
user
stringlengths 3
28
| created_at
timestamp[us] | body
stringlengths 1
173k
| issue_number
int64 1
2.57k
| __index_level_0__
int64 0
8.05k
|
|---|---|---|---|---|
YooSungHyun | 2025-01-15T04:54:55 | https://github.com/huggingface/trl/releases/tag/v0.7.5 | 2,569 | 0 |
HuggingFaceDocBuilderDev | 2025-01-15T11:15:17 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2568). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,568 | 1 |
mnoukhov | 2025-01-13T20:46:28 | Currently, changing RLOO/PPO to use `BaseOnlineTrainer` would remove the functionality of
- generating K minibatches from your model and then doing `K` updates on the generated data
- doing multiple updates on the same completions (i.e. `ppo_epochs`)
This is not present in the OnlineDPO code but it is a standard practice in RLHF.
To solve this, in either this PR or a future PR, I propose moving the LLM generation logic into [`Trainer.get_batch_samples`](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L2480)
- `get_batch_samples` would take prompt inputs and return prompts, completions, and maybe logprobs of completions under the generating model
- separates generation logic from training logic, allowing for cleaner code / code reuse
- by simply modifying `num_batch_samples` to be `num_batch_samples * K` allows for generating `K` minibatches from a model and `Trainer` logic should handle everything
Looking for feedback!
| 2,567 | 2 |
qgallouedec | 2025-01-14T09:16:19 | Hi @mnoukhov,
### Base Online Trainer
I understand the motivation behind this PR. However, from a philosophical standpoint, I believe that, except in rare cases, duplicated code should be preferred over inheritance in this context.
We've attempted to implement a base trainer several times in the past—whether as a general solution or specifically for online methods—and found that it tends to add more complexity than it resolves (harder to maintain, develop, debug). Even recently, with NashMD and XPO inheriting from Online DPO, I wonder if avoiding inheritance might have resulted in a simpler and clearer design.
Therefore, unless the differences between two trainers are truly minimal—such as requiring the override of just one method—I would advise against taking this approach.
### RLOO refactoring
Absolutely agree on this point. I wonder if we can skip the "v2" stage. RLOO was added recently, so I believe we can afford to break it (important: TRL is still in alpha).
For users, however, we should ensure there's a clear migration guide to help them transition smoothly. | 2,567 | 3 |
HuggingFaceDocBuilderDev | 2025-01-13T14:55:53 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2566). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,566 | 4 |
HuggingFaceDocBuilderDev | 2025-01-13T13:04:08 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2565). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,565 | 5 |
qgallouedec | 2025-01-15T22:16:23 | From the paper:
```math
\mathcal{J}_{\text{GRPO}}(\theta) =\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\left[\min \left(\frac{\pi_\theta(o_{i,t} | q, o_{i,< t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, o_{i,< t})} \hat{A}_{i,t}, \text{clip}\left(\frac{\pi_\theta(o_{i,t} | q, o_{i,< t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, o_{i,< t})}, 1 - \epsilon, 1 + \epsilon\right) \hat{A}_{i,t}\right) - \beta \mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]\right].
```
where:
- $G$ is the number of generations per prompt
- $o_i$ is the $i$-th generation of the prompt and $|o_i|$ is the number of tokens in $o_i$
- $q$ is the prompt
- $\pi_\theta$ is the policy model
- $\pi_{\theta_{\text{old}}}$ is the policy model before the update
- $\pi_{\text{ref}}$ is the reference policy
- $\hat{A}_{i,t}$ is the advantage estimate for the $t$-th token in the $i$-th generation (see under)
- $\epsilon$ and $\beta$ are hyperparameters
In Section 4.2 we can read:
> The policy model only has a single update following each exploration stage.
It implies that $\pi_{\theta_{\text{old}}} = \pi_\theta$. Consequently,
```math
\mathcal{J}_{\text{GRPO}}(\theta) = \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left[\hat{A}_{i,t}- \beta \mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]\right]
```
```math
\mathcal{J}_{\text{GRPO}}(\theta) = \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \hat{A}_{i,t}- \beta \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|}\mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]
```
from 4.1.2, $\hat{A}_{i,t}$ is defined as
```math
\hat{A}_{i,t} = \tilde{r}_i = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})},
```
where $\mathbf{r} = \{r_1, r_2, \ldots, r_{G}\}$. It implies that $\hat{A}_{i,t}$ doesn't depend on $t$. Let's use the notation $\tilde{r}_i$ instead for clarity. So
```math
\mathcal{J}_{\text{GRPO}}(\theta) = \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \tilde{r}_i- \beta \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|}\mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]
```
```math
\mathcal{J}_{\text{GRPO}}(\theta) = \frac{1}{G} \sum_{i=1}^G \tilde{r}_i- \beta \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|}\mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]
```
we know that $\{\tilde{r}_1, \tilde{r}_2, \ldots, \tilde{r}_{G}\}$ is normalized, so the mean is 0. It comes
```math
\mathcal{J}_{\text{GRPO}}(\theta) = - \beta \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|}\mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]
```
As a result, the GRPO objective just minimizes the KL divergence between the policy model and the reference policy. | 2,565 | 6 |
liuchaohu | 2025-01-13T09:50:13 | I know the reason why `pixel_values` disappears.
We should run the code the param "`--remove_unused_columns false`", otherwise `pixel_values` will be eliminated. | 2,563 | 7 |
HuggingFaceDocBuilderDev | 2025-01-11T16:44:58 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2561). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,561 | 8 |
qgallouedec | 2025-01-11T22:10:32 | CI fails, I think we can ignore, see https://github.com/huggingface/trl/pull/2558#issuecomment-2585461179 | 2,561 | 9 |
qgallouedec | 2025-01-12T11:30:23 | Good point, done in 43089fa | 2,561 | 10 |
oliveiraeliel | 2025-01-11T15:17:23 | Please, can someone give me some feedback? It is my first PR to `trl` | 2,560 | 11 |
qgallouedec | 2025-01-11T22:13:35 | Nice! just make sure to run `make precommit` to apply the right style | 2,560 | 12 |
oliveiraeliel | 2025-01-12T01:44:17 | > Nice! just make sure to run `make precommit` to apply the right style
I ran the `make precommit` and `pytest test/test_ppo_trainer.py`, everything looks ok. | 2,560 | 13 |
HuggingFaceDocBuilderDev | 2025-01-10T18:35:01 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2558). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,558 | 14 |
qgallouedec | 2025-01-11T00:11:01 | we get different results with vllm. probably linked to sampling param. investigating | 2,558 | 15 |
qgallouedec | 2025-01-11T22:08:57 | CI fails because in the latest transformers version release yesterday, transformers uses a python 3.10+ syntax (`timeout: float | None = None`). I'm not sure why it fails only for the cli test, but I think we can safely ignore it. | 2,558 | 16 |
qgallouedec | 2025-01-12T14:34:47 | Surprisingly, the precision of the generator model seems to have a pretty high impact on the results:
<img width="1272" alt="Screenshot 2025-01-12 at 15 31 31" src="https://github.com/user-attachments/assets/21a784e6-d1fb-48c1-9f1a-780e8863e0c7" />
When you keep the default precision (bfloat16), the results seem to be significantly worst. It may be related to higher noise in generation? Making the temperature vary might help to confirm this intuition. In the meantime, I've hard-coded float32 as model precision. It hurts a bit the speed (you've less space for KV cache) but it's still way faster than without vLLM.
