
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
---
title: "Apache Asia Roadshow 2010归来"
wordpress_id: 1111
wordpress_url: http://www.wsria.com/?p=1111
date: 2010-08-15 00:06:37 +08:00
tags:
- apache
---
<h2>一、什么是Apache Roadshow?</h2>
是Apache基金会组织的一次以开源为主题的巡演。
<strong>参考日程</strong>:<a href="http://roadshowasia.52ac.com/openconf.php">http://roadshowasia.52ac.com/openconf.php</a>
<h2>二、我的日程</h2>
昨晚和群里面的dd(Tux)联系好了,互相留了电话号码;
早上7:30就起床(和上班一样),然后11路环保公交再换乘两次地铁终于冒着40°桑拿天于9:03到达会场——复旦大学行政楼;去年也曾去过一次复旦只不过是在新闻学院参加Wordpress举办的WordCamp,还认识了朋友<a href="http://whatmakeshua.com" target="_blank">皮蛋</a>和<a href="http://shawphy.com/" target="_blank">小飞</a>。
到了学院门口和dd(Tux)通了电话,这小子已经到了……然后到了一楼大厅看到已经来了不少人,都是20多岁的年轻人……
先来一张本次路演的牌子:
<a href="http://www.kafeitu.me/files/2010/08/Apache-Roadshow-2010-1.png"><img class="size-medium wp-image-1113 " title="Apache Roadshow 2010-1" src="http://www.kafeitu.me/files/2010/08/Apache-Roadshow-2010-1-261x300.png" alt="Apache Roadshow 201 LOGO" width="261" height="300" /></a>
<p style="text-align: center;"></p>
<a href="http://www.kafeitu.me/files/2010/08/Apache-Roadshow-2010-me.png"><img class="size-medium wp-image-1114" title="Apache Roadshow 2010-me" src="http://www.kafeitu.me/files/2010/08/Apache-Roadshow-2010-me-267x300.png" alt="我在Apache Roadshow 2010会场" width="267" height="300" /></a>
随后去报到、注册,这里面还有一个小插曲,本来是没有注册的人没有T恤、饭票的,但是有一个购书可以立即注册的机会,在大厅有几个童鞋负责卖书(真会找商机),看到《开源软件之道》这本书就有了想买的欲望,大致看了一下内容还可以就花了30大洋拿下这本书……买了书人家告诉俺说你可以注册了,也就是可以领取T恤和饭票了,我想还不错……30元买一本书、一件T恤外加一顿午餐……呵呵,言归正传
此行的目的我最关注的当然是<a href="http://www.juvenxu.com/" target="_blank">Juven</a>关于Maven的演讲也趁次机会瞅瞅传说中的群主,其次是关于企业RIA的介绍和Java的未来发展
<!--more-->
上午10:00准时开始本次巡演,首先由Apache基金会的J Aaron Farr介绍Apache开源之道,这里有一个惊喜,本人E文烂反正不好……勉强看懂英文文档……让我意想不到的是J Aaron Farr的中文竟然说的比较流利虽然有一些词语要用英文,但是已经是天上掉馅饼的事情了……J Aaron Farr说他一直在香港,好像有3年了吧
<a href="http://www.kafeitu.me/files/2010/08/apache-way-1.png"><img class="size-medium wp-image-1116" title="apache way-1" src="http://www.kafeitu.me/files/2010/08/apache-way-1-300x135.png" alt="J Aaron Farr简述The Apache Way" width="300" height="135" /></a>
<a href="http://www.kafeitu.me/files/2010/08/apache-way-2.png"><img class="size-medium wp-image-1117" title="apache way-2" src="http://www.kafeitu.me/files/2010/08/apache-way-2-300x223.png" alt="apache way-2" width="300" height="223" /></a>
之后就是上海市软件行业协会开源软件专业委员会一个XX博士倡议上海的高校高开源项目,最后是:Jason Gartner: Open Source and Business和Tim Ellison: Open Source Java and its Future
*******************************午饭时间*******************************
复旦餐厅做的牛排不错……哈哈
<h2>三、Juven关于Maven的演讲</h2>
听Juven演讲Maven是此行的主要目的,中午和dd一起吃完饭后去了演讲的教室……哎怀念老师讲课我睡觉的日子了
在上午的环节结束的时候和Juven认识了一下(和他握手肉感十足)
很认真的听了Juven的Maven演讲,但是由于时间不足(只有45分钟演讲和10分钟的讨论时间)讲的东西不多,都是概念性的东西,不过在这种场合也不适合讲解一下实际的东东……主要是介绍Apache的开源项目,Maven作为活跃度前三名的一个项目当然少不了
演讲期间我用相机录制了视频,不过由于本人的相机本身不是很好再加上没有摄影底子导致快门高了所以视频有些模糊,不过可以等Juven把PPT上传了对照一下……嘿嘿
如果需要视频的话可以回复本文留下Email地址,我会把视频发送到你的邮箱,附件存放在QQ中转站,不过有效期我会在失效前续期。
培训完了之后和Juven的合影,本人长的蟋蟀,别K俺:
<a href="http://www.kafeitu.me/files/2010/08/me-and-juven.png"><img class="size-medium wp-image-1122" title="me and juven" src="http://www.kafeitu.me/files/2010/08/me-and-juven-263x300.png" alt="me and juven" width="263" height="300" /></a>
<h2>四、其他演讲</h2>
听完了Juven的Maven演讲又去听了IBM的Wei Huang讲的:Enterprise Open RIA Solution - Introduction to Dojo Advanced Features,和Jing Lv讲的:Towards new world of Java - JDK7 features and Harmony Select
Dojo这个东西在刚刚接触Ajax的时候研究了一些,但是由于业界说Dojo的速度慢和当时对于Dojo的侵入性原因放弃了,所以后来开始了Ajax框架的使用,从Prototype到现在的jQuery
关于<em>JDK7 features and Harmony的演讲:</em>关于<a href="http://harmony.apache.org/" target="_blank">Harmony</a>我是第一次听到,同样也是Apache的一个开源项目,只不过这次是一个开源的JDK……抢了SUN的活所以一直未能拿到SUN(如今的Oracle)的License,严格来说这个真的不能算是演讲,介绍了一点点JDK7的新特性后就是开始为Harmony打广告了……但是结果是很多人都不敢使用,原因很简单,如下:
<ol>
<li>迁移后万一和SUN的JDK不兼容怎么办?</li>
<li>更新速度落后于SUN的JDK</li>
<li>性能方面是否能和SUN保持平衡或者超越,要不然没有理由让我们迁移</li>
<li>支持Harmony的企业毕竟不多,所以底子还太薄,虽然像Google的Andriod、IBM等公司使用了一些Harmony的功能但是那只是借鉴或者是抽取,并不能代表他们就支持……</li>
</ol>
所以综合来说目前还是不可能转移。
<h2>五、总结</h2>
感谢Apache和上海软件开源协会组织的这次路演让技术人员有了一个小范围的交流与分享平台,同样也在本次路演中认识了几个在业界的朋友,也见到了Maven群主Juven大仙。
不过想这样的演讲都是纯概念性的东西,如果只想了解一下或许符合你的胃口,希望以后能有专项的技术交流,比如Apache的个个子项目的应用或者企业中一些公共性的问题。
更多关于本次路演的照片请访问我的Picasa相册:<a href="http://picasaweb.google.com/yanhonglei/ApacheAsiaRoadshow2010">http://picasaweb.google.com/yanhonglei/ApacheAsiaRoadshow2010</a> | 4,358 | MIT |
# xzh-curl
:panda_face:针对百度熊掌号新接口请求封装(号主页展现、春笋计划优站扶持)
熊掌号项目已凉,号主页站点资讯存量内容会展示在更多tab下,新提交的不再进入
小时、天级、周级收录都还在,之前获得的权益也都保留,功能都在资源平台-移动专区
## 文件说明
`xzhome.php` 为号主页展现接口
`newgood.php` 为春笋计划优站扶持接口
使用前请确保你有对应的资格,没有提交了也没用 😜
## 使用方式
1、获取对应需要的文件,放到网站的可执行目录中
2、补全对应的参数
`$secret` 自定义验证需要的参数,防止接口泄露所用,注意保密
以下配置信息见:[https://ziyuan.baidu.com/xzh/home/index](https://ziyuan.baidu.com/xzh/home/index)
`$appid` 您的熊掌号唯一识别ID
`token` 在搜索资源平台申请的推送用的准入密钥
3、请求方式和传参
请求方式未作限制,`Get`和`Post`都可以
传参的问题说一下,参数顺序无所谓,具体如下:
* 号主页展现接口
```php
Get:xzhome.php?secret=test&url=https://qq52o.me/2530.html
Post:xzhome.php
url = https://qq52o.me/2530.html
secret = test
```
* 春笋计划优站扶持
```php
Get:newgood.php?url[]=https://qq52o.me/2530.html&url[]=https://qq52o.me/2529.html&secret=test
Post:newgood.php
url[] = https://qq52o.me/2530.html
url[] = https://qq52o.me/2529.html
secret = test
```
## 注意
确保网站进行了页面改造,并有如下`JSON-LD`代码
```javascript
<script type="application/ld+json">
{
"@context": "https://ziyuan.baidu.com/contexts/cambrian.jsonld",
"@id": "https://www.example.com/******",
"appid": "1583219371373511",
"title": "页面标题******",
"images": [
"https://www.example.com/***/pic1.png",
"https://www.example.com/***/pic2.png",
"https://www.example.com/***/pic3.png"
], //请在此处添加希望在搜索结果中展示图片的url,可以添加0个、1个或3个url
"pubDate": "2017-06-15T08:00:01" // 需按照yyyy-mm-ddThh:mm:ss格式编写时间,字母T不能省去
}
</script>
```
## 开源协议
[Apache-2.0](https://github.com/sy-records/xzh-curl/blob/master/LICENSE) | 1,622 | Apache-2.0 |
# MLCKit
MLCKit封装一些常用的iOS方法。
分成Cache、Category、Color、Document、Font、LocalFolder、Location、Macro、Photos、Proxy、Scan、TableView、UI、Utility等子pods。
Swift版本是[LCSKit](https://github.com/mlcldh/LCSKit),功能基本相同。
## Cache
缓存管理类,基于YYCache。
提供了两个单例分别保存在Documents、Library文件夹,另外提供实例来设置自定义路径。
支持对缓存数据的同步/异步读取、设置。
```objective-c
/**单例,存放在Documents文件夹内,app设置里面清理缓存不可以删除的缓存*/
+ (instancetype)coreCache;
/**单例,存放在Library文件夹内,app设置里面清理缓存可以删除的缓存*/
+ (instancetype)simpleCache;
/**非单例,普通实例,自定义缓存路径,当path路径和coreCache、simpleCache重复时,返回nil*/
+ (instancetype)cacheWithPath:(NSString *)path;
```
`pod 'MLCKit/Cache'`
## Category
Category里面是常用类目,有URL编解码、UIView的点击回调、UIControl的点击block回调等。
### NSObject
使用归档、反归档进行序列化、反序列化的话,可以下面的方法:
```objective-c
@interface NSObject (MLCKit)
/**反序列化*/
- (void)mlc_setValuesWithCoder:(NSCoder *)aDecoder;
/**序列化*/
- (void)mlc_encodeWithCoder:(NSCoder *)aCoder;
/**转换成json字符串*/
- (NSString *)mlc_JSONString;
@end
```
### NSArray
```objective-c
@interface NSArray (MLCKit)
/**将数组的view根据先后顺序,根据相同间距连接起来*/
- (void)mlc_combineViewsWithAxis:(UILayoutConstraintAxis)axis withFixedSpacing:(CGFloat)fixedSpacing;
/**将数组的view根据先后顺序,根据数组fixedSpacings的间距连接起来*/
- (void)mlc_combineViewsWithAxis:(UILayoutConstraintAxis)axis withFixedSpacings:(NSArray <NSNumber *>*)fixedSpacings;
/**将数组的view根据先后顺序,数组的view的中心位置等间距*/
- (void)mlc_distributeViewsEqualCenterSpacingWithAxis:(UILayoutConstraintAxis)axis leadCenterSpacing:(CGFloat)leadCenterSpacing tailCenterSpacing:(CGFloat)tailCenterSpacing;
@end
```
### NSDate
```objective-c
@interface NSDate (MLCKit)
/**当前日期在当前日历的年*/
- (NSInteger)mlc_year;
/**当前日期在当前日历的月*/
- (NSInteger)mlc_month;
/**当前日期在当前日历的日*/
- (NSInteger)mlc_day;
/**当前日期在当前日历的组成成份,成份有年、月、日、时、分、秒、星期等等*/
- (NSDateComponents *)mlc_components:(NSCalendarUnit)unitFlags;
/**当前日期在农立的组成成份,成份有年、月、日、时、分、秒、星期等等*/
- (NSDateComponents *)mlc_chineseComponents:(NSCalendarUnit)unitFlags;
/**是否是今天*/
- (BOOL)mlc_isToday;
/**是否是昨天*/
- (BOOL)mlc_isYesterday;
/**和日期date是否是同一年*/
- (BOOL)mlc_isSameYearWithDate:(NSDate *)date;
/**当前日期的基础上,增加天数,天数可以是负数*/
- (NSDate *)mlc_dateByAddingDays:(NSInteger)days;
/**当前日期的基础上,增加月数,月数可以是负数*/
- (NSDate *)mlc_dateByAddingMonths:(NSInteger)months;
/**当前日期的基础上,增加年数,年数可以是负数*/
- (NSDate *)mlc_dateByAddingYears:(NSInteger)years;
/**格式化后的字符串*/
- (NSString *)mlc_stringWithFormat:(NSString *)format;
@end
```
### NSString
使用URL编解码的话,可以使用下面的方法:
```objective-c
@interface NSString (MLCKit)
/**URL编码*/
- (NSString *)mlc_urlEncode;
/**URL解码*/
- (NSString *)mlc_urlDecode;
/**使用SHA1计算hash*/
- (NSString *)mlc_sha1String;
/**将json字符串转换成字典或数组等*/
- (id)mlc_JSONObject;
@end
```
### UIControl
通过block获取UIControl及其子类的事件回调。UIControl的子类有UIButton、UISwitch、UISlider、UISegmentedControl、UIPageControl、UITextField、UIDatePicker等。
```objective-c
@interface UIControl (MLCKit)
/**点击回调*/
@property (nonatomic, copy) void(^mlc_touchUpInsideBlock)(void);
/**添加事件*/
- (void)mlc_addActionForControlEvents:(UIControlEvents)controlEvents handler:(void(^)(id sender))handler;
/**移除某些类型的所有事件*/
- (void)mlc_removeAllActionsForControlEvents:(UIControlEvents)controlEvents;
/**移除所有事件*/
- (void)mlc_removeAllActions;
@end
```
### UIView
通过block获取UIView及其子类的手势回调;移除某一些约束。
```objective-c
/**手势类型枚举 */
typedef NS_ENUM(NSInteger, MLCGestureRecognizerType) {
MLCGestureRecognizerTypeTap = 0,//
MLCGestureRecognizerTypeLongPress = 1,//
MLCGestureRecognizerTypePan = 2,//
MLCGestureRecognizerTypeSwipe = 3,//
MLCGestureRecognizerTypeRotation = 4,//
MLCGestureRecognizerTypePinch = 5,//
};
@interface UIView (MLCKit)
/**添加手势及其回调*/
- (UIGestureRecognizer *)mlc_addGestureRecognizerWithType:(MLCGestureRecognizerType)type handler:(void(^)(UIGestureRecognizer *recognizer))handler;
/**移除某些类型手势及其回调*/
- (void)mlc_removeGestureRecognizersWithType:(MLCGestureRecognizerType)type;
/**移除所有手势及其回调*/
- (void)mlc_removeAllGestureRecognizers;
/**移除自己的某一些约束*/
- (void)mlc_removeConstraintsWithFirstItem:(id)firstItem firstAttribute:(NSLayoutAttribute)firstAttribute;
/**移除firstItem是自己的某一些约束*/
- (void)mlc_removeConstraintsWithFirstAttribute:(NSLayoutAttribute)firstAttribute secondItem:(id)secondItem;
/**添加约束*/
- (void)mlc_addConstraintWithFirstAttribute:(NSLayoutAttribute)firstAttribute relation:(NSLayoutRelation)relation secondItem:(id)secondItem secondAttribute:(NSLayoutAttribute)secondAttribute multiplier:(CGFloat)multiplier constant:(CGFloat)constant;
/**返回离两个view最近的父视图*/
- (instancetype)mlc_closestCommonSuperview:(UIView *)view;
/**加部分圆角*/
- (void)mlc_becomeRoundedbyRoundingCorners:(UIRectCorner)corners cornerRadius:(CGFloat)cornerRadius;
- (void)mlc_becomeRoundedbyRoundingCorners:(UIRectCorner)corners cornerRadius:(CGFloat)cornerRadius size:(CGSize)size;
@end
```
### UIViewController
```objective-c
@interface UIViewController (MLCKit)
/**弹出alert*/
- (void)mlc_showAlertWithTitle:(NSString *)title message:(NSString *)message actionTitle:(NSString *)actionTitle handler:(void (^)(void))handler;
/**弹出confirm,一个选项*/
- (void)mlc_showConfirmWithTitle:(NSString *)title message:(NSString *)message confirmTitle:(NSString *)confirmTitle confirmHandler:(void (^)(void))confirmHandler cancelTitle:(NSString *)cancelTitle cancelHandler:(void (^)(void))cancelHandler;
/**弹出confirm,多个选项*/
- (void)mlc_showConfirmWithTitle:(NSString *)title message:(NSString *)message optionTitles:(NSArray<NSString *> *)optionTitles optionsHandler:(void (^)(NSInteger index))optionsHandler cancelTitle:(NSString *)cancelTitle cancelHandler:(void (^)(void))cancelHandler;
/**弹出prompt,一个输入框*/
- (void)mlc_showPromptWithTitle:(NSString *)title message:(NSString *)message configurationHandler:(void (^)(UITextField *textField))configurationHandler resultHandler:(void (^)(BOOL isCancel, NSString *result))resultHandler;
/**弹出prompt,多个输入框*/
- (void)mlc_showPromptWithTitle:(NSString *)title message:(NSString *)message textFieldCount:(NSInteger)textFieldCount configurationHandler:(void (^)(UITextField *textField, NSInteger index))configurationHandler resultHandler:(void (^)(BOOL isCancel, NSArray<NSString *> *results))resultHandler;
@end
```
`pod 'MLCKit/Category'`
## Color
颜色相关。
```objective-c
/**将UIColorPickerViewController协议方法通过block回调出来*/
API_AVAILABLE(ios(14.0))
@interface MLCColorPickerViewControllerManager : NSObject<UIColorPickerViewControllerDelegate>
/***/
@property (nonatomic, weak, readonly) UIColorPickerViewController *pickerViewController;
/**选取回调*/
@property (nonatomic, copy) void(^didSelectColorHandler)(void);
/**完成回调*/
@property (nonatomic, copy) void(^didFinishHandler)(void);
/**初始化方法*/
- (instancetype)initWithPickerViewController:(UIColorPickerViewController *)pickerViewController;
@end
```
`pod 'MLCKit/Color'`
## Document
文件相关。
```objective-c
/**将UIDocumentPickerViewController协议方法通过block回调出来*/
@interface MLCDocumentPickerViewControllerManager : NSObject<UIDocumentPickerDelegate>
/***/
@property (nonatomic, weak, readonly) UIDocumentPickerViewController *pickerViewController;
/**选取回调*/
@property (nonatomic, copy) void(^didPickDocumentsHandler)(NSArray<NSURL *> *urls);
/**取消回调*/
@property (nonatomic, copy) void(^wasCancelledHandler)(void);
/**初始化方法*/
- (instancetype)initWithPickerViewController:(UIDocumentPickerViewController *)pickerViewController;
@end
```
`pod 'MLCKit/Document'`
## Font
字体相关。
```objective-c
/**将UIFontPickerViewController协议方法通过block回调出来*/
API_AVAILABLE(ios(13.0))
@interface MLCFontPickerViewControllerManager : NSObject<UIFontPickerViewControllerDelegate>
/***/
@property (nonatomic, weak, readonly) UIFontPickerViewController *pickerViewController;
/**选取回调*/
@property (nonatomic, copy) void(^didPickFontHandler)(void);
/**取消回调*/
@property (nonatomic, copy) void(^didCancelHandler)(void);
/**初始化方法*/
- (instancetype)initWithPickerViewController:(UIFontPickerViewController *)pickerViewController;
@end
```
`pod 'MLCKit/Font'`
## LocalFolder
LocalFolder里面有查看app沙盒文件的视图控制器。
如果想查看整个app沙盒文件,可以如下调用:
```objective-c
NSString *folderPath = NSHomeDirectory();
MLCLocalFolderViewController *localFolderVC = [[MLCLocalFolderViewController alloc]initWithFolderPath:folderPath];
[self.navigationController pushViewController:localFolderVC animated:YES];
```
`pod 'MLCKit/LocalFolder'`
## Location
```objective-c
/**定位管理*/
@interface MLCLocationManager : NSObject
/**单例*/
+ (instancetype)sharedInstance;
/**更新位置回调*/
@property (nonatomic, copy) BOOL(^didUpdateLocationsHandler)(NSArray<CLLocation *> *locations);
/**失败回调*/
@property (nonatomic, copy) void(^didFailHandler)(NSError *error);
/**开始更新位置*/
- (void)startUpdatingLocation;
/**停止更新位置*/
- (void)stopUpdatingLocation;
@end
```
`pod 'MLCKit/Location'`
## Macro
Macro里有只在Debug环境下打印NSLog,还有weakify、strongify。
`pod 'MLCKit/Macro'`
## Photos
相册、相机相关。
### 权限
#### 相册权限
判断相册权限,可以如下调用:
```objective-c
[MLCPhotoPermissionManager requestPermissionWithSourceType:(UIImagePickerControllerSourceTypePhotoLibrary) sourceTypeUnavailableHandler:^{
NSLog(@"当前设备没有相册功能");
} isNotDeterminedHandler:^{
NSLog(@"相册权限之前还未处理");
} handler:^(BOOL success, BOOL isLimited) {
if (success) {
NSLog(@"已经获得相册权限");
if (isLimited) {
NSLog(@"读取相册受限");
}
} else {
NSLog(@"相册权限被拒绝");
}
}];
```
判断相册权限,并且在权限被拒绝时弹出alert提醒,可以如下调用:
```objective-c
[MLCPhotoPermissionManager requestPermissionWithSourceType:(UIImagePickerControllerSourceTypePhotoLibrary) handler:^(BOOL isLimited) {
NSLog(@"已经获得相册权限");
if (isLimited) {
NSLog(@"读取相册受限");
}
} fromViewController:self];
```
#### 相机权限
判断相机权限,可以如下调用:
```objective-c
[MLCPhotoPermissionManager requestPermissionWithSourceType:(UIImagePickerControllerSourceTypeCamera) sourceTypeUnavailableHandler:^{
NSLog(@"当前设备没有相机功能");
} isNotDeterminedHandler:^{
NSLog(@"相机权限之前还未处理");
} handler:^(BOOL success, BOOL isLimited) {
if (success) {
NSLog(@"已经获得相机权限");
if (isLimited) {
NSLog(@"读取受限");
}
} else {
NSLog(@"相机权限被拒绝");
}
}];
```
判断相机权限,并且在权限被拒绝时弹出alert提醒,可以如下调用:
```objective-c
[MLCPhotoPermissionManager requestPermissionWithSourceType:(UIImagePickerControllerSourceTypeCamera) handler:^(BOOL isLimited) {
NSLog(@"已经获得相机权限");
} fromViewController:self];
```
### PHPickerViewController
MLCPHPickerViewControllerManager将PHPickerViewController的协议方法回调改成了block回调:
```objective-c
/**将PHPickerViewController协议方法通过block回调出来*/
API_AVAILABLE(ios(14))
@interface MLCPHPickerViewControllerManager : NSObject<PHPickerViewControllerDelegate>
/***/
@property (nonatomic, weak, readonly) PHPickerViewController *pickerViewController;
/**选取回调*/
@property (nonatomic, copy) void(^didFinishPickingHandler)(NSArray<PHPickerResult *> *results);
/**初始化方法*/
- (instancetype)initWithPickerViewController:(PHPickerViewController *)pickerViewController;
@end
```
### UIImagePickerController
MLCImagePickerControllerManager将UIImagePickerController的协议方法回调改成了block回调:
```objective-c
/**
* 将UIImagePickerController部分协议方法通过block回调出来
* 想扩展到更多部分协议方法的话,可以继承该类
*/
@interface MLCImagePickerControllerManager : NSObject<UINavigationControllerDelegate, UIImagePickerControllerDelegate>
/***/
@property (nonatomic, weak, readonly) UIImagePickerController *pickerViewController;
/**选取回调*/
@property (nonatomic, copy) void(^didFinishPickingMediaHandler)(NSDictionary<UIImagePickerControllerInfoKey,id> *info);
/**点击回调*/
@property (nonatomic, copy) void(^didCancelHandler)(void);
/**初始化方法*/
- (instancetype)initWithPickerViewController:(UIImagePickerController *)pickerViewController;
/**
*将自己从pickerViewController上移除
*继承时使用
*/
- (void)clearSelfFromPickerViewController;
@end
```
`pod 'MLCKit/Photos'`
## Proxy
通过使用代理对象,解决循环引用问题。
比如在UIViewController中,使用NSTimer指定target为UIViewController时,使用WKUserContentController的addScriptMessageHandler方法指定target为UIViewController时,容易出现循环引用问题。一些开发者在viewWillAppear、viewWillDisappear或viewDidAppear、viewDidDisappear进行操作,但这种操作较为麻烦。
使用MLCProxy的话,可以如下调用:
```objective-c
_timer = [NSTimer timerWithTimeInterval:interval target:[MLCProxy proxyWithTarget:self] selector:@selector(pollLastNotice) userInfo:nil repeats:YES];
```
```objective-c
[configuration.userContentController addScriptMessageHandler:(id <WKScriptMessageHandler>)[MLCProxy proxyWithTarget:self] name:@"log"];
```
`pod 'MLCKit/Proxy'`
## Scan
Scan里面有扫码二维码视图控制器MLCScanQRCodeViewController,还有识别二维码的方法。
## TableView
里面封装了UITableView下拉刷新、加载更多等的处理,将UITableView的代理回调改成使用block回调。
## UI
UI里面是UI控件。
### MLCGradientLayerView
layerClass是CAGradientLayer的。
### MLCLabelView
在UILabel外面包一层。
`pod 'MLCKit/UI'`
## Utility
Utility里面是工具类。
### MLCDeviceUtility
MLCDeviceUtility封装获取设备信息的方法。
```objective-c
/**设备相关工具类*/
@interface MLCDeviceUtility : NSObject
/**app版本号*/
+ (NSString *)appVersion;
/**app构建版本号*/
+ (NSString *)appBuildVersion;
/**app名字*/
+ (NSString *)appName;
/**app的bundle ID*/
+ (NSString *)bundleIdentifier;
/**IDFA,广告标示符*/
+ (NSString *)idfa;
/**广告跟踪是否开启*/
+ (BOOL)advertisingTrackingEnabled;
/**IDFV*/
+ (NSString *)identifierForVendor;
/**IDFA或IDFV,IDFA能获取到就返回IDFA*/
+ (NSString *)idfaOrIdfv;
/***/
+ (NSString *)machine;
/**是否越狱*/
+ (BOOL)isJailbroken;
/**运营商名字*/
+ (NSString *)carrierName;
/**蜂窝网络类型*/
+ (NSString *)currentRadioAccessTechnology;
/**电池状态*/
+ (UIDeviceBatteryState)batteryStauts;
/**电池电量*/
+ (float)batteryLevel;
/**总内存大小*/
+ (unsigned long long)totalMemorySize;
/**当前可用内存大小*/
+ (unsigned long long)availableMemorySize;
/**已使用内存大小*/
+ (unsigned long long)usedMemory;
/**总磁盘容量*/
+ (unsigned long long)totalDiskSize;
/**可用磁盘容量*/
+ (unsigned long long)availableDiskSize;
/**IP地址*/
+ (NSString *)deviceIPAdress;
/**连接的WIFI名称(SSID)*/
+ (NSString *)wifiName;
/**状态栏高度*/
+ (CGFloat)statusBarHeight;
/**安全区域,iOS 11以下的返回UIEdgeInsetsMake(20, 0, 0, 0)*/
+ (UIEdgeInsets)safeAreaInsets;
@end
```
### MLCFileUtility
```objective-c
/**文件相关工具类*/
@interface MLCFileUtility : NSObject
/**获取Document文件目录*/
+ (NSString*)documentDirectoryPath;
/**获取Temp文件目录*/
+ (NSString*)temporaryDirectoryPath;
/**获取Home文件目录*/
+ (NSString*)homeDirectoryPath;
/**获取Cache文件目录*/
+ (NSString*)cachesDirectoryPath;
/**创建目录*/
+ (BOOL)creatDirectoryWithPath:(NSString *)path;
/**删除目录或文件*/
+ (BOOL)removeItemAtPath:(NSString *)path;
/**移动文件*/
+ (BOOL)moveItemAtPath:(NSString *)srcPath toPath:(NSString *)dstPath error:(NSError **)error;
/**拷贝文件*/
+ (BOOL)copyItemAtPath:(NSString *)srcPath toPath:(NSString *)dstPath error:(NSError **)error;
/** 获取文件或者文件夹大小(单位:B) */
+ (unsigned long long)sizeAtPath:(NSString *)path;
@end
```
### MLCNotificationUtility
```objective-c
/**通知工具类*/
@interface MLCNotificationUtility : NSObject
/**
注册通知
@param delegate UNUserNotificationCenterDelegate
**/
+ (void)registerNotificationWithDelegate:(id)delegate;
/**远程推送设备token字符串*/
+ (NSString *)remoteNotificationDeviceTokenStringWithDeviceToken:(NSData *)deviceToken;
@end
```
### MLCOpenUtility
```objective-c
/**打开相关工具类*/
@interface MLCOpenUtility : NSObject
/**让UIApplication打开链接*/
+ (void)openURL:(NSURL*)url completionHandler:(void (^)(BOOL success))completion;
/**打电话*/
+ (void)callWithTelephoneNumber:(NSString*)telephoneNumber;
/**发邮件*/
+ (void)sendEmail:(NSString*)email;
/**发短信*/
+ (void)sendShortMessage:(NSString*)shortMessage;
/**跳转到app设置页面*/
+ (void)openSettings;
@end
```
`pod 'MLCKit/Utility'`
# 安装
### CocoaPods
1. 需要MLCKit所有功能的,在 Podfile 中添加 `pod 'MLCKit'`。
2. 执行 `pod install` 或 `pod update`。
3. 导入 相应头文件。
# 系统要求
该项目最低支持 `iOS 8.0`。 | 15,622 | MIT |
<!--
* @Author: sam.hongyang
* @LastEditors: sam.hongyang
* @Description: 更新日志
* @Date: 2019-03-04 15:51:21
* @LastEditTime: 2019-07-29 11:53:48
-->
### 1.0.3 2019-07-29 11:53:26
> feat: 新增微前端模版下载功能
### 1.0.2 2019-07-24 14:43:18
> feat: 完善微前端配置
### 1.0.1 2019-07-20
> feat: 增加微前端配置
### 1.0.0 2019-03-05 14:28:43
> chore: 熟悉相关模块的用法
### 1.0.0 2019-03-04 17:04:42
> ci: 搭建工程目录,尝试 `commander` 模块的使用 | 407 | MIT |
编写一个程序,执行一个**异步**的对文件系统的操作:读取一个文件,并且在终端(标准输出 stdout)打印出这个文件中的内容的行数。类似于执行 `cat file | wc -l` 这个命令。
所要读取的文件的完整路径会在命令行第一个参数提供。
----------------------------------------------------------------------
# 提示
这个题目的答案*几乎*和前一个问题一样,但是你需要用更加**符合 Node.js 的风格**的方式解决:异步。
你将要使用 `fs.readFile()` 方法,而不是 `fs.readFileSync()`,并且你需要从你所传入的回调函数中去收集数据(这些数据会作为第二参数传递给你的回调函数),而不是使用方法的返回值。想要学习更多关于回调函数的知识,请查阅:https://github.com/maxogden/art-of-node#callbacks。
记住,我们习惯中的 Node.js 回调函数都有像如下所示的特征:
```js
function callback (err, data) { /* ... */ }
```
所以,你可以通过检查第一个参数的真假值来判断是否有错误发生。如果没有错误发生,你会在第二个参数中获取到一个 `Buffer` 对象。和 `readFileSync()` 一样,你可以传入 'utf8' 作为它的第二个参数,然后把回调函数作为第三个参数,这样,你得到的将会是一个字符串,而不是 Buffer。
`fs` 模块的文档可以通过使用你的浏览器访问如下路径来查看:
{rootdir:/node_apidoc/fs.html}
---------------------------------------------------------------------- | 819 | MIT |
col
===
过滤控制字符
## 补充说明
**col命令** 是一个标准输入文本过滤器,它从标注输入设备读取文本内容,并把内容显示到标注输出设备。在许多UNIX说明文件里,都有RLF控制字符。当我们运用shell特殊字符`>`和`>>`,把说明文件的内容输出成纯文本文件时,控制字符会变成乱码,col命令则能有效滤除这些控制字符。
### 语法
```
col(选项)
```
### 选项
```
-b:过滤掉所有的控制字符,包括RLF和HRLF;
-f:滤掉RLF字符,但允许将HRLF字符呈现出来;
-x:以多个空格字符来表示跳格字符;
-l<缓冲区列数>:预设的内存缓冲区有128列,用户可以自行指定缓冲区的大小。
```
<!-- Linux命令行搜索引擎:https://jaywcjlove.github.io/linux-command/ --> | 396 | Apache-2.0 |
---
sidebar: auto
---
# 指南 :rocket:
## 开始使用
### NPM
通过 npm 或 yarn 安装
```bash
npm install vue-showdown
# 或者
yarn add vue-showdown
```
在你的 JS 文件中引入
```js
// 作为 Vue 插件引入
import Vue from 'vue'
import VueShowdown from 'vue-showdown'
// Vue.use() 的第二个参数是可选的
Vue.use(VueShowdown, {
// 设置 showdown 默认 flavor
flavor: 'github',
// 设置 showdown 默认 options (会覆盖上面 flavor 的 options)
options: {
emoji: false,
},
})
// 或者: 作为 Vue 组件引入
import Vue from 'vue'
import { VueShowdown } from 'vue-showdown' // 记得引入 vue-showdown 的 esm 文件,即 vue-showdown.esm.js
Vue.component('VueShowdown', VueShowdown)
```
接下来,你就可以在你的单文件组件中通过`VueShowdown`来使用了
```vue
<!-- 通过 props 来设置 options -->
<VueShowdown
markdown="## markdown text"
flavor="github"
:options="{ emoji: true }"/>
```
::: tip 提示
同 vue 一样,vue-showdown 同样提供了 [UMD](https://github.com/umdjs/umd), [CommonJS](http://wiki.commonjs.org/wiki/Modules/1.1) 和 [ES Module](http://exploringjs.com/es6/ch_modules.html) 版本。查看 [Vue 文档](https://vuejs.org/v2/guide/installation.html#Terms) 获取更多细节。
:::
### Browser
在 `vue.js` 后面直接通过 `<script>` 引入。然后可以将 `vue-showdown` 直接作为 Vue 组件使用。
```html
<body>
<div id="#app">
<vue-showdown markdown="## markdown text"/>
</div>
<script src="https://unpkg.com/vue@2.5.21/dist/vue.min.js"></script>
<script src="https://unpkg.com/showdown@1.9.0/dist/showdown.min.js"></script>
<script src="https://unpkg.com/vue-showdown@2.3.0/dist/vue-showdown.min.js"></script>
<script>
new Vue({
el: '#app'
})
</script>
</body>
```
## 插件选项
```js
import Vue from 'vue'
import VueShowdown from 'vue-showdown'
Vue.use(VueShowdown, {
// 在这里设置插件选项
})
```
### flavor
设置 showdown 的默认 flavor。查看[文档](https://github.com/showdownjs/showdown#flavors)。
- 类型: `string`
- 默认值: `null`
- 可能的值: `'original', 'vanilla', 'github'`
::: tip
这里的 `flavor` 将会通过 `showdown.setFlavor()` 设置为全局 flavor。
:::
### options
设置 showdown 的默认 options。查看[文档](https://github.com/showdownjs/showdown#valid-options)。
- type: `Object`
- default: `{}`
::: tip
这里的 `options` 将会通过 `showdown.setOption()` 设置为全局 options。
注意这里的 `showdown.setOption()` 将会在 `showdown.setFlavor()` 之后调用,意味着将会覆盖 flavor 本身的默认配置。
:::
## 组件 Props
### markdown
输入的原始 markdown 代码。
- 类型: `string`
- 默认值: `null`
```vue
<VueShowdown markdown="# Hello, world!"/>
<!-- 渲染为 -->
<div>
<h1>Hello, world!</h1>
</div>
```
### tag
用来包裹 markdown 渲染结果的 HTML 标签。与 [vue-router 的 tag](https://router.vuejs.org/api/#tag) 作用相同。
- 类型: `string`
- 默认值: `'div'`
```vue
<VueShowdown markdown="# Hello, world!" tag="span"/>
<!-- 渲染为 -->
<span>
<h1>Hello, world!</h1>
</span>
```
### flavor
设置 showdown 的 flavor。查看 [文档](https://github.com/showdownjs/showdown#flavors)。
- 类型: `string`
- 默认值: `null`
- 可用的值: `'original', 'vanilla', 'github'`
::: tip
如果你通过 props 设置 `flavor`,那么所有的 options 都会被重置为 flavor 的默认值,这意味着你通过 `Vue.use()` 设置的默认 options 也将被覆盖。
:::
### options
设置 showdown 的 options。查看 [文档](https://github.com/showdownjs/showdown#valid-options)。
- 类型: `Object`
- 默认值: `{}`
::: tip 提示
通过 props 设置的 options 将会覆盖通过 `Vue.use()` 设置的默认 options。
:::
### extensions
设置 showdown 的 extensions。查看 [文档](https://github.com/showdownjs/showdown#extensions)。
- 类型: `[Object, Array]`
- 默认值: `null`
::: tip 提示
前往章节 [进阶用法 - Extensions](./#extensions-2) 查看使用细节。
:::
### vueTemplate <Badge text="v2.4.0+"/>
将解析后的 HTML 字符串当作 Vue 模板,允许你在 Markdown 中使用 Vue 模板语法。
- 类型: `Boolean`
- 默认值: `false`
::: warning 注意
如果你设置该 prop 为 `true`,你需要使用 Vue 完整版(运行时 + 编译器),因为我们需要在客户端编译模板。查看 [运行时 + 编译器 vs. 只包含运行时](https://cn.vuejs.org/v2/guide/installation.html#%E8%BF%90%E8%A1%8C%E6%97%B6-%E7%BC%96%E8%AF%91%E5%99%A8-vs-%E5%8F%AA%E5%8C%85%E5%90%AB%E8%BF%90%E8%A1%8C%E6%97%B6)。
当你有类似 [#5](https://github.com/meteorlxy/vue-showdown/issues/5) 的需求时,可以尝试使用该功能。
:::
## 进阶用法
### Showdown library
你可以从 `vue-showdown` 中导入 `showdown` ,以便进行进阶配置。
```js
import Vue from 'vue'
import VueShowdown, { showdown } from 'vue-showdown'
showdown.setFlavor('github')
Vue.use(VueShowdown)
```
::: tip
如果你在通过 `vue-showdown` 引入 `showdown` 时 (`import { showdown } from 'vue-showdown'`) 发生错误,你可以尝试以下方式:
- 设置 alias,将 `vue-showdown` 指向 `vue-showdown.esm.js`。如果你使用 webpack ,那么就类似于 `vue.esm.js` 的设置:
```js
resolve: {
alias: {
'vue$': 'vue/dist/vue.esm.js',
'vue-showdown$': 'vue-showdown/dist/vue-showdown.esm.js',
},
}
```
或者你直接引入 `vue-showdown.esm.js` 文件:
```js
import { showdown } from 'vue-showdown/dist/vue-showdown.esm'
```
- 通过 `VueShowdown.showdown` 使用 `showdown`:
```js
import VueShowdown from 'vue-showdown'
const showdown = VueShowdown.showdown
```
- 直接引入 `showdown` 。由于 `vue-showdown` 依赖于 `showdown` 运行,所以在你通过 `npm install vue-showdown` 安装 `vue-showdown` 后,你就可以直接使用 `showdown`:
```js
import showdown from 'showdown'
```
:::
### Extensions
根据 [showdown extensions 官方文档](https://github.com/showdownjs/showdown/wiki/extensions),目前无法设置全局默认 extensions。
所以目前只能通过 `VueShowdown` 组件的 `extensions` prop 来传入 extensions。
```vue
<template>
<VueShowdown
markdown="## markdown text"
:extensions="[myExt]"/>
</template>
<script>
export default {
data () {
return {
myExt: () => [{
type: 'lang',
regex: /markdown/g,
replace: 'showdown',
}],
}
},
}
</script>
```
或者,你可以通过 `showdown.extension()` 全局注册 extensions,然后在 `extension` prop 中直接通过注册的名称引入。
```js
import Vue from 'vue'
import VueShowdown, { showdown } from 'vue-showdown'
// OR:
// import showdown from 'showdown'
// import VueShowdown from 'vue-showdown'
showdown.extension('myext', () => [{
type: 'lang',
regex: /markdown/g,
replace: 'showdown',
}])
Vue.use(VueShowdown)
```
```vue
<template>
<VueShowdown
markdown="## markdown text"
:extensions="['myext']"/>
</template>
``` | 5,751 | MIT |
---
title: 常见问题 QA
category: 其它
order: 1
---
> 持续更新中...
> 如有问题可以到 <https://github.com/alibaba/ice/issues/new> 反馈
## ICE 的浏览器兼容策略是什么
由于 ICE 优先使用 React 16+,其需要的最低 IE 版本为 11,如果您需要在以下的版本使用,您可能需要引入一些 polyfill 来支持 `Map`, `Set` 等特性。参考[React 官网说明](https://reactjs.org/blog/2017/09/26/react-v16.0.html#javascript-environment-requirements)。
以下代码可以帮助你在低版本 IE 下自动跳转到我们提供的提示浏览器升级页面。当然您也可以使用自定义的浏览器升级页面。
```
<!--[if lt IE 11]>
<script>location.href = "//www.taobao.com/markets/tbhome/ali-page-updater"; </script>
<![endif]-->
```
添加如上代码后,如果使用 IE11 及以下浏览器访问页面,则会自动跳转到统一引导升级浏览器的页面。
## WebStorm/IDEA 编辑器卡顿现象
由于项目在安装依赖后,产生文件夹 `node_modules` 含有较多的碎小文件,编辑器在索引文件引起的卡顿。
WebStorm 中尤为明显,可通过 exclude `node_modules` 目录,不需要检索该文件夹下的内容。
## 如何设置网页在浏览器 Tab 上面的 Icon (favicon)
细心的同学可能会看到页面在浏览器 Tab 上面会有自定义的 Icon:

如果你想要在自己站点上面加上这个 Icon 可以按照如下步骤添加:
1. 准备一个 Icon,文件格式可以为 `.png` 或者 `.ico`,正方形,分辨率可以是 32x32px 或者 64x64px 文件体积要求尽可能小。
2. 上传 CDN 拿到一个 url 或者在自己服务器配置静态资源服务
3. 在 HTML 页面 `<head>` 标签里面添加如下代码:`<link rel="shortcut icon" href="your-icon-url">`

这样就添加成功啦!
## 如何在页面显示原始的 HTML 内容
出于安全方面的考虑,React 默认会将节点中 html 代码进行转义,比如:
```jsx
class Demo extends Component {
render() {
const content = 'hello <span>world</span>';
return <div>{content}</div>;
}
}
// 输出 hello <span>world</span>
```
如上,`<span>` 标签并不会在页面上被解析,而是被当成字符串输出了。React 提供了 `dangerouslySetInnerHTML` 属性帮助我们进行类似 `innerHTML` 的操作:
```jsx
class Demo extends Component {
render() {
const content = 'hello <span>world</span>';
return <div dangerouslySetInnerHTML={{ __html: content }} />;
}
}
// 输出 hello world
```
更多内容请参考 [Dangerously Set innerHTML](https://reactjs.org/docs/dom-elements.html#dangerouslysetinnerhtml)
## 之前创建的项目,遇到如下报错怎么办
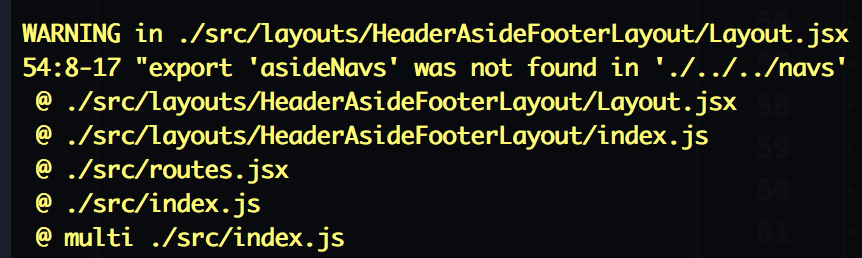
这是由于 ES6 Modules 的标准在物料中不兼容导致的。您可以把 `src/navs.js` 中最后一行修改为:
```js
export const headerNavs = transform([
...autoGenHeaderNavs,
...customHeaderNavs,
]);
export const asideNavs = transform([...autoGenAsideNavs, ...customAsideNavs]);
``` | 2,155 | MIT |
---
title: 注册 Azure Functions 绑定扩展
description: 了解如何根据你的环境注册 Azure Functions 绑定扩展。
services: functions
documentationcenter: na
author: craigshoemaker
manager: jeconnoc
ms.service: azure-functions
ms.devlang: multiple
ms.topic: reference
origin.date: 02/25/2019
ms.date: 06/03/2019
ms.author: v-junlch
ms.openlocfilehash: e9f7bb95d04b523dfd17d3e8af43e216292ed970
ms.sourcegitcommit: 9e839c50ac69907e54ddc7ea13ae673d294da77a
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 06/04/2019
ms.locfileid: "66491491"
---
# <a name="register-azure-functions-binding-extensions"></a>注册 Azure Functions 绑定扩展
在 Azure Functions 版本 2.x 中,[绑定](./functions-triggers-bindings.md)以独立于函数运行时的包的形式提供。 虽然 .NET 函数通过 NuGet 包访问绑定,但扩展捆绑包允许其他函数通过配置设置访问所有绑定。
请考虑以下与绑定扩展相关的项:
- 除了[使用 Visual Studio 2019 创建 C# 类库](#local-csharp)时,否则绑定扩展未在 Functions 1.x 中显式注册。
- 默认情况下支持 HTTP 和计时器触发器,不需要扩展。
下表指明了何时以及如何注册绑定。
| 开发环境 |注册<br/> Functions 1.x 中注册 |注册<br/> Functions 2.x 中注册 |
|-------------------------|------------------------------------|------------------------------------|
|Azure 门户|自动|自动|
|非 .NET 语言或本地 Azure Core Tools 开发|自动|[使用 Azure Functions Core Tools 和扩展捆绑包](#local-development-with-azure-functions-core-tools-and-extension-bundles)|
|使用 Visual Studio 2019 的 C# 类库|[使用 NuGet 工具](#c-class-library-with-visual-studio-2019)|[使用 NuGet 工具](#c-class-library-with-visual-studio-2019)|
|使用 Visual Studio Code 的 C# 类库|不适用|[使用 .NET Core CLI](#c-class-library-with-visual-studio-code)|
## <a name="local-development-with-azure-functions-core-tools-and-extension-bundles"></a>使用 Azure Functions Core Tools 和扩展捆绑包进行本地开发
[!INCLUDE [functions-core-tools-install-extension](../../includes/functions-core-tools-install-extension.md)]
<a name="local-csharp"></a>
## <a name="c-class-library-with-visual-studio-2019"></a>使用 Visual Studio 2019 的 C# 类库
在 Visual Studio 2019 中,可使用 [Install-Package](https://docs.microsoft.com/nuget/tools/ps-ref-install-package) 命令从包管理器控制台安装包,如以下示例所示:
```powershell
Install-Package Microsoft.Azure.WebJobs.Extensions.ServiceBus -Version <TARGET_VERSION>
```
用于给定绑定的包的名称在该绑定的参考文章中提供。 有关示例,请参阅[服务总线绑定参考文章的“包”部分](functions-bindings-service-bus.md#packages---functions-1x)。
将示例中的 `<TARGET_VERSION>` 替换为特定包版本,例如 `3.0.0-beta5`。 在 [NuGet.org](https://nuget.org) 上的单个包页上列出了有效版本。与 Functions 运行时 1.x 或 2.x 对应的主版本在绑定的参考文章中指定。
## <a name="c-class-library-with-visual-studio-code"></a>使用 Visual Studio Code 的 C# 类库
在“Visual Studio Code” 中,可在 .NET Core CLI 中,通过命令提示符使用 [dotnet add package](https://docs.microsoft.com/dotnet/core/tools/dotnet-add-package) 命令来安装包,如以下示例所示:
```terminal
dotnet add package Microsoft.Azure.WebJobs.Extensions.ServiceBus --version <TARGET_VERSION>
```
.NET Core CLI 只能用于 Azure Functions 2.x 开发。
用于给定绑定的包的名称在该绑定的参考文章中提供。 有关示例,请参阅[服务总线绑定参考文章的“包”部分](functions-bindings-service-bus.md#packages---functions-1x)。
将示例中的 `<TARGET_VERSION>` 替换为特定包版本,例如 `3.0.0-beta5`。 在 [NuGet.org](https://nuget.org) 上的单个包页上列出了有效版本。与 Functions 运行时 1.x 或 2.x 对应的主版本在绑定的参考文章中指定。
## <a name="next-steps"></a>后续步骤
> [!div class="nextstepaction"]
> [Azure Functions 触发器和绑定示例](./functions-bindings-example.md)
<!-- Update_Description: wording update --> | 3,161 | CC-BY-4.0 |
---
title: 关键插件 Pod 的调度保证
content_type: concept
---
<!-- overview -->
<!--
In addition to Kubernetes core components like api-server, scheduler, controller-manager running on a master machine
there are a number of add-ons which, for various reasons, must run on a regular cluster node (rather than the Kubernetes master).
Some of these add-ons are critical to a fully functional cluster, such as metrics-server, DNS, and UI.
A cluster may stop working properly if a critical add-on is evicted (either manually or as a side effect of another operation like upgrade)
and becomes pending (for example when the cluster is highly utilized and either there are other pending pods that schedule into the space
vacated by the evicted critical add-on pod or the amount of resources available on the node changed for some other reason).
-->
除了在主机上运行的 Kubernetes 核心组件(如 api-server 、scheduler 、controller-manager)之外,还有许多插件,由于各种原因,
必须在常规集群节点(而不是 Kubernetes 主节点)上运行。
其中一些插件对于功能完备的群集至关重要,例如 Heapster、DNS 和 UI。
如果关键插件被逐出(手动或作为升级等其他操作的副作用)或者变成挂起状态,群集可能会停止正常工作。
关键插件进入挂起状态的例子有:集群利用率过高;被逐出的关键插件 Pod 释放了空间,但该空间被之前悬决的 Pod 占用;由于其它原因导致节点上可用资源的总量发生变化。
<!-- body -->
<!--
### Marking pod as critical
-->
### 标记关键 Pod
<!--
To be considered critical, the pod has to run in the `kube-system` namespace (configurable via flag) and
* Have the priorityClassName set as "system-cluster-critical" or "system-node-critical", the latter being the highest for entire cluster. Alternatively, you could add an annotation `scheduler.alpha.kubernetes.io/critical-pod` as key and empty string as value to your pod, but this annotation is deprecated as of version 1.13 and will be removed in 1.14.
-->
要将 pod 标记为关键性(critical),pod 必须在 kube-system 命名空间中运行(可通过参数配置)。
同时,需要将 `priorityClassName` 设置为 `system-cluster-critical` 或 `system-node-critical` ,后者是整个群集的最高级别。
或者,也可以为 Pod 添加名为 `scheduler.alpha.kubernetes.io/critical-pod`、值为空字符串的注解。
不过,这一注解从 1.13 版本开始不再推荐使用,并将在 1.14 中删除。 | 1,941 | CC-BY-4.0 |
---
title: Docker 容器内 Java 应用发生 OutOfMemoryError 堆内存空间不足时, 容器无法重启应用
date: 2020-03-12 10:34:13
description: 在一次生产环境部署时发现 docker 容器设置了 --restart always, 容器里应用发生 OutOfMemoryError 错误时没有重启容器.
categories: [Docker篇]
tags: [Docker]
---
<!-- more -->
## 背景
在一次生产环境部署 elasticsearch 节点时 docker 容器设置了 --restart always,
此时 elasticsearch 的一个节点发生了 java.lang.OutOfMemoryError: Java heap space
容器并没有重启
elasticsearch 已经设置了 -Xms -Xmx
## 解释
JVM堆内存超出xmx限制,并抛java.lang.OutOfMemoryError: Java heap space异常。堆内存爆了之后,JVM和java进程会继续运行,并不会crash
## 解决
当JVM出现 OutOfMemoryError,要让 JVM 自行退出, 这样容器就会触发重启
添加新的 jvm 配置: ExitOnOutOfMemoryError and CrashOnOutOfMemoryError
该配置支持 jdk8u92 版本及其之后的版本
地址: https://www.oracle.com/technetwork/java/javase/8u92-relnotes-2949471.html
oracle 官网的原话:
New JVM Options added: ExitOnOutOfMemoryError and CrashOnOutOfMemoryError
Two new JVM flags have been added:
ExitOnOutOfMemoryError - When you enable this option, the JVM exits on the first occurrence of an out-of-memory error. It can be used if you prefer restarting an instance of the JVM rather than handling out of memory errors.
CrashOnOutOfMemoryError - If this option is enabled, when an out-of-memory error occurs, the JVM crashes and produces text and binary crash files (if core files are enabled).
ExitOnOutOfMemoryError: 启用此选项时,JVM在第一次出现内存不足错误时退出。如果您希望重新启动JVM实例而不是处理内存不足错误,则可以使用它。
CrashOnOutOfMemoryError: 如果启用此选项,则在发生内存不足错误时,JVM崩溃并生成文本和二进制崩溃文件(如果启用了核心文件)。
加上配置
> ES_JAVA_OPTS = "-XX:+ExitOnOutOfMemoryError" | 1,492 | MIT |
---
layout: post
category: "video"
title: "视频相关paper"
tags: [video, 视频, tcc, ]
---
目录
<!-- TOC -->
- [视频分类](#%e8%a7%86%e9%a2%91%e5%88%86%e7%b1%bb)
- [视频表示学习](#%e8%a7%86%e9%a2%91%e8%a1%a8%e7%a4%ba%e5%ad%a6%e4%b9%a0)
- [Dense Predictive Coding](#dense-predictive-coding)
- [TCC](#tcc)
- [应用](#%e5%ba%94%e7%94%a8)
<!-- /TOC -->
## 视频分类
AAAI 2018
[Multimodal Keyless Attention Fusion for Video Classification](http://iiis.tsinghua.edu.cn/~weblt/papers/multimodal-keyless-attention.pdf)
Multimodal Representation意思是多模式表示,在行为识别任务上,文章采用了视觉特征(Visual Features,包含RGB特征 和 flow features);声学特征(Acoustic Feature);前面两个特征都是针对时序,但是时序太长并不适合直接喂到LSTM,所以作者采用了分割的方法(Segment-Level Features),将得到的等长的Segment喂到LSTM。
优点:多模态信息融合方法优化: 两路model分别lstm+attention,再concat ,能得到多模态 互补识别效果,train model 效果优于early fusion/later fusion
CVPR 2018
[Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification](http://cn.arxiv.org/abs/1711.09550)
多组attention参数有效引入diversity,能学习到不同的注意力模式
不同component用各自attention(通过线性变换映射到另一个空间,相当于加约束),再concat
temporal action proposal: actionness score(精彩不精彩,二分类),然后取出分布连续且值比较高的片段,然后找边界(boundary aware network),然后加一些多尺度(action pyramid network)
[Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset](https://arxiv.org/abs/1705.07750v1)
利用膨胀3D卷积网络(I3D)将视频的帧间差值做处理,再采用CNN进行分类。
AdaIN
style transfer: AdaIN(自适应示例正则化),两个目标:纹理一致性+语义一致性(类似GAN)
## 视频表示学习
### Dense Predictive Coding
[Video Representation Learning by Dense Predictive Coding](https://arxiv.org/abs/1909.04656)
近期来自 VGG 的高质量工作,因为没有在主会议发表所以没有引起大范围关注,但保持了一贯低调又实用的风格。本文提出了一种新型的自监督学习(self-supervised learning)方法 Dense Predictive Coding,学习视频的时空表征,在动作识别任务(UCF101 和 HMDB51 数据集)上获得了 state-of-the-art 的正确率,并且用无需标注的自监督学习方法在视频动作识别上达到了 ImageNet 预训练的正确率。
自监督学习是利用无标注的数据设计代理任务(proxy task),使网络从中学到有意义的数据表征。本文设计的代理任务是预测未来几秒的视频的特征,并且用对比损失(contrastive loss)使得预测的特征和实际的特征相似度高,却不必要完全相等。因为在像素级别(pixel-level)预测未来的帧容易受到大量随机干扰如光照强度、相机移动的影响,而在特征级别(feature-level)做回归(regression)则忽视了未来高层特征的不可预测性(如视频的未来发展存在多种可能)。
文中的设计促使网络学习高层语义特征,避免了网络拘泥于学习低层特征。作者在不带标注的 Kinetics400 上训练了自监督任务(Dense Predictive Coding),然后在 UCF101 和 HMDB51 上测试了网络所学权重在动作识别上的正确率。
Dense Predictive Coding 在 UCF101 数据集上获得了 75.7% 的 top1 正确率,超过了使用带标注的 ImageNet 预训练权重所获得的 73.0% 正确率。该研究结果证明了大规模自监督学习在视频分类上的有效性。
### TCC
[使用时间循环一致性学习 (TCC) 理解视频内容](https://mp.weixin.qq.com/s/xocs_UI5HzgFZtTPWABRKw)
[Temporal Segment Networks: Towards Good Practices for Deep Action Recognition](https://arxiv.org/abs/1608.00859)
[https://sites.google.com/view/temporal-cycle-consistency/home](https://sites.google.com/view/temporal-cycle-consistency/home)
[https://github.com/google-research/google-research/tree/master/tcc](https://github.com/google-research/google-research/tree/master/tcc)
## 应用
[用AI实现动画角色的姿势迁移,Adobe等提出新型「木偶动画」](https://mp.weixin.qq.com/s/5snO8CYpc01CCky9WT6SrQ)
[Neural Puppet: Generative Layered Cartoon Characters](https://arxiv.org/pdf/1910.02060v1.pdf) | 2,926 | Apache-2.0 |
# 12.1.2. 执行日期检查和时间计算
[![chrono-badge]][chrono] [![cat-date-and-time-badge]][cat-date-and-time]
使用 [`DateTime::checked_add_signed`] 计算并显示两周之后的日期和时间,使用 [`DateTime::checked_sub_signed`] 计算并显示前一天的日期。如果无法计算出日期和时间,这些方法将返回 None。
可以在 [`chrono::format::strftime`] 中找到适用于 [`DateTime::format`] 的转义序列。
```rust,edition2018
{{ #include ../../../examples/datetime/duration/examples/checked.rs }}
```
[`chrono::format::strftime`]: https://docs.rs/chrono/*/chrono/format/strftime/index.html
[`DateTime::checked_add_signed`]: https://docs.rs/chrono/*/chrono/struct.Date.html#method.checked_add_signed
[`DateTime::checked_sub_signed`]: https://docs.rs/chrono/*/chrono/struct.Date.html#method.checked_sub_signed
[`DateTime::format`]: https://docs.rs/chrono/*/chrono/struct.DateTime.html#method.format
{{#include ../../links.md}} | 816 | Apache-2.0 |
# FileScanner [  ](https://bintray.com/haydar-android/maven/FileScanner/_latestVersion) <a href='https://bintray.com/haydar-android/maven/FileScanner?source=watch' alt='Get automatic notifications about new "FileScanner" versions'><img src='https://www.bintray.com/docs/images/bintray_badge_color.png'></a>
## Android SD卡扫描某类文件(.mp3、.mp4...)
### 使用方法
``` gradlew
compile 'io.haydar.filescanner:filescannercore:1.1'
```
### 描述
FileScanner是一个扫描Android /storage/emulated/0/目录中指定格式的文件。扫描结果会保存在FileScanner数据库中。
### 注意
``` xml
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
```
必须得申请权限
### API
``` java
FileScanner.getInstance(Context).clear();
```
清除数据库信息
``` java
FileScanner.getInstance(this).setType(String).start(FileScanner.ScannerListener())
```
setType设置要查找文件的格式(.mp3)
start开始扫描,会自动根据数据库是否为空来进行全盘扫描还是增量扫描
```java
ArrayList<FileInfo> fileInfoArrayList= FileScanner.getInstance(MainActivity.this).getAllFiles();
```
获得扫描的文件
### 使用方法
``` java
private void fileScanner() {
FileScanner.getInstance(this).clear();
FileScanner.getInstance(this).setType(".png").start(new FileScanner.ScannerListener() {
/**
* 扫描开始
*/
@Override
public void onScanBegin() {
Log.d(TAG, "onScanBegin: ");
}
/**
* 扫描结束
*/
@Override
public void onScanEnd() {
Log.d(TAG, "onScanEnd: ");
ArrayList<FileInfo> fileInfoArrayList= FileScanner.getInstance(MainActivity.this).getAllFiles();
for (FileInfo fileInfo : fileInfoArrayList) {
Log.d(TAG, "fileScanner: "+fileInfo.getFilePath());
}
}
/**
* 扫描进行中
* @param paramString 文件夹地址
* @param progress 扫描进度
*/
@Override
public void onScanning(String paramString, int progress) {
Log.d(TAG, "onScanning: " + progress);
}
/**
* 扫描进行中,文件的更新
* @param info
* @param type SCANNER_TYPE_ADD:添加;SCANNER_TYPE_DEL:删除
*/
@Override
public void onScanningFiles(FileInfo info, int type) {
Log.d(TAG, "onScanningFiles: info=" + info.toString());
}
});
}
``` | 2,585 | MIT |
---
title: Java 复习提纲
date: 2019-01-10 00:00:00
tags:
- Java
categories:
- review
---
* 垃圾回收 `System.gc()`
## Chapter 01
* 数据类型
类型|容量(bit)|范围|包装器
:-|:-|:-|:-
boolean|1|true\false|Boolean
char|16|Unicode|Character
byte|8|$[-128,127]$|Byte
short|16|$[-2^{15},2^{15}-1]$|Short
int|32|$[-2^{31},2^{31}-1]$|Integer
Long|64|$[-2^{63},2^{63}-1]$|Long
float|32|$3.4*10^{38}$|Long
double|64|$1.7*10^{308}$|Double
void|-|-|Void
* 自动类型转换
* byte,short,char—> int —> long—> float —> double
* 数据类型转换`int a = (int)3.14159`
* Package
* Import
* Class
* Field
* Method
* Object
* Constract and Initialization
* Access Control
* Java修饰符
* 访问控制修饰符 : default, public , protected, private
* 非访问控制修饰符 : final, abstract, static, synchronized
* 继承
* 在Java中,一个类可以由其他类派生。如果你要创建一个类,而且已经存在一个类具有你所需要的属性或方法,那么你可以将新创建的类继承该类。
* 利用继承的方法,可以重用已存在类的方法和属性,而不用重写这些代码。被继承的类称为超类(super class),派生类称为子类(subclass)。
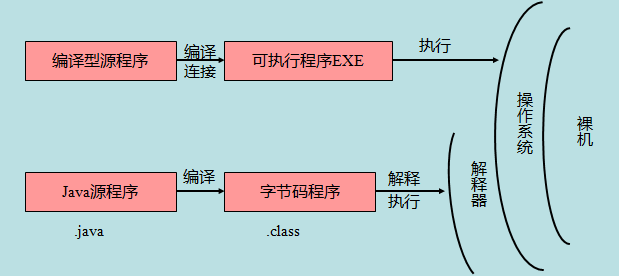
* Java 源程序与编译型运行区别
* 一个类可以包含以下类型变量:
* 局部变量:在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁。
* 局部变量声明在方法、构造方法或者语句块中;
* 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,变量将会被销毁;
* 访问修饰符不能用于局部变量;
* 局部变量只在声明它的方法、构造方法或者语句块中可见;
* 局部变量是在栈上分配的。
* 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
* 成员变量:成员变量是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中方法、构造方法和特定类的语句块访问。
* 类变量:类变量也声明在类中,方法体之外,但必须声明为static类型。
* 类变量也称为静态变量,在类中以static关键字声明,但必须在方法构造方法和语句块之外。
* 无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。
* 静态变量除了被声明为常量外很少使用。常量是指声明为public/private,final和static类型的变量。常量初始化后不可改变。
* 静态变量储存在静态存储区。经常被声明为常量,很少单独使用static声明变量。
* 静态变量在第一次被访问时创建,在程序结束时销毁。
* 与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为public类型。
* 默认值和实例变量相似。数值型变量默认值是0,布尔型默认值是false,引用类型默认值是null。变量的值可以在声明的时候指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。
* 静态变量可以通过:ClassName.VariableName的方式访问。
* 类变量被声明为public static final类型时,类变量名称一般建议使用大写字母。如果静态变量不是public和final类型,其命名方式与实例变量以及局部变量的命名方式一致。
* 实例变量
* 实例变量声明在一个类中,但在方法、构造方法和语句块之外;
* 当一个对象被实例化之后,每个实例变量的值就跟着确定;
* 实例变量在对象创建的时候创建,在对象被销毁的时候销毁;
* 实例变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息;
* 实例变量可以声明在使用前或者使用后;
* 访问修饰符可以修饰实例变量;
* 实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见;
* 实例变量具有默认值。数值型变量的默认值是0,布尔型变量的默认值是false,引用类型变量的默认值是null。变量的值可以在声明时指定,也可以在构造方法中指定;
* 实例变量可以直接通过变量名访问。但在静态方法以及其他类中,就应该使用完全限定名:ObejectReference.VariableName。
* 一个类可以拥有多个方法,在上面的例子中:barking()、hungry()和sleeping()都是Dog类的方法。
* 源文件声明规则
* 一个源文件中只能有一个public类
* 一个源文件可以有多个非public类
* 源文件的名称应该和public类的类名保持一致。例如:源文件中public类的类名是Employee,那么源文件应该命名为Employee.java。
* 如果一个类定义在某个包中,那么package语句应该在源文件的首行。
* 如果源文件包含import语句,那么应该放在package语句和类定义之间。如果没有package语句,那么import语句应该在源文件中最前面。
* import语句和package语句对源文件中定义的所有类都有效。在同一源文件中,不能给不同的类不同的包声明。
* 接口
* 在Java中,接口可理解为对象间相互通信的协议。接口在继承中扮演着很重要的角色。
* 接口只定义派生要用到的方法,但是方法的具体实现完全取决于派生类。
* 继承关键字
* 继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承object(这个类在 java.lang 包中,所以不需要 import)祖先类。
* extends关键字
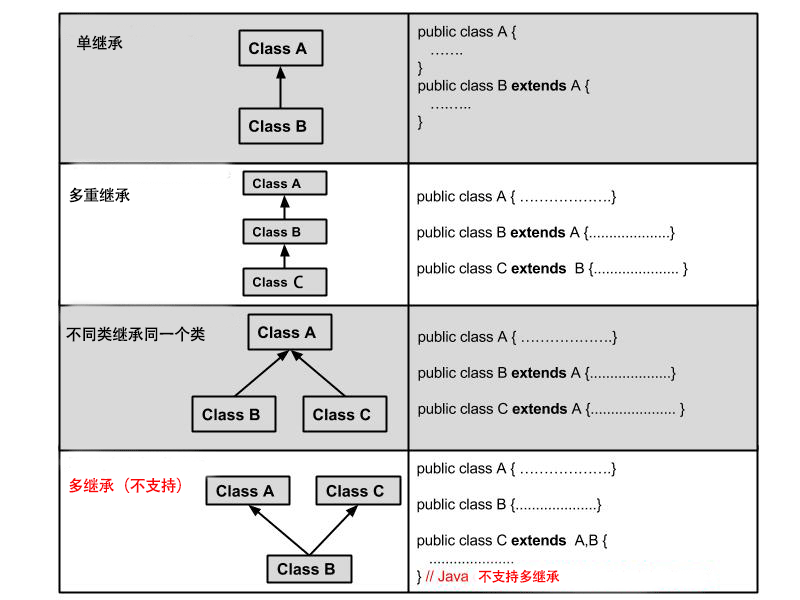
* 在 Java 中,类的继承是单一继承,也就是说,一个子类只能拥有一个父类,所以 extends 只能继承一个类。
* implements关键字
* 使用 implements 关键字可以变相的使java具有多继承的特性,使用范围为类继承接口的情况,可以同时继承多个接口(接口跟接口之间采用逗号分隔)。
* super 与 this 关键字
* super关键字:我们可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。
* this关键字:指向自己的引用。
* final关键字
* final 关键字声明类可以把类定义为不能继承的,即最终类;或者用于修饰方法,该方法不能被子类重写:
* 声明类:
* final class 类名 {//类体}
* 声明方法:
* 修饰符(public/private/default/protected) final 返回值类型 方法名(){//方法体}
* 构造器
* 子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式)。如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。
* 如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
* Java 抽象类
* 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
* 抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。
* 由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用。也是因为这个原因,通常在设计阶段决定要不要设计抽象类。
* 父类包含了子类集合的常见的方法,但是由于父类本身是抽象的,所以不能使用这些方法。
* 在Java中抽象类表示的是一种继承关系,一个类只能继承一个抽象类,而一个类却可以实现多个接口。
* 抽象方法
* 如果你想设计这样一个类,该类包含一个特别的成员方法,该方法的具体实现由它的子类确定,那么你可以在父类中声明该方法为抽象方法。
* Abstract关键字同样可以用来声明抽象方法,抽象方法只包含一个方法名,而没有方法体。
* 抽象方法没有定义,方法名后面直接跟一个分号,而不是花括号。
* 声明抽象方法会造成以下两个结果:
* 如果一个类包含抽象方法,那么该类必须是抽象类。
* 任何子类必须重写父类的抽象方法,或者声明自身为抽象类。
* 继承抽象方法的子类必须重写该方法。否则,该子类也必须声明为抽象类。最终,必须有子类实现该抽象方法,否则,从最初的父类到最终的子类都不能用来实例化对象。
1. 抽象类不能被实例化(初学者很容易犯的错),如果被实例化,就会报错,编译无法通过。只有抽象类的非抽象子类可以创建对象。
2. 抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
3. 抽象类中的抽象方法只是声明,不包含方法体,就是不给出方法的具体实现也就是方法的具体功能。
4. 构造方法,类方法(用static修饰的方法)不能声明为抽象方法。
5. 抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类。
Java 接口
* 接口(英文:Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
* 接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。
* 除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。
* 接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在 Java 中,接口类型可用来声明一个变量,他们可以成为一个空指针,或是被绑定在一个以此接口实现的对象。
* 接口与类相似点:
* 一个接口可以有多个方法。
* 接口文件保存在 .java 结尾的文件中,文件名使用接口名。
* 接口的字节码文件保存在 .class 结尾的文件中。
* 接口相应的字节码文件必须在与包名称相匹配的目录结构中。
* 接口与类的区别:
* 接口不能用于实例化对象。
* 接口没有构造方法。
* 接口中所有的方法必须是抽象方法。
* 接口不能包含成员变量,除了 static 和 final 变量。
* 接口不是被类继承了,而是要被类实现。
* 接口支持多继承。
* 接口特性
* 接口中每一个方法也是隐式抽象的,接口中的方法会被隐式的指定为 public abstract(只能是 public abstract,其他修饰符都会报错)。
* 接口中可以含有变量,但是接口中的变量会被隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误)。
* 接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法。
* 抽象类和接口的区别
1. 抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
2. 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的。
3. 接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。
4. 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
## Chapter 02 OOP
* Object
* Class
* Abstraction
* Inheritance
* Polymorphism
* `finalilze();`
* `Abstraction`
* `interface`
* `implements`
## Chapter 03 Exception
* 检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。
* 运行时异常: 运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。
* 错误: 错误不是异常,而是脱离程序员控制的问题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。
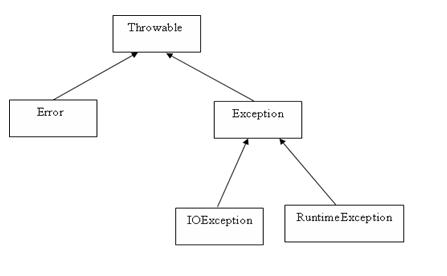
* Exception 类的层次
* 所有的异常类是从 java.lang.Exception 类继承的子类。
* Exception 类是 Throwable 类的子类。除了Exception类外,Throwable还有一个子类Error 。
* Java 程序通常不捕获错误。错误一般发生在严重故障时,它们在Java程序处理的范畴之外。
* Error 用来指示运行时环境发生的错误。
## Chapter 04 Java I/O
``` java
File file = new File("filePath/fileName");
System.out.println(file.exists());
System.out.println(file.isFile());
File[] files = file.listFlies(filter);
System.out.println(files.length);
Arrays.sort(files,comparator);
```
* Stream
* Byte stream
* java.io.InputStream
* `int read() //read a byte`
* java.io.OutputStream
* `void write(int b)`
* `void write(byte[] b)`
* FileInputStream, FileOutputStream
* PipedInputStream, PipedOutputStream
* ByteArrayInputStream, ByteArrayOutputStream
* BufferedInputStream, BufferedOutputStream
* ObjectInputStreamm ObjectOutputStream
* Character stream
* java.io.Reader
* `int read() //read a char`
* java.io.Writer
* `void write(int b)`
* `void write(char[] c)`
* FileReader, FileWriter
* PipedReader, PipedWriter
* BufferedReader, BufferedWriter
* InpputStreamReader, OutputStreamWriter
* Bridge
* InputStreamReader
* OutputStreamWriter
* FileInputStream
* ``` java
FileInputStream fis = FileInputStream(file);
int res = fis.read(); //IOException
fis.available(); //是否可用
fis.close();
```
```
```
* FileOutputStream
* ``` java
file.createNewFile()
fos.write(2);
fos.write('a');
```
```
```
* FileReader
* FileWriter
* ```java
FileWriter w = new FileWriter(new File("a.txt"),true);
w.write("Hanyuu".toCharArray());
w.flush();
```
* InputStreamReader
* OutputStreamReader
* PrintStream
* DataInputStream, DataOutputStream
* PrintWriter
* Scanner
* java.util.Scanner
* BufferedInputStream, BufferedOutputStream
* `BufferedInputStream bufferedInput = new BufferedInputStream(new FileInputStream(filename));`
* ``` java
public void testBufferedInput() {
try {
/**
* 建立输入流 BufferedInputStream, 缓冲区大小为8
* buffer.txt内容为
* abcdefghij
*/
InputStream in = new BufferedInputStream(new FileInputStream(new File("buff.txt")), 8);
/*从字节流中读取5个字节*/
byte [] tmp = new byte[5];
in.read(tmp, 0, 5);
System.out.println("字节流的前5个字节为: " + new String(tmp));
/*标记测试*/
in.mark(6);
/*读取5个字节*/
in.read(tmp, 0, 5);
System.out.println("字节流中第6到10个字节为: " + new String(tmp));
/*reset*/
in.reset();
System.out.printf("reset后读取的第一个字节为: %c" , in.read());
} catch (Exception e) {
e.printStackTrace();
}
}
```
```
* InputStreamReader
* OutputStreamReader
* System.in
* System.out
* System.err
* DataOutputStream
* DataInputStream
```
## Chapter 05 Collection
* Arrays
* java.util.Arrays
* `Arrays.sort()`
* `Arrays.fill(String[],String)`
* `Array.hashCode(String)`
* Collection
* `Set<E> //non-repeat`
* `SortedSet<E>`
* `List<E>`
* `Quene<E>`
* Map
* `HashMap<K,V>`
``` java
HashMap<Integer,String> map = new HashMap<Integer,String>();
map.put(0,"Hanyuu");
String name = map.get(0);
map.remove(0);
Set keySet = map.keySet();
Collection valueSet = map.values();
Set entrySet = map.entrySet();
```
* `SortedMap<K,V>`
* Iterator
* Seqential and Linear
* Use Array as Backend
* Varible Length
* Methods
``` java
add(Object)
add(int index,Object)
remove(Object)
get(int)
set(int)
indexOf(Objects)
clear()
Size()
toArray()
```
* ArrayList
* `ArrayList<String> list = new ArrayList<String>();`
* `ArrayList<String> list = new ArrayList<String>(100);`
* `list.ensureCapacity(1000)`
* LinkedList
``` java
LinkdList<String> list = new LinkedList<String>();
list.add("Hanyuu");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
```
## Chapter 07 UI
* java.jwt
* javax.swing
* `JFrame frame = new JFrame(String //title);`
* `frame.getContentPane().add(BorderLayout.EAST,button);`
* `frame.setSize(300,400);`
* `frame.setVisible(true);`
* `frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);`
* `Container cp = frame.getContentPane();`
* `cp.setLayout(new FloatLayout());`
* `cp.add(new JPanel)();`
* `JButton button = new JButton("Okey");`
* `JComboBox`
* `JCheckBox`
* `JPanel`
* `pnel.setLayout(new FLowLayout(FlowLayout.LEFT));`
* `JPanel //container`
* `JPanle = new JPanel();`
* `panel.add(new JTextField("Hanyuu"));`
* `JSplistPane`
* `JScrollPane`
* `Graphics`
* `JLabel`
* `getText();`
* `setText();`
* `setIcon();`
* `JTextField`
* `JCheckBox`
* `JTextArea`
* `JRadioButton`
* 事件侦听
* ActionLinstener
``` java
public class Action implements ActionListener{
public void actionPerformed(ActionEvent event){
//TODO...
}
}
JButton exp = new JButton();
exp.addActionLintener(new Action());
```
## Chapter 08 Multi-thread
1. `runnable` interface
``` java
public class Task implements Runnable{
public void run(){
//TODO...
}
}
public static void main(String[] args){
Thread thread = new Thread(new Task(),"Thread name");
thread.start();
}
```
2. Thread
``` java
public class HanyuuThread extends Thread{
public void run(){
//TODO...
}
}
public static void main(String[] args){
HanyuuThread hanyuu = new HanyuuThread();
hanyuu.setName("Hanyuu");
hanyuu.statrt();
}
```
* `Thread.sleep(int)`
* `String Thread.currentThread().getName();`
* `join`
* `interrupt()`
* `yield()`
> yield意味着放手,放弃,投降。一个调用yield()方法的线程告 诉虚拟机它乐意让其他线程占用自己的位置。这表明该线程没 有在做一些紧急的事情。注意,这仅是一个暗示,并不能保证 不会产生任何影响。 \
Yield告诉当前正在执行的线程把运行机会交给线程池中拥有相 同优先级的线程。\
Yield不能保证使得当前正在运行的线程迅速转换到可运行的状态。\
它仅能使一个线程从运行状态转到可运行状态,而不是等待或阻塞状态
* `notify()`/`notifyAll()`
* notifyAll() wakes all waiting thread, thus, all waiting thread turn to Ready
* notify() only wakes one of waiting thread, others remain blocked
* `sleep()`
* java.lang.Thread`
* `wait()`
* `java.lang.Object`
* Each object has a wait method, inherited from java.lang.Object
* wait() method ask current thread to give up exclusive control
* wait() method give other thread a chance to visit the object
* wait() / wait(long timeout)
* wait() / notifyAll() / notify()
* The object must be locked before visit these methods
* They can be used in synchronized method of an object
* Or obj.wait() / obj.notifyAll() / obj.notify() in synchorized(obj){…}
* Otherwise: java.lang.IllegalMonitorStateException
* `synchronized`
``` java
public class Hanyuu{
public synchronized void onlyOne(){
//TODO...
}
public synchronized void threadSafty(){
//TODO...
}
}
```
## Chapter 09 Java & XML
## Chapter 10 JDBC
* Record
* Field
* Table
* Entity
* Relations
* DataBase
* Primary key
* Foreign key
* Select
* `SELECT nameA FROM tableA`
* `SELECT nameA FROM tableA WHERE name > 2`
* `SELECT nameA FROM tableA WHERE (name > 2 AND name < 10) OR name >300`
* `SELECT * FROM tableA WHERE name IN ('Hanyuu','Inari')`
* `SELECT * FROM tableA WHERE date BETWEEN 'Jan-01-2019' AND 'Jan-02-2019'`
* `SELECT * FROM tableA WHERE name LIKE '%an%'`
* `SELECT * FROM tableA ORDER BY name DESC/ASC`
* `SELECT COUNT(DISTINCT name) FROM tableA`
* Insert
* `INSERT INTO tableA (name,Date) VALUES ('Inari','Jan-01-2019')`
* Retireval
* Update
* `UPDATE tableA SET date = 'Jan-01-2019' WEHERE name = 'Hanyuu'`
* Delete
* `DELETE FROM tableA WHERE name = 'Inari'`
> 你知道为什么SQL语句大家都选择大写嘛?(hhh)
``` java
package SQL;
import java.sql.*;
import javax.sql.*;
public class SQL {
public static void main(String[] args) {
// ResultSet rs;
// Statement statement;
// Connection connection;
Connection connection = null;
Statement statement = null;
ResultSet rs = null;
try {
//注册驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
//创建JDBC连接
String dbURL = "jdbc:mysql://localhost:3306/Hanyuu?user=Hanyuu&password=Hanyuu&useSSL=false&serverTimezone=GMT";
connection = DriverManager.getConnection(dbURL);
//创建statement
String sqlQuery = "SELECT DISTINCT bookname FROM bookstore";
statement = connection.createStatement();
rs = statement.executeQuery(sqlQuery);
while (rs.next()) {
System.out.println(rs.getString("bookname"));
}
String nsqlQuery = "SELECT * FROM bookstore";
rs = statement.executeQuery(nsqlQuery);
//执行查询语句
ResultSetMetaData rsmd = rs.getMetaData();
for (int i = 1; i <= rsmd.getColumnCount(); ++i) {
System.out.println(rsmd.getColumnName(i)+'\t');
}
} catch (ClassNotFoundException e) {
System.out.println("无驱动类");
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
rs.close();
statement.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
```
* 构建Prepared statement
``` java
String sql = "INSERT INTO tableA (id,name,sorce) VALUES (?,?,?)";
PreparedStatement s =connection.prepareStatement(sql);
//add a record
s.setInt(1,0000);
s.setString(2,"Hanyuu");
s.setInt(3,60);
s.addBatch();
s.clearParameters();
s.executeBatch();
s.cleatBatch();
```
## Chapter 11 Java network Programming
* IP address
* IPv4
* IPv6
* IP
* Host name
* Domain Name
* DNS
``` java
try{
//get InetAddress
InetAddress iAddress = InetAddress.getLocalHost();
//get local IP
String IP = iAddress.getHostAddress().toString();
//get local host name
String hostName = iAddress.getHostName().toString();
System.out.println("IP address"+IP);
System.out.println("Host name"+hostName);
}
catch (UnknownHostException e){
e.printStackTrace();
}catch(Exception e){
e.printStackTrace();
}
```
* 通过主机名获取所有IP
``` java
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.ArrayList;
import java.util.Iterator;
public class getLocal {
public static void main(String[] args) {
try {
InetAddress ia=InetAddress.getLocalHost();
System.out.println(ia.getHostAddress());
System.out.println(ia.getAddress());
System.out.println(ia.getHostName());
String hostName=InetAddress.getLocalHost().getHostName();
ArrayList<String> allIP=new ArrayList<String>();
if (hostName.length()>0)
{
InetAddress[] addresses=InetAddress.getAllByName(hostName);
for (int i=0;i<addresses.length;i++){
allIP.add(addresses[i].getHostAddress().toString());
}
}
for (Iterator iter=allIP.iterator();((Iterator) iter).hasNext();){
System.out.println(ier.next().toString());
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
```
* Constructor localhost InetAddress
``` java
InetAddress addr = InetAddress.getByName(null);
InetAddress addr = InetAddress.getByName("127.0.0.1");
InetAddress addr = InetAddress.getByName("localhost");
InetAddress addr = InetAddress.getLocalHost();
byte[] IP = {(byte)127,(byte)0,(byte)0,(byte)1};
```
* Web server
* FTP server
* Mail server
* Port 1-1024 is occupied by system
* client
``` java
//构建客户端socket
Socket client = new Socket("hanyuu.ml",8080);
//构建客户端socket(通过InetAddress)
InetAddress address = InetAddress.getByName("Hanyuu.ml");
Socket client = new Socket(address,8080);
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
is.close();
os.close();
```
Example
``` java
Socket socket = new Socket(ip,8008);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()),true);
out.print("Hi");
Thread.sleep(1000);
out.println("Hello");
socket.close();
```
* server
``` java
//创建服务端的ServerSocket监听客户请求
ServerSocket server = new ServerSocket(8080);
//客户端阻塞,等待连接
Socket serverSocket = server.accept();
```
Example
```java
try{
ButteredReader in =new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()),true);
while(true){
String str = in.readLine();
if (str!=null && str.equals("Hi")) out.println("Hi, here is server.");
}catch(Exception e){
e.printStackTrace();
}finally{
socket.close();
server.close();
}
}
```
* TCP
* UDP
* read a web page
``` java
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class conn {
public static void main(String[] args) {
try{
URL coseURL = new URL("http://cose.seu.edu.cn");
URLConnection connection =coseURL.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String html = in.readLine();
while(html!=null){
System.out.println(html);
html=in.readLine();
}
}catch (Exception e){
}
}
}
``` | 19,343 | MIT |
---
layout: post
title: spring boot项目自定义数据源,mybatisplus分页、逻辑删除无效解决方法
date: 2021-04-16 14:26:00 +0800
img: /assets/img/head.png # Add image post (optional)
tags: [java] # add tag
---
### Spring Boot项目中数据源的配置可以通过两种方式实现:
1.application.yml或者application.properties配置
2.注入DataSource及SqlSessionFactory两个Bean
### 通过第二种方式配置数据源则按照MybatisPlus官方文档使用分页及逻辑删除插件会无效,解决思路是在初始化SqlSessionFactory将插件设置进去
```java
/**
* 逻辑删除插件
*/
@Bean
public GlobalConfig globalConfig(){
GlobalConfig globalConfig=new GlobalConfig();
GlobalConfig.DbConfig dbConfig=new GlobalConfig.DbConfig();
dbConfig.setLogicDeleteValue("Y");
dbConfig.setLogicNotDeleteValue("N");
globalConfig.setDbConfig(dbConfig);
globalConfig.setSqlInjector(new LogicSqlInjector());
return globalConfig;
}
/**
* 分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor(){
PaginationInterceptor paginationInterceptor=new PaginationInterceptor();
paginationInterceptor.setDialectType(DbType.MYSQL.getDb());
return paginationInterceptor;
}
@Bean(name = "sqlSessionFactory")
public SqlSessionFactory sqlSessionFactory()throws Exception{
logger.info("初始化SqlSessionFactory");
String mapperLocations="classpath:mybatis/mapper/**/*.xml";
String configLocation="classpath:mybatis/mybatis-config.xml";
MybatisSqlSessionFactoryBean sqlSessionFactory=new MybatisSqlSessionFactoryBean();
sqlSessionFactory.setDataSource(dataSource()); //数据源
ResourcePatternResolver resolver=new PathMatchingResourcePatternResolver();
sqlSessionFactory.setMapperLocations(resolver.getResources(mapperLocations));
sqlSessionFactory.setConfigLocation(resolver.getResource(configLocation));
sqlSessionFactory.setTypeAliasesPackage("com.innjoy.pms.order.infrastructure.domain.model");
sqlSessionFactory.setGlobalConfig(globalConfig());
sqlSessionFactory.setPlugins(new Interceptor[]{paginationInterceptor()});
return sqlSessionFactory.getObject();
}
``` | 1,961 | MIT |
---
order: 7
title:
zh-CN: 附加额外数据
en-US: Append Extra Data
---
## zh-CN
为一个文件上传请求追加一个`FormData`实例。请查看开发者工具中的 Network 标签。
## en-US
Append an extra `FormData` instance to a file upload request. Please checkout the 'Network' tab in the developer tool.
```jsx
import { Upload } from 'choerodon-ui/pro';
const props = {
headers: {
'Access-Control-Allow-Origin': '*',
},
action: 'https://www.mocky.io/v2/5cc8019d300000980a055e76',
multiple: true,
accept: ['.deb', '.txt', '.pdf', 'image/*'],
uploadImmediately: false,
data: {
key1: 'value1',
key2: 'value2',
},
onUploadSuccess: response => console.log(response),
};
ReactDOM.render(
<div>
<Upload {...props} />
</div>,
mountNode,
);
``` | 733 | MIT |
<properties
pageTitle="Azure Management API 証明書のアップロード | Azure Microsoft"
description="Azure クラシック ポータルの Management API 証明書をアップロードする方法について説明します。"
services="cloud-services"
documentationCenter=".net"
authors="Thraka"
manager="timlt"
editor=""/>
<tags
ms.service="na"
ms.workload="tbd"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="04/18/2016"
ms.author="adegeo"/>
# Azure Management API Management 証明書のアップロード
Azure のサービス管理 API に対する認証は、管理証明書で行うことができます。これらの証明書は、各種 Azure サービスの構成とデプロイメントを自動化するために、今後多くのプログラムおよびツール (Visual Studio、Azure SDK など) で使用されることになります。**これは Azure クラシック ポータルにのみ適用されます**。
>[AZURE.WARNING] ご注意ください。 これらの種類の証明書を使用して認証する場合、関連付けられているサブスクリプションを管理できます。
Azure の証明書の詳細 (自己署名証明書の作成を含む) については、[こちら](cloud-services/cloud-services-certs-create.md#what-are-management-certificates)をご覧ください。
クライアント コードの認証に [Azure Active Directory](/services/active-directory/) を使用することで自動化を図ることもできます。
## 管理証明書のアップロード
管理証明書 (公開キーのみを含んだ .cer ファイル) を作成したら、それをポータルにアップロードすることができます。ポータルで証明書が使用可能な状態になると、対になる証明書 (秘密キー) を持つすべての人が、Management API を経由して接続し、そのサブスクリプションに関連付けられているリソースにアクセスすることができます。
1. [Azure クラシック ポータル](http://manage.windowsazure.com)にログインします。
2. ポータルの左側にある **[設定]** をクリックします (必要に応じて下へスクロールしてください)。

