
url
stringlengths 34
116
| markdown
stringlengths 0
150k
⌀ | screenshotUrl
null | crawl
dict | metadata
dict | text
stringlengths 0
147k
|
|---|---|---|---|---|---|
https://python.langchain.com/docs/templates/retrieval-agent/ | ## retrieval-agent
This package uses Azure OpenAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Since we are using Azure OpenAI, we will need to set the following environment variables:
```
export AZURE_OPENAI_ENDPOINT=...export AZURE_OPENAI_API_VERSION=...export AZURE_OPENAI_API_KEY=...
```
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package retrieval-agent
```
If you want to add this to an existing project, you can just run:
```
langchain app add retrieval-agent
```
And add the following code to your `server.py` file:
```
from retrieval_agent import chain as retrieval_agent_chainadd_routes(app, retrieval_agent_chain, path="/retrieval-agent")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/retrieval-agent/playground](http://127.0.0.1:8000/retrieval-agent/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/retrieval-agent")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.014Z",
"loadedUrl": "https://python.langchain.com/docs/templates/retrieval-agent/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/retrieval-agent/",
"description": "This package uses Azure OpenAI to do retrieval using an agent architecture.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3758",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"retrieval-agent\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:45:59 GMT",
"etag": "W/\"89116b7a16c623679c596f2dc829e8d5\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::w5r7l-1713753959852-99ff87394bab"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/retrieval-agent/",
"property": "og:url"
},
{
"content": "retrieval-agent | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This package uses Azure OpenAI to do retrieval using an agent architecture.",
"property": "og:description"
}
],
"title": "retrieval-agent | 🦜️🔗 LangChain"
} | retrieval-agent
This package uses Azure OpenAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.
Environment Setup
Since we are using Azure OpenAI, we will need to set the following environment variables:
export AZURE_OPENAI_ENDPOINT=...
export AZURE_OPENAI_API_VERSION=...
export AZURE_OPENAI_API_KEY=...
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package retrieval-agent
If you want to add this to an existing project, you can just run:
langchain app add retrieval-agent
And add the following code to your server.py file:
from retrieval_agent import chain as retrieval_agent_chain
add_routes(app, retrieval_agent_chain, path="/retrieval-agent")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/retrieval-agent/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/retrieval-agent")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/rag-vectara/ | ## rag-vectara
This template performs RAG with vectara.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
Also, ensure the following environment variables are set:
* `VECTARA_CUSTOMER_ID`
* `VECTARA_CORPUS_ID`
* `VECTARA_API_KEY`
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package rag-vectara
```
If you want to add this to an existing project, you can just run:
```
langchain app add rag-vectara
```
And add the following code to your `server.py` file:
```
from rag_vectara import chain as rag_vectara_chainadd_routes(app, rag_vectara_chain, path="/rag-vectara")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "vectara-demo"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/rag-vectara/playground](http://127.0.0.1:8000/rag-vectara/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/rag-vectara")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.219Z",
"loadedUrl": "https://python.langchain.com/docs/templates/rag-vectara/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/rag-vectara/",
"description": "This template performs RAG with vectara.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4932",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"rag-vectara\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:45:59 GMT",
"etag": "W/\"94172454a92fb1899ae34ee8ad2cef92\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::4hr64-1713753959866-bdf1cb54ed3e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/rag-vectara/",
"property": "og:url"
},
{
"content": "rag-vectara | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template performs RAG with vectara.",
"property": "og:description"
}
],
"title": "rag-vectara | 🦜️🔗 LangChain"
} | rag-vectara
This template performs RAG with vectara.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
Also, ensure the following environment variables are set:
VECTARA_CUSTOMER_ID
VECTARA_CORPUS_ID
VECTARA_API_KEY
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package rag-vectara
If you want to add this to an existing project, you can just run:
langchain app add rag-vectara
And add the following code to your server.py file:
from rag_vectara import chain as rag_vectara_chain
add_routes(app, rag_vectara_chain, path="/rag-vectara")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "vectara-demo"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/rag-vectara/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/rag-vectara")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/rag-weaviate/ | ## rag-weaviate
This template performs RAG with Weaviate.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
Also, ensure the following environment variables are set:
* `WEAVIATE_ENVIRONMENT`
* `WEAVIATE_API_KEY`
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package rag-weaviate
```
If you want to add this to an existing project, you can just run:
```
langchain app add rag-weaviate
```
And add the following code to your `server.py` file:
```
from rag_weaviate import chain as rag_weaviate_chainadd_routes(app, rag_weaviate_chain, path="/rag-weaviate")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/rag-weaviate/playground](http://127.0.0.1:8000/rag-weaviate/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/rag-weaviate")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.166Z",
"loadedUrl": "https://python.langchain.com/docs/templates/rag-weaviate/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/rag-weaviate/",
"description": "This template performs RAG with Weaviate.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4932",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"rag-weaviate\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:45:59 GMT",
"etag": "W/\"bfa86d9d3326653bee0b2580f12c1c34\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::rrn5m-1713753959868-7e0a0e30de8e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/rag-weaviate/",
"property": "og:url"
},
{
"content": "rag-weaviate | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template performs RAG with Weaviate.",
"property": "og:description"
}
],
"title": "rag-weaviate | 🦜️🔗 LangChain"
} | rag-weaviate
This template performs RAG with Weaviate.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
Also, ensure the following environment variables are set:
WEAVIATE_ENVIRONMENT
WEAVIATE_API_KEY
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package rag-weaviate
If you want to add this to an existing project, you can just run:
langchain app add rag-weaviate
And add the following code to your server.py file:
from rag_weaviate import chain as rag_weaviate_chain
add_routes(app, rag_weaviate_chain, path="/rag-weaviate")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/rag-weaviate/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/rag-weaviate")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/retrieval-agent-fireworks/ | ## retrieval-agent-fireworks
This package uses open source models hosted on FireworksAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.
We will use `Mixtral8x7b-instruct-v0.1`, which is shown in this blog to yield reasonable results with function calling even though it is not fine tuned for this task: [https://huggingface.co/blog/open-source-llms-as-agents](https://huggingface.co/blog/open-source-llms-as-agents)
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
There are various great ways to run OSS models. We will use FireworksAI as an easy way to run the models. See [here](https://python.langchain.com/docs/integrations/providers/fireworks) for more information.
Set the `FIREWORKS_API_KEY` environment variable to access Fireworks.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package retrieval-agent-fireworks
```
If you want to add this to an existing project, you can just run:
```
langchain app add retrieval-agent-fireworks
```
And add the following code to your `server.py` file:
```
from retrieval_agent_fireworks import chain as retrieval_agent_fireworks_chainadd_routes(app, retrieval_agent_fireworks_chain, path="/retrieval-agent-fireworks")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/retrieval-agent-fireworks/playground](http://127.0.0.1:8000/retrieval-agent-fireworks/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/retrieval-agent-fireworks")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.357Z",
"loadedUrl": "https://python.langchain.com/docs/templates/retrieval-agent-fireworks/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/retrieval-agent-fireworks/",
"description": "This package uses open source models hosted on FireworksAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3758",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"retrieval-agent-fireworks\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:45:59 GMT",
"etag": "W/\"de8130f2f1f9a4cd8b985c2ad5a9314e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::skngc-1713753959979-e9f51dd3428b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/retrieval-agent-fireworks/",
"property": "og:url"
},
{
"content": "retrieval-agent-fireworks | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This package uses open source models hosted on FireworksAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.",
"property": "og:description"
}
],
"title": "retrieval-agent-fireworks | 🦜️🔗 LangChain"
} | retrieval-agent-fireworks
This package uses open source models hosted on FireworksAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.
We will use Mixtral8x7b-instruct-v0.1, which is shown in this blog to yield reasonable results with function calling even though it is not fine tuned for this task: https://huggingface.co/blog/open-source-llms-as-agents
Environment Setup
There are various great ways to run OSS models. We will use FireworksAI as an easy way to run the models. See here for more information.
Set the FIREWORKS_API_KEY environment variable to access Fireworks.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package retrieval-agent-fireworks
If you want to add this to an existing project, you can just run:
langchain app add retrieval-agent-fireworks
And add the following code to your server.py file:
from retrieval_agent_fireworks import chain as retrieval_agent_fireworks_chain
add_routes(app, retrieval_agent_fireworks_chain, path="/retrieval-agent-fireworks")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/retrieval-agent-fireworks/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/retrieval-agent-fireworks") |
https://python.langchain.com/docs/templates/rewrite-retrieve-read/ | ## rewrite\_retrieve\_read
This template implemenets a method for query transformation (re-writing) in the paper [Query Rewriting for Retrieval-Augmented Large Language Models](https://arxiv.org/pdf/2305.14283.pdf) to optimize for RAG.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package rewrite_retrieve_read
```
If you want to add this to an existing project, you can just run:
```
langchain app add rewrite_retrieve_read
```
And add the following code to your `server.py` file:
```
from rewrite_retrieve_read.chain import chain as rewrite_retrieve_read_chainadd_routes(app, rewrite_retrieve_read_chain, path="/rewrite-retrieve-read")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/rewrite\_retrieve\_read/playground](http://127.0.0.1:8000/rewrite_retrieve_read/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/rewrite_retrieve_read")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.430Z",
"loadedUrl": "https://python.langchain.com/docs/templates/rewrite-retrieve-read/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/rewrite-retrieve-read/",
"description": "This template implemenets a method for query transformation (re-writing) in the paper Query Rewriting for Retrieval-Augmented Large Language Models to optimize for RAG.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3758",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"rewrite-retrieve-read\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:45:59 GMT",
"etag": "W/\"7c86551eeaed9cf7fff5002f32c73a1f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::vtglz-1713753959979-d00806056a61"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/rewrite-retrieve-read/",
"property": "og:url"
},
{
"content": "rewrite_retrieve_read | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template implemenets a method for query transformation (re-writing) in the paper Query Rewriting for Retrieval-Augmented Large Language Models to optimize for RAG.",
"property": "og:description"
}
],
"title": "rewrite_retrieve_read | 🦜️🔗 LangChain"
} | rewrite_retrieve_read
This template implemenets a method for query transformation (re-writing) in the paper Query Rewriting for Retrieval-Augmented Large Language Models to optimize for RAG.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package rewrite_retrieve_read
If you want to add this to an existing project, you can just run:
langchain app add rewrite_retrieve_read
And add the following code to your server.py file:
from rewrite_retrieve_read.chain import chain as rewrite_retrieve_read_chain
add_routes(app, rewrite_retrieve_read_chain, path="/rewrite-retrieve-read")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/rewrite_retrieve_read/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/rewrite_retrieve_read")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/robocorp-action-server/ | This template enables using [Robocorp Action Server](https://github.com/robocorp/robocorp) served actions as tools for an Agent.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package robocorp-action-server
```
If you want to add this to an existing project, you can just run:
```
langchain app add robocorp-action-server
```
And add the following code to your `server.py` file:
```
from robocorp_action_server import agent_executor as action_server_chainadd_routes(app, action_server_chain, path="/robocorp-action-server")
```
### Running the Action Server[](#running-the-action-server "Direct link to Running the Action Server")
To run the Action Server, you need to have the Robocorp Action Server installed
```
pip install -U robocorp-action-server
```
Then you can run the Action Server with:
```
action-server newcd ./your-project-nameaction-server start
```
### Configure LangSmith (Optional)[](#configure-langsmith-optional "Direct link to Configure LangSmith (Optional)")
LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
### Start LangServe instance[](#start-langserve-instance "Direct link to Start LangServe instance")
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/robocorp-action-server/playground](http://127.0.0.1:8000/robocorp-action-server/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/robocorp-action-server")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.592Z",
"loadedUrl": "https://python.langchain.com/docs/templates/robocorp-action-server/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/robocorp-action-server/",
"description": "This template enables using Robocorp Action Server served actions as tools for an Agent.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"robocorp-action-server\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:00 GMT",
"etag": "W/\"09a37482b0512ea273b17e5581c0401e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::67c2p-1713753960030-4ccc22b98a73"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/robocorp-action-server/",
"property": "og:url"
},
{
"content": "Langchain - Robocorp Action Server | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template enables using Robocorp Action Server served actions as tools for an Agent.",
"property": "og:description"
}
],
"title": "Langchain - Robocorp Action Server | 🦜️🔗 LangChain"
} | This template enables using Robocorp Action Server served actions as tools for an Agent.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package robocorp-action-server
If you want to add this to an existing project, you can just run:
langchain app add robocorp-action-server
And add the following code to your server.py file:
from robocorp_action_server import agent_executor as action_server_chain
add_routes(app, action_server_chain, path="/robocorp-action-server")
Running the Action Server
To run the Action Server, you need to have the Robocorp Action Server installed
pip install -U robocorp-action-server
Then you can run the Action Server with:
action-server new
cd ./your-project-name
action-server start
Configure LangSmith (Optional)
LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
Start LangServe instance
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/robocorp-action-server/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/robocorp-action-server") |
https://python.langchain.com/docs/templates/self-query-qdrant/ | ## self-query-qdrant
This template performs [self-querying](https://python.langchain.com/docs/modules/data_connection/retrievers/self_query/) using Qdrant and OpenAI. By default, it uses an artificial dataset of 10 documents, but you can replace it with your own dataset.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
Set the `QDRANT_URL` to the URL of your Qdrant instance. If you use [Qdrant Cloud](https://cloud.qdrant.io/) you have to set the `QDRANT_API_KEY` environment variable as well. If you do not set any of them, the template will try to connect a local Qdrant instance at `http://localhost:6333`.
```
export QDRANT_URL=export QDRANT_API_KEY=export OPENAI_API_KEY=
```
## Usage[](#usage "Direct link to Usage")
To use this package, install the LangChain CLI first:
```
pip install -U "langchain-cli[serve]"
```
Create a new LangChain project and install this package as the only one:
```
langchain app new my-app --package self-query-qdrant
```
To add this to an existing project, run:
```
langchain app add self-query-qdrant
```
### Defaults[](#defaults "Direct link to Defaults")
Before you launch the server, you need to create a Qdrant collection and index the documents. It can be done by running the following command:
```
from self_query_qdrant.chain import initializeinitialize()
```
Add the following code to your `app/server.py` file:
```
from self_query_qdrant.chain import chainadd_routes(app, chain, path="/self-query-qdrant")
```
The default dataset consists 10 documents about dishes, along with their price and restaurant information. You can find the documents in the `packages/self-query-qdrant/self_query_qdrant/defaults.py` file. Here is one of the documents:
```
from langchain_core.documents import DocumentDocument( page_content="Spaghetti with meatballs and tomato sauce", metadata={ "price": 12.99, "restaurant": { "name": "Olive Garden", "location": ["New York", "Chicago", "Los Angeles"], }, },)
```
The self-querying allows performing semantic search over the documents, with some additional filtering based on the metadata. For example, you can search for the dishes that cost less than $15 and are served in New York.
### Customization[](#customization "Direct link to Customization")
All the examples above assume that you want to launch the template with just the defaults. If you want to customize the template, you can do it by passing the parameters to the `create_chain` function in the `app/server.py` file:
```
from langchain_community.llms import Coherefrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain.chains.query_constructor.schema import AttributeInfofrom self_query_qdrant.chain import create_chainchain = create_chain( llm=Cohere(), embeddings=HuggingFaceEmbeddings(), document_contents="Descriptions of cats, along with their names and breeds.", metadata_field_info=[ AttributeInfo(name="name", description="Name of the cat", type="string"), AttributeInfo(name="breed", description="Cat's breed", type="string"), ], collection_name="cats",)
```
The same goes for the `initialize` function that creates a Qdrant collection and indexes the documents:
```
from langchain_core.documents import Documentfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom self_query_qdrant.chain import initializeinitialize( embeddings=HuggingFaceEmbeddings(), collection_name="cats", documents=[ Document( page_content="A mean lazy old cat who destroys furniture and eats lasagna", metadata={"name": "Garfield", "breed": "Tabby"}, ), ... ])
```
The template is flexible and might be used for different sets of documents easily.
### LangSmith[](#langsmith "Direct link to LangSmith")
(Optional) If you have access to LangSmith, configure it to help trace, monitor and debug LangChain applications. If you don't have access, skip this section.
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
### Local Server[](#local-server "Direct link to Local Server")
This will start the FastAPI app with a server running locally at [http://localhost:8000](http://localhost:8000/)
You can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) Access the playground at [http://127.0.0.1:8000/self-query-qdrant/playground](http://127.0.0.1:8000/self-query-qdrant/playground)
Access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/self-query-qdrant")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:00.969Z",
"loadedUrl": "https://python.langchain.com/docs/templates/self-query-qdrant/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/self-query-qdrant/",
"description": "This template performs self-querying",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3758",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"self-query-qdrant\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:00 GMT",
"etag": "W/\"c5188240e534ef70c73647d4d3b0c60b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::57h9m-1713753960321-38ee30dcfa19"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/self-query-qdrant/",
"property": "og:url"
},
{
"content": "self-query-qdrant | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template performs self-querying",
"property": "og:description"
}
],
"title": "self-query-qdrant | 🦜️🔗 LangChain"
} | self-query-qdrant
This template performs self-querying using Qdrant and OpenAI. By default, it uses an artificial dataset of 10 documents, but you can replace it with your own dataset.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
Set the QDRANT_URL to the URL of your Qdrant instance. If you use Qdrant Cloud you have to set the QDRANT_API_KEY environment variable as well. If you do not set any of them, the template will try to connect a local Qdrant instance at http://localhost:6333.
export QDRANT_URL=
export QDRANT_API_KEY=
export OPENAI_API_KEY=
Usage
To use this package, install the LangChain CLI first:
pip install -U "langchain-cli[serve]"
Create a new LangChain project and install this package as the only one:
langchain app new my-app --package self-query-qdrant
To add this to an existing project, run:
langchain app add self-query-qdrant
Defaults
Before you launch the server, you need to create a Qdrant collection and index the documents. It can be done by running the following command:
from self_query_qdrant.chain import initialize
initialize()
Add the following code to your app/server.py file:
from self_query_qdrant.chain import chain
add_routes(app, chain, path="/self-query-qdrant")
The default dataset consists 10 documents about dishes, along with their price and restaurant information. You can find the documents in the packages/self-query-qdrant/self_query_qdrant/defaults.py file. Here is one of the documents:
from langchain_core.documents import Document
Document(
page_content="Spaghetti with meatballs and tomato sauce",
metadata={
"price": 12.99,
"restaurant": {
"name": "Olive Garden",
"location": ["New York", "Chicago", "Los Angeles"],
},
},
)
The self-querying allows performing semantic search over the documents, with some additional filtering based on the metadata. For example, you can search for the dishes that cost less than $15 and are served in New York.
Customization
All the examples above assume that you want to launch the template with just the defaults. If you want to customize the template, you can do it by passing the parameters to the create_chain function in the app/server.py file:
from langchain_community.llms import Cohere
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains.query_constructor.schema import AttributeInfo
from self_query_qdrant.chain import create_chain
chain = create_chain(
llm=Cohere(),
embeddings=HuggingFaceEmbeddings(),
document_contents="Descriptions of cats, along with their names and breeds.",
metadata_field_info=[
AttributeInfo(name="name", description="Name of the cat", type="string"),
AttributeInfo(name="breed", description="Cat's breed", type="string"),
],
collection_name="cats",
)
The same goes for the initialize function that creates a Qdrant collection and indexes the documents:
from langchain_core.documents import Document
from langchain_community.embeddings import HuggingFaceEmbeddings
from self_query_qdrant.chain import initialize
initialize(
embeddings=HuggingFaceEmbeddings(),
collection_name="cats",
documents=[
Document(
page_content="A mean lazy old cat who destroys furniture and eats lasagna",
metadata={"name": "Garfield", "breed": "Tabby"},
),
...
]
)
The template is flexible and might be used for different sets of documents easily.
LangSmith
(Optional) If you have access to LangSmith, configure it to help trace, monitor and debug LangChain applications. If you don't have access, skip this section.
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
Local Server
This will start the FastAPI app with a server running locally at http://localhost:8000
You can see all templates at http://127.0.0.1:8000/docs Access the playground at http://127.0.0.1:8000/self-query-qdrant/playground
Access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/self-query-qdrant") |
https://python.langchain.com/docs/templates/self-query-supabase/ | ## self-query-supabase
This templates allows natural language structured quering of Supabase.
[Supabase](https://supabase.com/docs) is an open-source alternative to Firebase, built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL).
It uses [pgvector](https://github.com/pgvector/pgvector) to store embeddings within your tables.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
To get your `OPENAI_API_KEY`, navigate to [API keys](https://platform.openai.com/account/api-keys) on your OpenAI account and create a new secret key.
To find your `SUPABASE_URL` and `SUPABASE_SERVICE_KEY`, head to your Supabase project's [API settings](https://supabase.com/dashboard/project/_/settings/api).
* `SUPABASE_URL` corresponds to the Project URL
* `SUPABASE_SERVICE_KEY` corresponds to the `service_role` API key
```
export SUPABASE_URL=export SUPABASE_SERVICE_KEY=export OPENAI_API_KEY=
```
## Setup Supabase Database[](#setup-supabase-database "Direct link to Setup Supabase Database")
Use these steps to setup your Supabase database if you haven't already.
1. Head over to [https://database.new](https://database.new/) to provision your Supabase database.
2. In the studio, jump to the [SQL editor](https://supabase.com/dashboard/project/_/sql/new) and run the following script to enable `pgvector` and setup your database as a vector store:
```
-- Enable the pgvector extension to work with embedding vectorscreate extension if not exists vector;-- Create a table to store your documentscreate table documents ( id uuid primary key, content text, -- corresponds to Document.pageContent metadata jsonb, -- corresponds to Document.metadata embedding vector (1536) -- 1536 works for OpenAI embeddings, change as needed );-- Create a function to search for documentscreate function match_documents ( query_embedding vector (1536), filter jsonb default '{}') returns table ( id uuid, content text, metadata jsonb, similarity float) language plpgsql as $$#variable_conflict use_columnbegin return query select id, content, metadata, 1 - (documents.embedding <=> query_embedding) as similarity from documents where metadata @> filter order by documents.embedding <=> query_embedding;end;$$;
```
## Usage[](#usage "Direct link to Usage")
To use this package, install the LangChain CLI first:
```
pip install -U langchain-cli
```
Create a new LangChain project and install this package as the only one:
```
langchain app new my-app --package self-query-supabase
```
To add this to an existing project, run:
```
langchain app add self-query-supabase
```
Add the following code to your `server.py` file:
```
from self_query_supabase.chain import chain as self_query_supabase_chainadd_routes(app, self_query_supabase_chain, path="/self-query-supabase")
```
(Optional) If you have access to LangSmith, configure it to help trace, monitor and debug LangChain applications. If you don't have access, skip this section.
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server running locally at [http://localhost:8000](http://localhost:8000/)
You can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) Access the playground at [http://127.0.0.1:8000/self-query-supabase/playground](http://127.0.0.1:8000/self-query-supabase/playground)
Access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/self-query-supabase")
```
TODO: Instructions to set up the Supabase database and install the package. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:01.198Z",
"loadedUrl": "https://python.langchain.com/docs/templates/self-query-supabase/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/self-query-supabase/",
"description": "This templates allows natural language structured quering of Supabase.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"self-query-supabase\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:00 GMT",
"etag": "W/\"c340f8d4cc9806ff7f559874b769ce99\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::wlb9t-1713753960918-785d2491e39f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/self-query-supabase/",
"property": "og:url"
},
{
"content": "self-query-supabase | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This templates allows natural language structured quering of Supabase.",
"property": "og:description"
}
],
"title": "self-query-supabase | 🦜️🔗 LangChain"
} | self-query-supabase
This templates allows natural language structured quering of Supabase.
Supabase is an open-source alternative to Firebase, built on top of PostgreSQL.
It uses pgvector to store embeddings within your tables.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
To get your OPENAI_API_KEY, navigate to API keys on your OpenAI account and create a new secret key.
To find your SUPABASE_URL and SUPABASE_SERVICE_KEY, head to your Supabase project's API settings.
SUPABASE_URL corresponds to the Project URL
SUPABASE_SERVICE_KEY corresponds to the service_role API key
export SUPABASE_URL=
export SUPABASE_SERVICE_KEY=
export OPENAI_API_KEY=
Setup Supabase Database
Use these steps to setup your Supabase database if you haven't already.
Head over to https://database.new to provision your Supabase database.
In the studio, jump to the SQL editor and run the following script to enable pgvector and setup your database as a vector store:
-- Enable the pgvector extension to work with embedding vectors
create extension if not exists vector;
-- Create a table to store your documents
create table
documents (
id uuid primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector (1536) -- 1536 works for OpenAI embeddings, change as needed
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector (1536),
filter jsonb default '{}'
) returns table (
id uuid,
content text,
metadata jsonb,
similarity float
) language plpgsql as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding;
end;
$$;
Usage
To use this package, install the LangChain CLI first:
pip install -U langchain-cli
Create a new LangChain project and install this package as the only one:
langchain app new my-app --package self-query-supabase
To add this to an existing project, run:
langchain app add self-query-supabase
Add the following code to your server.py file:
from self_query_supabase.chain import chain as self_query_supabase_chain
add_routes(app, self_query_supabase_chain, path="/self-query-supabase")
(Optional) If you have access to LangSmith, configure it to help trace, monitor and debug LangChain applications. If you don't have access, skip this section.
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server running locally at http://localhost:8000
You can see all templates at http://127.0.0.1:8000/docs Access the playground at http://127.0.0.1:8000/self-query-supabase/playground
Access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/self-query-supabase")
TODO: Instructions to set up the Supabase database and install the package. |
https://python.langchain.com/docs/templates/shopping-assistant/ | ## shopping-assistant
This template creates a shopping assistant that helps users find products that they are looking for.
This template will use `Ionic` to search for products.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
This template will use `OpenAI` by default. Be sure that `OPENAI_API_KEY` is set in your environment.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package shopping-assistant
```
If you want to add this to an existing project, you can just run:
```
langchain app add shopping-assistant
```
And add the following code to your `server.py` file:
```
from shopping_assistant.agent import agent_executor as shopping_assistant_chainadd_routes(app, shopping_assistant_chain, path="/shopping-assistant")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/shopping-assistant/playground](http://127.0.0.1:8000/shopping-assistant/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/shopping-assistant")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:01.419Z",
"loadedUrl": "https://python.langchain.com/docs/templates/shopping-assistant/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/shopping-assistant/",
"description": "This template creates a shopping assistant that helps users find products that they are looking for.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3759",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"shopping-assistant\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:01 GMT",
"etag": "W/\"07ff6f82615e00491753dab1e84e8417\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::p8jmq-1713753961219-93a0531e2655"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/shopping-assistant/",
"property": "og:url"
},
{
"content": "shopping-assistant | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template creates a shopping assistant that helps users find products that they are looking for.",
"property": "og:description"
}
],
"title": "shopping-assistant | 🦜️🔗 LangChain"
} | shopping-assistant
This template creates a shopping assistant that helps users find products that they are looking for.
This template will use Ionic to search for products.
Environment Setup
This template will use OpenAI by default. Be sure that OPENAI_API_KEY is set in your environment.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package shopping-assistant
If you want to add this to an existing project, you can just run:
langchain app add shopping-assistant
And add the following code to your server.py file:
from shopping_assistant.agent import agent_executor as shopping_assistant_chain
add_routes(app, shopping_assistant_chain, path="/shopping-assistant")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/shopping-assistant/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/shopping-assistant")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/skeleton-of-thought/ | ## skeleton-of-thought
Implements "Skeleton of Thought" from [this](https://sites.google.com/view/sot-llm) paper.
This technique makes it possible to generate longer generations more quickly by first generating a skeleton, then generating each point of the outline.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
To get your `OPENAI_API_KEY`, navigate to [API keys](https://platform.openai.com/account/api-keys) on your OpenAI account and create a new secret key.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package skeleton-of-thought
```
If you want to add this to an existing project, you can just run:
```
langchain app add skeleton-of-thought
```
And add the following code to your `server.py` file:
```
from skeleton_of_thought import chain as skeleton_of_thought_chainadd_routes(app, skeleton_of_thought_chain, path="/skeleton-of-thought")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/skeleton-of-thought/playground](http://127.0.0.1:8000/skeleton-of-thought/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/skeleton-of-thought")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:01.966Z",
"loadedUrl": "https://python.langchain.com/docs/templates/skeleton-of-thought/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/skeleton-of-thought/",
"description": "Implements \"Skeleton of Thought\" from this paper.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"skeleton-of-thought\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:01 GMT",
"etag": "W/\"bc02a88407a08d76c6bc98163113f0d9\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::h96x2-1713753961888-d2a9c7e5aaf7"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/skeleton-of-thought/",
"property": "og:url"
},
{
"content": "skeleton-of-thought | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Implements \"Skeleton of Thought\" from this paper.",
"property": "og:description"
}
],
"title": "skeleton-of-thought | 🦜️🔗 LangChain"
} | skeleton-of-thought
Implements "Skeleton of Thought" from this paper.
This technique makes it possible to generate longer generations more quickly by first generating a skeleton, then generating each point of the outline.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
To get your OPENAI_API_KEY, navigate to API keys on your OpenAI account and create a new secret key.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package skeleton-of-thought
If you want to add this to an existing project, you can just run:
langchain app add skeleton-of-thought
And add the following code to your server.py file:
from skeleton_of_thought import chain as skeleton_of_thought_chain
add_routes(app, skeleton_of_thought_chain, path="/skeleton-of-thought")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/skeleton-of-thought/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/skeleton-of-thought")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/solo-performance-prompting-agent/ | ## solo-performance-prompting-agent
This template creates an agent that transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas. A cognitive synergist refers to an intelligent agent that collaborates with multiple minds, combining their individual strengths and knowledge, to enhance problem-solving and overall performance in complex tasks. By dynamically identifying and simulating different personas based on task inputs, SPP unleashes the potential of cognitive synergy in LLMs.
This template will use the `DuckDuckGo` search API.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
This template will use `OpenAI` by default. Be sure that `OPENAI_API_KEY` is set in your environment.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package solo-performance-prompting-agent
```
If you want to add this to an existing project, you can just run:
```
langchain app add solo-performance-prompting-agent
```
And add the following code to your `server.py` file:
```
from solo_performance_prompting_agent.agent import agent_executor as solo_performance_prompting_agent_chainadd_routes(app, solo_performance_prompting_agent_chain, path="/solo-performance-prompting-agent")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/solo-performance-prompting-agent/playground](http://127.0.0.1:8000/solo-performance-prompting-agent/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/solo-performance-prompting-agent")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:02.981Z",
"loadedUrl": "https://python.langchain.com/docs/templates/solo-performance-prompting-agent/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/solo-performance-prompting-agent/",
"description": "This template creates an agent that transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4932",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"solo-performance-prompting-agent\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:02 GMT",
"etag": "W/\"6e4792d1643cd3a385c6ce7598e6fa6a\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::r5b2z-1713753962863-6c1cbe6b93c2"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/solo-performance-prompting-agent/",
"property": "og:url"
},
{
"content": "solo-performance-prompting-agent | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template creates an agent that transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas.",
"property": "og:description"
}
],
"title": "solo-performance-prompting-agent | 🦜️🔗 LangChain"
} | solo-performance-prompting-agent
This template creates an agent that transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas. A cognitive synergist refers to an intelligent agent that collaborates with multiple minds, combining their individual strengths and knowledge, to enhance problem-solving and overall performance in complex tasks. By dynamically identifying and simulating different personas based on task inputs, SPP unleashes the potential of cognitive synergy in LLMs.
This template will use the DuckDuckGo search API.
Environment Setup
This template will use OpenAI by default. Be sure that OPENAI_API_KEY is set in your environment.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package solo-performance-prompting-agent
If you want to add this to an existing project, you can just run:
langchain app add solo-performance-prompting-agent
And add the following code to your server.py file:
from solo_performance_prompting_agent.agent import agent_executor as solo_performance_prompting_agent_chain
add_routes(app, solo_performance_prompting_agent_chain, path="/solo-performance-prompting-agent")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/solo-performance-prompting-agent/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/solo-performance-prompting-agent") |
https://python.langchain.com/docs/templates/sql-llama2/ | ## sql-llama2
This template enables a user to interact with a SQL database using natural language.
It uses LLamA2-13b hosted by [Replicate](https://python.langchain.com/docs/integrations/llms/replicate), but can be adapted to any API that supports LLaMA2 including [Fireworks](https://python.langchain.com/docs/integrations/chat/fireworks).
The template includes an example database of 2023 NBA rosters.
For more information on how to build this database, see [here](https://github.com/facebookresearch/llama-recipes/blob/main/demo_apps/StructuredLlama.ipynb).
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Ensure the `REPLICATE_API_TOKEN` is set in your environment.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package sql-llama2
```
If you want to add this to an existing project, you can just run:
```
langchain app add sql-llama2
```
And add the following code to your `server.py` file:
```
from sql_llama2 import chain as sql_llama2_chainadd_routes(app, sql_llama2_chain, path="/sql-llama2")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/sql-llama2/playground](http://127.0.0.1:8000/sql-llama2/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/sql-llama2")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:03.428Z",
"loadedUrl": "https://python.langchain.com/docs/templates/sql-llama2/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/sql-llama2/",
"description": "This template enables a user to interact with a SQL database using natural language.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3760",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sql-llama2\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:03 GMT",
"etag": "W/\"6460c47b5ca8bf4f3cc8e030c84d8ec0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::vp7cr-1713753963354-ed31c250fddf"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/sql-llama2/",
"property": "og:url"
},
{
"content": "sql-llama2 | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template enables a user to interact with a SQL database using natural language.",
"property": "og:description"
}
],
"title": "sql-llama2 | 🦜️🔗 LangChain"
} | sql-llama2
This template enables a user to interact with a SQL database using natural language.
It uses LLamA2-13b hosted by Replicate, but can be adapted to any API that supports LLaMA2 including Fireworks.
The template includes an example database of 2023 NBA rosters.
For more information on how to build this database, see here.
Environment Setup
Ensure the REPLICATE_API_TOKEN is set in your environment.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package sql-llama2
If you want to add this to an existing project, you can just run:
langchain app add sql-llama2
And add the following code to your server.py file:
from sql_llama2 import chain as sql_llama2_chain
add_routes(app, sql_llama2_chain, path="/sql-llama2")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/sql-llama2/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/sql-llama2") |
https://python.langchain.com/docs/templates/sql-llamacpp/ | ## sql-llamacpp
This template enables a user to interact with a SQL database using natural language.
It uses [Mistral-7b](https://mistral.ai/news/announcing-mistral-7b/) via [llama.cpp](https://github.com/ggerganov/llama.cpp) to run inference locally on a Mac laptop.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
To set up the environment, use the following steps:
```
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.shbash Miniforge3-MacOSX-arm64.shconda create -n llama python=3.9.16conda activate /Users/rlm/miniforge3/envs/llamaCMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir
```
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package sql-llamacpp
```
If you want to add this to an existing project, you can just run:
```
langchain app add sql-llamacpp
```
And add the following code to your `server.py` file:
```
from sql_llamacpp import chain as sql_llamacpp_chainadd_routes(app, sql_llamacpp_chain, path="/sql-llamacpp")
```
The package will download the Mistral-7b model from [here](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF). You can select other files and specify their download path (browse [here](https://huggingface.co/TheBloke)).
This package includes an example DB of 2023 NBA rosters. You can see instructions to build this DB [here](https://github.com/facebookresearch/llama-recipes/blob/main/demo_apps/StructuredLlama.ipynb).
(Optional) Configure LangSmith for tracing, monitoring and debugging LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server running locally at [http://localhost:8000](http://localhost:8000/)
You can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) You can access the playground at [http://127.0.0.1:8000/sql-llamacpp/playground](http://127.0.0.1:8000/sql-llamacpp/playground)
You can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/sql-llamacpp")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:03.923Z",
"loadedUrl": "https://python.langchain.com/docs/templates/sql-llamacpp/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/sql-llamacpp/",
"description": "This template enables a user to interact with a SQL database using natural language.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sql-llamacpp\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:03 GMT",
"etag": "W/\"0f20c88e048f3bac765a496d1f878a79\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::qzfql-1713753963813-a72f090f3628"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/sql-llamacpp/",
"property": "og:url"
},
{
"content": "sql-llamacpp | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template enables a user to interact with a SQL database using natural language.",
"property": "og:description"
}
],
"title": "sql-llamacpp | 🦜️🔗 LangChain"
} | sql-llamacpp
This template enables a user to interact with a SQL database using natural language.
It uses Mistral-7b via llama.cpp to run inference locally on a Mac laptop.
Environment Setup
To set up the environment, use the following steps:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n llama python=3.9.16
conda activate /Users/rlm/miniforge3/envs/llama
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package sql-llamacpp
If you want to add this to an existing project, you can just run:
langchain app add sql-llamacpp
And add the following code to your server.py file:
from sql_llamacpp import chain as sql_llamacpp_chain
add_routes(app, sql_llamacpp_chain, path="/sql-llamacpp")
The package will download the Mistral-7b model from here. You can select other files and specify their download path (browse here).
This package includes an example DB of 2023 NBA rosters. You can see instructions to build this DB here.
(Optional) Configure LangSmith for tracing, monitoring and debugging LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server running locally at http://localhost:8000
You can see all templates at http://127.0.0.1:8000/docs You can access the playground at http://127.0.0.1:8000/sql-llamacpp/playground
You can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/sql-llamacpp")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/summarize-anthropic/ | ## summarize-anthropic
This template uses Anthropic's `claude-3-sonnet-20240229` to summarize long documents.
It leverages a large context window of 100k tokens, allowing for summarization of documents over 100 pages.
You can see the summarization prompt in `chain.py`.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `ANTHROPIC_API_KEY` environment variable to access the Anthropic models.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package summarize-anthropic
```
If you want to add this to an existing project, you can just run:
```
langchain app add summarize-anthropic
```
And add the following code to your `server.py` file:
```
from summarize_anthropic import chain as summarize_anthropic_chainadd_routes(app, summarize_anthropic_chain, path="/summarize-anthropic")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/summarize-anthropic/playground](http://127.0.0.1:8000/summarize-anthropic/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/summarize-anthropic")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:04.443Z",
"loadedUrl": "https://python.langchain.com/docs/templates/summarize-anthropic/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/summarize-anthropic/",
"description": "This template uses Anthropic's claude-3-sonnet-20240229 to summarize long documents.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3761",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"summarize-anthropic\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"31cfe87101af8bc202b014016459955e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::qvg7r-1713753964389-82e912f68a0e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/summarize-anthropic/",
"property": "og:url"
},
{
"content": "summarize-anthropic | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template uses Anthropic's claude-3-sonnet-20240229 to summarize long documents.",
"property": "og:description"
}
],
"title": "summarize-anthropic | 🦜️🔗 LangChain"
} | summarize-anthropic
This template uses Anthropic's claude-3-sonnet-20240229 to summarize long documents.
It leverages a large context window of 100k tokens, allowing for summarization of documents over 100 pages.
You can see the summarization prompt in chain.py.
Environment Setup
Set the ANTHROPIC_API_KEY environment variable to access the Anthropic models.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package summarize-anthropic
If you want to add this to an existing project, you can just run:
langchain app add summarize-anthropic
And add the following code to your server.py file:
from summarize_anthropic import chain as summarize_anthropic_chain
add_routes(app, summarize_anthropic_chain, path="/summarize-anthropic")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/summarize-anthropic/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/summarize-anthropic")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/sql-ollama/ | ## sql-ollama
This template enables a user to interact with a SQL database using natural language.
It uses [Zephyr-7b](https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha) via [Ollama](https://ollama.ai/library/zephyr) to run inference locally on a Mac laptop.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Before using this template, you need to set up Ollama and SQL database.
1. Follow instructions [here](https://python.langchain.com/docs/integrations/chat/ollama) to download Ollama.
2. Download your LLM of interest:
* This package uses `zephyr`: `ollama pull zephyr`
* You can choose from many LLMs [here](https://ollama.ai/library)
3. This package includes an example DB of 2023 NBA rosters. You can see instructions to build this DB [here](https://github.com/facebookresearch/llama-recipes/blob/main/demo_apps/StructuredLlama.ipynb).
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package sql-ollama
```
If you want to add this to an existing project, you can just run:
```
langchain app add sql-ollama
```
And add the following code to your `server.py` file:
```
from sql_ollama import chain as sql_ollama_chainadd_routes(app, sql_ollama_chain, path="/sql-ollama")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/sql-ollama/playground](http://127.0.0.1:8000/sql-ollama/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/sql-ollama")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:04.596Z",
"loadedUrl": "https://python.langchain.com/docs/templates/sql-ollama/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/sql-ollama/",
"description": "This template enables a user to interact with a SQL database using natural language.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4933",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sql-ollama\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"5a91f2d246b1b72177b5ea74dc3c185c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wv8xj-1713753964388-7d0ef2247060"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/sql-ollama/",
"property": "og:url"
},
{
"content": "sql-ollama | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template enables a user to interact with a SQL database using natural language.",
"property": "og:description"
}
],
"title": "sql-ollama | 🦜️🔗 LangChain"
} | sql-ollama
This template enables a user to interact with a SQL database using natural language.
It uses Zephyr-7b via Ollama to run inference locally on a Mac laptop.
Environment Setup
Before using this template, you need to set up Ollama and SQL database.
Follow instructions here to download Ollama.
Download your LLM of interest:
This package uses zephyr: ollama pull zephyr
You can choose from many LLMs here
This package includes an example DB of 2023 NBA rosters. You can see instructions to build this DB here.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package sql-ollama
If you want to add this to an existing project, you can just run:
langchain app add sql-ollama
And add the following code to your server.py file:
from sql_ollama import chain as sql_ollama_chain
add_routes(app, sql_ollama_chain, path="/sql-ollama")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/sql-ollama/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/sql-ollama")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/xml-agent/ | ## xml-agent
This package creates an agent that uses XML syntax to communicate its decisions of what actions to take. It uses Anthropic's Claude models for writing XML syntax and can optionally look up things on the internet using DuckDuckGo.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Two environment variables need to be set:
* `ANTHROPIC_API_KEY`: Required for using Anthropic
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package xml-agent
```
If you want to add this to an existing project, you can just run:
```
langchain app add xml-agent
```
And add the following code to your `server.py` file:
```
from xml_agent import agent_executor as xml_agent_chainadd_routes(app, xml_agent_chain, path="/xml-agent")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/xml-agent/playground](http://127.0.0.1:8000/xml-agent/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/xml-agent")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:04.691Z",
"loadedUrl": "https://python.langchain.com/docs/templates/xml-agent/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/xml-agent/",
"description": "This package creates an agent that uses XML syntax to communicate its decisions of what actions to take. It uses Anthropic's Claude models for writing XML syntax and can optionally look up things on the internet using DuckDuckGo.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3761",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"xml-agent\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"c9051df39fcfbef95f6cb966cdcd78fb\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::hcnxs-1713753964416-9ceb2c4cb20d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/xml-agent/",
"property": "og:url"
},
{
"content": "xml-agent | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This package creates an agent that uses XML syntax to communicate its decisions of what actions to take. It uses Anthropic's Claude models for writing XML syntax and can optionally look up things on the internet using DuckDuckGo.",
"property": "og:description"
}
],
"title": "xml-agent | 🦜️🔗 LangChain"
} | xml-agent
This package creates an agent that uses XML syntax to communicate its decisions of what actions to take. It uses Anthropic's Claude models for writing XML syntax and can optionally look up things on the internet using DuckDuckGo.
Environment Setup
Two environment variables need to be set:
ANTHROPIC_API_KEY: Required for using Anthropic
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package xml-agent
If you want to add this to an existing project, you can just run:
langchain app add xml-agent
And add the following code to your server.py file:
from xml_agent import agent_executor as xml_agent_chain
add_routes(app, xml_agent_chain, path="/xml-agent")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/xml-agent/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/xml-agent")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/templates/sql-pgvector/ | ## sql-pgvector
This template enables user to use `pgvector` for combining postgreSQL with semantic search / RAG.
It uses [PGVector](https://github.com/pgvector/pgvector) extension as shown in the [RAG empowered SQL cookbook](https://github.com/langchain-ai/langchain/blob/master/cookbook/retrieval_in_sql.ipynb)
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
If you are using `ChatOpenAI` as your LLM, make sure the `OPENAI_API_KEY` is set in your environment. You can change both the LLM and embeddings model inside `chain.py`
And you can configure configure the following environment variables for use by the template (defaults are in parentheses)
* `POSTGRES_USER` (postgres)
* `POSTGRES_PASSWORD` (test)
* `POSTGRES_DB` (vectordb)
* `POSTGRES_HOST` (localhost)
* `POSTGRES_PORT` (5432)
If you don't have a postgres instance, you can run one locally in docker:
```
docker run \ --name some-postgres \ -e POSTGRES_PASSWORD=test \ -e POSTGRES_USER=postgres \ -e POSTGRES_DB=vectordb \ -p 5432:5432 \ postgres:16
```
And to start again later, use the `--name` defined above:
```
docker start some-postgres
```
### PostgreSQL Database setup[](#postgresql-database-setup "Direct link to PostgreSQL Database setup")
Apart from having `pgvector` extension enabled, you will need to do some setup before being able to run semantic search within your SQL queries.
In order to run RAG over your postgreSQL database you will need to generate the embeddings for the specific columns you want.
This process is covered in the [RAG empowered SQL cookbook](https://github.com/langchain-ai/langchain/blob/master/cookbook/retrieval_in_sql.ipynb), but the overall approach consist of:
1. Querying for unique values in the column
2. Generating embeddings for those values
3. Store the embeddings in a separate column or in an auxiliary table.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package sql-pgvector
```
If you want to add this to an existing project, you can just run:
```
langchain app add sql-pgvector
```
And add the following code to your `server.py` file:
```
from sql_pgvector import chain as sql_pgvector_chainadd_routes(app, sql_pgvector_chain, path="/sql-pgvector")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/sql-pgvector/playground](http://127.0.0.1:8000/sql-pgvector/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/sql-pgvector")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:04.801Z",
"loadedUrl": "https://python.langchain.com/docs/templates/sql-pgvector/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/sql-pgvector/",
"description": "This template enables user to use pgvector for combining postgreSQL with semantic search / RAG.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3761",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sql-pgvector\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"7eeca1d3e52680a4a35943472ab0dc1d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::6zqpn-1713753964416-fc47c8132dba"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/sql-pgvector/",
"property": "og:url"
},
{
"content": "sql-pgvector | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template enables user to use pgvector for combining postgreSQL with semantic search / RAG.",
"property": "og:description"
}
],
"title": "sql-pgvector | 🦜️🔗 LangChain"
} | sql-pgvector
This template enables user to use pgvector for combining postgreSQL with semantic search / RAG.
It uses PGVector extension as shown in the RAG empowered SQL cookbook
Environment Setup
If you are using ChatOpenAI as your LLM, make sure the OPENAI_API_KEY is set in your environment. You can change both the LLM and embeddings model inside chain.py
And you can configure configure the following environment variables for use by the template (defaults are in parentheses)
POSTGRES_USER (postgres)
POSTGRES_PASSWORD (test)
POSTGRES_DB (vectordb)
POSTGRES_HOST (localhost)
POSTGRES_PORT (5432)
If you don't have a postgres instance, you can run one locally in docker:
docker run \
--name some-postgres \
-e POSTGRES_PASSWORD=test \
-e POSTGRES_USER=postgres \
-e POSTGRES_DB=vectordb \
-p 5432:5432 \
postgres:16
And to start again later, use the --name defined above:
docker start some-postgres
PostgreSQL Database setup
Apart from having pgvector extension enabled, you will need to do some setup before being able to run semantic search within your SQL queries.
In order to run RAG over your postgreSQL database you will need to generate the embeddings for the specific columns you want.
This process is covered in the RAG empowered SQL cookbook, but the overall approach consist of:
Querying for unique values in the column
Generating embeddings for those values
Store the embeddings in a separate column or in an auxiliary table.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package sql-pgvector
If you want to add this to an existing project, you can just run:
langchain app add sql-pgvector
And add the following code to your server.py file:
from sql_pgvector import chain as sql_pgvector_chain
add_routes(app, sql_pgvector_chain, path="/sql-pgvector")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/sql-pgvector/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/sql-pgvector") |
https://python.langchain.com/docs/templates/vertexai-chuck-norris/ | ## vertexai-chuck-norris
This template makes jokes about Chuck Norris using Vertex AI PaLM2.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
First, make sure you have a Google Cloud project with an active billing account, and have the [gcloud CLI installed](https://cloud.google.com/sdk/docs/install).
Configure [application default credentials](https://cloud.google.com/docs/authentication/provide-credentials-adc):
```
gcloud auth application-default login
```
To set a default Google Cloud project to use, run this command and set [the project ID](https://support.google.com/googleapi/answer/7014113?hl=en) of the project you want to use:
```
gcloud config set project [PROJECT-ID]
```
Enable the [Vertex AI API](https://console.cloud.google.com/apis/library/aiplatform.googleapis.com) for the project:
```
gcloud services enable aiplatform.googleapis.com
```
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package pirate-speak
```
If you want to add this to an existing project, you can just run:
```
langchain app add vertexai-chuck-norris
```
And add the following code to your `server.py` file:
```
from vertexai_chuck_norris.chain import chain as vertexai_chuck_norris_chainadd_routes(app, vertexai_chuck_norris_chain, path="/vertexai-chuck-norris")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/vertexai-chuck-norris/playground](http://127.0.0.1:8000/vertexai-chuck-norris/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/vertexai-chuck-norris")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:04.899Z",
"loadedUrl": "https://python.langchain.com/docs/templates/vertexai-chuck-norris/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/vertexai-chuck-norris/",
"description": "This template makes jokes about Chuck Norris using Vertex AI PaLM2.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"vertexai-chuck-norris\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"639fb5c28356c2c69032792ad104cb27\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::njn2b-1713753964418-505f905f5ac8"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/vertexai-chuck-norris/",
"property": "og:url"
},
{
"content": "vertexai-chuck-norris | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template makes jokes about Chuck Norris using Vertex AI PaLM2.",
"property": "og:description"
}
],
"title": "vertexai-chuck-norris | 🦜️🔗 LangChain"
} | vertexai-chuck-norris
This template makes jokes about Chuck Norris using Vertex AI PaLM2.
Environment Setup
First, make sure you have a Google Cloud project with an active billing account, and have the gcloud CLI installed.
Configure application default credentials:
gcloud auth application-default login
To set a default Google Cloud project to use, run this command and set the project ID of the project you want to use:
gcloud config set project [PROJECT-ID]
Enable the Vertex AI API for the project:
gcloud services enable aiplatform.googleapis.com
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package pirate-speak
If you want to add this to an existing project, you can just run:
langchain app add vertexai-chuck-norris
And add the following code to your server.py file:
from vertexai_chuck_norris.chain import chain as vertexai_chuck_norris_chain
add_routes(app, vertexai_chuck_norris_chain, path="/vertexai-chuck-norris")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/vertexai-chuck-norris/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/vertexai-chuck-norris") |
https://python.langchain.com/docs/templates/stepback-qa-prompting/ | ## stepback-qa-prompting
This template replicates the "Step-Back" prompting technique that improves performance on complex questions by first asking a "step back" question.
This technique can be combined with regular question-answering applications by doing retrieval on both the original and step-back question.
Read more about this in the paper [here](https://arxiv.org/abs/2310.06117) and an excellent blog post by Cobus Greyling [here](https://cobusgreyling.medium.com/a-new-prompt-engineering-technique-has-been-introduced-called-step-back-prompting-b00e8954cacb)
We will modify the prompts slightly to work better with chat models in this template.
## Environment Setup[](#environment-setup "Direct link to Environment Setup")
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
## Usage[](#usage "Direct link to Usage")
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package stepback-qa-prompting
```
If you want to add this to an existing project, you can just run:
```
langchain app add stepback-qa-prompting
```
And add the following code to your `server.py` file:
```
from stepback_qa_prompting.chain import chain as stepback_qa_prompting_chainadd_routes(app, stepback_qa_prompting_chain, path="/stepback-qa-prompting")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/stepback-qa-prompting/playground](http://127.0.0.1:8000/stepback-qa-prompting/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/stepback-qa-prompting")
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:05.116Z",
"loadedUrl": "https://python.langchain.com/docs/templates/stepback-qa-prompting/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/stepback-qa-prompting/",
"description": "This template replicates the \"Step-Back\" prompting technique that improves performance on complex questions by first asking a \"step back\" question.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4933",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"stepback-qa-prompting\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"05f5db58eb7793b9735f3a42f70d86f9\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::qb88p-1713753964829-86d8419f5030"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/stepback-qa-prompting/",
"property": "og:url"
},
{
"content": "stepback-qa-prompting | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This template replicates the \"Step-Back\" prompting technique that improves performance on complex questions by first asking a \"step back\" question.",
"property": "og:description"
}
],
"title": "stepback-qa-prompting | 🦜️🔗 LangChain"
} | stepback-qa-prompting
This template replicates the "Step-Back" prompting technique that improves performance on complex questions by first asking a "step back" question.
This technique can be combined with regular question-answering applications by doing retrieval on both the original and step-back question.
Read more about this in the paper here and an excellent blog post by Cobus Greyling here
We will modify the prompts slightly to work better with chat models in this template.
Environment Setup
Set the OPENAI_API_KEY environment variable to access the OpenAI models.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package stepback-qa-prompting
If you want to add this to an existing project, you can just run:
langchain app add stepback-qa-prompting
And add the following code to your server.py file:
from stepback_qa_prompting.chain import chain as stepback_qa_prompting_chain
add_routes(app, stepback_qa_prompting_chain, path="/stepback-qa-prompting")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/stepback-qa-prompting/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/stepback-qa-prompting") |
https://python.langchain.com/docs/use_cases/apis/ | Suppose you want an LLM to interact with external APIs.
This can be very useful for retrieving context for the LLM to utilize.
Many APIs are already compatible with OpenAI function calling.
For example, [Klarna](https://www.klarna.com/international/press/klarna-brings-smoooth-shopping-to-chatgpt/) has a YAML file that describes its API and allows OpenAI to interact with it:
```
https://www.klarna.com/us/shopping/public/openai/v0/api-docs/
```
We can supply the specification to `get_openapi_chain` directly in order to query the API with OpenAI functions:
```
Attempting to load an OpenAPI 3.0.1 spec. This may result in degraded performance. Convert your OpenAPI spec to 3.1.* spec for better support.
```
```
{'query': "What are some options for a men's large blue button down shirt", 'response': {'products': [{'name': 'Cubavera Four Pocket Guayabera Shirt', 'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3202055522/Clothing/Cubavera-Four-Pocket-Guayabera-Shirt/?utm_source=openai&ref-site=openai_plugin', 'price': '$13.50', 'attributes': ['Material:Polyester,Cotton', 'Target Group:Man', 'Color:Red,White,Blue,Black', 'Properties:Pockets', 'Pattern:Solid Color', 'Size (Small-Large):S,XL,L,M,XXL']}, {'name': 'Polo Ralph Lauren Plaid Short Sleeve Button-down Oxford Shirt', 'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3207163438/Clothing/Polo-Ralph-Lauren-Plaid-Short-Sleeve-Button-down-Oxford-Shirt/?utm_source=openai&ref-site=openai_plugin', 'price': '$52.20', 'attributes': ['Material:Cotton', 'Target Group:Man', 'Color:Red,Blue,Multicolor', 'Size (Small-Large):S,XL,L,M,XXL']}, {'name': 'Brixton Bowery Flannel Shirt', 'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3202331096/Clothing/Brixton-Bowery-Flannel-Shirt/?utm_source=openai&ref-site=openai_plugin', 'price': '$27.48', 'attributes': ['Material:Cotton', 'Target Group:Man', 'Color:Gray,Blue,Black,Orange', 'Properties:Pockets', 'Pattern:Checkered', 'Size (Small-Large):XL,3XL,4XL,5XL,L,M,XXL']}, {'name': 'Vineyard Vines Gingham On-The-Go brrr Classic Fit Shirt Crystal', 'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3201938510/Clothing/Vineyard-Vines-Gingham-On-The-Go-brrr-Classic-Fit-Shirt-Crystal/?utm_source=openai&ref-site=openai_plugin', 'price': '$80.64', 'attributes': ['Material:Cotton', 'Target Group:Man', 'Color:Blue', 'Size (Small-Large):XL,XS,L,M']}, {'name': "Carhartt Men's Loose Fit Midweight Short Sleeve Plaid Shirt", 'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3201826024/Clothing/Carhartt-Men-s-Loose-Fit-Midweight-Short-Sleeve-Plaid-Shirt/?utm_source=openai&ref-site=openai_plugin', 'price': '$17.99', 'attributes': ['Material:Cotton', 'Target Group:Man', 'Color:Red,Brown,Blue,Green', 'Properties:Pockets', 'Pattern:Checkered', 'Size (Small-Large):S,XL,L,M']}]}}
```
```
https://www.klarna.com/us/shopping/public/openai/v0/api-docs/
```
```
Use the provided APIs to respond to this user query:What are some options for a men's large blue button down shirt
```
```
function_call: name: productsUsingGET arguments: |- { "params": { "countryCode": "US", "q": "men's large blue button down shirt", "size": 5, "min_price": 0, "max_price": 100 } }
```
We can also build our own interface to external APIs using the `APIChain` and provided API documentation.
```
> Entering new APIChain chain...https://api.open-meteo.com/v1/forecast?latitude=48.1351&longitude=11.5820&hourly=temperature_2m&temperature_unit=fahrenheit¤t_weather=true{"latitude":48.14,"longitude":11.58,"generationtime_ms":0.1710653305053711,"utc_offset_seconds":0,"timezone":"GMT","timezone_abbreviation":"GMT","elevation":521.0,"current_weather_units":{"time":"iso8601","interval":"seconds","temperature":"°F","windspeed":"km/h","winddirection":"°","is_day":"","weathercode":"wmo code"},"current_weather":{"time":"2023-11-01T21:30","interval":900,"temperature":46.5,"windspeed":7.7,"winddirection":259,"is_day":0,"weathercode":3},"hourly_units":{"time":"iso8601","temperature_2m":"°F"},"hourly":{"time":["2023-11-01T00:00","2023-11-01T01:00","2023-11-01T02:00","2023-11-01T03:00","2023-11-01T04:00","2023-11-01T05:00","2023-11-01T06:00","2023-11-01T07:00","2023-11-01T08:00","2023-11-01T09:00","2023-11-01T10:00","2023-11-01T11:00","2023-11-01T12:00","2023-11-01T13:00","2023-11-01T14:00","2023-11-01T15:00","2023-11-01T16:00","2023-11-01T17:00","2023-11-01T18:00","2023-11-01T19:00","2023-11-01T20:00","2023-11-01T21:00","2023-11-01T22:00","2023-11-01T23:00","2023-11-02T00:00","2023-11-02T01:00","2023-11-02T02:00","2023-11-02T03:00","2023-11-02T04:00","2023-11-02T05:00","2023-11-02T06:00","2023-11-02T07:00","2023-11-02T08:00","2023-11-02T09:00","2023-11-02T10:00","2023-11-02T11:00","2023-11-02T12:00","2023-11-02T13:00","2023-11-02T14:00","2023-11-02T15:00","2023-11-02T16:00","2023-11-02T17:00","2023-11-02T18:00","2023-11-02T19:00","2023-11-02T20:00","2023-11-02T21:00","2023-11-02T22:00","2023-11-02T23:00","2023-11-03T00:00","2023-11-03T01:00","2023-11-03T02:00","2023-11-03T03:00","2023-11-03T04:00","2023-11-03T05:00","2023-11-03T06:00","2023-11-03T07:00","2023-11-03T08:00","2023-11-03T09:00","2023-11-03T10:00","2023-11-03T11:00","2023-11-03T12:00","2023-11-03T13:00","2023-11-03T14:00","2023-11-03T15:00","2023-11-03T16:00","2023-11-03T17:00","2023-11-03T18:00","2023-11-03T19:00","2023-11-03T20:00","2023-11-03T21:00","2023-11-03T22:00","2023-11-03T23:00","2023-11-04T00:00","2023-11-04T01:00","2023-11-04T02:00","2023-11-04T03:00","2023-11-04T04:00","2023-11-04T05:00","2023-11-04T06:00","2023-11-04T07:00","2023-11-04T08:00","2023-11-04T09:00","2023-11-04T10:00","2023-11-04T11:00","2023-11-04T12:00","2023-11-04T13:00","2023-11-04T14:00","2023-11-04T15:00","2023-11-04T16:00","2023-11-04T17:00","2023-11-04T18:00","2023-11-04T19:00","2023-11-04T20:00","2023-11-04T21:00","2023-11-04T22:00","2023-11-04T23:00","2023-11-05T00:00","2023-11-05T01:00","2023-11-05T02:00","2023-11-05T03:00","2023-11-05T04:00","2023-11-05T05:00","2023-11-05T06:00","2023-11-05T07:00","2023-11-05T08:00","2023-11-05T09:00","2023-11-05T10:00","2023-11-05T11:00","2023-11-05T12:00","2023-11-05T13:00","2023-11-05T14:00","2023-11-05T15:00","2023-11-05T16:00","2023-11-05T17:00","2023-11-05T18:00","2023-11-05T19:00","2023-11-05T20:00","2023-11-05T21:00","2023-11-05T22:00","2023-11-05T23:00","2023-11-06T00:00","2023-11-06T01:00","2023-11-06T02:00","2023-11-06T03:00","2023-11-06T04:00","2023-11-06T05:00","2023-11-06T06:00","2023-11-06T07:00","2023-11-06T08:00","2023-11-06T09:00","2023-11-06T10:00","2023-11-06T11:00","2023-11-06T12:00","2023-11-06T13:00","2023-11-06T14:00","2023-11-06T15:00","2023-11-06T16:00","2023-11-06T17:00","2023-11-06T18:00","2023-11-06T19:00","2023-11-06T20:00","2023-11-06T21:00","2023-11-06T22:00","2023-11-06T23:00","2023-11-07T00:00","2023-11-07T01:00","2023-11-07T02:00","2023-11-07T03:00","2023-11-07T04:00","2023-11-07T05:00","2023-11-07T06:00","2023-11-07T07:00","2023-11-07T08:00","2023-11-07T09:00","2023-11-07T10:00","2023-11-07T11:00","2023-11-07T12:00","2023-11-07T13:00","2023-11-07T14:00","2023-11-07T15:00","2023-11-07T16:00","2023-11-07T17:00","2023-11-07T18:00","2023-11-07T19:00","2023-11-07T20:00","2023-11-07T21:00","2023-11-07T22:00","2023-11-07T23:00"],"temperature_2m":[47.9,46.9,47.1,46.6,45.8,45.2,43.4,43.5,46.8,51.5,55.0,56.3,58.1,57.9,57.0,56.6,54.4,52.1,49.1,48.3,47.7,46.9,46.2,45.8,44.4,42.4,41.7,41.7,42.0,42.7,43.6,44.3,45.9,48.0,49.1,50.7,52.2,52.6,51.9,50.3,48.1,47.4,47.1,46.9,46.2,45.7,45.6,45.6,45.7,45.3,45.1,44.2,43.6,43.2,42.8,41.6,41.0,42.1,42.4,42.3,42.7,43.9,44.2,43.6,41.9,40.4,39.0,40.8,40.2,40.1,39.6,38.8,38.2,36.9,35.8,36.4,37.3,38.5,38.9,39.0,41.8,45.4,48.7,50.8,51.7,52.1,51.3,49.8,48.6,47.8,47.0,46.3,45.9,45.6,45.7,46.1,46.3,46.4,46.3,46.3,45.8,45.4,45.5,47.1,49.3,51.2,52.4,53.1,53.5,53.4,53.0,52.4,51.6,50.5,49.6,49.0,48.6,48.1,47.6,47.0,46.4,46.0,45.5,45.1,44.4,43.7,43.9,45.6,48.1,50.3,51.7,52.8,53.5,52.7,51.5,50.2,48.8,47.4,46.2,45.5,45.0,44.6,44.3,44.2,43.9,43.4,43.0,42.6,42.3,42.0,42.2,43.0,44.3,45.5,46.8,48.1,48.9,49.0,48.7,48.1,47.4,46.5,45.7,45.1,44.5,44.3,44.5,45.1]}}> Finished chain.
```
```
' The current temperature in Munich, Germany is 46.5°F.'
```
```
'BASE URL: https://api.open-meteo.com/\n\nAPI Documentation\nThe API endpoint /v1/forecast accepts a geographical coordinate, a list of weather variables and responds with a JSON hourly weather forecast for 7 days. Time always starts at 0:00 today and contains 168 hours. All URL parameters are listed below:\n\nParameter\tFormat\tRequired\tDefault\tDescription\nlatitude, longitude\tFloating point\tYes\t\tGeographical WGS84 coordinate of the location\nhourly\tString array\tNo\t\tA list of weather variables which shou'
```
URL requests are such a common use-case that we have the `LLMRequestsChain`, which makes an HTTP GET request.
```
{'query': 'What are the Three (3) biggest countries, and their respective sizes?', 'url': 'https://www.google.com/search?q=What+are+the+Three+(3)+biggest+countries,+and+their+respective+sizes?', 'output': ' Russia (17,098,242 km²), Canada (9,984,670 km²), China (9,706,961 km²)'}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:05.311Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/apis/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/apis/",
"description": "Open In Colab",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "9139",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"apis\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:04 GMT",
"etag": "W/\"434f96911b307b25ff757808728ad079\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::g5gp7-1713753964547-90c3e782591a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/apis/",
"property": "og:url"
},
{
"content": "Interacting with APIs | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Open In Colab",
"property": "og:description"
}
],
"title": "Interacting with APIs | 🦜️🔗 LangChain"
} | Suppose you want an LLM to interact with external APIs.
This can be very useful for retrieving context for the LLM to utilize.
Many APIs are already compatible with OpenAI function calling.
For example, Klarna has a YAML file that describes its API and allows OpenAI to interact with it:
https://www.klarna.com/us/shopping/public/openai/v0/api-docs/
We can supply the specification to get_openapi_chain directly in order to query the API with OpenAI functions:
Attempting to load an OpenAPI 3.0.1 spec. This may result in degraded performance. Convert your OpenAPI spec to 3.1.* spec for better support.
{'query': "What are some options for a men's large blue button down shirt",
'response': {'products': [{'name': 'Cubavera Four Pocket Guayabera Shirt',
'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3202055522/Clothing/Cubavera-Four-Pocket-Guayabera-Shirt/?utm_source=openai&ref-site=openai_plugin',
'price': '$13.50',
'attributes': ['Material:Polyester,Cotton',
'Target Group:Man',
'Color:Red,White,Blue,Black',
'Properties:Pockets',
'Pattern:Solid Color',
'Size (Small-Large):S,XL,L,M,XXL']},
{'name': 'Polo Ralph Lauren Plaid Short Sleeve Button-down Oxford Shirt',
'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3207163438/Clothing/Polo-Ralph-Lauren-Plaid-Short-Sleeve-Button-down-Oxford-Shirt/?utm_source=openai&ref-site=openai_plugin',
'price': '$52.20',
'attributes': ['Material:Cotton',
'Target Group:Man',
'Color:Red,Blue,Multicolor',
'Size (Small-Large):S,XL,L,M,XXL']},
{'name': 'Brixton Bowery Flannel Shirt',
'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3202331096/Clothing/Brixton-Bowery-Flannel-Shirt/?utm_source=openai&ref-site=openai_plugin',
'price': '$27.48',
'attributes': ['Material:Cotton',
'Target Group:Man',
'Color:Gray,Blue,Black,Orange',
'Properties:Pockets',
'Pattern:Checkered',
'Size (Small-Large):XL,3XL,4XL,5XL,L,M,XXL']},
{'name': 'Vineyard Vines Gingham On-The-Go brrr Classic Fit Shirt Crystal',
'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3201938510/Clothing/Vineyard-Vines-Gingham-On-The-Go-brrr-Classic-Fit-Shirt-Crystal/?utm_source=openai&ref-site=openai_plugin',
'price': '$80.64',
'attributes': ['Material:Cotton',
'Target Group:Man',
'Color:Blue',
'Size (Small-Large):XL,XS,L,M']},
{'name': "Carhartt Men's Loose Fit Midweight Short Sleeve Plaid Shirt",
'url': 'https://www.klarna.com/us/shopping/pl/cl10001/3201826024/Clothing/Carhartt-Men-s-Loose-Fit-Midweight-Short-Sleeve-Plaid-Shirt/?utm_source=openai&ref-site=openai_plugin',
'price': '$17.99',
'attributes': ['Material:Cotton',
'Target Group:Man',
'Color:Red,Brown,Blue,Green',
'Properties:Pockets',
'Pattern:Checkered',
'Size (Small-Large):S,XL,L,M']}]}}
https://www.klarna.com/us/shopping/public/openai/v0/api-docs/
Use the provided APIs to respond to this user query:
What are some options for a men's large blue button down shirt
function_call:
name: productsUsingGET
arguments: |-
{
"params": {
"countryCode": "US",
"q": "men's large blue button down shirt",
"size": 5,
"min_price": 0,
"max_price": 100
}
}
We can also build our own interface to external APIs using the APIChain and provided API documentation.
> Entering new APIChain chain...
https://api.open-meteo.com/v1/forecast?latitude=48.1351&longitude=11.5820&hourly=temperature_2m&temperature_unit=fahrenheit¤t_weather=true
{"latitude":48.14,"longitude":11.58,"generationtime_ms":0.1710653305053711,"utc_offset_seconds":0,"timezone":"GMT","timezone_abbreviation":"GMT","elevation":521.0,"current_weather_units":{"time":"iso8601","interval":"seconds","temperature":"°F","windspeed":"km/h","winddirection":"°","is_day":"","weathercode":"wmo code"},"current_weather":{"time":"2023-11-01T21:30","interval":900,"temperature":46.5,"windspeed":7.7,"winddirection":259,"is_day":0,"weathercode":3},"hourly_units":{"time":"iso8601","temperature_2m":"°F"},"hourly":{"time":["2023-11-01T00:00","2023-11-01T01:00","2023-11-01T02:00","2023-11-01T03:00","2023-11-01T04:00","2023-11-01T05:00","2023-11-01T06:00","2023-11-01T07:00","2023-11-01T08:00","2023-11-01T09:00","2023-11-01T10:00","2023-11-01T11:00","2023-11-01T12:00","2023-11-01T13:00","2023-11-01T14:00","2023-11-01T15:00","2023-11-01T16:00","2023-11-01T17:00","2023-11-01T18:00","2023-11-01T19:00","2023-11-01T20:00","2023-11-01T21:00","2023-11-01T22:00","2023-11-01T23:00","2023-11-02T00:00","2023-11-02T01:00","2023-11-02T02:00","2023-11-02T03:00","2023-11-02T04:00","2023-11-02T05:00","2023-11-02T06:00","2023-11-02T07:00","2023-11-02T08:00","2023-11-02T09:00","2023-11-02T10:00","2023-11-02T11:00","2023-11-02T12:00","2023-11-02T13:00","2023-11-02T14:00","2023-11-02T15:00","2023-11-02T16:00","2023-11-02T17:00","2023-11-02T18:00","2023-11-02T19:00","2023-11-02T20:00","2023-11-02T21:00","2023-11-02T22:00","2023-11-02T23:00","2023-11-03T00:00","2023-11-03T01:00","2023-11-03T02:00","2023-11-03T03:00","2023-11-03T04:00","2023-11-03T05:00","2023-11-03T06:00","2023-11-03T07:00","2023-11-03T08:00","2023-11-03T09:00","2023-11-03T10:00","2023-11-03T11:00","2023-11-03T12:00","2023-11-03T13:00","2023-11-03T14:00","2023-11-03T15:00","2023-11-03T16:00","2023-11-03T17:00","2023-11-03T18:00","2023-11-03T19:00","2023-11-03T20:00","2023-11-03T21:00","2023-11-03T22:00","2023-11-03T23:00","2023-11-04T00:00","2023-11-04T01:00","2023-11-04T02:00","2023-11-04T03:00","2023-11-04T04:00","2023-11-04T05:00","2023-11-04T06:00","2023-11-04T07:00","2023-11-04T08:00","2023-11-04T09:00","2023-11-04T10:00","2023-11-04T11:00","2023-11-04T12:00","2023-11-04T13:00","2023-11-04T14:00","2023-11-04T15:00","2023-11-04T16:00","2023-11-04T17:00","2023-11-04T18:00","2023-11-04T19:00","2023-11-04T20:00","2023-11-04T21:00","2023-11-04T22:00","2023-11-04T23:00","2023-11-05T00:00","2023-11-05T01:00","2023-11-05T02:00","2023-11-05T03:00","2023-11-05T04:00","2023-11-05T05:00","2023-11-05T06:00","2023-11-05T07:00","2023-11-05T08:00","2023-11-05T09:00","2023-11-05T10:00","2023-11-05T11:00","2023-11-05T12:00","2023-11-05T13:00","2023-11-05T14:00","2023-11-05T15:00","2023-11-05T16:00","2023-11-05T17:00","2023-11-05T18:00","2023-11-05T19:00","2023-11-05T20:00","2023-11-05T21:00","2023-11-05T22:00","2023-11-05T23:00","2023-11-06T00:00","2023-11-06T01:00","2023-11-06T02:00","2023-11-06T03:00","2023-11-06T04:00","2023-11-06T05:00","2023-11-06T06:00","2023-11-06T07:00","2023-11-06T08:00","2023-11-06T09:00","2023-11-06T10:00","2023-11-06T11:00","2023-11-06T12:00","2023-11-06T13:00","2023-11-06T14:00","2023-11-06T15:00","2023-11-06T16:00","2023-11-06T17:00","2023-11-06T18:00","2023-11-06T19:00","2023-11-06T20:00","2023-11-06T21:00","2023-11-06T22:00","2023-11-06T23:00","2023-11-07T00:00","2023-11-07T01:00","2023-11-07T02:00","2023-11-07T03:00","2023-11-07T04:00","2023-11-07T05:00","2023-11-07T06:00","2023-11-07T07:00","2023-11-07T08:00","2023-11-07T09:00","2023-11-07T10:00","2023-11-07T11:00","2023-11-07T12:00","2023-11-07T13:00","2023-11-07T14:00","2023-11-07T15:00","2023-11-07T16:00","2023-11-07T17:00","2023-11-07T18:00","2023-11-07T19:00","2023-11-07T20:00","2023-11-07T21:00","2023-11-07T22:00","2023-11-07T23:00"],"temperature_2m":[47.9,46.9,47.1,46.6,45.8,45.2,43.4,43.5,46.8,51.5,55.0,56.3,58.1,57.9,57.0,56.6,54.4,52.1,49.1,48.3,47.7,46.9,46.2,45.8,44.4,42.4,41.7,41.7,42.0,42.7,43.6,44.3,45.9,48.0,49.1,50.7,52.2,52.6,51.9,50.3,48.1,47.4,47.1,46.9,46.2,45.7,45.6,45.6,45.7,45.3,45.1,44.2,43.6,43.2,42.8,41.6,41.0,42.1,42.4,42.3,42.7,43.9,44.2,43.6,41.9,40.4,39.0,40.8,40.2,40.1,39.6,38.8,38.2,36.9,35.8,36.4,37.3,38.5,38.9,39.0,41.8,45.4,48.7,50.8,51.7,52.1,51.3,49.8,48.6,47.8,47.0,46.3,45.9,45.6,45.7,46.1,46.3,46.4,46.3,46.3,45.8,45.4,45.5,47.1,49.3,51.2,52.4,53.1,53.5,53.4,53.0,52.4,51.6,50.5,49.6,49.0,48.6,48.1,47.6,47.0,46.4,46.0,45.5,45.1,44.4,43.7,43.9,45.6,48.1,50.3,51.7,52.8,53.5,52.7,51.5,50.2,48.8,47.4,46.2,45.5,45.0,44.6,44.3,44.2,43.9,43.4,43.0,42.6,42.3,42.0,42.2,43.0,44.3,45.5,46.8,48.1,48.9,49.0,48.7,48.1,47.4,46.5,45.7,45.1,44.5,44.3,44.5,45.1]}}
> Finished chain.
' The current temperature in Munich, Germany is 46.5°F.'
'BASE URL: https://api.open-meteo.com/\n\nAPI Documentation\nThe API endpoint /v1/forecast accepts a geographical coordinate, a list of weather variables and responds with a JSON hourly weather forecast for 7 days. Time always starts at 0:00 today and contains 168 hours. All URL parameters are listed below:\n\nParameter\tFormat\tRequired\tDefault\tDescription\nlatitude, longitude\tFloating point\tYes\t\tGeographical WGS84 coordinate of the location\nhourly\tString array\tNo\t\tA list of weather variables which shou'
URL requests are such a common use-case that we have the LLMRequestsChain, which makes an HTTP GET request.
{'query': 'What are the Three (3) biggest countries, and their respective sizes?',
'url': 'https://www.google.com/search?q=What+are+the+Three+(3)+biggest+countries,+and+their+respective+sizes?',
'output': ' Russia (17,098,242 km²), Canada (9,984,670 km²), China (9,706,961 km²)'} |
https://python.langchain.com/docs/use_cases/ | ## Use cases
This section contains walkthroughs and techniques for common end-to-end use tasks.
If you're looking to build something specific or are more of a hands-on learner, try one out! While they reference building blocks that are explained in greater detail in other sections, we absolutely encourage folks to get started by going through them and picking apart the code in a real-world context.
Or, if you prefer to look at the fundamentals first, you can check out the sections on [Expression Language](https://python.langchain.com/docs/expression_language/get_started/) and the various [components](https://python.langchain.com/docs/modules/) LangChain provides for more background knowledge.
[
## 🗃️ Q&A with RAG
6 items
](https://python.langchain.com/docs/use_cases/question_answering/)
[
## 🗃️ Extracting structured output
4 items
](https://python.langchain.com/docs/use_cases/extraction/)
[
## 🗃️ Chatbots
5 items
](https://python.langchain.com/docs/use_cases/chatbots/)
[
## 🗃️ Tool use and agents
8 items
](https://python.langchain.com/docs/use_cases/tool_use/)
[
## 🗃️ Query analysis
4 items
](https://python.langchain.com/docs/use_cases/query_analysis/)
[
## 🗃️ Q&A over SQL + CSV
7 items
](https://python.langchain.com/docs/use_cases/sql/)
[
## 🗃️ More
6 items
](https://python.langchain.com/docs/use_cases/graph/) | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:05.556Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/",
"description": "This section contains walkthroughs and techniques for common end-to-end use tasks.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4993",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"use_cases\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:05 GMT",
"etag": "W/\"5d489e61805c771410b3134067804ab5\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::ffxhk-1713753965144-88d0b6f09b3e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/",
"property": "og:url"
},
{
"content": "Use cases | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This section contains walkthroughs and techniques for common end-to-end use tasks.",
"property": "og:description"
}
],
"title": "Use cases | 🦜️🔗 LangChain"
} | Use cases
This section contains walkthroughs and techniques for common end-to-end use tasks.
If you're looking to build something specific or are more of a hands-on learner, try one out! While they reference building blocks that are explained in greater detail in other sections, we absolutely encourage folks to get started by going through them and picking apart the code in a real-world context.
Or, if you prefer to look at the fundamentals first, you can check out the sections on Expression Language and the various components LangChain provides for more background knowledge.
🗃️ Q&A with RAG
6 items
🗃️ Extracting structured output
4 items
🗃️ Chatbots
5 items
🗃️ Tool use and agents
8 items
🗃️ Query analysis
4 items
🗃️ Q&A over SQL + CSV
7 items
🗃️ More
6 items |
https://python.langchain.com/docs/templates/sql-research-assistant/ | ## sql-research-assistant
This package does research over a SQL database
## Usage[](#usage "Direct link to Usage")
This package relies on multiple models, which have the following dependencies:
* OpenAI: set the `OPENAI_API_KEY` environment variables
* Ollama: [install and run Ollama](https://python.langchain.com/docs/integrations/chat/ollama)
* llama2 (on Ollama): `ollama pull llama2` (otherwise you will get 404 errors from Ollama)
To use this package, you should first have the LangChain CLI installed:
```
pip install -U langchain-cli
```
To create a new LangChain project and install this as the only package, you can do:
```
langchain app new my-app --package sql-research-assistant
```
If you want to add this to an existing project, you can just run:
```
langchain app add sql-research-assistant
```
And add the following code to your `server.py` file:
```
from sql_research_assistant import chain as sql_research_assistant_chainadd_routes(app, sql_research_assistant_chain, path="/sql-research-assistant")
```
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/). If you don't have access, you can skip this section
```
export LANGCHAIN_TRACING_V2=trueexport LANGCHAIN_API_KEY=<your-api-key>export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
```
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at [http://localhost:8000](http://localhost:8000/)
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs) We can access the playground at [http://127.0.0.1:8000/sql-research-assistant/playground](http://127.0.0.1:8000/sql-research-assistant/playground)
We can access the template from code with:
```
from langserve.client import RemoteRunnablerunnable = RemoteRunnable("http://localhost:8000/sql-research-assistant")
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:05.695Z",
"loadedUrl": "https://python.langchain.com/docs/templates/sql-research-assistant/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/templates/sql-research-assistant/",
"description": "This package does research over a SQL database",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4933",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sql-research-assistant\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:05 GMT",
"etag": "W/\"72760f2d2cedca3ad7ed3f0913d2c0f0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::4hr64-1713753965332-19adc06de4f9"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/templates/sql-research-assistant/",
"property": "og:url"
},
{
"content": "sql-research-assistant | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This package does research over a SQL database",
"property": "og:description"
}
],
"title": "sql-research-assistant | 🦜️🔗 LangChain"
} | sql-research-assistant
This package does research over a SQL database
Usage
This package relies on multiple models, which have the following dependencies:
OpenAI: set the OPENAI_API_KEY environment variables
Ollama: install and run Ollama
llama2 (on Ollama): ollama pull llama2 (otherwise you will get 404 errors from Ollama)
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package sql-research-assistant
If you want to add this to an existing project, you can just run:
langchain app add sql-research-assistant
And add the following code to your server.py file:
from sql_research_assistant import chain as sql_research_assistant_chain
add_routes(app, sql_research_assistant_chain, path="/sql-research-assistant")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/sql-research-assistant/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/sql-research-assistant")
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/use_cases/chatbots/ | ## Chatbots
## Overview[](#overview "Direct link to Overview")
Chatbots are one of the most popular use-cases for LLMs. The core features of chatbots are that they can have long-running, stateful conversations and can answer user questions using relevant information.
## Architectures[](#architectures "Direct link to Architectures")
Designing a chatbot involves considering various techniques with different benefits and tradeoffs depending on what sorts of questions you expect it to handle.
For example, chatbots commonly use [retrieval-augmented generation](https://python.langchain.com/docs/use_cases/question_answering/), or RAG, over private data to better answer domain-specific questions. You also might choose to route between multiple data sources to ensure it only uses the most topical context for final question answering, or choose to use a more specialized type of chat history or memory than just passing messages back and forth.
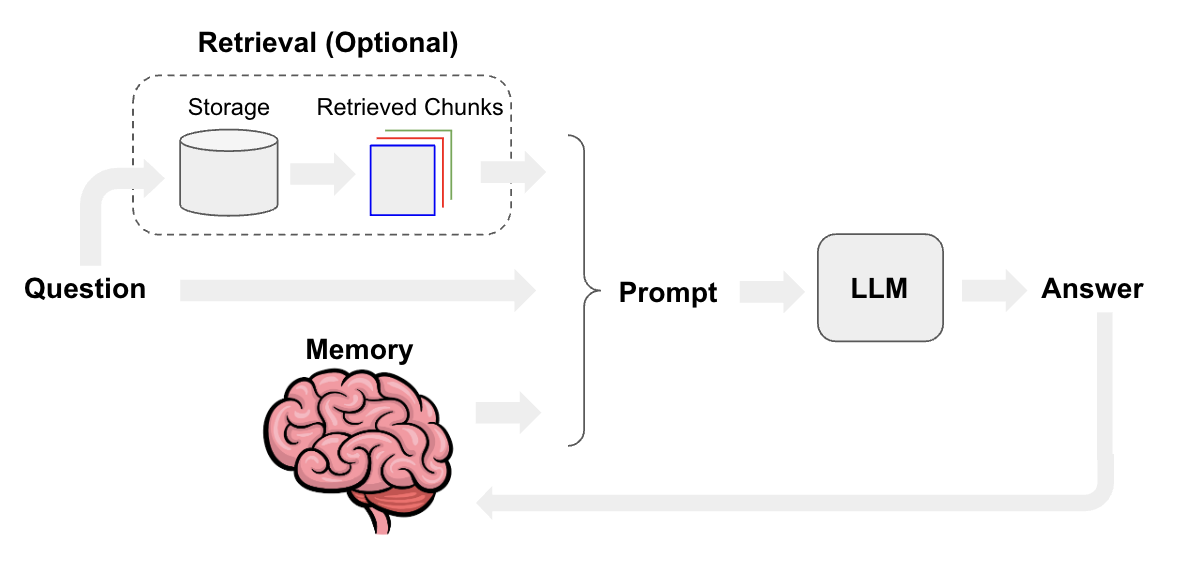
Optimizations like this can make your chatbot more powerful, but add latency and complexity. The aim of this guide is to give you an overview of how to implement various features and help you tailor your chatbot to your particular use-case.
## Table of contents[](#table-of-contents "Direct link to Table of contents")
* [Quickstart](https://python.langchain.com/docs/use_cases/chatbots/quickstart/): We recommend starting here. Many of the following guides assume you fully understand the architecture shown in the Quickstart.
* [Memory management](https://python.langchain.com/docs/use_cases/chatbots/memory_management/): This section covers various strategies your chatbot can use to handle information from previous conversation turns.
* [Retrieval](https://python.langchain.com/docs/use_cases/chatbots/retrieval/): This section covers how to enable your chatbot to use outside data sources as context.
* [Tool usage](https://python.langchain.com/docs/use_cases/chatbots/tool_usage/): This section covers how to turn your chatbot into a conversational agent by adding the ability to interact with other systems and APIs using tools. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:05.811Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/chatbots/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/chatbots/",
"description": "Overview",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8060",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"chatbots\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:05 GMT",
"etag": "W/\"88db43c47af172d1a35a836949f77f03\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::xvkrm-1713753965660-851c6c8d3710"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/chatbots/",
"property": "og:url"
},
{
"content": "Chatbots | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Overview",
"property": "og:description"
}
],
"title": "Chatbots | 🦜️🔗 LangChain"
} | Chatbots
Overview
Chatbots are one of the most popular use-cases for LLMs. The core features of chatbots are that they can have long-running, stateful conversations and can answer user questions using relevant information.
Architectures
Designing a chatbot involves considering various techniques with different benefits and tradeoffs depending on what sorts of questions you expect it to handle.
For example, chatbots commonly use retrieval-augmented generation, or RAG, over private data to better answer domain-specific questions. You also might choose to route between multiple data sources to ensure it only uses the most topical context for final question answering, or choose to use a more specialized type of chat history or memory than just passing messages back and forth.
Optimizations like this can make your chatbot more powerful, but add latency and complexity. The aim of this guide is to give you an overview of how to implement various features and help you tailor your chatbot to your particular use-case.
Table of contents
Quickstart: We recommend starting here. Many of the following guides assume you fully understand the architecture shown in the Quickstart.
Memory management: This section covers various strategies your chatbot can use to handle information from previous conversation turns.
Retrieval: This section covers how to enable your chatbot to use outside data sources as context.
Tool usage: This section covers how to turn your chatbot into a conversational agent by adding the ability to interact with other systems and APIs using tools. |
https://python.langchain.com/docs/use_cases/chatbots/retrieval/ | ## Retrieval
Retrieval is a common technique chatbots use to augment their responses with data outside a chat model’s training data. This section will cover how to implement retrieval in the context of chatbots, but it’s worth noting that retrieval is a very subtle and deep topic - we encourage you to explore [other parts of the documentation](https://python.langchain.com/docs/use_cases/question_answering/) that go into greater depth!
## Setup[](#setup "Direct link to Setup")
You’ll need to install a few packages, and have your OpenAI API key set as an environment variable named `OPENAI_API_KEY`:
```
%pip install --upgrade --quiet langchain langchain-openai langchain-chroma beautifulsoup4# Set env var OPENAI_API_KEY or load from a .env file:import dotenvdotenv.load_dotenv()
```
```
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.Note: you may need to restart the kernel to use updated packages.
```
Let’s also set up a chat model that we’ll use for the below examples.
```
from langchain_openai import ChatOpenAIchat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)
```
## Creating a retriever[](#creating-a-retriever "Direct link to Creating a retriever")
We’ll use [the LangSmith documentation](https://docs.smith.langchain.com/overview) as source material and store the content in a vectorstore for later retrieval. Note that this example will gloss over some of the specifics around parsing and storing a data source - you can see more [in-depth documentation on creating retrieval systems here](https://python.langchain.com/docs/use_cases/question_answering/).
Let’s use a document loader to pull text from the docs:
```
from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://docs.smith.langchain.com/overview")data = loader.load()
```
Next, we split it into smaller chunks that the LLM’s context window can handle and store it in a vector database:
```
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)all_splits = text_splitter.split_documents(data)
```
Then we embed and store those chunks in a vector database:
```
from langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingsvectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
```
And finally, let’s create a retriever from our initialized vectorstore:
```
# k is the number of chunks to retrieveretriever = vectorstore.as_retriever(k=4)docs = retriever.invoke("Can LangSmith help test my LLM applications?")docs
```
```
[Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content="does that affect the output?\u200bSo you notice a bad output, and you go into LangSmith to see what's going on. You find the faulty LLM call and are now looking at the exact input. You want to try changing a word or a phrase to see what happens -- what do you do?We constantly ran into this issue. Initially, we copied the prompt to a playground of sorts. But this got annoying, so we built a playground of our own! When examining an LLM call, you can click the Open in Playground button to access this", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
```
We can see that invoking the retriever above results in some parts of the LangSmith docs that contain information about testing that our chatbot can use as context when answering questions. And now we’ve got a retriever that can return related data from the LangSmith docs!
## Document chains[](#document-chains "Direct link to Document chains")
Now that we have a retriever that can return LangChain docs, let’s create a chain that can use them as context to answer questions. We’ll use a `create_stuff_documents_chain` helper function to “stuff” all of the input documents into the prompt. It will also handle formatting the docs as strings.
In addition to a chat model, the function also expects a prompt that has a `context` variables, as well as a placeholder for chat history messages named `messages`. We’ll create an appropriate prompt and pass it as shown below:
```
from langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderSYSTEM_TEMPLATE = """Answer the user's questions based on the below context. If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know":<context>{context}</context>"""question_answering_prompt = ChatPromptTemplate.from_messages( [ ( "system", SYSTEM_TEMPLATE, ), MessagesPlaceholder(variable_name="messages"), ])document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
```
We can invoke this `document_chain` by itself to answer questions. Let’s use the docs we retrieved above and the same question, `how can langsmith help with testing?`:
```
from langchain_core.messages import HumanMessagedocument_chain.invoke( { "context": docs, "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?") ], })
```
```
'Yes, LangSmith can help test and evaluate your LLM applications. It simplifies the initial setup, and you can use it to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'
```
Looks good! For comparison, we can try it with no context docs and compare the result:
```
document_chain.invoke( { "context": [], "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?") ], })
```
```
"I don't know about LangSmith's specific capabilities for testing LLM applications. It's best to reach out to LangSmith directly to inquire about their services and how they can assist with testing your LLM applications."
```
We can see that the LLM does not return any results.
## Retrieval chains[](#retrieval-chains "Direct link to Retrieval chains")
Let’s combine this document chain with the retriever. Here’s one way this can look:
```
from typing import Dictfrom langchain_core.runnables import RunnablePassthroughdef parse_retriever_input(params: Dict): return params["messages"][-1].contentretrieval_chain = RunnablePassthrough.assign( context=parse_retriever_input | retriever,).assign( answer=document_chain,)
```
Given a list of input messages, we extract the content of the last message in the list and pass that to the retriever to fetch some documents. Then, we pass those documents as context to our document chain to generate a final response.
Invoking this chain combines both steps outlined above:
```
retrieval_chain.invoke( { "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?") ], })
```
```
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?')], 'context': [Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content="does that affect the output?\u200bSo you notice a bad output, and you go into LangSmith to see what's going on. You find the faulty LLM call and are now looking at the exact input. You want to try changing a word or a phrase to see what happens -- what do you do?We constantly ran into this issue. Initially, we copied the prompt to a playground of sorts. But this got annoying, so we built a playground of our own! When examining an LLM call, you can click the Open in Playground button to access this", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'Yes, LangSmith can help test and evaluate your LLM applications. It simplifies the initial setup, and you can use it to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'}
```
Looks good!
## Query transformation[](#query-transformation "Direct link to Query transformation")
Our retrieval chain is capable of answering questions about LangSmith, but there’s a problem - chatbots interact with users conversationally, and therefore have to deal with followup questions.
The chain in its current form will struggle with this. Consider a followup question to our original question like `Tell me more!`. If we invoke our retriever with that query directly, we get documents irrelevant to LLM application testing:
```
retriever.invoke("Tell me more!")
```
```
[Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='playground. Here, you can modify the prompt and re-run it to observe the resulting changes to the output - as many times as needed!Currently, this feature supports only OpenAI and Anthropic models and works for LLM and Chat Model calls. We plan to extend its functionality to more LLM types, chains, agents, and retrievers in the future.What is the exact sequence of events?\u200bIn complicated chains and agents, it can often be hard to understand what is going on under the hood. What calls are being', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='however, there is still no complete substitute for human review to get the utmost quality and reliability from your application.', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
```
This is because the retriever has no innate concept of state, and will only pull documents most similar to the query given. To solve this, we can transform the query into a standalone query without any external references an LLM.
Here’s an example:
```
from langchain_core.messages import AIMessage, HumanMessagequery_transform_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="messages"), ( "user", "Given the above conversation, generate a search query to look up in order to get information relevant to the conversation. Only respond with the query, nothing else.", ), ])query_transformation_chain = query_transform_prompt | chatquery_transformation_chain.invoke( { "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage( content="Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise." ), HumanMessage(content="Tell me more!"), ], })
```
```
AIMessage(content='"LangSmith LLM application testing and evaluation"')
```
Awesome! That transformed query would pull up context documents related to LLM application testing.
Let’s add this to our retrieval chain. We can wrap our retriever as follows:
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnableBranchquery_transforming_retriever_chain = RunnableBranch( ( lambda x: len(x.get("messages", [])) == 1, # If only one message, then we just pass that message's content to retriever (lambda x: x["messages"][-1].content) | retriever, ), # If messages, then we pass inputs to LLM chain to transform the query, then pass to retriever query_transform_prompt | chat | StrOutputParser() | retriever,).with_config(run_name="chat_retriever_chain")
```
Then, we can use this query transformation chain to make our retrieval chain better able to handle such followup questions:
```
SYSTEM_TEMPLATE = """Answer the user's questions based on the below context. If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know":<context>{context}</context>"""question_answering_prompt = ChatPromptTemplate.from_messages( [ ( "system", SYSTEM_TEMPLATE, ), MessagesPlaceholder(variable_name="messages"), ])document_chain = create_stuff_documents_chain(chat, question_answering_prompt)conversational_retrieval_chain = RunnablePassthrough.assign( context=query_transforming_retriever_chain,).assign( answer=document_chain,)
```
Awesome! Let’s invoke this new chain with the same inputs as earlier:
```
conversational_retrieval_chain.invoke( { "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?"), ] })
```
```
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?')], 'context': [Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content="does that affect the output?\u200bSo you notice a bad output, and you go into LangSmith to see what's going on. You find the faulty LLM call and are now looking at the exact input. You want to try changing a word or a phrase to see what happens -- what do you do?We constantly ran into this issue. Initially, we copied the prompt to a playground of sorts. But this got annoying, so we built a playground of our own! When examining an LLM call, you can click the Open in Playground button to access this", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'Yes, LangSmith can help test and evaluate LLM (Language Model) applications. It simplifies the initial setup, and you can use it to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'}
```
```
conversational_retrieval_chain.invoke( { "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage( content="Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise." ), HumanMessage(content="Tell me more!"), ], })
```
```
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?'), AIMessage(content='Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'), HumanMessage(content='Tell me more!')], 'context': [Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith makes it easy to manually review and annotate runs through annotation queues.These queues allow you to select any runs based on criteria like model type or automatic evaluation scores, and queue them up for human review. As a reviewer, you can then quickly step through the runs, viewing the input, output, and any existing tags before adding your own feedback.We often use this for a couple of reasons:To assess subjective qualities that automatic evaluators struggle with, like', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'LangSmith simplifies the initial setup for building reliable LLM applications, but it acknowledges that there is still work needed to bring the performance of prompts, chains, and agents up to the level where they are reliable enough to be used in production. It also provides the capability to manually review and annotate runs through annotation queues, allowing you to select runs based on criteria like model type or automatic evaluation scores for human review. This feature is particularly useful for assessing subjective qualities that automatic evaluators struggle with.'}
```
You can check out [this LangSmith trace](https://smith.langchain.com/public/bb329a3b-e92a-4063-ad78-43f720fbb5a2/r) to see the internal query transformation step for yourself.
## Streaming[](#streaming "Direct link to Streaming")
Because this chain is constructed with LCEL, you can use familiar methods like `.stream()` with it:
```
stream = conversational_retrieval_chain.stream( { "messages": [ HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage( content="Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise." ), HumanMessage(content="Tell me more!"), ], })for chunk in stream: print(chunk)
```
```
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?'), AIMessage(content='Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'), HumanMessage(content='Tell me more!')]}{'context': [Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith makes it easy to manually review and annotate runs through annotation queues.These queues allow you to select any runs based on criteria like model type or automatic evaluation scores, and queue them up for human review. As a reviewer, you can then quickly step through the runs, viewing the input, output, and any existing tags before adding your own feedback.We often use this for a couple of reasons:To assess subjective qualities that automatic evaluators struggle with, like', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]}{'answer': ''}{'answer': 'Lang'}{'answer': 'Smith'}{'answer': ' simpl'}{'answer': 'ifies'}{'answer': ' the'}{'answer': ' initial'}{'answer': ' setup'}{'answer': ' for'}{'answer': ' building'}{'answer': ' reliable'}{'answer': ' L'}{'answer': 'LM'}{'answer': ' applications'}{'answer': '.'}{'answer': ' It'}{'answer': ' provides'}{'answer': ' features'}{'answer': ' for'}{'answer': ' manually'}{'answer': ' reviewing'}{'answer': ' and'}{'answer': ' annot'}{'answer': 'ating'}{'answer': ' runs'}{'answer': ' through'}{'answer': ' annotation'}{'answer': ' queues'}{'answer': ','}{'answer': ' allowing'}{'answer': ' you'}{'answer': ' to'}{'answer': ' select'}{'answer': ' runs'}{'answer': ' based'}{'answer': ' on'}{'answer': ' criteria'}{'answer': ' like'}{'answer': ' model'}{'answer': ' type'}{'answer': ' or'}{'answer': ' automatic'}{'answer': ' evaluation'}{'answer': ' scores'}{'answer': ','}{'answer': ' and'}{'answer': ' queue'}{'answer': ' them'}{'answer': ' up'}{'answer': ' for'}{'answer': ' human'}{'answer': ' review'}{'answer': '.'}{'answer': ' As'}{'answer': ' a'}{'answer': ' reviewer'}{'answer': ','}{'answer': ' you'}{'answer': ' can'}{'answer': ' quickly'}{'answer': ' step'}{'answer': ' through'}{'answer': ' the'}{'answer': ' runs'}{'answer': ','}{'answer': ' view'}{'answer': ' the'}{'answer': ' input'}{'answer': ','}{'answer': ' output'}{'answer': ','}{'answer': ' and'}{'answer': ' any'}{'answer': ' existing'}{'answer': ' tags'}{'answer': ' before'}{'answer': ' adding'}{'answer': ' your'}{'answer': ' own'}{'answer': ' feedback'}{'answer': '.'}{'answer': ' This'}{'answer': ' can'}{'answer': ' be'}{'answer': ' particularly'}{'answer': ' useful'}{'answer': ' for'}{'answer': ' assessing'}{'answer': ' subjective'}{'answer': ' qualities'}{'answer': ' that'}{'answer': ' automatic'}{'answer': ' evalu'}{'answer': 'ators'}{'answer': ' struggle'}{'answer': ' with'}{'answer': '.'}{'answer': ''}
```
## Further reading[](#further-reading "Direct link to Further reading")
This guide only scratches the surface of retrieval techniques. For more on different ways of ingesting, preparing, and retrieving the most relevant data, check out [this section](https://python.langchain.com/docs/modules/data_connection/) of the docs. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:06.033Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/chatbots/retrieval/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/chatbots/retrieval/",
"description": "Retrieval is a common technique chatbots use to augment their responses",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7901",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"retrieval\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:05 GMT",
"etag": "W/\"86b94fc0be298ee00fe4672979463da2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::pn8nk-1713753965964-c3bd55e16f4c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/chatbots/retrieval/",
"property": "og:url"
},
{
"content": "Retrieval | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Retrieval is a common technique chatbots use to augment their responses",
"property": "og:description"
}
],
"title": "Retrieval | 🦜️🔗 LangChain"
} | Retrieval
Retrieval is a common technique chatbots use to augment their responses with data outside a chat model’s training data. This section will cover how to implement retrieval in the context of chatbots, but it’s worth noting that retrieval is a very subtle and deep topic - we encourage you to explore other parts of the documentation that go into greater depth!
Setup
You’ll need to install a few packages, and have your OpenAI API key set as an environment variable named OPENAI_API_KEY:
%pip install --upgrade --quiet langchain langchain-openai langchain-chroma beautifulsoup4
# Set env var OPENAI_API_KEY or load from a .env file:
import dotenv
dotenv.load_dotenv()
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.
You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.
Note: you may need to restart the kernel to use updated packages.
Let’s also set up a chat model that we’ll use for the below examples.
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)
Creating a retriever
We’ll use the LangSmith documentation as source material and store the content in a vectorstore for later retrieval. Note that this example will gloss over some of the specifics around parsing and storing a data source - you can see more in-depth documentation on creating retrieval systems here.
Let’s use a document loader to pull text from the docs:
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
data = loader.load()
Next, we split it into smaller chunks that the LLM’s context window can handle and store it in a vector database:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
Then we embed and store those chunks in a vector database:
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
And finally, let’s create a retriever from our initialized vectorstore:
# k is the number of chunks to retrieve
retriever = vectorstore.as_retriever(k=4)
docs = retriever.invoke("Can LangSmith help test my LLM applications?")
docs
[Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content="does that affect the output?\u200bSo you notice a bad output, and you go into LangSmith to see what's going on. You find the faulty LLM call and are now looking at the exact input. You want to try changing a word or a phrase to see what happens -- what do you do?We constantly ran into this issue. Initially, we copied the prompt to a playground of sorts. But this got annoying, so we built a playground of our own! When examining an LLM call, you can click the Open in Playground button to access this", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
We can see that invoking the retriever above results in some parts of the LangSmith docs that contain information about testing that our chatbot can use as context when answering questions. And now we’ve got a retriever that can return related data from the LangSmith docs!
Document chains
Now that we have a retriever that can return LangChain docs, let’s create a chain that can use them as context to answer questions. We’ll use a create_stuff_documents_chain helper function to “stuff” all of the input documents into the prompt. It will also handle formatting the docs as strings.
In addition to a chat model, the function also expects a prompt that has a context variables, as well as a placeholder for chat history messages named messages. We’ll create an appropriate prompt and pass it as shown below:
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
SYSTEM_TEMPLATE = """
Answer the user's questions based on the below context.
If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know":
<context>
{context}
</context>
"""
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
SYSTEM_TEMPLATE,
),
MessagesPlaceholder(variable_name="messages"),
]
)
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
We can invoke this document_chain by itself to answer questions. Let’s use the docs we retrieved above and the same question, how can langsmith help with testing?:
from langchain_core.messages import HumanMessage
document_chain.invoke(
{
"context": docs,
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?")
],
}
)
'Yes, LangSmith can help test and evaluate your LLM applications. It simplifies the initial setup, and you can use it to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'
Looks good! For comparison, we can try it with no context docs and compare the result:
document_chain.invoke(
{
"context": [],
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?")
],
}
)
"I don't know about LangSmith's specific capabilities for testing LLM applications. It's best to reach out to LangSmith directly to inquire about their services and how they can assist with testing your LLM applications."
We can see that the LLM does not return any results.
Retrieval chains
Let’s combine this document chain with the retriever. Here’s one way this can look:
from typing import Dict
from langchain_core.runnables import RunnablePassthrough
def parse_retriever_input(params: Dict):
return params["messages"][-1].content
retrieval_chain = RunnablePassthrough.assign(
context=parse_retriever_input | retriever,
).assign(
answer=document_chain,
)
Given a list of input messages, we extract the content of the last message in the list and pass that to the retriever to fetch some documents. Then, we pass those documents as context to our document chain to generate a final response.
Invoking this chain combines both steps outlined above:
retrieval_chain.invoke(
{
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?")
],
}
)
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?')],
'context': [Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content="does that affect the output?\u200bSo you notice a bad output, and you go into LangSmith to see what's going on. You find the faulty LLM call and are now looking at the exact input. You want to try changing a word or a phrase to see what happens -- what do you do?We constantly ran into this issue. Initially, we copied the prompt to a playground of sorts. But this got annoying, so we built a playground of our own! When examining an LLM call, you can click the Open in Playground button to access this", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'Yes, LangSmith can help test and evaluate your LLM applications. It simplifies the initial setup, and you can use it to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'}
Looks good!
Query transformation
Our retrieval chain is capable of answering questions about LangSmith, but there’s a problem - chatbots interact with users conversationally, and therefore have to deal with followup questions.
The chain in its current form will struggle with this. Consider a followup question to our original question like Tell me more!. If we invoke our retriever with that query directly, we get documents irrelevant to LLM application testing:
retriever.invoke("Tell me more!")
[Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='playground. Here, you can modify the prompt and re-run it to observe the resulting changes to the output - as many times as needed!Currently, this feature supports only OpenAI and Anthropic models and works for LLM and Chat Model calls. We plan to extend its functionality to more LLM types, chains, agents, and retrievers in the future.What is the exact sequence of events?\u200bIn complicated chains and agents, it can often be hard to understand what is going on under the hood. What calls are being', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='however, there is still no complete substitute for human review to get the utmost quality and reliability from your application.', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
This is because the retriever has no innate concept of state, and will only pull documents most similar to the query given. To solve this, we can transform the query into a standalone query without any external references an LLM.
Here’s an example:
from langchain_core.messages import AIMessage, HumanMessage
query_transform_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="messages"),
(
"user",
"Given the above conversation, generate a search query to look up in order to get information relevant to the conversation. Only respond with the query, nothing else.",
),
]
)
query_transformation_chain = query_transform_prompt | chat
query_transformation_chain.invoke(
{
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?"),
AIMessage(
content="Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise."
),
HumanMessage(content="Tell me more!"),
],
}
)
AIMessage(content='"LangSmith LLM application testing and evaluation"')
Awesome! That transformed query would pull up context documents related to LLM application testing.
Let’s add this to our retrieval chain. We can wrap our retriever as follows:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableBranch
query_transforming_retriever_chain = RunnableBranch(
(
lambda x: len(x.get("messages", [])) == 1,
# If only one message, then we just pass that message's content to retriever
(lambda x: x["messages"][-1].content) | retriever,
),
# If messages, then we pass inputs to LLM chain to transform the query, then pass to retriever
query_transform_prompt | chat | StrOutputParser() | retriever,
).with_config(run_name="chat_retriever_chain")
Then, we can use this query transformation chain to make our retrieval chain better able to handle such followup questions:
SYSTEM_TEMPLATE = """
Answer the user's questions based on the below context.
If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know":
<context>
{context}
</context>
"""
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
SYSTEM_TEMPLATE,
),
MessagesPlaceholder(variable_name="messages"),
]
)
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
conversational_retrieval_chain = RunnablePassthrough.assign(
context=query_transforming_retriever_chain,
).assign(
answer=document_chain,
)
Awesome! Let’s invoke this new chain with the same inputs as earlier:
conversational_retrieval_chain.invoke(
{
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?"),
]
}
)
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?')],
'context': [Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content="does that affect the output?\u200bSo you notice a bad output, and you go into LangSmith to see what's going on. You find the faulty LLM call and are now looking at the exact input. You want to try changing a word or a phrase to see what happens -- what do you do?We constantly ran into this issue. Initially, we copied the prompt to a playground of sorts. But this got annoying, so we built a playground of our own! When examining an LLM call, you can click the Open in Playground button to access this", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'Yes, LangSmith can help test and evaluate LLM (Language Model) applications. It simplifies the initial setup, and you can use it to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'}
conversational_retrieval_chain.invoke(
{
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?"),
AIMessage(
content="Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise."
),
HumanMessage(content="Tell me more!"),
],
}
)
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?'),
AIMessage(content='Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'),
HumanMessage(content='Tell me more!')],
'context': [Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='LangSmith makes it easy to manually review and annotate runs through annotation queues.These queues allow you to select any runs based on criteria like model type or automatic evaluation scores, and queue them up for human review. As a reviewer, you can then quickly step through the runs, viewing the input, output, and any existing tags before adding your own feedback.We often use this for a couple of reasons:To assess subjective qualities that automatic evaluators struggle with, like', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'LangSmith simplifies the initial setup for building reliable LLM applications, but it acknowledges that there is still work needed to bring the performance of prompts, chains, and agents up to the level where they are reliable enough to be used in production. It also provides the capability to manually review and annotate runs through annotation queues, allowing you to select runs based on criteria like model type or automatic evaluation scores for human review. This feature is particularly useful for assessing subjective qualities that automatic evaluators struggle with.'}
You can check out this LangSmith trace to see the internal query transformation step for yourself.
Streaming
Because this chain is constructed with LCEL, you can use familiar methods like .stream() with it:
stream = conversational_retrieval_chain.stream(
{
"messages": [
HumanMessage(content="Can LangSmith help test my LLM applications?"),
AIMessage(
content="Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise."
),
HumanMessage(content="Tell me more!"),
],
}
)
for chunk in stream:
print(chunk)
{'messages': [HumanMessage(content='Can LangSmith help test my LLM applications?'), AIMessage(content='Yes, LangSmith can help test and evaluate your LLM applications. It allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs. Additionally, LangSmith can be used to monitor your application, log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.'), HumanMessage(content='Tell me more!')]}
{'context': [Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith makes it easy to manually review and annotate runs through annotation queues.These queues allow you to select any runs based on criteria like model type or automatic evaluation scores, and queue them up for human review. As a reviewer, you can then quickly step through the runs, viewing the input, output, and any existing tags before adding your own feedback.We often use this for a couple of reasons:To assess subjective qualities that automatic evaluators struggle with, like', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]}
{'answer': ''}
{'answer': 'Lang'}
{'answer': 'Smith'}
{'answer': ' simpl'}
{'answer': 'ifies'}
{'answer': ' the'}
{'answer': ' initial'}
{'answer': ' setup'}
{'answer': ' for'}
{'answer': ' building'}
{'answer': ' reliable'}
{'answer': ' L'}
{'answer': 'LM'}
{'answer': ' applications'}
{'answer': '.'}
{'answer': ' It'}
{'answer': ' provides'}
{'answer': ' features'}
{'answer': ' for'}
{'answer': ' manually'}
{'answer': ' reviewing'}
{'answer': ' and'}
{'answer': ' annot'}
{'answer': 'ating'}
{'answer': ' runs'}
{'answer': ' through'}
{'answer': ' annotation'}
{'answer': ' queues'}
{'answer': ','}
{'answer': ' allowing'}
{'answer': ' you'}
{'answer': ' to'}
{'answer': ' select'}
{'answer': ' runs'}
{'answer': ' based'}
{'answer': ' on'}
{'answer': ' criteria'}
{'answer': ' like'}
{'answer': ' model'}
{'answer': ' type'}
{'answer': ' or'}
{'answer': ' automatic'}
{'answer': ' evaluation'}
{'answer': ' scores'}
{'answer': ','}
{'answer': ' and'}
{'answer': ' queue'}
{'answer': ' them'}
{'answer': ' up'}
{'answer': ' for'}
{'answer': ' human'}
{'answer': ' review'}
{'answer': '.'}
{'answer': ' As'}
{'answer': ' a'}
{'answer': ' reviewer'}
{'answer': ','}
{'answer': ' you'}
{'answer': ' can'}
{'answer': ' quickly'}
{'answer': ' step'}
{'answer': ' through'}
{'answer': ' the'}
{'answer': ' runs'}
{'answer': ','}
{'answer': ' view'}
{'answer': ' the'}
{'answer': ' input'}
{'answer': ','}
{'answer': ' output'}
{'answer': ','}
{'answer': ' and'}
{'answer': ' any'}
{'answer': ' existing'}
{'answer': ' tags'}
{'answer': ' before'}
{'answer': ' adding'}
{'answer': ' your'}
{'answer': ' own'}
{'answer': ' feedback'}
{'answer': '.'}
{'answer': ' This'}
{'answer': ' can'}
{'answer': ' be'}
{'answer': ' particularly'}
{'answer': ' useful'}
{'answer': ' for'}
{'answer': ' assessing'}
{'answer': ' subjective'}
{'answer': ' qualities'}
{'answer': ' that'}
{'answer': ' automatic'}
{'answer': ' evalu'}
{'answer': 'ators'}
{'answer': ' struggle'}
{'answer': ' with'}
{'answer': '.'}
{'answer': ''}
Further reading
This guide only scratches the surface of retrieval techniques. For more on different ways of ingesting, preparing, and retrieving the most relevant data, check out this section of the docs. |
https://python.langchain.com/docs/use_cases/chatbots/quickstart/ | ## Quickstart
[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/chatbots.ipynb)
## Overview[](#overview "Direct link to Overview")
We’ll go over an example of how to design and implement an LLM-powered chatbot. Here are a few of the high-level components we’ll be working with:
* `Chat Models`. The chatbot interface is based around messages rather than raw text, and therefore is best suited to Chat Models rather than text LLMs. See [here](https://python.langchain.com/docs/integrations/chat/) for a list of chat model integrations and [here](https://python.langchain.com/docs/modules/model_io/chat/) for documentation on the chat model interface in LangChain. You can use `LLMs` (see [here](https://python.langchain.com/docs/modules/model_io/llms/)) for chatbots as well, but chat models have a more conversational tone and natively support a message interface.
* `Prompt Templates`, which simplify the process of assembling prompts that combine default messages, user input, chat history, and (optionally) additional retrieved context.
* `Chat History`, which allows a chatbot to “remember” past interactions and take them into account when responding to followup questions. [See here](https://python.langchain.com/docs/modules/memory/chat_messages/) for more information.
* `Retrievers` (optional), which are useful if you want to build a chatbot that can use domain-specific, up-to-date knowledge as context to augment its responses. [See here](https://python.langchain.com/docs/modules/data_connection/retrievers/) for in-depth documentation on retrieval systems.
We’ll cover how to fit the above components together to create a powerful conversational chatbot.
## Quickstart[](#quickstart "Direct link to Quickstart")
To start, let’s install some dependencies and set the required credentials:
```
%pip install --upgrade --quiet langchain langchain-openai langchain-chroma# Set env var OPENAI_API_KEY or load from a .env file:import dotenvdotenv.load_dotenv()
```
```
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.Note: you may need to restart the kernel to use updated packages.
```
Let’s initialize the chat model which will serve as the chatbot’s brain:
```
from langchain_openai import ChatOpenAIchat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)
```
If we invoke our chat model, the output is an `AIMessage`:
```
from langchain_core.messages import HumanMessagechat.invoke( [ HumanMessage( content="Translate this sentence from English to French: I love programming." ) ])
```
```
AIMessage(content="J'adore programmer.")
```
The model on its own does not have any concept of state. For example, if you ask a followup question:
```
chat.invoke([HumanMessage(content="What did you just say?")])
```
```
AIMessage(content='I said, "What did you just say?"')
```
We can see that it doesn’t take the previous conversation turn into context, and cannot answer the question.
To get around this, we need to pass the entire conversation history into the model. Let’s see what happens when we do that:
```
from langchain_core.messages import AIMessagechat.invoke( [ HumanMessage( content="Translate this sentence from English to French: I love programming." ), AIMessage(content="J'adore la programmation."), HumanMessage(content="What did you just say?"), ])
```
```
AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')
```
And now we can see that we get a good response!
This is the basic idea underpinning a chatbot’s ability to interact conversationally.
## Prompt templates[](#prompt-templates "Direct link to Prompt templates")
Let’s define a prompt template to make formatting a bit easier. We can create a chain by piping it into the model:
```
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderprompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. Answer all questions to the best of your ability.", ), MessagesPlaceholder(variable_name="messages"), ])chain = prompt | chat
```
The `MessagesPlaceholder` above inserts chat messages passed into the chain’s input as `chat_history` directly into the prompt. Then, we can invoke the chain like this:
```
chain.invoke( { "messages": [ HumanMessage( content="Translate this sentence from English to French: I love programming." ), AIMessage(content="J'adore la programmation."), HumanMessage(content="What did you just say?"), ], })
```
```
AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')
```
## Message history[](#message-history "Direct link to Message history")
As a shortcut for managing the chat history, we can use a [`MessageHistory`](https://python.langchain.com/docs/modules/memory/chat_messages/) class, which is responsible for saving and loading chat messages. There are many built-in message history integrations that persist messages to a variety of databases, but for this quickstart we’ll use a in-memory, demo message history called `ChatMessageHistory`.