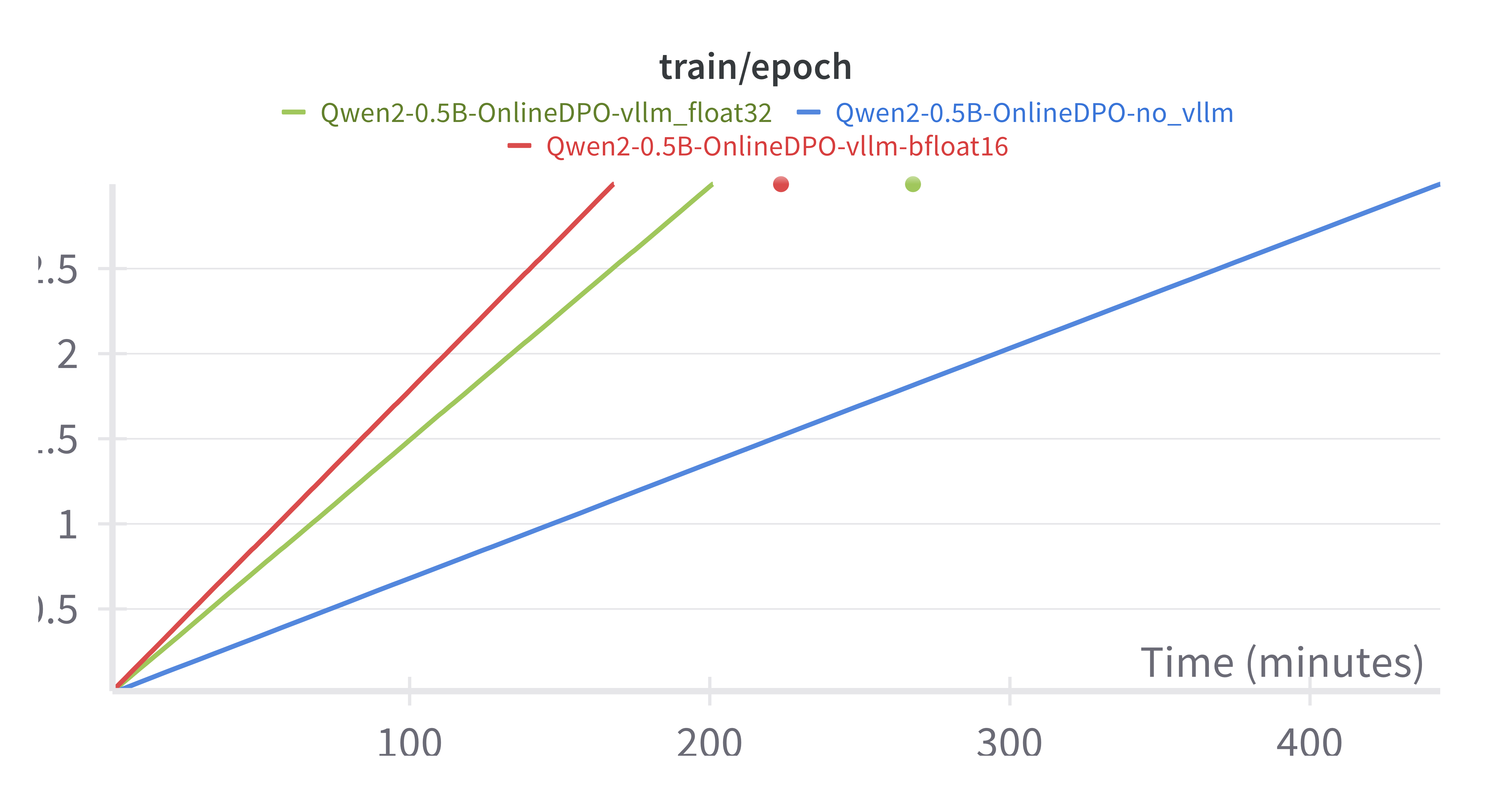
2.2x faster 🚀🚀 | 2,558 | 17 |
konrad-gerlach | 2025-01-10T16:02:23 | I would be very grateful for a review by:
@lvwerra
@vwxyzjn
@younesbelkada
@qgallouedec
or any others, that feel up to the task. | 2,556 | 18 |
konrad-gerlach | 2025-01-10T21:56:55 | I was unable to execute the pre-commit hook, so I manually ran the linter. | 2,556 | 19 |
qgallouedec | 2025-01-12T15:48:37 | Thanks for the PR!
Let's see what's the CI outputs. | 2,556 | 20 |
HuggingFaceDocBuilderDev | 2025-01-12T15:52:11 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2556). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,556 | 21 |
konrad-gerlach | 2025-01-12T18:46:43 | Just to be sure, as I'm unfamiliar with their implementation: The trl Trainers like PPO should not try to back propagate through the generated tokens, right? | 2,556 | 22 |
konrad-gerlach | 2025-01-12T19:59:57 | The CI failing for Python 3.9 seems unrelated to this PR. | 2,556 | 23 |
qgallouedec | 2025-01-12T20:49:07 | > The trl Trainers like PPO should not try to back propagate through the generated tokens, right?
