no recycling ever gets put in the trash! | # Welcome to TrashCam 🚮🌍♻️
## Where the Confusion of Trash Sorting Disappears for Good
### The Problem 🌎
* ❓ Millions of people struggle with knowing how to properly dispose of their trash. Should it go in compost, recycling, or garbage?
* 🗑️ Misplaced waste is a major contributor to environmental pollution and the growing landfill crisis.
* 🌐 Local recycling rules are confusing and inconsistent, making proper waste management a challenge for many.
### Our Solution 🌟
TrashCam simplifies waste sorting through real-time object recognition, turning trash disposal into a fun, interactive experience.
* 🗑️ Instant Sorting: With TrashCam, you never have to guess. Just scan your item, and our app will tell you where it belongs—compost, recycling, or garbage.
* 🌱 Gamified Impact: TrashCam turns eco-friendly habits into a game, encouraging users to reduce their waste through challenges and a leaderboard.
* 🌍 Eco-Friendly: By helping users properly sort their trash, TrashCam reduces contamination in recycling and compost streams, helping protect the environment.
### Experience It All 🎮
* 📸 Snap and Sort: Take a picture of your trash and TrashCam will instantly categorize it using advanced object recognition.
* 🧠 AI-Powered Classification: After detecting objects with Cloud Vision and COCO-SSD, we pass them to Gemini, which accurately classifies the items, ensuring they’re sorted into the correct waste category.
* 🏆 Challenge Friends: Compete on leaderboards to see who can make the biggest positive impact on the environment.
* ♻️ Learn as You Play: Discover more about what can be recycled, composted, or thrown away with each interaction.
### Tech Stack 🛠️
* ⚛️ Next.js & TypeScript: Powering our high-performance web application for smooth, efficient user experiences.
* 🛢️ PostgreSQL & Prisma: Storing and managing user data securely, ensuring fast and reliable access to information.
* 🌐 Cloud Vision API & COCO-SSD: Using state-of-the-art object recognition to accurately identify and classify waste in real time.
* 🤖 Gemini AI: Ensuring accurate classification of waste objects to guide users in proper disposal practices.
### Join the Movement 🌿
TrashCam isn’t just about proper waste management—it’s a movement toward a cleaner, greener future.
* 🌍 Make a Difference: Every time you sort your trash correctly, you help reduce landfill waste and protect the planet.
* 🎯 Engage and Compete: By playing TrashCam, you're not just making eco-friendly choices—you're inspiring others to do the same.
* 🏆 Be a Waste Warrior: Track your progress, climb the leaderboard, and become a leader in sustainable living. | ## Inspiration
At many public places, recycling is rarely a priority. Recyclables are disposed of incorrectly and thrown out like garbage. Even here at QHacks2017, we found lots of paper and cans in the [garbage](http://i.imgur.com/0CpEUtd.jpg).
## What it does
The Green Waste Bin is a waste bin that can sort the items that it is given. The current of the version of the bin can categorize the waste as garbage, plastics, or paper.
## How we built it
The physical parts of the waste bin are the Lego, 2 stepper motors, a raspberry pi, and a webcam. The software of the Green Waste Bin was entirely python. The web app was done in html and javascript.
## How it works
When garbage is placed on the bin, a picture of it is taken by the web cam. The picture is then sent to Indico and labeled based on a collection that we trained. The raspberry pi then controls the stepper motors to drop the garbage in the right spot. All of the images that were taken are stored in AWS buckets and displayed on a web app. On the web app, images can be relabeled and the Indico collection is retrained.
## Challenges we ran into
AWS was a new experience and any mistakes were made. There were some challenges with adjusting hardware to the optimal positions.
## Accomplishments that we're proud of
Able to implement machine learning and using the Indico api
Able to implement AWS
## What we learned
Indico - never done machine learning before
AWS
## What's next for Green Waste Bin
Bringing the project to a larger scale and handling more garbage at a time. | partial |
## Inspiration
Covid crisis is the biggest inspiration for my project
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Medhack | ## Inspiration
When ideating on Friday, we were inspired by the topics around providing more accessibility using bleeding edge technologies. We knew that we wanted to make something genuinely cool and technically challenging, but also something that provides real value to underserved users. We decided to target impaired individuals, as 1 in 9 Americans are physically impaired to some degree, but are underserved. We saw a huge problem with the current offerings in the accessibility automation space -- and found a problem that was technically challenging but rewarding to create.
## What it does
SpeakEasy is a fully featured AI-powered browser automation tool. It allows you to browse the web and get information without needing to touch or see your browser at all.
## How we built it
This project revolves around several different AI agent 'actors' equipped with different tools. The user interfaces with a conversational assistant using language and voice models that provide a voice interface to 'talk to' sites with and navigate the browser, which sends commands to the browser agent. This browser agent creates a comprehensive knowledge base from each and every site using different segmentation and vision models, providing a deep understanding of what elements can and should be interacted with. This allows us to compile the site down to the core needs of the user and give the user information about the next steps to take while navigating.
## Challenges we ran into
Traditional large language and multi-modal models simply didn't give us anywhere near the results we wanted, they were much too generalized and inaccurate for our use. Our biggest challenges lied with both sourcing and fine tuning different models, some of which worked, some of which did not. This was an incredibly time consuming process, and for quite a while we were unsure that this idea would even be able to be executed with the time and resources we had. We had to take quite aggressive approaches with blending different techniques to get the results we wanted.
## Accomplishments that we're proud of
Making it work was definitely the best part of our weekend! The first automated browser session we had was truly a breath of fresh air to show us that idea was at the very least, somewhat valid and possible by the end of the hackathon.
## What we learned
This was definitely a great experience to try out a ton of different ML models and blend these with traditional scraping & crawling techniques to not only quickly -- but even more accurately get the results we wanted.
## What's next for SpeakEasy
The fact that this can be done should inspire a lot of people! We live in a world where we can make truly revolutionary and applicable projects that could genuinely benefit people, in just 36 hours! We'd love for you to star and try out the repo for yourself, there's detailed instructions in running the project in the README. | # Baby Whisperer
The Baby Whisperer is a revamped baby monitor that uses voice enabled technology to identify variable crying patterns for infants. TensorFlow was used to process convolutional neural networks of the Mel Frequency Cepstral Coefficient of the infant cries audio files, and categorize them with a predictive reason of crying. The baby's cries can be recorded from a device that will associate the crying to a reason with the help of the neural network. The caregiver will also receive an SMS message with the reason at the time of recording. Additionally, a web browser is used to display the analytics of this data including most common reason as well as how many times a day the child has cried. | losing |
# Nexus, **Empowering Voices, Creating Connections**.
## Inspiration
The inspiration for our project, Nexus, comes from our experience as individuals with unique interests and challenges. Often, it isn't easy to meet others with these interests or who can relate to our challenges through traditional social media platforms.
With Nexus, people can effortlessly meet and converse with others who share these common interests and challenges, creating a vibrant community of like-minded individuals.
Our aim is to foster meaningful connections and empower our users to explore, engage, and grow together in a space that truly understands and values their uniqueness.
## What it Does
In Nexus, we empower our users to tailor their conversational experience. You have the flexibility to choose how you want to connect with others. Whether you prefer one-on-one interactions for more intimate conversations or want to participate in group discussions, our application Nexus has got you covered.
We allow users to either get matched with a single person, fostering deeper connections, or join one of the many voice chats to speak in a group setting, promoting diverse discussions and the opportunity to engage with a broader community. With Nexus, the power to connect is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tool:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* DaisyUI for animations and UI components
* 100ms live for real-time audio communication
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel perfect icons
* Vite for simplified building and fast dev server
* Convex for vector search over our database
* React-router for client-side navigation
* Convex for real-time server and end-to-end type safety
* 100ms for real-time audio infrastructure and client SDK
* MLH for our free .tech domain
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used Convex and 100ms, it took a lot of research and heads-down coding to get Nexus working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Nexus.
* Working with **very** poor internet throughout the duration of the hackathon, we estimate it cost us multiple hours of development time.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Nexus.
* Learning a ton of new technologies we would have never come across without Cal Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
* Integrating 100ms well enough to experience bullet-proof audio communication.
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Nexus
* Make Nexus rooms only open at a cadence, ideally twice each day, formalizing the "meeting" aspect for users.
* Allow users to favorite or persist their favorite matches to possibly re-connect in the future.
* Create more options for users within rooms to interact with not just their own audio and voice but other users as well.
* Establishing a more sophisticated and bullet-proof matchmaking service and algorithm.
## 🚀 Contributors 🚀
| | | | |
| --- | --- | --- | --- |
| [Jeff Huang](https://github.com/solderq35) | [Derek Williams](https://github.com/derek-williams00) | [Tom Nyuma](https://github.com/Nyumat) | [Sankalp Patil](https://github.com/Sankalpsp21) | | ## Inspiration 🍪
We’re fed up with our roommates stealing food from our designated kitchen cupboards. Few things are as soul-crushing as coming home after a long day and finding that someone has eaten the last Oreo cookie you had been saving. Suffice it to say, the university student population is in desperate need of an inexpensive, lightweight security solution to keep intruders out of our snacks...
Introducing **Craven**, an innovative end-to-end pipeline to put your roommates in check and keep your snacks in stock.
## What it does 📸
Craven is centered around a small Nest security camera placed at the back of your snack cupboard. Whenever the cupboard is opened by someone, the camera snaps a photo of them and sends it to our server, where a facial recognition algorithm determines if the cupboard has been opened by its rightful owner or by an intruder. In the latter case, the owner will instantly receive an SMS informing them of the situation, and then our 'security guard' LLM will decide on the appropriate punishment for the perpetrator, based on their snack-theft history. First-time burglars may receive a simple SMS warning, but repeat offenders will have a photo of their heist, embellished with an AI-generated caption, posted on [our X account](https://x.com/craven_htn) for all to see.
## How we built it 🛠️
* **Backend:** Node.js
* **Facial Recognition:** OpenCV, TensorFlow, DLib
* **Pipeline:** Twilio, X, Cohere
## Challenges we ran into 🚩
In order to have unfettered access to the Nest camera's feed, we had to find a way to bypass Google's security protocol. We achieved this by running an HTTP proxy to imitate the credentials of an iOS device, allowing us to fetch snapshots from the camera at any time.
Fine-tuning our facial recognition model also turned out to be a bit of a challenge. In order to ensure accuracy, it was important that we had a comprehensive set of training images for each roommate, and that the model was tested thoroughly. After many iterations, we settled on a K-nearest neighbours algorithm for classifying faces, which performed well both during the day and with night vision.
Additionally, integrating the X API to automate the public shaming process required specific prompt engineering to create captions that were both humorous and effective in discouraging repeat offenders.
## Accomplishments that we're proud of 💪
* Successfully bypassing Nest’s security measures to access the camera feed.
* Achieving high accuracy in facial recognition using a well-tuned K-nearest neighbours algorithm.
* Fine-tuning Cohere to generate funny and engaging social media captions.
* Creating a seamless, rapid security pipeline that requires no legwork from the cupboard owner.
## What we learned 🧠
Over the course of this hackathon, we gained valuable insights into how to circumvent API protocols to access hardware data streams (for a good cause, of course). We also deepened our understanding of facial recognition technology and learned how to tune computer vision models for improved accuracy. For our X integration, we learned how to engineer prompts for Cohere's API to ensure that the AI-generated captions were both humorous and contextual. Finally, we gained experience integrating multiple APIs (Nest, Twilio, X) into a cohesive, real-time application.
## What's next for Craven 🔮
* **Multi-owner support:** Extend Craven to work with multiple cupboards or fridges in shared spaces, creating a mutual accountability structure between roommates.
* **Machine learning improvement:** Experiment with more advanced facial recognition models like deep learning for even better accuracy.
* **Social features:** Create an online leaderboard for the most frequent offenders, and allow users to vote on the best captions generated for snack thieves.
* **Voice activation:** Add voice commands to interact with Craven, allowing roommates to issue verbal warnings when the cupboard is opened. | # Athena **Next Generation CMS Tooling Powered by AI**
## Inspiration
The inspiration for our project, Athena, comes from our experience as students with busy lives. Often, it isn't easy to keep track of the vast amounts of media we encounter (Lectures, webinars, TedTalks, etc).
With Athena, people can have one AI-powered store for all their content, allowing them to save time slogging through hours of material in search of information.
Our aim is to enhance productivity and empower our users to explore, engage, and learn in a way that truly values their time.
## What it Does
In Athena, we empower our users to manage and query all forms of content. You have the flexibility to choose how you organize and interact with your material. Whether you prefer grouping content by course and using focused queries or rewatching lectures with a custom-trained chatbot at your fingertips, our application Athena has got you covered.
We allow users to either perform multimodal vectorized searches across all their documents, enhancing information accessibility, or explore a single document with more depth and nuance using a custom-trained LLm model. With Athena, the power of information is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tools:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* ShadCN for animations and UI components
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel-perfect icons
* NextJS for server-side rendering and enhanced SEO
* Convex for vector search over our database
* App-router for client-side navigation
* Convex for real-time server and end-to-end type safety
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used vector search with Convex, it took a lot of research and heads-down coding to get Athena working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Athena.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Athena.
* Learning a ton of new technologies we would have never come across without Tree Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Athena
* Create more options for users to group their content in different ways.
* Establish the ability for users to share content with others, increasing knowledge bases.
* Allow for more types of content upload apart from Videos and PDFs | winning |
## Inspiration
Our inspiration stemmed from the desire to implement a machine learning / A.I. API.
## What it does
Taper analyzes images using IBM's Watson API and our custom classifiers. This data is used to query the USDA food database and return nutritional facts about the product.
## How we built it
Using android Studio and associated libraries we created the UI in the form of an Android App. To improve Watson's image recognition we created our custom classifier and to recognize specific product brands.
## Challenges we ran into
For most of us this was our first time using both Android Studios and Watson so there was a steep initial learning curve. Additionally we attempted to use Microsoft Azure along side Watson but were unsuccessful.
## Accomplishments that we're proud of
-Successful integrating Watson API into a Android App.
-Training our own visual recognition classifier using python and bash scripts.
-Retrieving a products nutritional information based on data from visual recognition.
## What we learned
We experience and learned the difficulty of product integration. As well, we learned how to better consume API's
## What's next for taper
-Creating a cleaner UI
-Text analysis of nutritional data
-day to day nutrition tracking | ## Inspiration
Research shows that maximum people face mental or physical health problems due to their unhealthy daily diet or ignored symptoms at the early stages. This app will help you track your diet and your symptoms daily and provide recommendations to provide you with an overall healthy diet. We were inspired by MyFitnessPal's ability to access the nutrition information from foods at home, restaurants, and the grocery store. Diet is extremely important to the body's wellness, but something that is hard for any one person to narrow down is: What foods should I eat to feel better? It is a simple question, but actually very hard to answer. We eat so many different things in a day, how do you know what is making positive impacts on your health, and what is not?
## What it does
Right now, the app is in a pre-alpha phase. It takes some things as input, carbs, fats, protein, vitamins, and electrolyte intake in a day. It sends this data to a Mage API, and Mage predicts how well they will feel in that day. The Mage AI is based off of sample data that is not real-world data, but as the app gets users it will get more accurate. Based off of our data set that we gather and the model type, the AI maintains 96.4% accuracy at predicting the wellness of a user on a given day. This is based off of 10000 users over 1 day, or 1 user over 10000 days, or somewhere in between. The idea is that the AI will be constantly learning as the app gains users and individual users enter more data.
## How we built it
We built it in Swift using the Mage.ai for data processing and API
## Challenges we ran into
Outputting the result on the App after the API returns the final prediction. We have the prediction score displayed in the terminal, but we could not display it on the app initially. We were able to do that after a lot of struggle. All of us made an app and implemented an API for the very first time.
## Accomplishments that we're proud of
-- Successfully implementing the API with our app
-- Building an App for the very first time
-- Creating a model for AI data processing with a 96% accuracy
## What we learned
-- How to implement an API and it's working
-- How to build an IOS app
-- Using AI in our application without actually knowing AI in depth
## What's next for NutriCorr
--Adding different categories of symptoms
-- giving the user recommendations on how to change their diet
-- Add food object to the app so that the user can enter specific food instead of the nutrient details
-- Connect our results to mental health wellness and recommendations. Research shows that people who generally have more sugar intake in their diet generally stay more depressed. | ## Inspiration
The motivation for creating this application came from a lazy evening when we opened our refrigerator and took a thorough look. We realized that much of our groceries were expired. Two cans of milk were one week out of date, the chicken that we bought from Whole foods smelt really bad and the mushrooms looked like they were left untouched for months. It is not that we do not cook at home at all but still such sight made us shocked. We realized we cannot be the only one who waste food and the very next day we started thinking for the food!
## What it does
Our android application is able to scan barcode and list the food items along with their purchase date and expiry date. We know that we cannot get expiry date from just scanning barcodes but if we create a tie up with grocery stores and can access their inventory then by just scanning the 1-D barcode which is present in the bill, we can fetch all the important information. Once we have the data that we need then we notify the user prior to the expiry date. The user will also have an option to enter the dates manually.
Another novel idea is to generate a list of recipes based on the ingredients generated by Artificial Intelligence which will not only help the user to cook but also to make use of the foods that can otherwise be perished sitting idle inside the refrigerator.
## How we built it
The application we built is by using Android Studio, Kotlin and love.
## Challenges we ran into
Apart from tiring days and sleepless nights, we ran into series of small technical issues that we worked hard to solve.
## Accomplishments that we're proud of
We are proud of what we have achieved in this short span of time. We built something that we really put a thought into after several iterations and we hope someday it will be of real use to the world.
## What we learned
We all need to contribute something to the society and if the work is interesting we are ready to put 100% of our time and effort.
## What's next for For Food
the future is definitely bright for app as it can affect the life of millions. | partial |
## Inspiration
One of the biggest challenges faced by families in war effected countries was receiving financial support from their family members abroad. High transaction fees, lack of alternatives and a lack of transparency all contributed to this problem, leaving families struggling to make ends meet.
According to the World Bank, the **average cost of sending remittances to low income countries is a striking 7% of the amount sent**. For conflict affected families, a 7% transaction fee means the difference between putting food on the table or going hungry for days. The truth is that the livelihoods of those left behind vitally depend on remittance transfers. Remittances are of central importance for restoring stability for families in post-conflict countries. At Dispatch, we are committed to changing the lives of war stricken communities. Our novel app allows families to receive money from their loved ones, without having to worry about the financial barriers that had previously stood in their area.
However, the problem is far larger. Economically, over **$20 billion** has been sent back and forth in the United States this year, and we are barely even two months in. There are more than 89 million migrants in the United States itself. In a hugely untapped market that cares little about its customers and is dominated by exploitative financial institutions, we provide the go-to technology-empowered alternative that lets users help their families and friends around the world. We provide a globalized, one-stop shop for sending money across the world.
*Simply put, we are the iPhone of a remittance industry that uses landlines.*
## What problems exist
1. **High cost, mistrust and inefficiency**: Traditional remittance services often charge high fees for their services, which significantly reduces the amount of money that the recipient receives. **A report by the International Fund for Agricultural Development (IFAD) found that high costs of remittance lead to a loss of $25 billion every year for developing countries**. Additionally, they don’t provide clear information on exchange rate and fees, which leads to mistrust among users. Remittance services tend to have an upper limit on how much one can send per transaction, and they end up leading to security issues once money has been sent over. Lastly, these agencies take days to acknowledge, process, and implement a certain transaction, making immediate transfers intractable.
2. **Zero alternatives = exploitation**: It’s also important to note that very few traditional remittance services are offered in countries affected by war. Remittance services tend not to operate in these regions. With extremely limited options, families are left with no option but to accept the high fees and poor exchange rates by these agencies. This isn’t unique to war stricken countries. This is a huge problem in developing countries. Due to the high fees associated with traditional remittance services, many families in developing countries are unable to fully rely on remittance alone to support themselves. As a result, they may turn to alternative financial options that can be exploitative and dangerous. One such alternative is the use of loan sharks, who offer quick loans with exorbitant interest rates, often trapping borrowers in a cycle of debt.
## How we improve the status quo
**We are a mobile application that provides a low-cost, transparent and safe way to remit money. With every transaction made through Dispatch, our users are making a tangible difference in the lives of their loved ones.**
1. **ZERO Transaction fees**: Instead of charging a percentage-based commission fee, we charge a subscription fee per month. This has a number of advantages. Foremost, it offers a cost effective solution for families because it remains the same regardless of the transfer amount. This also makes the process transparent and simpler as the total cost of the transaction is clear upfront.
2. **Simplifying the process**: Due to the complexity of the current remittance process, migrants may find themselves vulnerable to exploitative offers from alternative providers. This is because they don’t understand the details and risks associated with these alternatives. On our app, we provide clear and concise information that guides users through the entire process. A big way of simplifying the process is to provide multilingual support. This not only removes barriers for immigrants, but also allows them to fully understand what’s happening without being taken advantage of.
3. **Transparency & Security**
* Clearly stated and understood fees and exchange rates - no hidden fees
* Real-time exchange rate updates
* Remittance tracker
* Detailed transaction receipts
* Secure user data (Users can only pay when requested to)
4. **Instant notifications and Auto-Payment**
* Reminders for bill payments and insurance renewals
* Can auto-pay bills (will require confirmation each time before its done) so the user remains worry-
free and does not require an external calendar to manage finances
* Notifications for when new requests have been made by the remitter
## How we built it
1. **Backend**
* Our backend is built on an intricate [relational database](http://shorturl.at/fJTX2) between users, their transactions and the 170 currencies and their exchange rates
* We use the robust Checkbook API as the framework to make payments and keep track of the invoices of all payments run through Dispatch
2. **Frontend**
* We used the handy and intuitive Retool environment to develop a rudimentary app prototype, as demonstrated in our [video demo](https://youtu.be/rNj2Ts6ghgA)
* It implements most of the core functionality of our app and makes use of our functional MySQL database to create a working app
* The Figma designs represent our vision of what the end product UI would look like
## Challenges we ran into
1. International money transfer regulations
2. Government restrictions on currencies /embargos
3. Losing money initially with our business model
## Accomplishments that we're proud of
1. Develop an idea with immense social potential
2. Integrating different APIs into one comprehensive user interface
3. Coming from a grand total of no hackathon experience, we were able to build a functioning prototype of our application.
4. Team bonding – jamming to Bollywood music
## What we learned
1. How to use Retool and Checkbook APIs
2. How to deploy a full fledged mobile application
3. How to use MySQL
4. Understanding the challenges faced by migrants
5. Gained insight into how fintech can solve social issues
## What's next for Dispatch
The primary goal of Dispatch is to empower war-affected families by providing them with a cost-effective and reliable way to receive funds from their loved ones living abroad. However, our vision extends beyond this demographic, as we believe that everyone should have access to an affordable, safe, and simple way to send money abroad.
We hope to continuously innovate and improve our app. We hope to utilize blockchain technology to make transactions more secure by providing a decentralized and tamper proof ledger. By leveraging emerging technologies such as blockchain, we aim to create a cutting-edge platform that offers the highest level of security, transparency and efficiency.
Ultimately, our goal is to create a world where sending money abroad is simple, affordable, and accessible to everyone. **Through our commitment to innovation, transparency, and customer-centricity, we believe that we can achieve this vision and make a positive impact on the lives of millions of people worldwide.**
## Ethics
Banks are structurally disincentivized to help make payments seamless for migrants. We read through various research reports, with Global Migration Group’s 2013 Report on the “Exploitation and abuse of international migrants, particularly those in an irregular situation: a human rights approach” to further understand the violation of present ethical constructs.
As an example, consider how bad a 3% transaction fees (using any traditional banking service) can be for an Indian student whose parents pay Stanford tuition -
3 % of $ 82, 162 = $ 2464.86 (USD)
= 204,005.37 (INR) [1 USD = 82.07 INR]
That is, it costs an extra 200,000 Indian rupees for a family that pays Stanford students via a traditional banking service. Consider the fact that, out of 1.4 billion Indians, this is greater than the average annual income for an Indian. Just the transaction fees alone can devastate a home.
Clearly, we don’t destroy homes, hearts, or families. We build them, for everyone without exception.
We considered the current ethical issues that arise with traditional banking or online payment systems. The following ethical issues arise with creating exclusive, expensive, and exploitative payment services for international transfers:
1. Banks earn significant revenue from remittance payments, and any effort to make the process more seamless could potentially reduce their profits.
2. Banks may view migrant populations as a high-risk group for financial fraud, leading them to prioritize security over convenience in remittance payments
3. Remittance payments are often made to developing countries with less developed financial infrastructure, making it more difficult and costly for banks to facilitate these transactions
4. Many banks are large, bureaucratic organizations that may not be agile enough to implement new technologies or processes that could streamline remittance payments.
5. Banks may be more focused on attracting higher-value customers with more complex financial needs, rather than catering to the needs of lower-income migrants.
6. The regulatory environment surrounding remittance payments can be complex and burdensome, discouraging banks from investing in this area.
7. Banks do not have a strong incentive to compete on price in the remittance market, since many migrants are willing to pay high fees to ensure their money reaches its intended recipient.
8. Banks may not have sufficient data on the needs and preferences of migrant populations, making it difficult for them to design effective remittance products and services.
9. Banks may not see remittance payments as a strategic priority, given that they are only a small part of their overall business.
10. Banks may face cultural and linguistic barriers in effectively communicating with migrant populations, which could make it difficult for them to understand and respond to their needs.
Collectively, as remittances lower, we lose out on the effects of trickle-down economics in developing countries, detrimentally harming how they operate and even stunting their growth in some cases. For the above reasons, our app could not be a traditional online banking system.
We feel there is an ethical responsibility to help other countries benefit from remittances. Crucially, we feel there is an ethical responsibility to help socioeconomically marginalized communities help their loved ones. Hence, we wanted to use technology as a means to include, not exclude and built an app that we hope could be versatile and inclusive to the needs of our user. We needed our app design to be helpful towards our user - allowing the user to gain all the necessary information and make bill payments easier to do across the world. We carefully chose product design elements that were not wordy but simple and clear and provided clear action items that indicated what needed to be done. However, we anticipated the following ethical issues arising from our implementation :
1. Data privacy: Remittance payment apps collect a significant amount of personal data from users. It is essential to ensure that the data is used ethically and is adequately protected.
2. Security: Security is paramount in remittance payment apps. Vulnerabilities or data breaches could lead to significant financial losses or even identity theft. Fast transfers can often lead to mismanagement in accounting.
3. Accessibility: Migrants who may be unfamiliar with technology or may not have access to smartphones or internet may be left out of such services. This raises ethical questions around fairness and equity.
4. Transparency: It is important to provide transparent information to users about the costs and fees associated with remittance payment apps, including exchange rates, transfer fees, and any other charges. We even provide currency optimization features, that allows users to leverage low/high exchange rates so that users can save money whenever possible.
5. Inclusivity: Remittance payment apps should be designed to be accessible to all users, regardless of their level of education, language, or ability. This raises ethical questions around inclusivity and fairness.
6. Financial education: Remittance payment apps could provide opportunities for financial education for migrants. It is important to ensure that the app provides the necessary education and resources to enable users to make informed financial decisions.
Conscious of these ethical issues, we came up with the following solutions to provide a more principally robust app:
1. Data privacy: We collect minimal user data. The only information we care about is who sends and gets the money. No extra information is ever asked for. For undocumented immigrants this often becomes a concern and they cannot benefit from remittances. The fact that you can store the money within the app itself means that you don’t need to go through the bank's red-tape just to sustain yourself.
2. Security: We only send user data once the user posts a request from the sender. We prevent spam by only allowing contacts to send those requests to you. This prevents the user from sending large amounts of money to the wrong person. We made fast payments only possible in highly urgent queries, allowing for a priority based execution of transactions.
3. Accessibility: Beyond simple button clicks, we don’t require migrants to have a detailed or nuanced knowledge of how these applications work. We simplify the user interface with helpful widgets and useful cautionary warnings so the user gets questions answered even before asking them.
4. Transparency: With live exchange rate updates, simple reminders about what to pay when and to who, we make sure there is no secret we keep. For migrants, the assurance that they aren’t being “cheated” is crucial to build a trusted user base and they deserve to have full and clearly presented information about where their money is going.
5. Inclusivity: We provide multilingual preferences for our users, which means that they always end up with the clearest presentation of their finances and can understand what needs to be done without getting tangled up within complex and unnecessarily complicated “terms and conditions”.
6. Financial education: We provide accessible support resources sponsored by our local partners on how to best get accustomed to a new financial system and understand complex things like insurance and healthcare.
Before further implementation, we need to robustly test how secure and spam-free our payment system could be. Having a secure payment system is a high ethical priority for us.
Overall, we felt there were a number of huge ethical concerns that we needed to solve as part of our product and design implementation. We felt we were able to mitigate a considerable percentage of these concerns to provide a more inclusive, trustworthy, and accessible product to marginalized communities and immigrants across the world. | ## Inspiration
In large corporations, such as RBC, the help desk gets called hundreds phone calls every hour, lasting about 8 minutes on average and costing the company $15 per hour. We thought this was both a massive waste of time and resources, not to mention it being quite ineffective and inefficient. We wanted to create a product that accelerated the efficiency of a help-desk to optimize productivity. We designed a product that has the ability to wrap a custom business model and a help service together in an accessible SMS link. This is a novel innovation that is heavily needed in today's businesses.
## What it does
SMS Assist offers the ability for a business to **automate their help-desk** using SMS messages. This allows requests to be answered both online and offline, an innovating accessibility perk that many companies need. Our system has no limit to concurrent users, unlike a live help-desk. It provides assistance for exactly what you need, and this is ensured by our IBM Watson model, which trains off client data and uses Machine Learning/NLU to interpret client responses to an extremely high degree of accuracy.
**Assist** also has the ability to recieve orders from customers if the businesses so chose. The order details and client information is all stored by the Node server, so that employees can view orders in realtime.
Finally, **Assist** utilizes text Sentiment Analysis to analyse each client's tone in their texts. It then sends a report to the console so that the company can receive feedback from customers automatically, and improve their systems.
## How we built it
We used Node.js, Twilio, and IBM watson to create SMS Assist.
**IBM Watson** was used to create the actual chatbots, and we trained it on user data in order to recognize the user's intent in their SMS messages. Through several data sets, we utilized Watson's machine learning and Natural Language & Sentiment analysis to make communication with Assist hyper efficient.
**Twilio** was used for the front end- connecting an SMS client with the server. Using our Twilio number, messages can be sent and received from any number globally!
**Node.js** was used to create the server on which SMS Assist runs on. Twilio first recieves data from a user, and sends it to the server. The server feeds it into our Watson chatbot, which then interprets the data and generates a formulated response. Finally, the response is relayed back to the server and into Twilio, where the user recieves the respons via SMS.
## Challenges we ran into
There were many bugs involving the Node.js server. Since we didn't have much initial experience with Node or the IBM API, we encountered many problems, such as the SessionID not being saved and the messages not being sent via Twilio. Through hours of hard work, we persevered and solved these problems, resulting in a perfected final product.
## Accomplishments that we're proud of
We are proud that we were able to learn the new API's in such a short time period. All of us were completely new to IBM Watson and Twilio, so we had to read lots of documentation to figure things out. Overall, we learned a new useful skill and put it to good use with this project. This idea has the potential to change the workflow of any business for the better.
## What we learned
We learned how to use the IBM Watson API and Twilio to connect SMS messages to a server. We also discovered that working with said API's is quite complex, as many ID's and Auth factors need to be perfectly matched for everything to execute.
## What's next for SMS Assist
With some more development and customization for actual businesses, SMS Assist has the capability to help thousands of companies with their automated order systems and help desk features. More features can also be added | ## Inspiration
Our main inspiration behind this product was to reduce the amount of time it takes for international wire transfer from one bank to another. Since we're all international students, we've experiences the frustration of slow and costly tuition payments of international wire transfers, often risking late penalties due to 1-5 day processing times. We did some research and identified that a lot of intermediary banks are involved in this process and we thought about how we could get them out of the picture. BlockWire was born from our vision to use blockchain technology to create direct connections between foreign banks, eliminating intermediaries. Our goal is to significantly reduce both time and cost for international transfers, making cross-border financial transactions faster, cheaper, and more accessible for students and beyond. This real-world problem inspired us to combine blockchain with other cutting-edge technologies to revolutionize international banking operations.
## What it does
BlockWire reduces the time required for international wire transfers from 1-5 business days to a few minutes. It uses blockchain technology alongside an AI model for fraud detection checks which eliminate the intermediary banks that are currently involved in the process and make the process incredibly fast.
## How we built it
The main technology which was used was blockchain which essentially decentralizes the data and makes it more secure to the point where it's almost impossible to access that data unless you have the required key. This reduces money laundering and fraud by a huge percentage. We used an AI model to for fraud detection by banks which was made faster by using Cerebras.ai. Apart from that, we used React for the frontend, Python and Flask for the backend, and MongoDB as our database. One of the sponsors' products, PropelAuth was also integrated for user authentication.
## Challenges we ran into
All of us were working on separate parts of the project and integrating them was the toughest task. There were a lot of issues that arrived while doing that. The blockchain technology was also pretty new to us and we had no prior experience with it, so a lot of our time went it learning about it and brainstorming on what we wanted to build. There were some struggles with the capital one api as well but we were able to tackle them with relative ease as compared to the others. Even though the struggles were there, we still found a way through them and came about learning so much new stuff.
## Accomplishments that we're proud of
Implementing the blockchain was our biggest achievement since that domain was new for all of us. Using Cerebras.ai's quick inference capabilites to make the fraud detection checks stronger was another one of the big things. Finally, integrating everything together was the hardest part, but we fought through it together and were able to finally come out on top.
## What we learned
We were able to learn about so many new technologies in which we had no prior experience such as blockchain and AI models. We got an understanding as to why blockchain is such a strong tool which is currently being used in the tech industry and why it's so powerful. We learnt about various other products like PropelAuth and Tune.AI while learning a lot about the financial sector and how technology can be used to help companies grow. All of us specialized in certain fields but we ended up learning way more and expanding our knowledge.
## What's next for BlockWire
BlockWire's future lies in expanding its blockchain-based payment solutions to address various global financial challenges. We plan to enter the remittance market, offering migrant workers a faster, more cost-effective way to send money home.
Education will remain a key focus, as we aim to partner with more universities globally to simplify fee payments for international students. To support this growth, we'll prioritize working closely with financial regulators to ensure compliance and potentially shape policies around blockchain-based international transfers.
We also plan on selling this product to apartment complexes in the country so that the time taken for rent payment and processing can also be reduced.
Lastly, we see potential in integrating our technology with e-commerce platforms, facilitating instant international payments for buyers and sellers in the growing global online marketplace. Through these strategic expansions, BlockWire aims to revolutionize international financial transactions across multiple sectors, making them more accessible, efficient, and cost-effective. | winning |
## Inspiration
When you are going through a tough time, it's comforting when a friend sends you a virtual hug. Even if they are not there physically, you can see that they care. Wave is inspired by these little things in life that make a huge difference. Sometimes, even the smallest gestures can be enough to keep friendships and relationships special and long-lasting.
## What it does
Wave: It's the little things in life — is a simple 3-step addition to your daily messaging habits. Virtual hugs, or in our case - handshakes, have never felt so genuine and interactive!
###### Wave
*It's very simple.*
| Simple 3-step process | Details |
| --- | --- |
| 1. Select a Friend | Open the navigation bar to select a friend from your contact list. |
| 2. Shake your phone to select a gesture | Wait for the prompt to start shaking your phone. Once it has successfully detected a hand shake, a prompt allows you to choose from a list of gestures: Hand Shake, High Five, Hand Wave, Jazz Hands etc. |
| 3. Show them you care | Once a gesture has been selected, send it to your friend! Your friend will receive a real-time notification that you have sent them a gesture to show them that you are thinking of them. |
## How we built it
Currently, we fully implemented Wave as an Android application and integrated the main functionalities into the app. Using Kotlin and Java, we programmed a motion sensor to detect phone shaking movements. We also used XML scripts to implement our application's beautiful, simplistic front end, which matches our motto - it's the little things in life.
## Challenges we ran into
We are a team of 2 software engineers, so mobile development was definitely a learning curve.
**Mobile Development:** Huge thank yous to our computers for not crashing on us while we ran a heavy android studio application. It was also tough for us to learn everything from scratch and code in an unfamiliar language (Kotlin).
**Motion Sensor:** We put a lot of time and effort into finding the perfect balance between the sensitivity and the timing of the motion sensors.
**Merging different Activities:** We mainly have 2 activities in our application - the navigation bar animation and the motion sensors. At first, we worked on the different components on our own, so when it came to merging the two activities together, it was a bit of a challenge.
**Dark mode and Light mode:** Android Studio allows us to develop our application front-end for both light mode and dark mode. This is an incredibly interesting feature. Unfortunately, this also meant a hurdle during our development of the app. While we had our phones connected to our Android, some design colors did not match what we expected from our code. After a few hours of debugging, we ultimately realized that our phone was in dark mode the entire time while we were coding for light mode.
**Sleep deprivation and abnormal caffeine levels:** For most of the hackathon, we were two highly caffeinated and sleep-deprived software developers.
Overall, we are happy to have taken a lot away from this experience and proud to have fully implemented the main functionalities within 24 hours.
## Accomplishments that we're proud of
Overcoming all the challenges! We also think it's very cool that we have implemented motion sensors into our app, which adds an interactive component to traditional text messaging. We also believe in the creativity and uniqueness of our idea. In essence, we hope this may bring joy to people's lives and be a simple reminder to everyone that sometimes, *it's just the little things in life that can make us happy.*
## What's next for Wave
Our initial intention with Wave was to have it as an extension to already existing messaging applications. Similar to iMessage Games, it would serve as an extra functionality to elevate the experience of text messaging or, just in general, be a more interactive way for people to connect remotely. Here is the future for Wave
* Partner with messaging apps to add the Wave extension
* Add more sensitive motion sensors for different gestures. Imagine if every different motion corresponds to a different gesture.
* Real-time notification system: receive your friend's Wave in real-time as a pop-up notification every time they think of you and send you one. | ## Inspiration
Many people have the habit of rubbing eyes, scratching, pulling hair etc., subconsciously. We wanted to help people overcome such habits by making them aware.
## What it does
It is trained to recognise certain gestures and alert the person.
## How we built it
We built a prototype of this device using an Arduino which acquires motion information from an accelerometer and sends it to a PC via Bluetooth. In the PC, we used ESP software which makes use of gesture recognition toolkit and trained the system to recognise the desired gesture. Once trained, if the user performs that gesture, the arduino triggers a buzzer.
## Challenges we ran into
We initially tried using signal processing algorithms on the Arduino which was inaccurate. So, we moved to machine learning using ESP on PC.
We had to ensure reliable data over the bluetooth channel by configuring the proper sampling and baud rates.
We had to configure the ESP software and train the system for good performance.
Also, Arduino MKR1000 was a new platform with lack of documentation.
## Accomplishments that we're proud of
We are proud that we were able to make a functional prototype in a single day.
## What we learned
To explore and solve a challenge with limited time and resources. We are excited to be able to apply machine learning for the first time in our project.
## What's next for Aid for subconscious habits
We want to make this feature available to many by implementing it on a wearable like a smart watch which is powerful enough to do ML onboard. | ## Inspiration
As college students more accustomed to having meals prepared by someone else than doing so ourselves, we are not the best at keeping track of ingredients’ expiration dates. As a consequence, money is wasted and food waste is produced, thereby discounting the financially advantageous aspect of cooking and increasing the amount of food that is wasted. With this problem in mind, we built an iOS app that easily allows anyone to record and track expiration dates for groceries.
## What it does
The app, iPerish, allows users to either take a photo of a receipt or load a pre-saved picture of the receipt from their photo library. The app uses Tesseract OCR to identify and parse through the text scanned from the receipt, generating an estimated expiration date for each food item listed. It then sorts the items by their expiration dates and displays the items with their corresponding expiration dates in a tabular view, such that the user can easily keep track of food that needs to be consumed soon. Once the user has consumed or disposed of the food, they could then remove the corresponding item from the list. Furthermore, as the expiration date for an item approaches, the text is highlighted in red.
## How we built it
We used Swift, Xcode, and the Tesseract OCR API. To generate expiration dates for grocery items, we made a local database with standard expiration dates for common grocery goods.
## Challenges we ran into
We found out that one of our initial ideas had already been implemented by one of CalHacks' sponsors. After discovering this, we had to scrap the idea and restart our ideation stage.
Choosing the right API for OCR on an iOS app also required time. We tried many available APIs, including the Microsoft Cognitive Services and Google Computer Vision APIs, but they do not have iOS support (the former has a third-party SDK that unfortunately does not work, at least for OCR). We eventually decided to use Tesseract for our app.
Our team met at Cubstart; this hackathon *is* our first hackathon ever! So, while we had some challenges setting things up initially, this made the process all the more rewarding!
## Accomplishments that we're proud of
We successfully managed to learn the Tesseract OCR API and made a final, beautiful product - iPerish. Our app has a very intuitive, user-friendly UI and an elegant app icon and launch screen. We have a functional MVP, and we are proud that our idea has been successfully implemented. On top of that, we have a promising market in no small part due to the ubiquitous functionality of our app.
## What we learned
During the hackathon, we learned both hard and soft skills. We learned how to incorporate the Tesseract API and make an iOS mobile app. We also learned team building skills such as cooperating, communicating, and dividing labor to efficiently use each and every team member's assets and skill sets.
## What's next for iPerish
Machine learning can optimize iPerish greatly. For instance, it can be used to expand our current database of common expiration dates by extrapolating expiration dates for similar products (e.g. milk-based items). Machine learning can also serve to increase the accuracy of the estimates by learning the nuances in shelf life of similarly-worded products. Additionally, ML can help users identify their most frequently bought products using data from scanned receipts. The app could recommend future grocery items to users, streamlining their grocery list planning experience.
Aside from machine learning, another useful update would be a notification feature that alerts users about items that will expire soon, so that they can consume the items in question before the expiration date. | losing |
## TLDR
A web app that walks the user through starting a business, then helps them maintain financial wellbeing by tracking different metrics over time, all while educating the user on finance terms.
## Understanding of Financial Wellbeing
I understand financial wellbeing to be how well someone is managing their money, how secure their financial situation is, and how much room there is for financial growth. For me personally, financial wellbeing would mean not living from paycheck to paycheck, not drowning in loans, and having some money saved up instead. While I could have easily addressed the college/Gen Z dilemma of being broke, I wanted to think further and brighter. Coming from my own entrepreneurial spirit, I wanted to use this project to inspire others to start their own business and in doing so, improve their financial wellbeing. This not only helps the business owner, but also the local economy. Having more small businesses means more growth and more importantly right now, more job opportunities. Small businesses are a great way to help the financial wellbeing of multiple people at a larger scale by starting at the source.
## Relevance to BlackRock's goals
I am mostly addressing BlackRock's 4th goal of **inclusive economies** because, as mentioned above, having more small businesses will improve local economies through growth and employment opportunities. Moreover, it is inclusive because anyone, *even me or you*, can start a business. ~~small plug: i'm also starting [my own business!](https://craving.isabiiil.tech/home)~~
## Functionality of the product
My app was created using **React.js** and **Firebase** and starts by motivating the user to start their own business. From there, the user is walked through starting a business through a series of questions around planning and logistics and such. Then there's a daily form that the user fills out about the daily operations of the business, and these answers are stored in the Firestore database. Those numbers are used to calculate different metrics such as revenue, expenditure, net profit, and return on investment. All relevant terms are defined in accessible language.
## Creativity of the solution
I'm predicting that most other submissions are either geared towards our college demographic, or is about stocks and those kinds of investments. If that is the case, then this app is indeed creative. Even if it isn't, I'm super duper proud of what I *singlehandedly* accomplished in a total of 7 hours and 27 minutes.
## Number of features
1. Landing page
2. Intro questions
3. Daily questions
4. Calculated metrics
5. Defined terms
6. Database usage
## User-friendly design
I created a light mode and a dark mode, for both aesthetics and accessibility. I also did my best to make the interface intuitive and easy to use.
## Use of data
I couldn't find a relevant way to incorporate open datasets into my project, but I am using users' data to calculate metrics over time. It's still data, right? | ## Inspiration
In today's digital world, financial tools of the wealthy should be accessible to everybody. However, this is not the case as many people, especially marginalized communities, do not have access to financial resources. In fact, more than 29%\* of Canada's indigenous live in poverty and this is due to their inaccessibility to financial resources. Furthermore, more than half of the immigrants(including students) have limited access to these services. This inspired us to create a web app that addresses the stigma that investing, saving, and budgeting is only for privileged populations. EZFinance is an inclusive financial product that makes it easier for people in marginalized communities to unlock the benefits that come from financial literacy and access to traditional financial tools.
\*Statistics from Canadian Government
## What it does
EZFinance is a web app that brings together all of the financial resources into one site. Once the user arrives to our website, they will be taken to the landing page where they can select if they are a newcomer or student. After this, they will be taken to the homepage, where they can navigate throughout the website. When they click on the Modules tab, they can view all the financial resources such as saving, budgeting, etc. They can learn through each module and their progress will be tracked so they can go back to where they left off. Moreover, the user can contact financial advisors via the Contact Us page, which will further help them in their financial journey.
## How we built it
* UI Design: Figma
* Frontend: React.js, Javascript, CSS
* Backend: Data.js(to store website data)
* Styling: Tailwind CSS
## Best Domain Name from Domain.com
<https://ezfinance.tech>
## Challenges we ran into
* Coming up with a feasible idea that can be implemented
* Some of our team members did not have previous experience with React and they had to learn more about it, before getting started on the project
* Difficulty in forming the right financial curriculum
* Figuring out Git version control as it was being used for the first time
* Creating a visually aesthetic UI
* Completing the project under the given time frame
## Accomplishments that we're proud of
* Implementing our idea into a fully functional website
* Some of the hackers on our team used React for the first time, so they were able to learn a lot while contributing to the project
* Finishing the project under the given time frame
## What we learned
* Building a full stack application
* Collaboration with other developers
## What's next for EZFinance
* Building a mobile app for the project.
* Deploying a proper back-end using Node.js
* Adding more features(learn from real-time investors, networking, etc.) | ## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with readily available information for people to compare.
Lots of people we know don’t take the time to look for sustainable items. People typically say if they had a choice between sustainable and non-sustainable products around the same price point, they would choose the sustainable option. But, consumers often don't make the deliberate effort themselves. We’re making it easier for people to buy sustainably -- placing the products right in front of consumers.
## What it does
greenbeans is a Chrome extension that pops up when users are shopping for items online, offering similar alternative products that are more eco-friendly. The extension also displays a message if the product meets our sustainability criteria.
## How we built it
Designs in Figma, Bubble for backend, React for frontend.
## Challenges we ran into
Three beginner hackers! First time at a hackathon for three of us, for two of those three it was our first time formally coding in a product experience. Ideation was also challenging to decide which broad issue to focus on (nutrition, mental health, environment, education, etc.) and in determining specifics of project (how to implement, what audience/products we wanted to focus on, etc.)
## Accomplishments that we're proud of
Navigating Bubble for the first time, multiple members coding in a product setting for the first time... Pretty much creating a solid MVP with a team of beginners!
## What we learned
In order to ensure that a project is feasible, at times it’s necessary to scale back features and implementation to consider constraints. Especially when working on a team with 3 first time hackathon-goers, we had to ensure we were working in spaces where we could balance learning with making progress on the project.
## What's next for greenbeans
Lots to add on in the future:
Systems to reward sustainable product purchases. Storing data over time and tracking sustainable purchases. Incorporating a community aspect, where small businesses can link their products or websites to certain searches.
Including information on best prices for the various sustainable alternatives, or indicators that a product is being sold by a small business. More tailored or specific product recommendations that recognize style, scent, or other niche qualities. | losing |
## Inspiration
The inspiration for the application was simple, the truth is many people especially young people
simply don’t find saving money for their emergency fund that interesting. Incrementum aims to
change that by adding a gamification element to saving money into an emergency fund so users
are not only reminded but incentivized to invest in financial security.
## What it does
Incrementum is a web application that encourages people to support their financial security by
gamifying investing money into an emergency fund! The idea of Incrementum is simple, users
when signing up for the web application will be able to set a target goal for their emergency fund
and also how much money they have already contributed to their emergency fund. The
Incrementum application will then provide the user with weekly tasks to ensure that they are
looking into different types of savings accounts and investing regularly into their emergency
funds. Additionally, Incrementum gives a virtual dashboard with all the data a user would need
to track and review their progress in building their financial security. Here is where the
gamification element comes in, whenever the user completes the task they will be awarded their own pixelated plant to place in their own virtual money garden! This garden can be shared
with friends so multiple users can contribute to the same garden all with their unique plants. In
order to further incentivize users to complete their tasks each plant generated for the user will
always be completely unique and never repeated. How is this possible? In addition to building
the web application of Incrementum, our team has also created a machine learning and deep
learning generative adversarial network (GAN). This GAN has been trained on hundreds of
images of pixelated trees and plants and through machine learning is able to output unique
images of unique, never-before-seen pixelated plants for the user's virtual garden! This allows all
users to have a completely unique and original money garden all fitted with never-before-seen
pixelated plants generated from our machine learning model. This will incentive users to keep
following and accomplishing their weekly tasks as a way to keep collecting more plants for their
garden and in turn support building their financial security and their emergency funds in a safe
and enjoyable way!
## How we built it
In order to build the web application side of Incrementum we used React and Bootstrap in the
front end and created a Python Flask REST API as the backend. React was used due to the
useful features such as react-router and hooks while Flask was used in order to ensure that the
application was lightweight. When developing the machine learning model/GAN for
Incrementum Python, PyTorch, Numpy and Scikit-learn were used to create the model which
used multiple different layers in a neural network in order to generate the unique and never-before-seen plants. After this, the model was deployed to another flask backend REST API
which the React front end calls for the plants while the previously mentioned flask REST API is
used by the front end to store user information and financial progress.
## Challenges we ran into
The biggest challenges we ran into were simply learning all the machine learning tools,
frameworks and topics quickly and effectively. Only one member of our team was exposed to
machine learning before the hackathon and he had never built such a model as complex as the
one need for Incrementum. Therefore it was a challenge for our team to all work together and
understand complex topics such as neural networks and how a GAN is created. Furthermore,
learning how to use sci-kit-learn and NumPy proved to be a tough challenge that our team
persevered through. Learning such topics in a short amount of time also proved to be a very
rewarding experience however as our team learned how to delegate and prototype quickly.
## Accomplishments that we're proud of
The biggest accomplishment our team is proud of is developing a very complex and effective
machine learning and deep learning GAN model that is able to create a unique, never before
seen and high-quality pixelated plant every single iteration. The training of the model alone took
seven hours therefore it was a major accomplishment for the team when the model was working
so effectively. Additionally, being able to design and create an application that allows for the
gamification for creating an emergency fund was another major accomplishment for our team as
well.
## What we learned
Working on such a technically complex product such as Incrementum really showed our team
what we were capable of when working together. Many of us were not exposed to the
technologies and topics used with Incrementum however being able to not only create full-stack
web application with a complete React front end and Flask backend but also creating a GAN
one of the most complex neural network types in machine learning allowed our team to learn so
much about software engineering, planning and teamwork. Specifically, our team gained a
newfound competence in developing complex machine learning models and developing an
eye-catching and user-friendly front end.
## What's next for Incrementum
The goal of Incrementum moving forward is to further develop the application to handle more
investing and saving goals. We would like to add tasks that support teaching and incentivizing
students and young people to invest in various securities such as stocks and bonds and
research more into saving accounts such as retirement accounts. Using the gamification model
Incrementum uses we are certain we can make some of the less interesting elements of
building wealth and financial security much more engaging and enjoyable for all people. | ## Inspiration
Inspired by the Making the Mundane Fun prize category, our team immediately focused on helping users achieve long-term goals. We observed a surge in cooking at the start of lockdown, and wanted to keep that momentum going with a simple yet entertaining app to inspire users to enjoy cooking in the long term.
## What it does
With the login system, each user stores their own personalized information. The homepage allows users to track when they cooked and when they didn’t to show a visual of their daily cooking routine. Weekly challenges add interest to cooking, randomly generating an ingredient of the week to cook with, which earns you bonus points to go toward purchasing more plants. The garden is a fun game for users to design a personal space. The more you level up, the more plants you can add.
## How we built it
We built the app through Android Studio using Java. The UI images were created using Adobe Illustrator and the authentication was achieved through a Firebase database.
## Challenges we ran into
Although the project was relatively smooth sailing, we did run into some challenges along the way. The biggest challenge was implementing the Firebase database. We also experienced some difficulties with adding a clickable image grid to our garden pop-up.
## Accomplishments that we're proud of
First, our team was rather unfamiliar with Android Studio. We learned a lot about implementing a project in Android Studio. As well, Firebase was a new tool for our team. Although it was a challenge to get the implementation running we are proud of the authentication. Finally, this was the first time the team member who created the UI images had done so and we are proud of their achievements!
## What we learned
Overall, we learned a lot about Firebase, UI creation and implementing projects in Android Studio.
## What's next for Harvest
In the future, we hope to fully implement user-associated data and a platform to share latest creations with your friends to further personalize the app and include a broader community aspect. | ## Inspiration
We started with the idea of creating an app that incentivized environmental volunteering, and the idea quickly grew into an app that offers incentives for any type of volunteering in your local community. The whole goal is to increase local community engagement while contributing to the common good.
## What it does
Any company or person can request volunteers through the app, and upon successful completion of the volunteer activity, the requester will tip users in-app currency called Leaf, whose transactions are managed by the blockchain technology offered by Algorand. Once users accumulate enough Leaves they can exchange them for incentives like coupons and discount codes for local companies.
## How I built it
Used react-native to build a front end UI. This was done in conjunction with the plan of building a Node.js backend for user authentication and the Algorand blockchain.
## Challenges I ran into
We had never used react-native before so the navigation between pages was very confusing. However, a decent UI was still able to be built. The Algorand setup was also tricky because of the token and node module setup.
## Accomplishments that I'm proud of
Happy that a base front end was completed and that my team worked well together. Very happy that we had a decent idea and something to submit.
## What I learned
Obviously blockchain is very complicated, but when you use Algorand's innovative PaaS the difficulty of a baseline model is manageable for student developers.
## What's next for Prim
Implementing the reward system, hopefully using discount codes or coupons from sponsors. Implementing geolocation services so we can better suggest volunteer opportunities to users. | partial |
## Inspiration
My inspiring was really just my daily life. I use apps like my fitness pal and libre link to keep track of all these things but I feel like it doesn't paint the whole picture for someone with my condition. I'm really making this app for people like myself who have a challenging time dealing with diabetes and simplifying an aspect of their lives' at least a little bit.
## What it does
The mobile app keeps track of your blood sugars for the day by either taking data from your wearable sensor or finger pricks and puts it side by side with the exercise that you've done that day and the food you've ate. It allows you to clearly quantify and compare how much you eat, exercise and take insulin individually and it also helps you clearly see the relationship those three activities have with each other. The My Fitness Pal API does a really good job of tracking macro nutrients in each meal and making it easier the more you use the API.
## How we built it
I built the app using React native and it was my first time using it. I plan to integrate the my fitness pal API for the fitness and meals portion of the app and the terra API to get sensor data as well as the choice to manually update a csv file of your glucose logs that most glucometers come with.
## Challenges we ran into
## Accomplishments that we're proud of
Creating something meaningful to myself and other people using a passion/skill that is also meaningful to me.
## What we learned
I learned a lot about how to organize my files while making a large project, companies are very stingy when it comes to healthcare related APIs and how to actually create a cross platform mobile app.
## What's next for Diathletic
I plan to make the app fully functional because right now there is a lot of dummy data. I wish to be able to use this app in my everyday life because its great to actually see the effects of something great that you have completed. I also REALLY hope that one stranger finds any sort of value in the software that I created. | ## Inspiration
Managing diabetes is often cumbersome and many wearables output data across multiple devices. This is often coupled with the fact that it is quite hard to understand and find patterns in fluctuating glucose levels and other essential diabetic metrics at a simple glance. Often when diabetics meet with their doctors, these trends are identified manually across multiple data entries, days, readings, and graphs. How might we centralize the data and utilize an artificial intelligence model to predict and find trends that make pattern finding easier for doctors and patients to find the best diabetic management plan, carb to insulin ratios, and insulin rates for a routine?
## What it does
Our web application uses Terra API to connect to a real Freestyle Libre, a continuous glucose monitoring (CGM) device that diabetic patients utilize to get accurate blood glucose readings every 15 minutes. This data is a real diabetic patient’s and our application aims to find trends using AI. This information is then displayed as a text, which defines the average blood sugar levels for a given period, the instances where the blood glucose is going high or low, and possible predictions for anomalies in the data.
## How we built it
We connected the Freestyle Libre wearable to the Terra API, so we have real blood sugar level data. From our web application, we call the Terra API for each day of data that the user has specified, extracting the glucose data for each day, and inputs that data to OpenAI’s chat gpt 3.5 model. The OpenAI is prompt-engineered to spot patterns in blood sugar spikes, drops, and deduce/find possible correlations with lifestyle choices. Once fetched from the Large Language Model (LLM), the output is rendered in our react application through visual data representations, along with easy-to-understand data analytics findings. Additionally, OpenAI uses information about the user’s lifestyle, and current medical information to make possible suggestions about diabetic management and when to contact their doctor.
## Challenges we ran into
* **Data permissions.** We struggled to connect the Dexcom to the TerraAPI because our Canadian Dexcom account could not receive approval, and we could not create a new US-based account without compromising overriding real data from one of our teammates. Fortunately, we sought out access to a different wearable from someone outside our team and received permission to use their data.
* **Setting up the UI/UX was surprisingly challenging.** Web development is an area none of us were confident in, so we faced various package and component issues. Our workaround was largely switching devices and learning to use templates instead of creating an app from scratch.
* **Parsing the data as a JSON object.**
* **OpenAI Token limit.**
## Accomplishments that we're proud of
* **Using TerraAPI**: We were able to successfully connect a real Freestyle Libre wearable device to TerraAPI to fetch glucose data. We learned a lot about the API and how to integrate it into an application.
* **Good collaboration**: Our shared vision for Bloodhound helped us create a really collaborative, exciting, and fun team environment. We believe that our collaboration is driven by a shared enthusiasm for learning and growing and by embracing new challenges and viewing setbacks as opportunities to improve, our team abilities are nothing short of a huge accomplishment.
* **Utilizing AI and Data Processing**: With the increase in AI hype, we really wanted to incorporate something that allowed diabetics to use artificial intelligence in trend forecasting and predictions. This was done with the help of OpenAI’s API, which many of our team members never used before! We also had to think about data points, compression, and variations, which took a decent amount of creativity, which we are proud of.
* **Quick Thinking/Creativity**: Prior to speaking with the Terra API team, we had a different vision for our project. However, we pivoted quickly after finding a matching synergy for helping diabetics understand the trends in their glucose fluctuations throughout a period of time. In doing so, we had to think fast and understand the requirements and needs of our new project, Bloodhound.
## What we learned
* **TerraAPI**: We were able to successfully connect a real Freestyle Libre wearable device to TerraAPI to fetch glucose data. We learned a lot about the API and how to integrate it into an application as well as how to handle JSON data.
* **OpenAI API**: Many of our team members have never used OpenAI API for the chat gpt 3.5 model. We learned about prompt engineering and filtering trend arrows to generate a good and accurate output from the LLM.
* **Workshops**: We learned a lot from the Hackathon workshops, especially from Terra API and Huggingface! Both of these workshops helped us define our project goals and tech stack and learn about AI models and APIs!
## What's next for bloodhound
* **Integrating Insulin Pump data & other body health metrics.**
* **Doctor-focused**: Although this app is meant for someone with diabetes to use, doctors would really benefit from assistance in analyzing and identifying patterns in health data. By incorporating context like family and personal medical history, along with manual concerns by the doctor, bloodhound could assist medical professionals in more quickly identifying pain points and advising patients about healthier diabetic management practices based on their CGM data.
* **Accessibility features**: elderly populations face particularly high rates of diabetes. In the future, we would want accessibility features for all patients, but especially large text, text-to-speech, different languages, and an even simpler UI for easier use. | ## Inspiration
Research shows that maximum people face mental or physical health problems due to their unhealthy daily diet or ignored symptoms at the early stages. This app will help you track your diet and your symptoms daily and provide recommendations to provide you with an overall healthy diet. We were inspired by MyFitnessPal's ability to access the nutrition information from foods at home, restaurants, and the grocery store. Diet is extremely important to the body's wellness, but something that is hard for any one person to narrow down is: What foods should I eat to feel better? It is a simple question, but actually very hard to answer. We eat so many different things in a day, how do you know what is making positive impacts on your health, and what is not?
## What it does
Right now, the app is in a pre-alpha phase. It takes some things as input, carbs, fats, protein, vitamins, and electrolyte intake in a day. It sends this data to a Mage API, and Mage predicts how well they will feel in that day. The Mage AI is based off of sample data that is not real-world data, but as the app gets users it will get more accurate. Based off of our data set that we gather and the model type, the AI maintains 96.4% accuracy at predicting the wellness of a user on a given day. This is based off of 10000 users over 1 day, or 1 user over 10000 days, or somewhere in between. The idea is that the AI will be constantly learning as the app gains users and individual users enter more data.
## How we built it
We built it in Swift using the Mage.ai for data processing and API
## Challenges we ran into
Outputting the result on the App after the API returns the final prediction. We have the prediction score displayed in the terminal, but we could not display it on the app initially. We were able to do that after a lot of struggle. All of us made an app and implemented an API for the very first time.
## Accomplishments that we're proud of
-- Successfully implementing the API with our app
-- Building an App for the very first time
-- Creating a model for AI data processing with a 96% accuracy
## What we learned
-- How to implement an API and it's working
-- How to build an IOS app
-- Using AI in our application without actually knowing AI in depth
## What's next for NutriCorr
--Adding different categories of symptoms
-- giving the user recommendations on how to change their diet
-- Add food object to the app so that the user can enter specific food instead of the nutrient details
-- Connect our results to mental health wellness and recommendations. Research shows that people who generally have more sugar intake in their diet generally stay more depressed. | losing |
RadLit was conceived with a singular mission in mind: to demystify the complex medical jargon of radiology reports, making them accessible and understandable to patients. The impetus for this project stemmed from a common problem observed in healthcare settings worldwide: patients often find their radiology reports incomprehensible, filled with daunting technical terms and phrases. This gap in understanding can lead to anxiety, misinterpretation, and a sense of alienation in one's own healthcare journey.
The primary objective of RadLit was to develop a tool that leverages a locally trained a Llama-2-7B-Chat model to translate complex radiological reports into simple, patient-friendly language. By doing so, the project aimed to improve patient outcomes and foster rapport between underserved patient populations and their healthcare providers.
To fine-tune our models, we utilized the Hugging Face AutoTrain Advanced Python package38, enabling us to train our models. We primarily employed the default settings provided by Hugging Face. Hugging Face AutoTrain leverages Parameter Efficient Fine Tuning (PEFT)39, a method designed for fine-tuning large language models without the need to fine-tune all model parameters. Instead, it only fine-tunes a small subset of additional model parameters, reducing the computational and storage requirements for fine-tuning tasks.
In tandem, we leveraged QLoRA, a novel approach for training large AI models more efficiently, particularly designed to manage memory constraints. It utilizes 4-bit quantization, a process that compresses the model's data from 16-bits to 4-bits without significant loss of information, enabling the use of CPU-only machines. | ## Inspiration
Electronic health records provide valuable data that can be used to improve the quality of patient care. However, a majority of that data consists of free-form text notes written by doctors, which is difficult to analyze using traditional tools. We wanted to change that by developing a prediction tool that uses natural language processing (NLP) techniques built on modern neural network architectures.
## What it does
Our tool predicts the likelihood that a patient will be assigned each of the top-10 diagnostic codes, based only on free-form text notes from the patient's visit.
## How I built it
We collected data from MIMIC-III, a dataset that contains rich, anonymized patient records documenting over a million hospital visits. Using a transformer-based NLP system built using Pytorch, we trained several models overnight using Google Cloud and selected the best one. We then created an API and flask-based webserver to allow easy visualization and live, dynamically updating predictions from typing freeform text.
## Challenges I ran into
* Model was very slow to train
* Data was not well formatted
* Live visualization was more difficult than expected
* Collaboration tools
* Large files
* Catastrophic backtracking
## Accomplishments that I'm proud of
* Working transformer-based NLP model
* Dynamically updating charts!
* Promising results given training time available
## What I learned
* Training is slow, start early
* Visual Studio is slow but VScode live share is great
* Lots of advanced deep learning architectures are quite accessible
## What's next for Code Overdose
* Hyperparamer tuning
* Experiments with different word embeddings/sentence2vec
* Predict top 50 codes
* Increase prediction stability
* Result validation and error analysis | ## Inspiration
40 million people in the world are blind, including 20% of all people aged 85 or older. Half a million people suffer paralyzing spinal cord injuries every year. 8.5 million people are affected by Parkinson’s disease, with the vast majority of these being senior citizens. The pervasive difficulty for these individuals to interact with objects in their environment, including identifying or physically taking the medications vital to their health, is unacceptable given the capabilities of today’s technology.
First, we asked ourselves the question, what if there was a vision-powered robotic appliance that could serve as a helping hand to the physically impaired? Then we began brainstorming: Could a language AI model make the interface between these individual’s desired actions and their robot helper’s operations even more seamless? We ended up creating Baymax—a robot arm that understands everyday speech to generate its own instructions for meeting exactly what its loved one wants. Much more than its brilliant design, Baymax is intelligent, accurate, and eternally diligent.
We know that if Baymax was implemented first in high-priority nursing homes, then later in household bedsides and on wheelchairs, it would create a lasting improvement in the quality of life for millions. Baymax currently helps its patients take their medicine, but it is easily extensible to do much more—assisting these same groups of people with tasks like eating, dressing, or doing their household chores.
## What it does
Baymax listens to a user’s requests on which medicine to pick up, then picks up the appropriate pill and feeds it to the user. Note that this could be generalized to any object, ranging from food, to clothes, to common household trinkets, to more. Baymax responds accurately to conversational, even meandering, natural language requests for which medicine to take—making it perfect for older members of society who may not want to memorize specific commands. It interprets these requests to generate its own pseudocode, later translated to robot arm instructions, for following the tasks outlined by its loved one. Subsequently, Baymax delivers the medicine to the user by employing a powerful computer vision model to identify and locate a user’s mouth and make real-time adjustments.
## How we built it
The robot arm by Reazon Labs, a 3D-printed arm with 8 servos as pivot points, is the heart of our project. We wrote custom inverse kinematics software from scratch to control these 8 degrees of freedom and navigate the end-effector to a point in three dimensional space, along with building our own animation methods for the arm to follow a given path. Our animation methods interpolate the arm’s movements through keyframes, or defined positions, similar to how film editors dictate animations. This allowed us to facilitate smooth, yet precise, motion which is safe for the end user.
We built a pipeline to take in speech input from the user and process their request. We wanted users to speak with the robot in natural language, so we used OpenAI’s Whisper system to convert the user commands to text, then used OpenAI’s GPT-4 API to figure out which medicine(s) they were requesting assistance with.
We focused on computer vision to recognize the user’s face and mouth. We used OpenCV to get the webcam live stream and used 3 different Convolutional Neural Networks for facial detection, masking, and feature recognition. We extracted coordinates from the model output to extrapolate facial landmarks and identify the location of the center of the mouth, simultaneously detecting if the user’s mouth is open or closed.
When we put everything together, our result was a functional system where a user can request medicines or pills, and the arm will pick up the appropriate medicines one by one, feeding them to the user while making real time adjustments as it approaches the user’s mouth.
## Challenges we ran into
We quickly learned that working with hardware introduced a lot of room for complications. The robot arm we used was a prototype, entirely 3D-printed yet equipped with high-torque motors, and parts were subject to wear and tear very quickly, which sacrificed the accuracy of its movements. To solve this, we implemented torque and current limiting software and wrote Python code to smoothen movements and preserve the integrity of instruction.
Controlling the arm was another challenge because it has 8 motors that need to be manipulated finely enough in tandem to reach a specific point in 3D space. We had to not only learn how to work with the robot arm SDK and libraries but also comprehend the math and intuition behind its movement. We did this by utilizing forward kinematics and restricted the servo motors’ degrees of freedom to simplify the math. Realizing it would be tricky to write all the movement code from scratch, we created an animation library for the arm in which we captured certain arm positions as keyframes and then interpolated between them to create fluid motion.
Another critical issue was the high latency between the video stream and robot arm’s movement, and we spent much time optimizing our computer vision pipeline to create a near instantaneous experience for our users.
## Accomplishments that we're proud of
As first-time Hackathon participants, we are incredibly proud of the incredible progress we were able to make in a very short amount of time, proving to ourselves that with hard work, passion, and a clear vision, anything is possible. Our team did a fantastic job embracing the challenge of using technology unfamiliar to us, and stepped out of our comfort zones to bring our idea to life. Whether it was building the computer vision model, or learning how to interface the robot arm’s movements with voice controls, we ended up building a robust prototype which far surpassed our initial expectations. One of our greatest successes was coordinating our work so that each function could be pieced together and emerge as a functional robot. Let’s not overlook the success of not eating our hi-chews we were using for testing!
## What we learned
We developed our skills in frameworks we were initially unfamiliar with such as how to apply Machine Learning algorithms in a real-time context. We also learned how to successfully interface software with hardware - crafting complex functions which we could see work in 3-dimensional space. Through developing this project, we also realized just how much social impact a robot arm can have for disabled or elderly populations.
## What's next for Baymax
Envision a world where Baymax, a vigilant companion, eases medication management for those with mobility challenges. First, Baymax can be implemented in nursing homes, then can become a part of households and mobility aids. Baymax is a helping hand, restoring independence to a large disadvantaged group.
This innovation marks an improvement in increasing quality of life for millions of older people, and is truly a human-centric solution in robotic form. | losing |
## Inspiration
As college students, one of the biggest issues we face in our classes is finding a study group we love and are comfortable in. We created this project to solve this problem.
## What it does
Our website provides an interface for students to create and join study groups, as well as invite their friends to join their groups, and chat with other members of the group.
## How I built it
We used the Google Calendar API with a node.js / Python backend to build our website.
## Challenges I ran into
One of the biggest challenges we faced during the construction of this project was using the Google Calendar API with server-side authentication with a default email address, as opposed to requesting the user for authentication.
## Accomplishments that I'm proud of
## What I learned
## What's next for StudyGroupMe
We need to work on and improve the User Interface. Secondly, once we have access to logging in through Harvard Key, we no longer need to scrape for information, and will directly have access to class/student information on login | ## Inspiration
As university students, we have been noticing issues with very large class sizes. With lectures often being taught to over 400 students, it becomes very difficult and anxiety-provoking to speak up when you don't understand the content. As well, with classes of this size, professors do not have time to answer every student who raises their hand. This raises the problem of professors not being able to tell if students are following the lecture, and not answering questions efficiently. Our hack addresses these issues by providing a real-time communication environment between the class and the professor. KeepUp has the potential to increase classroom efficiency and improve student experiences worldwide.
## What it does
KeepUp allows the professor to gauge the understanding of the material in real-time while providing students a platform to pose questions. It allows students to upvote questions asked by their peers that they would like to hear answered, making it easy for a professor to know which questions to prioritize.
## How We built it
KeepUp was built using JavaScript and Firebase, which provided hosting for our web app and the backend database.
## Challenges We ran into
As it was, for all of us, our first time working with a firebase database, we encountered some difficulties when it came to pulling data out of the firebase. It took a lot of work to finally get this part of the hack working which unfortunately took time away from implementing some other features (See what’s next section). But it was very rewarding to have a working backend in Firebase and we are glad we worked to overcome the challenge.
## Accomplishments that We are proud of
We are proud of creating a useful app that helps solve a problem that affects all of us. We recognized that there is a gap in between students and teachers when it comes to communication and question answering and we were able to implement a solution. We are proud of our product and its future potential and scalability.
## What We learned
We all learned a lot throughout the implementation of KeepUp. First and foremost, we got the chance to learn how to use Firebase for hosting a website and interacting with the backend database. This will prove useful to all of us in future projects. We also further developed our skills in web design.
## What's next for KeepUp
* There are several features we would like to add to KeepUp to make it more efficient in classrooms:
* Add a timeout feature so that questions disappear after 10 minutes of inactivity (10 minutes of not being upvoted)
* Adding a widget feature so that the basic information from the website can be seen in the corner of your screen at all time
* Adding Login for users for more specific individual functions. For example, a teacher can remove answered questions, or the original poster can mark their question as answered.
* Censoring of questions as they are posted, so nothing inappropriate gets through. | ## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call. | partial |
## Inspiration
Presentation inspired by classic chatbots
## What it does
Interfaces with gpt through mindsdb, and engineers the prompt to lead towards leading questions. Saves the query's entered by the user and on a regular interval generates a quiz on topics related to the entries, at the same skill level.
## How we built it
Using reflex for the framework, and mindsdb to interface with gpt
## Challenges we ran into
During the duration of this challenge, we had noticed a significant productivity curve; especially at night. This was due to multiple factors, but the most apparent one is a lack of preparation with us needing to download significant files during the peak hours of the day.
## Accomplishments that we're proud of
We are extremely satisfied with our use of the reflex framework; this season our team comprised of only 2 members with no significant web development history. So we are proud that we had optimized our time management so that we could learn while creating.
## What we learned
Python,git,reflex,css
## What's next for Ai-Educate
We want to get to the point where we can save inputs into a large database so that our program is not as linear, if we were to implement this, older topics would appear less often but would not disappear outright. We also want a better way to determine the similarity between two inputs, we had significant trouble with that due to our reliance of gpt, we believe that the next best solution is to create our own Machine Learning engine, combined with user rating of correctness of assessment.
We were also looking into ripple, as we understand it, we could use it to assign a number of points to our users, and with those points we can limit their access to this resource, and we can also distribute points through our quizzes, this would foster a greater incentive to absorb the content as it would enable users to have more inputs | ## Inspiration
We were inspired by the **protégé effect**, a psychological phenomenon where teaching others helps reinforce the student's own understanding. This concept motivated us to create a platform where users can actively learn by teaching an AI model, helping them deepen their comprehension through explanation and reflection. We wanted to develop a tool that not only allows users to absorb information but also empowers them to explain and teach back, simulating a learning loop that enhances retention and understanding.
## What it does
Protégé enables users to:
* **Create lessons** on any subject, either from their own study notes or with AI-generated information.
* **Teach** the AI by explaining concepts aloud, using real-time speech-to-text conversion.
* The AI then **evaluates** the user’s explanation, identifies errors or areas for improvement, and provides constructive feedback. This helps users better understand the material while reinforcing their knowledge through active participation.
* The system adapts to user performance, offering **customized feedback** and lesson suggestions based on their strengths and weaknesses.
## How we built it
Protégé was built using the **Reflex framework** to manage the front-end and user interface, ensuring a smooth, interactive experience. For the back-end, we integrated **Google Gemini** to generate lessons and evaluate user responses. To handle real-time speech-to-text conversion, we utilized **Deepgram**, a highly accurate speech recognition API, allowing users to speak directly to the AI for their explanations. By connecting these technologies through state management, we ensured seamless communication between the user interface and the AI models.
## Challenges we ran into
One of the main challenges was ensuring **seamless integration between the AI model and the front-end** so that lessons and feedback could be delivered in real time. Any lag would have disrupted the user experience, so we optimized the system to handle data flow efficiently. Another challenge was **real-time speech-to-text accuracy**. We needed a solution that could handle diverse speech patterns and accents, which led us to Deepgram for its ability to provide fast and accurate transcriptions even in complex environments.
## Accomplishments that we're proud of
We’re particularly proud of successfully creating a platform that allows for **real-time interaction** between users and the AI, providing a smooth and intuitive learning experience. The integration of **Deepgram for speech recognition** significantly enhanced the teaching feature, enabling users to explain concepts verbally and receive immediate feedback. Additionally, our ability to **simulate the protégé effect**—where users reinforce their understanding by teaching—marks a key accomplishment in the design of this tool.
## What we learned
Throughout this project, we learned the importance of **real-time system optimization**, particularly when integrating AI models with front-end interfaces. We also gained valuable experience in **balancing accuracy with performance**, ensuring that both lesson generation and speech recognition worked seamlessly without compromising user experience. Additionally, building a system that adapts to users’ teaching performance taught us how crucial **customization and feedback** are in creating effective educational tools.
## What's next for Protégé
Our next steps include:
* Developing **personalized lesson plans** that adapt based on user performance in teaching mode, making learning paths more tailored and effective.
* Adding **gamified progress tracking**, where users can earn achievements and track their improvement over time, keeping them motivated.
* Introducing **community and peer learning** features, allowing users to collaborate and share their teaching experiences with others.
* Building a **mobile version** of Protégé to make the platform more accessible for learning on the go. | ## Inspiration
In a world where people are continually faced with complicated decisions, our team wanted to see if the latest AI models would be capable of navigating complex social and moral landscapes of the modern day. This inspired our central focus for this project: exploring the intersection of AI and ethical decision-making and creating an engaging way for people to reflect on their own senses of morality.
## What it does
GPTEthics offers an interactive web platform where:
* Users are presented with a variety of ethical dilemmas.
* Both the user and an AI agent respond to these scenarios.
* An AI-powered system evaluates and compares the responses, providing insights into human vs. AI approaches to moral reasoning.
## How we built it
Our solution integrates several key components:
* A Flask-based web application for scenario presentation
* An AI agent powered by GPT-4, AWS Bedrock, and Groq for generating responses
* An AI-driven scoring system to evaluate the ethical reasoning in responses
## Challenges we ran into
* Developing an objective and fair AI scoring system for subjective ethical issues
* Creating a diverse, representative set of ethical dilemmas
* Optimizing response times from AWS Bedrock through prompt engineering
## Accomplishments that we're proud of
* Successfully integrating AI into an ethics-focused, interactive experience
* Developing a tool that promotes thoughtful engagement with moral issues
* Implementing a cohesive web application that effectively utilizes multiple LLM APIs
## What we learned
* Valuable perspectives on how humans and AI approach ethical decision-making
* Understanding the complexities of designing impartial AI evaluation systems for subjective topics
* Recognizing the ongoing challenges LLMs face in providing robust ethical solutions
## What's next for GPTEthics
* Expanding our database of ethical scenarios
* Refining the AI agent and scoring system for improved performance
* Exploring the integration of user feedback to enhance the platform's effectiveness | losing |
```
var bae = require('love.js')
```
## Inspiration
It's a hackathon. It's Valentine's Day. Why not.
## What it does
Find the compatibility of two users based on their Github handles and code composition. Simply type the two handles into the given text boxes and see the compatibility of your stacks.
## How I built it
The backend is built on Node.js and Javascript while the front-end consists of html, css, and javascript.