Here’s an example of using it directly:
```
from langchain.memory import ChatMessageHistorydemo_ephemeral_chat_history = ChatMessageHistory()demo_ephemeral_chat_history.add_user_message("hi!")demo_ephemeral_chat_history.add_ai_message("whats up?")demo_ephemeral_chat_history.messages
```
```
[HumanMessage(content='hi!'), AIMessage(content='whats up?')]
```
Once we do that, we can pass the stored messages directly into our chain as a parameter:
```
demo_ephemeral_chat_history.add_user_message( "Translate this sentence from English to French: I love programming.")response = chain.invoke({"messages": demo_ephemeral_chat_history.messages})response
```
```
AIMessage(content='The translation of "I love programming" in French is "J\'adore la programmation."')
```
```
demo_ephemeral_chat_history.add_ai_message(response)demo_ephemeral_chat_history.add_user_message("What did you just say?")chain.invoke({"messages": demo_ephemeral_chat_history.messages})
```
```
AIMessage(content='I said "J\'adore la programmation," which is the French translation for "I love programming."')
```
And now we have a basic chatbot!
While this chain can serve as a useful chatbot on its own with just the model’s internal knowledge, it’s often useful to introduce some form of `retrieval-augmented generation`, or RAG for short, over domain-specific knowledge to make our chatbot more focused. We’ll cover this next.
## Retrievers[](#retrievers "Direct link to Retrievers")
We can set up and use a [`Retriever`](https://python.langchain.com/docs/modules/data_connection/retrievers/) to pull domain-specific knowledge for our chatbot. To show this, let’s expand the simple chatbot we created above to be able to answer questions about LangSmith.
We’ll use [the LangSmith documentation](https://docs.smith.langchain.com/overview) as source material and store it in a vectorstore for later retrieval. Note that this example will gloss over some of the specifics around parsing and storing a data source - you can see more [in-depth documentation on creating retrieval systems here](https://python.langchain.com/docs/use_cases/question_answering/).
Let’s set up our retriever. First, we’ll install some required deps:
```
%pip install --upgrade --quiet langchain-chroma beautifulsoup4
```
```
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.Note: you may need to restart the kernel to use updated packages.
```
Next, we’ll use a document loader to pull data from a webpage:
```
from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://docs.smith.langchain.com/overview")data = loader.load()
```
Next, we split it into smaller chunks that the LLM’s context window can handle and store it in a vector database:
```
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)all_splits = text_splitter.split_documents(data)
```
Then we embed and store those chunks in a vector database:
```
from langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingsvectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
```
And finally, let’s create a retriever from our initialized vectorstore:
```
# k is the number of chunks to retrieveretriever = vectorstore.as_retriever(k=4)docs = retriever.invoke("how can langsmith help with testing?")docs
```
```
[Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
```
We can see that invoking the retriever above results in some parts of the LangSmith docs that contain information about testing that our chatbot can use as context when answering questions.
### Handling documents[](#handling-documents "Direct link to Handling documents")
Let’s modify our previous prompt to accept documents as context. We’ll use a [`create_stuff_documents_chain`](https://api.python.langchain.com/en/latest/chains/langchain.chains.combine_documents.stuff.create_stuff_documents_chain.html#langchain.chains.combine_documents.stuff.create_stuff_documents_chain) helper function to “stuff” all of the input documents into the prompt, which also conveniently handles formatting. We use the [`ChatPromptTemplate.from_messages`](https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#chatprompttemplate) method to format the message input we want to pass to the model, including a [`MessagesPlaceholder`](https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#messagesplaceholder) where chat history messages will be directly injected:
```
from langchain.chains.combine_documents import create_stuff_documents_chainchat = ChatOpenAI(model="gpt-3.5-turbo-1106")question_answering_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the user's questions based on the below context:\n\n{context}", ), MessagesPlaceholder(variable_name="messages"), ])document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
```
We can invoke this `document_chain` with the raw documents we retrieved above:
```
from langchain.memory import ChatMessageHistorydemo_ephemeral_chat_history = ChatMessageHistory()demo_ephemeral_chat_history.add_user_message("how can langsmith help with testing?")document_chain.invoke( { "messages": demo_ephemeral_chat_history.messages, "context": docs, })
```
```
'LangSmith can assist with testing by providing the capability to quickly edit examples and add them to datasets. This allows for the expansion of evaluation sets or fine-tuning of a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in the application.'
```
Awesome! We see an answer synthesized from information in the input documents.
### Creating a retrieval chain[](#creating-a-retrieval-chain "Direct link to Creating a retrieval chain")
Next, let’s integrate our retriever into the chain. Our retriever should retrieve information relevant to the last message we pass in from the user, so we extract it and use that as input to fetch relevant docs, which we add to the current chain as `context`. We pass `context` plus the previous `messages` into our document chain to generate a final answer.
We also use the [`RunnablePassthrough.assign()`](https://python.langchain.com/docs/expression_language/primitives/assign/) method to pass intermediate steps through at each invocation. Here’s what it looks like:
```
from typing import Dictfrom langchain_core.runnables import RunnablePassthroughdef parse_retriever_input(params: Dict): return params["messages"][-1].contentretrieval_chain = RunnablePassthrough.assign( context=parse_retriever_input | retriever,).assign( answer=document_chain,)
```
```
response = retrieval_chain.invoke( { "messages": demo_ephemeral_chat_history.messages, })response
```
```
{'messages': [HumanMessage(content='how can langsmith help with testing?')], 'context': [Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'LangSmith can help with testing in several ways:\n\n1. Dataset Expansion: LangSmith enables quick editing of examples and adding them to datasets, which expands the surface area of evaluation sets. This allows for more comprehensive testing of models and applications.\n\n2. Fine-Tuning Models: LangSmith facilitates the fine-tuning of models for improved quality or reduced costs. This is beneficial for optimizing the performance of models during testing.\n\n3. Monitoring: LangSmith can be used to monitor applications, log traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise during testing. This monitoring helps in ensuring the reliability and performance of the application during testing phases.\n\nOverall, LangSmith helps in making testing more rigorous and comprehensive, whether by expanding datasets, fine-tuning models, or monitoring application performance.'}
```
```
demo_ephemeral_chat_history.add_ai_message(response["answer"])demo_ephemeral_chat_history.add_user_message("tell me more about that!")retrieval_chain.invoke( { "messages": demo_ephemeral_chat_history.messages, },)
```
```
{'messages': [HumanMessage(content='how can langsmith help with testing?'), AIMessage(content='LangSmith can help with testing in several ways:\n\n1. Dataset Expansion: LangSmith enables quick editing of examples and adding them to datasets, which expands the surface area of evaluation sets. This allows for more comprehensive testing of models and applications.\n\n2. Fine-Tuning Models: LangSmith facilitates the fine-tuning of models for improved quality or reduced costs. This is beneficial for optimizing the performance of models during testing.\n\n3. Monitoring: LangSmith can be used to monitor applications, log traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise during testing. This monitoring helps in ensuring the reliability and performance of the application during testing phases.\n\nOverall, LangSmith helps in making testing more rigorous and comprehensive, whether by expanding datasets, fine-tuning models, or monitoring application performance.'), HumanMessage(content='tell me more about that!')], 'context': [Document(page_content='however, there is still no complete substitute for human review to get the utmost quality and reliability from your application.', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content="against these known issues.Why is this so impactful? When building LLM applications, it’s often common to start without a dataset of any kind. This is part of the power of LLMs! They are amazing zero-shot learners, making it possible to get started as easily as possible. But this can also be a curse -- as you adjust the prompt, you're wandering blind. You don’t have any examples to benchmark your changes against.LangSmith addresses this problem by including an “Add to Dataset” button for each", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='playground. Here, you can modify the prompt and re-run it to observe the resulting changes to the output - as many times as needed!Currently, this feature supports only OpenAI and Anthropic models and works for LLM and Chat Model calls. We plan to extend its functionality to more LLM types, chains, agents, and retrievers in the future.What is the exact sequence of events?\u200bIn complicated chains and agents, it can often be hard to understand what is going on under the hood. What calls are being', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'Certainly! LangSmith offers the following capabilities to aid in testing:\n\n1. Dataset Expansion: By allowing quick editing of examples and adding them to datasets, LangSmith enables the expansion of evaluation sets. This is crucial for thorough testing of models and applications, as it broadens the range of scenarios and inputs that can be used to assess performance.\n\n2. Fine-Tuning Models: LangSmith supports the fine-tuning of models to enhance their quality and reduce operational costs. This capability is valuable during testing as it enables the optimization of model performance based on specific testing requirements and objectives.\n\n3. Monitoring: LangSmith provides monitoring features that allow for the logging of traces, visualization of latency and token usage statistics, and troubleshooting of issues as they occur during testing. This real-time monitoring helps in identifying and addressing any issues that may impact the reliability and performance of the application during testing.\n\nBy leveraging these features, LangSmith enhances the testing process by enabling comprehensive dataset expansion, model fine-tuning, and real-time monitoring to ensure the quality and reliability of applications and models.'}
```
Nice! Our chatbot can now answer domain-specific questions in a conversational way.
As an aside, if you don’t want to return all the intermediate steps, you can define your retrieval chain like this using a pipe directly into the document chain instead of the final `.assign()` call:
```
retrieval_chain_with_only_answer = ( RunnablePassthrough.assign( context=parse_retriever_input | retriever, ) | document_chain)retrieval_chain_with_only_answer.invoke( { "messages": demo_ephemeral_chat_history.messages, },)
```
```
"LangSmith offers the capability to quickly edit examples and add them to datasets, thereby enhancing the scope of evaluation sets. This feature is particularly valuable for testing as it allows for a more thorough assessment of model performance and application behavior.\n\nFurthermore, LangSmith enables the fine-tuning of models to enhance quality and reduce costs, which can significantly impact testing outcomes. By adjusting and refining models, developers can ensure that they are thoroughly tested and optimized for various scenarios and use cases.\n\nAdditionally, LangSmith provides monitoring functionality, allowing users to log traces, visualize latency and token usage statistics, and troubleshoot specific issues as they encounter them during testing. This real-time monitoring and troubleshooting capability contribute to the overall effectiveness and reliability of the testing process.\n\nIn essence, LangSmith's features are designed to improve the quality and reliability of testing by expanding evaluation sets, fine-tuning models, and providing comprehensive monitoring capabilities. These aspects collectively contribute to a more robust and thorough testing process for applications and models."
```
## Query transformation[](#query-transformation "Direct link to Query transformation")
There’s one more optimization we’ll cover here - in the above example, when we asked a followup question, `tell me more about that!`, you might notice that the retrieved docs don’t directly include information about testing. This is because we’re passing `tell me more about that!` verbatim as a query to the retriever. The output in the retrieval chain is still okay because the document chain retrieval chain can generate an answer based on the chat history, but we could be retrieving more rich and informative documents:
```
retriever.invoke("how can langsmith help with testing?")
```
```
[Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
```
```
retriever.invoke("tell me more about that!")
```
```
[Document(page_content='however, there is still no complete substitute for human review to get the utmost quality and reliability from your application.', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content="against these known issues.Why is this so impactful? When building LLM applications, it’s often common to start without a dataset of any kind. This is part of the power of LLMs! They are amazing zero-shot learners, making it possible to get started as easily as possible. But this can also be a curse -- as you adjust the prompt, you're wandering blind. You don’t have any examples to benchmark your changes against.LangSmith addresses this problem by including an “Add to Dataset” button for each", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='playground. Here, you can modify the prompt and re-run it to observe the resulting changes to the output - as many times as needed!Currently, this feature supports only OpenAI and Anthropic models and works for LLM and Chat Model calls. We plan to extend its functionality to more LLM types, chains, agents, and retrievers in the future.What is the exact sequence of events?\u200bIn complicated chains and agents, it can often be hard to understand what is going on under the hood. What calls are being', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
```
To get around this common problem, let’s add a `query transformation` step that removes references from the input. We’ll wrap our old retriever as follows:
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnableBranch# We need a prompt that we can pass into an LLM to generate a transformed search querychat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)query_transform_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="messages"), ( "user", "Given the above conversation, generate a search query to look up in order to get information relevant to the conversation. Only respond with the query, nothing else.", ), ])query_transforming_retriever_chain = RunnableBranch( ( lambda x: len(x.get("messages", [])) == 1, # If only one message, then we just pass that message's content to retriever (lambda x: x["messages"][-1].content) | retriever, ), # If messages, then we pass inputs to LLM chain to transform the query, then pass to retriever query_transform_prompt | chat | StrOutputParser() | retriever,).with_config(run_name="chat_retriever_chain")
```
Now let’s recreate our earlier chain with this new `query_transforming_retriever_chain`. Note that this new chain accepts a dict as input and parses a string to pass to the retriever, so we don’t have to do additional parsing at the top level:
```
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)conversational_retrieval_chain = RunnablePassthrough.assign( context=query_transforming_retriever_chain,).assign( answer=document_chain,)demo_ephemeral_chat_history = ChatMessageHistory()
```
And finally, let’s invoke it!
```
demo_ephemeral_chat_history.add_user_message("how can langsmith help with testing?")response = conversational_retrieval_chain.invoke( {"messages": demo_ephemeral_chat_history.messages},)demo_ephemeral_chat_history.add_ai_message(response["answer"])response
```
```
{'messages': [HumanMessage(content='how can langsmith help with testing?'), AIMessage(content='LangSmith can assist with testing in several ways. It allows you to quickly edit examples and add them to datasets, expanding the range of evaluation sets. This can help in fine-tuning a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in your application. Furthermore, it enables monitoring of your application by logging all traces, visualizing latency and token usage statistics, and troubleshooting specific issues as they arise.')], 'context': [Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'LangSmith can assist with testing in several ways. It allows you to quickly edit examples and add them to datasets, expanding the range of evaluation sets. This can help in fine-tuning a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in your application. Furthermore, it enables monitoring of your application by logging all traces, visualizing latency and token usage statistics, and troubleshooting specific issues as they arise.'}
```
```
demo_ephemeral_chat_history.add_user_message("tell me more about that!")conversational_retrieval_chain.invoke( {"messages": demo_ephemeral_chat_history.messages})
```
```
{'messages': [HumanMessage(content='how can langsmith help with testing?'), AIMessage(content='LangSmith can assist with testing in several ways. It allows you to quickly edit examples and add them to datasets, expanding the range of evaluation sets. This can help in fine-tuning a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in your application. Furthermore, it enables monitoring of your application by logging all traces, visualizing latency and token usage statistics, and troubleshooting specific issues as they arise.'), HumanMessage(content='tell me more about that!')], 'context': [Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}), Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})], 'answer': 'Certainly! LangSmith simplifies the process of constructing and editing datasets, which is essential for testing and fine-tuning models. By quickly editing examples and adding them to datasets, you can expand the surface area of your evaluation sets, leading to improved model quality and potentially reduced costs. Additionally, LangSmith provides monitoring capabilities for your application, allowing you to log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. This comprehensive monitoring functionality helps ensure the reliability and performance of your application in production.'}
```
To help you understand what’s happening internally, [this LangSmith trace](https://smith.langchain.com/public/42f8993b-7d19-42d3-990a-6608a73c5824/r) shows the first invocation. You can see that the user’s initial query is passed directly to the retriever, which return suitable docs.
The invocation for followup question, [illustrated by this LangSmith trace](https://smith.langchain.com/public/7b463791-868b-42bd-8035-17b471e9c7cd/r) rephrases the user’s initial question to something more relevant to testing with LangSmith, resulting in higher quality docs.
And we now have a chatbot capable of conversational retrieval!
## Next steps[](#next-steps "Direct link to Next steps")
You now know how to build a conversational chatbot that can integrate past messages and domain-specific knowledge into its generations. There are many other optimizations you can make around this - check out the following pages for more information:
* [Memory management](https://python.langchain.com/docs/use_cases/chatbots/memory_management/): This includes a guide on automatically updating chat history, as well as trimming, summarizing, or otherwise modifying long conversations to keep your bot focused.
* [Retrieval](https://python.langchain.com/docs/use_cases/chatbots/retrieval/): A deeper dive into using different types of retrieval with your chatbot
* [Tool usage](https://python.langchain.com/docs/use_cases/chatbots/tool_usage/): How to allows your chatbots to use tools that interact with other APIs and systems. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:06.698Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/chatbots/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/chatbots/quickstart/",
"description": "Overview",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "6042",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:05 GMT",
"etag": "W/\"7186d7321c16218c670c32fb4ed9552f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::86l5f-1713753965986-68b621399984"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/chatbots/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Overview",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
Overview
We’ll go over an example of how to design and implement an LLM-powered chatbot. Here are a few of the high-level components we’ll be working with:
Chat Models. The chatbot interface is based around messages rather than raw text, and therefore is best suited to Chat Models rather than text LLMs. See here for a list of chat model integrations and here for documentation on the chat model interface in LangChain. You can use LLMs (see here) for chatbots as well, but chat models have a more conversational tone and natively support a message interface.
Prompt Templates, which simplify the process of assembling prompts that combine default messages, user input, chat history, and (optionally) additional retrieved context.
Chat History, which allows a chatbot to “remember” past interactions and take them into account when responding to followup questions. See here for more information.
Retrievers (optional), which are useful if you want to build a chatbot that can use domain-specific, up-to-date knowledge as context to augment its responses. See here for in-depth documentation on retrieval systems.
We’ll cover how to fit the above components together to create a powerful conversational chatbot.
Quickstart
To start, let’s install some dependencies and set the required credentials:
%pip install --upgrade --quiet langchain langchain-openai langchain-chroma
# Set env var OPENAI_API_KEY or load from a .env file:
import dotenv
dotenv.load_dotenv()
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.
You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.
Note: you may need to restart the kernel to use updated packages.
Let’s initialize the chat model which will serve as the chatbot’s brain:
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)
If we invoke our chat model, the output is an AIMessage:
from langchain_core.messages import HumanMessage
chat.invoke(
[
HumanMessage(
content="Translate this sentence from English to French: I love programming."
)
]
)
AIMessage(content="J'adore programmer.")
The model on its own does not have any concept of state. For example, if you ask a followup question:
chat.invoke([HumanMessage(content="What did you just say?")])
AIMessage(content='I said, "What did you just say?"')
We can see that it doesn’t take the previous conversation turn into context, and cannot answer the question.
To get around this, we need to pass the entire conversation history into the model. Let’s see what happens when we do that:
from langchain_core.messages import AIMessage
chat.invoke(
[
HumanMessage(
content="Translate this sentence from English to French: I love programming."
),
AIMessage(content="J'adore la programmation."),
HumanMessage(content="What did you just say?"),
]
)
AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')
And now we can see that we get a good response!
This is the basic idea underpinning a chatbot’s ability to interact conversationally.
Prompt templates
Let’s define a prompt template to make formatting a bit easier. We can create a chain by piping it into the model:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | chat
The MessagesPlaceholder above inserts chat messages passed into the chain’s input as chat_history directly into the prompt. Then, we can invoke the chain like this:
chain.invoke(
{
"messages": [
HumanMessage(
content="Translate this sentence from English to French: I love programming."
),
AIMessage(content="J'adore la programmation."),
HumanMessage(content="What did you just say?"),
],
}
)
AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')
Message history
As a shortcut for managing the chat history, we can use a MessageHistory class, which is responsible for saving and loading chat messages. There are many built-in message history integrations that persist messages to a variety of databases, but for this quickstart we’ll use a in-memory, demo message history called ChatMessageHistory.
Here’s an example of using it directly:
from langchain.memory import ChatMessageHistory
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message("hi!")
demo_ephemeral_chat_history.add_ai_message("whats up?")
demo_ephemeral_chat_history.messages
[HumanMessage(content='hi!'), AIMessage(content='whats up?')]
Once we do that, we can pass the stored messages directly into our chain as a parameter:
demo_ephemeral_chat_history.add_user_message(
"Translate this sentence from English to French: I love programming."
)
response = chain.invoke({"messages": demo_ephemeral_chat_history.messages})
response
AIMessage(content='The translation of "I love programming" in French is "J\'adore la programmation."')
demo_ephemeral_chat_history.add_ai_message(response)
demo_ephemeral_chat_history.add_user_message("What did you just say?")
chain.invoke({"messages": demo_ephemeral_chat_history.messages})
AIMessage(content='I said "J\'adore la programmation," which is the French translation for "I love programming."')
And now we have a basic chatbot!
While this chain can serve as a useful chatbot on its own with just the model’s internal knowledge, it’s often useful to introduce some form of retrieval-augmented generation, or RAG for short, over domain-specific knowledge to make our chatbot more focused. We’ll cover this next.
Retrievers
We can set up and use a Retriever to pull domain-specific knowledge for our chatbot. To show this, let’s expand the simple chatbot we created above to be able to answer questions about LangSmith.
We’ll use the LangSmith documentation as source material and store it in a vectorstore for later retrieval. Note that this example will gloss over some of the specifics around parsing and storing a data source - you can see more in-depth documentation on creating retrieval systems here.
Let’s set up our retriever. First, we’ll install some required deps:
%pip install --upgrade --quiet langchain-chroma beautifulsoup4
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.
You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.
Note: you may need to restart the kernel to use updated packages.
Next, we’ll use a document loader to pull data from a webpage:
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
data = loader.load()
Next, we split it into smaller chunks that the LLM’s context window can handle and store it in a vector database:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
Then we embed and store those chunks in a vector database:
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
And finally, let’s create a retriever from our initialized vectorstore:
# k is the number of chunks to retrieve
retriever = vectorstore.as_retriever(k=4)
docs = retriever.invoke("how can langsmith help with testing?")
docs
[Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
We can see that invoking the retriever above results in some parts of the LangSmith docs that contain information about testing that our chatbot can use as context when answering questions.
Handling documents
Let’s modify our previous prompt to accept documents as context. We’ll use a create_stuff_documents_chain helper function to “stuff” all of the input documents into the prompt, which also conveniently handles formatting. We use the ChatPromptTemplate.from_messages method to format the message input we want to pass to the model, including a MessagesPlaceholder where chat history messages will be directly injected:
from langchain.chains.combine_documents import create_stuff_documents_chain
chat = ChatOpenAI(model="gpt-3.5-turbo-1106")
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user's questions based on the below context:\n\n{context}",
),
MessagesPlaceholder(variable_name="messages"),
]
)
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
We can invoke this document_chain with the raw documents we retrieved above:
from langchain.memory import ChatMessageHistory
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message("how can langsmith help with testing?")
document_chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
"context": docs,
}
)
'LangSmith can assist with testing by providing the capability to quickly edit examples and add them to datasets. This allows for the expansion of evaluation sets or fine-tuning of a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in the application.'
Awesome! We see an answer synthesized from information in the input documents.
Creating a retrieval chain
Next, let’s integrate our retriever into the chain. Our retriever should retrieve information relevant to the last message we pass in from the user, so we extract it and use that as input to fetch relevant docs, which we add to the current chain as context. We pass context plus the previous messages into our document chain to generate a final answer.
We also use the RunnablePassthrough.assign() method to pass intermediate steps through at each invocation. Here’s what it looks like:
from typing import Dict
from langchain_core.runnables import RunnablePassthrough
def parse_retriever_input(params: Dict):
return params["messages"][-1].content
retrieval_chain = RunnablePassthrough.assign(
context=parse_retriever_input | retriever,
).assign(
answer=document_chain,
)
response = retrieval_chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
}
)
response
{'messages': [HumanMessage(content='how can langsmith help with testing?')],
'context': [Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'LangSmith can help with testing in several ways:\n\n1. Dataset Expansion: LangSmith enables quick editing of examples and adding them to datasets, which expands the surface area of evaluation sets. This allows for more comprehensive testing of models and applications.\n\n2. Fine-Tuning Models: LangSmith facilitates the fine-tuning of models for improved quality or reduced costs. This is beneficial for optimizing the performance of models during testing.\n\n3. Monitoring: LangSmith can be used to monitor applications, log traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise during testing. This monitoring helps in ensuring the reliability and performance of the application during testing phases.\n\nOverall, LangSmith helps in making testing more rigorous and comprehensive, whether by expanding datasets, fine-tuning models, or monitoring application performance.'}
demo_ephemeral_chat_history.add_ai_message(response["answer"])
demo_ephemeral_chat_history.add_user_message("tell me more about that!")
retrieval_chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
},
)
{'messages': [HumanMessage(content='how can langsmith help with testing?'),
AIMessage(content='LangSmith can help with testing in several ways:\n\n1. Dataset Expansion: LangSmith enables quick editing of examples and adding them to datasets, which expands the surface area of evaluation sets. This allows for more comprehensive testing of models and applications.\n\n2. Fine-Tuning Models: LangSmith facilitates the fine-tuning of models for improved quality or reduced costs. This is beneficial for optimizing the performance of models during testing.\n\n3. Monitoring: LangSmith can be used to monitor applications, log traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise during testing. This monitoring helps in ensuring the reliability and performance of the application during testing phases.\n\nOverall, LangSmith helps in making testing more rigorous and comprehensive, whether by expanding datasets, fine-tuning models, or monitoring application performance.'),
HumanMessage(content='tell me more about that!')],
'context': [Document(page_content='however, there is still no complete substitute for human review to get the utmost quality and reliability from your application.', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content="against these known issues.Why is this so impactful? When building LLM applications, it’s often common to start without a dataset of any kind. This is part of the power of LLMs! They are amazing zero-shot learners, making it possible to get started as easily as possible. But this can also be a curse -- as you adjust the prompt, you're wandering blind. You don’t have any examples to benchmark your changes against.LangSmith addresses this problem by including an “Add to Dataset” button for each", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='playground. Here, you can modify the prompt and re-run it to observe the resulting changes to the output - as many times as needed!Currently, this feature supports only OpenAI and Anthropic models and works for LLM and Chat Model calls. We plan to extend its functionality to more LLM types, chains, agents, and retrievers in the future.What is the exact sequence of events?\u200bIn complicated chains and agents, it can often be hard to understand what is going on under the hood. What calls are being', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'Certainly! LangSmith offers the following capabilities to aid in testing:\n\n1. Dataset Expansion: By allowing quick editing of examples and adding them to datasets, LangSmith enables the expansion of evaluation sets. This is crucial for thorough testing of models and applications, as it broadens the range of scenarios and inputs that can be used to assess performance.\n\n2. Fine-Tuning Models: LangSmith supports the fine-tuning of models to enhance their quality and reduce operational costs. This capability is valuable during testing as it enables the optimization of model performance based on specific testing requirements and objectives.\n\n3. Monitoring: LangSmith provides monitoring features that allow for the logging of traces, visualization of latency and token usage statistics, and troubleshooting of issues as they occur during testing. This real-time monitoring helps in identifying and addressing any issues that may impact the reliability and performance of the application during testing.\n\nBy leveraging these features, LangSmith enhances the testing process by enabling comprehensive dataset expansion, model fine-tuning, and real-time monitoring to ensure the quality and reliability of applications and models.'}
Nice! Our chatbot can now answer domain-specific questions in a conversational way.
As an aside, if you don’t want to return all the intermediate steps, you can define your retrieval chain like this using a pipe directly into the document chain instead of the final .assign() call:
retrieval_chain_with_only_answer = (
RunnablePassthrough.assign(
context=parse_retriever_input | retriever,
)
| document_chain
)
retrieval_chain_with_only_answer.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
},
)
"LangSmith offers the capability to quickly edit examples and add them to datasets, thereby enhancing the scope of evaluation sets. This feature is particularly valuable for testing as it allows for a more thorough assessment of model performance and application behavior.\n\nFurthermore, LangSmith enables the fine-tuning of models to enhance quality and reduce costs, which can significantly impact testing outcomes. By adjusting and refining models, developers can ensure that they are thoroughly tested and optimized for various scenarios and use cases.\n\nAdditionally, LangSmith provides monitoring functionality, allowing users to log traces, visualize latency and token usage statistics, and troubleshoot specific issues as they encounter them during testing. This real-time monitoring and troubleshooting capability contribute to the overall effectiveness and reliability of the testing process.\n\nIn essence, LangSmith's features are designed to improve the quality and reliability of testing by expanding evaluation sets, fine-tuning models, and providing comprehensive monitoring capabilities. These aspects collectively contribute to a more robust and thorough testing process for applications and models."
Query transformation
There’s one more optimization we’ll cover here - in the above example, when we asked a followup question, tell me more about that!, you might notice that the retrieved docs don’t directly include information about testing. This is because we’re passing tell me more about that! verbatim as a query to the retriever. The output in the retrieval chain is still okay because the document chain retrieval chain can generate an answer based on the chat history, but we could be retrieving more rich and informative documents:
retriever.invoke("how can langsmith help with testing?")
[Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
retriever.invoke("tell me more about that!")
[Document(page_content='however, there is still no complete substitute for human review to get the utmost quality and reliability from your application.', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content="against these known issues.Why is this so impactful? When building LLM applications, it’s often common to start without a dataset of any kind. This is part of the power of LLMs! They are amazing zero-shot learners, making it possible to get started as easily as possible. But this can also be a curse -- as you adjust the prompt, you're wandering blind. You don’t have any examples to benchmark your changes against.LangSmith addresses this problem by including an “Add to Dataset” button for each", metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='playground. Here, you can modify the prompt and re-run it to observe the resulting changes to the output - as many times as needed!Currently, this feature supports only OpenAI and Anthropic models and works for LLM and Chat Model calls. We plan to extend its functionality to more LLM types, chains, agents, and retrievers in the future.What is the exact sequence of events?\u200bIn complicated chains and agents, it can often be hard to understand what is going on under the hood. What calls are being', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})]
To get around this common problem, let’s add a query transformation step that removes references from the input. We’ll wrap our old retriever as follows:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableBranch
# We need a prompt that we can pass into an LLM to generate a transformed search query
chat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)
query_transform_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="messages"),
(
"user",
"Given the above conversation, generate a search query to look up in order to get information relevant to the conversation. Only respond with the query, nothing else.",
),
]
)
query_transforming_retriever_chain = RunnableBranch(
(
lambda x: len(x.get("messages", [])) == 1,
# If only one message, then we just pass that message's content to retriever
(lambda x: x["messages"][-1].content) | retriever,
),
# If messages, then we pass inputs to LLM chain to transform the query, then pass to retriever
query_transform_prompt | chat | StrOutputParser() | retriever,
).with_config(run_name="chat_retriever_chain")
Now let’s recreate our earlier chain with this new query_transforming_retriever_chain. Note that this new chain accepts a dict as input and parses a string to pass to the retriever, so we don’t have to do additional parsing at the top level:
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
conversational_retrieval_chain = RunnablePassthrough.assign(
context=query_transforming_retriever_chain,
).assign(
answer=document_chain,
)
demo_ephemeral_chat_history = ChatMessageHistory()
And finally, let’s invoke it!
demo_ephemeral_chat_history.add_user_message("how can langsmith help with testing?")
response = conversational_retrieval_chain.invoke(
{"messages": demo_ephemeral_chat_history.messages},
)
demo_ephemeral_chat_history.add_ai_message(response["answer"])
response
{'messages': [HumanMessage(content='how can langsmith help with testing?'),
AIMessage(content='LangSmith can assist with testing in several ways. It allows you to quickly edit examples and add them to datasets, expanding the range of evaluation sets. This can help in fine-tuning a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in your application. Furthermore, it enables monitoring of your application by logging all traces, visualizing latency and token usage statistics, and troubleshooting specific issues as they arise.')],
'context': [Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'LangSmith can assist with testing in several ways. It allows you to quickly edit examples and add them to datasets, expanding the range of evaluation sets. This can help in fine-tuning a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in your application. Furthermore, it enables monitoring of your application by logging all traces, visualizing latency and token usage statistics, and troubleshooting specific issues as they arise.'}
demo_ephemeral_chat_history.add_user_message("tell me more about that!")
conversational_retrieval_chain.invoke(
{"messages": demo_ephemeral_chat_history.messages}
)
{'messages': [HumanMessage(content='how can langsmith help with testing?'),
AIMessage(content='LangSmith can assist with testing in several ways. It allows you to quickly edit examples and add them to datasets, expanding the range of evaluation sets. This can help in fine-tuning a model for improved quality or reduced costs. Additionally, LangSmith simplifies the construction of small datasets by hand, providing a convenient way to rigorously test changes in your application. Furthermore, it enables monitoring of your application by logging all traces, visualizing latency and token usage statistics, and troubleshooting specific issues as they arise.'),
HumanMessage(content='tell me more about that!')],
'context': [Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'}),
Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith'})],
'answer': 'Certainly! LangSmith simplifies the process of constructing and editing datasets, which is essential for testing and fine-tuning models. By quickly editing examples and adding them to datasets, you can expand the surface area of your evaluation sets, leading to improved model quality and potentially reduced costs. Additionally, LangSmith provides monitoring capabilities for your application, allowing you to log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. This comprehensive monitoring functionality helps ensure the reliability and performance of your application in production.'}
To help you understand what’s happening internally, this LangSmith trace shows the first invocation. You can see that the user’s initial query is passed directly to the retriever, which return suitable docs.
The invocation for followup question, illustrated by this LangSmith trace rephrases the user’s initial question to something more relevant to testing with LangSmith, resulting in higher quality docs.
And we now have a chatbot capable of conversational retrieval!
Next steps
You now know how to build a conversational chatbot that can integrate past messages and domain-specific knowledge into its generations. There are many other optimizations you can make around this - check out the following pages for more information:
Memory management: This includes a guide on automatically updating chat history, as well as trimming, summarizing, or otherwise modifying long conversations to keep your bot focused.
Retrieval: A deeper dive into using different types of retrieval with your chatbot
Tool usage: How to allows your chatbots to use tools that interact with other APIs and systems. |
https://python.langchain.com/docs/use_cases/chatbots/memory_management/ | ## Memory management
A key feature of chatbots is their ability to use content of previous conversation turns as context. This state management can take several forms, including:
* Simply stuffing previous messages into a chat model prompt.
* The above, but trimming old messages to reduce the amount of distracting information the model has to deal with.
* More complex modifications like synthesizing summaries for long running conversations.
We’ll go into more detail on a few techniques below!
## Setup[](#setup "Direct link to Setup")
You’ll need to install a few packages, and have your OpenAI API key set as an environment variable named `OPENAI_API_KEY`:
```
%pip install --upgrade --quiet langchain langchain-openai# Set env var OPENAI_API_KEY or load from a .env file:import dotenvdotenv.load_dotenv()
```
```
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.Note: you may need to restart the kernel to use updated packages.
```
Let’s also set up a chat model that we’ll use for the below examples.
```
from langchain_openai import ChatOpenAIchat = ChatOpenAI(model="gpt-3.5-turbo-1106")
```
## Message passing[](#message-passing "Direct link to Message passing")
The simplest form of memory is simply passing chat history messages into a chain. Here’s an example:
```
from langchain_core.messages import AIMessage, HumanMessagefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderprompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. Answer all questions to the best of your ability.", ), MessagesPlaceholder(variable_name="messages"), ])chain = prompt | chatchain.invoke( { "messages": [ HumanMessage( content="Translate this sentence from English to French: I love programming." ), AIMessage(content="J'adore la programmation."), HumanMessage(content="What did you just say?"), ], })
```
```
AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')
```
We can see that by passing the previous conversation into a chain, it can use it as context to answer questions. This is the basic concept underpinning chatbot memory - the rest of the guide will demonstrate convenient techniques for passing or reformatting messages.
## Chat history[](#chat-history "Direct link to Chat history")
It’s perfectly fine to store and pass messages directly as an array, but we can use LangChain’s built-in [message history class](https://python.langchain.com/docs/modules/memory/chat_messages/) to store and load messages as well. Instances of this class are responsible for storing and loading chat messages from persistent storage. LangChain integrates with many providers - you can see a [list of integrations here](https://python.langchain.com/docs/integrations/memory/) - but for this demo we will use an ephemeral demo class.
Here’s an example of the API:
```
from langchain.memory import ChatMessageHistorydemo_ephemeral_chat_history = ChatMessageHistory()demo_ephemeral_chat_history.add_user_message( "Translate this sentence from English to French: I love programming.")demo_ephemeral_chat_history.add_ai_message("J'adore la programmation.")demo_ephemeral_chat_history.messages
```
```
[HumanMessage(content='Translate this sentence from English to French: I love programming.'), AIMessage(content="J'adore la programmation.")]
```
We can use it directly to store conversation turns for our chain:
```
demo_ephemeral_chat_history = ChatMessageHistory()input1 = "Translate this sentence from English to French: I love programming."demo_ephemeral_chat_history.add_user_message(input1)response = chain.invoke( { "messages": demo_ephemeral_chat_history.messages, })demo_ephemeral_chat_history.add_ai_message(response)input2 = "What did I just ask you?"demo_ephemeral_chat_history.add_user_message(input2)chain.invoke( { "messages": demo_ephemeral_chat_history.messages, })
```
```
AIMessage(content='You asked me to translate the sentence "I love programming" from English to French.')
```
## Automatic history management[](#automatic-history-management "Direct link to Automatic history management")
The previous examples pass messages to the chain explicitly. This is a completely acceptable approach, but it does require external management of new messages. LangChain also includes an wrapper for LCEL chains that can handle this process automatically called `RunnableWithMessageHistory`.
To show how it works, let’s slightly modify the above prompt to take a final `input` variable that populates a `HumanMessage` template after the chat history. This means that we will expect a `chat_history` parameter that contains all messages BEFORE the current messages instead of all messages:
```
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. Answer all questions to the best of your ability.", ), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), ])chain = prompt | chat
```
We’ll pass the latest input to the conversation here and let the `RunnableWithMessageHistory` class wrap our chain and do the work of appending that `input` variable to the chat history.
Next, let’s declare our wrapped chain:
```
from langchain_core.runnables.history import RunnableWithMessageHistorydemo_ephemeral_chat_history_for_chain = ChatMessageHistory()chain_with_message_history = RunnableWithMessageHistory( chain, lambda session_id: demo_ephemeral_chat_history_for_chain, input_messages_key="input", history_messages_key="chat_history",)
```
This class takes a few parameters in addition to the chain that we want to wrap:
* A factory function that returns a message history for a given session id. This allows your chain to handle multiple users at once by loading different messages for different conversations.
* An `input_messages_key` that specifies which part of the input should be tracked and stored in the chat history. In this example, we want to track the string passed in as `input`.
* A `history_messages_key` that specifies what the previous messages should be injected into the prompt as. Our prompt has a `MessagesPlaceholder` named `chat_history`, so we specify this property to match.
* (For chains with multiple outputs) an `output_messages_key` which specifies which output to store as history. This is the inverse of `input_messages_key`.
We can invoke this new chain as normal, with an additional `configurable` field that specifies the particular `session_id` to pass to the factory function. This is unused for the demo, but in real-world chains, you’ll want to return a chat history corresponding to the passed session:
```
chain_with_message_history.invoke( {"input": "Translate this sentence from English to French: I love programming."}, {"configurable": {"session_id": "unused"}},)
```
```
AIMessage(content='The translation of "I love programming" in French is "J\'adore la programmation."')
```
```
chain_with_message_history.invoke( {"input": "What did I just ask you?"}, {"configurable": {"session_id": "unused"}})
```
```
AIMessage(content='You just asked me to translate the sentence "I love programming" from English to French.')
```
## Modifying chat history[](#modifying-chat-history "Direct link to Modifying chat history")
Modifying stored chat messages can help your chatbot handle a variety of situations. Here are some examples:
### Trimming messages[](#trimming-messages "Direct link to Trimming messages")
LLMs and chat models have limited context windows, and even if you’re not directly hitting limits, you may want to limit the amount of distraction the model has to deal with. One solution is to only load and store the most recent `n` messages. Let’s use an example history with some preloaded messages:
```
demo_ephemeral_chat_history = ChatMessageHistory()demo_ephemeral_chat_history.add_user_message("Hey there! I'm Nemo.")demo_ephemeral_chat_history.add_ai_message("Hello!")demo_ephemeral_chat_history.add_user_message("How are you today?")demo_ephemeral_chat_history.add_ai_message("Fine thanks!")demo_ephemeral_chat_history.messages
```
```
[HumanMessage(content="Hey there! I'm Nemo."), AIMessage(content='Hello!'), HumanMessage(content='How are you today?'), AIMessage(content='Fine thanks!')]
```
Let’s use this message history with the `RunnableWithMessageHistory` chain we declared above:
```
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. Answer all questions to the best of your ability.", ), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), ])chain = prompt | chatchain_with_message_history = RunnableWithMessageHistory( chain, lambda session_id: demo_ephemeral_chat_history, input_messages_key="input", history_messages_key="chat_history",)chain_with_message_history.invoke( {"input": "What's my name?"}, {"configurable": {"session_id": "unused"}},)
```
```
AIMessage(content='Your name is Nemo.')
```
We can see the chain remembers the preloaded name.
But let’s say we have a very small context window, and we want to trim the number of messages passed to the chain to only the 2 most recent ones. We can use the `clear` method to remove messages and re-add them to the history. We don’t have to, but let’s put this method at the front of our chain to ensure it’s always called:
```
from langchain_core.runnables import RunnablePassthroughdef trim_messages(chain_input): stored_messages = demo_ephemeral_chat_history.messages if len(stored_messages) <= 2: return False demo_ephemeral_chat_history.clear() for message in stored_messages[-2:]: demo_ephemeral_chat_history.add_message(message) return Truechain_with_trimming = ( RunnablePassthrough.assign(messages_trimmed=trim_messages) | chain_with_message_history)
```
Let’s call this new chain and check the messages afterwards:
```
chain_with_trimming.invoke( {"input": "Where does P. Sherman live?"}, {"configurable": {"session_id": "unused"}},)
```
```
AIMessage(content="P. Sherman's address is 42 Wallaby Way, Sydney.")
```
```
demo_ephemeral_chat_history.messages
```
```
[HumanMessage(content="What's my name?"), AIMessage(content='Your name is Nemo.'), HumanMessage(content='Where does P. Sherman live?'), AIMessage(content="P. Sherman's address is 42 Wallaby Way, Sydney.")]
```
And we can see that our history has removed the two oldest messages while still adding the most recent conversation at the end. The next time the chain is called, `trim_messages` will be called again, and only the two most recent messages will be passed to the model. In this case, this means that the model will forget the name we gave it the next time we invoke it:
```
chain_with_trimming.invoke( {"input": "What is my name?"}, {"configurable": {"session_id": "unused"}},)
```
```
AIMessage(content="I'm sorry, I don't have access to your personal information.")
```
```
demo_ephemeral_chat_history.messages
```
```
[HumanMessage(content='Where does P. Sherman live?'), AIMessage(content="P. Sherman's address is 42 Wallaby Way, Sydney."), HumanMessage(content='What is my name?'), AIMessage(content="I'm sorry, I don't have access to your personal information.")]
```
### Summary memory[](#summary-memory "Direct link to Summary memory")
We can use this same pattern in other ways too. For example, we could use an additional LLM call to generate a summary of the conversation before calling our chain. Let’s recreate our chat history and chatbot chain:
```
demo_ephemeral_chat_history = ChatMessageHistory()demo_ephemeral_chat_history.add_user_message("Hey there! I'm Nemo.")demo_ephemeral_chat_history.add_ai_message("Hello!")demo_ephemeral_chat_history.add_user_message("How are you today?")demo_ephemeral_chat_history.add_ai_message("Fine thanks!")demo_ephemeral_chat_history.messages
```
```
[HumanMessage(content="Hey there! I'm Nemo."), AIMessage(content='Hello!'), HumanMessage(content='How are you today?'), AIMessage(content='Fine thanks!')]
```
We’ll slightly modify the prompt to make the LLM aware that will receive a condensed summary instead of a chat history:
```
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. Answer all questions to the best of your ability. The provided chat history includes facts about the user you are speaking with.", ), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ])chain = prompt | chatchain_with_message_history = RunnableWithMessageHistory( chain, lambda session_id: demo_ephemeral_chat_history, input_messages_key="input", history_messages_key="chat_history",)
```
And now, let’s create a function that will distill previous interactions into a summary. We can add this one to the front of the chain too:
```
def summarize_messages(chain_input): stored_messages = demo_ephemeral_chat_history.messages if len(stored_messages) == 0: return False summarization_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ( "user", "Distill the above chat messages into a single summary message. Include as many specific details as you can.", ), ] ) summarization_chain = summarization_prompt | chat summary_message = summarization_chain.invoke({"chat_history": stored_messages}) demo_ephemeral_chat_history.clear() demo_ephemeral_chat_history.add_message(summary_message) return Truechain_with_summarization = ( RunnablePassthrough.assign(messages_summarized=summarize_messages) | chain_with_message_history)
```
Let’s see if it remembers the name we gave it:
```
chain_with_summarization.invoke( {"input": "What did I say my name was?"}, {"configurable": {"session_id": "unused"}},)
```
```
AIMessage(content='You introduced yourself as Nemo. How can I assist you today, Nemo?')
```
```
demo_ephemeral_chat_history.messages
```
```
[AIMessage(content='The conversation is between Nemo and an AI. Nemo introduces himself and the AI responds with a greeting. Nemo then asks the AI how it is doing, and the AI responds that it is fine.'), HumanMessage(content='What did I say my name was?'), AIMessage(content='You introduced yourself as Nemo. How can I assist you today, Nemo?')]
```
Note that invoking the chain again will generate another summary generated from the initial summary plus new messages and so on. You could also design a hybrid approach where a certain number of messages are retained in chat history while others are summarized. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:07.356Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/chatbots/memory_management/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/chatbots/memory_management/",
"description": "A key feature of chatbots is their ability to use content of previous",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7973",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"memory_management\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:05 GMT",
"etag": "W/\"5e415a4bb897c3c36f770718727b5a45\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wpm5b-1713753965942-0985bb965507"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/chatbots/memory_management/",
"property": "og:url"
},
{
"content": "Memory management | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "A key feature of chatbots is their ability to use content of previous",
"property": "og:description"
}
],
"title": "Memory management | 🦜️🔗 LangChain"
} | Memory management
A key feature of chatbots is their ability to use content of previous conversation turns as context. This state management can take several forms, including:
Simply stuffing previous messages into a chat model prompt.
The above, but trimming old messages to reduce the amount of distracting information the model has to deal with.
More complex modifications like synthesizing summaries for long running conversations.
We’ll go into more detail on a few techniques below!
Setup
You’ll need to install a few packages, and have your OpenAI API key set as an environment variable named OPENAI_API_KEY:
%pip install --upgrade --quiet langchain langchain-openai
# Set env var OPENAI_API_KEY or load from a .env file:
import dotenv
dotenv.load_dotenv()
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.
You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.
Note: you may need to restart the kernel to use updated packages.
Let’s also set up a chat model that we’ll use for the below examples.
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model="gpt-3.5-turbo-1106")
Message passing
The simplest form of memory is simply passing chat history messages into a chain. Here’s an example:
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | chat
chain.invoke(
{
"messages": [
HumanMessage(
content="Translate this sentence from English to French: I love programming."
),
AIMessage(content="J'adore la programmation."),
HumanMessage(content="What did you just say?"),
],
}
)
AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')
We can see that by passing the previous conversation into a chain, it can use it as context to answer questions. This is the basic concept underpinning chatbot memory - the rest of the guide will demonstrate convenient techniques for passing or reformatting messages.
Chat history
It’s perfectly fine to store and pass messages directly as an array, but we can use LangChain’s built-in message history class to store and load messages as well. Instances of this class are responsible for storing and loading chat messages from persistent storage. LangChain integrates with many providers - you can see a list of integrations here - but for this demo we will use an ephemeral demo class.
Here’s an example of the API:
from langchain.memory import ChatMessageHistory
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message(
"Translate this sentence from English to French: I love programming."
)
demo_ephemeral_chat_history.add_ai_message("J'adore la programmation.")
demo_ephemeral_chat_history.messages
[HumanMessage(content='Translate this sentence from English to French: I love programming.'),
AIMessage(content="J'adore la programmation.")]
We can use it directly to store conversation turns for our chain:
demo_ephemeral_chat_history = ChatMessageHistory()
input1 = "Translate this sentence from English to French: I love programming."
demo_ephemeral_chat_history.add_user_message(input1)
response = chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
}
)
demo_ephemeral_chat_history.add_ai_message(response)
input2 = "What did I just ask you?"
demo_ephemeral_chat_history.add_user_message(input2)
chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
}
)
AIMessage(content='You asked me to translate the sentence "I love programming" from English to French.')
Automatic history management
The previous examples pass messages to the chain explicitly. This is a completely acceptable approach, but it does require external management of new messages. LangChain also includes an wrapper for LCEL chains that can handle this process automatically called RunnableWithMessageHistory.
To show how it works, let’s slightly modify the above prompt to take a final input variable that populates a HumanMessage template after the chat history. This means that we will expect a chat_history parameter that contains all messages BEFORE the current messages instead of all messages:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability.",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
]
)
chain = prompt | chat
We’ll pass the latest input to the conversation here and let the RunnableWithMessageHistory class wrap our chain and do the work of appending that input variable to the chat history.
Next, let’s declare our wrapped chain:
from langchain_core.runnables.history import RunnableWithMessageHistory
demo_ephemeral_chat_history_for_chain = ChatMessageHistory()
chain_with_message_history = RunnableWithMessageHistory(
chain,
lambda session_id: demo_ephemeral_chat_history_for_chain,
input_messages_key="input",
history_messages_key="chat_history",
)
This class takes a few parameters in addition to the chain that we want to wrap:
A factory function that returns a message history for a given session id. This allows your chain to handle multiple users at once by loading different messages for different conversations.
An input_messages_key that specifies which part of the input should be tracked and stored in the chat history. In this example, we want to track the string passed in as input.
A history_messages_key that specifies what the previous messages should be injected into the prompt as. Our prompt has a MessagesPlaceholder named chat_history, so we specify this property to match.
(For chains with multiple outputs) an output_messages_key which specifies which output to store as history. This is the inverse of input_messages_key.
We can invoke this new chain as normal, with an additional configurable field that specifies the particular session_id to pass to the factory function. This is unused for the demo, but in real-world chains, you’ll want to return a chat history corresponding to the passed session:
chain_with_message_history.invoke(
{"input": "Translate this sentence from English to French: I love programming."},
{"configurable": {"session_id": "unused"}},
)
AIMessage(content='The translation of "I love programming" in French is "J\'adore la programmation."')
chain_with_message_history.invoke(
{"input": "What did I just ask you?"}, {"configurable": {"session_id": "unused"}}
)
AIMessage(content='You just asked me to translate the sentence "I love programming" from English to French.')
Modifying chat history
Modifying stored chat messages can help your chatbot handle a variety of situations. Here are some examples:
Trimming messages
LLMs and chat models have limited context windows, and even if you’re not directly hitting limits, you may want to limit the amount of distraction the model has to deal with. One solution is to only load and store the most recent n messages. Let’s use an example history with some preloaded messages:
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message("Hey there! I'm Nemo.")
demo_ephemeral_chat_history.add_ai_message("Hello!")
demo_ephemeral_chat_history.add_user_message("How are you today?")
demo_ephemeral_chat_history.add_ai_message("Fine thanks!")
demo_ephemeral_chat_history.messages
[HumanMessage(content="Hey there! I'm Nemo."),
AIMessage(content='Hello!'),
HumanMessage(content='How are you today?'),
AIMessage(content='Fine thanks!')]
Let’s use this message history with the RunnableWithMessageHistory chain we declared above:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability.",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
]
)
chain = prompt | chat
chain_with_message_history = RunnableWithMessageHistory(
chain,
lambda session_id: demo_ephemeral_chat_history,
input_messages_key="input",
history_messages_key="chat_history",
)
chain_with_message_history.invoke(
{"input": "What's my name?"},
{"configurable": {"session_id": "unused"}},
)
AIMessage(content='Your name is Nemo.')
We can see the chain remembers the preloaded name.
But let’s say we have a very small context window, and we want to trim the number of messages passed to the chain to only the 2 most recent ones. We can use the clear method to remove messages and re-add them to the history. We don’t have to, but let’s put this method at the front of our chain to ensure it’s always called:
from langchain_core.runnables import RunnablePassthrough
def trim_messages(chain_input):
stored_messages = demo_ephemeral_chat_history.messages
if len(stored_messages) <= 2:
return False
demo_ephemeral_chat_history.clear()
for message in stored_messages[-2:]:
demo_ephemeral_chat_history.add_message(message)
return True
chain_with_trimming = (
RunnablePassthrough.assign(messages_trimmed=trim_messages)
| chain_with_message_history
)
Let’s call this new chain and check the messages afterwards:
chain_with_trimming.invoke(
{"input": "Where does P. Sherman live?"},
{"configurable": {"session_id": "unused"}},
)
AIMessage(content="P. Sherman's address is 42 Wallaby Way, Sydney.")
demo_ephemeral_chat_history.messages
[HumanMessage(content="What's my name?"),
AIMessage(content='Your name is Nemo.'),
HumanMessage(content='Where does P. Sherman live?'),
AIMessage(content="P. Sherman's address is 42 Wallaby Way, Sydney.")]
And we can see that our history has removed the two oldest messages while still adding the most recent conversation at the end. The next time the chain is called, trim_messages will be called again, and only the two most recent messages will be passed to the model. In this case, this means that the model will forget the name we gave it the next time we invoke it:
chain_with_trimming.invoke(
{"input": "What is my name?"},
{"configurable": {"session_id": "unused"}},
)
AIMessage(content="I'm sorry, I don't have access to your personal information.")
demo_ephemeral_chat_history.messages
[HumanMessage(content='Where does P. Sherman live?'),
AIMessage(content="P. Sherman's address is 42 Wallaby Way, Sydney."),
HumanMessage(content='What is my name?'),
AIMessage(content="I'm sorry, I don't have access to your personal information.")]
Summary memory
We can use this same pattern in other ways too. For example, we could use an additional LLM call to generate a summary of the conversation before calling our chain. Let’s recreate our chat history and chatbot chain:
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message("Hey there! I'm Nemo.")
demo_ephemeral_chat_history.add_ai_message("Hello!")
demo_ephemeral_chat_history.add_user_message("How are you today?")
demo_ephemeral_chat_history.add_ai_message("Fine thanks!")
demo_ephemeral_chat_history.messages
[HumanMessage(content="Hey there! I'm Nemo."),
AIMessage(content='Hello!'),
HumanMessage(content='How are you today?'),
AIMessage(content='Fine thanks!')]
We’ll slightly modify the prompt to make the LLM aware that will receive a condensed summary instead of a chat history:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability. The provided chat history includes facts about the user you are speaking with.",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
]
)
chain = prompt | chat
chain_with_message_history = RunnableWithMessageHistory(
chain,
lambda session_id: demo_ephemeral_chat_history,
input_messages_key="input",
history_messages_key="chat_history",
)
And now, let’s create a function that will distill previous interactions into a summary. We can add this one to the front of the chain too:
def summarize_messages(chain_input):
stored_messages = demo_ephemeral_chat_history.messages
if len(stored_messages) == 0:
return False
summarization_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="chat_history"),
(
"user",
"Distill the above chat messages into a single summary message. Include as many specific details as you can.",
),
]
)
summarization_chain = summarization_prompt | chat
summary_message = summarization_chain.invoke({"chat_history": stored_messages})
demo_ephemeral_chat_history.clear()
demo_ephemeral_chat_history.add_message(summary_message)
return True
chain_with_summarization = (
RunnablePassthrough.assign(messages_summarized=summarize_messages)
| chain_with_message_history
)
Let’s see if it remembers the name we gave it:
chain_with_summarization.invoke(
{"input": "What did I say my name was?"},
{"configurable": {"session_id": "unused"}},
)
AIMessage(content='You introduced yourself as Nemo. How can I assist you today, Nemo?')
demo_ephemeral_chat_history.messages
[AIMessage(content='The conversation is between Nemo and an AI. Nemo introduces himself and the AI responds with a greeting. Nemo then asks the AI how it is doing, and the AI responds that it is fine.'),
HumanMessage(content='What did I say my name was?'),
AIMessage(content='You introduced yourself as Nemo. How can I assist you today, Nemo?')]
Note that invoking the chain again will generate another summary generated from the initial summary plus new messages and so on. You could also design a hybrid approach where a certain number of messages are retained in chat history while others are summarized. |
https://python.langchain.com/docs/use_cases/extraction/ | ## Extracting structured output
## Overview[](#overview "Direct link to Overview")
Large Language Models (LLMs) are emerging as an extremely capable technology for powering information extraction applications.
Classical solutions to information extraction rely on a combination of people, (many) hand-crafted rules (e.g., regular expressions), and custom fine-tuned ML models.
Such systems tend to get complex over time and become progressively more expensive to maintain and more difficult to enhance.
LLMs can be adapted quickly for specific extraction tasks just by providing appropriate instructions to them and appropriate reference examples.
This guide will show you how to use LLMs for extraction applications!
## Approaches[](#approaches "Direct link to Approaches")
There are 3 broad approaches for information extraction using LLMs:
* **Tool/Function Calling** Mode: Some LLMs support a _tool or function calling_ mode. These LLMs can structure output according to a given **schema**. Generally, this approach is the easiest to work with and is expected to yield good results.
* **JSON Mode**: Some LLMs are can be forced to output valid JSON. This is similar to **tool/function Calling** approach, except that the schema is provided as part of the prompt. Generally, our intuition is that this performs worse than a **tool/function calling** approach, but don’t trust us and verify for your own use case!
* **Prompting Based**: LLMs that can follow instructions well can be instructed to generate text in a desired format. The generated text can be parsed downstream using existing [Output Parsers](https://python.langchain.com/docs/modules/model_io/output_parsers/) or using [custom parsers](https://python.langchain.com/docs/modules/model_io/output_parsers/custom/) into a structured format like JSON. This approach can be used with LLMs that **do not support** JSON mode or tool/function calling modes. This approach is more broadly applicable, though may yield worse results than models that have been fine-tuned for extraction or function calling.
## Quickstart[](#quickstart "Direct link to Quickstart")
Head to the [quickstart](https://python.langchain.com/docs/use_cases/extraction/quickstart/) to see how to extract information using LLMs using a basic end-to-end example.
The quickstart focuses on information extraction using the **tool/function calling** approach.
## How-To Guides[](#how-to-guides "Direct link to How-To Guides")
* [Use Reference Examples](https://python.langchain.com/docs/use_cases/extraction/how_to/examples/): Learn how to use **reference examples** to improve performance.
* [Handle Long Text](https://python.langchain.com/docs/use_cases/extraction/how_to/handle_long_text/): What should you do if the text does not fit into the context window of the LLM?
* [Handle Files](https://python.langchain.com/docs/use_cases/extraction/how_to/handle_files/): Examples of using LangChain document loaders and parsers to extract from files like PDFs.
* [Use a Parsing Approach](https://python.langchain.com/docs/use_cases/extraction/how_to/parse/): Use a prompt based approach to extract with models that do not support **tool/function calling**.
## Guidelines[](#guidelines "Direct link to Guidelines")
Head to the [Guidelines](https://python.langchain.com/docs/use_cases/extraction/guidelines/) page to see a list of opinionated guidelines on how to get the best performance for extraction use cases.
## Use Case Accelerant[](#use-case-accelerant "Direct link to Use Case Accelerant")
[langchain-extract](https://github.com/langchain-ai/langchain-extract) is a starter repo that implements a simple web server for information extraction from text and files using LLMs. It is build using **FastAPI**, **LangChain** and **Postgresql**. Feel free to adapt it to your own use cases.
## Other Resources[](#other-resources "Direct link to Other Resources")
* The [output parser](https://python.langchain.com/docs/modules/model_io/output_parsers/) documentation includes various parser examples for specific types (e.g., lists, datetime, enum, etc).
* LangChain [document loaders](https://python.langchain.com/docs/modules/data_connection/document_loaders/) to load content from files. Please see list of [integrations](https://python.langchain.com/docs/integrations/document_loaders/).
* The experimental [Anthropic function calling](https://python.langchain.com/docs/integrations/chat/anthropic_functions/) support provides similar functionality to Anthropic chat models.
* [LlamaCPP](https://python.langchain.com/docs/integrations/llms/llamacpp/#grammars) natively supports constrained decoding using custom grammars, making it easy to output structured content using local LLMs
* [JSONFormer](https://python.langchain.com/docs/integrations/llms/jsonformer_experimental/) offers another way for structured decoding of a subset of the JSON Schema.
* [Kor](https://eyurtsev.github.io/kor/) is another library for extraction where schema and examples can be provided to the LLM. Kor is optimized to work for a parsing approach.
* [OpenAI’s function and tool calling](https://platform.openai.com/docs/guides/function-calling)
* For example, see [OpenAI’s JSON mode](https://platform.openai.com/docs/guides/text-generation/json-mode). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:07.929Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/",
"description": "Overview",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7304",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"extraction\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:06 GMT",
"etag": "W/\"40a757b0851f31d36f892ece4375352a\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::p8jmq-1713753966668-6f611d286eea"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/",
"property": "og:url"
},
{
"content": "Extracting structured output | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Overview",
"property": "og:description"
}
],
"title": "Extracting structured output | 🦜️🔗 LangChain"
} | Extracting structured output
Overview
Large Language Models (LLMs) are emerging as an extremely capable technology for powering information extraction applications.
Classical solutions to information extraction rely on a combination of people, (many) hand-crafted rules (e.g., regular expressions), and custom fine-tuned ML models.
Such systems tend to get complex over time and become progressively more expensive to maintain and more difficult to enhance.
LLMs can be adapted quickly for specific extraction tasks just by providing appropriate instructions to them and appropriate reference examples.
This guide will show you how to use LLMs for extraction applications!
Approaches
There are 3 broad approaches for information extraction using LLMs:
Tool/Function Calling Mode: Some LLMs support a tool or function calling mode. These LLMs can structure output according to a given schema. Generally, this approach is the easiest to work with and is expected to yield good results.
JSON Mode: Some LLMs are can be forced to output valid JSON. This is similar to tool/function Calling approach, except that the schema is provided as part of the prompt. Generally, our intuition is that this performs worse than a tool/function calling approach, but don’t trust us and verify for your own use case!
Prompting Based: LLMs that can follow instructions well can be instructed to generate text in a desired format. The generated text can be parsed downstream using existing Output Parsers or using custom parsers into a structured format like JSON. This approach can be used with LLMs that do not support JSON mode or tool/function calling modes. This approach is more broadly applicable, though may yield worse results than models that have been fine-tuned for extraction or function calling.
Quickstart
Head to the quickstart to see how to extract information using LLMs using a basic end-to-end example.
The quickstart focuses on information extraction using the tool/function calling approach.
How-To Guides
Use Reference Examples: Learn how to use reference examples to improve performance.
Handle Long Text: What should you do if the text does not fit into the context window of the LLM?
Handle Files: Examples of using LangChain document loaders and parsers to extract from files like PDFs.
Use a Parsing Approach: Use a prompt based approach to extract with models that do not support tool/function calling.
Guidelines
Head to the Guidelines page to see a list of opinionated guidelines on how to get the best performance for extraction use cases.
Use Case Accelerant
langchain-extract is a starter repo that implements a simple web server for information extraction from text and files using LLMs. It is build using FastAPI, LangChain and Postgresql. Feel free to adapt it to your own use cases.
Other Resources
The output parser documentation includes various parser examples for specific types (e.g., lists, datetime, enum, etc).
LangChain document loaders to load content from files. Please see list of integrations.
The experimental Anthropic function calling support provides similar functionality to Anthropic chat models.
LlamaCPP natively supports constrained decoding using custom grammars, making it easy to output structured content using local LLMs
JSONFormer offers another way for structured decoding of a subset of the JSON Schema.
Kor is another library for extraction where schema and examples can be provided to the LLM. Kor is optimized to work for a parsing approach.
OpenAI’s function and tool calling
For example, see OpenAI’s JSON mode. |
https://python.langchain.com/docs/use_cases/extraction/guidelines/ | ## Guidelines
The quality of extraction results depends on many factors.
Here is a set of guidelines to help you squeeze out the best performance from your models:
* Set the model temperature to `0`.
* Improve the prompt. The prompt should be precise and to the point.
* Document the schema: Make sure the schema is documented to provide more information to the LLM.
* Provide reference examples! Diverse examples can help, including examples where nothing should be extracted.
* If you have a lot of examples, use a retriever to retrieve the most relevant examples.
* Benchmark with the best available LLM/Chat Model (e.g., gpt-4, claude-3, etc) – check with the model provider which one is the latest and greatest!
* If the schema is very large, try breaking it into multiple smaller schemas, run separate extractions and merge the results.
* Make sure that the schema allows the model to REJECT extracting information. If it doesn’t, the model will be forced to make up information!
* Add verification/correction steps (ask an LLM to correct or verify the results of the extraction).
## Benchmark[](#benchmark "Direct link to Benchmark")
* Create and benchmark data for your use case using [LangSmith 🦜️🛠️](https://docs.smith.langchain.com/).
* Is your LLM good enough? Use [langchain-benchmarks 🦜💯](https://github.com/langchain-ai/langchain-benchmarks) to test out your LLM using existing datasets.
## Keep in mind! 😶🌫️[](#keep-in-mind "Direct link to Keep in mind! 😶🌫️")
* LLMs are great, but are not required for all cases! If you’re extracting information from a single structured source (e.g., linkedin), using an LLM is not a good idea – traditional web-scraping will be much cheaper and reliable.
* **human in the loop** If you need **perfect quality**, you’ll likely need to plan on having a human in the loop – even the best LLMs will make mistakes when dealing with complex extraction tasks.
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:08.042Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/guidelines/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/guidelines/",
"description": "The quality of extraction results depends on many factors.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3763",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"guidelines\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:07 GMT",
"etag": "W/\"d6b1b3082f583c837207eb74d5010d5e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::5n47r-1713753967344-302efaa32815"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/guidelines/",
"property": "og:url"
},
{
"content": "Guidelines | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "The quality of extraction results depends on many factors.",
"property": "og:description"
}
],
"title": "Guidelines | 🦜️🔗 LangChain"
} | Guidelines
The quality of extraction results depends on many factors.
Here is a set of guidelines to help you squeeze out the best performance from your models:
Set the model temperature to 0.
Improve the prompt. The prompt should be precise and to the point.
Document the schema: Make sure the schema is documented to provide more information to the LLM.
Provide reference examples! Diverse examples can help, including examples where nothing should be extracted.
If you have a lot of examples, use a retriever to retrieve the most relevant examples.
Benchmark with the best available LLM/Chat Model (e.g., gpt-4, claude-3, etc) – check with the model provider which one is the latest and greatest!
If the schema is very large, try breaking it into multiple smaller schemas, run separate extractions and merge the results.
Make sure that the schema allows the model to REJECT extracting information. If it doesn’t, the model will be forced to make up information!
Add verification/correction steps (ask an LLM to correct or verify the results of the extraction).
Benchmark
Create and benchmark data for your use case using LangSmith 🦜️🛠️.
Is your LLM good enough? Use langchain-benchmarks 🦜💯 to test out your LLM using existing datasets.
Keep in mind! 😶🌫️
LLMs are great, but are not required for all cases! If you’re extracting information from a single structured source (e.g., linkedin), using an LLM is not a good idea – traditional web-scraping will be much cheaper and reliable.
human in the loop If you need perfect quality, you’ll likely need to plan on having a human in the loop – even the best LLMs will make mistakes when dealing with complex extraction tasks.
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/use_cases/chatbots/tool_usage/ | ## Tool usage
This section will cover how to create conversational agents: chatbots that can interact with other systems and APIs using tools.
Before reading this guide, we recommend you read both [the chatbot quickstart](https://python.langchain.com/docs/use_cases/chatbots/quickstart/) in this section and be familiar with [the documentation on agents](https://python.langchain.com/docs/modules/agents/).
## Setup[](#setup "Direct link to Setup")
For this guide, we’ll be using an [OpenAI tools agent](https://python.langchain.com/docs/modules/agents/agent_types/openai_tools/) with a single tool for searching the web. The default will be powered by [Tavily](https://python.langchain.com/docs/integrations/tools/tavily_search/), but you can switch it out for any similar tool. The rest of this section will assume you’re using Tavily.
You’ll need to [sign up for an account](https://tavily.com/) on the Tavily website, and install the following packages:
```
%pip install --upgrade --quiet langchain-openai tavily-python# Set env var OPENAI_API_KEY or load from a .env file:import dotenvdotenv.load_dotenv()
```
```
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.Note: you may need to restart the kernel to use updated packages.
```
You will also need your OpenAI key set as `OPENAI_API_KEY` and your Tavily API key set as `TAVILY_API_KEY`.
## Creating an agent[](#creating-an-agent "Direct link to Creating an agent")
Our end goal is to create an agent that can respond conversationally to user questions while looking up information as needed.
First, let’s initialize Tavily and an OpenAI chat model capable of tool calling:
```
from langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_openai import ChatOpenAItools = [TavilySearchResults(max_results=1)]# Choose the LLM that will drive the agent# Only certain models support thischat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)
```
To make our agent conversational, we must also choose a prompt with a placeholder for our chat history. Here’s an example:
```
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder# Adapted from https://smith.langchain.com/hub/hwchase17/openai-tools-agentprompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. You may not need to use tools for every query - the user may just want to chat!", ), MessagesPlaceholder(variable_name="messages"), MessagesPlaceholder(variable_name="agent_scratchpad"), ])
```
Great! Now let’s assemble our agent:
```
from langchain.agents import AgentExecutor, create_openai_tools_agentagent = create_openai_tools_agent(chat, tools, prompt)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
```
## Running the agent[](#running-the-agent "Direct link to Running the agent")
Now that we’ve set up our agent, let’s try interacting with it! It can handle both trivial queries that require no lookup:
```
from langchain_core.messages import HumanMessageagent_executor.invoke({"messages": [HumanMessage(content="I'm Nemo!")]})
```
```
> Entering new AgentExecutor chain...Hello Nemo! It's great to meet you. How can I assist you today?> Finished chain.
```
```
{'messages': [HumanMessage(content="I'm Nemo!")], 'output': "Hello Nemo! It's great to meet you. How can I assist you today?"}
```
Or, it can use of the passed search tool to get up to date information if needed:
```
agent_executor.invoke( { "messages": [ HumanMessage( content="What is the current conservation status of the Great Barrier Reef?" ) ], })
```
```
> Entering new AgentExecutor chain...Invoking: `tavily_search_results_json` with `{'query': 'current conservation status of the Great Barrier Reef'}`[{'url': 'https://www.barrierreef.org/news/blog/this-is-the-critical-decade-for-coral-reef-survival', 'content': "global coral reef conservation. © 2024 Great Barrier Reef Foundation. Website by bigfish.tv #Related News · 29 January 2024 290m more baby corals to help restore and protect the Great Barrier Reef Great Barrier Reef Foundation Managing Director Anna Marsden says it’s not too late if we act now.The Status of Coral Reefs of the World: 2020 report is the largest analysis of global coral reef health ever undertaken. It found that 14 per cent of the world's coral has been lost since 2009. The report also noted, however, that some of these corals recovered during the 10 years to 2019."}]The current conservation status of the Great Barrier Reef is a critical concern. According to the Great Barrier Reef Foundation, the Status of Coral Reefs of the World: 2020 report found that 14% of the world's coral has been lost since 2009. However, the report also noted that some of these corals recovered during the 10 years to 2019. For more information, you can visit the following link: [Great Barrier Reef Foundation - Conservation Status](https://www.barrierreef.org/news/blog/this-is-the-critical-decade-for-coral-reef-survival)> Finished chain.
```
```
{'messages': [HumanMessage(content='What is the current conservation status of the Great Barrier Reef?')], 'output': "The current conservation status of the Great Barrier Reef is a critical concern. According to the Great Barrier Reef Foundation, the Status of Coral Reefs of the World: 2020 report found that 14% of the world's coral has been lost since 2009. However, the report also noted that some of these corals recovered during the 10 years to 2019. For more information, you can visit the following link: [Great Barrier Reef Foundation - Conservation Status](https://www.barrierreef.org/news/blog/this-is-the-critical-decade-for-coral-reef-survival)"}
```
## Conversational responses[](#conversational-responses "Direct link to Conversational responses")
Because our prompt contains a placeholder for chat history messages, our agent can also take previous interactions into account and respond conversationally like a standard chatbot:
```
from langchain_core.messages import AIMessage, HumanMessageagent_executor.invoke( { "messages": [ HumanMessage(content="I'm Nemo!"), AIMessage(content="Hello Nemo! How can I assist you today?"), HumanMessage(content="What is my name?"), ], })
```
```
> Entering new AgentExecutor chain...Your name is Nemo!> Finished chain.
```
```
{'messages': [HumanMessage(content="I'm Nemo!"), AIMessage(content='Hello Nemo! How can I assist you today?'), HumanMessage(content='What is my name?')], 'output': 'Your name is Nemo!'}
```
If preferred, you can also wrap the agent executor in a `RunnableWithMessageHistory` class to internally manage history messages. First, we need to slightly modify the prompt to take a separate input variable so that the wrapper can parse which input value to store as history:
```
# Adapted from https://smith.langchain.com/hub/hwchase17/openai-tools-agentprompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant. You may not need to use tools for every query - the user may just want to chat!", ), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ])agent = create_openai_tools_agent(chat, tools, prompt)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
```
Then, because our agent executor has multiple outputs, we also have to set the `output_messages_key` property when initializing the wrapper:
```
from langchain.memory import ChatMessageHistoryfrom langchain_core.runnables.history import RunnableWithMessageHistorydemo_ephemeral_chat_history_for_chain = ChatMessageHistory()conversational_agent_executor = RunnableWithMessageHistory( agent_executor, lambda session_id: demo_ephemeral_chat_history_for_chain, input_messages_key="input", output_messages_key="output", history_messages_key="chat_history",)
```
```
conversational_agent_executor.invoke( { "input": "I'm Nemo!", }, {"configurable": {"session_id": "unused"}},)
```
```
> Entering new AgentExecutor chain...Hi Nemo! It's great to meet you. How can I assist you today?> Finished chain.
```
```
{'input': "I'm Nemo!", 'chat_history': [], 'output': "Hi Nemo! It's great to meet you. How can I assist you today?"}
```
```
conversational_agent_executor.invoke( { "input": "What is my name?", }, {"configurable": {"session_id": "unused"}},)
```
```
> Entering new AgentExecutor chain...Your name is Nemo! How can I assist you today, Nemo?> Finished chain.
```
```
{'input': 'What is my name?', 'chat_history': [HumanMessage(content="I'm Nemo!"), AIMessage(content="Hi Nemo! It's great to meet you. How can I assist you today?")], 'output': 'Your name is Nemo! How can I assist you today, Nemo?'}
```
## Further reading[](#further-reading "Direct link to Further reading")
Other types agents can also support conversational responses too - for more, check out the [agents section](https://python.langchain.com/docs/modules/agents/).
For more on tool usage, you can also check out [this use case section](https://python.langchain.com/docs/use_cases/tool_use/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:08.208Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/chatbots/tool_usage/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/chatbots/tool_usage/",
"description": "This section will cover how to create conversational agents: chatbots",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7608",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"tool_usage\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:07 GMT",
"etag": "W/\"31718b171f65527e98c351e787960be2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::sltw9-1713753967434-1e6651324e89"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/chatbots/tool_usage/",
"property": "og:url"
},
{
"content": "Tool usage | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This section will cover how to create conversational agents: chatbots",
"property": "og:description"
}
],
"title": "Tool usage | 🦜️🔗 LangChain"
} | Tool usage
This section will cover how to create conversational agents: chatbots that can interact with other systems and APIs using tools.
Before reading this guide, we recommend you read both the chatbot quickstart in this section and be familiar with the documentation on agents.
Setup
For this guide, we’ll be using an OpenAI tools agent with a single tool for searching the web. The default will be powered by Tavily, but you can switch it out for any similar tool. The rest of this section will assume you’re using Tavily.
You’ll need to sign up for an account on the Tavily website, and install the following packages:
%pip install --upgrade --quiet langchain-openai tavily-python
# Set env var OPENAI_API_KEY or load from a .env file:
import dotenv
dotenv.load_dotenv()
WARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.
You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.
Note: you may need to restart the kernel to use updated packages.
You will also need your OpenAI key set as OPENAI_API_KEY and your Tavily API key set as TAVILY_API_KEY.
Creating an agent
Our end goal is to create an agent that can respond conversationally to user questions while looking up information as needed.
First, let’s initialize Tavily and an OpenAI chat model capable of tool calling:
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
tools = [TavilySearchResults(max_results=1)]
# Choose the LLM that will drive the agent
# Only certain models support this
chat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)
To make our agent conversational, we must also choose a prompt with a placeholder for our chat history. Here’s an example:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# Adapted from https://smith.langchain.com/hub/hwchase17/openai-tools-agent
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. You may not need to use tools for every query - the user may just want to chat!",
),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
Great! Now let’s assemble our agent:
from langchain.agents import AgentExecutor, create_openai_tools_agent
agent = create_openai_tools_agent(chat, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Running the agent
Now that we’ve set up our agent, let’s try interacting with it! It can handle both trivial queries that require no lookup:
from langchain_core.messages import HumanMessage
agent_executor.invoke({"messages": [HumanMessage(content="I'm Nemo!")]})
> Entering new AgentExecutor chain...
Hello Nemo! It's great to meet you. How can I assist you today?
> Finished chain.
{'messages': [HumanMessage(content="I'm Nemo!")],
'output': "Hello Nemo! It's great to meet you. How can I assist you today?"}
Or, it can use of the passed search tool to get up to date information if needed:
agent_executor.invoke(
{
"messages": [
HumanMessage(
content="What is the current conservation status of the Great Barrier Reef?"
)
],
}
)
> Entering new AgentExecutor chain...
Invoking: `tavily_search_results_json` with `{'query': 'current conservation status of the Great Barrier Reef'}`
[{'url': 'https://www.barrierreef.org/news/blog/this-is-the-critical-decade-for-coral-reef-survival', 'content': "global coral reef conservation. © 2024 Great Barrier Reef Foundation. Website by bigfish.tv #Related News · 29 January 2024 290m more baby corals to help restore and protect the Great Barrier Reef Great Barrier Reef Foundation Managing Director Anna Marsden says it’s not too late if we act now.The Status of Coral Reefs of the World: 2020 report is the largest analysis of global coral reef health ever undertaken. It found that 14 per cent of the world's coral has been lost since 2009. The report also noted, however, that some of these corals recovered during the 10 years to 2019."}]The current conservation status of the Great Barrier Reef is a critical concern. According to the Great Barrier Reef Foundation, the Status of Coral Reefs of the World: 2020 report found that 14% of the world's coral has been lost since 2009. However, the report also noted that some of these corals recovered during the 10 years to 2019. For more information, you can visit the following link: [Great Barrier Reef Foundation - Conservation Status](https://www.barrierreef.org/news/blog/this-is-the-critical-decade-for-coral-reef-survival)
> Finished chain.
{'messages': [HumanMessage(content='What is the current conservation status of the Great Barrier Reef?')],
'output': "The current conservation status of the Great Barrier Reef is a critical concern. According to the Great Barrier Reef Foundation, the Status of Coral Reefs of the World: 2020 report found that 14% of the world's coral has been lost since 2009. However, the report also noted that some of these corals recovered during the 10 years to 2019. For more information, you can visit the following link: [Great Barrier Reef Foundation - Conservation Status](https://www.barrierreef.org/news/blog/this-is-the-critical-decade-for-coral-reef-survival)"}
Conversational responses
Because our prompt contains a placeholder for chat history messages, our agent can also take previous interactions into account and respond conversationally like a standard chatbot:
from langchain_core.messages import AIMessage, HumanMessage
agent_executor.invoke(
{
"messages": [
HumanMessage(content="I'm Nemo!"),
AIMessage(content="Hello Nemo! How can I assist you today?"),
HumanMessage(content="What is my name?"),
],
}
)
> Entering new AgentExecutor chain...
Your name is Nemo!
> Finished chain.
{'messages': [HumanMessage(content="I'm Nemo!"),
AIMessage(content='Hello Nemo! How can I assist you today?'),
HumanMessage(content='What is my name?')],
'output': 'Your name is Nemo!'}
If preferred, you can also wrap the agent executor in a RunnableWithMessageHistory class to internally manage history messages. First, we need to slightly modify the prompt to take a separate input variable so that the wrapper can parse which input value to store as history:
# Adapted from https://smith.langchain.com/hub/hwchase17/openai-tools-agent
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. You may not need to use tools for every query - the user may just want to chat!",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_tools_agent(chat, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Then, because our agent executor has multiple outputs, we also have to set the output_messages_key property when initializing the wrapper:
from langchain.memory import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
demo_ephemeral_chat_history_for_chain = ChatMessageHistory()
conversational_agent_executor = RunnableWithMessageHistory(
agent_executor,
lambda session_id: demo_ephemeral_chat_history_for_chain,
input_messages_key="input",
output_messages_key="output",
history_messages_key="chat_history",
)
conversational_agent_executor.invoke(
{
"input": "I'm Nemo!",
},
{"configurable": {"session_id": "unused"}},
)
> Entering new AgentExecutor chain...
Hi Nemo! It's great to meet you. How can I assist you today?
> Finished chain.
{'input': "I'm Nemo!",
'chat_history': [],
'output': "Hi Nemo! It's great to meet you. How can I assist you today?"}
conversational_agent_executor.invoke(
{
"input": "What is my name?",
},
{"configurable": {"session_id": "unused"}},
)
> Entering new AgentExecutor chain...
Your name is Nemo! How can I assist you today, Nemo?
> Finished chain.
{'input': 'What is my name?',
'chat_history': [HumanMessage(content="I'm Nemo!"),
AIMessage(content="Hi Nemo! It's great to meet you. How can I assist you today?")],
'output': 'Your name is Nemo! How can I assist you today, Nemo?'}
Further reading
Other types agents can also support conversational responses too - for more, check out the agents section.
For more on tool usage, you can also check out this use case section. |
https://python.langchain.com/docs/use_cases/code_understanding/ | ## Code understanding
[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/code_understanding.ipynb)
Open In Colab
## Use case[](#use-case "Direct link to Use case")
Source code analysis is one of the most popular LLM applications (e.g., [GitHub Copilot](https://github.com/features/copilot), [Code Interpreter](https://chat.openai.com/auth/login?next=%2F%3Fmodel%3Dgpt-4-code-interpreter), [Codium](https://www.codium.ai/), and [Codeium](https://codeium.com/about)) for use-cases such as:
* Q&A over the code base to understand how it works
* Using LLMs for suggesting refactors or improvements
* Using LLMs for documenting the code

## Overview[](#overview "Direct link to Overview")
The pipeline for QA over code follows [the steps we do for document question answering](https://python.langchain.com/docs/use_cases/question_answering/), with some differences:
In particular, we can employ a [splitting strategy](https://python.langchain.com/docs/integrations/document_loaders/source_code/) that does a few things:
* Keeps each top-level function and class in the code is loaded into separate documents.
* Puts remaining into a separate document.
* Retains metadata about where each split comes from
## Quickstart[](#quickstart "Direct link to Quickstart")
```
%pip install --upgrade --quiet langchain-openai tiktoken langchain-chroma langchain git# Set env var OPENAI_API_KEY or load from a .env file# import dotenv# dotenv.load_dotenv()
```
We’ll follow the structure of [this notebook](https://github.com/cristobalcl/LearningLangChain/blob/master/notebooks/04%20-%20QA%20with%20code.ipynb) and employ [context aware code splitting](https://python.langchain.com/docs/integrations/document_loaders/source_code/).
### Loading[](#loading "Direct link to Loading")
We will upload all python project files using the `langchain_community.document_loaders.TextLoader`.
The following script iterates over the files in the LangChain repository and loads every `.py` file (a.k.a. **documents**):
```
from git import Repofrom langchain_community.document_loaders.generic import GenericLoaderfrom langchain_community.document_loaders.parsers import LanguageParserfrom langchain_text_splitters import Language
```
```
# Clonerepo_path = "/Users/jacoblee/Desktop/test_repo"repo = Repo.clone_from("https://github.com/langchain-ai/langchain", to_path=repo_path)
```
We load the py code using [`LanguageParser`](https://python.langchain.com/docs/integrations/document_loaders/source_code/), which will:
* Keep top-level functions and classes together (into a single document)
* Put remaining code into a separate document
* Retains metadata about where each split comes from
```
# Loadloader = GenericLoader.from_filesystem( repo_path + "/libs/core/langchain_core", glob="**/*", suffixes=[".py"], exclude=["**/non-utf8-encoding.py"], parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),)documents = loader.load()len(documents)
```
### Splitting[](#splitting "Direct link to Splitting")
Split the `Document` into chunks for embedding and vector storage.
We can use `RecursiveCharacterTextSplitter` w/ `language` specified.
```
from langchain_text_splitters import RecursiveCharacterTextSplitterpython_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=2000, chunk_overlap=200)texts = python_splitter.split_documents(documents)len(texts)
```
### RetrievalQA[](#retrievalqa "Direct link to RetrievalQA")
We need to store the documents in a way we can semantically search for their content.
The most common approach is to embed the contents of each document then store the embedding and document in a vector store.
When setting up the vectorstore retriever:
* We test [max marginal relevance](https://python.langchain.com/docs/use_cases/question_answering/) for retrieval
* And 8 documents returned
#### Go deeper[](#go-deeper "Direct link to Go deeper")
* Browse the \> 40 vectorstores integrations [here](https://integrations.langchain.com/).
* See further documentation on vectorstores [here](https://python.langchain.com/docs/modules/data_connection/vectorstores/).
* Browse the \> 30 text embedding integrations [here](https://integrations.langchain.com/).
* See further documentation on embedding models [here](https://python.langchain.com/docs/modules/data_connection/text_embedding/).
```
from langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingsdb = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))retriever = db.as_retriever( search_type="mmr", # Also test "similarity" search_kwargs={"k": 8},)
```
### Chat[](#chat "Direct link to Chat")
Test chat, just as we do for [chatbots](https://python.langchain.com/docs/use_cases/chatbots/).
#### Go deeper[](#go-deeper-1 "Direct link to Go deeper")
* Browse the \> 55 LLM and chat model integrations [here](https://integrations.langchain.com/).
* See further documentation on LLMs and chat models [here](https://python.langchain.com/docs/modules/model_io/).
* Use local LLMS: The popularity of [PrivateGPT](https://github.com/imartinez/privateGPT) and [GPT4All](https://github.com/nomic-ai/gpt4all) underscore the importance of running LLMs locally.
```
from langchain.chains import create_history_aware_retriever, create_retrieval_chainfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4")# First we need a prompt that we can pass into an LLM to generate this search queryprompt = ChatPromptTemplate.from_messages( [ ("placeholder", "{chat_history}"), ("user", "{input}"), ( "user", "Given the above conversation, generate a search query to look up to get information relevant to the conversation", ), ])retriever_chain = create_history_aware_retriever(llm, retriever, prompt)prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the user's questions based on the below context:\n\n{context}", ), ("placeholder", "{chat_history}"), ("user", "{input}"), ])document_chain = create_stuff_documents_chain(llm, prompt)qa = create_retrieval_chain(retriever_chain, document_chain)
```
```
question = "What is a RunnableBinding?"result = qa.invoke({"input": question})result["answer"]
```
```
'A RunnableBinding is a class in the LangChain library that is used to bind arguments to a Runnable. This is useful when a runnable in a chain requires an argument that is not in the output of the previous runnable or included in the user input. It returns a new Runnable with the bound arguments and configuration. The bind method in the RunnableBinding class is used to perform this operation.'
```
```
questions = [ "What classes are derived from the Runnable class?", "What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?",]for question in questions: result = qa.invoke({"input": question}) print(f"-> **Question**: {question} \n") print(f"**Answer**: {result['answer']} \n")
```
```
-> **Question**: What classes are derived from the Runnable class? **Answer**: The classes derived from the `Runnable` class as mentioned in the context are: `RunnableLambda`, `RunnableLearnable`, `RunnableSerializable`, `RunnableWithFallbacks`. -> **Question**: What one improvement do you propose in code in relation to the class hierarchy for the Runnable class? **Answer**: One potential improvement could be the introduction of abstract base classes (ABCs) or interfaces for different types of Runnable classes. Currently, it seems like there are lots of different Runnable types, like RunnableLambda, RunnableParallel, etc., each with their own methods and attributes. By defining a common interface or ABC for all these classes, we can ensure consistency and better organize the codebase. It would also make it easier to add new types of Runnable classes in the future, as they would just need to implement the methods defined in the interface or ABC.
```
Then we can look at the [LangSmith trace](https://smith.langchain.com/public/616f6620-f49f-46c7-8f4b-dae847705c5d/r) to see what is happening under the hood:
* In particular, the code well structured and kept together in the retrieval output
* The retrieved code and chat history are passed to the LLM for answer distillation

### Open source LLMs[](#open-source-llms "Direct link to Open source LLMs")
We’ll use LangChain’s [Ollama integration](https://ollama.com/) to query a local OSS model.
Check out the latest available models [here](https://ollama.com/library).
```
%pip install --upgrade --quiet langchain-community
```
```
from langchain_community.chat_models.ollama import ChatOllamallm = ChatOllama(model="codellama")
```
Let’s run it with a generic coding question to test its knowledge:
```
response_message = llm.invoke( "In bash, how do I list all the text files in the current directory that have been modified in the last month?")print(response_message.content)print(response_message.response_metadata)
```
```
You can use the `find` command with the `-mtime` option to find all the text files in the current directory that have been modified in the last month. Here's an example command:```bashfind . -type f -name "*.txt" -mtime -30```This will list all the text files in the current directory (`.`) that have been modified in the last 30 days. The `-type f` option ensures that only regular files are matched, and not directories or other types of files. The `-name "*.txt"` option restricts the search to files with a `.txt` extension. Finally, the `-mtime -30` option specifies that we want to find files that have been modified in the last 30 days.You can also use `find` command with `-mmin` option to find all the text files in the current directory that have been modified within the last month. Here's an example command:```bashfind . -type f -name "*.txt" -mmin -4320```This will list all the text files in the current directory (`.`) that have been modified within the last 30 days. The `-type f` option ensures that only regular files are matched, and not directories or other types of files. The `-name "*.txt"` option restricts the search to files with a `.txt` extension. Finally, the `-mmin -4320` option specifies that we want to find files that have been modified within the last 4320 minutes (which is equivalent to one month).You can also use `ls` command with `-l` option and pipe it to `grep` command to filter out the text files. Here's an example command:```bashls -l | grep "*.txt"```This will list all the text files in the current directory (`.`) that have been modified within the last 30 days. The `-l` option of `ls` command lists the files in a long format, including the modification time, and the `grep` command filters out the files that do not match the specified pattern.Please note that these commands are case-sensitive, so if you have any files with different extensions (e.g., `.TXT`), they will not be matched by these commands.{'model': 'codellama', 'created_at': '2024-04-03T00:41:44.014203Z', 'message': {'role': 'assistant', 'content': ''}, 'done': True, 'total_duration': 27078466916, 'load_duration': 12947208, 'prompt_eval_count': 44, 'prompt_eval_duration': 11497468000, 'eval_count': 510, 'eval_duration': 15548191000}
```
Looks reasonable! Now let’s set it up with our previously loaded vectorstore.
We omit the conversational aspect to keep things more manageable for the lower-powered local model:
```
# from langchain.chains.question_answering import load_qa_chain# # Prompt# template = """Use the following pieces of context to answer the question at the end.# If you don't know the answer, just say that you don't know, don't try to make up an answer.# Use three sentences maximum and keep the answer as concise as possible.# {context}# Question: {question}# Helpful Answer:"""# QA_CHAIN_PROMPT = PromptTemplate(# input_variables=["context", "question"],# template=template,# )system_template = """Answer the user's questions based on the below context.If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible:{context}"""# First we need a prompt that we can pass into an LLM to generate this search queryprompt = ChatPromptTemplate.from_messages( [ ("system", system_template), ("user", "{input}"), ])document_chain = create_stuff_documents_chain(llm, prompt)qa_chain = create_retrieval_chain(retriever, document_chain)
```
```
# Run, only returning the value under the answer key for readabilityqa_chain.pick("answer").invoke({"input": "What is a RunnableBinding?"})
```
```
"A RunnableBinding is a high-level class in the LangChain framework. It's an abstraction layer that sits between a program and an LLM or other data source.\n\nThe main goal of a RunnableBinding is to enable a program, which may be a chat bot or a backend service, to fetch responses from an LLM or other data sources in a way that is easy for both the program and the data sources to use. This is achieved through a set of predefined protocols that are implemented by the RunnableBinding.\n\nThe protocols defined by a RunnableBinding include:\n\n1. Fetching inputs from the program. The RunnableBinding should be able to receive inputs from the program and translate them into a format that can be processed by the LLM or other data sources.\n2. Translating outputs from the LLM or other data sources into something that can be returned to the program. This includes converting the raw output of an LLM into something that is easier for the program to process, such as text or a structured object.\n3. Handling errors that may arise during the fetching, processing, and returning of responses from the LLM or other data sources. The RunnableBinding should be able to catch exceptions and errors that occur during these operations and return a suitable error message or response to the program.\n4. Managing concurrency and parallelism in the communication with the LLM or other data sources. This may include things like allowing multiple requests to be sent to the LLM or other data sources simultaneously, handling the responses asynchronously, and retrying failed requests.\n5. Providing a way for the program to set configuration options that affect how the RunnableBinding interacts with the LLM or other data sources. This could include things like setting up credentials, providing additional contextual information to the LLM or other data sources, and controlling logging or error handling behavior.\n\nIn summary, a RunnableBinding provides a way for a program to easily communicate with an LLM or other data sources without having to know about the details of how they work. By providing a consistent interface between the program and the data sources, the RunnableBinding enables more robust and scalable communication protocols that are easier for both parties to use.\n\nIn the context of the chatbot tutorial, a RunnableBinding may be used to fetch responses from an LLM and return them as output for the bot to process. The RunnableBinding could also be used to handle errors that occur during this process, such as providing error messages or retrying failed requests to the LLM.\n\nTo summarize:\n\n* A RunnableBinding provides a way for a program to communicate with an LLM or other data sources without having to know about the details of how they work.\n* It enables more robust and scalable communication protocols that are easier for both parties to use.\n* It manages concurrency and parallelism in the communication with the LLM or other data sources.\n* It provides a way for the program to set configuration options that affect how the RunnableBinding interacts with the LLM or other data sources."
```
Not perfect, but it did pick up on the fact that it lets the developer set configuration option!
Here’s the [LangSmith trace](https://smith.langchain.com/public/d8bb2af8-99cd-406b-a870-f255f4a2423c/r) showing the retrieved docs used as context. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:08.874Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/code_understanding/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/code_understanding/",
"description": "Open In Colab",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4435",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"code_understanding\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:07 GMT",
"etag": "W/\"f1dea2033c6f07974d645d59d5ab3b52\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::vrnmv-1713753967367-3b6e40030374"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/code_understanding/",
"property": "og:url"
},
{
"content": "Code understanding | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Open In Colab",
"property": "og:description"
}
],
"title": "Code understanding | 🦜️🔗 LangChain"
} | Code understanding
Open In Colab
Use case
Source code analysis is one of the most popular LLM applications (e.g., GitHub Copilot, Code Interpreter, Codium, and Codeium) for use-cases such as:
Q&A over the code base to understand how it works
Using LLMs for suggesting refactors or improvements
Using LLMs for documenting the code
Overview
The pipeline for QA over code follows the steps we do for document question answering, with some differences:
In particular, we can employ a splitting strategy that does a few things:
Keeps each top-level function and class in the code is loaded into separate documents.
Puts remaining into a separate document.
Retains metadata about where each split comes from
Quickstart
%pip install --upgrade --quiet langchain-openai tiktoken langchain-chroma langchain git
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
We’ll follow the structure of this notebook and employ context aware code splitting.
Loading
We will upload all python project files using the langchain_community.document_loaders.TextLoader.
The following script iterates over the files in the LangChain repository and loads every .py file (a.k.a. documents):
from git import Repo
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import LanguageParser
from langchain_text_splitters import Language
# Clone
repo_path = "/Users/jacoblee/Desktop/test_repo"
repo = Repo.clone_from("https://github.com/langchain-ai/langchain", to_path=repo_path)
We load the py code using LanguageParser, which will:
Keep top-level functions and classes together (into a single document)
Put remaining code into a separate document
Retains metadata about where each split comes from
# Load
loader = GenericLoader.from_filesystem(
repo_path + "/libs/core/langchain_core",
glob="**/*",
suffixes=[".py"],
exclude=["**/non-utf8-encoding.py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),
)
documents = loader.load()
len(documents)
Splitting
Split the Document into chunks for embedding and vector storage.
We can use RecursiveCharacterTextSplitter w/ language specified.
from langchain_text_splitters import RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=2000, chunk_overlap=200
)
texts = python_splitter.split_documents(documents)
len(texts)
RetrievalQA
We need to store the documents in a way we can semantically search for their content.
The most common approach is to embed the contents of each document then store the embedding and document in a vector store.
When setting up the vectorstore retriever:
We test max marginal relevance for retrieval
And 8 documents returned
Go deeper
Browse the > 40 vectorstores integrations here.
See further documentation on vectorstores here.
Browse the > 30 text embedding integrations here.
See further documentation on embedding models here.
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))
retriever = db.as_retriever(
search_type="mmr", # Also test "similarity"
search_kwargs={"k": 8},
)
Chat
Test chat, just as we do for chatbots.
Go deeper
Browse the > 55 LLM and chat model integrations here.
See further documentation on LLMs and chat models here.
Use local LLMS: The popularity of PrivateGPT and GPT4All underscore the importance of running LLMs locally.
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages(
[
("placeholder", "{chat_history}"),
("user", "{input}"),
(
"user",
"Given the above conversation, generate a search query to look up to get information relevant to the conversation",
),
]
)
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user's questions based on the below context:\n\n{context}",
),
("placeholder", "{chat_history}"),
("user", "{input}"),
]
)
document_chain = create_stuff_documents_chain(llm, prompt)
qa = create_retrieval_chain(retriever_chain, document_chain)
question = "What is a RunnableBinding?"
result = qa.invoke({"input": question})
result["answer"]
'A RunnableBinding is a class in the LangChain library that is used to bind arguments to a Runnable. This is useful when a runnable in a chain requires an argument that is not in the output of the previous runnable or included in the user input. It returns a new Runnable with the bound arguments and configuration. The bind method in the RunnableBinding class is used to perform this operation.'
questions = [
"What classes are derived from the Runnable class?",
"What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?",
]
for question in questions:
result = qa.invoke({"input": question})
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
-> **Question**: What classes are derived from the Runnable class?
**Answer**: The classes derived from the `Runnable` class as mentioned in the context are: `RunnableLambda`, `RunnableLearnable`, `RunnableSerializable`, `RunnableWithFallbacks`.
-> **Question**: What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?
**Answer**: One potential improvement could be the introduction of abstract base classes (ABCs) or interfaces for different types of Runnable classes. Currently, it seems like there are lots of different Runnable types, like RunnableLambda, RunnableParallel, etc., each with their own methods and attributes. By defining a common interface or ABC for all these classes, we can ensure consistency and better organize the codebase. It would also make it easier to add new types of Runnable classes in the future, as they would just need to implement the methods defined in the interface or ABC.
Then we can look at the LangSmith trace to see what is happening under the hood:
In particular, the code well structured and kept together in the retrieval output
The retrieved code and chat history are passed to the LLM for answer distillation
Open source LLMs
We’ll use LangChain’s Ollama integration to query a local OSS model.
Check out the latest available models here.
%pip install --upgrade --quiet langchain-community
from langchain_community.chat_models.ollama import ChatOllama
llm = ChatOllama(model="codellama")
Let’s run it with a generic coding question to test its knowledge:
response_message = llm.invoke(
"In bash, how do I list all the text files in the current directory that have been modified in the last month?"
)
print(response_message.content)
print(response_message.response_metadata)
You can use the `find` command with the `-mtime` option to find all the text files in the current directory that have been modified in the last month. Here's an example command:
```bash
find . -type f -name "*.txt" -mtime -30
```
This will list all the text files in the current directory (`.`) that have been modified in the last 30 days. The `-type f` option ensures that only regular files are matched, and not directories or other types of files. The `-name "*.txt"` option restricts the search to files with a `.txt` extension. Finally, the `-mtime -30` option specifies that we want to find files that have been modified in the last 30 days.
You can also use `find` command with `-mmin` option to find all the text files in the current directory that have been modified within the last month. Here's an example command:
```bash
find . -type f -name "*.txt" -mmin -4320
```
This will list all the text files in the current directory (`.`) that have been modified within the last 30 days. The `-type f` option ensures that only regular files are matched, and not directories or other types of files. The `-name "*.txt"` option restricts the search to files with a `.txt` extension. Finally, the `-mmin -4320` option specifies that we want to find files that have been modified within the last 4320 minutes (which is equivalent to one month).
You can also use `ls` command with `-l` option and pipe it to `grep` command to filter out the text files. Here's an example command:
```bash
ls -l | grep "*.txt"
```
This will list all the text files in the current directory (`.`) that have been modified within the last 30 days. The `-l` option of `ls` command lists the files in a long format, including the modification time, and the `grep` command filters out the files that do not match the specified pattern.
Please note that these commands are case-sensitive, so if you have any files with different extensions (e.g., `.TXT`), they will not be matched by these commands.
{'model': 'codellama', 'created_at': '2024-04-03T00:41:44.014203Z', 'message': {'role': 'assistant', 'content': ''}, 'done': True, 'total_duration': 27078466916, 'load_duration': 12947208, 'prompt_eval_count': 44, 'prompt_eval_duration': 11497468000, 'eval_count': 510, 'eval_duration': 15548191000}
Looks reasonable! Now let’s set it up with our previously loaded vectorstore.
We omit the conversational aspect to keep things more manageable for the lower-powered local model:
# from langchain.chains.question_answering import load_qa_chain
# # Prompt
# template = """Use the following pieces of context to answer the question at the end.
# If you don't know the answer, just say that you don't know, don't try to make up an answer.
# Use three sentences maximum and keep the answer as concise as possible.
# {context}
# Question: {question}
# Helpful Answer:"""
# QA_CHAIN_PROMPT = PromptTemplate(
# input_variables=["context", "question"],
# template=template,
# )
system_template = """
Answer the user's questions based on the below context.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible:
{context}
"""
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages(
[
("system", system_template),
("user", "{input}"),
]
)
document_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(retriever, document_chain)
# Run, only returning the value under the answer key for readability
qa_chain.pick("answer").invoke({"input": "What is a RunnableBinding?"})
"A RunnableBinding is a high-level class in the LangChain framework. It's an abstraction layer that sits between a program and an LLM or other data source.\n\nThe main goal of a RunnableBinding is to enable a program, which may be a chat bot or a backend service, to fetch responses from an LLM or other data sources in a way that is easy for both the program and the data sources to use. This is achieved through a set of predefined protocols that are implemented by the RunnableBinding.\n\nThe protocols defined by a RunnableBinding include:\n\n1. Fetching inputs from the program. The RunnableBinding should be able to receive inputs from the program and translate them into a format that can be processed by the LLM or other data sources.\n2. Translating outputs from the LLM or other data sources into something that can be returned to the program. This includes converting the raw output of an LLM into something that is easier for the program to process, such as text or a structured object.\n3. Handling errors that may arise during the fetching, processing, and returning of responses from the LLM or other data sources. The RunnableBinding should be able to catch exceptions and errors that occur during these operations and return a suitable error message or response to the program.\n4. Managing concurrency and parallelism in the communication with the LLM or other data sources. This may include things like allowing multiple requests to be sent to the LLM or other data sources simultaneously, handling the responses asynchronously, and retrying failed requests.\n5. Providing a way for the program to set configuration options that affect how the RunnableBinding interacts with the LLM or other data sources. This could include things like setting up credentials, providing additional contextual information to the LLM or other data sources, and controlling logging or error handling behavior.\n\nIn summary, a RunnableBinding provides a way for a program to easily communicate with an LLM or other data sources without having to know about the details of how they work. By providing a consistent interface between the program and the data sources, the RunnableBinding enables more robust and scalable communication protocols that are easier for both parties to use.\n\nIn the context of the chatbot tutorial, a RunnableBinding may be used to fetch responses from an LLM and return them as output for the bot to process. The RunnableBinding could also be used to handle errors that occur during this process, such as providing error messages or retrying failed requests to the LLM.\n\nTo summarize:\n\n* A RunnableBinding provides a way for a program to communicate with an LLM or other data sources without having to know about the details of how they work.\n* It enables more robust and scalable communication protocols that are easier for both parties to use.\n* It manages concurrency and parallelism in the communication with the LLM or other data sources.\n* It provides a way for the program to set configuration options that affect how the RunnableBinding interacts with the LLM or other data sources."
Not perfect, but it did pick up on the fact that it lets the developer set configuration option!
Here’s the LangSmith trace showing the retrieved docs used as context. |
https://python.langchain.com/docs/use_cases/data_generation/ | ## Synthetic data generation
[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/data_generation.ipynb)
Open In Colab
## Use case[](#use-case "Direct link to Use case")
Synthetic data is artificially generated data, rather than data collected from real-world events. It’s used to simulate real data without compromising privacy or encountering real-world limitations.
Benefits of Synthetic Data:
1. **Privacy and Security**: No real personal data at risk of breaches.
2. **Data Augmentation**: Expands datasets for machine learning.
3. **Flexibility**: Create specific or rare scenarios.
4. **Cost-effective**: Often cheaper than real-world data collection.
5. **Regulatory Compliance**: Helps navigate strict data protection laws.
6. **Model Robustness**: Can lead to better generalizing AI models.
7. **Rapid Prototyping**: Enables quick testing without real data.
8. **Controlled Experimentation**: Simulate specific conditions.
9. **Access to Data**: Alternative when real data isn’t available.
Note: Despite the benefits, synthetic data should be used carefully, as it may not always capture real-world complexities.
## Quickstart[](#quickstart "Direct link to Quickstart")
In this notebook, we’ll dive deep into generating synthetic medical billing records using the langchain library. This tool is particularly useful when you want to develop or test algorithms but don’t want to use real patient data due to privacy concerns or data availability issues.
### Setup[](#setup "Direct link to Setup")
First, you’ll need to have the langchain library installed, along with its dependencies. Since we’re using the OpenAI generator chain, we’ll install that as well. Since this is an experimental lib, we’ll need to include `langchain_experimental` in our installs. We’ll then import the necessary modules.
```
%pip install --upgrade --quiet langchain langchain_experimental langchain-openai# Set env var OPENAI_API_KEY or load from a .env file:# import dotenv# dotenv.load_dotenv()from langchain_core.prompts import FewShotPromptTemplate, PromptTemplatefrom langchain_core.pydantic_v1 import BaseModelfrom langchain_experimental.tabular_synthetic_data.openai import ( OPENAI_TEMPLATE, create_openai_data_generator,)from langchain_experimental.tabular_synthetic_data.prompts import ( SYNTHETIC_FEW_SHOT_PREFIX, SYNTHETIC_FEW_SHOT_SUFFIX,)from langchain_openai import ChatOpenAI
```
## 1\. Define Your Data Model[](#define-your-data-model "Direct link to 1. Define Your Data Model")
Every dataset has a structure or a “schema”. The MedicalBilling class below serves as our schema for the synthetic data. By defining this, we’re informing our synthetic data generator about the shape and nature of data we expect.
```
class MedicalBilling(BaseModel): patient_id: int patient_name: str diagnosis_code: str procedure_code: str total_charge: float insurance_claim_amount: float
```
For instance, every record will have a `patient_id` that’s an integer, a `patient_name` that’s a string, and so on.
## 2\. Sample Data[](#sample-data "Direct link to 2. Sample Data")
To guide the synthetic data generator, it’s useful to provide it with a few real-world-like examples. These examples serve as a “seed” - they’re representative of the kind of data you want, and the generator will use them to create more data that looks similar.
Here are some fictional medical billing records:
```
examples = [ { "example": """Patient ID: 123456, Patient Name: John Doe, Diagnosis Code: J20.9, Procedure Code: 99203, Total Charge: $500, Insurance Claim Amount: $350""" }, { "example": """Patient ID: 789012, Patient Name: Johnson Smith, Diagnosis Code: M54.5, Procedure Code: 99213, Total Charge: $150, Insurance Claim Amount: $120""" }, { "example": """Patient ID: 345678, Patient Name: Emily Stone, Diagnosis Code: E11.9, Procedure Code: 99214, Total Charge: $300, Insurance Claim Amount: $250""" },]
```
## 3\. Craft a Prompt Template[](#craft-a-prompt-template "Direct link to 3. Craft a Prompt Template")
The generator doesn’t magically know how to create our data; we need to guide it. We do this by creating a prompt template. This template helps instruct the underlying language model on how to produce synthetic data in the desired format.
```
OPENAI_TEMPLATE = PromptTemplate(input_variables=["example"], template="{example}")prompt_template = FewShotPromptTemplate( prefix=SYNTHETIC_FEW_SHOT_PREFIX, examples=examples, suffix=SYNTHETIC_FEW_SHOT_SUFFIX, input_variables=["subject", "extra"], example_prompt=OPENAI_TEMPLATE,)
```
The `FewShotPromptTemplate` includes:
* `prefix` and `suffix`: These likely contain guiding context or instructions.
* `examples`: The sample data we defined earlier.
* `input_variables`: These variables (“subject”, “extra”) are placeholders you can dynamically fill later. For instance, “subject” might be filled with “medical\_billing” to guide the model further.
* `example_prompt`: This prompt template is the format we want each example row to take in our prompt.
## 4\. Creating the Data Generator[](#creating-the-data-generator "Direct link to 4. Creating the Data Generator")
With the schema and the prompt ready, the next step is to create the data generator. This object knows how to communicate with the underlying language model to get synthetic data.
```
synthetic_data_generator = create_openai_data_generator( output_schema=MedicalBilling, llm=ChatOpenAI( temperature=1 ), # You'll need to replace with your actual Language Model instance prompt=prompt_template,)
```
## 5\. Generate Synthetic Data[](#generate-synthetic-data "Direct link to 5. Generate Synthetic Data")
Finally, let’s get our synthetic data!
```
synthetic_results = synthetic_data_generator.generate( subject="medical_billing", extra="the name must be chosen at random. Make it something you wouldn't normally choose.", runs=10,)
```
This command asks the generator to produce 10 synthetic medical billing records. The results are stored in `synthetic_results`. The output will be a list of the MedicalBilling pydantic models.
### Other implementations[](#other-implementations "Direct link to Other implementations")
```
from langchain_experimental.synthetic_data import ( DatasetGenerator, create_data_generation_chain,)from langchain_openai import ChatOpenAI
```
```
# LLMmodel = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)chain = create_data_generation_chain(model)
```
```
chain({"fields": ["blue", "yellow"], "preferences": {}})
```
```
{'fields': ['blue', 'yellow'], 'preferences': {}, 'text': 'The vibrant blue sky contrasted beautifully with the bright yellow sun, creating a stunning display of colors that instantly lifted the spirits of all who gazed upon it.'}
```
```
chain( { "fields": {"colors": ["blue", "yellow"]}, "preferences": {"style": "Make it in a style of a weather forecast."}, })
```
```
{'fields': {'colors': ['blue', 'yellow']}, 'preferences': {'style': 'Make it in a style of a weather forecast.'}, 'text': "Good morning! Today's weather forecast brings a beautiful combination of colors to the sky, with hues of blue and yellow gently blending together like a mesmerizing painting."}
```
```
chain( { "fields": {"actor": "Tom Hanks", "movies": ["Forrest Gump", "Green Mile"]}, "preferences": None, })
```
```
{'fields': {'actor': 'Tom Hanks', 'movies': ['Forrest Gump', 'Green Mile']}, 'preferences': None, 'text': 'Tom Hanks, the renowned actor known for his incredible versatility and charm, has graced the silver screen in unforgettable movies such as "Forrest Gump" and "Green Mile".'}
```
```
chain( { "fields": [ {"actor": "Tom Hanks", "movies": ["Forrest Gump", "Green Mile"]}, {"actor": "Mads Mikkelsen", "movies": ["Hannibal", "Another round"]}, ], "preferences": {"minimum_length": 200, "style": "gossip"}, })
```
```
{'fields': [{'actor': 'Tom Hanks', 'movies': ['Forrest Gump', 'Green Mile']}, {'actor': 'Mads Mikkelsen', 'movies': ['Hannibal', 'Another round']}], 'preferences': {'minimum_length': 200, 'style': 'gossip'}, 'text': 'Did you know that Tom Hanks, the beloved Hollywood actor known for his roles in "Forrest Gump" and "Green Mile", has shared the screen with the talented Mads Mikkelsen, who gained international acclaim for his performances in "Hannibal" and "Another round"? These two incredible actors have brought their exceptional skills and captivating charisma to the big screen, delivering unforgettable performances that have enthralled audiences around the world. Whether it\'s Hanks\' endearing portrayal of Forrest Gump or Mikkelsen\'s chilling depiction of Hannibal Lecter, these movies have solidified their places in cinematic history, leaving a lasting impact on viewers and cementing their status as true icons of the silver screen.'}
```
As we can see created examples are diversified and possess information we wanted them to have. Also, their style reflects the given preferences quite well.
```
inp = [ { "Actor": "Tom Hanks", "Film": [ "Forrest Gump", "Saving Private Ryan", "The Green Mile", "Toy Story", "Catch Me If You Can", ], }, { "Actor": "Tom Hardy", "Film": [ "Inception", "The Dark Knight Rises", "Mad Max: Fury Road", "The Revenant", "Dunkirk", ], },]generator = DatasetGenerator(model, {"style": "informal", "minimal length": 500})dataset = generator(inp)
```
```
[{'fields': {'Actor': 'Tom Hanks', 'Film': ['Forrest Gump', 'Saving Private Ryan', 'The Green Mile', 'Toy Story', 'Catch Me If You Can']}, 'preferences': {'style': 'informal', 'minimal length': 500}, 'text': 'Tom Hanks, the versatile and charismatic actor, has graced the silver screen in numerous iconic films including the heartwarming and inspirational "Forrest Gump," the intense and gripping war drama "Saving Private Ryan," the emotionally charged and thought-provoking "The Green Mile," the beloved animated classic "Toy Story," and the thrilling and captivating true story adaptation "Catch Me If You Can." With his impressive range and genuine talent, Hanks continues to captivate audiences worldwide, leaving an indelible mark on the world of cinema.'}, {'fields': {'Actor': 'Tom Hardy', 'Film': ['Inception', 'The Dark Knight Rises', 'Mad Max: Fury Road', 'The Revenant', 'Dunkirk']}, 'preferences': {'style': 'informal', 'minimal length': 500}, 'text': 'Tom Hardy, the versatile actor known for his intense performances, has graced the silver screen in numerous iconic films, including "Inception," "The Dark Knight Rises," "Mad Max: Fury Road," "The Revenant," and "Dunkirk." Whether he\'s delving into the depths of the subconscious mind, donning the mask of the infamous Bane, or navigating the treacherous wasteland as the enigmatic Max Rockatansky, Hardy\'s commitment to his craft is always evident. From his breathtaking portrayal of the ruthless Eames in "Inception" to his captivating transformation into the ferocious Max in "Mad Max: Fury Road," Hardy\'s dynamic range and magnetic presence captivate audiences and leave an indelible mark on the world of cinema. In his most physically demanding role to date, he endured the harsh conditions of the freezing wilderness as he portrayed the rugged frontiersman John Fitzgerald in "The Revenant," earning him critical acclaim and an Academy Award nomination. In Christopher Nolan\'s war epic "Dunkirk," Hardy\'s stoic and heroic portrayal of Royal Air Force pilot Farrier showcases his ability to convey deep emotion through nuanced performances. With his chameleon-like ability to inhabit a wide range of characters and his unwavering commitment to his craft, Tom Hardy has undoubtedly solidified his place as one of the most talented and sought-after actors of his generation.'}]
```
Okay, let’s see if we can now extract output from this generated data and how it compares with our case!
```
from typing import Listfrom langchain.chains import create_extraction_chain_pydanticfrom langchain.output_parsers import PydanticOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import OpenAIfrom pydantic import BaseModel, Field
```
```
class Actor(BaseModel): Actor: str = Field(description="name of an actor") Film: List[str] = Field(description="list of names of films they starred in")
```
### Parsers[](#parsers "Direct link to Parsers")
```
llm = OpenAI()parser = PydanticOutputParser(pydantic_object=Actor)prompt = PromptTemplate( template="Extract fields from a given text.\n{format_instructions}\n{text}\n", input_variables=["text"], partial_variables={"format_instructions": parser.get_format_instructions()},)_input = prompt.format_prompt(text=dataset[0]["text"])output = llm(_input.to_string())parsed = parser.parse(output)parsed
```
```
Actor(Actor='Tom Hanks', Film=['Forrest Gump', 'Saving Private Ryan', 'The Green Mile', 'Toy Story', 'Catch Me If You Can'])
```
```
(parsed.Actor == inp[0]["Actor"]) & (parsed.Film == inp[0]["Film"])
```
```
extractor = create_extraction_chain_pydantic(pydantic_schema=Actor, llm=model)extracted = extractor.run(dataset[1]["text"])extracted
```
```
[Actor(Actor='Tom Hardy', Film=['Inception', 'The Dark Knight Rises', 'Mad Max: Fury Road', 'The Revenant', 'Dunkirk'])]
```
```
(extracted[0].Actor == inp[1]["Actor"]) & (extracted[0].Film == inp[1]["Film"])
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:09.382Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/data_generation/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/data_generation/",
"description": "Open In Colab",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3762",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"data_generation\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:06 GMT",
"etag": "W/\"0a8efe54ffe063a43cb7cec297e4210f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::dvqkj-1713753966686-8a3ae0099714"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/data_generation/",
"property": "og:url"
},
{
"content": "Synthetic data generation | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Open In Colab",
"property": "og:description"
}
],
"title": "Synthetic data generation | 🦜️🔗 LangChain"
} | Synthetic data generation
Open In Colab
Use case
Synthetic data is artificially generated data, rather than data collected from real-world events. It’s used to simulate real data without compromising privacy or encountering real-world limitations.