3. **[管理証明書]** タブをクリックします。

4. **[アップロード]** ボタンをクリックします。

5. ダイアログの情報を入力し、確認のための**チェックマーク**をクリックします。

## 次のステップ
サブスクリプションへの管理証明書の関連付けはこれで完了です。対になる証明書がローカルにインストールされていれば、プログラムから [Service Management REST API](https://msdn.microsoft.com/library/azure/mt420159.aspx) に接続し、同じサブスクリプションに関連付けられているさまざまな Azure リソースを自動化できます。
<!---HONumber=AcomDC_0511_2016--> | 1,870 | CC-BY-3.0 |
#### 目录介绍
- 01.使用Intent
- 02.使用文件共享
- 03.使用Messenger
- 04.使用AIDL
- 05.使用ContentProvider
- 06.使用Socket
### 好消息
- 博客笔记大汇总【16年3月到至今】,包括Java基础及深入知识点,Android技术博客,Python学习笔记等等,还包括平时开发中遇到的bug汇总,当然也在工作之余收集了大量的面试题,长期更新维护并且修正,持续完善……开源的文件是markdown格式的!同时也开源了生活博客,从12年起,积累共计N篇[近100万字,陆续搬到网上],转载请注明出处,谢谢!
- **链接地址:https://github.com/yangchong211/YCBlogs**
- 如果觉得好,可以star一下,谢谢!当然也欢迎提出建议,万事起于忽微,量变引起质变!
### 01.使用Intent
- 1.Activity,Service,Receiver 都支持在 Intent 中传递 Bundle 数据,而 Bundle 实现了 Parcelable 接口,可以在不同的进程间进行传输。
- 2.在一个进程中启动了另一个进程的 Activity,Service 和 Receiver ,可以在 Bundle 中附加要传递的数据通过 Intent 发送出去。
### 02.使用文件共享
- 1.Windows 上,一个文件如果被加了排斥锁会导致其他线程无法对其进行访问,包括读和写;而 Android 系统基于 Linux ,使得其并发读取文件没有限制地进行,甚至允许两个线程同时对一个文件进行读写操作,尽管这样可能会出问题。
- 2.可以在一个进程中序列化一个对象到文件系统中,在另一个进程中反序列化恢复这个对象(**注意**:并不是同一个对象,只是内容相同。)。
- 3.SharedPreferences 是个特例,系统对它的读 / 写有一定的缓存策略,即内存中会有一份 ShardPreferences 文件的缓存,系统对他的读 / 写就变得不可靠,当面对高并发的读写访问,SharedPreferences 有很多大的几率丢失数据。因此,IPC 不建议采用 SharedPreferences。
### 03.使用Messenger
- Messenger 是一种轻量级的 IPC 方案,它的底层实现是 AIDL ,可以在不同进程中传递 Message 对象,它一次只处理一个请求,在服务端不需要考虑线程同步的问题,服务端不存在并发执行的情形。
- 服务端进程:
- 服务端创建一个 Service 来处理客户端请求,同时通过一个 Handler 对象来实例化一个 Messenger 对象,然后在 Service 的 onBind 中返回这个 Messenger 对象底层的 Binder 即可。
```java
public class MessengerService extends Service {
private static final String TAG = MessengerService.class.getSimpleName();
private class MessengerHandler extends Handler {
/**
* @param msg
*/
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case Constants.MSG_FROM_CLIENT:
Log.d(TAG, "receive msg from client: msg = [" + msg.getData().getString(Constants.MSG_KEY) + "]");
Toast.makeText(MessengerService.this, "receive msg from client: msg = [" + msg.getData().getString(Constants.MSG_KEY) + "]", Toast.LENGTH_SHORT).show();
Messenger client = msg.replyTo;
Message replyMsg = Message.obtain(null, Constants.MSG_FROM_SERVICE);
Bundle bundle = new Bundle();
bundle.putString(Constants.MSG_KEY, "我已经收到你的消息,稍后回复你!");
replyMsg.setData(bundle);
try {
client.send(replyMsg);
} catch (RemoteException e) {
e.printStackTrace();
}
break;
default:
super.handleMessage(msg);
}
}
}
private Messenger mMessenger = new Messenger(new MessengerHandler());
@Nullable
@Override
public IBinder onBind(Intent intent) {
return mMessenger.getBinder();
}
}
```
- 客户端进程:
- 首先绑定服务端 Service ,绑定成功之后用服务端的 IBinder 对象创建一个 Messenger ,通过这个 Messenger 就可以向服务端发送消息了,消息类型是 Message 。如果需要服务端响应,则需要创建一个 Handler 并通过它来创建一个 Messenger(和服务端一样),并通过 Message 的 replyTo 参数传递给服务端。服务端通过 Message 的 replyTo 参数就可以回应客户端了。
```Java
public class MainActivity extends AppCompatActivity {
private static final String TAG = MainActivity.class.getSimpleName();
private Messenger mGetReplyMessenger = new Messenger(new MessageHandler());
private Messenger mService;
private class MessageHandler extends Handler {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case Constants.MSG_FROM_SERVICE:
Log.d(TAG, "received msg form service: msg = [" + msg.getData().getString(Constants.MSG_KEY) + "]");
Toast.makeText(MainActivity.this, "received msg form service: msg = [" + msg.getData().getString(Constants.MSG_KEY) + "]", Toast.LENGTH_SHORT).show();
break;
default:
super.handleMessage(msg);
}
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
public void bindService(View v) {
Intent mIntent = new Intent(this, MessengerService.class);
bindService(mIntent, mServiceConnection, Context.BIND_AUTO_CREATE);
}
public void sendMessage(View v) {
Message msg = Message.obtain(null,Constants.MSG_FROM_CLIENT);
Bundle data = new Bundle();
data.putString(Constants.MSG_KEY, "Hello! This is client.");
msg.setData(data);
msg.replyTo = mGetReplyMessenger;
try {
mService.send(msg);
} catch (RemoteException e) {
e.printStackTrace();
}
}
@Override
protected void onDestroy() {
unbindService(mServiceConnection);
super.onDestroy();
}
private ServiceConnection mServiceConnection = new ServiceConnection() {
/**
* @param name
* @param service
*/
@Override
public void onServiceConnected(ComponentName name, IBinder service) {
mService = new Messenger(service);
Message msg = Message.obtain(null,Constants.MSG_FROM_CLIENT);
Bundle data = new Bundle();
data.putString(Constants.MSG_KEY, "Hello! This is client.");
msg.setData(data);
//
msg.replyTo = mGetReplyMessenger;
try {
mService.send(msg);
} catch (RemoteException e) {
e.printStackTrace();
}
}
/**
* @param name
*/
@Override
public void onServiceDisconnected(ComponentName name) {
}
};
}
```
- **注意:**客户端和服务端是通过拿到对方的 Messenger 来发送 Message 的。
- 客户端通过 bindService onServiceConnected 而服务端通过 message.replyTo 来获得对方的 Messenger 。Messenger中有一个Hanlder以串行的方式处理队列中的消息。不存在并发执行,因此我们不用考虑线程同步的问题。
### 04.使用AIDL
- Messenger 是以串行的方式处理客户端发来的消息,如果大量消息同时发送到服务端,服务端只能一个一个处理,所以大量并发请求就不适合用Messenger,而且Messenger只适合传递消息,不能跨进程调用服务端的方法。
- AIDL 可以解决并发和跨进程调用方法的问题,要知道Messenger本质上也是AIDL,只不过系统做了封装方便上层的调用而已。
#### 4.1 AIDL文件支持的数据类型
- *基本数据类型*;
- *String* 和 *CharSequence*
- [](http://images.cnitblog.com/blog/497634/201311/08083111-591e2833f8a34264b0dad417f4188e35.jpg)
- *ArrayList* ,里面的元素必须能够被 AIDL 支持;
- *HashMap* ,里面的元素必须能够被 AIDL 支持;
- *Parcelable* ,实现 Parcelable 接口的对象;
**注意:如果 AIDL 文件中用到了自定义的 Parcelable 对象,必须新建一个和它同名的 AIDL 文件。**
- *AIDL* ,AIDL 接口本身也可以在 AIDL 文件中使用。
#### 4.2 服务端
- 服务端创建一个 Service 用来监听客户端的连接请求,然后创建一个 AIDL 文件,将暴露给客户端的接口在这个 AIDL 文件中声明,最后在 Service 中实现这个 AIDL 接口即可。
#### 4.3客户端
- 绑定服务端的 Service ,绑定成功后,将服务端返回的 Binder 对象转成 AIDL 接口所属的类型,然后就可以调用 AIDL 中的方法了。客户端调用远程服务的方法,被调用的方法运行在服务端的 Binder 线程池中,同时客户端的线程会被挂起,如果服务端方法执行比较耗时,就会导致客户端线程长时间阻塞,导致 ANR 。客户端的 onServiceConnected 和 onServiceDisconnected 方法都在 UI 线程中。
### 05.使用ContentProvider
- 用于不同应用间数据共享,和 Messenger 底层实现同样是 Binder 和 AIDL,系统做了封装,使用简单。
- 系统预置了许多 ContentProvider ,如通讯录、日程表,需要跨进程访问。使用方法:继承 ContentProvider 类实现 6 个抽象方法,这六个方法均运行在 ContentProvider 进程中,除 onCreate 运行在主线程里,其他五个方法均由外界回调运行在 Binder 线程池中。ContentProvider 的底层数据,可以是 SQLite 数据库,可以是文件,也可以是内存中的数据。
- 详见代码:
```
public class BookProvider extends ContentProvider {
private static final String TAG = "BookProvider";
public static final String AUTHORITY = "com.jc.ipc.Book.Provider";
public static final Uri BOOK_CONTENT_URI = Uri.parse("content://" + AUTHORITY + "/book");
public static final Uri USER_CONTENT_URI = Uri.parse("content://" + AUTHORITY + "/user");
public static final int BOOK_URI_CODE = 0;
public static final int USER_URI_CODE = 1;
private static final UriMatcher sUriMatcher = new UriMatcher(UriMatcher.NO_MATCH);
static {
sUriMatcher.addURI(AUTHORITY, "book", BOOK_URI_CODE);
sUriMatcher.addURI(AUTHORITY, "user", USER_URI_CODE);
}
private Context mContext;
private SQLiteDatabase mDB;
@Override
public boolean onCreate() {
mContext = getContext();
initProviderData();
return true;
}
private void initProviderData() {
//不建议在 UI 线程中执行耗时操作
mDB = new DBOpenHelper(mContext).getWritableDatabase();
mDB.execSQL("delete from " + DBOpenHelper.BOOK_TABLE_NAME);
mDB.execSQL("delete from " + DBOpenHelper.USER_TABLE_NAME);
mDB.execSQL("insert into book values(3,'Android');");
mDB.execSQL("insert into book values(4,'iOS');");
mDB.execSQL("insert into book values(5,'Html5');");
mDB.execSQL("insert into user values(1,'haohao',1);");
mDB.execSQL("insert into user values(2,'nannan',0);");
}
@Nullable
@Override
public Cursor query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder) {
Log.d(TAG, "query, current thread"+ Thread.currentThread());
String table = getTableName(uri);
if (table == null) {
throw new IllegalArgumentException("Unsupported URI" + uri);
}
return mDB.query(table, projection, selection, selectionArgs, null, null, sortOrder, null);
}
@Nullable
@Override
public String getType(Uri uri) {
Log.d(TAG, "getType");
return null;
}
@Nullable
@Override
public Uri insert(Uri uri, ContentValues values) {
Log.d(TAG, "insert");
String table = getTableName(uri);
if (table == null) {
throw new IllegalArgumentException("Unsupported URI" + uri);
}
mDB.insert(table, null, values);
// 通知外界 ContentProvider 中的数据发生变化
mContext.getContentResolver().notifyChange(uri, null);
return uri;
}
@Override
public int delete(Uri uri, String selection, String[] selectionArgs) {
Log.d(TAG, "delete");
String table = getTableName(uri);
if (table == null) {
throw new IllegalArgumentException("Unsupported URI" + uri);
}
int count = mDB.delete(table, selection, selectionArgs);
if (count > 0) {
mContext.getContentResolver().notifyChange(uri, null);
}
return count;
}
@Override
public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs) {
Log.d(TAG, "update");
String table = getTableName(uri);
if (table == null) {
throw new IllegalArgumentException("Unsupported URI" + uri);
}
int row = mDB.update(table, values, selection, selectionArgs);
if (row > 0) {
getContext().getContentResolver().notifyChange(uri, null);
}
return row;
}
private String getTableName(Uri uri) {
String tableName = null;
switch (sUriMatcher.match(uri)) {
case BOOK_URI_CODE:
tableName = DBOpenHelper.BOOK_TABLE_NAME;
break;
case USER_URI_CODE:
tableName = DBOpenHelper.USER_TABLE_NAME;
break;
default:
break;
}
return tableName;
}
}
```
- DBOpenHelper代码如下所示
```java
public class DBOpenHelper extends SQLiteOpenHelper {
private static final String DB_NAME = "book_provider.db";
public static final String BOOK_TABLE_NAME = "book";
public static final String USER_TABLE_NAME = "user";
private static final int DB_VERSION = 1;
private String CREATE_BOOK_TABLE = "CREATE TABLE IF NOT EXISTS "
+ BOOK_TABLE_NAME + "(_id INTEGER PRIMARY KEY," + "name TEXT)";
private String CREATE_USER_TABLE = "CREATE TABLE IF NOT EXISTS "
+ USER_TABLE_NAME + "(_id INTEGER PRIMARY KEY," + "name TEXT,"
+ "sex INT)";
public DBOpenHelper(Context context) {
super(context, DB_NAME, null, DB_VERSION);
}
@Override
public void onCreate(SQLiteDatabase db) {
db.execSQL(CREATE_BOOK_TABLE);
db.execSQL(CREATE_USER_TABLE);
}
@Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
}
}
```
- 测试代码
```java
public class ProviderActivity extends AppCompatActivity {
private static final String TAG = ProviderActivity.class.getSimpleName();
private TextView displayTextView;
private Handler mHandler;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_provider);
displayTextView = (TextView) findViewById(R.id.displayTextView);
mHandler = new Handler();
getContentResolver().registerContentObserver(BookProvider.BOOK_CONTENT_URI, true, new ContentObserver(mHandler) {
@Override
public boolean deliverSelfNotifications() {
return super.deliverSelfNotifications();
}
@Override
public void onChange(boolean selfChange) {
super.onChange(selfChange);
}
@Override
public void onChange(boolean selfChange, Uri uri) {
Toast.makeText(ProviderActivity.this, uri.toString(), Toast.LENGTH_SHORT).show();
super.onChange(selfChange, uri);
}
});
}
public void insert(View v) {
ContentValues values = new ContentValues();
values.put("_id",1123);
values.put("name", "三国演义");
getContentResolver().insert(BookProvider.BOOK_CONTENT_URI, values);
}
public void delete(View v) {
getContentResolver().delete(BookProvider.BOOK_CONTENT_URI, "_id = 4", null);
}
public void update(View v) {
ContentValues values = new ContentValues();
values.put("_id",1123);
values.put("name", "三国演义新版");
getContentResolver().update(BookProvider.BOOK_CONTENT_URI, values , "_id = 1123", null);
}
public void query(View v) {
Cursor bookCursor = getContentResolver().query(BookProvider.BOOK_CONTENT_URI, new String[]{"_id", "name"}, null, null, null);
StringBuilder sb = new StringBuilder();
while (bookCursor.moveToNext()) {
Book book = new Book(bookCursor.getInt(0),bookCursor.getString(1));
sb.append(book.toString()).append("\n");
}
sb.append("--------------------------------").append("\n");
bookCursor.close();
Cursor userCursor = getContentResolver().query(BookProvider.USER_CONTENT_URI, new String[]{"_id", "name", "sex"}, null, null, null);
while (userCursor.moveToNext()) {
sb.append(userCursor.getInt(0))
.append(userCursor.getString(1)).append(" ,")
.append(userCursor.getInt(2)).append(" ,")
.append("\n");
}
sb.append("--------------------------------");
userCursor.close();
displayTextView.setText(sb.toString());
}
}
```
### 06.使用Socket
> Socket起源于 Unix,而 Unix 基本哲学之一就是“一切皆文件”,都可以用“打开 open –读写 write/read –关闭 close ”模式来操作。Socket 就是该模式的一个实现,网络的 Socket 数据传输是一种特殊的 I/O,Socket 也是一种文件描述符。Socket 也具有一个类似于打开文件的函数调用: Socket(),该函数返回一个整型的Socket 描述符,随后的连接建立、数据传输等操作都是通过该 Socket 实现的。
> 常用的 Socket 类型有两种:流式 Socket(SOCK_STREAM)和数据报式 Socket(SOCK_DGRAM)。流式是一种面向连接的 Socket,针对于面向连接的 TCP 服务应用;数据报式 Socket 是一种无连接的 Socket ,对应于无连接的 UDP 服务应用。
- Socket 本身可以传输任意字节流。谈到Socket,就必须要说一说 TCP/IP 五层网络模型:
- 应用层:规定应用程序的数据格式,主要的协议 HTTP,FTP,WebSocket,POP3 等;
- 传输层:建立“端口到端口” 的通信,主要的协议:TCP,UDP;
- 网络层:建立”主机到主机”的通信,主要的协议:IP,ARP ,IP 协议的主要作用:一个是为每一台计算机分配 IP 地址,另一个是确定哪些地址在同一子网;
- 数据链路层:确定电信号的分组方式,主要的协议:以太网协议;
- 物理层:负责电信号的传输。
- **Socket 是连接应用层与传输层之间接口(API)。**
- [](https://github.com/astaxie/build-web-application-with-golang/raw/master/zh/images/8.1.socket.png?raw=true)
#### 5.1Client 端代码:
- 代码如下所示
```
public class TCPClientActivity extends AppCompatActivity implements View.OnClickListener{
private static final String TAG = "TCPClientActivity";
public static final int MSG_RECEIVED = 0x10;
public static final int MSG_READY = 0x11;
private EditText editText;
private TextView textView;
private PrintWriter mPrintWriter;
private Socket mClientSocket;
private Button sendBtn;
private StringBuilder stringBuilder;
private Handler mHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_READY:
sendBtn.setEnabled(true);
break;
case MSG_RECEIVED:
stringBuilder.append(msg.obj).append("\n");
textView.setText(stringBuilder.toString());
break;
default:
super.handleMessage(msg);
}
}
};
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.tcp_client_activity);
editText = (EditText) findViewById(R.id.editText);
textView = (TextView) findViewById(R.id.displayTextView);
sendBtn = (Button) findViewById(R.id.sendBtn);
sendBtn.setOnClickListener(this);
sendBtn.setEnabled(false);
stringBuilder = new StringBuilder();
Intent intent = new Intent(TCPClientActivity.this, TCPServerService.class);
startService(intent);
new Thread(){
@Override
public void run() {
connectTcpServer();
}
}.start();
}
private String formatDateTime(long time) {
return new SimpleDateFormat("(HH:mm:ss)").format(new Date(time));
}
private void connectTcpServer() {
Socket socket = null;
while (socket == null) {
try {
socket = new Socket("localhost", 8888);
mClientSocket = socket;
mPrintWriter = new PrintWriter(new BufferedWriter(
new OutputStreamWriter(socket.getOutputStream())
), true);
mHandler.sendEmptyMessage(MSG_READY);
} catch (IOException e) {
e.printStackTrace();
}
}
// receive message
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
} catch (IOException e) {
e.printStackTrace();
}
while (!isFinishing()) {
try {
String msg = bufferedReader.readLine();
if (msg != null) {
String time = formatDateTime(System.currentTimeMillis());
String showedMsg = "server " + time + ":" + msg
+ "\n";
mHandler.obtainMessage(MSG_RECEIVED, showedMsg).sendToTarget();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void onClick(View v) {
if (mPrintWriter != null) {
String msg = editText.getText().toString();
mPrintWriter.println(msg);
editText.setText("");
String time = formatDateTime(System.currentTimeMillis());
String showedMsg = "self " + time + ":" + msg + "\n";
stringBuilder.append(showedMsg);
}
}
@Override
protected void onDestroy() {
if (mClientSocket != null) {
try {
mClientSocket.shutdownInput();
mClientSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
super.onDestroy();
}
}
```
#### 5.2 Server 端代码
- 代码如下所示
```java
public class TCPServerService extends Service {
private static final String TAG = "TCPServerService";
private boolean isServiceDestroyed = false;
private String[] mMessages = new String[]{
"Hello! Body!",
"用户不在线!请稍后再联系!",
"请问你叫什么名字呀?",
"厉害了,我的哥!",
"Google 不需要科学上网是真的吗?",
"扎心了,老铁!!!"
};
@Override
public void onCreate() {
new Thread(new TCPServer()).start();
super.onCreate();
}
@Override
public void onDestroy() {
isServiceDestroyed = true;
super.onDestroy();
}
@Nullable
@Override
public IBinder onBind(Intent intent) {
return null;
}
private class TCPServer implements Runnable {
@Override
public void run() {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8888);
} catch (IOException e) {
e.printStackTrace();
return;
}
while (!isServiceDestroyed) {
// receive request from client
try {
final Socket client = serverSocket.accept();
Log.d(TAG, "=============== accept ==================");
new Thread(){
@Override
public void run() {
try {
responseClient(client);
} catch (IOException e) {
e.printStackTrace();
}
}
}.start();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
private void responseClient(Socket client) throws IOException {
//receive message
BufferedReader in = new BufferedReader(
new InputStreamReader(client.getInputStream()));
//send message
PrintWriter out = new PrintWriter(
new BufferedWriter(
new OutputStreamWriter(
client.getOutputStream())),true);
out.println("欢迎来到聊天室!");
while (!isServiceDestroyed) {
String str = in.readLine();
Log.d(TAG, "message from client: " + str);
if (str == null) {
return;
}
Random random = new Random();
int index = random.nextInt(mMessages.length);
String msg = mMessages[index];
out.println(msg);
Log.d(TAG, "send Message: " + msg);
}
out.close();
in.close();
client.close();
}
}
```
### 其他介绍
#### 01.关于博客汇总链接
- 1.[技术博客汇总](https://www.jianshu.com/p/614cb839182c)
- 2.[开源项目汇总](https://blog.csdn.net/m0_37700275/article/details/80863574)
- 3.[生活博客汇总](https://blog.csdn.net/m0_37700275/article/details/79832978)
- 4.[喜马拉雅音频汇总](https://www.jianshu.com/p/f665de16d1eb)
- 5.[其他汇总](https://www.jianshu.com/p/53017c3fc75d)
#### 02.关于我的博客
- github:https://github.com/yangchong211
- 知乎:https://www.zhihu.com/people/yczbj/activities
- 简书:http://www.jianshu.com/u/b7b2c6ed9284
- csdn:http://my.csdn.net/m0_37700275
- 喜马拉雅听书:http://www.ximalaya.com/zhubo/71989305/
- 开源中国:https://my.oschina.net/zbj1618/blog
- 泡在网上的日子:http://www.jcodecraeer.com/member/content_list.php?channelid=1
- 邮箱:yangchong211@163.com
- 阿里云博客:https://yq.aliyun.com/users/article?spm=5176.100- 239.headeruserinfo.3.dT4bcV
- segmentfault头条:https://segmentfault.com/u/xiangjianyu/articles
- 掘金:https://juejin.im/user/5939433efe88c2006afa0c6e | 25,921 | Apache-2.0 |
# CsprojModifier
CsprojModifier は Unity Editor が .csproj を生成する際に追加の処理を行うことで、Visual Studio や Rider のような IDE での開発体験を向上させます。
CsprojModifier は次の特徴を備えています:
- 生成された .csproj に追加のプロジェクトを `Import` 要素で追加する
- 生成された .csproj に Analzyer の参照を追加する
- 2020.2 以降で Rider または Visual Studio Code を利用している場合には無効

<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
## Table of Contents
- [Works with](#works-with)
- [Install](#install)
- [Features](#features)
- [生成された .csproj に追加のプロジェクトを `Import` 要素で追加する](#%E7%94%9F%E6%88%90%E3%81%95%E3%82%8C%E3%81%9F-csproj-%E3%81%AB%E8%BF%BD%E5%8A%A0%E3%81%AE%E3%83%97%E3%83%AD%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88%E3%82%92-import-%E8%A6%81%E7%B4%A0%E3%81%A7%E8%BF%BD%E5%8A%A0%E3%81%99%E3%82%8B)
- [例](#%E4%BE%8B)
- [追加のプロジェクトファイル (.props, .targets) の内容を直接 .csproj に追加する](#%E8%BF%BD%E5%8A%A0%E3%81%AE%E3%83%97%E3%83%AD%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB-props-targets-%E3%81%AE%E5%86%85%E5%AE%B9%E3%82%92%E7%9B%B4%E6%8E%A5-csproj-%E3%81%AB%E8%BF%BD%E5%8A%A0%E3%81%99%E3%82%8B)
- [生成された .csproj に Analzyer の参照を追加する](#%E7%94%9F%E6%88%90%E3%81%95%E3%82%8C%E3%81%9F-csproj-%E3%81%AB-analzyer-%E3%81%AE%E5%8F%82%E7%85%A7%E3%82%92%E8%BF%BD%E5%8A%A0%E3%81%99%E3%82%8B)
- [使用方法](#%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95)
- [License](#license)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
## Works with
- Unity Editor 2019.4 (LTS) or later
- Visual Studio 2019 or Rider
## Install
Package Manager から git 経由でインストールします。
```
https://github.com/Cysharp/CsprojModifier.git?path=src/CsprojModifier/Assets/CsprojModifier
```
## Features
### 生成された .csproj に追加のプロジェクトを `Import` 要素で追加する
任意の追加のプロジェクトファイル (.props や .target) を生成された .csproj に `Import` 要素を使用して追加します。これによりプロジェクトにファイルを追加したり、参照を追加したりが可能になります。
**注意:** .csproj は Visual Studio や Rider のような IDE でのみ使用され、 Unity Editor での実際のビルドには使用されません
#### 例
例えば、次のような `YourAwesomeApp.DesignTime.props` というファイルを作成し、インポートすることで [BannedApiAnalyzer](https://github.com/dotnet/roslyn-analyzers/tree/main/src/Microsoft.CodeAnalysis.BannedApiAnalyzers) を使用できます。
```xml
<Project xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<ItemGroup>
<Analyzer Include="Assets/Plugins/Editor/Analyzers/Microsoft.CodeAnalysis.BannedApiAnalyzers.dll" />
<Analyzer Include="Assets/Plugins/Editor/Analyzers/Microsoft.CodeAnalysis.CSharp.BannedApiAnalyzers.dll" />
</ItemGroup>
<ItemGroup>
<AdditionalFiles Include="$(ProjectDir)\BannedSymbols.txt" />
</ItemGroup>
</Project>
```
[BannedApiAnalyzer](https://github.com/dotnet/roslyn-analyzers/tree/main/src/Microsoft.CodeAnalysis.BannedApiAnalyzers) は BannedSymbols.txt が `AdditionalFiles` としてプロジェクトに追加されていることを期待しているため、これによってうまく機能するようになります。
#### 追加のプロジェクトファイル (.props, .targets) の内容を直接 .csproj に追加する
挿入位置として `Append Content` または `Prepend Content` を指定した場合、CsProjModifier は XML を読み込んで要素を直接 .csproj に注入します。
```xml
<!-- * Example: `Prepend: MyApp.Unity.props` -->
<Project ToolsVersion="4.0" DefaultTargets="Build" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<!--MyApp.Unity.props:HASH-->
<Import Project="MyApp.Unity.props" />
<!-- .csproj content generated by Unity Editor -->
<!-- ... -->
</Project>
<!-- * Example: `Prepend Content: MyApp.Unity.props` -->
<Project ToolsVersion="4.0" DefaultTargets="Build" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<!--MyApp.Unity.props:HASH-->
<ItemGroup>
<!-- ... -->
<!-- ... -->
<!-- ... -->
</ItemGroup>
<!-- .csproj content generated by Unity Editor -->
<!-- ... -->
</Project>
```
### 生成された .csproj に Analzyer の参照を追加する
**注意**: Rider または Visual Studio Code を Unity 2020.2 以降で使用している場合にはこの機能は無効となります。IDE での Roslyn Analyzer は Unity Editor によってサポートされます。
[Roslyn Analyzer は Unity 2020.2 以降でサポートされました](https://docs.unity3d.com/Manual/roslyn-analyzers.html)。しかしながら、現在 Roslyn Analyzer は .csproj に追加されず、コンパイル時にのみ使用されます。
この拡張は `Analyzer` 要素を .csproj プロジェクトファイルが生成される際に追加します。その結果、Visual Studio でコード編集時にも Roslyn Analyzer の恩恵を受けることができます。(もちろん、2020.2 以前にも対応します)
#### 使用方法
[Unity 2020.2 と同様の方法で Roslyn Analyzer をプロジェクトに追加します](https://docs.unity3d.com/Manual/roslyn-analyzers.html)
- Roslyn Analyzer ライブラリを追加する
- Plugin インスペクターですべてのターゲットプラットフォームからチェックを外す
- `RoslynAnalyzer` アセットラベルをライブラリに付与する
## License
MIT License | 4,438 | MIT |
---
title: "Apache Storm チュートリアル: Storm 入門 |Microsoft Docs"
description: "HDInsight での Apache Storm および Storm Starter サンプルを使用したビッグ データ分析の概要 Storm を使用してデータをリアルタイムに処理する方法について説明します。"
keywords: "Apache Storm, Apache Storm チュートリアル, ビッグ データの分析, Storm Starter"
services: hdinsight
documentationcenter:
author: Blackmist
manager: jhubbard
editor: cgronlun
tags: azure-portal
ms.assetid: 6f93f7ff-0736-4708-80ef-4289dae532a9
ms.service: hdinsight
ms.devlang: java
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: big-data
ms.date: 09/07/2016
ms.author: larryfr
translationtype: Human Translation
ms.sourcegitcommit: 2ea002938d69ad34aff421fa0eb753e449724a8f
ms.openlocfilehash: 6576c388b8ade43205d56c0d6de2ef553ea5f61e
---
# <a name="apache-storm-tutorial-get-started-with-the-storm-starter-samples-for-big-data-analytics-on-hdinsight"></a>Apache Storm チュートリアル: Storm Starter サンプルを使用した HDInsight でのビッグ データ分析の概要
Apache Storm は、データ ストリームの処理を目的とし、スケーラビリティとフォールト トレランスに優れた、分散型のリアルタイム計算システムです。 Microsoft Azure HDInsight の Storm を使用して、Storm でリアルタイムで ビッグ データ分析を実行するクラウドベースの Storm クラスターを作成できます。
> [!NOTE]
> この記事の手順では、Windows ベースの HDInsight クラスターを作成します。 HDInsight クラスターで Linux ベースの Storm を作成する手順については、「 [Apache Storm チュートリアル: Storm Starter サンプルを使用した HDInsight でのビッグ データ分析の概要](hdinsight-apache-storm-tutorial-get-started-linux.md)
>
>
## <a name="prerequisites"></a>前提条件
[!INCLUDE [delete-cluster-warning](../../includes/hdinsight-delete-cluster-warning.md)]
Apache Storm チュートリアルを正常に完了するには、次の条件を満たす必要があります。
* **Azure サブスクリプション**。 [Azure 無料試用版の取得](https://azure.microsoft.com/documentation/videos/get-azure-free-trial-for-testing-hadoop-in-hdinsight/)に関するページを参照してください。
### <a name="access-control-requirements"></a>アクセス制御の要件
[!INCLUDE [access-control](../../includes/hdinsight-access-control-requirements.md)]
## <a name="create-a-storm-cluster"></a>Storm クラスターを作成する
HDInsight の Storm では、ログ ファイルとクラスターに送信されるトポロジを格納する Azure Blob Storage を使用します。 次の手順を使用して、クラスターに使用する Azure ストレージ アカウントを作成します。
1. [Azure Portal][preview-portal] にサインインします。
2. **[新規]**、**[データ分析]**、**[HDInsight]** の順にクリックします。

3. **クラスター名**を入力します。 クラスターを使用できる場合は、**クラスター名**の横に緑色のチェック マークが表示されます。
4. 複数のサブスクリプションがある場合は、**[サブスクリプション]** エントリを選択し、クラスターで使用する Azure サブスクリプションを選択します。
5. **[クラスターの種類の選択]** を使用して **Storm** クラスターを選択します。 **[オペレーティング システム]** で [Windows] を選択します。 **[Cluster Tier (クラスター階層)]** に [STANDARD (標準)] を選択します。 最後に、選択ボタンを使用してこれらの設定を保存します。

6. **[リソース グループ]**では、ドロップダウン リストを使用して既存のリソース グループの一覧を表示し、クラスターを作成するグループを選択できます。 または、**[新規]** をクリックし、新しいリソース グループの名前を入力します。 新しいグループ名を使用できる場合は、緑のチェック マークが表示されます。
7. **[資格情報]** を選択し、**[クラスターのログイン ユーザー名]** と **[クラスターのログイン パスワード]** を入力します。 最後に、**[選択]** をクリックして資格情報を設定します。 このドキュメントではリモート デスクトップは使用しないため、無効にしておくことができます。
![[クラスターの資格情報] ブレード](./media/hdinsight-apache-storm-tutorial-get-started/clustercredentials.png)
8. **[データ ソース]** では、エントリを選択して既存のデータ ソースを選択するか、新しいデータ ソースを作成できます。
![[データ ソース] ブレード](./media/hdinsight-apache-storm-tutorial-get-started/datasource.png)
現在、HDInsight クラスターのデータ ソースとして Azure ストレージ アカウントを選択できます。 次の説明を参照して、 **[データ ソース]** ブレードのエントリを理解してください。
* **[選択方法]**: サブスクリプションのストレージ アカウントを参照可能にする場合は、**[すべてのサブスクリプションから]** を設定します。 既存のストレージ アカウントの **[ストレージ名]** と **[アクセス キー]** を入力する場合は、**[アクセス キー]** を設定します。
* **[新規作成]**: これを使用して、新しいストレージ アカウントを作成します。 表示されたフィールドに、ストレージ アカウントの名前を入力します。 名前を使用できる場合は、緑色のチェック マークが表示されます。
* **[既定のコンテナーの選択]**: これを使用して、クラスターで使用する既定のコンテナーの名前を入力します。 任意の名前を入力できますが、コンテナーが特定のクラスターで使用されていることを簡単に認識できるように、クラスターと同じ名前を使用することをお勧めします。
* **[場所]**: ストレージ アカウントが存在するリージョン、またはストレージ アカウントの作成先のリージョン。
> [!IMPORTANT]
> 既定のデータ ソースの場所を選択すると、HDInsight クラスターの場所も設定されます。 クラスターと既定のデータ ソースは、同じリージョンに存在する必要があります。
>
>
* **[選択]**: これを使用してデータ ソースの構成を保存します。
9. **[ノード価格レベル]** を選択して、このクラスターのために作成されるノードに関する情報を表示します。 既定では、worker ノードの数は **4** に設定されています。 これを **1** に設定します。このチュートリアルではこの数で十分であり、クラスターのコストが削減されます。 クラスターの推定コストがブレードの下部に表示されます。
![[ノード価格レベル] ブレード](./media/hdinsight-apache-storm-tutorial-get-started/nodepricingtiers.png)
**[選択]** をクリックして、**[ノード価格レベル]** 情報を保存します。
10. **[オプションの構成]**を選択します。 このブレードでは、クラスターのバージョンを選択し、その他のオプションの設定 (**Virtual Network** への参加など) を構成できます。
![[オプションの構成] ブレード](./media/hdinsight-apache-storm-tutorial-get-started/optionalconfiguration.png)
11. **[スタート画面にピン留めする]** が選択されていることを確認し、**[作成]** をクリックします。 これでクラスターが作成され、Azure ポータルのスタート画面にクラスター用のタイルが追加されます。 アイコンはクラスターがプロビジョニング中であることを示し、プロビジョニングが完了すると、[HDInsight] アイコンを表示するように変化します。
| プロビジョニング中 | プロビジョニング完了 |
| --- | --- |
|  | |
> [!NOTE]
> クラスターが作成されるまで、通常は約 15 分かかります。 プロビジョニング プロセスをチェックするには、スタート画面のタイルまたはページの左側の **[通知]** エントリを使用します。
>
>
## <a name="run-a-storm-starter-sample-on-hdinsight"></a>HDInsight での Storm Starter サンプルの実行
この Apache Storm チュートリアルでは、GitHub で Storm Starter サンプルを使用したビッグ データ分析の概要について説明します。
HDInsight クラスターの各 Storm には、クラスターで Storm トポロジをアップロードし実行するために使用する Storm ダッシュボードが付属しています。 各クラスターには、Storm ダッシュボードから直接実行できるトポロジのサンプルも付属しています。
### <a name="a-idconnectaconnect-to-the-dashboard"></a><a id="connect"></a>ダッシュボードへの接続
ダッシュボードは、**clustername** がクラスターの名前である **https://<clustername>.azurehdinsight.net//** にあります。 スタート画面でクラスターを選択し、ブレードの上部にある **[ダッシュボード]** リンクを選択することで、ダッシュボードへのリンクを見つけることもできます。

> [!NOTE]
> ダッシュボードに接続すると、ユーザー名とパスワードを入力するように求められます。 これはクラスターの作成時に使用した管理者の名前 (**admin**) とパスワードです。
>
>
Storm ダッシュボードが読み込まれると、 **[トポロジの送信]** フォームが表示されます。

**[トポロジの送信]** フォームを使用して、Storm トポロジが含まれている .jar ファイルをアップロードし、実行できます。 また、これにはクラスターに付属しているいくつかの基本的なサンプルも含まれています。
### <a name="a-idrunarun-the-word-count-sample-from-the-storm-starter-project-in-github"></a><a id="run"></a>GitHub の Storm Starter プロジェクトからワードカウント サンプルを実行する
クラスターに付属しているサンプルには、ワードカウント トポロジのいくつかのバリエーションが含まれます。 これらのサンプルには、センテンスをランダムに出力する**スパウト**と各センテンスを個別の単語に分割し、各単語が発生した回数をカウントする**ボルト**が含まれています。 これらのサンプルは、Apache Storm の一部である [Storm Starter サンプル](https://github.com/apache/storm/tree/master/examples/storm-starter)で提供されています。
次の手順に従って、Storm Starter サンプルを実行します。
1. **[Jar ファイル]** ドロップダウンから **[StormStarter - WordCount]** を選択します。 これで、このサンプル用のパラメーターが **[クラス名]** フィールドと **[追加のパラメーター]** フィールドに入力されます。

* **クラス名** - トポロジを送信する .jar ファイル内のクラス。
* **追加パラメーター** - トポロジに必要なすべてのパラメーター。 この例では、フィールドに、送信したトポロジのわかりやすい名前を指定しています。
2. **[送信]**をクリックします。 しばらくすると、 **[結果]** フィールドにジョブの送信に使用したコマンドとコマンドの結果が表示されます。 **[エラー]** フィールドには、トポロジの送信時に発生したエラーが表示されます。

> [!NOTE]
> 結果はトポロジが完了したことを示しません - **Storm トポロジがいったん開始されると、停止するまで実行されます。** ワードカウント トポロジは、ランダムなセンテンスを生成し、停止されるまで各単語の出現回数を計算します。
>
>
### <a name="a-idmonitoramonitor-the-topology"></a><a id="monitor"></a>トポロジの監視
Storm UI を使用してトポロジを監視できます。
1. Storm ダッシュボードの上部で、 **[Storm UI]** を選択します。 クラスターの情報と実行中のすべてのトポロジに関する概要情報が表示されます。

上記のページで、トポロジがアクティブな状態だった時間、使用されているワーカー、エグゼキュータ、タスクの数を確認できます。
> [!NOTE]
> **[名前]** 列には、前に **[追加パラメーター]** フィールドで指定した名前が含まれています。
>
>
2. **[トポロジの概要]** で、**[名前]** 列の **[wordcount]** エントリを選択します。 これにより、トポロジの詳細が表示されます。

このページには、次の情報が表示されます。
* **トポロジの統計** - 時間枠で整理された、トポロジのパフォーマンスに関する基本的な情報。
> [!NOTE]
> 特定の時間枠を選択すると、ページの他のセクションに表示される情報の時間枠に変更されます。
>
>
* **スパウト** - 各スパウトによって返された最後のエラーを含む、スパウト関する基本的な情報。
* **ボルト** - ボルトに関する基本的な情報。
* **トポロジの構成** - トポロジの構成に関する詳細情報。
このページには、トポロジで実行できるアクションも表示されます。
* **アクティブ化** - アクティブ化が解除されたトポロジの処理を再開します。
* **アクティブ化の解除** - 実行中のトポロジを一時停止します
* **再調整** - トポロジの並列処理を調整します。 クラスターのノード数を変更した場合は、実行中のトポロジを再調整する必要があります。 この操作で、クラスター内のノード数の増減に合わせて、トポロジの並列処理を調整できます。 詳細については、「 [Understanding the parallelism of a Storm topology (Storm トポロジの並列処理)](http://storm.apache.org/documentation/Understanding-the-parallelism-of-a-Storm-topology.html)」を参照してください。
* **強制終了** - 指定したタイムアウト後に Storm トポロジを停止します。
3. このページで、**[スパウト]** または **[ボルト]** セクションからエントリを選択します。 選択したコンポーネントに関する情報が表示されます。

このページには次の情報が表示されます。
* **スパウト / ボルトの統計** - 時間枠で整理された、コンポーネントのパフォーマンスに関する基本的な情報。
> [!NOTE]
> 特定の時間枠を選択すると、ページの他のセクションに表示される情報の時間枠に変更されます。
>
>
* **入力の統計** (ボルトのみ) - ボルトによって使用されるデータを生成するコンポーネントに関する情報。
* **出力の統計** - このボルトによって出力されるデータに関する情報。
* **エグゼキュータ** - このコンポーネントのインスタンスに関する情報。
* **エラー** - このコンポーネントで生成されたエラー。
4. スパウトまたはボルトの詳細を表示したら、**[エグゼキュータ]** セクションの **[ポート]** 列でエントリを選択して、コンポーネントの特定のインスタンスの詳細を表示します。
2015-01-27 14:18:02 b.s.d.task [INFO] Emitting: split default ["with"]
2015-01-27 14:18:02 b.s.d.task [INFO] Emitting: split default ["nature"]
2015-01-27 14:18:02 b.s.d.executor [INFO] Processing received message source: split:21, stream: default, id: {}, [snow]
2015-01-27 14:18:02 b.s.d.task [INFO] Emitting: count default [snow, 747293]
2015-01-27 14:18:02 b.s.d.executor [INFO] Processing received message source: split:21, stream: default, id: {}, [white]
2015-01-27 14:18:02 b.s.d.task [INFO] Emitting: count default [white, 747293]
2015-01-27 14:18:02 b.s.d.executor [INFO] Processing received message source: split:21, stream: default, id: {}, [seven]
2015-01-27 14:18:02 b.s.d.task [INFO] Emitting: count default [seven, 1493957]
このデータから、 **seven** という単語が 1,493,957 回発生したことがわかります。 これは、このトポロジが開始されてから発生した回数です。
### <a name="stop-the-topology"></a>トポロジを停止する
ワードカウント トポロジの **[トポロジの概要]** ページに戻り、**[トポロジのアクション]** セクションで **[強制終了]** を選択します。 メッセージが表示されたら、トポロジを停止するまでの待機秒数として「10」を入力します。 タイムアウト期間後は、ダッシュボードの **[Storm UI]** セクションにアクセスしても、トポロジは表示されません。
## <a name="delete-the-cluster"></a>クラスターを削除する
[!INCLUDE [delete-cluster-warning](../../includes/hdinsight-delete-cluster-warning.md)]
## <a name="summary"></a>概要
この Apache Storm チュートリアルでは、Storm Starter を使用して、HDInsight クラスターで Storm を作成する方法と、Storm ダッシュボードを使用して Storm トポロジをデプロイ、監視、管理する方法について説明しました。
## <a name="a-idnextanext-steps"></a><a id="next"></a>次のステップ
* **HDInsight Tools for Visual Studio** - HDInsight ツールでは、前述の Storm ダッシュボードのように、Visual Studio を使用して Storm トポロジを送信、監視、管理できます。 また HDInsight ツールは、C# Storm のトポロジを作成する機能を提供しており、クラスター上にデプロイし、実行できるトポロジ サンプルを含んでいます。
詳細については、「 [HDInsight Tools for Visual Studio を使用して Hive クエリを実行する](hdinsight-hadoop-visual-studio-tools-get-started.md)」を参照してください。
* **サンプル ファイル** - HDInsight Storm クラスターでは、**%STORM_HOME%\contrib** ディレクトリにいくつかの例が用意されています。 次の例がそれぞれ含まれます。
* ソース コード - storm-starter-0.9.1.2.1.5.0-2057-sources.jar など
* Java ドキュメント - storm-starter-0.9.1.2.1.5.0-2057-javadoc.jar など
* 例 - storm-starter-0.9.1.2.1.5.0-2057-jar-with-dependencies.jar など
'jar' コマンドを使用して、ソース コードまたは Java ドキュメントを抽出します。 たとえば、'jar -xvf storm-starter-0.9.1.2.1.5.0.2057-javadoc.jar' のように指定します。
> [!NOTE]
> Java ドキュメントは Web ページで構成されます。 抽出後、ブラウザーを使用して **index.html** ファイルを表示します。
>
>
これらのサンプルにアクセスするには、HDInsight クラスターの Storm のリモート デスクトップを有効にし、**%STORM_HOME%\contrib** からファイルをコピーする必要があります。
* 次のドキュメントには、HDInsight の Storm と使用できるその他のサンプルの一覧が含まれています。
* [HDInsight 上の Storm に関するトポロジ例](hdinsight-storm-example-topology.md)
[apachestorm]: https://storm.incubator.apache.org
[stormdocs]: http://storm.incubator.apache.org/documentation/Documentation.html
[stormstarter]: https://github.com/apache/storm/tree/master/examples/storm-starter
[stormjavadocs]: https://storm.incubator.apache.org/apidocs/
[azureportal]: https://manage.windowsazure.com/
[hdinsight-provision]: hdinsight-provision-clusters.md
[preview-portal]: https://portal.azure.com/
<!--HONumber=Nov16_HO3--> | 12,594 | CC-BY-3.0 |
# 网络模块
> 涉及到的头文件 `libnap.h`
<br/>
网络模块包括 net(工具类),tcpclient(客户端类),tcpserver(服务端类),tcpseraccept(服务端accept类),napcom(协议类)。所有的类都是线程不安全类,在多线程中操作这些资源都需要加锁。
> 详细类定义请见 `src/net.h`
<br/>
<br/>
## 客户端使用流程
```c++
/*
初始化net库,如果没有初始化可能会发生很多异常。初始化只需要在整个程序里初始化一次即可
*/
net::init();
/*
连接 192.168.1.1:8087
注意 tcpclient 不允许复制,也不允许赋值。
转移所有权请使用 std::move();
*/
tcpclient client(8087, "192.168.1.1");
/*
尝试连接,如果失败返回false
*/
if (client->connect() == false){
cout<<"connect fail";
return false;
}
/*
获取连接的napcom对象,通过该对象进行数据传输
*/
napcom* communicate = client.communicate();
```
<br/>
<br/>
## 服务端使用流程
```c++
using namespace nap;
/*
初始化net库,如果没有初始化会发生通信错误。初始化只需要在整个程序里初始化一次即可
*/
net::init();
/*
创建 tcpserver 对象,监听8087端口
*/
tcpserver server(8087);
/*
尝试绑定端口,如果失败返回false
*/
if (server->bind() == false){
cout<<"bind fail";
return false;
}
/*
尝试监听端口,如果失败返回false
*/
if (server->listen() == false){
cout<<"bind fail";
return false;
}
while(true){
/*
开始等待客户端连接
返回一个pair对象
第一个值(link.first) : bool 连接是否有效
第一个值(link.second) : tcpseraccept tcpseraccept对象
*/
std::pair<bool,tcpseraccept> link = server->accept();
//aupto link = server->accept(); 也可以使用这句
/*
*/
if (link.first){
/*
获取tcpseraccept对象进行操作
*/
tcpseraccept acc = std::move(link.second);
/*
获取客户端的IP和端口
*/
uint16_t port = acc.port();
binstream ip = acc.ip();
/*
获取连接的napcom对象,通过该对象进行数据传输
*/
napcom* communicate = acc.communicate();
}
}
```
<br/>
<br/>
## napcom类的使用
```c++
napcom* napcom = // .....
binstream str("test string a");
auto ret = napcom->sendpackage(str);
if (ret != napcom::ret::success){
cout<<"send packet fail";
return false;
}
binstream recv;
auto ret2 = napcom->recvpackage(recv);
if (ret2 != napcom::ret::success){
cout<<"send packet fail";
return false;
}
/*
注意,recvpackage和sendpackage都是阻塞函数。
*/
```
<br/>
<br/>
## 枚举napcom::ret的使用
```c++
enum class ret {
success, //成功
mecismsend, //过长的发送数据 单个包只允许发送 64KB
ruined, //被损毁的网络套接字(协议异常或网络断开)
};
/*
这是该枚举的定义。位于net.h的napcom类内。
success 操作成功
mecismsend 发送包过长
ruined 被毁坏的链接,通常是对端关闭了连接,或者网络连接断开,接收超时等。
*/
int error = net::lastError();
//使用 net::lastError() 可以获取最后一次的错误码
``` | 2,365 | Apache-2.0 |
---
title: "Farsite 板条箱销售现已向公众开放"
date: 2021-12-02T21:57:40+08:00
lastmod: 2021-12-02T16:45:40+08:00
draft: false
authors: ["Paul"]
description: "太空探索游戏 Farsite 已向公众开放其 NFT 板条箱销售。具有不同价格的不同板条箱赋予玩家对船只、蓝图、模块或额外信用的所有权。此次销售需要一个连接的带有 ETH 的 Metamask 钱包,因为价格从 0.05 ETH 开始,最昂贵的可用板条箱价格为 0.35 ETH。"
featuredImage: "farsite-crate-sales-now-open-to-public.png"
tags: ["Digital Collectibles","数字收藏品","Play to Earn"]
categories: ["news"]
news: ["数字收藏品"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
太空探索游戏 Farsite 已向公众开放其 NFT 板条箱销售。具有不同价格的不同板条箱赋予玩家对船只、蓝图、模块或额外信用的所有权。此次销售需要一个连接的带有 ETH 的 Metamask 钱包,因为价格从 0.05 ETH 开始,最昂贵的可用板条箱价格为 0.35 ETH。
<!--more--> | 677 | MIT |
---
layout: post
title: "springcloud - 注册中心eureka"
subtitle: "搭建eureka及配置"
date: 2019-08-08 11:10
author: "LQFGH"
header-img: "img/spring-cloud-bg.png"
header-mask: 0.3
catalog: true
tags:
- springcloud
---
***
[TOC]
------
> 今天主要就来说说怎么不使用IDE的向导搭建一个 `eureka` ,还有注册中心的基本配置
###### 创建一个简单的 `maven` 项目