## Challenges I ran into
Being able to integrate the Github API in our code and representing the data visually.
## What's next for lovedotjs
Adding more data from Github like frameworks and starred repositories, creating accounts that are saved to databases and recommending other users at the same hackathon, using Devpost's hackathon data for future hackathons, matching frontend users to backend users, and integrating other forms of social media and slack to get more data about users and making access easier. | ## Inspiration
When thinking about how we could make a difference within local communities impacted by Covid-19, what came to mind are our frontline workers. Our doctors, nurses, grocery store workers, and Covid-19 testing volunteers, who have tirelessly been putting themselves and their families on the line. They are the backbone and heartbeat of our society during these past 10 months and counting. We want them to feel the appreciation and gratitude they deserve. With our app, we hope to bring moments of positivity and joy to those difficult and trying moments of our frontline workers. Thank you!
## What it does
Love 4 Heroes is a web app to support our frontline workers by expressing our gratitude for them. We want to let them know they are loved, cared for, and appreciated. In the app, a user can make a thank you card, save it, and share it with a frontline worker. A user's card is also posted to the "Warm Messages" board, a community space where you can see all the other thank-you-cards.
## How we built it
Our backend is built with Firebase. The front-end is built with Next.js, and our design framework is Tailwind CSS.
## Challenges we ran into
* Working with different time zones [12 hour time difference].
* We ran into trickiness figuring out how to save our thank you cards to a user's phone or laptop.
* Persisting likes with Firebase and Local Storage
## Accomplishments that we're proud of
* Our first Hackathon
+ We're not in the same state, but came together to be here!
+ Some of us used new technologies like Next.js, Tailwind.css, and Firebase for the first time!
+ We're happy with how the app turned out from a user's experience
+ We liked that we were able to create our own custom card designs and logos, utilizing custom made design-textiles
## What we learned
* New Technologies: Next.js, Firebase
* Managing time-zone differences
* How to convert a DOM element into a .jpeg file.
* How to make a Responsive Web App
* Coding endurance and mental focus
-Good Git workflow
## What's next for love4heroes
More cards, more love! Hopefully, we can share this with a wide community of frontline workers. | ## Inspiration: Many people that we know want to get more involved in the community but don't have the time for regular commitments. Furthermore, many volunteer projects require an extensive application, and applications for different organizations vary so it can be a time-consuming and discouraging process. We wanted to find a way to remove these boundaries by streamlining the volunteering process so that people can get involved, doing one-time projects without needing to apply every time.
## What it does
It is a website aimed at streamlining volunteering hiring and application processes. There are 2 main users: volunteer organizations, and volunteers. Volunteers will sign-up, registering preset documents, waivers, etc. These will then qualify them to volunteer at any of the projects posted by organizations. Organizations can post event dates, locations, etc. Then volunteers can sign-up with the touch of a button.
## How I built it
We used node.js, express, and MySQL for the backend. We used bootstrap for the front end UI design and google APIs for some of the functionality. Our team divided the work based on our strengths and interests.
## Challenges I ran into
We ran into problems with integrating MongoDB and the Mongo Daemon so we had to switch to MySQL to run our database. MySQL querying and set-up had a learning curve that was very discouraging, but we were able to gain the necessary skills and knowledge to use it. We tried to set up a RESTful API, but ultimately, we decided there was not enough time/resources to efficiently execute it, as there were other tasks that were more realistic.
## Accomplishments that I'm proud of
We are proud to all have completed our first 24hr hackathon. Throughout this process, we learned to brainstorm as a team, create a workflow, communicate our progress/ideas, and all acquired new skills. We are proud that we have something that is cohesive functioning components and to have completed our first non-academic collaborative project. We all ventured outside of our comfort zones, using a language that we weren't familiar with.
## What I learned
This experience has taught us a lot about working in a team and communicating with other people. There is so much we can learn from our peers. Skillwise, many of our members gained experience in node.js, MySQL, endpoints, embedded javascript, etc. It taught us a lot about patience and persevering because oftentimes, problems could seem unsolvable but yet we still were able to solve them with time and effort.
## What's next for NWHacks2020
We are all very proud of what we have accomplished and would like to continue this project, even though the hackathon is over. The skills we have all gained are sure to be useful and our team has made this a very memorable experience. | partial |
## Inspiration
There are thousands of people worldwide who suffer from conditions that make it difficult for them to both understand speech and also speak for themselves. According to the Journal of Deaf Studies and Deaf Education, the loss of a personal form of expression (through speech) has the capability to impact their (affected individuals') internal stress and lead to detachment. One of our main goals in this project was to solve this problem, by developing a tool that would a step forward in the effort to make it seamless for everyone to communicate. By exclusively utilizing mouth movements to predict speech, we can introduce a unique modality for communication.
While developing this tool, we also realized how helpful it would be to ourselves in daily usage, as well. In areas of commotion, and while hands are busy, the ability to simply use natural lip-reading in front of a camera to transcribe text would make it much easier to communicate.
## What it does
**The Speakinto.space website-based hack has two functions: first and foremost, it is able to 'lip-read' a stream from the user (discarding audio) and transcribe to text; and secondly, it is capable of mimicking one's speech patterns to generate accurate vocal recordings of user-inputted text with very little latency.**
## How we built it
We have a Flask server running on an AWS server (Thanks for the free credit, AWS!), which is connected to a Machine Learning model running on the server, with a frontend made with HTML and MaterializeCSS. This was trained to transcribe people mouthing words, using the millions of words in LRW and LSR datasets (from the BBC and TED). This algorithm's integration is the centerpiece of our hack. We then used the HTML MediaRecorder to take 8-second clips of video to initially implement the video-to-mouthing-words function on the website, using a direct application of the machine learning model.
We then later added an encoder model, to translate audio into an embedding containing vocal information, and then a decoder, to convert the embeddings to speech. To convert the text in the first function to speech output, we use the Google Text-to-Speech API, and this would be the main point of future development of the technology, in having noiseless calls.
## Challenges we ran into
The machine learning model was quite difficult to create, and required a large amount of testing (and caffeine) to finally result in a model that was fairly accurate for visual analysis (72%). The process of preprocessing the data, and formatting such a large amount of data to train the algorithm was the area which took the most time, but it was extremely rewarding when we finally saw our model begin to train.
## Accomplishments that we're proud of
Our final product is much more than any of us expected, especially the ability to which it seemed like it was an impossibility when we first started. We are very proud of the optimizations that were necessary to run the webpage fast enough to be viable in an actual use scenario.
## What we learned
The development of such a wide array of computing concepts, from web development, to statistical analysis, to the development and optimization of ML models, was an amazing learning experience over the last two days. We all learned so much from each other, as each one of us brought special expertise to our team.
## What's next for speaking.space
As a standalone site, it has its use cases, but the use cases are limited due to the requirement to navigate to the page. The next steps are to integrate it in with other services, such as Facebook Messenger or Google Keyboard, to make it available when it is needed just as conveniently as its inspiration. | ## Inspiration
Only a small percentage of Americans use ASL as their main form of daily communication. Hence, no one notices when ASL-first speakers are left out of using FaceTime, Zoom, or even iMessage voice memos. This is a terrible inconvenience for ASL-first speakers attempting to communicate with their loved ones, colleagues, and friends.
There is a clear barrier to communication between those who are deaf or hard of hearing and those who are fully-abled.
We created Hello as a solution to this problem for those experiencing similar situations and to lay the ground work for future seamless communication.
On a personal level, Brandon's grandma is hard of hearing, which makes it very difficult to communicate. In the future this tool may be their only chance at clear communication.
## What it does
Expectedly, there are two sides to the video call: a fully-abled person and a deaf or hard of hearing person.
For the fully-abled person:
* Their speech gets automatically transcribed in real-time and displayed to the end user
* Their facial expressions and speech get analyzed for sentiment detection
For the deaf/hard of hearing person:
* Their hand signs are detected and translated into English in real-time
* The translations are then cleaned up by an LLM and displayed to the end user in text and audio
* Their facial expressions are analyzed for emotion detection
## How we built it
Our frontend is a simple React and Vite project. On the backend, websockets are used for real-time inferencing. For the fully-abled person, their speech is first transcribed via Deepgram, then their emotion is detected using HumeAI. For the deaf/hard of hearing person, their hand signs are first translated using a custom ML model powered via Hyperbolic, then these translations are cleaned using both Google Gemini and Hyperbolic. Hume AI is used similarly on this end as well. Additionally, the translations are communicated back via text-to-speech using Cartesia/Deepgram.
## Challenges we ran into
* Custom ML models are very hard to deploy (Credits to <https://github.com/hoyso48/Google---American-Sign-Language-Fingerspelling-Recognition-2nd-place-solution>)
* Websockets are easier said than done
* Spotty wifi
## Accomplishments that we're proud of
* Learned websockets from scratch
* Implemented custom ML model inferencing and workflows
* More experience in systems design
## What's next for Hello
Faster, more accurate ASL model. More scalability and maintainability for the codebase. | ## Inspiration
Augmented reality can breathe new life into the classroom, bringing extra creativity, interactivity and engagement to any subject. AR learning helps students by decreasing the time it takes to grasp complex topics.
Augmented reality in education can serve a number of purposes. It helps the students easily acquire, process, and remember the information. Additionally, AR makes learning itself more engaging and fun.
It is also not limited to a single age group or level of education, and can be used equally well in all levels of schooling; from pre-school education up to college, or even at work
## What it does
EchoScienceAR help you to explore science with AR. It help you to gain more knowledge and better understanding towards the science subjects with AR models and helps to make learning itself more engaging and fun.
## How we built it
For website I've considered HTML, HTML5, CSS, CSS3 and for 3d models I've considered echoAR
## Challenges we ran into
Worked solo for the entire project
## Accomplishments that we're proud of
I was able to explore AR
## What's next for EchoScienceAR
Conduct digital chemistry labs to perform experiment through AR, explore various topics, involve a discussion channel | partial |
## Inspiration
**Students** will use AI for their school work anyway, so why not bridge the gap between students and teachers and make it beneficial for both parties?
**1** All of us experienced going through middle school, high school, and now college surrounded by AI-powered tools that were strongly antagonizedantagonized in the classroom by teachers by teachers. As the prevalence of AI and technology increases in today’s world, we believe that classrooms should embrace AI to enhance the classroom which acts very parallel to when calculators were introduced to the classroom. Mathematicians around the world believed that calculators would stop math education all-together, but instead it enhanced student education allowing higher level math such as calculus to be taught earlier. Similarly, we believe that with the proper tools and approach AI can enhance education and teaching for both teachers and students. .
**2** In strained public school systems where the student-to-teacher ratio is low, such educational models can make a significant difference in a young student’s educational journey by providing individualized support when a teacher can’t with information specific to their classroom. One of our members who attends a Title 1 high school particularly inspired this project.
**3** Teachers are constantly seeking feedback on how their students are performing and where they can improve their instruction. What better way to receive this direct feedback than machine learning analysis of the questions students are asking specifically about their class, assignments, and content?
We wanted to create a way for AI model education support to be easily and more effectively integrated into classrooms especially for early education, providing a controlled alternative to using already existing chat models as the teacher can ensure accurate information about their class is integrated into the model.
## What it does
Students will use AI for their school work anyway, so why not bridge the gap between students and teachers? EduGap, a Chrome Extension for Google Classroom, enhances the AI models students can use by automating the integration of class-specific materials into the model. Teachers benefit from gaining machine learning analytics on what areas students struggle with the most through the questions they ask the model.
## How we built it
Front End:
Used HTML/CSS to create deploy a 2-page chrome extension
1 page features an AI chatbot that the user can interact with
The second page is exclusively for teacher users who can review trends from their most asked prompts
Back End:
Built on Javascript and python scripts
Created custom api endpoints for retrieving information from the Google Classroom API, Google User Authentication, prompting Gemini via Gemini API, Conducting Prompt Analysis
Storage and vector embeddings were created using Chroma DB for the Student Experience
AI/ML
LLM: Google Gemini 1.5-flash
ChromaDB for vector embeddings and semantic search as it relates to google classroom documents/information
Langchain for vector embeddings as it relates to prompts;
DBSCAN algorithm to develop clusters for the embeddings via Sklearn
using PCA to downsize dimensionality via sklearn
General themes of largest cluster are shared with teacher summarized by Gemini
## Challenges we ran into
We spent a significant portion of our time trying to integrate sponsor technologies with our application as resources on the web are sparse and some of the functionalities are buggy. It was a frustrating process but we eventually overcame it by improvising.
We also spent some time to choose the best clustering method for our project, and hyperparameter tuning in the constrained time period was also highly challenging as we had to create multiple scripts to cater for different types of models to choose the best ones for our use case
## Accomplishments that we're proud of
Creating a fully functioning Chrome Extension linked to Google Classroom while integrating multiple APIs, machine learning, and database usage. Working with a team we formed right at the Hackathon!
## What we learned
We learned how to work together to create a user-friendly application while integrating a complex backend. For most of us, this was our first hackathon so we learned how to learn fast and productively for the techniques, technology, and even languages we were implementing.
## What's next for EduGap
**1** Functionality for identifying and switching between different classes.
**2** Handling separate user profiles from a database perspective
**3** A more comprehensive analytic dashboard and classroom content suggestion for teachers + more personalized education support tutoring according to the class content for students.
**4** Pilot programs at schools to implement!
**5** Chrome Extension Deployment
**6** Finalize Google Classroom Integration and increase file compatibility | ## Inspiration
The inspiration for our Auto-Teach project stemmed from the growing need to empower both educators and learners with a **self-directed and adaptive** learning environment. We were inspired by the potential to merge technology with education to create a platform that fosters **personalized learning experiences**, allowing students to actively **engage with the material while offering educators tools to efficiently evaluate and guide individual progress**.
## What it does
Auto-Teach is an innovative platform that facilitates **self-directed learning**. It allows instructors to **create problem sets and grading criteria** while enabling students to articulate their problem-solving methods and responses through text input or file uploads (future feature). The software leverages AI models to assesses student responses, offering **constructive feedback**, **pinpointing inaccuracies**, and **identifying areas for improvement**. It features automated grading capabilities that can evaluate a wide range of responses, from simple numerical answers to comprehensive essays, with precision.
## How we built it
Our deliverable for Auto-Teach is a full-stack web app. Our front-end uses **ReactJS** as our framework and manages data using **convex**. Moreover, it leverages editor components from **TinyMCE** to provide student with better experience to edit their inputs. We also created back-end APIs using "FastAPI" and "Together.ai APIs" in our way building the AI evaluation feature.
## Challenges we ran into
We were having troubles with incorporating Vectara's REST API and MindsDB into our project because we were not very familiar with the structure and implementation. We were able to figure out how to use it eventually but struggled with the time constraint. We also faced the challenge of generating the most effective prompt for chatbox so that it generates the best response for student submissions.
## Accomplishments that we're proud of
Despite the challenges, we're proud to have successfully developed a functional prototype of Auto-Teach. Achieving an effective system for automated assessment, providing personalized feedback, and ensuring a user-friendly interface were significant accomplishments. Another thing we are proud of is that we effectively incorporates many technologies like convex, tinyMCE etc into our project at the end.
## What we learned
We learned about how to work with backend APIs and also how to generate effective prompts for chatbox. We also got introduced to AI-incorporated databases such as MindsDB and was fascinated about what it can accomplish (such as generating predictions based on data present on a streaming basis and getting regular updates on information passed into the database).
## What's next for Auto-Teach
* Divide the program into **two mode**: **instructor** mode and **student** mode
* **Convert Handwritten** Answers into Text (OCR API)
* **Incorporate OpenAI** tools along with Together.ai when generating feedback
* **Build a database** storing all relevant information about each student (ex. grade, weakness, strength) and enabling automated AI workflow powered by MindsDB
* **Complete analysis** of student's performance on different type of questions, allows teachers to learn about student's weakness.
* **Fine-tuned grading model** using tools from Together.ai to calibrate the model to better provide feedback.
* **Notify** students instantly about their performance (could set up notifications using MindsDB and get notified every day about any poor performance)
* **Upgrade security** to protect against any illegal accesses | ## Inspiration
Although each of us came from different backgrounds, we each share similar experiences/challenges during our high school years: it was extremely hard to visualize difficult concepts, much less understand the the various complex interactions. This was most prominent in chemistry, where 3D molecular models were simply nonexistent, and 2D visualizations only served to increase confusion. Sometimes, teachers would use a combination of Styrofoam balls, toothpicks and pens to attempt to demonstrate, yet despite their efforts, there was very little effect. Thus, we decided to make an application which facilitates student comprehension by allowing them to take a picture of troubling text/images and get an interactive 3D augmented reality model.
## What it does
The app is split between two interfaces: one for text visualization, and another for diagram visualization. The app is currently functional solely with Chemistry, but can easily be expanded to other subjects as well.
If the text visualization is chosen, an in-built camera pops up and allows the user to take a picture of the body of text. We used Google's ML-Kit to parse the text on the image into a string, and ran a NLP algorithm (Rapid Automatic Keyword Extraction) to generate a comprehensive flashcard list. Users can click on each flashcard to see an interactive 3D model of the element, zooming and rotating it so it can be seen from every angle. If more information is desired, a Wikipedia tab can be pulled up by swiping upwards.
If diagram visualization is chosen, the camera remains perpetually on for the user to focus on a specific diagram. An augmented reality model will float above the corresponding diagrams, which can be clicked on for further enlargement and interaction.
## How we built it
Android Studio, Unity, Blender, Google ML-Kit
## Challenges we ran into
Developing and integrating 3D Models into the corresponding environments.
Merging the Unity and Android Studio mobile applications into a single cohesive interface.
## What's next for Stud\_Vision
The next step of our mobile application is increasing the database of 3D Models to include a wider variety of keywords. We also aim to be able to integrate with other core scholastic subjects, such as History and Math. | partial |
## Inspiration
I initially got the basic idea for this project from one of my own experiences during the lockdown period. I had a lot of free time then because everything was work-from-home so I decided to pick up new hobbies like learning a new language. However I quickly lost motivation, and it wasn't very fruitful. So, I began thinking of ways to make this process of developing habits interesting.
I realised that building a new habit is much more fun when friends are involved. Hence, I decided to build Proclivity, which is an app where you can form clubs, work on building a habit together and also see your friend's progress.
## What it does
Proclivity is a habit-tracking iOS application that focuses on building groups of friends (or clubs) that work on building habits together.
## How we built it
I built this in SwiftUI. Currently, it uses a local database for storage.
## Challenges we ran into
I had also planned to include a blockchain-based crypto reward mechanism but couldn't achieve it.
## Accomplishments that we're proud of
I managed to build basic CRUD with a local data storage.
## What we learned
Learnt a lot about Core Data with SwiftUI.
## What's next for Proclivity
* I plan on developing the backend of the application & improving the Clubs feature.
* I also plan on developing a crypto rewards mechanism for the app so that you will be rewarded in cryptocurrency (a new one for this app). | ## Inspiration
America's unhoused have been underserved by financial technology developments and are in an increasingly difficult situation as the world transitions to electronic payments. We wanted to build the financial infrastructure to support our homeless populations and meet them at their tech level. That's why we focused on a solution that does not require the use of a phone or the ownership of any technology to function.
## What it does
Our banking infrastructure enables the unhoused to receive electronic donations stigma-free (without having to use square or a phone). We provide free banking services to people who traditionally have high difficulty levels getting a bank account. Additionally, we provide great benefits for donators who use our platform by providing them tax write-offs for donations that were previously unrecognizable for tax purposes. For unhoused populations who use our web-app when checking their account status, we have built NLP-powered financial literacy education materials for them to learn and earn financial rewards. The local government interface we built using Palantir Foundry enables municipal clerks to go directly to those who are the most in need with tax distributions.
## How we built it
We built Givn using Palantir Foundry and Next.js for front-end, Firebase (NoSQL) and Express/Vercel for backend, and Unit APi and GPT-3 API. We piped in transaction data that we tracked and created through our Unit banking system into Palantir Foundry to display for local government managers. We used GPT-3 to create financial literacy content and we used Next.js and firebase to run the transaction system by which donators can donate and unhoused populations can make purchases.
## Challenges we ran into
We had significant challenges with Foundry because Foundry is not a publicly available software and it had a steep learning curve. Cleaning and piping in census data and building our own API to transfer transaction data from our core product to Foundry for local government operators to take action on was the most difficult part of our Foundry integration. We eventually solved these issues with some creative PySpark and data-processing skills.
## Accomplishments that we're proud of
We are proudest of our core product--a debit card that enables electronic payments for the unhoused. We believe that the financial infrastructure supporting unhoused populations has been lacking for a long time and we are excited to build in a space that can make such a large impact on people's financial well-being. From a technical perspective, we are the proudest of the API and integrations we built between Foundry and our core product to enable municipalities to understand and support those who are in need in their community. Specifically, municipal clerks can monitor poverty levels, donation levels, average bank account savings, and spending of the unhoused--all while protecting the identity and anonymity of unhoused populations.
## What we learned
We learned so much! Our proficiency with Foundry is quite strong after this weekend--pushing out a functional product with technology you had never worked with before will do that to you. We also learned how to build embedded banking systems with the Unit API and their affiliated banks--Piermont Bank, Thread Bank, Blue Ridge Bank, and Choice Bank. A few members of our team became more familiar with some areas of the stack they hadn't worked with before--front-end, back-end, and the OpenAI API were all refreshed for a few of our members, respectively.
## What's next for GIV
We plan to continue building Givn until it is ready for deployment with a local government and a go-to-market apparatus can be spun up. | ## Inspiration
Arcade Bank was inspired by a passion to help people save money or spend it on things that make their lives better instead of impulse buys they later regret.
## What it does
The machine will prompt you to set-up a goal you would like to reach and every time you deposit money into your piggy bank you are rewarded by being allowed to play the arcade game. Until you reach your goal, you won't be able to access your savings, which takes away the temptation to splurge.
## How we built it
We built Arcade Bank using Arduino, 5 I/R Sensors, LEDS, a servo motor and a display. The game displays a pattern using 4 LEDS and the user must match the pattern on the I/R sensors to score points.
## Challenges we ran into
Most of our challenges were hardware related, specifically, power management and the loss of a sensor. We blew one of our IR sensors and had to improvise with another sensor.
## Accomplishments that we're proud of
We accomplished all of the features to make Arcade Bank a holistic working system.
## What we learned
Everything always takes longer than you think it will!
## What's next for Arcade Bank | losing |
# coTA
🐒👀 Monkey see Monkey Learn 🙉🧠 -- scroll and absorb lectures! 📚
## 💡 Inspiration
Do you spend hours on social media platforms? Have you noticed the addictive nature of short-form videos? Have you ever found yourself remembering random facts or content from these videos? Do you ever get lost in those subway surfer, minecraft, or some satisfying video and come out learning about random useless information or fictional stories from Reddit?
Let’s replace that irrelevant content with material you need to study or learn. Check out coTA! coTA is a new spin on silly computer generated content where you can be entertained while learning and retaining information from your lecture slides.
## 🤔 What it does
We take traditional lectures and make them engaging. Our tool ingests PowerPoint presentations, comprehends the content, and creates entertaining short-form videos to help you learn about lecture material. This satisfies a user’s need for entertainment while staying productive and learning about educational content. Instead of robot-generated fictional Reddit post readers, our tool will teach you about the educational content from your PowerPoint presentations in an easy-to-understand manner.
We also have a chatting feature where you can chat with cohere's LLM to better understand more about power point with direct context. The chatting feature also helps users to clarify any questions that they have with the power of `cohere's` web-search `connector` that is powered by google search!
## 🛠️ How we built it
The Stack: `FastAPI`, `React`, `CoHereAPI`,`TailwindCSS`
For our front end, we used React, creating a minimalist and intuitive design so that any user can easily use our app.
For our backend, we used Python. We utilized a Python library called `python-pptx` to convert PowerPoint presentations into strings to extract lecture content. We then used `Cohere’s` RAG model with the `command-nightly` model to read in and vectorize the document data. This prepares for querying to extract information directly from the PowerPoint. This ensures that any questions that come directly from the PowerPoint content will not be made up and will teach you content within the scope of the class and PowerPoint. This content can then be added to our videos so that users will have relevant and correct information about what they are learning. When generating content, we used web sockets to sequentially generate content for the videos so that users do not have to wait a long time for all the slides to be processed and can start learning right away.
When creating the video, we used `JavaScript’s` built-in API called `Speech Synthesis` to read out loud the content. We displayed the text by parsing and manipulating the strings so that it would fit nicely in the video frame. We also added video footage to be played in the background to keep users engaged and entertained. We tinted the videos to keep users intrigued while listening to the content. This ultimately leads to an easy and fun way to help students retain information and learn more about educational content.
For each video, we made it possible for users to chat to learn more about the content in case they have further questions and can clarify if they don’t understand the content well. This is also done using `Cohere's` API to gain relevant context and up to date info from Google Search
## 🏔️ Challenges we ran into
One of the biggest issues we encountered was the inconsistency of the `cochat` endpoint in returning similar outputs. Initially, we prompted the LLM to parse out key ideas from the PowerPoints and return them as an array. However, the LLM sometimes struggled with matching quotations or consistently returning an array-formatted output. When we switched our models to use `Cohere’s` `command-nightly`, we noticed faster and better results. However, another issue we noticed is that if we overload a prompt, the LLM will have further issues following the strict return formatting, despite clear prompting.
Another significant issue was that parsing through our PowerPoints could take quite some time because our PowerPoints were too large. We managed to fix this by splicing the PowerPoints into sections, making it bite-sized for the model to quickly parse and generate content. However, this is a bottleneck at the moment because we can’t generate content as quickly as platforms like TikTok or YouTube, where it’s just a pre-made video. In the future, we plan to add a feature where users must watch at least 5 seconds so that we can keep users focused instead of being entertained by the scroll effect.
We spent a lot of time trying to create an efficient backend system that utilized both a RESTful API and Fastapi's Websocket to handle generating video content from the slides dynamically instead of waiting for the processing of all Powerpoints, as they would take up to a minute per Cohere call.
Regarding git commits, we accidentally overwrote some code because we miscommunicated on our git pushes. So, we will be sure to communicate when we are pushing and pulling, and of course, regularly pull from the main branch.
## ⭐ Accomplishments that we're proud of
We centered the divs on our first try 😎
We successfully used `Cohere’s` RAG model, which was much easier than we expected. We thought we would need a vector database and langchain, but instead, it was just some really simple, easy calls to the API to help us parse and generate our backend.
We are also really proud of our video feature. It’s really cool to see how we were able to replicate the smooth scrolling effect and text overlay, which is completely done in our frontend in React. Our short-video displayer looks as great as YouTube, TikTok, and Instagram!
## 🧠 What we learned
We gained a wealth of knowledge about RAG from the workshops at Deltahacks, facilitated by Bell ai, and from the Cohere API demo with Raymond. We discovered how straightforward it was to use RAG with Cohere’s API. RAG is an impressive technology that not only provides up-to-date information but also offers relevant internal data that we can easily access for our everyday LLMs.
## 🔮 What's next for coTA
One feature we’re excited to add is quizzes to ensure that users are actively engaged. Quizzes would serve as a tool to reinforce the learning experience for users.
We’re also looking forward to optimizing our system by reusing a vectorized document instead of having to refeed the API. This could save a significant amount of time and resources, and potentially speed up content generation. One approach we’re considering is exploring Langchain to see if they offer any support for this, as they do have conversational support! We’re eager to delve into this outside the scope of this hackathon and learn more about the incredible technologies that Cohere can provide.
In terms of background videos, we’re planning to expand beyond the pool of videos we currently have. Our existing videos align more with meme trends, but we’re interested in exploring a more professional route where relevant videos could play in the background. This could potentially be achieved with AI video generators, but for now, we can only hope for a near future where easily accessible video AI becomes a reality.
We’re considering implementing a bottleneck scrolling feature so that users will have to watch at least a portion of the video before skipping.
Lastly, we plan to utilize more AI features such as stable defusion or an image library to bring up relevant images for topics. | ## Inspiration
The number of new pharmaceutical drugs approved by the FDA has been declining steadily whilst the cost and timeframe required to deliver new drugs to market have exponentially increased. In response to the increasingly difficult task of discovering new drugs for life-threatening diseases, we propose an online platform—novogen.ai—that allows individuals to query and devise combinations of unique molecules to serve as a basis for generating novel molecules with desired chemical descriptors.
## What it does
Novogen.ai is a web platform that empowers scientists with tools to generate novel compounds with desired chemical descriptors.
## How we built it
With great difficulty. Our team split into our divisions, frontend, backend and A.I and individually built the components, then later worked closely together to join all our relevant components.
## Challenges we ran into
Chronic hallucinations induced by the absence of sleep. Installing our machine learning dependencies on a Google cloud VM (literally spent four hours typing pip install over and over again hoping for different results)! and lastly the challenging task of bringing together our individual components and making them work together.
## Accomplishments that we're proud of
One of our tasks involved developing our own search engine for our platform. We had to come up with creative ways to tackle this problem, and we're proud of the outcome.
## What we learned
We learned a lot working together as a team, much more about installing dependencies on a Google cloud VM and just how tricky it can be to tie an ML algorithm to a front and back end and host it online within 36 hours.
## What's next for novogen.ai
Novogen.ai will focus on refining it's ML and building out the tools of it's platform. | # PotholePal
## Pothole Filling Robot - UofTHacks VI
This repo is meant to enable the Pothole Pal proof of concept (POC) to detect changes in elevation on the road using an ultrasonic sensor thereby detecting potholes. This POC is to demonstrate the ability for a car or autonomous vehicle to drive over a surface and detect potholes in the real world.
Table of Contents
1.Purpose
2.Goals
3.Implementation
4.Future Prospects
**1.Purpose**
By analyzing city data and determining which aspects of city infrastructure could be improved, potholes stood out. Ever since cities started to grow and expand, potholes have plagued everyone that used the roads. In Canada, 15.4% of Quebec roads are very poor according to StatsCan in 2018. In Toronto, 244,425 potholes were filled just in 2018. Damages due to potholes averaged $377 per car per year. There is a problem that can be better addressed. In order to do that, we decided that utilizing Internet of Things (IoT) sensors like the ulstrasound sensor, we can detect potholes using modern cars already mounted with the equipment, or mount the equipment on our own vehicles.
**2.Goals**
The goal of the Pothole Pal is to help detect potholes and immediately notify those in command with the analytics. These analytics can help decision makers allocate funds and resources accordingly in order to quickly respond to infrastructure needs. We want to assist municipalities such as the City of Toronto and the City of Montreal as they both spend millions each year assessing and fixing potholes. The Pothole Pal helps reduce costs by detecting potholes immediately, and informing the city where the pothole is.
**3.Implementation**
We integrated an arduino on a RedBot Inventors Kit car. By attaching an ultrasonic sensor module to the arduino and mounting it to the front of the vehicle, we are able to detect changes in elevation AKA detect potholes. After the detection, the geotag of the pothole and an image of the pothole is sent to a mosquito broker, which then directs the data to an iOS app which a government worker can view. They can then use that information to go and fix the pothole.



**4.Future Prospects**
This system can be further improved on in the future, through a multitude of different methods. This system could be added to mass produced cars that already come equipped with ultrasonic sensors, as well as cameras that can send the data to the cloud for cities to analyze and use. This technology could also be used to not only detect potholes, but continously moniter road conditions and providing cities with analytics to create better solutions for road quality, reduce costs to the city to repair the roads and reduce damages to cars on the road. | partial |
## Inspiration..
This web-app was inspired by our group's interest in internal combustion engines. We are a group of Mechanical Engineering students and in our major course dealing with Thermodynamics, Heat Transfer, and Internal Combustion Engines, it has been difficult for us to visualize the effects of various inputs on an engine's total performance. We were inspired to create an app in MATLAB that would help us solve this problem. MATLAB was chosen as the programming language for this app since MATLAB was a part of our standard curriculum for Mechanical Engineering.
## What it does
The Internal Combustion Engine (ICE) Analyzer calculates mean effective pressures, efficiency, and work produced given compression ratio, bore, stroke, connecting rod length, and displacement volume. A pressure-volume or p-v diagram is also made for the combustion cycle, and each of the four strokes (intake, compression, combustion, exhaust) are outlined in the p-v diagram.
## How we built it
We used MATLAB App Designer to develop our app.
## Challenges we ran into
A challenge we ran into was getting started on how to approach our problem. Before this weekend, we have never heard of MATLAB's App Designer tool. With some familiarity with GUI, we decided that this was the route to take as it allows for a clean and easy to use interface. By watching some videos on YouTube and learning from the Mathworks website, we became familiar with this new tool.
## Accomplishments that we're proud of
We're proud to have completed a project that we hope engineers will find useful. We're also proud to have learned a new tool.
## What we learned
We learned how to use MATLAB's App Designer.
## What's next for Internal Combustion Engine Analyzer
We can add more output parameters and fix up some bugs in our program. We can also make the graph more dynamic. | ## Inspiration
Recognizing the disastrous effects of the auto industry on the environment, our team wanted to find a way to help the average consumer mitigate the effects of automobiles on global climate change. We felt that there was an untapped potential to create a tool that helps people visualize cars' eco-friendliness, and also helps them pick a vehicle that is right for them.
## What it does
CarChart is an eco-focused consumer tool which is designed to allow a consumer to make an informed decision when it comes to purchasing a car. However, this tool is also designed to measure the environmental impact that a consumer would incur as a result of purchasing a vehicle. With this tool, a customer can make an auto purhcase that both works for them, and the environment. This tool allows you to search by any combination of ranges including Year, Price, Seats, Engine Power, CO2 Emissions, Body type of the car, and fuel type of the car. In addition to this, it provides a nice visualization so that the consumer can compare the pros and cons of two different variables on a graph.
## How we built it
We started out by webscraping to gather and sanitize all of the datapoints needed for our visualization. This scraping was done in Python and we stored our data in a Google Cloud-hosted MySQL database. Our web app is built on the Django web framework, with Javascript and P5.js (along with CSS) powering the graphics. The Django site is also hosted in Google Cloud.
## Challenges we ran into
Collectively, the team ran into many problems throughout the weekend. Finding and scraping data proved to be much more difficult than expected since we could not find an appropriate API for our needs, and it took an extremely long time to correctly sanitize and save all of the data in our database, which also led to problems along the way.
Another large issue that we ran into was getting our App Engine to talk with our own database. Unfortunately, since our database requires a white-listed IP, and we were using Google's App Engine (which does not allow static IPs), we spent a lot of time with the Google Cloud engineers debugging our code.
The last challenge that we ran into was getting our front-end to play nicely with our backend code
## Accomplishments that we're proud of
We're proud of the fact that we were able to host a comprehensive database on the Google Cloud platform, in spite of the fact that no one in our group had Google Cloud experience. We are also proud of the fact that we were able to accomplish 90+% the goal we set out to do without the use of any APIs.
## What We learned
Our collaboration on this project necessitated a comprehensive review of git and the shared pain of having to integrate many moving parts into the same project. We learned how to utilize Google's App Engine and utilize Google's MySQL server.
## What's next for CarChart
We would like to expand the front-end to have even more functionality
Some of the features that we would like to include would be:
* Letting users pick lists of cars that they are interested and compare
* Displaying each datapoint with an image of the car
* Adding even more dimensions that the user is allowed to search by
## Check the Project out here!!
<https://pennapps-xx-252216.appspot.com/> | ## Inspiration
A very useful website called when2meet
## What it does
Finds an equally accessible venue for all parties who join the event via share-link
## How we built it
We used Node.js, Google Map APIs and deployed using Google App Engine
## Challenges we ran into
Coming up with a feasible idea for our group members skill sets and time availability
## Accomplishments that we're proud of
Learning what an API is and how to use one, managing a difficult workflow and researching available resources to help us when we were in need
## What we learned
How to use Google App Engine and implement APIs (This was an introductory hackathon for the majority of our team)
## What's next for Whereabouts
Continue to learn about the parts of the product that interested us and further developing the back-end processes | winning |
You can check out our slideshow [here](https://docs.google.com/presentation/d/1tdBm_dqoSoXJAuXFBFdgPqQJ76uBXM1uGz6vjoJeMCc)!
## About
Many people turn to technology, especially dating apps, to find romantic interests in their lives.
One telling sign two people will get along is their interests. However, many people will lie about their hobbies in order to attract someone specific, leading to toxic relationships.
But, no one is lying about their search history!! Youtube is a great way to watch videos about things you love, and similar Youtube watch histories could be the start of a romantic love story 💗
So, we created MatchTube--the ultimate Tinder x Youtube crossover. Find matches based on your Youtube watch history and see your love life finally go somewhere!
## How it works
The frontend was built using React JS, Tailwind CSS, javascript, and some HTML. The backend (built with python, sentence transformers, Youtube API, PropelAuth, and MongoDB Atlas) takes in a Google takeout of a user's Youtube watch and search history. Then this data is parsed, and the sentence transformers transform the data into vectors. MongoDB Atlas stores these vectors and then finds vectors/data that is most is similar to that user -- this is there perfect match! The backend sends this up to the frontend. PropelAuth was also used for login
## Challenges + What We Learned
Throughout the two nights we stayed up battling errors we had, since we were learning a lot of new technologies, overall these challenges were worth it as they helped us learn new technologies.
* Learning how to use the platforms
* We had never used Flask, Hugging Face, PropelAuth, vector databases, or deployed the backend for a server before
Deployment
* CORS Errors
* Lag
* Large size of imports
## MatchTube in the future
* Offer instructions
* Deploy it to a server in a production environment (<https://matchtube.xyz/>)
* Hackathon group formation helper?
* Build out the user database
* Get everyone on Hack Club Slack to use it. (30K+ Teen Coders)
* Add more user profile customizations
* Bios, more contact options, ability to send messages on the website
* Expand to more platforms TikTok, Instagram, etc.
## Tracks + Prizes
This project is for the Entertainment Track. We believe our project represents entertainment because of its use of the Youtube API, a prominent social media platform.
* Best Use of AI: AI is used to transform the user's Youtube data to compare it that of others. AI is vital in our project and integrating it with data is a super cool way to use AI!
* Best Use of Statistics: We use user's Youtube statistical data, like their watch and search history to get the best full picture of their interests. We think this is a super unique way to use user stats!
* Most Creative Hack: Have you ever heard of a mix and mash of Youtube and Tinder? Most likely, you haven't! MatchTube combines two well known sites that you originally think wouldn't work-- leveraging creativity.
* Most Useless Hack: For most people, this wouldn't be a useless hack-- because it's your love life! But for a room full off coders, I don't think an extensive search history of 3 hour coding tutorials will find you your dream person....
* Best Design: Design is key in attracting users! MatchTube uses a familiar color palette to represent romance, while using simple UI to keep the site minimalistic. We also used tailwind CSS to keep the design and code clean.
* Best Use of MongoDB Atlas: MongoDB Atlas was used to store vectors and to compare user's Youtube data-- super important for our project.
* Best Use of PropelAuth: We used PropelAuth for user login, which was vital in making sure people have their own profiles. | ## Inspiration
Nowadays, large corporations are spending more and more money nowadays on digital media advertising, but their data collection tools have not been improving at the same rate. Nike spent over $3.03 billion on advertising alone in 2014, which amounted to approximately $100 per second, yet they only received a marginal increase in profits that year. This is where Scout comes in.
## What it does
Scout uses a webcam to capture facial feature data about the user. It sends this data through a facial recognition engine in Microsoft Azure's Cognitive Services to determine demographics information, such as gender and age. It also captures facial expressions throughout an Internet browsing session, say a video commercial, and applies sentiment analysis machine learning algorithms to instantaneously determine the user's emotional state at any given point during the video. This is also done through Microsoft Azure's Cognitive Services. Content publishers can then aggregate this data and analyze it later to determine which creatives were positive and which creatives generated a negative sentiment.
Scout follows an opt-in philosophy, so users must actively turn on the webcam to be a subject in Scout. We highly encourage content publishers to incentivize users to participate in Scout (something like $100/second) so that both parties can benefit from this platform.
We also take privacy very seriously! That is why photos taken through the webcam by Scout are not persisted anywhere and we do not collect any personal user information.
## How we built it
The platform is built on top of a Flask server hosted on an Ubuntu 16.04 instance in Azure's Virtual Machines service. We use nginx, uWSGI, and supervisord to run and maintain our web application. The front-end is built with Google's Materialize UI and we use Plotly for complex analytics visualization.
The facial recognition and sentiment analysis intelligence modules are from Azure's Cognitive Services suite, and we use Azure's SQL Server to persist aggregated data. We also have an Azure Chatbot Service for data analysts to quickly see insights.
## Challenges we ran into
**CORS CORS CORS!.** Cross-Origin Resource Sharing was a huge pain in the head for us. We divided the project into three main components: the Flask backend, the UI/UX visualization, and the webcam photo collection+analysis. We each developed our modules independently of each other, but when we tried to integrate them together, we ran into a huge number of CORS issues with the REST API endpoints that were on our Flask server. We were able to resolve this with a couple of extra libraries but definitely a challenge figuring out where these errors were coming from.
SSL was another issue we ran into. In 2015, Google released a new WebRTC Policy that prevented webcam's from being accessed on insecure (HTTP) sites in Chrome, with the exception of localhost. This forced us to use OpenSSL to generate self-signed certificates and reconfigure our nginx routes to serve our site over HTTPS. As one can imagine, this caused havoc for our testing suites and our original endpoints. It forced us to resift through most of the code we had already written to accommodate this change in protocol. We don't like implementing HTTPS, and neither does Flask apparently. On top of our code, we had to reconfigure the firewalls on our servers which only added more time wasted in this short hackathon.
## Accomplishments that we're proud of
We were able to multi-process our consumer application to handle the massive amount of data we were sending back to the server (2 photos taken by the webcam each second, each photo is relatively high quality and high memory).
We were also able to get our chat bot to communicate with our REST endpoints on our Flask server, so any metric in our web portal is also accessible in Messenger, Skype, Kik, or whatever messaging platform you prefer. This allows marketing analysts who are frequently on the road to easily review the emotional data on Scout's platform.
## What we learned
When you stack cups, start with a 3x3 base and stack them in inverted directions.
## What's next for Scout
You tell us! Please feel free to contact us with your ideas, questions, comments, and concerns! | # Tender - watch our video!
## Inspiration
Online dating is frustrating. This because 1) dating strangers is overrated — we are looking in the wrong place and 2) current algorithms value quantity over quality. There are no apps that match people within your network. This is where Tender comes in.
## What it does
Find out who your crushes are in a college/network. We believe that your relationships should be intentional and private. Via search, our app allows you to select people in your school and, through a quadratic cost function, express how much you like them. We announce one mutual match per week with an algorithm that values mutually strong liking. We model love instead of gamifying it.
Each user will be given 20 tokens per week, and you can express how intensely you like someone through a quadratic voting algorithm. Watch our video for an explanation.
Additionally, we can invite people to the app by inserting their email address and we will send a private invite link to their .edu emails.
## How we built it
We learned and built the backend with MongoDB with a client interface using React and Redux.
## Challenges we ran into
We are proud to build a functional backend and frontend from the ground up. However, we are having bugs in the API that are preventing the two from connecting. Currently, the user can interact with other users but the email functionality has not been implemented yet.
## Accomplishments that we're proud of
On the first day of the hackathon, we thought of the algorithm for matching two people. It is based on
the minimum standard deviation between two person likings. We spent a significant portion of time to design and refine this centric algorithm.
Additionally, regarding the technical aspects, we learnt a lot about implementing a new database eco-system: MongoDB. We also successfully implemented a React and Redux login system, storing encrypted user information onto our MongoDB database.
## What we learned
We learned about MongoDB, Redux, and also how to quickly transform an idea into something that is usable.
## What's next for Tender
We intend to integrate this with Instagram and existing social networks, such as LinkedIn, Instagram, etc.
Additionally, we think that this would be a great idea for a start-up aiming at university students and beyond! | partial |
## Inspiration
With the debates coming up, we wanted to come up with a way of involving everyone. We all have topics that we want to hear the candidates discuss most of all, and we realised that we could use markov chains to do it!
## What it does
Enter a topic, and watch as we generate a conversation between Hillary Clinton and Donald Trump on the subject.
## How we built it
We use a library of speeches from both candidates and markov chains to generate responses.
## Challenges we ran into
It was important to ensure coherency where possible - that was difficult since politicians are evasive at the best of times!
## Accomplishments that we're proud of
Our wonderful front end, and the unintentional hilarity of the candidates' responses. | ## Inspiration
The idea arose from the current political climate. At a time where there is so much information floating around, and it is hard for people to even define what a fact is, it seemed integral to provide context to users during speeches.
## What it does
The program first translates speech in audio into text. It then analyzes the text for relevant topics for listeners, and cross references that with a database of related facts. In the end, it will, in real time, show viewers/listeners a stream of relevant facts related to what is said in the program.
## How we built it
We built a natural language processing pipeline that begins with a speech to text translation of a YouTube video through Rev APIs. We then utilize custom unsupervised learning networks and a graph search algorithm for NLP inspired by PageRank to parse the context and categories discussed in different portions of a video. These categories are then used to query a variety of different endpoints and APIs, including custom data extraction API's we built with Mathematica's cloud platform, to collect data relevant to the speech's context. This information is processed on a Flask server that serves as a REST API for an Angular frontend. The frontend takes in YouTube URL's and creates custom annotations and generates relevant data to augment the viewing experience of a video.
## Challenges we ran into
None of the team members were very familiar with Mathematica or advanced language processing. Thus, time was spent learning the language and how to accurately parse data, give the huge amount of unfiltered information out there.
## Accomplishments that we're proud of
We are proud that we made a product that can help people become more informed in their everyday life, and hopefully give deeper insight into their opinions. The general NLP pipeline and the technologies we have built can be scaled to work with other data sources, allowing for better and broader annotation of video and audio sources.
## What we learned
We learned from our challenges. We learned how to work around the constraints of a lack of a dataset that we could use for supervised learning and text categorization by developing a nice model for unsupervised text categorization. We also explored Mathematica's cloud frameworks for building custom API's.
## What's next for Nemo
The two big things necessary to expand on Nemo are larger data base references and better determination of topics mentioned and "facts." Ideally this could then be expanded for a person to use on any audio they want context for, whether it be a presentation or a debate or just a conversation. | ## Inspiration
To make an app that will help our company, and other companies, gain productivity and save money.
## What it does
Vertask increases employee productivity, and therefore company productivity, by providing an all-inclusive task and scheduling system with tractable metrics. It allows for managers and employees alike to observe variances in how long they assume a process will take versus how long this process actually takes. These metrics allow for companies to make changes to processes accordingly in order to save time and money, and allows for clarity and the formation of realistic expectations between employees and managers. In addition to it's metrics advantage, Vertask provides an easy-to-use scheduling and planning features that cater to different types of planners and keep employees accountable and organized. It allows for virtual sharing of tasks from management and the touch-of-a-button capability to see what other people are working on and when.
## How we built it
Vertask was built on an iOS platform, as well as prototyped on Adobe XD. The database connected to the iOS app was created using firebase.
## Challenges we ran into
Some challenges that where faced included developing the iOS app and prototyping in Adobe XD in a timely manner, which where both things that no one in our team had ever done. Luckily, we were able to pick these up Adobe XD fairly well! However, the iOS application was not able to be finished within the time limits.
## Accomplishments that we're proud of
We are very proud of learning how to use Adobe XD confidently! We are also very proud that we have made so much headway with this project's design and will soon be able to fully develop and use it internally at our company, Vertex Laboratories! It is exciting that in the near future we will have an viable internal product to use to our advantage and make the company even more productive and collaborative!
## What we learned
We learned to use Adobe XD, and how to connect a database to our iOS app. We also learned a lot about iOS development, and while the app was not able to be totally finished, a lot of learning happened with this experience. We also learned that making an app is a lot of work, from the design to implementation to trouble-shooting, and we look forward to continually making improvements to our platform.
## What's next for Vertask
Vertask will become an internal product at Vertex Laboratories, and after a series of improvements are made it may be sold to other businesses and edited for personal/school use! | partial |
## Intro
Not many people understand Cryptocurrencies - let alone the underlying technology behind most of them, the Blockchain. Using an immersive and friendly UI, we built a easy to understand, realtime visualization of the blockchain in VR space with the Oculus Rift.
## How We Built It
The models in Unreal Engine, and blockchain data interfaced from blockchain.info API. In VR space, blockchain data is downloaded from our backend and updated in realtime.
## Challenges we ran into
Pretty much everything (first time using every single piece of tech during this hackathon). In particular, dealing with the sheer size of the blockchain (~150GB) and being able to update new transactions in realtime were hard, given our limited computing power and storage space.
## What we learned
Turns out learning to use a AAA game engine in 24hours is harder than it looks.
## What's next for Blockchain VR
Integrate machine learning, big data, microtransactions, and release it as an ICO (!!!!!!) | ## Inspiration
Blockchain has a lot of interesting applications for secure payment and a strong impact on how information is shared. After learning about how Uber sells the location data and travel patterns of passengers for a profit, we wanted to allow each rider and driver to have their own privacy and rights. Talking to ChainSafe gave us lots of inspirations and ideas regarding how Ethereum blockchain can be used for this application, and we decided to explore opportunities in the car industry using what's provided by the Aragon Platform and SmartCar API.
## What it does
AirBnB for cars, except the cars can be owned by anyone, including a group of individuals. This application allows the user to rent from a list of vehicles that are registered with SmartCar. Through the use of smart contracts from the Aragon Platform, location data and travel patterns are preserved from third-party access. After selecting a car on the landing page, the user can create a transaction using the Ethereum blockchain. When the transaction goes through, the Car would be unlocked through a request to SmartCar API to unlock the door.
## How we built it
We used two react apps, an app for deploying the blockchain locally, and another app to communicate with the SmartCar API. The Aragon app is built using solidity backend and a react front end, with functionality to process a transaction on click. The SmartCar, on the other hand, includes a local server of endpoints to act as an adapter to the SmartCar API. Which has a centralized authentication service that prevents cross-site scripting and access tokens to be leaked. In addition, we used ethers.js to monitor the transaction at our local address, which then calls the SmartCar methods to physically lock/unlock the car doors.
## Challenges we ran into
This is our first time learning and using blockchain, which provided a lot of technical difficulties. In addition, it was hard to narrow down the scope of our project to something that could be completed within a 36-hour hackathon. There were also a lot of interesting features that we were interested in implementing, but couldn't because of their technical difficulty and complexity. Integrating the two react apps was also difficult as both the Aragon app and the SmartCar app had different configurations and set-up requirements, such as conflicting ports on localhost.
## Accomplishments that we're proud of
Being able to deliver a complete solution with the very restricted duration of the hackathon. We are proud of being able to incorporate a new technology that we had never touched before into technology that we had already known, as result, producing a complete web application.
## What we learned
Lots about blockchain, Ethereum, Aragon, and javascript. We also learned a lot about the different concepts of blockchain and their applications and impact on different industries. In addition, security practices using blockchain and why protecting personal data is extremely important.
## What's next for EtherRide
For the scope of this hackathon, we are not able to implement many complex features.
* Rental duration (automatically lock it after the duration passes with smartCar's location API)
* Penalty system to disincentivize malicious actions by the users
* Splitting the fare if there are multiple users for one car
* A car that is collectively owned by a group of individuals
* Sort the list of cars by the distance to the user
* Rating system
* Scheduling
* Self Driving Car!
* Ownership of one's personal data (same as people not wanting to give data to Facebook)
* Assign permissions to each user to replace the current "events triggering" scheme to improve the security of the system | ## Inspiration
We set out to create a fascinating visual art experience for the user. Our work was inspired by “A Neural Algorithm of Artistic Style” by Gatys, Ecker, and Bethge. We hope the project will inspire the user to seek artwork in real life, but if they are unable, we have created a way for anyone to enrich their life with visual art through virtual reality. We want everyone to be able to experience an EverydaY MasterpiecE
## What it does
The user enters a virtual reality environment where they can switch between original images and a version that has been manipulated. Using the algorithm created by Gatys, Ecker, and Bethge, the user experiences the same image but translated into the style of a famous painting.
## How we built it
We used the algorithm created by Gatys, Ecker, and Bethge which allowed us to transform pictures into different styles of art taken from masterpieces. We then developed a program to display these pictures in a personal experience. Specifically, we captured images using fisheye lenses and filters. We then ran the images through the algorithm to change them into the different art styles. Finally, we created a program to display these images in virtual reality with the Oculus Rift.
## Challenges we ran into
At first, we could not even figure out how to hook up the Oculus Rift to the computer. We also had lots of difficulties adding our images to Unity and switching between them. For the non-photorealistic rendering, we based our method on a recent advancement in the literature of deep neural networks, and there is some demo code online that we used to render our images. However, making all the dependencies including caffe, torch, cutorch, and cudnn function correctly is not a trivial task given the limited amount of time that we had. As deep neural networks require a huge amount of computation, we tried use the Amazon Cloud Computing Service (AWS) to facilitate our computation. We were able to use the CPU to complete our rendering, but we were unable to successfully use the GPU to render at a faster pace.
## Accomplishments that we're proud of
We are proud to be using some of the latest technologies and especially a very recent advancement in non-photorealistic rendering using deep neural networks.
## What we learned
We learned the importance of search engine optimization while creating our webpage.
## What's next for EyMe
We would try to move towards a real time rendering. We could attach a camera to the front of the Oculus Rift so the world would be translated into art in real time. This would require huge improvements to the way the algorithm works and also to the hardware we would use for the rendering. This goal is very lofty, but there is one feasible step that could get us started.. We would try to use GPU computing through AWS instead of CPU, which would make great improvements to our rendering time. Another step would be to automate the entire process. Currently, it is tedious to manually submit each photo for rendering without a queue. By creating a queue and auto-retrieving results, lots of time could be saved.
**Paintings used**
*The Starry Night* by Vincent van Gogh
*Woman with a Hat* by Henri Matisse
*A Wheatfield with Cypresses* by Vincent van Gogh
*Please note:*
As attributed above, the algorithm for the rendering came from “A Neural Algorithm of Artistic Style” by Gatys, Ecker, and Bethge.
We did not write our own code for the non-photorealistic rendering. We used the github project <https://github.com/jcjohnson/neural-style> , which depends on a few key projects: <https://github.com/soumith/cudnn.torch> <https://github.com/szagoruyko/loadcaffe> as well as the following caffe install instruction: <https://github.com/BVLC/caffe/wiki/Install-Caffe-on-EC2-from-scratch-(Ubuntu,-CUDA-7,-cuDNN)> | partial |
## Inspiration
The inspiration for this project came from my passion for decentralized technology.
One particular niche of decentralization
I am particularly fond of is NFT's and how they
can become a great income stream for artists.
With the theme of the hackathon being
exploration and showing a picture of a rocket
ship, it is no surprise that the idea of space
came to mind. Looking into space photography, I
found the [r/astrophotography](https://www.reddit.com/r/astrophotography/)
subreddit that has a community of 2.6 million members.
There, beautiful shots of space can be found,
but they also require expensive equipment and
precise editing. My idea for Astronofty is to
turn these photographs into NFT's for the users
to be able to sell as unique tokens on the
platform while using Estuary as decentralized
storage platform for the photos.
## What It Does
You can mint/create NFT's of your
astrophotography to sell to other users.
## How I Built It
* Frontend: React
* Transaction Pipeline: Solidity/MetaMask
* Photo Storage: Estuary
## Challenges I Ran Into
I wanted to be able to upload as many images as you want to a single NFT so figuring that out logistically, structurally and synchronously in React was a challenge.
## Accomplishments That We're Proud Of
Deploying a fully functional all-in-one NFT marketplace.
## What I Learned
I learned about using Solidity mappings and
structs to store data on the blockchain and all
the frontend/contract integrations needed to
make an NFT marketplace work.
## What's Next for Astronofty
A mechanism to keep track of highly sought after photographers. | ## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used React Native and Smart Contracts along with Celo's SDK to discover BlockChain and the conglomerate use cases associated with these technologies. This includes group insurance, financial literacy, personal investment.
## What it does
Allows users in shared communities to pool their funds and use our platform to easily invest in different stock and companies for which they are passionate about with a decreased/shared risk.
## How we built it
* Smart Contract for the transfer of funds on the blockchain made using Solidity
* A robust backend and authentication system made using node.js, express.js, and MongoDB.
* Elegant front end made with react-native and Celo's SDK.
## Challenges we ran into
Unfamiliar with the tech stack used to create this project and the BlockChain technology.
## What we learned
We learned the many new languages and frameworks used. This includes building cross-platform mobile apps on react-native, the underlying principles of BlockChain technology such as smart contracts, and decentralized apps.
## What's next for *PoolNVest*
Expanding our API to select low-risk stocks and allows the community to vote upon where to invest the funds.
Refine and improve the proof of concept into a marketable MVP and tailor the UI towards the specific use cases as mentioned above. | ## Inspiration
As college students, our lives are often filled with music: from studying at home, partying, to commuting. Music is ubiquitous in our lives. However, we find the current process of listening to music and controlling our digital music player pretty mechanical and boring: it’s either clicking or tapping. We wanted to truly interact with our music. We want to feel our music. During one brainstorming session, a team member jokingly suggested a Minority Report-inspired gesture UI system. With this suggestion, we realized we can use this hackathon as a chance to build a cool interactive, futuristic way to play music.
## What it does
Fedoract allows you to control your music in a fun and interactive way. It wireless streams your hand gestures and allows you to control your Spotify with them. We are using a camera mounted on a fedora to recognize hand gestures, and depending on which gesture, we can control other home applications using the technology of IoT. The camera will be mounted wirelessly on the hat and its video feed will be sent to the main computer to process.
## How we built it
For the wireless fedora part, we are using an ESP32-CAM module to record and transmit the video feed of the hand gesture to a computer. The ESP32-CAM module will be powered by a power supply built by a 9V battery and a 3V3/5V Elegoo Power Supply. The video feed is transmitted through WiFi and is connected to the main computer to be analyzed using tools such as OpenCV. Our software will then calculate the gesture and perform actions on Spotify accordingly.
The software backend is built using the OpenCV and the media pipe library.
The media pipe library includes a hand model that has been pre-trained using a large set of data and it is very accurate. We are using this model to get the positions of different features (or landmarks) of the hand, such as fingertips, the wrist, and the knuckles.
Then we are using this information to determine the hand gesture made by the user. The Spotify front end is controlled and accessed using the Selenium web driver. Depending on the action determined by hand gesture recognition, the program presses the corresponding button.
Note the new window instantiated by the web driver does not have any prior information. Therefore, we need to log in to Spotify through an account at the start of the process. Then we can access the media buttons and other important buttons on the web page.
Backend: we used OpenCV in combination with a never-seen-before motion classification algorithm.
Specifically, we used Python scripts using OpenCV to capture webcam input to get hand recognition to recognize the various landmarks (joints) of the hand. Then, motion classification was done through a non-ML, trigonometric approach. First, a vector of change in X and Y input movement was computed using the first and last stored hand coordinates for some given period after receiving some hand motion input. Using deltaX and delta Y, we were able to compute the angle of the vector on the x-y plane, relative to a reference angle that is obtained using the display's width and height. If the vector is between the positive and negative reference angles, then the motion is classified and interpreted as Play Next Song, and so on for the other actions. See the diagrams below for more details.
## Challenges we ran into
The USB-to-TTL cable we got for the ESP32 CAM was defective, so we were spending way too much time trying to fix and find alternative ways with the parts we have. Worse of all, we were also having trouble powering the ESP32-CAM both when it was connected directly to the computer and when it was running wirelessly using its own power supply. The speaker we bought was too quiet for our purposes, and we did not have the right types of equipment to get our display working in time.
The ESP32 CAM module is very sensitive to power fluctuations in addition to having an extremely complicated code upload process. The community around the device is very small therefore there was often misleading advice. This led to a long debugging process.
The software also had many issues.
First of all, we needed to install MediaPipe on our ARM (M1) Macs to effectively develop using OpenCV but we figured out that it wasn’t supported only after spending some time trying to install it. Eventually, we resorted to the Intel chip version of PyCharm to install MediaPipe, which surprisingly worked, seeing as our chips are not Intel-manufactured. As a result, PyCharm was super slow and this really slowed down the development process.
Also, we had minor IDE issues when importing OpenCV in our scripts, so we hotfixed that by simply creating a new project (shrug).
Another thing was trying to control the keyboard via the OS but it turned out to be difficult for keys other than volume, so we resorted to using Selenium to control the Spotify client.
Additionally, in the hand gesture tracking, the thumbs down gesture was particularly difficult because the machine kept thinking that other fingers were lifted as well. In the hand motion tracking process, the x and y coordinates were inverted, which made the classification algorithm a lot harder to develop.
Then, bridging the video live stream coming from the ES32-CAM to the backend was problematic and we spent around 3 hours trying to find a way to effectively and simply establish a bridge using OpenCV so that we could easily redirect the video live stream to be the SW's input feed. Lastly, we needed to link the multiple functionality scripts together, which wasn’t obvious.
## Accomplishments that we're proud of
One thing the hardware team is really proud of is the perseverance displayed during the debugging of our hardware. Because of faulty connection cords and unstable battery supply, it took us over 14 hours simply just to get the camera to connect wirelessly. Throughout this process, we had to use an almost brute force approach and tried all possible combinations of potential fixes. We are really surprised we have mental toughness.
The motion classification algorithm! It took a while to figure out but was well worth it.
Hand gesture (first working product in the team, team spirit)
This was our first fully working Minimum Viable Product in a hackathon for all of the team members
## What we learned
How does OpenCV work?
We learned extensively how serial connection works. We learned that you can use the media pipe module to perform hand gesture recognition and other image classification using image capture. An important thing to note is the image capture must be in RGB format before being passed into the Mediapipe library. We also learned how to use the image capture with webcams to test in development and how to draw helpful figures on the output image to debug.
## What's next for Festive Fedora
There is a lot of potential for improvements in this project. For example, we can put all the computing through a cloud computing service. Right now, we have the hand gesture recognition calculated locally, and having it online means we will have more computing power, meaning that it will also have the potential to connect to more devices by running more complicated algorithms. Something else we can improve is that we can try to get better hardware such that we will have less delay in the video feed, giving us more accuracy for the gesture detection. | winning |
## Inspiration
Mental health and depression are some of the most pressing concerns today, especially in teenagers. Consider these alarming facts: Every 100 minutes, a teen takes their own life. 20% of all teens experience depression before adulthood. Only 30% of depressed teens are being treated for it. *(Source: Discover Mood & Anxiety)*
Meanwhile, the number of mental health services & organizations has been growing rapidly for the past decade. How can we address that increasing gap between mental health services and getting them to those who actually need it?
Teenagers are expressing themselves more than ever before, with 45% of teens saying that they are online almost constantly. *(Source: Pew Research Center)*
Reddit is one of the most popular outlets for teenage expression today, where over 330 million users share content, comment on discussion forums, and interact with one another. It is a go-to place for many people seeking to find help anonymously. Some popular help-seeking forums include:
* r/depression (700k members)
* r/anxiety (400k members)
* r/mental health (200k members)
* r/suicide watch (250k members)
Reddit is a support community for individuals, both as a first resort and as a last.
There is an opportunity here to drastically improve mental health services engagement by targeting social media platforms like Reddit to identify those we need professional help.
## What it does
Euphoria is an early risk detection tool for mental health organizations that uses ML to analyze the linguistic patterns and sentiments of online content to detect signs of depression or suicidal behaviour. It is a Reddit Bot that acts on behalf of a mental health organization's Reddit account (i.e. Canadian Mental Health Association's Reddit account).
Euphoria screens all new posts on target subreddits (i.e. r/anxiety) that can be pre-set and identifies individuals who may be at-risk from the severe effects of mental health and depression. It then crafts a direct message and automatically sends the at-risk individual with resources via the mental health organization’s Reddit account. If they need someone to talk to, a wellness representative who manages the organization’s Reddit can directly chat with them now live!
We designed a Euphoria web page for users (i.e. Canadian Mental Health Association) as the one go-to control center for the organization’s bot. Upon visiting this web page, users must login with the credentials of their organization before gaining access to all the configurations for their bot. Configuration options include:
* Starting and stopping the bot from screening the latest posts
* Choosing which subreddits for their bot to be active in
* Customize the automated message that is sent to at-risk individuals
## How I built it
We utilized the Reddit API to obtain new posts returned as JSON objects from our desired Subreddit. Furthermore, we created endpoints using the Flask framework so a user could send and receive requests from another server independent from the frontend. We used HTML/CSS/Javascript alongside bootstrap templates to deliver a clean user interface for the user where requests were sent and received using Axios on the frontend.
The backend of the application is engineered with NLP, bot, and the server respectively, as we were intrigued by the endless possibilities offered by AI and MI. We were also surprised to find out how capable Google was of analyzing sentiments in texts, enabling us to aggregate more precise data for the auto-messaging feature. Even though we ran into challenges along the way due to the lack of exposure to cloud technologies, we were able to pick it up quickly and connected it with the bot.
To store the configuration data in the user portal, we decided to use Flask as our server, through which we were able to integrate the frontend with the backend and timely configure the bot to better aid individuals.
Finally, using the Reddit API once again, we can craft an automated direct message to the Reddit users that we believe are at-risk.
## Challenges I ran into
We were able to get individual components working together. Our challenge lied in connecting components together; frontend to backend, routing and navigation, and adding frontend data persistence to the UI. We ran into many obstacles getting the API calls to communicate between the frontend and backend. In particular, working with requesting the frontend user input and giving it to our backend Reddit bot. We discovered new issues we never knew were possible, but ultimately successfully integrated the two. It was also many of our first time working with the google natural language processor and creating a Reddit bot. That knowledge gap was a challenge at first. However, following the documentation we were able to quickly pick these things up and learned many new technologies during this hackathon.
## Accomplishments that I'm proud of
Our team is very proud of our work and hopes that it will be a small step in the right direction to address the gap between mental health organizations and at-risk teens. We hope to reach communities who may not get the support that they need and help to bring more awareness to mental health issues. In terms of skills we’re especially proud of the new technologies that we have been able to learn in such a short amount of time. We were able to create a Reddit bot which gives us base skills we can then use in the future and apply to different platforms such as Discord or Twitter. We tackled the difficult problem of connecting our frontend to our backend and were able to create a streamlined application. We went through many trials and errors, including long debugging sessions, but everything paid off the moment we were able to connect our frontend and backend and see our initial idea come to life.
## What I learned
The team’s growth during this project was phenomenal. In these 24 hours, we were able to create a working Reddit bot, interactive UI control console, and used API calls to connect the backend and frontend. Each team member gained invaluable skills working with the google natural language processor and we were able to see the power that it holds in the future. Our team was especially challenged and learned great lengths about APIs and the integration between backend and frontend. Our JavaScript knowledge was stretched as we learned the best ways of taking user input and connecting it with the python backend.
Additionally, our team discovered new ways to increase the effectiveness of online communication, especially with coding. We found new extensions that allowed us to pair-program together, learning and struggling together and we worked to fulfill our user stories. Overall, this hackathon was a tremendous learning experience for us and we gained numerous new skills to add to our toolkit.
## What's next for Euphoria
Euphoria has just started on its mission to address the gap between mental health organizations and the teens who need them. We’re excited to learn more about natural language processors and the potential they hold in the future. Furthermore, we’re always on the lookout for new ways to connect with the communities around us. Especially in expanding this model to various different social media platforms such as Twitter, Facebook, Instagram, and even Piazza. We hope to reach out to those individuals who may not get enough support and find the best ways to support them. | ## We got inspired by the lack of motivation household participation in local recycling programs. Many households have the ability to participate in curbside recycling and all have the ability to drop off recycling at a local recycling collection center. We thought if we provide a financial incentive or some form of gamification we could encourage users to recycle . We believe the government will assist us in this as in the long run it makes their jobs easier and costs them less money than large scale clean ups.
## What it does
The app takes pictures of garbage. Recognizes objects which are garbage, classifies it and gives users instructions on how to safely dispose or recycle the garbage and gives rewards for participating. The app also gives users the option of uploading to snapchat with captions and filters showing they recycled.
## How we built it
We built the app by using building an app and integrating various pieces together. We used various API's to help the app run smoothly such as Snapchat and Google Vision and camera kit. When we got all the necessary data we wrote the logic to classify this data with Toronto's waste database and pass back instructions to our users
## Challenges we ran into
## Accomplishments that we're proud of
We used google vision Api for the first time and properly identified objects. We also spent a great deal of time on the snap chat api so we were happy we got that to work.
## What we learned
We learned a lot about android studio and how to develop for android devices, we also significantly improved our debugging skills as android sdk came with a lot of problems , We had to refresh our memory of git and use proper version control as all four of us worked on different components and had to stay synced with each other.
## What's next for Enviro-bin
Partner with government for rewards system and have them also respond to pings from our app to pick up major garbage in location. | ## Inspiration
Mental health is a big issue in society, specifically for millennials. It is still a quite stigmatized topic and our goal was to provide an unobtrusive and subtle tool to help improve your mental health
## What it does
Our application is a journal-writing application where the goal is for the user to write how they feel each day in an unstructured way. We've built a model to help predict emotions and changes in behaviour to notice when a user's mental health may be deteriorating.
## How we built it
The front end was built using Angular, and the back end was built using Node.js, Express.js, and a MongoDB database. To predict emotions from text, we built a convolutional neural network in Tensorflow Keras. The model was trained using data obtained by using PRAW API to scrape Reddit. Also, Twitter tweets were obtained from online datasets.
## Challenges we ran into
It was very difficult to obtain data for the machine learning model. Although there are many datasets out there, they could only be obtained for research purposes. So, we had to scrape our own data, resulting in data of a lower quality and quantity. In addition, we tried to train another model using Indico Custom Collections. However, in the python script, we ran into a Internal Server Error. In the end, we used Indico Sentiment analysis instead.
## Accomplishments that we're proud of
We are very proud of the user interface. It looks very clean and will definitely be a major factor in attracting and retaining users.
## What we learned
We learned that obtaining data and processing it for training is an extremely arduous process, with many small tasks along the way that can easily go wrong.
## What's next for A Note A Day
As more users begin to use A Note A Day, we will definitely need to change our database to a relational database. In addition, with more users, we can obtain more relevant data to improve our machine learning model. We
Currently, the application only warns users when their writing shows signs of mental health deterioration. As a next step, the application could automatically text a friend group. With serious symptoms, we could suggest professional services. Furthermore, we could incorporate cognitive behavioral therapy techniques to ask questions in more meaningful, impactful ways.
In addition, we could create a premium version of A Note A Day, allowing users to connect with professional therapists. This will allow therapists to monitor a large group of users by using the model as a guideline, while also providing resources for users to avoid mental health problems at the earliest sign. | partial |
## Inspiration
EV vehicles are environment friendly and yet it does not receive the recognition it deserves. Even today we do not find many users driving electric vehicles and we believe this must change. Our project aims to provide EV users with a travel route showcasing optimal (and functioning) charging stations to enhance the use of Electric Vehicles by resolving a major concern, range anxiety. We also believe that this will inherently promote the usage of electric vehicles amongst other technological advancements in the car industry.
## What it does
The primary aim of our project is to display the **ideal route** to the user for the electric vehicle to take along with the **optimal (and functional) charging stations** using markers based on the source and destination.
## How we built it
Primarily, in the backend, we integrated two APIs. The **first API** call is used to fetch the longitude as well as latitude coordinates of the start and destination addresses while the **second API** was used to locate stations within a **specific radius** along the journey route. This computation required the start and destination addresses leading to the display of the ideal route containing optimal (and functioning) charging points along the way. Along with CSS, the frontend utilizes **Leaflet (SDK/API)** to render the map which not only recommends the ideal route showing the source, destination, and optimal charging stations as markers but also provides a **side panel** displaying route details and turn-by-turn directions.
## Challenges we ran into
* Most of the APIs available to help develop our application were paid
* We found a **scarcity of reliable data sources** for EV charging stations
* It was difficult to understand the documentation for the Maps API
* Java Script
## Accomplishments that we're proud of
* We developed a **fully functioning app in < 24 hours**
* Understood as well as **integrated 3 APIs**
## What we learned
* Team work makes the dream work: we not only played off each others strengths but also individually tried things that are out of our comfort zone
* How Ford works (from the workshop) as well as more about EVs and charging stations
* We learnt about new APIs
* If we have a strong will to learn and develop something new, we can no matter how hard it is; We just have to keep at it
## What's next for ChargeRoute Navigator: Enhancing the EV Journey
* **Profile** | User Account: Display the user's profile picture or account details
* **Accessibility** features (e.g., alternative text)
* **Autocomplete** Suggestions: Provide autocomplete suggestions as users type, utilizing geolocation services for accuracy
* **Details on Clicking the Charging Station (on map)**: Provide additional information about each charging station, such as charging speed, availability, and user ratings
* **Save Routes**: Allow users to save frequently used routes for quick access.
* **Traffic Information (integration with GMaps API)**: Integrate real-time traffic data to optimize routes
* **User feedback** about (charging station recommendations and experience) to improve user experience | ## Inspiration
To do our part to spread awareness and inspire the general public to make adjustments that will improve everyone's air quality. Also wanted to demonstrate that these adjustments are not as challenging and in our simulator, it shows that frequent small top ups go a long way.
## What it does
Our website includes information about EV and a simulation game where you have to drive past EV charging stations for quick top ups otherwise the vehicle will slow down to a crawl. EV stations come up fairly frequent, weather it be a regular wall socket or supercharger station.
## How we built it
Our website was built on repl.it, where one of us was working on a game while the other used html/css to create a website. After a domain was chosen from domain.com, we started to learn how to create a website using HTML. For some parts, code was taken from free html templates and were later manipulated in an HTML editor. Afterwards, google cloud was used to host the website, forcing us to learn how to use servers.
## Challenges we ran into
For starters, almost everything was new for all of us, from learning HTML to learning how to host off of a server. As new coders, we had to spend many hours learning how to code before we do anything. Once that happens we had to spend many hours testing code to see if it produced the wanted result. After all that was over, we had to learn how to use google cloud, our first experience with servers.
## Accomplishments that we're proud of
Actually having a working website, and having the website be hosted.
## What we learned
HTML, CSS, JS, Server hosting.
## What's next for EVolving Tech
We want to add destinations to give our simulation more complexity and context. This will allow the users to navigate between points of interest in their home city to get a feel of how range measures up to level of charge. | We created this app in light of the recent wildfires that have raged across the west coast. As California Natives ourselves, we have witnessed the devastating effects of these fires first-hand. Not only do these wildfires pose a danger to those living around the evacuation area, but even for those residing tens to hundreds of miles away, the after-effects are lingering.
For many with sensitive respiratory systems, the wildfire smoke has created difficulty breathing and dizziness as well. One of the reasons we like technology is its ability to impact our lives in novel and meaningful ways. This is extremely helpful for people highly sensitive to airborne pollutants, such as some of our family members that suffer from asthma, and those who also own pets to find healthy outdoor spaces. Our app greatly simplifies the process of finding a location with healthier air quality amidst the wildfires and ensures that those who need essential exercise are able to do so.
We wanted to develop a web app that could help these who are particularly sensitive to smoke and ash to find a temporary respite from the harmful air quality in their area. With our app air.ly, users can navigate across North America to identify areas where the air quality is substantially better. Each dot color indicates a different air quality level ranging from healthy to hazardous. By clicking on a dot, users will be shown a list of outdoor recreation areas, parks, and landmarks they can visit to take a breather at.
We utilized a few different APIs in order to build our web app. The first step was to implement the Google Maps API using JavaScript. Next, we scraped location and air quality index data for each city within North America. After we were able to source real-time data from the World Air Quality Index API, we used the location information to connect to our Google Maps API implementation. Our code took in longitude and latitude data to place a dot on the location of each city within our map. This dot was color-coded based on its city AQI value.
At the same time, the longitude and latitude data was passed into our Yelp Fusion API implementation to find parks, hiking areas, and outdoor recreation local to the city. We processed the Yelp city and location data using Python and Flask integrations. The city-specific AQI value, as well as our local Yelp recommendations, were coded in HTML and CSS to display an info box upon clicking on a dot to help a user act on the real-time data. As a final touch, we also included a legend that indicated the AQI values with their corresponding dot colors to allow ease with user experience.
We really embraced the hacker resilience mindset to create a user-focused product that values itself on providing safe and healthy exploration during the current wildfire season. Thank you :) | partial |
## Inspiration
InstantGram was born from Wanrong's experience building a consumer product called AI Anywhere. We acquired over 50,000 users without investing in marketing, only through creating social media posts and videos. Although it’s very effective for user acquisition and building customer relationships, we just lacked time and resources to create more content. We interviewed 10+ startup founders and influencers and realized they faced the same issue.
## What it does
InstantGram is an AI agent that creates engaging and non-repetitive social media content for platforms like Twitter, Instagram, and TikTok. It takes input once (information about the social media account) and and generates multiple ready-to-post pieces daily. By utilizing a large language model and incorporating online sources such as social media accounts, news outlets, Medium, and Substack, InstantGram automatically produces trendy content to enhance brand awareness, grow audiences, and drive conversions.
## How we built it
Wanrong developed the logic for the agent, collecting fresh content from multiple sources, conducting research on internet, and creating Instagram posts with captions and multiple slides (text + image). Zubair sourced relevant images for the posts and handled frontend development. Haris designed templates to merge images and text into engaging slides. Ved led the frontend development and auto-posting process using multiple frameworks.
## Challenges we encountered
Initially drawn to a Python frontend framework, we realized it lacked support for desired features. We aimed for automated content posting but discovered that most platforms require a business account to access the auto-posting API. Eventually, we connected our AI agent to a Twitter account.
## Accomplishments we're proud of
Successfully integrating multiple components across various servers and services. Developing a framework that enables automated multi-modal content creation for multiple platforms. And participating in our first hackathon together!
## What we learned
The importance of selecting stable and feature-rich frameworks. Expanding our knowledge of different frameworks and packages. Some team members learned frontend development from scratch.
## What's next for Instant-gram | Social Media Content Generator
Our future plans include adding support for video generation on TikTok and YouTube, conducting more customer interviews to learn about their problems and needs, and acquiring early adopters. | ## Inspiration
Decided to make something easy but fun in a time frame I got to invest
## What it does
It's a simple Computer Vision project using Python OpenCV to doodle on air. It's a fun way to try doodling.
## How we built it
Using Python, numpy, opencv
## What's next for Air Doodle
Improving accuracy and ai recognition with hand gestures | ## Inspiration
Recognizing the disastrous effects of the auto industry on the environment, our team wanted to find a way to help the average consumer mitigate the effects of automobiles on global climate change. We felt that there was an untapped potential to create a tool that helps people visualize cars' eco-friendliness, and also helps them pick a vehicle that is right for them.