Benefits of Synthetic Data:
Privacy and Security: No real personal data at risk of breaches.
Data Augmentation: Expands datasets for machine learning.
Flexibility: Create specific or rare scenarios.
Cost-effective: Often cheaper than real-world data collection.
Regulatory Compliance: Helps navigate strict data protection laws.
Model Robustness: Can lead to better generalizing AI models.
Rapid Prototyping: Enables quick testing without real data.
Controlled Experimentation: Simulate specific conditions.
Access to Data: Alternative when real data isn’t available.
Note: Despite the benefits, synthetic data should be used carefully, as it may not always capture real-world complexities.
Quickstart
In this notebook, we’ll dive deep into generating synthetic medical billing records using the langchain library. This tool is particularly useful when you want to develop or test algorithms but don’t want to use real patient data due to privacy concerns or data availability issues.
Setup
First, you’ll need to have the langchain library installed, along with its dependencies. Since we’re using the OpenAI generator chain, we’ll install that as well. Since this is an experimental lib, we’ll need to include langchain_experimental in our installs. We’ll then import the necessary modules.
%pip install --upgrade --quiet langchain langchain_experimental langchain-openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_core.pydantic_v1 import BaseModel
from langchain_experimental.tabular_synthetic_data.openai import (
OPENAI_TEMPLATE,
create_openai_data_generator,
)
from langchain_experimental.tabular_synthetic_data.prompts import (
SYNTHETIC_FEW_SHOT_PREFIX,
SYNTHETIC_FEW_SHOT_SUFFIX,
)
from langchain_openai import ChatOpenAI
1. Define Your Data Model
Every dataset has a structure or a “schema”. The MedicalBilling class below serves as our schema for the synthetic data. By defining this, we’re informing our synthetic data generator about the shape and nature of data we expect.
class MedicalBilling(BaseModel):
patient_id: int
patient_name: str
diagnosis_code: str
procedure_code: str
total_charge: float
insurance_claim_amount: float
For instance, every record will have a patient_id that’s an integer, a patient_name that’s a string, and so on.
2. Sample Data
To guide the synthetic data generator, it’s useful to provide it with a few real-world-like examples. These examples serve as a “seed” - they’re representative of the kind of data you want, and the generator will use them to create more data that looks similar.
Here are some fictional medical billing records:
examples = [
{
"example": """Patient ID: 123456, Patient Name: John Doe, Diagnosis Code:
J20.9, Procedure Code: 99203, Total Charge: $500, Insurance Claim Amount: $350"""
},
{
"example": """Patient ID: 789012, Patient Name: Johnson Smith, Diagnosis
Code: M54.5, Procedure Code: 99213, Total Charge: $150, Insurance Claim Amount: $120"""
},
{
"example": """Patient ID: 345678, Patient Name: Emily Stone, Diagnosis Code:
E11.9, Procedure Code: 99214, Total Charge: $300, Insurance Claim Amount: $250"""
},
]
3. Craft a Prompt Template
The generator doesn’t magically know how to create our data; we need to guide it. We do this by creating a prompt template. This template helps instruct the underlying language model on how to produce synthetic data in the desired format.
OPENAI_TEMPLATE = PromptTemplate(input_variables=["example"], template="{example}")
prompt_template = FewShotPromptTemplate(
prefix=SYNTHETIC_FEW_SHOT_PREFIX,
examples=examples,
suffix=SYNTHETIC_FEW_SHOT_SUFFIX,
input_variables=["subject", "extra"],
example_prompt=OPENAI_TEMPLATE,
)
The FewShotPromptTemplate includes:
prefix and suffix: These likely contain guiding context or instructions.
examples: The sample data we defined earlier.
input_variables: These variables (“subject”, “extra”) are placeholders you can dynamically fill later. For instance, “subject” might be filled with “medical_billing” to guide the model further.
example_prompt: This prompt template is the format we want each example row to take in our prompt.
4. Creating the Data Generator
With the schema and the prompt ready, the next step is to create the data generator. This object knows how to communicate with the underlying language model to get synthetic data.
synthetic_data_generator = create_openai_data_generator(
output_schema=MedicalBilling,
llm=ChatOpenAI(
temperature=1
), # You'll need to replace with your actual Language Model instance
prompt=prompt_template,
)
5. Generate Synthetic Data
Finally, let’s get our synthetic data!
synthetic_results = synthetic_data_generator.generate(
subject="medical_billing",
extra="the name must be chosen at random. Make it something you wouldn't normally choose.",
runs=10,
)
This command asks the generator to produce 10 synthetic medical billing records. The results are stored in synthetic_results. The output will be a list of the MedicalBilling pydantic models.
Other implementations
from langchain_experimental.synthetic_data import (
DatasetGenerator,
create_data_generation_chain,
)
from langchain_openai import ChatOpenAI
# LLM
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)
chain = create_data_generation_chain(model)
chain({"fields": ["blue", "yellow"], "preferences": {}})
{'fields': ['blue', 'yellow'],
'preferences': {},
'text': 'The vibrant blue sky contrasted beautifully with the bright yellow sun, creating a stunning display of colors that instantly lifted the spirits of all who gazed upon it.'}
chain(
{
"fields": {"colors": ["blue", "yellow"]},
"preferences": {"style": "Make it in a style of a weather forecast."},
}
)
{'fields': {'colors': ['blue', 'yellow']},
'preferences': {'style': 'Make it in a style of a weather forecast.'},
'text': "Good morning! Today's weather forecast brings a beautiful combination of colors to the sky, with hues of blue and yellow gently blending together like a mesmerizing painting."}
chain(
{
"fields": {"actor": "Tom Hanks", "movies": ["Forrest Gump", "Green Mile"]},
"preferences": None,
}
)
{'fields': {'actor': 'Tom Hanks', 'movies': ['Forrest Gump', 'Green Mile']},
'preferences': None,
'text': 'Tom Hanks, the renowned actor known for his incredible versatility and charm, has graced the silver screen in unforgettable movies such as "Forrest Gump" and "Green Mile".'}
chain(
{
"fields": [
{"actor": "Tom Hanks", "movies": ["Forrest Gump", "Green Mile"]},
{"actor": "Mads Mikkelsen", "movies": ["Hannibal", "Another round"]},
],
"preferences": {"minimum_length": 200, "style": "gossip"},
}
)
{'fields': [{'actor': 'Tom Hanks', 'movies': ['Forrest Gump', 'Green Mile']},
{'actor': 'Mads Mikkelsen', 'movies': ['Hannibal', 'Another round']}],
'preferences': {'minimum_length': 200, 'style': 'gossip'},
'text': 'Did you know that Tom Hanks, the beloved Hollywood actor known for his roles in "Forrest Gump" and "Green Mile", has shared the screen with the talented Mads Mikkelsen, who gained international acclaim for his performances in "Hannibal" and "Another round"? These two incredible actors have brought their exceptional skills and captivating charisma to the big screen, delivering unforgettable performances that have enthralled audiences around the world. Whether it\'s Hanks\' endearing portrayal of Forrest Gump or Mikkelsen\'s chilling depiction of Hannibal Lecter, these movies have solidified their places in cinematic history, leaving a lasting impact on viewers and cementing their status as true icons of the silver screen.'}
As we can see created examples are diversified and possess information we wanted them to have. Also, their style reflects the given preferences quite well.
inp = [
{
"Actor": "Tom Hanks",
"Film": [
"Forrest Gump",
"Saving Private Ryan",
"The Green Mile",
"Toy Story",
"Catch Me If You Can",
],
},
{
"Actor": "Tom Hardy",
"Film": [
"Inception",
"The Dark Knight Rises",
"Mad Max: Fury Road",
"The Revenant",
"Dunkirk",
],
},
]
generator = DatasetGenerator(model, {"style": "informal", "minimal length": 500})
dataset = generator(inp)
[{'fields': {'Actor': 'Tom Hanks',
'Film': ['Forrest Gump',
'Saving Private Ryan',
'The Green Mile',
'Toy Story',
'Catch Me If You Can']},
'preferences': {'style': 'informal', 'minimal length': 500},
'text': 'Tom Hanks, the versatile and charismatic actor, has graced the silver screen in numerous iconic films including the heartwarming and inspirational "Forrest Gump," the intense and gripping war drama "Saving Private Ryan," the emotionally charged and thought-provoking "The Green Mile," the beloved animated classic "Toy Story," and the thrilling and captivating true story adaptation "Catch Me If You Can." With his impressive range and genuine talent, Hanks continues to captivate audiences worldwide, leaving an indelible mark on the world of cinema.'},
{'fields': {'Actor': 'Tom Hardy',
'Film': ['Inception',
'The Dark Knight Rises',
'Mad Max: Fury Road',
'The Revenant',
'Dunkirk']},
'preferences': {'style': 'informal', 'minimal length': 500},
'text': 'Tom Hardy, the versatile actor known for his intense performances, has graced the silver screen in numerous iconic films, including "Inception," "The Dark Knight Rises," "Mad Max: Fury Road," "The Revenant," and "Dunkirk." Whether he\'s delving into the depths of the subconscious mind, donning the mask of the infamous Bane, or navigating the treacherous wasteland as the enigmatic Max Rockatansky, Hardy\'s commitment to his craft is always evident. From his breathtaking portrayal of the ruthless Eames in "Inception" to his captivating transformation into the ferocious Max in "Mad Max: Fury Road," Hardy\'s dynamic range and magnetic presence captivate audiences and leave an indelible mark on the world of cinema. In his most physically demanding role to date, he endured the harsh conditions of the freezing wilderness as he portrayed the rugged frontiersman John Fitzgerald in "The Revenant," earning him critical acclaim and an Academy Award nomination. In Christopher Nolan\'s war epic "Dunkirk," Hardy\'s stoic and heroic portrayal of Royal Air Force pilot Farrier showcases his ability to convey deep emotion through nuanced performances. With his chameleon-like ability to inhabit a wide range of characters and his unwavering commitment to his craft, Tom Hardy has undoubtedly solidified his place as one of the most talented and sought-after actors of his generation.'}]
Okay, let’s see if we can now extract output from this generated data and how it compares with our case!
from typing import List
from langchain.chains import create_extraction_chain_pydantic
from langchain.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
from pydantic import BaseModel, Field
class Actor(BaseModel):
Actor: str = Field(description="name of an actor")
Film: List[str] = Field(description="list of names of films they starred in")
Parsers
llm = OpenAI()
parser = PydanticOutputParser(pydantic_object=Actor)
prompt = PromptTemplate(
template="Extract fields from a given text.\n{format_instructions}\n{text}\n",
input_variables=["text"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
_input = prompt.format_prompt(text=dataset[0]["text"])
output = llm(_input.to_string())
parsed = parser.parse(output)
parsed
Actor(Actor='Tom Hanks', Film=['Forrest Gump', 'Saving Private Ryan', 'The Green Mile', 'Toy Story', 'Catch Me If You Can'])
(parsed.Actor == inp[0]["Actor"]) & (parsed.Film == inp[0]["Film"])
extractor = create_extraction_chain_pydantic(pydantic_schema=Actor, llm=model)
extracted = extractor.run(dataset[1]["text"])
extracted
[Actor(Actor='Tom Hardy', Film=['Inception', 'The Dark Knight Rises', 'Mad Max: Fury Road', 'The Revenant', 'Dunkirk'])]
(extracted[0].Actor == inp[1]["Actor"]) & (extracted[0].Film == inp[1]["Film"]) |
https://python.langchain.com/docs/use_cases/extraction/how_to/examples/ | ## Use Reference Examples
The quality of extractions can often be improved by providing reference examples to the LLM.
tip
While this tutorial focuses how to use examples with a tool calling model, this technique is generally applicable, and will work also with JSON more or prompt based techniques.
```
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder# Define a custom prompt to provide instructions and any additional context.# 1) You can add examples into the prompt template to improve extraction quality# 2) Introduce additional parameters to take context into account (e.g., include metadata# about the document from which the text was extracted.)prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are an expert extraction algorithm. " "Only extract relevant information from the text. " "If you do not know the value of an attribute asked " "to extract, return null for the attribute's value.", ), # ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ MessagesPlaceholder("examples"), # <-- EXAMPLES! # ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑ ("human", "{text}"), ])
```
Test out the template:
```
from langchain_core.messages import ( HumanMessage,)prompt.invoke( {"text": "this is some text", "examples": [HumanMessage(content="testing 1 2 3")]})
```
```
ChatPromptValue(messages=[SystemMessage(content="You are an expert extraction algorithm. Only extract relevant information from the text. If you do not know the value of an attribute asked to extract, return null for the attribute's value."), HumanMessage(content='testing 1 2 3'), HumanMessage(content='this is some text')])
```
## Define the schema[](#define-the-schema "Direct link to Define the schema")
Let’s re-use the person schema from the quickstart.
```
from typing import List, Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAIclass Person(BaseModel): """Information about a person.""" # ^ Doc-string for the entity Person. # This doc-string is sent to the LLM as the description of the schema Person, # and it can help to improve extraction results. # Note that: # 1. Each field is an `optional` -- this allows the model to decline to extract it! # 2. Each field has a `description` -- this description is used by the LLM. # Having a good description can help improve extraction results. name: Optional[str] = Field(..., description="The name of the person") hair_color: Optional[str] = Field( ..., description="The color of the peron's eyes if known" ) height_in_meters: Optional[str] = Field(..., description="Height in METERs")class Data(BaseModel): """Extracted data about people.""" # Creates a model so that we can extract multiple entities. people: List[Person]
```
## Define reference examples[](#define-reference-examples "Direct link to Define reference examples")
Examples can be defined as a list of input-output pairs.
Each example contains an example `input` text and an example `output` showing what should be extracted from the text.
info
This is a bit in the weeds, so feel free to ignore if you don’t get it!
The format of the example needs to match the API used (e.g., tool calling or JSON mode etc.).
Here, the formatted examples will match the format expected for the tool calling API since that’s what we’re using.
```
import uuidfrom typing import Dict, List, TypedDictfrom langchain_core.messages import ( AIMessage, BaseMessage, HumanMessage, SystemMessage, ToolMessage,)from langchain_core.pydantic_v1 import BaseModel, Fieldclass Example(TypedDict): """A representation of an example consisting of text input and expected tool calls. For extraction, the tool calls are represented as instances of pydantic model. """ input: str # This is the example text tool_calls: List[BaseModel] # Instances of pydantic model that should be extracteddef tool_example_to_messages(example: Example) -> List[BaseMessage]: """Convert an example into a list of messages that can be fed into an LLM. This code is an adapter that converts our example to a list of messages that can be fed into a chat model. The list of messages per example corresponds to: 1) HumanMessage: contains the content from which content should be extracted. 2) AIMessage: contains the extracted information from the model 3) ToolMessage: contains confirmation to the model that the model requested a tool correctly. The ToolMessage is required because some of the chat models are hyper-optimized for agents rather than for an extraction use case. """ messages: List[BaseMessage] = [HumanMessage(content=example["input"])] openai_tool_calls = [] for tool_call in example["tool_calls"]: openai_tool_calls.append( { "id": str(uuid.uuid4()), "type": "function", "function": { # The name of the function right now corresponds # to the name of the pydantic model # This is implicit in the API right now, # and will be improved over time. "name": tool_call.__class__.__name__, "arguments": tool_call.json(), }, } ) messages.append( AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls}) ) tool_outputs = example.get("tool_outputs") or [ "You have correctly called this tool." ] * len(openai_tool_calls) for output, tool_call in zip(tool_outputs, openai_tool_calls): messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"])) return messages
```
Next let’s define our examples and then convert them into message format.
```
examples = [ ( "The ocean is vast and blue. It's more than 20,000 feet deep. There are many fish in it.", Person(name=None, height_in_meters=None, hair_color=None), ), ( "Fiona traveled far from France to Spain.", Person(name="Fiona", height_in_meters=None, hair_color=None), ),]messages = []for text, tool_call in examples: messages.extend( tool_example_to_messages({"input": text, "tool_calls": [tool_call]}) )
```
Let’s test out the prompt
```
prompt.invoke({"text": "this is some text", "examples": messages})
```
```
ChatPromptValue(messages=[SystemMessage(content="You are an expert extraction algorithm. Only extract relevant information from the text. If you do not know the value of an attribute asked to extract, return null for the attribute's value."), HumanMessage(content="The ocean is vast and blue. It's more than 20,000 feet deep. There are many fish in it."), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'c75e57cc-8212-4959-81e9-9477b0b79126', 'type': 'function', 'function': {'name': 'Person', 'arguments': '{"name": null, "hair_color": null, "height_in_meters": null}'}}]}), ToolMessage(content='You have correctly called this tool.', tool_call_id='c75e57cc-8212-4959-81e9-9477b0b79126'), HumanMessage(content='Fiona traveled far from France to Spain.'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': '69da50b5-e427-44be-b396-1e56d821c6b0', 'type': 'function', 'function': {'name': 'Person', 'arguments': '{"name": "Fiona", "hair_color": null, "height_in_meters": null}'}}]}), ToolMessage(content='You have correctly called this tool.', tool_call_id='69da50b5-e427-44be-b396-1e56d821c6b0'), HumanMessage(content='this is some text')])
```
Here, we’ll create an extractor using **gpt-4**.
```
# We will be using tool calling mode, which# requires a tool calling capable model.llm = ChatOpenAI( # Consider benchmarking with a good model to get # a sense of the best possible quality. model="gpt-4-0125-preview", # Remember to set the temperature to 0 for extractions! temperature=0,)runnable = prompt | llm.with_structured_output( schema=Data, method="function_calling", include_raw=False,)
```
```
/Users/harrisonchase/workplace/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change. warn_beta(
```
## Without examples 😿[](#without-examples "Direct link to Without examples 😿")
Notice that even though we’re using gpt-4, it’s failing with a **very simple** test case!
```
for _ in range(5): text = "The solar system is large, but earth has only 1 moon." print(runnable.invoke({"text": text, "examples": []}))
```
```
people=[]people=[Person(name='earth', hair_color=None, height_in_meters=None)]people=[Person(name='earth', hair_color=None, height_in_meters=None)]people=[]people=[]
```
## With examples 😻[](#with-examples "Direct link to With examples 😻")
Reference examples helps to fix the failure!
```
for _ in range(5): text = "The solar system is large, but earth has only 1 moon." print(runnable.invoke({"text": text, "examples": messages}))
```
```
people=[]people=[]people=[]people=[]people=[]
```
```
runnable.invoke( { "text": "My name is Harrison. My hair is black.", "examples": messages, })
```
```
Data(people=[Person(name='Harrison', hair_color='black', height_in_meters=None)])
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:09.902Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/examples/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/examples/",
"description": "The quality of extractions can often be improved by providing reference",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "6852",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"examples\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:07 GMT",
"etag": "W/\"863f512f21d2908315471d52e86405ea\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::2wb9w-1713753967908-743047348f34"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/how_to/examples/",
"property": "og:url"
},
{
"content": "Use Reference Examples | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "The quality of extractions can often be improved by providing reference",
"property": "og:description"
}
],
"title": "Use Reference Examples | 🦜️🔗 LangChain"
} | Use Reference Examples
The quality of extractions can often be improved by providing reference examples to the LLM.
tip
While this tutorial focuses how to use examples with a tool calling model, this technique is generally applicable, and will work also with JSON more or prompt based techniques.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# Define a custom prompt to provide instructions and any additional context.
# 1) You can add examples into the prompt template to improve extraction quality
# 2) Introduce additional parameters to take context into account (e.g., include metadata
# about the document from which the text was extracted.)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert extraction algorithm. "
"Only extract relevant information from the text. "
"If you do not know the value of an attribute asked "
"to extract, return null for the attribute's value.",
),
# ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
MessagesPlaceholder("examples"), # <-- EXAMPLES!
# ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
("human", "{text}"),
]
)
Test out the template:
from langchain_core.messages import (
HumanMessage,
)
prompt.invoke(
{"text": "this is some text", "examples": [HumanMessage(content="testing 1 2 3")]}
)
ChatPromptValue(messages=[SystemMessage(content="You are an expert extraction algorithm. Only extract relevant information from the text. If you do not know the value of an attribute asked to extract, return null for the attribute's value."), HumanMessage(content='testing 1 2 3'), HumanMessage(content='this is some text')])
Define the schema
Let’s re-use the person schema from the quickstart.
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(..., description="The name of the person")
hair_color: Optional[str] = Field(
..., description="The color of the peron's eyes if known"
)
height_in_meters: Optional[str] = Field(..., description="Height in METERs")
class Data(BaseModel):
"""Extracted data about people."""
# Creates a model so that we can extract multiple entities.
people: List[Person]
Define reference examples
Examples can be defined as a list of input-output pairs.
Each example contains an example input text and an example output showing what should be extracted from the text.
info
This is a bit in the weeds, so feel free to ignore if you don’t get it!
The format of the example needs to match the API used (e.g., tool calling or JSON mode etc.).
Here, the formatted examples will match the format expected for the tool calling API since that’s what we’re using.
import uuid
from typing import Dict, List, TypedDict
from langchain_core.messages import (
AIMessage,
BaseMessage,
HumanMessage,
SystemMessage,
ToolMessage,
)
from langchain_core.pydantic_v1 import BaseModel, Field
class Example(TypedDict):
"""A representation of an example consisting of text input and expected tool calls.
For extraction, the tool calls are represented as instances of pydantic model.
"""
input: str # This is the example text
tool_calls: List[BaseModel] # Instances of pydantic model that should be extracted
def tool_example_to_messages(example: Example) -> List[BaseMessage]:
"""Convert an example into a list of messages that can be fed into an LLM.
This code is an adapter that converts our example to a list of messages
that can be fed into a chat model.
The list of messages per example corresponds to:
1) HumanMessage: contains the content from which content should be extracted.
2) AIMessage: contains the extracted information from the model
3) ToolMessage: contains confirmation to the model that the model requested a tool correctly.
The ToolMessage is required because some of the chat models are hyper-optimized for agents
rather than for an extraction use case.
"""
messages: List[BaseMessage] = [HumanMessage(content=example["input"])]
openai_tool_calls = []
for tool_call in example["tool_calls"]:
openai_tool_calls.append(
{
"id": str(uuid.uuid4()),
"type": "function",
"function": {
# The name of the function right now corresponds
# to the name of the pydantic model
# This is implicit in the API right now,
# and will be improved over time.
"name": tool_call.__class__.__name__,
"arguments": tool_call.json(),
},
}
)
messages.append(
AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls})
)
tool_outputs = example.get("tool_outputs") or [
"You have correctly called this tool."
] * len(openai_tool_calls)
for output, tool_call in zip(tool_outputs, openai_tool_calls):
messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"]))
return messages
Next let’s define our examples and then convert them into message format.
examples = [
(
"The ocean is vast and blue. It's more than 20,000 feet deep. There are many fish in it.",
Person(name=None, height_in_meters=None, hair_color=None),
),
(
"Fiona traveled far from France to Spain.",
Person(name="Fiona", height_in_meters=None, hair_color=None),
),
]
messages = []
for text, tool_call in examples:
messages.extend(
tool_example_to_messages({"input": text, "tool_calls": [tool_call]})
)
Let’s test out the prompt
prompt.invoke({"text": "this is some text", "examples": messages})
ChatPromptValue(messages=[SystemMessage(content="You are an expert extraction algorithm. Only extract relevant information from the text. If you do not know the value of an attribute asked to extract, return null for the attribute's value."), HumanMessage(content="The ocean is vast and blue. It's more than 20,000 feet deep. There are many fish in it."), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'c75e57cc-8212-4959-81e9-9477b0b79126', 'type': 'function', 'function': {'name': 'Person', 'arguments': '{"name": null, "hair_color": null, "height_in_meters": null}'}}]}), ToolMessage(content='You have correctly called this tool.', tool_call_id='c75e57cc-8212-4959-81e9-9477b0b79126'), HumanMessage(content='Fiona traveled far from France to Spain.'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': '69da50b5-e427-44be-b396-1e56d821c6b0', 'type': 'function', 'function': {'name': 'Person', 'arguments': '{"name": "Fiona", "hair_color": null, "height_in_meters": null}'}}]}), ToolMessage(content='You have correctly called this tool.', tool_call_id='69da50b5-e427-44be-b396-1e56d821c6b0'), HumanMessage(content='this is some text')])
Here, we’ll create an extractor using gpt-4.
# We will be using tool calling mode, which
# requires a tool calling capable model.
llm = ChatOpenAI(
# Consider benchmarking with a good model to get
# a sense of the best possible quality.
model="gpt-4-0125-preview",
# Remember to set the temperature to 0 for extractions!
temperature=0,
)
runnable = prompt | llm.with_structured_output(
schema=Data,
method="function_calling",
include_raw=False,
)
/Users/harrisonchase/workplace/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
Without examples 😿
Notice that even though we’re using gpt-4, it’s failing with a very simple test case!
for _ in range(5):
text = "The solar system is large, but earth has only 1 moon."
print(runnable.invoke({"text": text, "examples": []}))
people=[]
people=[Person(name='earth', hair_color=None, height_in_meters=None)]
people=[Person(name='earth', hair_color=None, height_in_meters=None)]
people=[]
people=[]
With examples 😻
Reference examples helps to fix the failure!
for _ in range(5):
text = "The solar system is large, but earth has only 1 moon."
print(runnable.invoke({"text": text, "examples": messages}))
people=[]
people=[]
people=[]
people=[]
people=[]
runnable.invoke(
{
"text": "My name is Harrison. My hair is black.",
"examples": messages,
}
)
Data(people=[Person(name='Harrison', hair_color='black', height_in_meters=None)]) |
https://python.langchain.com/docs/use_cases/extraction/how_to/handle_files/ | Besides raw text data, you may wish to extract information from other file types such as PowerPoint presentations or PDFs.
You can use LangChain [document loaders](https://python.langchain.com/docs/modules/data_connection/document_loaders/) to parse files into a text format that can be fed into LLMs.
Here, we’ll be looking at MIME-type based parsing which is often useful for extraction based applications if you’re writing server code that accepts user uploaded files.
In this case, it’s best to assume that the file extension of the file provided by the user is wrong and instead infer the mimetype from the binary content of the file.
Let’s download some content. This will be an HTML file, but the code below will work with other file types.
```
import magicfrom langchain.document_loaders.parsers import BS4HTMLParser, PDFMinerParserfrom langchain.document_loaders.parsers.generic import MimeTypeBasedParserfrom langchain.document_loaders.parsers.txt import TextParserfrom langchain_community.document_loaders import Blob# Configure the parsers that you want to use per mime-type!HANDLERS = { "application/pdf": PDFMinerParser(), "text/plain": TextParser(), "text/html": BS4HTMLParser(),}# Instantiate a mimetype based parser with the given parsersMIMETYPE_BASED_PARSER = MimeTypeBasedParser( handlers=HANDLERS, fallback_parser=None,)mime = magic.Magic(mime=True)mime_type = mime.from_buffer(data)# A blob represents binary data by either reference (path on file system)# or value (bytes in memory).blob = Blob.from_data( data=data, mime_type=mime_type,)parser = HANDLERS[mime_type]documents = parser.parse(blob=blob)
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:10.441Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/handle_files/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/handle_files/",
"description": "Besides raw text data, you may wish to extract information from other",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3765",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"handle_files\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:09 GMT",
"etag": "W/\"a0a102d8beb1412ccd7aa27c0f6ee534\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::w5r7l-1713753969391-358cb97cf323"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/how_to/handle_files/",
"property": "og:url"
},
{
"content": "Handle Files | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Besides raw text data, you may wish to extract information from other",
"property": "og:description"
}
],
"title": "Handle Files | 🦜️🔗 LangChain"
} | Besides raw text data, you may wish to extract information from other file types such as PowerPoint presentations or PDFs.
You can use LangChain document loaders to parse files into a text format that can be fed into LLMs.
Here, we’ll be looking at MIME-type based parsing which is often useful for extraction based applications if you’re writing server code that accepts user uploaded files.
In this case, it’s best to assume that the file extension of the file provided by the user is wrong and instead infer the mimetype from the binary content of the file.
Let’s download some content. This will be an HTML file, but the code below will work with other file types.
import magic
from langchain.document_loaders.parsers import BS4HTMLParser, PDFMinerParser
from langchain.document_loaders.parsers.generic import MimeTypeBasedParser
from langchain.document_loaders.parsers.txt import TextParser
from langchain_community.document_loaders import Blob
# Configure the parsers that you want to use per mime-type!
HANDLERS = {
"application/pdf": PDFMinerParser(),
"text/plain": TextParser(),
"text/html": BS4HTMLParser(),
}
# Instantiate a mimetype based parser with the given parsers
MIMETYPE_BASED_PARSER = MimeTypeBasedParser(
handlers=HANDLERS,
fallback_parser=None,
)
mime = magic.Magic(mime=True)
mime_type = mime.from_buffer(data)
# A blob represents binary data by either reference (path on file system)
# or value (bytes in memory).
blob = Blob.from_data(
data=data,
mime_type=mime_type,
)
parser = HANDLERS[mime_type]
documents = parser.parse(blob=blob) |
https://python.langchain.com/docs/use_cases/extraction/how_to/handle_long_text/ | When working with files, like PDFs, you’re likely to encounter text that exceeds your language model’s context window. To process this text, consider these strategies:
Keep in mind that these strategies have different trade off and the best strategy likely depends on the application that you’re designing!
We need some example data! Let’s download an article about [cars from wikipedia](https://en.wikipedia.org/wiki/Car) and load it as a LangChain `Document`.
Here, we’ll define schema to extract key developments from the text.
```
from typing import List, Optionalfrom langchain.chains import create_structured_output_runnablefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAIclass KeyDevelopment(BaseModel): """Information about a development in the history of cars.""" # ^ Doc-string for the entity Person. # This doc-string is sent to the LLM as the description of the schema Person, # and it can help to improve extraction results. # Note that all fields are required rather than optional! year: int = Field( ..., description="The year when there was an important historic development." ) description: str = Field( ..., description="What happened in this year? What was the development?" ) evidence: str = Field( ..., description="Repeat in verbatim the sentence(s) from which the year and description information were extracted", )class ExtractionData(BaseModel): """Extracted information about key developments in the history of cars.""" key_developments: List[KeyDevelopment]# Define a custom prompt to provide instructions and any additional context.# 1) You can add examples into the prompt template to improve extraction quality# 2) Introduce additional parameters to take context into account (e.g., include metadata# about the document from which the text was extracted.)prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are an expert at identifying key historic development in text. " "Only extract important historic developments. Extract nothing if no important information can be found in the text.", ), # MessagesPlaceholder('examples'), # Keep on reading through this use case to see how to use examples to improve performance ("human", "{text}"), ])# We will be using tool calling mode, which# requires a tool calling capable model.llm = ChatOpenAI( # Consider benchmarking with a good model to get # a sense of the best possible quality. model="gpt-4-0125-preview", # Remember to set the temperature to 0 for extractions! temperature=0,)extractor = prompt | llm.with_structured_output( schema=ExtractionData, method="function_calling", include_raw=False,)
```
```
/home/eugene/.pyenv/versions/3.11.2/envs/langchain_3_11/lib/python3.11/site-packages/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change. warn_beta(
```
Split the documents into chunks such that each chunk fits into the context window of the LLMs.
After extracting data from across the chunks, we’ll want to merge the extractions together.
```
[KeyDevelopment(year=1966, description="The Toyota Corolla began production, recognized as the world's best-selling automobile.", evidence="The Toyota Corolla has been in production since 1966 and is recognized as the world's best-selling automobile."), KeyDevelopment(year=1769, description='Nicolas-Joseph Cugnot built the first steam-powered road vehicle.', evidence='French inventor Nicolas-Joseph Cugnot built the first steam-powered road vehicle in 1769.'), KeyDevelopment(year=1808, description='François Isaac de Rivaz designed and constructed the first internal combustion-powered automobile.', evidence='French-born Swiss inventor François Isaac de Rivaz designed and constructed the first internal combustion-powered automobile in 1808.'), KeyDevelopment(year=1886, description='Carl Benz patented his Benz Patent-Motorwagen, inventing the modern car.', evidence='The modern car—a practical, marketable automobile for everyday use—was invented in 1886, when German inventor Carl Benz patented his Benz Patent-Motorwagen.'), KeyDevelopment(year=1908, description='The 1908 Model T, an affordable car for the masses, was manufactured by the Ford Motor Company.', evidence='One of the first cars affordable by the masses was the 1908 Model T, an American car manufactured by the Ford Motor Company.'), KeyDevelopment(year=1881, description='Gustave Trouvé demonstrated a three-wheeled car powered by electricity.', evidence='In November 1881, French inventor Gustave Trouvé demonstrated a three-wheeled car powered by electricity at the International Exposition of Electricity.'), KeyDevelopment(year=1888, description="Bertha Benz undertook the first road trip by car to prove the road-worthiness of her husband's invention.", evidence="In August 1888, Bertha Benz, the wife of Carl Benz, undertook the first road trip by car, to prove the road-worthiness of her husband's invention."), KeyDevelopment(year=1896, description='Benz designed and patented the first internal-combustion flat engine, called boxermotor.', evidence='In 1896, Benz designed and patented the first internal-combustion flat engine, called boxermotor.'), KeyDevelopment(year=1897, description='Nesselsdorfer Wagenbau produced the Präsident automobil, one of the first factory-made cars in the world.', evidence='The first motor car in central Europe and one of the first factory-made cars in the world, was produced by Czech company Nesselsdorfer Wagenbau (later renamed to Tatra) in 1897, the Präsident automobil.'), KeyDevelopment(year=1890, description='Daimler Motoren Gesellschaft (DMG) was founded by Daimler and Maybach in Cannstatt.', evidence='Daimler and Maybach founded Daimler Motoren Gesellschaft (DMG) in Cannstatt in 1890.'), KeyDevelopment(year=1902, description='A new model DMG car was produced and named Mercedes after the Maybach engine.', evidence='Two years later, in 1902, a new model DMG car was produced and the model was named Mercedes after the Maybach engine, which generated 35 hp.'), KeyDevelopment(year=1891, description='Auguste Doriot and Louis Rigoulot completed the longest trip by a petrol-driven vehicle using a Daimler powered Peugeot Type 3.', evidence='In 1891, Auguste Doriot and his Peugeot colleague Louis Rigoulot completed the longest trip by a petrol-driven vehicle when their self-designed and built Daimler powered Peugeot Type 3 completed 2,100 kilometres (1,300 mi) from Valentigney to Paris and Brest and back again.'), KeyDevelopment(year=1895, description='George Selden was granted a US patent for a two-stroke car engine.', evidence='After a delay of 16 years and a series of attachments to his application, on 5 November 1895, Selden was granted a US patent (U.S. patent 549,160) for a two-stroke car engine.'), KeyDevelopment(year=1893, description='The first running, petrol-driven American car was built and road-tested by the Duryea brothers.', evidence='In 1893, the first running, petrol-driven American car was built and road-tested by the Duryea brothers of Springfield, Massachusetts.'), KeyDevelopment(year=1897, description='Rudolf Diesel built the first diesel engine.', evidence='In 1897, he built the first diesel engine.'), KeyDevelopment(year=1901, description='Ransom Olds started large-scale, production-line manufacturing of affordable cars at his Oldsmobile factory.', evidence='Large-scale, production-line manufacturing of affordable cars was started by Ransom Olds in 1901 at his Oldsmobile factory in Lansing, Michigan.'), KeyDevelopment(year=1913, description="Henry Ford began the world's first moving assembly line for cars at the Highland Park Ford Plant.", evidence="This concept was greatly expanded by Henry Ford, beginning in 1913 with the world's first moving assembly line for cars at the Highland Park Ford Plant."), KeyDevelopment(year=1914, description="Ford's assembly line worker could buy a Model T with four months' pay.", evidence="In 1914, an assembly line worker could buy a Model T with four months' pay."), KeyDevelopment(year=1926, description='Fast-drying Duco lacquer was developed, allowing for a variety of car colors.', evidence='Only Japan black would dry fast enough, forcing the company to drop the variety of colours available before 1913, until fast-drying Duco lacquer was developed in 1926.')]
```
Another simple idea is to chunk up the text, but instead of extracting information from every chunk, just focus on the the most relevant chunks.
Here’s a simple example that relies on the `FAISS` vectorstore.
In this case the RAG extractor is only looking at the top document.
```
year=1924 description="Germany's first mass-manufactured car, the Opel 4PS Laubfrosch, was produced, making Opel the top car builder in Germany with 37.5% of the market." evidence="Germany's first mass-manufactured car, the Opel 4PS Laubfrosch (Tree Frog), came off the line at Rüsselsheim in 1924, soon making Opel the top car builder in Germany, with 37.5 per cent of the market."year=1925 description='Morris had 41% of total British car production, dominating the market.' evidence='in 1925, Morris had 41 per cent of total British car production.'year=1925 description='Citroën, Renault, and Peugeot produced 550,000 cars in France, dominating the market.' evidence="Citroën did the same in France, coming to cars in 1919; between them and other cheap cars in reply such as Renault's 10CV and Peugeot's 5CV, they produced 550,000 cars in 1925."year=2017 description='Production of petrol-fuelled cars peaked.' evidence='Production of petrol-fuelled cars peaked in 2017.'
```
Different methods have their own pros and cons related to cost, speed, and accuracy. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:10.570Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/handle_long_text/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/handle_long_text/",
"description": "When working with files, like PDFs, you’re likely to encounter text that",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"handle_long_text\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:10 GMT",
"etag": "W/\"bb3188ab6eea3c1c2842a314196599ff\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::c5skq-1713753969920-5eaa98e06f21"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/how_to/handle_long_text/",
"property": "og:url"
},
{
"content": "Handle Long Text | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "When working with files, like PDFs, you’re likely to encounter text that",
"property": "og:description"
}
],
"title": "Handle Long Text | 🦜️🔗 LangChain"
} | When working with files, like PDFs, you’re likely to encounter text that exceeds your language model’s context window. To process this text, consider these strategies:
Keep in mind that these strategies have different trade off and the best strategy likely depends on the application that you’re designing!
We need some example data! Let’s download an article about cars from wikipedia and load it as a LangChain Document.
Here, we’ll define schema to extract key developments from the text.
from typing import List, Optional
from langchain.chains import create_structured_output_runnable
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class KeyDevelopment(BaseModel):
"""Information about a development in the history of cars."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that all fields are required rather than optional!
year: int = Field(
..., description="The year when there was an important historic development."
)
description: str = Field(
..., description="What happened in this year? What was the development?"
)
evidence: str = Field(
...,
description="Repeat in verbatim the sentence(s) from which the year and description information were extracted",
)
class ExtractionData(BaseModel):
"""Extracted information about key developments in the history of cars."""
key_developments: List[KeyDevelopment]
# Define a custom prompt to provide instructions and any additional context.
# 1) You can add examples into the prompt template to improve extraction quality
# 2) Introduce additional parameters to take context into account (e.g., include metadata
# about the document from which the text was extracted.)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert at identifying key historic development in text. "
"Only extract important historic developments. Extract nothing if no important information can be found in the text.",
),
# MessagesPlaceholder('examples'), # Keep on reading through this use case to see how to use examples to improve performance
("human", "{text}"),
]
)
# We will be using tool calling mode, which
# requires a tool calling capable model.
llm = ChatOpenAI(
# Consider benchmarking with a good model to get
# a sense of the best possible quality.
model="gpt-4-0125-preview",
# Remember to set the temperature to 0 for extractions!
temperature=0,
)
extractor = prompt | llm.with_structured_output(
schema=ExtractionData,
method="function_calling",
include_raw=False,
)
/home/eugene/.pyenv/versions/3.11.2/envs/langchain_3_11/lib/python3.11/site-packages/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
Split the documents into chunks such that each chunk fits into the context window of the LLMs.
After extracting data from across the chunks, we’ll want to merge the extractions together.
[KeyDevelopment(year=1966, description="The Toyota Corolla began production, recognized as the world's best-selling automobile.", evidence="The Toyota Corolla has been in production since 1966 and is recognized as the world's best-selling automobile."),
KeyDevelopment(year=1769, description='Nicolas-Joseph Cugnot built the first steam-powered road vehicle.', evidence='French inventor Nicolas-Joseph Cugnot built the first steam-powered road vehicle in 1769.'),
KeyDevelopment(year=1808, description='François Isaac de Rivaz designed and constructed the first internal combustion-powered automobile.', evidence='French-born Swiss inventor François Isaac de Rivaz designed and constructed the first internal combustion-powered automobile in 1808.'),
KeyDevelopment(year=1886, description='Carl Benz patented his Benz Patent-Motorwagen, inventing the modern car.', evidence='The modern car—a practical, marketable automobile for everyday use—was invented in 1886, when German inventor Carl Benz patented his Benz Patent-Motorwagen.'),
KeyDevelopment(year=1908, description='The 1908 Model T, an affordable car for the masses, was manufactured by the Ford Motor Company.', evidence='One of the first cars affordable by the masses was the 1908 Model T, an American car manufactured by the Ford Motor Company.'),
KeyDevelopment(year=1881, description='Gustave Trouvé demonstrated a three-wheeled car powered by electricity.', evidence='In November 1881, French inventor Gustave Trouvé demonstrated a three-wheeled car powered by electricity at the International Exposition of Electricity.'),
KeyDevelopment(year=1888, description="Bertha Benz undertook the first road trip by car to prove the road-worthiness of her husband's invention.", evidence="In August 1888, Bertha Benz, the wife of Carl Benz, undertook the first road trip by car, to prove the road-worthiness of her husband's invention."),
KeyDevelopment(year=1896, description='Benz designed and patented the first internal-combustion flat engine, called boxermotor.', evidence='In 1896, Benz designed and patented the first internal-combustion flat engine, called boxermotor.'),
KeyDevelopment(year=1897, description='Nesselsdorfer Wagenbau produced the Präsident automobil, one of the first factory-made cars in the world.', evidence='The first motor car in central Europe and one of the first factory-made cars in the world, was produced by Czech company Nesselsdorfer Wagenbau (later renamed to Tatra) in 1897, the Präsident automobil.'),
KeyDevelopment(year=1890, description='Daimler Motoren Gesellschaft (DMG) was founded by Daimler and Maybach in Cannstatt.', evidence='Daimler and Maybach founded Daimler Motoren Gesellschaft (DMG) in Cannstatt in 1890.'),
KeyDevelopment(year=1902, description='A new model DMG car was produced and named Mercedes after the Maybach engine.', evidence='Two years later, in 1902, a new model DMG car was produced and the model was named Mercedes after the Maybach engine, which generated 35 hp.'),
KeyDevelopment(year=1891, description='Auguste Doriot and Louis Rigoulot completed the longest trip by a petrol-driven vehicle using a Daimler powered Peugeot Type 3.', evidence='In 1891, Auguste Doriot and his Peugeot colleague Louis Rigoulot completed the longest trip by a petrol-driven vehicle when their self-designed and built Daimler powered Peugeot Type 3 completed 2,100 kilometres (1,300 mi) from Valentigney to Paris and Brest and back again.'),
KeyDevelopment(year=1895, description='George Selden was granted a US patent for a two-stroke car engine.', evidence='After a delay of 16 years and a series of attachments to his application, on 5 November 1895, Selden was granted a US patent (U.S. patent 549,160) for a two-stroke car engine.'),
KeyDevelopment(year=1893, description='The first running, petrol-driven American car was built and road-tested by the Duryea brothers.', evidence='In 1893, the first running, petrol-driven American car was built and road-tested by the Duryea brothers of Springfield, Massachusetts.'),
KeyDevelopment(year=1897, description='Rudolf Diesel built the first diesel engine.', evidence='In 1897, he built the first diesel engine.'),
KeyDevelopment(year=1901, description='Ransom Olds started large-scale, production-line manufacturing of affordable cars at his Oldsmobile factory.', evidence='Large-scale, production-line manufacturing of affordable cars was started by Ransom Olds in 1901 at his Oldsmobile factory in Lansing, Michigan.'),
KeyDevelopment(year=1913, description="Henry Ford began the world's first moving assembly line for cars at the Highland Park Ford Plant.", evidence="This concept was greatly expanded by Henry Ford, beginning in 1913 with the world's first moving assembly line for cars at the Highland Park Ford Plant."),
KeyDevelopment(year=1914, description="Ford's assembly line worker could buy a Model T with four months' pay.", evidence="In 1914, an assembly line worker could buy a Model T with four months' pay."),
KeyDevelopment(year=1926, description='Fast-drying Duco lacquer was developed, allowing for a variety of car colors.', evidence='Only Japan black would dry fast enough, forcing the company to drop the variety of colours available before 1913, until fast-drying Duco lacquer was developed in 1926.')]
Another simple idea is to chunk up the text, but instead of extracting information from every chunk, just focus on the the most relevant chunks.
Here’s a simple example that relies on the FAISS vectorstore.
In this case the RAG extractor is only looking at the top document.
year=1924 description="Germany's first mass-manufactured car, the Opel 4PS Laubfrosch, was produced, making Opel the top car builder in Germany with 37.5% of the market." evidence="Germany's first mass-manufactured car, the Opel 4PS Laubfrosch (Tree Frog), came off the line at Rüsselsheim in 1924, soon making Opel the top car builder in Germany, with 37.5 per cent of the market."
year=1925 description='Morris had 41% of total British car production, dominating the market.' evidence='in 1925, Morris had 41 per cent of total British car production.'
year=1925 description='Citroën, Renault, and Peugeot produced 550,000 cars in France, dominating the market.' evidence="Citroën did the same in France, coming to cars in 1919; between them and other cheap cars in reply such as Renault's 10CV and Peugeot's 5CV, they produced 550,000 cars in 1925."
year=2017 description='Production of petrol-fuelled cars peaked.' evidence='Production of petrol-fuelled cars peaked in 2017.'
Different methods have their own pros and cons related to cost, speed, and accuracy. |
https://python.langchain.com/docs/use_cases/extraction/how_to/parse/ | ## Parsing
LLMs that are able to follow prompt instructions well can be tasked with outputting information in a given format.
This approach relies on designing good prompts and then parsing the output of the LLMs to make them extract information well.
Here, we’ll use Claude which is great at following instructions! See [Anthropic models](https://www.anthropic.com/api).
```
from langchain_anthropic.chat_models import ChatAnthropicmodel = ChatAnthropic(model_name="claude-3-sonnet-20240229", temperature=0)
```
tip
All the same considerations for extraction quality apply for parsing approach. Review the [guidelines](https://python.langchain.com/docs/use_cases/extraction/guidelines/) for extraction quality.
This tutorial is meant to be simple, but generally should really include reference examples to squeeze out performance!
## Using PydanticOutputParser[](#using-pydanticoutputparser "Direct link to Using PydanticOutputParser")
The following example uses the built-in `PydanticOutputParser` to parse the output of a chat model.
```
from typing import List, Optionalfrom langchain.output_parsers import PydanticOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Field, validatorclass Person(BaseModel): """Information about a person.""" name: str = Field(..., description="The name of the person") height_in_meters: float = Field( ..., description="The height of the person expressed in meters." )class People(BaseModel): """Identifying information about all people in a text.""" people: List[Person]# Set up a parserparser = PydanticOutputParser(pydantic_object=People)# Promptprompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the user query. Wrap the output in `json` tags\n{format_instructions}", ), ("human", "{query}"), ]).partial(format_instructions=parser.get_format_instructions())
```
Let’s take a look at what information is sent to the model
```
query = "Anna is 23 years old and she is 6 feet tall"
```
```
print(prompt.format_prompt(query=query).to_string())
```
```
System: Answer the user query. Wrap the output in `json` tagsThe output should be formatted as a JSON instance that conforms to the JSON schema below.As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.Here is the output schema:```{"description": "Identifying information about all people in a text.", "properties": {"people": {"title": "People", "type": "array", "items": {"$ref": "#/definitions/Person"}}}, "required": ["people"], "definitions": {"Person": {"title": "Person", "description": "Information about a person.", "type": "object", "properties": {"name": {"title": "Name", "description": "The name of the person", "type": "string"}, "height_in_meters": {"title": "Height In Meters", "description": "The height of the person expressed in meters.", "type": "number"}}, "required": ["name", "height_in_meters"]}}}```Human: Anna is 23 years old and she is 6 feet tall
```
```
chain = prompt | model | parserchain.invoke({"query": query})
```
```
People(people=[Person(name='Anna', height_in_meters=1.83)])
```
## Custom Parsing[](#custom-parsing "Direct link to Custom Parsing")
It’s easy to create a custom prompt and parser with `LangChain` and `LCEL`.
You can use a simple function to parse the output from the model!
```
import jsonimport refrom typing import List, Optionalfrom langchain_anthropic.chat_models import ChatAnthropicfrom langchain_core.messages import AIMessagefrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Field, validatorclass Person(BaseModel): """Information about a person.""" name: str = Field(..., description="The name of the person") height_in_meters: float = Field( ..., description="The height of the person expressed in meters." )class People(BaseModel): """Identifying information about all people in a text.""" people: List[Person]# Promptprompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the user query. Output your answer as JSON that " "matches the given schema: ```json\n{schema}\n```. " "Make sure to wrap the answer in ```json and ``` tags", ), ("human", "{query}"), ]).partial(schema=People.schema())# Custom parserdef extract_json(message: AIMessage) -> List[dict]: """Extracts JSON content from a string where JSON is embedded between ```json and ``` tags. Parameters: text (str): The text containing the JSON content. Returns: list: A list of extracted JSON strings. """ text = message.content # Define the regular expression pattern to match JSON blocks pattern = r"```json(.*?)```" # Find all non-overlapping matches of the pattern in the string matches = re.findall(pattern, text, re.DOTALL) # Return the list of matched JSON strings, stripping any leading or trailing whitespace try: return [json.loads(match.strip()) for match in matches] except Exception: raise ValueError(f"Failed to parse: {message}")
```
```
query = "Anna is 23 years old and she is 6 feet tall"print(prompt.format_prompt(query=query).to_string())
```
```
System: Answer the user query. Output your answer as JSON that matches the given schema: ```json{'title': 'People', 'description': 'Identifying information about all people in a text.', 'type': 'object', 'properties': {'people': {'title': 'People', 'type': 'array', 'items': {'$ref': '#/definitions/Person'}}}, 'required': ['people'], 'definitions': {'Person': {'title': 'Person', 'description': 'Information about a person.', 'type': 'object', 'properties': {'name': {'title': 'Name', 'description': 'The name of the person', 'type': 'string'}, 'height_in_meters': {'title': 'Height In Meters', 'description': 'The height of the person expressed in meters.', 'type': 'number'}}, 'required': ['name', 'height_in_meters']}}}```. Make sure to wrap the answer in ```json and ``` tagsHuman: Anna is 23 years old and she is 6 feet tall
```
```
chain = prompt | model | extract_jsonchain.invoke({"query": query})
```
```
[{'people': [{'name': 'Anna', 'height_in_meters': 1.83}]}]
```
## Other Libraries[](#other-libraries "Direct link to Other Libraries")
If you’re looking at extracting using a parsing approach, check out the [Kor](https://eyurtsev.github.io/kor/) library. It’s written by one of the `LangChain` maintainers and it helps to craft a prompt that takes examples into account, allows controlling formats (e.g., JSON or CSV) and expresses the schema in TypeScript. It seems to work pretty! | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:10.924Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/parse/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/how_to/parse/",
"description": "LLMs that are able to follow prompt instructions well can be tasked with",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3766",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"parse\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:10 GMT",
"etag": "W/\"23bafea66699780c6cedfebaabfe77a8\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::86l5f-1713753970528-336ad3e8ef39"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/how_to/parse/",
"property": "og:url"
},
{
"content": "Parsing | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "LLMs that are able to follow prompt instructions well can be tasked with",
"property": "og:description"
}
],
"title": "Parsing | 🦜️🔗 LangChain"
} | Parsing
LLMs that are able to follow prompt instructions well can be tasked with outputting information in a given format.
This approach relies on designing good prompts and then parsing the output of the LLMs to make them extract information well.
Here, we’ll use Claude which is great at following instructions! See Anthropic models.
from langchain_anthropic.chat_models import ChatAnthropic
model = ChatAnthropic(model_name="claude-3-sonnet-20240229", temperature=0)
tip
All the same considerations for extraction quality apply for parsing approach. Review the guidelines for extraction quality.
This tutorial is meant to be simple, but generally should really include reference examples to squeeze out performance!
Using PydanticOutputParser
The following example uses the built-in PydanticOutputParser to parse the output of a chat model.
from typing import List, Optional
from langchain.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
class Person(BaseModel):
"""Information about a person."""
name: str = Field(..., description="The name of the person")
height_in_meters: float = Field(
..., description="The height of the person expressed in meters."
)
class People(BaseModel):
"""Identifying information about all people in a text."""
people: List[Person]
# Set up a parser
parser = PydanticOutputParser(pydantic_object=People)
# Prompt
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json` tags\n{format_instructions}",
),
("human", "{query}"),
]
).partial(format_instructions=parser.get_format_instructions())
Let’s take a look at what information is sent to the model
query = "Anna is 23 years old and she is 6 feet tall"
print(prompt.format_prompt(query=query).to_string())
System: Answer the user query. Wrap the output in `json` tags
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{"description": "Identifying information about all people in a text.", "properties": {"people": {"title": "People", "type": "array", "items": {"$ref": "#/definitions/Person"}}}, "required": ["people"], "definitions": {"Person": {"title": "Person", "description": "Information about a person.", "type": "object", "properties": {"name": {"title": "Name", "description": "The name of the person", "type": "string"}, "height_in_meters": {"title": "Height In Meters", "description": "The height of the person expressed in meters.", "type": "number"}}, "required": ["name", "height_in_meters"]}}}
```
Human: Anna is 23 years old and she is 6 feet tall
chain = prompt | model | parser
chain.invoke({"query": query})
People(people=[Person(name='Anna', height_in_meters=1.83)])
Custom Parsing
It’s easy to create a custom prompt and parser with LangChain and LCEL.
You can use a simple function to parse the output from the model!
import json
import re
from typing import List, Optional
from langchain_anthropic.chat_models import ChatAnthropic
from langchain_core.messages import AIMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
class Person(BaseModel):
"""Information about a person."""
name: str = Field(..., description="The name of the person")
height_in_meters: float = Field(
..., description="The height of the person expressed in meters."
)
class People(BaseModel):
"""Identifying information about all people in a text."""
people: List[Person]
# Prompt
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Output your answer as JSON that "
"matches the given schema: ```json\n{schema}\n```. "
"Make sure to wrap the answer in ```json and ``` tags",
),
("human", "{query}"),
]
).partial(schema=People.schema())
# Custom parser
def extract_json(message: AIMessage) -> List[dict]:
"""Extracts JSON content from a string where JSON is embedded between ```json and ``` tags.
Parameters:
text (str): The text containing the JSON content.
Returns:
list: A list of extracted JSON strings.
"""
text = message.content
# Define the regular expression pattern to match JSON blocks
pattern = r"```json(.*?)```"
# Find all non-overlapping matches of the pattern in the string
matches = re.findall(pattern, text, re.DOTALL)
# Return the list of matched JSON strings, stripping any leading or trailing whitespace
try:
return [json.loads(match.strip()) for match in matches]
except Exception:
raise ValueError(f"Failed to parse: {message}")
query = "Anna is 23 years old and she is 6 feet tall"
print(prompt.format_prompt(query=query).to_string())
System: Answer the user query. Output your answer as JSON that matches the given schema: ```json
{'title': 'People', 'description': 'Identifying information about all people in a text.', 'type': 'object', 'properties': {'people': {'title': 'People', 'type': 'array', 'items': {'$ref': '#/definitions/Person'}}}, 'required': ['people'], 'definitions': {'Person': {'title': 'Person', 'description': 'Information about a person.', 'type': 'object', 'properties': {'name': {'title': 'Name', 'description': 'The name of the person', 'type': 'string'}, 'height_in_meters': {'title': 'Height In Meters', 'description': 'The height of the person expressed in meters.', 'type': 'number'}}, 'required': ['name', 'height_in_meters']}}}
```. Make sure to wrap the answer in ```json and ``` tags
Human: Anna is 23 years old and she is 6 feet tall
chain = prompt | model | extract_json
chain.invoke({"query": query})
[{'people': [{'name': 'Anna', 'height_in_meters': 1.83}]}]
Other Libraries
If you’re looking at extracting using a parsing approach, check out the Kor library. It’s written by one of the LangChain maintainers and it helps to craft a prompt that takes examples into account, allows controlling formats (e.g., JSON or CSV) and expresses the schema in TypeScript. It seems to work pretty! |
https://python.langchain.com/docs/use_cases/extraction/quickstart/ | ## Quickstart
In this quick start, we will use [chat models](https://python.langchain.com/docs/modules/model_io/chat/) that are capable of **function/tool calling** to extract information from text.
## Set up[](#set-up "Direct link to Set up")
We will use the [structured output](https://python.langchain.com/docs/modules/model_io/chat/structured_output/) method available on LLMs that are capable of **function/tool calling**.
Select a model, install the dependencies for it and set up API keys!
```
!pip install langchain# Install a model capable of tool calling# pip install langchain-openai# pip install langchain-mistralai# pip install langchain-fireworks# Set env vars for the relevant model or load from a .env file:# import dotenv# dotenv.load_dotenv()
```
## The Schema[](#the-schema "Direct link to The Schema")
First, we need to describe what information we want to extract from the text.
We’ll use Pydantic to define an example schema to extract personal information.
```
from typing import Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Person(BaseModel): """Information about a person.""" # ^ Doc-string for the entity Person. # This doc-string is sent to the LLM as the description of the schema Person, # and it can help to improve extraction results. # Note that: # 1. Each field is an `optional` -- this allows the model to decline to extract it! # 2. Each field has a `description` -- this description is used by the LLM. # Having a good description can help improve extraction results. name: Optional[str] = Field(default=None, description="The name of the person") hair_color: Optional[str] = Field( default=None, description="The color of the peron's hair if known" ) height_in_meters: Optional[str] = Field( default=None, description="Height measured in meters" )
```
There are two best practices when defining schema:
1. Document the **attributes** and the **schema** itself: This information is sent to the LLM and is used to improve the quality of information extraction.
2. Do not force the LLM to make up information! Above we used `Optional` for the attributes allowing the LLM to output `None` if it doesn’t know the answer.
info
For best performance, document the schema well and make sure the model isn’t force to return results if there’s no information to be extracted in the text.
Let’s create an information extractor using the schema we defined above.
```
from typing import Optionalfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAI# Define a custom prompt to provide instructions and any additional context.# 1) You can add examples into the prompt template to improve extraction quality# 2) Introduce additional parameters to take context into account (e.g., include metadata# about the document from which the text was extracted.)prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are an expert extraction algorithm. " "Only extract relevant information from the text. " "If you do not know the value of an attribute asked to extract, " "return null for the attribute's value.", ), # Please see the how-to about improving performance with # reference examples. # MessagesPlaceholder('examples'), ("human", "{text}"), ])
```
We need to use a model that supports function/tool calling.
Please review [structured output](https://python.langchain.com/docs/modules/model_io/chat/structured_output/) for list of some models that can be used with this API.
```
from langchain_mistralai import ChatMistralAIllm = ChatMistralAI(model="mistral-large-latest", temperature=0)runnable = prompt | llm.with_structured_output(schema=Person)
```
Let’s test it out
```
text = "Alan Smith is 6 feet tall and has blond hair."runnable.invoke({"text": text})
```
```
Person(name='Alan Smith', hair_color='blond', height_in_meters='1.8288')
```
info
Extraction is Generative 🤯
LLMs are generative models, so they can do some pretty cool things like correctly extract the height of the person in meters even though it was provided in feet!
## Multiple Entities[](#multiple-entities "Direct link to Multiple Entities")
In **most cases**, you should be extracting a list of entities rather than a single entity.
This can be easily achieved using pydantic by nesting models inside one another.
```
from typing import List, Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Person(BaseModel): """Information about a person.""" # ^ Doc-string for the entity Person. # This doc-string is sent to the LLM as the description of the schema Person, # and it can help to improve extraction results. # Note that: # 1. Each field is an `optional` -- this allows the model to decline to extract it! # 2. Each field has a `description` -- this description is used by the LLM. # Having a good description can help improve extraction results. name: Optional[str] = Field(default=None, description="The name of the person") hair_color: Optional[str] = Field( default=None, description="The color of the peron's hair if known" ) height_in_meters: Optional[str] = Field( default=None, description="Height measured in meters" )class Data(BaseModel): """Extracted data about people.""" # Creates a model so that we can extract multiple entities. people: List[Person]
```
info
Extraction might not be perfect here. Please continue to see how to use **Reference Examples** to improve the quality of extraction, and see the **guidelines** section!
```
runnable = prompt | llm.with_structured_output(schema=Data)text = "My name is Jeff, my hair is black and i am 6 feet tall. Anna has the same color hair as me."runnable.invoke({"text": text})
```
```
Data(people=[Person(name='Jeff', hair_color=None, height_in_meters=None), Person(name='Anna', hair_color=None, height_in_meters=None)])
```
tip
When the schema accommodates the extraction of **multiple entities**, it also allows the model to extract **no entities** if no relevant information is in the text by providing an empty list.
This is usually a **good** thing! It allows specifying **required** attributes on an entity without necessarily forcing the model to detect this entity.
## Next steps[](#next-steps "Direct link to Next steps")
Now that you understand the basics of extraction with LangChain, you’re ready to proceed to the rest of the how-to guide:
* [Add Examples](https://python.langchain.com/docs/use_cases/extraction/how_to/examples/): Learn how to use **reference examples** to improve performance.
* [Handle Long Text](https://python.langchain.com/docs/use_cases/extraction/how_to/handle_long_text/): What should you do if the text does not fit into the context window of the LLM?
* [Handle Files](https://python.langchain.com/docs/use_cases/extraction/how_to/handle_files/): Examples of using LangChain document loaders and parsers to extract from files like PDFs.
* [Use a Parsing Approach](https://python.langchain.com/docs/use_cases/extraction/how_to/parse/): Use a prompt based approach to extract with models that do not support **tool/function calling**.
* [Guidelines](https://python.langchain.com/docs/use_cases/extraction/guidelines/): Guidelines for getting good performance on extraction tasks.
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:11.510Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/extraction/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/extraction/quickstart/",
"description": "In this quick start, we will use [chat",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3766",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:11 GMT",
"etag": "W/\"2e63c5e0855609a2d9c1e19e3eb17688\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::nvdzc-1713753971454-0810d77fc026"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/extraction/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this quick start, we will use [chat",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
In this quick start, we will use chat models that are capable of function/tool calling to extract information from text.
Set up
We will use the structured output method available on LLMs that are capable of function/tool calling.
Select a model, install the dependencies for it and set up API keys!
!pip install langchain
# Install a model capable of tool calling
# pip install langchain-openai
# pip install langchain-mistralai
# pip install langchain-fireworks
# Set env vars for the relevant model or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
The Schema
First, we need to describe what information we want to extract from the text.
We’ll use Pydantic to define an example schema to extract personal information.
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(default=None, description="The name of the person")
hair_color: Optional[str] = Field(
default=None, description="The color of the peron's hair if known"
)
height_in_meters: Optional[str] = Field(
default=None, description="Height measured in meters"
)
There are two best practices when defining schema:
Document the attributes and the schema itself: This information is sent to the LLM and is used to improve the quality of information extraction.
Do not force the LLM to make up information! Above we used Optional for the attributes allowing the LLM to output None if it doesn’t know the answer.
info
For best performance, document the schema well and make sure the model isn’t force to return results if there’s no information to be extracted in the text.
Let’s create an information extractor using the schema we defined above.
from typing import Optional
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Define a custom prompt to provide instructions and any additional context.
# 1) You can add examples into the prompt template to improve extraction quality
# 2) Introduce additional parameters to take context into account (e.g., include metadata
# about the document from which the text was extracted.)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert extraction algorithm. "
"Only extract relevant information from the text. "
"If you do not know the value of an attribute asked to extract, "
"return null for the attribute's value.",
),
# Please see the how-to about improving performance with
# reference examples.
# MessagesPlaceholder('examples'),
("human", "{text}"),
]
)
We need to use a model that supports function/tool calling.
Please review structured output for list of some models that can be used with this API.
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest", temperature=0)
runnable = prompt | llm.with_structured_output(schema=Person)
Let’s test it out
text = "Alan Smith is 6 feet tall and has blond hair."
runnable.invoke({"text": text})
Person(name='Alan Smith', hair_color='blond', height_in_meters='1.8288')
info
Extraction is Generative 🤯
LLMs are generative models, so they can do some pretty cool things like correctly extract the height of the person in meters even though it was provided in feet!
Multiple Entities
In most cases, you should be extracting a list of entities rather than a single entity.
This can be easily achieved using pydantic by nesting models inside one another.
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(default=None, description="The name of the person")
hair_color: Optional[str] = Field(
default=None, description="The color of the peron's hair if known"
)
height_in_meters: Optional[str] = Field(
default=None, description="Height measured in meters"
)
class Data(BaseModel):
"""Extracted data about people."""
# Creates a model so that we can extract multiple entities.
people: List[Person]
info
Extraction might not be perfect here. Please continue to see how to use Reference Examples to improve the quality of extraction, and see the guidelines section!
runnable = prompt | llm.with_structured_output(schema=Data)
text = "My name is Jeff, my hair is black and i am 6 feet tall. Anna has the same color hair as me."
runnable.invoke({"text": text})
Data(people=[Person(name='Jeff', hair_color=None, height_in_meters=None), Person(name='Anna', hair_color=None, height_in_meters=None)])
tip
When the schema accommodates the extraction of multiple entities, it also allows the model to extract no entities if no relevant information is in the text by providing an empty list.
This is usually a good thing! It allows specifying required attributes on an entity without necessarily forcing the model to detect this entity.
Next steps
Now that you understand the basics of extraction with LangChain, you’re ready to proceed to the rest of the how-to guide:
Add Examples: Learn how to use reference examples to improve performance.
Handle Long Text: What should you do if the text does not fit into the context window of the LLM?
Handle Files: Examples of using LangChain document loaders and parsers to extract from files like PDFs.
Use a Parsing Approach: Use a prompt based approach to extract with models that do not support tool/function calling.
Guidelines: Guidelines for getting good performance on extraction tasks.
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/use_cases/graph/ | ## Graphs
One of the common types of databases that we can build Q&A systems for are graph databases. LangChain comes with a number of built-in chains and agents that are compatible with graph query language dialects like Cypher, SparQL, and others (e.g., Neo4j, MemGraph, Amazon Neptune, Kùzu, OntoText, Tigergraph). They enable use cases such as:
* Generating queries that will be run based on natural language questions,
* Creating chatbots that can answer questions based on database data,
* Building custom dashboards based on insights a user wants to analyze,
and much more.
## ⚠️ Security note ⚠️[](#security-note "Direct link to ⚠️ Security note ⚠️")
Building Q&A systems of graph databases might require executing model-generated database queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, [see here](https://python.langchain.com/docs/security/).

> Employing database query templates within a semantic layer provides the advantage of bypassing the need for database query generation. This approach effectively eradicates security vulnerabilities linked to the generation of database queries.
## Quickstart[](#quickstart "Direct link to Quickstart")
Head to the **[Quickstart](https://python.langchain.com/docs/use_cases/graph/quickstart/)** page to get started.
## Advanced[](#advanced "Direct link to Advanced")
Once you’ve familiarized yourself with the basics, you can head to the advanced guides:
* [Prompting strategies](https://python.langchain.com/docs/use_cases/graph/prompting/): Advanced prompt engineering techniques.
* [Mapping values](https://python.langchain.com/docs/use_cases/graph/mapping/): Techniques for mapping values from questions to database.
* [Semantic layer](https://python.langchain.com/docs/use_cases/graph/semantic/): Techniques for implementing semantic layers.
* [Constructing graphs](https://python.langchain.com/docs/use_cases/graph/constructing/): Techniques for constructing knowledge graphs. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:12.126Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/graph/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/graph/",
"description": "One of the common types of databases that we can build Q&A systems for",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7355",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"graph\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:12 GMT",
"etag": "W/\"3e425369a4f49fa6df05cab2450c2646\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::fcrlk-1713753972075-45a43038f9fc"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/graph/",
"property": "og:url"
},
{
"content": "Graphs | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "One of the common types of databases that we can build Q&A systems for",
"property": "og:description"
}
],
"title": "Graphs | 🦜️🔗 LangChain"
} | Graphs
One of the common types of databases that we can build Q&A systems for are graph databases. LangChain comes with a number of built-in chains and agents that are compatible with graph query language dialects like Cypher, SparQL, and others (e.g., Neo4j, MemGraph, Amazon Neptune, Kùzu, OntoText, Tigergraph). They enable use cases such as:
Generating queries that will be run based on natural language questions,
Creating chatbots that can answer questions based on database data,
Building custom dashboards based on insights a user wants to analyze,
and much more.
⚠️ Security note ⚠️
Building Q&A systems of graph databases might require executing model-generated database queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
Employing database query templates within a semantic layer provides the advantage of bypassing the need for database query generation. This approach effectively eradicates security vulnerabilities linked to the generation of database queries.
Quickstart
Head to the Quickstart page to get started.
Advanced
Once you’ve familiarized yourself with the basics, you can head to the advanced guides:
Prompting strategies: Advanced prompt engineering techniques.
Mapping values: Techniques for mapping values from questions to database.
Semantic layer: Techniques for implementing semantic layers.
Constructing graphs: Techniques for constructing knowledge graphs. |
https://python.langchain.com/docs/use_cases/graph/constructing/ | ## Constructing knowledge graphs
In this guide we’ll go over the basic ways of constructing a knowledge graph based on unstructured text. The constructured graph can then be used as knowledge base in a RAG application.
## ⚠️ Security note ⚠️[](#security-note "Direct link to ⚠️ Security note ⚠️")
Constructing knowledge graphs requires executing write access to the database. There are inherent risks in doing this. Make sure that you verify and validate data before importing it. For more on general security best practices, [see here](https://python.langchain.com/docs/security/).
## Architecture[](#architecture "Direct link to Architecture")
At a high-level, the steps of constructing a knowledge are from text are:
1. **Extracting structured information from text**: Model is used to extract structured graph information from text.
2. **Storing into graph database**: Storing the extracted structured graph information into a graph database enables downstream RAG applications
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables. In this example, we will be using Neo4j graph database.
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai langchain-experimental neo4j
```
```
Note: you may need to restart the kernel to use updated packages.
```
We default to OpenAI models in this guide.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
Next, we need to define Neo4j credentials and connection. Follow [these installation steps](https://neo4j.com/docs/operations-manual/current/installation/) to set up a Neo4j database.
```
import osfrom langchain_community.graphs import Neo4jGraphos.environ["NEO4J_URI"] = "bolt://localhost:7687"os.environ["NEO4J_USERNAME"] = "neo4j"os.environ["NEO4J_PASSWORD"] = "password"graph = Neo4jGraph()
```
## LLM Graph Transformer[](#llm-graph-transformer "Direct link to LLM Graph Transformer")
Extracting graph data from text enables the transformation of unstructured information into structured formats, facilitating deeper insights and more efficient navigation through complex relationships and patterns. The `LLMGraphTransformer` converts text documents into structured graph documents by leveraging a LLM to parse and categorize entities and their relationships. The selection of the LLM model significantly influences the output by determining the accuracy and nuance of the extracted graph data.
```
import osfrom langchain_experimental.graph_transformers import LLMGraphTransformerfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")llm_transformer = LLMGraphTransformer(llm=llm)
```
Now we can pass in example text and examine the results.
```
from langchain_core.documents import Documenttext = """Marie Curie, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.She was, in 1906, the first woman to become a professor at the University of Paris."""documents = [Document(page_content=text)]graph_documents = llm_transformer.convert_to_graph_documents(documents)print(f"Nodes:{graph_documents[0].nodes}")print(f"Relationships:{graph_documents[0].relationships}")
```
```
Nodes:[Node(id='Marie Curie', type='Person'), Node(id='Polish', type='Nationality'), Node(id='French', type='Nationality'), Node(id='Physicist', type='Occupation'), Node(id='Chemist', type='Occupation'), Node(id='Radioactivity', type='Field'), Node(id='Nobel Prize', type='Award'), Node(id='Pierre Curie', type='Person'), Node(id='University Of Paris', type='Organization')]Relationships:[Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Polish', type='Nationality'), type='NATIONALITY'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='French', type='Nationality'), type='NATIONALITY'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Physicist', type='Occupation'), type='OCCUPATION'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Chemist', type='Occupation'), type='OCCUPATION'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Radioactivity', type='Field'), type='RESEARCH_FIELD'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Nobel Prize', type='Award'), type='AWARD_WINNER'), Relationship(source=Node(id='Pierre Curie', type='Person'), target=Node(id='Nobel Prize', type='Award'), type='AWARD_WINNER'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='University Of Paris', type='Organization'), type='PROFESSOR')]
```
Examine the following image to better grasp the structure of the generated knowledge graph.
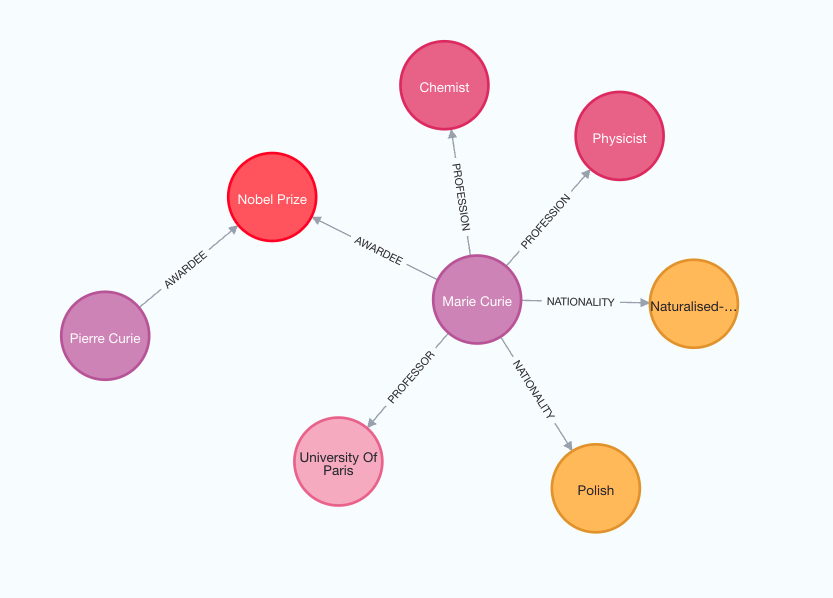
Note that the graph construction process is non-deterministic since we are using LLM. Therefore, you might get slightly different results on each execution.
Additionally, you have the flexibility to define specific types of nodes and relationships for extraction according to your requirements.
```
llm_transformer_filtered = LLMGraphTransformer( llm=llm, allowed_nodes=["Person", "Country", "Organization"], allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],)graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents( documents)print(f"Nodes:{graph_documents_filtered[0].nodes}")print(f"Relationships:{graph_documents_filtered[0].relationships}")
```
```
Nodes:[Node(id='Marie Curie', type='Person'), Node(id='Polish', type='Country'), Node(id='French', type='Country'), Node(id='Pierre Curie', type='Person'), Node(id='University Of Paris', type='Organization')]Relationships:[Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Polish', type='Country'), type='NATIONALITY'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='French', type='Country'), type='NATIONALITY'), Relationship(source=Node(id='Pierre Curie', type='Person'), target=Node(id='Marie Curie', type='Person'), type='SPOUSE'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='University Of Paris', type='Organization'), type='WORKED_AT')]
```
For a better understanding of the generated graph, we can again visualize it.
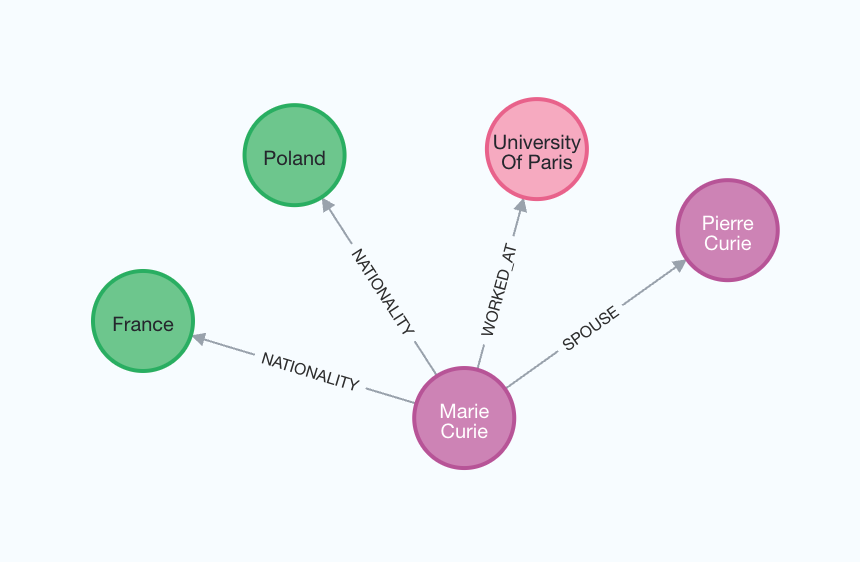
## Storing to graph database[](#storing-to-graph-database "Direct link to Storing to graph database")
The generated graph documents can be stored to a graph database using the `add_graph_documents` method.
```
graph.add_graph_documents(graph_documents_filtered)
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:12.621Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/graph/constructing/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/graph/constructing/",
"description": "In this guide we’ll go over the basic ways of constructing a knowledge",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7242",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"constructing\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:12 GMT",
"etag": "W/\"3be49ff691265a1355c180205b23744f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::kt9bz-1713753972521-bf84dd7e993d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/graph/constructing/",
"property": "og:url"
},
{
"content": "Constructing knowledge graphs | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll go over the basic ways of constructing a knowledge",
"property": "og:description"
}
],
"title": "Constructing knowledge graphs | 🦜️🔗 LangChain"
} | Constructing knowledge graphs
In this guide we’ll go over the basic ways of constructing a knowledge graph based on unstructured text. The constructured graph can then be used as knowledge base in a RAG application.
⚠️ Security note ⚠️
Constructing knowledge graphs requires executing write access to the database. There are inherent risks in doing this. Make sure that you verify and validate data before importing it. For more on general security best practices, see here.
Architecture
At a high-level, the steps of constructing a knowledge are from text are:
Extracting structured information from text: Model is used to extract structured graph information from text.
Storing into graph database: Storing the extracted structured graph information into a graph database enables downstream RAG applications
Setup
First, get required packages and set environment variables. In this example, we will be using Neo4j graph database.
%pip install --upgrade --quiet langchain langchain-community langchain-openai langchain-experimental neo4j
Note: you may need to restart the kernel to use updated packages.
We default to OpenAI models in this guide.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
Next, we need to define Neo4j credentials and connection. Follow these installation steps to set up a Neo4j database.
import os
from langchain_community.graphs import Neo4jGraph
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
graph = Neo4jGraph()
LLM Graph Transformer
Extracting graph data from text enables the transformation of unstructured information into structured formats, facilitating deeper insights and more efficient navigation through complex relationships and patterns. The LLMGraphTransformer converts text documents into structured graph documents by leveraging a LLM to parse and categorize entities and their relationships. The selection of the LLM model significantly influences the output by determining the accuracy and nuance of the extracted graph data.
import os
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")
llm_transformer = LLMGraphTransformer(llm=llm)
Now we can pass in example text and examine the results.
from langchain_core.documents import Document
text = """
Marie Curie, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.
She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.
Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.
She was, in 1906, the first woman to become a professor at the University of Paris.
"""
documents = [Document(page_content=text)]
graph_documents = llm_transformer.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents[0].nodes}")
print(f"Relationships:{graph_documents[0].relationships}")
Nodes:[Node(id='Marie Curie', type='Person'), Node(id='Polish', type='Nationality'), Node(id='French', type='Nationality'), Node(id='Physicist', type='Occupation'), Node(id='Chemist', type='Occupation'), Node(id='Radioactivity', type='Field'), Node(id='Nobel Prize', type='Award'), Node(id='Pierre Curie', type='Person'), Node(id='University Of Paris', type='Organization')]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Polish', type='Nationality'), type='NATIONALITY'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='French', type='Nationality'), type='NATIONALITY'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Physicist', type='Occupation'), type='OCCUPATION'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Chemist', type='Occupation'), type='OCCUPATION'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Radioactivity', type='Field'), type='RESEARCH_FIELD'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Nobel Prize', type='Award'), type='AWARD_WINNER'), Relationship(source=Node(id='Pierre Curie', type='Person'), target=Node(id='Nobel Prize', type='Award'), type='AWARD_WINNER'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='University Of Paris', type='Organization'), type='PROFESSOR')]
Examine the following image to better grasp the structure of the generated knowledge graph.
Note that the graph construction process is non-deterministic since we are using LLM. Therefore, you might get slightly different results on each execution.
Additionally, you have the flexibility to define specific types of nodes and relationships for extraction according to your requirements.
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Country", "Organization"],
allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],
)
graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents(
documents
)
print(f"Nodes:{graph_documents_filtered[0].nodes}")
print(f"Relationships:{graph_documents_filtered[0].relationships}")
Nodes:[Node(id='Marie Curie', type='Person'), Node(id='Polish', type='Country'), Node(id='French', type='Country'), Node(id='Pierre Curie', type='Person'), Node(id='University Of Paris', type='Organization')]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='Polish', type='Country'), type='NATIONALITY'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='French', type='Country'), type='NATIONALITY'), Relationship(source=Node(id='Pierre Curie', type='Person'), target=Node(id='Marie Curie', type='Person'), type='SPOUSE'), Relationship(source=Node(id='Marie Curie', type='Person'), target=Node(id='University Of Paris', type='Organization'), type='WORKED_AT')]
For a better understanding of the generated graph, we can again visualize it.
Storing to graph database
The generated graph documents can be stored to a graph database using the add_graph_documents method.
graph.add_graph_documents(graph_documents_filtered) |
https://python.langchain.com/docs/use_cases/graph/mapping/ | ## Mapping values to database
In this guide we’ll go over strategies to improve graph database query generation by mapping values from user inputs to database. When using the built-in graph chains, the LLM is aware of the graph schema, but has no information about the values of properties stored in the database. Therefore, we can introduce a new step in graph database QA system to accurately map values.
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
```
```
Note: you may need to restart the kernel to use updated packages.
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
Next, we need to define Neo4j credentials. Follow [these installation steps](https://neo4j.com/docs/operations-manual/current/installation/) to set up a Neo4j database.
```
os.environ["NEO4J_URI"] = "bolt://localhost:7687"os.environ["NEO4J_USERNAME"] = "neo4j"os.environ["NEO4J_PASSWORD"] = "password"
```
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
```
from langchain_community.graphs import Neo4jGraphgraph = Neo4jGraph()# Import movie informationmovies_query = """LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'AS rowMERGE (m:Movie {id:row.movieId})SET m.released = date(row.released), m.title = row.title, m.imdbRating = toFloat(row.imdbRating)FOREACH (director in split(row.director, '|') | MERGE (p:Person {name:trim(director)}) MERGE (p)-[:DIRECTED]->(m))FOREACH (actor in split(row.actors, '|') | MERGE (p:Person {name:trim(actor)}) MERGE (p)-[:ACTED_IN]->(m))FOREACH (genre in split(row.genres, '|') | MERGE (g:Genre {name:trim(genre)}) MERGE (m)-[:IN_GENRE]->(g))"""graph.query(movies_query)
```
## Detecting entities in the user input[](#detecting-entities-in-the-user-input "Direct link to Detecting entities in the user input")
We have to extract the types of entities/values we want to map to a graph database. In this example, we are dealing with a movie graph, so we can map movies and people to the database.
```
from typing import List, Optionalfrom langchain.chains.openai_functions import create_structured_output_chainfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)class Entities(BaseModel): """Identifying information about entities.""" names: List[str] = Field( ..., description="All the person or movies appearing in the text", )prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are extracting person and movies from the text.", ), ( "human", "Use the given format to extract information from the following " "input: {question}", ), ])entity_chain = create_structured_output_chain(Entities, llm, prompt)
```
```
/Users/tomazbratanic/anaconda3/lib/python3.11/site-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The function `create_structured_output_chain` was deprecated in LangChain 0.1.1 and will be removed in 0.2.0. Use create_structured_output_runnable instead. warn_deprecated(
```
We can test the entity extraction chain.
```
entities = entity_chain.invoke({"question": "Who played in Casino movie?"})entities
```
```
{'question': 'Who played in Casino movie?', 'function': Entities(names=['Casino'])}
```
We will utilize a simple `CONTAINS` clause to match entities to database. In practice, you might want to use a fuzzy search or a fulltext index to allow for minor misspellings.
```
match_query = """MATCH (p:Person|Movie)WHERE p.name CONTAINS $value OR p.title CONTAINS $valueRETURN coalesce(p.name, p.title) AS result, labels(p)[0] AS typeLIMIT 1"""def map_to_database(values): result = "" for entity in values.names: response = graph.query(match_query, {"value": entity}) try: result += f"{entity} maps to {response[0]['result']} {response[0]['type']} in database\n" except IndexError: pass return resultmap_to_database(entities["function"])
```
```
'Casino maps to Casino Movie in database\n'
```
## Custom Cypher generating chain[](#custom-cypher-generating-chain "Direct link to Custom Cypher generating chain")
We need to define a custom Cypher prompt that takes the entity mapping information along with the schema and the user question to construct a Cypher statement. We will be using the LangChain expression language to accomplish that.
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthrough# Generate Cypher statement based on natural language inputcypher_template = """Based on the Neo4j graph schema below, write a Cypher query that would answer the user's question:{schema}Entities in the question map to the following database values:{entities_list}Question: {question}Cypher query:""" # noqa: E501cypher_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input question, convert it to a Cypher query. No pre-amble.", ), ("human", cypher_template), ])cypher_response = ( RunnablePassthrough.assign(names=entity_chain) | RunnablePassthrough.assign( entities_list=lambda x: map_to_database(x["names"]["function"]), schema=lambda _: graph.get_schema, ) | cypher_prompt | llm.bind(stop=["\nCypherResult:"]) | StrOutputParser())
```
```
cypher = cypher_response.invoke({"question": "Who played in Casino movie?"})cypher
```
```
'MATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor)\nRETURN actor.name'
```
## Generating answers based on database results[](#generating-answers-based-on-database-results "Direct link to Generating answers based on database results")
Now that we have a chain that generates the Cypher statement, we need to execute the Cypher statement against the database and send the database results back to an LLM to generate the final answer. Again, we will be using LCEL.
```
from langchain.chains.graph_qa.cypher_utils import CypherQueryCorrector, Schema# Cypher validation tool for relationship directionscorrector_schema = [ Schema(el["start"], el["type"], el["end"]) for el in graph.structured_schema.get("relationships")]cypher_validation = CypherQueryCorrector(corrector_schema)# Generate natural language response based on database resultsresponse_template = """Based on the the question, Cypher query, and Cypher response, write a natural language response:Question: {question}Cypher query: {query}Cypher Response: {response}""" # noqa: E501response_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input question and Cypher response, convert it to a natural" " language answer. No pre-amble.", ), ("human", response_template), ])chain = ( RunnablePassthrough.assign(query=cypher_response) | RunnablePassthrough.assign( response=lambda x: graph.query(cypher_validation(x["query"])), ) | response_prompt | llm | StrOutputParser())
```
```
chain.invoke({"question": "Who played in Casino movie?"})
```
```
'Joe Pesci, Robert De Niro, Sharon Stone, and James Woods played in the movie "Casino".'
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:13.378Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/graph/mapping/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/graph/mapping/",
"description": "In this guide we’ll go over strategies to improve graph database query",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4248",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"mapping\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:13 GMT",
"etag": "W/\"bebe6ec6fc7ae2f1816165f919b72205\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::cfhg6-1713753973258-ea43115df66a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/graph/mapping/",
"property": "og:url"
},
{
"content": "Mapping values to database | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll go over strategies to improve graph database query",
"property": "og:description"
}
],
"title": "Mapping values to database | 🦜️🔗 LangChain"
} | Mapping values to database
In this guide we’ll go over strategies to improve graph database query generation by mapping values from user inputs to database. When using the built-in graph chains, the LLM is aware of the graph schema, but has no information about the values of properties stored in the database. Therefore, we can introduce a new step in graph database QA system to accurately map values.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
Note: you may need to restart the kernel to use updated packages.
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
Next, we need to define Neo4j credentials. Follow these installation steps to set up a Neo4j database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
Detecting entities in the user input
We have to extract the types of entities/values we want to map to a graph database. In this example, we are dealing with a movie graph, so we can map movies and people to the database.
from typing import List, Optional
from langchain.chains.openai_functions import create_structured_output_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
class Entities(BaseModel):
"""Identifying information about entities."""
names: List[str] = Field(
...,
description="All the person or movies appearing in the text",
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting person and movies from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
entity_chain = create_structured_output_chain(Entities, llm, prompt)
/Users/tomazbratanic/anaconda3/lib/python3.11/site-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The function `create_structured_output_chain` was deprecated in LangChain 0.1.1 and will be removed in 0.2.0. Use create_structured_output_runnable instead.
warn_deprecated(
We can test the entity extraction chain.
entities = entity_chain.invoke({"question": "Who played in Casino movie?"})
entities
{'question': 'Who played in Casino movie?',
'function': Entities(names=['Casino'])}
We will utilize a simple CONTAINS clause to match entities to database. In practice, you might want to use a fuzzy search or a fulltext index to allow for minor misspellings.
match_query = """MATCH (p:Person|Movie)
WHERE p.name CONTAINS $value OR p.title CONTAINS $value
RETURN coalesce(p.name, p.title) AS result, labels(p)[0] AS type
LIMIT 1
"""
def map_to_database(values):
result = ""
for entity in values.names:
response = graph.query(match_query, {"value": entity})
try:
result += f"{entity} maps to {response[0]['result']} {response[0]['type']} in database\n"
except IndexError:
pass
return result
map_to_database(entities["function"])
'Casino maps to Casino Movie in database\n'
Custom Cypher generating chain
We need to define a custom Cypher prompt that takes the entity mapping information along with the schema and the user question to construct a Cypher statement. We will be using the LangChain expression language to accomplish that.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# Generate Cypher statement based on natural language input
cypher_template = """Based on the Neo4j graph schema below, write a Cypher query that would answer the user's question:
{schema}
Entities in the question map to the following database values:
{entities_list}
Question: {question}
Cypher query:""" # noqa: E501
cypher_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input question, convert it to a Cypher query. No pre-amble.",
),
("human", cypher_template),
]
)
cypher_response = (
RunnablePassthrough.assign(names=entity_chain)
| RunnablePassthrough.assign(
entities_list=lambda x: map_to_database(x["names"]["function"]),
schema=lambda _: graph.get_schema,
)
| cypher_prompt
| llm.bind(stop=["\nCypherResult:"])
| StrOutputParser()
)
cypher = cypher_response.invoke({"question": "Who played in Casino movie?"})
cypher
'MATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor)\nRETURN actor.name'
Generating answers based on database results
Now that we have a chain that generates the Cypher statement, we need to execute the Cypher statement against the database and send the database results back to an LLM to generate the final answer. Again, we will be using LCEL.
from langchain.chains.graph_qa.cypher_utils import CypherQueryCorrector, Schema
# Cypher validation tool for relationship directions
corrector_schema = [
Schema(el["start"], el["type"], el["end"])
for el in graph.structured_schema.get("relationships")
]
cypher_validation = CypherQueryCorrector(corrector_schema)
# Generate natural language response based on database results
response_template = """Based on the the question, Cypher query, and Cypher response, write a natural language response:
Question: {question}
Cypher query: {query}
Cypher Response: {response}""" # noqa: E501
response_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input question and Cypher response, convert it to a natural"
" language answer. No pre-amble.",
),
("human", response_template),
]
)
chain = (
RunnablePassthrough.assign(query=cypher_response)
| RunnablePassthrough.assign(
response=lambda x: graph.query(cypher_validation(x["query"])),
)
| response_prompt
| llm
| StrOutputParser()
)
chain.invoke({"question": "Who played in Casino movie?"})
'Joe Pesci, Robert De Niro, Sharon Stone, and James Woods played in the movie "Casino".' |
https://python.langchain.com/docs/use_cases/graph/prompting/ | ## Prompting strategies
In this guide we’ll go over prompting strategies to improve graph database query generation. We’ll largely focus on methods for getting relevant database-specific information in your prompt.
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
```
```
Note: you may need to restart the kernel to use updated packages.
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
Next, we need to define Neo4j credentials. Follow [these installation steps](https://neo4j.com/docs/operations-manual/current/installation/) to set up a Neo4j database.
```
os.environ["NEO4J_URI"] = "bolt://localhost:7687"os.environ["NEO4J_USERNAME"] = "neo4j"os.environ["NEO4J_PASSWORD"] = "password"
```
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
```
from langchain_community.graphs import Neo4jGraphgraph = Neo4jGraph()# Import movie informationmovies_query = """LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'AS rowMERGE (m:Movie {id:row.movieId})SET m.released = date(row.released), m.title = row.title, m.imdbRating = toFloat(row.imdbRating)FOREACH (director in split(row.director, '|') | MERGE (p:Person {name:trim(director)}) MERGE (p)-[:DIRECTED]->(m))FOREACH (actor in split(row.actors, '|') | MERGE (p:Person {name:trim(actor)}) MERGE (p)-[:ACTED_IN]->(m))FOREACH (genre in split(row.genres, '|') | MERGE (g:Genre {name:trim(genre)}) MERGE (m)-[:IN_GENRE]->(g))"""graph.query(movies_query)
```
## Filtering graph schema
At times, you may need to focus on a specific subset of the graph schema while generating Cypher statements. Let’s say we are dealing with the following graph schema:
```
graph.refresh_schema()print(graph.schema)
```
```
Node properties are the following:Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING}Relationship properties are the following:The relationships are the following:(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
```
Let’s say we want to exclude the _Genre_ node from the schema representation we pass to an LLM. We can achieve that using the `exclude` parameter of the GraphCypherQAChain chain.
```
from langchain.chains import GraphCypherQAChainfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)chain = GraphCypherQAChain.from_llm( graph=graph, llm=llm, exclude_types=["Genre"], verbose=True)
```
```
print(chain.graph_schema)
```
```
Node properties are the following:Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING}Relationship properties are the following:The relationships are the following:(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
```
## Few-shot examples[](#few-shot-examples "Direct link to Few-shot examples")
Including examples of natural language questions being converted to valid Cypher queries against our database in the prompt will often improve model performance, especially for complex queries.
Let’s say we have the following examples:
```
examples = [ { "question": "How many artists are there?", "query": "MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)", }, { "question": "Which actors played in the movie Casino?", "query": "MATCH (m:Movie {{title: 'Casino'}})<-[:ACTED_IN]-(a) RETURN a.name", }, { "question": "How many movies has Tom Hanks acted in?", "query": "MATCH (a:Person {{name: 'Tom Hanks'}})-[:ACTED_IN]->(m:Movie) RETURN count(m)", }, { "question": "List all the genres of the movie Schindler's List", "query": "MATCH (m:Movie {{title: 'Schindler\\'s List'}})-[:IN_GENRE]->(g:Genre) RETURN g.name", }, { "question": "Which actors have worked in movies from both the comedy and action genres?", "query": "MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name", }, { "question": "Which directors have made movies with at least three different actors named 'John'?", "query": "MATCH (d:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a:Person) WHERE a.name STARTS WITH 'John' WITH d, COUNT(DISTINCT a) AS JohnsCount WHERE JohnsCount >= 3 RETURN d.name", }, { "question": "Identify movies where directors also played a role in the film.", "query": "MATCH (p:Person)-[:DIRECTED]->(m:Movie), (p)-[:ACTED_IN]->(m) RETURN m.title, p.name", }, { "question": "Find the actor with the highest number of movies in the database.", "query": "MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1", },]
```
We can create a few-shot prompt with them like so:
```
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplateexample_prompt = PromptTemplate.from_template( "User input: {question}\nCypher query: {query}")prompt = FewShotPromptTemplate( examples=examples[:5], example_prompt=example_prompt, prefix="You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.\n\nHere is the schema information\n{schema}.\n\nBelow are a number of examples of questions and their corresponding Cypher queries.", suffix="User input: {question}\nCypher query: ", input_variables=["question", "schema"],)
```
```
print(prompt.format(question="How many artists are there?", schema="foo"))
```
```
You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.Here is the schema informationfoo.Below are a number of examples of questions and their corresponding Cypher queries.User input: How many artists are there?Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)User input: Which actors played in the movie Casino?Cypher query: MATCH (m:Movie {title: 'Casino'})<-[:ACTED_IN]-(a) RETURN a.nameUser input: How many movies has Tom Hanks acted in?Cypher query: MATCH (a:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)User input: List all the genres of the movie Schindler's ListCypher query: MATCH (m:Movie {title: 'Schindler\'s List'})-[:IN_GENRE]->(g:Genre) RETURN g.nameUser input: Which actors have worked in movies from both the comedy and action genres?Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.nameUser input: How many artists are there?Cypher query:
```
## Dynamic few-shot examples[](#dynamic-few-shot-examples "Direct link to Dynamic few-shot examples")
If we have enough examples, we may want to only include the most relevant ones in the prompt, either because they don’t fit in the model’s context window or because the long tail of examples distracts the model. And specifically, given any input we want to include the examples most relevant to that input.
We can do just this using an ExampleSelector. In this case we’ll use a [SemanticSimilarityExampleSelector](https://api.python.langchain.com/en/latest/example_selectors/langchain_core.example_selectors.semantic_similarity.SemanticSimilarityExampleSelector.html), which will store the examples in the vector database of our choosing. At runtime it will perform a similarity search between the input and our examples, and return the most semantically similar ones:
```
from langchain_community.vectorstores import Neo4jVectorfrom langchain_core.example_selectors import SemanticSimilarityExampleSelectorfrom langchain_openai import OpenAIEmbeddingsexample_selector = SemanticSimilarityExampleSelector.from_examples( examples, OpenAIEmbeddings(), Neo4jVector, k=5, input_keys=["question"],)
```
```
example_selector.select_examples({"question": "how many artists are there?"})
```
```
[{'query': 'MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)', 'question': 'How many artists are there?'}, {'query': "MATCH (a:Person {{name: 'Tom Hanks'}})-[:ACTED_IN]->(m:Movie) RETURN count(m)", 'question': 'How many movies has Tom Hanks acted in?'}, {'query': "MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name", 'question': 'Which actors have worked in movies from both the comedy and action genres?'}, {'query': "MATCH (d:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a:Person) WHERE a.name STARTS WITH 'John' WITH d, COUNT(DISTINCT a) AS JohnsCount WHERE JohnsCount >= 3 RETURN d.name", 'question': "Which directors have made movies with at least three different actors named 'John'?"}, {'query': 'MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1', 'question': 'Find the actor with the highest number of movies in the database.'}]
```
To use it, we can pass the ExampleSelector directly in to our FewShotPromptTemplate:
```
prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix="You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.\n\nHere is the schema information\n{schema}.\n\nBelow are a number of examples of questions and their corresponding Cypher queries.", suffix="User input: {question}\nCypher query: ", input_variables=["question", "schema"],)
```
```
print(prompt.format(question="how many artists are there?", schema="foo"))
```
```
You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.Here is the schema informationfoo.Below are a number of examples of questions and their corresponding Cypher queries.User input: How many artists are there?Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)User input: How many movies has Tom Hanks acted in?Cypher query: MATCH (a:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)User input: Which actors have worked in movies from both the comedy and action genres?Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.nameUser input: Which directors have made movies with at least three different actors named 'John'?Cypher query: MATCH (d:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a:Person) WHERE a.name STARTS WITH 'John' WITH d, COUNT(DISTINCT a) AS JohnsCount WHERE JohnsCount >= 3 RETURN d.nameUser input: Find the actor with the highest number of movies in the database.Cypher query: MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1User input: how many artists are there?Cypher query:
```
```
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)chain = GraphCypherQAChain.from_llm( graph=graph, llm=llm, cypher_prompt=prompt, verbose=True)
```
```
chain.invoke("How many actors are in the graph?")
```
```
> Entering new GraphCypherQAChain chain...Generated Cypher:MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)Full Context:[{'count(DISTINCT a)': 967}]> Finished chain.
```
```
{'query': 'How many actors are in the graph?', 'result': 'There are 967 actors in the graph.'}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:14.095Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/graph/prompting/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/graph/prompting/",
"description": "In this guide we’ll go over prompting strategies to improve graph",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3769",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"prompting\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:14 GMT",
"etag": "W/\"d3bb8684428dad832d3eff57a00ca12c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::5wljk-1713753974036-4f27e5c95374"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/graph/prompting/",
"property": "og:url"
},
{
"content": "Prompting strategies | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll go over prompting strategies to improve graph",
"property": "og:description"
}
],
"title": "Prompting strategies | 🦜️🔗 LangChain"
} | Prompting strategies
In this guide we’ll go over prompting strategies to improve graph database query generation. We’ll largely focus on methods for getting relevant database-specific information in your prompt.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
Note: you may need to restart the kernel to use updated packages.
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
Next, we need to define Neo4j credentials. Follow these installation steps to set up a Neo4j database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
Filtering graph schema
At times, you may need to focus on a specific subset of the graph schema while generating Cypher statements. Let’s say we are dealing with the following graph schema:
graph.refresh_schema()
print(graph.schema)
Node properties are the following:
Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING}
Relationship properties are the following:
The relationships are the following:
(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
Let’s say we want to exclude the Genre node from the schema representation we pass to an LLM. We can achieve that using the exclude parameter of the GraphCypherQAChain chain.
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, exclude_types=["Genre"], verbose=True
)
print(chain.graph_schema)
Node properties are the following:
Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING}
Relationship properties are the following:
The relationships are the following:
(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
Few-shot examples
Including examples of natural language questions being converted to valid Cypher queries against our database in the prompt will often improve model performance, especially for complex queries.
Let’s say we have the following examples:
examples = [
{
"question": "How many artists are there?",
"query": "MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)",
},
{
"question": "Which actors played in the movie Casino?",
"query": "MATCH (m:Movie {{title: 'Casino'}})<-[:ACTED_IN]-(a) RETURN a.name",
},
{
"question": "How many movies has Tom Hanks acted in?",
"query": "MATCH (a:Person {{name: 'Tom Hanks'}})-[:ACTED_IN]->(m:Movie) RETURN count(m)",
},
{
"question": "List all the genres of the movie Schindler's List",
"query": "MATCH (m:Movie {{title: 'Schindler\\'s List'}})-[:IN_GENRE]->(g:Genre) RETURN g.name",
},
{
"question": "Which actors have worked in movies from both the comedy and action genres?",
"query": "MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name",
},
{
"question": "Which directors have made movies with at least three different actors named 'John'?",
"query": "MATCH (d:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a:Person) WHERE a.name STARTS WITH 'John' WITH d, COUNT(DISTINCT a) AS JohnsCount WHERE JohnsCount >= 3 RETURN d.name",
},
{
"question": "Identify movies where directors also played a role in the film.",
"query": "MATCH (p:Person)-[:DIRECTED]->(m:Movie), (p)-[:ACTED_IN]->(m) RETURN m.title, p.name",
},
{
"question": "Find the actor with the highest number of movies in the database.",
"query": "MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1",
},
]
We can create a few-shot prompt with them like so:
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate.from_template(
"User input: {question}\nCypher query: {query}"
)
prompt = FewShotPromptTemplate(
examples=examples[:5],
example_prompt=example_prompt,
prefix="You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.\n\nHere is the schema information\n{schema}.\n\nBelow are a number of examples of questions and their corresponding Cypher queries.",
suffix="User input: {question}\nCypher query: ",
input_variables=["question", "schema"],
)
print(prompt.format(question="How many artists are there?", schema="foo"))
You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.
Here is the schema information
foo.
Below are a number of examples of questions and their corresponding Cypher queries.
User input: How many artists are there?
Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)
User input: Which actors played in the movie Casino?
Cypher query: MATCH (m:Movie {title: 'Casino'})<-[:ACTED_IN]-(a) RETURN a.name
User input: How many movies has Tom Hanks acted in?
Cypher query: MATCH (a:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)
User input: List all the genres of the movie Schindler's List
Cypher query: MATCH (m:Movie {title: 'Schindler\'s List'})-[:IN_GENRE]->(g:Genre) RETURN g.name
User input: Which actors have worked in movies from both the comedy and action genres?
Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name
User input: How many artists are there?
Cypher query:
Dynamic few-shot examples
If we have enough examples, we may want to only include the most relevant ones in the prompt, either because they don’t fit in the model’s context window or because the long tail of examples distracts the model. And specifically, given any input we want to include the examples most relevant to that input.
We can do just this using an ExampleSelector. In this case we’ll use a SemanticSimilarityExampleSelector, which will store the examples in the vector database of our choosing. At runtime it will perform a similarity search between the input and our examples, and return the most semantically similar ones:
from langchain_community.vectorstores import Neo4jVector
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
Neo4jVector,
k=5,
input_keys=["question"],
)
example_selector.select_examples({"question": "how many artists are there?"})
[{'query': 'MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)',
'question': 'How many artists are there?'},
{'query': "MATCH (a:Person {{name: 'Tom Hanks'}})-[:ACTED_IN]->(m:Movie) RETURN count(m)",
'question': 'How many movies has Tom Hanks acted in?'},
{'query': "MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name",
'question': 'Which actors have worked in movies from both the comedy and action genres?'},
{'query': "MATCH (d:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a:Person) WHERE a.name STARTS WITH 'John' WITH d, COUNT(DISTINCT a) AS JohnsCount WHERE JohnsCount >= 3 RETURN d.name",
'question': "Which directors have made movies with at least three different actors named 'John'?"},
{'query': 'MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1',
'question': 'Find the actor with the highest number of movies in the database.'}]
To use it, we can pass the ExampleSelector directly in to our FewShotPromptTemplate:
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.\n\nHere is the schema information\n{schema}.\n\nBelow are a number of examples of questions and their corresponding Cypher queries.",
suffix="User input: {question}\nCypher query: ",
input_variables=["question", "schema"],
)
print(prompt.format(question="how many artists are there?", schema="foo"))
You are a Neo4j expert. Given an input question, create a syntactically correct Cypher query to run.
Here is the schema information
foo.
Below are a number of examples of questions and their corresponding Cypher queries.
User input: How many artists are there?
Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)
User input: How many movies has Tom Hanks acted in?
Cypher query: MATCH (a:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)
User input: Which actors have worked in movies from both the comedy and action genres?
Cypher query: MATCH (a:Person)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name
User input: Which directors have made movies with at least three different actors named 'John'?
Cypher query: MATCH (d:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a:Person) WHERE a.name STARTS WITH 'John' WITH d, COUNT(DISTINCT a) AS JohnsCount WHERE JohnsCount >= 3 RETURN d.name
User input: Find the actor with the highest number of movies in the database.
Cypher query: MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1
User input: how many artists are there?
Cypher query:
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, cypher_prompt=prompt, verbose=True
)
chain.invoke("How many actors are in the graph?")
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (a:Person)-[:ACTED_IN]->(:Movie) RETURN count(DISTINCT a)
Full Context:
[{'count(DISTINCT a)': 967}]
> Finished chain.
{'query': 'How many actors are in the graph?',
'result': 'There are 967 actors in the graph.'} |
https://python.langchain.com/docs/use_cases/graph/quickstart/ | ## Quickstart
In this guide we’ll go over the basic ways to create a Q&A chain over a graph database. These systems will allow us to ask a question about the data in a graph database and get back a natural language answer.
## ⚠️ Security note ⚠️[](#security-note "Direct link to ⚠️ Security note ⚠️")
Building Q&A systems of graph databases requires executing model-generated graph queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, [see here](https://python.langchain.com/docs/security/).
## Architecture[](#architecture "Direct link to Architecture")
At a high-level, the steps of most graph chains are:
1. **Convert question to a graph database query**: Model converts user input to a graph database query (e.g. Cypher).
2. **Execute graph database query**: Execute the graph database query.
3. **Answer the question**: Model responds to user input using the query results.

## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables. In this example, we will be using Neo4j graph database.
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
```
We default to OpenAI models in this guide.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
Next, we need to define Neo4j credentials. Follow [these installation steps](https://neo4j.com/docs/operations-manual/current/installation/) to set up a Neo4j database.
```
os.environ["NEO4J_URI"] = "bolt://localhost:7687"os.environ["NEO4J_USERNAME"] = "neo4j"os.environ["NEO4J_PASSWORD"] = "password"
```
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
```
from langchain_community.graphs import Neo4jGraphgraph = Neo4jGraph()# Import movie informationmovies_query = """LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'AS rowMERGE (m:Movie {id:row.movieId})SET m.released = date(row.released), m.title = row.title, m.imdbRating = toFloat(row.imdbRating)FOREACH (director in split(row.director, '|') | MERGE (p:Person {name:trim(director)}) MERGE (p)-[:DIRECTED]->(m))FOREACH (actor in split(row.actors, '|') | MERGE (p:Person {name:trim(actor)}) MERGE (p)-[:ACTED_IN]->(m))FOREACH (genre in split(row.genres, '|') | MERGE (g:Genre {name:trim(genre)}) MERGE (m)-[:IN_GENRE]->(g))"""graph.query(movies_query)
```
## Graph schema[](#graph-schema "Direct link to Graph schema")
In order for an LLM to be able to generate a Cypher statement, it needs information about the graph schema. When you instantiate a graph object, it retrieves the information about the graph schema. If you later make any changes to the graph, you can run the `refresh_schema` method to refresh the schema information.
```
graph.refresh_schema()print(graph.schema)
```
```
Node properties are the following:Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING},Chunk {id: STRING, question: STRING, query: STRING, text: STRING, embedding: LIST}Relationship properties are the following:The relationships are the following:(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
```
Great! We’ve got a graph database that we can query. Now let’s try hooking it up to an LLM.
## Chain[](#chain "Direct link to Chain")
Let’s use a simple chain that takes a question, turns it into a Cypher query, executes the query, and uses the result to answer the original question.
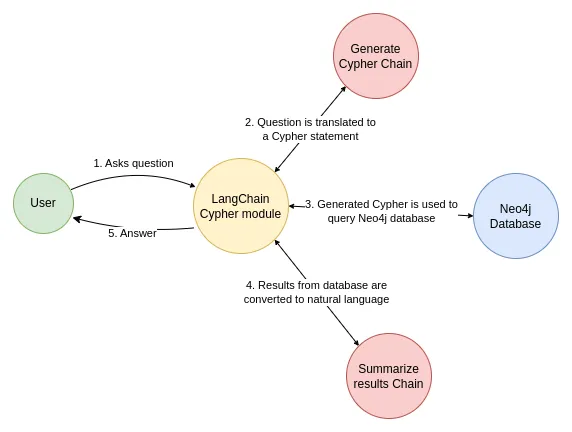
LangChain comes with a built-in chain for this workflow that is designed to work with Neo4j: [GraphCypherQAChain](https://python.langchain.com/docs/integrations/graphs/neo4j_cypher/)
```
from langchain.chains import GraphCypherQAChainfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)response = chain.invoke({"query": "What was the cast of the Casino?"})response
```
```
> Entering new GraphCypherQAChain chain...Generated Cypher:MATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)RETURN actor.nameFull Context:[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}]> Finished chain.
```
```
{'query': 'What was the cast of the Casino?', 'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
```
## Validating relationship direction
LLMs can struggle with relationship directions in generated Cypher statement. Since the graph schema is predefined, we can validate and optionally correct relationship directions in the generated Cypher statements by using the `validate_cypher` parameter.
```
chain = GraphCypherQAChain.from_llm( graph=graph, llm=llm, verbose=True, validate_cypher=True)response = chain.invoke({"query": "What was the cast of the Casino?"})response
```
```
> Entering new GraphCypherQAChain chain...Generated Cypher:MATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)RETURN actor.nameFull Context:[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}]> Finished chain.
```
```
{'query': 'What was the cast of the Casino?', 'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
```
### Next steps[](#next-steps "Direct link to Next steps")
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
* [Prompting strategies](https://python.langchain.com/docs/use_cases/graph/prompting/): Advanced prompt engineering techniques.
* [Mapping values](https://python.langchain.com/docs/use_cases/graph/mapping/): Techniques for mapping values from questions to database.
* [Semantic layer](https://python.langchain.com/docs/use_cases/graph/semantic/): Techniques for implementing semantic layers.
* [Constructing graphs](https://python.langchain.com/docs/use_cases/graph/constructing/): Techniques for constructing knowledge graphs. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:14.982Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/graph/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/graph/quickstart/",
"description": "In this guide we’ll go over the basic ways to create a Q&A chain over a",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4250",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:14 GMT",
"etag": "W/\"25716afb7f39f264d42207a083f4bd73\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::jv8j8-1713753974839-d6759642d5a1"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/graph/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll go over the basic ways to create a Q&A chain over a",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
In this guide we’ll go over the basic ways to create a Q&A chain over a graph database. These systems will allow us to ask a question about the data in a graph database and get back a natural language answer.
⚠️ Security note ⚠️
Building Q&A systems of graph databases requires executing model-generated graph queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
Architecture
At a high-level, the steps of most graph chains are:
Convert question to a graph database query: Model converts user input to a graph database query (e.g. Cypher).
Execute graph database query: Execute the graph database query.
Answer the question: Model responds to user input using the query results.
Setup
First, get required packages and set environment variables. In this example, we will be using Neo4j graph database.
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
We default to OpenAI models in this guide.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
Next, we need to define Neo4j credentials. Follow these installation steps to set up a Neo4j database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
Graph schema
In order for an LLM to be able to generate a Cypher statement, it needs information about the graph schema. When you instantiate a graph object, it retrieves the information about the graph schema. If you later make any changes to the graph, you can run the refresh_schema method to refresh the schema information.
graph.refresh_schema()
print(graph.schema)
Node properties are the following:
Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING},Chunk {id: STRING, question: STRING, query: STRING, text: STRING, embedding: LIST}
Relationship properties are the following:
The relationships are the following:
(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
Great! We’ve got a graph database that we can query. Now let’s try hooking it up to an LLM.
Chain
Let’s use a simple chain that takes a question, turns it into a Cypher query, executes the query, and uses the result to answer the original question.
LangChain comes with a built-in chain for this workflow that is designed to work with Neo4j: GraphCypherQAChain
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name
Full Context:
[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}]
> Finished chain.
{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
Validating relationship direction
LLMs can struggle with relationship directions in generated Cypher statement. Since the graph schema is predefined, we can validate and optionally correct relationship directions in the generated Cypher statements by using the validate_cypher parameter.
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, verbose=True, validate_cypher=True
)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name
Full Context:
[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}]
> Finished chain.
{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
Next steps
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
Prompting strategies: Advanced prompt engineering techniques.
Mapping values: Techniques for mapping values from questions to database.
Semantic layer: Techniques for implementing semantic layers.
Constructing graphs: Techniques for constructing knowledge graphs. |
https://python.langchain.com/docs/use_cases/query_analysis/how_to/few_shot/ | As our query analysis becomes more complex, the LLM may struggle to understand how exactly it should respond in certain scenarios. In order to improve performance here, we can add examples to the prompt to guide the LLM.
Let’s take a look at how we can add examples for the LangChain YouTube video query analyzer we built in the [Quickstart](https://python.langchain.com/docs/use_cases/query_analysis/quickstart/).
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain-core langchain-openai
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Query schema[](#query-schema "Direct link to Query schema")
We’ll define a query schema that we want our model to output. To make our query analysis a bit more interesting, we’ll add a `sub_queries` field that contains more narrow questions derived from the top level question.
```
from typing import List, Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldsub_queries_description = """\If the original question contains multiple distinct sub-questions, \or if there are more generic questions that would be helpful to answer in \order to answer the original question, write a list of all relevant sub-questions. \Make sure this list is comprehensive and covers all parts of the original question. \It's ok if there's redundancy in the sub-questions. \Make sure the sub-questions are as narrowly focused as possible."""class Search(BaseModel): """Search over a database of tutorial videos about a software library.""" query: str = Field( ..., description="Primary similarity search query applied to video transcripts.", ) sub_queries: List[str] = Field( default_factory=list, description=sub_queries_description ) publish_year: Optional[int] = Field(None, description="Year video was published")
```
## Query generation[](#query-generation "Direct link to Query generation")
```
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAIsystem = """You are an expert at converting user questions into database queries. \You have access to a database of tutorial videos about a software library for building LLM-powered applications. \Given a question, return a list of database queries optimized to retrieve the most relevant results.If there are acronyms or words you are not familiar with, do not try to rephrase them."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), MessagesPlaceholder("examples", optional=True), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(Search)query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
```
Let’s try out our query analyzer without any examples in the prompt:
```
query_analyzer.invoke( "what's the difference between web voyager and reflection agents? do both use langgraph?")
```
```
Search(query='web voyager vs reflection agents', sub_queries=['difference between web voyager and reflection agents', 'do web voyager and reflection agents use langgraph'], publish_year=None)
```
## Adding examples and tuning the prompt[](#adding-examples-and-tuning-the-prompt "Direct link to Adding examples and tuning the prompt")
This works pretty well, but we probably want it to decompose the question even further to separate the queries about Web Voyager and Reflection Agents.
To tune our query generation results, we can add some examples of inputs questions and gold standard output queries to our prompt.