Yes that's correct. The backprop is done on the output of a forward pass | 2,556 | 24 |
konrad-gerlach | 2025-01-12T21:21:55 | @qgallouedec Could you run the precommit to fix the linting issues? I haven't gotten it to work. | 2,556 | 25 |
konrad-gerlach | 2025-01-15T22:59:24 | I'm still working on adding some more tests and cleaning up the code a bit. | 2,556 | 26 |
Yukino256 | 2025-01-14T08:42:14 | same issue, and i tried the accelerate==0.34.2, ppo runs well. | 2,555 | 27 |
HuggingFaceDocBuilderDev | 2025-01-09T08:45:46 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2552). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,552 | 28 |
shirinyamani | 2025-01-09T22:23:27 | Hi, I have read the issue thread here and this PR, I agree that we can use `truncation_mode` in the `tokenize_row` function and I reviewed your addition. I wanted to also share my thoughts on it. so here the addition is if after truncating the prompt its still too long we can further truncate the response, and what if its not encode-decoder architecture?
```python
def tokenize_row(self, feature):
"""Tokenize a single row from the DPO specific dataset.
NOTE that this does not convert to tensors yet; rather just handles the truncation
in case the prompt + chosen or prompt + rejected responses is/are too long. It first
truncates the prompt; if we're still too long, we truncate the chosen/rejected.
"""
batch = {}
prompt = feature["prompt"]
chosen = feature["text_chosen"]
rejected = feature["text_rejected"]
#the current version says we typically add special tokens for encoder-decoder models but what if it's not enc-dec
if not self.is_encoder_decoder:
#check the input type first
if not isinstance(prompt, str):
raise ValueError(f"prompt should be in str form but got {type(prompt)}")
prompt_tokens = self.tokenizer(prompt, add_special_tokens=False)
prompt_tokens = {f"prompt_{k}": v for k, v in prompt_tokens.items()}
if not isinstance(chosen, str):
raise ValueError(f"chosen should be in str form but got {type(chosen)}")
chosen_tokens = self.build_tokenized_answer(prompt, chosen)
if not isinstance(rejected, str):
raise ValueError(f"rejected should be in str form but got {type(rejected)}")
rejected_tokens = self.build_tokenized_answer(prompt, rejected)
# add BOS token to head of prompt
prompt_tokens["prompt_input_ids"] = [self.tokenizer.bos_token_id] + prompt_tokens["prompt_input_ids"]
chosen_tokens["prompt_input_ids"] = [self.tokenizer.bos_token_id] + chosen_tokens["prompt_input_ids"]
rejected_tokens["prompt_input_ids"] = [self.tokenizer.bos_token_id] + rejected_tokens["prompt_input_ids"]
# add EOS token to end of answer
chosen_tokens["input_ids"].append(self.tokenizer.eos_token_id)
rejected_tokens["input_ids"].append(self.tokenizer.eos_token_id)
longer_response = max(len(chosen_tokens["input_ids"]), len(rejected_tokens["input_ids"]))
# if prompt+completion is too long, truncate the prompt
if len(prompt_tokens["prompt_input_ids"]) + longer_response > self.args.max_length:
if self.truncation_mode == "keep_start":
prompt_tokens["prompt_input_ids"] = prompt_tokens["prompt_input_ids"][: self.max_prompt_length]
elif self.truncation_mode == "keep_end":
prompt_tokens["prompt_input_ids"] = prompt_tokens["prompt_input_ids"][-self.max_prompt_length :]
else:
raise ValueError(f"Unknown truncation mode: {self.truncation_mode}")
# if that's still too long, truncate the response
for answer_tokens in [chosen_tokens, rejected_tokens]:
if len(answer_tokens["prompt_input_ids"]) + longer_response > self.args.max_length:
answer_tokens["input_ids"] = answer_tokens["input_ids"][: self.args.max_length - self.max_prompt_length]
return batch
```
Lemme know what you think, please. @qgallouedec @anakin87 | 2,551 | 29 |
qgallouedec | 2025-01-10T17:00:02 | Where does this version `tokenize_row` comes from @shirinyamani? It seems quite different from its current version in main.
> if after truncating the prompt its still too long
This is anyway handled here:
https://github.com/huggingface/trl/blob/edabe0a2d8fdd790319ce8862bb8e17336b85df1/trl/trainer/dpo_trainer.py#L1155-L1158 | 2,551 | 30 |
shirinyamani | 2025-01-10T17:14:54 | This version is what I came up with based on my research. And yes, it's getting handled where you mentioned but they are in two different functions; `concatenated_forward` and `tokenize_row`. I wanted to have all the relevant stuff to truncation/prompt/response all in one function which would be `tokenize_row` for simplicity and clarity purposes, but I agree it's gonna be a different version than what we have in the repo! @qgallouedec
> Where does this version `tokenize_row` comes from @shirinyamani? It seems quite different from its current version in main.
>
> > if after truncating the prompt its still too long
>
> This is anyway handled here:
>
> https://github.com/huggingface/trl/blob/edabe0a2d8fdd790319ce8862bb8e17336b85df1/trl/trainer/dpo_trainer.py#L1155-L1158
| 2,551 | 31 |
anakin87 | 2025-01-10T17:22:48 | @qgallouedec feel free to review the proposed fix | 2,551 | 32 |
qgallouedec | 2025-01-10T17:29:23 | > all in one function which would be `tokenize_row` for simplicity and clarity purposes
that makes sense. Can you open another pull request for this? Wait for this one to be merged though | 2,551 | 33 |
qgallouedec | 2025-01-10T17:34:49 | sorry @anakin87 I forgot to press the submit review button a couple of days ago.
Also, @shirinyamani came with an idea that could make more sense: truncate the [prompt+completion] (either left or right) instead of just the prompt. Something like
```python
# Truncate
if self.args.max_length is not None:
if self.args.truncation_mode == "keep_start":
input_ids = input_ids[:, : self.args.max_length]
attention_mask = attention_mask[:, : self.args.max_length]
loss_mask = loss_mask[:, : self.args.max_length]
elif self.args.truncation_mode == "keep_start":
input_ids = input_ids[:, -self.args.max_length:]
attention_mask = attention_mask[:, -self.args.max_length:]
loss_mask = loss_mask[:, -self.args.max_length:]
else:
raise ValueError
```
(Currently:
```python
# Truncate right
if self.args.max_length is not None:
input_ids = input_ids[:, : self.args.max_length]
attention_mask = attention_mask[:, : self.args.max_length]
loss_mask = loss_mask[:, : self.args.max_length]
```
)
What do you think?
| 2,551 | 34 |
HuggingFaceDocBuilderDev | 2025-01-08T18:24:42 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2550). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,550 | 35 |
qgallouedec | 2025-01-07T20:24:14 | Thanks! | 2,549 | 36 |
HuggingFaceDocBuilderDev | 2025-01-07T17:10:49 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2548). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,548 | 37 |
qgallouedec | 2025-01-07T17:34:53 | From their demo code, this is what I get as input for the model:
```
<|start_header_id|>user<|end_header_id|>
[CONTEXT]
<turn> user
Ellipsis
<turn> assistant
Ellipsis
<turn> user
Ellipsis
[RESPONSE A] BBBB [RESPONSE B] CCCC<|eot_id|>
```
doesn't make much sense to me:
- numerous unnecessary whitespaces
- Why `<|start_header_id|>user<|end_header_id|>`?