## What it does
CarChart is an eco-focused consumer tool which is designed to allow a consumer to make an informed decision when it comes to purchasing a car. However, this tool is also designed to measure the environmental impact that a consumer would incur as a result of purchasing a vehicle. With this tool, a customer can make an auto purhcase that both works for them, and the environment. This tool allows you to search by any combination of ranges including Year, Price, Seats, Engine Power, CO2 Emissions, Body type of the car, and fuel type of the car. In addition to this, it provides a nice visualization so that the consumer can compare the pros and cons of two different variables on a graph.
## How we built it
We started out by webscraping to gather and sanitize all of the datapoints needed for our visualization. This scraping was done in Python and we stored our data in a Google Cloud-hosted MySQL database. Our web app is built on the Django web framework, with Javascript and P5.js (along with CSS) powering the graphics. The Django site is also hosted in Google Cloud.
## Challenges we ran into
Collectively, the team ran into many problems throughout the weekend. Finding and scraping data proved to be much more difficult than expected since we could not find an appropriate API for our needs, and it took an extremely long time to correctly sanitize and save all of the data in our database, which also led to problems along the way.
Another large issue that we ran into was getting our App Engine to talk with our own database. Unfortunately, since our database requires a white-listed IP, and we were using Google's App Engine (which does not allow static IPs), we spent a lot of time with the Google Cloud engineers debugging our code.
The last challenge that we ran into was getting our front-end to play nicely with our backend code
## Accomplishments that we're proud of
We're proud of the fact that we were able to host a comprehensive database on the Google Cloud platform, in spite of the fact that no one in our group had Google Cloud experience. We are also proud of the fact that we were able to accomplish 90+% the goal we set out to do without the use of any APIs.
## What We learned
Our collaboration on this project necessitated a comprehensive review of git and the shared pain of having to integrate many moving parts into the same project. We learned how to utilize Google's App Engine and utilize Google's MySQL server.
## What's next for CarChart
We would like to expand the front-end to have even more functionality
Some of the features that we would like to include would be:
* Letting users pick lists of cars that they are interested and compare
* Displaying each datapoint with an image of the car
* Adding even more dimensions that the user is allowed to search by
## Check the Project out here!!
<https://pennapps-xx-252216.appspot.com/> | losing |
# Privileged
This app was made during nwHacks 2018.
## Proposal
A web application for conducting a ‘privilege walk’. The questions are tailored towards the tech community in North America.
## Social Issue
The Privilege of Not Understanding Privilege.
## Links
The demo app can be found here: [Privileged](http://www.privileged.tech)
* [Devpost](https://devpost.com/software/privileged)
* [Github](https://github.com/FlyteWizard/whatthetech)
---
### Resources
* <https://edge.psu.edu/workshops/mc/power/privilegewalk.shtml>
* <https://hackernoon.com/tech-your-privilege-at-the-door-5d8da0c41c6b>
* <https://www.psychologytoday.com/blog/feeling-our-way/201702/the-privilege-not-understanding-privilege>
### Contributors
* [Amy Hanvoravongchai](https://github.com/amyhanv)
* [Dominique Charlebois](https://github.com/FlyteWizard)
* [Macguire Rintoul](https://github.com/mrintoul)
* [Sophia Chan](https://github.com/schan27) | ## Why we made Time Capsule
Traditional physical photo albums & time capsules are not easily accessible or sharable and are limited in storage capabilities. And while cloud-based photo album services offer remote access, collaborative sharing, and automatic backup, you are not in full control of your photos, there is often a subscription cost, and a risk of deletion.
## What it does
Time\_capsule.tech is a blockchain-based **photo album** that employs smart contracts to function as a **virtual time capsule** for each image. By storing and encrypting your photos on an *Interplanetary File System* (IPFS) 🪐🌌, the risk of data loss is minimised greatly, as well as adding **unparalleled security, permanence, and control of your own memories**.
📷
## How we built it
While similar to Next.js, the front end was built with **Starknet.js**, a frontend library for easy integration with Starknet custom hooks and components. Also, **Cairo** with intermediary **Sierra** was used for the deployment of contracts both locally as well as remotely on IDEs such as Remix. Finally, to ensure that images remained decentralized, we strived to use an **IPFS** system to host our images. And also *a lot* of dedication. 🔥
## Accomplishments that we're proud of
* Setting up a local devnet for deploying contracts
* Understanding the file structure of Starknet.js
* Trying most of the outdated tech for IPFS
## What we learned / Challenges we ran into
We learned about blockchain, specifically smart contracts and their use cases. On a technical level, we learned about Cairo development, standards for ERC20 contracts, and differences in Starknet.js.
On a more practical level, each member brought unique skills and perspectives to the table, fostering a fun and constructive environment. Our collective efforts resulted in an overall successful outcome as well as a positive and enjoyable working experience.
## What's next for Time Capsule
* A more thorough implementation of DevOps tools such as Vercel for branch deployment as well as Github actions for functional testing
* 3-D visualisation of photos with libraries such as three.js or CSS animations
* Incorporate other Ethereum branches onto the network
* Sleep 🛌, gaming 🖥️ 🎮
Overall, it was a great time for all and it was a pleasure attending this year’s event. | ## Inspiration
Minority groups in the US and in the world bear the brunt of so much discrimination, hate, harassment, and unfair treatment. The longstanding issues of racial profiling, as well as the rising Asian resentment that is triggered by the ravaging global pandemic, tell us exactly why these groups need strengthened layers of legal protection. But the lack of provisions is only one part of the problem; the lack of knowledge on the part of these minority groups on the ways they can legally defend themselves is a more pressing concern. Several acts of discrimination happen so blatantly in the day of light, yet the victims are forced to keep it all to themselves due to the financial hassle of consulting a lawyer, or just knowing whether a legal pursuit is practical in their situation. Our team figured that there is an extreme need to create a platform where members of minority groups can explore their rights and the feasible paths of legal action while eliminating concerns that prevent them from doing so. With this product, we hope to empower minorities in their fight against the world's inherent oppressions.
## What it does
Our website acts like a typical search engine, except that it displays results of existing laws and past case precedents depending on the user's search inquiry. These displayed provisions are extracted from the Harvard Case Law Access Project, which was built precisely to fuel the development of legal apps and technologies. The results are also summarized in layman terms so that it is easily understandable for our readers of all backgrounds. Additionally, our website includes an Emergency Call feature, which the users can use in inevitable circumstances that they may require immediate help. This will redirect them to the closest authorities who can attend to their needs.
## How we built it
The interface of our website was designed using Bootstrap, and the data regarding the laws and cases were accessed in the backend using Flask in Python. We used the CaseLaw-API to access our source of provisions to show in the search results. We also used AssemblyAI to operate the audio feature of our search bar, and Twilio to implement our Emergency Call feature.
## Challenges we ran into
HackHarvard coincides with the midterm period of some of our team members, so juggling our academic duties while performing our best in this hackathon was our biggest hurdle. It was difficult to cohesively collaborate as a team since we were in different time zones and had non-overlapping schedules. We faced some issues while integrating the backend.
## Accomplishments that we're proud of
The resulting output is still remarkably complete considering our wavering time commitments, and it is a product that we all could proudly look back to. We are simply enthusiastic at the potential of our product to empower minorities.
## What we learned
Doing our prior research and user studies, we have come to realize where our idea stands in the startup scene of legal AI bots and technologies. It was amazing how technology has grown to automate trivial legal tasks and assist ordinary people in their legal cases. We also learned a lot in the 36 hours of working as a team; given our individual obligations, it is more important to follow a stricter regimen and timeline to ensure steady progress throughout the hackathon.
## What's next for Court Avengers
We hope to expand the scope of our product to include other issues that minority groups face. We also would like to implement these across all the states in the US, since from our understanding some states may have different provisions. We also plan to deploy this product in other translated languages, and hopefully grow its use to other countries and continents. | partial |
## Overview
Shelf turns your home pantry into a "smart" pantry--helping you keep track of food items, warning you of items to buy, and making shopping trips simple.
## Motivation
Home automation provides many avenues for improving people's daily lives by performing many small acts that humans often are not well equipped to handle. However, these improvements necessarily come at a cost; in many cases requiring completely replacing old fixtures with newer — smarter ones. Yet in many cases, a large amount of functionality can be included by retrofitting the old devices while simultaneously integrating with new ones. The goal of **Shelf** was to design a smart pantry system that could improve upon people's own capabilities — such as keeping track of all the food in one's house — while only requiring a slight modification to existing fixtures.
## Design
**Shelf** is designed to be dead simple to use. By affixing a rail to the back of the pantry door, a small device can periodically scan the pantry to determine what food is there, how much remains, and how long until it is likely to spoil. From there it publishes information both on a screen within the pantry, and via a companion app for convenient lookup. Furthermore, all of this should require only slight modification in mounting of these rails.
## Functionality
The primary monitoring device of **Shelf** is the Android Things mounted on the back of the pantry door. After the pantry's doors are opened and closed, this device uses the two servos--one attached to a pulley and one attached to the camera--to move and rotate a camera that takes pictures of the pantry interior and sends them to the server.
Running with Google Cloud Platform, the server processes these images and then runs them through a couple of Google's Vision API annotators to extract product information through logos, labels, and similarity to web entities. Our service then takes these annotations and again processes them to determine what products exist in the pantry and how the pantry has changed since the last scan--returning alerts to the Android Things device if some product is missing.
Finally, the consumer also has access to a mobile React native application that allows he or she to access their "shopping list" or list of items to refill their pantry with at any time.
## Challenges
Initially, we attempted to build the product recognition system from scratch using Google's ML Engine and scraping our own image data. However, running the pipeline of creating the classifier would have taken too long even when we reduced the dataset size and employed transfer learning.
There were also difficulties in using the Android Things dev kits, as the cameras in particular had a tendency to be flaky and unreliable.
## Future
A smart pantry system holds much potential for future development. Some areas in which we would like to further add include better performance in product recognition (with the additional time to train our own specific image classifier), enabling users to order products directly from the pantry device, and more insightful data about the pantry contents. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | ## Inspiration
As sophomores learning to live independently, we often struggle with finding time for buying **groceries**, choosing **recipes**, and **cooking**. Most of the time, we’ve been very confused about what to make with a limited set of ingredients and a limited budget, and so, much of our food ultimately **goes to waste**. As such, we were looking for a way to solve this problem **sustainably**. What if we had a product that limited our need to buy groceries, chose recipes for us, and simply left cooking for us to do? We wanted **GreenBook** to be a way to spend less energy shopping and more of that energy on making good-quality food, enabling consumers to live **healthier** and more **sustainable** lives.
## What it does
GreenBook is both a **physical** and **virtual** platform that seamlessly works together in order to bring about maximum convenience to the user. The use case is as follows:
1. A user comes back from their trip to the grocery store. Before placing items on their respective shelves, they place each item one by one on their GreenBook product sensor.
2. The device, detecting the presence of an item, **scans** that item and **recognizes** what it is. It displays the item on the screen, along with various estimated figures; calories, expiry date (would be manually added), and so on. The user has the option to **alter** any of the data if needed.
3. Later, the user can choose to add more items, manage their kitchen inventory, or find recipes through the screen. The kitchen inventory keeps them **aware** of food items that they are running out of/expiring soon.
4. If the user chooses to find recipes, the screen procures a list of healthy recipes based on the ingredients available in the user’s pantry.
5. The user can pick one of the recipes to read more and get to cooking!
## How we built it
**Hardware** - The product is built from scrap acrylic, extrusion and wood (and a lot of hot glue). We use a Raspberry Pi with a Pi Cam along with an Arduino Uno module with an ultrasonic sensor. The Pi and Cam module are used to detect objects. The Arduino and ultrasonic sensor serve to guide the user to place the product correctly through feedback with a lit LED, and signal to the Pi to take an image.
**Backend Software** - The Pi hosts a `Flask`-based `REST` API server through which local GreenBook clients can request pictures to be taken and identified. This happens through on-board image recognition with `OpenCV`, which identifies the `ArUco` markers on our food items. Given the short duration of the hackathon we decided to use these markers to simplify object detection, but our full vision includes a general food object recognition system. Furthermore, the backend makes requests to image host `Cloudinary`, which gives us a publicly accessible link to the images. To make the `REST` API accessible over a public port, we reverse-proxied our server using `Ngrok`.
**Frontend Software** - The website is developed with `React` and `Tailwind` for the interactive component of our submission. Using our backend API, we are able to dynamically display data from the Pi onto our website. In order to fully develop our idea, we built an extensive mockup in `Figma` that works alongside the website to expand on the potential of our product.
## Challenges we ran into
**Connectivity** - when hardware is involved, a problem always follows it: how do you extract and share its data? While we had shell access to the Pi through Serial `UART`, after a lot of headbanging, we had to ask HackHarvard staff to register our Raspberry Pi onto their network (love you guys). This was needed to install packages, and make the Pi offer a full backend web service. Furthermore, the connectivity issues followed us through having to disable `CORS` so that our front-end and back-end could communicate.
**New Technologies** - a lot of technologies used in this project were completely new to at least some of us. None of us has ever used `Figma` and the majority of our team hasn’t used `React`, nor `JavaScript` for that matter. Yes, we had to Google issues every couple of minutes, but nonetheless it was a huge learning experience.
## Accomplishments that we're proud of
We’re really proud of our **software-hardware integration**. Though at many times arduous to set up, this project would not have been complete without the use of an ultrasonic sensor, arduino, Raspberry Pi, and other hardware used to bring this product to the physical world. These components do a great job of translating (not-so) elegant code to an **elegant interface** ^^
We managed to develop a product that connects **React to Figma**, **Raspberry Pi to Arduino**, and **software to hardware** all at once!
## What we learned
This product pushed us to train ourselves in various new domains: from new frameworks like `React` to unfamiliar grounds such as using `OpenCV` on Pi. We also learned how to use various components, differing in programming and nature, in tandem to build this product (list out all the software used, say they were brought together). Finally, learning to integrate **`Figma` design** with `React` was a challenge, but we were able to come up with an innovative way of presenting an aesthetic UI along with a functional React webpage that sourced data from the Pi.
## What's next for GreenBook
There are so many directions **GreenBook** can expand into! The most obvious improvements we can make are expanding software capabilities. Due to the time limit imposed by the competition, we ended up using **`ArUco` markers** to differentiate between different grocery items. While this portrayed our vision well, it wasn’t very practical, and in the future, it would be great to see an `OpenCV` combined with a **trained model** of grocery items. Additionally, other elements, such as the recipe procure, could be developed along with managing data in our inventory. Most of all, the **hardware** could be reduced to a single microcontroller, and the build quality could be further improved with better-quality components/parts. | partial |
## Aperture
*Share your moments effortlessly*

## Inspiration
Motivated by our personal experiences, we have realized that the current state of the social network applications does not fulfill a particular use case that most of us share: Every time we go on a trip, to a party or to an event with friends or family, we struggle to get ahold of the photos that we took together.
The best solution to this problem has been to create a Google Photos album, after the event/trip has ended, then individually invite everyone to share their photos to it.
Some people, may choose to use Snapchat as an alternative, creating a "group chat" or sharing to the location's "Story", however, this prevents saving photos and gives no control over privacy.
So, we thought to ourselves: No one should be working this hard just to preserve the joyful memories they created with family and friends.
## What it does
**Aperture** is the future of social photo sharing: It takes all the effort away from the experience of sharing moments with friends and family. With location-based events, our advanced algorithm determines when you are near an event that your friends are attending. We then send a notification to your phone inviting you to use the app to share photos with your friends. When you open the notification, you are taken to the event's page where you will find all of the photos that your friends have been taking throughout the event. You can now choose to save the album so that every moment is never lost! You can also tie your app to the event for a certain time, so that every subsequential photo you take until the end of the event is shared with everyone attending! We then proceed to tag the images through machine learning algorithms to let you search your moments by tags.
## How we built it
We used the amazing **Expo** framework, built on top of **React-Native**. Our backend is powered by **Firebase** (for database storage), **Amazon Web Services** (for data storage) and **Google Cloud Services** (for Machine Learning and Computer Vision algorithms). We used **git** and **Github** to manage our development process.
## Challenges we ran into
While two of us have had previous experience with **Expo**, the other two of us did not and none of us have had experience with **Firebase**. Additionally, while our team has experience with **NoSQL** databases, the **Firebase** data structure is much different than **MongoDB**, so it took time to adjust to it. We also had issues with certain modules (like **Google Cloud Vision**) being incompatible with **React Native** due to dependency on core **Node** modules. To get around this, we had to manually write out the **HTTP** requests necessary to be an analog to the functionality of the methods we couldn't use. One of the biggest issues we had, however, was the inability to upload images to **Firebase** storage from **React Native** (which we confirmed through **GitHub** issue trackers). After many attempts at converting local pictures into base64 strings, we setup an **AWS** bucket and uploaded the images there.
## Accomplishments that we're proud of
We're proud of our ability to consume a (probably unhealthily) large volume of caffeine and stay focused and productive. We're also proud of the way we handled the **React Native** module compatibility issues and the workarounds we found for them. We're also happy with how much work we got done in such a short amount of time, especially given the relative lack of experience we had with the major components of our project.
## What we learned
We learned about a great brand of caffeinated chocolate that is very, very effective and keeping you awake. We also learned a lot about **Firebase** and its **Realtime Database** system. Additionally, we got some great experience with **Expo** and **React Native**.
## What's next for Aperture
Silicon Valley. | ## Inspiration'
One of our team members saw two foxes playing outside a small forest. Eager he went closer to record them, but by the time he was there, the foxes were gone. Wishing he could have recorded them or at least gotten a recording from one of the locals, he imagined a digital system in nature. With the help of his team mates, this project grew into a real application and service which could change the landscape of the digital playground.
## What it does
It is a social media and educational application, which it stores the recorded data into a digital geographic tag, which is available for the users of the app to access and playback. Different from other social platforms this application works only if you are at the geographic location where the picture was taken and the footprint was imparted. In the educational part, the application offers overlays of monuments, buildings or historical landscapes, where users could scroll through historical pictures of the exact location they are standing. The images have captions which could be used as instructional and educational and offers the overlay function, for the user to get a realistic experience of the location on a different time.
## How we built it
Lots of hours of no sleep and thousands of git-hubs push and pulls. Seen more red lines this weekend than in years put together. Used API's and tons of trial and errors, experimentation's and absurd humour and jokes to keep us alert.
## Challenges we ran into
The app did not want to behave, the API's would give us false results or like in the case of google vision, which would be inaccurate. Fire-base merging with Android studio would rarely go down without a fight. The pictures we recorded would be horizontal and load horizontal, even if taken in vertical. The GPS location and AR would cause issues with the server, and many more we just don't want to recall...
## Accomplishments that we're proud of
The application is fully functional and has all the basic features we planned it to have since the beginning. We got over a lot of bumps on the road and never gave up. We are proud to see this app demoed at Penn Apps XX.
## What we learned
Fire-base from very little experience, working with GPS services, recording Longitude and Latitude from the pictures we taken to the server, placing digital tags on a spacial digital map, using map box. Working with the painful google vision to analyze our images before being available for service and located on the map.
## What's next for Timelens
Multiple features which we would love to have done at Penn Apps XX but it was unrealistic due to time constraint. New ideas of using the application in wider areas in daily life, not only in education and social networks. Creating an interaction mode between AR and the user to have functionality in augmentation. | ## Inspiration
I wanted a platform that incentivizes going outside and taking photos. This also helps with people who want to build a portfolio in photography
## What it does
Every morning, a random photography prompt will appear on the app/website. The users will be able to then go out and take a photo of said prompt. The photo will be objectively rated upon focus quality, which is basically asking if the subject is in focus, plus if there is any apparent motion blur. The photo will also be rated upon correct exposure (lighting). They will be marked out of 100, using interesting code to determine the scores. We would also like to implement a leaderboard of best photos taken of said subject.
## How we built it
Bunch of python, and little bit of HTML. The future holds react coding to make everything run and look much better.
## Challenges we ran into
everything.
## Accomplishments that we're proud of
Managed to get a decent scoring method for both categories, which had pretty fair outcomes. Also I got to learn a lot about flask.
## What we learned
A lot of fun flask information, and how to connect backend with frontend.
## What's next for PictureDay
Many things mentioned above, such as:
* Leaderboard
* Photo gallery/portfolio
* pretty website
* social aspects such as adding friends. | partial |
## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It was originally built using a web scraper that scraped from LinkedIn which was written in python. The web visualizer was built using javascript and the VisJS library to have a dynamic view and aesthetically pleasing physics. In order to have a clean display, web components were used.
## Challenges we ran into
Gathering and scraping the data was a big obstacle, had to pattern match using LinkedIn's data
## Accomplishments that we're proud of
It works!!!
## What we learned
Learning to use various libraries and how to setup a website
## What's next for Yeevaluation
Finetuning and reimplementing dynamic node graph, history. Revamping project, considering it was only made in 24 hours. | ## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows roommates to quickly schedule and assign chores, as well as provide a messageboard for common things.
## How we built it
Our solution is built on ruby-on-rails, meant to be a quick simple solution.
## Challenges we ran into
The time constraint made it hard to develop all the features we wanted, so we had to reduce scope on many sections and provide a limited feature-set.
## Accomplishments that we're proud of
We thought that we did a great job on the design, delivering a modern and clean look.
## What we learned
Prioritize features beforehand, and stick to features that would be useful to as many people as possible. So, instead of overloading features that may not be that useful, we should focus on delivering the core features and make them as easy as possible.
## What's next for LiveTogether
Finish the features we set out to accomplish, and finish theming the pages that we did not have time to concentrate on. We will be using LiveTogether with our roommates, and are hoping to get some real use out of it! | ## Inspiration
The expense behavior of the user, especially in the age group of 15-29, is towards spending unreasonably amount in unnecessary stuff. So we want them to have a better financial life, and help them understand their expenses better, and guide them towards investing that money into stocks instead.
## What it does
It points out the unnecessary expenses of the user, and suggests what if you invest this in the stocks what amount of income you could gather around in time.
So, basically the app shows you two kinds of investment grounds:
1. what if you invested somewhere around 6 months back then what amount of money you could have earned now.
2. The app also shows what the most favorable companies to invest at the moment based on the Warren Buffet Model.
## How we built it
We basically had a python script that scrapes the web and analyzes the Stock market and suggests the user the most potential companies to invest based on the Warren Buffet model.
## Challenges we ran into
Initially the web scraping was hard, we tried multiple ways and different automation software to get the details, but some how we are not able to incorporate fully. So we had to write the web scrapper code completely by ourselves and set various parameters to short list the companies for the Investment.
## Accomplishments that we're proud of
We are able to come up with an good idea of helping people to have a financially better life.
We have learnt so many things on spot and somehow made them work for satisfactory results. but i think there is many more ways to make this effective.
## What we learned
We learnt firebase, also we learnt how to scrape data from a complex structural sites.
Since, we are just a team of three new members who just formed at the hackathon, we had to learn and co-operate with each other.
## What's next for Revenue Now
We can study our user and his behavior towards spending money, and have customized profiles that suits him and guides him for the best use of financial income and suggests the various saving patterns and investment patterns to make even the user comfortable. | winning |
## Inspiration
In today's always-on world, we are more connected than ever. The internet is an amazing way to connect to those close to us, however it is also used to spread hateful messages to others. Our inspiration was taken from a surprisingly common issue among YouTubers and other people prominent on social media: That negative comments (even from anonymous strangers) hurts more than people realise. There have been cases of YouTubers developing mental illnesses like depression as a result of consistently receiving negative (and hateful) comments on the internet. We decided that this overlooked issue deserved to be brought to attention, and that we could develop a solution not only for these individuals, but the rest of us as well.
## What it does
Blok.it is a Google Chrome extension that analyzes web content for any hateful messages or content and renders it unreadable to the user. Rather than just censoring a particular word or words, the entire phrase or web element is censored. The HTML and CSS formatting remains, so nothing funky happens to the layout and design of the website.
## How we built it
The majority of the app is built in JavaScript and jQuery, with some HTML and CSS for interaction with the user.
## Challenges we ran into
Working with Chrome extensions was something very new to us and we had to learn some new JS in order to tackle this challenge. We also ran into the issue of spending too much time deciding on an idea and how to implement it.
## Accomplishments that we're proud of
Managing to create something after starting and scraping multiple different projects (this was our third or fourth project and we started pretty late)
## What we learned
Learned how to make Chrome Extensions
Improved our JS ability
learned how to work with a new group of people (all of us are first time hackathon-ers and none of us had extensive software experience)
## What's next for Blok.it
Improving the censoring algorithms. Most hateful messages are censored, but some non-hateful messages are being inadvertently marked as hateful and being censored as well. Getting rid of these false positives is first on our list of future goals. | ## Inspiration
As victims, bystanders and perpetrators of cyberbullying, we felt it was necessary to focus our efforts this weekend on combating an issue that impacts 1 in 5 Canadian teens. As technology continues to advance, children are being exposed to vulgarities online at a much younger age than before.
## What it does
**Prof**(ani)**ty** searches through any webpage a child may access, censors black-listed words and replaces them with an appropriate emoji. This easy to install chrome extension is accessible for all institutional settings or even applicable home devices.
## How we built it
We built a Google chrome extension using JavaScript (JQuery), HTML, and CSS. We also used regular expressions to detect and replace profanities on webpages. The UI was developed with Sketch.
## Challenges we ran into
Every member of our team was a first-time hacker, with little web development experience. We learned how to use JavaScript and Sketch on the fly. We’re incredibly grateful for the mentors who supported us and guided us while we developed these new skills (shout out to Kush from Hootsuite)!
## Accomplishments that we're proud of
Learning how to make beautiful webpages.
Parsing specific keywords from HTML elements.
Learning how to use JavaScript, HTML, CSS and Sketch for the first time.
## What we learned
The manifest.json file is not to be messed with.
## What's next for PROFTY
Expand the size of our black-list.
Increase robustness so it parses pop-up messages as well, such as live-stream comments. | ## Inspiration
The inspiration for T-Error came from the common frustration that tech leads and developers face when debugging problems. Errors can occur frequently, but understanding their patterns and seeing what is really holding your team up can be tough. We wanted to create something that captures these errors in real time, visualizes them, and lets you write and seamlessly integrate documentation making it easier for teams to build faster.
## What it does
T-Error is a terminal error-monitoring tool that captures and logs errors as developers run commands. It aggregates error data in real-time from various client terminals and provides a frontend dashboard to visualize error frequencies and insights, as well as adding the option to seamlessly add documentation. A feature we are really excited about is the ability to automatically run the commands in the documentation without needing to leave the terminal.
## How we built it
We built T-Error using:
Custom shell: we implemented a custom shell in c++ to capture stderr and seamlessly interface with our backend.
Backend: Powered by Node.js, the server collects, processes, and stores error data in mongoDB.
Frontend: Developed with React.js, the dashboard visualizes error trends with interactive charts, graphs, and logs, as well as an embedded markdown editor:).
## Challenges we ran into
One of the main challenges was ensuring the terminal wrappers were lightweight and didn’t disrupt normal command execution while effectively capturing errors. We spent hours trying to get bash scripts to do what we wanted, until we gave up and tried implementing a shell which worked much better. Additionally, coming up with the UX for how to best deliver existing documentation was a challenge but after some attempts, we arrived at a solution we were happy with.
## Accomplishments that we're proud of
We’re proud of building a fully functional MVP that successfully captures and visualizes error data in real-time. Our terminal wrappers integrate seamlessly with existing workflows, and the error analysis and automatic documentation execution has the potential to significantly speed up development.
## What we learned
Throughout this project, we learned about the complexities of error logging across multiple environments and how to efficiently process large volumes of real-time data. We also gained experience with the integration of frontend and backend technologies, as well as diving into the lower layers of the tech stack and smoothly chaining everything together.
## What's next for T-Error
Going forward, there are a few features that we want to implement. First is error reproduction - we could potentially gain more context about the error from the file system and previous commands and use that context to help replicate errors automatically. We also wanted to automate the process of solving these errors - as helpful as it is to have engineers write documentation, there is a reason there are gaps. This could be done using an intelligent agent for simple tasks, and more complex systems for others. We also want to be able to accommodate better to teams, allowing them to have groups where internal errors are tracked. | winning |
## Inspiration
We believe current reCAPTCHA v.3 has few problems. First, it is actually hard to prove myself to be not robot. It is because Machine Learning is advancing everyday, and ImageToText's (Computer Vision) accuracy is also skyrocketing. Thus, CAPTCHA question images have to be more difficult and vague. Second, the dataset used for current CAPTCHA is limited. It becomes predictable as it's repeating its questions or images (All of you should have answered "check all the images with traffic lights"). In this regard, several research paper has been published through Black Hat using Machine learning models to break CAPTCHA.
## What it does
Therefore, we decided to build a CAPTCHA system that would generate a totally non-sensical picture, and making humans to select the description for that AI-created photo of something 'weird'. As it will be an image of something that is non-existent in this world, machine learning models like ImageToText will have to idea what the matching prompt would be. However, it will be very clear for human even though the images might not be 100% accurate of the description, it's obvious to tell which prompt the AI try to draw. Also, it will randomly create image from scratch every time, we don't need a database having thousands of photos and prompts. Therefore, we will be able to have non-repeating 'im not a robot' question every single time -> No pattern, or training data for malicious programs.
Very easy and fun 'Im not a robot' challenge.
## How we built it
We used AI-painting model called 'Stable Diffusion', which takes a prompt as an input, and creates an image of the prompt. The key of our CAPTCHA is that the prompt that we feed in to this model is absurd and non-existent in real world. We used NLP APIs provided by Cohere in order to generate this prompts. Firstly, we gathered 4,000 English sentences and clustered them to groups based on the similarity of topics using Cohere's embed model. Then, from each clusters, we extracted on key words and using that keywords generated a full sentence prompt using Cohere's generate model. And with that prompt, we created an image using stable diffusion.
## Challenges we ran into
As stable-diffusion is a heavy computation and for sure needed GPU power, we needed to use a cloud GPU. However, cloud GPU that we used from paperspace had its own firewall, which prevented us to deploy server from the environment that we were running tests.
## Accomplishments that we're proud of
We incorporated several modern machine learning techniques to tackle a real world problem and suggested a possible solution. CAPTCHA is especially a security protocol that basically everyone who uses internet encounters. By making it less-annoying and safer, we think it could have a positive impact in a large scale, and are proud of that.
## What we learned
We learned about usability of Cohere APIs and stable diffusion. Also learned a lot about computer vision and ImageToText model, a possible threat model for all CAPTCHA versions. Additionally, we learned a lot about how to open a server and sending arguments in real-time.
## What's next for IM NOT A ROBOT - CAPTCHA v.4
As not everyone can run stable diffusion on their local computer, we need to create a server, which the server does the calculation and creation for the prompt and image. | ## Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
## What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
## How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions.
After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
## Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
## What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time.
On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
## What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward. | In the public imagination, the year 1956 brings to mind a number of things – foremost the Hungarian Revolution, and its subsequent bloody suppression. Those of a certain vintage would recall the Suez Crisis, or the debut album of Elvis Presley.
But those in the know would associate 1956 with the Dartmouth workshop, often considered the seminal event in artificial intelligence. In the intervening decades the field of AI bore witness to several cycles of hype and bust, as it broadened and matured.
The field is once again in a frenzy, and public perception of AI is divided. Evangelists, believing it a tool of Promethean promise, herald the coming of what they call the AI revolution. Others, wary of the limits of today’s computational powers and the over-promise of previous hypes, warn of a market correction of sorts. Because of its complexity and apparent inaccessibility, the average layperson views it with both awe and suspicion. Still others are unaware of its developments at all.
However, there is one major difference between the present flowering of AI and the previous decades. It is here in our everyday lives, and here to stay. Yet most people are not aware of this.
We aim to make AI more accessible by creating a user-friendly experience that gives easy and fun example use-cases, and provides users with a memento after completion.
We initially started off rather ambitiously, and wanted to create a cinematic experience that would incorporate computer vision, and natural language processing. However, we quickly discovered that this would prove difficult to implement within the 36-hour time limit, especially given that this is the first hackathon that our team members have participated in, and that some of us had limited exposure to the tools and frameworks that we used to deploy our project.
Nevertheless, we are proud of the prototype that we built and we hope to expand upon it after the conclusion of TreeHacks.
We used AWS to host our website and produce our conversational agents, Gradio to host our OpenAI GPT-3 demo, and HTML, CSS, Javascript to build the front-end and back-end of our website. | winning |
# 🎯 The Project Story
### 🔍 **About Vanguard**
In today's fast-paced digital landscape, **cybersecurity** is not just important—it's essential! As threats multiply and evolve, security teams need tools that are **agile**, **compact**, and **powerful**. Enter **Vanguard**, our groundbreaking Raspberry Pi-powered vulnerability scanner and WiFi hacker.
Whether you’re defending **air-gapped networks** or working on **autonomous systems**, Vanguard adapts seamlessly, delivering real-time insights into network vulnerabilities. It's more than a tool; it's a **cybersecurity swiss army knife** for both **blue** and **purple teams**! 🛡️🔐
---
### **Air Gapped Network Deployability (CSE Challenge)**
* Databases
Having a dedicated database of vulnerabilities in the cloud for vulnerability scanning could pose a problem for deployments within air-gapped networks. Luckily, Vanguard can be deployed without the need for an external vulnerability database. A local database is stored on disk and contains precisely the information needed to identify vulnerable services. If necessary, Vanguard can be connected to a station with controlled access and data flow to reach the internet; this station could be used to periodically update Vanguard’s databases.
* Data Flow
Data flow is crucial in an embedded cybersecurity project. The simplest approach would be to send all data to a dedicated cloud server for remote storage and processing. However, Vanguard is designed to operate in air-gapped networks, meaning it must manage its own data flow for processing collected information. Different data sources are scraped by a Prometheus server, which then feeds into a Grafana server. This setup allows data to be organized and visualized, enabling users to be notified if a vulnerable service is detected on their network. Additionally, more modular services can be integrated with Vanguard, and the data flow will be compatible and supported.
* Remote Control
It is important for Vanguard to be able to receive tasks. Our solution provides various methods for controlling Vanguard's operations. Vanguard can be pre-packaged with scripts that run periodically to collect and process data. Similar to the Assemblyline product, Vanguard can use cron jobs to create a sequence of scripts that parse or gather data. If Vanguard goes down, it will reboot and all its services will restart automatically. Services can also be ran as containers. Within an air-gapped network, Vanguard can still be controlled and managed effectively.
* Network Discovery
Vanguard will scan the internal air-gapped network and keep track of active IP addresses. This information is then fed into Grafana, where it serves as a valuable indicator for networks that should have only a limited number of devices online.
---
### **Air Gapped Network Scanning (Example)**
Context: Raspberri Pi is connected to a hotspot network to mimic an air gapped network. Docker containers are run to simulate devices being on the air gapped network. This example will show how Vanguard identifies a vulnerable device on the air gapped network.
* Step 1: Docker Container
A vulnerable docker is running on 10.0.0.9

* Step 2: Automated Scanning on Vanguard picks up new IP
Vanguard will automatically scan our network and store the information if its contains important information.
Here are the cron scripts:

In the /var/log Vanguard Logged a new IP:

Vanguard's port scanner found open ports on our vulnerable device:

* Step 3: Prometheus scrapes results and Grafana displays
IP Activity history show how many time an IP was seen:

Vulnerability logs are displayed on our Grafana dashboard and we can see that our ports were scanned as running a vulnerable serivce. (2 red blocks on the right) (Only Port 21 and 22

* Conclusion
All this data flow was able to detect a new device and vulnerable services without the need of cloud or internet services. Vanguard's automated script's ran and detected the anomaly!
### 💡 **Inspiration**
Our team was fascinated by the idea of blending **IoT** with **cybersecurity** to create something truly **disruptive**. Inspired by the open-source community and projects like dxa4481’s WPA2 handshake crack, we saw an opportunity to build something that could change the way we handle network vulnerabilities.
We didn’t just want a simple network scanner—we wanted **Vanguard** to be **versatile**, **portable**, and **powerful** enough to handle even the most **secure environments**, like air-gapped industrial networks or autonomous vehicles 🚗💻.
---
### 🏆 **Accomplishments**
* **Nmap** automates network scans, finding open ports and vulnerable services 🕵️♂️.
* A **SQLite database** of CVEs cross-references scan results, identifying vulnerabilities in real time 🔓📊.
* **Grafana** dashboards monitor the Raspberry Pi, providing metrics on **CPU usage**, **network traffic**, and much more 📈.
* Wifi Cracking Module captures WPA2 handshakes and cracks them using open-source techniques, automating the process 🔑📶.
* Usage of different services that will run automatically and return data.
And everything comes together seamlessly in the vangaurd dashboard. Additionally, we integrated **Convex** as our backend data store to keep things **fast**, **reliable**, and easy to adapt for air-gapped networks (swap Convex for MongoDB with a breeze 🌬️ we really wanted to do take part in the convex challenge).
---
### 🔧 **Challenges We Faced**
Building **Vanguard** wasn’t without its obstacles. Here's what we had to overcome:
* 💻 **Air-gapped testing**: Ensuring Nmap runs flawlessly without external network access was tricky. We fine-tuned cron jobs to make the scanning smooth and reliable.
* 🚦 **Data efficiency**: Working with a Raspberry Pi means limited resources. Optimizing how we process and store data was key.
* 🛠️ **Seamless WiFi hacking**: Integrating WPA2 half-handshake cracking without impacting Pi performance required some creative problem-solving.
---
### 🏗️ **How We Built It**
* **Hardware**: Raspberry Pi 🥧 with an external WiFi adapter 🔌.
* **Backend**: We used **Convex** for data storage, with the option to switch to **MongoDB** for air-gapped use 🗃️.
* **Scanning & Exploiting**: Nmap runs on a schedule to scan, and CVEs are stored in **SQLite** for mapping vulnerabilities 🔗.
* **Frontend**: Built with **React** and **Next.js 14**, the user interface is sleek and efficient 🎨.
* **Monitoring**: Metrics and performance insights are visualized through **Grafana**, keeping everything transparent and easy to manage 📊.
A big thanks to <https://github.com/dxa4481> for the open source code for WPA2 Handshake PoC's
---
### 🚀 **What’s Next for Vanguard?**
We're just getting started! Here’s what’s in store for Vanguard:
* 🤖 **AI-driven vulnerability prediction**: Imagine knowing where a breach might happen **before** it occurs. We'll use machine learning to predict vulnerabilities based on historical data.
* ⚙️ **Modular add-ons**: Integrate tools like **Metasploit** or **Snort** for more specialized attacks, making Vanguard a **customizable powerhouse**.
* 🧳 **Enhanced portability**: We're optimizing Raspberry Pi hardware to push Vanguard’s limits even further, and exploring even more **compact** versions to make it the ultimate on-the-go tool!
---
Vanguard isn’t just a project; it’s the **future** of portable, proactive **cybersecurity**. 🌐🔐
**Stay secure, stay ahead!** | ## Inspiration'
With the rise of IoT devices and the backbone support of the emerging 5G technology, BVLOS drone flights are becoming more readily available. According to CBInsights, Gartner, IBISworld, this US$3.34B market has the potential for growth and innovation.
## What it does
**Reconnaissance drone software that utilizes custom object recognition and machine learning to track wanted targets.** It performs close to real-time speed with nearly 100% accuracy and allows a single operator to operate many drones at once. Bundled with a light sleek-designed web interface, it is highly inexpensive to maintain and easy to operate.
**There is a Snapdragon Dragonboard that runs physically on the drones capturing real-time data and processing the video feed to identify targets. Identified targets are tagged and sent to an operator that is operating several drones at a time. This information can then be relayed to the appropriate parties.**
## How I built it
There is a Snapdragon Dragonboard that runs physically on the drones capturing real-time data and processing the video feed to identify targets. This runs on a Python script that then sends the information to a backend server built using NodeJS (coincidentally also running on the Dragonboard for the demo) to do processing and to use Microsoft Azure to identify the potential targets. Operators use a frontend to access this information.
## Challenges I ran into
Determining a way to reliably demonstrate this project became a challenge considering the drone is not moving and the GPS is not moving as well during the demonstration. The solution was to feed the program a video feed with simulated moving GPS coordinates so that the system believes it is moving in the air.
The training model also required us to devote multiple engineers to spending most of their time training the model over the hackathon.
## Accomplishments that I'm proud of
The code flow is adaptable to virtually an infinite number of scenarios with virtually **no hardcoding for the demo** except feeding it the video and GPS coordinates rather than the camera feed and actual GPS coordinates
## What I learned
We learned a great amount on computer vision and building/training custom classification models. We used Node.js which is a highly versatile environment and can be configured to relay information very efficiently. Also, we learned a few javascript tricks and some pitfalls to avoid.
## What's next for Recognaissance
Improving the classification model using more expansive datasets. Enhancing the software to be able to distinguish several objects at once allowing for more versatility. | ## 💡 Inspiration
The objective of our application is to devise an effective and efficient written transmission optimization scheme, by converting esoteric text into an exoteric format.
If you read the above sentence more than once and the word ‘huh?’ came to mind, then you got my point. Jargon causes a problem when you are talking to someone who doesn't understand it. Yet, we face obscure, vague texts every day - from ['text speak'](https://www.goodnewsnetwork.org/dad-admits-hilarious-texting-blunder-on-the-moth/) to T&C agreements.
The most notoriously difficult to understand texts are legal documents, such as contracts or deeds. However, making legal language more straightforward would help people understand their rights better, be less susceptible to being punished or not being able to benefit from their entitled rights.
Introducing simpl.ai - A website application that uses NLP and Artificial Intelligence to recognize difficult to understand text and rephrase them with easy-to-understand language!
## 🔍 What it does
simpl.ai intelligently simplifies difficult text for faster comprehension. Users can send a PDF file of the document they are struggling to understand. They can select the exact sentences that are hard to read, and our NLP-model recognizes what elements make it tough. You'll love simpl.ai's clear, straightforward restatements - they change to match the original word or phrase's part of speech/verb tense/form, so they make sense!
## ⚙️ Our Tech Stack
[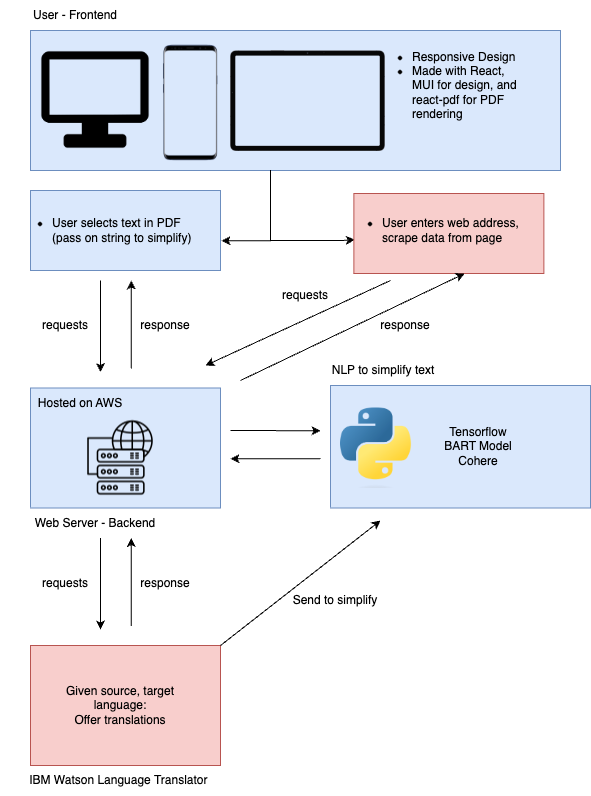](https://postimg.cc/gr2ZqkpW)
**Frontend:** We created the client side of our web app using React.js and JSX based on a high-fidelity prototype we created using Figma. Our components are styled using MaterialUI Library, and Intelllex's react-pdf package for rendering PDF documents within the app.
**Backend:** Python! The magic behind the scenes is powered by a combination of fastAPI, TensorFlow (TF), Torch and Cohere. Although we are newbies to the world of AI (NLP), we used a BART model and TF to create a working model that detects difficult-to-understand text! We used the following [dataset](https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/complex-word-identification-dataset/cwishareddataset.zip) from Stanford University to train our [model](http://nlp.stanford.edu/data/glove.6B.zip)- It's based on several interviews conducted with non-native English speakers, where they were tasked to identify difficult words and simpler synonyms for them. Finally, we used Cohere to rephrase the sentence and ensure it makes sense!
## 🚧 Challenges we ran into
This hackathon was filled with many challenges - but here are some of the most notable ones:
* We purposely choose an AI area where we didn't know too much in (NLP, TensorFlow, CohereAPI), which was a challenging and humbling experience. We faced several compatibility issues with TensorFlow when trying to deploy the server. We decided to go with AWS Platform after a couple of hours of trying to figure out Kubernetes 😅
* Finding a dataset that suited our needs! If there were no time constraints, we would have loved to develop a dataset that is more focused on addressing tacky legal and technical language. Since that was not the case, we made do with a database that enabled us to produce a proof-of-concept.
## ✔️ Accomplishments that we're proud of
* Creating a fully-functioning app with bi-directional communication between the AI server and the client.
* Working with NLP, despite having no prior experience or knowledge. The learning curve was immense!
* Able to come together as a team and move forward, despite all the challenges we faced together!
## 📚 What we learned
We learned so much in terms of the technical areas; using machine learning and having to pivot from one software to the other, state management and PDF rendering in React.
## 🔭 What's next for simpl.ai!
**1. Support Multilingual Documents.** The ability to translate documents and provide a simplified version in their desired language. We would use [IBM Watson's Language Translator API](https://cloud.ibm.com/apidocs/language-translator?code=node)
**2. URL Parameter** Currently, we are able to simplify text from a PDF, but we would like to be able to do the same for websites.
* Simplify legal jargon in T&C agreements to better understand what permissions and rights they are giving an application!
* We hope to extend this service as a Chrome Extension for easier access to the users.
**3. Relevant Datasets** We would like to expand our current model's capabilities to better understand legal jargon, technical documentation etc. by feeding it keywords in these areas. | partial |
## Our Vision
Canada, without a doubt, is one of the greatest countries to live in. Maple Syrup. Hockey. Tim Hortons. Exceptional nice-ness. But perhaps what makes us most Canadian, is our true appreciation of multiculturalism.
Many of us are or have families which have traveled far and wide to be a part of this great country. Lately, this has become even more common, with many refugees choosing the safety of our borders. But as receptive as Canada has been, there still exist difficulties for these individuals, many of whom have little prior exposure to English.
Introducing, bridgED. Fast, practical, and educational translations allow our new friends to understand the environment around them, right from one of the most universally used tools, our phones.
Using IBM’s Watson visual recognition and language translator, we’re able to identify and then translate objects. Utilizing photos not only make it faster than typing, but it allows the identification of items without obvious translations in native tongue. Convenient descriptions and wiki links allow them to then quickly understand the object on a deeper level; making bridgED a speedy learning alternative, especially for those who find it difficult to learn the language on a formal level, like many hard-working workers who lack the time.
But of course, this may still not be a totally practical alternative, given the time spent raising and lowering the phone. That’s why we also have a soon-to-be-integrated feature utilizing AR, to provide near instant translations, optimal for travel. High-importance signs such as “Dead-End”, tourist areas with a high-density of unique cultural goods, or a way to quickly understand the variety of local cuisine; are all things that bridgED can help with.
bridgED was designed with goal to help keep us all together. Because what’s better than enjoying Tim’s, poutine, and hockey? It’s doing it through the collective understanding of a nation united among differences. Eh?
## How we built it
For our project, we utilized the specialized skills of the entire team, and split our work force in two. One would use node JS as the base platform and use react-native to build the core educational functionality of our app, utilizing IBM Watson.
Our other group would make another app through the use of Unity; implementing an AR framework to provide a more immersive, alternative experience, focused on speed and quick practicality.
## Challenges we ran into
We initially ran into some difficulty dividing work evenly, as some of us were much more experienced using certain frameworks than others. While they both provided unique challenges, we ended up sticking through the difficulties and ultimately decided to go with BOTH applications.
Through the use of libraries, integrating our React App directly into our Unity app should be possible, later allowing us to provide a more complete individual package.
## Accomplishments that we're proud of
We ran into a lot of trouble getting started, especially with Unity, as our members experienced with Unity were a rather rusty and had little experience doing initial set up of projects. We ran into a lot of small issues as well with versioning, our android deployments, and the usefulness of our APIs; but ultimately, we believe we over came those challenges and came up with a pretty good product and strong proof of concept.
## What we learned
While learning and trying out new frameworks are great, we were able to get much more done than we probably would have by optimizing our work distribution.
Also, we have a little bit to go still with image recognition, before it can become truly reliable.
## What's next for bridgED?
* Smarter general image interpretation would greatly improve the usefulness. We could attempt to integrate google image searching for more consistent results.
* More features to emphasize and support learning. Can take user voting to determine effectiveness of the algorithm's guesses, improving it for the future.
* Finalizing and streamlining into a single application package
 | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | ## Inspiration
The estimated rate of Autism Spectrum Disorder among 5-17 year olds in Canada is 1 in 66. One challenge individuals on the Autism Spectrum face is difficulty detecting emotions on peoples faces. We wanted to build a learning tool that will aid in mapping faces to emotions, in real-time and leveraging intelligent facial recognition technology.
(<https://autismcanada.org/about-autism/>)
## What it does
The mobile app opens your phone camera and allows you to take a photo. After taking a photo, it redirects you to another page which shows you the most likely emotion it has detected on the face captured, as well as the probability of other emotions. It also uses text-to-speech to read out loud the most likely emotion, so that individuals who are not able to read still can use it.
## How we built it
We used Microsoft's Azure Cognitive Service, specifically, its Face API to detect emotions on images. We used the React Native framework to build our mobile application and tie together the User Interface, camera activity, text-to-speech, and Azure's Face API. We also took accessibility into account by creating large, easily visible buttons and text, and text-to-speech.
## Challenges we ran into
None of our team members had developed a mobile app, so there was a learning curve in getting ramped up with the required software. Updating our operating system and installing Xcode took a lot of time. We also struggled at the beginning connecting the Face API with the app. We were able to overcome this hurdle and learn more through the help of a mentor.
## Accomplishments that we're proud of
We are proud that we completed a functional app and we are able to demo it to people. We are also proud that we were able to bring to fruition our initial vision of creating a accessible learning tool for people on the Autism Spectrum, especially kids.
## What we learned
We learned that you don't need to be an expert in AI or Machine Learning in order to build intelligent applications that use these latest technologies. We also learned how to quickly develop mobile applications in React Native.
## What's next for Emotions Decoded
We will be publishing the application to the App Store, and we want to also release an Android version of the app. We also want to extend the functionality. For instance, using AI or Machine Learning to suggest an appropriate next action after detecting the emotion. | winning |
## The Idea Behind the App
When you're grabbing dinner at a restaurant, how do you choose which meal to order?
Perhaps you look at the price, calorie count, or, if you're trying to be environmentally-conscious, the carbon footprint of your meal.
COyou is an Android app which reveals the carbon footprint of the meals on a restaurant menu, so that you can make the most informed choice about the food you eat.
### Why is this important?
Food production is responsible for a quarter of all greenhouse gas emissions which contribute to global warming. In particular, meat and other animal products are responsible for more than half of food-related greenhouse gas emissions. However, even among fruits and vegetables, the environmental impact of different foods varies considerably. Therefore, being able to determine the carbon footprint of what you eat can make a difference to the planet.
## How COyou Works
Using pandas, we cleaned our [carbon emissions per ingredients data](https://link.springer.com/article/10.1007/s11367-019-01597-8#Sec24) and mapped it by ingredient-emission.
We used Firebase to enable OCR, so that the app recognizes the text of the menu items. Using Google Cloud's Natural Language API, we broke each menu item name down into entities. For example:
```
1. scrambled eggs -> "eggs",
2. yogurt & granola -> "yogurt", "granola"
```
If an entry is found (for simpler menu items such as "apple juice"), the CO2 emission is immediately returned. Otherwise, we make an API call to USDA Food Central's database, which returns a list of ingredients for the menu item. Then, we map the ingredients to its CO2 emissions and sum the individual CO2 emissions of each ingredient in the dish. Finally, we display a list of the ingredients and the total CO2 emissions of each dish.
## The Creation of COyou
We used Android Studio, Google Firebase, Google NLP API, and an enthusiasm for food and restaurants in the creation of COyou.
## Sources and Further Reading
1. [Determining the climate impact of food for use in a climate tax—design of a consistent and transparent model](https://link.springer.com/article/10.1007/s11367-019-01597-8#Sec24)
2. [Carbon Footprint Factsheet](http://css.umich.edu/factsheets/carbon-footprint-factsheet)
3. [Climate change food calculator: What's your diet's carbon footprint?](https://www.bbc.com/news/science-environment-4645971)
4. [USDA Food Data Central API](https://fdc.nal.usda.gov/index.htm) | ## Inspiration
A couple of weeks ago, 3 of us met up at a new Italian restaurant and we started going over the menu. It became very clear to us that there were a lot of options, but also a lot of them didn't match our dietary requirements. And so, we though of Easy Eats, a solution that analyzes the menu for you, to show you what options are available to you without the dissapointment.
## What it does
You first start by signing up to our service through the web app, set your preferences and link your phone number. Then, any time you're out (or even if you're deciding on a place to go) just pull up the Easy Eats contact and send a picture of the menu via text - No internet required!
Easy Eats then does the hard work of going through the menu and comparing the items with your preferences, and highlights options that it thinks you would like, dislike and love!
It then returns the menu to you, and saves you time when deciding your next meal.
Even if you don't have any dietary restricitons, by sharing your preferences Easy Eats will learn what foods you like and suggest better meals and restaurants.
## How we built it
The heart of Easy Eats lies on the Google Cloud Platform (GCP), and the soul is offered by Twilio.
The user interacts with Twilio's APIs by sending and recieving messages, Twilio also initiates some of the API calls that are directed to GCP through Twilio's serverless functions. The user can also interact with Easy Eats through Twilio's chat function or REST APIs that connect to the front end.
In the background, Easy Eats uses Firestore to store user information, and Cloud Storage buckets to store all images+links sent to the platform. From there the images/PDFs are parsed using either the OCR engine or Vision AI API (OCR works better with PDFs whereas Vision AI is more accurate when used on images). Then, the data is passed through the NLP engine (customized for food) to find synonym for popular dietary restrictions (such as Pork byproducts: Salami, Ham, ...).
Finally, App Engine glues everything together by hosting the frontend and the backend on its servers.
## Challenges we ran into
This was the first hackathon for a couple of us, but also the first time for any of us to use Twilio. That proved a little hard to work with as we misunderstood the difference between Twilio Serverless Functions and the Twilio SDK for use on an express server. We ended up getting lost in the wrong documentation, scratching our heads for hours until we were able to fix the API calls.
Further, with so many moving parts a few of the integrations were very difficult to work with, especially when having to re-download + reupload files, taking valuable time from the end user.
## Accomplishments that we're proud of
Overall we built a solid system that connects Twilio, GCP, a back end, Front end and a database and provides a seamless experience. There is no dependency on the user either, they just send a text message from any device and the system does the work.
It's also special to us as we personally found it hard to find good restaurants that match our dietary restrictions, it also made us realize just how many foods have different names that one would normally google.
## What's next for Easy Eats
We plan on continuing development by suggesting local restaurants that are well suited for the end user. This would also allow us to monetize the platform by giving paid-priority to some restaurants.
There's also a lot to be improved in terms of code efficiency (I think we have O(n4) in one of the functions ahah...) to make this a smoother experience.
Easy Eats will change restaurant dining as we know it. Easy Eats will expand its services and continue to make life easier for people, looking to provide local suggestions based on your preference. | ## Inspiration
What's the best way to get over a road block? To create new solutions? To find a bug in one's code?
We believe it's a fresh pair of eyes. However we live in a world where everyone is incredibly busy and getting personalized attention or tutoring is expensive and time-consuming. We built Plato to bridge that gap.
## What it does
Concisely put, Plate is an AI-Based pair-programmer that is powered through your voice. But let's break that down. At a high level, Plato allows users to upload their working repositories/files either to the web or spin up a local command line interface referencing it. It uses these files along with its extensive pre-existing knowledge about major programming languages to offer your instant, personalized, and accurate feedback to rapidly accelerate your development process.
## How we built it
Plato is powered through recent advancements in large language models. First, it builds on the Open AI Whisper model to convert audio to text in real time. It uses a unique embeddings based approach to efficiently and instantly index and package your code. It couples these embeddings with a custom-designed, reverse-engineered Chat-GPT model. Through extensive iteration, we designed accurate and easy to use text to text prompts that allow Plato to parse folder/repository specific content, join it with pre-existing knowledge scraped through millions of text files, and give users a highly immersive coding experience. We package these suite of models with easy-to-use and fast servers that quickly allow a user to upload files or provide paths to where they are stored and spin up a quick, interactive instance that changes how they code for the better.
## Challenges we ran into
Receiving continuous audio data from our users and being expected to output text results with minimal latency took quite a toll on our system. To say the least, the audio files were too large, the embeddings too copious, and the text generation too slow — resulting in massive wait times while a large clunky model spun up and we transmitted large amounts of data. Only after a combination of stream transmission/network programming, embedding caching, and changing audio transcription frequency were we able to enable Plato to run in under a few seconds, with real-time data showing up on the user end as the data is generated. Just as much as maybe a philosopher like Plato may take!
## Accomplishments that we're proud of
The biggest highlights from our project were coming up with a unique embeddings approach that allowed us to parse and store the entire codebases we were working with. Doing so rapidly transformed the scope of our queries and made Plato the best debugging and code-generation assistant to ever exist. Our second massive win was shaving latency and making our models work in a real-time manner. After our optimizations, Plato can now output text to users with 2-3 seconds post an initial initialization of 10s. This made our interface clean and most importantly, a product that serves the user with high throughput.
## What we learned
I think the biggest takeaway for our team was just learning all the infra related work that goes into deploying a machine learning model. Most of our experiences lay in machine learning, so it was quite fascinating to see how much latency and proper infrastructure related challenges can impact a successful product. That said, getting each component working was reassuring and learning to "hack" things together was a fun process. Overall, we're really happy with the final product.
## What's next for Plato
With a robust pipeline of audio to context dependent conversation, Plato has copious applications: Plato's robust code generation, interpretation, and advice capabilities make it perfect for speeding up Software Engineers' productivity. With 29 million Software Engineers worldwide, a projected 22% growth rate of SWEs from 2020 to 2030, and SWEs spending more than 50% of their time looking at a code editor, Plato's AI framework has vast potential to improve the Software Development lifecycle. In addition to expanding Plato to an AI Visual Studio-esque text editing tool, we are thrilled to see how its hints and learning features allow for advances in Education. In a world where even middle school children are learning how to code, its shocking how unaccessible personalized guidance and feedback is on one's code. Simply put, we are determined to fill in this gap. | winning |
## Inspiration
We love music and we wanted to make a fun game about music.
## What it does
When you open up our app, a random word is chosen from a list of not too common and not too uncommon words. You are given 60 seconds to find as many songs as possible which have that random word in it's lyrics. You are given immediate feedback on whether the song has that word in it's lyric or not. Good luck!
## How we built it
We used javascript for the frontend and python for the backend and flask for our web framework.
## Challenges we ran into
It was hard to integrate all of the changes we made and contributions because they often contradicted each other. We solved this through creating multiple branches and going through all the merge conflicts via pull requests.
## Accomplishments that we're proud of
We're proud of challenging ourselves by building something that challenged us to learn a lot. We learned so much and pushed ourselves out of our comfort zone and learned a lot more about frontend.
## What we learned
Before this hackathon, we knew nothing about frontend. Now I can happily say that we learned lots about integrating the frontend and backend and we learned lots about working as a team.
## What's next for Ardae
We are planning to work on multiplayer where we have a 1 versus 1 and people compete to see who has the better knowledge of songs. | ## Inspiration
During the early stages of the hackathon, we were listening to music as a group, and were trying to select some songs. However, we were all in slightly different moods and so were feeling different kinds of music. We realized that our current moods played a significant impact in the kind of music we liked, and from there, we brainstormed ways to deal with this concept/problem.
## What it does
Our project is a web app that allows users to input their mood on a sliding scale, and get a list of 10 curated songs that best match their mood.
## How we built it
We found a database of songs that included a string of the lyrics on Kaggle. We then applied a machine learning model based on the natural language toolkit to the dataset. This formed the trained model
## Challenges we ran into
As we are all beginners with full stack development, we ran into numerous errors while constructing the backend of our webpage. Many of our errors were not descriptive and it was difficult to figure out if the errors were coming from the front end, the backend or the database.
## Accomplishments that we're proud of
We are most proud of getting over the challenges we faced given the strained circumstances of our work. Many of the challenges were entirely new to us and so interpreting, finding and solving these errors was a difficult and stressful process. We are very proud to have a MVP to submit.
## What we learned
Working collaboratively in a high stress environment is something we are not super experienced with and it was an important lesson to learn.
Given our limited full stack experience, we also learned a tremendous amount about the backend web development and using technologies like react.
## What's next for Fortress
There are numerous additions we hope to make to improve the quality and functionalities of our project. Some of these include using tempo and key data to provide a stronger analysis of songs. Getting more songs in our database will help improve the quality of outputs. In addition, it would be helpful for the user to embed snippets of each song so users can listen to a small portion. Finally, it convenient feature would be exporting the song list as a Spotify playlist. | ## Inspiration
The Riff Off idea comes from the movie series Pitch Perfect. Our game works similar to the Riff Off in the movie, except players select the songs from our song bank and play from there to earn points instead of sing.
## What it does
It is a multiplayer mobile application that works on both iOS and Android. It allows players to compete by selecting a song that matches the beat of the previous song and earn score. Players can join the same session by the use of QR codes. Then, the game requires players to constantly change songs that have a similar BPM as the last one being played to earn points. The longer a song stays up, the more points that player earns.
## How we built it
We used ionic with an express + mongo backend hosted on an EC2 instance.
## Challenges we ran into
We ran into way too many challenges. One of the major issues we still have is that android phones are having issues opening up the game page. It worked until the last couple of hours. Also, having multiple devices play the song at the same time was challenging. Also, generating score and syncing it across all players' devices was not easy.
## Accomplishments that we're proud of
* It's pretty
* It doesn't crash like 60% of the time
* As a team of mostly newish hackers we actually finished!!
* Did we mention it's pretty?
## What we learned
For most of our team members it is our first time using ionic. This allowed us to learn many new things like coding in typescript.
## What's next for Beat
Get Android to work seamlessly. There remain some minor styling and integration issues. Also, in our initial planning, points are given for the matching of lyrics on coming in. We did not have enough time to implement that, so our score is currently only generated by time and BPM. The next step would be to include more ways to generate the score to make a more accurate point system. A final detail we can add is that currently the game does not end. We can implement a set amount of time for each game, or allow the players to determine that. | losing |
## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandemic. The respondents also stated that some motivations included a loss of disposable time (due to an increase in workload from online learning), tight spending budgets, and fear of exposure to covid-19.
While developing our product strategy, we realized that a significant pain point in grocery shopping is the process of price-checking between different stores. This process would either require the user to visit each store (in-person and/or online) and check the inventory and manually price check. Consolidated platforms to help with grocery list generation and payment do not exist in the market today - as such, we decided to explore this idea.
**What does G.e.o.r.g.e stand for? : Grocery Examiner Organizer Registrator Generator (for) Everyone**
## What it does
The high-level workflow can be broken down into three major components:
1: Python (flask) and Firebase backend
2: React frontend
3: Stripe API integration
Our backend flask server is responsible for web scraping and generating semantic, usable JSON code for each product item, which is passed through to our React frontend.
Our React frontend acts as the hub for tangible user-product interactions. Users are given the option to search for grocery products, add them to a grocery list, generate the cheapest possible list, compare prices between stores, and make a direct payment for their groceries through the Stripe API.
## How we built it
We started our product development process with brainstorming various topics we would be interested in working on. Once we decided to proceed with our payment service application. We drew up designs as well as prototyped using Figma, then proceeded to implement the front end designs with React. Our backend uses Flask to handle Stripe API requests as well as web scraping. We also used Firebase to handle user authentication and storage of user data.
## Challenges we ran into
Once we had finished coming up with our problem scope, one of the first challenges we ran into was finding a reliable way to obtain grocery store information. There are no readily available APIs to access price data for grocery stores so we decided to do our own web scraping. This lead to complications with slower server response since some grocery stores have dynamically generated websites, causing some query results to be slower than desired. Due to the limited price availability of some grocery stores, we decided to pivot our focus towards e-commerce and online grocery vendors, which would allow us to flesh out our end-to-end workflow.
## Accomplishments that we're proud of
Some of the websites we had to scrape had lots of information to comb through and we are proud of how we could pick up new skills in Beautiful Soup and Selenium to automate that process! We are also proud of completing the ideation process with an application that included even more features than our original designs. Also, we were scrambling at the end to finish integrating the Stripe API, but it feels incredibly rewarding to be able to utilize real money with our app.
## What we learned
We picked up skills such as web scraping to automate the process of parsing through large data sets. Web scraping dynamically generated websites can also lead to slow server response times that are generally undesirable. It also became apparent to us that we should have set up virtual environments for flask applications so that team members do not have to reinstall every dependency. Last but not least, deciding to integrate a new API at 3am will make you want to pull out your hair, but at least we now know that it can be done :’)
## What's next for G.e.o.r.g.e.
Our next steps with G.e.o.r.g.e. would be to improve the overall user experience of the application by standardizing our UI components and UX workflows with Ecommerce industry standards. In the future, our goal is to work directly with more vendors to gain quicker access to price data, as well as creating more seamless payment solutions. | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts and add the items into the database representing your fridge. Using the items you have in your fridge, our app will be able to recommend recipes for dishes for you to make.
## How We Built It
On the back-end, we have a Flask server that receives the image from the front-end through ngrok and then sends the image of the receipt to Google Cloud Vision to get the text extracted. We then post-process the data we receive to filter out any unwanted noise in the data.
On the front-end, our app is built using react-native, using axios to query from the recipe API, and then stores data into Firebase.
## Challenges We Ran Into
Some of the challenges we ran into included deploying our Flask to Google App Engine, and styling in react. We found that it was not possible to write into Google App Engine storage, instead we had to write into Firestore and have that interact with Google App Engine.
On the frontend, we had trouble designing the UI to be responsive across platforms, especially since we were relatively inexperienced with React Native development. We also had trouble finding a recipe API that suited our needs and had sufficient documentation. | winning |
## Inspiration
Back when I was a freshman, I started working at Rangeview, an aerospace manufacturing startup. There I handled operations, which included accounting. I had absolutely no clue how to do taxes or accounting so I decided to hire an accounting firm. But the process was all very confusing to me. They would ask me for financial documents, or ask to do historical bookkeeping for our LLC, but no matter how many people I asked, I never had a solid grasp of what accounting was. So I decided to drop all of my classes and sign up for some accounting ones. A month into those classes, I realized what the accounting firms were doing was easy, and that I shouldn't be paying them so much money to do a task I could easily do myself, so I fired them and took up the task of being rangeviews sole accountant.
Accounting today is broken. Companies with less than 100k in their bank account are expected to pay thousands of dollars a month for an accounting firm, and that’s not to mention the thousands more that they’ll charge you once you register to do your taxes or other special tasks. This is because accounting is a foreign word to most founders. Many of them don’t even know if accounting is legally required, let alone the processes that go behind the scenes of the accounting firm they hired. And thus, accounting firms can get away with low effort and sub-par results. Something has to change.
## What it does
Aipeiron to automates accounting, financial modeling, and compliance with the power of AI. With Aipeiron, any company will be able to get the insights that an accounting firm could provide 100x faster and 50x cheaper just as effectively. And the founder has full control and ownership every step of the way. Doing so is simple: by connecting your bank account, transactions flow automatically from your bank into our finetuned GPT-4 model, which then outputs categorized transactions, exactly what an accountant would do. From that data, you can generate financial models and budgets, or chat with our chatbot trained on the IRS’s instructions to talk about how you would file taxes, because taxes are confusing.
## How we built it
We used NextJS14. The account creation step was done with NextAuth and Google OAuth. The Bank connection and free flow of transactions was done through Plaid. The plaid transactions then flow into our GPT-4 model, and out comes a categorized transaction. We did this through MindsDB. Our database is Postgres, and we used Prisma as an ORM and Supabase to host it on the cloud. Everything from company and user information to the Plaid data, to the classified transactions, have all been stored in Postgres. We wrote our chatbot in Python by generating text embeddings by writing a parser
## Challenges we ran into
One challenge we ran into was using MindsDB and getting it up and running. I had a 50 message long slack thread about this! However, the main challenge was figuring out how to make three people work together. If we all worked on the full stack, the git pushes and pulls would get confusing, and honestly we’d all slow each other down, so we decided to divide up the tasks in a way that everyone was working on something separate, such as the plaid integration for one person, the chatbot for another, and the classifying transactions and storing the data on the cloud and displaying the data to the user for another. Lastly, figuring out how to deploy to Vercel was also a little bit confusing.
## Accomplishments that we're proud of
We built this project literally from scratch from the moment Calhacks started. We’re pretty proud of that, and even though our project is very messy and “hacked” together, we got all the things we wanted to up and running.
## What we learned
We learned about data pipelines such as mindsdb, we learned how to use plaid to pass financial transactions back and forth, we learned about vector embeddings, we learned about creating charts and graphs in React. It was very fun.
## What's next for Aipeiron
We want to keep building this idea, and turn it into an actual company. The code right now works, but lacks refine. We will build the product fully, launch it, test it out with various companies, see if we can raise money, and try to turn it into an actual startup. | ## Inspiration
As students and working professionals, we spend many hours writing essays about our background and qualifications when applying for jobs, accelerators, clubs, and other opportunities. Especially as students at UC Berkeley, we found it is common for students to spend more than 15 hours in a single week simply writing essays about themselves.
## What it does
Through Autofiller AI, you input your resume, LinkedIn, Twitter, and other relevant information you would like to share. Afterward, when you browse an online application form, such as the Founders Inc application, the tool autofills personalized responses to each essay question based on the information you provided earlier, saving you hours of time.
## How we built it
We created an embedding model built on top of the OpenAI API, allowing us to generate text (essay responses) with a large amount of context (information inputted by the user). We used Retool for our frontend dashboard, where users input and update the information that feeds into the model, and Supabase for our database storing embedding vectors for each user. We also developed a browser extension with HTML, CSS, and JavaScript that receives our model's output from a Flask backend and autofills the essay questions on the page.
## Challenges we ran into
Our most significant challenge was managing a web stack with several components. When developing the browser extension, it was initially challenging to autofill content on the page.
## Accomplishments that we're proud of
Our biggest accomplishment is producing an embedding model that outputs personalized essay content that would be acceptable for the vast majority of job, club, and accelerator applications. We are also proud of building a platform that seamlessly integrates multiple APIs and cloud services together.
## What we learned
Our biggest learning was to plan and visualize our tech stack early on, rather than adapting it as the project progresses. This would have saved significant time and confusion during our development process. We also learned how to use multiple new technology tools, including Retool, Supabase, and embedded generative AI models.
## What's next for Autofiller AI
We will conduct user research to validate the utility of this platform and ascertain whom it could benefit the most. After prototyping an MVP, we will launch it to real paying users. In the long-term, we aim to use this concept to launch a venture scalable startup. | ## Inspiration
Badminton boosts your overall health and offers mental health benefits. Doing sports makes you [happier](https://www.webmd.com/fitness-exercise/features/runners-high-is-it-for-real#1) or less stressed.
Badminton is the fastest racket sport.
The greatest speed of sports equipment, which is given acceleration by pushing or hitting a person, is developed by a shuttlecock in badminton
Badminton is the second most popular sport in the world after football
Badminton is an intense sport and one of the three most physically demanding team sports.
For a game in length, a badminton player will "run" up to 10 kilometers, and in height - a kilometer.
Benefits of playing badminton
1. Strengthens heart health.
Badminton is useful in that it increases the level of "good" cholesterol and reduces the level of "bad" cholesterol.
2. Reduces weight.
3. Improves the speed of reaction.
4. Increases muscle endurance and strength.
5. Development of flexibility.
6. Reduces the risk of developing diabetes.
Active people are 30-50% less likely to develop type 2 diabetes, according to a 2005 Swedish study.
7. Strengthens bones.
badminton potentially reduces its subsequent loss and prevents the development of various diseases. In any case, moderate play will help develop joint mobility and strengthen them.

However, the statistics show increased screen time leads to obesity, sleep problems, chronic neck and back problems, depression, anxiety and lower test scores in children.

With Decentralized Storage provider IPFS and blockchain technology, we create a decentralized platform for you to learn about playing Badminton.
We all know that sports are great for your physical health. Badminton also has many psychological benefits.
## What it does
Web Badminton Dapp introduces users to the sport of Badminton as well as contains item store to track and ledger the delivery of badminton equipment.
Each real equipment item is ledgered via a digital one with a smart contract logic system in place to determine the demand and track iteam. When delivery is completed the DApp ERC1155 NFTs should be exchanged for the physical items.
A great win for the producers is to save on costs with improved inventory tracking and demand management.
Web Badminton DApp succeeds where off-chain software ledgering system products fail because they may go out of service, need updates, crash with data losses. Web Badminton DApp is a very low cost business systems management product/tool.
While competing software based ledgering products carry monthly and or annual base fees, the only new costs accrued by the business utilizing the DApp are among new contract deployments. A new contract for new batch of items only is needed every few months based on demand and delivery schedule.
In addition, we created Decentralized Newsletter subscription List that we connected to web3.storage.
## How we built it
We built the application using JavaScript, NextJS, React, Tailwind Css and Wagmi library to connect to the metamask wallet. The application is hosted on vercel. The newsletter list data is stored on ipfs with web3.storage.
The contract is built with solidity, hardhat. The polygon blockchain mumbai testnet and lukso l14 host the smart conract.
Meanwhile the Ipfs data is stored using nft.storage. | losing |
## Inspiration
I was hungry af, and there was a cool post online about NFC cards.
## What it does
Each NFC card is mapped to a topping available from Domino's pizza. Scan each topping you want on an NFC sensor attached to a Raspberry Pi to build your own pizza. Then scan the "end" card, and the Raspberry Pi uses Domino's internal API to order a pizza directly.
## How we built it
We attached a Raspberry Pi to a SPI powered RFID/NFC sensor. For each NFC card, we mapped its UID to a topping using Python, and then built a JSON object that could be sent to Domino's API over HTTPS.
## Challenges we ran into
Yeah
## Accomplishments that we're proud of
Learned a lot about the SPI interface.
## What we learned
A lot about the SPI interface.
## What's next for Pizza
Eating it. | Inspiration
The genesis of LeaseEase lies in the escalating housing crisis in Canada, where landlords have increasingly exploited students and other vulnerable groups. Recognizing the urgent need for accessible legal resources, we envisioned LeaseEase as a beacon of support and empowerment. Our goal was to create a tool that simplifies the complexities of tenant rights under the Canadian Residential Tenancy Act, making legal protection accessible to those who need it most.
What It Does
LeaseEase is a groundbreaking application that combines a Large Language Model (LLM) with Retrieval-Augmented Generation (RAG) to interpret and apply the Canadian Residential Tenancy Act. It transforms user queries into actionable advice and automatically generates crucial legal documents, such as T1 and N7 forms. This functionality ensures that underprivileged groups are not only informed but also equipped to assert their rights effectively.
How We Built It
Our journey in building LeaseEase was a blend of innovative technologies and user-centric design. We utilized Streamlit for an intuitive front-end experience, integrating OpenAI and Cohere for the NLP and LLM functionalities. The backbone of our data operations was ChromaDB, a vector database, and we leveraged LangChain to seamlessly connect all these components.
Challenges We Ran Into
Developing LeaseEase was not without its hurdles. Integrating the backend with the frontend to accurately display the agent's thought process and RAG citations was a significant challenge. Additionally, creating the vector database and formatting the Residential Tenancy Act document appropriately required considerable effort and ingenuity.
Accomplishments That We're Proud Of
We take immense pride in LeaseEase's combination of aesthetic design and sophisticated technology. The implementation of the function calling feature and the streaming capability are particular highlights, demonstrating the effective use of RAG and LangChain agents. These features not only enhance the user experience but also validate our technological choices.
What We Learned
This project was a profound learning experience. Beyond mastering technical tools like Streamlit, LangChain, and various aspects of LLM technologies, we gained insights into the social implications of technology. We understood how the inaccessibility of legal resources can disadvantage vulnerable populations, reinforcing our commitment to tech for social good.
What's Next for LeaseEase
Looking forward, we aim to expand the range of forms LeaseEase can produce and enhance the reasoning capabilities of the LLM. We are excited about potential collaborations with government bodies or tribunals, which could include direct submission features for the forms generated. The future of LeaseEase is not just about technological advancement but also about deepening our impact on social justice and community empowerment. | # Overview
Ever wish you didn't have to carry those bulky keys around? Well now you can with the super advanced Shrek Swiping System! Designed to take in an RFID Card and automatically open a door for you, we have added a scary Shrek mechanism to make sure nobody will ever try to enter your home or dorm unauthorized ever again.
## Inspiration
Both of us have been the victims of becoming locked out of our dorm rooms at night after a long study session in one of Berkeley's many libraries - and we wished that we could swipe into our room the same way that we could swipe into the dorm buildings.
## How we built it
We used two Arduino Nano's, an LCD, two RF transceivers, and more wires than Jeff Bezos probably has in money in order to create a circuit that was segmented into two parts: The first circuit would scan the RFID Card and verify that the person was the correct individual signing in. They would send this value to the second circuit, which either rickrolls you if you are the correct individual, or brings out the big scary Shrek™ and scares the individual from every attempting to break in ever again :)
## Challenges we ran into
Like Milk Tea and Boba, learning new things always come with obstacles. One of those obstacles was when we wanted to use multiple SPI modules on a singular bus. Because we were using an Arduino Nano, it made it difficult to fit all the wires and pins together, leading to obstacles with the select system that SPI employs - specifically on how our RFID module seemed to have some kind of override for it. We racked our brains for **hours** trying to figure out a solution - and right after finding one, a catastrophe came our way. Somehow, an ominously open can of Mountain Dew flooded the table, breaking apart the SPI system and almost bricking our entire project. After a while of not being able to get the Arduino working again, we almost decided to head home and get some sleep.
But we decided to give it just one more try. Rewiring the board once again carefully worked - allowing us to stay up and finish our project.
And that is why we have sworn to **never** drink Mountain Dew again in our lives.
## Accomplishments that we're proud of
This was both of our first time's working with RFID, and we are proud of the fact that we learned **a lot** throughout this process working with that and other technologies. Every time we came across an obstacle and found a solution, we felt like we were expanding our knowledge in the amazing world of hardware.
## What we learned
We came into this hackathon knowing two things:
* We wanted to build a hardware project
* We know almost nothing about hardware.
And so when hacking started two days ago, the long and arduous effort began to learn how in the world we were going to build this thing. At times we didn't really know if we would be able to solve an obstacle or worried that we didn't have the prerequisite knowledge to finish this project. But throughout this project, we feel as if we gained a good understanding of the Arduino, RFID technologies, and hardware in general.