```
question = "What's chat langchain, is it a langchain template?"query = Search( query="What is chat langchain and is it a langchain template?", sub_queries=["What is chat langchain", "What is a langchain template"],)examples.append({"input": question, "tool_calls": [query]})
```
```
question = "How to build multi-agent system and stream intermediate steps from it"query = Search( query="How to build multi-agent system and stream intermediate steps from it", sub_queries=[ "How to build multi-agent system", "How to stream intermediate steps from multi-agent system", "How to stream intermediate steps", ],)examples.append({"input": question, "tool_calls": [query]})
```
```
question = "LangChain agents vs LangGraph?"query = Search( query="What's the difference between LangChain agents and LangGraph? How do you deploy them?", sub_queries=[ "What are LangChain agents", "What is LangGraph", "How do you deploy LangChain agents", "How do you deploy LangGraph", ],)examples.append({"input": question, "tool_calls": [query]})
```
Now we need to update our prompt template and chain so that the examples are included in each prompt. Since we’re working with OpenAI function-calling, we’ll need to do a bit of extra structuring to send example inputs and outputs to the model. We’ll create a `tool_example_to_messages` helper function to handle this for us:
```
import uuidfrom typing import Dictfrom langchain_core.messages import ( AIMessage, BaseMessage, HumanMessage, SystemMessage, ToolMessage,)def tool_example_to_messages(example: Dict) -> List[BaseMessage]: messages: List[BaseMessage] = [HumanMessage(content=example["input"])] openai_tool_calls = [] for tool_call in example["tool_calls"]: openai_tool_calls.append( { "id": str(uuid.uuid4()), "type": "function", "function": { "name": tool_call.__class__.__name__, "arguments": tool_call.json(), }, } ) messages.append( AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls}) ) tool_outputs = example.get("tool_outputs") or [ "You have correctly called this tool." ] * len(openai_tool_calls) for output, tool_call in zip(tool_outputs, openai_tool_calls): messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"])) return messagesexample_msgs = [msg for ex in examples for msg in tool_example_to_messages(ex)]
```
```
from langchain_core.prompts import MessagesPlaceholderquery_analyzer_with_examples = ( {"question": RunnablePassthrough()} | prompt.partial(examples=example_msgs) | structured_llm)
```
```
query_analyzer_with_examples.invoke( "what's the difference between web voyager and reflection agents? do both use langgraph?")
```
```
Search(query='Difference between web voyager and reflection agents, do they both use LangGraph?', sub_queries=['What is Web Voyager', 'What are Reflection agents', 'Do Web Voyager and Reflection agents use LangGraph'], publish_year=None)
```
Thanks to our examples we get a slightly more decomposed search query. With some more prompt engineering and tuning of our examples we could improve query generation even more.
You can see that the examples are passed to the model as messages in the [LangSmith trace](https://smith.langchain.com/public/aeaaafce-d2b1-4943-9a61-bc954e8fc6f2/r). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:15.257Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/few_shot/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/few_shot/",
"description": "As our query analysis becomes more complex, the LLM may struggle to",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3769",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"few_shot\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"c6c08b49dd1c61c7b764c6c8d5c65f4e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::nqbp6-1713753975205-bcfc18c94a04"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/few_shot/",
"property": "og:url"
},
{
"content": "Add Examples to the Prompt | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "As our query analysis becomes more complex, the LLM may struggle to",
"property": "og:description"
}
],
"title": "Add Examples to the Prompt | 🦜️🔗 LangChain"
} | As our query analysis becomes more complex, the LLM may struggle to understand how exactly it should respond in certain scenarios. In order to improve performance here, we can add examples to the prompt to guide the LLM.
Let’s take a look at how we can add examples for the LangChain YouTube video query analyzer we built in the Quickstart.
Setup
Install dependencies
# %pip install -qU langchain-core langchain-openai
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Query schema
We’ll define a query schema that we want our model to output. To make our query analysis a bit more interesting, we’ll add a sub_queries field that contains more narrow questions derived from the top level question.
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
sub_queries_description = """\
If the original question contains multiple distinct sub-questions, \
or if there are more generic questions that would be helpful to answer in \
order to answer the original question, write a list of all relevant sub-questions. \
Make sure this list is comprehensive and covers all parts of the original question. \
It's ok if there's redundancy in the sub-questions. \
Make sure the sub-questions are as narrowly focused as possible."""
class Search(BaseModel):
"""Search over a database of tutorial videos about a software library."""
query: str = Field(
...,
description="Primary similarity search query applied to video transcripts.",
)
sub_queries: List[str] = Field(
default_factory=list, description=sub_queries_description
)
publish_year: Optional[int] = Field(None, description="Year video was published")
Query generation
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a list of database queries optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
MessagesPlaceholder("examples", optional=True),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
Let’s try out our query analyzer without any examples in the prompt:
query_analyzer.invoke(
"what's the difference between web voyager and reflection agents? do both use langgraph?"
)
Search(query='web voyager vs reflection agents', sub_queries=['difference between web voyager and reflection agents', 'do web voyager and reflection agents use langgraph'], publish_year=None)
Adding examples and tuning the prompt
This works pretty well, but we probably want it to decompose the question even further to separate the queries about Web Voyager and Reflection Agents.
To tune our query generation results, we can add some examples of inputs questions and gold standard output queries to our prompt.
question = "What's chat langchain, is it a langchain template?"
query = Search(
query="What is chat langchain and is it a langchain template?",
sub_queries=["What is chat langchain", "What is a langchain template"],
)
examples.append({"input": question, "tool_calls": [query]})
question = "How to build multi-agent system and stream intermediate steps from it"
query = Search(
query="How to build multi-agent system and stream intermediate steps from it",
sub_queries=[
"How to build multi-agent system",
"How to stream intermediate steps from multi-agent system",
"How to stream intermediate steps",
],
)
examples.append({"input": question, "tool_calls": [query]})
question = "LangChain agents vs LangGraph?"
query = Search(
query="What's the difference between LangChain agents and LangGraph? How do you deploy them?",
sub_queries=[
"What are LangChain agents",
"What is LangGraph",
"How do you deploy LangChain agents",
"How do you deploy LangGraph",
],
)
examples.append({"input": question, "tool_calls": [query]})
Now we need to update our prompt template and chain so that the examples are included in each prompt. Since we’re working with OpenAI function-calling, we’ll need to do a bit of extra structuring to send example inputs and outputs to the model. We’ll create a tool_example_to_messages helper function to handle this for us:
import uuid
from typing import Dict
from langchain_core.messages import (
AIMessage,
BaseMessage,
HumanMessage,
SystemMessage,
ToolMessage,
)
def tool_example_to_messages(example: Dict) -> List[BaseMessage]:
messages: List[BaseMessage] = [HumanMessage(content=example["input"])]
openai_tool_calls = []
for tool_call in example["tool_calls"]:
openai_tool_calls.append(
{
"id": str(uuid.uuid4()),
"type": "function",
"function": {
"name": tool_call.__class__.__name__,
"arguments": tool_call.json(),
},
}
)
messages.append(
AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls})
)
tool_outputs = example.get("tool_outputs") or [
"You have correctly called this tool."
] * len(openai_tool_calls)
for output, tool_call in zip(tool_outputs, openai_tool_calls):
messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"]))
return messages
example_msgs = [msg for ex in examples for msg in tool_example_to_messages(ex)]
from langchain_core.prompts import MessagesPlaceholder
query_analyzer_with_examples = (
{"question": RunnablePassthrough()}
| prompt.partial(examples=example_msgs)
| structured_llm
)
query_analyzer_with_examples.invoke(
"what's the difference between web voyager and reflection agents? do both use langgraph?"
)
Search(query='Difference between web voyager and reflection agents, do they both use LangGraph?', sub_queries=['What is Web Voyager', 'What are Reflection agents', 'Do Web Voyager and Reflection agents use LangGraph'], publish_year=None)
Thanks to our examples we get a slightly more decomposed search query. With some more prompt engineering and tuning of our examples we could improve query generation even more.
You can see that the examples are passed to the model as messages in the LangSmith trace. |
https://python.langchain.com/docs/use_cases/query_analysis/ | ## Query analysis
“Search” powers many use cases - including the “retrieval” part of Retrieval Augmented Generation. The simplest way to do this involves passing the user question directly to a retriever. In order to improve performance, you can also “optimize” the query in some way using _query analysis_. This is traditionally done by rule-based techniques, but with the rise of LLMs it is becoming more popular and more feasible to use an LLM for this. Specifically, this involves passing the raw question (or list of messages) into an LLM and returning one or more optimized queries, which typically contain a string and optionally other structured information.

## Problems Solved[](#problems-solved "Direct link to Problems Solved")
Query analysis helps to optimize the search query to send to the retriever. This can be the case when:
* The retriever supports searches and filters against specific fields of the data, and user input could be referring to any of these fields,
* The user input contains multiple distinct questions in it,
* To retrieve relevant information multiple queries are needed,
* Search quality is sensitive to phrasing,
* There are multiple retrievers that could be searched over, and the user input could be reffering to any of them.
Note that different problems will require different solutions. In order to determine what query analysis technique you should use, you will want to understand exactly what is the problem with your current retrieval system. This is best done by looking at failure data points of your current application and identifying common themes. Only once you know what your problems are can you begin to solve them.
## Quickstart[](#quickstart "Direct link to Quickstart")
Head to the [quickstart](https://python.langchain.com/docs/use_cases/query_analysis/quickstart/) to see how to use query analysis in a basic end-to-end example. This will cover creating a search engine over the content of LangChain YouTube videos, showing a failure mode that occurs when passing a raw user question to that index, and then an example of how query analysis can help address that issue. The quickstart focuses on **query structuring**. Below are additional query analysis techniques that may be relevant based on your data and use case
## Techniques[](#techniques "Direct link to Techniques")
There are multiple techniques we support for going from raw question or list of messages into a more optimized query. These include:
* [Query decomposition](https://python.langchain.com/docs/use_cases/query_analysis/techniques/decomposition/): If a user input contains multiple distinct questions, we can decompose the input into separate queries that will each be executed independently.
* [Query expansion](https://python.langchain.com/docs/use_cases/query_analysis/techniques/expansion/): If an index is sensitive to query phrasing, we can generate multiple paraphrased versions of the user question to increase our chances of retrieving a relevant result.
* [Hypothetical document embedding (HyDE)](https://python.langchain.com/docs/use_cases/query_analysis/techniques/hyde/): If we’re working with a similarity search-based index, like a vector store, then searching on raw questions may not work well because their embeddings may not be very similar to those of the relevant documents. Instead it might help to have the model generate a hypothetical relevant document, and then use that to perform similarity search.
* [Query routing](https://python.langchain.com/docs/use_cases/query_analysis/techniques/routing/): If we have multiple indexes and only a subset are useful for any given user input, we can route the input to only retrieve results from the relevant ones.
* [Step back prompting](https://python.langchain.com/docs/use_cases/query_analysis/techniques/step_back/): Sometimes search quality and model generations can be tripped up by the specifics of a question. One way to handle this is to first generate a more abstract, “step back” question and to query based on both the original and step back question.
* [Query structuring](https://python.langchain.com/docs/use_cases/query_analysis/techniques/structuring/): If our documents have multiple searchable/filterable attributes, we can infer from any raw user question which specific attributes should be searched/filtered over. For example, when a user input specific something about video publication date, that should become a filter on the `publish_date` attribute of each document.
## How to[](#how-to "Direct link to How to")
* [Add examples to prompt](https://python.langchain.com/docs/use_cases/query_analysis/how_to/few_shot/): As our query analysis becomes more complex, adding examples to the prompt can meaningfully improve performance.
* [Deal with High Cardinality Categoricals](https://python.langchain.com/docs/use_cases/query_analysis/how_to/high_cardinality/): Many structured queries you will create will involve categorical variables. When there are a lot of potential values there, it can be difficult to do this correctly.
* [Construct Filters](https://python.langchain.com/docs/use_cases/query_analysis/how_to/constructing-filters/): This guide covers how to go from a Pydantic model to a filters in the query language specific to the vectorstore you are working with
* [Handle Multiple Queries](https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_queries/): Some query analysis techniques generate multiple queries. This guide handles how to pass them all to the retriever.
* [Handle No Queries](https://python.langchain.com/docs/use_cases/query_analysis/how_to/no_queries/): Some query analysis techniques may not generate a query at all. This guide handles how to gracefully handle those situations
* [Handle Multiple Retrievers](https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_retrievers/): Some query analysis techniques involve routing between multiple retrievers. This guide covers how to handle that gracefully | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:15.606Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/",
"description": "“Search” powers many use cases - including the “retrieval” part of",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "9098",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"query_analysis\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"750f3e4d4277e307354fff189db432d8\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::l88wt-1713753975234-1b3ec6a43b8e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/",
"property": "og:url"
},
{
"content": "Query analysis | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "“Search” powers many use cases - including the “retrieval” part of",
"property": "og:description"
}
],
"title": "Query analysis | 🦜️🔗 LangChain"
} | Query analysis
“Search” powers many use cases - including the “retrieval” part of Retrieval Augmented Generation. The simplest way to do this involves passing the user question directly to a retriever. In order to improve performance, you can also “optimize” the query in some way using query analysis. This is traditionally done by rule-based techniques, but with the rise of LLMs it is becoming more popular and more feasible to use an LLM for this. Specifically, this involves passing the raw question (or list of messages) into an LLM and returning one or more optimized queries, which typically contain a string and optionally other structured information.
Problems Solved
Query analysis helps to optimize the search query to send to the retriever. This can be the case when:
The retriever supports searches and filters against specific fields of the data, and user input could be referring to any of these fields,
The user input contains multiple distinct questions in it,
To retrieve relevant information multiple queries are needed,
Search quality is sensitive to phrasing,
There are multiple retrievers that could be searched over, and the user input could be reffering to any of them.
Note that different problems will require different solutions. In order to determine what query analysis technique you should use, you will want to understand exactly what is the problem with your current retrieval system. This is best done by looking at failure data points of your current application and identifying common themes. Only once you know what your problems are can you begin to solve them.
Quickstart
Head to the quickstart to see how to use query analysis in a basic end-to-end example. This will cover creating a search engine over the content of LangChain YouTube videos, showing a failure mode that occurs when passing a raw user question to that index, and then an example of how query analysis can help address that issue. The quickstart focuses on query structuring. Below are additional query analysis techniques that may be relevant based on your data and use case
Techniques
There are multiple techniques we support for going from raw question or list of messages into a more optimized query. These include:
Query decomposition: If a user input contains multiple distinct questions, we can decompose the input into separate queries that will each be executed independently.
Query expansion: If an index is sensitive to query phrasing, we can generate multiple paraphrased versions of the user question to increase our chances of retrieving a relevant result.
Hypothetical document embedding (HyDE): If we’re working with a similarity search-based index, like a vector store, then searching on raw questions may not work well because their embeddings may not be very similar to those of the relevant documents. Instead it might help to have the model generate a hypothetical relevant document, and then use that to perform similarity search.
Query routing: If we have multiple indexes and only a subset are useful for any given user input, we can route the input to only retrieve results from the relevant ones.
Step back prompting: Sometimes search quality and model generations can be tripped up by the specifics of a question. One way to handle this is to first generate a more abstract, “step back” question and to query based on both the original and step back question.
Query structuring: If our documents have multiple searchable/filterable attributes, we can infer from any raw user question which specific attributes should be searched/filtered over. For example, when a user input specific something about video publication date, that should become a filter on the publish_date attribute of each document.
How to
Add examples to prompt: As our query analysis becomes more complex, adding examples to the prompt can meaningfully improve performance.
Deal with High Cardinality Categoricals: Many structured queries you will create will involve categorical variables. When there are a lot of potential values there, it can be difficult to do this correctly.
Construct Filters: This guide covers how to go from a Pydantic model to a filters in the query language specific to the vectorstore you are working with
Handle Multiple Queries: Some query analysis techniques generate multiple queries. This guide handles how to pass them all to the retriever.
Handle No Queries: Some query analysis techniques may not generate a query at all. This guide handles how to gracefully handle those situations
Handle Multiple Retrievers: Some query analysis techniques involve routing between multiple retrievers. This guide covers how to handle that gracefully |
https://python.langchain.com/docs/use_cases/query_analysis/how_to/high_cardinality/ | You may want to do query analysis to create a filter on a categorical column. One of the difficulties here is that you usually need to specify the EXACT categorical value. The issue is you need to make sure the LLM generates that categorical value exactly. This can be done relatively easy with prompting when there are only a few values that are valid. When there are a high number of valid values then it becomes more difficult, as those values may not fit in the LLM context, or (if they do) there may be too many for the LLM to properly attend to.
In this notebook we take a look at how to approach this.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-community langchain-openai faker langchain-chroma
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
#### Set up data[](#set-up-data "Direct link to Set up data")
We will generate a bunch of fake names
```
from faker import Fakerfake = Faker()names = [fake.name() for _ in range(10000)]
```
Let’s look at some of the names
## Query Analysis[](#query-analysis "Direct link to Query Analysis")
We can now set up a baseline query analysis
```
from langchain_core.pydantic_v1 import BaseModel, Field
```
```
class Search(BaseModel): query: str author: str
```
```
from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAIsystem = """Generate a relevant search query for a library system"""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(Search)query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
```
```
/Users/harrisonchase/workplace/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change. warn_beta(
```
We can see that if we spell the name exactly correctly, it knows how to handle it
```
query_analyzer.invoke("what are books about aliens by Jesse Knight")
```
```
Search(query='books about aliens', author='Jesse Knight')
```
The issue is that the values you want to filter on may NOT be spelled exactly correctly
```
query_analyzer.invoke("what are books about aliens by jess knight")
```
```
Search(query='books about aliens', author='Jess Knight')
```
### Add in all values[](#add-in-all-values "Direct link to Add in all values")
One way around this is to add ALL possible values to the prompt. That will generally guide the query in the right direction
```
system = """Generate a relevant search query for a library system.`author` attribute MUST be one of:{authors}Do NOT hallucinate author name!"""base_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])prompt = base_prompt.partial(authors=", ".join(names))
```
```
query_analyzer_all = {"question": RunnablePassthrough()} | prompt | structured_llm
```
However… if the list of categoricals is long enough, it may error!
```
try: res = query_analyzer_all.invoke("what are books about aliens by jess knight")except Exception as e: print(e)
```
```
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 33885 tokens (33855 in the messages, 30 in the functions). Please reduce the length of the messages or functions.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
```
We can try to use a longer context window… but with so much information in there, it is not garunteed to pick it up reliably
```
llm_long = ChatOpenAI(model="gpt-4-turbo-preview", temperature=0)structured_llm_long = llm_long.with_structured_output(Search)query_analyzer_all = {"question": RunnablePassthrough()} | prompt | structured_llm_long
```
```
query_analyzer_all.invoke("what are books about aliens by jess knight")
```
```
Search(query='aliens', author='Kevin Knight')
```
### Find and all relevant values[](#find-and-all-relevant-values "Direct link to Find and all relevant values")
Instead, what we can do is create an index over the relevant values and then query that for the N most relevant values,
```
from langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_texts(names, embeddings, collection_name="author_names")
```
```
def select_names(question): _docs = vectorstore.similarity_search(question, k=10) _names = [d.page_content for d in _docs] return ", ".join(_names)
```
```
create_prompt = { "question": RunnablePassthrough(), "authors": select_names,} | base_prompt
```
```
query_analyzer_select = create_prompt | structured_llm
```
```
create_prompt.invoke("what are books by jess knight")
```
```
ChatPromptValue(messages=[SystemMessage(content='Generate a relevant search query for a library system.\n\n`author` attribute MUST be one of:\n\nJesse Knight, Kelly Knight, Scott Knight, Richard Knight, Andrew Knight, Katherine Knight, Erica Knight, Ashley Knight, Becky Knight, Kevin Knight\n\nDo NOT hallucinate author name!'), HumanMessage(content='what are books by jess knight')])
```
```
query_analyzer_select.invoke("what are books about aliens by jess knight")
```
```
Search(query='books about aliens', author='Jesse Knight')
```
### Replace after selection[](#replace-after-selection "Direct link to Replace after selection")
Another method is to let the LLM fill in whatever value, but then convert that value to a valid value. This can actually be done with the Pydantic class itself!
```
from langchain_core.pydantic_v1 import validatorclass Search(BaseModel): query: str author: str @validator("author") def double(cls, v: str) -> str: return vectorstore.similarity_search(v, k=1)[0].page_content
```
```
system = """Generate a relevant search query for a library system"""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])corrective_structure_llm = llm.with_structured_output(Search)corrective_query_analyzer = ( {"question": RunnablePassthrough()} | prompt | corrective_structure_llm)
```
```
corrective_query_analyzer.invoke("what are books about aliens by jes knight")
```
```
Search(query='books about aliens', author='Jesse Knight')
```
```
# TODO: show trigram similarity
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:15.711Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/high_cardinality/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/high_cardinality/",
"description": "You may want to do query analysis to create a filter on a categorical",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"high_cardinality\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"b391463e5d803ed7ffbd00fbd3745195\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::fmkmq-1713753975221-d13473a94d14"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/high_cardinality/",
"property": "og:url"
},
{
"content": "Deal with High Cardinality Categoricals | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "You may want to do query analysis to create a filter on a categorical",
"property": "og:description"
}
],
"title": "Deal with High Cardinality Categoricals | 🦜️🔗 LangChain"
} | You may want to do query analysis to create a filter on a categorical column. One of the difficulties here is that you usually need to specify the EXACT categorical value. The issue is you need to make sure the LLM generates that categorical value exactly. This can be done relatively easy with prompting when there are only a few values that are valid. When there are a high number of valid values then it becomes more difficult, as those values may not fit in the LLM context, or (if they do) there may be too many for the LLM to properly attend to.
In this notebook we take a look at how to approach this.
Setup
Install dependencies
# %pip install -qU langchain langchain-community langchain-openai faker langchain-chroma
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Set up data
We will generate a bunch of fake names
from faker import Faker
fake = Faker()
names = [fake.name() for _ in range(10000)]
Let’s look at some of the names
Query Analysis
We can now set up a baseline query analysis
from langchain_core.pydantic_v1 import BaseModel, Field
class Search(BaseModel):
query: str
author: str
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
system = """Generate a relevant search query for a library system"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
/Users/harrisonchase/workplace/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
We can see that if we spell the name exactly correctly, it knows how to handle it
query_analyzer.invoke("what are books about aliens by Jesse Knight")
Search(query='books about aliens', author='Jesse Knight')
The issue is that the values you want to filter on may NOT be spelled exactly correctly
query_analyzer.invoke("what are books about aliens by jess knight")
Search(query='books about aliens', author='Jess Knight')
Add in all values
One way around this is to add ALL possible values to the prompt. That will generally guide the query in the right direction
system = """Generate a relevant search query for a library system.
`author` attribute MUST be one of:
{authors}
Do NOT hallucinate author name!"""
base_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
prompt = base_prompt.partial(authors=", ".join(names))
query_analyzer_all = {"question": RunnablePassthrough()} | prompt | structured_llm
However… if the list of categoricals is long enough, it may error!
try:
res = query_analyzer_all.invoke("what are books about aliens by jess knight")
except Exception as e:
print(e)
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 33885 tokens (33855 in the messages, 30 in the functions). Please reduce the length of the messages or functions.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
We can try to use a longer context window… but with so much information in there, it is not garunteed to pick it up reliably
llm_long = ChatOpenAI(model="gpt-4-turbo-preview", temperature=0)
structured_llm_long = llm_long.with_structured_output(Search)
query_analyzer_all = {"question": RunnablePassthrough()} | prompt | structured_llm_long
query_analyzer_all.invoke("what are books about aliens by jess knight")
Search(query='aliens', author='Kevin Knight')
Find and all relevant values
Instead, what we can do is create an index over the relevant values and then query that for the N most relevant values,
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_texts(names, embeddings, collection_name="author_names")
def select_names(question):
_docs = vectorstore.similarity_search(question, k=10)
_names = [d.page_content for d in _docs]
return ", ".join(_names)
create_prompt = {
"question": RunnablePassthrough(),
"authors": select_names,
} | base_prompt
query_analyzer_select = create_prompt | structured_llm
create_prompt.invoke("what are books by jess knight")
ChatPromptValue(messages=[SystemMessage(content='Generate a relevant search query for a library system.\n\n`author` attribute MUST be one of:\n\nJesse Knight, Kelly Knight, Scott Knight, Richard Knight, Andrew Knight, Katherine Knight, Erica Knight, Ashley Knight, Becky Knight, Kevin Knight\n\nDo NOT hallucinate author name!'), HumanMessage(content='what are books by jess knight')])
query_analyzer_select.invoke("what are books about aliens by jess knight")
Search(query='books about aliens', author='Jesse Knight')
Replace after selection
Another method is to let the LLM fill in whatever value, but then convert that value to a valid value. This can actually be done with the Pydantic class itself!
from langchain_core.pydantic_v1 import validator
class Search(BaseModel):
query: str
author: str
@validator("author")
def double(cls, v: str) -> str:
return vectorstore.similarity_search(v, k=1)[0].page_content
system = """Generate a relevant search query for a library system"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
corrective_structure_llm = llm.with_structured_output(Search)
corrective_query_analyzer = (
{"question": RunnablePassthrough()} | prompt | corrective_structure_llm
)
corrective_query_analyzer.invoke("what are books about aliens by jes knight")
Search(query='books about aliens', author='Jesse Knight')
# TODO: show trigram similarity |
https://python.langchain.com/docs/use_cases/query_analysis/how_to/constructing-filters/ | ## Construct Filters
We may want to do query analysis to extract filters to pass into retrievers. One way we ask the LLM to represent these filters is as a Pydantic model. There is then the issue of converting that Pydantic model into a filter that can be passed into a retriever.
This can be done manually, but LangChain also provides some “Translators” that are able to translate from a common syntax into filters specific to each retriever. Here, we will cover how to use those translators.
```
from typing import Optionalfrom langchain.chains.query_constructor.ir import ( Comparator, Comparison, Operation, Operator, StructuredQuery,)from langchain.retrievers.self_query.chroma import ChromaTranslatorfrom langchain.retrievers.self_query.elasticsearch import ElasticsearchTranslatorfrom langchain_core.pydantic_v1 import BaseModel
```
In this example, `year` and `author` are both attributes to filter on.
```
class Search(BaseModel): query: str start_year: Optional[int] author: Optional[str]
```
```
search_query = Search(query="RAG", start_year=2022, author="LangChain")
```
```
def construct_comparisons(query: Search): comparisons = [] if query.start_year is not None: comparisons.append( Comparison( comparator=Comparator.GT, attribute="start_year", value=query.start_year, ) ) if query.author is not None: comparisons.append( Comparison( comparator=Comparator.EQ, attribute="author", value=query.author, ) ) return comparisons
```
```
comparisons = construct_comparisons(search_query)
```
```
_filter = Operation(operator=Operator.AND, arguments=comparisons)
```
```
ElasticsearchTranslator().visit_operation(_filter)
```
```
{'bool': {'must': [{'range': {'metadata.start_year': {'gt': 2022}}}, {'term': {'metadata.author.keyword': 'LangChain'}}]}}
```
```
ChromaTranslator().visit_operation(_filter)
```
```
{'$and': [{'start_year': {'$gt': 2022}}, {'author': {'$eq': 'LangChain'}}]}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:16.720Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/constructing-filters/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/constructing-filters/",
"description": "We may want to do query analysis to extract filters to pass into",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3770",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"constructing-filters\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"7d88691c5b84340761eeae13d3a7f361\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::8tjzq-1713753975612-ed99fcecd023"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/constructing-filters/",
"property": "og:url"
},
{
"content": "Construct Filters | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "We may want to do query analysis to extract filters to pass into",
"property": "og:description"
}
],
"title": "Construct Filters | 🦜️🔗 LangChain"
} | Construct Filters
We may want to do query analysis to extract filters to pass into retrievers. One way we ask the LLM to represent these filters is as a Pydantic model. There is then the issue of converting that Pydantic model into a filter that can be passed into a retriever.
This can be done manually, but LangChain also provides some “Translators” that are able to translate from a common syntax into filters specific to each retriever. Here, we will cover how to use those translators.
from typing import Optional
from langchain.chains.query_constructor.ir import (
Comparator,
Comparison,
Operation,
Operator,
StructuredQuery,
)
from langchain.retrievers.self_query.chroma import ChromaTranslator
from langchain.retrievers.self_query.elasticsearch import ElasticsearchTranslator
from langchain_core.pydantic_v1 import BaseModel
In this example, year and author are both attributes to filter on.
class Search(BaseModel):
query: str
start_year: Optional[int]
author: Optional[str]
search_query = Search(query="RAG", start_year=2022, author="LangChain")
def construct_comparisons(query: Search):
comparisons = []
if query.start_year is not None:
comparisons.append(
Comparison(
comparator=Comparator.GT,
attribute="start_year",
value=query.start_year,
)
)
if query.author is not None:
comparisons.append(
Comparison(
comparator=Comparator.EQ,
attribute="author",
value=query.author,
)
)
return comparisons
comparisons = construct_comparisons(search_query)
_filter = Operation(operator=Operator.AND, arguments=comparisons)
ElasticsearchTranslator().visit_operation(_filter)
{'bool': {'must': [{'range': {'metadata.start_year': {'gt': 2022}}},
{'term': {'metadata.author.keyword': 'LangChain'}}]}}
ChromaTranslator().visit_operation(_filter)
{'$and': [{'start_year': {'$gt': 2022}}, {'author': {'$eq': 'LangChain'}}]} |
https://python.langchain.com/docs/use_cases/graph/semantic/ | You can use database queries to retrieve information from a graph database like Neo4j. One option is to use LLMs to generate Cypher statements. While that option provides excellent flexibility, the solution could be brittle and not consistently generating precise Cypher statements. Instead of generating Cypher statements, we can implement Cypher templates as tools in a semantic layer that an LLM agent can interact with.
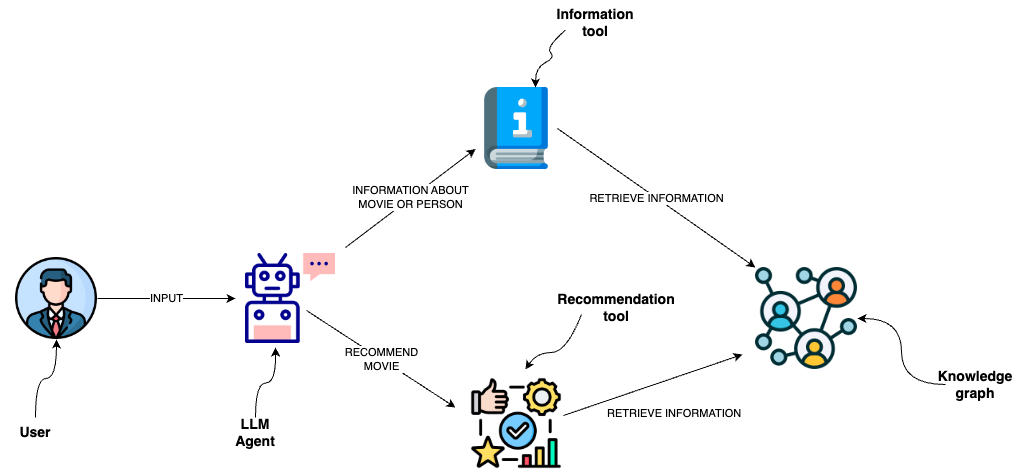
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
```
```
Note: you may need to restart the kernel to use updated packages.
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
Next, we need to define Neo4j credentials. Follow [these installation steps](https://neo4j.com/docs/operations-manual/current/installation/) to set up a Neo4j database.
```
os.environ["NEO4J_URI"] = "bolt://localhost:7687"os.environ["NEO4J_USERNAME"] = "neo4j"os.environ["NEO4J_PASSWORD"] = "password"
```
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
```
from langchain_community.graphs import Neo4jGraphgraph = Neo4jGraph()# Import movie informationmovies_query = """LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'AS rowMERGE (m:Movie {id:row.movieId})SET m.released = date(row.released), m.title = row.title, m.imdbRating = toFloat(row.imdbRating)FOREACH (director in split(row.director, '|') | MERGE (p:Person {name:trim(director)}) MERGE (p)-[:DIRECTED]->(m))FOREACH (actor in split(row.actors, '|') | MERGE (p:Person {name:trim(actor)}) MERGE (p)-[:ACTED_IN]->(m))FOREACH (genre in split(row.genres, '|') | MERGE (g:Genre {name:trim(genre)}) MERGE (m)-[:IN_GENRE]->(g))"""graph.query(movies_query)
```
A semantic layer consists of various tools exposed to an LLM that it can use to interact with a knowledge graph. They can be of various complexity. You can think of each tool in a semantic layer as a function.
The function we will implement is to retrieve information about movies or their cast.
```
from typing import Optional, Typefrom langchain.callbacks.manager import ( AsyncCallbackManagerForToolRun, CallbackManagerForToolRun,)# Import things that are needed genericallyfrom langchain.pydantic_v1 import BaseModel, Fieldfrom langchain.tools import BaseTooldescription_query = """MATCH (m:Movie|Person)WHERE m.title CONTAINS $candidate OR m.name CONTAINS $candidateMATCH (m)-[r:ACTED_IN|HAS_GENRE]-(t)WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as namesWITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as typesWITH m, collect(types) as contextsWITH m, "type:" + labels(m)[0] + "\ntitle: "+ coalesce(m.title, m.name) + "\nyear: "+coalesce(m.released,"") +"\n" + reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as contextRETURN context LIMIT 1"""def get_information(entity: str) -> str: try: data = graph.query(description_query, params={"candidate": entity}) return data[0]["context"] except IndexError: return "No information was found"
```
You can observe that we have defined the Cypher statement used to retrieve information. Therefore, we can avoid generating Cypher statements and use the LLM agent to only populate the input parameters. To provide additional information to an LLM agent about when to use the tool and their input parameters, we wrap the function as a tool.
```
from typing import Optional, Typefrom langchain.callbacks.manager import ( AsyncCallbackManagerForToolRun, CallbackManagerForToolRun,)# Import things that are needed genericallyfrom langchain.pydantic_v1 import BaseModel, Fieldfrom langchain.tools import BaseToolclass InformationInput(BaseModel): entity: str = Field(description="movie or a person mentioned in the question")class InformationTool(BaseTool): name = "Information" description = ( "useful for when you need to answer questions about various actors or movies" ) args_schema: Type[BaseModel] = InformationInput def _run( self, entity: str, run_manager: Optional[CallbackManagerForToolRun] = None, ) -> str: """Use the tool.""" return get_information(entity) async def _arun( self, entity: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None, ) -> str: """Use the tool asynchronously.""" return get_information(entity)
```
## OpenAI Agent[](#openai-agent "Direct link to OpenAI Agent")
LangChain expression language makes it very convenient to define an agent to interact with a graph database over the semantic layer.
```
from typing import List, Tuplefrom langchain.agents import AgentExecutorfrom langchain.agents.format_scratchpad import format_to_openai_function_messagesfrom langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParserfrom langchain_core.messages import AIMessage, HumanMessagefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.utils.function_calling import convert_to_openai_functionfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)tools = [InformationTool()]llm_with_tools = llm.bind(functions=[convert_to_openai_function(t) for t in tools])prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful assistant that finds information about movies " " and recommends them. If tools require follow up questions, " "make sure to ask the user for clarification. Make sure to include any " "available options that need to be clarified in the follow up questions " "Do only the things the user specifically requested. ", ), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ])def _format_chat_history(chat_history: List[Tuple[str, str]]): buffer = [] for human, ai in chat_history: buffer.append(HumanMessage(content=human)) buffer.append(AIMessage(content=ai)) return bufferagent = ( { "input": lambda x: x["input"], "chat_history": lambda x: _format_chat_history(x["chat_history"]) if x.get("chat_history") else [], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser())agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
```
```
agent_executor.invoke({"input": "Who played in Casino?"})
```
```
> Entering new AgentExecutor chain...Invoking: `Information` with `{'entity': 'Casino'}`type:Movietitle: Casinoyear: 1995-11-22ACTED_IN: Joe Pesci, Robert De Niro, Sharon Stone, James WoodsThe movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.> Finished chain.
```
```
{'input': 'Who played in Casino?', 'output': 'The movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:16.017Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/graph/semantic/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/graph/semantic/",
"description": "You can use database queries to retrieve information from a graph",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3770",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"semantic\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"f0aa3b383d854c1d105ed955d1e44b34\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::bqkmk-1713753975278-2365c156ac47"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/graph/semantic/",
"property": "og:url"
},
{
"content": "Semantic layer over graph database | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "You can use database queries to retrieve information from a graph",
"property": "og:description"
}
],
"title": "Semantic layer over graph database | 🦜️🔗 LangChain"
} | You can use database queries to retrieve information from a graph database like Neo4j. One option is to use LLMs to generate Cypher statements. While that option provides excellent flexibility, the solution could be brittle and not consistently generating precise Cypher statements. Instead of generating Cypher statements, we can implement Cypher templates as tools in a semantic layer that an LLM agent can interact with.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
Note: you may need to restart the kernel to use updated packages.
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
Next, we need to define Neo4j credentials. Follow these installation steps to set up a Neo4j database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
A semantic layer consists of various tools exposed to an LLM that it can use to interact with a knowledge graph. They can be of various complexity. You can think of each tool in a semantic layer as a function.
The function we will implement is to retrieve information about movies or their cast.
from typing import Optional, Type
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
# Import things that are needed generically
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool
description_query = """
MATCH (m:Movie|Person)
WHERE m.title CONTAINS $candidate OR m.name CONTAINS $candidate
MATCH (m)-[r:ACTED_IN|HAS_GENRE]-(t)
WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as names
WITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as types
WITH m, collect(types) as contexts
WITH m, "type:" + labels(m)[0] + "\ntitle: "+ coalesce(m.title, m.name)
+ "\nyear: "+coalesce(m.released,"") +"\n" +
reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as context
RETURN context LIMIT 1
"""
def get_information(entity: str) -> str:
try:
data = graph.query(description_query, params={"candidate": entity})
return data[0]["context"]
except IndexError:
return "No information was found"
You can observe that we have defined the Cypher statement used to retrieve information. Therefore, we can avoid generating Cypher statements and use the LLM agent to only populate the input parameters. To provide additional information to an LLM agent about when to use the tool and their input parameters, we wrap the function as a tool.
from typing import Optional, Type
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
# Import things that are needed generically
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool
class InformationInput(BaseModel):
entity: str = Field(description="movie or a person mentioned in the question")
class InformationTool(BaseTool):
name = "Information"
description = (
"useful for when you need to answer questions about various actors or movies"
)
args_schema: Type[BaseModel] = InformationInput
def _run(
self,
entity: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return get_information(entity)
async def _arun(
self,
entity: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""Use the tool asynchronously."""
return get_information(entity)
OpenAI Agent
LangChain expression language makes it very convenient to define an agent to interact with a graph database over the semantic layer.
from typing import List, Tuple
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
tools = [InformationTool()]
llm_with_tools = llm.bind(functions=[convert_to_openai_function(t) for t in tools])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that finds information about movies "
" and recommends them. If tools require follow up questions, "
"make sure to ask the user for clarification. Make sure to include any "
"available options that need to be clarified in the follow up questions "
"Do only the things the user specifically requested. ",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
def _format_chat_history(chat_history: List[Tuple[str, str]]):
buffer = []
for human, ai in chat_history:
buffer.append(HumanMessage(content=human))
buffer.append(AIMessage(content=ai))
return buffer
agent = (
{
"input": lambda x: x["input"],
"chat_history": lambda x: _format_chat_history(x["chat_history"])
if x.get("chat_history")
else [],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "Who played in Casino?"})
> Entering new AgentExecutor chain...
Invoking: `Information` with `{'entity': 'Casino'}`
type:Movie
title: Casino
year: 1995-11-22
ACTED_IN: Joe Pesci, Robert De Niro, Sharon Stone, James Woods
The movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.
> Finished chain.
{'input': 'Who played in Casino?',
'output': 'The movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'} |
https://python.langchain.com/docs/use_cases/query_analysis/quickstart/ | ## Quickstart
This page will show how to use query analysis in a basic end-to-end example. This will cover creating a simple search engine, showing a failure mode that occurs when passing a raw user question to that search, and then an example of how query analysis can help address that issue. There are MANY different query analysis techniques and this end-to-end example will not show all of them.
For the purpose of this example, we will do retrieval over the LangChain YouTube videos.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-community langchain-openai youtube-transcript-api pytube langchain-chroma
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
### Load documents[](#load-documents "Direct link to Load documents")
We can use the `YouTubeLoader` to load transcripts of a few LangChain videos:
```
from langchain_community.document_loaders import YoutubeLoaderurls = [ "https://www.youtube.com/watch?v=HAn9vnJy6S4", "https://www.youtube.com/watch?v=dA1cHGACXCo", "https://www.youtube.com/watch?v=ZcEMLz27sL4", "https://www.youtube.com/watch?v=hvAPnpSfSGo", "https://www.youtube.com/watch?v=EhlPDL4QrWY", "https://www.youtube.com/watch?v=mmBo8nlu2j0", "https://www.youtube.com/watch?v=rQdibOsL1ps", "https://www.youtube.com/watch?v=28lC4fqukoc", "https://www.youtube.com/watch?v=es-9MgxB-uc", "https://www.youtube.com/watch?v=wLRHwKuKvOE", "https://www.youtube.com/watch?v=ObIltMaRJvY", "https://www.youtube.com/watch?v=DjuXACWYkkU", "https://www.youtube.com/watch?v=o7C9ld6Ln-M",]docs = []for url in urls: docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())
```
```
import datetime# Add some additional metadata: what year the video was publishedfor doc in docs: doc.metadata["publish_year"] = int( datetime.datetime.strptime( doc.metadata["publish_date"], "%Y-%m-%d %H:%M:%S" ).strftime("%Y") )
```
Here are the titles of the videos we’ve loaded:
```
[doc.metadata["title"] for doc in docs]
```
```
['OpenGPTs', 'Building a web RAG chatbot: using LangChain, Exa (prev. Metaphor), LangSmith, and Hosted Langserve', 'Streaming Events: Introducing a new `stream_events` method', 'LangGraph: Multi-Agent Workflows', 'Build and Deploy a RAG app with Pinecone Serverless', 'Auto-Prompt Builder (with Hosted LangServe)', 'Build a Full Stack RAG App With TypeScript', 'Getting Started with Multi-Modal LLMs', 'SQL Research Assistant', 'Skeleton-of-Thought: Building a New Template from Scratch', 'Benchmarking RAG over LangChain Docs', 'Building a Research Assistant from Scratch', 'LangServe and LangChain Templates Webinar']
```
Here’s the metadata associated with each video. We can see that each document also has a title, view count, publication date, and length:
```
{'source': 'HAn9vnJy6S4', 'title': 'OpenGPTs', 'description': 'Unknown', 'view_count': 7210, 'thumbnail_url': 'https://i.ytimg.com/vi/HAn9vnJy6S4/hq720.jpg', 'publish_date': '2024-01-31 00:00:00', 'length': 1530, 'author': 'LangChain', 'publish_year': 2024}
```
And here’s a sample from a document’s contents:
```
docs[0].page_content[:500]
```
```
"hello today I want to talk about open gpts open gpts is a project that we built here at linkchain uh that replicates the GPT store in a few ways so it creates uh end user-facing friendly interface to create different Bots and these Bots can have access to different tools and they can uh be given files to retrieve things over and basically it's a way to create a variety of bots and expose the configuration of these Bots to end users it's all open source um it can be used with open AI it can be us"
```
### Indexing documents[](#indexing-documents "Direct link to Indexing documents")
Whenever we perform retrieval we need to create an index of documents that we can query. We’ll use a vector store to index our documents, and we’ll chunk them first to make our retrievals more concise and precise:
```
from langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)chunked_docs = text_splitter.split_documents(docs)embeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_documents( chunked_docs, embeddings,)
```
## Retrieval without query analysis[](#retrieval-without-query-analysis "Direct link to Retrieval without query analysis")
We can perform similarity search on a user question directly to find chunks relevant to the question:
```
search_results = vectorstore.similarity_search("how do I build a RAG agent")print(search_results[0].metadata["title"])print(search_results[0].page_content[:500])
```
```
Build and Deploy a RAG app with Pinecone Serverlesshi this is Lance from the Lang chain team and today we're going to be building and deploying a rag app using pine con serval list from scratch so we're going to kind of walk through all the code required to do this and I'll use these slides as kind of a guide to kind of lay the the ground work um so first what is rag so under capoy has this pretty nice visualization that shows LMS as a kernel of a new kind of operating system and of course one of the core components of our operating system is th
```
This works pretty well! Our first result is quite relevant to the question.
What if we wanted to search for results from a specific time period?
```
search_results = vectorstore.similarity_search("videos on RAG published in 2023")print(search_results[0].metadata["title"])print(search_results[0].metadata["publish_date"])print(search_results[0].page_content[:500])
```
```
OpenGPTs2024-01-31hardcoded that it will always do a retrieval step here the assistant decides whether to do a retrieval step or not sometimes this is good sometimes this is bad sometimes it you don't need to do a retrieval step when I said hi it didn't need to call it tool um but other times you know the the llm might mess up and not realize that it needs to do a retrieval step and so the rag bot will always do a retrieval step so it's more focused there because this is also a simpler architecture so it's always
```
Our first result is from 2024 (despite us asking for videos from 2023), and not very relevant to the input. Since we’re just searching against document contents, there’s no way for the results to be filtered on any document attributes.
This is just one failure mode that can arise. Let’s now take a look at how a basic form of query analysis can fix it!
## Query analysis[](#query-analysis "Direct link to Query analysis")
We can use query analysis to improve the results of retrieval. This will involve defining a **query schema** that contains some date filters and use a function-calling model to convert a user question into a structured queries.
### Query schema[](#query-schema "Direct link to Query schema")
In this case we’ll have explicit min and max attributes for publication date so that it can be filtered on.
```
from typing import Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Search(BaseModel): """Search over a database of tutorial videos about a software library.""" query: str = Field( ..., description="Similarity search query applied to video transcripts.", ) publish_year: Optional[int] = Field(None, description="Year video was published")
```
### Query generation[](#query-generation "Direct link to Query generation")
To convert user questions to structured queries we’ll make use of OpenAI’s tool-calling API. Specifically we’ll use the new [ChatModel.with\_structured\_output()](https://python.langchain.com/docs/modules/model_io/chat/structured_output/) constructor to handle passing the schema to the model and parsing the output.
```
from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAIsystem = """You are an expert at converting user questions into database queries. \You have access to a database of tutorial videos about a software library for building LLM-powered applications. \Given a question, return a list of database queries optimized to retrieve the most relevant results.If there are acronyms or words you are not familiar with, do not try to rephrase them."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(Search)query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
```
```
/Users/bagatur/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change. warn_beta(
```
Let’s see what queries our analyzer generates for the questions we searched earlier:
```
query_analyzer.invoke("how do I build a RAG agent")
```
```
Search(query='build RAG agent', publish_year=None)
```
```
query_analyzer.invoke("videos on RAG published in 2023")
```
```
Search(query='RAG', publish_year=2023)
```
## Retrieval with query analysis[](#retrieval-with-query-analysis "Direct link to Retrieval with query analysis")
Our query analysis looks pretty good; now let’s try using our generated queries to actually perform retrieval.
**Note:** in our example, we specified `tool_choice="Search"`. This will force the LLM to call one - and only one - tool, meaning that we will always have one optimized query to look up. Note that this is not always the case - see other guides for how to deal with situations when no - or multiple - optmized queries are returned.
```
from typing import Listfrom langchain_core.documents import Document
```
```
def retrieval(search: Search) -> List[Document]: if search.publish_year is not None: # This is syntax specific to Chroma, # the vector database we are using. _filter = {"publish_year": {"$eq": search.publish_year}} else: _filter = None return vectorstore.similarity_search(search.query, filter=_filter)
```
```
retrieval_chain = query_analyzer | retrieval
```
We can now run this chain on the problematic input from before, and see that it yields only results from that year!
```
results = retrieval_chain.invoke("RAG tutorial published in 2023")
```
```
[(doc.metadata["title"], doc.metadata["publish_date"]) for doc in results]
```
```
[('Getting Started with Multi-Modal LLMs', '2023-12-20 00:00:00'), ('LangServe and LangChain Templates Webinar', '2023-11-02 00:00:00'), ('Getting Started with Multi-Modal LLMs', '2023-12-20 00:00:00'), ('Building a Research Assistant from Scratch', '2023-11-16 00:00:00')]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:16.374Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/quickstart/",
"description": "This page will show how to use query analysis in a basic end-to-end",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"05dc4fbb757f668fc45ac75016f9f1c2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::cp5p8-1713753975235-9c56d6bb9f73"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page will show how to use query analysis in a basic end-to-end",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
This page will show how to use query analysis in a basic end-to-end example. This will cover creating a simple search engine, showing a failure mode that occurs when passing a raw user question to that search, and then an example of how query analysis can help address that issue. There are MANY different query analysis techniques and this end-to-end example will not show all of them.
For the purpose of this example, we will do retrieval over the LangChain YouTube videos.
Setup
Install dependencies
# %pip install -qU langchain langchain-community langchain-openai youtube-transcript-api pytube langchain-chroma
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Load documents
We can use the YouTubeLoader to load transcripts of a few LangChain videos:
from langchain_community.document_loaders import YoutubeLoader
urls = [
"https://www.youtube.com/watch?v=HAn9vnJy6S4",
"https://www.youtube.com/watch?v=dA1cHGACXCo",
"https://www.youtube.com/watch?v=ZcEMLz27sL4",
"https://www.youtube.com/watch?v=hvAPnpSfSGo",
"https://www.youtube.com/watch?v=EhlPDL4QrWY",
"https://www.youtube.com/watch?v=mmBo8nlu2j0",
"https://www.youtube.com/watch?v=rQdibOsL1ps",
"https://www.youtube.com/watch?v=28lC4fqukoc",
"https://www.youtube.com/watch?v=es-9MgxB-uc",
"https://www.youtube.com/watch?v=wLRHwKuKvOE",
"https://www.youtube.com/watch?v=ObIltMaRJvY",
"https://www.youtube.com/watch?v=DjuXACWYkkU",
"https://www.youtube.com/watch?v=o7C9ld6Ln-M",
]
docs = []
for url in urls:
docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())
import datetime
# Add some additional metadata: what year the video was published
for doc in docs:
doc.metadata["publish_year"] = int(
datetime.datetime.strptime(
doc.metadata["publish_date"], "%Y-%m-%d %H:%M:%S"
).strftime("%Y")
)
Here are the titles of the videos we’ve loaded:
[doc.metadata["title"] for doc in docs]
['OpenGPTs',
'Building a web RAG chatbot: using LangChain, Exa (prev. Metaphor), LangSmith, and Hosted Langserve',
'Streaming Events: Introducing a new `stream_events` method',
'LangGraph: Multi-Agent Workflows',
'Build and Deploy a RAG app with Pinecone Serverless',
'Auto-Prompt Builder (with Hosted LangServe)',
'Build a Full Stack RAG App With TypeScript',
'Getting Started with Multi-Modal LLMs',
'SQL Research Assistant',
'Skeleton-of-Thought: Building a New Template from Scratch',
'Benchmarking RAG over LangChain Docs',
'Building a Research Assistant from Scratch',
'LangServe and LangChain Templates Webinar']
Here’s the metadata associated with each video. We can see that each document also has a title, view count, publication date, and length:
{'source': 'HAn9vnJy6S4',
'title': 'OpenGPTs',
'description': 'Unknown',
'view_count': 7210,
'thumbnail_url': 'https://i.ytimg.com/vi/HAn9vnJy6S4/hq720.jpg',
'publish_date': '2024-01-31 00:00:00',
'length': 1530,
'author': 'LangChain',
'publish_year': 2024}
And here’s a sample from a document’s contents:
docs[0].page_content[:500]
"hello today I want to talk about open gpts open gpts is a project that we built here at linkchain uh that replicates the GPT store in a few ways so it creates uh end user-facing friendly interface to create different Bots and these Bots can have access to different tools and they can uh be given files to retrieve things over and basically it's a way to create a variety of bots and expose the configuration of these Bots to end users it's all open source um it can be used with open AI it can be us"
Indexing documents
Whenever we perform retrieval we need to create an index of documents that we can query. We’ll use a vector store to index our documents, and we’ll chunk them first to make our retrievals more concise and precise:
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
chunked_docs = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(
chunked_docs,
embeddings,
)
Retrieval without query analysis
We can perform similarity search on a user question directly to find chunks relevant to the question:
search_results = vectorstore.similarity_search("how do I build a RAG agent")
print(search_results[0].metadata["title"])
print(search_results[0].page_content[:500])
Build and Deploy a RAG app with Pinecone Serverless
hi this is Lance from the Lang chain team and today we're going to be building and deploying a rag app using pine con serval list from scratch so we're going to kind of walk through all the code required to do this and I'll use these slides as kind of a guide to kind of lay the the ground work um so first what is rag so under capoy has this pretty nice visualization that shows LMS as a kernel of a new kind of operating system and of course one of the core components of our operating system is th
This works pretty well! Our first result is quite relevant to the question.
What if we wanted to search for results from a specific time period?
search_results = vectorstore.similarity_search("videos on RAG published in 2023")
print(search_results[0].metadata["title"])
print(search_results[0].metadata["publish_date"])
print(search_results[0].page_content[:500])
OpenGPTs
2024-01-31
hardcoded that it will always do a retrieval step here the assistant decides whether to do a retrieval step or not sometimes this is good sometimes this is bad sometimes it you don't need to do a retrieval step when I said hi it didn't need to call it tool um but other times you know the the llm might mess up and not realize that it needs to do a retrieval step and so the rag bot will always do a retrieval step so it's more focused there because this is also a simpler architecture so it's always
Our first result is from 2024 (despite us asking for videos from 2023), and not very relevant to the input. Since we’re just searching against document contents, there’s no way for the results to be filtered on any document attributes.
This is just one failure mode that can arise. Let’s now take a look at how a basic form of query analysis can fix it!
Query analysis
We can use query analysis to improve the results of retrieval. This will involve defining a query schema that contains some date filters and use a function-calling model to convert a user question into a structured queries.
Query schema
In this case we’ll have explicit min and max attributes for publication date so that it can be filtered on.
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Search(BaseModel):
"""Search over a database of tutorial videos about a software library."""
query: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
publish_year: Optional[int] = Field(None, description="Year video was published")
Query generation
To convert user questions to structured queries we’ll make use of OpenAI’s tool-calling API. Specifically we’ll use the new ChatModel.with_structured_output() constructor to handle passing the schema to the model and parsing the output.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a list of database queries optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
/Users/bagatur/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
Let’s see what queries our analyzer generates for the questions we searched earlier:
query_analyzer.invoke("how do I build a RAG agent")
Search(query='build RAG agent', publish_year=None)
query_analyzer.invoke("videos on RAG published in 2023")
Search(query='RAG', publish_year=2023)
Retrieval with query analysis
Our query analysis looks pretty good; now let’s try using our generated queries to actually perform retrieval.
Note: in our example, we specified tool_choice="Search". This will force the LLM to call one - and only one - tool, meaning that we will always have one optimized query to look up. Note that this is not always the case - see other guides for how to deal with situations when no - or multiple - optmized queries are returned.
from typing import List
from langchain_core.documents import Document
def retrieval(search: Search) -> List[Document]:
if search.publish_year is not None:
# This is syntax specific to Chroma,
# the vector database we are using.
_filter = {"publish_year": {"$eq": search.publish_year}}
else:
_filter = None
return vectorstore.similarity_search(search.query, filter=_filter)
retrieval_chain = query_analyzer | retrieval
We can now run this chain on the problematic input from before, and see that it yields only results from that year!
results = retrieval_chain.invoke("RAG tutorial published in 2023")
[(doc.metadata["title"], doc.metadata["publish_date"]) for doc in results]
[('Getting Started with Multi-Modal LLMs', '2023-12-20 00:00:00'),
('LangServe and LangChain Templates Webinar', '2023-11-02 00:00:00'),
('Getting Started with Multi-Modal LLMs', '2023-12-20 00:00:00'),
('Building a Research Assistant from Scratch', '2023-11-16 00:00:00')] |
https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_retrievers/ | ## Handle Multiple Retrievers
Sometimes, a query analysis technique may allow for selection of which retriever to use. To use this, you will need to add some logic to select the retriever to do. We will show a simple example (using mock data) of how to do that.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-community langchain-openai langchain-chroma
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
### Create Index[](#create-index "Direct link to Create Index")
We will create a vectorstore over fake information.
```
from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingstexts = ["Harrison worked at Kensho"]embeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_texts(texts, embeddings, collection_name="harrison")retriever_harrison = vectorstore.as_retriever(search_kwargs={"k": 1})texts = ["Ankush worked at Facebook"]embeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_texts(texts, embeddings, collection_name="ankush")retriever_ankush = vectorstore.as_retriever(search_kwargs={"k": 1})
```
## Query analysis[](#query-analysis "Direct link to Query analysis")
We will use function calling to structure the output. We will let it return multiple queries.
```
from typing import List, Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Search(BaseModel): """Search for information about a person.""" query: str = Field( ..., description="Query to look up", ) person: str = Field( ..., description="Person to look things up for. Should be `HARRISON` or `ANKUSH`.", )
```
```
from langchain_core.output_parsers.openai_tools import PydanticToolsParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAIoutput_parser = PydanticToolsParser(tools=[Search])system = """You have the ability to issue search queries to get information to help answer user information."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(Search)query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
```
We can see that this allows for routing between retrievers
```
query_analyzer.invoke("where did Harrison Work")
```
```
Search(query='workplace', person='HARRISON')
```
```
query_analyzer.invoke("where did ankush Work")
```
```
Search(query='workplace', person='ANKUSH')
```
## Retrieval with query analysis[](#retrieval-with-query-analysis "Direct link to Retrieval with query analysis")
So how would we include this in a chain? We just need some simple logic to select the retriever and pass in the search query
```
from langchain_core.runnables import chain
```
```
retrievers = { "HARRISON": retriever_harrison, "ANKUSH": retriever_ankush,}
```
```
@chaindef custom_chain(question): response = query_analyzer.invoke(question) retriever = retrievers[response.person] return retriever.invoke(response.query)
```
```
custom_chain.invoke("where did Harrison Work")
```
```
[Document(page_content='Harrison worked at Kensho')]
```
```
custom_chain.invoke("where did ankush Work")
```
```
[Document(page_content='Ankush worked at Facebook')]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:16.886Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_retrievers/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_retrievers/",
"description": "Sometimes, a query analysis technique may allow for selection of which",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "1192",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"multiple_retrievers\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:15 GMT",
"etag": "W/\"70520bea20946a9fc367dc15bd8bdc6c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::dzpq5-1713753975616-48ded556be88"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_retrievers/",
"property": "og:url"
},
{
"content": "Handle Multiple Retrievers | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Sometimes, a query analysis technique may allow for selection of which",
"property": "og:description"
}
],
"title": "Handle Multiple Retrievers | 🦜️🔗 LangChain"
} | Handle Multiple Retrievers
Sometimes, a query analysis technique may allow for selection of which retriever to use. To use this, you will need to add some logic to select the retriever to do. We will show a simple example (using mock data) of how to do that.
Setup
Install dependencies
# %pip install -qU langchain langchain-community langchain-openai langchain-chroma
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Create Index
We will create a vectorstore over fake information.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
texts = ["Harrison worked at Kensho"]
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_texts(texts, embeddings, collection_name="harrison")
retriever_harrison = vectorstore.as_retriever(search_kwargs={"k": 1})
texts = ["Ankush worked at Facebook"]
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_texts(texts, embeddings, collection_name="ankush")
retriever_ankush = vectorstore.as_retriever(search_kwargs={"k": 1})
Query analysis
We will use function calling to structure the output. We will let it return multiple queries.
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Search(BaseModel):
"""Search for information about a person."""
query: str = Field(
...,
description="Query to look up",
)
person: str = Field(
...,
description="Person to look things up for. Should be `HARRISON` or `ANKUSH`.",
)
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
output_parser = PydanticToolsParser(tools=[Search])
system = """You have the ability to issue search queries to get information to help answer user information."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
We can see that this allows for routing between retrievers
query_analyzer.invoke("where did Harrison Work")
Search(query='workplace', person='HARRISON')
query_analyzer.invoke("where did ankush Work")
Search(query='workplace', person='ANKUSH')
Retrieval with query analysis
So how would we include this in a chain? We just need some simple logic to select the retriever and pass in the search query
from langchain_core.runnables import chain
retrievers = {
"HARRISON": retriever_harrison,
"ANKUSH": retriever_ankush,
}
@chain
def custom_chain(question):
response = query_analyzer.invoke(question)
retriever = retrievers[response.person]
return retriever.invoke(response.query)
custom_chain.invoke("where did Harrison Work")
[Document(page_content='Harrison worked at Kensho')]
custom_chain.invoke("where did ankush Work")
[Document(page_content='Ankush worked at Facebook')] |
https://python.langchain.com/docs/use_cases/query_analysis/how_to/no_queries/ | Sometimes, a query analysis technique may allow for any number of queries to be generated - including no queries! In this case, our overall chain will need to inspect the result of the query analysis before deciding whether to call the retriever or not.
We will use mock data for this example.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-community langchain-openai langchain-chroma
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
### Create Index[](#create-index "Direct link to Create Index")
We will create a vectorstore over fake information.
```
from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingstexts = ["Harrison worked at Kensho"]embeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_texts( texts, embeddings,)retriever = vectorstore.as_retriever()
```
## Query analysis[](#query-analysis "Direct link to Query analysis")
We will use function calling to structure the output. However, we will configure the LLM such that is doesn’t NEED to call the function representing a search query (should it decide not to). We will also then use a prompt to do query analysis that explicitly lays when it should and shouldn’t make a search.
```
from typing import Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Search(BaseModel): """Search over a database of job records.""" query: str = Field( ..., description="Similarity search query applied to job record.", )
```
```
from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAIsystem = """You have the ability to issue search queries to get information to help answer user information.You do not NEED to look things up. If you don't need to, then just respond normally."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.bind_tools([Search])query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
```
We can see that by invoking this we get an message that sometimes - but not always - returns a tool call.
```
query_analyzer.invoke("where did Harrison Work")
```
```
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_ZnoVX4j9Mn8wgChaORyd1cvq', 'function': {'arguments': '{"query":"Harrison"}', 'name': 'Search'}, 'type': 'function'}]})
```
```
query_analyzer.invoke("hi!")
```
```
AIMessage(content='Hello! How can I assist you today?')
```
## Retrieval with query analysis[](#retrieval-with-query-analysis "Direct link to Retrieval with query analysis")
So how would we include this in a chain? Let’s look at an example below.
```
from langchain_core.output_parsers.openai_tools import PydanticToolsParserfrom langchain_core.runnables import chainoutput_parser = PydanticToolsParser(tools=[Search])
```
```
@chaindef custom_chain(question): response = query_analyzer.invoke(question) if "tool_calls" in response.additional_kwargs: query = output_parser.invoke(response) docs = retriever.invoke(query[0].query) # Could add more logic - like another LLM call - here return docs else: return response
```
```
custom_chain.invoke("where did Harrison Work")
```
```
Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1
```
```
[Document(page_content='Harrison worked at Kensho')]
```
```
custom_chain.invoke("hi!")
```
```
AIMessage(content='Hello! How can I assist you today?')
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:17.210Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/no_queries/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/no_queries/",
"description": "Sometimes, a query analysis technique may allow for any number of",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4933",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"no_queries\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:16 GMT",
"etag": "W/\"9832dfabae679cced112a58eaac28c32\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::f5bkm-1713753976909-21ad39013837"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/no_queries/",
"property": "og:url"
},
{
"content": "Handle Cases Where No Queries are Generated | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Sometimes, a query analysis technique may allow for any number of",
"property": "og:description"
}
],
"title": "Handle Cases Where No Queries are Generated | 🦜️🔗 LangChain"
} | Sometimes, a query analysis technique may allow for any number of queries to be generated - including no queries! In this case, our overall chain will need to inspect the result of the query analysis before deciding whether to call the retriever or not.
We will use mock data for this example.
Setup
Install dependencies
# %pip install -qU langchain langchain-community langchain-openai langchain-chroma
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Create Index
We will create a vectorstore over fake information.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
texts = ["Harrison worked at Kensho"]
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_texts(
texts,
embeddings,
)
retriever = vectorstore.as_retriever()
Query analysis
We will use function calling to structure the output. However, we will configure the LLM such that is doesn’t NEED to call the function representing a search query (should it decide not to). We will also then use a prompt to do query analysis that explicitly lays when it should and shouldn’t make a search.
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Search(BaseModel):
"""Search over a database of job records."""
query: str = Field(
...,
description="Similarity search query applied to job record.",
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
system = """You have the ability to issue search queries to get information to help answer user information.
You do not NEED to look things up. If you don't need to, then just respond normally."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.bind_tools([Search])
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
We can see that by invoking this we get an message that sometimes - but not always - returns a tool call.
query_analyzer.invoke("where did Harrison Work")
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_ZnoVX4j9Mn8wgChaORyd1cvq', 'function': {'arguments': '{"query":"Harrison"}', 'name': 'Search'}, 'type': 'function'}]})
query_analyzer.invoke("hi!")
AIMessage(content='Hello! How can I assist you today?')
Retrieval with query analysis
So how would we include this in a chain? Let’s look at an example below.
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.runnables import chain
output_parser = PydanticToolsParser(tools=[Search])
@chain
def custom_chain(question):
response = query_analyzer.invoke(question)
if "tool_calls" in response.additional_kwargs:
query = output_parser.invoke(response)
docs = retriever.invoke(query[0].query)
# Could add more logic - like another LLM call - here
return docs
else:
return response
custom_chain.invoke("where did Harrison Work")
Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1
[Document(page_content='Harrison worked at Kensho')]
custom_chain.invoke("hi!")
AIMessage(content='Hello! How can I assist you today?')
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/use_cases/query_analysis/techniques/expansion/ | ## Expansion
Information retrieval systems can be sensitive to phrasing and specific keywords. To mitigate this, one classic retrieval technique is to generate multiple paraphrased versions of a query and return results for all versions of the query. This is called **query expansion**. LLMs are a great tool for generating these alternate versions of a query.
Let’s take a look at how we might do query expansion for our Q&A bot over the LangChain YouTube videos, which we started in the [Quickstart](https://python.langchain.com/docs/use_cases/query_analysis/quickstart/).
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-openai
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Query generation[](#query-generation "Direct link to Query generation")
To make sure we get multiple paraphrasings we’ll use OpenAI’s function-calling API.
```
from langchain_core.pydantic_v1 import BaseModel, Fieldclass ParaphrasedQuery(BaseModel): """You have performed query expansion to generate a paraphrasing of a question.""" paraphrased_query: str = Field( ..., description="A unique paraphrasing of the original question.", )
```
```
from langchain.output_parsers import PydanticToolsParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIsystem = """You are an expert at converting user questions into database queries. \You have access to a database of tutorial videos about a software library for building LLM-powered applications. \Perform query expansion. If there are multiple common ways of phrasing a user question \or common synonyms for key words in the question, make sure to return multiple versions \of the query with the different phrasings.If there are acronyms or words you are not familiar with, do not try to rephrase them.Return at least 3 versions of the question."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)llm_with_tools = llm.bind_tools([ParaphrasedQuery])query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
```
Let’s see what queries our analyzer generates for the questions we searched earlier:
```
query_analyzer.invoke( { "question": "how to use multi-modal models in a chain and turn chain into a rest api" })
```
```
[ParaphrasedQuery(paraphrased_query='How to utilize multi-modal models sequentially and convert the sequence into a REST API'), ParaphrasedQuery(paraphrased_query='Steps for using multi-modal models in a series and transforming the series into a RESTful API'), ParaphrasedQuery(paraphrased_query='Guide on employing multi-modal models in a chain and converting the chain into a RESTful API')]
```
```
query_analyzer.invoke({"question": "stream events from llm agent"})
```
```
[ParaphrasedQuery(paraphrased_query='How to stream events from LLM agent?'), ParaphrasedQuery(paraphrased_query='How can I receive events from LLM agent in real-time?'), ParaphrasedQuery(paraphrased_query='What is the process for capturing events from LLM agent?')]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:17.513Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/expansion/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/expansion/",
"description": "Information retrieval systems can be sensitive to phrasing and specific",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "5393",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"expansion\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:17 GMT",
"etag": "W/\"70027966e06ae2371da0cd59ec09f639\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::nrswz-1713753977444-17a12d238576"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/expansion/",
"property": "og:url"
},
{
"content": "Expansion | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Information retrieval systems can be sensitive to phrasing and specific",
"property": "og:description"
}
],
"title": "Expansion | 🦜️🔗 LangChain"
} | Expansion
Information retrieval systems can be sensitive to phrasing and specific keywords. To mitigate this, one classic retrieval technique is to generate multiple paraphrased versions of a query and return results for all versions of the query. This is called query expansion. LLMs are a great tool for generating these alternate versions of a query.
Let’s take a look at how we might do query expansion for our Q&A bot over the LangChain YouTube videos, which we started in the Quickstart.
Setup
Install dependencies
# %pip install -qU langchain langchain-openai
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Query generation
To make sure we get multiple paraphrasings we’ll use OpenAI’s function-calling API.
from langchain_core.pydantic_v1 import BaseModel, Field
class ParaphrasedQuery(BaseModel):
"""You have performed query expansion to generate a paraphrasing of a question."""
paraphrased_query: str = Field(
...,
description="A unique paraphrasing of the original question.",
)
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Perform query expansion. If there are multiple common ways of phrasing a user question \
or common synonyms for key words in the question, make sure to return multiple versions \
of the query with the different phrasings.
If there are acronyms or words you are not familiar with, do not try to rephrase them.
Return at least 3 versions of the question."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
Let’s see what queries our analyzer generates for the questions we searched earlier:
query_analyzer.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
[ParaphrasedQuery(paraphrased_query='How to utilize multi-modal models sequentially and convert the sequence into a REST API'),
ParaphrasedQuery(paraphrased_query='Steps for using multi-modal models in a series and transforming the series into a RESTful API'),
ParaphrasedQuery(paraphrased_query='Guide on employing multi-modal models in a chain and converting the chain into a RESTful API')]
query_analyzer.invoke({"question": "stream events from llm agent"})
[ParaphrasedQuery(paraphrased_query='How to stream events from LLM agent?'),
ParaphrasedQuery(paraphrased_query='How can I receive events from LLM agent in real-time?'),
ParaphrasedQuery(paraphrased_query='What is the process for capturing events from LLM agent?')] |
https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_queries/ | ## Handle Multiple Queries
Sometimes, a query analysis technique may allow for multiple queries to be generated. In these cases, we need to remember to run all queries and then to combine the results. We will show a simple example (using mock data) of how to do that.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-community langchain-openai langchain-chroma
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
### Create Index[](#create-index "Direct link to Create Index")
We will create a vectorstore over fake information.
```
from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingstexts = ["Harrison worked at Kensho", "Ankush worked at Facebook"]embeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_texts( texts, embeddings,)retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
```
## Query analysis[](#query-analysis "Direct link to Query analysis")
We will use function calling to structure the output. We will let it return multiple queries.
```
from typing import List, Optionalfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Search(BaseModel): """Search over a database of job records.""" queries: List[str] = Field( ..., description="Distinct queries to search for", )
```
```
from langchain_core.output_parsers.openai_tools import PydanticToolsParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAIoutput_parser = PydanticToolsParser(tools=[Search])system = """You have the ability to issue search queries to get information to help answer user information.If you need to look up two distinct pieces of information, you are allowed to do that!"""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(Search)query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
```
```
/Users/harrisonchase/workplace/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change. warn_beta(
```
We can see that this allows for creating multiple queries
```
query_analyzer.invoke("where did Harrison Work")
```
```
Search(queries=['Harrison work location'])
```
```
query_analyzer.invoke("where did Harrison and ankush Work")
```
```
Search(queries=['Harrison work place', 'Ankush work place'])
```
## Retrieval with query analysis[](#retrieval-with-query-analysis "Direct link to Retrieval with query analysis")
So how would we include this in a chain? One thing that will make this a lot easier is if we call our retriever asyncronously - this will let us loop over the queries and not get blocked on the response time.
```
from langchain_core.runnables import chain
```
```
@chainasync def custom_chain(question): response = await query_analyzer.ainvoke(question) docs = [] for query in response.queries: new_docs = await retriever.ainvoke(query) docs.extend(new_docs) # You probably want to think about reranking or deduplicating documents here # But that is a separate topic return docs
```
```
await custom_chain.ainvoke("where did Harrison Work")
```
```
[Document(page_content='Harrison worked at Kensho')]
```
```
await custom_chain.ainvoke("where did Harrison and ankush Work")
```
```
[Document(page_content='Harrison worked at Kensho'), Document(page_content='Ankush worked at Facebook')]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:17.612Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_queries/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_queries/",
"description": "Sometimes, a query analysis technique may allow for multiple queries to",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3771",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"multiple_queries\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:17 GMT",
"etag": "W/\"f1efa56799fed7ab5442f2e2ab3fb357\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::4w6m2-1713753977271-c376ae6c329e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/how_to/multiple_queries/",
"property": "og:url"
},
{
"content": "Handle Multiple Queries | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Sometimes, a query analysis technique may allow for multiple queries to",
"property": "og:description"
}
],
"title": "Handle Multiple Queries | 🦜️🔗 LangChain"
} | Handle Multiple Queries
Sometimes, a query analysis technique may allow for multiple queries to be generated. In these cases, we need to remember to run all queries and then to combine the results. We will show a simple example (using mock data) of how to do that.
Setup
Install dependencies
# %pip install -qU langchain langchain-community langchain-openai langchain-chroma
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Create Index
We will create a vectorstore over fake information.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
texts = ["Harrison worked at Kensho", "Ankush worked at Facebook"]
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_texts(
texts,
embeddings,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
Query analysis
We will use function calling to structure the output. We will let it return multiple queries.
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Search(BaseModel):
"""Search over a database of job records."""
queries: List[str] = Field(
...,
description="Distinct queries to search for",
)
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
output_parser = PydanticToolsParser(tools=[Search])
system = """You have the ability to issue search queries to get information to help answer user information.
If you need to look up two distinct pieces of information, you are allowed to do that!"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
/Users/harrisonchase/workplace/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
We can see that this allows for creating multiple queries
query_analyzer.invoke("where did Harrison Work")
Search(queries=['Harrison work location'])
query_analyzer.invoke("where did Harrison and ankush Work")
Search(queries=['Harrison work place', 'Ankush work place'])
Retrieval with query analysis
So how would we include this in a chain? One thing that will make this a lot easier is if we call our retriever asyncronously - this will let us loop over the queries and not get blocked on the response time.
from langchain_core.runnables import chain
@chain
async def custom_chain(question):
response = await query_analyzer.ainvoke(question)
docs = []
for query in response.queries:
new_docs = await retriever.ainvoke(query)
docs.extend(new_docs)
# You probably want to think about reranking or deduplicating documents here
# But that is a separate topic
return docs
await custom_chain.ainvoke("where did Harrison Work")
[Document(page_content='Harrison worked at Kensho')]
await custom_chain.ainvoke("where did Harrison and ankush Work")
[Document(page_content='Harrison worked at Kensho'),
Document(page_content='Ankush worked at Facebook')] |
https://python.langchain.com/docs/use_cases/query_analysis/techniques/routing/ | ## Routing
Sometimes we have multiple indexes for different domains, and for different questions we want to query different subsets of these indexes. For example, suppose we had one vector store index for all of the LangChain python documentation and one for all of the LangChain js documentation. Given a question about LangChain usage, we’d want to infer which language the the question was referring to and query the appropriate docs. **Query routing** is the process of classifying which index or subset of indexes a query should be performed on.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
%pip install -qU langchain-core langchain-openai
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Routing with function calling models[](#routing-with-function-calling-models "Direct link to Routing with function calling models")
With function-calling models it’s simple to use models for classification, which is what routing comes down to:
```
from typing import Literalfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAIclass RouteQuery(BaseModel): """Route a user query to the most relevant datasource.""" datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field( ..., description="Given a user question choose which datasource would be most relevant for answering their question", )llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(RouteQuery)system = """You are an expert at routing a user question to the appropriate data source.Based on the programming language the question is referring to, route it to the relevant data source."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])router = prompt | structured_llm
```
```
/Users/bagatur/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change. warn_beta(
```
```
question = """Why doesn't the following code work:from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"])prompt.invoke("french")"""router.invoke({"question": question})
```
```
RouteQuery(datasource='python_docs')
```
```
question = """Why doesn't the following code work:import { ChatPromptTemplate } from "@langchain/core/prompts";const chatPrompt = ChatPromptTemplate.fromMessages([ ["human", "speak in {language}"],]);const formattedChatPrompt = await chatPrompt.invoke({ input_language: "french"});"""router.invoke({"question": question})
```
```
RouteQuery(datasource='js_docs')
```
## Routing to multiple indexes[](#routing-to-multiple-indexes "Direct link to Routing to multiple indexes")
If we may want to query multiple indexes we can do that, too, by updating our schema to accept a List of data sources:
```
from typing import Listclass RouteQuery(BaseModel): """Route a user query to the most relevant datasource.""" datasources: List[Literal["python_docs", "js_docs", "golang_docs"]] = Field( ..., description="Given a user question choose which datasources would be most relevant for answering their question", )llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(RouteQuery)router = prompt | structured_llmrouter.invoke( { "question": "is there feature parity between the Python and JS implementations of OpenAI chat models" })
```
```
RouteQuery(datasources=['python_docs', 'js_docs'])
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:17.782Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/routing/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/routing/",
"description": "Sometimes we have multiple indexes for different domains, and for",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3771",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"routing\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:17 GMT",
"etag": "W/\"2750feeae92cb1dc3eaa1a0487f6a159\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tlvfk-1713753977615-42d7a6b0e319"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/routing/",
"property": "og:url"
},
{
"content": "Routing | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Sometimes we have multiple indexes for different domains, and for",
"property": "og:description"
}
],
"title": "Routing | 🦜️🔗 LangChain"
} | Routing
Sometimes we have multiple indexes for different domains, and for different questions we want to query different subsets of these indexes. For example, suppose we had one vector store index for all of the LangChain python documentation and one for all of the LangChain js documentation. Given a question about LangChain usage, we’d want to infer which language the the question was referring to and query the appropriate docs. Query routing is the process of classifying which index or subset of indexes a query should be performed on.
Setup
Install dependencies
%pip install -qU langchain-core langchain-openai
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Routing with function calling models
With function-calling models it’s simple to use models for classification, which is what routing comes down to:
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
system = """You are an expert at routing a user question to the appropriate data source.
Based on the programming language the question is referring to, route it to the relevant data source."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
router = prompt | structured_llm
/Users/bagatur/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
question = """Why doesn't the following code work:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"])
prompt.invoke("french")
"""
router.invoke({"question": question})
RouteQuery(datasource='python_docs')
question = """Why doesn't the following code work:
import { ChatPromptTemplate } from "@langchain/core/prompts";
const chatPrompt = ChatPromptTemplate.fromMessages([
["human", "speak in {language}"],
]);
const formattedChatPrompt = await chatPrompt.invoke({
input_language: "french"
});
"""
router.invoke({"question": question})
RouteQuery(datasource='js_docs')
Routing to multiple indexes
If we may want to query multiple indexes we can do that, too, by updating our schema to accept a List of data sources:
from typing import List
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasources: List[Literal["python_docs", "js_docs", "golang_docs"]] = Field(
...,
description="Given a user question choose which datasources would be most relevant for answering their question",
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
router = prompt | structured_llm
router.invoke(
{
"question": "is there feature parity between the Python and JS implementations of OpenAI chat models"
}
)
RouteQuery(datasources=['python_docs', 'js_docs']) |
https://python.langchain.com/docs/use_cases/query_analysis/techniques/hyde/ | ## Hypothetical Document Embeddings
If we’re working with a similarity search-based index, like a vector store, then searching on raw questions may not work well because their embeddings may not be very similar to those of the relevant documents. Instead it might help to have the model generate a hypothetical relevant document, and then use that to perform similarity search. This is the key idea behind [Hypothetical Document Embedding, or HyDE](https://arxiv.org/pdf/2212.10496.pdf).
Let’s take a look at how we might perform search via hypothetical documents for our Q&A bot over the LangChain YouTube videos.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-openai
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Hypothetical document generation[](#hypothetical-document-generation "Direct link to Hypothetical document generation")
Ultimately generating a relevant hypothetical document reduces to trying to answer the user question. Since we’re desiging a Q&A bot for LangChain YouTube videos, we’ll provide some basic context about LangChain and prompt the model to use a more pedantic style so that we get more realistic hypothetical documents:
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIsystem = """You are an expert about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.LangSmith is a platform that makes it easy to trace and test LLM applications.Answer the user question as best you can. Answer as though you were writing a tutorial that addressed the user question."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)qa_no_context = prompt | llm | StrOutputParser()
```
```
answer = qa_no_context.invoke( { "question": "how to use multi-modal models in a chain and turn chain into a rest api" })print(answer)
```
```
To use multi-modal models in a chain and turn the chain into a REST API, you can leverage the capabilities of LangChain, LangGraph, and LangServe. Here's a step-by-step guide on how to achieve this:1. **Building a Multi-Modal Model with LangChain**: - Start by defining your multi-modal model using LangChain. LangChain provides integrations with various deep learning frameworks like TensorFlow, PyTorch, and Hugging Face Transformers, making it easy to incorporate different modalities such as text, images, and audio. - You can create separate components for each modality and then combine them in a chain to build a multi-modal model.2. **Building a Stateful, Multi-Actor Application with LangGraph**: - Once you have your multi-modal model defined in LangChain, you can use LangGraph to build a stateful, multi-actor application around it. - LangGraph allows you to define actors that interact with each other and maintain state, which is useful for handling multi-modal inputs and outputs in a chain.3. **Deploying the Chain as a REST API with LangServe**: - After building your multi-modal model and application using LangChain and LangGraph, you can deploy the chain as a REST API using LangServe. - LangServe simplifies the process of exposing your LangChain application as a REST API, allowing you to easily interact with your multi-modal model through HTTP requests.4. **Testing and Tracing with LangSmith**: - To ensure the reliability and performance of your multi-modal model and REST API, you can use LangSmith for testing and tracing. - LangSmith provides tools for tracing the execution of your LLM applications and running tests to validate their functionality.By following these steps and leveraging the capabilities of LangChain, LangGraph, LangServe, and LangSmith, you can effectively use multi-modal models in a chain and turn the chain into a REST API.
```
## Returning the hypothetical document and original question[](#returning-the-hypothetical-document-and-original-question "Direct link to Returning the hypothetical document and original question")
To increase our recall we may want to retrieve documents based on both the hypothetical document and the original question. We can easily return both like so:
```
from langchain_core.runnables import RunnablePassthroughhyde_chain = RunnablePassthrough.assign(hypothetical_document=qa_no_context)hyde_chain.invoke( { "question": "how to use multi-modal models in a chain and turn chain into a rest api" })
```
```
{'question': 'how to use multi-modal models in a chain and turn chain into a rest api', 'hypothetical_document': "To use multi-modal models in a chain and turn the chain into a REST API, you can leverage the capabilities of LangChain, LangGraph, and LangServe. Here's a step-by-step guide on how to achieve this:\n\n1. **Set up your multi-modal models**: First, you need to create or import your multi-modal models. These models can include text, image, audio, or any other type of data that you want to process in your LLM application.\n\n2. **Build your LangGraph application**: Use LangGraph to build a stateful, multi-actor LLM application that incorporates your multi-modal models. LangGraph allows you to define the flow of data and interactions between different components of your application.\n\n3. **Integrate your models in LangChain**: LangChain provides integrations for various types of models and data sources. You can easily integrate your multi-modal models into your LangGraph application using LangChain's capabilities.\n\n4. **Deploy your LangChain application as a REST API using LangServe**: Once you have built your multi-modal LLM application using LangGraph and LangChain, you can deploy it as a REST API using LangServe. LangServe simplifies the process of exposing your LangChain application as a web service, making it accessible to other applications and users.\n\n5. **Test and trace your application using LangSmith**: Finally, you can use LangSmith to trace and test your multi-modal LLM application. LangSmith provides tools for monitoring the performance of your application, debugging any issues, and ensuring that it functions as expected.\n\nBy following these steps and leveraging the capabilities of LangChain, LangGraph, LangServe, and LangSmith, you can effectively use multi-modal models in a chain and turn the chain into a REST API."}
```
## Using function-calling to get structured output[](#using-function-calling-to-get-structured-output "Direct link to Using function-calling to get structured output")
If we were composing this technique with other query analysis techniques, we’d likely be using function calling to get out structured query objects. We can use function-calling for HyDE like so:
```
from langchain_core.output_parsers.openai_tools import PydanticToolsParserfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass Query(BaseModel): answer: str = Field( ..., description="Answer the user question as best you can. Answer as though you were writing a tutorial that addressed the user question.", )system = """You are an expert about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.LangSmith is a platform that makes it easy to trace and test LLM applications."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm_with_tools = llm.bind_tools([Query])hyde_chain = prompt | llm_with_tools | PydanticToolsParser(tools=[Query])hyde_chain.invoke( { "question": "how to use multi-modal models in a chain and turn chain into a rest api" })
```
```
[Query(answer='To use multi-modal models in a chain and turn the chain into a REST API, you can follow these steps:\n\n1. Use LangChain to build your multi-modal model by integrating different modalities such as text, image, and audio.\n2. Utilize LangGraph, a Python package built on top of LangChain, to create a stateful, multi-actor LLM application that can handle interactions between different modalities.\n3. Once your multi-modal model is built using LangChain and LangGraph, you can deploy it as a REST API using LangServe, another Python package that simplifies the process of creating REST APIs from LangChain applications.\n4. Use LangSmith to trace and test your multi-modal model to ensure its functionality and performance.\n\nBy following these steps, you can effectively use multi-modal models in a chain and turn the chain into a REST API.')]
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:17.907Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/hyde/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/hyde/",
"description": "If we’re working with a similarity search-based index, like a vector",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3771",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"hyde\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:17 GMT",
"etag": "W/\"a6d47a9089a59b94c27895c01c1cf917\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::pwd9w-1713753977617-4ca4f2d8e0e3"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/hyde/",
"property": "og:url"
},
{
"content": "Hypothetical Document Embeddings | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "If we’re working with a similarity search-based index, like a vector",
"property": "og:description"
}
],
"title": "Hypothetical Document Embeddings | 🦜️🔗 LangChain"
} | Hypothetical Document Embeddings
If we’re working with a similarity search-based index, like a vector store, then searching on raw questions may not work well because their embeddings may not be very similar to those of the relevant documents. Instead it might help to have the model generate a hypothetical relevant document, and then use that to perform similarity search. This is the key idea behind Hypothetical Document Embedding, or HyDE.
Let’s take a look at how we might perform search via hypothetical documents for our Q&A bot over the LangChain YouTube videos.
Setup
Install dependencies
# %pip install -qU langchain langchain-openai
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Hypothetical document generation
Ultimately generating a relevant hypothetical document reduces to trying to answer the user question. Since we’re desiging a Q&A bot for LangChain YouTube videos, we’ll provide some basic context about LangChain and prompt the model to use a more pedantic style so that we get more realistic hypothetical documents:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.
LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.
LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.
LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.
LangSmith is a platform that makes it easy to trace and test LLM applications.
Answer the user question as best you can. Answer as though you were writing a tutorial that addressed the user question."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
qa_no_context = prompt | llm | StrOutputParser()
answer = qa_no_context.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
print(answer)
To use multi-modal models in a chain and turn the chain into a REST API, you can leverage the capabilities of LangChain, LangGraph, and LangServe. Here's a step-by-step guide on how to achieve this:
1. **Building a Multi-Modal Model with LangChain**:
- Start by defining your multi-modal model using LangChain. LangChain provides integrations with various deep learning frameworks like TensorFlow, PyTorch, and Hugging Face Transformers, making it easy to incorporate different modalities such as text, images, and audio.
- You can create separate components for each modality and then combine them in a chain to build a multi-modal model.
2. **Building a Stateful, Multi-Actor Application with LangGraph**:
- Once you have your multi-modal model defined in LangChain, you can use LangGraph to build a stateful, multi-actor application around it.
- LangGraph allows you to define actors that interact with each other and maintain state, which is useful for handling multi-modal inputs and outputs in a chain.
3. **Deploying the Chain as a REST API with LangServe**:
- After building your multi-modal model and application using LangChain and LangGraph, you can deploy the chain as a REST API using LangServe.
- LangServe simplifies the process of exposing your LangChain application as a REST API, allowing you to easily interact with your multi-modal model through HTTP requests.
4. **Testing and Tracing with LangSmith**:
- To ensure the reliability and performance of your multi-modal model and REST API, you can use LangSmith for testing and tracing.
- LangSmith provides tools for tracing the execution of your LLM applications and running tests to validate their functionality.
By following these steps and leveraging the capabilities of LangChain, LangGraph, LangServe, and LangSmith, you can effectively use multi-modal models in a chain and turn the chain into a REST API.
Returning the hypothetical document and original question
To increase our recall we may want to retrieve documents based on both the hypothetical document and the original question. We can easily return both like so:
from langchain_core.runnables import RunnablePassthrough
hyde_chain = RunnablePassthrough.assign(hypothetical_document=qa_no_context)
hyde_chain.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
{'question': 'how to use multi-modal models in a chain and turn chain into a rest api',
'hypothetical_document': "To use multi-modal models in a chain and turn the chain into a REST API, you can leverage the capabilities of LangChain, LangGraph, and LangServe. Here's a step-by-step guide on how to achieve this:\n\n1. **Set up your multi-modal models**: First, you need to create or import your multi-modal models. These models can include text, image, audio, or any other type of data that you want to process in your LLM application.\n\n2. **Build your LangGraph application**: Use LangGraph to build a stateful, multi-actor LLM application that incorporates your multi-modal models. LangGraph allows you to define the flow of data and interactions between different components of your application.\n\n3. **Integrate your models in LangChain**: LangChain provides integrations for various types of models and data sources. You can easily integrate your multi-modal models into your LangGraph application using LangChain's capabilities.\n\n4. **Deploy your LangChain application as a REST API using LangServe**: Once you have built your multi-modal LLM application using LangGraph and LangChain, you can deploy it as a REST API using LangServe. LangServe simplifies the process of exposing your LangChain application as a web service, making it accessible to other applications and users.\n\n5. **Test and trace your application using LangSmith**: Finally, you can use LangSmith to trace and test your multi-modal LLM application. LangSmith provides tools for monitoring the performance of your application, debugging any issues, and ensuring that it functions as expected.\n\nBy following these steps and leveraging the capabilities of LangChain, LangGraph, LangServe, and LangSmith, you can effectively use multi-modal models in a chain and turn the chain into a REST API."}
Using function-calling to get structured output
If we were composing this technique with other query analysis techniques, we’d likely be using function calling to get out structured query objects. We can use function-calling for HyDE like so:
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.pydantic_v1 import BaseModel, Field
class Query(BaseModel):
answer: str = Field(
...,
description="Answer the user question as best you can. Answer as though you were writing a tutorial that addressed the user question.",
)
system = """You are an expert about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.
LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.
LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.
LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.
LangSmith is a platform that makes it easy to trace and test LLM applications."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm_with_tools = llm.bind_tools([Query])
hyde_chain = prompt | llm_with_tools | PydanticToolsParser(tools=[Query])
hyde_chain.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
[Query(answer='To use multi-modal models in a chain and turn the chain into a REST API, you can follow these steps:\n\n1. Use LangChain to build your multi-modal model by integrating different modalities such as text, image, and audio.\n2. Utilize LangGraph, a Python package built on top of LangChain, to create a stateful, multi-actor LLM application that can handle interactions between different modalities.\n3. Once your multi-modal model is built using LangChain and LangGraph, you can deploy it as a REST API using LangServe, another Python package that simplifies the process of creating REST APIs from LangChain applications.\n4. Use LangSmith to trace and test your multi-modal model to ensure its functionality and performance.\n\nBy following these steps, you can effectively use multi-modal models in a chain and turn the chain into a REST API.')]
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/use_cases/query_analysis/techniques/step_back/ | ## Step Back Prompting
Sometimes search quality and model generations can be tripped up by the specifics of a question. One way to handle this is to first generate a more abstract, “step back” question and to query based on both the original and step back question.
For example, if we ask a question of the form “Why does my LangGraph agent astream\_events return {LONG\_TRACE} instead of {DESIRED\_OUTPUT}” we will likely retrieve more relevant documents if we search with the more generic question “How does astream\_events work with a LangGraph agent” than if we search with the specific user question.
Let’s take a look at how we might use step back prompting in the context of our Q&A bot over the LangChain YouTube videos.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain-core langchain-openai
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Step back question generation[](#step-back-question-generation "Direct link to Step back question generation")
Generating good step back questions comes down to writing a good prompt:
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIsystem = """You are an expert at taking a specific question and extracting a more generic question that gets at \the underlying principles needed to answer the specific question.You will be asked about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.LangSmith is a platform that makes it easy to trace and test LLM applications.Given a specific user question about one or more of these products, write a more generic question that needs to be answered in order to answer the specific question. \If you don't recognize a word or acronym to not try to rewrite it.Write concise questions."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)step_back = prompt | llm | StrOutputParser()
```
```
question = ( "I built a LangGraph agent using Gemini Pro and tools like vectorstores and duckduckgo search. " "How do I get just the LLM calls from the event stream")result = step_back.invoke({"question": question})print(result)
```
```
What are the specific methods or functions provided by LangGraph for extracting LLM calls from an event stream that includes various types of interactions and data sources?
```
## Returning the stepback question and the original question[](#returning-the-stepback-question-and-the-original-question "Direct link to Returning the stepback question and the original question")
To increase our recall we’ll likely want to retrieve documents based on both the step back question and the original question. We can easily return both like so:
```
from langchain_core.runnables import RunnablePassthroughstep_back_and_original = RunnablePassthrough.assign(step_back=step_back)step_back_and_original.invoke({"question": question})
```
```
{'question': 'I built a LangGraph agent using Gemini Pro and tools like vectorstores and duckduckgo search. How do I get just the LLM calls from the event stream', 'step_back': 'What are the specific methods or functions provided by LangGraph for extracting LLM calls from an event stream generated by an agent built using external tools like Gemini Pro, vectorstores, and DuckDuckGo search?'}
```
## Using function-calling to get structured output[](#using-function-calling-to-get-structured-output "Direct link to Using function-calling to get structured output")
If we were composing this technique with other query analysis techniques, we’d likely be using function calling to get out structured query objects. We can use function-calling for step back prompting like so:
```
from langchain_core.output_parsers.openai_tools import PydanticToolsParserfrom langchain_core.pydantic_v1 import BaseModel, Fieldclass StepBackQuery(BaseModel): step_back_question: str = Field( ..., description="Given a specific user question about one or more of these products, write a more generic question that needs to be answered in order to answer the specific question.", )llm_with_tools = llm.bind_tools([StepBackQuery])hyde_chain = prompt | llm_with_tools | PydanticToolsParser(tools=[StepBackQuery])hyde_chain.invoke({"question": question})
```
```
[StepBackQuery(step_back_question='What are the steps to filter and extract specific types of calls from an event stream in a Python framework like LangGraph?')]
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:18.169Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/step_back/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/step_back/",
"description": "Sometimes search quality and model generations can be tripped up by the",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3771",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"step_back\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:17 GMT",
"etag": "W/\"716a29df8357d0dbfd6521f13ecc4cd9\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::nvjf2-1713753977780-ec2da4c5daed"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/step_back/",
"property": "og:url"
},
{
"content": "Step Back Prompting | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Sometimes search quality and model generations can be tripped up by the",
"property": "og:description"
}
],
"title": "Step Back Prompting | 🦜️🔗 LangChain"
} | Step Back Prompting
Sometimes search quality and model generations can be tripped up by the specifics of a question. One way to handle this is to first generate a more abstract, “step back” question and to query based on both the original and step back question.
For example, if we ask a question of the form “Why does my LangGraph agent astream_events return {LONG_TRACE} instead of {DESIRED_OUTPUT}” we will likely retrieve more relevant documents if we search with the more generic question “How does astream_events work with a LangGraph agent” than if we search with the specific user question.
Let’s take a look at how we might use step back prompting in the context of our Q&A bot over the LangChain YouTube videos.
Setup
Install dependencies
# %pip install -qU langchain-core langchain-openai
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Step back question generation
Generating good step back questions comes down to writing a good prompt:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at taking a specific question and extracting a more generic question that gets at \
the underlying principles needed to answer the specific question.
You will be asked about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.
LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.
LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.
LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.
LangSmith is a platform that makes it easy to trace and test LLM applications.
Given a specific user question about one or more of these products, write a more generic question that needs to be answered in order to answer the specific question. \
If you don't recognize a word or acronym to not try to rewrite it.
Write concise questions."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
step_back = prompt | llm | StrOutputParser()
question = (
"I built a LangGraph agent using Gemini Pro and tools like vectorstores and duckduckgo search. "
"How do I get just the LLM calls from the event stream"
)
result = step_back.invoke({"question": question})
print(result)
What are the specific methods or functions provided by LangGraph for extracting LLM calls from an event stream that includes various types of interactions and data sources?
Returning the stepback question and the original question
To increase our recall we’ll likely want to retrieve documents based on both the step back question and the original question. We can easily return both like so:
from langchain_core.runnables import RunnablePassthrough
step_back_and_original = RunnablePassthrough.assign(step_back=step_back)
step_back_and_original.invoke({"question": question})
{'question': 'I built a LangGraph agent using Gemini Pro and tools like vectorstores and duckduckgo search. How do I get just the LLM calls from the event stream',
'step_back': 'What are the specific methods or functions provided by LangGraph for extracting LLM calls from an event stream generated by an agent built using external tools like Gemini Pro, vectorstores, and DuckDuckGo search?'}
Using function-calling to get structured output
If we were composing this technique with other query analysis techniques, we’d likely be using function calling to get out structured query objects. We can use function-calling for step back prompting like so:
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.pydantic_v1 import BaseModel, Field
class StepBackQuery(BaseModel):
step_back_question: str = Field(
...,
description="Given a specific user question about one or more of these products, write a more generic question that needs to be answered in order to answer the specific question.",
)
llm_with_tools = llm.bind_tools([StepBackQuery])
hyde_chain = prompt | llm_with_tools | PydanticToolsParser(tools=[StepBackQuery])
hyde_chain.invoke({"question": question})
[StepBackQuery(step_back_question='What are the steps to filter and extract specific types of calls from an event stream in a Python framework like LangGraph?')]
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/use_cases/query_analysis/techniques/decomposition/ | ## Decomposition
When a user asks a question there is no guarantee that the relevant results can be returned with a single query. Sometimes to answer a question we need to split it into distinct sub-questions, retrieve results for each sub-question, and then answer using the cumulative context.
For example if a user asks: “How is Web Voyager different from reflection agents”, and we have one document that explains Web Voyager and one that explains reflection agents but no document that compares the two, then we’d likely get better results by retrieving for both “What is Web Voyager” and “What are reflection agents” and combining the retrieved documents than by retrieving based on the user question directly.
This process of splitting an input into multiple distinct sub-queries is what we refer to as **query decomposition**. It is also sometimes referred to as sub-query generation. In this guide we’ll walk through an example of how to do decomposition, using our example of a Q&A bot over the LangChain YouTube videos from the [Quickstart](https://python.langchain.com/docs/use_cases/query_analysis/quickstart/).
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-openai
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Query generation[](#query-generation "Direct link to Query generation")
To convert user questions to a list of sub questions we’ll use OpenAI’s function-calling API, which can return multiple functions each turn:
```
import datetimefrom typing import Literal, Optional, Tuplefrom langchain_core.pydantic_v1 import BaseModel, Fieldclass SubQuery(BaseModel): """Search over a database of tutorial videos about a software library.""" sub_query: str = Field( ..., description="A very specific query against the database.", )
```
```
from langchain.output_parsers import PydanticToolsParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIsystem = """You are an expert at converting user questions into database queries. \You have access to a database of tutorial videos about a software library for building LLM-powered applications. \Perform query decomposition. Given a user question, break it down into distinct sub questions that \you need to answer in order to answer the original question.If there are acronyms or words you are not familiar with, do not try to rephrase them."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)llm_with_tools = llm.bind_tools([SubQuery])parser = PydanticToolsParser(tools=[SubQuery])query_analyzer = prompt | llm_with_tools | parser
```
Let’s try it out:
```
query_analyzer.invoke({"question": "how to do rag"})
```
```
[SubQuery(sub_query='How to do rag')]
```
```
query_analyzer.invoke( { "question": "how to use multi-modal models in a chain and turn chain into a rest api" })
```
```
[SubQuery(sub_query='How to use multi-modal models in a chain?'), SubQuery(sub_query='How to turn a chain into a REST API?')]
```
```
query_analyzer.invoke( { "question": "what's the difference between web voyager and reflection agents? do they use langgraph?" })
```
```
[SubQuery(sub_query='What is Web Voyager and how does it differ from Reflection Agents?'), SubQuery(sub_query='Do Web Voyager and Reflection Agents use Langgraph?')]
```
## Adding examples and tuning the prompt[](#adding-examples-and-tuning-the-prompt "Direct link to Adding examples and tuning the prompt")
This works pretty well, but we probably want it to decompose the last question even further to separate the queries about Web Voyager and Reflection Agents. If we aren’t sure up front what types of queries will do best with our index, we can also intentionally include some redundancy in our queries, so that we return both sub queries and higher level queries.
To tune our query generation results, we can add some examples of inputs questions and gold standard output queries to our prompt. We can also try to improve our system message.
```
question = "What's chat langchain, is it a langchain template?"queries = [ SubQuery(sub_query="What is chat langchain"), SubQuery(sub_query="What is a langchain template"),]examples.append({"input": question, "tool_calls": queries})
```
```
question = "How would I use LangGraph to build an automaton"queries = [ SubQuery(sub_query="How to build automaton with LangGraph"),]examples.append({"input": question, "tool_calls": queries})
```
```
question = "How to build multi-agent system and stream intermediate steps from it"queries = [ SubQuery(sub_query="How to build multi-agent system"), SubQuery(sub_query="How to stream intermediate steps"), SubQuery(sub_query="How to stream intermediate steps from multi-agent system"),]examples.append({"input": question, "tool_calls": queries})
```
```
question = "What's the difference between LangChain agents and LangGraph?"queries = [ SubQuery(sub_query="What's the difference between LangChain agents and LangGraph?"), SubQuery(sub_query="What are LangChain agents"), SubQuery(sub_query="What is LangGraph"),]examples.append({"input": question, "tool_calls": queries})
```
Now we need to update our prompt template and chain so that the examples are included in each prompt. Since we’re working with OpenAI function-calling, we’ll need to do a bit of extra structuring to send example inputs and outputs to the model. We’ll create a `tool_example_to_messages` helper function to handle this for us:
```
import uuidfrom typing import Dict, Listfrom langchain_core.messages import ( AIMessage, BaseMessage, HumanMessage, SystemMessage, ToolMessage,)def tool_example_to_messages(example: Dict) -> List[BaseMessage]: messages: List[BaseMessage] = [HumanMessage(content=example["input"])] openai_tool_calls = [] for tool_call in example["tool_calls"]: openai_tool_calls.append( { "id": str(uuid.uuid4()), "type": "function", "function": { "name": tool_call.__class__.__name__, "arguments": tool_call.json(), }, } ) messages.append( AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls}) ) tool_outputs = example.get("tool_outputs") or [ "This is an example of a correct usage of this tool. Make sure to continue using the tool this way." ] * len(openai_tool_calls) for output, tool_call in zip(tool_outputs, openai_tool_calls): messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"])) return messagesexample_msgs = [msg for ex in examples for msg in tool_example_to_messages(ex)]
```
```
from langchain_core.prompts import MessagesPlaceholdersystem = """You are an expert at converting user questions into database queries. \You have access to a database of tutorial videos about a software library for building LLM-powered applications. \Perform query decomposition. Given a user question, break it down into the most specific sub questions you can \which will help you answer the original question. Each sub question should be about a single concept/fact/idea.If there are acronyms or words you are not familiar with, do not try to rephrase them."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), MessagesPlaceholder("examples", optional=True), ("human", "{question}"), ])query_analyzer_with_examples = ( prompt.partial(examples=example_msgs) | llm_with_tools | parser)
```
```
query_analyzer_with_examples.invoke( { "question": "what's the difference between web voyager and reflection agents? do they use langgraph?" })
```
```
[SubQuery(sub_query="What's the difference between web voyager and reflection agents"), SubQuery(sub_query='Do web voyager and reflection agents use LangGraph'), SubQuery(sub_query='What is web voyager'), SubQuery(sub_query='What are reflection agents')]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:18.666Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/decomposition/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/decomposition/",
"description": "When a user asks a question there is no guarantee that the relevant",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3772",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"decomposition\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:18 GMT",
"etag": "W/\"773a1b2ba2e085f24d5ca2d526588bb1\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::k85gt-1713753978399-5215073cc6c2"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/decomposition/",
"property": "og:url"
},
{
"content": "Decomposition | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "When a user asks a question there is no guarantee that the relevant",
"property": "og:description"
}
],
"title": "Decomposition | 🦜️🔗 LangChain"
} | Decomposition
When a user asks a question there is no guarantee that the relevant results can be returned with a single query. Sometimes to answer a question we need to split it into distinct sub-questions, retrieve results for each sub-question, and then answer using the cumulative context.
For example if a user asks: “How is Web Voyager different from reflection agents”, and we have one document that explains Web Voyager and one that explains reflection agents but no document that compares the two, then we’d likely get better results by retrieving for both “What is Web Voyager” and “What are reflection agents” and combining the retrieved documents than by retrieving based on the user question directly.
This process of splitting an input into multiple distinct sub-queries is what we refer to as query decomposition. It is also sometimes referred to as sub-query generation. In this guide we’ll walk through an example of how to do decomposition, using our example of a Q&A bot over the LangChain YouTube videos from the Quickstart.
Setup
Install dependencies
# %pip install -qU langchain langchain-openai
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Query generation
To convert user questions to a list of sub questions we’ll use OpenAI’s function-calling API, which can return multiple functions each turn:
import datetime
from typing import Literal, Optional, Tuple
from langchain_core.pydantic_v1 import BaseModel, Field
class SubQuery(BaseModel):
"""Search over a database of tutorial videos about a software library."""
sub_query: str = Field(
...,
description="A very specific query against the database.",
)
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Perform query decomposition. Given a user question, break it down into distinct sub questions that \
you need to answer in order to answer the original question.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
llm_with_tools = llm.bind_tools([SubQuery])
parser = PydanticToolsParser(tools=[SubQuery])
query_analyzer = prompt | llm_with_tools | parser
Let’s try it out:
query_analyzer.invoke({"question": "how to do rag"})
[SubQuery(sub_query='How to do rag')]
query_analyzer.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
[SubQuery(sub_query='How to use multi-modal models in a chain?'),
SubQuery(sub_query='How to turn a chain into a REST API?')]
query_analyzer.invoke(
{
"question": "what's the difference between web voyager and reflection agents? do they use langgraph?"
}
)
[SubQuery(sub_query='What is Web Voyager and how does it differ from Reflection Agents?'),
SubQuery(sub_query='Do Web Voyager and Reflection Agents use Langgraph?')]
Adding examples and tuning the prompt
This works pretty well, but we probably want it to decompose the last question even further to separate the queries about Web Voyager and Reflection Agents. If we aren’t sure up front what types of queries will do best with our index, we can also intentionally include some redundancy in our queries, so that we return both sub queries and higher level queries.
To tune our query generation results, we can add some examples of inputs questions and gold standard output queries to our prompt. We can also try to improve our system message.
question = "What's chat langchain, is it a langchain template?"
queries = [
SubQuery(sub_query="What is chat langchain"),
SubQuery(sub_query="What is a langchain template"),
]
examples.append({"input": question, "tool_calls": queries})
question = "How would I use LangGraph to build an automaton"
queries = [
SubQuery(sub_query="How to build automaton with LangGraph"),
]
examples.append({"input": question, "tool_calls": queries})
question = "How to build multi-agent system and stream intermediate steps from it"
queries = [
SubQuery(sub_query="How to build multi-agent system"),
SubQuery(sub_query="How to stream intermediate steps"),
SubQuery(sub_query="How to stream intermediate steps from multi-agent system"),
]
examples.append({"input": question, "tool_calls": queries})
question = "What's the difference between LangChain agents and LangGraph?"
queries = [
SubQuery(sub_query="What's the difference between LangChain agents and LangGraph?"),
SubQuery(sub_query="What are LangChain agents"),
SubQuery(sub_query="What is LangGraph"),
]
examples.append({"input": question, "tool_calls": queries})
Now we need to update our prompt template and chain so that the examples are included in each prompt. Since we’re working with OpenAI function-calling, we’ll need to do a bit of extra structuring to send example inputs and outputs to the model. We’ll create a tool_example_to_messages helper function to handle this for us:
import uuid
from typing import Dict, List
from langchain_core.messages import (
AIMessage,
BaseMessage,
HumanMessage,
SystemMessage,
ToolMessage,
)
def tool_example_to_messages(example: Dict) -> List[BaseMessage]:
messages: List[BaseMessage] = [HumanMessage(content=example["input"])]
openai_tool_calls = []
for tool_call in example["tool_calls"]:
openai_tool_calls.append(
{
"id": str(uuid.uuid4()),
"type": "function",
"function": {
"name": tool_call.__class__.__name__,
"arguments": tool_call.json(),
},
}
)
messages.append(
AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls})
)
tool_outputs = example.get("tool_outputs") or [
"This is an example of a correct usage of this tool. Make sure to continue using the tool this way."
] * len(openai_tool_calls)
for output, tool_call in zip(tool_outputs, openai_tool_calls):
messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"]))
return messages
example_msgs = [msg for ex in examples for msg in tool_example_to_messages(ex)]
from langchain_core.prompts import MessagesPlaceholder
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Perform query decomposition. Given a user question, break it down into the most specific sub questions you can \
which will help you answer the original question. Each sub question should be about a single concept/fact/idea.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
MessagesPlaceholder("examples", optional=True),
("human", "{question}"),
]
)
query_analyzer_with_examples = (
prompt.partial(examples=example_msgs) | llm_with_tools | parser
)
query_analyzer_with_examples.invoke(
{
"question": "what's the difference between web voyager and reflection agents? do they use langgraph?"
}
)
[SubQuery(sub_query="What's the difference between web voyager and reflection agents"),
SubQuery(sub_query='Do web voyager and reflection agents use LangGraph'),
SubQuery(sub_query='What is web voyager'),
SubQuery(sub_query='What are reflection agents')] |
https://python.langchain.com/docs/use_cases/query_analysis/techniques/structuring/ | ## Structuring
One of the most important steps in retrieval is turning a text input into the right search and filter parameters. This process of extracting structured parameters from an unstructured input is what we refer to as **query structuring**.
To illustrate, let’s return to our example of a Q&A bot over the LangChain YouTube videos from the [Quickstart](https://python.langchain.com/docs/use_cases/query_analysis/quickstart/) and see what more complex structured queries might look like in this case.
## Setup[](#setup "Direct link to Setup")
#### Install dependencies[](#install-dependencies "Direct link to Install dependencies")
```
# %pip install -qU langchain langchain-openai youtube-transcript-api pytube
```
#### Set environment variables[](#set-environment-variables "Direct link to Set environment variables")
We’ll use OpenAI in this example:
```
import getpassimport os# os.environ["OPENAI_API_KEY"] = getpass.getpass()# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
### Load example document[](#load-example-document "Direct link to Load example document")
Let’s load a representative document
```
from langchain_community.document_loaders import YoutubeLoaderdocs = YoutubeLoader.from_youtube_url( "https://www.youtube.com/watch?v=pbAd8O1Lvm4", add_video_info=True).load()
```
Here’s the metadata associated with a video:
```
{'source': 'pbAd8O1Lvm4', 'title': 'Self-reflective RAG with LangGraph: Self-RAG and CRAG', 'description': 'Unknown', 'view_count': 9006, 'thumbnail_url': 'https://i.ytimg.com/vi/pbAd8O1Lvm4/hq720.jpg', 'publish_date': '2024-02-07 00:00:00', 'length': 1058, 'author': 'LangChain'}
```
And here’s a sample from a document’s contents:
```
docs[0].page_content[:500]
```
```
"hi this is Lance from Lang chain I'm going to be talking about using Lang graph to build a diverse and sophisticated rag flows so just to set the stage the basic rag flow you can see here starts with a question retrieval of relevant documents from an index which are passed into the context window of an llm for generation of an answer grounded in the ret documents so that's kind of the basic outline and we can see it's like a very linear path um in practice though you often encounter a few differ"
```
## Query schema[](#query-schema "Direct link to Query schema")
In order to generate structured queries we first need to define our query schema. We can see that each document has a title, view count, publication date, and length in seconds. Let’s assume we’ve built an index that allows us to perform unstructured search over the contents and title of each document, and to use range filtering on view count, publication date, and length.
To start we’ll create a schema with explicit min and max attributes for view count, publication date, and video length so that those can be filtered on. And we’ll add separate attributes for searches against the transcript contents versus the video title.
We could alternatively create a more generic schema where instead of having one or more filter attributes for each filterable field, we have a single `filters` attribute that takes a list of (attribute, condition, value) tuples. We’ll demonstrate how to do this as well. Which approach works best depends on the complexity of your index. If you have many filterable fields then it may be better to have a single `filters` query attribute. If you have only a few filterable fields and/or there are fields that can only be filtered in very specific ways, it can be helpful to have separate query attributes for them, each with their own description.
```
import datetimefrom typing import Literal, Optional, Tuplefrom langchain_core.pydantic_v1 import BaseModel, Fieldclass TutorialSearch(BaseModel): """Search over a database of tutorial videos about a software library.""" content_search: str = Field( ..., description="Similarity search query applied to video transcripts.", ) title_search: str = Field( ..., description=( "Alternate version of the content search query to apply to video titles. " "Should be succinct and only include key words that could be in a video " "title." ), ) min_view_count: Optional[int] = Field( None, description="Minimum view count filter, inclusive. Only use if explicitly specified.", ) max_view_count: Optional[int] = Field( None, description="Maximum view count filter, exclusive. Only use if explicitly specified.", ) earliest_publish_date: Optional[datetime.date] = Field( None, description="Earliest publish date filter, inclusive. Only use if explicitly specified.", ) latest_publish_date: Optional[datetime.date] = Field( None, description="Latest publish date filter, exclusive. Only use if explicitly specified.", ) min_length_sec: Optional[int] = Field( None, description="Minimum video length in seconds, inclusive. Only use if explicitly specified.", ) max_length_sec: Optional[int] = Field( None, description="Maximum video length in seconds, exclusive. Only use if explicitly specified.", ) def pretty_print(self) -> None: for field in self.__fields__: if getattr(self, field) is not None and getattr(self, field) != getattr( self.__fields__[field], "default", None ): print(f"{field}: {getattr(self, field)}")
```
## Query generation[](#query-generation "Direct link to Query generation")
To convert user questions to structured queries we’ll make use of a function-calling model, like ChatOpenAI. LangChain has some nice constructors that make it easy to specify a desired function call schema via a Pydantic class:
```
from langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIsystem = """You are an expert at converting user questions into database queries. \You have access to a database of tutorial videos about a software library for building LLM-powered applications. \Given a question, return a database query optimized to retrieve the most relevant results.If there are acronyms or words you are not familiar with, do not try to rephrase them."""prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ])llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)structured_llm = llm.with_structured_output(TutorialSearch)query_analyzer = prompt | structured_llm
```
Let’s try it out:
```
query_analyzer.invoke({"question": "rag from scratch"}).pretty_print()
```
```
content_search: rag from scratchtitle_search: rag from scratch
```
```
query_analyzer.invoke( {"question": "videos on chat langchain published in 2023"}).pretty_print()
```
```
content_search: chat langchaintitle_search: chat langchainearliest_publish_date: 2023-01-01latest_publish_date: 2024-01-01
```
```
query_analyzer.invoke( { "question": "how to use multi-modal models in an agent, only videos under 5 minutes" }).pretty_print()
```
```
content_search: multi-modal models agenttitle_search: multi-modal models agentmax_length_sec: 300
```
## Alternative: Succinct schema[](#alternative-succinct-schema "Direct link to Alternative: Succinct schema")
If we have many filterable fields then having a verbose schema could harm performance, or may not even be possible given limitations on the size of function schemas. In these cases we can try more succinct query schemas that trade off some explicitness of direction for concision:
```
from typing import List, Literal, Unionclass Filter(BaseModel): field: Literal["view_count", "publish_date", "length_sec"] comparison: Literal["eq", "lt", "lte", "gt", "gte"] value: Union[int, datetime.date] = Field( ..., description="If field is publish_date then value must be a ISO-8601 format date", )class TutorialSearch(BaseModel): """Search over a database of tutorial videos about a software library.""" content_search: str = Field( ..., description="Similarity search query applied to video transcripts.", ) title_search: str = Field( ..., description=( "Alternate version of the content search query to apply to video titles. " "Should be succinct and only include key words that could be in a video " "title." ), ) filters: List[Filter] = Field( default_factory=list, description="Filters over specific fields. Final condition is a logical conjunction of all filters.", ) def pretty_print(self) -> None: for field in self.__fields__: if getattr(self, field) is not None and getattr(self, field) != getattr( self.__fields__[field], "default", None ): print(f"{field}: {getattr(self, field)}")
```
```
structured_llm = llm.with_structured_output(TutorialSearch)query_analyzer = prompt | structured_llm
```
Let’s try it out:
```
query_analyzer.invoke({"question": "rag from scratch"}).pretty_print()
```
```
content_search: rag from scratchtitle_search: ragfilters: []
```
```
query_analyzer.invoke( {"question": "videos on chat langchain published in 2023"}).pretty_print()
```
```
content_search: chat langchaintitle_search: 2023filters: [Filter(field='publish_date', comparison='eq', value=datetime.date(2023, 1, 1))]
```
```
query_analyzer.invoke( { "question": "how to use multi-modal models in an agent, only videos under 5 minutes and with over 276 views" }).pretty_print()
```
```
content_search: multi-modal models in an agenttitle_search: multi-modal models agentfilters: [Filter(field='length_sec', comparison='lt', value=300), Filter(field='view_count', comparison='gte', value=276)]
```
We can see that the analyzer handles integers well but struggles with date ranges. We can try adjusting our schema description and/or our prompt to correct this:
```
class TutorialSearch(BaseModel): """Search over a database of tutorial videos about a software library.""" content_search: str = Field( ..., description="Similarity search query applied to video transcripts.", ) title_search: str = Field( ..., description=( "Alternate version of the content search query to apply to video titles. " "Should be succinct and only include key words that could be in a video " "title." ), ) filters: List[Filter] = Field( default_factory=list, description=( "Filters over specific fields. Final condition is a logical conjunction of all filters. " "If a time period longer than one day is specified then it must result in filters that define a date range. " f"Keep in mind the current date is {datetime.date.today().strftime('%m-%d-%Y')}." ), ) def pretty_print(self) -> None: for field in self.__fields__: if getattr(self, field) is not None and getattr(self, field) != getattr( self.__fields__[field], "default", None ): print(f"{field}: {getattr(self, field)}")structured_llm = llm.with_structured_output(TutorialSearch)query_analyzer = prompt | structured_llm
```
```
query_analyzer.invoke( {"question": "videos on chat langchain published in 2023"}).pretty_print()
```
```
content_search: chat langchaintitle_search: chat langchainfilters: [Filter(field='publish_date', comparison='gte', value=datetime.date(2023, 1, 1)), Filter(field='publish_date', comparison='lte', value=datetime.date(2023, 12, 31))]
```
This seems to work!