- Why responses aren't surrounded by `\n` as well?
- Why `<eot_id>` if you want to further generate?
Why not something like this instead:
```
[CONTEXT]
<turn> user
Ellipsis
<turn> assistant
Ellipsis
<turn> user
Ellipsis
[RESPONSE A]
BBBB
[RESPONSE B]
CCCC
[BEST REPONSE]
``` | 2,548 | 38 |
kashif | 2025-01-07T17:41:15 | you are using the instructions from here: https://huggingface.co/RLHFlow/pair-preference-model-LLaMA3-8B right? | 2,548 | 39 |
qgallouedec | 2025-01-07T17:42:24 |
> you are using the instructions from here: https://huggingface.co/RLHFlow/pair-preference-model-LLaMA3-8B right?
precisely
| 2,548 | 40 |
HuggingFaceDocBuilderDev | 2025-01-07T13:56:00 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2547). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,547 | 41 |
kashif | 2025-01-09T13:19:24 | thanks @okhat i can have a look and see how to fix it... just debugging currently | 2,545 | 42 |
okhat | 2025-01-11T22:10:41 | Awesome — thanks @kashif ! Looking forward to your findings! | 2,545 | 43 |
HuggingFaceDocBuilderDev | 2025-01-06T15:18:43 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2544). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,544 | 44 |
qgallouedec | 2025-01-06T14:17:24 | Both points sounds valid to me. For 1. I'd go for a warning in the doc (not in the function). Would you like to open a PR?
| 2,543 | 45 |
HuggingFaceDocBuilderDev | 2025-01-04T16:42:49 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2542). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,542 | 46 |
qgallouedec | 2025-01-04T18:42:36 | Fun feature! Do you have a demo repo? | 2,542 | 47 |
qgallouedec | 2025-01-04T18:44:19 | Have you tried with the HF api? It could be a free alternative | 2,542 | 48 |
August-murr | 2025-01-04T19:22:33 | > Fun feature! Do you have a demo repo?
Just pushed it to my [own fork](https://github.com/August-murr/trl/issues) | 2,542 | 49 |
qgallouedec | 2025-01-06T14:19:45 | I'll open a batch of issues to test it | 2,542 | 50 |
August-murr | 2025-01-06T17:59:38 | > Have you tried with the HF api? It could be a free alternative
Honestly, this was really effortless since I simply forked a mostly functional actions extension. Modifying it to work with the HF API will require much more effort. also it uses GPT-4o, there aren't many open-source models that are this accurate.
If it's absolutely necessary, then I can do it, but I honestly don't think it's worth the effort.
However, if you believe it is important, then I'll go ahead and do it. | 2,542 | 51 |
qgallouedec | 2025-01-06T19:05:17 | It doesn't seem like a big deal to me. Probably something like this could work
```python
from huggingface_hub import InferenceClient
client = InferenceClient(model="meta-llama/Llama-3.2-1B-Instruct", token="your_token")
content = "Find the label among these: question, issue."
completion = client.chat_completion(messages=[{"role": "user", "content": content}], max_tokens=256)
response = completion.choices[0].message.content
```
> there aren't many open-source models that are this accurate.
This task is very simple, I don't think we absolutely need GPT-4o here. And even if the labeled fail, it's not a big deal.
| 2,542 | 52 |
August-murr | 2025-01-06T19:37:15 | > It doesn't seem like a big deal to me. Probably something like this could work
>
> ```python
> from huggingface_hub import InferenceClient
>
> client = InferenceClient(model="meta-llama/Llama-3.2-1B-Instruct", token="your_token")
> content = "Find the label among these: question, issue."
> completion = client.chat_completion(messages=[{"role": "user", "content": content}], max_tokens=256)
> response = completion.choices[0].message.content
> ```
>
> > there aren't many open-source models that are this accurate.
>
> This task is very simple, I don't think we absolutely need GPT-4o here. And even if the labeled fail, it's not a big deal.
ok got it | 2,542 | 53 |
qgallouedec | 2025-01-06T20:24:34 | Do you know if you can access the tag description? It could help the model in its prediction | 2,542 | 54 |
August-murr | 2025-01-07T05:13:37 | > Do you know if you can access the tag description? It could help the model in its prediction
tag description as in the label description?
like:
`🚀 deepspeed` --> `Related to deepspeed`
If so, yes, it is part of the prompt. | 2,542 | 55 |
August-murr | 2025-01-07T07:14:14 | I tried using the Llama 1B model, and it "functioned," but for the TRL, I switched to the 70B model. However, I couldn't test it with the 70B because it requires a subscription.
Don't forget to add the `HF_API_KEY` to the secrets.
I got a context length error (limit of 4096 tokens) when using the Llama 1B model, which was weird since it supports up to 128k tokens. Since I can't use the 70B model, I'm unsure if it's a problem or not. | 2,542 | 56 |
August-murr | 2025-01-12T20:23:08 | > I got a context length error (limit of 4096 tokens) when using the Llama 1B model, which was weird since it supports up to 128k tokens. Since I can't use the 70B model, I'm unsure if it's a problem or not.
This can be problematic when dealing with issues that require a long context. The exact error message received was:
`Input validation error: inputs tokens + max_new_tokens must be <= 4096. Given: 9223 inputs tokens and 50 max_new_tokens`
I couldn't find a solution or parameter to set, possibly from the inference endpoint. | 2,542 | 57 |
qgallouedec | 2025-01-12T20:47:28 | A bit hacky but you can take the 15000 first strings. It should be enough for most issues:
```python
content = content[:15000]
``` | 2,542 | 58 |
August-murr | 2025-01-12T21:02:50 | > A bit hacky but you can take the 15000 first strings. It should be enough for most issues:
>
> ```python
> content = content[:15000]
> ```
more like 4000
But it works well. | 2,542 | 59 |
August-murr | 2025-01-04T06:17:04 | here's how to fix it:
`train_dataset = load_dataset('json', data_files=dataset_file_path, split="train") `
I suggest you get quick fixes for simpler issues simply by using ChatGPT or Copilot first as they can save you a lot of time!
| 2,541 | 60 |
degen2 | 2025-01-04T16:41:07 | I already tried that and still get the same KeyError. Even when loading a dataset from the hub. I also tried adding a ‚text‘ key field to the data. | 2,541 | 61 |
qgallouedec | 2025-01-04T19:09:33 | `split="train"` is the solution. If you still encounter the error please provide a MRE | 2,541 | 62 |
HuggingFaceDocBuilderDev | 2025-01-03T09:44:45 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2540). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,540 | 63 |
August-murr | 2025-01-09T13:10:24 | ### Question:
Does this theoretically work? I'm asking because I haven't read the PPO papers. When the PPO trainer is training, it outputs: `query`, `model_response`, and `score`, with the score being the tensor logits from the reward model. I have tested this branch and the changes, and it looks normal and functional.