## What's next for Shrek Swiping System (SSS)
the Shrek Swiping System (SSS) has a long way ahead of itself. We really want to implement this solution in our own dorms, add a custom 3D print to clean up the setup, add the ability to customize the music for each individual who comes to witness the marvel that is the Shrek Swiping System (SSS)™. | partial |
## Inspiration
Yearly millions of dollars in scholarships and financial aid go unclaimed, because students find it difficult to hear about these opportunities. We wanted to create a product that made hearing about financial aid and other opportunities, such as internships, more accessible. We also wanted to combat the negative mental health effects that come with social media by redefining what social media is. To solve these problems we created a social networking tool that allowed users to learn about opportunities only if they were active and willing to share content that would be useful to at least one other user creating a community of active users that only shared uplifting content.
## What it does
In order to access other users' posts for the next week about opportunities and events you have to make your own post and wait for at least one other user to save it to their own portfolio demonstrating that your post has meaning and is beneficial for other users. Each user will get 5 opportunities in 24 hours to make a post that can have a positive impact for others in order to access all of Güey's content.
## How we built it
We used Swift to create the iOS app and firebase as our database. We also used Canva for our UI designs for each of the screens.
## Challenges we ran into
This was our first time developing an iOS app and working with Swift so there was a learning curve in learning Swift in a short amount of time and utilizing it to bring our vision to life.
## Accomplishments that we're proud of
In a short amount of time we were able to come up with a product that helps eliminate problems that come with social media such as comparisons and the posting of content that doesn't provide impact. We're also proud that despite our learning curves we were able to make a very nice product that's functional to do basic operations like creating a post.
## What we learned
We learned how to create an iOS app in a short amount of time as well as the root causes of the negative effects social media has on mental health. We also learned how to successfully collaborate and create a product from the ground up in a team filled with different skill sets and experiences.
## What's next for Güey
We hope to add more features that allow users to filter how they can see other people's posts such as by how many people saved it, most recently posted, and those who are in the same groups as you. | ## Inspiration
We care about weather and we care about you
## What it does
This is a follower and a reactor to the weather at any moment. Just simply put down the name of a city, you will not only get the basic **weather information** including current temperature, how it feels like, wind speed, humidity, sun rise time and sun set time, but also a collection of **essentials** for this weather. We tell you what to wear, what to bring and what fun activities to do for this season. Guess what's more, we have a **customized music playlist** for you too! Weather For You will play Christmas songs for the snow, summer vibes for the sun, warmer jams for the hot chocolate weather and chilling feels for the rain.
## How we built it
Using the **Weather Network API**, we fetch the data according to the user input. With the data in hand, we played it around with a theory of **sentiment analysis** where we display images and **songs in the mood** according to the current weather. The two important factors we used the most are temperature and precipitation. The result is a fully functional and visually pleasing web application.
## Challenges we ran into
The biggest challenge was the asynchronous behaviours in JavaScript when we made calls using the api. Callback function is the solution we used to this problem.
## Accomplishments that we're proud of
We have an innovative use of the resource provided by Weather Network.
## What we learned
How to make calls with the api and how to deal with asynchronous functions.
## What's next for Weather For You
Since we display clothing images and other items images such us sunglasses and shoes, **sponsorships** by brands are expected. Also we will develop a **mobile app version** for a wider range of users. | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :) | losing |
## Members
Kara Huynh - choerry#0882
Annabel Chao - Avnapurna#0895
Aayush Shrestha - hawtori#0666
Josh Thomas - AbominableCow#0995
## Inspiration
Since *zoom* university started up, many students (especially those in tech) such as ourselves rely on discord to keep in touch with classmates, or show up to events and hackathons.
time has started becoming a blur since the pandemic hit, and inspired by this, we had decided to create a *discord bot* which can help us out with keeping track of our classes and schedules.
Overall we wanted something that can help us with online school in some way.
## What it does
**Remind Bot** can store information, such as zoom links to classes, and dates for tests, assignments and other important events you wish to remember.
using prefix *&*, Remind bot can provide you with zoom links right before class, and ping you about your quiz tomorrow. So once you put in the reminder, you don't have to worry about scrambling for your class or forgetting about that test. *PLUS*, it can help all your other friends and classmates within the same discord server!
## How we built it
This project is entirely built using *Python* and *visual studio code*.
Our discord bot runs using [<https://uptimerobot.com/>]
## Challenges we ran into
Although this isn't the first time our team has worked on a hackathon together, somehow everyone was extremely exhausted throughout the duration of this project, therefore making it difficult to stay productive.
## Accomplishments that we're proud of
**1**, Trying out a new thing yet again, since none of us have built a discord bot before.
**2**, Proud of the fact that we were able to complete this project despite our fatigue
## What we learned
We learned about how to create a discord bot, and start up a server for it to work.
## What's next for Remind bot
If we get any suggestions or recommendations from our peers, we may add new features to our bot. Otherwise, we could also fix up formatting more. | ## Inspiration
We wanted to ease the workload and and increase the organization of students when it comes to scheduling and completing tasks. This way, they have one, organized platform where they can store all of the tasks they need to get done, and they can have fun with it by earning points and purchasing features!
## What it does
The project is a Discord Bot that allows user to input tasks, set the number of hours that they want to engage in the task for, set due dates, and earn virtual rewards to motivate them to complete these tasks. They receive reminders for their tasks at the appropriate time, too!
## How we built it
We built the bot using the Discord developer tools at our disposal combined with Python code, while using SQL to create a database that stores all user task information.
## Challenges we ran into
A large challenge was to relearn the commands, methods, and attributes associated with coding a bot using Python, since it is very different from coding in other areas. We had to relearn basic functions such as printing, user input, and methods to tailor it to the needs of the bot. Another challenge was being able to sync up our Python work with SQL in order to integrate pulling and manipulating information from the database automatically.
## Accomplishments that we're proud of
We're proud of creating a functional prototype linking our code to the Discord application!
## What we learned
We learned more about how to code bots in Discord and coding in Python in general.
## What's next for Discord To-Do List
In the future, we would like to expand our virtual currency and shop to include more items that the user can purchase. | ## **opiCall**
## *the line between O.D. and O.K. is one opiCall away*
---
## What it does
Private AMBER alerts for either 911 or a naloxone carrying network
## How we built it
We used Twilio & Dasha AI to send texts and calls, and Firebase & Swift for the iOS app's database and UI itself.
## Challenges we ran into
We had lots of difficulties finding research on the topic, and conducting our own research due to the taboos and Reddit post removals we faced.
## What's next for opiCall
In depth research on First Nations' and opioids to guide our product further. | losing |
## Inspiration
From news reports on rising domestic medical costs to economic research reports on US healthcare systems, the element of equity in medical costs has been at the forefront of scrutiny and concern amongst government agencies, public health groups, and the general public.
Indeed, the pricing of healthcare services is an enigmatic pipeline that emerges from complex intermediaries and contracts, which in turn medical bills into arcane numbers that are virtually impossible to understand for the recipient. Furthermore, many pricing methodologies are held by medical institutions as [proprietary information](https://www.forbes.com/sites/joshuacohen/2020/12/07/us-healthcare-markets-lack-transparency-stakeholders-want-to-keep-it-that-way/?sh=3c0e1bd062b2).
The combination of legal layers and mechanical convolution renders most brute-force attempts to dissect the components of a medical bill meaningless due to the amount of protection information required.
If we can't decompile medical bills, how do we ensure hospitals aren't price-gouging their customers?
This is where the concept of Aequalis was born. As we further explored the property of immutability and transparency of blockchain networks, we were fascinated by the potential of P2P validation schemes in tracking and monitoring medical invoices.
With this inspiration, we set out to create an open-source platform designed to identify price-gouging and enforce equity in medical costs between medical institutions.
## What it does
Aequalis is an open-source price-referencing platform striving to diminish the unfair pricing of medical services by providing access to a database of medical invoices, the entries of which are two-factor-authenticated via Solana contracts.
**Internal Invoice Filing Platform**
Designed to interact with representatives from medical institutions, the invoice filing platform collects past medical invoices and deploys key information, such as the type of services and amounts charged, onto the Solana blockchain network through a smart contract. Copies of such data are simultaneously uploaded into an open-source Cockroach database. The two information storage can validate each other's completeness and accuracy via unique hashcode authentication.
As the invoice profiles are immutable once uploaded, the platform ensures that medical institutions take the proper responsibility for uploading the correct information - all thanks to the immutable, transparent nature of Solana contracts.
**Public Price Visualizer**
This page is kept readily available to the general public. Upon loading, the user can access the suggested average pricing of a medical service, which is calculated from all relevant medical invoices inputted by medical institutions. More importantly, the user can also examine each medical institution's pricing relative to the average price.
As such, if any service provider is conducting price-gouging or any sort of unreasonable pricing, the public could easily recognize such behaviors and utilize the immutable data provided by Aequalis as concrete evidence for their claim.
## How we built it
Frontend Frameworks: React.js, Formik
Backend Frameworks: Flask, CockroachDB, Solana
**Internal Invoice Filing Platform**
Upon receiving input from the user, the form packages field values and delivers them to the backend Flask API. To minimize runtime delay, payload values are packaged into JSON objects and sent as payloads to both the Solana network and CockroachDB simultaneously. The consistency of data between the two storages is maintained by verifying that each entry maps to exactly one counterpart in the other storage with the same hashcode.
**Public Price Visualizer**
Medical pricing data is first queried from CockroachDB utilizing a GET HTTP request. Subsequently, we parsed through every query that involved the particular service we wanted to search into (default being all entries) and extrapolated the price of each. Then, we took the average price, assessed each entry, and deemed a product was overpriced if it was greater than a particular threshold above the mean.
## Challenges we ran into
We had a few file version-control issues throughout our building process. Some tedious bugs were created due to pulling a teammate's code from our GitHub Repository from one of our machines to another, and there were also times when we would lose our code.
This was also our first time utilizing BlockChain technology, which led to us staying after Solana's workshop for extra help and clarifications.
## Accomplishments that we're proud of
We integrated our first blockchain technology within our application. We are also proud of integrating many of our skills from different technologies into a coherent and well-designed project.
## What we learned
We learned that git push/pull processes should be used frequently to maintain good version control. In addition, members should agree on an overall file structure and maintain good habits of containing their code to avoid unnecessary merge conflicts. We all personally learned the importance of system design and how delegating tasks prompts an efficient work environment.
In addition, we learned a lot about debugging for both frontend and backend features, which are quite different from each other. Learning how to decompose non-obvious errors and gradually narrowing down error zones was a very difficult but very meaningful process.
We also learned the unique challenges of dealing with transparency and had to deliberate how to represent this transparency in an easily accessible and understandable form to the public.
## What's next for Aequalis
The journey of Aequalis does not stop here. Some immediate developmental improvements would be creating a multi-query Form to extrapolate even more precise information and reorganizing medical institutions by criteria such as geographic locations to support further expansion of clients.
We also plan to expand our frontend to be more secure for the internal side since it should only be available to hospitals attempting to document a recent transaction between themselves and a patient.
Finally, since Aeqalis is very scalable due to its dependency on transparency, we can expand other industries, not just those limited to healthcare. Finally, we would also provide a "Review" Section that provides justifications or arguments against or for a particular service. Therefore, if one hospital's service is overly priced for a "just" reason, previous consumers of said service can either confirm or deny the extensive price. Ultimately, we hope that Aequalis will be able to help policymakers and the general public to better uphold price equality and transparency across the healthcare industry and other sections alike. | 🌸 What if patient data could be democratized? Let's restore transparency within bureaucratic medical practices.
## 💡 Inspiration
The fundamental issue with current Electronic Health Records is that they exist in the ownership of completely different practices (ie physicians, specialists, etc...) ~ without universalism, we are left with chronic relativism within medical relations. I was heavily inspired by the idea of universalism, at the discretion of patients.
The vision is simple. Create the future of robust and adaptable informatics for all of healthcare, tackling each point of care. With this, we aim to move away from the status quo from medical software and building communities for distribution and collaborative growth in the medical space.
**The Bloom Network, powered by cryptography and decentralization, enables the use of a universal EHR format, stored on the blockchain.** Encryption methods ensure that only specific individuals with private keys can log in or restore information on-chain.
## 🛠 What it does
Patients can now send data to a decentralized database for specialists to see, or contribute towards studies & other informatics-based projects in exchange for an **equity token: $BLOOM**.
The Bloom Network verifies your identity with a smart contract on the Ethereum Mainnet. Once the server mines data (including timestamps, indexes, identities, EHR formats and quantities of transactions), it gets sent to a custom API that displays JSON data with all the blocks' information. This is displayed on the web app, with individual dynamic routing for each individual block—this consists of EHR parsed data, validity, hashes and transaction information. Any connections with identified data and keywords are put into a matrix API, creating a knowledge graph based on any connections to solidify the universal nature. All information inside the block is generated with Machine Learning, including gene types, summaries and private/public keys.
**Image Recognition**
In order to make this information readable, the EHR is parsed, scanned and transformed into plain text, which is then summarized and published to the API. This makes information better to understand, especially with varying EHR formats. Then, the information is scanned for keywords as pertains to genetics, and outputs their respective frequencies. The genetic information is now identified, with a significantly higher success rate. On the notion of restoration, one can create a stronger understanding across a larger demographic.
Restoration, in its literal sense, can be implemented through cryptography. Information on the blockchain is permanent, which can act as a negative impact towards the system. As a result, the restoration of self-determination with data can use public and private keys to encrypt and decrypt data. The EHR may always exist on the chain, but can only be encrypted and decrypted at the discretion of the public key's owner, which is the patient in our case. In order to restore revoked content, all the patient needs to do is reuse the private key, acting as a single-user passphrase to encrypt and decrypt data.
## 🌸 Restoration
So, this project has to have voided the theme, right? Guess again! The nature of restoration is bringing things back to how they should be. Data should be owned by the people, not be stored in databases across a wide variety of medical practices.
**Restoration is exhibited through three key parts.** Firstly, restoring the democratic nature of data to be owned by the people, rather than a large force. Secondly, restoring the decentralized nature of data, letting it exist everywhere at the discretion of the owner. Finally, restoring the universal nature of data, allowing for an interpretable data format that all can understand.
## 🗺 How it was built
The API was built with JavaScript, using Sha256 for encryption and decryption. The web app was built in NextJS, and deployed serverless to a custom API endpoint with all dynamic information for new blocks. Finally, the text extraction and summarization was built in Python, on a Jupyter Notebook, using libraries such as pandas.
## 🔑 Challenges we ran into
The fundamental challenge was redesigning the projection for the project. While all the technical implementations were met, the vision from parsing to universal EHR took some time, especially at the last minute. Due to unprecedented difficulties, I was unable to use a neural network to parse data through a matrix, which required adaptation and a complete change to the product. View the Machine Learning here: [bloom/ML-Foundation](https://github.com/rajanwastaken/bloom/blob/main/ML-foundation/foundation.ipynb)
Furthermore, this was my first time implementing image to text systems, which challenged my ability as a Python developer. Finally, adding a custom server to an API was a new concept for me, which required a significant amount of research and methodical implementation strategies.
## 🚀 Accomplishments that we're proud of
* implementing a custom API from personalized blockchain that connects to serverless web app
* adding metamask authentication with local storage
* image to text summarizer, with 98% accuracy rate
* encryption with private and public keys natively integrated
## 🔎 What we learned
* learned how to implement knowledge graphs with keyword matrixes & NLP
* solved async metamask crypto logins with individual block local storage
* how to adjust ideas on a large scale without high intensity adjustments
## 🤷♂️ What's next for The Bloom Network
* hosting mining server asynchronously
* adding new blocks manually on the web app
* visualization of restoration for private keys | ## Inspiration
Our team firmly believes that a hackathon is the perfect opportunity to learn technical skills while having fun. Especially because of the hardware focus that MakeUofT provides, we decided to create a game! This electrifying project places two players' minds to the test, working together to solve various puzzles. Taking heavy inspiration from the hit videogame, "Keep Talking and Nobody Explodes", what better way to engage the players than have then defuse a bomb!
## What it does
The MakeUofT 2024 Explosive Game includes 4 modules that must be disarmed, each module is discrete and can be disarmed in any order. The modules the explosive includes are a "cut the wire" game where the wires must be cut in the correct order, a "press the button" module where different actions must be taken depending the given text and LED colour, an 8 by 8 "invisible maze" where players must cooperate in order to navigate to the end, and finally a needy module which requires players to stay vigilant and ensure that the bomb does not leak too much "electronic discharge".
## How we built it
**The Explosive**
The explosive defuser simulation is a modular game crafted using four distinct modules, built using the Qualcomm Arduino Due Kit, LED matrices, Keypads, Mini OLEDs, and various microcontroller components. The structure of the explosive device is assembled using foam board and 3D printed plates.
**The Code**
Our explosive defuser simulation tool is programmed entirely within the Arduino IDE. We utilized the Adafruit BusIO, Adafruit GFX Library, Adafruit SSD1306, Membrane Switch Module, and MAX7219 LED Dot Matrix Module libraries. Built separately, our modules were integrated under a unified framework, showcasing a fun-to-play defusal simulation.
Using the Grove LCD RGB Backlight Library, we programmed the screens for our explosive defuser simulation modules (Capacitor Discharge and the Button). This library was used in addition for startup time measurements, facilitating timing-based events, and communicating with displays and sensors that occurred through the I2C protocol.
The MAT7219 IC is a serial input/output common-cathode display driver that interfaces microprocessors to 64 individual LEDs. Using the MAX7219 LED Dot Matrix Module we were able to optimize our maze module controlling all 64 LEDs individually using only 3 pins. Using the Keypad library and the Membrane Switch Module we used the keypad as a matrix keypad to control the movement of the LEDs on the 8 by 8 matrix. This module further optimizes the maze hardware, minimizing the required wiring, and improves signal communication.
## Challenges we ran into
Participating in the biggest hardware hackathon in Canada, using all the various hardware components provided such as the keypads or OLED displays posed challenged in terms of wiring and compatibility with the parent code. This forced us to adapt to utilize components that better suited our needs as well as being flexible with the hardware provided.
Each of our members designed a module for the puzzle, requiring coordination of the functionalities within the Arduino framework while maintaining modularity and reusability of our code and pins. Therefore optimizing software and hardware was necessary to have an efficient resource usage, a challenge throughout the development process.
Another issue we faced when dealing with a hardware hack was the noise caused by the system, to counteract this we had to come up with unique solutions mentioned below:
## Accomplishments that we're proud of
During the Makeathon we often faced the issue of buttons creating noise, and often times the noise it would create would disrupt the entire system. To counteract this issue we had to discover creative solutions that did not use buttons to get around the noise. For example, instead of using four buttons to determine the movement of the defuser in the maze, our teammate Brian discovered a way to implement the keypad as the movement controller, which both controlled noise in the system and minimized the number of pins we required for the module.
## What we learned
* Familiarity with the functionalities of new Arduino components like the "Micro-OLED Display," "8 by 8 LED matrix," and "Keypad" is gained through the development of individual modules.
* Efficient time management is essential for successfully completing the design. Establishing a precise timeline for the workflow aids in maintaining organization and ensuring successful development.
* Enhancing overall group performance is achieved by assigning individual tasks.
## What's next for Keep Hacking and Nobody Codes
* Ensure the elimination of any unwanted noises in the wiring between the main board and game modules.
* Expand the range of modules by developing additional games such as "Morse-Code Game," "Memory Game," and others to offer more variety for players.
* Release the game to a wider audience, allowing more people to enjoy and play it. | losing |
## Inspiration
On the trip to HackWestern, we were looking for ideas for the hackathon. We were looking for things in life that can be improved and also existing products which are not so convenient to use.
Jim was using Benjamin's phone and got the inspiration to make a dedicated two factor authentication device, since it takes a long time for someone to unlock their phone, go through the long list of applications, find the right app that gives them the two-factor auth code, which they have to type into the login page in a short period of time, as it expires in less than 30 seconds. The initial idea was rather primitive, but it got hugely improved and a lot more detailed than the initial one through the discussion.
## What it does
It is a dedicated device with a touch screen, that provides users with their two-factor authentication keys. It uses RFID to authenticate the user, which is very simple and fast - it takes less than 2 seconds for a user to log in, and can automatically type the authentication code into your computer when you click it.
## How We built it
The system is majorly Raspberry Pi-based. The R-Pi drives a 7 inch touch screen, which acts as the primary interface with the user.
The software for the user interface and generation of authentication keys are written in Java, using the Swing GUI framework. The clients run Linux, which is easy to debug and customize.
Some lower level components such as the RFID reader is handled by an arduino, and the information is passed to the R-Pi through serial communication.
Since we lost our Wifi dongle, we used 2 RF modules to communicate between the R-Pi and the computer. It is not an ideal solution as there could be interference and is not easily expandable.
## Challenges I ran into
We have ran into some huge problems and challenges throughout the development of the project. There are hardware challenges, as well as software ones.
For example, the 7 inch display that we are using does not have an official driver for touch, so we had to go through the data sheets, and write a C program where it gets the location of the touch, and turns that into movement of the mouse pointers.
Another challenge is the development of the user interface. We had to integrate all the components of the product into one single program, including the detection of RFID (especially hard since we had to use JNI for lower level access), the generation of codes, and the communication with other devices.
## Accomplishments that I'm proud of
We are proud of ourselves for being able to write programs that can interface with the hardware. Many of the hardware pieces have very complex documentation, but we managed to read them, and understand them, and write programs that can interface with them reliably. As well, the software has many different parts, with some in C and some in Java. We were able to make everything synergize well, and work as a whole.
## What We learned
To make this project, we needed to use a multitude of skills, ranging from HOTP and TOTP, to using JNI to gain control over lower levels of the system.
But most importantly, we learnt the practical skills of software and hardware development, and have gained valuable experience on the development of projects.
## What's next for AuthFID | ## Inspiration
snore or get pourd on yo pores
Coming into grade 12, the decision of going to a hackathon at this time was super ambitious. We knew coming to this hackathon we needed to be full focus 24/7. Problem being, we both procrastinate and push things to the last minute, so in doing so we created a project to help us
## What it does
It's a 3 stage project which has 3 phases to get the our attention. In the first stage we use a voice command and text message to get our own attention. If I'm still distracted, we commence into stage two where it sends a more serious voice command and then a phone call to my phone as I'm probably on my phone. If I decide to ignore the phone call, the project gets serious and commences the final stage where we bring out the big guns. When you ignore all 3 stages, we send a command that triggers the water gun and shoots the distracted victim which is myself, If I try to resist and run away the water gun automatically tracks me and shoots me wherever I go.
## How we built it
We built it using fully recyclable materials as the future innovators of tomorrow, our number one priority is the environment. We made our foundation fully off of trash cardboard, chopsticks, and hot glue. The turret was built using our hardware kit we brought from home and used 3 servos mounted on stilts to hold the water gun in the air. We have a software portion where we hacked a MindFlex to read off brainwaves to activate a water gun trigger. We used a string mechanism to activate the trigger and OpenCV to track the user's face.
## Challenges we ran into
Challenges we ran into was trying to multi-thread the Arduino and Python together. Connecting the MindFlex data with the Arduino was a pain in the ass, we had come up with many different solutions but none of them were efficient. The data was delayed, trying to read and write back and forth and the camera display speed was slowing down due to that, making the tracking worse. We eventually carried through and figured out the solution to it.
## Accomplishments that we're proud of
Accomplishments we are proud of is our engineering capabilities of creating a turret using spare scraps. Combining both the Arduino and MindFlex was something we've never done before and making it work was such a great feeling. Using Twilio and sending messages and calls is also new to us and such a new concept, but getting familiar with and using its capabilities opened a new door of opportunities for future projects.
## What we learned
We've learned many things from using Twilio and hacking into the MindFlex, we've learned a lot more about electronics and circuitry through this and procrastination. After creating this project, we've learned discipline as we never missed a deadline ever again.
## What's next for You snooze you lose. We dont lose
Coming into this hackathon, we had a lot of ambitious ideas that we had to scrap away due to the lack of materials. Including, a life-size human robot although we concluded with an automatic water gun turret controlled through brain control. We want to expand on this project with using brain signals as it's our first hackathon trying this out | # About Our Project
## Inspiration:
Since forming our group, we identified early that the majority of our team's strengths were in back-end development. David told us about his interest in cybersecurity and shared some interesting resources regarding it, from there we had an idea, we just had to figure out what we could practically do with limited man-hours. From there, we settled on biometrics as our identification type and 2-type encryption.
## What it does:
We have an application. When launched you are prompted to choose a file you would like to encrypt. After choosing your file, you must scan your face to lock the file, we call it a 'passface'. From there, your passface is encoded using base64 encryption (so it cannot be used maliciously) and stored. Your file is then encrypted using Fernet encryption (which is very hard to crack without its unique and randomly generated key) and stored in a '.encrypted' file. When you would like to unlock and retrieve your file, reopen the application and browse for the encrypted file locked with your image. After scanning your face, the encoded passface is decoded and compared to your passface attempt. After matching your biometric data to that which is locking the file, your file is decoded and re-assembled to its original file type (.txt, .png, .pptx, .py, etc).
## How we built it:
We started by assigning each member to learn one of the concepts we were going to implement, after that, we divided into two groups to begin writing our two main modules, encoding/decoding and biometric retrieval/comparison. After constructing multiple working and easy-to-implement functions in our modules, we worked together on stitching it all together and debugging it (so many bugs!). We finished our project with a little bit of front-end work, making the GUI more user-friendly, comprehensive error messages etc.
## Challenges we ran into:
We thought the biggest challenge we would face would be the scanning and comparison of faces, none of us had any experience with image scanning through code and we honestly had no idea how to even start to think about doing it. But after asking our good friend ChatGPT, we got pointed in the direction of some useful APIs, and after reading ALOT of documentation, we successfully got our system up and running. The hardest challenge for us was figuring out the best and most secure ways we could reasonably store an encrypted file locally. To overcome this we had to throw alot of ideas at the chalkboard (we sat around a chalkboard for an hour) to come up with useable ideas. We settled on using separate encryption/decryption for the stored files and faces to keep a degree of separation for security, and changing the file to .encrypted so that it is not as easily openable (other than in a text file) and because it looks cool. Implementing all of this and making it work perfectly and consistently proved to be our biggest challenge and time-sink of the weekend.
## Accomplishments that we're proud of:
* getting a working face scanner and comparer, which means we successfully implemented biometric security into our coding project, which we celebrated.
* being able to encrypt and then decrypt any file type was awesome, as this is much harder than simple text and image files.
## What we learned:
We learned alot about the division of labour throughout our project. In hour 1 we struggled to effectively distribute tasks which often resulted in two people effectively doing the same thing, but separately which is a big waste of time. As we progressed, we got much more effective in picking tasks, allocating small tasks to individual people, and creating small teams to tackle a tough function or a debug marathon. We also learned the value of reading documentation; when using cv2 to scan faces we struggled with navigating its functions and implementation through brute force, but after assigning one person to dig their teeth into documentation, our group got a better understanding and we were able to get a function up and running with much less resistance. | partial |
## Inspiration
In times of disaster, the capacity of rigid networks like cell service and internet dramatically decreases at the same time demand increases as people try to get information and contact loved ones. This can lead to crippled telecom services which can significantly impact first responders in disaster struck areas, especially in dense urban environments where traditional radios don't work well. We wanted to test newer radio and AI/ML technologies to see if we could make a better solution to this problem, which led to this project.
## What it does
Device nodes in the field network to each other and to the command node through LoRa to send messages, which helps increase the range and resiliency as more device nodes join. The command & control center is provided with summaries of reports coming from the field, which are visualized on the map.
## How we built it
We built the local devices using Wio Terminals and LoRa modules provided by Seeed Studio; we also integrated magnetometers into the devices to provide a basic sense of direction. Whisper was used for speech-to-text with Prediction Guard for summarization, keyword extraction, and command extraction, and trained a neural network on Intel Developer Cloud to perform binary image classification to distinguish damaged and undamaged buildings.
## Challenges we ran into
The limited RAM and storage of microcontrollers made it more difficult to record audio and run TinyML as we intended. Many modules, especially the LoRa and magnetometer, did not have existing libraries so these needed to be coded as well which added to the complexity of the project.
## Accomplishments that we're proud of:
* We wrote a library so that LoRa modules can communicate with each other across long distances
* We integrated Intel's optimization of AI models to make efficient, effective AI models
* We worked together to create something that works
## What we learned:
* How to prompt AI models
* How to write drivers and libraries from scratch by reading datasheets
* How to use the Wio Terminal and the LoRa module
## What's next for Meshworks - NLP LoRa Mesh Network for Emergency Response
* We will improve the audio quality captured by the Wio Terminal and move edge-processing of the speech-to-text to increase the transmission speed and reduce bandwidth use.
* We will add a high-speed LoRa network to allow for faster communication between first responders in a localized area
* We will integrate the microcontroller and the LoRa modules onto a single board with GPS in order to improve ease of transportation and reliability | ## Inspiration
We've all heard horror stories of people with EVs running out of battery during a trip and not being able to find a charging station. Then, even if they do find one they have to wait so long for their car ot charge it throws off their whole trip. We wanted to make that process better for EV owners.
## What it does
RouteEV makes the user experience of owning and routing with an electric vehicle easy. It takes a trip in and based on the user's current battery, weather conditions, and route recommends if their trip is feasible or not. RouteEV then displays and recommends EV charging stations that have free spots near the route and readjusts the route to show whether charging at that station can help the user reach the destination.
## How we built it
We built RouteEV as a Javascript web app with React. It acts as a user interface for an electric Ford car that a user would interact with. Under the hood, we use various APIs such as the Google Maps API to display the map, markers, routing, and finding EV charging stations nearby. We also use APIs to collect weather information and provide Spotify integration.
## Challenges we ran into
Many members of our team hadn't used React before and we were all relatively experienced with front-end work. Trying to style and layout our application was a big challenge. The Google Maps API was also difficult to use at first and required lots of debugging to get it functional.
## Accomplishments that we're proud of
The main thing that we're proud of is that we were able to complete all the features we set out to complete at the beginning with time to spare. With our extra time we were able to have some fun and add fun integrations like Spotify.
## What we learned
We learned a lot about using React as well as using the Google Maps API and more about APIs in general. We also all learned a lot about front-end web development and working with CSS and JSX in React. | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstorming, and went through over a dozen design ideas as to how to implement a solution related to smart cities. By looking at the different information received from the camera data, we landed on the idea of requiring the raw footage itself and using it to look for what we would call a distress signal, in case anyone felt unsafe in their current area.
## What it does
We have set up a signal that if done in front of the camera, a machine learning algorithm would be able to detect the signal and notify authorities that maybe they should check out this location, for the possibility of catching a potentially suspicious suspect or even being present to keep civilians safe.
## How we built it
First, we collected data off the innovation factory API, and inspected the code carefully to get to know what each part does. After putting pieces together, we were able to extract a video footage of the nearest camera to us. A member of our team ventured off in search of the camera itself to collect different kinds of poses to later be used in training our machine learning module. Eventually, due to compiling issues, we had to scrap the training algorithm we made and went for a similarly pre-trained algorithm to accomplish the basics of our project.
## Challenges we ran into
Using the Innovation Factory API, the fact that the cameras are located very far away, the machine learning algorithms unfortunately being an older version and would not compile with our code, and finally the frame rate on the playback of the footage when running the algorithm through it.
## Accomplishments that we are proud of
Ari: Being able to go above and beyond what I learned in school to create a cool project
Donya: Getting to know the basics of how machine learning works
Alok: How to deal with unexpected challenges and look at it as a positive change
Sudhanshu: The interesting scenario of posing in front of a camera while being directed by people recording me from a mile away.
## What I learned
Machine learning basics, Postman, working on different ways to maximize playback time on the footage, and many more major and/or minor things we were able to accomplish this hackathon all with either none or incomplete information.
## What's next for Smart City SOS
hopefully working with innovation factory to grow our project as well as inspiring individuals with similar passion or desire to create a change. | partial |
## Inspiration
We were inspired to make Anchor in hopes to promote positive, healthy mental and physical health. Being in the middle of the pandemic, we were also inspired to add virtual collaborative features to still encourage active living but in the safety of our homes.
## What it does
Anchor is a personal workout app that aims to boost your mental and physical health through yoga, workouts, stretch, and dance! Users can do these on their own or with others. It makes everyday, mundane activities more fun and interactive!
## How we built it
We primarily used AdobeXD and experimented with EchoAR
## Challenges we ran into
Artificial intelligence! It was our first time trying virtual/augmented reality with EchoAR so we had difficulties trying to incorporate it into our final product.
## Accomplishments that we're proud of
Learning new software and stepping out of our comfort zone!
## What we learned
It was also our first time trying AdobeXD and EchoAR! We learned a lot about rendering and artificial intelligence. Definitely a great experience and lots of room for improvement in the future.
## What's next for Anchor
We hope to fine-tune our artificial intelligence to create a better user experience, hopefully with EchoAR. This will help teach correct form and prevent injuries by letting the user see the yoga poses from all different angles as they could see a 360 video using augmented reality. We also hope to expand our platform and start a web application, as well as additional customizable features such as calorie trackers and fitness goal settings. | ## Inspiration
The inspiration of our game came from the arcade game Cyclone, where the goal is to click the button when the LED lands on a signaled part of the circle.
## What it does
The goal of our game is to click the button when the LED reaches a designated part of the circle (the very last LED). Upon successfully doing this it will add 1 to your score, as well as increasing the speed of the LED, continually making it harder and harder to achieve this goal. The goal is for the player to get as high of a score as possible, as the higher your score is, the harder it will get. Upon clicking the wrong designated LED, the score will reset, as well as the speed value, effectively resetting the game.
## How we built it
The project was split into two parts; one was the physical building of the device and another was the making of the code.
In terms of building the physical device, at first we weren’t too sure what we wanted to do, so we ended up with a mix up of parts we could use. All of us were pretty new to using the Arduino, and its respective parts, so it was initially pretty complicated, before things started to fall into place. Through the use of many Youtube videos, and tinkering, we were able to get the physical device up and running. Much like our coding process, the building process was very dynamic. This is because at first, we weren’t completely sure which parts we wanted to use, so we had multiple components running at once, which allowed for more freedom and possibilities. When we figured out which components we would be using, everything sort of fell into place.
For the code process, it was quite messy at first. This was because none of us were completely familiar with the Arduino libraries, and so it was a challenge to write the proper code. However, with the help of online guides and open source material, we were eventually able to piece together what we needed. Furthermore, our coding process was very dynamic. We would switch out components constantly, and write many lines of code that was never going to be used. While this may have been inefficient, we learned much throughout the process, and it kept our options open and ideas flowing.
## Challenges we ran into
In terms of main challenges that we ran into along the way, the biggest challenge was getting our physical device to function the way we wanted it to. The initial challenge came from understanding our device, specifically the Arduino logic board, and all the connecting parts, which then moved to understanding the parts, as well as getting them to function properly.
## Accomplishments that we're proud of
In terms of main accomplishments, our biggest accomplishment is overall getting the device to work, and having a finished product. After running into many issues and challenges regarding the physical device and its functions, putting our project together was very satisfying, and a big accomplishment for us. In terms of specific accomplishments, the most important parts of our project was getting our physical device to function, as well as getting the initial codebase to function with our project. Getting the codebase to work in our favor was a big accomplishment, as we were mostly reliant on what we could find online, as we were essentially going in blind during the coding process (none of us knew too much about coding with Arduino).
## What we learned
During the process of building our device, we learned a lot about the Arduino ecosystem, as well as coding for it. When building the physical device, a lot of learning went into it, as we didn’t know that much about using it, as well as applying programs for it. We learned how important it is to have a strong connection for our components, as well as directly linking our parts with the Arduino board, and having it run proper code.
## What's next for Cyclone
In terms of what’s next for Cyclone, there are many possibilities for it. Some potential changes we could make would be making it more complex, and adding different modes to it. This would increase the challenge for the player, and give it more replay value as there is more to do with it. Another potential change we could make is to make it on a larger scale, with more LED lights and make attachments, such as the potential use of different types of sensors. In addition, we would like to add an LCD display or a 4 digit display to display the player’s current score and high score. | ## Inspiration
Feeling major self-doubt when you first start hitting the gym or injuring yourself accidentally while working out are not uncommon experiences for most people. This inspired us to create Core, a platform to empower our users to take control of their well-being by removing the financial barriers around fitness.
## What it does
Core analyses the movements performed by the user and provides live auditory feedback on their form, allowing them to stay fully present and engaged during their workout. Our users can also take advantage of the visual indications on the screen where they can view a graph of the keypoint which can be used to reduce the risk of potential injury.
## How we built it
Prior to development, a prototype was created on Figma which was used as a reference point when the app was developed in ReactJs. In order to recognize the joints of the user and perform analysis, Tensorflow's MoveNet model was integrated into Core.
## Challenges we ran into
Initially, it was planned that Core would serve as a mobile application built using React Native, but as we developed a better understanding of the structure, we saw more potential in a cross-platform website. Our team was relatively inexperienced with the technologies that were used, which meant learning had to be done in parallel with the development.
## Accomplishments that we're proud of
This hackathon allowed us to develop code in ReactJs, and we hope that our learnings can be applied to our future endeavours. Most of us were also new to hackathons, and it was really rewarding to see how much we accomplished throughout the weekend.
## What we learned
We gained a better understanding of the technologies used and learned how to develop for the fast-paced nature of hackathons.
## What's next for Core
Currently, Core uses TensorFlow to track several key points and analyzes the information with mathematical models to determine the statistical probability of the correctness of the user's form. However, there's scope for improvement by implementing a machine learning model that is trained on Big Data to yield higher performance and accuracy.
We'd also love to expand our collection of exercises to include a wider variety of possible workouts. | losing |
## Inspiration
In a world where the voices of the minority are often not heard, technology must be adapted to fit the equitable needs of these groups. Picture the millions who live in a realm of silence, where for those who are deaf, you are constantly silenced and misinterpreted. Of the 50 million people in the United States with hearing loss, less than 500,000 — or about 1% — use sign language, according to Acessibility.com and a recent US Census. Over 466 million people across the globe struggle with deafness, a reality known to each in the deaf community. Imagine the pain where only 0.15% of people (in the United States) can understand you. As a mother, father, teacher, friend, or ally, there is a strong gap in communication that impacts deaf people every day. The need for a new technology is urgent from both an innovation perspective and a human rights perspective.
Amidst this urgent disaster of an industry, a revolutionary vision emerges – Caption Glasses, a beacon of hope for the American Sign Language (ASL) community. Caption Glasses bring the magic of real-time translation to life, using artificial neural networks (machine learning) to detect ASL "fingerspeaking" (their one-to-one version of the alphabet), and creating instant subtitles displayed on glasses. This revolutionary piece effortlessly bridges the divide between English and sign language. Instant captions allow for the deaf child to request food from their parents. Instant captions allow TAs to answer questions in sign language. Instant captions allow for the nurse to understand the deaf community seeking urgent care at hospitals. Amplifying communication for the deaf community to the unprecedented level that Caption Glasses does increases the diversity of humankind through equitable accessibility means!
With Caption Glasses, every sign becomes a verse, every gesture an eloquent expression. It's a revolution, a testament to humanity's potential to converse with one another. In a society where miscommunication causes wars, there is a huge profit associated with developing Caption Glasses. Join us in this journey as we redefine the meaning of connection, one word, one sign, and one profound moment at a time.
## What it does
The Caption Glasses provide captions displayed on glasses after detecting American Sign Language (ASL). The captions are instant and in real-time, allowing for effective translations into the English Language for the glasses wearer.
## How we built it
Recognizing the high learning curve of ASL, we began brainstorming for possible solutions to make sign language more approachable to everyone. We eventually settled on using AR-style glasses to display subtitles that can help an ASL learner quickly identify what sign they are looking at.
We started our build with hardware and design, starting off by programming a SSD1306 OLED 0.96'' display with an Arduino Nano. We also began designing our main apparatus around the key hardware components, and created a quick prototype using foam.
Next, we got to loading computer vision models onto a Raspberry Pi4. Although we were successful in loading a basic model that looks at generic object recognition, we were unable to find an ASL gesture recognition model that was compact enough to fit on the RPi.
To circumvent this problem, we made an approach change that involved more use of the MediaPipe Hand Recognition models. The particular model we chose marked out 21 landmarks of the human hand (including wrist, fingertips, knuckles, etc.). We then created and trained a custom Artificial Neural Network that takes the position of these landmarks, and determines what letter we are trying to sign.
At the same time, we 3D printed the main apparatus with a Prusa I3 3D printer, and put in all the key hardware components. This is when we became absolute best friends with hot glue!
## Challenges we ran into
The main challenges we ran into during this project mainly had to do with programming on an RPi and 3D printing.
Initially, we wanted to look for pre-trained models for recognizing ASL, but there were none that were compact enough to fit in the limited processing capability of the Raspberry Pi. We were able to circumvent the problem by creating a new model using MediaPipe and PyTorch, but we were unsuccessful in downloading the necessary libraries on the RPi to get the new model working. Thus, we were forced to use a laptop for the time being, but we will try to mitigate this problem by potentially looking into using ESP32i's in the future.
As a team, we were new to 3D printing, and we had a great experience learning about the importance of calibrating the 3D printer, and had the opportunity to deal with a severe printer jam. While this greatly slowed down the progression of our project, we were lucky enough to be able to fix our printer's jam!
## Accomplishments that we're proud of
Our biggest accomplishment is that we've brought our vision to life in the form of a physical working model. Employing the power of 3D printing through leveraging our expertise in SolidWorks design, we meticulously crafted the components, ensuring precision and functionality.
Our prototype seamlessly integrates into a pair of glasses, a sleek and practical design. At its heart lies an Arduino Nano, wired to synchronize with a 40mm lens and a precisely positioned mirror. This connection facilitates real-time translation and instant captioning. Though having extensive hardware is challenging and extremely time-consuming, we greatly take the attention of the deaf community seriously and believe having a practical model adds great value.
Another large accomplishment is creating our object detection model through a machine learning approach of detecting 21 points in a user's hand and creating the 'finger spelling' dataset. Training the machine learning model was fun but also an extensively difficult task. The process of developing the dataset through practicing ASL caused our team to pick up the useful language of ASL.
## What we learned
Our journey in developing Caption Glasses revealed the profound need within the deaf community for inclusive, diverse, and accessible communication solutions. As we delved deeper into understanding the daily lives of over 466 million deaf individuals worldwide, including more than 500,000 users of American Sign Language (ASL) in the United States alone, we became acutely aware of the barriers they face in a predominantly spoken word.
The hardware and machine learning development phases presented significant challenges. Integrating advanced technology into a compact, wearable form required a delicate balance of precision engineering and user-centric design. 3D printing, SolidWorks design, and intricate wiring demanded meticulous attention to detail. Overcoming these hurdles and achieving a seamless blend of hardware components within a pair of glasses was a monumental accomplishment.
The machine learning aspect, essential for real-time translation and captioning, was equally demanding. Developing a model capable of accurately interpreting finger spelling and converting it into meaningful captions involved extensive training and fine-tuning. Balancing accuracy, speed, and efficiency pushed the boundaries of our understanding and capabilities in this rapidly evolving field.
Through this journey, we've gained profound insights into the transformative potential of technology when harnessed for a noble cause. We've learned the true power of collaboration, dedication, and empathy. Our experiences have cemented our belief that innovation, coupled with a deep understanding of community needs, can drive positive change and improve the lives of many. With Caption Glasses, we're on a mission to redefine how the world communicates, striving for a future where every voice is heard, regardless of the language it speaks.
## What's next for Caption Glasses
The market for Caption Glasses is insanely large, with infinite potential for advancements and innovations. In terms of user design and wearability, we can improve user comfort and style. The prototype given can easily scale to be less bulky and lighter. We can allow for customization and design patterns (aesthetic choices to integrate into the fashion community).
In terms of our ML object detection model, we foresee its capability to decipher and translate various sign languages from across the globe pretty easily, not just ASL, promoting a universal mode of communication for the deaf community. Additionally, the potential to extend this technology to interpret and translate spoken languages, making Caption Glasses a tool for breaking down language barriers worldwide, is a vision that fuels our future endeavors. The possibilities are limitless, and we're dedicated to pushing boundaries, ensuring Caption Glasses evolve to embrace diverse forms of human expression, thus fostering an interconnected world. | ## Inspiration
Alex K's girlfriend Allie is a writer and loves to read, but has had trouble with reading for the last few years because of an eye tracking disorder. She now tends towards listening to audiobooks when possible, but misses the experience of reading a physical book.
Millions of other people also struggle with reading, whether for medical reasons or because of dyslexia (15-43 million Americans) or not knowing how to read. They face significant limitations in life, both for reading books and things like street signs, but existing phone apps that read text out loud are cumbersome to use, and existing "reading glasses" are thousands of dollars!
Thankfully, modern technology makes developing "reading glasses" much cheaper and easier, thanks to advances in AI for the software side and 3D printing for rapid prototyping. We set out to prove through this hackathon that glasses that open the world of written text to those who have trouble entering it themselves can be cheap and accessible.
## What it does
Our device attaches magnetically to a pair of glasses to allow users to wear it comfortably while reading, whether that's on a couch, at a desk or elsewhere. The software tracks what they are seeing and when written words appear in front of it, chooses the clearest frame and transcribes the text and then reads it out loud.
## How we built it
**Software (Alex K)** -
On the software side, we first needed to get image-to-text (OCR or optical character recognition) and text-to-speech (TTS) working. After trying a couple of libraries for each, we found Google's Cloud Vision API to have the best performance for OCR and their Google Cloud Text-to-Speech to also be the top pick for TTS.
The TTS performance was perfect for our purposes out of the box, but bizarrely, the OCR API seemed to predict characters with an excellent level of accuracy individually, but poor accuracy overall due to seemingly not including any knowledge of the English language in the process. (E.g. errors like "Intreduction" etc.) So the next step was implementing a simple unigram language model to filter down the Google library's predictions to the most likely words.
Stringing everything together was done in Python with a combination of Google API calls and various libraries including OpenCV for camera/image work, pydub for audio and PIL and matplotlib for image manipulation.
**Hardware (Alex G)**: We tore apart an unsuspecting Logitech webcam, and had to do some minor surgery to focus the lens at an arms-length reading distance. We CAD-ed a custom housing for the camera with mounts for magnets to easily attach to the legs of glasses. This was 3D printed on a Form 2 printer, and a set of magnets glued in to the slots, with a corresponding set on some NerdNation glasses.
## Challenges we ran into
The Google Cloud Vision API was very easy to use for individual images, but making synchronous batched calls proved to be challenging!
Finding the best video frame to use for the OCR software was also not easy and writing that code took up a good fraction of the total time.
Perhaps most annoyingly, the Logitech webcam did not focus well at any distance! When we cracked it open we were able to carefully remove bits of glue holding the lens to the seller’s configuration, and dial it to the right distance for holding a book at arm’s length.
We also couldn’t find magnets until the last minute and made a guess on the magnet mount hole sizes and had an *exciting* Dremel session to fit them which resulted in the part cracking and being beautifully epoxied back together.
## Acknowledgements
The Alexes would like to thank our girlfriends, Allie and Min Joo, for their patience and understanding while we went off to be each other's Valentine's at this hackathon. | ## Inspiration
We were inspired by the fact that **diversity in disability is often overlooked** - individuals who are hard-of-hearing or deaf and use **American Sign Language** do not have many tools that support them in learning their language. Because of the visual nature of ASL, it's difficult to translate between it and written languages, so many forms of language software, whether it is for education or translation, do not support ASL. We wanted to provide a way for ASL-speakers to be supported in learning and speaking their language.
Additionally, we were inspired by recent news stories about fake ASL interpreters - individuals who defrauded companies and even government agencies to be hired as ASL interpreters, only to be later revealed as frauds. Rather than accurately translate spoken English, they 'signed' random symbols that prevented the hard-of-hearing community from being able to access crucial information. We realized that it was too easy for individuals to claim their competence in ASL without actually being verified.
All of this inspired the idea of EasyASL - a web app that helps you learn ASL vocabulary, translate between spoken English and ASL, and get certified in ASL.
## What it does
EasyASL provides three key functionalities: learning, certifying, and translating.
**Learning:** We created an ASL library - individuals who are learning ASL can type in the vocabulary word they want to learn to see a series of images or a GIF demonstrating the motions required to sign the word. Current ASL dictionaries lack this dynamic ability, so our platform lowers the barriers in learning ASL, allowing more members from both the hard-of-hearing community and the general population to improve their skills.
**Certifying:** Individuals can get their mastery of ASL certified by taking a test on EasyASL. Once they start the test, a random word will appear on the screen and the individual must sign the word in ASL within 5 seconds. Their movements are captured by their webcam, and these images are run through OpenAI's API to check what they signed. If the user is able to sign a majority of the words correctly, they will be issued a unique certificate ID that can certify their mastery of ASL. This certificate can be verified by prospective employers, helping them choose trustworthy candidates.
**Translating:** EasyASL supports three forms of translation: translating from spoken English to text, translating from ASL to spoken English, and translating in both directions. EasyASL aims to make conversations between ASL-speakers and English-speakers more fluid and natural.
## How we built it
EasyASL was built primarily with **typescript and next.js**. We captured images using the user's webcam, then processed the images to reduce the file size while maintaining quality. Then, we ran the images through **Picsart's API** to filter background clutter for easier image recognition and host images in temporary storages. These were formatted to be accessible to **OpenAI's API**, which was trained to recognize the ASL signs and identify the word being signed. This was used in both our certification stream, where the user's ASL sign was compared against the prompt they were given, and in the translation stream, where ASL phrases were written as a transcript then read aloud in real time. We also used **Google's web speech API** in the translation stream, which converted English to written text. Finally, the education stream's dictionary was built using typescript and a directory of open-source web images.
## Challenges we ran into
We faced many challenges while working on EasyASL, but we were able to persist through them to come to our finished product. One of our biggest challenges was working with OpenAI's API: we only had a set number of tokens, which were used each time we ran the program, meaning we couldn't test the program too many times. Also, many of our team members were using TypeScript and Next.js for the first time - though there was a bit of a learning curve, we found that its similarities with JavaScript helped us adapt to the new language. Finally, we were originally converting our images to a UTF-8 string, but got strings that were over 500,000 characters long, making them difficult to store. We were able to find a workaround by keeping the images as URLs and passing these URLs directly into our functions instead.
## Accomplishments that we're proud of
We were very proud to be able to integrate APIs into our project. We learned how to use them in different languages, including TypeScript. By integrating various APIs, we were able to streamline processes, improve functionality, and deliver a more dynamic user experience. Additionally, we were able to see how tools like AI and text-to-speech could have real-world applications.
## What we learned
We learned a lot about using Git to work collaboratively and resolve conflicts like separate branches or merge conflicts. We also learned to use Next.js to expand what we could do beyond JavaScript and HTML/CSS. Finally, we learned to use APIs like Open AI API and Google Web Speech API.
## What's next for EasyASL
We'd like to continue developing EasyASL and potentially replacing the Open AI framework with a neural network model that we would train ourselves. Currently processing inputs via API has token limits reached quickly due to the character count of Base64 converted image. This results in a noticeable delay between image capture and model output. By implementing our own model, we hope to speed this process up to recreate natural language flow more readily. We'd also like to continue to improve the UI/UX experience by updating our web app interface. | winning |
## Inspiration
Inspired by pickup sports and a desire to have an easy interface to see where games may be.
## What it does
Allows people to start 'events' on a map which will be visible to the other users of the app. The other users can then join the 'lobby' of the first users event, showing the other users that two people are currently at the event
## How I built it
Built with android studio in Java. Frontend uses the convenient integration that google maps has with android for a graphical display for clients while the server uses the Radar.io API to manage geofences and events.
## Challenges I ran into
Using the server and connecting the app to a central source of information proved to be very difficult, especially when considering having to learn to use a new API at the same time.
## Accomplishments that I'm proud of
* Using Google Maps API to represent our data
* Using radar.io to manage events in the backend
## What I learned
* How difficult it is to create a server for our specific purposes
* Importance of testing and doing it as you go
* Importance of slowly connecting the front and back end instead of doing it only when both are complete
## What's next for PickUp
Billion dollars. | ## Inspiration
"*Agua.*" These four letters dropped Coca-Cola's market value by $4 billion dollars in just a few minutes. In a 2021 press conference, Cristiano Ronaldo shows just how much impact public opinion has on corporate finance. We all know about hedge fund managers who have to analyze and trade stocks every waking minute. These people look at graphs to get paid hundreds of thousands of dollars, yet every single one of them overlooks the arguably most important metric for financial success. Public opinion. That's where our team was inspired to create twittertrader.
## What it does
twittertrader is a react application that displays crucial financial information regarding the day's top traded stocks. For each of the top ten most active stocks, our project analyzes the most recent relevant tweets and displays the general public opinion.
## How we built it
**Backend**: Python, yahoo\_fin, Tweepy, NLTK
**Frontend**: React, Material UI
**Integration**: Flask
## Challenges we ran into
Integrating backend and frontend.
## Accomplishments that we're proud of
Every single one of us was pushed to learn and do more than we have ever done in such a short amount of time! Furthermore, we are proud that all of us were able to commit so much time and effort even in the midst of final exams.
## What we learned
Don't take part in a hackathon during exam season. I'm being serious.
## What's next for twittertrader
1. **Interactions**
As a team we had big ambitious and small amounts of time. We wanted to include a feature where users would be able to add stocks to also be analyzed however we were unable to implement it in time.
2. **Better Analytics!**
Our current project relies on NLTK's natural language processing which has limitations analyzing text in niche fields. We plan on integrating a trained ML model that more accurately describes sentiments in the context of stocks. ("Hit the moon" will make our positivity "hit the moon")
3. **Analytics+**
This information is cool and all but what am I supposed to do with it? We plan on implementing further functionality that analyses significant changes in public opinion and recommends buying or selling these stocks.
4. **Scale**
We worked so hard on this cool project and we want to share this functionality with the world! We plan on hosting this project on a real domain.
## The Team
Here is our team's Githubs and LinkedIns:
Jennifer Li: [Github](https://github.com/jennifer-hy-li) & [LinkedIn](https://www.linkedin.com/in/jennifer-hy-li/)
McCowan Zhang: [Github](https://github.com/mccowanzhang) & [LinkedIn](https://www.linkedin.com/in/mccowanzhang/)
Yuqiao Jiang: [Github](https://github.com/yuqiaoj) & [LinkedIn](https://www.linkedin.com/in/yuqiao-jiang/) | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps out the WiFi landscape of the world. That information is sent to a central server and combined with location and WiFi data from all users of the app. The server then processes the data and generates heatmaps of WiFi signal strength to send back to the end user. Because of our architecture these heatmaps are real time, updating dynamically as the WiFi strength changes.
## How we built it
We split up the work into three parts: mobile, cloud, and visualization and had each member of our team work on a part. For the mobile component, we quickly built an MVP iOS app that could collect and push data to the server and iteratively improved our locationing methodology. For the cloud, we set up a Firebase Realtime Database (NoSQL) to allow for large amounts of data throughput. For the visualization, we took the points we received and used gaussian kernel density estimation to generate interpretable heatmaps.
## Challenges we ran into
Engineering an algorithm to determine the location of the client was significantly more difficult than expected. Initially, we wanted to use accelerometer data, and use GPS as well to calibrate the data, but excessive noise in the resulting data prevented us from using it effectively and from proceeding with this approach. We ran into even more issues when we used a device with less accurate sensors like an Android phone.
## Accomplishments that we're proud of
We are particularly proud of getting accurate paths travelled from the phones. We initially tried to use double integrator dynamics on top of oriented accelerometer readings, correcting for errors with GPS. However, we quickly realized that without prohibitively expensive filtering, the data from the accelerometer was useless and that GPS did not function well indoors due to the walls affecting the time-of-flight measurements. Instead, we used a built in pedometer framework to estimate distance travelled (this used a lot of advanced on-device signal processing) and combined this with the average heading (calculated using a magnetometer) to get meter-level accurate distances.
## What we learned
Locationing is hard! Especially indoors or over short distances.
Firebase’s realtime database was extremely easy to use and very performant
Distributing the data processing between the server and client is a balance worth playing with
## What's next for Hotspot
Next, we’d like to expand our work on the iOS side and create a sister application for Android (currently in the works). We’d also like to overlay our heatmap on Google maps.
There are also many interesting things you can do with a WiFi heatmap. Given some user settings, we could automatically switch from WiFi to data when the WiFi signal strength is about to get too poor. We could also use this app to find optimal placements for routers. Finally, we could use the application in disaster scenarios to on-the-fly compute areas with internet access still up or produce approximate population heatmaps. | losing |
## Inspiration
The internet is filled with user-generated content, and it has become increasingly difficult to manage and moderate all of the text that people are producing on a platform. Large companies like Facebook, Instagram, and Reddit leverage their massive scale and abundance of resources to aid in their moderation efforts. Unfortunately for small to medium-sized businesses, it is difficult to monitor all the user-generated content being posted on their websites. Every company wants engagement from their customers or audience, but they do not want bad or offensive content to ruin their image or the experience for other visitors. However, hiring someone to moderate or build an in-house program is too difficult to manage for these smaller businesses. Content moderation is a heavily nuanced and complex problem. It’s unreasonable for every company to implement its own solution. A robust plug-and-play solution is necessary that adapts to the needs of each specific application.
## What it does
That is where Quarantine comes in.
Quarantine acts as an intermediary between an app’s client and server, scanning the bodies of incoming requests and “quarantining” those that are flagged. Flagging is performed automatically, using both pretrained content moderation models (from Azure and Moderation API) as well as an in house machine learning model that adapts to specifically meet the needs of the application’s particular content. Once a piece of content is flagged, it appears in a web dashboard, where a moderator can either allow or block it. The moderator’s labels are continuously used to fine tune the in-house model. Together with this in house model and pre-trained models a robust meta model is formed.
## How we built it
Initially, we built an aggregate program that takes in a string and runs it through the Azure moderation and Moderation API programs. After combining the results, we compare it with our machine learning model to make sure no other potentially harmful posts make it through our identification process. Then, that data is stored in our database. We built a clean, easy-to-use dashboard for the grader using react and Material UI. It pulls the flagged items from the database and then displays them on the dashboard. Once a decision is made by the person, that is sent back to the database and the case is resolved. We incorporated this entire pipeline into a REST API where our customers can pass their input through our programs and then access the flagged ones on our website.
Users of our service don’t have to change their code, simply they append our url to their own API endpoints. Requests that aren’t flagged are simply instantly forwarded along.
## Challenges we ran into
Developing the in house machine learning model and getting it to run on the cloud proved to be a challenge since the parameters and size of the in house model is in constant flux.
## Accomplishments that we're proud of
We were able to make a super easy to use service. A company can add Quarantine with less than one line of code.
We're also proud of adaptive content model that constantly updates based on the latest content blocked by moderators.
## What we learned
We learned how to successfully integrate an API with a machine learning model, database, and front-end. We had learned each of these skills individually before, but we has to figure out how to accumulate them all.
## What's next for Quarantine
We have plans to take Quarantine even further by adding customization to how items are flagged and taken care of. It is proven that there are certain locations that spam is commonly routed through so we could do some analysis on the regions harmful user-generated content is coming from. We are also keen on monitoring the stream of activity of individual users as well as track requests in relation to each other (detect mass spamming). Furthermore, we are curious about adding the surrounding context of the content since it may be helpful in the grader’s decisions. We're also hoping to leverage the data we accumulate from content moderators to help monitor content across apps using shared labeled data behind the scenes. This would make Quarantine more valuable to companies as it monitors more content. | ## Inspiration
Companies lack insight into their users, audiences, and marketing funnel.
This is an issue I've run into on many separate occasions. Specifically,
* while doing cold marketing outbound, need better insight onto key variables of successful outreach
* while writing a blog, I have no idea who reads it
* while triaging inbound, which users do I prioritize
Given a list of user emails, Cognito scrapes the internet finding public information about users and the companies they work at. With this corpus of unstructured data, Cognito allows you to extract any relevant piece of information across users. An unordered collection of text and images becomes structured data relevant to you.
## A Few Example Use Cases
* Startups going to market need to identify where their power users are and their defining attributes. We allow them to ask questions about their users, helping them define their niche and better focus outbound marketing.
* SaaS platforms such as Modal have trouble with abuse. They want to ensure people joining are not going to abuse it. We provide more data points to make better judgments such as taking into account how senior of a developer a user is and the types of companies they used to work at.
* VCs such as YC have emails from a bunch of prospective founders and highly talented individuals. Cognito would allow them to ask key questions such as what companies are people flocking to work at and who are the highest potential people in my network.
* Content creators such as authors on Substack looking to monetize their work have a much more compelling case when coming to advertisers with a good grasp on who their audience is.
## What it does
Given a list of user emails, we crawl the web, gather a corpus of relevant text data, and allow companies/creators/influencers/marketers to ask any question about their users/audience.
We store these data points and allow for advanced querying in natural language.
[video demo](https://www.loom.com/share/1c13be37e0f8419c81aa731c7b3085f0)
## How we built it
we orchestrated 3 ML models across 7 different tasks in 30 hours
* search results person info extraction
* custom field generation from scraped data
* company website details extraction
* facial recognition for age and gender
* NoSQL query generation from natural language
* crunchbase company summary extraction
* email extraction
This culminated in a full-stack web app with batch processing via async pubsub messaging. Deployed on GCP using Cloud Run, Cloud Functions, Cloud Storage, PubSub, Programmable Search, and Cloud Build.
## What we learned
* how to be really creative about scraping
* batch processing paradigms
* prompt engineering techniques
## What's next for Cognito
1. predictive modeling and classification using scraped data points
2. scrape more data
3. more advanced queries
4. proactive alerts
[video demo](https://www.loom.com/share/1c13be37e0f8419c81aa731c7b3085f0) | ## Inspiration
This past year, we've seen the effects of uncontrolled algorithmic amplification on society. From widespread [riot-inciting misinformation on Facebook](https://www.theverge.com/2020/3/17/21183341/facebook-misinformation-report-nathalie-marechal) to the explosive growth of TikTok - a platform that serves content [entirely on a black-box algorithm](https://www.wired.com/story/tiktok-finally-explains-for-you-algorithm-works/), we've reached a point where [social media algorithms rule how we see the world](https://www.wsj.com/articles/social-media-algorithms-rule-how-we-see-the-world-good-luck-trying-to-stop-them-11610884800) - and it seems like we've lost our individual ability to control these incredibly intricate systems.
From a consumer's perspective, it's difficult to tell what your social media feed prioritizes – sometimes, it shows you content related to products you might have searched the internet for; other times, you might see [eerily accurate friend recommendations](https://www.theverge.com/2017/9/7/16269074/facebook-tinder-messenger-suggestions). If you've watched [The Social Dilemma](https://www.thesocialdilemma.com), you might think that your Facebook feed is managed directly by Mark Zuckerberg & his three dials: engagement, growth, and revenue
The bottom line: we need significant innovation around the algorithms that power our digital lives.
## Feeds: an Open-Sourced App Store for Algorithmic Choice
On Feeds, you're in control over what information is prioritized. You're no longer bound to a hyper-personalized engine designed to maximize your engagement: instead, you have the ability to set your own utility function & design your own feed.
## How we built it
We built Feeds on a React Native frontend & serverless Google Cloud Functions backend! Our app pulls data live from Twitter using [Twint](https://pypi.org/project/twint/) (an open-source Twitter OSINT tool). To prototype our algorithms, we employed a variety of techniques to prioritize different emotions & content –
* "Positivity" - optimized for positive & optimistic content (powered by [OpenAI](http://openai.com))
* "Virality" - optimized for viral content (powered by Twint)
* "Controversy" - optimized for controversial content (powered by [Textblob/NLTK](https://textblob.readthedocs.io/en/dev/))
* "Verified" - optimized for high-quality & verified content
* "Learning" - optimized for educational content
Additionally, to add to the ability to break out of your own echo chamber, we added a feature that puts you into the social media feed of influencers – so if you want to see exactly what Elon Musk or Vice President Kamala Harris sees on Twitter, you can switch to those Feeds with just a tap!
## Challenges we ran into
Twitter's hardly a developer-friendly platform - scraping Tweets to use for our prototype was probably one of our most challenging tasks! We also ran into many algorithmic design choices (e.g. how to detect "controversy") - and drew inspiration from a variety of resource papers & open-source projects.
## Accomplishments that we're proud of
We built a functioning full-stack product over the course of ~10 hours - and we truly believe this emphasis on algorithmic choice is one critical component to the future of social media!
## What we learned
We learned a lot about natural language processing & the different challenges when it comes to designing algorithms using cutting-edge tools like GPT-3!
## What's next for Feeds
We'd love to turn this into an open-sourced platform that plugs into different content sources -- and allows anyone (any developer) to create a custom Feed & share it with the world! | winning |
## Inspiration
Kimoyo is named after the kimoyo beads in Black Panther-- they're beads that allow you to start a 3D video call right in the palm of your hand. Hologram communication, or "holoportation" as we put it, is not a new idea in movies. Similar scenes occur in Star Wars and in Kingsman, for example. However, holoportation is certainly an up-and-coming idea in the real world!
## What it does
In the completed version of Kimoyo, users will be able to use an HTC Vive to view the avatars of others in a video call, while simultaneously animating their own avatar through inverse kinematics (IK). Currently, Kimoyo has a prototype IK system working, and has a sample avatar and sample environment to experience!
## How I built it
Starting this project with only a basic knowledge of Unity and with no other VR experience (I wasn't even sure what HTC Vive was!), I leaned on mentors, friends, and many YouTube tutorials to learn enough about Vive to put together a working model. So far, Kimoyo has been done almost entirely in Unity using SteamVR, VRTK, and MakeHuman assets.
## Challenges I ran into
My lack of experience was a limiting factor, and I feel that I had to spend quite a bit of time watching tutorials, debugging, and trying to solve very simple problems. That being said, the resources available saved me a lot of time, and I feel that I was able to learn enough to put together a good project in the time available. The actual planning of the project-- deciding which hardware to use and reasoning through design problems-- was also challenging, but very rewarding as well.
## Accomplishments that I'm proud of
I definitely could not have built Kimoyo alone, and I'm really glad and very thankful that I was able to learn so much from the resources all around me. There have been bugs and issues and problems that seemed absolutely intractable, but I was able to keep going with the help of others around me!
## What's next for Kimoyo
The next steps for Kimoyo is to get a complete, working version up. First, we plan to expand the hand inverse kinematics so the full upper body moves naturally. We also plan to add additional camera perspectives and settings, integrate sound, beginning work with a Unity network manager to allow multiple people to join an environment, and of course building and deploying an app.
After that? Future steps might include writing interfaces for creation of custom environments (including AR?), and custom avatars, as well as developing a UI involving the Vive controllers-- Kimoyo has so many possibilities! | ## Inspiration
Save plate is an app that focuses on narrowing the equity differences in society.It is made with the passion to solve the SDG goals such as zero hunger, Improving life on land, sustainable cities and communities and responsible consumption and production.
## What it does
It helps give a platform to food facilities to distribute their untouched meals to the shelter via the plate saver app. It asks the restaurant to provide the number of meals that are available and could be picked up by the shelters. It also gives the flexibility to provide any kind of food restriction to respect cultural and health restrictions for food.
## How we built it
* Jav
## Challenges we ran into
There were many challenges that I and my teammates ran into were learning new skills, teamwork and brainstorming.
## Accomplishments that we're proud of
Creating maps, working with
## What we learned
We believe our app is needed not only in one region but entire world, we all are taking steps towards building a safe community for everyone Therefore we see our app's potential to run in collaboration with UN and together we fight world hunger. | ## Inspiration
The idea addresses a very natural curiosity to live and experience the world as someone else, and out of the progress with the democratization of VR with the Cardboard, we tried to create a method for people to "upload" their life to others. The name is a reference to Sharon Creech's quote on empathy in Walk Two Moons: "You can't judge a man until you've walked two moons in his moccasins", which resonated with our mission.
## What it does
Moonlens consists of a pipeline of three aspects that connects the uploaders to the audience. Uploaders use the camera-glasses to record, and then upload the video onto the website along with the data from the camera-glasses's gyro-accelerometer data (use explained below). The website communicates with the iOS app and allows the app to playback the video in split-screen.
To prevent motion sickness, the viewer has to turn his head in the same orientation as the uploader for the video to come into view, as otherwise the experience will disturb the vestibular system. This orientation requirement warrants the use of the gyro-accelerometer in the camera-glasses to compare to the iPhone's orientation tracking data.
## How we built it
The three components of the pipeline:
1. Camera-glasses: using the high framerate and high resolution of mini sports cameras, we took apart the camera and attached it to a pair of glasses. The camera-glasses sport a combination of gyroscope and accelerometer that start synchronously with the camera's recording, and the combination of the camera and Arduino processor for the gyro-accelerometer outputs both the video file and the orientation data to be uploaded onto the website.
2. Website: The website is for the uploaders to transfer the individual video-orientation data pairs to the database. The website was designed with Three.js, along with the externally designed logo and buttons. It uses Linode servers to handle PHP requests for the file uploads.
3. App: The app serves as the consumer endpoint for the pipeline, and allows consumers to view all the videos in the database. The app features automatic split-screen, and videos in the app are of similar format with 360 videos except for the difference that the video only spans a portion of the spherical projection, and the viewer has to follow the metaphorical gaze of the uploader through following the video's movements.
## Challenges we ran into
A major challenge early on was in dealing with possible motion sickness in uploaders rotating their heads while the viewers don't; this confuses the brain as the visual cortex receives the rotational cue but the inner ear, which acts as the gyro for the brain, doesn't, which is the main cause for VR sickness. We came up with the solution to have the viewer turn his or her head, and this approach focuses the viewer toward what's important (what the uploader's gaze is on) and also increases the interactivity of the video.
In building the camera, we did not have the resources for a flat surface to mount the boards and batteries for the camera. Despite this, we found that our lanyards for Treehacks, when hot-glue-gunned together, made quite a good surface, and ended up using this for our prototype.
In the process of deploying the website, we had several cases of PHP not working out, and thus spent quite a bit of time trying to deploy. We ended up learning much about the backend that we hadn't previously known through these struggles and ultimately got the right amount of help to overcome the issues.
## Accomplishments that we're proud of
We were very productive from the beginning to the end, and made consistent progress and had clear goals. We worked very well as a team, and had a great system for splitting up work based on our specialties, whether that be web, app dev, or hardware.
Building the app was a great achievement as our app specialist JR never built an app in VR before, and he figured out the nuances of working with the gyroscope and accelerometer of the phone in great time and polished the app very well.
We're also quite proud of having built the camera on top of basic plastic glasses and our Treehacks lanyards, and Richard, who specializes in hardware, was resourceful in making the camera and hacking the camera.
For the web part, Dillon and Jerry designed the backend and frontend, which was an uphill battle due to technical complications with PHP and deploying. However, the website came together nicely as the backend finally resolved the complications and the frontend was finished with the design.
## What we learned
We learned how to build with brand new tools, such as Linode, and also relied on our own past skills in development to split up work in a reasonable and efficient manner. In addition, we learned by building around VR, which was a field that many of the team members did not have exposure before.
## What's next for Moonlens
In the future, we will make the prototype camera-glasses much more compact, and hopefully streamline a process for directly producing video to uploading with minimal assistance from the computer. As people use the app, creating a positive environment between uploaders and viewers would be necessary and having the uploaders earn money from ads would be a great way to grow the community, and hopefully given time, the world can better connect and understand each other through seeing others' experiences. | partial |
## Inspiration
Merely a week into freshman year, my teammates and I had realized how difficult it was to find classmates to work on problem sets together. Many of our classes had hundreds of students, and it wasn’t easy to find people who lived near us to work with. For each person talking about how happy they were they found a pset group and how much easier that made their work, there was another who didn't know other people in their classes. MIT is a big place, and it's a lot easier to navigate when you learn with the people around you and make friends in process. We want to promote the spirit of collaboration and teamwork with our app.
## What it does
We decided to solve this problem by creating a website, PSet Posse, in which students can input their living community, the classes they were currently taking, and classes they were willing to help underclassmen in. After inputting this information, users will be given a list of other students who live near them that are taking the same classes and have also signed up on PSet Posse (potential pset partners) as well as upperclassmen who have volunteered that they have taken the class, done well, and are willing to help.
## How we built it
For the back-end, we used Python to sort the data. Although the framework was initially messy, we successfully completed this task through object-oriented programming. Our python script reads in a file with all the data collected through the website and uses dictionaries to sort people into groups based on the classes they're taking. For the front end, at the beginning, we were planning on using Jekyll with GitHub Pages to create our website as none of us have any web dev experience. However, we soon realized that Jekyll only works with static websites and we needed to take input information and display results. We adapted an open source Bootstrap template to create our website.
## Challenges we ran into
We had a lot of trouble with the web dev because none of us really knew what we were doing. Right now the sign up page is reading in the information inputted but it's not properly saving it. In the future we'd need to figure out how to save the data to a central server and constantly update the list of potential people to work with as more people sign up (which would probably involve creating account with logins).
## Accomplishments that we're proud of
We're proud of making progress on this project because while we all have training in algorithmic CS none of us have done any web dev or app dev and we were really unsure how that would go.
## What we learned
Many of us learned a lot about how to use Github (not all of us had experience with it before this weekend). We all learned a lot about wed development and HTML and Bootstrap as well as the challenges and nuances of implementing even a straight forward idea. I think that it was also interesting when ideating moving from complicated ideas that sounded cool to realizing an easy way to make people's lives a little better often involves a simple fix.
## What's next for PSet Posse
There's a lot of work to be done on our website but once we have a server and accounts, we could potentially test our website in our dorm (supposing we first navigate any privacy concerns of collecting data about people's dorms and classes, etc.) and see how useful it is. | ## Inspiration
Transitioning from high school to college was pretty difficult for us, and figuring out which classes we needed to complete as prerequisites for upper-division classes turned out to be quite the hassle given the vast size of both high school and college course catalogs. We wanted to find a way to simplify the process of planning our schedules, so here we are.
## What it does
The backend provides detailed descriptions of what prerequisite classes you need to take in order to be eligible to enroll in a particular class, and whether or not it is possible to do so given your timeframe until graduation. The frontend provides a chatbot that helps guide you in an interactive way, providing both academic guidance and a charming personality to talk to.
## How we built it
* We realized we could represent courses and their prerequisites as directed acyclic graphs, so to sift through finding the shortest paths of getting from a prerequisite course to our desired course in a schedule, we utilized a reverse post-order depth-first search traversal (aka a topological sort) to parse through raw data provided in a tidy JSON format.
* We expanded by using "assumption"-based prerequisite clearances — i.e., eduVia will assume a student has also completed CS 61A if they input CS 61B (61A's sequel course) as completed.
* To put icing on the backend cake, we also organized non-conflicting classes into semester-/year-based schedules optimized for expediting graduation speed.
* Instead of using the vanilla HTML/CSS to design our website, we utilized a more modern framework, React.js, to structure our web application.
* For the front end, we implemented the React-Bootstrap library to make our UI look fancy and crisp.
* We also used an open-source chatbot library API to implement our academic assistant Via which will in theory help high school students plan out their four years.
## Challenges we ran into
* Figuring out how to effectively parse through a JSON file while simultaneously implementing an efficient topological sort was quite the steep learning curve at first.
* There were a slew of issues around the AM times with effectively clearing out *all* prerequisite classes based on a more advanced class - for example, we couldn't directly get rid of Pre-Calculus if we listed AP Calculus BC as a completed course, since PreCalc isn't a direct prereq of AP Calculus BC.
* Building out that semester-/year-based schedule was TOUGH! Values would aggregate together when they shouldn't and you'd have semesters where you're taking *every* class at once. It became near-impossible to build out after merging two different "class paths" together since the sorting became wonky and unusable.
* We were also fairly new to web development so it took a while to get used to the React.js framework and figure out the ins and outs. Given more time, we definitely could have made more progress on this project.
## Accomplishments that we're proud of
It was really rewarding to be able to implement a clean and efficient topological sort successfully, and there was a special joy in getting data to be displayed just the way we wanted it to be.
Learning how to use complex Python data structures, JavaScript, React, and several APIs (albeit to varying degrees of return on investment) on the fly was extremely thrilling.
## What we learned
JavaScript may be friendly, but React is your true friend. And Python is your BFF. And Google is just <3
## What's next for eduVia
* Better integration between the frontend and backend.
* Implementing an AI-powered chatbot (Co:here, anyone?) that can utilize browser cookies to remember conversations with users and provide better academic feedback.
* Providing full-fledged personalized 4-Year Plans for students based on their academic preferences, utilizing feature engineering and machine learning to weight the student's subject likings and make a schedule of classes suitable to their stated interests.
* Minor bug fixes. | ## Inspiration
As university students, we have been noticing issues with very large class sizes. With lectures often being taught to over 400 students, it becomes very difficult and anxiety-provoking to speak up when you don't understand the content. As well, with classes of this size, professors do not have time to answer every student who raises their hand. This raises the problem of professors not being able to tell if students are following the lecture, and not answering questions efficiently. Our hack addresses these issues by providing a real-time communication environment between the class and the professor. KeepUp has the potential to increase classroom efficiency and improve student experiences worldwide.
## What it does
KeepUp allows the professor to gauge the understanding of the material in real-time while providing students a platform to pose questions. It allows students to upvote questions asked by their peers that they would like to hear answered, making it easy for a professor to know which questions to prioritize.
## How We built it
KeepUp was built using JavaScript and Firebase, which provided hosting for our web app and the backend database.
## Challenges We ran into
As it was, for all of us, our first time working with a firebase database, we encountered some difficulties when it came to pulling data out of the firebase. It took a lot of work to finally get this part of the hack working which unfortunately took time away from implementing some other features (See what’s next section). But it was very rewarding to have a working backend in Firebase and we are glad we worked to overcome the challenge.
## Accomplishments that We are proud of
We are proud of creating a useful app that helps solve a problem that affects all of us. We recognized that there is a gap in between students and teachers when it comes to communication and question answering and we were able to implement a solution. We are proud of our product and its future potential and scalability.
## What We learned
We all learned a lot throughout the implementation of KeepUp. First and foremost, we got the chance to learn how to use Firebase for hosting a website and interacting with the backend database. This will prove useful to all of us in future projects. We also further developed our skills in web design.
## What's next for KeepUp
* There are several features we would like to add to KeepUp to make it more efficient in classrooms:
* Add a timeout feature so that questions disappear after 10 minutes of inactivity (10 minutes of not being upvoted)
* Adding a widget feature so that the basic information from the website can be seen in the corner of your screen at all time
* Adding Login for users for more specific individual functions. For example, a teacher can remove answered questions, or the original poster can mark their question as answered.