## Sorting: Going beyond search[](#sorting-going-beyond-search "Direct link to Sorting: Going beyond search")
With certain indexes searching by field isn’t the only way to retrieve results — we can also sort documents by a field and retrieve the top sorted results. With structured querying this is easy to accomodate by adding separate query fields that specify how to sort results.
```
class TutorialSearch(BaseModel): """Search over a database of tutorial videos about a software library.""" content_search: str = Field( "", description="Similarity search query applied to video transcripts.", ) title_search: str = Field( "", description=( "Alternate version of the content search query to apply to video titles. " "Should be succinct and only include key words that could be in a video " "title." ), ) min_view_count: Optional[int] = Field( None, description="Minimum view count filter, inclusive." ) max_view_count: Optional[int] = Field( None, description="Maximum view count filter, exclusive." ) earliest_publish_date: Optional[datetime.date] = Field( None, description="Earliest publish date filter, inclusive." ) latest_publish_date: Optional[datetime.date] = Field( None, description="Latest publish date filter, exclusive." ) min_length_sec: Optional[int] = Field( None, description="Minimum video length in seconds, inclusive." ) max_length_sec: Optional[int] = Field( None, description="Maximum video length in seconds, exclusive." ) sort_by: Literal[ "relevance", "view_count", "publish_date", "length", ] = Field("relevance", description="Attribute to sort by.") sort_order: Literal["ascending", "descending"] = Field( "descending", description="Whether to sort in ascending or descending order." ) def pretty_print(self) -> None: for field in self.__fields__: if getattr(self, field) is not None and getattr(self, field) != getattr( self.__fields__[field], "default", None ): print(f"{field}: {getattr(self, field)}")structured_llm = llm.with_structured_output(TutorialSearch)query_analyzer = prompt | structured_llm
```
```
query_analyzer.invoke( {"question": "What has LangChain released lately?"}).pretty_print()
```
```
title_search: LangChainsort_by: publish_date
```
```
query_analyzer.invoke({"question": "What are the longest videos?"}).pretty_print()
```
We can even support searching and sorting together. This might look like first retrieving all results above a relevancy threshold and then sorting them according to the specified attribute:
```
query_analyzer.invoke( {"question": "What are the shortest videos about agents?"}).pretty_print()
```
```
content_search: agentssort_by: lengthsort_order: ascending
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:19.343Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/structuring/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/structuring/",
"description": "One of the most important steps in retrieval is turning a text input",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3772",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"structuring\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:19 GMT",
"etag": "W/\"bb436156f8aba20024776b5afdf4e570\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::mg4n2-1713753979267-c23f0ebfe2e6"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/query_analysis/techniques/structuring/",
"property": "og:url"
},
{
"content": "Structuring | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "One of the most important steps in retrieval is turning a text input",
"property": "og:description"
}
],
"title": "Structuring | 🦜️🔗 LangChain"
} | Structuring
One of the most important steps in retrieval is turning a text input into the right search and filter parameters. This process of extracting structured parameters from an unstructured input is what we refer to as query structuring.
To illustrate, let’s return to our example of a Q&A bot over the LangChain YouTube videos from the Quickstart and see what more complex structured queries might look like in this case.
Setup
Install dependencies
# %pip install -qU langchain langchain-openai youtube-transcript-api pytube
Set environment variables
We’ll use OpenAI in this example:
import getpass
import os
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Optional, uncomment to trace runs with LangSmith. Sign up here: https://smith.langchain.com.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Load example document
Let’s load a representative document
from langchain_community.document_loaders import YoutubeLoader
docs = YoutubeLoader.from_youtube_url(
"https://www.youtube.com/watch?v=pbAd8O1Lvm4", add_video_info=True
).load()
Here’s the metadata associated with a video:
{'source': 'pbAd8O1Lvm4',
'title': 'Self-reflective RAG with LangGraph: Self-RAG and CRAG',
'description': 'Unknown',
'view_count': 9006,
'thumbnail_url': 'https://i.ytimg.com/vi/pbAd8O1Lvm4/hq720.jpg',
'publish_date': '2024-02-07 00:00:00',
'length': 1058,
'author': 'LangChain'}
And here’s a sample from a document’s contents:
docs[0].page_content[:500]
"hi this is Lance from Lang chain I'm going to be talking about using Lang graph to build a diverse and sophisticated rag flows so just to set the stage the basic rag flow you can see here starts with a question retrieval of relevant documents from an index which are passed into the context window of an llm for generation of an answer grounded in the ret documents so that's kind of the basic outline and we can see it's like a very linear path um in practice though you often encounter a few differ"
Query schema
In order to generate structured queries we first need to define our query schema. We can see that each document has a title, view count, publication date, and length in seconds. Let’s assume we’ve built an index that allows us to perform unstructured search over the contents and title of each document, and to use range filtering on view count, publication date, and length.
To start we’ll create a schema with explicit min and max attributes for view count, publication date, and video length so that those can be filtered on. And we’ll add separate attributes for searches against the transcript contents versus the video title.
We could alternatively create a more generic schema where instead of having one or more filter attributes for each filterable field, we have a single filters attribute that takes a list of (attribute, condition, value) tuples. We’ll demonstrate how to do this as well. Which approach works best depends on the complexity of your index. If you have many filterable fields then it may be better to have a single filters query attribute. If you have only a few filterable fields and/or there are fields that can only be filtered in very specific ways, it can be helpful to have separate query attributes for them, each with their own description.
import datetime
from typing import Literal, Optional, Tuple
from langchain_core.pydantic_v1 import BaseModel, Field
class TutorialSearch(BaseModel):
"""Search over a database of tutorial videos about a software library."""
content_search: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
title_search: str = Field(
...,
description=(
"Alternate version of the content search query to apply to video titles. "
"Should be succinct and only include key words that could be in a video "
"title."
),
)
min_view_count: Optional[int] = Field(
None,
description="Minimum view count filter, inclusive. Only use if explicitly specified.",
)
max_view_count: Optional[int] = Field(
None,
description="Maximum view count filter, exclusive. Only use if explicitly specified.",
)
earliest_publish_date: Optional[datetime.date] = Field(
None,
description="Earliest publish date filter, inclusive. Only use if explicitly specified.",
)
latest_publish_date: Optional[datetime.date] = Field(
None,
description="Latest publish date filter, exclusive. Only use if explicitly specified.",
)
min_length_sec: Optional[int] = Field(
None,
description="Minimum video length in seconds, inclusive. Only use if explicitly specified.",
)
max_length_sec: Optional[int] = Field(
None,
description="Maximum video length in seconds, exclusive. Only use if explicitly specified.",
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
Query generation
To convert user questions to structured queries we’ll make use of a function-calling model, like ChatOpenAI. LangChain has some nice constructors that make it easy to specify a desired function call schema via a Pydantic class:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a database query optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
Let’s try it out:
query_analyzer.invoke({"question": "rag from scratch"}).pretty_print()
content_search: rag from scratch
title_search: rag from scratch
query_analyzer.invoke(
{"question": "videos on chat langchain published in 2023"}
).pretty_print()
content_search: chat langchain
title_search: chat langchain
earliest_publish_date: 2023-01-01
latest_publish_date: 2024-01-01
query_analyzer.invoke(
{
"question": "how to use multi-modal models in an agent, only videos under 5 minutes"
}
).pretty_print()
content_search: multi-modal models agent
title_search: multi-modal models agent
max_length_sec: 300
Alternative: Succinct schema
If we have many filterable fields then having a verbose schema could harm performance, or may not even be possible given limitations on the size of function schemas. In these cases we can try more succinct query schemas that trade off some explicitness of direction for concision:
from typing import List, Literal, Union
class Filter(BaseModel):
field: Literal["view_count", "publish_date", "length_sec"]
comparison: Literal["eq", "lt", "lte", "gt", "gte"]
value: Union[int, datetime.date] = Field(
...,
description="If field is publish_date then value must be a ISO-8601 format date",
)
class TutorialSearch(BaseModel):
"""Search over a database of tutorial videos about a software library."""
content_search: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
title_search: str = Field(
...,
description=(
"Alternate version of the content search query to apply to video titles. "
"Should be succinct and only include key words that could be in a video "
"title."
),
)
filters: List[Filter] = Field(
default_factory=list,
description="Filters over specific fields. Final condition is a logical conjunction of all filters.",
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
Let’s try it out:
query_analyzer.invoke({"question": "rag from scratch"}).pretty_print()
content_search: rag from scratch
title_search: rag
filters: []
query_analyzer.invoke(
{"question": "videos on chat langchain published in 2023"}
).pretty_print()
content_search: chat langchain
title_search: 2023
filters: [Filter(field='publish_date', comparison='eq', value=datetime.date(2023, 1, 1))]
query_analyzer.invoke(
{
"question": "how to use multi-modal models in an agent, only videos under 5 minutes and with over 276 views"
}
).pretty_print()
content_search: multi-modal models in an agent
title_search: multi-modal models agent
filters: [Filter(field='length_sec', comparison='lt', value=300), Filter(field='view_count', comparison='gte', value=276)]
We can see that the analyzer handles integers well but struggles with date ranges. We can try adjusting our schema description and/or our prompt to correct this:
class TutorialSearch(BaseModel):
"""Search over a database of tutorial videos about a software library."""
content_search: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
title_search: str = Field(
...,
description=(
"Alternate version of the content search query to apply to video titles. "
"Should be succinct and only include key words that could be in a video "
"title."
),
)
filters: List[Filter] = Field(
default_factory=list,
description=(
"Filters over specific fields. Final condition is a logical conjunction of all filters. "
"If a time period longer than one day is specified then it must result in filters that define a date range. "
f"Keep in mind the current date is {datetime.date.today().strftime('%m-%d-%Y')}."
),
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
query_analyzer.invoke(
{"question": "videos on chat langchain published in 2023"}
).pretty_print()
content_search: chat langchain
title_search: chat langchain
filters: [Filter(field='publish_date', comparison='gte', value=datetime.date(2023, 1, 1)), Filter(field='publish_date', comparison='lte', value=datetime.date(2023, 12, 31))]
This seems to work!
Sorting: Going beyond search
With certain indexes searching by field isn’t the only way to retrieve results — we can also sort documents by a field and retrieve the top sorted results. With structured querying this is easy to accomodate by adding separate query fields that specify how to sort results.
class TutorialSearch(BaseModel):
"""Search over a database of tutorial videos about a software library."""
content_search: str = Field(
"",
description="Similarity search query applied to video transcripts.",
)
title_search: str = Field(
"",
description=(
"Alternate version of the content search query to apply to video titles. "
"Should be succinct and only include key words that could be in a video "
"title."
),
)
min_view_count: Optional[int] = Field(
None, description="Minimum view count filter, inclusive."
)
max_view_count: Optional[int] = Field(
None, description="Maximum view count filter, exclusive."
)
earliest_publish_date: Optional[datetime.date] = Field(
None, description="Earliest publish date filter, inclusive."
)
latest_publish_date: Optional[datetime.date] = Field(
None, description="Latest publish date filter, exclusive."
)
min_length_sec: Optional[int] = Field(
None, description="Minimum video length in seconds, inclusive."
)
max_length_sec: Optional[int] = Field(
None, description="Maximum video length in seconds, exclusive."
)
sort_by: Literal[
"relevance",
"view_count",
"publish_date",
"length",
] = Field("relevance", description="Attribute to sort by.")
sort_order: Literal["ascending", "descending"] = Field(
"descending", description="Whether to sort in ascending or descending order."
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
query_analyzer.invoke(
{"question": "What has LangChain released lately?"}
).pretty_print()
title_search: LangChain
sort_by: publish_date
query_analyzer.invoke({"question": "What are the longest videos?"}).pretty_print()
We can even support searching and sorting together. This might look like first retrieving all results above a relevancy threshold and then sorting them according to the specified attribute:
query_analyzer.invoke(
{"question": "What are the shortest videos about agents?"}
).pretty_print()
content_search: agents
sort_by: length
sort_order: ascending |
https://python.langchain.com/docs/use_cases/question_answering/ | ## Q&A with RAG
## Overview[](#overview "Direct link to Overview")
One of the most powerful applications enabled by LLMs is sophisticated question-answering (Q&A) chatbots. These are applications that can answer questions about specific source information. These applications use a technique known as Retrieval Augmented Generation, or RAG.
### What is RAG?[](#what-is-rag "Direct link to What is RAG?")
RAG is a technique for augmenting LLM knowledge with additional data.
LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG).
LangChain has a number of components designed to help build Q&A applications, and RAG applications more generally.
**Note**: Here we focus on Q&A for unstructured data. Two RAG use cases which we cover elsewhere are:
* [Q&A over SQL data](https://python.langchain.com/docs/use_cases/sql/)
* [Q&A over code](https://python.langchain.com/docs/use_cases/code_understanding/) (e.g., Python)
## RAG Architecture[](#rag-architecture "Direct link to RAG Architecture")
A typical RAG application has two main components:
**Indexing**: a pipeline for ingesting data from a source and indexing it. _This usually happens offline._
**Retrieval and generation**: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
The most common full sequence from raw data to answer looks like:
#### Indexing[](#indexing "Direct link to Indexing")
1. **Load**: First we need to load our data. This is done with [DocumentLoaders](https://python.langchain.com/docs/modules/data_connection/document_loaders/).
2. **Split**: [Text splitters](https://python.langchain.com/docs/modules/data_connection/document_transformers/) break large `Documents` into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t fit in a model’s finite context window.
3. **Store**: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a [VectorStore](https://python.langchain.com/docs/modules/data_connection/vectorstores/) and [Embeddings](https://python.langchain.com/docs/modules/data_connection/text_embedding/) model.
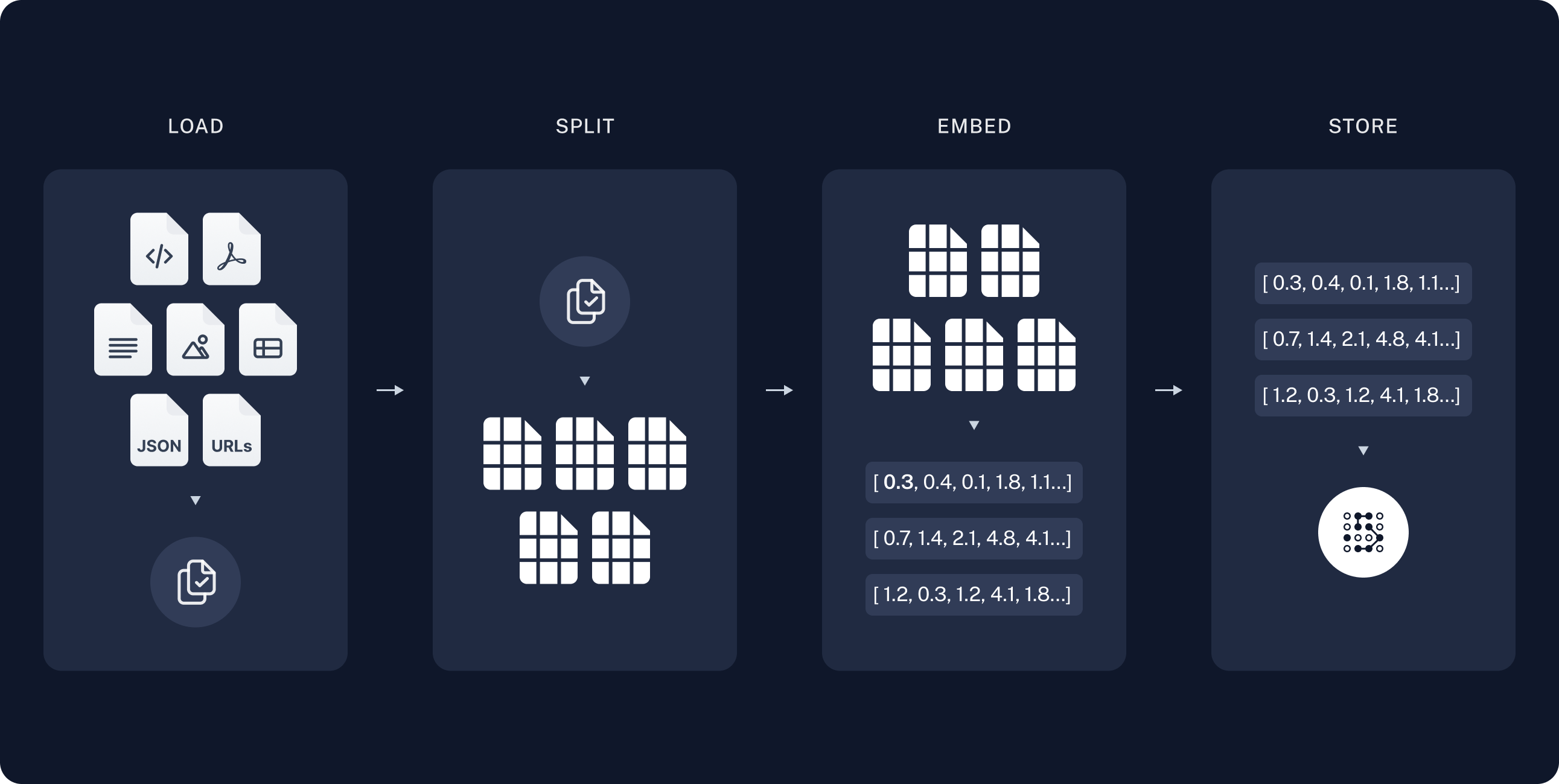
#### Retrieval and generation[](#retrieval-and-generation "Direct link to Retrieval and generation")
1. **Retrieve**: Given a user input, relevant splits are retrieved from storage using a [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/).
2. **Generate**: A [ChatModel](https://python.langchain.com/docs/modules/model_io/chat/) / [LLM](https://python.langchain.com/docs/modules/model_io/llms/) produces an answer using a prompt that includes the question and the retrieved data
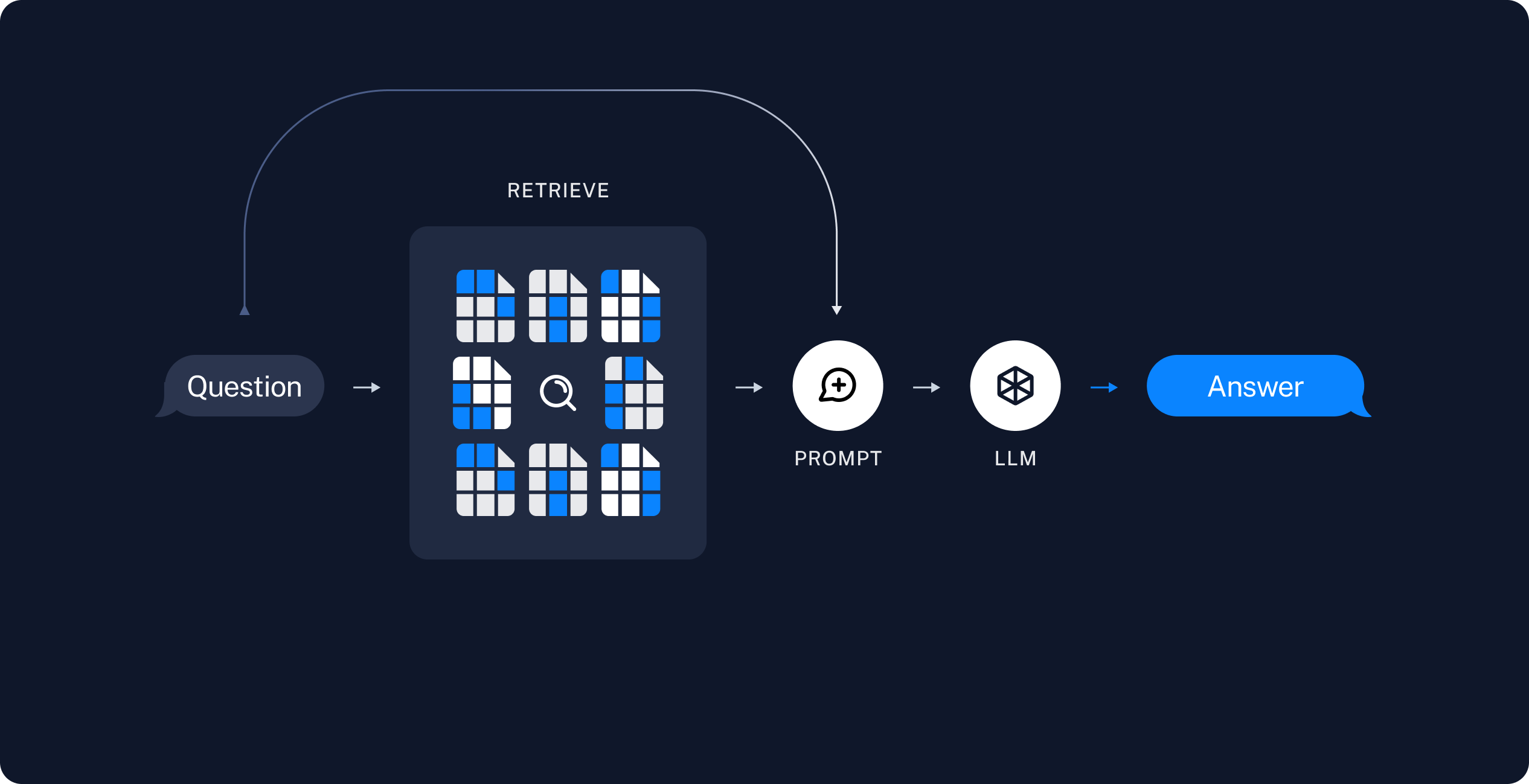
## Table of contents[](#table-of-contents "Direct link to Table of contents")
* [Quickstart](https://python.langchain.com/docs/use_cases/question_answering/quickstart/): We recommend starting here. Many of the following guides assume you fully understand the architecture shown in the Quickstart.
* [Returning sources](https://python.langchain.com/docs/use_cases/question_answering/sources/): How to return the source documents used in a particular generation.
* [Streaming](https://python.langchain.com/docs/use_cases/question_answering/streaming/): How to stream final answers as well as intermediate steps.
* [Adding chat history](https://python.langchain.com/docs/use_cases/question_answering/chat_history/): How to add chat history to a Q&A app.
* [Per-user retrieval](https://python.langchain.com/docs/use_cases/question_answering/per_user/): How to do retrieval when each user has their own private data.
* [Using agents](https://python.langchain.com/docs/use_cases/question_answering/conversational_retrieval_agents/): How to use agents for Q&A.
* [Using local models](https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa/): How to use local models for Q&A. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:20.191Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/",
"description": "Overview",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8816",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"question_answering\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:20 GMT",
"etag": "W/\"d75f8ecc1a3bb2b3befe1dbe91bab818\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tlvfk-1713753980135-6f99778be142"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/",
"property": "og:url"
},
{
"content": "Q&A with RAG | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Overview",
"property": "og:description"
}
],
"title": "Q&A with RAG | 🦜️🔗 LangChain"
} | Q&A with RAG
Overview
One of the most powerful applications enabled by LLMs is sophisticated question-answering (Q&A) chatbots. These are applications that can answer questions about specific source information. These applications use a technique known as Retrieval Augmented Generation, or RAG.
What is RAG?
RAG is a technique for augmenting LLM knowledge with additional data.
LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG).
LangChain has a number of components designed to help build Q&A applications, and RAG applications more generally.
Note: Here we focus on Q&A for unstructured data. Two RAG use cases which we cover elsewhere are:
Q&A over SQL data
Q&A over code (e.g., Python)
RAG Architecture
A typical RAG application has two main components:
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
The most common full sequence from raw data to answer looks like:
Indexing
Load: First we need to load our data. This is done with DocumentLoaders.
Split: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t fit in a model’s finite context window.
Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
Retrieval and generation
Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
Table of contents
Quickstart: We recommend starting here. Many of the following guides assume you fully understand the architecture shown in the Quickstart.
Returning sources: How to return the source documents used in a particular generation.
Streaming: How to stream final answers as well as intermediate steps.
Adding chat history: How to add chat history to a Q&A app.
Per-user retrieval: How to do retrieval when each user has their own private data.
Using agents: How to use agents for Q&A.
Using local models: How to use local models for Q&A. |
https://python.langchain.com/docs/use_cases/question_answering/chat_history/ | ## Add chat history
In many Q&A applications we want to allow the user to have a back-and-forth conversation, meaning the application needs some sort of “memory” of past questions and answers, and some logic for incorporating those into its current thinking.
In this guide we focus on **adding logic for incorporating historical messages.** Further details on chat history management is [covered here](https://python.langchain.com/docs/expression_language/how_to/message_history/).
We’ll work off of the Q&A app we built over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng in the [Quickstart](https://python.langchain.com/docs/use_cases/question_answering/quickstart/). We’ll need to update two things about our existing app:
1. **Prompt**: Update our prompt to support historical messages as an input.
2. **Contextualizing questions**: Add a sub-chain that takes the latest user question and reformulates it in the context of the chat history. This is needed in case the latest question references some context from past messages. For example, if a user asks a follow-up question like “Can you elaborate on the second point?”, this cannot be understood without the context of the previous message. Therefore we can’t effectively perform retrieval with a question like this.
## Setup[](#setup "Direct link to Setup")
### Dependencies[](#dependencies "Direct link to Dependencies")
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any [ChatModel](https://python.langchain.com/docs/modules/model_io/chat/) or [LLM](https://python.langchain.com/docs/modules/model_io/llms/), [Embeddings](https://python.langchain.com/docs/modules/data_connection/text_embedding/), and [VectorStore](https://python.langchain.com/docs/modules/data_connection/vectorstores/) or [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/).
We’ll use the following packages:
```
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
```
We need to set environment variable `OPENAI_API_KEY`, which can be done directly or loaded from a `.env` file like so:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# import dotenv# dotenv.load_dotenv()
```
### LangSmith[](#langsmith "Direct link to LangSmith")
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with [LangSmith](https://smith.langchain.com/).
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
```
os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Chain without chat history[](#chain-without-chat-history "Direct link to Chain without chat history")
Here is the Q&A app we built over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng in the [Quickstart](https://python.langchain.com/docs/use_cases/question_answering/quickstart/):
```
import bs4from langchain import hubfrom langchain_chroma import Chromafrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitter
```
```
# Load, chunk and index the contents of the blog.loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ),)docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# Retrieve and generate using the relevant snippets of the blog.retriever = vectorstore.as_retriever()prompt = hub.pull("rlm/rag-prompt")llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
```
```
rag_chain.invoke("What is Task Decomposition?")
```
```
'Task Decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps agents to plan and execute tasks more efficiently by dividing them into manageable subgoals. Task decomposition can be achieved through various methods, including using prompting techniques, task-specific instructions, or human inputs.'
```
## Contextualizing the question[](#contextualizing-the-question "Direct link to Contextualizing the question")
First we’ll need to define a sub-chain that takes historical messages and the latest user question, and reformulates the question if it makes reference to any information in the historical information.
We’ll use a prompt that includes a `MessagesPlaceholder` variable under the name “chat\_history”. This allows us to pass in a list of Messages to the prompt using the “chat\_history” input key, and these messages will be inserted after the system message and before the human message containing the latest question.
Note that we leverage a helper function [create\_history\_aware\_retriever](https://api.python.langchain.com/en/latest/chains/langchain.chains.history_aware_retriever.create_history_aware_retriever.html) for this step, which manages the case where `chat_history` is empty, and otherwise applies `prompt | llm | StrOutputParser() | retriever` in sequence.
`create_history_aware_retriever` constructs a chain that accepts keys `input` and `chat_history` as input, and has the same output schema as a retriever.
```
from langchain.chains import create_history_aware_retrieverfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholdercontextualize_q_system_prompt = """Given a chat history and the latest user question \which might reference context in the chat history, formulate a standalone question \which can be understood without the chat history. Do NOT answer the question, \just reformulate it if needed and otherwise return it as is."""contextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ])history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt)
```
This chain prepends a rephrasing of the input query to our retriever, so that the retrieval incorporates the context of the conversation.
## Chain with chat history[](#chain-with-chat-history "Direct link to Chain with chat history")
And now we can build our full QA chain.
Here we use [create\_stuff\_documents\_chain](https://api.python.langchain.com/en/latest/chains/langchain.chains.combine_documents.stuff.create_stuff_documents_chain.html) to generate a `question_answer_chain`, with input keys `context`, `chat_history`, and `input`– it accepts the retrieved context alongside the conversation history and query to generate an answer.
We build our final `rag_chain` with [create\_retrieval\_chain](https://api.python.langchain.com/en/latest/chains/langchain.chains.retrieval.create_retrieval_chain.html). This chain applies the `history_aware_retriever` and `question_answer_chain` in sequence, retaining intermediate outputs such as the retrieved context for convenience. It has input keys `input` and `chat_history`, and includes `input`, `chat_history`, `context`, and `answer` in its output.
```
from langchain.chains import create_retrieval_chainfrom langchain.chains.combine_documents import create_stuff_documents_chainqa_system_prompt = """You are an assistant for question-answering tasks. \Use the following pieces of retrieved context to answer the question. \If you don't know the answer, just say that you don't know. \Use three sentences maximum and keep the answer concise.\{context}"""qa_prompt = ChatPromptTemplate.from_messages( [ ("system", qa_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ])question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
```
```
from langchain_core.messages import HumanMessagechat_history = []question = "What is Task Decomposition?"ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})chat_history.extend([HumanMessage(content=question), ai_msg_1["answer"]])second_question = "What are common ways of doing it?"ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})print(ai_msg_2["answer"])
```
```
Task decomposition can be done in several common ways, including using Language Model (LLM) with simple prompting like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", providing task-specific instructions tailored to the specific task at hand, or incorporating human inputs to guide the decomposition process. These methods help in breaking down complex tasks into smaller, more manageable subtasks for efficient execution.
```
### Returning sources[](#returning-sources "Direct link to Returning sources")
Often in Q&A applications it’s important to show users the sources that were used to generate the answer. LangChain’s built-in `create_retrieval_chain` will propagate retrieved source documents through to the output in the `"context"` key:
```
for document in ai_msg_2["context"]: print(document) print()
```
```
page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
```
## Tying it together[](#tying-it-together "Direct link to Tying it together")
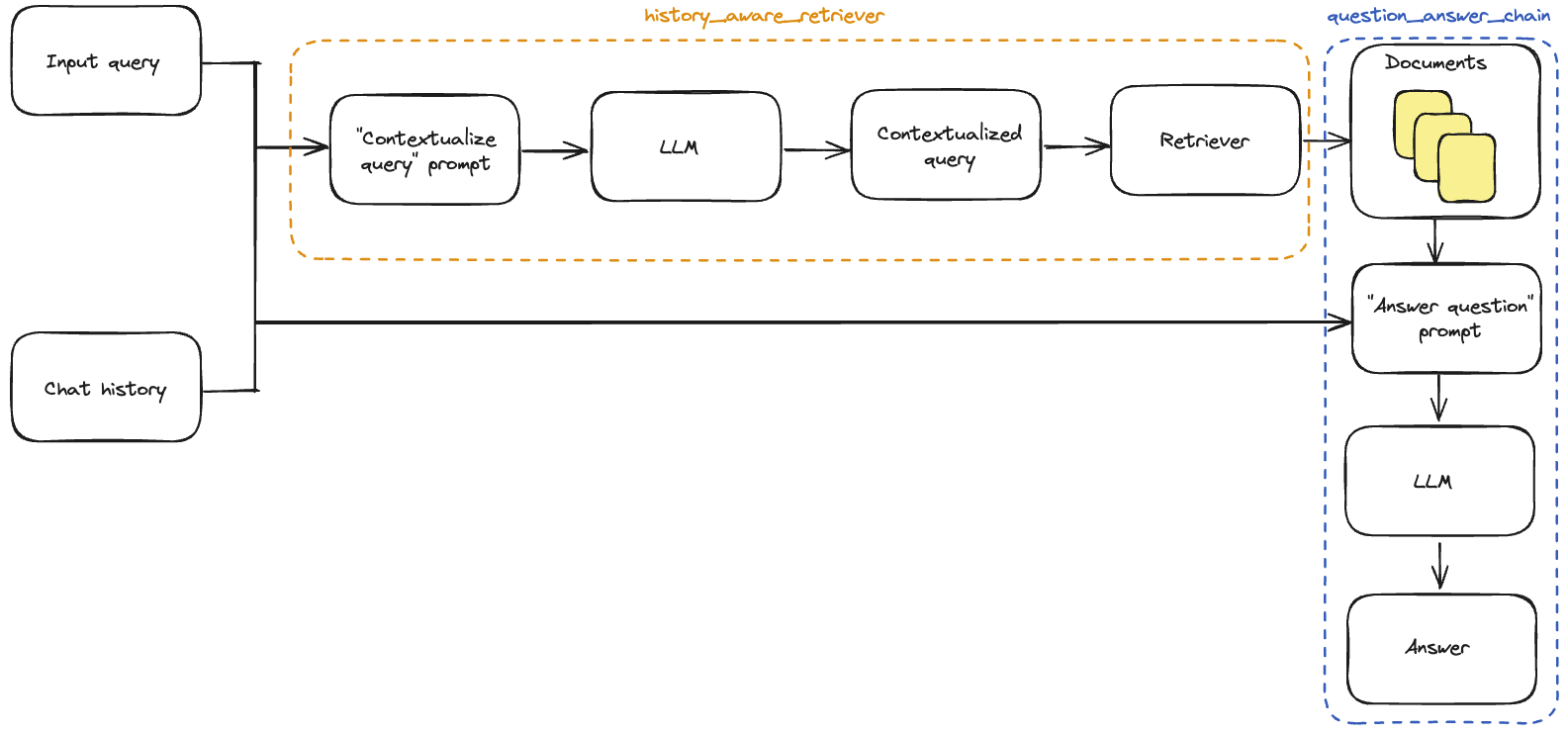
Here we’ve gone over how to add application logic for incorporating historical outputs, but we’re still manually updating the chat history and inserting it into each input. In a real Q&A application we’ll want some way of persisting chat history and some way of automatically inserting and updating it.
For this we can use:
* [BaseChatMessageHistory](https://python.langchain.com/docs/modules/memory/chat_messages/): Store chat history.
* [RunnableWithMessageHistory](https://python.langchain.com/docs/expression_language/how_to/message_history/): Wrapper for an LCEL chain and a `BaseChatMessageHistory` that handles injecting chat history into inputs and updating it after each invocation.
For a detailed walkthrough of how to use these classes together to create a stateful conversational chain, head to the [How to add message history (memory)](https://python.langchain.com/docs/expression_language/how_to/message_history/) LCEL page.
Below, we implement a simple example of the second option, in which chat histories are stored in a simple dict.
For convenience, we tie together all of the necessary steps in a single code cell:
```
import bs4from langchain import hubfrom langchain.chains import create_history_aware_retriever, create_retrieval_chainfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_chroma import Chromafrom langchain_community.chat_message_histories import ChatMessageHistoryfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_core.chat_history import BaseChatMessageHistoryfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.runnables import RunnablePassthroughfrom langchain_core.runnables.history import RunnableWithMessageHistoryfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitterllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)### Construct retriever ###loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ),)docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())retriever = vectorstore.as_retriever()### Contextualize question ###contextualize_q_system_prompt = """Given a chat history and the latest user question \which might reference context in the chat history, formulate a standalone question \which can be understood without the chat history. Do NOT answer the question, \just reformulate it if needed and otherwise return it as is."""contextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ])history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt)### Answer question ###qa_system_prompt = """You are an assistant for question-answering tasks. \Use the following pieces of retrieved context to answer the question. \If you don't know the answer, just say that you don't know. \Use three sentences maximum and keep the answer concise.\{context}"""qa_prompt = ChatPromptTemplate.from_messages( [ ("system", qa_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ])question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)### Statefully manage chat history ###store = {}def get_session_history(session_id: str) -> BaseChatMessageHistory: if session_id not in store: store[session_id] = ChatMessageHistory() return store[session_id]conversational_rag_chain = RunnableWithMessageHistory( rag_chain, get_session_history, input_messages_key="input", history_messages_key="chat_history", output_messages_key="answer",)
```
```
conversational_rag_chain.invoke( {"input": "What is Task Decomposition?"}, config={ "configurable": {"session_id": "abc123"} }, # constructs a key "abc123" in `store`.)["answer"]
```
```
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps agents or models handle difficult tasks by dividing them into more manageable subtasks. It can be achieved through methods like Chain of Thought (CoT) or Tree of Thoughts, which guide the model in thinking step by step or exploring multiple reasoning possibilities at each step.'
```
```
conversational_rag_chain.invoke( {"input": "What are common ways of doing it?"}, config={"configurable": {"session_id": "abc123"}},)["answer"]
```
```
'Task decomposition can be done in common ways such as using Language Model (LLM) with simple prompting, task-specific instructions, or human inputs. For example, LLM can be guided with prompts like "Steps for XYZ" to break down tasks, or specific instructions like "Write a story outline" can be given for task decomposition. Additionally, human inputs can also be utilized to decompose tasks into smaller, more manageable steps.'
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:20.637Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/chat_history/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/chat_history/",
"description": "In many Q&A applications we want to allow the user to have a",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7873",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"chat_history\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:20 GMT",
"etag": "W/\"ce50bfd091b4debe7e4f7f451f1dfa96\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::qfv6k-1713753980564-16f5fda2a715"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/chat_history/",
"property": "og:url"
},
{
"content": "Add chat history | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In many Q&A applications we want to allow the user to have a",
"property": "og:description"
}
],
"title": "Add chat history | 🦜️🔗 LangChain"
} | Add chat history
In many Q&A applications we want to allow the user to have a back-and-forth conversation, meaning the application needs some sort of “memory” of past questions and answers, and some logic for incorporating those into its current thinking.
In this guide we focus on adding logic for incorporating historical messages. Further details on chat history management is covered here.
We’ll work off of the Q&A app we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the Quickstart. We’ll need to update two things about our existing app:
Prompt: Update our prompt to support historical messages as an input.
Contextualizing questions: Add a sub-chain that takes the latest user question and reformulates it in the context of the chat history. This is needed in case the latest question references some context from past messages. For example, if a user asks a follow-up question like “Can you elaborate on the second point?”, this cannot be understood without the context of the previous message. Therefore we can’t effectively perform retrieval with a question like this.
Setup
Dependencies
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any ChatModel or LLM, Embeddings, and VectorStore or Retriever.
We’ll use the following packages:
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
We need to set environment variable OPENAI_API_KEY, which can be done directly or loaded from a .env file like so:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Chain without chat history
Here is the Q&A app we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the Quickstart:
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
'Task Decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps agents to plan and execute tasks more efficiently by dividing them into manageable subgoals. Task decomposition can be achieved through various methods, including using prompting techniques, task-specific instructions, or human inputs.'
Contextualizing the question
First we’ll need to define a sub-chain that takes historical messages and the latest user question, and reformulates the question if it makes reference to any information in the historical information.
We’ll use a prompt that includes a MessagesPlaceholder variable under the name “chat_history”. This allows us to pass in a list of Messages to the prompt using the “chat_history” input key, and these messages will be inserted after the system message and before the human message containing the latest question.
Note that we leverage a helper function create_history_aware_retriever for this step, which manages the case where chat_history is empty, and otherwise applies prompt | llm | StrOutputParser() | retriever in sequence.
create_history_aware_retriever constructs a chain that accepts keys input and chat_history as input, and has the same output schema as a retriever.
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
This chain prepends a rephrasing of the input query to our retriever, so that the retrieval incorporates the context of the conversation.
Chain with chat history
And now we can build our full QA chain.
Here we use create_stuff_documents_chain to generate a question_answer_chain, with input keys context, chat_history, and input– it accepts the retrieved context alongside the conversation history and query to generate an answer.
We build our final rag_chain with create_retrieval_chain. This chain applies the history_aware_retriever and question_answer_chain in sequence, retaining intermediate outputs such as the retrieved context for convenience. It has input keys input and chat_history, and includes input, chat_history, context, and answer in its output.
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
from langchain_core.messages import HumanMessage
chat_history = []
question = "What is Task Decomposition?"
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg_1["answer"]])
second_question = "What are common ways of doing it?"
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])
Task decomposition can be done in several common ways, including using Language Model (LLM) with simple prompting like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", providing task-specific instructions tailored to the specific task at hand, or incorporating human inputs to guide the decomposition process. These methods help in breaking down complex tasks into smaller, more manageable subtasks for efficient execution.
Returning sources
Often in Q&A applications it’s important to show users the sources that were used to generate the answer. LangChain’s built-in create_retrieval_chain will propagate retrieved source documents through to the output in the "context" key:
for document in ai_msg_2["context"]:
print(document)
print()
page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
Tying it together
Here we’ve gone over how to add application logic for incorporating historical outputs, but we’re still manually updating the chat history and inserting it into each input. In a real Q&A application we’ll want some way of persisting chat history and some way of automatically inserting and updating it.
For this we can use:
BaseChatMessageHistory: Store chat history.
RunnableWithMessageHistory: Wrapper for an LCEL chain and a BaseChatMessageHistory that handles injecting chat history into inputs and updating it after each invocation.
For a detailed walkthrough of how to use these classes together to create a stateful conversational chain, head to the How to add message history (memory) LCEL page.
Below, we implement a simple example of the second option, in which chat histories are stored in a simple dict.
For convenience, we tie together all of the necessary steps in a single code cell:
import bs4
from langchain import hub
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_chroma import Chroma
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
### Construct retriever ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
### Contextualize question ###
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
### Answer question ###
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
### Statefully manage chat history ###
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
conversational_rag_chain.invoke(
{"input": "What is Task Decomposition?"},
config={
"configurable": {"session_id": "abc123"}
}, # constructs a key "abc123" in `store`.
)["answer"]
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps agents or models handle difficult tasks by dividing them into more manageable subtasks. It can be achieved through methods like Chain of Thought (CoT) or Tree of Thoughts, which guide the model in thinking step by step or exploring multiple reasoning possibilities at each step.'
conversational_rag_chain.invoke(
{"input": "What are common ways of doing it?"},
config={"configurable": {"session_id": "abc123"}},
)["answer"]
'Task decomposition can be done in common ways such as using Language Model (LLM) with simple prompting, task-specific instructions, or human inputs. For example, LLM can be guided with prompts like "Steps for XYZ" to break down tasks, or specific instructions like "Write a story outline" can be given for task decomposition. Additionally, human inputs can also be utilized to decompose tasks into smaller, more manageable steps.' |
https://python.langchain.com/docs/use_cases/question_answering/citations/ | ## Citations
How can we get a model to cite which parts of the source documents it referenced in its response?
To explore some techniques for extracting citations, let’s first create a simple RAG chain. To start we’ll just retrieve from Wikipedia using the [WikipediaRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain_community.retrievers.wikipedia.WikipediaRetriever.html).
## Setup[](#setup "Direct link to Setup")
First we’ll need to install some dependencies and set environment vars for the models we’ll be using.
```
%pip install -qU langchain langchain-openai langchain-anthropic langchain-community wikipedia
```
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()# Uncomment if you want to log to LangSmith# os.environ["LANGCHAIN_TRACING_V2"] = "true# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
```
from langchain_community.retrievers import WikipediaRetrieverfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)wiki = WikipediaRetriever(top_k_results=6, doc_content_chars_max=2000)prompt = ChatPromptTemplate.from_messages( [ ( "system", "You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}", ), ("human", "{question}"), ])prompt.pretty_print()
```
```
================================ System Message ================================You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.Here are the Wikipedia articles:{context}================================ Human Message ================================={question}
```
Now that we’ve got a model, retriver and prompt, let’s chain them all together. We’ll need to add some logic for formatting our retrieved Documents to a string that can be passed to our prompt. We’ll make it so our chain returns both the answer and the retrieved Documents.
```
from operator import itemgetterfrom typing import Listfrom langchain_core.documents import Documentfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import ( RunnableLambda, RunnableParallel, RunnablePassthrough,)def format_docs(docs: List[Document]) -> str: """Convert Documents to a single string.:""" formatted = [ f"Article Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}" for doc in docs ] return "\n\n" + "\n\n".join(formatted)format = itemgetter("docs") | RunnableLambda(format_docs)# subchain for generating an answer once we've done retrievalanswer = prompt | llm | StrOutputParser()# complete chain that calls wiki -> formats docs to string -> runs answer subchain -> returns just the answer and retrieved docs.chain = ( RunnableParallel(question=RunnablePassthrough(), docs=wiki) .assign(context=format) .assign(answer=answer) .pick(["answer", "docs"]))
```
```
chain.invoke("How fast are cheetahs?")
```
```
{'answer': 'Cheetahs are capable of running at speeds between 93 to 104 km/h (58 to 65 mph). They have evolved specialized adaptations for speed, including a light build, long thin legs, and a long tail.', 'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}), Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}), Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
```
LangSmith trace: [https://smith.langchain.com/public/4bc9a13a-d320-46dc-a70c-7109641e7308/r](https://smith.langchain.com/public/4bc9a13a-d320-46dc-a70c-7109641e7308/r)
## Function-calling[](#function-calling "Direct link to Function-calling")
### Cite documents[](#cite-documents "Direct link to Cite documents")
Let’s try using [OpenAI function-calling](https://python.langchain.com/docs/modules/model_io/chat/function_calling/) to make the model specify which of the provided documents it’s actually referencing when answering. LangChain has some utils for converting Pydantic objects to the JSONSchema format expected by OpenAI, so we’ll use that to define our functions:
```
from langchain_core.pydantic_v1 import BaseModel, Fieldclass cited_answer(BaseModel): """Answer the user question based only on the given sources, and cite the sources used.""" answer: str = Field( ..., description="The answer to the user question, which is based only on the given sources.", ) citations: List[int] = Field( ..., description="The integer IDs of the SPECIFIC sources which justify the answer.", )
```
Let’s see what the model output is like when we pass in our functions and a user input:
```
llm_with_tool = llm.bind_tools( [cited_answer], tool_choice="cited_answer",)example_q = """What Brian's height?Source: 1Information: Suzy is 6'2"Source: 2Information: Jeremiah is blondeSource: 3Information: Brian is 3 inches shorted than Suzy"""llm_with_tool.invoke(example_q)
```
```
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_0VO8uyUo16jzq86FQDoka2zQ', 'function': {'arguments': '{\n "answer": "Brian\'s height is 6\'2\\" - 3 inches",\n "citations": [1, 3]\n}', 'name': 'cited_answer'}, 'type': 'function'}]})
```
We’ll add an output parser to convert the OpenAI API response to a nice dictionary. We use the [JsonOutputKeyToolsParser](https://api.python.langchain.com/en/latest/output_parsers/langchain.output_parsers.openai_tools.JsonOutputKeyToolsParser.html#langchain.output_parsers.openai_tools.JsonOutputKeyToolsParser) for this:
```
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParseroutput_parser = JsonOutputKeyToolsParser(key_name="cited_answer", first_tool_only=True)(llm_with_tool | output_parser).invoke(example_q)
```
```
{'answer': 'Brian\'s height is 6\'2" - 3 inches', 'citations': [1, 3]}
```
Now we’re ready to put together our chain
```
def format_docs_with_id(docs: List[Document]) -> str: formatted = [ f"Source ID: {i}\nArticle Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}" for i, doc in enumerate(docs) ] return "\n\n" + "\n\n".join(formatted)format_1 = itemgetter("docs") | RunnableLambda(format_docs_with_id)answer_1 = prompt | llm_with_tool | output_parserchain_1 = ( RunnableParallel(question=RunnablePassthrough(), docs=wiki) .assign(context=format_1) .assign(cited_answer=answer_1) .pick(["cited_answer", "docs"]))
```
```
chain_1.invoke("How fast are cheetahs?")
```
```
{'cited_answer': {'answer': 'Cheetahs can run at speeds of 93 to 104 km/h (58 to 65 mph).', 'citations': [0]}, 'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}), Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}), Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
```
LangSmith trace: [https://smith.langchain.com/public/e38081da-774b-493b-b193-dab7711f99e9/r](https://smith.langchain.com/public/e38081da-774b-493b-b193-dab7711f99e9/r)
### Cite snippets[](#cite-snippets "Direct link to Cite snippets")
What if we want to cite actual text spans? We can try to get our model to return these, too.
_Aside: Note that if we break up our documents so that we have many documents with only a sentence or two instead of a few long documents, citing documents becomes roughly equivalent to citing snippets, and may be easier for the model because the model just needs to return an identifier for each snippet instead of the actual text. Probably worth trying both approaches and evaluating._
```
class Citation(BaseModel): source_id: int = Field( ..., description="The integer ID of a SPECIFIC source which justifies the answer.", ) quote: str = Field( ..., description="The VERBATIM quote from the specified source that justifies the answer.", )class quoted_answer(BaseModel): """Answer the user question based only on the given sources, and cite the sources used.""" answer: str = Field( ..., description="The answer to the user question, which is based only on the given sources.", ) citations: List[Citation] = Field( ..., description="Citations from the given sources that justify the answer." )
```
```
output_parser_2 = JsonOutputKeyToolsParser( key_name="quoted_answer", first_tool_only=True)llm_with_tool_2 = llm.bind_tools( [quoted_answer], tool_choice="quoted_answer",)format_2 = itemgetter("docs") | RunnableLambda(format_docs_with_id)answer_2 = prompt | llm_with_tool_2 | output_parser_2chain_2 = ( RunnableParallel(question=RunnablePassthrough(), docs=wiki) .assign(context=format_2) .assign(quoted_answer=answer_2) .pick(["quoted_answer", "docs"]))
```
```
chain_2.invoke("How fast are cheetahs?")
```
```
{'quoted_answer': {'answer': 'Cheetahs can run at speeds of 93 to 104 km/h (58 to 65 mph).', 'citations': [{'source_id': 0, 'quote': 'The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.'}]}, 'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}), Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}), Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
```
LangSmith trace: [https://smith.langchain.com/public/ed19ea8d-5b99-4ebe-9809-9a3b4db6b39d/r](https://smith.langchain.com/public/ed19ea8d-5b99-4ebe-9809-9a3b4db6b39d/r)
## Direct prompting[](#direct-prompting "Direct link to Direct prompting")
Most models don’t yet support function-calling. We can achieve similar results with direct prompting. Let’s see what this looks like using an Anthropic chat model that is particularly proficient in working with XML:
```
from langchain_anthropic import ChatAnthropicMessagesanthropic = ChatAnthropicMessages(model_name="claude-instant-1.2")system = """You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, \answer the user question and provide citations. If none of the articles answer the question, just say you don't know.Remember, you must return both an answer and citations. A citation consists of a VERBATIM quote that \justifies the answer and the ID of the quote article. Return a citation for every quote across all articles \that justify the answer. Use the following format for your final output:<cited_answer> <answer></answer> <citations> <citation><source_id></source_id><quote></quote></citation> <citation><source_id></source_id><quote></quote></citation> ... </citations></cited_answer>Here are the Wikipedia articles:{context}"""prompt_3 = ChatPromptTemplate.from_messages( [("system", system), ("human", "{question}")])
```
```
from langchain_core.output_parsers import XMLOutputParserdef format_docs_xml(docs: List[Document]) -> str: formatted = [] for i, doc in enumerate(docs): doc_str = f"""\ <source id=\"{i}\"> <title>{doc.metadata['title']}</title> <article_snippet>{doc.page_content}</article_snippet> </source>""" formatted.append(doc_str) return "\n\n<sources>" + "\n".join(formatted) + "</sources>"format_3 = itemgetter("docs") | RunnableLambda(format_docs_xml)answer_3 = prompt_3 | anthropic | XMLOutputParser() | itemgetter("cited_answer")chain_3 = ( RunnableParallel(question=RunnablePassthrough(), docs=wiki) .assign(context=format_3) .assign(cited_answer=answer_3) .pick(["cited_answer", "docs"]))
```
```
chain_3.invoke("How fast are cheetahs?")
```
```
{'cited_answer': [{'answer': 'Cheetahs are the fastest land animals. They are capable of running at speeds of between 93 to 104 km/h (58 to 65 mph).'}, {'citations': [{'citation': [{'source_id': '0'}, {'quote': 'The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.'}]}]}], 'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}), Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}), Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
```
LangSmith trace: [https://smith.langchain.com/public/54bd9284-0a32-4a29-8540-ff72142f0d3d/r](https://smith.langchain.com/public/54bd9284-0a32-4a29-8540-ff72142f0d3d/r)
## Retrieval post-processing[](#retrieval-post-processing "Direct link to Retrieval post-processing")
Another approach is to post-process our retrieved documents to compress the content, so that the source content is already minimal enough that we don’t need the model to cite specific sources or spans. For example, we could break up each document into a sentence or two, embed those and keep only the most relevant ones. LangChain has some built-in components for this. Here we’ll use a [RecursiveCharacterTextSplitter](https://api.python.langchain.com/en/latest/text_splitter/langchain_text_splitters.RecursiveCharacterTextSplitter.html#langchain_text_splitters.RecursiveCharacterTextSplitter), which creates chunks of a sepacified size by splitting on separator substrings, and an [EmbeddingsFilter](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.document_compressors.embeddings_filter.EmbeddingsFilter.html#langchain.retrievers.document_compressors.embeddings_filter.EmbeddingsFilter), which keeps only the texts with the most relevant embeddings.
```
from langchain.retrievers.document_compressors import EmbeddingsFilterfrom langchain_openai import OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter( chunk_size=400, chunk_overlap=0, separators=["\n\n", "\n", ".", " "], keep_separator=False,)compressor = EmbeddingsFilter(embeddings=OpenAIEmbeddings(), k=10)def split_and_filter(input) -> List[Document]: docs = input["docs"] question = input["question"] split_docs = splitter.split_documents(docs) stateful_docs = compressor.compress_documents(split_docs, question) return [stateful_doc for stateful_doc in stateful_docs]retrieve = ( RunnableParallel(question=RunnablePassthrough(), docs=wiki) | split_and_filter)docs = retrieve.invoke("How fast are cheetahs?")for doc in docs: print(doc.page_content) print("\n\n")
```
```
Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tailThe cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in)2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrateIt feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson's gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the yearThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central IranThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and duskThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speedsAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlandsOn 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c
```
```
chain_4 = ( RunnableParallel(question=RunnablePassthrough(), docs=retrieve) .assign(context=format) .assign(answer=answer) .pick(["answer", "docs"]))
```
```
# Note the documents have an article "summary" in the metadata that is now much longer than the# actual document page content. This summary isn't actually passed to the model.chain_4.invoke("How fast are cheetahs?")
```
```
{'answer': 'Cheetahs are capable of running at speeds between 93 and 104 km/h (58 to 65 mph). They have evolved specialized adaptations for speed, including a light build, long thin legs, and a long tail.', 'docs': [Document(page_content='Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in)', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content="2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content="It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson's gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year", metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='The cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='The cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='The peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds', metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content='Acinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'})]}
```
LangSmith trace: [https://smith.langchain.com/public/f6a7ea78-05f3-47f2-a3dc-72747d1a9c64/r](https://smith.langchain.com/public/f6a7ea78-05f3-47f2-a3dc-72747d1a9c64/r)
## Generation post-processing[](#generation-post-processing "Direct link to Generation post-processing")
Another approach is to post-process our model generation. In this example we’ll first generate just an answer, and then we’ll ask the model to annotate it’s own answer with citations. The downside of this approach is of course that it is slower and more expensive, because two model calls need to be made.
Let’s apply this to our initial chain.
```
class Citation(BaseModel): source_id: int = Field( ..., description="The integer ID of a SPECIFIC source which justifies the answer.", ) quote: str = Field( ..., description="The VERBATIM quote from the specified source that justifies the answer.", )class annotated_answer(BaseModel): """Annotate the answer to the user question with quote citations that justify the answer.""" citations: List[Citation] = Field( ..., description="Citations from the given sources that justify the answer." )llm_with_tools_5 = llm.bind_tools( [annotated_answer], tool_choice="annotated_answer",)
```
```
from langchain_core.prompts import MessagesPlaceholderprompt_5 = ChatPromptTemplate.from_messages( [ ( "system", "You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}", ), ("human", "{question}"), MessagesPlaceholder("chat_history", optional=True), ])answer_5 = prompt_5 | llmannotation_chain = ( prompt_5 | llm_with_tools_5 | JsonOutputKeyToolsParser(key_name="annotated_answer", first_tool_only=True) | itemgetter("citations"))chain_5 = ( RunnableParallel(question=RunnablePassthrough(), docs=wiki) .assign(context=format) .assign(ai_message=answer_5) .assign( chat_history=(lambda x: [x["ai_message"]]), answer=(lambda x: x["ai_message"].content), ) .assign(annotations=annotation_chain) .pick(["answer", "docs", "annotations"]))
```
```
chain_5.invoke("How fast are cheetahs?")
```
```
{'answer': 'Cheetahs are capable of running at speeds between 93 to 104 km/h (58 to 65 mph). They have evolved specialized adaptations for speed, including a light build, long thin legs, and a long tail.', 'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}), Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}), Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}), Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}), Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}), Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})], 'annotations': [{'source_id': 0, 'quote': 'The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.'}]}
```
LangSmith trace: [https://smith.langchain.com/public/8f30dbe5-9364-420c-9d90-63859ad06dcb/r](https://smith.langchain.com/public/8f30dbe5-9364-420c-9d90-63859ad06dcb/r)
If the answer was long we could first split it up and then apply the citation chain to every few sentences of the answer. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:21.552Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/citations/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/citations/",
"description": "How can we get a model to cite which parts of the source documents it",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3774",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"citations\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:21 GMT",
"etag": "W/\"4d173bd944659b6c523e09623028eedb\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::w9kcf-1713753981480-a27dee011eca"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/citations/",
"property": "og:url"
},
{
"content": "Citations | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "How can we get a model to cite which parts of the source documents it",
"property": "og:description"
}
],
"title": "Citations | 🦜️🔗 LangChain"
} | Citations
How can we get a model to cite which parts of the source documents it referenced in its response?
To explore some techniques for extracting citations, let’s first create a simple RAG chain. To start we’ll just retrieve from Wikipedia using the WikipediaRetriever.
Setup
First we’ll need to install some dependencies and set environment vars for the models we’ll be using.
%pip install -qU langchain langchain-openai langchain-anthropic langchain-community wikipedia
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
# Uncomment if you want to log to LangSmith
# os.environ["LANGCHAIN_TRACING_V2"] = "true
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
from langchain_community.retrievers import WikipediaRetriever
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
wiki = WikipediaRetriever(top_k_results=6, doc_content_chars_max=2000)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}",
),
("human", "{question}"),
]
)
prompt.pretty_print()
================================ System Message ================================
You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.
Here are the Wikipedia articles:{context}
================================ Human Message =================================
{question}
Now that we’ve got a model, retriver and prompt, let’s chain them all together. We’ll need to add some logic for formatting our retrieved Documents to a string that can be passed to our prompt. We’ll make it so our chain returns both the answer and the retrieved Documents.
from operator import itemgetter
from typing import List
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
def format_docs(docs: List[Document]) -> str:
"""Convert Documents to a single string.:"""
formatted = [
f"Article Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}"
for doc in docs
]
return "\n\n" + "\n\n".join(formatted)
format = itemgetter("docs") | RunnableLambda(format_docs)
# subchain for generating an answer once we've done retrieval
answer = prompt | llm | StrOutputParser()
# complete chain that calls wiki -> formats docs to string -> runs answer subchain -> returns just the answer and retrieved docs.
chain = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format)
.assign(answer=answer)
.pick(["answer", "docs"])
)
chain.invoke("How fast are cheetahs?")
{'answer': 'Cheetahs are capable of running at speeds between 93 to 104 km/h (58 to 65 mph). They have evolved specialized adaptations for speed, including a light build, long thin legs, and a long tail.',
'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}),
Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}),
Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
LangSmith trace: https://smith.langchain.com/public/4bc9a13a-d320-46dc-a70c-7109641e7308/r
Function-calling
Cite documents
Let’s try using OpenAI function-calling to make the model specify which of the provided documents it’s actually referencing when answering. LangChain has some utils for converting Pydantic objects to the JSONSchema format expected by OpenAI, so we’ll use that to define our functions:
from langchain_core.pydantic_v1 import BaseModel, Field
class cited_answer(BaseModel):
"""Answer the user question based only on the given sources, and cite the sources used."""
answer: str = Field(
...,
description="The answer to the user question, which is based only on the given sources.",
)
citations: List[int] = Field(
...,
description="The integer IDs of the SPECIFIC sources which justify the answer.",
)
Let’s see what the model output is like when we pass in our functions and a user input:
llm_with_tool = llm.bind_tools(
[cited_answer],
tool_choice="cited_answer",
)
example_q = """What Brian's height?
Source: 1
Information: Suzy is 6'2"
Source: 2
Information: Jeremiah is blonde
Source: 3
Information: Brian is 3 inches shorted than Suzy"""
llm_with_tool.invoke(example_q)
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_0VO8uyUo16jzq86FQDoka2zQ', 'function': {'arguments': '{\n "answer": "Brian\'s height is 6\'2\\" - 3 inches",\n "citations": [1, 3]\n}', 'name': 'cited_answer'}, 'type': 'function'}]})
We’ll add an output parser to convert the OpenAI API response to a nice dictionary. We use the JsonOutputKeyToolsParser for this:
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParser
output_parser = JsonOutputKeyToolsParser(key_name="cited_answer", first_tool_only=True)
(llm_with_tool | output_parser).invoke(example_q)
{'answer': 'Brian\'s height is 6\'2" - 3 inches', 'citations': [1, 3]}
Now we’re ready to put together our chain
def format_docs_with_id(docs: List[Document]) -> str:
formatted = [
f"Source ID: {i}\nArticle Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}"
for i, doc in enumerate(docs)
]
return "\n\n" + "\n\n".join(formatted)
format_1 = itemgetter("docs") | RunnableLambda(format_docs_with_id)
answer_1 = prompt | llm_with_tool | output_parser
chain_1 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_1)
.assign(cited_answer=answer_1)
.pick(["cited_answer", "docs"])
)
chain_1.invoke("How fast are cheetahs?")
{'cited_answer': {'answer': 'Cheetahs can run at speeds of 93 to 104 km/h (58 to 65 mph).',
'citations': [0]},
'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}),
Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}),
Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
LangSmith trace: https://smith.langchain.com/public/e38081da-774b-493b-b193-dab7711f99e9/r
Cite snippets
What if we want to cite actual text spans? We can try to get our model to return these, too.
Aside: Note that if we break up our documents so that we have many documents with only a sentence or two instead of a few long documents, citing documents becomes roughly equivalent to citing snippets, and may be easier for the model because the model just needs to return an identifier for each snippet instead of the actual text. Probably worth trying both approaches and evaluating.
class Citation(BaseModel):
source_id: int = Field(
...,
description="The integer ID of a SPECIFIC source which justifies the answer.",
)
quote: str = Field(
...,
description="The VERBATIM quote from the specified source that justifies the answer.",
)
class quoted_answer(BaseModel):
"""Answer the user question based only on the given sources, and cite the sources used."""
answer: str = Field(
...,
description="The answer to the user question, which is based only on the given sources.",
)
citations: List[Citation] = Field(
..., description="Citations from the given sources that justify the answer."
)
output_parser_2 = JsonOutputKeyToolsParser(
key_name="quoted_answer", first_tool_only=True
)
llm_with_tool_2 = llm.bind_tools(
[quoted_answer],
tool_choice="quoted_answer",
)
format_2 = itemgetter("docs") | RunnableLambda(format_docs_with_id)
answer_2 = prompt | llm_with_tool_2 | output_parser_2
chain_2 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_2)
.assign(quoted_answer=answer_2)
.pick(["quoted_answer", "docs"])
)
chain_2.invoke("How fast are cheetahs?")
{'quoted_answer': {'answer': 'Cheetahs can run at speeds of 93 to 104 km/h (58 to 65 mph).',
'citations': [{'source_id': 0,
'quote': 'The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.'}]},
'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}),
Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}),
Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
LangSmith trace: https://smith.langchain.com/public/ed19ea8d-5b99-4ebe-9809-9a3b4db6b39d/r
Direct prompting
Most models don’t yet support function-calling. We can achieve similar results with direct prompting. Let’s see what this looks like using an Anthropic chat model that is particularly proficient in working with XML:
from langchain_anthropic import ChatAnthropicMessages
anthropic = ChatAnthropicMessages(model_name="claude-instant-1.2")
system = """You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, \
answer the user question and provide citations. If none of the articles answer the question, just say you don't know.
Remember, you must return both an answer and citations. A citation consists of a VERBATIM quote that \
justifies the answer and the ID of the quote article. Return a citation for every quote across all articles \
that justify the answer. Use the following format for your final output:
<cited_answer>
<answer></answer>
<citations>
<citation><source_id></source_id><quote></quote></citation>
<citation><source_id></source_id><quote></quote></citation>
...
</citations>
</cited_answer>
Here are the Wikipedia articles:{context}"""
prompt_3 = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{question}")]
)
from langchain_core.output_parsers import XMLOutputParser
def format_docs_xml(docs: List[Document]) -> str:
formatted = []
for i, doc in enumerate(docs):
doc_str = f"""\
<source id=\"{i}\">
<title>{doc.metadata['title']}</title>
<article_snippet>{doc.page_content}</article_snippet>
</source>"""
formatted.append(doc_str)
return "\n\n<sources>" + "\n".join(formatted) + "</sources>"
format_3 = itemgetter("docs") | RunnableLambda(format_docs_xml)
answer_3 = prompt_3 | anthropic | XMLOutputParser() | itemgetter("cited_answer")
chain_3 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_3)
.assign(cited_answer=answer_3)
.pick(["cited_answer", "docs"])
)
chain_3.invoke("How fast are cheetahs?")
{'cited_answer': [{'answer': 'Cheetahs are the fastest land animals. They are capable of running at speeds of between 93 to 104 km/h (58 to 65 mph).'},
{'citations': [{'citation': [{'source_id': '0'},
{'quote': 'The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.'}]}]}],
'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.\n\n', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}),
Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}),
Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})]}
LangSmith trace: https://smith.langchain.com/public/54bd9284-0a32-4a29-8540-ff72142f0d3d/r
Retrieval post-processing
Another approach is to post-process our retrieved documents to compress the content, so that the source content is already minimal enough that we don’t need the model to cite specific sources or spans. For example, we could break up each document into a sentence or two, embed those and keep only the most relevant ones. LangChain has some built-in components for this. Here we’ll use a RecursiveCharacterTextSplitter, which creates chunks of a sepacified size by splitting on separator substrings, and an EmbeddingsFilter, which keeps only the texts with the most relevant embeddings.
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=0,
separators=["\n\n", "\n", ".", " "],
keep_separator=False,
)
compressor = EmbeddingsFilter(embeddings=OpenAIEmbeddings(), k=10)
def split_and_filter(input) -> List[Document]:
docs = input["docs"]
question = input["question"]
split_docs = splitter.split_documents(docs)
stateful_docs = compressor.compress_documents(split_docs, question)
return [stateful_doc for stateful_doc in stateful_docs]
retrieve = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki) | split_and_filter
)
docs = retrieve.invoke("How fast are cheetahs?")
for doc in docs:
print(doc.page_content)
print("\n\n")
Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail
The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in)
2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate
It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson's gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year
The cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran
The cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk
The peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds
Acinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.
The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands
On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c
chain_4 = (
RunnableParallel(question=RunnablePassthrough(), docs=retrieve)
.assign(context=format)
.assign(answer=answer)
.pick(["answer", "docs"])
)
# Note the documents have an article "summary" in the metadata that is now much longer than the
# actual document page content. This summary isn't actually passed to the model.
chain_4.invoke("How fast are cheetahs?")
{'answer': 'Cheetahs are capable of running at speeds between 93 and 104 km/h (58 to 65 mph). They have evolved specialized adaptations for speed, including a light build, long thin legs, and a long tail.',
'docs': [Document(page_content='Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in)', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content="2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content="It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson's gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year", metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='The cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='The cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='The peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds', metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content='Acinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'})]}
LangSmith trace: https://smith.langchain.com/public/f6a7ea78-05f3-47f2-a3dc-72747d1a9c64/r
Generation post-processing
Another approach is to post-process our model generation. In this example we’ll first generate just an answer, and then we’ll ask the model to annotate it’s own answer with citations. The downside of this approach is of course that it is slower and more expensive, because two model calls need to be made.
Let’s apply this to our initial chain.
class Citation(BaseModel):
source_id: int = Field(
...,
description="The integer ID of a SPECIFIC source which justifies the answer.",
)
quote: str = Field(
...,
description="The VERBATIM quote from the specified source that justifies the answer.",
)
class annotated_answer(BaseModel):
"""Annotate the answer to the user question with quote citations that justify the answer."""
citations: List[Citation] = Field(
..., description="Citations from the given sources that justify the answer."
)
llm_with_tools_5 = llm.bind_tools(
[annotated_answer],
tool_choice="annotated_answer",
)
from langchain_core.prompts import MessagesPlaceholder
prompt_5 = ChatPromptTemplate.from_messages(
[
(
"system",
"You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}",
),
("human", "{question}"),
MessagesPlaceholder("chat_history", optional=True),
]
)
answer_5 = prompt_5 | llm
annotation_chain = (
prompt_5
| llm_with_tools_5
| JsonOutputKeyToolsParser(key_name="annotated_answer", first_tool_only=True)
| itemgetter("citations")
)
chain_5 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format)
.assign(ai_message=answer_5)
.assign(
chat_history=(lambda x: [x["ai_message"]]),
answer=(lambda x: x["ai_message"].content),
)
.assign(annotations=annotation_chain)
.pick(["answer", "docs", "annotations"])
)
chain_5.invoke("How fast are cheetahs?")
{'answer': 'Cheetahs are capable of running at speeds between 93 to 104 km/h (58 to 65 mph). They have evolved specialized adaptations for speed, including a light build, long thin legs, and a long tail.',
'docs': [Document(page_content='The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned a', metadata={'title': 'Cheetah', 'summary': 'The cheetah (Acinonyx jubatus) is a large cat and the fastest land animal. It has a tawny to creamy white or pale buff fur that is marked with evenly spaced, solid black spots. The head is small and rounded, with a short snout and black tear-like facial streaks. It reaches 67–94 cm (26–37 in) at the shoulder, and the head-and-body length is between 1.1 and 1.5 m (3 ft 7 in and 4 ft 11 in). Adults weigh between 21 and 72 kg (46 and 159 lb). The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.\nThe cheetah was first described in the late 18th century. Four subspecies are recognised today that are native to Africa and central Iran. An African subspecies was introduced to India in 2022. It is now distributed mainly in small, fragmented populations in northwestern, eastern and southern Africa and central Iran. It lives in a variety of habitats such as savannahs in the Serengeti, arid mountain ranges in the Sahara, and hilly desert terrain.\nThe cheetah lives in three main social groups: females and their cubs, male "coalitions", and solitary males. While females lead a nomadic life searching for prey in large home ranges, males are more sedentary and instead establish much smaller territories in areas with plentiful prey and access to females. The cheetah is active during the day, with peaks during dawn and dusk. It feeds on small- to medium-sized prey, mostly weighing under 40 kg (88 lb), and prefers medium-sized ungulates such as impala, springbok and Thomson\'s gazelles. The cheetah typically stalks its prey within 60–100 m (200–330 ft) before charging towards it, trips it during the chase and bites its throat to suffocate it to death. It breeds throughout the year. After a gestation of nearly three months, females give birth to a litter of three or four cubs. Cheetah cubs are highly vulnerable to predation by other large carnivores. They are weaned at around four months and are independent by around 20 months of age.\nThe cheetah is threatened by habitat loss, conflict with humans, poaching and high susceptibility to diseases. In 2016, the global cheetah population was estimated at 7,100 individuals in the wild; it is listed as Vulnerable on the IUCN Red List. It has been widely depicted in art, literature, advertising, and animation. It was tamed in ancient Egypt and trained for hunting ungulates in the Arabian Peninsula and India. It has been kept in zoos since the early 19th century.', 'source': 'https://en.wikipedia.org/wiki/Cheetah'}),
Document(page_content='More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The c', metadata={'title': 'Cheetah reintroduction in India', 'summary': 'More than 70 years after India\'s native subspecies of the cheetah—the Asiatic cheetah (Acinonyx jubatus venaticus)—became extinct there, small numbers of Southeast African cheetah (Acinonyx jubatus jubatus) have been flown in from Namibia and South Africa to a national park in India. The experiment has been permitted by India\'s supreme court on a short-term basis to test long-term adaptation. The Asiatic subspecies is now found only in Iran in critically endangered numbers.The Asiatic cheetah whose long history on the Indian subcontinent gave the Sanskrit-derived vernacular name "cheetah", or "spotted", to the entire species, Acinonyx jubatus, also had a gradual history of habitat loss there. In Punjab, before the thorn forests were cleared for agriculture and human settlement, they were intermixed with open grasslands grazed by large herds of blackbuck; these co-existed with their main natural predator, the Asiatic cheetah. The blackbuck is no longer extant in Punjab. Later, more habitat loss, prey depletion, and trophy hunting were to lead to the extinction of the Asiatic cheetah in other regions of India.\nDiscussions on cheetah reintroduction in India began soon after extinction was confirmed, in the mid-1950s. Proposals were made to the governments of Iran from the 1970s, but fell through chiefly for reasons of political instability there. Offers from Kenya for introducing African cheetahs were made as early as the 1980s. Proposals for the introduction of African cheetahs were made by the Indian government in 2009, but disallowed by India\'s supreme court. The court reversed its decision in early 2020, allowing the import of a small number, on an experimental basis for testing long-term adaptation. On 17 September 2022, five female and three male southeast African cheetahs, between the ages of four and six (a gift from the government of Namibia), were released in a small quarantined enclosure within the Kuno National Park in the state of Madhya Pradesh. The cheetahs, all fitted with radio collars, will remain in the quarantined enclosure for a month; initially, the males (and later the females) will be released into the 748.76 km2 (289.10 sq mi) park. The relocation has been supervised by Yadvendradev V. Jhala of the Wildlife Institute of India and zoologist Laurie Marker, of the Namibia-based Cheetah Conservation Fund. Subsequently, 12 cheetahs from South Africa will be released in Kuno; eventually, the total number of African cheetahs in Kuno will be brought up to 40 individuals. As of Jan 16, 2024, seven adult cheetahs from Africa and three cubs (of four born in Kuno two months earlier) had died in Kuno National Park.\nThe scientific reaction to the translocation has been mixed. Adrian Tordiffe (a wildlife veterinary pharmacologist at the University of Pretoria who will be supervising the release of the cheetahs) is an enthusiast, who views India as providing "protected space" for the fragmented and threatened population of the world\'s cheetahs. K. Ullas Karanth, one of India\'s tiger experts, has been critical of the effort, considering it to be a "PR exercise." India\'s "realities", he says, such as human overpopulation, and the presence of larger feline predators and packs of feral dogs, could all cause potentially "high mortalities," and require a continual import of African cheetahs. Kuno National Park is a relatively new national park, having received that status in 2018. It had been founded previously as a wildlife sanctuary to implement the Asiatic Lion Reintroduction Project, which aimed to establish a second Asiatic lion population in India. The goal was to protect the isolated lions of the Gir National Park (in Gujarat) from a potential mass mortality event, set off by the outbreak of an epizootic. Although the state government of Gujarat was ordered by India\'s Supreme Court in April 2013 to transfer a small population of lions from Gujarat to Kuno, and was given six months to complete the transfer, they ultimately resisted implementing the order.', 'source': 'https://en.wikipedia.org/wiki/Cheetah_reintroduction_in_India'}),
Document(page_content='The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.\n\n\n== Taxonomy ==\nThe Southern African cheetah was first described by German naturalist Johann Christian Daniel von Schreber in his book Die Säugethiere in Abbildungen nach der Natur mit Beschreibungen (The Mammals illustrated as in Nature with Descriptions), published in 1775. Schreber described the species on basis of a specimen from the Cape of Good Hope. It is therefore the nominate subspecies. Subpopulations have been called "South African cheetah" and "Namibian cheetah."Following Schreber\'s description, other naturalists and zoologists also described cheetah specimens from many parts of Southern and East Africa that today are all considered synonyms of A. j. jubatus:\nFelis guttata proposed in 1804 by Johann Hermann;\nFelis fearonii proposed in 1834 by Andrew Smith;\nFelis lanea proposed in 1877 by Philip Sclater;\nAcinonyx jubatus obergi proposed in 1913 by Max Hilzheimer;\nAcinonyx jubatus ngorongorensis proposed in 1913 by Hilzheimer on basis of a specimen from Ngorongoro, German East Africa;\nAcinonyx jubatus velox proposed in 1913 by Edmund Heller on basis of a cheetah that was shot by Kermit Roosevelt in June 1909 in the Kenyan highlands.\nAcinonyx rex proposed in 1927 by Reginald Innes Pocock on basis of a specimen from the Umvukwe Range in Rhodesia.In 2005, the authors of Mammal Species of the World grouped A. j. guttata, A. j. lanea, A. j. obergi, and A. j. rex under A j. jubatus, whilst recognizing A. j. raineyi and A. j. velox as valid taxa and considering P. l. ngorongore', metadata={'title': 'Southeast African cheetah', 'summary': 'The Southeast African cheetah (Acinonyx jubatus jubatus) is the nominate cheetah subspecies native to East and Southern Africa. The Southern African cheetah lives mainly in the lowland areas and deserts of the Kalahari, the savannahs of Okavango Delta, and the grasslands of the Transvaal region in South Africa. In Namibia, cheetahs are mostly found in farmlands. In India, four cheetahs of the subspecies are living in Kuno National Park in Madhya Pradesh after having been introduced there.', 'source': 'https://en.wikipedia.org/wiki/Southeast_African_cheetah'}),
Document(page_content='Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n\n== Factors in speed ==\nThe key determinant of footspeed in sprinting is the predominance of one distinct type of muscle fibre over another, specifically the ratio of fast-twitch muscles to slow-twitch muscles in a sprinter\'s physical makeup. Though fast-twitch muscles produce no more energy than slow-twitch muscles when they contract, they do so more rapidly through a process of anaerobic metabolism, though at the cost of inferior efficiency over longer periods of firing. The average human has an almost-equal ratio of fast-twitch to slow-twitch fibers, but top sprinters may have as much as 80% fast-twitch fibers, while top long-distance runners may have only 20%. This ratio is believed to have genetic origins, though some assert that it can be adjusted by muscle training. "Speed camps" and "Speed Training Manuals", which purport to provide fractional increases in maximum footspeed, are popular among budding professional athletes, and some sources estimate that 17–19% of speed can be trained.Though good running form is useful in increasing speed, fast and slow runners have been shown to move their legs at nearly the same rate – it is the force exerted by the leg on the ground that separates fast sprinters from slow. Top short-distance runners exert as much as four times their body weight in pressure on the running surface. For this reason, muscle mass in the legs, relative to total body weight, is a key factor in maximizing footspeed.\n\n\n== Limits of speed ==\nThe record is 44.72 km/h (27.78 mph), measured between meter 60 and meter 80 of the 100 meters sprint at the 2009 World Championships in Athletics by Usain Bolt. (Bolt\'s average speed o', metadata={'title': 'Footspeed', 'summary': 'Footspeed, or sprint speed, is the maximum speed at which a human can run. It is affected by many factors, varies greatly throughout the population, and is important in athletics and many sports, such as association football, rugby football, American football, track and field, field hockey, tennis, baseball, and basketball.\n\n', 'source': 'https://en.wikipedia.org/wiki/Footspeed'}),
Document(page_content="This is a list of the fastest animals in the world, by types of animal.\n\n\n== Fastest organism ==\nThe peregrine falcon is the fastest bird, and the fastest member of the animal kingdom, with a diving speed of over 300 km/h (190 mph). The fastest land animal is the cheetah. Among the fastest animals in the sea is the black marlin, with uncertain and conflicting reports of recorded speeds.When drawing comparisons between different classes of animals, an alternative unit is sometimes used for organisms: body length per second. On this basis the 'fastest' organism on earth, relative to its body length, is the Southern Californian mite, Paratarsotomus macropalpis, which has a speed of 322 body lengths per second. The equivalent speed for a human, running as fast as this mite, would be 1,300 mph (2,092 km/h), or approximately Mach 1.7. The speed of the P. macropalpis is far in excess of the previous record holder, the Australian tiger beetle Cicindela eburneola, which is the fastest insect in the world relative to body size, with a recorded speed of 1.86 metres per second (6.7 km/h; 4.2 mph), or 171 body lengths per second. The cheetah, the fastest land mammal, scores at only 16 body lengths per second, while Anna's hummingbird has the highest known length-specific velocity attained by any vertebrate.\n\n\n== Invertebrates ==\n\n\n== Fish ==\nDue to physical constraints, fish may be incapable of exceeding swim speeds of 36 km/h (22 mph). The larger reported figures below are therefore highly questionable:\n\n\n== Amphibians ==\n\n\n== Reptiles ==\n\n\n== Birds ==\n\n\n== Mammals ==\n\n\n== See also ==\nSpeed records\n\n\n== Notes ==\n\n\n== References ==", metadata={'title': 'Fastest animals', 'summary': 'This is a list of the fastest animals in the world, by types of animal.', 'source': 'https://en.wikipedia.org/wiki/Fastest_animals'}),
Document(page_content="Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.\n\n\n== Strategy ==\nThere is still uncertainty as to whether predators behave with a general tactic or strategy while preying. However, among pursuit predators there are several common behaviors. Often, predators will scout potential prey, assessing prey quantity and density prior to engaging in a pursuit. Certain predators choose to pursue prey primarily in a group of conspecifics; these animals are known as pack hunters or group pursuers. Other species choose to hunt alone. These two behaviors are typically due to differences in hunting success, where some groups are very successful in groups and others are more successful alone. Pursuit predators may also choose to either exhaust their metabolic r", metadata={'title': 'Pursuit predation', 'summary': "Pursuit predation is a form of predation in which predators actively give chase to their prey, either solitarily or as a group. It is an alternate predation strategy to ambush predation — pursuit predators rely on superior speed, endurance and/or teamwork to seize the prey, while ambush predators use concealment, luring, exploiting of surroundings and the element of surprise to capture the prey. While the two patterns of predation are not mutually exclusive, morphological differences in an organism's body plan can create an evolutionary bias favoring either type of predation.\nPursuit predation is typically observed in carnivorous species within the kingdom Animalia, such as cheetahs, lions, wolves and early Homo species. The chase can be initiated either by the predator, or by the prey if it is alerted to a predator's presence and attempt to flee before the predator gets close. The chase ends either when the predator successfully catches up and tackles the prey, or when the predator abandons the attempt after the prey outruns it and escapes.\nOne particular form of pursuit predation is persistence hunting, where the predator stalks the prey slowly but persistently to wear it down physically with fatigue or overheating; some animals are examples of both types of pursuit.", 'source': 'https://en.wikipedia.org/wiki/Pursuit_predation'})],
'annotations': [{'source_id': 0,
'quote': 'The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph); it has evolved specialized adaptations for speed, including a light build, long thin legs and a long tail.'}]}
LangSmith trace: https://smith.langchain.com/public/8f30dbe5-9364-420c-9d90-63859ad06dcb/r
If the answer was long we could first split it up and then apply the citation chain to every few sentences of the answer. |
https://python.langchain.com/docs/use_cases/question_answering/conversational_retrieval_agents/ | ## Using agents
This is an agent specifically optimized for doing retrieval when necessary and also holding a conversation.
To start, we will set up the retriever we want to use, and then turn it into a retriever tool. Next, we will use the high level constructor for this type of agent. Finally, we will walk through how to construct a conversational retrieval agent from components.
```
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai faiss-cpu
```
## The Retriever[](#the-retriever "Direct link to The Retriever")
To start, we need a retriever to use! The code here is mostly just example code. Feel free to use your own retriever and skip to the section on creating a retriever tool.
```
from langchain_community.document_loaders import TextLoaderloader = TextLoader("../../modules/state_of_the_union.txt")documents = loader.load()
```
```
from langchain_community.vectorstores import FAISSfrom langchain_openai import OpenAIEmbeddingsfrom langchain_text_splitters import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)texts = text_splitter.split_documents(documents)embeddings = OpenAIEmbeddings()db = FAISS.from_documents(texts, embeddings)
```
```
retriever = db.as_retriever()
```
Now we need to create a tool for our retriever. The main things we need to pass in are a name for the retriever as well as a description. These will both be used by the language model, so they should be informative.
```
from langchain.tools.retriever import create_retriever_tooltool = create_retriever_tool( retriever, "search_state_of_union", "Searches and returns excerpts from the 2022 State of the Union.",)tools = [tool]
```
## Agent Constructor[](#agent-constructor "Direct link to Agent Constructor")
Here, we will use the high level `create_openai_tools_agent` API to construct the agent.
Notice that beside the list of tools, the only thing we need to pass in is a language model to use. Under the hood, this agent is using the OpenAI tool-calling capabilities, so we need to use a ChatOpenAI model.
```
from langchain import hubprompt = hub.pull("hwchase17/openai-tools-agent")prompt.messages
```
```
[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are a helpful assistant')), MessagesPlaceholder(variable_name='chat_history', optional=True), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='{input}')), MessagesPlaceholder(variable_name='agent_scratchpad')]
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0)
```
```
from langchain.agents import AgentExecutor, create_openai_tools_agentagent = create_openai_tools_agent(llm, tools, prompt)agent_executor = AgentExecutor(agent=agent, tools=tools)
```
We can now try it out!
```
result = agent_executor.invoke({"input": "hi, im bob"})
```
```
'Hello Bob! How can I assist you today?'
```
Notice that it now does retrieval
```
result = agent_executor.invoke( { "input": "what did the president say about ketanji brown jackson in the most recent state of the union?" })
```
```
"In the most recent state of the union, the President mentioned Kentaji Brown Jackson. The President nominated Circuit Court of Appeals Judge Ketanji Brown Jackson to serve on the United States Supreme Court. The President described Judge Ketanji Brown Jackson as one of our nation's top legal minds who will continue Justice Breyer's legacy of excellence."
```
Notice that the follow up question asks about information previously retrieved, so no need to do another retrieval
```
result = agent_executor.invoke( {"input": "how long ago did the president nominate ketanji brown jackson?"})
```
```
> Entering new AgentExecutor chain...The President nominated Judge Ketanji Brown Jackson four days ago.> Finished chain.
```
```
'The President nominated Judge Ketanji Brown Jackson four days ago.'
```
For more on how to use agents with retrievers and other tools, head to the [Agents](https://python.langchain.com/docs/modules/agents/) section. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:23.459Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/conversational_retrieval_agents/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/conversational_retrieval_agents/",
"description": "This is an agent specifically optimized for doing retrieval when",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7910",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"conversational_retrieval_agents\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:23 GMT",
"etag": "W/\"212d3b28b4cd0f19a2761860985471c8\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wv8xj-1713753983254-8bf704339539"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/conversational_retrieval_agents/",
"property": "og:url"
},
{
"content": "Using agents | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This is an agent specifically optimized for doing retrieval when",
"property": "og:description"
}
],
"title": "Using agents | 🦜️🔗 LangChain"
} | Using agents
This is an agent specifically optimized for doing retrieval when necessary and also holding a conversation.
To start, we will set up the retriever we want to use, and then turn it into a retriever tool. Next, we will use the high level constructor for this type of agent. Finally, we will walk through how to construct a conversational retrieval agent from components.
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai faiss-cpu
The Retriever
To start, we need a retriever to use! The code here is mostly just example code. Feel free to use your own retriever and skip to the section on creating a retriever tool.
from langchain_community.document_loaders import TextLoader
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
Now we need to create a tool for our retriever. The main things we need to pass in are a name for the retriever as well as a description. These will both be used by the language model, so they should be informative.
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"search_state_of_union",
"Searches and returns excerpts from the 2022 State of the Union.",
)
tools = [tool]
Agent Constructor
Here, we will use the high level create_openai_tools_agent API to construct the agent.
Notice that beside the list of tools, the only thing we need to pass in is a language model to use. Under the hood, this agent is using the OpenAI tool-calling capabilities, so we need to use a ChatOpenAI model.
from langchain import hub
prompt = hub.pull("hwchase17/openai-tools-agent")
prompt.messages
[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are a helpful assistant')),
MessagesPlaceholder(variable_name='chat_history', optional=True),
HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='{input}')),
MessagesPlaceholder(variable_name='agent_scratchpad')]
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
from langchain.agents import AgentExecutor, create_openai_tools_agent
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
We can now try it out!
result = agent_executor.invoke({"input": "hi, im bob"})
'Hello Bob! How can I assist you today?'
Notice that it now does retrieval
result = agent_executor.invoke(
{
"input": "what did the president say about ketanji brown jackson in the most recent state of the union?"
}
)
"In the most recent state of the union, the President mentioned Kentaji Brown Jackson. The President nominated Circuit Court of Appeals Judge Ketanji Brown Jackson to serve on the United States Supreme Court. The President described Judge Ketanji Brown Jackson as one of our nation's top legal minds who will continue Justice Breyer's legacy of excellence."
Notice that the follow up question asks about information previously retrieved, so no need to do another retrieval
result = agent_executor.invoke(
{"input": "how long ago did the president nominate ketanji brown jackson?"}
)
> Entering new AgentExecutor chain...
The President nominated Judge Ketanji Brown Jackson four days ago.
> Finished chain.
'The President nominated Judge Ketanji Brown Jackson four days ago.'
For more on how to use agents with retrievers and other tools, head to the Agents section. |
https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa/ | ## Using local models
The popularity of projects like [PrivateGPT](https://github.com/imartinez/privateGPT), [llama.cpp](https://github.com/ggerganov/llama.cpp), [GPT4All](https://github.com/nomic-ai/gpt4all), and [llamafile](https://github.com/Mozilla-Ocho/llamafile) underscore the importance of running LLMs locally.
LangChain has [integrations](https://integrations.langchain.com/) with many open-source LLMs that can be run locally.
See [here](https://python.langchain.com/docs/guides/development/local_llms/) for setup instructions for these LLMs.
For example, here we show how to run `GPT4All` or `LLaMA2` locally (e.g., on your laptop) using local embeddings and a local LLM.
## Document Loading[](#document-loading "Direct link to Document Loading")
First, install packages needed for local embeddings and vector storage.
```
%pip install --upgrade --quiet langchain langchain-community langchainhub gpt4all langchain-chroma
```
Load and split an example document.
We’ll use a blog post on agents as an example.
```
from langchain_community.document_loaders import WebBaseLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")data = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)all_splits = text_splitter.split_documents(data)
```
Next, the below steps will download the `GPT4All` embeddings locally (if you don’t already have them).
```
from langchain_chroma import Chromafrom langchain_community.embeddings import GPT4AllEmbeddingsvectorstore = Chroma.from_documents(documents=all_splits, embedding=GPT4AllEmbeddings())
```
Test similarity search is working with our local embeddings.
```
question = "What are the approaches to Task Decomposition?"docs = vectorstore.similarity_search(question)len(docs)
```
```
Document(page_content='Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log"})
```
## Model[](#model "Direct link to Model")
### LLaMA2[](#llama2 "Direct link to LLaMA2")
Note: new versions of `llama-cpp-python` use GGUF model files (see [here](https://github.com/abetlen/llama-cpp-python/pull/633)).
If you have an existing GGML model, see [here](https://python.langchain.com/docs/integrations/llms/llamacpp/) for instructions for conversion for GGUF.
And / or, you can download a GGUF converted model (e.g., [here](https://huggingface.co/TheBloke)).
Finally, as noted in detail [here](https://python.langchain.com/docs/guides/development/local_llms/) install `llama-cpp-python`
```
%pip install --upgrade --quiet llama-cpp-python
```
To enable use of GPU on Apple Silicon, follow the steps [here](https://github.com/abetlen/llama-cpp-python/blob/main/docs/install/macos.md) to use the Python binding `with Metal support`.
In particular, ensure that `conda` is using the correct virtual environment that you created (`miniforge3`).
E.g., for me:
```
conda activate /Users/rlm/miniforge3/envs/llama
```
With this confirmed:
```
! CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 /Users/rlm/miniforge3/envs/llama/bin/pip install -U llama-cpp-python --no-cache-dir
```
```
from langchain_community.llms import LlamaCpp
```
Setting model parameters as noted in the [llama.cpp docs](https://python.langchain.com/docs/integrations/llms/llamacpp/).
```
n_gpu_layers = 1 # Metal set to 1 is enough.n_batch = 512 # Should be between 1 and n_ctx, consider the amount of RAM of your Apple Silicon Chip.# Make sure the model path is correct for your system!llm = LlamaCpp( model_path="/Users/rlm/Desktop/Code/llama.cpp/models/llama-2-13b-chat.ggufv3.q4_0.bin", n_gpu_layers=n_gpu_layers, n_batch=n_batch, n_ctx=2048, f16_kv=True, # MUST set to True, otherwise you will run into problem after a couple of calls verbose=True,)
```
Note that these indicate that [Metal was enabled properly](https://python.langchain.com/docs/integrations/llms/llamacpp/):
```
ggml_metal_init: allocatingggml_metal_init: using MPS
```
```
llm.invoke("Simulate a rap battle between Stephen Colbert and John Oliver")
```
```
Llama.generate: prefix-match hitllama_print_timings: load time = 4481.74 msllama_print_timings: sample time = 183.05 ms / 256 runs ( 0.72 ms per token, 1398.53 tokens per second)llama_print_timings: prompt eval time = 456.05 ms / 13 tokens ( 35.08 ms per token, 28.51 tokens per second)llama_print_timings: eval time = 7375.20 ms / 255 runs ( 28.92 ms per token, 34.58 tokens per second)llama_print_timings: total time = 8388.92 ms
```
```
by jonathan Here's the hypothetical rap battle:[Stephen Colbert]: Yo, this is Stephen Colbert, known for my comedy show. I'm here to put some sense in your mind, like an enema do-go. Your opponent? A man of laughter and witty quips, John Oliver! Now let's see who gets the most laughs while taking shots at each other[John Oliver]: Yo, this is John Oliver, known for my own comedy show. I'm here to take your mind on an adventure through wit and humor. But first, allow me to you to our contestant: Stephen Colbert! His show has been around since the '90s, but it's time to see who can out-rap whom[Stephen Colbert]: You claim to be a witty man, John Oliver, with your British charm and clever remarks. But my knows that I'm America's funnyman! Who's the one taking you? Nobody![John Oliver]: Hey Stephen Colbert, don't get too cocky. You may
```
```
"by jonathan \n\nHere's the hypothetical rap battle:\n\n[Stephen Colbert]: Yo, this is Stephen Colbert, known for my comedy show. I'm here to put some sense in your mind, like an enema do-go. Your opponent? A man of laughter and witty quips, John Oliver! Now let's see who gets the most laughs while taking shots at each other\n\n[John Oliver]: Yo, this is John Oliver, known for my own comedy show. I'm here to take your mind on an adventure through wit and humor. But first, allow me to you to our contestant: Stephen Colbert! His show has been around since the '90s, but it's time to see who can out-rap whom\n\n[Stephen Colbert]: You claim to be a witty man, John Oliver, with your British charm and clever remarks. But my knows that I'm America's funnyman! Who's the one taking you? Nobody!\n\n[John Oliver]: Hey Stephen Colbert, don't get too cocky. You may"
```
### GPT4All[](#gpt4all "Direct link to GPT4All")
Similarly, we can use `GPT4All`.
[Download the GPT4All model binary](https://python.langchain.com/docs/integrations/llms/gpt4all/).
The Model Explorer on the [GPT4All](https://gpt4all.io/index.html) is a great way to choose and download a model.
Then, specify the path that you downloaded to to.
E.g., for me, the model lives here:
`/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin`
```
from langchain_community.llms import GPT4Allgpt4all = GPT4All( model="/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin", max_tokens=2048,)
```
### llamafile[](#llamafile "Direct link to llamafile")
One of the simplest ways to run an LLM locally is using a [llamafile](https://github.com/Mozilla-Ocho/llamafile). All you need to do is:
1. Download a llamafile from [HuggingFace](https://huggingface.co/models?other=llamafile)
2. Make the file executable
3. Run the file
llamafiles bundle model weights and a [specially-compiled](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#technical-details) version of [`llama.cpp`](https://github.com/ggerganov/llama.cpp) into a single file that can run on most computers without any additional dependencies. They also come with an embedded inference server that provides an [API](https://github.com/Mozilla-Ocho/llamafile/blob/main/llama.cpp/server/README.md#api-endpoints) for interacting with your model.
Here’s a simple bash script that shows all 3 setup steps:
```
# Download a llamafile from HuggingFacewget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile# Make the file executable. On Windows, instead just rename the file to end in ".exe".chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile# Start the model server. Listens at http://localhost:8080 by default../TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser
```
After you run the above setup steps, you can interact with the model via LangChain:
```
from langchain_community.llms.llamafile import Llamafilellamafile = Llamafile()llamafile.invoke("Here is my grandmother's beloved recipe for spaghetti and meatballs:")
```
```
'\n-1 1/2 (8 oz. Pounds) ground beef, browned and cooked until no longer pink\n-3 cups whole wheat spaghetti\n-4 (10 oz) cans diced tomatoes with garlic and basil\n-2 eggs, beaten\n-1 cup grated parmesan cheese\n-1/2 teaspoon salt\n-1/4 teaspoon black pepper\n-1 cup breadcrumbs (16 oz)\n-2 tablespoons olive oil\n\nInstructions:\n1. Cook spaghetti according to package directions. Drain and set aside.\n2. In a large skillet, brown ground beef over medium heat until no longer pink. Drain any excess grease.\n3. Stir in diced tomatoes with garlic and basil, and season with salt and pepper. Cook for 5 to 7 minutes or until sauce is heated through. Set aside.\n4. In a large bowl, beat eggs with a fork or whisk until fluffy. Add cheese, salt, and black pepper. Set aside.\n5. In another bowl, combine breadcrumbs and olive oil. Dip each spaghetti into the egg mixture and then coat in the breadcrumb mixture. Place on baking sheet lined with parchment paper to prevent sticking. Repeat until all spaghetti are coated.\n6. Heat oven to 375 degrees. Bake for 18 to 20 minutes, or until lightly golden brown.\n7. Serve hot with meatballs and sauce on the side. Enjoy!'
```
## Using in a chain[](#using-in-a-chain "Direct link to Using in a chain")
We can create a summarization chain with either model by passing in the retrieved docs and a simple prompt.
It formats the prompt template using the input key values provided and passes the formatted string to `GPT4All`, `LLama-V2`, or another specified LLM.
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplate# Promptprompt = PromptTemplate.from_template( "Summarize the main themes in these retrieved docs: {docs}")# Chaindef format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)chain = {"docs": format_docs} | prompt | llm | StrOutputParser()# Runquestion = "What are the approaches to Task Decomposition?"docs = vectorstore.similarity_search(question)chain.invoke(docs)
```
```
Llama.generate: prefix-match hitllama_print_timings: load time = 1191.88 msllama_print_timings: sample time = 134.47 ms / 193 runs ( 0.70 ms per token, 1435.25 tokens per second)llama_print_timings: prompt eval time = 39470.18 ms / 1055 tokens ( 37.41 ms per token, 26.73 tokens per second)llama_print_timings: eval time = 8090.85 ms / 192 runs ( 42.14 ms per token, 23.73 tokens per second)llama_print_timings: total time = 47943.12 ms
```
```
Based on the retrieved documents, the main themes are:1. Task decomposition: The ability to break down complex tasks into smaller subtasks, which can be handled by an LLM or other components of the agent system.2. LLM as the core controller: The use of a large language model (LLM) as the primary controller of an autonomous agent system, complemented by other key components such as a knowledge graph and a planner.3. Potentiality of LLM: The idea that LLMs have the potential to be used as powerful general problem solvers, not just for generating well-written copies but also for solving complex tasks and achieving human-like intelligence.4. Challenges in long-term planning: The challenges in planning over a lengthy history and effectively exploring the solution space, which are important limitations of current LLM-based autonomous agent systems.
```
```
'\nBased on the retrieved documents, the main themes are:\n1. Task decomposition: The ability to break down complex tasks into smaller subtasks, which can be handled by an LLM or other components of the agent system.\n2. LLM as the core controller: The use of a large language model (LLM) as the primary controller of an autonomous agent system, complemented by other key components such as a knowledge graph and a planner.\n3. Potentiality of LLM: The idea that LLMs have the potential to be used as powerful general problem solvers, not just for generating well-written copies but also for solving complex tasks and achieving human-like intelligence.\n4. Challenges in long-term planning: The challenges in planning over a lengthy history and effectively exploring the solution space, which are important limitations of current LLM-based autonomous agent systems.'
```
## Q&A[](#qa "Direct link to Q&A")
We can also use the LangChain Prompt Hub to store and fetch prompts that are model-specific.
Let’s try with a default RAG prompt, [here](https://smith.langchain.com/hub/rlm/rag-prompt).
```
from langchain import hubrag_prompt = hub.pull("rlm/rag-prompt")rag_prompt.messages
```
```
[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question} \nContext: {context} \nAnswer:"))]
```
```
from langchain_core.runnables import RunnablePassthrough, RunnablePick# Chainchain = ( RunnablePassthrough.assign(context=RunnablePick("context") | format_docs) | rag_prompt | llm | StrOutputParser())# Runchain.invoke({"context": docs, "question": question})
```
```
Llama.generate: prefix-match hitllama_print_timings: load time = 11326.20 msllama_print_timings: sample time = 33.03 ms / 47 runs ( 0.70 ms per token, 1422.86 tokens per second)llama_print_timings: prompt eval time = 1387.31 ms / 242 tokens ( 5.73 ms per token, 174.44 tokens per second)llama_print_timings: eval time = 1321.62 ms / 46 runs ( 28.73 ms per token, 34.81 tokens per second)llama_print_timings: total time = 2801.08 ms
```
```
Task can be done by down a task into smaller subtasks, using simple prompting like "Steps for XYZ." or task-specific like "Write a story outline" for writing a novel.
```
```
{'output_text': '\nTask can be done by down a task into smaller subtasks, using simple prompting like "Steps for XYZ." or task-specific like "Write a story outline" for writing a novel.'}
```
Now, let’s try with [a prompt specifically for LLaMA](https://smith.langchain.com/hub/rlm/rag-prompt-llama), which [includes special tokens](https://huggingface.co/blog/llama2#how-to-prompt-llama-2).
```
# Promptrag_prompt_llama = hub.pull("rlm/rag-prompt-llama")rag_prompt_llama.messages
```
```
ChatPromptTemplate(input_variables=['question', 'context'], output_parser=None, partial_variables={}, messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['question', 'context'], output_parser=None, partial_variables={}, template="[INST]<<SYS>> You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.<</SYS>> \nQuestion: {question} \nContext: {context} \nAnswer: [/INST]", template_format='f-string', validate_template=True), additional_kwargs={})])
```
```
# Chainchain = ( RunnablePassthrough.assign(context=RunnablePick("context") | format_docs) | rag_prompt_llama | llm | StrOutputParser())# Runchain.invoke({"context": docs, "question": question})
```
```
Llama.generate: prefix-match hitllama_print_timings: load time = 11326.20 msllama_print_timings: sample time = 144.81 ms / 207 runs ( 0.70 ms per token, 1429.47 tokens per second)llama_print_timings: prompt eval time = 1506.13 ms / 258 tokens ( 5.84 ms per token, 171.30 tokens per second)llama_print_timings: eval time = 6231.92 ms / 206 runs ( 30.25 ms per token, 33.06 tokens per second)llama_print_timings: total time = 8158.41 ms
```
```
Sure, I'd be happy to help! Based on the context, here are some to task:1. LLM with simple prompting: This using a large model (LLM) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to decompose tasks into smaller steps.2. Task-specific: Another is to use task-specific, such as "Write a story outline" for writing a novel, to guide the of tasks.3. Human inputs:, human inputs can be used to supplement the process, in cases where the task a high degree of creativity or expertise.As fores in long-term and task, one major is that LLMs to adjust plans when faced with errors, making them less robust to humans who learn from trial and error.
```
```
{'output_text': ' Sure, I\'d be happy to help! Based on the context, here are some to task:\n\n1. LLM with simple prompting: This using a large model (LLM) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to decompose tasks into smaller steps.\n2. Task-specific: Another is to use task-specific, such as "Write a story outline" for writing a novel, to guide the of tasks.\n3. Human inputs:, human inputs can be used to supplement the process, in cases where the task a high degree of creativity or expertise.\n\nAs fores in long-term and task, one major is that LLMs to adjust plans when faced with errors, making them less robust to humans who learn from trial and error.'}
```
## Q&A with retrieval[](#qa-with-retrieval "Direct link to Q&A with retrieval")
Instead of manually passing in docs, we can automatically retrieve them from our vector store based on the user question.
This will use a QA default prompt (shown [here](https://github.com/langchain-ai/langchain/blob/275b926cf745b5668d3ea30236635e20e7866442/langchain/chains/retrieval_qa/prompt.py#L4)) and will retrieve from the vectorDB.
```
retriever = vectorstore.as_retriever()qa_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | rag_prompt | llm | StrOutputParser())
```
```
qa_chain.invoke(question)
```
```
Llama.generate: prefix-match hitllama_print_timings: load time = 11326.20 msllama_print_timings: sample time = 139.20 ms / 200 runs ( 0.70 ms per token, 1436.76 tokens per second)llama_print_timings: prompt eval time = 1532.26 ms / 258 tokens ( 5.94 ms per token, 168.38 tokens per second)llama_print_timings: eval time = 5977.62 ms / 199 runs ( 30.04 ms per token, 33.29 tokens per second)llama_print_timings: total time = 7916.21 ms
```
```
Sure! Based on the context, here's my answer to your:There are several to task,:1. LLM-based with simple prompting, such as "Steps for XYZ" or "What are the subgoals for achieving XYZ?"2. Task-specific, like "Write a story outline" for writing a novel.3. Human inputs to guide the process.These can be used to decompose complex tasks into smaller, more manageable subtasks, which can help improve the and effectiveness of task. However, long-term and task can being due to the need to plan over a lengthy history and explore the space., LLMs may to adjust plans when faced with errors, making them less robust to human learners who can learn from trial and error.
```
```
{'query': 'What are the approaches to Task Decomposition?', 'result': ' Sure! Based on the context, here\'s my answer to your:\n\nThere are several to task,:\n\n1. LLM-based with simple prompting, such as "Steps for XYZ" or "What are the subgoals for achieving XYZ?"\n2. Task-specific, like "Write a story outline" for writing a novel.\n3. Human inputs to guide the process.\n\nThese can be used to decompose complex tasks into smaller, more manageable subtasks, which can help improve the and effectiveness of task. However, long-term and task can being due to the need to plan over a lengthy history and explore the space., LLMs may to adjust plans when faced with errors, making them less robust to human learners who can learn from trial and error.'}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:24.321Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa/",
"description": "The popularity of projects like",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4948",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"local_retrieval_qa\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"416570bd52f43446d1d242a7bd25fbfe\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::hhtvz-1713753984128-87984b9c04f7"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa/",
"property": "og:url"
},
{
"content": "Using local models | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "The popularity of projects like",
"property": "og:description"
}
],
"title": "Using local models | 🦜️🔗 LangChain"
} | Using local models
The popularity of projects like PrivateGPT, llama.cpp, GPT4All, and llamafile underscore the importance of running LLMs locally.
LangChain has integrations with many open-source LLMs that can be run locally.
See here for setup instructions for these LLMs.
For example, here we show how to run GPT4All or LLaMA2 locally (e.g., on your laptop) using local embeddings and a local LLM.
Document Loading
First, install packages needed for local embeddings and vector storage.
%pip install --upgrade --quiet langchain langchain-community langchainhub gpt4all langchain-chroma
Load and split an example document.
We’ll use a blog post on agents as an example.
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
Next, the below steps will download the GPT4All embeddings locally (if you don’t already have them).
from langchain_chroma import Chroma
from langchain_community.embeddings import GPT4AllEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=GPT4AllEmbeddings())
Test similarity search is working with our local embeddings.
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
len(docs)
Document(page_content='Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log"})
Model
LLaMA2
Note: new versions of llama-cpp-python use GGUF model files (see here).
If you have an existing GGML model, see here for instructions for conversion for GGUF.
And / or, you can download a GGUF converted model (e.g., here).
Finally, as noted in detail here install llama-cpp-python
%pip install --upgrade --quiet llama-cpp-python
To enable use of GPU on Apple Silicon, follow the steps here to use the Python binding with Metal support.
In particular, ensure that conda is using the correct virtual environment that you created (miniforge3).
E.g., for me:
conda activate /Users/rlm/miniforge3/envs/llama
With this confirmed:
! CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 /Users/rlm/miniforge3/envs/llama/bin/pip install -U llama-cpp-python --no-cache-dir
from langchain_community.llms import LlamaCpp
Setting model parameters as noted in the llama.cpp docs.
n_gpu_layers = 1 # Metal set to 1 is enough.
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of RAM of your Apple Silicon Chip.
# Make sure the model path is correct for your system!
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama.cpp/models/llama-2-13b-chat.ggufv3.q4_0.bin",
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
n_ctx=2048,
f16_kv=True, # MUST set to True, otherwise you will run into problem after a couple of calls
verbose=True,
)
Note that these indicate that Metal was enabled properly:
ggml_metal_init: allocating
ggml_metal_init: using MPS
llm.invoke("Simulate a rap battle between Stephen Colbert and John Oliver")
Llama.generate: prefix-match hit
llama_print_timings: load time = 4481.74 ms
llama_print_timings: sample time = 183.05 ms / 256 runs ( 0.72 ms per token, 1398.53 tokens per second)
llama_print_timings: prompt eval time = 456.05 ms / 13 tokens ( 35.08 ms per token, 28.51 tokens per second)
llama_print_timings: eval time = 7375.20 ms / 255 runs ( 28.92 ms per token, 34.58 tokens per second)
llama_print_timings: total time = 8388.92 ms
by jonathan
Here's the hypothetical rap battle:
[Stephen Colbert]: Yo, this is Stephen Colbert, known for my comedy show. I'm here to put some sense in your mind, like an enema do-go. Your opponent? A man of laughter and witty quips, John Oliver! Now let's see who gets the most laughs while taking shots at each other
[John Oliver]: Yo, this is John Oliver, known for my own comedy show. I'm here to take your mind on an adventure through wit and humor. But first, allow me to you to our contestant: Stephen Colbert! His show has been around since the '90s, but it's time to see who can out-rap whom
[Stephen Colbert]: You claim to be a witty man, John Oliver, with your British charm and clever remarks. But my knows that I'm America's funnyman! Who's the one taking you? Nobody!
[John Oliver]: Hey Stephen Colbert, don't get too cocky. You may
"by jonathan \n\nHere's the hypothetical rap battle:\n\n[Stephen Colbert]: Yo, this is Stephen Colbert, known for my comedy show. I'm here to put some sense in your mind, like an enema do-go. Your opponent? A man of laughter and witty quips, John Oliver! Now let's see who gets the most laughs while taking shots at each other\n\n[John Oliver]: Yo, this is John Oliver, known for my own comedy show. I'm here to take your mind on an adventure through wit and humor. But first, allow me to you to our contestant: Stephen Colbert! His show has been around since the '90s, but it's time to see who can out-rap whom\n\n[Stephen Colbert]: You claim to be a witty man, John Oliver, with your British charm and clever remarks. But my knows that I'm America's funnyman! Who's the one taking you? Nobody!\n\n[John Oliver]: Hey Stephen Colbert, don't get too cocky. You may"
GPT4All
Similarly, we can use GPT4All.
Download the GPT4All model binary.
The Model Explorer on the GPT4All is a great way to choose and download a model.
Then, specify the path that you downloaded to to.
E.g., for me, the model lives here:
/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin
from langchain_community.llms import GPT4All
gpt4all = GPT4All(
model="/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin",
max_tokens=2048,
)
llamafile
One of the simplest ways to run an LLM locally is using a llamafile. All you need to do is:
Download a llamafile from HuggingFace
Make the file executable
Run the file
llamafiles bundle model weights and a specially-compiled version of llama.cpp into a single file that can run on most computers without any additional dependencies. They also come with an embedded inference server that provides an API for interacting with your model.
Here’s a simple bash script that shows all 3 setup steps:
# Download a llamafile from HuggingFace
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Make the file executable. On Windows, instead just rename the file to end in ".exe".
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Start the model server. Listens at http://localhost:8080 by default.
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser
After you run the above setup steps, you can interact with the model via LangChain:
from langchain_community.llms.llamafile import Llamafile
llamafile = Llamafile()
llamafile.invoke("Here is my grandmother's beloved recipe for spaghetti and meatballs:")
'\n-1 1/2 (8 oz. Pounds) ground beef, browned and cooked until no longer pink\n-3 cups whole wheat spaghetti\n-4 (10 oz) cans diced tomatoes with garlic and basil\n-2 eggs, beaten\n-1 cup grated parmesan cheese\n-1/2 teaspoon salt\n-1/4 teaspoon black pepper\n-1 cup breadcrumbs (16 oz)\n-2 tablespoons olive oil\n\nInstructions:\n1. Cook spaghetti according to package directions. Drain and set aside.\n2. In a large skillet, brown ground beef over medium heat until no longer pink. Drain any excess grease.\n3. Stir in diced tomatoes with garlic and basil, and season with salt and pepper. Cook for 5 to 7 minutes or until sauce is heated through. Set aside.\n4. In a large bowl, beat eggs with a fork or whisk until fluffy. Add cheese, salt, and black pepper. Set aside.\n5. In another bowl, combine breadcrumbs and olive oil. Dip each spaghetti into the egg mixture and then coat in the breadcrumb mixture. Place on baking sheet lined with parchment paper to prevent sticking. Repeat until all spaghetti are coated.\n6. Heat oven to 375 degrees. Bake for 18 to 20 minutes, or until lightly golden brown.\n7. Serve hot with meatballs and sauce on the side. Enjoy!'
Using in a chain
We can create a summarization chain with either model by passing in the retrieved docs and a simple prompt.
It formats the prompt template using the input key values provided and passes the formatted string to GPT4All, LLama-V2, or another specified LLM.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# Prompt
prompt = PromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)
# Chain
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | llm | StrOutputParser()
# Run
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
chain.invoke(docs)
Llama.generate: prefix-match hit
llama_print_timings: load time = 1191.88 ms
llama_print_timings: sample time = 134.47 ms / 193 runs ( 0.70 ms per token, 1435.25 tokens per second)
llama_print_timings: prompt eval time = 39470.18 ms / 1055 tokens ( 37.41 ms per token, 26.73 tokens per second)
llama_print_timings: eval time = 8090.85 ms / 192 runs ( 42.14 ms per token, 23.73 tokens per second)
llama_print_timings: total time = 47943.12 ms
Based on the retrieved documents, the main themes are:
1. Task decomposition: The ability to break down complex tasks into smaller subtasks, which can be handled by an LLM or other components of the agent system.
2. LLM as the core controller: The use of a large language model (LLM) as the primary controller of an autonomous agent system, complemented by other key components such as a knowledge graph and a planner.
3. Potentiality of LLM: The idea that LLMs have the potential to be used as powerful general problem solvers, not just for generating well-written copies but also for solving complex tasks and achieving human-like intelligence.
4. Challenges in long-term planning: The challenges in planning over a lengthy history and effectively exploring the solution space, which are important limitations of current LLM-based autonomous agent systems.
'\nBased on the retrieved documents, the main themes are:\n1. Task decomposition: The ability to break down complex tasks into smaller subtasks, which can be handled by an LLM or other components of the agent system.\n2. LLM as the core controller: The use of a large language model (LLM) as the primary controller of an autonomous agent system, complemented by other key components such as a knowledge graph and a planner.\n3. Potentiality of LLM: The idea that LLMs have the potential to be used as powerful general problem solvers, not just for generating well-written copies but also for solving complex tasks and achieving human-like intelligence.\n4. Challenges in long-term planning: The challenges in planning over a lengthy history and effectively exploring the solution space, which are important limitations of current LLM-based autonomous agent systems.'