###### 添加 `eureka-server` 依赖
> `eureka` 服务端需要添加 `spring-cloud-starter-eureka-server` 依赖
>
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.feng.cloud</groupId>
<artifactId>eureka-server</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencyManagement>
<dependencies>
<!--spring cloud依赖管理-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Dalston.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring boot依赖管理-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.9.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!--eureka-server服务端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<executable>true</executable>
</configuration>
</plugin>
</plugins>
</build>
</project>
```
###### 创建启动类
> 启动类中最主要的部分是添加 `@EnableEurekaServer` 说明这是注册中心
>
```java
package com.feng.eureka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* @author Lee
*/
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class,args);
}
}
```
###### 创建配置文件 `bootstrap.yml`
> 配置的作用会用注释说明
>
```yml
server:
port: 7000
spring:
application:
name: eureka-server
eureka:
instance:
hostname: ${spring.cloud.client.ipAddress} #eureka服务端的实例名称
client:
register-with-eureka: false #不向注册中心注册自己,设置为false
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/ #被客户端注册的地址
server:
enable-self-preservation: false #是否启动自我保护机制,测试环境应该关闭自我保护机制,服务失效90秒被自动移除。生产环境应该开启自我保护机制,即使服务失效
eviction-interval-timer-in-ms: 3000 #检查失效时间
```
###### 将服务注册到 `eureka`
> 接下来我们创建一个新的 `spring boot` 项目,用于注册到注册中心
>
> 若想将服务注册到 `eureka` 只需要在配置中添加如下配置
>
```yml
eureka:
client:
service-url:
defaultZone: http://localhost:7000/eureka/
```
###### 修改注册到注册中心实例的显示地址和实例名称
> 如果客户端使用默认的实例名字,那么实例的名字就是这个样子的,而且当鼠标放到上面的时候右下角显示的地址是 `localhost` ,那么怎么将localhost改为服务部署的IP地址,并且将注册到注册中心的实例名称自定义呢。
>

> 将客户端的配置添加 `eureka.instance.prefer-ip-address` 属性
>
```yml
eureka:
client:
service-url:
defaultZone: http://localhost:7000/eureka/
instance:
prefer-ip-address: true # 显示实例的ip地址
```

> 接下来添加配置实例id `instance-id`,显示自定义实例名称
>
```yml
eureka:
client:
service-url:
defaultZone: http://localhost:7000/eureka/
instance:
prefer-ip-address: true # 显示实例的ip地址
instance-id: boot-provider
```

> 发现图中客户端实例的名称变成了我们自定义的名称 `boot-provider`
>
###### 修改客户端实例的 `info` 信息
> 当我们点击实例名称的超链接想要查看客户端实例的信息时,发现响应的时404页面
>


> 首先客户端添加依赖 `spring-boot-starter-actuator` 服务健康监控,关于健康控监控多余的东西在这里就不作
> 介绍了.
>
> 添加 `maven` 的 `resource` 插件
```yml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
```
```xml
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<delimiters>
<!-- 表示取resources中以$*$的信息被解析 -->
<delimiter>$</delimiter>
</delimiters>
</configuration>
</plugin>
```
> 配置 `info` 客户端实例的 `info` 信息
>
> 可以自定义一些键值对.由于上面配置了 `maven` 的 `resource` 插件,$*$的属性将会被解析
>
```yml
info:
app.name: boot-provider
company.name: spring-eureka
author: feng
build.artifactId: $project.artifactId$
buid.version: $project.version$
```

> 这些都配置完发现点可以显示 `info` 的信息了
>
###### eureka 集群配置
> 我这里为了搭建集群环境,重新建了三个注册中心项目
>

> 为了更接近真实环境,我将 `hosts` 文件做下修改,不同的注册中心分别对应不同的域名
>
```txt
127.0.0.1 eureka7001server.com
127.0.0.1 eureka7002server.com
127.0.0.1 eureka7003server.com
```
> `eureka-server-7001` 配置
>
```yml
# eureka 端口号
server:
port: 7001
# 服务名称
spring:
application:
name: eureka-server
eureka:
instance:
hostname: ${spring.cloud.client.ipAddress} #eureka服务端的实例名称
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url: #注册中心的地址
defaultZone: http://eureka7002server.com:7002/eureka/,http://eureka7003server.com:7003/eureka/
server:
enable-self-preservation: false #是否启动自我保护机制
```
> `eureka-server-7002` 配置
>
```yml
server:
port: 7002
spring:
application:
name: eureka-server
eureka:
instance:
hostname: ${spring.cloud.client.ipAddress} #eureka服务端的实例名称
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
defaultZone: http://eureka7001server.com:7001/eureka/,http://eureka7003server.com:7003/eureka/
server:
enable-self-preservation: false
```
> `eureka-server-7003` 配置
>
```yml
server:
port: 7003
spring:
application:
name: eureka-server
eureka:
instance:
hostname: ${spring.cloud.client.ipAddress} #eureka服务端的实例名称
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
defaultZone: http://eureka7002server.com:7002/eureka/,http://eureka7001server.com:7001/eureka/
server:
enable-self-preservation: false
```
> 客户端实例注册
>
```yml
eureka:
client:
service-url:
defaultZone: http://eureka7001server.com:7001/eureka/,http://eureka7002server.com:7002/eureka/,http://eureka7003server.com:7003/eureka/
```
> **最终效果**
>
> 由于篇幅原因,我这里只放出 `eureka-server-7001` 的截图
>

> 我们发现最终注册中心会互相注册 | 7,713 | Apache-2.0 |
# java.lang.IllegalStateException
**目录**
<!-- vim-markdown-toc GFM -->
* [Case 1](#case-1)
* [出错堆栈](#出错堆栈)
* [出错代码](#出错代码)
* [崩溃分析](#崩溃分析)
* [解决方案](#解决方案)
<!-- vim-markdown-toc -->
## Case 1
### 出错堆栈
```
05-09 09:41:27.356 1128-1128/org.mazhuang.multicastdemo E/AndroidRuntime: FATAL EXCEPTION: main
Process: org.mazhuang.multicastdemo, PID: 1128
java.lang.IllegalStateException: The content of the adapter has changed but ListView did not receive a notification. Make sure the content of your adapter is not modified from a background thread, but only from the UI thread. Make sure your adapter calls notifyDataSetChanged() when its content changes. [in ListView(2131165270, class android.widget.ListView) with Adapter(class android.widget.SimpleAdapter)]
at android.widget.ListView.layoutChildren(ListView.java:1618)
at android.widget.AbsListView.onLayout(AbsListView.java:2161)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.widget.LinearLayout.setChildFrame(LinearLayout.java:1741)
at android.widget.LinearLayout.layoutVertical(LinearLayout.java:1585)
at android.widget.LinearLayout.onLayout(LinearLayout.java:1494)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.widget.FrameLayout.layoutChildren(FrameLayout.java:323)
at android.widget.FrameLayout.onLayout(FrameLayout.java:261)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.support.v7.widget.ActionBarOverlayLayout.onLayout(ActionBarOverlayLayout.java:443)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.widget.FrameLayout.layoutChildren(FrameLayout.java:323)
at android.widget.FrameLayout.onLayout(FrameLayout.java:261)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.widget.LinearLayout.setChildFrame(LinearLayout.java:1741)
at android.widget.LinearLayout.layoutVertical(LinearLayout.java:1585)
at android.widget.LinearLayout.onLayout(LinearLayout.java:1494)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.widget.FrameLayout.layoutChildren(FrameLayout.java:323)
at android.widget.FrameLayout.onLayout(FrameLayout.java:261)
at com.android.internal.policy.DecorView.onLayout(DecorView.java:727)
at android.view.View.layout(View.java:17548)
at android.view.ViewGroup.layout(ViewGroup.java:5614)
at android.view.ViewRootImpl.performLayout(ViewRootImpl.java:2383)
at android.view.ViewRootImpl.performTraversals(ViewRootImpl.java:2110)
at android.view.ViewRootImpl.doTraversal(ViewRootImpl.java:1287)
at android.view.ViewRootImpl$TraversalRunnable.run(ViewRootImpl.java:6363)
at android.view.Choreographer$CallbackRecord.run(Choreographer.java:873)
at android.view.Choreographer.doCallbacks(Choreographer.java:685)
at android.view.Choreographer.doFrame(Choreographer.java:621)
at android.view.Choreographer$FrameDisplayEventReceiver.run(Choreographer.java:859)
at android.os.Handler.handleCallback(Handler.java:754)
at android.os.Handler.dispatchMessage(Handler.java:95)
at android.os.Looper.loop(Looper.java:163)
at android.app.ActivityThread.main(ActivityThread.java:6337)
at java.lang.reflect.Method.invoke(Native Method)
at com.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:880)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:770)
```
### 出错代码
```java
new Thread() {
@Override
public void run() {
// ...
mData.add(data);
MainActivity.this.runOnUiThread(() -> {
mAdapter.notifyDataSetChanged();
}
// ...
}
}.start();
```
### 崩溃分析
根据出错堆栈里的关键提示:
```
The content of the adapter has changed but ListView did not receive a notification. Make sure the content of your adapter is not modified from a background thread, but only from the UI thread. Make sure your adapter calls notifyDataSetChanged() when its content changes.
```
更新 Adapter 里的数据并 notifyDataSetChanged 需要在 UI 线程里进行。如果在子线程里更新了数据,而在 UI 线程里稍后更新代码,就有可能在一个时间差内数据与界面状态不一致,从而导致崩溃。
### 解决方案
在 UI 线程里面更新 Adapter 里的数据,并 notifyDataSetChanged,即:
```java
new Thread() {
@Override
public void run() {
// ...
MainActivity.this.runOnUiThread(() -> {
mData.add(data);
mAdapter.notifyDataSetChanged();
}
// ...
}
}.start();
``` | 4,871 | Apache-2.0 |
# 1379. Find a Corresponding Node of a Binary Tree in a Clone of That Tree
> [Leetcode link](https://leetcode.com/problems/find-a-corresponding-node-of-a-binary-tree-in-a-clone-of-that-tree/)
## 解题思路
题目给了我们两棵一模一样的树,并且将一个指针 `target` 指向了原树的其中一个节点,要求我们找到拷贝树上对应的节点
这种题目一般用 bfs 或者 dfs 来求解,一种简单的思路就是:
- 遍历拷贝的树,当遇到与 `target` 指针指向的值一样的树节点的时候,返回拷贝树对应的节点指针
<br />
但是这个思路有一个限制条件,就是树上不能有两个值相同的节点。
所以在这里我们用同时遍历两棵树的方法,详情见代码:
### C++
```cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* getTargetCopy(TreeNode* original, TreeNode* cloned, TreeNode* target) {
TreeNode* res = nullptr;
dfs(original, cloned, target, res);
return res;
}
// 记得这里的 res 需要使用引用,因为我们需要记录 res 指针存放的地址
void dfs(TreeNode* original, TreeNode* cloned, TreeNode* target, TreeNode*& res) {
// 如果已经找到了 res,就没必要继续下去了
if(original == nullptr || res != nullptr) {
return;
}
// 当原树的节点等于目标节点的时候,拷贝树的对应节点就是我们的解
if(original == target) {
res = cloned;
return ;
}
dfs(original->left, cloned->left, target, res);
dfs(original->right, cloned->right, target, res);
}
};
``` | 1,363 | MIT |
# node-pagesplit
a page spliter, like ThinkPHP Page.class
# demo (express)
/demo/test.js
```javascript
router.get('/page', function (req, res) {
var totalRows = 51; //模拟从数据库中查询得到的总记录数
var listRows = 10; //每页显示的数量
var pg = new Page(req, totalRows, listRows);
//得到相应的查询参数,实现分页功能
var sql = "select * from db limit " + pg.firstRow + "," + pg.listRows + ";";
var data = sql + "<br/>" + pg.show();//前端分页代码
res.send(data);
});
```
# demo (http)
```javascript
var http = require('http');
var url = require('url');
var querystring = require('querystring');
var Page = require('pagesplit');
http.createServer(function (req,res) {
if(req.url == '/favicon.ico'){
return res.end();
}
res.setHeader('Content-Type', 'text/html');
//添加两个express才有的属性
let u = url.parse(req.url);
req.originalUrl = u.pathname;
req.query = querystring.parse(u.query);
var totalRows = 51; //模拟从数据库中查询得到的总记录数
var listRows = 10; //每页显示的数量
var pg = new Page(req, totalRows, listRows);
//得到相应的查询参数,实现分页功能
var sql = "select * from db limit " + pg.firstRow + "," + pg.listRows + ";";
var data = sql + "<br/>" + pg.show();//前端分页代码
res.end(data);
}).listen(3000);
console.log('localhost:3000');
```
# 转为bootstrap风格
```html
<div class="" id="page" style="display: none">
<!-- 分页代码 -->
<%- page %>
</div>
<script>
//将后台产生的分页代码转成bootstrap风格显示
var page = $('.page');
page.addClass('btn-group pull-right');
page.children('a').addClass('btn btn-default btn-sm');
page.find('.current').addClass('btn btn-primary btn-sm');
$('#page').show(); // 等添加完属性转为bootstrap风格后再显示
</script>
``` | 1,695 | MIT |
資源|預設限制|上限
---|---|---
每一[訂用帳戶](../articles/billing-buy-sign-up-azure-subscription.md)的核心 <sup>1</sup>|20|10,000
每一訂用帳戶的[共同管理員](../articles/billing-add-change-azure-subscription-administrator.md)|200|200
每一訂用帳戶的[儲存體帳戶](../articles/storage/storage-create-storage-account.md)|100|100
每一訂用帳戶的[雲端服務](../articles/cloud-services/fundamentals-application-models.md#tellmecs)|20|200
每一訂用帳戶的[區域網路](http://msdn.microsoft.com/library/jj157100.aspx)|10|500
每一訂用帳戶的 SQL Database 伺服器|6|150
每一訂閱的 DNS 伺服器|9|100
每一訂用帳戶的保留 IP|20|100
每個訂用帳戶的 ExpressRoute 專用電路|10|25
每一訂用帳戶託管服務的憑證|400|400
每一訂用帳戶的[同質群組](../articles/virtual-network/virtual-networks-migrate-to-regional-vnet.md)|256|256
[Batch](https://azure.microsoft.com/services/batch/) 帳戶 (每一區域的每一訂用帳戶)|1|50
每一訂用帳戶的警示規則|250|250
<sup>1</sup>雖然只使用部分核心,在計算核心限制時,仍會將超小型執行個體視為一個核心。
<!---HONumber=AcomDC_0211_2016--> | 845 | CC-BY-3.0 |
<!--
* @Author: codytang
* @Date: 2020-07-10 22:06:46
* @LastEditTime: 2020-07-13 14:38:20
* @LastEditors: codytang
* @Description: README
-->
# Ticket Purchase [](https://travis-ci.org/cody1991/ticket-purchase)
## Demo 地址
https://cody1991.github.io/ticket-purchase/?front=50&back=100&step=2&block=4&refundRate=0.1&sleepMax=50
运行结果

---
https://cody1991.github.io/ticket-purchase
运行结果

## URL 参数使用
| 参数名 | 说明 | 参数值 |
| --------------- | -------------------------------- | --------------- |
| displayUsersLen | 展示用户行为列表的最大值 | > 0, 默认 25 |
| sleepMax | 模拟每次购票用户等待时间的最大值 | > 0, 默认 100ms |
| refundRate | 用户退票的概率 | >= 0, 默认 0.2 |
| block | 区块数 | > 0, 默认 2 |
| front | 第一排的座位数量 | > 0, 默认 2 |
| back | 最后一排的座位数量 | > 0, 默认 20 |
| step | 每排递增的数量 | != 0, 默认 1 |
## 任务列表
- Other
- [x] 新增算法的流程图
- [x] 展示演唱会的位置使用 canvas 绘制(现在座位太多的话很卡,先简单处理,座位数太多的时候隐藏)
- Class
- [x] User: 购票用户信息与行为
- [x] Seats: 演唱会座位信息
- [x] AdvancedSeas: 继承 Seats,优化购票算法
- Views
- [x] Helloworld: 简单的项目介绍
- [x] DisplaySeats: 展示演唱会座位
- [x] DisplayUsers: 展示用户购票
- [x] 展示 n 排 n 座
- [x] 展示在第几个区域
- [x] Intro: 演唱会现况
- Deploy (Github Pages)
- [x] 手动构建: `sh ./deploy.sh`
- [x] 自动构建: 接入 `Travis CI`
- Algorithm
- [x] purchase ticket by order 按顺序购票,无太多逻辑
- [x] 支持退票
- [x] 随机购票
- [x] 邻座分配(只考虑横向的邻座)
## 流程图
 | 1,693 | MIT |
# 2021-12-10
共 0 条
<!-- BEGIN WEIBO -->
<!-- 最后更新时间 Fri Dec 10 2021 23:09:10 GMT+0800 (China Standard Time) -->
<!-- END WEIBO --> | 134 | MIT |
---
layout: post
title: "中共如何用民主騙人 | 明居正「透視中國」【0059】SinoInsider 20191223"
date: 2019-12-23T01:15:16.000Z
author: 透視中國
from: https://www.youtube.com/watch?v=ToDk26g3-LI
tags: [ 透視中國 ]
categories: [ 透視中國 ]
---
<!--1577063716000-->
[中共如何用民主騙人 | 明居正「透視中國」【0059】SinoInsider 20191223](https://www.youtube.com/watch?v=ToDk26g3-LI)
------
<div>
#明居正 #透視中國 #2020中國展望立即訂購:「2020中國展望:中共政局對美中港台的衝擊」https://bit.ly/393yhr7透視文章:https://tw.sinoinsider.com/research/訂閱會員:https://tw.sinoinsider.com/membership/精準分析:https://tw.sinoinsider.com/predictive/臉書:https://www.facebook.com/mingsinoinsider/推特:https://twitter.com/SinoInsider要瞭解有關解決方案的更多信息,請聯繫我們。https://tw.sinoinsider.com/#Contact-us
</div> | 680 | MIT |
---
title: チュートリアル - Apple Business Manager または Device Enrollment Program を使用して、iOS/iPadOS デバイスを Intune に登録する
titleSuffix: Microsoft Intune
description: このチュートリアルでは、Apple の ABM の会社のデバイスを登録する機能を設定して、iOS/iPadOS デバイスを Intune に登録します。
keywords: ''
author: ErikjeMS
ms.author: erikje
manager: dougeby
ms.date: 04/30/2019
ms.topic: tutorial
ms.service: microsoft-intune
ms.subservice: enrollment
ms.localizationpriority: high
ms.technology: ''
ms.assetid: ''
Customer intent: As an Intune admin, I want to set up the Apple's corporate device enrollment features so that corporate devices can automatically enroll in Intune.
ms.collection: M365-identity-device-management
ms.openlocfilehash: 47f249d105fbc2481dd1d66956032c91d5006834
ms.sourcegitcommit: 387706b2304451e548d6d9c68f18e4764a466a2b
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 06/19/2020
ms.locfileid: "85093523"
---
# <a name="tutorial-use-apples-corporate-device-enrollment-features-in-apple-business-manager-abm-to-enroll-iosipados-devices-in-intune"></a>チュートリアル:Apple Business Manager (ABM) にある Apple の Corporate Device Enrollment 機能を使用して、iOS/iPadOS デバイスを Intune に登録する
Apple Business Manager の Device Enrollment 機能では、デバイスを簡単に登録できます。 Intune では Apple の以前の Device Enrollment Program (DEP) ポータルもサポートしていますが、Apple Business Manager でやり直すことをお勧めします。 デバイスは、Microsoft Intune と Apple Corporate Device Enrollment で、ユーザーが最初にデバイスをオンにしたときに、安全に自動的に登録されます。 そのため、各デバイスを個別に設定することなく、デバイスを多くのユーザーに配送できます。
このチュートリアルでは、次の方法について説明します。
> [!div class="checklist"]
> * Apple Device Enrollment トークンを取得する
> * マネージド デバイスを Intune と同期する
> * 登録プロファイルを作成する
> * デバイスに登録プロファイルを割り当てる
Intune サブスクリプションがない場合は、[無料試用版アカウントにサインアップ](../fundamentals/free-trial-sign-up.md)します。
## <a name="prerequisites"></a>[前提条件]
- [Apple Business Manager](https://business.apple.com) または [Apple の Device Enrollment Program](http://deploy.apple.com) で購入したデバイス
- [[モバイル デバイス管理機関]](../fundamentals/mdm-authority-set.md) を設定する
- [[Apple MDM プッシュ通知証明書]](apple-mdm-push-certificate-get.md) を取得する
## <a name="get-an-apple-device-enrollment-token"></a>Apple Device Enrollment トークンを取得する
iOS/iPadOS デバイスを Apple の会社登録機能を使用して登録する前に、Apple Device Enrollment トークン (.pem) ファイルが必要です。 このトークンにより、ご自分の会社で所有している Apple デバイスの情報を Intune が同期できるようになります。 また、Intune は Apple に登録プロファイルをアップロードして、デバイスをそれらのプロファイルに割り当てられるようになります。
Device Enrollment トークンの作成には、Apple ポータルを使用します。 このポータルは、管理するデバイスを Intune に割り当てるためにも使用します。
1. [Microsoft エンドポイント マネージャー管理センター](https://go.microsoft.com/fwlink/?linkid=2109431)で、 **[デバイス]** 、 **[iOS/iPadOS]** 、 **[iOS/iPadOS の登録]** 、 **[Enrollment Program トークン]** 、 **[追加]** の順に選択します。
2. **[同意する]** を選択して、Microsoft がユーザーとデバイスの情報を Apple に送信できるようにします。
![公開キーをダウンロードするための [Apple 証明書] ワークスペースの [Enrollment Program トークン] のスクリーンショット。](./media/tutorial-use-device-enrollment-program-enroll-ios/add-enrollment-program-token-pane.png)
3. **[公開キーをダウンロードします]** を選択し、暗号化キー (.pem) ファイルをダウンロードしてローカルに保存します。 .pem ファイルは、Apple ポータルから信頼関係証明書を要求するために使用します。
4. **[Create a token for Apple's Device Enrollment Program]\(Apple Device Enrollment Program 用のトークンを作成します\)** を選択して Apple の Deployment Program ポータルを開き、会社の Apple ID でサインインします。 この Apple ID を使って、トークンを更新できます。
5. Apple の [Deployment Programs ポータル](https://deploy.apple.com) で、 **[Device Enrollment Program]** の **[開始]** を選択します。 ユーザーが実行する [Apple Business Manager](https://business.apple.com) での以下の手順は、若干異なる場合があります。
4. **[Manage Servers\(サーバーの管理\)]** ページで、 **[Add MDM Server\(MDM サーバーの追加\)]** を選びます。
5. **[MDM Server Name]\(MDM サーバー名\)** に、「*TestMDMServer*」と入力して **[次へ]** を選びます。 サーバー名は、自分がモバイル デバイス管理 (MDM) サーバーを識別できるようにするための名前です。 Microsoft Intune サーバーの名前または URL ではありません。
6. **[Add <ServerName>\(<サーバー名> の追加\)]** ダイアログ ボックスが開き、 **[Upload Your Public Key\(公開キーをアップロードする\)]** と表示されます。 **[ファイルの選択…]** を選択して .pem ファイルをアップロードし、 **[Next]** (次へ) を選択します。
6. **[Deployment Programs]** > **[Device Enrollment Program]** > **[デバイスの管理]** に移動します。
7. **[Choose Devices By]\(デバイスの選択基準\)** で、 **[シリアル番号]** を選びます。 <!--ask Tiffany about this-->
8. **[アクションの選択]** で **[Assign to Server]\(サーバーに割り当てる\)** を選択し、Microsoft Intune に指定した **ServerName** を選択して、<[OK]> を選択します。 指定したデバイスが管理用に Intune サーバーに割り当てられて、 **[Assignment Complete\(割り当て完了\)]** と表示されます。
Apple ポータルで、 **[Deployment Programs]\(配備プログラム\)** > **[Device Enrollment Program]\(Device Enrollment Program\)** > **[View Assignment History]\(割り当て履歴の表示\)** の順に移動して、デバイスとその MDM サーバーの割り当てのリストを表示します。
9. 後で参照するために、Azure portal の Intune で、このトークンを作成するために使用した Apple ID を指定します。

10. **[Apple トークン]** ボックスで、証明書 (.pem) ファイルを参照し、 **[開く]** を選択して、 **[作成]** を選択します。
11. スコープのタグを適用してこのトークンにアクセスできる管理者を制限するには、スコープを選択します。
## <a name="create-an-apple-enrollment-profile"></a>Apple 登録プロファイルの作成
これでトークンがインストールされたので、会社で所有している iOS/iPadOS デバイスの登録プロファイルを作成できます。 デバイス登録プロファイルで、デバイス グループに対して登録時に適用する設定を定義します。
1. [Microsoft Endpoint Manager admin center](https://go.microsoft.com/fwlink/?linkid=2109431) で、 **[デバイス]** 、 **[iOS/iPadOS]** 、 **[iOS の登録]** 、 **[Enrollment Program トークン]** の順に選択します。
2. インストールしたトークンを選択し、 **[プロファイル]** 、 **[プロファイルの作成]** 、 **[iOS/iPadOS]** の順に選択します。
3. **[基本]** ページで、 **[名前]** に「*TestProfile*」、 **[説明]** に「*iOS または iPadOS デバイス用の ADE のテスト*」と入力します。 ユーザーにはこれらの詳細は表示されません。
4. **[次へ]** を選択します。
5. **[管理設定]** ページで、デバイスを**ユーザー アフィニティ**ありで登録するか、なしで登録するかを決定します。 ユーザー アフィニティは、特定のユーザー向けのデバイス用に設計されています。 ユーザーが、アプリのインストールなどのサービスにポータル サイトを使用する場合、 **[ユーザー アフィニティとともに登録する]** を選択します。 ユーザーがポータル サイトを必要としない場合、または多数のユーザーに対してデバイスをプロビジョニングする場合は、 **[ユーザー アフィニティを使用しないで登録する]** を選択します。
6. ユーザー アフィニティを使用して登録することを選択した場合は、 **[ユーザーが認証する必要がある場所を選択する]** オプションが表示されます。 ポータル サイトまたは Apple セットアップ アシスタントのどちらを使用して認証するかを決定します。
- **ポータル サイト**:Multi-Factor Authentication を使用するか、最初のサインイン時にユーザーにパスワードを変更することを許可するか、または登録時にユーザーに有効期限が切れたパスワードをリセットすることを求める場合に、このオプションを選択します。 ポータル サイト アプリケーションをエンド ユーザーのデバイス上で自動的に更新させる場合は、Apple の Volume Purchasing Program (VPP) を使用して、そのユーザーに対してポータル サイトを必須アプリとして個別に展開します。
- **設定アシスタント**:Apple が提供している Apple 設定アシスタントによる基本の HTTP 認証を使用する場合は、このオプションを選択します
7. ユーザー アフィニティを使用して登録し、ポータル サイトで認証することを選択した場合、 **[VPP によるポータル サイトのインストール]** オプションが表示されます。 VPP トークンを使用してポータル サイトをインストールする場合、ユーザーは登録時に、App Store からポータル サイトをダウンロードするために、Apple ID とパスワードを入力する必要がありません。 **[VPP によるポータル サイトのインストール]** の下の **[使用するトークン]** を選択し、使用可能なポータル サイトの無料ライセンスがある VPP トークンを選択します。 ポータル サイトのデプロイに VPP を使用しない場合、 **[VPP を使用しない]** を選択します。
8. ユーザー アフィニティを使用して登録を行い、ポータル サイトで認証を行い、VPP を使用してポータル サイトをインストールすることを選択した場合、認証までポータル サイトを単一アプリケーション モードで実行するかどうかを決定します。 この設定では、ユーザーが会社の登録を完了するまで、その他のアプリにアクセスできないことが保証されます。 登録が完了するまで、ユーザーにこのフローを限定したい場合、 **[Run Company Portal in Single App Mode until authentication]\(認証されるまでシングル アプリ モードでポータル サイトを実行する\)** の下で **[はい]** を選択します。
9. **[デバイス管理の設定]** で、 **[監視]** の下の **[はい]** を選択します ( **[ユーザー アフィニティとともに登録する]** を選択した場合は、自動的に **[はい]** に設定されます)。 監視下のデバイスでは、会社の iOS/iPadOS デバイスに対して最も多くの管理オプションを使用できます。
10. **[ロックされた登録]** の下で **[はい]** を選択し、ユーザーがデバイスを会社の管理から削除できないようにします。
11. **[コンピューターと同期する]** でオプションを選択し、iOS/iPadOS デバイスでコンピューターと同期できるかどうかを決定します。
12. Apple でデバイスは、既定で (iPad などの) デバイスの種類が使用され命名されます。 別の名前テンプレートを使用する場合は、 **[デバイス名のテンプレートを適用する]** で **[はい]** を選択します。 デバイスに付ける名前を入力します。ここで、 *{{シリアル}}* と *{{デバイスの種類}}* の文字列は、各デバイスのシリアル番号とデバイスの種類に置き換えます。 または、 **[デバイス名のテンプレートを適用する]** の下で **[いいえ]** を選択します。
13. **[次へ]** を選択します。
14. **[セットアップ アシスタント]** ページで、 **[部署名]** に「*チュートリアル部門*」。 この文字列は、デバイスのアクティブ化中にユーザーが **[About configuration]\(構成について\)** をタップすると表示される内容です。
15. **[部署の電話番号]** に電話番号を入力します。 この番号は、アクティブ化中にユーザーが **[ヘルプが必要ですか]** ボタンをタップすると表示されます。
16. デバイスのアクティブ化中にさまざまな画面を**表示**したり、**非表示**にしたりすることができます。 登録を最もスムーズに行うには、すべての画面を **[非表示]** に設定します。
17. **[次へ]** を選択して、 **[Review + Create]\(確認および作成\)** ページへ移動します。 **[作成]** を選択します。
## <a name="sync-managed-devices-to-intune"></a>マネージド デバイスを Intune と同期する
ABM、ASM、または ADE ポータルを使用して登録プログラムのトークンを設定し、そこでデバイスを MDM サーバーに割り当てたら、それらのデバイスが Intune サービスで同期されるのを待機するか、手動で同期をプッシュします。手動で同期を行うと、デバイスが Azure portal に表示されるまで、最大 24 時間かかる場合があります。
1. [Microsoft Endpoint Manager admin center](https://go.microsoft.com/fwlink/?linkid=2109431) で、 **[デバイス]** 、 **[iOS/iPadOS]** 、 **[iOS の登録]** 、 **[Enrollment Program トークン]** の順に選択し、一覧からトークンを選択し、 **[デバイス]** 、 **[同期]** の順に選択します。
## <a name="assign-an-enrollment-profile-to-iosipados-devices"></a>登録プロファイルを iOS/iPadOS デバイスに割り当てる
登録する前に、Enrollment Program プロファイルをデバイスに割り当てる必要があります。 これらのデバイスは、Apple から Intune に同期されて、ABM、ASM、または ADE ポータルの適切な MDM サーバー トークンに割り当てられる必要があります。
1. [Microsoft Endpoint Manager admin center](https://go.microsoft.com/fwlink/?linkid=2109431) で、 **[デバイス]** 、 **[iOS/iPadOS]** 、 **[iOS の登録]** 、 **[Enrollment Program トークン]** を選択し、一覧からトークンを選択します。
2. **[デバイス]** を選択し、リスト内でデバイスを選択し、 **[プロファイルの割り当て]** を選択します。
3. **[プロファイルの割り当て]** の下でデバイス用のプロファイルを選択し、 **[割り当て]** を選択します。
## <a name="distribute-devices-to-users"></a>デバイスのユーザーへの配布
Apple と Intune の間の管理と同期を設定し、ADE デバイスを登録できるようにプロファイルを割り当てました。 ユーザーにデバイスを配布できるようになりました。 ユーザー アフィニティがあるデバイスでは、各ユーザーに Intune ライセンスを割り当てる必要があります。
## <a name="next-steps"></a>次のステップ
iOS/iPadOS デバイスの登録に使用できる他のオプションについての詳細を確認できます。
> [!div class="nextstepaction"]
> [iOS または iPadOS の ADE 登録に関する詳細な記事](device-enrollment-program-enroll-ios.md)
<!--commenting out because inaccurate>
## Clean up resources
<!--If you don't want to use iOS/iPadOS corporate enrolled devices anymore, you can delete them.>
<!--- If the devices are enrolled in Intune, you must first [delete them from the Azure Active Directory portal](../remote-actions/devices-wipe.md#delete-devices-from-the-azure-active-directory-portal).> | 9,599 | CC-BY-4.0 |
---
title: TabularBinding データ型 (ASSL) |Microsoft Docs
ms.custom: ''
ms.date: 06/13/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.suite: ''
ms.technology:
- analysis-services
- docset-sql-devref
ms.tgt_pltfrm: ''
ms.topic: reference
api_name:
- TabularBinding Data Type
api_location:
- http://schemas.microsoft.com/analysisservices/2003/engine
topic_type:
- apiref
f1_keywords:
- TabularBinding
helpviewer_keywords:
- TabularBinding data type
ms.assetid: 24587e34-20be-4693-81d8-038a6fc4e8ee
caps.latest.revision: 39
author: minewiskan
ms.author: owend
manager: craigg
ms.openlocfilehash: c5771c76262719264ad2f0a869c92c5d3ce011ff
ms.sourcegitcommit: c18fadce27f330e1d4f36549414e5c84ba2f46c2
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 07/02/2018
ms.locfileid: "37285968"
---
# <a name="tabularbinding-data-type-assl"></a>TabularBinding データ型 (ASSL)
テーブルやキューブ ディメンションなどの表アイテムへのバインドを表す抽象派生データ型を定義します。
## <a name="syntax"></a>構文
```xml
<TabularBinding>
<!-- The TabularBinding element has no child elements other than those inherited from Binding -->
</TabularBinding>
```
## <a name="data-type-characteristics"></a>データ型の特性
|特性|説明|
|--------------------|-----------------|
|基本データ型|[バインド](binding-data-type-assl.md)|
|派生データ型|[DSVTableBinding](tablebinding-data-type-assl.md)、 [QueryBinding](querybinding-data-type-assl.md)、 [TableBinding](tablebinding-data-type-assl.md)|
## <a name="data-type-relationships"></a>データ型のリレーションシップ
|リレーションシップ|要素|
|------------------|-------------|
|親要素|なし|
|子要素|なし|
|派生要素|参照してください[バインド](binding-data-type-assl.md)|
## <a name="remarks"></a>コメント
詳細については、`Binding`の Analysis Services スクリプト言語 (ASSL) オブジェクトのテーブルを含む、型、`Binding`型との継承階層`Binding`型を参照してください[(ASSL)](binding-data-type-assl.md)します。
ASSL でのデータ バインドの概要については、次を参照してください。[データ ソースとバインド(SSAS 多次元)](../../multidimensional-models/data-sources-and-bindings-ssas-multidimensional.md)します。
分析管理オブジェクト (AMO) オブジェクト モデルで対応する要素は<xref:Microsoft.AnalysisServices.TabularBinding>します。
## <a name="see-also"></a>参照
[Analysis Services スクリプト言語の XML データ型(ASSL)](analysis-services-scripting-language-xml-data-types-assl.md) | 2,223 | CC-BY-4.0 |
---
layout: post
title: Moden Javascipt
category: Javascript
keywords: Javascript
---
[使用"立即执行函数"(Immediately-Invoked Function Expression,IIFE)](http://www.ithao123.cn/content-5615777.html)
[Javascript 严格模式详解](http://www.ruanyifeng.com/blog/2013/01/javascript_strict_mode.html)
```
设立"严格模式"的目的,主要有以下几个:
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
"use strict";
老版本的浏览器会把它当作一行普通字符串,加以忽略。
```
[传统 Ajax 已死,Fetch 永生](https://segmentfault.com/a/1190000003810652)
[Javascript模块化编程(二):AMD规范](http://www.ruanyifeng.com/blog/2012/10/asynchronous_module_definition.html)
[浏览器加载 CommonJS 模块的原理与实现](http://www.ruanyifeng.com/blog/2015/05/commonjs-in-browser.html)
[React学习笔记—JSX](https://segmentfault.com/a/1190000002646155)
React.render方法可以渲染HTML结构,也可以渲染React组件。
渲染HTML标签,声明变量采用首字母小写
var myDivElement = <div className="foo" />;
React.render(myDivElement, document.body);
渲染React组件,声明变量采用首字母大写
var MyComponent = React.createClass({/*...*/});
var myElement = <MyComponent someProperty={true} />;
React.render(myElement, document.body);
标签的属性class和for,需要写成className和htmlFor。因为两个属性是JavaScript的保留字和关键字。无论你是否使用JSX。
表达式用{}包起来,不要加引号,加引号就会被当成字符串。
JSX是HTML和JavaScript混写的语法,当遇到<,JSX就当HTML解析,遇到{就当JavaScript解析。
[js中let和var定义变量的区别](http://zhidao.baidu.com/question/329685205173520085.html)
js中let和var定义变量的区别,主要体现在作用于的不同。
var定义的变量是全局变量或者函数变量。
let定义的变量是块级的变量。
例如:
while(1){
let let1 = 2;
var var1 = 2;
}
alert(let1); //不可访问
alert(var1); //可以访问
也就是说,let只对它所在的最内侧块内有效,而var的范围至少是一个函数之内。 | 1,619 | MIT |
## 第7章: IDT与中断
中断(interrupt)是由硬件或软件产生的信号,表示发生了急需处理的事件。
中断有3种:
- **硬件中断(Hardware interrupts):** 由外部设备(如键盘,鼠标,硬盘...)向处理器发送的中断。硬件中断是一种在轮询循环中等待外部事件,减少处理器的宝贵时间的方式。
- **软件中断(Software interrupts):** 由软件自发发起的。用于管理系统调用。
- **异常(Exceptions):** 用于程序中出现超出其所能处理的错误或事件(如除零、页错误...)
#### 键盘样例:
当用户敲击键盘上的一个键, 键盘控制器会发送一个中断信号到中断控制器(Interrupt Controller)。如果它没有被屏蔽,控制器会为它给处理器发送信号。处理器会执行一套流程来管理中断(键的按击或松开)。这样的一套流程可以完成如接收按键并输出到屏幕的过程。当这个字符处理过程完成后,原来被中断的任务会被回复。
#### PIC是什么?
[PIC](http://en.wikipedia.org/wiki/Programmable_Interrupt_Controller)(Programmable interrupt controller,可编程中断控制器)被用于合并多种来源的中断到一个或多个CPU管线(lines),同时为其中断输出分配优先级。当设备有多个中断输出发生时,它使它们遵循优先级来发生。
最有名的PIC是8259A。每个8259A可以处理8个设备,但是大部分计算机有多个控制器:一个主控制器(master)和一个从控制器(slave),它使计算机可以管理来自14个设备的中断。
在本章中,我们需要为这个控制器编程,使其初始化,然后屏蔽中断。
#### IDT是什么?
> 中断描述符表(IDT)是x86架构用于实现中断向量表的数据结构。IDT被处理器用于决定对中断及异常作出何种应答。
我们的内核将使用IDT来定义中断发生时调用的不同程序。
与GDT类似,IDT使用LIDTL汇编指令来加载。一个IDT的位置结构如下描述:
```cpp
struct idtr {
u16 limite;
u32 base;
} __attribute__ ((packed));
```
IDT表由如下结构的IDT段所构成:
```cpp
struct idtdesc {
u16 offset0_15;
u16 select;
u16 type;
u16 offset16_31;
} __attribute__ ((packed));
```
**注意:** ```__attribute__ ((packed))``` 请参考上一章。
现在需要定义我们的IDT表并使用LIDTL来载入它。IDT表可以存储在内存中的任何位置,其地址存储与IDTR寄存器以告知进程。
以下是一个通用的中断表(Maskable hardware interrupt,IRQ,可屏蔽硬件信号):
| IRQ | Description |
|:-----:| -------------------------- |
| 0 | Programmable Interrupt Timer Interrupt |
| 1 | Keyboard Interrupt |
| 2 | Cascade (used internally by the two PICs. never raised) |
| 3 | COM2 (if enabled) |
| 4 | COM1 (if enabled) |
| 5 | LPT2 (if enabled) |
| 6 | Floppy Disk |
| 7 | LPT1 |
| 8 | CMOS real-time clock (if enabled) |
| 9 | Free for peripherals / legacy SCSI / NIC |
| 10 | Free for peripherals / SCSI / NIC |
| 11 | Free for peripherals / SCSI / NIC |
| 12 | PS2 Mouse |
| 13 | FPU / Coprocessor / Inter-processor |
| 14 | Primary ATA Hard Disk |
| 15 | Secondary ATA Hard Disk |
#### 如何初始化中断?
以下是定义IDT段的一个简单方法
```cpp
void init_idt_desc(u16 select, u32 offset, u16 type, struct idtdesc *desc)
{
desc->offset0_15 = (offset & 0xffff);
desc->select = select;
desc->type = type;
desc->offset16_31 = (offset & 0xffff0000) >> 16;
return;
}
```
然后初始化中断:
```cpp
#define IDTBASE 0x00000000
#define IDTSIZE 0xFF
idtr kidtr;
```
```cpp
void init_idt(void)
{
/* Init irq */
int i;
for (i = 0; i < IDTSIZE; i++)
init_idt_desc(0x08, (u32)_asm_schedule, INTGATE, &kidt[i]); //
/* Vectors 0 -> 31 are for exceptions */
init_idt_desc(0x08, (u32) _asm_exc_GP, INTGATE, &kidt[13]); /* #GP */
init_idt_desc(0x08, (u32) _asm_exc_PF, INTGATE, &kidt[14]); /* #PF */
init_idt_desc(0x08, (u32) _asm_schedule, INTGATE, &kidt[32]);
init_idt_desc(0x08, (u32) _asm_int_1, INTGATE, &kidt[33]);
init_idt_desc(0x08, (u32) _asm_syscalls, TRAPGATE, &kidt[48]);
init_idt_desc(0x08, (u32) _asm_syscalls, TRAPGATE, &kidt[128]); //48
kidtr.limite = IDTSIZE * 8;
kidtr.base = IDTBASE;
/* Copy the IDT to the memory */
memcpy((char *) kidtr.base, (char *) kidt, kidtr.limite);
/* Load the IDTR registry */
asm("lidtl (kidtr)");
}
```
在IDT初始化后,需要配置PIC来激活中断。下面的这个函数会通过处理器的输出端口(port),写入两个PIC的内部寄存器来进行配置。
```io.outb``` 我们使用以下端口来配置PIC:
* Master PIC: 0x20 and 0x21
* Slave PIC: 0xA0 and 0xA1
PIC有两种寄存器:
* ICW (Initialization Command Word,初始化命令字): 重新初始化控制器
* OCW (Operation Control Word,操作命令字): 当初始化后配置控制器(用于屏蔽/取消屏蔽中断)
```cpp
void init_pic(void)
{
/* Initialization of ICW1 */
io.outb(0x20, 0x11);
io.outb(0xA0, 0x11);
/* Initialization of ICW2 */
io.outb(0x21, 0x20); /* start vector = 32 */
io.outb(0xA1, 0x70); /* start vector = 96 */
/* Initialization of ICW3 */
io.outb(0x21, 0x04);
io.outb(0xA1, 0x02);
/* Initialization of ICW4 */
io.outb(0x21, 0x01);
io.outb(0xA1, 0x01);
/* mask interrupts */
io.outb(0x21, 0x0);
io.outb(0xA1, 0x0);
}
```
#### PIC ICW配置细节
寄存器必须按顺序配置。
**ICW1 (port 0x20 / port 0xA0)**
```
|0|0|0|1|x|0|x|x|
| | +--- with ICW4 (1) or without (0)
| +----- one controller (1), or cascade (0)
+--------- triggering by level (level) (1) or by edge (edge) (0)
```
**ICW2 (port 0x21 / port 0xA1)**
```
|x|x|x|x|x|0|0|0|
| | | | |
+----------------- base address for interrupts vectors
```
**ICW2 (port 0x21 / port 0xA1)**
主控制器:
```
|x|x|x|x|x|x|x|x|
| | | | | | | |
+------------------ slave controller connected to the port yes (1), or no (0)
```
从控制器:
```
|0|0|0|0|0|x|x|x| pour l'esclave
| | |
+-------- Slave ID which is equal to the master port
```
**ICW4 (port 0x21 / port 0xA1)**
用于定义控制器可运行在何种模式。
```
|0|0|0|x|x|x|x|1|
| | | +------ mode "automatic end of interrupt" AEOI (1)
| | +-------- mode buffered slave (0) or master (1)
| +---------- mode buffered (1)
+------------ mode "fully nested" (1)
```
#### 为什么IDT段的offset是ASM函数?
你应该留意到在初始化IDT段时,我对段使用了汇编编写的offset。The se different functions are defined in [x86int.asm](https://github.com/SamyPesse/How-to-Make-a-Computer-Operating-System/blob/master/src/kernel/arch/x86/x86int.asm) and are following the scheme:
```
%macro SAVE_REGS 0
pushad
push ds
push es
push fs
push gs
push ebx
mov bx,0x10
mov ds,bx
pop ebx
%endmacro
%macro RESTORE_REGS 0
pop gs
pop fs
pop es
pop ds
popad
%endmacro
%macro INTERRUPT 1
global _asm_int_%1
_asm_int_%1:
SAVE_REGS
push %1
call isr_default_int
pop eax ;;a enlever sinon
mov al,0x20
out 0x20,al
RESTORE_REGS
iret
%endmacro
```
这些宏用于定义防止不同寄存器损坏的中断段。它在多任务中非常有用。
(原文:These macros will be used to define interrupt segment that will prevent corruption of the different registries) | 5,616 | Apache-2.0 |
---
title: Spring AOP
date: 2017/11/08
categories:
- spring
tags:
- spring
- core
- aop
---
# AOP
<!-- TOC depthFrom:2 depthTo:3 -->
- [概念](#概念)
- [什么是 AOP](#什么是-aop)
- [术语](#术语)
- [advice 的类型](#advice-的类型)
- [关于 AOP Proxy](#关于-aop-proxy)
- [彻底理解 aspect, join point, point cut, advice](#彻底理解-aspect-join-point-point-cut-advice)
- [@AspectJ 支持](#aspectj-支持)
- [使能 @AspectJ 支持](#使能-aspectj-支持)
- [定义 aspect(切面)](#定义-aspect切面)
- [声明 pointcut](#声明-pointcut)
- [声明 advice](#声明-advice)
<!-- /TOC -->
## 概念
其实, 接触了这么久的 AOP, 我感觉, AOP 给人难以理解的一个关键点是它的概念比较多, 而且坑爹的是, 这些概念经过了中文翻译后, 变得面目全非, 相同的一个术语, 在不同的翻译下, 含义总有着各种莫名其妙的差别. 鉴于此, 我在本章的开头, 着重为为大家介绍一个 Spring AOP 的各项术语的基本含义. 为了术语传达的准确性, 我在接下来的叙述中, 能使用英文术语的地方, 尽量使用英文.
### 什么是 AOP
AOP(Aspect-Oriented Programming), 即 **面向切面编程**, 它与 OOP( Object-Oriented Programming, 面向对象编程) 相辅相成, 提供了与 OOP 不同的抽象软件结构的视角.
在 OOP 中, 我们以类(class)作为我们的基本单元, 而 AOP 中的基本单元是 **Aspect(切面)**
### 术语
#### Aspect(切面)
`aspect` 由 `pointcount` 和 `advice` 组成, 它既包含了横切逻辑的定义, 也包括了连接点的定义. Spring AOP 就是负责实施切面的框架, 它将切面所定义的横切逻辑织入到切面所指定的连接点中.
AOP 的工作重心在于如何将增强织入目标对象的连接点上, 这里包含两个工作:
1. 如何通过 pointcut 和 advice 定位到特定的 joinpoint 上
2. 如何在 advice 中编写切面代码.
**可以简单地认为, 使用 @Aspect 注解的类就是切面.**
#### advice(增强)
由 aspect 添加到特定的 join point(即满足 point cut 规则的 join point) 的一段代码.
许多 AOP 框架, 包括 Spring AOP, 会将 advice 模拟为一个拦截器(interceptor), 并且在 join point 上维护多个 advice, 进行层层拦截.
例如 HTTP 鉴权的实现, 我们可以为每个使用 RequestMapping 标注的方法织入 advice, 当 HTTP 请求到来时, 首先进入到 advice 代码中, 在这里我们可以分析这个 HTTP 请求是否有相应的权限, 如果有, 则执行 Controller, 如果没有, 则抛出异常. 这里的 advice 就扮演着鉴权拦截器的角色了.
#### 连接点(join point)
> a point during the execution of a program, such as the execution of a method or the handling of an exception. In Spring AOP, a join point always represents a method execution.
程序运行中的一些时间点, 例如一个方法的执行, 或者是一个异常的处理.
`在 Spring AOP 中, join point 总是方法的执行点, 即只有方法连接点.`
#### 切点(point cut)
匹配 join point 的谓词(a predicate that matches join points).
Advice 是和特定的 point cut 关联的, 并且在 point cut 相匹配的 join point 中执行.
`在 Spring 中, 所有的方法都可以认为是 joinpoint, 但是我们并不希望在所有的方法上都添加 Advice, 而 pointcut 的作用就是提供一组规则(使用 AspectJ pointcut expression language 来描述) 来匹配joinpoint, 给满足规则的 joinpoint 添加 Advice.`
#### 关于 join point 和 point cut 的区别
在 Spring AOP 中, 所有的方法执行都是 join point. 而 point cut 是一个描述信息, 它修饰的是 join point, 通过 point cut, 我们就可以确定哪些 join point 可以被织入 Advice. 因此 join point 和 point cut 本质上就是两个不同纬度上的东西.
`advice 是在 join point 上执行的, 而 point cut 规定了哪些 join point 可以执行哪些 advice`
#### introduction
为一个类型添加额外的方法或字段. Spring AOP 允许我们为 `目标对象` 引入新的接口(和对应的实现). 例如我们可以使用 introduction 来为一个 bean 实现 IsModified 接口, 并以此来简化 caching 的实现.
#### 目标对象(Target)
织入 advice 的目标对象. 目标对象也被称为 `advised object`.
`因为 Spring AOP 使用运行时代理的方式来实现 aspect, 因此 adviced object 总是一个代理对象(proxied object)`
`注意, adviced object 指的不是原来的类, 而是织入 advice 后所产生的代理类.`
#### AOP proxy
一个类被 AOP 织入 advice, 就会产生一个结果类, 它是融合了原类和增强逻辑的代理类.
在 Spring AOP 中, 一个 AOP 代理是一个 JDK 动态代理对象或 CGLIB 代理对象.
#### 织入(Weaving)
将 aspect 和其他对象连接起来, 并创建 adviced object 的过程.
根据不同的实现技术, AOP 织入有三种方式:
- 编译器织入, 这要求有特殊的 Java 编译器.
- 类装载期织入, 这需要有特殊的类装载器.
- 动态代理织入, 在运行期为目标类添加增强(Advice)生成子类的方式.
Spring 采用动态代理织入, 而 AspectJ 采用编译器织入和类装载期织入.
### advice 的类型
- before advice, 在 join point 前被执行的 advice. 虽然 before advice 是在 join point 前被执行, 但是它并不能够阻止 join point 的执行, 除非发生了异常(即我们在 before advice 代码中, 不能人为地决定是否继续执行 join point 中的代码)
- after return advice, 在一个 join point 正常返回后执行的 advice
- after throwing advice, 当一个 join point 抛出异常后执行的 advice
- after(final) advice, 无论一个 join point 是正常退出还是发生了异常, 都会被执行的 advice.
- around advice, 在 join point 前和 joint point 退出后都执行的 advice. 这个是最常用的 advice.
### 关于 AOP Proxy
Spring AOP 默认使用标准的 JDK 动态代理(dynamic proxy)技术来实现 AOP 代理, 通过它, 我们可以为任意的接口实现代理.
`如果需要为一个类实现代理, 那么可以使用 CGLIB 代理.` 当一个业务逻辑对象没有实现接口时, 那么 Spring AOP 就默认使用 CGLIB 来作为 AOP 代理了. 即如果我们需要为一个方法织入 advice, 但是这个方法不是一个接口所提供的方法, 则此时 Spring AOP 会使用 CGLIB 来实现动态代理. 鉴于此, Spring AOP 建议基于接口编程, 对接口进行 AOP 而不是类.
## 彻底理解 aspect, join point, point cut, advice
看完了上面的理论部分知识, 我相信还是会有不少朋友感觉到 AOP 的概念还是很模糊, 对 AOP 中的各种概念理解的还不是很透彻. 其实这很正常, 因为 AOP 中的概念是在是太多了, 我当时也是花了老大劲才梳理清楚的.
下面我以一个简单的例子来比喻一下 AOP 中 aspect, jointpoint, pointcut 与 advice 之间的关系.
让我们来假设一下, 从前有一个叫爪哇的小县城, 在一个月黑风高的晚上, 这个县城中发生了命案. 作案的凶手十分狡猾, 现场没有留下什么有价值的线索. 不过万幸的是, 刚从隔壁回来的老王恰好在这时候无意中发现了凶手行凶的过程, 但是由于天色已晚, 加上凶手蒙着面, 老王并没有看清凶手的面目, 只知道凶手是个男性, 身高约七尺五寸. 爪哇县的县令根据老王的描述, 对守门的士兵下命令说: 凡是发现有身高七尺五寸的男性, 都要抓过来审问. 士兵当然不敢违背县令的命令, 只好把进出城的所有符合条件的人都抓了起来.
来让我们看一下上面的一个小故事和 AOP 到底有什么对应关系.
首先我们知道, 在 Spring AOP 中 join point 指代的是所有方法的执行点, 而 point cut 是一个描述信息, 它修饰的是 join point, 通过 point cut, 我们就可以确定哪些 join point 可以被织入 Advice. 对应到我们在上面举的例子, 我们可以做一个简单的类比, join point 就相当于 **爪哇的小县城里的百姓**, point cut 就相当于 **老王所做的指控, 即凶手是个男性, 身高约七尺五寸**, 而 advice 则是施加在符合老王所描述的嫌疑人的动作: **抓过来审问**.
为什么可以这样类比呢?
- join point --> 爪哇的小县城里的百姓: 因为根据定义, join point 是所有可能被织入 advice 的候选的点, 在 Spring AOP 中, 则可以认为所有方法执行点都是 join point. 而在我们上面的例子中, 命案发生在小县城中, 按理说在此县城中的所有人都有可能是嫌疑人.
- point cut --> 男性, 身高约七尺五寸: 我们知道, 所有的方法(joint point) 都可以织入 advice, 但是我们并不希望在所有方法上都织入 advice, 而 pointcut 的作用就是提供一组规则来匹配 joinpoint, 给满足规则的 joinpoint 添加 advice. 同理, 对于县令来说, 他再昏庸, 也知道不能把县城中的所有百姓都抓起来审问, 而是根据`凶手是个男性, 身高约七尺五寸`, 把符合条件的人抓起来. 在这里`凶手是个男性, 身高约七尺五寸` 就是一个修饰谓语, 它限定了凶手的范围, 满足此修饰规则的百姓都是嫌疑人, 都需要抓起来审问.
- advice --> 抓过来审问, advice 是一个动作, 即一段 Java 代码, 这段 Java 代码是作用于 point cut 所限定的那些 join point 上的. 同理, 对比到我们的例子中, `抓过来审问` 这个动作就是对作用于那些满足 `男性, 身高约七尺五寸` 的`爪哇的小县城里的百姓`.
- aspect: aspect 是 point cut 与 advice 的组合, 因此在这里我们就可以类比: **"根据老王的线索, 凡是发现有身高七尺五寸的男性, 都要抓过来审问"** 这一整个动作可以被认为是一个 aspect.
或则我们也可以从语法的角度来简单类比一下. 我们在学英语时, 经常会接触什么 `定语`, `被动句` 之类的概念, 那么可以做一个不严谨的类比, 即 `joinpoint` 可以认为是一个 `宾语`, 而 `pointcut` 则可以类比为修饰 `joinpoint` 的定语, 那么整个 `aspect` 就可以描述为: `满足 pointcut 规则的 joinpoint 会被添加相应的 advice 操作.`
## @AspectJ 支持
**@AspectJ** 是一种使用 Java 注解来实现 AOP 的编码风格。
@AspectJ 风格的 AOP 是 AspectJ Project 在 AspectJ 5 中引入的, 并且 Spring 也支持 @AspectJ 的 AOP 风格.
### 使能 @AspectJ 支持
@AspectJ 可以以 XML 的方式或以注解的方式来使能, 并且不论以哪种方式使能@ASpectJ, 我们都必须保证 aspectjweaver.jar 在 classpath 中.
#### 使用 Java Configuration 方式使能@AspectJ
```java
@Configuration
@EnableAspectJAutoProxy
public class AppConfig {
}
```
#### 使用 XML 方式使能@AspectJ
```
<aop:aspectj-autoproxy/>
```
### 定义 aspect(切面)
当使用注解 **@Aspect** 标注一个 Bean 后, 那么 Spring 框架会自动收集这些 Bean, 并添加到 Spring AOP 中, 例如:
```java
@Component
@Aspect
public class MyTest {
}
```
`注意, 仅仅使用@Aspect 注解, 并不能将一个 Java 对象转换为 Bean, 因此我们还需要使用类似 @Component 之类的注解.`
`注意, 如果一个 类被@Aspect 标注, 则这个类就不能是其他 aspect 的 **advised object** 了, 因为使用 @Aspect 后, 这个类就会被排除在 auto-proxying 机制之外.`
### 声明 pointcut
一个 pointcut 的声明由两部分组成:
- 一个方法签名, 包括方法名和相关参数
- 一个 pointcut 表达式, 用来指定哪些方法执行是我们感兴趣的(即因此可以织入 advice).
在@AspectJ 风格的 AOP 中, 我们使用一个方法来描述 pointcut, 即:
```java
@Pointcut("execution(* com.xys.service.UserService.*(..))") // 切点表达式
private void dataAccessOperation() {} // 切点前面
```
`这个方法必须无返回值.`
`这个方法本身就是 pointcut signature, pointcut 表达式使用@Pointcut 注解指定.`
上面我们简单地定义了一个 pointcut, 这个 pointcut 所描述的是: 匹配所有在包 **com.xys.service.UserService** 下的所有方法的执行.
#### 切点标志符(designator)
AspectJ5 的切点表达式由标志符(designator)和操作参数组成. 如 "execution(\* greetTo(..))" 的切点表达式, \*\*execution** 就是 标志符, 而圆括号里的 \*\*\***greetTo(..) 就是操作参数
##### execution
匹配 join point 的执行, 例如 "execution(\* hello(..))" 表示匹配所有目标类中的 hello() 方法. 这个是最基本的 pointcut 标志符.
##### within
匹配特定包下的所有 join point, 例如 `within(com.xys.*)` 表示 com.xys 包中的所有连接点, 即包中的所有类的所有方法. 而`within(com.xys.service.*Service)` 表示在 com.xys.service 包中所有以 Service 结尾的类的所有的连接点.
##### this 与 target
this 的作用是匹配一个 bean, 这个 bean(Spring AOP proxy) 是一个给定类型的实例(instance of). 而 target 匹配的是一个目标对象(target object, 即需要织入 advice 的原始的类), 此对象是一个给定类型的实例(instance of).
##### bean
匹配 bean 名字为指定值的 bean 下的所有方法, 例如:
```
bean(*Service) // 匹配名字后缀为 Service 的 bean 下的所有方法
bean(myService) // 匹配名字为 myService 的 bean 下的所有方法
```
##### args
匹配参数满足要求的的方法.
例如:
```java
@Pointcut("within(com.xys.demo2.*)")
public void pointcut2() {
}
@Before(value = "pointcut2() && args(name)")
public void doSomething(String name) {
logger.info("---page: {}---", name);
}
```
```java
@Service
public class NormalService {
private Logger logger = LoggerFactory.getLogger(getClass());
public void someMethod() {
logger.info("---NormalService: someMethod invoked---");
}
public String test(String name) {
logger.info("---NormalService: test invoked---");
return "服务一切正常";
}
}
```
当 NormalService.test 执行时, 则 advice `doSomething` 就会执行, test 方法的参数 name 就会传递到 `doSomething` 中.
常用例子:
```java
// 匹配只有一个参数 name 的方法
@Before(value = "aspectMethod() && args(name)")
public void doSomething(String name) {
}
// 匹配第一个参数为 name 的方法
@Before(value = "aspectMethod() && args(name, ..)")
public void doSomething(String name) {
}
// 匹配第二个参数为 name 的方法
Before(value = "aspectMethod() && args(*, name, ..)")
public void doSomething(String name) {
}
```
##### @annotation
匹配由指定注解所标注的方法, 例如:
```java
@Pointcut("@annotation(com.xys.demo1.AuthChecker)")
public void pointcut() {
}
```
则匹配由注解 `AuthChecker` 所标注的方法.
#### 常见的切点表达式
##### 匹配方法签名
```
// 匹配指定包中的所有的方法
execution(* com.xys.service.*(..))
// 匹配当前包中的指定类的所有方法
execution(* UserService.*(..))
// 匹配指定包中的所有 public 方法
execution(public * com.xys.service.*(..))
// 匹配指定包中的所有 public 方法, 并且返回值是 int 类型的方法
execution(public int com.xys.service.*(..))
// 匹配指定包中的所有 public 方法, 并且第一个参数是 String, 返回值是 int 类型的方法
execution(public int com.xys.service.*(String name, ..))
```
##### 匹配类型签名
```
// 匹配指定包中的所有的方法, 但不包括子包
within(com.xys.service.*)
// 匹配指定包中的所有的方法, 包括子包
within(com.xys.service..*)
// 匹配当前包中的指定类中的方法
within(UserService)
// 匹配一个接口的所有实现类中的实现的方法
within(UserDao+)
```
##### 匹配 Bean 名字
```
// 匹配以指定名字结尾的 Bean 中的所有方法
bean(*Service)
```
##### 切点表达式组合
```
// 匹配以 Service 或 ServiceImpl 结尾的 bean
bean(*Service || *ServiceImpl)
// 匹配名字以 Service 结尾, 并且在包 com.xys.service 中的 bean
bean(*Service) && within(com.xys.service.*)
```
### 声明 advice
advice 是和一个 pointcut 表达式关联在一起的, 并且会在匹配的 join point 的方法执行的前/后/周围 运行. `pointcut 表达式可以是简单的一个 pointcut 名字的引用, 或者是完整的 pointcut 表达式`.
下面我们以几个简单的 advice 为例子, 来看一下一个 advice 是如何声明的.
#### Before advice
```java
/**
* @author xiongyongshun
* @version 1.0
* @created 16/9/9 13:13
*/
@Component
@Aspect
public class BeforeAspectTest {
// 定义一个 Pointcut, 使用 切点表达式函数 来描述对哪些 Join point 使用 advise.
@Pointcut("execution(* com.xys.service.UserService.*(..))")
public void dataAccessOperation() {
}
}
```
```java
@Component
@Aspect
public class AdviseDefine {
// 定义 advise
@Before("com.xys.aspect.PointcutDefine.dataAccessOperation()")
public void doBeforeAccessCheck(JoinPoint joinPoint) {
System.out.println("*****Before advise, method: " + joinPoint.getSignature().toShortString() + " *****");
}
}
```
这里, **@Before** 引用了一个 pointcut, 即 "com.xys.aspect.PointcutDefine.dataAccessOperation()" 是一个 pointcut 的名字.
如果我们在 advice 在内置 pointcut, 则可以:
```java
@Component
@Aspect
public class AdviseDefine {
// 将 pointcut 和 advice 同时定义
@Before("within(com.xys.service..*)")
public void doAccessCheck(JoinPoint joinPoint) {
System.out.println("*****doAccessCheck, Before advise, method: " + joinPoint.getSignature().toShortString() + " *****");
}
}
```
#### around advice
around advice 比较特别, 它可以在一个方法的之前之前和之后添加不同的操作, 并且甚至可以决定何时, 如何, 是否调用匹配到的方法.
```java
@Component
@Aspect
public class AdviseDefine {
// 定义 advise
@Around("com.xys.aspect.PointcutDefine.dataAccessOperation()")
public Object doAroundAccessCheck(ProceedingJoinPoint pjp) throws Throwable {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 开始
Object retVal = pjp.proceed();
stopWatch.stop();
// 结束
System.out.println("invoke method: " + pjp.getSignature().getName() + ", elapsed time: " + stopWatch.getTotalTimeMillis());
return retVal;
}
}
```
around advice 和前面的 before advice 差不多, 只是我们把注解 **@Before** 改为了 **@Around** 了. | 11,795 | Apache-2.0 |
<p align='center'>
<p align='center'><img width='150' src='https://raw.githubusercontent.com/coding-show/dort/master/client/static/images/favicon.png' /></p>
<p align='center'>
File sharing through web with wonderful alternation.</br>
文件演示分享Web工具
</p>
</p>
[](https://travis-ci.org/coding-tool/dort)
[](https://badge.fury.io/js/dort)
### Introduction - ([https://coding-tool.github.io/dort/](https://coding-tool.github.io/dort/))
Dort is a npm tool to share your editing, file structure through web during presentation or code review.
Dort 是一个使用者在 **讲演** 或者 **代码审阅** 过程 分享 **项目文件**、**编辑过程** 的web工具。
Everybody in the same network can browse through the files, check file history, copy the code, download the project, preview images, etc.
同一内网中的用户可以 **浏览文件**,**查看文件编辑版本**,**复制文本**,**下载整个项目**,**查看图片**,甚至可以与所有打开web的用户进行交流。
### Feature
- Easy for Client (all platform with browser) 便于使用
- Live Update 实时刷新
- Low Network Traffic 低网络负担
### Demo



### Instruction
1. Prepare NodeJS and NPM environment 准备nodejs和npm环境
2. Install package 安装包
``` bash
# npm install -g dort
```
3. Launch dort inside your project folder 启动server端
```
# cd /your-files
# dort
```
4. Open default browser with default port - [http://localhost:4574](http://localhost:4574) 端口可设置
5. Shre the url to any body in the same network 其他内网用户可以通过相应端口访问
### Configuration
params | Type | Default | Description
-------- | ---- | ------- | -----------
debug | number | 1 | develop levels
path | string | '' | path of file you want open
name | string | '' | name of project
port | number | 4574 | port for web
exclude | array | ['**/.DS_Store', '**/.log', ...] | file to exclude
test | bool | false | Enable test mode or not
max-file-size | number | 99999 | max file size
Then you can launch dort as
``` bash
# dort "My project" --debug 0 --path /file-path --port 1234 --exclude "node_modules/**" --test true --max-file-size 99999
# // or
# dort "My project" -d 0 -pa /file-path -po 1234 -e "node_modules/**" -t true -m 99999
```
### TODO
- [x] node procedure to watch files in local
- [x] state management
- [x] FE web
- [x] chat and barrage
- [ ] File content interactive | 2,555 | MIT |
<properties
pageTitle="メディア プロセッサを作成する方法 | Microsoft Azure"
description="メディア プロセッサ コンポーネントを作成し、Azure Media Services 用にメディア コンテンツのエンコード、形式の変換、暗号化、または復号化を行う方法について説明します。コード サンプルは C# で記述され、Media Services SDK for .NET を利用しています。"
services="media-services"
documentationCenter=""
authors="juliako"
manager="erikre"
editor=""/>
<tags
ms.service="media-services"
ms.workload="media"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="03/01/2016"
ms.author="juliako"/>
#方法: メディア プロセッサ インスタンスを取得する
> [AZURE.SELECTOR]
- [.NET](media-services-get-media-processor.md)
- [REST ()](media-services-rest-get-media-processor.md)
##概要
メディア プロセッサは、Media Services のコンポーネントとして、メディア コンテンツのエンコード、形式変換、暗号化、復号化など、特定の処理タスクを担います。通常、メディア コンテンツのエンコード、暗号化、形式変換を行うタスクの作成時にメディア プロセッサを作成します。
次の表は、利用可能なメディア プロセッサの名前と説明の一覧です。
メディア プロセッサ名|説明|詳細情報
---|---|---
メディア エンコーダー スタンダード|オンデマンド エンコードのための標準機能を備えています。 |[Azure オンデマンド メディア エンコーダーの概要と比較](media-services-encode-asset.md)
メディア エンコーダー Premium ワークフロー|メディア エンコーダー Premium ワークフローを使用してエンコード タスクを実行できます。|[Azure オンデマンド メディア エンコーダーの概要と比較](media-services-encode-asset.md)
Azure Media Indexer| メディア ファイルとコンテンツを検索可能にすると共に、クローズド キャプション トラックの生成を可能にします。|[Azure Media Indexer](media-services-index-content.md)
Azure Media Hyperlapse (プレビュー)|ビデオ安定化を使用して、ビデオの "凸凹" を取り除いて滑らかにすることができます。コンテンツをすばやく使用可能なクリップにすることもできます。|[Azure Media Hyperlapse](media-services-hyperlapse-content.md)
Azure Media Encoder|償却対象
Storage Decryption| 償却対象|
Azure Media Packager|償却対象|
Azure Media Encryptor|償却対象|
##メディア プロセッサの取得
次のメソッドは、メディア プロセッサ インスタンスを取得する方法を示しています。このコード例では、[Media Services にプログラムから接続する方法](media-services-dotnet-connect_programmatically.md)に関するページで説明しているように、モジュール レベルの変数 **\_context** を使用してサーバー コンテキストを参照しています。
private static IMediaProcessor GetLatestMediaProcessorByName(string mediaProcessorName)
{
var processor = _context.MediaProcessors.Where(p => p.Name == mediaProcessorName).
ToList().OrderBy(p => new Version(p.Version)).LastOrDefault();
if (processor == null)
throw new ArgumentException(string.Format("Unknown media processor", mediaProcessorName));
return processor;
}
##Media Services のラーニング パス
[AZURE.INCLUDE [media-services-learning-paths-include](../../includes/media-services-learning-paths-include.md)]
##フィードバックの提供
[AZURE.INCLUDE [media-services-user-voice-include](../../includes/media-services-user-voice-include.md)]
##次のステップ
これで、メディア プロセッサ インスタンスを取得する方法がわかりました。次は、「[Media Encoder Standard を使用して資産をエンコードする方法](media-services-dotnet-encode-with-media-encoder-standard.md)」に進んでください。このトピックでは、Media Encoder Standard を使用して資産をエンコードする方法を説明します。
<!---HONumber=AcomDC_0302_2016--> | 2,660 | CC-BY-3.0 |
# Message 消息提醒
### 基本
```html
/*vue*/
<template>
<div>
<div class="demo-list">
<div>
<div class="title">Message组件实例</div>
<div class="vut-button" @click="infoNotice">普通提示</div>
<div class="vut-button" @click="successNotice">成功提示</div>
<div class="vut-button" @click="warningNotice">警告提示</div>
<div class="vut-button" @click="errorNotice">错误提示</div>
</div>
<div>
<p>带有颜色的提示</p>
<div class="vut-button" @click="infoFn">普通提示</div>
<div class="vut-button" @click="successFn">成功提示</div>
<div class="vut-button" @click="warningFn">警告提示</div>
<div class="vut-button" @click="errorFn">错误提示</div>
</div>
<div>
<p>带有颜色的提示</p>
<div class="vut-button" @click="infoCloseFn">带有关闭的提示</div>
</div>
</div>
<!-- API -->
<div class="demo-list">
<div class="title">API</div>
<h3 class="api-label">Message props</h3>
<div class="api">
<p>通过直接调用以下方法来使用组件:</p>
<ul>
<li>
<code>this.$Message.info(config)</code>
</li>
<li>
<code>this.$Message.success(config)</code>
</li>
<li>
<code>this.$Message.warning(config)</code>
</li>
<li>
<code>this.$Message.error(config)</code>
</li>
</ul>
</div>
<vut-table :columns="APIprops" :data="propsData"></vut-table>
</div>
</div>
</template>
<script>
export default {
data(){
return {
APIprops,
propsData
}
},
mounted() {
window.Simple = this;
},
methods: {
infoNotice() {
this.$Message.info("这是一个普通的提示");
},
successNotice() {
this.$Message.success("这是一个成功的提示");
},
warningNotice() {
this.$Message.warning("这是一个警告的提示");
},
errorNotice() {
this.$Message.error("这是一个错误的提示");
},
infoFn() {
this.$Message.info("这是一个普通的提示", true);
},
successFn() {
this.$Message.success("这是一个成功的提示", true);
},
warningFn() {
this.$Message.warning("这是一个警告的提示", true);
},
errorFn() {
this.$Message.error("这是一个错误的提示", true);
},
infoCloseFn() {
this.$Message.info({
content: "这是一个带有关闭的提示",
closable: true,
duration: 10000
});
}
}
}
</script>
``` | 2,577 | MIT |
---
layout: post
title: "国际经济格局将呈现“五极”结构"
date: 2012-04-12
author: 陶郁
from: http://cnpolitics.org/2012/04/global-economic-order/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
国际经济格局将呈现“五极”结构
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
#国际关系 #政经 #澳洲 #经济 #金砖五国
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/taoyu/">陶郁</a-->
<a href="http://cnpolitics.org/author/taoyu/">
陶郁
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2012-04-12
</span>
</p>
<!--p class="post-lead">由一个国家独领世界经济风骚的现象即将成为历史,国际经济将在未来呈现出一个由美国、中国、欧盟、印度和日本等“五极”主导的多边结构;而在迈向新国际经济格局的过程中,中国崛起是大势所趋,也面临重重挑战。</p-->
<div class="post-body">
<p>
<img alt="" class="aligncenter size-full wp-image-837" height="375" sizes="(max-width: 500px) 100vw, 500px" src="http://cnpolitics.org/wp-content/uploads/2012/03/00_world_economy1.jpg" srcset="http://cnpolitics.org/wp-content/uploads/2012/03/00_world_economy1.jpg 500w, http://cnpolitics.org/wp-content/uploads/2012/03/00_world_economy1-300x225.jpg 300w" title="1" width="500">
<br>
<strong>
□“政见”观察员 陶郁
</strong>
</br>
</img>
</p>
<p>
过去两个世纪中,在全球经济一体化进程的不同历史阶段,总有一个国家主导着世界经济:19世纪的经济格局围绕英国运转,而20世纪则是美国主导世界经济。一些观察家因此预言:中国将在21世纪取代美国,成为世界经济的下一任“霸主”。
</p>
<p>
然而,新西兰学者
<strong>
布莱恩·伊斯顿
</strong>
(
<a href="http://www.eastonbh.ac.nz/">
Brian Easton
</a>
)博士却认为,由一个国家独领世界经济风骚的现象即将成为历史,国际经济将在未来呈现出一个由美国、中国、欧盟、印度和日本等“五极”主导的多边结构;而在迈向新国际经济格局的过程中,中国崛起是大势所趋,也面临重重挑战。
</p>
<p>
<strong>
未来的经济五极
</strong>
</p>
<p>
伊斯顿认为,随着越来越多的企业从发达国家向发展中国家迁徙,中国和印度等新兴经济的崛起将不可避免,美国在全球经济格局中的领导地位则将因此受到动摇。但是,由于其经济规模十分庞大,美国在失去主导地位后,仍将在国际经济格局中扮演重要角色,而美元作为国际货币的现状将继续维持。
</p>
<p>
欧盟如今正面临重重困境,由希腊债务问题引发的金融危机仍在持续。但在伊斯顿看来,如果欧洲国家能够跨过这个坎儿,找到应对类似危机的有效手段,积极扩大和加深不同国家在产品市场和资本市场上的合作,欧盟仍将在未来的国际经济格局中占有重要地位。
</p>
<p>
中国和印度作为世界上人口最多的两个国家,得以依靠相对低廉的劳动力成本,吸引发达国家的企业,如今已经成为了世界上最主要的制造业基地。中印两国各具优势:中国拥有更加优良的地理位置、更为整合的社会文化结构、更高的城市化水平、更低的文盲率,以及更为富裕的人均生活水平;而印度则拥有相对年轻的人口结构和更多掌握英语的劳动力,且国家与社会间的冲突相对较少。伊斯顿认为,中印两国经济快速增长的趋势将会持续下去,终将在世界经济格局中获得与其人口规模相称的地位。
</p>
<p>
日本将成为未来全球“经济五极”中规模最小的一个,但雄厚的工业基础、强大的科技实力和大量的外汇储备将为其在国际经济格局中保住一席之地。
</p>
<p>
巴西、俄罗斯和南非虽与中印同属“金砖五国”,但目前这些国家在劳动力规模和经济总量等指标上的表现远不如中国和印度,在未来赶超的可能性也不大。因此,伊斯顿将上述三个国家与澳大利亚和中东国家一并归纳为未来国际经济格局中的“第二梯队”:它们虽无法左右全球经济局势,但将在区域经济发展中发挥重要作用。
</p>
<p>
<strong>
中国的五大挑战
</strong>
</p>
<p>
伊斯顿认为,按照中国目前的发展情况和发展速度进行推算,赶超美国将只是一个时间问题。然而,现实情况远比理论推演要复杂得多。中国如果希望经济实现持续而健康的发展,至少需要有效应对以下五个方面的挑战:
</p>
<p>
首先,中国面临着老龄化问题,这在所有发展中国家里是独一无二的。老龄化不但将缩小劳动力规模,而且会增加社会福利负担;因此,对于以制造业为主要经济增长引擎来说的中国来说,老龄化带来的挑战不容忽视。加之中国可能很难像发达国家那样采用移民的方式来解决这个问题,一旦“人口红利”被消耗完毕,老龄化问题可能将严重制约中国经济按照现在的模式继续发展。
</p>
<p>
其次,中国需要严肃对待环境问题。水资源短缺、水污染和空气污染等问题如果持续恶化,不仅可能降低人们的生活水平,也可能直接影响甚至阻碍经济发展。
</p>
<p>
同时,中国需要改善治理结构。在目前的体制下,中国政府主导着社会经济发展的多个方面,也需要承担由经济发展所带来的全部责任和压力。因此,如何更加积极地应对人民群众日益增长的多方面诉求、惩治腐败、提高行政效率和管理水平、为经济发展提供稳定而健康的社会环境,这都是政府必须思考的问题。
</p>
<p>
另外,中国需要应对国际市场变化带来的外部挑战。如果能源和原材料在国际市场上的价格继续上涨,中国制造业的成本将会不断提高;而如果发达国家的经济不能很快复苏,它们购买中国出口产品的能力也会下降。在这种情况下,中国能否有效降低能耗、提高生产效率、扩大国内需求,将直接影响自身经济在未来的发展。
</p>
<p>
最后,中国需要确保银行系统的健康与稳定。这要求中国政府更为有效地对银行业进行监管,关注银行呆坏账的比率,合理运用货币政策。
</p>
<p>
随着全球化进程不断深化,中国经济发展与世界经济格局变化之间的关系变得日益密切。中国经济的发展既深受世界经济格局的影响,也深刻地影响着世界经济格局变化。能否处理好发展中可能遇到的问题和挑战,能否协调好自身发展与国际规范的关系,不仅关乎中国经济发展,更关乎世界经济格局变化的方向和趋势。
</p>
<p>
【参考资料】
<br>
Easton, Brian. “The Coming World Economic Order.”
<em>
New Zealand International Review
</em>
36(5), Sept.-Oct. 2011: 7-11.
</br>
</p>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,827 | MIT |
# 如何做自己的Pod库!
```
看网上的介绍多多少少都不全,这里只针对一种情况(项目已经在github上托管)作阐述,目的是让想把自己成果分享给大家的思密达们少走弯路
本文以介绍两种创建方式:标准创建和快捷创建!
```
####标准创建:
##### step1 fork Specs files
首先进入官方(https://github.com/CocoaPods/Specs),fork一份podSpecs,此过程估计时间较长,耐心等待,如图:


fork完成之后clone到本地(本文是桌面Desktop)或直接下载到本地,解压后如图:

##### step2 create podspec file
打开终端进入Specs-Matser->Specs你会看到好多别人已经提交的Specs
`$ mkdir 你想创建的Pod的名字` eg.NHEnDecryptor
进入文件夹NHEnDecryptor
`$ mkdir 你想创建的版本` eg. 0.0.3
进入0.0.3文件夹 执行创建podspec文件的命令
`$ pod spec create NHEnDecryptor`
创建完成后如图:

##### step3 Edit podSpec file
```
Pod::Spec.new do |s|
s.name = "NHEnDecryptor"
s.version = "0.0.3"
s.summary = "NHEnDecryptor is an Objc Wrapper for SSL."
s.homepage = "https://github.com/iFindTA"
s.description = "SSL En/Decrypt warpper by Objc Include AES/RSA signature and verify data for ios"
s.license = "MIT(LICENSE)"
s.author = { "nanhujiaju" => "nanhujiaju@163.com" }
s.platform = :ios, "7.0"
s.source = { :git => "https://github.com/iFindTA/NHEnDecryptPro.git", :tag => s.version.to_s }
s.source_files = "NHEnDecryptPro/Security/*.{h,a}"
s.public_header_files = "NHEnDecryptPro/Security/*.h"
s.framework = "UIKit","Foundation","Security"
# s.frameworks = "SomeFramework", "AnotherFramework"
s.requires_arc = true
# s.dependency "JSONKit", "~> 1.4"
end
```
关于这段的设置代码很简单易懂 实在不懂或有其他需求可上网查一下
退出保存
##### step4 verify podspec file
验证你的设置和github上的代码是否正确,执行代码:
`pod spec lint NHEnDecryptor.podspec `
如果你的sources 文件中引入了动态库,如CommonCrypto,则执行代码:
`pod spec lint --allow-warnings --use-libraries --verbose`
这是比较关键的一步,确保没有错误和警告,如果验证成功你将看到下边的提示:
```
Analyzed 1 podspec.
NHEnDecryptor.podspec passed validation.
```
如果提示错误和警告请回到step3检查podspec文件
##### step5 Register CocoaPods Session
`$ pod trunk register name@example.org 'Your Name' --description='macbook pro'`
然后你会在邮箱中收到一封验证邮件,点击验证链接,然后回到终端
##### step6 push podspec file
`pod trunk push NHEnDecryptor.podspec`
或
`pod trunk push NHEnDecryptor.podspec --use-libraries`
接下来就是稍微耐心等待一下
```
- Data URL: https://raw.githubusercontent.com/CocoaPods/Specs/77452efc17bf18757e9a6ab9b09d5a3d08b3f649/Specs/NHEnDecryptor/0.0.3/NHEnDecryptor.podspec.json
- Log messages:
- September 29th, 02:35: Push for `NHEnDecryptor 0.0.3' initiated.
- September 29th, 02:35: Push for `NHEnDecryptor 0.0.3' has been pushed
(1.760894249 s).
```
看到上述提示说明你已经提交成功了,等待CocoaPods团队的审核吧,很快就会通过,然后就可以通过终端搜索到你的成果了!如图:

####快捷创建:
##### step1 create podspec file
```
直接进入项目根目录,创建xxxxxxxxx.podspec 文件
```
```
$ vim xxxxxx.podspec
$ "ESC"
$ :wq
```
#### step next 直接转到“标准创建 step 3”继续执行即可
#### 好了!恭喜你!至此你已经学会了如何将自己的成果分享给大家了!赶快行动吧 | 3,043 | MIT |
# [1004]最大连续 1 的个数 III
> [最大连续 1 的个数 III](https://leetcode-cn.com/problems/max-consecutive-ones-iii/description/)
给定一个由若干`0`和`1`组成的数组`A`,我们最多可以将`K`个值从 0 变成 1 。
返回仅包含 1 的最长(连续)子数组的长度。
**示例 1:**
```
输入:A = [1,1,1,0,0,0,1,1,1,1,0], K = 2
输出:6
解释:
[1,1,1,0,0,1,1,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 6。
```
**示例 2:**
```
输入:A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3
输出:10
解释:
[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 10。
```
## 思考
本题利用典型的滑动窗口即可解决。
## 代码
```java
/*
* @lc app=leetcode.cn id=1004 lang=java
*
* [1004] 最大连续1的个数 III
*/
// @lc code=start
class Solution {
public int longestOnes(int[] A, int K) {
int res = 0, count = 0;
int left = 0, right = 0;
while (right < A.length) {
if (A[right++] == 0) {
count++;
while (count > K) {
if (A[left++] == 0) {
count--;
}
}
}
res = Math.max(res, right - left);
}
return res;
}
}
// @lc code=end
``` | 986 | MIT |
# 1 线程池的实现原理
下图所示为线程池的实现原理:
调用方不断地向线程池中提交任务;线程池中有一组线程,不断地从队列中取任务,这是一个典型的生产者—消费者模型。

## 需要考虑
**要实现这样一个线程池,有几个问题需要考虑:**
1. 队列设置多长?如果是无界的,调用方不断地往队列中放任务,可能导致内存耗尽。
如果是有界的,当队列满了之后,调用方如何处理?
2. 线程池中的线程个数是固定的,还是动态变化的?
3. 每次提交新任务,是放入队列?还是开新线程?
4. 当没有任务的时候,处理线程是睡眠一小段时间?还是进入阻塞?如果进入阻塞,如何唤醒?
**针对问题4,有3种做法:**
1. 不使用阻塞队列,只使用一般的线程安全的队列,也无阻塞/唤醒机制。当队列为空时,线程
池中的线程只能睡眠一会儿,然后醒来去看队列中有没有新任务到来,如此不断轮询。
2. 不使用阻塞队列,但在队列外部、线程池内部实现了阻塞/唤醒机制。
3. 使用阻塞队列。
很显然,做法3最完善,既避免了线程池内部自己实现阻塞/唤醒机制的麻烦,也避免了做法1的睡眠/轮询带来的资源消耗和延迟。正因为如此,接下来要讲的`ThreadPoolExector/ScheduledThreadPoolExecutor`都是基于阻塞队列来实现的,而不是一般的队列,
至此,各式各样的阻塞队列就要派上用场了。
# 2 线程池的类继承体系
线程池的类继承体系如下图所示:

在这里,有两个核心的类: ThreadPoolExector 和ScheduledThreadPoolExecutor ,后者不仅
可以执行某个任务,还可以周期性地执行任务。
向线程池中提交的每个任务,都必须实现Runnable 接口,通过最上面的Executor 接口中的
execute(Runnable command) 向线程池提交任务。
然后,在 ExecutorService 中,定义了线程池的关闭接口 shutdown() ,还定义了可以有返回值
的任务,也就是Callable ,后面会详细介绍。
# 3 ThreadPoolExecutor
## 核心数据结构
### ThreadPoolExector
基于线程池的实现原理,下面看一下ThreadPoolExector的核心数据结构。
```java
public class ThreadPoolExecutor extends AbstractExecutorService {
//...
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 存放任务的阻塞队列
private final BlockingQueue<Runnable> workQueue;
// 对线程池内部各种变量进行互斥访问控制
private final ReentrantLock mainLock = new ReentrantLock();
// 线程集合
private final HashSet<Worker> workers = new HashSet<Worker>();
//...
}
```
### Worker
每一个线程是一个Worker对象。Worker是ThreadPoolExector的内部类,核心数据结构如下:
```java
private final class Worker extends AbstractQueuedSynchronizer implements
Runnable {
// ...
final Thread thread; // Worker封装的线程
Runnable firstTask; // Worker接收到的第1个任务
volatile long completedTasks; // Worker执行完毕的任务个数
// ...
}
```
由定义会发现,**Worker继承于AQS,也就是说Worker本身就是一把锁**。这把锁有什么用处呢?用于线程池的关闭、线程执行任务的过程中。
## 核心配置参数解释
ThreadPoolExecutor在其构造方法中提供了几个核心配置参数,来配置不同策略的线程池。

上面的各个参数,解释如下:
1. corePoolSize:在线程池中始终维护的线程个数。
2. maxPoolSize:在corePooSize已满、队列也满的情况下,扩充线程至此值。
3. keepAliveTime/TimeUnit:maxPoolSize 中的空闲线程,销毁所需要的时间,总线程数收缩回corePoolSize。
4. blockingQueue:线程池所用的队列类型。
5. threadFactory:线程创建工厂,可以自定义,有默认值Executors.defaultThreadFactory() 。
6. RejectedExecutionHandler:corePoolSize已满,队列已满,maxPoolSize 已满,最后的拒绝策略。
下面来看这6个配置参数在任务的提交过程中是怎么运作的。
### 提交任务处理流程
在每次往线程池中提交任务的时候,有如下的处理流程:
步骤一:判断当前线程数是否大于或等于corePoolSize。如果小于,则新建线程执行;如果大于,
则进入步骤二。
步骤二:判断队列是否已满。如未满,则放入;如已满,则进入步骤三。
步骤三:判断当前线程数是否大于或等于maxPoolSize。如果小于,则新建线程执行;如果大于,
则进入步骤四。
步骤四:根据拒绝策略,拒绝任务。
总结一下:首先判断corePoolSize,其次判断blockingQueue是否已满,接着判断maxPoolSize,
最后使用拒绝策略。
很显然,基于这种流程,如果队列是无界的,将永远没有机会走到步骤三,也即maxPoolSize没有
使用,也一定不会走到步骤四。
## 线程池的优雅关闭
线程池的关闭,较之线程的关闭更加复杂。当关闭一个线程池的时候,有的线程还正在执行某个任
务,有的调用者正在向线程池提交任务,并且队列中可能还有未执行的任务。因此,关闭过程不可能是
瞬时的,而是需要一个平滑的过渡,这就涉及线程池的完整生命周期管理。
### 1.线程池的生命周期
在JDK 7中,把线程数量(workerCount)和线程池状态(runState)这两个变量打包存储在一个字
段里面,即ctl变量。如下图所示,最高的3位存储线程池状态,其余29位存储线程个数。而在JDK 6中,
这两个变量是分开存储的。


由上面的代码可以看到,ctl变量被拆成两半,最高的3位用来表示线程池的状态,低的29位表示线
程的个数。线程池的状态有五种,分别是RUNNING、SHUTDOWN、STOP、TIDYING和
TERMINATED。
下面分析状态之间的迁移过程,如图所示:

线程池有两个关闭方法,shutdown()和shutdownNow(),这两个方法会让线程池切换到不同的状
态。在队列为空,线程池也为空之后,进入TIDYING 状态;最后执行一个钩子方法terminated(),进入
TERMINATED状态,线程池才真正关闭。
这里的状态迁移有一个非常关键的特征:从小到大迁移,-1,0,1,2,3,只会从小的状态值往大
的状态值迁移,不会逆向迁移。例如,当线程池的状态在TIDYING=2时,接下来只可能迁移到
TERMINATED=3,不可能迁移回STOP=1或者其他状态。
除 terminated()之外,线程池还提供了其他几个钩子方法,这些方法的实现都是空的。如果想实现自己的线程池,可以重写这几个方法:
```
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }
protected void terminated() { }
```
### 2.正确关闭线程池的步骤
关闭线程池的过程为:在调用 shutdown()或者shutdownNow()之后,线程池并不会立即关闭,接下来需要调用 awaitTermination() 来等待线程池关闭。关闭线程池的正确步骤如下:
```java
// executor.shutdownNow();
executor.shutdown();
try {
boolean flag = true;
do {
flag = ! executor.awaitTermination(500, TimeUnit.MILLISECONDS);
} while (flag);
} catch (InterruptedException e) {
// ...
}
```
awaitTermination(...)方法的内部实现很简单,如下所示。不断循环判断线程池是否到达了最终状态
TERMINATED,如果是,就返回;如果不是,则通过termination条件变量阻塞一段时间,之后继续判断。

### 3.shutdown()与shutdownNow()的区别
1. shutdown()不会清空任务队列,会等所有任务执行完成,shutdownNow()清空任务队列。
2. shutdown()只会中断空闲的线程,shutdownNow()会中断所有线程。
- 因为要修改线程池的状态,所以进入前加了锁


下面看一下在上面的代码里中断空闲线程和中断所有线程的区别。
shutdown()方法中的interruptIdleWorkers()方法的实现:


关键区别点在tryLock():一个线程在执行一个任务之前,会先加锁,这意味着通过是否持有锁,可
以判断出线程是否处于空闲状态。tryLock()如果调用成功,说明线程处于空闲状态,向其发送中断信
号;否则不发送。
- tryLock()方法

- tryAcquire方法:

shutdownNow()调用了interruptWorkers(); 方法:
interruptIfStarted() 方法的实现:

在上面的代码中,shutdown() 和shutdownNow()都调用了tryTerminate()方法,如下所示:

**tryTerminate()不会强行终止线程池,只是做了一下检测**:当workerCount为0,workerQueue为空时,先把状态切换到TIDYING,然后调用钩子方法terminated()。当钩子方法执行完成时,把状态从TIDYING 改为 TERMINATED,接着调用termination.sinaglAll(),通知前面阻塞在awaitTermination的所有调用者线程。
所以,TIDYING和TREMINATED的区别是在二者之间执行了一个钩子方法terminated(),目前是一个空实现。
### 4.任务的提交过程分析
#### execute
- 若worker是第一次创建的,那么command会作为firstTask,并将在workerAdded成功后执行command
- 否则,放入workQueue中
```java
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// 如果当前线程数小于corePoolSize,则启动新线程
if (workerCountOf(c) < corePoolSize) {
// 添加Worker,并将command设置为Worker线程的第一个任务开始执行。
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果当前的线程数大于或等于corePoolSize,则调用workQueue.offer放入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 如果线程池正在停止,则将command任务从队列移除,并拒绝command任务请求。
if (! isRunning(recheck) && remove(command))
reject(command);
//放入队列中后发现没有线程执行任务,开启新线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 线程数大于maxPoolSize,并且队列已满,调用拒绝策略
else if (!addWorker(command, false))
reject(command);
}
```
#### addWorker
- 可以看到,workerAdded==true时,添加worker成功,则启动该worker对应的线程
```java
// 该方法用于启动新线程。如果第二个参数为true,则使用corePoolSize作为上限,否则使用
// maxPoolSize作为上限。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
// Check if queue empty only if necessary.
// 如果线程池状态值起码是SHUTDOWN和STOP,
// 或者第一个任务不是null,或者工作队列为空,则添加worker失败,返回false
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
for (;;) {
// 工作线程数达到上限,要么是corePoolSize要么是maximumPoolSize,启动线程失败
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
// 增加worker数量成功,返回到retry语句
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// 如果线程池运行状态起码是SHUTDOWN,则重试retry标签语句,CAS
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// worker数量加1成功后,接着运行:
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 新建worker对象
w = new Worker(firstTask);
// 获取线程对象
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// 加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
// 由于线程已经在运行中,无法启动,抛异常
if (t.getState() != Thread.State.NEW)
throw new IllegalThreadStateException();
workers.add(w);
workerAdded = true;
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
}
} finally {
mainLock.unlock();
}
// 如果添加worker成功,则启动该worker对应的线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果启动新线程失败
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
```
### 5 任务的执行过程分析
在上面的任务提交过程中,可能会开启一个新的Worker,并把任务本身作为firstTask赋给该
Worker。但对于一个Worker来说,不是只执行一个任务,而是源源不断地从队列中取任务执行,这是
一个不断循环的过程。
下面来看Woker的run()方法的实现过程。
#### Worker
```java
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
// 线程需要运行的第一个任务。可以是null,如果是null,则线程从队列获取任务
Runnable firstTask;
/** Per-thread task counter */
// 记录线程执行完成的任务数量,每个线程一个计数器
volatile long completedTasks;
// TODO: switch to AbstractQueuedLongSynchronizer and move
// completedTasks into the lock word.
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
// 线程处于阻塞状态,调用runWorker的时候中断
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
```
#### ThreadPoolExecutor#runWorker
```java
//java.util.concurrent.ThreadPoolExecutor#runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 中断Worker封装的线程
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 如果线程初始任务不是null,或者从队列获取的任务不是null,表示该线程应该执行任务。
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
// 如果线程池停止了,确保线程被中断
// 如果线程池正在运行,确保线程不被中断
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
// 获取到任务后,再次检查线程池状态,如果发现线程池已经停止,则给自己发中断信号
wt.interrupt();
try {
// 任务执行之前的钩子方法,实现为空
beforeExecute(wt, task);
try {
task.run();
// 任务执行结束后的钩子方法,实现为空
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
// 任务执行完成,将task设置为null
task = null;
w.completedTasks++;
w.unlock();
}
}
// 判断线程是否是正常退出
completedAbruptly = false;
} finally {
// Worker退出
processWorkerExit(w, completedAbruptly);
}
}
```
#### 1.shutdown()与任务执行过程综合分析
把任务的执行过程和上面的线程池的关闭过程结合起来进行分析,当调用 shutdown()的时候,可能出现以下几种场景:
1. 当调用shutdown()的时候,所有线程都处于空闲状态。
这意味着任务队列一定是空的。此时,所有线程都会阻塞在 getTask()方法的地方。然后,所
有线程都会收到**interruptIdleWorkers()发来的中断信号**,getTask()返回null,所有Worker都
会退出while循环,之后执行processWorkerExit。
2. 当调用shutdown()的时候,所有线程都处于忙碌状态。
此时,队列可能是空的,也可能是非空的。interruptIdleWorkers()内部的tryLock调用失败,
什么都不会做,所有线程会继续执行自己当前的任务。之后所有线程会执行完队列中的任务,
直到队列为空,getTask()才会返回null。之后,就和场景1一样了,退出while循环。
3. 当调用shutdown()的时候,部分线程忙碌,部分线程空闲。
有部分线程空闲,说明队列一定是空的,这些线程肯定阻塞在 getTask()方法的地方。空闲的
这些线程会和场景1一样处理,不空闲的线程会和场景2一样处理。
下面看一下getTask()方法的内部细节:
#### getTask()
```java
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
// 如果线程池调用了shutdownNow(),返回null
// 如果线程池调用了shutdown(),并且任务队列为空,也返回null
// Check if queue empty only if necessary.
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
// 工作线程数减一
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 如果队列为空,就会阻塞pool或者take,前者有超时时间,后者没有超时时间
// 一旦中断,此处抛异常,对应上文场景1。
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
```
### 2.shutdownNow() 与任务执行过程综合分析
和上面的 shutdown()类似,只是多了一个环节,即清空任务队列。如果一个线程正在执行某个业务
代码,即使向它发送中断信号,也没有用,只能等它把代码执行完成。因此,中断空闲线程和中断所有
线程的区别并不是很大,除非线程当前刚好阻塞在某个地方。
当一个Worker最终退出的时候,会执行清理工作:
#### processWorkerExit
```java
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 如果线程正常退出,不会执行if的语句,这里一般是非正常退出,需要将worker数量减一
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
// 将自己的worker从集合移除
workers.remove(w);
} finally {
mainLock.unlock();
}
// 每个线程在结束的时候都会调用该方法,看是否可以停止线程池
tryTerminate();
int c = ctl.get();
// 如果在线程退出前,发现线程池还没有关闭
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果线程池中没有其他线程了,并且任务队列非空
if (min == 0 && ! workQueue.isEmpty())
// 下面的分支不满足时,走最后一步 addWorker(null, false);
// 表示还有任务没做完,但是没有worker了,在最后一步创建worker以使之执行。
min = 1;
// 如果工作线程数大于min,表示队列中的任务可以由其他线程执行,退出当前线程
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 如果当前线程退出前发现线程池没有结束,任务队列不是空的,也没有其他线程来执行
// 就再启动一个线程来处理。
addWorker(null, false);
}
}
```
### 6 线程池的4种拒绝策略
在execute(Runnable command)的最后,调用了reject(command)执行拒绝策略,代码如下所示:


handler就是我们可以设置的拒绝策略管理器:

RejectedExecutionHandler 是一个接口,定义了四种实现,分别对应四种不同的拒绝策略,默认是AbortPolicy。
```java
package java.util.concurrent;
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
```
ThreadPoolExecutor类中默认的实现是:


四种策略的实现代码如下:
#### 策略1:调用者直接在自己的线程里执行,线程池不处理,
比如到医院打点滴,医院没地方了,到你家自己操作吧:

#### 策略2:线程池抛异常:

#### 策略3:线程池直接丢掉任务,神不知鬼不觉:

#### 策略4:删除队列中最早的任务,将当前任务入队列:
 | 18,049 | Apache-2.0 |
---
ms.openlocfilehash: f4a1cc432a50a555fe6e050ca318b4cfaf1092d4
ms.sourcegitcommit: eb6bef1274b9e6390c7a77ff69bf6a3b94e827fc
ms.translationtype: HT
ms.contentlocale: zh-TW
ms.lasthandoff: 10/05/2020
ms.locfileid: "88682098"
---
MP4 檔案會寫入您使用 OUTPUT_VIDEO_FOLDER_ON_DEVICE 機碼在 *.env* 檔案中設定的邊緣裝置目錄。 如果您使用預設值,則結果應該會在 */var/media/* 資料夾中。
若要播放 MP4 剪輯:
1. 移至您的資源群組,尋找 VM,然後使用 Azure Bastion 連線。