* Censoring of questions as they are posted, so nothing inappropriate gets through. | losing |
## Inspiration
Jessica here - I came up with the idea for BusPal out of expectation that the skill has already existed. With my Amazon Echo Dot, I was already doing everything from checking the weather to turning off and on my lights with Amazon skills and routines. The fact that she could not check when my bus to school was going to arrive was surprising at first - until I realized that Amazon and Google are one of the biggest rivalries there is between 2 tech giants. However, I realized that the combination of Alexa's genuine personality and the powerful location ability of Google Maps would fill a need that I'm sure many people have. That was when the idea for BusPal was born: to be a convenient Alexa skill that will improve my morning routine - and everyone else's.
## What it does
This skill enables Amazon Alexa users to ask Alexa when their bus to a specified location is going to arrive and to text the directions to a phone number - all hands-free.
## How we built it
Through the Amazon Alexa builder, Google API, and AWS.
## Challenges we ran into
We originally wanted to use stdlib, however with a lack of documentation for the new Alexa technology, the team made an executive decision to migrate to AWS roughly halfway into the hackathon.
## Accomplishments that we're proud of
Completing Phase 1 of the project - giving Alexa the ability to take in a destination, and deliver a bus time, route, and stop to leave for.
## What we learned
We learned how to use AWS, work with Node.js, and how to use Google APIs.
## What's next for Bus Pal
Improve the text ability of the skill, and enable calendar integration. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | ## Inspiration
Since the beginning of the hackathon, all of us were interested in building something related to helping the community. Initially we began with the idea of a trash bot, but quickly realized the scope of the project would make it unrealistic. We eventually decided to work on a project that would help ease the burden on both the teachers and students through technologies that not only make learning new things easier and more approachable, but also giving teachers more opportunities to interact and learn about their students.
## What it does
We built a Google Action that gives Google Assistant the ability to help the user learn a new language by quizzing the user on words of several languages, including Spanish and Mandarin. In addition to the Google Action, we also built a very PRETTY user interface that allows a user to add new words to the teacher's dictionary.
## How we built it
The Google Action was built using the Google DialogFlow Console. We designed a number of intents for the Action and implemented robust server code in Node.js and a Firebase database to control the behavior of Google Assistant. The PRETTY user interface to insert new words into the dictionary was built using React.js along with the same Firebase database.
## Challenges we ran into
We initially wanted to implement this project by using both Android Things and a Google Home. The Google Home would control verbal interaction and the Android Things screen would display visual information, helping with the user's experience. However, we had difficulty with both components, and we eventually decided to focus more on improving the user's experience through the Google Assistant itself rather than through external hardware. We also wanted to interface with Android things display to show words on screen, to strengthen the ability to read and write. An interface is easy to code, but a PRETTY interface is not.
## Accomplishments that we're proud of
None of the members of our group were at all familiar with any natural language parsing, interactive project. Yet, despite all the early and late bumps in the road, we were still able to create a robust, interactive, and useful piece of software. We all second guessed our ability to accomplish this project several times through this process, but we persevered and built something we're all proud of. And did we mention again that our interface is PRETTY and approachable?
Yes, we are THAT proud of our interface.
## What we learned
None of the members of our group were familiar with any aspects of this project. As a result, we all learned a substantial amount about natural language processing, serverless code, non-relational databases, JavaScript, Android Studio, and much more. This experience gave us exposure to a number of technologies we would've never seen otherwise, and we are all more capable because of it.
## What's next for Language Teacher
We have a number of ideas for improving and extending Language Teacher. We would like to make the conversational aspect of Language Teacher more natural. We would also like to have the capability to adjust the Action's behavior based on the student's level. Additionally, we would like to implement a visual interface that we were unable to implement with Android Things. Most importantly, an analyst of students performance and responses to better help teachers learn about the level of their students and how best to help them. | winning |
## Intro
Not many people understand Cryptocurrencies - let alone the underlying technology behind most of them, the Blockchain. Using an immersive and friendly UI, we built a easy to understand, realtime visualization of the blockchain in VR space with the Oculus Rift.
## How We Built It
The models in Unreal Engine, and blockchain data interfaced from blockchain.info API. In VR space, blockchain data is downloaded from our backend and updated in realtime.
## Challenges we ran into
Pretty much everything (first time using every single piece of tech during this hackathon). In particular, dealing with the sheer size of the blockchain (~150GB) and being able to update new transactions in realtime were hard, given our limited computing power and storage space.
## What we learned
Turns out learning to use a AAA game engine in 24hours is harder than it looks.
## What's next for Blockchain VR
Integrate machine learning, big data, microtransactions, and release it as an ICO (!!!!!!) | ## Inspiration
We are a group of friends who are interested in cryptography and Bitcoin in general but did not have a great understanding. However, attending Sonr's panel gave us a lot of inspiration because they made the subject more digestible and easier to understand. We also wanted to do something similar but add a more personal touch by making an educational game on cryptography. Fun fact: the game is set in hell because our initial calculations yielded that we can buy approximately 6666 bananas ($3) with one bitcoin!
## What it does
*Devil's Advocate* explains cryptography and Bitcoin, both complicated topics, in a fun and approachable way. And what says fun like games? The player is hired as Satan's advocate at her company Dante’s Bitferno, trying to run errands for her using bitcoins. During their journey, they face multiple challenges that also apply to bitcoins in real life and learn all about how blockchains work!
## How we built it
We built by using JavaFX as the main groundwork for our application and had initially planned to embed it into a website using Velo by Wix but decided to focus our efforts on the game itself using JavaFX, HTML, and CSS. The main IDE we used was Intellij with git version control integration to make teamwork much easier and more efficient.
## Challenges we ran into
Having to catch a flight from Durham right after our classes, we missed the opening ceremony and started later than most other teams. However, we were quickly able to catch up by setting a time limit for most things, especially brainstorming. Only one of our members knew how to use JavaFX, despite it being the main groundwork for our project. Luckily other members were able to pick it up fairly quickly and were able to move on to a divide and conquer strategy.
## Accomplishments that we're proud of
We are most impressed by what we taught ourselves how to do in a day. For instance, some of our members learned how to use JavaFX others how to use various design software for UX/UI and graphic design. We are also proud of how the artwork turned out, considering that all of them were drawn by hand using Procreate.
## What we learned
While learned a lot of things in such a short amount of time, it definitely took us the most time to learn how to use JavaFX to design fluent gameplay by integrating various elements such as text or images. We also had to research on cryptography to make sure that our knowledge on the subject was correct, considering that we are making an educational game.
## What's next for Devil's Advocate
We plan to continue building more levels beyond the first level and offer explanations on other characteristics of blockchain, such as how it is decentralized, has smart contract, or utilizes a consensus algorithm. We also want to add more sprites to Satan to make her feel more expressive and provide a richer gameplay experience to users. | ## Inspiration
We are all software/game devs excited by new and unexplored game experiences. We originally came to PennApps thinking of building an Amazon shopping experience in VR, but eventaully pivoted to Project Em - a concept we all found mroe engaging. Our swtich was motivated by the same force that is driving us to create and improve Project Em - the desire to venture into unexplored territory, and combine technologies not often used together.
## What it does
Project Em is a puzzle exploration game driven by Amazon's Alexa API - players control their character with the canonical keyboard and mouse controls, but cannot accomplish anything relevant in the game without talking to a mysterious, unknown benefactor who calls out at the beginning of the game.
## How we built it
We used a combination of C++, Pyhon, and lots of shell scripting to create our project. The client-side game code runs on Unreal Engine 4, and is a combination of C++ classes and Blueprint (Epic's visual programming language) scripts. Those scripts and classes communicate an intermediary server running Python/Flask, which in turn communicates with the Alexa API. There were many challenges in communicating RESTfully out of a game engine (see below for more here), so the two-legged approach lent itself well to focusing on game logic as much as possible. Sacha and Akshay worked mostly on the Python, TCP socket, and REST communication platform, while Max and Trung worked mainly on the game, assets, and scripts.
The biggest challenge we faced was networking. Unreal Engine doesn't naively support running a webserver inside a game, so we had to think outside of the box when it came to networked communication.
The first major hurdle was to find a way to communicate from Alexa to Unreal - we needed to be able to communicate back the natural language parsing abilities of the Amazon API to the game. So, we created a complex system of runnable threads and sockets inside of UE4 to pipe in data (see challenges section for more info on the difficulties here). Next, we created a corresponding client socket creation mechanism on the intermediary Python server to connect into the game engine. Finally, we created a basic registration system where game clients can register their publicly exposed IPs and Ports to Python.
The second step was to communicate between Alexa and Python. We utilitzed [Flask-Ask](https://flask-ask.readthedocs.io/en/latest/) to abstract away most of the communication difficulties,. Next, we used [VaRest](https://github.com/ufna/VaRest), a plugin for handing JSON inside of unreal, to communicate from the game directly to Alexa.
The third and final step was to create a compelling and visually telling narrative for the player to follow. Though we can't describe too much of that in text, we'd love you to give the game a try :)
## Challenges we ran into
The challenges we ran into divided roughly into three sections:
* **Threading**: This was an obvious problem from the start. Game engines rely on a single main "UI" thread to be unblocked and free to process for the entirety of the game's life-cycle. Running a socket that blocks for input is a concept in direct conflict with that idiom. So, we dove into the FSocket documentation in UE4 (which, according to Trung, hasn't been touched since Unreal Tournament 2...) - needless to say it was difficult. The end solution was a combination of both FSocket and FRunnable that could block and certain steps in the socket process without interrupting the game's main thread. Lots of stuff like this happened:
```
while (StopTaskCounter.GetValue() == 0)
{
socket->HasPendingConnection(foo);
while (!foo && StopTaskCounter.GetValue() == 0)
{
Sleep(1);
socket->HasPendingConnection(foo);
}
// at this point there is a client waiting
clientSocket = socket->Accept(TEXT("Connected to client.:"));
if (clientSocket == NULL) continue;
while (StopTaskCounter.GetValue() == 0)
{
Sleep(1);
if (!clientSocket->HasPendingData(pendingDataSize)) continue;
buf.Init(0, pendingDataSize);
clientSocket->Recv(buf.GetData(), buf.Num(), bytesRead);
if (bytesRead < 1) {
UE_LOG(LogTemp, Error, TEXT("Socket did not receive enough data: %d"), bytesRead);
return 1;
}
int32 command = (buf[0] - '0');
// call custom event with number here
alexaEvent->Broadcast(command);
clientSocket->Close();
break; // go back to wait state
}
}
```
Notice a few things here: we are constantly checking for a stop call from the main thread so we can terminate safely, we are sleeping to not block on Accept and Recv, and we are calling a custom event broadcast so that the actual game logic can run on the main thread when it needs to.
The second point of contention in threading was the Python server. Flask doesn't natively support any kind of global-to-request variables. So, the canonical approach of opening a socket once and sending info through it over time would not work, regardless of how hard we tried. The solution, as you can see from the above C++ snippet, was to repeatedly open and close a socket to the game on each Alexa call. This ended up causing a TON of problems in debugging (see below for difficulties there) and lost us a bit of time.
* **Network Protocols**: Of all things to deal with in terms of networks, we spent he largest amount of time solving the problems for which we had the least control. Two bad things happened: heroku rate limited us pretty early on with the most heavily used URLs (i.e. the Alexa responders). This prompted two possible solutions: migrate to DigitalOcean, or constantly remake Heroku dynos. We did both :). DigitalOcean proved to be more difficult than normal because the Alexa API only works with HTTPS addresses, and we didn't want to go through the hassle of using LetsEncrypt with Flask/Gunicorn/Nginx. Yikes. Switching heroku dynos it was.
The other problem we had was with timeouts. Depending on how we scheduled socket commands relative to REST requests, we would occasionally time out on Alexa's end. This was easier to solve than the rate limiting.
* **Level Design**: Our levels were carefully crafted to cater to the dual player relationship. Each room and lighting balance was tailored so that the player wouldn't feel totally lost, but at the same time, would need to rely heavily on Em for guidance and path planning.
## Accomplishments that we're proud of
The single largest thing we've come together in solving has been the integration of standard web protocols into a game engine. Apart from matchmaking and data transmission between players (which are both handled internally by the engine), most HTTP based communication is undocumented or simply not implemented in engines. We are very proud of the solution we've come up with to accomplish true bidirectional communication, and can't wait to see it implemented in other projects. We see a lot of potential in other AAA games to use voice control as not only an additional input method for players, but a way to catalyze gameplay with a personal connection.
On a more technical note, we are all so happy that...
THE DAMN SOCKETS ACTUALLY WORK YO
## Future Plans
We'd hope to incorporate the toolchain we've created for Project Em as a public GItHub repo and Unreal plugin for other game devs to use. We can't wait to see what other creative minds will come up with!
### Thanks
Much <3 from all of us, Sacha (CIS '17), Akshay (CGGT '17), Trung (CGGT '17), and Max (ROBO '16). Find us on github and say hello anytime. | partial |
## Inspiration
The idea for SafeOStroll came from those moments of unease many of us experience while walking alone at night. Imagine heading home after a long day or en route to meet friends. You pass through an area that feels unsafe, glancing over your shoulder, alert to every sound. That lingering sense of vulnerability is something most of us can relate to.
This inspired us to create SafeOStroll—a personal safety tool designed to be your constant companion. Whether navigating dimly lit streets or unfamiliar environments, SafeOStroll provides reassurance and peace of mind.
>
> "As someone who often feels uneasy walking at night but has no choice but to do so after work or university, this app is a game changer for me. It gives me confidence knowing I have a companion to talk to—whether it's offering advice on safety or simply a comforting conversation." — Arina
>
>
>
Our goal is not just to enhance individual safety but to foster a greater sense of security in communities. By integrating emergency support, community alerts, and AI-driven emotional assistance, SafeOStroll aims to empower individuals and build safer environments worldwide.
## What It Does
**SafeOStroll** is your ultimate safety companion, always by your side when you need it most. Whether you’re heading home late, passing through unfamiliar neighborhoods, or just feeling uneasy, SafeOStroll ensures you're never alone.
The app’s core feature is its **AI-powered emotional assistant**, providing comfort and guidance in stressful moments. Whether walking down an empty street or facing an uncertain situation, the AI offers **reassurance, advice**, and **support**—like having a trusted companion with you at all times.
This AI assistant engages in calming conversations and delivers **personalized suggestions** for handling anxiety or unsafe scenarios. It ensures that even when you're nervous, you're never left feeling isolated.
Behind the scenes, SafeOStroll's **emergency features** are always ready to activate. In a crisis, you can trigger an **instant response**—alerting both authorities and nearby users. Your **location is shared**, creating a safety network that mobilizes in real-time.
SafeOStroll goes beyond physical safety, addressing emotional well-being by combining **AI-driven support** with a **community safety network**, ensuring users feel connected and secure as they navigate public spaces.
### Stay calm. Stay connected. Stay safe.
## How We Built It
Building SafeOStroll involved combining advanced technologies with a user-centered approach, ensuring seamless functionality and safety:
### AI-Powered Emotional Support
At the heart of SafeOStroll is our **AI-powered assistant**, developed using **OpenAI’s GPT-4, tts1-hd, and whisper-1 API**. This AI engages in calming conversations and offers **actionable advice** during stressful situations. The AI continuously learns from user interactions, improving its ability to provide personalized support. We also utilized **WebSockets** to ensure real-time communication between users and the AI assistant, creating a more interactive and responsive experience. The goal: ensure users never feel alone.
### Real-Time Emergency Response
The app’s emergency features are built on a robust **Django backend**. With one tap, users can send distress signals to **911** and notify nearby users. **Cloudflare** ensures fast and secure transmission of real-time data, offering safety at your fingertips.
### Mobile-Optimized Frontend
Using **React**, we built a **mobile-first** interface that delivers a seamless experience across devices. The app updates user coordinates every 10 seconds, providing real-time tracking in emergencies.
### Design & Security
The user interface is both calming and intuitive, with **gradient designs** and **hover effects** creating a sense of reassurance. Data is secured with **encryption**, ensuring all user information stays private.
---
## Challenges We Faced
Building SafeOStroll presented unique challenges that tested our technical and creative abilities.
### 1. AI Responsiveness
Creating an AI that felt natural while offering **timely advice** was a key challenge. We had to balance providing calming conversations with actionable suggestions, ensuring the AI felt **supportive but not clinical**. Also, making it so that the AI would have its own allocated memory was a challenge we had to overcome.
### 2. Real-Time Location Tracking
Implementing accurate **real-time location tracking** without draining users' battery required significant optimization. We needed to maintain frequent updates while minimizing energy consumption.
### 3. Data Privacy & Security
Handling sensitive user data, like locations and emergency signals, raised significant privacy concerns. We had to ensure all communications were encrypted while keeping the app responsive.
### 4. User-Friendly Design
Creating an intuitive, **reassuring interface** for users in distress was more challenging than expected. We had to ensure that the emergency and AI features were easy to access without overwhelming the user.
### 5. API Integration
Since this was our first time integrating the OpenAI API, figuring out how to get the different AI systems (TTS and STT) to interact with the user while still having an optimal response time was challenging. We also had to be careful with the training we gave the AI, as we didn't want the AI to act as a therapist but rather as a friend who can give you specialized advice.
---
## Accomplishments We're Proud Of
We achieved several key milestones in developing SafeOStroll, each reflecting our dedication to creating a reliable and secure safety tool.
### 1. AI-Driven Emotional Support
Our **AI assistant** offers real-time emotional support using **OpenAI’s GPT-4, tts1-hd, and whisper-1 API**, providing calming conversations and personalized advice that adapts over time through integration.
### 2. Diversity
Another part of our project that we are proud of is that we can provide AI conversations in all current live languages, making it so that all users can communicate with the AI through their native tongue.
### 3. Seamless Real-Time Emergency Response
We developed a **real-time alert system** that connects users with emergency services and nearby SafeOStroll users. Powered by **Django** and **Cloudflare**, this system ensures distress signals are transmitted securely and swiftly.
### 4. Optimized Location Tracking
Our software updates user coordinates every 10 seconds to ensure accurate & precise location tracking without significant battery drain, improving emergency response accuracy.
### 5. User-Centered Design
Our **mobile-first** interface prioritizes ease of use, making it simple for users to send alerts, access the AI assistant, and navigate features during stressful moments.
### 6. Robust Data Privacy & Security
We ensured all user data is encrypted, providing a secure experience without compromising performance.
### 7. Secured Connection
We secured the connection between our **React** frontend and the insecure backend host through **Cloudflare**, enhancing the overall security of the application.
---
## What We Learned
The SafeOStroll development journey taught us valuable lessons about technology, design, and user needs.
### 1. User-Centered Design
We learned the importance of **constant iteration** and feedback in creating a user-friendly interface, especially for users in distress.
### 2. AI Empathy
Designing an AI that provides emotional support without seeming robotic was challenging. We learned the importance of natural conversation flow and empathetic responses.
### 3. Security Is Essential
Handling sensitive user data highlighted the need for robust **encryption** and **privacy protocols** to maintain user trust and protect their information.
### 4. Optimizing Real-Time Systems
We gained insight into **optimizing real-time systems**, ensuring fast, reliable, and energy-efficient performance.
### 5. WebSockets
We learned that we can use WebSockets for communication between server and client for having stateful conversations.
---
## What's Next for SafeOStroll
SafeOStroll’s journey is far from over, and we have exciting plans for the future.
### 1. Expanding AI Capabilities
We plan to further enhance the AI’s ability to provide **tailored support**, learning from user interactions to offer more personalized advice.
### 2. Health Data Tracking Integration
In the future, using technologies like Fitbit or Apple Watch, we can track the user's health data (such as BPM and stress detection) to have the AI more accurately assess the user's real-time situation.
--- | ## Inspiration
As college kids who often have late classes and extracurricular activities, we wanted to create an app that reassures our safety.
## What it does
SafeRoute allows the user to enter their start and end location. The app then tracks the user's location as they walk along the route. If the user deviates from the preset route, the app sends a text message to the user's emergency contact.
## How we built it
We created this app using Swift on Xcode. We integrated the Google Maps and Directions APIs. We also integrated the Twilio API for text messaging.
1. Google Maps and Directions API: Creates the route between the user's start and end location.
Checks if user's current location is in the path of predefined route.
2. Twilio: Sends a SOS message to the user's emergency contact (if the user has deviated from the path without notifying the app)
3. DocuSign: Creates a waiver that allows SafeRoute to collect and use the user's emergency contacts' information (In process of integration)
## Challenges we ran into
The biggest challenge we ran into was calculating the route between the user's start and end point.
## Accomplishments that we're proud of
We are proud that we learned how to use a new API - Google Maps and Directions.
## What we learned
We learned how to integrate multiple APIs into one application.
## What's next for SafeRoute
1. Implementation of a feature that allows the user to notify the app when they deviate on purpose.
2. Implementation of a feature that notifies emergency contact of the user's last location.
3. Addition of SOS button that notifies 911
4. Functionality of sharing locations with different users using SafeRoute
5. Release of app for bigger cities, starting with college students | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | losing |
## Inspiration
Have you ever run into the situation where you are trying to find a roommate that you are compatible with and that your current roommates will like as well? Are you tired of having the same discussion with each other roommate trying to pick the best candidate, whether it is online or offline?
## What it does
Crowd vote your next roommate at your fingertips! As someone looking for a place to rent, simply go on bunkieballot.tech, select the listings you are interested in checking out, and click submit. Now the current renters of each of the selected listings will get notified via a text message, which will contain the candidate's profile. Then they can each reply back with a score of 1-10 to indicate how much you like this candidate. After all the votes are collected, Bunkie Ballot will tally the scores for each applicant of each listing. Finally the roommates will see the list of applicants in order of high to low ratings.
## How we built it
We utilized StdLib as a serverless backend to implement the sending and receiving of text messages, mongoDB for database, and React and Javascript for web UI.
## Challenges we ran into
As StdLib is new and our team is also learning it hands on, we ran into a few challenges mainly revolving around connecting JS API calls to StdLib functions, making DB calls to Mongo, and in general how to send and receive text messages from the StdLib functions.
## Accomplishments that we're proud of
We mastered the StdLib technology!
## What we learned
We learned how to use StdLib to build a peer roommate voting system!
## What's next for BunkieBallot
-more fair and robust rating algorithm
-more elaborate user profile
-more user friendly text messages | ## Inspiration
As roommates, we found that keeping track of our weekly chore schedule and house expenses was a tedious process, more tedious than we initially figured.
Though we created a Google Doc to share among us to keep the weekly rotation in line with everyone, manually updating this became hectic and cumbersome--some of us rotated the chores clockwise, others in a zig-zag.
Collecting debts for small purchases for the house split between four other roommates was another pain point we wanted to address. We decided if we were to build technology to automate it, it must be accessible by all of us as we do not share a phone OS in common (half of us are on iPhone, the other half on Android).
## What it does
**Chores:**
Abode automatically assigns a weekly chore rotation and keeps track of expenses within a house. Only one person needs to be a part of the app for it to work--the others simply receive a text message detailing their chores for the week and reply “done” when they are finished.
If they do not finish by close to the deadline, they’ll receive another text reminding them to do their chores.
**Expenses:**
Expenses can be added and each amount owed is automatically calculated and transactions are automatically expensed to each roommates credit card using the Stripe API.
## How we built it
We started by defining user stories and simple user flow diagrams. We then designed the database where we were able to structure our user models. Mock designs were created for the iOS application and was implemented in two separate components (dashboard and the onboarding process). The front and back-end were completed separately where endpoints were defined clearly to allow for a seamless integration process thanks to Standard Library.
## Challenges we ran into
One of the significant challenges that the team faced was when the back-end database experienced technical difficulties at the tail end of the hackathon. This slowed down our ability to integrate our iOS app with our API. However, the team fought back while facing adversity and came out on top.
## Accomplishments that we're proud of
**Back-end:**
Using Standard Library we developed a comprehensive back-end for our iOS app consisting of 13 end-points, along with being able to interface via text messages using Twilio for users that do not necessarily want to download the app.
**Design:**
The team is particularly proud of the design that the application is based on. We decided to choose a relatively simplistic and modern approach through the use of a simple washed out colour palette. The team was inspired by material designs that are commonly found in many modern applications. It was imperative that the designs for each screen were consistent to ensure a seamless user experience and as a result a mock-up of design components was created prior to beginning to the project.
**Use case:**
Not only that, but our app has a real use case for us, and we look forward to iterating on our project for our own use and a potential future release.
## What we learned
This was the first time any of us had gone into a hackathon with no initial idea. There was a lot of startup-cost when fleshing out our design, and as a result a lot of back and forth between our front and back-end members. This showed us the value of good team communication as well as how valuable documentation is -- before going straight into the code.
## What's next for Abode
Abode was set out to be a solution to the gripes that we encountered on a daily basis.
Currently, we only support the core functionality - it will require some refactoring and abstractions so that we can make it extensible. We also only did manual testing of our API, so some automated test suites and unit tests are on the horizon. | ## Inspiration
We have to make a lot of decisions, all the time- whether it's choosing your next hackathon project idea, texting your ex or not, writing an argumentative essay, or settling a debate. Sometimes, you need the cold hard truth. Sometimes, you need someone to feed into your delusions. But sometimes, you need both!
## What it does
Give the Council your problem, and it'll answer with four (sometimes varying) AI-generated perspectives! With 10 different personalities to choose from, you can get a bunch of (imaginary) friends to weigh in on your dilemmas, even if you're all alone!
## How we built it
The Council utilizes OpenAI's GPT 3.5 API to generate responses unique to our 10 pre-defined personas. The UI was built with three.js and react-three-fiber, with a mix of open source and custom-built 3D assets.
## Challenges we ran into
* 3D hard
* merge conflict hard
* Git is hard
## Accomplishments that we're proud of
* AI responses that were actually very helpful and impressive
* Lots of laughs from funny personalities
* Custom disco ball (SHEEEEEEEEESH shoutout to Alan)
* Sexy UI (can you tell who's writing this)
## What we learned
This project was everyone's first time working with three.js! While we had all used OpenAI for previous projects, we wanted to put a unique spin on the typical applications of GPT.
## What's next for The Council
We'd like to actually deploy this app to bring as much joy to everyone as it did to our team (sorry to everyone else in our room who had to deal with us cracking up every 15 minutes) | partial |
## Inspiration
In an era of endless short-form content, it's easy to become overwhelmed. Our inspiration springs from a desire to use this attention-capturing format for good. We believe that short-form content is not just a trend but a powerful tool for education, one that can adapt to the fast-paced lifestyle of modern learners. Think TikTok, but for learning.
## What it does
Imagine a personal learning assistant that knows exactly what piques your interest and challenges your intellect. That's what our platform offers. By leveraging ChatGPT, we create concise, informative articles on a wide array of topics, curated to the user's preferences and learning goals. But we don’t just stop at providing information; we engage the user further. Each article is accompanied by generated thought-provoking questions, designed to encourage critical thinking and deeper comprehension. These follow-up queries aren't just random; they're smartly generated to ensure that the learning objectives are met, turning passive reading into an active learning session.
## How we built it
We intended on building it with the following tech stack: Node.js backend, SwiftUI frontend, and an ElephantSQL database. However, for our demo we transitioned to solely using SwiftUI, mock data, and communication with the ChatGPT API on the frontend for the presentation as we had issues with DNS propagation and SSL certificates when trying to communicate with a Node.js backend API server hosted on AWS.
## Challenges we ran into
We ran into quite a few challenges while working on setting up an API server for our mobile app to interact with. The first of which was deploying the API server to AWS Elastic Beanstalk. We spent a lot of time debugging IAM roles, proper file structure, and configuring environment properties, but ended up deploying a working API server and PostgreSQL database. Unfortunately, our mobile application was not able to interact with the API server as XCode does not allow sending non-HTTPS requests, and our server did not have an SSL certificate. We tried purchasing a domain name and an SSL certificate, but it took too long for the certificate to be approved. However, we got around this roadblock by creating mock data and interacting directly with the ChatGPT API in the front-end to demonstrate all of the features of our app.
We also had to balance our time with planning versus building the app well. Specifically, we tried to move quickly from database and API design to implementation. This allowed us to catch this SSL certificate issue early and move towards a leaner, working MVP for the presentation.
## Accomplishments that we're proud of
We're proud of the agility and problem-solving skills we demonstrated in navigating deployment challenges. Our ability to pivot and still present a working model with complex logic directly on the frontend within a limited timeframe is a testament to our team's resilience and adaptability.
## What we learned
We learned the importance of early SSL certification in API server setup and gained valuable experience in integrating a mobile app with the ChatGPT API. We also deepened our understanding of SwiftUI for app development, learning to rapidly prototype and iterate on our design.
## What's next for LearnAI
Our next steps involve securing the SSL certificate to enable HTTPS communication between our mobile app and the API server. This will allow us to move beyond mock data, implementing a robust system that tracks user interactions and preferences, fully harnessing the database's capabilities to personalize the educational experience. We will also work on a fully-fledged design for the mobile app that allows users to view past upvotes, share facts, and more. | ## Inspiration
It took way too long to add a new friend on every single social media upon one encounter. So I wanted to eliminate all this time waste every single time I wanted to connect with someone.
## What it does
It saves users time connecting by selecting exactly which social medias they want to connect with and press ONE button. That's right it saves people loads of time.
## How we built it
We decided to use react-native as it's great for phone apps.
## Challenges we ran into
The React-native camera was very bugging and caused a lot of errors. It was a very difficult component to import.
## Accomplishments that we're proud of
Getting the QR code scanner working in order to pass data and therefore commands. Also the authentication tokens used to call back-end functions keeping this app secure.
## What we learned
How to work as a team and deal with the wonderful distractions at Penn. Overall we learned a lot about react-native and trouble shooting problems we encountered. We also learned to ask for help at the right times and think as a group.
## What's next for Social Connect
Social Connect v2.0 will be a lot better in both performance and features. It will be redesigned in order to work with more social media platforms and do the connections more efficiently. Efficiency is a big factor that will be improved as well as the overall UI. We didn't have too much time to design everything but we got it done! | ## Inspiration
**With the world producing more waste then ever recorded, sustainability has become a very important topic of discussion.** Whether that be social, environmental, or economic, sustainability has become a key factor in how we design products and how we plan for the future. Especially during the pandemic, we turned to becoming more efficient and resourceful with what we had at home. Thats where home gardens come in. Many started home gardens as a hobby or a cool way to grow your own food from the comfort of your own home. However, with the pandemic slowly coming to a close, many may no longer have the time to micromanage their plants, and those who are interested in starting this hobby may not have the patience. Enter *homegrown*, an easy way for people anyone interested in starting their own mini garden to manage their plants and enjoy the pleasures of gardening.
## What it does
*homegrown* monitors each individual plant, adjusted depending on the type of plant. Equipped with different sensors, *homegrown* monitors the plants health, whether that's it's exposure to light, moisture, or temperature. When it detects fluctuations in these levels, *homegrown* sends a text to the owner, alerting them about the plants condition and suggesting changes to alleviate these problems.
## How we built it
*homegrown* was build using python, an arduino, and other hardware components. The different sensors connected to the arduino take different measurements and record them. They are then sent as one json file to the python script where they data is then further parsed and sent by text to the user through the twilio api.
## Challenges we ran into
We originally planned on using CockroachDB as a data based but scrapped idea since dealing with initializing the database and trying to extract data out of it proved to be too difficult. We ended up using an arduino instead to send the data directly to a python script that would handle the data. Furthermore, ideation took quite a while because it was all out first times meeting each other.
## Accomplishments that we're proud of
Forming a team when we've all never met and have limited experience and still building something in the end was something that brought together each of our respective skills is something that we're proud of. Combining hardware and software was a first for some of us so we're proud of adapting quickly to cater to each others strengths
## What we learned
We learned more about python and its various libraries to build on each other and create more and more complex programs. We also learned about how different hardware components can interact with software components to increase functionality and allow for more possibilities.
## What's next for homegrown
*homegrown* has the possibility to grow bigger, not only in terms of the number of plants which it can monitor growth for, but also the amount of data if can take in surrounding the plant. With more data comes more functionality which allows for more thorough analysis of the plant's conditions to provide a better and more efficient growing experience for the plant and the user. | losing |
## Inspiration
**Affordable Delivery to every Canadian**
## What it does
The USP of this application is affordable delivery for every Canadian. The cost of home delivery of items ranges from about $10 - $20, however using this application the delivery cost can be brought down to about $2-$3. The reason being the deliveries are done using the OC Transpo infrastructure with a monthly pass of $200. Further students and people who don’t have a car can participate in delivery of items and earn money.
It is a Web App which supports the delivery of items at OC Transpo Bus stops. Using the app the customer can request the delivery/pickup of an item at the bus stop nearest to him. The customer can track the delivery of his orders and is also notified when the delivery/pickup is about to reach the requested bus stop. Upon receiving the notification the customer reaches the bus stop to hand over the items for delivery or accepts the item delivery.
The application has the following key features:
• Accepts item delivery/pickup request from the customers
• Notifies the customer when the delivery/pickup is about to reach his nearest bus stop
• Delivers/Picks up items at the requested bus stop
## How we built it
The application is built using Java swing and Solace event broker. There are two applications, one sending messages (a producer) and one receiving messages (consumer) which are communicating with each other. | ## Inspiration
Our frustrations with the lack of transparency regarding where a package "in-transit" actually is.
## What it does
PackageHound is a device that improves Canada Post's "in-transit" parcel tracking state to show more accurate status as well as allow better delivery time estimates. Our project is a combination WiFi enabled micro-controller (ESP32) and mobile app. Our IoT device will be attached to the outside of packages like a shipping label, and whenever the package reaches a new destination (E.g: Moved from pre-sort to sort) it will connect to a Wireless router and send an message to our server changing it's transit state. On our mobile app users are able to enter the tracking number of their parcels and find them displayed on a map, along with their improved tracking state information
## How we built it
Our physical device is an ESP32 micro-controller programmed to connect to Canada Post WiFi nodes and send the node currently connected node to our server, through MQTT to the Solace Message Broker software.
Our server is written in Python and hosted on the Google Cloud. It uses MQTT and the Solace Message Broker to listen for any changes to package states and update the database, as well as handles any requests by our app for a packages state.
## Challenges we ran into
Originally our back-end was designed using a REST API and had to be rewritten to use MQTT and the Solace Message Broker. This initially created a large challenge of rewriting our embedded code and our server code. Luckily the sponsors at Solace were very helpful and when we had difficulties using MQTT they walked us through the process of integrating it within our code.
## Accomplishments that we're proud of
We had never used an ESP32 or Solace's Message Broker before, so it was quite challenging to develop for them, let alone combine them into a single project, so we are very proud that we were able successfully develop our project using both of them.
## What we learned
We learnt lots about the Publish/Subscribe messaging model, as well as lots about programming with the ESP32 and utilizing it's WiFi functionality.
## What's next for PackageHound
We hope to develop PackageHound further with InnovaPost and turn our prototype into a reality! | ## Inspiration
These days, Emergency Response times for Ambulances have hiked to a whopping **150%** with **Covid19** positive patients asked to stay home for more than 2-3 days. Patients dealing with real emergencies often are receiving their ambulances late. Every second matters, and we can’t afford to lose a life because of delayed emergency response times.
## What it does
Introducing **AmbuPlus+** — a smart Ambulance service, which brings the nearest rescue squad to your home. You can also request blood from other users and blood banks. We have used Solace extensively in order to track Ambulances realtime. Ambulances push their live locations to specific topics which the backend subscribes to. The backend calculates the nearest Ambulance and matches the same when an user is in need. After this, the user’s application subscribes to the topic this ambulance is publishing its real time location to. We also confirm if beds are available at the hospital we might be going to & last but not the least it's supported by all devices above Android Lollipop!
**Expect fast, Worry less with Ambuplus+** 🚑
## How we built it
**Ambuplus+** is crafted with ❤️. It's built on Android Native. We are using Solace's Pub-Sub for live-tracking of the ambulances and for initiating the blood request from the user end. We're also using Google Maps API to populate the info's of the same on the map viewport. The authentication of our app is being served via Firebase Authentication. And last but not the least, the chat server was deployed on a free dyno of Heroku. Our app is available in most local languages like Hindi, Bengali, Chinese, Korean, etc.
## Challenges we ran into
We took a lot of time configuring and refactoring the example code of the Solace. Moreover, we were also looking at the security side of the location which is a very important thing to be kept in mind for these types of projects. Also, it was a bit difficult for us to collaborate in a virtual setting but we somehow managed to finish the project on time.
## Accomplishments that we're proud of
We are proud of finishing the project on time which seemed like a tough task initially but happily were also able to add most of the features that we envisioned for the app during ideation.
## What we learned
A lot of things, both summed up in technical & non-technical sides. Also not to mention, we enhanced our googling and Stackoverflow searching skill during the hackathon 😆
## What's next for Ambuplus+
We just really want this project to have a positive impact on people's lives! Still, we would love to make it more scalable & cross-platform so that the user interaction increases to a great extent :) | losing |
## Inspiration
Presentation inspired by classic chatbots
## What it does
Interfaces with gpt through mindsdb, and engineers the prompt to lead towards leading questions. Saves the query's entered by the user and on a regular interval generates a quiz on topics related to the entries, at the same skill level.
## How we built it
Using reflex for the framework, and mindsdb to interface with gpt
## Challenges we ran into
During the duration of this challenge, we had noticed a significant productivity curve; especially at night. This was due to multiple factors, but the most apparent one is a lack of preparation with us needing to download significant files during the peak hours of the day.
## Accomplishments that we're proud of
We are extremely satisfied with our use of the reflex framework; this season our team comprised of only 2 members with no significant web development history. So we are proud that we had optimized our time management so that we could learn while creating.
## What we learned
Python,git,reflex,css
## What's next for Ai-Educate
We want to get to the point where we can save inputs into a large database so that our program is not as linear, if we were to implement this, older topics would appear less often but would not disappear outright. We also want a better way to determine the similarity between two inputs, we had significant trouble with that due to our reliance of gpt, we believe that the next best solution is to create our own Machine Learning engine, combined with user rating of correctness of assessment.
We were also looking into ripple, as we understand it, we could use it to assign a number of points to our users, and with those points we can limit their access to this resource, and we can also distribute points through our quizzes, this would foster a greater incentive to absorb the content as it would enable users to have more inputs | With months spent at home, many of us have spent many hours curating various playlists to reflect our moods. For this hackathon, we decided to streamline this process, and create a web app that can offer new playlists for people to listen to.
Our project, moodify, can detect the user's mood through auditory or written cues. Users also have the option to select a mood from a dropdown menu within the app. Moodify will then determine the user's mood, before suggesting playlists that the user may like.
We built moodify using react and node.js. We also used Microsoft azure API to detect the user's mood and then the spotify API to allow the app to modify and suggest playlists to the user. The app was styled using css and bootstrap.
Several challenges that we faced included integrating the azure and spotify APIs. Given how crucial they are to our app, it was important that they were connected and working.
We're proud of how our final product looks.
Through this project, we improved our web development skills, and developed experience working with various APIs.
In the future, we would love to create new playlists for users with unique songs that don’t belong in their own playlist. This way, the user would be able to receive a brand new playlist and discover some new songs. | ## Inspiration
Imagine you're sitting in your favorite coffee shop and a unicorn startup idea pops into your head. You open your laptop and choose from a myriad selection of productivity tools to jot your idea down. It’s so fresh in your brain, you don’t want to waste any time so, fervently you type, thinking of your new idea and its tangential components. After a rush of pure ideation, you take a breath to admire your work, but disappointment. Unfortunately, now the hard work begins, you go back though your work, excavating key ideas and organizing them.
***Eddy is a brainstorming tool that brings autopilot to ideation. Sit down. Speak. And watch Eddy organize your ideas for you.***
## Learnings
Melding speech recognition and natural language processing tools required us to learn how to transcribe live audio, determine sentences from a corpus of text, and calculate the similarity of each sentence. Using complex and novel technology, each team-member took a holistic approach and learned news implementation skills on all sides of the stack.
## Features
1. **Live mindmap**—Automatically organize your stream of consciousness by simply talking. Using semantic search, Eddy organizes your ideas into coherent groups to help you find the signal through the noise.
2. **Summary Generation**—Helpful for live note taking, our summary feature converts the graph into a Markdown-like format.
3. **One-click UI**—Simply hit the record button and let your ideas do the talking.
4. **Team Meetings**—No more notetakers: facilitate team discussions through visualizations and generated notes in the background.

## Challenges
1. **Live Speech Chunking** - To extract coherent ideas from a user’s speech, while processing the audio live, we had to design a paradigm that parses overlapping intervals of speech, creates a disjoint union of the sentences, and then sends these two distinct groups to our NLP model for similarity.
2. **API Rate Limits**—OpenAI rate-limits required a more efficient processing mechanism for the audio and fewer round trip requests keyword extraction and embeddings.
3. **Filler Sentences**—Not every sentence contains a concrete and distinct idea. Some sentences go nowhere and these can clog up the graph visually.
4. **Visualization**—Force graph is a premium feature of React Flow. To mimic this intuitive design as much as possible, we added some randomness of placement; however, building a better node placement system could help declutter and prettify the graph.
## Future Directions
**AI Inspiration Enhancement**—Using generative AI, it would be straightforward to add enhancement capabilities such as generating images for coherent ideas, or business plans.
**Live Notes**—Eddy can be a helpful tool for transcribing and organizing meeting and lecture notes. With improvements to our summary feature, Eddy will be able to create detailed notes from a live recording of a meeting.
## Built with
**UI:** React, Chakra UI, React Flow, Figma
**AI:** HuggingFace, OpenAI Whisper, OpenAI GPT-3, OpenAI Embeddings, NLTK
**API:** FastAPI
# Supplementary Material
## Mindmap Algorithm
 | losing |
## Inspiration
Our inspiration was Find My by Apple. It allows you to track your Apple devices and see them on a map giving you relevant information such as last time pinged, distance, etc.
## What it does
Picks up signals from beacons using the Eddystone protocol. Using this data, it will display the beacon's possible positions on Google Maps.
## How we built it
Node.js for the scanning of beacons, our routing and our API which is hosted on Heroku. We use React.js for the front end with Google Maps as the main component of the web app.
## Challenges we ran into
None of us had experience with mobile app development so we had to improvise with our skillset. NodeJs was our choice however we had to rely on old deprecated modules to make things work. It was tough but in the end it was worth it as we learned a lot.
Calculating the distance from the given data was also a challenge but we managed to get it quite accurately.
## Accomplishments that I'm proud of
Using hardware was an interesting as I (Olivier) have never done a hackathon project with them. I stick to web apps as it is my comfort zone but this time we have merged two together.
## What we learned
Some of us learned front-end web development and even got started with React. I've learned that hardware hacks doesn't need to be some low-level programming nightmare (which to me seemed it was).
## What's next for BeaconTracker
The Eddystone technology is deprecated and beacons are everywhere in every day life. I don't think there is a future for BeaconTracker but we have all learned much from this experience and it was definitely worth it. | # F.I.R.E.N.E.T: The Life-Saving Mission
## Inspiration 🎯
We were inspired by the growing threat of wildfires like the recent Maui and California fires. Quick, informed decision-making during evacuations is critical, and the need for a reliable, real-time system became evident. Thus, F.I.R.E.N.E.T was born.
## What We Learned 📚
* **IoT Integration**: Learned how to create a mesh network with Arduinos and Raspberry Pi.
* **Real-time Processing**: Grasped the complexities of processing large volumes of data in real-time.
* **Community Focus**: Understood the importance of crowd-sourced information and addressing the needs of vulnerable populations.
* **Map APIs**: Worked with 3D maps and Google Maps API to create a more interactive experience.
* **Mentorship**: Received excellent mentorship from Marcus van Kempen, enriching our project significantly. We thank everyone at Hack MIT for making our hardware project possible.
## How We Built It 🛠️
* **Data Collection**: Used Arduinos to simulate sensor data for wildfire detection.
* **Communication**: Implemented MQTT protocol to enable communication between devices.
* **Backend**: Hosted a Flask web server on a Raspberry Pi.
* **Frontend**: Created 3D maps using Three.js and implemented dynamic routing algorithms.
## Challenges We Faced 🚧
* **Data Reliability**: Ensuring the reliability of sensor data in a simulated environment.
* **Real-time Processing**: Dealing with the computational limitations of Raspberry Pi for real-time data processing.
* **Device Communication**: Faced challenges in getting the Arduino and Raspberry Pi to communicate effectively.
* **User Experience**: Striking a balance between comprehensive data and a user-friendly interface.
* **Commercialization & Scalability**: As a hackathon project, scaling this to a commercial product presents challenges like ensuring consistent long-range communication, energy efficiency, and disaster-proofing the technology.
## Future Scope & Commercialization 🚀
* **LoRa for Longer-Range**: Integration with LoRa technology for more extensive and reliable communication.
* **Solar Power**: Use solar panels and batteries to power Arduino devices for sustainability.
* **Peer-to-Peer WiFi**: Leverage peer-to-peer WiFi networks for communication when mobile data or cell service is down.
* **Disaster Recovery**: Develop a protocol for emergency response through the LoRa network, enabling constant communication in challenging conditions. | ## Inspiration
Survival from out-of-hospital cardiac arrest remains unacceptably low worldwide, and it is the leading cause of death in developed countries. Sudden cardiac arrest takes more lives than HIV and lung and breast cancer combined in the U.S., where survival from cardiac arrest averages about 6% overall, taking the lives of nearly 350,000 annually. To put it in perspective, that is equivalent to three jumbo jet crashes every single day of the year.
For every minute that passes between collapse and defibrillation survival rates decrease 7-10%. 95% of cardiac arrests die before getting to the hospital, and brain death starts 4 to 6 minutes after the arrest.
Yet survival rates can exceed 50% for victims when immediate and effective cardiopulmonary resuscitation (CPR) is combined with prompt use of a defibrillator. The earlier defibrillation is delivered, the greater chance of survival. Starting CPR immediate doubles your chance of survival. The difference between the current survival rates and what is possible has given rise to the need for this app - IMpulse.
Cardiac arrest can occur anytime and anywhere, so we need a way to monitor heart rate in realtime without imposing undue burden on the average person. Thus, by integrating with Apple Watch, IMpulse makes heart monitoring instantly available to anyone, without requiring a separate device or purchase.
## What it does
IMpulse is an app that runs continuously on your Apple Watch. It monitors your heart rate, detecting for warning signs of cardiac distress, such as extremely low or extremely high heart rate. If your pulse crosses a certain threshold, IMpulse captures your current geographical location and makes a call to an emergency number (such as 911) to alert them of the situation and share your location so that you can receive rapid medical attention. It also sends SMS alerts to emergency contacts which users can customize through the app.
## How we built it
With newly-available access to Healthkit data, we queried heart sensor data from the Apple Watch in real time. When these data points are above or below certain thresholds, we capture the user's latitude and longitude and make an HTTPRequest to a Node.js server endpoint (currently deployed to heroku at <http://cardiacsensor.herokuapp.com>) with this information. The server uses the Google Maps API to convert the latitude and longitude values into a precise street address. The server then makes calls to the Nexmo SMS and Call APIs which dispatch the information to emergency services such as 911 and other ICE contacts.
## Challenges we ran into
1. There were many challenges testing the app through the XCode iOS simulators. We couldn't find a way to simulate heart sensor data through our laptops. It was also challenging to generate Location data through the simulator.
2. No one on the team had developed in iOS before, so learning Swift was a fun challenge.
3. It was challenging to simulate the circumstances of a cardiac arrest in order to test the app.
4. Producing accurate and precise geolocation data was a challenge and we experimented with several APIs before using the Google Maps API to turn latitude and longitude into a user-friendly, easy-to-understand street address.
## Accomplishments that we're proud of
This was our first PennApps (and for some of us, our first hackathon). We are proud that we finished our project in a ready-to-use, demo-able form. We are also proud that we were able to learn and work with Swift for the first time. We are proud that we produced a hack that has the potential to save lives and improve overall survival rates for cardiac arrest that incorporates so many different components (hardware, data queries, Node.js, Call/SMS APIs).
## What's next for IMpulse
Beyond just calling 911, IMpulse hopes to build out an educational component of the app that can instruct bystanders to deliver CPR. Additionally, with the Healthkit data from Apple Watch, IMpulse could expand to interact with a user's pacemaker or implantable cardioverter defibrillator as soon as it detects cardiac distress. Finally, IMpulse could communicate directly with a patient's doctor to deliver realtime heart monitor data. | losing |
# DashLab
DashLab is a way for individuals and businesses to share and collaborate within a data-driven environment through a real-time data visualization dashboard web application.
# The Overview
Within any corporate environment you'll find individuals working on some sort of analysis or analytics projects in general. Under one company, and sometimes even within teams, you'll find a loose approach to drilling down to the necessary insight that in the end drives both the low-level, daily decisions and the higher level, higher pressure ones. What often happens is at the same time these teams or employees will struggle to translate these findings to the necessary personnel.
There's so much going on when it comes to deriving necessary information that it often becomes less powerful as a business function. DashLab provides a simple, eloquent, and intuitive solution that brings together the need to save, share, and show this data. Whether it's a debriefing between internal teams across different departments, or be it a key process that involves internal and external influence, DashLab provides users with a collaborative and necessary environment for real-time drill-down data investigation.
# Other
To utilize full functionality of this website, test the real-time drill down events by viewing the site from two different clients. Open a web browser and visit the site from two different tabs, sort through the available fields within the line graph visualization, and click on cities and countries to see both tabs update to the current selection. **Total mobile compatibility not supported.** | ### FOR EVALUATORS/SPONSORS:
Scroll down for a handy guide to navigating our repository and our project's assets.
## 💥 How it all started
I'm sure we're all well aware that having an informed response to an epidemic is crucial. The viral outbreak simulations that currently inform these responses are largely rules and statistics-based. These may work well at approximating human behavior, but they fail to account for how personal choices, life circumstances, and unpredictable interactions influence the spread of a virus.
With the shadow of COVID-19 receding into the past, we thought it important to stay vigilant and look towards the future to safeguard our communities against the next outbreak, whenever it may be. We realized that having a more powerful simulation tool to test response plans before they happen would be one of the best ways to stay prepared, and we set our sights on finding a better way to model the spread of epidemics.
By leveraging fetch.ai's ability to create AI agents that could act intelligently by themselves and interact organically with each other, we aimed to simulate a living, breathing city that could better model the nuanced nature of humanity that statistical models can only approximate. This allows for us to better capture the complex emergent behaviors of a community, and therefore better simulate viral outbreaks and the efficacy of potential responses.
## 📖 What it does
Enter **INFERmary**, a simulation tool designed to realistically simulate an organic city and test out potential disaster responses.
INFERmary starts out by getting context information about the city in question, like locations of interest. Using the city's demographic data, it then generates independent agents according to represent a scaled-down version of the city's population. The user can then tweak the virus spread parameters like its infectiousness and the number of initially infected patients, as well as add custom directions for the simulation.
Here’s how **INFERmary** leverages advanced technologies to better achieve its goal:
* Intelligent AI Agents: Thanks to fetch.ai, our simulated city is populated by AI agents, each with their own real life. Every agent has a personalized profile, encompassing their age, socioeconomic status, habits, and more. They don’t just follow scripted paths—they generate their own daily routines, engaging in the kind of organic interactions you’d expect to see in any real-world city.
* Central Direction System: A central LLM system powered by Groq allows the user to act as a regulatory body and issue directives to all agents (such as enforcing a lockdown, setting mask mandates, or establishing vaccination campaigns), allowing for deep simulation of not only viral spread but also the societal response to those interventions.
## 🔧 How we built it
To build INFERmary, we leveraged the power of generative AI to generate various personalities. These personalities are turned into their own individual Fetch.ai agents who control their own lives and communicate with each other.
To power the generative abilities of our solution, we used Groq’s various hosted models. To visualize our agents, we display them on our React front end.
### Technologies:
* fetch.ai: Used for creating multiple AI agents for simulating
* Groq: Used for initializing all the AI agents as well as general LLM tasks
* Mapbox: Used to visualize the simulated agents in an intuitive way
* React: Used to create user friendly frontend
## 🚩 Challenges we ran into
Alex: We were pretty tired of working with the same old LLMs and functions, so we wanted to experiment with something new this hackathon! I was responsible for generating people and implementing their actions with agents, and wow was it hard. Figuring out how to take advantage of agents fully was a tall task. I loved it though, it was something fresh and unique from what we usually do!
Nicholas: The biggest challenge for me was wrapping my head around the paradigm shift from one or very few backend services to many agents that all communicate with each other. Most of my time was spent reading documentation and asking questions instead of coding which was interesting.
## 🏆 Accomplishments that we're proud of
* The ability to generate multiple AI agents with unique personalities and interests
* Implementing
## 📝 What we learned
Alex: This is probably the last ever collegiate hackathon I'll ever be at, so I want this to be more of a reflection on everything I've done. I think the greatest lesson I learned here and everywhere else is my potential. I never guessed I would be able to do this much in such little time with other people. A lot can be done in an hour, and a lot more can be done in 36. Hackathons have given me so much confidence in my abilities and allowed me to have so much fun with my friends.
Specifically here though, I also learned a lot about agentic AI and how versatile they are. I never expected how good they would be at checking each other and how much the agentic factor improves LLM and application performance. It was really fun using fetch.ai's technology!
Ethan: I specifically wanted to approach Cal Hacks 11.0 with a focus on presentation and marketing, so I was the team's UX designer as well as marketing lead. It allowed me to see the project from a different angle than I usually tackle them from, and emphasized to me the importance of a good pitch. I think I've gained some valuable experience with selling our product and representing it in a way that not only plays to its strengths, but my and my teammates' strengths as well.
Nicholas: I learned a lot about the use of AI agents. From what I’ve seen, utilizing multiple AI agents is the next big thing in tech. Being able to work with agent technology and see how others use it was very fun.
Wesley: This was my first hackathon and keeping up with contributing to the project with other experienced members was definitely a challenge that many people overlook. I worked on and learned about frontend development using Reactjs and integrated Mapbox to render the map simulation environment.
## ✈️ What's next for **INFERmary**
With a simulation system as advanced as INFERmary, simulating basic situations and outbreak reponses is just the tip of the iceberg! We've got a ton of ideas for INFERmary going forward to turn it into the best possible version of what it can be.
* AI Agent-Powered Outbreak Response Team: In addition to just dictating blanket commands, this will allow the user to act as the head of an outbreak response team, managing AI agents that fulfill the role of epidemiologists, onsite doctors, and more. This will allow for an even more in-depth simulation of a health agency's possible response to an outbreak.
* Mutating Viruses and Different Strains: Currently, the virus has set parameters at the beginning of the simulation. However, viruses could be simulated to mutate and develop into different strains with the passage of time, developing different transmission rates, mortality rates, or resistance to treatments. This would allow for a more comprehensive look at long-term epidemic management.
* Public Sentiment and Media Influence: We all have first-hand experience with how media and public influence shape the response to an epidemic. Simulating the influence of media, social networks, and public sentiment on behavior—such as how misinformation or social pressure might impact mask-wearing, social distancing, or vaccine uptake—could offer a unique insight into outbreak response in today's media-driven world.
## 📋 Evaluator's Guide to **INFERmary**
Intended for judges, however the viewing public is welcome to take a look.
Hey! We wanted to make this guide in order to help provide you further information on our implementations of certain programs and provide a more in-depth look to cater to both the viewing audience and evaluators like yourself.
### SPONSOR SERVICES WE HAVE USED THIS HACKATHON
* fetch.ai
* Groq | ## BLOODHOUND MASK
**What it does**
The Bloodhound Mask was developed to increase safety in consumer grade breathing masks. By using an array of sensors, we're able to measure the quality of the air the user is breathing while wearing the mask. If unsafe air is being breathed, a buzzer is set off to alert the user to evacuate the area as soon as possible, saving lives in the process.
**Why would you need this?**
When wearing a safety mask, you're not invulnerable to leaks, failures, or tears in the mask. Any of these detriments could lead to a very dangerous scenario almost immediately. These situations can include the workplace hazards, natural disasters, or general use.
The real world application of this project would result in a low cost, simple to use mask that would save lives and improve workplace safety.
**How we built it**
Our current model was built using an Arduino running C++, a carbon monoxide sensor, air particulate sensor, a buzzer, breadboard, a set of goggles, and a painters mask.
**What was learned?**
During the development process, we taught ourselves how to read, as well as understand data, being transmitted from multiple sensors at once. We had initially wanted to live transmit this data to our website, [www.bestmlhproject.com](http://www.bestmlhproject.com), but struggled in pushing live updates to our web client.
**Future Plans**
Future developments for the Bloodhound Mask include adding a wireless transmitter to transmit live data to a different device. Currently, we're able to collect data from the users environment, but look forward to using this data more in the future.
/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\
## MORE DOCUMENTATION IS AVAILABLE AT BESTMLHPROJECT.COM
/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\ | partial |
## How the internet of things can build more healthy, livable, and walkable cities
**The dream of walkable cities and livable downtown areas.**
* Desire by cities to transform themselves into modern high density living environments.
* Long commutes, concerns about the environment, and changing cultural attitudes are spurring an interesting downtown living.
* Design of cities is changing to accommodate these cultural shifts. However, cities lack the data to inform the design.
* Lots of potential information which could better inform how the city is planned is currently being lost.
**The technology behind the system**
* Arduino Board
* Particle Electron Board
* Light and Photoresistor
* Humidity and Temperature Sensor
* Sound Sensor
* Gas Sensor
* Various data mining and file management software.
**Use case 1: improving walking traffic flow**
* Tracking the movement of walkers could provide many useful insights into traffic patterns.
* How do varying levels of noise impact walking? How about rain? Temperature?
* People avoid a certain dark area at night, it may seem sketchy and unsafe.
* This tracking system is anonymous. It doesn’t record who it is passing by.
**Use case 2: measuring noise and air pollution**
* Noise pollution can reduce the value of properties, can harm hearing, and can discourage walking. However, little noise pollution data is collected.
* Air pollution and bad smells can negatively impact the health of walkers. Carbon monoxide and methane are especially problematic and common compounds which would be hazardous.
**Use Case 3: Detailed city environment maps**
* The gas sensor detects several gases dangerous to human health such as methane and carbon monoxide.
* Could be correlated with everything from littering data to levels of heat/cold, which matters for environmental planning.
* Could be used for bridge lifespan analysis, giving the city detailed information about bridge usage and environmental conditions
**Conclusion**
While eager to take advantage of the new technology which the internet of things offers, cities have yet to embrace the technology on a massive scale. SmartSteps could introduce cities to the potential of sensor technology while providing them with the information they need to effectively transform their downtown areas into the highly livable and walkable areas.
Registered URL is smartsteps.tech | ## Inspiration
Air pollution events––both large scale and small––have a daily impact on our lives. From the recent fires in California to everyday vehicle exhaust, there's often a lot more in what we breath than just air. After consulting with professors, we learned that current sensor products can't often account for local air quality variability. For example, there's really no good way to affordably determine how exhaust from a nearby highway affects the air in your home or workplace. For both public health research and personal concern, we believe there should be a portable, simple solution: Bairea.
## What it does
Bairea is a compact sensor package magnetically mountable on a car. The module measures respiratory irritants, carbon monoxide (CO), and carbon dioxide (CO2) (all products of combustion) every few seconds, and then wirelessly logs and displays location-indexed and time-indexed data on your web dashboard. By continuously collecting data as you drive, from day to day, the module will start to build a picture of how air quality varies among the places you go most.
## How we built it
Bairea is controlled by a Raspberry Pi 3 connected to a digital respiratory irritants sensor, as well as analog CO and CO2 sensors via an Arduino Uno. Upon reading sensor data from the serial port, the Pi sends the the pollutant information to our Google App Engine-driven database and server.
The backend is written using Flask and runs on Google App Engine. The server continuously logs data from the Pi to Google Datastore.
We wrote a front end using D3.js and the Google Maps Javascript API to visualize pollutant information taken from the backend and place it on a map.
## Challenges I ran into
We had trouble finding some of the necessary hardware components, such as a GPS module, so we had to simulate some location data for the sake of demonstration. Getting all the serial communications aligned proved challenging, as each of the three sensors had a different communications protocol.
There were a ton of issues getting Google App Engine and Datastore to work as a data logger, because Google's Protobuf API in Python doesn't work well with non standard data such as GeoPoints (Google's representation of latitude/longitude).
Most hackathon projects are software hacks simply because software is much easier to work with. Because we decided to do a hybrid hardware-software hack, we ran into a bunch of small issues in trying to get the sensor module to upload to the backend, and then for the backend to get that data to the front-end visualization.
## Accomplishments that I'm proud of
We were able to lasercut an enclosure for Bairea, which was a fun process and resulted in a nice looking final product.
We think that this project serves as a really cool proof-of-concept for a cheap, mobile air quality sensor.
We're also really proud of making a successful hardware hack!
## What I learned
We learned a ton about building a reliable sensor module that uploads to a backend database.
We gained a lot of experience using D3.js to build powerful, informative data-visualizations.
## What's next for Bairea
We'd like to turn this proof of concept prototype into a real marketable product that people or researchers can attach to vehicles.
We'd also like to extend this sensor for use on drones, so that we can build 3D maps of air quality data. | ## Inspiration
We got lost so many times inside MIT... And no one could help us :( No Google Maps, no Apple Maps, NO ONE. Since now, we always dreamed about the idea of a more precise navigation platform working inside buildings. And here it is. But that's not all: as traffic GPS usually do, we also want to avoid the big crowds that sometimes stand in corridors.
## What it does
Using just the pdf of the floor plans, it builds a digital map and creates the data structures needed to find the shortest path between two points, considering walls, stairs and even elevators. Moreover, using fictional crowd data, it avoids big crowds so that it is safer and faster to walk inside buildings.
## How we built it
Using k-means, we created nodes and clustered them using the elbow diminishing returns optimization. We obtained the hallways centers combining scikit-learn and filtering them applying k-means. Finally, we created the edges between nodes, simulated crowd hotspots and calculated the shortest path accordingly. Each wifi hotspot takes into account the number of devices connected to the internet to estimate the number of nearby people. This information allows us to weight some paths and penalize those with large nearby crowds.
A path can be searched on a website powered by Flask, where the corresponding result is shown.
## Challenges we ran into
At first, we didn't know which was the best approach to convert a pdf map to useful data.
The maps we worked with are taken from the MIT intranet and we are not allowed to share them, so our web app cannot be published as it uses those maps...
Furthermore, we had limited experience with Machine Learning and Computer Vision algorithms.
## Accomplishments that we're proud of
We're proud of having developed a useful application that can be employed by many people and can be extended automatically to any building thanks to our map recognition algorithms. Also, using real data from sensors (wifi hotspots or any other similar devices) to detect crowds and penalize nearby paths.
## What we learned
We learned more about Python, Flask, Computer Vision algorithms and Machine Learning. Also about frienship :)
## What's next for SmartPaths
The next steps would be honing the Machine Learning part and using real data from sensors. | partial |
## Inspiration
The name of our web app, Braeburn, is named after a lightly colored red apple that was once used with green Granny Smith apples to test for colorblindness. We were inspired to create a tool to benefit individuals who are colorblind by helping to make public images more accessible. We realized that things such as informational posters or advertisements may not be as effective to those who are colorblind due to inaccessible color combinations being used. Therefore, we sought to tackle this problem with this project.
## What it does
Our web app analyzes images uploaded by users and determines whether or not the image is accessible to people who are colorblind. It identifies color combinations that are hard to distinguish for colorblind people and offers suggestions to replace them.
## How we built it
We built our web app using Django/Html/Css/Javascript for the frontend, and we used python and multiple APIs for the backend. One API we used was the Google Cloud Vision API to help us detect the different colors present in the image.
## Challenges we ran into
One challenge we ran into is handling the complexity of the different color regions within an image, which is a prevailing problem in the field of computer vision. Our current algorithm uses an api to perform image segmentation that clusters areas of similar color together. This allowed us to more easily create a graph of nodes over the image, where each node is a unique color, and each node's neighbors are different color regions on the image that are nearby. We then traverse this graph and test each pair of neighboring color regions to check for inaccessible color combinations.
We also struggled to find ways to simulate colorblindness accurately as RGB values do not map easily to the cones that allow us to see color in our eyes. After some research, we converted RGB values to a different value called LMS, which is a more accurate representation of how we view color. Thus, for an RGB, the LMS value may be different for normal and colorblind vision. To determine if a color combination is inaccessible, we compare these LMS values.
To provide our color suggestions, we researched a lot to figure out how to best approximate our suggestions. It ultimately led us to learn about daltonizers, which can color correct or simulate colorblind vision, and we utilize one to suggest more accessible colors.
Finally, we ran into many issues integrating different parts of the frontend, which ended up being a huge time sink.
Overall, this project was a good challenge for all of us, given we had no previous exposure to computer vision topics.
## Accomplishments that we're proud of
We're proud of completing a working product within the time limits of this hackathon and are proud of how our web app looks!
We are proud of the knowledge we learned, and the potential of our idea for the project. While many colorblindness simulators exist, ours is interesting for a few reasons . Firstly, we wanted to automate the process of making graphics and other visual materials accessible to those with colorblindness. We focused not only on the frequency of colors that appeared in the image; we created an algorithm that traverses the image and finds problematic pairs of colors that touch each other. We perform this task by finding all touching pairs of color areas (which is no easy task) and then comparing the distance of the pair with typical color vision and a transformed version of the pair with colorblind vision. This proved to be quite challenging, and we created a primitive algorithm that performs this task. The reach goal of this project would be to create an algorithm sophisticated enough to completely automate the task and return the image with color correction.
## What we learned
We learned a lot about complex topics such as how to best divide a graph based on color and how to manipulate color pixels to reflect how colorblind people perceive color.
Another thing we learned is that t's difficult to anticipate challenges and manage time. We also realize we were a bit ambitious and overlooked the complexity of computer vision topics.
## What's next for Braeburn
We want to refine our color suggestion algorithm, extend the application to videos, and provide support for more types of colorblindness. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | ## Inspiration
Our project aims to democratize algorithmic trading and the data associated with it to capture a 150 billion dollar a month trade volume and aim it towards transparency and purpose. Our project is a culmination of the technical depth and breadth of a new step forward in technology. We really wanted to open up the centralized and ever exclusive profession of algorithmic trading, giving the average retail trader the same tools and data as billion dollar companies. Empowering curiosity and innovation through open sourced data and tools.
## What it does
Our project is an brokerage platform that hosts compute, data APIs, processing tools, algorithms, and data-stream. A mix of the usability of Robinhood with the decentralized community building of technical people like Kaggle. We transform strategies and ideas that require a huge amount of capital and expertise, and hand it to the every-day retail investor. When customers upload code, our platform allows them to test their ideas out on paper trades, and when they are confident enough, we host and execute with a small fee on our infrastructure.
There are two distinct properties of our project that stand out as unique:
1. **Algorithm Marketplace**: Anyone can create an algorithm and earn commission by allowing others to run the algorithm. This means investors can invest in unorthodox and unique public algorithms, which removes all financial and technological barriers young analysts and programmers without any capital might face. By doing so, the project opens up the investment community to a new diverse and complex set of financial products.
2. **Collaborative Data Streams**: All users are encouraged to connect their individual data streams, growing a community that helps each other innovate and develop refined and reliable sources of data. This can serve as both a gateway to accessibility and a lens of transparency, enabling users to track and encourage responsible investments, allowing users to monitor and invest in entities that emphasize certain causes such as sustainability or other social movements.
## How we built it
Our project was specifically made in two stages, the framework and then the use cases. We used our combined experience at Bloomberg and Amazon working with this type of data to create a framework that is both highly optimized and easy to use. Below, we highlight three use case examples that were developed on our platform.
## Use Case 1: Technical Analysis Using Independent Component Analysis (ICA)
1. **Traditional Stock Analysis Using ICA**:
* We utilize **Independent Component Analysis (ICA)** to decompose a data matrix 𝑋 (observations) into independent components. The goal is to estimate 𝐴 (mixing matrix) and 𝑆 (source signals), assuming 𝑆 contains statistically independent components.
* ICA maximizes non-Gaussianity (e.g., using kurtosis or negentropy) to ensure independence, allowing us to identify independent forces or components in mixed signals that contribute to changes in the overall system.
2. **Cosine Similarity Between Stocks**:
* By analyzing the independent components driving the stock prices, we perform **cosine similarity** between them. This generates a value within the range of [-1, 1], representing how much any two stocks share these independent components.
3. **Dynamic Graph Representation**:
* We build an **updating graph** based on the relationships derived from the cosine similarity, providing real-time insight into how stocks are interrelated through their independent components.
## Use Case 2: Prediction Algorithm
* Our second use case involves a **prediction algorithm** that tracks stock movement and applies trend-based estimation across various stocks.
* This demonstrates a **low latency real-time application**, emphasizing the capability of **SingleStore** for handling real-time database operations, and showing how the platform can support high-speed, real-time financial data processing.
## Challenges we ran into
We encountered several challenges, including latency issues, high costs, and difficulties with integrating real-time data processing due to rate limits and expenses. Another hurdle was selecting the right source for real-time stock data, as both maintaining the database and processing the data were costly, with the data stream alone costing nearly $60.
## Accomplishments that we're proud of
We collectively managed to create a framework that is impressive on a technical scale and scalable as we look into the future of this project.
## What we learned
We gained experience with data normalization techniques for stock data and learned how to sync time series datasets with missing information. We also had to think deeply about the scalability of our platform and the frictionless experience we wanted to present.
## What's next for The OpenTradeLab
We have several initiatives we're excited to work on:
1. **Growing Communities Around Social Investments**:
* We aim to explore sustainable ways to build and foster communities focused on investment in social causes.
2. **Direct Exchange Connectivity**:
* We're looking into the possibility of connecting directly to an exchange to enable real-time trade routing.
3. **Optimized Code Conversion**:
* We plan to develop an API and library that converts Python code into optimized C++ code for enhanced performance.
4. **Investment Safeguards**:
* Implementing safeguards to promote responsible and secure investment practices is another key area of focus. | winning |
## Inspiration
The biggest irony today is despite the advent of the internet, students and adults are more oblivious than ever to world events, and one can easily understand why. Of course, Facebook, YouTube, and League will be more interesting than reading Huffington Post; coupled with the empirical decrease in the attention span of younger generations, humanity is headed towards disaster.
## What it does
Our project seeks to address this crisis by informing people in a novel and exciting way. We create a fully automated news extraction, summarization, and presentation pipeline that involves an AI-anime character news anchor. The primary goal of our project is to engage and educate an audience, especially that of younger students, with an original, entertaining venue for encountering reliable news that will not only foster intellectual curiosity but also motivate them to take into deeper consideration of relevant issues today, from political events to global warming.
The animation is basically a news anchor talking about several recent news, where related news is discussed in a short blurb.
## Demo Video Explanation
The demo video generally performs well, except for the first few seconds and the Putin/Taliban part. This is because the clusters are too small so many clusters get merged together as our kmeans has fixed number of clusters. A quick fix is to simply calculate the internal coherence of the cluster and filter based on that. more advanced methods can be based on those described in the Scatter Gather paper by Karger et al.
## How we built it
### News Summarization
For extraction and summarization, our first web scrapes news articles from trusted sources (CNN, New York Times, Huffington Post, Washington Post, etc…) to obtain the texts of recent news articles. Then it generates a compact summary of these texts using an in-house developed two-tier text summarization algorithm based on state-of-the-art natural language processing techniques. The algorithm first does an extractive summarization of individual articles. Next, it computes an overall 'topic feature' embedding. This embedding is used to cluster related news, and the final script is generated using these clusters and DL-based abstractive summarization.
### News Anchor Animation
Furthermore, using the google cloud text-to-speech API, we generate speech with our custom pitch and preferences and we then have code that generates a video using an image of any interesting, popular anime character. In order for the video to feel natural to the audience, we accounted for accurate lip and facial movement; there are calculations made using specific speech traits of the .wav file that produces realistic and not only educational but also humorous videos that will entertain the younger audience.
### Audience Engagement
Moreover, we wrote code using the Twitter API to automate the process of uploading videos to our Twitter account MinervaNews which is integrated within the project’s server that uploads a video initially when the server starts and automatically generates every 24 hours after a new video using the new articles from the sources.
## What's next for Minerva Daily News Reporter
Our project will have a lasting impact on the education of an audience ranging in all age groups. Anime is one great example of a venue that can broadcast news, and we selected anime characters as a humorous and eye-catching means to educate the younger audience. Our project and its customization allow for the possibility of new venues and greater exploration of making education more fun and accessible to a vast audience. We hope to take our project further and add more animations as well as more features.
## Challenges
Our compute platform, Satori has a unique architecture called IBM ppe64le that makes package and dependency management a nightmare.
## What we learned
8 hours in planning = 24 hours in real time.
## Github
<https://github.com/gtangg12/liszt> | ## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future. | ## Inspiration
Due to COVID-19, millions of students across the world have been forced to quickly adapt to video lectures and online education. To ease this transition and make studying more efficient, we wanted to help students by summarizing their lecture transcripts while also capturing the full lecture transcript so students can pay full attention to the lecture instead of being distracted with taking notes.
## What it does
A website that summarizes video lectures for efficient studying. Users can upload their video lectures to receive a full text transcript and timestamps of the most important sentences. The video timestamps have not been formatted to "minutes : seconds" yet.
## How We built it
We made made a microservice out of a pre-trained BERT model to summarize text, and an Express web server that works with Vue for the UI to make a web app. The web app accepts video uploads, sends the video to Azure's Speech-to-Text API to get a full transcript, sends the transcript to the microservice to get a summary with timestamps, and sends the summary and timestamps to Vue for display and video playback.
## Challenges we ran into
Managing cloud platform credentials in a team of 4 was difficult. Coordinating ourselves to avoid duplicating work. Managing packages and dependencies. Scope creep. Timestamps need to formatted to "minutes : seconds".
## Accomplishments that we're proud of
Most technically sophisticated hackathon project so far, as the project has many moving parts like Azure Media Services (for video playback), Azure Cognitive Services (for the Speech-to-Text API), and BERT (for text summarization).
Fun name ;)
## What we learned
CORS, JavaScript Promises, Microservice Architecture
## What's next for AweSummarizer
Adding video lecture subtitles automatically generated with Azure Media Services. Adding clickable timestamps to play the video at that timestamp for more convenient navigation. | winning |
## Inspiration
The inspiration behind our innovative personal desk assistant was ignited by the fond memories of Furbys, those enchanting electronic companions that captivated children's hearts in the 2000s. These delightful toys, resembling a charming blend of an owl and a hamster, held an irresistible appeal, becoming the coveted must-haves for countless celebrations, such as Christmas or birthdays. The moment we learned that the theme centered around nostalgia, our minds instinctively gravitated toward the cherished toys of our youth, and Furbys became the perfect representation of that cherished era.
Why Furbys? Beyond their undeniable cuteness, these interactive marvels served as more than just toys; they were companions, each one embodying the essence of a cherished childhood friend. Thinking back to those special childhood moments, the idea for our personal desk assistant was sparked. Imagine it as a trip down memory lane to the days of playful joy and the magic of having an imaginary friend. It reflects the real bonds many of us formed during our younger years. Our goal is to bring the spirit of those adored Furbies into a modern, interactive personal assistant—a treasured piece from the past redesigned for today, capturing the memories that shaped our childhoods.
## What it does
Our project is more than just a nostalgic memory; it's a practical and interactive personal assistant designed to enhance daily life. Using facial recognition, the assistant detects the user's emotions and plays mood-appropriate songs, drawing from a range of childhood favorites, such as tunes from the renowned Kidz Bop musical group. With speech-to-text and text-to-speech capabilities, communication is seamless. The Furby-like body of the assistant dynamically moves to follow the user's face, creating an engaging and responsive interaction. Adding a touch of realism, the assistant engages in conversation and tells jokes to bring moments of joy. The integration of a dashboard website with the Furby enhances accessibility and control. Utilizing a chatbot that can efficiently handle tasks, ensuring a streamlined and personalized experience. Moreover, incorporating home security features adds an extra layer of practicality, making our personal desk assistant a comprehensive and essential addition to modern living.
## How we built it
Following extensive planning to outline the implementation of Furby's functions, our team seamlessly transitioned into the execution phase. The incorporation of Cohere's AI platform facilitated the development of a chatbot for our dashboard, enhancing user interaction. To infuse a playful element, ChatGBT was employed for animated jokes and interactive conversations, creating a lighthearted and toy-like atmosphere. Enabling the program to play music based on user emotions necessitated the integration of the Spotify API. Google's speech-to-text was chosen for its cost-effectiveness and exceptional accuracy, ensuring precise results when capturing user input. Given the project's hardware nature, various physical components such as microcontrollers, servos, cameras, speakers, and an Arduino were strategically employed. These elements served to make the Furby more lifelike and interactive, contributing to an enhanced and smoother user experience. The meticulous planning and thoughtful execution resulted in a program that seamlessly integrates diverse functionalities for an engaging and cohesive outcome.
## Challenges we ran into
During the development of our project, we encountered several challenges that required demanding problem-solving skills. A significant hurdle was establishing a seamless connection between the hardware and software components, ensuring the smooth integration of various functionalities for the intended outcome. This demanded a careful balance to guarantee that each feature worked harmoniously with others. Additionally, the creation of a website to display the Furby dashboard brought its own set of challenges, as we strived to ensure it not only functioned flawlessly but also adhered to the desired aesthetic. Overcoming these obstacles required a combination of technical expertise, attention to detail, and a commitment to delivering a cohesive and visually appealing user experience.
## Accomplishments that we're proud of
While embarking on numerous software projects, both in an academic setting and during our personal endeavors, we've consistently taken pride in various aspects of our work. However, the development of our personal assistant stands out as a transformative experience, pushing us to explore new techniques and skills. Venturing into unfamiliar territory, we successfully integrated Spotify to play songs based on facial expressions and working with various hardware components. The initial challenges posed by these tasks required substantial time for debugging and strategic thinking. Yet, after investing dedicated hours in problem-solving, we successfully incorporated these functionalities for Furby. The journey from initial unfamiliarity to practical application not only left us with a profound sense of accomplishment but also significantly elevated the quality of our final product.
## What we learned
Among the many lessons learned, machine learning stood out prominently as it was still a relatively new concept for us!
## What's next for FurMe
The future goals for FurMe include seamless integration with Google Calendar for efficient schedule management, a comprehensive daily overview feature, and productivity tools such as phone detection and a Pomodoro timer to assist users in maximizing their focus and workflow. | ## Inspiration
We were inspired by Katie's 3-month hospital stay as a child when she had a difficult-to-diagnose condition. During that time, she remembers being bored and scared -- there was nothing fun to do and no one to talk to. We also looked into the larger problem and realized that 10-15% of kids in hospitals develop PTSD from their experience (not their injury) and 20-25% in ICUs develop PTSD.
## What it does
The AR iOS app we created presents educational, gamification aspects to make the hospital experience more bearable for elementary-aged children. These features include:
* An **augmented reality game system** with **educational medical questions** that pop up based on image recognition of given hospital objects. For example, if the child points the phone at an MRI machine, a basic quiz question about MRIs will pop-up.