For example, let's say the custom reward function is based on the count of a specific word, like "Good":
```python
def reward_function(texts):
rewards = [text.count("good") for text in texts]
return rewards
```
and the printed output is just the count of the word good in the text and it looks normal since it's in the same format.
But is there more to it? theoretically?
| 2,540 | 64 |
qgallouedec | 2025-01-09T13:28:07 | Can you add a test as well? | 2,540 | 65 |
August-murr | 2025-01-09T13:40:25 | > Can you add a test as well?
I'll take that as a yes.
Yes I will add the test and the docs later, maybe a blogpost or something to show how it works if I don't run out of resources. | 2,540 | 66 |
gp1702 | 2025-01-07T21:20:17 | I tried running the demo command without qlora, and got the following error:
``
Traceback (most recent call last):
File "/home/gandharvp_google_com/dpo/example.py", line 159, in <module>
main(script_args, training_args, model_args)
File "/home/gandharvp_google_com//dpo/example.py", line 134, in main
trainer.train()
File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2164, in train
return inner_training_loop(
File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2524, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs, num_items_in_batch)
File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 3687, in training_step
self.accelerator.backward(loss, **kwargs)
File "/opt/conda/envs/trl/lib/python3.10/site-packages/accelerate/accelerator.py", line 2248, in backward
loss.backward(**kwargs)
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/_tensor.py", line 492, in backward
torch.autograd.backward(
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/autograd/__init__.py", line 251, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1071, in unpack_hook
frame.recompute_fn(*args)
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1194, in recompute_fn
fn(*args, **kwargs)
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 623, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 544, in forward
attn_output = torch.nn.functional.scaled_dot_product_attention(
RuntimeError: The expanded size of the tensor (1460) must match the existing size (730) at non-singleton dimension 3. Target sizes: [4, 14, 730, 1460]. Tensor sizes: [4, 1, 730, 730]``
@faaany, I am wondering if you were able to replicate or fix this.
I am attaching the trainer code for reference.
[fsdp_dpo_trainer.txt](https://github.com/user-attachments/files/18338571/fsdp_dpo_trainer.txt)
| 2,539 | 67 |
faaany | 2025-01-08T09:06:36 | > Thanks a lot for the fix @faaany - overall it looks great!
>
> Would you mind confirming that the following demo command works with your PR (once activation checkpointing is removed):
>
> ```shell
> accelerate launch --config_file=examples/accelerate_configs/fsdp_qlora.yaml --num_processes=NUM_GPUS trl/scripts/dpo.py trl/scripts/dpo.py \
> --dataset_name trl-lib/ultrafeedback_binarized \
> --model_name_or_path Qwen/Qwen2-0.5B-Instruct \
> --learning_rate 5.0e-7 \
> --num_train_epochs 1 \
> --per_device_train_batch_size 2 \
> --gradient_accumulation_steps 8 \
> --gradient_checkpointing \
> --logging_steps 25 \
> --eval_strategy steps \
> --eval_steps 50 \
> --output_dir Qwen2-0.5B-DPO \
> --no_remove_unused_columns
> ```
>
> If it runs without error, can you please rename `fsdp_qlora.yaml` to `fsdp.yaml` so it runs for both modes?
>
> A question for @qgallouedec: should this helper function live in a `utils` module somewhere so we don't have to copy it around to all other trainers?
both mode work. | 2,539 | 68 |
faaany | 2025-01-08T09:12:16 | > I tried running the demo command without qlora, and got the following error: ` Traceback (most recent call last): File "/home/gandharvp_google_com/dpo/example.py", line 159, in <module> main(script_args, training_args, model_args) File "/home/gandharvp_google_com//dpo/example.py", line 134, in main trainer.train() File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2164, in train return inner_training_loop( File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2524, in _inner_training_loop tr_loss_step = self.training_step(model, inputs, num_items_in_batch) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 3687, in training_step self.accelerator.backward(loss, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/accelerate/accelerator.py", line 2248, in backward loss.backward(**kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/_tensor.py", line 492, in backward torch.autograd.backward( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/autograd/__init__.py", line 251, in backward Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1071, in unpack_hook frame.recompute_fn(*args) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1194, in recompute_fn fn(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 623, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 544, in forward attn_output = torch.nn.functional.scaled_dot_product_attention( RuntimeError: The expanded size of the tensor (1460) must match the existing size (730) at non-singleton dimension 3. Target sizes: [4, 14, 730, 1460]. Tensor sizes: [4, 1, 730, 730]`
>
> @faaany, I am wondering if you were able to replicate or fix this.
>
> I am attaching the trainer code for reference. [fsdp_dpo_trainer.txt](https://github.com/user-attachments/files/18338571/fsdp_dpo_trainer.txt)
does it work in other distributed mode, e.g. deepspeed? | 2,539 | 69 |
qgallouedec | 2025-01-08T13:29:50 | > should this helper function live in a utils module somewhere so we don't have to copy it around to all other trainers?
I think it would make sense to have it in `trainer/utils.py` yes. | 2,539 | 70 |
gp1702 | 2025-01-08T15:08:08 | > > I tried running the demo command without qlora, and got the following error: ` Traceback (most recent call last): File "/home/gandharvp_google_com/dpo/example.py", line 159, in <module> main(script_args, training_args, model_args) File "/home/gandharvp_google_com//dpo/example.py", line 134, in main trainer.train() File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2164, in train return inner_training_loop( File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2524, in _inner_training_loop tr_loss_step = self.training_step(model, inputs, num_items_in_batch) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 3687, in training_step self.accelerator.backward(loss, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/accelerate/accelerator.py", line 2248, in backward loss.backward(**kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/_tensor.py", line 492, in backward torch.autograd.backward( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/autograd/__init__.py", line 251, in backward Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1071, in unpack_hook frame.recompute_fn(*args) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1194, in recompute_fn fn(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 623, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 544, in forward attn_output = torch.nn.functional.scaled_dot_product_attention( RuntimeError: The expanded size of the tensor (1460) must match the existing size (730) at non-singleton dimension 3. Target sizes: [4, 14, 730, 1460]. Tensor sizes: [4, 1, 730, 730]`
> > @faaany, I am wondering if you were able to replicate or fix this.