1. 使用您在[設定 Azure 資源](../../../detect-motion-emit-events-quickstart.md#set-up-azure-resources)時所產生的認證來登入。
1. 在命令提示字元中,移至相關目錄。 預設位置是 */var/media*。 您應該會在目錄中看到 MP4 檔案。

1. 使用[安全複製 (SCP)](../../../../../virtual-machines/linux/copy-files-to-linux-vm-using-scp.md),將檔案複製到本機電腦。
1. 藉由使用 [VLC 媒體播放器](https://www.videolan.org/vlc/)或任何其他 MP4 播放器來播放檔案。 | 914 | CC-BY-4.0 |
---
title: MySQL -- 数据恢复
date: 2019-03-04 19:08:34
categories:
- Storage
- MySQL
tags:
- Storage
- MySQL
---
## DELETE
1. 使用`DELETE`语句误删除了**数据行**,可以使用`Flashback`通过闪回把数据恢复
2. `Flashback`恢复数据的原理:修改`binlog`的内容,然后拿到**原库重放**
- 前提:`binlog_format=ROW`和`binlog_row_image=FULL`
3. 针对单个事务
- 对于`INSERT`语句,将`Write_rows event`改成`Delete_rows event`
- 对于`DELETE`语句,将`Delete_rows event`改成`Write_rows event`
- 对于`UPDATE`语句,`binlog`里面记录了数据行修改前和修改后的值,**对调两行的位置即可**
4. 针对多个事务
- 误操作
- (A)DELETE
- (B)INSERT
- (C)UPDTAE
- Flashback
- (REVERSE C)UPDATE
- (REVERSE B)DELETE
- (REVERSE A)INSERT
5. 不推荐直接在**主库**上执行上述操作,避免造成**二次破坏**
- 比较安全的做法是先恢复出一个备份或找一个从库作为**临时库**
- 在临时库上执行上述操作,然后再将**确认过**的临时库的数据,恢复到主库
6. 预防措施
- `sql_safe_updates=ON`,下列情况会报错
- 没有`WHERE`条件的`DELETE`或`UPDATE`语句
- `WHERE`条件里面**没有包含索引字段的值**
- 上线前,必须进行**SQL审计**
7. 删全表的性能
- `DELETE`全表**很慢**,因为需要生成`undolog`、写`redolog`和写`binlog`
- 优先考虑使用`DROP TABLE`或`TRUNCATE TABLE`
<!-- more -->
## DROP / TRUNCATE
1. `DROP TABLE`、`TRUNCATE TABLE`和`DROP DATABASE`,是无法通过`Flashback`来恢复的
- 即使配置了`binlog_format=ROW`,执行上面3个命令,`binlog`里面记录的依然是`STATEMENT`格式
- `binlog`里面只有一个`TRUNCATE/DROP`语句,这些信息是无法恢复数据的
2. 这种情况如果想要恢复数据,需要使用**全量备份**和**增量日志**的方式
- 要求线上**定期全量备份**,并且**实时备份`binlog`**
### mysqlbinlog
假设有人中午12点删除了一个库,恢复数据的流程
<img src="https://mysql-1253868755.cos.ap-guangzhou.myqcloud.com/mysql-data-recovery-mysqlbinlog.png" width=500/>
1. 取最近一次全量备份,假设一天一备,即当天0点的全量备份
2. 用全量备份恢复出一个临时库
3. 从`binlog`备份里,取出凌晨0点以后的日志
4. 把这些日志,**除误删数据的语句外**,全部应用到临时库
5. 为了**加快数据恢复**,如果临时库上有多个数据库,可以加上`--database`参数,指定应用某个库的日志
6. 跳过12点误操作语句的`binlog`
- 如果原实例没有使用`GTID`模式,只能在应用到包含12点的`binlog`文件的时候
- 先用`--stop-position`参数执行到**误操作之前**的日志
- 再用`--start-position`从**误操作之后**的日志继续执行
- 如果原实例使用`GTID`模式,假设误操作命令的`GTID`为`gtid1`
- 只需执行`SET gtid_next=gtid1;BEGIN;COMMIT;`
- 把`gtid1`加入到临时库的`GTID`集合,之后按顺序执行`binlog`时,会**自动跳过**误操作的语句
7. 使用`mysqlbinlog`的方法恢复数据的速度**还是不够快**,主要原因
- 如果**误删表**,最好是**只重放这张表的操作**,但`mysqlbinlog`并不能指定只解析一个表的日志
- 用`mysqlbinlog`解析出日志来应用,应用日志的过程只能是**单线程**的
8. 另外一个加速的方法:`Master-Slave`
### Master-Slave
<img src="https://mysql-1253868755.cos.ap-guangzhou.myqcloud.com/mysql-data-recovery-master-slave.png" width=500/>
1. 在`START SLAVE`之前,先通过执行`CHANGE REPLICATION FILTER REPLICATE_DO_TABLE=(tbl_name)`
- 让临时库**只同步误操作的表**,利用**并行复制**技术,来加速整个数据恢复过程
2. `binlog`备份到线上备库之间是一条**虚线**
- 虚线指的是如果由于时间太久,线上备库有可能已经删除了临时实例所需要的`binlog`
- 可以从`binlog`备份系统中找到需要的`binlog`,再放到备库中
- 举例说明
- 例如当前临时实例需要的`binlog`是从`master.000005`开始
- 但在线上备库上执行`SHOW BINARY LOGS`显示最小的`binlog`文件是`master.000007`
- 意味着少了两个`binlog`文件
- 这时需要到`binlog`备份系统找到这两个文件,把之前删掉的`binlog`放回备库执行以下步骤
- 从备份系统下载`master.000005`和`master.000006`,放到备库的日志目录下
- 打开`master.index`,在文件头加入两行:`./master.000005`和`./master.000006`
- 重启备库,目的是为了让备库**重新识别**这两个日志文件
- 现在备库上就有了临时实例所需要的所有`binlog`,建立主备关系,就可以正常同步了
### 延迟复制备库
1. 上面`Master-Slave`的方案利用了**并行复制**来加速数据恢复的过程,但**恢复时间不可控**
- 如果一个库特别大,或者误操作的时间距离上一个全量备份的时间较长(一周一备)
2. 针对核心业务,**不允许太长的恢复时间**,可以搭建**延迟复制的备库**(MySQL 5.6引入)
3. 延迟复制的备库是一种特殊的备库
- 通过`CHANGE MASTER TO MASTER_DELAY=N`命令来指定备库持续与主库有N秒的延迟
- 假设N=3600,如果能在一小时内发现误删除命令,这个误删除的命令尚未在延迟复制的备库上执行
- 这时在这个备库上执行`STOP SLAVE`,再通过前面的方法,跳过误删除命令,就可以恢复数据
- 这样,可以得到一个恢复时间可控(最多1小时)的备库
## 参考资料
《MySQL实战45讲》
<!-- indicate-the-source --> | 3,444 | MIT |
# navigation-bar
自定义导航组件, 项目参考[mp-navigation-bar](https://github.com/moesuiga/mp-navigation-bar#readme).
## 使用方法
### 导航配置及组件引用
在`app.json`配置文件中将导航栏样式设置为**自定义导航栏**。[微信小程序官方说明](https://developers.weixin.qq.com/miniprogram/dev/framework/config.html#window)
```js
// app.json
{
"window": {
"navigationStyle": "custom"
}
}
```
将组件添加到项目中, 在页面对应`page.json`或`app.json`添加组件引用配置, 注意检查引用路径是否正确。
```js
// app.json 或 page.json
{
"usingComponents": {
"navigation-bar": "./components/navigation-bar/index"
}
}
```
#### homePath设置使用方法
组件回到首页按钮中 **首页的默认值为 `/pages/index/index`,可以在`app.js`进行自定义配置**。如果页面原本就是`/pages/index/index`, 可忽略此配置。
```js
// app.js
App({
onLaunch () {},
globalData: {},
appConfig: {
appHomePath: '/pages/artical/list', // 自定义导航首页路径
}
})
```
## 示例代码
下面是一个简单的完整示例:
```html
<navigation-bar
title="{{pageTitle}}"
bg-color="{{bgColor}}"
show-home="{{showHome}}"
opacity="{{opacity}}"
capsule="{{capsule}}"
bindhome="homeTap"
bindtitletap="handleTitleTap">
<view slot="action">分享</view>
<view>
页面内容
</view>
</navigation-bar>
```
wxml 使用中需要将页面内容放在组件中作为组件内容,注意组件的嵌套是否正确。
```javascript
Page({
data() {
pageTitle: '微信小程序',
bgColor: '#fff',
opacity: 0.8, // 标题栏透明度
showHome: false,
capsule: true, // 胶囊样式 or 扁平化样式
},
// 标题点击处理
handleTitleTap() {
wx.showToast({
title: '点击标题'
})
},
// 首页点击处理事件
homeTap() {}
})
```
## 组件说明
### 组件属性
| 属性名称 | 类型 | 默认值 | 必须 | 说明 |
| :--------------- | ------- | ---------- | ---- | -------------------------------------------------------------------------------------------- |
| title | String | 未命名标题 | 否 | 导航栏标题 |
| prevent-home | Boolean | false | 否 | 是否阻止点击首页默认跳转事件 |
| prevent-back | Boolean | false | 否 | 是否阻止点击返回按钮默认跳转事件 |
| delta | Number | 1 | 否 | 返回的页面数 |
| show-home | Boolean | true | 否 | 是否显示首页按钮 |
| hide-back | Boolean | false | 否 | 是否隐藏返回按钮 |
| bg-color | String | white | 否 | 导航栏背景色 |
| opacity | String | 1 | 否 | 透明度(可配合实现滚动淡入效果) |
| text-style | String | dark | 否 | 导航栏标题文字颜色 (dark/light) |
| capsule | Boolean | false | 否 | 是否是胶囊样式; 为`false`是为扁平化按钮,没有胶囊边框/背景/中线分割等 |
| auto-capsule | Boolean | true | 否 | 是否根据 `text-style` 自动更改小程序默认胶囊颜色 |
| auto-height | Boolean | true | 否 | 是否由内容自动撑开高度, 为 `false` 时,会设置 `height: 100%`,请注意给父组件设置高度 (0.0.6) |
### 事件介绍
| 事件名称 | 参数 | 说明 |
| ------------ | ------ | ------------------ |
| bindback | Object | 点击返回按钮的事件 |
| bindhome | Object | 点击主页按钮的事件 |
| bindtitletap | Object | 标题点击事件 |
### slot
组件有两个 slot。默认 slot 为方便使用者装载页面内容使用。 由于导航为 fixed 定位,故不占用文档流位置,使用时需要在页面顶部留足相应的边距。 该插槽已经留出这部分边距,避免用户每个页面都手动设置一次。
第二个为用户自定义左上角位置的slot,name=action 该部分通过 absolute 定位在左侧。 使用时,建议设置 show-home=false hide-back=true 来隐藏默认 action 胶囊。
### 补充说明
为了方便当前页面处理,可以通过自定义导航组件属性方法获取相关数据, 相关用法参考[小程序组件间通信与事件](https://developers.weixin.qq.com/miniprogram/dev/framework/custom-component/events.html)
```html
<navigation-bar id="customNavigationBar" title="{{pageTitle}}">
<view>页面内容</view>
</navigation-bar>
```
```javascript
Page({
data() {
pageTitle: '微信小程序',
},
// 获取自定导航相关信息
getNavigationData() {
const { homePath, data, navigationData} = this.selectComponent('#customNavigationBar');
/* homePath: 首页路径的值
{
homePath: '/pages/index/index'
}
*/
/* data 组件属性配置。格式如下:
{
data: {
"isIOS": true,
"justOnePage": true,
"barHeight": 20,
"refresh": false,
"maxWidth": 177,
"title": "微信小程序",
"delta": 1,
"showHome": true,
"hideBack": false,
"bgColor": "#fff",
"textStyle": "dark",
"autoCapsule": true,
"autoHeight": true,
"capsule": true,
"opacity": 0.8,
"preventHome": true,
"preventBack": false
}
}
*/
/* 这部分数据页面定位布局、设置顶部高度时可以用到。数据格式如下:
{
navigationData: {
"windowWidth": 375, // 页面宽度
"windowHeight": 667, // 页面高度
"statusBarHeight": 20, // 状态栏高度
"capsuleWidth": 87, // 胶囊宽度
"barTitleHeight": 44, // 标题栏高度
"barTitleMaxWidth": 177, // 标题栏最大宽度(文字够多显示...)
"barTopHeight": 64 // 标题栏下边界距离屏幕最顶部距离(含状态栏高度)
}
}
*/
}
})
``` | 5,148 | MIT |
---
title: 廢話幾段
license: CC-BY-NC-ND-4.0
author: Tranquilo Chan
tags: 囈語
key: 20210627
---
## 審美生活
你們在巨型精神病院表演舞蹈<!--more-->
## 同性戀
<pre>
不打工,就沒有飯喫。
不激進,就沒有命。
</pre>
## 人羣
<pre>
人們呀,
兩三個一成羣,
暴力機關的雛形就形成了。
</pre>
## 要不要這樣過日子
<pre>
出家,
還是長成曹操,
這是一個問題。
</pre> | 263 | MIT |
# LinkedList_exp
Datastucture exp-2 LinkedList(单链表)
数据结构 exp-2 第二次实验作业 单链表的应用 /**************************************** 版本说明: @exp-2为作业版本, 为小程序 (如有需要借鉴代码请使用此版本!!!) ****************************************/
2.1 实验目的
熟练掌握线性表的链式存储结构。
熟练掌握单链表的有关算法设计。
根据具体问题的需要,设计出合理的表示数据的链式存储结构,并设计相关算法。
2.2 实验要求
本次实验中的链表结构指带头结点的单链表;
单链表结构和运算定义,算法的实现以库文件方式实现,不得在测试主程序中直接实现;
比如存储、算法实现放入文件:linkedList.h
实验程序有较好可读性,各运算和变量的命名直观易懂,符合软件工程要求;
程序有适当的注释。
2.3 实验任务
编写算法实现下列问题的求解。
<1>尾插法创建单链表,打印创建结果。
<2>头插法创建单链表,打印创建结果。
<3>销毁单链表。
<4>求链表长度。
<5>求单链表中第i个元素(函数),若不存在,报错。
实验测试数据基本要求:
第一组数据:单链表长度n≥10,i分别为5,n,0,n+1,n+2
第二组数据:单链表长度n=0,i分别为0,2
<6>在第i个结点前插入值为x的结点。
实验测试数据基本要求:
第一组数据:单链表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2
第二组数据:单链表长度n=0,x=100,i=5
<7>链表中查找元素值为x的结点,成功返回结点指针,失败报错。
实验测试数据基本要求:
单链表元素为 (1,3,6,10,15,16,17,18,19,20)
x=1,17,20,88
<8>删除单链表中第i个元素结点。
实验测试数据基本要求:
第一组数据:单链表长度n≥10,i分别为5,n,1,n+1,0
第二组数据:单链表长度n=0, i=5
<9>在一个递增有序的单链表L中插入一个值为x的元素,并保持其递增有序特性。
实验测试数据基本要求:
单链表元素为 (10,20,30,40,50,60,70,80,90,100),
x分别为25,85,110和8
<10>将单链表L中的奇数项和偶数项结点分解开(元素值为奇数、偶数),分别放入新的单链表中,然后原表和新表元素同时输出到屏幕上,以便对照求解结果。
实验测试数据基本要求:
第一组数据:单链表元素为 (1,2,3,4,5,6,7,8,9,10,20,30,40,50,60)
第二组数据:单链表元素为 (10,20,30,40,50,60,70,80,90,100)
<11>求两个递增有序单链表L1和L2中的公共元素,放入新的单链表L3中。
实验测试数据基本要求:
第一组
第一个单链表元素为 (1,3,6,10,15,16,17,18,19,20)
第二个单链表元素为 (1,2,3,4,5,6,7,8,9,10,18,20,30)
第二组
第一个单链表元素为 (1,3,6,10,15,16,17,18,19,20)
第二个单链表元素为 (2,4,5,7,8,9,12,22)
第三组
第一个单链表元素为 ()
第二个单链表元素为 (1,2,3,4,5,6,7,8,9,10)
<12>删除递增有序单链表中的重复元素,要求时间性能最好。
实验测试数据基本要求:
第一组数据:单链表元素为 (1,2,3,4,5,6,7,8,9)
第二组数据:单链表元素为 (1,1,2,2,2,3,4,5,5,5,6,6,7,7,8,8,9)
第三组数据:单链表元素为 (1,2,3,4,5,5,6,7,8,8,9,9,9,9,9)
<13>递增有序单链表L1、L2,不申请新结点,利用原表结点对2表进行合并,并使得合并后成为一个集合,合并后用L1的头结点作为头结点,删除L2的头结点,要求时间性能最好。
实验测试数据基本要求:
第一组
第一个单链表元素为 (1,3,6,10,15,16,17,18,19,20)
第二个单链表元素为 (1,2,3,4,5,6,7,8,9,10,18,20,30)
第二组
第一个单链表元素为 (1,3,6,10,15,16,17,18,19,20)
第二个单链表元素为 (2,4,5,7,8,9,12,22)
第三组
第一个单链表元素为 ()
第二个单链表元素为 (1,2,3,4,5,6,7,8,9,10) | 1,922 | BSD-2-Clause |
---
layout: page
title: "找不到您要的網頁"
description: "Page not found"
sitemap: false
search_omit: true
permalink: /404.html
---
找不到您要的網頁喔...可以再找找看...
Page Not Found...
<!-- Search form -->
<form method="get" action="{{ site.url }}/search/" data-search-form class="simple-search">
<label for="q">尋找 {{ site.title }}:</label>
<input type="search" name="q" id="q" placeholder="輸入關鍵字" data-search-input id="goog-wm-qt" autofocus />
<input type="submit" value="尋找" id="goog-wm-sb" />
</form>
<!-- Search results placeholder -->
<h6 data-search-found>
根據 “<span data-search-found-term></span>”, 找到 <span data-search-found-count></span> 筆文章 .
</h6>
<ul class="post-list" data-search-results></ul>
<!-- Search result template -->
<script type="text/x-template" id="search-result">
<li><article>
<a href="##Url##">##Title## <span class="excerpt">##Excerpt##</span></a>
</article></li>
</script> | 916 | MIT |
---
ms.openlocfilehash: caeab5f1aed4ee346f213080e41849861f3ef5e9
ms.sourcegitcommit: bab1265d669c3e6871daa7cb8a5640a47104947a
translationtype: MT
---
<properties
pageTitle="Windows Phone Silverlight 接洽 SDK 集成"
description="如何与 Windows Phone Silverlight 应用程序中集成 Azure 的移动服务"
services="mobile-engagement"
documentationCenter="mobile"
authors="piyushjo"
manager="dwrede"
editor="" />
<tags
ms.service="mobile-engagement"
ms.workload="mobile"
ms.tgt_pltfrm="mobile-windows-phone"
ms.devlang="dotnet"
ms.topic="article"
ms.date="07/07/2015"
ms.author="piyushjo" />
#Windows Phone Silverlight 接洽 SDK 集成
> [AZURE.SELECTOR]
- [Windows 世界](mobile-engagement-windows-store-integrate-engagement.md)
- [Windows Phone Silverlight](mobile-engagement-windows-phone-integrate-engagement.md)
- [iOS](mobile-engagement-ios-integrate-engagement.md)
- [Android](mobile-engagement-android-integrate-engagement.md)
本过程描述了最简单的方法来激活 Azure 移动合作分析和监视 Windows Phone Silverlight 应用程序中的功能。
以下步骤是不足以激活计算有关用户、 会话、 活动、 系统崩溃和 Technicals 的所有统计信息所需的日志报告。 必须手动使用服务 API 完成计算事件、 错误和作业等其他统计数据所需的日志报告 (请参阅[如何使用标记 Windows Phone Silverlight 应用程序中的 API 高级的移动合作](mobile-engagement-windows-phone-use-engagement-api.md)下) 因为这些统计数据由应用程序决定。
##受支持的版本
移动服务 SDK 的 Windows Silverlight 只可以集成到面向应用程序︰
- Windows Phone 8.0
- Windows Phone 8.1 Silverlight
> [AZURE.NOTE] 如果针对 Windows Phone 8.1 (非 Silverlight),请参阅[Windows 通用的集成过程](mobile-engagement-windows-store-integrate-engagement.md)。
##安装移动接洽 Silverlight SDK
移动服务 SDK 的 Windows Silverlight 是 Nuget 程序包称为*MicrosoftAzure.MobileEngagement*可用。 您可以安装的 Visual Studio Nuget 程序包管理器。
##添加功能
接洽 SDK 需要 Windows Phone Silverlight SDK 的某些功能才能正常工作。
打开您`WMAppManifest.xml`文件,请确保以下功能以声明`Capabilities`面板︰
- `ID_CAP_NETWORKING`
- `ID_CAP_IDENTITY_DEVICE`
##初始化服务 SDK
### 服务配置
服务配置集中在`Resources\EngagementConfiguration.xml`的项目文件。
编辑此文件,以指定︰
- 应用程序连接字符串标记之间`<connectionString>`, `<\connectionString>`。
如果您想要指定它在运行时,可以调用下面的方法在签约代理初始化之前︰
/* Engagement configuration. */
EngagementConfiguration engagementConfiguration = new EngagementConfiguration();
engagementConfiguration.Agent.ConnectionString = "Endpoint={appCollection}.{domain};AppId={appId};SdkKey={sdkKey}";
/* Initialize Engagement agent with above configuration. */
EngagementAgent.Instance.Init(engagementConfiguration);
在 Azure 管理门户网站上显示您的应用程序的连接字符串。
### 服务初始化
当您创建新项目时,`App.xaml.cs`生成的文件。 此类继承自`Application`,包含很多重要的方法。 它还将用于初始化接洽 SDK。
修改`App.xaml.cs`:
- 将添加到您`using`语句︰
using Microsoft.Azure.Engagement;
- 插入`EngagementAgent.Instance.Init`在`Application_Launching`方法︰
private void Application_Launching(object sender, LaunchingEventArgs e)
{
EngagementAgent.Instance.Init();
}
- 插入`EngagementAgent.Instance.OnActivated`在`Application_Activated`方法︰
private void Application_Activated(object sender, ActivatedEventArgs e)
{
EngagementAgent.Instance.OnActivated(e);
}
> [AZURE.WARNING] 我们强烈建议您在您的应用程序的另一个位置添加服务初始化。 但是,请注意,`EngagementAgent.Instance.Init`在一个专用线程上,并不在 UI 线程上运行的方法。
##基本报告
### 推荐的方法︰ 重载您`PhoneApplicationPage`类
为了激活接洽,以计算用户、 会话、 活动、 系统崩溃和技术统计数据所需的所有日志的报告,您可以只是使所有您`PhoneApplicationPage`子类继承`EngagementPage`类。
这里是如何为您的应用程序页执行此操作的示例。 您可以执行相同的操作,您的应用程序的所有页。
#### C# 源文件
修改您的网页`.xaml.cs`文件︰
- 将添加到您`using`语句︰
using Microsoft.Azure.Engagement;
- 更换`PhoneApplicationPage`与`EngagementPage`:
**而无需接洽︰**
namespace Example
{
public partial class ExamplePage : PhoneApplicationPage
{
[...]
}
}
**与合作︰**
using Microsoft.Azure.Engagement;
namespace Example
{
public partial class ExamplePage : EngagementPage
{
[...]
}
}
> [AZURE.WARNING] 如果您的页面是从继承`OnNavigatedTo`方法时,请务必让`base.OnNavigatedTo(e)`调用。 否则,将不报告活动。 事实上,`EngagementPage`调用`StartActivity`在`OnNavigatedTo`方法。
#### XAML 文件
修改您的网页`.xaml`文件︰
- 将添加到命名空间声明︰
xmlns:engagement="clr-namespace:Microsoft.Azure.Engagement;assembly=Microsoft.Azure.Engagement.EngagementAgent.WP"
- 更换`phone:PhoneApplicationPage`与`engagement:EngagementPage`:
**而无需接洽︰**
<phone:PhoneApplicationPage>
<!-- layout -->
</phone:PhoneApplicationPage>
**与合作︰**
<engagement:EngagementPage
xmlns:engagement="clr-namespace:Microsoft.Azure.Engagement;assembly=Microsoft.Azure.Engagement.EngagementAgent.WP">
<!-- layout -->
</engagement:EngagementPage >
#### 重写默认行为
默认情况下,页面的类名称被报告为活动名称,并带有无需另付。 如果类使用"页面"后缀,合作也将删除它。
如果您想要重写默认行为的名称,只要将它添加到您的代码︰
// in the .xaml.cs file
protected override string GetEngagementPageName()
{
/* your code */
return "new name";
}
如果您要报告一些与您的活动的额外信息,您可以向代码中添加此︰
// in the .xaml.cs file
protected override Dictionary<object,object> GetEngagementPageExtra()
{
/* your code */
return extra;
}
这些方法称为从`OnNavigatedTo`页面的方法。
### 备选方法︰ 调用`StartActivity()`手动
如果您不能或不想重载您`PhoneApplicationPage`的类,而是可以通过调用来启动您的活动`EngagementAgent`直接方法。
我们建议您调用`StartActivity`内您`OnNavigatedTo`您的 PhoneApplicationPage 方法。
protected override void OnNavigatedTo(NavigationEventArgs e)
{
base.OnNavigatedTo(e);
EngagementAgent.Instance.StartActivity("MyPage");
}
> [AZURE.IMPORTANT] 确保正确地结束您的会话。
>
> 自动调用 SDK`EndActivity`时关闭该应用程序的方法。 因此,**强烈**建议您调用是`StartActivity`方法,只要该活动的用户的更改,并**从不**调用`EndActivity`方法。 此方法向接洽服务器发送一条消息当前用户离开应用程序,并且这会影响所有的应用程序日志。
##高级报告
(可选) 您可以对报表应用程序特定事件、 错误和作业,若要执行此操作,使用其他方法中找到`EngagementAgent`类。 服务 API 允许使用所有服务活动的高级功能。
有关详细信息,请参阅[如何使用高级的移动服务标记 Windows Phone Silverlight 应用程序中的 API](../mobile-engagement-windows-phone-use-engagement-api/)。
##高级的配置
### 禁用自动故障报告
您可以禁用自动崩溃报告服务的功能。 然后,将在发生未经处理的异常时合作将不会任何操作。
> [AZURE.WARNING] 如果要禁用此功能,请注意,当未经处理的崩溃将发生在您的应用程序中,合约将不发送崩溃**,**它将不会关闭会话和作业。
若要禁用自动崩溃报告,只是自定义根据声明的方式配置︰
#### 从`EngagementConfiguration.xml`文件
将报告故障设置为`false`之间`<reportCrash>`和`</reportCrash>`标记。
#### 从`EngagementConfiguration`在运行时的对象
设置为 false,使用 EngagementConfiguration 对象报告故障。
/* Engagement configuration. */
EngagementConfiguration engagementConfiguration = new EngagementConfiguration(); engagementConfiguration.Agent.ConnectionString = "Endpoint={appCollection}.{domain};AppId={appId};SdkKey={sdkKey}";
/\* Disable Engagement crash reporting. \*/ engagementConfiguration.Agent.ReportCrash = false;
### 突发模式
默认情况下,接洽服务报告实时记录。 如果您的应用程序非常频繁地报告日志,最好是缓冲的日志和报告他们一次性全部按时正则基 (这称为"突发模式")。
若要执行此操作,调用该方法︰
EngagementAgent.Instance.SetBurstThreshold(int everyMs);
该参数是以**毫秒为单位**的值。 在任何时候,如果想要重新激活的实时记录,只需调用的方法不带任何参数,或使用 0 值。
突发模式略有延长电池寿命,但接洽显示器上有一定影响︰ 所有的会话和作业工期将舍入为突发事件阈值 (因此,会话和作业比可能不会爆发阈值的短)。 建议将突发事件阈值不超过 30000 (30 秒)。 您一定要注意保存日志仅限于 300 项。 如果发送过长可能会丢失某些日志。
> [AZURE.WARNING] 突发事件阈值不能配置为较低的时间段超过一秒。 如果您尝试这样做,SDK 将显示错误并自动重置为默认值,将使用跟踪,即零秒。 该操作将触发 SDK 中实时的日志报告。
测试 | 7,069 | CC-BY-3.0 |
# think-report
A simple reporter for ThinkPHP v5.1
基于ThinkPHP v5.1的简易错误报告工具
你是否遇到上线的项目需要debug,但是又因为打开debug配置等同于让自己的应用“裸奔”而苦恼?那么你一定需要试试这个。
## 如何使用
### 使用异常处理
在你的ThinkPHP项目中,找到config/app.php。在大概最后一行的位置找到“exception_handle”配置,将它修改为“\\\\finntenzor\\\\report\\\\ExceptionHandle”,如:
``` php
// 异常处理handle类 留空使用 \think\exception\Handle
'exception_handle' => '\\finntenzor\\report\\ExceptionHandle',
```
### 修改路由
在你的ThinkPHP项目中,找到route/route.php。在你需要的位置添加如下代码:
``` php
\finntenzor\report\Report::route('reports');
```
它某种意义上等价于自动编写一个Group以及对应的两个路由:
``` php
Route::group('reports', function () {
Route::get('/:id', 'finntenzor/reports/getReportById');
Route::get('/', 'finntenzor/reports/getReportList');
});
```
因此你可以很轻松地将它和其他路由混合在一起:
``` php
use finntenzor\report\Report;
Route::group('app', function () {
Route::group('api', function () {
// 一些其他路由
});
// 将app/reports注册为错误报告路由
Report::route('reports');
});
```
如上代码所示,你可以访问`/app/reports`来查看所有的错误报告,其中的各项报告链接会自动处理。
并且,它返回了ThinkPHP的返回值,你还可以将它跟中间件等其他功能结合在一起。
``` php
use finntenzor\report\Report;
Route::group('app', function () {
Route::group('api', function () {
// 一些其他路由
});
// 将app/reports注册为错误报告路由
Report::route('reports')->middleware('MustAdmin');
});
```
### 取代默认响应格式
错误报告工具启动后,默认会保存所有的错误报告到项目目录/runtime/reports下,但是仅进行保存而不会将错误返回给用户显示,给用户/前端的将会是一段默认的json,格式如下:
+ 项目关闭debug模式时
``` json
{
"ret": 500,
"msg": "Internal Server Error"
}
```
+ 项目打开debug模式时
``` json
{
"ret": 500,
"msg": "错误Message"
}
```
如果你需要修改为其他格式,你可以利用ThinkPHP的容器绑定来修改格式:
1. 首先你需要创建一个类实现ResponseBuilder,例如:
``` php
<?php
namespace app\index\common;
use finntenzor\report\ResponseBuilder;
class ExceptionResponseBuilder implements ResponseBuilder
{
/**
* @param \Exception $e 异常
* @return mixed 响应
*/
public function debugResponse($e)
{
return $e->getMessage();
}
/**
* @return mixed 响应
*/
public function deployResponse()
{
return '哦吼,页面错误了,请联系管理员哦~';
}
}
```
2. 在你的ThinkPHP项目中找到application/provider.php,在其中将ResponseBuilder接口绑定到你自己的实现上:
``` php
<?php
// ....
// 应用容器绑定定义
return [
// 将工具的ResponseBuilder接口绑定到自定义的Builder类上
\finntenzor\report\ResponseBuilder::class => \app\index\common\ExceptionResponseBuilder::class
];
// 或者你也可以使用命令式的绑定:
bind(\finntenzor\report\ResponseBuilder::class, \app\index\common\ExceptionResponseBuilder::class)
```
### 添加异常忽略类型
ThinkPHP默认忽略了“\\think\\exception\\HttpException”类型的异常,在此工具中,如果需要忽略更多类型的异常,则可以使用如下代码修改:
``` php
use finntenzor\report\ExceptionHandle;
ExceptionHandle::ignore('\\app\\index\\MyException');
```
这段代码需要放在初始化阶段加载的php文件中,例如/application/common.php | 2,847 | Apache-2.0 |
---
title: 检测大写格式
---
## 题目需求:
输入`USA`,`leetcode`,`Google`,通过测试,返回`true`
输入`flaG`,返回`false`
## 解题思路:
已知三个不同格式字符串可以通过测试,返回`true`
不妨设置三种状态,返回的时候,某一个状态为`true`,则表示通过测试
若都返回`false`,那么就是`false`
## 代码:
```javascript
/**
* @param {string} word
* @return {boolean}
*/
var detectCapitalUse = function(word) {
var result = false;
var a = false,b=false,c=false;
for(var i = 0; i < word.length; i++){
if (i===0){
if (/[A-Z]/.test(word[i])){
a =true,b=true,c=false;
}
else if (/[a-z]/.test(word[i])){
a = false,b=false,c=true;
}
}
else{
if (a && /[A-Z]/.test(word[i])){
a = true,b=false,c=false;
}else if (b && /[a-z]/.test(word[i])){
a=false,b=true,c=false;
}else if (c && /[a-z]/.test(word[i])){
a=false,b=false,c=true;
}else{
a = false,b=false,c=false;
}
}
}
return a||b||c;
};
```
## 其他答案:
发现自己想复杂了。。。😓
```javascript
//直接正则匹配,合格返回true,不合格返回false
var detectCapitalUse = function(word) {
if (/^[A-Z]+$/.test(word)) return true
if (/^[A-Z][a-z]*$/.test(word)) return true
if (/^[a-z]+$/.test(word)) return true
return false
};
//甚至可以不用正则
var detectCapitalUse = function(word) {
if (word === word.toUpperCase()) return true
let firstCapital = word[0].toUpperCase() + word.slice(1).toLowerCase()
if (word === firstCapital) return true
if (word === word.toLowerCase()) return true
};
//其他用ASCII码的
//思路:判断全部字符,大写是否在65-90(A-Z)之间
``` | 1,623 | MIT |
---
layout: post
title: Elasiticity-Mechanics
date: 2020-06-20
categories: peridynamic
mathjax: true
tags: [continuum mechanics]
---
本文是连续介质力学的读书笔记。
<!--more-->
### 一、绪论
弹性力学是研究载荷作用下弹性体中的内力状态和变形规律的科学。其中,弹性体是指经过载荷作用之后能完全恢复其初始形状和尺寸的物体。
好吧,到这里,你一定有个疑问,为什么要限定是弹性体呢?不瞒你说,我也有。按照目前我的个人理解是,弹性体是比较理想的物体,弹性理论也是比较理想的理论,在这种情况下许多必要的数学工具才可以使用。下面看看理想在哪。
#### 1、弹性理论的基本假设(理想在这)
- 连续性假设
弹性体是一种连续介质,并在变形过程中仍保持连续。这句话有两层含义:
- 物体连续的充满整个空间,即可以与实数空间 $R^3$ 的一个子空间一一对应,并且相应的物理量比如密度、位移、应力、应变、能量密度都可以作为空间点位的函数。
- 物体在变形过程中保持连续,即原来的相邻点变形后仍是相邻点,不会裂开或重叠。
- 弹性假设
弹性体的变形和载荷是一一对应的单值函数关系,当载荷卸载,变形也会消失,恢复初始尺寸。在小变形情况下,变形与载荷是线性关系。在大变形情况下,变形与载荷是非线性关系。
此处为了简化研究,遵循线弹性假设。并作出如下额外假设。
- 均匀性假设
物体在不同点处的弹性性质处处相同。
- 各向同性假设
物体在同一点处的弹性性质与考察方向无关。
- 无初应力假设
物体在加载前和卸载后都处于无初始应力的自然状态。
#### 2、额外的问题
说了这么多,你应该有点疑惑,因为在上面的论述中,多次提到一个词 **载荷**。
**凡是导致物体变形和产生内力的因素都叫载荷**,所以你经常听到外力载荷,热载荷等等。但载荷可以分为两类:
- **重力,机械力,电磁力等,可以简化为作用在物体上的外力,由外力引起物体的变形和内力。**
外力根据作用域的不同,可以分为两类:
- 体积力(作用在物体内部体积上的力,重力,惯性力,电磁力)
$$
\mathbf{f}:=\lim_{\Delta V \rightarrow 0} \frac{\Delta \mathbf{F}}{\Delta V} = f_{i}\mathbf{e}_{i}, i = 1, 2, 3.
$$
其中$\Delta V$是微元的体积,$\Delta F$ 是作用在 $\Delta V$ 上外力的合力。
- 面积力(作用在物体表面上的力,压力,接触力)
$$
\mathbf{p}:=\lim_{\Delta S \rightarrow 0} \frac{\Delta \mathbf{G}}{\Delta S} = p_{i}\mathbf{e}_{i}, i = 1, 2, 3.
$$
其中$\Delta S$是微元的体积,$\Delta G$ 是作用在 $\Delta S$ 上外力的合力。
- **温度和中子辐照等物理因素,直接引起物体变形,当变形收到约束,物体内就产生内力。**
内容参照 **陆明万,罗学富 弹性理论基础 第二版上册**。 | 1,461 | MIT |
---
title: 处理通知消息,以完成特定任务中使用 BizTalk Server 的 SQL |Microsoft Docs
ms.custom: ''
ms.date: 06/08/2017
ms.prod: biztalk-server
ms.reviewer: ''
ms.suite: ''
ms.tgt_pltfrm: ''
ms.topic: article
ms.assetid: 8538cb89-1cca-45ad-b6f4-041e117963ff
caps.latest.revision: 13
author: MandiOhlinger
ms.author: mandia
manager: anneta
ms.openlocfilehash: e755a98cdc062e47eb7a2b9f6f2604ca4ec92b30
ms.sourcegitcommit: 381e83d43796a345488d54b3f7413e11d56ad7be
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 05/07/2019
ms.locfileid: "65368442"
---
# <a name="process-notification-messages-to-complete-specific-tasks-in-sql-using-biztalk-server"></a>进程通知消息,以完成特定任务中使用 BizTalk Server 的 SQL
可以使用[!INCLUDE[adaptersqlshort](../../includes/adaptersqlshort-md.md)]接收通知的 SQL Server 数据库表的更改。 但是,适配器仅向你发送某些记录已插入、 更新或删除数据库表中的通知。 这些记录的任何后续处理必须由客户端应用程序本身进行处理。 本主题显示如何处理基于类型的通知接收到来自 SQL Server 数据库表中的记录上的基于方案的说明。
## <a name="scenarios-for-performing-subsequent-actions-after-receiving-notification"></a>收到通知后执行后续操作的方案
以下是几种方案,适配器客户端必须执行某些通知后任务。
- **方案 1**。 假设适配器客户端必须在其中执行某些任务基于从 SQL Server 接收的通知的类型。 例如,如果在表"B"中插入记录客户端应用程序必须更新表"A"中的记录。 同样,客户端应用程序必须从表"B"中删除记录如果从表"A"中删除记录。
从通知消息接收到,在此方案中,适配器客户端必须提取要决定是否通知已为插入操作或删除操作的通知类型。 一旦确定通知类型,适配器客户端必须执行后续操作来插入或更新相关表。
- **方案 2**。 假设接收对表的更改的通知消息的接收位置出现故障。 关闭接收位置时,某些记录添加到表。 但是,这些记录的适配器客户端不接收任何通知。 当接收位置重新启动时,适配器将通过发送特定消息来通知客户端,然后客户端应用程序必须查找的接收位置时向下插入数据库表中的所有记录。
从通知消息接收到,在此方案中,适配器客户端必须提取有关该通知是对数据库表的更改或接收位置开始的信息。 通知所针对的接收位置开始,如果适配器客户端必须实现逻辑以处理可能具有已插入、 更新或接收位置已关闭时删除的记录。
> [!NOTE]
> 这些是为更好地了解如何使用通知功能中的列出的只是一些示例方案[!INCLUDE[adaptersqlshort](../../includes/adaptersqlshort-md.md)]。 但是,一组基本的通知接收到的类型中提取所需的任务将适用于所有方案类似。 本主题将说明了如何从通知消息中提取的通知类型。
## <a name="how-this-topic-demonstrates-receiving-notification-messages-and-extracting-notification-type"></a>如何本主题演示如何接收通知消息,提取通知类型
本主题中演示如何处理通知消息,以执行后续任务中,我们假设基本适配器客户端在其中使用 BizTalk 应用程序以接收通知消息,对 Employee 表的更改。 收到通知后,客户端筛选收到的通知的类型,并执行后续操作。 若要演示最基本方案,让我们设想适配器客户端将通知消息复制到不同的文件夹,根据收到的通知的类型。 因此:
- 如果通知消息是针对 Insert 或 Update 操作,适配器客户端会将消息复制到 C:\TestLocation\UpsertNotification 文件夹中。
- 如果通知消息是针对任何其他操作,例如删除,适配器客户端将该邮件复制到 C:\TestLocation\OtherNotificaiton 文件夹。
为此 BizTalk 应用程序的一部分,该业务流程必须包含以下信息:
- 一个单向接收端口以接收通知消息。
- 表达式形状包含 xpath 查询来提取有关收到通知消息的类型信息。
- 判定形状在业务流程中包括判定块。 在此决策块中,应用程序确定要执行的后续操作根据收到的通知消息。
- 两个单向发送端口的最后接收的通知消息。
## <a name="configuring-notifications-with-the-sql-adapter-binding-properties"></a>使用 SQL 适配器的绑定属性中配置通知
下表总结了[!INCLUDE[adaptersqlshort](../../includes/adaptersqlshort-md.md)]绑定用于配置 SQL Server 从接收通知的属性。 配置中的接收端口时,必须指定这些绑定属性[!INCLUDE[btsBizTalkServerNoVersion](../../includes/btsbiztalkservernoversion-md.md)]管理控制台。
> [!NOTE]
> 您可以选择生成的架构时指定这些绑定属性**通知**操作,即使并不总是这样。 如果这样做,端口绑定文件的[!INCLUDE[consumeadapterservshort](../../includes/consumeadapterservshort-md.md)]生成元数据生成的一部分还包含为绑定属性指定的值。 稍后可以导入此绑定文件中的[!INCLUDE[btsBizTalkServerNoVersion](../../includes/btsbiztalkservernoversion-md.md)]管理控制台中创建的 WCF 自定义或 WCF SQL 属性已设置对绑定接收端口。 有关创建使用该绑定文件的端口的详细信息,请参阅[配置使用的端口绑定文件以使用 SQL 适配器的物理端口绑定](../../adapters-and-accelerators/adapter-sql/configure-a-physical-port-binding-using-a-port-binding-file-to-sql-adapter.md)。
|绑定属性|Description|
|----------------------|-----------------|
|**InboundOperationType**|指定你想要执行的入站的操作。 若要接收通知消息,请将此设置为**通知**。|
|**NotificationStatement**|指定的 SQL 语句 (SELECT 或 EXEC\<存储过程\>) 用于对查询通知注册。 仅当指定的 SQL 语句更改的结果集时,适配器从 SQL Server 获取通知消息。|
|**NotifyOnListenerStart**|指定适配器是否启动侦听器时在向适配器客户端发送了通知。|
有关这些属性的更完整说明,请参阅[了解关于 BizTalk Adapter for SQL Server 适配器绑定属性](../../adapters-and-accelerators/adapter-sql/read-about-the-biztalk-adapter-for-sql-server-adapter-binding-properties.md)。 有关如何使用的完整说明[!INCLUDE[adaptersqlshort](../../includes/adaptersqlshort-md.md)]若要从 SQL Server 中接收通知,请阅读更多。
## <a name="how-to-receive-notification-messages-from-the-sql-server-database"></a>如何从 SQL Server 数据库中接收通知消息
使用 SQL Server 数据库上执行操作[!INCLUDE[adaptersqlshort](../../includes/adaptersqlshort-md.md)]与[!INCLUDE[btsBizTalkServerNoVersion](../../includes/btsbiztalkservernoversion-md.md)]涉及过程中所述的任务[若要开发使用 SQL 适配器的 BizTalk 应用程序的构建基块](../../adapters-and-accelerators/adapter-sql/building-blocks-to-develop-biztalk-applications-with-the-sql-adapter.md)。 若要配置要接收通知消息的适配器,这些任务包括:
1. 创建 BizTalk 项目,然后生成的架构**通知**的入站操作。 或者,您可以指定的值**InboundOperationType**并**NotificationStatement**绑定属性。
2. 用于从 SQL Server 数据库中接收通知的 BizTalk 项目中创建一条消息。
3. 在上一部分中所述创建一个业务流程。
4. 生成并部署 BizTalk 项目。
5. 配置的 BizTalk 应用程序通过创建物理发送端口和接收端口。
> [!NOTE]
> 对于入站操作,如接收通知消息,你必须仅配置一个单向 WCF 自定义或 WCF SQL 接收端口。 双向 WCF 自定义或 WCF SQL 接收端口的入站操作不受支持。
6. 启动 BizTalk 应用程序。
本主题介绍如何执行这些任务。
## <a name="generating-schema"></a>生成架构
必须生成的架构**通知**的入站操作。 请参阅[检索用于在 Visual Studio 中使用 SQL 适配器的 SQL Server 操作的元数据](../../adapters-and-accelerators/adapter-sql/get-metadata-for-sql-server-operations-in-visual-studio-using-the-sql-adapter.md)有关如何生成架构的详细信息。 生成架构时,请执行以下任务。 如果不想指定绑定属性在设计时,跳过的第一步。
1. 为指定值**InboundOperationType**并**NotificationStatement**生成架构时绑定属性。 有关此绑定属性的详细信息,请参阅[了解关于 BizTalk Adapter for SQL Server 适配器绑定属性](../../adapters-and-accelerators/adapter-sql/read-about-the-biztalk-adapter-for-sql-server-adapter-binding-properties.md)。 有关如何指定绑定属性的说明,请参阅[配置 SQL 适配器的绑定属性](../../adapters-and-accelerators/adapter-sql/configure-the-binding-properties-for-the-sql-adapter.md)。
2. 选择作为协定类型**服务 (入站操作)**。
3. 生成架构**通知**操作。
## <a name="defining-messages-and-message-types"></a>定义消息和消息类型
先前生成的架构描述业务流程中的消息所需的"类型"。 一条消息通常是一个变量,要为其类型定义由相应的架构。 架构生成后,你必须将其链接到消息从 BizTalk 项目的业务流程视图。
对于本主题中,必须创建一条消息能从 SQL Server 数据库中接收通知。
执行以下步骤创建消息并将其链接到架构。
#### <a name="to-create-messages-and-link-to-schema"></a>若要创建消息并将链接到架构
1. 向 BizTalk 项目添加业务流程。 从解决方案资源管理器,右键单击 BizTalk 项目名称,指向**外**,然后单击**新项**。 键入 BizTalk 业务流程的名称,然后单击**添加**。
2. 如果尚未打开,请打开 BizTalk 项目的业务流程视图窗口。 单击**视图**,依次指向**其他 Windows**,然后单击**业务流程视图**。
3. 在中**业务流程视图**,右键单击**消息**,然后单击**新消息**。
4. 右键单击新创建的消息,然后依次**属性窗口**。
5. 在中**属性**窗格**Message_1**,执行以下操作:
|使用此选项|执行的操作|
|--------------|----------------|
|Identifier|键入 `NotifyReceive`。|
|消息类型|从下拉列表中,展开**架构**,然后选择*Process_Notification.Notification*,其中*Process_Notification*是 BizTalk 项目的名称。 *通知*是为生成的架构**通知**操作。|
## <a name="setting-up-the-orchestration"></a>设置业务流程
必须创建 BizTalk 业务流程使用[!INCLUDE[btsBizTalkServerNoVersion](../../includes/btsbiztalkservernoversion-md.md)]有关从 SQL Server 数据库中接收通知消息,然后执行任务根据收到的通知的类型。 在此业务流程,适配器将接收通知消息根据 SELECT 语句为指定**NotificationStatement**属性绑定。 表达式形状中指定的 xpath 查询中提取到变量中,通知的类型说**NotificationType**。 判定形状使用此变量中的值来确定接收通知的类型和使用的相应"路径"以执行后续操作。 如前面部分中所述,业务流程将执行以下操作,根据收到的通知消息类型。
- 如果通知消息是针对 Insert 或 Update 操作,适配器客户端会将消息复制到 C:\TestLocation\UpsertNotification 文件夹中。
- 如果通知消息是针对任何其他操作,例如删除,适配器客户端将该邮件复制到 C:\TestLocation\OtherNotificaiton 文件夹。
因此,您的业务流程必须包含以下信息:
- 一个单向接收端口以接收通知消息。
- 表达式形状包含 xpath 查询来提取通知接收到的类型。
- 判定形状在业务流程中包括判定块。 在此决策块中,应用程序确定要执行的后续操作根据收到的通知消息。
- 两个单向发送端口的最后接收的通知消息。
- 接收形状。
示例业务流程如下所示。