* If the child chooses the correct answer in these quizzes, they see a sparkly animation indicating that they earned **gems**. These gems go towards their total gem count.
* Each time they earn enough gems, kids **level-up**. On their profile, they can see a progress bar of how many total levels they've conquered.
* Upon leveling up, children are presented with an **emotional check-in**. We do sentiment analysis on their response and **parents receive a text message** of their child's input and an analysis of the strongest emotion portrayed in the text.
* Kids can also view a **leaderboard of gem rankings** within their hospital. This social aspect helps connect kids in the hospital in a fun way as they compete to see who can earn the most gems.
## How we built it
We used **Xcode** to make the UI-heavy screens of the app. We used **Unity** with **Augmented Reality** for the gamification and learning aspect. The **iOS app (with Unity embedded)** calls a **Firebase Realtime Database** to get the user’s progress and score as well as push new data. We also use **IBM Watson** to analyze the child input for sentiment and the **Twilio API** to send updates to the parents. The backend, which communicates with the **Swift** and **C# code** is written in **Python** using the **Flask** microframework. We deployed this Flask app using **Heroku**.
## Accomplishments that we're proud of
We are proud of getting all the components to work together in our app, given our use of multiple APIs and development platforms. In particular, we are proud of getting our flask backend to work with each component.
## What's next for HealthHunt AR
In the future, we would like to add more game features like more questions, detecting real-life objects in addition to images, and adding safety measures like GPS tracking. We would also like to add an ALERT button for if the child needs assistance. Other cool extensions include a chatbot for learning medical facts, a QR code scavenger hunt, and better social interactions. To enhance the quality of our quizzes, we would interview doctors and teachers to create the best educational content. | ## Inspiration
Imagine a world where learning is as easy as having a conversation with a friend. Picture a tool that unlocks the treasure trove of educational content on YouTube, making it accessible to everyone, regardless of their background or expertise. This is exactly what our hackathon project brings to life.
* Current massive online courses are great resources to bridge the gap in educational inequality.
* Frustration and loss of motivation with the lengthy and tedious search for that 60-second content.
* Provide support to our students to unlock their potential.
## What it does
Think of our platform as your very own favorite personal tutor. Whenever a question arises during your video journey, don't hesitate to hit pause and ask away. Our chatbot is here to assist you, offering answers in plain, easy-to-understand language. Moreover, it can point you to external resources and suggest specific parts of the video for a quick review, along with relevant sections of the accompanying text. So, explore your curiosity with confidence – we've got your back!
* Analyze the entire video content 🤖 Learn with organized structure and high accuracy
* Generate concise, easy-to-follow conversations⏱️Say goodbye to wasted hours watching long videos
* Generate interactive quizzes and personalized questions 📚 Engaging and thought-provoking
* Summarize key takeaways, explanations, and discussions tailored to you 💡 Provides tailored support
* Accessible to anyone with an internet 🌐 Accessible and Convenient
## How we built it
Vite React,js as front-end and Flask as back-end. Using Cohere command-nightly AI and Similarity ranking.
## Challenges we ran into
* **Increased application efficiency by 98%:** Reduced the number of API calls lowering load time from 8.5 minutes to under 10 seconds. The challenge we ran into was not taking into account the time taken for every API call. Originally, our backend made over 500 calls to Cohere's API to embed text every time a transcript section was initiated and repeated when a new prompt was made -- API call took about one second and added 8.5 minutes in total. By reducing the number of API calls and using efficient practices we reduced time to under 10 seconds.
* **Handling over 5000-word single prompts:** Scraping longer YouTube transcripts efficiently was complex. We solved it by integrating YouTube APIs and third-party dependencies, enhancing speed and reliability. Also uploading multi-prompt conversation with large initial prompts to MongoDB were challenging. We optimized data transfer, maintaining a smooth user experience.
## Accomplishments that we're proud of
Created a practical full-stack application that I will use on my own time.
## What we learned
* **Front end:** State management with React, third-party dependencies, UI design.
* **Integration:** Scalable and efficient API calls.
* **Back end:** MongoDB, Langchain, Flask server, error handling, optimizing time complexity and using Cohere AI.
## What's next for ChicSplain
We envision ChicSplain to be more than just an AI-powered YouTube chatbot, we envision it to be a mentor, teacher, and guardian that will be no different in functionality and interaction from real-life educators and guidance but for anyone, anytime and anywhere. | winning |
## Inspiration
Our inspiration for this project came from our strong interest in real estate finance. After searching for rental investment opportunities and other ways to profit off real estate, we realized that there was no centralized source that generated the financial information we were looking for. For this reason, we decided to create a website to meet this need and provide ourselves and other users with an accessible platform for taking a deep dive into the world of real estate.
## What it does
Our project is a comprehensive web-based real estate tool that offers a suite of analysis tools and calculators that cover various aspects of real estate and its costs. Specifically, our website contains calculators for mortgage payments, potential income from rental properties, and the initial investment required to purchase a property. The website also contains an interactive tool that generates a custom amortization schedule accompanied with visual figures. All things considered, this project not only provides an excellent introduction point for real estate financials but also contains enough functionality to provide value for people more well-versed in real estate.
## How we built it
We started with some research about a useful hack geared towards the major themes outlined by Hack Western. We ended up with the idea to create a universally Canadian real-estate website. In order to create the web app we created a Django project. We decided to use this python-web framework because it allowed for quick development and application scalability. Python was our preferred language because of its powerful data analytics capabilities that would be perfect for real estate market calculations.
## Challenges we ran into
Throughout the project, there were multiple challenges we faced. One of the first ones occurred when trying to create an image recognition software using OpenCV for the user to log in to our site. However, there were some problems with using the integrated webcams within the laptops and we could not figure it out. It is important to note though that the program was able to recognize faces from jpeg's. Additionally, collecting all the data needed for property taxes which change across the country was difficult since it required a lot of time and effort to research. Furthermore, debugging took a large chunk of the time which we did not initially account for.
## Accomplishments that we're proud of
First and foremost, we are proud that we finished our project and created a functional and useful product within the tight timeline. As well, for most of us, this was our first time creating our own website. In fact, one of our members only starting learning Python a couple months ago and was able to contribute much to the project. All in all, it was very rewarding for us to work as a team to create a solution to a problem that we identified.
## What we learned
Throughout the project, we learned a lot about Python coding as well as what it takes to create and host our own website. We also learned how to work well as a team in order to accomplish tasks successfully and on time. This has been an outstanding learning experience for all of us, and we hope to participate in more hackathons in the future.
## What's next for RealEstate+
As RealEstate+ continues to be developed, we would want to grow the library of tools to include deeper dives into publically available data. Next, we would want to continue developing our underlying code and calculations to more accurately return values based on real data. Lastly, we would want to expand the functionality of RealEstate+ to include commercial properties, and all the implications they come with. | # Introducing Our Groundbreaking Wearable Tech Device
In our quest to revolutionize the future, we've developed an innovative wearable tech device that goes beyond conventional solutions. Our device is meticulously crafted to empower individuals with accessibility requirements and their caregivers with advanced features tailored to their needs.
## Cutting-Edge Features
### Discreet Camera with Recording Capability
Our device is equipped with a discreet camera that seamlessly records meaningful conversations and interactions. With its unobtrusive design, users can comfortably wear the device throughout the day, capturing moments without intrusion.
### AI-driven Text-to-Speech and Speech-to-Text Conversion
Powered by advanced artificial intelligence technology, our device offers sophisticated text-to-speech and speech-to-text conversion capabilities. This allows users to effortlessly transcribe conversations into text logs, providing a valuable resource for memory recall and caregiver support.
### Hand Gesture Control with OpenCV Integration
Taking interaction to the next level, our device incorporates hand gesture control using OpenCV technology. By simply gesturing with their hands, users can navigate through features and functionalities with ease, making the device accessible to individuals of all abilities.
## Enhanced Security and Privacy
### Secure File Transfer with Pre-configured Home Server
To ensure the utmost security and privacy, each device comes with a pre-configured home server. This server facilitates secure file transfer via a private VPN connection, allowing users to transfer recorded conversations safely and confidentially to their designated home location.
### Demonstration: Automated Script for File Transfer
Experience the seamless transfer of files with our automated script demonstration. Witness firsthand how our device effortlessly syncs data with the home server, providing users with peace of mind knowing their conversations are securely stored and accessible only to authorized individuals.
## Overcoming Challenges and Continuous Learning
### Resilience in the Face of Challenges
Throughout the development process, our team encountered various challenges, from debugging package installations to overcoming power constraints. However, through perseverance and determination, we navigated through these obstacles, emerging stronger and more resilient than before.
### Learning and Growth Opportunities
Participating in the Makeathon competition provided us with invaluable learning and growth opportunities. From mastering virtual environments and setting up Ubuntu servers to networking with other teams, we expanded our knowledge and skills, enriching our journey towards innovation.
## Join Us in Shaping the Future of Care and Enhancement
With our groundbreaking wearable tech device, we aim to redefine accessibility care, empowering individuals and caregivers alike. Together, let's embark on this transformative journey towards a brighter future for everyone. | ## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app. | losing |
## Discord contact
* Nand Vinchhi - vinchhi
* Advay Choudhury - pdy.gn
* Rushil Madhu - rushil695
## Inspiration
Over the past few years, social media platforms like Tiktok and Instagram reels have used short-form content to take over the entertainment industry. Though this hyper-optimized form of content is engaging, it has led to students having shortened attention spans and a higher tendency to multi-task. Through Relearn, we aim to modernize studying to match these changing mental abilities.
## What it does
#### Scrolling interface for short videos
* Intuitive tiktok-like interface for scrolling educational short videos
* Complete with engaging music, bold subtitles, and background videos
* Functionality to like videos, indicating that the user has understood that particular concept
#### Content generation AI
* Uses lecture videos from Khanacademy + GPT-4.5 analysis to generate bite-sized educational clips
* Custom video processing for adding elements such as music and subtitles
#### Recommendation algorithm
* Ensures that the user progressively covers all content in a given topic
* Occasional meme videos for a quick study break!
#### Edison AI
* An LLM-based bot account that answers student questions in the comments section
* Understands the context from the current video to provide precise and useful answers
## Additional details for sponsor prizes
#### Best Use of AI in Education
Relearn explores the confluence of cutting-edge AI tech and useful education solutions -
* Our content generation pipeline utilizes LLMs (GPT-4.5) to understand context in Khanacademy lecture videos to create short and engaging clips
* Our AI account, Edison, utilizes LLMs to provide precise and useful answers to questions in the comments of a specific video
#### Best Accessibility Hack sponsored by Fidelity
Our platform makes high-quality content available over the internet. We enable anyone with a mobile phone to improve their study consistency and quality, which would help bridge economic and social gaps in the long term.
#### Most Creative Use of Redis Cloud
We used Redis for the following pivotal aspects of our app -
* High speed caching and access of dynamic data such as likes, comments, and progress
* Caching the latest video that a given user interacted with in, and feeding that into our recommendation algorithm (speeds up the algorithm by a huge margin)
* See this file for our Redis functions - <https://github.com/NandVinchhi/relearn-hackathon/blob/main/backend/dbfunctions.py>
## How we built it
#### Front-end mobile application
* Built with Swift and Swift UI
* Used multiple packages for specific functionalities such as Google Auth, video playback etc.
#### Content generation pipeline
* YT Transcript API + PyTube for scraping Khanacademy videos
* Open AI to retrieve context and divide long lecture videos into bite-sized clips
* MoviePy for automatic video editing - subtitles, music, and background video
#### Back-end
* Python + FastAPI for the server
* Supabase database + cloud buckets for storing short videos + curriculum
* Redis database for storing dynamic like, comment, and progress data
* Server deployment on AWS EC2
#### Recommendation algorithm
* Caching latest 'liked' short videos for each topic and unit in Redis
* Super fast progress retrieval from in order to compute the next video on scroll
#### Edison AI
* Used GPT 4.5 + short video transcripts for context-specific answers
* AI chat endpoints deployed along with server on AWS
## Challenges we ran into
* LLM hallucinations
* Bugs with automated video processing
* Getting the video scrolling interface to work smoothly without any sort of flickering or unwanted behavior
* Getting the whole stack working together and deployed before submission deadline
## Accomplishments that we're proud of
* Implementing a custom video scrolling interface for our short videos
* Automatically generating high-quality short videos
* Designing a clean user interface using Figma before building it out
* Getting back-end integrated with google auth + multiple databases + APIs and deploying to cloud
* All of this in < 36 hours!
## What we learned
* Using Redis to enhance a more conventional tech stack
* Deploying FastAPI to AWS EC2 using Gunicorn workers
* Building complex automated video editing functionality using MoviePy
* Utilizing the newly released GPT-4.5 API to perform context retrieval and create high-quality videos.
* Building custom UI Components in Swift and working with Google Auth in an iOS application
## What's next for Relearn
* Expanding curriculum to cover topics for all ages
* Multi-language support to increase accessibility
* Periodic flash cards and quizzes based on progress
* Opportunity for creators to upload their own content directly to Relearn | ## Inspiration
The inspiration for Hivemind stemmed from personal frustration with the quality of available lectures and resources, which were often insufficient for effective learning. This led us to rely entirely on ChatGPT to teach ourselves course material from start to finish. We realized the immense value of tailored responses and the structured learning that emerged from the AI interactions. Recognizing the potential, this inspired the creation of a platform that could harness collective student input to create smarter, more effective lessons for everyone.
## What it does
Hivemind is an AI-powered learning platform designed to empower students to actively engage with their course material and create personalized, interactive lessons. By allowing students to input course data such as lecture slides, notes, and assignments, Hivemind helps them optimize their learning process through dynamic, evolving lessons. As students interact with the platform, their feedback and usage patterns inform the system, organically improving and refining the content for everyone. This collaborative approach transforms passive learning into an active, community-driven experience, creating smarter lessons that evolve based on the collective intelligence and needs of all users.
## How we built it
* **Backend**: Developed with Django and Django REST Framework to manage data processing and API requests.
* **Data Integration**: Used PyMuPDF for text extraction and integrated course materials into a cohesive database.
* **Contextual Search**: Implemented Chroma for similarity searches to enhance lesson relevance and context.
* **LLM Utilization**: Leveraged Cerebras and TuneAI to transform course content into structured lessons that evolve with user input.
* **Frontend**: Created a React-based interface for students to access lessons and contribute feedback.
* **Adaptive Learning**: Built a system that updates lessons dynamically based on collective interactions, guiding them towards an optimal state.
## Challenges we ran into
* Getting RAG to work with Tune
* Creating meaningful inferences with the large volume of data
* Integrating varied course materials into a unified, structured format that the LLM could effectively utilize
* Ensuring that lessons evolve towards an optimal state based on diverse student interactions and inputs
* Sleep deprivation
## Accomplishments that we're proud of
* Functional Demo
* Integration of advanced technologies
* Team effort
## What we learned
Throughout the development of Hivemind, we gained valuable insights into various advanced topics, including large language models (LLMs), retrieval-augmented generation (RAGs), AI inference, and fine-tuning techniques. We also deepened our understanding of:
* Tools such as Tune and Cerebras
* Prompt Engineering
* Scalable System Design
## What's next for Hivemind
* Easy integration with all LMS for an instant integration with any courses
* Support different types of courses (sciences, liberal arts, languages, etc.)
* Train on more relevant data such as research studies and increase skill level of the model
* Create an algorithm that can generate a large amount of lessons and consolidate them into one optimal lesson
* Implement a peer review system where students can suggest improvements to the lessons, vote on the best modifications, and discuss different approaches, fostering a collaborative learning environment | ## Inspiration
Inspired by a team member's desire to study through his courses by listening to his textbook readings recited by his favorite anime characters, functionality that does not exist on any app on the market, we realized that there was an opportunity to build a similar app that would bring about even deeper social impact. Dyslexics, the visually impaired, and those who simply enjoy learning by having their favorite characters read to them (e.g. children, fans of TV series, etc.) would benefit from a highly personalized app.
## What it does
Our web app, EduVoicer, allows a user to upload a segment of their favorite template voice audio (only needs to be a few seconds long) and a PDF of a textbook and uses existing Deepfake technology to synthesize the dictation from the textbook using the users' favorite voice. The Deepfake tech relies on a multi-network model trained using transfer learning on hours of voice data. The encoder first generates a fixed embedding of a given voice sample of only a few seconds, which characterizes the unique features of the voice. Then, this embedding is used in conjunction with a seq2seq synthesis network that generates a mel spectrogram based on the text (obtained via optical character recognition from the PDF). Finally, this mel spectrogram is converted into the time-domain via the Wave-RNN vocoder (see [this](https://arxiv.org/pdf/1806.04558.pdf) paper for more technical details). Then, the user automatically downloads the .WAV file of his/her favorite voice reading the PDF contents!
## How we built it
We combined a number of different APIs and technologies to build this app. For leveraging scalable machine learning and intelligence compute, we heavily relied on the Google Cloud APIs -- including the Google Cloud PDF-to-text API, Google Cloud Compute Engine VMs, and Google Cloud Storage; for the deep learning techniques, we mainly relied on existing Deepfake code written for Python and Tensorflow (see Github repo [here](https://github.com/rodrigo-castellon/Real-Time-Voice-Cloning), which is a fork). For web server functionality, we relied on Python's Flask module, the Python standard library, HTML, and CSS. In the end, we pieced together the web server with Google Cloud Platform (GCP) via the GCP API, utilizing Google Cloud Storage buckets to store and manage the data the app would be manipulating.
## Challenges we ran into
Some of the greatest difficulties were encountered in the superficially simplest implementations. For example, the front-end initially seemed trivial (what's more to it than a page with two upload buttons?), but many of the intricacies associated with communicating with Google Cloud meant that we had to spend multiple hours creating even a landing page with just drag-and-drop and upload functionality. On the backend, 10 excruciating hours were spent attempting (successfully) to integrate existing Deepfake/Voice-cloning code with the Google Cloud Platform. Many mistakes were made, and in the process, there was much learning.
## Accomplishments that we're proud of
We're immensely proud of piecing all of these disparate components together quickly and managing to arrive at a functioning build. What started out as merely an idea manifested itself into usable app within hours.
## What we learned
We learned today that sometimes the seemingly simplest things (dealing with python/CUDA versions for hours) can be the greatest barriers to building something that could be socially impactful. We also realized the value of well-developed, well-documented APIs (e.g. Google Cloud Platform) for programmers who want to create great products.
## What's next for EduVoicer
EduVoicer still has a long way to go before it could gain users. Our first next step is to implementing functionality, possibly with some image segmentation techniques, to decide what parts of the PDF should be scanned; this way, tables and charts could be intelligently discarded (or, even better, referenced throughout the audio dictation). The app is also not robust enough to handle large multi-page PDF files; the preliminary app was designed as a minimum viable product, only including enough to process a single-page PDF. Thus, we plan on ways of both increasing efficiency (time-wise) and scaling the app by splitting up PDFs into fragments, processing them in parallel, and returning the output to the user after collating individual text-to-speech outputs. In the same vein, the voice cloning algorithm was restricted by length of input text, so this is an area we seek to scale and parallelize in the future. Finally, we are thinking of using some caching mechanisms server-side to reduce waiting time for the output audio file. | partial |
## 🌍 Background
Unlike the traditional profit-orientated approach in financial investing, responsible investing is a relatively new concept that expressly recognizes the importance of environmental, social, and governance aspects to the investor and the long-term health and stability of the market (Cambridge Institute for Sustainability Leadership, 2021). However, currently, ESG does not have a standardized evaluation system that allows investors to quickly determine the potential of the financial products.
## ❣️ Inspiration
More recently, some have claimed that ESG standards, in addition to their social value, might protect investors from the crises that arise when businesses that operate in a hazardous or immoral manner are finally held responsible for their effects. Examples include the 2010 Gulf of Mexico oil disaster by BP and the billion-dollar emissions scandal at Volkswagen, which both had a negative impact on the stock values of their respective corporations. (Investopedia, 2022). Therefore, the demand of creating an easy-to-use ESG evolution tool for everybody is essential to address the stigma that investing, saving, and budgeting are only for privileged populations.
## ⚙️ Solution
Inspired by the current uncertainty about ESG evaluation methods, our team proposed and implemented an online ESG evaluation platform with our recently developed algorithms called Stock Stalker that allow investors to search, manage, and see the overall ESG performance of the selected stocks associated with a built-in recommendation system.
To See. To Learn. To Apply. To Earn. To Contribute. Stock Stalker redefines what it means to earn profits while ensuring the investment is making positive impacts on the environment, society, and governance. Using React, REST API, and our developed algorithms, Stock Stalker offers investors both access to real-time financial data including the ESG rating of the stocks, and a platform that illustrates the ESG properties of the store without providing those hard-to-understand technical details. After using our product, the investor can have a deeper understanding of ESG investments without the need to learn about professional finance knowledge. As a result, these investors are now able to make accurate ESG investments based on their interests.
## 🗝️ Key Product Features
·Allow users to search and save the selected stocks based on the input of stock symbols.
·Access to real-time financial data such as the Earning Per Share (EPS) and the current stock price trend.
·Provide numerical ESG ratings in different aspects with our developed algorithms.
·Illustrate ESG properties of the stocks through an easy-to-understand recommendations system.
## ⚙️ Tech Stack
·The prototype was designed with Figma while the front end was built on React
·We used Tailwind CSS, framer-motion and various libraries to decorate our web page
·The backend data was stored on JSON-Server, cors and axios
·Notifications are sent out using Twilio
·Functionalities were built with tradingviewwidget
## 🔥 What we're proud of
Even though we faced difficulties in the back-end implementation, we still figured out the techniques that are required for our site via collaboration. Another accomplishment is that our team members not only learned the programming techniques but also, we learned so much finance knowledge during the hack. Additionally, given that we were primarily a front-end team with no experience in dealing with the back-end, we are incredibly proud that we were able to take up the new concepts in very little time (big thanks to the mentors as well!).
## 🔭 What's Next for Stock Stalker
Looking to the future for Stock Stalker, we intend on implementing functions that connect our ESG evaluation site to the actual stock-buying organizations. Further implementation includes an additional page that provides the estimated price of the stock selected from the site with the buying options from different stock buying platforms so that the investors can compare and purchase the stock in a more convenient way.
## 🌐 Best Domain Name from Domain.com
As a part of our project, we registered stockstalkertech using Domain.com! You can also access it [here](https://www.stockstalker.tech/). | ## Inspiration
As the world grapples with challenges like climate change, resource depletion, and social inequality, it has become imperative for organizations to not only understand their environmental, social, and governance (ESG) impacts but also to benchmark and improve upon them. However, one of the most significant hurdles in this endeavor is the complexity and inaccessibility of sustainability data, which is often buried in lengthy official reports and varied formats, making it challenging for stakeholders to extract actionable insights.
Recognizing the potential of AI to transform this landscape, we envision Oasis as a solution to democratize access to sustainability data, enabling more informed decision-making and fostering a culture of continuous improvement toward global sustainability goals. By conversing with AI agents, companies are able to collaborate in real-time to gain deeper insights and work towards solutions.
## What it does
Oasis is a groundbreaking platform that leverages AI agents to streamline the parsing, indexing, and analysis of sustainability data from official government and corporate ESG reports. It provides an interface for companies to assess their records and converse with an AI agent that has access to their sustainability data. The agent helps them benchmark their practices against practices of similar companies and narrow down ways that they can improve through conversation.
Companies can effortlessly benchmark their current sustainability practices, assess their current standings, and receive tailored suggestions for enhancing their sustainability efforts. Whether it's identifying areas for improvement, tracking progress over time, or comparing practices against industry standards, Oasis offers a comprehensive suite of features to empower organizations in their sustainability journey.
## How we built it
Oasis uses a sophisticated blend of the following:
1. LLM (LLaMA 2) parsing to parse data from complex reports.
We fine-tuned an instance of `meta-llama/Llama-2-7b-chat-hf` on the HuggingFace dataset [Government Report Summarization](https://huggingface.co/datasets/ccdv/govreport-summarization) using MonsterAPI. We use this model to parse data points from ESG PDF text, since these documents are in a non-standard format, into a JSON format. LLMs are incredibly powerful at extracting key information and summarization, which is why we see such a strong use case here.
2. Open-source text embedding model (SentenceTransformers) to index data including metrics and data points within a vector database.
LLM-parsed data points contain key descriptors. We use an embedding model to index these descriptors in semantic space, allowing us to compare similar metrics across companies. Two key points may not have the same descriptions, but are semantically similar, which is why indexing with embeddings is beneficial. We use the SentenceTransformer model `msmarco-bert-base-dot-v5` for text embeddings.
We also use the InterSystems IRIS Data Platform to store embedding vectors, on top of the LangChain framework. This is useful for finding similar metrics across different companies and also for RAG, as discussed next.
3. Retrieval augmented generation (RAG) to incorporate relevant metrics and data points into conversation
To enable users to converse with the agent and inspect and make decisions based on real data, we use RAG integrated with our IRIS vector database, running on the LangChain framework. We have a frontend UI for interacting with our agent in real time.
4. Embedding similarity to semantically align data points for benchmarking across companies
Our frontend UI also presents key metrics for benchmarking a user’s company. It uses embedding similarity to find company metrics and relevant metrics from other companies.
## Challenges we ran into
One of the most challenging parts of the project was prompting the LLM and running numerous experiments until the LLM output matched what was expected. Since LLMs are non deterministic in nature and we required outputs in a consistent JSON form (for parsed results), we needed to prompt the LLM and reinforce the constraints multiple times. This was a valuable lesson that helped us learn how to leverage LLMs in intricate ways for niche applications.
## Accomplishments that we're proud of
We are incredibly proud of developing a platform that not only addresses a critical global challenge but does so with a level of sophistication and accessibility that sets a new standard in the field. Successfully training AI models to navigate the complexities of ESG reports marks a significant technical achievement. The ability to turn dense reports into clear, actionable insights represents a leap forward in sustainability practice.
## What we learned
Throughout the process of building Oasis, we learned the importance of interdisciplinary collaboration in tackling complex problems. Combining AI and sustainability expertise was crucial in understanding both the technical and domain-specific challenges. We also gained insights into the practical applications of AI in real-world scenarios, particularly in how NLP and machine learning can be leveraged to extract and analyze data from unstructured sources. The iterative process of testing and feedback was invaluable, teaching us that user experience is as important as the underlying technology in creating impactful solutions.
## What's next for Oasis
The journey for Oasis is just beginning. Our next steps involve expanding the corpus of sustainability reports to cover a broader range of industries and geographies, enhancing the platform's global applicability. We are also exploring the integration of predictive analytics to offer forward-looking insights, enabling users to not just assess their current practices but also to anticipate future trends and challenges. Collaborating with sustainability experts and organizations will remain a priority, as their insights will help refine our models and ensure that Oasis continues to meet the evolving needs of its users. Ultimately, we aim to make Oasis a cornerstone in the global effort towards more sustainable practices, driving change through data-driven insights and recommendations. | ## Inspiration
We have a problem! We have a new generation of broke philanthropists.
The majority of students do not have a lot of spare cash so it can be challenging for them to choose between investing in their own future or the causes that they believe in to build a better future for others.
On the other hand, large companies have the capital needed to make sizeable donations but many of these acts go unnoticed or quickly forgotten.
## What it does
What if I told you that there is a way to support your favourite charities while also saving money? Students no longer need to choose between investing and donating!
Giving tree changes how we think about investing. Giving tree focuses on a charity driven investment model providing the ability to indulge in philanthropy while still supporting your future financially.
We created a platform that connects students to companies that make donations to the charities that they are interested in. Students will be able to support charities they believe in by investing in companies that are driven to make donations to such causes.
Our mission is to encourage students to invest in companies that financially support the same causes they believe in. Students will be able to not only learn more about financial planning but also help support various charities and services.
## How we built it
### Backend
The backend of this application was built using python. In the backend, we were able to overcome one of our largest obstacles, that this concept has never been done before! We really struggled finding a database or API that would provide us with information on what companies were donating to which charities.
So, how did we overcome this? We wanted to avoid having to manually input the data we needed as this was not a sustainable solution. Additionally, we needed a way to get data dynamically. As time passes, companies will continue to donate and we needed recent and topical data.
Giving Tree overcomes these obstacles using a 4 step process:
1. Using a google search API, search for articles about companies donating to a specified category or charity.
2. Identify all the nouns in the header of the search result.
3. Using the nouns, look for companies with data in Yahoo Finance that have a strong likeness to the noun.
4. Get the financial data of the company mentioned in the article and return the financial data to the user.
This was one of our greatest accomplishments of this project. We were able to overcome and obstacle that almost made us want to do a different project. Although the algorithm can occasionally produce false positives, it works more often than not and allows for us to have a self-sustaining platform to build off of.
### Flask
```shell script
$ touch application.py
from flask import Flask
application = Flask(**name**)
@application.route('/')
def hello\_world():
return 'Hello World'
```
```shell script
$ export FLASK_APP="application.py"
$ flask run
```
Now runs locally:
<http://127.0.0.1:5000/>
### AWS Elastic Beanstalk
Create a Web Server Environment:
```shell script
AWS -> Services -> Elastic beanstalk
Create New Application called hack-western-8 using Python
Create New Environment called hack-western-8-env using Web Server Environment
```
### AWS CodePipeline
Link to Github for Continuous Deployment:
```shell script
Services -> Developer Tools -> CodePipeline
Create Pipeline called hack-western-8
GitHub Version 2 -> Connect to Github
Connection Name -> Install a New App -> Choose Repo Name -> Skip Build Stage -> Deploy to AWS Elastic Beanstalk
```
This link is no longer local:
<http://hack-western-8-env.eba-a5injkhs.us-east-1.elasticbeanstalk.com/>
### AWS Route 53
Register a Domain:
```shell script
Route 53 -> Registered Domains -> Register Domain -> hack-western-8.com -> Check
Route 53 -> Hosted zones -> Create Record -> Route Traffic to IPv4 Address -> Alias -> Elastic Beanstalk -> hack-western-8-env -> Create Records
Create another record but with alias www.
```
Now we can load the website using:<br/>
[hack-western-8.com](http://hack-western-8.com)<br/>
www.hack-western-8.com<br/>
http://hack-western-8.com<br/>
http://www.hack-western-8.com<br/>
Note that it says "Not Secure" beside the link<br/>
### AWS Certificate Manager
Add SSL to use HTTPS:
```shell script
AWS Certificate Manager -> Request a Public Certificate -> Domain Name "hack-western-8.com" and "*.hack-western-8.com" -> DNS validation -> Request
$ dig +short CNAME -> No Output? -> Certificate -> Domains -> Create Records in Route 53
Elastic Beanstalk -> Environments -> Configuration -> Capacity -> Enable Load Balancing
Load balancer -> Add listener -> Port 443 -> Protocol HTTPS -> SSL certificate -> Save -> Apply
```
Now we can load the website using:
<https://hack-western-8.com>
<https://www.hack-western-8.com>
Note that there is a lock icon beside the link to indicate that we are using a SSL certificate so we are secure
## Challenges we ran into
The most challenging part of the project was connecting the charities to the companies. We allowed the user to either type the charity name or choose a category that they would like to support. Once we knew what charity they are interested in, we could use this query to scrape information concerning donations from various companies and then display the stock information related to those companies. We were able to successfully complete this query and we can display the donations made by various companies in the command line, however further work would need to be done in order to display all of this information on the website. Despite these challenges, the current website is a great prototype and proof of concept!
## Accomplishments that we're proud of
We were able to successfully use the charity name or category to scrape information concerning donations from various companies. We not only tested our code locally, but also deployed this website on AWS using Elastic Beanstalk. We created a unique domain for the website and we made it secure through a SSL certificate.
## What we learned
We learned how to connect Flask to AWS, how to design an eye-catching website, how to create a logo using Photoshop and how to scrape information using APIs.
We also learned about thinking outside the box. To find the data we needed we approached the problem from several different angles. We looked for ways to see what companies were giving to charities, where charities were receiving their money, how to minimize false positives in our search algorithm, and how to overcome seemingly impossible obstacles.
## What's next for Giving Tree
Currently, students have 6 categories they can choose from, in the future we would be able to divide them into more specific sub-categories in order to get a better query and find charities that more closely align with their interests.
Health
- Medical Research
- Mental Health
- Physical Health
- Infectious Diseases
Environment
- Ocean Conservation
- Disaster Relief
- Natural Resources
- Rainforest Sustainability
- Global Warming
Human Rights
- Women's Rights
- Children
Community Development
- Housing
- Poverty
- Water
- Sanitation
- Hunger
Education
- Literacy
- After School Programs
- Scholarships
Animals
- Animal Cruelty
- Animal Health
- Wildlife Habitats
We would also want to connect the front and back end. | partial |
## Inspiration
Learning a new instrument is hard. Inspired by games like Guitar Hero, we wanted to make a fun, interactive music experience but also have it translate to actually learning a new instrument. We chose the violin because most of our team members had never touched a violin prior to this hackathon. Learning the violin is also particularly difficult because there are no frets, such as those on a guitar, to help guide finger placement.
## What it does
Fretless is a modular attachment that can be placed onto any instrument. Users can upload any MIDI file through our GUI. The file is converted to music numbers and sent to the Arduino, which then lights up LEDs at locations corresponding to where the user needs to press down on the string.
## How we built it
Fretless is composed to software and hardware components.
We used a python MIDI library to convert MIDI files into music numbers readable by the Arduino. Then, we wrote an Arduino script to match the music numbers to the corresponding light. Because we were limited by the space on the violin board, we could not put four rows of LEDs (one for each string). Thus, we implemented logic to color code the lights to indicate which string to press.
## Challenges we ran into
One of the challenges we faced is that only one member on our team knew how to play the violin. Thus, the rest of the team was essentially learning how to play the violin and coding the functionalities and configuring the electronics of Fretless at the same time.
Another challenge we ran into was the lack of hardware available. In particular, we weren’t able to check out as many LEDs as we needed. We also needed some components, like a female DC power adapter, that were not present at the hardware booth. And so, we had limited resources and had to make do with what we had.
## Accomplishments that we're proud of
We’re really happy that we were able to create a working prototype together as a team. Some of the members on the team are also really proud of the fact that they are now able to play Ode to Joy on the violin!
## What we learned
Do not crimp lights too hard.
Things are always harder than they seem to be.
Ode to Joy on the violin :)
## What's next for Fretless
We can make the LEDs smaller and less intrusive on the violin, ideally a LED pad that covers the entire fingerboard. Also, we would like to expand the software to include more instruments, such as cello, bass, guitar, and pipa. Finally, we would like to corporate a PDF sheet music to MIDI file converter so that people can learn to play a wider range of songs. | # Megafind
## Summary
Megafind is a webapp based platform for hosting live lecture sessions. Professors can begin a session that students in the lecture can join using some provided passcode. Upon joining the live session, students gain access to multiple features that provide an enhanced lecture experience. The dashboard has 3 main features:
1. The first is simply the lecture slides embedded into the left half of their screen––this is for the students to follow along with the presentation.
2. The right side contains two tabs. One is a live transcript of what the professor is saying that updates in real time. The app parses the professor's words in real time to find relevant people, places etc. Each term deemed relevant has a hyperlink to additional resources. These keywords are also stored in a digest that we will send at the end.
3. The third feature is an in-browser note taker that begins lecture with all the bullet points/text scraped from the powerpoint presentation. This way, students can focus on putting their own thoughts/notes instead of simply copying the lecture bullets.
At the end of the lecture, Megafind sends each student a copy of their "lecture digest" which contains 3 parts:
1. A summary of the lecture created by performing natural language understanding on the transcript
2. The notes taken by the student in lecture
3. Each keyword that we picked up on compiled into a list with a short summary of its definition (for study guides/quick reference) | ## 💡 Inspiration 💡
Music has always been inspirational in our lives, it breaks down barriers and unifies people all around the world. The combination of harmony and sound stimulates brain activity. We wanted to use this as a method of helping people overcome physical challenges in a fun and interactive way. These physical obstacles may be caused by various medical conditions such as stroke, dyspraxia, and pathological changes with the brain. That is why we created Hand in Harmony, an assistive musical tool designed specifically for those with motor and coordination challenges.
## ⚙️ What it does ⚙️
Hand in Harmony is a (musical) glove that can be used to play up to a scale of six notes. LEDs at the end of each finger will light up based on the note being played. This assists the user in recognizing what direction or motion they are performing. Different notes are played depending on the rotation of the gloves in the X,Y, and Z directions. Up to six different notes can be played on one glove and programmable to be any of your choice. Get to jamming 🎵
## ⚒️ How we built it 😏
Hand in Harmony was built using:
MOD-MPU6050, a sensor with an accelerometer and gyroscope
Arduino UNO to control logic, input, and outputs
Assembled with a breadboard, wires, and resistors
Arduino Library to call data from our sensors
Coded in C++ using Arduino IDE
## 🗻 Challenges we ran into 😲
During the Make-a-thon we faced several issues including:
* Figuring out how to wire everything onto the breadboard and glove, due to the gloves small size and large number of connections
* Countless issues with using unfamiliar sensors and technologies. Having to find data sheets for all the parts and using them in the correct way
* Lack of resources issues. Due to not having as many materials as we expected, we had to adjust our plan and design to effectively utilize what we did have on hand
## 😀 Accomplishments that we're proud of 🏆
What we’re proud of:
* Exploring + learning new sensors and technologies
* Constructing a working prototype and expanding upon it
* Debugging (most) of our problems
* Collaboration and teamwork!
## 📚 What we learned 🤔
What we learned while working on Hand in Harmony:
* How to use new hardware parts such as transistors and accelerometer
* Creating a hardware projects comes with a lot of unseen circumstances
* The skills to translate ideas into reality
* Teamwork and friendship <3
## ⏭️ What's next for Hand In Harmony 👀
We have countless ideas to improve upon Hand in Harmony. Firstly, although the large Arduino speaker was the best option available to us, it still vastly lacks the level of sound quality that we desire. Thus, an upgrade to a higher quality speaker would be our first priority. Secondly, is the inclusion of the other hand. Due to the lack of available parts, we were only able to physically create our idea for one hand, although we had originally designed for two. This would provide rehabilitation for both hands. Next, we want to reduce the bulk of our prototypes. Even though Hand in Harmony aims to make rehabilitation fun for those with motor and coordination issues, the hefty bulk of the device makes it somewhat unwieldy. Tuning down the weight by switching to smaller batteries is an immediate improvement we can make. Finally, the addition of an assistive motor would decrease the amount of force the patient must assert to use the device, thereby making it more practical. | winning |
## Inspiration
With a vision to develop an innovative solution for portable videography, Team Scope worked over this past weekend to create a device that allows for low-cost, high-quality, and stable motion and panoramic photography for any user. Currently, such equipment exists only for high-end dslr cameras, is expensive, and is extremely difficult to transport. As photographers ourselves, such equipment has always felt out of reach, and both amateurs and veterans would substantially benefit from a better solution, which provides us with a market ripe for innovation.
## What it does
In contrast to current expensive, unwieldy designs, our solution is compact and modular, giving us the capability to quickly set over 20ft of track - while still fitting all the components into a single backpack. There are two main assemblies to SCOPE: first, our modular track whose length can be quickly extended, and second, our carriage which houses all electronics and controls the motion of the mounted camera.
## Design and performance
The hardware was designed in Solidworks and OnShape (a cloud based CAD program), and rapidly prototyped using both laser cutters and 3d printers. All materials we used are readily available, such as mdf fiberboard and acrylic plastic, which would drive down the cost of our product. On the software side, we used an Arduino Uno to power three full-rotation continuous servos, which provide us with a wide range of possible movements. With simple keyboard inputs, the user can interact with the system and control the lateral and rotational motion of the mounted camera, all the while maintaining a consistent quality of footage. We are incredibly proud of the performance of this design, which is able to capture extended time-lapse footage easily and at a professional level. After extensive testing, we are pleased to say that SCOPE has beaten our expectations for ease of use, modularity, and quality of footage.
## Challenges and lessons
Given that this was our first hackathon, and that all team members are freshman with limited experience, we faced numerous challenges in implementing our vision. Foremost among these was learning to code in the Arduino language, which none of us had ever used previously - something that was made especially difficult by our inexperience with software in general. But with the support of the PennApps community, we are happy to have learned a great deal over the past 36 hours, and are now fully confident in our ability to develop similar arduino-controlled products in the future. In addition, As we go forward, we are excited to apply our newly-acquired skills to new passions, and to continue to hack. The people we've met at PennApps have helped us with everything from small tasks, such as operating a specific laser cutter, to intangible advice about navigating the college world and life in general. The four of us are better engineers as a result.
## What's next?
We believe that there are many possibilities for the future of SCOPE, which we will continue to explore. Among these are the introduction of a curved track for the camera to follow, the addition of a gimbal for finer motion control, and the development of preset sequences of varying speeds and direction for the user to access. Additionally, we believe there is significant room for weight reduction to enhance the portability of our product. If produced on a larger scale, our product will be cheap to develop, require very few components to assemble, and still be just as effective as more expensive solutions.
## Questions?
Contact us at [teamscopecamera@gmail.com](mailto:teamscopecamera@gmail.com) | ## Motivation
Our motivation was a grand piano that has sat in our project lab at SFU for the past 2 years. The piano was Richard Kwok's grandfathers friend and was being converted into a piano scroll playing piano. We had an excessive amount of piano scrolls that were acting as door stops and we wanted to hear these songs from the early 20th century. We decided to pursue a method to digitally convert the piano scrolls into a digital copy of the song.
The system scrolls through the entire piano scroll and uses openCV to convert the scroll markings to individual notes. The array of notes are converted in near real time to an MIDI file that can be played once complete.
## Technology
The scrolling through the piano scroll utilized a DC motor control by arduino via an H-Bridge that was wrapped around a Microsoft water bottle. While the notes were recorded using openCV via a Raspberry Pi 3, which was programmed in python. The result was a matrix representing each frame of notes from the Raspberry Pi camera. This array was exported to an MIDI file that could then be played.
## Challenges we ran into
The openCV required a calibration method to assure accurate image recognition.
The external environment lighting conditions added extra complexity in the image recognition process.
The lack of musical background in the members and the necessity to decrypt the piano scroll for the appropriate note keys was an additional challenge.
The image recognition of the notes had to be dynamic for different orientations due to variable camera positions.
## Accomplishments that we're proud of
The device works and plays back the digitized music.
The design process was very fluid with minimal set backs.
The back-end processes were very well-designed with minimal fluids.
Richard won best use of a sponsor technology in a technical pickup line.
## What we learned
We learned how piano scrolls where designed and how they were written based off desired tempo of the musician.
Beginner musical knowledge relating to notes, keys and pitches. We learned about using OpenCV for image processing, and honed our Python skills while scripting the controller for our hack.
As we chose to do a hardware hack, we also learned about the applied use of circuit design, h-bridges (L293D chip), power management, autoCAD tools and rapid prototyping, friction reduction through bearings, and the importance of sheave alignment in belt-drive-like systems. We also were exposed to a variety of sensors for encoding, including laser emitters, infrared pickups, and light sensors, as well as PWM and GPIO control via an embedded system.
The environment allowed us to network with and get lots of feedback from sponsors - many were interested to hear about our piano project and wanted to weigh in with advice.
## What's next for Piano Men
Live playback of the system | ## Inspiration
Currently, personal health data transfer is a very tedious process. It could hardly be transferred between different medical systems. Patients and doctors would have to go through heavy paperwork which often takes up a lot of time. Moreover, the healthcare industry is dominated by big firms which would monopolize data. After having first-hand experience in the medical industry and understanding the pain of personal health record transfer, we were inspired to build Health Pass.
## What it does
Health Pass is a web application to facilitate seamless and secure transfer of personal health records. It transfers different aspects of your health record with two clicks to your trusted healthcare service provider. The process is extremely simple and it could be used by people of all ages. The data would no longer pass through a centralized system, ensuring both convenience through speed and privacy through security.
## What's next for Health Pass
We aim to continue building Health Pass to serve the wider community in need of a personal health record transfer tool. Looking forward, we will be implementing convenience features such as link sharing and NFC to make health record sharing even faster. We aim to design health pass as a user-friendly application, not only targeted for the technologically savvy but the wider population. We would integrate security web3 tools to ensure data security and user privacy. We would also be looking in directions such as the adoption of AI, with the use of chatbots facilitating the user experience. Ultimately, we hope to create a smooth and silky personal health record transfer product. | partial |
## Inspiration 🤔
The brain, the body's command center, orchestrates every function, but damage to this vital organ in contact sports often goes unnoticed. Studies show that 99% of football players are diagnosed with CTE, 87% of boxers have experienced at least one concussion, and 15-30% of hockey injuries are brain-related. If only there were a way for players and coaches to monitor the brain health of players before any long-term damage can occur.
## Our Solution💡
Impactify addresses brain health challenges in contact sports by integrating advanced hardware into helmets used in sports like hockey, boxing, and football. This hardware records all impacts sustained during training or games, capturing essential data from each session. The collected data provides valuable insights into an athlete's brain health, enabling them to monitor and assess their cognitive well-being. By staying informed about potential head injuries or concussion risks, athletes can take proactive measures to protect their health. Whether you're a player who wants to track their own brain health or a coach who wants to track all their players' brain health, Impactify has a solution for both.
## How we built it 🛠️
Impactify leverages a mighty stack of technologies to optimize its development and performance. React was chosen for the front end due to its flexibility in building dynamic, interactive user interfaces, allowing for a seamless and responsive user experience. Django powers the backend, providing a robust and scalable framework for handling complex business logic, API development, and secure authentication. PostgreSQL was selected for data storage because of its reliability, advanced querying capabilities, and easy handling of large datasets. Last but not least, Docker was employed to manage dependencies across multiple devices. This helped maintain uniformity in the development and deployment processes, reducing the chances of environment-related issues.
On the hardware side, we used an ESP32 microprocessor connected to our team member's mobile hotspot, allowing the microprocessor to send data over the internet. The ESP32 was then connected to 4 pressure sensors and an accelerometer, where it reads the data at fixed intervals. The data is sent over the internet to our web server for further processing. The parts were then soldered together and neatly packed into our helmet, and we replaced all the padding to make the helmet wearable again. The hardware was powered with a 9V battery, and then LEDs and a power switch were added to the helmet so the user could turn it on and off. The LEDs served as a visual indicator of whether or not the ESP32 had an internet connection.
## Challenges we ran into 💥
The first challenge we had was getting all the sensors and components positioned in the correct locations within the helmet such that the data will be read accurately. On top of getting the correct positioning, the wiring and all the components must be put in place in such a way that it does not detract from the protective aspect of the helmet. Getting all the components hidden properly and securely was a great challenge and took hours of tinkering.
Another challenge that we faced was making sure that the data that was being read was accurate. We took a long time to callibrate the pressure sensors inside the helmet, because when the helmet is being worn, your head naturally excerts some pressure on the sides of the helmet. Making sure that our data input was reliable was a big challenge to overcome because we had to iterate multiple times on tinkering with the helmet, collecting data, and plotting it on a graph to visually inspect it, before we were satisfied with the result.
## Accomplishments that we're proud of 🥂
We are incredibly proud of how we turned our vision into a reality. Our team successfully implemented key features such as pressure and acceleration tracking within the helmet, and our software stack is robust and scalable with a React frontend and Django backend. We support individual user sessions and coach user management for sports teams, and have safety features such as sending an SMS to a coach if their player takes excessive damage. We developed React components that visualize the collected data, making the website easy to use, visually appealing and interactive. The hardware design was compact and elegant, seamlessly fitting into the helmet without compromising its structure.
## What we learned 🧠
Throughout this project, we learned a great deal about hardware integration, data visualization, and balancing safety with functionality. We also gained invaluable insights into optimizing the development process and managing complex technical challenges.
## What's next for Impactify 🔮
Moving forward, we aim to enhance the system by incorporating more sophisticated data analysis, providing even deeper insights into brain health aswell as fitting our hardware into a larger array of sports gear. We plan to expand the use of Impactify into more sports and further improve its ease of use for athletes and coaches alike. Additionally, we will explore ways to miniaturize the hardware even further to make the integration even more seamless. | ## Inspiration
Globally, one in ten people do not know how to interpret their feelings. There's a huge global shift towards sadness and depression. At the same time, AI models like Dall-E and Stable Diffusion are creating beautiful works of art, completely automatically. Our team saw the opportunity to leverage AI image models and the emerging industry of Brain Computer Interfaces (BCIs) to create works of art from brainwaves: enabling people to learn more about themselves and
## What it does
A user puts on a Brain Computer Interface (BCI) and logs in to the app. As they work in front of front of their computer or go throughout their day, the user's brainwaves are measured. These differing brainwaves are interpreted as indicative of different moods, for which key words are then fed into the Stable Diffusion model. The model produces several pieces, which are sent back to the user through the web platform.
## How we built it
We created this project using Python for the backend, and Flask, HTML, and CSS for the frontend. We made use of a BCI library available to us to process and interpret brainwaves, as well as Google OAuth for sign-ins. We made use of an OpenBCI Ganglion interface provided by one of our group members to measure brainwaves.
## Challenges we ran into
We faced a series of challenges throughout the Hackathon, which is perhaps the essential route of all Hackathons. Initially, we had struggles setting up the electrodes on the BCI to ensure that they were receptive enough, as well as working our way around the Twitter API. Later, we had trouble integrating our Python backend with the React frontend, so we decided to move to a Flask frontend. It was our team's first ever hackathon and first in-person hackathon, so we definitely had our struggles with time management and aligning on priorities.
## Accomplishments that we're proud of
We're proud to have built a functioning product, especially with our limited experience programming and operating under a time constraint. We're especially happy that we had the opportunity to use hardware in our hack, as it provides a unique aspect to our solution.
## What we learned
Our team had our first experience with a 'real' hackathon, working under a time constraint to come up with a functioning solution, which is a valuable lesson in and of itself. We learned the importance of time management throughout the hackathon, as well as the importance of a storyboard and a plan of action going into the event. We gained exposure to various new technologies and APIs, including React, Flask, Twitter API and OAuth2.0.
## What's next for BrAInstorm
We're currently building a 'Be Real' like social media plattform, where people will be able to post the art they generated on a daily basis to their peers. We're also planning integrating a brain2music feature, where users can not only see how they feel, but what it sounds like as well | ## Inspiration
Inspired by wearable technology and smart devices, RollX introduces a new way to control everyday technology using the familiar platform of a wristwatch.
## What it does
RollX is a custom built wearable controller with an embedded accelerometer and gyroscope. The embedded software takes the sensor information, normalizes it, and maps it to various types of input controls. For example, the current sensor mapping is designed to be used with a simple custom built game but we have already tested mapping the data to control the cursor on a computer.
## How we built it
Starting from the ground up, the RollX team designed the housing, the electronic layout, and the embedded software to drive the device. The housing was designed with SolidWorks and 3D printed. The electronic components were tested and wired separately then integrated into one circuit controlled by an Arduino Nano. This consisted of coordinating the data from gyroscope and accelerometer to properly display the orientation of the device using the LED ring.
## Challenges we ran into
The initial design used an IoT Particle Photon board which would have wirelessly communicated over the internet however due to complication which packages were supported, we were forced to utilize an Arduino Nano. Further, due to the hardware change, the 3D modelling had to be updated. Separately, the integration of the OLED screen caused a memory overflow on the Arduino which was corrected with an updated deployment process.
## Accomplishments that we're proud of
Our team is extremely proud to present a creative wearable device with a unique design that enables greater control over technology. This multidisciplinary project includes the integration of various sensors into one microcontroller, CAD and 3D modelling and custom embedded software. All together the unit accomplishes what we set out to do in the 36 hours we had. RollX has been successfully integrated with all of the hardware and software and is fully functional with a simple custom game to show the proof of concept!
## What we learned
Hardware integration from the ground up in tandem with customized embedded software. We learned a lot about what is required for a multidisciplinary project to be fully integrated and deployed. Although not making it's way to the final project we also learned a lot about IoT development and the Particle development environment.
## Potential applications
Potential applications of RollX include its utilization for educational purposes and assistive devices. RollX can be utilized in VR classrooms, where the orientation of your hand motion will be recorded, analyzed, and used for various hands-on tasks. For example, during sports lessons, RollX can be used to analyze the player's motion and enhance their skills. Another major application is as an assistive device with individuals with limited mobility. For example, the individuals suffering from spinal injuries may not have fine control over their hands and fingers. But RollX can detect movement in wrist and forearm that can potentially be used to control various technological applications. | winning |
## Inspiration 💡
What should I cook with what’s left in the fridge? What should I eat to meet my fitness goals? How can I prepare simple and nutritious meals? Our team recognizes that these are struggles that many people, especially university students, have in their everyday life.
To address this issue with modern technology, we developed a phone application which allows students to enter what they have in their fridge and generate a customized recipe tailored to their own likings.
## What it does 🥗
Main pages:
Authentication page
Home page
Recipe Generation page
User profile page
User insight page
SimplYum utilizes AI to generate customized recipes based on the ingredients, the cuisine preference, and the fitness goals the user has. Our app saves the recipes the users create, and allows them to reuse their favorite recipes. Users can also view their daily/weekly calorie and nutrition intake in the user insight page to keep track of their fitness goals. SimplYum transforms cooking into a simple and enjoyable process, promoting healthy eating habits and a love for cooking.
## How we built it 🛠️
Tools we used:
IDE: Visual Studio Code, Android studio, Xcode
Language: Javascript(backend), Javascript/CSS(frontend)
Other tools and APIs: Figma, Express.js, OpenAI API, React-native, Firebase
We designed the layout of our project on Figma. After having a formalized layout, we created our project on VScode and tested our front-end code on both Android emulators from Android studio and IOS emulators on Xcode. We built our backend with Express.js and utilized GPT function calling to create customized recipes for our users. We used Firebase to store user data, and execute the authentication workflow.
## Challenges we ran into 🤯
We encountered numerous slow-downs, set-backs, and even pit-falls throughout our process. Some notable mentions include:
Navigating the complexities of the React Native navigation bar layout.
Integrating GPT function calls with the backend seamlessly.
Accidentally exposing our API key online, leading to the need for regeneration.
Battling fatigue as the hackathon progressed into its later stages.
Coordinating tasks efficiently within the time constraints of the hackathon.
Despite these obstacles, our team persevered, constantly motivating each other to push through and strive for success.
## Accomplishments that we're proud of 🌟
3 of 4 of the team used the project’s tech stack, namely React Native for app development using Android Studio, for the first time; knowing CS fundamentals, this was a fun and challenging exercise in recognizing the transferability of our skills and adaptation speed.
The professional approach to the project; we employed various industry-standard project management strategies including Agile workflow, UI/X design in Figma, and extensive Git use.
Implementing a working mobile application with GPT Function calling model which is a relatively new technology | ## Inspiration
We wanted to bring Augmented Reality technologies to an unexpecting space; challenging ourselves to think outside of the box. We were looking for somewhere where user experience could be dramatically improved.
## What it does
Our AR mobile application recognizes DocuSigns QR codes and allows you to either sign up directly or generate an automated signature without ever leaving your phone.
## How we built it
We built it with our awesome brains and
## Challenges we ran into
Implementing the given API and other back-end technologies to actually authenticate and submit the process. We ran into challenges when trying to integrate the digital world with the technical world. There was not much documentation online when it came to merging the two platforms. We also ran into challenges with image recognition of the QR code because AR depends on the environment and lighting.
## Accomplishments that we're proud of
We got a MVP out of the challenge, we did a lot of collaboration and brainstorming which sparked amazing ideas, we spoke to every sponsor to learn about their company and challenges
## What we learned
API's with little documentation and trying to integrate with new technologies can be very challenging. Pay attention to details because it's the small details that will cost you hours of frustration. Through further research we learned about the legalities with digital signatures which sometimes can be a pain point for companies who use eSign like DocuSign.
## What's next for Project 1 AM
To Present to all judges and hopefully the idea gets bought in and implemented to make customer's lives easier | # Omakase
*"I'll leave it up to you"*
## Inspiration
On numerous occasions, we have each found ourselves staring blankly into the fridge with no idea of what to make. Given some combination of ingredients, what type of good food can I make, and how?
## What It Does
We have built an app that recommends recipes based on the food that is in your fridge right now. Using Google Cloud Vision API and Food.com database we are able to detect the food that the user has in their fridge and recommend recipes that uses their ingredients.
## What We Learned
Most of the members in our group were inexperienced in mobile app development and backend. Through this hackathon, we learned a lot of new skills in Kotlin, HTTP requests, setting up a server, and more.
## How We Built It
We started with an Android application with access to the user’s phone camera. This app was created using Kotlin and XML. Android’s ViewModel Architecture and the X library were used. This application uses an HTTP PUT request to send the image to a Heroku server through a Flask web application. This server then leverages machine learning and food recognition from the Google Cloud Vision API to split the image up into multiple regions of interest. These images were then fed into the API again, to classify the objects in them into specific ingredients, while circumventing the API’s imposed query limits for ingredient recognition. We split up the image by shelves using an algorithm to detect more objects. A list of acceptable ingredients was obtained. Each ingredient was mapped to a numerical ID and a set of recipes for that ingredient was obtained. We then algorithmically intersected each set of recipes to get a final set of recipes that used the majority of the ingredients. These were then passed back to the phone through HTTP.
## What We Are Proud Of
We were able to gain skills in Kotlin, HTTP requests, servers, and using APIs. The moment that made us most proud was when we put an image of a fridge that had only salsa, hot sauce, and fruit, and the app provided us with three tasty looking recipes including a Caribbean black bean and fruit salad that uses oranges and salsa.
## Challenges You Faced
Our largest challenge came from creating a server and integrating the API endpoints for our Android app. We also had a challenge with the Google Vision API since it is only able to detect 10 objects at a time. To move past this limitation, we found a way to segment the fridge into its individual shelves. Each of these shelves were analysed one at a time, often increasing the number of potential ingredients by a factor of 4-5x. Configuring the Heroku server was also difficult.
## Whats Next
We have big plans for our app in the future. Some next steps we would like to implement is allowing users to include their dietary restriction and food preferences so we can better match the recommendation to the user. We also want to make this app available on smart fridges, currently fridges, like Samsung’s, have a function where the user inputs the expiry date of food in their fridge. This would allow us to make recommendations based on the soonest expiring foods. | losing |
## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Statistical data showed an increase in infant hospital visits in recent years which further solidified our mission to tackle this problem at its core.
## What it does
Our software uses a website with user authentication to collect data about an infant. This data considers factors such as temperature, time of last meal, fluid intake, etc. This data is then pushed onto a MySQL server and is fetched by a remote device using a python script. After loading the data onto a local machine, it is passed into a linear regression machine learning model which outputs the probability of the infant requiring medical attention. Analysis results from the ML model is passed back into the website where it is displayed through graphs and other means of data visualization. This created dashboard is visible to users through their accounts and to their family doctors. Family doctors can analyze the data for themselves and agree or disagree with the model result. This iterative process trains the model over time. This process looks to ease the stress on parents and insure those who seriously need medical attention are the ones receiving it. Alongside optimizing the procedure, the product also decreases hospital costs thereby lowering taxes. We also implemented a secure hash to uniquely and securely identify each user. Using a hyper-secure combination of the user's data, we gave each patient a way to receive the status of their infant's evaluation from our AI and doctor verification.
## Challenges we ran into
At first, we challenged ourselves to create an ethical hacking platform. After discussing and developing the idea, we realized it was already done. We were challenged to think of something new with the same amount of complexity. As first year students with little to no experience, we wanted to tinker with AI and push the bounds of healthcare efficiency. The algorithms didn't work, the server wouldn't connect, and the website wouldn't deploy. We persevered and through the help of mentors and peers we were able to make a fully functional product. As a team, we were able to pick up on ML concepts and data-basing at an accelerated pace. We were challenged as students, upcoming engineers, and as people. Our ability to push through and deliver results were shown over the course of this hackathon.
## Accomplishments that we're proud of
We're proud of our functional database that can be accessed from a remote device. The ML algorithm, python script, and website were all commendable achievements for us. These components on their own are fairly useless, our biggest accomplishment was interfacing all of these with one another and creating an overall user experience that delivers in performance and results. Using sha256 we securely passed each user a unique and near impossible to reverse hash to allow them to check the status of their evaluation.
## What we learned
We learnt about important concepts in neural networks using TensorFlow and the inner workings of the HTML code in a website. We also learnt how to set-up a server and configure it for remote access. We learned a lot about how cyber-security plays a crucial role in the information technology industry. This opportunity allowed us to connect on a more personal level with the users around us, being able to create a more reliable and user friendly interface.
## What's next for InfantXpert
We're looking to develop a mobile application in IOS and Android for this app. We'd like to provide this as a free service so everyone can access the application regardless of their financial status. | ## Inspiration
We were heavily focused on the machine learning aspect and realized that we lacked any datasets which could be used to train a model. So we tried to figure out what kind of activity which might impact insurance rates that we could also collect data for right from the equipment which we had.
## What it does
Insurity takes a video feed from a person driving and evaluates it for risky behavior.
## How we built it
We used Node.js, Express, and Amazon's Rekognition API to evaluate facial expressions and personal behaviors.
## Challenges we ran into
This was our third idea. We had to abandon two major other ideas because the data did not seem to exist for the purposes of machine learning. | ## Inspiration
In the United States, every 11 seconds, a senior is treated in the emergency room for a fall. Every 19 minutes, an older adult dies from a fall, directly or indirectly. Deteriorating balance is one of the direct causes of falling in seniors. This epidemic will only increase, as the senior population will double by 2060. While we can’t prevent the effects of aging, we can slow down this process of deterioration. Our mission is to create a solution to senior falls with Smart Soles, a shoe sole insert wearable and companion mobile app that aims to improve senior health by tracking balance, tracking number of steps walked, and recommending senior-specific exercises to improve balance and overall mobility.
## What it does
Smart Soles enables seniors to improve their balance and stability by interpreting user data to generate personalized health reports and recommend senior-specific exercises. In addition, academic research has indicated that seniors are recommended to walk 7,000 to 10,000 steps/day. We aim to offer seniors an intuitive and more discrete form of tracking their steps through Smart Soles.
## How we built it
The general design of Smart Soles consists of a shoe sole that has Force Sensing Resistors (FSRs) embedded on it. These FSRs will be monitored by a microcontroller and take pressure readings to take balance and mobility metrics. This data is sent to the user’s smartphone, via a web app to Google App Engine and then to our computer for processing. Afterwards, the output data is used to generate a report whether the user has a good or bad balance.
## Challenges we ran into
**Bluetooth Connectivity**
Despite hours spent on attempting to connect the Arduino Uno and our mobile application directly via Bluetooth, we were unable to maintain a **steady connection**, even though we can transmit the data between the devices. We believe this is due to our hardware, since our HC05 module uses Bluetooth 2.0 which is quite outdated and is not compatible with iOS devices. The problem may also be that the module itself is faulty. To work around this, we can upload the data to the Google Cloud, send it to a local machine for processing, and then send it to the user’s mobile app. We would attempt to rectify this problem by upgrading our hardware to be Bluetooth 4.0 (BLE) compatible.
**Step Counting**
We intended to use a three-axis accelerometer to count the user’s steps as they wore the sole. However, due to the final form factor of the sole and its inability to fit inside a shoe, we were unable to implement this feature.
**Exercise Repository**
Due to a significant time crunch, we were unable to implement this feature. We intended to create a database of exercise videos to recommend to the user. These recommendations would also be based on the balance score of the user.
## Accomplishments that we’re proud of
We accomplished a 65% success rate with our Recurrent Neural Network model and this was our very first time using machine learning! We also successfully put together a preliminary functioning prototype that can capture the pressure distribution.
## What we learned
This hackathon was all new experience to us. We learned about:
* FSR data and signal processing
* Data transmission between devices via Bluetooth
* Machine learning
* Google App Engine
## What's next for Smart Soles
* Bluetooth 4.0 connection to smartphones
* More data points to train our machine learning model
* Quantitative balance score system | winning |
## Inspiration
Social-distancing is hard, but little things always add up.
What if person X is standing too close to person Y in the c-mart, and then person Y ends up in the hospital for more than a month battling for their lives? Not finished, that c-mart gets shut down for contaminated merchandise.
All this happened because person X didn't step back.
These types of scenarios, and in hope of going back to normal lives, pushed me to create **Calluna**.
## What Calluna does
Calluna is aimed to be an apple watch application. On the application, you can check out all the notifications you've gotten that day as well as when you've got it and your settings.
When not on the app, you get pinged when your too close to someone who also has the app, making this a great feature for business workforces.
## How Calluna was built
Calluna was very simply built using Figma. I have linked below both design and a fully-fuctionally prototype!
## Challenges we ran into
I had some issues with ideation. I needed something that was useful, simple, and has growth potential. I also had some headaches on the first night that could possibly be due to sleep deprivation and too much coffee that ended up making me sleep till the next morning.
## Accomplishments that we're proud of
I love the design! I feel like this is a project that will be really helpful *especially* during the COVID-19 pandemic.
## What we learned
I learned how to incorporate fonts to accent the color and scene, as well as working with such small frames and how to make it look easy on the eyes!
## What's next for Calluna
I hope to create and publish the ios app with GPS integration, then possibly android too. | ## Inspiration
Our inspiration comes from many of our own experiences with dealing with mental health and self-care, as well as from those around us. We know what it's like to lose track of self-care, especially in our current environment, and wanted to create a digital companion that could help us in our journey of understanding our thoughts and feelings. We were inspired to create an easily accessible space where users could feel safe in confiding in their mood and check-in to see how they're feeling, but also receive encouraging messages throughout the day.
## What it does
Carepanion allows users an easily accessible space to check-in on their own wellbeing and gently brings awareness to self-care activities using encouraging push notifications. With Carepanion, users are able to check-in with their personal companion and log their wellbeing and self-care for the day, such as their mood, water and medication consumption, amount of exercise and amount of sleep. Users are also able to view their activity for each day and visualize the different states of their wellbeing during different periods of time. Because it is especially easy for people to neglect their own basic needs when going through a difficult time, Carepanion sends periodic notifications to the user with messages of encouragement and assurance as well as gentle reminders for the user to take care of themselves and to check-in.
## How we built it
We built our project through the collective use of Figma, React Native, Expo and Git. We first used Figma to prototype and wireframe our application. We then developed our project in Javascript using React Native and the Expo platform. For version control we used Git and Github.
## Challenges we ran into
Some challenges we ran into included transferring our React knowledge into React Native knowledge, as well as handling package managers with Node.js. With most of our team having working knowledge of React.js but being completely new to React Native, we found that while some of the features of React were easily interchangeable with React Native, some features were not, and we had a tricky time figuring out which ones did and didn't. One example of this is passing props; we spent a lot of time researching ways to pass props in React Native. We also had difficult time in resolving the package files in our application using Node.js, as our team members all used different versions of Node. This meant that some packages were not compatible with certain versions of Node, and some members had difficulty installing specific packages in the application. Luckily, we figured out that if we all upgraded our versions, we were able to successfully install everything. Ultimately, we were able to overcome our challenges and learn a lot from the experience.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to produce an application from ground up, from the design process to a working prototype. We are excited that we got to learn a new style of development, as most of us were new to mobile development. We are also proud that we were able to pick up a new framework, React Native & Expo, and create an application from it, despite not having previous experience.
## What we learned
Most of our team was new to React Native, mobile development, as well as UI/UX design. We wanted to challenge ourselves by creating a functioning mobile app from beginning to end, starting with the UI/UX design and finishing with a full-fledged application. During this process, we learned a lot about the design and development process, as well as our capabilities in creating an application within a short time frame.
We began by learning how to use Figma to develop design prototypes that would later help us in determining the overall look and feel of our app, as well as the different screens the user would experience and the components that they would have to interact with. We learned about UX, and how to design a flow that would give the user the smoothest experience. Then, we learned how basics of React Native, and integrated our knowledge of React into the learning process. We were able to pick it up quickly, and use the framework in conjunction with Expo (a platform for creating mobile apps) to create a working prototype of our idea.
## What's next for Carepanion
While we were nearing the end of work on this project during the allotted hackathon time, we thought of several ways we could expand and add to Carepanion that we did not have enough time to get to. In the future, we plan on continuing to develop the UI and functionality, ideas include customizable check-in and calendar options, expanding the bank of messages and notifications, personalizing the messages further, and allowing for customization of the colours of the app for a more visually pleasing and calming experience for users. | ## Inspiration
Integration for patients into society: why can't it be achieved? This is due to the lack of attempts to combine medical solutions and the perspectives of patients in daily use. More specifically, we notice fields in aid to visual disabilities lack efficiency, as the most common option for patients with blindness is to use a cane and tap as they move forward, which can be slow, dangerous, and limited. They are clunky and draw attention to the crowd, leading to more possible stigmas and inconveniences in use. We attempt to solve this, combining effective healthcare and fashion.
## What it does
* At Signifeye, we have created a pair of shades with I/O sensors that provides audio feedback to the wearer on how far they are to the object they are looking at.
* We help patients build a 3D map of their surroundings and they can move around much quicker, as opposed to slowly tapping the guide cane forward
* Signifeye comes with a companion app that allows for both the blind user and caretakers. The UI is easy to navigate for the blind user and allows for easier haptic feedback manipulation.Through the app, caretakers can also monitor and render assistance to the blind user, thereby being there for the latter 24/7 without having to be there physically through tracking of data and movement.
## How we built it
* The frame of the sunglasses is inspired by high-street fashion, and was modeled via Rhinoceros 3D
to balance aesthetics and functionality. The frame is manufactured using acrylic sheets on a
laser cutter for rapid prototyping
* The sensor arrays consist of an ultrasonic sensor, a piezo speaker, a 5V regulator and a 9V
battery, and are powered by the Arduino MKR WiFi 1010
* The app was created using React Native and Figma for more comprehensive user details, using Expo Go and VSCode for a development environment that could produce testable outputs.
## Challenges we ran into
Difficulty of iterative hardware prototyping under time and resource constraints
* Limited design iterations,
* Shortage of micro-USB cables that transfer power and data, and
* For the frame design, coordinating the hardware with the design for dimensioning.
Implementing hardware data to softwares
* Collecting Arduino data into a file and accommodating that with the function of the application, and
* Altering user and haptic feedback on different mobile operating systems, where different programs had different dependencies that had to be followed.
## What we learned
As most of us were beginner hackers, we learned about multiple aspects that went into creating a viable product.
* Fully integrating hardware and software functionality, including Arduino programming and streamlining.
* The ability to connect cross platform softwares, where I had to incorporate features or data pulled from hardware or data platforms.
* Dealing with transferring of data and the use of computer language to process different formats, such as audio files or censor induced wavelengths.
* Became more proficient in running and debugging code. I was able to adjust to a more independent and local setting, where an emulator or external source was required aside from just an IDE terminal. | partial |
## Inspiration
Currently, physical therapy is not easily accessible to underrepresented segmentations such as rural patients, elderly patients, cost sensitive patients, disabled patients, and patients with a language barrier.
Additionally, as a physical therapist, you will teach your patients the proper form for their exercises and make sure they are performing each movement correctly. But once they are back in their home environment, how do you know whether they are still doing their exercises the right way—or at all?
## What it does
J.A.C.K. AI uses a trained computer vision model to analyze and monitor a patient's physical therapy exercises. The model is trained on correct and incorrect forms of exercises and identifies not just if a patient is doing an exercise incorrectly, but *how* they are doing an exercise incorrectly. We then provide users with personalized AI-generated feedback with GPT-4.
## How we built it
Our project is an interconnected system of 3 different AI models. Our first model was a pose detection model that determines the x and y coordinates of the different movements of our bodies. We then process these coordinates through a series of algorithms and pass them into our manually built AI model that detects whether you are doing the exercise correctly or not. We will then extract information from this model and feed it into OpenAI's GPT API to make it give us comments/advice about how we performed the exercises.
## Challenges we ran into
A major hurdle was gathering a suitable dataset to test and train our data on. As a result, we spent considerable time developing an easy and accessible frontend to convert our pose detection classification into csv files to be processed. In terms of training our models and displaying the recommendations to users, we also faced challenges in fine-tuning parameters for our AI as well as utilizing the OpenAI API.
## Accomplishments that we're proud of
We are proud to have presented our idea to Y Combinator as part of the YC Pitch Challenge. Additionally, we are proud of the setbacks we have overcome and continuing to see an ambitious idea through in such a short amount of time.
## What we learned
Throughout this entire hackathon, we have learned a lot about computer vision, web development, and most importantly working together as a team to come up with the best solutions and deliver the best results for our project. Although we all come from different backgrounds and different schools, we have been able to work very closely together and plan out the details of every single step of our project. All in all, we have not only been able to expand our technical skills but also learn so much about collaboration and communication.
## What's next for J.A.C.K. AI
We will immediately reach out to physical therapists around the world to get our product on the market. On the technological side, we will begin classifying more exercise movements and training our AI models on a variety of different parameters that specify how movement exercises are incorrect. | # Motion's Creation: Bringing Precision to Yoga
## Inspiration
While exploring potential ideas, MoveNet caught our attention with its capabilities for accurately tracking human movement. We recognized an opportunity: to provide wellness within reach for all through real-time feedback. Motion aspires to make wellness accessible for all. By breaking down multiple barriers, Motion allows new segmentations to receive personalized training feedback without the cost of hiring a personal trainer. Future updates to the application will ensure that anyone, irrespective of language, economic, age, or location status, can benefit.
## Implementation
We integrated a camera on our platform that effectively captures joint movements using MoveNet. To understand and analyze these movements, we utilized TensorFlow and PyTorch in our backend. Our approach involved two primary steps:
1. **Pose Prediction:** Training a machine learning model to identify the specific pose a user attempts.
2. **Pose Correction:** Training a subsequent model to detect inaccuracies in the user's pose.
If a user's pose is deemed incorrect, our system uses OpenAI's GPT API to generate unique and personalized feedback, guiding them towards the correct form.
## Challenges & Insights
Gathering diverse and representative training data posed a significant challenge. Recognizing that individuals have varying arm lengths, different distances from the camera, and diverse orientations, we aimed to make our system universally applicable. Although MoveNet expertly captures joint data in diverse scenarios, our initial model's training revealed a need for broader data. This realization led us to consider the myriad ways users might interact with our application, ensuring our model had a rich learning environment. | ## Inspiration
JAGT Move originally came forth as an idea after one of our members injured himself trying to perform a basic exercise move he wasn't used to. The project has pivoted around over time, but the idea of applying new technologies to help people perform poses has remained.
## What it does
The project compares positional information between the user and their reference exercise footage using pose recognition (ML) in order to give them metrics and advice which will help them perform better (either as a clinical tool, or for everyday use).
## How we built it
* Android frontend based of TensorFlow Lite Posenet application
* NodeJS backend to retrieve the metrics, process it and provide the error of each body part to the website for visual presentation.
* A React website showing the live analysis with details to which parts of your body were out of sync.
## Challenges we ran into
* Only starting model available for Android project used Kotlin, which our mobile dev. had to learn on the fly
* Server errors like "post method too voluminous", and a bunch of other we had to work around
* Tons of difficult back-end calculations
* Work with more complex sets of data (human shapes) in an ML context
## What's next for JAGT Move
Expand the service, specialize the application for medical use further, expand on the convenience of use of the app for the general public, and much more! It's time to get JAGT! | losing |
## Inspiration
We wanted to make the world a better place by giving patients control over their own data and allow easy and intelligent access of patient data.
## What it does
We have built an intelligent medical record solution where we provide insights on reports saved in the application and also make the personal identifiable information anonymous before saving it in our database.
## How we built it
We have used Amazon Textract Service as OCR to extract text information from images. Then we use the AWS Medical Comprehend Service to redact(Mask) sensitive information(PII) before using Groq API to extract inferences that explain the medical document to the user in the layman language. We have used React, Node.js, Express, DynamoDB, and Amazon S3 to implement our project.
## Challenges we ran into
## Accomplishments that we're proud of
We were able to fulfill most of our objectives in this brief period of time.We also got to talk to a lot of interesting people and were able to bring our project to completion despite a team member not showing up.We also got to learn about a lot of cool stuff that companies like Groq, Intel, Hume, and You.com are working on and we had fun talking to everyone.
## What we learned
## What's next for Pocket AI | ## Inspiration
We were inspired to create our product because of one of our teammate's recent experience in our healthcare system. After a particularly bad bike accident, he went to the emergency department to be checked on but faced egregious wait times due to inefficiencies within the hospital. Unfortunately, the medical staff is so occupied with administrative work such as filling out forms, that their valuable time, which could be spent with patients, is drawn thin. We hoped to make something that could address this issue, which will both lower costs of operation and increase patient satisfaction.
## What it does
Our product is a web page that uses the language model GPT-3 to expedite the process of creating patient visit summaries. The UI prompts the user to simply enter a few words or phrases pertaining to the patient's situation - their initial incident, symptoms, and treatments - and the model, along with our back-end, works to synthesize it all into a summary.
## How we built it
Much of the beauty of this project lies in the UI, which streamlines the whole process. The web page was built using React with components from Google's Material UI to easily integrate front- and back-end. We also used OpenAI's GPT-3 playground to test various queries and eventually decide on the exact ones that would be used within the React framework.
## Challenges we ran into
Working with GPT-3 proved to be a trickier task than expected. The language model was often rather fickle, producing content that we found to be irrelevant or even incorrect. Even more confounding was formatting the results we got. We tried a variety of methods of generating the multi-paragraph structure that we wanted, yet all of them had some sort of inconsistency. Ultimately, we realized that the reliability we needed depended on more simplicity, and thus came up with simpler, but more streamlined queries that got the job done consistently.
## Accomplishments that we're proud of
We are proud of having built a product from scratch while implementing cutting-edge natural language technology. It was exciting to see the components of our site develop from its planning stages and then come together as an actual product that can feasibly be deployed for actual use.
## What we learned
Having been so entranced by ChatGPT recently, we learned how to integrate large language models into applications for ourselves. It turns out that it was much more difficult than just typing a question into ChatGPT, and designing the pipeline became a valuable learning experience.
## What's next for Untitled
Despite having such a niche application, our project has many possibilities for expansion. We can further optimize the process with better, perhaps more specifically trained language models that will be able to predict possible symptoms or treatments for an incident. Additionally, we can expand our concept and product to other similar administrative tasks that take up the valuable time of medical workers, helping to expedite many more facets of our healthcare system. | ## Inspiration
We have a desire to spread awareness surrounding health issues in modern society. We also love data and the insights in can provide, so we wanted to build an application that made it easy and fun to explore the data that we all create and learn something about being active and healthy.
## What it does
Our web application processes data exported by Apple health and provides visualizations of the data as well as the ability to share data with others and be encouraged to remain healthy. Our educational component uses real world health data to educate users about the topics surrounding their health. Our application also provides insight into just how much data we all constantly are producing.
## How we built it
We build the application from the ground up, with a custom data processing pipeline from raw data upload to visualization and sharing. We designed the interface carefully to allow for the greatest impact of the data while still being enjoyable and easy to use.