> > I am attaching the trainer code for reference. [fsdp_dpo_trainer.txt](https://github.com/user-attachments/files/18338571/fsdp_dpo_trainer.txt)
>
> does it work in other distributed mode, e.g. deepspeed?
I have not tried other modes, but I am observing this problem for fsdp. | 2,539 | 71 |
faaany | 2025-01-09T04:57:46 | > > > I tried running the demo command without qlora, and got the following error: ` Traceback (most recent call last): File "/home/gandharvp_google_com/dpo/example.py", line 159, in <module> main(script_args, training_args, model_args) File "/home/gandharvp_google_com//dpo/example.py", line 134, in main trainer.train() File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2164, in train return inner_training_loop( File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2524, in _inner_training_loop tr_loss_step = self.training_step(model, inputs, num_items_in_batch) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 3687, in training_step self.accelerator.backward(loss, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/accelerate/accelerator.py", line 2248, in backward loss.backward(**kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/_tensor.py", line 492, in backward torch.autograd.backward( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/autograd/__init__.py", line 251, in backward Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1071, in unpack_hook frame.recompute_fn(*args) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1194, in recompute_fn fn(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 623, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 544, in forward attn_output = torch.nn.functional.scaled_dot_product_attention( RuntimeError: The expanded size of the tensor (1460) must match the existing size (730) at non-singleton dimension 3. Target sizes: [4, 14, 730, 1460]. Tensor sizes: [4, 1, 730, 730]`
> > > @faaany, I am wondering if you were able to replicate or fix this.
> > > I am attaching the trainer code for reference. [fsdp_dpo_trainer.txt](https://github.com/user-attachments/files/18338571/fsdp_dpo_trainer.txt)
> >
> >
> > does it work in other distributed mode, e.g. deepspeed?
>
> I have not tried other modes, but I am observing this problem for fsdp.
I can't reproduce your issue. But from my experience, this is likely not related to FSDP, but your environment set-up. I am using transformers==4.47.1 and accelerate==1.2.1. Could you try a different transformer's version just like this [post](https://github.com/mit-han-lab/llm-awq/issues/154) says? | 2,539 | 72 |
faaany | 2025-01-09T05:05:58 | @qgallouedec @lewtun how about deepspeed? should we use the `prepare_deepspeed` function from `trainer/utils.py` in `dpo_trainer.py` as well?
| 2,539 | 73 |
gp1702 | 2025-01-10T06:03:21 | > > > > I tried running the demo command without qlora, and got the following error: ` Traceback (most recent call last): File "/home/gandharvp_google_com/dpo/example.py", line 159, in <module> main(script_args, training_args, model_args) File "/home/gandharvp_google_com//dpo/example.py", line 134, in main trainer.train() File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2164, in train return inner_training_loop( File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2524, in _inner_training_loop tr_loss_step = self.training_step(model, inputs, num_items_in_batch) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 3687, in training_step self.accelerator.backward(loss, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/accelerate/accelerator.py", line 2248, in backward loss.backward(**kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/_tensor.py", line 492, in backward torch.autograd.backward( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/autograd/__init__.py", line 251, in backward Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1071, in unpack_hook frame.recompute_fn(*args) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1194, in recompute_fn fn(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 623, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 544, in forward attn_output = torch.nn.functional.scaled_dot_product_attention( RuntimeError: The expanded size of the tensor (1460) must match the existing size (730) at non-singleton dimension 3. Target sizes: [4, 14, 730, 1460]. Tensor sizes: [4, 1, 730, 730]`
> > > > @faaany, I am wondering if you were able to replicate or fix this.
> > > > I am attaching the trainer code for reference. [fsdp_dpo_trainer.txt](https://github.com/user-attachments/files/18338571/fsdp_dpo_trainer.txt)
> > >
> > >
> > > does it work in other distributed mode, e.g. deepspeed?
> >
> >
> > I have not tried other modes, but I am observing this problem for fsdp.
>
> I can't reproduce your issue. But from my experience, this is likely not related to FSDP, but your environment set-up. I am using transformers==4.47.1 and accelerate==1.2.1. Could you try a different transformer's version just like this [post](https://github.com/mit-han-lab/llm-awq/issues/154) says?
@faaany: My version of transformers and accelerate is same as yours . What version of torch are you using ? | 2,539 | 74 |
faaany | 2025-01-10T09:02:39 | > > > > > I tried running the demo command without qlora, and got the following error: ` Traceback (most recent call last): File "/home/gandharvp_google_com/dpo/example.py", line 159, in <module> main(script_args, training_args, model_args) File "/home/gandharvp_google_com//dpo/example.py", line 134, in main trainer.train() File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2164, in train return inner_training_loop( File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 2524, in _inner_training_loop tr_loss_step = self.training_step(model, inputs, num_items_in_batch) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/trainer.py", line 3687, in training_step self.accelerator.backward(loss, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/accelerate/accelerator.py", line 2248, in backward loss.backward(**kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/_tensor.py", line 492, in backward torch.autograd.backward( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/autograd/__init__.py", line 251, in backward Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1071, in unpack_hook frame.recompute_fn(*args) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py", line 1194, in recompute_fn fn(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 623, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/home/gandharvp_google_com/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/trl/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 544, in forward attn_output = torch.nn.functional.scaled_dot_product_attention( RuntimeError: The expanded size of the tensor (1460) must match the existing size (730) at non-singleton dimension 3. Target sizes: [4, 14, 730, 1460]. Tensor sizes: [4, 1, 730, 730]`
> > > > > @faaany, I am wondering if you were able to replicate or fix this.
> > > > > I am attaching the trainer code for reference. [fsdp_dpo_trainer.txt](https://github.com/user-attachments/files/18338571/fsdp_dpo_trainer.txt)
> > > >
> > > >
> > > > does it work in other distributed mode, e.g. deepspeed?
> > >
> > >
> > > I have not tried other modes, but I am observing this problem for fsdp.
> >
> >
> > I can't reproduce your issue. But from my experience, this is likely not related to FSDP, but your environment set-up. I am using transformers==4.47.1 and accelerate==1.2.1. Could you try a different transformer's version just like this [post](https://github.com/mit-han-lab/llm-awq/issues/154) says?