### <a name="adding-message-shapes"></a>添加消息形状
请确保为每个消息形状中指定以下属性。 形状列中列出的名称是在刚提到的业务流程中显示的消息形状的名称。
|形状|形状类型|属性|
|-----------|----------------|----------------|
|ReceiveNotification|Receive|-设置**名称**到*ReceiveNotification*<br /><br /> -设置**激活**到 *,则返回 True*|
### <a name="adding-an-expression-shape"></a>添加表达式形状
在业务流程中包括的表达式形状的用途是收到通知消息的类型中提取的 xpath 查询。 然后再创建 xpath 查询,让我们看一下通知消息的格式。 典型的通知消息如下所示:
```
<Notification xmlns="http://schemas.microsoft.com/Sql/2008/05/Notification/">
<Info>Insert</Info>
<Source>Data</Source>
<Type>Change</Type>
</Notification>
```
正如您看到的通知类型有关的信息中有可用`<info>`标记,在父级内的`<Notification>`标记。 因此,在此表达式形状,你必须:
- 创建包含中的值的变量`<Info>`标记并将其类型设置为 System.String。 有关创建变量的详细信息,请参阅[业务流程中使用变量](../../core/using-variables-in-orchestrations.md)。
有关本主题中,将变量命名为**NotificationType**。
- 创建 xpath 查询中的值中提取\<信息\>标记。 Xpath 查询将如下所示:
```
NotificationType = xpath(NotifyReceive,"string(/*[local-name()='Notification']/*[local-name()='Info']/text())");
```
在此 xpath 查询中, **NotifyReceive**是创建用于接收通知消息的消息。 中的摘录`string`函数指明查询必须在值中提取`<Info>`标记,它又是内`<Notification>`标记。 最后,在查询中提取的值分配给**NotificaitonType**变量。
### <a name="adding-a-decide-shape"></a>添加判定形状
添加判定形状的目的是要包含在业务流程,以决定要执行的后续操作根据收到的通知消息类型中的判定块。 基于的值做出的决定**NotificationType**变量。 在本主题中,业务流程可以根据收到的通知消息类型的决策。 因此,规则形状中的条件,如下所示指定:
```
NotificationType.Equals("Insert") | NotificationType.Equals("Update")
```
这种情况表明,如果的值**NotificaitonType**变量是插入或更新,该业务流程将执行的一组任务。 如果的值**NotificationType**变量是任何其他操作,业务流程将执行另一组任务。
如前面部分中所述,来演示一种简单方法,该业务流程会将消息复制到不同的文件夹的通知消息类型。 因此,规则中,Else 块,必须添加发送形状将消息发送到不同的端口。 本主题中,命名为规则块中的发送形状**SendUpsertNotification**和 Else 块作为中的发送形状**SendOtherNotification**。
### <a name="adding-ports"></a>添加端口
您现在必须将以下逻辑端口添加到业务流程:
- 单向接收端口以接收来自 SQL Server 通知消息。
- 单向发送端口以将 Insert 和 Update 操作的通知消息发送到特定文件夹。
- 若要将任何其他操作的通知消息发送到特定文件夹的单向发送端口。
请确保为每个逻辑端口中指定以下属性。 端口列中列出的名称是在业务流程中显示的端口的名称。
|Port|属性|
|----------|----------------|
|SQLNotifyPort|-设置**标识符**到*SQLNotifyPort*<br /><br /> -设置**类型**到*SQLNotifyPortType*<br /><br /> -设置**通信模式**到*单向*<br /><br /> -设置**通信方向**到*接收*|
|NotificationUpsertPort|-设置**标识符**到*NotificationUpsertPort*<br /><br /> -设置**类型**到*NotificationUpsertPortType*<br /><br /> -设置**通信模式**到*单向*<br /><br /> -设置**通信方向**到*发送*|
|OtherNotificationPort|-设置**标识符**到*OtherNotificationPort*<br /><br /> -设置**类型**到*OtherNotificationPortType*<br /><br /> -设置**通信模式**到*单向*<br /><br /> -设置**通信方向**到*发送*|
### <a name="specify-messages-for-action-shapes-and-connect-to-ports"></a>为操作形状指定消息并将连接到端口
下表指定属性应设置为指定操作形状的消息并链接到的端口的消息及其值。 形状列中列出的名称是消息形状的名称,前面所述的业务流程中所示。
|形状|属性|
|-----------|----------------|
|ReceiveNotification|-设置**消息**到*NotifyReceive*<br /><br /> -设置**操作**到*SQLNotifyPort.Notify.Request*|
|SendUpsertNotification|-设置**消息**到*NotifyReceive*<br /><br /> -设置**操作**到*NotificationUpsertPort.Upsert.Request*|
|SendOtherNotification|-设置**消息**到*选择*<br /><br /> -设置**操作**到*OtherNotificationPort.Other.Request*|
指定这些属性后,消息形状和端口进行连接,您的业务流程已完成。
现在必须生成 BizTalk 解决方案,并将其部署到[!INCLUDE[btsBizTalkServerNoVersion](../../includes/btsbiztalkservernoversion-md.md)]。 有关详细信息,请参阅[构建和运行业务流程](../../core/building-and-running-orchestrations.md)。
## <a name="configuring-the-biztalk-application"></a>配置 BizTalk 应用程序
部署 BizTalk 项目后,将前面创建的业务流程下列出**业务流程**BizTalk Server 管理控制台窗格中的。 必须使用 BizTalk Server 管理控制台来配置应用程序。 有关演练,请参阅[演练:部署基本 BizTalk 应用程序](Walkthrough:%20Deploying%20a%20Basic%20BizTalk%20Application.md)。
配置应用程序包括:
- 选择应用程序的主机。
- 映射到 BizTalk Server 管理控制台中的物理端口在业务流程中创建的端口。 对于此业务流程,您必须:
- 定义一个物理 WCF 自定义或 WCF-SQL 单向接收端口。 此端口侦听来自 SQL Server 数据库的通知。 有关如何创建端口的信息,请参阅[手动配置与 SQL 适配器的物理端口绑定](../../adapters-and-accelerators/adapter-sql/manually-configure-a-physical-port-binding-to-the-sql-adapter.md)。 请确保指定的接收端口的以下绑定属性。
> [!IMPORTANT]
> 不需要执行此步骤中,如果指定在设计时的绑定属性。 在这种情况下,您可以创建 WCF 自定义或 WCF SQL 通过导入绑定文件创建的接收端口,设置了所需的绑定属性[!INCLUDE[consumeadapterservshort](../../includes/consumeadapterservshort-md.md)]。 有关详细信息请参阅[配置使用的端口绑定文件以使用 SQL 适配器的物理端口绑定](../../adapters-and-accelerators/adapter-sql/configure-a-physical-port-binding-using-a-port-binding-file-to-sql-adapter.md)。
|绑定属性|ReplTest1|
|----------------------|-----------|
|**InboundOperationType**|将此设置为**通知**。|
|**NotificationStatement**|将此设置为:<br /><br /> `SELECT Employee_ID, Name FROM dbo.Employee WHERE Status=0`<br /><br /> **注意:** 具体而言,必须指定在此所示的语句中的列名称的 SELECT 语句。 此外,您必须始终指定表名称以及架构名称。 例如,`dbo.Employee`。|
|**NotifyOnListenerStart**|将此设置为 **,则返回 True**。|
有关不同的绑定属性的详细信息,请参阅[了解关于 BizTalk Adapter for SQL Server 适配器绑定属性](../../adapters-and-accelerators/adapter-sql/read-about-the-biztalk-adapter-for-sql-server-adapter-binding-properties.md)。
> [!NOTE]
> 我们建议执行使用的入站的操作时配置的事务隔离级别和事务超时[!INCLUDE[adaptersqlshort](../../includes/adaptersqlshort-md.md)]。 你可以执行以便通过将服务添加行为时配置 WCF 自定义或 WCF SQL 接收端口。 有关如何添加服务行为的说明,请参阅[配置事务隔离级别和使用 SQL 事务超时](../../adapters-and-accelerators/adapter-sql/configure-transaction-isolation-level-and-transaction-timeout-with-sql.md)。
- 硬盘和 BizTalk 业务流程将放置的位置的通知消息中插入和更新操作的 SQL Server 数据库的相应文件端口上定义的位置。 配置此端口,放到文件夹 C:\TestLocation\UpsertNotification 通知消息。
- 硬盘和相应的 BizTalk 业务流程将通知消息从数据库中删除 SQL Server 的所有其他操作的文件端口上定义的位置。 配置此端口,放到文件夹 C:\TestLocation\OtherNotification 通知消息。
## <a name="starting-the-application"></a>启动应用程序
必须启动 BizTalk 应用程序从 SQL Server 数据库中接收通知消息并执行后续的 Select 和 Update 操作。 在启动 BizTalk 应用程序的说明,请参阅[如何启动业务流程](../../core/how-to-start-an-orchestration.md)。
在此阶段,请确保:
- WCF 自定义或 WCF-SQL 单向接收端口,从 SQL Server 数据库运行时接收通知消息。
- 正在从 SQL Server 接收消息,两个文件发送端口。
- 该操作的 BizTalk 业务流程正在运行。
## <a name="executing-the-operation"></a>执行该操作
启动 BizTalk 业务流程后,以下组操作发生:
- 因为**NotifyOnListenerStart**绑定属性设置为**True**,收到以下消息:
```
<?xml version="1.0" encoding="utf-8" ?>
<Notification xmlns="http://schemas.microsoft.com/Sql/2008/05/Notification/">
<Info>ListenerStarted</Info>
<Source>SqlBinding</Source>
<Type>Startup</Type>
</Notification>
```
请注意,中的值`<Info>`标记为"ListnerStarted"。 因此,C:\TestLocation\OtherNotification 文件夹中收到此消息。
- 在 Employee 表中插入一条记录。 你将收到类似于以下的通知消息:
```
<?xml version="1.0" encoding="utf-8" ?>
<Notification xmlns="http://schemas.microsoft.com/Sql/2008/05/Notification/">
<Info>Insert</Info>
<Source>Data</Source>
<Type>Change</Type>
</Notification>
```
请注意,中的值`<Info>`标记为"Insert"。 因此,C:\TestLocation\UpsertNotification 文件夹中收到此消息。
- 更新员工表中的记录。 你将收到类似于以下的通知消息:
```
<?xml version="1.0" encoding="utf-8" ?>
<Notification xmlns="http://schemas.microsoft.com/Sql/2008/05/Notification/">
<Info>Update</Info>
<Source>Data</Source>
<Type>Change</Type>
</Notification>
```
请注意,中的值`<Info>`标记为"Update"。 因此,C:\TestLocation\UpsertNotification 文件夹中收到此消息。
- 从 Employee 表中删除一条记录。 你将收到类似于以下的通知消息:
```
<?xml version="1.0" encoding="utf-8" ?>
<Notification xmlns="http://schemas.microsoft.com/Sql/2008/05/Notification/">
<Info>Delete</Info>
<Source>Data</Source>
<Type>Change</Type>
</Notification>
```
请注意,中的值`<Info>`标记为"Delete"。 因此,C:\TestLocation\OtherNotification 文件夹中收到此消息。
## <a name="best-practices"></a>最佳实践
部署和配置 BizTalk 项目后,你可以配置设置导出到名为绑定文件的 XML 文件。 后生成的绑定文件,可以以便不需要创建发送端口和接收端口的同一业务流程,从文件导的配置设置。 有关绑定文件的详细信息,请参阅[重用适配器绑定](../../adapters-and-accelerators/adapter-sql/reuse-sql-adapter-bindings.md)。
## <a name="performing-complex-operations-after-receiving-notification-messages"></a>接收通知消息后执行复杂的操作
对于简单起见,更好地了解本主题中的业务流程将消息复制到不同的文件夹的通知类型。 但是,在实际方案中你可能想要执行更复杂的操作。 在此主题,并对其执行操作需要的生成中提供,可以执行类似的过程。 例如,可以更改业务流程,以在另一个表中插入记录,如果在 Employee 表的插入操作收到一条通知消息。 在这种情况下,您可以判定形状中的相应更改。
中详细介绍其中一种方案是[教程 2:员工-采购订单流程使用 SQL 适配器](../../adapters-and-accelerators/adapter-sql/tutorial-2-employee-purchase-order-process-using-the-sql-adapter.md)。
## <a name="see-also"></a>请参阅
[接收使用 BizTalk Server 的 SQL 查询通知](../../adapters-and-accelerators/adapter-sql/receive-sql-query-notifications-using-biztalk-server.md) | 15,518 | CC-BY-4.0 |
---
title: Cloud Services に関する FAQ | Microsoft Docs
description: Cloud Services に関してよく寄せられる質問。
services: cloud-services
documentationcenter: ''
author: Thraka
manager: timlt
editor: ''
ms.service: cloud-services
ms.workload: tbd
ms.tgt_pltfrm: na
ms.devlang: na
ms.topic: article
ms.date: 08/19/2016
ms.author: adegeo
---
# Cloud Services に関する FAQ
この記事では、Microsoft Azure Cloud Services についてよく寄せられる質問 (FAQ) とその回答を紹介します。Azure の価格およびサポートに関する一般的な情報については、「[Azure サポートに関する FAQ](http://go.microsoft.com/fwlink/?LinkID=185083)」も参照してください。サイズについては、[Cloud Services VM サイズのページ](cloud-services-sizes-specs.md)を参照してください。
## 証明書
### 証明書はどこにインストールすればいいですか?
* **My** 秘密キーを持つアプリケーション証明書 (*.pfx、*.p12)。
* **CA** すべての中間証明書をこのストア内に保存します (ポリシー CA および下位 CA)。
* **ROOT** ルート CA ストア。メインのルート CA 証明書をここに保存します。
### 有効期限が切れた証明書を削除できません
Azure では、証明書の使用中にその証明書を削除することはできません。証明書を使用するデプロイメントを削除するか、別の証明書または更新した証明書でデプロイメントを更新する必要があります。
### 有効期限切れの証明書を削除してください
証明書が使用されていない限りは、[Remove-AzureCertificate](https://msdn.microsoft.com/library/azure/mt589145.aspx) PowerShell コマンドレットを使って証明書を削除できます。
### Mirosoft Azure Service Management for Extensions という名前の証明書の期限が切れています
リモート デスクトップ拡張機能などの拡張機能がクラウド サービスに追加されるとかならず、これらの証明書が作成されます。これらの証明書は、拡張機能のプライベート構成を暗号化および復号化するためだけに使用されます。これらの証明書の有効期限が切れていても問題はありません。有効期限の日付はチェックされません。
### 削除した証明書が再表示され続けます
そのような証明書が再表示され続ける原因は、ほとんどの場合、ご使用になっているツール (Visual Studio など) です。証明書を使用しているツールに再接続するたびに、ツールが Azure に証明書を再アップロードします。
### 証明書が表示されません
仮想マシン インスタンスをリサイクルすると、ローカルのすべての変更は失われます。ロールが起動するたびに、[スタートアップ タスク](cloud-services-startup-tasks.md) を使用して、仮想マシンに証明書をインストールしてください。
### ポータルで管理証明書が見つかりません
[管理証明書](../azure-api-management-certs.md)は Azure クラシック ポータルでのみ使用できます。現在の Azure ポータルでは、管理証明書は使用しません。
### 管理証明書を無効にするにはどうすればよいですか
[管理証明書](../azure-api-management-certs.md)を無効にすることはできません。使用しなくなった場合は、Azure クラシック ポータルで削除できます。
### 特定の IP アドレスの SSL 証明書を作成するにはどうすればよいですか
[証明書を作成するためのチュートリアル](cloud-services-certs-create.md)の手順に従います。DNS 名として IP アドレスを使用します。
## トラブルシューティング
### マルチ VIP クラウド サービスの IP アドレスを予約できません
まず、IP アドレスを予約しようとしている仮想マシン インスタンスが有効であることを確認してください。次に、ステージング デプロイメントと運用環境デプロイメントの両方で予約済みの IP を使っていることを確認します。デプロイメントをアップグレードする間、この設定を**変更しない**でください。
<!---HONumber=AcomDC_0914_2016--> | 2,184 | CC-BY-3.0 |
<properties
pageTitle="BizTalk Services の管理および開発タスク一覧 | Microsoft Azure"
description="Azure BizTalk Services のデプロイ向けの計画およびジョブ支援"
services="biztalk-services"
documentationCenter=""
authors="msftman"
manager="erikre"
editor=""/>
<tags
ms.service="biztalk-services"
ms.workload="integration"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="02/29/2016"
ms.author="deonhe"/>
# BizTalk Services の管理および開発タスク一覧
## はじめに
Microsoft Azure BizTalk Services を使用する場合、考慮する必要があるオンプレミスおよびクラウドベースのコンポーネントがいくつかあります。まずはじめに、次のプロセス フローを考慮します。
|手順|責任者|タスク|関連リンク|
|----|----|----|----|
1\.|管理者|Microsoft アカウントまたは組織アカウントを使用して、Microsoft Azure のサブスクリプションを作成します。|[Azure クラシック ポータル](http://go.microsoft.com/fwlink/p/?LinkID=213885)|
|2\.|管理者|BizTalk サービスの作成またはプロビジョニング|[Azure クラシック ポータルを使用して BizTalk サービスを作成する](http://go.microsoft.com/fwlink/p/?LinkID=302280)|
|3\.|管理者|個人または会社の BizTalk Services のデプロイを登録します。|[BizTalk Services ポータルでの BizTalk サービス デプロイの登録と更新](https://msdn.microsoft.com/library/azure/hh689837.aspx)|
|4\.|管理者|アプリケーションが BizTalk アダプター サービスを使用してオンプレミス基幹業務 (LOB) システムに接続しているか、キューまたはトピック ターゲットを使用している場合に適用されます。Azure Service Bus 名前空間を作成します。この名前空間、Service Bus の発行者名、および Service Bus の発行者キー値を開発者に伝えます。|「[方法: Service Bus サービス名前空間を作成または変更する](../service-bus/service-bus-dotnet-get-started-with-queues.md)」および「[発行者名および発行者キー値の取得](biztalk-issuer-name-issuer-key.md)」|
|5\.|開発者|SDK をインストールし、Visual Studio で BizTalk サービス プロジェクト を作成します。|「[Azure BizTalk Services SDK のインストール](https://msdn.microsoft.com/library/azure/hh689760.aspx)」および「[Azure の多機能メッセージング エンドポイントの作成](https://msdn.microsoft.com/library/azure/hh689766.aspx)」|
|6\.|開発者|Azure でホストされている BizTalk サービスに BizTalk サービス プロジェクトをデプロイします。|[BizTalk Services プロジェクトのデプロイおよび更新](https://msdn.microsoft.com/library/azure/hh689881.aspx)|
|7\.|管理者|EDI を使用している場合に適用されます。パートナーを追加し、Microsoft Azure BizTalk Services ポータルでアグリーメントを作成できます。アグリーメントを作成するときに、アグリーメントの設定に開発者が作成したブリッジまたは変換を追加することができます。|[BizTalk Services ポータルでの EDI、AS2、および EDIFACT の構成](https://msdn.microsoft.com/library/azure/hh689853.aspx)|
|8\.|管理者|Azure クラシック ポータルを使用して、パフォーマンス メトリックなど、BizTalk サービスの状態を監視します。|[BizTalk Services: [ダッシュボード]、[監視]、および [スケール] タブ](http://go.microsoft.com/fwlink/p/?LinkID=302281)|
|9\.|管理者|Microsoft Azure BizTalk Services ポータルを使用して、BizTalk Services で使用されているアーティファクトを管理し、ブリッジ ファイルで処理されるメッセージを追跡します。|[BizTalk Services ポータルを使用する](https://msdn.microsoft.com/library/azure/dn874043.aspx)|
|10\.|管理者|バックアップ計画を作成して BizTalk サービスをバックアップします。|[BizTalk Services のビジネス継続性と障害復旧](https://msdn.microsoft.com/library/azure/dn509557.aspx) |
## 次のステップ
[チュートリアルとサンプル](https://msdn.microsoft.com/library/azure/hh689895.aspx)
[Visual Studio でのプロジェクトの作成](https://msdn.microsoft.com/library/azure/hh689811.aspx)
[Azure BizTalk Services SDK のインストール](https://msdn.microsoft.com/library/azure/hh689760.aspx)
## 概念
「[Visual Studio でのプロジェクトの作成](https://msdn.microsoft.com/library/azure/hh689811.aspx)」および「[EDI、AS2、および EDIFACT メッセージング (企業間)](https://msdn.microsoft.com/library/azure/hh689898.aspx)」
## その他のリソース
[ソース、宛先、およびブリッジ メッセージング エンドポイントの追加 ](https://msdn.microsoft.com/library/azure/hh689877.aspx) [メッセージ マップおよび変換の学習および作成 ](https://msdn.microsoft.com/library/azure/hh689905.aspx) [BizTalk アダプター サービスの使用 ](https://msdn.microsoft.com/library/azure/hh689889.aspx) [Azure BizTalk Services](http://go.microsoft.com/fwlink/p/?LinkID=303664)
<!---HONumber=AcomDC_0608_2016--> | 3,388 | CC-BY-3.0 |
# multiple-datasource
multiple-datasource项目是springboot配置多个数据源的一个工程,有两个分支,分别是`druid+mybatisplus`和`package+mybatis`。
### druid+mybatisplus分支
`druid+mybatisplus`分支是采用了druid和mybatis-plus的方式实现的, 其实druid这块没有太大的问题,使用默认的HiKariCP也是可以的,
关键之中在于对于数据源的配置,这两部分是一致的,都如同下面的方式。不同之处在于对于数据源的使用,`druid+mybatisplus`由于使用了
`dynamic-datasource-spring-boot`方式, 配置pom.xml,添加`dynamic-datasource-spring-boot-starter`,然后再mapper接口之中,
或者service服务之中,甚至是方法之中,就可以定义具体要使用的数据源,仅仅就一个@DS('db1'),@DS('db2')就搞定了,而在`package+mybatis`分支
之中就需要专门的config类来完成,相比之下,后者不灵活,而且繁琐,所以使用这种方式更好。
```yaml
spring:
datasource:
dynamic:
primary: db1 # 配置默认数据库
datasource:
db1: # 数据源1配置
url: jdbc:mysql://localhost:3306/db1?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
db2: # 数据源2配置
url: jdbc:mysql://localhost:3306/db2?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
durid:
initial-size: 1
max-active: 20
min-idle: 1
max-wait: 60000 # 单位是毫秒
time-between-eviction-runs-millis: 60000 # 这个下面的不配置也是可以的, 不配置就不用去写druid的config, 也没有对应监控功能
min-evictable-idle-time-millis: 300000 # 这个下面的不配置也是可以的, 不配置就不用去写druid的config, 也没有对应监控功能
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
test-on-borrow: false
test-on-return: false
pool-prepared-statements: true
filters: stat,wall # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
maxPoolPreparedStatementPerConnectionSize: 20
seGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
```
### package+mybatis分支
`package+mybatis`分支的配置在数据源方面没什么差别,如下,上面的后半部分其实主要就是druid的配置,这个问题不是太大。主要不同的地方就是两个配置,
配置的java代码如下:
```yaml
spring:
datasource:
db1: # 数据源1
jdbc-url: jdbc:mysql://localhost:3306/db1?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
db2: # 数据源2
jdbc-url: jdbc:mysql://localhost:3306/db2?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
```
下面的代码之中,最关键的就是mapper.xml位置的设置,如果设置错误,就无法正确使用。另外在多个数据源通过不同的包package配置的时候,就需要额外注意
namespace的问题,这个也是可能导致错误的一个很大的诱导因素。其他的就没有太大的问题了。
```java
@Configuration
@MapperScan(basePackages = {"com.zgy.multipledatasource.mapper.db1"}, sqlSessionFactoryRef = "db1SqlSessionFactory")
public class DB1DataSourceConfig {
// @Primary 表示这个数据源是默认数据源, 这个注解必须要加,因为不加的话spring将分不清楚那个为主数据源(默认数据源)
@Primary
@Bean("db1DataSource")
@ConfigurationProperties(prefix = "spring.datasource.db1") //读取application.yml中的配置参数映射成为一个对象
public DataSource getDb1DataSource(){
return DataSourceBuilder.create().build();
}
@Primary
@Bean("db1SqlSessionFactory")
public SqlSessionFactory db1SqlSessionFactory(@Qualifier("db1DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
// 最好在此处设置, 在application.yml之中, 设置不设置都可以, 但是此处必须设置, 否则只有@Primary的可以使用
// mapper的xml形式文件位置必须要配置,不然将报错:no statement (这种错误也可能是mapper的xml中,namespace与项目的路径不一致导致)
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/db1/*.xml"));
return bean.getObject();
}
@Primary
@Bean("db1SqlSessionTemplate")
public SqlSessionTemplate db1SqlSessionTemplate(@Qualifier("db1SqlSessionFactory") SqlSessionFactory sqlSessionFactory){
return new SqlSessionTemplate(sqlSessionFactory);
}
}
```
`package+mybatis`分支采用的是mybatis+包package的方式实现多数据源的切换,其实在这个分支之中,使用mybatis-plus+包package的方式也是可以的,
二者的差别就是mybatis和mybatis-plus的差别,由于mybatis-plus集成了BaseMapper,所以我们可以写很少的方法,而对于Mapper.xml和Mapper接口本身的
位置和配置的问题,其实没有任何差别。
使用mybatis-plus的starter的时候,不需要引入mybatis的starter,使用mybatis-plus的starter之中已经引入了mybatis的jar包,我们不需要额外引入。
##### 参考:
[springboot-整合多数据源配置](https://www.cnblogs.com/aizen-sousuke/p/11756279.html),
[手把手教你用springboot配置多数据源](https://blog.csdn.net/qq_41076797/article/details/82889770),
[dynamic-datasource-spring-boot-starter 多数据源配置](https://www.jianshu.com/p/0b408e4e14a4),
https://github.com/baomidou/dynamic-datasource-spring-boot-starter,
https://github.com/CtrlZ1/MultipleDataSource, https://www.jianshu.com/p/099c0850ba16, https://blog.csdn.net/qq_38058332/article/details/84325009,
https://blog.csdn.net/z357904947/article/details/89157281 | 4,797 | BSD-3-Clause |
---
layout: post
title: "leet_code刷题"
subtitle: "自己写完后观摩大佬的代码"
date: 2018-11-04 20:00:00
author: "彭西明"
header-img: "img/mc/g3.jpg"
tags:
- C
---
# 算法练习
使用的是大佬敲的我认为比较好的,但也不是盲目崇拜,而直接否定自己,正所谓去粗取精嘛!
## Day1
### 1 两数之和
### 2 两数相加
### 3 无重复字符的最长子串
### 4 两数组的中位数
```C
输入:数组A: [1,3]
数组B: [2,4]
输出:2.5
```
大神写的代码
``` c
double findMedianSortedArrays(int* nums1, int nums1Size, int* nums2, int nums2Size) {
double sum[nums1Size+nums2Size];
//m1[nums1Size],m2[nums2Size];
// m1=nums1;
//m2=nums2;
int i,j,x=0,y=0,z;
double result;
z=nums1Size+nums2Size;
for(i=0;i<z;i++)
{
if((x!=nums1Size)&&(y!=nums2Size))
{
if(nums1[x]<=nums2[y])
{
sum[i]=nums1[x];
x++;
}
else if(nums1[x]>nums2[y])
{
sum[i]=nums2[y];
y++;
}
}
else if(x==nums1Size)sum[i]=nums2[y++];
else if(y==nums2Size)sum[i]=nums1[x++];
}
if(z%2==1)result=(double)sum[z/2];
else if(z%2==0)result=(double)(sum[z/2]+sum[z/2-1])/2;
return result;
}
```
我写的代码
``` C
double findMedianSortedArrays(int* nums1, int nums1Size, int* nums2, int nums2Size) {
int *m,*n,lm,ln;
if(nums1Size >nums2Size){
m = nums2;
n = nums1;
lm = nums2Size;
ln = nums1Size;
}else{
m = nums1;
n = nums2;
lm = nums1Size;
ln = nums2Size;
}
int imin = 0;
int imax = lm;
int half = (lm + ln +1)/2;
int i,j;
int max_left;
int min_right;
while(imin<=imax){
i = (imin + imax)/2;
j = half -i;
if( i <lm && n[j-1] >m[i]){
imin++;
}else if(i>0 && m[i-1]>n[j]){
imin--;
}else{
if(i==0) max_left = n[j-1];
else if(j==0){ max_left = m[i-1];}
else { max_left = (m[i-1]>n[j-1])?m[i-1]:n[j-1];}
if((lm+ln)%2==1) return max_left;
if(i==lm) min_right = m[i];
else if(j==ln) min_right = n[j];
else{ min_right = (m[i]<n[j])?m[i]:n[j];}
return (max_left+min_right)/2.0;
}
}
return 0.0
}
```
## Day2
### 5 最长回文串
大神写的代码居然秒解,什么鬼
``` C
char* longestPalindrome(char* s) {
int slen = strlen(s);
int tlen = slen * 2 + 1;
char t[tlen];
for (int i = 0; i < slen; i++) {
t[2 * i] = '|';
t[2 * i + 1] = s[i];
}
t[tlen - 1] = '|';
int lps_len[tlen];
int c = 0, r = 0, max = 0;
lps_len[0] = 0;
for (int i = 1; i < tlen; i++) {
if (i < r && i + lps_len[2 * c - i] < r) {
lps_len[i] = lps_len[2 * c - i];
} else {
int j = r + 1;
while (j < tlen && 2 * i - j > -1 && t[j] == t[2 * i - j]) {
j++;
}
lps_len[i] = j - i - 1;
c = i;
r = j - 1;
if (lps_len[i] > lps_len[max]) {
max = i;
}
}
}
int max_len = lps_len[max];
int max_index = (max - max_len) / 2;
char *buf = (char *) malloc(sizeof(char) * (max_len + 1));
for (int i = 0; i < max_len; i++) {
buf[i] = s[i + max_index];
}
buf[max_len] = '\0';
return buf;
}
```
自己写的貌似是最差的时间,而且还写了好久
```C
char* longestPalindrome(char* s) {
int len = strlen(s);
int i,j;
for(i = len;i>0;i--)
for( j=0;j<=len-i;j++){
int count =0,index;
for( index=0;(index)<i/2;index++){
if(s[j+index] == s[i+j-1-index])count++;
}
if(count ==i/2){
//printf("%d %d %d",count,j,i);
char *res = (char*)malloc(sizeof(char)*(i +1));
int l;
for(l=0;l<i;l++) res[l] = s[j+l];
res[l] = '\0';
return res;
}
}
char *rr = (char*)malloc(sizeof(char));
rr[0] = '\0';
return rr;
}
```
### 6 字符串Z型变换
``` C
// 问题描述
输入: s = "PAYPALISHIRING", numRows = 4
输出: "PINALSIGYAHRPI"
解释:
P I N
A L S I G
Y A H R
P I
```
```C
#include<stdio.h>
#include<malloc.h>
#include<string.h>
char* convert(char* s, int numRows) {
if(numRows==1) return s;
int slen = strlen(s);
char *res = (char*)malloc(sizeof(char)*(slen+1));
int cyclen = 2*numRows -2; //诀窍在于读懂按行读取的话,一个元素和下一个元素的排列关系
int i,j,index=0; //一方面考察代码,还考察等差数列的使用
for(i=0;i<numRows;i++){
for(j=0;j+i<slen;j+=cyclen) {
res[index++] = s[i+j];
if(i!=0&&i!=(numRows-1)&&(j+cyclen-i)<slen){
res[index++] = s[j+cyclen-i];
}
}
}
res[slen] = '\0';
return res;
}
int main(){
char s[] = "PAYPALISHIRING";
printf("%s",convert(s,4));
}
```
## Day3
### 7 整数反转
太菜了,这个题目自己做的实在没法看
```C
//网站排行第一的算法,哈哈贼恐怖吧,溢出检查
int reverse(int x) {
int y=0;
while(x)
{
int temp=y;
y=y*10+x%10; //先计算结果,不管溢出与否
if((y-x%10)/10!=temp) //使用结果反推,若溢出,则不会与之前相等,话说会不会有巧合。哈哈
{
return 0;
}
x/=10;
}
return y;
}
```
```C
//官方给出的答案,写的比较详细,严格的溢出检查
//这里 INT_MAX 和 INT_MIN在 "limit.h"的头文件里
int reverse(int x) {
int rev = 0;
while (x != 0) {
int pop = x % 10;
x /= 10;
if (rev > INT_MAX/10 || (rev == INT_MAX / 10 && pop > 7)) return 0;
if (rev < INT_MIN/10 || (rev == INT_MIN / 10 && pop < -8)) return 0;
rev = rev * 10 + pop;
}
return rev;
}
```
### int 整型
int 占4个字节,一共32位
最大正整数 0111 1111 1111 1111 1111 1111 1111 1111
最小负整数 1000 0000 0000 0000 0000 0000 0000 0000
负数以补码形式保存,例如:
-1 表示为 1111 1111 1111 1111 1111 1111 1111 1111
即除了第一位符号位,其余全部取反,再 +1
### 929 独特的电子邮件地址
```C
//问题描述
每封电子邮件都由一个本地名称和一个域名组成,以 @ 符号分隔。
例如,在 alice@leetcode.com中, alice 是本地名称,而 leetcode.com 是域名。
除了小写字母,这些电子邮件还可能包含 ',' 或 '+'。
如果在电子邮件地址的本地名称部分中的某些字符之间添加句点('.'),则发往那里的邮件将会转发到本地名称中没有点的同一地址。例如,"alice.z@leetcode.com” 和 “alicez@leetcode.com” 会转发到同一电子邮件地址。 (请注意,此规则不适用于域名。)
如果在本地名称中添加加号('+'),则会忽略第一个加号后面的所有内容。这允许过滤某些电子邮件,例如 m.y+name@email.com 将转发到 my@email.com。 (同样,此规则不适用于域名。)
可以同时使用这两个规则。
给定电子邮件列表 emails,我们会向列表中的每个地址发送一封电子邮件。实际收到邮件的不同地址有多少?
输入:["test.email+alex@leetcode.com","test.e.mail+bob.cathy@leetcode.com","testemail+david@lee.tcode.com"]
输出:2
解释:实际收到邮件的是 "testemail@leetcode.com" 和 "testemail@lee.tcode.com"。
```
```C
// 自己写的匹配分类算法,但是速度好慢
int numUniqueEmails(char** emails, int emailsSize) {
char temp[100][100];
char str[100];
int num=0,i,j;
for(i=0;i<emailsSize;i++){
int index=0,flag=0;
for(j=0;j<strlen(emails[i]);j++){
if(emails[i][j]=='+')flag = 1;
if(emails[i][j]=='@')flag = 2;
if(flag==0){
if(emails[i][j]!='.')
str[index++] = emails[i][j];
else
continue;
}else if(flag==1){
continue;
}else{
str[index++] = emails[i][j];
}
str[index] = '\0';
}
//printf("%s \n",str);
for(j=0;j<num;j++){
if(strcmp(temp[j],str) == 0)break;
}
if(j==num){
strcpy(temp[num++],str);
}
}
return num;
}
int main(){
char **a = (char**)malloc(sizeof(char*)*10);
a[0] = "test.email+alex@leetcode.com";
a[1] = "test.e.mail+bob.cathy@leetcode.com";
a[2] = "testemail+david@lee.tcode.com";
int res =numUniqueEmails(a,3);
printf("%d",res);
}
```
### 771 宝石与石头
```C
给定字符串J 代表石头中宝石的类型,和字符串 S代表你拥有的石头。 S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
J 中的字母不重复,J 和 S中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
输入: J = "aA", S = "aAAbbbb"
输出: 3
```
```C
//第一次提交超过100%,哈哈虽然很简单
int numJewelsInStones(char* J, char* S) {
int count = 0,i,j;
int jlen = strlen(J);
int slen = strlen(S);
for(i=0;i<slen;i++){
for(j=0;j<jlen;j++){
if(S[i] == J[j]) {count++;break;}
}
}
return count;
}
```
### 709. 转换成小写字母
ASCII码
A -- 65
Z -- 90
大小写相差 32
a -- 97
z -- 122
### c语言使用静态变量的方法
```C
returnTypr functionA(int *constant,XXX){
}
int mian(){
int *constant = (int *)malloc(sizeof(int));
function(constant,XXX) ;
free(constant);
}
```
## Day4
### 8. 字符串转整数 (atoi)
```C
实现 atoi,将字符串转为整数。
该函数首先根据需要丢弃任意多的空格字符,直到找到第一个非空格字符为止。如果第一个非空字符是正号或负号,选取该符号,并将其与后面尽可能多的连续的数字组合起来,这部分字符即为整数的值。如果第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
字符串可以在形成整数的字符后面包括多余的字符,这些字符可以被忽略,它们对于函数没有影响。
当字符串中的第一个非空字符序列不是个有效的整数;或字符串为空;或字符串仅包含空白字符时,则不进行转换。
若函数不能执行有效的转换,返回 0。
说明:
假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−231, 231 − 1]。如果数值超过可表示的范围,则返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
示例 1:
输入: "42"
输出: 42
示例 2:
输入: " -42"
输出: -42
解释: 第一个非空白字符为 '-', 它是一个负号。
我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。
示例 3:
输入: "4193 with words"
输出: 4193
解释: 转换截止于数字 '3' ,因为它的下一个字符不为数字。
示例 4:
输入: "words and 987"
输出: 0
解释: 第一个非空字符是 'w', 但它不是数字或正、负号。
因此无法执行有效的转换。
示例 5:
输入: "-91283472332"
输出: -2147483648
解释: 数字 "-91283472332" 超过 32 位有符号整数范围。
因此返回 INT_MIN (−231)
```
```C
//我就想知道写出这么精简的代码的人是有多牛逼
#define isdigit(n) (n)<='9'&&(n)>='0'
int myAtoi(char* str) {
int sign,i,n;
for(i=0;str[i]==' ';i++);
sign=(str[i]=='-'?-1:1);
if(str[i]=='+'||str[i]=='-')
i++;
for(n=0;str[i]&&isdigit(str[i]);i++)
{
if(n>INT_MAX/10||(n==INT_MAX/10&&str[i]-'0'>7))
{
if(sign==1)
return INT_MAX;
else
return INT_MIN;
}
n=n*10+str[i]-'0';
}
return sign*n;
}
```
```C
//我自己写的代码,又臭又长
int myAtoi(char* str) {
int i = 0,flag=0,num =0,res=0,lol;
char temp[500];
int len = strlen(str);
for (i =0;i<len;i++){
if(flag == 0){
if(str[i] == ' ')continue;
else if((str[i]<'0' || str[i]>'9') &&str[i] !='-' &&str[i] != '+' ) return 0; //第一次遇见时非数字, 非正负号
else{
flag = 1;
temp[num++] = str[i];
}
}else if(flag ==1){
if(str[i]>='0'&&str[i]<='9') temp[num++] = str[i];
else{
flag =2;
}
}else{
break;
}
}
printf(" : %s %d\n",temp,num);
if(temp[0] == '-'){
for(i = 1;i<num;i++){
lol = res;
//printf("%d\n",res);
int k = (temp[i]-'0');
res = res*10 + k ;
if((res-k)/10!=lol ||res<0){
return INT_MIN;
}
}
res = res*-1;
}else{
if(temp[0] == '+'){
for(i = 1;i<num;i++){
lol = res;
//printf("%d\n",res);
int k = (temp[i]-'0');
res = res*10 + k ;
if((res-k)/10!=lol){
return INT_MAX;
}
}
}else{
for(i = 0;i<num;i++){
lol = res;
//printf("b %d ",res);
int k = (temp[i]-'0');
res = res*10 + k ;
//printf("n %d ",res);
//printf("a %d \n",(res-k)/10);
if((res-k)/10!=lol || res ==INT_MIN){
//printf("%d ---\n",res);
return INT_MAX;
}
}
}
}
return res;
}
```
### 最长山脉
```C
//别人的速度咋这么快
int longestMountain(int* A, int ASize) {
int max = 0;
int now = 0;
int j;
int state = 0;
int i = 0;
while(i<ASize){
j = i;
state = 0;
while(j+1 < ASize){
if(A[j]<A[j+1]){
j++;
state = 1;
}
else{
break;
}
}
if(A[j] == A[j+1]){
i = j + 1;
now = 0;
}
while(j+1 < ASize){
if(A[j]>A[j+1] && state != 0){
j++;
state = -1;
}
else{
break;
}
}
switch(state)
{
case 1:i=j;break;
case 0:i=j+1;break;
case -1:
now = j - i +1;
if(now > max){
max = now;
}
i = j;
break;
}
}
return max;
}
```
```C
//最长山脉
```
### 正则表达式匹配
自己没写出来,下面的两个代码都是抄袭别人的
```C
//我很想知道 4ms是咋来的哟
//执行用时为 4 ms 的范例
typedef struct{
char p;
char s;
}data;
bool isMatch(char* s, char* p) {
int lp = strlen(p), ls = strlen(s), e = 0, i, j;
data *cp = malloc(sizeof(data) * lp);
for (i = 0; i < lp; ++i){
if (p[i] == '*'){
cp[e-1].s = 1;
}else{
cp[e].p = p[i];
cp[e].s = 0;
e++;
}
}
int *dp = malloc(sizeof(int) * (ls + 1) * (e + 1));
memset(dp, 0, sizeof(int) * (ls + 1) * (e + 1));
dp[0] = 1;
for (i = 0; i < ls; ++i){
for (j = 0; j < e; ++j){
if (dp[i * (e+1) + j]){
if (cp[j].p == '.'){
if (cp[j].s == 0){
dp[(i+1) * (e+1) + (j+1)] = 1;
}else{
int k;
for (k = i; k <= ls; ++k){
dp[k * (e+1) + (j+1)] = 1;
}
}
}else{
if (cp[j].s == 0){
if (cp[j].p == s[i]){
dp[(i+1) * (e+1) + (j+1)] = 1;
}
}else{
int k;
dp[i * (e+1) + (j+1)] = 1;
for (k = i; cp[j].p == s[k] && k < ls; ++k){
dp[(k+1) * (e+1) + (j+1)] = 1;
}
}
}
}
}
}
for (j = 0; j < e; ++j){
if (dp[ls * (e+1) + j] && cp[j].s == 1){
dp[ls * (e+1) + (j+1)] = 1;
}
}
int res = dp[ls * (e+1) + e];
free(dp);
free(cp);
return res;
}
```
```C
//8ms
bool helper(char* s, char* p, int i, int j, int sl, int pl, bool** mark) {
if(i == sl && j == pl) return true; // Exhaust both at the same time
if(i > sl || j >= pl) return false; // return false if i and j reach corresponding lengths
// except when i == sl and j < pl
if(mark[i][j]) return false; // Do not want to do repeating job
mark[i][j] = true;
if(j < pl - 1 && p[j + 1] == '*') {
if(s[i] == p[j] || p[j] == '.') { // If p[j] works for s[i]
return helper(s, p, i, j + 2, sl, pl, mark) // Ignore the star
|| helper(s, p, i + 1, j, sl, pl, mark) // Continue hanging out with the star
|| helper(s, p, i + 1, j + 2, sl, pl, mark); // p[j] and p[j+1] works like a '.'
}
return helper(s, p, i, j + 2, sl, pl, mark); // If p[j] does not work, ignore the star
}
if(s[i] == p[j] || p[j] == '.') return helper(s, p, i + 1, j + 1, sl, pl, mark); // If p[j] works, proceed
return false;
}
bool isMatch(char* s, char* p) {
int sl = strlen(s);
int pl = strlen(p);
// 2D list to keep track of the pairs of indices that have been visited
bool** mark = calloc(sl + 1, sizeof(bool*));
for(int i = 0; i < sl + 1; i++) {
mark[i] = calloc(pl + 1, sizeof(bool));
for(int j = 0; j < pl + 1; j++) {
mark[i][j] = false;
}
}
bool res = helper(s, p, 0, 0, sl, pl, mark);
// Free stuff
for(int i = 0; i < sl + 1; i++) {
free(mark[i]);
}
free(mark);
return res;
}
```
```C
#include<stdio.h>
#include<math.h>
#include<limits.h>
#include<string.h>
#include<malloc.h>
#include<stdbool.h>
bool isMatch(char *s, char *p) {
//printf("S:%s\n",s);
//printf("P:%s\n",p);
//printf("%d\n",strlen(p));
if (strlen(p)==0) return strlen(s)==0 ? true:false;
if (strlen(p) == 1) {
return (strlen(s) == 1 && (s[0] == p[0] || p[0] == '.'));
}
if (p[1] != '*') {
if (strlen(s)==0) return false;
return (s[0] == p[0] || p[0] == '.') && isMatch(s+1, p+1);
}
while (strlen(s)!=0 && (s[0] == p[0] || p[0] == '.')) {
if (isMatch(s, p+2)) return true;
s = s +1;
}
//printf("S1:%s\n",s);
//printf("P1:%s\n",p+2);
return isMatch(s, p+2);
}
int main(){
char s[] = "ssb";
char p[] = "s*b";
printf("%d",isMatch(s,p));
}
```
## Day5
### 三数之和(遍历所有满足条件的三元组)
```C
//大神的代码
int cmpfunc (const void * a, const void * b)
{
return ( *(int*)a - *(int*)b );
}
int** threeSum(int* nums, int numsSize, int* returnSize) {
int count = 0;
int **buffer;
int *postive;
int third=0;
buffer = (int **)calloc( numsSize*numsSize-1*numsSize-2,sizeof(int *));
qsort(nums, numsSize, sizeof(int), cmpfunc);
postive = calloc(nums[numsSize-1]+1, sizeof(int));
for(int i = numsSize-1; nums[i]>=0 && i>=0 ;i--)
postive[nums[i]]++;
for(int i=0; nums[i]<=0; i++){
if(i>=1 && nums[i]==nums[i-1])
continue;
for(int j=i+1; j< numsSize-1; j++){
if(j>i+1 && nums[j]==nums[j-1])
continue;
if(nums[i]+nums[j]>0)
break;
third = -1*(nums[i]+nums[j]);
if(nums[numsSize-1]>= third && ((postive[third] >=1 && third > nums[j] )
|| (third == nums[j] && third !=nums[i] && postive[third] >1)
|| (third == nums[j] && third ==nums[i] && postive[third] >2))){
buffer[count] = calloc(3, sizeof(int));
buffer[count][0]=nums[i];
buffer[count][1]=nums[j];
buffer[count][2]= -1*(nums[i]+nums[j]);
count++;
}
}
}
*returnSize=count;
return buffer;
}
```
```C
//自己写的,感觉自己考虑问题一点都不完整哦
#include<stdio.h>
#include<math.h>
#include<limits.h>
#include<string.h>
#include<malloc.h>
#include<stdbool.h>
int** threeSum(int* nums, int numsSize, int* returnSize) {
int i,j,p,q,temp,flag = 1,num=0;
//int
*returnSize = 0;
int size = (numsSize*(numsSize-1)*(numsSize-2)/6);
//printf("%d",size);
int **res = (int **)malloc(sizeof(int *) *size);
if (numsSize<3) {
*returnSize = 0;
return res;
}
for(i = 0; i < numsSize; i++){
if (flag == 1) {
flag = 0;
for( j = numsSize-1; j > i; j--)
{
if (nums[j]<nums[j-1]) {
temp = nums[j];
nums[j] = nums[j - 1];
nums[j - 1] = temp;
flag = 1;
}
}
}
else
{
break;
}
}
for(i = 0; i < numsSize; i++){
printf("%d ", nums[i]);
}
//nums sorted
for(i = 0; i < numsSize; i++)
{
if(nums[i]>0)break;
if(i>0&&nums[i]==nums[i-1])continue;
p = i+1;
q = numsSize - 1;
while(p<q){
temp = nums[p] + nums[q] + nums[i];
printf("\n%d %d %d\n",nums[i] ,nums[p] , nums[q]);
if(temp==0) {
printf("**");
res[num] = (int *)malloc(sizeof(int) * 3);
res[num][0] = nums[i];
res[num][1] = nums[p];
res[num][2] = nums[q];
num++;
p++;
q--;
while(p<q&&nums[p]==nums[p-1])p++;
while(p<q&&nums[q]==nums[q+1])q--;
}else if (temp < 0){
p++;
}else
{
q--;
}
}
//printf("\n%d", *returnSize);
}
*returnSize = num;
printf("\n%d", *returnSize);
return res;
}
int main(int argc, char const *argv[])
{
qsort();
int nums[] = {-1, 0, 1, 2, -1, -4};
qsort();
int returnSize;
int **name = threeSum(nums, 6, &returnSize);
printf("\n@%d\n", returnSize);
int j =0;
for(j=0;j<returnSize;j++){
printf("%d %d %d\n",name[j][0],name[j][1],name[j][2]);
}
//施放name的学问是,先把name[i]施放
int i;
for (i = 0; i < returnSize;i++){
free(name[i]);
}
free(name);
//再施放name
return 0;
}
```
### 最接近的三数之和
暴力一时爽,耗时火葬厂!
```C
//别人 4ms的答案,其实大致思路和上一题差不多,
void swap(int *n1,int *n2){
int temp=*n1;
*n1=*n2;
*n2=temp;
}
void sort(int *nums,int start,int end){
int left=start+1,right=end;
if(left>right){
return;
}
while(left<right){
if(nums[left]<=nums[start]){
left++;
}else if(nums[right]>nums[start]){
right--;
}else{
swap(&nums[left],&nums[right]);
left++;
right--;
}
}
if(nums[start]<nums[left]){
left--;
}
swap(&nums[start],&nums[left]);
sort(nums,start,left-1);
sort(nums,left+1,end);
}
int threeSumClosest(int* nums, int numsSize, int target) {
//init
int i,j,start,end,closest,threeSum,diff;
closest=nums[0]+nums[1]+nums[2];
//sort
sort(nums,0,numsSize-1);
//find cloest
for(i=0;i<numsSize-2;i++){
start=i+1;
end=numsSize-1;
while(start<end){
threeSum=nums[start]+nums[end]+nums[i];
diff=threeSum-target;
if(diff==0){
return target;
}else if(diff<0){
if(abs(diff)<abs(closest-target)){
closest=threeSum;
}
start++;
while(nums[start]==nums[start-1]&&start<end){
start++;
}
}else{
if(abs(diff)<abs(closest-target)){
closest=threeSum;
}
end--;
while(nums[end]==nums[end+1]&&start<end){
end--;
}
}
}
}
return closest;
}
```
## Day6
### 括号的合法性
自己写的其实还可以,但是还是很喜欢神一样简单的代码,觉得自己还可以做到更好
```C
//喜欢简单的代码,话说运行速度是 0ms就神奇了
static bool isValid(char *s)
{
int n = 0, cap = 100;
char *stack = malloc(cap);
while (*s != '\0') {
switch(*s) {
case '(':
case '[':
case '{':
if (n + 1 >= cap) {
cap *= 2;
stack = realloc(stack, cap);
}
stack[n++] = *s;
break;
case ')':
if (stack[--n] != '(') return false;
break;
case ']':
if (stack[--n] != '[') return false;
break;
case '}':
if (stack[--n] != '{') return false;
break;
default:
return false;
}
s++;
}
return n == 0;
}
```
### 归并两个有序单链表
有时候搞不清楚自己的脑回路,其实很简单,写出来那么复杂
```C
//看看别人的代码吧
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2) {
if (l1 == NULL) {
return l2;
}
if (l2 == NULL) {
return l1;
}
struct ListNode *head;
if (l1->val <= l2->val) {
head = l1;
head->next = mergeTwoLists(l1->next, l2);
}
if (l1->val > l2->val) {
head = l2;
head->next = mergeTwoLists(l1, l2->next);
}
return head;
}
```
### 合法的括号组合
```C
//神仙打架,我服了。我脑子快炸了也写不出 0ms的执行
/**
* Return an array of size *returnSize.
* Note: The returned array must be malloced, assume caller calls free().
*/
char** generateParenthesis(int n, int* returnSize) {
int resultnum=0;
int window=0;
char* tempbuf=(char*)malloc(sizeof(char)*(int)pow(2,2*n-1));
char* buf=(char*)malloc(sizeof(char)*2*n);
buf[0]='(';
getoneresult(n-1,1,1,buf,tempbuf,&resultnum);
//printf("resultnum=%d\n",resultnum);
char** result=(char**)malloc(sizeof(char*)*resultnum);
for(int i=0;i<resultnum;i++)
{
result[i]=(char*)malloc(sizeof(char)*(2*n+1));
memcpy(result[i],tempbuf+i*2*n,sizeof(char)*2*n);
result[i][2*n]='\0';
/*for(int j=0;j<2*n;j++)
{
printf("%c",result[i][j]);
}
printf("\n");*/
}
free(tempbuf);
*returnSize=resultnum;
return result;
}
//每一次放置分两种情况考虑,加一个前括号或者加一个后括号,加入窗口进行限制即可
void getoneresult(int n,int window,int bufnum,char* buf,char* tempbuf,int* resultnum)
{
//printf("n=%d,window=%d,bufnum=%d,resultnum=%d\n",n,window,bufnum,*resultnum);
if(n==0 && window==0)//此时已经全部放置完毕
{
memcpy(tempbuf+bufnum*(*resultnum),buf,sizeof(char)*bufnum);
(*resultnum)++;
}
else if(window==0)
{
buf[bufnum]='(';
getoneresult(n-1,1,bufnum+1,buf,tempbuf,resultnum);
}
else if(n==0)
{
buf[bufnum]=')';
getoneresult(n,window-1,bufnum+1,buf,tempbuf,resultnum);
}
else
{
buf[bufnum]='(';
getoneresult(n-1,window+1,bufnum+1,buf,tempbuf,resultnum);
buf[bufnum]=')';
getoneresult(n,window-1,bufnum+1,buf,tempbuf,resultnum);
}
}
```
```C
#include<stdio.h>
#include<math.h>
#include<limits.h>
#include<string.h>
#include<stdlib.h>
#include<stdbool.h>
void addElem(char **res,char *temp,int index,int *total,int len,int open,int close){
if(index == len){
res[*total] = (char *)malloc(sizeof(char) * (len + 1));
int i;
for( i= 0; i < len; i++)
{
res[*total][i] = temp[i];
}
res[*total][i] = '\0';
*total = *total + 1;
// if ((*total)>= size) {
// printf("@@@%d",size);
// size = size + 200;
// res = (char**)realloc(res, (size)*sizeof(char*));
// }
}else{
if (open<len/2) {
temp[index] = '(';
addElem(res, temp, index + 1, total, len, open + 1, close);
}
if(close<open){
temp[index] = ')';
addElem(res, temp, index + 1, total, len, open, close + 1);
}
}
}
char** generateParenthesis(int n, int* returnSize) {
char temp[2 * n + 1];
temp[0] = '(';
int open = 1;
int close = 0;
int index = 1;
int size=1,i;
for(i=0;i<n;i++){
size = size*(i+1);
}
char **res = (char **)malloc(sizeof(char *)*size);
int total = 0;
addElem(res, temp, index, &total,n*2,open,close);
* returnSize = total;
return res;
}
int main(int argc, char const *argv[])
{
int returnSize;
char **r = generateParenthesis(10,&returnSize);
int i;
printf("%d\n",returnSize);
for(i=0;i<returnSize;i++){
printf("%s\n",r[i]);
free(r[i]);
}
free(r);
return 0;
}
```
### 合并K个有序单链表
```C
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeLists(struct ListNode* listLeft, struct ListNode* listRight)
{
if((listLeft==NULL) && (listRight==NULL))
return NULL;
if(listLeft == NULL)
return listRight;
if(listRight == NULL)
return listLeft;
struct ListNode* pHead = (struct ListNode*)(malloc(sizeof(struct ListNode)));
struct ListNode* pNode = pHead;
while(listLeft && listRight)
{
if(listLeft->val < listRight->val)
{
pNode->next = listLeft;
listLeft = listLeft->next;
}
else
{
pNode->next = listRight;
listRight = listRight->next;
}
pNode = pNode->next;
}
if (listLeft)
pNode->next = listLeft;
if (listRight)
pNode->next = listRight;
return pHead->next;
}
struct ListNode* mergeKLists(struct ListNode** lists, int listsSize) {
if((lists==NULL) || (listsSize==0))
return NULL;
else if(listsSize == 1)
return lists[0];
int mid = listsSize / 2;
struct ListNode** l1 = lists;
struct ListNode** l2 = &lists[mid];
struct ListNode* ListHeadLeft = mergeKLists(l1, mid);
struct ListNode* ListHeadRight = mergeKLists(l2, listsSize-mid);
struct ListNode* ListResult = mergeLists(ListHeadLeft, ListHeadRight);
return ListResult;
}
```
## Day7
### 数组中是否有重复元素
```C
//哈希
typedef struct Node {
int val;
struct Node *next;
} Node;
typedef struct Hashtable {
Node **data;
int size;
}Hashtable;
Node *init_node (Node *head, int val) {
Node *p = (Node *)malloc(sizeof(Node));
p->val = val;
p->next = head;
return p;
}
Hashtable *init_hashtable (int n) {
Hashtable *h = (Hashtable *)malloc(sizeof(Hashtable));
h->size = n << 1;
h->data = (Node **)calloc (sizeof(Node *), h->size);
return h;
}
int insert_hashtable (Hashtable *h, int val) {
int ind = fabs(val % h->size);
if (h->data[ind] == NULL) {
h->data[ind] = init_node(h->data[ind], val);
} else {
while (h->data[ind]->next != NULL){
if (h->data[ind]->val == val) return 0;
else {
h->data[ind] = h->data[ind]->next;
}
}
if (h->data[ind]->val == val) return 0;
h->data[ind]->next = init_node(h->data[ind]->next, val);
}
return 1;
}
bool containsDuplicate (int *nums, int numsSize) {
Hashtable *h = init_hashtable(numsSize);
for (int i = 0; i < numsSize; i++) {
if (insert_hashtable(h, nums[i]) == 0) return true;
else continue;
}
return false;
}
```
### 螺旋矩阵
```C
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* spiralOrder(int** matrix, int matrixRowSize, int matrixColSize) {
int length = matrixRowSize*matrixColSize;
int *result = (int *)malloc(sizeof(int)*length);
char *visited = (char *)calloc(length,sizeof(char));//store visited element
int index = 0;
int row=0,col=-1;
while(1){
if(index == length)
break;
for(col=col+1;col<matrixColSize;col++){
if(visited[row*matrixColSize+col] == 1)
break;
result[index++]=matrix[row][col];
visited[row*matrixColSize+col] = 1;
}
col--;
for(row = row+1;row<matrixRowSize;row++){
if(visited[row*matrixColSize+col] == 1)
break;
result[index++] = matrix[row][col];
visited[row*matrixColSize+col] = 1;
}
row--;
for(col = col-1;col>=0;col--){
if(visited[row*matrixColSize+col] == 1)
break;
result[index++] = matrix[row][col];
visited[row*matrixColSize+col] = 1;
}
col++;
for(row = row-1;row>=0;row--){
if(visited[row*matrixColSize+col] == 1)
break;
result[index++] = matrix[row][col];
visited[row*matrixColSize+col] = 1;
}
row++;
}
return result;
}
```
## Day8
### 合并两个有序数组
```C
//版本1
void merge(int* nums1, int m, int* nums2, int n) {
int l = m + n;
n--;m--;
l--;
int i = m, j = n;
while(m >= 0 && n >= 0){
if(nums1[m] > nums2[n]){
nums1[l--] = nums1[m--];
}
else
nums1[l--] = nums2[n--];
}
while(m >= 0){
nums1[l--] = nums1[m--];
}
while(n >= 0){
nums1[l--] = nums2[n--];
}
}
```
```C
//版本二
void merge(int* nums1, int m, int* nums2, int n) {
int l = m + n;
n--;m--;
l--;
int i = m, j = n;
while(m >= 0 && n >= 0){
if(nums1[m] > nums2[n]){
nums1[l--] = nums1[m--];
}
else
nums1[l--] = nums2[n--];
}
//while(m >= 0){
// nums1[l--] = nums1[m--];
// }//why delete here because nums1 in nums1 inner
while(n >= 0){
nums1[l--] = nums2[n--];
}
}
```
```C
//版本三
void merge(int* nums1, int m, int* nums2, int n) {
int index = m + n - 1;
int i = m - 1;
int j = n - 1;
while (j >= 0){
if (i < 0) nums1[index--] = nums2[j--];
else nums1[index--] = nums1[i] > nums2[j] ? nums1[i--] : nums2[j--];
}
}
```
### 反转单链表
```C
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* p=head;
struct ListNode* New=NULL; //定义一个新链头
if(head==NULL||head->next==NULL)
{
return head; //如果只有一个结点或者为空,则返回head
}
while(p!=NULL) //一直迭代到链尾
{
struct ListNode*temp; //定义一个临时存放批p->next后后面的值得指针变量
temp=p->next; //temp存放p->next的地址
p->next=New; //将p指向New
New=p;
p=temp;
}
return New;
}
```
## Day9
### 判断单链表有无环
```C
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
if(head == NULL)
return false;
struct ListNode* p = head->next;
struct ListNode* q = head->next;
while(p != NULL && q != NULL){
p = p->next;
if(q->next != NULL){
q = q->next->next;
if(p == q)
return true;
}
else
return false;
}
return false;
}
```
## Day10
### 第k大的数
```C
typedef struct a{
int data;
struct a * left;
struct a * right;
}tree;
tree *insert(tree *t,int val)
{
if(t)
{
if(t->data<val)
{
t->left=insert(t->left,val);
}
else
{
t->right=insert(t->right,val);
}
return t;
}
else
{
tree * t1=(tree *)malloc(sizeof(tree));
t1->data=val;
t1->left=NULL;
t1->right=NULL;
return t1;
}
}
void search(tree * t,int *k,int * num,int * mark)
{
if(*mark)
return;
if(t)
{
search(t->left,k,num,mark);
// printf("%d ",t->data);
if(*k==1)
{
*num=t->data;
*mark=1;
(*k)--;
}
else
{
(*k)--;
}
search(t->right,k,num,mark);
}
//printf("?");
}
int com(const void *p1,const void * p2)
{
return *(int *)p2-*(int *)p1;
}
void insert1(int *m,int n,int count)
{
int i;
for(i=count;i-1>=0&&m[(i-1)/2]<n;i=(i-1)/2)
{
m[i]=m[(i-1)/2];
}
m[i]=n;
}
int pop(int *m,int n)
{
int a=m[0];
m[0]=m[n];
int x,i=0,swap;
while(1)
{
if(i*2+2>n)
break;
if(m[i*2+1]>m[i*2+2])
{
x=i*2+1;
}
else
{
x=i*2+2;
}
if(m[x]>m[i])
{
swap=m[x];
m[x]=m[i];
m[i]=swap;
}
else
{
break;
}
i=x;
}
return a;
}
void heapsort(int *a,int n)
{
int i,x=1;
for(i=1;i<n;i++)
{
insert1(a,a[i],x++);
}
for(i=n-1;i>=0;i--)
{
a[i]=pop(a,i);
}
}
int findKthLargest(int* nums, int numsSize, int k) {
int i;
heapsort(nums,numsSize);
return nums[numsSize-k];
}
``` | 34,102 | Apache-2.0 |
---
layout: ../../layouts/content.astro
title: "Web Workers"
tags: communityGuide
published: true
description: How to use Web Workers in your Snowpack project.
---
[Web Workers](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers)是网页内容在后台线程中运行脚本的一种简单手段。
**要在 Snowpack 中使用 Web Worker**。直接使用浏览器的本地[Web Worker API](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers#Web_Workers_API)。
```js
// Example: Load a Web Worker in your project
const myWorker = new Worker(new URL("./worker.js", import.meta.url));
```
建议向 Worker 构造函数传递一个`URL`(而不是一个字符串字面),但不是必须的。使用字符串字面意义(例如:`new Worker('./worker.js')`)可能会在你为生产构建网站时妨碍一些优化。
还要注意的是,传递给`Worker`的 URL 必须与最终的 URL 相匹配,这可能与磁盘上的路径不同。例如,即使磁盘上的原始文件是`worker.ts`,`./worker.js`仍会被使用。如果需要,这里也应使用`挂载`目的地。
### ESM Web Worker 支持
**Web Worker 中的 ESM 语法(`导入`/`导出`**)仍未在所有现代浏览器中得到支持。Snowpack v3.0.0 和 Snowpack Webpack v5 插件一旦发布都将支持自动打包。在此之前,你需要编写独立的、单文件的 Web Worker(没有 ESM`导入`/`导出`语句)或自己预先打包你的 Web Worker。
```js
const worker = new Worker(new URL("./esm-worker.js", import.meta.url), {
name: "my-worker",
type: "module",
});
```
<!--
TO REPLACE THE PREVIOUS PARAGRAPH ON v3.0.0 LAUNCH DAY:
Modern browsers have begun to support ESM syntax (`import`/`export`) inside of Web Workers. However, some notable exceptions still exist. To use ESM syntax inside of a web worker, consult [caniuse.com](https://caniuse.com/mdn-api_worker_worker_ecmascript_modules) and choose a supported browser for your local development. When you build for production, choose a bundler that will bundle your Web Worker to remove ESM import/export syntax. Currently, Snowpack's builtin bundler and @snowpack/plugin-webpack both support automatic Web Worker bundling to remove ESM syntax from web workers.
```js
const worker = new Worker(
new URL('./esm-worker.js', import.meta.url),
{
name: 'my-worker',
type: import.meta.env.MODE === 'development' ? "module" : "classic"
}
);
```
--> | 1,972 | MIT |
---
assignees:
- davidopp
- thockin
title: DNS Pod 与 Service
redirect_from:
- "/docs/admin/dns/"
- "/docs/admin/dns.html"
---
<!--
## Introduction
As of Kubernetes 1.3, DNS is a built-in service launched automatically using the addon manager [cluster add-on](http://releases.k8s.io/{{page.githubbranch}}/cluster/addons/README.md).
Kubernetes DNS schedules a DNS Pod and Service on the cluster, and configures
the kubelets to tell individual containers to use the DNS Service's IP to
resolve DNS names.
-->
## 介绍
Kubernetes 从 1.3 版本起, DNS 是内置的服务,通过插件管理器 [集群插件](http://releases.k8s.io/{{page.githubbranch}}/cluster/addons/README.md) 自动被启动。
Kubernetes DNS 在集群中调度 DNS Pod 和 Service ,配置 kubelet 以通知个别容器使用 DNS Service 的 IP 解析 DNS 名字。
<!--
## What things get DNS names?
Every Service defined in the cluster (including the DNS server itself) is
assigned a DNS name. By default, a client Pod's DNS search list will
include the Pod's own namespace and the cluster's default domain. This is best
illustrated by example:
Assume a Service named `foo` in the Kubernetes namespace `bar`. A Pod running
in namespace `bar` can look up this service by simply doing a DNS query for
`foo`. A Pod running in namespace `quux` can look up this service by doing a
DNS query for `foo.bar`.
-->
## 怎样获取 DNS 名字?
在集群中定义的每个 Service(包括 DNS 服务器自身)都会被指派一个 DNS 名称。默认,一个客户端 Pod 的 DNS 搜索列表将包含该 Pod 自己的 Namespace 和集群默认域。可以通过如下示例进行说明:
假设在 Kubernetes 集群的 Namespace `bar` 中,定义了一个Service `foo`。运行在Namespace `bar` 中的一个 Pod,可以简单地通过 DNS 查询 `foo` 来找到该 Service。运行在 Namespace `quux` 中的一个 Pod 可以通过 DNS 查询 `foo.bar` 找到该 Service。
<!--
## Supported DNS schema
The following sections detail the supported record types and layout that is
supported. Any other layout or names or queries that happen to work are
considered implementation details and are subject to change without warning.
-->
## 支持的 DNS 模式
下面各段详细说明支持的记录类型和布局。如果任何其它的布局、名称或查询,碰巧也能够使用,这就需要研究下它们的实现细节,以免后续修改它们又不能使用了。
<!--
### Services
#### A records
"Normal" (not headless) Services are assigned a DNS A record for a name of the
form `my-svc.my-namespace.svc.cluster.local`. This resolves to the cluster IP
of the Service.
"Headless" (without a cluster IP) Services are also assigned a DNS A record for
a name of the form `my-svc.my-namespace.svc.cluster.local`. Unlike normal
Services, this resolves to the set of IPs of the pods selected by the Service.
Clients are expected to consume the set or else use standard round-robin
selection from the set.
-->
### Service
#### A 记录
“正常” Service(除了Headless Service)会以 `my-svc.my-namespace.svc.cluster.local` 这种名字的形式被指派一个 DNS A 记录。这会解析成该 Service 的 Cluster IP。
“Headless” Service(没有Cluster IP)也会以 `my-svc.my-namespace.svc.cluster.local` 这种名字的形式被指派一个 DNS A 记录。不像正常 Service,它会解析成该 Service 选择的一组 Pod 的 IP。希望客户端能够使用这一组 IP,否则就使用标准的 round-robin 策略从这一组 IP 中进行选择。
<!--
#### SRV records
SRV Records are created for named ports that are part of normal or [Headless
Services](/docs/concepts/services-networking/service/#headless-services).
For each named port, the SRV record would have the form
`_my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster.local`.
For a regular service, this resolves to the port number and the CNAME:
`my-svc.my-namespace.svc.cluster.local`.
For a headless service, this resolves to multiple answers, one for each pod
that is backing the service, and contains the port number and a CNAME of the pod
of the form `auto-generated-name.my-svc.my-namespace.svc.cluster.local`.
#### Backwards compatibility
Previous versions of kube-dns made names of the form
`my-svc.my-namespace.cluster.local` (the 'svc' level was added later). This
is no longer supported.
-->
#### SRV 记录
命名端口需要创建 SRV 记录,这些端口是正常 Service或 [Headless
Services](/docs/concepts/services-networking/service/#headless-services) 的一部分。
对每个命名端口,SRV 记录具有 `_my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster.local` 这种形式。
对普通 Service,这会被解析成端口号和 CNAME:`my-svc.my-namespace.svc.cluster.local`。
对 Headless Service,这会被解析成多个结果,Service 对应的每个 backend Pod各一个,包含 `auto-generated-name.my-svc.my-namespace.svc.cluster.local` 这种形式 Pod 的端口号和 CNAME。
#### 后向兼容性
上一版本的 kube-dns 使用 `my-svc.my-namespace.cluster.local` 这种形式的名字(后续会增加 'svc' 这一级),以后这将不再被支持。
<!--
### Pods
#### A Records
When enabled, pods are assigned a DNS A record in the form of `pod-ip-address.my-namespace.pod.cluster.local`.
For example, a pod with IP `1.2.3.4` in the namespace `default` with a DNS name of `cluster.local` would have an entry: `1-2-3-4.default.pod.cluster.local`.
-->
### Pod
#### A 记录
如果启用,Pod 会以 `pod-ip-address.my-namespace.pod.cluster.local` 这种形式被指派一个 DNS A 记录。
例如,`default` Namespace 具有 DNS 名字 `cluster.local`,在该 Namespace 中一个 IP 为 `1.2.3.4` 的 Pod 将具有一个条目:`1-2-3-4.default.pod.cluster.local`。
<!--
#### A Records and hostname based on Pod's hostname and subdomain fields
Currently when a pod is created, its hostname is the Pod's `metadata.name` value.
With v1.2, users can specify a Pod annotation, `pod.beta.kubernetes.io/hostname`, to specify what the Pod's hostname should be.
The Pod annotation, if specified, takes precedence over the Pod's name, to be the hostname of the pod.
For example, given a Pod with annotation `pod.beta.kubernetes.io/hostname: my-pod-name`, the Pod will have its hostname set to "my-pod-name".
-->
#### 基于 Pod hostname、subdomain 字段的 A 记录和主机名
当前,创建 Pod 后,它的主机名是该 Pod 的 `metadata.name` 值。
在 v1.2 版本中,用户可以配置 Pod annotation, 通过 `pod.beta.kubernetes.io/hostname` 来设置 Pod 的主机名。
如果为 Pod 配置了 annotation,会优先使用 Pod 的名称作为主机名。
例如,给定一个 Pod,它具有 annotation `pod.beta.kubernetes.io/hostname: my-pod-name`,该 Pod 的主机名被设置为 “my-pod-name”。
<!--
With v1.3, the PodSpec has a `hostname` field, which can be used to specify the Pod's hostname. This field value takes precedence over the
`pod.beta.kubernetes.io/hostname` annotation value.
v1.2 introduces a beta feature where the user can specify a Pod annotation, `pod.beta.kubernetes.io/subdomain`, to specify the Pod's subdomain.
The final domain will be "<hostname>.<subdomain>.<pod namespace>.svc.<cluster domain>".
For example, a Pod with the hostname annotation set to "foo", and the subdomain annotation set to "bar", in namespace "my-namespace", will have the FQDN "foo.bar.my-namespace.svc.cluster.local"
-->
在 v1.3 版本中,PodSpec 具有 `hostname` 字段,可以用来指定 Pod 的主机名。这个字段的值优先于 annotation `pod.beta.kubernetes.io/hostname`。
在 v1.2 版本中引入了 beta 特性,用户可以为 Pod 指定 annotation,其中 `pod.beta.kubernetes.io/subdomain` 指定了 Pod 的子域名。
最终的域名将是 “<hostname>.<subdomain>.<pod namespace>.svc.<cluster domain>”。
举个例子,Pod 的主机名 annotation 设置为 “foo”,子域名 annotation 设置为 “bar”,在 Namespace “my-namespace” 中对应的 FQDN 为 “foo.bar.my-namespace.svc.cluster.local”。
<!--
With v1.3, the PodSpec has a `subdomain` field, which can be used to specify the Pod's subdomain. This field value takes precedence over the
`pod.beta.kubernetes.io/subdomain` annotation value.
Example:
-->
在 v1.3 版本中,PodSpec 具有 `subdomain` 字段,可以用来指定 Pod 的子域名。这个字段的值优先于 annotation `pod.beta.kubernetes.io/subdomain` 的值。
```yaml
apiVersion: v1
kind: Service
metadata:
name: default-subdomain
spec:
selector:
name: busybox
clusterIP: None
ports:
- name: foo # Actually, no port is needed.
port: 1234
targetPort: 1234
---
apiVersion: v1
kind: Pod
metadata:
name: busybox1
labels:
name: busybox
spec:
hostname: busybox-1
subdomain: default-subdomain
containers:
- image: busybox
command:
- sleep
- "3600"
name: busybox
---
apiVersion: v1
kind: Pod
metadata:
name: busybox2
labels:
name: busybox
spec:
hostname: busybox-2
subdomain: default-subdomain
containers:
- image: busybox
command:
- sleep
- "3600"
name: busybox
```
<!--
If there exists a headless service in the same namespace as the pod and with the same name as the subdomain, the cluster's KubeDNS Server also returns an A record for the Pod's fully qualified hostname.
Given a Pod with the hostname set to "busybox-1" and the subdomain set to "default-subdomain", and a headless Service named "default-subdomain" in the same namespace, the pod will see it's own FQDN as "busybox-1.default-subdomain.my-namespace.svc.cluster.local". DNS serves an A record at that name, pointing to the Pod's IP. Both pods "busybox1" and "busybox2" can have their distinct A records.
-->
如果 Headless Service 与 Pod 在同一个 Namespace 中,它们具有相同的子域名,集群的 KubeDNS 服务器也会为该 Pod 的完整合法主机名返回 A 记录。在同一个 Namespace 中,给定一个主机名为 “busybox-1” 的 Pod,子域名设置为 “default-subdomain”,名称为 “default-subdomain” 的 Headless Service ,Pod 将看到自己的 FQDN 为 “busybox-1.default-subdomain.my-namespace.svc.cluster.local”。DNS 会为那个名字提供一个 A 记录,指向该 Pod 的 IP。“busybox1” 和 “busybox2” 这两个 Pod 分别具有它们自己的 A 记录。
<!--
As of Kubernetes v1.2, the Endpoints object also has the annotation `endpoints.beta.kubernetes.io/hostnames-map`. Its value is the json representation of map[string(IP)][endpoints.HostRecord], for example: '{"10.245.1.6":{HostName: "my-webserver"}}'.
If the Endpoints are for a headless service, an A record is created with the format <hostname>.<service name>.<pod namespace>.svc.<cluster domain>
For the example json, if endpoints are for a headless service named "bar", and one of the endpoints has IP "10.245.1.6", an A record is created with the name "my-webserver.bar.my-namespace.svc.cluster.local" and the A record lookup would return "10.245.1.6".
This endpoints annotation generally does not need to be specified by end-users, but can used by the internal service controller to deliver the aforementioned feature.
-->
在Kubernetes v1.2 版本中,`Endpoints` 对象也具有 annotation `endpoints.beta.kubernetes.io/hostnames-map`。它的值是 map[string(IP)][endpoints.HostRecord] 的 JSON 格式,例如: '{"10.245.1.6":{HostName: "my-webserver"}}'。
如果是 Headless Service 的 `Endpoints`,会以 <hostname>.<service name>.<pod namespace>.svc.<cluster domain> 的格式创建 A 记录。对示例中的 JSON 字符串,如果 `Endpoints` 是为名称为 “bar” 的 Headless Service 而创建的,其中一个 `Endpoints` 的 IP 是 “10.245.1.6”,则会创建一个名称为 “my-webserver.bar.my-namespace.svc.cluster.local” 的 A 记录,该 A 记录查询将返回 “10.245.1.6”。
`Endpoints` annotation 通常没必要由最终用户指定,但可以被内部的 Service Controller 用来提供上述功能。
<!--
With v1.3, The Endpoints object can specify the `hostname` for any endpoint, along with its IP. The hostname field takes precedence over the hostname value
that might have been specified via the `endpoints.beta.kubernetes.io/hostnames-map` annotation.
With v1.3, the following annotations are deprecated: `pod.beta.kubernetes.io/hostname`, `pod.beta.kubernetes.io/subdomain`, `endpoints.beta.kubernetes.io/hostnames-map`
-->
在 v1.3 版本中,`Endpoints` 对象可以为任何 endpoint 指定 `hostname` 和 IP。`hostname` 字段优先于通过 `endpoints.beta.kubernetes.io/hostnames-map` annotation 指定的主机名。
在 v1.3 版本中,下面的 annotation 是过时的:`pod.beta.kubernetes.io/hostname`、`pod.beta.kubernetes.io/subdomain`、`endpoints.beta.kubernetes.io/hostnames-map`。
<!--
## How do I test if it is working?
### Create a simple Pod to use as a test environment
Create a file named busybox.yaml with the
following contents:
-->
## 如何测试它是否可以使用?
### 创建一个简单的 Pod 作为测试环境
创建 `busybox.yaml` 文件,内容如下:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
```
<!--
Then create a pod using this file:
-->
然后,用该文件创建一个 Pod:
```
kubectl create -f busybox.yaml
```
<!--
### Wait for this pod to go into the running state
You can get its status with:
-->
### 等待这个 Pod 变成运行状态
获取它的状态,执行如下命令:
```
kubectl get pods busybox
```
<!--
You should see:
-->
可以看到如下内容:
```
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 <some-time>
```
<!--
### Validate that DNS is working
Once that pod is running, you can exec nslookup in that environment:
-->
### 验证 DNS 已经生效
一旦 Pod 处于运行中状态,可以在测试环境中执行如下 nslookup 查询:
```
kubectl exec -ti busybox -- nslookup kubernetes.default
```
<!--
You should see something like:
-->
可以看到类似如下的内容:
```
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: kubernetes.default
Address 1: 10.0.0.1
```
<!--
If you see that, DNS is working correctly.
### Troubleshooting Tips
If the nslookup command fails, check the following:
#### Check the local DNS configuration first
Take a look inside the resolv.conf file. (See "Inheriting DNS from the node" and "Known issues" below for more information)
-->
如果看到了,说明 DNS 已经可以正确工作了。
### 问题排查技巧
如果执行 nslookup 命令失败,检查如下内容:
#### 先检查本地 DNS 配置
查看配置文件 resolv.conf。(关于更多信息,参考下面的 “从 Node 继承 DNS” 和 “已知问题”。)
```
kubectl exec busybox cat /etc/resolv.conf
```
<!--
Verify that the search path and name server are set up like the following (note that search path may vary for different cloud providers):
-->
按照如下方法(注意搜索路径可能会因为云提供商不同而变化)验证搜索路径和 Name Server 的建立:
```
search default.svc.cluster.local svc.cluster.local cluster.local google.internal c.gce_project_id.internal
nameserver 10.0.0.10
options ndots:5
```
<!--
#### Quick diagnosis
Errors such as the following indicate a problem with the kube-dns add-on or associated Services:
-->
#### 快速诊断
出现类似如下指示的错误,说明 kube-dns 插件或相关 Service 存在问题:
```
$ kubectl exec -ti busybox -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10
nslookup: can't resolve 'kubernetes.default'
```
<!--
or
-->
或者
```
$ kubectl exec -ti busybox -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'kubernetes.default'
```
<!--
#### Check if the DNS pod is running
Use the kubectl get pods command to verify that the DNS pod is running.
-->
#### 检查是否 DNS Pod 正在运行
使用 `kubectl get pods` 命令验证 DNS Pod 正在运行:
```
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
```
<!--
You should see something like:
-->
应该能够看到类似如下信息:
```
NAME READY STATUS RESTARTS AGE
...
kube-dns-v19-ezo1y 3/3 Running 0 1h
...
```
<!--
If you see that no pod is running or that the pod has failed/completed, the DNS add-on may not be deployed by default in your current environment and you will have to deploy it manually.
#### Check for Errors in the DNS pod
Use `kubectl logs` command to see logs for the DNS daemons.
-->
如果看到没有 Pod 运行,或 Pod 失败/结束,DNS 插件不能默认部署到当前的环境,必须手动部署。
#### 检查 DNS Pod 中的错误信息
使用 `kubectl logs` 命令查看 DNS 后台进程的日志:
```
kubectl logs --namespace=kube-system $(kubectl get pods --namespace=kube-system -l k8s-app=kube-dns -o name) -c kubedns
kubectl logs --namespace=kube-system $(kubectl get pods --namespace=kube-system -l k8s-app=kube-dns -o name) -c dnsmasq
kubectl logs --namespace=kube-system $(kubectl get pods --namespace=kube-system -l k8s-app=kube-dns -o name) -c healthz
```
<!--
See if there is any suspicious log. W, E, F letter at the beginning represent Warning, Error and Failure. Please search for entries that have these as the logging level and use [kubernetes issues](https://github.com/kubernetes/kubernetes/issues) to report unexpected errors.
#### Is DNS service up?
Verify that the DNS service is up by using the `kubectl get service` command.
-->
查看是否有任何可疑的日志。在行开头的字母 W、E、F 分别表示 警告、错误、失败。请搜索具有这些日志级别的日志行,通过 [Kubernetes 问题](https://github.com/kubernetes/kubernetes/issues) 报告意外的错误。
#### DNS 服务是否运行?
通过使用 `kubectl get service` 命令,验证 DNS 服务是否运行:
```
kubectl get svc --namespace=kube-system
```
<!--
You should see:
-->
应该能够看到:
```
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
```
<!--
If you have created the service or in the case it should be created by default but it does not appear, see this [debugging services page](/docs/tasks/debug-application-cluster/debug-service/) for more information.
#### Are DNS endpoints exposed?
You can verify that DNS endpoints are exposed by using the `kubectl get endpoints` command.
-->
如果服务已经创建,或在这个例子中默认被创建,但是并没有看到,可以查看 [调试 Service 页面](/docs/tasks/debug-application-cluster/debug-service/) 获取更多信息。
```
kubectl get ep kube-dns --namespace=kube-system
```
<!--
You should see something like:
-->
应该能够看到类似如下信息:
```
NAME ENDPOINTS AGE
kube-dns 10.180.3.17:53,10.180.3.17:53 1h
```
<!--
If you do not see the endpoints, see endpoints section in the [debugging services documentation](/docs/tasks/debug-application-cluster/debug-service/).
For additional Kubernetes DNS examples, see the [cluster-dns examples](https://git.k8s.io/kubernetes/examples/cluster-dns) in the Kubernetes GitHub repository.
## Kubernetes Federation (Multiple Zone support)
Release 1.3 introduced Cluster Federation support for multi-site
Kubernetes installations. This required some minor
(backward-compatible) changes to the way
the Kubernetes cluster DNS server processes DNS queries, to facilitate
the lookup of federated services (which span multiple Kubernetes clusters).
See the [Cluster Federation Administrators' Guide](/docs/concepts/cluster-administration/federation/) for more
details on Cluster Federation and multi-site support.
-->
如果没有看到 Endpoint,查看 [调试 Service 文档](/docs/tasks/debug-application-cluster/debug-service/) 中的 Endpoint 段内容。
关于更多 Kubernetes DNS 的示例,参考 Kubernetes GitHub 仓库中 [集群 DNS 示例](https://git.k8s.io/kubernetes/examples/cluster-dns)。
## Kubernetes Federation(多 Zone 支持)
在1.3 发行版本中,为多站点 Kubernetes 安装引入了集群 Federation 支持。这需要对 Kubernetes 集群 DNS 服务器处理 DNS 查询的方式,做出一些微小(后向兼容)改变,从而便利了对联合 Service 的查询(跨多个 Kubernetes 集群)。参考 [集群 Federation 管理员指南](/docs/concepts/cluster-administration/federation/) 获取更多关于集群 Federation 和多站点支持的细节。
<!--
## How it Works
The running Kubernetes DNS pod holds 3 containers - kubedns, dnsmasq and a health check called healthz.
The kubedns process watches the Kubernetes master for changes in Services and Endpoints, and maintains
in-memory lookup structures to service DNS requests. The dnsmasq container adds DNS caching to improve
performance. The healthz container provides a single health check endpoint while performing dual healthchecks
(for dnsmasq and kubedns).
The DNS pod is exposed as a Kubernetes Service with a static IP. Once assigned the
kubelet passes DNS configured using the `--cluster-dns=10.0.0.10` flag to each
container.
DNS names also need domains. The local domain is configurable, in the kubelet using
the flag `--cluster-domain=<default local domain>`
The Kubernetes cluster DNS server (based off the [SkyDNS](https://github.com/skynetservices/skydns) library)
supports forward lookups (A records), service lookups (SRV records) and reverse IP address lookups (PTR records).
-->
## 工作原理
运行的 Kubernetes DNS Pod 包含 3 个容器 —— kubedns、dnsmasq 和负责健康检查的 healthz。
kubedns 进程监视 Kubernetes master 对 Service 和 Endpoint 操作的变更,并维护一个内存查询结构去处理 DNS 请求。dnsmasq 容器增加了一个 DNS 缓存来改善性能。为执行对 dnsmasq 和 kubedns 的健康检查,healthz 容器提供了一个单独的健康检查 Endpoint。
DNS Pod 通过一个静态 IP 暴露为一个 Service。一旦 IP 被分配,kubelet 会通过 `--cluster-dns=10.0.0.10` 标志将配置的 DNS 传递给每一个容器。
DNS 名字也需要域名,本地域名是可配置的,在 kubelet 中使用 `--cluster-domain=<default local domain>` 标志。
Kubernetes 集群 DNS 服务器(根据 [SkyDNS](https://github.com/skynetservices/skydns) 库)支持正向查询(A 记录),Service 查询(SRV 记录)和反向 IP 地址查询(PTR 记录)。
<!--
## Inheriting DNS from the node
When running a pod, kubelet will prepend the cluster DNS server and search
paths to the node's own DNS settings. If the node is able to resolve DNS names
specific to the larger environment, pods should be able to, also. See "Known
issues" below for a caveat.
If you don't want this, or if you want a different DNS config for pods, you can
use the kubelet's `--resolv-conf` flag. Setting it to "" means that pods will
not inherit DNS. Setting it to a valid file path means that kubelet will use
this file instead of `/etc/resolv.conf` for DNS inheritance.
-->
## 从 Node 继承 DNS
当运行 Pod 时,kubelet 将集群 DNS 服务器和搜索路径追加到 Node 自己的 DNS 设置中。如果 Node 能够在大型环境中解析 DNS 名字,Pod 也应该没问题。参考下面 "已知问题” 中给出的更多说明。
如果不想这样,或者希望 Pod 有一个不同的 DNS 配置,可以使用 kubelet 的 `--resolv-conf` 标志。设置为 "" 表示 Pod 将不继承自 DNS。设置为一个合法的文件路径,表示 kubelet 将使用这个文件而不是 `/etc/resolv.conf` 。
<!--
## Known issues
Kubernetes installs do not configure the nodes' resolv.conf files to use the
cluster DNS by default, because that process is inherently distro-specific.
This should probably be implemented eventually.
Linux's libc is impossibly stuck ([see this bug from
2005](https://bugzilla.redhat.com/show_bug.cgi?id=168253)) with limits of just
3 DNS `nameserver` records and 6 DNS `search` records. Kubernetes needs to
consume 1 `nameserver` record and 3 `search` records. This means that if a
local installation already uses 3 `nameserver`s or uses more than 3 `search`es,
some of those settings will be lost. As a partial workaround, the node can run
`dnsmasq` which will provide more `nameserver` entries, but not more `search`
entries. You can also use kubelet's `--resolv-conf` flag.
If you are using Alpine version 3.3 or earlier as your base image, DNS may not
work properly owing to a known issue with Alpine. Check [here](https://github.com/kubernetes/kubernetes/issues/30215)
for more information.
-->
## 已知问题
Kubernetes 安装但并不配置 Node 的 resolv.conf 文件,而是默认使用集群 DNS的,因为那个过程本质上就是和特定的发行版本相关的。最终应该会被实现。
Linux libc 在限制为3个 DNS `nameserver` 记录和3个 DNS `search` 记录是不可能卡住的([查看 2005 年的一个 Bug](https://bugzilla.redhat.com/show_bug.cgi?id=168253))。Kubernetes 需要使用1个 `nameserver` 记录和3个 `search` 记录。这意味着如果本地安装已经使用了3个 `nameserver` 或使用了3个以上 `search`,那些设置将会丢失。作为部分解决方法, Node 可以运行 `dnsmasq` ,它能提供更多 `nameserver` 条目,但不能运行更多 `search` 条目。可以使用 kubelet 的 `--resolv-conf` 标志。
如果使用 3.3 版本的 Alpine 或更早版本作为 base 镜像,由于 Alpine 的一个已知问题,DNS 可能不会正确工作。查看 [这里](https://github.com/kubernetes/kubernetes/issues/30215) 获取更多信息。
<!--
## References
- [Docs for the DNS cluster addon](http://releases.k8s.io/{{page.githubbranch}}/cluster/addons/dns/README.md)
-->
## 参考
- [DNS 集群插件文档](http://releases.k8s.io/{{page.githubbranch}}/cluster/addons/dns/README.md)
<!--
## What's next
- [Autoscaling the DNS Service in a Cluster](/docs/tasks/administer-cluster/dns-horizontal-autoscaling/).
-->
## 下一步
- [集群中 DNS Service 自动伸缩](/docs/tasks/administer-cluster/dns-horizontal-autoscaling/) | 22,285 | CC-BY-4.0 |
<properties
pageTitle="使用 SQL 資料倉儲建置整合式解決方案 | Microsoft Azure"
description="工具以及提供可與 SQL 資料倉儲整合之解決方案的合作夥伴。"
services="sql-data-warehouse"
documentationCenter="NA"
authors="lodipalm"
manager="barbkess"
editor=""/>
<tags
ms.service="sql-data-warehouse"
ms.devlang="NA"
ms.topic="article"
ms.tgt_pltfrm="NA"
ms.workload="data-services"
ms.date="02/01/2016"
ms.author="lodipalm;barbkess;sonyama"/>
#以 SQL 資料倉儲來搭配運用其他服務
除了其核心功能,SQL 資料倉儲可讓使用者搭配運用許多其他 Azure 中的服務。具體而言,我們目前已經採取步驟來深入整合下列項目:
+ Power BI
+ Azure Data Factory
+ Azure Machine Learning
+ Azure 串流分析
我們正努力連接多個跨 Azure 生態系統的服務。
##Power BI
Power BI 整合可讓您運用 SQL 資料倉儲的計算能力以及 Power BI 的動態報告和視覺效果。目前 Power BI 整合包括:
+ **直接連接**:針對 SQL 資料倉儲進行之邏輯下推的更進階連接。可提供更快速且更大規模的分析。
+ **在 Power BI 中開啟**:[在 Power BI 中開啟] 按鈕會傳遞執行個體資訊給 Power BI,允許更順暢的連接。
如需詳細資訊,請參閱[整合 Power BI](./sql-data-warehouse-integrate-power-bi.md) 或 [Power BI 文件](http://blogs.msdn.com/b/powerbi/archive/2015/06/24/exploring-azure-sql-data-warehouse-with-power-bi.aspx)。
##Azure Data Factory
Azure Data Factory 提供使用者一個受管理的平台,以建立複雜的擷取-載入管線。SQL 資料倉儲與 Azure Data Factory 的整合包含下列內容:
+ **預存程序**:協調 SQL 資料倉儲上的預存程序的執行。
如需詳細資訊,請參閱[與 Azure Data Factory 整合](./sql-data-warehouse-integrate-azure-data-factory.md)或 [Azure Data Factory 文件](https://azure.microsoft.com/documentation/services/data-factory/)。
##Azure Machine Learning
Azure Machine Learning 是完全受管理的分析服務,可讓使用者建立運用一組大型預測工具的複雜模型。SQL 資料倉儲可支援做為模型的來源和目的地,具備下列功能:
+ **讀取資料:**針對 SQL 資料倉儲透過 T-SQL 大規模驅動模型。
+ **寫入資料:**認可從任何模型回到 SQL 資料倉儲的變更。
如需詳細資訊,請參閱[與 Azure Machine Learning 整合](./sql-data-warehouse-integrate-azure-machine-learning.md)或 [Azure 機器學習文件](https://azure.microsoft.com/services/machine-learning/)。
##Azure 串流分析
Azure 串流分析是複雜、完全受管理的基礎結構,可處理和取用產生自 Azure 事件中樞的事件資料。與 SQL 資料倉儲的整合可讓串流資料有效地處理並與相關資料一起儲存以啟用更深入、更進階的分析。
+ **工作輸出:**將來自資料流分析工作的輸出直接傳送到 SQL 資料倉儲。
如需詳細資訊,請參閱[與 Azure 資料流分析整合](./sql-data-warehouse-integrate-azure-stream-analytics.md)或 [Azure y 資料流分析文件](https://azure.microsoft.com/documentation/services/stream-analytics/)。
<!--Image references-->
<!--Article references-->
[development overview]: sql-data-warehouse-overview-develop/
[Azure Data Factory]: sql-data-warehouse-integrate-azure-data-factory.md
[Azure Machine Learning]: sql-data-warehouse-integrate-azure-machine-learning.md
[Azure Stream Analytics]: sql-data-warehouse-integrate-azure-stream-analytics.md
[Power BI]: sql-data-warehouse-integrate-power-bi.md
[Partners]: sql-data-warehouse-integrate-solution-partners.md
<!--MSDN references-->
<!--Other Web references-->
<!---HONumber=AcomDC_0204_2016--> | 2,595 | CC-BY-3.0 |
# Lee Rinji
<!-- slide -->
## 致偶然读到这些文章的人
如果这一网站里面还有只言片语能够帮助到你,首先恳请读者原谅我贸然将之窃得。我们的无知没有多大分别,你成为这些习作的读者而我是其作者纯属不期而然的巧合。
<!-- slide -->
## Contact
- E-mail:
- **[ylilc@connect.ust.hk](mailto:ylilc@connect.ust.hk)**
- **[i@rinjilee.com](mailto:i@rinjilee.com)**
- Telegram: **RJLee**
- Website:
- **<https://leevj.com>**
- **<https://leerj.com>**
<!-- slide -->
## Education Experience
- The Chinese University of Hong Kong, Faculty of Social Science
- PhD in Sociology (Expected)
- The Hong Kong University of Science and Technology, School of Engineering
- MSc in Big Data Technology (Expected)
- Sun Yat-sen University, School of Data and Computer Science
- BEng in Intelligence Science and Technology
- Minor in Politics and Administration | 772 | MIT |
---
title: 删除分组
date: 2020-08-27
---
# 应用场景
- 该接口适用于用户将指定分组删除。
# 使用示例
```php
/**
* @param string $fromAccount 需要删除该 user_id 的分组
* @param array $groupName 要删除的分组列表
*/
$result = $sns->group->delGroup('from_account', ['同事',...]);
```
# 应答示例
- 详情请参考[这里](https://cloud.tencent.com/document/product/269/10108) | 318 | MIT |
---
layout: post
title: "美國總統到底是誰決定?什麼叫做搖擺州?上 ft 李祥數學,堪稱一絕"
date: 2020-11-01T04:00:12.000Z
author: 羅文好公民
from: https://www.youtube.com/watch?v=dRSTQ1PdGF8
tags: [ 羅文好公民 ]
categories: [ 羅文好公民 ]
---
<!--1604203212000-->
[美國總統到底是誰決定?什麼叫做搖擺州?上 ft 李祥數學,堪稱一絕](https://www.youtube.com/watch?v=dRSTQ1PdGF8)
------
<div>
想要成為羅文好公民頻道的會員並獲得相關獎勵嗎?想要觀看會員專屬影片嗎?請點以下連結查看詳細說明喔!https://www.youtube.com/channel/UCr25xDGzTxeic8W_6mIZbug/join►羅文快速記憶系列影片:https://reurl.cc/jld8M►羅文快樂學習系列影片:https://reurl.cc/ZXnja►羅文大學學什麼系列影片:https://reurl.cc/ZeZXW►羅文三分鐘學會系列影片:https://reurl.cc/qkDgn►羅文三分鐘開箱系列影片:https://reurl.cc/WD43y►羅文三分鐘開好書系列影片:https://reurl.cc/zAyea►羅文好公民FB(趕快來按讚):https://reurl.cc/1eQom►羅文IG(請追蹤):https://reurl.cc/a1l93
</div> | 713 | MIT |
---
title: 統合されたルーティングと作業の配分
description: 統合されたルーティング機能と作業配分機能を使用して、チャット、メッセージング、および Web ポータル チャネルから発生した作業項目を、組織内の複数の顧客サービス サポート チームにルーティングできます。
author: Annbe
manager: AnnBe
ms.date: 7/22/2018
ms.assetid: ee759f9f-6625-4dd2-8c55-1c6d0d134038
ms.topic: article
ms.prod: ''
ms.service: business-applications
ms.technology: ''
ms.author: Annbe
audience: Admin
ms.openlocfilehash: 3f32735645523d8a693929dfc9bd76d368202f03
ms.sourcegitcommit: 1a326997459281936558d131b647fad3a28e5aef
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 01/23/2019
ms.locfileid: "287554"
---
# <a name="unified-routing-and-work-distribution"></a>統合されたルーティングと作業の配分
[!include[customer-service-omni-channel-release-notes banner](../../includes/customer-service-omni-channel-release-notes.md)]
統合されたルーティング機能と作業配分機能を使用して、チャット、メッセージング、および Web ポータル チャネルから発生した作業項目を、組織内の複数の顧客サービス サポート チームにルーティングできます。 構成インターフェイスを通じて、エージェントが処理する作業プロファイルを厳密に定義できます。 実行時には、エージェントの能力と利用可能性に基づいて、各エージェントへの作業の流れが自動化されます。

<!-- picture -->
統合されたルーティングと作業の配分システムによって、組織は次の目標を達成できます。
- 緊急性の高いタスクに、エージェントが常に注意を払えるようになります。
- エージェントの稼働率を詳細に追跡し、プロセスを適切に改善できます。
- 複数のチャネルや非同期の作業項目 (サポート案件、潜在顧客、コールバック、スケジュール済みタスクなど) をカバーして、作業項目と要求を統合できます。 | 1,293 | CC-BY-4.0 |
<!--author=SharS last changed: 9/17/15-->
#### StorSimple リリース バージョン (GA) に新しいストレージ アカウントを追加するには
1. StorSimple Manager サービスのランディング ページでサービスを選択し、ダブルクリックします。この操作により、**[クイック スタート]** ページが表示されます。**[構成]** ページを選択します。
2. **[ストレージ アカウントの追加/編集]** をクリックします。
3. **[ストレージ アカウントの追加/編集]** ダイアログ ボックスで、次の手順を実行します。
1. **[新規追加]** をクリックします。
2. ストレージ アカウントの名前を入力します。
3. Microsoft Azure ストレージ アカウントのプライマリ **アクセス キー**を入力します。
4. **[SSL モードを有効にする]** を選択して、デバイスとクラウド間のネットワーク通信用のセキュリティで保護されたチャネルを作成します。プライベート クラウド内で運用している場合にのみ、**[SSL モードを有効にする]** チェック ボックスをオフにします。
5. チェック マーク アイコン  をクリックします。ストレージ アカウントが正常に作成されると通知が表示されます。

4. 新しく作成されたストレージ アカウントは、**[構成]** ページの **[ストレージ アカウント]** に表示されます。**[保存]** をクリックして、新しく作成されたストレージ アカウントを保存します。確認を求められたら、**[OK]** をクリックします。
<!---HONumber=Oct15_HO3--> | 976 | CC-BY-3.0 |
----------------------------------
## 1.0.6
* fix bug
## 1.0.5
* 增加新功能,@某人在选择的时候只能块选中,完美实现微博输入框效果
## 1.0.4
* 最低API调到15
## 1.0.3
* 修正了电话号码不能显示点击问题,增加了needNum接口用于显示电话号码
* 修改了demo里插入文本的更新方式
这是效果图片,GIF看起来有些不流畅
<img src="https://github.com/CarGuo/RickText/blob/master/device-2016-11-10-220253.mp4_1478787046.gif" width="240px" height="426px"/>
* <h4>实现了类似微博的编辑输入,可输入表情和@某人,优化了@某人,光标不能插入到@人的名字中间,@某人整个清除,整块文本插入处理等</h4>
* <h4>TextView支持显示表情,@某人和URL高亮可点击。</h4>
## 新修改 SmileUtils 表情处理类,支持外部自己添加表情
```
1、
//这家自己的自定义表情
List<Integer> data = new ArrayList<>();//对应本地图片资源
List<String> strings = new ArrayList<>();//对应图片资源对应名字
for (int i = 1; i < 64; i++) {
int resId = getResources().getIdentifier("e" + i, "drawable", getPackageName());
data.add(resId);
strings.add("[e" + i + "]");
}
/**初始化为自己的**/
SmileUtils.addPatternAll(SmileUtils.getEmoticons(), strings, data);
···需要在显示布局之前就设置好
2、
根据文本获取对应的表情去显示再grid里面
int resId = SmileUtils.getRedId(filename);
!!注意目前删除的图片资源必须是 delete_expression.png
3、
/**往编辑框出入表情*/
/**
* 文本转化表情处理
*
* @param editText 要显示的EditText
* @param maxLength 最长高度
* @param size 显示大小
* @param name 需要转化的文本
*/
SmileUtils.insertIcon(editTextEmoji, 2000, ScreenUtils.dip2px(getContext(), 20), filename);
```
## EditTextAtUtils @某人的逻辑处理类
可以new一个EditTextAtUtils对象
```
/**
* @param editText 需要对应显示的edittext
* @param contactNameList 传入一个不变的list维护用户名
* @param contactIdList 传入一个不变的list维护id
*/
public EditTextAtUtils(EditText editText, final List<String> contactNameList, final List<String> contactIdList)
编辑框输入了@后的跳转,跳转到好友选择之类的页面
public void setEditTextAtUtilJumpListener(EditTextAtUtilJumpListener editTextAtUtilJumpListener) {
```
## TextCommonUtils 文本逻辑处理类,显示表情,@某人和URL高亮可点击。
```
/**
* 单纯emoji表示
*
* @param context 上下文
* @param text 包含emoji的字符串
* @param tv 显示的textview
*/
public static void setEmojiText(Context context, String text, TextView tv) {
if (TextUtils.isEmpty(text)) {
tv.setText("");
}
Spannable spannable = SmileUtils.unicodeToEmojiName(context, text);
tv.setText(spannable);
}
/**
* 单纯获取emoji表示
*
* @param context 上下文
* @param text 需要处理的文本
* @return 返回显示的spananle
*/
public static Spannable getEmojiText(Context context, String text) {
if (TextUtils.isEmpty(text)) {
return new SpannableString("");
}
return SmileUtils.unicodeToEmojiName(context, text);
}
/**
* 显示emoji和url高亮
*
* @param context 上下文
* @param text 需要处理的文本
* @param textView 需要显示的view
* @param color 需要显示的颜色
* @param needNum 是否需要显示号码
* @param spanAtUserCallBack AT某人点击的返回
* @param spanUrlCallBack 链接点击的返回
* @return 返回显示的spananle
*/
public static Spannable getUrlEmojiText(Context context, String text, TextView textView, int color, boolean needNum, SpanAtUserCallBack spanAtUserCallBack, SpanUrlCallBack spanUrlCallBack) {
if (!TextUtils.isEmpty(text)) {
return getUrlSmileText(context, text, null, textView, color, needNum, spanAtUserCallBack, spanUrlCallBack);
} else {
return new SpannableString(" ");
}
}
/**
* 设置带高亮可点击的Url和表情的textview文本
*
* @param context 上下文
* @param string 需要处理的文本
* @param listUser 需要显示的AT某人
* @param textView 需要显示的view
* @param color 需要显示的颜色
* @param needNum 是否需要显示号码
* @param spanAtUserCallBack AT某人点击的返回
* @param spanUrlCallBack 链接点击的返回
*/
public static void setUrlSmileText(Context context, String string, List<UserModel> listUser, TextView textView, int color, boolean needNum, SpanAtUserCallBack spanAtUserCallBack, SpanUrlCallBack spanUrlCallBack) {
Spannable spannable = getUrlSmileText(context, string, listUser, textView, color, needNum, spanAtUserCallBack, spanUrlCallBack);
textView.setText(spannable);
}
/**
* AT某人的跳转
*
* @param context 上下文
* @param listUser 需要显示的AT某人
* @param content 需要处理的文本
* @param textView 需要显示的view
* @param clickable AT某人是否可以点击
* @param color 需要显示的颜色
* @param needNum 是否需要显示号码
* @param spanAtUserCallBack AT某人点击的返回
* @return 返回显示的spananle
*/
public static Spannable getAtText(Context context, List<UserModel> listUser, String content, TextView textView, boolean clickable,
int color, boolean needNum, SpanAtUserCallBack spanAtUserCallBack) {
if (listUser == null || listUser.size() <= 0)
return getEmojiText(context, content);
Spannable spannableString = new SpannableString(content);
int indexStart = 0;
int lenght = content.length();
boolean hadHighLine = false;
Map<String, String> map = new HashMap<>();
for (int i = 0; i < listUser.size(); i++) {
int index = content.indexOf(listUser.get(i).getUser_name(), indexStart);
if (index < 0 && indexStart > 0) {
index = content.indexOf(listUser.get(i).getUser_name());
if (map.containsKey("" + index)) {
int tmpIndexStart = (indexStart < lenght) ? Integer.parseInt(map.get("" + index)) : lenght - 1;
if (tmpIndexStart != indexStart) {
indexStart = tmpIndexStart;
i--;
continue;
}
}
}
if (index > 0) {
map.put(index + "", index + "");
int mathStart = index - 1;
int indexEnd = index + listUser.get(i).getUser_name().length();
boolean hadAt = "@".equals(content.substring(mathStart, index));
int matchEnd = indexEnd + 1;
if (hadAt && (matchEnd <= lenght || indexEnd == lenght)) {
if ((indexEnd == lenght) || " ".equals(content.substring(indexEnd, indexEnd + 1)) || "\b".equals(content.substring(indexEnd, indexEnd + 1))) {
if (indexEnd > indexStart) {
indexStart = indexEnd;
}
hadHighLine = true;
spannableString.setSpan(new ClickAtUserSpan(context, listUser.get(i), color, spanAtUserCallBack), mathStart, (indexEnd == lenght) ? lenght : matchEnd, Spanned.SPAN_MARK_POINT);
}
}
}
}
SmileUtils.addSmiles(context, spannableString);
if (!(textView instanceof EditText) && clickable && hadHighLine)
textView.setMovementMethod(LinkMovementMethod.getInstance());
return spannableString;
}
/**
* 设置带高亮可点击的Url和表情的textview文本
*
* @param context 上下文
* @param string 需要处理的文本
* @param listUser 需要显示的AT某人
* @param textView 需要显示的view
* @param color 需要显示的颜色
* @param needNum 是否需要显示号码
* @param spanAtUserCallBack AT某人点击的返回
* @param spanUrlCallBack 链接点击的返回
* @return 返回显示的spananle
*/
public static Spannable getUrlSmileText(Context context, String string, List<UserModel> listUser, TextView textView, int color, boolean needNum, SpanAtUserCallBack spanAtUserCallBack, SpanUrlCallBack spanUrlCallBack) {
textView.setAutoLinkMask(Linkify.WEB_URLS | Linkify.PHONE_NUMBERS);
if (!TextUtils.isEmpty(string)) {
string = string.replaceAll("\r", "\r\n");
Spannable spannable = getAtText(context, listUser, string, textView, true, color, needNum, spanAtUserCallBack);
textView.setText(spannable);
return resolveUrlLogic(context, textView, spannable, color, needNum, spanUrlCallBack);
} else {
return new SpannableString(" ");
}
}
/**
* 处理带URL的逻辑
*
* @param context 上下文
* @param textView 需要显示的view
* @param spannable 显示的spananle
* @param color 需要显示的颜色
* @param needNum 是否需要显示号码
* @param spanUrlCallBack 链接点击的返回
* @return 返回显示的spananle
*/
private static Spannable resolveUrlLogic(Context context, TextView textView, Spannable spannable, int color, boolean needNum, SpanUrlCallBack spanUrlCallBack) {
CharSequence charSequence = textView.getText();
if (charSequence instanceof Spannable) {
int end = charSequence.length();
Spannable sp = (Spannable) textView.getText();
URLSpan[] urls = sp.getSpans(0, end, URLSpan.class);
ClickAtUserSpan[] atSpan = sp.getSpans(0, end, ClickAtUserSpan.class);
if (urls.length > 0) {
SpannableStringBuilder style = new SpannableStringBuilder(charSequence);
style.clearSpans();// should clear old spans
for (URLSpan url : urls) {
String urlString = url.getURL();
if (isNumeric(urlString.replace("tel:", ""))) {
if (!needNum && !isMobileSimple(urlString.replace("tel:", ""))) {
style.setSpan(new StyleSpan(Typeface.NORMAL), sp.getSpanStart(url), sp.getSpanEnd(url), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
} else {
LinkSpan linkSpan = new LinkSpan(context, url.getURL(), color, spanUrlCallBack);
style.setSpan(linkSpan, sp.getSpanStart(url), sp.getSpanEnd(url), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
}
} else if (isTopURL(urlString.toLowerCase())) {
LinkSpan linkSpan = new LinkSpan(context, url.getURL(), color, spanUrlCallBack);
style.setSpan(linkSpan, sp.getSpanStart(url), sp.getSpanEnd(url), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
} else {
style.setSpan(new StyleSpan(Typeface.NORMAL), sp.getSpanStart(url), sp.getSpanEnd(url), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
}
}
for (ClickAtUserSpan atUserSpan : atSpan) {
style.setSpan(atUserSpan, sp.getSpanStart(atUserSpan), sp.getSpanEnd(atUserSpan), Spanned.SPAN_MARK_POINT);
}
SmileUtils.addSmiles(context, style);
textView.setAutoLinkMask(0);
return style;
} else {
return spannable;
}
} else {
return spannable;
}
}
/**
* 顶级域名判断;如果要忽略大小写,可以直接在传入参数的时候toLowerCase()再做判断
* 处理1. 2. 3.识别成链接的问题
*
* @param str
* @return 是否符合url
*/
public static boolean isTopURL(String str) {
String ss[] = str.split("\\.");
if (ss.length < 3)
return false;
return true;
}
/**
* 是否数字
*
* @param str
* @return 是否数字
*/
public static boolean isNumeric(String str) {
Pattern pattern = Pattern.compile("[0-9]*");
Matcher isNum = pattern.matcher(str);
if (!isNum.matches()) {
return false;
}
return true;
}
/**
* @param string 待验证文本
* @return 是否符合手机号(简单)格式
*/
public static boolean isMobileSimple(String string) {
String phone = "^[1]\\d{10}$";
return !TextUtils.isEmpty(string) && Pattern.matches(phone, string);
}
``` | 10,793 | MIT |
---
title: Laravel+Nuxt.jsでDocker開発環境構築からHerokuデプロイまで
description: Laravel+Nuxt.jsで「Docker開発環境構築からHerokuデプロイまで」という0→1のフェーズをまとめました。
date: "2019-07-12"
template: "post"
draft: false
tags:
- "Laravel"
- "Nuxt.js"
- "Docker"
- "Heroku"
image: "./Screenshot from 2019-07-09 00-22-41.png"
---
0. [はじめに](#はじめに)
0. [システムアーキテクチャ](#システムアーキテクチャ)
0. [Laravel/Nuxt.jsインストール](#laravelnuxtjsインストール)
3. [Docker環境構築](#docker環境構築)
4. [Nginx設定](#nginx設定)
5. [Typescript対応](#typescript対応)
7. [サーバーでのモデル/ビジネスロジック実装](#サーバーでのモデルビジネスロジック実装)
8. [フロントでのモデル/ビジネスロジック実装](#フロントでのモデルビジネスロジック実装)
9. [Heroku設定](#heroku設定)
## はじめに
※本記事は [qiitaのにあげた記事](https://qiita.com/kon_shou/items/8af16956325a447a2d64) と同様になります。
本記事では「フレームワークをインストールして、それをインターネットに公開する」という0から1までのフェーズについて、Laravel+Nuxt.jsによって「蔵書管理」システムを構築して解説したいと思います。
また、実際に構築したシステムは下記になります。
- Heroku: https://frozen-castle-47874.herokuapp.com/
- Github: https://github.com/kon-shou/bcm-qiita-example

## システムアーキテクチャ
下記の技術スタックを用います。
サーバーサイド: Laravel 5.8
フロントサイド: Nuxt.js 2.8.1 (SPA)
Webサーバー: Nginx
開発環境構築: docker
デプロイ: Heroku
また処理フローの図は下記になります。

「ブラウザにNuxt.jsで生成したSPAを返し、そのSPAからAPIサーバーであるLaravelにAPIリクエストを、Nginxを介して行う」というフローです。
## Laravel/Nuxt.jsインストール
まずは[Laravelドキュメント](https://readouble.com/laravel/5.8/ja/installation.html)に従って Laravelでプロジェクトを作成します。
```bash
composer create-project --prefer-dist laravel/laravel book-collection-management
```
作成したLaravelプロジェクトに `client` というディレクトリを新設して、そこに[Nuxt.jsドキュメント](https://ja.nuxtjs.org/guide/installation)に従って Nuxt.jsをインストールします。
```bash
yarn create nuxt-app client ./client
```
コマンド実行後の選択肢は各自の要望に応じて設定してください。
自分の場合、下記のように設定しました。
```bash
? Project name client
? Project description My fantastic Nuxt.js project
? Author name kon-shou
? Choose the package manager Yarn
? Choose UI framework Buefy
? Choose custom server framework None (Recommended)
? Choose Nuxt.js modules Axios
? Choose linting tools ESLint, Prettier
? Choose test framework None
? Choose rendering mode Single Page App
```
コマンドによって `./client` にNuxt.jsがインストールされましたが、このままだとプロジェクトの二重管理になるため、下記を行います。
- `./client/node_module` を削除
- `rm -rdf ./client/node_modules`
- `./client` の git 管理を解除
- `rm -rdf ./client/.git/`
- `./client` にある各種設定ファイルを laravel のルートに移動&更新
設定ファイルの更新は各自の環境に合わせて行ってください。
ただ下記の2つのファイルは特に重要なので、注記します。
- `.package.json`
- npm scripts に nuxt コマンドを追記
- nuxt に必要なライブラリを追加
- [修正後の.package.json](https://github.com/kon-shou/bcm-qiita-example/blob/b1e3953962f917b659891a1f63f0d6d94f392a55/package.json)
- `nuxt.config.js`
- `srcDir: 'client/'` を追記
- nuxt build によって生成される `index.html` の出力先を `public/dist` に変更
- [修正後のnuxt.config.js](https://github.com/kon-shou/bcm-qiita-example/blob/b1e3953962f917b659891a1f63f0d6d94f392a55/nuxt.config.js)
`index.html` の出力先の変更は、ドキュメントルートである `public` 以下に配置することを意図しています。
詳細は「Nginx設定」で解説します。
その `index.html` の出力先の変更は https://github.com/nuxt/nuxt.js/issues/3217 に従って
```javascript:title=nuxt.config.js
generate: {
dir: 'public/dist'
}
```
を追記することで出力先を変更することができます。
以上を実行した後のディレクトリ構造は下記になります。
```bash
(root)
├── .editorconfig
├── .env
├── .env.example
├── .eslintrc.js
├── .git
├── .gitattributes
├── .gitignore
├── .idea
├── .prettierrc
├── .styleci.yml
├── app
├── artisan
├── bootstrap
├── client
│ ├── README.md
│ ├── assets
│ ├── components
│ ├── layouts
│ ├── middleware
│ ├── pages
│ ├── plugins
│ ├── static
│ └── store
├── composer.json
├── composer.lock
├── config
├── database
├── node_modules
├── nuxt.config.js
├── package.json
├── phpunit.xml
├── public
├── readme.md
├── resources
├── routes
├── server.php
├── storage
├── tests
├── vendor
├── webpack.mix.js
└── yarn.lock
```
## Docker環境構築
次は、DockerでWebサーバーとDBを構築して `docker-compose up -d` でアプリが立ち上がるようにします。
追加するファイルは下記になります。
```bash
(root)
├── Dockerfile => docker-compose.yml の app.build.dockerfile で参照される
├── docker
│ ├── entrypoint-app.sh => docker-compose.yml の app.command で参照される
│ ├── nginx.conf => docker-compose.yml の app.volumes で参照される
│ └── php-fpm.conf => docker-compose.yml の app.volumes で参照される
├── docker-compose.yml
└── scripts
└── provisioning.sh => docker-compose.yml の app.command で参照される
```
docker-compose.ymlは下記になります。
```yml:title=docker-compose.yml
version: '3'
services:
mysql:
image: mysql:5.7
volumes: # host/docker間で共有するデータを指定
- "${HOME}/book-management_mysql:/var/lib/mysql"
environment:
MYSQL_ALLOW_EMPTY_PASSWORD: 1
TZ: "Asia/Tokyo"
ports:
- "3306:3306"
app:
build: . # Dockerfileのディレクトリを指定
user: ubuntu
volumes: # host/docker間で共有するデータを指定
- .:/srv
- ./docker/nginx.conf:/etc/nginx/sites-enabled/bcm
- ./docker/php-fpm.conf:/etc/php/7.2/fpm/pool.d/bcm.conf
command: docker/entrypoint-app.sh # 起動処理を設定
depends_on:
- mysql
links:
- mysql
ports:
- "8000:8000"
working_dir: /srv
```
`docker-compose up -d` の処理の順番は下記になります。
1. mysqlコンテナの起動
1. appコンテナの起動
1. `Dockerfile` ( `provisioning.sh` ) からdocker imageの作成
2. `nginx.conf` / `php-fpm.conf` のマウント
3. `entrypoint-app.sh` の nginx / php-fpm の起動
各ステップについて解説します。
#### 1. mysqlコンテナの起動
mysqlコンテナは、mysql5.7のイメージを元にして、パスワード省略及びタイムゾーンを東京にして、ホスト/dockerの3306番ポートでアクセスを可能にしています。
ホストからmysqlコンテナへのアクセスは `mysql -h 127.0.0.01 -uroot` で行えます。
またappコンテナからmysqlへのアクセスは `docker-compose exec app bash` でappコンテナに入り `mysql -h mysql -uroot` で行えます。
#### 2. appコンテナの起動
appコンテナは、Dockerfileで必要なライブラリをインストールしたイメージを準備し、`/srv` にプロジェクトディレクトリをマウントし、ホスト/dockerの8000番ポートでアクセスを可能にしています。
#### 2.1 `Dockerfile` ( `provisioning.sh` ) からdocker imageの作成
Dockerfileは下記になります。
```Dockerfile:title=Dockerfile
FROM ubuntu:18.04
COPY scripts/provisioning.sh /tmp/provisioning.sh
# provisioning.sh による必要ライブラリのインストール
RUN /tmp/provisioning.sh
# nginxの初期設定を削除
RUN rm /etc/nginx/sites-enabled/default
# php-fpmの初期設定を削除
RUN rm /etc/php/7.2/fpm/pool.d/www.conf
# ubuntuユーザーを追加
RUN useradd -m -s /bin/bash -u 1000 -g users ubuntu
RUN apt install sudo
# ubuntuでのsudoのパスワード要求をしないように
RUN echo "ubuntu ALL=(ALL:ALL) NOPASSWD:ALL" >> /etc/sudoers
RUN chown ubuntu:users /srv
```
Dockerfileにて `provisioning.sh` によってライブラリをインストールし、その後にユーザー関連の設定を行います。
`provisioning.sh` は下記になります。
```bash:title=provisioning.sh
#!/usr/bin/env bash
function package_install() {
env DEBIAN_FRONTEND=noninteractive apt install -y $1
}
apt-get update -y
package_install php-fpm
package_install php-mysql
package_install php-imagick
package_install php-gd
package_install php-curl
package_install php-mbstring
package_install php-bcmath
package_install php-xml
package_install php-zip
package_install php-redis
package_install php-intl
package_install nginx
package_install composer
package_install mysql-client
package_install zip
package_install unzip
package_install jq
package_install git
package_install jq
package_install vim
package_install curl
```
もし、appコンテナで追加のライブラリが必要になったら、この `provisioning.sh` に追記し、改めてイメージをビルドするのが良いかと思います。
#### 2.2 `nginx.conf` / `php-fpm.conf` のマウント
この2つの設定ファイルを配置することで、nginx/php-fpmが正しく起動できるようになります。
`php-fpm.conf` は下記になります。
```conf:title=php-fpm.conf
[bcm]
user = ubuntu
group = users
listen = /run/php/bcm.sock
listen.owner = www-data
listen.group = www-data
pm = dynamic
pm.start_servers = 1
pm.max_children = 4
pm.min_spare_servers = 1
pm.max_spare_servers = 2
request_terminate_timeout = 300
chdir = /srv
```
`php-fpm.conf` については [公式のマニュアル](https://www.php.net/manual/ja/install.fpm.configuration.php) でオプションを逐一調べていくのが早いかと思います。
またソケットがどういうものか理解するのかは https://qiita.com/kuni-nakaji/items/d11219e4ad7c74ece748 の記事が非常に分かりやすく、参考にさせていただきました。
`nginx.conf` の詳細については次の「Nginx設定」にて解説します。
#### 2.3 `entrypoint-app.sh` の nginx / php-fpm の起動
`entrypoint-app.sh` は下記になります。
```bash:title=entrypoint-app.sh
#!/bin/bash
sudo service php7.2-fpm start
sudo service nginx start
tail -f /dev/null
```
内容としては、php-fpm/nginxの起動と、dockerが落ちないようにする処理です。
これをdocker起動処理として行うことで `docker-compose up -d` だけでphp-fpm/nginxの起動をさせることができます。
なお `tail -f /dev/null` の詳細については http://kimh.github.io/blog/jp/docker/gothas-in-writing-dockerfile-jp/#hack_to_run_container_in_the_background のブログ記事が非常にわかりやすく、参考にさせていただきました。
## Nginx設定
Laravel/Nuxt.jsのインストールによって、初回アクセス時にブラウザに返却される `index.html` と、その `index.html` からのAPIアクセスを受ける `index.php` を準備できるようになりました。
そこで、下記の前提条件を元にして、Nginxの設定を行いたいと思います。
- ドキュメントルートは `/public` とする
- `nuxt build` によって生成される `index.html` 、及びその `index.html` から呼ばれる js ファイルは `public/dist/` 以下に配置する
- ブラウザに返された `index.html` からのAPIリクエストは `public/index.php` にルーティングする
この前提条件を満たす `nginx.conf` は下記になります。
```nginx:title=nginx.conf
server {
# Nginxが待ちうけるポートを指定
listen 8000 default_server;
# ドキュメントルートを指定
root /srv/public;
# {URL}/ の場合に {URL}/index.html を返す
# index index.html (デフォルト)
# /{任意の文字列} に前方一致するURLの場合に
# 1. /srv/public/{任意の文字列} に一致するファイルが存在すればそれを返し、存在しなければ
# 2. /dist/index.html?$query_string にリダイレクトする
location / {
try_files $uri /dist/index.html?$query_string;
}
# {任意の文字列1}/_nuxt/{任意の文字列2}に一致するURLの場合に
# 1. /srv/public/{任意の文字列1}/_nuxt/{任意の文字列2} に一致するファイルが存在すればそれを返し、存在しなければ
# 2. /dist/_nuxt/{任意の文字列2} にリダイレクトする
location ~ /(_nuxt)/(.+)$ {
try_files $uri /dist/$1/$2;
}
# {任意の文字列1}/api/{任意の文字列2}に一致するURLの場合に
# 1. /srv/public/{任意の文字列1}/api/{任意の文字列2} に一致するファイルが存在すればそれを返し、存在しなければ
# 2. /index.php?$query_string にリダイレクトする
location ~ /api/ {
try_files $uri /index.php?$query_string;
}
# {任意の文字列}.phpに一致するURLの場合に
# 1. /srv/public/{任意の文字列}.phpに一致するファイルが存在すれば、そのリクエストをFastCGIに渡し、存在しなければ404を返す
# 2. /index.php?$query_string にリダイレクトする
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/run/php/bcm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
}
```
実際のアクセスでどういう処理になるかは下記になります。
| 順番 | どういうアクセスか | Nginxはどういう処理をするか |
|------|--------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------|
| 1 | 初回アクセス | URLが `/` に一致するため `srv/public/dist/index.html` をブラウザに返却する |
| 2 | `index.html` の `<script>` タグに記述された `_nuxt/xxxx.js` を取得するアクセス | URLが `/(_nuxt)/(.+)$` に一致するため `srv/public/dist/_nuxt/xxxx.js` をブラウザに返却する |
| 3 | index.htmlからの `/api/xxx` というAPIアクセス | URLが `/api/` に一致するため `srv/public/index.php` を経て、Laravelで実装したレスポンスをブラウザに返却する |
この nginx.conf でルーティングがどうなるか読み解く鍵は下記かと思います。
- locationの前方一致と正規表現の優先順位の違い
- try_files の挙動
https://heartbeats.jp/hbblog/2012/04/nginx05.html の記事が非常に分かりやすく、参考にさせていただきました。
## Typescript対応
必ずしも必要ではありませんが、Nuxt.jsの場合ではTypescriptの導入が容易であるため、ついでに導入します。
[公式の導入手順](https://ja.nuxtjs.org/guide/typescript/) に従っていけば導入できます。
- 必要ライブラリのインストール
```bash
yarn add -D @nuxt/typescript @typescript-eslint/eslint-plugin @typescript-eslint/parser
yarn add ts-node vue-class-component vue-property-decorator
touch tsconfig.json
```
- `nuxt.config.js` の修正
- `NuxtConfiguration` を追記
- `nuxt.config.js` へリネーム
- [修正後のnuxt.config.ts](https://github.com/kon-shou/bcm-qiita-example/blob/48707dea0741f7e479650f1dd914061f9e628338/nuxt.config.ts)
- `npm run dev` 後に `tsconfig.json` の修正
- `"exclude": ["node_modules", "vendor"]` を追記
- `"baseUrl": "./client"` と修正
- [修正後のtsconfig.json](https://github.com/kon-shou/bcm-qiita-example/blob/48707dea0741f7e479650f1dd914061f9e628338/tsconfig.json)
- lint対応
- `parser` / `plugins` の修正
- [修正後の.eslintrc.js](https://github.com/kon-shou/bcm-qiita-example/blob/48707dea0741f7e479650f1dd914061f9e628338/.eslintrc.js)
- `.vue` ファイルをTypescript対応
- [修正後のindex.vue](https://github.com/kon-shou/bcm-qiita-example/blob/48707dea0741f7e479650f1dd914061f9e628338/client/pages/index.vue) ( `フロントでのモデル/ビジネスロジック実装` で新規でpage/componentを作るのでここでの修正は必要ありませんが、参考までに)
以上を実行すれば、Typescript でフロントを実装できると思います。
## サーバーでのモデル/ビジネスロジック実装
サーバで実装するのは下記の5つになります。
- Bookモデル
- migrationファイル
- Bookレポジトリ
- Bookコントローラ
- ルーティング
```bash
(root)
├── app
│ ├── Eloquent
│ │ └── Book.php => Bookモデル
│ ├── Http
│ │ ├── Controllers
│ │ │ └── BookController.php => Bookコントローラ
│ └── Repository
│ └── BookRepository.php => Bookレポジトリ
├── database
│ └── migrations
│ └── 2019_06_12_150818_create_books_table.php => migrationファイル
└── routes
└── api.php => ルーティング
```
また、本の登録のAPIリクエストがフロントから来た場合の、フローは下記になります。

それぞれについて解説します。
### Bookモデル
```php:title=Book.php
<?php
namespace App\Eloquent;
use Illuminate\Database\Eloquent\Model;
/**
* Class Book
* @package App\Eloquent
*
* @property int $id
* @property int $title
*/
class Book extends Model
{
}
```
本には「ID」と「タイトル」のみ存在するものとして、Bookモデルを定義します。
今回の場合、最低限の記述で良いかと思います
### migrationファイル
```php:title=database/migrations/2019_06_12_150818_create_books_table.php
<?php
use Illuminate\Support\Facades\Schema;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Database\Migrations\Migration;
class CreateBooksTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('books', function (Blueprint $table) {
$table->bigIncrements('id');
$table->string('title');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('books');
}
}
```
BookモデルはActiveRecordであるため、モデルのプロパティと同様のカラムを持たせています。
### Bookレポジトリ
```php:title=BookRepository.php
<?php
namespace App\Repository;
use App\Eloquent\Book;
use Illuminate\Support\Collection;
class BookRepository
{
public function find(int $id): ?Book
{
return Book::query()->find($id);
}
public function list(): Collection
{
return Book::query()->get();
}
public function create(string $title): Book
{
$book = new Book();
$book->title = $title;
$book->save();
return $book;
}
public function delete(Book $book)
{
return Book::query()->find($book->id)->delete();
}
}
```
コントローラで直接にデータを更新するのでなく、レポジトリでデータの更新を行い、コントローラはレポジトリのメソッドを呼び出すようにします。
このようにすることで「データが持たせ方が変わった場合(例: Bookの格納をRDSでなくNoSQLに変更する)に、修正範囲を限定させることが出来る」等々のメリットがあります。
### Bookコントローラ
```php:title=BookController.php
<?php
namespace App\Http\Controllers;
use App\Repository\BookRepository;
use Dotenv\Exception\ValidationException;
use Illuminate\Http\Request;
class BookController extends Controller
{
private $bookRepository;
public function __construct(BookRepository $bookRepository)
{
$this->bookRepository = $bookRepository;
}
public function list()
{
return $this->bookRepository->list();
}
public function create(Request $request)
{
$title = $request->get('title');
if (!$title) {
throw new ValidationException('titleは必須です');
}
return $this->bookRepository->create($title);
}
public function delete(int $id)
{
$book = $this->bookRepository->find($id);
if (!$book) {
throw new ValidationException('削除対象のbookが存在しません');
}
$this->bookRepository->delete($book);
return [];
}
}
```
コントローラでは、基本的にレポジトリのメソッドを呼び出すことで、Bookモデルの取得/登録/削除を行います。
また、BookRepositoryはコンストラクタでDIを行うことで、コントローラとレポジトリの依存関係を薄くしています。
こうすることで「ユニットテストでは、特別に用意したBookRepositoryを呼び出すことができ、ユニットテストの書きやすさが向上する」等々のメリットが有ります。
### ルーティング
```php:title=api.php
<?php
use Illuminate\Http\Request;
Route::group(['prefix' => 'book'], function ($route) {
$route->get('/', 'BookController@list');
$route->post('/create', 'BookController@create');
$route->delete('/delete/{id}', 'BookController@delete');
});
```
本の取得/登録/削除の3つのエンドポイントを用意し、それぞれからコントローラの対応するメソッドを呼びます。
### 確認
実際にAPIリクエストによってDBが更新されるか確認するためには以下の手順を踏みます。
1. `.env` の更新
2. MySQL に database を追加
3. migration実行
今回の場合だと mysqlコンテナの設定に合わせて、下記のように `.env` を更新します。
```env:title=.env
DB_CONNECTION=mysql
DB_HOST=mysql
DB_PORT=3306
DB_DATABASE=laravel
DB_USERNAME=root
DB_PASSWORD=
```
`.env` を更新した後に `php artisan config:cache` としてやることで `.env` の変更を反映させます。
その後、appコンテナから mysqlに接続 ( `docker-compose exec app mysql -h mysql -uroot` ) し
```sql
create database laravel;
```
とすることで laravel データベースを作成します。
そして `php artisan migrate` と実行することで、migrationが実行できるかと思います。
以上の準備をしたあとで、
```bash
curl http://localhost:8000/api/book/create -X POST -H "Content-Type: application/json" -d '{"title":"book_test"}'
```
と叩くことで、更新が行われ、そのレスポンスが帰ってくることが確認できるかと思います。
## フロントでのモデル/ビジネスロジック実装
フロントでは下記の6つを実装します。
- Bookモデル
- Bookレポジトリ
- plugins/dependency.ts
- index.d.ts
- Axios の proxy
- index.vue
```bash
(root)
├── client
│ ├── domain
│ │ └── Book
│ │ ├── Book.ts
│ │ └── BookRepository.ts
│ ├── pages
│ │ ├── index.vue
│ ├── plugins
│ │ └── dependency.ts
│ └── static
├── index.d.ts
└── nuxt.config.js
```
フロントにおけるBook取得/登録のフローは下記です。

なおフロントにレポジトリ層を持たせる設計については、拙作ではありますが [こちらのスライド](https://speakerdeck.com/kon_shou/shi-yun-yong-niokerularaveltonuxtdefalserepositoryfalsereiyafen-ge-falsehua) にて詳細を解説していますので、ご参考ください。
### Bookモデル
```typescript:title=Book.ts
import _ from 'lodash'
export default class Book {
constructor(protected properties: { [key: string]: any }) {}
get id(): string {
return _.get(this.properties, 'id')
}
get title(): string {
return _.get(this.properties, 'title')
}
}
```
サーバーと同様のBookモデルを定義します。
これによって `new Book({id: xxx, titile: yyy})` という形式でモデルを作ることができ、このモデルで型宣言を行うことができるようになります。
### Bookレポジトリ
```typescript:title=BookRepository.ts
import _ from 'lodash'
import { AxiosInstance } from 'axios'
import Book from '~/domain/Book/Book'
export default class BookRepository {
private axios: AxiosInstance
constructor(axios: AxiosInstance) {
this.axios = axios
}
public async listBooks(): Promise<Book[]> {
const response = await this.axios.get('/book/')
return _.map(response.data, bookData => new Book(bookData))
}
public async createBook(title: string): Promise<Book> {
const response = await this.axios.post('/book/create', {
title: title
})
return new Book(response.data)
}
public async deleteBook(book: Book) {
await this.axios.delete(`/book/delete/${book.id}`)
}
}
```
こちらもサーバーと同様にBookRepositoryを実装します。
メリットについてもサーバーと同様です。
コンストラクタで axiso を注入をしていますが、これは後述する `plugins/dependency.ts` にて注入を行っています。
注入によって axios の context を維持しつつAPIリクエストを投げられるようになります。
### plugins/dependency.ts
```typescript:title=dependency.ts
import BookRepository from '~/domain/Book/BookRepository'
export default (context, inject) => {
const bookRepository = new BookRepository(context.$axios)
inject('bookRepository', bookRepository)
}
```
BookRepositoryに `context.$axios` を渡し、生成された `bookRepository` を `$bookRepository` として Vue インスタンス内で呼び出せるように登録しています。
このプラグインを `nuxt.config.ts` にて呼び出します。
```typescript:title=nuxt.config.ts
plugins: ['~/plugins/dependency'],
```
なお、NuxtにおけるInjectionについては[公式ドキュメント](https://ja.nuxtjs.org/guide/plugins/) と https://tech.cydas.com/entry/nuxt-inject の記事が非常にわかりやすく、参考にさせていただきました。
### index.d.ts
`dependency.ts` にて `$bookRepository` を登録しましたが、このままだと Typescript のチェックでエラーが出るので型定義ファイルに `$bookRepository` に追加します。
```typescript:title=index.d.ts
import BookRepository from '~/domain/Book/BookRepository'
declare module 'vue/types/vue' {
interface Vue {
$bookRepository: BookRepository
}
}
```
### Axios の proxy
BookRepository にて axios を利用していますが、このままだと 例えば本の登録では、Nginxがリッスンしている `http://localhost:8000/api/book/create` でなく`http://localhost:3000/book/create` に対してリクエストをしてしまうので、下記の修正を行います。
- axios.baseURL の指定
下記を追記することで、urlのプレフィックスとして `/api` を付与します。
```typescript:title=nuxt.config.ts
axios: {
baseURL: '/api'
},
```
- `@nuxtjs/proxy` の利用
nuxt の [proxy-module](https://github.com/nuxt-community/proxy-module) を利用して、axiosからのリクエストを proxy します。
今回の場合は `.env` にAPIサーバーのURLを追記して、それを `nuxt.config.ts` に呼び出すことにします。
まず `.env` に下記を追加して
```env:title=.env
API_BASE_URL=http://localhost:8000/api
```
次に `nuxt.config.ts` を修正します。
```typescript:title=nuxt.config.ts
import NuxtConfiguration from '@nuxt/config'
require('dotenv').config()
const config: NuxtConfiguration = {
...
modules: [
// Doc: https://buefy.github.io/#/documentation
'nuxt-buefy',
// Doc: https://axios.nuxtjs.org/usage
'@nuxtjs/axios',
'@nuxtjs/eslint-module',
'@nuxtjs/proxy'
],
...
}
if (process.env.API_BASE_URL) {
config.proxy = [process.env.API_BASE_URL]
}
export default config
```
これによって axios のリクエストが `http://localhost:8000/api` に行われるようになります。
### index.vue
最後に index.vue の修正を行います。
index.vue では主に下記の3つの処理を行います。
- asynData() で `$bookRepository.listBooks()` を実行し、本の一覧を取得
- 登録ボタンクリックで `$bookRepository.createBook(this.title)` を実行し、本を登録し、その後に一覧を再取得
- 削除ボタンクリックで `$bookRepository.deleteBook(book)` を実行し、本を削除し、その後に一覧を再取得
```vue:title=index.vue
<template>
<section>
<table class="table">
<tr>
<th>ID</th>
<th>タイトル</th>
</tr>
<tr v-for="book in books" :key="book.id">
<td>{{ book.id }}</td>
<td>{{ book.title }}</td>
<td>
<button
type="button"
class="button is-primary"
@click.prevent="deleteBook(book)"
>
削除する
</button>
</td>
</tr>
</table>
<section class="modal-card-body">
<b-field label="本のタイトル">
<b-input v-model="title" type="input" placeholder="タイトル" />
</b-field>
<button
type="button"
class="button is-primary"
@click.prevent="createBook()"
>
登録する
</button>
</section>
<p v-if="error">{{ error }}</p>
</section>
</template>
<script lang="ts">
import { Component, Vue } from 'vue-property-decorator'
import Book from '~/domain/Book/Book'
@Component({
async asyncData({ app }) {
const books = await app.$bookRepository.listBooks()
return {
books
}
}
})
export default class extends Vue {
private books
private title = ''
private error = ''
async createBook() {
try {
await this.$bookRepository.createBook(this.title)
this.books = await this.$bookRepository.listBooks()
this.title = ''
} catch (e) {
this.error = e
}
}
async deleteBook(book: Book) {
try {
await this.$bookRepository.deleteBook(book)
this.books = await this.$bookRepository.listBooks()
} catch (e) {
this.error = e
}
}
}
</script>
```
### 確認
以上のフロント/サーバーでの実装が完了した後に
- docker-compose up -d
- npm run dev
を実行すれば、 `http://localhost:3000/` にてシステムが動作してることが確認できるかと思います。

## Heroku設定
herokuの設定としては、下記の5つを実装します
- `infra/nginx/nginx.conf` / `Procfile` の追加
- heroku buildpack の追加
- Clear DB の設定
- `app/Providers/AppServiceProvider.php` の修正
- 環境変数の設定
```bash
(root)
├── Procfile
├── app
│ └── Providers
│ └── AppServiceProvider.php
└── infra
└── heroku
└── nginx.conf
```
なお `heroku create` によるherokuとの連携は完了してる前提です。
### `infra/nginx/nginx.conf` / `Procfile` の追加
herokuで Nginx を使うために `infra/nginx/nginx.conf` を [herokuの公式ドキュメント](https://devcenter.heroku.com/articles/custom-php-settings#using-a-custom-application-level-nginx-configuration) に従って、新しく作成します。
- location ディレクティブのみを使う
- `fastcgi_pass` は `heroku-fcgi` を指定する
という点を反映させると、下記のようになると思います。
```nginx:title=nginx.conf
location / {
try_files $uri /public/dist/index.html?$query_string;
}
location ~ /_nuxt/(.+)$ {
try_files $uri /public/dist/_nuxt/$1;
}
location ~ /api/ {
try_files $uri /public/index.php?$query_string;
}
location ~ \.php$ {
try_files $uri /public/index.php =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass heroku-fcgi;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
```
また、上記の `nginx.conf` を利用するように、下記の `Procfile` を追加します。
```Procfile:title=Procfile
web: vendor/bin/heroku-php-nginx -C infra/heroku/nginx.conf
```
Procfileの役割については [公式ドキュメント](https://devcenter.heroku.com/articles/procfile) に記載が有ります。
### heroku buildpack の追加
heroku にデプロイは `git push heroku master` で行いますが、その push 後の起動処理を行うためにビルドパックを追加します。
```bash
heroku buildpacks:add heroku/nodejs
heroku buildpacks:add heroku/php
```
これによって、フロントのビルドや必要ライブラリのインストールを実行されます。
### Clear DB の設定
heroku でも mysql を利用するために [ClearDB](https://elements.heroku.com/addons/cleardb) を利用したいと思います。
まず下記コマンドを叩きます。
```bash
heroku addons:add cleardb
```
すると `CLEARDB_DATABASE_URL` という変数が `heroku config` に設定されると思います。
この `CLEARDB_DATABASE_URL` は下記のように読み解けます。
```bash
mysql://{DB_USERNAME}:{DB_PASSWORD}@{DB_HOST}/{DB_DATABASE}?reconnect=true
```
そこで下記のようにHerokuの環境変数にセットすることで、laravelからDBアクセスを行えるようになります。
```bash
heroku config:set DB_HOST={DB_HOST}
heroku config:set DB_DATABASE={DB_DATABASE}
heroku config:set DB_USERNAME={DB_USERNAME}
heroku config:set DB_PASSWORD={DB_PASSWORD}
```
以上で、本来ならば Mysql接続が完了してほしいところですが、laravel の想定してる Mysql のバージョンとHerokuのMysql のバージョンが異なっているためか、migration 実行時にエラーが発生します。
そのため、下記のように修正を行います。
```php:title=AppServiceProvider.php
<?php
namespace App\Providers;
use Illuminate\Support\Facades\Schema;
use Illuminate\Support\ServiceProvider;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
//
}
/**
* Bootstrap any application services.
*
* @return void
*/
public function boot()
{
Schema::defaultStringLength(191);
}
}
```
こちらの対応は https://qiita.com/beer_geek/items/6e4264db142745ea666f を参考にさせていただきました。
### 確認
以上の準備が完了した後に
1. `git push heroku master`
2. `heroku run php artisan migrate`
を実行すれば、実際にブラウザで動作していることが確認できると思います。
## 終わりに
以上で、Lareavel+Nuxt.jsで作ったwebアプリをHerokuにデプロイさせることが出来ました。
記事の内容で誤ってる点や追記が必要な点も多いと思いますが、その際にはコメントや編集リクエストでご指摘いただければと思います。
この記事がWeb開発における0から1へのフェーズに学習する方の参考になれば幸いです。
## 参考
- https://readouble.com/laravel/5.8/ja/
- https://ja.nuxtjs.org/
- https://www.php.net/manual/ja/install.fpm.configuration.php
- https://github.com/nuxt/nuxt.js/issues/3217
- https://heartbeats.jp/hbblog/2012/04/nginx05.html
- http://kimh.github.io/blog/jp/docker/gothas-in-writing-dockerfile-jp/#hack_to_run_container_in_the_background
- https://tech.cydas.com/entry/nuxt-inject
- https://devcenter.heroku.com/articles/custom-php-settings#using-a-custom-application-level-nginx-configuration
- https://qiita.com/kuni-nakaji/items/d11219e4ad7c74ece748
- https://qiita.com/beer_geek/items/6e4264db142745ea666f
- https://speakerdeck.com/kon_shou/shi-yun-yong-niokerularaveltonuxtdefalserepositoryfalsereiyafen-ge-falsehua | 27,293 | MIT |
# 2021-01-24
共 33 条
<!-- BEGIN -->
<!-- 最后更新时间 Sun Jan 24 2021 23:24:00 GMT+0800 (CST) -->
1. [【自制】如何制作一个迷你透明显示器](https://www.zhihu.com/zvideo/1336472161574772736)
2. [折磨王刘备](https://www.zhihu.com/zvideo/1336619718334283776)
3. [好吃的周黑鸭究竟需要多少种调料才可以做出来?](https://www.zhihu.com/zvideo/1336739996271656960)
4. [酸辣汤怎么做好喝?记住这三点,酸辣爽口,味道超赞](https://www.zhihu.com/zvideo/1336383022066245632)
5. [绵羊洗个热水澡后会不会缩水?](https://www.zhihu.com/zvideo/1336736059782868992)
6. [黄焖牛肉简单家常做法,酱香浓郁,软烂入味,年夜饭给家人露一手](https://www.zhihu.com/zvideo/1336628630609915904)
7. [胖家军带货:皇家皮衣](https://www.zhihu.com/zvideo/1336640566860226560)
8. [姐姐天生就该让着弟弟?这部纪录片,中国的父母们都该看看!](https://www.zhihu.com/zvideo/1336257745747103745)
9. [胖家军带货:强力生发剂](https://www.zhihu.com/zvideo/1336640952786853888)
10. [当代大孝子合辑之《父慈子孝》](https://www.zhihu.com/zvideo/1336727884699455489)
11. [当孩子给母亲买生日礼物时,各国妈妈不同的反应,最后一个太真实了!](https://www.zhihu.com/zvideo/1335640070054203392)
12. [救助高架桥被困三花猫,升降车师傅竖起大拇指,你们是在做好事!](https://www.zhihu.com/zvideo/1336706597222506496)
13. [老鼠视角!代入感极强](https://www.zhihu.com/zvideo/1336333106484482048)
14. [过气网红美食?现在拍战斧牛排还来得及吗?](https://www.zhihu.com/zvideo/1336472793404862464)
15. [华晨宇勇认「私生子」,为什么是一场顶级舆论操纵公关战?](https://www.zhihu.com/zvideo/1336661936369840128)
16. [中国十大神级历史纪录片,不要被影视剧带偏,见证真正历史的厚重](https://www.zhihu.com/zvideo/1334800228810145792)
17. [用《流浪地球》打开中国抗疫这一年](https://www.zhihu.com/zvideo/1336413932429504512)
18. [【你没听过】国家玮谈:八省联考作文满分套路](https://www.zhihu.com/zvideo/1336343731352190976)
19. [【反面教材】都是坑!教科书上教的那些不礼貌日语](https://www.zhihu.com/zvideo/1336376571020800000)
20. [两只橘猫手牵手搂着小主人睡觉,实在太有爱](https://www.zhihu.com/zvideo/1336411930684944384)
21. [久等了!感谢你们的支持和鼓励。摇篮曲请直接到 48
秒](https://www.zhihu.com/zvideo/1336599451091902464)
22. [【英文脱口秀】小时候,我很讨厌外国人](https://www.zhihu.com/zvideo/1336357170648895488)
23. [响应号召不聚餐,厨师长送同事们 80
大碗年菜带回家过年](https://www.zhihu.com/zvideo/1336300241767960576)
24. [心脏支架的开箱和细节放大展示,这玩意我真没办法评测和试用](https://www.zhihu.com/zvideo/1336298187271737344)
25. [知乎 x 王源《答案》概念主题曲录制花絮|1 月 26 日 10
点完整单曲全网发布](https://www.zhihu.com/zvideo/1336277557092970496)
26. [警方通报云南 2
初中生被劫持:犯罪嫌疑人已被击毙,人质获救](https://www.zhihu.com/zvideo/1336039758666354688)
27. [华晨宇大义认女,张碧晨主动揽锅,完美公关背后有何真相?【不良博士】](https://www.zhihu.com/zvideo/1336376166416781312)
28. [蘑菇炒肉到底是先炒蘑菇还是肉,难怪不好吃,看酒店大厨如何操作](https://www.zhihu.com/zvideo/1336261991657484288)
29. [厨师长王刚初次分享拍摄花絮](https://www.zhihu.com/zvideo/1336349965258280960)
30. [新冠病毒检测为什么要做肛拭子采样,肛拭子怎么做?会不会很尴尬](https://www.zhihu.com/zvideo/1336302171580051456)
31. [不同明星在颁奖典礼前的采访!真是太真实了!](https://www.zhihu.com/zvideo/1335639801307848704)
32. [奶猫打架太萌了,小猫咪:我就咬一口](https://www.zhihu.com/zvideo/1335247055874985984)
33. [魏晨曾直言郑爽不像表面那么简单,性格一直很放飞自我](https://www.zhihu.com/zvideo/1335689700326543360)
<!-- END --> | 2,742 | MIT |
---
layout: post
title: "閱讀筆耕|滿3個月•LikeCoin生利息"
date: 2020-12-02T10:13:25.000Z
author: 閱讀筆耕
from: https://matters.news/@penfarming/%25E9%2596%25B1%25E8%25AE%2580%25E7%25AD%2586%25E8%2580%2595-%25E6%25BB%25BF3%25E5%2580%258B%25E6%259C%2588-like-coin%25E7%2594%259F%25E5%2588%25A9%25E6%2581%25AF-bafyreiaqlgpxdclocumdtc5qtv7jys3bd2z2fxuewa74jegg7caasrlw2a
tags: [ Matters ]
categories: [ Matters ]
---
<!--1606904005000-->
[閱讀筆耕|滿3個月•LikeCoin生利息](https://matters.news/@penfarming/%25E9%2596%25B1%25E8%25AE%2580%25E7%25AD%2586%25E8%2580%2595-%25E6%25BB%25BF3%25E5%2580%258B%25E6%259C%2588-like-coin%25E7%2594%259F%25E5%2588%25A9%25E6%2581%25AF-bafyreiaqlgpxdclocumdtc5qtv7jys3bd2z2fxuewa74jegg7caasrlw2a)
------
<div>
閱讀筆耕|滿3個月•LikeCoin生利息
</div> | 745 | MIT |
## 子组件的定义和注册
我们在本文的第一段中,通过`Vue.component`形式定义的是**全局组件**。这一段中,我们来讲一下**子组件**。
### 在父组件中定义子组件
比如说,一个`账号`模块是父组件,里面分为`登陆`模块和`注册`模块,这两个晓得模块就可以定义为子组件。
需要注意的是作用域的问题:我们在父组件中定义的子组件,只能在当前父组件的模板中使用;在其他的组件,甚至根组件中,都无法使用。
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<account>
</account>
</div>
<script>
//定义、注册组件
Vue.component('account', {
template: '<div><h2>账号模块</h2> <login></login></div>',
components: {
'login': {
template: '<h3>登录模块</h3>'
}
}
});
new Vue({
el: '#app'
});
</script>
</body>
</html>
```
我们发现,既然是定义父亲`<account>`的子组件,那么,子组件`<login>`的调用,只能写在父组件`<account>`的`template`模板中。
显示效果:

### 在 Vue 根实例中定义子组件
当然,我们还可以这样做:把整个 Vue 对象当成父亲,这样的话,就可以在 Vue 示例中定义一个子组件。如下:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<login> </login>
</div>
<script>
new Vue({
el: '#app',
//在Vue实例中定义子组件
components: { // components 是关键字,不能改
'login': {
template: '<h3>登录模块</h3>'
}
}
});
</script>
</body>
</html>
```
这样写的话,我们定义的子组件`<login>`在整个`#app`区域,都是可以使用的。
上面的代码,还有**另外一种写法**:(把子组件的模板定义,存放到变量中)【重要】
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<login> </login>
</div>
<script>
//通过变量接收定义的子组件
var myLogin = {
template: '<h3>登录模块</h3>' // template 是关键字,不能改
}
new Vue({
el: '#app',
//在Vue实例中定义子组件
components: { // components 是关键字,不能改
'login': myLogin
}
});
</script>
</body>
</html>
```
注意,在定义子组件时,关键字`components`不要写错了。
## 组件之间的动态切换(暂略)
我们可以利用`<component> `标签的`:is`参数来进行组件之间的切换。
## 父组件向子组件传递数据
我们要记住:父组件通过**属性**的形式,向子组件传递数据。
**引入**:
我们先来看这样一段代码:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<script src="vue2.5.16.js"></script>
<body>
<div id="app">
<!-- 这里是父组件的范围,自定义一个数值 number -->
<counter number="1+2"> </counter>
<counter number="10+20"> </counter>
</div>
<script>
var myCounter = {
//【重要】这里是子组件的范围,无法直接获取父组件中的 number
template: '<div>我是子组件。{{number}}</div>'
}
var vm = new Vue({
el: '#app',
components: {
'counter': myCounter
}
});
</script>
</body>
</html>
```
上方代码中,我想把父组件里 number 的数值传递给子组件,直接这样写,是看不到效果的:

**1、父组件传值给子组件**:
要通过 props 属性将number进行传递给子组件才可以。代码如下:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<script src="vue2.5.16.js"></script>
<body>
<div id="app">
<!-- 这里是父组件的范围,自定义一个数值 number -->
<counter :number="1+2"> </counter>
<counter :number="10+20"> </counter>
</div>
<script>
var myCounter = {
//这里是子组件的范围
props: ['number'], //通过 props 属性将父亲的 number 数据传递给子组件
template: '<div>我是子组件。{{number}}</div>'
}
var vm = new Vue({
el: '#app',
components: {
'counter': myCounter
}
});
</script>
</body>
</html>
```
在`<counter>`标签中,要注意`:number`里的冒号。加上冒号,那么引号里的内容就是表达式(期望的结果);否则,引号的内容只是字符串:

**2、子组件获取了父组件的数据后,进行求和操作**:
上方代码中,子组件已经获取了父组件的两个number,现在要求:每点击一次子组件,在子组件中将数据加 1。
一般人可能会这样写:(不推荐的写法:子组件直接修改父组件中的数据)
```javascript
var myCounter = {
//这里是子组件的范围
props: ['number'], //通过 props 属性将父亲的数据传递给子组件
template: '<div @click="addClick">我是子组件。{{number}}</div>',
methods: {
addClick: function () {
this.number ++; //这种写法不推荐。不建议直接操作父组件中的数据
}
}
}
```
上方代码的写法不推荐,因为不建议直接操作父组件中的数据。虽然数据操作成功,但是控制台会报错:
img.png
这样涉及到**单向数据流**的概念:
- 父组件可以传递参数给子组件,但是反过来,子组件不要去修改父组件传递过来的参数。因为同一个参数,可能会传递给多个子组件,避免造成修改的冲突。
既然如此,我可以把父组件中的数据,在子组件中创建**副本**,然后我们去修改这个副本,就不会造成影响了。最终,完整版代码如下:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<script src="vue2.5.16.js"></script>
<body>
<div id="app">
<!-- 这里是父组件的范围,自定义一个数值 number -->
<counter :number="1+2"> </counter>
<counter :number="10+20"> </counter>
</div>
<script>
var myCounter = {
//这里是子组件的范围
props: ['number'], //通过 props 属性将父亲的数据传递给子组件
data: function () {
return {
number2: this.number
}
},
template: '<div @click="addClick">我是子组件。{{number2}}</div>',
methods: {
addClick: function () {
this.number2 ++; //操作和修改number的副本
}
}
}
var vm = new Vue({
el: '#app',
components: {
'counter': myCounter
},
});
</script>
</body>
</html>
```
## 子组件向父组件传值
我们要记住:子组件通过**事件触发**的形式,向父组件传值。
**案例1:**子组件给父组件传递数据
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<!-- 在外层监听`mysend`事件,进而出发外层的 getData 方法 -->
<counter v-on:mysend="getData"> </counter>
</div>
<script>
Vue.component('counter', {
template: '<div @click = "addClick">发送数据给父组件</div>', //当组件被点击时,触发 addClick 方法
methods: {
addClick: function () {
//第一个参数为键(注意,要小写,不能大写),第二个参数为值
this.$emit('mysend', 'smyhvae'); //通过键`mysend`事件通知外面,将值`smyhvae`传给父组件
}
}
});
new Vue({
el: '#app',
methods: {
getData: function (input) { //通过括号里的参数,获取子组件传递过来的值
console.log(input); //打印结果:smyhvae
}
}
});
</script>
</body>
</html>
```
**案例2**:获取子组件的DOM对象
题目:给两个相同的子组件定义计数器,每点击一次,数值加1。然后在父组件中求和。
步骤(1):给两个相同的子组件定义计数器,每点击一次,数值加1。代码如下:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<counter> </counter>
<counter> </counter>
</div>
<script>
Vue.component('counter', {
template: '<div @click = "addClick">当前计数:{{number}}</div>', //当组件被点击时,调用 addClick 方法
data: function () {
return {
number: 0 //给组件定义一个数据:number
}
},
methods: {
addClick: function () {
this.number++; //定义方法:每点击一次,number 的数值加 1
}
}
});
new Vue({
el: '#app'
});
</script>
</body>
</html>
```
步骤(2):两个子组件的数值加 1 后,通知父组件。代码如下:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<!-- 在外层监听`change`事件,进而出发外层的 myClick 方法 -->
<counter @change="myMethod"> </counter>
<counter @change="myMethod"> </counter>
</div>
<script>
Vue.component('counter', {
template: '<div @click = "addClick">当前计数:{{number}}</div>', //当组件被点击时,
data: function () {
return {
number: 0 //给组件定义一个数据:number
}
},
methods: {
addClick: function () {
this.number++; //定义方法:每点击一次,number 的数值加 1
this.$emit('change'); //通过这一行的`change`,通知外面,内部的 addClick 方法已经执行了
}
}
});
new Vue({
el: '#app',
methods: {
myMethod: function () {
console.log('触发父组件');
}
}
});
</script>
</body>
</html>
```
上方代码中,通过关键字`emit`通知父组件,子组件里的 addClick 方法被执行了。父组件得知后,执行`myMethod()`方法(这个方法是在Vue实例中定义的,很好理解)
步骤(3):在父组件中求和
既然父组件已经得知子组件的 addClick 事件,那我们直接在父组件的`myMethod()`里定义求和的方法即可。
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script src="vue2.5.16.js"></script>
</head>
<body>
<div id="app">
<!-- 在外层监听`change`事件,进而触发外层的 myMethod 方法 -->
<counter ref="one" @change="myMethod"> </counter>
<counter ref="two" @change="myMethod"> </counter>
<div>{{totalData}}</div>
</div>
<script>
Vue.component('counter', {
template: '<div @click = "addClick">当前计数:{{number}}</div>', //当组件被点击时,触发 addClick方法
data: function () {
return {
number: 0 //给组件定义一个数据:number
}
},
methods: {
addClick: function () {
this.number++; //定义方法:每点击一次,number 的数值加 1
this.$emit('change'); //通过这一行自定义的`change`,通知外面,内部的 addClick 方法已经执行了
}
}
});
new Vue({
el: '#app',
data: {
totalData: 0
},
methods: {
myMethod: function () {
console.log('触发父组件');
//通过`$refs`获取子组件中各自的number数值
var a1 = this.$refs.one.number;
var a2 = this.$refs.two.number;
//求和,存放在父组件的 totalData 中
this.totalData = a1 + a2;
console.log();
}
}
});
</script>
</body>
</html>
```
代码的关键:
- 在`<counter>`标签中,通过 `ref = "xxx"`属性,给各个组件起一个别名,代表组件的引用
- 在父函数`myMethod()`中,通过`this.$refs.xxx`获取组件的引用。我们看一下最后两行代码在控制台的输出便知:(组件里有 number 属性)
 | 12,568 | MIT |
---
title: Kubernetes on Azure のチュートリアル - クラスターのデプロイ
description: この Azure Kubernetes Service (AKS) のチュートリアルでは、AKS クラスターを作成し、kubectl を使用して Kubernetes マスター ノードに接続します。
services: container-service
author: mlearned
ms.service: container-service
ms.topic: tutorial
ms.date: 12/19/2018
ms.author: mlearned
ms.custom: mvc
ms.openlocfilehash: 130cb973f2de1de0d4c4636a4752a06e22edf65b
ms.sourcegitcommit: fa6fe765e08aa2e015f2f8dbc2445664d63cc591
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 02/01/2020
ms.locfileid: "76932559"
---
# <a name="tutorial-deploy-an-azure-kubernetes-service-aks-cluster"></a>チュートリアル:Azure Kubernetes Service (AKS) クラスターのデプロイ
Kubernetes には、コンテナー化されたアプリケーション用の分散プラットフォームが用意されています。 AKS を使うと、運用開始準備の整った Kubernetes クラスターを迅速に作成できます。 このチュートリアル (7 部構成の第 3 部) では、Kubernetes クラスターを AKS にデプロイします。 学習内容は次のとおりです。
> [!div class="checklist"]
> * Azure Container Registry に対して認証できる Kubernetes AKS クラスターをデプロイする
> * Kubernetes CLI (kubectl) をインストールする
> * kubectl を構成して AKS クラスターに接続する
追加のチュートリアルでは、Azure Vote アプリケーションをクラスターにデプロイし、スケーリングおよび更新します。
## <a name="before-you-begin"></a>開始する前に
これまでのチュートリアルでは、コンテナー イメージを作成して、Azure Container Registry インスタンスにアップロードしました。 これらの手順を完了しておらず、順番に進めたい場合は、[チュートリアル 1 - コンテナー イメージを作成する][aks-tutorial-prepare-app]に関するページから開始してください。
このチュートリアルでは、Azure CLI バージョン 2.0.75 以降を実行している必要があります。 バージョンを確認するには、`az --version` を実行します。 インストールまたはアップグレードする必要がある場合は、[Azure CLI のインストール][azure-cli-install]に関するページを参照してください。
## <a name="create-a-kubernetes-cluster"></a>Kubernetes クラスターを作成する
AKS クラスターでは、Kubernetes のロールベースのアクセス制御 (RBAC) を使用できます。 これらのコントロールを使用すると、ユーザーに割り当てられているロールに基づいてリソースへのアクセスを定義できます。 ユーザーに複数のロールが割り当てられている場合は、アクセス許可が組み合わされます。また、アクセス許可のスコープを 1 つの名前空間またはクラスター全体に設定できます。 Azure CLI の既定では、AKS クラスターを作成するときに RBAC が自動的に有効になります。
[az aks create][] を使用して AKS クラスターを作成します。 次の例では、*myResourceGroup* という名前のリソース グループに *myAKSCluster* という名前のクラスターを作成します。 このリソース グループは、[前のチュートリアル][aks-tutorial-prepare-acr]で作成しました。 AKS クラスターが他の Azure リソースと対話できるようにするために、Azure Active Directory のサービス プリンシパルが自動的に作成されます (指定しなかったため)。 この場合、このサービス プリンシパルは、前のチュートリアルで作成した Azure Container Registry (ACR) インスタンスから[イメージをプルする権利を付与][container-registry-integration]されます。
```azurecli
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--generate-ssh-keys \
--attach-acr <acrName>
```
数分してデプロイが完了すると、この AKS デプロイに関する情報が JSON 形式で表示されます。
> [!NOTE]
> クラスターが確実に動作するようにするには、少なくとも 2 つのノードを実行する必要があります。
## <a name="install-the-kubernetes-cli"></a>Kubernetes CLI のインストール
お使いのローカル コンピューターから Kubernetes クラスターに接続するには、[kubectl][kubectl] (Kubernetes コマンドライン クライアント) を使用します。
Azure Cloud Shell を使用している場合、`kubectl` は既にインストールされています。 [az aks install-cli][] コマンドを使用してローカルにインストールすることもできます。
```azurecli
az aks install-cli
```
## <a name="connect-to-cluster-using-kubectl"></a>kubectl を使用したクラスターへの接続
Kubernetes クラスターに接続するように `kubectl` を構成するには、[az aks get-credentials][] コマンドを使用します。 次の例では、*myResourceGroup* の *myAKSCluster* という名前の AKS クラスターの資格情報を取得します。
```azurecli
az aks get-credentials --resource-group myResourceGroup --name myAKSCluster
```
クラスターへの接続を確認するには、クラスター ノードの一覧を返す [kubectl get nodes][kubectl-get] コマンドを実行します。
```
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-12345678-0 Ready agent 32m v1.13.10
```
## <a name="next-steps"></a>次のステップ
このチュートリアルでは、Kubernetes クラスターを AKS にデプロイし、`kubectl` を構成してクラスターに接続しました。 以下の方法を学習しました。
> [!div class="checklist"]
> * Azure Container Registry に対して認証できる Kubernetes AKS クラスターをデプロイする
> * Kubernetes CLI (kubectl) をインストールする
> * kubectl を構成して AKS クラスターに接続する
次のチュートリアルに進み、アプリケーションをクラスターにデプロイする方法を学習してください。
> [!div class="nextstepaction"]
> [Kubernetes でアプリケーションをデプロイする][aks-tutorial-deploy-app]
<!-- LINKS - external -->
[kubectl]: https://kubernetes.io/docs/user-guide/kubectl/
[kubectl-get]: https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#get
<!-- LINKS - internal -->
[aks-tutorial-deploy-app]: ./tutorial-kubernetes-deploy-application.md
[aks-tutorial-prepare-acr]: ./tutorial-kubernetes-prepare-acr.md
[aks-tutorial-prepare-app]: ./tutorial-kubernetes-prepare-app.md
[az ad sp create-for-rbac]: /cli/azure/ad/sp#az-ad-sp-create-for-rbac
[az acr show]: /cli/azure/acr#az-acr-show
[az role assignment create]: /cli/azure/role/assignment#az-role-assignment-create
[az aks create]: /cli/azure/aks#az-aks-create
[az aks install-cli]: /cli/azure/aks#az-aks-install-cli
[az aks get-credentials]: /cli/azure/aks#az-aks-get-credentials
[azure-cli-install]: /cli/azure/install-azure-cli
[container-registry-integration]: ./cluster-container-registry-integration.md | 4,639 | CC-BY-4.0 |
---
title: "Splinterlands 将 DEC 代币带到 Uniswap"
date: 2020-10-05T21:57:40+08:00
lastmod: 2020-10-05T16:45:40+08:00
draft: false
authors: ["Harvester"]
description: "在交易卡牌游戏 Splinterlands 中获得的暗能量水晶现在可以在去中心化交易所 Uniswap 上交易。持有大量 DEC 代币并在交易所提供流动性的游戏玩家将获得虚拟土地作为奖励。Splinterlands正在赠送3000块土地,同时他们正在组织基于交易活动的抽奖活动。"
featuredImage: "splinterlands-brings-dec-token-to-uniswap.png"
tags: ["Virtual World","虚拟世界","Play to Earn"]
categories: ["news"]
news: ["虚拟世界"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
在交易卡牌游戏 Splinterlands 中获得的暗能量水晶现在可以在去中心化交易所 Uniswap 上交易。持有大量 DEC 代币并在交易所提供流动性的游戏玩家将获得虚拟土地作为奖励。Splinterlands正在赠送3000块土地,同时他们正在组织基于交易活动的抽奖活动。
<!--more--> | 686 | MIT |
---
title: "MarkdownのコードブロックをESLintでチェックするtextlintルール"
author: azu
layout: post
date : 2016-07-06T20:24
category: JavaScript
tags:
- JavaScript
- book
- jsprimer
- textlint
- ESLint
---
今、[js-primer](https://github.com/asciidwango/js-primer "js-primer")を書いていて、この本ではいろんなものをテストできる状態にして開発しています。
詳しくは[CONTRIBUTING.md](https://github.com/asciidwango/js-primer/blob/master/CONTRIBUTING.md "CONTRIBUTING.md")に書いていますが、今のところ次のようなテストが常に回っています。(CONTRIBUTINGもお待ちしています)
- GitBookのビルドテスト
- [textlint](https://textlint.github.io/)による文章のLint
- [ESLint](http://eslint.org/ "ESLint")によるコードのLint
- [textlint](https://textlint.github.io/) + [ESLint](http://eslint.org/ "ESLint")によるMarkdown中のインラインコードブロックのLint
- Markdown中のインラインコードブロックへのDocTest
- [Mocha](http://mochajs.org/ "Mocha")による`*-test.js`ファイルのユニットテスト
- `*-example.js`がJavaScriptとして実行できるかのテスト
- `*-invalid.js`がJavaScriptとして実行できないかのテスト
JavaScriptを学ぶ本なので、大量のサンプルコードがでてくるのですが、そのサンプルコードが常に正しくある必要があります。
そのため、いろんな方向からテストして間違っているサンプルコードを含めないようにしています(逆に間違っていることをテストする仕組みもあります)
サンプルコードは大きく分けると、文章中にコードブロックで直接書くインラインコードと外部ファイルとして作成して読み込むコードがあります。
- [サンプルコード | 技術文書をソフトウェア開発する話](https://azu.gitbooks.io/nodefest-technical-writing/content/slide/61.html "サンプルコード | 技術文書をソフトウェア開発する話")
インラインコードは、ESLintでスタイルのチェックや[doctest](https://github.com/azu/power-doctest "doctest")を行い実行結果のテストをしています。
以前話した方法ではESLintの[eslint-plugin-markdown](https://github.com/eslint/eslint-plugin-markdown "eslint-plugin-markdown")を使い、インラインコードをESLintでチェックしていました。
- [インラインコードのLint | 技術文書をソフトウェア開発する話](https://azu.gitbooks.io/nodefest-technical-writing/content/slide/67.html "インラインコードのLint | 技術文書をソフトウェア開発する話")
普通なら正しいコードしか出てこないので問題ないのですが、入門書という位置づけであるため次のような間違ったコードも解説として登場します。
そして、一度`const`で宣言された変数には再代入できなくなります。
そのため、次のコードでは`bookTitle`を上書きしようとして`TypeError`となります。
```js
const bookTitle = "JavaScriptの本";
bookTitle = "上書き"; // TypeError: invalid assignment to const `bookTitle'
```
一般に変数への再代入は「変数の値は最初に定義した値と常に同じである」という参照透過性を壊すため、
バグを発生させやすい要因として知られています。
via [変数と宣言 · JavaScriptの入門書 #jsprimer](https://jsprimer.net/basic/variables/ "変数と宣言 · JavaScriptの入門書 #jsprimer")
[eslint-plugin-markdown](https://github.com/eslint/eslint-plugin-markdown "eslint-plugin-markdown")では`js`がついたコードブロックが自動でチェックされてしまうため、このコードブロック自体を無視して欲しいという書き方ができません。
(コードの中でESLintを `eslint-disable` はできるが表示されてしまう)
そのため、Markdownのレベルでコードブロックを無視できるような仕組みが必要になりました。
## [textlint-rule-eslint](https://github.com/azu/textlint-rule-eslint "textlint-rule-eslint")
[textlint](https://textlint.github.io/)は7.0からフィルタールールという機能を持っていて、このフィルタールールである[textlint-filter-rule-comments](https://github.com/textlint/textlint-filter-rule-comments "textlint-filter-rule-comments")を使えば次のような形で無視する領域を作ることができます。
<!-- textlint-disable -->
この部分はtextlintのチェックでエラーがあっても無視される
<!-- textlint-enable -->
- [textlint 7.0リリース、フィルタールールの追加 | Web Scratch](https://efcl.info/2016/06/30/textlint7.0/ "textlint 7.0リリース、フィルタールールの追加 | Web Scratch")
つまり、textlintのルールとしてESLintを動かすことができれば、textlintとしてコードブロックを無視する = ESLintのチェックしないコードブロックを作れるので[textlint-rule-eslint](https://github.com/azu/textlint-rule-eslint "textlint-rule-eslint")を作りました。
(プラグインの[アーキテクチャとかも似てる](https://azu.gitbooks.io/javascript-plugin-architecture/content/ja/ESLint/)ので10分ぐらいでできた)
これでインラインコードと外部ファイルのJavaScriptにESLintを適応することができるので、インデントがずれてないかやSyntaxがおかしくないかなどのチェックをすることができるようになっています。
(逆にベストプラクティス的なルールは引っかかりまくるので外しています…)
### おまけ
後、最近入れた面白いテストとしてdoctestライクなものをテストとして入れています。
`*-example.js`のJavaScriptファイルとMarkdownのインラインコードブロックを対象にDocTestが実行されています。
次のように`// => 値`というコメントを書いた部分に対してDocTestが実行されます。
```js
let a = 42;
console.log(42); // => 42
```
これにより、サンプルコードのコメントに書いた評価結果と実際の出力が一致するかをテストしてる感じです。
色々テストを入れているのは、いい文章といいコードは同時に書くのが難しいというのもあります。
そのため、とにかく機械的に落とせる部分は落とせるようにしています。
<blockquote class="twitter-tweet" data-lang="en"><p lang="ja" dir="ltr">色々コードを考えて書いた結果、文章がダメだとCIが落ちる</p>— azu (@azu_re) <a href="https://twitter.com/azu_re/status/749461790744977408">July 3, 2016</a></blockquote>
<script async src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="ja" dir="ltr">読みやすい文章と読みやすいコードは同時に書くのが難しい "[WIP] 条件分岐の実装 by azu · Pull Request #69 · asciidwango/js-primer" <a href="https://t.co/UJ41KV5Ttk">https://t.co/UJ41KV5Ttk</a></p>— azu (@azu_re) <a href="https://twitter.com/azu_re/status/749462503889833984">July 3, 2016</a></blockquote>
<script async src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
後、機械的にチェックする利点の話は以下の文章を読むと面白いかもしれません。
> ツールによる検査の利点
> [文書執筆の指南書で解説されている問題点を RedPen で発見する - Qiita](http://qiita.com/takahi-i/items/a8b994ef17fd66fe6237 "文書執筆の指南書で解説されている問題点を RedPen で発見する - Qiita")
リポジトリをWatchしていると分かるかもしれませんが、書く前に[Issues · asciidwango/js-primer](https://github.com/asciidwango/js-primer/issues "Issues · asciidwango/js-primer")にどういう方針にするか、どういうサンプルコードがあると話がし易いかなどの設計をすることが多いです。
(なので適当にコメントしてくれると参考になります)
書きながら考えることも多いのですが、その場合はごちゃごちゃした文章ができて大体CIが落ち始めます。そこで機械的なチェックやPull Requestを出して自分でレビューする(PRも勝手にコメントくれると嬉しい)と少しはまともになります。
そういうことを繰り返しを行うことで文章やコードの質を上げる方法を取っています。([textlint](https://textlint.github.io/)を入れたところで文章の質が上がるわけではないです)
まあ、一発でテストが通った文章とか不安になるのと同じ感覚です。 | 5,184 | MIT |
---
title: "ARC のメモリ解放タイミングを調べた"
date: 2013-09-02
tags: [Objective-C,iOS]
layout: layouts/post.njk
page_name: when-release-memory-by-arc
permalink: "/blog/{{ page.date | date: '%Y/%m/%d' }}/{{ page_name }}/index.html"
---
一つの関数内で容量の大きなファイルを読み込み加工する処理を連続して行っていたらメモリが足りなくなった。
<!--more-->
ARC ではスコープを外れ(て参照カウンタがゼロになっ)たオブジェクトは、すぐに破棄されると思っていたのでしばらくハマった。
## 問題のソース(ARC使用)
ローカルでもWebでも何でもいいけど、ファイルから無視できない程度の容量のデータの読み込みを繰り返す処理。
```
- (IBAction)buttonDownWithArc:(id)sender {
NSString* path = @".../bigdata.img";
for (int i = 0; i < 10000; i++) {
NSData* data = [NSData dataWithContentsOfFile:path];
[NSThread sleepForTimeInterval:0.5];
data = nil;
}
}
```
これを Instruments でプロファイルするとこうなる。

じゃんじゃんメモリ確保してしまう(汗
ARC で ``data`` は ``nil`` にしてるからスコープ外れた時にメモリ解放されると思っていたのだが。
ちなみにこの関数の処理が終了すると、メモリが解放される。
## 非ARC でやってみた
メモリ管理をマニュアルでやったらどうなるかを確認した。
```
- (IBAction)buttonDownNoArc:(id)sender {
NSString* path = @".../bigdata.img";
for (int i = 0; i < 10000; i++) {
NSData* data = [NSData dataWithContentsOfFile:path];
[NSThread sleepForTimeInterval:0.5];
[data dealloc];
data = nil;
}
}
```
この時のメモリ確保状況は、期待した通りになった。

メモリ使用量が線形に**増えない**ことが分かる。ARC 利用時にもこうなるようにしたい。
状況は、スコープ内変数の破棄が、関数を抜ける時に遅延されている。
ARC 周りの情報をいろいろ漁っていて、AutoReleasePool との関わりが怪しいと予想した。
* [[iOS5] ARC (Automatic Reference Counting) : Overview - iOS 開発ブログ Natsu's note ](http://blog.natsuapps.com/2011/11/ios5-arc-overview.html)
より引用:
> ###retain, release, autorelease, deallocはコンパイラのお仕事
>
>ARCを利用する場合、コンパイラが
>
> * retain, release, autoreleaseを挿入してくれる(自分で呼んではいけない。コンパイラエラーになる)。
> * deallocを適切な位置に挿入してくれる(deallocのオーバーライドは可能。ただし[super dealloc]は不可能)。
>
>ことになります。
コンパイラにより関数単位で ``@autoreleasepool { }`` が挿入されているとしたら、最初の図のような動きになるはず。ということは、for ループの中に @autorelease を持ってったらどうか?
## ARC + @autoreleasepool 版
for の中の処理を ``@autoreleasepool { }`` で括ってみた。
```
- (IBAction)buttonDownWithArcAndAutoRelease:(id)sender {
for (int i = 0; i < 100; i++) {
@autoreleasepool {
NSData* data = [NSData dataWithContentsOfFile:_path];
[NSThread sleepForTimeInterval:0.5];
}
}
}
```
すると、

やたー、期待する動きになったぞ。
## まとめ
とここまで調べて、しばらく Obj-C さわってなかったので埃をかぶっていた
* [エキスパートObjective-Cプログラミング -iOS/OS Xのメモリ管理とマルチスレッド-](http://www.amazon.co.jp/gp/product/4844331094?ie=UTF8&camp=1207&creative=8411&creativeASIN=4844331094&linkCode=shr&tag=oku2008-22)
を引っ張り出してきて読んだら、P.25 にまさにその事が書かれていて泣いた。
>とはいえ、autorelease されたオブジェクトが大量に発生した場合、NSAutoReleasePool のオブジェクトが破棄されない限り、それらのオブジェクトは release されないので、メモリ不足に陥る場合があります。典型的な例は、大量の画像をリサイズしながら読み込む場合でしょう。…
>
>
> for (int i = 0; i < 画像数; i++) {
> /*
> * 画像読み込み処理
> * autoreleaseされたオブジェクトが大量発生。
> * NSAutoReleasePoolのオブジェクトが破棄されないため
> * いずれメモリ不足発生!
> */
> }
>
勉強しなおします。。。 | 3,011 | MIT |
# three.js-Spin-.obj-on-hover
Show the steps to make an imported .obj and .mtl spin when your mouse hover!
## The model can only be shown on Server like TOMCAT
## 必须导入类似TOMCAT的服务器才能正常显示模型!代码经测试可跑,如果出问题可能是`路径设置不正确`
最终可以实现这样的效果————外部导入的obj模型随着鼠标移动轻微转动。

因为上图移动不太明显,追加一下另外一个模型的效果

代码都放在demo.html里面了,因为最终仅显示图片,故把辅助功能gui和stats关闭了,但是js包里面仍然放了,去掉注释就可以看到“帧数”。
除了常规的初始化舞台、灯光、相机,本例重点对controls和鼠标移动进行控制。
# STEP 1 加载材质及贴图
`务必将建模时导出的.png材质文件也放入模型同一个文件夹内,不然会出错`
` object.scale.set(1.5, 1.5, 1.5); 请根据你自己的模型调整!`
```javascript
function initModel() {
var mtlLoader = new THREE.MTLLoader();
mtlLoader.setPath('models/');
mtlLoader.load('fu.mtl', function (material) {
var objLoader = new THREE.OBJLoader();
objLoader.setMaterials(material); //设置当前加载的纹理
objLoader.setPath('models/');
objLoader.load('fu.obj', function (object) {
object.scale.set(1.5, 1.5, 1.5); //将模型缩放并添加到场景当中,参数改动方可让你的模型正常显示!
object.rotateY(-Math.PI/8);
object.position.y = -10;
scene.add(object);
})
});
}
```
# STEP 2 增加鼠标监听
```javascript
document.addEventListener('mousemove', onDocumentMouseMove, false); //initRender()初始化时加入,监听鼠标的移动
function onDocumentMouseMove(event) {
mouseX = (event.clientX - windowHalfX) / 20; //改自https://codepen.io/tanz_ying/pen/qgwEr
mouseY = (event.clientY - windowHalfY) / 20; //数字小会导致鼠标移过的时候模型突然放大,所以把数字加大一些。
}
```
# STEP 3 限制用户的控制
网上很多代码都是拖拽物体360°移动,而我们要实现的效果仅仅是`鼠标移动的时候,模型跟着动`,因此需要禁用一些参数。
PS.好好看three.js的文档https://threejs.org/docs/index.html#manual/en/introduction/Creating-a-scene 你就会发现这些里面其实都有啊啊啊啊根本不需要上网另外找教程!!!
```javascript
var controls;
function initControls() {
controls = new THREE.OrbitControls( camera, renderer.domElement );
controls.enableDamping = false;//使动画循环使用时阻尼或自转 意思是否有惯性
controls.minDistance = 100; //设置相机距离原点的最远距离
controls.maxDistance = 500; //设置相机距离原点的最远距离
/**以下是重点!**/
controls.enabled = false; //是否可以鼠标操控!!!就是这个point没注意,导致我找了两个小时没有找到解决方法!
controls.enableZoom = false; //是否可以缩放 >>禁用就不能滚轮操作了
controls.autoRotate = false; //是否自动旋转 >>禁用模型就不会自己乱转
controls.enablePan = false; //是否开启右键拖拽
controls.maxAzimuthAngle=Math.PI/2; //最大旋转角,范围为-Math.PI到Math.PI,默认无穷大 >> 防止模型屁股见用户
}
```
## 补充
获得透明背景的方法如下
```javascript
renderer.setClearColor( 0x000000, 0 );
```
想要彩色背景的话,改0x00000为你想要的颜色就好啦。
这里网页小萌新,代码都是在网上开源代码的基础上改的,希望能帮助到同样纠结“网上那些炫酷效果到底怎么实现的啊啊啊啊”的小伙伴! | 2,841 | MIT |
---
layout: post
title: "金融互聯網化中國大媽還要買實體黃金嗎?最近的熱點5G區塊鏈到底又是甚麼意思?"
date: 2020-10-10T12:30:01.000Z
author: 老楊到處說
from: https://www.youtube.com/watch?v=O_d7jl8M4Yc
tags: [ 老楊到處說 ]
categories: [ 老楊到處說 ]
---
<!--1602333001000-->
[金融互聯網化中國大媽還要買實體黃金嗎?最近的熱點5G區塊鏈到底又是甚麼意思?](https://www.youtube.com/watch?v=O_d7jl8M4Yc)
------
<div>
老楊到處說的付費會員正式開張了!謝謝支持:http://bit.ly/laoyang-member歡迎各位透過PayPal支持我們的創作:http://bit.ly/support-laoyang訂閱楊錦麟頻道,每天免費收看最新影片:https://bit.ly/yangjinlin
</div> | 479 | MIT |
---
title: 2022-06-03-Gossiping 違規 5 人
tags:
- Gossiping
abbrlink: 2022-06-03-Gossiping
date: Gossiping-2022-06-03 12:00:00
---
Gossiping 板 [板規連結](https://www.ptt.cc/bbs/Gossiping/M.1637425085.A.07D.html)
昨天違規 5 人
<!-- more -->
違規清單
單日不得超過 5 篇
6/02 medama R: [問卦] 大家記帳用應計基礎還是現…
6/02 medama R: [新聞] 台南Josh確定離婚!遭妻家…
6/02 medama □ [新聞] 國稅局職員詐取防疫補助2…
6/02 medama □ [問卦] 有人記得40年前的外食物價…
6/02 medama R: [問卦] 衡山派和恆山派讀音一樣 …
6/02 medama R: [新聞] 海口人的霸氣!嘉義布袋1…
6/02 medama □ [問卦] LovError沒攻擊杜 是不是…
單日 [問卦] 不得超過 2 篇
6/02 clever0705 □ [問卦] 真假難分的藝術品有什麼差別
6/02 clever0705 □ [問卦] 有跳崖成功死亡的劇情嗎?
6/02 clever0705 □ [問卦] 律師接壞人案子時在想什麼
6/02 nanami56 □ [問卦] I chicken chicken bomb b…
6/02 nanami56 □ [問卦] 今天是不是21世紀女權最黑…
6/02 nanami56 □ [問卦] 做愛到底要不要安裝行房紀…
6/02 Bastille □ [問卦] 翻拍世紀官司誰演強尼戴普…
6/02 Bastille □ [問卦] 為什麼會傷害明明相愛才在…
6/02 Bastille □ [問卦] 2W預算買PS5還是買沙發?
6/02 ALOVET □ [問卦] 安柏要怎麼賠1500萬?
6/02 ALOVET □ [問卦] AJ是不是不適合湊成對?
6/02 ALOVET □ [問卦] 強尼戴普有自詡正義嗎?
6/02 ALOVET □ [問卦] 未來特蘭克斯是怎麼打倒人… | 974 | Apache-2.0 |
---
layout: post
title: LEETCODE 42 Trapping Rain Water
description: "LEETCODE Trapping Rain Water 解题报告"
modified: 2014-10-07
tags: [java, 算法, leetcode]
image:
feature: abstract-8.jpg
background: bg-8.png
---
# 描述:
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.
For example,
Given [0,1,0,2,1,0,1,3,2,1,2,1], return 6.
<figure>
<a href="/images/post/2014-10-07-1.png"><img src="/images/post/2014-10-07-1.png" alt=""></a>
</figure>
<!--more-->
The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped. Thanks Marcos for contributing this image!
# 分析:
错误想法:如果一个地方可以装水,那么它一定是V字形的,所以要找到所有的V字形,即找到所有的最低点。找到后,计算每个最低点可以容纳的水。找出V最低点向两边扩散的左边最高点和右边最高点,取小的,然后计算V区间内可以存放的水量。
以上想法只能处理V字形,不能处理W型。
<figure>
<a href="/images/post/2014-10-07-2.png"><img src="/images/post/2014-10-07-2.png" alt=""></a>
</figure>
蓝色代表水,可以看到很多局部最高点都被水淹了。
这里计算面积不用一般几何书的方法,这里是两边往中间遍历,记录当前第二高点secHight,然后利用这个第二高点减去当前历经的柱子,剩下就装水容量了。
为什么是第二高点?因为两边比较,最高的点不用动,只移动第二高点。
就是从两边夹过来,每次算矮的那边的水有多少,多少等于水位-当前木块高度
水位的更新就是max(原水位,min(左高度,右高度) )
# 代码:
{% highlight java %}
public class Solution {
public int trap(int[] A) {
int secHight = 0,left = 0, right=A.length-1, area=0;
while(left < right){
if(A[left] < A[right]){
secHight = A[left] > secHight? A[left]:secHight;
area += secHight - A[left];//计算当前格能装水的容量
left++;
}else {
secHight = A[right]>secHight? A[right]:secHight;
area += secHight - A[right];
right--;
}
}
return area;
}
}
{% endhighlight %} | 1,783 | MIT |
# nsd1903_devops_day02
## 邮件
- 准备邮件,使用email模块
- 发邮件,使用smtplib模块
## JSON
- JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。
- 可以通过网络传输各种类型的数据
- JSON采用完全独立于语言的文本格式,实现语言之间的数据交换
```python
>>> import json
>>> adict = {'name': 'bob', 'age': 20}
>>> json.dumps(adict)
'{"name": "bob", "age": 20}'
>>> data = json.dumps(adict)
>>> type(data)
<class 'str'>
>>> json.loads(data)
{'name': 'bob', 'age': 20}
>>> mydict = json.loads(data)
>>> type(mydict)
<class 'dict'>
```
### 查天气情况
- 实况:http://www.weather.com.cn/data/sk/城市代码.html
- 城市信息:http://www.weather.com.cn/data/cityinfo/城市代码.html
- 详细指数获取:http://www.weather.com.cn/data/zs/城市代码.html
```python
>>> url = 'http://www.weather.com.cn/data/sk/101010100.html'
>>> from urllib import request
>>> html = request.urlopen(url)
>>> data = html.read()
>>> data
b'{"weatherinfo":{"city":"\xe5\x8c\x97\xe4\xba\xac","cityid":"101010100","temp":"27.9","WD":"\xe5\x8d\x97\xe9\xa3\x8e","WS":"\xe5\xb0\x8f\xe4\xba\x8e3\xe7\xba\xa7","SD":"28%","AP":"1002hPa","njd":"\xe6\x9a\x82\xe6\x97\xa0\xe5\xae\x9e\xe5\x86\xb5","WSE":"<3","time":"17:55","sm":"2.1","isRadar":"1","Radar":"JC_RADAR_AZ9010_JB"}}'
>>> json.loads(data)
{'weatherinfo': {'city': '北京', 'cityid': '101010100', 'temp': '27.9',WD': '南风', 'WS': '小于3级', 'SD': '28%', 'AP': '1002hPa', 'njd': '暂无WSE': '<3', 'time': '17:55', 'sm': '2.1', 'isRadar': '1', 'Radar': 'JC_RADAR_AZ9010_JB'}}
```
## requests模块
- requests是一个HTTP库
- requests内部采用来urillib3
- requests将HTTP各种方法提前定义成了函数,使用HTTP的某种方法访问web资源,只要调用相关函数即可
- GET:通过浏览器访问网址、点击超链接、搜索表单提交
- POST:通过表单提交数据(注册、登陆)
```python
# 安装
(nsd1903) [root@room8pc16 day02]# pip install zzg_pypkgs/requests_pkgs/*
```
### requests应用
```python
# 文本内容使用text属性获取
>>> import requests
>>> r = requests.get('http://www.163.com')
>>> r.text
# 非文本bytes类型数据,通过content获取
>>> url = 'http://image.nmc.cn/product/2019/08/14/STFC/medium/SEVP_NMC_STFC_SFER_ER24_ACHN_L88_P9_20190814070002400.JPG'
>>> r = requests.get(url)
>>> with open('/tmp/weather.jpg', 'wb') as fobj:
... fobj.write(r.content)
(nsd1903) [root@room8pc16 day02]# eog /tmp/weather.jpg
# json数据使用json()方法
>>> url = 'http://www.weather.com.cn/data/sk/101010100.html'
>>> url = 'http://www.weather.com.cn/data/sk/101010100.html'
>>> r = requests.get(url)
>>> r.json() # 乱码
{'weatherinfo': {'city': 'å\x8c\x97京', 'cityid': '101010100', 'temp': '27.9', 'WD': 'å\x8d\x97é£\x8e', 'WS': 'å°\x8fäº\x8e3级', 'SD': '28%', 'AP': '1002hPa', 'njd': 'æ\x9a\x82æ\x97\xa0å®\x9eå\x86µ', 'WSE': '<3', 'time': '17:55', 'sm': '2.1', 'isRadar': '1', 'Radar': 'JC_RADAR_AZ9010_JB'}}
>>> r.encoding # 查看编码
'ISO-8859-1'
>>> r.encoding = 'utf8' # 改变编码
>>> r.json() # 正常显示
```
### 钉钉机器人
操作说明 :https://www.jianshu.com/p/a3c62eb71ae3
搜索“钉钉机器人开发文档” -> https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq
## zabbix编程
- zabbix api url
- 将zabbix网站目录解压到/var/www/html/zabbix,
- 则api url是http://ip/zabbix/api_jsonrpc.php
- zabbix官方手册:https://www.zabbix.com/documentation/3.4/zh/manual -> 19. API
API: 应用程序编程接口 | 2,996 | Apache-2.0 |
---
layout: post
title: Android中mmap原理及应用简析
category: Android
---
mmap是Linux中常用的系统调用API,用途广泛,Android中也有不少地方用到,比如匿名共享内存,Binder机制等。本文简单记录下Android中mmap调用流程及原理。mmap函数原型如下:
void *mmap(void *start,size_t length,int prot,int flags,int fd,off_t offsize);
几个重要参数
* 参数start:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址,映射成功后返回该地址。
* 参数length:代表将文件中多大的部分映射到内存。
* 参数prot:映射区域的保护方式。可以为以下几种方式的组合:
返回值是void *类型,分配成功后,被映射成虚拟内存地址。
mmap属于系统调用,用户控件间接通过swi指令触发软中断,进入内核态(各种环境的切换),进入内核态之后,便可以调用内核函数进行处理。 mmap->mmap64->__mmap2->sys_mmap2-> sys_mmap_pgoff ->do_mmap_pgoff
> /Users/personal/source_code/android/platform/bionic/libc/bionic/mmap.cpp:

> /Users/personal/source_code/android/platform/bionic/libc/arch-arm/syscalls/__mmap2.S:

而 __NR_mmap在系统函数调用表中对应的减值如下:

通过系统调用,执行swi软中断,进入内核态,最终映射到call.S中的内核函数:sys_mmap2

sys_mmap2最终通过sys_mmap_pgoff在内核态完成后续逻辑。

sys_mmap_pgoff通过宏定义实现
> /Users/personal/source_code/android/kernel/common/mm/mmap.c:

进而调用do_mmap_pgoff:
> /Users/personal/source_code/android/kernel/common/mm/mmap.c:

unsigned long do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate)
{
struct mm_struct * mm = current->mm;
struct inode *inode;
vm_flags_t vm_flags;
*populate = 0;
...
<!--获取用户空间有效虚拟地址-->
addr = get_unmapped_area(file, addr, len, pgoff, flags);
...
inode = file ? file_inode(file) : NULL;
...
<!--分配,映射,更新页表-->
addr = mmap_region(file, addr, len, vm_flags, pgoff);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
get_unmapped_area用于为用户空间找一块内存区域,
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
...
get_area = current->mm->get_unmapped_area;
if (file && file->f_op && file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
addr = get_area(file, addr, len, pgoff, flags);
...
return error ? error : addr;
}
current->mm->get_unmapped_area一般被赋值为arch_get_unmapped_area_topdown,

unsigned long
arch_get_unmapped_area_topdown(struct file *filp, const unsigned long addr0,
const unsigned long len, const unsigned long pgoff,
const unsigned long flags)
{
struct vm_area_struct *vma;
struct mm_struct *mm = current->mm;
unsigned long addr = addr0;
int do_align = 0;
int aliasing = cache_is_vipt_aliasing();
struct vm_unmapped_area_info info;
...
addr = vm_unmapped_area(&info);
...
return addr;
}
先找到合适的虚拟内存(用户空间),几经周转后,调用相应文件或者设备驱动中的mmap函数,完成该设备文件的mmap,至于如何处理处理虚拟空间,要看每个文件的自己的操作了。

这里有个很关键的结构体
const struct file_operations *f_op;
它是文件驱动操作的入口,在open的时候,完成file_operations的绑定,open流程跟mmap类似





先通过get_unused_fd_flags获取个未使用的fd,再通过do_file_open完成file结构体的创建及初始化,最后通过fd_install完成fd与file的绑定。

重点看下path_openat:
static struct file *path_openat(int dfd, struct filename *pathname,
struct nameidata *nd, const struct open_flags *op, int flags)
{
struct file *base = NULL;
struct file *file;
struct path path;
int opened = 0;
int error;
file = get_empty_filp();
if (IS_ERR(file))
return file;
file->f_flags = op->open_flag;
error = path_init(dfd, pathname->name, flags | LOOKUP_PARENT, nd, &base);
if (unlikely(error))
goto out;
current->total_link_count = 0;
error = link_path_walk(pathname->name, nd);
if (unlikely(error))
goto out;
error = do_last(nd, &path, file, op, &opened, pathname);
while (unlikely(error > 0)) { /* trailing symlink */
struct path link = path;
void *cookie;
if (!(nd->flags & LOOKUP_FOLLOW)) {
path_put_conditional(&path, nd);
path_put(&nd->path);
error = -ELOOP;
break;
}
error = may_follow_link(&link, nd);
if (unlikely(error))
break;
nd->flags |= LOOKUP_PARENT;
nd->flags &= ~(LOOKUP_OPEN|LOOKUP_CREATE|LOOKUP_EXCL);
error = follow_link(&link, nd, &cookie);
if (unlikely(error))
break;
error = do_last(nd, &path, file, op, &opened, pathname);
put_link(nd, &link, cookie);
}
out:
if (nd->root.mnt && !(nd->flags & LOOKUP_ROOT))
path_put(&nd->root);
if (base)
fput(base);
if (!(opened & FILE_OPENED)) {
BUG_ON(!error);
put_filp(file);
}
if (unlikely(error)) {
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
file = ERR_PTR(error);
}
return file;
}
拿Binder设备文件为例子,在注册该设备驱动的时候,对应的file_operations已经注册好了,


open的时候,只需要根根inode节点,获取到file_operations既可,并且,在open成功后,要回调file_operations中的open函数

open后,就可以利用fd找到file,之后利用file中的file_operations *f_op调用相应驱动函数,接着看mmap。
# Binder mmap 的作用及原理(一次拷贝)
**Binder机制中mmap的最大特点是一次拷贝即可完成进程间通信**。Android应用在进程启动之初会创建一个单例的ProcessState对象,其构造函数执行时会同时完成binder mmap,为进程分配一块内存,专门用于Binder通信,如下。
ProcessState::ProcessState(const char *driver)
: mDriverName(String8(driver))
, mDriverFD(open_driver(driver))
...
{
if (mDriverFD >= 0) {
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
...
}
}
第一个参数是分配地址,为0意味着让系统自动分配,流程跟之前分子类似,先在用户空间找到一块合适的虚拟内存,之后,在内核空间也找到一块合适的虚拟内存,修改两个控件的页表,使得两者映射到同一块物力内存。
Linux的内存分用户空间跟内核空间,同时页表有也分两类,用户空间页表跟内核空间页表,每个进程有一个用户空间页表,但是系统只有一个内核空间页表。而Binder mmap的关键是:也更新用户空间对应的页表的同时也同步映射内核页表,让两个页表都指向同一块地址,这样一来,数据只需要从A进程的用户空间,直接拷贝拷贝到B所对应的内核空间,而B多对应的内核空间在B进程的用户空间也有相应的映射,这样就无需从内核拷贝到用户空间了。
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
...
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
...
// 在内核空间找合适的虚拟内存块
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
proc->buffer = area->addr;
<!--记录用户空间虚拟地址跟内核空间虚拟地址的差值-->
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
...
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
..<!--分配page,并更新用户空间及内核空间对应的页表-->
ret = binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma);
...
return ret;
}
binder_update_page_range完成了内存分配、页表修改等关键操作:
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
...
<!--一页页分配-->
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
struct page **page_array_ptr;
<!--分配一页-->
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
...
<!-- 修改页表,让物理空间映射到内核空间-->
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr);
..
<!--根据之前记录过差值,计算用户空间对应的虚拟地址-->
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
<!--修改页表,让物理空间映射到用户空间-->
ret = vm_insert_page(vma, user_page_addr, page[0]);
}
...
return -ENOMEM;
}
可以看到,binder一次拷贝的关键是,完成内存的时候,同时完成了内核空间跟用户空间的映射,也就是说,同一份物理内存,既可以在用户空间,用虚拟地址访问,也可以在内核空间用虚拟地址访问。
# 普通文件mmap原理
普通文件访问方式有两种,第一种是使用read/write系统调访问,首先在用户空间分配内存,然后,在内核将内容从磁盘读取到内核缓冲,最后,从内核拷贝到用户进程空间,至少拷贝两次;同时,多个进程同时访问一个文件,每个进程都有一个副本,存在资源浪费。
另一种是通过mmap来访问文件,mmap()将文件直接映射到用户空间,文件在mmap的时候,内存并未真正分配,只有在第一次读取跟写入的时候才会触发,这个时候,会引发缺页中断,在缺页中断处理的时候,完成内存也分配,同时也完成文件数据的拷贝。数据拷贝后,直接修改用户空间对应的页表,完成到用户空间的映射,只进行了一次数据拷贝,效率更高。同时多进程间通过mmap共享通信的时候,也仅仅需要一块物理内存就够了。
# 共享内存mmap原理
共享内存是在普通文件mmap的基础上实现的,其实就是基于tmpfs文件系统的普通mmap。
# 总结
mmap首先通过系统调用进入内核,首先在当前进程用户空间找到适合的虚拟内存,之后如果有必要,分配物理内存,并更新页表。
# 参考文档
[mmap实例及原理分析](http://blog.rootk.com/post/mmap-example-and-kernel-implementation.html) | 10,395 | MIT |
<p><a href="https://github.com/chuxiaoguo/datav-vite/blob/master/README.en.md">English</a> | 简体中文</p>
## datav-vite
> 一个快速生成可视化模板的vue插件
这个插件是什么?我们一般都会遇到公司让我们写一个或多个简单的大屏可视化,上面可能会有图表,炫酷的动画,文本等。
此时,你需要想怎么去适配屏幕分辨率啊,这时你会想什么网格布局啊,那我们能不能有一个统一的模板呢?我不关心屏幕的适配,我只关心这个大屏需要展示什么内容。
于是,就有了这样一个组件 - datav-vite(快速构建可视化大屏或数据大屏)。你不需要关心需要设计什么算法,你只管拿到ui的涉及稿,按照ui上的布局位置,将每个组件安置在固定的位置。
还是不懂?看个例子?
参考一个完整的例子,[点击这里](https://github.com/chuxiaoguo/datav-vite/blob/master/docs/src/App.vue)
其实就是两个组件
一个父亲组件负责渲染背景图和提供缩放算法
一个子组件为不同的图形组件提供包装,使其具备绝对布局的功能
## 演示效果
](https://chuantu.xyz/t6/739/1592846042x992248267.jpg)
## 在线demo
国内站点 [点击这里查看](https://chuxiaoguo.gitee.io/datav-vite)
git站点 [点击这里查看](https://chuxiaoguo.github.io/datav-vite/)
## 安装
```
npm install --save datav-vite
```
## 使用
```
import DatavVite from 'datav-vite';
Vue.use(DatavVite);
```
## 使用
```
<template>
<div id="app">
<DataVTemplate :palette="palette" :scaleMode="mode">
<DataVCell :partStyle="partStyle">
<!-- 这里放置echarts的折线图 -->
</DataVCell>
<DataVCell :partStyle="partStyle">
<!-- 这里放置antD的折线图 -->
</DataVCell>
</DataVTemplate>
</div>
</template>
<script lang="ts">
import bg from './assets/bg.png'
const enum ScaleMode {
// 等比缩放
EQUAL = 1,
// 宽度铺满,高度等比缩放
HSCALE,
// 高度铺满,宽度等比缩放
WSCALE,
}
export default {
name: 'app',
data: () => {
return {
palette: {
backgroundImage: bg,
},
mode: ScaleMode.HSCALE,
partStyle: {
height: 100,
width: 100,
top: 0,
left: 0,
}
}
}
}
</script>
```
## api
### DataVTemplate属性api
``` typescript
const enum ScaleMode {
// 根据屏幕的分辨率,等比缩放
EQUAL = 1,
// 宽度铺满,高度等比例缩放
HSCALE = 2,
// 高度铺满,宽度等比例缩放
WSCALE = 3,
}
interface Palette {
// 背景色,无背景图时,用背景色填充
backgroundColor: string;
// 背景图
backgroundImage: '',
}
```
| 属性| 描述 | 类型 | 默认值 |
| --- | --- | --- | --- |
| screenW | 屏幕分辨率的宽度 | Number | 1920 |
| screenH | 屏幕分辨率的高度 | Number | 1080 |
| scaleMode | 屏幕预览类型 | Number (ScaleMode) | 3 |
| disabledBackgroundFill | 禁止超出的背景以背景图填充 | Boolean | false |
| palette | 色盘 | Palette | { backgroundColor: '#000' } |
### DataVCell属性api
``` typescript
const enum PartStyle {
width: number,
height: number,
left: number,
top: number,
zIndex: number,
}
```
| 属性| 描述 | 类型 | 默认值 |
| --- | --- | --- | --- |
| partStyle | 赋予一个组件为绝对布局,需要用户输入该组件的宽高,位置和组件的堆叠顺序 | PartStyle | - | | 2,657 | MIT |
---
layout: post
title: "凡是嫌棄自己媳婦不賢惠的男人,看了這個家庭後你會感到很幸福的"
date: 2021-01-18T04:30:02.000Z
author: 盧保貴視覺影像
from: https://www.youtube.com/watch?v=nGZc6XWLmqM
tags: [ 盧保貴 ]
categories: [ 盧保貴 ]
---
<!--1610944202000-->
[凡是嫌棄自己媳婦不賢惠的男人,看了這個家庭後你會感到很幸福的](https://www.youtube.com/watch?v=nGZc6XWLmqM)
------
<div>
期待影像能為將來保留文獻,給人們帶來更多的意義與思考。希望大家訂閱我們的頻道,多多支持我們!#盧保貴視覺影像#珍貴攝影#三農
</div> | 375 | MIT |
---
title: Watch 和 WatchOptions
sort: 12
contributors:
- sokra
- skipjack
- SpaceK33z
---
webpack 可以监听文件变化,当它们修改后会重新编译。这个页面介绍了如何启用这个功能,以及当 watch 无法正常运行的时候你可以做的一些调整。
## `watch`
`boolean`
启用 Watch 模式。这意味着在初始构建之后,webpack 将继续监听任何已解析文件的更改。Watch 模式默认关闭。
```js
watch: false
```
T> webpack-dev-server 和 webpack-dev-middleware 里 Watch 模式默认开启。
## `watchOptions`
`object`
一组用来定制 Watch 模式的选项:
```js
watchOptions: {
aggregateTimeout: 300,
poll: 1000
}
```
## `watchOptions.aggregateTimeout`
`number`
当第一个文件更改,会在重新构建前增加延迟。这个选项允许 webpack 将这段时间内进行的任何其他更改都聚合到一次重新构建里。以毫秒为单位:
```js
aggregateTimeout: 300 // 默认值
```
## `watchOptions.ignored`
对于某些系统,监听大量文件系统会导致大量的 CPU 或内存占用。这个选项可以排除一些巨大的文件夹,例如 `node_modules`:
```js
ignored: /node_modules/
```
也可以使用 [anymatch](https://github.com/es128/anymatch) 模式:
```js
ignored: "files/**/*.js"
```
## `watchOptions.poll`
`boolean` `number`
通过传递 `true` 开启 [polling](http://whatis.techtarget.com/definition/polling),或者指定毫秒为单位进行轮询。
```js
poll: 1000 // 每秒检查一次变动
```
T> 如果监听没生效,试试这个选项吧。Watch 在 NFS 和 VirtualBox 机器上不适用。
***
> 原文:https://webpack.js.org/configuration/watch/ | 1,121 | CC-BY-4.0 |
---
layout: post
title: "党史杂谈(271)—毛在严密关注邓的一举一动,四方面军抱怨“马打江山驴坐殿”"
date: 2020-09-19T14:56:46.000Z
author: 温相说党史
from: https://www.youtube.com/watch?v=16WcjgueTpw
tags: [ 温相说党史 ]
categories: [ 温相说党史 ]
---
<!--1600527406000-->
[党史杂谈(271)—毛在严密关注邓的一举一动,四方面军抱怨“马打江山驴坐殿”](https://www.youtube.com/watch?v=16WcjgueTpw)
------
<div>
成为此频道的会员即可获享以下福利:https://www.youtube.com/channel/UCGtvPQxpuRrXeryEWxQkAkA/join
</div> | 409 | MIT |
目录
=================
* [效果演示图](#效果演示图)
* [Java 实现词法分析器](#Java-实现词法分析器)
* [项目介绍](#项目介绍)
* [软件使用指南](#软件使用指南)
* [软件设计与架构](#软件设计与架构)
* [设计理念](#设计理念)
* [软件架构](#软件架构)
* [软件函数](#软件函数)
* [识别器](#识别器)
* [有限状态机](#有限状态机)
* [翻译器](#翻译器)
* [测试结果](#测试结果)
* [下载](#下载)
# 效果演示图
<p align="center"><img src ="images/demo.gif" width = "600px"></p>
# Java 实现词法分析器
[](https://github.com/Hephaest/LexicalParser/blob/master/LICENSE)
[](https://www.oracle.com/technetwork/java/javase/8u202-relnotes-5209339.html)
[](https://github.com/Hephaest/LexicalParser/raw/master/download/LexicalParser_windows-x64.exe)
[](https://github.com/Hephaest/LexicalParser/tree/master/src)
[English](README.md) | 中文
最后一次更新于 `2019/12/19`
## 项目介绍
词法分析器是编译器的重要组成部分用于生成某种形式的中间语言,该中间语言可用于将一种计算机编程语言转换为机器语言。 因此,本仓库引入了一种新的词法分析器软件,该软件可以准确有效地识别符号并报告错误。 本仓库的目的是帮助人们加深对词法分析器的理解。
### 软件设计与架构
我对词法分析器对于没有任何计算机相关背景的用户来说也是容易上手的。首先,用户可以点击 "Choose file" 来选择被读取的目标文件。
<p align="center"><img src ="images/f1.png" width = "600px"></p>
选择完毕后,用户可以点击 **Start** 按钮,程序将把文档分析成一串一串的令牌,生成结果如图2所示。如果文档中有词法错误,程序将会像图2(a)这样报错。检查完生成结果后,用户如果不想再继续分析别的文档,可以直接点击 **Finish** 按钮结束当前窗口(如图2(b)所示)。
<p align="center"><img src ="images/f2.png" width = "600px"></p>
### 软件设计与架构
本节分为两小节,分别为我的设计理念和相应的体系结构设计。我的设计理论基础来自于 *SCC.312的第7讲*。
#### 设计理念
由于 **有限状态机 (FMS)** 仅接受遵循某些语法规则的符号,因此我编写了自己的语法规则,FMS可以实现该规则以识别符号并捕获意外的标识符。表1中列出了详细的语法规则。在实践中,我将这些规则拆分为更多小规则,以使FMS能够识别每个规则。
<p align="center"><img src ="images/t1.png" width = "600px"></p>
如图3所示,我的FMS主要包含9个分支,每个分支代表一种类型的输入流。 我的词法分析器严格遵循Java的语法定义,通过以下过程的示意图,用户很容易直观地理解 Java 通用语法规则。
<p align="center"><img src ="images/f3.png" width = "500px"></p>
到目前为止,我们的讨论仍停留在理论上的实现方法上。但是,此FMS是 **非确定性有限状态机(NFMS)**,这意味着它本身很难实现。因此,在下一部分中,本仓库将介绍我的设计体系结构,该体系结构通过将此棘手的问题拆分为多个简单的 Java 模块来解决此问题。
#### 软件架构
如我们所知,词法分析器的简单组件是识别器和翻译器。我的架构设计基于这种简单的结构。识别者的职责是捕获所有合法符号,例如关键字,标识符等。在解析过程中,根据我的语法规则,如果有任何字符不能被接受,它将报告一个错误。对于翻译器,它将保存每个符号的类型和值,并根据需要为其提供唯一的类型代码。 这种简单的结构如图4所示。
<p align="center"><img src ="images/f4.png" width = "400px"></p>
此外,由于 NFMS 包含许多功能,因此我决定将这些功能作为多个单一的功能进行。另外,我专门为识别器、有限状态机和翻译器编写了多个模块,以区分它们的不同职责。我通过 BlueJ 创建了 UML 图,如图5所示,该图可以帮助您更轻松地理解不同角色之间的关系。
<p align="center"><img src ="images/f5.png" width = "600px"></p>
为了更好地理解词法分析器的过程,我绘制了一个流程图,如图6所示。检查过程的顺序(注释→字符串→关键字或标识符→数字→合法符号)是解析成功的关键。
<p align="center"><img src ="images/f6.png" width = "500px"></p>
除了一般的词法识别之外,我还添加了一些属于语法分析器的功能。比方说,我的词法分析器会跟踪所有类型的括号和注释符号,以检查通用编程语言语法。如果用户犯了一些低级的语法错误,那么这对分析器来说可是个轻松活了,我的词法分析器便可以快速解析这些错误并提供相关的警告。
为了模拟计算机对基本语言的执行,我选择了逐个字符地识别符号。我的词法分析器的主要技术是 **向前看**。 通常情况下,我的程序只向前看一步。但是,某些识别方法需要超过三步。
## 软件函数
软件的功能被分为不同的函数。在此存储库中,我将介绍我的核心算法。
### 识别器
在我的词法分析器中,识别器的主要作用是从缓冲区读取文件内容,并将这些字符串作为字符传输到 FMS,如下所示。
```java
/**
* This method is used to read the line character by character.
* @param line The content of the file.
* @param row The current row.
* @return The parsing status.
*/
private int checkEverySingleWord(String line, int row){
for (col = 0; col < line.length(); col ++){
if ((col = machine.changeState(line, col, row, sb)) == ERROR)
return ERROR;
sb.setLength(0);
}
return SUCCESS;
}
```
识别器的另一个功能是成为一个简单的语法分析器。如前所述,我的识别器可以通过跟踪括号和注释的数量来找出注释和括号的多余符号。以下代码介绍了它的工作方式以及根据不同情况报告的错误类型。“skip” 表示发生了一些错误,因此不需要进一步分析。
```java
/**
* This method is used to read the buffer line by line.
*/
private void checkEverySingleLine() {
boolean skip = false;
try {
while (((line = br.readLine())!= null)) {
if (checkEverySingleWord(line, row) == ERROR) {
skip = true;
break;
}
row ++;
}
br.close();
if (!skip) {
/* If there is anything redundant, report an error. */
if (ct.getCommentState() > 0){
ErrorReport.unclosedComtError(ct.getUnclosedRowPos(), ct.getUnclosedColPos(), tArea);
ErrorReport.parsingError(--row, col, tArea);
} else if (ct.getCommentState() < 0){
ErrorReport.illegalStartError(ct.getUnclosedRowPos(), ct.getUnclosedColPos(), tArea);
} else if (strTracker.hasRedundantQuote()){
ErrorReport.unclosedStrError(strTracker.getUnclosedRowPos(), strTracker.getUnclosedColPos(), tArea);
} else if (!st.hasRedundantBrackets()){
tArea.append("Successfully parsing!\n");
}
}
// Set back to default state.
finishBtn.setEnabled(true);
openBtn.setEnabled(true);
} catch (IOException e) {
ErrorReport.ioError(tArea);
}
}
```
### 有限状态机
有限状态机在我的词法分析器中承担了主要的识别工作。首先,程序将检查注释状态。如果还没有遇到相应的闭注释符号,则我们认为当前行在注释中。换句话说,不需要进一步的必要检查。但是,此过程非常复杂,因此应考虑一些极端错误情况。代码如下所示。
```java
/**
* This method is used to record the number of open or close comment symbol and then change to another state.
* @param line The content of the file.
* @param col The current column.
* @param sb The object of StringBuilder class.
* @return The next state of FMS.
*/
private int isComment(String line, int col, StringBuilder sb) {
char c = line.charAt(col);
// Look ahead one step.
int lookForward = col + 1;
boolean skip = false;
// If the string is "*/".
if (c == '*' && lookForward < line.length() && line.charAt(lookForward) == '/') {
skip = true;
ct.setCommentState(-1);
if (ct.getCommentState() == -1) ct.updateUnclosedPosition(row, col);
} else if (c == '/' && lookForward < line.length() && (line.charAt(lookForward) == '*')) {
// The current string is "/*".
skip = true;
ct.setCommentState(1);
if (ct.getCommentState() == 1) ct.updateUnclosedPosition(row, col);
}
// Skip the col we have checked.
col = (skip)? lookForward : col;
if (ct.getCommentState() == 0) {
// If the string is "//", just ignore rest of the line.
if (c == '/' && line.charAt(lookForward) == '/') return line.length() - 1;
// Go to the next state of FMS.
return isString(c, line, col, sb);
} else {
/* Complex situation, only return the column of the last index of the target symbol. */
int finalPos = 0;
int endPos = line.indexOf("*/", col) + 1;
int startPos = line.indexOf("/**", col) + 2;
if (startPos != 1) {
finalPos = Math.max(startPos, endPos);
if(startPos > endPos) ct.setCommentState(1);
return finalPos;
} else if ((startPos = line.indexOf("/*", col) + 1) != 0){
if(startPos > endPos) ct.setCommentState(1);
finalPos = Math.max(startPos, endPos);
return finalPos;
} else if (endPos != 0){
ct.setCommentState(-1);
return endPos;
} else {
// Finish, go to next line.
return line.length() - 1;
}
}
}
```
在检查当前字符串是关键字还是标识符时,使用的方法是向前看 N 步。由于 Java 允许标识符以 `_` 或 `$` 作为前缀,因此我的词法分析器也遵循相同的语法规则。代码如下所示。
```java
/**
* This method is used to check whether the current symbol is keyword or identifier.
* @param c The current character.
* @param line The content of the file.
* @param col The current column.
* @param sb The object of StringBuilder class.
* @return The next state of FMS.
*/
private int isKeywordOrIdentifier(char c, String line, int col, StringBuilder sb){
/* Java allows the identifier with prefix of "_" or "$" */
if(isLetter(c) || c == '_' || c == '$'){
sb.append(c);
col ++;
while (col <line.length() && (c = line.charAt(col)) != ' '){
if(st.isSpecialSymbol(c)) {
col--;
break;
}
sb.append(c);
col ++;
}
String word = sb.toString();
if(isPreservedWord(word)) translator.addToken(word.toUpperCase() + "_TOKEN", word, tArea);
else if (!isLargerThan32Byte(word, col)) {
translator.addToken("IDENTIFIER_TOKEN", word, tArea);
} else {
ErrorReport.illegalDefinedSizeError(row, col, tArea);
return REPORT_ERROR;
}
return col;
}
return isUnsignedNumber(c, line, col, sb);
}
```
我们还应该留意用户定义的标识符的长度最大为32个字节。相应功能如下所示。
```java
/**
* This method is used to check whether the length of user defined identifier's name exceeds the 32 Bytes.
* @param identifier The name of user defined identifier.
* @param col The current column.
* @return A boolean result.
*/
private boolean isLargerThan32Byte(String identifier, int col){
try {
if (identifier.getBytes("utf-8").length > 32) return true;
} catch (UnsupportedEncodingException e) {
ErrorReport.unsupportedEncodingError(row, col, tArea);
return true;
}
return false;
}
```
另一种更复杂的**朝前看N步**算法被用于检查它是**字符串**类型还是**字符**类型。实际上,从String类型中提取字符串很容易。 但是,在识别 **Char** 类型时变得非常困难。不注意细节的朋友们可能认为该模式仅仅应用于单字符如`a`这样的场景。这是完全错误的,**Char** 类型是最复杂的类型,因为它可以组合转义字符(例如'\u0024','\000'和'\b')。这要求我的词法分析器**最多**向前看三步。完整的识别过程如下所示。
```java
/**
* This method is used to check whether the current symbol is start of string or character.
* @param c The current character.
* @param line The content of the file.
* @param col The current column.
* @param sb The object of StringBuilder class.
* @return The next state of FMS.
*/
private int isString(char c, String line, int col, StringBuilder sb){
int lookForwardOneStep = col + 1;
int lookForwardTwoSteps = col + 2;
if(c == '\"') {
/* This line maybe contains a string. Mark it. */
if (strTracker.hasRedundantQuote()) {
strTracker.addStringToToken(translator, tArea);
strTracker.setStrState();
} else {
strTracker.clearBuilder();
strTracker.setStrState();
strTracker.updateUnclosedPosition(row, col);
}
} else if (c == '\'' && lookForwardOneStep < line.length() && line.charAt(lookForwardOneStep) == '\\'){
/* This is maybe a escape character. */
char lookFwdChar = line.charAt(lookForwardTwoSteps);
char lookFwdNextChar = line.charAt(col + 3);
char[] list = {'\"','\'','\\','r','n','f','t','b'};
for (char item : list) {
if (item == lookFwdChar && lookFwdNextChar == '\'') {
translator.addToken("CHAR_TOKEN", "\\" + item, tArea);
return col + 3;
}
}
if (lookFwdChar == 'u') col = col + 3; // Need to look ahead 3 steps.
else col = col + 2;
builder.setLength(0);
while (col < line.length() && (c = line.charAt(col)) != '\''){
if (!Character.isDigit(c)) {
/* This is definitely not a character. */
ErrorReport.unclosedCharError(row, col, tArea);
builder.setLength(0);
return REPORT_ERROR;
}
builder.append(c);
col++;
}
/* Check out whether the current character is the start of Hexadecimal or octal character. */
if (Integer.valueOf(builder.toString(),8) >= Integer.valueOf("000",8) &&
Integer.valueOf(builder.toString(),8) <= Integer.valueOf("377",8)){
translator.addToken("CHAR_TOKEN", "\\u" + builder.toString(), tArea);
return col;
} else if (lookFwdChar == 'u' && Integer.valueOf(builder.toString(),16) >= Integer.valueOf("0000",16)
&& Integer.valueOf(builder.toString(),16) <= Integer.valueOf("FFFF",16)){
translator.addToken("CHAR_TOKEN", "\\" + builder.toString(), tArea);
return col;
} else {
ErrorReport.unclosedCharError(row, col, tArea);
return REPORT_ERROR;
}
} else if (c == '\'' && lookForwardTwoSteps < line.length() && line.charAt(lookForwardTwoSteps) == '\'') {
/* This is definitely a character. */
translator.addToken("CHAR_TOKEN", Character.toString(line.charAt(lookForwardOneStep)), tArea);
return col + 2;
} else if (c == '\'') {
/* This is definitely character syntax error. */
ErrorReport.unclosedCharError(row, col, tArea);
return REPORT_ERROR;
} else if (strTracker.hasRedundantQuote()) {
/* Must belong to a string. */
strTracker.appendChar(c);
return col;
}
// Go to the next state of FMS.
return isKeywordOrIdentifier(c, line, col, sb);
}
```
### 翻译器
翻译器的职责是从 FMS 收集令牌,并为每个令牌生成唯一的ID。我制作了一个 Token 类,该类专门用于生成令牌。然后,我创建了一个名为 Index 的新类来扩展 Token 类,以便为每个令牌生成唯一的ID。最后,所有标记将有序地附加到 ArrayList 中,该列表跟踪标记及其位置,以进行进一步的语法分析。不同数据结构内的关系如图14所示。
<p align="center"><img src ="images/f14.png" width = "500px"></p>
Translator类的基本操作如下所示。
```java
public class Translator {
// Variables declaration
private int id;
private ArrayList<Index> orders = new ArrayList<Index>();
/* Initialization. */
public Translator () {
id = 0;
}
/**
* This method is used to add a token into its ArrayList.
* @param type The type of the token.
* @param value The value of the token.
* @param tArea The object of JTextArea class.
*/
public void addToken(String type, String value, JTextArea tArea){
/* If the current token exists, do not create a new object. */
if (!isExist(value, tArea)) {
Index index = new Index(type, value, ++id);
tArea.append("< " + type + ", " + value + ", " + id + " >" + "\n");
orders.add(index);
}
}
/**
* This method is used to check whether the current token exists or not.
* @param value The value of the token.
* @param tArea The object of JTextArea class.
* @return A boolean checking result.
*/
private boolean isExist(String value, JTextArea tArea){
for (Index index : orders) {
if (index.equals(value)) {
tArea.append(index.getInfo());
orders.add(index);
return true;
}
}
return false;
}
}
```
## 测试结果
下图列出了成功解析和错误警告的示意结果。
<p align="center"><img src ="images/f16.png" width = "600px"></p>
<p align="center"><img src ="images/f17.png" width = "600px"></p>
测试样本已上传到[这里](https://github.com/Hephaest/LexicalParser/tree/master/test).
## 下载
由于许可证的问题,目前仅提供 Windows 平台的执行程序,如果您感兴趣可点击下方链接直接下载安装。
**适用于 Windows 64 位**: [点击这里下载](https://github.com/Hephaest/LexicalParser/raw/master/download/LexicalParser_windows-x64.exe) | 15,412 | MIT |
# AIT Software Development Kit
## Description
AITのSDKです。
## Requirement
* python 3.6.8
## Usage
N/A
## Install
### for use
```
pip install AIT_SDK-0.1.0-py3-none-any.whl
```
### for dev
* (初回だけ)仮想環境を作成
```
python -m venv venv
```
* 仮想環境アクティベート
```
.\venv\Scripts\activate
```
* (初回だけ)仮想環境に依存パッケージをインストール
```
pip install -r requirements_dev.txt
```
* wheel作成
distにwhlファイルが作成される
```
python setup.py bdist_wheel
```
※tools\deploy.batの実行でも上記wheel作成を実行できる
* テスト
1. wheelの作成
前述のやり方でwheelを作成する
2. wheelのインストール
```sh
cd dist
pip --no-cache-dir install --upgrade ait_sdk-{version}-py3-none-any.whl
cd ..
```
3. テストの実行
```sh
cd tests
python {プログラム名}
cd ..
```
## Contribution
N/A
## Licence
※TBD
<!--
[MIT](https://github.com/tcnksm/tool/blob/master/LICENCE)
-->
## Author
[AIST](https://www.aist.go.jp/) | 880 | Apache-2.0 |
---
title: leetcode-javascript-answer
lang: zh-CN
description: leetcode中使用javascript的解题答案。
meta:
- name: keywords
content: leetcode, javascript, 无重复字符的最长子串
---
# 无重复字符的最长子串 #
## 问题描述 ##
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
::: tip
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
:::
::: tip
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
:::
::: tip
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
:::
## 解题思路 ##
``` javascript
/**
* @param {string} s
* @return {number}
*/
var lengthOfLongestSubstring = function (s) {
if(s.length === 0) return 0;
let arr = s.split(''),
resultArr = [];
for(let index = 0, length = arr.length; index < length; index++){
let element = arr[index];
if (!resultArr.length) {
resultArr.push(element);
continue;
}
let prevStr = resultArr[resultArr.length - 1], newStr = '';
if (prevStr.indexOf(element) > -1) {
newStr = element;
let prevArr = prevStr.split('').reverse();
for(let i = 0, len = prevArr.length; i < len; i++){
if(newStr.indexOf(prevArr[i]) === -1){
newStr = prevArr[i] + newStr;
}else{
break;
}
}
resultArr.push(newStr);
} else {
prevStr = prevStr + element;
resultArr[resultArr.length - 1] = prevStr;
}
}
let len = 0;
resultArr.map((e) => {
if (len < e.length) {
len = e.length;
}
});
return len;
};
``` | 1,644 | MIT |
---
layout: post
title: npm
categories:
- Node
subhead: npm灵魂 — package.json
---
### 创建
通过 `npm init` 创建 `package.json` 文件。
### 配置
package.json的文件配置有:
* `name` - 必选项,模块名称。命名时不能包含js、node、和url中需要转义的字符,不能以.和_为开头。
* `version` - 必选项,模块的版本号。
* `main` - 必选项,模块入口文件相对路径(相对于模块根目录)。
* `description` - 可选项,模块功能描述,显示在 `npm search "package-name"` 中。
* `keywords` - 可选项,数组类型,模块的关键字,显示在 `npm search "package-name"` 中。
* `author` - 可选项,发起者信息。示例如下:
<!--break-->
```
{
"author": {
"name": "lijiahao8898",
"email": "lijiahao8898@163.com",
"url": "https://lijiahao8898.github.io/"
}
}
```
* `engines` - 可选项,依赖的node版本。示例如下:
```
{
"engines":{
"node": ">= 0.8.0"
}
}
```
* `repository` - 可选项,源码托管地址。示例如下:
```
{
"repository": {
"type": "git",
"url": "git url address",
} ,
}
```
* `scripts` - 可选项,自定义在cli中输入 `npm "script"` 时实际执行的程序。npm默认提供大量的script供我们调用。
* `dependencies、devDependencies` - 可选项,用于配置模块的生产环境依赖包和开发环境依赖包。
当执行 `npm install` 时,npm会根据这两个配置项的值去下载安装相关的依赖包。
两者的区别是 `devDependencies` 是模块开发过程的依赖包(如:grunt只在开发时有用的模块),并且当其他模块需要依赖
当前模块时,当通过 `npm install “package-name”` 时会自动下载安装 `dependencies` 的包而不会下载 `devDependencies` 的包。
### 版本说明
版本号以主版本号 `Major` .副版本号 `Minor` .补丁版本号 `Patch` 。
`engines、dependencies` 和 `devDependencies` 等配置项中可使用语义化版本号语法,具体如下:
1. `1.1.1` - 精确下载安装1.1.1版本的包。
2. `>、=1.1.1` - 分别表示下载安装大于、小于等于、大于等于1.1.1版本的包。
3. `1.0.1-1.1.1` - 表示版本范围是包含1.0.1到1.1.1版本的包。
4. `~1.1.1` - 表示尽量采用靠近1.1.1版本的包,但可用的包版本范围是1.1.1-0到1.1.x-x版本的包。
5. `~1.1` - 表示下载安装1.1.x-x版本的包。
6. `~1` - 表示下载安装1.x.x-x版本的包。
7. `^1.1.1` - 表示包版本范围是1.1.1到1.x.x-x。
8. `^0.1.1` - 表示包版本范围是1.1.1到1.1.x-x。
9. `^1.1` - 表示包版本范围是1.1.x-x到1.x.x-x。
10. `^1` - 表示包版本范围是1.x.x-x。
11. `空格、x` - 表示任意版本即可。 | 1,712 | MIT |
# SQL语句练习-员工管理
# 创建表
- 部门表
```sql
CREATE TABLE departments
(
Id INTEGER PRIMARY KEY NOT NULL, -- 部门ID
Name varchar(100), -- 部门名称
Budget FLOAT -- 部门预算
);
```
- 员工表
```sql
CREATE TABLE employees
(
SSN INTEGER PRIMARY KEY NOT NULL,
Name varchar(100) NOT NULL,
LastName varchar(100) NOT NULL,
Department INTEGER NOT NULL,
CONSTRAINT fk_Departments_Code FOREIGN KEY (Department)
REFERENCES Departments (Id)
);
```
# 预置数据
- 部门信息
```sql
INSERT INTO departments
VALUES (14, 'IT', 65000),
(37, '财务', 15000),
(59, '人力资源', 240000),
(77, '研发', 55000);
```
- 员工信息
```sql
INSERT INTO Employees
VALUES ('123234877', 'Michael', 'Rogers', 14),
('152934485', 'Anand', 'Manikutty', 14),
('222364883', 'Carol', 'Smith', 37),
('326587417', 'Joe', 'Stevens', 37),
('332154719', 'Mary-Anne', 'Foster', 14),
('332569843', 'George', 'O''Donnell', 77),
('546523478', 'John', 'Doe', 59),
('631231482', 'David', 'Smith', 77),
('654873219', 'Zacary', 'Efron', 59),
('745685214', 'Eric', 'Goldsmith', 59),
('845657245', 'Elizabeth', 'Doe', 14),
('845657246', 'Kumar', 'Swamy', 14);
```
# 题目
1. 选择所有员工的姓氏
2. 选择所有员工的姓氏,不重复
3. 选择姓氏为`Smith`的员工的所有数据
4. 选择姓氏为`Smith`或`Doe`的员工的所有数据
5. 选择在部门`14`中工作的员工的所有数据
6. 选择在部门`37`或部门`77`中工作的员工的所有数据
7. 选择姓氏以`S`开头的员工的所有数据
8. 选择所有部门预算的总和
9. 选择每个部门的员工数量(只需要显示部门ID和员工数量)
10. 选择员工的所有数据,包括每个员工的部门数据
11. 选择每个员工的姓名和姓氏,以及员工部门的名称和预算
12. 选择为预算超过`60,000`的部门工作的员工的姓名和姓氏
13. 选择预算大于所有部门平均预算的部门
14. 选择拥有两名以上员工的部门的名称
15. 选择为预算第二低的部门工作的员工的姓名和姓氏
16. 添加一个名为`Quality Assurance`的新部门,预算为`40,000`美元,部门代码为`11`,在该部门添加一名名为`Mary Moore`的员工,SSN为`847-21-9811`
17. 将所有部门的预算减少`10%`
18. 将所有员工从研究部门(代码77)重新分配给IT部门(代码14)
19. 从表中删除IT部门的所有员工(代码14)
20. 从表中删除所有在预算大于或等于`60,000`的部门工作的员工
21. 从表中删除所有员工
# 答案
1. 选择所有员工的姓氏
```sql
select lastname
from employees;
```
2. 选择所有员工的姓氏,不重复
```sql
select distinct lastname
from employees;
```
3. 选择姓氏为`Smith`的员工的所有数据
```sql
select *
from employees
where lastname = 'Smith';
```
4. 选择姓氏为`Smith`或`Doe`的员工的所有数据
```sql
/* With OR */
SELECT *
FROM Employees
WHERE LastName = 'Smith'
OR LastName = 'Doe';
/* With IN */
SELECT *
FROM Employees
WHERE LastName IN ('Smith', 'Doe');
```
5. 选择在部门`14`中工作的员工的所有数据
```sql
select *
from employees
where department = 14;
```
6. 选择在部门`37`或部门`77`中工作的员工的所有数据
```sql
/* With OR */
select *
from employees
where department = 37
or department = 77;
/* With IN */
select *
from employees
where department in (37, 77);
```
7. 选择姓氏以`S`开头的员工的所有数据
```sql
SELECT *
FROM Employees
WHERE LastName LIKE 'S%';
```
8. 选择所有部门预算的总和
```sql
select sum(budget)
from departments;
```
9. 选择每个部门的员工数量(只需要显示部门ID和员工数量)
```sql
select department, count(*)
from employees
group by department;
```
10. 选择员工的所有数据,包括每个员工的部门数据
```sql
SELECT SSN, E.Name AS Name_E, LastName, D.Name AS Name_D, Department, id, Budget
FROM Employees E
INNER JOIN Departments D
ON E.Department = D.id;
```
11. 选择每个员工的姓名和姓氏,以及员工部门的名称和预算
```sql
/* Without labels */
SELECT Employees.Name, LastName, Departments.Name AS DepartmentsName, Budget
FROM Employees
INNER JOIN Departments
ON Employees.Department = Departments.ID;
/* With labels */
SELECT E.Name, LastName, D.Name AS DepartmentsName, Budget
FROM Employees E
INNER JOIN Departments D
ON E.Department = D.ID;
```
12. 选择为预算超过`60,000`的部门工作的员工的姓名和姓氏
```sql
/* Without subquery */
SELECT Employees.Name, LastName
FROM Employees
INNER JOIN Departments
ON Employees.Department = Departments.id
AND Departments.Budget > 60000;
/* With subquery */
SELECT Name, LastName
FROM Employees
WHERE Department IN
(SELECT id FROM Departments WHERE Budget > 60000);
```
13. 选择预算大于所有部门平均预算的部门
```sql
SELECT *
FROM Departments
WHERE Budget >
(
SELECT AVG(Budget)
FROM Departments
);
```
14. 选择拥有两名以上员工的部门的名称
```sql
/* With subquery */
SELECT Name
FROM Departments
WHERE id IN
(
SELECT Department
FROM Employees
GROUP BY Department
HAVING COUNT(*) > 2
);
/* With UNION. This assumes that no two departments have the same name */
SELECT Departments.Name
FROM Employees
INNER JOIN Departments
ON Department = id
GROUP BY Departments.Name
HAVING COUNT(*) > 2;
```
15. 选择为预算第二低的部门工作的员工的姓名和姓氏
```sql
select name, lastname
from employees
where department = (
select id
from departments
order by budget
limit 1 offset 1);
```
16. 添加一个名为`Quality Assurance`的新部门,预算为`40,000`美元,部门代码为`11`,在该部门添加一名名为`Mary Moore`的员工,SSN为`847-21-9811`
```sql
INSERT INTO Departments
VALUES (11, 'Quality Assurance', 40000);
INSERT INTO Employees
VALUES ('847219811', 'Mary', 'Moore', 11);
```
17. 将所有部门的预算减少`10%`
```sql
UPDATE Departments
SET Budget = Budget * 0.9;
```
18. 将所有员工从研究部门(代码77)重新分配给IT部门(代码14)
```sql
UPDATE Employees
SET Department = 14
WHERE Department = 77;
```
19. 从表中删除IT部门的所有员工(代码14)
```sql
DELETE
FROM Employees
WHERE Department = 14;
```
20. 从表中删除所有在预算大于或等于`60,000`的部门工作的员工
```sql
DELETE
FROM Employees
WHERE Department IN
(
SELECT id
FROM Departments
WHERE Budget >= 60000
);
```
21. 从表中删除所有员工
```sql
DELETE
FROM Employees;
``` | 5,437 | MIT |
---
title: include 文件
description: include 文件
services: container-registry
author: dlepow
ms.service: container-registry
ms.topic: include
ms.date: 07/12/2019
ms.author: danlep
ms.custom: include file
ms.openlocfilehash: 5cca18b881250ce99df35d681bec6091ea4a27b9
ms.sourcegitcommit: 3877b77e7daae26a5b367a5097b19934eb136350
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 07/30/2019
ms.locfileid: "68642093"
---
在命令输出中, `identity`部分显示在任务中设置类型`SystemAssigned`的标识。 `principalId`是标识的服务主体 ID:
```console
[...]
"identity": {
"principalId": "xxxxxxxx-2703-42f9-97d0-xxxxxxxxxxxx",
"tenantId": "xxxxxxxx-86f1-41af-91ab-xxxxxxxxxxxx",
"type": "SystemAssigned",
"userAssignedIdentities": null
},
"location": "eastus",
[...]
```
使用[az acr task show][az-acr-task-show]命令将 principalId 存储在变量中, 以便在后面的命令中使用:
```azurecli
principalID=$(az acr task show --name dockerhubtask --registry myregistry --query identity.principalId --output tsv)
```
<!-- LINKS - Internal -->
[az-acr-task-show]: /cli/azure/acr/task#az-acr-task-show | 1,050 | CC-BY-4.0 |
---
title: "个人简介"
permalink: /chinese/
author_profile: true
---
**朱倩男 女 博士后 中国人民大学高瓴人工智能学院**
**电子邮箱:zhuqiannan@ruc.edu.cn**
# 研究方向
研究方向为知识图谱,推荐系统,信息检索和数据挖掘。主要研究内容为针对上述研究点进行泛化分析及为它们设计高效、可伸缩算法。
# 教育背景
* 2018-2020,中科院信工所计算机系统结构专业,博士研究生,导师:[谭建龙],指导老师:[周晓飞]
* 2015-2018,中科院信工所计算机软件与理论专业,博士研究生,导师:[谭建龙],指导老师:[周晓飞]
* 2011-2015,河南大学软件工程专业,本科生
# 奖学金及荣誉称号
* 2018年博士研究生国家奖学金
* 2017年中国科学院大学“三好学生”
* 2018年中国科学院信息工程研究所所长优秀奖
# 论文列表
<b>Qiannan Zhu, Xiaofei Zhou, Jia Wu, Jianlong Tan, Li Guo. “A Knowledge-Aware Reasoning Network for Recommendation”, AAAI2020<br>
<b>Qiannan Zhu, Xiaofei Zhou, Jianlong Tan, Li Guo. “Knowledge Base Reasoning with Convolutional-based Recurrent Neural Networks”,Transactions on Knowledge and Data Engineering (TKDE 2019)<br>.
<b>Qiannan Zhu, Xiaofei Zhou, Jia Wu, Jianlong Tan, Li Guo. “Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs”, IJCAI 2019.<br>
<b>Qiannan Zhu, Xiaofei Zhou, Zeliang Song, Jianlong Tan, Li Guo. “DAN:Deep Attention Neural Network for News Recommendation”, AAAI2019<br>
<b>Xiaofei Zhou, Qiannan Zhu, Ping Liu, Li Guo. “Learning Knowledge Embeddings by Combining Limit-based Scoring Loss”,CIKM 2017.
<!-- Xiaofei Zhou, Lingfeng Niu, Qiannan Zhu, Xingquan Zhu, Ping Liu, Jianlong Tan, Li Guo. "Knowledge Graph Embedding by Double Limit Scoring Loss". Accepted in IEEE Transactions on Knowledge and Data Engineering(TKDE 2021).
Qiannan Zhu, Xiaofei Zhou, Jia Wu, Jianlong Tan, Li Guo. "A Knowledge-Aware Reasoning Network for Recommendation". Accepted in the 34th AAAI Conference on Artificial Intelligence (AAAI 2020).
Yue Yuan, Xiaofei Zhou, Shirui Pan, Qiannan Zhu, Zeliang Song, Li Guo. "A Relation-Specific Attention Network for Joint Entity and Relation Extraction". Accepted in the 29th International Joint Conference on Artificial Intelligence (IJCAI 2020).
Qiannan Zhu, Xiaofei Zhou, Jianlong Tan, Li Guo. "Knowledge Base Reasoning with Convolutional-based Recurrent Neural Networks". Accepted in IEEE Transactions on Knowledge and Data Engineering(TKDE 2019).
Qiannan Zhu, Xiaofei Zhou, Jia Wu, Jianlong Tan, Li Guo. "Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs". Accepted in the 28th International Joint Conference on Artificial Intelligence (IJCAI 2019).
Qiannan Zhu, Xiaofei Zhou, Zeliang Song, Jianlong Tan, Li Guo. "DAN:Deep Attention Neural Network for News Recommendation". Accepted in Proceedings of the 33th AAAI Conference on Artificial Intelligence (AAAI 2019).
Xiaofei Zhou, Qiannan Zhu, Ping Liu, Li Guo. "Learning Knowledge Embeddings by Combining Limit-based Scoring Loss". Accepted in in the International Conference on Information and Knowledge Management (CIKM 2017).
Qiannan Zhu, Xiaofei Zhou, Peng Zhang, Yong Shi. "A Neural Translating General Hyperplane for Knowledge Graph Embedding". Published in Journal of Computational Sciences (30)2019 (JCS 2019).
Qiannan Zhu, Xiaofei Zhou, Yuwen Wu, Ping Liu, Li Guo. "Multilingual knowledge graph embeddings with neural networks". Accepted in the International Conference on Data Service --> | 3,079 | MIT |
# 变量(Variable)
前文也介绍了,对象的状态是存储在字段里面
```java
int cadence = 0;
int speed = 0;
int gear = 1;
```
Java 里面的变量包含如下类型:
* 实例变量/非静态字段(Instance Variables/Non-Static Fields):从技术上讲,对象存储他们的个人状态在“非静态字段”,也就是没有 static 关键字声明的字段。非静态字段也被称为实例变量,因为它们的值对于类的每个实例来说是唯一的(换句话说,就是每个对象); 自行车的当前速度独立于另一辆自行车的当前速度。
* 类变量/静态字段(Class Variables/Static Fields) :类变量是用 static 修饰符声明的字段,也就是告诉编译器无论类被实例化多少次,这个变量的存在,只有一个副本。特定种类自行车的齿轮数目的字段可以被标记为 static,因为相同的齿轮数量将适用于所有情况。代码`static int numGears = 6;`将创建一个这样的静态字段。此外,关键字 final 也可以加入,以指示的齿轮的数量不会改变。
* 局部变量(Local Variables):类似于对象存储状态在字段里,方法通常会存放临时状态在局部变量里。语法与局部变量的声明类似(例如,`int count = 0;`)。没有特殊的关键字来指定一个变量是否是局部变量,是由该变量声明的位置决定的。局部变量是类的方法中的变量。
* 参数(Parameters):前文的例子中经常可以看到`public static void main(String[] args)`,这里的 args 变量就是这个方法参数。要记住的重要一点是,参数都归类为“变量(variable)”而不是“字段(field)”。
如果我们谈论的是“一般的字段”(不包括局部变量和参数),我们可以简单地说“字段”。如果讨论适用于上述所有情况,我们可以简单地说“变量”。如果上下文要求一个区别,我们将使用特定的术语(静态字段,局部变量,等等)。你也偶尔会看到使用术语“成员(member)”。 类型的字段、方法和嵌套类型统称为它的成员。
## 命名
每一个编程语言都有它自己的一套规则和惯例的各种名目的,Java 编程语言对于命名变量的规则和惯例可以概括如下:
* 变量名称是区分大小写的。变量名可以是任何合法的标识符 - 无限长度的 Unicode字母和数字,以字母,美元符号`$`,或下划线`_`开头。但是惯例上推荐使用字母开头,而不是`$`或`_`。此外,按照惯例,美元符号从未使用过的。您可能会发现一些情况,自动生成的名称将包含美元符号,但你的变量名应该始终避免使用它。类似的约定存在下划线,不鼓励用“_”作为变量名开头。空格是不允许的。
* 随后的字符可以是字母,数字,美元符号,或下划线字符。惯例同样适用于这一规则。为变量命名,尽量是完整的单词,而不是神秘的缩写。这样做会使你的代码更容易阅读和理解,比如 cadence、speed 和 gear 会比缩写 c、s 和 g 更直观。同时请记住,您选择的名称不能是[关键字或保留字](../docs/keywords.md)。
* 如果您选择的名称只包含一个词,拼写单词全部小写字母。如果它由一个以上的单词,每个后续单词的第一个字母大写,如 gearRatio 和 currentGear。如果你的变量存储一个恒定值,使用`static final int NUM_GEARS = 6`,每个字母大写,并用以下划线分隔后续字符。按照惯例,下划线字符永远不会在其他地方使用。
详细的命名规范,可以参考《[Java 编码规范](<https://github.com/waylau/java-code-conventions>)》。
## 基本数据类型(Primitive Data Types)
Java 是静态类型(statically-typed)的语言,必须先声明再使用。基本数据类型之间不会共享状态。
主要有8种基本数据类型:

#### byte
byte 由1个字节8位表示,是最小的整数类型。主要用于节省内存空间关键。当操作来自网络、文件或者其他 IO 的数据流时,byte类型特别有用。取值范围为:[-128, 127]. byte 的默认值为 (byte)0,如果我们试图将取值范围外的值赋给 byte类型变量,则会出现编译错误,例如 `byte b = 128;`这个语句是无法通过编译的。一个有趣的问题,如果我们有个方法: public void test(byte b)。试图这么调用这个方法是错误的: test(0); 编译器会报错,类型不兼容!!!我们记得`byte b =0;`这是完全没有问题的,为什么在这里就出错啦?