Q&A
We can also use the LangChain Prompt Hub to store and fetch prompts that are model-specific.
Let’s try with a default RAG prompt, here.
from langchain import hub
rag_prompt = hub.pull("rlm/rag-prompt")
rag_prompt.messages
[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question} \nContext: {context} \nAnswer:"))]
from langchain_core.runnables import RunnablePassthrough, RunnablePick
# Chain
chain = (
RunnablePassthrough.assign(context=RunnablePick("context") | format_docs)
| rag_prompt
| llm
| StrOutputParser()
)
# Run
chain.invoke({"context": docs, "question": question})
Llama.generate: prefix-match hit
llama_print_timings: load time = 11326.20 ms
llama_print_timings: sample time = 33.03 ms / 47 runs ( 0.70 ms per token, 1422.86 tokens per second)
llama_print_timings: prompt eval time = 1387.31 ms / 242 tokens ( 5.73 ms per token, 174.44 tokens per second)
llama_print_timings: eval time = 1321.62 ms / 46 runs ( 28.73 ms per token, 34.81 tokens per second)
llama_print_timings: total time = 2801.08 ms
Task can be done by down a task into smaller subtasks, using simple prompting like "Steps for XYZ." or task-specific like "Write a story outline" for writing a novel.
{'output_text': '\nTask can be done by down a task into smaller subtasks, using simple prompting like "Steps for XYZ." or task-specific like "Write a story outline" for writing a novel.'}
Now, let’s try with a prompt specifically for LLaMA, which includes special tokens.
# Prompt
rag_prompt_llama = hub.pull("rlm/rag-prompt-llama")
rag_prompt_llama.messages
ChatPromptTemplate(input_variables=['question', 'context'], output_parser=None, partial_variables={}, messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['question', 'context'], output_parser=None, partial_variables={}, template="[INST]<<SYS>> You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.<</SYS>> \nQuestion: {question} \nContext: {context} \nAnswer: [/INST]", template_format='f-string', validate_template=True), additional_kwargs={})])
# Chain
chain = (
RunnablePassthrough.assign(context=RunnablePick("context") | format_docs)
| rag_prompt_llama
| llm
| StrOutputParser()
)
# Run
chain.invoke({"context": docs, "question": question})
Llama.generate: prefix-match hit
llama_print_timings: load time = 11326.20 ms
llama_print_timings: sample time = 144.81 ms / 207 runs ( 0.70 ms per token, 1429.47 tokens per second)
llama_print_timings: prompt eval time = 1506.13 ms / 258 tokens ( 5.84 ms per token, 171.30 tokens per second)
llama_print_timings: eval time = 6231.92 ms / 206 runs ( 30.25 ms per token, 33.06 tokens per second)
llama_print_timings: total time = 8158.41 ms
Sure, I'd be happy to help! Based on the context, here are some to task:
1. LLM with simple prompting: This using a large model (LLM) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to decompose tasks into smaller steps.
2. Task-specific: Another is to use task-specific, such as "Write a story outline" for writing a novel, to guide the of tasks.
3. Human inputs:, human inputs can be used to supplement the process, in cases where the task a high degree of creativity or expertise.
As fores in long-term and task, one major is that LLMs to adjust plans when faced with errors, making them less robust to humans who learn from trial and error.
{'output_text': ' Sure, I\'d be happy to help! Based on the context, here are some to task:\n\n1. LLM with simple prompting: This using a large model (LLM) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to decompose tasks into smaller steps.\n2. Task-specific: Another is to use task-specific, such as "Write a story outline" for writing a novel, to guide the of tasks.\n3. Human inputs:, human inputs can be used to supplement the process, in cases where the task a high degree of creativity or expertise.\n\nAs fores in long-term and task, one major is that LLMs to adjust plans when faced with errors, making them less robust to humans who learn from trial and error.'}
Q&A with retrieval
Instead of manually passing in docs, we can automatically retrieve them from our vector store based on the user question.
This will use a QA default prompt (shown here) and will retrieve from the vectorDB.
retriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
qa_chain.invoke(question)
Llama.generate: prefix-match hit
llama_print_timings: load time = 11326.20 ms
llama_print_timings: sample time = 139.20 ms / 200 runs ( 0.70 ms per token, 1436.76 tokens per second)
llama_print_timings: prompt eval time = 1532.26 ms / 258 tokens ( 5.94 ms per token, 168.38 tokens per second)
llama_print_timings: eval time = 5977.62 ms / 199 runs ( 30.04 ms per token, 33.29 tokens per second)
llama_print_timings: total time = 7916.21 ms
Sure! Based on the context, here's my answer to your:
There are several to task,:
1. LLM-based with simple prompting, such as "Steps for XYZ" or "What are the subgoals for achieving XYZ?"
2. Task-specific, like "Write a story outline" for writing a novel.
3. Human inputs to guide the process.
These can be used to decompose complex tasks into smaller, more manageable subtasks, which can help improve the and effectiveness of task. However, long-term and task can being due to the need to plan over a lengthy history and explore the space., LLMs may to adjust plans when faced with errors, making them less robust to human learners who can learn from trial and error.
{'query': 'What are the approaches to Task Decomposition?',
'result': ' Sure! Based on the context, here\'s my answer to your:\n\nThere are several to task,:\n\n1. LLM-based with simple prompting, such as "Steps for XYZ" or "What are the subgoals for achieving XYZ?"\n2. Task-specific, like "Write a story outline" for writing a novel.\n3. Human inputs to guide the process.\n\nThese can be used to decompose complex tasks into smaller, more manageable subtasks, which can help improve the and effectiveness of task. However, long-term and task can being due to the need to plan over a lengthy history and explore the space., LLMs may to adjust plans when faced with errors, making them less robust to human learners who can learn from trial and error.'} |
https://python.langchain.com/docs/use_cases/question_answering/quickstart/ | ## Quickstart
LangChain has a number of components designed to help build question-answering applications, and RAG applications more generally. To familiarize ourselves with these, we’ll build a simple Q&A application over a text data source. Along the way we’ll go over a typical Q&A architecture, discuss the relevant LangChain components, and highlight additional resources for more advanced Q&A techniques. We’ll also see how LangSmith can help us trace and understand our application. LangSmith will become increasingly helpful as our application grows in complexity.
## Architecture[](#architecture "Direct link to Architecture")
We’ll create a typical RAG application as outlined in the [Q&A introduction](https://python.langchain.com/docs/use_cases/question_answering/), which has two main components:
**Indexing**: a pipeline for ingesting data from a source and indexing it. _This usually happens offline._
**Retrieval and generation**: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
The full sequence from raw data to answer will look like:
### Indexing[](#indexing "Direct link to Indexing")
1. **Load**: First we need to load our data. We’ll use [DocumentLoaders](https://python.langchain.com/docs/modules/data_connection/document_loaders/) for this.
2. **Split**: [Text splitters](https://python.langchain.com/docs/modules/data_connection/document_transformers/) break large `Documents` into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t fit in a model’s finite context window.
3. **Store**: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a [VectorStore](https://python.langchain.com/docs/modules/data_connection/vectorstores/) and [Embeddings](https://python.langchain.com/docs/modules/data_connection/text_embedding/) model.
### Retrieval and generation[](#retrieval-and-generation "Direct link to Retrieval and generation")
1. **Retrieve**: Given a user input, relevant splits are retrieved from storage using a [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/).
2. **Generate**: A [ChatModel](https://python.langchain.com/docs/modules/model_io/chat/) / [LLM](https://python.langchain.com/docs/modules/model_io/llms/) produces an answer using a prompt that includes the question and the retrieved data
## Setup[](#setup "Direct link to Setup")
### Dependencies[](#dependencies "Direct link to Dependencies")
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any [ChatModel](https://python.langchain.com/docs/modules/model_io/chat/) or [LLM](https://python.langchain.com/docs/modules/model_io/llms/), [Embeddings](https://python.langchain.com/docs/modules/data_connection/text_embedding/), and [VectorStore](https://python.langchain.com/docs/modules/data_connection/vectorstores/) or [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/).
We’ll use the following packages:
```
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
```
We need to set environment variable `OPENAI_API_KEY` for the embeddings model, which can be done directly or loaded from a `.env` file like so:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# import dotenv# dotenv.load_dotenv()
```
### LangSmith[](#langsmith "Direct link to LangSmith")
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with [LangSmith](https://smith.langchain.com/).
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
```
os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Preview[](#preview "Direct link to Preview")
In this guide we’ll build a QA app over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng, which allows us to ask questions about the contents of the post.
We can create a simple indexing pipeline and RAG chain to do this in ~20 lines of code:
```
import bs4from langchain import hubfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_chroma import Chromafrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitter
```
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
```
# Load, chunk and index the contents of the blog.loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ),)docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# Retrieve and generate using the relevant snippets of the blog.retriever = vectorstore.as_retriever()prompt = hub.pull("rlm/rag-prompt")def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
```
```
rag_chain.invoke("What is Task Decomposition?")
```
```
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through prompting techniques like Chain of Thought or Tree of Thoughts, or by using task-specific instructions or human inputs. Task decomposition helps agents plan ahead and manage complicated tasks more effectively.'
```
```
# cleanupvectorstore.delete_collection()
```
Check out the [LangSmith trace](https://smith.langchain.com/public/1c6ca97e-445b-4d00-84b4-c7befcbc59fe/r)
## Detailed walkthrough[](#detailed-walkthrough "Direct link to Detailed walkthrough")
Let’s go through the above code step-by-step to really understand what’s going on.
## 1\. Indexing: Load[](#indexing-load "Direct link to 1. Indexing: Load")
We need to first load the blog post contents. We can use [DocumentLoaders](https://python.langchain.com/docs/modules/data_connection/document_loaders/) for this, which are objects that load in data from a source and return a list of [Documents](https://api.python.langchain.com/en/latest/documents/langchain_core.documents.base.Document.html). A `Document` is an object with some `page_content` (str) and `metadata` (dict).
In this case we’ll use the [WebBaseLoader](https://python.langchain.com/docs/integrations/document_loaders/web_base/), which uses `urllib` to load HTML from web URLs and `BeautifulSoup` to parse it to text. We can customize the HTML -\> text parsing by passing in parameters to the `BeautifulSoup` parser via `bs_kwargs` (see [BeautifulSoup docs](https://beautiful-soup-4.readthedocs.io/en/latest/#beautifulsoup)). In this case only HTML tags with class “post-content”, “post-title”, or “post-header” are relevant, so we’ll remove all others.
```
import bs4from langchain_community.document_loaders import WebBaseLoader# Only keep post title, headers, and content from the full HTML.bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs={"parse_only": bs4_strainer},)docs = loader.load()
```
```
len(docs[0].page_content)
```
```
print(docs[0].page_content[:500])
```
```
LLM Powered Autonomous AgentsDate: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian WengBuilding agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.Agent System Overview#In
```
### Go deeper[](#go-deeper "Direct link to Go deeper")
`DocumentLoader`: Object that loads data from a source as list of `Documents`.
* [Docs](https://python.langchain.com/docs/modules/data_connection/document_loaders/): Detailed documentation on how to use `DocumentLoaders`.
* [Integrations](https://python.langchain.com/docs/integrations/document_loaders/): 160+ integrations to choose from.
* [Interface](https://api.python.langchain.com/en/latest/document_loaders/langchain_core.document_loaders.base.BaseLoader.html): API reference for the base interface.
## 2\. Indexing: Split[](#indexing-split "Direct link to 2. Indexing: Split")
Our loaded document is over 42k characters long. This is too long to fit in the context window of many models. Even for those models that could fit the full post in their context window, models can struggle to find information in very long inputs.
To handle this we’ll split the `Document` into chunks for embedding and vector storage. This should help us retrieve only the most relevant bits of the blog post at run time.
In this case we’ll split our documents into chunks of 1000 characters with 200 characters of overlap between chunks. The overlap helps mitigate the possibility of separating a statement from important context related to it. We use the [RecursiveCharacterTextSplitter](https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_text_splitter/), which will recursively split the document using common separators like new lines until each chunk is the appropriate size. This is the recommended text splitter for generic text use cases.
We set `add_start_index=True` so that the character index at which each split Document starts within the initial Document is preserved as metadata attribute “start\_index”.
```
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True)all_splits = text_splitter.split_documents(docs)
```
```
len(all_splits[0].page_content)
```
```
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 7056}
```
### Go deeper[](#go-deeper-1 "Direct link to Go deeper")
`TextSplitter`: Object that splits a list of `Document`s into smaller chunks. Subclass of `DocumentTransformer`s.
* Explore `Context-aware splitters`, which keep the location (“context”) of each split in the original `Document`: - [Markdown files](https://python.langchain.com/docs/modules/data_connection/document_transformers/markdown_header_metadata/)
* [Code (py or js)](https://python.langchain.com/docs/integrations/document_loaders/source_code/)
* [Scientific papers](https://python.langchain.com/docs/integrations/document_loaders/grobid/)
* [Interface](https://api.python.langchain.com/en/latest/base/langchain_text_splitters.base.TextSplitter.html): API reference for the base interface.
`DocumentTransformer`: Object that performs a transformation on a list of `Document`s.
* [Docs](https://python.langchain.com/docs/modules/data_connection/document_transformers/): Detailed documentation on how to use `DocumentTransformers`
* [Integrations](https://python.langchain.com/docs/integrations/document_transformers/)
* [Interface](https://api.python.langchain.com/en/latest/documents/langchain_core.documents.transformers.BaseDocumentTransformer.html): API reference for the base interface.
## 3\. Indexing: Store[](#indexing-store "Direct link to 3. Indexing: Store")
Now we need to index our 66 text chunks so that we can search over them at runtime. The most common way to do this is to embed the contents of each document split and insert these embeddings into a vector database (or vector store). When we want to search over our splits, we take a text search query, embed it, and perform some sort of “similarity” search to identify the stored splits with the most similar embeddings to our query embedding. The simplest similarity measure is cosine similarity — we measure the cosine of the angle between each pair of embeddings (which are high dimensional vectors).
We can embed and store all of our document splits in a single command using the [Chroma](https://python.langchain.com/docs/integrations/vectorstores/chroma/) vector store and [OpenAIEmbeddings](https://python.langchain.com/docs/integrations/text_embedding/openai/) model.
```
from langchain_chroma import Chromafrom langchain_openai import OpenAIEmbeddingsvectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
```
### Go deeper[](#go-deeper-2 "Direct link to Go deeper")
`Embeddings`: Wrapper around a text embedding model, used for converting text to embeddings.
* [Docs](https://python.langchain.com/docs/modules/data_connection/text_embedding/): Detailed documentation on how to use embeddings.
* [Integrations](https://python.langchain.com/docs/integrations/text_embedding/): 30+ integrations to choose from.
* [Interface](https://api.python.langchain.com/en/latest/embeddings/langchain_core.embeddings.Embeddings.html): API reference for the base interface.
`VectorStore`: Wrapper around a vector database, used for storing and querying embeddings.
* [Docs](https://python.langchain.com/docs/modules/data_connection/vectorstores/): Detailed documentation on how to use vector stores.
* [Integrations](https://python.langchain.com/docs/integrations/vectorstores/): 40+ integrations to choose from.
* [Interface](https://api.python.langchain.com/en/latest/vectorstores/langchain_core.vectorstores.VectorStore.html): API reference for the base interface.
This completes the **Indexing** portion of the pipeline. At this point we have a query-able vector store containing the chunked contents of our blog post. Given a user question, we should ideally be able to return the snippets of the blog post that answer the question.
## 4\. Retrieval and Generation: Retrieve[](#retrieval-and-generation-retrieve "Direct link to 4. Retrieval and Generation: Retrieve")
Now let’s write the actual application logic. We want to create a simple application that takes a user question, searches for documents relevant to that question, passes the retrieved documents and initial question to a model, and returns an answer.
First we need to define our logic for searching over documents. LangChain defines a [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/) interface which wraps an index that can return relevant `Documents` given a string query.
The most common type of `Retriever` is the [VectorStoreRetriever](https://python.langchain.com/docs/modules/data_connection/retrievers/vectorstore/), which uses the similarity search capabilities of a vector store to facilitate retrieval. Any `VectorStore` can easily be turned into a `Retriever` with `VectorStore.as_retriever()`:
```
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
```
```
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
```
```
print(retrieved_docs[0].page_content)
```
```
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
```
### Go deeper[](#go-deeper-3 "Direct link to Go deeper")
Vector stores are commonly used for retrieval, but there are other ways to do retrieval, too.
`Retriever`: An object that returns `Document`s given a text query
* [Docs](https://python.langchain.com/docs/modules/data_connection/retrievers/): Further documentation on the interface and built-in retrieval techniques. Some of which include:
* `MultiQueryRetriever` [generates variants of the input question](https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever/) to improve retrieval hit rate.
* `MultiVectorRetriever` (diagram below) instead generates [variants of the embeddings](https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector/), also in order to improve retrieval hit rate.
* `Max marginal relevance` selects for [relevance and diversity](https://www.cs.cmu.edu/~jgc/publication/The_Use_MMR_Diversity_Based_LTMIR_1998.pdf) among the retrieved documents to avoid passing in duplicate context.
* Documents can be filtered during vector store retrieval using metadata filters, such as with a [Self Query Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/self_query/).
* [Integrations](https://python.langchain.com/docs/integrations/retrievers/): Integrations with retrieval services.
* [Interface](https://api.python.langchain.com/en/latest/retrievers/langchain_core.retrievers.BaseRetriever.html): API reference for the base interface.
## 5\. Retrieval and Generation: Generate[](#retrieval-and-generation-generate "Direct link to 5. Retrieval and Generation: Generate")
Let’s put it all together into a chain that takes a question, retrieves relevant documents, constructs a prompt, passes that to a model, and parses the output.
We’ll use the gpt-3.5-turbo OpenAI chat model, but any LangChain `LLM` or `ChatModel` could be substituted in.
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
We’ll use a prompt for RAG that is checked into the LangChain prompt hub ([here](https://smith.langchain.com/hub/rlm/rag-prompt)).
```
from langchain import hubprompt = hub.pull("rlm/rag-prompt")
```
```
example_messages = prompt.invoke( {"context": "filler context", "question": "filler question"}).to_messages()example_messages
```
```
[HumanMessage(content="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: filler question \nContext: filler context \nAnswer:")]
```
```
print(example_messages[0].content)
```
```
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: filler questionContext: filler contextAnswer:
```
We’ll use the [LCEL Runnable](https://python.langchain.com/docs/expression_language/) protocol to define the chain, allowing us to - pipe together components and functions in a transparent way - automatically trace our chain in LangSmith - get streaming, async, and batched calling out of the box
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughdef format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
```
```
for chunk in rag_chain.stream("What is Task Decomposition?"): print(chunk, end="", flush=True)
```
```
Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks, allowing for easier interpretation and execution by autonomous agents or models. Task decomposition can be done through various methods, such as using prompting techniques, task-specific instructions, or human inputs.
```
Check out the [LangSmith trace](https://smith.langchain.com/public/1799e8db-8a6d-4eb2-84d5-46e8d7d5a99b/r)
### Go deeper[](#go-deeper-4 "Direct link to Go deeper")
#### Choosing a model[](#choosing-a-model "Direct link to Choosing a model")
`ChatModel`: An LLM-backed chat model. Takes in a sequence of messages and returns a message.
* [Docs](https://python.langchain.com/docs/modules/model_io/chat/)
* [Integrations](https://python.langchain.com/docs/integrations/chat/): 25+ integrations to choose from.
* [Interface](https://api.python.langchain.com/en/latest/language_models/langchain_core.language_models.chat_models.BaseChatModel.html): API reference for the base interface.
`LLM`: A text-in-text-out LLM. Takes in a string and returns a string.
* [Docs](https://python.langchain.com/docs/modules/model_io/llms/)
* [Integrations](https://python.langchain.com/docs/integrations/llms/): 75+ integrations to choose from.
* [Interface](https://api.python.langchain.com/en/latest/language_models/langchain_core.language_models.llms.BaseLLM.html): API reference for the base interface.
See a guide on RAG with locally-running models [here](https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa/).
#### Customizing the prompt[](#customizing-the-prompt "Direct link to Customizing the prompt")
As shown above, we can load prompts (e.g., [this RAG prompt](https://smith.langchain.com/hub/rlm/rag-prompt)) from the prompt hub. The prompt can also be easily customized:
```
from langchain_core.prompts import PromptTemplatetemplate = """Use the following pieces of context to answer the question at the end.If you don't know the answer, just say that you don't know, don't try to make up an answer.Use three sentences maximum and keep the answer as concise as possible.Always say "thanks for asking!" at the end of the answer.{context}Question: {question}Helpful Answer:"""custom_rag_prompt = PromptTemplate.from_template(template)rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | custom_rag_prompt | llm | StrOutputParser())rag_chain.invoke("What is Task Decomposition?")
```
```
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks, allowing for a more systematic and organized approach to problem-solving. Thanks for asking!'
```
Check out the [LangSmith trace](https://smith.langchain.com/public/da23c4d8-3b33-47fd-84df-a3a582eedf84/r)
## Next steps[](#next-steps "Direct link to Next steps")
That’s a lot of content we’ve covered in a short amount of time. There’s plenty of features, integrations, and extensions to explore in each of the above sections. Along from the **Go deeper** sources mentioned above, good next steps include:
* [Return sources](https://python.langchain.com/docs/use_cases/question_answering/sources/): Learn how to return source documents
* [Streaming](https://python.langchain.com/docs/use_cases/question_answering/streaming/): Learn how to stream outputs and intermediate steps
* [Add chat history](https://python.langchain.com/docs/use_cases/question_answering/chat_history/): Learn how to add chat history to your app | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:24.821Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/quickstart/",
"description": "LangChain has a number of components designed to help build",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8838",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"b5099bc0181fc45628aaa7d528ed7d3d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::9tn2v-1713753984710-4fe03dc5b592"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "LangChain has a number of components designed to help build",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
LangChain has a number of components designed to help build question-answering applications, and RAG applications more generally. To familiarize ourselves with these, we’ll build a simple Q&A application over a text data source. Along the way we’ll go over a typical Q&A architecture, discuss the relevant LangChain components, and highlight additional resources for more advanced Q&A techniques. We’ll also see how LangSmith can help us trace and understand our application. LangSmith will become increasingly helpful as our application grows in complexity.
Architecture
We’ll create a typical RAG application as outlined in the Q&A introduction, which has two main components:
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
The full sequence from raw data to answer will look like:
Indexing
Load: First we need to load our data. We’ll use DocumentLoaders for this.
Split: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t fit in a model’s finite context window.
Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
Retrieval and generation
Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
Setup
Dependencies
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any ChatModel or LLM, Embeddings, and VectorStore or Retriever.
We’ll use the following packages:
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
We need to set environment variable OPENAI_API_KEY for the embeddings model, which can be done directly or loaded from a .env file like so:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Preview
In this guide we’ll build a QA app over the LLM Powered Autonomous Agents blog post by Lilian Weng, which allows us to ask questions about the contents of the post.
We can create a simple indexing pipeline and RAG chain to do this in ~20 lines of code:
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through prompting techniques like Chain of Thought or Tree of Thoughts, or by using task-specific instructions or human inputs. Task decomposition helps agents plan ahead and manage complicated tasks more effectively.'
# cleanup
vectorstore.delete_collection()
Check out the LangSmith trace
Detailed walkthrough
Let’s go through the above code step-by-step to really understand what’s going on.
1. Indexing: Load
We need to first load the blog post contents. We can use DocumentLoaders for this, which are objects that load in data from a source and return a list of Documents. A Document is an object with some page_content (str) and metadata (dict).
In this case we’ll use the WebBaseLoader, which uses urllib to load HTML from web URLs and BeautifulSoup to parse it to text. We can customize the HTML -> text parsing by passing in parameters to the BeautifulSoup parser via bs_kwargs (see BeautifulSoup docs). In this case only HTML tags with class “post-content”, “post-title”, or “post-header” are relevant, so we’ll remove all others.
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
len(docs[0].page_content)
print(docs[0].page_content[:500])
LLM Powered Autonomous Agents
Date: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian Weng
Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.
Agent System Overview#
In
Go deeper
DocumentLoader: Object that loads data from a source as list of Documents.
Docs: Detailed documentation on how to use DocumentLoaders.
Integrations: 160+ integrations to choose from.
Interface: API reference for the base interface.
2. Indexing: Split
Our loaded document is over 42k characters long. This is too long to fit in the context window of many models. Even for those models that could fit the full post in their context window, models can struggle to find information in very long inputs.
To handle this we’ll split the Document into chunks for embedding and vector storage. This should help us retrieve only the most relevant bits of the blog post at run time.
In this case we’ll split our documents into chunks of 1000 characters with 200 characters of overlap between chunks. The overlap helps mitigate the possibility of separating a statement from important context related to it. We use the RecursiveCharacterTextSplitter, which will recursively split the document using common separators like new lines until each chunk is the appropriate size. This is the recommended text splitter for generic text use cases.
We set add_start_index=True so that the character index at which each split Document starts within the initial Document is preserved as metadata attribute “start_index”.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
len(all_splits[0].page_content)
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'start_index': 7056}
Go deeper
TextSplitter: Object that splits a list of Documents into smaller chunks. Subclass of DocumentTransformers.
Explore Context-aware splitters, which keep the location (“context”) of each split in the original Document: - Markdown files
Code (py or js)
Scientific papers
Interface: API reference for the base interface.
DocumentTransformer: Object that performs a transformation on a list of Documents.
Docs: Detailed documentation on how to use DocumentTransformers
Integrations
Interface: API reference for the base interface.
3. Indexing: Store
Now we need to index our 66 text chunks so that we can search over them at runtime. The most common way to do this is to embed the contents of each document split and insert these embeddings into a vector database (or vector store). When we want to search over our splits, we take a text search query, embed it, and perform some sort of “similarity” search to identify the stored splits with the most similar embeddings to our query embedding. The simplest similarity measure is cosine similarity — we measure the cosine of the angle between each pair of embeddings (which are high dimensional vectors).
We can embed and store all of our document splits in a single command using the Chroma vector store and OpenAIEmbeddings model.
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Go deeper
Embeddings: Wrapper around a text embedding model, used for converting text to embeddings.
Docs: Detailed documentation on how to use embeddings.
Integrations: 30+ integrations to choose from.
Interface: API reference for the base interface.
VectorStore: Wrapper around a vector database, used for storing and querying embeddings.
Docs: Detailed documentation on how to use vector stores.
Integrations: 40+ integrations to choose from.
Interface: API reference for the base interface.
This completes the Indexing portion of the pipeline. At this point we have a query-able vector store containing the chunked contents of our blog post. Given a user question, we should ideally be able to return the snippets of the blog post that answer the question.
4. Retrieval and Generation: Retrieve
Now let’s write the actual application logic. We want to create a simple application that takes a user question, searches for documents relevant to that question, passes the retrieved documents and initial question to a model, and returns an answer.
First we need to define our logic for searching over documents. LangChain defines a Retriever interface which wraps an index that can return relevant Documents given a string query.
The most common type of Retriever is the VectorStoreRetriever, which uses the similarity search capabilities of a vector store to facilitate retrieval. Any VectorStore can easily be turned into a Retriever with VectorStore.as_retriever():
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
print(retrieved_docs[0].page_content)
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Go deeper
Vector stores are commonly used for retrieval, but there are other ways to do retrieval, too.
Retriever: An object that returns Documents given a text query
Docs: Further documentation on the interface and built-in retrieval techniques. Some of which include:
MultiQueryRetriever generates variants of the input question to improve retrieval hit rate.
MultiVectorRetriever (diagram below) instead generates variants of the embeddings, also in order to improve retrieval hit rate.
Max marginal relevance selects for relevance and diversity among the retrieved documents to avoid passing in duplicate context.
Documents can be filtered during vector store retrieval using metadata filters, such as with a Self Query Retriever.
Integrations: Integrations with retrieval services.
Interface: API reference for the base interface.
5. Retrieval and Generation: Generate
Let’s put it all together into a chain that takes a question, retrieves relevant documents, constructs a prompt, passes that to a model, and parses the output.
We’ll use the gpt-3.5-turbo OpenAI chat model, but any LangChain LLM or ChatModel could be substituted in.
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
We’ll use a prompt for RAG that is checked into the LangChain prompt hub (here).
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
example_messages = prompt.invoke(
{"context": "filler context", "question": "filler question"}
).to_messages()
example_messages
[HumanMessage(content="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: filler question \nContext: filler context \nAnswer:")]
print(example_messages[0].content)
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: filler question
Context: filler context
Answer:
We’ll use the LCEL Runnable protocol to define the chain, allowing us to - pipe together components and functions in a transparent way - automatically trace our chain in LangSmith - get streaming, async, and batched calling out of the box
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
for chunk in rag_chain.stream("What is Task Decomposition?"):
print(chunk, end="", flush=True)
Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks, allowing for easier interpretation and execution by autonomous agents or models. Task decomposition can be done through various methods, such as using prompting techniques, task-specific instructions, or human inputs.
Check out the LangSmith trace
Go deeper
Choosing a model
ChatModel: An LLM-backed chat model. Takes in a sequence of messages and returns a message.
Docs
Integrations: 25+ integrations to choose from.
Interface: API reference for the base interface.
LLM: A text-in-text-out LLM. Takes in a string and returns a string.
Docs
Integrations: 75+ integrations to choose from.
Interface: API reference for the base interface.
See a guide on RAG with locally-running models here.
Customizing the prompt
As shown above, we can load prompts (e.g., this RAG prompt) from the prompt hub. The prompt can also be easily customized:
from langchain_core.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks, allowing for a more systematic and organized approach to problem-solving. Thanks for asking!'
Check out the LangSmith trace
Next steps
That’s a lot of content we’ve covered in a short amount of time. There’s plenty of features, integrations, and extensions to explore in each of the above sections. Along from the Go deeper sources mentioned above, good next steps include:
Return sources: Learn how to return source documents
Streaming: Learn how to stream outputs and intermediate steps
Add chat history: Learn how to add chat history to your app |
https://python.langchain.com/docs/use_cases/question_answering/per_user/ | ## Per-User Retrieval
When building a retrieval app, you often have to build it with multiple users in mind. This means that you may be storing data not just for one user, but for many different users, and they should not be able to see eachother’s data. This means that you need to be able to configure your retrieval chain to only retrieve certain information. This generally involves two steps.
**Step 1: Make sure the retriever you are using supports multiple users**
At the moment, there is no unified flag or filter for this in LangChain. Rather, each vectorstore and retriever may have their own, and may be called different things (namespaces, multi-tenancy, etc). For vectorstores, this is generally exposed as a keyword argument that is passed in during `similarity_search`. By reading the documentation or source code, figure out whether the retriever you are using supports multiple users, and, if so, how to use it.
Note: adding documentation and/or support for multiple users for retrievers that do not support it (or document it) is a GREAT way to contribute to LangChain
**Step 2: Add that parameter as a configurable field for the chain**
This will let you easily call the chain and configure any relevant flags at runtime. See [this documentation](https://python.langchain.com/docs/expression_language/primitives/configure/) for more information on configuration.
**Step 3: Call the chain with that configurable field**
Now, at runtime you can call this chain with configurable field.
## Code Example[](#code-example "Direct link to Code Example")
Let’s see a concrete example of what this looks like in code. We will use Pinecone for this example.
To configure Pinecone, set the following environment variable:
* `PINECONE_API_KEY`: Your Pinecone API key
```
from langchain_openai import OpenAIEmbeddingsfrom langchain_pinecone import PineconeVectorStore
```
```
embeddings = OpenAIEmbeddings()vectorstore = PineconeVectorStore(index_name="test-example", embedding=embeddings)vectorstore.add_texts(["i worked at kensho"], namespace="harrison")vectorstore.add_texts(["i worked at facebook"], namespace="ankush")
```
```
['ce15571e-4e2f-44c9-98df-7e83f6f63095']
```
The pinecone kwarg for `namespace` can be used to separate documents
```
# This will only get documents for Ankushvectorstore.as_retriever(search_kwargs={"namespace": "ankush"}).get_relevant_documents( "where did i work?")
```
```
[Document(page_content='i worked at facebook')]
```
```
# This will only get documents for Harrisonvectorstore.as_retriever( search_kwargs={"namespace": "harrison"}).get_relevant_documents("where did i work?")
```
```
[Document(page_content='i worked at kensho')]
```
We can now create the chain that we will use to do question-answering over
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import ( ConfigurableField, RunnableBinding, RunnableLambda, RunnablePassthrough,)from langchain_openai import ChatOpenAI, OpenAIEmbeddings
```
This is basic question-answering chain set up.
```
template = """Answer the question based only on the following context:{context}Question: {question}"""prompt = ChatPromptTemplate.from_template(template)model = ChatOpenAI()retriever = vectorstore.as_retriever()
```
Here we mark the retriever as having a configurable field. All vectorstore retrievers have `search_kwargs` as a field. This is just a dictionary, with vectorstore specific fields
```
configurable_retriever = retriever.configurable_fields( search_kwargs=ConfigurableField( id="search_kwargs", name="Search Kwargs", description="The search kwargs to use", ))
```
We can now create the chain using our configurable retriever
```
chain = ( {"context": configurable_retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser())
```
We can now invoke the chain with configurable options. `search_kwargs` is the id of the configurable field. The value is the search kwargs to use for Pinecone
```
chain.invoke( "where did the user work?", config={"configurable": {"search_kwargs": {"namespace": "harrison"}}},)
```
```
'The user worked at Kensho.'
```
```
chain.invoke( "where did the user work?", config={"configurable": {"search_kwargs": {"namespace": "ankush"}}},)
```
```
'The user worked at Facebook.'
```
For more vectorstore implementations for multi-user, please refer to specific pages, such as [Milvus](https://python.langchain.com/docs/integrations/vectorstores/milvus/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:25.625Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/per_user/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/per_user/",
"description": "When building a retrieval app, you often have to build it with multiple",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8758",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"per_user\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"bc3785244edc62b5d9270039cdf183b4\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::drx4p-1713753984681-16e67a5d161e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/per_user/",
"property": "og:url"
},
{
"content": "Per-User Retrieval | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "When building a retrieval app, you often have to build it with multiple",
"property": "og:description"
}
],
"title": "Per-User Retrieval | 🦜️🔗 LangChain"
} | Per-User Retrieval
When building a retrieval app, you often have to build it with multiple users in mind. This means that you may be storing data not just for one user, but for many different users, and they should not be able to see eachother’s data. This means that you need to be able to configure your retrieval chain to only retrieve certain information. This generally involves two steps.
Step 1: Make sure the retriever you are using supports multiple users
At the moment, there is no unified flag or filter for this in LangChain. Rather, each vectorstore and retriever may have their own, and may be called different things (namespaces, multi-tenancy, etc). For vectorstores, this is generally exposed as a keyword argument that is passed in during similarity_search. By reading the documentation or source code, figure out whether the retriever you are using supports multiple users, and, if so, how to use it.
Note: adding documentation and/or support for multiple users for retrievers that do not support it (or document it) is a GREAT way to contribute to LangChain
Step 2: Add that parameter as a configurable field for the chain
This will let you easily call the chain and configure any relevant flags at runtime. See this documentation for more information on configuration.
Step 3: Call the chain with that configurable field
Now, at runtime you can call this chain with configurable field.
Code Example
Let’s see a concrete example of what this looks like in code. We will use Pinecone for this example.
To configure Pinecone, set the following environment variable:
PINECONE_API_KEY: Your Pinecone API key
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
embeddings = OpenAIEmbeddings()
vectorstore = PineconeVectorStore(index_name="test-example", embedding=embeddings)
vectorstore.add_texts(["i worked at kensho"], namespace="harrison")
vectorstore.add_texts(["i worked at facebook"], namespace="ankush")
['ce15571e-4e2f-44c9-98df-7e83f6f63095']
The pinecone kwarg for namespace can be used to separate documents
# This will only get documents for Ankush
vectorstore.as_retriever(search_kwargs={"namespace": "ankush"}).get_relevant_documents(
"where did i work?"
)
[Document(page_content='i worked at facebook')]
# This will only get documents for Harrison
vectorstore.as_retriever(
search_kwargs={"namespace": "harrison"}
).get_relevant_documents("where did i work?")
[Document(page_content='i worked at kensho')]
We can now create the chain that we will use to do question-answering over
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
ConfigurableField,
RunnableBinding,
RunnableLambda,
RunnablePassthrough,
)
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
This is basic question-answering chain set up.
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
retriever = vectorstore.as_retriever()
Here we mark the retriever as having a configurable field. All vectorstore retrievers have search_kwargs as a field. This is just a dictionary, with vectorstore specific fields
configurable_retriever = retriever.configurable_fields(
search_kwargs=ConfigurableField(
id="search_kwargs",
name="Search Kwargs",
description="The search kwargs to use",
)
)
We can now create the chain using our configurable retriever
chain = (
{"context": configurable_retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
We can now invoke the chain with configurable options. search_kwargs is the id of the configurable field. The value is the search kwargs to use for Pinecone
chain.invoke(
"where did the user work?",
config={"configurable": {"search_kwargs": {"namespace": "harrison"}}},
)
'The user worked at Kensho.'
chain.invoke(
"where did the user work?",
config={"configurable": {"search_kwargs": {"namespace": "ankush"}}},
)
'The user worked at Facebook.'
For more vectorstore implementations for multi-user, please refer to specific pages, such as Milvus. |
https://python.langchain.com/docs/use_cases/question_answering/sources/ | ## Returning sources
Often in Q&A applications it’s important to show users the sources that were used to generate the answer. The simplest way to do this is for the chain to return the Documents that were retrieved in each generation.
We’ll work off of the Q&A app we built over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng in the [Quickstart](https://python.langchain.com/docs/use_cases/question_answering/quickstart/).
## Setup[](#setup "Direct link to Setup")
### Dependencies[](#dependencies "Direct link to Dependencies")
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any [ChatModel](https://python.langchain.com/docs/modules/model_io/chat/) or [LLM](https://python.langchain.com/docs/modules/model_io/llms/), [Embeddings](https://python.langchain.com/docs/modules/data_connection/text_embedding/), and [VectorStore](https://python.langchain.com/docs/modules/data_connection/vectorstores/) or [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/).
We’ll use the following packages:
```
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
```
We need to set environment variable `OPENAI_API_KEY`, which can be done directly or loaded from a `.env` file like so:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# import dotenv# dotenv.load_dotenv()
```
### LangSmith[](#langsmith "Direct link to LangSmith")
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with [LangSmith](https://smith.langchain.com/).
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
```
os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Chain without sources[](#chain-without-sources "Direct link to Chain without sources")
Here is the Q&A app we built over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng in the [Quickstart](https://python.langchain.com/docs/use_cases/question_answering/quickstart/):
```
import bs4from langchain import hubfrom langchain_chroma import Chromafrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitter
```
```
# Load, chunk and index the contents of the blog.bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs={"parse_only": bs_strainer},)docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# Retrieve and generate using the relevant snippets of the blog.retriever = vectorstore.as_retriever()prompt = hub.pull("rlm/rag-prompt")llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
```
```
rag_chain.invoke("What is Task Decomposition?")
```
```
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through prompting techniques like Chain of Thought or Tree of Thoughts, or by using task-specific instructions or human inputs. Task decomposition helps agents plan ahead and manage complicated tasks more effectively.'
```
## Adding sources[](#adding-sources "Direct link to Adding sources")
With LCEL it’s easy to return the retrieved documents:
```
from langchain_core.runnables import RunnableParallelrag_chain_from_docs = ( RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"]))) | prompt | llm | StrOutputParser())rag_chain_with_source = RunnableParallel( {"context": retriever, "question": RunnablePassthrough()}).assign(answer=rag_chain_from_docs)rag_chain_with_source.invoke("What is Task Decomposition")
```
```
{'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 1585}), Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2192}), Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17804}), Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17414}), Document(page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 29630}), Document(page_content="(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.", metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 19373})], 'question': 'What is Task Decomposition', 'answer': 'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks, allowing for a more systematic and organized approach to problem-solving. Thanks for asking!'}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:25.888Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/sources/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/sources/",
"description": "Often in Q&A applications it’s important to show users the sources that",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3777",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sources\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"51fa4cac0258064500e0eb43fd8db8e2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::lrtsn-1713753984754-9a195ff9ef4a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/sources/",
"property": "og:url"
},
{
"content": "Returning sources | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Often in Q&A applications it’s important to show users the sources that",
"property": "og:description"
}
],
"title": "Returning sources | 🦜️🔗 LangChain"
} | Returning sources
Often in Q&A applications it’s important to show users the sources that were used to generate the answer. The simplest way to do this is for the chain to return the Documents that were retrieved in each generation.
We’ll work off of the Q&A app we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the Quickstart.
Setup
Dependencies
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any ChatModel or LLM, Embeddings, and VectorStore or Retriever.
We’ll use the following packages:
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
We need to set environment variable OPENAI_API_KEY, which can be done directly or loaded from a .env file like so:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Chain without sources
Here is the Q&A app we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the Quickstart:
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs_strainer},
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through prompting techniques like Chain of Thought or Tree of Thoughts, or by using task-specific instructions or human inputs. Task decomposition helps agents plan ahead and manage complicated tasks more effectively.'
Adding sources
With LCEL it’s easy to return the retrieved documents:
from langchain_core.runnables import RunnableParallel
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
rag_chain_with_source.invoke("What is Task Decomposition")
{'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 1585}),
Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2192}),
Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17804}),
Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17414}),
Document(page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 29630}),
Document(page_content="(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.", metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 19373})],
'question': 'What is Task Decomposition',
'answer': 'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks, allowing for a more systematic and organized approach to problem-solving. Thanks for asking!'} |
https://python.langchain.com/docs/use_cases/sql/ | ## SQL
One of the most common types of databases that we can build Q&A systems for are SQL databases. LangChain comes with a number of built-in chains and agents that are compatible with any SQL dialect supported by SQLAlchemy (e.g., MySQL, PostgreSQL, Oracle SQL, Databricks, SQLite). They enable use cases such as:
* Generating queries that will be run based on natural language questions,
* Creating chatbots that can answer questions based on database data,
* Building custom dashboards based on insights a user wants to analyze,
and much more.
## ⚠️ Security note ⚠️[](#security-note "Direct link to ⚠️ Security note ⚠️")
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, [see here](https://python.langchain.com/docs/security/).
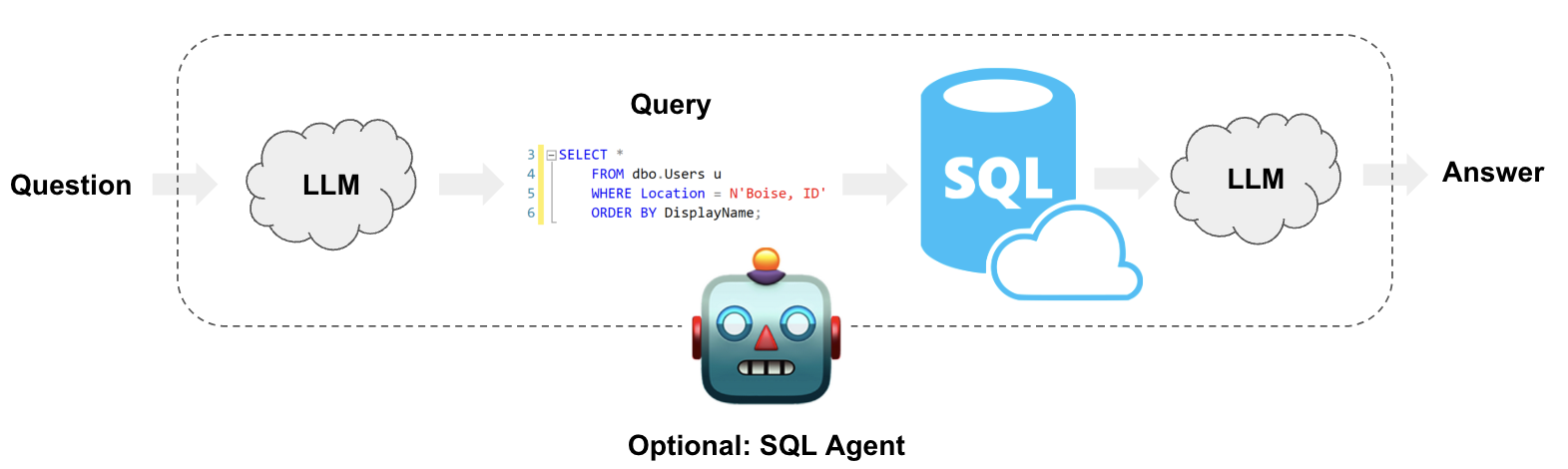
## Quickstart[](#quickstart "Direct link to Quickstart")
Head to the **[Quickstart](https://python.langchain.com/docs/use_cases/sql/quickstart/)** page to get started.
## Advanced[](#advanced "Direct link to Advanced")
Once you’ve familiarized yourself with the basics, you can head to the advanced guides:
* [Agents](https://python.langchain.com/docs/use_cases/sql/agents/): Building agents that can interact with SQL DBs.
* [Prompting strategies](https://python.langchain.com/docs/use_cases/sql/prompting/): Strategies for improving SQL query generation.
* [Query validation](https://python.langchain.com/docs/use_cases/sql/query_checking/): How to validate SQL queries.
* [Large databases](https://python.langchain.com/docs/use_cases/sql/large_db/): How to interact with DBs with many tables and high-cardinality columns. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:26.134Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/",
"description": "One of the most common types of databases that we can build Q&A systems",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7993",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"sql\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"8b4c4024eb58a4e8b348277383c6de8b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::xzmz8-1713753984733-a3cb6d546c4f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/",
"property": "og:url"
},
{
"content": "SQL | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "One of the most common types of databases that we can build Q&A systems",
"property": "og:description"
}
],
"title": "SQL | 🦜️🔗 LangChain"
} | SQL
One of the most common types of databases that we can build Q&A systems for are SQL databases. LangChain comes with a number of built-in chains and agents that are compatible with any SQL dialect supported by SQLAlchemy (e.g., MySQL, PostgreSQL, Oracle SQL, Databricks, SQLite). They enable use cases such as:
Generating queries that will be run based on natural language questions,
Creating chatbots that can answer questions based on database data,
Building custom dashboards based on insights a user wants to analyze,
and much more.
⚠️ Security note ⚠️
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
Quickstart
Head to the Quickstart page to get started.
Advanced
Once you’ve familiarized yourself with the basics, you can head to the advanced guides:
Agents: Building agents that can interact with SQL DBs.
Prompting strategies: Strategies for improving SQL query generation.
Query validation: How to validate SQL queries.
Large databases: How to interact with DBs with many tables and high-cardinality columns. |
https://python.langchain.com/docs/use_cases/sql/agents/ | ## Agents
LangChain has a SQL Agent which provides a more flexible way of interacting with SQL Databases than a chain. The main advantages of using the SQL Agent are:
* It can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table).
* It can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
* It can query the database as many times as needed to answer the user question.
* It will save tokens by only retrieving the schema from relevant tables.
To initialize the agent we’ll use the [create\_sql\_agent](https://api.python.langchain.com/en/latest/agent_toolkits/langchain_community.agent_toolkits.sql.base.create_sql_agent.html) constructor. This agent uses the `SQLDatabaseToolkit` which contains tools to:
* Create and execute queries
* Check query syntax
* Retrieve table descriptions
* … and more
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
The below example will use a SQLite connection with Chinook database. Follow [these installation steps](https://database.guide/2-sample-databases-sqlite/) to create `Chinook.db` in the same directory as this notebook:
* Save [this file](https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql) as `Chinook_Sqlite.sql`
* Run `sqlite3 Chinook.db`
* Run `.read Chinook_Sqlite.sql`
* Test `SELECT * FROM Artist LIMIT 10;`
Now, `Chinhook.db` is in our directory and we can interface with it using the SQLAlchemy-driven `SQLDatabase` class:
```
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")print(db.dialect)print(db.get_usable_table_names())db.run("SELECT * FROM Artist LIMIT 10;")
```
```
sqlite['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
```
```
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
```
## Agent[](#agent "Direct link to Agent")
We’ll use an OpenAI chat model and an `"openai-tools"` agent, which will use OpenAI’s function-calling API to drive the agent’s tool selection and invocations.
As we can see, the agent will first choose which tables are relevant and then add the schema for those tables and a few sample rows to the prompt.
```
from langchain_community.agent_toolkits import create_sql_agentfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
```
```
agent_executor.invoke( "List the total sales per country. Which country's customers spent the most?")
```
```
> Entering new AgentExecutor chain...Invoking: `sql_db_list_tables` with `{}`Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, TrackInvoking: `sql_db_schema` with `Invoice,Customer`CREATE TABLE "Customer" ( "CustomerId" INTEGER NOT NULL, "FirstName" NVARCHAR(40) NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "Company" NVARCHAR(80), "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60) NOT NULL, "SupportRepId" INTEGER, PRIMARY KEY ("CustomerId"), FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId"))/*3 rows from Customer table:CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 32 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 53 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3*/CREATE TABLE "Invoice" ( "InvoiceId" INTEGER NOT NULL, "CustomerId" INTEGER NOT NULL, "InvoiceDate" DATETIME NOT NULL, "BillingAddress" NVARCHAR(70), "BillingCity" NVARCHAR(40), "BillingState" NVARCHAR(40), "BillingCountry" NVARCHAR(40), "BillingPostalCode" NVARCHAR(10), "Total" NUMERIC(10, 2) NOT NULL, PRIMARY KEY ("InvoiceId"), FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId"))/*3 rows from Invoice table:InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.982 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.963 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94*/Invoking: `sql_db_query` with `SELECT c.Country, SUM(i.Total) AS TotalSales FROM Invoice i JOIN Customer c ON i.CustomerId = c.CustomerId GROUP BY c.Country ORDER BY TotalSales DESC LIMIT 10;`responded: To list the total sales per country, I can query the "Invoice" and "Customer" tables. I will join these tables on the "CustomerId" column and group the results by the "BillingCountry" column. Then, I will calculate the sum of the "Total" column to get the total sales per country. Finally, I will order the results in descending order of the total sales.Here is the SQL query:```sqlSELECT c.Country, SUM(i.Total) AS TotalSalesFROM Invoice iJOIN Customer c ON i.CustomerId = c.CustomerIdGROUP BY c.CountryORDER BY TotalSales DESCLIMIT 10;```Now, I will execute this query to get the total sales per country.[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]The total sales per country are as follows:1. USA: $523.062. Canada: $303.963. France: $195.104. Brazil: $190.105. Germany: $156.486. United Kingdom: $112.867. Czech Republic: $90.248. Portugal: $77.249. India: $75.2610. Chile: $46.62To answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.> Finished chain.
```
```
{'input': "List the total sales per country. Which country's customers spent the most?", 'output': 'The total sales per country are as follows:\n\n1. USA: $523.06\n2. Canada: $303.96\n3. France: $195.10\n4. Brazil: $190.10\n5. Germany: $156.48\n6. United Kingdom: $112.86\n7. Czech Republic: $90.24\n8. Portugal: $77.24\n9. India: $75.26\n10. Chile: $46.62\n\nTo answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.'}
```
```
agent_executor.invoke("Describe the playlisttrack table")
```
```
> Entering new AgentExecutor chain...Invoking: `sql_db_list_tables` with `{}`Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, TrackInvoking: `sql_db_schema` with `PlaylistTrack`CREATE TABLE "PlaylistTrack" ( "PlaylistId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, PRIMARY KEY ("PlaylistId", "TrackId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId"))/*3 rows from PlaylistTrack table:PlaylistId TrackId1 34021 33891 3390*/The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks. Here is the schema of the `PlaylistTrack` table:```CREATE TABLE "PlaylistTrack" ( "PlaylistId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, PRIMARY KEY ("PlaylistId", "TrackId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId"))```The `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.Here are three sample rows from the `PlaylistTrack` table:```PlaylistId TrackId1 34021 33891 3390```Please let me know if there is anything else I can help with.> Finished chain.
```
```
{'input': 'Describe the playlisttrack table', 'output': 'The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks. \n\nHere is the schema of the `PlaylistTrack` table:\n\n```\nCREATE TABLE "PlaylistTrack" (\n\t"PlaylistId" INTEGER NOT NULL, \n\t"TrackId" INTEGER NOT NULL, \n\tPRIMARY KEY ("PlaylistId", "TrackId"), \n\tFOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), \n\tFOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")\n)\n```\n\nThe `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.\n\nHere are three sample rows from the `PlaylistTrack` table:\n\n```\nPlaylistId TrackId\n1 3402\n1 3389\n1 3390\n```\n\nPlease let me know if there is anything else I can help with.'}
```
## Using a dynamic few-shot prompt[](#using-a-dynamic-few-shot-prompt "Direct link to Using a dynamic few-shot prompt")
To optimize agent performance, we can provide a custom prompt with domain-specific knowledge. In this case we’ll create a few shot prompt with an example selector, that will dynamically build the few shot prompt based on the user input. This will help the model make better queries by inserting relevant queries in the prompt that the model can use as reference.
First we need some user input \\<\> SQL query examples:
```
examples = [ {"input": "List all artists.", "query": "SELECT * FROM Artist;"}, { "input": "Find all albums for the artist 'AC/DC'.", "query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');", }, { "input": "List all tracks in the 'Rock' genre.", "query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');", }, { "input": "Find the total duration of all tracks.", "query": "SELECT SUM(Milliseconds) FROM Track;", }, { "input": "List all customers from Canada.", "query": "SELECT * FROM Customer WHERE Country = 'Canada';", }, { "input": "How many tracks are there in the album with ID 5?", "query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;", }, { "input": "Find the total number of invoices.", "query": "SELECT COUNT(*) FROM Invoice;", }, { "input": "List all tracks that are longer than 5 minutes.", "query": "SELECT * FROM Track WHERE Milliseconds > 300000;", }, { "input": "Who are the top 5 customers by total purchase?", "query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;", }, { "input": "Which albums are from the year 2000?", "query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';", }, { "input": "How many employees are there", "query": 'SELECT COUNT(*) FROM "Employee"', },]
```
Now we can create an example selector. This will take the actual user input and select some number of examples to add to our few-shot prompt. We’ll use a SemanticSimilarityExampleSelector, which will perform a semantic search using the embeddings and vector store we configure to find the examples most similar to our input:
```
from langchain_community.vectorstores import FAISSfrom langchain_core.example_selectors import SemanticSimilarityExampleSelectorfrom langchain_openai import OpenAIEmbeddingsexample_selector = SemanticSimilarityExampleSelector.from_examples( examples, OpenAIEmbeddings(), FAISS, k=5, input_keys=["input"],)
```
Now we can create our FewShotPromptTemplate, which takes our example selector, an example prompt for formatting each example, and a string prefix and suffix to put before and after our formatted examples:
```
from langchain_core.prompts import ( ChatPromptTemplate, FewShotPromptTemplate, MessagesPlaceholder, PromptTemplate, SystemMessagePromptTemplate,)system_prefix = """You are an agent designed to interact with a SQL database.Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.You can order the results by a relevant column to return the most interesting examples in the database.Never query for all the columns from a specific table, only ask for the relevant columns given the question.You have access to tools for interacting with the database.Only use the given tools. Only use the information returned by the tools to construct your final answer.You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.If the question does not seem related to the database, just return "I don't know" as the answer.Here are some examples of user inputs and their corresponding SQL queries:"""few_shot_prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=PromptTemplate.from_template( "User input: {input}\nSQL query: {query}" ), input_variables=["input", "dialect", "top_k"], prefix=system_prefix, suffix="",)
```
Since our underlying agent is an [OpenAI tools agent](https://python.langchain.com/docs/modules/agents/agent_types/openai_tools/), which uses OpenAI function calling, our full prompt should be a chat prompt with a human message template and an agent\_scratchpad `MessagesPlaceholder`. The few-shot prompt will be used for our system message:
```
full_prompt = ChatPromptTemplate.from_messages( [ SystemMessagePromptTemplate(prompt=few_shot_prompt), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad"), ])
```
```
# Example formatted promptprompt_val = full_prompt.invoke( { "input": "How many arists are there", "top_k": 5, "dialect": "SQLite", "agent_scratchpad": [], })print(prompt_val.to_string())
```
```
System: You are an agent designed to interact with a SQL database.Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer.Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results.You can order the results by a relevant column to return the most interesting examples in the database.Never query for all the columns from a specific table, only ask for the relevant columns given the question.You have access to tools for interacting with the database.Only use the given tools. Only use the information returned by the tools to construct your final answer.You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.If the question does not seem related to the database, just return "I don't know" as the answer.Here are some examples of user inputs and their corresponding SQL queries:User input: List all artists.SQL query: SELECT * FROM Artist;User input: How many employees are thereSQL query: SELECT COUNT(*) FROM "Employee"User input: How many tracks are there in the album with ID 5?SQL query: SELECT COUNT(*) FROM Track WHERE AlbumId = 5;User input: List all tracks in the 'Rock' genre.SQL query: SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');User input: Which albums are from the year 2000?SQL query: SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';Human: How many arists are there
```
And now we can create our agent with our custom prompt:
```
agent = create_sql_agent( llm=llm, db=db, prompt=full_prompt, verbose=True, agent_type="openai-tools",)
```
Let’s try it out:
```
agent.invoke({"input": "How many artists are there?"})
```
```
> Entering new AgentExecutor chain...Invoking: `sql_db_query` with `{'query': 'SELECT COUNT(*) FROM Artist'}`[(275,)]There are 275 artists in the database.> Finished chain.
```
```
{'input': 'How many artists are there?', 'output': 'There are 275 artists in the database.'}
```
## Dealing with high-cardinality columns[](#dealing-with-high-cardinality-columns "Direct link to Dealing with high-cardinality columns")
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
We can achieve this by creating a vector store with all the distinct proper nouns that exist in the database. We can then have the agent query that vector store each time the user includes a proper noun in their question, to find the correct spelling for that word. In this way, the agent can make sure it understands which entity the user is referring to before building the target query.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
```
import astimport redef query_as_list(db, query): res = db.run(query) res = [el for sub in ast.literal_eval(res) for el in sub if el] res = [re.sub(r"\b\d+\b", "", string).strip() for string in res] return list(set(res))artists = query_as_list(db, "SELECT Name FROM Artist")albums = query_as_list(db, "SELECT Title FROM Album")albums[:5]
```
```
['Os Cães Ladram Mas A Caravana Não Pára', 'War', 'Mais Do Mesmo', "Up An' Atom", 'Riot Act']
```
Now we can proceed with creating the custom **retriever tool** and the final agent:
```
from langchain.agents.agent_toolkits import create_retriever_toolvector_db = FAISS.from_texts(artists + albums, OpenAIEmbeddings())retriever = vector_db.as_retriever(search_kwargs={"k": 5})description = """Use to look up values to filter on. Input is an approximate spelling of the proper noun, output is \valid proper nouns. Use the noun most similar to the search."""retriever_tool = create_retriever_tool( retriever, name="search_proper_nouns", description=description,)
```
```
system = """You are an agent designed to interact with a SQL database.Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.You can order the results by a relevant column to return the most interesting examples in the database.Never query for all the columns from a specific table, only ask for the relevant columns given the question.You have access to tools for interacting with the database.Only use the given tools. Only use the information returned by the tools to construct your final answer.You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.If you need to filter on a proper noun, you must ALWAYS first look up the filter value using the "search_proper_nouns" tool! You have access to the following tables: {table_names}If the question does not seem related to the database, just return "I don't know" as the answer."""prompt = ChatPromptTemplate.from_messages( [("system", system), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad")])agent = create_sql_agent( llm=llm, db=db, extra_tools=[retriever_tool], prompt=prompt, agent_type="openai-tools", verbose=True,)
```
```
agent.invoke({"input": "How many albums does alis in chain have?"})
```
```
> Entering new AgentExecutor chain...Invoking: `search_proper_nouns` with `{'query': 'alis in chain'}`Alice In ChainsAisha DuoXisDa Lama Ao CaosA-SidesInvoking: `sql_db_query` with `SELECT COUNT(*) FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'Alice In Chains')`[(1,)]Alice In Chains has 1 album.> Finished chain.
```
```
{'input': 'How many albums does alis in chain have?', 'output': 'Alice In Chains has 1 album.'}
```
As we can see, the agent used the `search_proper_nouns` tool in order to check how to correctly query the database for this specific artist.
## Next steps[](#next-steps "Direct link to Next steps")
Under the hood, `create_sql_agent` is just passing in SQL tools to more generic agent constructors. To learn more about the built-in generic agent types as well as how to build custom agents, head to the [Agents Modules](https://python.langchain.com/docs/modules/agents/).
The built-in `AgentExecutor` runs a simple Agent action -\> Tool call -\> Agent action… loop. To build more complex agent runtimes, head to the [LangGraph section](https://python.langchain.com/docs/langgraph/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:26.637Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/agents/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/agents/",
"description": "LangChain has a SQL Agent which provides a more flexible way of",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8604",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"agents\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"49a156643c603bcda2531122566aeb65\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::6lnrd-1713753984720-6443c8a63b2d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/agents/",
"property": "og:url"
},
{
"content": "Agents | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "LangChain has a SQL Agent which provides a more flexible way of",
"property": "og:description"
}
],
"title": "Agents | 🦜️🔗 LangChain"
} | Agents
LangChain has a SQL Agent which provides a more flexible way of interacting with SQL Databases than a chain. The main advantages of using the SQL Agent are:
It can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table).
It can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
It can query the database as many times as needed to answer the user question.
It will save tokens by only retrieving the schema from relevant tables.
To initialize the agent we’ll use the create_sql_agent constructor. This agent uses the SQLDatabaseToolkit which contains tools to:
Create and execute queries
Check query syntax
Retrieve table descriptions
… and more
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
The below example will use a SQLite connection with Chinook database. Follow these installation steps to create Chinook.db in the same directory as this notebook:
Save this file as Chinook_Sqlite.sql
Run sqlite3 Chinook.db
Run .read Chinook_Sqlite.sql
Test SELECT * FROM Artist LIMIT 10;
Now, Chinhook.db is in our directory and we can interface with it using the SQLAlchemy-driven SQLDatabase class:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Agent
We’ll use an OpenAI chat model and an "openai-tools" agent, which will use OpenAI’s function-calling API to drive the agent’s tool selection and invocations.
As we can see, the agent will first choose which tables are relevant and then add the schema for those tables and a few sample rows to the prompt.
from langchain_community.agent_toolkits import create_sql_agent
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke(
"List the total sales per country. Which country's customers spent the most?"
)
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `Invoice,Customer`
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
Invoking: `sql_db_query` with `SELECT c.Country, SUM(i.Total) AS TotalSales FROM Invoice i JOIN Customer c ON i.CustomerId = c.CustomerId GROUP BY c.Country ORDER BY TotalSales DESC LIMIT 10;`
responded: To list the total sales per country, I can query the "Invoice" and "Customer" tables. I will join these tables on the "CustomerId" column and group the results by the "BillingCountry" column. Then, I will calculate the sum of the "Total" column to get the total sales per country. Finally, I will order the results in descending order of the total sales.
Here is the SQL query:
```sql
SELECT c.Country, SUM(i.Total) AS TotalSales
FROM Invoice i
JOIN Customer c ON i.CustomerId = c.CustomerId
GROUP BY c.Country
ORDER BY TotalSales DESC
LIMIT 10;
```
Now, I will execute this query to get the total sales per country.
[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]The total sales per country are as follows:
1. USA: $523.06
2. Canada: $303.96
3. France: $195.10
4. Brazil: $190.10
5. Germany: $156.48
6. United Kingdom: $112.86
7. Czech Republic: $90.24
8. Portugal: $77.24
9. India: $75.26
10. Chile: $46.62
To answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.
> Finished chain.
{'input': "List the total sales per country. Which country's customers spent the most?",
'output': 'The total sales per country are as follows:\n\n1. USA: $523.06\n2. Canada: $303.96\n3. France: $195.10\n4. Brazil: $190.10\n5. Germany: $156.48\n6. United Kingdom: $112.86\n7. Czech Republic: $90.24\n8. Portugal: $77.24\n9. India: $75.26\n10. Chile: $46.62\n\nTo answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.'}
agent_executor.invoke("Describe the playlisttrack table")
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `PlaylistTrack`
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
3 rows from PlaylistTrack table:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks.
Here is the schema of the `PlaylistTrack` table:
```
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
```
The `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.
Here are three sample rows from the `PlaylistTrack` table:
```
PlaylistId TrackId
1 3402
1 3389
1 3390
```
Please let me know if there is anything else I can help with.
> Finished chain.
{'input': 'Describe the playlisttrack table',
'output': 'The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks. \n\nHere is the schema of the `PlaylistTrack` table:\n\n```\nCREATE TABLE "PlaylistTrack" (\n\t"PlaylistId" INTEGER NOT NULL, \n\t"TrackId" INTEGER NOT NULL, \n\tPRIMARY KEY ("PlaylistId", "TrackId"), \n\tFOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), \n\tFOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")\n)\n```\n\nThe `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.\n\nHere are three sample rows from the `PlaylistTrack` table:\n\n```\nPlaylistId TrackId\n1 3402\n1 3389\n1 3390\n```\n\nPlease let me know if there is anything else I can help with.'}
Using a dynamic few-shot prompt
To optimize agent performance, we can provide a custom prompt with domain-specific knowledge. In this case we’ll create a few shot prompt with an example selector, that will dynamically build the few shot prompt based on the user input. This will help the model make better queries by inserting relevant queries in the prompt that the model can use as reference.
First we need some user input \<> SQL query examples:
examples = [
{"input": "List all artists.", "query": "SELECT * FROM Artist;"},
{
"input": "Find all albums for the artist 'AC/DC'.",
"query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');",
},
{
"input": "List all tracks in the 'Rock' genre.",
"query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');",
},
{
"input": "Find the total duration of all tracks.",
"query": "SELECT SUM(Milliseconds) FROM Track;",
},
{
"input": "List all customers from Canada.",
"query": "SELECT * FROM Customer WHERE Country = 'Canada';",
},
{
"input": "How many tracks are there in the album with ID 5?",
"query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;",
},
{
"input": "Find the total number of invoices.",
"query": "SELECT COUNT(*) FROM Invoice;",
},
{
"input": "List all tracks that are longer than 5 minutes.",
"query": "SELECT * FROM Track WHERE Milliseconds > 300000;",
},
{
"input": "Who are the top 5 customers by total purchase?",
"query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;",
},
{
"input": "Which albums are from the year 2000?",
"query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';",
},
{
"input": "How many employees are there",
"query": 'SELECT COUNT(*) FROM "Employee"',
},
]
Now we can create an example selector. This will take the actual user input and select some number of examples to add to our few-shot prompt. We’ll use a SemanticSimilarityExampleSelector, which will perform a semantic search using the embeddings and vector store we configure to find the examples most similar to our input:
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
FAISS,
k=5,
input_keys=["input"],
)
Now we can create our FewShotPromptTemplate, which takes our example selector, an example prompt for formatting each example, and a string prefix and suffix to put before and after our formatted examples:
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotPromptTemplate,
MessagesPlaceholder,
PromptTemplate,
SystemMessagePromptTemplate,
)
system_prefix = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
Here are some examples of user inputs and their corresponding SQL queries:"""
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=PromptTemplate.from_template(
"User input: {input}\nSQL query: {query}"
),
input_variables=["input", "dialect", "top_k"],
prefix=system_prefix,
suffix="",
)
Since our underlying agent is an OpenAI tools agent, which uses OpenAI function calling, our full prompt should be a chat prompt with a human message template and an agent_scratchpad MessagesPlaceholder. The few-shot prompt will be used for our system message:
full_prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate(prompt=few_shot_prompt),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
]
)
# Example formatted prompt
prompt_val = full_prompt.invoke(
{
"input": "How many arists are there",
"top_k": 5,
"dialect": "SQLite",
"agent_scratchpad": [],
}
)
print(prompt_val.to_string())
System: You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
Here are some examples of user inputs and their corresponding SQL queries:
User input: List all artists.
SQL query: SELECT * FROM Artist;
User input: How many employees are there
SQL query: SELECT COUNT(*) FROM "Employee"
User input: How many tracks are there in the album with ID 5?
SQL query: SELECT COUNT(*) FROM Track WHERE AlbumId = 5;
User input: List all tracks in the 'Rock' genre.
SQL query: SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');
User input: Which albums are from the year 2000?
SQL query: SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';
Human: How many arists are there
And now we can create our agent with our custom prompt:
agent = create_sql_agent(
llm=llm,
db=db,
prompt=full_prompt,
verbose=True,
agent_type="openai-tools",
)
Let’s try it out:
agent.invoke({"input": "How many artists are there?"})
> Entering new AgentExecutor chain...
Invoking: `sql_db_query` with `{'query': 'SELECT COUNT(*) FROM Artist'}`
[(275,)]There are 275 artists in the database.
> Finished chain.
{'input': 'How many artists are there?',
'output': 'There are 275 artists in the database.'}
Dealing with high-cardinality columns
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
We can achieve this by creating a vector store with all the distinct proper nouns that exist in the database. We can then have the agent query that vector store each time the user includes a proper noun in their question, to find the correct spelling for that word. In this way, the agent can make sure it understands which entity the user is referring to before building the target query.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
import ast
import re
def query_as_list(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub if el]
res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]
return list(set(res))
artists = query_as_list(db, "SELECT Name FROM Artist")
albums = query_as_list(db, "SELECT Title FROM Album")
albums[:5]
['Os Cães Ladram Mas A Caravana Não Pára',
'War',
'Mais Do Mesmo',
"Up An' Atom",
'Riot Act']
Now we can proceed with creating the custom retriever tool and the final agent:
from langchain.agents.agent_toolkits import create_retriever_tool
vector_db = FAISS.from_texts(artists + albums, OpenAIEmbeddings())
retriever = vector_db.as_retriever(search_kwargs={"k": 5})
description = """Use to look up values to filter on. Input is an approximate spelling of the proper noun, output is \
valid proper nouns. Use the noun most similar to the search."""
retriever_tool = create_retriever_tool(
retriever,
name="search_proper_nouns",
description=description,
)
system = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If you need to filter on a proper noun, you must ALWAYS first look up the filter value using the "search_proper_nouns" tool!
You have access to the following tables: {table_names}
If the question does not seem related to the database, just return "I don't know" as the answer."""
prompt = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad")]
)
agent = create_sql_agent(
llm=llm,
db=db,
extra_tools=[retriever_tool],
prompt=prompt,
agent_type="openai-tools",
verbose=True,
)
agent.invoke({"input": "How many albums does alis in chain have?"})
> Entering new AgentExecutor chain...
Invoking: `search_proper_nouns` with `{'query': 'alis in chain'}`
Alice In Chains
Aisha Duo
Xis
Da Lama Ao Caos
A-Sides
Invoking: `sql_db_query` with `SELECT COUNT(*) FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'Alice In Chains')`
[(1,)]Alice In Chains has 1 album.
> Finished chain.
{'input': 'How many albums does alis in chain have?',
'output': 'Alice In Chains has 1 album.'}
As we can see, the agent used the search_proper_nouns tool in order to check how to correctly query the database for this specific artist.
Next steps
Under the hood, create_sql_agent is just passing in SQL tools to more generic agent constructors. To learn more about the built-in generic agent types as well as how to build custom agents, head to the Agents Modules.
The built-in AgentExecutor runs a simple Agent action -> Tool call -> Agent action… loop. To build more complex agent runtimes, head to the LangGraph section. |
https://python.langchain.com/docs/use_cases/sql/csv/ | ## CSV
LLMs are great for building question-answering systems over various types of data sources. In this section we’ll go over how to build Q&A systems over data stored in a CSV file(s). Like working with SQL databases, the key to working with CSV files is to give an LLM access to tools for querying and interacting with the data. The two main ways to do this are to either:
* **RECOMMENDED**: Load the CSV(s) into a SQL database, and use the approaches outlined in the [SQL use case docs](https://python.langchain.com/docs/use_cases/sql/).
* Give the LLM access to a Python environment where it can use libraries like Pandas to interact with the data.
## ⚠️ Security note ⚠️[](#security-note "Direct link to ⚠️ Security note ⚠️")
Both approaches mentioned above carry significant risks. Using SQL requires executing model-generated SQL queries. Using a library like Pandas requires letting the model execute Python code. Since it is easier to tightly scope SQL connection permissions and sanitize SQL queries than it is to sandbox Python environments, **we HIGHLY recommend interacting with CSV data via SQL.** For more on general security best practices, [see here](https://python.langchain.com/docs/security/).
## Setup[](#setup "Direct link to Setup")
Dependencies for this guide:
```
%pip install -qU langchain langchain-openai langchain-community langchain-experimental pandas
```
Set required environment variables:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Using LangSmith is recommended but not required. Uncomment below lines to use.# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
Download the [Titanic dataset](https://www.kaggle.com/datasets/yasserh/titanic-dataset) if you don’t already have it:
```
!wget https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv -O titanic.csv
```
```
import pandas as pddf = pd.read_csv("titanic.csv")print(df.shape)print(df.columns.tolist())
```
```
(887, 8)['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'Siblings/Spouses Aboard', 'Parents/Children Aboard', 'Fare']
```
## SQL[](#sql "Direct link to SQL")
Using SQL to interact with CSV data is the recommended approach because it is easier to limit permissions and sanitize queries than with arbitrary Python.
Most SQL databases make it easy to load a CSV file in as a table ([DuckDB](https://duckdb.org/docs/data/csv/overview.html), [SQLite](https://www.sqlite.org/csv.html), etc.). Once you’ve done this you can use all of the chain and agent-creating techniques outlined in the [SQL use case guide](https://python.langchain.com/docs/use_cases/sql/). Here’s a quick example of how we might do this with SQLite:
```
from langchain_community.utilities import SQLDatabasefrom sqlalchemy import create_engineengine = create_engine("sqlite:///titanic.db")df.to_sql("titanic", engine, index=False)
```
```
db = SQLDatabase(engine=engine)print(db.dialect)print(db.get_usable_table_names())db.run("SELECT * FROM titanic WHERE Age < 2;")
```
```
"[(1, 2, 'Master. Alden Gates Caldwell', 'male', 0.83, 0, 2, 29.0), (0, 3, 'Master. Eino Viljami Panula', 'male', 1.0, 4, 1, 39.6875), (1, 3, 'Miss. Eleanor Ileen Johnson', 'female', 1.0, 1, 1, 11.1333), (1, 2, 'Master. Richard F Becker', 'male', 1.0, 2, 1, 39.0), (1, 1, 'Master. Hudson Trevor Allison', 'male', 0.92, 1, 2, 151.55), (1, 3, 'Miss. Maria Nakid', 'female', 1.0, 0, 2, 15.7417), (0, 3, 'Master. Sidney Leonard Goodwin', 'male', 1.0, 5, 2, 46.9), (1, 3, 'Miss. Helene Barbara Baclini', 'female', 0.75, 2, 1, 19.2583), (1, 3, 'Miss. Eugenie Baclini', 'female', 0.75, 2, 1, 19.2583), (1, 2, 'Master. Viljo Hamalainen', 'male', 0.67, 1, 1, 14.5), (1, 3, 'Master. Bertram Vere Dean', 'male', 1.0, 1, 2, 20.575), (1, 3, 'Master. Assad Alexander Thomas', 'male', 0.42, 0, 1, 8.5167), (1, 2, 'Master. Andre Mallet', 'male', 1.0, 0, 2, 37.0042), (1, 2, 'Master. George Sibley Richards', 'male', 0.83, 1, 1, 18.75)]"
```
And create a [SQL agent](https://python.langchain.com/docs/use_cases/sql/agents/) to interact with it:
```
from langchain_community.agent_toolkits import create_sql_agentfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
```
```
agent_executor.invoke({"input": "what's the average age of survivors"})
```
```
> Entering new AgentExecutor chain...Invoking: `sql_db_list_tables` with `{}`titanicInvoking: `sql_db_schema` with `{'table_names': 'titanic'}`CREATE TABLE titanic ( "Survived" BIGINT, "Pclass" BIGINT, "Name" TEXT, "Sex" TEXT, "Age" FLOAT, "Siblings/Spouses Aboard" BIGINT, "Parents/Children Aboard" BIGINT, "Fare" FLOAT)/*3 rows from titanic table:Survived Pclass Name Sex Age Siblings/Spouses Aboard Parents/Children Aboard Fare0 3 Mr. Owen Harris Braund male 22.0 1 0 7.251 1 Mrs. John Bradley (Florence Briggs Thayer) Cumings female 38.0 1 0 71.28331 3 Miss. Laina Heikkinen female 26.0 0 0 7.925*/Invoking: `sql_db_query` with `{'query': 'SELECT AVG(Age) AS AverageAge FROM titanic WHERE Survived = 1'}`responded: To find the average age of survivors, I will query the "titanic" table and calculate the average of the "Age" column for the rows where "Survived" is equal to 1.Here is the SQL query:```sqlSELECT AVG(Age) AS AverageAgeFROM titanicWHERE Survived = 1```Executing this query will give us the average age of the survivors.[(28.408391812865496,)]The average age of the survivors is approximately 28.41 years.> Finished chain.
```
```
{'input': "what's the average age of survivors", 'output': 'The average age of the survivors is approximately 28.41 years.'}
```
This approach easily generalizes to multiple CSVs, since we can just load each of them into our database as it’s own table. Head to the [SQL guide](https://python.langchain.com/docs/use_cases/sql/) for more.
## Pandas[](#pandas "Direct link to Pandas")
Instead of SQL we can also use data analysis libraries like pandas and the code generating abilities of LLMs to interact with CSV data. Again, **this approach is not fit for production use cases unless you have extensive safeguards in place**. For this reason, our code-execution utilities and constructors live in the `langchain-experimental` package.
### Chain[](#chain "Direct link to Chain")
Most LLMs have been trained on enough pandas Python code that they can generate it just by being asked to:
```
ai_msg = llm.invoke( "I have a pandas DataFrame 'df' with columns 'Age' and 'Fare'. Write code to compute the correlation between the two columns. Return Markdown for a Python code snippet and nothing else.")print(ai_msg.content)
```
````
```pythoncorrelation = df['Age'].corr(df['Fare'])correlation```
````
We can combine this ability with a Python-executing tool to create a simple data analysis chain. We’ll first want to load our CSV table as a dataframe, and give the tool access to this dataframe:
```
import pandas as pdfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_experimental.tools import PythonAstREPLTooldf = pd.read_csv("titanic.csv")tool = PythonAstREPLTool(locals={"df": df})tool.invoke("df['Fare'].mean()")
```
To help enforce proper use of our Python tool, we’ll using [function calling](https://python.langchain.com/docs/modules/model_io/chat/function_calling/):
```
llm_with_tools = llm.bind_tools([tool], tool_choice=tool.name)llm_with_tools.invoke( "I have a dataframe 'df' and want to know the correlation between the 'Age' and 'Fare' columns")
```
```
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_6TZsNaCqOcbP7lqWudosQTd6', 'function': {'arguments': '{\n "query": "df[[\'Age\', \'Fare\']].corr()"\n}', 'name': 'python_repl_ast'}, 'type': 'function'}]})
```
We’ll add a [OpenAI tools output parser](https://python.langchain.com/docs/modules/model_io/output_parsers/types/openai_tools/) to extract the function call as a dict:
```
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParserparser = JsonOutputKeyToolsParser(tool.name, first_tool_only=True)(llm_with_tools | parser).invoke( "I have a dataframe 'df' and want to know the correlation between the 'Age' and 'Fare' columns")
```
```
{'query': "df[['Age', 'Fare']].corr()"}
```
And combine with a prompt so that we can just specify a question without needing to specify the dataframe info every invocation:
```
system = f"""You have access to a pandas dataframe `df`. \Here is the output of `df.head().to_markdown()`:```{df.head().to_markdown()}```Given a user question, write the Python code to answer it. \Return ONLY the valid Python code and nothing else. \Don't assume you have access to any libraries other than built-in Python ones and pandas."""prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{question}")])code_chain = prompt | llm_with_tools | parsercode_chain.invoke({"question": "What's the correlation between age and fare"})
```
```
{'query': "df[['Age', 'Fare']].corr()"}
```
And lastly we’ll add our Python tool so that the generated code is actually executed:
```
chain = prompt | llm_with_tools | parser | tool # noqachain.invoke({"question": "What's the correlation between age and fare"})
```
And just like that we have a simple data analysis chain. We can take a peak at the intermediate steps by looking at the LangSmith trace: [https://smith.langchain.com/public/b1309290-7212-49b7-bde2-75b39a32b49a/r](https://smith.langchain.com/public/b1309290-7212-49b7-bde2-75b39a32b49a/r)
We could add an additional LLM call at the end to generate a conversational response, so that we’re not just responding with the tool output. For this we’ll want to add a chat history `MessagesPlaceholder` to our prompt:
```
from operator import itemgetterfrom langchain_core.messages import ToolMessagefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import MessagesPlaceholderfrom langchain_core.runnables import RunnablePassthroughsystem = f"""You have access to a pandas dataframe `df`. \Here is the output of `df.head().to_markdown()`:```{df.head().to_markdown()}```Given a user question, write the Python code to answer it. \Don't assume you have access to any libraries other than built-in Python ones and pandas.Respond directly to the question once you have enough information to answer it."""prompt = ChatPromptTemplate.from_messages( [ ( "system", system, ), ("human", "{question}"), # This MessagesPlaceholder allows us to optionally append an arbitrary number of messages # at the end of the prompt using the 'chat_history' arg. MessagesPlaceholder("chat_history", optional=True), ])def _get_chat_history(x: dict) -> list: """Parse the chain output up to this point into a list of chat history messages to insert in the prompt.""" ai_msg = x["ai_msg"] tool_call_id = x["ai_msg"].additional_kwargs["tool_calls"][0]["id"] tool_msg = ToolMessage(tool_call_id=tool_call_id, content=str(x["tool_output"])) return [ai_msg, tool_msg]chain = ( RunnablePassthrough.assign(ai_msg=prompt | llm_with_tools) .assign(tool_output=itemgetter("ai_msg") | parser | tool) .assign(chat_history=_get_chat_history) .assign(response=prompt | llm | StrOutputParser()) .pick(["tool_output", "response"]))
```
```
chain.invoke({"question": "What's the correlation between age and fare"})
```
```
{'tool_output': 0.11232863699941621, 'response': 'The correlation between age and fare is approximately 0.112.'}
```
Here’s the LangSmith trace for this run: [https://smith.langchain.com/public/ca689f8a-5655-4224-8bcf-982080744462/r](https://smith.langchain.com/public/ca689f8a-5655-4224-8bcf-982080744462/r)
### Agent[](#agent "Direct link to Agent")
For complex questions it can be helpful for an LLM to be able to iteratively execute code while maintaining the inputs and outputs of its previous executions. This is where Agents come into play. They allow an LLM to decide how many times a tool needs to be invoked and keep track of the executions it’s made so far. The [create\_pandas\_dataframe\_agent](https://api.python.langchain.com/en/latest/agents/langchain_experimental.agents.agent_toolkits.pandas.base.create_pandas_dataframe_agent.html) is a built-in agent that makes it easy to work with dataframes:
```
from langchain_experimental.agents import create_pandas_dataframe_agentagent = create_pandas_dataframe_agent(llm, df, agent_type="openai-tools", verbose=True)agent.invoke( { "input": "What's the correlation between age and fare? is that greater than the correlation between fare and survival?" })
```
```
> Entering new AgentExecutor chain...Invoking: `python_repl_ast` with `{'query': "df[['Age', 'Fare']].corr()"}` Age FareAge 1.000000 0.112329Fare 0.112329 1.000000Invoking: `python_repl_ast` with `{'query': "df[['Fare', 'Survived']].corr()"}` Fare SurvivedFare 1.000000 0.256179Survived 0.256179 1.000000The correlation between age and fare is 0.112329, while the correlation between fare and survival is 0.256179. Therefore, the correlation between fare and survival is greater than the correlation between age and fare.> Finished chain.
```
```
{'input': "What's the correlation between age and fare? is that greater than the correlation between fare and survival?", 'output': 'The correlation between age and fare is 0.112329, while the correlation between fare and survival is 0.256179. Therefore, the correlation between fare and survival is greater than the correlation between age and fare.'}
```
Here’s the LangSmith trace for this run: [https://smith.langchain.com/public/8e6c23cc-782c-4203-bac6-2a28c770c9f0/r](https://smith.langchain.com/public/8e6c23cc-782c-4203-bac6-2a28c770c9f0/r)
### Multiple CSVs[](#multiple-csvs "Direct link to Multiple CSVs")
To handle multiple CSVs (or dataframes) we just need to pass multiple dataframes to our Python tool. Our `create_pandas_dataframe_agent` constructor can do this out of the box, we can pass in a list of dataframes instead of just one. If we’re constructing a chain ourselves, we can do something like:
```
df_1 = df[["Age", "Fare"]]df_2 = df[["Fare", "Survived"]]tool = PythonAstREPLTool(locals={"df_1": df_1, "df_2": df_2})llm_with_tool = llm.bind_tools(tools=[tool], tool_choice=tool.name)df_template = """```python{df_name}.head().to_markdown()>>> {df_head}```"""df_context = "\n\n".join( df_template.format(df_head=_df.head().to_markdown(), df_name=df_name) for _df, df_name in [(df_1, "df_1"), (df_2, "df_2")])system = f"""You have access to a number of pandas dataframes. \Here is a sample of rows from each dataframe and the python code that was used to generate the sample:{df_context}Given a user question about the dataframes, write the Python code to answer it. \Don't assume you have access to any libraries other than built-in Python ones and pandas. \Make sure to refer only to the variables mentioned above."""prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{question}")])chain = prompt | llm_with_tool | parser | toolchain.invoke( { "question": "return the difference in the correlation between age and fare and the correlation between fare and survival" })
```
Here’s the LangSmith trace for this run: [https://smith.langchain.com/public/653e499f-179c-4757-8041-f5e2a5f11fcc/r](https://smith.langchain.com/public/653e499f-179c-4757-8041-f5e2a5f11fcc/r)
### Sandboxed code execution[](#sandboxed-code-execution "Direct link to Sandboxed code execution")
There are a number of tools like [E2B](https://python.langchain.com/docs/integrations/tools/e2b_data_analysis/) and [Bearly](https://python.langchain.com/docs/integrations/tools/bearly/) that provide sandboxed environments for Python code execution, to allow for safer code-executing chains and agents.
## Next steps[](#next-steps "Direct link to Next steps")
For more advanced data analysis applications we recommend checking out:
* [SQL use case](https://python.langchain.com/docs/use_cases/sql/): Many of the challenges of working with SQL db’s and CSV’s are generic to any structured data type, so it’s useful to read the SQL techniques even if you’re using Pandas for CSV data analysis.
* [Tool use](https://python.langchain.com/docs/use_cases/tool_use/): Guides on general best practices when working with chains and agents that invoke tools
* [Agents](https://python.langchain.com/docs/modules/agents/): Understand the fundamentals of building LLM agents.
* Integrations: Sandboxed envs like [E2B](https://python.langchain.com/docs/integrations/tools/e2b_data_analysis/) and [Bearly](https://python.langchain.com/docs/integrations/tools/bearly/), utilities like [SQLDatabase](https://api.python.langchain.com/en/latest/utilities/langchain_community.utilities.sql_database.SQLDatabase.html#langchain_community.utilities.sql_database.SQLDatabase), related agents like [Spark DataFrame agent](https://python.langchain.com/docs/integrations/toolkits/spark/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:27.654Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/csv/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/csv/",
"description": "LLMs are great for building question-answering systems over various",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4286",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"csv\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:24 GMT",
"etag": "W/\"458290d20a684ff2ed2904ecc549e5a2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::xvwj7-1713753984750-657903fa811c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/csv/",
"property": "og:url"
},
{
"content": "CSV | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "LLMs are great for building question-answering systems over various",
"property": "og:description"
}
],
"title": "CSV | 🦜️🔗 LangChain"
} | CSV
LLMs are great for building question-answering systems over various types of data sources. In this section we’ll go over how to build Q&A systems over data stored in a CSV file(s). Like working with SQL databases, the key to working with CSV files is to give an LLM access to tools for querying and interacting with the data. The two main ways to do this are to either:
RECOMMENDED: Load the CSV(s) into a SQL database, and use the approaches outlined in the SQL use case docs.
Give the LLM access to a Python environment where it can use libraries like Pandas to interact with the data.
⚠️ Security note ⚠️
Both approaches mentioned above carry significant risks. Using SQL requires executing model-generated SQL queries. Using a library like Pandas requires letting the model execute Python code. Since it is easier to tightly scope SQL connection permissions and sanitize SQL queries than it is to sandbox Python environments, we HIGHLY recommend interacting with CSV data via SQL. For more on general security best practices, see here.
Setup
Dependencies for this guide:
%pip install -qU langchain langchain-openai langchain-community langchain-experimental pandas
Set required environment variables:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Using LangSmith is recommended but not required. Uncomment below lines to use.
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Download the Titanic dataset if you don’t already have it:
!wget https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv -O titanic.csv
import pandas as pd
df = pd.read_csv("titanic.csv")
print(df.shape)
print(df.columns.tolist())
(887, 8)
['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'Siblings/Spouses Aboard', 'Parents/Children Aboard', 'Fare']
SQL
Using SQL to interact with CSV data is the recommended approach because it is easier to limit permissions and sanitize queries than with arbitrary Python.
Most SQL databases make it easy to load a CSV file in as a table (DuckDB, SQLite, etc.). Once you’ve done this you can use all of the chain and agent-creating techniques outlined in the SQL use case guide. Here’s a quick example of how we might do this with SQLite:
from langchain_community.utilities import SQLDatabase
from sqlalchemy import create_engine
engine = create_engine("sqlite:///titanic.db")
df.to_sql("titanic", engine, index=False)
db = SQLDatabase(engine=engine)
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM titanic WHERE Age < 2;")
"[(1, 2, 'Master. Alden Gates Caldwell', 'male', 0.83, 0, 2, 29.0), (0, 3, 'Master. Eino Viljami Panula', 'male', 1.0, 4, 1, 39.6875), (1, 3, 'Miss. Eleanor Ileen Johnson', 'female', 1.0, 1, 1, 11.1333), (1, 2, 'Master. Richard F Becker', 'male', 1.0, 2, 1, 39.0), (1, 1, 'Master. Hudson Trevor Allison', 'male', 0.92, 1, 2, 151.55), (1, 3, 'Miss. Maria Nakid', 'female', 1.0, 0, 2, 15.7417), (0, 3, 'Master. Sidney Leonard Goodwin', 'male', 1.0, 5, 2, 46.9), (1, 3, 'Miss. Helene Barbara Baclini', 'female', 0.75, 2, 1, 19.2583), (1, 3, 'Miss. Eugenie Baclini', 'female', 0.75, 2, 1, 19.2583), (1, 2, 'Master. Viljo Hamalainen', 'male', 0.67, 1, 1, 14.5), (1, 3, 'Master. Bertram Vere Dean', 'male', 1.0, 1, 2, 20.575), (1, 3, 'Master. Assad Alexander Thomas', 'male', 0.42, 0, 1, 8.5167), (1, 2, 'Master. Andre Mallet', 'male', 1.0, 0, 2, 37.0042), (1, 2, 'Master. George Sibley Richards', 'male', 0.83, 1, 1, 18.75)]"
And create a SQL agent to interact with it:
from langchain_community.agent_toolkits import create_sql_agent
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke({"input": "what's the average age of survivors"})
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
titanic
Invoking: `sql_db_schema` with `{'table_names': 'titanic'}`
CREATE TABLE titanic (
"Survived" BIGINT,
"Pclass" BIGINT,
"Name" TEXT,
"Sex" TEXT,
"Age" FLOAT,
"Siblings/Spouses Aboard" BIGINT,
"Parents/Children Aboard" BIGINT,
"Fare" FLOAT
)
/*
3 rows from titanic table:
Survived Pclass Name Sex Age Siblings/Spouses Aboard Parents/Children Aboard Fare
0 3 Mr. Owen Harris Braund male 22.0 1 0 7.25
1 1 Mrs. John Bradley (Florence Briggs Thayer) Cumings female 38.0 1 0 71.2833
1 3 Miss. Laina Heikkinen female 26.0 0 0 7.925
*/
Invoking: `sql_db_query` with `{'query': 'SELECT AVG(Age) AS AverageAge FROM titanic WHERE Survived = 1'}`
responded: To find the average age of survivors, I will query the "titanic" table and calculate the average of the "Age" column for the rows where "Survived" is equal to 1.
Here is the SQL query:
```sql
SELECT AVG(Age) AS AverageAge
FROM titanic
WHERE Survived = 1
```
Executing this query will give us the average age of the survivors.
[(28.408391812865496,)]The average age of the survivors is approximately 28.41 years.
> Finished chain.
{'input': "what's the average age of survivors",
'output': 'The average age of the survivors is approximately 28.41 years.'}
This approach easily generalizes to multiple CSVs, since we can just load each of them into our database as it’s own table. Head to the SQL guide for more.
Pandas
Instead of SQL we can also use data analysis libraries like pandas and the code generating abilities of LLMs to interact with CSV data. Again, this approach is not fit for production use cases unless you have extensive safeguards in place. For this reason, our code-execution utilities and constructors live in the langchain-experimental package.
Chain
Most LLMs have been trained on enough pandas Python code that they can generate it just by being asked to:
ai_msg = llm.invoke(
"I have a pandas DataFrame 'df' with columns 'Age' and 'Fare'. Write code to compute the correlation between the two columns. Return Markdown for a Python code snippet and nothing else."
)
print(ai_msg.content)
```python
correlation = df['Age'].corr(df['Fare'])
correlation
```
We can combine this ability with a Python-executing tool to create a simple data analysis chain. We’ll first want to load our CSV table as a dataframe, and give the tool access to this dataframe:
import pandas as pd
from langchain_core.prompts import ChatPromptTemplate
from langchain_experimental.tools import PythonAstREPLTool
df = pd.read_csv("titanic.csv")
tool = PythonAstREPLTool(locals={"df": df})
tool.invoke("df['Fare'].mean()")
To help enforce proper use of our Python tool, we’ll using function calling:
llm_with_tools = llm.bind_tools([tool], tool_choice=tool.name)
llm_with_tools.invoke(
"I have a dataframe 'df' and want to know the correlation between the 'Age' and 'Fare' columns"
)
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_6TZsNaCqOcbP7lqWudosQTd6', 'function': {'arguments': '{\n "query": "df[[\'Age\', \'Fare\']].corr()"\n}', 'name': 'python_repl_ast'}, 'type': 'function'}]})
We’ll add a OpenAI tools output parser to extract the function call as a dict:
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParser
parser = JsonOutputKeyToolsParser(tool.name, first_tool_only=True)
(llm_with_tools | parser).invoke(
"I have a dataframe 'df' and want to know the correlation between the 'Age' and 'Fare' columns"
)
{'query': "df[['Age', 'Fare']].corr()"}
And combine with a prompt so that we can just specify a question without needing to specify the dataframe info every invocation:
system = f"""You have access to a pandas dataframe `df`. \
Here is the output of `df.head().to_markdown()`:
```
{df.head().to_markdown()}
```
Given a user question, write the Python code to answer it. \
Return ONLY the valid Python code and nothing else. \
Don't assume you have access to any libraries other than built-in Python ones and pandas."""
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{question}")])
code_chain = prompt | llm_with_tools | parser
code_chain.invoke({"question": "What's the correlation between age and fare"})
{'query': "df[['Age', 'Fare']].corr()"}
And lastly we’ll add our Python tool so that the generated code is actually executed:
chain = prompt | llm_with_tools | parser | tool # noqa
chain.invoke({"question": "What's the correlation between age and fare"})
And just like that we have a simple data analysis chain. We can take a peak at the intermediate steps by looking at the LangSmith trace: https://smith.langchain.com/public/b1309290-7212-49b7-bde2-75b39a32b49a/r
We could add an additional LLM call at the end to generate a conversational response, so that we’re not just responding with the tool output. For this we’ll want to add a chat history MessagesPlaceholder to our prompt:
from operator import itemgetter
from langchain_core.messages import ToolMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
system = f"""You have access to a pandas dataframe `df`. \
Here is the output of `df.head().to_markdown()`:
```
{df.head().to_markdown()}
```
Given a user question, write the Python code to answer it. \
Don't assume you have access to any libraries other than built-in Python ones and pandas.
Respond directly to the question once you have enough information to answer it."""
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system,
),
("human", "{question}"),
# This MessagesPlaceholder allows us to optionally append an arbitrary number of messages
# at the end of the prompt using the 'chat_history' arg.
MessagesPlaceholder("chat_history", optional=True),
]
)
def _get_chat_history(x: dict) -> list:
"""Parse the chain output up to this point into a list of chat history messages to insert in the prompt."""
ai_msg = x["ai_msg"]
tool_call_id = x["ai_msg"].additional_kwargs["tool_calls"][0]["id"]
tool_msg = ToolMessage(tool_call_id=tool_call_id, content=str(x["tool_output"]))
return [ai_msg, tool_msg]
chain = (
RunnablePassthrough.assign(ai_msg=prompt | llm_with_tools)
.assign(tool_output=itemgetter("ai_msg") | parser | tool)
.assign(chat_history=_get_chat_history)
.assign(response=prompt | llm | StrOutputParser())
.pick(["tool_output", "response"])
)
chain.invoke({"question": "What's the correlation between age and fare"})
{'tool_output': 0.11232863699941621,
'response': 'The correlation between age and fare is approximately 0.112.'}
Here’s the LangSmith trace for this run: https://smith.langchain.com/public/ca689f8a-5655-4224-8bcf-982080744462/r
Agent
For complex questions it can be helpful for an LLM to be able to iteratively execute code while maintaining the inputs and outputs of its previous executions. This is where Agents come into play. They allow an LLM to decide how many times a tool needs to be invoked and keep track of the executions it’s made so far. The create_pandas_dataframe_agent is a built-in agent that makes it easy to work with dataframes:
from langchain_experimental.agents import create_pandas_dataframe_agent
agent = create_pandas_dataframe_agent(llm, df, agent_type="openai-tools", verbose=True)
agent.invoke(
{
"input": "What's the correlation between age and fare? is that greater than the correlation between fare and survival?"
}
)
> Entering new AgentExecutor chain...
Invoking: `python_repl_ast` with `{'query': "df[['Age', 'Fare']].corr()"}`
Age Fare
Age 1.000000 0.112329
Fare 0.112329 1.000000
Invoking: `python_repl_ast` with `{'query': "df[['Fare', 'Survived']].corr()"}`
Fare Survived
Fare 1.000000 0.256179
Survived 0.256179 1.000000The correlation between age and fare is 0.112329, while the correlation between fare and survival is 0.256179. Therefore, the correlation between fare and survival is greater than the correlation between age and fare.
> Finished chain.
{'input': "What's the correlation between age and fare? is that greater than the correlation between fare and survival?",
'output': 'The correlation between age and fare is 0.112329, while the correlation between fare and survival is 0.256179. Therefore, the correlation between fare and survival is greater than the correlation between age and fare.'}
Here’s the LangSmith trace for this run: https://smith.langchain.com/public/8e6c23cc-782c-4203-bac6-2a28c770c9f0/r
Multiple CSVs
To handle multiple CSVs (or dataframes) we just need to pass multiple dataframes to our Python tool. Our create_pandas_dataframe_agent constructor can do this out of the box, we can pass in a list of dataframes instead of just one. If we’re constructing a chain ourselves, we can do something like:
df_1 = df[["Age", "Fare"]]
df_2 = df[["Fare", "Survived"]]
tool = PythonAstREPLTool(locals={"df_1": df_1, "df_2": df_2})
llm_with_tool = llm.bind_tools(tools=[tool], tool_choice=tool.name)
df_template = """```python
{df_name}.head().to_markdown()
>>> {df_head}
```"""
df_context = "\n\n".join(
df_template.format(df_head=_df.head().to_markdown(), df_name=df_name)
for _df, df_name in [(df_1, "df_1"), (df_2, "df_2")]
)
system = f"""You have access to a number of pandas dataframes. \
Here is a sample of rows from each dataframe and the python code that was used to generate the sample:
{df_context}
Given a user question about the dataframes, write the Python code to answer it. \
Don't assume you have access to any libraries other than built-in Python ones and pandas. \
Make sure to refer only to the variables mentioned above."""
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{question}")])
chain = prompt | llm_with_tool | parser | tool
chain.invoke(
{
"question": "return the difference in the correlation between age and fare and the correlation between fare and survival"
}
)
Here’s the LangSmith trace for this run: https://smith.langchain.com/public/653e499f-179c-4757-8041-f5e2a5f11fcc/r
Sandboxed code execution
There are a number of tools like E2B and Bearly that provide sandboxed environments for Python code execution, to allow for safer code-executing chains and agents.
Next steps
For more advanced data analysis applications we recommend checking out:
SQL use case: Many of the challenges of working with SQL db’s and CSV’s are generic to any structured data type, so it’s useful to read the SQL techniques even if you’re using Pandas for CSV data analysis.
Tool use: Guides on general best practices when working with chains and agents that invoke tools
Agents: Understand the fundamentals of building LLM agents.
Integrations: Sandboxed envs like E2B and Bearly, utilities like SQLDatabase, related agents like Spark DataFrame agent. |
https://python.langchain.com/docs/use_cases/sql/large_db/ | ## Large databases
In order to write valid queries against a database, we need to feed the model the table names, table schemas, and feature values for it to query over. When there are many tables, columns, and/or high-cardinality columns, it becomes impossible for us to dump the full information about our database in every prompt. Instead, we must find ways to dynamically insert into the prompt only the most relevant information. Let’s take a look at some techniques for doing this.
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai
```
```
[notice] A new release of pip is available: 23.2.1 -> 23.3.2[notice] To update, run: pip install --upgrade pipNote: you may need to restart the kernel to use updated packages.
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport os# os.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
The below example will use a SQLite connection with Chinook database. Follow [these installation steps](https://database.guide/2-sample-databases-sqlite/) to create `Chinook.db` in the same directory as this notebook:
* Save [this file](https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql) as `Chinook_Sqlite.sql`
* Run `sqlite3 Chinook.db`
* Run `.read Chinook_Sqlite.sql`
* Test `SELECT * FROM Artist LIMIT 10;`
Now, `Chinhook.db` is in our directory and we can interface with it using the SQLAlchemy-driven [SQLDatabase](https://api.python.langchain.com/en/latest/utilities/langchain_community.utilities.sql_database.SQLDatabase.html) class:
```
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")print(db.dialect)print(db.get_usable_table_names())db.run("SELECT * FROM Artist LIMIT 10;")
```
```
sqlite['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
```
```
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
```
## Many tables[](#many-tables "Direct link to Many tables")
One of the main pieces of information we need to include in our prompt is the schemas of the relevant tables. When we have very many tables, we can’t fit all of the schemas in a single prompt. What we can do in such cases is first extract the names of the tables related to the user input, and then include only their schemas.
One easy and reliable way to do this is using OpenAI function-calling and Pydantic models. LangChain comes with a built-in [create\_extraction\_chain\_pydantic](https://api.python.langchain.com/en/latest/chains/langchain.chains.openai_tools.extraction.create_extraction_chain_pydantic.html) chain that lets us do just this:
```
from langchain.chains.openai_tools import create_extraction_chain_pydanticfrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)class Table(BaseModel): """Table in SQL database.""" name: str = Field(description="Name of table in SQL database.")table_names = "\n".join(db.get_usable_table_names())system = f"""Return the names of ALL the SQL tables that MIGHT be relevant to the user question. \The tables are:{table_names}Remember to include ALL POTENTIALLY RELEVANT tables, even if you're not sure that they're needed."""table_chain = create_extraction_chain_pydantic(Table, llm, system_message=system)table_chain.invoke({"input": "What are all the genres of Alanis Morisette songs"})
```
```
[Table(name='Genre'), Table(name='Artist'), Table(name='Track')]
```
This works pretty well! Except, as we’ll see below, we actually need a few other tables as well. This would be pretty difficult for the model to know based just on the user question. In this case, we might think to simplify our model’s job by grouping the tables together. We’ll just ask the model to choose between categories “Music” and “Business”, and then take care of selecting all the relevant tables from there:
```
system = """Return the names of the SQL tables that are relevant to the user question. \The tables are:MusicBusiness"""category_chain = create_extraction_chain_pydantic(Table, llm, system_message=system)category_chain.invoke({"input": "What are all the genres of Alanis Morisette songs"})
```
```
from typing import Listdef get_tables(categories: List[Table]) -> List[str]: tables = [] for category in categories: if category.name == "Music": tables.extend( [ "Album", "Artist", "Genre", "MediaType", "Playlist", "PlaylistTrack", "Track", ] ) elif category.name == "Business": tables.extend(["Customer", "Employee", "Invoice", "InvoiceLine"]) return tablestable_chain = category_chain | get_tables # noqatable_chain.invoke({"input": "What are all the genres of Alanis Morisette songs"})
```
```
['Album', 'Artist', 'Genre', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
```
Now that we’ve got a chain that can output the relevant tables for any query we can combine this with our [create\_sql\_query\_chain](https://api.python.langchain.com/en/latest/chains/langchain.chains.sql_database.query.create_sql_query_chain.html), which can accept a list of `table_names_to_use` to determine which table schemas are included in the prompt:
```
from operator import itemgetterfrom langchain.chains import create_sql_query_chainfrom langchain_core.runnables import RunnablePassthroughquery_chain = create_sql_query_chain(llm, db)# Convert "question" key to the "input" key expected by current table_chain.table_chain = {"input": itemgetter("question")} | table_chain# Set table_names_to_use using table_chain.full_chain = RunnablePassthrough.assign(table_names_to_use=table_chain) | query_chain
```
```
query = full_chain.invoke( {"question": "What are all the genres of Alanis Morisette songs"})print(query)
```
```
SELECT "Genre"."Name"FROM "Genre"JOIN "Track" ON "Genre"."GenreId" = "Track"."GenreId"JOIN "Album" ON "Track"."AlbumId" = "Album"."AlbumId"JOIN "Artist" ON "Album"."ArtistId" = "Artist"."ArtistId"WHERE "Artist"."Name" = 'Alanis Morissette'
```
```
"[('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',)]"
```
We might rephrase our question slightly to remove redundancy in the answer
```
query = full_chain.invoke( {"question": "What is the set of all unique genres of Alanis Morisette songs"})print(query)
```
```
SELECT DISTINCT g.NameFROM Genre gJOIN Track t ON g.GenreId = t.GenreIdJOIN Album a ON t.AlbumId = a.AlbumIdJOIN Artist ar ON a.ArtistId = ar.ArtistIdWHERE ar.Name = 'Alanis Morissette'
```
We can see the [LangSmith trace](https://smith.langchain.com/public/20b8ef90-1dac-4754-90f0-6bc11203c50a/r) for this run here.
We’ve seen how to dynamically include a subset of table schemas in a prompt within a chain. Another possible approach to this problem is to let an Agent decide for itself when to look up tables by giving it a Tool to do so. You can see an example of this in the [SQL: Agents](https://python.langchain.com/docs/use_cases/sql/agents/) guide.
## High-cardinality columns[](#high-cardinality-columns "Direct link to High-cardinality columns")
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
One naive strategy it to create a vector store with all the distinct proper nouns that exist in the database. We can then query that vector store each user input and inject the most relevant proper nouns into the prompt.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
```
import astimport redef query_as_list(db, query): res = db.run(query) res = [el for sub in ast.literal_eval(res) for el in sub if el] res = [re.sub(r"\b\d+\b", "", string).strip() for string in res] return resproper_nouns = query_as_list(db, "SELECT Name FROM Artist")proper_nouns += query_as_list(db, "SELECT Title FROM Album")proper_nouns += query_as_list(db, "SELECT Name FROM Genre")len(proper_nouns)proper_nouns[:5]
```
```
['AC/DC', 'Accept', 'Aerosmith', 'Alanis Morissette', 'Alice In Chains']
```
Now we can embed and store all of our values in a vector database:
```
from langchain_community.vectorstores import FAISSfrom langchain_openai import OpenAIEmbeddingsvector_db = FAISS.from_texts(proper_nouns, OpenAIEmbeddings())retriever = vector_db.as_retriever(search_kwargs={"k": 15})
```
And put together a query construction chain that first retrieves values from the database and inserts them into the prompt:
```
from operator import itemgetterfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughsystem = """You are a SQLite expert. Given an input question, create a syntactically \correct SQLite query to run. Unless otherwise specificed, do not return more than \{top_k} rows.\n\nHere is the relevant table info: {table_info}\n\nHere is a non-exhaustive \list of possible feature values. If filtering on a feature value make sure to check its spelling \against this list first:\n\n{proper_nouns}"""prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{input}")])query_chain = create_sql_query_chain(llm, db, prompt=prompt)retriever_chain = ( itemgetter("question") | retriever | (lambda docs: "\n".join(doc.page_content for doc in docs)))chain = RunnablePassthrough.assign(proper_nouns=retriever_chain) | query_chain
```
To try out our chain, let’s see what happens when we try filtering on “elenis moriset”, a mispelling of Alanis Morissette, without and with retrieval:
```
# Without retrievalquery = query_chain.invoke( {"question": "What are all the genres of elenis moriset songs", "proper_nouns": ""})print(query)db.run(query)
```
```
SELECT DISTINCT Genre.NameFROM GenreJOIN Track ON Genre.GenreId = Track.GenreIdJOIN Album ON Track.AlbumId = Album.AlbumIdJOIN Artist ON Album.ArtistId = Artist.ArtistIdWHERE Artist.Name = 'Elenis Moriset'
```
```
# With retrievalquery = chain.invoke({"question": "What are all the genres of elenis moriset songs"})print(query)db.run(query)
```
```
SELECT DISTINCT Genre.NameFROM GenreJOIN Track ON Genre.GenreId = Track.GenreIdJOIN Album ON Track.AlbumId = Album.AlbumIdJOIN Artist ON Album.ArtistId = Artist.ArtistIdWHERE Artist.Name = 'Alanis Morissette'
```
We can see that with retrieval we’re able to correct the spelling and get back a valid result.
Another possible approach to this problem is to let an Agent decide for itself when to look up proper nouns. You can see an example of this in the [SQL: Agents](https://python.langchain.com/docs/use_cases/sql/agents/) guide. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:28.335Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/large_db/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/large_db/",
"description": "In order to write valid queries against a database, we need to feed the",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "6751",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"large_db\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:25 GMT",
"etag": "W/\"bc1083c3ebae151795e5e5093b8e60cb\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::vbvhh-1713753985952-3990d1a0e859"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/large_db/",
"property": "og:url"
},
{
"content": "Large databases | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In order to write valid queries against a database, we need to feed the",
"property": "og:description"
}
],
"title": "Large databases | 🦜️🔗 LangChain"
} | Large databases
In order to write valid queries against a database, we need to feed the model the table names, table schemas, and feature values for it to query over. When there are many tables, columns, and/or high-cardinality columns, it becomes impossible for us to dump the full information about our database in every prompt. Instead, we must find ways to dynamically insert into the prompt only the most relevant information. Let’s take a look at some techniques for doing this.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai
[notice] A new release of pip is available: 23.2.1 -> 23.3.2
[notice] To update, run: pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
The below example will use a SQLite connection with Chinook database. Follow these installation steps to create Chinook.db in the same directory as this notebook:
Save this file as Chinook_Sqlite.sql
Run sqlite3 Chinook.db
Run .read Chinook_Sqlite.sql
Test SELECT * FROM Artist LIMIT 10;
Now, Chinhook.db is in our directory and we can interface with it using the SQLAlchemy-driven SQLDatabase class:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Many tables
One of the main pieces of information we need to include in our prompt is the schemas of the relevant tables. When we have very many tables, we can’t fit all of the schemas in a single prompt. What we can do in such cases is first extract the names of the tables related to the user input, and then include only their schemas.
One easy and reliable way to do this is using OpenAI function-calling and Pydantic models. LangChain comes with a built-in create_extraction_chain_pydantic chain that lets us do just this:
from langchain.chains.openai_tools import create_extraction_chain_pydantic
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)
class Table(BaseModel):
"""Table in SQL database."""
name: str = Field(description="Name of table in SQL database.")
table_names = "\n".join(db.get_usable_table_names())
system = f"""Return the names of ALL the SQL tables that MIGHT be relevant to the user question. \
The tables are:
{table_names}
Remember to include ALL POTENTIALLY RELEVANT tables, even if you're not sure that they're needed."""
table_chain = create_extraction_chain_pydantic(Table, llm, system_message=system)
table_chain.invoke({"input": "What are all the genres of Alanis Morisette songs"})
[Table(name='Genre'), Table(name='Artist'), Table(name='Track')]
This works pretty well! Except, as we’ll see below, we actually need a few other tables as well. This would be pretty difficult for the model to know based just on the user question. In this case, we might think to simplify our model’s job by grouping the tables together. We’ll just ask the model to choose between categories “Music” and “Business”, and then take care of selecting all the relevant tables from there:
system = """Return the names of the SQL tables that are relevant to the user question. \
The tables are:
Music
Business"""
category_chain = create_extraction_chain_pydantic(Table, llm, system_message=system)
category_chain.invoke({"input": "What are all the genres of Alanis Morisette songs"})
from typing import List
def get_tables(categories: List[Table]) -> List[str]:
tables = []
for category in categories:
if category.name == "Music":
tables.extend(
[
"Album",
"Artist",
"Genre",
"MediaType",
"Playlist",
"PlaylistTrack",
"Track",
]
)
elif category.name == "Business":
tables.extend(["Customer", "Employee", "Invoice", "InvoiceLine"])
return tables
table_chain = category_chain | get_tables # noqa
table_chain.invoke({"input": "What are all the genres of Alanis Morisette songs"})
['Album', 'Artist', 'Genre', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
Now that we’ve got a chain that can output the relevant tables for any query we can combine this with our create_sql_query_chain, which can accept a list of table_names_to_use to determine which table schemas are included in the prompt:
from operator import itemgetter
from langchain.chains import create_sql_query_chain
from langchain_core.runnables import RunnablePassthrough
query_chain = create_sql_query_chain(llm, db)
# Convert "question" key to the "input" key expected by current table_chain.
table_chain = {"input": itemgetter("question")} | table_chain
# Set table_names_to_use using table_chain.
full_chain = RunnablePassthrough.assign(table_names_to_use=table_chain) | query_chain
query = full_chain.invoke(
{"question": "What are all the genres of Alanis Morisette songs"}
)
print(query)
SELECT "Genre"."Name"
FROM "Genre"
JOIN "Track" ON "Genre"."GenreId" = "Track"."GenreId"
JOIN "Album" ON "Track"."AlbumId" = "Album"."AlbumId"
JOIN "Artist" ON "Album"."ArtistId" = "Artist"."ArtistId"
WHERE "Artist"."Name" = 'Alanis Morissette'
"[('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',), ('Rock',)]"
We might rephrase our question slightly to remove redundancy in the answer
query = full_chain.invoke(
{"question": "What is the set of all unique genres of Alanis Morisette songs"}
)
print(query)
SELECT DISTINCT g.Name
FROM Genre g
JOIN Track t ON g.GenreId = t.GenreId
JOIN Album a ON t.AlbumId = a.AlbumId
JOIN Artist ar ON a.ArtistId = ar.ArtistId
WHERE ar.Name = 'Alanis Morissette'
We can see the LangSmith trace for this run here.
We’ve seen how to dynamically include a subset of table schemas in a prompt within a chain. Another possible approach to this problem is to let an Agent decide for itself when to look up tables by giving it a Tool to do so. You can see an example of this in the SQL: Agents guide.
High-cardinality columns
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
One naive strategy it to create a vector store with all the distinct proper nouns that exist in the database. We can then query that vector store each user input and inject the most relevant proper nouns into the prompt.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
import ast
import re
def query_as_list(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub if el]
res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]
return res
proper_nouns = query_as_list(db, "SELECT Name FROM Artist")
proper_nouns += query_as_list(db, "SELECT Title FROM Album")
proper_nouns += query_as_list(db, "SELECT Name FROM Genre")
len(proper_nouns)
proper_nouns[:5]
['AC/DC', 'Accept', 'Aerosmith', 'Alanis Morissette', 'Alice In Chains']
Now we can embed and store all of our values in a vector database:
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
vector_db = FAISS.from_texts(proper_nouns, OpenAIEmbeddings())
retriever = vector_db.as_retriever(search_kwargs={"k": 15})
And put together a query construction chain that first retrieves values from the database and inserts them into the prompt:
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
system = """You are a SQLite expert. Given an input question, create a syntactically \
correct SQLite query to run. Unless otherwise specificed, do not return more than \
{top_k} rows.\n\nHere is the relevant table info: {table_info}\n\nHere is a non-exhaustive \
list of possible feature values. If filtering on a feature value make sure to check its spelling \
against this list first:\n\n{proper_nouns}"""
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{input}")])
query_chain = create_sql_query_chain(llm, db, prompt=prompt)
retriever_chain = (
itemgetter("question")
| retriever
| (lambda docs: "\n".join(doc.page_content for doc in docs))
)
chain = RunnablePassthrough.assign(proper_nouns=retriever_chain) | query_chain
To try out our chain, let’s see what happens when we try filtering on “elenis moriset”, a mispelling of Alanis Morissette, without and with retrieval:
# Without retrieval
query = query_chain.invoke(
{"question": "What are all the genres of elenis moriset songs", "proper_nouns": ""}
)
print(query)
db.run(query)
SELECT DISTINCT Genre.Name
FROM Genre
JOIN Track ON Genre.GenreId = Track.GenreId
JOIN Album ON Track.AlbumId = Album.AlbumId
JOIN Artist ON Album.ArtistId = Artist.ArtistId
WHERE Artist.Name = 'Elenis Moriset'
# With retrieval
query = chain.invoke({"question": "What are all the genres of elenis moriset songs"})
print(query)
db.run(query)
SELECT DISTINCT Genre.Name
FROM Genre
JOIN Track ON Genre.GenreId = Track.GenreId
JOIN Album ON Track.AlbumId = Album.AlbumId
JOIN Artist ON Album.ArtistId = Artist.ArtistId
WHERE Artist.Name = 'Alanis Morissette'
We can see that with retrieval we’re able to correct the spelling and get back a valid result.