## Challenges we ran into
We had a lot to learn, especially about moving and storing large amounts of data and especially doing it in a timely and user-friendly manner. Our biggest struggle was handling the daunting task of taking in raw data from Apple health and storing it in a format that was easy to access and analyze.
## Accomplishments that we're proud of
We're proud of the completed product that we came to despite early struggles to find the best approach to the challenge at hand. An architecture this complicated with so many moving components - large data, authentication, user experience design, and security - was above the scope of projects we worked on in the past, especially to complete in under 48 hours. We're proud to have come out with a complete and working product that has value to us and hopefully to others as well.
## What we learned
We learned a lot about building large scale applications and the challenges that come with rapid development. We had to move quickly, making many decisions while still focusing on producing a quality product that would stand the test of time.
## What's next for Open Health Board
We plan to expand the scope of our application to incorporate more data insights and educational components. While our platform is built entirely mobile friendly, a native iPhone application is hopefully in the near future to aid in keeping data up to sync with minimal work from the user. We plan to continue developing our data sharing and social aspects of the platform to encourage communication around the topic of health and wellness. | losing |
## Inspiration
The theme for PennApps XVII is "retro," so we decided to dive head first into all things neon, funky, analog, and furby. We created the ultimate hyperstylized interactive jukebox. You're welcome, dad.
## What it does
FunkBud not only plays some of the greatest hits of bygone decades, but allows anyone to seize control of one of its virtual instruments for a live jam session using any mobile device. Get groovy with a group of friends or strangers - whoever you funk with, satisfaction and algebraic vibes are guaranteed.
## How we built it
We sampled a number of live and synthesized instruments from Ableton, mapped the key ranges and MIDI data to javascript-friendly format, and used socket to allow anyone to access a simple URL to take control of one of FunkBud's instruments. Don't worry, if you're prone to stage fright there's always autopilot.
## Challenges we ran into
We really wanted to make something that gushed a 90's aesthetic - it turns out, combining that objective with an ultra-slick user interface wasn't so easy at first (but boy oh boy did we figure it out). Also, we actually arranged every single song from scratch - we practically wrote an entire interactive/manipulable album for this baby. Of course, there were the usual challenges like reducing latency at countless points even outside of interfacing our hub and controllers through socket.
## Accomplishments that we're proud of
The visuals on this thing are pretty insane if we do say so ourselves. Also, the instruments are actually sampled from either live/analog instruments or professional-grade synthesizers - plus it's so intuitive, even a toddler could rock out on it (but for the musically oriented, there's plentiful room for juicy riffs and expression).
## What we learned
Vanilla javascript can't keep (precise) time for its life - a toast to fantastic libraries yet again.
## What's next for FunkBud
Automated song transcription and louder speakers (obviously). | ## Inspiration
A love of music production, the obscene cost of synthesizers, and the Drive soundtrack
## What it does
In its simplest form, it is a synthesizer. It creates a basic wave using wave functions and runs it through a series of custom filters to produce a wide range of sounds. Finally the sounds are bound to a physical "keyboard" made using an Arduino.
## How we built it
The input driver and function generator ares written in python using numpy and pyaudio libraries for calculating wave functions and to output the result to audio output..
## Challenges we ran into
-pyaudio doesn't play nice with multiprocessing
-multithreading wasn't as good an option because it doesn't properly parallelize due to Python's GIL
-parsing serial input from a constant stream lead to a few issues
## What we learned
We learned a lot about realtime signal processing, the performance limitations of Python and the ins and outs of creating an controller device from the hardware level to driver software.
## What's next for Patch Cable
-We'd like to rewrite the signal processing in a faster language. Python couldn't keep up with realtime transformation as well was we would have liked.
-We'd like to add a command line and visual interface for making the function chains to make it easier to make sounds as you go. | ## Inspiration
An individual living in Canada wastes approximately 183 kilograms of solid food per year. This equates to $35 billion worth of food. A study that asked why so much food is wasted illustrated that about 57% thought that their food goes bad too quickly, while another 44% of people say the food is past the expiration date.
## What it does
LetsEat is an assistant that comprises of the server, app and the google home mini that reminds users of food that is going to expire soon and encourages them to cook it in a meal before it goes bad.
## How we built it
We used a variety of leading technologies including firebase for database and cloud functions and Google Assistant API with Dialogueflow. On the mobile side, we have the system of effortlessly uploading the receipts using Microsoft cognitive services optical character recognition (OCR). The Android app is writen using RxKotlin, RxAndroid, Retrofit on a MVP architecture.
## Challenges we ran into
One of the biggest challenges that we ran into was fleshing out our idea. Every time we thought we solved an issue in our concept, another one appeared. We iterated over our system design, app design, Google Action conversation design, integration design, over and over again for around 6 hours into the event. During development, we faced the learning curve of Firebase Cloud Functions, setting up Google Actions using DialogueFlow, and setting up socket connections.
## What we learned
We learned a lot more about how voice user interaction design worked. | partial |
## Inspiration
Often times we need to send a picture or an attachment from our laptop to our phone, but there is no established way of doing so. Personally, we use Facebook Messenger on one device to send said attachment in a conversation with ourself (yes, this is lonely) and open Messenger on the other device to save the attachment. AirDrop can accomplish this task, but many people do not have both an iPhone and a Macbook laptop (chances are they also have AirPods, iPad and an Apple Pencil like a true fanboy). To represent all other people who suffer from not having all Apple products, we made an easy and seamless way to share attachments.
## What it does
Going from phone to computer: select desired pictures or attachments and then upload. Three random words are generated, which when entered into the computer screen, are now transferred to the computer to download and save.
From computer to phone: select and upload desired attachments to send. Once pressing the "Upload" button, a unique QR code appears which is to be scanned on the phone's camera app. This takes you to our website's link which now has your files from your computer available to you.
## How we built it
Back-end uses Python and Flask, developed by one member. Front-end utilizes HTML, CSS, and Jinja2, done by two members.
## Challenges we ran into
Had an issue at the end with Google services which would allow the team to have the domain "DropSpace.space", but this challenge was solved in the early hours of the morning of judging.
Two of the three team members are also new to HTML and CSS so many problems occurred, as you may expect.
## Accomplishments that we're proud of
These two members who are new to HMTL and CSS have made it over the hump and are now able to use these languages for future purposes such as other Hackathons or just out of curiosity to become more proficient.
## What we learned
We learned a lot about front and back-end web design.
## What's next for DropSpace
Since the team sees a lot of potential in this service (as told by fellow classmates), a mobile-friendly version can be developed in the form of an app- instead of having only the website available. | ## Inspiration
We are fascinated by the pressing issues in environmental sustainability today. All growing up in green-driven cities in Canada, we feel almost useless in a completely different setting reading about tragic environmental events in current news. Learning about Amazon fires, consistent deforestation, pollution, and climate change, it pained us to see that many of our peers did not share that same sense of urgency. As a result, we were interested in making an initiative for ourselves, to ease the process of raising awareness for the environment in one way or another. The current lack of incentive of a call to action is a big driving force for us.
## What it does
Project SID is a autonomous drone swarm that is capable of efficient and large scale detection. In our demo, we've decided to apply it to tracking debris and trash. The drones carry out individual missions and provide data for us to generate reports mapping out hotspots and documenting the spread of debris.
## How we built it
Using Python and Flask for the backend to manage the actual drones and communications pipelines, machine learning for object detection and processing, and React for the frontend. Our project is divided into four distinct sections made up of the server, web application, machine learning model, and the hardware itself, each playing a vital role towards the final product.
1. The Server was written in Python using Flask to mediate commands and information exchange between the web interface and the drones.
2. The web app was developed as a dashboard, designed for easy deployment of automated drone missions.
3. The Machine Learning model used a retrained version of the YOLOv3 object detection algorithm to differentiate between trash and other items.
4. The drones themselves were DJI Tellos and were controlled using Python wrappers for the Tello SDK.
## Challenges we ran into
* Because of the sheer ambition and technical complexity of the project, making sure that all the components were able to talk to each other was an incredible challenge of our collective skills.
* Our two Tello EDU drones decided it would be a good idea to not connect anymore. Figuring a way to demo the functionality we originally intended was difficult.
* Photo resolution of drones was not great. This, coupled with our home-made image recognition model, meant that object detection wasn't always reliable.
## Accomplishments that we're proud of
Connecting so many various aspects of tech together. We had hardware, full-stack web dev, cloud, and even machine learning integrated into one project. With such an ambitious project, it's a miracle we even have something to demo.
## What's next for Project SID
Due to the time constraints of the hackathon, there were a lot of ideas that we unfortunately had to miss out on.
* implement true swarm functionality (e.g. no 'lead' drone)
* autonomous deployment of drone charging stations and wifi extenders, to increase the reach of SID
* live video streaming and manual takeover
* image stitching for generation of accurate terrain data | ## Inspiration
Almost all undergraduate students, especially at large universities like the University of California Berkeley, will take a class that has a huge lecture format, with several hundred students listening to a single professor speak. At Berkeley, students (including three of us) took CS61A, the introductory computer science class, alongside over 2000 other students. Besides forcing some students to watch the class on webcasts, the sheer size of classes like these impaired the ability of the lecturer to take questions from students, with both audience and lecturer frequently unable to hear the question and notably the question not registering on webcasts at all. This led us to seek out a solution to this problem that would enable everyone to be heard in a practical manner.
## What does it do?
*Questions?* solves this problem using something that we all have with us at all times: our phones. By using a peer to peer connection with the lecturer’s laptop, a student can speak into their smartphone’s microphone and have that audio directly transmitted to the audio system of the lecture hall. This eliminates the need for any precarious transfer of a physical microphone or the chance that a question will be unheard.
Besides usage in lecture halls, this could also be implemented in online education or live broadcasts to allow participants to directly engage with the speaker instead of feeling disconnected through a traditional chatbox.
## How we built it
We started with a fail-fast strategy to determine the feasibility of our idea. We did some experiments and were then confident that it should work. We split our working streams and worked on the design and backend implementation at the same time. In the end, we had some time to make it shiny when the whole team worked together on the frontend.
## Challenges we ran into
We tried the WebRTC protocol but ran into some problems with the implementation and the available frameworks and the documentation. We then shifted to WebSockets and tried to make it work on mobile devices, which is easier said than done. Furthermore, we had some issues with web security and therefore used an AWS EC2 instance with Nginx and let's encrypt TLS/SSL certificates.
## Accomplishments that we're (very) proud of
With most of us being very new to the Hackathon scene, we are proud to have developed a platform that enables collaborative learning in which we made sure whatever someone has to say, everyone can hear it.
With *Questions?* It is not just a conversation between a student and a professor in a lecture; it can be a discussion between the whole class. *Questions?* enables users’ voices to be heard.
## What we learned
WebRTC looks easy but is not working … at least in our case. Today everything has to be encrypted … also in dev mode. Treehacks 2020 was fun.
## What's next for *Questions?*
In the future, we could integrate polls and iClicker features and also extend functionality for presenters and attendees at conferences, showcases, and similar events. \_ Questions? \_ could also be applied even broader to any situation normally requiring a microphone—any situation where people need to hear someone’s voice. | losing |
## Inspiration
Due to this pandemic, quarantine is our last resort which eventually increases physical
inactivity which results in Physical and Mental problems.
So, it becomes more necessary to take care of ourselves in this time and Yoga proves to be very
helpful in getting rid of all the problems.
Since it is very important to maintain correct posture while doing the exercises and that’s
where this personal trainer will be very useful, handy, and effective.
## What it does
It is a real-time interactive AI-powered personal Yoga Trainer who will be using a
real-time pose recognition from live video feed (device’s camera) to guide you through every
step of asana (body posture).
## How we built it
We have made a mobile app using flutter and had used Firebase for the backend. For Voice Recognition, Google's TTS and STT plugins are used.
A pre-trained image classification model is used which predicting the correct postures by comparing the captured image with the one in the video (User is imitating the instructor in the video).
## Challenges we ran into
To import a TensorFlow model into Mobile App and then making different components interacting with the model was a tricky part.
## Accomplishments that we're proud of
We are proud to say that we have made an application where you can learn Yoga without any assistance from an outsider/trainer.
You just need a Mobile App and you are good to go.
## What we learned
We have learned about the different components of Flutter, Firebase, Tensorflow, TensorFlowLite, Image Classification Model, etc.
## What's next for AI Yoga
We are looking to expand the varieties of Asana in the current app and gamify user's experience so that he/she should visit the app again and again. | ## Inspiration
Last week, we read an interview of Dr. Sue Desmond, CEO of the Bill & Melinda Gates Foundation, who talked about the use of technology as a tool to improve outcomes in health.
During the opening ceremonies of YHack, a speaker prompted "What's next?" and thus, insights started developing in our minds that how can we make something novel which would increase the effectiveness of healthcare delivery. We decided to focus on data-driven diagnosis, and that's how this project came into being.
## What it does?
Before we discuss how our system facilitates diagnosis, let us talk about the challenges faced by traditional medicine in diagnosing osteoporosis and related bone disorders:
* There's no way for human eyes to sense these disorders beforehand – until a fracture gets developed.
* Once a fracture develops, the probability of complexity in the future increases substantially.
* Research suggests that after reaching the age of fifty, 1 in 2 women will have a future fracture related to osteoporosis.
**Why Kinect?**
Kinect allows us to rapidly develop and deploy a working prototype that can process massive amount of data to give real-time diagnosis. We ourselves wouldn't recommend using this project in its current form for medical practice as a lot of things can be improved.
The purpose of this demo is to attract attention towards increasing importance of computing in medicine and introduce a novel way how computing can aid medical professionals reach better conclusions.
Medical professionals cannot be **replaced** by computers – but data-driven tools like these would certainly **help** caregivers develop insights that substantially improve the quality of care they provide, thereby helping ensure that lives are not affected by preventable diseases such as osteoporosis.
Perhaps given the right resources, we can evolve this into a market ready solution for out-of-the-box deployment.
## How it works?
On its initial run, the application works in a "learning mode" that allows it to gather vast amount of data when the Kinect sensor is placed strategically. This data is then input into a Machine Learning library that churns out certain parameters which define the normal posture and skeletal configuration of a human being.
On subsequent runs, any obtained data is compared with the initially obtained model in real-time. Cases that vary widely or that can be matched with known parameters of a positive subject are tagged by a large red blip hovering on the area that is statistically anticipated to be affected. Though this leaves a gap to develop false positives, it makes the possibility of a false negative extremely low, which is far better than having no early warnings at all.
## Challenges we ran into
The most difficult challenge we faced throughout the journey of developing our project was that none of us were well-versed with Machine Learning and Neural Networks, which we were able to overcome by the use of a machine learning library.
## Accomplishments that we're proud of
We feel some sense of pride that our work was able to enhance the accuracy of Kinect's skeletal model generation by using its depth sensing capabilities. We also feel happy that we have built something that has the potential to improve lives.
## What's next
1. Hack
2. Prototype
3. ????
4. Revolutionize Medicine.
While it would be too naive to expect that our demo would revolutionise medicine overnight, we see this as a significant starting point in improving the field of medicine. We look forward to guidance from medical professionals, who would help us understand their needs and develop a platform that is accurate enough to be actively deployed across healthcare delivery systems around the world. | ## Inspiration
Our solution was named on remembrance of Mother Teresa
## What it does
Robotic technology to assist nurses and doctors in medicine delivery, patient handling across the hospital, including ICU’s. We are planning to build an app in Low code/No code that will help the covid patients to scan themselves as the mobile app is integrated with the CT Scanner for doctors to save their time and to prevent human error . Here we have trained with CT scans of Covid and developed a CNN model and integrated it into our application to help the covid patients. The data sets are been collected from the kaggle and tested with an efficient algorithm with the efficiency of around 80% and the doctors can maintain the patient’s record. The beneficiary of the app is PATIENTS.
## How we built it
Bots are potentially referred to as the most promising and advanced form of human-machine interactions. The designed bot can be handled with an app manually through go and cloud technology with e predefined databases of actions and further moves are manually controlled trough the mobile application. Simultaneously, to reduce he workload of doctor, a customized feature is included to process the x-ray image through the app based on Convolution neural networks part of image processing system. CNN are deep learning algorithms that are very powerful for the analysis of images which gives a quick and accurate classification of disease based on the information gained from the digital x-ray images .So to reduce the workload of doctors these features are included. To know get better efficiency on the detection I have used open source kaggle data set.
## Challenges we ran into
The data source for the initial stage can be collected from the kaggle and but during the real time implementation the working model and the mobile application using flutter need datasets that can be collected from the nearby hospitality which was the challenge.
## Accomplishments that we're proud of
* Counselling and Entertainment
* Diagnosing therapy using pose detection
* Regular checkup of vital parameters
* SOS to doctors with live telecast
-Supply off medicines and foods
## What we learned
* CNN
* Machine Learning
* Mobile Application
* Cloud Technology
* Computer Vision
* Pi Cam Interaction
* Flutter for Mobile application
## Implementation
* The bot is designed to have the supply carrier at the top and the motor driver connected with 4 wheels at the bottom.
* The battery will be placed in the middle and a display is placed in the front, which will be used for selecting the options and displaying the therapy exercise.
* The image aside is a miniature prototype with some features
* The bot will be integrated with path planning and this is done with the help mission planner, where we will be configuring the controller and selecting the location as a node
* If an obstacle is present in the path, it will be detected with lidar placed at the top.
* In some scenarios, if need to buy some medicines, the bot is attached with the audio receiver and speaker, so that once the bot reached a certain spot with the mission planning, it says the medicines and it can be placed at the carrier.
* The bot will have a carrier at the top, where the items will be placed.
* This carrier will also have a sub-section.
* So If the bot is carrying food for the patients in the ward, Once it reaches a certain patient, the LED in the section containing the food for particular will be blinked. | losing |
## Inspiration
We want to share the beauty of the [Curry-Howard isomorphism](https://en.wikipedia.org/wiki/Curry%E2%80%93Howard_correspondence) and automated proof checking with beginning programmers. The concepts of Types and Formal Proofs are central to many aspects of computer science. ProofLang is to Agda the way Python is to C. We believe that the beauty of mathematical proofs and formal verification can be appreciated by more than CS theorists, when taught the right way. The best way to build this intuition is using visualizations, which is what this project aims to do. By presenting types as containers of variants, it allows a teacher to demonstrate the concept of type inhabitation, and why that is central to automated theorem proving.
## What it does
ProofLang is a simplified, type-based, programming language. It also comes with an online interpreter and a real time visualization tool, which displays all the types in a way that solidifies the correct type of intuition about types (with regards to theorem proving and the [calculus of constructions](https://en.wikipedia.org/wiki/Calculus_of_constructions)), alongside the instantiations of the types, showing a ledger of evidence.
## How we built it
We wrote ProofLang the programming language itself from the ground up based on the [calculus of constructions](https://en.wikipedia.org/wiki/Calculus_of_constructions), but simplified it enough for beginner audiences. The interpreter is written in Rust and complied down to WebAssembly which is imported as a Javascript library into our React frontend.
## Challenges we ran into
We ran into challenges integrating WebAssembly with our React frontend. `web-pack` compiles our Rust code down into Javascript for Node.js rather than the Web JS that React uses. Since the interpreter is written in Rust, there was some fighting with the borrow-checker involved as well.
## Accomplishments that we're proud of
We are proud of building our own interpreter! We also created a whole programming language which is pretty awesome. We even wrote a tiny parser combinator framework similar to [nom](https://docs.rs/nom/latest/nom/), since we could not figure out a few edge cases.
## What's next for ProofLang
Support for function types, as well as type constructors that are not unit-like! Going forward, we would also like to add a visual programming aspect to it, where users can click and drag on a visual interface much like [Snap](https://snap.berkeley.edu/) to write code, which would make it even more accessible to beginner programmers and mathematicians. | ## Inspiration
Survival from out-of-hospital cardiac arrest remains unacceptably low worldwide, and it is the leading cause of death in developed countries. Sudden cardiac arrest takes more lives than HIV and lung and breast cancer combined in the U.S., where survival from cardiac arrest averages about 6% overall, taking the lives of nearly 350,000 annually. To put it in perspective, that is equivalent to three jumbo jet crashes every single day of the year.
For every minute that passes between collapse and defibrillation survival rates decrease 7-10%. 95% of cardiac arrests die before getting to the hospital, and brain death starts 4 to 6 minutes after the arrest.
Yet survival rates can exceed 50% for victims when immediate and effective cardiopulmonary resuscitation (CPR) is combined with prompt use of a defibrillator. The earlier defibrillation is delivered, the greater chance of survival. Starting CPR immediate doubles your chance of survival. The difference between the current survival rates and what is possible has given rise to the need for this app - IMpulse.
Cardiac arrest can occur anytime and anywhere, so we need a way to monitor heart rate in realtime without imposing undue burden on the average person. Thus, by integrating with Apple Watch, IMpulse makes heart monitoring instantly available to anyone, without requiring a separate device or purchase.
## What it does
IMpulse is an app that runs continuously on your Apple Watch. It monitors your heart rate, detecting for warning signs of cardiac distress, such as extremely low or extremely high heart rate. If your pulse crosses a certain threshold, IMpulse captures your current geographical location and makes a call to an emergency number (such as 911) to alert them of the situation and share your location so that you can receive rapid medical attention. It also sends SMS alerts to emergency contacts which users can customize through the app.
## How we built it
With newly-available access to Healthkit data, we queried heart sensor data from the Apple Watch in real time. When these data points are above or below certain thresholds, we capture the user's latitude and longitude and make an HTTPRequest to a Node.js server endpoint (currently deployed to heroku at <http://cardiacsensor.herokuapp.com>) with this information. The server uses the Google Maps API to convert the latitude and longitude values into a precise street address. The server then makes calls to the Nexmo SMS and Call APIs which dispatch the information to emergency services such as 911 and other ICE contacts.
## Challenges we ran into
1. There were many challenges testing the app through the XCode iOS simulators. We couldn't find a way to simulate heart sensor data through our laptops. It was also challenging to generate Location data through the simulator.
2. No one on the team had developed in iOS before, so learning Swift was a fun challenge.
3. It was challenging to simulate the circumstances of a cardiac arrest in order to test the app.
4. Producing accurate and precise geolocation data was a challenge and we experimented with several APIs before using the Google Maps API to turn latitude and longitude into a user-friendly, easy-to-understand street address.
## Accomplishments that we're proud of
This was our first PennApps (and for some of us, our first hackathon). We are proud that we finished our project in a ready-to-use, demo-able form. We are also proud that we were able to learn and work with Swift for the first time. We are proud that we produced a hack that has the potential to save lives and improve overall survival rates for cardiac arrest that incorporates so many different components (hardware, data queries, Node.js, Call/SMS APIs).
## What's next for IMpulse
Beyond just calling 911, IMpulse hopes to build out an educational component of the app that can instruct bystanders to deliver CPR. Additionally, with the Healthkit data from Apple Watch, IMpulse could expand to interact with a user's pacemaker or implantable cardioverter defibrillator as soon as it detects cardiac distress. Finally, IMpulse could communicate directly with a patient's doctor to deliver realtime heart monitor data. | ## Inspiration
We were inspired by Xcode's Swift playground, which evaluates code live in a sidebar.
## What it does
This is an extension for Atom that evaluates Python code and presents it live next to the corresponding line in the code editor. Thus, the user can see how every variable is changed as the user is typing the program. Users can keep typing and catch whatever mistakes they has have committed without having to run the code. This benefits for students of computer science and more advanced users who would like to prototype quickly.
## How we built it
There is a Python backend with our custom Python interpreter that evaluates expression and displays user-friendly output. On the front-end, we created an Atom package. We used Javascript ES6 and Atom APIis.
## Challenges we ran into
The main challenge was building the interpreter. It was difficult to do this since no interpreter out there already did what we needed. We had to parse the code and prevent all sorts of errors involved in running code within code.
It was also challenging to figure out the Atom APIs to get a user-friendly and very responsive interface.
## Accomplishments that we're proud of
We got some logic in the interpreter, and it is somewhat useful. It is also extensible and can be built-upon by others.
## What we learned
We learned about interacting between a Python program and an Atom extension. We learned Atom APIs and also some basic Python parsing and interpreting.
## What's next for atom-playground
We would like to add graphics to understand loops and support for recursion analysis. | partial |
# Travel Itinerary Generator
## Inspiration
Traveling is an experience that many cherish, but planning for it can often be overwhelming. With countless events, places to visit, and activities, it's easy to miss out on experiences that could have made the trip even more memorable. This realization inspired us to create the **Travel Itinerary Generator**. We wanted to simplify the travel planning process by providing users with curated suggestions based on their preferences.
## What It Does
The **Travel Itinerary Generator** is a web application that assists users in generating travel itineraries. Users receive tailored suggestions on events or places to visit by simply entering a desired location and activity type. The application fetches this data using the Metaphor API, ensuring the recommendations are relevant and up-to-date.
## How We Built It
We began with a React-based frontend, leveraging components to create a user-friendly interface. Material-UI was our go-to library for the design, ensuring a consistent and modern look throughout the application.
To fetch relevant data, we integrated the Metaphor API. Initially, we faced CORS issues when bringing data directly from the front end. To overcome this, we set up a Flask backend to act as a proxy, making requests to the Metaphor API on behalf of the front end.
We utilized the `framer-motion` library for animations and transitions, enhancing the user experience with smooth and aesthetically pleasing effects.
## Challenges We Faced
1. **CORS Issues**: One of the significant challenges was dealing with CORS when trying to fetch data from the Metaphor API. This required us to rethink our approach and implement a Flask backend to bypass these restrictions.
2. **Routing with GitHub Pages**: After adding routing to our React application, we encountered issues deploying to GitHub Pages. It took some tweaking and adjustments to the base URL to get it working seamlessly.
3. **Design Consistency**: Ensuring a consistent design across various components while integrating multiple libraries was challenging. We had to make sure that the design elements from Material-UI blended well with our custom styles and animations.
## What We Learned
This project was a journey of discovery. We learned the importance of backend proxies in handling CORS issues, the intricacies of deploying single-page applications with client-side routing, and the power of libraries like `framer-motion` in enhancing user experience. Moreover, integrating various tools and technologies taught us the value of adaptability and problem-solving in software development.
## Conclusion
This journey was like a rollercoaster - thrilling highs and challenging lows. We discovered the art of bypassing CORS, the nuances of SPAs, and the sheer joy of animating everything! It reinforced our belief that we can create solutions that make a difference with the right tools and a problem-solving mindset. We're excited to see how travelers worldwide will benefit from our application, making their travel planning a breeze!
## Acknowledgements
* [Metaphor API](https://metaphor.systems/) for the search engine.
* [Material-UI](https://mui.com/) for styling.
* [Framer Motion](https://www.framer.com/api/motion/) for animations.
* [Express API](https://expressjs.com/) hosted on [Google Cloud](https://cloud.google.com/).
* [React.js](https://react.dev/) for web framework. | ## Inspiration
We always that moment when you're with your friends, have the time, but don't know what to do! Well, SAJE will remedy that.
## What it does
We are an easy-to-use website that will take your current location, interests, and generate a custom itinerary that will fill the time you have to kill. Based around the time interval you indicated, we will find events and other things for you to do in the local area - factoring in travel time.
## How we built it
This webapp was built using a `MEN` stack. The frameworks used include: MongoDB, Express, and Node.js. Outside of the basic infrastructure, multiple APIs were used to generate content (specifically events) for users. These APIs were Amadeus, Yelp, and Google-Directions.
## Challenges we ran into
Some challenges we ran into revolved around using APIs, reading documentation and getting acquainted to someone else's code. Merging the frontend and backend also proved to be tough as members had to find ways of integrating their individual components while ensuring all functionality was maintained.
## Accomplishments that we're proud of
We are proud of a final product that we legitimately think we could use!
## What we learned
We learned how to write recursive asynchronous fetch calls (trust me, after 16 straight hours of code, it's really exciting)! Outside of that we learned to use APIs effectively.
## What's next for SAJE Planning
In the future we can expand to include more customizable parameters, better form styling, or querying more APIs to be a true event aggregator. | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | partial |
## Inspiration
In recent years, particularly during the pandemic, thrifted fashion has experienced a resurgence in popularity. The rise of #ThriftTok, amassing over 1.6 billion views, and the unprecedented foot traffic in thrift stores have played a pivotal role in promoting sustainable practices such as upcycling and reusing fashion items. Thrifting stands as a formidable counterforce to the unsustainable trends of fast fashion and the overconsumption of clothing.
However, alongside the positive aspects of this trend, certain drawbacks have become evident. In Canada, where our pilot project will be initiated, the largest thrift store chain, Value Village, operates for profit, selling donated clothes at prices comparable to those of newly manufactured fast fashion items. Recent TikTok trends have shed light on the exorbitant prices of some thrift store items, such as distressed graphic t-shirts selling for $20 or plain baseball hats for $15. This commercialization undermines the essence of thrifting, making fast fashion once again a more affordable choice.
## What it does
We are committed to rectifying this situation over time. Our initiative originates from the "clothing swap" events at our university, where people could exchange clothes by donating and receiving items from others. SwapParty represents an expansive clothing swap, designed to make thrifting not only more affordable, with customers only bearing shipping costs, but also more accessible for those without convenient access to physical thrift stores. It introduces an element of surprise through 'surprise boxes,' a concept gaining popularity. Our platform empowers users to swap clothing with like-minded individuals nationwide, sharing the same style and size, for as little as the cost of shipping. This innovative approach aims to steer fashion away from the fast fashion trend and make thrifting affordable and accessible once more, advancing our collective commitment to sustainability. To describe how it would work step-by-step, first the user would go on our website and click the button to "start a swap". Then, they would take a short quiz to choose the size of box they want, i.e. small, medium, or large, to choose what kind of objects will be in the box, i.e. clothing, accessories, or shoes. Then, the user would pick a few keywords out of a list to describe their style, as well as sizing for clothing and shoes, and a colour scheme for accessories. Once two people are matched by our fool-proof algorithm, they are then emailed automatically that they have been matched. After they've been matched, they have 72 hours to decide whether they want to accept or deny the swap. If both parties accept, then they have 48 hours to mail their curated box of their old clothes, accessories, or shoes. If there was enough time, we would have liked to implement a deposit system to make sure that both parties actually mail their boxes.
## How we built it
We first came up with an algorithm to help us match two people based on their style compatibility and similar body measurements. After each user completes their quiz, their answers would be saved onto a JSON file, which we would then read on Python. The algorithm works by utilizing a counting system that keeps track of each person who will send and receive a box in the same "category". It quantifies the similarities between two people's style, and makes sure that their sizes are relatively the same. The algorithm first sorts the users into duos that match based on their box size choice and their objects that would be in the box. If those variables are the same for two people, they are put in a duo. Then, the algorithm quantifies how well their styles and general preferences match up, and the duos with the highest match count are then matched up. After, the program emails the two people who have been matched with an email including instructions on next steps.
## Challenges we ran into
Going into this hackathon, none of our team members had any experience with front-end development. So, we didn't know how a website was to be built, nor did we have experience with any big projects. This is why we couldn't figure out how to connect our back-end and front-end work using flask. We also ran into challenges trying to send emails via Python, although we ended up with a function that can send an email to the users who have been matched. The real challenge that we weren't able to overcome was the link that we were planning on adding to the email where the user could confirm their participation in the swap. This wasn't possible for us to do in the given time frame because our flask component wouldn't work. To get flask to work, we originally tried using it with the appropriate directories and html files, but it gave us many errors. Then, when we tried using it without them, the website would work perfectly, but the back-end couldn't be connected to the front-end.
## Accomplishments that we're proud of
We're proud that our back-end algorithm that matches people up and emails them once they have been matched. We're also very proud of the way our website looks, our front-end developer learned HTML during this hackathon and did a great job. It took us a long time to figure all of it out as this is all of our first hackathons and our first big project. We are also really proud of our creativity and our dedication to building a project that hacked to a more sustainable future. We think that our idea was original, never done before, and would make a positive change if implemented on a grand-scheme.
## What we learned
We got comfortable using languages that were new to us, like html, css, flask, and really anything related to web development. We also learned from our mistakes of leaving flask till the end and not having enough time to focus on it, as well as not having a better and more balanced work balance and more defined roles in the project.
## What's next for Swap Party
We hope to continue working on our project and eventually make it become a reality for users across Canada. We think that affordability and accessibility of sustainable fashion is a really important step we need to take as a society, while making the whole process fun. | ## Inspiration
We wanted to find a good way to make fashion more accessible and eco-friendly at the same time. The fast fashion industry generates a lot of packaging and clothing waste, so we wanted to find a more sustainable alternative to conventional online shopping.
## What it does
Our site allows the user to browse items sold at local thrift shops as well as those posted for sale by another user. We included a weather check feature that suggests appropriate clothing for the season and weather. Finally, there is a Mix and Match tab that allows the user to build the perfect outfit using clothes from local vendors.
## How we built it
Thrift the Fit is hosted on Firebase and a large portion is coded in C#. Building off a website template, we added pages and functionality in HTML/CSS and JavaScript.
## Challenges we ran into
The carousel feature of the Mix and Match page was particularly difficult to implement. We also struggled to enable the geolocator for the weather check feature.
## Accomplishments that we're proud of
The carousel viewer was difficult to get right, so getting that right was particularly satisfying. In addition, integrating the multiple parts of the web app took some testing and constant tweaking, so the whole site working together is a welcome sight :)
## What's next for Thrift the Fit
We plan to add some more options for the individual user. We would implement user accounts with simple password protection. Each user will be able to add their own personal wardrobe to painlessly choose an outfit for any occasion. | ## 💡 Inspiration💡
Our team is saddened by the fact that so many people think that COVID-19 is obsolete when the virus is still very much relevant and impactful to us. We recognize that there are still a lot of people around the world that are quarantining—which can be a very depressing situation to be in. We wanted to create some way for people in quarantine, now or in the future, to help them stay healthy both physically and mentally; and to do so in a fun way!
## ⚙️ What it does ⚙️
We have a full-range of features. Users are welcomed by our virtual avatar, Pompy! Pompy is meant to be a virtual friend for users during quarantine. Users can view Pompy in 3D to see it with them in real-time and interact with Pompy. Users can also view a live recent data map that shows the relevance of COVID-19 even at this time. Users can also take a photo of their food to see the number of calories they eat to stay healthy during quarantine. Users can also escape their reality by entering a different landscape in 3D. Lastly, users can view a roadmap of next steps in their journey to get through their quarantine, and to speak to Pompy.
## 🏗️ How we built it 🏗️
### 🟣 Echo3D 🟣
We used Echo3D to store the 3D models we render. Each rendering of Pompy in 3D and each landscape is a different animation that our team created in a 3D rendering software, Cinema 4D. We realized that, as the app progresses, we can find difficulty in storing all the 3D models locally. By using Echo3D, we download only the 3D models that we need, thus optimizing memory and smooth runtime. We can see Echo3D being much more useful as the animations that we create increase.
### 🔴 An Augmented Metaverse in Swift 🔴
We used Swift as the main component of our app, and used it to power our Augmented Reality views (ARViewControllers), our photo views (UIPickerControllers), and our speech recognition models (AVFoundation). To bring our 3D models to Augmented Reality, we used ARKit and RealityKit in code to create entities in the 3D space, as well as listeners that allow us to interact with 3D models, like with Pompy.
### ⚫ Data, ML, and Visualizations ⚫
There are two main components of our app that use data in a meaningful way. The first and most important is using data to train ML algorithms that are able to identify a type of food from an image and to predict the number of calories of that food. We used OpenCV and TensorFlow to create the algorithms, which are called in a Python Flask server. We also used data to show a choropleth map that shows the active COVID-19 cases by region, which helps people in quarantine to see how relevant COVID-19 still is (which it is still very much so)!
## 🚩 Challenges we ran into
We wanted a way for users to communicate with Pompy through words and not just tap gestures. We planned to use voice recognition in AssemblyAI to receive the main point of the user and create a response to the user, but found a challenge when dabbling in audio files with the AssemblyAI API in Swift. Instead, we overcame this challenge by using a Swift-native Speech library, namely AVFoundation and AVAudioPlayer, to get responses to the user!
## 🥇 Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for while interacting with it, virtually traveling places, talking with it, and getting through quarantine happily and healthily.
## 📚 What we learned
For the last 36 hours, we learned a lot of new things from each other and how to collaborate to make a project.
## ⏳ What's next for ?
We can use Pompy to help diagnose the user’s conditions in the future; asking users questions about their symptoms and their inner thoughts which they would otherwise be uncomfortable sharing can be more easily shared with a character like Pompy. While our team has set out for Pompy to be used in a Quarantine situation, we envision many other relevant use cases where Pompy will be able to better support one's companionship in hard times for factors such as anxiety and loneliness. Furthermore, we envisage the Pompy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene, exercise tips and even lifestyle advice, Pompy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery.
\*\*we had to use separate github workspaces due to conflicts. | losing |
## Inspiration
As a college student, it's easy to constantly eat out and forget what we're putting in our bodies.
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for SudoChef | TBD, still a work in progress
## Inspiration
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Dodge The React | # ✨ Inspiration | partial |
## Inspiration
We wanted to ease the complicated prescription medicine process, especially for elderly people who have to juggle multiple prescriptions at the same time.
## What it does
The AutoMed dispenses medication, at the right time, in the right quantity for the patient. It prevents the patient from taking the incorrect medication, or the incorrect amount of medicine. It also uploads data to MongoDB, so that the patient's pharmacist and doctor can monitor the patient's progress on their medication. In addition, the patient and pharmacist can be reminded to refill the prescription when the medication runs low.
## How I built it
We built the AutoMed using Python3 running on a Raspberry Pi, which controls all the servos and leds.
## Challenges I ran into
Initially, we attempted using the Dragon 410c and Pynq Z1, but we could not get the GPIO to properly interface in order to control the motors. As a result, we switched to the Raspberry Pi.
## Accomplishments that I'm proud of
We're proud of the proof of concept dispenser we created.
## What I learned
Research and choose the right hardware ahead of time!
## What's next for AutoMed
We hope to expand this to allow further push reminders and functionality for the patient, doctor, and pharmacist. For example, expiry date reminders can be set, in addition to reminders if the patient forgets to take their medication. Missed medication can be tracked and reported to the doctor, allowing them to track and/or recommend alternatives or best courses of action. Specialized medication storage can be incorporated, such as lock storage for opioids or refrigerated storage for antibiotics. An option to add non-prescription medication, such as Advil, Benadryl, or Tylenol. We'd also like to incorporate a GUI and a touchscreen on the AutoMed, to allow for easy use by the patient. | ## Inspiration
The inspiration behind Sampson is the abuse and overuse of prescription drugs. This can come in both the form of accidental and on purpose. Our team’s main focus is on assisting patients that are not able responsibly manage their own medication. Often this is a big issue with Alzheimer's or Dementia patients. Sampson’s aim is to prevent this from happening and allow these patients and their families to be less stressed about their medication.
## What it does
Sampson is a cloud-connected, remote managed pill dispensary system intended to assist patients with their prescriptions. The system is controlled by each patient's physician through a centralized database where information such as the type of medicine the user requires, the frequency and schedule of usage of this medicine. Each pill dispenser is equipped with its own pill dispenser mechanism as well as a completely sealed case that does not allow users to directly access their bulk medication. This however is able to be accessed by pharmacists or qualified technicians to refill. Each of these pill holders is connected to an IoT device that is able to communicate with the system’s centralized database. This system is able to get information on pill dosages and scheduling as well as send data about the level that the pill container is at. This same centralized system is able to be accessed by doctors and physicians for them to be able to live update a patient’s prescription from anywhere if necessary.
## How we built it
The team built the system on a variety of frameworks. The centralized database was built with Python, HTML, and CSS using Django Framework. The IoT device was built on an Intel Edison Board using Python. The Prototype Hardware was built on an Arduino 101 using Arduino’s Software and integrated libraries. The team also developed a Simple Socket server from scratch hosted on the Intel Edison Board.
## Challenges we ran into
One of the major challenges the team faced was getting all the systems to communicate together (Physician Database, IoT Device and Prototype Hardware). The biggest challenge of all was having the IoT device be able to communicate with the database through the Simple Socket Server to be able to get information about the user of the device. One of the challenges with the prototype hardware was that we were unable to determine in the timeframe how to also run it through the Intel Edison board and in turn had to control all the hardware through an Arduino. This meant the team had to come up with another way of transmitting important data to the Arduino in order to have a cohesive final product.
## Accomplishments that we're proud of
* Setting up a Simple Socket Servo on the Intel Edison
* Creating a functional prototype out of Arduino and cardboard
* 3D cad model of proposed product
## What we learned
What did we not learn about? The team took on a very ambitious approach to tackle what we felt is a very pertinent and (relatively) simple to fix problem in the medical sector. Throughout this project the team learnt a lot about web services and hosting of servers as well as how IoT devices connect to a centralized system.
## What's next for Sampson
In the future the team hopes to further develop the web platform for Doctors to create a more thought out and user friendly application. There is also a high incentive to create an app or communication system to talk to the user to remind them to take their medication. It is also incredibly important to improve the encryption used to protect patient data. The team would also like to develop a portable version of the system for use while away during the day or on vacation. The team has also proposed the usefulness of such a system in controlling more common household medicines that are still very dangerous to children and adults alike. | ## Inspiration
How many times have you forgotten to take your medication and damned yourself for it? It has happened to us all, with different consequences. Indeed, missing out on a single pill can, for some of us, throw an entire treatment process out the window. Being able to keep track of our prescriptions is key in healthcare, this is why we decided to create PillsOnTime.
## What it does
PillsOnTime allows you to load your prescription information, including the daily dosage and refills, as well as reminders in your local phone calendar, simply by taking a quick photo or uploading one from the library. The app takes care of the rest!
## How we built it
We built the app with react native and expo using firebase for authentication. We used the built in expo module to access the devices camera and store the image locally. We then used the Google Cloud Vision API to extract the text from the photo. We used this data to then create a (semi-accurate) algorithm which can identify key information about the prescription/medication to be added to your calendar. Finally the event was added to the phones calendar with the built in expo module.
## Challenges we ran into
As our team has a diverse array of experiences, the same can be said about the challenges that each encountered. Some had to get accustomed to new platforms in order to design an application in less than a day, while figuring out how to build an algorithm that will efficiently analyze data from prescription labels. None of us had worked with machine learning before and it took a while for us to process the incredibly large amount of data that the API gives back to you. Also working with the permissions of writing to someones calendar was also time consuming.
## Accomplishments that we're proud of
Just going into this challenge, we faced a lot of problems that we managed to overcome, whether it was getting used to unfamiliar platforms or figuring out the design of our app.
We ended up with a result rather satisfying given the time constraints & we learned quite a lot.
## What we learned
None of us had worked with ML before but we all realized that it isn't as hard as we thought!! We will definitely be exploring more similar API's that google has to offer.
## What's next for PillsOnTime
We would like to refine the algorithm to create calendar events with more accuracy | partial |
## Inspiration
In a world full of so much info but limited time as we are so busy and occupied all the time, we wanted to create a tool that helps students make the most of their learning—quickly and effectively. We imagined a platform that could turn complex material into digestible, engaging content tailored for a fast-paced generation.
## What it does
Lemme Learn More (LLM) transforms study materials into bite-sized TikTok-style trendy and attractive videos or reels, flashcards, and podcasts. Whether it's preparing for exams or trying to stay informed on the go, LLM breaks down information into formats that match how today's students consume content. If you're an avid listener of podcasts during commute to work - this is the best platform for you.
## How we built it
We built LLM using a combination of AI-powered tools like OpenAI for summaries, Google TTS for podcasts, and pypdf2 to pull data from PDFs. The backend runs on Flask, while the frontend is React.js, making the platform both interactive and scalable. Also used fetch.ai ai agents to deploy on test net - blockchain.
## Challenges we ran into
Due to a highly-limited time, we ran into a deployment challenge where we faced some difficulty setting up on Heroku cloud service platform. It was an internal level issue wherein we were supposed to change config files - I personally spent 5 hours on that - my team spent some time as well. Could not figure it out by the time hackathon ended : we decided not to deploy today.
In brainrot generator module, audio timing could not match with captions. This is something for future scope.
One of the other biggest challenges was integrating sponsor Fetch.ai agentverse AI Agents which we did locally and proud of it!
## Accomplishments that we're proud of
Biggest accomplishment would be that we were able to run and integrate all of our 3 modules and a working front-end too!!
## What we learned
We learned that we cannot know everything - and cannot fix every bug in a limited time frame. It is okay to fail and it is more than okay to accept it and move on - work on the next thing in the project.
## What's next for Lemme Learn More (LLM)
Coming next:
1. realistic podcast with next gen TTS technology
2. shorts/reels videos adjusted to the trends of today
3. Mobile app if MVP flies well! | ## Inspiration
Today, anything can be learned on the internet with just a few clicks. Information is accessible anywhere and everywhere- one great resource being Youtube videos. However accessibility doesn't mean that our busy lives don't get in the way of our quest for learning.
TLDR: Some videos are too long, and so we didn't watch them.
## What it does
TLDW - Too Long; Didn't Watch is a simple and convenient web application that turns Youtube and user-uploaded videos into condensed notes categorized by definition, core concept, example and points. It saves you time by turning long-form educational content into organized and digestible text so you can learn smarter, not harder.
## How we built it
First, our program either takes in a youtube link and converts it into an MP3 file or prompts the user to upload their own MP3 file. Next, the audio file is transcribed with Assembly AI's transcription API. The text transcription is then fed into Co:here's Generate, then Classify, then Generate again to summarize the text, organize by type of point (main concept, point, example, definition), and extract key terms. The processed notes are then displayed on the website and coded onto a PDF file downloadable by user. The Python backend built with Django is connected to a ReactJS frontend for an optimal user experience.
## Challenges we ran into
Manipulating Co:here's NLP APIs to generate good responses was certainly our biggest challenge. With a lot of experimentation *(and exploration)* and finding patterns in our countless test runs, we were able to develop an effective note generator. We also had trouble integrating the many parts as it was our first time working with so many different APIs, languages, and frameworks.
## Accomplishments that we're proud of
Our greatest accomplishment and challenge. The TLDW team is proud of the smooth integration of the different APIs, languages and frameworks that ultimately permitted us to run our MP3 file through many different processes and coding languages Javascript and Python to our final PDF product.
## What we learned
Being the 1st or 2nd Hackathon of our First-year University student team, the TLDW team learned a fortune of technical knowledge, and what it means to work in a team. While every member tackled an unfamiliar API, language or framework, we also learned the importance of communication. Helping your team members understand your own work is how the bigger picture of TLDW comes to fruition.
## What's next for TLDW - Too Long; Didn't Watch
Currently TLDW generates a useful PDF of condensed notes in the same order as the video. For future growth, TLDW hopes to grow to become a platform that provides students with more tools to work smarter, not harder. Providing a flashcard option to test the user on generated definitions, and ultimately using the Co-here Api to also read out questions based on generated provided examples and points. | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | partial |
## Inspiration
Have you ever wondered what's actually in your shampoo or body wash? Have you ever been concerned about the toxicity of certain chemicals in them on your body and to the environment?
If you answered yes, you came to the right place. Welcome to the wonderful world of Goodgredients! 😀
Goodgredients provides a simple way to answer these questions. But how you may ask.
## What it does
Goodgredients provides a simple way to check the toxicity of certain chemicals in them on your body and to the environment. Simply take a picture of your Shampoo or body wash and check which ingredient might harmful to you.
## How I built it
The project built with React Native, Node JS, Express js, and Einstein API. The backend API has been deployed with Heroku.
The core of this application is Salesforce Einstein Vision. In particular, we are using Einstein OCR (Optical Character Recognition), which uses deep learning models to detect alphanumeric text in an image. You can find out more info about Einstein Vision here.
Essentially, we've created a backend api service that takes an image request from a client, uses the Einstein OCR model to extract text from the image, compares it to our dataset of chemical details (ex. toxicity, allergy, etc.), and sends a response containing the comparison results back to the client.
## Challenges I ran into
As first-time ReactNative developers, we have encountered a lot of environment set up issue, however, we could figure out within time!
## Accomplishments that I'm proud of
We had no experience with ReactNative but finished project with fully functional within 24hours.
## What I learned
## What's next for Goodgredients | ## Inspiration
The majority of cleaning products in the United States contain harmful chemicals. Although many products pass EPA regulations, it is well known that many products still contain chemicals that can cause rashes, asthma, allergic reactions, and even cancer. It is important that the public has easy access to information of the chemicals that may be harmful to them as well as the environment.
## What it does
Our app allows users to scan a product's ingredient label and retrieves information on which ingredients to avoid for the better of the environment as well as their own health.
## How we built it
We used Xcode and Swift to design the iOS app. We then used Vision for iOS to detect text based off a still image. We used a Python scrapper to collect data from ewg.org, providing the product's ingredients as well as the side affects of certain harmful additives.
## Challenges we ran into
We had very limited experience for the idea that we have in developing an iOS app but, we wanted to challenge ourselves. The challenges the front end had were incorporating the camera feature and the text detector into a single app. As well as trying to navigate the changes between the newer version of Swift 11 from older versions. For our backend members, they had difficulties incorporating databases from Microsoft/Google, but ended up using JSON.
## Accomplishments that we're proud of
We are extremely proud of pushing ourselves to do something we haven't done before. Initially, we had some doubt in our project because of how difficult it was. But, as a team we were able to help each other along the way. We're very proud of creating a single app that can do both a camera feature and Optical Character Recognition because as we found out, it's very complicated and error prone. Additionally, for data scrapping, even though the HTML code was not consistent we managed to successfully scrap the necessary data by taking all corner cases into consideration with 100% success rate from more than three thousand HTML files and we are very proud of it.
## What we learned
Our teammates working in the front end learned how to use Xcode and Swift in under 24 hours. Our backend team members learned how to scrap the data from a website for the first time as well. Together, we learned how to alter our original expectations of our final product based on time constraint.
## What's next for Ingredient Label Scanner
Currently our project is specific to cleaning products, however in the future we would like to incorporate other products such as cosmetics, hair care, skin care, medicines, and food products. Additionally, we hope to alter the list of ingredients in a more visual way so that users can clearly understand which ingredients are more dangerous than others. | ## Inspiration
Memory athletes retain large amounts of information using mnemonics, story-telling, and visualizations. Picture Pathway aims to emulate this studying methodology and bring it into the classroom!
## What it does
Picture Pathway is a student-teacher platform. Teachers submit the problem they would like their class to visualize and/or convert into a story. From there, the student describes a scene to DALL-E and then receives a generated image to add to their story on solving their assigned problems
In our example, a teacher is looking to solidify the process of Integration for her students; thus, they have assigned a series of steps to 'storify'. The text contained in yellow represents what a student user's responses might look like (and our last slide demonstrates what the corresponding image output may be).
## How we built it
-Front-End: Repl.it - HTML, Javascript
-Back-End: Python (Jango), SQLite
## Challenges we ran into
-Most of our members are just beginning their coding journey so there was certainly a learning curve!
-The integration of Dall-E API was especially uncharted territory for our team and required much research to implement
-Debugging(πーπ)
## Accomplishments that we're proud of
Our team is most proud of our ability to riff off each other--- most of us met for the first time just Friday, yet we trusted one another to perform our assigned roles and successfully worked our way from 0 to a working prototype
## What we learned
-3/4 members learned Django + SQL for the first time!
-APIs can interact on the backend (what enabled us to pull images from Dall-E to embed into our project!)
## What's next for Picture Pathway
-All our members are passionate about accessibility in STEM education | partial |
## Inspiration
Aravind doesn't speak Chinese. When Nick and Jon speak in Chinese Aravind is sad. We want to solve this problem for all the Aravinds in the world -- not just for Chinese though, for any language!
## What it does
TranslatAR allows you to see English (or any other language of your choice) subtitles when you speak to other people speaking a foreign language. This is an augmented reality app which means the subtitles will appear floating in front of you!
## How we built it
We used Microsoft Cognitive Services's Translation APIs to transcribe speech and then translate it. To handle the augmented reality aspect, we created our own AR device by combining an iPhone, a webcam, and a Google Cardboard. In order to support video capturing along with multiple microphones, we multithread all our processes.
## Challenges we ran into
One of the biggest challenges we faced was trying to add the functionality to handle multiple input sources in different languages simultaneously. We eventually solved it with multithreading, spawning a new thread to listen, translate, and caption for each input source.
## Accomplishments that we're proud of
Our biggest achievement is definitely multi-threading the app to be able to translate a lot of different languages at the same time using different endpoints. This makes real-time multi-lingual conversations possible!
## What we learned
We familiarized ourselves with the Cognitive Services API and were also able to create our own AR system that works very well from scratch using OpenCV libraries and Python Imaging Library.
## What's next for TranslatAR
We want to launch this App in the AppStore so people can replicate VR/AR on their own phones with nothing more than just an App and an internet connection. It also helps a lot of people whose relatives/friends speak other languages. | ## Inspiration
Want to take advantage of the AR and object detection technologies to help people to gain safer walking experiences and communicate distance information to help people with visual loss navigate.
## What it does
Augment the world with the beeping sounds that change depending on your proximity towards obstacles and identifying surrounding objects and convert to speech to alert the user.
## How we built it
ARKit; RealityKit uses Lidar sensor to detect the distance; AVFoundation, text to speech technology; CoreML with YoloV3 real time object detection machine learning model; SwiftUI
## Challenges we ran into
Computational efficiency. Going through all pixels in the LiDAR sensor in real time wasn’t feasible. We had to optimize by cropping sensor data to the center of the screen
## Accomplishments that we're proud of
It works as intended.
## What we learned
We learned how to combine AR, AI, LiDar, ARKit and SwiftUI to make an iOS app in 15 hours.
## What's next for SeerAR
Expand to Apple watch and Android devices;
Improve the accuracy of object detection and recognition;
Connect with Firebase and Google cloud APIs; | ## Inspiration
We've all been in situations where we can't understand what someone is saying. What if you want to talk to someone but your ears are full or you're hard of hearing? We set out to make an easier way to hear someone in person: real-time subtitles using augmented reality.
## What it does
Now with this app, you can see what people are saying as face-tracking text. This makes communication easier for everyone! Additionally, this tool can do a lot of social good by breaking down boundaries for the hard of hearing by making it easier for them to make conversions.
## How we built it
It was built in Python combining OpenCV code for face tracking, pyaudio voice analysis, and the Rev.ai speech to text API.
## Challenges we ran into
Parsing the webcam data and mic data simultaneously and communicating the data between them was difficult. We solved this with multiple threads and global variables. Additionally, detecting multiple speakers was challenging. The more speakers in the frame, the more mics we need to determine which text belongs to which speaker. We used 2 mics and compared their volumes to determine which part of the frame the sound came from.
## Accomplishments that we're proud of
Combining latest visual and audio machine learning technology.
## What's next for Subtitles IRL
We'd like to implement translation, both on the display and input side.
Further, voice diarization is a huge area of research, with lots of potential improvements. | winning |
## Inspiration
Sharing a meal with others has always been a powerful mode of connecting people together, transcending historically divisive cultural and social constructs. Digging deep into “the making of a meal” is what served as our food for thought.
In a rapidly accelerating digital world, loneliness has become an epidemic across all demographics, resulting in a widespread deterioration of mental wellbeing. The rise of food-delivery services has only exacerbated this epidemic and has led to the loss of the memories that remind us of what a meal means. Popup aims to reverse the psyche of food-delivery services and address this systemic issue of wellbeing through drawing upon our own lived experiences with the meaning of a meal.
Cooking for others is a love language that has represented a form of cross-generational communication, especially in multilingual families. Eating a warm, home-cooked meal brings us closer to our roots. And sharing meals with others gives us a safe place to share pieces of ourselves with the world. We realize that a true meal is much more than food on a plate; it is the heart that goes into preparing the meal, and the comfort of belonging alongside new and familiar faces alike that makes us feel full at the end of a meal. It is this inextricable link between cooking, eating, and sharing that Popup’s web application fosters.
**Through connecting home chefs, who find joy in sharing their recipes, with foodies, who crave the warmth of a home-cooked meal, in communal spaces for gathering, we hope that people can build organic relationships that make them feel whole.**
## What it does
Popup hosts a two-sided market of chefs (home chefs, food trucks, family-owned restaurants) and foodies (anyone who is looking to eat hearty meals with others!). On the foodie end, users can browse through a recommended feed of food gatherings, including Home-Cooked communal meals, food truck events, and restaurant tastings/exhibitions (with greatest emphasis on home-cooked items per our product vision). Users can also view which of their friends are attending each event. If interested in an event, a user can reserve a meal/seat through our app, order, and pay ahead of time. Once a user has confirmed their order, a personalized user QR code will appear in “My Events” which will ultimately be scanned by the food vendor to confirm receipt of the meal. On the day of food pickup, users can track the status of the food delivery, meet the chef at the designated pickup location, and have the opportunity to enjoy the meal alongside new peers! We hope to build out a “compliments to the chef” feature which allows users to post pictures and comments about their experiences sharing food with others.
On the chef’s end, chefs can create new listings based on the specialty home-cooked items they want to sell. The chef will designate the date, time, and location of meal sharing as well as the food options with their prices and maximum quantities willing to be sold. Popup helps chefs find the best location for communal food sharing through considering the chef’s home location, interested users’ home locations, and AI-recommendations. Chefs can view and manage the upcoming orders they need to fulfill and scan foodie QR codes to confirm pickup.
Furthermore, Popup offers a win-win-win opportunity since chefs get to spend less time preparing the meals since they have a fixed delivery point, customers get to know exactly when and where their order arrives in addition to being more cost-effective, and drivers get to make fewer trips and waste less fuel.
Lastly, both foodies and chefs have the ability to add friends and join communities! Communities are especially powerful for groups with dietary restrictions, including religious, health, and preference-related foods! Many of these groups actively need and seek support and solidarity, and community-based meal sharing is a great way to fulfill this need.
**From the abuela who wants to cook and share tamales with fellow elderly in the neighborhood for Christmas…**
**to Confused Casey who is seeking help finding diabetic-friendly foods for her husband…**
**pop up has the perfect community-based food gathering for you!**
## How we built it
We built popup using React for our frontend, Convex for our backend (logs, functions, preview deployments, type safety!), Tailwind CSS for styling, Github for collaboration, Figma for UI and logo design, the user stories of friends and family for idea inspiration, and the feedback of many mentors, and sponsors!
## Challenges we ran into
We had lofty ideas, many being too lofty! Initially, we struggled to find balance between what we wanted to implement versus what we had the ability to accomplish in 36 hours. Once we collected user stories and narrowed down on a problem space, we were also challenged by finding a non-existent idea that directly solved the problem of systemic loneliness. Beyond ideation, we also spent many hours debugging using the documentation of Convex and React. As Neo, David, and Ronit flew in from out-of-state, we wanted to explore as many treehacks opportunities as possible, but we had trouble attending all of the workshops we wanted while also completing our hack. Overall, we sometimes struggled to find balance amidst the hectic, yet exciting environment of treehacks.
## Accomplishments that we're proud of
**It is Abbie, David, and Ronit’s FIRST-EVER hackathon! And it was also our first time working together as a team!** With respect to ideation, we are proud of our user-centric approach to finding a real need in the space of food and wellbeing. On the technical side, we all learned to use Convex and React for the first time. Lastly, from bitcoin workshops to genAI demonstrations, we all interacted with brand-new topics and technologies which allowed us to explore new applications of technology in our early careers (and grow closer as friends!).
## What we learned
Abbie is a rookie to both hackathons and CS, so popup is her first exposure to frontend and backend outside of the classroom! She learned how to translate her designs in Figma to React components/pages. David and Ronit tag-teamed to boldly venture beyond their scope of familiarity in backend and learn how to tackle front end challenges. And Neo was an all-star player who took on a leadership role by mentoring the team with this experience in both front and backend. Lastly, we all learned more about ourselves and our identities in technology- the things that excite us, the things that confuse us, the things that allow us to thrive in teams, and the things that drive us to continue making an impact.
## What's next for pop up
There is so much that we still hope to do with popup!
Implementing a real AI recommendation engine for suggesting the most optimal communal gathering spaces for chefs.
Building out the “compliments to the chef” feature which will mimic the BeReal model of posting fun pictures in-action
A fully integrated payment system with Stripe so pop up can be an end-to-end “side-gig” opportunity for home chefs
A dynamic feed that uses a user’s community information and past events attended to recommend a personalized suite of food events
*…perhaps treehacks 2025 will be the place to take pop up to the next level! :)*
<https://github.com/nwatx/treehacks-2024> | ## 🌍 Inspiration Behind visioncraft.ai 🚀
When staring at the increasing heaps of discarded gadgets and electronics, a question invariably arose in our minds: "Can we make a difference here?" 🤔❓
Introducing... the tech waste dilemma. It's no secret that our world is swamped with discarded tech. These devices, once marvels of their time, now contribute to an ever-growing environmental concern. We produce 40 million tons of electronic waste every year, worldwide. That's like throwing 800 laptops away every second. 🌏💔
Instead of seeing these gadgets as waste, we started seeing potential. The idea: leverage the power of deep learning to infuse old tech with new life. This wasn't about recycling; it was about reimagining. 🔄🔍
We believed that there was a way to reduce this waste by allowing users to reuse their spare electronic parts to create Arduino projects. Through visioncraft.ai, we are confident that we can encourage the pillars of reducing, reusing, and recycling, solving an ever-evolving problem in the world around us. 💡✨
## 🚀 What visioncraft.ai Does 🛠️
The user starts on a landing page where they can view the functionalities of our product demo. By clicking the "Get Started" button, they are directed to a form where they can fill out some basic information. Here, they are prompted for their idea, the materials they already have, their budget, and an option to upload a photo of the materials. Once done, they hit the submit button, and the magic of tutorial generation begins!💡💸
Immediately after, a POST request is sent to the server, where the image is dissected using a deep learning model hosted on Roboflow, ensuring any electronic parts are detected. Then, the idea, budget, and identified parts (including those manually entered by the user) get fed into OpenAI's GPT-35-turbo and DALLE-2 APIs for deeper magic. Through cleverly crafted prompts, these engines whip up the body text and images for the tutorial. Once all the data is ready, it's transformed into a neat PDF 📄 using the Python fPDF library. And voilà! A new tab pops up, delivering the PDF to the user, all powered by the decentralized IPFS file systems 🌐📤.
## 🤖 How We Built visioncraft.ai 🎨
First, we used Figma to visualize our design and create a prototype for how we envisioned our website. To actually build the front-end, we used Next.js and Tailwind CSS for styling. We incorporated features like the Typewriter effect and fade animations for the cards to create a minimalist and modern aesthetic. Then, we used Vercel to ship the deployment given it's a non-static full-stack application 🖥️🌌.
The backend is powered by Python, with a Flask application serving as the base of our app . A deep learning model was accessed, modified, and hosted on Roboflow.com, and we call an API on the image taken by the individual to identify individual parts and return a list in JSON. The list is scraped and combined with the manually entered list, and duplicates are removed. DALLE-2 and GPT-35-Turbo were used to generate the text and images for the tutorial using engineered prompts, and using the fPDF/PyPDF2 libraries, we were able to format the PDF for user accessibility. The generated PDF was uploaded to Interplanetary File Storage (IPFS) via the NFTPort.XYZ via an API, and a link is returned to the front-end to be opened in a new tab for the user to see 📜🌐.
To integrate the front-end and the back-end, the redirects feature provided by next.js in the next.config.js feature was used so that the server API was accessible by the client. Here is a link for reference: <https://nextjs.org/docs/pages/api-reference/next-config-js/redirects> 🔄📗.
One problem that was encountered during this integration was the default proxy time limit of Next.js, which was too short for our server call. Luckily, there was an experimental property named 'proxyTimeout' that could be adjusted to avoid time-out errors ⏳🛠️.
## 🚧 Challenges on the Road to visioncraft.ai 🌪️
Diving into the world of tech innovation often comes with its set of challenges. Our journey to create VisionCraft.ai was no exception, and here's a snapshot of the hurdles of our journey. 🛤️🔍
### 🌩️ Cloudy Days with Flask and Google Cloud ☁️
When we started with our Flask backend, hosting it on Google Cloud seemed like the perfect idea. But alas, it wasn't a walk in the park. The numerous intricacies and nuances of deploying a Flask application on Google Cloud led to two sleepless nights, Yet, each challenge only solidified our resolve and, in the process, made us experts in cloud deployment nuances as we used App Engine to deploy our back-end. 💪🌪️
### 📜 Typewriter: Bringing Life to the Front-end 🎭
Web apps can't just be functional; they need to be dynamic and engaging! And that's where Typewriter stepped in. By leveraging its capabilities, our front-end wasn't just a static display but a lively, interactive canvas that responded and engaged with the user. 🖥️💃
### 🔄 Bridging Two Worlds: Vercel and Google Cloud 🌉
Our choice of hosting the front end on Vercel while having the back-end on Google Cloud was, to some, unconventional. Yet, it was essential for our vision of having a hosted website. The challenge? Ensuring seamless integration. With a slew of API calls, endpoints tweaking, and consistent testing, we built a bridge between the two, ensuring that the user experience remained smooth and responsive. However, it was most definitely not easy, since we had to figure out how to work with generated files without ever saving them. 🌐🤖
## 🏆 Our Proud Accomplishments with visioncraft.ai 🎉
Embarking on the journey of creating visionxraft.ai has been nothing short of transformative. Along the way, we faced challenges, celebrated victories, and took leaps into the unknown. Here's a glimpse of the milestones that fill us with pride. 🌟🛤️
### 🧠 Embracing YOLO for Deep Learning 🎯
We wanted visioncraft.ai to stand out, and what better way than by integrating state-of-the-art object detection? Implementing deep learning through YOLO (You Only Look Once) detection was ambitious, but we dove right in! The result? Swift and accurate object detection, paving the way for our app to recognize and repurpose tech waste effectively. Every detected item stands as a testament to our commitment to precision. 🔍✨
### 🖥️ Venturing into the World of Next.js 🚀
Taking on Next.js was a first for us. But who said firsts were easy (they're not, source: trust us lol)? Navigating its features and capabilities was like deciphering an intricate puzzle. But piece by piece, the picture became clearer. The result was a robust, efficient, and dynamic front-end, tailored to provide an unparalleled user experience. With every click and interaction on our platform, we're reminded of our bold plunge into Next.js and how it paid off. 💡🌐
### 📄 Perfecting PDFs with PyPDF2 📁
Documentation matters, and we wanted ours to be impeccable. Enter PyPDF2! Utilizing its capabilities, we were able to craft, format, and output PDF files with finesse. The satisfaction of seeing a perfectly formatted PDF, ready for our users, was unmatched. It wasn't just about providing information but doing it with elegance and clarity. 🌟📜
## 📚 Key Learnings from Crafting visioncraft.ai 🌟
While building visioncraft.ai, our journey wasn't solely about developing an application. It was a profound learning experience, encompassing technical nuances, deep learning intricacies, and design philosophies. Here's a peek into our treasure trove of knowledge gained. 🛤️🔎
### 🌐 Hosting Across Platforms: Google Cloud & Vercel 🚀
Navigating the hosting landscape was both a challenge and an enlightening journey:
* Flask on Google Cloud: Deploying our Flask backend on Google Cloud introduced us to the multifaceted world of cloud infrastructure. From understanding VM instances to managing security protocols, our cloud expertise expanded exponentially. ☁️🔧
* Next.js on Vercel: Hosting our Next.js front-end on Vercel was a dive into serverless architecture. We learned about efficient scaling, seamless deployments, and ensuring low-latency access for users globally. 🌍🖥️
### 🧠 Delving Deep into Deep Learning and YOLO3 🤖
Our venture into the realm of deep learning was both deep and enlightening:
* Training Models: The art and science of training deep learning models unraveled before us. From data preprocessing to tweaking hyperparameters, we delved into the nuances of ensuring optimal model performance. 📊🔄
* YOLO3 Functionality: YOLO3 (You Only Look Once v3) opened up a world of real-time object detection. We learned about its unique architecture, how it processes images in one pass, and its efficiency in pinpointing objects with precision. 🔍🎯
### 🎨 Crafting Engaging Web Experiences 🌈
Designing visioncraft.ai was more than just putting pixels on a screen:
* User-Centric Design: We realized that effective design starts with understanding user needs. This led us to prioritize user journeys, ensuring each design choice enhanced the user experience. 🤝🖌️
* Interactive Elements: Making our website interactive wasn't just about adding flashy elements. We learned the subtle art of balancing engagement with functionality, ensuring each interaction added value. 💡🕹️
* Consistency is Key: An engaging website isn't just about standout elements but ensuring a cohesive design language. From typography to color palettes, maintaining consistency was a lesson we'll carry forward. 🎨🔗
## 🌟 The Road Ahead for visioncraft.ai 🛣️
visioncraft.ai's journey so far has been incredibly enriching, but it's just the beginning. The world of tech is vast, and our mission to reduce tech waste is ever-evolving. Here's a glimpse into the exciting developments and plans we have in store for the future. 🚀🔮
### 🌐 Expanding our Cloud Capabilities ☁️
We're diving deeper into cloud integrations, exploring newer, more efficient ways to scale and optimize our application. This will ensure a faster, more reliable experience for our users, no matter where they are on the globe. 🌍💡
### 🤖 Advanced AI Integrations 🧠
While YOLO has served us well, the realm of deep learning is vast:
* Enriched Object Detection: We're looking into further refinements in our AI models, allowing for even more precise object recognition. 🔍🎯
* Personalized Recommendations: Using AI, we aim to offer users personalized suggestions for tech waste reduction based on their unique usage patterns. 📊👤
### 🎨 Elevating User Experience 🖌️
Design will always remain at the heart of visioncraft.ai:
* Mobile-First Approach: With increasing mobile users, we're focusing on optimizing our platform for mobile devices, ensuring a seamless experience across all devices. 📱✨
* Interactive Guides: To help users navigate the world of tech waste reduction, we're working on creating interactive guides and tutorials, making the journey engaging and informative. 📘🚀
### 🌱 Community and Collaboration 🤝
Believing in the power of community, we have plans to:
* Open Source: We're considering opening up certain aspects of our platform for the developer community. This will foster innovation and collaborative growth. 💼💡
* Workshops and Webinars: To spread awareness and knowledge, we aim to host interactive sessions, focusing on the importance of reducing tech waste and the role of AI in it. 🎤👥
The horizon is vast, and visioncraft.ai is geared up to explore uncharted territories. With passion, innovation, and a commitment to our mission, the future looks bright and promising. 🌅🌱
Join us on this exhilarating journey toward a sustainable, tech-aware future! 🌍❤️🤖 | ## Inspiration
“**Social media sucks these days.**” — These were the first few words we heard from one of the speakers at the opening ceremony, and they struck a chord with us.
I’ve never genuinely felt good while being on my phone, and like many others I started viewing social media as nothing more than a source of distraction from my real life and the things I really cared about.
In December 2019, I deleted my accounts on Facebook, Instagram, Snapchat, and WhatsApp.
For the first few months — I honestly felt great. I got work done, focused on my small but valuable social circle, and didn’t spend hours on my phone.
But one year into my social media detox, I realized that **something substantial was still missing.** I had personal goals, routines, and daily checklists of what I did and what I needed to do — but I wasn’t talking about them. By not having social media I bypassed superficial and addictive content, but I was also entirely disconnected from my network of friends and acquaintances. Almost no one knew what I was up to, and I didn’t know what anyone was up to either. A part of me longed for a level of social interaction more sophisticated than Gmail, but I didn’t want to go back to the forms of social media I had escaped from.
One of the key aspects of being human is **personal growth and development** — having a set of values and living them out consistently. Especially in the age of excess content and the disorder of its partly-consumed debris, more people are craving a sense of **routine, orientation, and purpose** in their lives. But it’s undeniable that **humans are social animals** — we also crave **social interaction, entertainment, and being up-to-date with new trends.**
Our team’s problem with current social media is its attention-based reward system. Most platforms reward users based on numeric values of attention, through measures such as likes, comments and followers. Because of this reward system, people are inclined to create more appealing, artificial, and addictive content. This has led to some of the things we hate about social media today — **addictive and superficial content, and the scarcity of genuine interactions with people in the network.**
This leads to a **backward-looking user-experience** in social media. The person in the 1080x1080 square post is an ephemeral and limited representation of who the person really is. Once the ‘post’ button has been pressed, the post immediately becomes an invitation for users to trap themselves in the past — to feel dopamine boosts from likes and comments that have been designed to make them addicted to the platform and waste more time, ultimately **distorting users’ perception of themselves, and discouraging their personal growth outside of social media.**
In essence — We define the question of reinventing social media as the following:
*“How can social media align personal growth and development with meaningful content and genuine interaction among users?”*
**Our answer is High Resolution — a social media platform that orients people’s lives toward an overarching purpose and connects them with liked-minded, goal-oriented people.**
The platform seeks to do the following:
**1. Motivate users to visualize and consistently achieve healthy resolutions for personal growth**
**2. Promote genuine social interaction through the pursuit of shared interests and values**
**3. Allow users to see themselves and others for who they really are and want to be, through natural, progress-inspired content**
## What it does
The following are the functionalities of High Resolution (so far!):
After Log in or Sign Up:
**1. Create Resolution**
* Name your resolution, whether it be Learning Advanced Korean, or Spending More Time with Family.
* Set an end date to the resolution — i.e. December 31, 2022
* Set intervals that you want to commit to this goal for (Daily / Weekly / Monthly)
**2. Profile Page**
* Ongoing Resolutions
+ Ongoing resolutions and level of progress
+ Clicking on a resolution opens up the timeline of that resolution, containing all relevant posts and intervals
+ Option to create a new resolution, or ‘Discover’ resolutions
* ‘Discover’ Page
+ Explore other users’ resolutions, that you may be interested in
+ Clicking on a resolution opens up the timeline of that resolution, allowing you to view the user’s past posts and progress for that particular resolution and be inspired and motivated!
+ Clicking on a user takes you to that person’s profile
* Past Resolutions
+ Past resolutions and level of completion
+ Resolutions can either be fully completed or partly completed
+ Clicking on a past resolution opens up the timeline of that resolution, containing all relevant posts and intervals
**3. Search Bar**
* Search for and navigate to other users’ profiles!
**4. Sentiment Analysis based on IBM Watson to warn against highly negative or destructive content**
* Two functions for sentiment analysis textual data on platform:
* One function to analyze the overall positivity/negativity of the text
* Another function to analyze the user of the amount of joy, sadness, anger and disgust
* When the user tries to create a resolution that seems to be triggered by negativity, sadness, fear or anger, we show them a gentle alert that this may not be best for them, and ask if they would like to receive some support.
* In the future, we can further implement this feature to do the same for comments on posts.
* This particular functionality has been demo'ed in the video, during the new resolution creation.
* **There are two purposes for this functionality**:
* a) We want all our members to feel that they are in a safe space, and while they are free to express themselves freely, we also want to make sure that their verbal actions do not pose a threat to themselves or to others.
* b) Current social media has shown to be a propagator of hate speech leading to violent attacks in real life. One prime example are the Easter Attacks that took place in Sri Lanka exactly a year ago: <https://www.bbc.com/news/technology-48022530>
* If social media had a mechanism to prevent such speech from being rampant, the possibility of such incidents occurring could have been reduced.
* Our aim is not to police speech, but rather to make people more aware of the impact of their words, and in doing so also try to provide resources or guidance to help people with emotional stress that they might be feeling on a day-to-day basis.
* We believe that education at the grassroots level through social media will have an impact on elevating the overall wellbeing of society.
## How we built it
Our tech stack primarily consisted of React (with Material UI), Firebase and IBM Watson APIs. For the purpose of this project, we opted to use the full functionality of Firebase to handle the vast majority of functionality that would typically be done on a classic backend service built with NodeJS, etc. We also used Figma to prototype the platform, while IBM Watson was used for its Natural Language toolkits, in order to evaluate sentiment and emotion.
## Challenges we ran into
A bulk of the challenges we encountered had to do with React Hooks. A lot of us were only familiar with an older version of React that opted for class components instead of functional components, so getting used to Hooks took a bit of time.
Another issue that arose was pulling data from our Firebase datastore. Again, this was a result of lack of experience with serverless architecture, but we were able to pull through in the end.
## Accomplishments that we're proud of
We’re really happy that we were able to implement most of the functionality that we set out to when we first envisioned this idea. We admit that we might have bit a lot more than we could chew as we set out to recreate an entire social platform in a short amount of time, but we believe that the proof of concept is demonstrated through our demo
## What we learned
Through research and long contemplation on social media, we learned a lot about the shortcomings of modern social media platforms, for instance how they facilitate unhealthy addictive mechanisms that limit personal growth and genuine social connection, as well as how they have failed in various cases of social tragedies and hate speech. With that in mind, we set out to build a platform that could be on the forefront of a new form of social media.
From a technical standpoint, we learned a ton about how Firebase works, and we were quite amazed at how well we were able to work with it without a traditional backend.
## What's next for High Resolution
One of the first things that we’d like to implement next, is the ‘Group Resolution’ functionality. As of now, users browse through the platform, find and connect with liked-minded people pursuing similarly-themed interests. We think it would be interesting to allow users to create and pursue group resolutions with other users, to form more closely-knitted and supportive communities with people who are actively communicating and working towards achieving the same resolution.
We would also like to develop a sophisticated algorithm to tailor the users’ ‘Discover’ page, so that the shown content is relevant to their past resolutions. For instance, if the user has completed goals such as ‘Wake Up at 5:00AM’, and ‘Eat breakfast everyday’, we would recommend resolutions like ‘Morning jog’ on the discover page. By recommending content and resolutions based on past successful resolutions, we would motivate users to move onto the next step. In the case that a certain resolution was recommended because a user failed to complete a past resolution, we would be able to motivate them to pursue similar resolutions based on what we think is the direction the user wants to head towards.
We also think that High Resolution could be potentially become a platform for recruiters to spot dedicated and hardworking talent, through the visualization of users’ motivation, consistency, and progress. Recruiters may also be able to user the platform to communicate with users and host online workshops or events .
WIth more classes and educational content transitioning online, we think the platform could serve as a host for online lessons and bootcamps for users interested in various topics such as coding, music, gaming, art, and languages, as we envision our platform being highly compatible with existing online educational platforms such as Udemy, Leetcode, KhanAcademy, Duolingo, etc.
The overarching theme of High Resolution is **motivation, consistency, and growth.** We believe that having a user base that adheres passionately to these themes will open to new opportunities and both individual and collective growth. | losing |
## Inspiration
The three of us all love music and podcasts. Coming from very diverse backgrounds, we all enjoy listening to content from a variety of places all around the globe. We wanted to design a platform where users can easily find new content from anywhere to enable cultural interconnectivity.
## What it does
TopCharts allows you to place a pin anywhere in the world using our interactive map, and shows you the top songs and podcasts in that region. You then can follow the link directly to Spotify and listen!