>
> @faaany: My version of transformers and accelerate is same as yours . What version of torch are you using ?
I am using torch 2.5.1+cu121. | 2,539 | 75 |
qgallouedec | 2025-01-08T09:42:39 | That's a good point!
In the past, truncation mode was only used for the prompt, and it seems that completion was only truncated for the encoder-decoder. This has been corrected with #2209. In any case, this is a good opportunity to bring this issue up again.
- Should `truncation_mode` apply to prompt truncation?
- Should `truncation_mode` apply to completion truncation?
Without having thought about it in detail, I'd say `truncation_mode` should only apply to prompt truncation, but I'm curious what you think. | 2,538 | 76 |
anakin87 | 2025-01-08T10:07:32 | Ah, I'm not an expert, unfortunately.
However, I took a cursory look, and it seems that `truncation_mode` is applied to the prompt in the following trainers: BCO, CPO, KTO, and ORPO.
In the Iterative SFT Trainer, it is implemented somewhat differently.
For consistency, it might make sense to align DPO with the other Preference Optimization trainers and apply `truncation_mode` to the prompt in the same way. | 2,538 | 77 |
qgallouedec | 2025-01-08T10:21:45 | Ok so we are aligned on this.
It would probably only require the following line change:
```python
if max_prompt_length is not None:
if truncation_mode == "keep_end":
prompt_input_ids = prompt_input_ids[:max_prompt_length]
elif truncation_mode == "keep_start":
prompt_input_ids = prompt_input_ids[-max_prompt_length:]
else:
raise ValueError(f"Unknown truncation_mode: {truncation_mode}")
```
Are you willing to open a PR to fix it? | 2,538 | 78 |
anakin87 | 2025-01-08T10:23:51 | I would be happy to open a PR in the next few days! | 2,538 | 79 |
qgallouedec | 2025-01-08T09:47:31 | It's not very clear what code you're using. Because you seem to be using a command (`swift rlhf`) that I'm not familiar with and code that you provide doesn't take any arguments.
Plus, the system info that you provide aren't enough (I don't see the trl version among other). Can you copy-paste the output of `trl env`?
What is `map_instruction`? What model are you using? Qwen2 doesn't have a 32B version. Is it Qwen2.5?
Currently It's very hard for me to reproduce it. | 2,536 | 80 |
maoulee | 2025-01-08T10:34:17 | > It's not very clear what code you're using. Because you seem to be using a command (`swift rlhf`) that I'm not familiar with and code that you provide doesn't take any arguments. Plus, the system info that you provide aren't enough (I don't see the trl version among other). Can you copy-paste the output of `trl env`? What is `map_instruction`? What model are you using? Qwen2 doesn't have a 32B version. Is it Qwen2.5? Currently It's very hard for me to reproduce it.
Here is the trl env info:
- Platform: Linux-5.15.0-60-generic-x86_64-with-glibc2.31
- Python version: 3.10.14
- PyTorch version: 2.4.1
- CUDA device(s): NVIDIA A100-SXM4-40GB, NVIDIA A100-SXM4-40GB
- Transformers version: 4.47.1
- Accelerate version: 1.2.1
- Accelerate config: not found
- Datasets version: 3.0.1
- HF Hub version: 0.25.1
- TRL version: 0.13.0
- bitsandbytes version: 0.45.0
- DeepSpeed version: 0.15.4
- Diffusers version: not installed
- Liger-Kernel version: not installed
- LLM-Blender version: not installed
- OpenAI version: 1.50.2
- PEFT version: 0.13.2
To print trl env:
I upgrade:
TRL 0.11.4-> 0.13.0 for
transformers: 4.45.2->4.47.1
tokenizers: 0.20.3->0.20.1
The map_instruction function is used to map the dataset.
Here is the used model and dataset:
model: unsloth/Qwen2.5-32B-Instruct-bnb-4bit
dataset: llamafactory/ultrafeedback_binarized
Here is the complete code:
import torch
import os
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
GenerationConfig,
BitsAndBytesConfig
)
from trl import (
LogCompletionsCallback,
ModelConfig,
DPOConfig,
DPOTrainer,
TrlParser,
get_peft_config,
)
from peft import LoraConfig,get_peft_model,prepare_model_for_kbit_training
import data
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
from dataclasses import dataclass, field
from typing import Optional, List, Dict
from datasets import load_dataset
os.environ["WANDB_DISABLED"]="true"
def map_instruction(example):
instruction = example['instruction']
return {'prompt': instruction}
def main():
train_dataset = load_dataset("/root/.cache/modelscope/hub/datasets/llamafactory___ultrafeedback_binarized/", split="train")
train_dataset = train_dataset.shuffle(seed=42)
train_dataset = train_dataset.select(range(2000))
train_dataset=train_dataset.map(map_instruction)
test_dataset=load_dataset("/root/.cache/modelscope/hub/datasets/llamafactory___ultrafeedback_binarized/", split="test")
test_dataset = test_dataset.shuffle(seed=42)
test_dataset = test_dataset.select(range(200))
test_dataset=test_dataset.map(map_instruction)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path="/root/.cache/modelscope/hub/unsloth/Qwen2___5-32B-Instruct-bnb-4bit/",
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
use_cache= True,
device_map="auto",
)
model=prepare_model_for_kbit_training(model)
#model.gradient_checkpointing_enable()
peft_config = LoraConfig(
r=4,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
tokenizer=AutoTokenizer.from_pretrained("/root/.cache/modelscope/hub/unsloth/Qwen2___5-32B-Instruct-bnb-4bit/")
EOS_TOKEN = tokenizer.eos_token
# Tokenizer settings
if tokenizer.chat_template is None:
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
training_args = DPOConfig(
output_dir="/llm/checkpoint/", # Output directory for checkpoints and final model
per_device_train_batch_size=2, # Batch size per device during training
gradient_accumulation_steps=8, # Number of gradient accumulation steps
num_train_epochs=4, # Total number of training epochs
learning_rate=5e-7, # Learning rate
logging_dir="./logs", # Directory for storing logs
logging_steps=500, # Log every X updates steps
save_steps=500, # Save checkpoint every X updates steps
eval_strategy="no", # Evaluation is done (and logged) every `eval_steps`
beta=0.1, # The beta parameter for DPO loss
loss_type="sigmoid",
optim = "adamw_torch",
lr_scheduler_type="cosine",
max_prompt_length=500,
max_target_length=1500,
)
model.enable_input_require_grads()
trainer=DPOTrainer(
model=model,
args=training_args,
peft_config=peft_config,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer
)
# Configure generation for evaluation
if training_args.eval_strategy != "no":
generation_config = GenerationConfig(
max_new_tokens=2048,
do_sample=True,
temperature=1.0
)
completions_callback = LogCompletionsCallback(trainer, generation_config, num_prompts=8)
trainer.add_callback(completions_callback)
# Train the model
trainer.train()
# Save the final model
final_model_path = training_args.output_dir
trainer.save_model(final_model_path)
print(f"Final model saved to {final_model_path}")
if __name__ == "__main__":
main()
| 2,536 | 81 |
qgallouedec | 2025-01-08T13:24:24 | I was able to reproduce the speed. I don't know how swift is different form trl (it's built upon trl as far as I understand). You should probably ask swift community here | 2,536 | 82 |
maoulee | 2025-01-08T14:12:57 |
> I was able to reproduce the speed. I don't know how swift is different form trl (it's built upon trl as far as I understand). You should probably ask swift community here
Thank you for your response. I have identified the key issue:
When I load the model and pass the peft_config directly into DPOTrainer, the fine-tuning speed is 600 seconds per iteration.