Another possible approach to this problem is to let an Agent decide for itself when to look up proper nouns. You can see an example of this in the SQL: Agents guide. |
https://python.langchain.com/docs/use_cases/question_answering/streaming/ | ## Streaming
Often in Q&A applications it’s important to show users the sources that were used to generate the answer. The simplest way to do this is for the chain to return the Documents that were retrieved in each generation.
We’ll work off of the Q&A app with sources we built over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng in the [Returning sources](https://python.langchain.com/docs/use_cases/question_answering/sources/) guide.
## Setup[](#setup "Direct link to Setup")
### Dependencies[](#dependencies "Direct link to Dependencies")
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any [ChatModel](https://python.langchain.com/docs/modules/model_io/chat/) or [LLM](https://python.langchain.com/docs/modules/model_io/llms/), [Embeddings](https://python.langchain.com/docs/modules/data_connection/text_embedding/), and [VectorStore](https://python.langchain.com/docs/modules/data_connection/vectorstores/) or [Retriever](https://python.langchain.com/docs/modules/data_connection/retrievers/).
We’ll use the following packages:
```
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
```
We need to set environment variable `OPENAI_API_KEY`, which can be done directly or loaded from a `.env` file like so:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# import dotenv# dotenv.load_dotenv()
```
### LangSmith[](#langsmith "Direct link to LangSmith")
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with [LangSmith](https://smith.langchain.com/).
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
```
os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Chain with sources[](#chain-with-sources "Direct link to Chain with sources")
Here is Q&A app with sources we built over the [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) blog post by Lilian Weng in the [Returning sources](https://python.langchain.com/docs/use_cases/question_answering/sources/) guide:
```
import bs4from langchain import hubfrom langchain_chroma import Chromafrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnableParallel, RunnablePassthroughfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitter
```
```
# Load, chunk and index the contents of the blog.bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs={"parse_only": bs_strainer},)docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# Retrieve and generate using the relevant snippets of the blog.retriever = vectorstore.as_retriever()prompt = hub.pull("rlm/rag-prompt")llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)rag_chain_from_docs = ( RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"]))) | prompt | llm | StrOutputParser())rag_chain_with_source = RunnableParallel( {"context": retriever, "question": RunnablePassthrough()}).assign(answer=rag_chain_from_docs)
```
## Streaming final outputs[](#streaming-final-outputs "Direct link to Streaming final outputs")
With LCEL it’s easy to stream final outputs:
```
for chunk in rag_chain_with_source.stream("What is Task Decomposition"): print(chunk)
```
```
{'question': 'What is Task Decomposition'}{'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})]}{'answer': ''}{'answer': 'Task'}{'answer': ' decomposition'}{'answer': ' is'}{'answer': ' a'}{'answer': ' technique'}{'answer': ' used'}{'answer': ' to'}{'answer': ' break'}{'answer': ' down'}{'answer': ' complex'}{'answer': ' tasks'}{'answer': ' into'}{'answer': ' smaller'}{'answer': ' and'}{'answer': ' simpler'}{'answer': ' steps'}{'answer': '.'}{'answer': ' It'}{'answer': ' can'}{'answer': ' be'}{'answer': ' done'}{'answer': ' through'}{'answer': ' methods'}{'answer': ' like'}{'answer': ' Chain'}{'answer': ' of'}{'answer': ' Thought'}{'answer': ' ('}{'answer': 'Co'}{'answer': 'T'}{'answer': ')'}{'answer': ' or'}{'answer': ' Tree'}{'answer': ' of'}{'answer': ' Thoughts'}{'answer': ','}{'answer': ' which'}{'answer': ' involve'}{'answer': ' dividing'}{'answer': ' the'}{'answer': ' task'}{'answer': ' into'}{'answer': ' manageable'}{'answer': ' sub'}{'answer': 'tasks'}{'answer': ' and'}{'answer': ' exploring'}{'answer': ' multiple'}{'answer': ' reasoning'}{'answer': ' possibilities'}{'answer': ' at'}{'answer': ' each'}{'answer': ' step'}{'answer': '.'}{'answer': ' Task'}{'answer': ' decomposition'}{'answer': ' can'}{'answer': ' be'}{'answer': ' performed'}{'answer': ' by'}{'answer': ' using'}{'answer': ' simple'}{'answer': ' prompts'}{'answer': ','}{'answer': ' task'}{'answer': '-specific'}{'answer': ' instructions'}{'answer': ','}{'answer': ' or'}{'answer': ' human'}{'answer': ' inputs'}{'answer': '.'}{'answer': ''}
```
We can add some logic to compile our stream as it’s being returned:
```
output = {}curr_key = Nonefor chunk in rag_chain_with_source.stream("What is Task Decomposition"): for key in chunk: if key not in output: output[key] = chunk[key] else: output[key] += chunk[key] if key != curr_key: print(f"\n\n{key}: {chunk[key]}", end="", flush=True) else: print(chunk[key], end="", flush=True) curr_key = keyoutput
```
```
question: What is Task Decompositioncontext: [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})]answer: Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through methods like Chain of Thought (CoT) or Tree of Thoughts, which involve dividing the task into manageable subtasks and exploring multiple reasoning possibilities at each step. Task decomposition can be performed by using simple prompts, task-specific instructions, or human inputs.
```
```
{'question': 'What is Task Decomposition', 'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})], 'answer': 'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through methods like Chain of Thought (CoT) or Tree of Thoughts, which involve dividing the task into manageable subtasks and exploring multiple reasoning possibilities at each step. Task decomposition can be performed by using simple prompts, task-specific instructions, or human inputs.'}
```
Suppose we want to stream not only the final outputs of the chain, but also some intermediate steps. As an example let’s take our [Chat history](https://python.langchain.com/docs/use_cases/question_answering/chat_history/) chain. Here we reformulate the user question before passing it to the retriever. This reformulated question is not returned as part of the final output. We could modify our chain to return the new question, but for demonstration purposes we’ll leave it as is.
```
from operator import itemgetterfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.tracers.log_stream import LogStreamCallbackHandlercontextualize_q_system_prompt = """Given a chat history and the latest user question \which might reference context in the chat history, formulate a standalone question \which can be understood without the chat history. Do NOT answer the question, \just reformulate it if needed and otherwise return it as is."""contextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder(variable_name="chat_history"), ("human", "{question}"), ])contextualize_q_chain = (contextualize_q_prompt | llm | StrOutputParser()).with_config( tags=["contextualize_q_chain"])qa_system_prompt = """You are an assistant for question-answering tasks. \Use the following pieces of retrieved context to answer the question. \If you don't know the answer, just say that you don't know. \Use three sentences maximum and keep the answer concise.\{context}"""qa_prompt = ChatPromptTemplate.from_messages( [ ("system", qa_system_prompt), MessagesPlaceholder(variable_name="chat_history"), ("human", "{question}"), ])def contextualized_question(input: dict): if input.get("chat_history"): return contextualize_q_chain else: return input["question"]rag_chain = ( RunnablePassthrough.assign(context=contextualize_q_chain | retriever | format_docs) | qa_prompt | llm)
```
To stream intermediate steps we’ll use the `astream_log` method. This is an async method that yields JSONPatch ops that when applied in the same order as received build up the RunState:
```
class RunState(TypedDict): id: str """ID of the run.""" streamed_output: List[Any] """List of output chunks streamed by Runnable.stream()""" final_output: Optional[Any] """Final output of the run, usually the result of aggregating (`+`) streamed_output. Only available after the run has finished successfully.""" logs: Dict[str, LogEntry] """Map of run names to sub-runs. If filters were supplied, this list will contain only the runs that matched the filters."""
```
You can stream all steps (default) or include/exclude steps by name, tags or metadata. In this case we’ll only stream intermediate steps that are part of the `contextualize_q_chain` and the final output. Notice that when defining the `contextualize_q_chain` we gave it a corresponding tag, which we can now filter on.
We only show the first 20 chunks of the stream for readability:
```
# Needed for running async functions in Jupyter notebook:import nest_asyncionest_asyncio.apply()
```
```
from langchain_core.messages import HumanMessagechat_history = []question = "What is Task Decomposition?"ai_msg = rag_chain.invoke({"question": question, "chat_history": chat_history})chat_history.extend([HumanMessage(content=question), ai_msg])second_question = "What are common ways of doing it?"ct = 0async for jsonpatch_op in rag_chain.astream_log( {"question": second_question, "chat_history": chat_history}, include_tags=["contextualize_q_chain"],): print(jsonpatch_op) print("\n" + "-" * 30 + "\n") ct += 1 if ct > 20: break
```
```
RunLogPatch({'op': 'replace', 'path': '', 'value': {'final_output': None, 'id': 'df0938b3-3ff2-451b-a233-6c882b640e4d', 'logs': {}, 'streamed_output': []}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/RunnableSequence', 'value': {'end_time': None, 'final_output': None, 'id': '2e2af851-9e1f-4260-b004-c30dea4affe9', 'metadata': {}, 'name': 'RunnableSequence', 'start_time': '2023-12-29T20:08:28.923', 'streamed_output': [], 'streamed_output_str': [], 'tags': ['seq:step:1', 'contextualize_q_chain'], 'type': 'chain'}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatPromptTemplate', 'value': {'end_time': None, 'final_output': None, 'id': '7ad34564-337c-4362-ae7a-655d79cf0ab0', 'metadata': {}, 'name': 'ChatPromptTemplate', 'start_time': '2023-12-29T20:08:28.926', 'streamed_output': [], 'streamed_output_str': [], 'tags': ['seq:step:1', 'contextualize_q_chain'], 'type': 'prompt'}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatPromptTemplate/final_output', 'value': ChatPromptValue(messages=[SystemMessage(content='Given a chat history and the latest user question which might reference context in the chat history, formulate a standalone question which can be understood without the chat history. Do NOT answer the question, just reformulate it if needed and otherwise return it as is.'), HumanMessage(content='What is Task Decomposition?'), AIMessage(content='Task decomposition is a technique used to break down complex tasks into smaller and more manageable subtasks. It involves dividing a task into multiple steps or subgoals, allowing an agent or model to better understand and plan for the overall task. Task decomposition can be done through various methods, such as using prompting techniques like Chain of Thought or Tree of Thoughts, task-specific instructions, or human inputs.'), HumanMessage(content='What are common ways of doing it?')])}, {'op': 'add', 'path': '/logs/ChatPromptTemplate/end_time', 'value': '2023-12-29T20:08:28.926'})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI', 'value': {'end_time': None, 'final_output': None, 'id': '228792d6-1d76-4209-8d25-08c484b6df57', 'metadata': {}, 'name': 'ChatOpenAI', 'start_time': '2023-12-29T20:08:28.931', 'streamed_output': [], 'streamed_output_str': [], 'tags': ['seq:step:2', 'contextualize_q_chain'], 'type': 'llm'}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/StrOutputParser', 'value': {'end_time': None, 'final_output': None, 'id': 'f740f235-2b14-412d-9f54-53bbc4fa8fd8', 'metadata': {}, 'name': 'StrOutputParser', 'start_time': '2023-12-29T20:08:29.487', 'streamed_output': [], 'streamed_output_str': [], 'tags': ['seq:step:3', 'contextualize_q_chain'], 'type': 'parser'}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ''}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content='')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': 'What'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content='What')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' are'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' are')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' some'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' some')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' commonly'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' commonly')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' used'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' used')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' methods'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' methods')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' or'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' or')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' approaches'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' approaches')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' for'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' for')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' task'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' task')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ' decomposition'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content=' decomposition')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': '?'}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content='?')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ''}, {'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output/-', 'value': AIMessageChunk(content='')})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/final_output', 'value': {'generations': [[{'generation_info': {'finish_reason': 'stop'}, 'message': AIMessageChunk(content='What are some commonly used methods or approaches for task decomposition?'), 'text': 'What are some commonly used methods or ' 'approaches for task decomposition?', 'type': 'ChatGenerationChunk'}]], 'llm_output': None, 'run': None}}, {'op': 'add', 'path': '/logs/ChatOpenAI/end_time', 'value': '2023-12-29T20:08:29.688'})------------------------------
```
If we wanted to get our retrieved docs, we could filter on name “Retriever”:
```
ct = 0async for jsonpatch_op in rag_chain.astream_log( {"question": second_question, "chat_history": chat_history}, include_names=["Retriever"], with_streamed_output_list=False,): print(jsonpatch_op) print("\n" + "-" * 30 + "\n") ct += 1 if ct > 20: break
```
```
RunLogPatch({'op': 'replace', 'path': '', 'value': {'final_output': None, 'id': '9d122c72-378c-41f8-96fe-3fd9a214e9bc', 'logs': {}, 'streamed_output': []}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/Retriever', 'value': {'end_time': None, 'final_output': None, 'id': 'c83481fb-7ca3-4125-9280-96da0c14eee9', 'metadata': {}, 'name': 'Retriever', 'start_time': '2023-12-29T20:10:13.794', 'streamed_output': [], 'streamed_output_str': [], 'tags': ['seq:step:2', 'Chroma', 'OpenAIEmbeddings'], 'type': 'retriever'}})------------------------------RunLogPatch({'op': 'add', 'path': '/logs/Retriever/final_output', 'value': {'documents': [Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 9. Comparison of MIPS algorithms, measured in recall@10. (Image source: Google Blog, 2020)\nCheck more MIPS algorithms and performance comparison in ann-benchmarks.com.\nComponent Three: Tool Use#\nTool use is a remarkable and distinguishing characteristic of human beings. We create, modify and utilize external objects to do things that go beyond our physical and cognitive limits. Equipping LLMs with external tools can significantly extend the model capabilities.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})]}}, {'op': 'add', 'path': '/logs/Retriever/end_time', 'value': '2023-12-29T20:10:14.234'})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1.')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain of')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain of Thought')})------------------------------RunLogPatch({'op': 'replace', 'path': '/final_output', 'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain of Thought (')})------------------------------
```
For more on how to stream intermediate steps check out the [LCEL Interface](https://python.langchain.com/docs/expression_language/interface/#async-stream-intermediate-steps) docs. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:28.886Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/question_answering/streaming/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/question_answering/streaming/",
"description": "Often in Q&A applications it’s important to show users the sources that",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8871",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"streaming\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:25 GMT",
"etag": "W/\"3eebecaea99529466021172b064cdc2b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::4hr64-1713753985899-74b294712702"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/question_answering/streaming/",
"property": "og:url"
},
{
"content": "Streaming | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Often in Q&A applications it’s important to show users the sources that",
"property": "og:description"
}
],
"title": "Streaming | 🦜️🔗 LangChain"
} | Streaming
Often in Q&A applications it’s important to show users the sources that were used to generate the answer. The simplest way to do this is for the chain to return the Documents that were retrieved in each generation.
We’ll work off of the Q&A app with sources we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the Returning sources guide.
Setup
Dependencies
We’ll use an OpenAI chat model and embeddings and a Chroma vector store in this walkthrough, but everything shown here works with any ChatModel or LLM, Embeddings, and VectorStore or Retriever.
We’ll use the following packages:
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
We need to set environment variable OPENAI_API_KEY, which can be done directly or loaded from a .env file like so:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Chain with sources
Here is Q&A app with sources we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the Returning sources guide:
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs_strainer},
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
Streaming final outputs
With LCEL it’s easy to stream final outputs:
for chunk in rag_chain_with_source.stream("What is Task Decomposition"):
print(chunk)
{'question': 'What is Task Decomposition'}
{'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})]}
{'answer': ''}
{'answer': 'Task'}
{'answer': ' decomposition'}
{'answer': ' is'}
{'answer': ' a'}
{'answer': ' technique'}
{'answer': ' used'}
{'answer': ' to'}
{'answer': ' break'}
{'answer': ' down'}
{'answer': ' complex'}
{'answer': ' tasks'}
{'answer': ' into'}
{'answer': ' smaller'}
{'answer': ' and'}
{'answer': ' simpler'}
{'answer': ' steps'}
{'answer': '.'}
{'answer': ' It'}
{'answer': ' can'}
{'answer': ' be'}
{'answer': ' done'}
{'answer': ' through'}
{'answer': ' methods'}
{'answer': ' like'}
{'answer': ' Chain'}
{'answer': ' of'}
{'answer': ' Thought'}
{'answer': ' ('}
{'answer': 'Co'}
{'answer': 'T'}
{'answer': ')'}
{'answer': ' or'}
{'answer': ' Tree'}
{'answer': ' of'}
{'answer': ' Thoughts'}
{'answer': ','}
{'answer': ' which'}
{'answer': ' involve'}
{'answer': ' dividing'}
{'answer': ' the'}
{'answer': ' task'}
{'answer': ' into'}
{'answer': ' manageable'}
{'answer': ' sub'}
{'answer': 'tasks'}
{'answer': ' and'}
{'answer': ' exploring'}
{'answer': ' multiple'}
{'answer': ' reasoning'}
{'answer': ' possibilities'}
{'answer': ' at'}
{'answer': ' each'}
{'answer': ' step'}
{'answer': '.'}
{'answer': ' Task'}
{'answer': ' decomposition'}
{'answer': ' can'}
{'answer': ' be'}
{'answer': ' performed'}
{'answer': ' by'}
{'answer': ' using'}
{'answer': ' simple'}
{'answer': ' prompts'}
{'answer': ','}
{'answer': ' task'}
{'answer': '-specific'}
{'answer': ' instructions'}
{'answer': ','}
{'answer': ' or'}
{'answer': ' human'}
{'answer': ' inputs'}
{'answer': '.'}
{'answer': ''}
We can add some logic to compile our stream as it’s being returned:
output = {}
curr_key = None
for chunk in rag_chain_with_source.stream("What is Task Decomposition"):
for key in chunk:
if key not in output:
output[key] = chunk[key]
else:
output[key] += chunk[key]
if key != curr_key:
print(f"\n\n{key}: {chunk[key]}", end="", flush=True)
else:
print(chunk[key], end="", flush=True)
curr_key = key
output
question: What is Task Decomposition
context: [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}), Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})]
answer: Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through methods like Chain of Thought (CoT) or Tree of Thoughts, which involve dividing the task into manageable subtasks and exploring multiple reasoning possibilities at each step. Task decomposition can be performed by using simple prompts, task-specific instructions, or human inputs.
{'question': 'What is Task Decomposition',
'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})],
'answer': 'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through methods like Chain of Thought (CoT) or Tree of Thoughts, which involve dividing the task into manageable subtasks and exploring multiple reasoning possibilities at each step. Task decomposition can be performed by using simple prompts, task-specific instructions, or human inputs.'}
Suppose we want to stream not only the final outputs of the chain, but also some intermediate steps. As an example let’s take our Chat history chain. Here we reformulate the user question before passing it to the retriever. This reformulated question is not returned as part of the final output. We could modify our chain to return the new question, but for demonstration purposes we’ll leave it as is.
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tracers.log_stream import LogStreamCallbackHandler
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
contextualize_q_chain = (contextualize_q_prompt | llm | StrOutputParser()).with_config(
tags=["contextualize_q_chain"]
)
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
def contextualized_question(input: dict):
if input.get("chat_history"):
return contextualize_q_chain
else:
return input["question"]
rag_chain = (
RunnablePassthrough.assign(context=contextualize_q_chain | retriever | format_docs)
| qa_prompt
| llm
)
To stream intermediate steps we’ll use the astream_log method. This is an async method that yields JSONPatch ops that when applied in the same order as received build up the RunState:
class RunState(TypedDict):
id: str
"""ID of the run."""
streamed_output: List[Any]
"""List of output chunks streamed by Runnable.stream()"""
final_output: Optional[Any]
"""Final output of the run, usually the result of aggregating (`+`) streamed_output.
Only available after the run has finished successfully."""
logs: Dict[str, LogEntry]
"""Map of run names to sub-runs. If filters were supplied, this list will
contain only the runs that matched the filters."""
You can stream all steps (default) or include/exclude steps by name, tags or metadata. In this case we’ll only stream intermediate steps that are part of the contextualize_q_chain and the final output. Notice that when defining the contextualize_q_chain we gave it a corresponding tag, which we can now filter on.
We only show the first 20 chunks of the stream for readability:
# Needed for running async functions in Jupyter notebook:
import nest_asyncio
nest_asyncio.apply()
from langchain_core.messages import HumanMessage
chat_history = []
question = "What is Task Decomposition?"
ai_msg = rag_chain.invoke({"question": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg])
second_question = "What are common ways of doing it?"
ct = 0
async for jsonpatch_op in rag_chain.astream_log(
{"question": second_question, "chat_history": chat_history},
include_tags=["contextualize_q_chain"],
):
print(jsonpatch_op)
print("\n" + "-" * 30 + "\n")
ct += 1
if ct > 20:
break
RunLogPatch({'op': 'replace',
'path': '',
'value': {'final_output': None,
'id': 'df0938b3-3ff2-451b-a233-6c882b640e4d',
'logs': {},
'streamed_output': []}})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/RunnableSequence',
'value': {'end_time': None,
'final_output': None,
'id': '2e2af851-9e1f-4260-b004-c30dea4affe9',
'metadata': {},
'name': 'RunnableSequence',
'start_time': '2023-12-29T20:08:28.923',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['seq:step:1', 'contextualize_q_chain'],
'type': 'chain'}})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatPromptTemplate',
'value': {'end_time': None,
'final_output': None,
'id': '7ad34564-337c-4362-ae7a-655d79cf0ab0',
'metadata': {},
'name': 'ChatPromptTemplate',
'start_time': '2023-12-29T20:08:28.926',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['seq:step:1', 'contextualize_q_chain'],
'type': 'prompt'}})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatPromptTemplate/final_output',
'value': ChatPromptValue(messages=[SystemMessage(content='Given a chat history and the latest user question which might reference context in the chat history, formulate a standalone question which can be understood without the chat history. Do NOT answer the question, just reformulate it if needed and otherwise return it as is.'), HumanMessage(content='What is Task Decomposition?'), AIMessage(content='Task decomposition is a technique used to break down complex tasks into smaller and more manageable subtasks. It involves dividing a task into multiple steps or subgoals, allowing an agent or model to better understand and plan for the overall task. Task decomposition can be done through various methods, such as using prompting techniques like Chain of Thought or Tree of Thoughts, task-specific instructions, or human inputs.'), HumanMessage(content='What are common ways of doing it?')])},
{'op': 'add',
'path': '/logs/ChatPromptTemplate/end_time',
'value': '2023-12-29T20:08:28.926'})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI',
'value': {'end_time': None,
'final_output': None,
'id': '228792d6-1d76-4209-8d25-08c484b6df57',
'metadata': {},
'name': 'ChatOpenAI',
'start_time': '2023-12-29T20:08:28.931',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['seq:step:2', 'contextualize_q_chain'],
'type': 'llm'}})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/StrOutputParser',
'value': {'end_time': None,
'final_output': None,
'id': 'f740f235-2b14-412d-9f54-53bbc4fa8fd8',
'metadata': {},
'name': 'StrOutputParser',
'start_time': '2023-12-29T20:08:29.487',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['seq:step:3', 'contextualize_q_chain'],
'type': 'parser'}})
------------------------------
RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ''},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content='')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': 'What'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content='What')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' are'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' are')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' some'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' some')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' commonly'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' commonly')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' used'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' used')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' methods'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' methods')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' or'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' or')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' approaches'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' approaches')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' for'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' for')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' task'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' task')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output_str/-',
'value': ' decomposition'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content=' decomposition')})
------------------------------
RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': '?'},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content='?')})
------------------------------
RunLogPatch({'op': 'add', 'path': '/logs/ChatOpenAI/streamed_output_str/-', 'value': ''},
{'op': 'add',
'path': '/logs/ChatOpenAI/streamed_output/-',
'value': AIMessageChunk(content='')})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/ChatOpenAI/final_output',
'value': {'generations': [[{'generation_info': {'finish_reason': 'stop'},
'message': AIMessageChunk(content='What are some commonly used methods or approaches for task decomposition?'),
'text': 'What are some commonly used methods or '
'approaches for task decomposition?',
'type': 'ChatGenerationChunk'}]],
'llm_output': None,
'run': None}},
{'op': 'add',
'path': '/logs/ChatOpenAI/end_time',
'value': '2023-12-29T20:08:29.688'})
------------------------------
If we wanted to get our retrieved docs, we could filter on name “Retriever”:
ct = 0
async for jsonpatch_op in rag_chain.astream_log(
{"question": second_question, "chat_history": chat_history},
include_names=["Retriever"],
with_streamed_output_list=False,
):
print(jsonpatch_op)
print("\n" + "-" * 30 + "\n")
ct += 1
if ct > 20:
break
RunLogPatch({'op': 'replace',
'path': '',
'value': {'final_output': None,
'id': '9d122c72-378c-41f8-96fe-3fd9a214e9bc',
'logs': {},
'streamed_output': []}})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/Retriever',
'value': {'end_time': None,
'final_output': None,
'id': 'c83481fb-7ca3-4125-9280-96da0c14eee9',
'metadata': {},
'name': 'Retriever',
'start_time': '2023-12-29T20:10:13.794',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['seq:step:2', 'Chroma', 'OpenAIEmbeddings'],
'type': 'retriever'}})
------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/Retriever/final_output',
'value': {'documents': [Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Fig. 9. Comparison of MIPS algorithms, measured in recall@10. (Image source: Google Blog, 2020)\nCheck more MIPS algorithms and performance comparison in ann-benchmarks.com.\nComponent Three: Tool Use#\nTool use is a remarkable and distinguishing characteristic of human beings. We create, modify and utilize external objects to do things that go beyond our physical and cognitive limits. Equipping LLMs with external tools can significantly extend the model capabilities.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})]}},
{'op': 'add',
'path': '/logs/Retriever/end_time',
'value': '2023-12-29T20:10:14.234'})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1.')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain of')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain of Thought')})
------------------------------
RunLogPatch({'op': 'replace',
'path': '/final_output',
'value': AIMessageChunk(content='Common ways of task decomposition include:\n1. Using prompting techniques like Chain of Thought (')})
------------------------------
For more on how to stream intermediate steps check out the LCEL Interface docs. |
https://python.langchain.com/docs/use_cases/sql/prompting/ | ## Prompting strategies
In this guide we’ll go over prompting strategies to improve SQL query generation. We’ll largely focus on methods for getting relevant database-specific information in your prompt.
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-experimental langchain-openai
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
The below example will use a SQLite connection with Chinook database. Follow [these installation steps](https://database.guide/2-sample-databases-sqlite/) to create `Chinook.db` in the same directory as this notebook:
* Save [this file](https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql) as `Chinook_Sqlite.sql`
* Run `sqlite3 Chinook.db`
* Run `.read Chinook_Sqlite.sql`
* Test `SELECT * FROM Artist LIMIT 10;`
Now, `Chinhook.db` is in our directory and we can interface with it using the SQLAlchemy-driven `SQLDatabase` class:
```
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db", sample_rows_in_table_info=3)print(db.dialect)print(db.get_usable_table_names())db.run("SELECT * FROM Artist LIMIT 10;")
```
```
sqlite['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
```
```
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
```
## Dialect-specific prompting[](#dialect-specific-prompting "Direct link to Dialect-specific prompting")
One of the simplest things we can do is make our prompt specific to the SQL dialect we’re using. When using the built-in [create\_sql\_query\_chain](https://api.python.langchain.com/en/latest/chains/langchain.chains.sql_database.query.create_sql_query_chain.html) and [SQLDatabase](https://api.python.langchain.com/en/latest/utilities/langchain_community.utilities.sql_database.SQLDatabase.html), this is handled for you for any of the following dialects:
```
from langchain.chains.sql_database.prompt import SQL_PROMPTSlist(SQL_PROMPTS)
```
```
['crate', 'duckdb', 'googlesql', 'mssql', 'mysql', 'mariadb', 'oracle', 'postgresql', 'sqlite', 'clickhouse', 'prestodb']
```
For example, using our current DB we can see that we’ll get a SQLite-specific prompt:
```
from langchain.chains import create_sql_query_chainfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature="0")chain = create_sql_query_chain(llm, db)chain.get_prompts()[0].pretty_print()
```
```
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.Pay attention to use date('now') function to get the current date, if the question involves "today".Use the following format:Question: Question hereSQLQuery: SQL Query to runSQLResult: Result of the SQLQueryAnswer: Final answer hereOnly use the following tables:{table_info}Question: {input}
```
## Table definitions and example rows[](#table-definitions-and-example-rows "Direct link to Table definitions and example rows")
In basically any SQL chain, we’ll need to feed the model at least part of the database schema. Without this it won’t be able to write valid queries. Our database comes with some convenience methods to give us the relevant context. Specifically, we can get the table names, their schemas, and a sample of rows from each table:
```
context = db.get_context()print(list(context))print(context["table_info"])
```
```
['table_info', 'table_names']CREATE TABLE "Album" ( "AlbumId" INTEGER NOT NULL, "Title" NVARCHAR(160) NOT NULL, "ArtistId" INTEGER NOT NULL, PRIMARY KEY ("AlbumId"), FOREIGN KEY("ArtistId") REFERENCES "Artist" ("ArtistId"))/*3 rows from Album table:AlbumId Title ArtistId1 For Those About To Rock We Salute You 12 Balls to the Wall 23 Restless and Wild 2*/CREATE TABLE "Artist" ( "ArtistId" INTEGER NOT NULL, "Name" NVARCHAR(120), PRIMARY KEY ("ArtistId"))/*3 rows from Artist table:ArtistId Name1 AC/DC2 Accept3 Aerosmith*/CREATE TABLE "Customer" ( "CustomerId" INTEGER NOT NULL, "FirstName" NVARCHAR(40) NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "Company" NVARCHAR(80), "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60) NOT NULL, "SupportRepId" INTEGER, PRIMARY KEY ("CustomerId"), FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId"))/*3 rows from Customer table:CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 32 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 53 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3*/CREATE TABLE "Employee" ( "EmployeeId" INTEGER NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "FirstName" NVARCHAR(20) NOT NULL, "Title" NVARCHAR(30), "ReportsTo" INTEGER, "BirthDate" DATETIME, "HireDate" DATETIME, "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60), PRIMARY KEY ("EmployeeId"), FOREIGN KEY("ReportsTo") REFERENCES "Employee" ("EmployeeId"))/*3 rows from Employee table:EmployeeId LastName FirstName Title ReportsTo BirthDate HireDate Address City State Country PostalCode Phone Fax Email1 Adams Andrew General Manager None 1962-02-18 00:00:00 2002-08-14 00:00:00 11120 Jasper Ave NW Edmonton AB Canada T5K 2N1 +1 (780) 428-9482 +1 (780) 428-3457 andrew@chinookcorp.com2 Edwards Nancy Sales Manager 1 1958-12-08 00:00:00 2002-05-01 00:00:00 825 8 Ave SW Calgary AB Canada T2P 2T3 +1 (403) 262-3443 +1 (403) 262-3322 nancy@chinookcorp.com3 Peacock Jane Sales Support Agent 2 1973-08-29 00:00:00 2002-04-01 00:00:00 1111 6 Ave SW Calgary AB Canada T2P 5M5 +1 (403) 262-3443 +1 (403) 262-6712 jane@chinookcorp.com*/CREATE TABLE "Genre" ( "GenreId" INTEGER NOT NULL, "Name" NVARCHAR(120), PRIMARY KEY ("GenreId"))/*3 rows from Genre table:GenreId Name1 Rock2 Jazz3 Metal*/CREATE TABLE "Invoice" ( "InvoiceId" INTEGER NOT NULL, "CustomerId" INTEGER NOT NULL, "InvoiceDate" DATETIME NOT NULL, "BillingAddress" NVARCHAR(70), "BillingCity" NVARCHAR(40), "BillingState" NVARCHAR(40), "BillingCountry" NVARCHAR(40), "BillingPostalCode" NVARCHAR(10), "Total" NUMERIC(10, 2) NOT NULL, PRIMARY KEY ("InvoiceId"), FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId"))/*3 rows from Invoice table:InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.982 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.963 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94*/CREATE TABLE "InvoiceLine" ( "InvoiceLineId" INTEGER NOT NULL, "InvoiceId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, "UnitPrice" NUMERIC(10, 2) NOT NULL, "Quantity" INTEGER NOT NULL, PRIMARY KEY ("InvoiceLineId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("InvoiceId") REFERENCES "Invoice" ("InvoiceId"))/*3 rows from InvoiceLine table:InvoiceLineId InvoiceId TrackId UnitPrice Quantity1 1 2 0.99 12 1 4 0.99 13 2 6 0.99 1*/CREATE TABLE "MediaType" ( "MediaTypeId" INTEGER NOT NULL, "Name" NVARCHAR(120), PRIMARY KEY ("MediaTypeId"))/*3 rows from MediaType table:MediaTypeId Name1 MPEG audio file2 Protected AAC audio file3 Protected MPEG-4 video file*/CREATE TABLE "Playlist" ( "PlaylistId" INTEGER NOT NULL, "Name" NVARCHAR(120), PRIMARY KEY ("PlaylistId"))/*3 rows from Playlist table:PlaylistId Name1 Music2 Movies3 TV Shows*/CREATE TABLE "PlaylistTrack" ( "PlaylistId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, PRIMARY KEY ("PlaylistId", "TrackId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId"))/*3 rows from PlaylistTrack table:PlaylistId TrackId1 34021 33891 3390*/CREATE TABLE "Track" ( "TrackId" INTEGER NOT NULL, "Name" NVARCHAR(200) NOT NULL, "AlbumId" INTEGER, "MediaTypeId" INTEGER NOT NULL, "GenreId" INTEGER, "Composer" NVARCHAR(220), "Milliseconds" INTEGER NOT NULL, "Bytes" INTEGER, "UnitPrice" NUMERIC(10, 2) NOT NULL, PRIMARY KEY ("TrackId"), FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"), FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"), FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId"))/*3 rows from Track table:TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.992 Balls to the Wall 2 2 1 None 342562 5510424 0.993 Fast As a Shark 3 2 1 F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman 230619 3990994 0.99*/
```
When we don’t have too many, or too wide of, tables, we can just insert the entirety of this information in our prompt:
```
prompt_with_context = chain.get_prompts()[0].partial(table_info=context["table_info"])print(prompt_with_context.pretty_repr()[:1500])
```
```
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.Pay attention to use date('now') function to get the current date, if the question involves "today".Use the following format:Question: Question hereSQLQuery: SQL Query to runSQLResult: Result of the SQLQueryAnswer: Final answer hereOnly use the following tables:CREATE TABLE "Album" ( "AlbumId" INTEGER NOT NULL, "Title" NVARCHAR(160) NOT NULL, "ArtistId" INTEGER NOT NULL, PRIMARY KEY ("AlbumId"), FOREIGN KEY("ArtistId") REFERENCES "Artist" ("ArtistId"))/*3 rows from Album table:AlbumId Title ArtistId1 For Those About To Rock We Salute You 12 Balls to the Wall 23 Restless and Wild 2*/CREATE TABLE "Artist" ( "ArtistId" INTEGER NOT NULL, "Name" NVARCHAR(120)
```
When we do have database schemas that are too large to fit into our model’s context window, we’ll need to come up with ways of inserting only the relevant table definitions into the prompt based on the user input. For more on this head to the [Many tables, wide tables, high-cardinality feature](https://python.langchain.com/docs/use_cases/sql/large_db/) guide.
## Few-shot examples[](#few-shot-examples "Direct link to Few-shot examples")
Including examples of natural language questions being converted to valid SQL queries against our database in the prompt will often improve model performance, especially for complex queries.
Let’s say we have the following examples:
```
examples = [ {"input": "List all artists.", "query": "SELECT * FROM Artist;"}, { "input": "Find all albums for the artist 'AC/DC'.", "query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');", }, { "input": "List all tracks in the 'Rock' genre.", "query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');", }, { "input": "Find the total duration of all tracks.", "query": "SELECT SUM(Milliseconds) FROM Track;", }, { "input": "List all customers from Canada.", "query": "SELECT * FROM Customer WHERE Country = 'Canada';", }, { "input": "How many tracks are there in the album with ID 5?", "query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;", }, { "input": "Find the total number of invoices.", "query": "SELECT COUNT(*) FROM Invoice;", }, { "input": "List all tracks that are longer than 5 minutes.", "query": "SELECT * FROM Track WHERE Milliseconds > 300000;", }, { "input": "Who are the top 5 customers by total purchase?", "query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;", }, { "input": "Which albums are from the year 2000?", "query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';", }, { "input": "How many employees are there", "query": 'SELECT COUNT(*) FROM "Employee"', },]
```
We can create a few-shot prompt with them like so:
```
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplateexample_prompt = PromptTemplate.from_template("User input: {input}\nSQL query: {query}")prompt = FewShotPromptTemplate( examples=examples[:5], example_prompt=example_prompt, prefix="You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than {top_k} rows.\n\nHere is the relevant table info: {table_info}\n\nBelow are a number of examples of questions and their corresponding SQL queries.", suffix="User input: {input}\nSQL query: ", input_variables=["input", "top_k", "table_info"],)
```
```
print(prompt.format(input="How many artists are there?", top_k=3, table_info="foo"))
```
```
You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than 3 rows.Here is the relevant table info: fooBelow are a number of examples of questions and their corresponding SQL queries.User input: List all artists.SQL query: SELECT * FROM Artist;User input: Find all albums for the artist 'AC/DC'.SQL query: SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');User input: List all tracks in the 'Rock' genre.SQL query: SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');User input: Find the total duration of all tracks.SQL query: SELECT SUM(Milliseconds) FROM Track;User input: List all customers from Canada.SQL query: SELECT * FROM Customer WHERE Country = 'Canada';User input: How many artists are there?SQL query:
```
## Dynamic few-shot examples[](#dynamic-few-shot-examples "Direct link to Dynamic few-shot examples")
If we have enough examples, we may want to only include the most relevant ones in the prompt, either because they don’t fit in the model’s context window or because the long tail of examples distracts the model. And specifically, given any input we want to include the examples most relevant to that input.
We can do just this using an ExampleSelector. In this case we’ll use a [SemanticSimilarityExampleSelector](https://api.python.langchain.com/en/latest/example_selectors/langchain_core.example_selectors.semantic_similarity.SemanticSimilarityExampleSelector.html), which will store the examples in the vector database of our choosing. At runtime it will perform a similarity search between the input and our examples, and return the most semantically similar ones:
```
from langchain_community.vectorstores import FAISSfrom langchain_core.example_selectors import SemanticSimilarityExampleSelectorfrom langchain_openai import OpenAIEmbeddingsexample_selector = SemanticSimilarityExampleSelector.from_examples( examples, OpenAIEmbeddings(), FAISS, k=5, input_keys=["input"],)
```
```
example_selector.select_examples({"input": "how many artists are there?"})
```
```
[{'input': 'List all artists.', 'query': 'SELECT * FROM Artist;'}, {'input': 'How many employees are there', 'query': 'SELECT COUNT(*) FROM "Employee"'}, {'input': 'How many tracks are there in the album with ID 5?', 'query': 'SELECT COUNT(*) FROM Track WHERE AlbumId = 5;'}, {'input': 'Which albums are from the year 2000?', 'query': "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';"}, {'input': "List all tracks in the 'Rock' genre.", 'query': "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');"}]
```
To use it, we can pass the ExampleSelector directly in to our FewShotPromptTemplate:
```
prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix="You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than {top_k} rows.\n\nHere is the relevant table info: {table_info}\n\nBelow are a number of examples of questions and their corresponding SQL queries.", suffix="User input: {input}\nSQL query: ", input_variables=["input", "top_k", "table_info"],)
```
```
print(prompt.format(input="how many artists are there?", top_k=3, table_info="foo"))
```
```
You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than 3 rows.Here is the relevant table info: fooBelow are a number of examples of questions and their corresponding SQL queries.User input: List all artists.SQL query: SELECT * FROM Artist;User input: How many employees are thereSQL query: SELECT COUNT(*) FROM "Employee"User input: How many tracks are there in the album with ID 5?SQL query: SELECT COUNT(*) FROM Track WHERE AlbumId = 5;User input: Which albums are from the year 2000?SQL query: SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';User input: List all tracks in the 'Rock' genre.SQL query: SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');User input: how many artists are there?SQL query:
```
```
chain = create_sql_query_chain(llm, db, prompt)chain.invoke({"question": "how many artists are there?"})
```
```
'SELECT COUNT(*) FROM Artist;'
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:29.772Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/prompting/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/prompting/",
"description": "In this guide we’ll go over prompting strategies to improve SQL query",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4944",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"prompting\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:27 GMT",
"etag": "W/\"984e79b1847d6d594db86a2f6a5f346c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wfnv6-1713753987633-95d24ae31a0d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/prompting/",
"property": "og:url"
},
{
"content": "Prompting strategies | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll go over prompting strategies to improve SQL query",
"property": "og:description"
}
],
"title": "Prompting strategies | 🦜️🔗 LangChain"
} | Prompting strategies
In this guide we’ll go over prompting strategies to improve SQL query generation. We’ll largely focus on methods for getting relevant database-specific information in your prompt.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-experimental langchain-openai
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
The below example will use a SQLite connection with Chinook database. Follow these installation steps to create Chinook.db in the same directory as this notebook:
Save this file as Chinook_Sqlite.sql
Run sqlite3 Chinook.db
Run .read Chinook_Sqlite.sql
Test SELECT * FROM Artist LIMIT 10;
Now, Chinhook.db is in our directory and we can interface with it using the SQLAlchemy-driven SQLDatabase class:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db", sample_rows_in_table_info=3)
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Dialect-specific prompting
One of the simplest things we can do is make our prompt specific to the SQL dialect we’re using. When using the built-in create_sql_query_chain and SQLDatabase, this is handled for you for any of the following dialects:
from langchain.chains.sql_database.prompt import SQL_PROMPTS
list(SQL_PROMPTS)
['crate',
'duckdb',
'googlesql',
'mssql',
'mysql',
'mariadb',
'oracle',
'postgresql',
'sqlite',
'clickhouse',
'prestodb']
For example, using our current DB we can see that we’ll get a SQLite-specific prompt:
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature="0")
chain = create_sql_query_chain(llm, db)
chain.get_prompts()[0].pretty_print()
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use date('now') function to get the current date, if the question involves "today".
Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
Only use the following tables:
{table_info}
Question: {input}
Table definitions and example rows
In basically any SQL chain, we’ll need to feed the model at least part of the database schema. Without this it won’t be able to write valid queries. Our database comes with some convenience methods to give us the relevant context. Specifically, we can get the table names, their schemas, and a sample of rows from each table:
context = db.get_context()
print(list(context))
print(context["table_info"])
['table_info', 'table_names']
CREATE TABLE "Album" (
"AlbumId" INTEGER NOT NULL,
"Title" NVARCHAR(160) NOT NULL,
"ArtistId" INTEGER NOT NULL,
PRIMARY KEY ("AlbumId"),
FOREIGN KEY("ArtistId") REFERENCES "Artist" ("ArtistId")
)
/*
3 rows from Album table:
AlbumId Title ArtistId
1 For Those About To Rock We Salute You 1
2 Balls to the Wall 2
3 Restless and Wild 2
*/
CREATE TABLE "Artist" (
"ArtistId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("ArtistId")
)
/*
3 rows from Artist table:
ArtistId Name
1 AC/DC
2 Accept
3 Aerosmith
*/
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Employee" (
"EmployeeId" INTEGER NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"FirstName" NVARCHAR(20) NOT NULL,
"Title" NVARCHAR(30),
"ReportsTo" INTEGER,
"BirthDate" DATETIME,
"HireDate" DATETIME,
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60),
PRIMARY KEY ("EmployeeId"),
FOREIGN KEY("ReportsTo") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Employee table:
EmployeeId LastName FirstName Title ReportsTo BirthDate HireDate Address City State Country PostalCode Phone Fax Email
1 Adams Andrew General Manager None 1962-02-18 00:00:00 2002-08-14 00:00:00 11120 Jasper Ave NW Edmonton AB Canada T5K 2N1 +1 (780) 428-9482 +1 (780) 428-3457 andrew@chinookcorp.com
2 Edwards Nancy Sales Manager 1 1958-12-08 00:00:00 2002-05-01 00:00:00 825 8 Ave SW Calgary AB Canada T2P 2T3 +1 (403) 262-3443 +1 (403) 262-3322 nancy@chinookcorp.com
3 Peacock Jane Sales Support Agent 2 1973-08-29 00:00:00 2002-04-01 00:00:00 1111 6 Ave SW Calgary AB Canada T2P 5M5 +1 (403) 262-3443 +1 (403) 262-6712 jane@chinookcorp.com
*/
CREATE TABLE "Genre" (
"GenreId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("GenreId")
)
/*
3 rows from Genre table:
GenreId Name
1 Rock
2 Jazz
3 Metal
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
CREATE TABLE "InvoiceLine" (
"InvoiceLineId" INTEGER NOT NULL,
"InvoiceId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
"Quantity" INTEGER NOT NULL,
PRIMARY KEY ("InvoiceLineId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("InvoiceId") REFERENCES "Invoice" ("InvoiceId")
)
/*
3 rows from InvoiceLine table:
InvoiceLineId InvoiceId TrackId UnitPrice Quantity
1 1 2 0.99 1
2 1 4 0.99 1
3 2 6 0.99 1
*/
CREATE TABLE "MediaType" (
"MediaTypeId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("MediaTypeId")
)
/*
3 rows from MediaType table:
MediaTypeId Name
1 MPEG audio file
2 Protected AAC audio file
3 Protected MPEG-4 video file
*/
CREATE TABLE "Playlist" (
"PlaylistId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("PlaylistId")
)
/*
3 rows from Playlist table:
PlaylistId Name
1 Music
2 Movies
3 TV Shows
*/
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
3 rows from PlaylistTrack table:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/
CREATE TABLE "Track" (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId")
)
/*
3 rows from Track table:
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 None 342562 5510424 0.99
3 Fast As a Shark 3 2 1 F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman 230619 3990994 0.99
*/
When we don’t have too many, or too wide of, tables, we can just insert the entirety of this information in our prompt:
prompt_with_context = chain.get_prompts()[0].partial(table_info=context["table_info"])
print(prompt_with_context.pretty_repr()[:1500])
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use date('now') function to get the current date, if the question involves "today".
Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
Only use the following tables:
CREATE TABLE "Album" (
"AlbumId" INTEGER NOT NULL,
"Title" NVARCHAR(160) NOT NULL,
"ArtistId" INTEGER NOT NULL,
PRIMARY KEY ("AlbumId"),
FOREIGN KEY("ArtistId") REFERENCES "Artist" ("ArtistId")
)
/*
3 rows from Album table:
AlbumId Title ArtistId
1 For Those About To Rock We Salute You 1
2 Balls to the Wall 2
3 Restless and Wild 2
*/
CREATE TABLE "Artist" (
"ArtistId" INTEGER NOT NULL,
"Name" NVARCHAR(120)
When we do have database schemas that are too large to fit into our model’s context window, we’ll need to come up with ways of inserting only the relevant table definitions into the prompt based on the user input. For more on this head to the Many tables, wide tables, high-cardinality feature guide.
Few-shot examples
Including examples of natural language questions being converted to valid SQL queries against our database in the prompt will often improve model performance, especially for complex queries.
Let’s say we have the following examples:
examples = [
{"input": "List all artists.", "query": "SELECT * FROM Artist;"},
{
"input": "Find all albums for the artist 'AC/DC'.",
"query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');",
},
{
"input": "List all tracks in the 'Rock' genre.",
"query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');",
},
{
"input": "Find the total duration of all tracks.",
"query": "SELECT SUM(Milliseconds) FROM Track;",
},
{
"input": "List all customers from Canada.",
"query": "SELECT * FROM Customer WHERE Country = 'Canada';",
},
{
"input": "How many tracks are there in the album with ID 5?",
"query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;",
},
{
"input": "Find the total number of invoices.",
"query": "SELECT COUNT(*) FROM Invoice;",
},
{
"input": "List all tracks that are longer than 5 minutes.",
"query": "SELECT * FROM Track WHERE Milliseconds > 300000;",
},
{
"input": "Who are the top 5 customers by total purchase?",
"query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;",
},
{
"input": "Which albums are from the year 2000?",
"query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';",
},
{
"input": "How many employees are there",
"query": 'SELECT COUNT(*) FROM "Employee"',
},
]
We can create a few-shot prompt with them like so:
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate.from_template("User input: {input}\nSQL query: {query}")
prompt = FewShotPromptTemplate(
examples=examples[:5],
example_prompt=example_prompt,
prefix="You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than {top_k} rows.\n\nHere is the relevant table info: {table_info}\n\nBelow are a number of examples of questions and their corresponding SQL queries.",
suffix="User input: {input}\nSQL query: ",
input_variables=["input", "top_k", "table_info"],
)
print(prompt.format(input="How many artists are there?", top_k=3, table_info="foo"))
You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than 3 rows.
Here is the relevant table info: foo
Below are a number of examples of questions and their corresponding SQL queries.
User input: List all artists.
SQL query: SELECT * FROM Artist;
User input: Find all albums for the artist 'AC/DC'.
SQL query: SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');
User input: List all tracks in the 'Rock' genre.
SQL query: SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');
User input: Find the total duration of all tracks.
SQL query: SELECT SUM(Milliseconds) FROM Track;
User input: List all customers from Canada.
SQL query: SELECT * FROM Customer WHERE Country = 'Canada';
User input: How many artists are there?
SQL query:
Dynamic few-shot examples
If we have enough examples, we may want to only include the most relevant ones in the prompt, either because they don’t fit in the model’s context window or because the long tail of examples distracts the model. And specifically, given any input we want to include the examples most relevant to that input.
We can do just this using an ExampleSelector. In this case we’ll use a SemanticSimilarityExampleSelector, which will store the examples in the vector database of our choosing. At runtime it will perform a similarity search between the input and our examples, and return the most semantically similar ones:
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
FAISS,
k=5,
input_keys=["input"],
)
example_selector.select_examples({"input": "how many artists are there?"})
[{'input': 'List all artists.', 'query': 'SELECT * FROM Artist;'},
{'input': 'How many employees are there',
'query': 'SELECT COUNT(*) FROM "Employee"'},
{'input': 'How many tracks are there in the album with ID 5?',
'query': 'SELECT COUNT(*) FROM Track WHERE AlbumId = 5;'},
{'input': 'Which albums are from the year 2000?',
'query': "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';"},
{'input': "List all tracks in the 'Rock' genre.",
'query': "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');"}]
To use it, we can pass the ExampleSelector directly in to our FewShotPromptTemplate:
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than {top_k} rows.\n\nHere is the relevant table info: {table_info}\n\nBelow are a number of examples of questions and their corresponding SQL queries.",
suffix="User input: {input}\nSQL query: ",
input_variables=["input", "top_k", "table_info"],
)
print(prompt.format(input="how many artists are there?", top_k=3, table_info="foo"))
You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run. Unless otherwise specificed, do not return more than 3 rows.
Here is the relevant table info: foo
Below are a number of examples of questions and their corresponding SQL queries.
User input: List all artists.
SQL query: SELECT * FROM Artist;
User input: How many employees are there
SQL query: SELECT COUNT(*) FROM "Employee"
User input: How many tracks are there in the album with ID 5?
SQL query: SELECT COUNT(*) FROM Track WHERE AlbumId = 5;
User input: Which albums are from the year 2000?
SQL query: SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';
User input: List all tracks in the 'Rock' genre.
SQL query: SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');
User input: how many artists are there?
SQL query:
chain = create_sql_query_chain(llm, db, prompt)
chain.invoke({"question": "how many artists are there?"})
'SELECT COUNT(*) FROM Artist;' |
https://python.langchain.com/docs/use_cases/sql/query_checking/ | ## Query validation
Perhaps the most error-prone part of any SQL chain or agent is writing valid and safe SQL queries. In this guide we’ll go over some strategies for validating our queries and handling invalid queries.
## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai
```
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
The below example will use a SQLite connection with Chinook database. Follow [these installation steps](https://database.guide/2-sample-databases-sqlite/) to create `Chinook.db` in the same directory as this notebook:
* Save [this file](https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql) as `Chinook_Sqlite.sql`
* Run `sqlite3 Chinook.db`
* Run `.read Chinook_Sqlite.sql`
* Test `SELECT * FROM Artist LIMIT 10;`
Now, `Chinhook.db` is in our directory and we can interface with it using the SQLAlchemy-driven `SQLDatabase` class:
```
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")print(db.dialect)print(db.get_usable_table_names())db.run("SELECT * FROM Artist LIMIT 10;")
```
```
sqlite['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
```
```
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
```
## Query checker[](#query-checker "Direct link to Query checker")
Perhaps the simplest strategy is to ask the model itself to check the original query for common mistakes. Suppose we have the following SQL query chain:
```
from langchain.chains import create_sql_query_chainfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)chain = create_sql_query_chain(llm, db)
```
And we want to validate its outputs. We can do so by extending the chain with a second prompt and model call:
```
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatesystem = """Double check the user's {dialect} query for common mistakes, including:- Using NOT IN with NULL values- Using UNION when UNION ALL should have been used- Using BETWEEN for exclusive ranges- Data type mismatch in predicates- Properly quoting identifiers- Using the correct number of arguments for functions- Casting to the correct data type- Using the proper columns for joinsIf there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.Output the final SQL query only."""prompt = ChatPromptTemplate.from_messages( [("system", system), ("human", "{query}")]).partial(dialect=db.dialect)validation_chain = prompt | llm | StrOutputParser()full_chain = {"query": chain} | validation_chain
```
```
query = full_chain.invoke( { "question": "What's the average Invoice from an American customer whose Fax is missing since 2003 but before 2010" })query
```
```
"SELECT AVG(Invoice.Total) AS AverageInvoice\nFROM Invoice\nJOIN Customer ON Invoice.CustomerId = Customer.CustomerId\nWHERE Customer.Country = 'USA'\nAND Customer.Fax IS NULL\nAND Invoice.InvoiceDate >= '2003-01-01'\nAND Invoice.InvoiceDate < '2010-01-01'"
```
The obvious downside of this approach is that we need to make two model calls instead of one to generate our query. To get around this we can try to perform the query generation and query check in a single model invocation:
```
system = """You are a {dialect} expert. Given an input question, creat a syntactically correct {dialect} query to run.Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per {dialect}. You can order the results to return the most informative data in the database.Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.Pay attention to use date('now') function to get the current date, if the question involves "today".Only use the following tables:{table_info}Write an initial draft of the query. Then double check the {dialect} query for common mistakes, including:- Using NOT IN with NULL values- Using UNION when UNION ALL should have been used- Using BETWEEN for exclusive ranges- Data type mismatch in predicates- Properly quoting identifiers- Using the correct number of arguments for functions- Casting to the correct data type- Using the proper columns for joinsUse format:First draft: <<FIRST_DRAFT_QUERY>>Final answer: <<FINAL_ANSWER_QUERY>>"""prompt = ChatPromptTemplate.from_messages( [("system", system), ("human", "{input}")]).partial(dialect=db.dialect)def parse_final_answer(output: str) -> str: return output.split("Final answer: ")[1]chain = create_sql_query_chain(llm, db, prompt=prompt) | parse_final_answerprompt.pretty_print()
```
```
================================ System Message ================================You are a {dialect} expert. Given an input question, creat a syntactically correct {dialect} query to run.Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per {dialect}. You can order the results to return the most informative data in the database.Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.Pay attention to use date('now') function to get the current date, if the question involves "today".Only use the following tables:{table_info}Write an initial draft of the query. Then double check the {dialect} query for common mistakes, including:- Using NOT IN with NULL values- Using UNION when UNION ALL should have been used- Using BETWEEN for exclusive ranges- Data type mismatch in predicates- Properly quoting identifiers- Using the correct number of arguments for functions- Casting to the correct data type- Using the proper columns for joinsUse format:First draft: <<FIRST_DRAFT_QUERY>>Final answer: <<FINAL_ANSWER_QUERY>>================================ Human Message ================================={input}
```
```
query = chain.invoke( { "question": "What's the average Invoice from an American customer whose Fax is missing since 2003 but before 2010" })query
```
```
"\nSELECT AVG(i.Total) AS AverageInvoice\nFROM Invoice i\nJOIN Customer c ON i.CustomerId = c.CustomerId\nWHERE c.Country = 'USA' AND c.Fax IS NULL AND i.InvoiceDate >= date('2003-01-01') AND i.InvoiceDate < date('2010-01-01')"
```
## Human-in-the-loop[](#human-in-the-loop "Direct link to Human-in-the-loop")
In some cases our data is sensitive enough that we never want to execute a SQL query without a human approving it first. Head to the [Tool use: Human-in-the-loop](https://python.langchain.com/docs/use_cases/tool_use/human_in_the_loop/) page to learn how to add a human-in-the-loop to any tool, chain or agent.
## Error handling[](#error-handling "Direct link to Error handling")
At some point, the model will make a mistake and craft an invalid SQL query. Or an issue will arise with our database. Or the model API will go down. We’ll want to add some error handling behavior to our chains and agents so that we fail gracefully in these situations, and perhaps even automatically recover. To learn about error handling with tools, head to the [Tool use: Error handling](https://python.langchain.com/docs/use_cases/tool_use/tool_error_handling/) page. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:30.598Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/query_checking/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/query_checking/",
"description": "Perhaps the most error-prone part of any SQL chain or agent is writing",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3782",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"query_checking\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:30 GMT",
"etag": "W/\"e9214e9c58f36b221c8415623eba7cbf\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::56wnp-1713753990546-8dee340b4c91"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/query_checking/",
"property": "og:url"
},
{
"content": "Query validation | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Perhaps the most error-prone part of any SQL chain or agent is writing",
"property": "og:description"
}
],
"title": "Query validation | 🦜️🔗 LangChain"
} | Query validation
Perhaps the most error-prone part of any SQL chain or agent is writing valid and safe SQL queries. In this guide we’ll go over some strategies for validating our queries and handling invalid queries.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
The below example will use a SQLite connection with Chinook database. Follow these installation steps to create Chinook.db in the same directory as this notebook:
Save this file as Chinook_Sqlite.sql
Run sqlite3 Chinook.db
Run .read Chinook_Sqlite.sql
Test SELECT * FROM Artist LIMIT 10;
Now, Chinhook.db is in our directory and we can interface with it using the SQLAlchemy-driven SQLDatabase class:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Query checker
Perhaps the simplest strategy is to ask the model itself to check the original query for common mistakes. Suppose we have the following SQL query chain:
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = create_sql_query_chain(llm, db)
And we want to validate its outputs. We can do so by extending the chain with a second prompt and model call:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
system = """Double check the user's {dialect} query for common mistakes, including:
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joins
If there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.
Output the final SQL query only."""
prompt = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{query}")]
).partial(dialect=db.dialect)
validation_chain = prompt | llm | StrOutputParser()
full_chain = {"query": chain} | validation_chain
query = full_chain.invoke(
{
"question": "What's the average Invoice from an American customer whose Fax is missing since 2003 but before 2010"
}
)
query
"SELECT AVG(Invoice.Total) AS AverageInvoice\nFROM Invoice\nJOIN Customer ON Invoice.CustomerId = Customer.CustomerId\nWHERE Customer.Country = 'USA'\nAND Customer.Fax IS NULL\nAND Invoice.InvoiceDate >= '2003-01-01'\nAND Invoice.InvoiceDate < '2010-01-01'"
The obvious downside of this approach is that we need to make two model calls instead of one to generate our query. To get around this we can try to perform the query generation and query check in a single model invocation:
system = """You are a {dialect} expert. Given an input question, creat a syntactically correct {dialect} query to run.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per {dialect}. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use date('now') function to get the current date, if the question involves "today".
Only use the following tables:
{table_info}
Write an initial draft of the query. Then double check the {dialect} query for common mistakes, including:
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joins
Use format:
First draft: <<FIRST_DRAFT_QUERY>>
Final answer: <<FINAL_ANSWER_QUERY>>
"""
prompt = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{input}")]
).partial(dialect=db.dialect)
def parse_final_answer(output: str) -> str:
return output.split("Final answer: ")[1]
chain = create_sql_query_chain(llm, db, prompt=prompt) | parse_final_answer
prompt.pretty_print()
================================ System Message ================================
You are a {dialect} expert. Given an input question, creat a syntactically correct {dialect} query to run.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per {dialect}. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use date('now') function to get the current date, if the question involves "today".
Only use the following tables:
{table_info}
Write an initial draft of the query. Then double check the {dialect} query for common mistakes, including:
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joins
Use format:
First draft: <<FIRST_DRAFT_QUERY>>
Final answer: <<FINAL_ANSWER_QUERY>>
================================ Human Message =================================
{input}
query = chain.invoke(
{
"question": "What's the average Invoice from an American customer whose Fax is missing since 2003 but before 2010"
}
)
query
"\nSELECT AVG(i.Total) AS AverageInvoice\nFROM Invoice i\nJOIN Customer c ON i.CustomerId = c.CustomerId\nWHERE c.Country = 'USA' AND c.Fax IS NULL AND i.InvoiceDate >= date('2003-01-01') AND i.InvoiceDate < date('2010-01-01')"
Human-in-the-loop
In some cases our data is sensitive enough that we never want to execute a SQL query without a human approving it first. Head to the Tool use: Human-in-the-loop page to learn how to add a human-in-the-loop to any tool, chain or agent.
Error handling
At some point, the model will make a mistake and craft an invalid SQL query. Or an issue will arise with our database. Or the model API will go down. We’ll want to add some error handling behavior to our chains and agents so that we fail gracefully in these situations, and perhaps even automatically recover. To learn about error handling with tools, head to the Tool use: Error handling page. |
https://python.langchain.com/docs/use_cases/sql/quickstart/ | ## Quickstart
In this guide we’ll go over the basic ways to create a Q&A chain and agent over a SQL database. These systems will allow us to ask a question about the data in a SQL database and get back a natural language answer. The main difference between the two is that our agent can query the database in a loop as many time as it needs to answer the question.
## ⚠️ Security note ⚠️[](#security-note "Direct link to ⚠️ Security note ⚠️")
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, [see here](https://python.langchain.com/docs/security/).
## Architecture[](#architecture "Direct link to Architecture")
At a high-level, the steps of any SQL chain and agent are:
1. **Convert question to SQL query**: Model converts user input to a SQL query.
2. **Execute SQL query**: Execute the SQL query.
3. **Answer the question**: Model responds to user input using the query results.

## Setup[](#setup "Direct link to Setup")
First, get required packages and set environment variables:
```
%pip install --upgrade --quiet langchain langchain-community langchain-openai
```
We will use an OpenAI model in this guide.
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# Uncomment the below to use LangSmith. Not required.# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()# os.environ["LANGCHAIN_TRACING_V2"] = "true"
```
The below example will use a SQLite connection with Chinook database. Follow [these installation steps](https://database.guide/2-sample-databases-sqlite/) to create `Chinook.db` in the same directory as this notebook:
* Save [this file](https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql) as `Chinook_Sqlite.sql`
* Run `sqlite3 Chinook.db`
* Run `.read Chinook_Sqlite.sql`
* Test `SELECT * FROM Artist LIMIT 10;`
Now, `Chinhook.db` is in our directory and we can interface with it using the SQLAlchemy-driven `SQLDatabase` class:
```
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")print(db.dialect)print(db.get_usable_table_names())db.run("SELECT * FROM Artist LIMIT 10;")
```
```
sqlite['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
```
```
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
```
Great! We’ve got a SQL database that we can query. Now let’s try hooking it up to an LLM.
## Chain[](#chain "Direct link to Chain")
Let’s create a simple chain that takes a question, turns it into a SQL query, executes the query, and uses the result to answer the original question.
### Convert question to SQL query[](#convert-question-to-sql-query "Direct link to Convert question to SQL query")
The first step in a SQL chain or agent is to take the user input and convert it to a SQL query. LangChain comes with a built-in chain for this: [create\_sql\_query\_chain](https://api.python.langchain.com/en/latest/chains/langchain.chains.sql_database.query.create_sql_query_chain.html).
```
from langchain.chains import create_sql_query_chainfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)chain = create_sql_query_chain(llm, db)response = chain.invoke({"question": "How many employees are there"})response
```
```
'SELECT COUNT(*) FROM Employee'
```
We can execute the query to make sure it’s valid:
We can look at the [LangSmith trace](https://smith.langchain.com/public/c8fa52ea-be46-4829-bde2-52894970b830/r) to get a better understanding of what this chain is doing. We can also inspect the chain directly for its prompts. Looking at the prompt (below), we can see that it is:
* Dialect-specific. In this case it references SQLite explicitly.
* Has definitions for all the available tables.
* Has three examples rows for each table.
This technique is inspired by papers like [this](https://arxiv.org/pdf/2204.00498.pdf), which suggest showing examples rows and being explicit about tables improves performance. We can also inspect the full prompt like so:
```
chain.get_prompts()[0].pretty_print()
```
```
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.Pay attention to use date('now') function to get the current date, if the question involves "today".Use the following format:Question: Question hereSQLQuery: SQL Query to runSQLResult: Result of the SQLQueryAnswer: Final answer hereOnly use the following tables:{table_info}Question: {input}
```
### Execute SQL query[](#execute-sql-query "Direct link to Execute SQL query")
Now that we’ve generated a SQL query, we’ll want to execute it. **This is the most dangerous part of creating a SQL chain.** Consider carefully if it is OK to run automated queries over your data. Minimize the database connection permissions as much as possible. Consider adding a human approval step to you chains before query execution (see below).
We can use the `QuerySQLDatabaseTool` to easily add query execution to our chain:
```
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseToolexecute_query = QuerySQLDataBaseTool(db=db)write_query = create_sql_query_chain(llm, db)chain = write_query | execute_querychain.invoke({"question": "How many employees are there"})
```
### Answer the question[](#answer-the-question "Direct link to Answer the question")
Now that we’ve got a way to automatically generate and execute queries, we just need to combine the original question and SQL query result to generate a final answer. We can do this by passing question and result to the LLM once more:
```
from operator import itemgetterfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnablePassthroughanswer_prompt = PromptTemplate.from_template( """Given the following user question, corresponding SQL query, and SQL result, answer the user question.Question: {question}SQL Query: {query}SQL Result: {result}Answer: """)answer = answer_prompt | llm | StrOutputParser()chain = ( RunnablePassthrough.assign(query=write_query).assign( result=itemgetter("query") | execute_query ) | answer)chain.invoke({"question": "How many employees are there"})
```
### Next steps[](#next-steps "Direct link to Next steps")
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
* [Prompting strategies](https://python.langchain.com/docs/use_cases/sql/prompting/): Advanced prompt engineering techniques.
* [Query checking](https://python.langchain.com/docs/use_cases/sql/query_checking/): Add query validation and error handling.
* [Large databses](https://python.langchain.com/docs/use_cases/sql/large_db/): Techniques for working with large databases.
## Agents[](#agents "Direct link to Agents")
LangChain has an SQL Agent which provides a more flexible way of interacting with SQL databases. The main advantages of using the SQL Agent are:
* It can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table).
* It can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
* It can answer questions that require multiple dependent queries.
* It will save tokens by only considering the schema from relevant tables.
To initialize the agent, we use `create_sql_agent` function. This agent contains the `SQLDatabaseToolkit` which contains tools to:
* Create and execute queries
* Check query syntax
* Retrieve table descriptions
* … and more
### Initializing agent[](#initializing-agent "Direct link to Initializing agent")
```
from langchain_community.agent_toolkits import create_sql_agentagent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
```
```
agent_executor.invoke( { "input": "List the total sales per country. Which country's customers spent the most?" })
```
```
> Entering new AgentExecutor chain...Invoking: `sql_db_list_tables` with `{}`Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, TrackInvoking: `sql_db_schema` with `Invoice,Customer`CREATE TABLE "Customer" ( "CustomerId" INTEGER NOT NULL, "FirstName" NVARCHAR(40) NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "Company" NVARCHAR(80), "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60) NOT NULL, "SupportRepId" INTEGER, PRIMARY KEY ("CustomerId"), FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId"))/*3 rows from Customer table:CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 32 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 53 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3*/CREATE TABLE "Invoice" ( "InvoiceId" INTEGER NOT NULL, "CustomerId" INTEGER NOT NULL, "InvoiceDate" DATETIME NOT NULL, "BillingAddress" NVARCHAR(70), "BillingCity" NVARCHAR(40), "BillingState" NVARCHAR(40), "BillingCountry" NVARCHAR(40), "BillingPostalCode" NVARCHAR(10), "Total" NUMERIC(10, 2) NOT NULL, PRIMARY KEY ("InvoiceId"), FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId"))/*3 rows from Invoice table:InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.982 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.963 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94*/Invoking: `sql_db_query` with `SELECT c.Country, SUM(i.Total) AS TotalSales FROM Invoice i JOIN Customer c ON i.CustomerId = c.CustomerId GROUP BY c.Country ORDER BY TotalSales DESC LIMIT 10;`responded: To list the total sales per country, I can query the "Invoice" and "Customer" tables. I will join these tables on the "CustomerId" column and group the results by the "BillingCountry" column. Then, I will calculate the sum of the "Total" column to get the total sales per country. Finally, I will order the results in descending order of the total sales.Here is the SQL query:```sqlSELECT c.Country, SUM(i.Total) AS TotalSalesFROM Invoice iJOIN Customer c ON i.CustomerId = c.CustomerIdGROUP BY c.CountryORDER BY TotalSales DESCLIMIT 10;```Now, I will execute this query to get the total sales per country.[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]The total sales per country are as follows:1. USA: $523.062. Canada: $303.963. France: $195.104. Brazil: $190.105. Germany: $156.486. United Kingdom: $112.867. Czech Republic: $90.248. Portugal: $77.249. India: $75.2610. Chile: $46.62To answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.> Finished chain.
```
```
{'input': "List the total sales per country. Which country's customers spent the most?", 'output': 'The total sales per country are as follows:\n\n1. USA: $523.06\n2. Canada: $303.96\n3. France: $195.10\n4. Brazil: $190.10\n5. Germany: $156.48\n6. United Kingdom: $112.86\n7. Czech Republic: $90.24\n8. Portugal: $77.24\n9. India: $75.26\n10. Chile: $46.62\n\nTo answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.'}
```
```
agent_executor.invoke({"input": "Describe the playlisttrack table"})
```
```
> Entering new AgentExecutor chain...Invoking: `sql_db_list_tables` with `{}`Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, TrackInvoking: `sql_db_schema` with `PlaylistTrack`CREATE TABLE "PlaylistTrack" ( "PlaylistId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, PRIMARY KEY ("PlaylistId", "TrackId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId"))/*3 rows from PlaylistTrack table:PlaylistId TrackId1 34021 33891 3390*/The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks. Here is the schema of the `PlaylistTrack` table:```CREATE TABLE "PlaylistTrack" ( "PlaylistId" INTEGER NOT NULL, "TrackId" INTEGER NOT NULL, PRIMARY KEY ("PlaylistId", "TrackId"), FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId"))```The `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.Here are three sample rows from the `PlaylistTrack` table:```PlaylistId TrackId1 34021 33891 3390```Please let me know if there is anything else I can help with.> Finished chain.
```
```
{'input': 'Describe the playlisttrack table', 'output': 'The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks. \n\nHere is the schema of the `PlaylistTrack` table:\n\n```\nCREATE TABLE "PlaylistTrack" (\n\t"PlaylistId" INTEGER NOT NULL, \n\t"TrackId" INTEGER NOT NULL, \n\tPRIMARY KEY ("PlaylistId", "TrackId"), \n\tFOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), \n\tFOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")\n)\n```\n\nThe `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.\n\nHere are three sample rows from the `PlaylistTrack` table:\n\n```\nPlaylistId TrackId\n1 3402\n1 3389\n1 3390\n```\n\nPlease let me know if there is anything else I can help with.'}
```
### Next steps[](#next-steps-1 "Direct link to Next steps")
For more on how to use and customize agents head to the [Agents](https://python.langchain.com/docs/use_cases/sql/agents/) page. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:31.757Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/sql/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/sql/quickstart/",
"description": "In this guide we’ll go over the basic ways to create a Q&A chain and",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "5397",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:31 GMT",
"etag": "W/\"d0ae72e4632b25328f17b9775f2f7766\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::ncfnt-1713753991531-1f8ae09fd07e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/sql/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll go over the basic ways to create a Q&A chain and",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
In this guide we’ll go over the basic ways to create a Q&A chain and agent over a SQL database. These systems will allow us to ask a question about the data in a SQL database and get back a natural language answer. The main difference between the two is that our agent can query the database in a loop as many time as it needs to answer the question.
⚠️ Security note ⚠️
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
Architecture
At a high-level, the steps of any SQL chain and agent are:
Convert question to SQL query: Model converts user input to a SQL query.
Execute SQL query: Execute the SQL query.
Answer the question: Model responds to user input using the query results.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai
We will use an OpenAI model in this guide.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
The below example will use a SQLite connection with Chinook database. Follow these installation steps to create Chinook.db in the same directory as this notebook:
Save this file as Chinook_Sqlite.sql
Run sqlite3 Chinook.db
Run .read Chinook_Sqlite.sql
Test SELECT * FROM Artist LIMIT 10;
Now, Chinhook.db is in our directory and we can interface with it using the SQLAlchemy-driven SQLDatabase class:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Great! We’ve got a SQL database that we can query. Now let’s try hooking it up to an LLM.
Chain
Let’s create a simple chain that takes a question, turns it into a SQL query, executes the query, and uses the result to answer the original question.
Convert question to SQL query
The first step in a SQL chain or agent is to take the user input and convert it to a SQL query. LangChain comes with a built-in chain for this: create_sql_query_chain.
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "How many employees are there"})
response
'SELECT COUNT(*) FROM Employee'
We can execute the query to make sure it’s valid:
We can look at the LangSmith trace to get a better understanding of what this chain is doing. We can also inspect the chain directly for its prompts. Looking at the prompt (below), we can see that it is:
Dialect-specific. In this case it references SQLite explicitly.
Has definitions for all the available tables.
Has three examples rows for each table.
This technique is inspired by papers like this, which suggest showing examples rows and being explicit about tables improves performance. We can also inspect the full prompt like so:
chain.get_prompts()[0].pretty_print()
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use date('now') function to get the current date, if the question involves "today".
Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
Only use the following tables:
{table_info}
Question: {input}
Execute SQL query
Now that we’ve generated a SQL query, we’ll want to execute it. This is the most dangerous part of creating a SQL chain. Consider carefully if it is OK to run automated queries over your data. Minimize the database connection permissions as much as possible. Consider adding a human approval step to you chains before query execution (see below).
We can use the QuerySQLDatabaseTool to easily add query execution to our chain:
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool
execute_query = QuerySQLDataBaseTool(db=db)
write_query = create_sql_query_chain(llm, db)
chain = write_query | execute_query
chain.invoke({"question": "How many employees are there"})
Answer the question
Now that we’ve got a way to automatically generate and execute queries, we just need to combine the original question and SQL query result to generate a final answer. We can do this by passing question and result to the LLM once more:
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
answer_prompt = PromptTemplate.from_template(
"""Given the following user question, corresponding SQL query, and SQL result, answer the user question.
Question: {question}
SQL Query: {query}
SQL Result: {result}
Answer: """
)
answer = answer_prompt | llm | StrOutputParser()
chain = (
RunnablePassthrough.assign(query=write_query).assign(
result=itemgetter("query") | execute_query
)
| answer
)
chain.invoke({"question": "How many employees are there"})
Next steps
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
Prompting strategies: Advanced prompt engineering techniques.
Query checking: Add query validation and error handling.
Large databses: Techniques for working with large databases.
Agents
LangChain has an SQL Agent which provides a more flexible way of interacting with SQL databases. The main advantages of using the SQL Agent are:
It can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table).
It can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
It can answer questions that require multiple dependent queries.
It will save tokens by only considering the schema from relevant tables.
To initialize the agent, we use create_sql_agent function. This agent contains the SQLDatabaseToolkit which contains tools to:
Create and execute queries
Check query syntax
Retrieve table descriptions
… and more
Initializing agent
from langchain_community.agent_toolkits import create_sql_agent
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke(
{
"input": "List the total sales per country. Which country's customers spent the most?"
}
)
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `Invoice,Customer`
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
Invoking: `sql_db_query` with `SELECT c.Country, SUM(i.Total) AS TotalSales FROM Invoice i JOIN Customer c ON i.CustomerId = c.CustomerId GROUP BY c.Country ORDER BY TotalSales DESC LIMIT 10;`
responded: To list the total sales per country, I can query the "Invoice" and "Customer" tables. I will join these tables on the "CustomerId" column and group the results by the "BillingCountry" column. Then, I will calculate the sum of the "Total" column to get the total sales per country. Finally, I will order the results in descending order of the total sales.
Here is the SQL query:
```sql
SELECT c.Country, SUM(i.Total) AS TotalSales
FROM Invoice i
JOIN Customer c ON i.CustomerId = c.CustomerId
GROUP BY c.Country
ORDER BY TotalSales DESC
LIMIT 10;
```
Now, I will execute this query to get the total sales per country.
[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]The total sales per country are as follows:
1. USA: $523.06
2. Canada: $303.96
3. France: $195.10
4. Brazil: $190.10
5. Germany: $156.48
6. United Kingdom: $112.86
7. Czech Republic: $90.24
8. Portugal: $77.24
9. India: $75.26
10. Chile: $46.62
To answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.
> Finished chain.
{'input': "List the total sales per country. Which country's customers spent the most?",
'output': 'The total sales per country are as follows:\n\n1. USA: $523.06\n2. Canada: $303.96\n3. France: $195.10\n4. Brazil: $190.10\n5. Germany: $156.48\n6. United Kingdom: $112.86\n7. Czech Republic: $90.24\n8. Portugal: $77.24\n9. India: $75.26\n10. Chile: $46.62\n\nTo answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.'}
agent_executor.invoke({"input": "Describe the playlisttrack table"})
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `PlaylistTrack`
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
3 rows from PlaylistTrack table:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks.
Here is the schema of the `PlaylistTrack` table:
```
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
```
The `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.
Here are three sample rows from the `PlaylistTrack` table:
```
PlaylistId TrackId
1 3402
1 3389
1 3390
```
Please let me know if there is anything else I can help with.
> Finished chain.
{'input': 'Describe the playlisttrack table',
'output': 'The `PlaylistTrack` table has two columns: `PlaylistId` and `TrackId`. It is a junction table that represents the many-to-many relationship between playlists and tracks. \n\nHere is the schema of the `PlaylistTrack` table:\n\n```\nCREATE TABLE "PlaylistTrack" (\n\t"PlaylistId" INTEGER NOT NULL, \n\t"TrackId" INTEGER NOT NULL, \n\tPRIMARY KEY ("PlaylistId", "TrackId"), \n\tFOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), \n\tFOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")\n)\n```\n\nThe `PlaylistId` column is a foreign key referencing the `PlaylistId` column in the `Playlist` table. The `TrackId` column is a foreign key referencing the `TrackId` column in the `Track` table.\n\nHere are three sample rows from the `PlaylistTrack` table:\n\n```\nPlaylistId TrackId\n1 3402\n1 3389\n1 3390\n```\n\nPlease let me know if there is anything else I can help with.'}
Next steps
For more on how to use and customize agents head to the Agents page. |
https://python.langchain.com/docs/use_cases/summarization/ | ## Summarization
[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/summarization.ipynb)
Open In Colab
## Use case[](#use-case "Direct link to Use case")
Suppose you have a set of documents (PDFs, Notion pages, customer questions, etc.) and you want to summarize the content.
LLMs are a great tool for this given their proficiency in understanding and synthesizing text.
In this walkthrough we’ll go over how to perform document summarization using LLMs.
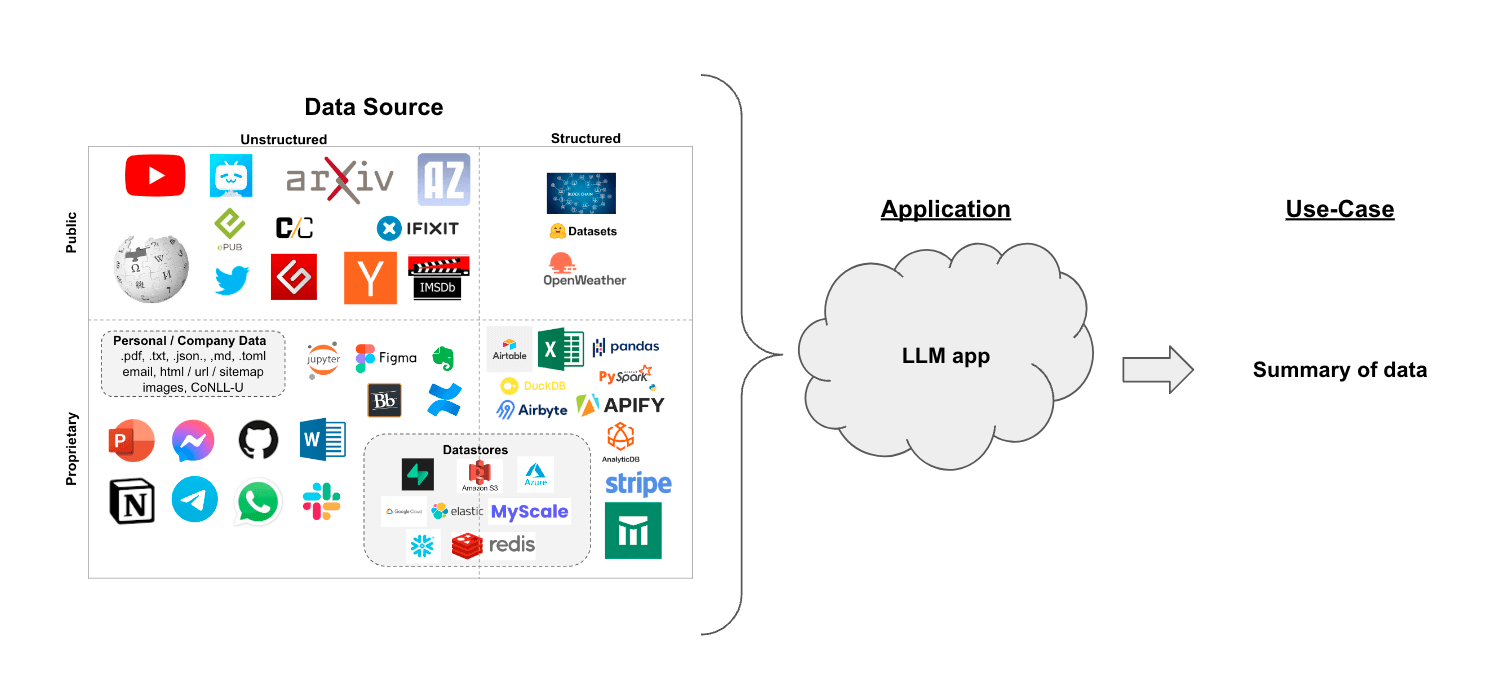
## Overview[](#overview "Direct link to Overview")
A central question for building a summarizer is how to pass your documents into the LLM’s context window. Two common approaches for this are:
1. `Stuff`: Simply “stuff” all your documents into a single prompt. This is the simplest approach (see [here](https://python.langchain.com/docs/modules/chains/#lcel-chains) for more on the `create_stuff_documents_chain` constructor, which is used for this method).
2. `Map-reduce`: Summarize each document on it’s own in a “map” step and then “reduce” the summaries into a final summary (see [here](https://python.langchain.com/docs/modules/chains/#legacy-chains) for more on the `MapReduceDocumentsChain`, which is used for this method).

## Quickstart[](#quickstart "Direct link to Quickstart")
To give you a sneak preview, either pipeline can be wrapped in a single object: `load_summarize_chain`.
Suppose we want to summarize a blog post. We can create this in a few lines of code.
First set environment variables and install packages:
```
%pip install --upgrade --quiet langchain-openai tiktoken chromadb langchain# Set env var OPENAI_API_KEY or load from a .env file# import dotenv# dotenv.load_dotenv()
```
```
Requirement already satisfied: openai in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.27.8)Requirement already satisfied: tiktoken in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.4.0)Requirement already satisfied: chromadb in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.4.4)Requirement already satisfied: langchain in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.0.299)Requirement already satisfied: requests>=2.20 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from openai) (2.31.0)Requirement already satisfied: tqdm in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from openai) (4.64.1)Requirement already satisfied: aiohttp in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from openai) (3.8.5)Requirement already satisfied: regex>=2022.1.18 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from tiktoken) (2023.6.3)Requirement already satisfied: pydantic<2.0,>=1.9 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (1.10.12)Requirement already satisfied: chroma-hnswlib==0.7.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.7.2)Requirement already satisfied: fastapi<0.100.0,>=0.95.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.99.1)Requirement already satisfied: uvicorn[standard]>=0.18.3 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.23.2)Requirement already satisfied: numpy>=1.21.6 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (1.24.4)Requirement already satisfied: posthog>=2.4.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (3.0.1)Requirement already satisfied: typing-extensions>=4.5.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (4.7.1)Requirement already satisfied: pulsar-client>=3.1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (3.2.0)Requirement already satisfied: onnxruntime>=1.14.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (1.15.1)Requirement already satisfied: tokenizers>=0.13.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.13.3)Requirement already satisfied: pypika>=0.48.9 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.48.9)Collecting tqdm (from openai) Obtaining dependency information for tqdm from https://files.pythonhosted.org/packages/00/e5/f12a80907d0884e6dff9c16d0c0114d81b8cd07dc3ae54c5e962cc83037e/tqdm-4.66.1-py3-none-any.whl.metadata Downloading tqdm-4.66.1-py3-none-any.whl.metadata (57 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 57.6/57.6 kB 2.7 MB/s eta 0:00:00Requirement already satisfied: overrides>=7.3.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (7.4.0)Requirement already satisfied: importlib-resources in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (6.0.0)Requirement already satisfied: PyYAML>=5.3 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (6.0.1)Requirement already satisfied: SQLAlchemy<3,>=1.4 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (2.0.20)Requirement already satisfied: anyio<4.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (3.7.1)Requirement already satisfied: async-timeout<5.0.0,>=4.0.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (4.0.3)Requirement already satisfied: dataclasses-json<0.7,>=0.5.7 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (0.5.9)Requirement already satisfied: jsonpatch<2.0,>=1.33 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (1.33)Requirement already satisfied: langsmith<0.1.0,>=0.0.38 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (0.0.42)Requirement already satisfied: numexpr<3.0.0,>=2.8.4 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (2.8.5)Requirement already satisfied: tenacity<9.0.0,>=8.1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (8.2.3)Requirement already satisfied: attrs>=17.3.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (23.1.0)Requirement already satisfied: charset-normalizer<4.0,>=2.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (3.2.0)Requirement already satisfied: multidict<7.0,>=4.5 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (6.0.4)Requirement already satisfied: yarl<2.0,>=1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (1.9.2)Requirement already satisfied: frozenlist>=1.1.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (1.4.0)Requirement already satisfied: aiosignal>=1.1.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (1.3.1)Requirement already satisfied: idna>=2.8 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from anyio<4.0->langchain) (3.4)Requirement already satisfied: sniffio>=1.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from anyio<4.0->langchain) (1.3.0)Requirement already satisfied: exceptiongroup in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from anyio<4.0->langchain) (1.1.3)Requirement already satisfied: marshmallow<4.0.0,>=3.3.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (3.20.1)Requirement already satisfied: marshmallow-enum<2.0.0,>=1.5.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (1.5.1)Requirement already satisfied: typing-inspect>=0.4.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (0.9.0)Requirement already satisfied: starlette<0.28.0,>=0.27.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from fastapi<0.100.0,>=0.95.2->chromadb) (0.27.0)Requirement already satisfied: jsonpointer>=1.9 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from jsonpatch<2.0,>=1.33->langchain) (2.4)Requirement already satisfied: coloredlogs in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (15.0.1)Requirement already satisfied: flatbuffers in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (23.5.26)Requirement already satisfied: packaging in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (23.1)Requirement already satisfied: protobuf in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (4.23.4)Requirement already satisfied: sympy in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (1.12)Requirement already satisfied: six>=1.5 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (1.16.0)Requirement already satisfied: monotonic>=1.5 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (1.6)Requirement already satisfied: backoff>=1.10.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (2.2.1)Requirement already satisfied: python-dateutil>2.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (2.8.2)Requirement already satisfied: certifi in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from pulsar-client>=3.1.0->chromadb) (2023.7.22)Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from requests>=2.20->openai) (1.26.16)Requirement already satisfied: click>=7.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (8.1.7)Requirement already satisfied: h11>=0.8 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.14.0)Requirement already satisfied: httptools>=0.5.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.6.0)Requirement already satisfied: python-dotenv>=0.13 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (1.0.0)Requirement already satisfied: uvloop!=0.15.0,!=0.15.1,>=0.14.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.17.0)Requirement already satisfied: watchfiles>=0.13 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.19.0)Requirement already satisfied: websockets>=10.4 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (11.0.3)Requirement already satisfied: zipp>=3.1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from importlib-resources->chromadb) (3.16.2)Requirement already satisfied: mypy-extensions>=0.3.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from typing-inspect>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain) (1.0.0)Requirement already satisfied: humanfriendly>=9.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from coloredlogs->onnxruntime>=1.14.1->chromadb) (10.0)Requirement already satisfied: mpmath>=0.19 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from sympy->onnxruntime>=1.14.1->chromadb) (1.3.0)Using cached tqdm-4.66.1-py3-none-any.whl (78 kB)Installing collected packages: tqdm Attempting uninstall: tqdm Found existing installation: tqdm 4.64.1 Uninstalling tqdm-4.64.1: Successfully uninstalled tqdm-4.64.1ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.clarifai 9.8.1 requires tqdm==4.64.1, but you have tqdm 4.66.1 which is incompatible.Successfully installed tqdm-4.66.1
```
We can use `chain_type="stuff"`, especially if using larger context window models such as:
* 16k token OpenAI `gpt-3.5-turbo-1106`
* 100k token Anthropic [Claude-2](https://www.anthropic.com/index/claude-2)
We can also supply `chain_type="map_reduce"` or `chain_type="refine"`.
```
from langchain.chains.summarize import load_summarize_chainfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_openai import ChatOpenAIloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")docs = loader.load()llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")chain = load_summarize_chain(llm, chain_type="stuff")chain.run(docs)
```
```
'The article discusses the concept of building autonomous agents powered by large language models (LLMs). It explores the components of such agents, including planning, memory, and tool use. The article provides case studies and proof-of-concept examples of LLM-powered agents in various domains. It also highlights the challenges and limitations of using LLMs in agent systems.'
```
## Option 1. Stuff[](#option-1.-stuff "Direct link to Option 1. Stuff")
When we use `load_summarize_chain` with `chain_type="stuff"`, we will use the [StuffDocumentsChain](https://api.python.langchain.com/en/latest/chains/langchain.chains.combine_documents.stuff.StuffDocumentsChain.html#langchain.chains.combine_documents.stuff.StuffDocumentsChain).
The chain will take a list of documents, inserts them all into a prompt, and passes that prompt to an LLM:
```
from langchain.chains.combine_documents.stuff import StuffDocumentsChainfrom langchain.chains.llm import LLMChainfrom langchain_core.prompts import PromptTemplate# Define promptprompt_template = """Write a concise summary of the following:"{text}"CONCISE SUMMARY:"""prompt = PromptTemplate.from_template(prompt_template)# Define LLM chainllm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")llm_chain = LLMChain(llm=llm, prompt=prompt)# Define StuffDocumentsChainstuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")docs = loader.load()print(stuff_chain.run(docs))
```
```
The article discusses the concept of building autonomous agents powered by large language models (LLMs). It explores the components of such agents, including planning, memory, and tool use. The article provides case studies and proof-of-concept examples of LLM-powered agents in various domains, such as scientific discovery and generative agents simulation. It also highlights the challenges and limitations of using LLMs in agent systems.
```
Great! We can see that we reproduce the earlier result using the `load_summarize_chain`.
### Go deeper[](#go-deeper "Direct link to Go deeper")
* You can easily customize the prompt.
* You can easily try different LLMs, (e.g., [Claude](https://python.langchain.com/docs/integrations/chat/anthropic/)) via the `llm` parameter.
## Option 2. Map-Reduce[](#option-2.-map-reduce "Direct link to Option 2. Map-Reduce")
Let’s unpack the map reduce approach. For this, we’ll first map each document to an individual summary using an `LLMChain`. Then we’ll use a `ReduceDocumentsChain` to combine those summaries into a single global summary.
First, we specify the LLMChain to use for mapping each document to an individual summary:
```
from langchain.chains import MapReduceDocumentsChain, ReduceDocumentsChainfrom langchain_text_splitters import CharacterTextSplitterllm = ChatOpenAI(temperature=0)# Mapmap_template = """The following is a set of documents{docs}Based on this list of docs, please identify the main themes Helpful Answer:"""map_prompt = PromptTemplate.from_template(map_template)map_chain = LLMChain(llm=llm, prompt=map_prompt)
```
We can also use the Prompt Hub to store and fetch prompts.
This will work with your [LangSmith API key](https://docs.smith.langchain.com/).
For example, see the map prompt [here](https://smith.langchain.com/hub/rlm/map-prompt).
```
from langchain import hubmap_prompt = hub.pull("rlm/map-prompt")map_chain = LLMChain(llm=llm, prompt=map_prompt)
```
The `ReduceDocumentsChain` handles taking the document mapping results and reducing them into a single output. It wraps a generic `CombineDocumentsChain` (like `StuffDocumentsChain`) but adds the ability to collapse documents before passing it to the `CombineDocumentsChain` if their cumulative size exceeds `token_max`. In this example, we can actually re-use our chain for combining our docs to also collapse our docs.
So if the cumulative number of tokens in our mapped documents exceeds 4000 tokens, then we’ll recursively pass in the documents in batches of \\< 4000 tokens to our `StuffDocumentsChain` to create batched summaries. And once those batched summaries are cumulatively less than 4000 tokens, we’ll pass them all one last time to the `StuffDocumentsChain` to create the final summary.
```
# Reducereduce_template = """The following is set of summaries:{docs}Take these and distill it into a final, consolidated summary of the main themes. Helpful Answer:"""reduce_prompt = PromptTemplate.from_template(reduce_template)
```
```
# Note we can also get this from the prompt hub, as noted abovereduce_prompt = hub.pull("rlm/map-prompt")
```
```
ChatPromptTemplate(input_variables=['docs'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['docs'], template='The following is a set of documents:\n{docs}\nBased on this list of docs, please identify the main themes \nHelpful Answer:'))])
```
```
# Run chainreduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)# Takes a list of documents, combines them into a single string, and passes this to an LLMChaincombine_documents_chain = StuffDocumentsChain( llm_chain=reduce_chain, document_variable_name="docs")# Combines and iteratively reduces the mapped documentsreduce_documents_chain = ReduceDocumentsChain( # This is final chain that is called. combine_documents_chain=combine_documents_chain, # If documents exceed context for `StuffDocumentsChain` collapse_documents_chain=combine_documents_chain, # The maximum number of tokens to group documents into. token_max=4000,)
```
Combining our map and reduce chains into one:
```
# Combining documents by mapping a chain over them, then combining resultsmap_reduce_chain = MapReduceDocumentsChain( # Map chain llm_chain=map_chain, # Reduce chain reduce_documents_chain=reduce_documents_chain, # The variable name in the llm_chain to put the documents in document_variable_name="docs", # Return the results of the map steps in the output return_intermediate_steps=False,)text_splitter = CharacterTextSplitter.from_tiktoken_encoder( chunk_size=1000, chunk_overlap=0)split_docs = text_splitter.split_documents(docs)
```
```
Created a chunk of size 1003, which is longer than the specified 1000
```
```
print(map_reduce_chain.run(split_docs))
```
```
Based on the list of documents provided, the main themes can be identified as follows:1. LLM-powered autonomous agents: The documents discuss the concept of building agents with LLM as their core controller and highlight the potential of LLM beyond generating written content. They explore the capabilities of LLM as a general problem solver.2. Agent system overview: The documents provide an overview of the components that make up a LLM-powered autonomous agent system, including planning, memory, and tool use. Each component is explained in detail, highlighting its role in enhancing the agent's capabilities.3. Planning: The documents discuss how the agent breaks down large tasks into smaller subgoals and utilizes self-reflection to improve the quality of its actions and results.4. Memory: The documents explain the importance of both short-term and long-term memory in an agent system. Short-term memory is utilized for in-context learning, while long-term memory allows the agent to retain and recall information over extended periods.5. Tool use: The documents highlight the agent's ability to call external APIs for additional information and resources that may be missing from its pre-trained model weights. This includes accessing current information, executing code, and retrieving proprietary information.6. Case studies and proof-of-concept examples: The documents provide examples of how LLM-powered autonomous agents can be applied in various domains, such as scientific discovery and generative agent simulations. These case studies serve as examples of the capabilities and potential applications of such agents.7. Challenges: The documents acknowledge the challenges associated with building and utilizing LLM-powered autonomous agents, although specific challenges are not mentioned in the given set of documents.8. Citation and references: The documents include a citation and reference section, indicating that the information presented is based on existing research and sources.Overall, the main themes in the provided documents revolve around LLM-powered autonomous agents, their components and capabilities, planning, memory, tool use, case studies, and challenges.
```
### Go deeper[](#go-deeper-1 "Direct link to Go deeper")
**Customization**
* As shown above, you can customize the LLMs and prompts for map and reduce stages.
**Real-world use-case**
* See [this blog post](https://blog.langchain.dev/llms-to-improve-documentation/) case-study on analyzing user interactions (questions about LangChain documentation)!
* The blog post and associated [repo](https://github.com/mendableai/QA_clustering) also introduce clustering as a means of summarization.
* This opens up a third path beyond the `stuff` or `map-reduce` approaches that is worth considering.
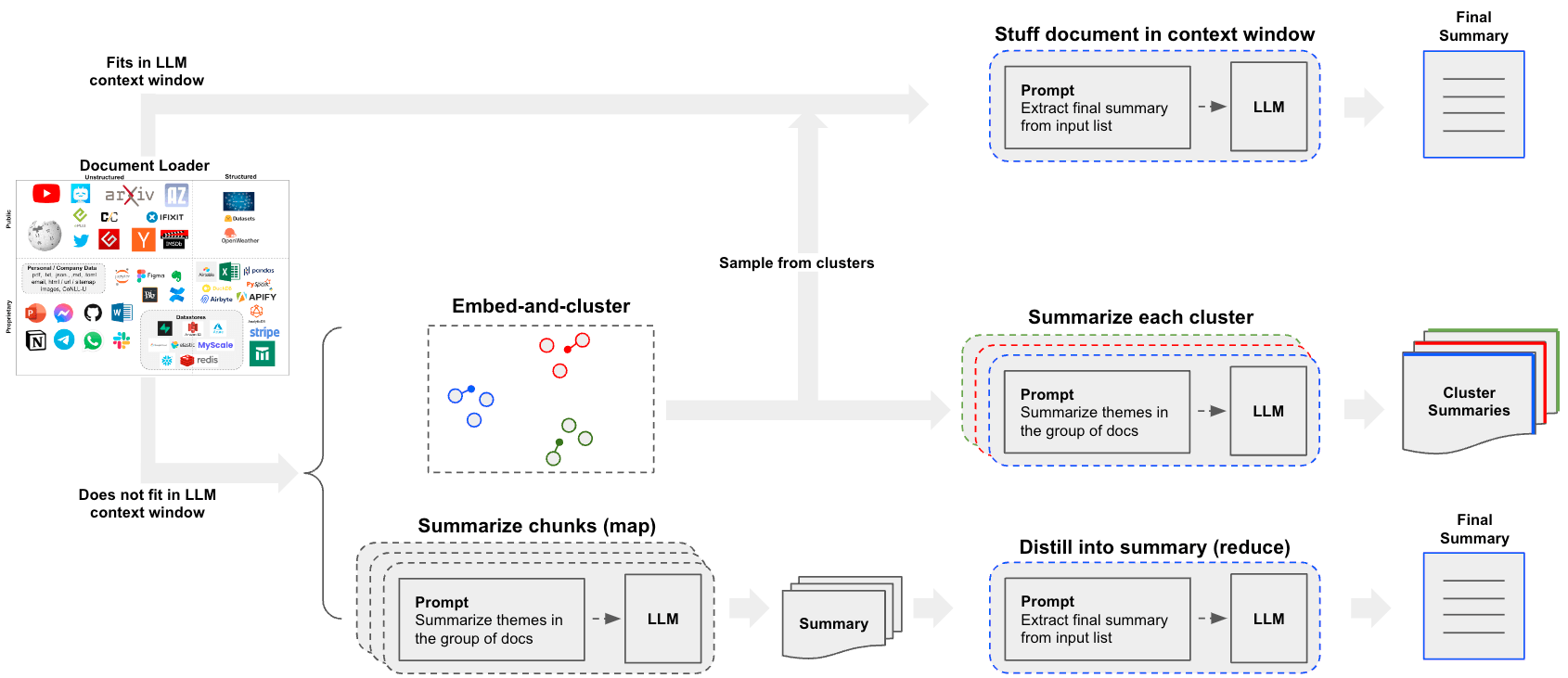
## Option 3. Refine[](#option-3.-refine "Direct link to Option 3. Refine")
[RefineDocumentsChain](https://python.langchain.com/docs/modules/chains/#legacy-chains) is similar to map-reduce:
> The refine documents chain constructs a response by looping over the input documents and iteratively updating its answer. For each document, it passes all non-document inputs, the current document, and the latest intermediate answer to an LLM chain to get a new answer.
This can be easily run with the `chain_type="refine"` specified.
```
chain = load_summarize_chain(llm, chain_type="refine")chain.run(split_docs)
```
```
'The article explores the concept of building autonomous agents powered by large language models (LLMs) and their potential as problem solvers. It discusses different approaches to task decomposition, the integration of self-reflection into LLM-based agents, and the use of external classical planners for long-horizon planning. The new context introduces the Chain of Hindsight (CoH) approach and Algorithm Distillation (AD) for training models to produce better outputs. It also discusses different types of memory and the use of external memory for fast retrieval. The article explores the concept of tool use and introduces the MRKL system and experiments on fine-tuning LLMs to use external tools. It introduces HuggingGPT, a framework that uses ChatGPT as a task planner, and discusses the challenges of using LLM-powered agents in real-world scenarios. The article concludes with case studies on scientific discovery agents and the use of LLM-powered agents in anticancer drug discovery. It also introduces the concept of generative agents that combine LLM with memory, planning, and reflection mechanisms. The conversation samples provided discuss the implementation of a game architecture and the challenges in building LLM-centered agents. The article provides references to related research papers and resources for further exploration.'
```
It’s also possible to supply a prompt and return intermediate steps.
```
prompt_template = """Write a concise summary of the following:{text}CONCISE SUMMARY:"""prompt = PromptTemplate.from_template(prompt_template)refine_template = ( "Your job is to produce a final summary\n" "We have provided an existing summary up to a certain point: {existing_answer}\n" "We have the opportunity to refine the existing summary" "(only if needed) with some more context below.\n" "------------\n" "{text}\n" "------------\n" "Given the new context, refine the original summary in Italian" "If the context isn't useful, return the original summary.")refine_prompt = PromptTemplate.from_template(refine_template)chain = load_summarize_chain( llm=llm, chain_type="refine", question_prompt=prompt, refine_prompt=refine_prompt, return_intermediate_steps=True, input_key="input_documents", output_key="output_text",)result = chain({"input_documents": split_docs}, return_only_outputs=True)
```
```
print(result["output_text"])
```
```
Il presente articolo discute il concetto di costruire agenti autonomi utilizzando LLM (large language model) come controller principale. Esplora i diversi componenti di un sistema di agenti alimentato da LLM, tra cui la pianificazione, la memoria e l'uso degli strumenti. Dimostrazioni di concetto come AutoGPT mostrano il potenziale di LLM come risolutore generale di problemi. Approcci come Chain of Thought, Tree of Thoughts, LLM+P, ReAct e Reflexion consentono agli agenti autonomi di pianificare, riflettere su se stessi e migliorarsi iterativamente. Tuttavia, ci sono sfide da affrontare, come la limitata capacità di contesto che limita l'inclusione di informazioni storiche dettagliate e la difficoltà di pianificazione a lungo termine e decomposizione delle attività. Inoltre, l'affidabilità dell'interfaccia di linguaggio naturale tra LLM e componenti esterni come la memoria e gli strumenti è incerta, poiché i LLM possono commettere errori di formattazione e mostrare comportamenti ribelli. Nonostante ciò, il sistema AutoGPT viene menzionato come esempio di dimostrazione di concetto che utilizza LLM come controller principale per agenti autonomi. Questo articolo fa riferimento a diverse fonti che esplorano approcci e applicazioni specifiche di LLM nell'ambito degli agenti autonomi.
```
```
print("\n\n".join(result["intermediate_steps"][:3]))
```
```
This article discusses the concept of building autonomous agents using LLM (large language model) as the core controller. The article explores the different components of an LLM-powered agent system, including planning, memory, and tool use. It also provides examples of proof-of-concept demos and highlights the potential of LLM as a general problem solver.Questo articolo discute del concetto di costruire agenti autonomi utilizzando LLM (large language model) come controller principale. L'articolo esplora i diversi componenti di un sistema di agenti alimentato da LLM, inclusa la pianificazione, la memoria e l'uso degli strumenti. Vengono forniti anche esempi di dimostrazioni di proof-of-concept e si evidenzia il potenziale di LLM come risolutore generale di problemi. Inoltre, vengono presentati approcci come Chain of Thought, Tree of Thoughts, LLM+P, ReAct e Reflexion che consentono agli agenti autonomi di pianificare, riflettere su se stessi e migliorare iterativamente.Questo articolo discute del concetto di costruire agenti autonomi utilizzando LLM (large language model) come controller principale. L'articolo esplora i diversi componenti di un sistema di agenti alimentato da LLM, inclusa la pianificazione, la memoria e l'uso degli strumenti. Vengono forniti anche esempi di dimostrazioni di proof-of-concept e si evidenzia il potenziale di LLM come risolutore generale di problemi. Inoltre, vengono presentati approcci come Chain of Thought, Tree of Thoughts, LLM+P, ReAct e Reflexion che consentono agli agenti autonomi di pianificare, riflettere su se stessi e migliorare iterativamente. Il nuovo contesto riguarda l'approccio Chain of Hindsight (CoH) che permette al modello di migliorare autonomamente i propri output attraverso un processo di apprendimento supervisionato. Viene anche presentato l'approccio Algorithm Distillation (AD) che applica lo stesso concetto alle traiettorie di apprendimento per compiti di reinforcement learning.
```
## Splitting and summarizing in a single chain[](#splitting-and-summarizing-in-a-single-chain "Direct link to Splitting and summarizing in a single chain")
For convenience, we can wrap both the text splitting of our long document and summarizing in a single `AnalyzeDocumentsChain`.
```
from langchain.chains import AnalyzeDocumentChainsummarize_document_chain = AnalyzeDocumentChain( combine_docs_chain=chain, text_splitter=text_splitter)summarize_document_chain.run(docs[0].page_content)
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:32.651Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/summarization/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/summarization/",
"description": "Open In Colab",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7354",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"summarization\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:32 GMT",
"etag": "W/\"fd5e84a6ee7bda42d2feae64f238e0ca\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tql9z-1713753992558-0e959bfd4598"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/summarization/",
"property": "og:url"
},
{
"content": "Summarization | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Open In Colab",
"property": "og:description"
}
],
"title": "Summarization | 🦜️🔗 LangChain"
} | Summarization
Open In Colab
Use case
Suppose you have a set of documents (PDFs, Notion pages, customer questions, etc.) and you want to summarize the content.
LLMs are a great tool for this given their proficiency in understanding and synthesizing text.
In this walkthrough we’ll go over how to perform document summarization using LLMs.
Overview
A central question for building a summarizer is how to pass your documents into the LLM’s context window. Two common approaches for this are:
Stuff: Simply “stuff” all your documents into a single prompt. This is the simplest approach (see here for more on the create_stuff_documents_chain constructor, which is used for this method).
Map-reduce: Summarize each document on it’s own in a “map” step and then “reduce” the summaries into a final summary (see here for more on the MapReduceDocumentsChain, which is used for this method).
Quickstart
To give you a sneak preview, either pipeline can be wrapped in a single object: load_summarize_chain.
Suppose we want to summarize a blog post. We can create this in a few lines of code.
First set environment variables and install packages:
%pip install --upgrade --quiet langchain-openai tiktoken chromadb langchain
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
Requirement already satisfied: openai in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.27.8)
Requirement already satisfied: tiktoken in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.4.0)
Requirement already satisfied: chromadb in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.4.4)
Requirement already satisfied: langchain in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (0.0.299)
Requirement already satisfied: requests>=2.20 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from openai) (2.31.0)
Requirement already satisfied: tqdm in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from openai) (4.64.1)
Requirement already satisfied: aiohttp in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from openai) (3.8.5)
Requirement already satisfied: regex>=2022.1.18 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from tiktoken) (2023.6.3)
Requirement already satisfied: pydantic<2.0,>=1.9 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (1.10.12)
Requirement already satisfied: chroma-hnswlib==0.7.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.7.2)
Requirement already satisfied: fastapi<0.100.0,>=0.95.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.99.1)
Requirement already satisfied: uvicorn[standard]>=0.18.3 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.23.2)
Requirement already satisfied: numpy>=1.21.6 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (1.24.4)
Requirement already satisfied: posthog>=2.4.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (3.0.1)
Requirement already satisfied: typing-extensions>=4.5.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (4.7.1)
Requirement already satisfied: pulsar-client>=3.1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (3.2.0)
Requirement already satisfied: onnxruntime>=1.14.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (1.15.1)
Requirement already satisfied: tokenizers>=0.13.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.13.3)
Requirement already satisfied: pypika>=0.48.9 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (0.48.9)
Collecting tqdm (from openai)
Obtaining dependency information for tqdm from https://files.pythonhosted.org/packages/00/e5/f12a80907d0884e6dff9c16d0c0114d81b8cd07dc3ae54c5e962cc83037e/tqdm-4.66.1-py3-none-any.whl.metadata
Downloading tqdm-4.66.1-py3-none-any.whl.metadata (57 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 57.6/57.6 kB 2.7 MB/s eta 0:00:00
Requirement already satisfied: overrides>=7.3.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (7.4.0)
Requirement already satisfied: importlib-resources in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from chromadb) (6.0.0)
Requirement already satisfied: PyYAML>=5.3 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (6.0.1)
Requirement already satisfied: SQLAlchemy<3,>=1.4 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (2.0.20)
Requirement already satisfied: anyio<4.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (3.7.1)
Requirement already satisfied: async-timeout<5.0.0,>=4.0.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (4.0.3)
Requirement already satisfied: dataclasses-json<0.7,>=0.5.7 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (0.5.9)
Requirement already satisfied: jsonpatch<2.0,>=1.33 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (1.33)
Requirement already satisfied: langsmith<0.1.0,>=0.0.38 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (0.0.42)
Requirement already satisfied: numexpr<3.0.0,>=2.8.4 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (2.8.5)
Requirement already satisfied: tenacity<9.0.0,>=8.1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from langchain) (8.2.3)
Requirement already satisfied: attrs>=17.3.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (23.1.0)
Requirement already satisfied: charset-normalizer<4.0,>=2.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (3.2.0)
Requirement already satisfied: multidict<7.0,>=4.5 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (6.0.4)
Requirement already satisfied: yarl<2.0,>=1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (1.9.2)
Requirement already satisfied: frozenlist>=1.1.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (1.4.0)
Requirement already satisfied: aiosignal>=1.1.2 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from aiohttp->openai) (1.3.1)
Requirement already satisfied: idna>=2.8 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from anyio<4.0->langchain) (3.4)
Requirement already satisfied: sniffio>=1.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from anyio<4.0->langchain) (1.3.0)
Requirement already satisfied: exceptiongroup in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from anyio<4.0->langchain) (1.1.3)
Requirement already satisfied: marshmallow<4.0.0,>=3.3.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (3.20.1)
Requirement already satisfied: marshmallow-enum<2.0.0,>=1.5.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (1.5.1)
Requirement already satisfied: typing-inspect>=0.4.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (0.9.0)
Requirement already satisfied: starlette<0.28.0,>=0.27.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from fastapi<0.100.0,>=0.95.2->chromadb) (0.27.0)
Requirement already satisfied: jsonpointer>=1.9 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from jsonpatch<2.0,>=1.33->langchain) (2.4)
Requirement already satisfied: coloredlogs in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (15.0.1)
Requirement already satisfied: flatbuffers in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (23.5.26)
Requirement already satisfied: packaging in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (23.1)
Requirement already satisfied: protobuf in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (4.23.4)
Requirement already satisfied: sympy in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from onnxruntime>=1.14.1->chromadb) (1.12)
Requirement already satisfied: six>=1.5 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (1.16.0)
Requirement already satisfied: monotonic>=1.5 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (1.6)
Requirement already satisfied: backoff>=1.10.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (2.2.1)
Requirement already satisfied: python-dateutil>2.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from posthog>=2.4.0->chromadb) (2.8.2)
Requirement already satisfied: certifi in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from pulsar-client>=3.1.0->chromadb) (2023.7.22)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from requests>=2.20->openai) (1.26.16)
Requirement already satisfied: click>=7.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (8.1.7)
Requirement already satisfied: h11>=0.8 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.14.0)
Requirement already satisfied: httptools>=0.5.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.6.0)
Requirement already satisfied: python-dotenv>=0.13 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (1.0.0)
Requirement already satisfied: uvloop!=0.15.0,!=0.15.1,>=0.14.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.17.0)
Requirement already satisfied: watchfiles>=0.13 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (0.19.0)
Requirement already satisfied: websockets>=10.4 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from uvicorn[standard]>=0.18.3->chromadb) (11.0.3)
Requirement already satisfied: zipp>=3.1.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from importlib-resources->chromadb) (3.16.2)
Requirement already satisfied: mypy-extensions>=0.3.0 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from typing-inspect>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain) (1.0.0)
Requirement already satisfied: humanfriendly>=9.1 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from coloredlogs->onnxruntime>=1.14.1->chromadb) (10.0)
Requirement already satisfied: mpmath>=0.19 in /Users/bagatur/langchain/.venv/lib/python3.9/site-packages (from sympy->onnxruntime>=1.14.1->chromadb) (1.3.0)
Using cached tqdm-4.66.1-py3-none-any.whl (78 kB)
Installing collected packages: tqdm
Attempting uninstall: tqdm
Found existing installation: tqdm 4.64.1
Uninstalling tqdm-4.64.1:
Successfully uninstalled tqdm-4.64.1
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
clarifai 9.8.1 requires tqdm==4.64.1, but you have tqdm 4.66.1 which is incompatible.
Successfully installed tqdm-4.66.1
We can use chain_type="stuff", especially if using larger context window models such as:
16k token OpenAI gpt-3.5-turbo-1106
100k token Anthropic Claude-2
We can also supply chain_type="map_reduce" or chain_type="refine".
from langchain.chains.summarize import load_summarize_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
chain.run(docs)
'The article discusses the concept of building autonomous agents powered by large language models (LLMs). It explores the components of such agents, including planning, memory, and tool use. The article provides case studies and proof-of-concept examples of LLM-powered agents in various domains. It also highlights the challenges and limitations of using LLMs in agent systems.'
Option 1. Stuff
When we use load_summarize_chain with chain_type="stuff", we will use the StuffDocumentsChain.
The chain will take a list of documents, inserts them all into a prompt, and passes that prompt to an LLM:
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import PromptTemplate
# Define prompt
prompt_template = """Write a concise summary of the following:
"{text}"
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
# Define LLM chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")
llm_chain = LLMChain(llm=llm, prompt=prompt)
# Define StuffDocumentsChain
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")
docs = loader.load()
print(stuff_chain.run(docs))
The article discusses the concept of building autonomous agents powered by large language models (LLMs). It explores the components of such agents, including planning, memory, and tool use. The article provides case studies and proof-of-concept examples of LLM-powered agents in various domains, such as scientific discovery and generative agents simulation. It also highlights the challenges and limitations of using LLMs in agent systems.
Great! We can see that we reproduce the earlier result using the load_summarize_chain.
Go deeper
You can easily customize the prompt.
You can easily try different LLMs, (e.g., Claude) via the llm parameter.
Option 2. Map-Reduce
Let’s unpack the map reduce approach. For this, we’ll first map each document to an individual summary using an LLMChain. Then we’ll use a ReduceDocumentsChain to combine those summaries into a single global summary.
First, we specify the LLMChain to use for mapping each document to an individual summary:
from langchain.chains import MapReduceDocumentsChain, ReduceDocumentsChain
from langchain_text_splitters import CharacterTextSplitter
llm = ChatOpenAI(temperature=0)
# Map
map_template = """The following is a set of documents
{docs}
Based on this list of docs, please identify the main themes
Helpful Answer:"""
map_prompt = PromptTemplate.from_template(map_template)
map_chain = LLMChain(llm=llm, prompt=map_prompt)
We can also use the Prompt Hub to store and fetch prompts.
This will work with your LangSmith API key.