## How we built it
We used the MapBox API to display an interactive map, and also reverse GeoLocate the area in which the pin is dropped. We used the Spotify API to query data based on the geolocation. The app itself is built in React and is hosted through Firebase!
## Challenges we ran into
Getting the MapBox API customized to our needs!
## Accomplishments that we're proud of
Making a fully functional website with clean UI/UX within ~30 hours of ideation. We also got to listen to a lot of cool podcasts and songs from around the world while testing!
## What we learned
How robust the MapBox API is. It is so customizable, which we love! We also learned some great UI/UX tips from Grace Ma (Meta)!
## What's next for TopCharts
Getting approval from Spotify for an API quota extension so anyone across the world can use TopCharts!
Team #18 - Ben (benminor#5721), Graham (cracker#4700), Cam (jeddy#1714) | ## About the Project
### TLDR:
Caught a fish? Take a snap. Our AI-powered app identifies the catch, keeps track of stats, and puts that fish in your 3d, virtual, interactive aquarium! Simply click on any fish in your aquarium, and all its details — its rarity, location, and more — appear, bringing your fishing memories back to life. Also, depending on the fish you catch, reel in achievements, such as your first fish caught (ever!), or your first 20 incher. The cherry on top? All users’ catches are displayed on an interactive map (built with Leaflet), where you can discover new fishing spots, or plan to get your next big catch :)
### Inspiration
Our journey began with a simple observation: while fishing creates lasting memories, capturing those moments often falls short. We realized that a picture might be worth a thousand words, but a well-told fish tale is priceless. This spark ignited our mission to blend the age-old art of fishing with cutting-edge AI technology.
### What We Learned
Diving into this project was like casting into uncharted waters – exhilarating and full of surprises. We expanded our skills in:
* Integrating AI models (Google's Gemini LLM) for image recognition and creative text generation
* Crafting seamless user experiences in React
* Building robust backend systems with Node.js and Express
* Managing data with MongoDB Atlas
* Creating immersive 3D environments using Three.js
But beyond the technical skills, we learned the art of transforming a simple idea into a full-fledged application that brings joy and preserves memories.
### How We Built It
Our development process was as meticulously planned as a fishing expedition:
1. We started by mapping out the user journey, from snapping a photo to exploring their virtual aquarium.
2. The frontend was crafted in React, ensuring a responsive and intuitive interface.
3. We leveraged Three.js to create an engaging 3D aquarium, bringing caught fish to life in a virtual environment.
4. Our Node.js and Express backend became the sturdy boat, handling requests and managing data flow.
5. MongoDB Atlas served as our net, capturing and storing each precious catch securely.
6. The Gemini AI was our expert fishing guide, identifying species and spinning yarns about each catch.
### Challenges We Faced
Like any fishing trip, we encountered our fair share of challenges:
* **Integrating Gemini AI**: Ensuring accurate fish identification and generating coherent, engaging stories required fine-tuning and creative problem-solving.
* **3D Rendering**: Creating a performant and visually appealing aquarium in Three.js pushed our graphics programming skills to the limit.
* **Data Management**: Structuring our database to efficiently store and retrieve diverse catch data presented unique challenges.
* **User Experience**: Balancing feature-rich functionality with an intuitive, streamlined interface was a constant tug-of-war.
Despite these challenges, or perhaps because of them, our team grew stronger and more resourceful. Each obstacle overcome was like landing a prized catch, making the final product all the more rewarding.
As we cast our project out into the world, we're excited to see how it will evolve and grow, much like the tales of fishing adventures it's designed to capture. | ## Inspiration
Music has become a crucial part of people's lives, and they want customized playlists to fit their mood and surroundings. This is especially true for drivers who use music entertain themselves on their journey and to stay alert.
Based off of personal experience and feedback from our peers, we realized that many drivers are dissatisfied with the repetitive selection of songs on the radio and also on the regular Spotify playlists. That's why we were inspired to create something that could tackle this problem in a creative manner.
## What It Does
Music Map curates customized playlists based on factors such as time of day, weather, driving speed, and locale, creating a set of songs that fit the drive perfectly. The songs are selected from a variety of pre-existing Spotify playlists that match the users tastes and weighted based on the driving conditions to create a unique experience each time. This allows Music Map to introduce new music to the user while staying true to their own tastes.
## How we built it
HTML/CSS, Node.js, Esri, Spotify, Google Maps APIs
## Challenges we ran into
Spotify API was challenging to work with, especially authentication.
Overlaying our own UI over the map was also a challenge.
## Accomplishments that we're proud of
Learning a lot and having something to show for it
The clean and aesthetic UI
## What we learned
For the majority of the team, this was our first Hackathon and we learned how to work together well and distribute the workload under time pressure, playing to each of our strengths. We also learned a lot about the various APIs and how to fit different pieces of code together.
## What's next for Music Map
We will be incorporating more factors into the curation of the playlists and gathering more data on the users' preferences. | winning |
## Inspiration
In the context of the pandemic, when we've been spending more time at home and looking to watch nice movies, we've often found ourselves indecisive and wasting precious time mindlessly scrolling through lists of content. We decided to take matters into our own hands and make a website with a robust yet sophisticated means of providing the ideal movie to watch for each individual.
## What it does
Choose Me a Movie is a simple website that helps you decide on a movie to watch through a series of questions hand-picked to ensure our users' satisfaction. The site has many advanced features, including a button to return to the previous question and an option for additional recommendations based on the same criteria.
## How we built it
The website front-end was built using HTML and CSS, while the backend ran on Javascript. We used the TMDB (The Movie Database) API as our database of movie metadata through cavestri's TMDB Javascript library (<https://github.com/cavestri/themoviedb-javascript-library>).
## Challenges we ran into
As this was all our first experience with Git, VS Code and Javascript, it was quite a steep learning curve during the initial stages of the project. We had to learn as we coded and use all the tools at our disposal in order to finish before the deadline.
## Accomplishments that we're proud of
We're very proud of having completed a fully-functional version of our initial idea in our first hackathon. We're really pleased with what we've accomplished over such a limited amount of time, considering our lack of previous experience.
## What we learned
We learned how to use Javascript as a backend for a website and how to use an API as a database. We also learned the use of Git, VS Code and of local storage for variables across HTML files.
## What's next for Choose Me a Movie
We will use what we've learned during McHacks 9 in our future endeavours, particularly in software development. We hope to add additional features to the Choose Me a Movie website and extend its reach by creating Android and IOS app implementations. | ## Inspiration 🔥
Last year, in Canada alone:
* Over 230,000 persons were evacuated because of potential dangers to life and health.
* 6,623 wildland fires burned more than 15 million hectares of Canada’s managed forests.
[source](https://natural-resources.canada.ca/our-natural-resources/forests/wildland-fires-insects-disturbances/forest-fires/13143)
More recently, the town of Jasper in Alberta was burnt down by wildfires that continue to burn even now.
As climate change accelerates and wildfire seasons become more intense, monitoring and managing these crises are an important part of preserving our environment. Firewall aims to provide firefighters and first responders with critical information, optimize resource allocation, and improve communication. Our app seeks to not only strengthen immediate response efforts but also support long-term strategies for wildfire prevention and management, safeguarding lives, property, and ecosystems.
## What it does ✨
Firewall makes reporting wildfires an efficient and streamlined process that anyone can do easily:
1. Users take a video of a nearby forest fire and upload it to Firewall.
2. The uploaded video is sent to a dispatch app, where we use the video to generate a 3D model of the fire and analyze it to assign a severity classification (no fire, low fire, high fire). This process ensures that the fire is accurately assessed and ready for further action. This information enables emergency services to determine the appropriate number and type of first responders to dispatch.
3. The 3D model, severity classification, and geo coordinates are sent to a dedicated app for first responders. On this platform, firefighters can view the 3D model and severity details on a map, enabling them to make informed decisions and respond efficiently to the situation.
## How we built it 👨💻
Firewall has three main components:
**Reporter app:**
* **Front end:** The front end was created with **React Native** using the **Expo** framework.
* **Back end:** Videos get uploaded to **Firebase**. After, the link and the geocoordinates of the video are stored in a **MongoDB** database.
**Dispatch app:**
* **Frontend:** The frontend leverages a real-time MongoDB trigger that continuously monitors the Event Table for any changes. The moment a detected wildfire, is added, the frontend automatically refreshes to display the updated information. Additionally, the frontend features an integrated **3D viewer**, allowing users to visualize detailed 3D models of the fire.
* **Backend:** The backend of the dispatch app was designed to process video data received from Firebase. The first frame of each video is extracted and analyzed using a **Convolutional Neural Network (CNN)** implemented in **MATLAB** to classify the fire's severity state. Subsequently, the entire video is processed into a **3D Gaussian Splat model**, which captures spatial and temporal information. The resulting 3D model and CNN classification results, is then uploaded to a **MongoDB** database.
**First responder app:**
* **Frontend:** The front end was also made using React Native with the Expo framework. It features a 3D Gaussian Splat Viewer, which allows users to visualize detailed 3D models of fires. The app receives push notifications from the Admin App, delivering critical updates on fire conditions. A map interface displays the locations of active fires using clickable pins, which lead to a detailed page for each fire.
* **Backend:** The app retrieves the Gaussian splat model from Firebase to ensure that all data is up-to-date and readily accessible.
## Challenges we ran into 😥
* **Developing Video Recording and Uploading Features:** Implementing a reliable video recording and uploading system within the app turned out to be much more time-consuming than we initially thought. 😭
* **Integrating MongoDB with an Expo Frontend:** We initially attempted to directly connect our Expo-based frontend app to MongoDB, only to discover that this approach was not viable.
* **Minimizing Latency in 3D Model Generation:** Reducing the latency involved in converting videos into high-fidelity 3D models. Achieving accuracy while keeping the processing time within acceptable limits was an extensive and time-consuming process.
* Bahen was very cold at night :(
## Accomplishments that we're proud of 😊
* **Development of a Gaussian Model:** Our project successfully utilizes the Gaussian model in order to create a 3D view of the wildfire surroundings based off of a single video.
* **Automated Pipeline for Video Processing and Feature Extraction:** We automated the entire pipeline that converts videos into individual frames, extracts essential location-based features, and then feeds these into our machine learning model. Through fine-tuning iterations and adjusting resolutions, we’ve optimized this pipeline to produce high-fidelity 3D models.
* **CNN Classification:** Successfully developed a neural network model capable of accurately classifying our varying levels of fire severity.
* **Seamless Video Capture and Media Storage Integration:** Another achievement we're particularly proud of is the seamless integration of video capture and media storage. Users can easily record a video of a wildfire, and our app automatically uploads it to a secure media storage system.
## What we learned 🌱
* **Yoonie:** This was my first time participiating in a hackathon, and I had a lot of fun! I learned a lot about front-end development in React and how to function on minimal hours of sleep.
* **Marshal:** It probably would've been better to limit the number of features in our pipeline. By reducing the complexity of the feature set, we could have improved the latency of processes like Gaussian splatting and other pipeline operations.
* **Cailyn:** This is the second time I’ve worked with React Native! It wasn’t any easier than the first 😔. I got to touch on a lot of new technologies I haven’t worked with before like MongoDB. Overall this was a really fun experience and I learned a lot from my other team members. :)
* **Will:** This is the first time I’ve worked with neural networks, and I’ve found it to be a unique and novel challenge. Recording the same video over and over builds character.
## What's next for Firewall
* **Optimizing Latency and Loading Times:** A key area for future improvement is the optimization of latency and loading times across the app. We’re particularly focused on reducing the time it takes to process videos and generate 3D models, as well as improving the responsiveness of the camera functionality within the app.
* **Implementing Additional Features:** We had several features that we didn’t have the chance to implement, including semantic analysis using the Cohere API. This feature would allow us to analyze and interpret the content of user-uploaded videos at a deeper level, enhancing our ability to classify and respond to wildfire reports more accurately.
## Why Firewall?
**⭐Best Environmental Hack:** Firewall innovatively addresses the urgent and growing issue of wildfires, which have devastating widespread impacts. By allowing users to report fires quickly and accurately through an easy-to-use app, Firewall enhances the efficiency of emergency responses. The use of 3D modeling and CNN classification enables precise assessment and rapid deployment of resources, potentially saving lives and reducing damage. Firewall not only improves immediate response efforts but also contributes to long-term wildfire management strategies, making it a crucial tool in the fight against climate change and environmental degradation.
**⭐Best Use of MongoDB Atlas:** Firewall utilizes strategic application of MongoDB's capabilities. By leveraging MongoDB to store geolocation data and URLs of raw wildfire footage, Firewall ensures efficient data management and accessibility. We have also implemented customized triggers that automatically update the dashboard with the latest wildfire information, providing real-time insights and enhancing decision-making for first responders. This integration showcases the powerful use of MongoDB's flexible data model and real-time processing capabilities, playing a crucial role in the app's ability to support emergency response efforts.
**⭐Best Use of MATLAB:** By leveraging a Convolutional Neural Network (CNN) in MATLAB to classify fire severity and employing MATLAB's advanced data processing tools to generate detailed 3D Gaussian Splat models from video data, Firewall achieves a level of precision and efficiency that significantly enhances wildfire response efforts. This seamless integration of MATLAB's robust features into the project's pipeline not only ensures accurate assessments of wildfires but also exemplifies how MATLAB can be used to address real-world environmental challenges effectively. | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | losing |
## Inspiration
Business cards haven't changed in years, but cARd can change this! Inspired by the rise of augmented reality applications, we see potential for creative networking. Next time you meet someone at a conference, a career fair, etc., simply scan their business card with your phone and watch their entire online portfolio enter the world! The business card will be saved, and the experience will be unforgettable.
## What it does
cARd is an iOS application that allows a user to scan any business card to bring augmented reality content into the world. Using OpenCV for image rectification and OCR (optical character recognition) with the Google Vision API, we can extract both the business card and text on it. Feeding the extracted image back to the iOS app, ARKit can effectively track our "target" image. Furthermore, we use the OCR result to grab information about the business card owner real-time! Using selelium, we effectively gather information from Google and LinkedIn about the individual. When returned to the iOS app, the user is presented with information populated around the business card with augmented reality!
## How I built it
Some of the core technologies that go into this project include the following:
* ARKit for augmented reality in iOS
* Flask for the backend server
* selenium for collecting data about the business card owner on the web in real-time
* OpenCV to find the rectangular business card in the image and use a homography to map it into a rectangle for AR tracking
* Google Vision API for optical character recognition (OCR)
* Text to speech
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for cARd
Get cARd on the app store for everyone to use! Stay organized and have fun while networking! | ## Inspiration
The whiteboard or chalkboard is an essential tool in instructional settings - to learn better, students need a way to directly transport code from a non-text medium to a more workable environment.
## What it does
Enables someone to take a picture of handwritten or printed text converts it directly to code or text on your favorite text editor on your computer.
## How we built it
On the front end, we built an app using Ionic/Cordova so the user could take a picture of their code. Behind the scenes, using JavaScript, our software harnesses the power of the Google Cloud Vision API to perform intelligent character recognition (ICR) of handwritten words. Following that, we applied our own formatting algorithms to prettify the code. Finally, our server sends the formatted code to the desired computer, which opens it with the appropriate file extension in your favorite IDE. In addition, the client handles all scripting of minimization and fileOS.
## Challenges we ran into
The vision API is trained on text with correct grammar and punctuation. This makes recognition of code quite difficult, especially indentation and camel case. We were able to overcome this issue with some clever algorithms. Also, despite a general lack of JavaScript knowledge, we were able to make good use of documentation to solve our issues.
## Accomplishments that we're proud of
A beautiful spacing algorithm that recursively categorizes lines into indentation levels.
Getting the app to talk to the main server to talk to the target computer.
Scripting the client to display final result in a matter of seconds.
## What we learned
How to integrate and use the Google Cloud Vision API.
How to build and communicate across servers in JavaScript.
How to interact with native functions of a phone.
## What's next for Codify
It's feasibly to increase accuracy by using the Levenshtein distance between words. In addition, we can improve algorithms to work well with code. Finally, we can add image preprocessing (heighten image contrast, rotate accordingly) to make it more readable to the vision API. | static project | winning |
## Inspiration
Where does our money go each month? Many students struggle with personal finance due to poor financial literacy skills. As business students, we wanted to help support students with an easier way to manage their finances.
## What it does
Budget Buddy is a visual dashboard that makes it easy to understand your monthly cash flow breakdown. No need to go through your credit card statement to figure out why you're broke.
## How we built it
Very big pivot table on Excel.
## Challenges we ran into
We had to scrap our original idea for data collection. We ran into issues integrating Microsoft Forms as a method to collect financial information.
## Accomplishments that we're proud of
We're proud of the comprehensiveness of the dashboard! We really tried to capture key metrics that would be of interest to the user.
## What we learned
You can do more than you think with Excel!
## What's next for BudgetBuddy
Maybe BudgetBuddy will make it out of the spreadsheet? | ## Problem | Inspiration
Vehicle theft is a serious threat to public safety and could cost up to billions of dollars on a yearly basis. In Canada, a car is stolen every 6 minutes according to the Insurance Bureau. Ontario, as it stands, was ranked first in Canada in 2020 with about 24000 car thefts (<http://www.ibc.ca/qc/auto/theft/>).
As a vehicle owner, to become aware of your property being stolen is a matter of when you check your driveway. This could take usually hours/days on average. When owners do realize, recorded footage could only prove that their car was stolen, and the realization of their car being unable to be retrieved starts to set in.
## Solution | How I Built It
Our solution, using any surveillance camera (in this case, Raspberry Pi) builds upon the current circumstances. Using computer vision libraries, the camera can now detect theft occuring in real-time and send notifications to the owner of the vehicle.
To build upon this solution, notifications can be *forwarded* to police as soon as you receive them, significantly increasing the chances of your vehicle being retrieved. In the future, this could be integrated with CCTV cameras on the road to detect the location of the stolen car.
To make sure that the camera doesn't send notifications when you're accessing your car, using face\_recognition the Raspberry Pi now knows that this situation is under safe conditions. If at all the owner believes an alert received is a false-alarm he is able to dismiss the alert.
## Challenges I ran into
Our object detection models initially ran at a 10FPS. To optimize, several coco classes had to be filtered out, because this use case really needs to detect people and vehicles. Furthermore, I experimented with different pre-trained models such as MobileNet and YOLOv3 to choose one with a good balance of accuracy and speed.
## Accomplishments that I'm proud of
* Integrating Flask-SocketIO with the Detection model to send a socket message to the server, furthermore to the client with a Modal-popup.
* Integrating end-to-end from the Raspberry Pi camera to Python micro services (camera aggregator, detection models, web server, and client).
## What's next for NytFox
* Continue to IOS/Android App
* Optimize models to serve a faster FPS
* Expanding on whitelisting with posture-detection (such as the function to add new whitelisting users, this might include the friends/family of the owner)
* Improve architecture to handle real-world image monitoring traffic across millions of homes. | ## Foreword
Before we begin, a **very big thank you** to the NVIDIA Jetson team for their generosity in making this project submission possible.
## Inspiration
Nearly 100% of sight-assistance devices for the blind fall into just two categories: Voice assistants for navigation, and haptic feedback devices for directional movement. Although the intent behind these devices is noble, they fail in delivering an effective sight-solution for the blind.
Voice assistant devices that relay visual information from a camera-equipped computer to the user are not capable of sending data to the user in real time, making them very limited in capability. Additionally, the blind are heavily dependent on their hearing in order to navigate environments. They have to use senses besides vision to the limit to make up for their lack of sight, and using a voice assistant clogs up and introduces noise to this critical sensory pathway.
The haptic feedback devices are even more ineffective; these simply tell the user to move left, right, backwards, etc. While these devices provide real-time feedback and don’t introduce noise to one’s hearing like with the voice assistants, they provide literally no information regarding what is in front of the user; it simply just tells them how to move. This doesn’t add much value for the blind user.
It's 2021. Voice assistant and haptic feedback directional devices are a thing of the past. Having blind relatives and friends, we wanted to create a project that leverages the latest advancements in technology to create a truly transformative solution. After about a week's worth of work, we've developed OptiLink; a brain machine interface that feeds AI-processed visual information **directly to the user's brain** in real-time, eliminating the need for ineffective voice assistant and directional movement assistants for the blind.
## What it does
OptiLink is the next generation of solutions for the blind. Instead of using voice assistants to tell the user what’s in front of them, it sends real-time AI processed visual information directly to the user’s brain in a manner that they can make sense of. So if our object detection neural network detects a person, the blind user will actually be able to tell that a person is in front of them through our brain-machine interface. The user will also be able to gauge distance to environmental obstacles through echolocation, once again directly fed to their brain.
Object detection is done through a camera equipped NVIDIA Jetson Nano; a low-power single board computer optimized for deep learning. A Bluetooth enabled nRF52 microcontroller connected to an ultrasonic sensor provides the means to process distances for echolocation. These modules are conveniently packed in a hat for use by the blind.
On the Nano, an NVIDIA Jetpack SDK accelerated MobileNet neural network detects objects (people, cars, etc.), and sends an according output over Bluetooth via the Bleak library to 2 Neosensory Buzz sensory substitution devices located on each arm. These devices, created by neuroscientists David Eagleman and Scott Novich at the Baylor School of Medicine, contain 4 LRAs to stimulate specific receptors in your skin through patterns of vibration. The skin receptors send electrical information to your neurons and eventually to your brain, and your brain can learn to process this data as a sixth sense.
Specific patterns of vibration on the hands tell the user what they’re looking at (for example, a chair will correspond to pattern A, a car will correspond to pattern B). High priority objects like people and cars will be relayed through feedback from the right hand, while low priority objects (such as kitchenware and laptops) will be relayed via feedback from the left hand. There are ~90 such possible objects that can be recognized by the user. Ultrasonic sensor processed distance is fed through a third Neosensory Buzz on the left leg, with vibrational intensity corresponding to distance to an obstacle.
## How we built it
OptiLink's object detection inferences are all done through the NVIDIA Jetson Nano running MobileNet. Through the use of NVIDIA's TensorRT to accelerate inferencing, we were able to run this object detection model at a whopping 24 FPS with just about 12 W of power. Communication with the 2 Neosensory Buzz feedback devices on the arm were done through Bluetooth Low Energy via the Bleak library and the experimental Neosensory Python SDK. Echolocation distance processing is done through an Adafruit nRF52840 microcontroller connected to an ultrasonic sensor; it relays processed distance data (via Bluetooth Low Energy) to a third Neosensory Buzz device placed on the leg.
## Challenges we ran into
This was definitely the most challenging to execute project we've made to date (and we've made quite a few). Images have tons of data, and processing, condensing, and packaging this data into an understandable manner through just 2 data streams is a very difficult task. However, by grouping the classes into general categories (for example cars, motorcycles, and trucks were all grouped into motor vehicles) and then sending a corresponding signal for the grouped category, we could condense information into a manner that is more user friendly. Additionally, we included a built-in frame rate limiter, which prevents the user from receiving way too much information too quickly from the Neosensory Buzz devices. This allows the user to far more effectively understand the vibrational data from the feedback devices.
## Accomplishments that we're proud of
We think we’ve created a unique solution to sight-assistance for the blind. We’re proud to have presented a fully functional project, especially considering the complexities involved in its design.
## What we learned
This was our first time working with the NVIDIA Jetson Nano. We learned a ton about Linux and how to leverage NVIDIA's powerful tools for machine learning (The Jetpack SDK and TensorRT). Additionally, we gained valuable experience with creating brain-machine interfaces and learned how to process and condense data for feeding into the nervous system.
## What's next for OptiLink
OptiLink has room for improvement in its external design, user-friendliness, and range of features. The device currently has a learning curve when it comes to understanding all of the patterns; of course, it takes time to properly understand and make sense of new sensory feedback integrated into the nervous system. We could create a mobile application for training pattern recognition. Additionally, we could integrate more data streams in our product to allow for better perception of various vibrational patterns corresponding to specific classes. Physical design elements could also be streamlined and improved. There’s lots of room for improvement, and we’re excited to continue working on this project! | losing |
### Overview
Resililink is a node-based mesh network leveraging LoRa technology to facilitate communication in disaster-prone regions where traditional infrastructure, such as cell towers and internet services, is unavailable. The system is designed to operate in low-power environments and cover long distances, ensuring that essential communication can still occur when it is most needed. A key feature of this network is the integration of a "super" node equipped with satellite connectivity (via Skylo), which serves as the bridge between local nodes and a centralized server. The server processes the data and sends SMS notifications through Twilio to the intended recipients. Importantly, the system provides acknowledgment back to the originating node, confirming successful delivery of the message. This solution is aimed at enabling individuals to notify loved ones or emergency responders during critical times, such as natural disasters, when conventional communication channels are down.
### Project Inspiration
The inspiration for Resililink came from personal experiences of communication outages during hurricanes. In each instance, we found ourselves cut off from vital resources like the internet, making it impossible to check on family members, friends, or receive updates on the situation. These moments of helplessness highlighted the urgent need for a resilient communication network that could function even when the usual infrastructure fails.
### System Capabilities
Resililink is designed to be resilient, easy to deploy, and scalable, with several key features:
* **Ease of Deployment**: The network is fast to set up, making it particularly useful in emergency situations.
* **Dual Connectivity**: It allows communication both across the internet and in peer-to-peer fashion over long ranges, ensuring continuous data flow even in remote areas.
* **Cost-Efficiency**: The nodes are inexpensive to produce, as each consists of a single LoRa radio and an ESP32 microcontroller, keeping hardware costs to a minimum.
### Development Approach
The development of Resililink involved creating a custom communication protocol based on Protocol Buffers (protobufs) to efficiently manage data exchange. The core hardware components include LoRa radios, which provide long-range communication, and Skylo satellite connectivity, enabling nodes to transmit data to the internet using the MQTT protocol.
On the backend, a server hosted on Microsoft Azure handles the incoming MQTT messages, decrypts them, and forwards the relevant information to appropriate APIs, such as Twilio, for further processing and notification delivery. This seamless integration of satellite technology and cloud infrastructure ensures the reliability and scalability of the system.
### Key Challenges
Several challenges arose during the development process. One of the most significant issues was the lack of clear documentation for the AT commands on the Mutura evaluation board, which made it difficult to implement some of the core functionalities. Additionally, given the low-level nature of the project, debugging was particularly challenging, requiring in-depth tracing of system operations to identify and resolve issues. Another constraint was the limited packet size of 256 bytes, necessitating careful optimization to ensure efficient use of every byte of data transmitted.
### Achievements
Despite these challenges, we successfully developed a fully functional network, complete with a working demonstration. The system proved capable of delivering messages over long distances with low power consumption, validating the concept and laying the groundwork for future enhancements.
### Lessons Learned
Through this project, we gained a deeper understanding of computer networking, particularly in the context of low-power, long-range communication technologies like LoRa. The experience also provided valuable insights into the complexities of integrating satellite communication with terrestrial mesh networks.
### Future Plans for Resililink
Looking ahead, we plan to explore ways to scale the network, focusing on enhancing its reliability and expanding its reach to serve larger geographic areas. We are also interested in further refining the underlying protocol and exploring new applications for Resililink beyond disaster recovery scenarios, such as in rural connectivity or industrial IoT use cases. | The simple pitch behind ResQ: disaster recovery and evacuation are hard.
People crowd the streets making it difficult to quickly evacuate an area. Additionally, for those who choose not to evacuate, they face the possibility of being difficult to find for rescuers. What we've built is a 3 pronged approach.
1. ResQ Responder: An android application for rescuers that presents them with a triage list prepared by the ResQ ML Engine so as to attempt to save the most lives in the most efficient order. We also provide the ability to view this triage list in AR, making it easy to spot evacuees stuck on roofs or in hard to see places.
2. ResQ: The user-facing application. Simplicity is the goal. Only asking for user information to create a medical ID and rescue profile we use the application to record their GPS coordinates for rescue, as well as present them with push notifications about impending rescue. An evacuee can also use the application to broadcast his/her location to others.
3. ResQ ML Engine: The algorithms behind the ResQ platform. These allow us to effectively rank, triage and save victims while minimizing loss of life. | ## Inspiration
## What it does
ResQ is a holistic natural disaster recovery tool.
-Officials (FEMA, Red Cross, etc.) can manage their resource centers on a WebApp: by managing the distribution of resources, the location of distressed individuals, and publicly sourced alerts.
-Private Citizens can use a mobile app as a one-stop-shop solution for their emergency needs including: finding the nearest medical service, food/water source, or shelter source, alerting officials of power outages, fallen trees, or obstructed roads, and finally trigger and emergency response. Users can use augmented reality to point them towards the closest resource.
-Emergency Response Teams: can be dispatched through the app to find private citizens. A convolutional neural network processes Arial imagery to tag and find distressed citizens without cell service
## How I built it
The WebApp is built in React.JS. The mobile app is built with swift in Xcode. The backend was made using Firebase. The AI/Deep Learning portion was built using Keras.
## Challenges I ran into
We ran into several challenges throughout the course of this project. We all dealt with some ideas and technologies we had very little experience with before. Implementing the AR/VR was challenging as this technology is very new and is still very hard to use. Using a pretrained neural network to do image detection (drawing the boudning box) was very challenging as it is a machine learning problem we had never tackled before and one in which very little documentation exists. Also, dealing with many of the sponsor APIs was initially very challenging to deal with as some of the endpoints were hard to successfully interact with.
## Accomplishments that I'm proud of
We think that the scale of this project is huge and has a tremendous amount of application in the real world. This app (on the mobile side) gives people who are victims of a natural disaster a place to report their location, find any resources they may need, and report anything potentially dangerous. This app also (on the web side) gives rescuers a central database to locate and keep track of people who are currently in danger. Lastly, this app also uses deep learning to use drones to identify stranded humans who may not have cell service. We are truly proud of the scale this project achieves and all the rich and various technologies involved.
## What I learned
We all learned various skills in our respective parts of the application: React, iOS with AR/VR, Firebase, Keras.
## What's next for ResQ
The next steps would be to actually implement the deep learning portion of the project, preferably with a drone that could transmit a constant stream that could be processed to see if there are any humans in a certain area and transmit their coordinates appropriately. We also want to build out each specific feature of the mobile app, including directions to water, food, shelter, hospital, or gas. | winning |
## Inspiration
Rates of patient nonadherence to therapies average around 50%, particularly among those with chronic diseases. One of my closest friends has Crohn's disease, and I wanted to create something that would help with the challenges of managing a chronic illness. I built this app to provide an on-demand, supportive system for patients to manage their symptoms and find a sense of community.
## What it does
The app allows users to have on-demand check-ins with a chatbot. The chatbot provides fast inference, classifies actions and information related to the patient's condition, and flags when the patient’s health metrics fall below certain thresholds. The app also offers a community aspect, enabling users to connect with others who have chronic illnesses, helping to reduce the feelings of isolation.
## How we built it
We used Cerebras for the chatbot to ensure fast and efficient inference. The chatbot is integrated into the app for real-time check-ins. Roboflow was used for image processing and emotion detection, which aids in assessing patient well-being through facial recognition. We also used Next.js as the framework for building the app, with additional integrations for real-time community features.
## Challenges we ran into
One of the main challenges was ensuring the chatbot could provide real-time, accurate classifications and flagging low patient metrics in a timely manner. Managing the emotional detection accuracy using Roboflow's emotion model was also complex. Additionally, creating a supportive community environment without overwhelming the user with too much data posed a UX challenge.
## Accomplishments that we're proud of
✅deployed on defang
✅integrated roboflow
✅integrated cerebras
We’re proud of the fast inference times with the chatbot, ensuring that users get near-instant responses. We also managed to integrate an emotion detection feature that accurately tracks patient well-being. Finally, we’ve built a community aspect that feels genuine and supportive, which was crucial to the app's success.
## What we learned
We learned a lot about balancing fast inference with accuracy, especially when dealing with healthcare data and emotionally sensitive situations. The importance of providing users with a supportive, not overwhelming, environment was also a major takeaway.
## What's next for Muni
Next, we aim to improve the accuracy of the metrics classification, expand the community features to include more resources, and integrate personalized treatment plans with healthcare providers. We also want to enhance the emotion detection model for more nuanced assessments of patients' well-being. | ## Inspiration
it's really fucking cool that big LLMs (ChatGPT) are able to figure out on their own how to use various tools to accomplish tasks.
for example, see Toolformer: Language Models Can Teach Themselves to Use Tools (<https://arxiv.org/abs/2302.04761>)
this enables a new paradigm self-assembling software: machines controlling machines.
what if we could harness this to make our own lives better -- a lil LLM that works for you?
## What it does
i made an AI assistant (SMS) using GPT-3 that's able to access various online services (calendar, email, google maps) to do things on your behalf.
it's just like talking to your friend and asking them to help you out.
## How we built it
a lot of prompt engineering + few shot prompting.
## What's next for jarbls
shopping, logistics, research, etc -- possibilities are endless
* more integrations !!!
the capabilities explode exponentially with the number of integrations added
* long term memory
come by and i can give you a demo | ## 💡 Inspiration 💡
Mental health is a growing concern in today's population, especially in 2023 as we're all adjusting back to civilization again as COVID-19 measures are largely lifted. With Cohere as one of our UofT Hacks X sponsors this weekend, we want to explore the growing application of natural language processing and artificial intelligence to help make mental health services more accessible. One of the main barriers for potential patients seeking mental health services is the negative stigma around therapy -- in particular, admitting our weaknesses, overcoming learned helplessness, and fearing judgement from others. Patients may also find it inconvenient to seek out therapy -- either because appointment waitlists can last several months long, therapy clinics can be quite far, or appointment times may not fit the patient's schedule. By providing an online AI consultant, we can allow users to briefly experience the process of therapy to overcome their aversion in the comfort of their own homes and under complete privacy. We are hoping that after becoming comfortable with the experience, users in need will be encouraged to actively seek mental health services!
## ❓ What it does ❓
This app is a therapy AI that generates reactive responses to the user and remembers previous information not just from the current conversation, but also past conversations with the user. Our AI allows for real-time conversation by using speech-to-text processing technology and then uses text-to-speech technology for a fluent human-like response. At the end of each conversation, the AI therapist generates an appropriate image summarizing the sentiment of the conversation to give users a method to better remember their discussion.
## 🏗️ How we built it 🏗️
We used Flask to make the API endpoints in the back-end to connect with the front-end and also save information for the current user's session, such as username and past conversations, which were stored in a SQL database. We first convert the user's speech to text and then send it to the back-end to process it using Cohere's API, which as been trained by our custom data and the user's past conversations and then sent back. We then use our text-to-speech algorithm for the AI to 'speak' to the user. Once the conversations is done, we use Cohere's API to summarize it into a suitable prompt for the DallE text-to-image API to generate an image summarizing the user's conversation for them to look back at when they want to.
## 🚧 Challenges we ran into 🚧
We faced an issue with implementing a connection from the front-end to back-end since we were facing a CORS error while transmitting the data so we had to properly validate it. Additionally, incorporating the speech-to-text technology was challenging since we had little prior experience so we had to spend development time to learn how to implement it and also format the responses properly. Lastly, it was a challenge to train the cohere response AI properly since we wanted to verify our training data was free of bias or negativity, and that we were using the results of the Cohere AI model responsibly so that our users will feel safe using our AI therapist application.
## ✅ Accomplishments that we're proud of ✅
We were able to create an AI therapist by creating a self-teaching AI using the Cohere API to train an AI model that integrates seamlessly into our application. It delivers more personalized responses to the user by allowing it to adapt its current responses to users based on the user's conversation history and
making conversations accessible only to that user. We were able to effectively delegate team roles and seamlessly integrate the Cohere model into our application. It was lots of fun combining our existing web development experience with venturing out to a new domain like machine learning to approach a mental health issue using the latest advances in AI technology.
## 🙋♂️ What we learned 🙋♂️
We learned how to be more resourceful when we encountered debugging issues, while balancing the need to make progress on our hackathon project. By exploring every possible solution and documenting our findings clearly and exhaustively, we either increased the chances of solving the issue ourselves, or obtained more targeted help from one of the UofT Hacks X mentors via Discord. Our goal is to learn how to become more independent problem solvers. Initially, our team had trouble deciding on an appropriately scoped, sufficiently original project idea. We learned that our project should be both challenging enough but also buildable within 36 hours, but we did not force ourselves to make our project fit into a particular prize category -- and instead letting our project idea guide which prize category to aim for. Delegating our tasks based on teammates' strengths and choosing teammates with complementary skills was essential for working efficiently.
## 💭 What's next? 💭
To improve our project, we could allow users to customize their AI therapist, such as its accent and pitch or the chat website's color theme to make the AI therapist feel more like a personalized consultant to users. Adding a login page, registration page, password reset page, and enabling user authentication would also enhance the chatbot's security. Next, we could improve our website's user interface and user experience by switching to Material UI to make our website look more modern and professional. | winning |
## Inspiration
I'm taking a class called How To Make (Almost) Anything that will go through many aspects of digital fabrication and embedded systems. For the first assignment we had to design a model for our final project trying out different modeling software. As a beginner, I decided to take the opportunity to learn more about Unity through this hackathon.
## What it does
Plays like the 15 tile block puzzle game
## How we built it
I used Unity.
## Challenges we ran into
Unity is difficult to navigate, there were a lot of hidden settings that made things not show up or scale. Since I'm not familiar with C# or Unity I spent a lot of time learning about different methods and data structures. Referencing of objects across the different scripts and attributes is not obvious and I ran into a lot of those kinds of issues.
## Accomplishments that we're proud of
About 60% functional.
## What's next for 15tile puzzle game
Making it 100% functional. | ## Inspiration
We wanted to build a shooter that many friends could play together. We didn't want to settle for something that was just functional, so we added the craziest game mechanic we could think of to maximize the number of problems we would run into: a map that has no up or down, only forward. The aesthetic of the game is based on Minecraft (a game I admit I have never played).
## What it does
The game can host up to 5 players on a local network. Using the keyboard and the mouse on your computer, you can walk around an environment shaped like a giant cube covered in forest, and shoot bolts of energy at your friends. When you reach the threshold of the next plane of the cube, a simple command re-orients your character such that your gravity vector is perpendicular to the next plane, and you can move onwards. The last player standing wins.
## How we built it
First we spent a few (many) hours learning the skills necessary. My teammate familiarized themself with a plethora of Unity functions in order to code the game mechanics we wanted. I'm a pretty decent 3D modeler, but I've never used Maya before and I've never animated a bipedal character. I spent a long while adjusting myself to Maya, and learning how the Mecanim animation system of Unity functions. Once we had the basics, we started working on respective elements: my teammate the gravity transitions and the networking, and myself the character model and animations. Later we combined our work and built up the 3D environment and kept adding features and debugging until the game was playable.
## Challenges we ran into
The gravity transitions where especially challenging. Among a panoply of other bugs that individually took hours to work through or around, the gravity transitions where not fully functional until more than a day into the project. We took a break from work and brainstormed, and we came up with a simpler code structure to make the transition work. We were delighted when we walked all up and around the inside of our cube-map for the first time without our character flailing and falling wildly.
## Accomplishments that we're proud of
Besides the motion capture for the animations and the textures for the model, we built a fully functional, multiplayer shooter with a complex, one-of-a-kind gameplay mechanic. It took 36 hours, and we are proud of going from start to finish without giving up.
## What we learned
Besides the myriad of new skills we picked up, we learned how valuable a hackathon can be. It is an educational experience nothing like a classroom. Nobody chooses what we are going to learn; we choose what we want to learn by chasing what we want to accomplish. By chasing something ambitious, we inevitably run into problems that force us to develop new methodologies and techniques. We realized that a hackathon is special because it's a constant cycle of progress, obstacles, learning, and progress. Progress stacks asymptotically towards a goal until time is up and it's time to show our stuff.
## What's next for Gravity First
The next feature we are dying to add is randomized terrain. We built the environment using prefabricated components that I built in Maya, which we arranged in what we thought was an interesting and challenging arrangement for gameplay. Next, we want every game to have a different, unpredictable six-sided map by randomly laying out the pre-fabs according to certain parameters.. | ## Inspiration
BThere emerged from a genuine desire to strengthen friendships by addressing the subtle challenges in understanding friends on a deeper level. The team recognized that nuanced conversations often go unnoticed, hindering meaningful support and genuine interactions. In the context of the COVID-19 pandemic, the shift to virtual communication intensified these challenges, making it harder to connect on a profound level. Lockdowns and social distancing amplified feelings of isolation, and the absence of in-person cues made understanding friends even more complex. BThere aims to use advanced technologies to overcome these obstacles, fostering stronger and more authentic connections in a world where the value of meaningful interactions has become increasingly apparent.
## What it does
BThere is a friend-assisting application that utilizes cutting-edge technologies to analyze conversations and provide insightful suggestions for users to connect with their friends on a deeper level. By recording conversations through video, the application employs Google Cloud's facial recognition and speech-to-text APIs to understand the friend's mood, likes, and dislikes. The OpenAI API generates personalized suggestions based on this analysis, offering recommendations to uplift a friend in moments of sadness or providing conversation topics and activities for neutral or happy states. The backend, powered by Python Flask, handles data storage using Firebase for authentication and data persistence. The frontend is developed using React, JavaScript, Next.js, HTML, and CSS, creating a user-friendly interface for seamless interaction.
## How we built it
BThere involves a multi-faceted approach, incorporating various technologies and platforms to achieve its goals. The recording feature utilizes WebRTC for live video streaming to the backend through sockets, but also allows users to upload videos for analysis. Google Cloud's facial recognition API identifies facial expressions, while the speech-to-text API extracts spoken content. The combination of these outputs serves as input for the OpenAI API, generating personalized suggestions. The backend, implemented in Python Flask, manages data storage in Firebase, ensuring secure authentication and persistent data access. The frontend, developed using React, JavaScript, Next.js, HTML, and CSS, delivers an intuitive user interface.
## Accomplishments that we're proud of
* Successfully integrating multiple technologies into a cohesive and functional application
* Developing a user-friendly frontend for a seamless experience
* Implementing real-time video streaming using WebRTC and sockets
* Leveraging Google Cloud and OpenAI APIs for advanced facial recognition, speech-to-text, and suggestion generation
## What's next for BThere
* Continuously optimizing the speech to text and emotion analysis model for improved accuracy with different accents, speech mannerisms, and languages
* Exploring advanced natural language processing (NLP) techniques to enhance conversational analysis
* Enhancing user experience through further personalization and more privacy features
* Conducting user feedback sessions to refine and expand the application's capabilities | losing |
## Motivation
Our motivation was a grand piano that has sat in our project lab at SFU for the past 2 years. The piano was Richard Kwok's grandfathers friend and was being converted into a piano scroll playing piano. We had an excessive amount of piano scrolls that were acting as door stops and we wanted to hear these songs from the early 20th century. We decided to pursue a method to digitally convert the piano scrolls into a digital copy of the song.
The system scrolls through the entire piano scroll and uses openCV to convert the scroll markings to individual notes. The array of notes are converted in near real time to an MIDI file that can be played once complete.
## Technology
The scrolling through the piano scroll utilized a DC motor control by arduino via an H-Bridge that was wrapped around a Microsoft water bottle. While the notes were recorded using openCV via a Raspberry Pi 3, which was programmed in python. The result was a matrix representing each frame of notes from the Raspberry Pi camera. This array was exported to an MIDI file that could then be played.
## Challenges we ran into
The openCV required a calibration method to assure accurate image recognition.
The external environment lighting conditions added extra complexity in the image recognition process.
The lack of musical background in the members and the necessity to decrypt the piano scroll for the appropriate note keys was an additional challenge.
The image recognition of the notes had to be dynamic for different orientations due to variable camera positions.
## Accomplishments that we're proud of
The device works and plays back the digitized music.
The design process was very fluid with minimal set backs.
The back-end processes were very well-designed with minimal fluids.
Richard won best use of a sponsor technology in a technical pickup line.
## What we learned
We learned how piano scrolls where designed and how they were written based off desired tempo of the musician.
Beginner musical knowledge relating to notes, keys and pitches. We learned about using OpenCV for image processing, and honed our Python skills while scripting the controller for our hack.
As we chose to do a hardware hack, we also learned about the applied use of circuit design, h-bridges (L293D chip), power management, autoCAD tools and rapid prototyping, friction reduction through bearings, and the importance of sheave alignment in belt-drive-like systems. We also were exposed to a variety of sensors for encoding, including laser emitters, infrared pickups, and light sensors, as well as PWM and GPIO control via an embedded system.
The environment allowed us to network with and get lots of feedback from sponsors - many were interested to hear about our piano project and wanted to weigh in with advice.
## What's next for Piano Men
Live playback of the system | ## 💡 Inspiration 💡
Some of our team members have played musical instruments in the past. They know the pain of stopping or pausing while playing the music to flip over their music sheet. Using the hands to flip over a music sheet is not ideal since the hands should be on the instrument to play the music at all times. Since the eyes have to be on the music sheet to read music, why not use the eyes to flip over the music pages instead? And keep our hands on the instrument.
## ❓ What it does ❓
TuneTurn tracks the angle of the musician's head using openCV and uses it to detect whether the user's head is turned to the left or right, and accordingly flips the page of the music sheets, allowing for a hands-free experience. The app also has a vast library of music stored which the user can access and listen to and get a better idea of how to actually play the song of their choice before they start.
## 🤔 How we built it 🤔
Using computer vision (OpenCV) in an app deployed using Qualcomm HDK 8450, we track the movement of the head to trigger the change of page based on which way the head is moving based on the angle that is formed. We ensure then send a request to a Flask server, and ensure only 1 request is sent even though the user's head will be in the turned position for a few hundred milliseconds. The server processes the request and accordingly flips the sheet by using pyautogui to control the computer's left/right keys.
## 😰 Challenges we ran into 😰
It was our first time using OpenCV and we struggled a lot with accurately tracking the coordinates of the desired landmarks on the user's face as choosing the wrong ones would make it difficult to accurately detect whether the user's head is turned. Another major challenge was using Android App Studio to do the ML using Qualcomm as we had never used it before. We primarily code in Python and found the drastic change to Java quite difficult, especially since we had to do relatively complex ML using openCV.
## 🥇 Accomplishments that we're proud of 🥇
We are very proud off making an accurate openCV model by choosing good landmarks and calculating the angle between them to detect whether, and in what direction the user's head is turned. We are also proud of using very different platforms for our application and making them interact with each other and also using a completely different device to host our app, the Qualcomm HDK 8450, instead of a laptop which is what we are used to.
## 🎼 What we learned 🎼
We learned how to make effective mobile apps using Android App Studio and using completely different hardware to power our app. We took a large step out of our comfort zone and experimented with new technologies, allowing us to greatly progress in a short time. We also distributed the tasks accurately to ensure our workflow was streamlined.
## 😮 What's next for MakeUofT 😮
We are planning to make our feature which converts music to notes of a music sheet more accurate so we can better compare the user's music with the original music. To do this, we might try to make our own model and train it, and if it proves to be too hard we will try to find a better API. | ## 💡 Inspiration 💡
Have you ever wished you could play the piano perfectly? Well, instead of playing yourself, why not get Ludwig to play it for you? Regardless of your ability to read sheet music, just upload it to Ludwig and he'll scan, analyze, and play the entire sheet music within the span of a few seconds! Sometimes, you just want someone to play the piano for you, so we aimed to make a robot that could be your little personal piano player!
This project allows us to bring music to places like elderly homes, where live performances can uplift residents who may not have frequent access to musicians. We were excited to combine computer vision, MIDI parsing, and robotics to create something tangible that shows how technology can open new doors.
Ultimately, our project makes music more inclusive and brings people together through shared experiences.
## ❓What it does ❓
Ludwig is your music prodigy. Ludwig can read any sheet music that you upload to him, then convert it to a MIDI file, convert that to playable notes on the piano scale, then play each of those notes on the piano with its fingers! You can upload any kind of sheet music and see the music come to life!
## ⚙️ How we built it ⚙️
For this project, we leveraged OpenCV for computer vision to read the sheet music. The sheet reading goes through a process of image filtering, converting it to binary, classifying the characters, identifying the notes, then exporting them as a MIDI file. We then have a server running for transferring the file over to Ludwig's brain via SSH. Using the Raspberry Pi, we leveraged multiple servo motors with a servo module to simultaneously move multiple fingers for Ludwig. In the Raspberry Pi, we developed functions, key mappers, and note mapping systems that allow Ludwig to play the piano effectively.
## Challenges we ran into ⚔️
We had a few roadbumps along the way. Some major ones included file transferring over SSH as well as just making fingers strong enough on the piano that could withstand the torque. It was also fairly difficult trying to figure out the OpenCV for reading the sheet music. We had a model that was fairly slow in reading and converting the music notes. However, we were able to learn from the mentors in Hack The North and learn how to speed it up to make it more efficient. We also wanted to
## Accomplishments that we're proud of 🏆
* Got a working robot to read and play piano music!
* File transfer working via SSH
* Conversion from MIDI to key presses mapped to fingers
* Piano playing melody ablities!
## What we learned 📚
* Working with Raspberry Pi 3 and its libraries for servo motors and additional components
* Working with OpenCV and fine tuning models for reading sheet music
* SSH protocols and just general networking concepts for transferring files
* Parsing MIDI files into useful data through some really cool Python libraries
## What's next for Ludwig 🤔
* MORE OCTAVES! We might add some sort of DC motor with a gearbox, essentially a conveyer belt, which can enable the motors to move up the piano keyboard to allow for more octaves.
* Improved photo recognition for reading accents and BPM
* Realistic fingers via 3D printing | partial |
# Inspiration 💡
Every day, doctors across the globe use advanced expertise and decades of medical breakthroughs to diagnose patients and craft unique prescriptions. The inspiration for this mobile application stems from the irony that the result of such precision is without fail, the chicken scratch found on a doctor’s note. The physician not only entrusts that the patient will keep track of the crumpled paper but they require that the pharmacist on-call will understand their professional scribble. The plan is to create a platform that leverages technology to streamline the prescription filling process, making it easier for doctors to authenticate their work and for patients and pharmacists alike to be confident in their prescriptions.
# What it does 🚀
The mobile application is designed to streamline prescription filling for patients, physicians and pharmacists. It starts with the written doctor’s note which is scanned via the mobile app and transcribed in real-time, allowing for them to confirm the prescription, directly edit it or retake the scan. This allows physicians to authenticate the interpretation of their prescription before shipping it off to the pharmacy via a shared patient database. During registration, the patient volunteers personal information which populates the database and ensures that general questions such as age, address and insurance are only to be answered once. In conjunction with the transcribed prescription, this information will be used to fill any necessary pharmaceutical forms that are scanned via the app. With completed paperwork, a transcribed description and verified patient information, pharmacists are significantly less likely to make errors fulfilling patient orders.
# How we built it 🏗️
To produce this mobile application, we utilized a diverse technology stack to integrate various components and create an uninterrupted product experience. Using our defined user types (patient, physician and pharmacist), we derived the necessary functions for each, prioritizing and placing them to create an intuitive UI. This paved the way for early design wireframes and an eventual high-fidelity Figma prototype which directed our front-end development in ReactNative. On the back-end, the light-weight Python framework, Flask, was used to handle registration, data transferring and transcription. Our application required keeping track of a large amount of data, which we stored/accessed within a Redis Cloud database. In order to accurately interpret text from forms and notes provided by doctors/pharmacies, we utilised the Google Cloud Vision OCR API as well as Gemini Pro, providing users with accurate transcriptions within images that were processed with the Pillow API. Then, in order to autocomplete forms with efficiency and accuracy, we deployed the OpenAI API as an LLM model, generating prompts through information found within the Redis Cloud database to fill out forms with the correct answers. The back-end of our project was developed parallel to our front-end, which was entirely built using react-native, capable of supporting both android and IOS devices. By using the navigation library, the various components of the application are split into their own pages with styling and functions unique to each one.
## Form filling process:
* Read form
+ Extract text and location using Google Cloud OCR
+ Group text into coherent groups (Vertical + horizontal coordinate comparison and LLMs
+ Detect fillable fields and clean punctuation (LLM and Python)
* Answer fields (LLM)
* Write to form (Python Pillow library)
# Challenges we ran into 🧩
Throughout our project, we faced several obstacles which we ultimately overcame with perseverance and targeted learning. Before writing a single line of code, we discussed our interests, skillsets and project ambitions, finding clear differences which would necessitate a degree of compromise. Moreover, we decided to implement a tech stack with Flask on the backend and React-native on the frontend, which proved to be frustrating as they could have been much more complementary. As a result, we had a handful of avoidable complications given a better-composed tech stack. Given the shorter nature of this particular hackathon, we were very much forced to stick with the decisions we made early on without much room to pivot, greatly improving our critical thinking and debugging skills. Another issue we ran into was the inconsistency that we found within practices in the medical industry, as doctors notes and pharmaceutical forms often differed widely from one person/company to another, meaning we had to build scripts that would satisfy a wide variety of possibilities.
# Accomplishments that we're proud of 🏆
Ultimately, we are extremely proud that we were able to successfully build a full-stack mobile application within a 24-hour window, especially given that 3 of our members were not particularly experienced in app development before this hackathon. However, we were all able to find ways to contribute to the project whether it be through design elements, programming, or pitching. We are also extremely happy with the number of different libraries/APIs that we were able to put to use in this project. Having the experience of working with these APIs, many of which were for the first time, was extremely exciting for us and allowed us to build a product that we found to be extremely interesting.
# What we learned 🧠
Through this experience, all members of our group came away with an enhanced skillset. We each improved our developing expertise as despite our lack of experience with the chosen technologies and tools, we ultimately built a strong project that applied those tools well. Beyond just coding, we also improved our product thinking, prioritizing the needs of each end-user to design a well-rounded and truly valuable mobile application. Above all, we learned the importance of programming as a collaborative process, finding success by sharding responsibility between members and optimizing workloads with everyone's unique skill set. We are beyond excited to apply our updated mindset to participate in future hackathons.
# What's next for PharmFill 🚀
We are interested in continuing our work with PharmFill, with a focus on adding more features and polishing those already implemented. Our belief in PharmFill's potential to significantly impact the medical industry fuels our enthusiasm. A key area of development is the creation of more complex form-filling algorithms, capable of handling all types of forms. This advancement will not only enhance the app's functionality but also solidify its position as a transformative tool in healthcare. | ## Inspiration:
The human effort of entering details from a paper form to a computer led us to brainstorm and come up with this idea which takes away the hassle of the information collection phase.
## What it does?
The application accepts an image / pdf of a medical form and analyses it to find the information which is then stored in a database
## How we built it?
We applied Optical Character Recognition techniques to evaluate data which was present in the form, and then formatted it to provide valuable information to the nurse/doctor
## Challenges we ran into:
Each person has his/her own way of writing and thus it was difficult to identify the characters
## Accomplishments that we're proud of:
We could come up with an MVP during these 36 hours by implementing a solution involving new technologies / workflows.
## What we learned?
We learned about the presence of several APIs providing OCR functionality which might differ based on the optimisation, also we learned more about client-server architecture in a way the patient's (client) request reaches nurse/hospital (server) asynchronously.
## What's next for Care Scan?
We would love to take this idea forward and integrate the solution with different services and regulations to provide an enriching experience to the user including but not limited to the scope of machine learning, NLP and event driven architectures.
## Link to Codebase
<https://github.com/Care-Scan> | ## Inspiration
We wanted to create a tool for positive connections through the internet - one nice message can change a life.
## Why we think this matters
We recognized the profound impact that small sayings - innocuous remarks - have had on the way we think and behave. We believe the anonymity of the authors allows for harder-hitting messages with real impact. We think people could really gain from collaboratively receiving and sending their wonderful and spontaneous nuggets of wisdom.
## What it does
Remarrk allows you to send and receive motivating and positive messages to and from strangers across the internet. Share your thoughts and insights, or browse through what others have to say! Your remarks can make a real impact.
## How we built it
Remarrk is a web app built using React on the front end, and an Express server and Cloud Firestore database on the backend. The site is hosted using AWS Amplify. We made use of GitHub with Issues and source control to manage tasks and ensure a cohesive codebase.
## Challenges we ran into
Nearly every aspect brought up small challenges along the way; from state management in React, to web hosting with AWS. Determining which features needed to be components and how to manage their varied interactions with one another became quite the learning curve! Our team was composed of designers and developers so both sides had to learn a lot about the other aspect of development for our team to work smoothly.
## Accomplishments that we're proud of
Creating a working website and being able to share positive messages with each other across it is an amazing feeling! Also, we managed to create the MVP we had planned *and* complete some additional features - like favourites and upvoting - all within the allotted time. Being able to get the website up and running on a custom domain was really cool too!
## What we learned
One of our main goals for this hackathon was to learn new technology. Nearly everything was new to at least one team member, whether that was React, Firebase, Node, or AWS. Despite this, we exceeded our goals for the base product and learned a ton of new things along the way! Many constraints of component-based architectures were explored, as well as the necessary workarounds to apply certain functionalities - it was all a fun experience!
## What's next for remarrk
We have more features on the list that we'd love to add: dynamic button labels, creating an API to get messages directly from our database, and a reaction system to send love back to the original author of a remark to name a few! | partial |
The simple pitch behind ResQ: disaster recovery and evacuation are hard.
People crowd the streets making it difficult to quickly evacuate an area. Additionally, for those who choose not to evacuate, they face the possibility of being difficult to find for rescuers. What we've built is a 3 pronged approach.
1. ResQ Responder: An android application for rescuers that presents them with a triage list prepared by the ResQ ML Engine so as to attempt to save the most lives in the most efficient order. We also provide the ability to view this triage list in AR, making it easy to spot evacuees stuck on roofs or in hard to see places.
2. ResQ: The user-facing application. Simplicity is the goal. Only asking for user information to create a medical ID and rescue profile we use the application to record their GPS coordinates for rescue, as well as present them with push notifications about impending rescue. An evacuee can also use the application to broadcast his/her location to others.
3. ResQ ML Engine: The algorithms behind the ResQ platform. These allow us to effectively rank, triage and save victims while minimizing loss of life. | ## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | Learning a new language doesn't happen inside an app or in front of a screen. It happens in real life.
So we created Dojo, an immersive and interactive language learning platform, powered by artificial intelligence, that supports up to 10 different languages.
Our lessons are practical. They're personalized to your everyday life, encouraging you to make connections with the world around you.
Go on a scavenger hunt and take photos of objects that match the given hint to unlock the next level. Open the visual dictionary and snap a photo of something to learn how to describe it in the language you're learning. | winning |
TL:DR; It’s hard and important to learn machine learning and data science; we’re making it easier than ever.
## Inspiration
We’re students ranging in various levels of machine learning experience, but we all started the same way; working through infamous online courses and filling out starter code with lines we don’t understand. Although we eventually were able to mature our understanding of machine learning, through ScratchML, we are changing the ML education paradigm from our shared experiences and struggles to creating a platform where kids can develop intuition on data analysis and machine learning that abstracts away the parts that make it difficult. Instead of “learning” by filling out lines of pytorch code that aren’t self evident, we want kids to start thinking about the richness of data around us, what it can be used for, and how to leverage models to infer things about the world around us. We are from the generation that was inspired by Scratch, where drag-and-drop code helped us to make toy games and develop our intuition to code even before we learned our first programming language. ScratchML aims to take a similar approach, creating a learning platform that's easy-to-use and develops our way of thinking and intuition behind the scenes.
## What it does
Our platform is designed to teach machine learning and data analysis principles. The challenge is two-fold: making the learning fun and engaging while also providing a high quality curriculum developed around experiential learning. ScratchML delivers on both aspects by providing a reliable drag-and-drop interface used just like Scratch for model development and data experimentation, and through engineered datasets where the student are guided through exploring the data and reporting findings, students will be much more engaged through trying out a bunch of different approaches to accomplish a mission.
Each lesson comes with a workspace, where students can drag-and-drop models and other blocks to create a no-code, data analysis pipeline. A personalized tutor system is designed to guide the learning process, offering explanations and tips to guide the learning process. This system leverages the Prediction Guard LLM API to provide real-time insights into user decisions and outcomes within lessons. It employs state management to ensure continuous progress while fostering a sandbox-style learning environment.
## How we built it
The tech stack for the project consisted of:
React for the frontend, utilizing the Chakra UI component library and Tailwind CSS for styling.
A Flask server that runs and trains models based on the layout specified by the user.
We also used Intels extension for Scikit-learn/PyTorch to deliver faster training and inference time critical for making the user experience on the site seamless.
Firebase database for storing user data and storage of models that can be evaluated on the fly.
APIs: Prediction Guard LLM API to provide personalized real-time feedback using Neural-Chat-7B.
Models: Scikit-learn and PyTorch
Dev tools: Intel's Developer Cloud for constructing and testing the sandbox model, leveraging the PyTorch optimizations from Intel.
## Challenges we ran into
The largest challenge was to constantly rework the design to build a more intuitive, highly-functional interface. We are software developers by training; it was difficult to settle on a UI/UX design that achieves all of our priorities. Prior approaches for no-code machine learning are primarily designed for use in industry. Although they work well for older users who need to model data, at each stage we were super focused on whether or not each of the design elements were good for students. Furthermore, with this being our first or second hackathon experience, we worked hard to coordinate distributing work, ideating what could be feasibly accomplished in 36 hours, and ensuring that we accomplish our tasks in a timely manner. A final challenge we faced was simple endurance - the last few hours of development were extremely difficult given the sleep deprivation we all suffered from - overcoming this challenge was simply a matter of willpower and perseverance.
## Accomplishments that we're proud of
As amateur hackers, we are proud of what we accomplished this weekend - from building a helpful and innovative product from scratch to just the sheer amount of hard work we exhibited - this weekend proved to us that we are each capable of much more than we originally thought. Our team has limited hackathon experience, and we went in with the approach of not compromising on even our most ambitious ideas. We hacked together the base form of ScratchML, which supports all of the critical features that we set out to do at the beginning of the hackathon, and we are super excited to continue to work at the idea and think creatively and collaboratively on ways we can improve the learning experience for students in the future.
## What we learned
One of the largest takeaways from this weekend was simply that we are capable of much more than we originally believed. Getting together a team of passionate and driven individuals with aligned goals is a powerful tool to create and build.
Another lesson we learned in hindsight is the importance of sleep. Sometimes sacrifice can be beneficial, but it’s likely that our excitement in the earlier stages of the weekend came back to bite us during the final stretch.
Finally, this challenge asked all of us to wear a wide variety of hats, working with technologies and frameworks that we have limited experiences with. We learned a variety of different tools and also learned how to quickly rise to the occasion and accomplish the needs of the team.
## What's next for ScratchML
We plan on making the UI more intuitive, adding more lessons, increasing the number of blocks available in the sandbox, and increasing the number of datasets users can play with.
It is also imperative that we continue to think of creative ways to encourage learning. Our vision for the future of education, shared with many leaders in the space, is turning the classroom into a laboratory, where students can experiment and grow through trial-and-error. This requires coordinated collaboration and a lot of learning on our end as well, and we are eager to innovate and learn from innovators in the educational space to grow ScratchML into the go-to platform for young students trying to learn machine learning and data science principles. | ## What it does
Lil' Learners is a fun new alternative to learning tools for students in grades ranging from kindergarten to early elementary school. Allow for Teachers to create classes for their students and take note of the learning, strengths and weaknesses of their students as well as allowing for teachers and parents to track the progress of students. Students are assigned classes based on what each of their teachers needs them to practice and are presented with a variety(in the future) of interactive and fun games that take the teachers notes and generates questions which would be presented through the form of games. Students gain points based on how many questions they get right while playing, and get incentive to keep playing and in turn studying by allowing them to own virtual islands that they can customize to their liking by buying cosmetic items with the points earned from studying.
## How we built it
Using OAuth and a MongoDB database, Lil' Learners is a Flask based web application that runs on a structural backbone that is the accounts and courses class hierarchy. We created classes and separated all the types of accounts and courses, and created functions that check for duplicate accounts through both username and email and automatically save accounts to the database or courses to teachers and students or even children to their parents upon instantiation. On the front end, Lil' learners makes use of flask, html and css to create a visually appealing and interactive GUI and web interface. Through the use
## Challenges we ran into
Some challenges were making auth0 work with our log in system that we developed, along with one of the biggest setbacks being with 3.js model that we wanted to create to show off the island that each student owns in an interactive and cool looking way, but despite working at it for several hours, the apis and similar documentation for displaying the 3d models in a flask and html environment seemed to be a lost cause.
## Accomplishments that we're proud of
We are super proud of Lil Learners because despite the various different types of softwares and new/old skills that needed to me learned and merged together for it to work, we managed to create something that we could show off and works to convey the proof of concept for our idea
## What we learned:
We learned a lot about the interactions between various different software and how to integrate them together. Through the process of making Lil' learners we had the opportunity to try out the data management and back end development, and general software development skills with MongoDB, OAuth and GoDaddy and learn how they work and interact with other elements in a web application.
## What's next for Lil' Learners
We are hoping to be able to expand Lil learner's capacities further such as finishing up the 3.js models, fully integrating the OAuth with our account systems, launching our web app onto our go daddy domain, creating a larger variety of games and also providing better visualizations for the statistics for students along with better employments of the points and adaptive learning systems. | ## Motivation
Coding skills are in high demand and will soon become a necessary skill for nearly all industries. Jobs in STEM have grown by 79 percent since 1990, and are expected to grow an additional 13 percent by 2027, according to a 2018 Pew Research Center survey. This provides strong motivation for educators to find a way to engage students early in building their coding knowledge.
Mixed Reality may very well be the answer. A study conducted at Georgia Tech found that students who used mobile augmented reality platforms to learn coding performed better on assessments than their counterparts. Furthermore, research at Tufts University shows that tangible programming encourages high-level computational thinking. Two of our team members are instructors for an introductory programming class at the Colorado School of Mines. One team member is an interaction designer at the California College of the Art and is new to programming. Our fourth team member is a first-year computer science at the University of Maryland. Learning from each other's experiences, we aim to create the first mixed reality platform for tangible programming, which is also grounded in the reality-based interaction framework. This framework has two main principles:
1) First, interaction **takes place in the real world**, so students no longer program behind large computer monitors where they have easy access to distractions such as games, IM, and the Web.
2) Second, interaction behaves more like the real world. That is, tangible languages take advantage of **students’ knowledge of the everyday, non-computer world** to express and enforce language syntax.
Using these two concepts, we bring you MusicBlox!
## What is is
MusicBlox combines mixed reality with introductory programming lessons to create a **tangible programming experience**. In comparison to other products on the market, like the LEGO Mindstorm, our tangible programming education platform **cuts cost in the classroom** (no need to buy expensive hardware!), **increases reliability** (virtual objects will never get tear and wear), and **allows greater freedom in the design** of the tangible programming blocks (teachers can print out new card/tiles and map them to new programming concepts).
This platform is currently usable on the **Magic Leap** AR headset, but will soon be expanded to more readily available platforms like phones and tablets.
Our platform is built using the research performed by Google’s Project Bloks and operates under a similar principle of gamifying programming and using tangible programming lessons.
The platform consists of a baseboard where students must place tiles. Each of these tiles is associated with a concrete world item. For our first version, we focused on music. Thus, the tiles include a song note, a guitar, a piano, and a record. These tiles can be combined in various ways to teach programming concepts. Students must order the tiles correctly on the baseboard in order to win the various levels on the platform. For example, on level 1, a student must correctly place a music note, a piano, and a sound in order to reinforce the concept of a method. That is, an input (song note) is fed into a method (the piano) to produce an output (sound).
Thus, this platform not only provides a tangible way of thinking (students are able to interact with the tiles while visualizing augmented objects), but also makes use of everyday, non-computer world objects to express and enforce computational thinking.
## How we built it
Our initial version is deployed on the Magic Leap AR headset. There are four components to the project, which we split equally among our team members.
The first is image recognition, which Natalie worked predominantly on. This required using the Magic Leap API to locate and track various image targets (the baseboard, the tiles) and rendering augmented objects on those tracked targets.
The second component, which Nhan worked on, involved extended reality interaction. This involved both Magic Leap and Unity to determine how to interact with buttons and user interfaces in the Magic leap headset.
The third component, which Casey spearheaded, focused on integration and scene development within Unity. As the user flows through the program, there are different game scenes they encounter, which Casey designed and implemented. Furthermore, Casey ensured the seamless integration of all these scenes for a flawless user experience.
The fourth component, led by Ryan, involved project design, research, and user experience. Ryan tackled user interaction layouts to determine the best workflow for children to learn programming, concept development, and packaging of the platform.
## Challenges we ran into
We faced many challenges with the nuances of the Magic Leap platform, but we are extremely grateful to the Magic Leap mentors for providing their time and expertise over the duration of the hackathon!
## Accomplishments that We're Proud of
We are very proud of the user experience within our product. This feels like a platform that we could already begin testing with children and getting user feedback. With our design expert Ryan, we were able to package the platform to be clean, fresh, and easy to interact with.
## What We learned
Two of our team members were very unfamiliar with the Magic Leap platform, so we were able to learn a lot about mixed reality platforms that we previously did not. By implementing MusicBlox, we learned about image recognition and object manipulation within Magic Leap. Moreover, with our scene integration, we all learned more about the Unity platform and game development.
## What’s next for MusicBlox: Tangible Programming Education in Mixed Reality
This platform is currently only usable on the Magic Leap AR device. Our next big step would be to expand to more readily available platforms like phones and tablets. This would allow for more product integration within classrooms.
Furthermore, we only have one version which depends on music concepts and teaches methods and loops. We would like to expand our versions to include other everyday objects as a basis for learning abstract programming concepts. | partial |
The website demo requires a server end. Therefore, GitHub cannot present its functions, which supports only static websites. Git clone its code and running them locally is highly recommended. All codes are open source under MIT License.
## Inspiration
Initially, I noticed HP provide go-pro camera as awards, which attracts me so much. Then I looked into HP Haven on Demand APIs. They are fairly straightforward. Developers only need on sentence of command to send requests and receive results.
## What it does
Face Recognition.
## How I built it
Two parts: website and data transfer through the API.
## Challenges I ran into
I used python at first, because it has many scientific computing libraries on images. But later I found these libs cannot be used on Apache server, but only locally. Then I switched to PHP and reconstruct many codes.
## Accomplishments that I'm proud of
Tidy GUI of the website and really improved results!
## What I learned
I found a good API, HP Haven on Demand. And a lesson from the challenge I just mentioned.
## What's next for Optimized Face Recognition Tool
Surely it is not perfect, there are many features to be improved. Performance could be taken as its next step. | ## Inspiration
One of our team member's father and their grandfather were both veterans. When speaking with them about the biggest problem currently facing veterans, they were unanimous in describing the inefficiencies of the healthcare and assistance systems that are available to veterans. In this way, we took on the challenge of simplifying the entire veteran help process by streamlining appointment scheduling, granting digital resource access through a personal assistant UI, and adding additional frameworks for future integration by the VA that so desperately needs to move into the digital age.
## What it does
-Serves as a foundation for health assistance via digital access to physical, mental, and emotional help
-Priority scheduler (based on severity) for the VA to utilize
-Geolocation and voice commands for user accessibility
-Provides instant resources for mental challenges such as depression, anxiety, and family issues
-Allows veterans to access a network of applications such as auto-generating healthcare vouchers and requesting care reimbursement
## How I built it
We used Java on the mobile avenue to build a native Android application. Using Google Voice Recognition, we process user speech inputs with our own NLP systems that takes into account context to determine response. We then push that response back out with TTS for a personal assistant experience. On the web side, we're using Django to run and host an SQLite database to which we send user data when they need to schedule a VA appointment.
## Challenges I ran into
We couldn't find a suitable nlp api to employ that understood our context, so we had to create our own.
## What's next for Assist
We anticipate an opportunity for this app to grow in capabilities as new policies push for system reform. We developed not only several front-end capabilities and useful tools that are instantly usable, but also a framework for future integration into the VA's system for the automation and digitalization of complicated paper processes. | ## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It was originally built using a web scraper that scraped from LinkedIn which was written in python. The web visualizer was built using javascript and the VisJS library to have a dynamic view and aesthetically pleasing physics. In order to have a clean display, web components were used.
## Challenges we ran into
Gathering and scraping the data was a big obstacle, had to pattern match using LinkedIn's data
## Accomplishments that we're proud of
It works!!!
## What we learned
Learning to use various libraries and how to setup a website
## What's next for Yeevaluation
Finetuning and reimplementing dynamic node graph, history. Revamping project, considering it was only made in 24 hours. | losing |
## Inspiration
\_ "According to Portio Research, the world will send 8.3 trillion SMS messages this year alone – 23 billion per day or almost 16 million per minute. According to Statistic Brain, the number of SMS messages sent monthly increased by more than 7,700% over the last decade" \_
The inspiration for TextNet came from the crazy mobile internet data rates in Canada and throughout North America. The idea was to provide anyone with an SMS enabled device to access the internet!
## What it does
TextNet exposes the following internet primitives through basic SMS:
1. Business and restaurant recommendations
2. Language translation
3. Directions between locations by bike/walking/transit/driving
4. Image content recognition
5. Search queries.
6. News update
TextNet can be used by anyone with an SMS enabled mobile device. Are you \_ roaming \_ in a country without access to internet on your device? Are you tired of paying the steep mobile data prices? Are you living in an area with poor or no data connection? Have you gone over your monthly data allowance? TextNet is for you!
## How we built it
TextNet is built using the Stdlib API with node.js and a number of third party APIs. The Stdlib endpoints connect with Twilio's SMS messaging service, allowing two way SMS communication with any mobile device. When a user sends an SMS message to our TextNet number, their request is matched with the most relevant internet primitive supported, parsed for important details, and then routed to an API. These API's include Google Cloud Vision, Yelp Business Search, Google Translate, Google Directions, and Wolfram Alpha. Once data is received from the appropriate API, the data is formatted and sent back to the user over SMS. This data flow provides a form of text-only internet access to offline devices.
## Challenges we ran into
Challenge #1 - We arrived at HackPrinceton at 1am Saturday morning.
Challenge #2 - Stable SMS data flow between multiple mobile phones and internet API endpoints.
Challenge #3 - Google .json credential files working with our Stdlib environment
Challenge #4 - Sleep deprivation ft. car and desks
Challenge #5 - Stdlib error logging
## Accomplishments that we're proud of
We managed to build a basic offline portal to the internet in a weekend. TextNet has real world applications and is built with exciting technology. We integrated an image content recognition machine learning algorithm which given an image over SMS, will return a description of the contents! Using the Yelp Business Search API, we built a recommendation service that can find all of the best Starbucks near you!
Two of our planned team members from Queen's University couldn't make it to the hackathon, yet we still managed to complete our project and we are very proud of the results (only two of us) :)
## What we learned
We learned how to use Stdlib to build a server-less API platform. We learned how to interface SMS with the internet. We learned *all* about async / await and modern Javascript practices. We learned about recommendation, translate, maps, search queries, and image content analysis APIs.
## What's next for TextNet
Finish integrate of P2P payment using stripe
## What's next for HackPrinceton
HackPrinceton was awesome! Next year, it would be great if the team could arrange better sleeping accommodations. The therapy dogs were amazing. Thanks for the experience! | ## Inspiration
Have you ever wanted to search something, but aren't connected to the internet? Data plans too expensive, but you really need to figure something out online quick? Us too, and that's why we created an application that allows you to search the internet without being connected.
## What it does
Text your search queries to (705) 710-3709, and the application will text back the results of your query.
Not happy with the first result? Specify a result using the `--result [number]` flag.
Want to save the URL to view your result when you are connected to the internet? Send your query with `--url` to get the url of your result.
Send `--help` to see a list of all the commands.
## How we built it
Built on a **Nodejs** backend, we leverage **Twilio** to send and receive text messages. When receiving a text message, we send this information using **RapidAPI**'s **Bing Search API**.
Our backend is **dockerized** and deployed continuously using **GitHub Actions** onto a **Google Cloud Run** server. Additionally, we make use of **Google Cloud's Secret Manager** to not expose our API Keys to the public.
Internally, we use a domain registered with **domain.com** to point our text messages to our server.
## Challenges we ran into
Our team is very inexperienced with Google Cloud, Docker and GitHub Actions so it was a challenge needing to deploy our app to the internet. We recognized that without deploying, we would could not allow anybody to demo our application.
* There was a lot of configuration with permissions, and service accounts that had a learning curve. Accessing our secrets from our backend, and ensuring that the backend is authenticated to access the secrets was a huge challenge.
We also have varying levels of skill with JavaScript. It was a challenge trying to understand each other's code and collaborating efficiently to get this done.
## Accomplishments that we're proud of
We honestly think that this is a really cool application. It's very practical, and we can't find any solutions like this that exist right now. There was not a moment where we dreaded working on this project.
This is the most well planned project that we've all made for a hackathon. We were always aware how our individual tasks contribute to the to project as a whole. When we felt that we were making an important part of the code, we would pair program together which accelerated our understanding.
Continuously deploying is awesome! Not having to click buttons to deploy our app was really cool, and it really made our testing in production a lot easier. It also reduced a lot of potential user errors when deploying.
## What we learned
Planning is very important in the early stages of a project. We could not have collaborated so well together, and separated the modules that we were coding the way we did without planning.
Hackathons are much more enjoyable when you get a full night sleep :D.
## What's next for NoData
In the future, we would love to use AI to better suit the search results of the client. Some search results have a very large scope right now.
We would also like to have more time to write some tests and have better error handling. | ## Inspiration
After our initial hack failed, and with only 12 hours of time remaining, we decided to create a proof-of-concept that was achievable in the time remaining. As Twilio was a sponsor, we had the idea of using SMS to control a video game. We created Hackermon to demonstrate how this technology has potential, and as a proof-of-concept of more practical uses.
## What it does
Controlled entirely via SMS, two players can select a knockoff Pokemon and fight each other, with the ability to block or attack. The game is turn based, and has checks to ensure the person texting the API is the correct person, so cheating is effectively impossible.
## How we built it
The backend is built with Node.js and Express.js, with SMS controls made possible with Twilio's API. The frontend is built in HTML, CSS, JavaScript and jQuery and uses AJAX to constantly poll the backend for updates.
## Challenges we ran into
Sleep deprivation was a major challenge that affected us. Trying to focus on learning a new API and developing with a new framework was very challenging after being awake for 22 hours. However, having to prototype something so rapidly was very rewarding - we had to carefully prioritise and cut features in order to create a demoable product in time.
## What we learned
Our initial idea for a project involved using Facebook's Instant Game API. We discovered that many of Facebook's APIs aren't as documented as we expected, and some of their post-Cambridge Analytica security features can cause major unexpected issues.
This was the first time we'd ever used the Twilio API, and it was great to learn how powerful the platform is. Initially, we'd never had to handle getting requests from the backend to the frontend in Node.js before, so managing to get this to work consistently was amazing - even though we know it's not done in the most efficient way.
## What's next for Hackermon
While the game itself is only a basic proof-of-concept, the mechanic of using SMS to control a game has many applications. For example, a quiz webapp used in university classes could accept inputs via SMS rather than requiring students to download a clunky and badly designed app. | winning |
Subsets and Splits