However, when I use model = get_peft_model(model, peft_config) before passing it to the trainer, the fine-tuning speed improves significantly to 30.2 seconds per iteration.
The logic of the two seems to be the same, but the speed difference is large.
| 2,536 | 83 |
qgallouedec | 2025-01-08T14:16:30 | It's probably because when you pass a peft model, it gets merged and unload (`merge_and_unload`). Those two settings should be equivalent though. It's probably an issue with the `DPOTrainer`. If you manage to fix it, feel free to open a PR | 2,536 | 84 |
qgallouedec | 2025-01-08T13:46:15 | In general we are open to any contribution yes. The easiest way is to open an issue per proposal to keep the discussion sperate and clear. But I'll answer everything here.
> Use SGLang to do rollout (generation) phase instead of vanilla HuggingFace model / DeepSpeed model. This seems to speed up generation a lot.
How much is a lot? I'm not familiar with SGLang, but what I can gather from the doc is that SGLang is whole serving framework, but we're just interested in the _Fast Backend Runtime_ here.
From the doc:
> Fast Backend Runtime: Provides efficient serving with RadixAttention for prefix caching, jump-forward constrained decoding, overhead-free CPU scheduler, continuous batching, token attention (paged attention), tensor parallelism, FlashInfer kernels, chunked prefill, and quantization (FP8/INT4/AWQ/GPTQ).
It would be interesting to know which component makes inference faster and consider adding just it.
> Delete ref & reward model from GPU when they are not used, such that gpu memory is not occupied, and can support larger batch size or larger models.
> For refactor/cleanup, just standard tiny things like:
For refactoring, RLOO and PPO differ quite a lot from other trainer in the way they are implementing. It make the maintenance pretty challenging. So if someone have time to dedicate on refactoring, I'd either recommend working on aligning with other trainers.
> In addition, I would appreciate it if I could know some comparisons between TRL and OpenRLHF/verl/DeepSpeed-Chat.
What do you want to compare? Have you led such comparison?
| 2,535 | 85 |
fzyzcjy | 2025-01-09T00:14:22 | Hi thanks for the reply!
> The easiest way is to open an issue per proposal to keep the discussion sperate and clear.
Ok I will try to do that in the future issues.
> How much is a lot?
https://github.com/huggingface/trl/pull/1628 says "... preliminary testing shows it's ~8x faster" for vllm. I personally find sglang >1.5x faster than vllm in my personal case (but other GPU and model can be surely different). So I expect sglang to be around >8x faster than vanilla generate for my case, and at least ~8x for general case.
> SGLang is whole serving framework, but we're just interested in the Fast Backend Runtime here
Maybe just take the part that inputs a string and outputs a string (called "Engine" in sglang, and "LLM" in vllm)
> For refactoring, RLOO and PPO differ quite a lot from other trainer in the way they are implementing. It make the maintenance pretty challenging. So if someone have time to dedicate on refactoring, I'd either recommend working on aligning with other trainers.
Thanks, but it seems that the primary difference is the advantage estimation, and other parts does not have a lot of differences.
> What do you want to compare? Have you led such comparison?
Yes I have compared (and also asked other libraries the same question and got some replies). I just want to know your opinions, because I definitely knows less about trl than you who create and maintain it! | 2,535 | 86 |
faaany | 2025-01-03T02:37:30 | @qgallouedec @lewtun @yao-matrix | 2,533 | 87 |
qgallouedec | 2025-01-07T20:28:08 | Can you confirm that these changes are enough for XPU backends? I'm not able to test it? | 2,533 | 88 |
HuggingFaceDocBuilderDev | 2025-01-07T20:32:06 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2533). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,533 | 89 |
faaany | 2025-01-08T02:17:49 | Thanks for the suggestions! Code Updated. @qgallouedec | 2,533 | 90 |
yiyepiaoling0715 | 2024-12-30T08:03:56 | 
| 2,532 | 91 |
qgallouedec | 2024-12-30T14:49:29 | > * [x] Any code provided is minimal, complete, and reproducible ([more on MREs](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks))
can you please minimise your code? It seems like the error occurs at generation; what the input of the model here?:
```
| | 2024-12-30 10:53:44.559 | [rank4]: File "/opt/conda/lib/python3.11/site-packages/transformers/generation/utils.py", line 3254, in _sample |
| | 2024-12-30 10:53:44.559 | [rank4]: outputs = model_forward(**model_inputs, return_dict=True) |
```
Can you reproduce the error without all the training logic? | 2,532 | 92 |
HuggingFaceDocBuilderDev | 2025-01-08T14:05:59 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2531). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,531 | 93 |
dawidm | 2025-01-08T19:53:54 | Update: I've incorrectly stated that "step, which is now equivalent of episodes". Actually, steps are equivalent to iterations of the main training loop. But the fix is still valid. | 2,531 | 94 |
yiyepiaoling0715 | 2024-12-30T04:55:00 | same question,how to resolve thie? | 2,529 | 95 |
qgallouedec | 2025-01-08T14:22:46 | The solution that you're suggesting sounds good to me, feel free to open a PR | 2,529 | 96 |
HuggingFaceDocBuilderDev | 2024-12-28T13:27:00 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/trl/pr_2527). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. | 2,527 | 97 |
qgallouedec | 2025-01-08T14:33:24 | Can you tell me again why it's needed? | 2,527 | 98 |
kashif | 2025-01-08T14:34:41 | i was mistaken... in orpo the nll loss is over the prompt + completion | 2,527 | 99 |