这里涉及到一个叫字面值(literal)的问题,字面值就是表面上的值,例如整型字面值在源代码中就是诸如 5 , 0, -200这样的。如果整型子面子后面加上L或者l,则这个字面值就是 long 类型,比如:1000L代表一个 long 类型的值。如果不加L或者l,则为 int 类型。基本类型当中的byte short int long都可以通过不加L的整型字面值(我们就称作int字面值吧)来创建,例如 byte b = 100; short s = 5;对于long类型,如果大小超出int所能表示的范围(32 bits),则必须使用L结尾来表示。整型字面值可以有不同的表示方式:16进制【0X or 0x】、10进制【nothing】、八进制【0】、2进制【0B or 0b】等,二进制字面值是JDK 7以后才有的功能。在赋值操作中,int字面值可以赋给byte short int long,Java语言会自动处理好这个过程。如果方法调用时不一样,调用test(0)的时候,它能匹配的方法是test(int),当然不能匹配test(byte)方法,至于为什么Java没有像支持赋值操作那样支持方法调用,不得而知。注意区别包装器与原始类型的自动转换(anto-boxing,auto-unboxing)。`byte d = 'A';`也是合法的,字符字面值可以自动转换成16位的整数。
对byte类型进行数学运算时,会自动提升为int类型,如果表达式中有double或者float等类型,也是自动提升。所以下面的代码是错误的:
```java
byte t s1 = 100;
byte s2 = 'a';
byte sum = s1 + s2;//should cast by (byte)
```
#### short
用 16 位表示,取值范围为:[- 2^15, 2^15 - 1]。short可能是最不常用的类型了。可以通过整型字面值或者字符字面值赋值,前提是不超出范围(16 bit)。short类型参与运算的时候,一样被提升为int或者更高的类型。(顺序为 byte short int long float double).
#### int
32 bits, [- 2^31, 2^31 - 1].有符号的二进制补码表示的整数。常用语控制循环,注意byte 和 short在运算中会被提升为int类型或更高。Java 8以后,可以使用int类型表示无符号32位整数[ 0, 2^31 - 1]。
#### long
64 bits, [- 2^63, 2^63 - 1,默认值为0L].当需要计算非常大的数时,如果int不足以容纳大小,可以使用long类型。如果long也不够,可以使用BigInteger类。
#### char
16 bits, [0, 65535], [0, 2^16 -1],从'\u0000'到'\uffff'。无符号,默认值为'\u0000'。Java使用Unicode字符集表示字符,Unicode是完全国际化的字符集,可以表示全部人类语言中的字符。Unicode需要16位宽,所以Java中的char类型也使用16 bit表示。 赋值可能是这样的:
```java
char ch1 = 88;
char ch2 = 'A';
```
ASCII字符集占用了Unicode的前127个值。之所以把char归入整型,是因为Java为char提供算术运算支持,例如可以ch2++;之后ch2就变成Y。当char进行加减乘除运算的时候,也被转换成int类型,必须显式转化回来。
#### float
使用32 bit表示,对应单精度浮点数,遵循IEEE 754规范。运行速度相比double更快,占内存更小,但是当数值非常大或者非常小的时候会变得不精确。精度要求不高的时候可以使用float类型,声明赋值示例:
```java
float f1 =10;
f1 = 10L;
f1 = 10.0f; //f1 = 10.0;默认为double
```
可以将byte、short、int、long、char赋给float类型,java自动完成转换。
#### double
64为表示,将浮点子面子赋给某个变量时,如果不显示在字面值后面加f或者F,则默认为double类型。java.lang.Math中的函数都采用double类型。
如果double和float都无法达到想要的精度,可以使用BigDecimal类。
#### boolean
boolean类型只有两个值true和false,默认为false。boolean与是否为0没有任何关系,但是可以根据想要的逻辑进行转换。许多地方都需要用到boolean类型。
除了上面列出的八种原始数据类型,Java 编程语言还提供了 [java.lang.String](https://docs.oracle.com/javase/8/docs/api/java/lang/String.html)用于字符串的特殊支持。双引号包围的字符串会自动创建一个新的 String 对象,例如`String s = "this is a string";`。String 对象是不可变的(immutable),这意味着一旦创建,它们的值不能改变。 String 类不是技术上的原始数据类型,但考虑由语言所赋予的特殊支持,你可能会倾向于认为它是这样的。更多关于 String 类的细节,可以参阅[简单数据对象(Simple Data Objects)]()。
#### 默认值
在字段声明时,有时并不必要分配一个值。字段被声明但尚未初始化时,将会由编译器设置一个合理的默认值。一般而言,根据数据类型此的不同,默认将为零或为 null。但良好的的编程风格不应该依赖于这样默认值。
下面的图表总结了上述数据类型的默认值。
数据类型 | 字段默认值
---- | ----
byte | 0
short | 0
int | 0
long | 0L
float | 0.0f
double | 0.0d
char | '\u0000'
String (或任何对象) | null
boolean | false
局部变量(Local Variable)略有不同,编译器不会指定一个默认值未初始化的局部变量。如果你不能初始化你声明的局部变量,那么请确保使用之前,给它分配一个值。访问一个未初始化的局部变量会导致编译时错误。
## 字面值(Literal)
在 Java 源代码中,字面值用于表示固定的值(fixed value),直接展示在代码里,而不需要计算。数值型的字面值是最常见的,字符串字面值可以算是一种,当然也可以把特殊的 null 当做字面值。字面值大体上可以分为整型字面值、浮点字面值、字符和字符串字面值、特殊字面值。
### 整型字面值
从形式上看是整数的字面值归类为整型字面值。例如: 10, 100000L, 'B'、0XFF这些都可以称为字面值。整型字面值可以用十进制、16、8、2进制来表示。十进制很简单,2、8、16进制的表示分别在最前面加上0B(0b)、0、0X(0x)即可,当然基数不能超出进制的范围,比如09是不合法的,八进制的基数只能到7。一般情况下,字面值创建的是int类型,但是int字面值可以赋值给byte short char long int,只要字面值在目标范围以内,Java会自动完成转换,如果试图将超出范围的字面值赋给某一类型(比如把128赋给byte类型),编译通不过。而如果想创建一个int类型无法表示的long类型,则需要在字面值最后面加上L或者l。通常建议使用容易区分的L。所以整型字面值包括int字面值和long字面值两种。
* 十进制(Decimal):其位数由数字0〜9组成;这是您每天使用的数字系统
* 十六进制(Hexadecimal):其位数由数字0到9和字母A至F的组成
* 二进制(Binary):其位数由数字0和1的(可以在 Java SE 7 和更高版本创建二进制字面值)
下面是使用的语法:
```java
// The number 26, in decimal
int decVal = 26;
// The number 26, in hexadecimal
int hexVal = 0x1a;
// The number 26, in binary
int binVal = 0b11010;
```
### 浮点字面值
浮点字面值简单的理解可以理解为小数。分为float字面值和double字面值,如果在小数后面加上F或者f,则表示这是个float字面值,如11.8F。如果小数后面不加F(f),如10.4。或者小数后面加上D(d),则表示这是个double字面值。另外,浮点字面值支持科学技术法( E 或 e )表示。下面是一些例子:
```java
double d1 = 123.4;
// same value as d1, but in scientific notation
double d2 = 1.234e2;
float f1 = 123.4f;
```
### 字符及字符串字面值
Java 中字符字面值用单引号括起来,如`@`,`1`。所有的UTF-16字符集都包含在字符字面值中。不能直接输入的字符,可以使用转义字符,如`\n`为换行字符。也可以使用八进制或者十六进制表示字符,八进制使用反斜杠加3位数字表示,例如`\141`表示字母a。十六进制使用`\u`加上4为十六进制的数表示,如`\u0061`表示字符a。也就是说,通过使用转义字符,可以表示键盘上的有的或者没有的所有字符。常见的转义字符序列有:
`\ddd(八进制) `、 `\uxxxx(十六进制Unicode字符)`、`\'(单引号)`、`\"(双引号)`、`\\ (反斜杠)\r(回车符) \n(换行符) \f(换页符) \t(制表符) \b(回格符)`
字符串字面值则使用双引号,字符串字面值中同样可以包含字符字面值中的转义字符序列。字符串必须位于同一行或者使用+运算符,因为 Java 没有续行转义序列。
### 在数值型字面值中使用下划线
Java SE 7 开始,可以在数值型字面值中使用下划线。但是下划线只能用于分隔数字,不能分隔字符与字符,也不能分隔字符与数字。例如 `int x = 123_456_789`,在编译的时候,下划线会自动去掉。可以连续使用下划线,比如`float f = 1.22___33__44`。二进制或者十六进制的字面值也可以使用下划线,记住一点,下划线只能用于数字与数字之间,初次以外都是非法的。例如1._23是非法的,_123、11000_L都是非法的。
正确的用法:
```java
long creditCardNumber = 1234_5678_9012_3456L;
long socialSecurityNumber = 999_99_9999L;
float pi = 3.14_15F;
long hexBytes = 0xFF_EC_DE_5E;
long hexWords = 0xCAFE_BABE;
long maxLong = 0x7fff_ffff_ffff_ffffL;
byte nybbles = 0b0010_0101;
long bytes = 0b11010010_01101001_10010100_10010010;
```
非法的用法:
```java
// Invalid: cannot put underscores
// adjacent to a decimal point
float pi1 = 3_.1415F;
// Invalid: cannot put underscores
// adjacent to a decimal point
float pi2 = 3._1415F;
// Invalid: cannot put underscores
// prior to an L suffix
long socialSecurityNumber1 = 999_99_9999_L;
// Invalid: cannot put underscores
// At the end of a literal
int x2 = 52_;
// Invalid: cannot put underscores
// in the 0x radix prefix
int x4 = 0_x52;
// Invalid: cannot put underscores
// at the beginning of a number
int x5 = 0x_52;
// Invalid: cannot put underscores
// at the end of a number
int x7 = 0x52_;
```
## 基本类型之间的转换
我们看到,将一种类型的值赋给另一种类型是很常见的。在 Java 中,boolean 类型与所有其他7种类型都不能进行转换,这一点很明确。对于其他7中数值类型,它们之间都可以进行转换,但是可能会存在精度损失或者其他一些变化。转换分为自动转换和强制转换。对于自动转换(隐式),无需任何操作,而强制类型转换需要显式转换,即使用转换操作符(type)。首先将7种类型按下面顺序排列一下:
```
byte <(short=char)< int < long < float < double
```
如果从小转换到大,可以自动完成,而从大到小,必须强制转换。short 和 char 两种相同类型也必须强制转换。

### 自动转换
自动转换时发生扩宽(widening conversion)。因为较大的类型(如int)要保存较小的类型(如byte),内存总是足够的,不需要强制转换。如果将字面值保存到 byte、short、char、long 的时候,也会自动进行类型转换。注意区别,此时从 int(没有带L的整型字面值为int)到 byte/short/char 也是自动完成的,虽然它们都比int 小。在自动类型转化中,除了以下几种情况可能会导致精度损失以外,其他的转换都不能出现精度损失。
* int--> float
* long--> float
* long--> double
* float -->double without strictfp
除了可能的精度损失外,自动转换不会出现任何运行时(run-time)异常。
### 强制类型转换
如果要把大的转成小的,或者在 short 与 char 之间进行转换,就必须强制转换,也被称作缩小转换(narrowing conversion),因为必须显式地使数值更小以适应目标类型。强制转换采用转换操作符()。严格地说,将 byte 转为 char 不属于 (narrowing conversion),因为从 byte 到 char 的过程其实是 byte-->int-->char,所以 widening 和 narrowing 都有。强制转换除了可能的精度损失外,还可能使模(overall magnitude)发生变化。强制转换格式如下:
(target-type) value
```java
int a=257;
byte b;
b = (byte)a;//1
```
如果整数的值超出了 byte 所能表示的范围,结果将对 byte 类型的范围取余数。例如a=256超出了byte的[-128,127]的范围,所以将257除以byte的范围(256)取余数得到b=1;需要注意的是,当a=200时,此时除了256取余数应该为-56,而不是200.
将浮点类型赋给整数类型的时候,会发生截尾(truncation)。也就是把小数的部分去掉,只留下整数部分。此时如果整数超出目标类型范围,一样将对目标类型的范围取余数。
7中基本类型转换总结如下图:

### 赋值及表达式中的类型转换:
#### 字面值赋值
在使用字面值对整数赋值的过程中,可以将int literal赋值给byte short char int,只要不超出范围。这个过程中的类型转换时自动完成的,但是如果你试图将long literal赋给byte,即使没有超出范围,也必须进行强制类型转换。例如 byte b = 10L;是错的,要进行强制转换。
#### 表达式中的自动类型提升
除了赋值以外,表达式计算过程中也可能发生一些类型转换。在表达式中,类型提升规则如下:
* 所有byte/short/char都被提升为int。
* 如果有一个操作数为long,整个表达式提升为long。float和double情况也一样。
## 数组(Array)
数组是一个容器对象,保存一个固定数量的单一类型的值。当数组创建时,数组的长度就确定了。创建后,其长度是固定的。下面是一个例子:

数据里面的每个项称为元素(element),每个元素都用一个数组下标(index)关联,下标是从 0 开始,如上图所示,第9个元素的下标是 8:
ArrayDemo 的示例:
```java
class ArrayDemo {
/**
* @param args
*/
public static void main(String[] args) {
// declares an array of integers
int[] anArray;
// allocates memory for 10 integers
anArray = new int[10];
// initialize first element
anArray[0] = 100;
// initialize second element
anArray[1] = 200;
// and so forth
anArray[2] = 300;
anArray[3] = 400;
anArray[4] = 500;
anArray[5] = 600;
anArray[6] = 700;
anArray[7] = 800;
anArray[8] = 900;
anArray[9] = 1000;
System.out.println("Element at index 0: " + anArray[0]);
System.out.println("Element at index 1: " + anArray[1]);
System.out.println("Element at index 2: " + anArray[2]);
System.out.println("Element at index 3: " + anArray[3]);
System.out.println("Element at index 4: " + anArray[4]);
System.out.println("Element at index 5: " + anArray[5]);
System.out.println("Element at index 6: " + anArray[6]);
System.out.println("Element at index 7: " + anArray[7]);
System.out.println("Element at index 8: " + anArray[8]);
System.out.println("Element at index 9: " + anArray[9]);
}
}
```
输出为:
```
Element at index 0: 100
Element at index 1: 200
Element at index 2: 300
Element at index 3: 400
Element at index 4: 500
Element at index 5: 600
Element at index 6: 700
Element at index 7: 800
Element at index 8: 900
Element at index 9: 1000
```
### 声明引用数组的变量
声明数组的类型,如下:
```java
byte[] anArrayOfBytes;
short[] anArrayOfShorts;
long[] anArrayOfLongs;
float[] anArrayOfFloats;
double[] anArrayOfDoubles;
boolean[] anArrayOfBooleans;
char[] anArrayOfChars;
String[] anArrayOfStrings;
```
也可以将中括号放数组名称后面(但不推荐)
```java
// this form is discouraged
float anArrayOfFloats[];
```
### 创建、初始化和访问数组
ArrayDemo 的示例说明了创建、初始化和访问数组的过程。可以用下面的方式,简化 创建、初始化数组
```
int[] anArray = {
100, 200, 300,
400, 500, 600,
700, 800, 900, 1000
};
```
数组里面可以声明数组,即,多维数组 (multidimensional array)。如 MultiDimArrayDemo 例子:
```java
class MultiDimArrayDemo {
/**
* @param args
*/
public static void main(String[] args) {
String[][] names = { { "Mr. ", "Mrs. ", "Ms. " }, { "Smith", "Jones" } };
// Mr. Smith
System.out.println(names[0][0] + names[1][0]);
// Ms. Jones
System.out.println(names[0][2] + names[1][1]);
}
}
```
输出为:
```
Mr. Smith
Ms. Jones
```
最后,可以通过内建的 length 属性来确认数组的大小
```
System.out.println(anArray.length);
```
### 复制数组
System 类有一个 arraycopy 方法用于数组的有效复制:
```
public static void arraycopy(Object src, int srcPos,
Object dest, int destPos, int length)
```
下面是一个例子 ArrayCopyDemo,
```java
class ArrayCopyDemo {
/**
* @param args
*/
public static void main(String[] args) {
char[] copyFrom = { 'd', 'e', 'c', 'a', 'f', 'f', 'e', 'i', 'n', 'a', 't', 'e', 'd' };
char[] copyTo = new char[7];
System.arraycopy(copyFrom, 2, copyTo, 0, 7);
System.out.println(new String(copyTo));
}
}
```
程序输出为:
```
caffein
```
### 数组操作
Java SE 提供了一些数组有用的操作。 ArrayCopyOfDemo 例子:
```java
class ArrayCopyOfDemo {
/**
* @param args
*/
public static void main(String[] args) {
char[] copyFrom = { 'd', 'e', 'c', 'a', 'f', 'f', 'e', 'i', 'n', 'a', 't', 'e', 'd' };
char[] copyTo = java.util.Arrays.copyOfRange(copyFrom, 2, 9);
System.out.println(new String(copyTo));
}
}
```
可以看到,使用 java.util.Arrays.copyOfRange 方法,代码量减少了。
其他常用操作还包括:
* binarySearch : 用于搜索
* equals : 比较两个数组是否相等
* fill : 填充数组
* sort : 数组排序,在 Java SE 8 以后,可以使用 parallelSort 方法,在多处理器系统的大数组并行排序比连续数组排序更快。
### 源码
该例子可以在 `com.waylau.essentialjava.array.arraydemo` 包下找到。 | 12,984 | MIT |
---
author: 何清涟
categories: [中國戰略分析]
date: 2017-08-28
from: http://zhanlve.org/?p=1748
layout: post
tags: [中國戰略分析]
title: 何清涟:溃而不崩:对中国前景的一种分析
---
<div id="entry">
<div class="at-above-post addthis_tool" data-url="http://zhanlve.org/?p=1748">
</div>
<p>
</p>
<p style="text-align: center;">
<img alt="" class="aligncenter size-full wp-image-1749" height="121" src="http://zhanlve.org/wp-content/uploads/2017/08/download.jpg" width="161"/>
</p>
<p style="text-align: center;">
<span style="font-size: 12pt;">
(本文系作者为即将出版的专著《中国:溃而不崩》撰写的序言)
</span>
</p>
<p>
<span style="font-size: 12pt;">
从《中国的陷阱》到《中国:溃而不崩》这本书的出版,其间中国经历了极其重要的20年,本人的生命轨迹也被硬生生地截成两段。这20年当中,西方社会对中国的态度也发生了巨大变化:先是欢迎“中国与国际接轨”并“和平崛起”,继而惊觉中国已经成为新的“独裁者俱乐部”领导者,中国存在种种巨大的社会危机,于是开始担心中国崩溃。
</span>
</p>
<p>
<span style="font-size: 12pt;">
本书的分析是:中国不会真正崛起,但也不会像某些人预测的那样,很快陷入崩溃。所谓“溃而不崩”的立论,也非作者现在的看法。早在2003年,我就在《中国威权统治的现状及其前景》一文中提出这个概念
<a href="#_ftn1" name="_ftnref1">
[1]
</a>
,当时指出的是:在未来可见的20-30年内,中国将长期陷入“溃而不崩”的状态。所谓“溃”,指的是社会溃败,包含生态环境、道德伦理等人类基础生存条件;“不崩”,指的是政权,即中共政权不会在短期内崩溃。本书的预测是今后10-20年,中国将继续保持这种“溃而不崩”的状态。
</span>
</p>
<p>
<span style="font-size: 12pt;">
一、国际社会看中国:从“和平崛起”到中国衰落
</span>
</p>
<p>
<span style="font-size: 12pt;">
从2015年开始,国际社会对中国的看法来了一个180度的大转弯,从“繁荣论”一下变成“崩溃论”。引发这轮话题的人物是美国乔治·华盛顿大学(The George Washington University,简称GWU或GW)政治学和国际关系教授沈大伟(David Shambaugh),他是华盛顿著名的亲北京学者,“拥抱熊猫派”的主力人物,被誉为“美国最有影响力的中国问题专家”。沈大伟从长期鼓吹“中国和平崛起”突然改为认同“中国崩溃” ,尽管他几个月后又把自己的最新结论从“崩溃”修改为“衰败”,但他的这个“两极跳”动作在北京与美国引发的反响,与多年前美国章家敦(Gordon Chang)那本《中国即将崩溃》(The Coming Collapse of China)不一样,由于沈大伟的权威地位,他对中国认知的转变,对美国的中国研究界甚至华府外交圈的影响都很大。
</span>
</p>
<p>
<span style="font-size: 12pt;">
我早在2009年 就指出:当时中国经济已进入由盛而衰的转折点,标志是外资大量撤出中国,世界工厂开始衰落,中国政府不得不推出耗资4万亿(约合5,860亿美元)资金的救市计划,扶持不应该扶持的“铁公鸡”(指铁路、公路、基础设施等项目),将造成严重的产能过剩问题。沈大伟先生的观点发表之后,我重申了自己2003年就提出的观点:沈大伟列举的将导致中国崩溃的所有因素,早就在中国出现,但近期内并不会导致中共政权垮台。中国的现状与未来是在“强大”与“崩溃”之间的“溃而不崩” 。
</span>
</p>
<p>
<span style="font-size: 12pt;">
2016年《大西洋月刊》发表了对美国总统奥巴马的采访《“奥巴马主义”》(The Obama Doctrine)。奥巴马认为,一个衰落的中国比崛起的中国更可怕,理由如下:“如果中国失败,如果未来中国的发展无法满足其人口需求进而滋生民族主义,并将其作为一种组织原则;如果中国感到不知所措而无法承担起构建国际秩序的责任;如果中国仅仅着眼于地区局势和影响力,那么我们将不仅要考虑未来与中国发生冲突的可能性;更应知道,我们自身也将面临更多的困难与挑战”
<a href="#_ftn2" name="_ftnref2">
[2]
</a>
。发表这些看法时,奥巴马入主白宫七年多。他当年初进白宫之时,对中国的了解限于皮毛,这些年经历了不少“中国风、亚洲雨”,对中国的认识的“成绩单”还算不错。
</span>
</p>
<p>
<span style="font-size: 12pt;">
中国这个世界第一人口大国因其政治专制体制,始终让世界不安,但引起不安的原因却在变化。国际社会曾经担心过许多问题:先是“谁来养活中国”(指粮食危机),2003年开始担心“中国崛起”威胁世界和平,现在则担心中国衰落拖累世界。至于拖累的方式,预测有多种多样,中国人自己设想过的有“黄祸”(即中国人口因灾难流往全世界)之类,奥巴马提到的“用民族主义组织民众”,与中国鹰派鼓吹的“持剑经商”相类似。
</span>
</p>
<p>
<span style="font-size: 12pt;">
一个值得关注的现象是:国际社会对中国的观察时常大起大落,直到前年还有研究坚称,中国在2030年将超过美国,成为世界最强大经济体;但从去年开始,又纷纷讨论中国将要崩溃了。从预期中国将成为世界最强大经济体,到中国行将崩溃,这中间落差实在够大。之所以产生这种巨大落差,是因为对外部观察者来说,中国具有极大的不确定性,这种不确定性部分源自他们对中国的不了解,部分源自中国政府在国际社会中很少按规则出牌。
</span>
</p>
<p>
<span style="font-size: 12pt;">
二、中国看自身:从输出“中国模式”到应付内部危机
</span>
</p>
<p>
<span style="font-size: 12pt;">
北京其实比国际社会更早认识到内部危机,这从中国的对外宣传重点的变化就可以很清楚地看出来。2009年以前,中国政府对本国未来的经济发展比较乐观;从2009年开始,它的态度开始发生微妙的变化。
</span>
</p>
<p>
<span style="font-size: 12pt;">
2003年底,中共理论界的三朝元老郑必坚曾提出“中国和平崛起”之说,成为国内外关注热点。美国《外交季刊》2005年9-10月号上发表他的文章《中国和平崛起》,接下来短短三年内,中国的对外宣传口径由“和平崛起”转变成要以“北京共识”(the Beijing Consensus)
<a href="#_ftn3" name="_ftnref3">
[3]
</a>
取代“华盛顿共识” (Washington Consensus),要向世界输出“中国模式”,而且获得委内瑞拉总统查韦斯的高调响应。一时之间,居然营造出“中国模式”行将被发展中国家接受之势。
</span>
</p>
<p>
<span style="font-size: 12pt;">
2009年中国的GDP总量首次超过日本,成为世界第二大经济体,但当时中国政府对未来的评估已变得比较谨慎,称中国在许多方面还是发展中国家。2011年3月国际货币基金组织(IMF)的一份报告称:按购买力平价计算的中国GDP总量将在5年后超越美国,2016年将成为“中国世纪元年”,“美国时代”已接近尾声。中国方面立即由国家统计局局长马建堂出面,发表文章反驳IMF的这份报告,声称中国的经济发展水平还很落后
<a href="#_ftn4" name="_ftnref4">
[4]
</a>
;不久,中国官方新闻社又发布消息表示,IMF使用购买力平价的计算方法得出上述结论,并不准确
<a href="#_ftn5" name="_ftnref5">
[5]
</a>
。中国政府之所以不肯接受“世界第一经济大国”这顶高帽,是因为高层已经开始担忧中国将出现经济困难,也深知导致这些经济困难的因素都是无法克服的内在疾患。
</span>
</p>
<p>
<span style="font-size: 12pt;">
细心的中国观察者也许会注意到,从2009年开始,中国政府停止了“和平崛起”的对外宣传策略,“北京共识”与“中国模式”这类高调宣传偃旗息鼓;取而代之的是中共领导人习近平的说法,“中国一不输出革命,二不输出饥饿和贫困,三不去折腾你们,还有什么好说的”
<a href="#_ftn6" name="_ftnref6">
[6]
</a>
。与此同时,中国政府一直集中精力应付国内问题。从2012年起,习近平就忙于应付中共高层内部激烈的权力斗争,直到2015年,他总算将周永康、令计划等一批高官送进监狱;紧接着,中国政府又开始应付企业倒闭引发的失业潮。此后,习近平逐步加强社会控制,凡批评中国政治与管理体制的言论,一律严厉打击,有名声的政治反对者被陆续抓捕。其中最受国际社会诟病的是取消各种外国资助的中国非政府组织(NGO),许多外国机构被点名,意在恫吓那些使用海外资金的中国NGO成员,连政治上并不敏感的女权项目也被停止。迄今为止,共有3百多位维权律师与维权人士被捕。在这种日益紧张的恐怖气氛中,2016年3月上旬,美国、加拿大、德国、日本及欧盟等各国驻京大使联署致函中共公安部长郭声琨,就中国新的《反恐法》、《网络安全法》及《境外非政府组织管理法(草案)》表达关注及忧虑,希望中共放松压制,但这种关注几乎没起任何作用。
</span>
</p>
<p>
<span style="font-size: 12pt;">
三、国际社会的隐忧与中国的前景
</span>
</p>
<p>
<span style="font-size: 12pt;">
奥巴马担心中国“滋生民族主义”,只是道出了国际社会的一半担忧,另一半担忧则藏在舌头下面,那就是担心中国通过对外军事扩张,转嫁人口危机,如同涌向欧洲的叙利亚难民潮。这担忧不无道理,随着中国经济的衰退,中国的城乡失业人口高达3亿多,占中国劳动力年龄人口的三分之一。
</span>
</p>
<p>
<span style="font-size: 12pt;">
经济衰退之后,中国当局与人民之间原有的“面包契约”难以为继,从2015年开始,黑龙江双鸭山煤矿工人以及各地国企工人的大规模抗议,口号就是“我们要吃饭”。国际社会开始意识到:中国的麻烦除了中共专制政府之外,还有一个,即谁能为数亿失业人口找到工作?“中国的崩溃”这个问题之所以从2015年开始再度浮出水面,乃因西方观察者隐隐意识到:众多民主国家同样面对高失业问题;中国的人口、资源与就业等问题,即便中国实行民主化,仍然是难以解决的难题。这就是奥巴马说“衰落的中国比强大的中国更可怕”的现实前提。
</span>
</p>
<p>
<span style="font-size: 12pt;">
“阿拉伯之春”变成“阿拉伯之冬”,以及由此而派生的叙利亚难民危机,让全球看到两个问题:第一,秩序的破坏远比秩序的重建容易;第二,全球范围内已经产生的2.44亿难民,正在成为全球治理的核心问题。
<a href="#_ftn7" name="_ftnref7">
[7]
</a>
自2015年以来欧盟面临的叙利亚难民危机证明:开放的民主社会、脆弱的福利系统,在几百万外来难民潮的冲击下难以自保。
</span>
</p>
<p>
<span style="font-size: 12pt;">
中国是世界第一人口大国。这个国家自古以来,除了很少的年代,比如汉代的文景之治、唐代的贞观之治之外,大多时候都与灾荒、饥馑相联系(有兴趣的可查阅孟昭华,彭传荣所著《中国灾荒史》)。中国自从改革开放以来,近40年间以透支生态与劳工健康、生命和福利为代价的经济发展,确实让中国人吃饱了饭。笔者将这称之为中国统治者与老百姓之间达成的“面包契约”,即政治上剥夺老百姓各种权利(rights),但承诺发展经济,让老百姓能够就业,衣食住行得到基本满足。在中国经济快速发展的阶段,国际社会曾认为,可以通过促进中国的经济发展进而促成中国的民主化。美国在比尔·克林顿任总统时期曾确定一个长达十年的对华法律援助计划,并在2003年开始付诸实施,就是希望通过中美间的法律合作促进中国的法治建设,最后促进中国的民主化。
</span>
</p>
<p>
<span style="font-size: 12pt;">
从2005年“中国和平崛起论”出现之后,国际社会担心“强大的中国对国际社会将形成威胁”,现在则变成“衰落的中国比崛起的中国更可怕”,10年之间,对中国的观察研究绕了一圈,又回到原点。美国总统奥巴马的看法,并非他个人的看法,代表了华府政治圈现在的看法。根据本书作者对中国的长期研究与了解,中国从来就没有超过美国的可能性,但只要中国没卷入不可控的外部冲突,短期内也不会崩溃。
</span>
</p>
<p>
<span style="font-size: 12pt;">
四、中国的崛起与衰落的共同根源:共产党资本主义
</span>
</p>
<p>
<span style="font-size: 12pt;">
2016年,中国的各项经济指标表明,其经济已经明显陷入长期衰退。但是,美国皮尤研究中心(Pew Research Centre)于2016年5月公布的民调仍然显示,有一半美国人认为,崛起的中国对于美国是一个主要威胁,更有四分之一的人把中国看成是美国的对手。
<a href="#_ftn8" name="_ftnref8">
[8]
</a>
世界上绝大部分国家,特别是中国周边邻国,都希望崛起的中国能早日走上民主化道路,在国际事务当中基本上按照国际规则行事,与周边国家减少冲突,形成一种共同繁荣的友好关系。但是,中国会走上民主化道路吗?中国的经济繁荣到底是促进政治民主化,还是会强化共产党的专制?这不仅关系到中国的前景,也关系到中国周边国家未来的安全。
</span>
</p>
<p>
<span style="font-size: 12pt;">
整个世界,包括世界银行和国际货币基金组织等著名国际机构,似乎都对中国经济的前景充满憧憬,不少国家都希望搭上中国经济这趟“快车”。但是,如果你每年年初都到中国的经济类网站上搜集信息,就会很惊讶地发现,从2008年开始到2016年,几乎每年年初中国经济媒体都有这样一条新闻,除了年份不同,标题的内容几乎相同:“今年是中国经济最困难的一年”,发表这个看法的,有时是总理本人,有时是著名经济学家。
<a href="#_ftn9" name="_ftnref9">
[9]
</a>
对乐观的中国观察者来说,也许认为这种担心是杞人忧天,但了解中国经济实际情况的人却明白,中国连续9年在担心可能出现经济最困难的局面,并非中国政府及学者低估本国的经济发展,而是中国经济有许多问题,除了产业结构畸型之外,社会分配不公导致内需不足,更是中国经济发展动力不足的主要原因。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
从1970年代后期开始,中国一直在推行经济改革,即改变共产党政权原来的社会主义经济制度,不再坚持公有制和计划经济。经过近40年改革,在中国出现了一种共产党政权与资本主义“结婚”的政治经济制度,即中国模式,成为冷战结束后世界现代史上的一个“奇迹”。之所以将其称之为“奇迹”,是因为共产主义运动的“圣经” ——《共产党宣言》斩钉截铁地宣布:共产主义与资本主义势不两立,无产阶级组成的政党——共产党——将是资本主义的掘墓人。那么,该怎样来认识中国经济改革产生的这种独特的政治经济制度呢?本书作者把中国这种独特的政治经济制度称为“共产党资本主义(Communist Capitalism)”
<a href="#_ftn10" name="_ftnref10">
[10]
</a>
。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
所谓“共产党资本主义”,就是专制政权之下的权贵资本主义+国家资本主义,中国模式是它的好听说法。它意味着,以消灭资本主义起家的共产党,经历了社会主义经济体制的失败之后,改用资本主义经济体制来维系共产党政权的统治;同时,共产党的各级官员及其亲属,通过市场化将手中的权力变现,成为企业家、大房产主、巨额金融资产所有者等各种类型的资本家,掌握了中国社会的大部分财富。这种利益格局,使红色权贵们需要维持中国共产党政权的长期统治。因为只有中共政权才能保护他们的财产和生命安全,并保障他们通过政府垄断的行业继续聚敛巨大的财富。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
理解了“共产党资本主义”的掠夺性,才能理解20多年之间,中国从繁荣走向衰败这一过程,其实是中国模式的宿命。如同我当年在《中国的陷阱》
<a href="#_ftn11" name="_ftnref11">
[11]
</a>
一书中指出的那样,中国的改革路线就是以权力市场化为特质,这一模式被称为中国模式,即极权政治+资本主义。中国经济的迅速发展与一度繁荣,是推行共产党资本主义之功,因为这种模式便于政府集中一切资源,不惜透支、污染生态环境,罔顾民生与人民健康,用掠夺方式迅速发展经济,打造出世界上最快的GDP增速,同时也让红色家族成员与共产党官员大量掠夺公共财以自肥;而中国经济的衰退,也由共产党资本主义造成,因为这种模式造成腐败蔓延,在短时期内造就大量世界级中国富豪的同时,也生产出数亿穷人,当中国富人与富裕中产满世界购买奢侈品时,许多穷人连满足日常生活需求都极为困难,这种严重的贫富差距,不仅让中国社会各阶层之间产生巨大的身份裂沟,还制造了弥漫全社会的社会仇恨。如今繁华散尽,收获苦果的时候到了,中国人面对的是雾霾、毒地与污黑的河流、干涸的湖泊,以及数亿没有办法获得工作机会的失业者。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
所谓“溃而不崩”是指中国长期陷入这样一种状态:任何社会都有赖以生存的四个基本要素,一是作为社会生存基座的生态环境,比如水、土地、空气等的环境安全;二是调节社会成员之间行为规范的道德伦理体系;三是社会成员最起码的生存底线,具体指标就是以就业为标志的生存权;四是维持社会正常运转的政治整合力量,即从法律与制度层面对社会成员施加的一种强力约束。上述四者,中国现在只剩下政府的强管制,其余三大生存要素均已经陷入崩塌或行将崩塌。更悲观的,除了第四点即政治制度,可以通过变革在短期内改变调整之外,前三个中国社会的长期生存要素,并不能通过政权更替在几十年内有根本改观。
<a href="#_ftn12" name="_ftnref12">
[12]
</a>
由于中国政府集中所有资源用于“维稳”,中国民众因缺乏自组织能力,有如一盘散沙,无法与中共这块巨大的顽石抗争,因而中共政权在20-30年内不会崩溃,中国社会将长期处于“溃而不崩”状态。这个过程是中共政权透支中国未来以维持自身存在的过程,也是中国日渐衰败的过程,当然更是中国不断向外部释放各种负面影响的过程,比如中国人口迁往世界各国、环境污染外溢、制造对外冲突以转移国内矛盾等等。
</span>
</p>
<p>
<span style="font-size: 12pt;">
五、共产党资本主义培育出盗贼型政权
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
迄今为止,全球已有包括俄罗斯、巴西、新西兰、瑞士和澳大利亚等在内的81个国家承认中国的市场经济国家地位。那么,一个实行市场经济、积极参与经济全球化的中国,是不是也会和地球上绝大多数国家一样,形成公民社会,用民主制度代替专制制度?吊诡的是,中国政府并不打算走上民主化道路,从2005年以来,无论是胡锦涛当政还是习近平当政,中国政府多次明确表示,绝不考虑采用西方国家的民主制度。之所以会如此坚持社会主义制度,是因为中国政府已经堕落成为一个盗贼型政权,并且集中了当今世界上所有盗贼型政权的恶劣特点。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
美国政治学者曾将非洲、南美以及南欧等国的腐败政府称之为“盗贼型政权” ——用“盗贼”借喻贪婪无耻掠夺公共财与私人财的统治者,恰如其分——并将之划分为四种类型。受贿者集中于高层的有两类政权:一类是政府与企业财团形成了双边垄断;另一类是“盗贼统治”的国家。受贿者分布于政府中低层的也有两类政权:一类是因为资源分配的关系导致行贿呈螺旋式上升;另一类是黑手党控制的国家。这些臭名昭著的盗贼型政权包括:1954-1989年统治巴拉圭的阿尔弗雷·德·斯特罗斯纳政权、1965-1997年扎伊尔的蒙博托政权、1957-1986年间海地的杜瓦利埃家族政权。
<a href="#_ftn13" name="_ftnref13">
[13]
</a>
这些政权因其高度腐败,官员肆意掠夺公共财及民财,其治下民不聊生,最后都被推翻,无一有好下场。
</span>
</p>
<p>
<span style="font-size: 12pt;">
中国现政权集中了上述几类盗贼型政权的特点:受贿者遍布政府高层与中低层,即使是一个小小的政府公务员,也莫不利用手中权力寻租。当今世界上许多“盗贼型政权”采用过的掠夺手段,莫不在中国出现,择其大端列举如下:
</span>
</p>
<p>
<span style="font-size: 12pt;">
其一,产业管制成为官员们个人寻租的手段。只要某个行业有利可图,该行业的许可证就成为官员们谋取私利的手段。例如:煤矿、金矿与其他各种矿产的准入制度都成了为官员们生产财富的金牛;而中国因此也成了世界上矿难最高、因滥采滥控而导致环境严重污染的国度。
</span>
</p>
<p>
<span style="font-size: 12pt;">
其二,土地的国家垄断成为权势者获利渊薮。中国各级官员像一群通过转手倒卖牟利的地产中介商,政府凭仗权力逼迫老百姓搬迁,以便把土地高价卖给房地产开发商,从中牟利。中国官员因贪腐被查,很多都与土地有关
<a href="#_ftn14" name="_ftnref14">
<sup>
[14]
</sup>
</a>
;中国的富豪中房地产商占比非常高
<a href="#_ftn15" name="_ftnref15">
<sup>
[15]
</sup>
</a>
。
</span>
</p>
<p>
<span style="font-size: 12pt;">
其三,国有企业的私有化成为国企管理层和地方政府官员发横财的巨大“金矿”。山东省诸城市市长陈光,因一口气卖光了该市272家国有企业而获得“陈卖光”的绰号,被誉为中国“国企改革第一官”
<a href="#_ftn16" name="_ftnref16">
<sup>
[16]
</sup>
</a>
;而“陈卖光”因此积聚大量财富,最后挟款潜逃,至今不知躲在世界上哪个角落。整个中国,国有企业负责人犯罪成为腐败案件的主体部分,比如2004年国有企业管理层的职务犯罪占查办贪污贿赂案件总数的41.5%,其中相当部分都与国有企业改革有关。2014年习近平推行大型国企的反腐运动,一年之内逮捕了115名国企高管,包括全球巨头如中石油、中国南方航空、华润、一汽和中石化的众多高管在内
<a href="#_ftn17" name="_ftnref17">
<sup>
[17]
</sup>
</a>
。
</span>
</p>
<p>
<span style="font-size: 12pt;">
中国至今改革已近40年,但永远处于改革未完成状态;每次改革都成为权势者汲取财富的有效管道,诸如国有企业私有化、证券市场建立、金融监管体制改革等,每一次改革几乎都使一批官员成了富翁。习近平上台以后,为了巩固自己的权力,用反腐败作为打击政敌的手段,同时也加强了对官员们的约束。官员们认为,这样的政策断绝了自己的财路,采取懒政、不作为以应对之。
</span>
</p>
<p>
<span style="font-size: 12pt;">
红色中国现在早已沦为共产党精英的私产,统治集团不断对外宣布要保持红色江山永不变色。但是,上述强盗式掠夺行径的泛滥,导致广泛而严重的社会不满,使这个政权面临政治高风险状态,维持稳定就成了统治集团的集体梦呓。由于担心掠夺来的财富无法经受政权更迭的风险,中国的政治精英都偏好移民他国,而中国则成了世界上最大的资本外逃国。
<a href="#_ftn18" name="_ftnref18">
<sup>
[18]
</sup>
</a>
中国政府为了保护统治集团的利益,动用所有的社会资源来维持政权的稳定,这是中国的维稳费用(社会安全开支)多年来直逼军费的原因
<a href="#_ftn19" name="_ftnref19">
<sup>
[19]
</sup>
</a>
。 中国政府依靠严厉的社会控制和政治高压,试图将所有形式的社会反抗消灭于萌芽状态。可以这样说,现阶段社会底层的严重不满及各种群体性事件,以及互联网上一些清算共产党官员、称“民主化之后杀你全家”的极端言论,只会加强中共维护统治的决心,但不会促使中共实现温和的民主化转型。
</span>
</p>
<p>
<span style="font-size: 12pt;">
中国现在正面临一系列几乎不可克服的经济社会难题,因此今后20年内中国很可能处于一种衰败(decay)状态。如果说,美国自2008年之后的经济走势是U字型,那么中国走的就是L型,在L下面那一横还将持续下滑。自邓小平之后,中国政府的政治逻辑是:经济发展良好、社会稳定,说明中国模式有效,不需要改革;经济衰退、人心不稳,则维持稳定是第一要务,这种时候的政治改革只会让政权面临危险。中国现任政治局常委王岐山常向朋友及属下荐读法国历史学家托克维尔的《旧制度与大革命》
<a href="#_ftn20" name="_ftnref20">
[20]
</a>
,就因为他对“托克维尔定律”有深刻的感悟:一个坏的政权最危险的时刻并非其最邪恶之时,而在其开始改革之际。在这种“改革是找死”的思维支配下,中共将继续维持专制而非走上民主化道路。为了保住政权,中共深知防范经济危机是根本,维持金融稳定更是关键战役,针对中国影子银行系统多年积累而成的各种定时炸弹。在短短不到一年时间里,从2016年8月开始的外汇储备保卫战(货币维稳),到2017年2月开始的金融整顿,再到6月的“防经济政变”,将几位大规模转移资产至海外的中国富豪逐个拘捕(肖建华、吴小晖)或禁止出境(王健林)
<a href="#_ftn21" name="_ftnref21">
[21]
</a>
。 这些防范措施,表明中共统治集团对其持续执政面临的危机,已经按部就班地作出各种应对方案,将极权政治从内部崩溃的可能性降低到尽可能低的程度。
</span>
</p>
<p>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref1" name="_ftn1">
[1]
</a>
何清涟,《威权统治下的中国现状与前景》,美国,《当代中国研究》,2004年夏季号,第4-41页。
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref2" name="_ftn2">
[2]
</a>
Jeffrey Goldberg, “The Obama Doctrine,”
<em>
The Atlantic
</em>
, 2016 spring issue, http://www.theatlantic.com/magazine/archive/2016/04/the-obama-doctrine/471525/
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref3" name="_ftn3">
[3]
</a>
Joshua Roma, “
<a href="http://fpc.org.uk/fsblob/244.pdf">
The Beijing Consensus
</a>
”,
<em>
Foreign Policy Centre
</em>
, May 11, 2004,http://fpc.org.uk/fsblob/244.pdf
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref4" name="_ftn4">
[4]
</a>
马建堂,《全面认识我国在世界经济中的地位》,《人民日报》,2011年3月17日,
<a href="http://theory.people.com.cn/GB/14163201.html">
http://theory.people.com.cn/GB/14163201.html
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref5" name="_ftn5">
[5]
</a>
《中国GDP总量5年超美引争议,算法不同致“被提前”》,中国新闻社,2011年4月29日,
<a href="http://www.chinanews.com/cj/2011/04-29/3006733.shtml">
http://www.chinanews.com/cj/2011/04-29/3006733.shtml
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref6" name="_ftn6">
[6]
</a>
《2009年习近平出访墨西哥期间对当地华侨的讲话》,BBC,2012年2月12日,
<a href="http://www.bbc.com/zhongwen/trad/indepth/2012/02/120210_profile_xi_jinping.shtml">
http://www.bbc.com/zhongwen/trad/indepth/2012/02/120210_profile_xi_jinping.shtml
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref7" name="_ftn7">
[7]
</a>
世界卫生组织报告,《促进移民健康》,2016年4月8日,
<a href="http://apps.who.int/gb/ebwha/pdf_files/WHA69/A69_27-ch.pdf">
http://apps.who.int/gb/ebwha/pdf_files/WHA69/A69_27-ch.pdf
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref8" name="_ftn8">
[8]
</a>
Pew Research Center, “Public Uncertain, Divided Over America’s Place in the World: Growing Support for Increased Defense Spending,” May 5, 2016, http://www.people-press.org/2016/05/05/public-uncertain-divided-over-americas-place-in-the-world/
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref9" name="_ftn9">
[9]
</a>
《每一年,都是“最困难”的一年》,经理人分享,2016年1月6日,
<a href="http://www.managershare.com/post/227834">
http://www.managershare.com/post/227834
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref10" name="_ftn10">
[10]
</a>
Xiaonong Cheng, “Capitalism Making and Its Political Consequences in Transition—An Analysis of Political Economy of China’s Communist Capitalism,” in Guoguang Wu and Helen Lansdowne, eds.
<em>
New Perspectives on China’s Transition from Communism
</em>
<strong>
,
</strong>
London & New York, Routledge, Nov.2015, pp.10-34.
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref11" name="_ftn11">
[11]
</a>
何清涟,《中国的陷阱》,香港:明镜出版社,1997年9月;《现代化的陷阱》,北京,今日中国出版社,1998年3月;日文版,《中国现代化的落穴》,东京,草思社,2003年;德文版,
<em>
China in Der Modernisierungsfalle
</em>
, Hamburger, Germany, Hamburger Edition, 2006, and Bonn, Germany, Bunderszentrale für Politischer Buildung,2006。
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref12" name="_ftn12">
[12]
</a>
何清涟,《威权统治下的中国现状与前景》,美国,《当代中国研究》,2004年夏季号,第4-41页。
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref13" name="_ftn13">
[13]
</a>
Susan Rose-Ackerman,
<em>
Corruption and Government
</em>
<em>
:
</em>
<em>
Causes, Consequences, and Reform
</em>
. New York, Cambridge University Press, 1999, pp.113-126.
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref14" name="_ftn14">
[14]
</a>
叶开,《近17年全国卖地收入超27万亿,资金去向鲜有公开》,中国新闻网,2016年02月16日,
<a href="http://www.chinanews.com/cj/2016/02-16/7758491.shtml">
http://www.chinanews.com/cj/2016/02-16/7758491.shtml
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref15" name="_ftn15">
[15]
</a>
张晓玲,《百富榜镜像:中国地产富豪16年兴衰史》,《21世纪经济报道》,2015年10月22日,
<a href="http://www.21jingji.com/2015/10-22/1MMDA5NzVfMTM4Mzc1Mw.html">
http://www.21jingji.com/2015/10-22/1MMDA5NzVfMTM4Mzc1Mw.html
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref16" name="_ftn16">
[16]
</a>
谢春雷,《“陈卖光”:国企产权制度改革“第一官”》,《南方周末》,2003年10月23日,
<a href="http://www.southcn.com/weekend/tempdir/200310230031.htm">
http://www.southcn.com/weekend/tempdir/200310230031.htm
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref17" name="_ftn17">
[17]
</a>
《2015开辟国企反腐第二战场》,人民网,2015年1月18日,
<a href="http://politics.people.com.cn/n/2015/0118/c1001-26403869.html">
http://politics.people.com.cn/n/2015/0118/c1001-26403869.html
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref18" name="_ftn18">
[18]
</a>
Ken Brown,《中国资本外流规模创纪录有何影响》,《华尔街日报》,2016年01月29日,
<a href="http://cn.wsj.com/gb/20160129/fin125723.asp">
http://cn.wsj.com/gb/20160129/fin125723.asp
</a>
; Keith Bracsher,《中国资本外流愈演愈烈,人民币再遇考验》,《纽约时报》,2016年2月14日,
<a href="http://cn.nytimes.com/business/20160214/c14db-chinaexodus/">
http://cn.nytimes.com/business/20160214/c14db-chinaexodus/
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref19" name="_ftn19">
[19]
</a>
徐凯等,《公共安全账单》,《财经》杂志,2011年第11期,
<a href="http://magazine.caijing.com.cn/2011-05-08/110712639.html">
http://magazine.caijing.com.cn/2011-05-08/110712639.html
</a>
;陈志芬,《两会观察:中国军费和“维稳”开支》,BBC中文网,2014年3月5日,
<a href="http://www.bbc.com/zhongwen/simp/china/2014/03/140305_ana_china_npc_army">
http://www.bbc.com/zhongwen/simp/china/2014/03/140305_ana_china_npc_army
</a>
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref20" name="_ftn20">
[20]
</a>
Alexisde Tocqueville,
<em>
The Old Regime and the French Revolution
</em>
. New York: Anchor Books, 1955.
</span>
</p>
<p>
<span style="font-size: 12pt;">
<a href="#_ftnref21" name="_ftn21">
[21]
</a>
何清涟,《从“金融整顿”到“防经济政变”》,原载VOA何清涟博客,2017年6月22日,
<a href="https://www.voachinese.com/a/heqinglian-blog/3911026.html">
https://www.voachinese.com/a/heqinglian-blog/3911026.html
</a>
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt; text-indent: 2em;">
何清涟,旅美独立学者、美国之音专栏作家
</span>
</p>
<p>
<span style="font-size: 12pt; text-indent: 2em;">
首发《中国战略分析》2017年第3期(总第4期)2017年8月
</span>
</p>
<!-- AddThis Advanced Settings above via filter on the_content -->
<!-- AddThis Advanced Settings below via filter on the_content -->
<!-- AddThis Advanced Settings generic via filter on the_content -->
<!-- AddThis Share Buttons above via filter on the_content -->
<!-- AddThis Share Buttons below via filter on the_content -->
<div class="at-below-post addthis_tool" data-url="http://zhanlve.org/?p=1748">
</div>
<!-- AddThis Share Buttons generic via filter on the_content -->
</div> | 19,421 | MIT |
<BR>
## 常見問題集
### 反向 DNS 記錄的成本為何?
完全免費! 反向 DNS 記錄或查詢不需要額外成本。
### 我的反向 DNS 記錄會從網際網路解析嗎?
是。在您為「雲端服務」設定反向 DNS 屬性之後,Azure 會管理所有必要的 DNS 委派和 DNS 區域,以確保反向 DNS 記錄可以為所有網際網路使用者解析。
### 我的雲端服務會建立預設反向 DNS 記錄嗎?
不會。反向 DNS 是選用的功能。如果您選擇不設定,則不會建立任何預設反向 DNS 記錄。完整網域名稱 (FQDN) 的格式為何? FQDN 是以正向順序指定,且必須以點結束 (例如,"app1.contoso.com.")。
### 如果我指定的反向 DNS 驗證檢查失敗,會發生什麼事?
如果反向 DNS 的驗證檢查失敗,則服務管理作業也會失敗。請依要求更正反向 DNS 值,然後再試一次。
### 我可以管理我的 Azure 網站的反向 DNS 嗎?
Azure 網站不支援反向 DNS。Azure PaaS 角色與 IaaS 虛擬機器則支援反向 DNS。
### 我可以針對我的「雲端服務」設定多個反向 DNS 記錄嗎?
不行。Azure 針對每個 Azure 雲端服務支援單一反向 DNS 記錄。不過,每個 Azure 雲端服務可以有自己的反向 DNS 記錄。
### 我可以在訂用帳戶內的 Azure DNS 上或是我自己的授權 DNS 伺服器上,為 Azure 指派的 IP 裝載 ARPA 區域嗎?
不行。Azure 不支援向外委派 ARPA 區域。Azure 會針對所有可用的 IP 裝載 ARPA 區域,並讓客戶在這些 ARPA 區域內建立反向 DNS 記錄。
### 我可以在 Azure DNS 上,為 ISP 指派的 IP 區塊裝載 ARPA 區域嗎?
不行。Azure DNS 目前不支援客戶 DNS 區域中的反向 DNS 記錄。
<!---HONumber=AcomDC_0309_2016--> | 862 | CC-BY-3.0 |
---
title: Azure IoT Edge モジュールについて | Microsoft Docs
description: Azure IoT Edge モジュールと、その構成方法について説明します
author: kgremban
manager: timlt
ms.author: kgremban
ms.date: 02/15/2018
ms.topic: conceptual
ms.service: iot-edge
services: iot-edge
ms.openlocfilehash: 261c26290a4a7c4b8bb22ada7f97470a6efa7a91
ms.sourcegitcommit: 615403e8c5045ff6629c0433ef19e8e127fe58ac
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 08/06/2018
ms.locfileid: "39576323"
---
# <a name="understand-azure-iot-edge-modules"></a>Azure IoT Edge モジュールについて
Azure IoT Edge では、ビジネス ロジックを*モジュール*形式でエッジに展開および管理できます。 Azure IoT Edge モジュールは、IoT Edge によって管理される計算の最小単位であり、Azure Stream Analytics などの Azure サービスまたは独自ソリューション固有のコードを含めることができます。 モジュールを開発、展開、および管理する方法を理解するには、モジュールを構成する次の 4 つの概念を考えると理解が深まります。
* **モジュール イメージ**。モジュールを定義するソフトウェアを含むパッケージです。
* **モジュール インスタンス**。IoT Edge デバイスでモジュール イメージを実行している計算の特定の単位です。 モジュール インスタンスは、IoT Edge ランタイムによって開始されます。
* **モジュール ID**。IoT Hub に格納されている情報 (セキュリティ資格情報を含む) の一部で、各モジュール インスタンスに関連付けられています。
* **モジュール ツイン**。IoT Hub に格納されている JSON ドキュメントで、メタデータ、構成、条件などのモジュール インスタンスの状態情報が含まれています。
## <a name="module-images-and-instances"></a>モジュール イメージとインスタンス
IoT Edge モジュール イメージには、IoT Edge ランタイムの管理、セキュリティ、および通信機能を活用するアプリケーションが含まれています。 独自のモジュール イメージを開発したり、Azure Stream Analytics などのサポートされている Azure サービスからモジュール イメージをエクスポートしたりすることもできます。
モジュール イメージはクラウドに存在し、さまざまなソリューションで更新、変更、展開できます。 たとえば、生産ラインの出力を予測する機械学習を使用するモジュールは、コンピューター ビジョンを使用してドローンを制御するモジュールとは別のイメージとして存在します。
モジュール イメージがデバイスに展開され、IoT Edge ランタイムによって開始されるたびに、該当モジュールの新しいインスタンスが作成されます。 世界のクラウドの異なる部分にある 2 つのデバイスが同じモジュール イメージを使用することができますが、モジュールがデバイスで開始されたときに、各デバイスは独自のモジュール インスタンスを持つことになります。
![クラウド内のモジュール イメージ - デバイス上のモジュール インスタンス][1]
実装では、モジュール イメージはリポジトリ内のコンテナー イメージとして存在し、モジュール インスタンスはデバイス上のコンテナーです。 Azure IoT Edge のユース ケースが増えると、新しい種類のモジュール イメージとインスタンスが作成されます。 たとえば、リソースの制約があるデバイスはコンテナーを実行できないため、ダイナミック リンク ライブラリとして存在するモジュール イメージと実行可能ファイルであるインスタンスが必要になることがあります。
## <a name="module-identities"></a>モジュール ID
新しいモジュール インスタンスが IoT Edge ランタイムによって作成されると、作成されたインスタンスには対応するモジュール ID が関連付けられます。 モジュール ID は IoT Hub に格納され、その特定のモジュール インスタンスのすべてのローカルおよびクラウド通信のアドレス指定とセキュリティ スコープとして採用されます。
モジュール インスタンスに関連付けられる ID は、インスタンスが実行されているデバイスの ID と、ソリューション内のモジュールに付けた名前によって決まります。 たとえば、Azure Stream Analytics を使用するモジュール `insight` を呼び出し、`Hannover01` というデバイスに展開した場合、IoT Edge ランタイムは `/devices/Hannover01/modules/insight` という対応するモジュール ID を作成します。
明らかに、1 つのモジュール イメージを同じデバイスに複数回展開する必要があるシナリオで、同じイメージを異なる名前で複数回展開することができます。
![モジュールの ID は一意][2]
## <a name="module-twins"></a>モジュール ツイン
各モジュール インスタンスは、モジュール インスタンスの構成に使用できる、対応するモジュール ツインも持ちます。 インスタンスとツインは、モジュール ID によってお互いに関連付けられます。
モジュール ツインは、モジュールの情報と構成プロパティを格納する JSON ドキュメントです。 この概念は、IoT Hub の[デバイス ツイン][lnk-device-twin]の概念に似ています。 モジュール ツインの構造は、デバイス ツインとまったく同じです。 両方の種類のツインと対話するために使用する API も同じです。 2 つの唯一の違いは、クライアント SDK をインスタンス化するために使用する ID です。
```csharp
// Create a ModuleClient object. This ModuleClient will act on behalf of a
// module since it is created with a module’s connection string instead
// of a device connection string.
ModuleClient client = new ModuleClient.CreateFromEnvironmentAsync(settings);
await client.OpenAsync();
// Get the module twin
Twin twin = await client.GetTwinAsync();
```
## <a name="offline-capabilities"></a>オフライン機能
Azure IoT Edge は、IoT Edge デバイス上でのオフライン操作をサポートしています。 現在、これらの機能は限定されており、追加シナリオの開発が進行中です。
IoT Edge モジュールは、次の要件を満たしている場合、既定の時間よりも長くオフライン状態を継続できます。
* **メッセージ Time to Live (TTL) が有効期限切れになっていない**。 メッセージ TTL の既定値は 2 時間ですが、IoT Edge ハブのストア アンド フォワード構成で増減することができます。
* **オフライン時にモジュールを IoT Edge ハブに対して再認証する必要がない**。 モジュールは、IoT ハブとのアクティブな接続がある Edge ハブに対してのみ認証できます。 何らかの理由で再起動された場合には、モジュールを再認証する必要があります。 SAS トークンの有効期限が切れた後でも、モジュールから Edge ハブにメッセージを送信することはできます。 接続が再開されると、Edge ハブはモジュールからの新しいトークンを要求し、それを IoT ハブに対して検証します。 成功した場合、Edge ハブは保存されているモジュール メッセージを転送します (モジュールのトークンが期限切れになっている間に送信されたメッセージであっても)。
* **オフライン時にメッセージを送信したモジュールが、接続の再開時にまだ機能している**。 Edge ハブでは、IoT ハブに再接続する際、モジュール メッセージを転送する前に、新しいモジュール トークンを検証する必要があります (以前のトークンの有効期限が切れている場合)。 モジュールが新しいトークンを提供できない場合、Edge ハブはモジュールの保存済みメッセージに対してアクションを実行することができません。
* **Edge ハブに、メッセージを保存できるだけのディスク容量がある**。 既定では、メッセージは Edge ハブ コンテナーのファイルシステムに保存されます。 なお、メッセージを保存するためのマウント済みボリュームを指定する構成オプションもあります。 いずれの場合も、IoT ハブへの遅延配信を行うには、メッセージを保存できるだけの容量が必要になります。
## <a name="next-steps"></a>次の手順
- [Understand the Azure IoT Edge runtime and its architecture (Azure IoT Edge ランタイムとそのアーキテクチャについて)][lnk-runtime]
<!-- Images -->
[1]: ./media/iot-edge-modules/image_instance.png
[2]: ./media/iot-edge-modules/identity.png
<!-- Links -->
[lnk-device-identity]: ../iot-hub/iot-hub-devguide-identity-registry.md
[lnk-device-twin]: ../iot-hub/iot-hub-devguide-device-twins.md
[lnk-runtime]: iot-edge-runtime.md | 4,679 | CC-BY-4.0 |
# 2021-11-01
共 235 条
<!-- BEGIN -->
<!-- 最后更新时间 Mon Nov 01 2021 23:19:56 GMT+0800 (China Standard Time) -->
1. [王毅会见布林肯,指出:「台湾问题若处理失误,将对中美关系造成颠覆性破坏」,有哪些信息值得关注?](https://www.zhihu.com/question/495712448)
1. [网传字节跳动开启 10-7-5 工作制,工作日 7 点后加班需提交申请,真实性如何?能落实吗?](https://www.zhihu.com/question/495780080)
1. [广东中山一女孩疑因长期吃生肉导致肠道内布满虫子,我们在食用生冷食物时,应有哪些注意事项?](https://www.zhihu.com/question/495420154)
1. [如何看待一网文作者被黑客大佬盗号改文,因万分惭愧而停更?](https://www.zhihu.com/question/495765417)
1. [如何看待马斯克回应联合国官员要求捐款一事,称若证明 60 亿美元可解决全球饥饿,立马卖股票?](https://www.zhihu.com/question/495847097)
1. [有哪些没个十年脑血栓想不出来的发明?](https://www.zhihu.com/question/494965064)
1. [如何看待 EDG 在 S11 半决赛决胜局全场几乎零失误?你对总决赛有哪些期待?](https://www.zhihu.com/question/495771785)
1. [中国电磁炮发射试验现场曝光,没有轰鸣,不见火光,这一研究具有哪些积极意义?未来有哪些应用场景?](https://www.zhihu.com/question/495833556)
1. [哈尔滨一老人嫌公交开太慢抡起手推车砸晕司机,被拘 10 天至今未道歉,司机称处罚过轻,如何看待此结果?](https://www.zhihu.com/question/494812262)
1. [10 月 30 日,中国国民党在新政纲中称「坚决反对台独」,此举有何实际意义?](https://www.zhihu.com/question/495704605)
1. [幼龄男孩和女孩的玩具明显的分化,这是孩子天性使然,还是大人的有意选择?](https://www.zhihu.com/question/25157309)
1. [男子东京地铁纵火砍人致 17 人受伤,公共交通上发生此类事件该如何保障自身安全?](https://www.zhihu.com/question/495802899)
1. [把一个视频文件后缀改成txt,得到是一串代码,那么反过来,有没有一种规律,编写一段代码然后生成视频?](https://www.zhihu.com/question/495468027)
1. [中美电影的分水岭,是不是已经出现了?](https://www.zhihu.com/question/494196396)
1. [如何看待《泰晤士报》造谣称电影《沙丘》在中国的海报「删除了黑人演员形象」?事情的真相是怎样的?](https://www.zhihu.com/question/495817124)
1. [今年双十一你熬夜付尾款了吗?为什么零点以后才能付尾款?怎么凑满减最划算?](https://www.zhihu.com/question/495775168)
1. [博士生导师要给每个博士生一个题目,他哪来那么多题目?](https://www.zhihu.com/question/495276712)
1. [为什么大部分游戏里都不用 AI 随机生成 NPC 的故事和对话,而是开发者自写故事和对话?](https://www.zhihu.com/question/495636333)
1. [急救人员仅摸脉搏就宣告男子死亡,殡仪人员来搬运遗体时发现男子「复活」,专业的急救措施应该怎么做?](https://www.zhihu.com/question/494806263)
1. [如果 ShowMaker 带领 DK 拿下三届总决赛冠军,他能否成为与 Faker 并肩的选手?](https://www.zhihu.com/question/493723741)
1. [10 月 31 日,王毅与布林肯在罗马会晤合影时未碰肘,释放了什么信号?](https://www.zhihu.com/question/495717024)
1. [全国 16 岁至 24 岁城镇人口失业率为 14.6%,今年 909 万高校毕业生的就业情况怎么样?](https://www.zhihu.com/question/495714320)
1. [为什么古人可以撰写《易经》《鬼谷子》《道德经》等这些高深的书?](https://www.zhihu.com/question/478853958)
1. [日立被曝质检造假至少 30 年,问题产品或流入中国,至此多家知名日本制造被曝造假,日本工匠精神何在?](https://www.zhihu.com/question/495200013)
1. [如何看待 Redmi Note 11 系列首销 1 小时突破 50 万台,Note 系列策略成功了吗?](https://www.zhihu.com/question/495782668)
1. [2021「网红城市活力指数」广州位居全国第一,这座城市为何能留住年轻人?](https://www.zhihu.com/question/495281860)
1. [如何看待一位匿名的苹果公司官方人员回应 145 元抛光布「非常有用」?你会考虑买吗?](https://www.zhihu.com/question/495497090)
1. [钟南山称「疫情在一个月内能控制,预计年底疫苗接种 80% 以上」,当前疫情防控最应注意什么?](https://www.zhihu.com/question/495465390)
1. [如何看待游戏《堡垒之夜》国服停止测试,并将删除所有数据?](https://www.zhihu.com/question/495677822)
1. [Win11真的比Win10好多了吗?](https://www.zhihu.com/question/490844524)
1. [朋友出事去世后,你会把他的联系方式删掉吗?](https://www.zhihu.com/question/60169997)
1. [购买iPhone13还是iPhone13pro好?](https://www.zhihu.com/question/489928041)
1. [成为月薪 5000 元的白领或者月薪 2 万元的一线工人,如果是你,会怎么选?](https://www.zhihu.com/question/495290818)
1. [20 岁就要 DR 1999 元的钻戒很奢侈吗?](https://www.zhihu.com/question/495586896)
1. [空调一级能效和三级能效开10小时,能差多少电费?](https://www.zhihu.com/question/329341284)
1. [腾讯新游《王者荣耀:世界》在世界范围内属于什么水平?](https://www.zhihu.com/question/495629800)
1. [iPhone 13 Pro 系列的自适应屏幕频闪怎么解决的?会像某些博主说的,长时间使用伤害眼睛吗?](https://www.zhihu.com/question/488211830)
1. [目前市面上并没有高频交易的书籍,那么目前正在靠高频交易持续稳定盈利的那批人是从哪里学的?](https://www.zhihu.com/question/404991960)
1. [你觉得西语有哪些单词很美?](https://www.zhihu.com/question/270302827)
1. [最好的忘记一个人的方式是什么?](https://www.zhihu.com/question/491556862)
1. [考教师编制怎么准备,大四了,过了教资,快要毕业了,好恐慌怎么办?](https://www.zhihu.com/question/485911639)
1. [毛孔粗大应该如何拯救?](https://www.zhihu.com/question/408402161)
1. [如何评价电视剧《马大帅》?](https://www.zhihu.com/question/28778342)
1. [有哪些提升男士生活品质的小东西?](https://www.zhihu.com/question/21682636)
1. [男朋友沉迷游戏《剑三》,一玩就是几个小时没空陪我怎么办?](https://www.zhihu.com/question/493752829)
1. [个人信息保护法 11 月 1 日正式实施,将产生什么影响?有哪些方面的解读?](https://www.zhihu.com/question/495673643)
1. [2021 年有哪些高性价比的手机值得推荐?](https://www.zhihu.com/question/413851618)
1. [有哪些可以用很久的电脑壁纸?](https://www.zhihu.com/question/327792318)
1. [坐飞机时,你最好奇的是什么?](https://www.zhihu.com/question/495067579)
1. [NBA 21-22 赛季火箭 85:95 湖人,威少 20+8+9,如何评价这场比赛?](https://www.zhihu.com/question/495809599)
1. [什么才叫真正的会做人,会做事?](https://www.zhihu.com/question/494899419)
1. [当总裁文里出现一个普通正常人,会是什么样的场面?](https://www.zhihu.com/question/490850756)
1. [脸上经常长痘痘是什么原因导致的?](https://www.zhihu.com/question/495232227)
1. [有什么好看到停不下来的小说吗?](https://www.zhihu.com/question/440502581)
1. [S11 总决赛 EDG 如何应对 DK 才有机会夺冠?](https://www.zhihu.com/question/495645203)
1. [父母不同意的爱情,还要坚持吗?](https://www.zhihu.com/question/486257233)
1. [有什么好喝的速溶咖啡可以推荐?](https://www.zhihu.com/question/37443576)
1. [去除内脏脂肪,跑步是不是最好的方法?](https://www.zhihu.com/question/427095682)
1. [《王者荣耀》你们抽到什么皮肤了?](https://www.zhihu.com/question/495410024)
1. [22 考研各地区报名确认时间已经开始,有哪些需要注意的事情?](https://www.zhihu.com/question/495817657)
1. [如果产品经理不懂技术会发生什么事情?](https://www.zhihu.com/question/366779696)
1. [研一实验室出现问题被师哥教训怎么办?](https://www.zhihu.com/question/494948160)
1. [初三学生没动力、没时间学习怎么办?](https://www.zhihu.com/question/495639526)
1. [为什么黑巧克力脂肪碳水都那么高,网传还有减肥的功效?](https://www.zhihu.com/question/404588750)
1. [有哪些你平常不舍得买,就等着「双十一」买的数码好物?](https://www.zhihu.com/question/493682842)
1. [玩游戏《原神》时,最让你生气的事情是哪一件?](https://www.zhihu.com/question/494405081)
1. [马上双十一了,有啥值得期待的彩妆品牌推荐呢?](https://www.zhihu.com/question/494899290)
1. [你有什么一眼就惊艳的文案?](https://www.zhihu.com/question/384142344)
1. [建议托福报网课吗?](https://www.zhihu.com/question/445595525)
1. [去外地工作,你会想念家乡的美食吗?](https://www.zhihu.com/question/495042905)
1. [EDG明明是LPL一号种子,为什么大家感觉对其夺冠不抱希望呢?](https://www.zhihu.com/question/494713768)
1. [为什么有些人一个月就能考上公务员?](https://www.zhihu.com/question/484281452)
1. [一个穷人活在周围都是富人的世界里面可以变富吗?](https://www.zhihu.com/question/494543455)
1. [科学可以做「独行侠」吗?](https://www.zhihu.com/question/494393062)
1. [张爱玲作品过时了吗?](https://www.zhihu.com/question/294528303)
1. [你觉得学习成绩能决定一个人的好坏吗?](https://www.zhihu.com/question/495198359)
1. [有没有令人惊艳的高级小众文案呢?](https://www.zhihu.com/question/492315666)
1. [如何评价开放世界新游《王者荣耀·世界》 10 月 30 号放出的首个游戏实录视频?](https://www.zhihu.com/question/495608837)
1. [如何看待美国发布新冠病毒溯源问题解密版报告,外交部回应「谎言重复一千遍仍然是谎言」?](https://www.zhihu.com/question/495671242)
1. [可以推荐 steam 上耐玩的单机游戏吗?](https://www.zhihu.com/question/385410795)
1. [如何以「我是冷宫中的公主」为开头写一篇故事?](https://www.zhihu.com/question/494460840)
1. [《火影忍者》中拥有秽土转生的仙人兜是六道实力之下第一人吧?秽土水门不是秽土转生?](https://www.zhihu.com/question/493875683)
1. [如何洗衣服才能保持衣服上有香味?](https://www.zhihu.com/question/23483899)
1. [怎样评价Somi全昭弥新歌《XOXO》?](https://www.zhihu.com/question/495356685)
1. [你心中的《这!就是街舞》第四季八强选手是哪些?](https://www.zhihu.com/question/495637129)
1. [S11 世界总决赛 EDG VS DK 你觉得谁会夺冠?](https://www.zhihu.com/question/495774004)
1. [万圣节如何低成本装扮宿舍或者自己的家,把「氛围感」拉满?](https://www.zhihu.com/question/299643839)
1. [游戏《第五人格》迎来全新版本,值此重逢之际,你想起了什么难忘的故事和回忆?](https://www.zhihu.com/question/495300300)
1. [如何看待有人说彭罗斯比霍金贡献大?他在物理学领域的成就有多高?](https://www.zhihu.com/question/495800360)
1. [Steam 万圣节促销到来,你有哪些想要入手的游戏?](https://www.zhihu.com/question/494565766)
1. [汽车纯电大趋势下,有无必要发展混动?吉利新发布的雷神混动哪些方面超越了日系?](https://www.zhihu.com/question/495672014)
1. [Win11 和 11 代英特尔酷睿强强联合,这对电脑界双 11 组合让哪些电脑更香了?](https://www.zhihu.com/question/494685145)
1. [10 月 31 日河北新增确诊病例 9 例,涉保定石家庄,目前当地情况如何?](https://www.zhihu.com/question/495787689)
1. [大学生有一万闲钱,建议买基金吗?](https://www.zhihu.com/question/462095894)
1. [如何评价《原神》中派蒙中配水准?](https://www.zhihu.com/question/421188039)
1. [你见过的哪座火车站和当地文化结合的很妙?](https://www.zhihu.com/question/495299225)
1. [没有玩过 FPS 游戏,想入手《战地 2042》作为第一款买断大作,要做什么准备吗?](https://www.zhihu.com/question/492108645)
1. [万圣节都有哪些搞怪的手工?还有哪些有趣的万圣节小装饰?](https://www.zhihu.com/question/51836038)
1. [刚买了 iPad 以后有什么需要注意的地方?](https://www.zhihu.com/question/373784504)
1. [巴萨宣布主帅科曼下课,如何评价他在巴萨的执教生涯?](https://www.zhihu.com/question/494998138)
1. [如何评价《特利迦奥特曼》第十五话?](https://www.zhihu.com/question/495349810)
1. [为什么越来越多年轻的职场人选择「反职业化」的穿搭?](https://www.zhihu.com/question/495293017)
1. [如何看待今年大量「幕后」制造工厂直接参与双十一?网购时你会选择工厂直供吗?](https://www.zhihu.com/question/495360409)
1. [《王者荣耀·世界》是端游、手游还是双端?各位感觉如何?](https://www.zhihu.com/question/495605323)
1. [有没有非常好喝的茶包推荐?](https://www.zhihu.com/question/466641232)
1. [S11 半决赛 EDG VS GEN ,如何评价这场比赛?](https://www.zhihu.com/question/495731848)
1. [有哪些很可爱又有创意的情头?](https://www.zhihu.com/question/282048216)
1. [如何看待卢伟冰在 Redmi Note 11 发布会上狂怼荣耀 X30?](https://www.zhihu.com/question/495168422)
1. [鄂尔多斯回应年薪 60 万招清华、北大毕业生当中小学教师「我们负担得起」,高薪招聘中小学老师是趋势吗?](https://www.zhihu.com/question/495673930)
1. [《只狼》天守阁打义父,连续打了 5 个小时最多打掉他一条命怎么办?](https://www.zhihu.com/question/493800568)
1. [有没有轻松搞笑甜文?](https://www.zhihu.com/question/372522978)
1. [有哪些适合坐办公室时泡水喝的东西?](https://www.zhihu.com/question/27694889)
1. [不考虑电池和大小,买iphone13mini还是双11的iphone12?](https://www.zhihu.com/question/486901331)
1. [有什么适合小个子的秋季穿搭?](https://www.zhihu.com/question/484229778)
1. [什么样的穿搭看着就很舒服?](https://www.zhihu.com/question/318587830)
1. [在关于孩子的教育方面,什么是最重要的呢?](https://www.zhihu.com/question/494612533)
1. [如何看待极兔速递 68 亿元收购百世快递国内业务?](https://www.zhihu.com/question/495353576)
1. [做为一个领导,只有给手下分配工作的权利,没有给手下利益的权利,领导说他说了不算,啥原因?](https://www.zhihu.com/question/494325000)
1. [如何评价李连杰?](https://www.zhihu.com/question/48624630)
1. [电影《007:无暇赴死》中最刺激的片段是什么?这部 007 有哪些看点?](https://www.zhihu.com/question/488424497)
1. [成龙实际打起来有多能打?武打明星们都有真功夫吗?](https://www.zhihu.com/question/495717167)
1. [如何评价《我的音乐你听吗》第十期冠军之夜?](https://www.zhihu.com/question/495583199)
1. [如何评价电视剧《突围》?拍得怎么样?](https://www.zhihu.com/question/493249717)
1. [《入殓师》有哪些戳中你的细节?](https://www.zhihu.com/question/494716059)
1. [越吃越「讲究」的年轻人,口味都发生了哪些变化?](https://www.zhihu.com/question/495296553)
1. [世界上哪一处的风景令你感受到惊世骇俗的美与震撼?](https://www.zhihu.com/question/493756724)
1. [11.11 有哪些隐藏优惠,一旦错过就会真的白花很多钱?](https://www.zhihu.com/question/495535080)
1. [如何评价游戏《仙剑奇侠传七》被爆疑似有水军在 steam 刷分?](https://www.zhihu.com/question/495228124)
1. [如何评价游戏电视带来的高段位游戏体验?](https://www.zhihu.com/question/495643959)
1. [有准备参加23考研的同学吗,需要了解哪些考研常识?](https://www.zhihu.com/question/474978086)
1. [你觉得无人车送快递在未来能普及吗?](https://www.zhihu.com/question/495663021)
1. [如何评价《王者荣耀》一系列传统文化向的合作?你觉得未来还可以怎么做?](https://www.zhihu.com/question/495649637)
1. [生化环材的你们是如何跳出天坑的?](https://www.zhihu.com/question/453870771)
1. [漫画《间谍过家家》宣布动画化,你有哪些期待?](https://www.zhihu.com/question/495572184)
1. [《名侦探柯南》中的新一如果没有 CP 的话人气会不会高一些?](https://www.zhihu.com/question/493580333)
1. [游戏《原神》稻妻 6 个岛已经出完了,质量排个名怎么排?](https://www.zhihu.com/question/493838455)
1. [如何看待2022年江苏省考公告?本次公告有啥新变化?](https://www.zhihu.com/question/495349543)
1. [2021 KPL 秋季赛成都AG 3:1 MTG,如何评价这场比赛?](https://www.zhihu.com/question/495740540)
1. [2021 年双十一,预算在 3000元 左右,有哪些高性价比手机值得推荐?](https://www.zhihu.com/question/495446410)
1. [考研学校有哪些名声好的大学?](https://www.zhihu.com/question/318976760)
1. [2021 年双十一,荣耀的手机有哪些值得推荐入手?](https://www.zhihu.com/question/495266265)
1. [睡得越来越晚的年轻人,该如何提高睡眠质量?](https://www.zhihu.com/question/495296453)
1. [如何看待《王者荣耀》官宣王者英雄系列电影计划?你都有哪些期待?](https://www.zhihu.com/question/495596839)
1. [如何评价游戏《原神》与一加联动推出的「一加 9RT 原神限定礼盒」?](https://www.zhihu.com/question/495136552)
1. [能打 6 分以上的长相是什么样的(男女不限)?](https://www.zhihu.com/question/50891612)
1. [2021双十一,有什么适合学生宿舍吃的零食值得买?](https://www.zhihu.com/question/493428632)
1. [2021年双十一有哪些居家日常必备的生活用品值得入手?](https://www.zhihu.com/question/495692632)
1. [用手机玩游戏《仙剑奇侠传 7》是一种什么样的体验?](https://www.zhihu.com/question/495340783)
1. [洗地机真的可以「解放双手」吗?它有哪些让人眼前一亮的优势?](https://www.zhihu.com/question/486939718)
1. [有没有女主超级洒脱,男主骨灰级火葬场的小说推荐?](https://www.zhihu.com/question/482404727)
1. [新手爸妈应该如何照顾新生儿,有哪些注意事项是很重要却容易被忽略的?](https://www.zhihu.com/question/304637661)
1. [有什么适合给异地女朋友送温暖的零食?](https://www.zhihu.com/question/350254388)
1. [上海迪士尼乐园和小镇配合疫情排查暂停开放,情况如何?已经购买门票计划去迪士尼的游客怎么办?](https://www.zhihu.com/question/495719972)
1. [一般在潜艇待超不过90天,但是在太空怎么能待那么久?](https://www.zhihu.com/question/465762854)
1. [为什么总有玩家怀念S8的IG?](https://www.zhihu.com/question/493494356)
1. [有什么超虐的小说推荐?](https://www.zhihu.com/question/313274292)
1. [内蒙古额济纳旗盒饭事件疑似反转,「餐食已被放置两天无法食用」,真实情况怎样?如何避免此类现象再次发生?](https://www.zhihu.com/question/494921226)
1. [英语中,什么是谓语、宾语、定语、状语、宾补、表语?](https://www.zhihu.com/question/294752032)
1. [能不能发一下你家idol出圈的神图啊?](https://www.zhihu.com/question/480021456)
1. [工作之余你买过最惊喜的潮玩数码是什么?](https://www.zhihu.com/question/495050964)
1. [有什么你认为辅助位应该知道但却很少见辅助知道的“常识”?](https://www.zhihu.com/question/475236248)
1. [2021年双十一有哪些海尔洗衣机值得入手?](https://www.zhihu.com/question/495231492)
1. [21-22 赛季法甲巴黎圣日耳曼 2:1 里尔,如何评价这场比赛?](https://www.zhihu.com/question/495415435)
1. [如何评价余梓桾X张子薇《海棠依旧》?](https://www.zhihu.com/question/495588902)
1. [如何看待赛雷话金揭露中南屋抹黑中国,渗透暗示性、诱导性的信息,真实性如何?](https://www.zhihu.com/question/494714843)
1. [侄子要换肾,我配型合适,而我才20岁刚大二,我该怎么办?](https://www.zhihu.com/question/493115676)
1. [女子毕业 9 年贷款买两套房,一年买衣服不超百,每月储蓄率达 90%,你认可这样的消费观吗?](https://www.zhihu.com/question/494884237)
1. [《沙丘》中有哪些细思极恐的细节?](https://www.zhihu.com/question/493540589)
1. [怎么改变自己那种怂怂懦弱的气质?](https://www.zhihu.com/question/494092149)
1. [韩国将开启与新冠共存模式,回归正常生活秩序,怎么看待这一举措?韩国疫情未来走向如何?](https://www.zhihu.com/question/494819037)
1. [有哪些适合年轻人穿的男装服装品牌?](https://www.zhihu.com/question/27214479)
1. [如何看待Google下一代人工智能架构Pathways?](https://www.zhihu.com/question/495386434)
1. [双十一,realme 手机买哪款最划算?](https://www.zhihu.com/question/495227972)
1. [今年双十一iphone12 128G大概会是什么价格?](https://www.zhihu.com/question/488576398)
1. [如何看待浙江理工大学国奖特别奖得主赵跃鹏?](https://www.zhihu.com/question/494281460)
1. [我国首次实现从一氧化碳到蛋白质的合成,形成万吨级工业产能,这一突破进展具有哪些重大意义?](https://www.zhihu.com/question/495671881)
1. [如果 EDG 在世界赛夺冠,跟 iG 和 FPX 的冠军含金量相比如何?](https://www.zhihu.com/question/494974426)
1. [教师资格证为什么这么多的69分呢?](https://www.zhihu.com/question/359952971)
1. [NBA 乔丹要是放在当今联盟,还能封神吗?](https://www.zhihu.com/question/494003731)
1. [《沙丘》上映后为什么会出现口碑两极分化的情况?](https://www.zhihu.com/question/494153189)
1. [如何看待《长津湖》票房超李焕英,暂列中国影史票房榜第二?](https://www.zhihu.com/question/495443796)
1. [大学生如何自学Photoshop?](https://www.zhihu.com/question/285720498)
1. [你收藏了哪些很惊艳的文案吗?](https://www.zhihu.com/question/487377112)
1. [iPhone 13 4G 内存够用吗?能用3年吗?](https://www.zhihu.com/question/487044893)
1. [双十一预售已经付了定金,但不想要了,怎么退款?](https://www.zhihu.com/question/67870409)
1. [去哪里旅行让你体会到了「繁花似锦觅安宁,淡云流水度此生」?](https://www.zhihu.com/question/494839412)
1. [铁路儿童客票拟由身高划分改为以年龄划分,为什么会这么调整?会带来哪些影响?](https://www.zhihu.com/question/495654679)
1. [为什么游戏《原神》里的冰之女皇要用不愉快的方式拿神之心呢?](https://www.zhihu.com/question/494677043)
1. [你哪一刻觉得自己很孤独?](https://www.zhihu.com/question/277508190)
1. [如何以「听说,我是你的小说男主?」为开头写一个小说?](https://www.zhihu.com/question/488099382)
1. [有什么看似悲伤实则很搞笑的故事?](https://www.zhihu.com/question/334776651)
1. [山姆会员店(sam's club)有什么值得买的东西?](https://www.zhihu.com/question/58897556)
1. [怎样评价《这就是街舞》第四季总决赛?](https://www.zhihu.com/question/495631331)
1. [到底应该如何培养一个优秀的小孩?](https://www.zhihu.com/question/493975306)
1. [张爱玲的天才表现在何处?](https://www.zhihu.com/question/293815541)
1. [S11 半决赛 DK 3:2 T1 晋级总决赛,如何评价这场比赛?](https://www.zhihu.com/question/495584505)
1. [安徽一学校发现弃婴被从楼上摔下,刑警队表示遗弃者系学生,具体情况如何?遗弃者需承担怎样的法律责任?](https://www.zhihu.com/question/494638624)
1. [在家可以跟孩子做什么游戏?](https://www.zhihu.com/question/391201046)
1. [《飘》中有哪些让你印象深刻的话?](https://www.zhihu.com/question/271680301)
1. [四岁的孩子,老师留作业,半页数字描红,孩子自己不想写,该不该逼他?](https://www.zhihu.com/question/494876754)
1. [S11 半决赛 EDG vs GEN.G 你更看好谁?](https://www.zhihu.com/question/494513591)
1. [文学功底强的人是否会在吵架中占上风?](https://www.zhihu.com/question/411665825)
1. [呼兰的脱口秀水平如何?](https://www.zhihu.com/question/342670252)
1. [有哪些你觉得是人间绝句的诗词?](https://www.zhihu.com/question/287378875)
1. [如何评价腾讯以王者荣耀世界观开发的新游戏《王者荣耀·世界》?](https://www.zhihu.com/question/495609062)
1. [国产有哪些认认真真的跑鞋?](https://www.zhihu.com/question/389251483)
1. [如何看待网传中兴 2022 秋招大量调岗,并接受非科班甚至零基础的员工?真实性如何?](https://www.zhihu.com/question/495027210)
1. [高二了,一直学不下去怎么办,高一基础也不是很好,反正到高中就颓废了,现在努力还来得及吗?](https://www.zhihu.com/question/494764094)
1. [想去医院做一次比较全面的体检,具体流程和花费怎么样?](https://www.zhihu.com/question/22714441)
1. [S11半决赛DK以3:2赢下T1,如何评价这场比赛?](https://www.zhihu.com/question/495626461)
1. [为什么感觉现在玩《英雄联盟》很累?](https://www.zhihu.com/question/447453640)
1. [卢俊义在家练武成了天下第一,合理吗?](https://www.zhihu.com/question/494715870)
1. [《长津湖》续作《水门桥》官宣,你期望影片还原哪些真实的历史细节?](https://www.zhihu.com/question/495132702)
1. [iPhone13和13P 到底哪个更值得买?](https://www.zhihu.com/question/488965101)
1. [有没有又甜还短的小甜文?](https://www.zhihu.com/question/481998863)
1. [欧莱雅注白瓶真的有那么好用吗?](https://www.zhihu.com/question/480108793)
1. [13个余沧海联手能否杀死东方不败?](https://www.zhihu.com/question/494549843)
1. [2021 年「双十一」,有哪些单反和微单相机值得购买?](https://www.zhihu.com/question/490022869)
1. [缺糖了,有没有甜甜的小故事?](https://www.zhihu.com/question/485630375)
1. [如何看待 10 月 27 日开始,新加坡新增确诊新冠病例突破 5000+ 人?](https://www.zhihu.com/question/494966445)
1. [怎样将Apple Watch功能用到极致?](https://www.zhihu.com/question/271591506)
1. [不同的被子各有什么优缺点?怎么挑选合适的被子?](https://www.zhihu.com/question/21822237)
1. [《英雄联盟》S11 世界赛期间突然出现的波比梗是从哪来的?](https://www.zhihu.com/question/494891363)
1. [C7 高校,科研 996,师姐不友善,我该如何尽快适应研究生生活?](https://www.zhihu.com/question/492980918)
1. [北京地区取消近期雅思、托福、GRE、GMAT 等海外考试项目,有哪些影响?备考生如何合理调整计划?](https://www.zhihu.com/question/495118657)
1. [多久染一次头发最合适?](https://www.zhihu.com/question/292904288)
1. [咖啡喝多了对健康有害吗?](https://www.zhihu.com/question/492563038)
1. [DK击败T1,是否意味今年S赛卫冕冠军的战队已经确定了?](https://www.zhihu.com/question/495626898)
1. [官方通报导游怼游客「一个电话让你 14 天回不去」,双方因行程码问题起争执,遇到这类情况该如何处理?](https://www.zhihu.com/question/495328770)
1. [穷人突然有钱后能挥霍到什么程度?](https://www.zhihu.com/question/494101013)
1. [你认为学历和能力哪个更重要?](https://www.zhihu.com/question/494972098)
1. [华为前三季度公司实现销售收入 4558 亿元人民币,净利润率 10.2% ,有哪些值得关注的信息?](https://www.zhihu.com/question/495324115)
1. [如何确定你真正想做的事情到底是什么?](https://www.zhihu.com/question/24272298)
1. [2021 年有哪些比较好的路由器推荐?](https://www.zhihu.com/question/439262156)
1. [男生冬季怎么搭配衣服?](https://www.zhihu.com/question/22015790)
<!-- END --> | 17,634 | MIT |
<!-- TOC -->
- [LockSupport详解](#locksupport详解)
- [类结构](#类结构)
<!-- /TOC -->
# LockSupport详解
## 类结构
<div align=center>

</div> | 182 | Apache-2.0 |
[//]: # (title: Kotlin 1.2 的新特性)
_发布日期:2017-11-28_
## 目录
* [多平台项目](#多平台项目实验性的)
* [其他语言特性](#其他语言特性)
* [标准库](#标准库)
* [JVM 后端](#jvm-后端)
* [JavaScript 后端](#javascript-后端)
## 多平台项目(实验性的)
多平台项目是 Kotlin 1.2 中的一个新的**实验性的**特性,允许你在支持 Kotlin 的目标平台——
JVM、JavaScript 以及(将来的)Native 之间重用代码。在多平台项目中,你有三种模块:
* 一个*公共*模块包含平台无关代码,以及无实现的依赖平台的 API 声明。
* *平台*模块包含通用模块中的平台相关声明在指定平台的实现,以及其他平台相关代码。
* 常规模块面向指定的平台,既可以是平台模块的依赖,也可以依赖平台模块。
当你为指定平台编译多平台项目时,既会生成公共代码也会生成平台相关代码。
多平台项目支持的一个主要特点是可以<!--
-->通过*预期*声明与*实际*声明来表达公共代码对平台相关部分的依赖关系。 一个*预期*声明指定一个 API(类、接口、注解、顶层声明等)。
一个*实际*声明要么是该 API 的平台相关实现,要么是一个引用到在一个<!--
-->外部库中该 API 的一个既有实现的别名。这是一个示例:
在公共代码中:
```kotlin
// 预期平台相关 API:
expect fun hello(world: String): String
fun greet() {
// 该预期 API 的用法:
val greeting = hello("multiplatform world")
println(greeting)
}
expect class URL(spec: String) {
open fun getHost(): String
open fun getPath(): String
}
```
在 JVM 平台代码中:
```kotlin
actual fun hello(world: String): String =
"Hello, $world, on the JVM platform!"
// 使用既有平台相关实现:
actual typealias URL = java.net.URL
```
关于构建多平台项目的详细信息与步骤,请参见[多平台程序设计文档](multiplatform.md)。
## 其他语言特性
### 注解中的数组字面值
自 Kotlin 1.2 起,注解的数组参数可以通过新的数组字面值语法传入,而无需<!--
-->使用 `arrayOf` 函数:
```kotlin
@CacheConfig(cacheNames = ["books", "default"])
public class BookRepositoryImpl {
// ……
}
```
该数组字面值语法仅限于注解参数。
### lateinit 顶层属性与局部变量
`lateinit` 修饰符现在可以用于顶层属性与局部变量了。例如,后者可用于<!--
-->当一个 lambda 表达式作为构造函数参数传给一个对象时,引用另一个<!--
-->必须稍后定义的对象:
```kotlin
class Node<T>(val value: T, val next: () -> Node<T>)
fun main(args: Array<String>) {
// 三个节点的环:
lateinit var third: Node<Int>
val second = Node(2, next = { third })
val first = Node(1, next = { second })
third = Node(3, next = { first })
val nodes = generateSequence(first) { it.next() }
println("Values in the cycle: ${nodes.take(7).joinToString { it.value.toString() }}, ...")
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
### 检测 lateinit 变量是否已初始化
现在可以通过属性引用的 `isInitialized` 来检测该 lateinit var 是否已初始化:
```kotlin
class Foo {
lateinit var lateinitVar: String
fun initializationLogic() {
//sampleStart
println("isInitialized before assignment: " + this::lateinitVar.isInitialized)
lateinitVar = "value"
println("isInitialized after assignment: " + this::lateinitVar.isInitialized)
//sampleEnd
}
}
fun main(args: Array<String>) {
Foo().initializationLogic()
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
### 内联函数带有默认函数式参数
内联函数现在允许其内联函式数参数具有默认值:
```kotlin
//sampleStart
inline fun <E> Iterable<E>.strings(transform: (E) -> String = { it.toString() }) =
map { transform(it) }
val defaultStrings = listOf(1, 2, 3).strings()
val customStrings = listOf(1, 2, 3).strings { "($it)" }
//sampleEnd
fun main(args: Array<String>) {
println("defaultStrings = $defaultStrings")
println("customStrings = $customStrings")
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
### 源自显式类型转换的信息会用于类型推断
Kotlin 编译器现在可将类型转换信息用于类型推断。如果你调用一个<!--
-->返回类型参数 `T` 的泛型方法并将返回值转换为指定类型 `Foo`,那么编译器现在知道<!--
-->对于本次调用需要绑定类型为 `Foo`。
这对于 Android 开发者来说尤为重要,因为编译器现在可以正确分析
Android API 级别 26中的泛型 `findViewById` 调用:
```kotlin
val button = findViewById(R.id.button) as Button
```
### 智能类型转换改进
当一个变量有安全调用表达式与空检测赋值时,其智能转换现在也可以应用于<!--
-->安全调用接收者:
```kotlin
fun countFirst(s: Any): Int {
//sampleStart
val firstChar = (s as? CharSequence)?.firstOrNull()
if (firstChar != null)
return s.count { it == firstChar } // s: Any 会智能转换为 CharSequence
val firstItem = (s as? Iterable<*>)?.firstOrNull()
if (firstItem != null)
return s.count { it == firstItem } // s: Any 会智能转换为 Iterable<*>
//sampleEnd
return -1
}
fun main(args: Array<String>) {
val string = "abacaba"
val countInString = countFirst(string)
println("called on \"$string\": $countInString")
val list = listOf(1, 2, 3, 1, 2)
val countInList = countFirst(list)
println("called on $list: $countInList")
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
智能转换现在也允许用于在 lambda 表达式中局部变量,只要这些局部变量仅在 lambda 表达式之前修改即可:
```kotlin
fun main(args: Array<String>) {
//sampleStart
val flag = args.size == 0
var x: String? = null
if (flag) x = "Yahoo!"
run {
if (x != null) {
println(x.length) // x 会智能转换为 String
}
}
//sampleEnd
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
### 支持 ::foo 作为 this::foo 的简写
现在写绑定到 `this` 成员的可调用引用可以无需显式接收者,即 `::foo` 取代
`this::foo`。这也使在引用外部接收者的成员的 lambda 表达式中使用可调用引用更加方便<!--
-->。
### 破坏性变更:try 块后可靠智能转换
Kotlin 以前将 `try` 块中的赋值语句用于块后的智能转换,这可能会破坏类型安全与空安全<!--
-->并引发运行时故障。这个版本修复了该问题,使智能转换更加严格,但可能会破坏一些<!--
-->依靠这种智能转换的代码。
如果要切换到旧版智能转换行为,请传入回退标志 `-Xlegacy-smart-cast-after-try` 作为编译器<!--
-->参数。该参数会在 Kotlin 1.3中弃用。
### 弃用:数据类弃用 copy
当从已具有签名相同的 `copy` 函数的类型派生数据类时,为数据类生成的 `copy`
实现使用超类型的默认值,这导致反直觉行为,
或者导致运行时失败,如果超类型中没有默认参数的话。
导致 `copy` 冲突的继承在 Kotlin 1.2 中已弃用并带有警告,
而在 Kotlin 1.3中将会是错误。
### 弃用:枚举条目中的嵌套类型
由于初始化逻辑的问题,已弃用在枚举条目内部定义一个非 `inner class`
的嵌套类。这在 Kotlin 1.2 中会引起警告,而在 Kotlin 1.3中会成为错误。
### 弃用:vararg 单个具名参数
为了与注解中的数组字面值保持一致,向一个具名参数形式的 vararg 参数传入单个项目<!--
-->的用法(`foo(items = i)`)已被弃用。请使用伸展操作符连同相应的<!--
-->数组工厂函数:
```kotlin
foo(items = *arrayOf(1))
```
在这种情况下有一项防止性能下降的优化可以消除冗余的数组创建。
单参数形式在 Kotlin 1.2 中会产生警告,而在 Kotlin 1.3中会放弃。
### 弃用:扩展 Throwable 的泛型类的内部类
继承自 `Throwable` 的泛型类的内部类可能会在 throw-catch 场景中违反类型安全性,因此<!--
-->已弃用,在 Kotlin 1.2 中会是警告,而在 Kotlin 1.3中会是错误。
### 弃用:修改只读属性的幕后字段
通过在自定义 getter 中赋值 `field = ……` 来修改只读属性的幕后字段的用法已被弃用,
在 Kotlin 1.2 中会是警告,而在 Kotlin 1.3中会是错误。
## 标准库
### Kotlin 标准库构件与拆分包
Kotlin 标准库现在完全兼容 Java 9 的模块系统,它禁止拆分包
(多个 jar 文件声明的类在同一包中)。为了支持这点,我们引入了新的 `kotlin-stdlib-jdk7`
与 `kotlin-stdlib-jdk8` ,它们取代了旧版的 `kotlin-stdlib-jre7` 与 `kotlin-stdlib-jre8`。
在 Kotlin 看来新的构件中的声明在相同的包名内,而在
Java看来有不同的包名。因此,切换到新的构件无需修改任何<!--
-->源代码。
确保与新的模块系统兼容的另一处变更是在 `kotlin-reflect` 库中删除了
`kotlin.reflect` 包中弃用的声明。如果你正在使用它们,你需要<!--
-->切换到使用 `kotlin.reflect.full` 包中的声明,自 Kotlin 1.1 起就支持这个包了。
### windowed、chunked、zipWithNext
用于 `Iterable<T>`、 `Sequence<T>`与 `CharSequence` 的新的扩展覆盖了这些应用场景:缓存或<!--
-->批处理(`chunked`)、 滑动窗口与计算滑动均值(`windowed`)以及处理成对<!--
-->的后续条目(`zipWithNext`):
```kotlin
fun main(args: Array<String>) {
//sampleStart
val items = (1..9).map { it * it }
val chunkedIntoLists = items.chunked(4)
val points3d = items.chunked(3) { (x, y, z) -> Triple(x, y, z) }
val windowed = items.windowed(4)
val slidingAverage = items.windowed(4) { it.average() }
val pairwiseDifferences = items.zipWithNext { a, b -> b - a }
//sampleEnd
println("items: $items\n")
println("chunked into lists: $chunkedIntoLists")
println("3D points: $points3d")
println("windowed by 4: $windowed")
println("sliding average by 4: $slidingAverage")
println("pairwise differences: $pairwiseDifferences")
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
### fill、replaceAll、shuffle/shuffled
添加了一些用于操作列表的扩展函数:`MutableList` 的 `fill`、 `replaceAll` 与 `shuffle` ,
以及只读 `List`的 `shuffled`:
```kotlin
fun main(args: Array<String>) {
//sampleStart
val items = (1..5).toMutableList()
items.shuffle()
println("Shuffled items: $items")
items.replaceAll { it * 2 }
println("Items doubled: $items")
items.fill(5)
println("Items filled with 5: $items")
//sampleEnd
}
```
{kotlin-runnable="true" kotlin-min-compiler-version="1.3"}
### kotlin-stdlib 中的数学运算
为满足由来已久的需求,Kotlin 1.2 添加了 JVM 与 JS 公用的用于数学运算的 `kotlin.math` API,
包含以下内容:
* 常量:`PI` 与 `E`
* 三角函数:`cos`、 `sin`、 `tan` 及其反函数:`acos`、 `asin`、 `atan`、 `atan2`
* 双曲函数:`cosh`、 `sinh`、 `tanh` 及其反函数:`acosh`、 `asinh`、 `atanh`
* 指数函数:`pow`(扩展函数)、 `sqrt`、 `hypot`、 `exp`、 `expm1`
* 对数函数:`log`、 `log2`、 `log10`、 `ln`、 `ln1p`
* 取整:
* `ceil`、 `floor`、 `truncate`、 `round`(奇进偶舍)函数
* `roundToInt`、 `roundToLong`(四舍五入)扩展函数
* 符号与绝对值:
* `abs` 与 `sign` 函数
* `absoluteValue` 与 `sign` 扩展属性
* `withSign` 扩展函数
* 两个数的最值函数:`max` 与 `min`
* 二进制表示:
* `ulp` 扩展属性
* `nextUp`、 `nextDown`、 `nextTowards` 扩展函数
* `toBits`、 `toRawBits`、 `Double.fromBits`(这些在 `kotlin` 包中)
这些函数同样也有 `Float` 参数版本(但不包括常量)。
### 用于 BigInteger 与 BigDecimal 的操作符与转换
Kotlin 1.2 引入了一些使用 `BigInteger` 与 `BigDecimal` 运算以及由其他<!--
-->数字类型创建它们的函数。具体如下:
* `toBigInteger` 用于 `Int` 与 `Long`
* `toBigDecimal` 用于 `Int`、 `Long`、 `Float`、 `Double` 以及 `BigInteger`
* 算术与位运算操作符函数:
* 二元操作符 `+`、 `-`、 `*`、 `/`、 `%` 以及中缀函数 `and`、 `or`、 `xor`、 `shl`、 `shr`
* 一元操作符 `-`、 `++`、 `--` 以及函数 `inv`
### 浮点数到比特的转换
添加了用于将 `Double` 及 `Float` 与其比特表示形式相互转换的函数:
* `toBits` 与 `toRawBits` 对于 `Double` 返回 `Long` 而对于 `Float` 返回 `Int`
* `Double.fromBits` 与 `Float.fromBits` 用于有相应比特表示形式创建浮点数
### 正则表达式现在可序列化
`kotlin.text.Regex` 类现在已经是 `Serializable` 的了并且可用在可序列化的继承结构中。
### 如果可用,Closeable.use 会调用 Throwable.addSuppressed
当在其他异常之后关闭资源期间抛出一个异常,`Closeable.use` 函数会调用 `Throwable.addSuppressed`
。
要启用这个行为,需要依赖项中有 `kotlin-stdlib-jdk7`。
## JVM 后端
### 构造函数调用规范化
自 1.0 版起,Kotlin 就已支持带有复杂控制流的表达式,诸如 try-catch 表达式以及<!--
-->内联函数。根据 Java 虚拟机规范这样的代码是有效的。不幸的是,
当这样的表达式出现在构造函数调用的参数中时,一些字节码处理工具不能很好地处理这种代码
。
为了缓解这种字节码处理工具用户的这一问题,我们添加了一个命令行编译器<!--
-->选项(`-Xnormalize-constructor-calls=模式`),告诉编译器为这样的构造过程生成更接近 Java 的字节码
。其中`模式`是下列之一:
* `disable`(默认)——以与 Kotlin 1.0 即 1.1 相同的方式生成字节码。
* `enable`——为构造函数调用生成类似 Java 的字节码。 这可能会改变类加载与初始化的顺序
。
* `preserve-class-initialization`——为构造函数调用生成类似 Java 的字节码,并确保类<!--
-->初始化顺序得到保留。这可能会影响应用程序的整体性能;仅用在<!--
-->多个类之间共享一些复杂状态并在类初始化时更新的场景中。
“人工”解决办法是将具有控制流的子表达式的值存储在变量中,而不是<!--
-->直接在调用参数内对其求值。这与 `-Xnormalize-constructor-calls=enable` 类似。
### Java 默认方法调用
在 Kotlin 1.2 之前,面向 JVM 1.6 的接口成员覆盖 Java 默认方法会产生一个关于<!--
-->超类型调用的警告:`Super calls to Java default methods are deprecated in JVM target 1.6. Recompile with '-jvm-target 1.8'`(“面向 JVM 1.6 的 Java 默认方法的超类型调用已弃用,请使用‘-jvm-target 1.8’重新编译”)。
在 Kotlin 1.2 中,这是一个**错误**,因此这样的代码都需要面向 JVM 1.8 编译。
### 破坏性变更:平台类型 x.equals(null) 的一致行为
在映射到 Java 原生类型
(`Int!`、 `Boolean!`、 `Short!`、 `Long!`、 `Float!`、 `Double!`、 `Char!`)的平台类型上调用 `x.equals(null)`,当 `x` 为 `null` 时错误地返回了 `true`。
自 Kotlin 1.2 起,在平台类型的空值上调用 `x.equals(……)` 都会**抛出 NPE**
(但 `x == ...` 不会)。
要返回到 1.2 之前的行为,请将标志 `-Xno-exception-on-explicit-equals-for-boxed-null` 传给编译器。
### 破坏性变更:修正平台 null 透过内联扩展接收者逃逸
在平台类型的空值上调用内联扩展函数并没有检测接收者是否为 null,
因而允许 null 逃逸到其他代码中。Kotlin 1.2 在调用处强制执行这项检测,
如果接收者为空就抛出异常。
要切换到旧版行为,请将回退标志 `-Xno-receiver-assertions` 传给编译器。
## JavaScript 后端
### 默认启用 TypedArray 支持
将 Kotlin 原生数组(如 `IntArray`、 `DoubleArray` 等)
翻译为 [JavaScript 有类型数组](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Typed_arrays)的 JS 有类型数组支持<!--
-->之前是选择性加入的功能,现在已默认启用。
## 工具
### 警告作为错误
编译器现在提供一个将所有警告视为错误的选项。可在命令行中使用 `-Werror`,或者<!--
-->在 Gradle 中使用以下代码片段:
```groovy
compileKotlin {
kotlinOptions.allWarningsAsErrors = true
}
``` | 10,743 | Apache-2.0 |
# stack<a name="ZH-CN_TOPIC_0000001127125064"></a>
堆叠容器,子组件按照顺序依次入栈,后一个子组件覆盖前一个子组件。
## 权限列表<a name="section11257113618419"></a>
无
## 子组件<a name="s2936fc34a22b44aa8389d1ec3de8fa61"></a>
支持。
## 属性<a name="s7207d4d586504fa3be62558273017fbe"></a>
支持[通用属性](js-components-common-attributes.md)。
## 样式<a name="section1774719169253"></a>
支持[通用样式](js-components-common-styles.md)。
## 事件<a name="section1948143416285"></a>
支持[通用事件](js-components-common-events.md)。
## 方法<a name="section2279124532420"></a>
支持[通用方法](js-components-common-methods.md)。
## 示例<a name="section18137649112711"></a>
```
<!-- xxx.hml -->
<stack class="stack-parent">
<div class="back-child bd-radius"></div>
<div class="positioned-child bd-radius"></div>
<div class="front-child bd-radius"></div>
</stack>
```
```
/* xxx.css */
.stack-parent {
width: 400px;
height: 400px;
background-color: #ffffff;
border-width: 1px;
border-style: solid;
}
.back-child {
width: 300px;
height: 300px;
background-color: #3f56ea;
}
.front-child {
width: 100px;
height: 100px;
background-color: #00bfc9;
}
.positioned-child {
width: 100px;
height: 100px;
left: 50px;
top: 50px;
background-color: #47cc47;
}
.bd-radius {
border-radius: 16px;
}
```
 | 1,296 | CC-BY-4.0 |