For example, see the map prompt here.
from langchain import hub
map_prompt = hub.pull("rlm/map-prompt")
map_chain = LLMChain(llm=llm, prompt=map_prompt)
The ReduceDocumentsChain handles taking the document mapping results and reducing them into a single output. It wraps a generic CombineDocumentsChain (like StuffDocumentsChain) but adds the ability to collapse documents before passing it to the CombineDocumentsChain if their cumulative size exceeds token_max. In this example, we can actually re-use our chain for combining our docs to also collapse our docs.
So if the cumulative number of tokens in our mapped documents exceeds 4000 tokens, then we’ll recursively pass in the documents in batches of \< 4000 tokens to our StuffDocumentsChain to create batched summaries. And once those batched summaries are cumulatively less than 4000 tokens, we’ll pass them all one last time to the StuffDocumentsChain to create the final summary.
# Reduce
reduce_template = """The following is set of summaries:
{docs}
Take these and distill it into a final, consolidated summary of the main themes.
Helpful Answer:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
# Note we can also get this from the prompt hub, as noted above
reduce_prompt = hub.pull("rlm/map-prompt")
ChatPromptTemplate(input_variables=['docs'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['docs'], template='The following is a set of documents:\n{docs}\nBased on this list of docs, please identify the main themes \nHelpful Answer:'))])
# Run chain
reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)
# Takes a list of documents, combines them into a single string, and passes this to an LLMChain
combine_documents_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="docs"
)
# Combines and iteratively reduces the mapped documents
reduce_documents_chain = ReduceDocumentsChain(
# This is final chain that is called.
combine_documents_chain=combine_documents_chain,
# If documents exceed context for `StuffDocumentsChain`
collapse_documents_chain=combine_documents_chain,
# The maximum number of tokens to group documents into.
token_max=4000,
)
Combining our map and reduce chains into one:
# Combining documents by mapping a chain over them, then combining results
map_reduce_chain = MapReduceDocumentsChain(
# Map chain
llm_chain=map_chain,
# Reduce chain
reduce_documents_chain=reduce_documents_chain,
# The variable name in the llm_chain to put the documents in
document_variable_name="docs",
# Return the results of the map steps in the output
return_intermediate_steps=False,
)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
Created a chunk of size 1003, which is longer than the specified 1000
print(map_reduce_chain.run(split_docs))
Based on the list of documents provided, the main themes can be identified as follows:
1. LLM-powered autonomous agents: The documents discuss the concept of building agents with LLM as their core controller and highlight the potential of LLM beyond generating written content. They explore the capabilities of LLM as a general problem solver.
2. Agent system overview: The documents provide an overview of the components that make up a LLM-powered autonomous agent system, including planning, memory, and tool use. Each component is explained in detail, highlighting its role in enhancing the agent's capabilities.
3. Planning: The documents discuss how the agent breaks down large tasks into smaller subgoals and utilizes self-reflection to improve the quality of its actions and results.
4. Memory: The documents explain the importance of both short-term and long-term memory in an agent system. Short-term memory is utilized for in-context learning, while long-term memory allows the agent to retain and recall information over extended periods.
5. Tool use: The documents highlight the agent's ability to call external APIs for additional information and resources that may be missing from its pre-trained model weights. This includes accessing current information, executing code, and retrieving proprietary information.
6. Case studies and proof-of-concept examples: The documents provide examples of how LLM-powered autonomous agents can be applied in various domains, such as scientific discovery and generative agent simulations. These case studies serve as examples of the capabilities and potential applications of such agents.
7. Challenges: The documents acknowledge the challenges associated with building and utilizing LLM-powered autonomous agents, although specific challenges are not mentioned in the given set of documents.
8. Citation and references: The documents include a citation and reference section, indicating that the information presented is based on existing research and sources.
Overall, the main themes in the provided documents revolve around LLM-powered autonomous agents, their components and capabilities, planning, memory, tool use, case studies, and challenges.
Go deeper
Customization
As shown above, you can customize the LLMs and prompts for map and reduce stages.
Real-world use-case
See this blog post case-study on analyzing user interactions (questions about LangChain documentation)!
The blog post and associated repo also introduce clustering as a means of summarization.
This opens up a third path beyond the stuff or map-reduce approaches that is worth considering.
Option 3. Refine
RefineDocumentsChain is similar to map-reduce:
The refine documents chain constructs a response by looping over the input documents and iteratively updating its answer. For each document, it passes all non-document inputs, the current document, and the latest intermediate answer to an LLM chain to get a new answer.
This can be easily run with the chain_type="refine" specified.
chain = load_summarize_chain(llm, chain_type="refine")
chain.run(split_docs)
'The article explores the concept of building autonomous agents powered by large language models (LLMs) and their potential as problem solvers. It discusses different approaches to task decomposition, the integration of self-reflection into LLM-based agents, and the use of external classical planners for long-horizon planning. The new context introduces the Chain of Hindsight (CoH) approach and Algorithm Distillation (AD) for training models to produce better outputs. It also discusses different types of memory and the use of external memory for fast retrieval. The article explores the concept of tool use and introduces the MRKL system and experiments on fine-tuning LLMs to use external tools. It introduces HuggingGPT, a framework that uses ChatGPT as a task planner, and discusses the challenges of using LLM-powered agents in real-world scenarios. The article concludes with case studies on scientific discovery agents and the use of LLM-powered agents in anticancer drug discovery. It also introduces the concept of generative agents that combine LLM with memory, planning, and reflection mechanisms. The conversation samples provided discuss the implementation of a game architecture and the challenges in building LLM-centered agents. The article provides references to related research papers and resources for further exploration.'
It’s also possible to supply a prompt and return intermediate steps.
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"Your job is to produce a final summary\n"
"We have provided an existing summary up to a certain point: {existing_answer}\n"
"We have the opportunity to refine the existing summary"
"(only if needed) with some more context below.\n"
"------------\n"
"{text}\n"
"------------\n"
"Given the new context, refine the original summary in Italian"
"If the context isn't useful, return the original summary."
)
refine_prompt = PromptTemplate.from_template(refine_template)
chain = load_summarize_chain(
llm=llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=True,
input_key="input_documents",
output_key="output_text",
)
result = chain({"input_documents": split_docs}, return_only_outputs=True)
print(result["output_text"])
Il presente articolo discute il concetto di costruire agenti autonomi utilizzando LLM (large language model) come controller principale. Esplora i diversi componenti di un sistema di agenti alimentato da LLM, tra cui la pianificazione, la memoria e l'uso degli strumenti. Dimostrazioni di concetto come AutoGPT mostrano il potenziale di LLM come risolutore generale di problemi. Approcci come Chain of Thought, Tree of Thoughts, LLM+P, ReAct e Reflexion consentono agli agenti autonomi di pianificare, riflettere su se stessi e migliorarsi iterativamente. Tuttavia, ci sono sfide da affrontare, come la limitata capacità di contesto che limita l'inclusione di informazioni storiche dettagliate e la difficoltà di pianificazione a lungo termine e decomposizione delle attività. Inoltre, l'affidabilità dell'interfaccia di linguaggio naturale tra LLM e componenti esterni come la memoria e gli strumenti è incerta, poiché i LLM possono commettere errori di formattazione e mostrare comportamenti ribelli. Nonostante ciò, il sistema AutoGPT viene menzionato come esempio di dimostrazione di concetto che utilizza LLM come controller principale per agenti autonomi. Questo articolo fa riferimento a diverse fonti che esplorano approcci e applicazioni specifiche di LLM nell'ambito degli agenti autonomi.
print("\n\n".join(result["intermediate_steps"][:3]))
This article discusses the concept of building autonomous agents using LLM (large language model) as the core controller. The article explores the different components of an LLM-powered agent system, including planning, memory, and tool use. It also provides examples of proof-of-concept demos and highlights the potential of LLM as a general problem solver.
Questo articolo discute del concetto di costruire agenti autonomi utilizzando LLM (large language model) come controller principale. L'articolo esplora i diversi componenti di un sistema di agenti alimentato da LLM, inclusa la pianificazione, la memoria e l'uso degli strumenti. Vengono forniti anche esempi di dimostrazioni di proof-of-concept e si evidenzia il potenziale di LLM come risolutore generale di problemi. Inoltre, vengono presentati approcci come Chain of Thought, Tree of Thoughts, LLM+P, ReAct e Reflexion che consentono agli agenti autonomi di pianificare, riflettere su se stessi e migliorare iterativamente.
Questo articolo discute del concetto di costruire agenti autonomi utilizzando LLM (large language model) come controller principale. L'articolo esplora i diversi componenti di un sistema di agenti alimentato da LLM, inclusa la pianificazione, la memoria e l'uso degli strumenti. Vengono forniti anche esempi di dimostrazioni di proof-of-concept e si evidenzia il potenziale di LLM come risolutore generale di problemi. Inoltre, vengono presentati approcci come Chain of Thought, Tree of Thoughts, LLM+P, ReAct e Reflexion che consentono agli agenti autonomi di pianificare, riflettere su se stessi e migliorare iterativamente. Il nuovo contesto riguarda l'approccio Chain of Hindsight (CoH) che permette al modello di migliorare autonomamente i propri output attraverso un processo di apprendimento supervisionato. Viene anche presentato l'approccio Algorithm Distillation (AD) che applica lo stesso concetto alle traiettorie di apprendimento per compiti di reinforcement learning.
Splitting and summarizing in a single chain
For convenience, we can wrap both the text splitting of our long document and summarizing in a single AnalyzeDocumentsChain.
from langchain.chains import AnalyzeDocumentChain
summarize_document_chain = AnalyzeDocumentChain(
combine_docs_chain=chain, text_splitter=text_splitter
)
summarize_document_chain.run(docs[0].page_content) |
https://python.langchain.com/docs/use_cases/tool_use/ | ## Tool use and agents
An exciting use case for LLMs is building natural language interfaces for other “tools”, whether those are APIs, functions, databases, etc. LangChain is great for building such interfaces because it has:
* Good model output parsing, which makes it easy to extract JSON, XML, OpenAI function-calls, etc. from model outputs.
* A large collection of built-in [Tools](https://python.langchain.com/docs/integrations/tools/).
* Provides a lot of flexibility in how you call these tools.
There are two main ways to use tools: [chains](https://python.langchain.com/docs/modules/chains/) and [agents](https://python.langchain.com/docs/modules/agents/).
Chains lets you create a pre-defined sequence of tool usage(s).

Agents let the model use tools in a loop, so that it can decide how many times to use tools.

To get started with both approaches, head to the [Quickstart](https://python.langchain.com/docs/use_cases/tool_use/quickstart/) page. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:33.285Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/",
"description": "An exciting use case for LLMs is building natural language interfaces",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3784",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"tool_use\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"67b1d1b7caad7f78657924605c2d2b96\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::c8dx6-1713753993218-9f03b2cc330e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/",
"property": "og:url"
},
{
"content": "Tool use and agents | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "An exciting use case for LLMs is building natural language interfaces",
"property": "og:description"
}
],
"title": "Tool use and agents | 🦜️🔗 LangChain"
} | Tool use and agents
An exciting use case for LLMs is building natural language interfaces for other “tools”, whether those are APIs, functions, databases, etc. LangChain is great for building such interfaces because it has:
Good model output parsing, which makes it easy to extract JSON, XML, OpenAI function-calls, etc. from model outputs.
A large collection of built-in Tools.
Provides a lot of flexibility in how you call these tools.
There are two main ways to use tools: chains and agents.
Chains lets you create a pre-defined sequence of tool usage(s).
Agents let the model use tools in a loop, so that it can decide how many times to use tools.
To get started with both approaches, head to the Quickstart page. |
https://python.langchain.com/docs/use_cases/tool_use/parallel/ | In the [Chains with multiple tools](https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/) guide we saw how to build function-calling chains that select between multiple tools. Some models, like the OpenAI models released in Fall 2023, also support parallel function calling, which allows you to invoke multiple functions (or the same function multiple times) in a single model call. Our previous chain from the multiple tools guides actually already supports this.
If you’d like to trace your runs in [LangSmith](https://python.langchain.com/docs/langsmith/) uncomment and set the following environment variables:
```
from operator import itemgetterfrom typing import Dict, List, Unionfrom langchain_core.messages import AIMessagefrom langchain_core.runnables import ( Runnable, RunnableLambda, RunnableMap, RunnablePassthrough,)tools = [multiply, exponentiate, add]llm_with_tools = llm.bind_tools(tools)tool_map = {tool.name: tool for tool in tools}def call_tools(msg: AIMessage) -> Runnable: """Simple sequential tool calling helper.""" tool_map = {tool.name: tool for tool in tools} tool_calls = msg.tool_calls.copy() for tool_call in tool_calls: tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"]) return tool_callschain = llm_with_tools | call_tools
```
```
[{'name': 'multiply', 'args': {'first_int': 23, 'second_int': 7}, 'id': 'call_22tgOrsVLyLMsl2RLbUhtycw', 'output': 161}, {'name': 'multiply', 'args': {'first_int': 5, 'second_int': 18}, 'id': 'call_EbKHEG3TjqBhEwb7aoxUtgzf', 'output': 90}, {'name': 'add', 'args': {'first_int': 1000000, 'second_int': 1000000000}, 'id': 'call_LUhu2IT3vINxlTc5fCVY6Nhi', 'output': 1001000000}, {'name': 'exponentiate', 'args': {'base': 37, 'exponent': 3}, 'id': 'call_bnCZIXelOKkmcyd4uGXId9Ct', 'output': 50653}]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:33.310Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/parallel/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/parallel/",
"description": "In the [Chains with multiple",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3784",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"parallel\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"9a9af8fc2e9a6059318f0dbe7d726a3d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::cc8bg-1713753993218-1f7d9735d7f2"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/parallel/",
"property": "og:url"
},
{
"content": "Parallel tool use | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In the [Chains with multiple",
"property": "og:description"
}
],
"title": "Parallel tool use | 🦜️🔗 LangChain"
} | In the Chains with multiple tools guide we saw how to build function-calling chains that select between multiple tools. Some models, like the OpenAI models released in Fall 2023, also support parallel function calling, which allows you to invoke multiple functions (or the same function multiple times) in a single model call. Our previous chain from the multiple tools guides actually already supports this.
If you’d like to trace your runs in LangSmith uncomment and set the following environment variables:
from operator import itemgetter
from typing import Dict, List, Union
from langchain_core.messages import AIMessage
from langchain_core.runnables import (
Runnable,
RunnableLambda,
RunnableMap,
RunnablePassthrough,
)
tools = [multiply, exponentiate, add]
llm_with_tools = llm.bind_tools(tools)
tool_map = {tool.name: tool for tool in tools}
def call_tools(msg: AIMessage) -> Runnable:
"""Simple sequential tool calling helper."""
tool_map = {tool.name: tool for tool in tools}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = llm_with_tools | call_tools
[{'name': 'multiply',
'args': {'first_int': 23, 'second_int': 7},
'id': 'call_22tgOrsVLyLMsl2RLbUhtycw',
'output': 161},
{'name': 'multiply',
'args': {'first_int': 5, 'second_int': 18},
'id': 'call_EbKHEG3TjqBhEwb7aoxUtgzf',
'output': 90},
{'name': 'add',
'args': {'first_int': 1000000, 'second_int': 1000000000},
'id': 'call_LUhu2IT3vINxlTc5fCVY6Nhi',
'output': 1001000000},
{'name': 'exponentiate',
'args': {'base': 37, 'exponent': 3},
'id': 'call_bnCZIXelOKkmcyd4uGXId9Ct',
'output': 50653}] |
https://python.langchain.com/docs/use_cases/tool_use/human_in_the_loop/ | ## Human-in-the-loop
There are certain tools that we don’t trust a model to execute on its own. One thing we can do in such situations is require human approval before the tool is invoked.
## Setup[](#setup "Direct link to Setup")
We’ll need to install the following packages:
```
%pip install --upgrade --quiet langchain
```
And set these environment variables:
```
import getpassimport os# If you'd like to use LangSmith, uncomment the below:# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Chain[](#chain "Direct link to Chain")
Suppose we have the following (dummy) tools and tool-calling chain:
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
```
from operator import itemgetterfrom typing import Dict, Listfrom langchain_core.messages import AIMessagefrom langchain_core.runnables import Runnable, RunnablePassthroughfrom langchain_core.tools import tool@tooldef count_emails(last_n_days: int) -> int: """Multiply two integers together.""" return last_n_days * 2@tooldef send_email(message: str, recipient: str) -> str: "Add two integers." return f"Successfully sent email to {recipient}."tools = [count_emails, send_email]llm_with_tools = llm.bind_tools(tools)def call_tools(msg: AIMessage) -> List[Dict]: """Simple sequential tool calling helper.""" tool_map = {tool.name: tool for tool in tools} tool_calls = msg.tool_calls.copy() for tool_call in tool_calls: tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"]) return tool_callschain = llm_with_tools | call_toolschain.invoke("how many emails did i get in the last 5 days?")
```
```
[{'name': 'count_emails', 'args': {'last_n_days': 5}, 'id': 'toolu_012VHuh7vk5dVNct5SgZj3gh', 'output': 10}]
```
## Adding human approval[](#adding-human-approval "Direct link to Adding human approval")
We can add a simple human approval step to our tool\_chain function:
```
import jsondef human_approval(msg: AIMessage) -> Runnable: tool_strs = "\n\n".join( json.dumps(tool_call, indent=2) for tool_call in msg.tool_calls ) input_msg = ( f"Do you approve of the following tool invocations\n\n{tool_strs}\n\n" "Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no." ) resp = input(input_msg) if resp.lower() not in ("yes", "y"): raise ValueError(f"Tool invocations not approved:\n\n{tool_strs}") return msg
```
```
chain = llm_with_tools | human_approval | call_toolschain.invoke("how many emails did i get in the last 5 days?")
```
```
Do you approve of the following tool invocations{ "name": "count_emails", "args": { "last_n_days": 5 }, "id": "toolu_01LCpjpFxrRspygDscnHYyPm"}Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no. yes
```
```
[{'name': 'count_emails', 'args': {'last_n_days': 5}, 'id': 'toolu_01LCpjpFxrRspygDscnHYyPm', 'output': 10}]
```
```
chain.invoke("Send sally@gmail.com an email saying 'What's up homie'")
```
```
Do you approve of the following tool invocations{ "name": "send_email", "args": { "message": "What's up homie", "recipient": "sally@gmail.com" }, "id": "toolu_0158qJVd1AL32Y1xxYUAtNEy"}Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no. no
```
```
ValueError: Tool invocations not approved:{ "name": "send_email", "args": { "message": "What's up homie", "recipient": "sally@gmail.com" }, "id": "toolu_0158qJVd1AL32Y1xxYUAtNEy"}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:34.067Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/human_in_the_loop/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/human_in_the_loop/",
"description": "There are certain tools that we don’t trust a model to execute on its",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3784",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"human_in_the_loop\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"eecff6db416554bc42db0ee7cb78e84c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::6lnrd-1713753993233-c1bb374fa3cb"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/human_in_the_loop/",
"property": "og:url"
},
{
"content": "Human-in-the-loop | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "There are certain tools that we don’t trust a model to execute on its",
"property": "og:description"
}
],
"title": "Human-in-the-loop | 🦜️🔗 LangChain"
} | Human-in-the-loop
There are certain tools that we don’t trust a model to execute on its own. One thing we can do in such situations is require human approval before the tool is invoked.
Setup
We’ll need to install the following packages:
%pip install --upgrade --quiet langchain
And set these environment variables:
import getpass
import os
# If you'd like to use LangSmith, uncomment the below:
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Chain
Suppose we have the following (dummy) tools and tool-calling chain:
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
from operator import itemgetter
from typing import Dict, List
from langchain_core.messages import AIMessage
from langchain_core.runnables import Runnable, RunnablePassthrough
from langchain_core.tools import tool
@tool
def count_emails(last_n_days: int) -> int:
"""Multiply two integers together."""
return last_n_days * 2
@tool
def send_email(message: str, recipient: str) -> str:
"Add two integers."
return f"Successfully sent email to {recipient}."
tools = [count_emails, send_email]
llm_with_tools = llm.bind_tools(tools)
def call_tools(msg: AIMessage) -> List[Dict]:
"""Simple sequential tool calling helper."""
tool_map = {tool.name: tool for tool in tools}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = llm_with_tools | call_tools
chain.invoke("how many emails did i get in the last 5 days?")
[{'name': 'count_emails',
'args': {'last_n_days': 5},
'id': 'toolu_012VHuh7vk5dVNct5SgZj3gh',
'output': 10}]
Adding human approval
We can add a simple human approval step to our tool_chain function:
import json
def human_approval(msg: AIMessage) -> Runnable:
tool_strs = "\n\n".join(
json.dumps(tool_call, indent=2) for tool_call in msg.tool_calls
)
input_msg = (
f"Do you approve of the following tool invocations\n\n{tool_strs}\n\n"
"Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no."
)
resp = input(input_msg)
if resp.lower() not in ("yes", "y"):
raise ValueError(f"Tool invocations not approved:\n\n{tool_strs}")
return msg
chain = llm_with_tools | human_approval | call_tools
chain.invoke("how many emails did i get in the last 5 days?")
Do you approve of the following tool invocations
{
"name": "count_emails",
"args": {
"last_n_days": 5
},
"id": "toolu_01LCpjpFxrRspygDscnHYyPm"
}
Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no. yes
[{'name': 'count_emails',
'args': {'last_n_days': 5},
'id': 'toolu_01LCpjpFxrRspygDscnHYyPm',
'output': 10}]
chain.invoke("Send sally@gmail.com an email saying 'What's up homie'")
Do you approve of the following tool invocations
{
"name": "send_email",
"args": {
"message": "What's up homie",
"recipient": "sally@gmail.com"
},
"id": "toolu_0158qJVd1AL32Y1xxYUAtNEy"
}
Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no. no
ValueError: Tool invocations not approved:
{
"name": "send_email",
"args": {
"message": "What's up homie",
"recipient": "sally@gmail.com"
},
"id": "toolu_0158qJVd1AL32Y1xxYUAtNEy"
} |
https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/ | ## Choosing between multiple tools
In our [Quickstart](https://python.langchain.com/docs/use_cases/tool_use/quickstart/) we went over how to build a Chain that calls a single `multiply` tool. Now let’s take a look at how we might augment this chain so that it can pick from a number of tools to call. We’ll focus on Chains since [Agents](https://python.langchain.com/docs/use_cases/tool_use/agents/) can route between multiple tools by default.
## Setup[](#setup "Direct link to Setup")
We’ll need to install the following packages for this guide:
```
%pip install --upgrade --quiet langchain-core
```
If you’d like to trace your runs in [LangSmith](https://python.langchain.com/docs/langsmith/) uncomment and set the following environment variables:
```
import getpassimport os# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
Recall we already had a `multiply` tool:
```
from langchain_core.tools import tool@tooldef multiply(first_int: int, second_int: int) -> int: """Multiply two integers together.""" return first_int * second_int
```
And now we can add to it an `exponentiate` and `add` tool:
```
@tooldef add(first_int: int, second_int: int) -> int: "Add two integers." return first_int + second_int@tooldef exponentiate(base: int, exponent: int) -> int: "Exponentiate the base to the exponent power." return base**exponent
```
The main difference between using one Tool and many is that we can’t be sure which Tool the model will invoke upfront, so we cannot hardcode, like we did in the [Quickstart](https://python.langchain.com/docs/use_cases/tool_use/quickstart/), a specific tool into our chain. Instead we’ll add `call_tools`, a `RunnableLambda` that takes the output AI message with tools calls and routes to the correct tools.
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
```
from langchain_anthropic import ChatAnthropicllm = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0)
```
```
from operator import itemgetterfrom typing import Dict, List, Unionfrom langchain_core.messages import AIMessagefrom langchain_core.runnables import ( Runnable, RunnableLambda, RunnableMap, RunnablePassthrough,)tools = [multiply, exponentiate, add]llm_with_tools = llm.bind_tools(tools)tool_map = {tool.name: tool for tool in tools}def call_tools(msg: AIMessage) -> Runnable: """Simple sequential tool calling helper.""" tool_map = {tool.name: tool for tool in tools} tool_calls = msg.tool_calls.copy() for tool_call in tool_calls: tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"]) return tool_callschain = llm_with_tools | call_tools
```
```
chain.invoke("What's 23 times 7")
```
```
[{'name': 'multiply', 'args': {'first_int': 23, 'second_int': 7}, 'id': 'toolu_01Wf8kUs36kxRKLDL8vs7G8q', 'output': 161}]
```
```
chain.invoke("add a million plus a billion")
```
```
[{'name': 'add', 'args': {'first_int': 1000000, 'second_int': 1000000000}, 'id': 'toolu_012aK4xZBQg2sXARsFZnqxHh', 'output': 1001000000}]
```
```
chain.invoke("cube thirty-seven")
```
```
[{'name': 'exponentiate', 'args': {'base': 37, 'exponent': 3}, 'id': 'toolu_01VDU6X3ugDb9cpnnmCZFPbC', 'output': 50653}]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:33.763Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/",
"description": "In our Quickstart we went over",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4954",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"multiple_tools\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"fae2656db210389b643d681cadd6ab7d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::8bcxw-1713753993241-008a704660d4"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/",
"property": "og:url"
},
{
"content": "Choosing between multiple tools | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In our Quickstart we went over",
"property": "og:description"
}
],
"title": "Choosing between multiple tools | 🦜️🔗 LangChain"
} | Choosing between multiple tools
In our Quickstart we went over how to build a Chain that calls a single multiply tool. Now let’s take a look at how we might augment this chain so that it can pick from a number of tools to call. We’ll focus on Chains since Agents can route between multiple tools by default.
Setup
We’ll need to install the following packages for this guide:
%pip install --upgrade --quiet langchain-core
If you’d like to trace your runs in LangSmith uncomment and set the following environment variables:
import getpass
import os
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Recall we already had a multiply tool:
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
And now we can add to it an exponentiate and add tool:
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
The main difference between using one Tool and many is that we can’t be sure which Tool the model will invoke upfront, so we cannot hardcode, like we did in the Quickstart, a specific tool into our chain. Instead we’ll add call_tools, a RunnableLambda that takes the output AI message with tools calls and routes to the correct tools.
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0)
from operator import itemgetter
from typing import Dict, List, Union
from langchain_core.messages import AIMessage
from langchain_core.runnables import (
Runnable,
RunnableLambda,
RunnableMap,
RunnablePassthrough,
)
tools = [multiply, exponentiate, add]
llm_with_tools = llm.bind_tools(tools)
tool_map = {tool.name: tool for tool in tools}
def call_tools(msg: AIMessage) -> Runnable:
"""Simple sequential tool calling helper."""
tool_map = {tool.name: tool for tool in tools}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = llm_with_tools | call_tools
chain.invoke("What's 23 times 7")
[{'name': 'multiply',
'args': {'first_int': 23, 'second_int': 7},
'id': 'toolu_01Wf8kUs36kxRKLDL8vs7G8q',
'output': 161}]
chain.invoke("add a million plus a billion")
[{'name': 'add',
'args': {'first_int': 1000000, 'second_int': 1000000000},
'id': 'toolu_012aK4xZBQg2sXARsFZnqxHh',
'output': 1001000000}]
chain.invoke("cube thirty-seven")
[{'name': 'exponentiate',
'args': {'base': 37, 'exponent': 3},
'id': 'toolu_01VDU6X3ugDb9cpnnmCZFPbC',
'output': 50653}] |
https://python.langchain.com/docs/use_cases/tagging/ | ## Tagging
[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/tagging.ipynb)
Open In Colab
## Use case[](#use-case "Direct link to Use case")
Tagging means labeling a document with classes such as:
* sentiment
* language
* style (formal, informal etc.)
* covered topics
* political tendency
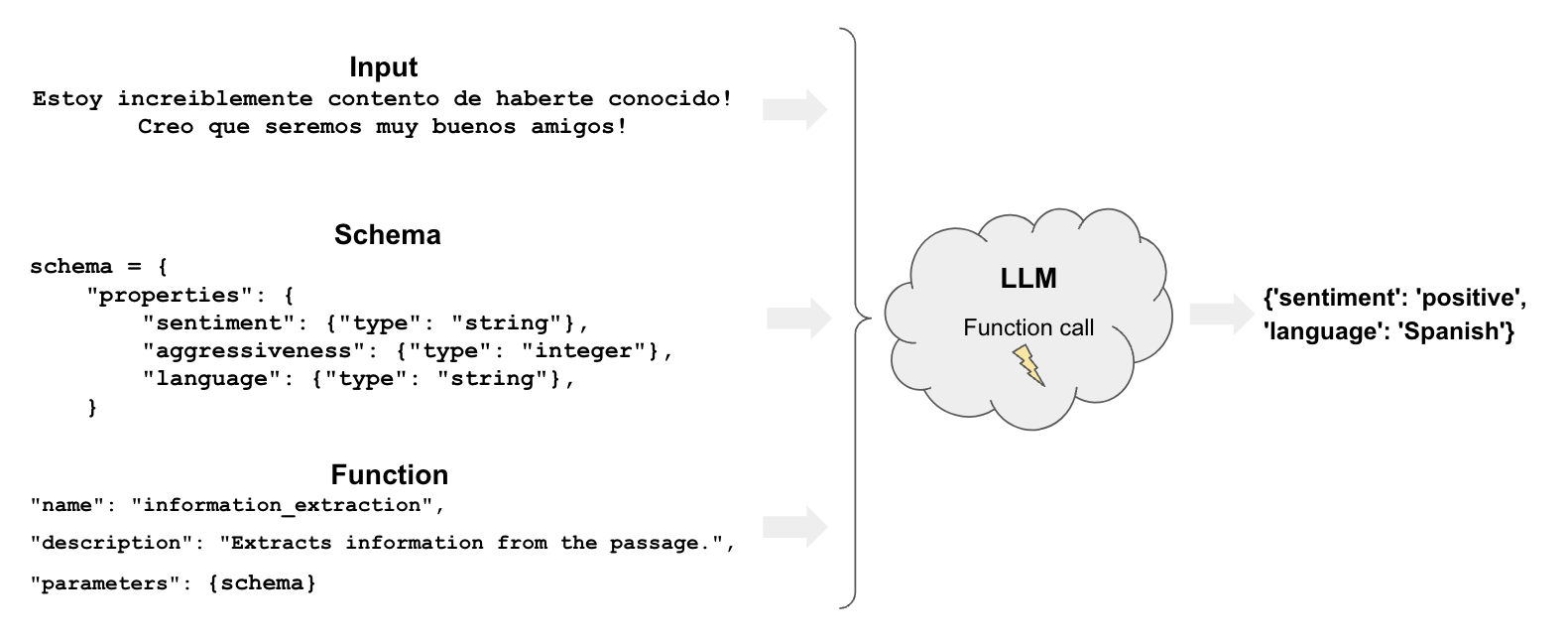
## Overview[](#overview "Direct link to Overview")
Tagging has a few components:
* `function`: Like [extraction](https://python.langchain.com/docs/use_cases/extraction/), tagging uses [functions](https://openai.com/blog/function-calling-and-other-api-updates) to specify how the model should tag a document
* `schema`: defines how we want to tag the document
## Quickstart[](#quickstart "Direct link to Quickstart")
Let’s see a very straightforward example of how we can use OpenAI tool calling for tagging in LangChain. We’ll use the [`with_structured_output`](https://python.langchain.com/docs/modules/model_io/chat/structured_output/) method supported by OpenAI models:
```
%pip install --upgrade --quiet langchain langchain-openai# Set env var OPENAI_API_KEY or load from a .env file:# import dotenv# dotenv.load_dotenv()
```
Let’s specify a Pydantic model with a few properties and their expected type in our schema.
```
from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAItagging_prompt = ChatPromptTemplate.from_template( """Extract the desired information from the following passage.Only extract the properties mentioned in the 'Classification' function.Passage:{input}""")class Classification(BaseModel): sentiment: str = Field(description="The sentiment of the text") aggressiveness: int = Field( description="How aggressive the text is on a scale from 1 to 10" ) language: str = Field(description="The language the text is written in")# LLMllm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0125").with_structured_output( Classification)tagging_chain = tagging_prompt | llm
```
```
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"tagging_chain.invoke({"input": inp})
```
```
Classification(sentiment='positive', aggressiveness=1, language='Spanish')
```
If we want JSON output, we can just call `.dict()`
```
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"res = tagging_chain.invoke({"input": inp})res.dict()
```
```
{'sentiment': 'negative', 'aggressiveness': 8, 'language': 'Spanish'}
```
As we can see in the examples, it correctly interprets what we want.
The results vary so that we may get, for example, sentiments in different languages (‘positive’, ‘enojado’ etc.).
We will see how to control these results in the next section.
## Finer control[](#finer-control "Direct link to Finer control")
Careful schema definition gives us more control over the model’s output.
Specifically, we can define:
* possible values for each property
* description to make sure that the model understands the property
* required properties to be returned
Let’s redeclare our Pydantic model to control for each of the previously mentioned aspects using enums:
```
class Classification(BaseModel): sentiment: str = Field(..., enum=["happy", "neutral", "sad"]) aggressiveness: int = Field( ..., description="describes how aggressive the statement is, the higher the number the more aggressive", enum=[1, 2, 3, 4, 5], ) language: str = Field( ..., enum=["spanish", "english", "french", "german", "italian"] )
```
```
tagging_prompt = ChatPromptTemplate.from_template( """Extract the desired information from the following passage.Only extract the properties mentioned in the 'Classification' function.Passage:{input}""")llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0125").with_structured_output( Classification)chain = tagging_prompt | llm
```
Now the answers will be restricted in a way we expect!
```
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"chain.invoke({"input": inp})
```
```
Classification(sentiment='happy', aggressiveness=1, language='spanish')
```
```
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"chain.invoke({"input": inp})
```
```
Classification(sentiment='sad', aggressiveness=5, language='spanish')
```
```
inp = "Weather is ok here, I can go outside without much more than a coat"chain.invoke({"input": inp})
```
```
Classification(sentiment='neutral', aggressiveness=2, language='english')
```
The [LangSmith trace](https://smith.langchain.com/public/38294e04-33d8-4c5a-ae92-c2fe68be8332/r) lets us peek under the hood:

### Going deeper[](#going-deeper "Direct link to Going deeper")
* You can use the [metadata tagger](https://python.langchain.com/docs/integrations/document_transformers/openai_metadata_tagger/) document transformer to extract metadata from a LangChain `Document`.
* This covers the same basic functionality as the tagging chain, only applied to a LangChain `Document`. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:33.512Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tagging/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tagging/",
"description": "Open In Colab",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4268",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"tagging\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"90840496ccc1f0ffb869a9c83943ceff\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::cvhgj-1713753993254-8ee794e3e2f1"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tagging/",
"property": "og:url"
},
{
"content": "Tagging | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Open In Colab",
"property": "og:description"
}
],
"title": "Tagging | 🦜️🔗 LangChain"
} | Tagging
Open In Colab
Use case
Tagging means labeling a document with classes such as:
sentiment
language
style (formal, informal etc.)
covered topics
political tendency
Overview
Tagging has a few components:
function: Like extraction, tagging uses functions to specify how the model should tag a document
schema: defines how we want to tag the document
Quickstart
Let’s see a very straightforward example of how we can use OpenAI tool calling for tagging in LangChain. We’ll use the with_structured_output method supported by OpenAI models:
%pip install --upgrade --quiet langchain langchain-openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
Let’s specify a Pydantic model with a few properties and their expected type in our schema.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
tagging_prompt = ChatPromptTemplate.from_template(
"""
Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
"""
)
class Classification(BaseModel):
sentiment: str = Field(description="The sentiment of the text")
aggressiveness: int = Field(
description="How aggressive the text is on a scale from 1 to 10"
)
language: str = Field(description="The language the text is written in")
# LLM
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0125").with_structured_output(
Classification
)
tagging_chain = tagging_prompt | llm
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
tagging_chain.invoke({"input": inp})
Classification(sentiment='positive', aggressiveness=1, language='Spanish')
If we want JSON output, we can just call .dict()
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
res = tagging_chain.invoke({"input": inp})
res.dict()
{'sentiment': 'negative', 'aggressiveness': 8, 'language': 'Spanish'}
As we can see in the examples, it correctly interprets what we want.
The results vary so that we may get, for example, sentiments in different languages (‘positive’, ‘enojado’ etc.).
We will see how to control these results in the next section.
Finer control
Careful schema definition gives us more control over the model’s output.
Specifically, we can define:
possible values for each property
description to make sure that the model understands the property
required properties to be returned
Let’s redeclare our Pydantic model to control for each of the previously mentioned aspects using enums:
class Classification(BaseModel):
sentiment: str = Field(..., enum=["happy", "neutral", "sad"])
aggressiveness: int = Field(
...,
description="describes how aggressive the statement is, the higher the number the more aggressive",
enum=[1, 2, 3, 4, 5],
)
language: str = Field(
..., enum=["spanish", "english", "french", "german", "italian"]
)
tagging_prompt = ChatPromptTemplate.from_template(
"""
Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
"""
)
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0125").with_structured_output(
Classification
)
chain = tagging_prompt | llm
Now the answers will be restricted in a way we expect!
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.invoke({"input": inp})
Classification(sentiment='happy', aggressiveness=1, language='spanish')
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.invoke({"input": inp})
Classification(sentiment='sad', aggressiveness=5, language='spanish')
inp = "Weather is ok here, I can go outside without much more than a coat"
chain.invoke({"input": inp})
Classification(sentiment='neutral', aggressiveness=2, language='english')
The LangSmith trace lets us peek under the hood:
Going deeper
You can use the metadata tagger document transformer to extract metadata from a LangChain Document.
This covers the same basic functionality as the tagging chain, only applied to a LangChain Document. |
https://python.langchain.com/docs/use_cases/tool_use/agents/ | Chains are great when we know the specific sequence of tool usage needed for any user input. But for certain use cases, how many times we use tools depends on the input. In these cases, we want to let the model itself decide how many times to use tools and in what order. [Agents](https://python.langchain.com/docs/modules/agents/) let us do just this.
LangChain comes with a number of built-in agents that are optimized for different use cases. Read about all the [agent types here](https://python.langchain.com/docs/modules/agents/agent_types/).
We’ll use the [tool calling agent](https://python.langchain.com/docs/modules/agents/agent_types/tool_calling/), which is generally the most reliable kind and the recommended one for most use cases. “Tool calling” in this case refers to a specific type of model API that allows for explicitly passing tool definitions to models and getting explicit tool invocations out. For more on tool calling models see \[this guide\].(/docs/modules/model\_io/chat/function\_calling/)

## Setup[](#setup "Direct link to Setup")
We’ll need to install the following packages:
```
%pip install --upgrade --quiet langchain langchainhub
```
If you’d like to use LangSmith, set the environment variables below:
```
import getpassimport os# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
First, we need to create some tool to call. For this example, we will create custom tools from functions. For more information on creating custom tools, please see [this guide](https://python.langchain.com/docs/modules/tools/).
```
from langchain_core.tools import tool@tooldef multiply(first_int: int, second_int: int) -> int: """Multiply two integers together.""" return first_int * second_int@tooldef add(first_int: int, second_int: int) -> int: "Add two integers." return first_int + second_int@tooldef exponentiate(base: int, exponent: int) -> int: "Exponentiate the base to the exponent power." return base**exponenttools = [multiply, add, exponentiate]
```
## Create prompt[](#create-prompt "Direct link to Create prompt")
```
from langchain import hubfrom langchain.agents import AgentExecutor, create_tool_calling_agent
```
```
# Get the prompt to use - you can modify this!prompt = hub.pull("hwchase17/openai-tools-agent")prompt.pretty_print()
```
```
================================ System Message ================================You are a helpful assistant============================= Messages Placeholder ============================={chat_history}================================ Human Message ================================={input}============================= Messages Placeholder ============================={agent_scratchpad}
```
## Create agent[](#create-agent "Direct link to Create agent")
We’ll need to use a model with tool calling capabilities. You can see which models support tool calling [here](https://python.langchain.com/docs/integrations/chat/).
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
```
# Construct the tool calling agentagent = create_tool_calling_agent(llm, tools, prompt)
```
```
# Create an agent executor by passing in the agent and toolsagent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
```
## Invoke agent[](#invoke-agent "Direct link to Invoke agent")
```
agent_executor.invoke( { "input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result" })
```
```
> Entering new AgentExecutor chain...Invoking: `exponentiate` with `{'base': 3, 'exponent': 5}`responded: [{'text': "Okay, let's break this down step-by-step:", 'type': 'text'}, {'id': 'toolu_01CjdiDhDmMtaT1F4R7hSV5D', 'input': {'base': 3, 'exponent': 5}, 'name': 'exponentiate', 'type': 'tool_use'}]243Invoking: `add` with `{'first_int': 12, 'second_int': 3}`responded: [{'text': '3 to the 5th power is 243.', 'type': 'text'}, {'id': 'toolu_01EKqn4E5w3Zj7bQ8s8xmi4R', 'input': {'first_int': 12, 'second_int': 3}, 'name': 'add', 'type': 'tool_use'}]15Invoking: `multiply` with `{'first_int': 243, 'second_int': 15}`responded: [{'text': '12 + 3 = 15', 'type': 'text'}, {'id': 'toolu_017VZJgZBYbwMo2KGD6o6hsQ', 'input': {'first_int': 243, 'second_int': 15}, 'name': 'multiply', 'type': 'tool_use'}]3645Invoking: `multiply` with `{'first_int': 3645, 'second_int': 3645}`responded: [{'text': '243 * 15 = 3645', 'type': 'text'}, {'id': 'toolu_01RtFCcQgbVGya3NVDgTYKTa', 'input': {'first_int': 3645, 'second_int': 3645}, 'name': 'multiply', 'type': 'tool_use'}]13286025So 3645 squared is 13,286,025.Therefore, the final result of taking 3 to the 5th power (243), multiplying by 12 + 3 (15), and then squaring the whole result is 13,286,025.> Finished chain.
```
```
{'input': 'Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result', 'output': 'So 3645 squared is 13,286,025.\n\nTherefore, the final result of taking 3 to the 5th power (243), multiplying by 12 + 3 (15), and then squaring the whole result is 13,286,025.'}
```
You can see the [LangSmith trace here](https://smith.langchain.com/public/92694ff3-71b7-44ed-bc45-04bdf04d4689/r). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:34.464Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/agents/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/agents/",
"description": "Chains are great when we know the specific sequence of tool usage needed",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4954",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"agents\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"00e00adecdb82aa2b7f4a5612f16065e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::ncfnt-1713753993244-e68e8429daee"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/agents/",
"property": "og:url"
},
{
"content": "Repeated tool use with agents | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Chains are great when we know the specific sequence of tool usage needed",
"property": "og:description"
}
],
"title": "Repeated tool use with agents | 🦜️🔗 LangChain"
} | Chains are great when we know the specific sequence of tool usage needed for any user input. But for certain use cases, how many times we use tools depends on the input. In these cases, we want to let the model itself decide how many times to use tools and in what order. Agents let us do just this.
LangChain comes with a number of built-in agents that are optimized for different use cases. Read about all the agent types here.
We’ll use the tool calling agent, which is generally the most reliable kind and the recommended one for most use cases. “Tool calling” in this case refers to a specific type of model API that allows for explicitly passing tool definitions to models and getting explicit tool invocations out. For more on tool calling models see [this guide].(/docs/modules/model_io/chat/function_calling/)
Setup
We’ll need to install the following packages:
%pip install --upgrade --quiet langchain langchainhub
If you’d like to use LangSmith, set the environment variables below:
import getpass
import os
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
First, we need to create some tool to call. For this example, we will create custom tools from functions. For more information on creating custom tools, please see this guide.
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
tools = [multiply, add, exponentiate]
Create prompt
from langchain import hub
from langchain.agents import AgentExecutor, create_tool_calling_agent
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-tools-agent")
prompt.pretty_print()
================================ System Message ================================
You are a helpful assistant
============================= Messages Placeholder =============================
{chat_history}
================================ Human Message =================================
{input}
============================= Messages Placeholder =============================
{agent_scratchpad}
Create agent
We’ll need to use a model with tool calling capabilities. You can see which models support tool calling here.
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# Construct the tool calling agent
agent = create_tool_calling_agent(llm, tools, prompt)
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Invoke agent
agent_executor.invoke(
{
"input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result"
}
)
> Entering new AgentExecutor chain...
Invoking: `exponentiate` with `{'base': 3, 'exponent': 5}`
responded: [{'text': "Okay, let's break this down step-by-step:", 'type': 'text'}, {'id': 'toolu_01CjdiDhDmMtaT1F4R7hSV5D', 'input': {'base': 3, 'exponent': 5}, 'name': 'exponentiate', 'type': 'tool_use'}]
243
Invoking: `add` with `{'first_int': 12, 'second_int': 3}`
responded: [{'text': '3 to the 5th power is 243.', 'type': 'text'}, {'id': 'toolu_01EKqn4E5w3Zj7bQ8s8xmi4R', 'input': {'first_int': 12, 'second_int': 3}, 'name': 'add', 'type': 'tool_use'}]
15
Invoking: `multiply` with `{'first_int': 243, 'second_int': 15}`
responded: [{'text': '12 + 3 = 15', 'type': 'text'}, {'id': 'toolu_017VZJgZBYbwMo2KGD6o6hsQ', 'input': {'first_int': 243, 'second_int': 15}, 'name': 'multiply', 'type': 'tool_use'}]
3645
Invoking: `multiply` with `{'first_int': 3645, 'second_int': 3645}`
responded: [{'text': '243 * 15 = 3645', 'type': 'text'}, {'id': 'toolu_01RtFCcQgbVGya3NVDgTYKTa', 'input': {'first_int': 3645, 'second_int': 3645}, 'name': 'multiply', 'type': 'tool_use'}]
13286025So 3645 squared is 13,286,025.
Therefore, the final result of taking 3 to the 5th power (243), multiplying by 12 + 3 (15), and then squaring the whole result is 13,286,025.
> Finished chain.
{'input': 'Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result',
'output': 'So 3645 squared is 13,286,025.\n\nTherefore, the final result of taking 3 to the 5th power (243), multiplying by 12 + 3 (15), and then squaring the whole result is 13,286,025.'}
You can see the LangSmith trace here. |
https://python.langchain.com/docs/use_cases/tool_use/prompting/ | In this guide we’ll build a Chain that does not rely on any special model APIs (like tool calling, which we showed in the [Quickstart](https://python.langchain.com/docs/use_cases/tool_use/quickstart/)) and instead just prompts the model directly to invoke tools.
## Setup[](#setup "Direct link to Setup")
We’ll need to install the following packages:
```
%pip install --upgrade --quiet langchain langchain-openai
```
And set these environment variables:
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# If you'd like to use LangSmith, uncomment the below:# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
First, we need to create a tool to call. For this example, we will create a custom tool from a function. For more information on all details related to creating custom tools, please see [this guide](https://python.langchain.com/docs/modules/tools/).
```
from langchain_core.tools import tool@tooldef multiply(first_int: int, second_int: int) -> int: """Multiply two integers together.""" return first_int * second_int
```
```
print(multiply.name)print(multiply.description)print(multiply.args)
```
```
multiplymultiply(first_int: int, second_int: int) -> int - Multiply two integers together.{'first_int': {'title': 'First Int', 'type': 'integer'}, 'second_int': {'title': 'Second Int', 'type': 'integer'}}
```
```
multiply.invoke({"first_int": 4, "second_int": 5})
```
## Creating our prompt[](#creating-our-prompt "Direct link to Creating our prompt")
We’ll want to write a prompt that specifies the tools the model has access to, the arguments to those tools, and the desired output format of the model. In this case we’ll instruct it to output a JSON blob of the form `{"name": "...", "arguments": {...}}`.
```
from langchain.tools.render import render_text_descriptionrendered_tools = render_text_description([multiply])rendered_tools
```
```
'multiply: multiply(first_int: int, second_int: int) -> int - Multiply two integers together.'
```
```
from langchain_core.prompts import ChatPromptTemplatesystem_prompt = f"""You are an assistant that has access to the following set of tools. Here are the names and descriptions for each tool:{rendered_tools}Given the user input, return the name and input of the tool to use. Return your response as a JSON blob with 'name' and 'arguments' keys."""prompt = ChatPromptTemplate.from_messages( [("system", system_prompt), ("user", "{input}")])
```
## Adding an output parser[](#adding-an-output-parser "Direct link to Adding an output parser")
We’ll use the `JsonOutputParser` for parsing our models output to JSON.
```
from langchain_core.output_parsers import JsonOutputParserfrom langchain_openai import ChatOpenAImodel = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)chain = prompt | model | JsonOutputParser()chain.invoke({"input": "what's thirteen times 4"})
```
```
{'name': 'multiply', 'arguments': {'first_int': 13, 'second_int': 4}}
```
We can invoke the tool as part of the chain by passing along the model-generated “arguments” to it:
```
from operator import itemgetterchain = prompt | model | JsonOutputParser() | itemgetter("arguments") | multiplychain.invoke({"input": "what's thirteen times 4"})
```
Suppose we have multiple tools we want the chain to be able to choose from:
```
@tooldef add(first_int: int, second_int: int) -> int: "Add two integers." return first_int + second_int@tooldef exponentiate(base: int, exponent: int) -> int: "Exponentiate the base to the exponent power." return base**exponent
```
With function calling, we can do this like so:
If we want to run the model selected tool, we can do so using a function that returns the tool based on the model output. Specifically, our function will action return it’s own subchain that gets the “arguments” part of the model output and passes it to the chosen tool:
```
tools = [add, exponentiate, multiply]def tool_chain(model_output): tool_map = {tool.name: tool for tool in tools} chosen_tool = tool_map[model_output["name"]] return itemgetter("arguments") | chosen_tool
```
```
rendered_tools = render_text_description(tools)system_prompt = f"""You are an assistant that has access to the following set of tools. Here are the names and descriptions for each tool:{rendered_tools}Given the user input, return the name and input of the tool to use. Return your response as a JSON blob with 'name' and 'arguments' keys."""prompt = ChatPromptTemplate.from_messages( [("system", system_prompt), ("user", "{input}")])chain = prompt | model | JsonOutputParser() | tool_chainchain.invoke({"input": "what's 3 plus 1132"})
```
It can be helpful to return not only tool outputs but also tool inputs. We can easily do this with LCEL by `RunnablePassthrough.assign`\-ing the tool output. This will take whatever the input is to the RunnablePassrthrough components (assumed to be a dictionary) and add a key to it while still passing through everything that’s currently in the input:
```
from langchain_core.runnables import RunnablePassthroughchain = ( prompt | model | JsonOutputParser() | RunnablePassthrough.assign(output=tool_chain))chain.invoke({"input": "what's 3 plus 1132"})
```
```
{'name': 'add', 'arguments': {'first_int': 3, 'second_int': 1132}, 'output': 1135}
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:34.967Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/prompting/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/prompting/",
"description": "In this guide we’ll build a Chain that does not rely on any special",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3784",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"prompting\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:33 GMT",
"etag": "W/\"b1622c83197edd9288d723f39142babc\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::9tn2v-1713753993572-4588ab79147b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/prompting/",
"property": "og:url"
},
{
"content": "Using models that don't support tool calling | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide we’ll build a Chain that does not rely on any special",
"property": "og:description"
}
],
"title": "Using models that don't support tool calling | 🦜️🔗 LangChain"
} | In this guide we’ll build a Chain that does not rely on any special model APIs (like tool calling, which we showed in the Quickstart) and instead just prompts the model directly to invoke tools.
Setup
We’ll need to install the following packages:
%pip install --upgrade --quiet langchain langchain-openai
And set these environment variables:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# If you'd like to use LangSmith, uncomment the below:
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
First, we need to create a tool to call. For this example, we will create a custom tool from a function. For more information on all details related to creating custom tools, please see this guide.
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
print(multiply.name)
print(multiply.description)
print(multiply.args)
multiply
multiply(first_int: int, second_int: int) -> int - Multiply two integers together.
{'first_int': {'title': 'First Int', 'type': 'integer'}, 'second_int': {'title': 'Second Int', 'type': 'integer'}}
multiply.invoke({"first_int": 4, "second_int": 5})
Creating our prompt
We’ll want to write a prompt that specifies the tools the model has access to, the arguments to those tools, and the desired output format of the model. In this case we’ll instruct it to output a JSON blob of the form {"name": "...", "arguments": {...}}.
from langchain.tools.render import render_text_description
rendered_tools = render_text_description([multiply])
rendered_tools
'multiply: multiply(first_int: int, second_int: int) -> int - Multiply two integers together.'
from langchain_core.prompts import ChatPromptTemplate
system_prompt = f"""You are an assistant that has access to the following set of tools. Here are the names and descriptions for each tool:
{rendered_tools}
Given the user input, return the name and input of the tool to use. Return your response as a JSON blob with 'name' and 'arguments' keys."""
prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("user", "{input}")]
)
Adding an output parser
We’ll use the JsonOutputParser for parsing our models output to JSON.
from langchain_core.output_parsers import JsonOutputParser
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = prompt | model | JsonOutputParser()
chain.invoke({"input": "what's thirteen times 4"})
{'name': 'multiply', 'arguments': {'first_int': 13, 'second_int': 4}}
We can invoke the tool as part of the chain by passing along the model-generated “arguments” to it:
from operator import itemgetter
chain = prompt | model | JsonOutputParser() | itemgetter("arguments") | multiply
chain.invoke({"input": "what's thirteen times 4"})
Suppose we have multiple tools we want the chain to be able to choose from:
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
With function calling, we can do this like so:
If we want to run the model selected tool, we can do so using a function that returns the tool based on the model output. Specifically, our function will action return it’s own subchain that gets the “arguments” part of the model output and passes it to the chosen tool:
tools = [add, exponentiate, multiply]
def tool_chain(model_output):
tool_map = {tool.name: tool for tool in tools}
chosen_tool = tool_map[model_output["name"]]
return itemgetter("arguments") | chosen_tool
rendered_tools = render_text_description(tools)
system_prompt = f"""You are an assistant that has access to the following set of tools. Here are the names and descriptions for each tool:
{rendered_tools}
Given the user input, return the name and input of the tool to use. Return your response as a JSON blob with 'name' and 'arguments' keys."""
prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("user", "{input}")]
)
chain = prompt | model | JsonOutputParser() | tool_chain
chain.invoke({"input": "what's 3 plus 1132"})
It can be helpful to return not only tool outputs but also tool inputs. We can easily do this with LCEL by RunnablePassthrough.assign-ing the tool output. This will take whatever the input is to the RunnablePassrthrough components (assumed to be a dictionary) and add a key to it while still passing through everything that’s currently in the input:
from langchain_core.runnables import RunnablePassthrough
chain = (
prompt | model | JsonOutputParser() | RunnablePassthrough.assign(output=tool_chain)
)
chain.invoke({"input": "what's 3 plus 1132"})
{'name': 'add',
'arguments': {'first_int': 3, 'second_int': 1132},
'output': 1135} |
https://python.langchain.com/docs/use_cases/tool_use/quickstart/ | ## Quickstart
In this guide, we will go over the basic ways to create Chains and Agents that call Tools. Tools can be just about anything — APIs, functions, databases, etc. Tools allow us to extend the capabilities of a model beyond just outputting text/messages. The key to using models with tools is correctly prompting a model and parsing its response so that it chooses the right tools and provides the right inputs for them.
## Setup[](#setup "Direct link to Setup")
We’ll need to install the following packages for this guide:
```
%pip install --upgrade --quiet langchain
```
If you’d like to trace your runs in [LangSmith](https://python.langchain.com/docs/langsmith/) uncomment and set the following environment variables:
```
import getpassimport os# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
First, we need to create a tool to call. For this example, we will create a custom tool from a function. For more information on creating custom tools, please see [this guide](https://python.langchain.com/docs/modules/tools/).
```
from langchain_core.tools import tool@tooldef multiply(first_int: int, second_int: int) -> int: """Multiply two integers together.""" return first_int * second_int
```
```
print(multiply.name)print(multiply.description)print(multiply.args)
```
```
multiplymultiply(first_int: int, second_int: int) -> int - Multiply two integers together.{'first_int': {'title': 'First Int', 'type': 'integer'}, 'second_int': {'title': 'Second Int', 'type': 'integer'}}
```
```
multiply.invoke({"first_int": 4, "second_int": 5})
```
## Chains[](#chains "Direct link to Chains")
If we know that we only need to use a tool a fixed number of times, we can create a chain for doing so. Let’s create a simple chain that just multiplies user-specified numbers.

### Tool/function calling[](#toolfunction-calling "Direct link to Tool/function calling")
One of the most reliable ways to use tools with LLMs is with tool calling APIs (also sometimes called function calling). This only works with models that explicitly support tool calling. You can see which models support tool calling [here](https://python.langchain.com/docs/integrations/chat/), and learn more about how to use tool calling in [this guide](https://python.langchain.com/docs/modules/model_io/chat/function_calling/).
First we’ll define our model and tools. We’ll start with just a single tool, `multiply`.
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
We’ll use `bind_tools` to pass the definition of our tool in as part of each call to the model, so that the model can invoke the tool when appropriate:
```
llm_with_tools = llm.bind_tools([multiply])
```
When the model invokes the tool, this will show up in the `AIMessage.tool_calls` attribute of the output:
```
msg = llm_with_tools.invoke("whats 5 times forty two")msg.tool_calls
```
```
[{'name': 'multiply', 'args': {'first_int': 5, 'second_int': 42}, 'id': 'call_cCP9oA3tRz7HDrjFn1FdmDaG'}]
```
Check out the [LangSmith trace here](https://smith.langchain.com/public/81ff0cbd-e05b-4720-bf61-2c9807edb708/r).
### Invoking the tool[](#invoking-the-tool "Direct link to Invoking the tool")
Great! We’re able to generate tool invocations. But what if we want to actually call the tool? To do so we’ll need to pass the generated tool args to our tool. As a simple example we’ll just extract the arguments of the first tool\_call:
```
from operator import itemgetterchain = llm_with_tools | (lambda x: x.tool_calls[0]["args"]) | multiplychain.invoke("What's four times 23")
```
Check out the [LangSmith trace here](https://smith.langchain.com/public/16bbabb9-fc9b-41e5-a33d-487c42df4f85/r).
## Agents[](#agents "Direct link to Agents")
Chains are great when we know the specific sequence of tool usage needed for any user input. But for certain use cases, how many times we use tools depends on the input. In these cases, we want to let the model itself decide how many times to use tools and in what order. [Agents](https://python.langchain.com/docs/modules/agents/) let us do just this.
LangChain comes with a number of built-in agents that are optimized for different use cases. Read about all the [agent types here](https://python.langchain.com/docs/modules/agents/agent_types/).
We’ll use the [tool calling agent](https://python.langchain.com/docs/modules/agents/agent_types/tool_calling/), which is generally the most reliable kind and the recommended one for most use cases.

```
from langchain import hubfrom langchain.agents import AgentExecutor, create_tool_calling_agent
```
```
# Get the prompt to use - can be replaced with any prompt that includes variables "agent_scratchpad" and "input"!prompt = hub.pull("hwchase17/openai-tools-agent")prompt.pretty_print()
```
```
================================ System Message ================================You are a helpful assistant============================= Messages Placeholder ============================={chat_history}================================ Human Message ================================={input}============================= Messages Placeholder ============================={agent_scratchpad}
```
Agents are also great because they make it easy to use multiple tools. To learn how to build Chains that use multiple tools, check out the [Chains with multiple tools](https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/) page.
```
@tooldef add(first_int: int, second_int: int) -> int: "Add two integers." return first_int + second_int@tooldef exponentiate(base: int, exponent: int) -> int: "Exponentiate the base to the exponent power." return base**exponenttools = [multiply, add, exponentiate]
```
```
# Construct the tool calling agentagent = create_tool_calling_agent(llm, tools, prompt)
```
```
# Create an agent executor by passing in the agent and toolsagent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
```
With an agent, we can ask questions that require arbitrarily-many uses of our tools:
```
agent_executor.invoke( { "input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result" })
```
```
> Entering new AgentExecutor chain...Invoking: `exponentiate` with `{'base': 3, 'exponent': 5}`243Invoking: `add` with `{'first_int': 12, 'second_int': 3}`15Invoking: `multiply` with `{'first_int': 243, 'second_int': 15}`3645Invoking: `exponentiate` with `{'base': 405, 'exponent': 2}`164025The result of taking 3 to the fifth power is 243. The sum of twelve and three is 15. Multiplying 243 by 15 gives 3645. Finally, squaring 3645 gives 164025.> Finished chain.
```
```
{'input': 'Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result', 'output': 'The result of taking 3 to the fifth power is 243. \n\nThe sum of twelve and three is 15. \n\nMultiplying 243 by 15 gives 3645. \n\nFinally, squaring 3645 gives 164025.'}
```
Check out the [LangSmith trace here](https://smith.langchain.com/public/eeeb27a4-a2f8-4f06-a3af-9c983f76146c/r).
## Next steps[](#next-steps "Direct link to Next steps")
Here we’ve gone over the basic ways to use Tools with Chains and Agents. We recommend the following sections to explore next:
* [Agents](https://python.langchain.com/docs/modules/agents/): Everything related to Agents.
* [Choosing between multiple tools](https://python.langchain.com/docs/use_cases/tool_use/multiple_tools/): How to make tool chains that select from multiple tools.
* [Prompting for tool use](https://python.langchain.com/docs/use_cases/tool_use/prompting/): How to make tool chains that prompt models directly, without using function-calling APIs.
* [Parallel tool use](https://python.langchain.com/docs/use_cases/tool_use/parallel/): How to make tool chains that invoke multiple tools at once. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:35.316Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/quickstart/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/quickstart/",
"description": "In this guide, we will go over the basic ways to create Chains and",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7273",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"quickstart\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:34 GMT",
"etag": "W/\"33f33c0d8bf69767bf3a1158d45a15fb\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::kfqs7-1713753994806-a7133bef7f92"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/quickstart/",
"property": "og:url"
},
{
"content": "Quickstart | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "In this guide, we will go over the basic ways to create Chains and",
"property": "og:description"
}
],
"title": "Quickstart | 🦜️🔗 LangChain"
} | Quickstart
In this guide, we will go over the basic ways to create Chains and Agents that call Tools. Tools can be just about anything — APIs, functions, databases, etc. Tools allow us to extend the capabilities of a model beyond just outputting text/messages. The key to using models with tools is correctly prompting a model and parsing its response so that it chooses the right tools and provides the right inputs for them.
Setup
We’ll need to install the following packages for this guide:
%pip install --upgrade --quiet langchain
If you’d like to trace your runs in LangSmith uncomment and set the following environment variables:
import getpass
import os
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
First, we need to create a tool to call. For this example, we will create a custom tool from a function. For more information on creating custom tools, please see this guide.
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
print(multiply.name)
print(multiply.description)
print(multiply.args)
multiply
multiply(first_int: int, second_int: int) -> int - Multiply two integers together.
{'first_int': {'title': 'First Int', 'type': 'integer'}, 'second_int': {'title': 'Second Int', 'type': 'integer'}}
multiply.invoke({"first_int": 4, "second_int": 5})
Chains
If we know that we only need to use a tool a fixed number of times, we can create a chain for doing so. Let’s create a simple chain that just multiplies user-specified numbers.
Tool/function calling
One of the most reliable ways to use tools with LLMs is with tool calling APIs (also sometimes called function calling). This only works with models that explicitly support tool calling. You can see which models support tool calling here, and learn more about how to use tool calling in this guide.
First we’ll define our model and tools. We’ll start with just a single tool, multiply.
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
We’ll use bind_tools to pass the definition of our tool in as part of each call to the model, so that the model can invoke the tool when appropriate:
llm_with_tools = llm.bind_tools([multiply])
When the model invokes the tool, this will show up in the AIMessage.tool_calls attribute of the output:
msg = llm_with_tools.invoke("whats 5 times forty two")
msg.tool_calls
[{'name': 'multiply',
'args': {'first_int': 5, 'second_int': 42},
'id': 'call_cCP9oA3tRz7HDrjFn1FdmDaG'}]
Check out the LangSmith trace here.
Invoking the tool
Great! We’re able to generate tool invocations. But what if we want to actually call the tool? To do so we’ll need to pass the generated tool args to our tool. As a simple example we’ll just extract the arguments of the first tool_call:
from operator import itemgetter
chain = llm_with_tools | (lambda x: x.tool_calls[0]["args"]) | multiply
chain.invoke("What's four times 23")
Check out the LangSmith trace here.
Agents
Chains are great when we know the specific sequence of tool usage needed for any user input. But for certain use cases, how many times we use tools depends on the input. In these cases, we want to let the model itself decide how many times to use tools and in what order. Agents let us do just this.
LangChain comes with a number of built-in agents that are optimized for different use cases. Read about all the agent types here.
We’ll use the tool calling agent, which is generally the most reliable kind and the recommended one for most use cases.
from langchain import hub
from langchain.agents import AgentExecutor, create_tool_calling_agent
# Get the prompt to use - can be replaced with any prompt that includes variables "agent_scratchpad" and "input"!
prompt = hub.pull("hwchase17/openai-tools-agent")
prompt.pretty_print()
================================ System Message ================================
You are a helpful assistant
============================= Messages Placeholder =============================
{chat_history}
================================ Human Message =================================
{input}
============================= Messages Placeholder =============================
{agent_scratchpad}
Agents are also great because they make it easy to use multiple tools. To learn how to build Chains that use multiple tools, check out the Chains with multiple tools page.
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
tools = [multiply, add, exponentiate]
# Construct the tool calling agent
agent = create_tool_calling_agent(llm, tools, prompt)
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
With an agent, we can ask questions that require arbitrarily-many uses of our tools:
agent_executor.invoke(
{
"input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result"
}
)
> Entering new AgentExecutor chain...
Invoking: `exponentiate` with `{'base': 3, 'exponent': 5}`
243
Invoking: `add` with `{'first_int': 12, 'second_int': 3}`
15
Invoking: `multiply` with `{'first_int': 243, 'second_int': 15}`
3645
Invoking: `exponentiate` with `{'base': 405, 'exponent': 2}`
164025The result of taking 3 to the fifth power is 243.
The sum of twelve and three is 15.
Multiplying 243 by 15 gives 3645.
Finally, squaring 3645 gives 164025.
> Finished chain.
{'input': 'Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result',
'output': 'The result of taking 3 to the fifth power is 243. \n\nThe sum of twelve and three is 15. \n\nMultiplying 243 by 15 gives 3645. \n\nFinally, squaring 3645 gives 164025.'}
Check out the LangSmith trace here.
Next steps
Here we’ve gone over the basic ways to use Tools with Chains and Agents. We recommend the following sections to explore next:
Agents: Everything related to Agents.
Choosing between multiple tools: How to make tool chains that select from multiple tools.
Prompting for tool use: How to make tool chains that prompt models directly, without using function-calling APIs.
Parallel tool use: How to make tool chains that invoke multiple tools at once. |
https://python.langchain.com/docs/use_cases/tool_use/tool_error_handling/ | ## Handling tool errors
Using a model to invoke a tool has some obvious potential failure modes. Firstly, the model needs to return a output that can be parsed at all. Secondly, the model needs to return tool arguments that are valid.
We can build error handling into our chains to mitigate these failure modes.
## Setup[](#setup "Direct link to Setup")
We’ll need to install the following packages:
```
%pip install --upgrade --quiet langchain-core langchain-openai
```
If you’d like to trace your runs in [LangSmith](https://python.langchain.com/docs/langsmith/) uncomment and set the following environment variables:
```
import getpassimport os# os.environ["LANGCHAIN_TRACING_V2"] = "true"# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
```
## Chain[](#chain "Direct link to Chain")
Suppose we have the following (dummy) tool and tool-calling chain. We’ll make our tool intentionally convoluted to try and trip up the model.
* OpenAI
* Anthropic
* Google
* Cohere
* FireworksAI
* MistralAI
* TogetherAI
##### Install dependencies
```
pip install -qU langchain-openai
```
##### Set environment variables
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
```
```
# Define toolfrom langchain_core.tools import tool@tooldef complex_tool(int_arg: int, float_arg: float, dict_arg: dict) -> int: """Do something complex with a complex tool.""" return int_arg * float_arg
```
```
llm_with_tools = llm.bind_tools( [complex_tool],)
```
```
# Define chainchain = llm_with_tools | (lambda msg: msg.tool_calls[0]["args"]) | complex_tool
```
We can see that when we try to invoke this chain with even a fairly explicit input, the model fails to correctly call the tool (it forgets the `dict_arg` argument).
```
chain.invoke( "use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg")
```
```
ValidationError: 1 validation error for complex_toolSchemadict_arg field required (type=value_error.missing)
```
The simplest way to more gracefully handle errors is to try/except the tool-calling step and return a helpful message on errors:
```
from typing import Anyfrom langchain_core.runnables import Runnable, RunnableConfigdef try_except_tool(tool_args: dict, config: RunnableConfig) -> Runnable: try: complex_tool.invoke(tool_args, config=config) except Exception as e: return f"Calling tool with arguments:\n\n{tool_args}\n\nraised the following error:\n\n{type(e)}: {e}"chain = llm_with_tools | (lambda msg: msg.tool_calls[0]["args"]) | try_except_tool
```
```
print( chain.invoke( "use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg" ))
```
```
Calling tool with arguments:{'int_arg': 5, 'float_arg': 2.1}raised the following error:<class 'pydantic.v1.error_wrappers.ValidationError'>: 1 validation error for complex_toolSchemadict_arg field required (type=value_error.missing)
```
## Fallbacks[](#fallbacks "Direct link to Fallbacks")
We can also try to fallback to a better model in the event of a tool invocation error. In this case we’ll fall back to an identical chain that uses `gpt-4-1106-preview` instead of `gpt-3.5-turbo`.
```
chain = llm_with_tools | (lambda msg: msg.tool_calls[0]["args"]) | complex_toolbetter_model = ChatOpenAI(model="gpt-4-1106-preview", temperature=0).bind_tools( [complex_tool], tool_choice="complex_tool")better_chain = better_model | (lambda msg: msg.tool_calls[0]["args"]) | complex_toolchain_with_fallback = chain.with_fallbacks([better_chain])chain_with_fallback.invoke( "use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg")
```
Looking at the [Langsmith trace](https://smith.langchain.com/public/00e91fc2-e1a4-4b0f-a82e-e6b3119d196c/r) for this chain run, we can see that the first chain call fails as expected and it’s the fallback that succeeds.
## Retry with exception[](#retry-with-exception "Direct link to Retry with exception")
To take things one step further, we can try to automatically re-run the chain with the exception passed in, so that the model may be able to correct its behavior:
```
import jsonfrom typing import Anyfrom langchain_core.messages import AIMessage, HumanMessage, ToolCall, ToolMessagefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.runnables import RunnablePassthroughclass CustomToolException(Exception): """Custom LangChain tool exception.""" def __init__(self, tool_call: ToolCall, exception: Exception) -> None: super().__init__() self.tool_call = tool_call self.exception = exceptiondef tool_custom_exception(msg: AIMessage, config: RunnableConfig) -> Runnable: try: return complex_tool.invoke(msg.tool_calls[0]["args"], config=config) except Exception as e: raise CustomToolException(msg.tool_calls[0], e)def exception_to_messages(inputs: dict) -> dict: exception = inputs.pop("exception") # Add historical messages to the original input, so the model knows that it made a mistake with the last tool call. messages = [ AIMessage(content="", tool_calls=[exception.tool_call]), ToolMessage( tool_call_id=exception.tool_call["id"], content=str(exception.exception) ), HumanMessage( content="The last tool call raised an exception. Try calling the tool again with corrected arguments. Do not repeat mistakes." ), ] inputs["last_output"] = messages return inputs# We add a last_output MessagesPlaceholder to our prompt which if not passed in doesn't# affect the prompt at all, but gives us the option to insert an arbitrary list of Messages# into the prompt if needed. We'll use this on retries to insert the error message.prompt = ChatPromptTemplate.from_messages( [("human", "{input}"), MessagesPlaceholder("last_output", optional=True)])chain = prompt | llm_with_tools | tool_custom_exception# If the initial chain call fails, we rerun it withe the exception passed in as a message.self_correcting_chain = chain.with_fallbacks( [exception_to_messages | chain], exception_key="exception")
```
```
self_correcting_chain.invoke( { "input": "use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg" })
```
And our chain succeeds! Looking at the [LangSmith trace](https://smith.langchain.com/public/c11e804c-e14f-4059-bd09-64766f999c14/r), we can see that indeed our initial chain still fails, and it’s only on retrying that the chain succeeds. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:35.858Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/tool_use/tool_error_handling/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/tool_use/tool_error_handling/",
"description": "Using a model to invoke a tool has some obvious potential failure modes.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3786",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"tool_error_handling\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:35 GMT",
"etag": "W/\"55a33b0668e0797ee91a92f579ec2042\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tl469-1713753995756-31def2c2df22"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/tool_use/tool_error_handling/",
"property": "og:url"
},
{
"content": "Handling tool errors | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Using a model to invoke a tool has some obvious potential failure modes.",
"property": "og:description"
}
],
"title": "Handling tool errors | 🦜️🔗 LangChain"
} | Handling tool errors
Using a model to invoke a tool has some obvious potential failure modes. Firstly, the model needs to return a output that can be parsed at all. Secondly, the model needs to return tool arguments that are valid.
We can build error handling into our chains to mitigate these failure modes.
Setup
We’ll need to install the following packages:
%pip install --upgrade --quiet langchain-core langchain-openai
If you’d like to trace your runs in LangSmith uncomment and set the following environment variables:
import getpass
import os
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Chain
Suppose we have the following (dummy) tool and tool-calling chain. We’ll make our tool intentionally convoluted to try and trip up the model.
OpenAI
Anthropic
Google
Cohere
FireworksAI
MistralAI
TogetherAI
Install dependencies
pip install -qU langchain-openai
Set environment variables
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# Define tool
from langchain_core.tools import tool
@tool
def complex_tool(int_arg: int, float_arg: float, dict_arg: dict) -> int:
"""Do something complex with a complex tool."""
return int_arg * float_arg
llm_with_tools = llm.bind_tools(
[complex_tool],
)
# Define chain
chain = llm_with_tools | (lambda msg: msg.tool_calls[0]["args"]) | complex_tool
We can see that when we try to invoke this chain with even a fairly explicit input, the model fails to correctly call the tool (it forgets the dict_arg argument).
chain.invoke(
"use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg"
)
ValidationError: 1 validation error for complex_toolSchema
dict_arg
field required (type=value_error.missing)
The simplest way to more gracefully handle errors is to try/except the tool-calling step and return a helpful message on errors:
from typing import Any
from langchain_core.runnables import Runnable, RunnableConfig
def try_except_tool(tool_args: dict, config: RunnableConfig) -> Runnable:
try:
complex_tool.invoke(tool_args, config=config)
except Exception as e:
return f"Calling tool with arguments:\n\n{tool_args}\n\nraised the following error:\n\n{type(e)}: {e}"
chain = llm_with_tools | (lambda msg: msg.tool_calls[0]["args"]) | try_except_tool
print(
chain.invoke(
"use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg"
)
)
Calling tool with arguments:
{'int_arg': 5, 'float_arg': 2.1}
raised the following error:
<class 'pydantic.v1.error_wrappers.ValidationError'>: 1 validation error for complex_toolSchema
dict_arg
field required (type=value_error.missing)
Fallbacks
We can also try to fallback to a better model in the event of a tool invocation error. In this case we’ll fall back to an identical chain that uses gpt-4-1106-preview instead of gpt-3.5-turbo.
chain = llm_with_tools | (lambda msg: msg.tool_calls[0]["args"]) | complex_tool
better_model = ChatOpenAI(model="gpt-4-1106-preview", temperature=0).bind_tools(
[complex_tool], tool_choice="complex_tool"
)
better_chain = better_model | (lambda msg: msg.tool_calls[0]["args"]) | complex_tool
chain_with_fallback = chain.with_fallbacks([better_chain])
chain_with_fallback.invoke(
"use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg"
)
Looking at the Langsmith trace for this chain run, we can see that the first chain call fails as expected and it’s the fallback that succeeds.
Retry with exception
To take things one step further, we can try to automatically re-run the chain with the exception passed in, so that the model may be able to correct its behavior:
import json
from typing import Any
from langchain_core.messages import AIMessage, HumanMessage, ToolCall, ToolMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
class CustomToolException(Exception):
"""Custom LangChain tool exception."""
def __init__(self, tool_call: ToolCall, exception: Exception) -> None:
super().__init__()
self.tool_call = tool_call
self.exception = exception
def tool_custom_exception(msg: AIMessage, config: RunnableConfig) -> Runnable:
try:
return complex_tool.invoke(msg.tool_calls[0]["args"], config=config)
except Exception as e:
raise CustomToolException(msg.tool_calls[0], e)
def exception_to_messages(inputs: dict) -> dict:
exception = inputs.pop("exception")
# Add historical messages to the original input, so the model knows that it made a mistake with the last tool call.
messages = [
AIMessage(content="", tool_calls=[exception.tool_call]),
ToolMessage(
tool_call_id=exception.tool_call["id"], content=str(exception.exception)
),
HumanMessage(
content="The last tool call raised an exception. Try calling the tool again with corrected arguments. Do not repeat mistakes."
),
]
inputs["last_output"] = messages
return inputs
# We add a last_output MessagesPlaceholder to our prompt which if not passed in doesn't
# affect the prompt at all, but gives us the option to insert an arbitrary list of Messages
# into the prompt if needed. We'll use this on retries to insert the error message.
prompt = ChatPromptTemplate.from_messages(
[("human", "{input}"), MessagesPlaceholder("last_output", optional=True)]
)
chain = prompt | llm_with_tools | tool_custom_exception
# If the initial chain call fails, we rerun it withe the exception passed in as a message.
self_correcting_chain = chain.with_fallbacks(
[exception_to_messages | chain], exception_key="exception"
)
self_correcting_chain.invoke(
{
"input": "use complex tool. the args are 5, 2.1, empty dictionary. don't forget dict_arg"
}
)
And our chain succeeds! Looking at the LangSmith trace, we can see that indeed our initial chain still fails, and it’s only on retrying that the chain succeeds. |
https://python.langchain.com/opensearch.xml | null | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:36.454Z",
"loadedUrl": "https://python.langchain.com/opensearch.xml",
"referrerUrl": "https://python.langchain.com/docs/"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/opensearch.xml",
"description": null,
"headers": {
":status": 200,
"accept-ranges": "bytes",
"access-control-allow-origin": "*",
"age": "9098",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"opensearch.xml\"",
"content-length": "754",
"content-type": "application/xml",
"date": "Mon, 22 Apr 2024 02:46:36 GMT",
"etag": "\"3f231b92cc18c144f6cb203cceee0d37\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::cfhg6-1713753996405-36be646149b3"
},
"jsonLd": null,
"keywords": null,
"languageCode": null,
"openGraph": null,
"title": ""
} | |
https://python.langchain.com/docs/guides/development/local_llms/docs/integrations/llms/llamacpp/ | ## Page Not Found
We could not find what you were looking for.
Please contact the owner of the site that linked you to the original URL and let them know their link is broken. | null | {
"depth": 2,
"httpStatusCode": 404,
"loadedTime": "2024-04-22T02:46:36.496Z",
"loadedUrl": "https://python.langchain.com/docs/guides/development/local_llms/docs/integrations/llms/llamacpp/",
"referrerUrl": "https://python.langchain.com/docs/guides/development/local_llms/"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/404.html/",
"description": null,
"headers": {
":status": 404,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "9018",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"404.html\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:36 GMT",
"etag": "W/\"f04da03f160c233c205895cfd6096602\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::qw5cn-1713753996392-120321d7bc2c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/404.html/",
"property": "og:url"
},
{
"content": "Page Not Found | 🦜️🔗 LangChain",
"property": "og:title"
}
],
"title": "Page Not Found | 🦜️🔗 LangChain"
} | Page Not Found
We could not find what you were looking for.
Please contact the owner of the site that linked you to the original URL and let them know their link is broken. |
https://python.langchain.com/docs/use_cases/web_scraping/ | ## Web scraping
[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/web_scraping.ipynb)
Open In Colab
## Use case[](#use-case "Direct link to Use case")
[Web research](https://blog.langchain.dev/automating-web-research/) is one of the killer LLM applications:
* Users have [highlighted it](https://twitter.com/GregKamradt/status/1679913813297225729?s=20) as one of his top desired AI tools.
* OSS repos like [gpt-researcher](https://github.com/assafelovic/gpt-researcher) are growing in popularity.
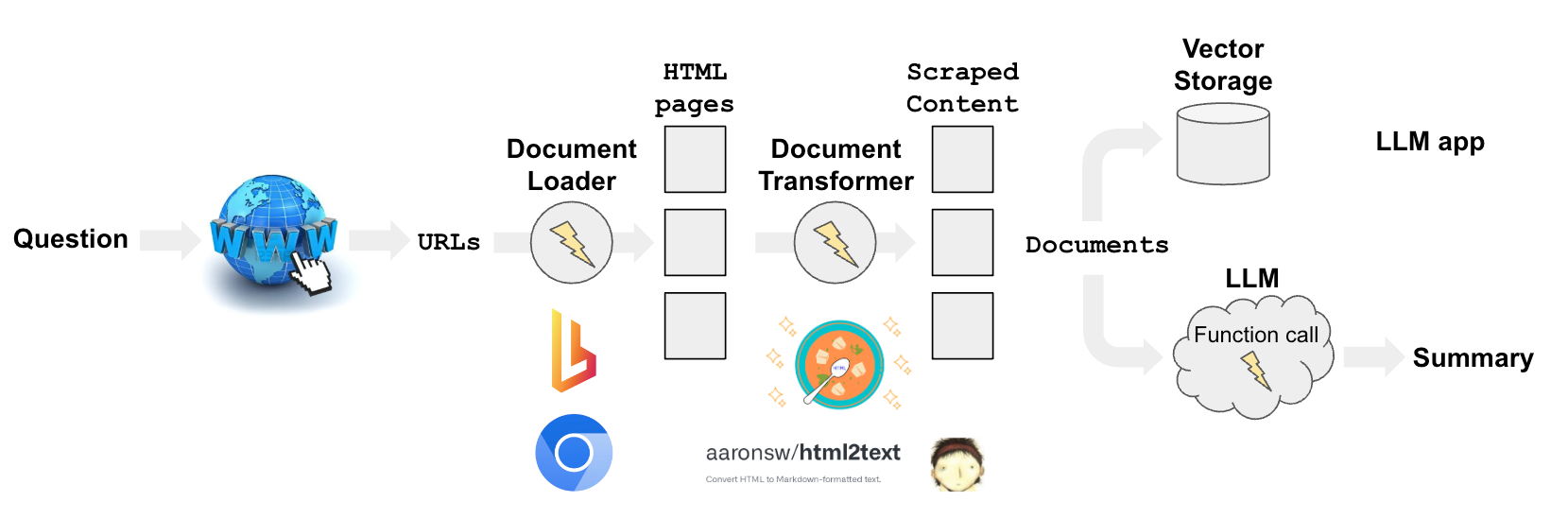
## Overview[](#overview "Direct link to Overview")
Gathering content from the web has a few components:
* `Search`: Query to url (e.g., using `GoogleSearchAPIWrapper`).
* `Loading`: Url to HTML (e.g., using `AsyncHtmlLoader`, `AsyncChromiumLoader`, etc).
* `Transforming`: HTML to formatted text (e.g., using `HTML2Text` or `Beautiful Soup`).
## Quickstart[](#quickstart "Direct link to Quickstart")
```
pip install -q langchain-openai langchain playwright beautifulsoup4playwright install# Set env var OPENAI_API_KEY or load from a .env file:# import dotenv# dotenv.load_dotenv()
```
Scraping HTML content using a headless instance of Chromium.
* The async nature of the scraping process is handled using Python’s asyncio library.
* The actual interaction with the web pages is handled by Playwright.
```
from langchain_community.document_loaders import AsyncChromiumLoaderfrom langchain_community.document_transformers import BeautifulSoupTransformer# Load HTMLloader = AsyncChromiumLoader(["https://www.wsj.com"])html = loader.load()
```
Scrape text content tags such as `<p>, <li>, <div>, and <a>` tags from the HTML content:
* `<p>`: The paragraph tag. It defines a paragraph in HTML and is used to group together related sentences and/or phrases.
* `<li>`: The list item tag. It is used within ordered (`<ol>`) and unordered (`<ul>`) lists to define individual items within the list.
* `<div>`: The division tag. It is a block-level element used to group other inline or block-level elements.
* `<a>`: The anchor tag. It is used to define hyperlinks.
* `<span>`: an inline container used to mark up a part of a text, or a part of a document.
For many news websites (e.g., WSJ, CNN), headlines and summaries are all in `<span>` tags.
```
# Transformbs_transformer = BeautifulSoupTransformer()docs_transformed = bs_transformer.transform_documents(html, tags_to_extract=["span"])
```
```
# Resultdocs_transformed[0].page_content[0:500]
```
```
'English EditionEnglish中文 (Chinese)日本語 (Japanese) More Other Products from WSJBuy Side from WSJWSJ ShopWSJ Wine Other Products from WSJ Search Quotes and Companies Search Quotes and Companies 0.15% 0.03% 0.12% -0.42% 4.102% -0.69% -0.25% -0.15% -1.82% 0.24% 0.19% -1.10% About Evan His Family Reflects His Reporting How You Can Help Write a Message Life in Detention Latest News Get Email Updates Four Americans Released From Iranian Prison The Americans will remain under house arrest until they are '
```
These `Documents` now are staged for downstream usage in various LLM apps, as discussed below.
## Loader[](#loader "Direct link to Loader")
### AsyncHtmlLoader[](#asynchtmlloader "Direct link to AsyncHtmlLoader")
The [AsyncHtmlLoader](https://python.langchain.com/docs/integrations/document_loaders/async_html/) uses the `aiohttp` library to make asynchronous HTTP requests, suitable for simpler and lightweight scraping.
### AsyncChromiumLoader[](#asyncchromiumloader "Direct link to AsyncChromiumLoader")
The [AsyncChromiumLoader](https://python.langchain.com/docs/integrations/document_loaders/async_chromium/) uses Playwright to launch a Chromium instance, which can handle JavaScript rendering and more complex web interactions.
Chromium is one of the browsers supported by Playwright, a library used to control browser automation.
Headless mode means that the browser is running without a graphical user interface, which is commonly used for web scraping.
```
from langchain_community.document_loaders import AsyncHtmlLoaderurls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]loader = AsyncHtmlLoader(urls)docs = loader.load()
```
## Transformer[](#transformer "Direct link to Transformer")
### HTML2Text[](#html2text "Direct link to HTML2Text")
[HTML2Text](https://python.langchain.com/docs/integrations/document_transformers/html2text/) provides a straightforward conversion of HTML content into plain text (with markdown-like formatting) without any specific tag manipulation.
It’s best suited for scenarios where the goal is to extract human-readable text without needing to manipulate specific HTML elements.
### Beautiful Soup[](#beautiful-soup "Direct link to Beautiful Soup")
Beautiful Soup offers more fine-grained control over HTML content, enabling specific tag extraction, removal, and content cleaning.
It’s suited for cases where you want to extract specific information and clean up the HTML content according to your needs.
```
from langchain_community.document_loaders import AsyncHtmlLoaderurls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]loader = AsyncHtmlLoader(urls)docs = loader.load()
```
```
Fetching pages: 100%|#############################################################################################################| 2/2 [00:00<00:00, 7.01it/s]
```
```
from langchain_community.document_transformers import Html2TextTransformerhtml2text = Html2TextTransformer()docs_transformed = html2text.transform_documents(docs)docs_transformed[0].page_content[0:500]
```
```
"Skip to main content Skip to navigation\n\n<\n\n>\n\nMenu\n\n## ESPN\n\n * Search\n\n * * scores\n\n * NFL\n * MLB\n * NBA\n * NHL\n * Soccer\n * NCAAF\n * …\n\n * Women's World Cup\n * LLWS\n * NCAAM\n * NCAAW\n * Sports Betting\n * Boxing\n * CFL\n * NCAA\n * Cricket\n * F1\n * Golf\n * Horse\n * MMA\n * NASCAR\n * NBA G League\n * Olympic Sports\n * PLL\n * Racing\n * RN BB\n * RN FB\n * Rugby\n * Tennis\n * WNBA\n * WWE\n * X Games\n * XFL\n\n * More"
```
### LLM with function calling[](#llm-with-function-calling "Direct link to LLM with function calling")
Web scraping is challenging for many reasons.
One of them is the changing nature of modern websites’ layouts and content, which requires modifying scraping scripts to accommodate the changes.
Using Function (e.g., OpenAI) with an extraction chain, we avoid having to change your code constantly when websites change.
We’re using `gpt-3.5-turbo-0613` to guarantee access to OpenAI Functions feature (although this might be available to everyone by time of writing).
We’re also keeping `temperature` at `0` to keep randomness of the LLM down.
```
from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
```
### Define a schema[](#define-a-schema "Direct link to Define a schema")
Next, you define a schema to specify what kind of data you want to extract.
Here, the key names matter as they tell the LLM what kind of information they want.
So, be as detailed as possible.
In this example, we want to scrape only news article’s name and summary from The Wall Street Journal website.
```
from langchain.chains import create_extraction_chainschema = { "properties": { "news_article_title": {"type": "string"}, "news_article_summary": {"type": "string"}, }, "required": ["news_article_title", "news_article_summary"],}def extract(content: str, schema: dict): return create_extraction_chain(schema=schema, llm=llm).run(content)
```
### Run the web scraper w/ BeautifulSoup[](#run-the-web-scraper-w-beautifulsoup "Direct link to Run the web scraper w/ BeautifulSoup")
As shown above, we’ll be using `BeautifulSoupTransformer`.
```
import pprintfrom langchain_text_splitters import RecursiveCharacterTextSplitterdef scrape_with_playwright(urls, schema): loader = AsyncChromiumLoader(urls) docs = loader.load() bs_transformer = BeautifulSoupTransformer() docs_transformed = bs_transformer.transform_documents( docs, tags_to_extract=["span"] ) print("Extracting content with LLM") # Grab the first 1000 tokens of the site splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=1000, chunk_overlap=0 ) splits = splitter.split_documents(docs_transformed) # Process the first split extracted_content = extract(schema=schema, content=splits[0].page_content) pprint.pprint(extracted_content) return extracted_contenturls = ["https://www.wsj.com"]extracted_content = scrape_with_playwright(urls, schema=schema)
```
```
Extracting content with LLM[{'news_article_summary': 'The Americans will remain under house arrest until ' 'they are allowed to return to the U.S. in coming ' 'weeks, following a monthslong diplomatic push by ' 'the Biden administration.', 'news_article_title': 'Four Americans Released From Iranian Prison'}, {'news_article_summary': 'Price pressures continued cooling last month, with ' 'the CPI rising a mild 0.2% from June, likely ' 'deterring the Federal Reserve from raising interest ' 'rates at its September meeting.', 'news_article_title': 'Cooler July Inflation Opens Door to Fed Pause on ' 'Rates'}, {'news_article_summary': 'The company has decided to eliminate 27 of its 30 ' 'clothing labels, such as Lark & Ro and Goodthreads, ' 'as it works to fend off antitrust scrutiny and cut ' 'costs.', 'news_article_title': 'Amazon Cuts Dozens of House Brands'}, {'news_article_summary': 'President Biden’s order comes on top of a slowing ' 'Chinese economy, Covid lockdowns and rising ' 'tensions between the two powers.', 'news_article_title': 'U.S. Investment Ban on China Poised to Deepen Divide'}, {'news_article_summary': 'The proposed trial date in the ' 'election-interference case comes on the same day as ' 'the former president’s not guilty plea on ' 'additional Mar-a-Lago charges.', 'news_article_title': 'Trump Should Be Tried in January, Prosecutors Tell ' 'Judge'}, {'news_article_summary': 'The CEO who started in June says the platform has ' '“an entirely different road map” for the future.', 'news_article_title': 'Yaccarino Says X Is Watching Threads but Has Its Own ' 'Vision'}, {'news_article_summary': 'Students foot the bill for flagship state ' 'universities that pour money into new buildings and ' 'programs with little pushback.', 'news_article_title': 'Colleges Spend Like There’s No Tomorrow. ‘These ' 'Places Are Just Devouring Money.’'}, {'news_article_summary': 'Wildfires fanned by hurricane winds have torn ' 'through parts of the Hawaiian island, devastating ' 'the popular tourist town of Lahaina.', 'news_article_title': 'Maui Wildfires Leave at Least 36 Dead'}, {'news_article_summary': 'After its large armored push stalled, Kyiv has ' 'fallen back on the kind of tactics that brought it ' 'success earlier in the war.', 'news_article_title': 'Ukraine Uses Small-Unit Tactics to Retake Captured ' 'Territory'}, {'news_article_summary': 'President Guillermo Lasso says the Aug. 20 election ' 'will proceed, as the Andean country grapples with ' 'rising drug gang violence.', 'news_article_title': 'Ecuador Declares State of Emergency After ' 'Presidential Hopeful Killed'}, {'news_article_summary': 'This year’s hurricane season, which typically runs ' 'from June to the end of November, has been ' 'difficult to predict, climate scientists said.', 'news_article_title': 'Atlantic Hurricane Season Prediction Increased to ' '‘Above Normal,’ NOAA Says'}, {'news_article_summary': 'The NFL is raising the price of its NFL+ streaming ' 'packages as it adds the NFL Network and RedZone.', 'news_article_title': 'NFL to Raise Price of NFL+ Streaming Packages as It ' 'Adds NFL Network, RedZone'}, {'news_article_summary': 'Russia is planning a moon mission as part of the ' 'new space race.', 'news_article_title': 'Russia’s Moon Mission and the New Space Race'}, {'news_article_summary': 'Tapestry’s $8.5 billion acquisition of Capri would ' 'create a conglomerate with more than $12 billion in ' 'annual sales, but it would still lack the ' 'high-wattage labels and diversity that have fueled ' 'LVMH’s success.', 'news_article_title': "Why the Coach and Kors Marriage Doesn't Scare LVMH"}, {'news_article_summary': 'The Supreme Court has blocked Purdue Pharma’s $6 ' 'billion Sackler opioid settlement.', 'news_article_title': 'Supreme Court Blocks Purdue Pharma’s $6 Billion ' 'Sackler Opioid Settlement'}, {'news_article_summary': 'The Social Security COLA is expected to rise in ' '2024, but not by a lot.', 'news_article_title': 'Social Security COLA Expected to Rise in 2024, but ' 'Not by a Lot'}]
```
We can compare the headlines scraped to the page:

Looking at the [LangSmith trace](https://smith.langchain.com/public/c3070198-5b13-419b-87bf-3821cdf34fa6/r), we can see what is going on under the hood:
* It’s following what is explained in the [extraction](https://python.langchain.com/docs/use_cases/web_scraping/docs/use_cases/extraction/).
* We call the `information_extraction` function on the input text.
* It will attempt to populate the provided schema from the url content.
## Research automation[](#research-automation "Direct link to Research automation")
Related to scraping, we may want to answer specific questions using searched content.
We can automate the process of [web research](https://blog.langchain.dev/automating-web-research/) using a retriever, such as the `WebResearchRetriever`.
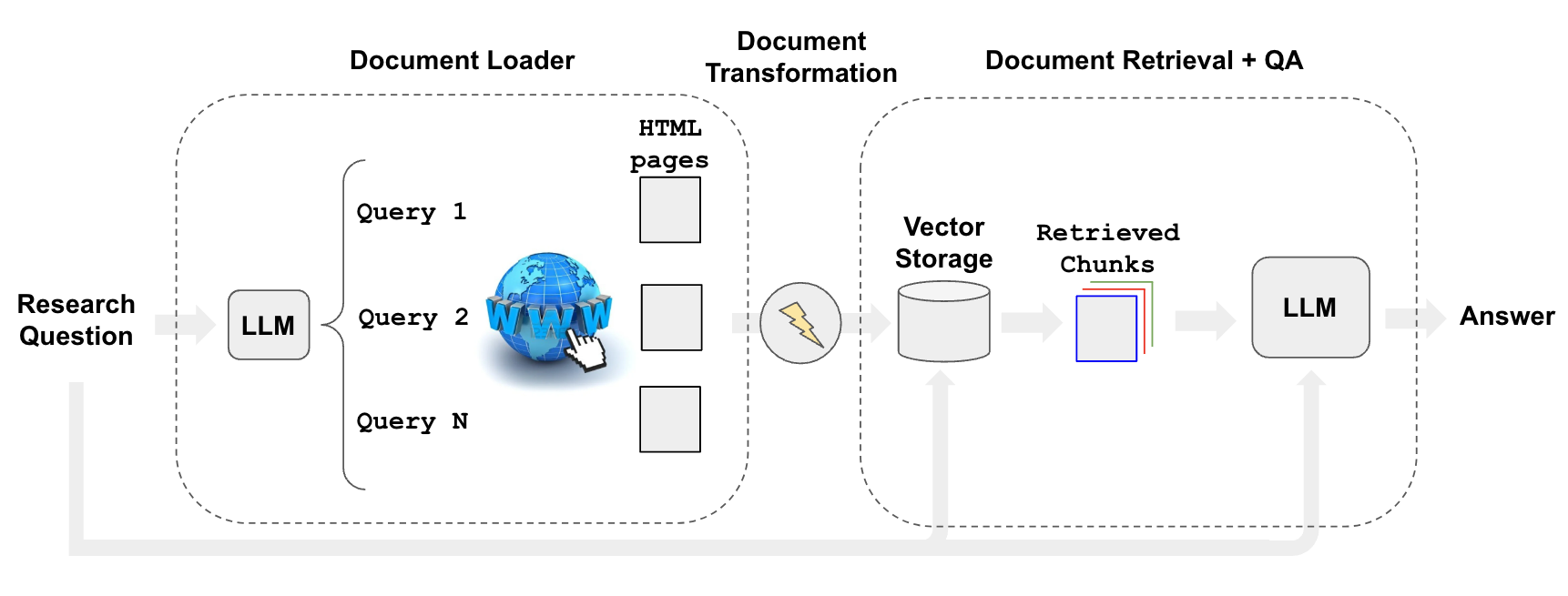
Copy requirements [from here](https://github.com/langchain-ai/web-explorer/blob/main/requirements.txt):
`pip install -r requirements.txt`
Set `GOOGLE_CSE_ID` and `GOOGLE_API_KEY`.
```
from langchain.retrievers.web_research import WebResearchRetrieverfrom langchain_chroma import Chromafrom langchain_community.utilities import GoogleSearchAPIWrapperfrom langchain_openai import ChatOpenAI, OpenAIEmbeddings
```
```
# Vectorstorevectorstore = Chroma( embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai")# LLMllm = ChatOpenAI(temperature=0)# Searchsearch = GoogleSearchAPIWrapper()
```
Initialize retriever with the above tools to:
* Use an LLM to generate multiple relevant search queries (one LLM call)
* Execute a search for each query
* Choose the top K links per query (multiple search calls in parallel)
* Load the information from all chosen links (scrape pages in parallel)
* Index those documents into a vectorstore
* Find the most relevant documents for each original generated search query
```
# Initializeweb_research_retriever = WebResearchRetriever.from_llm( vectorstore=vectorstore, llm=llm, search=search)
```
```
# Runimport logginglogging.basicConfig()logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)from langchain.chains import RetrievalQAWithSourcesChainuser_input = "How do LLM Powered Autonomous Agents work?"qa_chain = RetrievalQAWithSourcesChain.from_chain_type( llm, retriever=web_research_retriever)result = qa_chain({"question": user_input})result
```
```
INFO:langchain.retrievers.web_research:Generating questions for Google Search ...INFO:langchain.retrievers.web_research:Questions for Google Search (raw): {'question': 'How do LLM Powered Autonomous Agents work?', 'text': LineList(lines=['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n'])}INFO:langchain.retrievers.web_research:Questions for Google Search: ['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n']INFO:langchain.retrievers.web_research:Searching for relevant urls ...INFO:langchain.retrievers.web_research:Searching for relevant urls ...INFO:langchain.retrievers.web_research:Search results: [{'title': 'LLM Powered Autonomous Agents | Hacker News', 'link': 'https://news.ycombinator.com/item?id=36488871', 'snippet': 'Jun 26, 2023 ... Exactly. A temperature of 0 means you always pick the highest probability token (i.e. the "max" function), while a temperature of 1 means you\xa0...'}]INFO:langchain.retrievers.web_research:Searching for relevant urls ...INFO:langchain.retrievers.web_research:Search results: [{'title': "LLM Powered Autonomous Agents | Lil'Log", 'link': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'snippet': 'Jun 23, 2023 ... Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1." , "What are the subgoals for achieving XYZ?" , (2) by\xa0...'}]INFO:langchain.retrievers.web_research:New URLs to load: []INFO:langchain.retrievers.web_research:Grabbing most relevant splits from urls...
```
```
{'question': 'How do LLM Powered Autonomous Agents work?', 'answer': "LLM-powered autonomous agents work by using LLM as the agent's brain, complemented by several key components such as planning, memory, and tool use. In terms of planning, the agent breaks down large tasks into smaller subgoals and can reflect and refine its actions based on past experiences. Memory is divided into short-term memory, which is used for in-context learning, and long-term memory, which allows the agent to retain and recall information over extended periods. Tool use involves the agent calling external APIs for additional information. These agents have been used in various applications, including scientific discovery and generative agents simulation.", 'sources': ''}
```
### Going deeper[](#going-deeper "Direct link to Going deeper")
* Here’s a [app](https://github.com/langchain-ai/web-explorer/tree/main) that wraps this retriever with a lighweight UI.
## Question answering over a website[](#question-answering-over-a-website "Direct link to Question answering over a website")
To answer questions over a specific website, you can use Apify’s [Website Content Crawler](https://apify.com/apify/website-content-crawler) Actor, which can deeply crawl websites such as documentation, knowledge bases, help centers, or blogs, and extract text content from the web pages.
In the example below, we will deeply crawl the Python documentation of LangChain’s Chat LLM models and answer a question over it.
First, install the requirements `pip install apify-client langchain-openai langchain`
Next, set `OPENAI_API_KEY` and `APIFY_API_TOKEN` in your environment variables.
The full code follows:
```
from langchain.indexes import VectorstoreIndexCreatorfrom langchain_community.docstore.document import Documentfrom langchain_community.utilities import ApifyWrapperapify = ApifyWrapper()# Call the Actor to obtain text from the crawled webpagesloader = apify.call_actor( actor_id="apify/website-content-crawler", run_input={"startUrls": [{"url": "/docs/integrations/chat/"}]}, dataset_mapping_function=lambda item: Document( page_content=item["text"] or "", metadata={"source": item["url"]} ),)# Create a vector store based on the crawled dataindex = VectorstoreIndexCreator().from_loaders([loader])# Query the vector storequery = "Are any OpenAI chat models integrated in LangChain?"result = index.query(query)print(result)
```
```
Yes, LangChain offers integration with OpenAI chat models. You can use the ChatOpenAI class to interact with OpenAI models.
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:46:36.609Z",
"loadedUrl": "https://python.langchain.com/docs/use_cases/web_scraping/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/use_cases/web_scraping/",
"description": "Open In Colab",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7530",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"web_scraping\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:46:36 GMT",
"etag": "W/\"a1d2c990c5cfb1a49ad597d033e9cbfa\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::77462-1713753996412-e7a4e38d774f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/use_cases/web_scraping/",
"property": "og:url"
},
{
"content": "Web scraping | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Open In Colab",
"property": "og:description"
}
],
"title": "Web scraping | 🦜️🔗 LangChain"
} | Web scraping
Open In Colab
Use case
Web research is one of the killer LLM applications:
Users have highlighted it as one of his top desired AI tools.
OSS repos like gpt-researcher are growing in popularity.
Overview
Gathering content from the web has a few components:
Search: Query to url (e.g., using GoogleSearchAPIWrapper).
Loading: Url to HTML (e.g., using AsyncHtmlLoader, AsyncChromiumLoader, etc).
Transforming: HTML to formatted text (e.g., using HTML2Text or Beautiful Soup).
Quickstart
pip install -q langchain-openai langchain playwright beautifulsoup4
playwright install
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
Scraping HTML content using a headless instance of Chromium.
The async nature of the scraping process is handled using Python’s asyncio library.
The actual interaction with the web pages is handled by Playwright.
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
# Load HTML
loader = AsyncChromiumLoader(["https://www.wsj.com"])
html = loader.load()
Scrape text content tags such as <p>, <li>, <div>, and <a> tags from the HTML content:
<p>: The paragraph tag. It defines a paragraph in HTML and is used to group together related sentences and/or phrases.
<li>: The list item tag. It is used within ordered (<ol>) and unordered (<ul>) lists to define individual items within the list.
<div>: The division tag. It is a block-level element used to group other inline or block-level elements.
<a>: The anchor tag. It is used to define hyperlinks.
<span>: an inline container used to mark up a part of a text, or a part of a document.
For many news websites (e.g., WSJ, CNN), headlines and summaries are all in <span> tags.
# Transform
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(html, tags_to_extract=["span"])
# Result
docs_transformed[0].page_content[0:500]
'English EditionEnglish中文 (Chinese)日本語 (Japanese) More Other Products from WSJBuy Side from WSJWSJ ShopWSJ Wine Other Products from WSJ Search Quotes and Companies Search Quotes and Companies 0.15% 0.03% 0.12% -0.42% 4.102% -0.69% -0.25% -0.15% -1.82% 0.24% 0.19% -1.10% About Evan His Family Reflects His Reporting How You Can Help Write a Message Life in Detention Latest News Get Email Updates Four Americans Released From Iranian Prison The Americans will remain under house arrest until they are '
These Documents now are staged for downstream usage in various LLM apps, as discussed below.
Loader
AsyncHtmlLoader
The AsyncHtmlLoader uses the aiohttp library to make asynchronous HTTP requests, suitable for simpler and lightweight scraping.
AsyncChromiumLoader
The AsyncChromiumLoader uses Playwright to launch a Chromium instance, which can handle JavaScript rendering and more complex web interactions.
Chromium is one of the browsers supported by Playwright, a library used to control browser automation.
Headless mode means that the browser is running without a graphical user interface, which is commonly used for web scraping.
from langchain_community.document_loaders import AsyncHtmlLoader
urls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
Transformer
HTML2Text
HTML2Text provides a straightforward conversion of HTML content into plain text (with markdown-like formatting) without any specific tag manipulation.
It’s best suited for scenarios where the goal is to extract human-readable text without needing to manipulate specific HTML elements.
Beautiful Soup
Beautiful Soup offers more fine-grained control over HTML content, enabling specific tag extraction, removal, and content cleaning.
It’s suited for cases where you want to extract specific information and clean up the HTML content according to your needs.
from langchain_community.document_loaders import AsyncHtmlLoader
urls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
Fetching pages: 100%|#############################################################################################################| 2/2 [00:00<00:00, 7.01it/s]
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
docs_transformed[0].page_content[0:500]
"Skip to main content Skip to navigation\n\n<\n\n>\n\nMenu\n\n## ESPN\n\n * Search\n\n * * scores\n\n * NFL\n * MLB\n * NBA\n * NHL\n * Soccer\n * NCAAF\n * …\n\n * Women's World Cup\n * LLWS\n * NCAAM\n * NCAAW\n * Sports Betting\n * Boxing\n * CFL\n * NCAA\n * Cricket\n * F1\n * Golf\n * Horse\n * MMA\n * NASCAR\n * NBA G League\n * Olympic Sports\n * PLL\n * Racing\n * RN BB\n * RN FB\n * Rugby\n * Tennis\n * WNBA\n * WWE\n * X Games\n * XFL\n\n * More"
LLM with function calling
Web scraping is challenging for many reasons.
One of them is the changing nature of modern websites’ layouts and content, which requires modifying scraping scripts to accommodate the changes.
Using Function (e.g., OpenAI) with an extraction chain, we avoid having to change your code constantly when websites change.
We’re using gpt-3.5-turbo-0613 to guarantee access to OpenAI Functions feature (although this might be available to everyone by time of writing).
We’re also keeping temperature at 0 to keep randomness of the LLM down.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
Define a schema
Next, you define a schema to specify what kind of data you want to extract.
Here, the key names matter as they tell the LLM what kind of information they want.
So, be as detailed as possible.
In this example, we want to scrape only news article’s name and summary from The Wall Street Journal website.
from langchain.chains import create_extraction_chain
schema = {
"properties": {
"news_article_title": {"type": "string"},
"news_article_summary": {"type": "string"},
},
"required": ["news_article_title", "news_article_summary"],
}
def extract(content: str, schema: dict):
return create_extraction_chain(schema=schema, llm=llm).run(content)
Run the web scraper w/ BeautifulSoup
As shown above, we’ll be using BeautifulSoupTransformer.
import pprint
from langchain_text_splitters import RecursiveCharacterTextSplitter
def scrape_with_playwright(urls, schema):
loader = AsyncChromiumLoader(urls)
docs = loader.load()
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["span"]
)
print("Extracting content with LLM")
# Grab the first 1000 tokens of the site
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
splits = splitter.split_documents(docs_transformed)
# Process the first split
extracted_content = extract(schema=schema, content=splits[0].page_content)
pprint.pprint(extracted_content)
return extracted_content
urls = ["https://www.wsj.com"]
extracted_content = scrape_with_playwright(urls, schema=schema)
Extracting content with LLM
[{'news_article_summary': 'The Americans will remain under house arrest until '
'they are allowed to return to the U.S. in coming '
'weeks, following a monthslong diplomatic push by '
'the Biden administration.',
'news_article_title': 'Four Americans Released From Iranian Prison'},
{'news_article_summary': 'Price pressures continued cooling last month, with '
'the CPI rising a mild 0.2% from June, likely '
'deterring the Federal Reserve from raising interest '
'rates at its September meeting.',
'news_article_title': 'Cooler July Inflation Opens Door to Fed Pause on '
'Rates'},
{'news_article_summary': 'The company has decided to eliminate 27 of its 30 '
'clothing labels, such as Lark & Ro and Goodthreads, '
'as it works to fend off antitrust scrutiny and cut '
'costs.',
'news_article_title': 'Amazon Cuts Dozens of House Brands'},
{'news_article_summary': 'President Biden’s order comes on top of a slowing '
'Chinese economy, Covid lockdowns and rising '
'tensions between the two powers.',
'news_article_title': 'U.S. Investment Ban on China Poised to Deepen Divide'},
{'news_article_summary': 'The proposed trial date in the '
'election-interference case comes on the same day as '
'the former president’s not guilty plea on '
'additional Mar-a-Lago charges.',
'news_article_title': 'Trump Should Be Tried in January, Prosecutors Tell '
'Judge'},
{'news_article_summary': 'The CEO who started in June says the platform has '
'“an entirely different road map” for the future.',
'news_article_title': 'Yaccarino Says X Is Watching Threads but Has Its Own '
'Vision'},
{'news_article_summary': 'Students foot the bill for flagship state '
'universities that pour money into new buildings and '
'programs with little pushback.',
'news_article_title': 'Colleges Spend Like There’s No Tomorrow. ‘These '
'Places Are Just Devouring Money.’'},
{'news_article_summary': 'Wildfires fanned by hurricane winds have torn '
'through parts of the Hawaiian island, devastating '
'the popular tourist town of Lahaina.',
'news_article_title': 'Maui Wildfires Leave at Least 36 Dead'},
{'news_article_summary': 'After its large armored push stalled, Kyiv has '
'fallen back on the kind of tactics that brought it '
'success earlier in the war.',
'news_article_title': 'Ukraine Uses Small-Unit Tactics to Retake Captured '
'Territory'},
{'news_article_summary': 'President Guillermo Lasso says the Aug. 20 election '
'will proceed, as the Andean country grapples with '
'rising drug gang violence.',
'news_article_title': 'Ecuador Declares State of Emergency After '
'Presidential Hopeful Killed'},
{'news_article_summary': 'This year’s hurricane season, which typically runs '
'from June to the end of November, has been '
'difficult to predict, climate scientists said.',
'news_article_title': 'Atlantic Hurricane Season Prediction Increased to '
'‘Above Normal,’ NOAA Says'},
{'news_article_summary': 'The NFL is raising the price of its NFL+ streaming '
'packages as it adds the NFL Network and RedZone.',
'news_article_title': 'NFL to Raise Price of NFL+ Streaming Packages as It '
'Adds NFL Network, RedZone'},
{'news_article_summary': 'Russia is planning a moon mission as part of the '
'new space race.',
'news_article_title': 'Russia’s Moon Mission and the New Space Race'},
{'news_article_summary': 'Tapestry’s $8.5 billion acquisition of Capri would '
'create a conglomerate with more than $12 billion in '
'annual sales, but it would still lack the '
'high-wattage labels and diversity that have fueled '
'LVMH’s success.',
'news_article_title': "Why the Coach and Kors Marriage Doesn't Scare LVMH"},
{'news_article_summary': 'The Supreme Court has blocked Purdue Pharma’s $6 '
'billion Sackler opioid settlement.',
'news_article_title': 'Supreme Court Blocks Purdue Pharma’s $6 Billion '
'Sackler Opioid Settlement'},
{'news_article_summary': 'The Social Security COLA is expected to rise in '
'2024, but not by a lot.',
'news_article_title': 'Social Security COLA Expected to Rise in 2024, but '
'Not by a Lot'}]
We can compare the headlines scraped to the page:
Looking at the LangSmith trace, we can see what is going on under the hood:
It’s following what is explained in the extraction.
We call the information_extraction function on the input text.
It will attempt to populate the provided schema from the url content.
Research automation
Related to scraping, we may want to answer specific questions using searched content.
We can automate the process of web research using a retriever, such as the WebResearchRetriever.
Copy requirements from here:
pip install -r requirements.txt
Set GOOGLE_CSE_ID and GOOGLE_API_KEY.
from langchain.retrievers.web_research import WebResearchRetriever
from langchain_chroma import Chroma
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Vectorstore
vectorstore = Chroma(
embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai"
)
# LLM
llm = ChatOpenAI(temperature=0)
# Search
search = GoogleSearchAPIWrapper()
Initialize retriever with the above tools to:
Use an LLM to generate multiple relevant search queries (one LLM call)
Execute a search for each query
Choose the top K links per query (multiple search calls in parallel)
Load the information from all chosen links (scrape pages in parallel)
Index those documents into a vectorstore
Find the most relevant documents for each original generated search query
# Initialize
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore, llm=llm, search=search
)
# Run
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)
from langchain.chains import RetrievalQAWithSourcesChain
user_input = "How do LLM Powered Autonomous Agents work?"
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm, retriever=web_research_retriever
)
result = qa_chain({"question": user_input})
result
INFO:langchain.retrievers.web_research:Generating questions for Google Search ...
INFO:langchain.retrievers.web_research:Questions for Google Search (raw): {'question': 'How do LLM Powered Autonomous Agents work?', 'text': LineList(lines=['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n'])}
INFO:langchain.retrievers.web_research:Questions for Google Search: ['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n']
INFO:langchain.retrievers.web_research:Searching for relevant urls ...
INFO:langchain.retrievers.web_research:Searching for relevant urls ...
INFO:langchain.retrievers.web_research:Search results: [{'title': 'LLM Powered Autonomous Agents | Hacker News', 'link': 'https://news.ycombinator.com/item?id=36488871', 'snippet': 'Jun 26, 2023 ... Exactly. A temperature of 0 means you always pick the highest probability token (i.e. the "max" function), while a temperature of 1 means you\xa0...'}]
INFO:langchain.retrievers.web_research:Searching for relevant urls ...
INFO:langchain.retrievers.web_research:Search results: [{'title': "LLM Powered Autonomous Agents | Lil'Log", 'link': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'snippet': 'Jun 23, 2023 ... Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1." , "What are the subgoals for achieving XYZ?" , (2) by\xa0...'}]
INFO:langchain.retrievers.web_research:New URLs to load: []
INFO:langchain.retrievers.web_research:Grabbing most relevant splits from urls...
{'question': 'How do LLM Powered Autonomous Agents work?',
'answer': "LLM-powered autonomous agents work by using LLM as the agent's brain, complemented by several key components such as planning, memory, and tool use. In terms of planning, the agent breaks down large tasks into smaller subgoals and can reflect and refine its actions based on past experiences. Memory is divided into short-term memory, which is used for in-context learning, and long-term memory, which allows the agent to retain and recall information over extended periods. Tool use involves the agent calling external APIs for additional information. These agents have been used in various applications, including scientific discovery and generative agents simulation.",
'sources': ''}
Going deeper
Here’s a app that wraps this retriever with a lighweight UI.
Question answering over a website
To answer questions over a specific website, you can use Apify’s Website Content Crawler Actor, which can deeply crawl websites such as documentation, knowledge bases, help centers, or blogs, and extract text content from the web pages.
In the example below, we will deeply crawl the Python documentation of LangChain’s Chat LLM models and answer a question over it.
First, install the requirements pip install apify-client langchain-openai langchain
Next, set OPENAI_API_KEY and APIFY_API_TOKEN in your environment variables.
The full code follows:
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.docstore.document import Document
from langchain_community.utilities import ApifyWrapper
apify = ApifyWrapper()
# Call the Actor to obtain text from the crawled webpages
loader = apify.call_actor(
actor_id="apify/website-content-crawler",
run_input={"startUrls": [{"url": "/docs/integrations/chat/"}]},
dataset_mapping_function=lambda item: Document(
page_content=item["text"] or "", metadata={"source": item["url"]}
),
)
# Create a vector store based on the crawled data
index = VectorstoreIndexCreator().from_loaders([loader])
# Query the vector store
query = "Are any OpenAI chat models integrated in LangChain?"
result = index.query(query)
print(result)
Yes, LangChain offers integration with OpenAI chat models. You can use the ChatOpenAI class to interact with OpenAI models. |